






Bahasa
Halaman
Hukum


ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA INFORMÁTICA
INGENIERO EN INFORMÁTICA
TÉCNICAS SEO Y POSICIONAMIENTO
EN MOTORES DE BÚSQUEDA
Realizado por
ALBERTO L. FERNÁNDEZ REYES
Dirigido por
EDUARDO GUZMÁN DE LOS RISCOS
Departamento
LENGUAJES Y CIENCIAS DE LA COMPUTACIÓN
UNIVERSIDAD DE MÁLAGA
MÁLAGA, ABRIL 2015

2

3
UNIVERSIDAD DE MÁLAGA ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA INFORMÁTICA
INGENIERO EN INFORMÁTICA
Reunido el tribunal examinador en el día de la fecha, constituido por:
Presidente/a Dº/Dª. _____________________________________________________
Secretario/a Dº/Dª. _____________________________________________________
Vocal Dº/Dª. __________________________________________________________
para juzgar el proyecto Fin de Carrera titulado:
TÉCNICAS SEO Y POSICIONAMIENTO
EN MOTORES DE BÚSQUEDA
realizado por Dº/Dª ALBERTO LUIS FERNÁNDEZ REYES
tutorizado por Dº/Dª. EDUARDO GUZMÁN DE LOS RISCOS ,
y dirigido académicamente por Dº/Dª. EDUARDO GUZMÁN DE LOS RISCOS
ACORDÓ POR _____________ OTORGAR LA CALIFICACIÓN DE _____________
Y PARA QUE CONSTE, SE EXTIENDE FIRMADA POR LOS COMPARECIENTES
DEL TRIBUNAL, LA PRESENTE DILIGENCIA.
El/La Presidente El/La Secretario/a El/La Vocal
Fdo:
Fdo:
Fdo:
Málaga a ____ de______________ del 20__

4

5
Técnicas SEO y posicionamiento
en motores de búsqueda
Alberto L. Fernández Reyes
Abril 2015

6

7
Tabla de contenidos
Capítulo 1: Introducción ................................................................................................................. 17
1.1. Objetivos ................................................................................................................................ 19
1.2. Optimización orgánica ...................................................................................................... 20
1.3. Marketing para la optimización web ........................................................................... 22
1.4. Herramientas para la promoción y control web ...................................................... 23
1.5. Caso práctico ........................................................................................................................ 24
Capítulo 2: Motores de búsqueda y Optimización web ......................................................... 25
2.1. Motores de búsqueda web ............................................................................................... 26
2.1.1. Internet, directorios y motores de búsqueda web ....................................................... 26
2.1.2. Componentes de un motor de búsqueda .......................................................................... 28
2.2. Proceso de Crawling ........................................................................................................... 29
2.2.1. Sitemap Protocol ......................................................................................................................... 30
2.2.2. Robot Exclusion Protocol ........................................................................................................ 32
2.2.3. Conclusiones ................................................................................................................................. 33
2.3. Proceso de Indexación ...................................................................................................... 34
2.3.1. Control sobre los indexadores ............................................................................................... 35
2.3.2. Indexación de contenidos Ajax .............................................................................................. 39
2.3.3. Conclusiones ................................................................................................................................. 46
2.4. Optimizando documentos web: on-‐page ..................................................................... 47
2.4.1. Palabras clave ............................................................................................................................... 47
2.4.2. Nombre de Dominio ................................................................................................................... 50
2.4.3. Top-‐level Domain ........................................................................................................................ 53
2.4.4. Meta etiquetas .............................................................................................................................. 54
2.4.5. Encabezamientos HTML .......................................................................................................... 57
2.4.6. Atributo de texto ALT ................................................................................................................ 60
2.4.7. Canonicalización .......................................................................................................................... 61
2.4.8. Canibalización de palabras clave .......................................................................................... 63
2.4.9. Paginación web ............................................................................................................................ 64
2.4.10. Redireccionamientos .............................................................................................................. 67

8
2.4.11. Velocidad de carga ................................................................................................................... 69
2.4.12. Conclusiones ............................................................................................................................... 71
2.5. Optimización de documentos web: off-‐page .............................................................. 73
2.5.1. Anclas de texto y optimización interna ............................................................................. 73
2.5.2. Métricas Off-‐page ........................................................................................................................ 75
2.5.3. Link juice y Arquitectura web ............................................................................................... 84
2.5.4. Link building ................................................................................................................................. 88
2.5.5. Conclusiones ................................................................................................................................. 92
2.6. Blackhat SEO ......................................................................................................................... 93
2.6.1. Conectando con el grafo web ................................................................................................. 93
2.6.2. Construyendo documentos web ........................................................................................... 96
2.6.3. Captación de usuarios ............................................................................................................... 97
2.6.4. Secuestrando documentos web ............................................................................................ 98
2.6.5. Inyectando código en documentos web ......................................................................... 101
Capítulo 3: Marketing Online ...................................................................................................... 105
3.1. Planificación web .............................................................................................................. 106
3.1.1. Tipos de palabras clave ......................................................................................................... 106
3.1.2. Volumen de búsquedas, competencia y rentabilidad ............................................... 107
3.1.3. Benchmark .................................................................................................................................. 110
3.1.4. Conclusiones .............................................................................................................................. 112
3.2. Estrategias de publicidad online ................................................................................. 113
3.2.1. Sitios de afiliados ..................................................................................................................... 113
3.2.2. Publicidad online ...................................................................................................................... 119
3.2.3. E-‐mail ............................................................................................................................................ 122
3.2.4. Conclusiones .............................................................................................................................. 124
3.3. Optimización para la conversión ................................................................................. 125
3.3.1. Resultados de búsquedas ..................................................................................................... 126
3.3.2. Publicidad Online ..................................................................................................................... 134
3.3.3. Sitios Web .................................................................................................................................... 138
3.3.4. Conclusiones .............................................................................................................................. 143
3.4. Analítica web ...................................................................................................................... 144
3.4.1. Analítica web y objetivos de negocio .............................................................................. 144
3.4.2. Objetivos web ............................................................................................................................ 145

9
3.4.3. Métricas web .............................................................................................................................. 147
3.4.4. Key performance indicator .................................................................................................. 148
3.4.5. Conclusiones .............................................................................................................................. 151
Capítulo 4: Herramientas ............................................................................................................. 153
4.1. WebCEO ................................................................................................................................ 154
4.1.1. Auditoria del sitio web ........................................................................................................... 154
4.1.2. Link building .............................................................................................................................. 165
4.1.3. Métricas sociales ...................................................................................................................... 170
4.1.4. Analítica de Marketing ........................................................................................................... 173
4.1.5. Conclusiones .............................................................................................................................. 179
4.2. MailChimp ........................................................................................................................... 180
4.2.1. Lista y grupos ............................................................................................................................. 180
4.2.2. Formularios opt-‐in/re-‐opt ................................................................................................... 181
4.2.3. Emails transaccionales .......................................................................................................... 182
4.2.4. Segmentación ............................................................................................................................. 183
4.2.5. Personalización de e-‐mails .................................................................................................. 183
4.2.6. Campañas de e-‐mail ................................................................................................................ 184
4.2.7. Informe de Campañas ............................................................................................................ 185
4.2.8. Conclusiones .............................................................................................................................. 187
4.3. Google Webmasters Tool ............................................................................................... 187
4.3.1. Proceso de alta .......................................................................................................................... 188
4.3.2. Control sobre la apariencia en los SERPs ...................................................................... 188
4.3.3. Consulta sobre el tráfico de búsqueda ............................................................................ 190
4.3.4. Control sobre el índice de Google ..................................................................................... 193
4.3.5. Control sobre robots o crawlers ........................................................................................ 194
4.3.6. Conclusiones .............................................................................................................................. 195
4.4. Google Analytics ................................................................................................................ 196
4.4.1. Cálculo de métricas básicas ................................................................................................ 196
4.4.2. Cálculo de métricas Avanzadas .......................................................................................... 201
4.4.3. Errores de medición ............................................................................................................... 208
4.4.4. Conclusiones .............................................................................................................................. 209
4.5. Google AdWords ................................................................................................................ 209
4.5.1. Principios básicos y funcionamiento ............................................................................... 210

10
4.5.2. Definición del público objetivo .......................................................................................... 218
4.5.3. Creación de Campañas ........................................................................................................... 220
4.5.4. Campañas de remarketing ................................................................................................... 221
4.5.5. Optimización de pujas ............................................................................................................ 223
4.5.6. Conclusiones .............................................................................................................................. 228
Capítulo 5: Caso práctico ............................................................................................................... 229
5.1. Optimizaciones para la indexación de contenido .................................................. 230
5.1.1. Duplicación de contenido en Blogger .............................................................................. 230
5.1.2. X-‐Robots-‐tag ............................................................................................................................... 233
5.1.3. Robots.txt ..................................................................................................................................... 235
5.2. Optimización Web ............................................................................................................ 236
5.2.1. Títulos ........................................................................................................................................... 236
5.2.2. Direcciones web ....................................................................................................................... 238
5.2.3. Meta descripciones .................................................................................................................. 239
5.2.4. Plantilla web ............................................................................................................................... 240
5.2.5. Imágenes ...................................................................................................................................... 243
5.2.6. Palabras clave ............................................................................................................................ 244
5.3. Estrategia de link building ............................................................................................. 252
5.3.1. Directorios .................................................................................................................................. 252
5.3.2. Menciones web .......................................................................................................................... 254
5.4. Generación de leads ......................................................................................................... 256
5.4.1. Suscripción RSS ......................................................................................................................... 257
5.4.2. Landing pages ............................................................................................................................ 258
Capítulo 6: Conclusiones ............................................................................................................... 261
6.1. Visibilidad web en motores de búsqueda ................................................................. 261
6.2. Adquisición de tráfico desde motores de búsqueda ............................................. 262
6.3. Posicionamiento en motores de búsqueda .............................................................. 264
6.4. Dificultades ......................................................................................................................... 266
6.5. Futuras ampliaciones ...................................................................................................... 267
Bibliografía ........................................................................................................................................ 269
Glosario ............................................................................................................................................... 291

11
Índice de Figuras
Figura 1: Arquitectura inicial del motor de búsqueda de Google……………………29
Figura 2: Archivo Robots.txt procedente de la web About.com ................................. 34
Figura 3: Resultados de búsqueda para la web about.com .......................................... 34
Figura 4: Código javascript de carga de contenido asíncrona ..................................... 42
Figura 5: Direcciones web empleadas para la recuperación de contenido Ajax ......... 46
Figura 6: Búsqueda en Google con términos 'universidad de Málaga' ....................... 48
Figura 7: Resultados en Google para la búsqueda Julio Iglesias ................................ 49
Figura 8: Ejemplo de EMD desde la lista de resultados de Google ............................ 51
Figura 9: Índice de correlación de Spearman para EMD ............................................ 53
Figura 10: Meta description perteneciente a Amazon.com ......................................... 55
Figura 11: Ejemplo de marcado de palabras en Google.com ...................................... 57
Figura 12: Página de Amazon MP3 & Cloud Player .................................................. 58
Figura 13: Encabezamiento H1 Html empleados en la página de Amazon ................ 59
Figura 14: Encabezamiento H2-H3 Html empleados en la página de Amazon .......... 59
Figura 15: Paginación desarrollada por Amazon ........................................................ 64
Figura 16: Tiempos de respuesta TTFB y posicionamiento (Peters & Isham, 2013) . 71
Figura 17: Ejemplo de autoría de artículos de John Resig .......................................... 84
Figura 18: Flujo de PageRank entre webs (Brin & Page, 1998) ................................. 85
Figura 19: Estructura web jerárquica .......................................................................... 86
Figura 20: Estructura web con link colgante ............................................................... 87
Figura 21: Gastos dedicados a link building ............................................................... 89
Figura 22: Infografía extraída de HubSpot ................................................................. 91
Figura 24: Inserción de código malicioso en Apertium web .................................... 103
Figura 25: Interfaz gráfica de la herramienta Google Keyword Planner .................. 108
Figura 26: Benchmark ratio de clics por posición del documento ............................ 111
Figura 27: Marcado de palabras clave en una búsqueda web ................................... 127
Figura 28: CTR para head y long tail keywords por posición de documentos ......... 128
Figura 30: Modelo de Sitelink empleado actualmente .............................................. 130
Figura 31: Personalización de resultado: aplicacion de software ............................. 131

12
Figura 32: Personalización de resultado: oferta de producto .................................... 132
Figura 33: Personalización de resultado: oferta de producto con diferentes precios 132
Figura 34: Personalización de resultado: valoración de producto y precio ............... 133
Figura 35: Evolución del abandono de carritos de compra online ............................ 136
Figura 36: Squeeze page del sitio blogprofitcamp.com ............................................ 140
Figura 37: Formulario para capturar e-mails en la web Backlinko.com ................... 141
Figura 38: Ejemplo de landing page empleado por el sitio Advanced Data Systems
Corporation ........................................................................................................ 142
Figura 39: Herramienta WebCEO para la determinación de palabras clave ............. 155
Figura 40: Herramienta WebCEO para el análisis de las anclas de texto ................. 157
Figura 41: Herramienta WebCEO para analizar métricas de enlaces ....................... 158
Figura 42: Herramienta WebCEO para el estudio de enlaces por documento web .. 158
Figura 43: Herramienta WebCEO para la realización de auditoria técnica .............. 159
Figura 44: Herramienta WebCEO para la optimización on-page ............................. 161
Figura 45: Herramienta WebCEO para la optimización de documentos concretos .. 162
Figura 46: Herramienta WebCEO para la optimización de landing pages ............... 163
Figura 47: Herramienta WebCEO para mejorar la velocidad del sitio web .............. 164
Figura 48: Herramienta WebCEO para analizar las páginas mas populares ............. 165
Figura 49: Herramienta WebCEO para analizar el perfil de enlaces ........................ 166
Figura 50: Herramienta WebCEO para analizar las anclas de texto usadas ............. 167
Figura 51: Herramienta WebCEO para analizar enlaces entrantes ........................... 168
Figura 52: Herramienta WebCEO para analizar los documentos mas enlazados ..... 168
Figura 53: Herramienta WebCEO para analizar enlaces de la competencia ............. 169
Figura 54: Herramienta WebCEO para comprobar la existencia de enlaces ............ 170
Figura 55: Herramienta WebCEO para monitorear métricas de redes sociales ........ 171
Figura 56: Herramienta WebCEO para monitorear métricas sociales ...................... 172
Figura 57: Herramienta WebCEO para monitorear métricas sociales por dominio . 172
Figura 58: Herramienta WebCEO para analizar el tráfico por red social ................. 173
Figura 59: Herramienta WebCEO para monitorear el ranking en los SERPs ........... 174
Figura 60: Herramienta WebCEO para monitorear el ranking por motores ............. 174
Figura 61: Herramienta WebCEO para monitorear el ranking por etiquetas ............ 175
Figura 62: Herramienta WebCEO para monitorear la evolución de la competencia 175
Figura 63: Herramienta WebCEO para analizar la evolución del tráfico ................. 176
Figura 64: Herramienta WebCEO para analizar el tipo de usuario por red social .... 176

13
Figura 65: Herramienta WebCEO para analizar el porcentaje de nuevas visitas ...... 177
Figura 66: Herramienta WebCEO para comparar el ranking Alexa ......................... 178
Figura 67: Herramienta WebCEO para comparar métricas contra la competencia .. 179
Figura 68: Herramienta WebCEO para comparar citaciones en redes sociales ........ 179
Figura 69: Formulario de registro en lista de MailChimp ......................................... 181
Figura 70: Formulario de registro para la recepción del Excel de escandallos ......... 182
Figura 71: Formas de identificación en la herramienta Google Webmaster Tools ... 188
Figura 72: Herramienta Data Highlighter para resultados de búsqueda ................... 189
Figura 73: Información mostrada en la lista de resultados de Google ...................... 190
Figura 74: Sitelinks del sitio desdemiatalaya.com .................................................... 190
Figura 75: Herramienta GWT para el análisis de las palabras clave empleadas ....... 191
Figura 76: Herramienta GWT para el análisis de enlaces entrantes ......................... 191
Figura 77: Herramienta GWT para el análisis de enlaces internos ........................... 192
Figura 78: Herramienta GWT para el análisis de contenido indexado y bloqueado . 193
Figura 79: Herramienta GWT para conocer las palabras mas empleadas ................. 194
Figura 80: Herramienta GWT para eliminar direcciones web del índice de Google 194
Figura 81: Páginas vistas por usuario en Google Analytics ...................................... 197
Figura 82: Páginas vistas únicas por usuario en Google Analytics ........................... 197
Figura 83: Medición de sesiones en Google Analytics ............................................. 198
Figura 84: Medición de visitantes únicos en Google Analytics ................................ 198
Figura 85: Medición de Visitantes recurrentes en Google Analytics ........................ 199
Figura 86: Medición de tiempo en página en Google Analytics ............................... 200
Figura 87: Informe de adquisición de audiencia ....................................................... 205
Figura 88: Informe para medir sesiones necesarias hasta la conversión ................... 207
Figura 89: Ad Group con redefinición de puja para keywords específicas .............. 213
Figura 90: Formatos de anuncios disponibles por tipo de campaña en AdWords .... 214
Figura 91: Personalización de listas .......................................................................... 223
Figura 92: Herramienta de Google AdWords para especificar el público objetivo .. 225
Figura 93: Personalización de puja CPM .................................................................. 226
Figura 94: Puja condicional en Google AdWords .................................................... 227
Figura 95: Incremento del máximo CPC para usuarios móviles ............................... 228
Figura 96: Gráfica mostrando el CTR para artículos archivados ............................. 232
Figura 97: Gráfica mostrando el CTR para artículos no archivados ......................... 232
Figura 98: Panel de configuración en la plataforma Blogger .................................... 234

14
Figura 99: Respuesta Http para página archivada ..................................................... 234
Figura 100: Robots.txt empleado en el blog desdemiatalaya.com ............................ 235
Figura 101: Artículo sin meta descripción bloqueado por protocolo Robots.txt ...... 235
Figura 102: Lista de artículos del blog Desdemiatalaya.com ................................... 237
Figura 103: Lista de artículos con direcciones web faltas de contexto ..................... 238
Figura 104: Lista de artículos con direcciones web descriptivas .............................. 239
Figura 105: Lista de artículos con meta descripción poco descriptiva ..................... 240
Figura 106: Plantilla inicial proporcionada por Blogger ........................................... 241
Figura 107: Plantilla de Blogger modificada para página principal .......................... 242
Figura 108: Plantilla de Blogger modificada para páginas de artículos .................... 243
Figura 109: Páginas mas visitadas desde el canal de tráfico orgánico ...................... 244
Figura 110: Lista de palabras clave proporcionadas por GWT ................................. 246
Figura 111: Palabras clave empleadas para posicionar artículos Dealz .................... 247
Figura 112: Lista de resultados para la búsqueda "Dealz" ........................................ 248
Figura 113: Lista de palabras clave proporcionada por GWT .................................. 249
Figura 114: Long tail keywords empleadas para posicionar artículo específico ....... 251
Figura 115: Evolución del tráfico para el artículo de escandallos ............................ 251
Figura 116: Plantilla RankTank para analizar menciones web. ................................ 255
Figura 117: Métricas para visitas provenientes de FeedBurner ................................ 258
Figura 118: Evolución del tráfico web para el artículo de escandallos ..................... 259
Figura 119: Formulario de suscripción integrado con la plataforma MailChimp ..... 260

15
Índice de tablas
Tabla 1: Tags pertenecientes al archivo Sitemap.xml ................................................. 31
Tabla 2: Tags pertenecientes al archivo sitemapindex.xml ......................................... 32
Tabla 3: Identificación unívoca de palabra clave con documento a recuperar ........... 42
Tabla 4: Evolución del PageRank sobre web estructura jerárquicamente .................. 87
Tabla 5: Evolución de PageRank sobre estructura web con link colgante .................. 88
Tabla 6: Posicionamiento y ratio de clics .................................................................. 112
Tabla 7: Plataformas de afiliación y acciones que registra la plataforma ................. 119
Tabla 8: Definición de micro y macro goals para diferentes tipos de web ............... 147
Tabla 9: Definición de KPIs para objetivos web ....................................................... 151
Tabla 10: Lista de directorios que indexaron el blog ................................................ 252
Tabla 11: Lista de directorios a la espera de que indexen el blog ............................. 253
Tabla 12: Lista de directorios que rechazaron la indexación del blog ...................... 253
Tabla 13: Lista de directorios o agregadores de noticias no usados ......................... 254
Tabla 14: Lista de perfiles de redes sociales que enlazan al blog desdemiatalaya ... 256
Tabla 15: Lista de páginas web que mencionan al autor del blog ............................. 256
Tabla 16: Evolución del número de impresiones por meses ..................................... 262
Tabla 17: Evolución del CTR desde la lista de resultados por meses ....................... 263
Tabla 18: Evolución del número de visitas provenientes de Google ........................ 264
Tabla 19: Palabras clave para atraer público que busca asesoramiento .................... 265
Tabla 20: Palabras clave para atraer público interesado en gestión de negocios ...... 266
Tabla 21: Palabras clave empleadas para incrementar la visibilidad del blog .......... 266

16

17
Capítulo 1:
Introducción
El presente proyecto final de carrera tiene como objetivo el estudio y la documentación de las
técnicas de posicionamiento empleadas en el entorno web, recopiladas a través de libros
especializados en la materia, patentes publicadas por los principales motores de búsqueda
como Bing o Google, así como papers cuya información ha sido avalada por Google.
El uso de las tecnologías web se está extendiendo a un ritmo muy acelerado. Están presentes
en nuestro día a día, y actualmente están siendo incorporados a todo tipo de aparatos
electrónicos, como pueden ser neveras, televisores, móviles, etc.
La web, tal y como es entendida, ha pasado a ser el canal de comunicación por el cual
usuarios conectan con el mundo exterior: negocios, marcas, amistades o actividades de ocio
son solo unos pocos ejemplos. Para acceder a cada uno de estos sitios web es necesario el uso
de un navegador, así como tener conocimiento de la dirección web a la que se quiere acceder.
Esta dirección web es la que nos permitirá acceder a las páginas web. Pero, ¿cómo somos
capaces de conocer las direcciones web de millones de páginas web?
El desarrollo de nuevas formas de almacenar y extraer información en los sistemas de
información, así como los avances tecnológicos y la reducción de tiempos de acceso a
memoria han permitido encontrar formas eficientes de organizar documentos.
Los motores de búsqueda son el resultado final de aplicar estas técnicas de recuperación de
información al almacenamiento de documentos web. Mediante estos, los usuarios son
capaces de encontrar información web introduciendo un conjunto de palabras relacionadas

18
con el contenido que queremos buscar. A este conjunto de palabras claves se las conoce como
keywords.
Los motores de búsqueda web son sistemas expertos en encontrar información, para lo cual
primero tienen que recopilarla y almacenarla (Brin & Page, 1998). La recopilación de
información es realizada por los denominados crawlers, spiders o bots. Éstos tienen como
objetivo visitar todas y cada una de las páginas existentes en Internet. El indexador será la
entidad encargada de almacenar la información, de forma que pueda ser recuperada
rápidamente.
Además de las anteriores entidades, los motores de búsqueda web disponen de una interfaz
gráfica con la que interactúan con los usuarios. Los usuarios introducen una serie de términos
o keywords a través de la interfaz gráfica, y los motores de búsqueda recuperan aquellos
documentos webs relacionados con las keywords introducidas.
Para facilitar la labor que realizan los motores de búsqueda, estos dan a conocer un conjunto
de prácticas recomendadas a implementar por los webmasters. La adopción de estas prácticas
permite que los motores de búsqueda entiendan mejor el contenido del documento. Esto
puede ayudar la mejora de posiciones en la lista de resultados.
Al listado de resultados ofrecidos por los motores de búsqueda para unos términos de
búsqueda introducidos se los conoce como Search Engine Results Page o SERP. Al conjunto
de técnicas o metodologías aplicadas sobre documentos web cuyo principal objetivo es
posicionar estos en los motores de búsqueda se le conoce como Search Engine Optimization o
SEO.
Debido a que el posicionamiento de documentos web para términos clave muy solicitados
pueden derivar en miles de visitas, los negocios online están cada vez adoptando mejores
prácticas web con el objetivo de posicionar estos documentos.
En este afán por salir primero en los puestos de Google u otros motores de búsqueda, algunos
usuarios o dueños de sitios webs pueden emplear prácticas penalizadas por los motores de
búsqueda en pos de la consecución de un mejor posicionamiento.

19
En caso de que los motores de búsqueda las detecten, estos pueden penalizar estos sitios web.
Esta penalización supone la pérdida de posiciones en las páginas de resultados ofrecidas por
los motores de búsqueda o el borrado total del sitio web de los motores de búsqueda.
Como alternativa a la adquisición de usuarios desde los motores de búsqueda, es posible la
promoción de sitios web mediante anuncios, tanto en motores de búsqueda como en sitios
web.
Para ser capaces de analizar el progreso de nuestros esfuerzos en la adquisición de usuarios,
necesitaremos hacer uso de la herramientas que nos permitan analizar la evolución del sitio
web. A esta herramienta se la conoce como analítica web (web analytics). Nos permitirá
adquirir conocimientos sobre los usuarios que visitan el sitio web, de forma que podamos
determinar si estamos captando el perfil de usuario más adecuado. Mas allá de esto, nos
ayudará a conocer la evolución de nuestro sitio web, es decir, si cambios que realizados tienen
repercusión sobre el comportamiento de los usuarios.
1.1. Objetivos
El objetivo principal del proyecto es estudiar y presentar el conjunto de técnicas promovidas
por los principales motores de búsqueda, así como por expertos en la materia, para alcanzar
un buen posicionamiento web en las páginas de resultados de los buscadores.
Se presentarán técnicas y herramientas para controlar la forma en la que los motores de
búsqueda interactúan con los documentos web, prácticas para evitar ser penalizados, así como
técnicas a implementar con el objetivo de mejorar el posicionamiento web.
El presente proyecto final de carrera abarca también el estudio de técnicas de marketing
online como medio para adquirir usuarios desde los motores de búsqueda o sitios web.
Se expondrán técnicas de marketing para estudiar el potencial de un sitio web y de las
palabras clave de las cuales hace uso así como prácticas a implementar en sitios web para la
fidelización de usuarios mediante squeeze pages, landing pages o la velocidad de carga del

20
sitio web. Se introducirán también los principales conceptos de la analítica web como
herramienta para medir el comportamiento del usuario.
Para finalizar el presente proyecto final de carrera, se exponen las herramientas empleadas y
las técnicas de posicionamiento aplicadas sobre el sitio web desdemiatalaya.com.
El proyecto contempla las siguientes fases:
Optimización orgánica, fase en la que se introducen técnicas a aplicar para controlar la
visibilidad de los documentos web en los motores de búsqueda. Se expondrán estrategias u
optimizaciones a implementar en los documentos web para adquirir un mejor posicionamiento
en los motores de búsqueda.
Marketing para la optimización web, fase en la que se describen técnicas para la
adquisición de usuarios mediante la promoción online. Se expondrá cómo captar diferentes
tipos de audiencia, además de optimizaciones a implementar en el sitio web para retener. Esta
fase alberga además una sección relacionada con la analítica web, en donde expondremos
cómo comenzar a medir el progreso de un sitio web, y la importancia de conocer sus
objetivos.
Herramientas para la promoción y el control web, fase donde se muestran algunas de las
herramientas empleadas en el proyecto final de carrera para estudiar el potencial de las
palabras clave, analizar el posicionamiento web, realizar campañas de e-mail o de anuncios
patrocinados.
Proyecto web, fase en la que se describe cómo se han aplicado algunas de las técnicas
comentadas en el presente proyecto final de carrera para el sitio web desdemiatalaya.com y
los resultados obtenidos.
1.2. Optimización orgánica

21
El objetivo de esta fase es el estudio de las principales técnicas promovidas por expertos en el
posicionamiento de páginas web, así como las prácticas recomendadas por los principales
motores de búsqueda para la consecución de posiciones en los resultados de búsqueda.
Los motores de búsqueda están compuestos por multitud de subsistemas. En esta sección se
presentará la arquitectura de un motor de búsqueda, procesos para controlarlo así como
técnicas SEO a aplicar para optimizar el sitio web. Haremos distinción en los siguientes
puntos:
- Arquitectura web. Mostraremos los conceptos básicos sobre cómo debe construirse
un sitio web teniendo como objetivo que los motores de búsqueda puedan obtener
información sobre el sitio web.
- Control sobre los procesos que intervienen en los motores de búsqueda.
Expondremos las diferentes técnicas que nos permitirán interactuar con los
subsistemas que componen los motores de búsqueda.
- Optimizaciones on-page. A las optimizaciones llevadas a cabo en el documento web
se las conocen como optimizaciones on-page. Se expondrán las principales técnicas
on-page promovidas por los motores de búsqueda.
- Optimizaciones off-page. Se conoce como optimizaciones off-page a aquellas
optimizaciones que no pertenecen al propio documento web. Estas están generalmente
relacionadas con la adquisición de enlaces. En esta sección expondremos métricas off-
page consideradas por Google (autoridad, la fiabilidad o su popularidad de un
documento web), arquitectura web como medio para favorecer el posicionamiento así
como técnicas documentadas por expertos para la adquisición de enlaces hacia nuestro
sitio web.
- Blackhat SEO. Se conoce como Blackhat SEO a aquellas técnicas cuyo objetivo es
confundir a los motores de búsqueda para la adquisición de mejores posiciones en la
lista de resultados. Expondremos técnicas para la consecución de posiciones web que
están totalmente desaconsejadas por los motores de búsqueda bajo penalización.

22
1.3. Marketing para la optimización web
Se conoce con el término marketing en motores de búsqueda (cuyo acrónimo es representado
como SEM), al conjunto de técnicas de marketing cuyo objetivo es incrementar la visibilidad
de un sitio web a través de su promoción en los motores de búsqueda (SEMPO, 2011).
La definición oficial dada por el Search Engine Marketing Professional Organization,
conocida bajo los acrónimos SEMPO, define el marketing en los motores de búsqueda o SEM
como:
‘Una forma de realizar marketing en Internet la cual busca promocionar sitios web mediante
el incremento de su visibilidad en la lista de resultados de los motores de búsqueda. Los
métodos incluidos son: Search Engine Optimization (SEO), pago por posicionamiento del
anuncio, promoción mediante anuncios contextuales, optimizaciones digitales y pago por
inclusión en listados.’
Bajo las dos definiciones proporcionadas anteriormente, el objetivo de esta fase en este
proyecto final de carrera será documentar técnicas o estrategias que permitan incrementar la
visibilidad de un sitio web en la página de resultados de los motores de búsqueda.
Su desarrollo estará dividido en secciones, en función del objetivo de las prácticas que
persigue cada una de ellas. Haremos distinción entre las siguientes actividades :
- Planificación web. Se introducirán conceptos que nos ayudarán a planificar las
palabras clave para las cuales optimizar nuestro sitio web, en base al número de
búsquedas mensuales, el precio del clic o la competencia existente en Google
AdWords. Se acompañará de estudios que nos permitirán conocer el porcentaje de
clics medio a recibir en base al posicionamiento web adquirido en los motores de
búsqueda, pudiendo ser este empleado como benchmark para comparar los resultados
de nuestro posicionamiento.

23
- Estrategias de publicidad online. Se presentarán métodos para la promoción de
sitios web mediante afiliados, publicidad online así como el e-mail para la promoción
online.
- Optimización para la conversión. Presentaremos un conjunto de técnicas
documentadas por expertos que nos ayudarán a mejorar las conversiones en nuestro
sitio web.
- Analítica web. En esta sección se presentará la importancia que la analítica web
desempeña en la consecución de los objetivos de un negocio que apuesta por tener
presencia online. Se introducirán los principales conceptos de la analítica web así
como métodos que nos ayudarán a planificar los objetivos de un sitio web.
1.4. Herramientas para la promoción y control web
El objetivo de esta fase es exponer algunas de las herramientas disponibles de las cuales
puede hacerse uso para realizar las tareas mencionadas en las fases anteriores. Se presentarán
herramientas que facilitarán o permitirán llevar a cabo las siguientes tareas:
- Controlar el posicionamiento web. Presentaremos la herramienta WebCEO como
medio para realizar auditorias web, controlar las optimizaciones llevadas a cabo en un
sitio web, identificar errores, construir enlaces y analizar el posicionamiento adquirido
por los documentos web.
- Campañas de E-mail. Presentaremos el servicio de MailChimp como herramienta
para realizar campañas de e-mail, así como métricas que se emplean para analizar el
éxito de las campañas de e-mail realizadas.
- Controlar información en motores de búsqueda. Para controlar la información a la
que los motores de búsqueda tienen acceso, se hace uso de herramientas de
administración proporcionadas por estos motores. Se expondrá el uso de la

24
herramienta Google Webmaster tools para el control de la información que ofrecemos
a Google.
- Analítica web. Para realizar mediciones que nos ayuden a tomar decisiones
informadas haremos uso de la herramienta proporcionada por Google, conocida como
Google Analytics. Veremos los problemas que esta herramienta presenta y
expondremos la importancia de entender cómo los datos son recopilados para poder
realizar un buen diagnóstico sobre el progreso o evolución que un sitio web está
realizando con respecto a los objetivos iniciales marcados.
- Promoción online. Introduciremos al lector a la herramienta de Google AdWords.
Esta herramienta nos permite promocionar e incrementar la visibilidad de nuestra web
mediante la publicidad web. Expondremos las diferentes campañas de promoción
disponibles y cómo hacer uso de esta herramienta.
1.5. Caso práctico
En este apartado se presentarán los resultados que el sitio web desdemiatalaya.com
experimentó tras la implementación de optimizaciones SEO. Se presentarán las
optimizaciones llevadas a cabo en el dominio web en las siguientes áreas de optimización:
- Indexación de contenidos. Técnicas empleadas sobre el dominio desdemiatalaya.com
con el objetivo de mejorar la indexación de contenidos y evitar penalizaciones por
duplicación de contenido.
- Optimizaciones web. Optimizaciones on-page llevadas a cabo en el dominio
desdemiatalaya.com.
- Obtención de enlaces. Técnicas empleadas para la adquisición de enlaces hacia el
dominio web desdemiatalaya.com.
- Generación de leads. Estrategias llevadas a cabo en documentos específicos del sitio
desdemiatalaya.com para la adquisición de datos de los usuarios.

25
Capítulo 2:
Motores de búsqueda y Optimización web
En este capítulo vamos a exponer las principales técnicas empleadas en la optimización de
documentos web. Estas optimizaciones están basadas en prácticas recomendadas por los
principales motores de búsqueda.
La implementación de estas prácticas permiten que los motores de búsqueda puedan
encontrar, recuperar, analizar y entender el contenido del sitio web. Como veremos a lo largo
del capítulo, existen diferentes subsistemas en un motor de búsqueda. Cada uno de ellos está
especializado en realizar una función. Expondremos cuáles son estos y cómo podemos
optimizar los documentos para cada uno de ellos.
Además de las optimizaciones realizadas sobre los documentos web, los motores de búsqueda
son también capaces de analizar la popularidad de un sitio web. Para llevar a cabo este
análisis, los motores de búsqueda estudian el número de dominios que nos enlazan, la
autoridad de estos así como su reputación. En la sección 2.5. Optimización de documentos
web: off-page explicaremos las principales métricas estudiadas por los motores de búsqueda,
la importancia de optimizar los enlaces dentro de nuestro sitio web, así como algunas de las
prácticas empleadas hoy día para la adquisición de enlaces desde sitios web externos.
Por último, con el objetivo de evitar penalizaciones, se presentarán un conjunto de técnicas
cuya aplicación influye negativamente en los motores de búsqueda. Al finalizar el capítulo
seremos capaces de optimizar sitios web, evitando penalizaciones por parte de los motores de
búsqueda.

26
2.1. Motores de búsqueda web
En esta sección vamos a introducir cómo surgen los motores de búsqueda web, los principales
componentes por los que están formados y su funcionalidad. En secciones posteriores
expondremos cómo optimizar nuestro sitio web para cada uno de ellos. Tras finalizar la
sección, seremos capaces de enumerar las tres principales funcionalidades que realiza un
motor de búsqueda, así como identificar en qué subsistemas (del motor de búsqueda) existen
errores.
2.1.1. Internet, directorios y motores de búsqueda web
El acceso a Internet por parte de la población comenzó a principios de los 90. Hasta entonces
Internet había estado reservado únicamente para usuarios relacionados con el sector
académico, científico o gubernamental. Su accesibilidad al público creció rápidamente. Según
se documenta en (Internet World Stats, 2014), en 1995 era usado por 16 millones de usuarios
(representando el 0.4% de la población mundial) y para el 1998 Internet ya era accesible para
147 millones de personas (representando el 3.8% de la población mundial). Hoy día las
estimaciones realizadas por (Internet World Stats, 2014) indican que 2,937 millones de
personas disponen de acceso a Internet, representando el 40.9% de la población mundial.
Los datos ofrecidos por Matthew Gray del Instituto de tecnología de Massachusetts (Matthew
Gray, 1996) muestran como el número de dominios existentes en Junio del 1993 se limitaba a
130 dominios. Para finales de ese mismo año el número de dominios creció hasta 623, y en
diciembre del 1994 Internet albergaba 10,022 dominios.
El crecimiento de Internet junto con su rápida implantación hizo necesario disponer de
herramientas que ayudaran a los usuarios a buscar contenido publicado en la WWW (World
Wide Web).
Con el propósito de categorizar Internet surgieron los primeros directorios web. El primero
que puede considerarse como directorio web estaba formado por una lista de servidores web.
Esta lista de servidores era editada por Tim Berners-Lee (inventor de la World Wide Web), y
localizada en el servidor web del CERN (Organización europea para la investigación nuclear)
(Berners-Lee, 1992).

27
Los directorios estaban gestionados por personas, por lo que cada solicitud era supervisada
individualmente. Los usuarios de los sitios web debían acudir al directorio, encontrar la
categoría que define el contenido que alberga el sitio web que quisieran incluir y realizar la
petición de inclusión.
Una vez el sitio había sido incluido en el directorio, este podía ser encontrado por los usuarios
en la categoría especificada. Ejemplos de directorios web son “Jerry’s and David’s guide to
the World Wide Web” creado en 1994 y posteriormente renombrado como Yahoo! (Sullivan,
2014) o DMOZ lanzado en 1998 (WebHostingReports.com, 2009).
Frente a los directorios como herramientas para encontrar resultados, comenzaron a surgir
también los llamados motores de búsqueda web. El primer motor de búsqueda capaz de
escanear documentos web, indexarlos y recuperarlos fue JumpStation, desarrollado por
Jonathon Fletcher en 1993 (METRO, 2009). Este motor era capaz de realizar búsquedas en
base al título del sitio web y sus encabezamientos. En 1994 surgió WebCrawler, que a
diferencia de JumpStation era capaz de realizar búsquedas en todo el documento, sin
limitación para el título o los encabezamientos.
Con la expansión de Internet y el aumento del número de dominios y páginas web (Matthew
Gray, 1996), el funcionamiento de los directorios, gestionados por personas, comenzó a
mostrar su ineficiencia frente a la automatización que los motores de búsqueda web ofrecían.
En 1998 aparece el motor de búsqueda conocido como Google. Mediante la aplicación de un
algoritmo iterativo (conocido como PageRank) era capaz de ordenar los resultados en base a
la popularidad de la web. La idea de este algoritmo es que sitios con información útil reciben
mayor número de enlaces que sitios web con pobre contenido (Brin & Page, 1998). Con la
introducción de este algoritmo Google consiguió mejorar los resultados que se ofrecían a los
usuarios. Actualmente, PageRank es solo una métrica de las más de 200 empleadas en la
ordenación de resultados realizada por Google (Fleischner, 2011).
Google se ha convertido en el motor de búsqueda web por defecto. Según la última
evaluación realizada por ComScore, Google acapara el 67.3% de las búsquedas frente al

28
18.1% realizadas en el motor de búsqueda Bing y el 11.2% realizadas en Yahoo en Estados
Unidos (comScore, 2014).
2.1.2. Componentes de un motor de búsqueda
Los motores de búsqueda están compuestos por multitud de subsistemas. De entre los
subsistemas que conforman un motor de búsqueda, existen un conjunto presente en todos
ellos. En este apartado expondremos los tres principales subsistemas que se encuentran en
todos los motores de búsqueda:
Crawler: Esta entidad se la conoce bajo múltiples nombres, entre ellos crawler, spider o
robot. Los crawlers son alimentados por el servidor de direcciones. El servidor de direcciones
se encarga de almacenar listas de direcciones web y servirlas al crawler. El crawler es el
encargado de descargar los documentos web. El proceso empleado por los motores de
búsqueda para descargar documentos web se le denomina crawling (Cho;Garcia-Molina;&
Page, 1995).
Indexador: Se conoce como indexador a la entidad encargada de extraer, descomprimir y
procesar la información que obtiene del crawlers. Guarda la información en estructuras de
rápido acceso (Search, 2013).
Buscador: Interfaz de usuario empleada para la inserción de la búsqueda. Este componente
recibe la búsqueda introducida por el usuario e interacciona con el resto de componentes del
motor de búsqueda. Presenta los resultados de la búsqueda en lo que se conoce como página
de resultados o Search Engine Result Page (SERP).
Según lo expuesto, los motores de búsqueda distinguen tres subsistemas: crawler, indexador
y buscador. Cada uno de ellos realiza una función determinante en el buen funcionamiento
del motor de búsqueda. Mientras que el crawler recopila información, el indexador debe
almacenarla y organizarla en estructuras que permitan una rápida evaluación del contenido.
Esta evaluación y recuperación de contenido debe de ser suficientemente óptima para
responder en cuestión de milisegundos a las búsquedas de los usuarios.

29
En la Figura 1 podemos observar cómo la arquitectura inicial de Google (Brin & Page, 1998)
estaba compuesta por 12 subsistemas. En las siguientes secciones de este capítulo
expondremos los subsistemas con los cuales podemos interactuar para optimizar el proceso de
crawling, de indexación así como la optimización de documentos web interna y externamente
(conocidos como optimizaciones on-page y off-page respectivamente).
2.2. Proceso de Crawling Se conoce como crawling al proceso por el cual el crawler se provisiona de una lista de
direcciones web, descargando y almacenando el contenido que estas albergan. Los crawlers
obedecen a un conjunto de políticas que definen qué contenido descargar, cuándo visitar de
nuevo el sitio web o cómo evitar sobrecargar los sitios web (Baeza-Yates, 2004).
A lo largo de esta sección analizaremos formas de interactuar con los crawlers mediante el
protocolo de exclusión de robots y el archivo sitemap. Al finalizar la sección seremos capaces
de controlar el proceso de crawling, reconocer errores por un mal uso del protocolo robots así
Figura 1: Arquitectura inicial del motor de búsqueda de Google

30
como hacer uso del archivo sitemap para notificar a los crawlers sobre las direcciones web
existentes.
2.2.1. Sitemap Protocol
El protocolo Sitemap es un protocolo empleado para informar a los crawlers sobre las
direcciones existentes en un sitio web. Proporciona a los crawlers información sobre dónde
pueden encontrar los documentos presentes en el sitio web (Google, 2010).
Los crawlers adquieren nuevas direcciones web siguiendo enlaces que encuentran en otros
documentos web (Microsoft Corporation, 2008). El protocolo Sitemap es una forma
suplementaria de aportar direcciones web y meta información, tal como la frecuencia de
actualización del documento o su importancia.
A continuación mostramos cómo construir este archivo:
TAG Descripción
<urlset>
Encapsula el archivo XML y referencia el protocolo usado.
<url>
Encapsula el conjunto de reglas a aplicar por dirección web.
<loc>
Encapsula la dirección del documento web.
<lastmod>
Especifica la última vez que se modificó el archivo.
<changefreq>
Especifica la frecuencia con la que el documento web es actualizado.
Los posibles valores que puede adquirir son:
Always – Hourly – Daily – Weekly – Monthly – Yearly - Never.
<priority>
Permite especificar prioridades. Los posibles valores que pueden tomar
están entre 0.0 y 1.0. La prioridad por defecto es 0.5.

31
Tabla 1: Tags pertenecientes al archivo Sitemap.xml
Veamos un ejemplo de sitemap.xml para la web www.singon.com:
<?xml version="1.0" encoding="UTF-8"?>
<urlset xmlns="http://www.sitemaps.org/schemas/sitemap/0.9">
<url>
<loc>http://www.singon.com/</loc>
<lastmod>2012-06-18</lastmod>
<changefreq>weekly</changefreq>
<priority>0.9</priority>
</url>
…
<url>
<loc>http://www.singon.com/games/karaokegame/#register</loc>
<priority>0.8</priority>
</url>
</urlset>
Si el número de direcciones web a indexar es amplio, es posible definir archivos sitemaps.xml
por directorio (Microsoft Corporation, 2008). Para ello es necesario el uso de un archivo
conocido como sitemapindex.xml. Este archivo guarda un índice sobre dónde los motores de
búsqueda pueden localizar el conjunto de archivos sitemaps (Microsoft Corporation, 2008).
Las estructuras y tags XML que son empleados para construir este fichero son muy parecidas
al de un archivo Sitemap.xml. Veamos las etiquetas empleados por este fichero de índices:
TAG Descripción
<sitemapindex>
Encapsula todo el archivo XML y referencia el protocolo usado.
<sitemap>
Empleada para proporcionar datos sobre los sitemaps.

32
<loc> Localización del archivo sitemap.
<lastmod>
Especifica la última vez que se modificó el archivo.
Tabla 2: Tags pertenecientes al archivo sitemapindex.xml
A continuación mostramos un ejemplo de cómo hacer uso del archivo sitemapindex.xml
(Google Webmaster Tool, 2014):
<?xml version="1.0" encoding="UTF-8"?>
<sitemapindex xmlns="http://www.sitemaps.org/schemas/sitemap/0.9">
<sitemap>
<loc>http://www.example.com/carpetaA/sitemap1.xml.gz</loc>
<lastmod>2004-10-01T18:23:17+00:00</lastmod>
</sitemap>
<sitemap>
<loc>http://www.example.com/carpetaB/sitemap2.xml.gz</loc>
<lastmod>2005-01-01</lastmod>
</sitemap>
</sitemapindex>
2.2.2. Robot Exclusion Protocol
El archivo robots.txt es un archivo consultado por los crawlers. Se localiza en el directorio
raíz de un sitio web (Google Webmaster Tools, 2014). Este archivo es público, por lo que se
aconseja no introducir direcciones web con contenido confidencial (Jennifer Grappone, 2011).
Al archivo robots.txt se le conoce como Robot Exclusion Protocol o protocolo de exclusión
de robots. Su principal función es la de informar a los robots sobre las carpetas y documentos
para los que disponen de autorización, pudiendo descargar el contenido (Martijn, Koster,
1994).
El archivo robots.txt está compuesto por dos directivas (Martijn, Koster, 1994):
- User-agent identifica el crawler que tiene que atender la directiva Disallow. Si no
especificamos el nombre de ningún robot y usamos el símbolo ‘*’, estaremos
informando a todos los robots sobre la directiva Disallow a obedecer.

33
- Disallow especifica qué directorios o subdirectorios no deben de ser rastreados por el
User-agent especificado.
Desde el fichero robots.txt también es posible informar a los crawlers sobre la localización
del archivo ‘sitemap.xml’ (Google Webmaster Tools, 2014). Podemos indicarle la
localización donde encontrar este archivo de la siguiente forma: Sitemap: http://www.example.com/sitemap.xml
2.2.3. Conclusiones
En esta sección hemos visto cómo funciona el proceso de crawling a través de dos de sus
protocolos. Mientras que sitemap informa a los crawlers sobre los documentos que queremos
que sean escaneados, el protocolo de exclusión nos permite controlar cuáles no deben de
escanearse.
La aplicación del protocolo de exclusión actúa sobre el proceso de crawling pero no evita que
el proceso de indexación tenga lugar. Los procesos de crawling e indexación son diferentes.
Los resultados que encontramos en la lista de resultados de los motores de búsqueda
proceden de la información que estos almacenan en sus índices. Esto puede verse en el
siguiente ejemplo extraído del sitio web Moz.com (Rand Fishkin, 2013).
La siguiente figura (Figura 2) muestra la configuración del archivo robots.txt para la web
www.about.com:

34
Figura 2: Archivo Robots.txt procedente de la web About.com
La directiva Disallow informa a los crawlers que no deben escanear directorios como /cgi/,
/library/nosearch/, /zadz/, /zdynahubz/ y /seventsz/. El resultado de aplicar este archivo
robots.txt es el siguiente:
Figura 3: Resultados de búsqueda para la web about.com
Como podemos observar en la figura anterior (Figura 3), los directorios especificados no han
sido escaneados. Google no presenta contenido para aquellas direcciones web presentes en el
archivo robots.txt, sin embargo estos se encuentran en la lista de resultados de Google. El
archivo robots.txt actúa únicamente sobre los procesos de crawling pero no sobre el proceso
de indexación.
2.3. Proceso de Indexación
El componente que se encarga de procesar la información escaneada por los crawlers es el
indexador. Este componente descomprime, parsea, procesa e indexa la información extraída
de los crawlers, en estructuras de rápido acceso. En este proceso, Google realiza parte de la
evaluación que determinará la importancia de un documento web (Brin & Page, 1998).
Esta sección está dividida en dos apartados: el primero presenta formas de interactuar con el
indexador; el segundo apartado presenta soluciones al problema de indexación de
documentos.

35
Al finalizar esta sección seremos capaces de indexar sitios web desarrolladas en Ajax,
controlar la forma en la que los indexadores interpretan los enlaces salientes presentes en la
página, así como qué direcciones web aparecen en la lista de resultados de los motores de
búsqueda.
2.3.1. Control sobre los indexadores
Los motores de búsqueda determinan la posición de los documentos web en base a multitud
de métricas. Google reconoce la existencia de más de 200 factores estudiados para determinar
el posicionamiento web.
En la sección 2.5. Optimización de documentos web: off-page se explicará en detalle cómo la
adquisición de enlaces y una buena arquitectura web contribuyen en el posicionamiento web.
El motivo principal de ello es la forma en la que los motores de búsqueda interpretan la
relación entre sitios web. Cuando un sitio web A enlaza a un sitio web B, los motores de
búsqueda interpretan que la web A está emitiendo un voto positivo a la web B. Mantener el
control sobre a qué sitios web otorgamos votos positivos es crucial para que los motores de
búsqueda puedan distinguir cuándo transmitir estos votos positivos.
En esta sección expondremos técnicas que nos permitirán controlar qué enlaces transmiten
votos y qué contenidos son indexados en los motores de búsqueda. Tras finalizar esta sección
seremos capaces de controlar la información que Google tiene en su índice y evitar
penalizaciones por la compra de enlaces mediante el uso del atributo rel=”nofollow”.
Robots meta tag.
Según expusimos en la sección de 2.1.2. Componentes de un motor de búsqueda, el crawler
es el encargado de recuperar el contenido web. La información que el crawler recupera es
transmitida al indexador. Este procesa los documentos, extrae información sobre ellos y crear
estructuras de rápido acceso para su evaluación. La meta etiqueta robots nos ofrece un medio,
a nivel de documento web, para controlar ciertas funciones del indexador.

36
Mediante el uso de esta meta etiqueta podemos enviar instrucciones al indexador sobre cómo
debe tratar la información que recibe. A pesar de que el nombre de la meta etiqueta es robots,
el procesamiento de esta se produce en el indexador. Las páginas que albergan esta etiqueta
son escaneadas por los crawlers, pero es el indexador quien determina si la página debe
pertenecer al índice del motor de búsqueda (Jennifer Grappone, 2011).
Esta meta etiqueta es usada entre las etiquetas <head></head> del documento HTML sobre
el cual queremos aplicarla, ofrece múltiples opciones de configuración las cuales presentamos
a continuación:
- follow
Emplearemos el valor follow cuando queramos que se procesen los enlaces contenidos en el
documento web (Google Webmaster Tool, 2013). Esto tiene una doble funcionalidad en el
motor de búsqueda: informa al servidor de direcciones sobre las nuevas direcciones que debe
servir al crawler; notifica al indexador que la página es fiable.
Google así como otros motores de búsqueda interpretan los enlaces como votos positivos.
Con el valor follow informamos a los motores de búsqueda que somos conscientes de la
emisión de estos votos hacia otros sitios web.
- nofollow
Mediante el uso del atributo nofollow conseguimos que no se emitan votos positivos hacia las
páginas a las que enlazamos (Google Webmaster Tool, 2013). Este atributo nos permite
informar al indexador de que no tenga en cuenta los enlaces que encuentre en el documento
(Google Webmaster Tool, 2013). Más adelante veremos la necesidad de no emitir votos
positivos para enlaces comprados como forma de evitar penalizaciones.
- index

37
La instrucción index indica al indexador que procese el documento web y lo indexe. Por
defecto, todos los documentos web son indexados (Google Webmaster Tool, 2013). Cuando
el documento es indexado, este será candidato a ser incluido en la lista de resultados.
- noindex
La instrucción noindex indica al indexador de que no procese información relativa al
documento. Evita que la información sea indexada en la lista de resultados de Google. Se
hace uso de esta etiqueta para evitar que el documento sea mostrado en la lista de resultados
(Google Webmaster Tools - Using meta tags to block access to your site).
Otros atributos que pueden incluirse en esta meta etiqueta para informar a Google sobre qué
mostrar en su página de resultados son:
- noarchive: Indica al motor de búsqueda que no guarde una copia en caché del
documento web. Los motores de búsqueda no ofrecerán una copia del documento web
si éste se encuentra offline (Google Webmaster Tool, 2013).
- nosnippet: Indica al motor de búsqueda que no muestre snippets en la lista de
resultados. Los snippets son definidos por Google como una forma de resumir el
contenido de una página web (Google Webmaster Tools, 2013).
- noodp: Indica al motor de búsqueda que no emplee metadatos albergados en Open
Directory Project (ODP) en los resultados de búsqueda.
ODP es un directorio web empleado por motores de búsqueda como Google. Los
directorios web son sitios web cuyo propósito es categorizar Internet. Los webmasters
o autores de sitios web envían información a estos directorios categorizando el sitio
web del que son propietarios. Posteriormente un revisor analizará si este sitio web
cumple con un mínimo de requisitos y si está bien categorizado.
Google empleó hasta el año 2011 el directorio ODP como directorio de donde extraer
información en caso de que no pudiera determinar el contenido de una web (Google

38
Webmaster Tools, 2013). De entre los directorios más conocidos destacan ODP
(también conocido como DMOZ) y Yahoo!.
- notranslate: Indica al motor de búsqueda que no ofrezca la opción de traducir un
documento web en la lista de resultados (Google Webmaster Tool, 2013).
- noimageindex: Indica al motor de búsqueda que no indexe imágenes contenidas en el
documento web (Google Webmaster Tool, 2013).
La meta etiqueta robots permite la combinación de atributos. A continuación presentamos las
combinaciones más empleadas para controlar la forma en la que los enlaces son tratados y la
indexación de contenido:
- follow, index: Indica al indexador que el documento web es apto para aparecer en la lista de
resultados de Google. Junto con el atributo follow, el indexador tendrá en cuenta los enlaces
existentes en el sitio web.
<meta name="robots" content="index, follow" />
- follow, noindex: Indica al indexador que procese la información relativa a los enlaces que se
encuentran en el documento. El documento no será indexado. Evitamos que el documento
aparezca en la lista de resultados.
<meta name="robots" content="noindex, follow" />
- nofollow, index: Indica al indexador que indexe la información del documento pero no tenga
en cuenta los enlaces encontrados en el documento. Se evita el paso de votos hacia otros
documentos web.
<meta name="robots" content="index, nofollow" />

39
- nofollow, noindex: Indica al indexador que no procese los enlaces encontrados en el
documento web ni indexe su contenido.
<meta name="robots" content="noindex, nofollow" />
El uso de la meta etiqueta robots presenta el inconveniente de que actúa a nivel de
documento. Mientras que la indexación de documentos en el índice de Google es una decisión
dicotómica, la decisión de emitir votos positivos es a nivel de ancla de texto. Haciendo uso de
la meta etiqueta robots, o bien todos los enlaces transmiten votos positivos o bien ninguno.
Para poder aplicar esta directiva de forma más selectiva existe el atributo rel=nofollow.
Atributo rel=nofollow.
Recapitulando la sección anterior, el principal problema existente con el uso de la meta
etiqueta robots es que actúa a nivel de documento. Para disponer de un mayor control para
indicar a qué enlaces no transmitir votos positivos, disponemos del atributo rel con los valores
follow/nofollow (Google Webmaster Tool, 2013). Este atributo se emplea en las anclas
HTML de texto <a>. Permite indicar al indexador cómo tratar los enlaces de forma
individual.
A continuación vemos un ejemplo sobre cómo hacer uso de este atributo:.
<a href="signing.php" rel="nofollow">sign in</a>
Este atributo actúa de forma individual sobre cada ancla de texto. Si existe algún enlace que
no contenga la restricción nofollow, estaremos pasando votos positivos. Cuando un webmaster
compra un espacio promocional en un sitio web, es importante que el enlace disponga del
atributo rel = “nofollow”. De no usar este atributo, Google podría realizar penalizaciones
alegando una compra/venta de enlaces como método para mejorar el posicionamiento.
2.3.2. Indexación de contenidos Ajax

40
Los crawler son los sistemas encargados de la descargar documentos web. Si los crawlers no
recuperan satisfactoriamente el contenido de un documento web, el resto de procesos de un
motor de búsqueda no podrá funcionar correctamente.
Se habla de procesamiento en el lado del cliente, cuando se produce un procesamiento de
datos en la aplicación cliente. En el caso de páginas web, el cliente suele ser el navegador
web.
Para conseguir que nuestro contenido sea indexado en los motores de búsqueda, tendremos
que cerciorarnos de que éstos son capaces de leer correctamente la información que nuestro
sitio web contiene.
Si el documento web recupera información de forma asíncrona, mediante llamadas Ajax, esta
información no será procesada por los motores de búsqueda. Esto se debe a que ni el crawler
ni el indexador ejecutan código cliente.
Cuando los motores de búsqueda no son capaces de detectar el contenido que un documento
web genera, será muy difícil que la página web del negocio online aparezca bien posicionada
en la lista de resultados de los motores de búsqueda.
En esta sección expondremos cómo funciona la tecnología Ajax y esquemas que permiten a
los indexadores indexar estos contenidos.
Funcionamiento de la tecnología Ajax
La recuperación de contenido web mediante la tecnología Ajax es un proceso que sucede en el
lado del cliente. Este proceso incluye no solo la recuperación de contenido, sino también el
refresco de la interfaz gráfica, así como la actualización de la dirección web.
Las páginas web cuya recuperación de contenido es realizada mediante la tecnología Ajax,
presentan la información al usuario en dos fases: primero recuperan el template del sitio web;
en la segunda fase se realiza la recuperación de datos asíncronamente. El template es la base
del documento web. Se caracteriza por ser el elemento HTML que no presenta refresco visual.
Dicho de otra forma, su contenido es estático y no será modificado.

41
El contenido a recuperar se conoce mediante la identificación del símbolo # en la dirección
web. El conjunto de palabras que acompañan a este símbolo identifican unívocamente que
contenido debe de ser descargado.
A continuación, vamos a detallar la secuencia de acciones que suceden cuando visitamos la
página web www.ejemploajax.com/#pagina1 con nuestro navegador:
1. El navegador realiza una petición HTTP GET para recuperar el contenido de la web
www.ejemploajax.com/#pagina1.
2. El servidor recibe únicamente una petición para recuperar el contenido para la
dirección web www.ejemploajax.com/. El texto perteneciente a la dirección web
posterior al símbolo # no es enviado al servidor.
3. El servidor contesta a la petición devolviendo el contenido (HTML, código JavaScript
y librerías de estilos CSS, etc.). Este contenido es lo que identificamos como template.
La comunicación entre el cliente web y el servidor ha terminado momentáneamente.
4. A medida que el contenido va siendo recibido por el navegador, comienza el proceso
de decodificación de datos a texto, parseo de código HTML, creación de tokens y
construcción de estructuras conocidas como DOM y CSSOM, las cuales quedan fuera
del ámbito de este proyecto. En el momento en que el parseador HTML alcanza la
etiqueta <script>, éste detiene su proceso y comienza la ejecución de código
Javascript.
5. El intérprete de JavaScript comienza a ejecutar el código JavaScript que el documento
web contiene. Las páginas web que recuperan contenido mediante el uso de llamadas
Ajax necesitan identificar que recurso recuperar. Se emplea el símbolo # junto con un
identificador (tal como #identificador) para denotar el contenido que debe de ser
recuperado. En el ejemplo anterior, para la dirección web
www.ejemploajax.com/#pagina1 el elemento que nos ayudará a identificar
unívocamente el recurso a recuperar será #pagina1.

42
6. Una vez identificado la palabra clave, ésta nos ayudará a conocer donde realizar la
petición Ajax. El código Javascript tendrá que contener un mapa que asocie estas
palabras clave con recursos desde donde recuperar el contenido. La siguiente tabla
mostraría la asociación entre palabra clave y dirección web donde se alberga el
contenido:
Palabra Clave Dirección dónde encontrar el contenido
pagina1 www.ejemploajax.com/pages/home.php
pagina2 www.ejemploajax.com/pages/about.php
pagina3 www.ejemploajax.com/pages/company.php
Tabla 3: Identificación unívoca de palabra clave con documento a recuperar
Como podemos observar, para cada palabra clave existe un recurso web a consumir.
Dependiendo de la palabra clave existente en la dirección web, realizaremos una llamada Ajax
a una diferente dirección web. Traducido a Javascript y haciendo uso de la librería JQuery, el
código que realiza el mapeo entre palabra clave y dirección dónde recuperar contenido sería el
siguiente:
Figura 4: Código javascript de carga de contenido asíncrona

43
7. Una llamada Ajax es una petición asíncrona que se realiza desde el cliente al servidor.
El servidor responde con el contenido que alberga para la dirección web solicitada.
Una vez el contenido es recuperado, este se incorpora al sitio web.
Las páginas web que emplean la tecnología Ajax para recuperar contenido, presentan el
inconveniente de que necesitan realizar al menos dos peticiones al servidor: la primera para
conseguir el template; la segunda para recuperar el contenido específico a mostrar.
Ahora que entendemos cómo funciona la tecnología Ajax, la siguiente sección nos ayudará a
entender por qué los crawlers o los indexadores no detectan correctamente las páginas que
hacen uso de la tecnología Ajax. También se exponen los esquemas existentes que permiten
solventar estos problemas.
Esquemas de indexación de contenidos Ajax
Los crawlers descargan el contenido que alberga la dirección web. El contenido incluye el
código JavaScript, el código Html y CSS entre otros. Debido a que ni crawler ni indexador
interpretan código javascript, ninguno de ellos realiza la llamada Ajax para la palabra clave
existente en la dirección web. El contenido descargado por el crawler corresponde con el
documento web que se obtiene, es decir, con el template del que hablábamos en el apartado
anterior.
Para resolver la indexación de contenido recuperado mediante Ajax existen diferentes
soluciones, consistiendo la mayoría de ellas en componer el documento web completo en el
servidor para proporcionárselo a los crawlers. Al código HTML completo que se obtiene tras
la ejecución del código JavaScript se le conoce como snapshot. A continuación presentamos
los esquemas existente para solventar este problema:
Esquema Hijax
Se conoce como Hijax scheme (Keith, 2006), a la metodología de mejora progresiva de una
web que termina con la implantación de la tecnología Ajax. El término Hijack significa
secuestrar en inglés. Hace referencia al secuestro y procesamiento de la comunicación que se
produce entre el navegador y el servidor, mediante la tecnología Ajax.

44
El desarrollo lógico consiste en la realización de un website sin el uso de la tecnología Ajax.
Se hace uso de las anclas de texto para permitir la navegación web. En esta fase, la página se
carga completamente mientras el usuario navega por el sitio web. El contenido es recuperado
sin el uso de la tecnología Ajax.
Una vez completada la web, se incorpora la tecnología Ajax para la recuperación de
contenidos, mejora de usabilidad y tiempos de respuesta. Nuestras anclas de texto serán
modificadas para acoger estas mejoras de la siguiente forma:
<a href=”www.mywebsite.com/home”
onclick=”load(‘www.mywebsite.com#home’)”> Home </a>
Podemos observar cómo las anclas de texto poseen el atributo href que define la web a
descargar, así como el manejador de eventos JavaScript onclick. Aquellos usuarios que
tengan habilitado la ejecución de JavaScript en sus navegadores enviarán peticiones Ajax
mientras navegan por el sitio web. Crawlers o usuarios que no tengan habilitado la ejecución
de código JavaScript serán capaces de recuperar el contenido completo.
El principal problema de adoptar este esquema, es el mantenimiento del sitio web. Requiere
de una duplicación de contenidos para servir snapshots. Se aconseja su uso cuando el número
de documentos web es limitado y el contenido no es actualizado con frecuencia.
Esquema de recuperación de contenidos Ajax
Este esquema fue desarrollado por Google como medio para mejorar la indexación de
contenidos recuperados mediante el uso de la tecnología Ajax (Google Webmaster Tools,
2013). La idea principal es albergar el mismo documento web en dos direcciones: a una
acceden los usuarios y el contenido es servidor con la tecnología Ajax; a otra los crawlers,
recuperando una snapshot del contenido que visualizan los usuarios.
Aquellos sitios web se acojan a este esquema deben modificar las direcciones web que cargan
contenido usando la tecnología Ajax. Las direcciones web presentarán los símbolos #! en
lugar de #. Cuando el crawler percibe este cambio, entiende que el sitio web está de acuerdo

45
con el esquema de servir el mismo contenido para usuarios y crawlers en direcciones web
diferentes. Existirán dos direcciones web: una pública para los usuarios; una privada para los
crawlers.
La dirección web pública es la mostrada en los resultados de búsqueda para los usuarios.
Dispondrá de los símbolos #! tal y como se mencionó con anterioridad. El documento web
podrá recuperar contenido con la tecnología Ajax.
La dirección web privada, empleada por los crawlers, se forma sustituyendo los símbolos #!
por el fragmento _escaped_fragment_. Bajo esta dirección los crawlers esperan recibir una
snapshot del contenido albergado en la dirección web pública.
Es decir, para una dirección web pública del tipo www.ejemploajax.com/#!pagina1 su
traducción a dirección web privada quedaría como
www.ejemploajax.com/?_escaped_fragment_=pagina1.
Bajo la implementación de este esquema: el crawler se compromete a recuperar el contenido
de las direcciones web privadas; el indexador se compromete a asociar este contenido con la
dirección web pública. Por tanto, se indexa el contenido albergado en la dirección web
privada, mostrándose la dirección web pública en la lista de resultados de Google.
En la siguiente figura (Figura 5) presentamos cómo el usuario accede a documentos web
mediante la dirección pública www.singon.com/#!songs. Dado que la dirección web dispone
del símbolo #! los crawlers entienden que este mismo contenido puede ser encontrado en la
dirección web privada www.singon.com/?_escaped_fragment_=songs :

46
Figura 5: Direcciones web empleadas para la recuperación de contenido Ajax
Bajo este esquema, el contenido que los crawlers recuperan a través de la dirección web
privada debe ser el mismo al que los usuarios tienen acceso mediante la dirección web
pública. En caso de no ser así, podríamos ser penalizados por los motores de búsqueda por la
realización de prácticas conocidas como Cloaking, las cuales explicaremos en secciones
posteriores.
2.3.3. Conclusiones
En esta sección hemos presentado técnicas que nos proporcionan la capacidad de
comunicarnos con los indexadores, así como esquemas de indexación para sitios
desarrollados con la tecnología Ajax.
Mediante el uso de la meta etiqueta robots controlamos la indexación de documentos. Cuando
el objetivo es evitar el paso de votos positivos a todos los enlaces presentes en el documento,
usamos la meta etiqueta robots con valor noindex. Si necesitamos una herramienta que nos
permita controlar el paso de votos positivos a nivel de enlace, usaremos el atributo
rel=”nofollow” en las anclas de texto.

47
Los esquemas de indexación expuestos ofrecen formas de solventar los problemas de
indexación que los crawlers presentan a la hora de recuperar contenido en tecnologías como
Ajax o javascript. Mediante la aplicación de estos esquemas, los motores de búsqueda son
capaces de recuperar e interpretar el contenido de sitios web desarrollados bajo tecnología
Ajax.
En el presente proyecto final de carrera se optó por la implementación del esquema de
recuperación de contenidos Ajax propuesto por Google. Tras su implementación, Google fue
capaz de recuperar el contenido del sitio web, indexando este y mostrándolo en la lista de
resultados. Para acelerar el proceso de indexación de contenidos se procedió a notificar a
Google mediante el protocolo sitemap sobre las nuevas direcciones web existentes.
2.4. Optimizando documentos web: on-page
En apartados anterior explicamos la arquitectura de los motores de búsqueda (en particular la
de Google), el funcionamiento de los crawlers, indexadores y formas de mejorar la
interacción con ellos. Mediante la aplicación de las técnicas mostradas en las secciones
anteriores, somos capaces de hacer llegar el contenido de nuestra web a los motores de
búsqueda.
Para determinar la relevancia de un documento, los motores de búsqueda hacen uso de cientos
de métricas. Estas métricas son extraídas mediante algoritmos que estudian la estructura de
nuestro sitio web, su temática, el público al que está dirigido, la velocidad del sitio web, el
país al cual está orientado, si nuestro sitio web ofrece contenido relevante a nivel
internacional, nacional o local, ... El conjunto de estas métricas junto con el perfil de usuario
es empleado por los motores de búsqueda en la composición de la lista de resultados.
En esta sección expondremos prácticas para optimizar los documentos web, formas de hacer
rentables nuestros esfuerzos de creación de contenido así como formas de evitar
penalizaciones.
2.4.1. Palabras clave

48
Los motores de búsqueda determinan qué sitios web mostrar a los usuarios en función de los
términos de búsqueda introducidos. Cuando realizamos búsquedas web, la mayoría de
resultados que obtenemos en la lista de resultados contienen los términos que hemos
introducido.
En la Figura 6 podemos observar cómo los términos de búsqueda aparecen en todos los
resultados, destacándose en negrita.
Figura 6: Búsqueda en Google con términos 'Universidad de Málaga'
Los motores de búsqueda disponen de mecanismos por los cuales son capaces de crear y
reconocer ontologías. Esto les permite no solo ofrecer resultados ajustados a las palabras de
búsqueda, sino también ofrecer aquellos sitios web cuyo contenido guarda relación con los
términos introducidos (Google Corporation, 2012).

49
Realizando una búsqueda por el término “Julio Iglesias” obtenemos sitio web oficial del
cantante, discografía, canciones populares, así como personalidades relacionadas con los
términos de búsqueda.
Figura 7: Resultados en Google para la búsqueda Julio Iglesias
La importancia de disponer de palabras clave en los documentos web viene determinada por
las relaciones que los motores de búsqueda son capaces de inferir. Se conoce como palabras
clave o keywords, al conjunto de palabras por las cuales un sitio web quiere ser posicionado.
La principal recomendación realizada por expertos, es usar como palabras clave aquellas que
puedan ser introducidas como términos de búsqueda (Google Corporation, 2012) .

50
Los motores de búsqueda hacen uso de la ocurrencia o frecuencia de palabras clave
existentes en los documentos web para entender el contenido que este alberga (Google
Corporation, 2012). Matt Cutts detalla en el canal Google Webmasters de YouTube, que no
existe un porcentaje específico del número de repeticiones de palabras clave a emplear, en el
contenido de un sitio web (Matt Cutts, 2011). Sin embargo, una repetición excesiva puede
llevar a penalizaciones por parte de los motores de búsqueda (Matt Cutts, 2011).
A lo largo de las siguientes secciones destacaremos dónde es importante posicionar palabras
clave en un sitio web, con el objetivo de optimizar el posicionamiento de este para los
términos clave elegidos.
2.4.2. Nombre de Dominio
Se conoce como nombre de dominio al identificador unívoco que emplean los documentos
web como forma de ser representados alfanuméricamente. Expertos en el área de
optimización web (Dover & Dafforn, 2011) consideran el nombre de dominio como uno de
los factores más importantes para la consecución de un buen posicionamiento.
En 1999 el nombre de dominio business.com fue adquirido por 7.5 millones de dólares.
Casino.com se compró por 5.5 millones, worldwideweb por 3.5 millones y otros como
porn.com y sex.com por 9.5 y 12 millones de dólares respectivamente (Shontell, 2012).
La aparición de palabras clave en los nombres de dominio es una técnica usada por
webmasters para mejorar el posicionamiento de un sitio web para términos específicos
(Odom, SEO For 2010: Search Engine Optimization Secrets, 2010). En 2011, Google realizó
ajustes sobre su algoritmo (Singhal;Cutts;& Wu, Systems and methods for detecting
commercial queries, 2011) para corregir la importancia que estos adquirían (Cutts, 2011) .
En las siguientes secciones explicamos los diferentes tipos de nombres de dominio existentes
desde el punto de vista de la optimización web, y la evolución de su importancia en los
motores de búsqueda.
Clasificación SEO: nombres de dominio

51
Desde el punto de vista de la optimización web, cuando se habla de dominios web se
diferencia entre: nombres de dominio web que coinciden con los términos de búsqueda;
nombres de dominio que coinciden parcialmente con los términos de búsqueda; y nombres de
dominios formados mediante el uso de guiones. Explicamos a continuación cada uno de ellos:
Exact Match Domain
Se conoce como Exact Match Domain, representado bajo las siglas EMD, al conjunto de
nombres de dominio que se ajustan exactamente a las palabras de búsqueda introducidas por
los usuarios.
Un ejemplo de EMD lo vemos en la siguiente figura (Figura 8).
Figura 8: Ejemplo de EMD desde la lista de resultados de Google
Tal y como muestra la Figura 8, el primer resultado corresponde con la web
www.seobook.com. Este dominio contiene todos los términos de búsqueda, por lo que se
considera como perteneciente a los dominios EMD.
Partial Match Domain
Se conoce como Partial Match Domain, representado bajo las siglas PMD, a aquellos
dominios web que contienen palabras de búsqueda en la raíz del dominio o sub-dominio.
Dada la definición anterior para PMD, para una búsqueda que contenga las palabras clave
“sing karaoke” los siguientes dominios y subdominios serían considerados como PMD:
o Singkaraokeonline.com

52
o Singkaraokeparty.com
o Singkaraoke.example.com
Hyphen Domains
Se conoce como Hyphen domains a los dominios compuestos por palabras separadas
mediante el uso de guiones. El uso de guiones en los nombres de dominio es particularmente
usado por páginas consideradas como spam (Fetterly;Manasse;& Najork, 2004).
Motores de búsqueda como Google o Bing prestan especial atención a este tipo de dominios,
donde la posesión de más de un guión o de números en el nombre de dominio es interpretado
como una señal de posible spam (Singhal;Cutts;& Wu, 2011).
Influencia en el posicionamiento
Para conocer la evolución sobre cómo las actualizaciones de Google han afectado a los EMD,
se han consultado estudios realizados por Seomoz (Fishkin, 2010) y (Fishkin, 2011), así como
theopenalgorithm (Collier, 2012).
Los estudios realizados por estos proyectos determinan el grado de correlación existente entre
el posicionamiento que ocupan las páginas en Google y su relación con el factor en estudio
EMD. Para la determinación del grado de correlación entre el posicionamiento y el tipo de
nombre de dominio, los estudios anteriores emplearon la correlación de Spearman como
método de correlación estadística. Este método permite expresar cómo una función monótona
representa la relación existente entre dos variables bajo valores comprendidos entre +1 y -1
(Laerd Statistics, 2013).
La siguiente figura (Figura 9) recopila los resultados obtenidos en los estudios comentados
anteriormente, los cuales determinan el grado de correlación existente entre el
posicionamiento que ocupa una página web con dominio EMD para dominios .com y para el
resto de dominios:
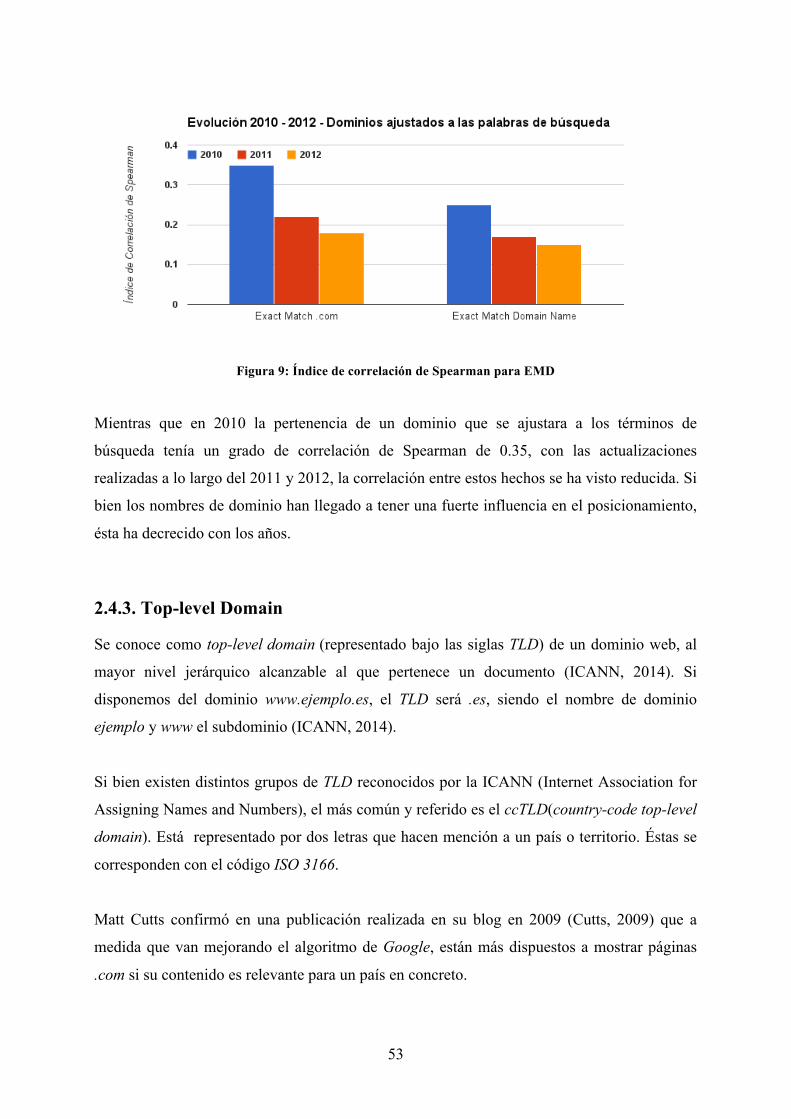
53
Figura 9: Índice de correlación de Spearman para EMD
Mientras que en 2010 la pertenencia de un dominio que se ajustara a los términos de
búsqueda tenía un grado de correlación de Spearman de 0.35, con las actualizaciones
realizadas a lo largo del 2011 y 2012, la correlación entre estos hechos se ha visto reducida. Si
bien los nombres de dominio han llegado a tener una fuerte influencia en el posicionamiento,
ésta ha decrecido con los años.
2.4.3. Top-level Domain
Se conoce como top-level domain (representado bajo las siglas TLD) de un dominio web, al
mayor nivel jerárquico alcanzable al que pertenece un documento (ICANN, 2014). Si
disponemos del dominio www.ejemplo.es, el TLD será .es, siendo el nombre de dominio
ejemplo y www el subdominio (ICANN, 2014).
Si bien existen distintos grupos de TLD reconocidos por la ICANN (Internet Association for
Assigning Names and Numbers), el más común y referido es el ccTLD(country-code top-level
domain). Está representado por dos letras que hacen mención a un país o territorio. Éstas se
corresponden con el código ISO 3166.
Matt Cutts confirmó en una publicación realizada en su blog en 2009 (Cutts, 2009) que a
medida que van mejorando el algoritmo de Google, están más dispuestos a mostrar páginas
.com si su contenido es relevante para un país en concreto.

54
En caso de hacer uso de un TLD .com para empresas que operan a nivel nacional, Google
Webmaster Tools dispone de una herramienta que permite especificar el país para el cual el
contenido del documento es relevante. Empresas locales o establecidas a nivel nacional que
hagan uso de un TLD .com podrán informar a Google sobre el país en el cual centran sus
actividades mediante la herramienta mencionada anteriormente.
(Dover & Dafforn, 2011) recomienda evitar el uso de TLDs como .tv, .biz o .info. Estos TLD
son comúnmente asociados a web spam.
2.4.4. Meta etiquetas
Las meta etiquetas están formadas por etiquetas HTML, situadas en la sección que
<head></head> del documento. Proporcionan información adicional a navegadores y
motores de búsqueda sobre los datos que contiene el documento. La información contenida
entre estas etiquetas no es visible a los usuarios.
El primer documento donde se introducen las meta etiquetas corresponde con el borrador de
Internet (Musella, 1995). En ella se definen las meta etiquetas y sus utilidades como sigue:
“The META element is used within the HEAD element to embed documents meta-
information not defined by other HTML elements. Such information can be
extracted by servers/clients for use in identifying, indexing and
cataloging specialized document meta-information.”
En esta sección explicaremos cómo los motores de búsqueda hacen uso de estas meta
etiquetas, así como de la etiqueta title encontrada en la cabecera de documentos HTML:
Meta description
Esta etiqueta sirve para informar a usuarios y motores de búsqueda sobre el contenido que
alberga el documento web. Esta información puede ser empleada por los motores de búsqueda
como resumen del contenido que alberga el documento web.

55
Los motores de búsqueda podrán emplear otras técnicas para determinar el contenido de la
web, especialmente en casos en los que esta meta etiqueta no se encuentre presente en el
documento o no sea suficientemente descriptiva.
En la siguiente imagen (Figura 10) podemos observar cómo Google emplea el contenido
albergado en esta meta etiqueta en la lista de resultados.
Figura 10: Meta descripción perteneciente a Amazon.com
La importancia de esta meta etiqueta reside en ser el único contenido que el usuario percibe
sobre nuestra web en la lista de resultados. Este contenido debe ser capaz de ofrecer
información relevante para los términos de búsqueda introducidos, de forma que consiga
convertir las impresiones en la lista de resultados en visitas.
Para determinar los término de búsqueda, puede hacerse uso de la herramienta de
planificación disponible en AdWords. Esta herramienta nos permitirá estimar el volumen de
usuarios que realizan búsquedas bajo los términos clave seleccionados.
Mediante el uso de la herramienta Google Webmaster Tools podremos conocer la evolución
del CTR (click-through-rate), es decir, el porcentaje de clics obtenidos en base a los términos
de búsqueda, cuando nuestro sitio web es impreso en la lista de resultados.
Meta keywords
Los primeros buscadores no eran capaces de determinar la materia que albergaban los
documentos web, por lo que recurrían a meta etiquetas que definieran explícitamente la
temática principal del sitio web.

56
Al conjunto de términos o palabras clave por las que un documento web es identificado se le
conoce como keywords. La meta etiqueta keywords era empleada para definir, mediante una
serie de palabras clave, el contenido del sitio web.
Un ejemplo del uso de esta meta etiqueta sería el siguiente;
<meta name=”keywords” content=”venta, ventas, alquiler,
alquileres, piso, pisos, inmuebles”>
Matt Cutts confirmó en un video publicado en el canal Google Webmasters de YouTube que
buscadores como Google o Bing no tienen en cuenta la meta etiqueta keywords a la hora de
posicionar un documento web. Por el contrario, esta meta etiqueta sí es empleada para
detectar páginas spam (Cutts, 2012).
Cuando el objetivo es hacer relevante un documento web para un conjunto de palabras clave,
es recomendable abandonar el uso de la meta etiqueta keywords y emplear los términos clave
en el documento y enlaces internos. Esto nos permitirá mejorará la relevancia del documento
para las palabras seleccionadas. La meta etiqueta keyword es únicamente empleada por
motores de búsqueda para detectar web spam. Expertos en SEO recomiendan no hacer uso de
ella (Fleischner, 2011).
Etiqueta Title
La etiqueta title no pertenece al grupo de meta etiquetas, a pesar de encontrarse en la sección
HTML <head></head>. Proporciona información para usuarios y motores de búsqueda,
describiendo con un número reducido de caracteres (entre 64 y 80 caracteres) el contenido
principal del documento web.
A diferencia de la meta etiqueta description, ésta presenta una mayor limitación en cuanto al
número de caracteres. Dado que el contenido es más conciso y dispone de un tamaño de letra
mayor, los usuarios suelen prestar mayor atención al título antes que al contenido presente en
la meta etiqueta description.

57
Sean Odom, experto en optimización en motores de búsqueda, cuantifica en (Odom, 2010)
que el empleo de palabras clave en la etiqueta title aumenta la relevancia de un documento
web hasta en un 6% con respecto a aquellos que no disponen de palabras clave.
Danny Dover en su libro Search Engine Optimization Secrets (Dover & Dafforn, 2011)
califica a esta etiqueta como la más importante de todos los factores on-page que puede tener
una web. Según este experto en motores de búsqueda, para la incrementar el número de clics
y mejorar la posición de una web, la etiqueta title debe de incorporar el nombre de la
compañía junto con un conjunto de las palabras clave relacionadas con el contenido web a
mostrar:
<BRAND NAME> | <KEYWORD > <KEYWORD >
<KEYWORD> - <KEYWORD> | <BRAND NAME>
Podemos observar un ejemplo del resultado de esta estructura en la siguiente figura (Figura
11):
Figura 11: Ejemplo de marcado de palabras en Google.com
2.4.5. Encabezamientos HTML
Los encabezamientos HTML permiten organizar documentos bajo la marcación de secciones
y subsecciones (W3C). Se distinguen hasta seis niveles de encabezamientos HTML
reconocidos bajo las etiquetas: <h1>, <h2>, <h3>,..., <h6>.
Los primeros motores de búsqueda determinaban el tipo de contenido que albergaba la página
mediante las meta etiquetas keywords y el estudio de los encabezamientos (Odom, 2010).

58
Debido a malas prácticas realizadas por los spammers para manipular los resultados de los
motores de búsqueda, la influencia que estos otorgan a estas etiquetas se ha visto reducido.
Google ha reconocido, en declaraciones realizadas por Matt Cutts, que la realización de un
excesivo e inapropiado uso de encabezamientos HTML lleva a penalizaciones por parte del
motor de búsqueda (Matt Cutts, 2009) .
La forma correcta de usar estos marcados es como sigue:
<h1> - Expresa el contenido general de la página. Libros especializados en optimización de
documentos web tales como (Dover & Dafforn, 2011) o (Odom, 2010) recomiendan el uso de
este tipo de encabezamientos en todas las páginas.
(Odom, 2010) recomienda emplear estos encabezamientos para situar palabras clave en estos.
Según detalla (Odom, 2010) este marcado puede incrementar la relevancia de los documentos
web para los términos de búsqueda entre un 4% - 5%.
<h2> ... <h6> - Subsecciones que aportan un nivel jerárquico con respecto a la sección
bajo la que se encuentran.
Como ejemplo, analicemos la página web de Amazon - sección Amazon MP3 & Cloud
Player:
Figura 12: Página de Amazon MP3 & Cloud Player

59
La temática principal de la página trata de Amazon MP3 & Cloud Player. Así lo muestra el
documento HTML a través del encabezamiento <h1>.
Figura 13: Encabezamiento H1 Html empleados en la página de Amazon
En la siguiente imagen (Figura 14) observamos cómo la página de Amazon define diferentes
niveles jerárquicos bajo el uso de encabezamientos HTML <h2> y <h3>.
Figura 14: Encabezamiento H2-H3 Html empleados en la página de Amazon
La estructura de encabezamientos quedaría resumida de la siguiente forma:
<h1> - Amazon MP3 & Cloud Placer
<h2> - Browse MP3
<h3> - Cloud Player
<h3> - Best Seller
<h3> - Top Offers
<h2> - …
…

60
El contenido está jerarquizado e incluye las palabras clave por las que queremos ser
posicionados, permitiendo a los indexadores entender la organización de la página, la temática
que alberga y la relación existente entre los contenidos.
2.4.6. Atributo de texto ALT
El atributo alt se sitúa en la etiqueta HTML <img> (etiqueta empleada para definir una
imagen). Este atributo es empleado como método para ofrecer una descripción textual
alternativa, en caso de que la imagen no pueda ser recuperada.
En el recurso web Using ALT attributes smartly (Cutts, 2007), Matt Cutts habla sobre el
inconveniente de situar información en imágenes. Los motores de búsqueda no son capaces de
interpretar imágenes. Este atributo es la única fuente de información que los indexadores
disponen para entender qué contenido alberga la imagen.
Cuanta mayor información reciban los motores de búsqueda, mejor podrán entender el
contenido del que disponemos. Usar texto descriptivo en el atributo alt o en el nombre del
archivo nos ayudará a enviar información sobre el contenido de la imagen (Cutts, 2007).
“Search engines can use the information in an image based link, including the name of the
image and the alt attribute to interpret what the linked-to page is about.”
The Anatomy of a HyperLink, SEO Education
El posicionamiento de palabras clave en el contenido del atributo alt es una técnica
documentada en (Dover & Dafforn, 2011), (Odom, 2010) o (Enge;Spencer;Fishkin;&
Stricchiola, 2009) para el posicionamiento de documentos web.
A continuación, mostramos un ejemplo práctico extraído del recurso (Linsley, Peter; Cutts,
Matt), donde se aplica el atributo alt y el nombre del archivo para describir el contenido de la
imagen:
<img src="cachorro.jpg" alt="cachorro de dálmata jugando con una pelota">

61
2.4.7. Canonicalización
Google está constantemente incorporando mejoras a su algoritmo de búsqueda. La
incorporación del algoritmo Panda realizada en febrero del 2012, tiene como objetivo
mejorar los contenidos ofrecidos en la página de resultados de los motores de búsqueda.
Este algoritmo penaliza páginas de baja calidad o con contenido duplicado, ofreciendo
mejores posiciones a sitios web con contenido original y de calidad (Singhal, Amit; Cutts,
Matt, 2011). El algoritmo fue actualizado en sucesivas ocasiones (Moz Team, 2014),
afectando a un gran número de sitios web. Los datos ofrecidos por Google (Singhal, Amit;
Cutts, Matt, 2011) estiman que un 11.8% de las búsquedas se vieron afectadas por esta
actualización.
Para evitar penalizaciones por duplicación de contenido, debemos de identificar aquellos
documentos web que presentan el mismo contenido bajo diferentes direcciones web. De entre
las direcciones con el mismo contenido, deberemos de elegir una, aquella cuya dirección web
represente mejor el contenido que alberga.
A esta dirección se le llama dirección canónica (Google Webmaster Tools, 2013). Será la
dirección web que aparecerá en los motores de búsqueda. En caso de no especificar cuál es la
dirección web canónica, los motores de búsqueda escogerán una de ellas como la principal.
Las restantes direcciones web con contenido duplicado serán omitidas en las páginas de
resultados (Google Webmaster Tools, 2013).
Según Google expresa en (Google Webmaster Tools, 2013), un sitio podrá ser penalizado
cuando ofrezca contenido duplicado sin optimizar, siendo este usado como medio para
manipular los resultados de búsqueda.
Existen diferentes métodos que nos ayudan a manejar la duplicidad de contenidos. Los
siguientes métodos que exponemos nos ayudarán a evitar penalizaciones, así como a recopilar
las métricas adquiridas por las páginas duplicadas en la dirección canónica (Google
Webmaster Tools, 2013).
Redireccionamiento 301

62
Este tipo de redireccionamiento es especialmente útil cuando diferentes direcciones web
acceden al mismo contenido. A través del establecimiento de redireccionamientos, cuando un
usuario intente acceder a alguna de las direcciones web duplicadas, este será redireccionado
hacia la dirección canónica.
A modo de ejemplo, supongamos que todas las direcciones web siguientes presentan al
usuario el mismo documento web:
[1] paginaweb.com
[2] www.paginaweb.com
[3] pagina.com/index.php
[4] www.pagina.com/index.php
Todas las direcciones web anteriores son diferentes a pesar de que responden con el mismo
contenido. Para evitar penalizaciones por albergar contenido duplicado, y con el objetivo de
recopilar todas las métricas adquiridas por cada documento en una misma dirección web,
disponemos la posibilidad de implementar redireccionamientos (Google Webmaster Tools,
2014). Para ello seleccionamos cuál es la dirección web que mejor representa el contenido
que alberga. Esta dirección web se la conoce como dirección canónica.
Una vez hemos seleccionado nuestra dirección canónica, deberemos configurar nuestro
servidor para que responda con un redireccionamiento 301 para aquellas direcciones que
albergaban el contenido duplicado. De esta forma, cuando el usuario intente acceder a las
direcciones con contenido duplicado será redireccionado a la dirección web canónica.
Etiqueta link
La etiqueta link se emplea para indicar a los motores de búsqueda cuál es la dirección
canónica sobre un conjunto de documentos web con similar contenido (Google Webmaster
Tools, 2013). Esta etiqueta se sitúa en la sección <head></head> del documento Html.
Dispone de dos atributos: rel=”canonical”; href=“dirección web canónica”. El atributo href
nos permite declarar la dirección web canónica de entre aquellas que tienen el mismo
contenido (Odom & Habermann, 2013).

63
Esta etiqueta debe de estar presente en todos los documentos web que sean duplicados o
semejantes a otros (Google Webmaster Tools, 2013). Su uso permite dirigir las métricas
adquiridas por los documentos web duplicados hacia una misma dirección web, en nuestro
caso la dirección web canónica (Kupke, 2009).
La principal diferencia entre el uso de esta etiqueta y el uso de redireccionamientos 301
reside en que el primero posibilita acceder a los contenidos similares o duplicados desde
diferentes direcciones web, mientras que el segundo redirecciona al usuario hacia la dirección
web canónica.
2.4.8. Canibalización de palabras clave
En esta sección introduciremos uno de los problemas más comunes que surgen cuando
webmasters, escritores o bloggers publican contenido sin tener en cuenta la optimización
web. Durante el proceso de creación de contenido, el escritor o blogger debe de planear cómo
el usuario llega a este contenido, es decir, cuáles serán las palabras clave que conducirán al
usuario desde el motor de búsqueda al artículo o documento web.
Si todos nuestros documentos promocionan el mismo conjunto de palabras clave,
experimentaremos lo que se conoce como canibalización de palabras clave (Rand Fishkin,
2007). Este término se atribuye a la competición interna surgida entre documentos
optimizados para el mismo conjunto de palabras clave (albergados bajo el mismo dominio)
por conseguir una posición en los SERPs.
La canibalización de palabras clave tiene su origen en las restricciones que los motores de
búsqueda imponen para no mostrar más de tres o cuatro documentos (pertenecientes a un
mismo dominio web) en la misma página de resultados (Cutts, 2013). De entre todos los
documentos web pertenecientes al mismo dominio y optimizados para el mismo conjunto de
palabras clave, los motores de búsqueda seleccionan un conjunto reducido de documentos
(Rand Fishkin, 2007), dejando el resto fuera de la lista de resultados (SERP).
Para evitar la canibalización de términos clave, deberemos disponer de herramientas que nos
informen de las palabras clave que hemos usado o estamos usando. En caso de no tener este
tipo de herramientas, disponer de una hoja Excel donde anotar las palabras clave empleadas

64
por documento dará el mismo servicio (Dimock, 2013). La incorporación de sinónimos para
las palabras clave nos ayudará a extender el vocabulario por el cual los usuarios pueden
encontrarnos en los motores de búsqueda.
Evitar la canibalización de palabras clave conseguirá que los esfuerzos invertidos en la
creación de contenidos sean más rentables. Como mencionamos anteriormente, disponer de
un documento que mantenga las principales palabras clave promovidas por artículo nos
ayudará a evitar este fenómeno.
2.4.9. Paginación web
Se denomina paginación web, a la división de un documento web en múltiples documentos.
Un ejemplo común lo podemos observar en la mayoría de los comercios online: debido a la
cantidad de productos que disponen y a la imposibilidad de mostrar todos en el mismo
documento, lo dividen en secciones, donde cada una de ellas a su vez muestra un número
finito determinado de artículos; si el número de artículos pertenecientes a una misma sección
es muy extenso, ofrecen un menú de navegación para movernos entre las páginas de
productos.
Figura 15: Paginación desarrollada por Amazon
La paginación de documentos web presenta una serie de problemas para los motores de
búsqueda:

65
1. La profundidad a la que se encuentran los documentos.
2. Imposibilidad de determinar el documento más relevante del conjunto de páginas.
3. Pérdida de integridad entre las páginas.
Maile Ohye, jefe de los programas de desarrollo técnico en Google, expone en el recurso
(Maile Ohye, 2012) cómo la división de un documento en múltiples páginas afecta
‘negativamente’ al posicionamiento web.
Existen dos tipos de estrategias documentadas en (Li & Kupke, 2011) y (Maile Ohye, 2012)
para tratar documentos con paginación de contenido y solventar los problemas mencionados
anteriormente:
• Crear dos versiones del documento (Maile Ohye, 2012): la primera versión alberga el
contenido completo; la segunda versión paginaría el contenido.
Debido a la existencia de dos versiones con contenido similar, esta opción conlleva la
duplicación parcial de contenido. Para evitar penalizaciones y recopilar todas las
métricas en una única dirección web, tenemos que usar la etiqueta link rel=canonical,
tal y como se explicó en la sección 2.4.7. Canonicalización - Etiqueta link. Todos los
documentos paginados tendrán que contener esta etiqueta, siendo la dirección
canónica el documento web que alberga completamente el contenido.
• Cuando el número de páginas que conforman el contenido es demasiado extenso para
albergarlo en un único documento, podemos indicar al motor de búsqueda que cada
uno de las páginas forman parte de un mismo documento (Li & Kupke, 2011).
Esto puede conseguirse mediante el uso de la etiqueta link, el atributo rel y los valores
prev y next. Esta etiqueta nos permite especificar la existencia de documentos y la
relación de precedencia existente entre éstos.
Con esta opción indicamos a Google que unifique todas las métricas de los
documentos paginados. En el recurso (Maile Ohye, 2012) Maile Ohye anuncia que

66
Google mostrará en los SERPs la primera página del conjunto de documentos
paginados que hacen uso de esta opción (Maile Ohye, 2012).
A continuación, exponemos un ejemplo de cómo haríamos uso de esta opción, si los
documentos son suficientemente grandes como para mostrarlos en un único
documento:
Página 1 del artículo
Dirección web: www.miwebsite.com/post/?id=127&pagina=1
<head>
<link href=”www.miwebsite.com/post/?id=127&pagina=2”
rel=”next”/>
</head>
<body>
…
</body>
-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐
Página 2 del artículo
Dirección web: www.miwebsite.com/post/?id=127&pagina=2
<head>
<link href=”www.miwebsite.com/post/?id=127&pagina=1”
rel=”prev”/>
<link href=”www.miwebsite.com/post/?id=127&pagina=3”
rel=”next”/>
</head>
<body>
…
</body>
-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐

67
Página 3 del artículo
Dirección web: www.miwebsite.com/post/?id=127&pagina=3
<head>
<link href=”www.miwebsite.com/post/?id=127&pagina=2”
rel=”prev”/>
</head>
<body>
…
</body>
En este ejemplo, el documento completo necesita tres páginas. Mediante la aplicación de la
etiqueta link y los atributos rel=”prev” y rel=”next”, conseguimos que los motores de
búsqueda interpreten estos tres documentos como documentos pertenecientes a un mismo
conjunto.
Conocidos los problemas de los crawlers para recuperar documentos web que se encuentran
localizados a varios enlaces de profundidad de la home page, la aplicación de cualquiera de
los métodos documentados en este apartado ayudará a los motores de búsqueda a entender la
arquitectura del documento.
2.4.10. Redireccionamientos
Los documentos web se encuentran alojados en direcciones web. Para descargar el contenido
de un documento, debemos de conocer la dirección web que lo alberga. Bajo estos supuestos,
disponemos de un documento web el cual es accesible mediante la dirección web
www.documentos.com/titulo. Por alguna razón, el documento web albergado en esta dirección
es movido a una nueva: www.documentos.com/nuevo-titulo. Si el documento albergado en la
dirección web www.documentos.com/titulo disponía de enlaces entrantes, dado que hemos
movido su contenido, debemos de notificar de alguna forma a los documentos que nos
enlazan sobre la nueva localización.

68
Si bien podríamos tratar de contactar con todas las páginas web que han enlazado nuestro
contenido empleando la dirección web www.documentos.com/titulo, informándoles de la
nueva dirección donde hemos alojado el documento, esta opción es ineficaz y poco factible.
Una forma mas factible de realizar esta labor, es mediante el establecimiento de
redireccionamientos web.
Un redireccionamiento web nos permite informar al navegador de que el recurso albergado en
la dirección www.documentos.com/titulo ha sido trasladado a www.documentos.com/nuevo-
titulo. Cuando el navegador intenta recuperar el contenido de la dirección
www.documentos.com/titulo, recibe información sobre la nueva localización del documento,
redireccionando al usuario allí.
Existen diferentes tipos de redireccionamientos, permitiéndonos informar al navegador sobre
si el redireccionamiento es temporal o permanente. El navegador actúa de la misma forma
ante los redireccionamientos: redirecciona al usuario hacia la nueva localización. Sin
embargo, desde el punto de vista de los motores de búsqueda, el tipo de redireccionamiento
usado importa.
A continuación exponemos los diferentes redireccionamientos que encontramos y como estos
son tratados por los motores de búsqueda:
Redireccionamiento 301
Definido en el protocolo HTTP 1.0, el redireccionamiento de tipo 301 es utilizado para
indicar que un documento ha cambiado su localización de forma permanente. Ejemplos de su
uso surgen cuando un sitio web cambia su dominio y quiere informar a los navegadores de
este cambio.
Este tipo de redireccionamiento traspasa todas las métricas adquiridas (por la anterior
dirección web) hacia la nueva dirección. (Matt Cutts, 2013)
Redireccionamiento 302

69
Definido en el protocolo HTTP 1.0, es empleado para indicar que un recurso web ha
cambiado su localización de forma temporal (World Wide Web Consortium, 2005). Cuando
el navegador recibe este código, redirecciona al usuario hacia la nueva localización donde se
encuentra el recurso.
A diferencia del redireccionamiento 301, este no traspasa las métricas adquiridas hacia la
dirección a la que se redirecciona (Moz, 2014). Actúa de forma contraria: las métricas que
adquiera la nueva dirección web pasarán hacia la dirección original (la que implementa el
redireccionamiento 302) (Peng & Dabek, 2010). Esto es debido a la interpretación que los
motores de búsqueda realizan sobre este redireccionamiento. Dado que el redireccionamiento
es temporal, en algún momento cesará. Las métricas adquiridas por la nueva dirección web
deberán de ser traspasadas hacia la dirección web que alberga el contenido.
En la sección de Blackhat SEO – Secuestrando documentos web, veremos cómo este tipo de
redireccionamiento ha sido empleado como método para apropiarse de las métricas de otras
webs.
Redireccionamientos 307
Definido en el protocolo HTTP 1.1, es el sucesor del redireccionamiento 302 en la versión del
protocolo HTTP 1.0. Se emplea para indicar que el recurso web al que se intenta acceder se
encuentra temporalmente localizado en otra dirección web. Este tipo de redireccionamiento,
al igual que pasa con el de tipo 302, no traspasa las métricas adquiridas a la página a la que
redirecciona.
La nueva versión del protocolo HTTP 1.1 ha cambiado el significado del código 302,
significando ‘Found’ en lugar de ‘Moved Temporarily’. Debido a la actualización del
protocolo y la imposibilidad de conocer si los motores de búsqueda conocen la versión del
protocolo empleada, web expertas (Moz, 2014) recomiendan usar el código 302 en lugar del
código 307.
2.4.11. Velocidad de carga

70
A lo largo de los años, Google ha manifestado la importancia de que los documentos web
sean de calidad y con contenidos únicos, además de que ofrezcan una gran experiencia al
usuario. Para conseguir esto, Google ha ido mejorando su algoritmo, penalizando contenidos
de baja calidad mediante el algoritmo Panda (Singhal, Amit; Cutts, Matt, 2011), penalizando
páginas con alto contenido de anuncios a través del algoritmo page layout (Cutts, 2012) o
penalizando contenidos duplicados mediante el algoritmo Penguin (Cutts, Matt, 2013) entre
otros muchos.
En 2010, Google anunció la adición de la métrica ‘velocidad de carga de una web’ en su
algoritmo para posicionar documentos. Esta nueva métrica se lanzó con baja repercusión
sobre el posicionamiento web, afectando tan solo al 1% de las búsquedas realizadas, según
documenta Google en su blog (Singhal & Cutts, 2010).
En la feria SMX Advanced 2013 celebrado en Seattle, Matt Cutts anunció (Schwartz, 2013)
que la velocidad de respuesta de las páginas web afectarían al posicionamiento web móvil.
Posterior al anuncio de Matt Cutts, las empresas Moz.com y Zoompf realizaron un estudio
(Peters & Isham, 2013) centrándose únicamente en factores que intervienen en la velocidad de
carga.
El estudió determinó que el único factor que guarda correlación con el posicionamiento web
corresponde con la métrica TTFB (tiempo que el usuario tarda en recibir el primer byte desde
que se realiza la petición):
“…our data shows there is a correlation between lower time-to-first-byte (TTFB)
metrics and higher search engine rankings. Websites with servers and back-end
infrastructure that could quickly deliver web content had a higher search ranking than those
that were slower” (Peters & Isham, 2013)
La siguiente gráfica (Figura 16) extraída de (Peters & Isham, 2013) muestra cómo las páginas
que se sitúan en las primeras posiciones responden su primer byte en tiempos del orden de
0.35 – 0.45 segundos:

71
Figura 16: Tiempos de respuesta TTFB y posicionamiento (Peters & Isham, 2013)
Teniendo en cuenta el estudio realizado por (Peters & Isham, 2013), las técnicas de
optimización que nos permitirían mejorar el tiempo de respuesta TTFB son:
• Uso de CDN (content delivery network) para distribuir el contenido web desde
servidores cercanos a los usuarios.
• Uso de accelerators en lenguajes compilados para cachear el bytecode/opcode
(evitando parsear y compilar el código en cada petición en lenguajes como PHP).
• Uso de caches en memoria para obtener tiempos de respuesta del orden de
milisegundos en comparación con tiempos de acceso a base de datos que gira en torno
a los 100-500 milisegundos.
• Uso de SQL cache para evitar procesar datos sobre respuestas a queries ya
respondidas.
2.4.12. Conclusiones
A la hora de elegir un nombre de dominio, el peso que los motores de búsqueda otorgan a la
disposición de palabras clave sigue influyendo considerablemente en el posicionamiento.
Elegir un EMD como nombre de dominio puede beneficiarnos, pero tenemos que conocer sus
implicaciones: alta competencia contra EMD o PMD por los mismos términos.

72
Optar por nombres de dominio compuestos por guiones (hyphen domain) no es una buena
opción debido a que estos nombres de dominio siempre han estado asociados a páginas spam.
En caso de optar por su uso, evitar usar más de un guión separador, caracteres especiales o
números.
A la hora de crear contenido, deberemos de optimizarlo tanto para motores de búsqueda como
para los usuarios. Para ello, el documento deberá HTML proporciona. Es decir, el documento
deberá de disponer de meta etiquetas title y description para cada documento web, optimizar
el contenido mediante el uso de palabras clave en encabezamientos (un encabezamiento H1
por página y posteriores subencabezamientos en caso de que sean necesarios), así como
proporcionar textos alternativos con palabras clave en el atributo alt de las imágenes.
Para evitar la canibalización web, considerar el uso de palabras clave sinónimas para
diferentes documentos web, ampliando el vocabulario para el cual nos posicionamos en los
motores de búsqueda.
En caso de disponer de documentos extensos que deban de ser separados en varias páginas,
hacer uso de los atributos next y prev disponibles para la meta etiqueta link. De esta forma,
indicamos a Google de que el documento se encuentra dividido en varias páginas y cuál es la
relación entre ellas.
Si bajo diferentes direcciones web accedemos al mismo contenido, usaremos el
redireccionamiento 301 o la meta etiqueta link con el atributo rel = “canonical”. Esto nos
permiten aunar las métricas adquiridas por los documentos duplicados hacia el documento
original, evitando penalizaciones y disponiendo de control sobre la dirección del documento
que se promociona en los motores de búsqueda.
Por último, controlar el tiempo de respuesta con la que los documentos webs son servidos.
Para mejorar estos tiempos, hacer uso de CDNs, optimizar el código en el servidor o hacer
uso de accelerators para evitar parsear código en cada petición en lenguajes como PHP.
Una vez el contenido está optimizado, tendremos que aplicar nuevas técnicas de optimización
conocidas como off-page. Estas técnicas permitirán a los motores de búsqueda conocer si
otros sitios nos consideran relevantes. Vemos estas en la siguiente sección.

73
2.5. Optimización de documentos web: off-page
En la sección anterior hemos presentado el conjunto de optimizaciones que pueden realizarse
en un documento web, con el objetivo de facilitar a los motores de búsqueda la evaluación del
contenido.
En este apartado introduciremos un conjunto de prácticas albergadas bajo la denominación de
prácticas off-page. Las prácticas off-page son aquellas que buscan la optimización de
documentos web mediante el establecimiento de enlaces internos y externos. Presentaremos
cómo optimizar para nuestros enlaces (internos y externos) desde un punto de vista SEO,
métricas que motores de búsqueda como Google han empleado para clasificar documentos en
la lista de resultados, la importancia de la arquitectura de nuestro sitio web así como técnicas
de link building empleadas para la adquisición de enlaces.
2.5.1. Anclas de texto y optimización interna
Se conoce como ancha de texto a la representación visual de un enlace. Esta representación
puede encontrarse en formatos de audio, video, animación, hojas de cálculo, etc. Las anclas
de texto se forman mediante la etiqueta HTML <a> y emplean el atributo href. para
referenciar el documento al que enlazan. Su principal funcionalidad es la permitir al usuario
recuperar recursos web.
Un ejemplo del uso de anclas de texto en Html para descargar el contenido almacenado en la
dirección www.google.com sería el siguiente:
<a href=”www.google.com”> Ir a Google </a>
Desde el punto de vista de los motores de búsqueda, Larry Page y Sergey Brin (creadores de
Google) ya expresaron en su tesis (Brin & Page, 1998) cómo el uso de anclas de texto es
usado como medio para extender información sobre la página a la que se enlaza.

74
Patentes como (Kumar;Sareen;Gupta;Clark;& Wang, 2013) y (Dou;Chen;Song;& Wen, 2013)
desarrolladas por Microsoft expresan nuevas formas de hacer uso de las anclas de texto,
pudiendo emplearse para determinar el contexto de una web (Kumar;Sareen;Gupta;Clark;&
Wang, 2013) o para determinar el posicionamiento de un documento web
(Enge;Spencer;Fishkin;& Stricchiola, 2009).
Reconocido por Matt Cutts en el canal Google Webmasters de YouTube (Cutts, 2011), Google
hace uso de las anclas de texto y el contexto en el que se encuentran como medio para
complementar la información de sitios web que no son accesibles por los crawlers (Google
Webmaster Tools, 2014).
Tal y como se expone en (Kumar;Sareen;Gupta;Clark;& Wang, 2013), las anclas de texto así
como el contenido existente alrededor de estas son estudiadas por los motores de búsqueda.
Esto permite a los motores de búsqueda incrementar el conocimiento sobre sitios web, de
forma que un documento web puede llegar a ser relevante para una serie de términos clave,
incluso cuando estos no se encuentran presente en el documento.
“… search engines can deem a page relevant to a user’s query simple because one or more
other pages reference that page by using anchor text that is similar or identical to the user’s
query. The page deemed relevant to the user’s query under such a system, however, may not
itself contain the user’s query.”
(Kumar;Sareen;Gupta;Clark;& Wang, 2013)
Expertos en SEO como Rand Fishkin en la publicación (Enge;Spencer;Fishkin;& Stricchiola,
2009) , Danny Dover en (Dover & Dafforn, 2011) o Sean Odom (Odom, 2010) manifiestan la
importancia de conseguir enlaces con las palabras clave por las cuales queremos ser
referencia en internet.
Un ejemplo de la importancia que Google otorga a las palabras localizadas en las anclas de
texto se han puesto de manifiesto con las llamadas Google Bombs. Se conoce con el término
de Google bomb al conjunto de prácticas que provocan que un sitio web adquiera un alto
posicionamiento en Google para búsquedas no relacionadas con la temática del sitio web.

75
La SGAE (sociedad general de autores y editores) ha sufrido el uso de Google Bombs. Para la
consecución de esta Google bomb multitud de recursos web decidieron enlazar a la página
principal de la SGAE bajo el término “ladrones”. Esto consiguió manipular los resultados de
los motores de búsqueda. Para búsquedas realizadas con el término “ladrones”, la página
principal de la SGAE era devuelta como primer resultado.
Desde el punto de vista de la optimización para el posicionamiento web, los términos por los
que una página es referenciada escapan del control de los webmasters. Un webmaster no
puede controlar el texto que otras páginas web emplean para enlazarle. A pesar de ello,
muchos usuarios enlazan webs parafraseando el título, textos resúmenes o textos concisos
albergados en el documento referenciado.
Ofrecer una descripción corta, concisa, con palabras clave que defina el contenido que
albergamos ayudará en el posicionamiento web, a la vez que ofrece palabras clave que
pueden ser usadas por los usuarios para enlazarnos (Kumar;Sareen;Gupta;Clark;& Wang,
2013).
2.5.2. Métricas Off-page
Los motores de búsqueda interpretan los enlaces como votos positivos. Mediante la
evaluación de los enlaces que un sitio web recibe, los motores de búsqueda son capaces de
determinar la popularidad del sitio, la autoridad de este en la temática o la reputación de
nuestro sitio web. En el presente apartado expondremos estos conceptos en mayor
profundidad.
Popularidad web
PageRank fue el nombre que se le atribuyó a uno de los algoritmos más importantes que
existen hoy día en el área de sistemas de recuperación de información en entornos web.
Desarrollado por Lawrence Page y Sergey Brin, su principal función es analizar el grafo web,
es decir, analizar el grafo que forman los sitios web cuando enlazan a otros sitios.
El PageRank, más allá de su formulación matemática que veremos mas adelante, es empleado
por Google como métrica para determinar la popularidad de un sitio web. Como si de un
sistema de votación se tratara, este algoritmo estudia las referencias entre los documentos

76
web. Estas referencias, realizadas mediante enlaces, son interpretadas como votos de
confianza emitidos desde unas webs hacia otras (Brin & Page, 1998).
El número de votos que una página puede emitir se determina en función de la popularidad
del documento (PageRank que tiene asociado) y del número de hiperenlaces salientes que
dispone el sitio web (Brin & Page, 1998).
Denominamos hiperenlaces salientes a aquellos enlaces que se producen desde el documento
web en el que nos encontramos hacia otros. Hablamos de hiperenlaces entrantes para denotar
aquellas citaciones provenientes de documentos webs.
La formulación que define el algoritmo de PageRank (Brin & Page, 1998) es la siguiente:
𝑷𝑹 𝑨 = 𝟏− 𝒅 + (𝑷𝑹 𝑻𝟏𝑪 𝑻𝟏 +
𝑷𝑹 𝑻𝟐𝑪 𝑻𝟐 …+ 𝑷𝑹(
𝑻𝒏𝑪 𝑻𝒏 ))
Donde:
- T1, … , Tn representan documentos web con citaciones hacia una página dada A.
- C(X) es una función que devuelve como resultado el número de citaciones que existen
hacia otros documentos webs desde una página X.
- d es el factor de amortiguamiento, que determina la probabilidad de que el usuario
termine saliendo de la web A realizando una búsqueda de forma aleatoria.
La mejor descripción que hemos encontrado para definir el significado de la fórmula anterior
proviene del autor de la misma, Lawrence Page en la patente (Page, 1997):
“The rank of a document is a function of the ranks of the documents which cite it.”
En base a lo explicado anteriormente, para maximizar el valor de PageRank de un documento
web disponemos de las siguientes opciones: conseguir miles de enlaces de baja calidad o
conseguir enlaces de alta calidad. (Craven, 2005) recomiendan la segunda opción, dado que la
consecución de enlaces de alta calidad también se tiene en cuenta en el cálculo de otras
métricas, contribuyendo así no solo a incrementar el PageRank sino también otras métricas
que influyen en el posicionamiento web.

77
Confiabilidad web
Se definen como web spam a aquellas páginas creadas con el objetivo de engañar a los
motores de búsqueda como forma de adquirir un mejor posicionamiento. El algoritmo de
TrustRank (Gyöngyi;Garcia-Molina;& Pedersen, 2004) nace con el objetivo de reducir el
número de páginas spam que los motores de búsqueda ofrecen en la lista de resultados.
La idea principal del funcionamiento de este algoritmo es que las páginas reputables y de
confianza, raramente apuntan hacia documentos webs considerados como spam
(Gyöngyi;Garcia-Molina;& Pedersen, 2004).
Para la determinación de la reputación de un sitio web, la métrica TrustRank
(Gyöngyi;Garcia-Molina;& Pedersen, 2004) tiene en cuenta la distancia a la que los
documentos se encuentran de páginas reputables, así como el número de enlaces salientes de
un sitio web.
Según se documenta en (Gyöngyi;Garcia-Molina;& Pedersen, 2004), a medida que un
documento web se encuentra más lejos de sitios webs considerados de confianza, la
probabilidad de que estos sean reputables disminuye. Así, páginas reputables con un número
reducido de citaciones son menos propensas a enlazar páginas spam.
El algoritmo TrustRank necesita de supervisión (Gyöngyi;Garcia-Molina;& Pedersen, 2004)
para la selección de los documentos web reputables desde los que iniciar los cálculos. Un
experto que colabore inicialmente con el algoritmo, proporcionando un conjunto de sitios web
conocidos y de confianza. A este conjunto inicial se le conoce como ‘seeds’.
Desde el punto de vista del posicionamiento web, conseguir enlaces desde páginas reputables
o cercanas a estas contribuirán en mejorar el posicionamiento web. Para posicionar
documentos web usando esta métrica, debemos de saber qué sitios web optan a ser
seleccionados como ‘seeds’. Si somos capaces de determinar cuales son los ‘seeds’, tenemos
un punto de partida desde donde comenzar las estrategias de adquisición de enlaces.

78
El documento (Gyöngyi;Garcia-Molina;& Pedersen, 2004) expone dos tipos estrategias para
la selección de seeds:
• PageRank inverso
Esta estrategia consistiría en seleccionar como ‘seeds’ aquellos sitios web que sean de
confianza (determinados por un supervisor), los cuales dispongan de multitud de
enlaces a otros documentos webs. Son sitios web que actúan como web conectoras. Se
habla de PageRank inversa porque los cálculos se realizan contabilizando el número
de enlaces salientes, a diferencia de la fórmula original de PageRank contabiliza los
enlaces entrantes (Brin & Page, 1998).
• PageRank elevado
Basa la selección de ‘seeds’ atendiendo al orden que ocupan los documentos webs
ante una búsqueda introducida en los motores de búsqueda. Esta estrategia se basa en
la idea de que documentos que ocupan altas posiciones en las listas de resultados de
los motores de búsqueda, tienen una mayor probabilidad de citar documentos
relevantes.
Basándonos en estos dos criterios, la adquisición de enlaces de páginas con un alto PageRank,
o que actúen como conectoras y sean reputables, ayudarán a incrementar la visibilidad de
nuestra web (tanto por el PageRank como por el TrustRank que traspasan).
Expertos en optimización en buscadores tales como Sean Odom (Odom, 2010), Danny Dover
y Erik Dafforn (Dover & Dafforn, 2011), recomiendan conseguir enlaces de sitios que
emplean la extensión .gov o .edu, dado que poseen una alta reputación y son fuente de
información fiable (Cutts, 2011).
Otro método para la obtención de enlaces desde páginas reputadas y que actúan como
conectoras es mediante la inclusión de nuestro sitio web en directorios. No todos los
directorios son reputables o de confianza, por lo que deberemos de evaluar cómo de
reputables son antes de incluir nuestro sitio web en estos. Algunos de los directorios más
populares son DMOZ, Yahoo directorio, Best of the web, Joe Ant, o whatuseek.

79
Especificidad web
La métrica conocida como PageRank supuso un importante avance en la clasificación de
documentos web. A pesar de mejorar la ordenación de documentos web, esta ordenación
atiende a criterios globales. La influencia de la métrica PageRank en el algoritmo de
posicionamiento era tan fuerte, que documentos especializados quedaban enterrados en la lista
de resultados de los motores de búsqueda (Bharat & Mihaila, 2003).
Desarrollado por Krishna Bharat y George Andrei Mihaila en 2003, el algoritmo Hilltop fue
empleado como algoritmo para identificar documentos web especializadas por temática. Este
algoritmo en conjunción con el algoritmo de PageRank disminuye el problema del
posicionamiento de documentos relevantes y específicos.
La base del conocimiento de este algoritmo opera sobre lo que se denominan como
‘documentos expertos’. Como documentos expertos se entiende a aquellos sitios web expertos
en una temática específica. Como ejemplo de documentos expertos, el recurso (Bharat &
Mihaila, 2003) identifica los directorios webs.
Los directorios web tienen como finalidad clasificar y ofrecer información especializada por
categorías. Cada uno de sus directorios está especializado en un temática, ofreciendo enlaces
hacia sitios considerados como expertos en la materia.
El algoritmo Hilltop hace uso de estos documentos expertos y de los documentos hacia los
que enlazan. Para que un documento web sea tenido en cuenta por este algoritmo, deberá de
ser referenciado por al menos dos documentos expertos (Bharat & Mihaila, 2003).
Google usó durante años del directorio DMOZ y fue en 2011 cuando Matt Cutts (jefe del
equipo de web spam en Google) dio a conocer que Google dejaba de usar el directorio
DMOZ. Desde entonces, el directorio es principalmente empleado debido al PageRank que
dispone (Cutts, 2011).
Si bien los directorios pueden haber dejado de realizar la función que prestaban anteriormente
a los motores de búsqueda, estos siguen siendo documentos expertos con un alto PageRank.
La consecución de enlaces desde documentos expertos, sean directorios o sitios web expertos

80
en una temática y reputable, nos ayudarán en el posicionamiento web y la adquisición de
relevancia en la materia.
Reputación web
Los motores de búsqueda estudian el grafo web para la determinación de métricas. Como
vimos en secciones anteriores, el PageRank es una métrica que mide la popularidad de un
recurso web, sin tener en cuenta la especialización de la fuente. Con el algoritmo de Hilltop,
existe la posibilidad de clasificar los documentos por categoría.
Para determinar la calidad o experiencia del contenido, Google desarrolla el algoritmo
conocido como Agent Rank, obteniendo su patente en 2007 (Minogue & Tucker, 2007). Este
algoritmo mide la reputación de los agentes, determinando como agentes a todas las entidades
capaces de crear, editar o revisar contenido.
Bajo la patente (Minogue & Tucker, 2007), el algoritmo Agent Rank es capaz de identificar y
evaluar de la reputación del contenido publicado por estos agentes. Esta reputación es
clasificada temáticamente y calificada numéricamente. Para identificar unívocamente qué
contenido pertenece a qué agente, éste debe firmarlo digitalmente. Esta firma certifica que el
agente es autor del documento (Minogue & Tucker, 2007).
Dado que la reputación online de los agentes influye en el posicionamiento de los
documentos, la firma de contenido de baja calidad con el objetivo de manipular los resultados
de búsqueda, penaliza a los agentes firmantes bajo la pérdida de reputación online.
Aquellos documentos que estén firmados digitalmente por agentes con una alta reputación,
adquieren métricas que ayudan en el posicionamiento en la lista de resultados (Minogue &
Tucker, 2007). Las implementaciones propuestas para calcular el Agent Rank son
derivaciones de otras ya estudiadas, como la fórmula del PageRank descrita en (Brin & Page,
1998) adaptada a agentes.
Microsoft presenta en la patente con número 20110246484
(Dumais;Weitz;Gounares;Gemmell;& Yiu, 2010) formas diferentes de analizar la reputación,
conocimiento y maestría mediante el análisis de las “fuentes de información”. Estas fuentes

81
de información pueden incluir individuos, organizaciones, instituciones, grupos,
compañías,…
Documentado en la patente (Dumais;Weitz;Gounares;Gemmell;& Yiu, 2010), la relevancia
de estas fuentes podría ser empleada por los motores de búsqueda para complementar sus
operaciones, otorgando un mayor peso a aquellos resultados cuyas fuentes de información
sean expertas en la materia.
“The determined authority of sources 110 may be used by the search engines to supplement
searching operations and/or to weight search results based upon the authority of the
resources 110 of content 106 identified during the search.”
En la misma patente se manifiesta la incorporación de estadísticas sociales como métricas
para medir la relevancia de las fuentes. De entre las métricas sociales mencionadas se
enumeran:
• Redes sociales como Facebook (número de publicaciones, comentarios, el número de
hiperenlaces proporcionados…)
• Redes sociales en tiempo real como Twitter (número de publicaciones, retweets,
número de seguidores, …)
• Servidores web (estadísticas sobre cómo el usuario interacciona con el contenido)
Si bien las patentes otorgadas a Google y Microsoft no significan que estas métricas estén
siendo usadas en los algoritmos de búsqueda, sí que encontramos implementaciones y
servicios desarrollados por Google que incitan a la reflexión sobre la aplicación de las
patentes mencionadas anteriormente para el posicionamiento web.
En el siguiente apartado expondremos cómo Google está realizando esfuerzos por identificar
a estos agentes, y como éstos pueden firmar el contenido que publican.
Identificación de los agentes
En este sentido, Google está realizando un gran esfuerzo por identificar físicamente a las
personas que crean un perfil en la red social Google+. Prueba de ello lo encontramos en la

82
página de ayuda de Google, donde se manifiesta la importancia de identificar a personas en la
red social de Google+:
“If we challenge the name you intend to use, you will be asked to submit proof that this is an
established identity with a meaningful following. You can do so by providing links to other
social networking sites, news articles, or official documents in which you are referred to by
this name.”
”Personal profiles on Google+ are meant to represent you, not someone or something else
with which you are associated. Therefore, your name may not represent a family, business,
avatar, gaming handle, or other group of people.”
”Name Changes are limited to 3 changes every 2 years.”
A través de este perfil, Google permite a los escritores firmar el contenido digital. Esto
establece una relación bidireccional entre el autor y el documento web. Esta firma de
contenido digital permite a Google ofrecer información sobre el autor en la lista de resultados
(Google Webmaster Tools, 2013).
Para la implementación de este marcado es necesario la disposición de una cuenta personal en
Google+. Esta cuenta identifica unívocamente a una entidad y es ésta y solo ésta la que puede
realizar cambios sobre el espacio de Google+.
Existen diferentes formas de relacionar al autor de un artículo con el artículo. Según se
manifiesta en (Google Webmaster Tools, 2013), pueden usarse los siguientes métodos para
firmar contenido digitalmente (Google Webmaster Tools, 2014):
• A través de e-mail (Google Webmaster Tools, 2013):
1. Disponer de una cuenta de correo electrónico en el dominio donde se realiza la
publicación. Por ejemplo, si publicamos artículos en el dominio
www.midominio.com, el e-mail asociado al dominio será de la forma nombre-de-

83
2. Cada artículo publicado deberá de terminar con una línea que identifique
fácilmente a su autor (por ejemplo, Autor: Alberto Fernández Reyes).
3. Es indispensable disponer de una cuenta en la red social de Google+ cuyos datos
se correspondan con el autor que se identifica en los artículos.
4. A través del siguiente link https://plus.google.com/authorship el usuario da a
conocer su e-mail. Google asociará los artículos publicados en
www.midominio.com con el autor especificado en el paso 2.
• A través de hiperenlaces (Google Webmaster Tools, 2014):
1. Este método está basado en una reciprocidad de enlaces entre el artículo y la
página del autor de Google+. Para cada artículo deberá existir un enlace de la
forma:
<a href=”[profile_url]?rel=author”>Alberto Fernández</a>
donde [profile_url] es la URL en Google+ que identifica al autor.
2. Desde Google+, añadir en la sección personal “Contributor to Section” un link que
apunte hacia el dominio donde se alberga el artículo.
El resultado puede verificarse empleando la herramienta web richsnippetcode que Google
pone a nuestra disposición:

84
Figura 17: Ejemplo de autoría de artículos de John Resig
Desde el canal GoogleWebmasterHelp (Cutts, 2013), Matt Cutts confirma que Google emplea
la información obtenida mediante la autoría de artículos en el posicionamiento web.
Esto pone de manifiesto la importancia de crear una reputación online. Basado en los
conceptos anteriores, la creación de artículos con contenido de calidad, la creación de una
reputación online o la publicación de artículos por parte de autores invitados puede ser
empleado como método para adquirir / mejorar el posicionamiento web.
2.5.3. Link juice y Arquitectura web
Se conoce como ‘link juice’ a la cantidad de PageRank que fluye desde unos documentos
webs hacia otros en el grafo web. El link juice representa el número de votos que un
documento web emite al referenciar a otro documento. También puede interpretarse como la
cantidad de PageRank que los documentos emiten cuando referencian otros documentos
(Cuuts, 2009).
La siguiente imagen (Figura 18) extraída de uno del documento original PageRank (Brin &
Page, 1998) muestra un ejemplo de cómo fluye este entre los documentos web:

85
Figura 18: Flujo de PageRank entre webs (Brin & Page, 1998)
Con cada nueva referencia o citación se producen fluctuaciones de PageRank desde unos
recursos web hacia otros. Cuanto mayor sea el número de enlaces salientes existentes en el
documento, menor será el PageRank que se transfiere a los documentos web a las que enlaza.
Mediante la adquisición de enlaces entrantes y una arquitectura web jerárquica podemos
conseguir centrar el PageRank en aquellos documentos que queremos posicionar mejor.
Como vimos anteriormente, la fórmula del PageRank es una función que depende del número
de enlaces disponibles en el sitio web. Cuanto mayor sea el número de enlaces en el sitio web,
menor será el link juice que se traspasa a los documentos.
A continuación explicaremos cómo la arquitectura de un sitio web determina la cantidad de
link juice que se traspasa a los documentos web. Emplearemos la fórmula del PageRank
original ofrecida en (Brin & Page, 1998) para el cálculo de este y el uso de la herramienta
web proporcionada por Phil Craven (Craven, 2005). Esta herramienta nos permitirá observar
la evolución del PageRank, iteración tras iteración, para las arquitecturas presentadas.
Para conocer cómo de efectiva es una arquitectura web con respecto al PageRank que
traspasa a otros documentos, Phil Craven describe en (Craven, 2005) los conceptos de
PageRank Total y PageRank Perdido:
• Se denomina PageRank total al PageRank máximo acumulado que podría alcanzar un
sitio web sin recibir enlaces entrantes. Este es equivalente al número de documentos

86
del sitio web (Craven, 2005). El PageRank total máximo de un sitio web viene
determinado por el número de documentos webs que dispone.
• Se define PageRank perdido como el PageRank que desperdiciamos debido a una
mala organización estructural del sitio web.
En la siguiente imagen (Figura 19) presentamos un ejemplo de cómo una estructura web
piramidal ayuda con el paso de PageRank, permitiendo que el sitio web alcance el máximo
PageRank posible para un sitio web cerrado sin enlaces entrantes:
Figura 19: Estructura web jerárquica
La tabla siguiente (Tabla 4) muestra la evolución del PageRank para cada uno de los
documentos web iteración tras iteración La aplicación para el cálculo de éstos ha sido
realizada a través de la herramienta documentada en (Craven, 2005).
Los valores de PageRank dejan de fluctuar tras la realización de cuarenta iteraciones:
Iteraciones 1 2 3 4 .. 39 40
Page A 1 2.7 2.48 2.32 ... 1.91 1.92
Page B 1 0.915 0.8535 0.809 ... 0.69 0.69

87
Page C 1 0.915 0. 8535 0.809 ... 0.69 0.69
Page D 1 0.915 0. 8535 0.809 ... 0.69 0.69
PR Total 4 5.445 5.0405 4.747 ... 3.98 3.99
PR
perdido
0 0 0 0 ... 0 0
Tabla 4: Evolución del PageRank sobre web estructura jerárquicamente
Tal y como podemos observar en la tabla (Tabla 4), el PageRank total sufre variaciones
durante las iteraciones hasta que el PageRank de cada página termina por estabilizarse. El
PageRank total teórico debería de ser equivalente al número de documentos que tiene el sitio
web. La pérdida de 0.01 que podemos observar tras cuarenta iteraciones, en la casilla PR
Total ha sido documentada por Phil Craven como el resultado del redondeo que emplea la
aplicación (Craven, 2005). No se produce pérdida de link juice entre los documentos webs
debido a la arquitectura jerárquica del sitio web.
En la siguiente ilustración (Figura 20) podemos observar una nueva estructura web donde se
introduce la variante de un enlace descolgando, es decir, un enlace hacia un documento el
cual no dispone de enlaces salientes.
Figura 20: Estructura web con link descolgado

88
A continuación veremos cómo los enlaces descolgados, al no ser tenidos en cuenta en el
cálculo del PageRank (Brin & Page, 1998), no traspasan link juice a ningún documento. El
resultado es que el sitio web ve reducido su PageRank total con respecto a la arquitectura
piramidal mostrada anteriormente.
Iteraciones 1 2 3 4 .. 25 26
Page A 1 1.85 1.741 1.663 ... 1.459 1.459
Page B 1 0.15 0.15 0.15 ... 0.15 0.15
Page C 1 0.9362 0. 89 0. 8569 ... 0.7703 0.7703
Page D 1 0.9362 0. 89 0. 8569 ... 0. 7703 0. 7703
PR Total 4 3.8724 3.671 3.5268 ... 3.1496 3.1496
PR
perdido
0 0.1276 0.329 0.4732 ... 0.8504 0. 8504
Tabla 5: Evolución de PageRank sobre estructura web con link descolgado
Observando la tabla anterior (Tabla 5) para la estructura web con enlace descolgado, se
produce una pérdida de PageRank cuantificada en 0.8504. El motivo por el cual no se
consigue el máximo PageRank total al que se aspira es que existe un documento web excluido
de los cálculos, el cual no aporta mayor PageRank que el inicial.
Si recapitulamos lo visto en este apartado, la arquitectura que un sitio web dispone influye en
la forma en la que fluye el link juice. Este link juice determina el PageRank que un
documento web adquiere. Según se documenta en (Rogers, 2006), la disposición de un sitio
web con estructura piramidal es la mejor opción. Para consultar cómo diferentes arquitecturas
web influyen en el paso de PageRank puede consultarse el recursos web The Google
PageRank algorithm and how it Works (Rogers, 2006).
2.5.4. Link building

89
Se conoce como link building al conjunto de prácticas SEO cuya finalidad es la obtención de
enlaces externos hacia un sitio web. La adquisición de enlaces externos mejora la visibilidad
del sitio web (incrementando las posibilidades de acceder a nuestro sitio web desde otros
sitios web), así como métricas tenidas en cuenta por los motores de búsqueda, tales como
PageRank o TrustRank.
El principal problema a la hora de establecer estrategias de link building, es que éstas
requieren de una inversión importante de capital. Moz.com realizó una encuesta en 2014
(Agate, 2014) a 315 personas relacionadas en el ámbito del posicionamiento web. La
encuesta recopila información sobre las prácticas de link building. En la Figura 21
presentamos los datos más significativos presentes en la encuesta (Agate, 2014):
Figura 21: Gastos dedicados a link building
En base a los resultados obtenidos en el estudio (Agate, 2014), el 20% declaró invertir
mensualmente un presupuesto de 0$ a 1,000$ en prácticas de link building. Por contra, el
restante 80% declaró invertir entre 1,000$ y 50,000$ mensuales para la consecución de
enlaces (Agate, 2014).
Siguiendo con la gráfica anterior (Figura 21), el 46% de los entrevistados declaró dedicar más
del 50% del presupuesto dedicado a SEO a la aplicación de técnicas de link building (Agate,
20%
20%
23%
37%
Gastos mensuales dedicados a link
building 0$ -‐ 1000$ 1000$ -‐ 5000$
5000$ 10000$ 10000$ -‐ 50000$
27%
27%
39%
7%
Porcentaje dedicado a link building del
presupuesto total SEO 0 -‐ 25% 26% -‐ 50%
51% -‐ 75% 75% -‐ 100%

90
2014). Preguntados sobre si incrementarían el presupuesto dedicado a link building durante
los próximos meses, el 73% de los entrevistados respondió de forma afirmativa. En base a
estos resultados, la adquisición de enlaces es un proceso costoso que requiere de una
inversión de capital constante.
Técnicas de link building
En esta sección expondremos un conjunto de técnicas que nos ayudarán en la adquisición de
enlaces. Mediante la adquisición de nuevos enlaces conseguiremos mejorar el
posicionamiento web de nuestro dominio.
Creación de contenido y outreach
Consiste en la práctica destinada a la creación y distribución de contenido informativo. Se
denomina outreach link building a la práctica manual de informar a sitios web del contenido
publicado. Cuando se hace uso de ella, se explica al usuario cómo puede beneficiarse cuando
establece un enlace hacia nuestro sitio web.
Dado que esta técnica de link building es tediosa y requiere una importante inversión de
tiempo, debemos de seleccionar los sitios webs a los que enviar nuestra proposición en base a
nuestras posibilidades de adquirir enlaces.
Creación de Infografías
Se conoce como infografía, a la presentación de información (generalmente compleja)
expresada de forma sencilla mediante una representación visual o gráfica. A continuación
presentamos un ejemplo de infografía extraído del blog de HubSpot (Bodnar, 2010):

91
Figura 22: Infografía extraída de HubSpot
El objetivo de las infografías es hacer el contenido conciso y atractivo. En la encuesta
destinada a evaluar la efectividad de las técnicas destinadas a link building (Agate, 2014), la
creación de infografías es recogida como la segunda técnica más importante en la adquisición
de enlaces.
Broken link building
Esta práctica consiste en establecer contacto con webmasters de sitios web que disponen de
enlaces salientes rotos. Se establece contacto con el webmaster del sitio web y se le informa
sobre el enlace roto, a la vez que se ofrecen alternativas para añadir otros enlaces o sustituir el
enlace roto.
De la misma forma que se realiza con la práctica de e-mail outreach, esta práctica requiere del
estudio del sitio web, la detección de enlaces rotos, la evaluación sobre la relevancia del
enlace, la adquisición del e-mail del webmaster y el envio de la proposición para sustituir el
enlace roto.

92
Esta práctica requiere un importante esfuerzo y dedicación. A pesar de ello, las posibilidades
de éxito son mayores en comparación con la práctica de e-mail outreach, dado que ofrece
valor directo al sitio web al que contactamos.
Directorios
Los directorios son sitios web que se caracterizan por categorizar Internet. Un directorio es un
sitio web que está separado en categorías y subcategorías. Cuando un usuario accede a un
directorio y selecciona una categoría, encuentra multitud de recursos web relacionados con la
categoría seleccionada, así como subcategorías más específicas que pueden consultarse.
La adquisición de enlaces desde directorios con reputación pueden ayudar a consolidar la
posición de un sitio web en la lista de resultados. Directorios que revisan manualmente cada
petición gozan del gusto de los motores de búsqueda. Hasta el 2011, Google usó DMOZ para
conocer sitios web expertos y reputables por temáticas. Si bien la importancia de estar
incluido en directorios se ha visto reducida con los años, adquirir enlaces desde estos es
todavía útil, dado el PageRank y la autoridad que transmiten.
Páginas de recursos
Se denomina página de recursos a la página que contiene un conjunto de artículos
relacionados con un tema específico. Se caracterizan por ofrecer una recopilación de los
mejores artículos encontrados para una temática específica.
En la entrevista realizada por Moz.com (Agate, 2014), esta práctica de link building se sitúa
como la quinta más eficaz, después de la creación de contenido y outreach email, promoción
de infografías, broken link building e inclusión en directorios de negocios.
2.5.5. Conclusiones
Las técnicas de link building nos ayudan a la generación de enlaces. Estas técnicas consiguen
incrementar el PageRank de nuestro sitio web, lo que repercute positivamente en el
posicionamiento de nuestro sitio online.

93
El principal problema a la hora de intentar incrementar el número de enlaces que disponemos,
es que las técnicas de link building son técnicas difíciles de escalar, lo que las hace costosas
en recursos, tiempo y capital. La mayoría de ellas requieren de esfuerzos para: adquisición de
la información de contacto; recopilación de información; establecimiento de relaciones con
personalidades del sector.
Técnicas como la creación de contenido atractivo mediante infografías, la inclusión en sitios
web en directorios, la generación de recursos web o la distribución de contenido de forma
manual son solo algunas de las técnicas destinadas a la generación de enlaces, las cuales nos
permitirán en última instancia mejorar nuestro posicionamiento web.
2.6. Blackhat SEO
En el área de optimización para buscadores, se denomina Blackhat SEO al conjunto de
técnicas de optimización empleadas para manipular los motores de búsqueda. Mediante la
manipulación de los motores de búsqueda se puede conseguir mejorar el posición de los
documentos web en la lista de resultados (Cutts, 2012).
En esta sección expondremos técnicas de Blackhat SEO empleadas para manipular el
posicionamiento web. Su uso se penaliza cono la pérdida de posicionamiento web o borrado
del contenido web del índice de los motores de búsqueda.
Google pone a disposición de los usuarios el recurso
https://www.google.com/webmasters/tools/spamreport a emplear en caso de que los usuarios
detecten webs que incumplan: políticas establecidas por Google; políticas de copyright;
páginas dedicadas a la extracción de información sensible; páginas dedicadas a la
compra/venta de enlaces.
2.6.1. Conectando con el grafo web
Toda adquisición de enlaces cuyo cometido sea la manipulación del PageRank o la influencia
en el procesamiento realizado por los algoritmos que estudian el grafo web, podrá ser
considerado como una violación de las normas que rigen el adecuado uso del motor de

94
búsqueda de Google. Esto puede conllevar penalizaciones en el posicionamiento web así
como la exclusión del sitio web de los motores de búsqueda (Cutts, 2012).
En las siguientes secciones expondremos algunas de las prácticas o técnicas que violan las
normas establecidas por Google. Estas técnicas son empleadas para manipular los resultados
de búsqueda mediante la obtención de enlaces.
Compra/venta de hiperenlaces
La compra o venta de enlaces, si es tratada siguiendo las líneas establecidas por los
principales motores de búsqueda, no supone una penalización. La compra de espacios webs
con fines o propósitos de marketing (captación de usuarios en dominios que manejan un gran
volumen de visitas) es una herramienta empleada en el marketing online.
La penalización tienen lugar cuando se quiere mejorar el posicionamiento a través de la
compra de enlaces de webs con una alta reputación, un alto índice de PageRank, relevantes
en una temática específica,...
Para evitar penalizaciones, Google manifiesta la importancia de evitar el paso de PageRank
en aquellos enlaces que hayan sido comprados/vendidos (Cutts, 2013). Para evitar que los
enlaces pasen PageRank podemos:
- Marcar los hiperenlaces comprados con la etiqueta rel=nofollow.
- Direccionar los enlaces hacia una página intermedia bloqueada por el archivo
robots.txt.
Estas técnicas evitan el paso de link juice hacia las webs a las que enlazan. Los motores de
búsqueda no tendrán en cuenta la relación entre las webs. El propósito de la compra o venta
de espacios con fines publicitarios debe ser acorde a tal fin, es decir, a la adquisición de
tráfico y no como medio para mejorar el posicionamiento web.
Spamming link building

95
Se conoce como spamming link building a la creación y distribución de enlaces de forma
masiva, sin la realización de méritos propios para la adquisición de estos (Davison, 2000). El
principal motivo para la creación masiva de enlaces es influir en los algoritmos que analizan
las relaciones entre las webs mediante enlaces web (PageRank, TrustRank, ....).
Así, webmasters optan por la creación masiva de enlaces a través de entradas de texto
habilitadas en otras web, tales como a través de la inserción de comentarios en blogs, foros,
grupos de ayuda, etc.
Otras formas consideradas como spamming links building son la creación de artículos y su
promoción o distribución en multitud de blogs o sitios web de baja calidad. La consecución
de estos enlaces es considerada por Google como no naturales. Es decir, son considerados
como una práctica destinada a influenciar en el posicionamiento web (Cutts, 2014).
Para evitar ser penalizados, Matt Cutts recomienda evitar distribuir artículos en sitios web de
baja reputación, así como evitar la obtención de link juice cuando se distribuye el artículo a
otras webs (Cutts, 2014).
Si lo que pretendemos es iniciar una campaña de creación de enlaces, deberemos crear
contenido interesante para el usuario, de forma que la construcción de enlaces sea natural.
En caso de optar por crear enlaces en foros, comentarios en artículos o blogs, artículos para
publicar en web externas, deberemos de extremar las precauciones para no infringir las
normativas de construcción de enlaces de Google (Google Webmaster Tools, 2013)
Intercambio de Enlaces Recíprocos
Se conoce como granjas de enlaces, a aquel conjunto de webs que intercambian menciones
recíprocamente con el objetivo de afectar el posicionamiento web (Google Webmaster Tools,
2013). Tal y como se menciona en la guía de Google, un excesivo intercambio de enlaces con
otros sitios web podrá impactar negativamente en el posicionamiento web (Google
Webmaster Tools, 2013).

96
2.6.2. Construyendo documentos web
Toda práctica dedicada a la construcción de contenido spam viola los términos que Google
especifica en el documento (Google Webmaster Tools, 2013). La violación de estos términos
influye negativamente en el posicionamiento web.
A continuación se enuncian las principales prácticas de spam llevadas a cabo por usuarios,
con el objetivo de conseguir un alto posicionamiento en un tiempo reducido.
Spamming keywords
Consiste en cargar el contenido de un sitio web con palabras clave o números, con la
intención de mejorar el posicionamiento web para un conjunto de palabras clave (Google
Webmaster Tools, 2013).
Un ejemplo de ello es el posicionamiento de palabras clave como ciudades en el sitio web.
Este tipo de palabras clave es interpretado por los motores de búsqueda como contenido de
interés para búsquedas locales. Si el contenido no guarda relación con la localidad
mencionada, generan una mala experiencia de usuario cuando Google ofrece estos resultados
en búsquedas locales. Este tipo de prácticas para atraer usuarios es penalizado por Google
(Google Webmaster Tools, 2013).
Spamming Ads
Consiste en sobreimpresionar anuncios en una página dificultando la visualización del
contenido de la misma (Cutts, 2012). Obliga al usuario al empleo de la barra lateral para
poder observar el contenido, dificultando con los anuncios la localización de éste.
A comienzos de Enero de 2012, Google anunció el lanzamiento del algoritmo conocido como
Page Layout (Cutts, 2012). Este algoritmo detecta aquellas webs que no ofrecen contenido
visible de forma directa y realiza penalizaciones sobre estos. Menos del 1% de las búsquedas
globales se vieron afectadas tras el lanzamiento de este algoritmo según fuentes de Google
(Cutts, 2012).

97
Cloaking
Se refiere a la práctica de presentar diferente contenido o direcciones web a los crawlers y a
los visitantes (Cutts, 2011). Este tipo de prácticas tienen como finalidad indexar contenido en
los motores de búsqueda diferente del que se presenta al usuario. Por contenido se entiende
todo aquello existente en la web y que es perceptible por el usuario. Son consideradas como
prácticas de cloaking:
- situar contenido de color blanco sobre un fondo blanco
- posicionar texto detrás de las imágenes
- uso de CSS para posicionar texto fuera de la pantalla del usuario
- crear contenido a indexar definiendo el tamaño de la letra a cero
Todas estas técnicas ofrecen diferentes versiones a usuarios y motores de búsqueda.
Webmaster o desarrolladores web pueden ser penalizados por prácticas de cloaking si no son
conscientes de las tecnologías que emplean, y de cómo éstas son procesadas por los motores
de búsqueda.
Tal y como comentábamos en la sección dedicada a la indexación de contenidos Ajax, Ajax es
una tecnología no es procesado correctamente por los robots o indexadores. Para evitar
penalizaciones por mostrar contenido diferente a robots y usuarios, será necesario
implementar algunos de los esquemas propuestos por Google (Google Webmasters, 2012) y
que ya tratamos en secciones anteriores.
2.6.3. Captación de usuarios
Aquellas prácticas cuya finalidad es la de captar usuarios sin ofrecer contenido de calidad, es
susceptible de ser penalizado. Google manifiesta continuamente en sus directrices generales
(Google Webmaster Tools, 2013) la importancia de ofrecer un verdadero valor al visitante.
Honey pots creados para direccionar al usuario hacia documentos web específicos están
totalmente desaconsejados bajo penalizaciones (Google Webmaster Tools, 2014).
Programas de Afiliaciones
Los programas de afiliados son una de las prácticas más empleadas en el marketing online. En
estas prácticas, un proveedor de servicios o productos ofrece un porcentaje sobre aquellas

98
ganancias que son iniciadas por acciones promovidas por los afiliados (IAB, 2010). Es decir,
el afiliado recibe un porcentaje sobre la compra que haya liderado desde su documento web.
Este tipo de prácticas son motivo de penalización si no se trabaja bien en el contenido.
Motores de búsqueda como Google consideran que la gran mayoría de los sitios web de
afiliación no ofrecen ningún valor a la visita, limitándose a repetir el mismo contenido que el
sitio original donde se realiza la compra (Google Webmaster Tools, 2014). Así, sin la
disposición de contenido exclusivo, motores como Google informan sobre las pocas
probabilidades de que las páginas de afiliados puedan conseguir un buen posicionamiento
(Google Webmaster Tools, 2014).
Doorways
Práctica consistente en la optimización de páginas de baja calidad para palabras clave
específicas, con el objetivo de captar usuarios y guiar éstos hacia un documento web en
concreto (Google Webmaster Tools, 2014). Este tipo de prácticas se pueden encontrar bajo el
uso de uno o varios dominios webs.
Ejemplos de este tipo de prácticas son:
- Creación de páginas optimizadas para captar usuarios por localización geográfica,
conduciendo la visita hacia una página general.
- Creación de páginas de similar contenido optimizadas para búsquedas por ciudades.
- Creación de páginas para captar usuarios y direccionarlos hacia páginas de afiliados.
Al igual que las técnicas mencionadas en esta sección, este tipo de práctica viola las normas
establecidas por Google así como otros motores de búsqueda. El uso de estas técnicas
conlleva penalizaciones (Google Webmaster Tools, 2014).
2.6.4. Secuestrando documentos web

99
En esta sección exponemos técnicas documentadas por expertos que han permitido suplantar
documentos web originales por documentos no oficiales. Las principales técnicas
documentadas corresponden a ataques sobre el funcionamiento de los motores de búsqueda.
Redireccionamiento 302
Es una práctica que aprovecha la forma en la que los motores de búsqueda interpretan los
redireccionamientos temporales de tipo 302. Este tipo de redireccionamiento es empleado
para indicar que una web ha sido movida temporalmente a otra dirección web.
Cuando los motores de búsqueda acuden a escanear una web y obtienen el código de
respuesta 302, interpretan este redireccionamiento como temporal. La dirección web que
responde con el código 302 es considera la página original, siendo la página donde se realiza
el redireccionamiento como un recurso temporal.
La siguiente figura (Figura 23) muestra el intercambio de mensajes que se produce entre
servidor y cliente (crawler en nuestro caso particular). El cliente requiere un recurso
index.html y es el servidor el que le facilita información sobre la localización temporal del
recurso:

100
Según vimos en la sección de redireccionamientos, los motores de búsqueda traspasan las
métricas adquiridas por la página temporal a la página que realiza el redireccionamiento 302.
Bajo este funcionamiento particular, existen webmasters que han aplicado esta técnica para
adquirir el PageRank de otras web (Schmidt, 2005).
En (Cutts, 2006) y (Cutts, 2012) Matt Cutts manifiesta que este tipo de prácticas están
controladas por Google. A pesar de sus afirmaciones, la combinación de redireccionamientos
302, la duplicación de contenido sobre el documento a secuestrar y la disposición de un alto
PageRank permitió al equipo de Dejan SEO suplantar la identidad de un documento web
original (Petrovic, 2012).
Duplicación de contenidos
Este método de suplantación de documentos web es causado por la eficiencia con la que los
motores de búsqueda detectan y actúan ante la duplicidad de contenido. Documentada en
Figura 23: Comunicación entre cliente y servidor con redireccionamiento 302

101
2005 por Claus Schmidt, fue parcialmente empleada por el equipo Dejan SEO (Petrovic,
2012) en 2012, como método para verificar la posibilidad de secuestrar documentos web.
Daniel Peng y Frank Dabek publican en 2010 el documento “Large-scale incremental
processing using distributed transactions and notifications” (Peng & Dabek, 2010).
En este documentan que los contenidos duplicados deben ser únicamente almacenados bajo
una única dirección web, evitando almacenar copias de contenido ya existente en el índice de
Google. Para ello, de entre un conjunto de documentos duplicados, se almacenará aquel que
disponga de mayor PageRank.
El PageRank es definido como métrica para determinar cuál de las direcciones web con
contenido duplicado debe de ser almacenada en el índice. Esto se expresa en el siguiente
párrafo extraído del documento original (Peng & Dabek, 2010):
“Consider the task of building an index of the web that can be used to answer search queries.
The indexing system starts by crawling every page on the web and processing them while
maintaining a set of invariants on the index. For example, if the same content is crawled
under multiple URLs, only the URL with the highest PageRank [28] appears in the index.
Each link is also inverted so that the anchor text from each outgoing link is attached to the
page the link points to. Link inversion must work across duplicates: links to a duplicate of a
page should be forwarded to the highest PageRank duplicate if necessary.”
Por tanto, para la suplantación de un documento web, es necesario la posesión de un mayor
PageRank en el documento duplicado que la que posee el documento original. El equipo
Dejan SEO ejecutó exitosamente esta técnica (Petrovic, 2012) como método para demostrar
que la suplantación de documentos web sigue siendo una amenaza temporal a la cual los
motores de búsqueda no han puesto fin. Temporal, debido a que Google notificó al equipo
Dejan SEO sobre la detección de contenido duplicado 17 días después de haberse secuestrado
el documento (Petrovic, 2012).
2.6.5. Inyectando código en documentos web

102
Es una práctica consistente en el estudio de las vulnerabilidades de una web para la posterior
inyección de código por parte una tercera entidad no autorizada. De entre las diversas formas
de explotar dominios web ajenos, se destacan las prácticas de inyección de código HTML
mediante ataques basados en XSS (cross-site scripting).
Ataques basados en XSS tienen como objetivo la introducción de código JavaScript en un
documento web, de forma que pueden hacerse con el control del propio documento (OWASP,
2014) permitiendo la modificación de contenidos, la creación de spam, etc.
Este tipo de ataque consigue sobrepasar controles de acceso tales como la política del mismo
origen, el cual evita que los scripts tengan acceso al árbol DOM del documento si el script no
pertenece al mismo dominio (Ruderman, 2014). Dado que el script es introducido en el propio
documento web, esta medida de restricción es esquivada por un ataque de tipo XSS.
Este tipo de ataque se produce generalmente por la falta de validación de los datos
introducidos en entradas de texto, formularios, parámetros HTTP, etc. (OWASP, 2014). En
2007, Symantec dio a conocer en su estudio (Turner, ym., 2007) que el 84% de las
vulnerabilidades documentadas pertenecían a ataques llevados a cabo a través de XSS.
Un ejemplo de este tipo de ataque puede verse en el proyecto Apertium, sistema de traducción
automática financiado por el gobierno español, que a pesar de ser un proyecto participante en
Google Summer of Code está sufriendo este tipo de ataques:

103
Figura 24: Inserción de código malicioso en Apertium web

104

105
Capítulo 3:
Marketing Online
En el presente capítulo expondremos las diferentes fases a tener en cuenta a la hora de
mejorar la visibilidad y el tráfico de un proyecto web. El capítulo se encuentra
dividido en cuatro secciones:
- Planificación web
Sección en la cual presentamos cómo hacer uso de la herramienta Google
Keyword Planner para conocer el volumen de tráfico al que un documento
web opta cuando es optimizado. Se acompaña de benchmarks empleados en la
industria SEO como método para estimar el ratio de clics esperado en función
del posicionamiento web.
- Estrategias de publicidad online
En esta sección exponemos estrategias de publicidad online a emplear como
medio para adquirir visibilidad, incrementar el tráfico y potenciar las
conversiones web.
- Optimizaciones para la conversión
En esta sección exponemos técnicas que nos pueden ayudar a incrementar el
éxito de las campañas de promoción online. La sección está dividida en
subapartados, en función del canal de promoción a optimizar.
- Análisis de la evolución web

106
En este apartado introducimos los conceptos básicos sobre la analítica web
como herramienta para conocer la evolución de un proyecto web.
3.1. Planificación web
En esta sección presentaremos métodos para analizar el volumen de búsquedas al que
optamos en base a las palabras clave seleccionadas. Para conocer el volumen de
búsquedas mensuales introduciremos la herramienta Google Keyword Planner.
Presentaremos también estudios que muestran el porcentaje de clics que reciben de
media los documentos, en función de la posición web en la que se encuentran. Estos
estudios nos permitirán disponer de un modelo contra el que comparar nuestros
resultados.
Al finalizar la sección, seremos capaces de analizar, para cada palabra clave, el
volumen de búsquedas del que dispone, así como la competitividad de esta. También
dispondremos de un marco de referencia contra el que evaluar el porcentaje de clics
que adquiere nuestro sitio web.
3.1.1. Tipos de palabras clave
Los motores de búsqueda hacen uso de las palabras de búsqueda introducidas por los
usuarios para determinar los resultados a mostrar. Prácticamente cualquier búsqueda
que realicemos termina mostrándonos resultados cuyos títulos y descripciones
contienen estas palabras.
Conocer las palabras de búsqueda que introducen los usuarios es primordial para la
optimización de documentos. Buscaremos en la medida de lo posible, optimizar
nuestros documentos empleando como palabras clave aquellas que son introducidas
por los usuarios.
Los términos de búsqueda empleados por los usuarios puede ser muy amplio.
Mientras que unos realizan búsquedas específicas, otros realizan búsquedas más

107
populares. El sector de marketing en motores de búsqueda categoriza las palabras
clave como:
- Head terms
Se conoce con el término head terms a los términos de búsqueda que son
cortos y populares. Como veremos posteriormente, este tipo de términos
dispone de un ratio de clics superior a los long tail keywords (SEMPO, 2011).
- Long tail keywords
Se conoce como long tail keywords o tail terms a aquellos términos de
búsqueda caracterizados por ser muy específicos y largos. A pesar de que este
tipo de términos disponen de un menor volumen de búsquedas, al ser más
descriptivos, los usuarios conocen lo que buscan. Es decir, se encuentran más
cerca de la conversión.
Según el estudio realizado por Optify (Siddiqi, 2012), la optimización de contenidos
con head terms consigue atraer un mayor volumen de tráfico cuando nuestro
documento se encuentra entre los primeros puestos de Google.
Por el contrario, documentos que no se encuentran entre los primeros puestos de
Google consiguen un mejor CTR si el contenido está optimizado para long tail
keywords.
3.1.2. Volumen de búsquedas, competencia y rentabilidad
Antes de comenzar la optimización de documentos, es conveniente analizar las
palabras clave para las cuales queremos optimizar estos. Estas palabras clave
determinan, junto con el posicionamiento que adquirimos en los motores de búsqueda,
el volumen de búsquedas al que optamos. Para analizar el volumen de búsquedas
vamos a emplear la herramienta Google Keyword Planner.
La herramienta Google Keyword Planner es una herramienta perteneciente al
programa Google AdWords. Google AdWords es una plataforma de anuncios online,

108
la cual funciona mediante un modelo de pujas en tiempo real. Los anunciantes crean
sus anuncios y fijan el precio a pagar por cada clic que recibe el anuncio.
A pesar de que la herramienta Google Keyword Planner está dedicada a ayudar a los
anunciantes a hacer campañas en Google AdWords, podemos emplear la información
que esta herramienta nos proporciona para conocer qué términos disponen de un
mayor volumen de búsquedas o cuáles son mas rentables.
Figura 25: Interfaz gráfica de la herramienta Google Keyword Planner
Para conocer datos sobre palabras clave específicas, deberemos introducir estos en la
herramienta Google Keyword Planner. Esta herramienta nos proporciona información
como: términos de búsqueda relacionados con los que hemos introducidos (Search
terms); media de búsquedas mensuales para cada término (avg. monthly searches);
puja sugerida para adquirir tráfico por publicidad (suggested bid).
A continuación explicamos cómo interpretar estos datos desde el punto de vista de la
optimización de documentos web:
• Volumen de búsquedas
Conocer el volumen de búsquedas de una palabra clave nos proporciona
información sobre el tráfico que podemos capturar si conseguimos posicionar
el contenido adecuadamente.

109
La selección de palabras clave con un alto volumen de búsquedas suele estar
relacionado con palabras clave populares, llamadas head terms. Centrarnos en
estas palabras puede ayudarnos a ganar visibilidad web si disponemos de una
buena posición.
Términos o palabras clave con un bajo índice de búsquedas reciben el nombre
de long tail terms. Este tipo de términos capturan un tráfico más cualificado
para la venta (Siddiqi, 2012).
• Competencia en Google AdWords
La herramienta Google Keyword Planner está diseñada para ayudar a usuarios
a estimar el volumen de tráfico esperado, el coste de los anuncios y la
competitividad existente para las palabras seleccionadas.
Los anuncios de AdWords son anuncios patrocinados, es decir, el anunciante
paga por cada clic que el usuario realiza en el anuncio. Términos con una alta
competitividad entre anunciantes implica competitividad para imprimir
anuncios usando la plataforma Google AdWords.
Dado que nosotros no estamos haciendo uso de Google AdWords para
promocionar nuestro contenido, sino que estamos buscando las palabras clave
a emplear para posicionar nuestros documentos, daremos una interpretación
diferente al calificativo de alta competitividad.
En Google AdWords, los anuncios son posicionados en base a las palabras
clave seleccionadas. Los anunciantes pagan por cada clic que adquiere el
anuncio. Palabras clave con una alta competitividad pueden ser interpretadas
como palabras que consiguen llegar al correcto usuario, es decir, palabras
clave cuyo precio es rentable dado que consigue conversiones.
El término conversión tiene un amplio contexto que puede abarcar:
incremento de visibilidad, consecución de leads o consecución de ventas,

110
entre otros. Para cada palabra clave con alta competitividad, deberemos
evaluar si representan el tipo de usuarios que nos interesa.
• Precio del clic en Google AdWords
Información sobre el precio del clic es indicativo sobre la rentabilidad del
tráfico y del producto en venta. Los anuncios que disponen de un alto precio
por clic son aquellos para los cuales los márgenes de beneficio son superiores.
Antes de optimizar documentos web, será conveniente analizar las palabras clave
seleccionadas con herramientas como Google Keyword Planner. Esta herramienta nos
permitirá conocer el volumen de búsquedas existente para los términos seleccionados,
así como el grado de conversión de la palabra clave o la rentabilidad de estas.
3.1.3. Benchmark
Se conoce como benchmark a la técnica utilizada para medir o comparar los
resultados de un sistema frente a otro. En este apartado exponemos algunos de los
benchmarks más empleados en la industria SEO a la hora de comparar la posición del
documento con el volumen de clics que recibe.
Entre los estudios empleados como benchmark por expertos en posicionamiento
online destacan los realizados por las empresas Enquiro (Enquiro, 2007), Optify
(Siddiqi, 2012) y Chitika (Chitika, 2013). En la siguiente imagen (Figura 26) vemos
los resultados de estos tres estudios:

111
Figura 26: Benchmark ratio de clics por posición del documento
La gráfica anterior (Figura 26) muestra el porcentaje de clics adquirido por
documentos web (conocido como click-through-rate o CTR) en base a la posición en
la que se encuentran. Los documentos que se sitúan en la primera posición de Google
son los que adquieren el mayor porcentaje de clics, triplicando el porcentaje de clics
adquiridos por los documentos que se encuentran en la segunda posición y obteniendo
hasta cuatro veces más clics que los situados en la tercera posición.
Según los resultados obtenidos para los anteriores estudios, deberíamos esperar que
nuestros documentos tuvieran ratios de clics cercanos a los indicados en la siguiente
tabla (Tabla 6), en función de la posición en la que se encuentren:
Posición CTR benchmark
#1 32.5 – 36.4 %
#2 11.7 – 17.6 %
#3 8.7 – 11.4 %
#4 5.1 – 8.1 %
#5 4.0 – 6.1 %
#6 4.1 – 4.4 %
#7 3.5 – 4.1 %
#8 3.1 – 3.5 %
0
5
10
15
20
25
30
35
40
0 2 4 6 8 10 12
Enquiro '07
Optify '10
Chitika '13

112
#9 2.6 – 3.0 %
#10 2.2 – 3.6 %
Tabla 6: Posicionamiento y ratio de clics
El principal objetivo de tener un benchmark es disponer de un punto de comparación,
de forma que podamos evaluar el progreso de nuestros resultados y dispongamos de
un objetivo a alcanzar.
Durante el desarrollo de este proyecto final de carrera, hemos encontrado que
porcentajes de CTR muy por debajo del benchmark suelen ser debido a errores de
medición o de crawling. A continuación explicamos este tipo de errores:
- Precisión de la herramienta web
Google Webmaster Tools es una herramienta bien diseñada para detectar
problemas de crawling o indexación. Desafortunadamente, durante la
realización de este proyecto final de carrera nos hemos enfrentado a
incoherencias con respecto a la posición que ocupan nuestros documentos y la
posición marcada por Google Webmaster Tools.
Para poder realizar un análisis de los datos que disponemos, debemos de
conocer bien las herramientas que usamos, su efectividad y sus defectos.
- Procesos de crawling o indexación
Si los procesos de crawling o indexación fallan, es muy probable que los título
y descripciones mostrados en la lista de resultados no sean los esperados.
En siguientes apartados desarrollaremos estrategias para aumentar el ratio de clics
adquiridos desde los motores de búsqueda, en base a las recomendaciones realizadas
por expertos en el sector.
3.1.4. Conclusiones
En este apartado hemos visto los tipos de palabras clave de los cuales podemos hacer
uso: head terms y long tail keywords. Se ha introducido el uso de la herramienta

113
Google Keyword Planner como medio para analizar las palabras clave a emplear en
los documentos web. Haremos uso de head terms para la adquisición de un alto
volumen de búsquedas o long tail keywords para adquirir usuarios más preparados
para la conversión.
Los documentos posicionados en las tres primeras posiciones adquieren entre el 50%
- 60% de los clics, obteniendo la primera posición de Google ratio de entre el 32% -
36% de las búsquedas.
Para finalizar, se ha expuesto un conjunto de benchmarks empleados en la industria
SEO, los cuales sirven como marco de referencia para evaluar como de desarrollado
se encuentra un proyecto que busca posicionamiento y adquisición de tráfico.
3.2. Estrategias de publicidad online
En este apartado presentaremos estrategias empleadas en marketing online para
incrementar la visibilidad y el tráfico que recibe un sitio web. Para ello se expondrán
los conceptos de marketing de afiliación y anuncios patrocinados como métodos para
alcanzar a los usuarios mientras realizan búsquedas o navegan entre páginas web.
También se expondrá el concepto de e-mail marketing como canal de comunicación,
permitiendo a las empresas incrementar la visibilidad de su marca mediante la
publicidad por e-mail.
3.2.1. Sitios de afiliados
Cuando los usuarios realizan búsquedas desde los motores de búsqueda, estos
devuelven una lista de resultados ordenados según la relevancia del documento, la
cual es estimada por el propio motor. Entre los resultados que nos ofrecen solemos
encontrar sitios web, sitios de cupones, sitios de empresas, comparadores de
productos o blogs.

114
Al conjunto de sitios web que promocionan servicios o productos y perciben un
margen por la venta, se los conoce como sitios de afiliados. Sitios de cupones y
comparadores son un ejemplo de sitios de afiliados.
En esta sección presentaremos los conceptos de marketing de afiliación y las ventajas
que ofrece para los anunciantes el uso de este tipo de marketing. Expondremos
también estudios desarrollados por Forrester Research y Google para comprender el
valor añadido que adquieren los anunciantes al usar este tipo de marketing como canal
de ventas y promoción online.
Marketing de afiliación
El marketing de afiliación es un tipo de marketing especializado en la obtención de
resultados. Trabaja con la figura de afiliados, entendiendo estos como “compañías,
grupos o personas individuales que promocionan servicios y productos de
anunciantes.” (IAB, 2010).
Los afiliados son especialistas en conseguir un tipo de tráfico y dirigirlo hacia otros
sitios web. Por cada uno de los usuarios que el afiliado envía al comercio online para
el que trabaja, si los usuarios terminan comprando, el afiliado percibe un porcentaje
sobre la venta que inicia.
Los afiliados trabajan con diferentes modelos de promoción para capturar tráfico y
derivarlo hacia otros sitios web. Entre ellos encontramos blogs o sitios web,
comparadores, sitios de ofertas, sitios de promociones y cupones o sitios de cash
back entre otros.
En los últimos años los sitios de ofertas y cupones han adquirido un mayor
protagonismo. Según destaca el informe desarrollado por Google (Google, 2012),
entre el 2009 y el 2012 el número de usuarios que navegan desde las tiendas de retail
hacia los sitios de ofertas y cupones experimentó un crecimiento de tráfico del 69%.

115
Este cambio de comportamiento es aprovechado por aquellos comercios online que
apuestan por el marketing de afiliación. Las principales ventajas de trabajar con
afiliados son:
• Rentabilidad
Los afiliados trabajan en base al resultado de sus acciones. Si no consiguen
tráfico valioso para los anunciantes, no reciben remuneración. Este modelo de
marketing no ofrece riesgos aunque el valor de la venta se devalúe por la
comisión que adquiere el afiliado.
• Visibilidad
El comportamiento del usuario online ha cambiado. Los usuarios están cada
vez mas involucrados en las compras que realizan. Mientras que en el 2010 la
media de fuentes consultadas antes de realizar una compra online era de 5.27
en 2011 el número de fuentes consultadas creció hasta las 10.4 (Google,
2012).
Según destaca el estudio (Forrester Consulting, 2012), el 57% de los usuarios
reconoce que ver anuncios de un producto en diferentes sitios web, incrementa
las posibilidades de compra del producto.
Los afiliados, mediante la implementación de blogs, comparadores y sitios de
cupones permiten alcanzar a los usuarios durante los diferentes ciclos de
compra (búsqueda de información, comparación de productos, búsqueda de
ofertas y compra), incrementando la visibilidad y ofreciendo descuentos que
pueden cerrar la compra.
• Tráfico Cualificado
Los afiliados son especialistas en la adquisición de tráfico de calidad. Tal y
como mencionábamos anteriormente, el estudio (Google, 2012) detectó un
incremento del 69% de usuarios que visitan sitios de cupones y descuentos
desde los sitios de retail.

116
Este tráfico es un tráfico cualificado (Forrester Research, 2011) para la venta,
el cual busca la mejor forma de rentabilizar los recursos económicos de los
que dispone.
• Ventas
Los afiliados son especialistas en la adquisición de tráfico de calidad. Esto se
debe al tipo de sitios web del que disponen. Sitios comparadores, de cash back
o cupones están dirigidos a un público que busca la conversión.
Mediante el ofrecimiento de pequeños descuentos, los afiliados incentivan
finalizar la venta. En el estudio (Forrester Research, 2011), el 88% de los
usuarios entrevistados reconoció que los códigos promocionales y cupones
cierran la venta cuando se encuentran dubitativos.
Tras conocer las ventajas que ofrece el marketing de afiliación, presentamos cómo
hacer uso de este tipo de marketing. En la siguiente sección se expone cómo alcanzar
a los afiliados mediante el uso de las redes de afiliación.
Redes de afiliados
El trabajo con afiliados se realiza a través de las redes de afiliación. Las redes de
afiliación son el punto de encuentro entre anunciantes y afiliados (IAB, 2010). En
una red de afiliados podemos distinguir tres tipos diferentes de entidades:
- Plataforma de afiliados
Plataforma que permite la comunicación entre los afiliados y anunciantes.
Ofrece opciones de registro para ambos. En ella, los afiliados definen los
métodos de publicidad de los que disponen (IAB, 2010).
La plataforma ofrece programas para que anunciantes y afiliados puedan estar
en contacto sobre el desarrollo de las campañas de publicidad y la medición de
los resultados de estas campañas (IAB, 2010).

117
- Afiliados
Los afiliados son compañías o personas que cuentan con un medio para
promocionar productos, a cambio de cobrar comisiones por la venta que
inician (IAB, 2010).
- Anunciantes
Compañías que buscan promocionar o vender productos. Hacen uso de
páginas de afiliados para anunciarse e incrementar su visibilidad, pagando una
comisión en base a los resultados obtenidos (IAB, 2010).
Los anunciantes entran en contacto con los afiliados a través de la plataforma de
afiliación. Una vez toman la decisión de anunciarse con algún afiliado, deberán de
acordar la cuantía de la comisión y la acción por la cual pagar una comisión. Los
modelos de pago existentes dependen de la plataforma de afiliación, aunque es común
encontrar los siguientes modelos:
- CPM (cost-per-thousand-impressions)
Se conoce como CPM o cost-per-thousand-impressions, al coste que el
anunciante paga por cada 1000 impresiones de su anuncio en el sitio web del
afiliado (IAB, 2010). Este tipo de modelo publicitario es el mas parecido a los
modelos tradicionales de publicidad presentes en televisión o radio.
Esta opción es utilizada como medio para incrementar la visibilidad o
exposición de una marca en Internet. La adquisición de usuarios no debe de
ser el objetivo, dado que existen otros modelos más rentables que nos
permitirán pagar por la adquisición de tráfico (Marshall & Todd, 2012).
- CPC (cost-per-click)
La modalidad CPC o cost-per-click define el coste a pagar por los anunciantes
por cada clic que los usuarios realizan en los anuncios que los afiliados
disponen en su web (IAB, 2010). Esta modalidad es especialmente útil cuando
el objetivo es la adquisición de tráfico.

118
A diferencia de la modalidad CPM, este modelo no tiene en cuenta el número
de impresiones. Los anunciantes pagan por la adquisición de usuarios en su
web.
- CPDC (cost-per-double-click)
La modalidad CPDC o cost-per-double-click define el coste que los
anunciantes pagan por cada segundo clic (IAB, 2010). Permite a los
anunciantes adquirir un tráfico que ha verificado su interés en el producto.
En esta modalidad, los afiliados son remunerados cuando envían tráfico tras
un segundo clic. El requerimiento de dos clics obliga a los afiliados a disponer
de una página intermedia donde enviar a los usuarios. Los clics realizados en
esta página intermedia serán aquellos por los que los anunciantes paguen.
Este tipo de páginas intermedias suelen ampliar la información del producto,
disponiendo de enlaces hacia la página del anunciante. Así, los anunciantes
reciben usuarios interesados en el producto y con conocimientos sobre este.
- CPL (cost-per-lead)
Se conoce como lead a la adquisición de los datos del usuario. La adquisición
de datos se realiza mediante el relleno de un formulario (IAB, 2010). Esta
información es valiosa para las empresas dado que les otorga la posibilidad de
establecer posteriores contactos con los usuarios.
La modalidad CPL o cost-per-lead define el precio a pagar por la adquisición
de los datos del usuario. Los afiliados envían tráfico hacia la página del
anunciante, la cual dispone de un formulario para la adquisición de datos. Los
anunciantes remuneran a los afiliados en función del número de formularios
que reciben.
- CPA (cost-per-adquisition)
La modalidad CPA o cost-per-acquisition es la modalidad de pago más
empleada en las tiendas online o e-commerce (IAB, 2010). Los anunciantes

119
pagan únicamente por aquellos usuarios enviados por sitios afiliados que
terminan comprando o adquiriendo productos.
En esta modalidad se establece el precio a pagar a los afiliados cuando inician
la venta de un producto. La comisión percibida por el afiliado puede ser fijada
de antemano o variable, dependiendo del precio del producto vendido.
Para finalizar el apartado, mostramos un cuadro resumen (Tabla 7) extraído de la web
afiliado.com con algunas de las plataformas de afiliación más conocidas y los
modelos de pago que soportan:
Red de afiliados Zanox Affilinet Adjal Afilead Argonas
Cost-per-thousand-impressions
NO
Sí
NO
Sí
NO
Cost-per-click
Sí Sí Sí Sí NO
Cost-per-double-click
Sí NO Sí NO NO
Cost-per-adquisition
Sí Sí Sí Sí Sí
Cost-per-lead Sí Sí Sí Sí Sí
Tabla 7: Plataformas de afiliación y acciones que registra la plataforma
3.2.2. Publicidad online
En este apartado presentamos el concepto de marketing contextual como medio para
publicitar en Internet un sitio web en base a un conjunto de palabras clave
seleccionadas.

120
A diferencia del marketing de afiliación, este tipo de marketing no requiere de la
selección de sitios afiliados, acuerdo de las comisiones o conversaciones con terceras
personas. Como veremos en este apartado, facilita la creación de publicidad online y
automatiza el proceso de publicación de anuncios en sitios externos.
Al finalizar el apartado dispondremos de los conocimientos básicos sobre la creación
de publicidad online y los modelos de publicidad existentes.
Marketing contextual
Según la definición ofrecida por la organización profesional de marketing para
motores de búsqueda conocida como SEMPO, el marketing contextual es un tipo de
marketing en el cual los anuncios son automáticamente seleccionados en base al
contexto del sitio web (contenido, el idioma, estructura web y palabras clave del
anunciante) (SEMPO, 2011).
Este tipo de marketing funciona bajo la figura del afiliado. Como en toda red de
afiliación, los afiliados reciben un incentivo económico por cada clic que los usuarios
realizan en el anuncio que promocionan, o por cada impresión de un anuncio.
Mientras que en el marketing de afiliados los anunciantes tienen que seleccionar los
sitios web en donde quieren ver impresos sus anuncios, el marketing contextual
realiza esta labor de forma automática.
Anunciantes y afiliados acceden a que Google AdWords actúe como distribuidor de
anuncios contextuales. El sistema determina automáticamente qué anuncios imprimir
en qué sitios web. Para ello hace uso de las palabras clave proporcionadas por el
anunciante y del contenido albergado en el sitio web.
Para hacer uso de este tipo de marketing, es necesario el uso de plataformas de
publicidad online específicas. Google AdWords es la más extendida, disponiendo de
dos redes de afiliados: Google display network (red de anuncios en sitios web) y
Google Search network (red de anuncios en el buscador de Google).

121
En este tipo de plataformas las palabras clave seleccionadas por los anunciantes y los
términos de búsqueda empleados por los usuarios determinan los anuncios a mostrar.
Cuando estos coinciden, los anuncios son considerados como candidatos a ser
mostrados.
La impresión de los anuncios depende de otros factores específicos de la plataforma
de publicidad a emplear. En el capítulo dedicado a las herramientas online usadas en
el presente proyecto final de carrera, presentaremos los factores la plataforma Google
AdWords tiene en cuenta a la hora de imprimir anuncios online.
Modelos de publicidad online
Las plataformas de anuncios contextuales ofrecen al menos dos modelos de
publicidad. Estos modelos de publicidad permiten a los anunciantes elegir las
acciones por las que pagar. Los modelos de publicidad soportados por plataformas
como Google AdWords o Bing Ads son:
- Pago por click
Se conoce como pago por click al modelo de promoción online por el cual el
anunciante paga únicamente por los clics que recibe el anuncio. También
conocido como pay-per-click, referencia al modelo de promoción online
basado en clics. Hablar de cost-per-click es hablar del coste que supone para el
anunciante el clic del usuario.
La fórmula que define el precio que pagamos por redireccionar a un usuario
hacia nuestro sitio web es la siguiente:
𝑃𝑟𝑒𝑐𝑖𝑜 𝑝𝑜𝑟 𝑎𝑑𝑞𝑢𝑖𝑠𝑖𝑐𝑖ó𝑛 𝑢𝑠𝑢𝑎𝑟𝑖𝑜 =𝐼𝑛𝑣𝑒𝑟𝑠𝑖ó𝑛 𝑒𝑛 𝑎𝑛𝑢𝑛𝑐𝑖𝑜𝑠
𝑁ú𝑚𝑒𝑟𝑜 𝑑𝑒 𝑐𝑙𝑖𝑐𝑠
- Coste por impresión
Se conoce como coste por impresión al modelo de promoción online por el
cual el anunciante paga por el número de impresiones que recibe el anuncio.

122
El término coste por impresión también es conocido como cost-per-
impression. Denota al modelo de publicidad por el cual el anunciante paga por
cada impresión.
Cuando se habla de cost-per-thousand-impressions, se hace mención al coste
que el anunciante pagará por cada mil impresiones del anuncio. Es un término
comúnmente empleado para hablar de modelo de coste por impresión, ya que
facilita el manejo de cifras y cuotas de pago.
Para conocer el coste de una impresión podemos hacer uso de la siguiente
formulación:
𝑃𝑟𝑒𝑐𝑖𝑜 𝑝𝑜𝑟 𝑖𝑚𝑝𝑟𝑒𝑠𝑖ó𝑛 =𝐼𝑛𝑣𝑒𝑟𝑠𝑖ó𝑛 𝑒𝑛 𝑎𝑛𝑢𝑛𝑐𝑖𝑜𝑠𝑁ú𝑚𝑒𝑟𝑜 𝑑𝑒 𝑖𝑚𝑝𝑟𝑒𝑠𝑖𝑜𝑛𝑒𝑠
En el capítulo siguiente, presentaremos cómo hacer uso de Google AdWords como
herramienta para realizar campañas de anuncios, tanto en buscadores como en sitios
web.
3.2.3. E-mail
Las estrategias de marketing online mostradas en los apartados anteriores son
estrategias conocidas como pasivas. Decimos pasivas porque requieren de la acción
del usuario (búsqueda web o visita a sitios web) para que la campaña de publicidad
pueda iniciarse.
En este apartado presentaremos el concepto de marketing por e-mail, los tipos de e-
mail existentes y los porcentajes de apertura de estos, como medio para incrementar la
eficacia de nuestro mensaje.
Email marketing
En 1971 Ray Tomlinson creó el e-mail. El propósito del e-mail era actuar como
herramienta de comunicación entre usuarios conectados a un mismo servidor. Hoy en

123
día, el e-mail es una herramienta fundamental como medio de comunicación, tanto
personal como promocional.
Email marketing es el término empleado para definir la acción de enviar mensajes
comerciales a un grupo de personas, empleando el e-mail como canal de
comunicación. El principal propósito que persigue esta técnica de marketing es
fidelizar al usuario, generar visibilidad sobre una marca y crear confianza mediante el
establecimiento de acciones informativas/educativas.
Proveedores de servicios de e-mail como iContact, Benchmark Email, Pinpointe o
MailChimp ofrecen la posibilidad de crear campañas promocionales mediante e-mail
de forma sencilla.
Este tipo de servicios son además capaces de obtener métricas sobre el
comportamiento de los usuarios cuando reciben un e-mail, tales como porcentajes de
apertura, porcentajes de clics o número de aperturas de e-mail entre otros. También
permiten la segmentación de usuarios en base a características definidas o grado de
interés.
Tipos de e-mail
El e-mail marketing es conocido en el sector de la publicidad online, como el segundo
medio de publicidad de entre los canales de marketing que ofrece mejores resultados.
Se encuentra únicamente por detrás de la promoción y rentabilidad que ofrece la
publicidad pay-per-click (Marketing Sherpa, 2009).
El e-mail marketing distingue dos tipos de e-mails, dependiendo de la acción que
motiva su envío. Los exponemos a continuación:
- E-mail transaccionales
Se conoce como e-mail transaccionales a los que son enviados como
respuesta a una acción realizada por el usuario. Este tipo de e-mails se
caracterizan por ser bien aceptados por los usuarios, contando con porcentajes

124
de apertura cercanos al 47% y siendo el ratio medio de clics del 20%
(McDonald, 2013).
Debido a que el porcentaje de apertura es bastante alto, cada vez es más usado
para el envío de información promocional, siempre y cuando el principal
propósito del e-mail sea la información sobre la transacción realizada.
Ejemplos de ello serían los e-mails que se envían cuando el usuario se registra
en un sitio web o cuando lleva a cabo una compra. Son e-mails con una alta
apertura debido a que el usuario espera recibir una notificación sobre sus
acciones.
- E-mail directos
A este tipo de promociones se las conoce como “Opt-in email”, y es el usuario
el que inicia la conversación con la compañía, dando su consentimiento para
recibir promociones por medio del e-mail.
La media de aperturas de e-mail promocionales se sitúa en torno al 20.1%,
contando con una media de clics del 2.3% - 2.5% (Silverpop, 2012), aunque
estos porcentajes varían según la industria y el sector.
En el año 2002, la Unión Europea introduce la directiva de privacidad y
comunicación electrónica (Directive on Privacy and Electronic
Communications). En ella se establece que para enviar e-mail directos es
necesario contar con el consentimiento previo del usuario. Desde entonces
algunos de los países miembros la han incorporado también en sus leyes.
En capítulos posteriores veremos cómo realizar campañas de e-mail, segmentar
usuarios y crear listas usando el servicio MailChimp.
3.2.4. Conclusiones

125
En este apartado hemos revisado los conceptos de marketing de afiliación como un
marketing basado en la consecución de objetivos. Su uso permite a los anunciantes
visibilidad web y tráfico cualificado. A cambio, los anunciantes tienen que ofrecer un
margen del beneficio por las ventas iniciadas por los afiliados.
Mediante el acceso a las redes de afiliados, los anunciantes contactan con los
afiliados, escogen el modelo de pago y disponen del software capaz de medir el
desarrollo de las campañas.
Como método para automatizar los anuncios o publicidad web se encuentra el
marketing contextual. Este nos permite mostrar publicidad en motores de búsqueda y
sitios web en base a un conjunto de palabras clave seleccionadas. Según el estudio
realizado por Marketing Sherpa, el modelo pay-per-click es el modelo más eficaz a la
hora de rentabilizar los esfuerzos publicitarios (Marketing Sherpa, 2009).
Como estrategia directa para iniciar el contacto con los usuarios, hemos presentado el
marketing por e-mail. Se han estudiado los diferentes tipos de e-mail de los cuales
pueden hacerse uso y sus tasas de apertura media. Debido a las altas tasas de apertura,
los e-mail transaccionales están incluyendo cada vez más publicidad en un intento por
conseguir incrementar la visibilidad de productos (McDonald, 2013).
3.3. Optimización para la conversión
El posicionamiento web, la publicidad contextual y el uso de afiliados nos permite
incrementar la visibilidad de nuestro sitio web. A cambio, la promoción por estos
canales genera costes. Para mejorar la rentabilidad de nuestro sitio web, deberemos de
trabajar en mejorar el porcentaje de usuarios que recibimos por posicionamiento
orgánico (desde los motores de búsqueda), así como mejorar la rentabilidad de los
usuarios que adquirimos mediante el uso de publicidad online.
Si el usuario no termina clicando en nuestro resultado de Google o en la publicidad
que dispongamos en sitios web externos, los esfuerzos en optimizar el sitio web habrá

126
sido en vano. De la misma forma, si los usuarios llegan a nuestro sitio web pero no
convierten, la inversión en publicidad realizada para captar usuarios no será rentable.
En este apartado presentaremos estrategias empleadas por expertos en marketing
online para mejorar el ratio de clics, incrementar la efectividad de los anuncios
contextuales así como prácticas para preparar un sitio web para captar usuarios y
llevarlos hasta la conversión.
La sección está dividida en varias subsecciones: optimizaciones a realizar en la lista
de resultados de Google; estrategias a usar en las campañas de publicidad online;
prácticas a implementar en sitios web para mejorar la captación de datos de usuarios y
herramientas para optimizar nuestras páginas de conversión.
3.3.1. Resultados de búsquedas
En el capítulo dedicado al posicionamiento de documentos web en motores de
búsqueda, hemos visto técnicas que nos ayudan a controlar el escaneo de documentos,
la indexación de contenidos y cómo optimizar los contenidos web. La consecución de
un buen posicionamiento era el objetivo principal.
A pesar de todas las técnicas mencionadas en el capítulo de posicionamiento online,
no siempre es posible alcanzar los primeros puestos en la lista de resultados de
Google. A continuación presentamos un conjunto de técnicas cuyo objetivo es
mejorar el ratio de clics de los documentos que aparecen en la lista de resultados:
Revisar palabras clave en títulos y descripciones
Cuando se realiza una búsqueda web en el motor de Google, éste proporciona una
lista de resultados, donde se distingue el título de la web, la dirección web así como
un texto resumen.
A veces los motores de búsqueda no indexan correctamente este contenido. Otras
veces este no aparece por error nuestro. Optimizar los títulos y descripciones para
captar al usuario es una de las primeras optimizaciones que podemos introducir.

127
La siguiente imagen (Figura 27) muestra como Google destaca en negrita las palabras
que coinciden con los términos de búsqueda. En la imagen de a continuación, los
términos de búsqueda fueron “low prices in electronics”.
Figura 27: Marcado de palabras clave en una búsqueda web
Aparecer en la primera página de Google es sinónimo de visibilidad. Estamos en la
primera página de Google y esto permite que nuestro resultado sea impreso para
cualquiera que realice una búsqueda con nuestros términos clave.
La adquisición de posiciones es también un factor importante a la hora de adquirir
usuarios. A pesar de ello, los usuarios disponen de ocho resultados en la lista sobre los
que clicar. Si no nos encontramos entre los primeros puestos, deberemos intentar
llamar la atención del usuario hacia nuestro resultado.
Especialistas en el posicionamiento de documentos web como Eduard Blacquiere o el
equipo de Catalyst indican que la personalización de resultados ayuda a incrementar
el número de clics (Eduard Blacquiere: Higher efficiency through Google Rich
Snippets, Catalyst team: How Rich Snippets Can Improve your CTR). Una opción
para que nuestro resultado sea más atractivo será estudiar las palabras clave
empleadas por los usuarios y optimizar las descripciones web y títulos acordes a estas.

128
Uso de head terms y long tail keywords
Según el estudio realizado por la empresa Optify (Siddiqi, 2012), la selección de las
palabras clave influye en el ratio de clics que reciben los documentos. La imagen
(Figura 28) extraída de (Siddiqi, 2012) muestra lo enunciado anteriormente:
Figura 28: CTR para head y long tail keywords por posición de documentos
Observamos como el ratio de clics varía en función de la posición ocupada por el
documento y el tipo de término empleado (head terms en rojo o tail term en verde).
El uso de head terms permite la adquisición de un alto volumen de clics si nuestros
documentos ocupan las primeras posiciones. Usando long tail keywords
incrementamos nuestras posibilidades de conseguir usuarios (existe un mayor CTR
por posición), aunque el volumen de búsquedas de long tail keywords es reducido, por
lo que el volumen de usuario también será inferior (Siddiqi, 2012).
Si nuestros documentos no disponen de un buen posicionamiento en la primera página
de Google, podría ser conveniente la optimización de documentos usando long tail
keywords. Optimizar nuestros documentos para este tipo de búsquedas nos permitirá
alcanzar un reducido volumen de público, pero más preparado para la conversión
(Siddiqi, 2012).
Sitelinks
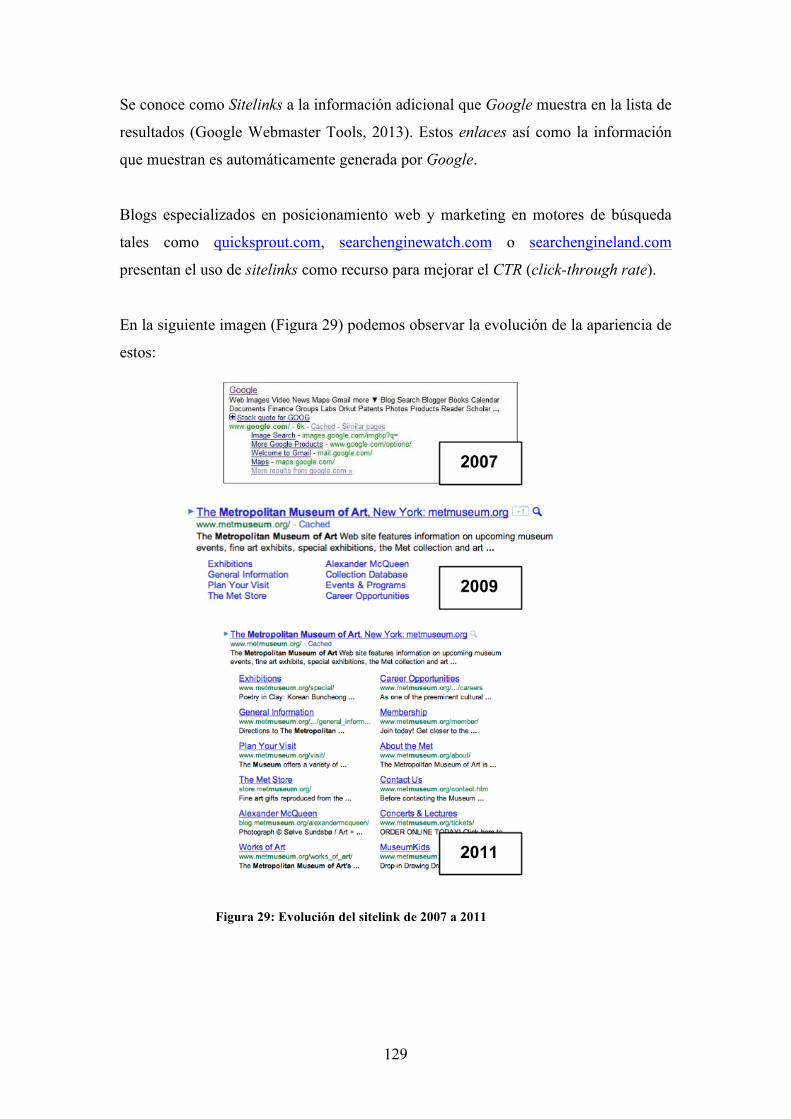
129
Se conoce como Sitelinks a la información adicional que Google muestra en la lista de
resultados (Google Webmaster Tools, 2013). Estos enlaces así como la información
que muestran es automáticamente generada por Google.
Blogs especializados en posicionamiento web y marketing en motores de búsqueda
tales como quicksprout.com, searchenginewatch.com o searchengineland.com
presentan el uso de sitelinks como recurso para mejorar el CTR (click-through rate).
En la siguiente imagen (Figura 29) podemos observar la evolución de la apariencia de
estos:
Figura 29: Evolución del sitelink de 2007 a 2011

130
Según documenta Google en su blog (Google Webmaster Tools, 2013), el correcto
uso de las marcaciones Html y la disposición de una buena arquitectura web son los
principales factores para que el motor de búsqueda sea capaz de generar sitelinks.
La apariencia actual de los sitelinks se muestra en la siguiente figura (Figura 30):
Figura 30: Modelo de Sitelinks empleado actualmente
Si optamos por el uso de publicidad online, plataformas como Google AdWords
permiten la creación de sitelinks en sus anuncios de enlaces. Especialistas como Dan
Friedman llega a cuantificar en un 30% de incremento del CTR cuando se emplea en
anuncios patrocinados (Friedman, 2011).
Marcando contenido web
Con el objetivo de proporcionar mayor información al usuario desde la lista de
resultados, Google incorpora una serie de marcadores HTML que permiten
personalizar estos (Google Webmaster Tools, 2013).
Esta personalización de resultados puede ayudarnos a destacar sobre el resto de
documentos presentes en la lista de resultados. Para personalizar nuestros resultados,
es necesario hacer uso de una marcación HTML específica. Esta marcación puede
realizarse a través de la herramienta Data Highlighter (Google Webmaster Tools,
2014), o manualmente mediante el uso del formato microdata.

131
En la web schema.org, podemos encontrar todos los tipos soportados, el conjunto de
propiedades de cada tipo, así como las relaciones de herencias o jerarquías que deben
respetar.
Actualmente, Google soporta la personalización de resultados para aquellas páginas o
documentos que dispongan de información sobre: personas, productos, recetas,
música, eventos, organizaciones, valoraciones de producto y aplicaciones software.
A continuación, presentamos ejemplos de personalización de resultados soportados
por Google:
Aplicaciones Software
Si queremos aportar información extra a los motores de búsqueda sobre el tipo de
aplicación que disponemos en nuestra web, podemos emplear el tipo
SoftwareApplication (Google Corporation , 2011).
El uso de este marcado nos permite indicar el tipo de sistema operativo soportado
o el tipo de aplicación:
Figura 31: Personalización de resultado: aplicación de software
Ofertas de productos
Si nuestro sitio web dispone de ofertas, es posible personalizar nuestros
documentos con marcadores HTML que destacarán nuestras productos en la lista
de resultados. Actualmente el marcador solo nos permite marcar un único
producto por página, aunque es posible marcar diferentes precios.

132
La marcación de productos u ofertas tiene restricciones (Google Corporation,
2011):
- El contenido de la página debe estar centrado en el producto anunciado.
- La compra del producto debe poder realizarse desde esa misma página.
- No puede emplearse este marcado para promocionar productos para adultos.
En las siguientes figuras (Figura 32 y Figura 33) pueden observarse las diferentes
personalizaciones que podemos conseguir dependiendo del uso de formato de
marcación usado:
Oferta del Producto
Figura 32: Personalización de resultado: oferta de producto
Oferta del Producto con varios vendedores
Figura 33: Personalización de resultado: oferta de producto con diferentes precios
Valoraciones
La adición de valoraciones e información social en la página de resultados de
Google permite a los webmasters incrementar el ratio de clics entre un 5% y un
10% (Google, 2012).
Si combinamos las valoraciones con información sobre el producto, podemos
conseguir resultados como la Figura 34:

133
Rating y precios
Figura 34: Personalización de resultado: valoración de producto y precio
Friendly-Urls
Se conoce con el término de friendly-url a la creación de direcciones web descriptivas
y concisas. La importancia que ha adquirido el uso de friendly-urls está relacionada
con la forma en la que los usuarios reaccionan ante estas. A continuación
enumeramos algunas de las ventajas:
• Evitar confusión
Multitud de usuarios estudian el contenido de las direcciones web antes de
pulsar sobre el enlace. La creación de direcciones web limpias favorecen el
entendimiento del contenido que albergan (Sherpa, 2008).
• Promoción de keywords
Las URLs o direcciones web son el lugar recomendado por los expertos para la
situación de keywords. Google resalta las palabras que coincidan con los
términos de búsqueda. Esto permite destacar la dirección web sobre el resto de
resultados.
• Incrementar CTR
Direcciones web limpias y con un número reducido de caracteres obtienen dos
veces mas clics comparado con direcciones largas y con direcciones
indescifrables (Sherpa, 2008).
La personalización de direcciones web debe permitir al usuario conocer dónde se
encuentra y qué contiene el documento. Según se documenta en (Sherpa, 2008), este
tipo de prácticas ayuda a incrementar el ratio de clics desde los motores de búsqueda.

134
3.3.2. Publicidad Online
En la sección anterior hemos presentado la publicidad contextual como una
publicidad online basada en palabras clave. Este tipo de publicidad hace fácil el
posicionamiento de anuncios en miles de sitios web, mientras el usuario navega o
realiza búsquedas. Este tipo de publicidad se centra en dónde posicionar anuncios y
no en el perfil al que nos estamos anunciando.
En esta sección presentamos formas de alcanzar al usuario en base a su perfil. No nos
centramos en los sitios donde promocionar nuestro contenido sino en el perfil del
usuario al que queremos anunciarnos, independientemente del sitio web donde se
encuentre. También introduciremos el concepto de remarketing, el cual nos permitirá
centrar nuestros anuncios en usuarios que ya visitaron nuestro sitio web.
Marketing por comportamiento
El marketing por comportamiento es una de las estrategias de marketing online
empleadas por anunciantes para mejorar la efectividad de las campañas publicitarias
(BlueLithium's BL Labs, 2006).
Este tipo de estrategia de marketing puede únicamente ser realizada por plataformas
de anuncios online populares. Estas plataformas son capaces de recopilar información
sobre el usuario (género, edad, localización), así como el comportamiento de este
mientras navega por sitios web (SEMPO, 2011). Métricas como el tiempo de estancia
en página, los enlaces pulsados, páginas visitadas, compras realizadas o términos de
búsquedas introducidos en motores de búsqueda son recopiladas por las plataformas
de anuncios como Google AdWords (Google AdWords Support, 2014).
En base a los datos recopilados, estas plataformas nos ofrecen opciones sobre las que
segmentar a los usuarios que recibirán la publicidad. Algunas de las características
sobre las que podemos segmentar los usuarios son: localización, edad, patrones de
comportamiento, intereses, etc. Servicios de publicidad online como Google AdWords
disponen de un mayor rango de opciones, permitiéndonos alcanzar a usuarios en base

135
a: estilo de vida, hábitos de compra, intereses o páginas visitadas (Google AdWords
Support, 2014).
Esta segmentación permite a los anunciantes elegir el público al cual mostrar los
anuncios, en lugar de elegir la web sobre la que anunciarse. Según el estudio
independiente realizado por la empresa BlueLithium (BlueLithium's BL Labs, 2006),
la combinación de anuncios contextuales que tienen en cuenta el público objetivo (es
decir, aquella campañas publicitarias que presenta anuncios en sitios web acordes con
los intereses del usuario) consiguen mejores porcentajes de clics en comparación con
campañas de publicidad contextual.
Este mismo estudio destaca que cuando los anuncios se presentan en sitios web fuera
de contexto, es decir, no existe relación entre el contexto del anuncio y el anuncio de
publicidad, el ratio de clics se reduce pero el tráfico adquirido produce mejores tasas
de conversión en comercios online (BlueLithium's BL Labs, 2006).
El siguiente fragmento extraído del estudio (BlueLithium's BL Labs, 2006) expresa lo
expuesto en los anteriores párrafos:
“As a top-line recommendation for advertisers, if your goal is traffic, use behavioral
targeting in context. If your goal is conversions, use behavioral targeting out of
context.”
En la sección dedicada al funcionamiento de la herramienta Google AdWords
introduciremos cómo hacer uso de la herramienta para realizar campañas de
marketing enfocadas en usuarios que reúnan características especificas.
Remarketing
A lo largo de este capítulo hemos presentado estrategias de publicidad que nos
permiten alcanzar al usuario en base a palabras de búsquedas, mientras navega, en
base a sus gustos, preferencias o patrones de comportamiento.

136
En este apartado hablaremos sobre una técnica de marketing centrada en alcanzar a
usuarios que interactuaron previamente con nuestro sitio web. A esta técnica se la
conoce con el nombre de remarketing.
Mediante la creación de campañas de remarketing seremos capaces de realizar
promociones online alcanzando a usuarios que previamente visitaron nuestro sitio
web.
Esta técnica es especialmente útil a la hora de recapturar tráfico web. Por ‘recaptura
de tráfico web’ nos referimos a la captura de tráfico que previamente se interesó por
nuestro sitio web.
El uso de este tipo de marketing ha crecido en los últimos años como respuesta al
creciente abandono de carritos de compra en comercios online. La media de abandono
de carritos de la compra online, desde el 2008 hasta el 2013 es del 67.45% según se
estima en documento presentado por el instituto Baymard (Baymard Institute, 2013).
La siguiente gráfica (Figura 35) presenta la evolución del abandono de carritos de la
compra online:
Figura 35: Evolución del abandono de carritos de compra online

137
Para hacer frente a esta tendencia creciente de abandonos, las tiendas de comercio
online han incrementado las prácticas de remarketing como método para recapturar a
usuarios que abandonaban los carritos de la compra (Oullet, 2013).
Mientras que en 2011 el 14.6% de los 1000 mas importantes retailers online
realizaban acciones para recapturar este tráfico, en 2012 la cifra creció hasta el 19%
(Ouellet, 2012), alcanzando el 24.5% en 2013 (Oullet, 2013).
El estudio llevado a cabo por la empresa SeeWhy (SeeWhy, 2011) documenta cómo
las campañas de remarketing realizadas en tiempo real consiguen recuperar al 26% de
los usuarios que abandonan el carrito de la compra, generando un 105% más de
ingresos que las campañas de remarketing realizadas 24 horas después de recibir la
visita del usuario. Esto pone de manifiesto la importancia de actuar con rapidez a la
hora de realizar campañas de remarketing.
Para la creación de campañas de remarketing es posible usar la plataforma de
anuncios Google AdWords. Google AdWords hace uso de cookies para salvaguardar
información sobre el visitante. Estas cookies son almacenadas en las listas de
remarketing.
Las listas de remarketing almacenan información sobre los usuarios que cumplen con
una acción específica (por ejemplo, la visita al sitio web o la adición de un producto al
carrito de la compra). Así, mientras el usuario navega por un sitio web, plataformas de
anuncios como Google AdWords analizan el comportamiento del usuario. Ante una
acción determinada por el anunciante, la cookie que identifica al usuario pasa a
formar parte de la lista de remarketing.
“At first, your list might not have any cookie IDs associated with it. Once you've
added the remarketing tag to your pages, as visitors come to your site, they'll start
getting added to your list.” (Google AdWords Program, 2013)
El anunciante puede crear campañas centradas en los usuarios cuyas cookies están
almacenadas en alguna de las listas de remarketing. En la sección dedicada a Google

138
AdWords expondremos cómo crear listas de remarketing y cómo hacer uso de éstas en
campañas de remarketing.
3.3.3. Sitios Web
La adquisición de tráfico es el primer paso hacia la consecución de ventas online. En
los apartado anteriores hemos expuesto diferentes estrategias para optimizar los
resultados de búsqueda o sobre estrategias para centrar nuestros esfuerzos en perfiles
específicos de usuarios.
En esta sección expondremos algunos de los conceptos más destacados a la hora de
preparar un sitio web para la conversión. Expondremos como la velocidad de carga de
un sitio web afecta al comportamiento del usuario. Veremos estrategias empleadas
por sitios web para la adquisición de datos mediante squeeze pages, formularios de
suscripción y landing pages. Como herramienta para mejorar la efectividad de estas
páginas introduciremos el concepto de A/B testing.
Velocidad de Carga
La velocidad de carga de un sitio web es un factor que los motores de búsqueda tienen
en cuenta a la hora de posicionar un documento. Independientemente de cómo afecta
al posicionamiento web, la velocidad de carga afecta a la usabilidad del sitio web y a
la forma en la que interactúan los usuarios con ella.
Según el estudio realizado por JupiterReseach para la empresa Akamai
(JupiterResearch, 2006), un tercio de los usuarios online no esperan más de cuatro
segundos a que un sitio web cargue el documento. Pasados cuatro segundos, si el sitio
web no ha terminado de cargar, un tercio de los usuarios abandonarán el sitio.
El mismo estudio manifiesta que el 40% de los entrevistados considera la velocidad
de carga de una página web como uno de los factores más importantes para proseguir
en un proceso de compra online.

139
Este no es el único experimento relacionado con el cambio de comportamiento en los
usuarios ante un sitio web lento. Google ha realizado también pruebas para determinar
como la velocidad de carga afecta a los usuarios. El experimento realizado por
(Brutlag, 2009) buscaba conocer cuál era el comportamiento del usuario cuando se
introducían retrasos de 100 ms y 400 ms en la página de resultados.
Los resultados del estudio determinaron que la introducción de retardos de 400 ms
impactaban negativamente en el número de búsquedas realizadas por usuarios.
Durante las tres primeras semanas del experimento, los usuarios reducían el número
de búsquedas en un -0.44%, alcanzando un -0.74% de búsquedas durante las tres
siguientes semanas de estudio (Brutlag, 2009).
Si bien estos datos puede parecer insignificantes, según cifras ofrecidas por
ComScore, Google procesa al año 1.2 billones de búsquedas (Internet Live Stats,
2013). La reducción de un búsquedas por usuario del 0.74% supone ocho mil
cuatrocientos millones de búsquedas menos al año. Recordemos que Google consigue
la mayor parte de sus ingresos de los anuncios que muestra.
Existen estudios más recientes, como el realizado por la empresa Tagman en
colaboración con Glasses Direct (Tagman, 2012). Para llevar a cabo el estudio la
empresa Tagman introdujo retrasos en la carga de la web Glass Direct. Tras la
finalización del periodo de estudio, Tagman determinó que la reducción de la
velocidad de carga del sitio web repercutió negativamente en la tasa conversión del
sitio web. El aumento de un segundo en el tiempo de carga del sitio web redujo el
número de conversiones en un 6.7%.
Optimizar un sitio web para conseguir la conversión online depende de múltiples
factores. Como hemos expuesto mediante los anteriores estudios, la velocidad es uno
de ellos, el cual influye negativamente en el comportamiento del usuario, pudiendo
afectar incluso en la conversión del sitio web.
Captación de leads

140
En el área de marketing online se conoce con el término lead a la captura de datos del
usuario (Miller, 2010). Para la consecución de leads, los sitios web deben de
prepararse. Algunas de las estrategias empleadas para la recolección de datos de
usuarios son:
• Squeeze pages
Se conocen como squeeze pages a las páginas especializadas en la captación
de los datos del usuario (Arnold;Lurie;Dickinson;Marsten;& Becker, 2009).
Se caracterizan por disponer de un formulario para dejar información y una o
dos llamadas a la acción (también conocidas como calls-to-actions).
Figura 36: Squeeze page del sitio blogprofitcamp.com
Por llamadas a la acción se entiende el uso de un lenguaje directo que incite al
usuario a realizar el clic. Este tipo de páginas suele ofrecer algún tipo de
recurso gratuito como infografías, e-books o similares.
• Formularios de subscripción
Formularios localizados en el sitio web que permiten al usuario suscribirse al
contenido. Este tipo de suscripción permite al usuario recibir noticias o

141
artículos en el e-mail. Los formularios pueden disponerse en sitios específicos
del sitio web o aparecer en forma de popups.
Figura 37: Formulario para capturar e-mails en la web Backlinko.com
La captación de datos de usuarios, puede ser empleado por el equipo de marketing
para conseguir ventas a posteriori mediante un proceso de educación. Este proceso de
educación puede ser llevado a cabo mediante e-mails, y puede servir para incrementar
la visibilidad de una marca, los servicios y/o productos que oferta o la profesionalidad
con la que se realizan estos. El objetivo es fidelizar al usuario (Marketo Blog, 2012)
para posteriormente intentar llevarlo hacia la conversión.
Landing pages
Se conoce como landing page a la página a la que llega una persona tras pulsar un
banner o un anuncio web. Este tipo de páginas suele extender la información del
banner, y su objetivo es la consecución de la venta (Ash;Ginty;& Page, 2012).
Las landing pages son páginas que han sido optimizadas para la conversión. Para
optimizar las landing pages se hace uso del A/B testing, el cual veremos en el
apartado siguiente.
En la siguiente figura (Figura 38) podemos observar un ejemplo de landing page:

142
Figura 38: Ejemplo de landing page del sitio Advanced Data Systems Corporation
A/B Testing
Se conoce como A/B testing a la comparación de dos versiones de una misma página
con el objetivo de conocer cuál ofrece mejores resultados. Este tipo de tests son
empleados para determinar, de forma empírica, qué variante obtiene mejores
resultados.
Hablar sobre páginas optimizadas para la conversión (como son las landing pages o
squeeze pages), es hablar sobre páginas que han sido diseñadas mediante el uso de
A/B testing.
Para realizar A/B testing de forma efectiva, es necesario disponer de un framework
que nos permita:
- Medir:
En un experimento A/B, lo primero que tenemos que decidir es la métrica que
determina el éxito del experimento. Esta métrica debe de poder ser medida por
el framework.
- Disponer de variaciones:

143
Disponer de dos versiones: la versión de control y una versión variante. Estas
serán mostradas paralelamente a los usuarios que accedan a la dirección web.
El uso de una única variante en el diseño nos permitirá determinar que es esta
variación la causante del cambio de comportamiento en los usuarios.
- Adquirir tráfico:
Para que los resultados obtenidos puedan ser considerados como válidos, estos
deben de ser estadísticamente significativos. Para ello es recomendable
realizar los tests en páginas con un alto volumen de tráfico.
Servicios como Optimizely, Visual Website Optimizer, KissMetrics o Google
Analytics proporcionan herramientas online para la creación de pruebas de A/B
testing.
En casos en los que sea difícil determinar si la introducción de cambios en un sitio
web mejorará los resultados, es conveniente realizar experimentos de A/B. Una vez
recopilados suficientes datos, podremos tomar decisiones informadas basadas en
hechos.
3.3.4. Conclusiones
En esta sección hemos visto diferentes técnicas que nos pueden ayudar a mejorar los
resultados de captación de usuarios desde Google, así como mediante la segmentación
de usuarios que reciben nuestros anuncios.
Como medio la usabilidad del sitio web, hemos destacado varios estudios que nos han
enseñado la repercusión de disponer de un sitio web con un tiempo de carga superior
a los 4 segundos.
Como medio para mejorar la conversión web, hemos presentado los términos de
landing pages, squeeze pages y formularios de suscripción. Mediante el uso de la

144
herramienta de trabajo de a/b testing seremos capaces de probar variaciones web y
determinar que cuales mejoran la conversión o ventas.
3.4. Analítica web
En los apartados anteriores hemos visto estrategias para la adquisición de tráfico,
desde buscadores, afiliados o mediante publicidad. Hemos introducido técnicas para
mejorar el CTR, así como elementos a optimizar para mejorar la conversión web. Se
ha presentado el A/B testing como herramienta para optimizar documentos web
específicos que buscan la adquisición de leads o el incremento de ventas.
En este apartado presentamos la analítica web como herramienta para medir la
evolución de un sitio web. Esta nos proporciona un framework para identificar las
acciones online que traen valor al negocio y aquellas que no son rentables.
3.4.1. Analítica web y objetivos de negocio
El uso de la analítica web nos permite recolectar, analizar y emitir informes de datos
(Digital Analytics Association, 2013). Herramientas como Google Analytics realiza
todas estas acciones de forma automática. A pesar de ello, el uso de estas
herramientas no significa que sepamos cómo interpretar los datos que nos
proporciona.
Para poder realizar un correcto análisis de estos necesitamos conocer el tipo de sitio
web (blog, comercio online, web de empresa que oferta servicios, …) y los objetivos
que tiene definidos (Munoz Vera & Elosegui Figueroa, 2011).
Antes de comenzar con cualquier análisis de datos, debemos de conocer cuál es el
objetivo del sitio web. Expertos en analítica web recomiendan formularse preguntas
sobre la existencia del sitio web, es decir, sobre la razón por la que se creó este
(Kaushik, 2010).

145
Estas suelen estar relacionadas con ideas para impulsar un negocio: como medio para
obtener visibilidad, para incrementar las ventas mediante un canal online, como canal
para resolver dudas y evitar colapsos en la línea de atención al cliente. Sea cual sea el
motivo por el cual se creo el sitio web, este nos determinará qué papel desempeña
para el negocio o comercio en cuestión.
Una vez conocemos el porqué se desarrolló el sitio web, es decir, cuales son las
necesidades de negocio que tiene que aportar el sitio web, estamos en disposición de
estudiar como transformar estas en acciones web. En la siguiente sección
presentaremos cómo traducir estos objetivos en acciones web (Kaushik, 2010).
3.4.2. Objetivos web
En el apartado anterior hemos destacado la importancia de reconocer la función que
debe de cumplir un sitio web con respecto a los objetivos de negocio. Conocer estas
nos ayudará a analizar y determinar cuales son las acciones web que traen valor al
negocio.
Para medir cómo el canal web contribuye a los objetivos de un negocio, es necesario
el establecimiento de objetivos web. Cada una de los documentos web pertenecientes
a un sitio web debe de tener un objetivo. A este objetivo lo denominaremos objetivo
web.
Los objetivos de un sitio web son empleados como herramienta para medir el progreso
de un sitio web. Expertos en analítica web como Avinash Kaushik (Kaushik, 2010) o
Vera Muñoz (Munoz Vera & Elosegui Figueroa, 2011) hacen distinción entre dos
tipos de objetivos web:
- Macro-Goals
Se conoce como macro-goals a los objetivos principales que definen la existencia
de un sitio web. Este tipo de objetivos conectan con los objetivos del negocio. Así,
estos objetivos son empleados como método para medir cómo el canal web
contribuye al desarrollo del negocio.

146
- Micro-Goals
Se conoce como micro-goals al tipo de objetivo que nos ofrece la información
necesaria como para entender la forma en la que se está educando al usuario, cuál
es su progreso, el interés que éste presenta sobre los contenidos ofrecidos, la
evaluación de la utilidad de estos contenidos desde el punto de vista del usuario,
etc.
La definición de micro-goals nos ayudarán a detectar y depurar dónde existen
problemas en el proceso de conversión, y cómo de efectivas son las prácticas
ejecutadas para persuadir al usuario.
A continuación mostramos una tabla con diferentes tipos de sitios web, definiendo
para cada uno de ellos posibles macro-goals y micro-goals a usar:
Tipo de Web Macro-goals Micro-goals
Blog
- Ser referencia en
Internet en la temática
tratada
- Branding
- Incrementar tráfico
- Incrementar el número de
páginas vistas
- Incrementar el promedio
de tiempo en el sitio web
- Incrementar la frecuencia
de visitas
- Disminuir bounce rate
Consultoría
- Incrementar la cartera
de clientes
- Incrementar los
- Adquisición de tráfico
web
- Incrementar el número de
usuarios que contacta a

147
beneficios por servicio
través de formularios
- Incrementar el número de
visitas a la sección de
servicios
E-commerce
- Incrementar el número
de ventas
- Incrementar los
beneficios por
producto/s vendido/s
- Adquisición de tráfico
- Incrementar las visitas a
páginas de artículos
- Incrementar las visitas a
las páginas de reviews
- Incrementar la adición de
artículos al carrito de
compra
- Incrementar el número de
conversiones de carritos
- Incrementar las visitas
cruzadas entre secciones
web / productos similares
Tabla 8: Definición de micro y macro goals para diferentes tipos de web
3.4.3. Métricas web
Una vez hemos definido los objetivos web del proyecto, comienza la fase de análisis
datos. Mediante el uso de herramientas de analítica web, como Google Analytics,
seremos capaces de recopilar información sobre el comportamiento de los visitantes
en nuestro sitio web, la procedencia de estos, el número de páginas que visitan o las
páginas por las que salen de nuestra web.

148
Para poder realizar un análisis sobre los datos que presentan herramientas como
Google Analytics, es necesario entender la forma en la que este calcula cada una de
las métricas que pone a nuestra disposición.
En el capítulo dedicado a las herramientas online empleadas en el presente proyecto
final de carrera, expondremos las métricas más básicas que Google Analytics es capaz
de recopilar, y cómo mide estas. Entender la naturaleza o la forma de cálculo de estas
es la base para entender qué métricas pueden servirnos a la hora de calcular nuestros
objetivos web.
Si bien todas ellas proporcionan información sobre la forma en la que el usuario
interactúa con el sitio web, no todas serán válidas para analizar el progreso o la
evolución del sitio web. De entre todas las métricas de las que disponemos, debemos
de analizar cuáles son las que representan la evolución hacia los objetivos
establecidos. A este tipo de métricas se las conoce como criterios de éxito o Key
Performance Indicators (KPI). En el siguiente apartado expondremos estas en más
detalle y proporcionaremos ejemplos de posibles KPI para diferentes tipos de sitios
web.
3.4.4. Key performance indicator
Una vez establecidos los objetivos del sitio web, tenemos que definir las métricas que
nos permitirán conocer la evolución de este, esto es, las KPI. A estas métricas se las
conoce como Key Performance Indicators y se representan mediante las siglas KPI.
Avinash Kaushik define informalmente las KPIs como “Measures that help you
understand how you are doing against your objectives.” (Kaushik, 2010).
Forman parte de las KPIs todas aquellas métricas que puedan ser empleadas por un
negocio para evaluar el éxito o progreso de una actividad relacionada con los
objetivos de este.
La correcta identificación de KPIs es una tarea que requiere de iteraciones. Encontrar
las KPIs que mejor representan la evolución del sitio web y que mejor conectan con

149
los objetivos del negocio requiere de tiempo (Munoz Vera & Elosegui Figueroa,
2011).
El proceso para la selección de KPIs comienza con el análisis de las métricas
proporcionadas por la herramienta de análisis elegida. El objetivo es encontrar
aquellas que son capaces de representar la evolución del sitio web, es decir, aquellas
que representan la evolución hacia los objetivos web especificados. De entre todas las
métricas disponibles, deberemos de seleccionar un conjunto que representará nuestras
hipotéticas KPIs.
El proceso continua con la fase de validación de hipótesis, donde se determina si éstas
representan el/los objetivos web definidos. Si las KPIs seleccionadas no representan
éstos correctamente, deberemos de seleccionar nuevas y comenzar el proceso de
nuevo.
Una KPI será útil si puede ser representada numéricamente, es indicativa del progreso
que se está llevando a cabo y es “accionable” (Munoz Vera & Elosegui Figueroa,
2011). Vera Muñoz define en su libro (Munoz Vera & Elosegui Figueroa, 2011)
“métrica accionable” como aquella sobre la que podemos influir.
A continuación presentamos para un conjunto de sitios web, cada uno de ellos con
diferentes objetivos, posibles KPIs a usar para medir el progreso de estos:
Sitio Web Objetivos Web KPI
Blog
- Referencia en Internet en
una temática específica
- Cuota de tráfico.
- Cuota de mercado.
- Cuota de adquisición de
nuevos visitantes.
- Fidelidad de nuevos visitantes.

150
Consultoría
de negocios
- Incrementar la cartera de
clientes
- Tasa de conversión a clientes
(clientes/visitantes).
- Tasa de conversión a leads
(leads/visitantes).
- Cuota de conversión de leads
(clientes/leads).
- Coste de adquisición per leads
- Coste de adquisición por
cliente.
- Ingreso medio por cliente
(ingreso/cliente).
E-commerce
- Incrementar el número de
ventas
- Porcentaje de usuarios que
visitan productos sin añadir al
carrito.
- Cuota de conversión.
- Cuota de carritos
abandonados.
- Porcentaje de conversión por
sesiones.
- Coste por cliente.
- Ratio de conversión entre
nuevos compradores y
repetidores.

151
Tabla 9: Definición de KPIs para objetivos web
3.4.5. Conclusiones
Existen multitud de herramientas que nos permiten hoy día recopilar datos basados en
las acciones que el usuario realiza en nuestra web. Antes de comenzar a hacer uso de
estas herramientas, tenemos que saber cómo funcionan y cómo miden los datos
(Kaushik, 2010). Una vemos entendemos las herramientas que manejamos y sus
limitaciones, seremos capaces de empezar a medir.
En este apartado hemos visto que para poder comenzar a medir el progreso de un sitio
web es necesario la definición de macro-goals y micro-goals. Una vez definidos
estos, tendremos que estudiar de entre todas las métricas que nos proporciona Google
Analytics, cuáles representan mejor los objetivos establecidos. Conocidas como KPI,
servirán para medir numéricamente la evolución del sitio web.

152

153
Capítulo 4:
Herramientas
En este capítulo expondremos las herramientas usadas durante el desarrollo del
proyecto final de carrera. Cada una de las herramientas empleadas nos ha permitido
analizar diferentes aspectos del sitio web desdemiatalaya:
- Estudio de palabras clave
Para el estudio de palabras clave, se emplearon las herramientas Google
Webmaster Tools, Google Analytics y Google AdWords.
- Análisis sobre la evolución en los motores de búsqueda
Para conocer el posicionamiento y las variaciones de posiciones en los
motores de búsqueda, se hizo uso de WebCEO.
- Análisis de tráfico y comportamiento del usuario
Para analizar el tráfico recibido y el comportamiento del usuario en el sitio
web, se hizo uso de Google Analytics.
- Captura de leads
Para la captura de leads empleamos el servicio MailChimp, creando
formularios de suscripción y automatizando la descarga de documentos.
En las siguientes secciones expondremos cómo funcionan las herramientas
comentadas anteriormente, así como los problemas encontrados durante el uso de las
mismas.

154
4.1. WebCEO
En esta sección expondremos las herramientas que ofrece la plataforma WebCEO para
auditar sitios web, estudiar el perfil de enlaces de nuestros clientes, analizar el
impacto de nuestro contenido en las redes sociales así como medir la evolución del
sitio web.
4.1.1. Auditoria del sitio web
La plataforma WebCEO pone a nuestra disposición una serie de herramientas para
ayudarnos en la realización de auditorias SEO. Mostramos a continuación el conjunto
de herramientas que ofrece, y como hemos hecho uso de algunas de estas durante el
desarrollo del proyecto final de carrera.
Análisis de palabras clave
Estudiar las palabras o términos a posicionar en el contenido web es clave para la
adquisición de un buen posicionamiento o la adquisición de tráfico. La selección de
palabras o términos clave determina el tipo de usuarios a adquirir, así como los sitios
webs contra los que competir por alcanzar los primeros puestos en Google.
La plataforma web WebCEO ofrece diversas herramientas para determinar las
palabras clave a emplear en el sitio web. Recopila información de herramientas como
Google AdWords o Google Webmaster Tools, ofreciendo la información que estas
herramientas proporcionan.
Vemos a continuación la información que nos proporciona esta herramienta para el
estudio de palabras clave como:
escandallos, escandallos de carnicería, dealz, pounland dealz,
dealz Málaga, dealz Madrid, supeco

155
Figura 39: Herramienta WebCEO para la determinación de palabras clave
En la imagen (Figura 39) podemos observar las palabras clave de búsqueda
introducidas (Keyword), las búsquedas globales (global searches) así como locales
(local searches), la competencia de pago (bid competition), un gráfico de barras
indicando la evolución de búsquedas a lo largo del año (Search trends) así como el
índice KEI.
Este índice conocido como KEI (Keyword Effectiveness Index) es un indicador que
determina la eficacia que tendría el uso de cada palabra clave. Según indican en el
propio software, esta fórmula matemática está basada en el número de búsquedas
globales y la competencia existente.
- Palabras con un KEI bajo son indicativos de un bajo volumen de búsquedas
para esa palabra clave con una alta competencia.
- Palabras con un KEI alto son indicativos de la existencia de un gran volumen
de usuarios empleando esa palabra clave con una baja competencia.

156
Al determinar el KEI empleando las búsquedas globales y al no determinar la fórmula
de la cual hacen uso, no hicimos uso de esta métrica en la selección de palabras clave.
La herramienta proporciona también sugerencias sobre palabras clave que podrían
estar relacionadas con los términos de búsqueda introducidos, basándose en los datos
recuperados de la herramienta Google Keyword Planner de Google AdWords.
Debido al desconocimiento del sector de la distribución alimentaria, se llevaron a
cabo entrevistas con el autor del blog para determinar las palabras clave a emplear,
viendo las búsquedas existentes y analizando el perfil de las búsquedas.
Optimización de enlaces internos
Se conocen como enlaces internos aquellos que se encuentran en nuestro sitio web.
Por optimización de enlaces internos, se entiende a la práctica de enlazar contenido
propio desde unos documentos web hacia otros, optimizando el texto de las anclas de
texto y disponiendo palabras clave en estas.
Para controlar el texto empleado en los enlaces, la herramienta WebCEO dispone del
panel Link Text Analysis. Este panel nos permite conocer las anclas de texto usadas en
los documentos, el número de enlaces que usan este texto, el text juice así como
información sobre si los enlaces llevan a páginas bloqueadas por el archivo robots.txt.
Mediante este panel podemos fácilmente detectar si nuestras palabras clave se
encuentran en las anclas de texto. Mostramos a continuación una imagen de este
panel:
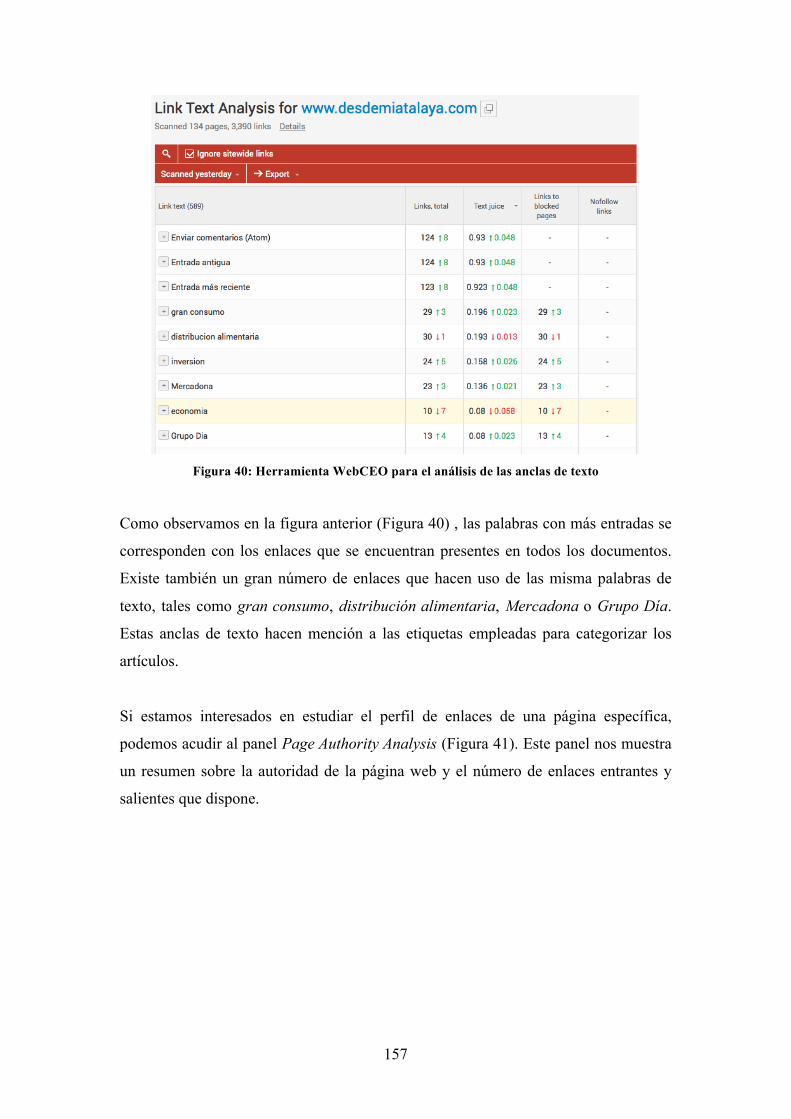
157
Figura 40: Herramienta WebCEO para el análisis de las anclas de texto
Como observamos en la figura anterior (Figura 40) , las palabras con más entradas se
corresponden con los enlaces que se encuentran presentes en todos los documentos.
Existe también un gran número de enlaces que hacen uso de las misma palabras de
texto, tales como gran consumo, distribución alimentaria, Mercadona o Grupo Día.
Estas anclas de texto hacen mención a las etiquetas empleadas para categorizar los
artículos.
Si estamos interesados en estudiar el perfil de enlaces de una página específica,
podemos acudir al panel Page Authority Analysis (Figura 41). Este panel nos muestra
un resumen sobre la autoridad de la página web y el número de enlaces entrantes y
salientes que dispone.
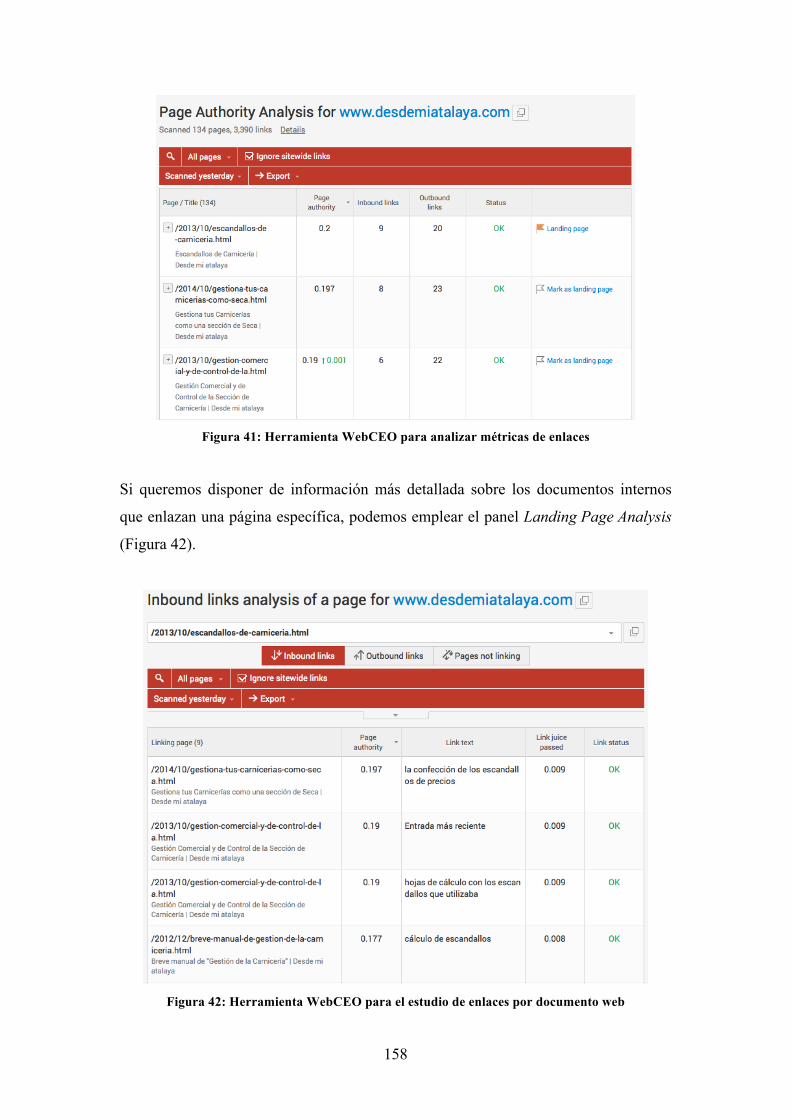
158
Figura 41: Herramienta WebCEO para analizar métricas de enlaces
Si queremos disponer de información más detallada sobre los documentos internos
que enlazan una página específica, podemos emplear el panel Landing Page Analysis
(Figura 42).
Figura 42: Herramienta WebCEO para el estudio de enlaces por documento web

159
Como vemos en la imagen anterior (Figura 42), para documento específico, esta panel
nos permite visualizar las páginas internas que enlazan el documento, el texto
empleado en el enlace y el link juice que pasan al documento especificado.
Auditoría técnica
La plataforma WebCEO ofrece esta herramienta para analizar errores técnicos como:
- Enlaces rotos hacia páginas web
- Enlaces rotos empleados en imágenes
- Páginas que responden con errores de servidor
- Páginas que responden con errores de acceso a páginas
- Páginas con un tiempo de respuesta alto
En la figura siguiente (Figura 43) podemos observar la interfaz gráfica de esta
herramienta:
Figura 43: Herramienta WebCEO para la realización de auditoria técnica

160
Se ha trabajado continuamente con el autor del sitio web asesorándole sobre los
problemas encontrados y cómo arreglarlos. Debido a la existencia de más de 500
artículos, hay todavía errores sobre los que el autor del blog deberá de trabajar.
Análisis SEO
Para detectar errores SEO y conocer optimizaciones a realizar sobre nuestros
documentos, en la plataforma WebCEO ofrece la herramienta SEO Analysis. Esta
herramienta está compuesta por 6 paneles diferentes:
- On-Site Issue Overview
Este panel ofrece una visión general sobre las errores encontrados y
optimizaciones implementadas en el sitio web. Con ella podemos detectar si
todas nuestras páginas disponen de un título, si estos sobrepasan los 70
caracteres, qué páginas no disponen de descripciones, cuáles deberían de ser
reducidas para no sobrepasar los 160 caracteres, la presencia correcta de
encabezamientos, estructura correcta de direcciones web o presencia del
fichero robots.txt entre otros.

161
Figura 44: Herramienta WebCEO para la optimización on-page
- Landing Pages Overview
Este panel nos ofrece una visión general sobre los documentos que hemos
elegido como nuestras landing pages a optimizar. Nos permite conocer el
porcentaje de optimización realizado para la página, errores críticos desde el
punto de vista SEO, velocidad del sitio web así como el número de veces que
ha sido mencionado el documento en las redes sociales. Dispone también de
información sobre posición media de la página extraída de la herramienta
Google Webmaster Tools (GWT).
Durante el proyecto final de carrera hemos comprobado grandes diferencias
entre la posición documentada por WebCEO y GWT. En este sentido,
WebCEO es una herramienta mas precisa que GWT.
En la siguiente figura (Figura 45) mostramos la interfaz de este panel:

162
Figura 45: Herramienta WebCEO para la optimización de documentos concretos
- Landing SEO Pages
Para analizar en mayor profundidad cómo mejorar una página web desde un
punto de vista SEO, la herramienta WebCEO nos ofrece el panel landing SEO
pages. Este panel nos ofrece información sobre cómo de optimizado se
encuentra nuestro documento para un conjunto de palabras clave.
Este panel ha sido usado para la optimización del documento de escandallos
publicado en la web desdemiatalaya. Mostramos a continuación una vista
sobre este panel y la puntuación SEO obtenida (Figura 46).

163
Figura 46: Herramienta WebCEO para la optimización de landing pages
El uso de esta herramienta nos ayudó a establecer las palabras clave
escandallos y escandallos de carnicería en títulos, encabezados, meta
descripción, artículo, dirección web, etiquetas alt así como en los enlaces que
referencian al artículo.
- Page Speed
Si recordamos secciones previas (2.4.11. Velocidad de carga), la velocidad del
sitio web es una de las métricas tenidas en cuenta por los motores de
búsqueda. Esta también tiene impacto en la usabilidad de nuestro sitio web.
Para conocer la velocidad de nuestros documentos y recibir instrucciones
sobre cómo mejorar esta, WebCEO nos proporciona un panel para ello. Esta
herramienta parece usar los datos extraídos de la herramienta Google Page
Speed. Mostramos una imagen a continuación sobre la información que nos
proporciona (Figura 47):
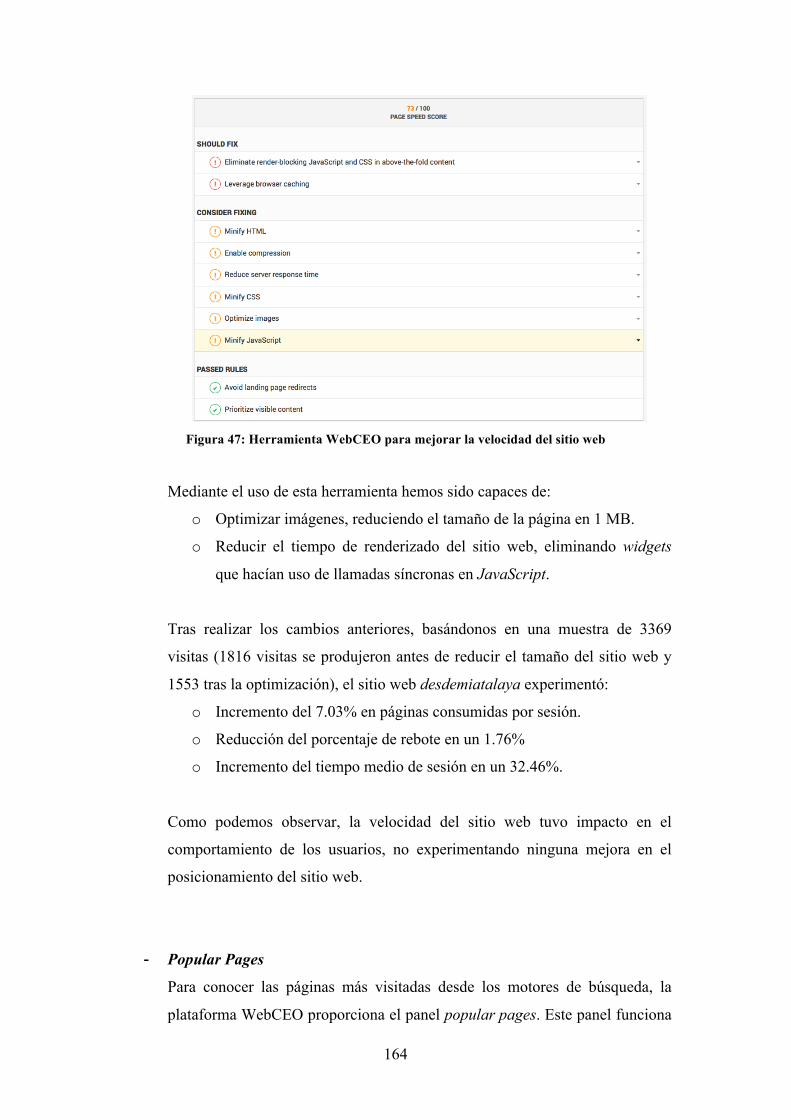
164
Figura 47: Herramienta WebCEO para mejorar la velocidad del sitio web
Mediante el uso de esta herramienta hemos sido capaces de:
o Optimizar imágenes, reduciendo el tamaño de la página en 1 MB.
o Reducir el tiempo de renderizado del sitio web, eliminando widgets
que hacían uso de llamadas síncronas en JavaScript.
Tras realizar los cambios anteriores, basándonos en una muestra de 3369
visitas (1816 visitas se produjeron antes de reducir el tamaño del sitio web y
1553 tras la optimización), el sitio web desdemiatalaya experimentó:
o Incremento del 7.03% en páginas consumidas por sesión.
o Reducción del porcentaje de rebote en un 1.76%
o Incremento del tiempo medio de sesión en un 32.46%.
Como podemos observar, la velocidad del sitio web tuvo impacto en el
comportamiento de los usuarios, no experimentando ninguna mejora en el
posicionamiento del sitio web.
- Popular Pages
Para conocer las páginas más visitadas desde los motores de búsqueda, la
plataforma WebCEO proporciona el panel popular pages. Este panel funciona

165
con las sesiones extraídas de Google Analytics (GA) y los datos (impresiones,
clics, CTR y posición media) extraídos Google Webmaster Tools (GWT).
En la siguiente imagen (Figura 48) podemos observar cómo el número de clics
que GWT documenta no se corresponde con el número de visitas que GA
documenta. Es un problema conocido en la comunidad SEO a la cual Google
no ha dado respuesta oficial.
Figura 48: Herramienta WebCEO para analizar las páginas mas populares
Generación de sitemap
Esta herramienta nos permite crear un archivo sitemap.xml del sitio web. Para que los
robots hagan uso de este, debemos alojar el archivo en el servidor. Desde la
herramienta GWT podemos indicar a Google sobre su localización.
4.1.2. Link building
Con el objetivo de conocer el desarrollo de nuestras estrategias de captación de
enlaces, WebCEO pone a nuestra disposición un conjunto de herramientas para
monitorizar los enlaces de los que disponemos, organizar y categorizar sitios a los que

166
contactar, espiar los enlaces de la competencia así como un listado de sitios web
desde dónde conseguir enlaces.
Detallamos a continuación cada uno de las herramientas mencionadas anteriormente:
Backlink Quality Check
Esta herramienta nos proporciona información sobre el perfil de enlaces de nuestro
cliente. Informaciones tales como la diversidad del texto empleado en las anclas de
texto, de subredes que nos enlazan, de dominios o enlaces follow (frente a nofollow).
En la siguiente imagen (Figura 49) podemos observar la forma en la que la
herramienta WebCEO muestra la información.
Figura 49: Herramienta WebCEO para analizar el perfil de enlaces
La anterior imagen muestra un panel resumen del perfil de enlaces del que dispone el
blog desdemiatalaya. En el diagrama de barras podemos observar cómo la mayoría de
los enlaces provienen de páginas con TLD.com.
De los gráficos circulares, el primero de los gráficos representa la diversidad de textos
usados en los enlaces (“Diversity of link texts”). Tal y como puede observarse, existen
ciertas palabras clave que han sido usadas bastante a menudo, formando algunas de
ellas incluso mas del 30% (primer gráfico circular en color rojo).

167
El siguiente de los gráficos circulares (posicionado en el centro) nos muestra
información sobre la diversidad de subnets desde donde hemos conseguido enlaces.
La última de las gráficas circulares corresponde a información relativa a la diversidad
de dominios que nos enlazan (“Diversity of linking domain”). blogs.bolsa.com
representa el 22.8% de los enlaces adquiridos (representado en rojo), seguido de
gurusblog.com, rankia.com e investia.com.
Para conocer el texto que han empleado dominios externos para enlazarnos, podemos
acceder al panel Link Texts. La siguiente figura (Figure 50) muestra las anclas de
texto empleadas por documentos externos para enlazarnos:
Figura 50: Herramienta WebCEO para analizar las anclas de texto usadas
Como vemos en la imagen anterior, existe una repetición continua de palabras a usar
para adquirir enlaces. Esto se debe a la forma en la que se promocionó el blog en sus
comienzos. Se usaron diferentes plataformas con el objetivo de publicar el mismo
artículo. A pesar de que es una práctica desaconsejada por Google, no se ha percibido
ningún tipo de acción manual por parte de Google.
A continuación mostramos una lista (Figura 51) con algunos de los dominios que
enlazan al sitio web desdemiatalaya.com. No todos los dominios se han hecho

168
visibles, manteniendo la privacidad del sitio desde donde se han conseguido los
enlaces.
Figura 51: Herramienta WebCEO para analizar enlaces entrantes
Para finalizar con la herramienta Backlink Quality Check, es posible conocer los
documentos más enlazados desde dominios externos. La siguiente imagen (Figura 52)
muestra algunas de las páginas más enlazadas del blog:
Figura 52: Herramienta WebCEO para analizar los documentos mas enlazados

169
Competitor Backlink Spy
Con el objetivo de analizar nuevas oportunidades para adquirir enlaces, la plataforma
WebCEO pone a disposición la herramienta Competitor Backlink Spy. Esta
herramienta nos proporciona información sobre los documentos que enlazan a
nuestros competidores o a páginas del sector que especifiquemos.
Con el objetivo de encontrar oportunidades desde donde conseguir enlaces para el
blog desdemiatalaya, identificamos dominios con contenido similar e hicimos uso de
la herramienta Competitor Backlink Spy. Esta herramienta nos ayudó a encontrar
dominios candidatos con los que establecer contacto para la adquisición de enlaces.
A continuación mostramos una lista (Figura 53) con algunos de los resultados que
ofrece esta herramienta:
Figura 53: Herramienta WebCEO para analizar enlaces de la competencia
Tras estudiar los enlaces conseguidos por los sitios de contenido similar, se optó por
la consecución de enlaces desde directorios y/o menciones (tal y como veremos en el
siguiente capítulo). Esta decisión fue tomada junto con el autor del sitio web.

170
Chosen Links Watch
El panel Chosen Links Watch de WebCEO nos ayuda a organizar los sitios web
objetivo desde donde adquirir un enlace o dominios desde donde ya los hemos
adquirido.
Para el blog desdemiatalaya, organizamos los enlaces bajo categorías: directorios,
enlaces nuevos, perfiles sociales, periódicos y web objetivos. La siguiente figura
(Figura 54) muestra los enlaces conseguidos desde directorios:
Figura 54: Herramienta WebCEO para comprobar la existencia de enlaces
Content Submission
Con el objetivo de conocer sitios donde adquirir enlaces o compartir material,
WebCEO dispone de un directorio con una recopilación de sitios webs. Estos se
encuentran categorizados bajo los siguientes grupos: Automatic, Standard, Local,
eCommerce, Content, Blog y PPC.
La mayoría de ellos corresponden a sitios de habla no hispana, motivo por el cual no
hemos hecho uso de ellos.
4.1.3. Métricas sociales

171
Esta herramienta WebCEO dispone de dos paneles relacionados con métricas
sociales, los cuales exponemos en las siguientes secciones.
Monitor de palabras
Esta herramienta nos permite recuperar la información existente alrededor de un
conjunto de palabras clave especificado. Nos permite realizar un seguimiento sobre
qué sucede en Internet acerca de un tema específico.
Esta herramienta no ha sido utilizada durante el proyecto final de carrera, debido a la
falta de filtros sobre el idioma del cual recuperar la información.
Actividad social
Para estudiar la evolución de nuestra actividad en las redes sociales, WebCEO pone a
nuestra disposición la herramienta Social Engagement (Figura 55). Con ella es posible
monitorear la evolución de las citaciones que ocurren en las redes sociales como
Twitter, Facebook o Google+.
Figura 55: Herramienta WebCEO para monitorear métricas de redes sociales

172
Ofrece también herramientas para analizar el número de visitas recibidas desde las
redes sociales a nivel de documento web, así como métricas propias de las redes
sociales Twitter, Google+ o Facebook (Figura 56).
Figura 56: Herramienta WebCEO para monitorear métricas sociales
Para conocer la evolución de nuestros canales sociales con respecto a páginas con
audiencia similar, WebCEO permite definir un máximo de cuatro competidores.
Definidos estos, nos proporciona un informe con el número de citaciones realizadas
hacia la página principal de cada uno de ellos (Figura 57).
Figura 57: Herramienta WebCEO para monitorear métricas sociales por dominio
También dispone de una herramienta para analizar el tráfico recibido proveniente de
las redes sociales (Figura 58). En el caso del blog desdemiatalaya, la red social que
mejor actúa como captadora de tráfico es Linkedin.

173
Figura 58: Herramienta WebCEO para analizar el tráfico por red social
4.1.4. Analítica de Marketing
Para conocer el resultado de nuestras acciones de marketing, la herramienta WebCEO
ofrece cuatro paneles. Estos nos permitirán conocer la efectividad de nuestras
campañas de marketing, ofreciéndonos cifras sobre las palabras de búsqueda
empleadas, el ranking que ocupa el sitio web para determinadas palabras clave, así
como datos sobre la adquisición de usuarios. Presentamos a continuación cada una de
estas herramientas:
Ranking web
Esta es la herramienta con la que más hemos monitorizado las posiciones del sitio
web durante el proyecto final de carrera. Simula la realización de búsquedas en los
principales motores de búsqueda, para un conjunto de palabras clave. Extrae de este
listado aquellos donde aparece el dominio especificado, en nuestro caso,
desdemiatalaya.com.
Para los documentos encontrados pertenecientes a nuestro dominio, ofrece
información sobre la posición que ocupan estos. Si estos no se encuentran entre las
tres primeras páginas, la herramienta no muestra información alguna.
Esta herramienta ofrece varios paneles para obtener más detalles de la posición que
ocupan nuestros documentos. Es posible obtener información a nivel de palabra
clave, mostrando el número de búsquedas realizadas para la palabra clave
especificada, las visitas provenientes desde Google (resultados provenientes de la

174
herramienta Google Webmaster Tools), las visitas totales así como el ranking de
nuestros documentos (para una palabra clave específica) en los motores de Google,
Bing y Yahoo. Mostramos a continuación una imagen (Figura 59) de este panel:
Figura 59: Herramienta WebCEO para monitorear el ranking en los SERPs
Ofrece la posibilidad de ver la información a nivel de motor de búsqueda (Figura 60),
así como a nivel de etiquetas (Figura 61):
Figura 60: Herramienta WebCEO para monitorear el ranking por motores

175
Figura 61: Herramienta WebCEO para monitorear el ranking por etiquetas
Es posible configurar la herramienta para monitorizar el posicionamiento de nuestros
competidores (Figura 62), ofreciéndonos una visión general del posicionamiento que
estos disponen para las palabras clave para las cuales intentamos posicionarnos.
Figura 62: Herramienta WebCEO para monitorear la evolución de la competencia
Durante el proyecto final de carrera hemos observado como las posiciones de los
documentos oscilan diariamente. Monitorizar las palabras por semana ha resultado
suficiente para controlar las posiciones de estas.
Analítica web

176
Esta herramienta nos ofrece información organizada extraída desde Google Analytics.
Ofrece diferentes vistas para visualizar la evolución del tráfico para los canales
orgánicos, directos, pagados, de campaña o bien de referencia.
En la siguiente imagen (Figura 63) podemos observar la evolución del sitio web
durante el año 2014, para los canales de tráfico referenciado y tráfico orgánico.
Figura 63: Herramienta WebCEO para analizar la evolución del tráfico
Si nuestro objetivo es analizar el tráfico procedente de las redes sociales, WebCEO
ofrece una sobrevista del comportamiento para cada una de las redes sociales. A
continuación mostramos una imagen (Figura 64) sobre la información que ofrece esta
herramienta:
Figura 64: Herramienta WebCEO para analizar el tipo de usuario por red social

177
Para conocer el porcentaje de visitas que son catalogadas como nuevas, WebCEO
dispone del panel Efficiency. Este panel nos permite conocer cómo han evolucionado
las campañas de adquisición de nuevos usuarios.
Si vemos los resultados obtenidos para el sitio web desdemiatalaya (Figura 65),
observamos cómo el porcentaje de nuevas visitas adquiridas a través de los motores
de búsqueda tuvo una ligera subida en Septiembre y Octubre, cayendo hasta el 48%
en Noviembre.
Este hecho se explica como consecuencia de la potenciación de canales de referencia
y campañas, los cuales consiguieron incrementar el porcentaje de adquisición de
nuevas visitas.
Figura 65: Herramienta WebCEO para analizar el porcentaje de nuevas visitas
La herramienta de analítica web ofrecida por WebCEO resulta ser útil para obtener
una visión general sobre la evolución del sitio web aunque no llegará a sustituir al
nivel de datos al que se tiene acceso desde los paneles ofrecidos por Google Analytics.
Palabras clave de búsqueda desde Google

178
Para conocer las palabras de búsqueda que emplean los usuarios en los motores de
búsqueda, WebCEO recupera los datos que ofrece la herramienta Google Webmaster
Tools (GWT).
Tal y como hace GWT, esta herramienta también muestra información sobre el
número de impresiones, clics, CTR y posición media para palabras de búsqueda y
documentos. En posteriores secciones explicaremos el uso de la GWT.
Métricas de la competencia
Para visualizar la evolución del sitio web con respecto a la competencia, la
herramienta WebCEO ofrece el panel Competitor metrics. Desde este panel se puede
consultar la evolución en el ranking de Alexa o el tráfico adquirido de la herramienta
Compete, el perfil de enlaces de nuestros competidores (extrayendo información
desde las herramientas Ahrefs y Moz Scape), así como el perfil social de estos.
Mostramos a continuación algunas imágenes (Figura 66, Figura 67 y Figura 68)
representativas de la información que presenta esta herramienta:
Figura 66: Herramienta WebCEO para comparar el ranking Alexa

179
Figura 67: Herramienta WebCEO para comparar métricas contra la competencia
Figura 68: Herramienta WebCEO para comparar citaciones en redes sociales
4.1.5. Conclusiones
La herramienta WebCEO se posiciona como una de las herramientas más completas
existentes en el mercado. Esto se debe a que hace uso de aplicaciones externas para

180
agregar información. Destacamos la información que extrae de Ahrefs (perfil de
enlaces), Moz.com (autoridad de dominio y de página web), Google Webmaster
Tools(palabras clave), Google Analytics (métricas web) así como Google
AdWords(estudio de palabras clave) o Google PageSpeed (consejos sobre cómo
mejorar la velocidad del sitio web).
Gracias a la integración de estas herramientas, es posible llevar a cabo autorías
internas (a nivel de dominio así como a nivel de landing page), estudiar las palabras
clave, el perfil de enlaces o monitorizar las posiciones que ocupan los documentos
para un conjunto de palabras clave.
El valor añadido de esta herramienta es sin duda la posibilidad de analizar la
competencia.
4.2. MailChimp
En esta sección se introducirá el uso de la herramienta MailChimp. MailChimp es una
herramienta diseñada para el envío de campañas de e-mail. Expondremos cómo crear
listas de usuarios, campañas de email e interpretación de las métricas que ofrece.
4.2.1. Lista y grupos
Se conoce como lista de e-mails al elemento básico empleado por MailChimp para la
creación de campañas de e-mail. Almacenan la información proporcionada por el
usuario.
La creación de listas en MailChimp se realiza importando los contactos a través de
servicios built-in como zendesk, eventbrite, salesforce, surveygizmo, etc. o bien a
través de la importación de archivos Excel. Los únicos e-mails que pueden importarse
al servicio de MailChimp son aquellos para los cuales los usuarios nos dieron su
consentimiento para recibir e-mails. MailChimp puede aplicar penalizaciones en caso
de que considere que el que hace uso de su servicio está realizando spam.

181
La importación de usuarios permite además importar información adicional o extra
que pueda considerarse valiosa para la creación de campañas de e-mail. Ofrece el uso
de grupos como medio para categorizar a los suscriptores en base a sus gustos o
intereses.
Un ejemplo del uso de grupos sería ofrecer a los suscriptores que seleccionen el tipo
de artículos que quieren recibir de entre actualidad, ciencias o economía.
Esta información será muy útil posteriormente como medio para segmentar nuestras
campañas de e-mail, llegando a ser más relevantes para los usuarios al recibir estos
únicamente la información en la que están interesados.
4.2.2. Formularios opt-in/re-opt
MailChimp proporciona funciones para la creación de formularios de opt-in o re-opt.
Estos formularios se emplean como medio para conseguir la autorización del usuario
para recibir e-mails. MailChimp proporciona varias opciones para la creación de
formularios, con diferentes niveles de personalización de éstos.
La siguiente es una vista (Figura 69) del uso de MailChimp para la creación de
formularios de registro:
Figura 69: Formulario de registro en lista de MailChimp

182
Una vez creado el formulario, Mailchimp dispone de diferentes modos de compartir el
formulario de opt-in: generación de HTML, dirección web donde se aloja el
formulario o integración en aplicaciones como WordPress.
Durante el proyecto final de carrera se ha hecho uso de varios formularios como
medio para adquirir usuarios. A continuación mostramos el formulario empleado para
la captura de usuarios interesados en recibir un Excel con hojas de escandallos (Figura
70).
Figura 70: Formulario de registro para la recepción del Excel de escandallos
4.2.3. Emails transaccionales
Este tipo de e-mails se caracterizan por ser enviado de forma individual como
consecuencia de una acción realizada por el usuario, en contraposición con el
concepto de bulk-email donde el envío se produce de forma masiva.
En la herramienta MailChimp se conocen como Autoresponders y permiten enviar
automáticamente una campaña de e-mail enfocada a un único usuario. Este tipo de e-
mails es empleado como respuesta a registros, descarga de ficheros, aniversarios, etc.
El envío se produce como consecuencia de acciones realizadas por el usuario.
Actualmente MailChimp soporta el envío de e-mails bajo las siguientes acciones:
eventos de campañas, fechas específicas, consecución de objetivos o bajo compras
realizadas o subscripción a listas.

183
El e-mail se configura previo envío, seleccionando la lista o el segmento al que debe
pertenecer el usuario, así como la acción que producirá la acción de envío del e-mail.
Para hacer uso de ellos, debe de disponerse de una cuenta premium en MailChimp.
4.2.4. Segmentación
MailChimp ofrece la posibilidad de segmentar las listas de usuarios como forma de
centrar las campañas en un tipo determinado de público, previa creación de la
campaña. A través de la segmentación podremos enfocar nuestros esfuerzos hacia un
tipo específico de público.
La segmentación se realiza a través del establecimiento de filtros sobre la información
almacenada en las listas de e-mails. Es posible la creación de filtros basados en el
comportamiento de usuarios (apertura o clics de campañas anteriores), cliente de
email o geolocalización entre otros.
4.2.5. Personalización de e-mails
La personalización de e-mails es posible mediante el uso de tags o etiquetas. Los tags
son empleados como medio para personalizar el envío de campañas de e-mails,
mostrando en estos el nombre del usuario, apellidos, e-mail, lista a la que esta
subscrito, etc.
Ofrece también funcionalidades para el uso de conditional merge tags. Estos tags
evalúan condiciones, permitiendo mostrar diferentes contenidos en base a la
información disponible.
A continuación presentamos uno de los posibles usos de conditional merge tags,
desarrollado por LaughYourWay.com. En el footer de esta website promocionan el
registro a su newsletter sorteando un iPod Touch.

184
Una vez han decidido el usuario ganador, emplean la siguiente lógica para informar a
sus usuarios del ganador, controlando a su vez los e-mails a enviar para los no
ganadores.
*|IF:[email protected]|*
Congratulations, you appear to be this month’s winner of an
iPod touch! Please contact us by replying to this message,
using the contact us form on our website, or giving us a call
to claim your prize. When you contact us, please mention
codeword: EXAMPLECODE to help us verify your identity.
*|ELSE:|*
<strong>joh*****@example.com is this month’s
winner!</strong><br>
Sorry, you didn’t win this month, please watch this area in
future issues to see if you’re our next iPod touch winner!
*|END:IF|*
En el anterior código se hace uso de tags condicionales. Cuando el campo e-mail es
evaluado y coincide con el valor [email protected], el e-mail que se envía es de
felicitaciones. En caso de que el usuario al que se envía el e-mail no tenga esa
dirección, el ejemplo anterior notifica el ganador del mes.
4.2.6. Campañas de e-mail
Mailchimp ofrece múltiples opciones a la hora de crear campañas de e-mail. Las
opciones ofrecidas por MailChimp son las siguientes:
- Regular Campaign y Plain Text Campaign.

185
Permite la creación de campañas bajo selección de templates prediseñados
pero con opción a edición de éstos. Las campañas basadas en formato de texto
no ofrecen esta posibilidad ni la adición de imágenes o formatos.
- A/B Split Campaign
Permite la realización de pruebas de A/B testing sobre el asunto del e-mail,
sender y horarios de envío. Las dos primeras opciones permiten testear sobre
un porcentaje de usuarios, además de poder especificar la métrica que define
el éxito. La versión ganadora será enviada al porcentaje restante.
- RSS Driven Campaign
Permite la creación de campañas basadas en RSS. Ofrece opciones para
controlar la lista de usuarios a la que enviar estas campañas, así como la
configuración sobre cuando enviarlas.
4.2.7. Informe de Campañas
Para determinar el éxito de una campaña de e-mail, es necesario saber qué se puede
medir, cuáles son los objetivos de la campaña (promoción de productos, relleno de
encuesta, atracción de tráfico,…) y definir las variables que medirán el éxito de esta.
A continuación expondremos cuáles son las métricas básicas que pueden consultarse
para conocer cómo los usuarios responden a las campañas de e-mails:
- Porcentaje de emails enviados
Esta métrica mide el porcentaje de emails que no son bloqueados por los
ISPs (Internet Service Providers). Es una métrica que no indica cuántos de
ellos han llegado a su destino, si han llegado a la carpeta de spam o a la
bandeja de entrada.
- Porcentaje de emails rechazados
Mide el porcentaje de emails que son rechazados debido a que no pueden ser
enviados. Esto puede deberse a errores sintácticos en el email al que se
envió, bien porque el servidor de correo esté temporalmente no disponible o

186
bien porque la cuenta de usuario no existe para ese dominio o bien el
dominio en sí.
- Porcentaje de envíos declarados spam
Mide el porcentaje de envíos que son declarados como spam por parte de los
usuarios. MailChimp dispone de un formulario en su web donde cualquier
usuario que haya recibido un email servido por MailChimp pueda notificarlo
como spam.
- Porcentaje de e-mails abiertos
Mide el grado de interés o compromiso de los subscriptores con respecto al
servicio del cual reciben el email. El cálculo obtenido de esta métrica no es
exacto.
La forma empleada para calcular esta métrica es través de los llamados “web
beacon” o “balizas web”. Consisten en pequeños fragmentos de código o
imágenes generalmente imperceptibles para los usuarios que se envían junto
con la campaña de e-mail. Cuando los usuarios abren el e-mail, la baliza
(generalmente formada por una imagen de 1px de tamaño) es descargado del
servidor. MailChimp detecta esta descarga y contabiliza la vista del
documento web.
Esta técnica es empleada por los ESP (e-mail service providers) para
computar cuando un e-mail es abierto. Para que la apertura del e-mail sea
contabilizada, el subscriptor debe de tener habilitado la “vista de imágenes”,
o bien debe de clicar en “mostrar imágenes” cuando abre el e-mail.
- Porcentaje de clics
Mide la relevancia del mensaje para los subscriptores. Analizando el
porcentaje de clics se puede conseguir valiosa información para determinar
cuáles son los principales intereses de los subscriptores con respecto al
servicio del cual reciben el e-mail.

187
- Porcentaje de cancelaciones
Mide el porcentaje de subscriptores que han perdido interés por el producto
o servicio y cancelan la subscripción a la lista de e-mail.
- Porcentaje de conversión
Mide el porcentaje de subscriptores que han respondido a una “llamada a la
acción” contenida en el e-mail. Para tener un mayor conocimiento sobre la
conversión del subscriptor es necesario integrarlo con herramientas de
analítica web.
- Porcentaje de reenvíos
Porcentaje de subscriptores que encuentran valioso el contenido y lo
reenvían.
4.2.8. Conclusiones
MailChimp es una herramienta fácil de usar, la cual puede ser empleada gratuitamente
por bloggers que cuentan con una lista mediana de suscriptores. Durante el proyecto
final de carrera, hemos encontrado deficiencias a la hora de configurar la hora de
envío o la muestra parcial de los artículos para las campañas RSS. Para este tipo de
campañas, las imágenes quedan excluidas.
4.3. Google Webmasters Tool
En este apartado vamos a introducir la herramienta Google Webmaster Tools (GWT).
Esta herramienta es ofrecida gratuitamente por Google. Proporciona información a los
webmaster sobre el estado en el cual se encuentran sus sitios webs.
El servicio de Google Webmaster Tools está categorizado por funcionalidades, de
forma que cada una de las categorías nos permitirá consultar y/o controlar cómo
Google interacciona con nuestro sitio web.

188
En los siguientes apartados veremos el proceso a seguir para dar el sitio de alta en
GWT, así como las herramientas que ofrece para controlar cómo se presenta el sitio
web en la lista de resultados (SERPs), información relacionada con las impresiones y
CTR así como información sobre el escaneo e indexación de nuestro sitio web.
4.3.1. Proceso de alta
El uso de Google Webmaster Tools requiere de un proceso de autenticación desde el
cual un usuario se identifica como autor del sitio web. El proceso de autenticación
requiere disponer de una cuenta de gmail para su identificación. Una vez creada esta,
el usuario puede solicitar el uso del servicio.
Google proporciona una serie de métodos para verificar que el usuario es legítimo con
la web que solicita. Generalmente estos métodos requieren de acceso al sitio web. El
dueño del sitio web tendrá que situar un archivo proporcionado por Google en el
directorio raíz aunque existen formas alternativas de verificar la autoría del sitio web
(Figura 71):
Figura 71: Formas de identificación en la herramienta Google Webmaster Tools
Una vez finalizado el proceso de autenticación, se puede comenzar a hacer uso de la
herramienta.
4.3.2. Control sobre la apariencia en los SERPs

189
Las herramientas que se mencionan a continuación nos van a permiten trabajar sobre
la apariencia de nuestra web en la página de resultados.
Bajo el nombre de Search Appearance, se ofrecen herramientas para consultar cómo
Google detecta los datos estructurados marcados en el sitio web. En secciones
anteriores ya mencionamos cómo el uso de datos estructurados permiten resaltar
información relevante para los usuarios directamente en los motores de búsqueda.
El marcado de datos estructurados puede realizarse manualmente (añadiendo el
pertinente marcado) u automáticamente. GWT ofrece una herramienta automática para
resaltar estos datos estructurados para aquellos usuarios menos técnicos.
A través de la herramienta Data Highlighter el usuario puede destacar los datos
estructurados (Figura 72) sin necesidad de emplear el esquema de marcado ofrecido
en schema.org.
Figura 72: Herramienta Data Highlighter para resultados de búsqueda
Otra de las herramientas ofrecidas en esta categoría permite al usuario conocer si
existen problemas con meta descriptions, títulos de página o contenido no indexable.
Detecta y sugiere correcciones con el objetivo de mejorar la experiencia del usuario.
En caso de que las meta descripciones no proporcionen información relevante,
Google seleccionará automáticamente el contenido que considere más significativo,
pudiendo extraerlo del directorio DMOZ, o bien de descripciones que Google pueda
encontrar sobre páginas que nos enlazan.

190
Figura 73: Información mostrada en la lista de resultados de Google
La última de las herramientas que ofrece para controlar la apariencia del sitio web en
los SERPs es la herramienta Sitelinks. Sitelink hace mención a la generación
automática de enlaces que pueden aparecer bajo la impresión del resultado del sitio
web (Figura 74).
Figura 74: Sitelinks del sitio desdemiatalaya.com
Como ejemplo, podemos observar el Sitelinks generado para el sitio web
desdemiatalaya.com (Figura 74). Dispone de seis resultados resaltados en el Sitelinks.
Mediante el uso de esta herramienta podemos controlar los enlaces que no queremos
mostrar en el Sitelink sin eliminar del índice de Google el documento web.
4.3.3. Consulta sobre el tráfico de búsqueda
En esta categoría se encuentran las herramientas necesarias para consultar
información relacionada con las búsquedas de los usuarios, enlaces internos de
nuestro sitio web o enlaces entrantes adquiridos.

191
Mediante la herramienta Search Queries podemos consultar las keywords para las
cuales optamos como resultado. Junto con las keywords se encuentran el número de
impresiones o visualizaciones de nuestros documentos en Google Search, el número
de clics conseguidos así como el porcentaje de CTR (click-through-rate) y la posición
que ocupamos para las keywords introducidas (Figura 75).
Figura 75: Herramienta GWT para el análisis de las palabras clave empleadas
La herramienta Links to your site (Figura 76) nos permite consultar quién nos enlaza,
los documentos más enlazados o el texto empleado por el cual nos enlazan. Esta
herramienta no es exacta y puede que no aparezcan todos los enlaces externos que
hemos adquiridos. Es por ello que durante el proyecto final de carrera se hizo uso de
la herramienta WebCEO como medio para obtener una visión completa de los enlaces
adquiridos.
Figura 76: Herramienta GWT para el análisis de enlaces entrantes

192
GWT también ofrece una herramienta que nos permite obtener información sobre los
enlaces internos de los que disponemos. Conocida como internal links (Figura 77),
esta herramienta puede emplearse para detectar páginas huérfanas, la estructura del
sitio web así información sobre las páginas reciben mayor promoción o son más
enlazadas.
Figura 77: Herramienta GWT para el análisis de enlaces internos
La última herramienta situada en esta categoría se denomina Manual Actions. Es
empleada por Google para notificar si estamos siendo penalizados. Las acciones
mostradas en este informe pueden tener impacto sobre todo el sitio web o sobre
páginas específicas.
Algunas de las acciones que pueden ser listadas en el informe incluyen: detección de
links no naturales hacia tu sitio web (pudiendo detectar patrones de construcción de
links, manipulación de links, compra de links, …), sitios que hayan sido hackeados,
aquellos que contengan puro spam o palabras clave ocultas, etc.

193
Durante el proyecto final de carrera se aplicaron únicamente las técnicas
recomendadas por los motores de búsqueda, evitando la creación masiva de enlaces
desde directorios y comentarios.
4.3.4. Control sobre el índice de Google
El índice de Google guarda información relevante sobre los sitios web. Gracias a la
información almacenada en este índice, Google hace frente a las keywords que los
usuarios introducen en el motor de búsqueda.
Las herramientas que GWT ofrece nos permiten consultar el número de documentos
web que se encuentran indexados (Figura 78) y las palabras clave empleadas en estos
(Figura 79).
Figura 78: Herramienta GWT para el análisis de contenido indexado y bloqueado

194
Figura 79: Herramienta GWT para conocer las palabras mas empleadas
También ofrece una herramienta para borrar información del índice de Google (Figura
80). El uso de esta última herramienta es para casos de emergencia, donde
información privada se haya visto comprometida y haya sido indexada.
Figura 80: Herramienta GWT para eliminar direcciones web del índice de Google
4.3.5. Control sobre robots o crawlers
La principal función de los robots y crawlers es visitar documento web, recuperar el
contenido y almacenarlo en los servidores de Google. Esta información permite a
Google ordenar los documentos y crear el índice de búsqueda.

195
De entre las herramientas que Google Webmaster Tool pone a disposición, Crawl
errors nos permitirá consultar si los robots han tenido problemas al visitar nuestra
web o si estamos enlazando a direcciones con enlaces rotos. También dispone de
información sobre el correcto funcionamiento de DNS o la conectividad al servidor.
En caso de que queramos consultar cuándo fue la última vez que googlebot visitó
nuestro sitio web, disponemos de estadísticas sobre las páginas visitadas por día, el
tamaño descargado así como el tiempo de descarga por página bajo el panel de crawl
stats.
Ofrece también una herramienta conocida bajo el nombre de Fetch as Google que
permite al dueño del sitio web conocer la información que es recuperada por los
robots.
Esta herramienta es especialmente útil si nuestro sitio web esta desarrollado en Ajax o
Flash. Nos permite conocer qué contenido es extraído, ayudándonos a depurar
posibles problemas de escaneo de documentos.
En caso de que queramos evitar que Google visite documentos web específicos, éstos
pueden ser especificados en el documento robots.txt. Actualmente Google Webmaster
Tool ofrece una herramienta denominada Blocked URLs que nos permite consultar el
archivo robots.txt existente, así como realizar pruebas previa actualización del
fichero.
El archivo Sitemap.xml puede ser enviado a Google a través de la herramienta
denominada Sitemap. El envío de este fichero informa a los robots sobre las páginas
que están disponibles en el sitio web.
4.3.6. Conclusiones
La herramienta Google Webmaster Tool ha sido utilizada intensamente durante el
proyecto final de carrera. Para ello se integró la información que esta herramienta
proporciona en las herramientas WebCEO y Google Analytics. Los principales
problemas encontrados están relacionados con la fiabilidad de los datos que

196
proporciona. El posicionamiento de los documentos así como el número de clics
adquiridos desde los motores de búsqueda no se corresponde con los documentados
por la herramienta WebCEO(posicionamiento web) o Google Analytics (visitas
adquiridas desde buscadores).
4.4. Google Analytics
Google Analytics es una herramienta desarrollada por Google cuyo objetivo es
proporcionar estadísticas para tomar decisiones informadas. Es una herramienta
analítica con la que podremos estudiar: la audiencia, la adquisición de tráfico, el
comportamiento de los usuarios y las conversiones para los objetivos web
establecidos.
En esta sección se introducirá al lector las métricas básicas y el cálculo de éstas,
cálculo de KPIs tales como el ratio de fidelización o el número de visitas necesarias
hasta la conversión, así como los problemas existentes para el cálculo de métricas
como recency y visitor loyalty.
4.4.1. Cálculo de métricas básicas
La comprensión sobre cómo se calculan las métricas básicas resulta clave para definir
y componer métricas. En este apartado describiremos cómo Google Analytics calcula
las métricas más básicas, tanto de navegación como en tiempo de permanencia en el
sitio web.
Métricas de usuario
Este tipo de métricas se caracterizan por almacenar información sobre cómo
interactúa el usuario. A continuación exponemos las métricas principales relacionadas
con el usuario (Google Analytics, 2013):
Páginas Vistas: Esta métrica proporciona el número total de páginas vistas o
visitadas (Google Analytics, 2014). Cada vez que un usuario realiza una petición de

197
un recurso al servidor web, se incrementa el contador interno de páginas vistas o
visitadas (Figura 81).
Figura 81: Páginas vistas por usuario en Google Analytics
Páginas Vista Únicas: Esta métrica mide el número de diferentes recursos webs que
han sido requeridos por una visita (Google Analytics, 2014). Es decir, cuenta el
número de páginas webs distintas servidas en una sesión (Figura 82).
Figura 82: Páginas vistas únicas por usuario en Google Analytics
Visita o Sesión: Esta métrica mide el número de sesiones o visitas que un usuario
realiza al sitio web. Identifica a cada uno de los visitantes, contabilizando una nueva
visita cuando el usuario interactúa con el sitio web tras 30 minutos de inactividad
(Google Analytics, 2013) o cuando cierra el navegador y vuelve al sitio web (Figura
83).

198
Figura 83: Medición de sesiones en Google Analytics
Visitante Único: Esta métrica mide el número de visitantes diferentes que realizaron
algún tipo de petición al servidor durante un periodo de tiempo específico (Figura 84).
Figura 84: Medición de visitantes únicos en Google Analytics
Visitantes Recurrentes: Son aquellos visitantes identificados con anterioridad que
realizan en diferentes sesiones peticiones de recursos webs (Figura 85).

199
Figura 85: Medición de Visitantes recurrentes en Google Analytics
Métricas de Tiempo
Estas métricas nos permiten estudiar el tiempo que los usuarios emplean en los
documentos web. Mediante ellas y junto con las métricas de usuarios anteriormente
explicadas, seremos capaces de estudiar el interés de los usuarios en los documentos
web.
Tiempo en Página: Para calcular el tiempo que un visitante está en una página web,
Google Analytics mide la diferencia en tiempo entre peticiones (Kaushik, 2010). El
tiempo transcurrido entre petición y petición es el tiempo que el usuario estuvo en la
página web.
El tiempo que un visitante se encuentra en una página es una medida inexacta. Google
Analytics únicamente calcula el tiempo cuando las peticiones son realizadas dentro
del mismo dominio. Si el usuario navega hacia una web externa a nuestro dominio, el
tiempo en página es considerado de 0 segundos (Kaushik, 2010).
Veamos un ejemplo para entenderlo:

200
Figura 86: Medición de tiempo en página en Google Analytics
Si observamos la Figura 86, tras visitar el documento 3 el usuario abandona el sitio
web. El tiempo que Google Analytics estima es que el usuario estuvo 0 segundos en
el documento 3. Esto es debido a que no hubo una nueva petición.
Tiempo medio en Página: Para el cálculo de esta métrica, Google Analytics tiene en
cuenta el tiempo de la visita en la página, excluyendo aquellas cuyo tiempo haya sido
cero, bien porque el visitante haya entrado y salido de la página rápidamente, porque
el visitante solo consumiera únicamente ese recurso web y se marchara, así como para
aquellas páginas que son mostradas y que terminan con la salida hacia el exterior del
visitante.
Tiempo medio en el site: El cálculo de esta medida, a diferencia de la anterior tiene
en cuenta aquellas páginas vistas que supusieron la salida del visitante hacia otro
dominio, contabilizando su tiempo en página como cero (Munoz Vera, Era cuestion
de tiempo..., 2008). Cuanto mayor sea el número de visitantes y menor el número de
recursos web que consumen, mayor será la distorsión del valor de esta métrica, dado
que las visitas sin interacción serán incluidas en los cálculos.
Una de las soluciones propuestas por Gemma Munoz Vera en su blog (Munoz Vera,
2008) para conseguir datos más exactos, es excluir a aquellos usuarios que solo

201
visitaron una única página. De esta forma, los resultados serán más exactos, pues
medirán el tiempo que emplean aquellos que están interesados en la web.
Bounce Rate: El ‘bounce rate’ es una métrica que por si sola, y sin necesidad de
ningún otro tipo de métrica, es capaz de informarnos sobre si el contenido que
ofrecemos es el esperado por los usuarios. Avinash Kaushik lo define con la célebre
frase ‘I came, I saw, I puked, I’m out of here’ (Kaushik, 2010). Viene a indicarnos el
porcentaje de visitas que empezaron la navegación en una página de entrada
determinada y se marcharon sin consumir ningún recurso.
4.4.2. Cálculo de métricas Avanzadas
En esta sección mostraremos como puede hacerse uso de la herramienta Google
Analytics para calcular KPIs relevantes para todo negocio web. Las KPIs mostradas a
continuación son de propósito general. En secciones posteriores veremos cómo no
todas las KPIs pueden calcularse con exactitud mediante el uso de Google Analytics.
KPI: Bounce Rate
El bounce rate es una métrica significativa. Se define en Google Analytics como el
porcentaje de sesiones que visitan una única página (Kaushik, 2010). Permite
responder a preguntas sobre el interés del usuario en base al tipo de tráfico adquirido,
campaña de marketing, palabras clave empleadas, etc.
Para hacer buen uso de esta KPI, es importante realizar una serie de ajustes de forma
que el porcentaje de bounce rate notificado en Google Analytics represente
correctamente a aquellos usuarios para los cuales no les hemos ofrecido lo que
buscaban.
Tal y como hemos comentado anteriormente, el cálculo de esta métrica está basado en
identificar la página de entrada y de salida como la misma, sin detección de acciones
desde que se accede hasta que se sale del sitio web.
Existen problemas asociados con el cálculo del bounce rate en los siguientes casos:

202
- Páginas formadas por una única pagina web:
Debido a que la web está concentrada totalmente en un único documento web,
Google Analytics no reconoce interacciones, de forma que identifica todas las
visitas como bounce rate.
- Páginas desarrolladas con Ajax:
Este tipo de páginas padecen mismo problema que las anteriores. Debido a
que cargan el código a través de funciones Ajax, la página o el elemento que
contiene el código de Google Analytics nunca es refrescado.
- Incorrecta adición del código de Google Analytics:
Este tipo de problemas suceden cuando no situamos el código de Google
Analytics en el lugar apropiado, compartido por todas las páginas.
De los problemas comentados anteriormente, el uso de eventos puede ayudarnos a
informar a Google Analytics cuando una visita es considerada como exitosa y debe no
ser contabilizada para el cálculo del bounce rate (Kaushik, 2010).
A continuación mostramos un ejemplo del código a añadir para ajustar el cálculo de
bounce rate:
<script type="text/javascript">
// Setting up Google Analytics code
var _gaq = _gaq || [];
// Setting up Account
_gaq.push(['_setAccount', 'UA-‐XXXXXXX-‐1']);
// Push trackPageView
_gaq.push(['_trackPageview']);
// Push asynchronous event
_gaq.push(['_trackEvent', '15_seconds', 'read']);
</script>

203
A través del método __trackEvent ( ) es posible informar a Google Analytics de que
el usuario ha interactuado con el sitio web, por lo que no debería de ser contabilizado
como bounce. A continuación exponemos dos ejemplos de cómo usar este método:
- Páginas formadas por una única pagina web.
<script type="text/javascript">
var _gaq = _gaq || [];
_gaq.push(['_setAccount', 'UA-‐XXXXXXX-‐1']);
_gaq.push(['_trackPageview']);
setTimeout("_gaq.push(['_trackEvent', '15_seconds',
'read'])",15000);
…
</script>
La adición del código anterior permitirá detectar cuándo un usuario permanece
más de 15 segundos en una página. Esto se consigue mediante la emisión de
un evento para notificar a Google Analytics sobre este hecho. No será
contabilizado como bounce rate dado que hay interacción a pesar de que las
webs de entrada y/o salida sean las mismas.
- Páginas desarrolladas con Ajax.
<a href="#"
onClick="_gaq.push(['_trackEvent', 'Videos', 'Play',
'Baby\'s First
Birthday']);loadPage('videos')">Play</a>
Esta solución consiste en disparar el método __trackEvent( ) cada vez que
vaya a realizarse una acción mediante llamadas Ajax. El método
__trackEvent( ) será disparado con la pulsación de los botones de navegación
que cargan contenido. De esta forma, cada vez que se realice la pulsación de
uno de estos botones se emitirá un evento.

204
El bounce rate es una métrica de fácil acceso desde cualquiera de los informes
proporcionados por Google Analytics. Deberemos prestar especial atención al bounce
rate de las páginas que sirven de entrada. Estas deben estar diseñadas para la
consecución de objetivos. Un alto índice de bounce rate en las páginas de entrada
puede ayudarnos a identificar problemas entre el contenido y la promoción de este.
KPI: Ratio de conversión de objetivos
Se conoce como ratio de conversión de objetivos, a la KPI que mide al número de
usuarios que convierten al menos uno de los objetivos establecidos en la web (Munoz
Vera & Elosegui Figueroa, 2011). Si bien Google Analytics dispone de herramientas
para medir el ratio de conversión sobre los objetivos, este se calcula en base a las
visitas y no en base a los usuarios únicos. Es importante hacer esta distinción a la hora
de interpretar resultados, pues un usuario único puede realizar varias sesiones y solo
en una de ellas completar el objetivo.
Para hacer uso de esta métrica tenemos que definir objetivos en Google Analytics. El
dueño del sitio web había definido algunos de estos pero su configuración no era la
adecuada para un blog. A principios de Octubre se definieron nuevos objetivos de la
siguiente forma:
- Interés del usuario
Número de usuarios que consumen más de un documento.
- Retención de usuarios
Número de usuarios que permanecen más de 25 segundos en el blog.
- Página de contacto
Número de usuarios que durante su sesión visitan la página de contacto.
- Página de autor
Número de usuarios que durante su sesión visitan la página del autor.

205
A continuación mostramos una tabla (Tabla 10) que muestra la evolución del
porcentaje de objetivos web alcanzados durante el proyecto final de carrera por
meses:
Mes Interés del
usuario
Retención de
usuarios
Página de
contacto
Página de
autor
Septiembre 7.53% 9.35% 0.38% 1.37%
Octubre 9% 10.91% 0.28% 1.10%
Noviembre 26.81% 24.34% 0.61% 1.06%
Media 15.66% 15.8% 0.44% 1.16% Tabla 10: Evolución del porcentaje de objetivos web
El informe sobre los resultados finales puede obtenerse a través del menú Audience –
Acquisition – All Traffic, en la pestaña Conjunto Objetivos 1. Mostramos una imagen
(Figura 87) extraída de Google Analytics que corrobora los datos anteriores.
Figura 87: Informe de adquisición de audiencia
KPI: Ratio de fidelización
Se conoce como ratio de fidelización al número de usuarios nuevos que son
necesarios para conseguir fidelizar uno (Munoz Vera & Elosegui Figueroa, 2011). La
fórmula que define el ratio de fidelización es la siguiente:
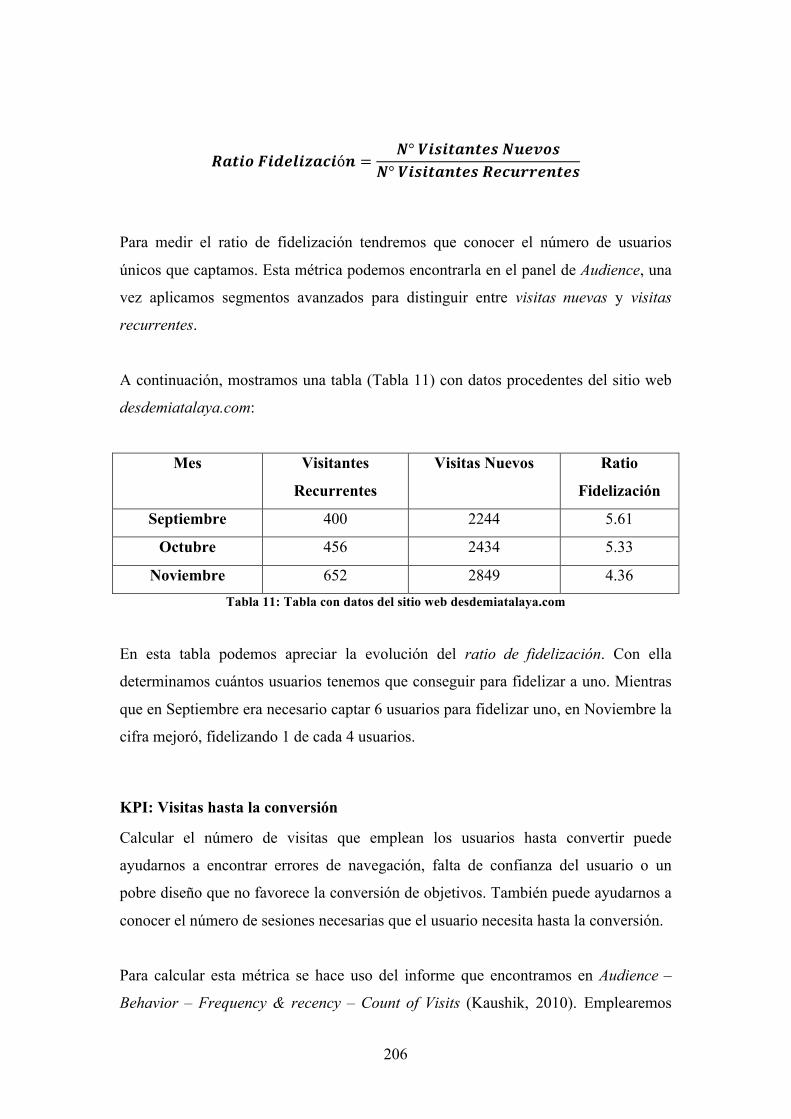
206
𝑹𝒂𝒕𝒊𝒐 𝑭𝒊𝒅𝒆𝒍𝒊𝒛𝒂𝒄𝒊ó𝒏 =𝑵° 𝑽𝒊𝒔𝒊𝒕𝒂𝒏𝒕𝒆𝒔 𝑵𝒖𝒆𝒗𝒐𝒔
𝑵° 𝑽𝒊𝒔𝒊𝒕𝒂𝒏𝒕𝒆𝒔 𝑹𝒆𝒄𝒖𝒓𝒓𝒆𝒏𝒕𝒆𝒔
Para medir el ratio de fidelización tendremos que conocer el número de usuarios
únicos que captamos. Esta métrica podemos encontrarla en el panel de Audience, una
vez aplicamos segmentos avanzados para distinguir entre visitas nuevas y visitas
recurrentes.
A continuación, mostramos una tabla (Tabla 11) con datos procedentes del sitio web
desdemiatalaya.com:
Mes Visitantes
Recurrentes
Visitas Nuevos Ratio
Fidelización
Septiembre 400 2244 5.61
Octubre 456 2434 5.33
Noviembre 652 2849 4.36 Tabla 11: Tabla con datos del sitio web desdemiatalaya.com
En esta tabla podemos apreciar la evolución del ratio de fidelización. Con ella
determinamos cuántos usuarios tenemos que conseguir para fidelizar a uno. Mientras
que en Septiembre era necesario captar 6 usuarios para fidelizar uno, en Noviembre la
cifra mejoró, fidelizando 1 de cada 4 usuarios.
KPI: Visitas hasta la conversión
Calcular el número de visitas que emplean los usuarios hasta convertir puede
ayudarnos a encontrar errores de navegación, falta de confianza del usuario o un
pobre diseño que no favorece la conversión de objetivos. También puede ayudarnos a
conocer el número de sesiones necesarias que el usuario necesita hasta la conversión.
Para calcular esta métrica se hace uso del informe que encontramos en Audience –
Behavior – Frequency & recency – Count of Visits (Kaushik, 2010). Emplearemos

207
este informe para conocer en qué visita se generó la conversión o la consecución de
un objetivo creado en Google Analytics. Para ello será necesario aplicar como
segmento avanzado el objetivo que queremos observar.
Mostramos a continuación un ejemplo (Figura 88) que nos indica el número de
sesiones que requiere la adquisición de un lead.
Figura 88: Informe para medir sesiones necesarias hasta la conversión
En la gráfica anterior (Figura 88) podemos observar que de las diez visitas que
terminaron en leads, seis de ellas se realizaron en la primera sesión, una en la segunda
y dos en la tercera. La sucesión de visitas no ayuda en la consecución de objetivos.
Si este sitio web fuera un blog, esta información sería suficiente para determinar que
la adquisición de leads está teniendo resultado. La generación de leads para blogs
suele estar en porcentajes de entre 2% - 15%, dependiendo del éxito del blog o de la
temática, de cómo y dónde se promociona el blog, de dónde se adquieren los usuarios
o de la audiencia.

208
4.4.3. Errores de medición
Google Analytics ofrece multitud de información sobre tráfico, comportamiento del
usuario, segmentos avanzados, etc. Si bien es una herramienta muy potente, gran
parte de las KPIs definidas en la literatura consultada durante el proyecto final de
carrera hacen referencia a usuarios únicos, mientras que Google Analytics realiza la
mayor parte de sus cálculos basados en visitas o sesiones; funciona a través del
procesamiento de datos agregados, es decir, las observaciones son transformadas en
estadísticas, por lo que no es posible el estudio de sucesos aislados. Otras
herramientas de analítica web permiten esto (por ejemplo, KissMetrics).
La evolución y crecimiento del uso de tablets y móviles y la imposibilidad de
identificar usuarios finales dificulta a su vez el cálculo de métricas.
A continuación mostramos algunos ejemplos de mediciones que son imposibles de
realizar a través de la herramienta de Google Analytics debido a la naturaleza del
cálculo de sus mediciones:
Usuarios Nuevos: para aquellos usuarios que realicen navegación multiscreen
(es decir, empleando múltiples dispositivos electrónicos), cada uno de estos
serán contabilizados como usuarios nuevos. No existe la identificación cross-
device.
Usuarios Únicos: para aquellos usuarios que realicen navegación multiscreen,
se identificará cada uno de los dispositivos electrónicos empleados para
consultar información como usuarios únicos.
Visitor loyalty: obtener el número de veces que un usuario visita un sitio web
resulta difícil o impreciso dado que se contabilizan las visitas como un cálculo
agregado.
Recency: medir la frecuencia de las visitas por usuario no es actualmente
posible. No existe informe que identifique a los usuarios de forma unívoca y

209
nos permita saber el número de sesiones o visitas que realizó en un periodo de
tiempo especificado.
4.4.4. Conclusiones
Google Analytics se presenta como la herramienta por excelencia para controlar qué
sucede en un sitio web. Durante la realización del proyecto final de carrera se ha
hecho uso de esta herramienta principalmente para conocer la evolución sobre la
captación de usuarios desde distintos canales.
Esto nos permitió conocer que las técnicas empleadas en la optimización de
contenidos consiguieron aumentar el volumen de visitas que capta el sitio web, tanto
el procedente desde los motores de búsqueda como el procedente de las redes
sociales.
Los análisis sobre el número de impresiones que recibe el sitio web en la lista de
resultados, así como el número de clics que documenta el informe Adquisición /
Optimización en buscadores nos hacen dudar sobre la exactitud de los datos
adquiridos. Estos datos no concuerdan con las cifras obtenidas que muestra el panel
Adquisición / Todo el tráfico / Canales / Organic Search.
4.5. Google AdWords
Google AdWords es el programa de anuncios online ofrecido por Google. Permite
patrocinar sitios web a través de distintas modalidades de anuncios y distintas redes
(Google AdWords, 2013). Funciona mediante la definición de keywords. Las
keywords son las palabras o frases que el anunciante elige para conectar con los
usuarios.
Los anuncios promocionados a través de Google AdWords optan a ser impresos para
aquellos usuarios que realizan búsquedas relacionadas con las keywords especificadas
por los anunciantes o bien en sitios web cuya temática está relacionada con ellas.

210
La impresión de los anuncios funciona bajo un sistema de subastas y pujas (Google
AdWords, 2014). Éstas son realizadas en tiempo real. Si varios anunciantes pujan por
la misma palabra o el mismo espacio, Google determina cuál se imprime y el orden de
estos mediante la métrica Ad Rank.
El Ad Rank es una combinación conjunta del máximo valor dispuesto a pagar por el
anunciante por la consecución de un clic (conocido como máximo CPC) y el quality
score (Google AdWords, 2013) .
Se conoce como quality score a la medida que califica la calidad de las keywords
seleccionadas, la calidad del anuncio en base a click-through-rate (abreviado como
CTR) para la posición conseguida, la calidad de la landing page así como otros
factores no dados a conocer (Google AdWords, 2013).
AdWords funciona para diferentes redes. Los anuncios pueden ser visualizados por los
usuarios que realizan búsquedas en Google Search o bien por los usuarios mientras
navegan entre páginas web (Google AdWords, 2013). El primero de los casos hace
mención hacia lo que se conoce como Search Network. La segunda red se conoce
como Google Display Network. En este segundo caso, si las pujas se realizan
empleando la opción cost-per-thousand impressions (abreviado como CPM), el
quality score se determina únicamente midiendo la calidad de la landing page.
En la siguiente sección mostraremos los conceptos básicos sobre el funcionamiento de
Google AdWords, cómo crear campañas, cómo realizar listas de remarketing, cómo
acotar la audiencia así como algunas de las posibilidades que Google AdWords ofrece
para actuar sobre las subastas y personalización de pujas. También veremos cómo
manejar herramientas para planificar las campañas en la Search Network así como en
la Display Network.
4.5.1. Principios básicos y funcionamiento
En esta sección se tratarán los principios básicos para entender la creación de
campañas y las diferentes redes a las cuales se tiene acceso desde Google AdWords.
Explicaremos cómo manejar eficientemente los anuncios a través de ad groups, cómo

211
emplear las keywords, veremos el funcionamiento de las subastas y cómo Google
AdWords determina la máxima cantidad a pagar en cada subasta.
Network
Se conoce como Google Network a la red de recursos donde Google AdWords puede
mostrar anuncios (Google AdWords, 2013). Esta red está formada por sitios web que
tienen acuerdos con Google, aplicaciones móviles, Google Search así como otros
servicios proporcionados por Google como Gmail, YouTube, grupos de Google, etc.
A la hora de crear una campaña publicitaria empleando AdWords es necesario
especificar el tipo de red a emplear. Google Network puede separarse en dos tipos de
redes diferenciadas por los sitios donde pueden mostrar anuncios.
La red Display Network, también conocida como Content Network, forma parte de la
red Google Network. Forman parte de ella todos los sitios web donde Google
AdWords puede añadir contenido, incluyendo Gmail, YouTube o Blogger entre otros
(Google AdWords, 2013).
Se conoce como Search Network al grupo de buscadores donde los anuncios de
Google AdWords pueden aparecer, incluyendo Google Search así como Shopping,
Maps, Images o partners de Google como AOL (Google AdWords, 2013).
Tipos de Campaña
Google AdWords ofrece la posibilidad de crear diferentes tipos de campaña. La red de
AdWords provee una serie de campañas sobre las que distribuir los anuncios. A
continuación mostramos un cuadro resumen de los tipos de campañas existentes y las
redes donde éstas pueden actuar (Google AdWords, 2013).
Search Network Search & Display
Network
Display Network

212
ALL FEATURES
STANDARD
MOBILE APS
REMARKETING
PRODUCT
LISTING
DYNAMIC ADS
Para obtener mayor información sobre las posibilidades que cada una de éstas ofrece,
así como de sus características, se puede consultar la página de soporte de AdWords.
Ad groups
Se conoce como ad groups, al elemento básico de trabajo de Google AdWords. Estos
nos permiten agrupar palabras clave, aplicando a todas ellas la misma configuración,
es decir, facilitando la gestión de estas (Google AdWords, 2014).
Cada ad groups puede contener uno o varios anuncios, empleando todos las mismas
palabras clave. Si determinamos que ciertas palabras clave atraen un tráfico de buena
calidad (es decir, un tráfico que convierte en nuestro sitio web), es posible redefinir el
CPC máximo a nivel de palabra clave (la puja máxima a pagar por el clic del usuario
en el anuncio) (Google AdWords, 2014).
A continuación podemos observar un ejemplo de ad group (Figura 89), donde se ha
definido un máximo CPC para todas las palabras clave, y redefinido una puja
superior para aquellas palabras clave que tienen un mejor rendimiento:

213
Figura 89: Ad Group con redefinición de puja para keywords específicas
Keywords
Se conocen como keywords o palabras clave a la representación más sencilla
empleada por Google AdWords para identificar y emparejar anuncios con las
búsquedas realizadas por los usuarios o con los sitios webs relacionadas que
establezcan alguna relación con las keywords.
Dependiendo del tipo de red seleccionada, las keywords serán empleadas de forma
diferente (Google AdWords Support, 2014). Si la red elegida es Google Search and
search partner sites, las keywords seleccionadas tendrán que ser relevantes para los
términos que los usuarios emplean al realizar las búsquedas. Como veremos a
continuación, en el caso de usar la Google Search Network es recomendable emplear
keywords relacionadas con los términos de búsqueda de los usuarios.
En caso de que la red seleccionada sea Google Display Network, estas keywords
sirven para identificar los sitios web que están relacionados con la misma temática. Si
conocemos bien a nuestra audiencia, Google AdWords nos permite especificar sitios
webs concretos donde lanzar nuestras campañas de anuncios. También es posible
centrar las campañas en base al interés de los usuarios o en base a categorías
predefinidas por Google AdWords (Google AdWords Support, 2014).
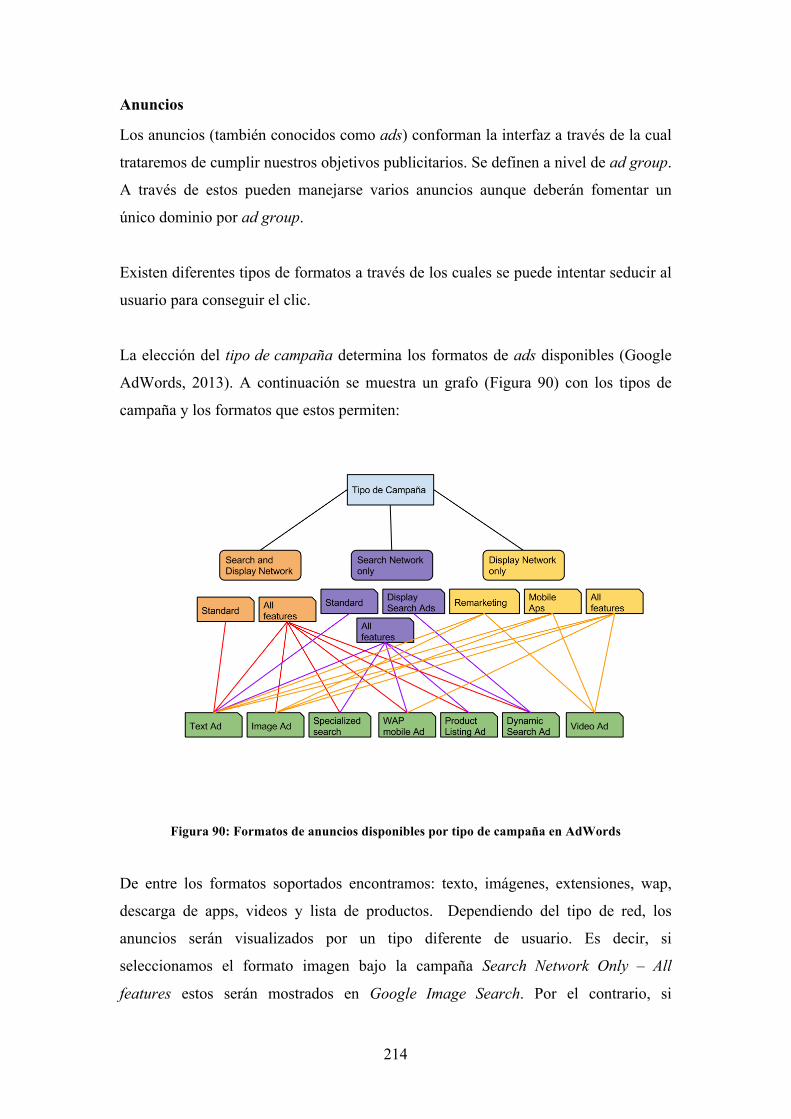
214
Anuncios
Los anuncios (también conocidos como ads) conforman la interfaz a través de la cual
trataremos de cumplir nuestros objetivos publicitarios. Se definen a nivel de ad group.
A través de estos pueden manejarse varios anuncios aunque deberán fomentar un
único dominio por ad group.
Existen diferentes tipos de formatos a través de los cuales se puede intentar seducir al
usuario para conseguir el clic.
La elección del tipo de campaña determina los formatos de ads disponibles (Google
AdWords, 2013). A continuación se muestra un grafo (Figura 90) con los tipos de
campaña y los formatos que estos permiten:
Figura 90: Formatos de anuncios disponibles por tipo de campaña en AdWords
De entre los formatos soportados encontramos: texto, imágenes, extensiones, wap,
descarga de apps, videos y lista de productos. Dependiendo del tipo de red, los
anuncios serán visualizados por un tipo diferente de usuario. Es decir, si
seleccionamos el formato imagen bajo la campaña Search Network Only – All
features estos serán mostrados en Google Image Search. Por el contrario, si

215
seleccionamos el mismo formato de imagen bajo Display Network Only – All features
el anuncio será mostrado en websites en lugar de Google Image Search.
Funcionamiento de las subastas
Google Adwords funciona a través de un proceso de subastas. Nos permite establecer
límites sobre el máximo presupuesto disponible del cual puede hacerse uso
diariamente por campaña (Google AdWords, 2014). A continuación expondremos el
funcionamiento de las subastas y cómo se determina el valor final a pagar en cada una
de ellas.
Si se emplea la red Search Network, con cada búsqueda que se realiza, Google
procesa la información para decidir que ads mostrar. Google determinar si las
keywords están relacionadas con la búsqueda realizada por el usuario. En caso
afirmativo, el ad es considerado para entrar en la subasta .
El sistema ignorará aquellos anuncios que no cumplan con ciertos requisitos sobre los
que tenemos control, tales como localización, país, etc. De los anuncios que han sido
seleccionados para entrar en la puja, se emplea la métrica Ad Rank (combinación del
máximo CPC y el quality score) para determinar cuáles serán mostrados, así como el
orden de éstos (Google AdWords, 2014).
Desde AdWords se enfatiza que si el quality score es suficientemente alto comparado
con los anuncios contra los que se compite, es posible la adquisición de una mejor
posición incluso cuando nuestra puja es inferior (Google AdWords, 2014).
El precio máximo a pagar por un clic se conoce como máximo CPC (Google
AdWords, 2014) . Google AdWords tiene en cuenta este valor para conocer la máxima
cantidad que estamos dispuestos a pagar para superar a otros anunciantes.
El precio que se paga por clic se denomina actual CPC (Google AdWords, 2014) . El
actual CPC se define como la mínima cantidad que es necesaria pagar por batir el Ad
Rank del anuncio que se encuentra por encima del nuestro.

216
En la red Search Network, el actual CPC se determina como el valor mínimo a pagar
para posicionar nuestro anuncio por encima del anuncio de nuestro competidor.
En la Display Network, el precio del clic se determina de forma diferente. Existe el
concepto de incremental clics. Hace referencia a la diferencia en el número clics que
consigue un anuncio por el mero hecho de aparecer en una mejor posición. En esta
red de anuncios, el actual CPC se determina como la media de las pujas a pagar para
superar al anuncio que se encuentra encima por encima.
A continuación vamos a explicar cómo funciona el sistema mediante dos ejemplos
proporcionados por Google AdWords (Google AdWords Support, 2014):
Subasta para un único Ad Unit
En este ejemplo existe únicamente un único lugar para posicionar el anuncio. Todos
los anunciantes disponen del mismo quality score (Tabla 12).
Anunciante Max CPC Bid Quality Score Muestra de Ad
Alice 5€ 10 SI
Bob 3€ 10 NO
Charlie 1€ 10 NO Tabla 12: Subasta para anuncio único
Bajo estas condiciones, Alice sería la única en imprimir su anuncio, debido a que en
igualdad de condiciones, su puja está por encima de la del resto de competidores.
El actual CPC es el importe a pagar para batir a su competidor (Google AdWords
Support, 2014). En este caso Bob tiene establecido una puja máxima de 3€, por lo que
Alice tendría que pagar por cada clic conseguido en esta subasta 3.01€.
Subasta para dos Ads Unit

217
En el caso de que exista más de un lugar donde posicionar los anuncios, Google
AdWords hace uso de métricas como el CTR por posición, de forma que pueda
cuantificar cuánto favorece a los anunciantes la adquisición de una posición más
visible (Google AdWords Support, 2014).
Anunciante Max CPC
Bid
Quality
Score
Muestra de
Ad
CTR por
posición
Alice 5€ 10 SI 3.0 %
Bob 3€ 10 SI 1.0 %
Charlie 1€ 10 NO NA Tabla 13: Subasta para dos anuncios
En estas subastas (Tabla 13), el actual CPC para Bob es aquel que le permite batir a
Charlie, resultando en 1.01€ por clic. El caso de Alice es diferente. En este caso se
calculará el actual CPC en función de los incremental clics conseguidos debidos a su
ventaja por posicionamiento así como en base al actual CPC de Bob. Este se aplicará
únicamente para aquellos clics que también hubiese conseguido sin disponer de una
posición privilegiada (Google AdWords Support, 2014).
Para el siguiente ejemplo vamos a suponer que Alice consigue 9 clics. Si observamos
la anterior tabla, Alice consigue tres veces más clics que Bob. Si comparamos la
primera con la segunda posición, dos tercios de los clics conseguidos por Alice son
ganados gracias a su mejor posicionamiento. Estos clics se contarán como
incrementales. El tercio restante será considerado con respecto al actual CPC de Bob,
dado que Alice habría podido conseguir ese tercio si se hubiese encontrado en la
segunda posición igualmente (Google AdWords Support, 2014).
De esta forma, los costes a pagar por Alice se calcularían de la siguiente forma:
Clics CPC Total cost

218
3 1.01€ (actual CPC de Bob) 3.03€
6 3.01€ (máximo CPC de Bob) 18.06€
Total: 9 Actual CPC: 2.34 € Tabla 14: Cálculo de costes de anuncios
Por tanto, el actual CPC que Alice paga por cada clic se calcula como la media del
CPC, que en la tabla anterior(Tabla 14) se determinó como 2.34 €.
Conocido cómo se calcula el coste de cada clic, en el siguiente apartado explicamos
cómo definir la audiencia que recibe el anuncio.
4.5.2. Definición del público objetivo
Durante la creación de campañas puede hacerse uso de filtros. Estos filtros nos
permiten dirigir las campañas hacia un público específico. Las opciones disponibles
para definir el público objetivo dependen de la campaña seleccionada.
A continuación mostramos una tabla resumen (Tabla 15) que especifica los filtros
posibles a emplear en las campañas de Google AdWords, en función de la red
seleccionada (Google AdWords, 2014):
Google Search
Basado en palabras clave
Permite mostrar los anuncios únicamente a aquellos
usuarios que introducen términos de búsqueda
relacionados con nuestras palabras clave.
Localización e idioma
Permite mostrar anuncios a los usuarios, en base a la
localidad donde se encuentran o al idioma.
Dispositivo

219
Permite centrar los anuncios a usuarios que hacen uso de
un dispositivo en concreto (móvil, tableta u ordenador),
pudiendo planificar cuando mostrarse (día y hora).
Google Display
Network
Basado en palabras clave
Permite mostrar el anuncio en sitios web relevantes para
las palabras claves que definen el producto.
Basado en temática
Permite mostrar el anuncio en sitios web relacionados
con la temática elegida.
Contextual
Permite mostrar el anuncio en sitios web relacionadas
con las palabras clave o temática elegidas.
Basado en dominio
Permite mostrar el anuncio en sitios web específicos, por
dominios o subdominios.
Tipo de audiencia
Permite mostrar anuncios en base a la audiencia en la
que estemos interesados en alcanzar. Mediante las
campañas de remarketing podemos alcanzar a los
usuarios en función de la actividad que han realizado en
el sitio web.
Dispositivo
Tal y como se definió en Google Search, este tipo de
anuncios permiten alcanzar a los usuarios en función del
dispositivo del que hacen uso.
Tabla 15: Filtros disponibles para campañas de AdWords

220
Los filtros se establecen a nivel de ad group. Google Adwords permite la aplicación
de varios a la vez. La aplicación de varios filtros limita el público que accede a estos,
aunque puede mejorar los porcentajes de conversión. En el siguiente apartado
veremos cómo configurar las pujas, permitiéndonos seleccionar un público objetivo
específico mediante la combinación de filtros.
4.5.3. Creación de Campañas
La creación de campañas en Google AdWords requiere estar registrado en Google
AdWords y haber configurado el método de pago. Una vez estamos dados de alta,
enumeraremos los pasos a seguir para la creación de campañas publicitarias en la
plataforma Google AdWords:
• Configuración de campaña: se conoce como campaña al conjunto de ad
groups que comparten un mismo tipo de campaña (Display & Search
Networks, Search Network only o Display Network only), localización, idioma,
así como presupuesto diario.
• Configuración de ad groups: Estos nos permitirán definir las keywords, la
personalización de pujas así como la creación de anuncios. Cada ad group
puede contener uno o más anuncios.
• Configuración de los anuncios o ads: Selección del formato de anuncio y
adición de textos, imágenes o videos que lo componen. Definición de
dirección web a mostrar. Cada ads o anuncio pertenece a un ad group.
• Configuración de la audiencia objetivo: Selección del tipo de usuario para el
cual se imprimirá el anuncio. Dependiendo del tipo de red seleccionado la
audiencia puede definirse para usuarios que ya visitaron la web, para aquellos
que visitan sitios web específicos o relacionados con una temática entre otras
opciones.

221
4.5.4. Campañas de remarketing
En este apartado expondremos cómo implementar campañas de remarketing en la
plataforma Google AdWords. Estas campañas se caracterizan por enfocarse en
usuarios que previamente han visitado nuestro sitio web.
Google AdWords implementa este tipo de campañas haciendo uso de listas de
remarketing. Estas listas almacenan las cookies de los visitantes. Mediante el
almacenamiento de estas cookies, Google AdWords es capaz de identificar los grupos
de usuarios que han acudido con anterioridad al sitio web (Google AdWords Support,
2014).
Etiqueta de Remarketing
Para poder centrar una campaña de Google AdWords en una audiencia que ya visitó
nuestro sitio web, es necesario añadir la etiqueta de remarketing al sitio web. La
obtención de esta etiqueta se encuentra en la sección Shared library – Audiences
(Google AdWords Support, 2014).
Una vez obtenida, esta debe de situarse en algún elemento HTML compartido por
todos los documentos web (como puede ser el footer de la web), aunque también será
posible ponerlo únicamente páginas específicas.
Una vez se ha insertado este en la web, podemos crear listas de remarketing. Estas
listas serán las que capturen las cookies de los usuarios, permitiendo a Google
AdWords determinar si los usuarios visitaron con anterioridad el sitio web.
Creación de listas
Si visitamos el panel Audiences, podemos observar cómo se ha creado una lista
denominada All visitors. Esta lista se crea por defecto con la creación de la etiqueta de
remarketing (Google AdWords Support, 2014). Desde este panel es posible comenzar

222
la creación de listas de remarketing basadas en las direcciones web (de nuestro propio
dominio) por las que el usuario navega.
Existe la posibilidad de añadir parámetros personalizables a las listas. Esto nos
permite controlar el valor de las pujas. Para ello es necesario la adición de pares key-
value que definan qué se mide y cuál es su valor (Google AdWords Support, 2014).
Un ejemplo de campaña usando la personalización de parámetros en las listas de
remarketing nos podría permitir enfocar nuestras campañas en usuarios que visitaron
artículos de más de un valor predefinido.
Restricciones para el uso de listas de remarketing
Una vez definidas las listas, será necesario recopilar un mínimo de cookies antes de
poder comenzar las campañas de remarketing. Asegurando un mínimo de cookies,
Google AdWords es capaz de proteger la privacidad y mantener el anonimato de los
usuarios (Google AdWords Support, 2014). El mínimo número de cookies depende de
la red donde vayamos a lanzar la campaña.
Si empleamos la Display Network deberá existir un mínimo de cien cookies (en los
últimos 30 días) antes de comenzar a imprimir ads (Google AdWords Support, 2014).
Si se hace uso de la red Search Network será necesario la recopilación de un mínimo
de mil cookies (Google AdWords Support, 2014).
Creación de campaña de remarketing
En este apartado mostraremos un ejemplo de cómo configurar una campaña centrada
en usuarios que visitaron nuestro sitio web, descargaron la información sobre los
servicios o la información de presentación de nuestra empresa pero no nos
proporcionaron sus datos (no generaron leads).
Para nuestro ejemplo será necesario la creación de tres tipos de listas:
- Lista para los usuarios que descargaron el archivo de presentación.
- Lista para los usuarios que descargaron la hoja de servicios.

223
- Lista para los usuarios que terminaron en leads.
Gracias al conjunto de listas definido anteriormente seremos capaces de crear una
lista de remarketing combinada. Esta lista nos permitirá alcanzar a los usuarios que se
descargaron alguno de archivos pero no nos proporcionaron su dirección web.
En la imagen siguiente (Figura 91) podemos observar el uso de operaciones OR y
NOT sobre las listas definidas anteriormente:
Figura 91: Personalización de listas
Una vez definida nuestra lista combinada, es necesario la creación de una campaña
cuya audiencia objetivo sea la lista que acabamos de definir.
En la siguiente sección veremos cómo optimizar las pujas, lo que nos permitirá
controlar la audiencia a la que exponemos nuestros anuncios.
4.5.5. Optimización de pujas
La herramienta Google Adwords permite la personalización de pujas. Con ello es
posible modificar el máximo CPC en base a las palabras clave o a la audiencia que
consideremos de mayor importancia para nuestro negocio.

224
El objetivo perseguido con la modificación del máximo CPC es incrementar las pujas.
Incrementando estas podemos mejorar las posibilidades de mostrar las campañas al
público más rentable. También es posible reducir estas para el público que es menos
rentable.
Existen diferentes métodos empleados en Google AdWords para modificar el máximo
CPC. A continuación, explicamos los diferentes tipos de pujas existentes (Google
AdWords Support, 2013):
Puja por defecto: Nos permiten fijar un precio en las pujas a nivel de ad group.
Este será el empleado por Google AdWords en caso de que no existan pujas
personalizadas.
Puja personalizada: Las pujas personalizadas son aquellas que nos permiten
modificar el máximo CPC o CPM por palabras clave, temática, interés del usuario,
etc. Estas pujas difieren entre sí en función de la red en la que nos encontremos.
Si estamos trabajando con una campaña de la Search Network, para hacer uso de
pujas personalizadas tendremos que definir la audiencia objetivo. Marcando la
opción Target and bid podremos filtrar la audiencia a la vez que personalizar las
pujas para esta (Google AdWords Support, 2013).
Si estamos trabajando con una campaña perteneciente a la Display Network,
haciendo uso de la opción Targeting podremos definir la audiencia a la que
dirigimos la campaña (Google AdWords Support, 2014). Mediante la opción
Target and bid filtramos la audiencia, pujando únicamente por aquellos que reúnan
los requisitos establecidos (Google AdWords Support, 2014).
Mostramos una imagen (Figura 92) sobre el público objetivo al que dirigimos
nuestras campañas cuando hacemos uso de la opción Target and bid para palabras
clave, intereses y edad:

225
Figura 92: Herramienta de Google AdWords para especificar el público objetivo
El público que recibe el anuncio es aquel que cumple todos los requisitos
especificados. Mientras más filtros establezcamos, menos será la audiencia a la que
optemos. El uso de Target and bid nos permite personalizar las pujas para
cualquiera de los filtros establecidos (Google AdWords Support, 2014).
En la siguiente imagen (Figura 93) podemos observar cómo se ha incrementado el
máximo CPM a 6€ para la audiencia que muestra interés en páginas relacionadas
con Business Plans & Presentations. Para los usuarios que navegan por sitios web
relacionadas con Outsourcing, Tax preparation & Planning o Consulting, las pujas
serán de 5€ por cada mil impresiones.

226
Figura 93: Personalización de puja CPM
Pujas Condicionales: Este tipo de pujas nos ayudan a aumentar el público que
recibirá los anuncios. Contraria a Target and bid, Google AdWords ofrece la
opción bid only como medio para realizar pujas condicionales. Esto nos permitirá
realizar pujas sobre la audiencia que presenta un valor extra para la empresa
(Google AdWords Support, 2014).
En la siguiente imagen (Figura 94) podemos observar un ejemplo de cómo
podemos centrar nuestra campaña en un público interesado en la temática business
services o business operations.

227
Figura 94: Puja condicional en Google AdWords
Como podemos observar en la imagen (Figura 94), hemos hecho uso de la opción
bid only para aquella audiencia que está interesada en Consulting o en usuarios que
no convirtieron en nuestro sitio web.
Si observamos el diagrama de Venn de la figura anterior (Figura 94), en azul se
representa la audiencia objetivo, es decir, la audiencia que recibirá la campaña.
Mediante el uso de la opción bid only, ahora somos capaces de incrementar o
decrementar nuestras pujas únicamente para aquellos usuarios están interesados en
Consulting o Interesados que no convirtieron (Figura 94).
Este tipo de pujas suele emplearse para incrementar las pujas para aquellos
usuarios los cuales son más propensos a comprar en nuestro sitio. Este
conocimiento se adquiere estudiando el perfil de usuario que convierte en el sitio
web.
Pujas condicionales multiscreen: En caso de que nuestro negocio disponga de una
tienda física, deberemos intentar capturar el máximo tráfico móvil posible. Esto es
debido a que las búsquedas iniciadas por los usuarios a través de móviles terminan

228
en acción (llamada a la tienda o visita) en un margen de veinticuatro horas desde la
búsqueda (Spero, 2012). Es decir, captar el tráfico móvil es captar tráfico que
busca dónde finalizar la conversión. Para gestionar pujas multiscreen, Google
AdWords dispone de la opción de ajuste de pujas (Google AdWords Support,
2013).
El ajuste de pujas indica el porcentaje a incrementar las pujas. Esto puede aplicarse
sobre diferentes opciones, siendo una de ellas sobre los dispositivos móviles. Este
incremento se realiza sobre el máximo CPC o CPM determinado (predefinido o
personalizado).
En la siguiente imagen (Figura 95) podemos observar cómo es posible realizar un
ajuste en nuestras pujas para tráfico móvil:
Figura 95: Incremento del máximo CPC para usuarios móviles
4.5.6. Conclusiones
Google AdWords es una herramienta de promoción que nos permite promocionar un
sitio web cuando los usuarios se encuentran realizando búsquedas o navegando entre
sitios web. Debido a la cantidad de sitios web afiliados a Google AdSense, Google
AdWords dispone de una amplia red de contenidos. Dispone de opciones para la
promoción de campañas, tanto enfocadas en el contexto del sitio web como aquellas
que buscan un tipo particular de visitante. El alto grado de personalización que
permiten las pujas es una de las características que pueden ayudar más a los
anunciantes, haciendo mas efectivas el CPC y el CPM.

229
Capítulo 5:
Caso práctico
En este capítulo expondremos el trabajo desarrollado para posicionar el blog
desdemiatalaya.com. El blog cuenta con mas de 400 artículos y está creado bajo la
plataforma de Blogger. El número de usuarios con los que cuenta ha crecido en los
últimos años, pero la audiencia a la que llega sigue siendo reducida. El objetivo es
incrementar las visitas al blog, incrementar la audiencia y posicionar sus artículos.
El capítulo está dividido en varias secciones donde exponemos el trabajo
desarrollado. Las secciones que encontramos son:
-‐ Optimizaciones para la indexación
En este apartado exponemos los protocolos empleados para mejorar la
indexación de contenido y evitar la duplicación de artículos.
-‐ Optimizaciones web
En este apartado se exponen los cambios realizados en el sitio web desde un
punto de vista SEO. Comprende la aplicación de técnicas mencionadas en el
capítulo dedicado a SEO.
-‐ Estrategias de posicionamiento
En este apartado exponemos las estrategias empleadas para el posicionamiento
de artículos mediante el uso de head terms y long-tail keywords.
-‐ Estrategias de Link Building

230
En este apartado exponemos las estrategias desarrolladas para la adquisición
de enlaces.
-‐ Generación de leads
En este apartado exponemos las principales estrategias desarrolladas por el
sitio web para la adquisición de leads. La adquisición de leads permitirá
incrementar la audiencia y la visibilidad del blog. Con ella, el blog dispondrá
de un medio directo para realizar campañas de marketing por e-mail.
5.1. Optimizaciones para la indexación de contenido
En el primer capítulo definíamos el indexador como el componente del motor de
búsqueda encargado de guardar información en estructuras que permitieran un rápido
acceso. También expusimos un conjunto de técnicas para controlar el contenido a
indexar.
En esta sección haremos uso de algunas de estas técnicas comentadas en el primer
capítulo. Estas técnicas nos ayudarán a evitar indexar contenido duplicado generado
por la plataforma en la cual se sustenta el blog Desdemiatalaya.
5.1.1. Duplicación de contenido en Blogger
La plataforma Blogger es una plataforma de creación de bitácoras. Los usuarios
disponen de control para crear, editar, borrar y publicar artículos. Cuando los usuarios
publican artículos, estos se hacen accesibles desde diferentes direcciones web dentro
del mismo dominio.
Disponer del mismo artículo bajo diferentes direcciones web es una de las prácticas
desaconsejadas por los principales motores de búsqueda. Cuando estos encuentran
contenido duplicado, seleccionan de entre las direcciones web la que consideran mas
relevante. Esta puede no ser la que nosotros queremos como webmasters del sitio
web.

231
La duplicación de contenidos web en la plataforma Blogger se hace presente en:
-‐ Página principal
Todo artículo publicado se sitúa en la página principal. Blogger ofrece
opciones para limitar el número de artículos a mostrar en esta página, así
como opciones para limitar el contenido de los artículos que muestra.
-‐ Páginas de Archivos
La plataforma Blogger archiva los artículos en base al mes y año en la que
fueron publicados. Cuando los usuarios acceden a la página de archivos,
encuentran todos los artículos publicados en ese mes. Además, este tipo de
páginas no permiten la personalización de título o meta descripciones que tan
importantes son para los buscadores.
-‐ Páginas de Etiquetas
Las etiquetas permiten categorizar la temática del artículo. Esto permite a los
usuarios acceder a artículos basados en una temática en concreta. Al igual que
sucedía con las páginas de archivos, este tipo de páginas no permite la
personalización de títulos o meta descripciones.
En el presente proyecto, el blog desdemiatalaya.com no disponía de control sobre el
contenido duplicado. Para las búsquedas introducidas por los usuarios, eran los
buscadores los que decidían, de entre las direcciones con el mismo contenido, cuál
mostrar en la lista de resultados.
Si bien el blog no fue penalizado por duplicación de contenido (no cuenta con
notificación por parte de Google), la duplicación afectaba a la adquisición de

232
usuarios. Los porcentajes de clics recibidos desde los buscadores para páginas
archivadas frente a páginas de artículos presentan grandes diferencias.
Cuando las páginas de archivos aparecen en la lista de resultados, adquieren el 2.69%
de los clics. Podemos ver estos datos en la siguiente imagen (Figura 96):
Figura 96: Gráfica mostrando el CTR para artículos archivados
Cuando las páginas de artículos aparecen en los motores de búsqueda, estos consiguen
un porcentaje de clics del 4.67%. En la siguiente imagen (Figura 97) podemos
observar estos resultados:
Figura 97: Gráfica mostrando el CTR para artículos no archivados

233
Ante una búsqueda, los motores de búsqueda muestran la dirección web que creen
más conveniente de entre los contenidos duplicados. Haciendo uso de la analítica
web, conocemos que los artículos publicados consiguen captar mayor número de
usuarios que las páginas archivadas.
Controlar el contenido a mostrar en la lista de resultados, en este caso particular, tiene
un impacto directo en la adquisición de tráfico desde los motores de búsqueda. La
aparición de artículos con títulos y descripciones personalizados consigue mejorar la
captación de usuarios desde los motores de búsqueda hasta en un 73.6% con respecto
a las páginas archivadas.
En el apartado siguiente exponemos cómo hemos procedido para controlar la
duplicación de contenidos en la plataforma Blogger.
5.1.2. X-Robots-tag
Para resolver el problema de duplicación de contenidos de artículos archivados y
páginas etiquetadas en la plataforma Blogger, realizamos los siguientes ajustes en el
panel de administración de Blogger. Estos pueden encontrarse bajo la sección
Configuración / Preferencias para motores de búsqueda.
Con el objetivo de evitar indexar artículos archivados, seleccionamos las siguientes
opciones en Archivo y páginas de búsqueda: noindex; noarchive; nosnippet;
noimageindex;
A continuación mostramos una imagen (Figura 98) con las opciones mencionadas
anteriormente.

234
Figura 98: Panel de configuración en la plataforma Blogger
La respuesta que ofrece Blogger cuando se realiza una petición a una de las páginas
archivadas es la siguiente (Figura 99):
Figura 99: Respuesta Http para página archivada
Cuando los crawlers o robots recuperan artículos archivados, reciben en el header de
la petición Http la etiqueta X-Robots-Tag con los valores noindex, noarchive,
nosnippet, noimageindex. Estos valores informan al indexador para que no muestre
resultados en cache, no indexe imágenes ni contenido y tampoco muestre
descripciones en la lista de resultados para estas páginas.

235
Mediante el uso de este tag y las opciones especificadas, hemos sido capaces de
controlar la presentación de contenido duplicado en la lista de resultados de los
motores de búsqueda.
5.1.3. Robots.txt
Blogger hace uso del archivo robots.txt como medio para evitar mostrar contenido
etiquetado en la lista de resultados. En la imagen siguiente (Figura 100) podemos
observar cómo el archivo robots.txt es usado para deshabilitar el escaneo de contenido
en páginas con etiquetas (páginas que contienen la dirección web /search ).
Figura 100: Robots.txt empleado en el blog desdemiatalaya.com
El problema es que el uso del protocolo robots.txt actúa sobre el crawler y no sobre el
indexador. El resultado podemos verlo en la siguiente imagen (Figura 101), donde el
contenido se muestra indexado en el motor de búsqueda de Google aunque no se
muestra descripción para este.
Figura 101: Artículo sin meta descripción bloqueado por protocolo Robots.txt

236
El uso de la cabecera X-Robots-tag comentada en el anterior apartado nos ayudará a
terminar con estos resultados. A medida que los crawlers vayan visitando las páginas
etiquetadas, la etiqueta X-Robots-tag será recuperada. Debido a que especificamos
noindex, este tipo de resultados sin descripción irá desapareciendo de la lista de
resultados de Google.
5.2. Optimización Web
En este apartado expondremos las optimizaciones SEO llevadas a cabo en el blog
desdemiatalaya.com. Para medir la efectividad de nuestras acciones se hizo uso de la
herramienta WebCEO y Google Analytics principalmente.
WebCEO es una herramienta online desarrollada para la optimización de contenidos
que buscan posicionamiento web. Dispone de herramientas para investigar las
palabras clave usadas por los usuarios, estudiar la competencia, optimizar el
contenido web o conocer el posicionamiento de nuestros documentos para un
conjunto de palabras clave especificadas.
Google Analytics, por su parte, es una herramienta online que nos proporciona
información sobre el comportamiento del usuario, la audiencia que recibe el sitio web
o la procedencia del tráfico. Permite también la posibilidad de definir objetivos web
entre otras muchas funciones.
A continuación, exponemos los cambios realizados en el sitio web con el objetivo de
posicionar los artículos en Google y aumentar el tráfico de usuarios.
5.2.1. Títulos
Los títulos de los artículos eran mostrados en los motores de búsqueda bajo el
formato:
<Título del blog> | <Título del artículo>

237
Debido a restricciones impuestas por los motores de búsqueda, los títulos con una
extensión superior a 70 caracteres no se visualizan completamente en la lista de
resultados.
El formato empleado por el blog hacía uso de 20 caracteres de forma fija (los relativos
al título del blog “Desde mi Atalaya”), dejando únicamente 50 caracteres para
representar el título del artículo.
Con el objetivo de aumentar el porcentaje de clics, se procedió a realizar cambios en
la plantilla de Blogger para otorgar mayor importancia a los títulos de los artículos
frente al título del blog.
El formato de títulos pasó a ser:
Título del artículo | Título del blog
Con este cambio el usuario recibe mayor información sobre el contenido que
encontrará desde la lista de resultados mostrada por los motores de búsqueda.
A continuación presentamos un ejemplo (Figura 102) de cómo quedan los títulos
después de haber realizado las modificaciones pertinentes:
Figura 102: Lista de artículos del blog Desdemiatalaya.com

238
5.2.2. Direcciones web
La plataforma Blogger genera una dirección web para cada artículo publicado. Por
defecto, esta dirección web emplea el título del artículo. Blogger ofrece la posibilidad
de personalizar la dirección web.
Debido al desconocimiento por parte del cliente de las prácticas SEO y de la propia
plataforma Blogger, las direcciones web no habían sido personalizadas. Tampoco se
habían introducido palabras clave en estas.
Como consecuencia, el blog dispone de artículos con direcciones web complicadas,
frases sin terminar, textos poco descriptivo o sin palabras clave.
A continuación mostramos algunos ejemplos (Figura 103):
Figura 103: Lista de artículos con direcciones web faltas de contexto
Como podemos observar, las direcciones web de los anteriores artículos pierden las
palabras clave:
www.desdemiatalaya.com/…/distribucion-‐alimentaria-‐hablemos-‐de.html
www.desdemiatalaya.com/2014/06/emprendedor-‐pasos-‐previos-‐para.html
El cliente fue informado sobre las recomendaciones y buenas prácticas promovidas
por expertos en SEO. Como vemos en la siguiente imagen (Figura 104), las
direcciones web son mas limpias, descriptivas y emplean las palabras clave
seleccionadas por el cliente.

239
Figura 104: Lista de artículos con direcciones web descriptivas
Las direcciones web de los siguientes artículos hacen uso de palabras clave como
“campaña de navidad”, “costco”, “dealz madrid”, quedando de la siguiente forma:
http://www.desdemiatalaya.com/2014/11/campana-‐de-‐navidad-‐claves.html
http://www.desdemiatalaya.com/2013/04/los-‐poderes-‐de-‐costco.html
http://www.desdemiatalaya.com/2014/10/dealz-‐abre-‐en-‐madrid.html
5.2.3. Meta descripciones
La plataforma Blogger incorpora la posibilidad de personalizar el texto que aparece
en la lista de resultados. Si no definimos ninguna descripción, Google seleccionará
automáticamente un texto que resuma el contenido existente en el artículo.
El cliente con el que hemos colaborado no hacía uso de las meta descripciones.
Google seleccionaba el texto más adecuado a mostrar en la lista de resultados en
función del texto contenido en el artículo. Esto presentaba dos problemas:
-‐ Pérdida de control sobre las descripciones
Cuando permitimos que Google seleccione los fragmentos de texto a mostrar
en la lista de resultados, perdemos control para optimizar las descripciones de
la lista de resultados.

240
Durante el presente proyecto, hemos visto como Google suele seleccionar el
comienzo del artículo como descripción en caso de no encontrar ninguna meta
descripción.
En las siguientes imágenes (Figura 105), observamos cómo este texto puede
no ser el que mejor describa el contenido del artículo.
Figura 105: Lista de artículos con meta descripción poco descriptiva
-‐ Pérdida de optimización SEO
La selección automática de texto por parte de Google reduce las posibilidades
de optimización SEO. Si recordamos de capítulos anteriores, las meta
descripciones forman parte de las localizaciones donde podemos realizar
optimizaciones SEO, promoviendo las palabras clave.
Durante el tiempo de colaboración, se ayudó al autor del blog en la re-escritura de
más de 30 artículos antiguos, además de trabajar en la creación de nuevos artículos.
5.2.4. Plantilla web
La plataforma Blogger hace uso de plantillas HTML como medio para configurar la
interfaz de usuario. Estas definen cómo aparece el contenido en el sitio web. La
plantilla empleada por defecto en la plataforma Blogger no está optimizada desde un
punto de vista SEO.

241
Si recordamos del primer capítulo, definíamos los encabezados como las estructuras
HTML encargadas de marcar las secciones que componen jerárquicamente un sitio
web.
En la siguiente imagen (Figura 106) podemos observar la estructura que compone la
plantilla de Blogger:
Figura 106: Plantilla inicial proporcionada por Blogger
Tal y como vemos en la imagen anterior, encontramos problemas de estructuración de
contenidos. Exponemos estos problemas y la solución que se adoptó:
-‐ Jerarquía de encabezados
Según la estructura web que define Blogger, el título del blog es el elemento
mas importante de todo el artículo (con encabezado H1), seguido de las fechas
y gadget laterales (con encabezados H2) y el título del propio artículo (con
encabezado H3).

242
Con el objetivo de estructurar el contenido, se realizaron modificaciones sobre
la estructura HTML. El título de los artículos dispondrán de encabezados H2
en lugar de H3, los gadgets harán uso de encabezados de nivel 3 y las fechas
dejarán de emplear encabezados HTML (Herrera, 2014).
Vemos el resultado final en la siguiente imagen (Figura 107):
Figura 107: Plantilla de Blogger modificada para página principal
-‐ Localización de encabezados
Los encabezados definen la jerarquía del documento. Para representar los
documentos del blog, se adoptó la jerarquización ofrecida por Fran Herrera
en su blog bloggerayuda (Herrera, 2014). La plantilla fue modificada para
tener en cuenta si nos encontramos en la página principal del blog o bien en un
artículo específico.
Si nos encontramos en la página principal del blog, haremos uso del marcador
H1 para otorgar mayor importancia al título del blog frente al título de los
artículos (los cuales harán uso de H2).

243
Si nos encontramos en un artículo específico, marcaremos el título del artículo
con la etiqueta H1 y el título del blog con la etiqueta H2.
Podemos observar como queda la plantilla tras realizar los cambios
anunciados cuando nos encontramos en un artículo específico del blog (Figura
108):
Figura 108: Plantilla de Blogger modificada para páginas de artículos
5.2.5. Imágenes
Con el objetivo de optimizar el contenido del blog, se procedió a revisar el título y el
atributo ALT de las imágenes presentes en los artículos. La mayoría de las imágenes
carecían del atributo ALT, así como de palabras clave relevantes para el
posicionamiento.
Se procedió a informar al cliente sobre el funcionamiento de los motores de búsqueda
y la importancia de usar palabras clave en el pie de foto, atributos ALT y nombres de
fichero.

244
5.2.6. Palabras clave
Como ya expresamos en capítulos anteriores, la disposición de palabras clave en un
sitio web es necesaria para aparecer en la lista de resultados cuando los usuarios
introducen estas.
La disposición de palabras clave en el contenido del blog desdemiatalaya era
prácticamente nula. La mayoría de los artículos no se encontraban optimizados para
ninguna palabra clave en particular.
Se examinó el contenido de los artículos más importantes (determinados por el autor
del blog), procediéndose a usar palabras clave en meta descripciones, contenido y
encabezados. Se asesoró al autor del blog sobre la importancia del uso de palabras
clave en las diferentes estructuras tenidas en cuenta por los motores de búsqueda.
Durante el periodo de optimización, observamos cómo ciertos artículos recibían mas
visitas que otros. Para conocer qué artículos recibían mas visitas hicimos uso de la
herramienta Analytics > Adquisición > Palabras Clave > Orgánica.
A continuación vemos los resultados mostrados por esta herramienta (Figura 109):
Figura 109: Páginas mas visitadas desde el canal de tráfico orgánico

245
Un estudio sobre el uso de palabras clave empleadas por los usuarios para llegar a
estas páginas nos permitió encontrar patrones de búsqueda empleadas por los
usuarios.
Para analizar las palabras de búsqueda empleadas para alcanzar el artículo Supeco, el
cash de la familia abrió en Chiclana se hizo uso de Google Analytics > Adquisición
> Palabras Clave > Orgánica. Las palabras clave de búsquedas empleadas por los
usuarios:
supeco, supermercados supeco, supeco cash, supeco el cash de la familia, el
cash de la familia, supeco Carrefour, supeco Chiclana, supeco Chiclana de
la Frontera, supeco los palacios
Si analizamos ahora las palabras de búsqueda empleadas para el segundo artículo (Los
nuevos cash para la familia experimentan en Sevilla) encontramos las siguientes
búsquedas:
cash mas, supermercado cash, supermercados cash mas, cash carry, cash
Ayala, cash mas Sevilla, tienda don cash en Sevilla, cash mas pino montano
Como vemos, ambos artículos son alcanzados desde los motores de búsqueda con
palabras clave las cuales siguen los siguientes patrones:
-‐ [palabra clave]
-‐ [palabra clave] + [localización]
-‐ [palabra clave] + [localización] + supermercado
En los siguientes apartados exponemos los resultados que obtuvimos al aplicar estos
patrones para los artículos de las aperturas de los supermercados Dealz en Madrid y
Málaga.
Localización de contenidos

246
Después de haber analizado los artículos con más búsquedas, procedimos a optimizar
los artículos relacionados con la inauguración de supermercados (“Dealz abre en
Madrid y continua su plan de expansión” y “Dealz en la Avda Velázquez de Málaga”)
con los patrones mencionados en la sección anterior.
Además de la aplicación de los patrones anteriores, se fueron analizando las palabras
de búsqueda introducidas por los usuarios para encontrar noticias sobre la
inauguración de estos supermercados.
En la siguiente imagen (Figura 110) observamos cómo los usuarios realizaron cerca
de 500 búsquedas empleando términos muy específicos sobre la localización de la
apertura de estos:
Figura 110: Lista de palabras clave proporcionadas por GWT
Este estudio nos proporcionó nuevas palabras clave para las que optimizar el
contenido web de los artículos. Conocido el nivel de detalle de búsqueda de los
usuarios, el segundo artículo fue optimizado teniendo en cuenta la granularidad de las

247
búsquedas de los usuarios, incluyendo término clave, ciudad y localización (“Dealz en
la Avda Velázquez de Málaga”)
Mostramos a continuación algunos de los términos de búsqueda para los que fueron
optimizados los artículos, las veces que apareció nuestro resultado en la lista de
resultados (extraído de la herramienta Google Webmaster Tools) y el posicionamiento
que adquirimos en Google para estos términos (extraído de WebCEO):
Términos de búsqueda Impresiones Posicionamiento
dealz malaga 279 8
dealz madrid 2667 13
dealz bravo murillo 415 6
dealz avenida velazquez 18 5
A continuación mostramos una imagen (Figura 111) donde se muestra la posición que
adquirieron los artículos y los términos clave para los cuales lo hicieron:
Figura 111: Palabras clave empleadas para posicionar artículos Dealz
El tráfico que aportaron estos dos artículos al sitio web se ha cuantificado en 416
visitas, representando el 19% del tráfico adquirido desde los motores de búsqueda y el
13.11% del tráfico total para el mes de Noviembre.
El uso de palabras clave junto con términos localizados será explotado por el blog
desdemiatalaya para artículos de aperturas e inauguraciones de supermercados.

248
Palabras clave relacionadas
Si los usuarios quieren obtener información sobre la apertura de Dealz en Málaga o
Madrid, las búsquedas con la palabras clave Dealz ofrece los siguientes resultados
(Figura 112):
Figura 112: Lista de resultados para la búsqueda "Dealz"
De los nueve resultados (siendo cuatro de ellos imágenes), solo dos de ellos
pertenecen a noticias relacionadas con Dealz (resultados 4 y 5). Los usuarios se ven
frente a la necesidad de realizar búsquedas más especificas como medio para obtener
mejores resultados.
En la siguiente imagen (Figura 113) podemos observar algunos de los términos
empleados por los usuarios (y registrados en Google Webmaster Tools) para alcanzar
información relacionada con dealz y sus aperturas:
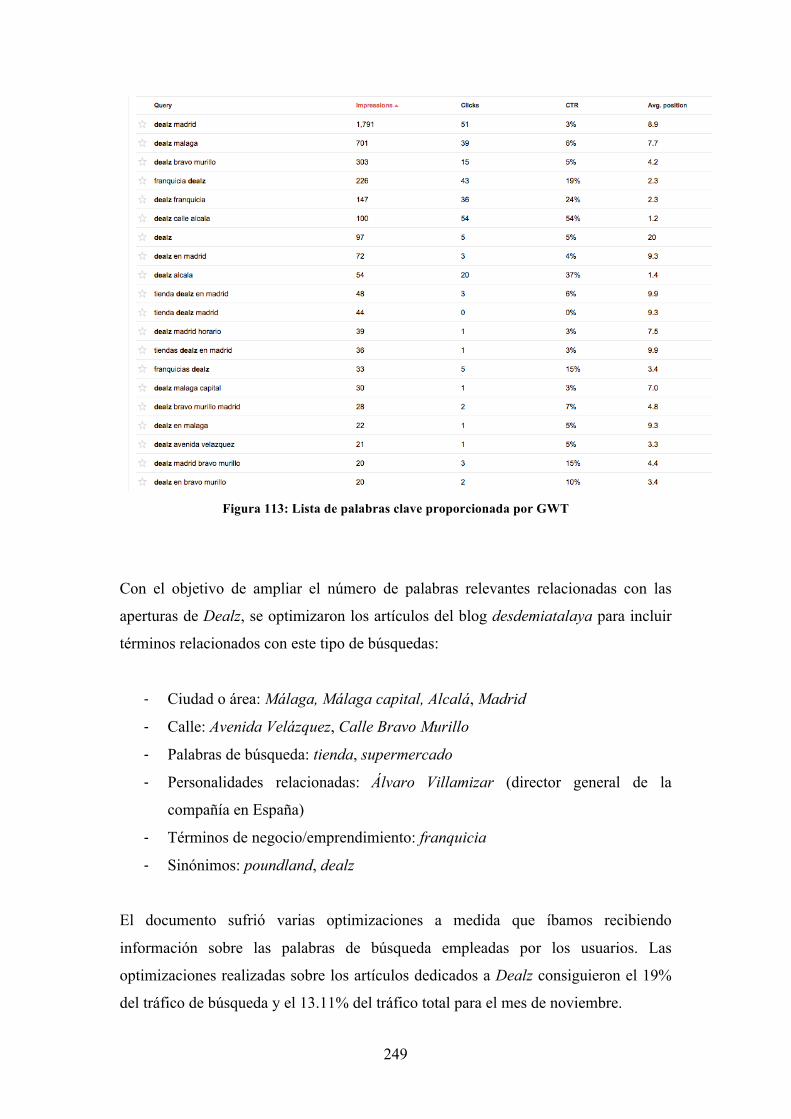
249
Figura 113: Lista de palabras clave proporcionada por GWT
Con el objetivo de ampliar el número de palabras relevantes relacionadas con las
aperturas de Dealz, se optimizaron los artículos del blog desdemiatalaya para incluir
términos relacionados con este tipo de búsquedas:
-‐ Ciudad o área: Málaga, Málaga capital, Alcalá, Madrid
-‐ Calle: Avenida Velázquez, Calle Bravo Murillo
-‐ Palabras de búsqueda: tienda, supermercado
-‐ Personalidades relacionadas: Álvaro Villamizar (director general de la
compañía en España)
-‐ Términos de negocio/emprendimiento: franquicia
-‐ Sinónimos: poundland, dealz
El documento sufrió varias optimizaciones a medida que íbamos recibiendo
información sobre las palabras de búsqueda empleadas por los usuarios. Las
optimizaciones realizadas sobre los artículos dedicados a Dealz consiguieron el 19%
del tráfico de búsqueda y el 13.11% del tráfico total para el mes de noviembre.

250
Long-tail keywords
En el sector del posicionamiento en motores de búsqueda, se conoce como long-tail
keyword al conjunto de palabras, específicas en contexto y con un bajo volumen de
búsquedas. Optimizamos contenidos para este tipo de términos cuando buscamos un
tráfico cualificado.
El blog desdemiatalaya no disponía de métodos para capturar leads o información de
usuario más que mediante el uso de FeedBurner. Con el objetivo de incrementar el
número de leads y abrir una vía de comunicación directa con los posibles clientes, se
procedió a analizar los artículos que disponían de material para la captura de leads.
Se seleccionó el artículo “escandallos de carnicería” como el artículo a optimizar.
Este artículo está centrado en un público con un perfil muy concreto. Para alcanzar a
este público, se procedió a estudiar las palabras clave mediante Google Keyword Tool
y Google AdWords. El documento fue optimizado para las siguientes long-tail
keywords:
escandallos de carnicería, escandallos de pollo,
escandallos de ternera, escandallos de cerdo
Se optimizó el documento, posicionando las palabras clave en las siguientes
localizaciones:
-‐ Título
-‐ Encabezados
-‐ Meta descripción
-‐ Contenido del texto
-‐ Dirección web
-‐ Atributo ALT de imágenes
-‐ Enlaces internos que enlazan el documento a posicionar
El uso de long-tail keywords nos ayudó a incrementar la visibilidad del artículo,
alcanzando un buen posicionamiento en los motores de búsqueda (Figura 114).

251
Debido a que para los términos seleccionados existía una menor competencia, el
artículo pudo situarse en la primera posición de Google.
Figura 114: Long tail keywords empleadas para posicionar artículo específico
Esto nos permitió adquirir un mayor volumen de usuarios, el cual podemos observar
en la siguiente imagen (Figura 115). Tras las optimizaciones realizadas sobre el
artículo, se produce un incremento de tráfico:
Figura 115: Evolución del tráfico para el artículo de escandallos

252
Tras la consecución de un buen posicionamiento, se procedió a optimizar el contenido
para la adquisición de leads. Las optimizaciones realizadas para la captura de leads
pueden consultarse en el apartado Captación de leads.
5.3. Estrategia de link building
En este apartado presentamos los medios empleados para la adquisición de enlaces
desde sitios externos. Expondremos cómo de efectivas han resultado las técnicas para
adquirir enlaces.
5.3.1. Directorios
Como medio para aumentar el número de enlaces, se dio de alta el blog en directorios
web. Presentamos los directorios investigados, el estado del directorio tras dar de alta
el blog, el tipo de enlace e información sobre si el directorio es de pago.
Indexados
Directorios Promoción Status Enlace Pago
LaBlogoteca RSS Indexado Follow NO
Webwiki.es Web Indexado No
Follow
NO
Bitacoras.com RSS Indexado Follow NO
Zonadeblogs.com Web Indexado Follow NO
Mktfan.com Artículos Indexado No Follow NO
MejoresBlogs.com Web Indexado No follow NO
Paperblog.es RSS Indexado Follow
No Follow
NO
Tabla 16: Lista de directorios que indexaron el blog
Esperando indexación

253
Directorios Promoción Status Enlace Pago
Dmoz.com Web Esperando Follow NO
Globeofblogs.com Web Esperando Follow NO
Blogesfera.com RSS Esperando Follow NO
Blogorama.com Web
RSS
Esperando: 90 días
Link Back
Premium:$ 4.90
No Follow NO
NO
SI
Tabla 17: Lista de directorios a la espera de que indexen el blog
Rechazados
Directorios Promoción Status Enlace Pago
AllTop.com - Rechazado
(inglés)
-
Tabla 18: Lista de directorios que rechazaron la indexación del blog
Otros directorios no usados
Directorios Promoción Status Enlace Pago
DivoBlogger Promoción
Artículos
Sin incluir - NO
Menéame Promoción
Artículos
Sin incluir - NO
GoogleDirectorio Web Sin incluir
Requiere enlace
- NO
Boosterlog.es Web Sin incluir
Requiere enlace
- NO
Directorios.org.es Web Sin incluir
Requiere enlace
- SI

254
25€ - 1 año
15€ - 1 año
10 € - 1 año
SitioEspana.com Web Sin incluir
Premium 9.99 €
- SI
Tabla 19: Lista de directorios o agregadores de noticias no usados
5.3.2. Menciones web
Con el objetivo de incrementar el perfil de enlaces del que dispone el sitio web, se
procedió a investigar menciones hacia el autor del blog y sus artículos. Para ello se
empleó el propio motor de búsqueda de Google, así como la plantilla Google
Spreadsheet ofrecida por RankTank.
La plantilla ofrecida por RankTank simula la realización de búsquedas en Google,
siendo capaz de comprobar si existen enlaces hacia una web especificada en los
resultados de búsqueda. Explota las características de la función ImportXML
disponible en Google Spreadsheet, a través de la cual es posible extraer contenido
XML, HTML, CSV o RSS.
La plantilla funciona mediante la configuración de tres parámetros:
-‐ Check links to
Especificación de la dirección web hacia donde deberían de enlazar los sitios
que aparecen en la lista de resultados.
-‐ Google query
Especificación de la búsqueda a introducir en Google.
-‐ Results page
Página de resultados de provenientes de Google. Cada página alberga 100
resultados de Google, es decir, las 10 primeras páginas de la lista que
proporciona Google Search.

255
Mostramos a continuación una imagen (Figura 116) sobre los resultados que ofrece
esta herramienta como medio para analizar menciones web:
Figura 116: Plantilla RankTank para analizar menciones web.
La plantilla también ofrece información para conocer qué resultados enlazan al sitio
web definido en el parámetro check links to. Como podemos observar, genera una
lista de resultados con información sobre las páginas que contienen la búsqueda:
”Francisco Fernandez Reguero” –site:desdemiatalaya-paco.blogspot.com –
site:www.desdemiatalaya.com
Esta plantilla nos ha permitido asesorar al sitio web desdemiatalaya.com sobre
perfiles sociales que no mencionaban el blog desdemiatalaya.com. Algunas de las
redes sociales desde las cuales se consiguieron enlaces fueron:
Sitio Web Autoridad del sitio web
(autoridad de la página)
Slideshare.net 96 (44) – No Follow
WordPress Blog 100 (1) – No Follow
About.me 92(58) – Follow
Google+ 100 (1) – Follow
Pinterest.com 100 (1) – No Follow
Klout.com 87 (1) – No follow

256
GranConsumo.com 30 (28) – Follow Tabla 20: Lista de perfiles de redes sociales que enlazan al blog desdemiatalaya
Detectamos también un conjunto de sitios web los cuales mencionaban artículos
publicados en el blog desdemiatalaya.com, pero no disponían de enlaces hacia este.
Se procedió a agradecerles la mención, invitándoles a enlazar los artículos a los que
hacían referencia.
La siguiente tabla muestra los sitios web mas destacados a los que se notificó:
Sitio Web Autoridad del sitio web
(medida por WebCEO)
ABC.es 89
Elcorreogallego.es 65
Finanzas.com 73
Es.finance.yahoo.com 100
GestionPyme.com 38 Tabla 21: Lista de páginas web que mencionan al autor del blog
5.4. Generación de leads
En este apartado expondremos estrategias implementadas en el blog desdemiatalaya
para la generación de leads (adquisición de información de usuarios). Mediante la
adquisición de información de usuario, el blog podrá desarrollar campañas de e-mail
donde notificar el nuevo material disponible en el blog, así como educar a los
visitantes y promocionar los servicios propios de una consultoría.
En este apartado exponemos cómo se ha explotado la suscripción a artículos del blog
como medio para generar leads. Veremos también cómo el uso de landing page ha
contribuido a la adquisición de leads.

257
5.4.1. Suscripción RSS
RSS denota las siglas Really Simple Syndication, formato XML empleado para
compartir contenidos en la web. La suscripción mediante la fuente web RSS es una
herramienta muy utilizada por bloggers como medio para distribuir artículos hacia los
suscriptores. Los suscriptores reciben estos en el e-mail.
FeedBurner es una herramienta gestora de fuentes web. En 2007 fue adquirido por
Google y obtuvo gran popularidad. Actualmente es un servicio al que Google no da
soporte.
El autor del blog trabaja haciendo uso de FeedBurner como servicio gestor de fuentes
web. Existen problemas asociados con su uso, especialmente en lo que se refiere a su
integración con Google Analytics. Como resultado, las visitas son categorizadas como
tráfico directo en lugar de tráfico proveniente del feed.
Otro de los problemas documentados en multitud de sitios web, corresponde con la
fiabilidad del servicio FeedBurner. Multitud de bloggers se han quejado de la
fiabilidad del servicio tanto en el envío de e-mails como en las estadísticas que
proporciona FeedBurner. Esto hace difícil conocer cual es la cobertura o visibilidad
que adquieren los artículos.
Por último, el blog desdemiatalaya.com hacía uso del servicio de FeedBurner como
medio para informar a los suscriptores de la existencia de nuevos artículos en el blog.
Junto con la notificación se enviaba el artículo completo a los suscriptores. El envío
del artículo completo a e-mails y readers presenta varios inconvenientes:
-‐ Imposibilidad de analizar el comportamiento del usuario
-‐ Evita que el usuario interactúe con el sitio web
Como medida para solventar los problemas comentados anteriormente, se asesoró al
autor del blog en el uso de nuevos gestores de fuentes web. Al no acceder
completamente al cambio hacia otro gestor de fuentes, como medida intermedia, se
limitó el contenido de los artículos enviados por RSS.

258
Los usuarios actualmente reciben los artículo con contenido limitado a un número fijo
de caracteres. Deben de acceder al sitio web para poder leer las noticias completas.
Limitando el contenido RSS en los e-mails se ha incrementado el número de visitas al
blog en un 5.09% (significando 553 visitas durante los meses de colaboración).
Estos usuarios han demostrado ser los que mejor responden a los objetivos marcados
para el sitio web con respecto al resto de canales. Al no enviar el artículo completo a
los suscriptores, estos tienen que acudir al sitio web para leer el artículo completo. En
su visita al sitio web mediante e-mail, el 32.55% de los usuarios consumen más de un
artículo, empleado una media de 4 minutos por sesión (Figura 117).
Figura 117: Métricas para visitas provenientes de FeedBurner
En base a estas estadísticas, el autor del blog accedió a desarrollar estrategias mas
agresivas para la captura de leads, así como a suplir el servicio RSS-to-email ofrecido
por FeedBurner hacia un servicio mas robusto y fiable como MailChimp.
5.4.2. Landing pages
Definimos en capítulos anteriores las landing page como páginas especializadas en la
consecución de un objetivo, pudiendo ser este la obtención de e-mails o ventas.
Durante el proyecto final de carrera, se asesoró al blog “Desde mi atalaya” en la
creación de landing pages como medio para capturar leads. De entre los artículos con

259
los que cuenta el blog, se procedió a optimizar el artículo “escandallos de carnicería”
como artículo para la captura de leads.
El artículo estaba formado por un texto corto (150 palabras), una imagen y un enlace
para la descarga de un libro Excel. Enfatizaba la descarga del libro Excel pero no
implementaba ningún tipo de captura de leads. Ofrecía el material gratuitamente, sin
previo registro del usuario.
Con el objetivo de capturar leads, se procedió a optimizar el documento web para su
posicionamiento en buscadores mediante long-tail keywords. Los resultados obtenidos
tras la optimización realizada durante Septiembre ya fueron comentadas en el
apartado “Long-tail keywords” y pueden verse a continuación (Figura 118):
Figura 118: Evolución del tráfico web para el artículo de escandallos
Como podemos observar, en el mes de Septiembre el número de usuarios se ve
incrementado, aumentado progresivamente durante Octubre y Noviembre.
Como medio para comenzar la captura de leads, se integró un formulario de registro
hacia una lista de e-mail disponible en el servicio de MailChimp. El formulario puede
verse a continuación (Figura 119):

260
Figura 119: Formulario de suscripción integrado con la plataforma MailChimp
El formulario de registro conecta con la plataforma de e-mail MailChimp. Cuando los
usuarios confirman su e-mail se inicia la descarga del libro Excel con los escandallos
mas comunes.
Desde la implantación para la captura de e-mails, el artículo “escandallos de
carnicería” ha recibido un total de 305 visitas en 20 días, disponiendo de un
porcentaje de leads del 7.8%.
La adquisición de leads permitirá al autor del blog abrir un nuevo canal de
comunicación con los usuarios interesados en la gestión de carnicería.

261
Capítulo 6:
Conclusiones
En esta sección exponemos las conclusiones extraídas durante la realización del
proyecto final de carrera desarrollado, en colaboración con el blog “Desde mi
atalaya”, blog centrado en el sector del gran consumo y la distribución alimentaria.
6.1. Visibilidad web en motores de búsqueda
Como medio para adquirir e incrementar el número de impresiones en los buscadores,
se optimizaron los documentos para palabras clave generales (distribución
alimentaria o gran consumo entre otras) así como para palabras clave específicas para
cada artículo (escandallos de carnicería o dealz Madrid).
Para medir la evolución de las impresiones de nuestro sitio web desde los motores de
búsqueda se integró la herramienta Google Webmaster Tools con Google Analytics.
Datos anteriores a la fecha de integración no se encuentran disponibles en Google
Analytics.
En la siguiente gráfica mostramos la evolución del número de impresiones web del
blog desdemiatalaya.com durante el periodo de asesoramiento:

262
Podemos observar la evolución del sitio web para los meses de Septiembre, Octubre y
Noviembre. Vemos cómo el sitio web ha evolucionado positivamente, incrementando
el volumen de impresiones mes a mes.
Para la construcción de la gráfica anterior se ha hecho uso de la herramienta Google
Analytics panel Adquisición > Optimización en buscadores > Consultas cuyos datos
son los siguientes.
Mes Septiembre Octubre Noviembre Optimización
Impresiones en
buscador
11609
13537
17318
32.96 %
Tabla 22: Evolución del número de impresiones por meses
La optimización del sitio web para palabras clave específicas, localizadas y con
contenido relacionado a los términos clave permitió mejorar la visibilidad de los
artículos, consiguiendo un 32.96 % más de impresiones.
6.2. Adquisición de tráfico desde motores de búsqueda
La personalización de títulos, meta descripciones y direcciones web son las
principales herramientas con las que trabajar para captar usuarios desde los motores
0
5000
10000
15000
20000
Septiembre Octubre Noviembre
Impresiones en buscador
Impresiones en buscador

263
de búsqueda una vez la web aparece impresa. El mensaje que transmiten debe estar en
sintonía con la intención de la búsqueda realizada por el usuario.
Las optimizaciones anteriormente mencionadas fueron aplicadas a artículos del blog
“Desde mi atalaya”. Según las mediciones ofrecidas por la herramienta Google
Webmaster Tools (GWT), estas optimizaciones incrementaron en un 23.9% el ratio de
clics adquiridos desde los motores de búsqueda.
Mes Septiembre Octubre Noviembre Optimización
CTR
3.89 %
4.65 %
4.82 %
23.9 % Tabla 23: Evolución del CTR desde la lista de resultados por meses
Haciendo uso de la herramienta Google Analytics panel Canales > Orgánico (la cual
mide el número de sesiones provenientes de los motores de búsqueda), hemos
obtenido datos muy cercanos a los facilitados por la herramienta GWT.
Las visitas provenientes de búsquedas realizadas en Google quedan representadas en
la siguiente gráfica:
0
500
1000
1500
2000
2500
Septiembre Octubre Noviembre
Visitas de Google
Visitas de Google

264
Mes Septiembre Octubre Noviembre Optimización
Visitas desde
buscador
1780
2087
2140
20.22 %
Tabla 24: Evolución del número de visitas provenientes de Google
Como podemos observar, el número de visitas provenientes desde los motores de
búsqueda se vio incrementado en un 20.22% según la herramienta Google Analytics.
6.3. Posicionamiento en motores de búsqueda
Posicionar un sitio web en los motores de búsqueda conlleva realizar mejoras a nivel
de crawler e indexador (robots.txt y robots meta tag), plantilla (encabezados,
direcciones web, canonicalización de documentos, … ), artículos (palabras clave,
atributos alt, meta descripciones, títulos, …), así como la consecución de enlaces
hacia el sitio web.
El principal problema encontrado a la hora de posicionar contenido en los motores de
búsqueda, es la falta de herramientas que nos ayuden a conocer la evolución y el
progreso del sitio web.
El sitio web desdemiatalaya.com es el medio principal de comunicación de la
consultoría de negocios Mavafer Consultores. Debido a ello, las prácticas SEO
empleadas han sido llevadas a cabo paulatinamente y evitando riesgos de
penalización.
A continuación mostraremos una tabla con algunas de las palabras clave para las
cuales hemos posicionado artículos del blog desdemiatalaya. Estas tablas disponen de
tres columnas:
-‐ Ranking inicial.
En esta columna encontramos la posición en la cual se encontraba el artículo
antes de realizar cambios en el blog. Valores numéricos son indicativos de la

265
posición que ocupaban. Se ha hecho uso del símbolo ‘-‘ para identificar que el
artículo era nuevo o se situaba por detrás de la tercera página de Google.
-‐ Ranking optimizado
Esta columna muestra el posicionamiento alcanzado después de las
optimizaciones realizadas en el blog.
-‐ Optimización
Columna que indica el número de posiciones mejoradas. Se ha hecho uso del
símbolo ‘+’ para indicar que es un nuevo artículo, y por tanto, no disponía de
posicionamiento.
Las tablas han sido separadas por temática, teniendo cada una de ellas un objetivo
diferente. La primera de las tablas busca atraer a usuarios interesados en recibir
asesoramiento, tanto para iniciarse en una franquicia como para ya franquiciados.
FRANQUICIA
Palabra Clave Ranking
Inicial
Ranking
Optimizado
Optimización
asesoramiento
franquiciados
5 4 +1
asesoramiento franquicia 10 3 +7
franquicia contratos de
adhesión
8 2 +6
franquicia día 24 22 +2 Tabla 25: Palabras clave para atraer público que busca asesoramiento
La siguiente tabla está etiquetada bajo el área de ‘gestión de negocios’. En ella
mostramos las palabras clave que nos permitieron posicionar artículos web en el
motor de búsqueda de Google.
GESTIÓN DE NEGOCIOS
Palabra Clave Ranking Ranking Optimización

266
Inicial Optimizado
Escandallos
Escandallos de carnicería
Escandallos de pollo
Escandallos de cerdo
Escandallos de ternera
15
-
-
-
-
15
1
1
7
1
0
+
+
+
+ Tabla 26: Palabras clave para atraer público interesado en gestión de negocios
Debido al posicionamiento adquirido y al interés de los usuarios, el sitio web
desdemiatalaya abrirá un nuevo canal de negocio basado en cursos de formación
dedicados a la gestión de carnicerías.
En esta última tabla, encontramos algunas de las palabras clave empleadas como
medio para adquirir visibilidad. El uso de estas palabras clave permitió al blog
alcanzar a un mayor número de usuarios desde los motores de búsqueda. La
localización de los artículos es una de las tácticas explotadas por el blog, tanto para el
posicionamiento como para la atracción de un público ya informado.
LÍNEAS DE NEGOCIO Y OPERADORES
Palabra Clave Ranking
Inicial
Ranking
Optimizado
Optimización
al lado supermercados 6 2 +4
cash and carry 27 8 +19
dealz Málaga
dealz Madrid
dealz bravo murillo
dealz avenida velazquez
-
-
-
-
6
15
6
4
+
+
+
+ Tabla 27: Palabras clave empleadas para incrementar la visibilidad del blog
6.4. Dificultades
Las principales dificultades encontradas durante la realización de este proyecto se
centran en la falta de datos que nos ayuden a medir el progreso SEO. La oscilación de

267
posiciones de los documentos web en la lista de resultados hace difícil conocer si las
optimizaciones han tenido algún efecto.
La falta de comunicación por parte de Google también ha representado una dificultad.
El dominio con el que hemos trabajado ha distribuido durante años el mismo material
a diferentes sitios web. Cuenta con más de cien artículos duplicados en diferentes
dominios. A pesar de ello, Google no ha comunicado al dueño del sitio web si existe
algún tipo de penalización por estas prácticas llevadas a cabo en años anteriores.
Para el presente proyecto final de carrera, se trabajó inicialmente en la optimización
del sitio web Karaokegame.com. Debido a un contrato de privacidad, el trabajo
realizado para el anterior dominio no fue autorizado a ser publicado.
Se procedió a buscar un nuevo proyecto de posicionamiento, encontrando la empresa
Verkkoasema, experta en SEO y SEM e interesada en colaborar con el presente
proyecto final de carrera. El proyecto a posicionar consistía en un sitio web de casas
rurales llamado mokkilappi.fi empleando el idioma finés. Se comprometieron a
ayudarme con la búsqueda de palabras clave y la escritura de textos en finés. Tras la
realización de una auditoria web técnica de 8 páginas, no hubo respuesta por parte de
ellos. Debido a la falta de implicación, se abortó el proyecto.
6.5. Futuras ampliaciones
Futuras ampliaciones de este proyecto pueden estar enfocadas en la búsqueda del
posicionamiento de documentos web empleando técnicas Blackhat, como medio para
conocer los límites que los motores de búsqueda tienen previa penalización del sitio
web.

268

269
Bibliografía Vryniotis, V. (2013). Web SEO Analytics. From The robots.txt, META-robots &
rel=nofollow and their impact on SEO:
http://www.webseoanalytics.com/blog/robotstxt-metarobots-relnofollow-the-impact-
on-seo/
W3C - Document Content, Structure and Presentation. (n.d.). Document Content,
Structure and Presentation. From W3C: http://www.w3.org/TR/WCAG10/#content-
structure
W3C - Html. (n.d.). Html. From Word Wide Web Consortium:
http://www.w3.org/community/webed/wiki/HTML
W3C - Html structural elements. (n.d.). Html structural elements. From W3C:
http://www.w3.org/wiki/HTML_structural_elements
W3C. (n.d.). W3. From The global structure of an HTML document:
http://www.w3.org/TR/html401/struct/global.html#h-7.5.5
Warnier, Y. (2012). BeezNest Open-Source Specialists. From BeezNest Open-Source
Specialists: http://beeznest.wordpress.com/2012/07/01/spider-a-website-with-wget/
WebHostingReports.com. (2009). The History Of DMOZ. From Web Hosting
Reports: http://www.webhostingreport.com/learn/dmoz.html
Weitz, David, S., Gounares, George, A., Kinsel, & A., P. (2011). Patent No.
20110246456.
World Wide Web Consortium. (2005). Status Code Definitions. From World Wide
Web Consortium: http://www.w3.org/Protocols/rfc2616/rfc2616-sec10.html

270
World Wide Web Consortium. (n.d.). The global structure of an HTML document.
From World Wide Web Consortium:
http://www.w3.org/TR/html401/struct/global.html
Zhicheng Dou, R. S.-Y.-R. (2009). Using Anchor Texts with Their Hyperlink
Structure for Web Search. Association for Computing Machinery, Inc.
Agate, J. (2014). The New Link Building Survey 2014. From Moz.com:
http://moz.com/blog/link-building-survey-2014-results
Arnold, J., Lurie, I., Dickinson, M., Marsten, E., & Becker, M. (2009). Web
Marketing All-in-One Desk Reference For Dummies. For Dummies.
Ash, T., Ginty, M., & Page, R. (2012). Landing Page Optimization: The Definitive
Guide to Testing and Tuning for Conversions. Wiley Publishing.
Baymard Institute. (2013). Cart Abandonment Rate Statistics. From Baymard
Institute: http://baymard.com/lists/cart-abandonment-rate
Baeza-Yates, R. (2004). Effective Web Crawling. Effective Web Crawling . From
http://www.chato.cl/papers/crawling_thesis/effective_web_crawling.pdf
Battelle, J. (2005). The birth of Google. From Wired:
http://www.wired.com/wired/archive/13.08/battelle.html
Berners-Lee, T. (1992). W3 servers. From World Web Wide Consortium:
http://www.w3.org/History/19921103-
hypertext/hypertext/DataSources/WWW/Servers.html
Berners-Lee, T. (1989). World Wide Web Consortium. From Berners-Lee's original
purposal to CERN: http://www.w3.org/History/1989/proposal.html
Bharat, K., & Mihaila, G. A. (2003). Hilltop: A Search Engine based on Expert
Documents.

271
BlueLithium's BL Labs. (2006). Study: Behavioral Ads Convert Better Out of Context
. From Clickz.com: http://www.clickz.com/clickz/news/1712836/study-behavioral-
ads-convert-better-out-context
Bodnar, K. (2010). 12 Amazing SEO Infographics. From HubSpot - Inbound Hub:
http://blog.hubspot.com/blog/tabid/6307/bid/6442/12-Amazing-SEO-
Infographics.aspx
Brutlag, J. (2009). Speed Matters for Google Web Search.
Brin, S., & Page, L. (1998). The Anatomy of a Large-Scale Hypertextual Web Search
Engine.
Cuuts, M. (2009). PageRank Sculping. From Matt Cutts: Gadgets, Google, and SEO:
http://www.mattcutts.com/blog/pagerank-sculpting/
Cutler, M., Shih, Y., & Meng, W. (1997). Using the structure of html documents to
improve retrieval.
Cutt, M. (2011). Cloaking. From YouTube - Google Webmaster Tools Channel:
https://www.youtube.com/watch?v=QHtnfOgp65Q
Cutts, M. (2011). Youtube - Google Webmasters . From How important is it to have
keywords in a domain name?: https://www.youtube.com/watch?v=rAWFv43qubI
Cutts, M. (2013). Will Google be evaluating the use of rel="author" moving forward?
From YouTube.com: http://www.youtube.com/watch?v=3QlY8ba0jYI
Cutts, M. (2013). Why does Google show multiple results from the same domain?
From YouTube.com:
http://www.youtube.com/watch?feature=player_embedded&v=sxv-AvNPoh8

272
Cutts, M. (2011). What role does being in DMOZ play in rankings? From YouTube -
Google Webmasters Channel: http://www.youtube.com/watch?v=KCY5pbAuYpk
Cutts, M. (2007). Using ALT attributes smartly. From Google Webmaster Central:
http://googlewebmastercentral.blogspot.fi/2007/12/using-alt-attributes-smartly.html
Cutts, M. (2013). A reminder about selling links that pass PageRank. From
Webmaster Central Blog: http://googlewebmastercentral.blogspot.fi/2013/02/a-
reminder-about-selling-links.html
Cutts, M. (2012). Another step to reward high-quality sites . From Google Webmaster
Central Blog: http://googlewebmastercentral.blogspot.fi/2012/04/another-step-to-
reward-high-quality.html
Cutts, M. (2009). Can the geographic location of a web server affect SEO? YouTube.
Cutts, M. (2011). Cloaking. From Google Webmaster Tools:
https://support.google.com/webmasters/answer/66355?hl=en&ref_topic=6001971
Cutts, M. (2012). How much time should I spend on meta tags, and which ones
matter? . How much time should I spend on meta tags, and which ones matter? .
Cutts, M. (2011). Lightning Round! From YouTube - Matt Cutts channel:
https://www.youtube.com/watch?v=0EE163OGjfo
Cutts, M. (2014). Matt Cutts: Gadget, Google, and SEO. From The decay and fall of
guest blogging for SEO: http://www.mattcutts.com/blog/guest-blogging/
Cutts, M. (2009). More about generic TLDs in (say) UK results . From Matt Cutts
personal page: http://www.mattcutts.com/blog/more-about-generic-tlds-in-say-uk-
results/

273
Cutts, M. (2012). Page Layout algorithm improvement. From
GoogleWebmasterCentral: googlewebmastercentral.blogspot.fi/2012/01/page-layout-
algorithm-improvement.html
Cutts, M. (2006). SEO advice: discussing 302 redirects. From Matt Cutts: Gadgets,
Google, and SEO: http://www.mattcutts.com/blog/seo-advice-discussing-302-
redirects/
Cutts, M. (2012). SEO tricks from patio11. From Hacker News:
https://news.ycombinator.com/item?id=3214397
Cutts, Matt. (2013). Penguin 2.0 rolled out today. From Matt Cutts Blog:
http://www.mattcutts.com/blog/penguin-2-0-rolled-out-today/
Catalyst Team. (2012). How Rich Snippets Can Improve your CTR. From Catalyst
Search Marketing: http://www.catalystsearchmarketing.com/how-rich-snippets-can-
improve-your-ctr/
Chitika. (06 de 2013). The Value of Google Result Positioning. From Chitika - Online
Advertising Network: http://chitika.com/google-positioning-value
Cho, J., Garcia-Molina, H., & Page, L. (1995). Efficient Crawling Through URL
Ordering.
Chopra, P. (2010). A/B test case study: how two magical words increased conversion
rate by 28%. From Visual Website Optimizer: visualwebsiteoptimizer.com/split-
testing-blog/case-study-how-two-magical-words-increased-conversion-rate-by-28
Chrome. (2014). Google Chrome Privacy Notice. From Google:
https://www.google.com/intl/en/chrome/browser/privacy/
Collier, M. (2012). From http://www.theopenalgorithm.com/correlation-data/domain-
name-seo/

274
comScore. (2014). Search Engine Rankings. From comScore:
http://www.comscore.com/Insights/Press-Releases/2014/1/comScore-Releases-
December-2013-US-Search-Engine-Rankings
Craven, P. (n.d.). From http://www.webworkshop.net
Experian. (2009). Benchmark data and analysis on connecting web behavior to email
marketing.
experts, M. t. (2013). Moz.com. From http://moz.com/search-ranking-factors#metrics-
2
Elkington, D., & Oldroyd, J. (2007). How Much Time Do You Have Before Web-
Generated Leads Go Cold? From Marketing Sherpa:
http://www.marketingsherpa.com/DG07SFSlides/LeadResponseManagementReport.p
df
Enge, E., Spencer, S., Fishkin, R., & Stricchiola, J. (2009). The Art of SEO:
Mastering Search Engine Optimization. O'Reilly Media.
Enquiro. (n.d.). Business to business survey. From Enquiro:
http://web.archive.org/web/20120131103323/http:/www.enquiroresearch.com/campai
gns/Business%20to%20Business%20Survey%202007.pdf
Dumais, T. S., Weitz, S. D., Gounares, A. G., Gemmell, D. J., & Yiu, P. (2012).
Patent No. US8260789 B2.
Dumais, T. S., Weitz, S. D., Gounares, A. G., Gemmell, D. J., & Yiu, P. (2010).
Patent No. 20110246484.
Davison, B. D. (n.d.). Recognizing Nepotistic Links on the Web.
Dean, J. A., Anderson, C., & Battle, A. (2010). Patent No. US 7716225 B1 .

275
Deswal, S. (2012). How changing a single word increased click through rate by
161%. From Visual Website Optimizer: visualwebsiteoptimizer.com/split-testing-
blog/increase-click-through-rate
Digital Analytics Association. (2013). What is Digital Analytics? From Digital
Analytics Association: http://www.digitalanalyticsassociation.org/about
Dimock, M. (2013). The Keyword Cannibalization Survival Guide . From iMarket
Solutions: http://www.imarketsolutions.com/blog/content-strategy/keyword-
cannibalization-survival-guide
Dover, D., & Dafforn, E. Search Engine Optimization (SEO) Secrets. Wiley.
Dou, Z., Chen, J., Song, R., & Wen, J.-R. (2013). Patent No. US 8380722 B2.
Fetterly, D., Manasse, M., & Najork, M. (2004). Spam, Damn Spam, and Statistics:
Using statistical analysis to locate spam web pages.
Fishkin, R. (2010). From http://moz.com/blog/smx-london-ranking-factors-in-2010
Fishkin, R. (08 de 06 de 2010). From http://moz.com/blog/google-vs-bing-
correlation-analysis-of-ranking-elements
Fishkin, R. (22 de 04 de 2010). From http://moz.com/blog/the-science-of-ranking-
correlations
Fishkin, R. (27 de 05 de 2010). From http://moz.com/blog/10-illustrations-on-search-
engines-valuation-of-links
Fishkin, R. (2011). From http://moz.com/search-ranking-factors/2011
Fleischner, M. M. (2011). SEO Made Simple (Second Edition): Strategies For
Dominating The World's Largest Search Engine. CreateSpace Independent Publishing
Platform.

276
Forrester Consulting. (2012). The direct and indirect value that affiliates deliver to
advertisers. From Internet Advertising Bureau:
http://www.iab.net/media/file/ForresterRakutenLinkShareFinal.pdf
Forrester Research. (2012). Affiliate Marketing - The direct and indirect value that
affiliates deliver to advertisers. From Interactive Advertising Bureau:
http://www.iab.net/media/file/ForresterRakutenLinkShareFinal.pdf
Forrester Research, I. (2011). The Impact Of Online Cuopons And Promotion Codes.
Friedman, D. (2011). 5 simple ways to improve your AdWords. From Google Inside
AdWords: adwords.blogspot.fi/2011/04/5-simple-ways-to-improve-your-
adwords.html
Gyöngyi, Z., Garcia-Molina, H., & Pedersen, J. (2004). Combating Web Spam with
TrustRank.
Google Webmaster tool - Como bloquear o eliminar páginas con un archivo
robots.txt. (n.d.). Cómo bloquear o eliminar páginas con un archivo robots.txt. From
Herramienta para Webmasters de Google:
https://support.google.com/webmasters/answer/156449?hl=es&ref_topic=2370588
Google Webmaster Tool. (2013). Google Webmaster Tool - rel=nofollow. From
rel="nofollow": https://support.google.com/webmasters/answer/96569
Google Webmaster Tool. (2013). Google Webmaster Tools. From Meta Tags:
https://support.google.com/webmasters/answer/79812?hl=en
Google Webmaster Tool. (2014). Sitemap index file. From Sitemap index file:
https://support.google.com/webmasters/answer/71453?hl=en

277
Google Webmaster Tools - User-genereted spam. (n.d.). User-genereted spam. From
Google Webmaster Tools:
https://support.google.com/webmasters/answer/81749?hl=en
Google Webmaster Tools - Doorway pages. (n.d.). Doorway pages. From Google
Webmaster Tools:
https://support.google.com/webmasters/answer/2721311?hl=en&ref_topic=6001971
Google Webmaster Tools. (2013). Author information in search results. From Google
Webmaster Tools: https://support.google.com/webmasters/answer/1408986?hl=en
Google Webmaster Tools. (2014). About Structured Data Markup Helper. From
Google Webmaster Tools - Structure Data Markup Helper:
https://support.google.com/webmasters/answer/3069489
Google Webmaster Tools. (2014). Affiliate programs. From Google Webmaster
Tools:
https://support.google.com/webmasters/answer/76465?hl=en&ref_topic=6001971
Google Webmaster Tools. (2014). Change page URLs with 301 redirects. From
Google Webmaster Tools:
https://support.google.com/webmasters/answer/93633?hl=en
Google Webmaster Tools. (2013). Duplicate Content. From Google Webmaster
Tools: https://support.google.com/webmasters/answer/66359?hl=en
Google Webmaster Tools. (2014). Doorway pages. From Google Webmaster Tools:
https://support.google.com/webmasters/answer/2721311?hl=en&ref_topic=6001971
Google Webmaster Tools. (2013). Guide to AJAX crawling for webmasters and
developers. From Google Webmaster Tools:
https://support.google.com/webmasters/answer/174992?hl=en

278
Google Webmaster Tools. (n.d.). Google Webmaster Tools. From Using meta tags to
block access to your site: https://support.google.com/webmasters/answer/93710?rd=1
Google Webmaster Tools. (2013). Google Webmaster Tools. From Rich snippets
guidelines: https://support.google.com/webmasters/answer/2722261?hl=en
Google Webmaster Tools. (2013). Google Webmaster Tools. From Blocking Google:
https://support.google.com/webmasters/answer/93708?hl=en
Google Webmaster Tools. (2014). Googlebot. From Google Webmaster Tools:
https://support.google.com/webmasters/answer/182072?hl=en
Google Webmaster Tools. (2013). Irrelevant keywords. From Google Webmaster
Tools: https://support.google.com/webmasters/answer/66358?hl=en
Google Webmaster Tools. (2013). Link schemes. From Google Webmaster Tools:
https://support.google.com/webmasters/answer/66356?hl=en
Google Webmaster Tools. (2014). Link to your Google+ profile using rel="author".
From Google Webmaster Tools:
https://support.google.com/webmasters/answer/2539557?hl=en&ref_topic=6003069
Google Webmaster Tools. (2014). Review your page titles and snippets. From
Webmaster Tools Help: https://support.google.com/webmasters/answer/35624?hl=en
Google Webmaster Tools. (2013). Sitelinks. From Google Webmaster Tools:
https://support.google.com/webmasters/answer/47334?hl=en
Google Webmaster Tools. (n.d.). Structure Data Testing Tool. From Webmaster
Tools: http://www.google.com/webmasters/tools/richsnippets
Google Webmasters. (2012). Making AJAX Applications Crawlable. From Google
Developers: https://developers.google.com/webmasters/ajax-crawling/

279
Google. (2012). ZMOT Ways to Win Shoppers at the Zero Moment Of Truth. From
Google Think Insights: www.google.com/think/research-studies/2012-zmot-
handbook.html
Google AdWords. (2014). Ad Groups. From Google AdWords:
https://support.google.com/adwords/answer/6298?hl=en
Google AdWords. (2013). Choosing the campaign type that's right for you. From
Google AdWords Help:
https://support.google.com/adwords/answer/2567043?hl=en&ref_topic=3121941
Google AdWords. (2013). Google Network. From Google AdWords:
https://support.google.com/adwords/answer/1752334?hl=en
Google AdWords. (2014). How ad groups work. From Google AdWords:
https://support.google.com/adwords/answer/2375404
Google AdWords. (2013). How AdWords works. From Google AdWords:
https://support.google.com/adwords/answer/2497976?hl=en
Google AdWords. (2014). How costs are calculated in AdWords. From Google
AdWords:
https://support.google.com/adwords/answer/1704424?hl=en&ref_topic=3121763
Google AdWords Program. (2013). Create a remarketing list. From Google
AdWords: https://support.google.com/adwords/answer/2454064?hl=en
Google Adwords. (n.d.). Remarketing. From Google Adwords:
https://support.google.com/adwords/answer/1752338?hl=en&ref_topic=24937
Google AdWords Support. (2014). Ad Targeting. From Google AdWords Support:
https://support.google.com/adsense/answer/160525?hl=en

280
Google AdWords Support. (2013). Bidding features on the Display Network . From
Google AdWords Support:
https://support.google.com/adwords/answer/2947304?hl=en
Google AdWords Support. (2014). Choose the campaign type that's right for you.
From Google Website Support:
https://support.google.com/adwords/answer/2567043?hl=en
Google AdWords Support. (2014). Create a remarketing list. From Google AdWords
Support: https://support.google.com/adwords/answer/2454064?hl=en
Google AdWords Support. (2014). Reach people interested in your products or
services. From Google AdWords Support:
https://support.google.com/adwords/answer/2497941?hl=en-GB
Google AdWords Support. (2013). Setting bid adjustments. From Google AdWords
Support: https://support.google.com/adwords/answer/2732132?hl=en
Google AdWords Support. (2014). Targeting the Display Network. From Google
AdWords Support: https://support.google.com/adwords/answer/6056342?hl=en&rd=1
Google AdWords. (2014). Targeting your ads. From Google AdWords - Help:
https://support.google.com/adwords/answer/1704368
Google Analytics. (n.d.). Bounce Rate. From Google Analytics:
https://support.google.com/analytics/answer/1009409?hl=en
Google Analytics. (2013). Cómo se calculan las visitas en Analytics. From Google
Analytics: https://support.google.com/analytics/answer/2731565?hl=es
Google Analytics. (2014). Diferencia entre clics y sesiones de AdWords, usuarios,
entradas, páginas vistas y páginas vistas únicas en Analytics. From Google Analytics:
https://support.google.com/analytics/answer/1257084?hl=es#pageviews_vs_unique_v
iews

281
Google Corporation . (2011). Software Application. From schema.org:
http://schema.org/SoftwareApplication
Google Corporation. (2011). Product. From Schema.org: http://schema.org/Product
Google Corporation. (2012). The Anatomy of a HyperLink. From SEO Education:
https://sites.google.com/site/freeseolinkexchange/the-anatomy-of-a-hyperlink
Google. (2010). Search Engine Optimization Starter Guide.
Google. (04 de 2011). The Zero Moment of Truth for Consumer Electronics Study.
From Google Think Insights: www.google.com/think/research-studies/zmot-
consumer-electronics.html
Google. (2011). The Zero Moment of Truth Macro Study. From Google Think
Insights: www.google.com/think/research-studies/the-zero-moment-of-truth-macro-
study.html
Google+ Platform. (2014). Google Platform. From Google Developers:
https://developers.google.com/+/web/+1button/?rd=1
IAB. (2010). Guía de Marketing de Afiliación.
ICANN. (n.d.). Internet Corporation for Assigned Names and Numbers. From IDN
Glossary - Domain Name: http://www.icann.org/en/resources/idn/glossary
ICANN. (2014). Internet Corporation for Assigned Names and Numbers. From
Glossary: http://www.icann.org/en/about/learning/glossary
Internet World Stats. (2014). Usage and population statistics. From Internet World
Stats: http://www.internetworldstats.com/list2.htm#a-c

282
Internet World Stats. (2014). History and Growth of the Internet from 1995 till Today.
From Internet World Stats: http://www.internetworldstats.com/emarketing.htm
Internet Live Stats. (2013). Google Search Statistics. From Internet Live Stats:
http://www.internetlivestats.com/google-search-statistics/#trend
Halligan, B., & Shah, D. (2009). Inbound Marketing: Get found using Google, Social
Media and Blogs.
Halligan, B., Shah, D., & Meerman Scott, D. Inbound Marketing: Get Found Using
Google, Social Media, and Blogs. Wiley.
Herrera, F. (2014). Como optimizar los encabezados. From Blogger y SEO:
http://www.bloggerayuda.com/2014/05/blogger-seo-optimizar-encabezado-h1.html
JupiterResearch. (2006). Retail Web Site Performance: Consumer Reaction to a Poor
Online Shopping Experience.
Jansen, J. (2010). Online Product Research. Pew Research Center.
Jennifer Grappone, G. C. (2011). Search Engine Optimization (SEO): An Hour a Day.
Sybex.
Kumar, G., Sareen, G., Gupta, N., Clark, C. L., & Wang, J. (2013). Patent No. US
8458207 B2.
Kupke, J. (2009). Specify your Canonical. From
http://googlewebmastercentral.blogspot.fi/:
http://googlewebmastercentral.blogspot.fi/2009/02/specify-your-canonical.html
Kaushik, A. (2010). Web Analytics 2.0: The Art of Online Accountability and Science
of Customer Centricity. Sybex.

283
Keith, J. (2006). Hijax: Progressive enhacement with Ajax. From domscripting.com:
http://domscripting.com/presentations/xtech2006/
Laerd Statistics. (2013). Laerd Statistics. From Spearman's Rank-Order Correlation:
https://statistics.laerd.com/statistical-guides/spearmans-rank-order-correlation-
statistical-guide.php
Leary, B. (2012). Inbound Marketing: The customer finds you. From Small Business
Trends.
Lecinski, J. (2011). Winning the Zero Moment of Truth eBook. From Google Think
Insights: www.google.com/think/research-studies/2011-winning-zmot-ebook.html
Li, B., & Kupke, J. (2011). Pagination with rel=“next” and rel=“prev”. From
Google Webmaster Central:
http://googlewebmastercentral.blogspot.fi/2011/09/pagination-with-relnext-and-
relprev.html
Nielsen. (2012). Nielsen Global Survey of New Product Purchase Sentiment.
Nielsen, L. (2004). Engaging Personas and Narrative Scenarios. Copenague.
Munoz Vera, G. (2008). Era cuestion de tiempo... From Dónde está Avinash cuando
se le necesita?: dondeestaavinashcuandoselenecesita.blogspot.fi/2008/03/era-cuestin-
de-tiempo.html
Munoz Vera, G., & Elosegui Figueroa, T. (2011). El arte de medir. Profit Editorial.
Musella, D. (1995). The META Tag of HTML. From http://tools.ietf.org/html/draft-
musella-html-metatag-01
Madison Logic. (2014). 10 Email Best Practices. From Madison Logic:
http://www.madisonlogic.com/10-email-best-practices/

284
MailChimp. (n.d.). Email Marketing Benchmarks. From MailChimp:
http://mailchimp.com/resources/research/email-marketing-benchmarks/
Maile Ohye. (2012). Pagination and SEO. From YouTube - Google Webmasters
Channel: http://www.youtube.com/watch?v=njn8uXTWiGg
Marketing Sherpa. (2009). Email’s ROI Makes Tactic Key for Marketers in 2009.
From Marketing Sherpa: http://www.marketingsherpa.com/article/emails-roi-makes-
tactic-key#
Marketo Blog. (2012). Lead Nurturing. From Marketo Blog:
http://www.marketo.com/_assets/uploads/LeadNurturing-cheatsheet2-10.pdf
Marshall, P., & Todd, B. (2012). Ultima Guide to Google AdWords.
Marshall, P., & Tood, B. (2012). Ultimate Guide to Google AdWords. Entrepreneur
Press.
Martijn, Koster. (1994). The Web Robots Pages. From Robots Exclusion Protocol:
http://www.robotstxt.org/
Matt Cutts. (2011). What is the ideal keyword density of a page? From Youtube:
https://www.youtube.com/watch?v=Rk4qgQdp2UA
Matt Cutts. (2013). What percentage of PageRank is lost through a 301 redirect?
From YouTube: http://www.youtube.com/watch?v=Filv4pP-1nw
Matt Cutts. (2009). More than one H1 on a page: good or bad? From YouTube:
http://www.youtube.com/watch?v=GIn5qJKU8VM
Matthew Gray. (1996). Growth and Usage of the Web and the Internet . From Internet
Statistics: http://www.mit.edu/~mkgray/net/

285
McDonald, L. (2013). Transactional Emails: Make Your First Impression Count.
From MediaPost: http://www.mediapost.com/publications/article/104687/
Meyer, M. (2006). Google Marissa Meyer speed research. From YouTube.com:
www.youtube.com/watch?=BQwAKsFmK_8
METRO. (2009). Why we nearly McGoogled it . From METRO:
http://metro.co.uk/2009/03/15/why-we-nearly-mcgoogled-it-545208/
Microsoft Corporation. (2008). Sitemap.org. From Using Sitemap index files:
http://www.sitemaps.org/protocol.html#index
Microsoft Corporation. (2008). sitemaps.org. From sitemaps.org:
http://www.sitemaps.org/protocol.html
Miller, J. (2010). What is a lead? From Marketo Blog:
http://blog.marketo.com/2010/11/what-is-a-lead.html
Minogue, D., & Tucker, P. (2007). Patent No. US 20070033168 A1.
Moz. (2014). Redirection. From Moz.com: http://moz.com/learn/seo/redirection
Moz Team. (2014). Moz. From Google Algorithm Change History:
http://moz.com/google-algorithm-change
Page, L. (1997). Patent No. US6285999 B1.
Peng, D., & Dabek, F. (2010). Large-scale Incremental Processing Using Distributed
Transactions and Notifications. From Research at Google:
http://research.google.com/pubs/pub36726.html
Peter Linsley, Matt Cutts. (n.d.). Image Publishing Guidelines. From Google
Webmaster Tools: https://support.google.com/webmasters/answer/114016?hl=en

286
Peters, M., & Isham, M. (2013). How Website Speed Actually Impacts Search
Ranking. From Moz.com: http://moz.com/blog/how-website-speed-actually-impacts-
search-ranking
Petrescu, P. (2014). Google Organic Click-Through Rates in 2014. From The moz
blog: http://moz.com/blog/google-organic-click-through-rates-in-2014
Petrovic, D. (2012). Google Does Take Action Against Content Scrapers. From
DejanSEO: http://dejanseo.com.au/google-against-content-scrapers/
Petrovic, D. (2012). How I Hijacked Rand Fishkin’s Blog. From Dejan SEO:
http://dejanseo.com.au/hijack/
Procopio, M. J. (2013). Patent No. US 8458192 B1 .
Procopio, M. J. (2013). Patent No. US 8458193 B1 .
Procopio, M. J. (2013). Patent No. US 8458194 B1 .
Procopio, M. J. (2013). Patent No. US 8458195 B1 .
Procopio, M. J. (2013). Patent No. US 8458196 B1 .
Procopio, M. J. (2013). Patent No. US 8458197 B1 .
OWASP. (2014). Cross-site Scripting (XSS). From OWASP:
https://www.owasp.org/index.php/Cross-site_Scripting_(XSS)
Ouellet, M. (2013). Fith annual shopping cart recovery tactics of the Internet retailer
1000. Listrak.
Ouellet, M. (2012). Shopping Carts Abandonment Review and lookbook.

287
Oullet, M. (2013). Shopping cart recovery tactics of the internet retailers 1000. From
Listrak: http://www.listrak.com/assets/resources/whitepapers/2013-shopping-cart-
abandonment.pdf
Odom, S. (2010). SEO For 2010: Search Engine Optimization Secrets. Media Works
publishing.
Odom, S., & Habermann, C. (2013). SEO for 2013: Search Engine Optimization
Made Easy. MediaWorks Publishing.
Oldroyd, J. B., McElheran, K., & Elkington, D. (2011). The Short Life of Online Sales
Leads. From Harvard Business Review: http://hbr.org/2011/03/the-short-life-of-
online-sales-leads/ar/1
Optify. (2011). Optify Organic Click Through Rate Webinar Slides. From Search
Marketing Now: http://www.slideshare.net/optify/optify-organic-click-through-rate-
webinar-slides
Ruderman, J. (2014). Same-origin policy. From Mozilla Developer Network:
https://developer.mozilla.org/en-
US/docs/Web/JavaScript/Same_origin_policy_for_JavaScript
Rand Fishkin. (2007). How to Solve Keyword Cannibalization. From Moz:
http://moz.com/blog/how-to-solve-keyword-cannibalization
Rand Fishkin. (2013). Moz.com. From What is Robots.txt?:
http://moz.com/learn/seo/robotstxt
Rogers, I. (n.d.). From http://www.sirgroane.net/google-page-rank/
Sullivan, D. (2014). Yahoo Directory. From Search Engine Land:
http://searchengineland.com/yahoo-directory-close-204370
Sciences, G. (2011). The Zero Moment of Truth. Google/Shopper Sciences.

288
Schwartz, B. (2013). Google: Site Speed Penalty Coming To Mobile Web Sites. From
Search Engine Land: http://searchengineland.com/google-mobile-site-speed-162977
Schwartz, B. (2012). Search Engine Rountable. From Google EMD Update: EMD no
longer rank as well: http://www.seroundtable.com/google-emd-update-15776.html
Schema. (n.d.). Recipes. From Schema.org: http://schema.org/Recipe
Schmidt, C. (2005). Page Hijack: The 302 Exploit, Redirects and Google . From
clsc.net: http://clsc.net/articles/google-302-page-hijack.php
Scott, D. M. (n.d.). About David. From David Meerman Scott:
http://www.davidmeermanscott.com/about-david/
Scott, D. M. (2011). The New Rules of Marketing & PR: How to Use Social Media,
Online Video, Mobile Applications, Blogs, News Releases, and Viral Marketing to
Reach Buyers Directly. Wiley.
Search Engine Land. (2013). Google: PageRank Dilution Through A 301 Redirect Is
A Myth . From Search Engine Land: http://searchengineland.com/google-pagerank-
dilution-through-a-301-redirect-is-a-myth-149656
Search, G. I. (2013). Google Inside - Crawling & Indexing. From Google Inside
Search: https://www.google.com/intl/en/insidesearch/howsearchworks/crawling-
indexing.html
SeeWhy. (2011). The science of shopping cart abandonment. From SeeWhy:
http://seewhy.com/wp-
content/uploads/SeeWhy_eBook_The_Science_of_Shopping_Cart_Abandonment.pdf
SEMPO. (2011). SEMPO. From SEMPO: http://www.sempo.org/?page=glossary

289
Siddiqi, A. (2012). Optify reports Click Through Rates (CTR) are outdated. From
MediaBuzz: http://www.mediabuzz.com.sg/asian-emarketing/search-mkting-n-
analytics/1630-optify-reports-click-through-rates-ctr-are-outdated-new
Silverpop. (2012). Silverpop Email Marketing Metrics Benchmark Study. From
Silverpop: http://www.silverpop.com/downloads/white-
papers/WP_2012_Benchmark.pdf
Singhal, A., & Cutts, M. (2010). Using site speed in web search ranking. From
Google Webmaster Central Blog:
http://googlewebmastercentral.blogspot.fi/2010/04/using-site-speed-in-web-search-
ranking.html
Singhal, A., Cutts, M., & Wu, J. W. (2011). Patent No. US 8046350 B1.
Singhal, Amit; Cutts, Matt. (2011). Google Blog. From Finding more high-quality
sites in search: http://googleblog.blogspot.fi/2011/02/finding-more-high-quality-sites-
in.html
Sherpa, M. (2008). Search Marketing Benchmark guide 2008. From
http://www.marketingsherpa.com/exs/Search08Excerpt.pdf
Shontell, A. (2012). Business Insider. From The 25 most expensive domain name of
all time: http://www.businessinsider.com/the-20-most-expensive-domain-names-
2012-12?op=1
Spero, J. (2012). The Mobile Playbook. From The Mobile Playbook:
www.themobileplaybook.com
Stevens, N. Zero to $1,000 with PPC: A Proven Blueprint to Making $1,000 a Month
with Pay Per Click Advertising in 30 Days or Less.
Turner, D., Entwisie, S., Johnson, E., Fossi, M., Blackbird, J., McKinney, D., et al.
(09 de 2007). Symantec Internet Security Threat Report. XII .

290
Tagman. (2012). Tagman case study: Glasses Direct. From Tagman.com:
www.tagman.com/wp-content/uploads/2013/08/tagman_casestudy_glasses_direct.pdf

291
Glosario
A
A/B testing
Término empleado en el área de marketing
online para describir la realización de
experimentos con dos variables: variable de
control; variable dependiente.
accelerators
Extensión que permite mejorar el
rendimiento en sistemas con lenguajes
compilados. Generalmente hacen uso de
caches donde guardan el bytecode/opcode
generado por el compilador, evitando
compilar el código en cada ejecución.
actual CPC
Término empleado en la plataforma de
anuncios Google AdWords para definir la
cantidad mínima a pagar por clic.
ad group
Elemento básico de trabajo en la plataforma
de anuncios Google AdWords. Facilitan la
organización y gestión de palabras clave,
pujas y anuncios.
Ad Rank
Métrica empleada por la plataforma Google
AdWords para determinar el orden de
impresión de los anuncios.
AdWords
Plataforma de anuncios online de Google.
afiliados
En el marketing de afiliación, se conoce a la
figura de afiliado como aquellos sitios web
especializados en conseguir tráfico y dirigirlo
hacia otros sitios web.
Agent Rank
Algoritmo empleado por Google como medio
para medir la calidad de los agentes que
crean, editan y producen contenido web.
Ajax
Acrónimo de Asynchronous JavaScript And
Xml. Técnica empleada en el desarrollo de
aplicaciones web. Ejecutada en el navegador,
permite establecer comunicación con el
servidor asíncronamente.
alt
Atributo perteneciente a la etiqueta Html img.
Permite añadir una descripción textual. Esta
descripción será visible únicamente cuando la
imagen no pueda ser recuperada del servidor.
analítica web
Herramienta empleada para medir la
evolución de un sitio web mediante la
recopilación, medición, evaluación y emisión
de informes de datos.
ancla de texto
Palabra o texto asociado a enlaces.
anuncios contextuales
Anuncios cuyo mensaje está relacionado con
el contenido del documento web donde
aparecen.

292
anuncios patrocinados
Anuncios donde el anunciante paga por cada
clic que el usuario realiza en el anuncio.
Autoresponders
Programa que responde automáticamente a la
recepción de e-‐mails. MailChimp permite
configurar autoresponders como respuesta a
acciones de registro o alta de usuarios en el
sistema.
autoridad de dominio
Métrica definida por el equipo de Moz.
Indicador del prestigio o crédito de un sitio
web.
B
benchmark
Técnica utilizada para medir o comparar los
resultados de un sistema frente a otro.
bid only
Tipo de puja disponible en Google AdWords
que permite modificar el precio de las pujas
en función del perfil del usuario. Este tipo de
pujas no limitan la impresión de anuncios al
perfil de usuario especificado. Otorga un
mayor control sobre las pujas.
Blackhat SEO
Técnica de optimización de documentos web
cuyo objetivo es confundir a los motores de
búsqueda como medio para mejorar el
posicionamiento web. Estas técnicas son
penalizadas por los motores de búsqueda,
bots
Sinónimo de crawler.
bounce rate
Término empleado en analítica web para
definir al porcentaje de usuarios que
abandonan el sitio web después de haber
consumido una sola página.
Buscador
Componente de un motor de búsqueda que
recibe las palabras introducidas por los
usuarios, interacciona con componentes del
motor de búsqueda y ofrece un listado
ordenado de resultados.
C
caches
Memoria de rápido acceso que permite
guardar temporalmente información. Este
tipo de memorias se emplea como medio para
mejorar el rendimiento de los sistemas,
reduciendo el tiempo de búsqueda de datos.
campañas de e-‐mail
Herramienta de marketing online para
establecer contacto con usuarios, difundir
mensajes y adquirir nuevos clientes
empleando el e-‐mail como canal de
comunicación.
canibalización de palabras clave
Documentos web optimizados para los
mismos términos compiten entre si por
aparecer en la lista de resultados para las
mismas palabras clave. Esto se produce como
consecuencia de la limitación que los motores
de búsqueda establecen para no mostrar más
de tres documentos web provenientes del
mismo dominio en la misma página de la lista
de resultados.
canonical
Valor aceptado por el atributo rel para la
etiqueta link. Junto con el atributo href
permite especificar la dirección web canónica.
CDN

293
Acrónimo de Content Delivery Network.
Sistema de servidores interconectados que
determina el servidor que responde a las
peticiones web en base a la localización
geográfica. Permite mejorar los tiempos de
respuesta debido a que el servidor que
responde es el que se encuentra más cercano
al usuario.
click-‐through-‐rate
Métrica empleada en el área de marketing
online para medir la eficacia de una campaña
de anuncios online. Representa el ratio de clics
que recibe un anuncio online.
cloaking
Técnica Blackhat SEO que presenta diferente
contenido a los crawlers y a los visitantes.
conditional merge tags
Etiquetas disponibles en la plataforma
MailChimp para implementar sentencias
condicional. Permiten personalizar e-‐mails en
base a estas condiciones.
Content Network
Sinónimo del término Display Network, red de
Google AdWords que agrupa al conjunto de
sitios web donde pueden disponerse anuncios
online.
conversión
Se conoce como conversión web a aquella
acción web identificada como objetivo web.
coste por impresión
Modelo de publicidad online por el cual el
anunciante paga por cada impresión.
cost-‐per-‐acquisition
Define el coste a pagar a un afiliado por cada
venta que inicia.
cost-‐per-‐click
Define el coste a pagar a un afiliado por cada
clic de anuncio que inicia.
cost-‐per-‐double-‐click
Define el coste a pagar a un afiliado por cada
clic de anuncio que consiguen, seguido de un
segundo clic en el sitio que anuncian o web
intermedia.
cost-‐per-‐impression
Término anglosajón que hace referencia al
modelo de publicidad conocido como coste
por impresión.
cost-‐per-‐lead
Define el coste que paga un anunciante por la
adquisición de datos personales de usuarios
(ej. adquisición de e-‐mail).
cost-‐per-‐thousand-‐impressions
Define el coste que paga un anunciante por
cada 1000 impresiones su anuncio.
CPA
Acrónimo de cost-‐per-‐acquisition.
CPC
Acrónimo de cost-‐per-‐click.
CPDC
Acrónimo de cost-‐per-‐double-‐click.
CPL
Acrónimo de cost-‐per-‐lead.
CPM
Acrónimo de cost-‐per-‐thousand-‐impressions.
crawlers
Componente de un motor de búsqueda
encargado de rastrear y descargar
documentos web.
crawling

294
Actividad de rastreo o descarga de
documentos realizada por crawlers.
CSS
Acrónimo de Cascading Style Sheet, es un
lenguaje empleado para definir la
presentación de contenidos web.
CSSOM
Acrónimo de Cascading Style Sheet Object
Model. Estructura creada por el navegador
para determinar el estilo que debe aplicar al
documento web.
CTR
Acrónimo del término click-‐through-‐rate.
D
Data Highlighter
Herramienta perteneciente a la plataforma
Google Webmaster Tools que nos permite
indicar a Google sobre patrones de datos
estructurados disponibles en nuestro sitio
web.
datos estructurados
Marcado que permite a Google entender el
contenido web, pudiendo este ser
representado como rich snippets en la lista de
resultados.
dirección canónica
Sinónimo del término dirección web canónica.
dirección web canónica
Se conoce como dirección web canónica a
aquella dirección web que aparecerá en los
motores de búsqueda de entre un conjunto de
direcciones web con contenido duplicado.
directorios web
Sitio web cuyo objetivo es categorizar los
documentos web presentes en Internet.
Directorio organizado de enlaces por
categorías y subcategorías.
Display Network
Red de Google AdWords que agrupa al
conjunto de sitios web donde pueden
disponerse anuncios online.
DMOZ
Conocido directorio web empleado por
motores de búsqueda para extraer
información. Google dejó de emplearlo en
2011.
DOM
Acrónimo de Document Object Model. Interfaz
de programación para documentos HTML,
XML y SVG. Proporciona una estructura para
definir documentos y manipularlos.
E
e-‐mail outreach
Práctica de link building por la que se
establece contacto con sitios web y se
promociona el contenido publicado. El
objetivo es la adquisición de enlaces de los
sitios contactados.
e-‐mail transaccionales
E-‐mails enviados como respuesta a una acción
realizada por el usuario.
EMD
Acrónimo del término Exact Match Domain.
encabezamientos
Estructuras HTML que permiten organizar
documentos marcando secciones y
subsecciones.
enlaces salientes

295
Dado un documento web, los enlaces salientes
son aquellos que apuntan hacia un nuevo
dominio.
Exact Match Domain
Nombres de dominio que se ajusta a palabras
de búsqueda introducidas por los usuarios.
F
follow/nofollow
Valores que puede adquirir el atributo content
de la meta etiqueta robots como medio para
controlar el comportamiento de los crawlers.
friendly-‐url
Práctica SEO consistente en optimizar el texto
asociado a las direcciones web.
G
Google AdSense
Programa de Google para permite a editores
monetizar sitios web mediante la impresión
de anuncios.
Google AdWords
Plataforma de anuncios online de Google que
permite a anunciantes realizar promociones
online.
Google Analytics
Herramienta analítica de Google que ofrece
datos sobre: la audiencia que accede al sitio
web; la procedencia del tráfico; el
comportamiento de los usuarios; las
conversiones que llevaron a cabo.
Google bomb
Conjunto de prácticas que provocan que un
sitio web adquiera un alto posicionamiento en
Google para búsquedas no relacionadas con la
temática del sitio web.
Google Keyword Planner
Herramienta de Google que permite obtener
datos relacionados con el número de
búsquedas, competencia o precio del clic de
un conjunto de términos especificados.
Google Network
Red de recursos donde Google AdWords
puede mostrar anuncios. Esta red está
formada por sitios web, Google Search así
como otros servicios proporcionados por
Google como Gmail, YouTube o grupos de
Google entre otros.
Google PageSpeed
Herramienta de Google que permite analizar
el tiempo que tarda en cargar un sitio web.
Ofrece información práctica para mejorar el
tiempo de carga de un sitio web.
Google Webmaster Tools
Plataforma de Google para administradores
de sitios web. Ofrece herramientas para
investigar problemas de escaneo, indexación
o penalizaciones. También dispone de
herramientas para estudiar la procedencia de
los usuarios: enlaces y palabras clave
empleadas.
googlebot
Robot de Google que rastrea y escanea sitios
web.
granjas de enlaces
Conjunto de webs que intercambian
menciones recíprocamente con el objetivo de
afectar el posicionamiento web.
H
head terms

296
Conjunto de palabras clave caracterizados por
disponer de un alto volumen de búsquedas en
los motores de búsqueda.
Hijax scheme
Metodología de mejora progresiva de una
web que termina con la implantación de la
tecnología Ajax.
Hilltop
Algoritmo empleado por Google para
identificar sitios web expertos en un temática
concreta.
hiperenlaces entrantes
Dado un documento web, los hiperenlaces
entrantes son aquellos enlaces externos que
apuntan hacia el documento web.
hiperenlaces salientes
Dado un documento web, los hiperenlaces
salientes son aquellos que apuntan hacia un
nuevo dominio.
Honey pots
Sitios web creados con la finalidad de captar
usuarios y direccionarlos hacia otros
documentos web.
Hyphen domains
Dominios formados por un conjunto de
palabras separadas mediante el uso de
guiones.
I
incremental clics
Término definido en la plataforma Google
AdWords para denotar la diferencia en el
número clics que consigue un anuncio por el
mero hecho de aparecer en una mejor
posición.
indexador
Entidad de un motor de búsqueda encargada
de extraer, descomprimir y procesar la
información que obtiene del crawlers.
infografía
Representación visual empleada para
presentar información compleja de forma
sencilla.
J
JavaScript
Lenguaje de programación interpretado
empleado por navegadores para interactuar
con el usuario.
K
KEI
Acrónimo de Keyword Effectiveness Index.
Key Performance Indicators
Métricas web empleadas para conocer la
evolución de un sitio web hacia los objetivos
que tiene establecidos.
Keyword Effectiveness Index
Métrica empleada para determinar la eficacia
de usar un conjunto de palabras claves
específicas.
keywords
Términos introducidos por los usuarios para
realizar búsquedas web
KPI
Acrónimo de Keyword Performance Indicator
L
landing page

297
Página a la que llega una usuario tras pulsar
un banner o un anuncio web. Este tipo de
páginas se caracterizan estar optimizadas
para la conversión.
landing pages
Conjunto de landing pages.
lead
Término empleado en el área de marketing
online para denotar la captura de datos de un
usuario.
leads
Término empleado en el área de marketing
online para denotar la captura de datos de un
usuario.
link building
Conjunto de prácticas cuyo objetivo es el de
adquirir enlaces o referencias web desde
sitios web externos.
link juice
Cantidad de PageRank que fluye desde unos
documentos webs hacia otros debido a los
enlaces que disponen.
listas de remarketing
Listas existentes en Google AdWords que
permiten identificar unívocamente a los
usuarios. Estas listas permiten crear
campañas de publicidad enfocadas en los
usuarios pertenecientes a estas listas.
llamadas a la acción
En el área de marketing online se conoce
como llamada a la acción al uso de un
lenguaje directo que incite al usuario a
realizar alguna acción, generalmente la
realización de clic sobre algún elemento web.
long tail keywords
Palabras clave caracterizadas por ser
específicas en contexto y con un bajo volumen
de búsquedas.
M
macro-‐goals
Conjunto de objetivos que definen la
existencia de un sitio web. Este tipo de
objetivos conectan con los objetivos del
negocio.
MailChimp
Herramienta de e-‐mail marketing.
marketing contextual
Marketing online en el que los anuncios son
automáticamente seleccionados en base al
contexto del sitio web.
marketing de afiliación
Marketing online en el cual un proveedor de
servicios ofrece un porcentaje sobre aquellas
ganancias que son iniciadas por acciones
promovidas por los afiliados.
marketing por comportamiento
Marketing online que permite segmentar
usuarios y realizar campañas publicitarias en
función del comportamiento de los usuarios.
meta etiqueta
Etiquetas HTML situadas en la cabecera del
documento. Proporcionar metadatos a los
navegadores.
meta etiqueta robots
Etiqueta HTML que permite controlar si el
indexador puede rastrear los enlaces del
documento web o escanear el contenido.
micro-‐goals
Conjunto de objetivos que nos permiten
conocer como se está educando al usuario.

298
N
navegación multiscreen
En el área de marketing online, se conoce
como navegación multiscreen a la navegación
que puede realizar un usuario empleando
múltiples dispositivos.
nofollow
Valor que puede adquirir el atributo content
de la meta etiqueta robots para evitar que los
indexadores rastreen enlaces en una página
web.
noindex
Valor que puede adquirir el atributo content
de la meta etiqueta robots como medio para
evitar que el indexador termine indexando el
contenido en el motor de búsqueda.
nombre de dominio
Identificador unívoco que emplean los
documentos web como forma de ser
representados alfanuméricamente.
O
objetivo web
Acciones web concretas empleadas por
analistas web como herramienta para medir
el progreso del sitio web.
objetivos de negocio
Acciones a alcanzar por un negocio que
reportan beneficio.
ontologías
Sistema empleado para representar el
conocimiento de un dominio o ámbito de
conocimiento.
optimizaciones off-‐page
Optimizaciones externas aplicadas a un sitio
web para mejorar el posicionamiento
orgánico de este. Este tipo de optimizaciones
están relacionadas con la adquisición de
enlaces.
optimizaciones on-‐page
Optimizaciones realizadas sobre un
documento web para mejorar el
posicionamiento orgánico de este.
Opt-‐in email
En el área de e-‐mail marketing, se conoce
como opt-‐in e-‐mail a aquellos e-‐mails
promocionales que pueden ser enviados a
usuarios han previamente dado su
consentimiento.
outreach link building
Estrategia de link building consistente en el
envío de e-‐mails informativos (no
automatizados) a sitios web externos. El
objetivo es la promoción del contenido web y
la adquisición de enlaces.
P
Page Layout
Algoritmo empleado por Google para
penalizar páginas con un alto contenido
publicitario, dóde resulta difícil distinguir la
publicidad del contenido.
PageRank
Algoritmo empleado por Google para analizar
la popularidad de un sitio web.
página de recursos
Página que contiene enlaces hacia artículos de
calidad de una temática específico.
paginación web

299
División de un documento web extenso en
múltiples documentos.
Páginas Vista Únicas
Métrica que mide el número total de
documentos web (distintos) visitados por un
usuario durante una sesión.
páginas vistas
Métrica que mide el número total de páginas
vistas por un usuario durante una sesión
palabra clave
Términos introducidos por los usuarios para
realizar búsquedas web.
palabras clave
Conjunto de palabras clave introducidas por
usuarios para iniciar búsquedas web.
Partial Match Domain
Dominios web que contienen palabras de
búsqueda en la raíz del dominio o sub-‐
dominio.
pay-‐per-‐click
Modelo de promoción online por el cual el
anunciante paga únicamente por los clics que
recibe el anuncio.
plataforma de afiliación
Plataforma que permite que los afiliados y
anunciantes contacten entre si. Ofrece
además servicios para medir el resultado de
las campañas.
PMD
Acrónimo de partial match domain.
programa de afiliados
Práctica de marketing online en la que un
proveedor de servicios o productos ofrece un
porcentaje a los afiliados sobre aquellas
ganancias iniciadas por acciones de estos.
protocolo de exclusión
También conocido como protocolo de
exclusión robots, informa a los crawlers
sobre las carpetas y documentos para los
cuales disponen de autorización para
rastrear/escanear.
pujas condicionales
Tipo de puja existente en la plataforma
Google AdWords que permite refinar el precio
de las pujas en base a criterios específicos.
Otorgan mayor control a los anunciantes,
permitiéndoles incrementar o decrementar el
precio de las pujas en base al perfil de los
usuarios.
Q
quality score
Métrica empleada en Google AdWords para
medir la calidad de una campaña publicitaria
en base a las keywords seleccionadas, la
calidad del anuncio y la landing page.
R
ratio de conversión
Porcentaje de visitantes web que realizan
una determinada acción en el sitio web.
redes de afiliación
Sitio web que anunciantes y afiliados
emplean para establecer contacto y colaborar
entre ellos.
redireccionamiento
Método utilizado para informar a los
navegadores sobre la reubicación de recursos
web.
rel = “nofollow”

300
Atributo empleado en enlaces como medio
para informar a Google de que no pase link
juice ni rastree estos enlaces
remarketing
Técnica de marketing online centrada en
alcanzar a usuarios que interactuaron
previamente con nuestro sitio web.
robots
Término sinónimo a crawler. Dependiendo
del contexto puede ser empleado para
denotar: crawler; el protocolo de exclusión
robots.txt; meta etiqueta robots.
robots.txt
Fichero que define el protocolo de exclusión
robots. Define los documentos que pueden
ser rastreados por los crawlers.
RSS
Acrónimo de Really Simple Syndication,
formato XML para sindicar contenidos web.
S
Search Engine Optimization
Conjunto de prácticas dedicadas a optimizar
documentos web, siendo su objetivo el de
mejorar el posicionamiento de estos en los
motores de busqueda.
Search Engine Results Page
Término usado para referenciar la página de
resultados de un buscador.
Search Network
Grupo de buscadores donde pueden
mostrarse anuncios pertenecientes a Google
AdWords.
SEO
Acrónimo de Search Engine Optimization.
SERP
Acrónimo de Search Engine Results Page.
servidor de direcciones
Componente perteneciente a motores de
búsqueda, se encarga de almacenar listas de
direcciones web y servirlas al crawler.
servidores web
Proceso o sistema encargado de recibir, procesar
y responder peticiones web.
Sesión
Conjunto de acciones que tienen lugar desde que
el usuario accede a un sitio web hasta que se
marcha o transcurran más de 30 minutos de
inactividad. En Google Analytics, sesión es
sinónimo de visita.
Sitelinks
Conjunto de enlaces adicional que Google
muestra en la lista de resultados.
sitemap
Protocolo empleado para informar a los
crawlers sobre las direcciones existentes en
un sitio web.
snapshot
Código HTML que se obtiene tras la ejecución
del código JavaScript.
spamming link building
Creación y distribución de enlaces de forma
masiva, sin la realización de méritos propios
para la adquisición de estos
spiders
Sinónimo de crawler.
squeeze pages

301
Documentos web especializados en la
captación de datos del usuario.
T
Target and bid
Opción que encontramos en la plataforma Google
AdWords para filtrar la audiencia que recibe la
campaña, pujando únicamente por aquellos que
reúnan los requisitos establecidos.
template
Elemento HTML que no presenta refresco visual
en sitios web que cargan contenido mediante la
tecnología Ajax.
términos de búsqueda
Conjunto de palabras empleadas por los
usuarios para realizar búsquedas web.
Tiempo en Página
Métrica de Google Analytics que mide el
tiempo que un visitante está en una página
web.
Tiempo medio en el site
Métrica de Google Analytics que mide el
tiempo medio que emplean los usuarios en el
sitio web, contabilizando en los cálculos
aquellas visitas cuyo tiempo en el sitio web es
cero.
Tiempo medio en Página
Métrica de Google Analytics que mide el
tiempo medio empleado por los usuarios en
un documento web, excluyendo visitas con
tiempo cero.
title
Etiqueta situada en la cabecera del documento
HTML, proporciona información concisa a
usuarios y motores de búsqueda.
TLD
Acrónimo de Top-‐Level Domain.
top-‐level domain
Mayor nivel jerárquico alcanzable al que
pertenece un documento.
TrustRank
Algoritmo empleado por Google para
determinar la reputación de un sitio web.
TTFB
Acrónimo de Time-‐To-‐First-‐Byte. Referencia al
tiempo que tarda el navegador en recibir el
primer byte cuando descarga un sitio web.
U
User-‐agent
Directiva empleada en el protocolo de exclusión
de robots, identifica qué crawlers deben
obedecer el protocolo.
V
versión de control
En experimentos de A/B testing se conoce como
versión de control a la versión contra la que se
comparan los resultados. Versión original sin
modificaciones.
versión variante
En experimentos de A/B testing se conoce como
versión variante a la versión sobre la que se
aplican cambios. Versión que sufre
modificaciones.
Visitante Único
Número de visitantes diferentes que realizaron
algún tipo de petición al servidor durante un
periodo de tiempo específico.
Visitantes Recurrentes

302
Visitantes identificados con anterioridad que
inician sesión más de una vez.
volumen de búsquedas
Cantidad de búsquedas realizadas empleando
palabras clave específicas.
volumen de tráfico
Cantidad de usuarios a los que se puede tener
acceso.
W
web spam
Páginas creadas y optimizadas para adquirir
un buen posicionamiento mediante el uso de
técnicas penalizadas por los motores de
búsqueda.
WebCEO
Plataforma online para realizar actividades de
optimización de contenidos y social media.
webmasters
Administrador de un dominio web.
X
XSS
Acrónimo de Cross-‐site scripting. Vulnerabilidad
encontrada en aplicaciones web.
Top Related
Copyright © 2022 FDOKUMEN

