







Bahasa
Halaman
Hukum


1
NSF Annual Report
2009-2010
Submitted to the National Science Foundation

2

3
NSF Annual Progress Report for 2009-2010
As outlined in the terms of grant DMS-0635449, the following is the Annual
Progress Report for the Statistical and Applied Mathematical Sciences Institute
(SAMSI), for the period August 1, 2009 – July 31, 2010. Past activities that
concluded during this period and future activities of SAMSI are also discussed.
0. Executive Summary
A. Outline of Activities and Initiatives for 2009-2010 and the Future ...............................3
B. Financial Overview ........................................................................................................5
C. Directorate‟s Summary of Challenges and Responses ...................................................6
D. Synopsis of Research, Human Resource Development, and Education ........................9
E. Evaluation by the SAMSI Governing Board ................................................................29
Annual Report Table of Contents ......................................................................................34
A. Outline of Activities and Initiatives
1. 2009-2010 Programs and Activities Schedule Space-time Analysis for Environmental Mapping, Epidemiology and Climate
Change
o Summer School (7/28/09-8/1/09)
o Opening Workshop and Tutorials (9/13/09-9/16/09)
o GEOMED 2009 and Spatial Epidemiology (11/14/09-11/17/09)
o Climate Change Workshop (2/17/10-2/19/10)
o Fundamentals of Spatial Modeling Workshop (3/20/10-3/21/10)
o Workshop on Statistical Aspects of Environmental Risk (4/7/10-4/9/10)
o Transition Workshop (10/11/10-10/13/10)
Stochastic Dynamics
o Opening Workshop and Tutorials (8/30/09-9/2/09)
o Workshop on Self-Organization and Multi-Scale Mathematical
Modeling
of Active Biological Systems (10/26/09-10/28/09)
o Workshop on Theory and Qualitative Behavior of Stochastic Dynamics
(2/8/10-2/10/10)
o Workshop on Molecular Motors, Neuron Models, and Epidemic on
Networks (4/15/10-4/17-10)
o Transition Workshop (9/27/10-9/29/10)
Summer Program: Semiparametric Bayesian Inference, with Applications in
Pharmacokinetics and Pharmacodynamics
o Tutorials and Opening Workshop (7/12/10-7/16/10)
o Intensive Research Week (7/19/10-7/23/10)
A Planning Meeting (4/6/10) was held for the Uncertainty Quantification (UQ)
Program for 2011-12. The afternoon session of this meeting was a public meeting
discussing the formation of UQ committees in the ASA and SIAM.

4
Education and Outreach 2-Day Workshop for Undergraduates (10/30/09-10/31/09)
2-Day Workshop for Undergraduates (2/26/10-2/27/10)
Interdisciplinary Workshop for Undergraduates (5/17/10-5/21/10)
The Industrial Mathematical and Statistical Modeling Workshop for Graduate
Students (7/19/10-7/27/10)
Graduate Courses at SAMSI
o Stochastic Dynamics, Fall 2009
o Theory of Continuous Space and Space-Time Processes, Fall 2009
o Spatial Epidemiology, Fall 2009
o Spatial Statistics in Climate, Ecology and Atmospherics, Spring 2010
2. Programs for 2010-2011 Analysis of Object Data
o Opening Workshop & Tutorials (9/12/10 – 9/15/10)
o Interface Functional & Longitudinal Data Analysis (11/8/10 –
11/10/10)
o AOOD Meets Evolutionary Biology (4/30/11 – 5/2/11)
Complex Networks
O Opening Workshops & Tutorials (10/20/10 – 10/22/10)
O Dynamics of Networks (1/10/11 – 1/12/11)
O Pedestrian Traffic Flow (2/14/11 – 2/16/11)
O Dynamics on Networks (3/21/11 – 3/23/11)
Summer Program: SAMSI/Sandia Summer School of Uncertainty Quantification
Education and Outreach 2-Day Workshop for Undergraduates (10/29/10-10/30/10)
2-Day Workshop for Undergraduates (2/25/11-2/26/11)
Graduate Student Probability Workshop (4/29/11 – 5/1/11)
Interdisciplinary Workshop for Undergraduates (5/16/11-5/20/11)
The Industrial Mathematical and Statistical Modeling Workshop for Graduate
Students (7/7/11-7/15/11)
Graduate Courses at SAMSI
o Complex Networks, Fall 2010
o Analysis of Object Data, Fall 2010
o Analysis of Object Data, Spring 2011
3. Programs for 2011-2012 Uncertainty Quantification: Climate Change Workshop
o Opening Workshop & Tutorials (8/29/11 - 8/31/11)
Uncertainty Quantification: Methodology
o Opening Workshop & Tutorials (9/7/11 – 9/10/11)
Uncertainty Quantification: Engineering & Renewable Energy
o Opening Workshop & Tutorials (9/19/11 – 9/21/11)
Uncertainty Quantification: Geosciences Applications
o Opening Workshop & Tutorials (9/21/11 – 9/23/11)

5
B. Financial Overview

6
C. Directorate’s Summary of Challenges and Responses
After eight years of SAMSI, the scientific programs have been of high caliber, and have
led to significant new and ongoing research collaborations between, statistics, applied
mathematics, and disciplinary sciences. There has been significant human resource
development, through the postdoctoral and graduate programs and through involvement
of senior researchers in new interdisciplinary areas. Many students across the country
have been shown the SAMSI vision through educational outreach programs and courses.
We feel that these successes are amply demonstrated throughout the report; some
highlights are given in section D of the Executive Summary. This section discusses the
challenges that arose this year and the Directorate‟s response to these challenges.
Changes in the Directorate: After eight years of sterling service as SAMSI‟s inaugural
Director, Jim Berger stood down from that position in 2010. After a national search took
place to appoint a new Director, Dr. Richard Smith of the University of North Carolina
(UNC) assumed that position from July 1, 2010.
Richard‟s appointment as Director meant that the UNC representative on the Directorate
(previously Michael Minion) moved from the Mathematics department to Statistics and
Operations Research. To maintain the statistics/mathematics balance on the Directorate, it
was logical to seek a new Associate Director from the Mathematics department at Duke.
Dr. Rick Durrett took up this role after moving from Cornell to Duke during the summer
of 2010.
As was reported in last year‟s report, Dr. Pierre Gremaud of NCSU was appointed as the
full-time Deputy Director from January 1, 2010, with half of his salary provided by the
home university (as previously), while the other half is provided from SAMSI NSF
money.
As of Summer 2010, the fourth member of the Directorate continued to be Nell Sedransk,
Associate Director of NISS and also of SAMSI.
The current arrangements mean that at any one time, only three of the eight Triangle
departments that support SAMSI have a representative on the Directorate. To ensure
direct input from all the involved departments, a new Local Department Liaisons
committee was formed including one member from each of the five departments not
directly represented on the Directorate. This committee will meet with the Directorate at
least once a semester and will be actively consulted about how to optimize local faculty
involvement in SAMSI. The initial members of this committee are Drs. Greg Forest
(UNC Math), Stephen George (Duke Biostatistics), Robert L.Wolpert (Duke Statistics),
Donglin Zeng (UNC Biostatistics) and
Helen Hao Zhang (NCSU Statistics).
Because this committee effectively takes over all the functions of the previous Local
Development committee, the latter committee no longer exists.

7
Space: The extension to the NISS/SAMSI building completed in Fall 2008 has greatly
expanded SAMSI‟s capacity to host visitors. The space has been well utilized during
2009-10 with the following numbers of visitors:
Long-term Participants in 2010-11 SAMSI Programs
Postdocs Postdoc Assoc
Graduate Visitor
Graduate Local Visitor
Faculty Fellow
1-2 Month Visitor
New Rschr Totals
Year-Long 8 12 3 12 1 36
Fall 4 16 25 1 46
Spring 1 1 13 11 26
Program Evaluation: Programs at SAMSI are evaluated through questionnaires
distributed at all workshops, and through annual surveys of SAMSI postdocs and
program participants. The information from these surveys is presented in Sections B and
C and in Appendix G.
Communication and Marketing
As part of SAMSI's branding efforts, a MP3 charger that can be used in an automobile
was given out at conferences, and at some of SAMSI's research workshops and Education
and Outreach workshops.
A tri-fold marketing brochure was produced that gives a brief explanation of what
SAMSI is and the programs that are offered. It is used as part of SAMSI's overall
marketing efforts and given to people at who visit SAMSI's exhibit at the math and
statistics conferences.
Posters were designed and distributed for the two main programs and for the Education
and Outreach program. A special poster was designed for the IMSM workshop, which is
jointly sponsored by SAMSI, the NSF, CRSC and NCSU. The posters are distributed to
colleges and universities across the United States.
SAMSI's newsletter was mailed out quarterly to a list of about 460 colleges and
universities. Another 2,643 email contacts receive the email edition of the newsletter as
well using the Bronto e-mail marketing system. Roughly 22 messages were sent using the
Bronto system to communicate with our target market. In addition to the newsletter, these
messages included announcements of upcoming workshops and programs, and any
special announcements the organization wanted to convey.
Two press releases were written and sent to local and national media. The first was about
the hiring of additional postdoctoral fellows and was used as part of a larger effort by all
13 mathematical institutes to publicize the new fellows that were able to be hired thanks
to an increase in funds by the NSF. This release went out on May 11, 2009 and was
picked up by 30 media outlets including dBusinessNews, Carolina Newswire, Business
Leader and others. The other press release publicized the hiring of Gordon Campbell as

8
the Operations Director for SAMSI. This release was distributed on July 13, 2009. This
release was picked up mainly by local media, such as the Durham Herald Sun and the
Duke Chronicle, but also was run in the ISM Bulletin.
SAMSI's efforts in the social media realm were recognized by the North Carolina chapter
of the Public Relations Society of America as the best social media campaign. SAMSI is
using three main areas of social media, which include LinkedIn, Facebook and Twitter to
communicate with its target market. See below for statistics on the reach that SAMSI has
had during the Fiscal 09-10 year.
A "Welcome to SAMSI" brochure was produced to give to new visitors to the area. The
brochure includes information such as area restaurants, places to live, places to shop,
recreation and places to see and a guide for parents. It was given to each new visitor to
SAMSI during the 2009-10 year.
SAMSI Twitter Followers
Date Number of Followers
5/15/09 28
8/2/09 45
10/27/09 406
11/16/09 446
1/5/10 510
08/24/10 578
Facebook Friends
Date Number of Friends Number of Visits that Week
3/25/10 87 53
4/19/10 95 98
7/26/10 123 88
8/30/10 135 68

9
D. Synopsis of Developments in Research, Human Resource
Development, and Education
1. Research
In this report, we cover both of SAMSI‟s full-year research programs for 2009-2010, as
well as the summer programs in both 2009 and 2010. It should be noted, however, that
the detailed statistics presented elsewhere in this report cover only the 2010 summer
program, not that from 2009.
The two main research programs were both highly successful. Stochastic Dynamics was
one of the few SAMSI programs up to this date to feature probability theory as a major
emphasis, though the program also included applied mathematics, statistics and several
fields of application, notably biology. Some major outcomes included new insights into
statistical aspects of multiscale computing methods; a collaboration among a probabilist,
an applied mathematician and a statistician to study “molecular motors”, and ongoing
collaborations on topics in stochastic neuronal dynamics and epidemic spread on
networks. The other program on Space-Time Analysis for Environmental Mapping,
Epidemiology and Climate Change was one of SAMSI‟s largest programs to date, with
no fewer than nine Working Groups resulting in numerous new theoretical and applied
developments in spatial and spatio-temporal statistics, as well as applications in both the
epidemiology and climate sub-themes. One outcome was the first fully Bayesian space-
time analysis for the problem of paleoclimatology – the reconstruction of historical
temperatures from proxies such as tree rings and ice cores. We also report on the
formation of a joint Working Group between the two programs – this first time that two
different SAMSI programs have combined forces in this way and further evidence of
SAMSI‟s goals of developing joint research among statisticians and applied
mathematicians.
In the following sections, we first present brief reports of the two summer programs,
followed by detailed summaries of the two year-long programs.
(a) SUMMER PROGRAM ON PSYCHOMETRIC MODELING AND
STATISTICAL INFERENCE
During the past 25 years, many new statistical methods have been introduced in
psychometrics. Examples include item response theory, structural equation models,
cognitive diagnosis models and generalized linear latent and mixed models. These
developments have been spearheaded by quantitative psychologists, who come primarily
from psychology and education departments. Within the same time frame, very similar
models have been developed by statisticians. The goal of this summer program was to
bring the two communities together to explore possible collaborations.
The progam organizers were Valen Johnson and Richard Swartz (University of Texas
M.D. Anderson Cancer Center), assisted by Jimmy de la Torre (Rutgers), Charles
Cleeland (M.D. Anderson Cancer Center) and David Banks (Duke). There were 71

10
participants, including 36 who were students or new researchers. The first four days of
the program consisted of a series of tutorial and overview lectures. For the second week,
the workshop broke up into three Working Groups.
The first Working Group was on Peer Review. This started with a statistical analysis by
David Banks (who at the time was one of the editors of JASA - the Journal of the
American Statistical Association) of review times and outcomes at JASA, and another by
Valen Johnson of peer review scores in NIH R01 grant proposals. Further discussions
during the week focused on Bayesian approaches to the analysis of rating and ranking
data.
The second Working Group was on Patient Reported Outcome (PRO) data, particularly
concerned with the longitudinal collection and analysis of PROs in clinical research,
regulatory review and disease management.
The third Working Group discussed Cognitive Diagnostic Models. This group identified
three objectives: first to survey the current state of the art; second, to develop a consensus
among the participants about the most promising lines for future research; and third, to
establish collaborative relationships among the participants to pursue these lines of
research.
All three groups met for initial presentations of the background on Monday, followed by
three days of discussions and collaboration, then a draft White Paper completed on
Friday. Each of the three White Papers was subsequently expanded into a full report,
copies of which are included in the final SAMSI Program Report for this program.
(b) SUMMER PROGRAM ON SEMIPARAMETRIC BAYESIAN INFERECE:
APPLICATIONS IN PHARMACOKINETICS AND
PHARMACODYNAMICS
Pharmacokinetics (PK) is the study of the time course of drug concentration resulting
from a particular dosing regimen. PK is often studied in conjunction with
pharmacodynamics (PD). PD explores what the drug does to the body, i.e., the
relationship of drug concentrations and a resulting pharmcological effect.
Pharmacogenetics (PGx) studies the genetic variation that determines differing response
to drugs. Understanding the PK, PD and PGx of a drug is important for evaluating
efficacy and determining how best to use such agents clinically.
Hierarchical models have allowed great progress in statistical inference in many
application areas. Hierarchical models for PK and PD data that allow borrowing of
strength across a patient population are known as population PK/PD models. These
models have allowed investigators to learn about important sources of variation in drug
absorption, disposition, metabolism, and excretion, allowing the researchers to begin to
tailor drug therapy to individuals. Newer Bayesian non-parametric population models and
semi-parametric models offer the promise of individualizing therapy and discovering
subgroups among patients even further, by freeing modelers from restrictive assumptions
about underlying distributions of key parameters across the population. The purpose of

11
this program is to bring together a mix of experts in PK and PD modeling, non-
parametric Bayesian inference, and computation.
This program was jointly organized by Gary Rosner and Peter Mueller (M.D. Anderson
Cancer Center). The first week of the program (July 12-16, 2010) consisted of a
workshop featuring one day of tutorials followed by four days of intensive research
discussions; the second week (July 19-23), participants split into five Working Groups
for intensive research discussions. The topics of the Working Groups were:
1. Model Fit and Comparison;
2. Joint PK and PD Modeling;
3. Nonparametric bayes and Clustering for Population PK and PD;
4. PK and PD Simulation for Design and Dose Individualization;
5. Pharmacogenomics and Networks.
Each of the Working Groups met several times during the week and had lively and
intensive discussions. Several groups formulated plans for continued research activities in
the future.
(c) FULL-YEAR PROGRAM ON STOCHASTIC DYNAMICS
The SAMSI program on Stochastic Dynamics brought together researchers from many
different fields of mathematics, such as probability theory, statistics, numerical analysis
and mathematical modeling, to study the mathematical analysis, computation and
applications of systems governed by stochastic differential equations. Applications of
stochastic dynamics are widespread, some examples being mathematical biology
studying transport on a cellular level, understanding stochastic forcing in dynamical
systems, the statistics of dynamic networks, and the relationship between atomistic and
continuum physics. However, these areas of research are too often treated as distinct
topics, not enough being done to disseminate research in one of those areas across the
spectrum of research in applied mathematics and statistics. The SAMSI program served
to bring together experts in different but highly inter-related research specializations
under the broader umbrella of stochastic dynamics in the hopes of creating collaborations
which could potentially lead to exciting advances in particular research areas.
Particular successes of the program include:
The establishment of a new collaboration, including two major grant proposals
submitted to date, involving a probabilist (Scott McKinley), an applied
mathematician (Peter Kramer), and a statistician (John Fricks) to develop a
systematic stochastic modeling framework for intracellular transport connecting
three important physical length scales.
A sustained research effort across SAMSI programs, with applied mathematicians
from the working group on Numerical Methods for Stochastic Systems (Peter
Kramer and Sorin Mitran) joining with statisticians from the program on Space-
Time Analysis for Environmental Mapping, Epidemiology, and Climate Change

12
program (Jim Berger, Susie Bayarri, Murali Haran, Emily Kang, Hans Kuensch)
to explore how statistical aspects of multiscale computing methods could be
enhanced.
Two research programs toward new modeling approaches in microswimming
(Peter Kramer) and swarming (Amarjit Budhiraja, Oliver Diaz and Xin Liu) that
were nucleated by presentations at the workshop on Self-Organization and Multi-
Scale Mathematical Modeling of Active Biological Systems in October, 2009.
Several ongoing collaborations between SAMSI postdocs on topics in stochastic
neuronal dynamics and epidemic spread on networks.
A project initiated and driven by two graduate students (Katherine Newhall and
Amanda Traud) participating in the working group on Network Dynamics, now
being prepared for submission for publication.
Two workshops in the spring which were designed to resonate with the specific
interests of the working groups, stimulating new ideas and helping to lead to
several submitted publications.
The Opening Workshop took place from August 30-September 2, 2009, and featured
tutorials from Peter Baxendale (University of Southern California), Mark Alber
(University of Notre Dame), Grant Lythe (Leeds University) and Andrew Stuart
(Warwick University). This was followed by five half-day research sessions, a poster
session and two “five-minute madness” sessions, and the formation of working groups.
Other workshops included one on Self-Organization and Multi-Scale Mathematical
Modeling of Active Biological Systems (October 26-28, 2009), one on Theory and
Qualitative Behavior of Stochastic Dynamics (February 8-10, 2010) and one on
Stochastic Dynamics: Molecular Motors, Neuron Models, and Epidemics on Networks
(April 15-17, 2010), as well as a transition workshop that took place at SAMSI
(November 17-19, 2010).
Working Group 1 was led by Jonathan Mattingly (Duke) and studied Qualitative
Behavior of Stochastic Dynamics. The objective of the group was to study a number of
topics in the qualitative description of stochastic dynamics. One example was some work
on planar dynamical system by Avanti Athreya, Tiffany Kolba, and Jonathan Mattingly.
They studied two specific systems of differential equations for which, without noise, the
equation has regions of instability, but with noise, it appears to stabilize. Another
example of this group‟s work was by Kevin Lin and Jonathan Mattingly, who were
concerned with simulation methods for estimating the sensitivity of solution of SDEs to
input parameters. Specifically, they came up with a new method of coupling, where the
basic idea is to construct two correlated realizations of the SDE for nearby parameters in
a way that ensures the two solutions remain near each other most of the time. By
constructing the simulations in this way, estimates of the sensitivity, that depend on the
differences between two realizations, have much smaller variance. The current focus of
the project is the numerical analysis of these methods. As a third example, Peter H.
Baxendale and Priscilla E. Greenwood have submitted a paper to the Journal of
Mathematical Biology that tries to explain why stochastic models for biological systems
often exhibit sustained oscillations at an amplitude well above the expected noise level.
Baxendale and Greenwood showed that in a general limiting sense the stochastic path

13
describes a circular motion modulated by a slowly varying Ornstein-Uhlenbeck process,
and gave numerical examples for several well-known models.
Working Group 2 was on Numerical Methods for Stochastic Systems, led by Alina
Chertock and Sorin Mitran. This group discussed a number of multi-scale numerical
methods that mix stochastic models at small scales with deterministic models at larger
scales. Particular issues included the incorporation of adaptive time stepping and the
initialization of microscale simulations consistent with the macroscale constraints. In
response to these challenges, Sorin Mitran proposed a novel time-parallel continuum-
kinetic-molecular (tpCKM) simulation scheme, which is designed to handle multiscale
systems where the microscale statistics do not relax quickly relative to the macroscopic
time scale. A third, mesoscopic, level of description was added and updated by an
adaptive predictor-corrector approach through communication with both the macroscale
and microscale simulations. Mitran and his graduate student Jennifer Young had
separately been studying polymeric and cellular blebbing with this method, while the
working group examined a one-dimensional string model where bonds could form and
break on the microscale with rates dependent on the local stress.
This Working Group also collaborated with Working Group 3 of the Space-Time
Analysis program (described in more detail under that program), which developed a
focused interest in multiscale computing. The collaboration looked at ways to improve
the statistical aspect of the communication between the mesoscale and microscale
dynamics in the tpCKM method. Statistical issues in multiscale computing appear not to
have been much pursued until now, but the close interaction of applied mathematicians
and statisticians at SAMSI has identified new areas of research along this direction.
Working Group 3 was on Data Assimilation, led by Cindy Greenwood, John Harlim and
Peter Kramer. Data Assimilation involves the incorporation of observational data into
mathematical models and is an area of high interaction between applied mathematicians
and statisticians. This working group was motivated by two specific examples, one
motivated by single neuron experiments where the input consists of an electrical current
and the output consists of voltage measurements across the neuron membrane, the other
by experimental ecologies consisting of micro-organisms observed in a laboratory
chemostat, where variables such a temperature and the supply of nutrients can be
controlled by the experimenter and are the inputs to the system. In both cases, the
problem is formulated as one of experiment design, i.e. how to vary the inputs so as to
achieve maximum information about unknown parameters of the system. The paradigm
that this group used to investigate such questions was optimal control theory. However,
there are some complications to the use of control theory in this context. The optimal
control is typically infinite, requiring some restriction on the range of admissible controls
or a penalty function. Another difficulty is that the Fisher information about unknown
parameters is very difficult to calculate and requires some approximation, such as the
information that would be obtained if the state of the system were exactly observable at
all time. Thus, the overall strategy is to simplify the problem to one that can be solved by
optimal control techniques.
Several papers are in preparation based on the work of this group. One approach uses an
implementation of particle filters for a nonlinear system. Another paper uses a linear

14
model but includes an analysis of the accuracy of the assumed approximations. A third
prospective paper involves a graduate student at Cornell University who is working on
deriving the optimal control in a discrete-state Hidden Markov model with application to
polymerese chain reactions.
Working Group 4 on Network Dynamics was led by Pierre Gremaud, Peter Kramer and
Peter Mucha. This group was concerned with understanding the way in which structural
properties of connections in a network of stochastic processes affect the behavior of the
network itself. The work was focused around three sub-themes.
Contagion Dynamics on Social Networks: This concerned the study of diseases and social
contagion on networks. One topic studied by John McSweeney and Bruce Rogers
concerned the spread of a disease through a population consisting of two communities,
where the probability of contact between two individuals of the same community is much
higher than the probability of contact between two individuals in opposite communities.
They showed a typical “stair step” solution, whereby the epidemic reaches equilibrium in
one community before spreading to the other. Work on this problem has continued into
the 2010-11 Complex Networks program; a paper is in preparation. Another topic studied
by Cindy Greenwood and Xeuying Wang concerned pairwise closure approximations for
two types of epidemic model. One example they studied let to a limiting process
exhibiting stochastic oscillations in the form of an Ornstein-Uhlenbeck process composed
with a time-dependent rotation; this led to a paper and a presentation at the Transition
Workshop.
Neuronal Network Dynamics: the focus of this subgroup was understanding how the
collective behavior of a network of neurons is influenced by neuronal-level dynamics and
the topology of the network. One focus was on the extension of kinetic theory to account
for the spatial distribution of the neurons. Another development was initiated by graduate
students Katie Newhall and Mandi Traud, with input from their advisors Kramer and
Mucha, concerning the relationship between statistical properties of neuron cascades and
the underlying network of interconnectivity. The work led to two presentations and a
paper being written up for the journal Chaos.
Institute-Participation Data in Mathematics: This subgroup was concerned with
understanding the social network of participants in NSF mathematical sciences institutes.
The group made some advances in understanding statistical methodologies and software,
but there was no immediate access to relevant data.
Working Group 5 on Biological Stochastic Dynamics was led by Amarjit Budhiraja,
Cindy Greenwood and Peter Kramer. The work of this group was motivated by the
explosion of interest in mathematical modeling in biological sciences, where stochasticity
is present at every scale.
The most successful outcome of this group was on the modeling and analysis of systems
of molecular motors bound to a single cargo. The central question concerns how the
details of the stochastic model characterizing individual molecular motors, including their
response to applied forces and proclivity to bind or unbind from the microtubule track, is
reflected in the effective dynamics of the complex of the cargo bound to multiple
molecular motors. The group's work was focused on constructing a physically consistent

15
spatial model, and applying stochastic averaging techniques to derive effective equations
for the motor-cargo complex from physically and biologically based stochastic dynamical
equations for the individual components. Avanti Athreya, John Fricks, Peter Kramer, and
Scott McKinley are currently writing up their work for publication under the title
“Cooperative dynamics of kinesin and dynein type molecular motors”. They plan to
continue their collaboration, which has led to two major grants submitted to the National
Science Foundation's Focused Research Group (FRG) program and the Joint
DMS/NIGMS Initiative to Support Research in the Area of Mathematical Biology. These
grant proposals extend the work of the SAMSI group to a mathematically integrated
stochastic model for cellular transport across multiple spatial scales.
Several other subgroups worked on Stochastic Single Neuron Models. One project by
Cindy Greenwood together with short-term visitor Laura Sacerdote and collaborator
Maria Teresa Giraudo led to the paper “How sample paths of Leaky Integrate and Fire
models are influenced by the presence of a firing threshold”, submitted to Neural
Computation. In another project, Avanti Athreya, Badal Joshi, and Xueying Wang
considered coherence and self-induced stochastic resonance in Morris-Lecar models for
neurons. The group extended previous work of Rowat into regimes where the
deterministic model has only a stable fixed point but no stable limit cycles. Part of the
work concerned the study and classification of behaviors in small networks of two or
three neurons, with the idea that qualitative understanding of such small networks could
lead to insights in larger, more biologically realistic, network sizes. A number of specific
questions were studied by simulation and are leading to more detailed analytic work.
Another subgroup studied microswimming, which is concerned with the dynamics of
tracer particles in a flow generated by a suspension of swimming microorganisms. The
work of this subgroup did not immediately lead to results, but has subsequently been
taken up Peter Kramer at his home institution together with a collaborator and a graduate
student.
(d) FULL-YEAR PROGRAM ON SPACE-TIME ANALYSIS FOR
ENVIRONMENTAL MAPPING, EPIDEMIOLOGY AND CLIMATE CHANGE
The program on Space-Time Analysis was extremely lively and resulted in many
research advances. The Opening Workshop was one of the best-attended workshops in
the history of SAMSI, and was followed by four others as well as a Transition Workshop.
Two of the mid-program workshops took place away from SAMSI itself – the one on
spatial epidemiology was held in conjunctions with the GEOMED conference, and hosted
by them at the Medical University of South Carolina. The was also a one-day workshop
on Objective Bayesian Analysis for Spatial-Temporal Models held in San Antonio,
Texas. SAMSI also played host to a joint workshop on environmental risk analysis, held
in conjunction with the European environmental statistics group SPRUCE. The fourth
mid-program workshop was on climate change and included a number of visiting climate
scientists as well as statisticians and applied mathematicians.
Educational activities hosted by this program included a pre-program summer school on
spatial statistics, featuring four visiting speakers who gave hands-on demonstrations of
software as well as lectures on the underlying theory. There were three regular graduate

16
student courses, and the program also contributed to SAMSI‟s undergraduate workshop
program.
The main bulk of the research activity was spread over nine working groups, covering
every aspect of space-time statistics, from the very theoretical (e.g. WG6, which included
comparisons of inference approaches), through to more applied and computational topics
(WG4 on computation and visualization; WG7 on geostatistics), to other forms of
stochastic models (WG8 on point processes, WG9 on nonstationary and non-Gaussian
processes) and three working groups on applications (WG1 on paleoclimate, WG2 on
spatial health effects and WG5 on spatial extremes, which although covering some
theoretical themes was mostly motivated by the combined application of spatial statistics
and extreme value theory to climatological datasets). The remaining working group,
WG3, was a joint working group between this program and the program on Stochastic
Dynamics.
The remainder of the present description outlines the main achievements of each of the
nine working groups.
Working Group 1 was concerned with Paleoclimate: the science of reconstructing past
temperatures based on proxy records such as tree rings, lake sediments and ice cores. The
modern instrumental records of weather date from about 1850. Proxies such as the ones
just mentioned allow us to extend the record of reconstructed temperature back by about
1000 years. These reconstructions have drawn particular attention because of the apparent
“hockey stick” shape that so many of them show: a steady or even slightly declining
record of temperatures for about 900 years prior to the twentieth century, then a sharp
increase in temperatures during the twentieth century. This is often interpreted as
evidence that the recent increases are human caused. However, there is no universal
agreement about the best statistical method for making these reconstructions, or indeed
the hockey stick shape, and all those that appear in the climate literature are limited when
it comes to giving realistic uncertainty estimates.
This Working Group went beyond previous reconstructions by considering the spatial as
well as temporal aspects of the data, in effect treating it as one of reconstructing the full
space-time field; and then using Bayesian Hierarchical Models (BHMs) to perform the
inference. Although BHMs have been used previously for paleoclimatic reconstructions,
they are still not a well-known technique among paleoclimatologists but this group
effectively demonstrated the power of this methodology.
The main activity was led by a group of six core members led by Stanford visitor (and
former SAMSI postdoc) Bala Rajaratnam and current SAMSI (later NCAR) postdoc
Martin Tingley, that led to a substantial paper submitted to Journal of Climate. The group
has continued working together since the SAMSI program ended, including helping to
organize a workshop at the National Center for Atmospheric Research (NCAR) in March
2011. Among the follow-up work is a forthcoming paper on the reconstruction of
temperature extremes (see also WG5, below).
Working Group 2 (Spatial Exposures and Health Effects) was the main group to take up
the “epidemiology” component of the program‟s title, though some other working group

17
activities (notably in WG7 and WG8) were also motivated by spatial disease mapping
problems. Much of modern epidemiology is concerned with studying how some adverse
health effect (such as mortality, hospitalization, asthma attacks) depends on air pollution,
ozone and particulate matter being the most common air pollutants studied. In recent
years, both more refined data collection techniques (e.g., geographical information
systems for mapping pollution fields, geocoding of addresses to associate individuals
with specific latitude-longitude coordinates) and more refined techniques for spatial
statistics have greatly expanded the possibilities for studying spatial associations in
epidemiology, which are potentially much more informative than either time series or
cohort studies. However, these methods create problems of their own, for example,
characterizing exposure measurement error has become a major topic of research.
This Working Group included researchers from all three local universities as well as one
senior outside visitor (Kate Calder from Ohio State) and several postdocs, graduate
students and researchers from the Environmental Protection Agency. Within this group,
six separate projects were identified covering various aspects of the spatial exposure
problem and also different health effects. For example, two of the projects were
concerned with the effect of air pollution on preterm birth. One particularly novel
application was the projection of future deaths in the southeast US taking into account
the effects of climate change, not only the direct effects on weather but also projected
increases in ozone that might arise as a side-effect of warmer temperatures, this neatly
tying together the “climate change” and “epidemiology” components of the program‟s
title.
One outcome of Working Group 2 was a jointly authored NIH proposal by five of the
participants, extending the climate change work just mentioned to propose a fully spatial-
temporal model for linking climate change, air pollution and human health outcomes.
Working Group 3 was on Interaction of Deterministic and Stochastic Models. This was
unusual in being a joint working group of the two SAMSI programs running in parallel,
Space-Time Analysis and Stochastic Dynamics. The goal was to work on statistical
issues in complex deterministic and stochastic models.
The goal of this group was to work on statistical issues in complex deterministic and
stochastic models. Particular themes included developing approximations, emulation and
calibration for complex computer models, and extending the “usual” statistics of spatial
modeling (accounting for dependence) to capture spatial dynamic processes that are of
scientific interest.
One subgroup that made particular progress looked at the use of multiscale simulation
and computational methods to study multiscale dynamical systems or heterogeneous
multiscale methods (HMMs). HMMs are used for simulating physical processes that have
both “macroscale” and “microscale” dynamics. This has become an active research area
in applied mathematics and scientific computing in the past decade and has lots of
important scientific applications, for example modeling complex fluid dynamics and
climate systems. This appears to be a rich and still unexplored area of research for
statisticians. Hence, a significant outcome of this Working Group's activities is the fact
that they opened up possibilities for a new and potential fruitful line of research. Specific
outcomes included a paper by SAMSI postdoc Emily Kang (whose training was in

18
statistics) and applied mathematician John Harlim on “A Fast Filtering Framework for
Assimilating Partially Observed Multiscale Systems”; plus several papers on simulation
and emulations in computer models, including applications to hydrology and climate
science.
Working Group 4 was on Computation, Visualization, and Dimension Reduction. This
was a very large Working Group that was formed to consider the computational and
visualization aspects of fitting complicated models to spatio-temporal data. Eventually
the group split into several subgroups. Brian Smith and Kate Cowles from the University
of Iowa worked on a R package “magma” (now publicly available) that enables parallel
matrix computations to be carried out on graphical processing units. Other subgroups
worked on specific scientific problems. For example, a group of seven participants led by
Noel Cressie (Ohio State) submitted a paper on “Dynamical random-set modeling of
concentrated precipitation in North America”, which used data from the North American
Regional Climate Change Assessment Project (NARCCAP), which is run out of NCAR,
viewing the set of locations where the precipitation exceeds a given threshold as a
random set. They then proposed a dynamical model for the temporal evolution of that
random set. The relevance of this work to climate change research is that the proposed
models can be used to project precipitation changes at smaller spatial scales than typical
global climate models; this is important because many of the potential impacts of climate
change involve intense precipitation and flooding at small spatial scales, and stochastic
models are needed to make meaningful statement about such events. Another subgroup
led by Bruno Sansό also used NARCCAP data to develop probabilistic projections of
future regional climate change by “blending” the projections from different climate
models; this paper has been submitted for publication and was also presented at a
NARCCAP users meeting in Boulder.
Working Group 5 was on Spatial Extremes. In recent years, extreme value theory –
widely used to study the statistical distribution of extremes in univariate time series – has
been extended first to the multivariate setting and then to spatial processes. One concept
that has been particularly widely studied is max-stable processes – a class of stochastic
processes that has the property of remaining invariant under the operation of forming
pointwise maxima, modulo location and scale transformations. However, statistical
inference for max-stable processes has until recently been considered problematic,
because of the nonavailability of a direct formula for the likelihood. Instead, recent
research has been concerned with a composite likelihood approach that requires only the
computation of pairwise joint densities. The resulting maximum composite likelihood
estimator (MCLE) has been proved asymptotically normal with a covariance matrix
defined by the well-known information sandwich formula; however, little is known about
its efficiency. This posed a number of problems for this Working Group, including the
development of a threshold-exceedances approach for estimating max-stable processes,
and Bayesian variants on the MCLE approach. From an applications point of view, most
of the motivation comes from the need to characterize the spatial distribution of extreme
meteorological events; two specific applications were the extension of paleoclimate
methods (see report of Working Group 1) to extreme events, and the recently developed
theory of “single-event attribution”, which is concerned with assessing the relative
probabilities of observed extreme events under either anthropogenic or natural causes.
Such calculations underlie statements about the extent to which extreme events such as

19
Hurricane Katrina or the 2010 Russian heatwave can be said to be “due to” human-
induced climate change.
This group benefitted from close interactions with the spatial extremes research group at
EPFL (Lausanne, Switzerland); two researchers from EPFL visited the group and others
participated in the weekly webex meetings. Outcomes included a new approach to
threshold-based estimation of max-stable process, and two contributions to Bayesian
estimation. Ben Shaby used Bayesian versions of the information sandwich approach to
develop valid inferences based on the composite likelihood, while graduate student Rob
Erhardt proposed an implementation of “Approximate Bayesian Computing” which, at
the cost of greatly increased computation time, avoids the problem of computing a
likelihood altogether. In simulations, he has succeeded in showing that the ABC method
improves on the composite likelihood method which, if the result is sustained in future
research, could lead to the ABC approach eventually displacing the composite likelihood
approach as the preferred method for fitting these models. A paper on this topic has been
submitted to Biometrika.
Working Group 6 was on Fundamentals of Spatial Modeling, led by Dongchu Sun of
the University of Missouri. This was the most theoretical of the working groups in this
program, concerned with fundamental inference issues. One subgroup was entitled
“Important issues in spatial and temporal models”, and was particularly concerned with
the relationship between traditional geostatistical models, that can be used equally well
with gridded or non-gridded data, and models of the “CAR” type, that require gridded
data. As one example of a new approach, Paul Speckman of the University of Missouri
has developed a theory of “Irregular Second Order Gaussian Markov Random Fields”.
Gaussian Markov random fields are standard for analysis of areal data or data on a grid.
The common models for areal data (e.g., CAR models) are first order. However, it is
possible to construct higher order priors for gridded data. A general method is proposed
for constructing second order priors for general point-referenced data. The priors
approximate Gaussian processes arising as solutions to stochastic differential or partial
differential equations. They can have higher order smoothness properties; they are
constructed to have sparse precision matrices. The new class of priors generalize higher
order Gaussian Markov random fields to arbitrary (gridded or not) data. The method has
been illustrated with an application to a rainfall data set.
A second subgroup worked on “Effects of spatial confounding”. This was motivated by
the fact that in spatial datasets there may well exist (measured or unmeasured)
confounding variables that also vary spatially; in this situation, it is hard to distinguish
the effect of the covariate from the effect of spatial dependence. This subgroup looked at
the effect of spatial confounding on covariate estimation.
A third subgroup was concerned with “Objective Bayesian and Fiducial Inference for
Spatial and Temporal Models”. This topic covers methods for determining prior
distributions in a Bayesian approach to have desirable frequentist properties. Another
approach is that of Generalized Fiducial Inference, that has been significantly extended in
recent years by Jan Hannig of UNC. A one-day workshop in San Antonio, TX, presented
recent results in both of these fields.

20
Working Group 7 on Geostatistics, led by Sudipto Banerjee of the University of
Minnesota, was another very large Working Group that split up into several subgroups.
One subgroup was on preferential sampling. This refers to situations where the selection
of sampling sites is not random but could be correlated with the outcome of interest in a
way that could possibly bias the results, e.g. when monitors are intentionally placed in
“hot spot” areas where pollution is expected to be high. The group planned to explore
underlying theoretical connections between preferential sampling and models for missing
data as well as the connections between spatial sampling designs and preferential
sampling. More generally, the group sought to understand the nature of preferential
sampling, modeling issues related to preferential sampling and the effect of preferential
sampling upon model performance and inference. Group member Jim Zidek has
continued the work of this subgroup since the end of the SAMSI program, and plans to
submit four research paper describing various theoretical and applied aspects of the topic.
Another subgroup worked on estimation techniques, in particular, devising efficient
inference and precision methods when the size of the dataset is too large to allow exact
implementation of the O(n3) matrix factorizations that are at the heart of tradition spatial
methods. One approach that the group explored was to combine effective modeling
aspects and inference methods. For instance, predictive process models provide
dimension-reduction while at the same time being amenable to approximate Bayesian
inference using Integrated Nested Laplace Approximation (INLA). Since the predictive
process models introduce no additional parameters over the regular (full) model
formulation, it is relatively straightforward to apply INLA. The speed-up compared with
MCMC is large. A technical report on this work has been produced by Eidsvik, FInley,
Banerjee and Rue.
Another project by this subgroup was parallel computing in the context of geostatistical
models. The group focused on composite likelihood models, where the structure is such
that parallelization is immediate. The variance of the estimate can be computed from the
Godambe sandwich estimate. Similar ideas, using composite likelihood models and the
sandwich estimate for variance, hold for prediction at unobserved sites too. A paper on
this work has been submitted by Eidsvik, Shaby and Reich.
Another subgroup of the Geostatistics working group focused on numerical model
evaluation. This was primarily concerned with developing Bayesian spatial methods for
calibrating deterministic forecasts to produce probabilistic forecasts. The work split in
two directions: spatial quantile regression and Bayesian spatial model averaging.
Numerical weather forecasts are often calibrated by adjusting the mean, and perhaps the
variance, of the predictive distribution. For non-Gaussian data such as precipitation, this
can lead to underestimation of extremes. To calibrate the entire conditional distribution
of precipitation given a forecast, the group proposed Bayesian spatial quantile regression.
The group also explored statistical methods to calibrate the spatial output generated by an
ensemble of numerical models. They extended previous work using Bayesian model
averaging (BMA) to produce probabilistic weather forecasts. The group produced a
productive and hopefully long-lasting collaboration between Ingelin Steinsland, Veronica
Berrocal, and Brian Reich. The group has so far submitted two papers for publication.

21
Working Group 8, on Point Patterns, was led by Alan Gelfand of Duke, with
substantive input from several SAMSI visitors. This group coalesced around three
primary research goals. The first (which yielded the “Mixture” subgroup) focused on
novel ways of introducing covariate information into modeling intensities. Special
settings here included mixture models for intensities, both parametric and Bayesian
nonparametric as well as generalized Neyman-Scott processes with covariate
information at parent level to drive locations and spreads for offspring.
The second goal (which yielded the “Practical” subgroup) was to bring to a more applied
level, spatial point processes with first and second order components (first order is a
usual nonhomogeneous Poisson process form λ(s), second order is a pairwise interaction
form γ(s,s'), inhibition, attraction). Issues here again included the introduction of
covariate information into such settings with interest in a fully model-based
implementation with associated technical questions such as integrability for the resulting
intensity. The third goal (which yielded the “Model diagnostics” subgroup) considered
an under-explored problem for point patterns, the question of model adequacy and model
comparison. For instance, how do we compare two nonhomogeneous point processes?
How do we compare a nonhomogeneous Poisson process with a pairwise interaction
process? What happens if we add dynamics, resulting in space time point processes?
Working Group 9, on Non-stationary and Non-Gaussian Processes, was led by David
Dunson (Duke), Jo Eidsvik (NTNU) and Montse Fuentes (NCSU), with considerable
input from visitors to SAMSI. The objective of the group was to explore non-stationarity
and non-Gaussianity for spatial and spatiotemporal models.
The main work here was split into three subgroups. The spectral domain subgroup was
based on using spectral methods to define new classes of covariance function. The group
proposed new models for nonstationarity by having a spectrum that is space-dependent.
More specifically, the group proposed a nonparametric estimate of the spectral density by
first defining a spatial periodogram estimate for each frequency, and then smoothing over
neighboring frequencies. The current methodology requires gridded data, but it could be
also extended to irregularly spaced data, by using a filtered spline representation across
space. This is work in progress. Open questions include asymptotic properties of the
estimators using fixed domain asymptotics, and extension to space-time processes.
A second subgroup worked on mixture models. This group built on much work from
Dirichlet processes, stick breaking processes, and other non-parametric models that have
become popular because of large flexibility and computational tractability. Dirichlet
mixture models are nonGaussian and nonstationary, but without replicates it is difficult to
determine if we have lack of stationarity or lack of normality. However, the Dirichlet
process (DP)-type of mixture models would allow for both. Mixture models are flexible
enough to characterize complex tail behavior, and can be used to model extremes through
a DP copula.
A third subgroup looked at non-stationarity models constructed by adding covariates in
the covariance function. Typically, the covariance structure is regarded as a nuisance that
we do not learn about, except specifying the scale and correlation range in some way.
The mean term, on the other hand, is constructed by sophisticated modeling from

22
available covariates. For prediction purposes, the covariates are important only through
the predictor, not the prediction variability. However, one can envision better prediction
and more useful prediction distributions by letting the covariance also depend on
covariates. One project that has been studied in the sub-group uses a mixture of Gaussian
processes with different scale and range, but weighted by covariates. The sub-group has
submitted a paper on this topic (Reich, Eidsvik, Guindani, Nail and Schmidt, 2010, A
class of covariate-dependent spatiotemporal covariance functions), applying the resulting
model to daily ozone levels in the South-Eastern US. It is currently under revision.
2. Human Resource Development
SAMSI‟s impact on human resource development is fully discussed in Sections I.B and
I.C, with impact on diversity highlighted in Section I.H. The individual program reports
also contain significant insight into human resource development.
SAMSI‟s postdoctoral fellows and associates again in 2009-10 have embraced the
interdisciplinary tenor of SAMSI programs and have engaged with visible enthusiasm in
the activities for graduate and undergraduate students. Most of those completing their
SAMSI fellowships are explicitly committed to continuation of interdisciplinary
collaborative research and/or interdisciplinary research with SAMSI collaborators.
The impact of new technology for remote participation in SAMSI working groups
continues to be steady; essentially every working group is actively using remote access to
working group meetings to include participants located outside the Triangle area, many
located outside the US. In some cases, even the working group leaders are remote.
An unexpected secondary success of incorporation of remote participants is the extension
of the lifetime of the working group. Numerous working groups from previous SAMSI
programs still operate, utilizing the SAMSI technology, even though none are actually
present at SAMSI.
The detailed participant lists for concluded programs provide ample evidence of the
national and international draw of SAMSI activities. SAMSI programs attracted 50
research fellows (visitors from outside the Triangle who played a major role in program
activities) plus 3 new researcher fellows, 12 local faculty fellows, 16 postdoctoral fellows
and 11 graduate fellows. The research workshops associated with the major programs
attracted a total of 540 participants; the undergraduate education and outreach workshops
a total of 130; the graduate probability workshop had 134 participants; the IMSM
graduate research workshop had 51; the planning workshop for Uncertainty
Quantification had 54, and the summer (2010) program in PKPD had 62 participants.
Altogether, this makes over 1,000 individuals who participated in SAMSI in some form
during the year.
Diversity: SAMSI puts considerable emphasis on contributing to the NSF‟s effort to
broaden the participation from underrepresented groups in the mathematical sciences.
During the past year, we have organized and co-sponsored many diversity related
activities. SAMSI has also developed a web page devoted to our diversity activities. The

23
page advertises the various program activities related to minority outreach and has links
to other diversity related information outside of SAMSI.
Pierre Gremaud has been serving as SAMSI‟s representative to the NSF Institutes
Diversity Coordination Committee which was formed in 2006 by Chris Jones (SAMSI)
and Helen Moore (formerly of AIM), and is now chaired by David Auckly (MSRI). The
Institutes Diversity Coordination Committee has been working together to promote
diversity in the Mathematical Sciences at national conferences and through other special
events.
Together with the other NSF mathematical sciences institutes, SAMSI has recently
secured supplemental NSF funding that will allow for the long term planning of an entire
portfolio of activities including the Modern Math workshop series, the Workshop
Celebrating Diversity series, the Minority Professional Development workshop, the
Careers for Minorities workshops, the Careers for Women workshops, the Blackwell
Tapia Conferences and some activities in conjunction with the Association for Women in
Mathematics. SAMSI took part in the Modern Math program at the 2009 SACNAS
National Convention in Dallas, TX, which included a presentation by one of the SAMSI
postdoctoral fellows.
Minority Participation in SAMSI Programs
At the postdoc level, out of 15 appointments associated with the 2009-10 Research
Programs, five were women and one was an underrepresented minority. For the 2010-11
Research programs, of seven postdocs hired, two are women and two are minorities. The
large number of postdocs hired in 2009-10 resulted from the supplemental NSF funding
for that purpose made available to the institutes that year.
SAMSI creates additional possibilities for under-represented groups through its education
and outreach activities. Of the four Education and Outreach workshops in 2009-10 (3
undergraduate, 1 graduate), there were 147 total participants, of whom 59 (40%) were
female and 11 (7%) were members of underrepresented minorities.
Overall Participations in Workshops by Underrepresented groups
The following chart shows an overall summary of the participation by underrepresented
groups at SAMSI events. The large spike in female and African-American participants in
2007-08 was partly due to the Infinite Possibilities conference, which focused specifically
on African-American women.

24
Workshop Evaluations: Detailed evaluations of workshops are given in Appendix F.
Here are the summary graphs indicating the satisfaction of participants.
0%
10%
20%
30%
40%
50%
60%
70%
% Female
% African-American
% Hispanic
% New Researcher-Students
0%
15%
30%
45%
60%
2002-032003-042004-052005-062006-072007-082008-092009-10
Perc
en
t o
f R
esp
on
ses
Year
Summary of Science at SAMSI Workshops (2002-April 2010)
Poor
Fair
Good
Very Good
Excellent

25
0%
10%
20%
30%
40%
50%
60%
70%
80%
90%
100%
Science Staff Facility Lodging Transport
Excellent
Very Good
Good
Fair
Poor
Workshop Evaluations Summary 2009-2010
0%
10%
20%
30%
40%
50%
60%
70%
80%
Science Staff Facility Lodging Transport
Poor
Fair
Good
Very Good
Excellent
Undergraduate Programs Evaluations Summary 2009-2010

26
It is SAMSI‟s policy always to attract and support the leading scientists, regardless of
nationality; but to otherwise focus resources on domestic participants. The table below
shows the nationality status of the participants who received some funding from SAMSI.
Year US Citizen or Permanent Resident
Foreign National Residing in US
Foreign National Not Residing in US
TOTAL
2002-03 209 87 36 332
2003-04 220 90 29 339
2004-05 158 71 21 250
2005-06 217 101 37 355
2006-07 222 146 60 428
2007-08 382 124 45 551
2008-2009 248 112 66 426
2009-2010
190 107 45 342
TOTAL 1,846 838 339 3,023
Percentage of all funded participants
61.1% 27.7% 11.2%
Includes all funded visitors and workshop participants. Total funded = 377
(342 + 35 people with no citizenship information.)
Broadening the DMS research impact: SAMSI‟s national impact also depends on
Institutional Diversity and the inclusion of participants whose home institutions are not
already heavily supported by NSF funding through DMS. Such inclusion develops the
national research base by significantly increasing the number of individuals that can
engage in cutting edge research. The SAMSI record in this regard during 2009-10 is
excellent, as shown in the following table (for both funded participants and all
participants). The „Other‟ category primarily includes individuals from other disciplines,
governmental agencies or laboratories, and industry.
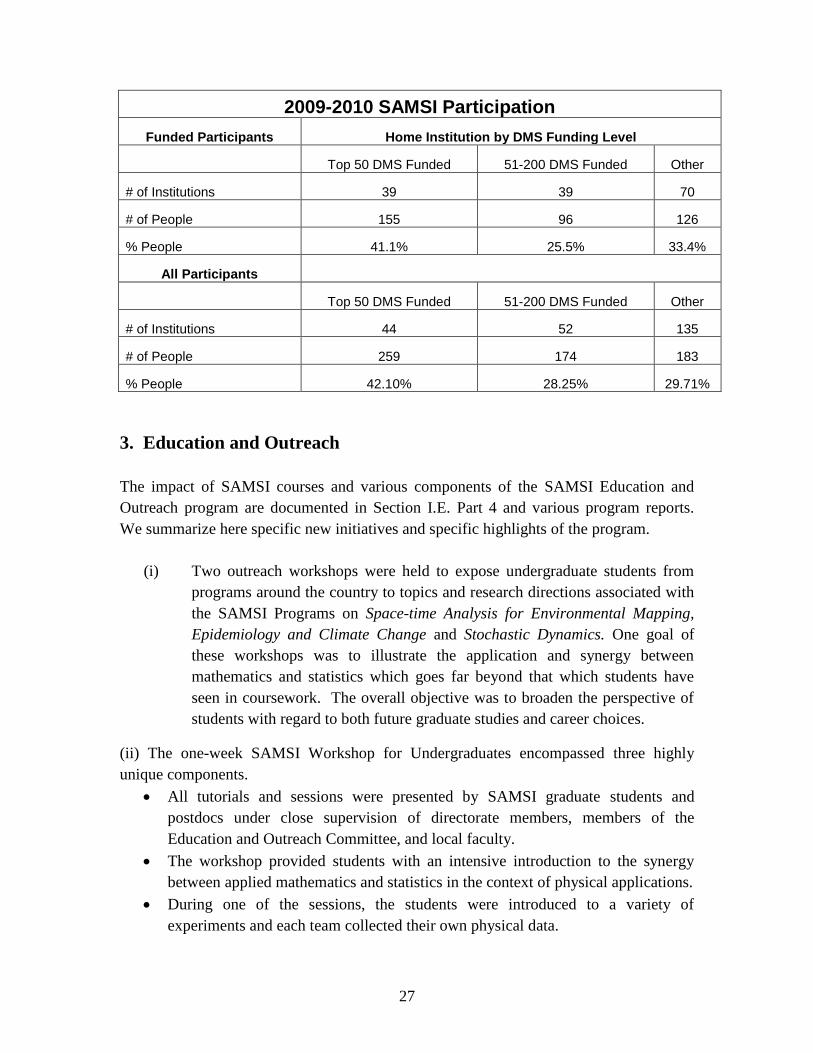
27
2009-2010 SAMSI Participation
Funded Participants Home Institution by DMS Funding Level
Top 50 DMS Funded 51-200 DMS Funded Other
# of Institutions 39 39 70
# of People 155 96 126
% People 41.1% 25.5% 33.4%
All Participants
Top 50 DMS Funded 51-200 DMS Funded Other
# of Institutions 44 52 135
# of People 259 174 183
% People 42.10% 28.25% 29.71%
3. Education and Outreach
The impact of SAMSI courses and various components of the SAMSI Education and
Outreach program are documented in Section I.E. Part 4 and various program reports.
We summarize here specific new initiatives and specific highlights of the program.
(i) Two outreach workshops were held to expose undergraduate students from
programs around the country to topics and research directions associated with
the SAMSI Programs on Space-time Analysis for Environmental Mapping,
Epidemiology and Climate Change and Stochastic Dynamics. One goal of
these workshops was to illustrate the application and synergy between
mathematics and statistics which goes far beyond that which students have
seen in coursework. The overall objective was to broaden the perspective of
students with regard to both future graduate studies and career choices.
(ii) The one-week SAMSI Workshop for Undergraduates encompassed three highly
unique components.
All tutorials and sessions were presented by SAMSI graduate students and
postdocs under close supervision of directorate members, members of the
Education and Outreach Committee, and local faculty.
The workshop provided students with an intensive introduction to the synergy
between applied mathematics and statistics in the context of physical applications.
During one of the sessions, the students were introduced to a variety of
experiments and each team collected their own physical data.

28
(iii) The overall goals of the ten-day Industrial Mathematical and Statistical Modeling
Workshop for Graduate Students were twofold:
Expose mathematics and statistics students to current research problems from
government laboratories and industry which have deterministic and stochastic
components;
Expose students to a team approach to problem solving.
For the 2009 workshop, research problems were presented by scientists from the National
Center for Atmospheric Research, the Environmental Protection Agency, the UNC
Institute for Pharmacogenomics, Sandia National Laboratory, MIT Lincoln Laboratory
and the Republic Mortgage Insurance Co. Each team gave a 30 minute oral presentation
summarizing their results on the final day of the workshop and written reports were
compiled as the SAMSI Technical Report 2010-02 which can be obtained at
http://www.samsi.info/communications/technical-reports
(iv) The Kenan Fellows Progam pairs mentors from the SAMSI community with K-12
public school teachers who have been selected to be Kenan Fellows. The program‟s goals
include promoting teacher leadership, developing and disseminating exciting new
curriculum in science, technology, and math education, and addressing the problem of
teacher retention in public schools.
No new Kenan Fellow was appointed in 2010 as a suitable match between candidates and
available projects could not be found. As of summer 2011, Lori Craven was appointed to
work with Richard Smith on Statistical Aspects of Climate Change.

29
E. Evaluation by the SAMSI Governing Board - 2010
(George Casella, Michael Crimmins, Donald Estep, James Landwehr, John
Simon, Daniel Solomon – Chair)
The Governing Board provides broad oversight for the Institute‟s administration,
finances, and evaluation, and for relationships among the partnering institutions. This
year‟s evaluation follows as responses to three broad questions:
1) What are some outcomes of the synthesis of applied mathematics and statistics?
Consistent with its founding vision, SAMSI continues to foster interaction between
applied mathematics and statistics through the creation of programs focused on topics
that involve both disciplines. Working groups established under these programs build
teams of researchers consisting of applied mathematicians and statisticians as well as
those from other areas of the mathematical sciences. The results of these efforts lie not
only in the production of papers and reports, but also in the continued interaction among
members of the teams after the formal program is completed, and, most importantly, in
the culture of multidisciplinary interaction it has established.
Some of the interactions between applied mathematics, statistics and other disciplines for
which primary activity ended or started in the past year, and that we noted in the annual
report, are listed below.
The most striking development was the formation of a joint working group
between the two year-long research programs. Working Group 3 of the Space-
Time program on Interaction of Deterministic and Stochastic Models was set up
in conjunction with several members of the Stochastic Dynamics program. Many
fields of research rely on complex computer models that are essentially
simulations of deterministic dynamics, but because of their complexity, behave in
many respects like stochastic models. There is by now a well-established
literature that treats static snapshots of such models as realizations of spatial
processes, but for simulations in time as well as space, more understanding is
needed of the dynamics of the process. One particular application was the use of
simulation methods to study heterogeneous multiscale methods (HMMs). This led
to a joint paper between a SAMSI postdoc in statistics, Emily Kang, and an
applied math faculty member, John Harlim.
Another compelling example of collaboration was among two applied
mathematicians, a probabilist and a statistician in the molecular motors subgroup
within the Stochastic Dynamics Working Group 5. Avanti Athreya, Peter Kramer,
John Fricks and Scott McKinley developed a systematic stochastic modeling

30
framework for intracellular transport connecting three physical length scales.
They are in the process of writing up their work for publication and have
submitted two joint grant proposals since the program ended.
Another fertile topic for interactions between statisticians and applied
mathematicians is data assimilation, which refers to the incorporation of
observational data into a dynamical model. A working group within the Stochastic
Dynamics program looked at two specific models, one motivated by neurobiology
and the other by ecology, where the problem is essentially to estimate unknown
parameters within a dynamical experiment. The statistical concept of Fisher
information is useful for determining how well parameters are estimated within a
given experimental set-up, and can therefore be used as a basis for optimal
experimental design. Key participants included the probabilist/statistician Cindy
Greenwood as well as applied mathematicians John Harlim and Peter Kramer, and
several papers are in preparation.
2) Is the impact and national recognition of SAMSI on science and human resources
commensurate with the scale of SAMSI?
Section D of the Executive Summary describes the developments in research, human
resource development, and education. As above, consistent with its founding vision
SAMSI continues to have a significant impact on disciplinary sciences. We highlight a
few areas below. SAMSI programs have also been influencing the research careers of
program participants, helping to refocus research directions for some senior researchers
and providing formative experiences for post-docs and other junior scientists.
Two research programs toward new modeling approaches in microswimming
(Peter Kramer) and swarming (Amarjit Budhiraja, Oliver Diaz and Xin Liu) that
were nucleated by presentations at the workshop on Self-Organization and Multi-
Scale Mathematical Modeling of Active Biological Systems in October, 2009.
Several ongoing collaborations between SAMSI postdocs on topics in stochastic
neuronal dynamics and epidemic spread on networks.
A project initiated and driven by two graduate students (Katherine Newhall and
Amanda Traud) participating in the working group on Network Dynamics, now
being prepared for submission for publication.
Working Group 1 within the Space-Time program was on Paleoclimatology, the
science of reconstructing historical temperatures from proxies such a tree rings
and ice cores. This working group involved a SAMSI postdoc (Martin Tingley)
whose training was in atmospheric science but whose main current research is in
the applications of Bayesian statistics, a SAMSI visitor (and former postdoc) from
Stanford (Bala Rajaratnam), three other visiting statisticians and another SAMSI

31
postdoc. At the end of the year they submitted a substantial paper to the Journal
of Climate, proposed a Bayesian hierarchical approach for the reconstruction of
the space-time field of temperatures.
Working Group 2 of the Space-Time program was the main group working on
epidemiology, with particular emphasis on the use of spatial statistics model for
exposure error. Another theme was the effect of climate change on human health,
on which topic three of the group members have submitted an NIH grant proposal
under NIH‟s climate change initiative.
Several other groups within the Space-Time program interacted with climate
scientists to utilize the NARCCAP dataset, a large database of regional climate
models being created at the National Center for Atmospheric Research. Noel
Cressie and co-authors used this dataset to study how the spatial extent of a
rainfall field evolves over time; Bruno Sansό and colleagues took a different tack,
using the NARCCAP data to extend their previous work on inference from
ensembles of climate models.
The lists of refereed publications associated with SAMSI programs (see Section I.G. of
the full report) provide another measure of the impact on the mathematical and
disciplinary sciences. There were 40 accepted publications over the year. There were an
additional 43 papers submitted and 48 papers in preparation.
Earlier evaluations have noted some of the long-term impacts of SAMSI programs, e.g.
the establishment of research and education centers at the interface of applied
mathematics, statistics and disciplinary science. One such example is the Center for
Quantitative Sciences in Biomedicine (http://www.ncsu.edu/cqsb) with director and co-
director a statistician and applied mathematician respectively. Evidence that such
impacts are maturing is that CQSB (jointly with two other institutions) recently won a
$12.5M grant from the National Cancer Institute.
As another example of long-term impacts, in 2010 SAMSI hosted a National Town Hall
meeting for members of SIAM, ASA, and USACM (United States Association for
Computational Mechanics) about the joint establishment of Interest Groups in
Uncertainty Quantification in SIAM and ASA. Both societies subsequently established
these interest groups and USACM followed suit shortly after. As a consequence, SIAM
and ASA are cooperating to organize the SIAM/ASA Conference on Uncertainty
Quantification (to be held every two years). The first Conference will be held in April of
2012. The organizing committee and co-chairs are drawn evenly from ASA and SIAM
(as well as USACM). In addition, Jim Berger, Don Estep and Max Gunzburger
submitted a joint proposal to SIAM and ASA to create a Journal of Uncertainty
Quantification in Models that is being evaluated.

32
These activities developed as a direct result of SAMSI organizing the National Town
Hall meeting that brought together the statistics, mathematics and computing
communities around this important topic.
SAMSI‟s strong commitment to the development of human resources in the mathematical
sciences is summarized in Section D.2 of the Executive Summary and detailed in
Sections I.B, I.C and I.H of the full report. Videoconference and WebEx technologies
have now been adopted by all working groups, some with an international reach. Indeed,
in some working groups, the majority of participants engage by these means, and some
working groups continue to be active after the end of the formal program.
Participation by women and other underrepresented groups remains high although a bit
lower than last year. In particular for 2009-2010, the participants were 31% female, 2%
African American and 4% Hispanic. Participation by new researchers and students this
year is at 52%. The SAMSI website now offers information about its diversity programs
at http://www.samsi.info/about/diversity-statement .
The inclusion in SAMSI programs of a substantial number of participants from
institutions not heavily supported by NSF-DMS funding is detailed in the full report.
Less than half of funded participants in SAMSI programs are from top 50 DMS funded
institutions.
The detailed participant lists for concluded programs provide ample evidence of the
national and international draw of SAMSI activities. SAMSI programs attracted 50
research fellows (non-local visitors who played a major role in program activities) plus 3
new researcher fellows, 12 local faculty fellows, 16 postdoctoral fellows, 11 graduate
fellows and an overall total of over 1,000 in all types of SAMSI activities.
3) Is the Directorate meeting the needs of an evolving SAMSI?
Founding Director James Berger stepped down in 2010 after eight years of distinguished
leadership that developed the effective SAMSI “model” that we have today. Following a
national search led by a broadly-based nomination committee, Richard Smith was named
Director effective July 1, 2010.
The directorate model continues to serve SAMSI very well, and transitions in the
directorate have gone smoothly. Pierre Gremaud became full-time Deputy Director on
January 1, 2010 and has taken responsibility for oversight of the program operations. He
is scheduled to remain in the position through the close of the current award period. Nell
Sedransk continued to serve as Associate Director from NISS while NISS Director Alan
Karr continued to work closely with SAMSI.

33
The Governing Board itself continues to operate in the expanded structure implemented
earlier that now includes two representatives from beyond the four SAMSI partner
institutions who are selected by the American Statistical Association (Casella) and the
Society for Industrial and Applied Mathematics (Estep). The UNC-Chapel Hill
representative on the Governing Board became Michael Crimmins, who took over from
Bruce Carney as Senior Associate Dean for Sciences at UNC. As a result, the Governing
Board now includes two domain scientists from chemistry (Crimmins and Simon).
The Governing Board Chair and the SAMSI Director continue to have a biweekly
telephone conference at which administrative and personnel matters are regularly
discussed and issues addressed where they have arisen. There is also excellent
cooperation among the partner universities and NISS to ensure that obligations are met
and that SAMSI continues to flourish. Most notable during the period of this report are
the successful three-university financial arrangements made in connection with the
change in home institution of the Director.

34
Table of Contents
0. Executive Summary………………………………………………………………….. 3
I. Annual Progress Report ..............................................................................................35
A. Program Personnel………..……………………………………………..….35
1. List of Programs and Organizers ...............................................................
2. Program Core Participants .........................................................................
B. Postdoctoral Fellows and Associates .................................................................
1. Overview……………….……………………………………………...48
2. Postdoc Mentoring Plan .……………………………………………...49
3. List of Postdocs 2009-10……………………………………………...50
4. 2009-10 Postdoc Activities……………………………………………51
5. Postdoc Evaluations…………………………………………...………87
C. Graduate Student Participation...…………………………………..…….111
D. Consulted Individuals…………………………………………………...…114
E. Program Activities…………………………………………………………115
1. Stochastic Dynamics…………………………………………………116
2. Space-Time Analysis for Environmental Mapping, Epidemiology, and Climate
Change………………………………………………………………134
3. Semiparametric Bayesian Inference: Applications in Pharmacokinetics
and Pharmacodynamics……………….………………………………169
4. Education and Outreach Program……….………………..………….179
F. Industrial and Governmental Participation…………………………...…185
G. Publications and Technical Reports………………………………….…...186
H. Diversity Efforts………………………………………………………..…..197
I. External Support and Affiliates……………………………………………200
J. Advisory Committees…………………………………………………….…203
K. Income and Expenditures…………………...………………………….…206
L. Report of the Mathematics Sciences Institutes Directors Meeting….......210
II. Special Report: Program Plan ..................................................... .. A. Programs for 2010-2011 .....................................................................................
1. Analysis of Object Data………………………………………………….217
2. Complex Networks…………………………………………………..228
B. Scientific Themes for Later Years……………………………………...…238
C. Budget for 2009-2010………………………………………………………251
D. Financial Plan for 2009-2010…………………………………………...…257
Appendix A. Final Program Report: Sequential Monte Carlo Methods…..……………260
B. Final Program Report: Algebraic Methods in Systems Biology .....………293
C. Final Program Report: Summer Program in Meta-Analysis…..…………303
D. Final Program Report: Summer Program in Pschometrics………………312
E. Workshop Participant List………………………………………………. 409
F. Workshop Programs and Abstracts………………………………………486
G. Workshop Evaluations…………………………………………………….600

35
I. Annual Progress Report
Year 8 programs were PKPD (Summer 2010); Stochastic Dynamics; Space-Time Analysis for
Environmental Mapping, Epidemiology and Climate Change; their final reports are in Appendices A
and B, respectively.
A. Program Personnel
1. Program and Activity Organizers
Program Organizers
Program Name Affiliation Field
PKPD Peter Mueller M.D. Anderson
Cancer Center
Biostats
(Summer 2010) Gary Rosner M.D. Anderson
Cancer Center Biostats
2009-10 SAMSI Program
Stochastic Dynamics Rick Durrett Cornell University Statistics
Alejandro Garcia San Jose State Physics
Cindy Greenwood Arizona State U Math and Stats
Alan Karr NISS Statistics
2009-10 SAMSI Program Jonathan Mattingly Duke U Mathematics
Michael Minion SAMSI/UNC Mathematics
Peter Mucha UNC Mathematics
Hongyun Wang UC Santa Cruz Mathematics
Space-Time Analysis for James Berger SAMSI Statistics
Environmental Mapping, Noel Cressie Ohio State U Statistics
Epidemiology and Climate Peter Diggle Lancaster U Biostatistics
Change Montse Fuentes NCSU Statistics
Alan Gelfand Duke U Statistics
2009-10 SAMSI Program Peter Guttorp U Washington Statistics
Jun Liu Harvard U Statistics
Jesper Møller Aalborg U Mathematics
Richard Smith UNC Statistics
Michael Stein U Chicago Statistics
Dongchu Sun U Missouri Statistics
Jim Zidek U British Columbia Statistics

36
Education & Outreach Program Negash Begashaw Benedict College Mathematical Sciences
Carlos Castillo-Chavez (ex officio)
Arizona State U Mathematics
Karen Chiswell NCSU Statistics
Cammey Cole Meredith College Mathematics & CS
Anne Fernando Norfolk State U Mathematics
Pierre Gremaud NCSU/SAMSI Mathematics
Leona Harris College of NJ Mathematics
Marian Hukle U of Kansas Biological Sciences
Masilamani Sambandham
Morehouse College Mathematics
Activity Organizers
2008-09 Programs
Program Year
Activity Name(s)
Sequential Monte Carlo Methods
2008-09 Transition Workshop – November 9-10, 2009
Julien Cornebise (SAMSI), Arnaud Doucet (The Institute of Statistical Mathematics, Japan, and U of
British, Columbia), Simon Godsill (Cambridge U), and Mike West (Duke U)
2010 Summer Program
2010 Program on Semiparametric Bayesian Inference in PKPD Analysis – July 12-23, 2010
Gary Rosner and Peter Mueller (M.D. Anderson Cancer Center)
2009-10 Programs
Program Year
Activity Name(s)
Space-time Analysis for Environmental Mapping, Epidemiology and Climate Change
2009-10 Opening Workshop -- September 13-16, 2009
Noel Cressie (Ohio State U), Peter Diggle (Lancaster U), Montse Fuentes (NCSU), Alan Gelfand (Duke U), Peter Guttorp (U of Washington), Richard Smith (UNC), Michael Stein (U of Chicago), Dongchu Sun (U of Missouri), Jim Zidek (Chair, UBC)
2009-10 GEOMED: Spatial Epidemiology 2009 Workshop (Charleston) – November 14-16, 2009
Andrew Lawson (MUSC), Lance Waller (Emory), Peter Rogerson (Buffalo), Robert Haining,
(Cambridge), Sudipto Banerjee (Minnesota: SAMSI), Linda Young (Florida SAMSI)
2009-10 Climate Change – February 17-19, 2010
Mark Berliner (Ohio State), Jim Zidek (British Columbia), Richard Smith (UNC), Bruno Sansó (UC Santa Cruz), Tapio Schneider (California Institute of Technology), Claudia Tebaldi (Climate Central), Ilya
Timofeyev (Houston).

37
2009-10
One-day workshop on Objective Bayesian for Spatial and Temporal Models (San Antonio) - March 20-21, 2010
James Berger (SAMSI)
2009-10 Statistical Aspects of Environmental Risk Workshop – April 7-9, 2010
Richard Smith, (UNC), Montse Fuentes, (NCSU), Sudipto Banerjee (U of Minnesota), Scott Holan (U of
Missouri), Marian Scott (Glasgow U), Feridun Turkman (U of Lisbon), Clive Anderson (Sheffield U)
Stochastic Dynamics
2009-10 Opening Workshop – August 30-September 2, 2009
Hongyun Wang (UC Santa Cruz), Alejandro Garcia (San Jose State),Cindy Greenwood (ASU), Alan Karr (NISS), Jonathan Mattingly (Duke), Peter Mucha (UNC), Michael Minion (SAMSI), Rick Durrett (Cornell)
2009-10
Self-Organization and Multi-Scale Mathematical Modeling of Active Biological Systems – October 26-28, 2009
Igor Aronson (Argonne National Laboratory), Leonid Berlyand (Penn State U); Directorate Liaison: Pierre
Gremaud (SAMSI)
2009-10 Theory and Qualitative Behavior of Stochastic Dynamics Workshop – February 8-10, 2010
Michael Cranston (U of California-Irvine), Yuri Bakhtin (Georgia Tech), Luc Rey-Bellet (U of Massachusetts),
Jonathan Mattingly (Duke U)
2009-10 Workshop on Molecular Motors, Neuron Models, and Epidemics on Networks – April 15-17, 2010
Priscilla Greenwood (ASU), John Fricks (Penn State), Lea Popovic (Concordia), Scott Schmidler (Duke)
Education and Outreach
2009-10 Two-Day Undergraduate Workshop -- October 30-31, 2009
Pierre Gremaud (NCSU), Murali Haran (Pennsylvania State U)
2009-10 Two-Day Undergraduate Workshop -- February 26-27, 2010
Pierre Gremaud (NCSU), Scott Schmidler (Duke U)
2009-10 4th Annual Graduate Student Probability Conference – April 30-May 2, 2010
Jessi Cisewski, Tiffany Kolba, Xin Liu, Dominik Reinhold, and Rachel Thomas under the supervision
of Prof. Amarjit Budhiraja and Prof. Jonathan Mattingly (Duke U)
2009-10 SAMSI/CRSC Interdisciplinary Workshop for Undergraduates -- May 17-21 2010
Pierre Gremaud (SAMSI), Cammey Cole Manning (Meredith)
2011-12 Programs
2011-12 Uncertainty Quantification Electronic Townhall Meeting – April 6, 2010
Amy Braverman (JPL, Cal. Tech and UCLA), Don Estep (Colorado State), Roger Ghanem (USC), David Higdon (LANL), Christine Shoemaker (Cornell), JeffWu (Georgia Tech), James Nolan (Duke), Jan Hannig (UNC), Pierre Gremaud (SAMSI), Max Gunzburger (Florida State)

38
2. Program Core Participants and Targeted Experts
For each of the major programs, the following tables present the key participants for the programs.
The participants are categorized and coded as follows:
DL Distinguished Lecturer Program affiliated speaker
FF Faculty Fellow Teaching release from local university
FA Faculty Associate Program affiliated local faculty for which no release time is allocated
GF Graduate Student Fellow Student from local university, assigned to a specific program and paid a stipend
GA Graduate Student
Associate Program-affiliated local student with no stipend
VGF Visiting Graduate Fellow Non-local student, paid only expenses
NRV New Researcher Visitor Non-local researchers (holding PhD 5 years or less) brought in for short intervals for interaction with program participants
NRC New Researcher Core
Visitor Non-local researchers (including fellows) who play a major role in program activities
PF Postdoctoral Fellow Program-affiliated individual, paid a stipend in association with a local university
PA Postdoctoral Associate Program-affiliated individual with appointment shorter than 1 year
SV Senior Visitor Researcher (holding PhD 6 or more years) brought in for short intervals for interaction with program participants
RF Research Fellow Non-local researchers who play a major role in program activities
WG Working group Participant local participants of SAMSI working groups (not fellows, visitors or persons otherwise designated)
WGR Remote working group
participant remote participants of SAMSI working groups (not otherwise designated)
Grey – is used to indicate funds that are provided by partner university cost sharing.
Note: For visitors who have yet to visit SAMSI or who are still at SAMSI, dollar amount in the tables
below are the expense allotment for the visitor.

39
Last Name First Name Gender Affiliation Department Status
Assuncao Renato Male Universidade Federal de Minas Gerais Statistics RF
Aune Erland Male NTNU Statistics GF
Banerjee Sudipto Male U Minnesota Statistics RF
Bayarri Susie Female U Valencia Statistics RF
Bernardo Jose Male U Valencia Statistics RF
Berrett Candace Female Ohio State U Statistics GF
Berrocal Veronica Female SAMSI Statistics PF
Bhat K. Sham Male Penn State Statistics GF
Calder Kate Female Ohio State Statistics RF
Chang Howard Male SAMSI Mathematics PF
Chen Lisha Female Yale University Statistics RF
Conesa David Male U Valencia Statistics RF
Cressie Noel Male Ohio State Statistics RF
Das Sourish Male SAMSI Statistics PF
Eidsvik Jo Male NTNU Statistics RF
Ferreira Marco Male U Missouri Statistics RF
Fine Jason Male UNC Statistics FF
Finley Andrew Male Michigan State Physics RF
Last Name First Name Gender Affiliation Department Status
Fortes Annabel Female U Valencia Statistics GF

40
Franca Villoria Maria Female U Glasgow Statistics GF
Fuentes Montse Female NCSU Statistics FF
Gamerman Dani Male Math Institute Math RF
Gelfand Alan Male Duke U Statistics FF
Gomez-Rubio Virgilio Male Universidad de Castilla-La Mancha Math RF
Green Peter Male Bristol U Statistics RF
Guindani Michele Male U New Mexico Statistics RF
Haran Murali Male Penn State Statistics NRC
Harlim John Male NYU Math FF
He Chong Female U Missouri Statistics RF
Held Leo Male U Zurich Statistics RF
Herring Amy Female UNC Stats FF
Holan Scott Male U Missouri Stats RF
Ickstadt Katja Female Technische Universität Darmstadt Math RF
Jackson Monica Female American U Statistics RF
Kang Emily Female SAMSI Statistics PF
Kuensch Hans Male ETHZ Math RF
Lee Jaeyong Male Seoul Nat’l U Statistics RF
Levins Mihails Male Purdue Statistics RF
Last Name First Name Gender Affiliation Department Status
Li Linyuan Male U New Hampshire Statistics NRV

41
Liu Yajun Female U Missouri Statistics GF
Lopez Quilez Antonio Male U Valencia Statistics RF
Mannshardt-Shamseldin Elizabeth Female SAMSI Statistics PF
Manolopoulou Ioanna Female Duke University Statistics PA
Martinelli Gabriele Male Norwegian U Math GF
Martínez Beneíto Miguel Ángel Male
Centro Superior de Investigación en Salud Pública Statistics RF
Matteson David Male Duke U Stats NRV
Micheas Sakis Male U Missouri Statistics RF
Nicolis Orietta Female University of Bergamo Math RF
Paulo Rui Male Technical U Lisbon Stats RF
Rajaratnam Bala Male Stanford Mathematics RF
Ratmann Oliver Male Duke U Stats PA
Reich Brian Male NCSU Statistics FF
Rios-Doria Daniel M Arizona State University Mathematics and Statistics GF
Rue Håvard Male NTNU Statistics RF
Salazar Esther Female SAMSI Stats PF
Sanso Bruno Male UCSC Statistics RF
Schmidt Alexandra Female Universidade federal do Rio de Janeiro Statistics RF
Scott Marian Female U Glasgow Stats RF
Last Name First Name Gender Affiliation Department Status
Shaby Benjamin Male SAMSI Stats PF
42
Smith Richard Male UNC Statistics FF
Steinsland Ingelin Female Norwegian University of Science and Technology Statistics RF
Sun Dongchu Male U Missouri Statistics RF
Tingley Martin Male SAMSI Math PF
Yasamin Saieed M Stanford University Statistics RF
Young Linda Female University of Florida Statistics RF
Zhang Jun Male SAMSI Statistics PF
Zidek Jim Male UBC Statistics RF
Last Name First Name Gender Affiliation Department Status
Avanti Athreya F Duke University Statistics PF
Bessaih Hakima F University of Wyoming Mathematics RF
Budhiraja Amarjit M UNC-CH Statistics FF
Chertock Alina F NC State University Mathematics FF
Cornebise Julien M Duke University Statistics PF
Deng Shaozhong M UNC-Charlotte Mathematics and Statistics RF
Last Name First Name Gender Affiliation Department Status
Deville Lee M UIUC Mathematics RF

43
deSilva Nuwan Indurwage M
Rensselaer Polytechnic Institute Mathematics GF
Diaz Espinoza Oliver M Duke University Statistics PF
Fricks John M
Pennsylvania State University Statistics RF
Greenwood Cindy F Arizona State University
Mathematics and Statistics RF
Induruwage Nuwan M Rensselaer Polytechnic Institute Stat GF
Kramer Peter M Rensselaer Polytechnic Institute Mathematics RF
Lin Kevin M University of Arizona Mathematics RF
Mattingly Jonathan M Duke University Mathematics FF
McKinley Scott M Duke University Mathematics PA
McSweeney John M UNC-Chapel Hill Mathematics PF
Mitran Sorin M UNC-CH Mathematics FF
Mora Carlos M Univ. de Concepcion Mathematical Engineering RF
Mueller Carl M University of Rochester Mathematics RF
Newhall Katie F Rensselaer Polytechnic Institute Mathematics GF
Ng H. K. Tony M Southern Methodist University Statistics RF
Owen Megan F NC State University Mathematics PA
Pego Robert M Carnegie Mellon Mathematical Sciences RF
Popovich Lea F Concordia University Mathematics and Statistics RF
Last Name First Name Gender Affiliation Department Status
Rogers Bruce M Duke University Mathematics PF
Schmidler Scott M Duke University Statistics FF

44
Srinivasan Ravi M Duke University Mathematics PF
Sun Yi M NC State University Mathematics PA
Wang Xueying F NC State University Mathematics PF
Last Name First Name Gender Affiliation Department Status
Armagan Artin Male Duke University STAT NRG
Banks David Male Duke University STAT FP
Barbare Ralph Male Gad Consulting Services STAT NRG
Bayarri M.J. Female University of Valencia STAT FP
Bhattacharya Anirban Male Duke University STAT NRG
Bonate Peter Male GlaxoSmithKline OTHR FP
Boonstra Philip Male
University of Michigan Department of Biostatistics STAT NRG
Burgette Lane Male Duke University STAT NRG
Chen Shuguang Male GlaxoSmithKline STAT FP
Choi Leena Female Vanderbilt University STAT FP
Cornebise Julien Male University of British Columbia STAT FP
Last Name First Name Gender Affiliation Department Status
Cui Kai Male Duke Unviersity STAT NRG
Dahl David Male Texas A&M University STAT FP
Davidian Marie Female North Carolina State University STAT FP
De Iorio Maria Female Imperial College STAT FP

45
Ding Lili Female
Cincinnati Children's Hospital Medical Center STAT NRG
Duncan Thomas Male University of Southern California BIOSTAT FP
Dunson David Male Duke University STAT FP
Dutta Ritabrata Male Purdue University STAT NRG
Escobar Michael Male University of Toronto STAT FP
Fronczyk Kassie Female University of California STAT NRG
Gan Kevin Male GlaxosmithKline STAT NRG
Ghosh Jayanta Male Purdue University STAT FP
Ghosh Joyee Female UNC Chapel Hill STAT NRG
Ghosh Kaushik Male University of Nevada - Las Vegas STAT FP
Guha Subharup Male University of Missouri STAT FP
Guindani Michele Male University of New Mexico STAT NRG
Johnson Brendan Male GlaxoSmithKline LIFE FP
Johnson Wesley Male University of California – Irvine STAT FP
Korman Alexander Male Duke University STAT NRG
Kottas Athanasios Male University of California, Santa Cruz STAT FP
Last Name First Name Gender Affiliation Department Status
Kundu Suprateek Male UNC STAT NRG
Lee Ju Hee Female Ohio State University STAT NRG
Lewandowski Andrew Male Purdue University STAT NRG
Li Lang Male Indiana University MED / MOLEC GENETICS FP

46
Maceachern Steven Male Ohio State University STAT FP
Mueller Peter Male MD Anderson Cancer Center STAT FP
Oluyede Broderick Male Georgia Southern University STAT FP
Omolo Bernard Male UNC Chapel Hill STAT FP
Pang Herbert Male Duke University STAT NRG
Pararai Mavis Female Indiana University of Pennsylvania MATH FP
Pati Debdeep Male Duke University STAT NRG
Quispe Vargas Walter Male University of Puerto Rico STAT NRG
Rizwan Ahsan Male UNC LIFE NRG
Rodriguez Abel Male University of California STAT NRG
Rosner Gary Male Johns Hopkins University STAT FP
Roura Jaime Male University of Puerto Rico, Rio Piedras STAT NRG
Tadesse Mahlet Female Georgetown University STAT FP
Telesca Donatello Male UCLA STAT NRG
Tokdar Surya Male Duke University STAT NRG
Tomasetti Cristian Male University of Maryland MATH NRG
Last Name First Name Gender Affiliation Department Status
Torres David Male University of Puerto Rico NRG
Vicini Paolo Male
Pfizer Global Research and Development LIFE FP
Wahed Abdus Male University of Pittsburgh STAT FP
Wang Yanpin Female UNIVERSITY OF FLORIDA STAT NRG

47
Wolpert Robert Male Duke University STAT FP
Wu Meihua University of Michigan BIOSTAT NRG
Xiaojing Wang Female Duke University STAT NRG
Xing Chuanhua Female Duke University STAT NRG
Xu Xinyi Female Ohio State University STAT FP
Yang Mingan Saint Louis University STAT NRG
Yao Ping Northern Illinois University STAT FP
Yu Li Female Medimmune STAT NRG
Zhu Hongxiao Female
University of Texas MD Anderson Cancer Center STAT NRG
Zou Yuanshu Female University of Cincinnati STAT NRG

48
B. Postdocs
1. Overview
SAMSI had an increased number of postdocs this year, thanks to additional funds received from
DMS in 2008 to compensate for the severe shortage in new PhD hiring opportunities. While this
additional funding was very welcome, the additional numbers overwhelmed the available mentoring
resources, as demonstrated by detailed reports in Sections B.4 and B.5. The Directorate is therefore in
the process of redefining the objectives and mentoring of the postdoc program. In this section, we
present our goals for the program, followed by the revised mentoring plan in Section B.2, and then the
detailed postdoc reports.
Our goals for postdocs are to:
(i) Facilitate a transition from being a graduate student who works on problems suggested by
their adviser to an independent researcher who can formulate their own problems.
(ii) Achieve a broader perspective on the use of mathematics in applications.
(iii) Improve their presentations on research through participation in the postdoc seminar and
the undergraduate workshops, giving talks at local universities, and at regional and national meetings.
(iv) Enhance their teaching skills by teaching in their second year.
(v) Experience the pleasures of service to the community and enhance their communication
skills through outreach activities.
Program participation is the primary activity, and the one that attracts outstanding postdocs to
SAMSI. Postdocs typically participate intensively in two Working Groups in their “home program,”
working with national and international leaders. One of these groups is their main research focus, while
the other may be a secondary interest or a topic about which they wish to learn. Each postdoc is
responsible, for one Working Group, for maintaining the web page and for managing the use of WebEx.
Postdocs attend all courses associated with their program, which provides the background needed to
carry out their research and broadens their scientific horizons. They are required to attend all
workshops conducted by their home program, and encouraged to attend the opening workshops of
other concurrent programs, as well as events at NISS and the university partners.
Postdocs also actively engage in SAMSI’s Education & Outreach activities. They are presenters
and mentors in the week-long Undergraduate Modeling Workshop and the Two-Day Undergraduate

49
Workshop associated with their home program. The benefits to the postdocs are improved
communication skills, and experience serving to the mathematics and statistics community. Some
postdocs function as team mentors for the IMSM workshops for graduate students, and on occasion, as
team leaders.
Community engagement is the third key postdoc activity. From the day of their arrival at SAMSI,
postdocs join a community of SAMSI postdocs, NISS postdocs and other early career researchers in the
NISS-SAMSI complex. In some ways, the informal relationships are the most potent component of the
community. But, there are also more formal activities, especially a weekly postdoc seminar. A typical
seminar has two parts, one focusing on general postdoc issues and upcoming events, and the second
comprising a 30-minute presentation by one of the postdocs on his or her research.
2. Postdoc Mentoring Plan
Two mentors. Each SAMSI postdoc has two mentors, a Scientific Mentor and an Administrative
Mentor. The latter is a member of the SAMSI Directorate and is the same for both years. The Scientific
Mentor in the first year is one of the program organizers or a long-term visitor. In many cases the first
year Scientific Mentor is a visitor from outside the Research Triangle, while in the second year the
Scientific Mentor is a professor at the postdoc's associated university with closely related interests. As
the names indicate, the Scientific Mentor advises the postdoc on his or her research and in the second
year on teaching, while the Administrative Mentor is concerned with other aspects of professional
development and supervises the postdoc's performance of duties at SAMSI. For example, while the
Administrative Mentor will explain what happens in the job search process and when the steps occur,
the Scientific Mentor is in a better position to give advice about specific positions that the postdoc may
be considering.
Postdoc Orientation. Before the scientific program begins the postdocs (and graduate students
associated with the current programs) come to SAMSI for an afternoon of orientation activities. Part of
this is technical – many people participate in Working Groups remotely using WebEx, and the Working
Group relies on its web page to facilitate the collaboration, so the postdocs and graduate students need
to be trained in the use of these tools. The orientation also covers other technical aspects such as
computing and the use of SAMSI's webpages. Another important aspect of orientation is to spell out in
detail what the postdocs will do during their first year.
The postdoc seminar plays an important role in the mentoring of postdocs. The seminar meets
once a week and is run by one or two members of the Directorate. All of the first year postdocs, and
some in their second year, participate in this seminar. In a typical meeting, the first fifteen minutes or so
are devoted to informal discussion of general postdoc issues and upcoming events. After this, there is a
30-minute presentation by one of the postdocs on his or her research. Owing to the wide variety of
research interests of the postdocs, this must be a talk for a general audience, which introduces
background and carefully explains new concepts. Participants are encouraged to ask questions when
they do not understand, and to give the speaker constructive criticism at the end of the presentation. An

50
important goal of the seminar is to teach the postdocs how to give clear talks accessible to a wide
audience at conferences and seminars.
On some occasions, there is a more structured discussion of some topic such as refereeing
papers, applying for jobs, or writing grant applications. The seminar is not an appropriate place to
discuss personal issues, so the Administrative Mentor will meet with each of his or her postdocs roughly
once a month in an informal setting over lunch or coffee to make sure things are going smoothly.
Postdoc reports are important for documenting activities and are also useful to ensure that
postdocs articulate their plans. Each first-year postdoc writes three reports: (i) a research plan for the
year due by October 15; (ii) a first progress report and updated research plan due by January 21; and (iii)
a final report on the year's activities due by July 1. A second-year postdoc writes two reports: (i) a plan
describing the postdoc's research objectives and job search due by October 15, and (ii) a final report, to
be turned in before leaving SAMSI, which indicates the postdoc's job placement and describes the work
done while at SAMSI.
3. List of 2009-10 Postdocs
Avanti Athreya (Ph.D., Applied Mathematics, 2009, University of Maryland)
SAMSI Program: Stochastic Dynamics
Research Mentor: Jonathan Mattingly
Administrative Mentor: Michael Minion
Veronica Berocal (Ph.D., Statistics, 2007, University of Washington)
SAMSI Program: Space-Time Analysis
Research Mentor: Alan Gelfand
Administrative Mentor: Jim Berger
Howard Chang (Ph.D., Biostatistics, 2009,Johns Hopkins University)
SAMSI Program: Space-Time Analysis
Research Mentor: Alan Gelfand
Administrative Mentor: Jim Berger
Oliver Diaz-Espinosa (Ph.D., Applied Mathematics, 2006, University of Texas – Austin)
SAMSI Program: Stochastic Dynamics
Research Mentor: Jonathan Mattingly
Administrative Mentor: Michael Minion
Emily Kang (Ph.D., Statistics, 2009, Ohio State University)
SAMSI Program: Space-Time Analysis
Research Mentor: John Harlim
Administrative Mentor: Pierre Gremaud

51
John McSweeney (Ph.D., Mathematics, 2009, Ohio State University)
SAMSI Program: Stochastic Dynamics
Research Mentor: Cynthia Greenwood
Administrative Mentor: Michael Minion
Oliver Ratmann (Ph.D., Epidemiology, 2009, University College, London)
SAMSI Program: Stochastic Dynamics
Research Mentor: Katia Koelle
Administrative Mentor: Pierre Gremaud
Bruce Rogers (Ph.D., Mathematics, 2009, Arizona State University)
SAMSI Program: Stochastic Dynamics
Research Mentor: Peter Mucha
Administrative Mentor: Michael Minion
Benjamin Shaby (Ph.D., Statistics, 2009, Cornell University)
SAMSI Program: Space-Time Analysis
Research Mentor: Alan Gelfand
Administrative Mentor: Jim Berger
Yi Sun (Ph.D., Applied and Computational Mathematics, 2006, Princeton University)
SAMSI Program: Stochastic Dynamics
Research Mentor: Pierre Gremaud
Administrative Mentor: Pierre Gremaud
Martin Tingley (Ph.D., Earth and Planetary Science, 2009, Harvard University)
SAMSI Program: Space-Time Analysis
Research Mentor: Bala Rajaratnam
Administrative Mentor: Jim Berger
Xueying Wang (Ph.D., Mathematics, 2009, Ohio State University)
SAMSI Program: Stochastic Dynamics
Research Mentor: Cynthia Greenwood
Administrative Mentor: Pierre Gremaud
Jun Zhang (Ph.D., Statistics, 2009 University of Wisconsin – Madison)
SAMSI Program: Space-Time Analysis
Research Mentor: Richard Smith
Administrative Mentor: Nell Sedransk
4. Postdoc Activity Reports: See following pages.

SAMSI Postdoctoral Fellow Research Plan
Date: October 12, 2009
1. Name: Avanti Athreya
2. PhD ProgramUniversity and department: University of Maryland, College Park, AppliedMathematicsDissertation advisor: Dr. Mark FreidlinYear of PhD: 2009
3. SAMSI ResearchSAMSI program title: Stochastic DynamicsSAMSI research mentor: Jonathan MattinglySAMSI administrative mentor: Michael Minion
4a. SAMSI Activities Courses (fall and spring): Stochastic Dynamics Course;presentation on large deviations given on October 7, 2009Workshops attended (and workshop support tasks): Opening workshop, Stochas-tic Dynamics Program; workshop support—assistance to speakersPostdoc seminar: Presentation on “Metastability in Nearly-Hamiltonian Sys-tems,” Monday, September 21, 2009Undergraduate Workshop: Will participate in upcoming undergraduate work-shop on February 26–27, 2010
4b. Other activities: Involved in the Probability working group at DukeUniversity; Large Deviations reading group at SAMSI
5a. Working group I (Qualitative Dynamics)Special tasks for working group I: WebmasterPresentations to working group: talk on large deviations and metastability,September 16, 2009.Research area—plans: 1) Stochastic resonance in Morris-Lecar and Hodgkins-Huxley models; 2) large deviations and estimates of extinction in stochasticpredator-prey models (possibly also joint with Biological working group); 3)averaging and large deviations for multiscale diffusion processes
5b. Working group II (Biological Systems)Special tasks for working group II: None as yetPresentations to working group: None as yet
1

Research area—plans: related to above topics in Qualitative Behavior
5c. Working group II (Network Dynamics)Special tasks for working group II: None as yetPresentations to working group: None as yetResearch area—plans: Understanding and extending the model of Eames andKeeling for disease spread in networks by adding stochasticity first to diseasespread and next to network growth
6. Other researchPapers from PhD research: I’m working on deriving an LDP for a multidi-mensional diffusion process with a first integral; extending some results onmetastable “distributions” for nearly-Hamiltonian systems; and analyzing metasta-bility for the case of n independent one-degree-of-freedom oscillators.Presentations of other research: Seminar talks at NCSU (October 5, 2009) andUNC (November 9, 2009); talk at the Third Workshop in Random DynamicalSystems in Bielefeld, Germany (November 18–20, 2009).
2

SAMSI Postdoctoral Fellow Research Plan
Date:
1. Name Veronica Berrocal
2. Ph.D. ProgramUniversity & Department: Department of Statistics, University of Washington
Dissertation Advisor: Adrian Raftery
Year of Ph.D.: 2007
3. SAMSI ResearchSAMSI Program Title: Space-Time Analysis for Environmental Mapping, Epidemiology and Climate Change
SAMSI Research Mentor: Sudipto Banerjee
SAMSI Administrative Mentor: Jim Berger
4a. SAMSI ActivitiesCourse(s) (fall & spring): Fall 2009: Spatial EpidemiologyFall 2009: Theory of Continuous Space and Space-Time Processes Spring 2010: Spatial Statistics in Climate, Ecology and Atmospherics
Workshops Attended (and Workshop Support Tasks): Opening workshops for the Space-Time program (helped assisting the speakers)
Postdoc-Grad Student Seminar – Presentation(s): Presentation on October 26, 2009: ``On the use of a PM 2.5 exposure simulator to explain birthweight''
Undergraduate Workshop(s) – Participation (specifics to be added later): 50-minute talk at the Undergraduate workshop on October 30-31, 2009.
4b. Other Activities (e.g., teaching)Guest lectured for Alan Gelfand's course on ``Theory of continuous space and space-time processes'' on October 15, 2009

5a. Working Group IModel-based geostatistics and preferential sampling
Special Tasks for Working Group:Webmaster
Presentations to Working Group:
Research Area – Plans:I am planning on developing/extending previous modeling approaches to calibrate computer models (calibration of the input) and downscale the output from computer models to point level thus addressing the problem of change of support between the two sources of data.
5b. Working Group IISpatial Exposure and Health Effects
Special Tasks for Working Group:
Presentations to Working Group:Presentation on October 1, 2009 on approaches to model individual exposure to contaminants/pollutants accounting for spatial dependence
Research Area – Plans: I plan to work on assessing the effect of spatial aggregation on the estimates of risk
factors. More specifically, I plan to study how inference changes when a spatial process occurring at a point level is included in an epidemiological model at somespatial aggregated unit, rather than at the point level.
Another research project that I am planning to work on is to develop spatio-temporal models that relate health effects to exposure to multiple pollutants while adjusting for other factors. In particular, one issue that I would like to address is how to include the entire distribution function of a risk factor (i.e. age) for the population living in a spatial unit as a covariate in an epidemiological model linking a spatially-aggregated response variable to exposure.
5c. Working Group III (if appropriate)Non Gaussian and non-stationary spatial models
Special Tasks for Working Group:
Presentations to Working Group:
Research Area – Plans:

I intend to work on employing Dirichlet process to model non-stationary non-Gaussian spatial process. In particular, I am planning on combining predictive processes and Dirichlet processes for spatial prediction purposes.
6. Other ResearchWork on Papers from Ph.D. Research:
Other Research started or continued at SAMSI:
Continuing Collaborations while at SAMSI:I am continuing my collaborations with Marie Lynn Miranda (from Duke University), Dave Holland (from EPA), Claudia Czado (from Technical University of Munich) and Tilmann Gneiting (from University of Heidelberg).
Presentations of Other Research:
Research Progress Report & SAMSI Program Final Report
Date:
7a-z. Research Contributions – Current Projects (grouped by Working Group)Research Project Title: Collaborator(s) & Mentor(s):Specific Goals & Accomplishments (results):Research Contributions (publication submissions, articles in preparation, etc.):Presentations outside SAMSI (including invitations for future talks):
8. Future Research Plans (after completion of SAMSI Program)Research Area – Plans:Continuing Collaborations (if appropriate):Presentations outside SAMSI:

SAMSI Postdoctoral Research Plan
Date: October 16 2009
Name: Howard Chang
Ph.D. Program:
Department of Biostatistics
Johns Hopkins Bloomberg School of Public Health
Advisor: Francesca Dominici
Co-advisor: Roger Peng
Year of Ph.D.: 2009
SAMSI Research:
SAMSI Program: Space-time analysis of environmental mapping, epidemiology,
and climate change
Research Mentor: Alan Gelfand
Admin. Mentor: Jim Berger
SAMSI Activities:
Courses: Spatial Epidemiology (Fall)
Theory of Continuous Space and Space-time Process (Fall)
Spatial Statistics in Climate, Ecology, and Atmospherics (Spring)
Workshop Attended: Sept 2009 Spatial Opening Workshop
Nov 2009 GEOMED
Undergraduate Workshop: Oct 2009 Two-day Undergraduate Workshop
Other Activities:
Teaching:
� Taught three sessions in the SAMSI Spatial Epidemiology class.
Topic: Multi-site Time Series Analysis.
� Will present at the Oct 2009 undergraduate workshop and lead a one-
hour R lab session on related materials.
Working Group 1: Spatial Exposures and Health Effects
Tasks: Webmaster
Presentations: Presented Oct 8 on the challenges in defining appropriate exposure
measures for the analysis of air pollution and health data.
Research Plans:

(1) Spatial survival model with time-varying coefficients to study the effects of
particulate matter exposure on preterm birth. The data is obtained from the Southern
Center on Environmentally-Driven Disparities in Birth Outcomes at Duke University.
This project will be supervised by Brian Reich (NCSU) and Marie Lynn Miranda
(Duke).
(2) National spatial time series analysis of air pollution and mortality between 2001 to
2007. We will utilize county-level mortality data linked to daily exposure to air
pollutants derived from monitoring, numerical or fused data. The study design is
similar to the National Mortality, Morbidity and Air Pollution study. This project will
be supervised by Montse Fuentes (NCSU) and Lucas Neas (EPA).
Additional projects are still being discussed within the working group. I am particularly
interested in individual versus aggregated analysis and exposure assessment.
Working Group 2: Model-based Geostatistics
Tasks: Participant
Presentation: None
Research Plans: Interested in examining preferential sampling in air pollution monitoring
design and its implications in health effect analysis.
Other Research
Duke University
50% of my effort is with the Children’s Environmental Health Initiatives supervised by Alan
Gelfand and Marie Lynn Miranda. The following projects are currently planned:
1. Time series and case cross-over analysis of adverse birth outcomes and air pollution
in North Carolina 1999-2007.
2. Develop a spatial model for joint modeling of birth weight and gestational week.
3. A simulation study to examine methods for estimating the health effects of air
pollution using semi-individual data.
Thesis Research
Two papers have been submitted:
Chang HH, Peng RD, and Dominici, F. Estimating the Acute Health Effects of Coarse
Particulate Matter Accounting for Exposure Measurement Error.
Chang HH, Dominici, F, and Peng, RD. Bayesian Model Averaging for Clustered data.
Another paper is in progress comparing difference exposure indicators for estimating the health
effects of coarse particulate matter.

59
59
SAMSI Postdoctoral Fellow Research Plan Date: October 14, 2009 1. Name Sourish Das 2. Ph.D. Program
University & Department: University of Connecticut, Department of Statistics Dissertation Advisor: Dipak K Dey Year of PhD : 2008
3. SAMSI Research
SAMSI Program Title: Space Time Program SAMSI Research Mentor: Sudipto Banerjee SAMSI Administrative Mentor: Nell Sedransk
4a. SAMSI Activities Course(s) (fall & spring):
1. Workshops Attended (and Workshop Support Tasks):
1. Adaptive Design, SMC and Computer Modeling Workshop, April 15-17, 2009 2. SAMSI/CRSC Undergraduate Workshop, May 18—20, 2009 3. Summer Program on Pshchometric, July 7 – 17, 2009 4. Summer school in Spatial Statistics, July 28 – August 1, 2009
2. Postdoc-Grad Student Seminar – Presentation(s):
Scheduled for December 7, 2009
3. Undergraduate Workshop(s) – Participation (specifics to be added later):
SAMSI/CRSC Undergraduate Workshop, May 18—20, 2009 Two presentations were given in the workshop.
a. Reflection on the Data Collection and Modeling Experiences b. Statistical Analysis of Vibrating Beam: Inverse Problem
4. Poster presentation at the SMC Opening workshop September 8, 2008 5. Poster presentation at Pshchometric, July 7 – 17, 2009
4b. Other Activities (e.g., teaching)
1. Teaching Stat 101 (class of __ students) in the Department of Statistical
Science at Duke University, during Fall 2009. 2. Review papers for Journal of Multivariate Analysis

60
60
3. Review papers for Epidemiology
4. Review papers for Computational Statistics and Data analysis 5. Review papers for Journal of Statistical Planning and Inference
6. Organizing invited session at JSM 2009 :
Speakers are: (i) Mike Daniels (U of Florida, Gainsville), (ii) Bani Mallick (Texas A & M), (iii) David Dunson (Duke University), (iv) Sourish Das (SAMSI and Duke University)
7. Organizing invited session at ENAR 2010: (Accepted)
Speakers are: (i) Sourish Das (SAMSI/Duke University) (ii) Peter Thall (M.D. Anderson) (iii) Mike Daniels (U of Florida, Gainsville) (iv) Peter Muller (M. D. Anderson)
8. Heading to India in December 16, 2009 for job interview talk at (i) Indian Institute of Technology (IIT), (ii) Indian Statistical Institute (ISI) (iii) Indian Institute of Management (IIM) Returning to India on January 15, 2010 5a. Working Group: Computation, Visualization, and Dimension Reduction in Spatio-Temporal Modeling (Spatio-
Temporal Modeling)
Special Tasks for Working Group:
(i) Webmaster of the WG (ii) Send WebEx invitation to every member of the WG every week. (iii) Take minutes of the WG meeting
Presentations to Working Group: N/A
Research Area – Plans: Currently, working with Sudipto Banerjee on ―Space-Time Data Analysis using
Sequential Monte Carlo Method‖. Our objective is to implement currently developed predictive process to reduce the dimension and take the advantage of parallel computation which is very natural to SMC method.

61
61
Manuscript in preparation: Yes 6. Other Research
Work on Papers from Ph.D. Research: Other Research started or continued at SAMSI:
1. Gaussian Process Latent Variables Dynamic Models (Work in progress with David Dunson)
2. Bayesian Methods for Dynamic Models with Dipak Dey (Ready for submission)
3. On Bayesian Inference for Generalized Multivariate Gamma Distribution with
Dipak Dey (submitted Statistics and Probability Letters) 4. Extreme Drinking Behavior of Patients suffering Alcohol Dependence Disorder
using Pareto Regression with Harel, Dey, and Kranzler (Resubmitted in Statistics in Medicine after reviewers suggetions)
5. Adaptive Bayesian analysis of binomial proportions (2009)
with Sonali Das (In Press in South African Journal of Statistics) 6. Efficacy of Endoscopic Ultrasound (EUS) Guided Celiac Plexus Block (CPB) and
Celiac Plexus Neurolysis (CPN) for Managing Abdominal Pain Associated with Chronic Pancreatitis and Pancreatic Cancer: a systematic review and Meta analysis. (2009) with Kaufman, M. , Singh, G., Das, S., Micames, C., and Gress, F. (Accepted in Journal of Clinical Gastroenterology)
7. Elicitation of Expert Prior opinion in Context of Presidential Election (2009) with David Banks (work in progress: Tentative title)
Continuing Collaborations while at SAMSI:
Sonali Das, CSIR, South Africa
Marina Kaufman and Gurpreet Singh at SUNY downstate medical center, Brooklyn, NY 11203
Presentations of Other Research:
Research Progress Report & SAMSI Program Final Report Date: 7a-z. Research Contributions – Current Projects (grouped by Working Group)

62
62
Research Project Title: Gaussian Process Latent Variable Models and Gaussian Process Dynamic Models
Collaborator(s) & Mentor(s): David Dunson
Specific Goals & Accomplishments (results):
Presentations outside SAMSI (including invitations for future talks): N/A 8. Future Research Plans (after completion of SAMSI Program)
Research Area – Plans:
Continuing Collaborations (if appropriate):

SAMSI Postdoctoral Fellow Research Plan
Date:
1. Name: Oliver Rodolfo Díaz Espinosa
2. Ph.D. ProgramUniversity & Department: University of Texas at Austin, MathematicsDissertation Advisor: Rafael de la LlaveYear of Ph.D.: 2006
3. SAMSI ResearchSAMSI Program Title: Stochastic DynamicsSAMSI Research Mentor: Jonathan Mattingly, Cindy GreenwoodSAMSI Administrative Mentor: Michael Minion
4a. SAMSI ActivitiesCourse(s) (fall): • Stochastic Dynamical Systems
Workshops Attended: • Program on Stochastic Dynamics Opening Workshop (August 30-September 2)• The Mathematics Institutes' Modern Math Workshop at SACNAS (Oct 14-Oct
15)Postdoc-Grad Student Seminar – Presentation(s): • Long wave expansions for water waves over a random bottom (at SAMSI)
Undergraduate Workshop(s) – Participation (specifics to be added later):
4b. Other Activities Teaching: M103 Intermediate Calculus, Duke University 5a. Working Group I (Qualitative behavior of dynamical systems) Special Tasks for Working Group: Presentations to Working Group: Doob’s h-Transform (to be presented)
Research Area – Plans: • Understanding of stochastic dynamical systems (maps) and the study of the
notions of bifurcation in this setting.• Develop some numerical techniques to implement the h-transform when
conditioning over sets of small measure
5b. Working Group II (Biological Dynamics) Special Tasks for Working Group: Web-master
• Setting up webex for the weekly meetings and maintaining the web-pages of the groups and its subgroups
Presentations to Working Group:

Research Area – Plans:• Understanding the dynamics of molecular motors• Analysis of the mechanism behind oscillations in stochastic biological models
epidemiology and in population dynamics.
6. Other ResearchWork on Papers from Ph.D. Research:• Long wave expansion for water waves over a random surface• Directed polymers in random environment with product structureOther Research started or continued at SAMSI:Continuing Collaborations while at SAMSI: • Walter Craig (McMaster Univ.)• Catherine Sulem (U. of Toronto)• Konstantin Khanin (U. of Toronto)Presentations of Other Research:• Long wave expansion for water waves over a random bottom(at Modern Math Workshop at SACNAS)
Research Progress Report & SAMSI Program Final Report
Date:
7a-z. Research Contributions – Current Projects (grouped by Working Group) Research Project Title: Collaborator(s) & Mentor(s):
Specific Goals & Accomplishments (results): Research Contributions (publication submissions, articles in preparation, etc.): Presentations outside SAMSI (including invitations for future talks):
8. Future Research Plans (after completion of SAMSI Program) Research Area – Plans: Continuing Collaborations (if appropriate): Presentations outside SAMSI:

65
SAMSI Postdoctoral Fellow Research Plan Date: 1. Name: Elizabeth Mannshardt-Shamseldin 2. Ph.D. Program
University & Department: University of North Carolina at Chapel Hill, Department of Statistics and Operations Research (Statistics PhD).
Dissertation Advisor: Prof. Richard L. Smith Year of Ph.D.: 2008
3. SAMSI Research
SAMSI Program Title: Space-Time Analysis for Environmental Mapping, Epidemiology and Climate Change
SAMSI Research Mentor: TBD very soon SAMSI Administrative Mentor: Nell Sedransk
4a. SAMSI Activities Course(s) (fall & spring):
Spring 2010 Course in Spatial Statistics in Climate, Ecology and Atmospherics. Workshops Attended (and Workshop Support Tasks): *Opening Workshop for Space-Time Analysis for Environmental Mapping, Epidemiology and Climate Change. Presented a poster “Severe Weather Under a Changing Climate: Large Scale Indicators of Extreme Events” at the poster session. Worked as support staff assisting the workshop presenters for the Monday morning session. *Workshop on Environmental Climate Change, Feb 17-19, 2010. Presenter in Spatiall Extremes Working Group session – topic TBD; Participant. *Environmental Risk Workshop, Apr 7-9 2010. Participant, possible presenter TBD.
Postdoc-Grad Student Seminar – Presentation(s): Oct 19th, 2009: “Severe Weather Under a Changing Climate: Large Scale Indicators of Extreme Events”. Joint work with Eric Gilleland, NCAR.
One of the more critical issues with a changing climate is the behavior of extreme weather events, as these can cause loss of life, and have huge economic impacts. It is generally thought that such events would increase under a changing climate. However, climate models are currently at too coarse of a resolution to capture the very fine scale extreme events such tornadoes or hurricanes. One approach is to look at the behavior of large scale indicators of severe weather. Here several factors are considered as large scale indicators of severe weather, including convective available potential energy and wind shear. This presents some interesting statistical issues. Numerous approaches, including the use of the generalized extreme value distribution for annual maxima, the generalized Pareto distribution for threshold excesses, a point process approach, and a Bayesian framework, are examined. Each approach is critiqued and compared for goodness of fit, model robustness,

66
and predictive attributes on both re-analysis data and climate model output data. For the univariate case, it is relatively straightforward to analyze such data though numerous issues must be resolved. These issues include appropriate techniques for threshold selection and prior specification. A bivariate approach can also be considered. In addition, when analyzing weather extremes, one is faced with a spatial field. Predicting extreme weather events is an important, growing area of research and there remain many avenues for further exploration. Acknowledgements to Harold Brooks, Patrick Marsh and Matt Pocernich.
Graduate Workshop(s) – Participation:
This last July (2009) I served as a faculty mentor for the Industrial Mathematical and Statistical Modeling Workshop for graduate students at North Carolina State University. The objective of the workshop is “to expose graduate students in mathematics, engineering, and statistics to challenging and exciting real-world problems arising in industrial and government laboratory research.” Students get experience in team problem solving and are mentored by a faculty adviser and the industry problem presenter while working on the project for several days during the workshop. The group deliverable is a paper to be included in the workshop proceedings. In my role as a faculty adviser I developed and taught a short-course in extreme value theory, suitable to the various backgrounds of the statistics, mathematics, and education majors in the group of graduate students. I also was on-site during the workshop to answer questions about concepts and programming techniques. The group of graduate students that I mentored, along with Prof. Richard Smith and Dr. Eric Gilleland from NCAR as the problem presenter, developed a Bayesian modeling approach for an extremes application, resulting in a paper to be submitted to Extremes. I am looking forward to participating as a faculty mentor again this coming year (July 19 – 27, 2010), and am also taking an active role in recruiting problem presenters from industry. 4b. Other Activities (e.g., teaching)
This academic year I am serving as the adviser for an undergraduate statistics major at Duke who is writing an honors thesis. The ultimate objective, via the Duke department honors requirements, is a publishable paper in an appropriate statistics or scientific journal. I have been working with the student to develop an appropriate project in the area of extreme value theory. My mentoring role includes everything from tutoring basic concepts and programming techniques, finding interesting data for a relevant application, critiquing and proof-reading progress, and steering the project as it develops towards a publishable product.
In the spring (2010), I will be teaching Sta10 – “Stats And Quantitativ Literacy”, a concept-based introduction to statistics course for non-science majors at Duke. This has provided an interesting perspective on teaching introductory material. The course uses the text “Seeing Through Statistics” by Jessica Utts, which focuses on presenting statistical ideas as they relate to non-mathematical disciplines. Students are taught how to read and critique scientific and news reports for statistical appropriateness and accuracy. Very basic formulas are presented as necessary to aid students’ understanding of the relationships being investigated.
This last spring (2009), I proposed, developed, and taught a special topics graduate course in “Extreme Value Theory and Applications with Bayesian Methods at Duke

67
University. The course combined material from Coles’ 2001 book “An Introduction to Statistical Modeling of Extreme Values” and several relevant journal articles on emerging techniques. It was a great opportunity to further develop my pedagogical skills.
5a. Working Group I - Spatial Extremes (Working Group 5 – Mondays 11am) Special Tasks for Working Group: Webmaster Presentations to Working Group: Oct 19th – “Regional Modeling of Extreme Storms via Max-Stable Processes” by Stuart Coles, JRSS-B 1993.
“Max-Stable Processes: What’s Out There and Open Problems.” (working title. Abstract available soon.) Presentation to the workshop on Spatio-temporal Extremes and Applications, November 2009 at Ecole Polytechnique Fédérale de Lausanne, Switzerland.
Research Area – Plans: There are 8 projects proposed for the working group at the present time. I am looking into four of them, and will focus on one or two as the group progresses. (The following is an excerpt from Richard’s Smith working group proposal.)
1. Are max-stable processes the right mathematical approach? What alternatives are available?
5. Are there “threshold” versions of max-stable processes, and how should they be estimated?
6. One of the major aims of spatial statistics, as conventionally formulated, is to predict from observed to unobserved sites. How should we do that in the context of max-stable processes?
8. Find applications and analyze data! Examples: meteorological data (e.g. rainfall, windspeeds), environmental data (e.g. ozone), financial data.
5b. Working Group II - Paleoclimate (Working Group 1 – Thursdays 1pm) Special Tasks for Working Group: Participant Presentations to Working Group: Nothing scheduled at this time.
Research Area – Plans: Learning about paleoclimate data, proxy data, climate model development and output, and statistical challenges when dealing with climate model and proxy data. Very applicable to my own research as I deal regularly with climate model output.
6. Other Research
Work on Papers from Ph.D. Research:
“Asymptotic Multivariate Kriging Using Estimated Parameters with Bayesian Prediction Methods for Non-linear Predictands.” Under Richard L. Smith, UNC-CH. Paper in preparation.
A difficulty that arises with traditional kriging methods is the fact that the standard formula for the mean squared prediction error does not take into account the estimation of the covariance parameters. This generally leads to underestimated prediction errors, even if the model is correct. Smith and Zhu (2004) establish a second-order expansion for predictive

68
distributions in Gaussian processes with estimated covariances. In my dissertation, I establish a similar expansion for multivariate kriging with non-linear predictands. The Bayesian coverage probability bias for prediction intervals is computed and compared with the frequentist plug-in method using the restricted maximum likelihood estimates of the covariance parameters. The expected length of a Bayesian prediction interval is computed. The form of the Bayesian predictive distribution can be expressed as partial derivatives of the restricted log-likelihood. This important development leads to possible analytical evaluation using a boot-strap method to obtain predictions for general, non-linear predictands, and overcomes the difficulties with iterative methods, such as MCMC, when the closed form of the distribution is not easily obtained. Future work can explore the existence of a matching prior. Applications include spatial analysis, environmental statistics, and network design.
Other Research started or continued at SAMSI:
“Downscaling Extremes: A Comparison of Extreme Value Distributions in Point-Source and Gridded Precipitation Data”. Joint work with Richard L. Smith, Stephen Sain, Linda Mearns, and Daniel Cooley. To appear (2009) Annals of Applied Statistics. (Finished this last month while at SAMSI.)
There is substantial empirical and climatological evidence that precipitation extremes have become more extreme during the twentieth century, and that this trend is likely to continue as global warming becomes more intense. However, understanding these issues is limited by a fundamental issue of spatial scaling: that most evidence of past trends comes from rain gauge data, whereas trends into the future are produced by climate models, which rely on gridded aggregates. To study this further, we fit the Generalized Extreme Value (GEV) distribution to the right tail of the distribution of both rain gauge and gridded events. The rain gauge data come from a network of 5873 U.S. stations, and the gridded data from a well-known re-analysis model (NCEP) and on climate model runs from NCAR's Community Climate System Model (CCSM). The results of this modeling exercise con_rm, as expected, that return values computed from rain gauge data are typically higher than those computed from gridded data; however, the size of the diverence is somewhat surprising with the rain gauge data exhibiting return values sometimes two or three times that of the gridded data. The main contribution of this paper is the development of a family of regression relationships between the two sets of return values that also take spatial variations into account. Based on these results, we now believe it is possible to project future changes in precipitation extremes at the point-location level based on results from climate models.
Continuing Collaborations while at SAMSI:
“Severe Weather Under a Changing Climate: Large Scale Indicators of Extreme Events”. Joint work with Eric Gilleland, NCAR.
There is much that can still be considered for this project. Once the data is available, a bivariate approach will be explored. The results so far indicate spatial dependence as well as multivariate dependence among the different large-scale indicators. Spatial extremes is an expanding field, and dependence structures can be introduced in different capacities to address both of these issues. There are several methods that can be investigated to resolve this dependence. In addition, while they provide an improvement in data retention, due to the tendency of extremes to occur in clusters and hence violate independence assumptions, threshold methods are susceptible to the same “loss of data” issues that they are intended to

69
resolve over the block-maxima approaches used in extreme value theory. The standard bias-variance trade-off is considered by Fawcett and Walshaw (2007), who provide an alternative approach to the standard errors which makes use of all of the data above the threshold while addressing the temporal dependence within extreme clusters. Heaton et al (2009, in preparation) considered a Bayesian modeling approach to address the tail behavior in physical regions for the indicators across the continental US, which could partially resolve the tail behavior issues occurring in the preliminary results for the global data. These approaches could both be considered.
Presentations of Other Research: “Max-Stable Processes: What’s Out There and Open Problems.” (Qorking title,
abstract available soon.) Presentation to the workshop on Spatio-temporal Extremes and Applications, November 2009 at Ecole Polytechnique Fédérale de Lausanne, Switzerland.
Research Progress Report & SAMSI Program Final Report Date: 7a-z. Research Contributions – Current Projects (grouped by Working Group) Research Project Title: Collaborator(s) & Mentor(s):
Specific Goals & Accomplishments (results): Research Contributions (publication submissions, articles in preparation, etc.): Presentations outside SAMSI (including invitations for future talks): 8. Future Research Plans (after completion of SAMSI Program) Research Area – Plans: Continuing Collaborations (if appropriate): Presentations outside SAMSI:

60
SAMSI Postdoctoral Fellow Research Plan Date: 10/15/2009 1. Name John McSweeney 2. Ph.D. Program
University & Department: The Ohio State University, Mathematics Dissertation Advisor: Boris Pittel Year of Ph.D.: 2009
3. SAMSI Research
SAMSI Program Title: Stochastic Dynamics SAMSI Research Mentor: Priscilla Greenwood SAMSI Administrative Mentor: Michael Minion
4a. SAMSI Activities Course(s) (fall & spring): Stochastic Dynamics: theory, modeling, and computation
(SAMSI); Jonathan Mattingly's probability course (Duke)
Workshops Attended (and Workshop Support Tasks): Stochastic Dynamics Opening workshop; technical support for speakers during Wednesday session
Postdoc-Grad Student Seminar – Presentation(s): None yet (scheduled for 11/23/09) Undergraduate Workshop(s) – Participation (specifics to be added later): None yet 4b. Other Activities (e.g., teaching) N/A 5a. Working Group I Biological Stochastic Dynamics Special Tasks for Working Group: local liaison for Lea Popovic, leader of the Reaction networks subgroup Presentations to Working Group: 10/20/09: Stochastic Reaction Networks (planned)
Research Area – Plans: -To understand the role of stochasticity in chemical and
intracellular reaction networks (including multi-scale). Based on the papers [BKPR], and [LW], under the theoretical framework presented in [K]
-To develop a single-neuron model for axonal transport (with B. Joshi, C. Greenwood, X. Wang)
5b. Working Group II Network Dynamics Special Tasks for Working Group: none

61
Presentations to Working Group: 9/30/09: Demonstration of iGraph software (with R interface) 10/21/09: Exploring the link between connectivity correlation properties of diesase dynamics on graphs (as presented in [EK]) and second-order connectivity properties of neuronal networks (as presented in [LN])
Research Area – Plans: -To develop stochastic versions of disease dyanmics on graphs -To establish links between social contagion networks and neuronal networks
(based on suggestions by P. Mucha and J. Nolen)
5c. Working Group III (if appropriate) N/A Special Tasks for Working Group: Presentations to Working Group:
Research Area – Plans: 6. Other Research
Work on Papers from Ph.D. Research: N/A Other Research started or continued at SAMSI: Informal working group on large
deviations (with A. Athreya and X. Wang), based on the textbook by Dembo and Zeitouni
Continuing Collaborations while at SAMSI: With D. Pearl, D. Schmidt (Ohio State/MBI) and B. Joshi (Duke): Coalescent models for parapatric speciation
Presentations of Other Research:
Bibliography [BKPR] Ball, K., Kurtz, T., Popovic, L., and Rempala, G. Asymptotic analysis of multiscale approximation to reaction networks. Annals of Applied Probability, Vol 16 no 4, 1925-1961. [EK] Eames, T.D. and Keeling, M.J. Modeling dynamic and network heterogeneities in the spread of sexually transmitted diseases, PNAS, vol 99 no. 20, 2002. [K] Kurtz, T. Averaging for Martingale problems and stochastic approximation. (1992) [LW] Lepzelter, D. and Wang, J. Exact probabilistic solution of spatial-dependent stochastics and associated spatial potential lasndscape for the bicoid protein Phys. rev. E. vol 77, 041917, 2008. [LN] Liu, C.-Y. and Nykamp, D.Q. A kinetic theory approach to capturing interneuronal correlation correlation: the feed-forward case. J. Computational Neuroscience, vol 26: 339-368, 2009.

72
SAMSI Postdoctoral Fellow Research Plan Date: October 15, 2009 1. Name: Bruce Rogers 2. Ph.D. Program
University & Department: Arizona State, Mathematics Dissertation Advisor: Thomas Taylor Year of Ph.D.: 2009
3. SAMSI Research
SAMSI Program Title: Stochastic Dynamics SAMSI Research Mentor: Peter Mucha SAMSI Administrative Mentor: Michael Minion
4a. SAMSI Activities Course(s) (fall & spring): Stochastic Dynamics (Fall)
Workshops Attended (and Workshop Support Tasks): Stochastic Dynamics Opening Workshop
Postdoc-Grad Student Seminar – Presentation(s): Poincare Inequalities on Markov Chains (Oct. 10)
Undergraduate Workshop(s) – Participation (specifics to be added later): 4b. Other Activities (e.g., teaching) Teaching Math 32 (Calc 2) at Duke 5a. Working Group I Special Tasks for Working Group: Data Assimilation Presentations to Working Group: Intro. to Stochastic Control (Oct. 6)
Research Area – Plans: We've formulated a problem in experimental design in the language of control theory; how can one find a maximally efficient asymptotic
estimator subject to some (multiplicative or additive) controls? Specifically, I would like to find an experimental regime that maximizes the power of estimating
parameters in the Lotka-Volterra model (over some control space).
5b. Working Group II Special Tasks for Working Group: Network Dynamics Presentations to Working Group: Statnet Tutorial (Sept. 30)
Research Area – Plans: Eames and Keeling (PNAS vol 99 (20)) have introduced a method for
incorporating network heterogeneities in a compartmental SIS model. In their

73
deterministic model, they subcompartmentalize by the degree of the individual. By making a
"natural" stochastic differential equation model from the deterministic framework, will
there be bimodality in the distribution of epidemic size as in the traditional stochastic
SI(R) model? What level of network information is needed in the
subcompartmentalized model to accurately capture the distribution of epidemic sizes?
5c. Working Group III (if appropriate) Special Tasks for Working Group: Presentations to Working Group:
Research Area – Plans: 6. Other Research
Work on Papers from Ph.D. Research: Poincare Inequalitites on Markov Chains--2 papers in preparation; Control of Consensus under Bounded Confidence--in prepartaion; Other Research started or continued at SAMSI: Mathematical models of Status Hierarchies Optimal Number of Food Sharing Partners Continuing Collaborations while at SAMSI: Network Affects on Computational Models of Generalized Reciprocity with
Cecelia Menjivar (in preparation) Stochastic Agro-Ecosystem Model with David Murillo (nearly submitted) Modeling Internet Traffic with Matthew Hindman (book and several
papers) Presentations of Other Research:
Research Progress Report & SAMSI Program Final Report Date: 7a-z. Research Contributions – Current Projects (grouped by Working Group) Research Project Title: Collaborator(s) & Mentor(s):
Specific Goals & Accomplishments (results): Research Contributions (publication submissions, articles in preparation, etc.): Presentations outside SAMSI (including invitations for future talks):

74
8. Future Research Plans (after completion of SAMSI Program) Research Area – Plans: Continuing Collaborations (if appropriate): Presentations outside SAMSI:

SAMSI Postdoctoral Fellow Research Plan
Date: 10/16/2009
1. NameBen Shaby
2. Ph.D. ProgramUniversity & Department: Cornell University, StatisticsDissertation Advisor: Martin Wells and David RuppertYear of Ph.D.: 2009
3. SAMSI ResearchSAMSI Program Title: Space-Time Analysis for Environmental Mapping, Epidemiology
and Climate ChangeSAMSI Research Mentor: Officially, Alan Gelfand, but he is not involved in any of
the working groups I have joined. The local faculty members who have been active in my working groups are David Dunson and Montse Fuentes, so I may end up being more involved with one or both of them.
SAMSI Administrative Mentor: Jim Berger
4a. SAMSI ActivitiesCourse(s) (fall & spring): Theory of Continuous Space and Space-Time ProcessesWorkshops Attended (and Workshop Support Tasks): Spatial opening workshop,
where I helped one or two speakers plug their usb thumb drives into the conference laptop.Postdoc-Grad Student Seminar – Presentation(s): I'm scheduled for 11/9, when I'll
talk about hierarchical Bayesian black box regression updating.Undergraduate Workshop(s) – Participation (specifics to be added later): I'll be
giving a short introduction to R.
4b. Other Activities (e.g., teaching)
5a. Working Group I Computation, Visualization, and Dimension Reduction in Spatio-Temporal Modeling
Special Tasks for Working Group:Presentations to Working Group: scheduled for 10/30 - “All you need to know about
(parameter estimation using) covariance tapering”Research Area – Plans: We don't seem to be quite far enough along to have specific
research plans. This is a little frustrating because there is a lot of talent and expertise in the group, but it really hasn't gotten off the starting block.
5b. Working Group II Non-Gaussian and Non-stationary Spatial ModelsSpecial Tasks for Working Group: WebmasterPresentations to Working Group:

Research Area – Plans: This is also a work in progress. So far it looks like there will be two foci: nonparametrics (via Dirichlet process type models), and models in the spectral domain. It's not yet clear how this will shape up.
5c. Working Group III (if appropriate) Spatial ExtremesSpecial Tasks for Working Group:Presentations to Working Group:Research Area – Plans:
6. Other ResearchWork on Papers from Ph.D. Research: Submitted a paper to JASA and one to JCGS
since I've been here. Also, I'm finishing up one for Biometrecs.Other Research started or continued at SAMSI: Working on some asymptotic theory
for spatial parameter estimation, an “open-faced sandwich” adjustment for m-estimation within MCMC, and a new method for dealing with huge datasets.
Continuing Collaborations while at SAMSI: I am still finishing papers with the Cornell Lab of Ornithology. I am also just starting a collaboration with Petros Drineas from RPI computer science, and I have continued to work with Cari Kaufman from UC Berkeley.
Presentations of Other Research: I'll be giving the weekly theory seminar in the computer science department at RPI 9/3.

SAMSI Postdoctoral Fellow Research Plan Date: 10/15/2009 1. Name Ravi Srinivasan
2. Ph.D. Program University & Department: Division of Applied Mathematics, Brown University Dissertation Advisor: Govind Menon Year of Ph.D.: 2009
3. SAMSI Research SAMSI Program Title: Stochastic Dynamics SAMSI Research Mentor: Jonathan Mattingly SAMSI Administrative Mentor: N/A
4a. SAMSI Activities Course(s) (fall & spring): -Stochastic Dynamics: Theory, Modeling, and Computation Workshops Attended (and Workshop Support Tasks): -Opening Workshop, 2009 Program on Stochastic Dynamics Postdoc-Grad Student Seminar – Presentation(s): -09/21/2009--Implementation of wikis to replace working group websites, jointwith Julien Cornebise (see below). -11/30/2009 (pending)--Will present work on `Kinetic theory of shock clusteringin Burgers turbulence.' Undergraduate Workshop(s) – Participation (specifics to be added later): -None at present time. 4b. Other Activities (e.g., teaching) -Designed, created, and implemented wiki to replace websites for working groups,assisted current postdocs in the transition, and packaged it for use in future years (jointlywith Julien Cornebise). 5a. Working Group I: Network Dynamics Special Tasks for Working Group: -Assisted in transition to wiki (see above). Presentations to Working Group: -09/30/2009--Presented intro to NetworkX software. Research Area – Plans: -A problem of current interest within the Network Dynamics group is toinvestigate the stochastic analogues of sub-compartmental models that arise in disease dynamics(and in other models of social contagion). At present, we have fairly detailed knowledgeregarding the SDE corresponding to a mean-field SIR model, which exhibits bimodality in thedistribution of total epidemic size. An interesting problem would be to consider similar

-09/21/2009--Implementation of wikis to replace working group websites, jointwith Julien Cornebise (see below). -11/30/2009 (pending)--Will present work on `Kinetic theory of shock clusteringin Burgers turbulence.' Undergraduate Workshop(s) – Participation (specifics to be added later): -None at present time. 4b. Other Activities (e.g., teaching) -Designed, created, and implemented wiki to replace websites for working groups,assisted current postdocs in the transition, and packaged it for use in future years (jointlywith Julien Cornebise). 5a. Working Group I: Network Dynamics Special Tasks for Working Group: -Assisted in transition to wiki (see above). Presentations to Working Group: -09/30/2009--Presented intro to NetworkX software. Research Area – Plans: -A problem of current interest within the Network Dynamics group is toinvestigate the stochastic analogues of sub-compartmental models that arise in disease dynamics(and in other models of social contagion). At present, we have fairly detailed knowledgeregarding the SDE corresponding to a mean-field SIR model, which exhibits bimodality in thedistribution of total epidemic size. An interesting problem would be to consider similar
distributional quantities in an SDE model obtained from a sub-compartmentalized SIR model (i.e.,one that drops the mean-field assumption). This modification has already proven more effectivethan the mean-field model in recovering average epidemic size in a model of STD spread (see K.Eames and M. Keeling (2002)). What is the proper SDE model in this case? Can we show that thissystem also exhibits the expected bimodality in epidemic size, at least numerically? How robustwould such a sub-compartmentalized model be with regards to the network structure? This projectwould be in collaboration with Peter Mucha and Cindy Greenwood, among others. 5b. Working Group II: Qualitative Behavior of Stochastic Dynamic Systems Special Tasks for Working Group: -Assisted in transition to wiki (see above). Presentations to Working Group: -10/21/2009 (pending)--Will present paper on `Rare Events in Stochastic PartialDifferential Equations on Large Spatial Domains' by E. Vanden-Eijnden and M. Westdickenberg. Thepurpose is to investigate the role of entropy provided by the large spatial extent in phenomenaexhibiting metastability, and how the large size of the system actually regularizes thetransition through a law of large number type of effect. Research Area – Plans: -There are several problems of interest that arise with regard to the paper tobe presented on 10/21/2009. One problem involves a proper derivation of kink formation in aone-dimensional sharp interface limit of the stochastic Allen-Cahn equation with symmetricpotential. The problem here reduces to an analysis of annihilating Brownian walkers on the realline. Although the dynamics of the model have been studied after kink formation has occurred(see, e.g., I. Fatkullin and E. Vanden-Eijnden (2003)), there is an issue with how kinks form tobegin with: two Brownian walkers are randomly spawned from the same location but instantlyannihilate a.s. due to sample path properties of Brownian motion. In the case of an asymmetricpotential there may be a finite probability of non-annihilation which would provide a mechanismfor kink formation in the model. I believe this would be an interesting problem to investigate. Another problem is to find a rigorous derivation of the JMAK nucleation andgrowth model from the large system SPDE model discussed in the paper. This is a subtle problemthat may not be feasible as a short-term project but it may be worth investigating with theworking group on a longer time scale. It may also be quite interesting to consider the problemof a multi-well potential corresponding to a cascade of nucleations and how it relates to thePNG model, an in turn, the problem of largest eigenvalues of random matrices (this statement isexplicitly made in the paper). Although these connections have already been studied in theliterature, it may be worth reviewing the steps that lead to this relationship.
5c. Working Group III (if appropriate) Numerical Methods for Stochastic Systems Special Tasks for Working Group: -Assisted in transition to wiki (see above). Presentations to Working Group: -None at present time. Research Area – Plans: -My main purpose in attending this working group is to broaden my perspective onproblems in numerical methods for multiscale systems (deterministic or In particular I wouldlike to obtain a deeper understanding of the relevance of kinetic theory in out-of-equilibriumproblems that exhibit non-Gaussian statistics.

distributional quantities in an SDE model obtained from a sub-compartmentalized SIR model (i.e.,one that drops the mean-field assumption). This modification has already proven more effectivethan the mean-field model in recovering average epidemic size in a model of STD spread (see K.Eames and M. Keeling (2002)). What is the proper SDE model in this case? Can we show that thissystem also exhibits the expected bimodality in epidemic size, at least numerically? How robustwould such a sub-compartmentalized model be with regards to the network structure? This projectwould be in collaboration with Peter Mucha and Cindy Greenwood, among others. 5b. Working Group II: Qualitative Behavior of Stochastic Dynamic Systems Special Tasks for Working Group: -Assisted in transition to wiki (see above). Presentations to Working Group: -10/21/2009 (pending)--Will present paper on `Rare Events in Stochastic PartialDifferential Equations on Large Spatial Domains' by E. Vanden-Eijnden and M. Westdickenberg. Thepurpose is to investigate the role of entropy provided by the large spatial extent in phenomenaexhibiting metastability, and how the large size of the system actually regularizes thetransition through a law of large number type of effect. Research Area – Plans: -There are several problems of interest that arise with regard to the paper tobe presented on 10/21/2009. One problem involves a proper derivation of kink formation in aone-dimensional sharp interface limit of the stochastic Allen-Cahn equation with symmetricpotential. The problem here reduces to an analysis of annihilating Brownian walkers on the realline. Although the dynamics of the model have been studied after kink formation has occurred(see, e.g., I. Fatkullin and E. Vanden-Eijnden (2003)), there is an issue with how kinks form tobegin with: two Brownian walkers are randomly spawned from the same location but instantlyannihilate a.s. due to sample path properties of Brownian motion. In the case of an asymmetricpotential there may be a finite probability of non-annihilation which would provide a mechanismfor kink formation in the model. I believe this would be an interesting problem to investigate. Another problem is to find a rigorous derivation of the JMAK nucleation andgrowth model from the large system SPDE model discussed in the paper. This is a subtle problemthat may not be feasible as a short-term project but it may be worth investigating with theworking group on a longer time scale. It may also be quite interesting to consider the problemof a multi-well potential corresponding to a cascade of nucleations and how it relates to thePNG model, an in turn, the problem of largest eigenvalues of random matrices (this statement isexplicitly made in the paper). Although these connections have already been studied in theliterature, it may be worth reviewing the steps that lead to this relationship.
5c. Working Group III (if appropriate) Numerical Methods for Stochastic Systems Special Tasks for Working Group: -Assisted in transition to wiki (see above). Presentations to Working Group: -None at present time. Research Area – Plans: -My main purpose in attending this working group is to broaden my perspective onproblems in numerical methods for multiscale systems (deterministic or In particular I wouldlike to obtain a deeper understanding of the relevance of kinetic theory in out-of-equilibriumproblems that exhibit non-Gaussian statistics.
6. Other Research Work on Papers from Ph.D. Research: -Submitted joint work with Govind Menon on `Kinetic theory and a Lax pair forshock clustering and Burgers turbulence,' Sept. 2009. -Edited/resubmitted work on `Rates of convergence for Smoluchowski's coagulationequations,' Oct. 2009 Other Research started or continued at SAMSI: -At present I am collaborating with Jonathan Mattingly and Scott McKinley on aproject closely connected to my Ph.D. research. The relevant problem here is to consider theBurgers turbulence problem with a stationary stochastic forcing at the boundary of thehalf-infinite domain in order to understand how randomness is propagated through the system viathe deterministic flux. That is, we seek to understand the asymptotic properties of theinvariant measure in space, and hope to be able to do this via the Lax pair formulationinvestigated in the random initial data problem in my thesis. Although the problem isinteresting from a purely mathematical perspective, it may be relevant in obtaining a deeperunderstanding of shell models of turbulence and other physically motivated problems. -Another problem I am working on is that of complete integrability of theBurgers turbulence model with white noise initial data. This problem is of fundamental interestin a variety of contexts since it is essentially the study of the convex hull of Brownian motionwith a parabolic drift. Here we seek an appropriate representation of the model as aninfinite-dimensional Hamiltonian system, and to use classical methods in integrable systemstheory (Riemann-Hilbert analysis, inverse scattering) to rederive the exact solution obtained byGroeneboom (1989) for white noise data. I have been discussing this problem with StephanosVenekides at Duke. Continuing Collaborations while at SAMSI: -None at present time. Presentations of Other Research: -None at present time.

SAMSI Postdoctoral Fellow Research Plan
Date: 16 October 2008
1. Martin Tingley
2. Ph.D. ProgramUniversity & Department: Harvard University, Department of Earth and Planetary Sciences.Dissertation Advisor: Peter Huybers.Year of Ph.D.: 2009.
3. SAMSI ResearchSAMSI Program Title: 2009-10 Program on Space-time Analysis for Environmental Mapping,Epidemiology and Climate Change.SAMSI Research Mentor: Bala Rajaratnam, Noel Cressie.SAMSI Administrative Mentor: Pierre Gremaud.
4a. SAMSI ActivitiesCourses: Theory of Continuous Space and Space-Time Processes (Fall), Spatial Statistics inClimate, Ecology and Atmospherics (Spring).Workshops Attended: Opening workshop for the spatial program, climate workshop in February,transition workshop when it occurs.Postdoc-Grad Student Seminar: Presentation: "A Bayesian approach to reconstructing climatefields from proxy time series, applied to 600 years of high northern latitude surfacetemperatures" (12 October 2009).Undergraduate Workshop: Presentation at the 30-31 October workshop, ""Paleoclimate!Reconstructing past temperatures using natural thermometers."
4b. Other Activities
I don't know what I'm supposed to put in this section.
5a. Working Group I : PaleoclimateSpecial Tasks for Working Group: Webmaster.
Presentations to Working Group: "A primer on climate proxy data," one hourpresentation on 24 Sept 2009. I will be lead the discussion on 29 October, "Open problems inpaleoclimate research."
Research Area – Plans: This working group is well aligned with my doctoral work,which I plan on continuing and expanding over the next few years. My goals with regards to thepaleoclimate working group and my own research are twofold: 1) learn more statistics from theother group members (and from the SAMSI community in general), to further my own researchagenda, and 2) interest the larger statistical community in paleoclimate research. There is a need

for more statistically sophisticated approaches to the analysis of paleoclimate data, and mybackground in both the earth sciences and statistics puts me in a unique position to makeadvancements in this regard. The paleoclimate working group at SAMSI is an excellent forum tomake progress on the statistical (as opposed to data) side of climate reconstruction problems, andI plan on taking full advantage of the opportunity.
Our working group is still in the exploratory stage, with the meeting so far focusing on thesources of paleoclimate data and various statistical approaches used to combine proxy records toinfer past temperatures. In the next few weeks, we plan on honing in on specific researchquestions, and I plan on being heavily involved in both this process, and the actual research.
My graduate work focused on the development of BARCAST, a "Bayesian Algorithm forReconstructing Climate Anomalies in Space and Time." As currently construed, this algorithmmakes the simplest set of assumptions that are at all reasonable. The submitted manuscript thatdescribes the algorithm (see section 6, below) includes a list of possible generalizations, and Iwould like to implement some of these over the next year. In particular, I currently make use ofan isotropic, exponentially decaying spatial covariance form, and assume that each proxyobservation is linearly related to the local (in space and time) value of the true field. Both ofthese assumptions can be generalized, and doing so will allow for the inclusion, for example, ofproxy observations that represent some average of a climate field in space and time. Afunctioning algorithm that can combine proxies that relate to the underlying climate field ondifferent spatial and temporal scales would be of broad interest to the paleoclimate community.
5b. Working Group II : Spatial ExtremesSpecial Tasks for Working Group: None.Presentations to Working Group: Nothing planned at this time.Research Area – Plans: I've been attending the meetings for this working group due to
the importance of extreme events in the science of climate change. The frequency of extremetemperature and precipitation events, and extreme storms, are all conjectured to increase as greenhouse gas concentrations continue to rise. The notion of space-time extremes is thereforerelevant to my own interests in studying the climate of the past as well as the current changes inthe climate system. My hope is that I learn something relevant to these problems in this workinggroup. So far, however, the meetings have been rather theoretical, and lacking a strong (actually,any) background in the statistics of extremes, I've felt rather lost. My hope is that at some point,the group deals with some practical applications, which will ground some of the theoreticalnotions in reality.
5c. Working Group III : Computation, Visualization, and Dimension Reduction inSpatio-Temporal Modeling
Special Tasks for Working Group: None.Presentations to Working Group: Nothing planned at this time.Research Area – Plans: Paleoclimate data sets are large, in both space and time. A
temperature reconstruction at a 5 by 5 degree resolution over the northern hemisphere involves1296 spatial locations, and many hundred to several thousand time points. The computational

challenges posed by these data sets are considerable, and I hope to learn techniques, tricks, andinsights for dealing with large space-time data sets. So far, the working group has lacked acohesive focus, perhaps due to the large number of people involved and the broad array ofsubjects covered in presentations made at the group meetings. When the group begins to laydown more specific problems and challenges, and perhaps defines subgroups to investigateparticular topics, I may become more involved.
With regards to the working groups in general, my goals are practical: to advance my ownresearch objectives, to learn more statistics, and to interest more statisticians in the science ofclimate change. That said, I am, of course, more than open to working on new problems thatmight fall outside of my current research plans, provided they are motivated by interesting real-world applications. One difference I have noticed between the earth sciences and SAMSI is thatresearch talks in the earth sciences are almost always motivated by a particular real-worldproblem, and the focus of the talk will be on advancing knowledge with regards to that problem.Theoretical developments and the fitting of complex models are considered steps towards asolution, rather than the main objects of intellectual interest. At SAMSI, I have seen a number oftalks that are very well motivated by real-world applications (monitoring fish stocks in theMissouri river, tsunami prediction, . . . . ), but which focus on theoretical developments, theconstruction of a sophisticated data model, or computational tricks that allow the analysis to beconducted. I have been somewhat alarmed at the number of times these talks have not comearound full circle, to explain how the theory feeds back to advance understanding of themotivating problem. Perhaps this is a difference in academic cultures, whereby the earth sciencecommunity sees the practical problem as of greatest interest, while the math/stats communityoften (it seems) considers the model building and theoretical developments to be of greatestinterest. I recognize the importance of theoretical work, but am most interested in problemsfirmly grounded in practical, real-world applications - preferably real world applications thathave some form of societal relevance.
While these remarks are perhaps somewhat off topic, I include them in this research proposal asthey provide background information about my own approach to research. The 'A' in SAMSI canjust as well apply to the 'S' as to the 'M,' and that has certainly been, and will likely continue tobe, the case in my own work.
6. Other Research
Work on Papers from Ph.D. Research:
Submitted manuscripts:
Tingley, Martin P. and Peter Huybers. A Bayesian Algorithm for Reconstructing ClimateAnomalies in Space and Time. Part 1: Development and applications to paleoclimatereconstruction problems.

Tingley, Martin P. and Peter Huybers. A Bayesian Algorithm for Reconstructing ClimateAnomalies in Space and Time. Part 2: Behavior and comparison with the regularizedexpectation-maximization algorithm.
Tingley, Martin P. and Peter Huybers. The spatial mean and dispersion of surface temperaturesover the last 1200 years: warm intervals are also variable intervals.
The first two papers are in revision at Journal of Climate. We are in the process of responding tothe second round of reviews, and the manuscripts will be resubmitted shortly. We are confidentthey will be accepted in short order.
The third paper, which concerns a project largely unrelated to the other papers and my main lineof research, was submitted to Climatic Change. The review process took well over a year, and asa result, the data sets used in the paper are somewhat out of date. The reviewers have asked forsignificant changes to the data analysis we present, as well as major changes to the structure andfocus of the paper. Dealing with these reviews will be a major effort, and while I do plan onmodifying the paper and resubmitting, doing so is a secondary priority.
The final chapter of my thesis presented an analysis of a high northern latitudes multi proxytemperature data set, which extends back to 1400. I have been talking about this work for a fewmonths now, and writing it up for publication is a high priority. My collaborators on the project(Peter Huybers and Konrad Hughen) feel that we should aim for a high profile publication, therationale being that the analysis is the longest temperature reconstruction for the region that isboth spatially complete and annually resolved, and it is the first practical application of a newapproach (BARCAST) to reconstructing past climate. Our plan is to submit to Science, and if weare rejected, to Nature and then Geophysical Research Letters.
Presentations of Other Research, Continuing Collaborations while at SAMSI:
Here is a list of non-SAMSI research activities I have planned for the coming academic year.
- I gave the weekly seminar at UNC's Department of Geological Sciences on 15 October 2009.
- I will be attending a symposium on Arctic climate and meeting with collaborators (PeterHuybers, Konrad Hughen) at Harvard University, 9-11 November 2009.
- I will be visiting NCAR on 9-10 December 2009, to meet with Doug Nychka, Stephen Sain,Caspar Ammann and others about the work I will be conducting there next year.
- AGU, 14-18 December 2009. The format of my presentation, entitled "High northern latitudetemperature extremes, 1400-1999," has yet to be assigned.
- I will be meeting with Michael Mann, Scott Rutherford, and other members of their researchteam at AGU, to discuss possible collaborations.

- Tentatively, I will be speaking at Lamont-Doherty Earth Observatory of Columbia Universitysometime in the spring, and exploring possible collaborations with a number of scientists there,including Ed Cook, Kevin Anchukaitis, and Jason Smerdon. That group has also been interactingwith Andrew Gelman, so I am excited about possible research opportunities at the intersection ofstatistics and the earth sciences.
Other Research started or continued at SAMSI:
One of the recurring themes in the continuous space-time processes class being taught at SAMSIthis semester is the inadequacy of separable models of space time covariance structures in realdata applications. In my own work on paleoclimate reconstructions, I assume a separablecovariance form, and most other approaches do not even consider temporal auto correlation. Inshort, the statistical techniques used to reconstruct past climate are primitive relative to thetechniques discussed in class. At some point, it seems likely that the paleoclimate communitywill adopt more sophisticated statistical models. I am interested in a starting a simple projectabout the issue of separability in the context of paleoclimate reconstructions.
I have no concrete plans at this time, but am thinking of something along the following lines.First, I am curious to see if the instrumental and proxy data sets I've been using display non-separable space-time covariance structures. I believe Alan Gelfand mentioned tests forseparability have been developed, so I would have to learn about those. If the data sets areseparable, then this is an interesting result, as it would show that relatively simple statisticalmodels are appropriate for the analysis. I suspect, however, that the tests will show that the datasets display non-separable space-time covariance. This is also an interesting result, as it showthat there is still room for improvements in the climate reconstruction business, and that currentstatistical models are not capturing the richness of the underlying space-time field. In addition, Iam curious to see how BARCAST, my own climate reconstruction algorithm which assumesseparability, performs on decidedly non separable data sets.The results of this research would (Ithink) form the basis of a nice paper, of interest to those who think about how to reconstruct thepast climate.
Bala and I are also in the initial stages of defining a project we can work on together.
See also section 5a.

85
SAMSI Postdoctoral Fellow Research Plan Date: 1. Name: Xueying Wang 2. Ph.D. Program
University & Department: The Ohio State University & Department of Mathematics Dissertation Advisor: Dr. David Terman Year of Ph.D.: 2009
3. SAMSI Research
SAMSI Program Title: Stochastic dynamics SAMSI Research Mentor: SAMSI Administrative Mentor: Dr. Pierre Gremaud
4a. SAMSI Activities Course(s) (fall & spring): Stochastic Dynamics: Theory, Modeling, and Computation
Workshops Attended (and Workshop Support Tasks): Opening workshop for 2009-2010 program on stochastic dynamics
Postdoc-Grad Student Seminar – Presentation(s): Undergraduate Workshop(s) – Participation (specifics to be added later): 4b. Other Activities (e.g., teaching) 5a. Working Group I Special Tasks for Working Group: to understand network dynamics for stochastic systems Presentations to Working Group:
Research Area – Plans: Avanti Athreya, John Mcsweeney and I plan to develop stochastic compartmental models to study epidemiology for infectious diseases under the supervision of Dr. Cindy Greenwood and Dr. Peter Mucha.
5b. Working Group II Special Tasks for Working Group: to characterize the qualitative behavior of the stochastic dynamic systems Presentations to Working Group: A sample path approach to stochastic resonance (based on Berglund and Gentz's work on stochastic resonance)
Research Area – Plans: Avanti Atheriya and I are working on stochastic resonance on Morris Lecar model under the supervision of Dr Cindy Greenwood. We would like to understand the noise-induced resonance by comparing the firing patterns of Fitzhugh Nagumo model and those of Morris Lecar model.
.
5c. Working Group III (if appropriate) Special Tasks for Working Group:

86
Presentations to Working Group: Research Area – Plans:
6. Other Research
Work on Papers from Ph.D. Research: I am writing a paper on my Ph.D. Thesis. Other Research started or continued at SAMSI: Continuing Collaborations while at SAMSI: Presentations of Other Research:
Research Progress Report & SAMSI Program Final Report Date: 7a-z. Research Contributions – Current Projects (grouped by Working Group) Research Project Title: Collaborator(s) & Mentor(s):
Specific Goals & Accomplishments (results): Research Contributions (publication submissions, articles in preparation, etc.): Presentations outside SAMSI (including invitations for future talks): 8. Future Research Plans (after completion of SAMSI Program) Research Area – Plans: Continuing Collaborations (if appropriate): Presentations outside SAMSI:

87
SAMSI Postdoctoral Fellow Research Plan Date: 1. Name: Jun Zhang 2. Ph.D. Program
University & Department: University of Wisconsin-Madison, Department of Statistics Dissertation Advisor: Murray Clayton Year of Ph.D.: 2009
3. SAMSI Research
SAMSI Program Title: Space-time Analysis for Environmental Mapping, Epidemiology and Climate Change
SAMSI Research Mentor: Richard Smith SAMSI Administrative Mentor: Nell Sedransk
4a. SAMSI Activities Course(s) (fall & spring): 1.Theory of Continuous Space and Space-Time Processes 2. Spatial Epidemiology
Workshops Attended (and Workshop Support Tasks): Opening workshop for spatial program Sept. 13-16,2009.
Postdoc-Grad Student Seminar – Presentation(s): Oct.26, 2009 on regression models for spatial images Undergraduate Workshop(s) – Participation (specifics to be added later):Oct 30-31, 2009, Matlab tutorial lab. 4b. Other Activities (e.g., teaching) None for this semester. 5a. Working Group I Spatial extremes Special Tasks for Working Group: None. Presentations to Working Group: In discussion with the group leader.
Research Area – Plans: possibly some topics related with max-stable process, I am discussing the details with Prof. Smith.
5b. Working Group II Fundamentals of spatial modeling Special Tasks for Working Group: Webmaster for this group. Presentations to Working Group: Nov. 11 on regression models for spatial images
Research Area – Plans:So far the main activities are presentations about previous research or paper reviews by group members.
5c. Working Group III (if appropriate) Computation, Visualization and Dimension reduction in spatial-temporal modeling Special Tasks for Working Group: None. Presentations to Working Group: In discussion with the group leader.

88
Research Area – Plans:We haven't settled down on any particular topics yet. So far mainly people gave presentations about their previous research. I have an idea on dimension reduction with 3-Dimensional data-cubes which include spatial-temporal data. Currently I am experimenting with toy datasets and the idea is still in its early stage. 6. Other Research
Work on Papers from Ph.D. Research: 1. working on the final revision of paper on regression models for spatial images. This paper has been submitted to JABES earlier this year and the current revision is a resubmission. 2. Will work on a new paper on how to deal with missing data when fitting regression models for spatial images
Other Research started or continued at SAMSI: 1. Collaboration with Lin Xie (Dept. of EE, University of Wisconsin-Madison) on path segmentation identification for post-silicon time delay in chip design. The time delay data is a spatial dataset and can become very large. It is a challenging application problem.
Continuing Collaborations while at SAMSI: I am still collaborating with my Ph.D. Adviser Murray Clayton on my second paper about regression models for spatial images.
Presentations of Other Research:I will think about this, once I have done some new topics at SASMI.
Research Progress Report & SAMSI Program Final Report Date: 7a-z. Research Contributions – Current Projects (grouped by Working Group) Research Project Title: Collaborator(s) & Mentor(s):
Specific Goals & Accomplishments (results): Research Contributions (publication submissions, articles in preparation, etc.): Presentations outside SAMSI (including invitations for future talks): 8. Future Research Plans (after completion of SAMSI Program) Research Area – Plans: Continuing Collaborations (if appropriate): Presentations outside SAMSI:

89
5. Postdoctoral Fellow Experience Evaluations
Avanti Athreya
1. Program Involvement:
Which SAMSI program(s) have you been involved with and at what level(s)? (e.g., “been doing
active research on …” or “just went to a tutorial/workshop to learn about that area which is new
to me”)
Stochastic Dynamics, with active research in molecular motors, qualitative behavior of SDEs,
and neuron models
2. Interactions with Other Institutions:
Describe your interactions with other institutions while at SAMSI. (e.g., a Triangle university,
NISS or CRSC)
Gave talks at UNC and NC State; mentored an undergraduate PRUV fellow at Duke on a project
in which we modeled escape times from a double-well potential with small noise and small
deterministic oscillations and level crossing from a breathing potential with noise
3. High Points at SAMSI:
What have been the high points of your SAMSI experience?
Interacting with other faculty and postdocs in the working groups; it’s great that SAMSI brings
together mathematicians and statisticians from all three major universities
4. Suggestions for Improvement:
How could your SAMSI experience have been improved?
Extend the postdocs by one additional year so that postdocs have an extra year before they apply
for jobs; encourage more junior faculty (assistant professors) to participate---they face some of
the same time and career pressures as the new postdocs, and it was very helpful to be able to
work with them
5. Mentoring:
SAMSI aims to provide solid mentoring of Postdocs. How successful has this been in your case?
I would have benefited from having a few more small-scale, soluble problems to address right
away, just from the perspective of going on the job market so soon. But I realize that this isn’t
always realistic, and I appreciated the scientific mentoring and constant encouragement I
received from Jonathan Mattingly, Cindy Greenwood, Pete Kramer, and John Fricks. Also, I
received helpful mathematical input, mentoring, and advice from the more senior postdocs (Scott
McKinley, Oliver Diaz, and Matthias Heymann at Duke). I think it’s great to have this mix of
senior faculty, junior faculty, and more advanced postdocs in the same place.
6. SAMSI Benefits for the Future:

90
Has your SAMSI experience met your expectations in preparing you for your next position? Are
there (new) benefits that you now perceive coming from your SAMSI experience that are
relevant to your career in the future?
Yes---I’ve been exposed to multiple avenues of research, particularly in more applied areas with
which I was unfamiliar before coming to SAMSI. Also, by mentoring undergraduates during the
workshops and through the PRUV program at Duke, I’ve learned quite a bit about appropriate
problem selection and the distillation of technical ideas to more manageable levels for
undergraduate teaching.
7. SAMSI in contrast with University Setting:
How do you think your SAMSI experience compares to what you might have encountered in a
typical university setting?
I think it was better in many ways, because I was exposed to a wide variety of problems and got
to interact with researchers from multiple institutions. Also, the opportunities to speak at
workshops, participate in working groups, and lead discussions on specific problems were
invaluable.
8. SAMSI in comparison to Other Experiences:
If you have had experience in an industrial, national or other lab setting, how would you compare
that experience with your SAMSI experience?
9. Other Research while at SAMSI:
If you have spent considerable time during your appointment with some other research group,
please comment on the benefits and drawbacks of this experience. (e.g., if your appointment was
extended via an appointment at NISS, CRSC or elsewhere)
10. Other Issues:
Are there other issues or concerns you would like to bring up?
Julien Cornebise
1. Program Involvement:
Part of the Tracking and Population Monte Carlo working groups of the Sequential Monte Carlo
program. See details in the mid-program report.
2. Interactions with Other Institutions:
Collaborations are ongoing with Duke University, with my former co-author from Lund
University, and with my former Ph.D. advisor from Télécom ParisTech, France. See details in
the mid-program report.

91
Past interactions include stays in Computer Science engineering school ESIEA (5 years),
Université Paris 6 (4 years), National engineering school Telecom ParisTech (3 years), private
pharmaceutical company’s statistical company (6 months), Lund University (1 month).
3. High Points at SAMSI:
I am literally amazed by the incredible opportunities to meet and interact with most of the best
researcher of the field. People which were so far only (somewhat mythic) names on articles are
now blood and flesh persons, researchers, colleagues, which is a tremendous transition from the
grad studies to the post-doctorate research. On a scientific point of view, these interactions bring
a deep re-evaluation of my earlier work, making it fit in a much broader view of the field,
stressing its advantages, seeing how it can be extended to neighboring areas. On a more human
point of view, they contribute to mutating a finishing student into a full and mature (though
young) member of the scientific community.
An especially remarkable high point is also the very consideration brought to the post-docs as
researchers. However rich and benefiting the experience as a grad student may have been, the
role of a post-doc is definitely one of a entire researcher, with the associated responsibilities – in
terms of research, organization of working groups, advises to graduate students – and the
associated consideration and status. I cannot stress enough the extremely positive impact this
change of perspective had on the very nature of my work and my approach to research. However
personal this might look, this newly acquired self-confidence, and realizing that, yes, I belong
here, I belong to the research community, are something that can hardly be expressed in its full
importance. Besides, discussions with several other postdocs have led me to realize that this
relief and the former doubts seem to be a common issue amongst young doctors, which help all
the most to reduce them and move on to the next stage.
On a more “local” scale, but nevertheless so important, I must thank the whole SAMSI staff, and
especially the “Fantastic Four”, “SAMSI’s angels”, Denise Auger, Rita Fortune, Sue McDonald,
Terri Nida, for their so precious help, from the first pre-hiring interview to the settling of all the
practical and administrative details upon arrival – from lodging to VISA issues, all the more
important to a newcoming foreigner –, and still keeping on through the day-to-day life in
SAMSI. Never, ever, did I meet such a dedicated, patient, helpful and welcoming team.
4. Suggestions for Improvement:
I hardly see any point that could be improved at SAMSI. Concerning the offered setting and
means for doing research, it seems like it cannot be more perfect that it is.
The only point I can find concern the computer resources. SAMSI is gifted with great hardware,
the brand new computers are “computational beasts”, and the number of computers is striking for
such an institute. However, it could really benefit a centered network administration, which
would first and foremost allow remote access – hence making them real work platforms available
from anywhere that one could rely on.
Please don’t read me wrong: the current IT responsible, James Thomas, is extremely willingful
to help, and I here wish to thank him for the reactivity and the help he provides to everyday
problems, from the failing printer to Matlab installation, from the need for a new mouse to the

92
addendum of a new software. James Thomas fulfills these IT needs with a dedication that forces
the admiration -- I saw him staying until the middle of the night setting up the new computers !
My only suggestion regarding improvements would be to evaluate whether the joint network
administration of both NISS and SAMSI networks can be dealt by a single administrator.
Though this is probably not the kind of advice expected from a post-doctoral fellow, I would
recommend thinking of doubling the resources allocated to this task: SAMSI’s potential is here
grand, but still dormant.
My experience so far (both as a user, and as a system administrator for several years in a
professional context) is that the network administrators are always a team of at least two people,
that hence provide completing competences and knowledge (network administration getting a
broader and broader field), as well as a mandatory double reflection and confronting (therefore
enriching !) point of views on crucial technical choices – especially in a sensitive networks such
as NISS and SAMSI have been outlined to be in the last postdoctoral lunch.
Up to an added increase of security (which has a price that can hardly be measured) and
efficiency, the cost would most likely not be as increased as expected, as the spending on a
salary would partly be compensated by reduced call to external maintenance and services.
5. Mentoring:
I here would like to express my gratitude for the great comprehension of SAMSI directorate, first
and foremost of its director – and my administrative advisor – Jim Berger. SAMSI allowed for
exceptional measures to adapt the post-doctoral contract to the late schedule of my dissertation
(whose completion was originally planned just before the beginning of SMC program), and
permit me to be part of this grand research occasion while still finishing my dissertation.
I will never forget the open-mindness I have witnessed (and benefited!) when discussing this
matter with Jim Berger, comparing efficiently the possible ways to tackle it, and the strong will I
perceived to find a solution optimal to both SAMSI and its postdoc. I was afraid that these delays
(for which I take entire responsibility) may have put an end to the warm welcome I found in
SAMSI. On the very contrary, an offer that was then worked out to finish my 3 months stay here,
then getting back to France for a couple of month – time to finish writing the manuscript while
keeping up to date to SAMSI’s program – then coming back as a full-time postdoctoral fellow.
This generous and ideal (from my point of view) agreement was a tremendous incentive to
wrapping up the leftover writing as fast as possible, and to give the best of my possibilities to
SAMSI, both while back in France to keep up to the progresses of the working groups, but, even
more important, now that I am back, done with the dissertation.
For this, again, I would like to renew my thanks to Jim Berger and the directorate of SAMSI.
On the scientific side, the mentoring from Arnaud Doucet has been extremely benefiting. Its long
stay during the whole Fall of 2008 was the occasion of fascinating conversations, extremely
enriching, as well as occasions to become a reviewer through an article to which editor he
recommended me. Beyond that, his mentoring keeps on going now that he is in Japan, by means
of email conversations and his support in a grant application to join him at the Institute for
Statistical Mathematics in Japan for a two months stay next Fall.
6. SAMSI Benefits for the Future:

93
The benefits from my SAMSI experience have been outlined at length in the question above, and
can be summarized as triggering the key mutation from a finishing grad student to a fulltime
researcher, active member of the community.
7. SAMSI in contrast with University Setting:
In my opinion, SAMSI’s uniqueness resides in the way it relies on the post-doctorates as the
coordinators of its day-to-day scientific life, from working group coherence to welcoming of
“anchor point” for visiting researchers and professors. In a university setting, my guess is that
this unique role and would be conferred to local assistant professors, rather than postdocs. This
responsibility, however, is the key benefit of SAMSI, as it pushes to a greater dynamism and
increased interaction with the members of the program.
8. SAMSI in comparison to Other Experiences:
I lack extra-university research experiences to make a comparison, e.g. with private research
institutes. However, I can compare with the average French position, when no post-doctoral
research position is found after a research, as “Teaching and Research Assistant” (A.T.E.R.),
which is a one-year once-renewable contract consisting of a full teaching load. It is commonly
reported by young French researchers – though I did not experiment it firsthand, so this is to be
taken with caution, while keeping in mind that, happily, this is only a tendency to which a lot of
exceptions do exist – that the young A.T.E.R. is mainly filling the gaps in the teaching schedule,
and that the only achievable research during this year can be finishing some articles taken from
the Ph.D. dissertation.
No need to stress how much this lies at the opposite extreme of SAMSI.
9. Other Research while at SAMSI:
As stated in the “Mentoring” section, during my first 3 months stay, I have both been acting in
two working groups and worked on finishing writing my Ph.D. dissertation. Now that I have
been back for a month, and as is further detailed in my mid-program report, the only other
research planned while at SAMSI consists on finishing two articles out of my dissertation.
Besides, these two articles are deeply related to SAMSI’s SMC program, as my whole Ph.D. is
about Adaptive SMC methods. Therefore, this “other research while at SAMSI” still can be seen
as part of the working group activities.
Here again, the benefits of being at SAMSI are blatant, in terms of the scientific maturity in the
field, gained by the never-ending interactions occurring there.
10. Other Comments:
I can only renew the expression of my joy to be part of SAMSI. From a professional and
scientific perspective, it brings incredible assets, and (as far as I can judge) a formidable booster
for a research career. On the human perspective, the dynamic and the energy flowing in SAMSI
are a precious gift. I already guess that meeting again such a highly stimulating environment will
not occur easily !

94
E m i l y K a n g
1. Program Involvement:
Which SAMSI program(s) have you been involved with and at what level(s)? (e.g., “been doing
active research on …” or “just went to a tutorial/workshop to learn about that area which is new to
me”)
I have involved in the 2009 program on Space-Time Analysis for Environmental Mapping,
Epidemiology and Climate Change. I have been working with Johan Harlim in multiscale
computation strategies in stochastic spatio-temporal systems, which is new to me. Meanwhile, I am
involved in a subgroup in one of the working groups, where we are analyzing ash data for the Iceland
volcano eruptions.
2. Interactions with Other Institutions:
Describe your interactions with other institutions while at SAMSI. (e.g., a Triangle university, NISS
or CRSC) I gave a presentation at the Bayesian Statistics Working Group at Department of Statistics
in NC State University I taught St371 at NC State University in the first summer session
3. High Points at SAMSI:
What have been the high points of your SAMSI experience?
Opportunities to know and collaborate people in and out of my fields
4. Suggestions for Improvement:
How could your SAMSI experience have been improved? I would prefer being given one specific
projects to work on while we are also given enough time and flexibility for our own interests.
5. Mentoring:
SAMSI aims to provide solid mentoring of Postdocs. How successful has this been in your case?
Good.
6. SAMSI Benefits for the Future:

95
Elizabeth Mannshardt Shamseldin
1. Program Involvement:
Which SAMSI program(s) have you been involved with and at what level(s)? (e.g., “been doing
active research on …” or “just went to a tutorial/workshop to learn about that area which is new
to me”)
I have been actively involved
in the Space-Time Analysis for Environmental Mapping, Epidemiology and Climate Change
program for 2009-2010. I have actively participated in two working
groups, Spatial Extremes and Paleoclimate, as well as two sub-groups,
Paleo Extremes and Extreme Attribution. Presented a poster “Severe Weather Under a Changing
Climate: Large Scale Indicators of Extreme
Events” at the Opening Workshop Poster Session
and a corresponding presentation 10/19 for the SAMSI Postdoc seminar series. I also presented
“Extremes in Paleoclimate Proxy Data” on 2/15 for Post-doc Seminar. I
will be presenting this work at the International Meetings for Statistics in
Climatology meeting in Edinburgh in July, as well as at JSM in August. I plan to participate in
the SAMSI program transition workshop in October.
2. Interactions with
Other Institutions:
Describe your interactions with other institutions while at SAMSI. (e.g., a Triangle university,
NISS or CRSC)
For the last two years, I have had a joint appointment as a Visiting Assistant Professor at
Duke University. In the spring (2010), I taught Sta10 – “Stats And Quantitativ Literacy”, a
concept-based introduction to statistics course for non-science majors at Duke. I also served as
the adviser for an undergraduate statistics major at Duke who wrote a senior thesis Fall of 2009 –
Spring 2010. I worked with the student to develop an appropriate project in the area of extreme
value theory. It will appear as a technical report.
Has your SAMSI experience met your expectations in preparing you for your next position? Are
there (new) benefits that you now perceive coming from your SAMSI experience that are relevant to
your career in the future?
Yes. I started two new research projects and learned a lot of new knowledge in some new fields.
7. SAMSI in contrast with University Setting:
How do you think your SAMSI experience compares to what you might have encountered in a
typical university setting?
I think that compared to a junior faculty, SAMSI postdocs may have more time for their own
research, and spend much less time on teaching or other service commitments.
8. SAMSI in comparison to Other Experiences:
If you have had experience in an industrial, national or other lab setting, how would you compare that
experience with your SAMSI experience?
Not applicable
9. Other Research while at SAMSI:
If you have spent considerable time during your appointment with some other research group, please
comment on the benefits and drawbacks of this experience. (e.g., if your appointment was extended
via an appointment at NISS, CRSC or elsewhere)
Not applicable
10. Other Issues:
Are there other issues or concerns you would like to bring up?
None

96
In Spring of 2009, I proposed, developed, and taught a special topics graduate course in
“Extreme Value Theory and Applications with Bayesian Methods at Duke University.
July of 2009 I served as a faculty mentor for the Industrial Mathematical and Statistical
Modeling (IMSM) Workshop for graduate students at North Carolina State University. The
group deliverable is a paper to be included in the workshop proceedings, which developed into a
paper that is to appear in Environmetrics. I am looking forward to participating as a faculty
mentor again this coming year (July 19 – 27, 2010), and have also taken an active role in
recruiting problem presenters from industry.
I reviewed two peer papers for a prominent journal, and also submitted an extensive
review for an NSF grant/request for funding for a $1.5 million project.
I also have continued to maintain contacts with researchers from NCAR, NOAA and
other institutes. I am finishing up the project with Eric Gilleland from NCAR, and will be
starting a project with Harold Brooks from the National Severe Storm Laboratory in conjunction
with the IMSM workshop.
3. High Points at SAMSI:
What have been the high points of your SAMSI experience?
The conferences and meetings that I am able to participate in due to my affiliation with SAMSI
and SAMSI’s support are definitely high points. To have exposure to the current research in my
area is extremely enriching, and the contacts made through these meetings – as well as through
the SAMSI working groups themselves – are invaluable for future research as well as career
prospects.
4. Suggestions for Improvement:
How could your SAMSI experience have been improved?
I thought the interactions among SAMSI members my second year here (2009-10) were
significantly different from those in 2008/9. My first year at SAMSI, substantial effort was
made (and was much appreciated) to have social interactions – dinners, lunches, etc – which
significantly added to the congenial atmosphere at SAMSI. I feel that atmosphere is a vital part
of what makes SAMSI so successful. This was lacking a bit the second year, possibly simply
due to personnel changes with the incoming not realizing that this had taken place previously.
5. Mentoring:
SAMSI aims to provide solid mentoring of Postdocs. How successful has this been in your case?
I personally did not have a postdoc adviser at SAMSI until my second year. This was in part due
to my involvement in the SAMSI program in 2008-2009 being minimum (as it was not my area),
but also in part due to not knowing who to ask, etc. My current adviser, Peter Craigmile, is
fantastic and has been very helpful and provided many helpful comments and guidance.
However, it was a bit tough to navigate on my own for that first year, while my colleagues
seemed to have someone to turn to for research advice, etc. Nell was very helpful and
approachable with regards to professional advice, but it is also useful to have someone in your
field.

97
In addition, in 2008-2009 the postdoc had regular question/answer “topics” lunches with the
SAMSI directorate. This was very helpful in many ways. First, it enables the postdocs to feel
comfortable with the directorate and those they might be working with while at SAMSI. Second,
the topics were timely, useful subjects that the directorate had very useful advice on. (CV’s, job
interviews, how to publish, authorship, research ethics, etc.) Third, this also served as a regular
“touch-base” session for everyone to briefly discuss with “those in charge” where they were on
any particular issues.
6. SAMSI Benefits for the Future:
Has your SAMSI experience met your expectations in preparing you for your next position? Are
there (new) benefits that you now perceive coming from your SAMSI experience that are
relevant to your career in the future?
I believe that learning “how to research” is extremely important, and is something that is
provided by the SAMSI experience. You learn how to work with others, what projects may or
may not be possibly suitable for a future publication, how to start/develop/hopefully complete a
project, etc. Postdocs often present their research several times - at meetings, conferences,
seminars - and in several different formats – posters, 15 min talks, hour sessions, etc – which is
very useful in becoming comfortable presenting as well as explaining your own research.
In addition, I reviewed two peer papers and submitted an NSF grant review while at
SAMSI, which certainly is good experience in preparation for a future academic position.
7. SAMSI in contrast with University Setting:
How do you think your SAMSI experience compares to what you might have encountered in a
typical university setting?
I think most SAMSI postdocs have a different experience than in the university setting for two
main reasons. One, university positions might involve teaching responsibilities – as mine did –
which takes away from available research time. (Teaching does provide valuable experience in
and of itself however.) Two, university postdocs are often off by themselves, or perhaps with
one or two others under the same professor/lab. However, at SAMSI, the postdocs are offered
the opportunity for collaborative work – with other postdocs as well as with experience
professors and researchers. This is invaluable in terms the learning experience and getting a
research base established.
8. SAMSI in comparison to Other Experiences:
If you have had experience in an industrial, national or other lab setting, how would you compare
that experience with your SAMSI experience?
I think the SAMSI experience is much more collaborative and supportive than the typical
position. Most certainly when compared to an industry position, where the “bottom-line” or
“client satisfaction” is often the main goal over novel research and applications.
9. Other Research while at SAMSI:
If you have spent considerable time during your appointment with some other research group,
please comment on the benefits and drawbacks of this experience. (e.g., if your appointment was
extended via an appointment at NISS, CRSC or elsewhere)

98
I have not extended my position within SAMSI to another research group, however I
have spent some of my time at SAMSI on collaborative projects with people from other
institutions. I am finishing up the project with Eric Gilleland from NCAR, and through IMSM
this July will be starting a project with Harold Brooks from the National Severe Storm. I am
continuing next year in my position as a Visiting Assistant Professor at Duke.
10. Other Issues:
Are there other issues or concerns you would like to bring up?
The snacks in the break-room should have more chocolate items.

99
John McSweeney
1. Program Involvement: Which SAMSI program(s) have you been involved with and at what level(s)? (e.g., “been doing
active research on …” or “just went to a tutorial/workshop to learn about that area which is new
to me”)
(a) Network Dynamics Group: I attended all the weekly meetings and was actively involved in
projects on epidemic spreads on networks. Specifically, I am working with Bruce Rogers now to
put together a paper on the analysis of SIS epidemics across a hierarchically structured
population. My talk and lab at the February undergraduate workshop were on these topics as
well.
(b) Dynamics of Biological Systems Group: I looked at the issue of reaction kinetics in a cellular
environment, things like determining applicability of kinetic models, chemical reaction systems
as applied to developmental biology, multiscale analysis of reactions. The most promising
direction was a problem proposed by R. Yamada which he, I, J. Fricks, and B. Joshi worked on.
It has to do with finding conditions in a gene expression network that will produce oscillations,
that could potentially explain observed oscillations in nature such as circadian rhythms. We are
still working on this and I gave a talk at the 2010 SIAM Life Sciences conference about our
initial investigations into this.
2. Interactions with Other Institutions: Describe your interactions with other institutions while at SAMSI. (e.g., a Triangle university,
NISS or CRSC)
I spent some time at Duke in 09-10, during which I sat in on some lectures (J. Mattingly's class
in the fall, S. McKinley's in the Winter). I also attended two instances of the social networks
weekly seminar.
I attended the 2010 Graduate student probability conference inApril/May which was held at
Duke this year, and I gave a talk related to my work at SAMSI on “Closure approximations for
epidemics on networks”.
I attended the UNC-Chapel Hill applied math seminar once as well.
3. High Points at SAMSI: What have been the high points of your SAMSI experience?
Having a constant stream of people coming in and out, but who stay long enough (months, as
opposed to just days) to be able to make meaningful progress on a project from scratch. Being
free from teaching to be able to focus on research 100%.
The staff was very helpful as well with all issues practical and logistical.
4. Suggestions for Improvement: How could your SAMSI experience have been improved?
The working groups could have been given a little more direction. As a (very) junior researcher
in a somewhat new field, I don't mind being told what to do to a certain extent. It's very hard to

100
come up with good problems in an unfamiliar field, and it seems like while I learned a great deal
in everything I did, a lot of the work I put in didn't get me much closer to getting a paper
published, which of course has to be the ultimate byproduct of such work.
5. Mentoring: SAMSI aims to provide solid mentoring of Postdocs. How successful has this been in your case?
Overall I thought the mentoring was very good, the mentors were enthusiastic and cared about
the postdocs. I think many of the postdocs could have used more direction/attention from faculty.
Although we were all assigned an academic mentor, it was not always easy to know where to go
for guidance: often the mentors were too busy with other things, or spent most of their time at
one of the local universities, or just had research interests that didn't line up particularly well. I
don't think it would hurt if the mentors delegated or gave specific tasks more (e.g. “read this
paper and tell me about it in a few days”), especially with postdocs who might appear to be
lakcing direction on a particular project.
6. SAMSI Benefits for the Future: Has your SAMSI experience met your expectations in preparing you for your next position? Are
there (new) benefits that you now perceive coming from your SAMSI experience that are
relevant to your career in the future?
Already I find I am able to get more out of conferences since there are so many people at them
that I may have met or at least heard of through SAMSI. It is too early to tell how important my
time at SAMSI will be in my current position because it's only just begun.
7. SAMSI in contrast with University Setting: How do you think your SAMSI experience compares to what you might have encountered in a
typical university setting?
I think I got a decent amount of the university experience since I spent about 2 days a week at
Duke. It might have been nice to have the stability and continuity of having say a 3-year postdoc
at the same institution, which might have allowed me to form deeper professional relationships
but at the same time not exposed me to as many people. It's a question of quantity versus quality
I guess.
8. SAMSI in comparison to Other Experiences: If you have had experience in an industrial, national or other lab setting, how would you compare
that experience with your SAMSI experience?
N/A
9. Other Research while at SAMSI: If you have spent considerable time during your appointment with some other research group,
please comment on the benefits and drawbacks of this experience. (e.g., if your appointment was
extended via an appointment at NISS, CRSC or elsewhere)
N/A

101
10. Other Issues: Are there other issues or concerns you would like to bring up?
Bruce Rogers
1. Program Involvement:
Which SAMSI program(s) have you been involved with and at what level(s)? I have been doing
research associated with the Stochastic Dynamics program in both the Network Dynamics and
Data Assimilation working groups.
2. Interactions with Other Institutions:
Describe your interactions with other institutions while at SAMSI. (e.g., a Triangle university,
NISS or CRSC)
My pay goes through Duke University. They have a nice library. My mentor is at UNC, and
they have free wireless for visitors.
3. High Points at SAMSI:
What have been the high points of your SAMSI experience?
Working at SAMSI is great. I have the freedom to pursue my own research with the support of
many experts working in my areas of interest. Plus there are always statisticians around to
answer questions.
4. Suggestions for Improvement:
How could your SAMSI experience have been improved?
The working groups were not well organized at the beginning of the year. We wasted a lot of
time because there weren't any senior researchers with specific tasks to bring to the table. Also,
see #5.
5. Mentoring:
SAMSI aims to provide solid mentoring of Postdocs. How successful has this been in your case?
My Scientific Mentor, Peter Mucha, has been incredible. I met with my Administrative Mentor
only one time. I'm not sure what an Administrative Mentor is supposed to do, but I could always
use some advice about preparing for the academic job market.
6. SAMSI Benefits for the Future:
Has your SAMSI experience met your expectations in preparing you for your next position? Are
there (new) benefits that you now perceive coming from your SAMSI experience that are
relevant to your career in the future?
My experience at SAMSI has more than met my expectations. Just having an additional year of
research experience is incredibly valuable. Also, the post-doc seminar has been great for helping
me improve my presentations.

102
7. SAMSI in contrast with University Setting:
How do you think your SAMSI experience compares to what you might have encountered in a
typical university setting?
There's certainly less time devoted to teaching at SAMSI, so I was able to devote more time to
research.
8. SAMSI in comparison to Other Experiences:
If you have had experience in an industrial, national or other lab setting, how would you compare
that experience with your SAMSI experience?
NA
9. Other Research while at SAMSI:
If you have spent considerable time during your appointment with some other research group,
please comment on the benefits and drawbacks of this experience. (e.g., if your appointment was
extended via an appointment at NISS, CRSC or elsewhere)
NA
10. Other Issues:
Are there other issues or concerns you would like to bring up?
No.
Benjamin Shaby
1. Program Involvement:
Which SAMSI program(s) have you been involved with and at what level(s)? (e.g., “been doing
active research on …” or “just went to a tutorial/workshop to learn about that area which is new
to me”)
I have been actively participating and contributing to the Spatial program.
2. Interactions with Other Institutions:
Describe your interactions with other institutions while at SAMSI. (e.g., a Triangle university,
NISS or CRSC)
This has been very limited. I have been to Duke only to sign employment papers and get a book
from the library. I've been to NCSU once or twice for meetings. I've spent more time at
Berkeley and UCSF working with collaborators there on projects that were not initiated through
SAMSI.

103
3. High Points at SAMSI:
What have been the high points of your SAMSI experience?
The workshops are great. I have been impressed with the number and quality of participants.
The best part of the experience, I think, has been getting to spend time with the visitors.
Interacting with them has really introduced me to a ton of new perspectives. In addition, it's nice
having contacts all over the world as a result of the visitor program.
4. Suggestions for Improvement:
How could your SAMSI experience have been improved?
Mentorship had been a real problem. Visitors are great, but those relationships are not conducive
to a longer-term mentorship model.
Working groups seem kind of scattered. I'm still not really clear on what they are supposed to
achieve. Two of the three in which I participated were run more like seminars than meetings
intended to produce actual work. That was frustrating. The third, I feel, was held together only
by Richard Smith's exceptional leadership. It seems that without someone really directing
traffic, the groups flounder. Maybe a problem is that they're too big? Or maybe there is not a
problem, and that they are not intended to produce any actual research.
5. Mentoring:
SAMSI aims to provide solid mentoring of Postdocs. How successful has this been in your case?
Completely unsuccessful. I am not alone in this regard either. I think a big part of the problem
is structural – with faculty at their universities and us at SAMSI, there are really barriers to
interaction. I feel like I have been completely on the basis of self-guidance. It would have been
great to have had a senior faculty member to talk to on a regular basis. I have no met with my
official scientific mentor once since I've been here. I don't hold it against him or anything – I
think the relationship was never clearly defined, and he's very busy and located in a different zip
code. This does not make for a successful mentorship relationship.
6. SAMSI Benefits for the Future:
Has your SAMSI experience met your expectations in preparing you for your next position? Are
there (new) benefits that you now perceive coming from your SAMSI experience that are
relevant to your career in the future?
It's impossible to say really. I think the big benefit has been meeting so many smart people from
all over the place. The networking opportunities have been immense. On the other hand, the
mentorship vacuum has probably been to my detriment.
Something else to consider is the openness of the work structure is great for incubating new ideas
and following interesting paths. The other side of the coin, however, is that the lack of focus
does not lead to immediate productivity as easily. So in the short term, the breadth of the
experience could make it harder to get a job (I have no new papers this year), even as it broadens
my longer-term horizons.

104
7. SAMSI in contrast with University Setting:
How do you think your SAMSI experience compares to what you might have encountered in a
typical university setting?
The lack of structure and the exposure to so many people are wonderful and exciting, but they
come at the expense of mentorship and focused research that one would expect working closely
with a single faculty member at a university.
8. SAMSI in comparison to Other Experiences:
If you have had experience in an industrial, national or other lab setting, how would you compare
that experience with your SAMSI experience?
I have worked in a lab setting, and it's so different that it's difficult to compare to SAMSI. The
lab seems to be more of a cohesive unit, with a single person supplying the overall vision. The
SAMSI model is totally decentralized. I am starting to think that the relative chaos of the
SAMSI setting will serve me better in the future.
9. Other Research while at SAMSI:
If you have spent considerable time during your appointment with some other research group,
please comment on the benefits and drawbacks of this experience. (e.g., if your appointment was
extended via an appointment at NISS, CRSC or elsewhere)
I have not.
10. Other Issues:
Are there other issues or concerns you would like to bring up?
Xueying Wang
1. Program Involvement:
Which SAMSI program(s) have you been involved with and at what level(s)? (e.g., “been doing
active research on …” or “just went to a tutorial/workshop to learn about that area which is new
to me”)
I have participated in the following workshops at SAMSI:
Opening workshop of stochastic dynamics program
Workshop on selforganization and multiscale mathematical modeling of active Biological
systems
Workshop on theory and qualitative behavior of stochastic dynamics
Workshop on molecular motors, neuron models, and epidemics on networks

105
I am very very interested in stochastic dynamics. In particular, I have been working on
stochastic neuroscience and epidemiology on networks and I am writing papers with my
collaborators in those areas.
2. Interactions with Other Institutions:
Describe your interactions with other institutions while at SAMSI. (e.g., a Triangle university,
NISS or CRSC)
N/A
3. High Points at SAMSI:
What have been the high points of your SAMSI experience?
SAMSI has built a great environment for graduate students, post-docs and faculty fellows to
communicate and to conduct mathematical, statistical and interdisciplinary research. The year-
long programs are fantastic. In particular, the workshops and group meetings for stochastic
dynamics program have been quite successful in making interesting discoveries and significant
progresses.
4. Suggestions for Improvement:
How could your SAMSI experience have been improved?
It would be really nice if the network of links to real applications could be broaden.
5. Mentoring:
SAMSI aims to provide solid mentoring of Postdocs. How successful has this been in your case?
It works well for my case. I have been benefiting a lot from both my administrative and scientific
mentoring.
6. SAMSI Benefits for the Future:
Has your SAMSI experience met your expectations in preparing you for your next position? Are
there (new) benefits that you now perceive coming from your SAMSI experience that are
relevant to your career in the future?
Yes. One of the most important things I have learned at SAMSI is to be able to independent
research, which definitely helps me a lot with the transition from a graduate student to a
postdoctoral fellow.
7. SAMSI in contrast with University Setting:
How do you think your SAMSI experience compares to what you might have encountered in a
typical university setting?

106
It was really great. Only scientific resources and the computer maintenance at SAMSI is
different from what I experienced at University.
8. SAMSI in comparison to Other Experiences:
If you have had experience in an industrial, national or other lab setting, how would you compare
that experience with your SAMSI experience?
N/A
9. Other Research while at SAMSI:
If you have spent considerable time during your appointment with some other research group,
please comment on the benefits and drawbacks of this experience. (e.g., if your appointment was
extended via an appointment at NISS, CRSC or elsewhere)
N/A
10. Other Issues:
Are there other issues or concerns you would like to bring up?
N/A
Jun Zhang
1. Program Involvement:
Which SAMSI program(s) have you been involved with and at what level(s)? (e.g., “been doing
active research on …” or “just went to a tutorial/workshop to learn about that area which is new
to me”)
I have been doing active research on spatial extremes and spatio-temporal point patterns at
SAMSI. Currently I have finished a spatial extremes project and I am writing a paper. For
spatio-temporal point patterns, I have recommended to use regional climate model output as the
data set and we are currently looking at the precipitation patterns. Also I am planning to start a
project on spatio-temporal max-stable processes.
2. Interactions with Other Institutions:

107
Describe your interactions with other institutions while at SAMSI. (e.g., a Triangle university,
NISS or CRSC)
It is very helpful to interact with NISS postdocs. Frank Zou, Feng Xingdong, Xia Fang and
Jessica Xia all provided very helpful suggestions and comments for my research and
presentations.
3. High Points at SAMSI:
What have been the high points of your SAMSI experience?
1)Met with many great statisticians and mathematicians from institutions all over the world.
2)Exposure to many interesting new topics.
2)Local staff members are very helpful. Karem helped me bind my print-outs. James helped me
on my computer issues.
3)Extremely clean and quiet working environment.
4. Suggestions for Improvement:
How could your SAMSI experience have been improved?
I don't think of anyone.
5. Mentoring:
SAMSI aims to provide solid mentoring of Postdocs. How successful has this been in your case?
I always felt lucky to have Nell Sedransk and Richard Smith as my mentors. Nell has been
wonderful and always gave me great tips on everything from presentation skills to research
skills. Richard has a deep understanding of extreme theory and risk assessment and helped me
start my research project. Richard also helped me solve numerous technical problems.
6. SAMSI Benefits for the Future:
Has your SAMSI experience met your expectations in preparing you for your next position? Are
there (new) benefits that you now perceive coming from your SAMSI experience that are
relevant to your career in the future?
Yes, I think my SAMSI experience exceeded my expectations.
My SAMSI experience helped me find one of my research focuses-spatial extremes. I have zero
knowledge before I came to SAMSI. However, after several months of exposure to the topic
including listening to the talks given by many wonderful researchers in that field, I started my
own project with the help from Prof. Richard Smith. In future, I think I will do more research on
spatial extremes. To be able to have a suitable research topic is very important to my future
career. In this point, SAMSI experience helped a lot.
7. SAMSI in contrast with University Setting:
How do you think your SAMSI experience compares to what you might have encountered in a
typical university setting?

108
In a typical university setting, I could never meet so many great statisticians from all over the
world in person and online through WEBEX. Also SAMSI uses WEBEX very well. WEBEX
created virtual research groups and connected the researchers at SAMSI with many researchers
in remote locations. In other word, at SAMSI, you felt you are connected with global research
community all the time without the geographical limit while in a typical university setting, your
connections are limited to the visitors coming to the university or limited to visitors coming to a
conference.
8. SAMSI in comparison to Other Experiences:
If you have had experience in an industrial, national or other lab setting, how would you compare
that experience with your SAMSI experience?
I don't have such experience and I can't comment on this one.
9. Other Research while at SAMSI:
If you have spent considerable time during your appointment with some other research group,
please comment on the benefits and drawbacks of this experience. (e.g., if your appointment was
extended via an appointment at NISS, CRSC or elsewhere)
I don't have such appointment and I can't comment on this one.
10. Other Issues:
Are there other issues or concerns you would like to bring up?
No.
Esther Salazar

Postdoc Questionnaire
1. Program Involvement: Which SAMSI program(s) have you been involved with and at what level(s)? (e.g., “been doing active research on …” or “just went to a tutorial/workshop to learn about that area which is new to me”)
I have been involved with the SAMSI program: “Space-Time Analysis for Environmental Mapping, Epidemiology and Climate Change” for the period January – August, 2010.
2. Interactions with Other Institutions: Describe your interactions with other institutions while at SAMSI. (e.g., a Triangle university, NISS or CRSC)
I have been working actively with researchers from Duke University, University of Chicago, University of California Santa Cruz (UCSC) and North Carolina State University (NCSU). More specifically in the following activities:
SAMSI sub-working group “Substantive Scientific Problems”. Joint work with Bruno Sanso (UCSC) and Montserrat Fuentes (NCSU)
Working paper “Dynamic Matrix-Variate Spatial Factor Analysis”. Joint work with Mike West (Duke) and Hedibert Lopes (U. Chicago)
3. High Points at SAMSI: What have been the high points of your SAMSI experience?
The high points are: Excellent infrastructure I can talk and interact with top researchers that help me in many projects and with which
I will continue to work for the next months in order to finish some papers.
4. Suggestions for Improvement: How could your SAMSI experience have been improved?
I feel that the postdocs are very isolated. On the other hand, the working group meetings should be more organized with more responsibilities for the members.
5. Mentoring: SAMSI aims to provide solid mentoring of Postdocs. How successful has this been in your case?
I feel confortable with my academic mentor and interacting with other researchers. I think that it was very beneficial for me and for my future research plans.

6. SAMSI Benefits for the Future: Has your SAMSI experience met your expectations in preparing you for your next position? Are there (new) benefits that you now perceive coming from your SAMSI experience that are relevant to your career in the future?
Definitely met my expectations. More important, I could find an academic position because of the contacts that I did during my SAMSI experience.
7. SAMSI in contrast with University Setting: How do you think your SAMSI experience compares to what you might have encountered in a typical university setting?
Although the postdocs spend more time working at SAMSI, many of them (including myself) had the opportunity to work at near Universities. That means that we can take advantages of the University infrastructure as well as SAMSI facilities.
8. SAMSI in comparison to Other Experiences: If you have had experience in an industrial, national or other lab setting, how would you compare that experience with your SAMSI experience?
I did not have other experience.
9. Other Research while at SAMSI: If you have spent considerable time during your appointment with some other research group, please comment on the benefits and drawbacks of this experience. (e.g., if your appointment was extended via an appointment at NISS, CRSC or elsewhere)
Parallel to my work at SAMSI I have been working on a project with researchers from Duke and University of Chicago. Benefit: I have had completely freedom to work in that project managing my daily activities and with help of SAMSI researchers. Drawbacks: none.
10. Other Issues: Are there other issues or concerns you would like to bring up?
None.

111
I.C Graduate Fellows
1. Space-time Analysis for Environmental Mapping, Epidemiology and Climate Change
K Sham Bhat (Pennsylvania State University, dissertation advisor: Murali Haran)
Sham was a member of both the Interaction of Deterministic and Stochastic Models and the Computation, Visualization, and Dimension Reduction in Spatio-Temporal Modeling working
groups. He attended many of the SAMSI workshops and the courses “Theory of Continuous
Space and Space-Time Processes” and “Spatial Epidemiology.” His dissertation research
involves calibration of very large computer climate models, which has been furthered by his
participation in the working groups.
He currently has submitted a book chapter for “Frontier of Statistical Decision Making and
Bayesian Analysis-In Celebrating James O. Berger's 60th Birthday”: “Computer model
calibration with multivariate spatial output: a case study in climate parameter learning” with
Murali Haran and Marlos Goes.
Laura Boehm (NCSU, SAMSI mentor: Brian Reich)
Laura was a member of the Spatial Health Effects working group and took the SAMSI course
“Spatial Epidemiology.” She also assisted with the undergraduate workshop held at SAMSI in
October. She plans to do research on the analysis of Texas birth defect data and air
pollution.
Avishek Chakraborty (Duke, dissertation advisor: Alan Gelfand)
Avishek was a member of the Spatial Point Patterns working group. He attended several
workshops at SAMSI and the courses “Theory Of Continuous Space” and “Spatial Statistics in
Climate, Ecology and Atmospherics.” Avishek was a key presenter in the undergraduate
workshop in October where he led a group as well as a lab.
Morgan Gieseke (NCSU, dissertation advisor: Len Stefansky)
Morgan was a member of the Spatial Exposures and Health Effects Working Group and gave a
presentation to the group on her work related to the geocoded data for the PIN3 study.
Soyoung Jeon (UNC-CH, dissertation advisor: Richard Smith)
Soyoung participated in the Spatial Extremes working group and took the courses “Theory of
Continuous Space and Space-Time Processes” and “Spatial Epidemiology.” Soyoung also
participated in several workshops. Her research is focused on the extreme value theory for
spatial data. The modeling of extreme values can be applied to lots of fields such as
environmental statistics or environmental epidemiology. One of the goals in her research is to

112
figure out existing approaches for max-stable processes and develop a new method or
extension to apply it for more realistic data sets.
Yajun Liu (University of Missouri, dissertation advisor: Dongchu Sun)
Yajun is participating in the Fundamentals of Spatial Modeling and the Computation,
Visualization, and Dimension Reduction in Spatio-Temporal Modeling working groups. She has
taken the SAMSI courses “Theory of Continuous Space and Space-Time Processes,” “Spatial
Epidemiology,” and “Spatial Statistics in Climate, Ecology and Atmospherics.” She also
participated in several SAMSI workshops and assisted with the undergraduate workshops.
Zhaowei Hua (UNC-CH, dissertation advisors David B. Dunson and Hongtu Zhu)
Zhaowei is participating in the Spatial Health working group and has taken the SAMSI courses “Theory of Continuous Space and Space-Time Processes.” Her general research area is methodology development for spatial data/functional data and applications to health effects. For her dissertation, she develops semiparametric Bayesian methods for functional data
2. Stochastic dynamics
Amogh Deshpande (NCSU, dissertation advisor Min Kang)
Amogh was a member of the qualitative behavior of stochastic dynamics systems. His research
deals with stochastic modeling and large deviation theory. He wrote a paper which applies
concepts on probability and stochastic analysis in finance and has submitted it to the journal
of Methodology and Computation in Applied Probability
Dan Fovargue (UNC-CH, dissertation advisor Sorin Mitran)
Dan was a member of the numerical methods for stochastic systems group. His research
involves multi-scale numerical methods relating computation at a microscopic level to
computation at a continuum level through probabilistic and stochastic methods. The goal is to
speed overall computation by averaging microscopic affects and allowing for larger continuum
level timesteps. His dissertation work involves numerical simulations of acoustic waves
propagating through non-uniform media. For non-uniformities at a microscopic scale, the
SAMSI research applies directly to the creation of a method to produce a continuum level
solution. Dan contributed presentations to the working group and was an active presenter of
the undergraduate workshop.
Nuwan Induruwage (Visiting graduate student from RPI, dissertation advisor: Pete
Kramer)

113
Nuwan attended several workshops and was working on how to effectively perform
averaging when there are metastable barriers in the potential landscape in the direction
of the fast variable.
Tiffany Kolba (Duke, dissertation advisor: Jonathan Mattingly)
Tiffany was a member of the Qualitative Behavior of Stochastic Dynamical Systems working
group. Tiffany’s work is related to noise induced stability for stochastic differential
equations. She made several presentations as part of her working group activities. Tiffany’s
poster at the graduate students poster day gave a wonderful description of her research
activities at SAMSI.
Katherine Newall (Visiting graduate student from RPI, dissertation advisor: Pete Kramer)
Katie was a very active participant to the program. She was an invaluable member of the
network working group. Through her multiple presentations, Katie influenced the
research direction of the group in significant and very productive ways.
She investigated the role of stochastic input into a single neuron model. Whereas a single
Hodgkin-Huxley (HH) neuron driven by constant deterministic input transitions due to a
bifurcation from a quiescent state to one of periodic firing as the input increases in
intensity, the stochastically driven neuron with equivalent mean input can demonstrate
oscillations between bursting firing periods and non firing periods, a state which is never
present in the deterministically driven case. It is thought that this is a result of
fluctuations in the input pushing the dynamics away from a fixed point in the phase space
and onto a limit cycle and then back to the fixed point. Her main goal is to work on an
analytic expression for the rate of transition between these two states.
Her thesis is also on oscillations, but in an entirely different form. She has looked at the
synchrony resulting from cascading total firing events, where every neuron in a network
of stochastic-driven, integrate-and-fire (IF), pulse-coupled, excitatory neurons fire.
Although the mechanism for these network firing events are fundamentally different from
the mechanism responsible for bursting of the single HH neuron, she believes the same
analytical tools of first-passage time calculations and probabilistic analysis will facilitate
understanding the HH bursting neuron, and the role of stochastic input. It is the
stochastic input into the system that makes the synchrony she studies fundamentally
different from its deterministic counter part.

114
D. Consulted Individuals
The individuals consulted for the broad selection of topics within programs and
workshops were the members of two groups:
The Program Organizers, listed in Section I.A.1
Members of the Advisory Committees, listed in Section I.J
The specific topics that Program Working Groups chose to pursue were, in general,
selected by the Working Group participants themselves, according to their combined
interests. In almost all cases, however, a Program Leader headed each working group, so
that specific research topics remained consistent with overall program goals. In Section
II.E, the various Working Groups, and their members, are discussed.

115
I.E PROGRAM ACTIVITIES
1. Stochastic Dynamics
2. Space-Time Analysis for Environmental Mapping, Epidemiology and Climate
Change
3. 2010 Summer Program: Semiparametric Bayesian Inference: Applications in
Pharmacokinetics and Pharmacodynamics
4. Education and Outreach

I.E.1 2009-2010 Program on Stochastic Dynamics
Program Leaders: Hongyun Wang (UC Santa Cruz), Martin Hairer (War-wick), Pete Kramer (RPI), Alejandro Garcia (San Jose State), Lea Popovic(Concordia), Cindy Greenwood (Arizona State University)
Local Scientific Coordinators: Alan Karr (NISS), Jonathan Mattingly (Duke),Peter Mucha (UNC)
Directorate Liaison: Michael Minion (SAMSI)
1. Introduction
This year-long SAMSI program was centered around the broad topic of Stochas-tic Dynamics with particular focus on analysis, computational methods, andapplications of systems governed by stochastic differential equations. The term“Stochastic Dynamics” is one which resonates within many fields in statis-tics and applied mathematics. The numerical analyst designing algorithms forstochastic differential equations, the math biologist studying transport on thecellular level, the analyst trying to understand the effect of stochastic forcingand data in dynamical systems, the statistician trying to characterize the statis-tics of dynamic networks, and the mathematical modeler trying to bridge thegap between atomistic and continuum physics are all examples of research instochastic dynamics. Unfortunately it is too often the case that research beingdone in one of the above scenarios is not being widely disseminated across thespectrum of statistics and applied math. This SAMSI program served to bringtogether experts in different but highly inter-related research specializationsunder the broader umbrella of stochastic dynamics in the hopes of creatingcollaborations which could potentially lead to exciting advances in particularresearch areas.
Particular successes of the program include:
• The establishment of a new collaboration, including two major grant pro-posals submitted to date, involving a probabilist (Scott McKinley), anapplied mathematician (Peter Kramer), and a statistician (John Fricks)to develop a systematic stochastic modeling framework for intracellulartransport connecting three important physical length scales.
• A sustained research effort across SAMSI programs, with applied math-ematicians from the working group on Numerical Methods for StochasticSystems (Peter Kramer and Sorin Mitran) joining with statisticians fromthe program on Space-Time Analysis for Environmental Mapping, Epi-demiology, and Climate Change program (Jim Berger, Susie Bayarri, Mu-rali Haran, Emily Kang, Hans Kunsch) to explore how statistical aspectsof multiscale computing methods could be enhanced.
116

• Two research programs toward new modeling approaches in microswim-ming (Peter Kramer) and swarming (Amarjit Budhiraja, Oliver Diaz andXin Liu) that were nucleated by presentations at the workshop on Self-Organization and Multi-Scale Mathematical Modeling of Active BiologicalSystems in October, 2009.
• Several ongoing collaborations between SAMSI postdocs on topics in stochas-tic neuronal dynamics and epidemic spread on networks.
• A project initiated and driven by two graduate students (Katherine Newhalland Amanda Traud) participating in the working group on Network Dy-namics, now being prepared for submission for publication.
• Two workshops in the spring which were designed to resonate with thespecific interests of the working groups, stimulating new ideas and helpingto lead to several submitted publications.
Below, we first review the content of the workshops, and then summarizethe activities of the working groups.
2. Workshops
Five workshops were organized as part of the program.
2.1. Opening Workshop & Tutorials, August 30 - September 2, 2009
Following the usual style of an opening workshop tutorials were given on Sunday,while from from Monday to Wednesday, invited speakers gave presentations.Following the talks, the research working groups formed and had their initialmeetings at SAMSI.
Speakers: Mark Alber (University of Notre Dame), Anna Amirdjanova (Uni-versity of Michigan), David Anderson (University of Wisconsin), Peter Baxen-dale (University of Southern California), Gerard Ben Arous (New York Uni-versity), David Cai (New York University), Sandra Cerrai (University of Mary-land), Lee DeVille (University of Illinois), Tim Elston (University of North Car-olina), Alejandro Garcia (San Jose State University), Cindy Greenwood (Ari-zona State University), Martin Hairer (New York University), Peter Imkeller(Humboldt University Berlin), Markos Katsoulakis (University of Massachusettsat Amherst), Peter Kotelenez (Case Western University), Rachel Kuske (Uni-versity of British Columbia), Kevin Lin (University of Arizona), Gabriel Lord(Heriot Watt University), Grant Lythe (University of Leeds), Katie Newhall(Rensselaer Polytechnic Institute), Houman Owhadi (California Institute ofTechnology), Grigorios Pavliotis (Imperial College, London), Lea Popovic (Con-cordia University), Mike Reed (Duke University), Gareth Roberts (Universityof Warwick), Christof Schuette (Free University, Berlin), Andrew Stuart (Uni-versity of Warwick), Anja Sturm (University of Delaware), Eric Vanden Eijnden
117

(New York University), Mike West (Duke University), Darren Wilkinson (New-castle University).
2.2. Workshop on Self-Organization and Multi-Scale MathematicalModeling of Active Biological Systems, October 26-28, 2009
Organizers: Igor Aronson (Argonne National Laboratory), Leonid Berlyand(Penn State University)
Topics: How do seemingly random mixtures of molecular components andswimming microorganisms organize themselves into large-scale cellular struc-tures and synchronize to execute collective motions? What is common to theseprocesses? Can we model them mathematically and simulate them computa-tionally? What can we learn about the biofluids flows and self-organizationof biological systems by developing and analyzing mathematical models? Theworkshop brought together mathematicians, statisticians, biophysicists and en-gineers to discuss these questions and focus on the following mathematical andstatistical issues:
• Homogenization and upscaling in active systems (suspensions of swim-mers, cytoskeletal networks, biological tissue),
• Analysis of mathematical model of self-organization in biological systems,
• Novel computational algorithms for simulations of biological processes.
Complementary research thrusts include the statistical properties of self-organized collective states and macroscopic effects of intrinsic stochasticity inactive systems, such as velocity and density fluctuations, phase transitions, crit-ical behavior, rheology and constitutive relations.
Speakers: Anna Balazs (University of Pittsburgh), Andrea Bertozzi (UCLA),John Brady (Caltech), Suncica Canic (University of Houston), Thierry Collin(University of Bourdeaux), Margaret Gardel (University of Chicago), JerryGolub (Haverford College), Yulia Gorb (Texas A&M), Michael Graham (Uni-versity of Wisconsin-Madison), Danielle Hilhorst (Universite Paris-Sud), JamesKeener (University of Utah), Simona Mancini (Universite d’Orleans), Tim Ped-ley (University of Cambridge), Benoit Perthame (Universite Pierre et MarieCurie), Jacques Prost (ESPCI), and Michael Shelley (Courant Institute).
2.3. Workshop on Theory and Qualitative Behavior of StochasticDynamics, February 8-10, 2010
Organizers: Michael Cranston (University of California-Irvine), Yuri Bakhtin(Georgia Tech), Luc Rey-Bellet (University of Massachusetts), Jonathan Mat-tingly (Duke University)
118

Topics: Stochastic modeling is becoming ubiquitous in science and engineer-ing. This conference brought together speakers addressing a number of advancesin describing the qualitative dynamics of stochastic systems such as stochasticbifurcation, structure of invariant measures, metastability, averaging, and suband super diffusive behavior. Although the presentations emphasized theoreti-cal aspects of the subject, there was a bias toward results which shed light onrelevant models of physical, biological or technological interest.
Speakers: Yuri Bakhtin (Georgia Tech), Peter Baxendale (USC), Dima Dol-gapyat (University of Maryland), Paul Dupuis (Brown University), BarbaraGentz (University of Bielefeld), Stanislav Molchanov (UNC-Charlotte), AlexeiNovikov (Penn State University), David Nualart (University of Kansas), Grig-orios Pavliotis (Imperial College London), Luc Ray-Bellet (University of Mas-sachusetts), Michael Scheutzow (Berlin University), Richard Sowers (Universityof Illinois)
2.4. Workshop on Molecular Motors, Neuron Models, and Epidemicson Networks, April 15-17, 2010
Organizers: Priscilla Greenwood (ASU), John Fricks (Penn State), Lea Popovic(Concordia), Scott Schmidler (Duke)
Topics: The workshop concentrated on primary topics of research in three ofthe SAMSI working groups. In addition to lectures by the speakers listed below,there were reports from the following working groups.
• Molecular motors. These are biological molecular machines that convertenergy into motion, producing movement in living organisms, operatingat a scale where thermal noise is significant. Because motor events arestochastic, they may be modeled in terms of random walks or Markovprocesses. An active topic is the stochastic dynamics of such models.
• Neuron models. Several well-known models are being studied with theaim of comparing the stochastic dynamics of the models. A fundamentalquestion is, in what cases the transition from firing to quiescence and backis governed by boundary crossing times of a stochastic process, as opposedto large deviation times. The larger question for stochastic dynamics isthe nature of transition times between domains of attraction of locallystable configurations.
• Epidemics. They have been defined on networks in various ways. Oneapproach is to fix a network and define a version of a classical mean fieldepidemic model on that network by specializing the interaction equationsto specific local interactions. The challenge is to devise models wheresolutions, or at least some of their properties, are accessible.
119

Speakers: Andrea Barriero (U. of Washington), Meredith Betterton (U. ofColorado), Susan Ditlevesen (Copenhagen), David Hunter (Penn State), DavidKinderleher (Carnegie Mellon), Martina Morris (U. of Washington), DuaneNykamp (U. of Minnesota), Laura Sacerdote (Toronto), E. Volz (U. of Michi-gan), Hongyun Wang (UC Sanata Cruz)
2.5. Transitions Workshop, November 17-19, 2010
Organizers: Peter Kramer (Rensselaer Polytechnic Institute), Jonathan Mat-tingly (Duke University) and Sorin Mitran (UNC-Chapel Hill)
Topics: The Stochastic Dynamics transition workshop was an opportunity forthe participants in the program to reconnect with each other and present theprogress of sustained research efforts that have proceeded beyond the end of theprogram at SAMSI. Presentations were given from each of the working groups:Network Dynamics, Data Assimilation, Numerical Methods for Stochastic Sys-tems, Qualitative Behavior of Stochastic Dynamical Systems, and BiologicalStochastic Dynamics.
Speakers: Meredith Betterton (Colorado), John Fricks (PennState), GilesHooker (Cornell), Peter Kramer (Rensselaer Polytechnic Institute), John Har-lim (NCState), Peter Kotelenez (Case Western), Jonathan Mattingly (DukeUniversity), Scott McKinley (Florida), Sorin Mitran (UNC Chapel Hill), BruceRogers (Duke), Ravi Srinivasan (Texas), Amanda Traub (NCState), XueyingWang (Texas A&M), Jennifer Young (Rice)
3. Working Groups
Five research working groups were organized as part of the program.
3.1. Working Group on Qualitative Behavior of Stochastic Dynamics
Group Leader: Jonathan Mattingly (Duke)
Participants: Avanti Athreya (SAMSI), Hakima Bessaih (Univ. of Wyoming),Esteban Chavez (Duke), Cindy Greenwood (ASU), Oliver Diaz (Duke), BarbaraGentz (Universitat Bielefeld), Boumedienne Hamzi (Duke), Badal Joshi (Duke),Tiffany Kolba (Duke), Jonathan Mattingly (Duke), Scott McKinley (Duke), Pe-ter Mucha (UNC), Scott Schmidler (Duke), Ravi Srinivasan (Duke), AndreaWatkins (Duke)
Topics: The group studied a number of topics in the qualitative description ofstochastic dynamics, such as stochastic resonance, Lyapunov exponents, quasi-invariant measures, h-transforms to condition stochastic systems, large devia-tion theory to understand nucleation in stochastic partial differential equations,structure of random attractors, and multiscale analysis in probability. Some
120

of the work by members of this group is described under the heading of singleneuron dynamics. A description of some of the other concrete results follows.
• Planar dynamical systems:
Avanti Athreya, Tiffany Kolba, and Jonathan Mattingly are currentlyexamining two specific systems with small additive noise where (a) withoutnoise, the unperturbed ODE has regions of instability and/or finite-timeblowup; and (b) with noise, the system seems to stabilize, either in thesense that near-periodic orbits emerge or in the sense that there exists aunique invariant probability measure (Scheutzow gave a nice example ofsuch a system in a 1991 paper). For one of the dynamical systems underconsideration, we know by asymptotic analysis how the invariant measuredecays far from the origin, and we’re still addressing the question of itsexistence. For the other, we are trying to see if we can reduce the problemof escape from a region of deterministic instability to a problem of escapefrom a double-well potential.
• Variance reduction for stochastic differential equations:
In many applications of stochastic modeling, the dynamics are governedby an SDE depending on certain parameters and key quantities of interestare expressed as the expected value of an observable with respect to the in-variant probability measure of the SDE, and computed by time-averagingover long trajectories. In some situations, for example when one wishes tooptimize the expected value with respect to the parameters, it is desirableto compute the change, or sensitivity of the expected value with respect tovariations in the parameter. A challenge is that sensitivities are typicallyrelatively small quantities, so very long trajectories may be required toestimate them accurately.
In an on-going effort to develop fast methods for computing sensitivities,Kevin Lin and Jonathan Mattingly are working on a class of methodsbased on couplings. The basic idea is to construct two correlated real-izations of the SDE for nearby parameters in a way that ensures the twosolutions remain near each other most of the time. One then obtains adirect, low-variance estimate of the sensitivity via integrating differencesalong the path. The current focus of the project is the numerical anal-ysis of these methods. Specifically, an investigation of different couplingstrategies and their effectiveness for some prototypical problems is beingcarried out, with the goal of understanding how details of the couplingconstruction and features of the stochastic dynamics together determinethe scaling of numerical errors with respect to the parameter perturbation.
• Sustained oscillations for density dependent Markov processes:
A paper has been written by Peter H. Baxendale and Priscilla E. Green-wood and submitted to the Journal of Mathematical Biology. Simula-tions of models of epidemics, biochemical systems, and other bio-systems
121

show that when deterministic models yield damped oscillations, stochasticcounterparts show sustained oscillations at an amplitude well above theexpected noise level. A characterization of damped oscillations in termsof the local linear structure of the associated dynamics is well known, butin general there remains the problem of identifying the stochastic processwhich is observed in stochastic simulations.
Here we show that in a general limiting sense the stochastic path describesa circular motion modulated by a slowly varying Ornstein-Uhlenbeck pro-cess. Numerical examples are shown for the Volterra predator-prey model,Sel’kov’s model for glycolysis, and a damped linear oscillator.
3.2. Working Group on Numerical Methods for Stochastic Systems
Group Leaders: Alina Chertock (NCSU), Sorin Mitran (UNC)
Participants: Anna Amirdjanova (Univ. of Michigan), Dave Anderson (Univ.of Wisconsin), Hakima Bessaih (Univ. of Wyoming), Alina Chertock (NCSU),Sean Cohen (UNCC), Dan Fovargue (UNC), John Fricks (Penn State), Pe-ter Kramer (Rensselaer), Kevin Lin (Univ. of Arizona), Jonathan Mattingly(Duke), Michael Minion (UNC), Sorin Mitran (UNC), Carlos Mora (Universi-dad de Concepci???n), Anuj Mubayi (Univ. of Texas at Arlington), Hon KeungTony Ng (SMU), Ravi Srinivasan (Duke), Ilya Timofeyev (Univ. of Houston)
Topics: The classical continuum equations arising in fluid flow, elasticity, orelectromagnetic propagation in materials require constitutive laws to derive aclosed-form system. The constitutive laws appropriate for a given set of equa-tions can be derived in two ways: i) from phenomenological considerations suchas the linear behavior underlying elastic deformation or Newtonian fluid flow,or ii) from averaging of kinetic theory results describing basic molecular dynam-ics. This has been possible for situations in which the microscopic behavior isclose to thermodynamic equilibrium. In such cases, Gaussian statistics are wellverified at the microscopic level and the moments of Gaussian distributions canbe computed analytically.
However, many physical processes exhibit significant localized departurefrom Gaussian statistics. When a solid breaks, the motion of the atoms inthe crystalline lattice along the crack propagation path is no longer governed bya Maxwell-Boltzmann distribution. When a material undergoes a phase change,large scale correlations among atoms are formed (or destroyed) which modifythe typically Gaussian statistics of the equilibrium phases. Protein folding canbe seen as a large-scale modulation imposed by polymer links of the Gaussianstatistics of the component atoms. A common characteristic of these situationsis that macroscopic features impose the departure from local thermodynamicequilibrium and macroscopic quantities of are practical interest. Crack propa-gation is initiated by a force acting on a solid and we wish to know how far thesolid deforms before it breaks. In solidification, a heat flux evacuates energy
122

from the melt at some rate and we wish to characterize the type of order arisingin the material.
In all such cases, a basic problem is how to extract the statistical distribu-tions of physical quantities when the system is away from thermodynamic equi-librium. Knowledge of the distribution would allow local constitutive laws to beformulated. Direct numerical simulation is prohibitively expensive. Continuumlevel simulation is incomplete due to lack of constitutive laws. Furthermore,while it is clear that higher-order moments characterizing the microscopic sta-tistical distribution are required, it is not known how many of these momentsare needed and what their persistence time might be. The microscopic dynam-ics are stochastic but subject to multiple macroscopic constraints. One majorstatistical challenge is how to characterize the microscopic motion in a mannerthat can be used to derive a constitutive law. A basic computational questionis how to advance the system in time efficiently at both the microscopic andmacroscopic level. An analysis challenge is how to combine this knowledge andform (e.g. through asymptotic expansions) particular constitutive laws.
The numerics group has been discussing a number of multi-scale numericalmethods that mix stochastic models at small scales with deterministic models atlarger scales. Particular issues on which we focused included the incorporation ofadaptive time stepping and the initialization of microscale simulations consistentwith the macroscale constraints. In spring, Sorin Mitran rolled out his noveltime-parallel continuum-kinetic-molecular (tpCKM) simulation scheme, whichis designed to handle multiscale systems where the microscale statistics do notrelax quickly relative to the macroscopic time scale. A third, mesoscopic, level ofdescription was added and updated by an adaptive predictor-corrector approachthrough communication with both the macroscale and microscale simulations.Mitran and his graduate student Jennifer Young had separately been studyingpolymeric and cellular blebbing with this method, while the working groupexamined a one-dimensional string model where bonds could form and breakon the microscale with rates dependent on the local stress. Implementations ofboth the classical Heterogeneous Multiscale Method and tpCKM method wereexplored.
One of the working groups in the contemporaneous Space-Time Analysis forEnvironmental Mapping, Epidemiology, and Climate Change, concerned withthe “Interaction of Deterministic and Stochastic Models”, developed a focusedinterest in multiscale computing and in particular the efforts of this NumericalMethods Working Group. This has led to a sustained collaboration across thesetwo working groups, now dedicated to improving a statistical aspect of thecommunication between the mesoscale and microscale dynamics in the tpCKMmethod. Statistical issues in multiscale computing appear not to have beenmuch pursued until now, but the close interaction of applied mathematicians andstatisticians at SAMSI has identified new areas of research along this direction.
123

3.3. Working Group on Data Assimilation
Group Leaders: Cindy Greenwood (ASU), John Harlim (NCSU), Peter Kramer(RPI)
Participants: Cindy Greenwood (ASU), Boumendiene Hamzi (Duke), JohnHarlim (NCSU), Giles Hooker (Cornell), Peter Kramer (RPI), Huitian Lu (SanDiego State University), Jonathan Mattingly (Duke), Anuj Mubayi (Univ. Texasat Arlington), Bruce Rogers (SAMSI)
Topics: This group has been striving to explore questions of interest to bothapplied mathematicians and statisticians. To this end, we have focused on theproblem of optimizing the design of experiments based on incoming data in astochastic system, and which can be formulated as a stochastic control problem.
When collecting data from experimental systems, the experimenter may beable to control the quantities measured, the measurement times, estimationmethods used for inference, and inputs into the system. We have focused onthe control-type question of what process-informed input to a system will yieldmaximal information about parameters governing system dynamics. Two real-world applications have motivated this study:
• Single neuron experiments involve stimulating a neuron with an electricalcurrent and measuring the electrical potential across the neuron mem-brane. Voltage measurements are typically available with very high fre-quency and accuracy; however complex models involving the interactionof several ion channels can underpin neural dynamics. In this context,experiments typically use step-inputs. Since these inputs can be readilycoupled to output systems, an automated control process can be readilydesigned to maximize information about parameters of interest.
• An experimental ecology typically consists of a few species of micro-organism kept in a chemostat (approx 500ml). In such systems ecolog-ical dynamics are of interest; predator-prey interactions, trait evolution orphenotype plasticity. These ecologies can be”tuned” by setting their ambi-ent temperature, the amount of nutrient provided to the ecology, and therate at which the ecology is diluted. These parameters are typically heldat constant values, chosen based on intuition, and changed, again basedon intuition, after observing the ecological dynamics. For such systems,measurements are less frequent and much noisier than for neural experi-ments, creating a more challenging, but possibly more important problemin providing principled programs for varying system settings dependingon the observation history.
These two examples can be represented by a sequence of increasingly complexmodels for real-world experimental problems. In adapting stochastic controltheory to the problem of experimental design, we have attempted to maximizethe Fisher information about the parameters of interest.
124

The paradigm of input-control that attempts to maximize an objective canbe represented within the framework of Control Theory. However, this is com-plicated by a number of factors:
• The optimal control is typically infinite, requiring either a restriction toa feasible range or some form of penalization. The use of these controlscan also destroy the stationarity of the system being observed, makinginferential methods more problematic.
• The evaluation of Fisher Information in noisily-observed nonlinear stochas-tic systems can be difficult and typically requires computationally expen-sive numerical approximation. Further, the Fisher Information is not rep-resentable as an integral over times, meaning the optimal control can de-pend on the entire sequence of past observations rather than, as is usuallythe case, the filtered estimate of the current state.
In order to derive algorithms to calculate the optimal control we have focusedon two approximations. First, we represent the system in terms of discrete-valued states and input. This allows restrictions on the range of values thatthe input can take to be naturally enforced. Second, the Fisher Informationis replaced with the Information that would be obtained were the states of thesystem to be observed exactly at all times. This framework reduces the problemto one of optimal control for noisily observed systems where it has been shownthat the control may be chosen based on a filtered estimate of the current state.
It is, of course, important to understand the properties of these approxi-mations. To that end we have investigated the case of a discrete-time linearsystem where algorithms to calculate the Fisher Information have been alreadydeveloped. We have derived the optimal control for this problem and shownthat the dependence of the optimal input on past observations decays exponen-tially as time moves forward. These calculations can be further used to suggestcorrections to the approximate methods derived above.
Further areas of investigation include solving the complete control problemfor discrete-valued systems, the approximation of control variables by basis ex-pansions for higher-dimensional systems and the use of particle filter methodsto evaluate Fisher Information, and the choice of measurement times and quan-tities.
These investigations have lead to a number of papers that are currentlyin preparation. One, based on the approximations above requires specializedparticle-filter code to be developed for nonlinear systems, but is already un-derway. A second, based on the linear model and the accuracy of the approx-imations above is being prepared. A graduate student at Cornell Universityis currently working on deriving the optimal control in a discrete-state hiddenMarkov model with applications to Polymerase chain reaction systems and apaper resulting from this work is expected in the new year.
125

3.4. Working Group on Network Dynamics
Group Leaders: Pierre Gremaud (NCSU), Peter Kramer (RPI), Peter Mucha(UNC)
Participants: Avanti Athreya (SAMSI), Cindy Greenwood (ASU), Badal Joshi(Duke), Peter Kramer (RPI), Kevin Lin (Univ. of Arizona), Jonathan Mattingly(Duke), Scott McKinley (Duke), John McSweeney (SAMSI), Anuj Mubayi (Univ.of Texas at Arlington), Peter Mucha (UNC), Katie Newhall (Rensselaer), JamesNolen (Duke), Bruce Rogers (ASU), Scott Schmidler (Duke), Ravi Srinivasan(Duke), Yi Sun (SAMSI), Rachel Thomas (Duke), Ilya Timofeyev (Univ. ofHouston), Mandi Traud (UNC), Xueying Wang (SAMSI)
Topics: This group organized under the common expectation that the net-work of connections coupling different stochastic processes are affected by theunderlying structure of such couplings, but with little a priori expectation aboutwhich structural characterizations might matter. Our working group discussionsrevolved around three topic areas: (i) biological diseases and social contagions,as examples of dynamics spreading on a network; (ii) neuronal network dynam-ics, as an example of dynamical systems coupled by selected network topologies;and (iii) NSF research institute participation data (this example of a social net-work is familiar to participants and might help develop ideas about the utilityof network analysis for the interests of this group).
• Contagion Dynamics on Social Networks:
The first common broad system of interest within the working group wasthe study of diseases and social contagions on networks.
John McSweeney and Bruce Rogers have considered the contact process(SIS epidemic) on a strongly clustered graph, described as a stochasticblock model. In the simplest case there are two communities with theprobability of an edge connecting two individuals within the same com-munity p1 and the probability of an edge connecting two individuals be-tween communities p2 much smaller than p1. In a range of parameters,a plot of the number of infected sites versus time shows a stair step: theepidemic reaches equilibrium in one community before spreading to theother. Work on this problem is continuing in the Dynamics ON Networksworking group of the Complex Networks in collaboration with new post-doc David Sivakoff and Rick Durrett. A proof has been sketched and workis proceeding on a paper.
Cindy Greenwood and Xueying Wang have been analyzing the pairwiseclosure approximation (PAC) theory for the stochastic SIRS model (whererecovery from an infective state leads to a temporary immune state) [GannaRozhnova and Ana Nunues, 2009] and comparing it with the stochasticSIS model (where recovery from infection leads directly to a susceptiblestate) [Eames and Keeling] on regular graphs. In one limiting case of the
126

PAC theory for the SIRS model, the two dimensional principal compo-nent of the stochastic paths exhibits sustained stochastic oscillations, inthe form of a Ornstein-Uhlenbeck process composed with a time depen-dent rotation. This work has led to a paper and was the subject of one ofthe presentations at the Transitions Workshop.
• Neuronal Network Dynamics:
One subgroup has explored a key question in neuronal networks: how toderive quantitative descriptions and models for the collective behavior ofa network of neurons starting from neuronal-level dynamical equations forthe membrane voltage and a description of the topology of the network.Stochasticity enters the description typically to describe irregularity ofsignaling inputs, which are then propagated by the network dynamics.Particularly interesting collective behaviors include synchronous oscilla-tions and the formation of mobile spatial patterns where neurons are firingintensely.
A starting point for the subgroup’s investigation is the kinetic theoryapproach developed by one of the opening workshop speakers, David Cai,and his co-workers to describe the overall network firing properties bycoarse-graining the neuronal dynamics in a manner parallel to describingthe evolution of a gas density by coarse-graining the dynamics of individualgas molecules.
The subgroup also found particular interest in recent work by Liu andNykamp on a ”second-order” kinetic theory that has some promise fordescribing large-scale synchrony. These neuronal kinetic theories have sofar not accounted for the spatial distribution (apart from the topologi-cal description) of the neurons, and the subgroup spent some time andeffort thinking about how to incorporate a spatial component into the ki-netic theories or some other mathematical framework that might make itpossible to develop a sort of spatio-temporal continuum equations for theneuronal firing patterns that upscale in a quantitative way the neuronal-level description of the dynamics.
In a related investigation, Katie Newhall, Mandi Traud, Peter Kramerand Peter Mucha have worked on a project which explores different dis-cretizations of simple integrate-and-fire dynamics and the relation betweenstatistical properties of the cascades in these models and the underlyingnetwork of interconnectivity. This project was actually initiated by thegraduate students Newhall and Traud at the intersection of their researchinterests, with their advisors Kramer and Mucha providing subsequentguidance and focus with regard to approaching the question they posed.This work has been presented by Traud in a minisymposium at the SIAMConference on the Life Sciences in July, 2010, by Newhall in a posterpresentation at the opening workshop of the Complex Networks programat SAMSI in August 2010, and is in the process of being written up forsubmission to the journal Chaos.
127

• Institute-Participation Data in Mathematics:
In order to develop network analysis experience and expertise more broadlywithin the working group, we endeavored to supplement our stochastic dy-namics interest with social network analysis of a specific data set. Therewas particular interest leading to direct discussions with the NSF to tryto efficiently gather public co-occurrence data about participants in pro-grams and workshops at SAMSI and the other NSF-funded mathematicalinstitutes. Working group discussions briefly explored standard softwaretools available for social network analysis which might be used on thesedata, along with more specialized tools of community detection and anal-ysis of co-occurrence hypergraphs within the working group and otherspecialists local to the triangle area. However, no easy access to the datawas immediately available from which to undertake this analysis withinthe group.
3.5. Working Group on Biological Stochastic Dynamics
Group Leaders: Amarjit Budhiraja (UNC), Cindy Greenwood (ASU), PeterKramer (Rensselaer)
Participants: Mark Alber (Notre Dame), Avanti Athreya (SAMSI), AmarjitBudhiraja (UNC), Esteban Chavez (Duke), Amogh Deshpande (NCSU), NuwandeSilva (Rensselaer), Oliver Diaz (Duke), John Fricks (Penn State), CindyGreenwood (ASU), Kazi Ito (NCSU), Badal Joshi (Duke), Min Kang (NCSU),Peter Kramer (Rensselaer), Mimi Lin (Duke), Kevin Lin (Arizona), Huitian Liu(San Diego State), Scott McKinley (Duke), John McSweeney (SAMSI), AnujMubayi (Univ. of Texas at Arlington), Katie Newhall (Rensselaer), Lea Popovic(Concordia), Bruce Rogers (ASU), Ravi Srinivasan (Duke), Rachel Thomas(Duke), Xueying Wang (Ohio State University), Richard Yamada (Universityof Michigan)
Topics: The explosion of interest in mathematical and statistical modelingand computation in the biological and medical sciences, where stochasticity ispresent at nearly every scale, has been one of the most exciting trends in thebiosciences in the last ten years. A sizable group has organized at SAMSI tostudy applications of stochastic models and methods to questions in biology,ranging from the population to the cellular and down to the molecular level.
To begin the year, members presented pedagogical overviews of stochasticmethods in biology as well as illustrations of research problems they had workedon and were interested to explore further. Stimulated by these discussions andthe presentations at the opening workshop, six project areas were identified ashaving substantial interest by midyear. These were each discussed on a rotatingbasis during the weekly group meetings.
The molecular motor topic crystallized into a sustained coherent researchcollaboration between four participants, with the ongoing work presented at
128

two SIAM conferences thus far, a first publication being prepared, and twomajor grant proposals submitted.
The single neuron dynamics project has also continued beyond the end ofthe Stochastic Dynamics program, with at least one publication likely to beforthcoming.
While the microswimming project generated a sustained collaborative re-search focus on a recent experimental paper through the early spring, it waslater abandoned as being less promising than originally thought. On the otherhand, one of the visiting faculty has launched a new research project in this areawith local collaborators through the stimulus provided by his time at SAMSI.
While the three other projects remained only in an exploratory phase, theyhelped broaden the exposure of the group, particularly the graduate studentsand postdocs to a wider range of topics of stochastic modeling in biology.
• Molecular motors:
An active collaboration emerged from the working group concerning themodeling and analysis of systems of molecular motors bound to a singlecargo. The central question concerns how the details of the stochasticmodel characterizing individual molecular motors, including their responseto applied forces and proclivity to bind or unbind from the microtubuletrack, is reflected in the effective dynamics of the complex of the cargobound to multiple molecular motors. The group’s effort has primarilyfocused thus far on constructing a serious, physically consistent spatialmodel, and applying stochastic averaging techniques to derive effectiveequations for the motor-cargo complex from physically and biologicallybased stochastic dynamical equations for the individual components.
Avanti Athreya, John Fricks, Peter Kramer, and Scott McKinley are cur-rently writing up their work for publication under the title “Cooperativedynamics of kinesin and dynein type molecular motors”. We plan to sus-tain this collaboration beyond this paper, and to this end, Fricks, Kramer,and McKinley, together with bioengineer William Hancock have submit-ted two major grants to the National Science Foundation’s Focused Re-search Group (FRG) program and the Joint DMS/NIGMS Initiative toSupport Research in the Area of Mathematical Biology. The work pro-posed in these grants would use the mesoscopic modeling developed bythe group at SAMSI as a scaffold from which to build a mathematicallyintegrated stochastic model for cellular transport, from the nanoscale tothe microscale of the whole cell.
• Stochastic Single Neuron Models:
Several collaborative subgroups worked between the biological stochasticdynamics group and the qualitative behavior working group in applyingstochastic analysis techniques to single-neuron models.
Cindy Greenwood together with short-term visitor Laura Sacerdote andcollaborator Maria Teresa Giraudo have submitted a paper “How sample
129

paths of Leaky Integrate and Fire models are influenced by the presence ofa firing threshold” to Neural Computation. This paper treats the statisticsand simulation of sample voltage paths taken by a neuron conditioned onit not having fired (reached threshold) by a certain time.
Avanti Athreya, Badal Joshi, and Xueying Wang considered coherenceand self-induced stochastic resonance in Morris-Lecar models for neurons.This project would advance the characterization of these phenomena byVanden-Eijnden, Muratov, and DeVille in FitzHugh-Nagumo models tothe more complex Morris-Lecar model. For a range of parameter val-ues, the single neuron deterministic Morris-Lecar model has a stable fixedpoint, an unstable limit cycle and a stable limit cycle. Here the stablefixed point corresponds biologically to quiescence of the neuron while thestable limit cycle corresponds to firing an action potential or spiking. Ithas been shown by Rowat [Neural Computation 19, 1215???1250 (2007)]that noise plays a role in spontaneously switching between the two modesof quiescence and firing.
The group extended this work of Rowat into regimes where the deter-ministic model has only a stable fixed point but no stable limit cycles.Even in this parameter regime, having noise in the model can result intwo modes of firing - quiescence and active, and the noise can cause spon-taneous switching between the modes. Thus noise not only plays a rolein switching, but introduces a completely new dynamic mode which doesnot exist in the deterministic model. This has important consequences forpredicting the behavior of a neuron when an external current is applied.Along these lines, Avanti Athreya, Scott McKinley, and Ravi Srinivasanexamined how to model escape from the stable equilibrium in Morris-Lecar models for a neuron, thinking of it as a ”breathing potential” nearthe fixed point. It seems valid to take a small-noise limit in the Morris-Lecar model because the noise can come from ion channels or from inputcurrent, but large deviation approaches don’t seem quite appropriate. Be-sides internal or channel noise in single neurons, another important sourceof noise arises in the synapse or the connection between neurons.
In an ongoing project, the subgroup is studying and classifying the rangeof behaviors of small networks of two or three neurons, connected in afeedforward or a feedback manner. In such small networks, the interactionof synaptic noise and channel noise can give rise to a range of novel andinteresting behaviors. The idea is to develop a framework that would helpqualitatively understand such small networks, and then possibly extendthe insights to larger, more biologically realistic network sizes.
Particular questions being addressed by this subgroup, first by simulation,then to be followed up by analytic work are: How are the firing patternsgenerated by the Morris-Lecar and Fitzhugh-Nagumo models related whensinusoidal forcing, ion channel noise, and synaptic noise are included inthese models? Is there a large deviation cycling effect in the Morris-Lecar
130

model as has been found in the Fitzhugh-Nagumo model, and how is thisrelated to neuron firing?
A related question being pursued by some of the neuron subgroup mem-bers is inference from the spike activity of two neurons. Suppose we havedata in the form of the time points when spikes occur as is usually de-picted in raster plots. A cross-correlogram is a commonly used measure forquantifying the dependence structure, but it has its difficulties in interpre-tation, for example, in inferring the network architecture from the spikingactivity of two neurons. For instance, if the spike times of two neurons arehighly correlated, it can be because they are connected directly or indi-rectly to each other or it can happen because they receive common input.This question of how to distinguish these two cases is being approachedfrom a modeling point of view. Suppose we start with two integrate andfire neurons which receive a common Poisson input. Can we predict thedependence structure in the spiking activity of the two neurons?
• Microswimming:
A workshop at SAMSI in Fall 2009 on Self-Organization and Multi- ScaleMathematical Modeling of Active Biological Systems has provided manystimulating ideas to the group, with two subgroups pursuing specific projects.
One subgroup studied in particular the paper “Dynamics of EnhancedTracer Diffusion in Suspensions of Swimming Eukaryotic Microorganisms”by Leptos, Guasto, Gollub, et al. The results of this paper were pre-sented by Gollub at the workshop. Experimental results for the dynamicsof tracer particles in a flow generated by a suspension of swimming mi-croorganisms showed a striking self-similar probability distribution for thedisplacement of a tracer with respect to time increment, which howeverdid not correspond to any known stable law.
The subgroup sought to develop simplified stochastic models for the dy-namics of these tracer particles that could explain this observation. Thisproject was eventually abandoned when questions began to arise abouthow exactly the data were being collected and processed, and the groupconcluded it was too far removed from the experiment to understand theseissues in adequate detail in order to proceed with confidence in modeling.
Another talk by Michael Shelley on kinetic theories for suspensions of mi-croswimmers elicited a remark by Peter Mucha that, from his experiencewith non-living suspensions, a stochastic treatment of diffusion could leadto important differences from the deterministic treatment of diffusion of-ten employed in kinetic theories. The issues of incorporating stochasticitymore faithfully in the kinetic theory of Shelley was discussed in the work-ing group, and has since been taken up by Peter Kramer at his homeinstitution together with a collaborator Patrick Underhill and a graduatestudent.
• Modeling Biological Swarmsusing Nonlinear Diffusions:
131

Another subgroup was motivated by a different set of talks in the workshopon Self-Organization and Multi-Scale Mathematical Modeling of Active Bi-ological Systems, particularly the one by Andrea Bertozzi on modeling thecollective motion of biological organisms, e.g., locust swarms, fish schools,ant track formation, etc. Her approach employs, for example in work withTopaz, a two-dimensional continuum kinetic model with a nonlocal socialinteraction.
Amarjit Budhiraja, Oliver Diaz and Xin Liu are exploring the use of tech-niques from the theory of nonlinear diffusions to see if they can capturethe key aspects of dynamical feature formation from the phenomenologicalcontinuum theories using a more fundamental stochastic particle systemwith a mean field type interaction. This nonlinear diffusion approach isexpected to not only yield flexible and tractable simulation schemes butalso give a greater insight to the underlying biological mechanism. Theinteracting particle models are expected to be related to the continuummodels through a Propagation of Chaos limit. Rigorously establishingsuch hydrodynamic limit theorems and the associated fluctuation theo-rems is the long term goal of this working group. This work is currentlyin progress.
• Reaction networks:
John Fricks, Badal Joshi, John McSweeney, and Richard Yamada exploreda specific genetic regulatory network in the suprachiasmatic nucleus, whichis responsible for maintaining circadian rhythms. A detailed stochasticsimulation of this network (which takes into account the finite number ofmolecules involved and the effectively random times at which they interactwith each other) exhibits oscillations of concentration levels, a qualitativefeature completely missed by a coarse-grained deterministic model for thisnetwork (based on mass-action principles). The group is seeking to explainthe oscillations observed in the simulation through a coarse-grained theorythat incorporates stochastic fluctuations, such as a van-Kampen (near-Gaussian) expansion.
132

FINAL REPORT: SAMSI PROGRAM ON
SPACE-TIME ANALYSIS FOR ENVIRONMENTAL
MAPPING, EPIDEMIOLOGY AND CLIMATE
CHANGE
Edited by Alan Gelfand, Montse Fuentes and Richard Smith
June 9, 2011
Organizers: Noel Cressie (Ohio State), Michael Stein (University of Chicago), Dongchu Sun(University of Missouri), Jim Zidek (University of British Columbia).
Scientific Advisory Committee: Peter Diggle (Lancaster University), Peter Guttorp (Universityof Washington), Jesper Møller (Aalborg)
Directorate Liaison: Jim Berger (Richard Smith after 07/01/2010)
Local Scientific Coordinators : Montse Fuentes (NCSU), Alan Gelfand (Duke), Richard Smith(UNC).
National Advisory Committee Liaison: Jun Liu (Harvard).
This 12 month SAMSI program focussed on problems encountered in dealing with randomspace-time fields, both those that arise in nature and those that are used as statistical represen-tations of other processes. The sub-themes of environmental mapping, spatial epidemiology, andclimate change are interrelated both in terms of key issues in underlying science and in the statis-tical and mathematical methodologies needed to address the science. Researchers from statistics,applied mathematics, environmental sciences, epidemiology and meteorology were involved, andthe program promoted many opportunities for interdisciplinary, methodological and theoreticalresearch.
The program began with a Summer School on Spatial Statistics (July 28-August 1, 2009, atSAMSI), which featured invited lectures and hands-on tutorials from Sudipto Banerjee (U. Min-nesota), Reinhard Furrer (U. Zurich), Doug Nychka (National Center for Atmospheric Research)and Stephen Sain (National Center for Atmospheric Research).
The Opening Workshop took place from September 13–16, 2009, and featured the followingtutorial lectures:
• Alan Gelfand, Duke University: Hierarchical Modeling for Analyzing Space and Space-timeData
• Jim Zidek, University of British Columbia: Designing Monitoring Networks
133

• Michael Stein, University of Chicago: Asymptotics for Spatial and Spatial-temporal Data
• Sylvia Richardson, Imperial College London: Introduction to Spatial Epidemiology
These were following by a workshop that included five invited paper sessions on “ClimateChange”, “Random Fields and Applications”, “Spatial Epidemiology”, “Spatial and Time-spacePoint Processes” and “Interface of Deterministic Modeling and Space-time Statistics”, as well astwo New Researcher sessions.
On Thursday, September 17, 2009, SAMSI was host to a visit from several scientists at theNational Climatic Data Center (NCDC). This included presentations from Matt Menne and JohnBates of NCDC.
Other workshops organized in connection with the program were:
• SAMSI was joint organizer of the GEOMED 2009 workshop, Nov. 14–16, 2009, at the MedicalUniversity of South Carolina
• Climate Change Workshop, at SAMSI — February 17-19, 2010
• One-day Workshop on Objective Bayesian for Spatial and Temporal Models, in San Antonio,TX — March 20-21, 2010
• Statistical Aspects of Environmental Risk, at SAMSI — April 7-9, 2010
• Transition Workshop, at SAMSI — October 11-13, 2010
Three graduate level courses were taught as part of the program:
• Spatial Epidemiology (Fall);
• Theory of Continuous Space and Space-Time Processes (Fall);
• Spatial Statistics in Climate, Ecology and Atmospherics (Spring).
As usual in SAMSI programs, the bulk of the research activity centered around the Work-ing Groups. Nine Working Groups were formed, and remainder of this report is concerned withreporting the research activities of each of these groups.
1 WG1: Paleoclimate
1.1 Goals and Outcomes of the Working group
A major challenge in climate work is the fact that surface temperatures before about 1850 canonly be indirectly inferred from temperature-sensitive geological proxy data. The same is trueof other climate variables, such as precipitation and the pressure field. An understanding of theclimate of the past is necessary in order to understand the natural variability of the system, and toplace observed changes in the system over the last century, and changes predicted for the future,in a broader context. Estimates of the past evolution of climate variables such as the surfacetemperature space-time field, along with estimates of the associated uncertainty, can be used to
134

assess the extent to which currently observed changes are unusual with respect to the naturalvariability of the system, and to make probabilistic assessments about dynamical hypotheses ofhow climate varies and changes.
While much work has been done on this sort of problem, there remains room for substantialimprovement in the statistical techniques used to reconstruct past climate from proxy data. Theworking group has three main objectives within which there are many sub-objectives:
1. Develop new and/or improve existing statistical methods for three different reconstructionproblems, where each will involve combining incomplete paleoclimatic data and instrumentalobservations:
(a) The reconstruction of univariate climate field, such as temperature.
(b) The reconstruction of a climate index, such as ENSO or the AO, that has major impactson weather and climate on a global scale.
(c) The reconstruction of a multivariate climate field, such as temperature and precipitation.
2. Test these methods against existing ones and objectively assess their performance.
3. Produce new paleoclimatic analyses for the last several hundred to several thousand years,beginning with surface temperatures over different spatial domains.
1.2 Summary of working group Activities: 2009 Sep–2010 October
1.2.1 Membership
Core members: Peter F. Craigmile (Ohio State); Murali Haran (Penn State); Bo Li - PurdueUniversity Elizabeth Mannshardt-Shamseldin (Duke); Martin P. Tingley (SAMSI postdoc, now atNCAR); Bala Rajaratnam (Stanford — chair of working group).
All the above were in residence during Fall 2009.
Other members: Priscilla Greenwood (Arizona State); Rajib Paul (Western Michigan)
1.2.2 Summary of administrative working of group activities
• Standard Meeting Time: Thursday 1pm EST
• Weekly meetings during the academic year 2009-2010 and now biweekly meetings
• First semester Activities (“soul searching”): 1) Presentations from both statisticians andenvironmental/geoscientists and consultations with experts. 2) Identification of problem areasdeemed to be important to the paleoclimate community. 3) Explore the feasibility of studyingproblems that were identified
• Second semester (and Summer) Activities: 1) Preliminary discussions of joint research work
I. Paleoclimate exploratory data analysis
II. Discussions of a theoretical nature and presentation of whether in the paleoclimate contextone should use separable covariance functions or not
135

– Contributions at Climate Change workshop (February, 2010)
– Development and Writing of paper that is currently in review
– JSM (2010) representation: Joint session of paleoclimate and extremes working groups
1.2.3 Paleoclimate Working Group Research Output
The group has been extremely productive and there is a tangible, approximately 100 page researchoutput from the working group in the following paper:
Tingley, M.P., Craigmile, P.F., Haran, M., Li, B., Mannshardt-Shamseldin, E. and RajaratnamB., “Piecing together the past: Statistical insights into paleoclimatic reconstructions”. Underreview at Journal of Climate.
Available at http://statistics.stanford.edu/∼ckirby/techreports/GEN/2010/2010-09.pdf
The paper identifies all the issues (as we see them) in the language of modern day statistics.The paper builds on recent work in the paleoclimate literature using Bayesian hierarchical models— gives a unifying framework. The “grand goal is to move paleoclimate reconstructions away fromsimple regression based approaches towards hierarchical models.” The aims of the paper are:
1. Establish a modeling and notational framework that is transparent to both the earth scienceand statistics communities.
2. Outline and distinguish between scientific and statistical challenges and indicate where mod-ern statistics can contribute.
3. Offer some suggestions for model construction and explain how to perform the required sta-tistical inference.
4. Identify issues that are important to both the earth science and applied statistics communities,and encourage greater collaboration between the two.
1.2.4 Other Research Activities
Craigmile, Peter and Bala Rajaratnam. DISCUSSION OF: A STATISTICAL ANALYSIS OFMULTIPLE TEMPERATURE PROXIES: ARE RECONSTRUCTIONS OF SURFACE TEM-PERATURES OVER THE LAST 1000 YEARS RELIABLE? The Annals of Applied Statistics2011, Vol. 5, No. 1, 88–90.
Haran, Murali and Nathan M. Urba. DISCUSSION OF: A STATISTICAL ANALYSIS OFMULTIPLE TEMPERATURE PROXIES: ARE RECONSTRUCTIONS OF SURFACE TEM-PERATURES OVER THE LAST 1000 YEARS RELIABLE? The Annals of Applied Statistics2011, Vol. 5, No. 1, 61–64
Nychka, Douglas and Bo Li. DISCUSSION OF: A STATISTICAL ANALYSIS OF MULTIPLETEMPERATURE PROXIES: ARE RECONSTRUCTIONS OF SURFACE TEMPERATURESOVER THE LAST 1000 YEARS RELIABLE? The Annals of Applied Statistics 2011, Vol. 5,No. 1, 80–82.
136

Smith, R.L. (2010), Understanding sensitivities in paleoclimate reconstructions. Submitted forpublication.
Tingley, Martin P. SPURIOUS PREDICTIONS WITH RANDOM TIME SERIES: THELASSO IN THE CONTEXT OF PALEOCLIMATIC RECONSTRUCTIONS. DISCUSSION OF: ASTATISTICAL ANALYSIS OF MULTIPLE TEMPERATURE PROXIES: ARE RECONSTRUC-TIONS OF SURFACE TEMPERATURES OVER THE LAST 1000 YEARS RELIABLE? TheAnnals of Applied Statistics 2011, Vol. 5, No. 1, 83–87
Tingley, M.P. and Li, B. (2011), Comments on “Reconstructing the NH mean temperature:Can underestimation of trends and variability be avoided?” by Bo Christiansen; under review atJournal of Climate.
1.3 List of Working group members
Mark Berliner, Ohio State UniversityK Sham Bhat, Penn StatePeter Craigmile, Ohio State UniversityNoel Cressie, Ohio State UniversityCindy Greenwood, Arizona State UniversityMichele Guindani, University of New MexicoMurali Haran, Penn StateJohn Harlim, Courant Institute/NCSUGardar Johannesson, Lawrence Livermore National LaboratoryKaren Kafadar, Indiana UniversityBo Li, PurdueErnst Linder, Univeristy of New HampshireElizabeth Mannshardt-Shamseldin, SAMSI/DukeDoug Nychka, NCARGarritt Page, DukeRajib Paul, Western Michigan UniversityBala Rajaratnam, STanfordBrian Reich, NCSUSteven Roberts, Australian National UniversityJulia Salzman, StanfordJenise Swall, EPARichard Smith, UNC/SAMSICarolyn Snyder, StanfordMartin Tingley, SAMSI/NCARSaeid Yasamin, SAMSIIan Wong, StanfordJun Zhang, SAMSI
137

2 WG2: Spatial Exposures and Health Effects (Montse Fuentes,Amy Herring and Brian Reich)
2.1 Summary
This working group developed and implemented spatial-temporal statistical models to study theimpact under climatic change conditions of air pollution on human health. We introduced Bayesianmultivariate spatial dependence structures in the environmental stressors, climatic variables, andhealth outcomes, while taking into account different sources of uncertainty in models and data.We developed novel spatial quantile regression models for the climatic and pollution variables forbetter characterization of extremes, tail behavior, and complex dependences between weather andpollution. We developed Bayesian hierarchical shrinkage methods for assessing spatial associationsbetween complex pollutant mixtures and health outcomes. We improved upon existing approachesby simultaneously accounting for different pollutant types, such as ozone and particulate matter(PM) or speciated PM, characterizing the spatial temporal structure of the susceptible periods offetal development (for pregnancy outcomes) and the exposure lag (for mortality outcome), whiletaking into account different sources of uncertainty in models and data.
This work had led to several papers, and the submission of an NIH proposal, as well as severalconference presentations.
NIH Proposal: Space-time Modeling for Linking Climate Change, Pollutant Exposure, BuiltEnvironments, and Health Outcomes. PI: Montserrat Fuentes, co-PIs: Amy Herring, Alan Gelfand,Brian Reich and Marie Lynn Miranda. $1.1M, NIH R-01 submitted
For the remainder of the report of this working group, we describe the outcomes of severalindividual projects that were conducted as part of the working group’s activities.
2.2 Estimating Individual Activity Spaces (Leader: Catherine Calder)
In this collaboration with sociologists and geographers, we are developing methods to estimateindividual activity spaces, or the space-time context for human exposures, and examining theconsequences of exposure to violence and disadvantage on health and behavioral outcomes.
Papers in preparation:
• Calder, C.A. and Darnieder, W.F. Bayesian Inference for Incomplete Marked Spatial PointPatterns.
• Krivo, L.J., Washington, H.M., Peterson, R.D., Browning, C.R., Calder, C.A., and Kwan,M.-P. Social Isolation of Disadvantage and Advantage: The Reproduction of Inequality inUrban Space.
Presentation:
• C.A. Calder, “Bayesian Estimation of Individual Activity Spaces from Incomplete ActivityPattern Data” Conference on the Dynamics of Space-Time Use, The Ohio State University,Columbus, OH, October 2-3, 2009
138

• C.A. Calder, “Bayesian Inference for Incomplete Marked Spatial Point Patterns: EstimatingIndividual Activity Spaces”. SAMSI Program on Space-Time Analysis Closing Workshop,October 11-13, 2010
Posters:
• “Bayesian Inference for Incomplete Marked Spatial Point Patterns” by C.A. Calder. Pre-sented at Valencia/ISBA Meeting, Benidorm, Spain, SAMSI Program on Space-Time Anal-ysis Closing Workshop, June 3–8, 2010.
Grants: NSF and NIH
2.3 Effects of Air Pollution Exposure on Cardiovascular Health (Leader: Cather-ine Calder)
Using spatially-referenced longitudinal data collected as part of the Dallas Heart Study, we areestimating the effects of exposure to particulate matter on cardiovascular health.
Grants: in preparation for the NIH
2.4 Identifying Critical Windows in Studies of Air Pollution and Preterm Births(Josh Warren, Montserrat Fuentes, Amy Herring)
We developed a model for examining the relationship between exposure to PM2.5 and ozone andthe probability of preterm birth, with a focus on identifying critical windows of pregnancy duringwhich increased exposure to these pollutants may be particularly dangerous. Our methods havebeen applied to data from Texas vital records, are currently being applied to a Texas birth defectsregistry, and will soon be applied a ten-state study that is the largest study of the etiology ofbirth defects ever conducted, the National Birth Defects Prevention Study. We are currentlyworking on extensions of these methods that relax some distributional assumptions and that lookat multivariate outcomes.
Paper:
• Warren, J., Fuentes, M., Herring, A., and Langlois, P. Air Pollution and Preterm Birth:Identifying Critical Windows of Exposure. Under Review.
2.5 Health Impacts of Future Ambient Ozone Levels due to Climate Change(Howard Chang, Jingwen Zhou, Montserrat Fuentes)
To quantify the health impacts of future air pollution due to climate change, we have developed amodeling framework that integrates data from climate model outputs, historical meteorology andozone observations, and a health surveillance database. We applied this approach to examine therisks of future ozone levels on non-accidental mortality across 19 urban communities in SoutheasternUnited States. We are currently extending the model to address the following statistical challenges:calibrating multivariate climate model outputs, spatial misalignment, and joint analysis of airquality and temperature.
Papers:
139

• Chang, H.H., Zhou, J. and Fuentes, M. (2010). Impact of Climate Change on Ambient OzoneLevel and Mortality in Southeastern United States. International Journal of EnvironmentalResearch and Public Health 7: 2866-2880.
• Zhou, J. and Fuentes, M. Calibration of air quality deterministic models using nonparametricspatial density functions. In preparation.
Talks:
• Impact of climate change on ambient ozone level and mortality in Southeastern United States.Multi-pollutant Multi-city Working Group, US Environmental Protection Agency, June 2010.Durham, NC
• Impact of climate change on ambient ozone level and mortality in Southeastern United States.SAMSI Workshop on Statistical Aspects of Environmental Risk, April, 2010.
2.6 Time-to-event Analysis of Air Pollution and Preterm Birth (Howard Chang,Brian Reich, Marie Lynn Miranda)
Most studies of preterm birth use a binary indicator of preterm birth as the response. We proposea flexible spatial survival model to estimate the effect of environmental exposure on the risk ofpreterm birth. We view gestational age as time-to-event data where each pregnancy enters therisk set at a pre-specified time (e.g. the 32th week). The pregnancy is then followed until either(1) a birth occurs before the 37th week (preterm); or (2) it reaches the 37th week and a full-termbirth is expected. Our simulation study shows that this is a more powerful study design than morecommon time series and case-control designs. Also, by analyzing these data as survival data, weare able to study effects of both acute and long-term exposures jointly. The proposed approachis applied to geocoded births during 2002-2007 in North Carolina and we report an increased riskof preterm birth associated with exposure to fine particulate matter during the first and secondtrimesters.
Papers:
• Chang, H.H., Reich, B.J., and Miranda, M.L. Spatial time-to-event analysis of fine particulatematter and preterm births. In preparation.
• Chang, H.H., Reich, B.J., and Miranda, M.L. Fine particle air pollution and preterm birthin North Carolina, 2003-2007. In preparation.
Talks:
• Fine particle air pollution and preterm birth in North Carolina, 2001-2005. Third NorthAmerican Congress of Epidemiology, June 2011, Montreal, Canada
• Spatial time-to-event analysis of fine particulate matter and preterm births. Summer ResearchConference, Southern Regional Council on Statistics, June 2010. Virginia Beach VA.
• Time-to-event analysis of preterm birth and fine particulate matter. Joint Statistical MeetingAugust 2010. Vancouver Canada.
140

• Time-to-event analysis of preterm birth and fine particulate matter. Environmental StatisticsSeminar, Harvard Department of Biostatistics, August 2010. Boston MA.
2.7 Exposure Measurement Error in Time Series Studies of Air Pollution andHealth (Howard Chang, Montserrat Fuentes)
In a time series design, the health outcome is only available as daily total number of adverse eventsin a community. Unbiased risk estimates require the exposure measure to coincide with the trueaverage exposure experienced by all at-risk individuals in the community. We have examined theeffects of exposure measurement error due to spatial heterogeneity in the pollutant concentrations,motivated by the health effects of coarse particulate matter. We are currently developing modelsto incorporate spatial distribution of the at-risk population and personal exposure simulations inthe times series design. The proposed approach is used to study the association between personalexposure to fine particulate matter and mortality in the New York City metropolitan area.
Paper:
• Chang, H.H., Peng, R.D., and Dominici, F. Estimating the acute health effects of coarseparticulate matter accounting for exposure measurement error. Under Revision.
Talk:
• Estimating the acute health effects of coarse particulate matter accounting for exposure mea-surement error. ENAR, 2010. New Orleans, LA.
2.8 Additional Activities
• Invited JABES highlight session at JSM 2011.
• 2011 ENAR short course: A Practical Introduction to the Analysis of Geocoded and ArealHealth Data.
• Collaboration with EPA on a national multi-site time series analysis of daily mortality andchemical constituents of fine particulate matter. Paper in preparation:
Chang HH, Baxter LK, Fuentes M, and Neas LM. Daily mortality and chemical constituentsof fine particle air pollution.
3 WG3: Interaction of Deterministic and Stochastic Models (Co-leaders: Murali Haran, Pennsylvania State University, and M.J.Bayarri, University of Valencia)
3.1 Overview
Core group members: M. J. Bayarri, University of Valencia, Spain; Jim Berger, Duke; MuraliHaran, Penn State; John Harlim, NC State (from SAMSI stochastic dynamics program); Emily
141

Kang, SAMSI postdoc: Peter Kramer, RPI (from SAMSI stochastic dynamics program); HansKuensch, ETH Zurich, Switzerland.
Other key members: Sham Bhat, Penn State: Anabel Forte, University of Valencia, Spain;Robert Wolpert, Duke; Danilo Lopes, Duke; Priscilla Greenwood, Arizona State.
The goal of our group was to work on statistical issues in complex deterministic and stochasticmodels. We identified the following potential areas:
1. Approximations, emulation and calibration for complex computer models, typically Gaussianprocess-based models, and inference for stochastic differential equations.
2. Bridging the gap between the “usual” statistics idea of spatial modeling (accounting fordependence) and capturing spatial dynamic processes that are of scientific interest, which weenvisioned as a potential avenue for interactions between the spatial program and the SAMSIstochastic dynamics program.
3. Using deterministic models/process to construct flexible space-time models.
4. Deterministic models as surrogate for probability/process model (“computer likelihoods”).
5. Embedding deterministic models within a hierarchical framework to learn about parametersof interest.
6. Developing efficient computational approaches for simulating from multiscale models.
This working group was unique among the SAMSI space-time modeling working groups of 2009–2010 in that the research involved a close collaboration between two SAMSI programs in 2009–2010, the stochastic dynamics program, predominantly involving applied mathematicians, and thespatial program, primarily involving statisticians. Two applied mathematicians, Peter Kramer fromRensselaer Polytechnic Institute, and John Harlim from North Carolina State University, have beencore members of the group, and have driven the research problem definition in conjunction withthe statisticians. The focus of this collaboration was work in multi-scale dynamical systems; to ourknowledge this is the first such collaboration between statisticians and applied mathematicians.
Summary of working group activities: The fall 2009 semester involved several research talksand discussions about potential projects by group members and collaborators of group members.Several of these problems included specific scientific applications:
(i) Modeling/inference for a component model for alcohol usage,
(ii) Dengue fever modeling based on a data set from Peru,
(iii) Exploring mathematics underlying a class of spatial dynamics models.
(iv) Studying multiscale dynamical systems or heterogeneous multiscale methods (HMMs).
(v) Emulation/calibration for complex computer models for multivariate spatial processes.
(iv) Bayesian model averaging of climate models for temperature projections.
142

Our group focused on projects (iv)-(vi); several related projects have either been completedor are ongoing projects involving the working group members. Projects (i)-(iii) represent futureavenues for research. Several of our research project proposals will continue through our recentlyformed collaborations. Others may find their home in future SAMSI programs. In particular, manyof the complex computer models problems may fit nicely into the “Uncertainty Quantification”SAMSI program in 2011.
3.2 Specific Activities
3.2.1 Multiscale modeling and simulation, spatio-temporal filtering
Project (iv) on multiscale modeling has been a focal point of research discussions. A coregroup of working group members listed above is meeting biweekly to discuss multiscale simula-tion/computation (HMM)-related research. HMMs are used for simulating physical processes thathave both “macroscale” and “microscale” dynamics. This has become an active research area inapplied mathematics and scientific computing in the past decade and has lots of important scientificapplications, for example modeling complex fluid dynamics and climate systems. This appears tobe a rich and still unexplored area of research for statisticians. Hence, a significant outcome of ourworking group’s activities is the fact that we have opened up possibilities for a new and potentialfruitful line of research.
Research manuscripts are planned and the group intends to submit multi-institutional grantproposals to the National Science Foundation, among other funding sources. The group is workingclosely with Sorin Mitran, an applied mathematician and participant in the stochastic dynamicsprogram at SAMSI, who is providing the specific examples and associated computer code and datawhich will act as a testbed for the new methods we develop.
Research manuscripts
J. Harlim, Numerical Strategies for Filtering Partially Observed Stiff Stochastic DifferentialEquations, J. Comput. Phys., 230(3), 744-762, 2011.
E.L. Kang and J. Harlim, A Fast Filtering Framework for Assimilating Partially ObservedMultiscale Systems: The Macro-Micro-Filter, submitted to Mon. Wea. Rev., 2010.
3.2.2 Complex computer models with multivariate spatial output
Project (v) above, on Gaussian process models for computer model emulation and calibration wasanother area of focus for the group.
Research manuscripts:
Bhat, K. S., Haran, M., Goes, M. (2010) Computer model calibration with multivariate spatialoutput: a case study in climate parameter learning. In Frontiers of Statistical Decision Makingand Bayesian Analysis (Ming-Hui Chen, Dipak K. Dey, Peter Mueller, Dongchu Sun, and KeyingYe, eds.). Springer
Bhat, K. S., Haran, M., Keller, K., Tonkonojenkov, R. (2010) Inferring likelihoods and climatesystem characteristics from climate models and multiple tracers, submitted.
143

M.J. Bayarri (2010). A methodological review of computer models. In Frontiers of StatisticalDecision Making and Bayesian Analysis (Ming-Hui Chen, Dipak K. Dey, Peter Mueller, DongchuSun, and Keying Ye, eds.). Springer, pp 157-168.
Reichert, P., White, G., Bayarri, M.J., Pitman, E.B. (2011). Mechanism-based emulation ofdynamic simulation models: concept and application in hydrology. Computational Statistics andData Analysis (in press).
Submitted grant proposal:
P. Kramer (RPI), Statistical Computing Methodologies in Dynamical Network and MultiscaleApplications, co-PI K. Bennett; submitted to National Science Foundation, Division of Mathemat-ical Sciences in December 2010; under review.
3.2.3 Bayesian model averaging for climate projections
Bhat, K. S., Haran, M., Keller, K. (2010) Combining multiple climate models using Bayesian modelaveraging to project surface temperature, in preparation.
4 WG4: Computation, Visualization, and Dimension Reduction(Frank Zou, NISS; Scott Holan, University of Missouri and NoelCressie, Ohio State)
Our Working Group (WG) consists of approximately 60 members, though some are not active. Ithas approximately 10 postdocs and 8 graduate students.
Active postdocs: Sourish Das, Emily Kang, Esther Salazar, Ben Shaby, Xia Wang, and FrankZou
Active graduate students: Sham Bhat, Matthias Dorit Hammerling, Katzfuss, and Yajun Liu
WG has attracted several outside members, including: Kate Cowles, Hedibert Lopes, and BrianSmith
Meetings started on 9/25/09, with an average attendance of 14 (on site) and 10 (remote).
4.1 Schedule of meetings (September 2009 through March 2010)
9/25/09. Introductory/Organizational meeting
10/2/09. Two presentations, on high performance computing and dimension reduction: AndrewFinley (Michigan State University), Peter Kramer (Rensselaer Polytechnic Institute).
10/9/09. Two presentations, on parallel computing and S4 classes in R: Ginger Davis (Universityof Virginia) and Blair Christian (EPA)
10/16/09. Two presentations, on regional climate models and spatially varying coefficient mod-els: Ernst Linder (University of New Hampshire) and Scott Holan (University of Missouri,Columbia)
144

10/23/09. Two presentations, on covariance tapering and petroleum applications: Jo Eidsvik(Norwegian University of Science and Technology) and Orietta Nicolis (University of Bergamo,Italy)
10/30/09. One presentation, on modeling dynamic controls on ice streams: Noel Cressie (TheOhio State University)
11/06/09. Two presentations, on parallel computing and hierarchical spatial process models: Vir-gilio Gomez-Rubio (Universidad de Castilla-La Mancha) and Sudipto Banerjee (University ofMinnesota)
11/13/09. Two presentations on RAMPS — an R package for complex spatio-temporal data:Brian Smith (University of Iowa) and Kate Cowles (University of Iowa).
11/20/09. Two presentations, on independent component analysis for multivariate time series andMonte Carlo strategies for calibration in climate models: David Matteson (Cornell University)and Gabriel Huerta (University of New Mexico)
12/04/09. Two presentations, on ancillary sufficient interweaving scheme and Monte Carlo strate-gies for calibration in climate models: Yajun Liu (University of Missouri) andMurali Haran(Penn State)
12/11/09. One presentation, on understanding covariance tapering: Ben Shaby (SAMSI)
1/15/10. Two presentations, on spatio-temporal statistics and models that include covariatesin covariance structures: Noel Cressie (Ohio State) and Alexandra Schmidt (UniversidadeFederal do Rio de Janeiro)
1/22/10. One presentation, on spatio-temporal analysis of total nitrate concentrations using dy-namic statistical models: Sujit Ghosh (North Carolina State)
1/29/10. Two presentations, on spatial dynamic factor analysis and using temporal variabilityto improve spatial mapping with application to satellite data: Hedibert Lopes (University ofChicago) and Emily Kang (SAMSI)
2/5/10. Two presentations, on dynamic spatial models and Bayesian methods in syndromicsurveillance: Dani Gamerman (Universidade Federal do Rio de Janeiro) and Frank Zou(NISS).
2/12/10. One presentation, on space-time modeling with Markov random fields, plus subgroupupdates: Marco Ferreira (University of Missouri, Columbia)
2/26/10. One presentation on Ensemble Kalman Filters, plus subgroup updates: Hans Kuench(Swiss Federal Institute of Technology)
3/12/10. One presentation, on surveillance for detecting emergent space-time clusters, plus sub-group updates: Renato Assuncao (Universidade Federal de Minas Gerais)
3/26/10. One presentation, on spatially varying autoregressive processes, plus subgroup updates:Bruno Sanso (University of California Santa Cruz).
145

In addition to the above, visits were paids to the CICS group at the National Climatic DataCenter (NCDC) by Scott Holan (12/08/09) and by Bruno Sanso and Richard Smith (03/25/10).At these meetings, the potential was discussed for applying the new statistical techniques to newspatio-temporal datasets from NCDC, though it was subsequently decided to concentrate instead onregional climate model output from the NARCCAP group at the National Canter for AtmosphericResearch.
In May, 2010, the groups split into four subgroups that subsequently met separately. The workof these subgroups will now be described.
4.2 Covariance Decomposition Using Wavelets (Leader: Orietta Nicolis)
The activities of the working group began by examining relevant papers on methods for reducing therank of large covariance matrices. Initially, their attention was directed toward methods based onmultiresolution techniques and wavelets functions. In particular, each member gave a presentationand wrote a summary of relevant papers.
In this context several issues were discussed including
1. Which wavelet was better than others in approximating spatial covariance functions?
2. How the computational burden can be reduced using a reduced/fixed rank covariances?
3. How to extend these methods using a Bayesian approach.
4. How methods based on spatial multiresolution covariances can be extended to the spatio-temporal domain.
The group decided to propose a covariance model (based on wavelet functions) for analyzingsatellite data. They considered the dataset of Aerosol and SO2 from the NASA website:
http://mirador.gsfc.nasa.gov/index.shtml.
The aim was to propose a spatio-temporal model for analyzing the ash plume of the Icelandvolcano during the month of April 2010.
The group realized that the data needed a pre-processing before being used and found severalproblems. The group decided to use simulated data, to start, and has ongoing meetings to discusstheir progress.
4.3 Spatio-Temporal Point Processes (Leader: Noel Cressie)
Noel Cressie led the SG on spatio-temporal point processes. Their first activity was to carry outa literature survey. The group read and wrote summaries of about 20 papers, and have postedthe summaries on ’SG2 Central,’ the subgroup website. After the literature survey, the grouplooked for an appropriate space-time dataset to analyze. The group eventually decided to use theNARCCAP dataset and to model the pixels of extreme rainfall. In fact, such thresholded pixelsare better modeled as a random set whose ”germs” are generated by a type of autoregressive (intime) Poisson spatial point process. Random sets are defined by their hitting functions and, as ofthis writing; the SG is calculating the hitting function of the proposed spatio-temporal set model.
146

The subgroups intention is to publish a joint paper. They communicate by telecon at a regulartime (10am Mon) most weeks, and the minutes of the meetings are posted on SG2 Central.
Submitted paper:
N. Cressie, R. Assuncao, S.H. Holan, M. Levine, O. Nicolis, J. Zhang and J. Zou (2011), Dynam-ical random-set modeling of concentrated precipitation in North America. Technical Report No.854, March, 2011, Department of Statistics The Ohio State University, Columbus, OH. Submittedto Statistics and Its Interface.
4.4 Spatial and Spatio-Temporal Classes in R (Leaders: Kate Cowles and BrianSmith)
Brian Smith developed an R class of spatial objects that can be used with both geostatistical modelsand conditional autoregressive models.
Brian Smith developed the R package ”magma” that enables parallelized matrix operations tobe carried out on graphical processing units (http://cran.r-project.org/package=magma).
Kate Cowles and summer students beta tested and benchmarked the ”magma” package andfound speed-ups of up to 40 fold for operations related to spatial data analysis.
Kate Cowles identified relevant funding sources (from both government and industry) for re-search in spatiotemporal modeling and computation.
4.5 Space-time models for regional climate model data (Leader: Bruno Sanso)
Subgroup 4, which eventually reduced to Xia Wang (NISS), Andrew Finley (MSU), Ingelin Steins-land (ntnu), Dorit Hammerling (UMich), Esther Salazar (Duke), Paul Delamater (MSU), andBruno Sanso (UCSC), has been meeting regularly to work on space-time models for regional cli-mate output. The following paper has been submitted for publication:
Salazar, E., Sanso, B., Finley, A.O., Hammerling, D., Steinsland, I., Wang, X. and Delamater, P.(2011), Comparing and Blending Regional Climate Model Predictions for the American Southwest.
Bruno Sanso presented a talk based on this paper at the SAMSI spatial transition workshopas well as at Workshop on Environmetrics in Boulder, CO, 10/11-13/2010. Dorit Hammerlingpresented a poster based on this paper at the 3rd NARCCAP user workshop, April 7-8 2011,Boulder, CO.
4.6 Syndromic Surveillance
Manuscripts:
Zou, J., Karr, A., Heaton, M., Banks, D., Datta, G., Lynch, J. and Vera, F. (2010), BayesianMethodology for Spatio-Temporal Syndromic Surveillance. Submitted to Statistical Analysis andData Mining.
Heaton, M., Banks, D., Zou, J., Karr, A., Datta, G., Lynch, J. and Vera, F. (2011), A Spatio-Temporal Absorbing State Model for Disease and Syndromic Surveillance. Submitted to Statisticsin Medicine.
147

Presentations and Posters:
Bayesian Methods in Syndromic Surveillance, QMDNS Meeting, Fairfax, VA, May 2010.
Bayesian Methods in Syndromic Surveillance, DTRA/NSF Algorithm Workshop, Chapel Hill,NC, June 2010.
Modeling the Spatio-temporal Dynamics of Risk with Application to Disease and SyndromicSurveillance, DTRA/NSF Algorithm Workshop, Chapel Hill, NC, June 2010.
Hierarchical Bayesian modeling in syndromic surveillance, ISBA World Meeting, Benidorm,Spain, June 2010.
5 WG5: Spatial Extremes (Richard Smith)
Membership:
Juliette Blanchet (WSL-Institut fur Schnee, Switzerland)Lisha Chen (Yale)James Christian (EPA)Dan Cooley (Colorado State)Peter Craigmile (Ohio State)Sourish Das (Duke/Samsi)Anthony Davison (EPFL, Switzerland)Robert Erhardt (UNC)Alan Gelfand (Duke)Souparno Ghosh (Texas A&M)Radu Herbei (Ohio State)David Holland (EPA)Scott Holan (Univ of Missouri)Gabriel Huerta (Univ of New Mexico)Janine Illian (Univ of St. Andrews)Soyoung Jeon (UNC)Matthias Katzfuss (Ohio State)Linyuan Li (Univ of New Hampshire)Kenny Lopiano (Univ of Florida)Jim Lynch (Univ of South Carolina)Elizabeth Mannshardt-Shamseldin (Duke/Samsi)Garritt Page (Duke)Abel Rodriguez (UC Santa Cruz)Huiyan Sang (Texas A&M)Bruno Sanso (UC Santa Cruz)Marian Scott (Univ of Glasgow, U.K.)Benjamin Shaby (SAMSI)Richard Smith (UNC/SAMSI)Martin Tingley (SAMSI/NCAR)Anand Vidyashankar (Cornell)Maria Franco Villoria (Univ Glasgow, U.K.)
148

Jianqiang Wang (NISS)Robert Wolpert (Duke)Linda Young (Univ of Florida)Jun Zhang (SAMSI)Zhengjun Zhang (Univ of Wisconsin)James Zidek (University of British Columbia)
Classical (univariate) extreme value theory revolves around the class of limiting distributions forsample extremes, which may be summarized by the Generalized Extreme Value (GEV) distribution
G(x ; µ, ψ, ξ) = exp
{−(
1 + ξx− µψ
)−1/ξ+
}(y+ = max(y, 0)).
The extension to higher dimensions, known as Multivariate Extreme Value Theory, leads tomultivariate distributions with the property that for and dimension K ≥ 1 and for each N ≥ 1there exist constants {ANk > 0, BNk, 1 ≤ k ≤ K} such that
GN (x1, ..., xK) = G(AN1x1 +BN1, ..., ANKxK +BNK).
Distributions satisfying this property are known as Max-Stable Distributions.
In studying spatial extremes, much attention recently has focussed on a class of processes knownas Max-Stable Processes: A stochastic process over some index set (typically space or time) suchthat all the finite-dimensional distributions are max-stable.
In recent years, a number of specific examples of max-stable processes have been examined,including the “Smith model” (originally given in an unpublished 1990 paper), the class of modelsdue to Schlather (2002), an extension of the Schlather model defined by Davison and Gholamrezaee,and the class of “Brown-Resnick” models and their extensions (Kabluchko, Schlather and de Haan,2009).
Each of these models is defined by a stochastic representation that does not lead to closed-form solutions for the multivariate densities of the process. Therefore, direct methods of statisticalestimation, such as maximum likelihood and Bayes, are not applicable. However, for each ofthe classes of max-stable models specified above, there do exist closed-form expressions for thebivariate densities. This suggests estimation based on maximizing the composite likelihood, wherethe composite likelihood in effect consists of the product of all bivariate densities (Padoan et al.2010).
This more or less defined the starting point for our working group: max-stable processes havebeen increasingly used over the last few years as a model for spatial extremes, and thanks to thecomposite likelihood theory, there is now a viable means of estimating them, but that still leaves alot of open questions, including the development of a “threshold” theory of estimation (comparablewith the extension of univariate and later multivariate extreme value theory from the generalizedextreme value distributions for sample maxima to univariate and multivariate generalized Paretodistributions for exceedances over thresholds), the development of a Bayesian theory of estimation(with associated applications to, for example, prediction of extreme events), and a wider range ofapplications. Among the latter were a special focus on paleoclimatic extremes (motivated in part bythe work of the parallel group on Paleoclimate, with whom we shared some common members) and
149

the recently developed theory of “single-event attribution” in climate change, which is concernedwith the problem of how well we can attribute a single extreme event to human-induced causes ofclimate change as opposed to natural variability.
After an initial series of meetings of the whole group, it was decided to focus future attentionwithin four subgroups concentrating on these four specific themes.
5.1 Threshold methods
Membership: Dan Cooley, Soyoung Jeon, Elizabeth Mannshardt-Shamseldin, Richard Smith,Robert Wolpert.
The challenge is to develop a version of the composite likelihood approach for max-stable pro-cesses based on threshold exceedances rather than the block maxima approach which is the mainone considered previously. It turns out that there is a fairly straightforward construction to writedown a possible composite likelihood in this setting, but understanding the properties of the result-ing estimators is a much harder task. This group benefitted considerably from interactions withthe spatial extremes group at EPFL (Lausanne, Switzerland), which included visits to SAMSI byAnthony Davison and Raphael Huser from EPFL; Huser gave a talk at the Transition Workshop onthe approach that he has developed in collaboration with Davison. Meanwhile, SAMSI GraduateFellow Soyoung Jeon worked independently on an alternative approach which uses the the second-order theory of bivariate extremes to develop bias and variance approximations to the compositelikelihood estimators in a threshold context; such approximations lead to theoretical expressionsfor the optimal threshold as well as establishing asymptotic normality of the resulting estimators.A paper is shortly to be submitted (Jeon and Smith 2011).
Independently, Robert Wolpert developed approximations and a simulation methodology forthe joint distibution of k ≥ 2 points from a class of max-stable processes, and for maxima overregions. The method has potential to lead to exact maximum likelihood or Bayesina inference incertain cases (Wolpert 2010).
References:
Jeon, S. and Smith, R.L. (2011), Max-Stable Processes for Threshold Exceedances in SpatialExtremes. Manuscript, shortly to be submitted.
Wolpert, R. (2010), Spatial extremes. Preliminary version of a paper.
5.2 Bayesian methods
Membership: Dan Cooley, Peter Craigmile, Rob Erhardt, Matthias Katzfuss, Ben Shaby, RobertWolpert.
Since there is no closed-form expression for the joint density of k observations from a max-stableprocess, when k > 2, there is no direct method of Bayesian inference. For frequentist inference,the method of composite likelihood has become fashionable (Padoan, Ribatet and Sisson, 2010).This therefore raises the question of whether the composite likelihood concept can be extended toa Bayesian context. A recent paper by Ribatet, Cooley and Davison (2010) has proposed such amodification. Independently, SAMSI postdoc Ben Shaby found an alternative construction (Shaby
150

2011). Both methods rely on “correcting” the composite likelihood function in the neighborhoodof its maximum to derive a more realistic approximation to the true likelihood function.
An alternative approach to approximating the likelihood by a simpler form is to approximatethe process itself. Reich and Shaby (2011) proposed a discrete approximation to one of the well-known classes of max-stable processes, resulting in a construction for which a standard MCMCalgorithm is applicable.
A different kind of alternative approach is to abandon the likelihood function altogether anduse the “approximate Bayesian computing” framework that has become popular for using Bayesiananalysis for problems with intractable likelihoods. The computational demands of this approachare considerable, but UNC graduate student Rob Erhardt has developed an approach using parallelcomputing that seems very promising. Although vastly more computationally intensive than thecomposite likelihood approach, recent simulations show that the resulting estimates are superior tothose computed via maximum composite likelihood. A paper has been submitted for publication(Erhardt and Smith, 2011).
Papers:
Erhardt, R. and Smith, R.L. (2011), Approximate Bayesian Computing for Spatial Extremes.Submitted for publication.
Reich, B.J. and Shaby, B. (2011), A finite-dimensional construction of a max-stable process forspatial extremes. Submitted.
Ribatet, M., Cooley, D. and Davison, A.C. (2010), Bayesian inference from composite likeli-hoods, with an application to spatial extremes. Under revision for Statistica Sinica.
Shaby, B. (2011), The open-faced sandwich adjustment for estimating function-based MCMC.In preparation.
5.3 Paleoclimatic Extremes
Membership: Peter Craigmile, Elizabeth Mannshardt-Shamseldin, Martin Tingley, Jim Zidek.
This group examined the relationship between changing climate and extreme climate events.Possible trends identified in temperature reconstructions lead to several questions about long-termclimate behavior, and how to interpret this behavior given the patterns seen in proxy series. Forexample, it is of interest to use proxy data to address questions such as “Is there evidence that theextreme events of recent decades are more extreme than previous decades?” This group looked atwhat the statistics of extremes has to offer the field of paleoclimatology through modeling of theoriginal proxy series, and sought to address several of the emerging areas of research that intertwineextreme value analysis and paleoclimatic reconstruction.
Paper in preparation:
Mannshardt-Shamseldin, E., Craigmile, P. and Tingley, M. (2011), Paleoclimatic extremes inproxy data. Shortly to be submitted.
151

5.4 Operational (Single-Event) Attribution
Membership: Richard Smith, Martin Tingley, Xuan Li (UNC), Matthias Katzfuss, Michael Wehner(Lawrence Berkeley Lab.), Jun Zhang.
Detection and Attribution is a well-established field of climate change research that is concernedwith deciding whether observed changes and trends in the climate can be attributed to humancauses. In a typical application of the method, a climate model (or several climate models) isrun under different combinations or forcing conditions, e.g. control runs (stationary climate; noexternal forcing), natural forcings (including solar fluctations and volcanoes) and a combinationof natural and anthropogenic forcings, where the anthropogenic forcings include greenhouse gasesand sulfate aerosols. By regressing an observed climate signal on different combinations of climatemodels, it is possible to say when the anthropogenic signal is “detected” (usually characterized bya regression coefficient being statistically significantly different from zero), and in that case, the“attribution” refers to the partioning of observed climate change to different forcing factors, asmeasured by their regression coefficients.
Recently, attention has shifted to the problem of attribution of single events, where a singleextreme meteorological event may be studied for evidence that it was in some sense “caused by”anthropogenic climate change. Following a landmark paper by Stott, Stone and Allen (Nature,2004), such evidence is often presented in terms of a fraction of attributable risk (FAR) of anextreme event that is derived from the anthropogenic components of a climate model (or models).
This working group sought a more rigorous derivation of FAR using extreme value theory. Theidea is to estimate the probability of an observed extreme event based on comparative runs ofclimate models under different combinations of control, natural-forcings or anthropogenic-forcingsscenarios; however, the confidence intervals associated with such probability estimates are invariablyvery wide. Smith and Wehner will shortly submit a paper proposing a profile likelihood solution tothis problem; Li (2011) is working for her PhD dissertation on an alternative Bayesian approach.
References:
Li, Xuan (2010), Bias and Variability Assumptions in a Bayesian Analysis of Climate Models.PhD Dissertation Proposal, Department of Statistics and Operations Research, University of NorthCarolina, Chapel Hill.
Smith, R.L. and Wehner, M. (2011), A Threshold-based Extreme Value Approach to EventAttribution. In preparation.
5.5 Other activity of this working group
SAMSI postdoc Jun Zhang worked on a penalized likelihood approach for estimating return valuesfrom multiple precipitation stations, where the penalty function is designed to ensure smoothnessin the variation of the GEV coefficients over space. This is an alternative to the popular Bayesianhierarchical approach to problems of this nature.
Montse Fuentes presented a talk on an alternative “nonparametric” approach to joint distribu-tions of spatial extremes, avoiding the assumptions concerned with max-stable processes:
152

Anthony Davison gave an invited talk at the Climate workshop and he, Juliette Blanchet andMathieu Ribatet also contributed to working group discussions a number of times by Webex linkfrom Switzerland.
References:
Blanchet, J. and Davison, A. C. (2011) Spatial modelling of extreme snow depth. Annals ofApplied Statistics, to appear.
Davison, A. C., Padoan, S. and Ribatet, M. (2010) Statistical modelling of spatial extremes.Under revision for Statistical Science.
Davison, A. C. and Gholamrezaee, M. M. (2010) Geostatistics of extremes. About to be resub-mitted.
Fuentes, M., Henry, J. and Reich, B. (2011), Nonparametric Spatial Models for Extremes:Application to Extreme Temperature Data. Extremes, accepted.
Zhang, J., and Zheng, W., (2011), A Penalized Likelihood Approach for m-year precipitationreturn values estimation. Submitted to Journal of Agricultural, Biological, and EnvironmentalStatistics.
6 WG6: Fundamentals of Spatial Modeling (Leader: DongchuSun, University of Missouri)
6.1 participants
Renato Assuncao, Universidade FederalSusie Bayarri, Universitat de ValenciaSudipto Banerjee, University of MinnesotaJim Berger, SAMSI/DukeJose M Bernardo, University of ValenciaHoward Chang, SAMSINoel Cressie, Ohio StateMarco Ferreira, University of MissouriAnabel Forte Deltell, Universitat de ValenciaSherry Gao, Missouri Department of ConservationVirgilio Gmez-Rubio, Bienvenidos a la Universidad de Castilla-La ManchaZhuoqiong He, Uinversity of MissouriJay Ver Hoef, NOAA, AlaskaMonica Jackson, American UniversityHannes Kazianka, Alpen Adria Universitat KlagenfurtAndrew Lawson, Medical University of South CarolinaJaeyong Lee, Soeul National UniversityMichael Levine, Purdue UniversityYe Liang, University of MissouriYajun Liu, University of MissouriDesheng Liu, Ohio State
153

Antonio Lopez Qulez, Universitat de ValenciaJim Lynch, University of South CarolinaMiguel A.Martinez-Beneito, Conselleria de Sanitat Generalitat ValencianaXiaoyi Min, University of MissouriShawn Ni, University of MissouriGarritt Page, DukeRui Paulo, Universidade Tecnica de LisboaGavino Puggioni, UNCBala Rajaratnam, StandfordBrian Reich, NCSUCuirong Ren, South Dakota StateChester Schmaltz, University of MissouriPaul Speckman, University of MissouriDongchu Sun, University of MissouriAnand Vidyashankar, CornellJianqiang Wang, NISSXiaojing Wang, DukeChang Xu, University of MissouriJun Zhang, SAMSIJing Zhang, Miami UniversityJian Zou, NISS
6.2 Presentations and Workshop
Weekly meetings took place on Wednesday, 11:00–12:45, during academic year, with irregularmeetings thereaafter. There were 12 meetings during Fall 2009; 14 meetinga during Spring 2010.Some of the meetings discussed existing literature; these led to Ongoing research with discussions.Outside experts were invited to give presentations (Sudipto Banerjee, Bala Rajaratnam), as wellas other group leaders.
The group organized a one-day Workshop on Objective Bayesian for Spatial and TemporalModels in San Antonio, TX, March 20, 2010.
6.3 Research Themes
6.3.1 Important issues in spatial and temporal models
• MCAR and Smoothed ANOVA with Spatial Effects (Sudipto Banerjee, University of Min-nesota)
• Relation between spatial models and graphical models, (Balakanapathy Rajaratnam, Stand-ford University)
• Spatio-temporal smoothing of risks based on spatial moving averages. (Miguel Angel MartnezBeneito)
• MCAR, Jointly modeling of spatial effects with given marginal, correlation between twonested and nonnested variables (Chester Schmaltz, University of Missouri)
154

• Irregular second order gaussian markov random fields (Paul Speckman, University of Mis-souri)
• Dynamic Multiscale Spatio-Temporal Models (Marco Ferreira, University of Missouri)
• Non-Gaussian Models, Zero-inflated Bayesian Spatial Models with Repeated Measurements(Jing Zhang, Miami University)
• Bayesian regression based on principal components for high dimensional data, Jaeyong Lee,Soeul National University
An Example: Irregular Second Order Gaussian Markov Random Fields (Paul Speckman)
• Gaussian Markov random fields are standard for analysis of areal data or data on a grid.
• The common models for areal data (e.g., CAR models) are first order.
• On the other hand, there are higher order priors for gridded data.
• A general method is proposed for constructing second order priors for general point-referenceddata.
• The priors approximate Gaussian processes arising as solutions to stochastic differential orpartial differential equations;
• Can have higher order smoothness properties; They are constructed to have sparse precisionmatrices;
• The new class of priors generalize higher order Gaussian MRF to arbitrary (gridded or not)data. The method is illustrated with an application to a rainfall data set.
6.3.2 Effects of spatial confounding
Core Members: Garritt Page, Duke; Yajun Liu, University of Missouri; Jaeyong Lee, Seoul NationalUniversity, Korea; Dongchu Sun, University of Missouri.
Research themes:
• For a spatially-varying error structure, there often exist (possibly unmeasured) covariatesthat also vary spatially.
• In these scenarios it is hard to distinguish the effect of the covariate from that of the residualspatial variation.
• In a iid normal error setting, it is well know that dependence between a covariate and errorproduces biased regression coefficient estimates. However, the consequences of this depen-dence in a spatial setting are not as well understood.
• It is needed to investigate the effect of spatial confounding on covariate estimation.
– the bias
155

– the variance
– the mean squared error
• Prediction
• Measurement errors
• Extension to the case of multiple (potentially unmeasured) covariates.
• Effect on the Bayes factors
6.3.3 Objective Bayesian and Fiducial Inference for spatial and temporal models
Core Members: Jose M Bernardo, University of Valencia, Spain; Jim Berger, SAMSI/Duke Uni-versity; Marco Ferreira, University of Missouri; Jan Hannig, UNC; Cuirong Ren, South DakotaState University; Jing Zhang, Miami University; Zhuoqiong He, Uinversity of Missouri; Shawn Ni,Uinversity of Missouri; Dongchu Sun, Uinversity of Missouri.
Other Participants: Victor De Oliveira, University of Texas at San Antonio; Rui Paulo, Univer-sidade Tecnica de Lisboa, Portugal; Bruno Sanso, University of California at Santa Cruz; StefanoCabras, University of Cagliari; Maria Eugenia Castellanos, Rey Carlos University, Spain; BruneroLiseo, University of Roma, Italy; Maria M. Barbieri, Universita Roma, Italy; Siva Sivaganesan,University of Cincinatti.
Research Objectives:
• In the absence of sufficiently quantifiable subjective knowledge concerning the unknown pa-rameters, it is typical to resort to objective noninformative or priors; these priors allow mostof the benefits of Bayesian analysis to be achieved, while avoiding the difficulty of obtaininga subjective prior.
• Alternatively, one could use Fiducial Analysis. The Recent work by Jan Hannig (UNC) andhis collaborators offers promising methods for spatial analysis.
6.3.4 One-day Workshop on Objective Bayesian for Spatial and Temporal Models atSan Antonio, TX, March 20–21, 2010
• The main theme is to explore appropriate prior distributions for parameters of spatial andtemporal models.
• Formal objective priors were introduced for AR (1) models by Berger and Yang (1994), andfor geo-statistical models by Berger, De Oleveira and Sanso (2001, JASA) and Paulo (2005,Annals of Statistics).
• However, the current results are mainly for situations in which there is no nugget effect andno measurement errors; in practice, both are ubiquitous.
Current and Future Work
• Group members are working on a monography summarize the work during the year
156

• To be published by Chapman and Hall
• About 10 Chapters, 5 papers on Spatial Models, one on Spatial Confounding, and 4 paperson Objective Bayesian and Fuducial Models
7 WG7: Geostatistics (Sudipto Banerjee, Veronica Berrocal, BrianReich and Alan Gelfand)
7.1 Working Group
Geostatistics: The Geostatistics working group is led by Sudipto Banerjee (UMN), Brian Reich(NCSU) and Alan E. Gelfand (Duke). This group will explore spatial and spatiotemporal modelsfor geostatistical data analysis with special emphasis on issues relating to preferential sampling.
The participants in this group include (in alphabetical order):
Sudipto Banerjee (University of Minnesota),Jarrett Barber (University of Wyoming),Francisco M Beltran (University of California Santa Cruz),Candace Berrett (Ohio State University),Veronica Berrocal (SAMSI),Avishek Chakraborty (Duke University),Howard Chang (SAMSI),David Conesa (University De Valencia, Spain),Sourish Das (SAMSI),Dipak Dey (University of Connecticut),Yiping Dou (University of British Columbia),David Dunson (Duke University),Jo Eidsvik (Norwegian University of Science and Technology),Andrew Finley (Michigan State University),Alan Gelfand (Duke University),Michele Guindani (University of New Mexico),Pritam Gupta (University of Wyoming),Sandra Hurtado Rua (University of Connecticut),Janine Illian (University of St. Andrews, U.K.),Karen Kafadar (Indiana University),Hannes Kazianka (University of Klagenfurt, Austria),David Kessler (University of North Carolina),Kenny Lopiano (University of Florida),Gabriele Martinelli (Norwegian University of Science and Technology),Amy Nail (Duke University),Orietta Nicolis (University of Bergamo, Italy),Garritt Page (Duke University),Juergen Pilz (University of Klagenfurt, Austria),Ana Rappold (EPA),Brian Reich (North Carolina State University),Huiyan Sang (Texas A& M University),
157

Alexandra Schmidt (University Federal do Rio de Janeiro, Brasil),Ron Smith (Centre for Ecology and Economics, Edinburgh, U.K.),Gunter Spoeck (University of Klagenfurt, Austria),Ingelin Steinsland (Norwegian University of Science and Technology),Jay Ver Hoef (NOAA),Linda Young (University of Florida),Chengwei Yuan (University of New Hampshire),Jing Zhang (Miami University),Zhengyuan Zhu (Iowa State University),James Zidek (University of British Columbia).
7.2 Research Activities and Findings
After the opening workshop and a series of weekly meetings, the working group identified someimportant issues for initial research. Given the large size and the broad spectrum of topics, theworking group was further subdivided into smaller subgroups, with each subgroup focusing uponone of the following topics.
• Preferential sampling and point-process modeling: (Leader: Alan Gelfand). This groupexplored hierarchical spatial and spatiotemporal models that account for stochastic depen-dencies in settings where the processes generating the data and the sampling locations aredependent. The group planned to explore underlying theoretical connections between pref-erential sampling and models for missing data as well as the connections between spatialsampling designs and preferential sampling. More generally, the group sought to understandthe nature of preferential sampling, modeling issues related to preferential sampling and theeffect of preferential sampling upon model performance and inference. Integrating point pro-cess models into hierarchical frameworks for large datasets has also been explored by thisgroup. There was substantial overlap in the activities of this subgroup and the group forpoint-processes.
• Spatial sampling designs: (Leader: Gunter Spoeck).. This working group carried outmethodological developments in spatial sampling design. In particular, this group exploreddeterministic algorithms based on spectral representations and experimental design ideas toassess the efficiency estimates that demonstrated how good sampling designs actually are usingconvex design functionals and convex optimization theory. The group also explored spatialsampling designs for non-stationary random fields having non-Gaussian skew distributionsgenerated using spectral representations of random fields and making use of the experimentaldesign theory for GLMMs. These methodologies were explored in applied contexts such asexploring the adequacy of existing pollution monitoring networks for protecting human health.
• Estimation techniques for geostatistical models: (Leader: Jo Eidsvik) This subgroup fo-cused on fast computation methods for large geostatistical models. There have been a numberof suggestions on how to solve the so-called “big-N” problem, i.e. to handle the O(n3) prob-lem of matrix factorization in large Gaussian or latent Gaussian models. One approach thatthe group explored was to combine effective modeling aspects and inference methods. Forinstance, predictive process models provide dimension-reduction while at the same time being
158

amenable to approximate Bayesian inference using Integrated Nested Laplace Approximation(INLA). Since the predictive process models introduce no additional parameters over the reg-ular (full) model formulation, it is relatively straightforward to apply INLA. The speed-upcompared with MCMC is large. At every evaluation the computational cost is reduced byusing a predictive process model, also providing large speed-ups. The statistical performanceis reduced a little for the estimates of covariance parameter, but we see small effects onestimates for regression effects and predictions.
This group also explored parallel computing in the context of geostatistical models. Parallelcomputing is getting easier on modern computers, and can be implemented on the Graphicalprocessing unit (GPU) as well as on many Central Processing Units (CPU). One could ap-proach this from a Bayesian or a frequentist viewpoint. The frequentist approach is somewhatsimilar to INLA, since an optimization routine is required. The group focused on compositelikelihood models, where the structure is such that parallelization is immediate. The varianceof the estimate can be computed from the Godambe sandwich estimate. Similar ideas, usingcomposite likelihood models and the sandwich estimate for variance, hold for prediction atunobserved sites too. This group also explored complex hierarchical models for analyzinglarge geostatistical datasets arising in forestry and the environmental sciences.
• Ozone process models:(Leader: Amy Nail). What separated the goals of this workinggroup from many ozone modeling efforts was the focus on developing statistical models ofozone that represent the chemical and physical mechanisms through which ozone is created,destroyed, and transported – that is, to do with a statistical model what is typically donewith a differential-equation-based deterministic model.
The group separated into the 5 sub-projects. The first project was led by Brian Reich andrepresents a cross-over project with the Non-Gaussian and Non-Stationary work group. Theobjective was to produce a methodological paper with application to ozone examining a newmethod for modeling the effects of covariates on the spatial covariance in a space-time model.
The purpose of the second project was to develop methodologies, with application to ozone, forexamining a nonparametric variable selection approaches that account for spatial correlation.
The third project sought to model the dispersion of NOx from multiple point sources, and tocombine such models with information about area-source emissions and transport to predictNOx concentrations in space and time. Statistical challenges included adapting determinis-tic dispersion modeling techniques (differential-equation-based or otherwise) to a statisticalmodel, tackling the change-of-support problem, performing sequential estimation while man-aging large spatial covariance matrices, and accounting for covariates in the covariance.
The group also looked at optimizing code for a dynamic linear model with spatial covariances.Since a process-based space-time model of either ozone or NOx will require the modeling oftransport, sequential estimation will ensure a fully-model-based framework. Experimenta-tions were conducted using R code to call C code to implement a dynamic linear model ofozone with spatial covariances, but this approach found computation time to be formidable(especially if this model is to be applied for the whole U.S. or eastern U.S.). Dimensionreduction approaches are currently being explored.
Note: The ozone process modeling workgroup was initiated by Amy Nail, who was employed
159

at the U.S. EPA at the time of heading up the group, but when the group separated into the5 sub-projects listed below, Brian Reich took charge of the first one.
• Numerical model validation: (Leader: Brian Reich) The numerical models subgroup fo-cused primarily on developing Bayesian spatial methods for calibrating deterministic forecaststo produce probabilistic forecasts. The work split in two directions: spatial quantile regressionand Bayesian spatial model averaging. Numerical weather forecasts are often calibrated by ad-justing the mean, and perhaps the variance, of the predictive distribution. For non-Gaussiandata such as precipitation, this can lead to underestimation of extremes. To calibrate theentire conditional distribution of precipitation given a forecast, we propose Bayesian spatialquantile regression. Quantile regression allows for a separate the relationship between theforecast and each quantile of the predictive distribution, therefore calibrating the probabilis-tic forecast at each quantile level. We show this leads to good performance in both the centerand tails of the predictive distribution.
Recognizing the several sources of uncertainty affecting the output of a numerical model,in recent years, there has been a shift from deterministic predictions to probabilistic ones,and runs of a single numerical model have been replaced by runs of ensembles of numericalmodels. Therefore, the working group also explored statistical methods to calibrate thespatial output generated by an ensemble of numerical models. We extend previous workusing Bayesian model averaging (BMA) to produce probabilistic weather forecasts. BMAassumes the predictive distribution is a mixture of density functions centered around eachbias-corrected forecast and BMA weights that depend on the past predictive performanceof each ensemble member. The proposed method is an extension of BMA in that both theweights and the parameters of each mixture component are assumed to vary in space. Thisis intuitively appealing as it is expected that the performance of each numerical model arenot constant in space, but might vary from location to location.
The working group produced a productive and hopefully long-lasting collaboration betweenIngelin Steinsland, Veronica Berrocal, and Brian Reich. The group also expects two papersto be submitted before the end of the year.
• Feedback: (Leader: Jarrett Barber). The ’feedback’ subgroup was interested in thecutting of edges in graphical models for the purpose of controlling undesirable feedbackamong model components. Focus was primarily on models of health effects and exposurein a Bayesian framework. Prototype R code was produced to begin simulation experimentsto explore feed back control. The subgroup is currently conducting extensive simulationexperiments.
The working group – and subsequently the subgroups – continued to meet on a weekly basisand focused on the above issues. The interactions produced several productive collaborationsbetween statisticians, deterministic modelers, scientists and GIS experts who embarked upon severalinteresting projects. A non-exhaustive list of publications emerging from the Geostatistics groupis provided below.
Banerjee, S. and Gelfand, A.E. (2010). Modelling spatial gradients on response surfaces. InFrontiers of Statistical Decision Making and Bayesian Analysis, eds. M.H. Chen, D.K. Dey,P. Mueller, D. Sun and K. Ye, New York: Springer
160

Berrocal, V.J., Gelfand, A.E., and Holland, D.M. (2010). A bivariate space-time downscaler underspace and time misalignment. Annals of Applied Statistics, (in press).
Luke Bornn, Gavin Shaddick and James V Zidek, The effects non-stationarity and preferentialsampling in modeling and measuring environmental fields for health effect analysis. Draftreport in preparation.
Song Cai, Xiaoli Yu, Gavin S Shaddick and James V Zidek, Preferential sampling in the monitoringblack smoke: a case study Draft report nearly completed.
Chakraborty, A., Gelfand, A.E., Wilson, A.M., Latimer, A.M. and Silander, J.A. (2010). Modelinglarge-scale species abundance with latent spatial processes. Annals of Applied Statistics (inpress).
Eidsvik, J., Shaby, B., Reich, B.J., Wheeler, M. and Niemi, J. (2010). Estimation and predictionin spatial models with block composite likelihoods using parallel computing. Submitted.
Eidsvik, J., Finley, A., Banerjee, S., and Rue, H. (2010). Approximate Bayesian inference for largespatial datasets using predictive process models. Under revision, Computational Statistics andData Analysis.
Finley, A.O., Banerjee, S. and MacFarlane, D.W. (2010). A hierarchical model for predicting forestvariables over large heterogeneous domains. Journal of the American Statistical Association106, 31–48.
Guhaniyogi, R., Finley, A.O., Banerjee, S. and Gelfand, A.E. (2010). Adaptive Gaussian predictiveprocess models for large spatial datasets. Environmetrics (in review).
Prates, M.O., Dey, D.K., Willig, M.R. and Yan, J. (2010), Intervention Analysis of HurricaneEffects on Snail Abundance in a Tropical Forest Using Long-Term Spatiotemporal Data,Journal of Agricultural, Biological, and Environmental Statistics, 1-15, doi: 10.1007/s13253-010-0039-1.
Prates, M.O., Dey, D.K., Willig, M.R., and Yan, J. (2011), Transformed Gaussian Markov RandomFields and Spatial Modeling. Submitted.
Reich, B., Eidsvik, J., Guindani, M., Nail, A. and Schmidt, A. (2010). A class of covariate-dependent spatiotemporal covariance functions. Accepted by Annals of Applied Statistics.
Reich, B. and Berrocal, V. (2010). Local Bayesian model averaging for numerical model calibra-tion. To be submitted to Environmetrics.
Spoeck, G., Zhu, Z. and Pilz, J.: Simplifying objective functions and avoiding stochastic searchalgorithms in spatial sampling design, submitted to: Stochastic Environmental Research andRisk Assessment, (2011).
Spoeck, G., Hussain I.: Spatial sampling design based on convex design ideas and using externaldrift variables for a rainfall monitoring network in Pakistan. In: Statistical Methodology,New York: Elsevier Science Inc, doi: 10.1016/j.stamet.2011.01.004, (2
161

Steinsland, I., Berrocal, V. and Reich, B. (2010). Bayesian spatial quantile regression for numericalmodel calibration. To be submitted to Journal of the Royal Statistical Society: Series C.
Wang, X., Dey, D.K. and Banerjee, S. (2010). Non-Gaussian hierarchical generalized linear geo-statistical model selection. In Frontiers of Statistical Decision Making and Bayesian Analysis,eds. M.H. Chen, D.K. Dey, P. Mueller, D. Sun and K. Ye, New York: Springer.
Xiaoli Yu, Gavin Shaddick and James V Zidek, Correcting for preferential sampling in monitoringenvironmental processes. Draft report of theory completed. Application pending.
Xiaoli Yu, Gavin Shaddick and James V Zidek, The effects of preferential sampling in environ-mental epidemiology. Draft report partially completed.
8 WG8: Point Patterns Working Group
8.1 Goals
The working group on point patterns coalesced around three primary research goals. The first(which yielded the “Mixture” subgroup) focused on novel ways of introducing covariate informa-tion into modeling intensities. Special settings here included mixture models for intensities, bothparametric and Bayesian nonparametric as well as generalized Neyman Scott processes with covari-ate information at parent level to drive locations and spreads for offspring. The second goal (whichyielded the “Practical” subgroup) was to bring to a more applied level, spatial point processeswith first and second order components (first order is a usual nonhomogeneous Poisson processform λ(s), second order is a pairwise interaction form γ(s, s′), inhibition, attraction). Issues hereagain included the introduction of covariate information into such settings with interest in a fullymodel-based implementation with associated technical questions such as integrability for the re-sulting intensity. The third goal (which yielded the “Model diagnostics” subgroup) considered anunder-explored problem for point patterns, the question of model adequacy and model comparison.For instance, how do we compare two nonhomogeneous point processes? How do we compare anonhomogeneous Poisson process with a pairwise interaction process. What happens if we adddynamics, resulting in space time point processes?
8.2 Active members
As a result of the three-pronged research agenda, three active subgroups emerged:
• “Mixture” group - Micheas, Chakraborty, Assuncao, Matteson, Gelfand
• “Practical” subgroup - Assuncao, Lopes, Waller, Illian
• “Model diagnostics” subgroup - Gomez Rubio, Chakraborty, Gelfand
8.3 More detail on the work of the “Mixture” subgroup
Considering covariates in this setting requires distinguishing spatially indexed covariates X(s) fromlabels (marks). For instance, X(s) might be elevation which might encourage more or fewer pointsbut this is apart from a mark which might label different species with associated point patterns.
162

Evidently, the issue is direction of conditioning, i.e., the covariate can be a mark at a location)yielding X|s as X(s) and {X(si)}|θ.
In this regard, Micheas (with Chakraborty and Gelfand), using λf(s; θ) form, {si}|λ, θ for theintensity add the covariate in form of discrete mark. In fact, he extends to a mixture form λf(s)where f(s) =
∑l πlfl(s|θl). In fact fl(s|θl) = BivN(µl,Σl)
Work of Chakraborty introduced covariates to explain where locations will tend to be. Here, theusual form is logλ(s) = X(s)Tβ + ω(s). However, again consider λf(s) where f(s) =
∑l πlfl(s|θl)
with fl(s|θl) = BivN(µl,Σl). So, µl provide “centers” for the intensity and πl = eX(µl)T β∑
jeX(µj)
T β.
Assuncao and Lopes developed a cluster model for point processes, driven by covariates but nota mixture model, rather with interacting neighbors.
Papers:
Assuncao, R. and Lopes, D. (2010), Visualizing Marked Spatial and Origin-destination PointPatterns With Dynamically Linked Windows. Journal of Graphical and Computational Statistics,accepted.
Chakraborty, A., Gelfand, A.E., Wilson, A. M., Latimer A. M. and Silander, J.A. 2011 Pointpattern modeling for degraded presence-only data over large regions. To appear, Journal of RoyalStatistical Society, Series C
Chakraborty, A. and Gelfand, A. E. 2011 Mixture modeling for spatial point patterns withlocation-specific covariates, manuscript in preparation
Matteson, D.S. and Micheas, A.C., A Finite Mixture Model for Spatio-temporal Poisson Process.In Preparation.
8.4 More detail on the work of the “Practical” subgroup
This group worked on the paper listed below. The context is temporal point process with spatialmarks in the form of binary indicators on a lattice. The application is to infection propagation. Avery high level of missingness arises; only 6 out of 30 weeks are observed, necessitating a challengingdata augmentation approach.
Jean Vaillant, Gavino Puggioni, Lance A Waller, and Jean Daugrois (2011), A spatio-temporalanalysis of the spread of sugar cane yellow leaf virus. Journal of Time Series Analysis, to appear.
8.5 More detail on the work of the “Model diagnostics” subgroup
Again, we assert that model adequacy and model comparison are underdeveloped for point patterndata. What exists follows the lead of Baddeley, with follow on work from Illian. Here, the widelyused Ripley - K function is not what is needed because it is only applicable under complete spatialrandomness, not a model of interest.
In comparing intensities we can envision various naive ideas such as binning and counts. Wecan imagine some version of AIC here. Also possible is discretized integrated squared differencebetween model intensity and empirical intensity (say kernel intensity estimate). Another option iscross-validation, thinning the point pattern to provide a hold-out sample.
163

Through normalization, there is a density associated with a point process realization, f(S; θ).
For homogeneous Poisson process it is f(S) = αλn(S).
For a nonhomogeneous Poisson process it is f(S) = αΠiλ(si).
For pairwise interaction process, f(S) = αΠiλ(si)Πi,jγ(si, sj).
From these, we can define the Papangelou conditional intensity: φ(u; S) = f(S ∪ u)/f(S).
In turn, we can create residuals (following ideas of Baddeley).
In particular, there is a realized - I(B; θ) = n(S ∩ B) −∫B φ(u; S; θ)du. Also, we have an
estimated — R(B; θ) = n(S ∩ B) −∫B φ(u; S; θ)du. These residuals provide a different path for
model assessment.
8.6 Ongoing research problems
Finally, we mention some continuing open research ideas. In the point pattern setting, how can weextend AIC to DIC with spatial random effects; how would we do the computation? From above,can we implement a Bayesian analysis of conditional intensity, hence, of realized residuals? Suchwork would begin with Cox processes first, then proceed to interaction processes. There seems tobe little experience in the literature with thinning and cross-validation ideas.
A novel way to model space time point patterns is through integro difference equations (space-time diffusions) and very recently through integral projection models (population demography).There is promising modeling opportunity here with considerable computational challenge.
There is also potential to revisit recent preferential sampling work (Diggle et al.) with regardto environmental exposure, raising the question of the effect of sampling design as well as where toput covariates in this investigation. There remain many open questions here.
Finally, Gomez Rubio has prepared a grant submission to study point patterns arising frompatients with respiratory and circulatory illness in Madrid.
9 WG9: Non-stationary and Non-Gaussian Processes
This working group is led by David Dunson (Duke), Jo Eidsvik (NTNU) and Montse Fuentes(NCSU). The objective is to explore non-stationarity and non-Gaussianity for spatial and spa-tiotemporal models.
The most active participants in this group include (in alphabetical order): Veronica Berrocal(SAMSI), Kate Calder (Ohio State), David Dunson (Duke), Jo Eidsvik (NTNU), Montse Fuentes(NCSU), Michele Guindani (U of New Mexico), Scott Holan (U of Missouri), Katja Ickstadt (Tech-nical University of Dortmund), Jaeyong Lee (Seoul U), Linyuan Li (U of New Hampshire), DavidKessler (UNC), Amy Nail (Duke), Orietta Nicolis (U of Bergamo), Brian Reich (NCSU), AlexandraSchmidt (U Federal do Rio de Janeiro), Ben Shaby (SAMSI), Michael Stein (U of Chicago), RobertWolpert (Duke).
164

9.1 Research
After the opening workshop the group had a series of weekly meetings covering a broad spectrumof topics. We learnt a lot during these meetings. They let us define common interests and set thestage for collaborations. In the late Fall the working group decided to split in 3 sub-groups. In theSpring the working group only had a handfull of joint meetings. The 3 sub-groups were defined asfollows:
• Spectral domain methods:
Spectral methods are powerful tools to introduce new classes of covariance functions. The sub-group proposes new models for nonstationarity by having a spectrum that is space-dependent.By introducing a spatial filtered periodogram we obtain a nonstationary nonparametric esti-mate of the covariance.
To every stationary Z(s) there can be assigned a process Y (ω) with orthogonal increments,such that we have for each fixed s the spectral representation:
Z(s) =
∫R2eis
TωdY (ω) (1)
The Y process is called the spectral process associated with a stationary process Z.
The periodogram In estimates the spectral density f of a process Z observed in a grid n×n,
In(ω) = (2πn)(−2)
∣∣∣∣∣∣∑j∈J
Z(j)e−iωT j
∣∣∣∣∣∣2
The sub-group looks at approaches for the spectral analysis of non-stationary spatial pro-cesses, Z(x), which is based on the concept of spatial spectra, this means spectral functionswhich are space dependent, fx(ω).
The spectral representation of Z(x) is always interpreted as its representation in the form ofsuperposition of sine and cosine waves of different frequencies ω
Z(x) =
∫R2
exp(ixTω)φx(ω)dY (ω)
We propose a nonparametric estimate of the spectral density. We first define Jx(ω0),
Jx(ω0) = ∆x1∑
u1=x1−n1
x2∑u2=x2−n2
g(∆u)Z(∆(x− u))
exp{−i∆(x− u)Tω0},
where s = (s1, s2), and {g(u)} is a filter. We refer to |Jx(ω)|2 as the spatial periodogram ata location x for a frequency ω. |Jx(ω)|2 is an approximately unbiased estimate of fx(ω), butas its variance may be shown to be independent of N it will not be a very useful estimate
165

in practice. Then, we estimate fx(ω) by “smoothing” the values of |Jx(ω)|2 over neighboringvalues of x.
The presented methodology requires gridded data, but it could be also extended to irregularlyspaced data, by using a filtered spline representation across space. This is work in progress.
There is need to study of the properties of the proposed nonparametric estimates using fixeddomain asymptotics. This is work in progress.
These methods could be generalized to space and time, and they would allow for nonsepa-rability. A reasonable approach would be semiparametric in space-time: with a parametricmodel for short distances in space, and a spline representation for large distances. This iswork in progress.
• Mixture models:
The sub-group builds on much work from Dirichlet processes, stick breaking processes, andother non-parametric models that have become popular because of large flexibility and com-putational tractability. Dirichlet mixture models are nonGaussian and nonstationary, butwithout replicates it is difficult to determine if we have lack of stationarity or lack of nor-mality. However, the Dirichlet process (DP)-type of mixture models would allow for both.Mixture models are flexible enough to characterize complex tail behavior, and can be used tomodel extremes (i.e a DP copula)
The stick-breaking prior for F is the potentially infinite mixture Fd=∑mi=1 piδ(θi), where
pi are the mixture probabilities and δ(θi), is the Dirac distribution with point mass at θi.The mixture probabilities “break the stick” into m pieces, so the sum of the pieces is one,∑mi=1 pi = 1. p1 = V1, and the subsequent probabilities are pi = Vi
∏i−1j=1(1 − Vj), where
1−∑i−1j=1 pj =
∏i−1j=1(1− Vj) is the probability not accounted by the first i− 1 components.
The sub-group looks at covariance regression, where a covariance matrix is in the support ofthe space of covariance stochastic processes. Let Σ(s) = Λ(s)Λ(s) + Σ0 induced through
y(si) = Λ(si)ηi + εi, ηi ∼ Nk(0, Ik), εi ∼ Np(0,Σ0)
We can let Λ(si) = Θξ(si) = Θ ∼ p×L = coefficients relating predictor-dependent factor load-ings matrix to dictionary functions comprising the L×k matrix ξ(s). This model for the non-parametric covariance model can also be modified to build upon a latent segmentation processproviding the label indeces at different locations. Then, y(si) =
∑k I[Z(si) ∈ Bk]ηk(si). The
ηk are Gaussian processes, while the labeling can take on many forms. This is related to workon latent stick breaking processes. There are working papers in these directions.
The nonparametric Bayesian spatial models should be extended to space and time to allow fornonseparable dependence. These models should also be extended to a multivariate setting,to allow for nonstationary cross-dependence.
• Covariates in the covariance:
166

This sub-group looks at non-stationarity models constructed by adding covariates in thecovariance function. Typically, the covariance structure is regarded as a nuisance that we donot learn about, except specifying the scale and correlation range in some way. The meanterm, on the other hand, is constructed by sophisticated modeling from available covariates.For prediction purposes, the covariates are important only through the predictor, not theprediction variability. We envision better prediction and more useful prediction distributionsby letting the covariance also depend on covariates.
One project that has been regarded in the sub-group is mixtures of Gaussian processes withdifferent scale and range, but weighted by covariates. Define the process as
y(si) =∑k
w(x(si);αk)ηk(si), ηk(si) ∼ N(0,Σk)
, where the weights w(x(si);αk) of the mixture varies as a function of covariates x(si). Theprocesses are parameterized by different range and variance in Σk. For instance, when there ismuch wind, the weight could be highest for a process with large correlation range and largervariance. When there is litte wind, the weight could be highest for a process with smallcorrelation range and less variance. The model is similar to the spatially varying coefficientmodel and other models using a spatially varying weights for a mixture of processes. The sub-group has submitted a paper on this topic (Reich, Eidsvik, Guindani, Nail and Schmidt, 2010,A class of covariate-dependent spatiotemporal covariance functions), applying the resultingmodel to daily ozone levels in the South-Eastern US. It is currently under revision.
The suggested mixture models for the covariance structures above naturally extends to includecovariates in the covariance structure. For instance, the factors could depend on covariates.Further, it is straightforward to let the prior mean of the latent segmentation process Z(si)depend on covariates. This would pull the labeling process to a high/low index in parts of thespace, and would naturally exhibit in the covariance for locations where the labels becomethe same or not.
The sub-groups (or parts of sub-groups) continue to meet to finish ongoing work.
9.2 Deliverables
• Sharing knowledge.
• Papers submitted or in progress.
• Several new collaborations.
10 Other Products of the Program
Submitted grant proposal:
Network for Statistics in Atmospheric and Oceanic Sciences (PI: M. Fuentes, NCSU; co-PIs:M. Stein, University of Chicago and P. Guttorp, University of Washington. Submitted to Program
167

Solicitation NSF 10-584 on Research Networks in the Mathematical Sciences, National ScienceFoundation, $5 million.
Papers:
Corberan, A. and Lawson, A. (2011), Conditional Predictive Inference for On-line Surveillanceof Spatial Disease Incidence. Submitted to Statistics in Medicine.
Dennis, Fox, Fuentes, Gilliland, Hanna, Hogrete, Irwin, Rao, Scheffe, Schere, Steyn, Venkatram.(2010). A framework for evaluating regional-scale numerical photochemical modeling systems.Environmental Fluid Mechanics Journal, in press.
Fuentes, M., and Banarjee, S. (2011). Bayesian Modeling for Large Spatial Datasets. WIREsComputational Statistics, accepted
Fuentes, M. and Foley, K. (2011). Ensembles methods, in upcoming Encyclopedia of Environ-metrics.
Fuentes, M., Xi, B. and Cleveland, W. (2010) Trellis Display for Modeling Data from DesignedExperiments. Journal of Statistical Analysis And Data Mining, in press.
Reich BJ, Fuentes M. Nonparametric Bayesian models for a spatial covariance. StatisticalMethodology. Accepted
Reich, B., Fuentes, M. and Dunson, D. (2011). Bayesian spatial quantile regression. JASACase Studies, accepted.
Reich BJ, Kalendra E, Storlie CB, Bondell HD, Fuentes M., Variable selection for high-dimensional Bayesian density estimation: Application to human exposure simulation. AppliedStatistics, accepted.
Zhang, J., Clayton, M. K., and Townsend, P. A., (2011), Missing Data and Functional Concur-rent Linear Model for Spatial Images, in preparation.
Zhang, J., Clayton, M. K., and Townsend, P. A., (2010), Functional Concurrent Linear Modelfor Spatial Images, accepted by Journal of Agricultural, Biological, and Environmental Statistics.
168

Final Program ReportSemiparametric Bayesian Inference: Applications in Pharmacokinetics and
PharmacodynamicsSummer 2010
1 Objectives
Pharmacokinetics (PK) is the part of pharmacology that is concerned with what happens to a drug afterit enters the body. One typically characterizes a drug’s PK through studies of the time course of drugconcentrations measured over time. Studies of a drug’s pharmacodynamics (PD) explore the reaction ofthe body to the drug. PD studies often include measurements of a drug’s PK. Pharmacogenetics (PGx)studies the genetic variation that explains person-to-person variation in a drug’s PK or determines differingresponse to drugs. Understanding the PK, PD, and PGx of a drug is important for evaluating efficacy anddetermining how best to use the drug clinically.
Because PK and PD studies often include multiple measurements from the same patient over time, anal-yses of these studies often include models that allow accounting for within-subject and between-subjectvariation. Such statistical models are sometimes called population models or hierarchical models. Hierar-chical models have allowed great progress in statistical inference in many application areas. One reasonthat hierarchical models are popular for PK and PD studies is that they allow borrowing of strength acrossa patient population, such as when one may have fewer measurements for some patients than for others.These models have allowed investigators to learn about important sources of variation in drug absorption,disposition, metabolism, and excretion, in some cases allowing clinicians to tailor drug therapy to individuals.
Typically, population PK and PD models characterize between-subject variability with a normal orlognormal distribution. While such distributions may be appropriate in some settings, it is not always thecase that this model characterizes very well the heterogeneity in a population. For example, there may besubpopulations of extreme values that lie farther away from the central population average than a normaldistribution would allow. Newer Bayesian nonparametric population models and semi-parametric modelsoffer the promise of individualizing therapy and discovering subgroups among patients even further, byfreeing modelers from restrictive assumptions about underlying distributions of key parameters across thepopulation.
The purpose of this program was to bring together a mix of experts in PK and PD modeling, non-parametric Bayesian inference, and computation. The motivation for this program was a recent surge inresearch in Bayesian nonparametric (BNP) statistics. BNP has traditionally focused on basic inferentialproblems, such as density estimation, survival analysis, and more recently mixed-effects models. Now, how-ever, BNP statistical methodology has sufficiently matured to allow addressing scientific research problemswith all the complexities and complications that arise in real applications.
A workshop during the first week of the program served to introduce participants from the BNP researchcommunity with current problems and challenges in PK andPD modeling, as well as providing PK and PDmodelers an introduction to BNP methodology. Tutorial reviews on Monday were important to introducenotation and to lay out basic problems and challenges. Tuesday through Friday mornings focused on severalareas of concentration, with more diverse talks following in the afternoon. Focus areas included priorelictation, joint modeling of PK and PD, dependent Dirichlet process models, and clustering. On Fridayafternoon, we formed working groups for the second week.
Summary: The program successfully brought together researchers from different areas to initiate newprojects that will hopefully lead to exciting advances in PK & PD research, driven by state-of-the-art BNPmodels. The program also served the purpose of establishing PK, PD, and PGx as natural application areasfor BNP.
1

2 Workshop
The workshop was held July 12-16, 2010.The first day was dedicated to tutorial introductions. The program started with an overview of current
research, opportunities and challenges for BNP in PK & PD, presented by Gary Rosner. A first tutorialon BNP was prepared by Wes Johnson and introduced basic notions of BNP. The tutorial defined the mostpopular models, including Dirichlet process (DP), DP mixture, and Polya tree (PT) models. The tutorialfocused also on the clustering structure that is implicitely defined by DP priors. This tutorial was followedby a second BNP tutorial by David Dunson, who showed some successful examples of biomedical researchproblems approached by BNP. The applications were not directly PK & PD, but the PK & PD modelers inthe audience could recognize opportunities for similar approaches in PK & PD.
In the afternoon, there were two tutorials on PK & PD modeling, presented by David D’Argenio, Univer-sity of Southern California, and Paolo Vicini, Pfizer Inc. Both tutorials provided an excellent introductionto research problems in PK & PD and were very well received by the BNP researchers in the audience. .
Tuesday through Thursday and Friday morning featured researchers discussing their work on BNPmethodology and PK, PD, and PGx. Some examples are prior elictation, joint modeling of PK and PD, de-velopment of physiologically-based PD models, computational challenges in PK and PD models, dependentDirichlet process models, and clustering.
On Friday afternoon, we formed working groups for the second week. The following groups were formed
W1: Model Fit and Comparison;
W2: Joint PK & PD Modeling;
W3: Nonparametric Bayes & Clustering for Population PK &PD;
W4: PK & PD Simulation for Design and Dose Individualization; and
W5: Pharmacogenomics and Networks.
3 Working Groups and Outcomes
W1: Report on Model Fit and Comparison
Keith O’Rourke served as working group leader.A brief summary of the deliberations and ongoing work of the SAMSI Summer PkPd Programs Model
Fit and Model Comparison working group (PkPdFit).
Monday. The members of the group introduced themselves and provided a very brief overview of theirbackground and interests. There were initially 16 members that joined this working group that were laterjoined by 3 additional members (list below). Most were from academic statistics or biostatistics depart-ments, with a few from either a pharmaceutical firm, pharmaceutical consulting firm or regulatory authority.Additionally, Jim Berger (Duke University), Jayanta Ghosh (Purdue University) and Robert Wolpert (DukeUniversity) attended one or more of the meetings. The group was lead by Keith ORourke (Health Canada).
After discussions of the major interests of the working group the group recognized that these themes werenot fully reflected in its current name - such as the intrinsic interactions between model Fitting, Criticism,Understanding and the pragmatic reality of usually needing to Keep (select) just one of the models. Thegroup, however, decided to just stick with the original name.
There was a brief discussion of some philosophy of science and vocabulary surrounding the identifiedthemes largely along the lines that all models are wrong (Fit) but can always be made less wrong (Crit-icism) and it was suggested that it would be better to speak of there being less or least wrong models(Understanding) rather than better or best models but some wished to stick (Keep) with more commonlyused statistical terms.
2

Most of the discussion was centered on the exact nature of Pk models and the Pk scientific process andespecially the current Pk community (the kinds of experiments they do, the statistical models they currentlyuse, why these are used or preferred and trying to anticipate opportunities to enable the Pk community toadopt different models and approaches that would likely provide highly visibly improvements). This waslargely lead by Peter Thall, drawing on his brief discussions about the nature of Pk models/communitieswith Paolo Vincini (Pfizer), at the end of the first week of the Summer PkPd program.
There was general agreement that there was a considerable amount of complexity, perhaps most visiblydescribed as a sea of parameters to swim through with some lurking sea monsters; such as the “Greekletter fallacy” (i.e. β changing its meaning in a simple multiple regression model when other covariatesare added), aliasing between parameters (i.e. parameters that could biologically cancel each other out)and both biological and mathematic constraints that might be very subtle but extremely important in Pkapplications. Pk models need to well represent physical/biological processes “what goes in must come out”and only highly dependent constrained life is actually possible - so priors, functions of covariates, etc. mustadequately reflect these realities. Whereas all models are wrong - in Pk there are many subtle but criticalaspects that can only be a little bit wrong. Additionally, as the data is very sparse in many Pk applications,we can not depend on the data to drag us away from faulty priors.
There was some concern raised about a possible tension between individual and population parame-ters/models and a possible reluctance in the Pk community to pragmatically borrow information in order todo any hierarchical modeling. This was perhaps best expressed in a rhetorical question that was repeatedlyraised “they can’t really want a different model for each individual rat or even a different model within anindividual rat at different instances of time?”
At the end of the meeting there seemed to be a general agreement that there was a need for some concretePk models and data sets for the group to utilize in working their interests, concerns and ideas through as agroup. Russell Barbare (North Carolina State University) offered to try to obtain some data and present itat the next meeting.
Tuesday. The meeting was opened with a short 15 minute informal presentation by Keith ORourke (HealthCanada) on a proposed general or default method for the plotting of distinguishable prior and data contri-butions in any complex statistical model. It was entitled “Painting inference pictures” and was based onobtaining marginal priors and marginal “almost individual observation” likelihoods for different parametersof interest or focus. The motivation was to clearly display - as is almost always done in the meta-analysisof separate study estimates - the consistency of the separate estimates and how they add together in thecombined analysis to provide the overall estimates. And especially to do this, directly in the parameter spaceof most interest, so that contributions are displayed in terms of what is of direct interest or convenience. Itwas also suggested as a general diagnostic plot for model fit in complex models. Peter Thall suggested thatmore than one parameter be displayed utilizing high dimensional graphical displays. There seemed to be thesense that it needed tried out for some concrete realistic Pk models and that Jim Berger (Duke University)suggest that calibration of the plots would be important.
Russel Barbare (North Carolina State University) then presented an available data set he had obtainedand anticipated some basic Pk models that might be considered when analyzing this data. There was adiscussion on simple one compartment versus two compartment Pk models with attendant parameterizationsin terms of rates and volume parameters (often called micro parameters) versus exponential fit parameters(often called macro parameters). This lead to the identification of a K parameter space (for the microparameters) versus a Beta parameter space (for the macro parameters). Many questions then arose aboutthe connections between them and the merits of these two apparently different spaces. Where can Pk peopleexpress priors most credibly? Where do they especially want to see the posteriors in the end? Are thereone to one functions between them (i.e. are they just reparameterizations)? Are there valid reasons for twospaces, or is just an historical artefact of previous numerical challenges?
After this, there was some discussion regarding the need to arrive at certain functions as being the modelto be fit (e.g. functions for specifying the expected values of observations assumed to be Normal distributed)through the solving differential equations. Succinctly - how to get the likelihood or data model in closed
3

form. As it might only be possible to solve the differential equations numerically, discussions of exactlyhow to implement this in MCMC algorithms also arose. As for more complex Pk models than just twocompartment models (up to 20 and beyond), and the possibility of different clusters within an experiment(i.e. a mixture of say two and three compartment models) a proposal for a simple mixture of say two modelsas a starting point was made by Mike Escobar (University of Toronto). In contrast to this, a more generalmodel that allows clusters through parameter value settings after some selection of a least wrong model froma well motivated set of about half a dozen or so models was proposed by Steve MacEachern (Ohio StateUniversity). Both were then briefly discussed.
There was then general acknowledgement that the group needed a simple but useful set of concrete Pkmodels and data sets to work with for the next meeting. Paolo Vincini (Pfizer) was sought to providethis kind of input. After the meeting, Susie Bayarri (University of Valencia) reiterated the concern aboutborrowing information between subjects with the question Does it have scientific sense to have a separate,entirely different scientific model for each individual?
Wednesday. Paolo Vincini (Pfizer) gave an invited presentation of some simple concrete models and theirconnections between the K space and Beta space (all being one to one functions in the specific models hepresented). This lead to considerable discussion of parameterizations, various re-parameterizations and allkinds of seemingly different and possible misleading notations is these models. However, there seemed to bea consensus that reasonably well motivated hierarchical models (that borrow information) were being usedand could be improved on in numerous ways. He later provided some helpful online Pk resources and links tosome well studied Pk examples and stylized statistical analyses that the group could utilize. There seemedto emerge a default preference for working in the K space for both priors and posteriors as well as for thespecification and fitting, criticising, understanding and selection of models needed to transform the priorsinto posteriors if possible. Insurmountable challenges might arise that prevent this given the way the Pkdata is collected and certain model specifications. There again was a contrast of model selection betweenbiological pieces (i.e. two versus three component models) the simple mixture model - versus parametervalues connecting the biological pieces (i.e. setting k23 and k 32 rate parameters to zero via spike and slab)the well selected sufficiently flexible model.
Concerns again arose about having to get the likelihoods numerically (via numerical solution of differentialequations) and anticipating MCMC implementation challenges because of this. Just before the meeting, MikeEscobar had met with William Gillespie (Metrum Instruments, who was participating in the Simulation forDesign and Dose Individualization working group) to get a sense of what WinBugs Pk models he had beensuccessful in implementing. At the end of the meeting there was an agreement to work through some simplemodels with standard but well used data sets as step one with some of the more seasoned Bayes NPershopefully getting an initial start on Bayes NP models.
Thursday. Mike Escobar outlined his progress in getting a set of Pk working examples in WinBugs. Aftera quick overview of WinBugs code specially modified by William Gillespie (Metrum Instruments) that isavailable in a package that can be downloaded. He commented on the new box that William had programmedessentially dealt with the numerical differential equation solving needed to get the likelihoods. Essentially,the group was given a first a glimpse of a set of working Pk models that could be put to use for parametricBayesian Pk modeling and extended to various Non-Parametric models. Attention was then drawn to a Pkmodel example provided by Russel Barbare where the m:n function from K space to Beta space was not 1:1(m > n), providing another reason to try and work in the K space if at all possible.
The group then sketched out a long list of existing goodness of fit and model comparison methods inthe statistical literature, broken into Goodness of Fit (GOF), model comparison (MC) measures (e.g. BIC,AIC, DIC), posterior predictive checking, cross validation and plotting. Jim Berger pointed out that all theGOF and MC had problems for random effects models and especially non-parametric random effects modelsthe group hopes to work with. This was confirmed by David Dunson (Duke University), even for standardNon-Parametric random effects models in much simpler application areas. Some of the reasons for this wereoutlined by Steven MacEachern (Ohio State University) and Jayanta Ghosh (Purdue University). Thanis
4

Kottas (University of California, Santa Cruz) mentioned some posterior predictive checking one could “tryand make do with” and David Dunson (Duke University) confirmed that his group so far had only usedcross-validation/ posterior predictive checking methods as a way to try to address model fit issues. At thispoint the group realized that they had, at last come to the sought after insurmountable opportunities andopen research questions seemed to be occurring to most.
At this point, some members of the group have started on some new approaches to model fit assessmentand hopefully with share their progress with the rest of the members, if and when appropriate. We arehoping to share some working examples amongst the group, hopefully initially in WinBugs, initially usingparametric approaches where the Pk modelling issues can be more clearly explicated, working through variousnon-parametric models of interest. But perhaps because it is easier, if not more enjoyable, to criticallyevaluate models others have lovingly and endlessly slaved away to create, many in the FIT group would lovethe opportunity to criticize (constructively) other groups Pk and even Pd models. It would be most helpfulto us and hopefully others!
Keith ORourke (Health Canada) has offered to try and plot out these models. As for offering up ourwork for consideration and criticism of others, Keith ORourke (Health Canada) has offered to circulate adraft of the mathematical basis for the elements in the “Painting inference plots”. A version of this draft,very kindly was reviewed after the Tuesday meeting by Jayanta Ghosh (Purdue University), and their hasbeen (will be) a subsequent addition of some clarification of how it can be related to Laplace approximations,as suggested by Jim Berger (Duke University) on Thursday.
W2: Report on Joint PK & PD Modeling
Michele Guindani, University of Texas M.D. Anderson Cancer Center, served as working group leader.
Monday. Paolo Vicini has connected remotely to give a brief presentation of PK and PD models andpresent the case for joint PK/PD modeling versus separate estimation. The discussion has covered therelevant features of common PK and PD models, with particular attention to the inferential interest ofthe investigators. In the last part of his presentation he explained how covariate information is usuallyintroduced in the modeling framework. Afterward, the on-site participants discussed and reviewed some ofthe issues presented by Paolo Vicini, as well as analyzed in more detail the differences between the modelspresented by Paolo Vicini and the model presented by Michele Guindani during the SAMSI opening week.The working group discussed how joint PK/PD modeling can be pursued by considering the vector of PKand PD parameters as one joint vector, generated from a random effects distribution with a non-parametricBayesian prior, for example a DP prior.
The features and limitations of such non-parametric Bayesian approaches were thoroughly discussed, bothfrom a computational and methodological perspective. Some participants briefly mentioned the possibilityto model the PK and PD vectors separately, or enforce subclustering of the vector components by means ofsome extension of the DP.
Tuesday. After summarizing the discussion from Monday, participants continued the discussion of possibleBayesian NP models for modeling the PK and PD parameters jointly. In particular, the working groupconsidered the possibility of separate non-parametric Bayesian models for PK and PD parameters. Thepossibility of specifying the DP prior for the PD parameters as a dependent DP, correlated with the randomeffects distribution for the PK parameters, was discussed. The working group considered the feasibilityof local partitions models to enforce subset clustering in the joint parameters’ vector. References to theproblem of differential weighting of the PK and PD has also been made. The problem had been hintedat by Paolo Vicini in our discussn yesterday, and it’s at the core of the paper by David Lunn, NickyBest, David Spiegelhalter, Gordon Graham and Beat Neuenschwander, ”Combining MCMC with sequentialPKPD modeling”, J. Pharmaokinetic and Pharmacodyn 2009. The group has then started discussing theintroduction of covariates in the model. We have reviewed the paper by David Lunn, ”Automated covariateselection and Bayesian model averaging in population PK/PD models”, J Pharmacokinet Pharmacodyn
5

(2008) 35:85100, as well as the paper by Wakefield J, Bennett J (1996) The Bayesian modeling of covariatesfor population pharmacokinetic models. J Am Statist Ass 91:917927. We have concluded with some hintsat the possible use of sequential MCMC in the inference of mixture of DP models.
Wednesday. Steven MacEachern has been invited to join our discussion, as some had expressed the desireto discuss more the differences among diverse modeling of Dependent Dirichlet process: single p (only theatoms are covariate dependent stochastic processes), single-theta (only the weights are covariate dependent)or full DDP (both weights and atoms may vary according to the covariate value). Then, we have discusseda mail by Paolo Vicini on different ways to include a dynamic component in the PK and PD parameters tobetter catch inter-occasion variability. The meeting concluded with a discussion of David Dhal’s distancebased MCMC scheme.
W3: Report on Nonparametric Bayes & Clustering for Population PK/PD
Siva Sivaganesan, University of Cincinnati, served as working group leader.The PK/PD Cluster Working Group met daily at 11am. Working group activities included presentations
and discussion of issues relating to the use of NPB clustering in PK modeling. This included some specificprojects, as well as general directions for potential projects. The following gives some specifics of the activitiesof the working group.
Monday. J.K. Ghosh gave a talk on the fundamentals of the Drichlet Process prior. Prof. Ghosh dis-cussedthe support of the DP process prior and its ability to identify mixing distributions generated from anyprobabilistic mechanism, a related consistency results, the relationship between DP prior based clusteringand K-Means clustering, and how DP with MCMC leads to clustering. Regarding the application of DPpriors in population PK modeling, he referred to Donoho’s six difficult curves and how they served as testingground for new density estimation methods, and suggested a similar approach – find some typical difficultPK data sets and evaluate DP modeling with those curves. He also suggested using David Dahl’s approachof using prior information with DP prior, and using SDE applied to DP.
Tuesday. Lili Ding gave a talk on Bayesian Semiparametric PopulationPharmacokinetic Models, in whichshe gave an overview of population PK modeling, use of semi-parametric models for population PK modeling,using DP process prior, and limitations of DP priors in capturing certain non-standard structure in covariateseffect. She pointed out that the use of dependent DP priors may be promising to capture these effects.. Therewas discussion on the choice of modling approach DDP and Conditional DP approaches were discussed.
Wednesday. JuHee Lee spoke on ”Local-Mass Preserving Prior Distributions for Nonparametric BayesianModels” In this talk Ju Hee gave an approach to assign a robust prior for DP mass parameter and the scaleparameter in the base measure. This approach was able to fit outliers as well as the center of the data betterthan standard DP prior.
This talk was followed by a brief discussion of the paper Cluster Analysis: An Alternative Method forCovariate Selection in Population Pharmacokinetic Modeling that was given by Paolo Vicini.
Thursday. We continued discussion on the above paper, which uses hierarchical (different nomenclaturehere) clustering to select covariates, and do modeling separately. It was felt that NPB can do the clusteringof covariates and the PK modeling simultaneously, and pick a specific cluster a posteriori, for use in drugguidelines. Assigning new patients to a cluster was discussed. There was discussion on the need to come upwith a simple rule, or guidelines on the use of the drug being studied, based on the important covariates,and it was suggested this could be accomplished even with a complex underlying PK/PD model.
Addressing model mis-specification using computer models and/or NPB methods was also discussed.Joinly, Athanasios Kottas, Mahlet Tadesse, Michele Guindani, and David Dahl, have started brainstorm-
ing about applying existing dependent nonparametric prior models (and possibly developing new priors) for
6

clustering subjects for which more than one source of data is available – one possible application is to estimateseparate, but related, clustering of the subject specific PK and PD parameters in a joint PK/PD model; itis also likely that the ideas and issues discussed will lead to more participants taking up new projects basedon the working group discussion and, more generally, from the experience of the whole workshop.
References. Some discussions in this working group were based on
http://www.springerlink.com/content/y0v14362r8j83274/
http://www.nature.com/clpt/journal/v83/n1/full/6100259a.html
Davidian, M. An Introduction to nonlinear mixed effects models and PK/PD analysis (ASA Biopharma-ceutical Section webinar, April 2010)
Wakefield, J. and Walker, S. (1997). Bayesian nonparametric population models: formulation and compar-ison with likelihood approaches. Journal of Pharmacokinetics and biopharmaceutics, 25(2):235-253.
De Iorio, M., Mueller, P., Rosner, G. and MacEachern, SN. (2004). An ANOVA model for dependentrandom measures. JASA, 99(465):205-215.
Rosner, G., Mueller, P., Tang, F., Madden, T. and Andersson, B. (2004). Dose individualization forhigh-dose anti-cancer chemotherapy. Advanced Methods of Pharmacokinetic and PharmacodynamicSystems Analysis Volume 3.
W4: Report on PK/PD Simulation for Design and Dose Individualization
Gary Rosner, Johns Hopkins University, served as working group leader.On Monday, July 19, 2010, the PK and PD simulation and Dose Individualization working group began
by discussing what we might try to accomplish during the second week of this SAMSI workshop/conference.We discussed the use of PK and PD models in clinical trial simulation. We reviewed terminology in drugdevelopment, particularly phase I, II, III, and IV clinical trials.
We then reviewed Bill Gillespie’s slides from his presentation during the first week of the workshop. Inthat talk, Bill presented the steps one might go through when carrying out trial simulation (including PKand PD prediction) to design a phase II study. The group decided to put together the pieces to carry out atrial simulation based on a joint PK and PD model.
We looked at potential decision paths as possible things for us to look at in our trial simulation.
• Different treatment regimens• Different trial designs• Different overall development strategies• Different indications• Different drug candidates
We decided to look at the first three items. Specifically, we chose to pretend we were designing a phaseII study with phase IIA and IIB objectives. The disease the study was targeting had a fairly short-term(2-4 weeks) efficacy outcome. There was a longitudinal biomarker measurement available to us for assessingefficacy, such as an early signal of lowering lipids. We considered simple linear pharmacokinetics and adirect-effect pharmacodynamic model. We would introduce complexity in the model of inter-individualvariation.
When designing the phase II study, we considered that we might have available some or all of the followinginformation.
• Animal safety, PK, & PBPK• Animal model for the disease (some PD)• (maybe) other drugs (competition) for disease
7

• In vitro studies (e.g, IC50, etc.)• Phase 1 data (healthy volunteers): safety and PK• A PK model• (maybe) PD model• (maybe) joint PK-PD model• (maybe) disease-biomarker model
We then discussed a GlaxoSmithKline (GSK) phase IIa study of a new INI antiretroviral drug for treatingHIV-positive patients. The drug is taken orally, once a day. Merck has competitor called Raltegravir. GSKhas a PD model.
The group decided
• to use the GSK study as a template.• to design a phase IIa & compare it to the one GSK actually carried out.• to design a phase IIb & compare our “optimal” design to the design of GSK’s ongoing phase IIb study.
Possible objectives of our simulation study:
• Include simulated data to allow for different subgroups and see how a Bayesian nonparametric priormodel based on the Dirichlet process mixture performs.
• Increase the sample size to find out when the Bayesian NP model shows the different subgroups.
Need PK & PD models for underlying truth. One-compartment PK model (w/1st-order absorption).Use GSK PD model with inter-individual variation for one element.
We developed a list of tasks.
• Code PK & PD models and figure out which parameters need priors.• Use BUGS code to simulate data and to fit model to data via separate calls to R.• Get priors for the parameters in the models.• Fit PK & PD model with mixture model priors for parameters.
We also considered the following design questions.
• When to sample viral load?• Dose levels of drug• How many dose levels in phase 2?• How to distribute patients across the dose levels (adaptive later, much later)?• Duration of treatment? (decision: 24 weeks in phase IIb)• Incorporate development of resistance?• What is objective of phase 2?• Primary endpoint (efficacy)?
– Keep viral load below 50 copy/mL
• Include safety considerations in the model? (need model)• Include pharmacogenetics?• How much heterogeneity is needed for individualization to pay off?
We then formed Task Groups:
• Code the PD model function with embedded PK model• Write WinBUGS code to generate concentrations over time & viral load measurements over time• Write program in R to call WinBUGS• Estimate parameters:
8

The group met each afternoon during the week, with several subgroups working together at other times.By the end of the second week, we produced a program that ran in WinBUGS program and generated PKand PD data similar to data we anticipate collecting as part of the clinical trials. We also had a WinBUGSprogram for fitting data with our joint PK & PD model that includes a Bayesian nonparametric prior modelfor the distribution of subject-specific parameters. We also have R code to call WinBUGS to simulate and thenanalyze these viral load data. We plan to run these programs under different design scenarios and therebydetermine the optimal biologic dose and also the best design for a future clinical trial further evaluating thisdrug. The group will continue working on this project after the SAMSI program and, hopefully, write upour results.
W5: Report on Pharmacogenomics and Networks
Peter Muller, University of Texas M.D. Anderson Cancer Center, served as working group leader.Disucssions in this WG focused on network modeling & graphical models. In the initial organizing
meeting we recognized that most WG members were new to the area and concluded that group activitiesshould therefore be mostly tutorial introductions.
Monday. The first presentation was given by Donatello Telesca, UC Los Angeles. Dontello Telesca deliv-ered an introductory lecture on graphical models, introducing notation, terminology and some basic models.
Tuesday. The theme was continued on Tuesday in a lecture by Abel Rodriguez, UC Santa Cruz, Priorson Graphs. The talk introduced informative priors for graphs, exploiting knowelege about properties of theexperimental units represented by the nodes. In particular this included attributes specific to each node(gene, person, etc.) and information about clustering of units. Participants noted that the use of clusteringto inform a probability model for a a random graph was unusual in biomedical applications, and perhaps aninteresting modeling approach.
Wednesday. Stan Young, NISS, gave a lecture on factorization of non-negative matrices. The lecturepointed out the relationship with traditional principal component analysis. The main difference between thetwo approaches is that the proposed factorization of non-negative matrices allows inference about the termsof a deconvolution of the non-negative matrix into a sum of matrices. This can be important in biomedicalapplications when a response arises as a sum of different mechanisms. Also, the solution tends to be sparse,with many zeros in the factor matrices. This might be useful in identifying structure and networks.
Thursday. The program of the working group concluded with a discussion lead by Peter Muller on Recip-rocal Graphs. The discussion tried to clarify the process of associating a graphical model with a probabilitymodel, and how posterior inference on the probability model implies posterior inference on the graph. Re-ciprocal graphs are a class of graphical models that are specifically suited for the representation of molecularnetworks in general, and in pharmacogenomics in particular. The models allow directed edges and allow theinclusion of cycles.
9

4 Feedback and Outcomes
Feedback from many participants seems to indicate that the program succeeded in the intention of connectingtwo traditionally separate research communities and drawing the attention of researchers in BNP to inter-esting opportunities in PK/PD related problems. In particular, we received feedback about the followingtentative new research projects initiated as a result of the program.
Steve MacEachern, Ohio State University, reports conversations with David Dahl, Mahlet Tadesse andThanasis Kottas about diagnostics for NP Bayesian models. They aim to develop graphical diagnosticsfor nonparametric Bayesian models.
Lang Li, IUPUI, reports initiating a collaboration with Wes Johnson, UCI. They are working on elcitingprior distributions for population PK/PD models.
Subha Guha is planning to work on several projects that resulted from my attending the conference.
Peter Thall says the workshop “. . . turned out to be a really terrific learning experience, and it has changedthe way I think about Bayesian data analysis.” He has initiated two projects during the workshop, oneon prior equivalent sample size for nonparametric Bayes priors, and another on non-parametric Bayesfor causal inference. Both are joint with Mike Escobar and Peter Muller.
Julien Cornebise says he learned a lot, “. . . and I am looking much forward to having other chances tocollaborate soon!” He has initiated work on a paper discussing the use of SDE’s for PK/PD modeling.population PK/PD model for illustration. Another project is on a “balanced Dirichlet process” model,jointly with Lane Burgette.
10

179
I.E.4 Education and Outreach Program
The SAMSI Education and Outreach (E&O) Program encompasses a variety of activities which
have achieved national stature for both their scientific and pedagogical content. The annual
activities include two-day Undergraduate Outreach Days held both in the Fall in the Spring, a
week-long Undergraduate Workshop (UGS) held in May, and the ten-day Industrial
Mathematical and Statistical Modeling (IMSM) Workshop for Graduate Students that is held in
July.
Undergraduate Outreach Days
The two outreach workshops are held annually to expose undergraduates from institutions
around the country to topics and research directions associated with concurrent SAMSI
programs. One goal of these workshops is to illustrate the application and synergy between
mathematics and statistics which goes far beyond that which students have seen in coursework.
The overall objective is to broaden the perspective of students with regard to both future
graduate studies and career choices.
Space-Time Analysis for Environmental Mapping, Epidemiology and Climate Change: October
30-31, 2009
The Fall outreach workshop focused on topics from the SAMSI Program on Space-time analysis.
The students were provided with an overview of SAMSI by Pierre Gremaud (SAMSI/NCSU) after
which program leaders, participants, postdocs and students gave a variety of presentations and
tutorials. During the Friday morning session, Murali Haran (Penn State) gave a general
introduction to statistical methods for environmental science and climate change. Ben Shaby
(SAMSI postdoc) then led a tutorial on R. This was followed by two applied presentations where
the students were shown how the type of methods under study can be used in practice. First,
Veronica Berrocal (SAMS postdoc; now on the faculty at the U. of Michigan) discussed how to
downscale outputs from computer models from averaged values to local ones. This presentation
was also paired with an interactive R session in the afternoon. The first presentation in the
afternoon was given by Martin Tingley (SAMSI postdoc; now at NCAR). Martin discussed the
field of paleoclimatology, i.e., the reconstruction of the climate using the very partial data at our
disposal. The presentation was also paired with a lab. For this, the students used MATLAB, after
having received an introduction to it by Jun Zhang (SAMSI postdoc; now at NOAA/CICS). The day
was concluded by an open discussion led by Pierre Gremaud on graduate school and career
options. During dinner on Friday, members of the Directorate as well as SAMSI visitors and
postdocs interacted with students to further discuss career opportunities. Two presentations
were given on Saturday morning by Susie Bayarri (University of Valencia, Spain) on the
construction of hazard maps for volcanic eruptions and by Howard Chang (SAMSI postdoc) on
epidemiology. Howard presentation was followed by an interactive session in R. Details
regarding the workshop can be obtained at http://www.samsi.info/workshop/two-day-
undergraduate-workshop-october-2009
There were 48 participants which included 21 females, 2 African Americans and 3 Hispanics Stochastic Dynamics: February 26, 27, 2010

180
The Spring outreach workshop was devoted to Stochastic Dynamics. The students were provided with an overview of SAMSI by Pierre Gremaud (SAMSI/NCSU) after which program leaders, participants, postdocs and students gave a variety of presentations and tutorials. The first talk in the workshop was given by Scott Schmidler (Duke) who gave a fascinating presentation on Markov chains, networks and molecules. This was followed by an introduction to R given by Xueying Wang (SAMSI postdoc; now at Texas A&M). John McSweeney (SAMSI postdoc; now at Concordia) introduced the students to models for epidemics in structured populations, i.e., by taking into account the social (for instance) interactions on the population members. The afternoon started with an interactive R session based in McSweeney’s application. Avani Athreya (SAMSI postdoc) presented introductory material on random walks and Brownian motion while an other SAMSI postdoc, Oliver Diaz discussed the sensitivity of dynamical systems to small random perturbations. Finally, Xueying Wang introduced to the students to the marvels of MATLAB. The day was concluded by an open discussion led by Pierre Gremaud on graduate school and career options. During dinner on Friday, members of the Directorate as well as SAMSI visitors and postdocs interacted with students to further discuss career opportunities. On Saturday morning, Cindy Greenwood, the overall program leader discussed general issues pertaining to stochastic dynamics. Bruce Rogers (SAMSI) addressed connections between graph theory and linear algebra; more specifically, how the former can be used very easily to get information on the former. This presentation was paired with a MATLAB interactive session. Details regarding the workshop can be obtained at http://www.samsi.info/workshop/two-day-undergraduate-workshop-february-2010 There were 35 participants which included 14 females, 1 African American and 1 Hispanic.
Undergraduate modeling workshop: May 17-21, 2010 The undergraduate modeling workshop is a yearly week event. The focus is different from the outreach workshop. Here, we consider one application and guide the students through the entire modeling process, from the design of a model, its mathematical analysis, its statistical properties, its implementation and finally discussion of the results. All tutorials and sessions are presented by SAMSI graduate students and postdocs under close supervision of a member of the Directorate and local faculty. This allows the undergraduates to interact with peers within educational and research programs they are considering and it provided valuable experience for the presenters, many of whom are considering academic careers. The workshop provides students with an intensive introduction to the synergy between applied mathematics and statistics within the context of timely physical applications and real data.
This year, we decided to build on the strengths present at SAMSI and consider an application
related to epidemiology. This field is in indeed at the intersection of the two 2009-10 programs.
Further, it pertains to one of the 2010-11 programs (Complex Networks). The students were
first guided through introductory presentations related to classical epidemiology models (SIR
and the likes). They were also given background in basic statistics and probability, R and
MATLAB. A first interactive session allowed to the students to test their skills on a “perfect” data
set: a well known boarding school influenza example for which perfectly mixed models such as
SIR work very well. After some background on complex network theory and parameter
estimation methods, the students were made to work on actual CDC flu data. That data set
corresponds to about ten regions in the US for which aggregated flu counts are given at regular
time intervals. The students had the task of adapting simple models to this situation. For the
part of the workshop, the students work in groups (of about three). Some groups successfully
adapted the models to specific regions, some others applied new tools from network theory. On
the final day of the workshops, each student team presented the results obtained during the

181
week.
The workshop was a resounding success, so much so in fact that the 2011 version will be
devoted to epidemiology again. Further, in 2011, we will run a parallel workshop involving
faculty from primarily teaching colleges with the goal of producing a teaching module. The 2010
heavily involved 15 SAMSI postdocs and 12 SAMSI graduate fellows who interacted with the
undergraduate students through lectures, interactive session and socially. In the middle of the
week on Wednesday morning, two panels are assembled to discuss professional development
issues. One panel gathers faculty with various background and addresses graduate school
opportunities. The other panel is devoted to career options after studies are completed; the
panelists come from various industries and companies. More details about the workshop can be
found at http://www.samsi.info/workshop/2009-10-undergraduate-modeling-workshop
There were 27 participants which included 10 females and 3 African Americans.
SAMSI Graduate Fellow Poster day, April 14, 2010 Through the year, the 11 SAMSI graduate fellows are involved in research projects directly related to working group activities. To recognize their achievements, the entire SAMSI community gathers to celebrate their achievements in a poster reception. Each student presents his/her results in the form of a poster. The students are encouraged to present their work at relevant conferences and make use of their SAMSI poster there. 4th Annual Graduate Student Probability Conference: April 30-May 2, 2010 SAMSI is proud to provide support for this conference cycle which is organized by graduate students and is for graduate students. The objectives of the conference are (i) to provide graduate students and postdoctoral fellows with the opportunity to speak on an area of interest within probability, (ii) to foster discussions with a friendly and informal atmosphere, (iii) to establish connections for potential future collaborations and (iv) to learn about recent development in probability. More details about the conference can be found at http://www.math.duke.edu/%7Etkolba/GSPC/ Industrial Mathematical and Statistical Modeling (IMSM) Workshop: July 20-28, 2009 The ten-day Industrial Mathematical and Statistical Modeling Workshop for Graduate Students
was the 15th year in the series and the 7th sponsored by SAMSI. The overall goals of the work-
shop are twofold: (i) expose mathematics and statistics students to current research problems
from government laboratories and industry which have deterministic and stochastic
components, and (ii) expose students to a team approach to problem solving. During the
workshop, the students learn to communicate with scientists outside their discipline, allocate
tasks among team members, and disseminate results through both oral presentations and
written reports.
Both the undergraduate modeling workshop and the graduate IMSM workshop share (and
achieve) the following goals with respect to intellectual merit:

182
Students gain experience in team work. Team work is indispensable in the approach to problem solving, in producing a final written report, and in preparing an oral presentation.
The students learn to communicate with scientists who are not academic mathematicians.
The workshops present a unique combination of applied mathematics and statistics that is not part of the usual class work.
The IMSM workshop goes further:
Students work on genuine industrial research problems. These are not the kind of academic exercises often considered in classrooms. The projects tend to be open-ended and require fresh new insight for both formulation and solution. Sometimes the biggest challenge is to figure out what the real problem is. The students also learn how to derive a useful result under a tight deadline.
Students acquire crucial insight into the aspects of a non-academic career. Some presenters may know more about their problems and can guide the students away from dead ends, while other presenters may have brought open-ended problems and are searching along with the students. This combination of approaches exposes the students to the variety of challenges facing scientists in industry.
The IMSM workshop helps students to decide what kind of career they want. The IMSM workshop provides a unique experience of how mathematics and statistics are applied outside academia. In some cases the help has been in the form of direct hiring by the participating companies.
The broad impact of our Education and Outreach activities is substantial:
Our workshops help to attract students to and prepare them for a non-academic career, by exposing them to real-world industrial problems.
The participating students represent a nationally diverse group, with a substantial number of women and minorities.
The workshops strengthen the interaction between applied mathematics and statistics. The workshops, and specifically, IMSM, benefit government and industry research. Often
the student teams come up with useful solutions to a project. Several projects initially presented at the IMSM workshop have resulted in long term collaborations between students and faculty on the one side and the companies on the other. Furthermore, several companies have taken advantage of the recruitment opportunity provided through direct contact with some of the most talented students in the mathematical and statistical sciences. Many companies, large and small, have shown continued interest and enthusiasm about the IMSM workshop.
For the 2009 IMSM workshop, there were 37 participants which included 14 females and 1 Hispanic.
The projects investigated during the workshop corresponded to current research problems presented by scientists from the Environmental Protection Agency, MIT Lincoln Laboratory, the National Center for Atmospheric Research, Republic Mortgage Insurance Company, Sandia National Research Laboratories and the UNC School of Pharmacy. Each team gave a 30 minute oral presentation summarizing their results on the final day of the workshop and written reports were compiled as the SAMSI Technical Report 2010-02 which is available at http://www.samsi.info/sites/default/files/tr2010-02.pdf Details regarding the workshop can

183
found at http://www.ncsu.edu/crsc/events/imsm09/ Diversity
See Section I.H for discussion of the efforts to promote diversity. Courses
See the program reviews in Section I.E for discussion of the SAMSI courses. Three courses were
offered during the Fall semester in 2009 and one during Spring 2010; these are credited 3
credits/units at each of the participating Universities.
The course attached to the Stochastic Dynamics program in Fall 2009 was taught by Priscilla Greenwood, Jonathan Mattingly, and guest lectures. This course introduced background material in dynamical systems theory and some basic principles regarding the behavior of associated stochastic dynamical systems. Examples were drawn from a number of settings including population dynamics, modeling of biological systems, fluid mixing and transport, and simple physical systems. No background in any particular field of application was assumed. The course examined both analytical and numerical approaches as well as discussed the art of stochastic modeling. Attendance: 16 students registered The Space-Time program generated two graduate courses in Fall 2009. Alan Gelfand (Duke) and Montse Fuentes (NCSU) and several long term SAMSI visitors offered a course on Theory of Continuous Space and Space-Time Processes. This course was intended to provide a strong theoretical foundation for space and space-time processes over continuous domains. Topics included continuous parameter stochastic process theory; spectral methods; spatial asymptotics; nonstationary spatial modeling; dynamic models and spatial time series; nonseparable space-time models; spatial design; space-time data fusion; low rank representations; nonparametric spatial methods; topics in shape analysis. Attendance: 27 students registered In parallel with that course, Richard Smith (UNC) taught a course on Spatial Epidemiology. Much of modern epidemiology is concerned with relationships between environmental factors and various types of human health outcome. When data are collected at many spatial locations, we may refer to the problem as one of spatial epidemiology. However in most cases, this includes a temporal component as well. Since modeling spatial dependence is often critical to the method of statistical inference, it is necessary to use methods from spatial or spatio-temporal statistics. Very often health data are aggregated (e.g. into zip code or county totals) so models for data at discrete spatial locations, such as Markov random fields, are more appropriate than geostatistical methods. Another kind of problem is exemplified by the NMMAPS study (http://www.ihapss.jhsph.edu/): an air pollution-mortality relationship is developed initially for many time series at individual cities, but inferences are then drawn by combining data across spatial locations. A third kind of problem is when there is uncertainty about the pollution field itself, for example, when data collected at monitors are interpolated to other locations. Sometimes this interpolation is performed by spatial statistics methods, but there is a growing trend to use air pollution models such as CMAQ (the EPA's Community Multiscale Air Quality model). Specific topics: Models for spatially distributed health data. Markov random fields; extensions to spatial-temporal processes. Multi-city time series studies; combining data across multiple studies at different spatial locations. Measurement error problems that involve spatial

184
interpolation; use of air quality models. Attendance: 19 students registered Finally, in Spring 2010, Montse Fuentes and several guest lecturers gave a course on Spatial Statistics in Climate, Ecology and Atmospherics. In this course, the instructors introduced the statistical methods to characterize uncertainties in climate, weather, ecological and air pollution deterministic models. They also presented statistical frameworks to combine disparate spatial data, from observations and output of deterministic models, and to measure the agreement between an artificially generated climate signal from a climate model and real data as measured by surface observation stations or satellites. Statistical methods for processing ensembles of climate models were covered. The instructors introduced different spatial temporal modeling approaches to characterize trends in space and time, as well as to estimate dependency structures, and to do space-time prediction for climate, weather, ecological and air pollution data. They also discussed state-of-the art methods for dimension reduction, spatial extreme events in climate and weather, and impact of climate change on mortality and human health. Attendance: 15 students registered

185
F. Industrial and Governmental Participation
Government and industry participation in SAMSI program and activities reflects broad
interest in the SAMSI vision. Most SAMSI workshops had extensive participation by
individuals from industry and government. Here, we summarize only the more intensive
involvements, e.g., participation of such individuals in program working groups.
Risk Analysis, Extreme Events and Decision Theory: This program had working
group members from IBM, the Center for Disease Control and Prevention (CDC), and
NCAR. Contact was also made to Genesys Lab of Alcatel-Lucent to obtain data for
testing methodology.
Environmental Sensor Networks: This program had working group members from
government agencies, laboratories, and industry, including EPA, CDC, Marine Biological
Laboratory, the IBM Watson Research Center, and the National Institute for Space
Research (Brazil).
Sequential Monte Carlo Methods:
The Tracking working group had close interactions with the UK's DSTL governmental
defense organization, with Nathan Green being on secondment from there. Mark Briers
was on secondment from QinetiQ Ltd. for his visit in Fall 08.
Algebraic Methods in Systems Biology and Statistics:
We had a number of participants who were from government agencies and industry:
Lawrence Cox (Amgen), Gilles Gnacadja (Amgen), and Richard Haney (Cellular
Statistics).
Education and Outreach Program: In the Industrial Mathematical and Statistical
Modeling Workshop, the attendees were divided into 6 teams to investigate current
research problems presented by scientists from Glaxo Smith Kline, MIT Lincoln
Laboratory, the National Institute of Statistical Sciences, Republic Mortgage Insurance
Co and SAS.

186
G. Publications and Technical Reports
I. STOCHASTIC DYNAMICS
Publications and Technical Reports
Athreya, A., Srinivasan, R., McKinley, S., “Understanding Quiescence for a
Morris-Lecar Model”
Athreya, A., Mattingly, J., Kolba, T. “Noise-Induced Stabilization for Certain
Planar System”
Bhamidi S., and Greenwood, P.E., Variants of Brownian motion. Chapter for
Encyclopedia of Operations Research, to in appear 2011:
Baxendale, P.H., and Greenwood P.E., Sustained oscillations for density-
dependent Markov processes, Journal of Math. Bio. to appear
Cooke B., Mattingly J.C., McKinley S.A., Schmidler S.C., Geometric
Ergodicity of Two-dimensional Hamiltonian systems with a Lennard-Jones-
like Repulsive Potential. Communications in Mathematical Sciences,
submitted, 2011. http://arxiv.org/abs/1104.3842
E, Weinan, Engquist, B., and Sun, Y. Heterogeneous multiscale methods with
application to combustion, in Turbulent Combustion Modeling: Advances,
Trends and Perspectives (T. Echekki and E. Mastorakos eds.), Springer,
pp.439–459, 2011. http://www.springerlink.com/content/k031788726183244/
Giraudo, M.T., Greenwood P.E., and Sacerdote L., How sample paths of leaky
integrate and fire models are influenced by the presence of a firing threshold.
Comp. Neuroscience, to appear.
Gremaud, P. and Sun, Y. Numerical study of singularity formation in
relativistic Euler flows, SIAM J. Sci. Comput., in review, 2011.
http://www.cims.nyu.edu/~yisun/paper/SISC.pdf
Srinivasan, R., Menon, G., “Kinetic Theory and a Lax Pair for Shock
Clustering and Burgers Turbulence” Submitted Sept. 2009.
Srinivasan, R., “Rates of Convergence for Smoluchowski's Coagulation
Equations” Edited/resubmitted Oct. 2009
Sun, Y., Caflisch, R. and Engquist, B. A multiscale method for epitaxial
growth, SIAM Multiscale Model. Simul., 9, pp.335–354, 2011.
http://dx.doi.org/10.1137/090747749

187
Sun, Y. Rangan, A.V., Zhou, D., and Cai, D. Coarse-grained event tree
analysis for quantifying Hodgkin-Huxley neuronal network dynamics, Journal
of Computational Neuroscience, in press, 2011.
http://www.springerlink.com/content/j6k86h53470332x1/
Vivar, J. and Banks, D. Models for Networks: A Cross-Disciplinary Science,
in: Wiley Interdisciplinary Reviews: Computational Statistics, to appear in
2011
Wang, H., Banks, D., Vivar, J., and Dunson, D. The Multiple Bayesian Elastic
Net, Journal of Machine Learning, submitted, 2011.
http://stat.duke.edu/~hy35/MBEN.pdf.
Reports in Preparation
Athreya, A “Large Deviations for a Diffusion Process with a First Integral”
(in preparation)
Athreya, A. “Stochastic Resonance for Hamiltonian Systems Perturbed by
Noise” (in preparation)
Athreya, A., Kramer, P., Fricks, J., McKinley, S., “Cooperative and Tug-Of-
War Models for Molecular Motors” (article in preparation)
Diaz-Espinosa, O., de la Llave, R., “Random Pertubations of Holomorphic
Maps with Siegel Disks”
Diaz-Espinosa, O., Schmidler, S., “Metastability”
Diaz-Espinosa, O., Khanin, K., “Directed Polymers in Random Environment
with Product Structure”
Diaz-Espinosa, O., “Long Wave Expansion for Water Waves Over a Random
Surface”
Rogers, B., “Poincare Inequalitites on Markov Chains” 2 papers in
preparation
Rogers, B., “Control of Consensus under Bounded Confidence” in
preparation
Rogers, B., Menjivar, C., “Network Affects on Computational Models of
Generalized Reciprocity” (in preparation)
Rogers, B., Murillo, D., “Stochastic Agro-Ecosystem Model” (nearly

188
submitted)
Rogers, B., Hindman, M., “Modeling Internet Traffic” (book and several
papers)
Wang, X., “Pairwise Closure Approximations of in Epidemic Models on
Networks”, in preparation.
Wang, X., “Stochastic Resonance Effects in Single and Coupled Morrislecar
Type Neurons”, in preparation.
II. SPACE-TIME ANALYSIS FOR ENVIRONMENTAL MAPPING,
EPIDEMIOLOGY AND CLIMATE CHANGE
Publications and Technical Reports
Assunçao, R. and Lopes, D. (2010), Visualizing Marked Spatial and Origin-
destination Point Patterns With Dynamically Linked Windows. Journal of
Graphical and Computational Statistics, accepted.
Banerjee, S., Gelfand, A. “Modelling Spatial Gradients on Response
Surfaces” Frontiers of Statistical Decision Making and Bayesian Analysis.
Eds. M.H. Chen, D.K. Dey, P. Mueller, D. Sun, K. Ye New York: Springer
(2010)
M.J. Bayarri (2010). A methodological review of computer models. In:
Frontiers of Statistical Decision Making and Bayesian Analysis (Ming-Hui
Chen, Dipak K. Dey, Peter Mueller, Dongchu Sun, and Keying Ye, eds.).
Springer, pp 157-168.
Berrocal, V., Gelfand, A., Holland, D.M. “A Bivariate Space-time
Downscaler Under Space and Time Misalignment” Annals of Applied
Statistics. In Press (2010)
Bhat, K. S., Haran, M., Goes, M. (2010). Computer model calibration with
multivariate spatial output: a case study in climate parameter learning. In:
Frontiers of Statistical Decision Making and Bayesian Analysis (Ming-Hui
Chen, Dipak K. Dey, Peter Mueller, Dongchu Sun, and Keying Ye, eds.).
Springer
Bhat, K. S., Haran, M., Keller, K., Tonkonojenkov, R. (2010). Inferring
likelihoods and climate system characteristics from climate models and
multiple tracers, submitted.
Blanchet, J. and Davison, A. C. (2011) Spatial modelling of extreme snow
depth. Annals of Applied Statistics, to appear.

189
Chakraborty, A., Gelfand, A., Wilson, A.E., Latimer, A.M., Silander, J.A.
"Modeling Large-scale Species Abundance with Latent Spatial Processes"
Annals of Applied Statistics. In Press (2010)
Chakraborty, A., Gelfand, A.E., Wilson, A. M., Latimer A. M. and Silander,
J.A. (2011), Point pattern modeling for degraded presence-only data over
large regions. To appear, Journal of Royal Statistical Society, Series C
Chang, H., Peng, R.D., Dominici, F. “Estimating the Acute Health Effects of
Coarse Particulate Matter Accounting for Exposure Measurement Error”
Under Revision 2010
Chang, H., Zhou, J., Fuentes, M. “Impact of Climate Change on Ambient
Ozone Level and Mortality in Southeastern United States” International
Journal of Environmental Research and Public Health 7:2866-2880 (2010)
Chang H, Dominici, F, and Peng, RD. “Bayesian Model Averaging for
Clustered Data” Submitted (2009)
Corberan, A. and Lawson, A. (2011), Conditional Predictive Inference for
On-line Surveillance of Spatial Disease Incidence. Submitted to Statistics in
Medicine.
Craigmile, Peter and Bala Rajaratnam (2011), Discussion of A statistical
analysis of multiple temperature proxies: Are reconstructions of surface
temperatures over the last 1000 years reliable? Annals of Applied Statistics,
Vol. 5, No. 1, 88--90.
N. Cressie, R. Assunçao, S.H. Holan, M. Levine, O. Nicolis, J. Zhang and J.
Zou (2011), Dynamical random-set modeling of concentrated precipitation in
North America. Technical Report No. 854, March, 2011, Department of
Statistics, The Ohio State University, Columbus, OH. Submitted to Statistics
and Its Interface.
Das, S., Dey, D., “Bayesian Methods for Dynamic Models” Submitted (2009)
Das, S., Kaufman, M., Singh, G., Micames, C., Gress, F.,“Efficacy of
Endoscopic Ultrasound (EUS) Guided Celiac Plexus Block (CPB) and Celiac
Plexus Neurolysis (CPN) for Managing Abdominal Pain Associated with
Chronic Pancreatitis and Pancreatic Cancer: a systematic review and Meta
analysis”. Accepted in Journal of Clinical Gastroenterology (2009)
Davison, A. C. and Gholamrezaee, M. M. (2010) Geostatistics of extremes.
Under revision.

190
Davison, A. C., Padoan, S. and Ribatet, M. (2010), Statistical modelling of
spatial extremes. Under revision for Statistical Science.
R. Dennis, Fox, M. Fuentes, A. Gilliland, A. Hanna, G. Hogrefe, Irwin,S. Rao,
R. Sheffe, H. Schere, Steyn, Venkatram. (2010). A framework for evaluating
regional-scale numerical photochemical modeling systems. Environmental
Fluid Mechanics Journal, in press.
Eidsvik, J., Finley, A., Banerjee, S., and Rue, H. (2010). Approximate
Bayesian inference for large spatial datasets using predictive process models.
Under revision, Computational Statistics and Data Analysis.
Eidsvik, J., Shaby, B., Reich, B.J., Wheeler, M. and Niemi, J. (2010).
Estimation and prediction in spatial models with block composite likelihoods
using parallel computing. Submitted.
Erhardt, R. and Smith, R.L. (2011), Approximate Bayesian Computing for
Spatial Extremes. Submitted for publication.
M. A. R. Ferreira, Using Proper Markov Random Fields to Build Highly
Structured Models for Gaussian Areal Data. Chapter for book edited by
Dongchu Sun, to appear.
M. A. R. Ferreira and J. C. Vivar, Spatiotemporal models for Poisson areal
data with an application to the AIDS epidemic in Rio de Janeiro. Journal of
the Royal Statistical Society - Series C, submitted.
Finley, A.O., Banerjee, S. and MacFarlane, D.W. (2010). A hierarchical
model for predicting forest variables over large heterogeneous domains.
Journal of the American Statistical Association 106, 31-48.
Fuentes, M., and Banerjee, S. (2011). Bayesian Modeling for Large Spatial
Datasets. WIREs Computational Statistics, accepted.
Fuentes, M. and Foley, K. (2011). Ensemble methods, in upcoming
Encyclopedia of Environmetrics.
Fuentes, M., Henry, J. and Reich, B. (2011), Nonparametric Spatial Models
for Extremes: Application to Extreme Temperature Data. Extremes, accepted.
Fuentes, W., Herring, A., Langlois, P. “Air Pollution and Preterm Birth:
Identifying Critical Windows of Exposure”. Under Review.
Fuentes, M., Xi, B. and Cleveland, W. (2010), Trellis Display for Modeling
Data from Designed Experiments. Journal of Statistical Analysis And Data
Mining, in press.

191
Ghosh, S.; Das, S. “Spatial Point Process Analysis of Maoist Insurgency in
India” June 19, 2010 SAMSI Tech Rep 2010-3
Guhaniyogi, R., Finley, A.O., Banerjee S., Gelfand, A.E. "Adaptive Gaussian
Predictive Process Models for Large Spatial Datasets" Environmetrics – In
Review (2010)
Haran, Murali and Nathan M. Urba (2011). Discussion of A statistical
analysis of multiple temperature proxies: Are reconstructions of surface
temperatures over the last 1000 years reliable? Annals of Applied Statistics,
Vol. 5, No. 1, 61-64.
J. Harlim (2011), Numerical Strategies for Filtering Partially Observed Stiff
Stochastic Differential Equations, J. Comput. Phys., 230(3), 744-762.
Heaton, M., Banks, D., Zou, J., Karr, A., Datta, G., Lynch, J. and Vera, F.
(2011), A Spatio-Temporal Absorbing State Model for Disease and Syndromic
Surveillance. Submitted to Statistics in Medicine.
Kang, E.L., Cressie, N., Sain, S.R. (2010) “Bayesian Hierarchical Models to
Combine Outputs from the NARCCAP Regional Climate Models”. Submitted
E.L. Kang and J. Harlim (2010), A Fast Filtering Framework for Assimilating
Partially Observed Multiscale Systems: The Macro-Micro-Filter, submitted to
Monthly Weather Review.
Mannshardt Shamsheldin, E., Smith R., Sain, S., Mearns, L., Cooley, D.
“Downscaling Extremes: A Comparison of Extreme Value Distributions in
Point-Source and Gridded Precipitation Data”. Annals of Applied Statistics,
March 2010.
Martinez-Beneito, M.A., Botella-Rocamora, P. and Zurriaga, O. (2011), A
kernel-based spatio-temporal surveillance system for monitoring influenza-
like illness incidence. Statistical Methods in Medical Research 20, 103-118.
Nychka, Douglas and Bo Li (2011), Discussion of A statistical analysis of
multiple temperature proxies: Are reconstructions of surface temperatures
over the last 1000 years reliable? Annals of Applied Statistics, Vol. 5, No. 1,
80-82.
Prates, M.O., Dey, D.K., Willig, M.R. and Yan, J. (2010), Intervention
Analysis of Hurricane Effects on Snail Abundance in a Tropical Forest Using
Long-Term Spatiotemporal Data, Journal of Agricultural, Biological, and
Environmental Statistics, 1-15, doi: 10.1007/s13253-010-0039-1.
Prates, M.O., Dey, D.K., Willig, M.R., and Yan, J. (2011), Transformed
Gaussian Markov Random Fields and Spatial Modeling. Submitted.

192
Reich, B., Eidsvik, J., Guindani, M., Nail, A., Schmidt “A Class of
Covariate-dependent Spatiotemporal Covariance Functions” Submitted to
Annals of Applied Statistics 2010
Reich BJ, Fuentes M. Nonparametric Bayesian models for a spatial
covariance. Statistical Methodology. Accepted
Reich, B., Fuentes, M. and Dunson, D. (2011). Bayesian spatial quantile
regression. JASA Case Studies 406, 6-20.
Reich BJ, Kalendra E, Storlie CB, Bondell HD, Fuentes M., Variable
selection for high-dimensional Bayesian density estimation: Application to
human exposure simulation. Applied Statistics, accepted.
Reich, B.J. and Shaby, B. (2011), A finite-dimensional construction of a max-
stable process for spatial extremes. Submitted.
Reichert, P., White, G., Bayarri, M.J., Pitman, E.B. (2011). Mechanism-based
emulation of dynamic simulation models: concept and application in
hydrology. Computational Statistics and Data Analysis (in press).
Ribatet, M., Cooley, D. and Davison, A.C. (2010), Bayesian inference from
composite likelihoods, with an application to spatial extremes. Under revision
for Statistica Sinica.
Salazar, E., Lopes, H., Gamerman, D., “Generalized Spatial Dynamic Factor
Analysis” (Submitted)
Salazar, E., Ferreira, M., “Temporal Aggregation of Lognormal
Autoregressive Processes” (Submitted)
Salazar E., Ferreira, M., Migon, H., “Objective Bayesian Analysis For
Exponential Power Regression Model” (Submitted to Sankhya B)
Salazar E., Lopes, H., Schmidt, A., Gomes, M., Achkar, M., “Measuring
Vulnerability Via Spatially Hierarchical Factor Models” (Submitted)
Smith, R.L. (2010), Understanding sensitivities in paleoclimate
reconstructions. Under revision.
Spöeck, G., Zhu, Z. and Pilz, J. (2011), Simplifying objective functions and
avoiding stochastic search algorithms in spatial sampling design, submitted
to: Stochastic Environmental Research and Risk Assessment, (2011).
Spöeck, G., Hussain I.: Spatial sampling design based on convex design ideas
and using external drift variables for a rainfall monitoring network in

193
Pakistan. In: Statistical Methodology, New York: Elsevier Science Inc, doi:
10.1016/j.stamet.2011.01.004.
Steinsland, I., Berrocal, V., Reich, B. "Bayesian Spatial Quantile Regression
for Numerical Model Calibration" Journal of the Royal Statistical Society:
Series C. To be submitted 2010
Tingley, Martin P. Spurious predictions with random time series: the lasso in
the context of paleoclimatic reconstructions. Discussion of A statistical
analysis of multiple temperature proxies: Are reconstructions of surface
temperatures over the last 1000 years reliable? Annals of Applied Statistics,
Vol. 5, No. 1, 83-87.
Tingley, M.P., Craigmile, P.F., Haran, M., Li, B., Mannshardt-Shamseldin, E.
and Rajaratnam B., Piecing together the past: Statistical insights into
paleoclimatic reconstructions. Under revision for Journal of Climate.
Tingley, M., Huybers, P., “A Bayesian Algorithm for Reconstructing Climate
Anomalies in Space and Time. Part 1: Development and applications to
paleoclimate reconstruction problems” In revision. Journal of Climate 2009
Tingley, Martin P. and Peter Huybers. A Bayesian Algorithm for
Reconstructing Climate Anomalies in Space and Time. Part 2: Behavior and
comparison with the regularized expectation-maximization algorithm. In
revision. Journal of Climate 2009
Tingley, Martin P. and Peter Huybers. The spatial mean and dispersion of
surface temperatures over the last 1200 years: warm intervals are also
variable intervals. In revision Climatic Change 2009
Tingley, M.P. and Li, B. (2011), Comments on “Reconstructing the NH mean
temperature: Can underestimation of trends and variability be avoided?” by
Bo Christiansen; under review at Journal of Climate.
Jean Vaillant, Gavino Puggioni, Lance A Waller, and Jean Daugrois (2011), A
spatio-temporal analysis of the spread of sugar cane yellow leaf virus. Journal
of Time Series Analysis, to appear.
Wang, X., Dey, D.K., Banerjee, S. “Non-Gaussian Hierarchical Generalized
Linear Geostatistical Model Selection” Frontiers of Statistical Decision
Making and Bayesian Analysis, eds. M.H. Chen, D.K. Day, P. Mueller, D.
Sun, K. Ye. New York: Springer 2010
Warren, J., Fuentes, M., Herring, A., Langlois, P. “Air Pollution and Preterm
Birth: Identifying Critical Windows of Exposure” Under Review 2010
Zhang, J., “Regression Models for Spatial Images” Submitted to JABES

194
Zhang, J., Clayton, M. K., and Townsend, P. A., (2010), Functional
Concurrent Linear Model for Spatial Images, accepted by Journal of
Agricultural, Biological, and Environmental Statistics.
Zhang, J., and Zheng, W., (2011), A Penalized Likelihood Approach for m-
year precipitation return values estimation. Submitted to Journal of
Agricultural, Biological, and Environmental Statistics.
Zou, J., Karr, A., Heaton, M., Banks, D., Datta, G., Lynch, J. and Vera, F.
(2010), Bayesian Methodology for Spatio-Temporal Syndromic Surveillance.
Submitted to Statistical Analysis and Data Mining.
Reports in Preparation
Bhat, K. S., Haran, M., Keller, K. (2010), Combining multiple climate models
using Bayesian model averaging to project surface temperature.
Luke Bornn, Gavin Shaddick and James V Zidek, The effects non-stationarity
and preferential sampling in modeling and measuring environmental fields for
health effect analysis.
Song Cai, Xiaoli Yu, Gavin S Shaddick and James V Zidek, Preferential
sampling in the monitoring black smoke: a case study.
Calder, C.A., Darnieder, W.F. “Bayesian Inference for Incomplete Marked
Spatial Point Patterns” 2010
Chakraborty, A. and Gelfand, A. E. 2011 Mixture modeling for spatial point
patterns with location-specific covariates.
Chang, H.H., Baxter, L.K., Fuentes, M., and Neas, L.M., Daily mortality and
chemical constituents of fine particle air pollution.
Chang, H.H., Reich, B.J., Miranda, M.L. “Spatial Time-to-event Analysis of
Fine Particulate Matter and Preterm Births” 2010
Chang, H.H., Reich, B.J., Miranda, M.L. “Fine Particle Air Pollution and
Preterm Birth in North Carolina” 2010
Das, S., Banerjee, S., “Space-Time Data Analysis using Sequential Monte
Carlo Method”. In preparation
Das, S., Dunson, D., “Gaussian Process Latent Variables Dynamic Models”.
Work in progress

195
Das, S., Banks, D., “Elicitation of Expert Prior opinion in Context of
Presidential Election” (2009) Work in progress: Tentative title
Jeon, S. and Smith, R.L. (2011), Max-Stable Processes for Threshold
Exceedances in Spatial Extremes.
Krivo, L.J., Washington, H.M., Peterson, R.D., Browning, C.R., Calder, C.A.,
Kwan, M.P. “Social Isolation of Disadvantage and Advantage: The
Reproduction of Inequality in Urban Space” 2010
Li, Xuan and Smith, R.L., Bias and Variability Assumptions in a Bayesian
Analysis of Climate Models.
Mannshardt-Shamseldin, E., Craigmile, P. and Tingley, M, Paleoclimatic
extremes in proxy data.
Mannshardt Shamsheldin, E., Gilleland, E., “Severe Weather Under a
Changing Climate: Large Scale Indicators of Extreme Events”.
Mannshardt Shamsheldin, E., Smith R., “Asymptotic Multivariate Kriging
Using Estimated Parameters with Bayesian Prediction Methods for Non-
linear Predictands.” Paper in preparation.
Matteson, D.S. and Micheas, A.C., A Finite Mixture Model for Spatio-
temporal Poisson Process.
Reich, B. and Berrocal, V. Local Bayesian model averaging for numerical
model calibration.
Salazar, E., Sansó, B., Finley, A.O., Hammerling, D., Steinsland, I., Wang, X.
and Delamater, P., Comparing and Blending Regional Climate Model
Predictions for the American Southwest.
Shaby, B., The open-faced sandwich adjustment for estimating function-based
MCMC.
Smith, R.L. and Wehner, M., A Threshold-based Extreme Value Approach to
Event Attribution.
Wolpert, R., Spatial extremes.
Xiaoli Yu, Gavin Shaddick and James V Zidek, Correcting for preferential
sampling in monitoring environmental processes.
Xiaoli Yu, Gavin Shaddick and James V Zidek, The effects of preferential
sampling in environmental epidemiology.

196
Zhang, J., “Penalized Concurrent GEV/GPD Likelihood Method”
Zhou, J., Fuentes, M. “Calibration of Air Quality Deterministic Models Using
Nonparametric Spatial Density Functions” In preparation.
III. SUMMER PROGRAM ON SEMIPARAMETRIC BAYESIAN INFERENCE:
APPLICATIONS IN PHARMACOKINETICS AND PHARMACODYNAMICS
Reports in Preparation
Cornebise, J., “Use of SDE's for PK/PD Modeling Population PK/PD Model
for Illustration” In preparation
Cornebise, J., Burgette, L., “Balanced Dirichlet Process Model” In
preparation
Lang, L, Johnson, W., “Elciting Prior Distributions for Population PK/PD
Models” In preparation.
MacEachern, S., Dahl, D., Tadesse, M., Kottas, T., “Diagnostics for NP
Bayesian Models” In preparation
Thall, P., Escobar, M., Muller, P., “Prior Equivalent Sample Size for
Nonparametric Bayes Priors” In preparation
Thall, P., Escobar, M., Muller, P., “Non-Parametric Bayes for Causal
Inference” In preparation

197
H. Efforts to Achieve Diversity
SAMSI puts considerable emphasis on contributing to the NSF’s effort to broaden the participation from underrepresented groups in the mathematical sciences. During the past year, we have organized and co-sponsored many diversity related activities. SAMSI has also developed a web page devoted to our diversity activities. The page advertises the various program activities related to minority outreach and has links to other diversity related information outside of SAMSI. Participation in the NSF Institutes’ Diversity Committee Pierre Gremaud has been serving as SAMSI’s representative to the NSF Institutes
Diversity Coordination Committee which was formed in 2006 by Chris Jones (SAMSI) and Helen Moore (formerly of AIM), and is now chaired by David Auckly (MSRI). The Institutes Diversity Coordination Committee has been working together to promote diversity in the Mathematical Sciences at national conferences and through other special events. Together with the other NSF mathematical sciences institutes, SAMSI has recently secured supplemental NSF funding that will allow for the long term planning of an entire portfolio of activities including the Modern Math workshop series, the Workshop Celebrating Diversity series, the Minority Professional Development workshop, the Careers for Minorities workshops, the Careers for Women workshops, the Blackwell Tapia Conferences and some activities in conjunction with the Association for Women in Mathematics. SAMSI took part in the Modern Math program at the 2009 SACNAS National Convention in Dallas, TX. This program was aimed at introducing young scientists to a variety of current research topics, providing mentorship and networking opportunities, and recruiting future participants in NSF Institute programs from underrepresented groups. Oliver Diaz-Espinosa, one of our SAMSI postdoctoral fellows and a member of the SAMSI program on Stochastic Dynamics presented an overview of his research. SAMSI was again a participant in the Modern Math program in Oct. of 2010, which will be reported in the next Annual Report of SAMSI. Minority Participation in SAMSI Programs SAMSI Postdoctoral Positions: For the 2009-10 Research Programs, of 15 post-docs hired, five are women: Emily Kang, Esther Salazar, Xueying Wang, Veronica Berrocal, and Avanti Athreya, and one is an underrepresented minority: Oliver Diaz. For the 2010-11 Research program, of seven post-docs hired, two are women: Sylvie Tchumtchoua and Hongxiao Zhu and two are minorities David Degras and Sylvie Tchumtchoua. The large number of postdocs hired in 2009-10 resulted from the supplemental NSF funding for that purpose made available to the institutes that year.

198
Education and Outreach Programs: SAMSI continues to create opportunities, through its E&O Program, to enhance its diversity efforts by recruitment of under-represented participants. We recruit from HBCU's for all programs. We collaborate with our National Advisory and Education and Outreach Committees to reach out to the Hispanic and Native American communities. Further, new efforts have been made to engage both faculty and students at primarily teaching colleges. The diversity breakdown in specific E&O workshops is as follows.
Industrial Mathematical and Statistical Modeling (IMSM) Workshop (July 2009): From the 37 participants, 14 were female, and 1 was Hispanic.
2-Day Undergraduate Workshop (Oct 2009): From the 48 participants, 21 were female, 2 were African American, and 3 were Hispanic.
2-Day Undergraduate Workshop (Feb. 2010): From the 35 participants, 14 were female, 1 was African American, and 1 was Hispanic.
Undergraduate Workshop (May 2010): From the 27 participants, 10 were female and 3 were African American.

199

200
I. External Support and Affiliates
1. External Support
SAMSI receives extensive support through the home institutions of our long-term visitors. On
average, SAMSI pays for approximately 1/3 of a long-term visitor’s salary during the visit to
SAMSI; the remainder is provided by the home institution.
Kenan Foundation: provided $50,000 of supplementary support, focused primarily on the K-12
Kenan Fellows program.
Sequential Monte Carlo Methods: The Adaptive Design Workshop was jointly funded by the
NISS project on Computer Models for Geophysical Risks.
Affiliates: Significant support arose from the Affiliates Program, as discussed in the next
section.
2. Affiliate Involvement
2.1. Background
The NISS Affiliates Program and NISS/SAMSI University Affiliates Program are the largest
programs of their kind among the DMS-funded mathematical sciences research institutes. The
entire directorate interacts directly with affiliates; NISS director Alan Karr and associate director
Nell Sedransk have major responsibility for operation of these programs.
Recent new affiliates in 2009-10 include the Department of Statistical Science at Cornell
University, the Department of Mathematics and Statistics at the University of Maryland
Baltimore County, the Departments of Biostatistics and Statistics at the University of Pittsburgh
and the Department of Statistics at Virginia Tech. A complete listing of affiliates as of May 2011
appears below.
As a benefit of membership, affiliates may receive reimbursement for expenses to attend SAMSI
workshops as well as NISS events, many of which derive from SAMSI programs.
A central role of the affiliates is as a bridge from SAMSI to the statistics and applied
mathematics communities (as well as to industry and government), especially to inform the
development of SAMSI programs. To illustrate, the 2007-08 program on Risk Analysis, Extreme
Events and Decision Theory, as well as the 2006–07 program on Development, Assessment and
Utilization of Complex Computer Models, the National Defense and Homeland Security
program in 2005–06, the Latent Variable Models in the Social Sciences (LVSS) program in
2004–05 and the DMML program for 2003–04, all reflect affiliate interest to a significant de-
gree. All 2009-10 and 2010-11 contain components and activities suggested by affiliates.

201
2.2 NISS Affiliates and NISS/SAMSI Affiliates
Corporations: Avaya Labs, AT&T Labs Research, Bayer HealthCare, GlaxoSmithKline, Eli
Lilly, Merck Research Laboratories, MetaMetrics, Inc., PNYLAB, RTI International, SAS
Institute, and Yahoo! Labs
Government Agencies and National Laboratories: Bureau of Labor Statistics, Census Bureau,
Energy Information Administration, National Agricultural Statistics Service, National Center for
Education Statistics, National Center for Health Statistics/CDC, National Security Agency, and
Office of the Comptroller of the Currency
NISS/SAMSI University Affiliates: University of California Berkeley, Department of Statistics;
Carnegie Mellon University, Department of Statistics; Columbia University, Department of
Biostatistics; University of Connecticut, Department of Statistics; Cornell University,
Department of Statistical Science; Duke University, Departments of Mathematics and Statistical
Science; University of Florida, Department of Statistics; Florida State University, Department of
Statistics; George Mason University; Georgetown University Department of Biostatistics,
Bioinformatics, and Biomathematics; University of Georgia, Department of Statistics; University
of Illinois Urbana-Champaign, Department of Statistics; Indiana University, Department of
Statistics; Iowa State University, Department of Statistics; Johns Hopkins University,
Department of Applied Mathematics and Statistics; University of Maryland Baltimore County,
Department of Mathematics and Statistics; Medical University of South Carolina, Department of
Biostatistics, Bioinformatics & Epidemiology; University of Michigan, Departments of Statistics
and Biostatistics; University of Missouri Columbia, Department of Statistics; North Carolina
State University, Department of Statistics; North Carolina State University, Department of
Mathematics; University of North Carolina at Chapel Hill, Department of Biostatistics;
University of North Carolina at Chapel Hill, Department of Mathematics; University of North
Carolina at Chapel Hill, Department of Statistics & Operations Research; Oakland University,
Department of Mathematics and Statistics; Ohio State University, Department of Statistics;
Pennsylvania State University, Department of Statistics; University of Pittsburgh, Departments
of Biostatistics and Statistics; Purdue University, Department of Statistics; Rice University,
Department of Statistics; Rutgers University, Department of Statistics; University of South
Carolina, Department of Statistics; Stanford University, Department of Statistics; Texas A&M
University, Department of Statistics; Virginia Commonwealth University, Department of
Biostatistics; Virginia Tech, Department of Statistics
2.3 Affiliate Participation
All SAMSI programs and events during 2009-10 had strong affiliate participation, nearing one-
half of attendees at some workshops. Expenditures from Affiliates Reimbursement Accounts to
attend SAMSI events exceeded $60,000.

202
2.4 Plans for the Future
Several affiliates initiatives will increase the attractiveness of the program, as well as guide the
development of future SAMSI programs. These initiatives include information exchange for
internships, forums for sharing problems and catalyzing collaborations, and more intense focus
on activities such as distance learning.

203
I.J Board and Advisory Committee Members
SAMSI
Governing Board Members
Bruce Carney UNC, Assoc. Dean Astronomy 2004-08
George Casella U of FL Stats 2005-08
Don Estep Colorado State U Math & Stats 2009-10
John Harer Duke, As.Provost Math 2002-04
Douglas Kelly UNC, Dean Stats 2002-04
Jon Kettenring Telecordia Math 2002-04
Tom Manteuffel U of CO Appl. Math 2005-08
James Landwehr NISS Trustees Chair Stats 2008-09
John Simon Duke, Asst. Provost Chemistry 2004-08
Daniel Solomon NCSU, Dean Stats 2002-08
NAC Members
Mary Ellen Bock Purdue Stats 2002-07
Peter Bickel UC Berkeley Stats 2002-05
Lawrence Brown Pennsylvania Stats 2002-07
Raymond Carroll Texas A&M Stats 2004-06
Carlos Castillo-Chavez Arizona State Math & Stats 2003-08
Ricardo Cortez Tulane U Math 2008-10
Rick Durrett Cornell Probability 2006-08
Jianqing Fan Princeton U Ops Research 2008-10
David Heckerman Microsoft CS & Stats 2002-04
Sallie Keller-McNulty LANL Stats 2002-05
Nancy Kopell Boston U Math 2005-08
John Lehoczky Carnegie-Mellon Probability 2002-05
Rod Little U of MI Biostats 2006-08
Jun Liu Harvard U Stats 2007-10
David Mumford Brown U Appl Math 2005-08
Susan Murphy U Michigan Stats 2008-10
George Papanicolaou Stanford Math 2002-03
Daryl Pregibon Google, Inc. CS 2003-08
Adrian Raftery Washington Stats 2002-03
G.W. Stewart Maryland CS 2003-08
Phillippe Tondeur Illinois Math 2003-05
Mary Wheeler U of TX Math & Eng 2004-07
Shmuel Winograd IBM Math 2002-03
Margaret Wright NYU CS 2002-04
Bin Yu (Co-Chair) U of CA Berkeley Stats 2006-11
LDC Members
David Banks Duke Bioinfo 2003-08
H. Thomas Banks NCSU Math 2005-08

204
Andrea Bertozzi Duke Math 2002-03
Lloyd Edwards UNC Biostats 2003-08
Gregory Forest UNC Math 2002-08
Jean-Pierre Fouque NCSU Math 2002-04
Montserrat Fuentes NCSU Stats 2004-08
Alan Gelfand Duke Stats 2002-03
Mark Genton NCSU Stats 2002-03
John Harer Duke Math 2004-08
Jacqueline Hughes-Oliver NCSU Stats 2002-04
Joseph Ibrahim UNC Biostats 2002-03
Christopher Jones UNC Math 2002-03
Thomas Kepler Duke Bioinfo 2002-04
Sharon Lubkin NCSU Math 2004-08
Sally Morton RTI Epidemiology 2005-08
Andrew Noble UNC Stats 2002-04
David Schaeffer Duke Math 2002-03
Scott Schmidler Duke Bioinfo 2002-03
Ralph Smith NCSU Math 2002-03
Richard Smith UNC Stats 2004-08
John Trangenstein Duke Math 2003-04
Butch Tsiatis NCSU Stats 2004-08
Mike West Duke Bioinfo/Stats 2004-08
Chairs Committee Members Jianwen Cai UNC Biostats 2005-06
Clarence E. Davis UNC Biostats 2003-05
Elizabeth DeLong Duke Biostats 2008-09
Patrick Eberlein UNC Math 2005-08
Jean-Pierre Fouque NCSU Math 2004-05
Alan Gelfand Duke Stats 2007-08
Richard Hain Duke Math 2004-06
Loek Helmnick NCSU Math 2005-08
Christopher Jones UNC Math 2003-04
Michael Kosorok UNC Biostats 2007-08
Vidyadhar Kulkarni UNC Oper. Res. 2003-08
Bernard Mair NCSU Math 2003-04
David Morrison Duke Math 2003-04
Sastry Pantula NCSU Stats 2003-08
William Smith UNC Math 2004-05
Dalene Stangl Duke Stats 2003-06
Mark Stern Duke Math 2007-08
William Wilkerson Duke Biostats 2003-05
E&O Committee Members
H.T. Banks NCSU Math 2004-05
Negash Begashaw Benedict College Math Sci 2004-08

205
Carlos Castillo-Chavez Arizona State Math & Stats 2004-08
Karen Chiswell GSK Stats 2004-08
Cammey Cole Meredith College Math & CS 2004-10
Wei Feng UNC-Wilmington Math & Stats 2004-08
Anne Fernando Norfolk U Math 2010-
Pierre Gremaud NCSU Math 2008-10
Leona Harris College of NJ Math 2010-
Gabriel Huerta U of New Mexico Stats 2010-
Marian Hukle U of Kansas Bio Sciences 2004-08
Negash Medhin NCSU Math 2004-08
Masilamani Sambandham Morehouse College Math 2004-08
Ralph Smith NCSU Math 2007-08

210
L. REPORT ON MATHEMATICAL SCIENCES
INSTITUTES DIRECTORS MEETING

Minutes and ReportMathematical Institutes Directors meeting
IASApril 30 – May 1, 2010
Brian Zuckerman of STPI gave an Overview of Feasibility Study (attached).
--Where do institutes fit in with the balance of the NSF? --Portfolio analysis of the Institutes within the field of math and in the area of training activities--There is a range of available tools for self-evaluation. Each institute now has its own way of collecting data. Could processes be shared to improve best practices? --Request to NSF for MIDs to see aggregate data that has been acquired from all of the math institutes. But there are privacy issues. An argument for use of data would have to be made to NSF counsel. --Are the institutes the most appropriate place to allocate funds or should the funds be used in another way? --60 data points suggested that the institutes do not have the same intellectual footprint. Almost no overlap among the participants at the institutes, i.e., very few people attend programs at more than one institute.
There was discussion of what areas of questions would produce useful data.
--How to track participants – some institutes (MSRI and IMA) use an identifier number, as opposed to an email address since email can change.
--The institutes responded quickly when federal funds became available and received a good amount of available funds. How can that be quantified?
--How do you know the effect of being at a particular institute several years down the road?
The institutes “enhance communities” – these relationships grow over the years and lead to collaboration. “Creating new knowledge” is very difficult to measure. Perhaps a qualitative as opposed to a quantitative approach should be used. David – change Goal 2 to “Increase interaction” (rather than impact) of math in other disciplines.Another goal could be the participation of mathematicians in non-mathematical fields and the participation of non-mathematicians in the math institutes.
How do the institutes effect the choice of where people end up?
It is important to add the collaboration of the institutes as a goal – create synergies. This can be a fifth goal. Add reaching out to the international community.
1A Change goal 3 from “solving problems” to “address the problems.”
Suggested that we not use bibliometrics approach, understanding that it has been 'gamed.'But some would like to include this - at least compile list of publications. One way to do this is to go

through the lists of publications that the institutes provide – self-reporting. Another way is to evaluate journals to get this information. But a lot can be missed and it doesn't really show the influence of the institutes. Also this may leave out people who are doing research in new areas so they are not publishing much right now. After discussion, this approach was rejected, although it was agreed to have a list of publications.
'Expert judgment approach' was rejected: The experts would have to be 'unconflicted” (no conflict of interest) which would mean that they wouldn't really know much about what the institutes do – which renders them “not expert.”
1b Stimulate development of new fields/disciplinesProblem – some effects that are cross disciplinary would not be discovered because the publications might be in a different disciplineMSRI uses an exit interview: How many new contacts did you make? Motivation: In order to get their key deposit back, they have to complete the survey!
1d Leveraging new fundingApplying for interdisciplinary grants is fairly new.
4a under-represented groupsMinority participants tend to be younger so if you ask about publications, you aren't going to get very many.
4b Effect of participating at an institute on the likelihood of getting an NSF grant.
4c train students and postdocs to become leaders in mathematicsHow did participation in an institute result in a different effect than non-participation? Looking at junior faculty, for instance.
Be careful of comparing positions with the same title that in fact may not be on the same level, such as an assistant professor at Princeton compared to an asst. professor at the U. of Maryland.
4d K-12 level and public understanding of mathematics Not associated with NSF.
Synergies (process evaluation question)
--Across the Institutes (example: quick response to the stimulus money granted through NSF)
--Interchange across NSF development of/participation in interdisciplinary programs--NSF used as a community resource
--More broadly, internationally

--Rotation of workshops on diversity that are already taking place
--In 2013 the collaboration on Climate Sustainability
--Joint website
The goal of STPI is to have the feasibility study done by the end of the summer.
Plan for ICERM – Proposed institute that is about interaction of math and computers/Jill PipherThe space is provided by Brown University. Not all higher math. For graduate students and postdocs; also for undergraduates in the summer. Should be operational by 2011. Microsoft, Google and IBM have representatives on the board. Board of Trustees is a governing board. Initially a course in “Connectic theory and computation.” Math, Applied Math and Theoretical Computer Science. The programs will be a semester-long. Postdoc positions may be a semester long or a year long.
MSRI tries to pair postdoc with a mentor before they get to campus. And then sometimes they encourage the postdoc to follow their mentor if the mentor leaves after a year.
All of the postdocs at IAS from the stimulus funds got jobs.
David reported on the COV.COV looked at the entire portfolio – 3,000 proposals. NSF gives a template of questions to look at the DMS portfolio. The purpose was to review the 'health' of the system. This committee was created in 2004. In 2007 it was recommended that the Math Institutes be reviewed, which resulted in STPI being here today. DMS wants to understand the value of the Institutes. They are interested in having some of the Institutes find additional sources of funding. The hope is that the released funding would be used to support new institutes.
David - What is being done in this meeting today is the beginning of a self-study, which will precede a review by DMS. Peter March wants some hard data so that he can defend the expenditure of funds for the Institutes.
4 items were reviewed: Looked at the studyLooked in detail at interdisciplinary programs and ARA fundingLooked at previous COV reportThere is a wide disparity in the way that the Institutes disseminate information.
It was suggested that the group come up with some ways to get hard data.
Review Action Items from 2009 meeting
IT Committee – Jim Kimmick of IPAM organized this.

Create a unified approach to video. It requires the directors to present the IT managers with a task to solve, or a directive. Suggestion: IT person at the host institution would give a report to the MIDs.Because MSRI is getting their videos organized into a usable data base, their IT manager might be able to work on this project for all of the Institutes. Maybe NSF could fund this project.
Action Item: Continue to support Association for Women in Mathematics. Contribution was supposed to be $550 per year per institution. Uncertain whether or not those contributions were made. Jill will look into this.
Report by Russel Caflisch (get it from him)--Plan for possibly sharing diversity programs--Infinite Possibilities Conference was held. --Modern Math workshop in Dallas was attended by about 120 people, including undergraduates.--Apply to NSF for support of mini-course. If that isn't funded, each institute would need to fund about $1,000 each for a scaled down version.
Brief report on Joint Postdoctoral Initiative: All of the postdocs at IAS funded by this Initiative found jobs. Several of the Institutes had 2-year postdocs so they haven't been job hunting yet. Brief AIM had a workshop last summer that was very successful. The information is on the AIM website. MSRI also had a one-day workshop that was successful.
Recommendation for JMN theme and for organizers: This is a joint meeting with 15 math institutes.Action item: The recommendation is Math That Connects the Dots or Mathematical Connections or Mathematical Networking. Russel Caflisch and Fadil Santosa volunteered to help organize the event.Bob Bryant and Marty Golubitsky will send the email with this information to the other math institutes.
MetricsIn collecting data for NSF, what is the definition of 'participant'? IMA has 'supported participants' and 'speaking participants'. The point of the question is how many people are benefiting from a workshop.
The directors want to continue to use surveys of participants/members in order to discern the effect of being at an institute on the participants' careers. It is difficult to standardize questions for participant/members a few years after they have left the institute. Perhaps look at one another's questionnaires. Action item: The questionnaires can be put on the MID password protected part of the website (MathInstitutes.org.) Write a brief description of what is done to collect the questionnaire.
Suggestions for ways to assess:--Number of new collaborations that can be attributed to the institutes--Number of new papers--Has the research become interdisciplinary (use DMS definition of 'interdisciplinary')--Number of hits on webpage (it was decided this is not useful)
--Number of hits on videos and length of time the videos were viewed
MSRI is tracking undergraduates who take their 6-week courses to see who continues on to grad school and who gets a Ph.D. They appoint a mentor for each class and that person is responsible for writing

an annual report.
There was a discussion of efforts to increase diversity.
NEXT YEAR – The MIDs will meet at AIM in Palo Alto.

203
II. Special Reports: Program Plan
A. Programs for 2010-2011
1. Analysis of Object Data
2. Complex Networks

INITIAL GOALS and OUTCOMES
STATEMENT for the Working Group
GEOMETRIC CORRESPONDENCE
Stephan Huckemann and Ross Whitaker (Administrators)
December 2010
Contents
1 Initial Goals 1
2 Series of Talks 3
3 Specific Research Projects for Current Pursuit 33.1 Generative Models for Registering Ensembles of Functions and
Images . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33.2 Minimax Correspondence for Shape Classification . . . . . . . . . 33.3 Measuring Landmark Importance for Planar Shapes . . . . . . . 43.4 Modeling Locus and Shape Variation by Partial Rotations . . . . 4
1 Initial Goals
In our first meetings we identified the following key goals
• alignment of functions
– with and without knots
– “vertical alignment”
– of an ensemble of functions
• alignment of shapes
– landmarks
∗ known labels but positions are free· pseudo landmarks· optimizing information theoretic content
∗ unknown labels but possibly fixed positions (e.g. protein match-ing/folding)
1

– mismatching configurations∗ Robustness∗ including occlusions∗ topological differences
– deterministic or not
• statistical issues
– formulation– bias– overfitting
∗ tradeoff between deformation and variability· where is the info: deformation vs. residual· marginalizing over the deformation
– automation based on statistical criteria– learning and classification by maximizing discriminality– hypothesis testing, regression, fair “p”-values
• applications to
– protein matching/folding∗ deformation is constrained by chemistry∗ matching of “blobs” between structures∗ 3D
– gels∗ mass and charge (2D)∗ comparison between organisms∗ register blobs with deformation and mismatch∗ E. paper by Mardia
– ensembles of surfaces of smooth biological shapes∗ bones, brains, faces, etc.∗ collections of hippocampi
– alignment of functions for growth curves– wings/leaves
∗ branching structures∗ discontinuities of shape∗ related to skeletal modeling
· graphs/trees· geometric trees
– projective shapes/cameras∗ allowinging for projective transformations∗ inheriting properties of the projective shape spaces
2

2 Series of Talks
As decided on in the first meetings, for the first period of approx. two monthssome group members gave kick off talks from their individual expertise, touchingthe above key goals. These talks were followed by extended discussions.
• Automated correspondences (Ross Whitaker),
• functional alignment (Daniel Gervini),
• curve matching landmarks (Leif Ellingson and Victor Patrangenu),
• alignment within Gaussian processes (John Moriarty) and
• correspondence using random fields (Ian Dryden).
3 Specific Research Projects for Current Pur-suit
In consequence of these talks and discussions, certain collaborative work mate-rialized in specific research projects.
3.1 Generative Models for Registering Ensembles of Func-tions and Images
Suppose we have a set of functions fi of which have sampled values fij . Un-derlying are unwarped signals fi = fi ◦ T−1
i with a warping Ti. We want toestimate the Ti from the data by setting up a generative process, that in thefirst instance we consider Gaussian
P (T, f) = G(Σ ef , µ ef
)G
(ΣT , µT )
which suggests a EM-approach to identify hidden parameters. E.g., such anapproach for images warps images not to each other but rather to a mean.Currently active researchers are Daniel Gervini and Ross Whitaker.
3.2 Minimax Correspondence for Shape Classification
Many applications deal with a specific classification problem. Here we presenta generic method of addressing this issue, a very specific method is presentedin Project 3.3 following below. E.g. in applications of forestry, assessing leafvariation of leaf shape over genotype, temperature gradient and leaf location inthe tree (e.g. crown or breast hight) is of great interest. Previous research usinglandmark based shape spaces has shown that for powers of tests the “correct”number and placement of landmarks is of great importance. In this projectfor a specific classification problem given, an automated landmarking schemeis to be developed that places landmarks such that the intra-group variation is
3

minimal while simultaneously the variation over the groups is maximal. Thismethod is to be based on purely statistical features building on Cates et al.(2006). Another potential application of this method lies in the early diagnosisof degenerative brain processes such as Alzheimer’s desease. Research in thisproject is currently at a very conceptional level, both working out a stringentmathematical formulation and making feasible a numerical approach. Currentlyactive researchers are Stephan Huckemann, Ross Whitaker, Martin Styner.
3.3 Measuring Landmark Importance for Planar Shapes
Planar landmark based Kendall shape space is a complex projective space. Aspace with less landmarks is a lower dimensional complex projective space thatcan be embedded in various ways. From a given data sample with k landmarks,in previously unpublished research, a method has been developed to computethe best fitting abstract shape space with k − 1 landmarks and in this the bestabstract shape space with k− 2 landmarks, etc. The entire procedure until theshape space of triangles is reached, or even further, up to a single geodesic anda single point can be called a
nested backward shape space principal component analysis
(cf. Jung et al. (2010a)). One way of assessing landmark importance is tocompare the total intrinsic variances in these abstract spaces with the totalintrinsic variances of concrete spaces obtained from leaving out one and morespecific landmarks. Algorithmic work has begun as well as some applications toIan Dryden’s digits 3 dataset (Dryden and Mardia (1998)) have been performed.Further application are planned to leaf data (cf. Huckemann et al. (2010)) inorder to automatically identify a minimal number of landmark placment forspecific discrimination problems arising in forestry. Currently active researchers:Stephan Huckemann, Sungkyu Jung and Steve Marron.
3.4 Modeling Locus and Shape Variation by Partial Ro-tations
A goal in computational anatomy is to keep track of rigid body motions as wellas of deformations of internal organs, one application being radiation therapy ofthe male prostate. In a novel approach, we are estimating few axes of rotationsof parts of organs in order to nearly exhaustively model rigid body rotation, androtations of parts of the organ, e.g. bending and pinching. Preliminary researchbased on modifications of principial arc analysis for spoke data on medial skele-tons (cf. Jung et al. (2010b)) has shown to have a very promising potential.Estimating dominating axes of (internal) rotations may also have applicationsto protein folding. Currently active researchers: Stephan Huckemann, SungkyuJung, Steve Marron and Steve Pizer.
4

References
Cates, J., Fletcher, P., Whitaker, R., 2006. Entropy-based particle systems forshape correspondence. Int Conf Med Image Comput Comput Assist Interv9(WS), 90–99.
Dryden, I. L., Mardia, K. V., 1998. Statistical Shape Analysis. Wiley, Chich-ester.
Huckemann, S., Hotz, T., Munk, A., 2010. Intrinsic MANOVA for Rieman-nian manifolds with an application to Kendall’s space of planar shapes. IEEETransactions on Pattern Analysis and Machine Intelligence 32 (4), 593–603.
Jung, S., Dryden, I., Marron, J., 2010a. Analysis of Principal Nested Spheres.Submitted in Biometrika.
Jung, S., Foskey, M., Marron, J. S., 2010b. Principal arc analysis on directproduct manifolds. Submitted to the Annals of Applied Statistics.
5

222
Analysis of Object Data Working Group: Dynamics and Inference Working Group Leader: Giles Hooker (Cornell University) After the initial workshop and some fruitful examination of background research, the working group has identified a number of directions for research during this year
- Populations of Dynamic Systems: while there has been significant recent interest in statistical inference for dynamical systems, there is a relatively small literature on collections of dynamic systems such as would occur for immune dynamics observed in different individuals or epidemiological dynamics in different cities. There is also very limited use of population-level data to assess Markovian assumptions about dynamical systems. At this level, dynamical systems (and their parameterizations) represent objects of study; our concerns here are to develop methods to incorporate covariate-dependent random effects within population models of dynamic systems, and to make use of multiple time-varying parameters to assess model fit.
- Signatures of Stochastic Features: a stochastic dynamic system requires the specification not just of a deterministic drift structure, but also a complete probabilistic description of the system evolution. It is common that this specification is simplified from a computationally-intractable model, or chosen from a class of tractable models in order to ‘noise-up’ a deterministic system. This portion of the project examines the use of spectral methods to determine the qualitative features of system stochasticity – are disturbances `rough’ or `smooth’? Can we distinguish these disturbances from measurement error? Will the change in the spectrum over time yield insight into potential inhomogeneous stochasticity? Given the computational cost and complexity of performing inference in dynamical systems, the ability to determine the type of stochastic evolution that is supported by the dynamics of the model will yield substantial benefits to the application of these models to real-world systems.
- Summary Selection: a common approach to inference in dynamical systems is to replace the observed data with summaries that describe qualitative dynamical features thought to be relevant. This is particularly well developed in the field of Approximate Bayesian Computation (ABC), but has also been suggested in other contexts. A focus of this group will be in the development of principled means of choosing summary statistics, based on loss-of-information from the original data, convexity of the likelihood surface, and robustness to model choices and assumptions.
Specific working group activities will include
- The development of methodology for non-parametric mixed-effects models in differential equation models for systems described by a multivariate state vector with unmeasured variables in the presence of covariates.
- The development of spectral-based tests for instantaneous noise in system forcing and for changes in noise variance.
- Methodology to select summary statistics that retain maximal information while remaining robust to specific model terms.
Working group participants: Giles Hooker (Cornell University), David Degras (SAMSI),
Yuefeng Wu (Cornell University), James Ramsay (McGill University), Darren Wilkinson
(University of Newcastle), Damla Senturk (Pennsylvania State University), Jiming Ding
(Washington University of St Louis), Sophia Olhede (University College London), Simon
Preston (University of Nottingham), Sy-Miin Chow (University of North Carolina, Chapel Hill),
Oliver Rattman (Duke University), Snehalata Huzurbazar (University of Wisconsin), Jaeyong

223
Lee (Seoul National University), Jiguo Cao (Simon Fraser University), David Campbell (Simon
Fraser University), Mark Girolami (University College London), Serge Guillas (Georgia Tech),
Hulin Wu (University of Rochester), Debashis Paul (University of California, Davis)

224
Analysis of Object Data: Working Group on Data Analysis on Sample Spaces
with a Manifold Stratification
Working Group Leaders: During the kick-off workshop, Vic Patrangenaru (F S U) realized that the objects that were studied (statistically or from a deterministic viewpoint) by speakers, were all sharing the nice property of being represented as points on certain metric spaces that admit a manifold stratification. Arguably, all object data may be represented as points on such spaces, therefore they should play a key role in the twenty first century Statistics. These sampling spaces include Hilbert manifolds ( functional data ), orbifolds ( of all sort of shapes), folded Euclidean spaces (of phylogenetic trees). Ezra Miller ( Duke ) took the leadership when it came to problems of understanding the singular part of stratified space and related geometry aspects. We started our broadcast meetings with the goal of understanding of the asymptotic
the early meetings, the working group has identified some important issues for initial research:
. The issue here is a new behavior
singular point, that does not change under small perturbations within the family, as first suggested by Steve Marron (U N C). This property was initially understood by a group
point of a spider ( the space of trees with 3 leafs happens to be a spider with 3 legs ); a proof resulting from the first group meeting, for the stickiness of the intrinsic sample means from a distribution on a spider a formalized by Thomas Hotz ( IMS, Germany ) in a paper in coauthored in that meeting was posted on the group website. I an ulterior subsequent paper Stephan Huckemann ( IMS, Germany ) started formalizing the group discussion on stickiness of the intrinsic mean singular points on higher dimensional tree spaces. Extrinsic sample means are asymptotically sticky to a singular extrinsic mean as well. As a consequence estimation of
large.
Nonprametr Gromov defined Cartan Alexandrov Toponogov spaces of curvature bounded from above by k, also known as CAT(k) spaces , by comparing geodesic triangles on such spaces with their corresponding counterparts on model Riemannian spaces of constant curvature k. In the case of folded Euclidean models for tree spaces, which are CAT(0)
a singular point is a phenomenon might that might not become evident when the samples are small. Therefore other slower consistent estimators, that are easier to compute might be useful in guessing the nature of the population mean ( singular or not ). In the case of CAT(0) spaces such an estimator, that is easy to compute is the so called Sturm estimator, that was brought up to our group attention by Sean Skewer(UNC). The asymptotics of the Sturm estimator are not known. Given that usually the coverage error can be improved by bootstrapping a pivotal statistic based on
from this bootstrap principle. Megan Owen ( Berkeley ) made progress in bootstrapping of Sturm estimators.
Projective Shape. Projective shape is widely accepted as the most appropriate notion of shape by computer scientists and others dealing with machine vision ( Hartley and Zisserman (2004) ). Two view points have been advanced in our group for dealing with

225
a statistical analysis of projective shape. One view, advanced by Vic Patrangenaru
(FSU), is an extension of the projective frame approach , presented in Comm. Statist.
Theory Methods , Ann. Statist. 2005, J. Multivariate Anal. 2008, 2010, 2011), and was
suggested by R. N. Bhattacharya. Consider a k-ad in general position in the m dimensional real projective space, with k > m+2. Let I be a set of m+2 indices in {1,…, k}. Consider the set P(I)∑(m,k) of all k-ads p = ((p(1),…,p(k))) such that $(p(i(1)),…, p(i(m+2))) is a projective frame, which is known to be a manifold diffeomorphic to a product of (k-m-2) copies of the projective space in m-dimensions. It has been shown by R.N. Bhattacharya (2010) that the full-projective space P(0)∑(m,k) of k-ads containing a projective frame is a differentiable manifold with smooth transitions among the P(I)∑(m,k), whose union over all sets I of indices cover P(0)∑(m,k) . The other approach, briefly presented in the opening workshop by John T. Kent (U. of Leeds ) and detailed by him in our group meetings in the particular case of a 4-ad on the projective line, is based on a representation of projective shape in a 2006 paper at the Leeds Annual
Statistics Workshop, that builds on a result of Tyler (Ann. Statist. 1987a,b) on the robust
estimation of a covariance matrix about the origin for vector data.
Extrinsic vs Intrinsic Data Analysis. The issue of what type of data analysis on manifolds, and by extension on stratified spaces is computationally faster is another issue discussed in our group. This topic was discussed in our group the case of data analysis on a hyperbolic plane, including data on impedances by Stephan Huckemann and Thomas Hotz ( IMS, Germany ) , Huling Le ( U.Nottingham,UK), Peter Kim (U of Gueph, Canada ) and Vic Patrangenaru (FSU) who started a joint collaboration on this subject. Another example discussed in the opening workshop by A. Schwartzman (Harvard) and Honk Tu Zhu (UNC) of extrinsic or intrinsic analysis of Diffusion Tensor Imaging data, is also on our group agenda.
The goals and expected outcomes include:
The ultimate goal of our working group is a nonparametric statistical data analysis of the twenty first century - an extension of nonparametric multivariate and functional data analysis to data analysis on spaces with a manifold stratification. An expected outcome is an extension to nonparametric data analysis on manifolds. Historically this was made possiblG. Watson, David G. Kendall (UK), Herbert Ziezold (Germany), and reached its current stage, due to work by Rudy Beran (U C Davis), Ted Chang (U. Virginia), Hendriks (Radboud U., Netherlands), Zinoviy Landsman (Haifa U., Israel), Frits Ruymgaart (TTU), Rabi N. Bhattacharya (U. Arizona), Steve Marron (UNC), Peter Kim (U Guelph, Canada), Vic Patrangenaru (FSU), A. Bhattacharya (Duke), A. Munk and Stephan Huckemann (IMS, Goettingen).
A data analysis of intrinsic means on folded Euclidean models for spaces of trees with p leafs
The role of nonparametric bootstrap in data analysis on stratified spaces
Derivation of the structure of the full projective shape space, and of ( preferably equivariant ) embeddings of this space leading to a projective analysis agreed upon by members of our group
Guidelines regarding a preference for a computational procedure intrinsic or intrinsic in object data analysis
Collaboration between applied mathematicians, bio-statisticians, statisticians and computer scientists.

226
Analysis of Object Data Working Group: Metrics in Shape Spaces
A. Personnel. The main people who have been active in the group include:
John Kent (administrator), Anuj Srivastava (administrator), Sungkyu Jung (local organizer), Hans Mueller,
Huiing Le, Ian Dryden, Irina Kogan, Hamid Krim, Ross Whittaker, Megan Owen, Sebastian Kurtek,
Stephan Huckemann, Victor Paneretos, Velentina Staneva, Christof Seiler
B. History of talks. We have had weekly talks from members of the group to make people aware of one
another's work and to suggest directions for collaboration
1. Anuj Srivastava. Shape Analysis of Elastic Curves in Euclidean Spaces
2. Han Mueller. Curve warping
3. Sebastian Kurtek. Riemannian Framework for Functional Analysis
4. Hamid Krim. Squigraph_modeling_of_Shapes
5. Irina Kogan. Geometric transformations, invariance, and congruence
6. John Kent. Basis expansions for shape variation
7. Valentina Staenva. Diffeomorphisms and RKHSs
C. Future talks
1. Anuj Srivastava. His new ideas on FDA
2. Irina Kogan. Curve matching
3. John Kent. Topology and metrics in projective shape spaces
4. Victor Paneretos. Shapes of closed curves and DNA geometry
5. Stephan Huckemann. Parallel transport on shape spaces
6. Ian Dryden. Matching unlabelled points using random fields.
D. Goals of the workgroup
The overall goal is to explore the implications of the choice of metric in various shape spaces. A metric
often induces a Riemannian structure, which in turn leads to geodesics and parallel transport. The
reason for our interest in metrics is that different metrics can highight different features of shape
differences.

227
Some of the main topics to be explored, and a brief summary of the progress so far, include the
following.
1. Better understanding of differential geometry on shape manifolds. Good progress, see below.
2. Interaction between modeling strategies for shape and for FDA. Good progress, see below.
3. Development of metrics for new shape spaces such as projective shape space -- good progress, see
below.
4. Robustness (e.g. L2 vs L1) -- not much explored yet.
5. Basis expansions of shape variation. Simplest ideas done. More on implications and extensions to be
explored.
6. Notions of deformation. E.g. landmarks, curves, surfaces, solids; all of these can also include the
ambient space. Basic understanding clear. No major new insights yet.
7. How sophisticated do models need to be? E.g. (a) Local (tangent space) vs global treatment of
deformations; and (b) landmark vs continuum models. We have explored the current knowledge;
nothing new yet.
E. Achievements. Several papers are in progress or near completion.
1. Splines on manifolds. Anuj Srivastava, Eric Klassen, Ian Dryden and Huiing Le
2. Application of shape models for curves to Functional data analysis. Anuj Srivastava, Sebastain Kurtek,
Eric Klassen and Hans Mueller.
3. The geometry and topology of projective shape spaces (John Kent, Thomas Hotz, Stephan Huckemann
and Ezra Miller)
4. Matching curves (Irina Kogan and student).

228
COMPLEX NETWORKS
Goals and Outcomes, Fall, 2010
DYNAMICS OF NETWORKS WORKING GROUP
The “Dynamics OF Networks” seeks to develop new collaborations to explore models,
methods, and implications of dynamic processes which change network topologies.
This working group formed as a natural outgrowth of common interests at the Opening
Workshop, has met weekly throughout Fall 2010, and plans to continue to meet during
Spring 2011. The group includes significant overlap of interests with the other CN
working groups, including but not limited to analysis of longitudinal data (overlapping
with the Geometrical/Spectral group), the modeling of networks via agent based models
(overlapping with Sampling/Inference), and the exploration of abstract voter models (as
just one specific project overlapping with the Dynamics ON Networks group). Indeed,
because of the significant overlap with the ON group, we plan to merge the weekly
meeting of the two groups for the Spring semester. That is, the ongoing subgroup
projects of both groups will continue to be represented and brought together in a single
weekly meeting, freeing up time for those subgroups to meet informally.
Starting at the OW, there has been intense early interest in the working group on
“bridging” the different network perspectives commonly attributed to communities in
statistics, probability, and statistical physics. Much of this interest in the group has
focused on the phenomenon of “explosive percolation” (described at the OW in the
presentation of Raissa D’Souza), namely the observation in some constructive models
where the giant component emerges in a seemingly sharp transition, cf. in classic models
such as the Erdos-Renyi random graph model. Quantifying this notion mathematically,
understanding the scaling window and understanding how small components merge into
larger components eventually leading to the formation of the giant component brings in
very interesting connections to the famous Smoluchowski equations in colloidal
chemistry, and Markov processes such as the multiplicative coalescent. One of the hopes
of the working group is to develop the techniques that will enable us to prove the first
mathematically rigorous results in this context. Our early efforts in this direction after
the opening workshop included conversations in the group led by Steve Fienberg and
Raissa D’Souza, among others. Our ongoing efforts aimed towards rigorous results are
currently led by Shirsendu Chatterjee, Charlie Brummitt, Shankar Bhamidi, Raissa
D’Souza, and Rick Durrett.
A second model problem of focus in the working group is the analysis of “Dynamic
Voter Models” [Holme & Newman, 2006], hybrid models that incorporate both a
rewiring dynamic, so the network changes in time, and a voter interaction process which
modifies the node/actor opinion to drive agreement between connected nodes in the
network. When the selected rewiring dynamic is to drop connections between
disagreeing actors, the two processes cooperate in pushing the network towards a final
state of complete consensus within each component, but the distribution of properties of

229
those components depends on the relative frequency of activity of the rewiring and
interaction processes (codified by a parameter). Our primary goals include the
demonstration of the existence of a critical value for this rewiring-frequency parameter,
at which the model changes behavior between the two extremes of a purely voter model
dynamic and a purely rewiring dynamic, the development of model moment-closure
equations for approximating this process, and the rigorous analysis of the process
(especially at and near criticality). Numerical simulations are being used to explore the
behavior of this system, including the different behaviors observed at different rewiring
frequencies, edge densities, and opinion initial conditions. We are using a pair-
approximation approach to gain a heuristic understanding of the process and the location
of the critical value. We are also using a rigorous large deviations approach to
demonstrate the existence of the critical value. This work is led by David Sivakoff, Bill
Shi, Rick Durrett, Alun Lloyd, Peter Mucha, and Mason Porter.
A third subgroup project is investigating the role of concurrent partners (overlapping in
time) in the spread of sexually transmitted diseases. STD transmission through the
dynamic contact network must obviously obey an arrow of time, requiring that the start
time and duration of each edge must be respected, and the resulting questions about the
influence of concurrency in enhancing rapid spread are important for modeling such
systems and for properly targeting behavioral and biological interventions. Multiple
researchers have developed competing measures for the level of concurrency in a
networks, and a wide variety of approaches have been used to study disease dynamics as
a function of concurrency, including but not limited to extensive use of simulations. One
part of this working group’s activity in this area is in addressing the utility of different
network representations thereof. For instance, the temporal information can be used to
create a directed network of possible transmissibility (either exactly or nearly obeying all
temporal rules). An alternative approach is to explore the allowed permutations in a fully
ordered edge list (those which do not change the available transmission paths). These
representations will be used to develop formal models of dynamic sexual networks,
targeting bounds on the size of the largest or expected disease outbreak as a function of
an appropriate global measure of concurrency. This work is led primarily by Bruce
Rogers, Alun Lloyd, Jim Moody, and Peter Mucha.
Additional prospective subgroup projects also remain under discussion. Such continued
exploration will remain an important emphasis for the working group in Spring 2011.
The Dynamics OF Networks workshop will be held at SAMSI in January 2011. The
workshop mixes a collection of invited speakers with presentations by members of the
working group, as well as extensive time blocked out for interaction with the visiting
speakers on the existing subgroup projects and the possible development of new
collaborations.

Dynamics ON Networks: Goals and OutcomesGroup Leaders: Rick Durrett and Alun Lloyd, Postdoc: David Sivakoff
Active group members: Shankar Bhamidi (UNC), Charlie Brummitt (UC Davis),Shirshendu Chatterjee (Cornell visiting Duke), Ariel Cintron-Arias (East TennesseeState U), Luis Gordillo (U Puerto Rico), Christian Gromoll (Virginia), Peter Kramer(Rensselaer), Jim Lynch (South Carolina), John McSweeney (Concorida), Peter Mucha(UNC), Mason Porter (Oxford), Michael Robert (NC State), Puck Rombach (Oxford),Bill Shi (UNC), Mandy Traud (NC State), Tipan Verella (Virginia)
At this point a number of projects have emerged for investigation.
SIS models on networks with communities. During the Stochastic Dynamicsprogram John McSweeney and Bruce Rogers considered the contact process (SIS epi-demic) on a strongly clustered graph, described as a stochastic block model. In thesimplest case there are two communities with the probability of an edge connectingtwo individuals within the same community p1 and the probability of an edge con-necting two individuals between communities p2 much smaller than p1. In a rangeof parameters, a plot of the number of infected sites versus time shows a stair step:the epidemic reaches equilibrium in one community before spreading to the other.Work on this problem is continuing in the Dynamics ON Networks working group ofthe with David Sivakoff and Rick Durrett. A proof has been sketched and work isproceeding on a paper.
Nonlinear voter models. The ordinary voter model with a linear response functionis now fairly well understood on complex networks due to its duality with coalescingrandom walk. Redner et al have studied various nonlinear versions. Chatterjee andDurrett will try to use ideas of Cox, Durrett, and Perkins to show that the mean fieldpredictions for the nonlinear voter model are accurate when the nonlinear responsefunction is almost linear. They think that this method can be used to cover the latentvoter model where voters who have just changed their opinions enter an inert statefor an exponential amount of time with mean λ if the rate λ is large. Although thisis a small perturbation of the voter model, the behavior changes disconintuously, thedensity converges to 1/2 starting from any poaitive level.
In Axelrod’s model, voters have a vector of F opinions, each of which can take oneof q values. Each voter x at rate 1 picks a neighbor y, and one of his opinions i. Ifthe two agree on issue i then x picks a j and imitates ys opinion on that issue. Whenq = F = 2 this reduces to the model with leftists (00), centrists (01, 10) and rightists(11). Lanchier has proved some results in one dimension about the clustering in thecase q = F = 2 and freezing when q is larger than F . Durrett and J.C. Li will workon generalizing the second result to two dimensions, starting with the case when bothq and F are large.
Pair approximation. Mandy Traud and Michael Roberts are coding and testing thefull pairwise approximation model for SIS epidemics using the equations exhibited in
1

Keeling and Eames - Modeling Dynamic and Network Heterogeneities in the Spreadof Sexually Transmitted Diseases. They plan to test actual network data with theseequations, code few different closure approximations, and test different selections ofparameters.
John McSweeney, Charlie Brummitt
There are four types of projects we are interested in:
Explaining Numerics. Two recent papers discuss approaches for analyzing pro-cesses on graphs that are a priori non-rigorous, but seem to give excellent results incertain circumstances. These are (i) the “unreasonable effectiveness” of tree-basedtheory to predict behavior on clustered networks (Melnik et al) and (ii) How accurateis mean field theory? (Gleeson et al.) In the first case, they find that the meaninter-vertex degree is a good predictor of whether the tree-based theory will be valid,despite the presence of clustering. In the second case they conclude that mean-fieldtheory is accurate when the mean of the size biased degree distribution is large. We’dlike to find out the theoretical reasoning behind this, in addition to finding out moreabout which statistics are predictive of the applicability of these techniques. Workon the contact process has shown that the mean field critical value is accurate whenthe number of neighbors is large, so perhaps a result can be proved in this directionfor some systems.
Clustering. The clustering coefficient C of the graph, the ratio of triangles to triplesin the graph, has been shown to be an important factor in determining propertiesof processes, for example the percolation threshold. However depending on how thegraph is built, this may increase or decrease the threshold; see conflicting resultsof Newman (2009) and Gleeson (2009), for example. The latter paper identifiesdegree correlations as an important factor to consider as well (beyond the obviouslyimportant factor of mean degree). We would like to identify a type of “clustering”that is not captured by the usual definition of C. There are three main themes as faras these issues are concerned:
• How to insert clustering (or, more generally, “non-locally-tree-like-ness”)?
• How to summarize it (i.e., find low-dimensional statistics that are useful forpredicting process behavior)?
• How to analyze it (i.e. come up with analytical formulas that include thequantity you want, and the right statistic of the graph)?
Another goal is to determine the appropriate “null models” for clustering. Recentpapers have reached different conclusions regarding the effect of clustering on thingslike the bond percolation threshold. How do we isolate the effect of clustering fromother effects (such as heterogeneity of degrees and degree-degree correlations)? Theremay be multiple useful null models, each with their own advantages and drawbacks.
2

Thresholds for the Watts’ cascade process. In this model for the spread of a fador new technology in a network, there are two transitions for the cascade threshold asedges are added: the first is around when the graph becomes sufficiently connected toeven have a giant component, obviously a necessary condition for existence of a giantcascade. The second transition occurs when the vertex degrees get large enough sothat having a single infected neighbor vertex is not often a high enough proportionto transmit excitation. Simulations in Gleeson and Cahalane indicate that when thedegree distribution is Poisson this transition is discontinuous, and the cluster sizedistribution decays exponentially at the critical value in contrast to the usual powerlaw behavior. We’d like to prove these conclusions rigorously and investigate theirgenerality.
We would also like to investigate the issue of cascades on clustered networks, re-cently tackled by Ikeda, Hasegawa, and Nemoto (2010). Their preliminary conclusionis that clustering decreases the cascade threshold, in the following sense. Let ϕ bethe “response function” for each vertex. Then they find an interval I = [ϕ1, ϕ2] suchthat for ϕ ∈ I, cascades happen with low but nonzero probability p on a clusterednetwork, and impossible on a similar but rewired unclustered network. We would liketo find out what is going on in this middle region: is the behavior sensitive to seedsize, as in Gleeson and Cahahlane (2007)? Does p increase predictably as ϕ increasesthrough I? Is there a way to analytically identify ϕ1 and ϕ2? More importantly, isclustering really the fundamental property dictating the changing threshold, or doesit just happen to be correlated in that way for their specific model?
Other kinds of percolation We are also thinking about other kinds of percolation.In what we are beginning to call 1/k-percolation, an edge from u to v percolates withprobability inversely proportional to the degree of v. This arises in the sandpile model(a model of load on a system), and it loosely captures the idea that more importantnodes have more edges and are less likely to join the cascade. This was studied fiveyears ago [?], and recently a couple members of this group studied it on modularnetworks using multi-type branching processes [?]. We are interested in extendingthis to non-tree-like networks with triangles or other subgraphs added, and perhapsto develop computational methods to predict cascade sizes for such networks.
Shankar Bhamidi has a number of ideas that are relevant to this group and toDynamics OF Networks
1. Flow processes through the network: Suppose the aim of the network is totransport flow between different parts of the network. We are interested in developingmathematical models and techniques to understand the build up of congestion overthe edges in the network in the large network limit, as well as understanding propertiesof the optimal path between different parts of the network.
2. Degree distribution of shortest path trees: One model of great interest forpractitioners is understanding properties of optimal path trees in networks with con-gestion across edges. Using techniques from first passage percolation and stochastic
3

process theory we shall try to deliver asymptotic results for a number of differentrandom graph models.
3. Networks evolving over time: In a number of models, networks evolve overtime with the addition of new vertices arriving into the system and new edges beingcreated between different parts of the network. One of the most popular modelsof such networks is the preferential attachment model which has been used in adiverse number of fields ranging from statistical physics to modeling the internet, fromlinguistics to systems biology. Most authors have focussed their attention only on thedegree distribution. However what we aim to do is develop a general set of techniqueswhich give asymptotic information about a wide range of functionals ranging fromlocal neighborhoods to global functionals such as the spectral distribution.
4. Boolean networks: Boolean networks are models inspired from biological appli-cations. Only in the last few years has there been rigorous work done in trying toprove the many conjectures proposed by experimentalists over the years. Our aim(along with Shirshendu Chatterjee) is to derive rigorous results when the underlyingdirected graph is inhomogeneous.
The Dual of a Random Intersection Graph. Christian Gromoll and Tipan Verella areinterested in studying the emergence of a giant component in the dual of a generalizedrandom intersection graph. Conceptually, given a set of nodes and a set of attributes,a random intersection graph is a graph on nodes induced by constructing a randombipartite graph between the nodes and the attributes. Interest in random intersectiongraphs, has increased in recent years. However, very little attention has been devotedto studying the dual graph naturally constructed by the same process that producesthe random intersection graph.
One of the interesting features of the dual of a random intersection graph isthat it has naturally occurring triangles and other complete subgraphs of varioussize. One can however show that the two random graphs do not have the samedistribution. We would like to study the emergence of a giant component in thedual of the random intersection graph. One of the difficulties of analyzing bothgeneralized random intersection graphs and their duals come from the fact that edgeoccurrence is dependent and not identically distributed, unlike in the Erdos-Renyırandom graph We will follow the approach in Chapter 10 of Alon and Spencer’s TheProbabilistic Method, in which one defines a process Yt keeping track of the boundaryof an exploration of the nodes of a given component of the graph.
4

Complex Networks: Geometry/Spectral Analysis Working Group Group leader: Mauro Maggioni (Duke), Michael Mahoney (Stanford)
Participants: Prakash Balachandran (Duke), Pietro Poggi Corradini (Kansas State), Mihail
Cucuringu (Princeton), Raymond Falk, Mauro Maggioni (Duke), Michael Mahoney (Stanford),
Peter Mucha (UNC Chapel Hill), Mason Porter (Oxford), Ali Shojaie (U. Wisconsin Madison),
Blair Sullivan (Oak Ridge Lab).
The group has been studying a number of topics in spectral and multiscale techniques for graphs,
and their geometric and algorithmic implications, with separate overview/tutorials/open
problems by Mason, Mauro, and Mike, as well as tree decomposition methods and their
algorithmic applications (Blair).
It is now focusing on several problems that emerged as interesting to subgroups of people:
1. Multiscale conductance and time-series Networks: Kash, Mason, Mauro, Mike, Peter.
Inspired by recent work by Mason and Peter on multislice networks, and by Mike on
multiscale conductance, we would like to understand the behavior of multiscale methods (e.g.
conductance, community detection, diffusions) on multislice networks.
2. Soft clustering: Alan, Mason, Mike, Ray. Most existing community-detection algorithms find
hard partitions in the network, while in some situations it seems more natural to construct soft-
partitions. Few methods do that, but it is a new topic and little is well-understood. It would
also be interesting to apply new ideas to the case of multislice networks.
3. Tree decompositions. Alan, Ali, Blair, Mike. These decompositions simplify graphs, leading
to faster optimization/solution of problems which are computationally hard. They are related
to important problems in statistics (especially in graphical models) but such ties are not well-
understood. Moreover, these decomposition algorithms are right now very combinatorial in
nature, and one may wonder if they would become easier/more stable by weaking some of the
requirements, while still being useful.
4. Community Detection: Mihail, Mike, Mauro, Kash. Spectral techniques based on intermediate
eigenvectors of the Laplacian and/or modularity may be used to detect communities. Mike’s
paper provides overview of the state-of-art in the field, and some of techniques could be used
on data sets that Mason can provide. Specific goals still to be defined.
5. Scan Statistics/sparse regression - Ali, Mauro, Alan, Ray, Mike. Scan statistics on graphs is
not well understood and only few technique exist, albeit many applications seem to be in need
of such tools, such as epidemics (early detection), genomics (identification of pathways
relevant in a disease), etc... Ali and Mauro working on a multiscale framework, with
applications to genetic data. Mason and Peter may provide charity network data where again
scan statistics may be a useful tool.
6. Epidemic/Reactive Networks: Pietro, Mauro. Pietro has collected and is processing data from
questionnaires that allow mapping social interactions and behavior in a community, both
under normal conditions and in the case of the emergence of an epidemics. Many questions
arise: would the network change enough to prevent the epidemics? How would the network
change? What would be efficacious ways of modifying the network to prevent the spread?

SAMSI Program on Complex Networks
Goals and Outcomes, Fall, 2010
WORKING GROUP ON SAMPLING, MODELING, & INFERENCE
The “Sampling/Modeling/Inference” working group is focused on topics that arguably involve some or all of “sampling,” “modeling,” and “inference” of networks. Much of our focus has been restricted to static networks, but some projects have nontrivial overlap with interests in the “Dynamics OF” working group as well.
Members of the working group are active on six group projects. Additionally, it appears to the organizers that many participants are doing individual research that is informed by our weekly discussion.
Project 1: Inference on Agent-Based Models for Networks
Agent based models (ABM) specify local interaction rules between individuals and implement these rules through computer simulation. Agents are placed together in a simulated environment, and then one can observe repeated realizations of the evolution of social networks among the agents. But such applications need methods for statistical inference that relate the parameters (agent rules) to the network behavior. Important open problems include how to estimate parameters given a time series of the (simulated) observables or how assess the goodness-of-fit of the model from the given data. These challenges are difficult because each agent can have its own set of parameters, so the dimension of the parameter space grows geometrically in the number of agents. To perform dimension reduction in parameter space and make inference possible, David Banks, Bruce Rogers and Cosma Shalizi are building statistical emulators for agent based models using a Bayesian framework for the calibration of computer models. As a proof of concept we are using the "Sugarscape" agent-based model from Axtel and Epstein's book Growing Artificial Societies.
Project 2: Fit Assessment for Attachment Models
Much of the recent literature on real-world networks concerns mathematical models which relate their characteristics, including degree distributions, small worldedness, and clustering coefficients to parameters in various preferential attachment models. At the simplest level new nodes enter the system and decide to link themselves to nodes in the pre-existing network with probability proportional to some functional of the vertices in the network, for example their present degree. Models based on such schemes arise in a number of areas, ranging from economic systems wherein nodes try to optimize two competing functionals to evolutionary biology (Yule processes). Often one looks at the degree distribution of the real network at hand and matches it to an appropriateattachment model and then uses various properties of the model to infer properties about the network (e.g., epidemic durations). However, there is no mathematical theory adequate to judge

such fits. Shankar Bhamidi, Shirshendu Chatterjee and Eric Kolaczyk are exploring this area in order to provide the necessary inferential theory.
Project 3: Baboon Grooming Data
A consortium of primatologists has collected data on social interactions in twelve baboon troops in Kenya. A subgroup consisting of David Banks, Yingbo Li, Bruce Rogers and Ali Shojie is attempting to fit a dynamic latent space model to grooming relationships over time, using covariate information on kinship, relatedness, age, health, gender, reproductive status, dominance hierarchy, and rainfall. The key aim is to product the observed fission in the baboon troop, which entails a block model for the the proximity matrix in the latent space.
Project 4: Effective Sample Size in Network Modeling
Stochastic models for network structure and processes have applications spanning the social, informational, and biological sciences. However, complex networks have complex structure, and when sophisticated models reflect this in their own dependence structure, ordinary sampling and asymptotic results used to quantify uncertainty often do not apply. Indeed, the only unambiguously independent sample for many network processes is repeated independent observations of realizations of that network over the same set of actors --- something that is, with a few exceptions, not possible. And yet, observing more actors in a network clearly provides more information about the network's structure than observing fewer. Pavel Krivitsky, Sean Simpson, Crystal Linkletter, and Eric Kolaczyk are doing work that seeks to establish notions of effective sample size for network models, taking into account the dependence structure and parametrization of these models and the process by which the network is observed.
Project 5: Estimation of the Degree Distributions
The degree distribution of a sampled network can differ from the degree distribution of the underlying population network, as pointed out, for example, in “Subnets of Scale-Free Networks are Not Scale-Free: Sampling Properties of Networks” Stumpf, Wiuf, May (PNAS, 2005). Work by Frank has shown how to obtain unbiased estimates of the number of nodes of any degree given a simple random sample of nodes, and normalizing that distribution yields an estimate of the degree distribution. Bruce Spencer and Eric Kolaczyk are working to extend those results in two directions. First, the mean and variance of the degree distribution can be calculated from the triad census, and hence they can be estimated from an induced graph sample. Work is underway to improve Frank's estimators by adjusting them to estimates of the mean and variance based on the sample triads. Second, work is underway to extend the results from samples where nodes are included with equal probabilities to samples based on unequal probability sampling.

Project 6: Comparison of Aggregated Relation Data and Ego-Centric Sampling
Tyler McCormick, Tian Zheng, and Eric Kolaczyk are studying a framework for inference in multi-relational data measured through standard surveys. Our goals are (i) formalizing the information contained in two sampling methods (aggregated relational data and ego-centric fixed-size nominations) (ii) exploring the relationship between these two methods (iii) learning about the relationship between two nested networks.
Mini-Project: Minimum Description Length Inference
Edo Airoldi and David Banks have written an NSF proposal that includes a studyof minimum description length inference for a class of latent space models. Iffunded, this project will surely move forward; if not, its pursuit will dependupon available energy and time.

B. Scientific Themes for Later Years:Uncertainty Quantification: 2011-2012
1 Introduction
Mathematical models intended for computational simulation of complex real-world processes area crucial ingredient in virtually every field of science, engineering, medicine, and business. Tworelated but independent phenomena have led to the near-ubiquity of models: the remarkable growthin computing power and the matching gains in algorithmic speed and accuracy. Together, thesefactors have vastly increased the applicability and reliability of simulation - not only by drasticallyreducing simulation time, thus permitting solution of larger and larger problems, but also byallowing simulation of previously intractable problems.
Utilization of such computer models of processes requires addressing Uncertainty Quantification,a greatly expanding field focusing on at least the following issues:
• Models are invariably not a completely accurate reflection of reality; this bias or discrepancyneeds to be acknowledged in analysis and prediction.
• The models are often so expensive to run that model outputs may be available for only a fewinputs; for practical purposes the model predictions are thus unknown at these other inputs.
• There are often uncertainties in the initial conditions for the models.
• The models typically have numerous unknown parameters.
• The models may have stochastic features.
• Predictions combining model output and noisy data (data assimilation) is often required.
The intellectual content of computational modeling comes from a variety of disciplines, includingapplied mathematics, statistics, probability, operations research, and computer science, and theapplication areas are remarkably diverse. Despite this diversity of methodology and application,there are a variety of common challenges detailed below in developing, evaluating and using complexcomputer models of processes, which directly relate to the mission of SAMSI.
Uncertainty Quantification (UQ) will be a year-long SAMSI program for 2011-2012. Thisnascent field and its recent developments are closely intertwined with several applications, mostnotably climate and engineering. To properly explore not only methodological issues but also ap-plications to specific fields, SAMSI will devote its entire resources in 2011-2012 to the UQ program.The structure of the 2011-12 UQ program is indeed unique among SAMSI programs in that, insteadof running two year long programs in parallel, we will run one UQ program with not only (i) amain methodological theme but also, stemming from it, three distinct application fields, namely, (ii)climate modeling, (iii) engineering and renewable energy and (iv) geosciences. This will foster theseamless integration into the program of these fields and their corresponding research communities.For the sake of simplicity, we hereafter refer to each of these four themes as “programs”.
238

239
Current Overall Program Leaders: Amy Braverman (JPL, Cal. Tech and UCLA), Don Es-tep (Colorado State), Roger Ghanem (USC), David Higdon (LANL), Christine Shoemaker(Cornell), Jeff Wu (Georgia Tech)
Local Scientific Coordinators: James Nolen (Duke), Jan Hannig (UNC)
Directorate Liaison: Pierre Gremaud (NCSU)
National Advisory Committee Liaison: Max Gunzburger (Florida State)
2 Research foci and programs
2.1 Methodology program
The program will focus on five complementary themes described below. It is expected that the workdone within the various working groups for this program will complement and address challengesof interest to the applied side of the program, see three applied programs below.
Program leaders:
Dan Cooley (Colorado State), Don Estep (Colorado State), Max Gunzburger (Florida State), JanHannig (UNC), David Higdon (LANL), Jeff Wu (Georgia Tech)
2.1.1 Methodology theme: Foundations
Fundamental questions of interest include treatment of model error, inference with multi-models,treatment of multiscale models, numerical error estimation, reduced order modeling, and theoreticalfoundations of various UQ problems.
More specifically, multiscale, multiphysics systems raise well known challenges for accuratemodeling and simulation and these all carry over to UQ. Particular challenges include combiningdifferent descriptions of uncertainties from different kinds of physical models and different kinds ofdata, treating the coupling and feedback between the uncertainties and errors generated in eachcomponent, and dealing with the effects of scale on uncertainty representations. Scale differences inbehavior of different physical components may lead to scale issues in computing and representinguncertainties.
Statistical analysis of computer models (e.g. use of MCMC methods) and operational use ofmodels (e.g. data assimilation, optimization, or use of the model for risk assessment) may requirehundreds or thousands of model evaluations. When a single computer model run is time-consuming,such analysis and use may be intractable. But a solution that is often almost as good, or at leastgood enough for many purposes, can sometimes be obtained through model approximations, oftencalled emulators, surrogates, or meta-models. In developing these approximations, ideas such asmodel reduction, dimension reduction and order reduction are very active research topics in severalareas of statistics, applied mathematics, computer science, and operations research. One ideais to develop an exact but much less complex (or much smaller) model that retains the mostimportant features of the original; another approach is to compute an approximate solution of the

240
original problem that retains a provable degree of closeness to the exact solution; and obviouslya combination of these ideas is possible. In all cases, a mixture of rigor and application-specificknowledge is needed to deal with increasingly high-dimensional spaces and data.
For stochastic PDEs, efficient algorithms for the characterization of lower dimensional manifoldsoccupied by solutions to specific stochastic partial differential equations are starting to emerge,which is another useful type of dimension reduction.
2.1.2 Methodology theme: Representation and propagation of uncertainty
Representing uncertainty and error in ways that are both descriptive and useful for computationis an ongoing research challenge. Research is particularly needed in high fidelity representations ofrandom quantities, e.g. polynomial chaos and probability distributions. Research is also needed inhow to combine different representations of uncertainty in one form and the effect of changing scalesbetween representations. The program will look at propagation of uncertainty through complexphysical models, specifically in conjunction with the three applied programs described below. Howto best exploit the mathematical structure of models for uncertainty propagation is also a promisingavenue of investigation.
Sensitivity analysis generates essential information for model development, design optimization,parameter estimation, model reduction to name but a few. It has been demonstrated that forwardsensitivities can be computed reliably and efficiently for many differential systems provided thenumber of parameters is not too large. For larger problems, the adjoint method is more appro-priate but comes with additional complexity in its implementation. The proper use of additionalinformation such as derivative information would open the way to more efficient algorithms. Opencomputational issues related to sensitivity analysis include analysis of the accuracy the sensitivitiesthemselves and their inclusion in general adaptive methods.
Another important class of methods for uncertainty propagation are variously termed sequentialMonte Carlo, particle methods, or ensemble methods. While SAMSI had a program on this topic in2008-09, it focused on the development of the theory behind such methods, and not their utilizationin dealing with uncertainty in complex computer models.
2.1.3 Methodology theme: Data assimilation
It is often crucial to combine data with computer models to provide accurate predictions. Thequintessential example is weather forecasting, where current data is used (together with ‘ensemble’runs from the model) to set the initial conditions. The computer model is then exercised fromthese initial conditions to make weather predictions. Data assimilation often involves very highdimensional data, and questions of modeling and computation abound, as well as the questions ofhow best to interface the data with the computer model, especially when data is of an unusualtype, such as Lagrangian data. Other issues include incorporating information from disparate andsparse data sets, filtering and forecasting, response surface techniques, sampling based approaches,derivative/variational-based approaches.

241
2.1.4 Methodology theme: Inverse problem and calibration
Large-scale computational models are a powerful tool for planning and decision-making. Suchmodels can be used to help assess important questions regarding the management of a particularsystem. Such issues are often posed as inverse or optimization problems. Use of models for thispurpose requires understanding of the uncertainty and error in predicted behavior.
The fidelity of models to reality (often termed model validation) is central to their effectivenessin understanding and predicting real phenomena. However, techniques for validating complexmodels are limited and are often based on informal heuristics. Validation seems straightforwardconceptually: data are collected that represent both the inputs and the outputs of the model, themodel is run with those inputs, and the outputs are compared with the observed data correspondingto the outputs. In reality, complications abound: observed data may be expensive, scarce or noisy,the model may be so complex or time-consuming that only a few runs are possible, there can besevere confounding between calibration and validation, and uncertainty enters the process at everyturn.
There is a very non-uniform understanding in what specific approach to use for model calibrationdepending on the models themselves. This is a field where the state-of-the-art methods in thedeterministic and statistical communities are very different and where both could clearly benefitfrom learning more about the other. Further, issues such as error and uncertainty analysis formodel calibration are still in their infancy. A better understanding of these is expected to bothgenerate new methods and greatly enhance the efficiency of existing ones.
2.1.5 Methodology theme: Rare events
A very difficult challenge is accurately representing the effects of events that have very low probabil-ity of occurring but which have very large or catastrophic effects when they do occur. Specific issuesinclude reduced order models, computational and physics models to detect rare events, investigationof relevant statistical methodologies, optimization techniques.
2.1.6 Prospective participants
Applied Math: Todd Arbogast (Austin), Guillaume Bal (Columbia), Leonid Berlyand (PennState), Liliana Borcea (Rice), Alexandre Chorin (Berkeley), Clint Dawson (Texas), John Dennis(Rice), Yalchin Efendiev (Texas A&M), Don Estep (Colorado State), Colin Fox (U. Auckland),James Glimm (SUNY Stonybook), Max Gunzburger (Florida State), Jan Hesthaven (Brown), TomHou (Caltech), Chris Jones (UNC), George Karniadakis (Brown), Andrew Majda (NYU), RichardMoore (NJIT), J. Tinsley Oden (Austin), Houman Owhadi (Caltech), George Papanicolaou (Stan-ford), Linda Petzold (UCSB), Liang Peng (Georgia Tech), Bruce Pitman (Buffalo), RosemaryRenaut (NSF), Juan Restrepo (U. of Arizona), Boris Rozovsky (Brown), Christoph Schwab (ETHZurich), Elaine Spiller (Marquette), Bill Symes (Rice), Mary Wheeler (Texas), Dongbin Xiu (Pur-due), Donxiao “Don” Zhang (USC).
Computational Probability: Amarjit Budhiraja (UNC), Paul Glasserman (Columbia), DennisTalay (INRIA), Harold Kushner (Brown), Eric van den Eiden (NYU), Pierre DelMoral (INRIA),

242
Eckhard Platen (University of Technology, Sydney), Paul Dupuis (Brown), Rene Carmona (Prince-ton), J.P. Fouque (UCSB), Andrew Stuart (Warwick), Bernt Oksendal (Uni. of Oslo), JoanthanWeare (NYU)
Engineering, Science, Computer Science: Hany Abdel-Khalik (NC State), Jeff Anderson(NOAA), Maarten Arnst (USC), Wolfgang Bangerth (Texas A&M), Tim Barth (NASA), IlleniaBattiato (Max Planck Inst.), Jose Blanchet (Columbia), Yanzhao Cao (Auburn), Wei Chen (North-western), Ruchi Choudhari (Cambridge), Peter Cummings (Vanderbilt), George Deodatis (Columbia),Alireza Doostan (Colorado), Debbie Dupuis (HEC Montreal), Howard Elman (Maryland), Char-bel Farhat (Stanford), Fariba Fahroo (AFOSR), Jacob Fish (RPI), Roger Ghanem (USC), OmarGhattas (Austin), Habib Najm (Sandia), Mandy Hering (Colorado Mines), Gianluca Iaccarino(Stanford), Chris Johnson (Utah), Yannis Kevrekidis (Princeton), Peter Kitanidis (Stanford),Steve Koutsourelakis (Cornell), Fredrik Larsson (Chalmers), Alan Laub (UCLA), Pierre Lermusi-aux (MIT), Wing Liu (Northwestern), Youssef Marzouk (MIT), Marc Mignolet (Arizona), BerndMoeller (Dresden), David Moens (Leuven), Dianne O’Leary (Maryland), Karen Pao (NNSA), AbaniPatra (Buffalo), Jaume Peraire (MIT), Serge Prudhomme (Austin), Adrian Sandu (Virginia Tech),Marcus Sarkis (WPI), Christine Shoemaker (Cornell), David Stargel (AFOSR), Laura Swiler (San-dia), Alexander Tartakovsky (USC), Daniel Tartakovsky (UCSD), Hai Wang (USC), Karen Willcox(MIT), Nichola Zabaras (Cornell), T.A. Zang (NASA).
Statistics: M.J. Bayarri (Valencia), Andrew Booker (Boeing), George Casella (U. Florida), PeterChalloner (Southampton U.), Hugh Chipman (Acadia U.), Dan Cooley (Colorado State), DanCornford (Aston U.), Dennis Cox (Rice), Gary Foley (EPA), Michael Goldstein (Durham), SergeGuillas (University City of London), Hary Iyer (Colorado State), Cari Kaufman (Berkeley), MaggieHan (Auburn), Dave Higdon (LANL), Lulu Kang (Illinois Inst. of Tech), Marc Kennedy (SheffieldU.), Herbie Lee (UCSC), Devon Lin (Queens U.), Max Morris (Iowa State), William Notz (OhioState U.), Jeremy Oakley (Sheffield U.), Tony O’Hagan (Sheffield Univ.), Angela Patterson (GeneralElectric Research), Peter Qian (U. WisconsinPritam Ranjan (Acadia U.), Shane Reese (BringhamYoung U.), Jonathan Rougier (Univ. Durham), Fabrizio Ruggeri (CNR-IMATI), Jerry Sacks,Tom Santner (Ohio State), Leonard Smith (London School of Economics), David Steinberg (TelAviv Univ.), Curtis Storlie (Colorado), Claudia Matt Taddy (Chicago), Tebaldi (NCAR), WilliamWelch (U. British Columbia), Darren Wilkinson (U. Newcastle), Henry Wynn (London School ofEconomics), Kenny Ye (SUNY Stony Brook), Jeff Wu (Georgia Tech).
The above Methodology program will be considered in parallel with three applied programwhich we now describe.
2.2 Climate program
The area of climate modeling is a quintessential field of application for UQ. In fact, a sizable partof the research done in the quantification of uncertainty in computer models has been driven by thepressing needs of climate modelers. Climate models are computer codes based on physical principlesthat simulates the complex interactions between the many parts of the Earth system such asatmosphere and oceans. A significant issue of interest is for instance the problem of regional climateas the global models cannot on their own give enough information at the regional/local scales.

243
Various strategies (downscaling and upscaling) can be considered whereby various combinations ofglobal and regional models are combined to gain information on model uncertainty. Other issuesinclude: development of reliable atmospheric and ocean models and interface between the two,regional and local risk assessment from models, paleoclimate models and how to best deal withmodels that have huge uncertainties and biases. Four specific themes, described below, have beenidentified.
Organizers
Amy Braverman (JPL, California Institute of Technology, and UCLA), Xabier Garaizar (LLNL),Dave Higdon (LANL), Gardar Johanneson (LLNL), Donald Lucas (LLNL)
2.2.1 Climate theme: Observations
Observations are key to uncertainty quantification in climate research because they provide a cor-roborating source of information about physical processes being modeled. However, observationshave uncertainties and this poses a set of methodological and practical issues for comparing themto model simulations: (i) quantifying observational uncertainty when the observations are them-selves inferences based on other quantities, (ii) change of support between model resolution and theresolution of remote sensing or in-situ data, (iii) rectifying or accounting for spatial and temporalinconsistencies, (iv) coping with dependence between observations used in model construction andobservations used for UQ, and (v) leveraging massive volumes of distributed data.
2.2.2 Climate theme: Climate models
Climate models remain our best tool for understanding past, present and future climate change.However, state-of-the-art climate models still contain many sources of uncertainty, including un-certainties from physical processes that are poorly known or are not resolved at the temporal andspatial scales represented in climate models. These uncertainties may cloud the analysis and in-terpretation of climate simulations. This theme focuses on the applications of UQ to characterizeuncertainties in climate model simulations.
2.2.3 Climate theme: Assimilation/calibration/forward UQ
With computational models that simulate climate 10s to 100s of years in the future, comes the needto quantify the uncertainties of the predictions they produce. Uncertainties in these large-scale com-putational models can stem from a variety of sources including numerical approximations, unknowninitial conditions, unknown model parameter settings, missing physics and other inadequacies inthe model. Some of these uncertainties can be reduced by constraining the model be consistentwith physical observations. This theme focuses on approaches for uncertainty propagation, dataassimilation and model calibration that help estimate and constrain uncertainties in model-basedpredictions. The use of large-scale models make such approaches challenging due to their compu-tational burden, their complexity, and their inadequacies. The incorporation of physical data leads

244
to challenges as well - data are recorded at different scales, the volume of data can be quite large,while their spatial and temporal coverage can be quite small.
2.2.4 Climate theme: Multiscale inference
Uncertainty in climate model projections is often represented by an ensemble of plausible simula-tions, which can either be a collection of simulations from multiple models or from a single climatemodel. Drawing inference from such ensembles can be challenging; for example, conclude aboutchanges in trends and extreme events. The theme of this topic is statistical analysis of climatemodel simulations, in particularly methods to draw inference from an ensemble of simulations andacross different spatial and temporal scales.
2.2.5 Prospective participants
Dorian Abbott (U. of Chicago), Rick Arichbald (ORNL), Dan Cooley (Colorado State), Noel Cressie(Ohio State), Marc Genton (Texas A&M), Gabi Hegerl (U. of Edinburgh), Charles Jackson (U. ofTexas), Eugenia Kalnay (U. of Maryland), Richard Katz (NCAR), Cari Kaufman (UC Berkeley),Shane Keating (NYU), Pete Kramer (RPI), Mikyoung Jun (Texas A&M), Ruby Leung (PNNL),Chunsheng Ma (Wichita State), Doug McNeall (Met Office Hadley Centre), Matt Menne (NOAA),Chris Paciorek (UC Berkeley), Robert Pincus (U. of Colorado), Juan Restrepo (U. of Arizona),Bruno Sanso (UC Santa Cruz), Christine Shoemaker (Cornell), Leonard Smith (London School ofEconomics and Political Science), Chris Wikle (U. of Missouri), Pen Zeng (Auburn)
2.3 Engineering/renewable energy program
Analyzing and predicting the behavior of complex systems with multiple length and time scaleshas become a central activity across the broad spectrum of engineering fields. For such systems,limited information can be obtained from observation and experiment. Consequently, simulation-based science has become an essential tool across engineering as well. Since important and costlyengineering decisions, e.g. product and system design, depend critically on simulation, uncertaintyquantification has become increasingly vital to engineering advances.
The program will consider uncertainty quantification issues arising in a number of engineeringfields, e.g., materials, circuits, aeronautics, fusion and fission reactors, nano/MEMS-scale devices.Given the increasing importance of sustainability to the national interest, we will place particularemphasis on engineering of green and renewable energy sources along with related environmental en-gineering issues. Some specific applications to be considered include smart grid models, solar power,fuel cells and batteries, green fuel sources, risk models (including environmental risk and financialrisk), economic impact models and eco-toxicology (carbon sequestration models for instance). Fivespecific themes are described below; each of these themes will be explored through a workshop withthe goal of identifying methodological issues and sustain the activities of a corresponding workinggroups.

245
Organizers
Don Estep (Colorado State), Roger Ghanem (University of Southern California), Miriam Heller(MHITech Systems).
2.3.1 Engineering theme: Renewable Energy
This part of the program will aim at improving our understanding of the uncertainties that af-fect renewable energies along their demand-supply chain. This include generations, transmission,demand, smartGrid technologies, and related pricing and financial instruments.
Organizers: Habib Najm (Sandia) and Youssef Marzouk (MIT)Prospective participants: Joseph F. DeCarolis (NCSU), Mike Eldred (SNL), Roger Ghanem
(USC), Marija Ilic (Carnegie Mellon U.), Omar Knio (Johns Hopkins), Josh Linn (RFF), ShuaiLu (PNNL), Dawn Manley (SNL), Steven Mitchell (BP), Hai Wang (USC), Jianhui Wang (ANL),Jean-Paul Watson (SNL), David Woodruff (UC Davis), Victor Zavala (ANL)
2.3.2 Engineering theme: Nuclear Energy
This theme will bring together stakeholders in nuclear assurance.Organizers: Jim Stewart (Sandia) and Hany Abdel-Khalik (NCSU)Prospective participants: Hany Abdel-Khalik (NCSU), Brian Adams (Sandia), Marv Adams
(Texas A&M), Mihai Anitescu (ANL), Dan Cacuci (NCSU), Nam Dinh (INL), Mike Eldred (San-dia), Roger Ghanem (USC), Urmila Ghia (U. of Cincinnati), Guang Lin (PNNL), Ryan McClarren(Texas A&M), Michael Pernice (INL), Simon Phillpot (U. of Florida), Eric Phipps (Sandia), JohnRed-Horse (Sandia), Ralph Smith (NCSU), Kiran Solanki (Mississippi State U.), Pavel Solin (U.of Nevada), Laura Swiler (Sandia), Yixing Sun (Westinghouse), Angel Urbina (Sandia), BrianWilliams (LANL), Nicholas Zabras (Cornell).
2.3.3 Engineering theme: Sustainability
The objective is to bring together people who are tasked with the practice of sustainability withthose at the frontier of sustainability science. This includes sustainable technologies (i.e. withcontrollable carbon footprint and transparent reuse cycle), complex interacting systems, and urbanplanning.
Organizers: Don Estep (Colorado State), Roger Ghanem (USC), Miriam Heller (MHITechSystems)
Prospective participants: Francis Alexander (LANL), Jeff Arnold (US Army), Godfried Augen-broe (GaTech), Ana Barros (Duke), Burcin Beceric-Gerber (USC), George Deodatis (Columbia),Alireza Doostan (U. Colorado, Boulder), Leonardo Duenas-Osorio (Rice), Joseph Fiksel (Ohio StateU.), David Gerber (USC), Robert Glass (Sandia/NISAC), Christian Hellmich (TU Vienna, Aus-tria), Sinan Keten (Northwestern), Yannis Kevrekidis (Princeton), Peter Louie (SoCal Metropoli-tan Water District), John McGrath (NSF), Anna Michalak (U-Mich), Anna Nagurney (U. Mass,Amherst), Habib Najm (Sandia), Priscilla Nelson (NJIT), Rosemary Renaut (Arizona State U.),

246
George Saad (American U. of Beirut, Lebanon), Alexander Tartakovsky (USC), Paul Torrens (Ari-zona State U), Franz Ulm (MIT), Peter Williams (IBM)
2.3.4 Engineering theme: Engineered Systems
This part of the program will bring together individuals who are close to operational constraints, toidentify common challenges and opportunities for advancing the relevance of UQ knowledge-base.
Organizers: Roger Ghanem (USC)Prospective participants: Wei Chen (Northwestern), Mike Eldred (Sandia), Albert Gilg (Siemens-
AG), Jerry Hefner (NIA), Chris Hoyle (Oregon), Gianluca Iaccarino (Stanford), Sean Kenny(NASA), Laura Laurati (Boeing), Pierre Lermusiaux (MIT), Marc Mignolet (ASU), Robert Moser(UT Austin), Abani Patra (SUNY, Buffalo), Lee Peterson (NASA), Mahadevan Sankaran (Van-derbilt), Matthew Sexton (Boeing), Pol Spanos (Rice), Karen Wilcox (MIT)
2.3.5 Engineering theme: Materials
Organizers: Wei Chen (Northwestern), Wing Kam Liu (Northwestern)Prospective participants: Janet Allen (Oklahoma), Guillaume Bal (Columbia), Craig Burkhart
(Goodyear), Wei Chen, (Northwestern), Tim Germann (LANL), Roger Ghanem (USC), SomnathGhosh (Ohio State), Lori Graham (Johns Hopkins), Steve Greene (Northwestern), Gary Harlow(Lehigh), Iwona Jasiuk, (UIUC), Mike Kassner (ONR), Wayne King (Lawrence Livermore), WingLiu (Northwestern), David McDowell (Georgia Tech), Bill Mullens (ONR), Greg Olson (North-western), Masoud Rais-Rohani, (Mississippi State), Tony Rollett (Carnegie Mellon), David Shahan(Univ of Texas-Austin), Jeff Simmons (Wright-Patterson AFB), Yan Wang (Georgia Tech), Dong-bin Xiu (Purdue), Nicholas Zabara (Cornell)
2.4 Geoscience applications program
Many problems in geoscience and environmental engineering are described by computationallyexpensive models. Computational time is arguably the main obstacle to doing rigorous statisticalanalysis of uncertainty. Further, multiple types of uncertainty need to be incorporated, includingdata error, model error, parameter error, randomness in model input (static and dynamic). Thetype of issues call for new algorithms.
Organizers
Omar Ghattas (Univ. of Texas-Austin), Christine Shoemaker (Cornell University), Daniel Tar-takovsky (University of California - San Diego)
Specific examples of problems requiring careful uncertainty quantification in this field include
• determination of spatial distribution of geologic materials in the subsurface based on soundwave and/or radar (many spatial points, low accuracy),
• determination of location of oil reservoirs or underground water based on exploratory drilling(few spatial points, high accuracy),

247
• forecast of contaminant transport.
Aside from hydrology driven applications, we will also consider the modeling of hurricanes, volcanosand tsunamis. Independent teams of researchers working on each of these three specific themeshave been identified, contacted and will actively participate in the program.
The opening workshop of that program is organized by Souheil Ezzedine (Lawrence LivermoreNational Laboratory), Mary C. Hill (USGS), Wolfgang Nowak (University of Stuttgart, Germany),Gowri Srinivasan (Los Alamos NL), Daniel Tartakovsky (University of California, San Diego).
2.4.1 Prospective participants
Vladimir Alvarado (U. of Wyoming), Vo Anh (Queensland University of Technology, Australia),Nicolas Christou (UCLA), Ian Cook (TIBCO Software Inc), Vladimir Cvetkovic (KTH Royal Inst.of Technology), Kossi Edoh (NC A&T), Samson Emeakpor (Jackson State U.), Michael Fienen (USGeological Survey), Genetha Gray (Sandia), Snehalata Huzurbazar (U. of Wyoming), George Kar-niadakis (Brown), Tim Kelley (NCSU), Peter Kitanidis (Stanford), Bo Li (Purdue), Bani Mallick(Texas A&M), Lucy Marshall (U. of Montana), Arnst Maarten (Universite de Liege, Belgium),Sean McKenna (Sandia), Sergey Oladyshkin (U. of Stuttgart), Bruce Pitman (U. at Buffalo), JuanRestrepo (U. of Arizona), Fabrizio Ruggeri (CNR IMATI, Italy), Leonard Smith (London Schoolof Economics & Political Science), Margaret Short (U. of Alaska), Robert Wolpert (Duke), YiminXiao (Michigan State), Peng Zeng (Auburn), Xiang Zhou (Brown).
3 Activities and timing
• A planning workshop was held at SAMSI on April 6, 2010. The goal of that meeting wastwofold. First, we gathered about 30 experts who helped us the design the program as it nowstands. Second, the meeting was the initiation point of both a new SIAM activity group onuncertainty quantification, see http://www.siam.org/activity/uq/, and a sister interestgroup within the ASA. The SIAM activity group is now fully operational. Its three mainofficers –Don Estep (Colorado State), Max Gunzburger (Florida State) and Habib Najm(Sandia)– have major organizational responsibilities with the SAMSI UQ program. Theefforts within the ASA are led by Dave Higdon (LANL) who is also heavily involved in thepreparation of the program.
• Linked to the above SIAM activity group, there will be a SIAM conference on UncertaintyQuantification, April 2-4, 2012, in Raleigh, NC, see http://www.siam.org/meetings/uq12/.The conference is organized in cooperation with SAMSI. The location was chosen to maxi-mize interactions with the SAMSI UQ program participants. Gremaud is on the organizingcommittee.
• In collaboration with Sandia (Jim Stewart), we have organized a UQ Summer School, seehttp://www.samsi.info/workshop/samsisandia-summer-school-uncertainty-quantification.The summer school will place in Albuquerque, NM, next to Sandia, June 20-24, 2011. Thefour main presenters are Dan Cooley (Colorado State), Doug Nychka (NCAR), Adrian Sandu

248
(Virginia Tech) and Dongbin Xiu (Purdue). They will respectively address the issues ofstatistical analysis of rare events, data assimilation and applications in climate modeling,variational data assimilation and sensitivity analysis and polynomial chaos for differentialequations. These main presentations will be complemented by talks from UQ practitioners,namely Mihail Anitescu (ANL), Mike Eldred (Sandia), Jon Helton (Sandia), Dave Higdon(LANL), Gardar Johannesson (LLNL), Laura Swiler (Sandia), Charles Tong (LLNL).
• The SAMSI UQ program will officially open in late August-September with four openingworkshops
– Climate opening workshop, August 29-31, 2011, Pleasanton, CA.
– Opening Workshop and tutorials: Methodology of Uncertainty Quantification, Septem-ber 7-10, 2011, Radisson/SAMSI, RTP, NC.
– Engineering/energy opening workshop, September 19-21, 2011, Radisson/SAMSI, RTP,NC.
– Geosciences opening workshop, September 21-23, 2011, Radisson/SAMSI, RTP, NC.
The Climate program will start in Pleasanton, CA, next to Lawrence Livermore NationalLaboratory to facilitate interactions with the climate research groups there. Satellite activitieswill be held at LLNL the day after the workshop. During the workshop proper, presentationson the LLNL activities related to climate will be given. The formation of SAMSI workinggroups located at the labs (LLNL and/or LANL) is expected.
• Specialized workshops will be held during the year. For the Engineering program for instance,we will organize individual mid-program workshops on (i) renewable energy (Habib Najm(Sandia) and Youssef Marzouk (MIT) organizers), (ii) nuclear energy (Jim Stewart (Sandia)and Hany Abdel-Khalik (NSCU) organizers), (iii) sustainability (Don Estep (Colorado State),Roger Ghanem (USC) and Miriam Heller (MHITech Systems) organizers), engineered systems(Roger Ghanem (USC) organizer) and materials (Wei Chen (Northwestern) and Wing KamLiu (Northwestern) organizers).
• We are also in the final stages of preparation for a workshop on SmartGrid (George Michai-lidis (Michigan) organizer), at SAMSI, Oct. 3-5, 2011. This workshop will be in cooperationwith the Future Renewable Electric Energy Delivery and Management (FREEDM) Systemscenter at NCSU. The program will cover some broad themes such as large scale dynamics,monitoring problems, design aspects of the SmartGrid. Prospective speakers include Rus-sell Bent (LANL), William Booth (US Energy Information Administration), Alex Huang(FREDM Center and NCSU), Marija Ilic (CMU), Sean Meyn (UIUC), Bryan Richardson(Sandia), Anna Scaglione (U. Washington), James Thorp, (Virginia Tech), Pravin Varaiya(UC Berkeley).
• Two graduate courses will be proposed. One in Fall 2011 will focus on methodology; the otherin Spring 2012 will focus on applications. Dongbin Xiu (Purdue) will be the lead instructorfor both courses.

249
• Working groups will pursue research throughout the year.
4 Relationships
4.1 Affiliates
Many of our university affiliates have researchers strongly involved with UQ issues. Our corporateaffiliates have interest in UQ, and have been contacted.
4.2 Partner universities
There is serious interest in this area in virtually every one of the SAMSI affiliated partner universitydepartments. Eleven faculty members will be given release from a course to participate in theprogram, along with 12 graduate students. Many others are expected to also participate.
4.3 National laboratories and governmental agencies
Several of the national labs have been significantly involved so far.
• We have organized an already successful (highly oversubscribed) UQ Summer School jointlywith Sandia, see above. Other potential participants include John Helton, Scott Mitchell,Martin Pilch, Laura Painton Swiler, Tim Trocano, James Stewart, Mike Eldred, Eric Phipps,Brian Adams, John Red-Horse, Brian Carnes, Angel Urbina, Rich Field, Paul Constantine,Keith Dalbey, Bert Debusschere, Habib Najm, Helgi Adalsteinsson, and Cosmin Safta.
• The opening workshop of the SAMSI UQ program on Climate will be held in Pleasanton, CA,next to LLNL. The organization of the workshop and indeed the program is done in closecollaboration with LLNL researchers (Don Lucas, Gardar Johannesson). Other potentialLLNL participants include Xabier Garaizar, Carol Woodward, Charles Tong, Jeff Hittinger,Jeff Banks, Bill Henshaw, Bjorn Sjogreen, Gardar Johannesson Gardar, Bill Hanley, SteveLee, Anders Petersson, Panayot Vassilevski, Stephen Guzik, Kambiz Salari, Ping Wang, DanLaney, Timo Bremer, Peter Lindstrom, and Fady Najjar.
• LANL will also be heavily involved in the program; David Higdon (Head of Statistical Sci-ences) is one the main organizers of the UQ program. Other potential participants in-clude Mark Anderson, Scott Doebling, Michael Hamada, Christine Anderson Cook, KenHanson, Francois Hemez, Nick Hengartner, Randy Michelsen, Lisa Moore, Charlie Nakhleh,Amanda Rutherford, Jim Smith, Chuck Farrar, Ryan Maupin, Jason Pepin, Francois Hemez,Derek Armstrong, David Sigetti, Diane Vaughan, Jim Cooley, Clint Scovel, Don Hush, FrankAlexander, Dave Moulton, Pieter Swart, Humberto Godinez, Brian Williams, Nick Hengart-ner, and Jim Gattiker.
• Smaller groups at Pacific Northwest National Laboratory, Idaho National Laboratory, Ar-gonne National Laboratory, and Oak Ridge National Laboratory have been contacted.

250
• NCAR has significant interests in the area, in the climate arena especially. Contacts includeJoe Tribbia, Chris Snyder, Jeff Anderson, Grant Branstator, Amik St Cyr, Thomas Hopson,Luca della Monache, Doug Nychka, Matt Pocernich, Eric Gilleland, Mandy Hering, RickKatz, Claudia Tebaldi and Steve Sain.
• Triangle-base organizations such as EPA and NIEHS have numerous interests in UQ, andthere involvement in the program is being sought.
4.4 Other NSF institutes
Several of the NSF math/stat institutes will be having programs and themes related to at least someof the issues outlined above at one point or another. There also are also recent workshops or eventsbeing planned that directly relate to UQ issues, such as the two IMA workshops described at http://www.ima.umn.edu/2010-2011/W10.18-22.10/ and http://www.ima.umn.edu/2010-2011/W6.
6-10.2011/. The overall focus of the IMA program is on modeling in general and in that senseis quite close to the 2006-07 SAMSI program on the Development, Assessment and Utilization ofComplex Computer Models. Our upcoming UQ program is much more focused on UQ proper andwill offer a unique link between methodology and the three applied fields of climate, engineeringand geosciences.

259
Appendices
A. Final Report: 2008-09 Program on Sequential Monte Carlo Methods
B. Final Report: 2008-09 Program on Algebraic Methods in Systems
Biology and Statistics
C. Final Report: Summer 2008 Program on Meta-analysis: Synthesis
and Appraisal of Multiple Sources of Empirical Evidence
D. Final Report: Summer 2009 Program on Psychometrics
E. Workshop Participant Lists
F. Workshop Programs and Abstracts
G. Workshop Evaluations

SEQUENTIAL MONTE CARLO METHODS
Final Report
Program Leaders: Arnaud Doucet and Simon Godsill
1 Program and its Objectives:
This aim of this 12 month SAMSI program was to develop new approaches to scientific/statisticalcomputing using innovative sequential Monte Carlo (SMC) methods. The program addressedfundamental challenges in developing effective sequential and adaptive simulation methodsfor computations underlying inference and decision analysis. The research blended concep-tual innovation in new and emerging methods with evaluation in substantial applied contextsdrawn from areas such as control, communications and robotics engineering, financial andmacro-economics, among others. Researchers from statistics, computer science, informationengineering and applied mathematics were involved, and the program promoted the oppor-tunity for both methodological and theoretical research. The interdisciplinary aspects of theprogram were substantial, as was the attractiveness for students and postdocs.
2 Background
Monte Carlo (MC) methods are central to modern numerical modelling and computation incomplex systems. Markov chain Monte Carlo (MCMC) methods provide enormous scope forrealistic statistical modelling and have attracted much attention from disciplinary scientistsas well as research statisticians. Many scientific problems are not, however, naturally posedin a form accessible to evaluation via MCMC, and many are inaccessible to such methodsin any practical sense. For example, for real-time, fast data processing problems that in-herently involve sequential analysis, MCMC methods are often not obviously appropriate atall due to their inherent ”batch” nature. The recent emergence of sequential MC conceptsand techniques has led to a swift uptake of basic forms of sequential methods across sev-eral areas, including communications engineering and signal processing, robotics, computervision and financial time series. This adoption by practitioners reflects the need for newmethods and the early successes and attractiveness of SMC methods. In such, probabilitydistributions of interest are approximated by large clouds of random samples that evolveas data is processed using a combination of sequential importance sampling and resamplingideas. Variants of particle filtering, sequential importance sampling, sequential and adaptiveMetropolis MC and stochastic search, and others have emerged and are becoming popularfor solving variants of ”filtering” problems; i.e. sequentially revising sequences of probabilitydistributions for complex state-space models. Useful entree material and examples SMC
260

methods can be found at the following SMC preprint site. Many problems and existingsimulation methods can be formulated for analysis via SMC: sequential and batch Bayesianinference, computation of p-values, inference in contingency tables, rare event probabili-ties, optimization, counting the number of objects with a certain property for combinatorialstructures, computation of eigenvalues and eigenmeasures of positive operators, PDE’s ad-mitting a Feynman-Kac representation and so on. This research area is poised to explode,as witnessed by this major growth in adoption of the methods.
The SAMSI SMC program aims were to:• Address methodological and theoretical problems of SMC methods, including syn-
thesis of concepts underlying variants of SMC that have proven apparently successful acrossmultiple fields, and the development of methodological and theoretical advances.
• Develop the methodological research – with broad opportunities for test-bed exam-ples, methods evaluation and refinement of generic approaches – in the contexts of a numberof important applied problems (e.g. data assimilation, inference for large state spaces, fi-nance, tracking, continuous time models).
The program was an opportunity for exchange between communities, helping, we hope, toshape the future of stochastic computation and sequential methods, involving statisticians,computer scientists and engineers as core participants as well as others working collabora-tively in a range of applied fields.
3 Core Group
A core group of researchers have been based at SAMSI, complemented by external partici-pants in the various working groups, which held weekly meetings via Webex connections toSAMSI.
3.1 Local faculty
• Mark Huber (Duke)
• Mike West (Duke)
• Nilay Argon (UNC)
3.2 Senior researchers (at SAMSI for significant periods of timein Fall, 2008):
• Susie Bayarri (University Valencia)
• Jaya Bishwal (University North Carolina Charlotte)
• Carlos Carvalho (University of Chicago)
• Arnaud Doucet (University British Columbia)
• Pena Edsel (University South Carolina)
261

• Liu Fei (University Missouri)
• Marco Ferrante (University Pavia)
• Nathan Green (DSTL)
• Hedibert Lopes (University of Chicago)
• Raquel Prado (University Santa Cruz)
• Sylvain Rubenthaler (University Nice)
• Yoshida Ryo (Institute Statistical Mathematics)
• Jochen Voss (University Warwick)
3.3 Researchers (Spring and Summer, 2009)
• Daniel Clark (University Herriott Watt)
• Mark Coates (University Mc Gill)
• Paul Fearnhead (University of Lancaster)
• Andrew Thomas (University St Andrews)
• James Lynch (University South Carolina)
• Ernest Fokoue (Kettering University US)
3.4 Postdoctoral fellows
• Ioanna Manolopoulou
• Das Sourish
3.5 Postdoctoral associates
• Armagan Artin (Duke)
• Christian Macaro (Duke)
• Julien Cornebise (University Paris VI)
• Gentry White (NSCU)
• Elizabeth Shamseldi (Duke)
• Bin Liu (Duke)
262

3.6 Graduate students
• Melanie Bain (Duke)
• Luke Bornn (University British Columbia)
• Deidra Coleman (NCSU)
• Ana Corberan (University of Valencia)
• Thomas Flury (Oxford University)
• Roman Holenstein (University British Columbia)
• Chunlin Ji (Duke)
• Olasunkanmi Obanubi (Imperial College)
• Gareth Peters (University New South Wales)
• Francesca Petralia (Duke)
• Sarah Schott (Duke)
• Minghui Shi (Duke)
• Baqun Zhang (NCSU)
4 Program Organization
4.1 Opening workshop
The Opening Workshop was held during September 7-10, 2008 at SAMSI, organized byArnaud Doucet (British Columbia), Simon Godsill (Cambridge) and Mike West (Duke Uni-versity). This highly successful event engaged significant parts of the statistical, engineeringand mathematics community, as well as others in econometrics and sciences, and includedthemed sessions from all of the main program topics (working groups).
Tutorial talks were given by four world leaders in the various areas of SMC: Pierre delMoral (Bordeaux), Paul Fearnhead (Lancaster), Hedibert Lopes (Chicago) and Jun Liu(Harvard). These were pitched at various levels, allowing useful participation by attendeesstarting in the area as much as those already expert in one or more topics. Themed conferencesessions were arranged to have a good balance between senior invited talks, new researchertalks and panel discussion. Most sessions stimulated very active discussion.
At a break-out session on the final afternoon, Working Group leaders were allocatedand a broad declaration of interest was obtained from all workshop participants for theirsubsequent participation in the program.
263

4.2 Undergraduate workshop
The SAMSI Two-Day Undergraduate Workshop was held from October 31 - November 1,2008. There were nine technical talks given by Jaya Bishwal, Jochen Voss, Gentry White,Nathan Green, Christian Macaro, Sourish Das, Julien Cornebise, Ioana Maolopoulou andFrancesca Petralia, covering many aspects of SMC from basic methodology to applicationsin finance and defence. There was be also an interactive R session.
4.3 Fall SAMSI course on sequential Monte Carlo
This course provided an introduction to sequential Monte Carlo methodology, theory andapplications. It was attended by approximately 40 people. Topics covered include: intro-duction to SMC, advanced SMC methods, SMC methods for parameter estimation in generalstate-space models, SMC methods as alternative to MCMC methods. The main instructorwas Arnaud Doucet and two ’invited’ instructors gave some lectures: Christophe Andrieu(Bristol) and Alexander Chorin (Berkeley).
4.4 Mid-term workshop
A mid-term workshop was organised on 19-20 Feb 2009 at the SAMSI Institute. This hadparticipants from most of the working groups, including the leaders of the Continuous Time(Fearnhead - Lancaster), Tracking (Godsill - Cambridge), Big Data (West - Duke), Parame-ter Learning (Lopes - Chicago) and Model Assessment (Carvalho - Chicago) working groups.These leaders gave overviews of progress in the different working groups and other partici-pants gave research updates on SAMSI related work. Three of the 15 talks were deliveredsuccessfully by Webex from remote locations. A particular focus of talks and discussion wasthe Tracking working group, which assembled many of its participants at the workshop.
4.5 Adaptive Design Workshop
An Adaptive Design, Computer Modeling and SMC workshop organized by Jim Berger andSuzie Bayarri was held from April 15-17, 2009; see http://www.samsi.info/workshop/smc-adaptive-design-sequential-monte-carlo-and-computer-modeling-workshop-april-15-17-2009 fordetails. There were 13 speakers.
4.6 Transition workshop
The transition workshop was held at SAMSI from 9-10 Nov. 2009; see http://legacy.samsi.info/workshops/2008smc-transition200911.shtml for details. There were 20 talks and all the working groups wererepresented.
4.7 Working groups
The working groups met weekly throughout the program. The topics were• Tracking and Large-Scale Dynamical Systems
264

• Theory• Population Monte Carlo• Continuous Time• Parameter• Model Assessment• Big Data
4.7.1 Tracking and Large-scale dynamical systems
The working group leaders were Simon Godsill (whole year) and Nathan Green (Fall 08).Regular participants included: Mark Briers (QinetiQ, UK), Daniel Clark (Heriot-Watt
University UK), Avishi Carmi (Cambridge University UK), Julien Cornebise (SAMSI post-doc), Ernest Fokoue (Kettering University US), Simon Godsill (Cambridge University -program leader), Nathan Green (DSTL UK, long-term Fall 08 visitor) Chunlin Ji (DukeUniversity - SAMSI Grad. student), Sze Kim Pang (Cambridge University UK), Gareth Pe-ters (Univ. New South Wales, SAMSI Fall 08 visitor), Viktor Rozgic (University of SouthernCalifornia), Francois Septier (Cambridge University, UK), Joshua Vogelstein (Johns HopkinsUniversity), Gentry White (N.C. State University - SAMSI Post-doc), Namrata Vaswani(Iowa State University)
Working group - organisation This working group has focussed on methodology forproblems in high-dimensional tracking, with applications in computer vision, tracking, me-teorology, biological imaging, etc. Standard particle filters do not perform satisfactorily inthis scenario and hence we are pushing the methodology further by development of novelapproaches. These include elements of Markov chain Monte Carlo-based filters, genetic al-gorithm approaches and SMC samplers. The goals of the working group are be to producepapers on various topics involving multiple participants from the group, leading to future col-laborative projects across a number of disciplines. The theme was organised into sub-groupsaddressing the following areas:
Subgroup 1: Multiple target tracking (lead Francois Septier (Cambridge)):Participants include Simon Godsill, Francois Septier, Chunlin Ji, Mark Briers, Viktor
Rozgic, Ernest Fokoue, Daniel ClarkThe aim of this sub-group was to research new methodologies for high-dimensional and
structured tracking problems using SMC. We have generated standard datasets, test sce-narios and data simulation code for multiple target tracking with random birth and deathof objects and various sensor characteristics based on point process models or pixellatedimage data. A number of methodologies have been tested on this scenario, including novelMCMC-based particle filters, resample-move filters, SMC samplers, variational Bayes, etc.New smoothing methods for random finite set models have also been developed by Dan Clark.In addition we have done work in detection and tracking of dynamic group objects, usinga virtual-leader formulation and adaptations of our previous SDE-based models, and withdynamic graph structures, tracked over time with SMC. The main interest here is to trackformations of objects which have a common pattern of motion. The movement of the wholegroup is of interest rather than tracking each object separately. Groups of targets can beconsidered as formations of entities whose number varies over time because targets can enter
265

a scene, or disappear at random times. The groups can split, merge, to be relatively nearto each other or move largely independently on each other. However, it is typical for groupformations to maintain some patterns of movement. Monte Carlo approaches combined withevolving random graphs is proposed for group object state and structure estimation weredeveloped and published by the Cambridge and Lancaster groups.
The Various participants have benefitted from the collaborations as can be seen from thelarge number of high quality publications arising from this working group.
1. S. K. Pang, S. Godsill, J. Li, F. Septier, and S. Hill. ”Sequential Inference for Dy-namically Evolving Groups of Objects” a Chapter in ”Bayesian Time Series Models”edited by D. Barber, A.T. Cemgil and S. Chiappa, Cambridge University Press, 2010ISBN : 9780521196765.
2. F. Septier, S. K. Pang, A. Carmi, and S. Godsill. ”On MCMC-Based Particle Methodsfor Bayesian Filtering : Application to Multitarget Tracking” in IEEE InternationalWorkshop on Computational Advances in Multi-Sensor Adaptive Processing (CAM-SAP 2009), Aruba, Dutch Antilles, Dec. 2009
3. F. Septier, A. Carmi, and S. Godsill. ”Tracking of Multiple Contaminant Clouds” inProc. Int. Conf. on Information Fusion (FUSION 2009), Seattle, USA, Jul. 2009Winner of the third best regular paper award.
4. A. Carmi, F. Septier, and S. Godsill. ”The Gaussian Mixture MCMC Particle Al-gorithm for Dynamic Cluster Tracking” in Proc. Int. Conf. on Information Fusion(FUSION 2009), Seattle, USA, Jul. 2009 [BIBTEX]
5. F. Septier, A. Carmi, S. K. Pang, and S. Godsill. ”Multiple Object Tracking UsingEvolutionary and Hybrid MCMC-Based Particle Algorithms” in 15th IFAC Symposiumon System Identification, (SYSID 2009), Saint-Malo, France, Jul. 2009 Invited paper.
6. . F. Septier, S. K. Pang, S. Godsill, and A. Carmi. ”Tracking of Coordinated Groupsusing Marginalised MCMC-based Particle Algorithm” in IEEE Aerospace Conference,Big Sky, Montana, Mar. 2009
7. A. Carmi, S. Godsill, and F. Septier. ”Evolutionary MCMC Particle Filtering forTarget Cluster Tracking” in IEEE 13th DSP Workshop and the 5th SPE Workshop,Marco Island, Florida, Jan. 2009
8. Variational Mean Field Approach to Efficient Multitarget Tracking. E. Fokoue. JSMProceedings 2009.
9. Sequential Monte Carlo Smoothing with Random Finite Set Observations. D. Clarkand M. Briers. JSM Proceedings 2009
10. First-Moment Multi-Object Forward-Backward Smoothing Daniel E. Clark Interna-tional Conference on Information Fusion, 2010
11. Extended object filtering using spatial independent cluster processes A Swain, D ClarkInternational Conference on Information Fusion, 2010
266

12. Improved SMC implementation of the PHD filter B Ristic, D Clark, B N Vo, Interna-tional Conference on Information Fusion, 2010
13. Performance evaluation of multi-target tracking using the OSPA metric B Ristic, B NVo, D Clark International Conference on Information Fusion 2010
14. First-moment filters for spatial independent cluster processes. A. Swain and D. E.Clark. SPIE Defense, Security and Sensing Symposium, 2010.
15. Forward-Backward Sequential Monte Carlo Smoothing for Joint Target Detection andTracking, D. Clark, B.-T. Vo and B.-N. Vo, IEEE Proc. 12th Annual Conf. InformationFusion, Seattle, Washington, 2009.
16. A. Gning, L. Mihaylova, S. Maskell, S. K. Pang, and S. Godsill, Group object struc-ture and state estimation with evolving networks and monte carlo methods, IEEETransactions on Signal Processing, 2010.
17. , Ground target group structure and state estimation with particle filtering, in Proc.of Interna- tional Conf. on Information Fusion, Germany, Cologne, 2008.
18. , Evolving networks for group object motion estimation, in Proc. of IET Seminar onTarget Tracking and Data Fusion: Algorithms and Applications, Birmingham, UK,2008, pp. 99106.
19. H. Bhaskar, L. Mihaylova, and S. Maskell, Population-based particle filters, in Proc.from the Insti- tution of Engineering and Technology (IET) Seminar on Target Trackingand Data Fusion: Algorithms and Applications, Birmingham, UK, 2008, pp. 3138.
20. H. Bhaskar, L. Mihaylova, S. Maskell, and S. Godsill, Evolving population MarkovChain Monte Carlo particle filtering, Journal paper (in preparation).
21. H. Bhaskar, L. Mihaylova, and A. Achim, Video foreground detection based on sym-metric alpha-stable mixture models, IEEE Transactions on Systems and Circuits forVideo Technology, 2010, in press.
22. D. Angelova and L. Mihaylova, Contour segmentation in 2d ultrasound medical imageswith particle filtering, Machine Vision and Applications Journal, 2010, in press.
23. L. Mihaylova, D. Angelova, D. Bull, and N. Canagarajah, Localisation of mobile nodesin wireless sensor networks with time correlated measurement noises, IEEE Transac-tions on Mobile Computing, 2010, in press.
24. L. Mihaylova and D. Angelova, Noise parameters estimation with Gibbs sampling forlocalisation of mobile nodes in wireless networks, in Proc. of the 13th InternationalConference on Information Fusion. ISIF, Edinburgh, UK, 2010.
25. A. Gning, L. Mihaylova, and F. Abdallah, Mixture of uniform probability densityfunctions for nonlinear state estimation using interval analysis, in Proc. of 13th Inter-national Conference on Information Fusion. ISIF, Edinburgh, UK, 2010.
267

26. L. Mihaylova, A. Gning, V. Doychinov, and R. Boel, Parallelised gaussian mixturefiltering for vehicular traffic flow estimation, in Informatik 2009, Lecture Notes inInformatics (LNI) - Proceedings Series of the Gesellschaft fur Informatik (GI), Eds. S.Fischer, E. Maehle, R. Reischuk, Vol. P-154. Germany, Luebeck, 2009, p. 2321 2333.
27. J.A. Pocock, S.L. Dance and A.S. Lawless (2010) State Estimation using the ParticleFilter with Mode Tracking, submitted to Computers and Fluids
28. M. Hong, M. F. Bugallo, and P. M. Djuric, ”Joint Model Selection and ParameterEstimation by Population Monte Carlo Simulation,” to appear in Journal of SelectedTopics in Signal Processing, 2009.
29. B. Shen, M. F. Bugallo, and P. M. Djuric, ”Multiple marginalized population MonteCarlo,” accepted in EUSIPCO 2010.
30. M. F. Bugallo and P. M. Djuric, ”Target tracking by symbiotic particle filtering,”Proceedings of the 2010 IEEE Aerospace Conference, Big Sky (Montana, USA), March2010.
31. M. F. Bugallo, M. Hong, and P. M. Djuric, ”Marginalized population Monte Carlo,”Proceedings of the IEEE 34th International Conference on Acoustics, Speech and SignalProcessing (ICASSP’2009), Taipei (Taiwan), April 2009.
32. P. M. Djuric and M. F. Bugallo, ”Improved target tracking with particle filtering,”Proceedings of the 2009 IEEE Aerospace Conference, Big Sky (Montana, USA), March2009.
33. M. F. Bugallo and P. M. Djuric, ”Complex systems and particle filtering,” Proceed-ings of the Asilomar Conference on Signals, Systems, and Computers, Paci c Grove(California, USA), November 2008.
PhD Student: Viktor Rozgik Viktor Rozgic PhD Student, Advisor: Prof. ShrikanthNarayanan
Signal Analysis and Interpretation Laboratory Viterbi School of Engineering Universityof Southern California
Research and Impact to ThesisI have found information about SAMSI opening workshop online and since I have been
using Sequential Monte Carlo (SMC) methods in my work before I decided to attend it.I found the talks very interesting and I got involved in work of the Tracking Workgroupwhich was the good match for the topic of my thesis ”Multimodal fusion for tracking andidentification in Smart Environments”. Collaboration with the grop members, talks I haveheard in the workshops and weekly group meedings; and references and papers in progressshared over the group’s webpage were very helpfull for my thesis work. Besides gettinga much better perspective on the state-of-the-art Sequntial Monte Carlo Algorithms andunderstanding the current research directions I had a hands-on-experience in implementationand testing of the SMC algorithms on the synthetic multi-target tracking problem. For thisoportunity I feel very gratefull to Prof. Simon Godsill and Dr. Francois Septier. I have
268

managed to transplant and adapt part of this work to problems of audio-visual tracking,speaker segmentation and identitfication in meeting scenarios. Proposed work for the finalpart of my thesis includes work on multitarget tracking algorithms which is not focused onlyon the Meeting Monitoring environments and I hope that I am going to be able to continuecollaboration with people I have meet during the workshop in the following period.
Subgroup 2: Biological Cell tracking (lead Chunlin Ji):Participants include: Chunlin Ji, Simon Godsill, Daniel Clark.This group interfaces also with the multiple target tracking sub-group, being concerned
with video imaging data involving fluorescently labelled multiple cells, which move around,grow, divide, etc. They have investigated a number of approaches including point processbased methods, including PHD filters, and also pixel-based likelihood functions. Datasetshave already been provided by Duke researchers. Two papers are in preparation:
• C. Ji & M. West (2009) Bayesian Nonparametric Modelling for Time-varying SpatialPoint Processes
Chunlin Ji (SAMSI RA) is attached to the Tracking (Godsill) working group and participatesactively in the Big data group with West on spatial dynamic modelling for biologicalcell tracking problems. Ji is developing SMC methods in the context of new classes ofmodels. This research has grown out of existing work of Ji & West in static problems,now extended with new dynamic models that will form an additional part of Ji’sPhD thesis research, and one initial paper is in draft at the time of this report (seemanuscripts section). Ji has led discussions on this work at several Tracking workinggroup and Big data group meetings, gave a talk at the February 2009 mid-programworkshop, and will present this work at the 7th Workshop on Bayesian Nonparametricsin Turin, Italy, in June 2009, and at the 2009 Joint Statistical Meetings in WashingtonDC 2009.
• C. Ji & M. West (2009) Bayesian Nonparametric Modelling for Time-varying SpatialPoint Processes
A grant application has gone in from Dan Clark to the UK’s BBSRC Tools and Resourcespanel (New Investigator program) on cell tracking work
[Bin Liu] (SAMSI RA) was attached to the Tracking (Godsill) working group.Since Feb. 2009, I participated this SMC program in SAMSI as a postdoc (or research
scholar). I have three papers, which are related to this program. Now I list them in thefollowing.
1) Bin Liu, Merlise Clyde, Tom Loredo and Jim Berger. Adaptive Annealed ImportanceSampling Method for Calculating Marginal Likelihood with Application to Bayesian Exo-planets Detection. We’re revising the manuscript and will submit it soon.
2) Bin Liu, Chunlin Ji, Yangyang Zhang and Chengpeng Hao. Multi-target Trackingin Clutter with Sequential Monte Carlo Methods (first drafft prior to coming to SAMSI).Accepted by IET Radar, Sonar & Navigation.
3) Bin Liu, Chunlin Ji, Yangyang Zhang, and Chengpeng Hao. Blending Sensor Schedul-ing Strategy with Particle Filter to Track a Smart Target, Wireless Sensor Networks.
269

All the above works are supported by Profs. Merlise Clyde and Jim Berger’s Astro fund,namely, National Science Foundation of the USA under Grant No. 0507481.
Subgroup 3: Covert chemical release (lead Nathan Green):Participants include: Nathan Green, Francois Septier, Avishy Carmi, Simon Godsill,
Mark Briers, Gareth Peters.This topic involves plume tracking and source term estimation, exploring contour track-
ing, cloud tracking, ABC methods, SMC samplers and other novel techniques. The subgrouphas produced models and simulation code for the source term estimation problem, in whichthe task is to estimate the location of a covert chemical release through sequential monitoringof the pattern of the resulting chemical plume. DSTL have agreed in principle to provideLIDAR data for this problem, and this is still being negotiated at the time of this report. Anumber of advances have been made in the area.
For the pure cloud tracking problem (without source term estimation), we have studiedthe problem of sequential inference about complex evolving cloud structures from LIDARdata, presently all simulated from models. A dynamic Gaussian mixture approximation withunknown number of components is used for the cloud intensity. Some very successful resultswere obtained from very ambiguous thresholded data, which have impressed specialists atQinetiQ UK Ltd. and DSTL UK Ltd. A paper is submitted to the 2009 Fusion conference,and a further paper is in preparation for the SYSID conference:
• Tracking of Multiple Contaminant Clouds. Francois Septier, Avishy Carmi, SimonGodsill. Fusion 2009 (submitted).
• Multiple Object Tracking Using Evolutionary and Hybrid MCMC-Based Particle Al-gorithms. F. Septier, A. Carmi, S. K. Pang and S. J. Godsill. SYSID 2009.
In addition to this, work on sequential source term estimation has been undertaken usinga new trans-dimensional ABC algorithm that is able for the first time to detect multipleunknown covert releases. A survey paper has been submitted already and a paper on theSTEM application is also under preparation:
• S.A. Sisson, G. W. Peters, Y. Fan, and M. Briers, Likelihood-free samplers, JournalSubmission, Dec 2008.
• G. W. Peters, M. Briers and ... Trans-dimensional ABC for source term estimation, Inpreparation.
This work has also led to an invite to the ABC workshop in Paris, June 2009. The workhas attracted serious attention from the UK’s DSTL defence organisation and is very likelyto lead to new grant funding in the near future.
A final sub-topic in this area concerns emulation-based methods for approximation ofcomplex source term simulation problems. A paper is in preparation:
• Emulation Based Priors for Source Term Estimation. Gentry White and Nathan Green,in preparation.
270

This looks into using an emulation based approach to construction priors for use in asequential Monte Carlo model for source term estimation. This emulation based approach al-lows for the construction of priors based on prior information from both computer models aswell as field data. These priors offer advantages over existing priors in that they avoid degen-eracy in the SMC simulation. This work draws on work from the previous SAMSI programon Development, Assessment and Utilization of Complex Computer Models, including workfrom the Engineering Methodology working group and the paper ”Mechanism-Based Emu-lation of Dynamic Simulation Models: Concept and Application in Hydrology” (Reichert et.al 2009). currently under submission.
Subgroup 4: Neuron tracking (lead Joshua Vogelstein):This topic involves tracking of multiple neuronal activity measured in living brains and
involves learning of sparse connectivity matrices in continuous-time spiking environments. Toinclude continuous time spike modelling, inference for multiple (sparsely connected) neurons,parameter estimation, image models.
The work progressed very pleasingly and the following papers were written:
• Spike Inference from Calcium Imaging Using Sequential Monte Carlo Methods, JoshuaT. Vogelstein, Brendon O. Watson, Adam M. Packer, Rafael Yuste, Bruno Jedynakand Liam Paninski, Biophysical Journal, Volume 97, Issue 2, 636-655, 22 July 2009.
• A BAYESIAN APPROACH FOR INFERRING NEURONAL CONNECTIVITY FROMCALCIUM FLUORESCENT IMAGING DATA, Yuriy Mishchencko, Joshua T. Vogel-stein, and Liam Paninski, to appear in the Annals of Applied Statistics
Other works are in progress, in particular, modifying the original smc work to utilize Rao-Blackwellization. They also plan on improving the parameter estimation in the work, po-tentially by replacing the EM step with a fully Bayesian sampling step.
Regular participants include: Mark Briers (QinetiQ, UK), Daniel Clark (Heriot-WattUniversity UK), Avishi Carmi (Cambridge University UK), Julien Cornebise (SAMSI post-doc), Ernest Fokoue (Kettering University US), Simon Godsill (Cambridge University -program leader), Nathan Green (DSTL UK, long-term Fall 08 visitor) Chunlin Ji (DukeUniversity - SAMSI Grad. student), Sze Kim Pang (Cambridge University UK), Gareth Pe-ters (Univ. New South Wales, SAMSI Fall 08 visitor), Viktor Rozgic (University of SouthernCalifornia), Francois Septier (Cambridge University, UK), Joshua Vogelstein (Johns HopkinsUniversity), Gentry White (N.C. State University - SAMSI Post-doc), Namrata Vaswani(Iowa State University)
4.7.2 Theory
The Theory working group was led by Mark Huber (Duke). The goal was to develop andanalyze algorithms arising in SMC and MCMC applications. The plan of attack was toexamine several techniques from both fields, and attempt to answer questions such as: 1)when can a method from one field be used in the other, and 2) is it possible to provesomething about the running time of these methods as algorithms? This second questiontypically reduces to questions about rate of convergence, or the variance of estimators.
271

Participants include Petar Djuric (Stony Brook), Jan Hannig (UNC), Jim Lynch (U.South Carolina), Jonathan Mattingly (Duke), Edsel Pena (U. South Carolina), Gareth Peters(SAMSI), Giovanni Petris (Arkansas), Clyde Schoolfield (Florida), Sarah Schott (Duke),Namrata Vaswani (Iowa State), Anand Vidyashankar (Cornell).
The theory working group has been exploring relationships between Markov chain ap-proximations and SMC methods, with an eye towards provably good methodologies. Un-fortunately, most of the existing work relies on having rapidly mixing Markov chains, atwhich point the use of SMC is not necessary. However, proper use of Monte Carlo samplesremains a difficult issue. Therefore, we have started concentrating on a very general method-ology called the ”Product Estimator” for moving from samples to approximate integration.This method is very versatile and does not rely on having bounded variance of the randomvariables used in the Monte Carlo algorithm. Current analysis, however, relies on usinga medians-of-averages approach. An approach using pure averages should converge morequickly, but this makes the analysis more difficult, requiring study of products of binomialrandom variables. The eventual goal is a tighter bound on the tails of these distributions,moving from what is now a constant of 16 to a value of 2.
Graduate student: Sarah Schott.Since our working group lacked a postdoc, Sarah was organizing the meetings and keeping
our web page. On the research side, she worked on the product estimator problem describedabove, beginning with simulation studies and currently working to extend large deviationsinequalities for binomials from sums to products.
Impact on researchInitially Mark Hubert introduced the product estimator as a side algorithm, a participant
in the working group asked the question about the tightness of the constant. This raised aninteresting point, and as Sarah and Huber studied the problem further, it proved far moredeep a question than at first realized. In addition to this research avenue, the participantshave learned much about SMC methodology over the course of the program, and still hopeto utilize some of these methods in improving perfect simulation algorithms (the focus of myresearch program.)
4.7.3 Population Monte Carlo
The population Monte Carlo working group was led by Arnaud Doucet and Julien Cornebise.Following up the discussions at the kick-off workshop in September 2008, the Population
Monte Carlo working group was created to demonstrate the potential of Sequential MonteCarlo (SMC) methods for general stochastic computation problems. Although most of thecurrent work on SMC address on-line inference problems, the objectives of this group isto focus on the development of SMC and its variants to address problems where Markovchain Monte Carlo (MCMC) methods are traditionally used. Standard MCMC are typicallyinefficient for multimodal target distributions and the objectives of this group is to developpowerful particle alternatives.
We have worked on five specific topics plus a side-collaboration on a connected matter.
Subgroup 1: Adaptive SMC samplers and Population Monte Carlo algorithmsSMC samplers and Population Monte Carlo is a general methodology which can be used
as an alternative to MCMC methods. However it requires specifying a cooling schedule and
272

some proposal distributions. We have developed several methods to automatize the tuningof these key parameters. We proposed a new method which allows us to compute on-the-flya relevant cooling schedule. The resulting algorithms have been used to solve ApproximateBayesian Computation problems (in junction with Subgroup 3), and to perform inference instochastic volatility models. We have developed methodologies to design automatically theparameters of the proposal distributions, both for SMC Samplers and for Population MonteCarlo variants. We also proposed algorithms that use Rao-Blackellisation of the key steps ofPMC-related widespread algorithms to achieve variance reduction of the final estimates.
1. (Subgroup 1 and 4) Adaptivity for ABC algorithms: the ABC-PMC scheme. Beau-mont, M., Robert, C.P., Marin, J.-M. and Cornuet, J.M., Biometrika 96(4), 983-990(2009)
2. On variance stabilisation by double Rao-Blackwellisation. Iacobucci, A., Marin, J.-M.,and Robert, C.P., Computational Statistics and Data Analysis 54, 698-710. (2009)
3. Adaptive Sequential Monte Carlo algorithms, J. Cornebise, Ph.D. thesis, UniversityPierre et Marie Curie Paris 6 (2009)
4. Chain Ladder Method: Bayesian Bootstrap versus Classical Bootstrap. Gareth Pe-ters, Mario Wuthrich, Pavel Shevchenko - Insurance: Mathematics and Economics, toappear (2010)
5. (Subgroup 1 and 4) An adaptive SMC method for approximate Bayesian computation.Pierre Del Moral, Arnaud Doucet and Ajay Jasra, submitted January 2009.
6. Inference in Levy-driven stochastic volatility models. Ajay Jasra, Dave Stephens andArnaud Doucet, Scandinavian Journal of Statistics, 2010.
7. A vanilla Rao–Blackwellisation of Metropolis-Hastings algorithms. Douc, R. and Robert,C.P, Annals of Statististics, 2010.
8. Adaptive Multiple Importance Sampling, Cornuet, J.M., Marin, J.-M., Mira, A. andRobert, C.P., available as arXiv:0907.1254, submitted (2009)
9. An adaptive sequential Monte Carlo sampler. Paul Fearnhead and Benjamin M Taylor,submitted May 2010.
10. (Subgroup 1 and 4) Auxiliary SMC samplers with applications to Partial RejectionControl and Approximate Bayesian Computation. J. Cornebise, G. Peters, O. Rat-mann in preparation.
11. (Subgroup 1 and 3) Adaptation strategies for Particle Markov Chain Monte Carlo. J.Cornebise, G. Peters, in preparation.
Subgroup 2: SMC samplers for Normalizing Constant CalculationsIt is possible to use SMC to compute normalizing constants of high-dimensional distri-
butions. In physics this strategy is known as Jarzinsky’s equality. Recently an alternative
273

method known as nested sampling has appeared in the literature. This method enjoys severaladvantages compared to standard techniques. However, it remains inefficient when appliedto multimodal distributions. We are currently studying an adaptive SMC version of nestedsampling. Our preliminary results indicated that this new method outperforms significantlythe original nested sampling algorithm in complex scenarios. We are currently investigatingthe theoretical properties of the resulting estimate.
1. Particle nested sampling, Arnaud Doucet and Christian P. Robert, in preparation.
Subgroup 3: Particle Markov chain Monte CarloParticle MCMC is a new class of methods which allows us to use SMC proposals within
MCMC algorithms (Andrieu, Doucet & Holenstein, 2010). There are several open questionsto address such as selecting the optimal trade-off between the number of MCMC itera-tions/number of particles or how to select adaptively the number of particles as a functionof the current parameter value so as to ensure that the variance of the marginal likelihoodis below a given threshold. We are currently studying theoretically the performance of thesealgorithms so as to identify the optimal tradeoff; our study relies on new sharp convergenceresults for SMC estimates of normalizing constants. We have also proposed some extensionsof Particle MCMC methods which allow us to solve optimization problems. These extensionsrely on new combinatorial identities for SMC schemes.
1. Particle Markov chain Monte Carlo methods. C. Andrieu, A. Doucet and R. Holenstein,Journal of the Royal Statistical Society B (with discussion) (2010).
2. Comment on ”Particle Markov Chain Monte Carlo”. Julien Cornebise and GarethPeters (SAMSI technical Report) merged version of two comments sent to JRSSB(2010)
3. Ecological non-linear state space model selection via adaptive particle Markov chainMonte Carlo (AdPMCMC). Gareth Peters, Keith Hayes, Geoff Hossack (2010)
4. Channel Tracking for Relay Networks via Adaptive Particle MCMC. Ido Nevat, GarethPeters, Arnaud Doucet and Jinhong Yuan (2010)
5. (Subgroup 1 and 3) J. Cornebise, G. Peters, Adaptation strategies for Particle MarkovChain Monte Carlo, in preparation.
Subgroup 4: Likelihood-free inference and Approximate Bayesian Computa-tion (ABC) Likelihood-free inference is a rising challenge in Statistics, for models where thelikelihood of the observations is either intractable or very expensive to compute.ApproximateBayesian Approximations (ABC) algorithms, which replace the likelihood of the observationsby a distance on a space of summary statistics between Monte-Carlo-based simulated obser-vations and the data. Our subgroup developed the use of SMC Samplers as the cornerstonein the MC part of ABC algorithms in lieu of crude MC or of MCMC, using the coolingschedule of SMC samplers as a series of progressive thresholds on the distance of the sum-mary statistics, thus fighting the depletion of the sample and increasing dramatically the
274

computational efficiency. We also brought those ABC algorithms to numerous models andapplied problems where classical likelihood-based methods are helpless, especially in financialengineering, telecommunication relay systems, and in model choice for spatially correlateddata.
1. Design Efficiency for ”likelihood free” Sequential Monte Carlo samplers. Gareth Peters,Scott Sisson, Yanan Fan (2008)
2. (Subgroup 1 and 4) Beaumont, M., Robert, C.P., Marin, J.-M. and Cornuet, J.M.Adaptivity for ABC algorithms: the ABC-PMC scheme. Biometrika 96(4), 983-990.
3. On Sequential Monte Carlo, Partial Rejection Control and Approximate Bayesian Com-putation. Gareth Peters, Yanan Fan, Scott Sisson (2009)
4. Likelihood-Free Bayesian Inference for Alpha-Stable Models. Gareth Peters, ScottSisson, Yanan Fan (2009)
5. Likelihood-free methods for model choice in Gibbs random fields. Grelaud, A., Marin,J.-M., Robert, C.P., Rodolphe, F. and Tally, F., Bayesian Analysis, 3(2), 427-442(2009)
6. Bayesian Symbol Detection for Relay Systems via Likelihood-free Inference. GarethPeters, Ido Nevat, Scott Sisson, Yanan Fan and Jinhong Yuan. IEEE Transactions onSignal Processing, to appear (2009)
7. Likelihood-free Samplers. Scott Sisson, Gareth Peters, Yanan Fan, Mark Briers, toappear (2010)
8. (Subgroup 1 and 4) An adaptive SMC method for approximate Bayesian computation.Pierre Del Moral, Arnaud Doucet and Ajay Jasra, submitted January 2009.
9. Filtering with Approximate Bayesian Computation. J. Cornebise, G. Peters, in prepa-ration
10. (Subgroup 1 and 4) Auxiliary SMC samplers with applications to Partial RejectionControl and Approximate Bayesian Computation. J. Cornebise, G. Peters, O. Rat-mann in preparation
Subgroup 5: Applications of PMC to cosmologySome of the participants of the SAMSI program were involved in an ongoing partnership
with Institut da Astrophysique de Paris, and therefore gave way to innovative applications ofPopulation Monte-Carlo on cosmology-related problems. They applied the easy paralleliza-tion and higher computational efficiency of PMC to lead Bayesian inference of the parame-ters for data consisting of CMB anisotropies, supernovae of type Ia, and weak cosmologicallensing, and provided a comparison of those results to those obtained using state-of-the-artMarkov chain Monte Carlo (MCMC), reducing the computation time from fays to hoursusing PMC on a cluster of processors.
275

In a second work, PMC was used to compare cosmological models in the context of darkenergy and primordial perturbations: cosmology has spawned a multitude of different models,which Bayesian paradigm compares using directly the posterior probabilities of models, infavour of each of one of the given models. From a practical viewpoint, especially for high-dimensional parameter spaces, the calculation of the evi- dence is very challenging. Whilefast approximations exist, such as the Bayesian Information Criterium or variational Bayesthey can fail dramatically for posterior distributions which are not well approximated bya multivariate Gaussian. They used PMC method to estimate the Bayesian evidence andassess the accuracy and reliability of this estimate, using the same set of sampled values usedfor parameter estimation and to to calculate the Bayesian evidence. Thus with the PMCmethod, model selection comes at the same computational cost as parameter estimation.
1. Estimation of cosmological parameters using adaptive importance sampling. Wraith,D., Kilbinger, M., Benabed, K., Cappe, O., Cardoso, J.-F., Fort, G., Prunet, S., Robert,C.P. Physical Review D, 80, 023502 (2009)
2. Kilbinger, M., Wraith, D., Robert, C.P. , Benabed, K., CappA c©, O., Cardoso, J.-F., Fort, G., Prunet, S., Bouchet, F. Bayesian model comparison in cosmology withpopulation Monte Carlo. Available as arXiv:0912.1614, submitted (2009)
Subgroup 6: Stability of Mixture Kalman FiltersA collaboration developed during the stay at SAMSI of two members of the PMC working
group on a neighboring topic. This stay at the SAMSI allowed Sylbain Rubenthaler to workwith Nicolas Chopin (CREST-ENSAE Paris) on a problem he had been considering for along time : the stability of the so-called “mixture Kalman filters”. They wrote an articleon the stability of particle algorithms with a Feynman-Kac representation such that thepotential function may be expressed as a recursive function which depends on the completestate trajectory. This includes the mixture Kalman filter. They studied the asymptoticstability of such particle algorithms as time goes to infinity. Sylvain Rubenthaler also starteda ongoing collaboration with Amarjit Budhiraja (UNC Chapel Hill) on reflected diffusion,more precisely: the numerical approximation of the stationnary law of a relfected diffusionby means.
1. Stability of Feynman-Kac formulae with path-dependent potentials. Chopin, Nicolasand Del Moral, Pierre and Rubenthaler, Sylvain, to appear in Stochastic Processes andtheir Applications (2010)
4.7.4 Particle Learning
The particle learning working group was led by Hedibert Lopes.
Key points
• PL as a flexible framework sequential Bayesian computation, comparable and comple-mentary to MCMC schemes;
276

• Empirical evidence of the superiority (in terms of MC error) of resample-sample filters(APF) over sample-resample filters (SIS).
• Hybrid filters that combines auxiliary particle filter (APF), Storvik’s and PL for stateand parameter learning;
Scientific papers Accepted papers
1. Particle learning and smoothing. Statistical Science (to appear). By CarlosCarvalho, Michael Johannes, Hedibert Lopes and Nicholas Polson.
2. Particle learning for sequential Bayesian computation (with discus-sion). Bayesian Statistics 9 (to appear). By Hedibert Lopes, Carlos Carvalho, MichaelJohannes and Nicholas Polson.
3. Particle filters and Bayesian inference in financial econometrics. Jour-nal of Forecasting (to appear). By Hedibert Lopes and Ruey Tsay.
4. Bayesian inference for stochastic volatility modeling. In Bocker, K.,editor, Rethinking Risk Measurement, Management and Reporting: Bayesian Analysisand Expert Elicitation (to appear). By Hedibert Lopes and Nicholas Polson.
5. Bayesian computation in finance. In Chen, M.-H., Dey, D., Muller, P., Sun, D.and Ye, K., editors, Frontiers of Statistical Decision Making and and Bayesian Analysis— In Honor of James O. Berger (to appear). By Satadru Hore, Michael Johannes,Hedibert Lopes, Robert McCulloch and Nicholas Polson.
6. Extracting SP500 and NASDAQ volatility: The credit crisis of 2007-2008. In O’Hagan, T. and West, M., editors, Handbook of Applied Bayesian Analysis.By Hedibert Lopes and Nicholas Polson.
Submitted papers
7. Tracking flu epidemics using Google trends and particle learning. ByVanja Dukic, Hedibert Lopes and Nicholas Polson.
8. Sequential parameter learning and filtering in structured AR models.By Raquel Prado and Hedibert Lopes.
9. Particle learning for general mixtures. By Carlos Carvalho, Hedibert Lopes,Nicholas Polson and Matt Taddy.
10. Bayesian statistics with a smile: a resampling-sampling perspective. ByNicholas Polson, Hedibert Lopes and Carlos Carvalho.
11. Sequential parameter estimation in stochastic volatility models. ByMaria Rıos and Hedibert Lopes.
Work in progress
277

12. Particle learning for generalized dynamic conditionally linear mod-els. By Carlos Carvalho, Hedibert Lopes and Nicholas Polson. (75% finished).
13. Particle learning for fat-tailed distributions. By Hedibert Lopes andNicholas Polson. (75% finished).
14. Sequential Monte Carlo estimation of DSGE models. By Hao Chen, FrancescaPetralia and Hedibert Lopes. (75% finished).
15. Learning in a regime-switching macro-finance Nelson-Siegel model. ByBruno Lund and Hedibert Lopes. (75% finished).
16. Learning expected inflation from nominal and real yields. By SatadruHore, Hedibert Lopes and Juha Seppala. (50% finished).
17. Sequential Monte Carlo methods for long memory stochastic volatil-ity models. By Christian Macaro and Hedibert Lopes. (50% finished).
Books Two books published by Working Group members during the 2008-2010 periodcontain chapters with detailed explanation, literature review, examples and comparisons ofsequential Monte Carlo filters.
Raquel Prado and Mike West (2010) Time Series: Modelling, Computation and Inference.Boca Raton: Chapman & Hall/CRC Press.
Giovanni Petris, Sonia Petrone and Patrizia Campagnoli (2009) Dynamic Linear Modelswith R. New York: Springer.
PhD Students
Francesca Petralia and Hao Chen
Francesca (Department of Statistical Sciences, Duke University), Hao (Fuqua Schoolof Business, Duke University) and I are finishing the paper Sequential Monte Carloestimation of dynamic stochastic general equilibrium models. The paper’s novelty isthe proposal of a full SMC scheme to estimate non-linear DSGE models in an on-linefashion, which allows simultaneous filtering of states and parameters. We apply ourfilter on a neoclassical growth model, where structural parameters are sequentiallyestimated compared to currently used MCMC schemes. In addition, we illustratesequential model checking/assessment via SMC by comparing the Smets and WoutersDSGE model for the Euro area with several Bayesian vector autoregressive (BVAR)models. Hao presented the paper during the 2009 JSM meetings in Washington, D.C.and during the 2010 Seminar on Bayesian Inference in Econometrics and Statistics(SBIES) in Austin, Texas.
Bruno Lund
December 2009 PhD Thesis on Term structure models with non-affine dynamics andmacro-variables, Graduate School of Economics, Getulio Vargas Foundation, Rio de
278

Janeiro. I was Bruno’s co-advisor along with Caio Almeida. Bruno spent the 2008-2009 academic year working under my supervision as a visiting PhD student at ChicagoBooth. We have just finished the paper Learning in a regime-switching macro-financeNelson-Siegel model, which study the US post-WW2 joint behavior of macro-variablesand the yield-curve, which extends previous work by incorporating the possibility ofregime changes in order to track NBER cycles. The paper contributes to the sequentialMonte-Carlo estimation literature by providing an interesting context for the combi-nation of our particle learning (PL) algorithm with Liu and West’s (2001) filter.
Maria Paula Rios
Maria is working under my supervision in the Statistics and Econometrics group atthe University of Chicago Booth School of Business. We have just finished the paperSequential parameter estimation in stochastic volatility models, which combines Liuand West’s (2001) with Storvik’s (2001) particle filters to the class of Markov switch-ing stochastic volatility (MSSV) models (Carvalho and Lopes, 2007). We show thatCarvalho and Lopes’ (2007) particle filter degenerates or has larger Monte Carlo errorthan our extension. Our filter takes advantage of recursive sufficient statistics thatare sequentially tracked and whose behavior resembles that of a latent state with con-ditionally deterministic updates. The performance of our filter is also assessed whencomparing its sequential estimation of SP500 volatilities to the VIX index, which isthe CBOE volatility index.
Post-doctoral researchers Christian Macaro (DSS, Duke University) and I are workingon the paper Sequential Monte Carlo Methods for Long Memory Stochastic Volatility Models,which proposes to implement an alternative representation based on the aggregation of firstorder autoregressive models. The resulting framework is particularly suitable for the imple-mentation of SMC methods, since only the marginal posterior distribution of the particlesis required. Comparisons with alternative truncation representation is also provided. Anapplication emphasizes the benefits of this proposal when dealing with real time estimationof volatility of financial high frequency data.
4.7.5 Model Assessment and Adaptive Design
The working group leader was Carlos Carvalho.
Summary Goals and Outcomes Following up the discussions in the kick-off workshop(September 2008) the “Model Selection and Adaptive Design” (MAAD) working groupwas formed with the intent to enhance, explore and demonstrate the potential of particlebased methods to address issues related to model uncertainty and sequential design/decisionmaking. The group focuses on applications (listed below) where either the computation ofmodel probabilities or the exploration of model spaces represent an enormous challenge thatrequires effective computation strategies. The central goal of our efforts is to make use of“state of the art” SMC techniques in trying to tackle these issues.
Since its formation, the group has met weekly at SAMSI for discussions of relevant issuesand to report on progress made by many of the participants.
279

Specific Goals and Areas of Focus At the current stage the group has identified fourmain areas of focus, as described below:
1. Particle Model SelectionOur goal is to develop a general class of particle methods to accommodate uncertainty invariable selection in high-dimensional settings. There is a rich Bayesian literature on variableselection and stochastic search methods for linear regression models, but very little work hasbeen done for nonparametric models that allow the conditional distribution of a responseto change flexibly with predictors. Our initial plan was to develop an efficient particlestochastic search (PSS) approach for high-dimensional variable selection in linear regression,while simultaneously developing a Particle Learning algorithm for posterior computationin probit stick-breaking processes (PSBPs). PSBPs are a recently proposed nonparametricBayes modeling framework, which allow conditional distributions to change flexible withpredictors. Due to the conjugacy of the PSBP after data augmentation, it should be possibleto adapt the Particle Learning algorithm to include a PSS component. This will allowselection of variables having any impact on the conditional distribution of a response, whilealso accommodating responses having arbitrary scales (continuous, categorical, count, etc).An additional topic that the group will focus on is development of efficient particle methodsfor calculating Bayes factors for comparing non-nested models. The idea is to initially devotea similar number of particles to each model, but then through resampling as the algorithmprogress, devote increasing numbers of particles to the better models in the list. This willallow accurate posterior computation and estimation of marginal likelihoods for good models,while not wasting computational effort on poor models.We have made substantial progress in the above areas. Here are specifics of each project:
• “Particle stochastic search for high-dimensional variable selection” (Shi andDunson) - we have continued to make progress in refining our particle stochastic search(PSS) algorithm and have compared the algorithm in a variety of settings to shotgunstochastic search (SSS). We also have results comparing to SSVS for simulated exam-ples and a real data application taken from Hans et al. SSS paper. The paper withthe above title is in final preparation stage and will be submitted within a few weeks.We will then move our focus to variable/model selection in nonparametric Bayes re-gression models, adapting PSS to allow for the inclusion of parameters/latent variablescommon to the different models in the particles. This will allow variable selection inPSBP mixture models and other interesting cases. We plan to apply this in dynamicmixture model settings as well.
• “Bayesian distribution regression via augmented particle learning” (Dun-son and Das) - we have continued to make progress in developing and implementingan efficient sequential Monte Carlo algorithm for posterior computation and marginallikelihood estimation in a broad class of mixture models that allow the mixing weightsto varying with time, space and predictors. This class of mixture models is referredto as probit stick-breaking mixtures and has the appealing property of facilitating ef-ficient computation through a data augmentation strategy. In particular, for manyuseful special cases, one can obtain the marginal likelihood in closed form integrating
280

out all of the parameters but conditioning on latent normal variables. Our proposed“augmented particle learning” (APL) algorithm proceeds by sequentially adding sub-jects in parallel to each of a large number of particles, sampling from the conditionalposterior distributions of the latent variables as subjects are added and resamplingappropriately. The method avoids the need for sequential importance sampling forupdating of particles, instead relying on direct sampling, with marginalization used toimprove efficiency. We have primarily code for count regression models which allow theconditional distribution of a count response to change flexibly with a predictor, andhave already obtained good results for a mixture of Poisson case with no predictors.A manuscript with the initial results will be submitted within few weeks. An abstractfollows:
To limit assumptions in modeling of conditional response distributions, hierarchicalmixtures-of-experts models allow the mixing weights in a regression model to vary flexi-bly with predictors. Nonparametric Bayes methods can be used to incorporate infinitely-many components, allowing effective model dimension to increase with sample size.However, MCMC algorithms for posterior computation often encounter mixing prob-lems due to multimodality of the posterior. Focusing on a broad class of probit stick-breaking process priors for conditional response distributions indexed by time, space orpredictors, we propose an efficient augmented particle filter for posterior computationand approximation of marginal likelihoods. The algorithm sequentially updates randomlength latent normal vectors within each particle as subjects are added, avoiding trun-cation of the infinite collection of random measures. Through marginalization afterdata augmentation, the approach bypasses the need to update parameters, dramaticallyimproving efficiency while avoiding degeneracies. The method can be applied broadlyfor continuous, count or categorical response variables. The methods are illustratedusing simulated examples and an epidemiologic application.
Primary subgroup participants: David Dunson (Duke Univ.), Minghui Shi (PhD stu-dent, Duke Univ.), Sourish Das (SAMSI and Duke Univ.) and Artin Armagan (Duke Univ.).
281

2. Adaptive DesignFor expensive data, as those arising from computer models, astronomy data, destructiveexperiments, etc, careful designs which contemplate how many data points will be obtained,where and when, is mandatory. These design problems, for these expensive experiments,have to, almost unavoidably, be sequential and adaptive so as to best use the very scarceand expensive information. Sequential decision problems (of which sequential designs areparticular cases) involve “look ahead” computations for all possible future observations,which might be computationally challenging for complex models. We intend to explore SMCmethods to help with these computations.
An initial paper is under way as detailed below:
• “Adaptive sampling for Bayesian variable selection” (Fei Liu, Fan Li and Dun-son) - the problem is to sequentially select subjects based on their predictor values,with the response value obtained for the selected subjects and the objective being opti-mal performance in model selection. We have the methods details worked out and FeiLiu has implemented a couple of simple examples where she demonstrates substantialadvantages relative to selecting the subjects in a random order. We have discussedstrategies for proving improvements theoretically under the assumption that the num-ber of subjects in the pool to draw from is large, so that we can avoid finite populationsampling complications. Fan has found an interesting data example to motivate theapproach and the paper should be completed in a month or two depending on Fei’stime. Fei and David have discussed moving on to a “active transfer learning” prob-lem in which there are multiple related regression models and one wants to borrowinformation in selection of models across the related models.
Primary subgroup participants: Susie Bayarri (Univ. of Valencia and SAMSI), JimBerger (SAMSI and Duke Univ.), Merlise Clyde (Duke Univ.), Tom Loredo (Cornell Univ.),Ana Corberan (PhD student, Univ. of Valencia), Fei Liu (Univ. of Missouri) and Fan Li(Duke Univ.).
3. Sequential Model MonitoringIn this subgroup we focus on problems of sequential model reassessment and model spaceexploration as new observations become available. The examples we have been developing sofar involve sequential posterior inference about graphical structures underlying the covariancematrix of innovations in dynamic linear models. These models have been applied in largescale sequential portfolio allocation where the graphs provide a regularization tool for thecovariance matrix of assets. The development of sequential model selection procedures thataddress uncertainty about graphs while allowing for on-line updates is an open research areaand one of key importance in further applications of DLMs in real forecasting problems. Inour first attempt to solve this problem, we have been using particles systems as discreteapproximations for the posterior distribution of models. Hao Wang has been coding some ofthe ideas discussed and the initial results are promising. We have made significant progressin this area and an first draft of a paper by Hao Wang, Craig Reeson and Carlos Carvalhois ready and should be submitted before the summer. It follows the title and abstract:
282

• “Sequential Learning in Dynamic Graphical Models” – We propose a naturalgeneralization of the dynamic matrix-variate graphical model (Carvalho and West 2007)to time varying graphs. The generalization uses the multi- process modelling idea tointroduce sequential graphical model selection procedures that address uncertainty aboutgraphs while allowing for efficient on-line updates. To develop an efficient Bayesianapproach for sequentially searching high-dimensional graphical models, we describe afeature-inclusion particle stochastic search algorithm, or FIPSS. The FIPSS algorithmallows parallel exploration of the search space using estimates of edge inclusion prob-abilities. The model is illustrated using financial time series for predictive portfolioanalysis.
Primary subgroup participants: Carlos M. Carvalho (Univ. of Chicago and SAMSI),Hao Wang (PhD student, Duke Univ.) and Craig Reeson (Undergraduate student, DukeUniv.)
4. Dynamic ControlThe main objective of this subgroup is to study problems that have a dynamic (sequential)decision making component as well as some uncertainty about the system parameters thatwould require Bayesian updating. We are particularly interested in problems that arise inhealth care settings where a decision maker (a doctor/nurse, emergency response officer,hospital management, etc.) will have to give decisions regarding the treatment options ofpatients or allocation of scarce resources to a group of patients. These decisions are dynamicin nature as the conditions of patients change with time. Such problems have been studiedcommonly in the Operations Research literature. However, almost all of the earlier studiesassume that the decision maker has complete information about the states of patients andthe system parameters. There are several situations where such an assumption of perfectinformation may not be realistic. For example, for rarely observed diseases or disasters thatinvolve nuclear agents, there does not exist sufficient data to estimate parameters that areneeded in solving the dynamic control problem. Our objective is to study such dynamiccontrol problems where the decision maker will learn about the disease or the emergencyevent under consideration as the decisions are made sequentially. As an initial step, we willconsider the following problem. Consider a system with several patients in need of care from asingle resource (a doctor or an operating room). The patients are affected by the same diseaseor the same traumatic event but they could be in different stages of criticality. The stage thata patient is in may affect the cost of keeping that patient waiting, the service requirement ofthat patient, and also the success probability of the operation. The decision maker cannotobserve the true states of patients but can observe certain signals that the patients send (forexample, heart rate, blood pressure, etc.). Based on these signals, the decision maker decideswhich patient should be taken into service next with the objective of maximizing the totalexpected utility. As we mentioned earlier, the decision maker does not know exactly howthe signals and the true states of patients relate and how the patients conditions degrade.When each patient is taken into service, we can observe the true condition of the patientand based on such information collected, we can update the unknown parameters related tothe disease/condition. Then, with this updated information, we make the next decision toserve another patient.
283

Nilay Argon and Melanie Bain are currently using SMC methods in solving a dynamiccontrol problem that arises in the aftermath of mass-casualty incidents. To be more specific,we consider a mass-casualty event (such as a plane crash or a terrorist bombing) that resultedin several casualties in need of care. Due to the massive number of casualties, the medicalresources are overwhelmed and decision makers need to prioritize patients for service. De-pending on their injuries, the patients could be in different stages of health. The stage thata patient is in may affect his/her probability of survival and also service requirement. Thedecision maker cannot observe the true states of patients but can observe certain signalsthat the patients send (for example, pulse, breathing rate, etc.). Based on these signals,the decision maker decides which patient should be taken into service dynamically with theobjective of maximizing the total expected number of survivors. We initially assume thatthe decision maker knows how the signals and the true states of patients relate. We alsoassume that the patientsO conditions degrade according to a discrete time Markov chainwith a known transition probability matrix.
We first formulated the above problem as a partially observable Markov decision process(POMDP). The POMDP we obtained could have a very large belief state depending on thenumber of patients involved and also the number of health stages that we define. Hence, wewill need to use an approximate method to solve this problem. We have thus far consideredtwo approaches from the literature. One is by Thrun (2000), where particle filtering is usedto reduce the size of the belief space, and the other is by Luo, Fu, and Marcus (2008),which is based on projecting the high-dimensional belief space to a low-dimensional familyof parametrized distributions. We are currently implementing ThrunOs approach.Primary subgroup participants: Nilay Tanik Argon (UNC), Abel Rodriguez (Univ. ofCalifornia, SC), Melanie Bain (PhD student, UNC) and Kai Wang (PhD student, DukeUniv.)
Papers
• Dynamic Financial Index Models: Modeling Conditional Dependenciesvia Graphs. By by Hao Wang, Craig Reeson and Carlos M. Carvalho. http://ftp.stat.duke.edu/WorkingP21.pdf (submitted to Bayesian Analysis)
• Dynamic Stock Selection: A Structured Factor Model Framework ByC. Carvalho et al., Invited paper, 2010 Valencia Meeting on Bayesian Statistics.
4.7.6 Continuous Time
The working group leaders are Jashya Bishwal, Paul Fearnhed and Jochen Voss. During theinitial formative phase, the working group in continuous time models, parameter estimationand finance started a review of the relevant literature. Several articles were presented duringthe group meetings. Topics covered include the following:
- filtering discrete observations of a continuous time signal- exact algorithms- filtering and parameter estimation using a windowed SMC method (in discrete time)- change point problems for continuous time processes- filtering for a CIR process given Poisson observations
284

The working group focussed on four areas. Firstly, SMC for hierarchical branching processmodels, with application for qPCR analysis. Secondly, methods for survival data, where theunderlying hazard depends on an unobserved stochastic process. The application for thiswork is to modelling, analysis and prediction of mortgage default rates. Thirdly, they havelooked at inference for diffusion models via ”least-action”: defining and calculating a bestpath for the unobserved diffusion, and constructing Laplace approximations to the transitiondensity of the diffusion. Applications here include models in systems biology. Finally, welooked at new inference methods for α-stable Levy processes.
The research has led to a grant proposal to the UK’s EPSRC, which will develop onthe least action filtering and α-stable models by Rogers, Godsill and West. This latter arealed to several grant proposals and a funded project from Fraunhoffer Institute in Germany(contact Ralf Korn) in which a PhD student, Tatjana Lemke, funded by Fraunhoffer, is basedin Cambridge with Simon Godsill and working on Monte Carlo inference for α-stable Levyprocesses. There is a further grant on Laplace approximations, with a focus on their use fordiffusion models, being prepared by Fearnhead, Tawn and Sherlock.
• ’Subprime Mortgage Default’ James B. Kau ,Donald C. Keenan, Constantine Lyubi-mov, V. Carlos Slawson (submitted 2010)
• Anand Vidyashankar (In prep).
• Simulation and Inference for Stochastic Kinetic Models via limiting Gaussian Processes.Paul Fearnhead, Vasilieos Giagos and Chris Sherlock (In prep).
• Inference for autoregulatory genetic networks using diffusion approximations. VasilieosGiagos, PhD Thesis, Lancaster University (In prep; submission by September 2010)
• ENHANCED POISSON SUM REPRESENTATION FOR ALPHA-STABLE PRO-CESSES, Tatjana Lemke and Simon Godsil, Accepted for Proc. IEEE ICASSP 2011.
4.7.7 Big Data & Distributed Computing
Summary Emerging from discussions at the Sept. 2008 opening workshop, the Big Data& Distributed Computing (BD&DC) working group was defined by research challenges andthemes cutting across numerous applications of stochastic computation and sequential meth-ods: scaling of models and analysis methods for increasingly large data sets and in problemswith increasing large spaces of underlying parameters and latent variables. Exploiting multi-core, cluster and parallel hardware promotes a need for basic research and innovations in thedevelopment of computational algorithms and also of model specification and structuring.The opportunity to make progress in these areas, linked to specific motivating applications,led to the formation of this focused working group. BD&DC subgroups were involved in spe-cific research projects under the general goals, with a series of interconnections with some ofthe other working groups involving cross-cutting projects.
Goals and Areas of Focus Exploration, evaluation, development and application of ef-fective computational methods for model fitting and model assessment in problems involvinglarge data sets and high-dimensional latent process parameters (the latter are examples of
285

“big missing data”): sequential Monte Carlo methods, stochastic model search, sequentialimportance sampling and also annealing/optimization methods. Specific research subgroupsare as follows.
BD&DC.1 Distributed computing for SMC (Manolopoulou, Mukherjee, West, Yoshida).
Sequential Monte Carlo methods for model learning, estimation and comparison usingdistributed computing on clusters. This is relevant to several of the specific modelling,methodology and application areas. Activities include study of theory and methods ofimplementing a variety of SMC methods on clusters, using some of the specific modelcontexts of interest to this working group for development. Strategies for parallelisedand cluster-based computation were explored for problems involving large data setsand high-dimensional latent processes, i.e., large missing data sets, the latter focusedon state-space modelling of long time series. This research interacted with researchersin the Tracking working group.
BD&DC.2 SMC in dynamic non-linear models in systems biology (Ji, Mukherjee, West).
SMC and distributed computing in mechanistic, nonlinear state-space models, withmotivating applications in dynamic stochastic models arising in studies of cellularcommunication in biological networks in systems biology. This area involves modeldevelopment and use of customised sequential Monte Carlo methods, and so interactedsubstantially with some of the other program working groups. Specific characteristicsof motivating problems were (a) state-space models with many uncertain parametersthat are observed over time, and for which sequential learning is either desirable ornecessary; (b) very high-dimensional latent processes. In systems biology problems,models are developed mathematically on very fine, discrete time scales, but actualdata is observed at much cruder time scales, so that the fine time scale states becomemissing data in very high dimensions.
This research area also intersected with studies involving stochastic computation formodel fitting in complex computer model emulation, related to the program activitiesat the intersection of research in computation and computer modelling design anddevelopment. This aspect of BD&DC research was represented in talks at the SAMSIworkshop on Adaptive Design, Sequential Monte Carlo and Computer Modeling in April2009 as well as in a SAMSI Topic Contributed Session at the 2009 Joint StatisticalMeetings in Washington DC 2009.
BD&DC.3 SMC for inference on “rare events” with very large data sets (Manolopoulou,West).
Sequential analysis and decision-guided sample selection and learning about rare eventsin mixture modelling with very large data sets. Motivating applications come fromproblems of inference on characteristics of rare sub-populations of biological cells instudies using flow cytometry technology in immunology, vaccine design and other ar-eas. In such studies, a single experiment can easily generate hundreds of millions ofobservations in, typically 10-20 dimensions, representing marker proteins on the sur-face of cells. Random sampling to fit models, such as mixture models for classification
286

and discrimination of sub-populations, is standard, though model fitting becomes chal-lenged by sample size and so sequential methods are inherently interesting. Moreover,a specific focus on generating maximal information of rare sub-populations leads tostatistical design and biased sampling strategies that are inherently sequential and forwhich simulation-based methods need to be developed. The interest in and role fordistributed computation is evident.
BD&DC.4 SMC in nonparametric analyses (Das, Dunson, Li, Liu).
Sequential methods in nonparametric statistical regression and density estimation mod-els, with motivating applications in problems in epidemiology and public health, andin studies of huge data sets in e-commerce and internet traffic research, among oth-ers. This study introduced new classes of SMC algorithms for posterior computationand marginal likelihood estimation in a flexible class of mixture models, which allowmixture weights to vary with time, space and predictors. The proposed augmentedparticle learning (APL) algorithm has had excellent performance in simulation exper-iments for a variety of data types, avoiding degeneracies common to SMC algorithmsthrough use of marginalization after data augmentation. The algorithm has majoradvantages over MCMC algorithms in avoiding mixing problems that plague MCMCfor mixture models, while also allowing marginal likelihood estimation, which allowstesting of competing nonparametric models and parametric vs nonparametric models.
Application areas are numerous. Part of this research generated components of asuccessful NIH proposal, that proposed the further development of the APL algorithmin applications in statistical genetics and gene-environment interactions studies. Thisinvolves models that allow quantitative traits to vary flexibly with high-dimensionalsingle nucleotide polymorphisms and environmental factors.
BD&DC.5 Adaptive sequential sampling for Bayesian variable selection (Li, Liu, Dunson).
Intersections of interests with the working group on sequential Monte Carlo in modelassessment focussed on adaptive strategies for the variable selection problems and ef-ficient Sequential Monte Carlo methods for the evaluation of designs in massive datasets. The problem is to sequentially select subjects based on their predictor values,with the response value obtained for the selected subjects and the the objective beingoptimal performance in model selection. The ideas were developed and methods de-tailed; implementations in a couple of demonstrate substantial advantages relative toselecting the variables in a random order. An interesting study now underway appliesthis to problems with censored data.
This aspect of BD&DC research was represented at the SAMSI workshop on AdaptiveDesign, Sequential Monte Carlo and Computer Modeling in April 2009, as well as in aSAMSI Topic Contributed Session at the 2009 Joint Statistical Meetings in WashingtonDC 2009.
BD&DC.6 Sequential model search in very large model spaces (Dunson, Shi, West, Yoshida).
Stochastic and related deterministic/annealing based methods of search over very large,discrete model spaces such as arising in sparse multivariate factor models with many
287

response variables, and in regression model uncertainty (linear and nonlinear) withmany candidate covariates. Advances in computational methods included innovationsin annealed entropy methods and Bayesian shotgun stochastic search methods. Somespecific motivating applications came from genomics and public health contexts. Onekey development involved including model indices within the particles of SMC methodsleading to an efficient algorithm for massive dimensional variable selection (Dunson andShi), another involved a synthesis of entropy annealing based global optimization withstochastic search for very large-scale sparse statistical models (Yoshida and West).
BD&DC.7 Novel modeling for tracking (Ji, Manolopoulou, West).
Intersections of interests with the working group on sequential Monte Carlo in compute-intensive tracking problems generated novel model and computational methods devel-opment for tracking problems with prototype applications in monitoring and trackingmany cells in systems biology experimental data. Data arising from motivating appli-cations include studies in computational immunology driven by experiments in vaccinedesign, where the motion of multiple different cell types is monitored by measuredfluorescent intensities of cell surface marker proteins. Research here involved novelBayesian dynamic, non-parametric models for inhomogeneous spatial intensity func-tions and sequential Monte Carlo methods development for model fitting.
BD&DC.8 SMC in very large inverse problems (Mukherjee, West).
Emerging from BD&DC discussions in spring 2009, a new project emerged involving asubgroup of this working group, involving approaches to computer model-data synthe-sis and inversion in atmospheric chemistry (CO) monitoring and data synthesis. Witha focus on short time-scale inference on improved understanding of the impact of earthsurface fires (tropical forest fires, savannah fires, etc) on variations atmospheric CO,a core challenge is integration of massive amounts of high-resolution data from newsatellites launched in 2009 with predictions from deterministic biophysical simulationmodels. Sequential Bayesian methods development were initiated as a spin-off fromthis BD&DC discussion, and have led to a new, free-standing collaboration with at-mospheric chemists as well as defining a core thesis topic for Mukherjee. Two papersare in draft (May 2010). This new collaboration with disciplinary computer modelersis an excellent example of a really big, and cluster compute-intense BD&DC problem.
Participants This working group involves local faculty participants, SAMSI postdoctoralfellows, SAMSI visitors, SAMSI and non-SAMSI graduate students, and represents variousareas of statistics and computational science. Several junior and female researchers areinvolved, including some who were quite new to the general area of Sequential Monte Carlo,as well as the specific areas of this working group, prior to the program. See Table 1 forthe list of primary and active participants, as well as additional participants who either hadsome engagement in formative discussions, or who had occasional interactions in BD&DCmeetings, or who were short-term SAMSI visitors.
Student Involvement
288

Name (gender) Position Affiliation Dept/Discipline
(A)Carlos Carvalho (m) Assistant Professor Chicago Statistics & Econ.Sourish Das (m) Postdoc SAMSI StatisticsDavid Dunson (m) Professor Duke Statistical ScienceChunlin Ji (m) Graduate RA Duke & SAMSI Statistical ScienceFan Li (f) Assistant Professor Duke Statistical ScienceFei Liu (f) Assistant Professor Missouri StatisticsIoanna Manolopoulou (f) Postdoc SAMSI StatisticsChiranjit Mukherjee (m) PhD student Duke Statistical ScienceMinghui Shi (f) Graduate RA Duke & SAMSI Statistical ScienceRyo Yoshida (m) Assistant Professor ISM Tokyo StatisticsHao Wang (m) Graduate student Duke Statistical Science‡Mike West (m) Professor Duke Statistical Science
(B)Ernest Fokoue (m) Assistant Professor Kettering MathematicsAmadou Gning (m) Postdoc Lancaster Communication SystemsSteve Koutsourelakis (m) Assistant Professor Cornell EngineeringLyudmila Mihaylova (f) Lecturer Lancaster Communication SystemsMario Morales (m) Consultant Emetricz Engineering/StatisticsDeb Roy (m) Assistant Professor Penn State StatisticsAndrew Thomas Lecturer St. Andrews University Ecology & StatisticsJoshua Vogelstein (m) PhD student Johns Hopkins Neuroscience
Table 1: (A) Primary and local participants (‡Working Group leader); (B) Addi-tional researchers (initial participants, collaborators and/or short-term visitors inthe BD&DC group) {tab:BigData1}
Chunlin Ji (SAMSI RA) was primarily attached to the Tracking (Godsill) working groupbut also participated actively in the BD&DC group with West on spatial dynamicmodelling for biological cell tracking problems and nonlinear modeling. Ji developedSMC methods in the context of new classes of models. This research grew out ofexisting work of Ji & West in static problems, now extended with new dynamic modelsthat will formed additional parts of Ji’s PhD thesis research, and led to expandedfollow-on research in the area with SMC postdoc Ioanna Manolopolou mentioned below.Ji led discussions on this work at several BD&DC meetings, gave a talk at the February2009 mid-program workshop, presented this work at the 7th Workshop on BayesianNonparametrics in Turin, Italy, in June 2009 and at the 2009 Joint Statistical Meetingsin Washington DC 2009. Ji defended his PhD in December 2009 and moved to apostdoctoral position with Jun Liu in Statistics at Harvard.
Chiranjit Mukherjee (Duke graduate student) actively participated in the BD&DC group(though was not officially supported by the program). Mukherjee developed studies of
289

SMC methods for model fitting and comparison in nonlinear dynamical models arisingfrom systems biology (and other applications). These studies involve very long timeseries but for which most of the underlying states are unobserved, and his work hasexplored, evaluated and developed novel approaches to SMC using distributed com-putation. In March 2009, Mukherjee presented and passed his PhD preliminary exambased on this work, has one paper published from this work, led several discussionson the topic at the BD&DC meetings, presented a poster at the February 2009 mid-program workshop, presented this work in a SAMSI Topic Contributed Session at the2009 Joint Statistical Meetings in Washington DC 2009 and at several Duke workshops.Mukhjeree then became involved in the new, emerging project initiated in a BD&DCmeeting on large-scale data integration for inverse inference and data synethesis withcomputer models in atmospheric chemistry. He will present this work at the ISBAWorld Meeting in Spain, June 2010. These two topics from his BD&DC interactionsform the basis of his ongoing thesis research; he will defend in May 2011.
Francesca Petralia (SAMSI RA) was attached to the Particle Learning (Lopes) workinggroup but also participated actively in the BD&DC group. Petralia presented a talkon her work with SMC in econometric models in the Particle Learning working group(Lopes, leader) in a SAMSI Topic Contributed Session at the 2009 Joint StatisticalMeetings in Washington DC 2009. Petralia is currently finalizing a paper, with Lopes,on this SMC project.
Minghui Shi (50% SAMSI RA) worked on sequential model search methodology for large,discrete model spaces, typified by “large p” regression model uncertainty. With Dun-son, Shi developed novel extensions of shotgun stochastic search that incorporate newideas from SMC. Shi passed her PhD preliminary exam on this topic in April 2009,and the topic underlies her emerging thesis area. Shi led discussions on this work atBD&DC meetings, presented a poster at the February 2009 mid-program workshop,presented this work in a SAMSI Topic Contributed Session at the 2009 Joint Statisti-cal Meetings in Washington DC 2009, and will present extensions at the ISBA WorldMeeting in Spain, June 2010.
Hao Wang (Duke graduate student) actively participated in the BD&DC group as well asother working groups, (though was not officially supported by the program). Wangworked, in part, on SMC methods for dynamic graphical models with Carvalho andWest, led discussions on the topic at the BD&DC meetings, presented a poster at theFebruary 2009 mid-program workshop, and presented this work at the SAMSI workshopon Adaptive Design, Sequential Monte Carlo and Computer Modeling in April 2009 aswell as in a SAMSI Topic Contributed Session at the 2009 Joint Statistical Meetingsin Washington DC 2009. With Carvalho, Wang wrote a paper on SMC in dynamicgraphical models (currently under review) and the work formed a component of hisPhD thesis. Wang successfully defended his PhD in spring 2009, and will move toa tenure-track faculty position, Assistant Professor of Statistics, University of SouthCarolina, in summer 2010.
Other Activities
290

• BD&DC short-term visitor Andrew Thomas (St. Andrews University) has, as a re-sult of discussions and interactions in the BD&DC group, initiated development ofnew software for SMC based on the OpenBUGS software, and this is expected to bedeveloped and set up as Open Source software.
Manuscripts Manuscripts linked to research in BD&DC and acknowledging SAMSI/NFSsupport:
1. D.B. Dunson & S. Das (2009) Bayesian distribution regression via augmented particlelearning. In preparation.
2. C. Ji & M. West (2009) Spatial dynamic mixture modelling for unobserved pointprocesses and tracking problems. Under revision.
3. F. Liu, D. B. Dunson & F. Zou (2010) High-dimensional variable selection in metaanalysis for censored data, Biometrics, to appear.
4. F. Liu, F. Li & D. B. Dunson (2010) Adaptive design for variable selection in normallinear models, in preparation.
5. F. Liu & M. West (2009) A dynamic modelling strategy for Bayesian computer modelemulation, Bayesian Analysis, 4(2), 393-412.
6. I. Manolopolou, C. Chan & M. West (2009). Selection sampling from large data setsfor targeted inference in mixture modeling, Bayesian Analysis, to appear.
7. I. Manolopolou, X. Wang, C. Ji, H.E. Lynch, S. Stewart, G.D. Sempowski, S.M. Alam,M. West and T.B. Kepler (2009) Statistical analysis of immunofluorescent histology,submitted for publication.
8. C. Mukherjee & M. West (2009) Sequential Monte Carlo in model comparison: Ex-ample in cellular dynamics in systems biology, JSM Proceedings, Section on BayesianStatistical Science. Alexandria, VA: American Statistical Association, 1274-1287.
9. M. Shi & D. Dunson (2009) Bayesian variable selection via particle stochastic search,submitted for publication.
10. H. Wang, C. Reeson & C.M. Carvalho (2009) Dynamic financial index models: Mod-eling conditional dependencies via graphs, invited revision resubmitted.
11. R. Yoshida & M. West (2009) Bayesian learning in sparse graphical factor models viaannealed entropy, Journal of Machine Learning Research, to appear.
291

5 Conclusions and expected outcomes
To conclude, the program has been successfull. It has generated much activity across awide range of topics. We had well-structured Working Groups, holding weekly meetings byWebex. The results of these collaborative research efforts have started appearing in leadingstatistical journals.The collaborations enabled by the program no doubt lead to major grantapplications in the area of SMC and its scientific applications.
292

SAMSI 2008-09 Program on Algebraic Methods
in Systems Biology and Statistics
Final
Reinhard LaubenbacherChair, Program Leaders
On behalf of the Working Groups Leaders
May 2010
1 Program Overview
In recent years, methods from algebra, algebraic geometry, and discrete mathematics have found newand unexpected applications in systems biology as well as in statistics, leading to the emerging newfields of “algebraic biology” and “algebraic statistics.” Furthermore, there are emerging applicationsof algebraic statistics to problems in biology. This year-long program provided a focus for the furtherdevelopment and maturation of these two areas of research as well as their interconnections. Theunifying theme is provided by the common mathematical tool set as well as the increasingly closeinteraction between biology and statistics. The program allowed researchers working in algebra,algebraic geometry, discrete mathematics, and mathematical logic to interact with statisticians andbiologists and make fundamental advances in the development and application of algebraic methodsto systems biology and statistics. The essential involvement of biologists and statisticians in theprogram provided the applied focus and a sounding board for theoretical research.
1.1 Research Foci
Systems Biology: The development of revolutionary new technologies for high-throughput datageneration in molecular biology in the last decades has made it possible for the first time to obtaina system-level view of the molecular networks that govern cellular and organismal function. Wholegenome sequencing is now commonplace, gene transcription can be observed at the system level andlarge-scale protein and metabolite measurements are maturing into a quantitative methodology. Thefield of systems biology has evolved to take advantage of this new type of data for the constructionof large-scale mathematical models. System-level approaches to biochemical network analysis andmodeling promise to have a major impact on biomedicine, in particular drug discovery.
Statistics: It has long been recognized that the geometry of the parameter spaces of statisticalmodels determines in fundamental ways the behavior of procedures for statistical inference. Thisconnection has in particular been the object of study in the field of information geometry, wheredifferential geometric techniques are applied to obtain an improved understanding of inference pro-cedures in smooth models. Many statistical models, however, have parameter spaces that are notsmooth but have singularities. Typical examples include hidden variables models such as the phylo-genetic tree models and the hidden Markov models that are ubiquitous in the analysis of biological
1

data. Algebraic geometry provides the necessary mathematical tools to study non-smooth modelsand is likely to be an influential ingredient in a general statistical theory for non-smooth models.
Algebraic methods
Algebraic biology is emerging as a new approach to modeling and analysis of biological systemsusing tools from algebra, algebraic geometry, discrete mathematics, and mathematical logic. Appli-cation areas cover a wide range of molecular biology, from the analysis of DNA and protein sequencedata to the study of secondary RNA structures, assembly of viruses, modeling of cellular biochemicalnetworks, and algebraic model checking for metabolic networks, to name a few.
Algebraic statistics is a new field, less than a decade old, whose precise scope is still emerging. Theterm itself was coined by Giovanni Pistone, Eva Riccomagno and Henry Wynn. Their book explainshow polynomial algebra arises in problems from experimental design and discrete probability, and itdemonstrates how computational algebra techniques can be applied to statistics. The first of theseapplications have focused on categorical data and include the study of Markov bases and conditionalinference, disclosure limitation, and parametric inference, to name a few.
The central idea underlying algebraic statistics is that the parameter spaces of many statisticalmodels are (semi-)algebraic sets. The geometry of such possibly non-smooth sets can be studied usingtools from algebraic geometry. Many problems in computational biology can be described withinthis framework. This is where algebraic statistics joins algebraic biology as a new methodology forsolving problems in systems biology.
The unifying theme of the program was the development and use of a particular set of tools fromalgebra, algebraic geometry, and discrete mathematics to solve problems in statistics and biology.
1.2 Organization and Program Leadership
Organizing Committee: Peter Beerli (School of Computational Sciences and Department of Bio-logical Sciences, Florida State University), Andreas Dress (Director, CAS-MPG Partner Institute forComputational Biology, Shanghai), Mathias Drton (Department of Statistics, University of Chicago),Ina Hoeschele (Department of Statistics, Virginia Tech, and Virginia Bioinformatics Institute), Chris-tine Heitsch (School of Mathematics, Georgia Tech), Serkan Hosten (Department of Mathematics,San Francisco State University), Reinhard Laubenbacher, Committee Chair (Department of Math-ematics, Virginia Tech, and Virginia Bioinformatics Institute), Bud Mishra (Departments of Com-puter Science, Mathematics, and Cell Biology, Courant Institute, NYU), Don Richards (Departmentof Statistics, Pennsylvania State University), Seth Sullivant (Department of Mathematics, NCSU),Brett Tyler (Department of Plant Pathology and Weed Science, Virginia Tech, and Virginia Bioin-formatics Institute), Ruriko Yoshida (Department of Statistics, University of Kentucky).
1.3 Major Participants
Long-Term Visitors: Edward Allen (Wake Forest University), Elizabeth Allman (Universityof Alaska), James Degnan (University of Canterbury), Alicia Dickenstein (University of BuenosAires), Luis Garcia-Puente (Sam Houston State University), Jeremy Gunawardena (Harvard MedicalSchool), Chris Hillar (MSRI), Serkan Hosten (San Francisco State University), Reinhard Lauben-bacher (VA Tech), Catherine Mathias (Universite d’Evry), Uwe Nagel (University of Kentucky),Edwin O’Shea (UNAM, Mexico), Sonja Petrovic (University of Illinois, Chicago), Giovanni Pistone(Politecnico di Torino), John Rhodes (University of Alaska), Eva Riccomagno (University of Genoa),Anne Shiu (UC Berkeley)
2

Postdoctoral Fellows: Megan Owen (Cornell University), Ahmad Saeid Yasamin (Indiana Uni-versity)
Graduate Students: Wenjie Chen (UNC), Julia Chifman (University of Kentucky), Deidra Cole-man (NCSU), Thomas Friedrich (FU- Berlin), Benjamin Wells (NCSU), Jason Yellick (NCSU)
Faculty Releases: Ian Dinwoodie (Duke), Scott Provan (UNC), Eric Stone (NCSU), Seth Sullivant(NCSU), Yung-Jing Tzeng (NCSU)
2 Description of Activities
2.1 Workshops
The SAMSI program on Algebraic Methods in Systems Biology and Statistics has been bolstered bya number of workshops and special sessions held throughout the year both at SAMSI and nearbylocations.
2.1.1 Opening Workshop:
The Kickoff Workshop and Tutorial was held September 14–17, 2008. The principal goal of theworkshop was to engage a broadly representative segment of the mathematical, statistical, and lifesciences communities to determine research directions to be pursued by working groups during theprogram. Four working groups were formed that eventually merged down to three working groups.
The workshop covered a very broad range of topics in the interactions of algebraic methods withsystems biology and statistics. After introductory tutorials on Sunday, more focuesed talks directedtowards the problem areas to be highlighted throughtout the year were given. Highlighted topicsincluded: algebraic statistical models, combinatorics of biological molecules, automata theory andfinite dynamical systems, phylogenetics, causal models, and random graph models.
The workshop also contained a number of discussion sessions with the goal of identifying re-search areas that would be highlighted throughout the yearlong program. After these intendedworking group target areas were identified, the program members formed breakout sessions to be-gin discussions of topics that would be discussed in the working groups throughout the year. Theparticular areas of the working groups are described below.
The tutorial speakers were: Bernd Sturmfels, Reinhard Laubenbacher, and Elizabeth Allman.The keynote speakers were: Mathias Drton, Jeremy Gunawardena, Christine Heitsch, Bud Mishra,Abdul Jarrah, Chris Schardl, Michael Savageau, Gheorghe Craciun, Sumio Watanabe, BrandilynStigler, Meera Sitharam, Lior Pachter, Brett Tyler, Niko Beerenwinkel, Eva Riccomagno, and SteveFienberg.
2.1.2 Discrete Models in Systems Biology Workshop
The discrete models workshop was held December 3-5, 2008 and was organized by Elena Dimitrova(Clemson University), Ilya Shmulevich (Institute for Systems Biology), and Brandilyn Stigler (South-ern Methodist University). The workshop focused on the use of discrete models in systems biology.Discrete modeling approaches have been applied to a wide variety of biological contexts, includinggene regulatory networks, epidemiology, and ecosystem dynamics. Examples of topics of interest inthe workshop were
1. discrete dynamical systems: multi-state models such as Boolean networks, logical models, andfinite dynamical systems; random networks; and analytic tools including statistical-mechanicalapproaches
3

2. Bayesian networks, including dynamic Bayesian networks and graphical models
3. static networks: interaction networks and graph-theoretic approaches
4. simulation: finite-state machines, agent-based networks, process algebras
A chief goal was to stimulate the organization of working groups focused on addressing keychallenges in discrete modeling in computational systems biology, particularly the establishment ofunifying themes and principles.
As part of our commitment to foster a synergistic community, we organized three question-and-discussion sessions to encourage interactions among workshop participants and two poster sessionsto showcase the work of junior researchers, including postdocs and graduate students.
2.1.3 Algebraic Statistical Models Workshop
Many classical statistical models, in particular Gaussian models from multivariate statistics andmodels for discrete random variables, exhibit algebraic structure in their parameter spaces. Thisworkshop focused on both algebraic and statistical aspects of such algebraic statistical models. It wasintended to complement other mid-program workshops, which focused more on particular applicationareas.
The workshop was held at SAMSI, January 15–17, 2009 and featured topics by working groupparticipants, as well as outside experts, whose opinions helped to provide new research directions inthe program. The organizers were Mathias Drton, Eva Riccomagno, and Seth Sullivant. Focus topicsof the workshop included Markov bases, graphical models, algebraic tools for maximum likelihoodestimation, identifiability problems, and cumulant methods.
The workshop included talks by Steffen Lauritzen, Thomas Richardson, Donald Richards, RurikoYoshida, Elizabeth Allman, Sonja Petrovic, Akimichi Takemura, Serkan Hosten, Hugo Maruri, andJason Morton and a poster session.
2.1.4 Miniworkshop on Systems Biology
A subgroup of the systems biology working group was formed to focus on software developmentfor parameter estimation for discrete models. As part of the subgroup activities a miniworkshopat SAMSI was conducted February 24-26, 2009. Participants included E. Dimitrova, L. Garcia,F. Hinkelmann, A. Jarrah, R. Laubenbacher, B. Stigler, and P. Vera-Licona. The workshop wasfocused on the design of the overall architecture of a software package for parameter estimation andsimulation for Boolean network models. A significant part of the time was devoted to actual codedevelopment.
2.1.5 Evolutionary Biology and Phylogenetics Workshop
Recently there has been a marked synergy between modern biology and higher mathematics. A num-ber of important connections have been established between computational biology and the emergingfield of “algebraic statistics,” which combines combinatorics, computational algebra, polyhedral ge-ometry and statistical modeling. The primary objective of this workshop was to bring together newand established researchers in mathematics, biology, and statistics in order to discuss the crossoverbetween algebraic statistics, molecular evolution, and phylogenetics.
As part of our commitment to foster a synergistic community, we organized several discussionsessions to encourage interactions among workshop participants to actively begin new collaborations,discuss new research directions, and make new connections. For example, we discussed phylogenetic
4

invariants on group-based models, such as Jukes-Cantor model and their applications to tree recon-struction as well as discussion on the phylogenetic mixture models. There were several discussionabout coalescent theory, such as coalescent approach to approximate the distribution of gene trees.Also we discussed inferences about the impact of phenotype on genotype from the ancestral lineageand also some reviews of phylogenetic reconstructions, what are known and unknown.
We invited four researchers to give a one-hour keynote address, and six researchers to give con-tributed (invited) talks of 45 minutes length (those include 5 minutes for questions at the end) atthe workshop. Invited speakers were: Jeff Thorne, Cecile Ane, Junhyong Kim, Tandy Warnow,Seth Sullivant, Eric Stone, Fumei Lam, Laura Kubatko, Jeremy Sumner, Sonja Petrovic, and JesusFernandez-Sanchez.
2.1.6 AMS Special Session: Mathematics of Biochemical Reaction Networks
The special session ”Mathematics of Biochemical Reaction Networks” was held during the South-eastern Section meeting of the AMS at North Carolina State University during the weekend of April4-5. The organizers were Gheorghe Craciun, Manoj Gopalkrishnan, and Anne Shiu. The idea toorganize this workshop in proximity to SAMSI, and close to the evolutionary biology workshop wasformed during the SAMSI opening workshop.
Our intent was to bring together individuals who study biochemical reaction networks, in orderto share ideas that range from those building upon the classical Feinberg-Horn-Jackson deficiencytheory, to those more recent algebraic techniques that highlight the rich algebraic structure inherentin these networks. For example, much work has focused on predicting dynamics and resolving ques-tions of stability simply from the topological structure of the underlying reaction network. Anothertopic to be covered is the class of ”monotone” systems. In particular, this session featured reportson collaborations that grew out of activities during the 2008-9 academic year at SAMSI in NorthCarolina and the Mathematical Biosciences Institute in Ohio.
Special 45-minute talks were given by Martin Feinberg, Jeremy Gunawardena, and EduardoSontag. Several talks in particular had a strong algebraic aspect. For example, Greg Rempalatalked about an algebraic statistical model for inferring biochemical reaction networks. Ezra Millerdiscussed results on binomial primary decomposition and its connection to boundary steady states ofa chemical reaction system. Luis Garcia connected Birch’s Theorem and chemical reaction networktheory to Bezier patches and their generalizations. Alicia Dickenstein shared results that comparedetailed balancing to complex balancing in terms of their associated algebraic varieties. In addition,there were speakers from various backgrounds ranging from theoretical computer science to controltheory to probability, and talks whose titles include the words ”homotopy” and ”number theory.”This session led to fruitful discussions and further collaborations.
2.1.7 Transition Workshop
The transition workshop was designed to synthesize the year’s activities and provide a blueprint togo forward with research in this field. Talks covered a range of topics related to the working grouptopics. Talks by Reinhard Laubenbacher, Seth Sullivant, and Ruriko Yoshida indicated how wewant to move forward beyond the program year. Some talks highlighted successes from the workinggroups, and some talks were chosen to increase the range of topics present in the program.
In addition to the talks, there was ample time for participants to discuss future plans for research,and for the research area. Each day included multiple “Second Chances” sessions, which gave par-ticipants a chance to further engage the speakers and to explore relations between talks, and futuredirections. One outgrowth of these discussions is that Laubenbacher, Sullivant, and Yoshida will
5

coorganize a workshop on Algebraic Methods during the MBI 2011-12 program year on “Stochasticsin Biological Systems”.
Invited speakers were: Reinhard Laubenbacher, Heike Siebert, Luis Garcia-Puente, KatherineSt. John, Megan Owen, Marcy Uyenoyama, Henry Wynn, Ruriko Yoshida, Peter Huggins, GilesGnacadja, Anne Shiu, Olgica Milenkovic, Elena Dimitrova, Paul Kidwell, and Seth Sullivant.
2.1.8 Joint Statistics Meeting Mini-symposium on Algebraic Methods in Systems Bi-ology and Statistics
Ian Dinwoodie organized a mini-symposium, at the Joint Statistics Meeting in Washington D.C. inAugust 2009, that will highlight some of the results that have come out of the SAMSI program. In-vited speakers were: Saeid Yasamin, Simon Lunagomez, Seth Sullivant, and Reinhard Laubenbacher.
2.2 Working Groups
At the end of the opening workshop in September, the afternoon was devoted to the formation ofworking groups for the year. Based on participant interest and program themes, the topics thatemerged were:
1. Systems biology: The relationship between the structure and dynamics of biological networks;
2. Algebraic statistics and experimental design;
3. Evolutionary biology and phylogenetics.
There was significant overlap between topics and membership of the different working groups.For instance, experimental design is a very important topic in systems biology as well.
2.2.1 Relationship between structure and dynamics of biological networks
The working group leaders are R. Laubenbacher (VT) and Brandilyn Stigler (SMU).
One of the dominant themes at the opening workshop was the relationship between the structureof biological networks and the kind of dynamics this structure supports. The questions about thisrelationship is appropriate for a variety of biological networks, ranging from molecular pathways tosocial networks that support the spread of epidemics. For the working group, the focus was entirelyon biochemical networks, encompassing two different modeling frameworks: polynomial dynamicalsystems over finite fields, in particular Boolean networks, and systems of polynomial differentialequations. The primary structure of a network is given by a directed graph that indicates thedependence of the network variables on each other. In both modeling frameworks, one of the goalsis to infer constraints on the dynamics of the network from properties of this graph. In the otherdirection, the goal is to infer the structure of the graph from a partial specification of the networkdynamics, e.g., through a collection of time course experiments.
Working Group Activities.
Since the background of the working group members varies considerably, a primary focus of thegroup activities in the fall and part of the spring were on presentations and discussions aimed atestablishing a common background in systems biology and the different approaches to modeling andsimulation. The group is now at a stage where first results are being presented, beginning with thework of the subgroup on software development, described below.
6

A major problem with the construction of large-scale algebraic models is that there are no so-phisticated tools available, comparable to ODE tools. Most importantly, the tool of fitting ODEmodel parameters to available data is key in continuous model construction, but completely absentfor algebraic models. Also, tools like bifurcation analysis, sensitivity analysis, stability analysis areall unavailable to the algebraic modeler. However, there exist several or all of these tools in the poly-nomial dynamical systems framework. The goal of this subgroup of the working group was to collecttogether available software and integrate it in a coherent package scheduled which was released inApril 2009.
Active participants.Carsten Conradi (MPI Magdeburg), Alicia Dickenstein (University of Buenos Aires), Elena Dim-
itrova (Clemson University), Ian Dinwoodie (Duke University), Lee Falin (Virginia Tech), ThomasFriedrich (TU Berlin), Gilles Gnacadja (Amgen), Richard Haney (Cellular Statistics), FranziskaHinkelmann (Virginia Tech), Serkan Hosten (San Francisco State University), Abdul Salam Jarrah(Virginia Tech), Reinhard Laubenbacher (Virginia Tech), Tong Lee (Virginia Tech), Shaowei Lin(Univ. of California-Berkeley), Megan Owen (SAMSI), Mercedes Soledad Perez Millan (Universityof Buenos Aires), Anne Shiu (Univ. of California-Berkeley), Heike Siebert (FU Berlin), BrandyStigler (Southern Methodist University), Seth Sullivant (NCSU), Jung-Ying Tzeng (N.C. State Uni-versity), Alan Veliz-Cuba (Virginia Tech), Benjamin Wells (N.C. State University), Henry Wynn(London School of Economics), Richard Yamada (University of Michigan), Shantia Yarahmadian(Indiana University), Saeid Yasamin (SAMSI),
2.2.2 Algebraic Statistics and Experimental Design
The Algebraic Statistics and Experimental Design (ASED) working group in the 2008-2009 SAMSIprogram Algebraic Methods in Systems Biology and Statistics had approximately 30 members, in-cluding many remote participants in England, Italy, Japan, and throughout the U.S. The group wasformed during the opening workshop in September, when all members were present and decidedupon research themes and meeting times. The working group leaders were Serkan Hosten of SanFrancisco State University and Ian Dinwoodie of Duke University.
The ASED group worked on a range of statistical applications that use computational tools ofcommutative algebra. These applications include sampling and Monte Carlo methods for discretedata (tables and sequences), experiments (data gathering) and data analysis for reverse engineeringof biological networks, disclosure limitation, and foundations of phylogenetic trees in evolutionaryand population biology. Each application area emphasizes certain algebraic tools and each has rootsin particular research groups with a wide international base. The different mathematical tools andresearch groups were well-represented in the group members. The working groups benefited fromthe active and steady participation of individuals with much depth and experience. In particular,Henry Wynn and Giovanni Pistone shepherded the experimental design part of ASED, and worked oncollaborations with the Systems Biology working group, where design issues are important for findingwiring diagrams and network connections. Phylogenetic trees were supported by John Rhodes,Elizabeth Allman, and Seth Sullivant, who completed foundational work on identifiable tree modelsin the course of the year, and shared their work from the Evolutionary Biology working group.Ongoing work in high-dimensional tables (sampling and disclosure limitation) was well-representedas well, with presentations by researchers and practitioners Akimichi Takemura, Larry Cox, EdwinO’Shea, Adrian Dobra, and others. Also some connections were made with the Sequential ImportanceSampling program through research on sequential Monte Carlo methods for statistical inference onBoolean dynamics in biological networks.
The ASED working group met formally on Mondays at noon, in addition to informal collabo-
7

rations. About half the participants logged-in from remote locations using the Webex networkingapplication. The list of talks and speakers is at www.samsi.info under the ASED working group link,together with supporting materials and documents.
The complete list of ASED working group members is below:Elizabeth Allman (University of Alaska-Fairbanks), Deidra Coleman (N.C. State University),
Lawrence H. Cox (CDC), Elena Dimitrova (Clemson University), Ian Dinwoodie (Duke University),Luis David Garcia-Puente (Sam Houston State University), Hisayuki Hara (Tokyo), Serkan Hosten(San Francisco State University), Thomas Kahle (Leipzig), Imre Risi Kondor (University College Lon-don), Reinhard Laubenbacher (Virginia Bioinformatics Institute), Tong Lee (Virginia Tech), HugoMaruri-Aguilar (London School of Economics), Catherine Matias (CNRS), Uwe Nagel (University ofKentucky), Edwin O’Shea (Avanzados del IPN), Vittorio Perduca, Mercedes Soledad Perez Millan(Universidad de Buenos Aires), Sonja Petrovic (University of Illinois at Chicago), Giovanni Pistone(Torino), Eva Riccomagno (Genoa), Seth Sullivant (NCSU), Akimichi Takemura (Tokyo), CarolineUhler (Univ. of California-Berkeley), Alan Veliz-Cuba (Virginia Tech), Benjamin Wells (N.C. StateUniversity), Henry Wynn (London School of Economics), Richard Yamada (University of Michigan),Ahmad S. Yasamin (SAMSI), Jason Yellick (N.C. State University), Ryo Yoshida (Japan), Yi MingZou (University of Wisconsin-Milwaukee), Or Zuk (M.I.T.), Piotr Zwiernik (University of Warwick)
2.2.3 Evolutionary Biology and Phylogenetics
As part of SAMSI’s 2008-09 program on Algebraic Methods in Systems Biology and Statistics aworking group in ‘Evolutionary Biology’ was formed during the opening workshop in September.Broadly speaking, members of this group were interested in finding, understanding, and solvingproblems arising in evolutionary biology that might require sophisticated mathematical and statisticaltechniques that have yet to be developed.
The group was lead by Seth Sullivant, Elizabeth Allman, and John Rhodes, and during theopening workshop interested participants indicated that primary areas of common interest includedphylogenetics, coalescent theory, population genetics, and comparative genomics.
Working Group Activities.
It was immediately clear that group members had widely diverse backgrounds in statistics, math-ematics, and biology, and that participants needed a ’common language’ and ’common backgroundknowledge’ in order to collaborate. During the first semester and spilling over into the beginningof the second semester, the working group met weekly. Each week a particular group member withexpertise in one of the areas of common interest, gave a talk at an introductory level to familiarizeother group members with the area, discuss his/her research, and suggest possible problems wherealgebraic techniques might yield results. Typically, after an hour or more of introduction by thespeaker, group members discussed the problems and a question-and-answer period began.
The main topics included: the structure of tree space for phylogenetic trees (2 sessions), mixturemodels in phylogenetics and invariants (3 sessions), the coalescent model (4 sessions), geometry ofcophylogeny (1 session), and comparative genomics (1 session).
8

9/23/08 Megan Owen on the space of phylogenetic trees and the geodesic distance: Space of Phylo-genetic Trees
9/30/08 John Rhodes on phylogenetic invariants10/07/08 Seth Sullivant: Some algebraic ideas for phylogenetic mixtures10/14/08 Peter Beerli (Part 1 of introduction to coalescent theory series): Population genetic calcu-
lations that do not fit on the back of an envelope10/21/08 Laura Salter Kubatko (Part 2 of introduction to coalescent theory series):10/28/08 Peter Beerli (Part 3 of the introduction to coalescent theory series): Finding good trees -
Simplifying Coaslescent trees11/04/08 Serkan Hosten: Extended UPGMA and phylogenetic tree reconstruction11/11/08 Rudy Yoshida: Open Problems in Geometry of Cophylogeny11/18/08 Julia Chifman: Group-based models01/19/09 James Degnan: Gene tree distributions and coalescent histories01/26/09 Or Zuk: Annotating the Human Genome Using Comparative Genomics
For a particularly successful ending to the fall semester, the evolutionary biology meeting con-sisted of a session in which individuals suggested open problems for the group to work on.
After an organizational meeting in mid-January, the working group decided to focus primarilyon reading papers to acquire a deeper understanding of tree space, gene-tree/species-tree problems(coalescent theory), models of speciation, and ancestral recombination graphs. Several talks werealso scheduled during the semester while researchers were visiting at SAMSI for collaborations andworkshops.
Weekly working group meetings ran differently the Spring term. The idea was to have all groupmembers read the papers for the week, and one person was assigned to lead a discussion. It wasassumed that no one was an expert in the the area, so that the group could learn by reading up ona topic together. This worked reasonably well, but the best discussions took place when there weremore group members physically present at SAMSI.
Group Membership.
The official number of group members was quite high, around 35, though the number of activeparticipants is closer to 20. The number of participants on a weekly basis (“the faithful”) wastypically about eight to ten. The meetings on the coalescent model were particularly well-attended.
The names of the active participants have been included below:Elizabeth Allman (University of Alaska-Fairbanks), Elisaveta Arnaudova (University of Ken-
tucky), Peter Beerli (Florida State University), Julia Chifman (University of Kentucky), Luis Garcia-Puente (Sam Houston State University), Serkan Hosten (San Francisco State University), LauraKubatko (Ohio State University), Jinze Liu (University of Kentucky), Catherine Matias (CNRS,Laboratoire Statistique et Genome), Uwe Nagel (University of Kentucky), Megan Owen (SAMSI),Sonja Petrovic (University of Illinois at Chicago) Scott Provan (University of North Carolina), JohnRhodes (University of Alaska-Fairbanks), Chris Schardl (University of Kentucky), Seth Sullivant(N.C. State University), Amelia Taylor (Colorado College), Jason Yellick (N.C. State University),Ruriko Yoshida (University of Kentucky), Or Zuk (M.I.T. Broad Institute) Piotr Zwiernik (Universityof Warwick)
Several new collaborations were formed among evolutionary biology group members, and theworking group format gave the opportunity for extended research interaction to both these new andpre-existing collaborations.
9

2.3 University Courses
Title: Algebraic Methods in Systems Biology and Statistics
Instructors: Seth Sullivant (NCSU) and Reinhard Laubenbacher (VA Tech)
Course Day and Time: Tuesday 4:30-7:00
Course Description: This course provided an introduction to the algebraic techniques that haveemerged as useful tools in biology and statistics. This course was intended to bridge the gap betweenabstract algebra and the application areas covered in the year-long program.
After providing an introduction to polynomial rings, ideals, and Grobner bases, we will surveya range of applications of these ideas. Possible topics include: Polynomial dynamical systems overfinite fields and applications, graphical and hierarchical models, Markov bases for contingency tableanalysis, phylogenetic models and the space of trees, applications of tropical geometry in MAPestimation.
10

Final Report
Meta-Analysis: Synthesis and Appraisalof Multiple Sources of Empirical Evidence
With the increasing concern in science and medicine for issues such as more complete use
of all sources of evidence and reproducibility for single statistical studies, multiple studies and
meta-analysis are becoming central to scientific advancement. The Statistical and Applied
Mathematical Sciences Institute (SAMSI) addressed this topic through a research program
from June 2-13, 2008. It brought together leading statisticians and scientists with interests
in meta-analysis, to assess the existing methodology, and develop needed new methodology,
and explore pedagogy for bringing the methodology to the broader scientific community.
1 Scientific Overview
1.1 General Background on Meta-Analysis
Seldom is there only a single empirical research study or source of evidence relevant to a
question of scientific interest. However, both experimental and observational studies have
traditionally been analyzed in isolation, without regard for previous similar or other closely
related studies. A new research area has arisen to address the location, appraisal, recon-
struction, quantification, contrast and possible combination of similar sources of evidence.
Variously called meta-analysis, systematic reviewing, research synthesis or evidence syn-
thesis, this new field is gaining popularity in diverse fields including medicine, psychology,
epidemiology, education, genetics, ecology and criminology.
Statistical methods for combining results across independent studies have long existed,
but require renewed consideration, development and wider dissemination by inclusion in
the mainstream statistics curriculum. The possibility that the due consideration of all
relevant evidence should be accepted as standard practice in statistical analyses deserves
investigation. The combination of results from similar studies is often known simply as
’meta-analysis’. Common examples are combining results of randomized controlled trials
of the same intervention in evidence-based medicine; of correlation coefficients for a pair of
constructs measured similarly across studies in social science; or of odds ratios measuring
association between an exposure and an outcome in epidemiology. More complex synthe-
ses of multiple sources of evidence have developed recently, including combined analyses of
clinical trials of different interventions, and combined analysis of data from multiple microar-
ray experiments (sometimes called cross study analysis). For straightforward meta-analyses,
1

general least-squares methods may be used, but for complex meta-analyses, the technical
statistical approach is not so obvious. Often likelihood and Bayesian approaches provide
very different perspectives; and in practice the possible benefits of more complex approaches
may be hard to discern as many meta-analyses are compromised by limited or biased avail-
ability of data from studies as well as by varying methodological limitations of the studies
themselves.
The presence of multiple sources of evidence has long been a recognized challenge in the
development and appraisal of statistical methods - from Laplace and Gauss to Fisher and
Lindley. In the 1980s Richard Peto argued that a combined analysis would be more important
than the individual analyses, a view taken still further by Greenland and O’Rourke who have
suggested that that individual study publications should not attempt to draw conclusions
at all, but should instead only describe and report results, so that a later meta-analysis can
more appropriately assess the study’s evidence fully informed by other study designs and
results. Will combined analyses actually replace individual analyses (or at least decrease
their impact)? If so, it is time to reexamine the perennial problems of statistical inference
in this context.
The concept of multiple sources of evidence itself needs to be generalized and applied
more generally and creatively through many areas of statistical research. Multiple sources
should not just be taken as separate studies or even the possible simple regrouping of subsets
of observations within studies but the bringing to bear of seemingly distinct information
sources on given question and even the ”creation” of multiple sources as in Bayesian Additive
Regression Trees (BART) where differing regression trees are purposefully grown to be later
advantageously combined. In some fields, terms like data fusion and data integration are
being used for this more general sense of utilizing multiple sources of evidence. A single
strategy of no pooling, complete pooling or partial pooling of separate studies perhaps needs
to give way to adaptive strategies where the degree of pooling is individually chosen for
each and possibly every parameter in the joint probability models used to represent all the
relevant sources of evidence.
1.2 Specific motivation for the focus of this program
This program comprised two weeks of research, mixing tutorials, research presentations and
working group activities on the subject. The goal of this program were three-fold: 1) to bring
the area to the attention of statistical researchers, whose expertise is critical to substanti-
ate and clarify the necessary statistical theory and methodology; 2) to nurture the necessary
interdisciplinary collaboration and communication between statistical researchers and statis-
ticians who currently work or plan to work with basic and applied science researchers and
2

3) to provide an entry point into the field to interested students and faculty, and to allow
researchers already specialized in the domain to exchange recent results and information.
2 Program Structure
2.1 Leaders
The program was initiated by Keith O’Rourke. The tutorials in the first week were organized
jointly by Vanja Dukic, Ken Rice and Keith O’Rourke. Ingram Olkin opened the program
with the lead tutorial followed by Keith O’Rourke, Ken Rice, Vanja Dukic and Julian Higgins.
The data analysis sessions were given by Keith O’Rourke and Ken Rice. The working group
leaders chosen for the second week of workshops were Dalene Stangl, Ken Rice, Vanja Dukic,
Julian Higgins, Keith O’Rourke and David Dunson.
2.2 Program Attendance
The program attracted 44 participants in the first week, which featured tutorials and data
analysis workshops (see below). A total of 31 participants either continued from the first
week or joined the program in the second week; the second week involved working groups
and a final summary session (see below). All in all, 55 participants attended some portion
of the program.
2.3 Tutorials and Opening Workshop
The introductory overview was given by Ingram Olkin, Stanford University. It provided par-
ticipants with an elementary but thorough introduction to the challenges and opportunities
of dealing with multiple studies in the context of biomedical and social science research.
Many real application examples were covered to illustrate basic and advanced methods and
highlighted the numerous scientific issues and challenges that inevitably arise.
An introductory overview on the likelihood basis for multiple data sources was then given
by Keith O’Rourke, Duke University. This provided participants with an elementary intro-
duction to working directly with likelihoods to contrast and combine data based information.
This was done both for individual observations - where individual observation likelihoods
were contrasted and combined to obtain the usual study estimates - and for studies where
study level likelihoods were contrasted and combined. A general meta-analysis approach was
then presented in terms of the contrast and combination of likelihoods. Various problems
that arise with likelihoods in meta-analysis were then discussed. These problems are largely
due to fact that although likelihood concentrates for common parameters (of interest) it
3

expands in dimension for arbitrary (nuisance) parameters and unfortunately there usually
are many of these arbitrary (nuisance) parameters.
The advanced tutorials were then started the next day with Keith O’Rourke more thor-
oughly reviewing the likelihood approach and underlining issues of sparseness with the histor-
ical Neyman-Scott examples. Vanja Dukic then covered the integrated likelihood approach
as well as some preliminaries for a Bayesian approach. Ken Rice then covered the conditional
likelihood approach both from a classical and Bayesian perspective as well as providing ma-
terial on exchangeability and other more general aspects of meta-analysis. Following this,
Vanja Dukic and Ken Rice more fully covered Bayesian approaches to meta-analysis. The
tutorial sessions ended with Julian Higgins giving a thorough overview of current (practical)
challenges in undertaking meta-analyses in clinical research.
Inter-dispersed with these tutorials, Keith O’Rourke gave a ”Data Analysis Session” on
likelihood calculations in R and Ken Rice gave one on implementing Bayesian meta-analyses
in WinBUGs.
3 Working Groups
In the second week, working groups were formed based on the participant research interests.
There were six working groups formed comprised of 31 participants, with group sizes ranging
from 7 to 17. The Working Groups were
1. Decision theory
2. The role of priors for bias and random effects
3. Bias modeling and information from observational studies
4. ROC and survival analysis
5. Networking, multiple treatments and multivariate
6. Genetics
Here is a summary of their activities.
3.1 Decision analysis group
During the week this group explored two questions:
1. In reporting estimates of treatment effect and heterogeneity, is there a loss function
for which usual estimates reported are optimal?
4

2. In non-inferiority trials, how does one choose the delta by which a new treatment is
considered ”good-enough” relative to the standard treatment and placebo [this question
was motivated by an FDA inquiry to the program].
The group studied what is currently done in non-inferiority trials, discussed the difference
between random and fixed effects, raised and discussed a concern about only looking at inter-
study variability in average treatment effect rather than also being concerned with within
study treatment effect variance in choosing between drugs and discussed how “ideally” one
would like to address the problems versus how one can take what is currently done and
make an improvement that has a chance of being implemented. At the end there seemed
to be a consensus that it was necessary to be clear about what the “real” question was and
for exactly what “population” so that a full and complete modeling of the decision and its
relevant consequences could be undertaken.
As a result of the discussions, some members of the group have written a technical report
that has been submitted for publication but is still under review. The reference of the paper
is: E. Moreno, F. J. Giron, F.J. Vazquez-Polo and M.A. Negrin (2008). Optimal decisions
in cost-benefit analysis. Tech. Report. Dpt. Statistics, University of Granada.
3.2 Role of priors for bias and random effects group
This group focused on priors for random effects and bias - two areas in meta-analysis where
there is usually a small amount of sample information and hence the choice of priors can be
critical.
The discussions around random effects necessarily started with the choice of the para-
metric distribution of random effects – meant to represent the physical variation in effects
from study to study – and then priors for the parameters in these distributions and then
non-parametric approaches to random effects. In this group, roughly as in the Decision
Analysis group, it was found necessary to be clear about what the “real” question was, what
the random effect distribution was meant to represent and exactly what parameters were of
inferential interest. A quick review of some current choices for priors for random effects seen
in the meta-analysis literature was also undertaken.
The discussion of priors for biases, such as may vary with varying assessed study quality,
largely revolved around the possibilities of obtaining empirically motivated priors from the
empirical literature. A possibly relevant data set of clinical research studies with various
methods of appraising their quality was acquired and a method for investigating quality
effects identified in a paper by Greenland and O’Rourke. This likely will become a student
project in the near future.
5

Currently, the group leader, Ken Rice is working on a paper with Keith Abrams entitled
Estimating population-averaged contrasts under exchangeability; the role and influence of
random-effects distributions.
3.3 Bias modeling group
The bias modeling group undertook the challenge of issues and methods for the contrast
and combination of biased and confounded sources of information. There ended up being a
focus on two main topics - 1) propensity score issues and methods in multiple observational
studies and 2) investigations of bias modeling using both RCTs and Non-Rcts together.
The propensity score focus ended up involving two projects, Project A where there was
individual-level data available from multiple observational studies and Project B where was
only study level data available. Project A , was lead by Elizabeth Stuart of John Hopkins
University and B was lead by Robert Platt of McGill University. The motivating question
for A was with regard to how propensity scores should be estimated in this setting and
the motivating question for B was with regard to whether or not and if so – how propensity
score-based subclass estimates from the multiple studies should be combined to get an overall
estimate of the effect. Elizabeth Stuart and Robert Platt have since been collaborating on
these projects and anticipate involving students in the future.
The investigations of bias modeling using both RCTs and Non-Rcts was lead by Dan
Jackson of MRC Cambridge and involved the adaption/extension of methods developed
by Steyerberg and the motivating question was with regard to explicating the necessary
assumptions and critically assessing their appropriateness. Dan Jackson is continuing to work
on the adaption of the Steyerberg method and its extensions and in related work with the
Fibrinogen Studies Collaboration [published in Statistics in Medicine (2009) – Systematically
missing confounders in individual participant data meta-analysis of observational cohort
studies]; he has found the discussions at SAMSI useful in his thinking further about applying
Steyerberg type methods.
Also of note, Elizabeth Stuart – partly as a result of the SAMSI meeting – is planning
to organize a 2010 JSM Invited Session on methods for assessing generalizability.
3.4 ROC and survival analysis group
This working group addressed the issues of synthesizing evidence from independent studies
about diagnostic test accuracy or survival times – both of which entail individual study
and pooled curves or distributions. Both parametric and non-parametric approaches were
of interest.
6

They currently have one paper in preparation, with Jean-Francois Plante of University of
Toronto, Vanja Dukic of Chicago University, David Dunson of Duke University and possibly
Dalene Stangl of Duke University on Bayesian non-parametric meta analysis of ROC curves.
The abstract is as follows: Most standard meta-analytic methods combine information on
single parameter, such as treatment effect. For meta-analysis of diagnostic test accuracy,
measures of both sensitivity and specificity from different trials are of meta-analytic in-
terest, summarized as a bivariate measure of accuracy, or possibly as a receiver operating
characteristic (ROC) curve. Motivated by an analysis of serum progesterone tests for diag-
nosing non-viable pregnancy, we develop simple fixed-effects and random-effects summary
ROC curve estimators, based on a flexible density estimation technique. We compare the
performance of the new estimator to the simpler bivariate normal summary ROC estimator.
3.5 Network meta-analysis group
Network meta-analysis refers to the situation in which studies brought together for synthesis
have compared different subsets from a finite collection of treatments. By exploiting ‘chains’
of evidence, such as making inference on treatment A vs treatment B by contrasting studies
of A vs C with studies of B vs C, a network of interrelationships among the studies is created.
These meta-analyses are often, and perhaps more appropriately, called multiple treatments
meta-analyses (MTM), or mixed treatment comparisons (MTC) meta-analyses.
The working group tackled a variety of problems associated with network meta-analysis.
Particular progress was made on methods for illustrating the network graphically. If every
study makes a pair-wise comparison – i.e. includes exactly two treatments – then simple
graphs with nodes for treatments and lines for comparisons are sufficient to represent the
dataset. However, if some studies include three or more treatments, as is typically the case,
then such representations do not adequately illustrate the important difference between
within-study (direct) comparisons and across-study (indirect) comparisons. In this case,
comparisons that come from the data are not independent. The group proposed a diagram
in which the distinction is made by using separate lines or shapes for different study designs.
Since the workshop, some progress has been made in using graph theory to examine ‘loops’
of evidence in the network.
The importance of separating direct from indirect evidence is largely in order to in-
vestigate whether the network of evidence is coherent. Coherence is defined informally as
mismatch between direct and indirect sources of evidence, or between two different indi-
rect sources of evidence, on any particular comparison. It is a special kind of heterogeneity
between studies that focuses on between-design differences rather than between-study differ-
ences. Two statistical methods for tackling incoherence have been proposed, by T. Lumley
7

(Network meta-analysis for indirect treatment comparisons, Stat Med 2002; 21: 2313-2324)
and Lu and Ades (Assessing evidence inconsistency in mixed treatment comparisons, JASA
2006; 101: 447-459). The former adds a random effect across all studied pair-wise compar-
isons and tests whether the variance of this random effect is zero. The Lu and Ades approach
adds a random effect across each independent evidence cycle, and tests whether the variance
of this random effect is zero. There are fewer independent evidence cycles than there are
comparisons. However, counting the number of independent evidence cycles is not trivial
when there are multi-arm studies. The group discussed other approaches, such as fitting
a model than assumes coherences and comparing deviances with a ‘free’ model that makes
no assumptions about chains of evidence. Three of the workgroup members (Dan Jackson,
Jessica Barrett, Julian Higgins; working with Ian White) have a paper in preparation about
some of these ideas.
The working group also discussed technical issues about making inferences in network
meta-analyses. Restricted maximum likelihood is often used; Lumley uses the function lme
in R with a slightly unusual construction for random-effects variances. Inference is less
straightforward with multi-arm trials or logistic models. We explored profile likelihood,
and inverting the observed information matrix. Plans were made to investigate the use of
conditional likelihood, integrated likelihood, and inverting expected information matrix.
3.6 Meta genetics group
This working group address issues of multiple sources of evidence for genetics, focusing
on Gene Expression Meta Analysis, Meta Analysis for Genetic Association Studies and
Accounting for Dependence in High-Dimensional Predictors. Since this summer’s program,
the meta-genetics working group has been quite productive. The active core of this group
consists of David Dunson at Duke University , Fei Zou at UNC Biostatistics and Fei Liu at the
University of Missouri Columbia. They have submitted the following paper to Biometrics:
Liu, F., Dunson, D.B. and Zou, F. (2008). High-dimensional variable selection in meta
analysis for censored data. Biometrics, submitted. In addition, they have another paper
under way: Liu, F., Dunson, D.B. and Zou, F. (2009). Annotated relevance vector machine
with application to polymorphism selection. In preparation.
Their following summary highlights some of the work undertaken to date which represents
the most exciting research happening in the program and provides a nice example of both a
generalized concept of multiple sources of evidence and the replacement of a single strategy
of no pooling, complete pooling or partial pooling of studies with an adaptive strategy where
the degree of pooling is individually chosen for different coefficients.
In large scale genetic epidemiology studies that collect massive numbers of single nu-
8

cleotide polymorphisms (SNPs) or gene expression measurements, it is extremely challenging
to identify genes that are predictive of disease phenotypes given the modest sample size of
most studies relative to the number of genes. Due to concern about false positive rates, it
is crucial to replicate findings about disease genes in multiple studies. Standard approaches
take multistage testing approaches in which one tests if genes identified in initial studies are
significant in follow-up studies. This strategy is shown to have major disadvantages in terms
of power and type I error rates compared with an innovative approach developed in the
SAMSI meta-genetics working group based on simultaneous selection through a multi-task
relevance vector machine (MT-RVM) procedure. This approach, which is related to methods
used in signal processing, borrows information across studies in the degree of shrinkage of
gene-specific coefficients towards zero. The method is scalable to large numbers of genes, can
accommodate censored data commonly collected in disease recurrence studies, and clearly
outperforms common competitors, such as Lasso. In addition, the meta-genetics group is
currently pursuing a new procedure that allows information on gene function annotation
to be incorporated, while automatically learning how predictive each annotation source is.
The annotated relevance vector machine (aRVM) procedure should be very widely useful
in machine learning and other applications beyond genetics, as it allows an adaptive tar-
geted search for important predictors enabling an effective reduction in dimensionality and
mechanism for borrowing information across disparate studies.
4 Post Program Activities
1. At the Eastern North American Region 2009 meeting of the International Biometric
Society most of the working group leaders and some of the participants presented their
research. In particular, a session “Advances in Meta-Analysis” was organized, based
on the program, with presentations by Eloise Kaizar, Robert Platt, Vanja Dukic,and
Dalene Stangl.
2. Professional Courses:
• Keith O’Rourke gave a two day course on meta-analysis for Statisticians and
Students at the University of Alberta in July 2008.
• Keith O’Rourke gave an Advanced Meta-analysis Short Course at the University
of Alberta.
9

Final Report2009 Summer SAMSI Program on
Psychometric Modeling and Statistical Inference
July 7-17, 2009
1 Scientific Overview and Program Objectives
Much of current psychometric research involves the development of novel statisticalmethodology to model educational and psychological processes, and a wide vari-ety of new psychometric models have appeared over the last quarter century. Suchmodels include (but are not limited to) extensions of item response theory (IRT)models, structural equation models (SEMs), cognitive diagnosis models, and gen-eralized linear latent and mixed models (GLLAMM). The development of severalof these models has been spearheaded by quantiative psychologists, a group of re-searchers who find their academic homes primarily in psychology and educationdepartments. During the same period, very similar models and methodologies weredeveloped—often independently—by academic statisticians residing in mathematicsand statistics departments. The lack of interaction between these two groups hasresulted in a substantial duplication of effort and, more importantly, a delay in thedevelopment of methodology crucial to both fields. The goal of this program wasto bring researchers from both areas together to explore possible avenues for mutualcollaboration.
2 Program Leadership
The program was organized by Valen Johnson and Richard Swartz (The Universityof Texas M.D. Anderson Cancer Center), with assistance from Jimmy de la Torre(Rutgers University), Charles Cleeland (The University of Texas M.D. AndersonCancer Center) and David Banks (Duke University).
1

3 Program Attendance
The program attracted 71 participants, of which 36 were students or new researchers.
4 Program Scope and Timing
The program was conducted during the two-week period between July 7 and July17, 2008 (Tuesday-Friday (July 7–10) and Monday-Friday (July13–17), The formalprogram included the following activities.
5 Program Activities
Week 1: July 7-10
The Psychometric Program kicked-off on Tuesday morning, July 7, 2009. Tutorialsand invited speakers are listed below.
Tuesday, July 7
9:00-12:00 Introduction to Item Response Theory. Yanyan Sheng
2:00-3:00 IRT PRO demonstration. David Thissen
Wednesday, July 8
9:00-12:00 A Nonlinear Mixed Models Approach to IRT. Mark Wilson, FrankRijmen.
2:00-4:00 Topics in Response Time Analysis. Mario Peruggia and Trish VanZandt
Thursday, July 9
9:00-12:00 An Introduction to Cognitive Diagnostic Models. Mathias vonDavier.
2:00-3:00 CDM Pitfalls and Recommendations. Sandip Sinaray.
2

Friday, July 10
9:00-12:00 An Introduction to Rater Models. Matthew Johnson.
2:00-4:00 Process de-association and signal detection. Dongchu Sun and JunLu.
Week 2: July 13-17
Peer Review Working GroupThe Peer Review WG met during the second week of the program. Talks pre-
sented during this week are listed below.
Monday, July 13
10:00-11:00 An Overview of Journal of the American Statistical AssociationArticle Reviews. David Banks.
1:30-2:30 An Overview of NIH R01 Peer-Review Scores. Valen E. Johnson.
Tuesday, July 14
10:00-11:00 A Bayesian Approach to Ranking and Rater Evaluation: AnApplication to Grant Reviews. Jing Cao.
1:30-2:30 A Bayesian Hierarchical Model for Multi-rater Data with Fine Scales.Song Zhang.
Friday, July 17
9:00-12:00 Discuss draft of white paper.
12:00 Adjourn.
Patient Reported Outcome Working Group (PRO WG)The PRO WG met during the second week of the program and the following talks
were presented.
Monday, July 13
3

10:00-11:00 Practical Issues in the use of Patient Reported Outcomes. Char-lie Cleeland.
11:00-12:00 Issues in longitudinal analysis of Patient Reported Outcomes.Bryce Reeves.
2:00-4:00 Group discussion of weeks agenda. Charlie Cleeland and BryceReeves.
Tuesday-FridayGroup collaboration on consensus agenda.
Friday, July 17
9:00-12:00 Discussion of the draft of white paper.
1:00-4:00 Finalize white paper.
4:00 Adjourn.
Applications and Challenges of Cognitive Diagnostic Models (CDM WG)The CDM WG also met during the second week of the program. The following
seminars were presented.
Monday, July 13
10:00-12:00 Discussion of cognitive diagnostic models and identification ofagenda by working group members. Jimmy de la Torre
Tuesday-FridayGroup collaboration on consensus agenda.
Friday, July 17
9:00-12:00 Discussion of the draft of white paper.
1:00-4:00 Finalize white paper.
4:00 Adjourn.
4

6 Program Outcomes
The goal of this program was to stimulate collaborations between researchers in thepsychometric and statistical communities. The desired outcome for the program wasa concrete list of specific research directions that would facilitate future methodolog-ical development in related psychometric/statistical models, and the education ofprogram participants with regard to the current state of research in each programarea. White papers summarizing research in the areas of cognitive diagnostic mod-els and patient reported outcomes were drafted, and a review paper on peer reviewfor articles submitted to the Journal of the American Statistical Association waspresented. These documents are included as attachments to this report.
7 Specific Information Requested
2 Government and Industrial Participation: None
3 Publications: Three white papers were produced during and after the workshop.These reports are included as attachments to this report. All three reports arein the process of being submitted for publication in refereed journals or havebeen submitted.
4 Diversity: The workshop was attended by a diverse group of participants, includingindividuals from psychometrics, psychology, statistics, and symptom researchdepartments. Yanyan Sheng, a junior female researcher from Southern IllinoisUniversity gave the first tutorial; Trish Van Zandt from Ohio State Universitygave another tutorial. Richard Swartz, a junior instructor from M.D. AndersonCancer Center, served as co-organizer.
5 No external support was obtained.
5

An Analysis of the JASA Editorial Process
David Banks, Duke University
Jing Cao, Southern Methodist University
Sourish Das, Duke University and SAMSI
Valen Johnson, University of Texas, M.D. Anderson Cancer Center
Jun Lu, American University
Michael McGill, Virginia Tech
Paul Speckman, University of Missouri-Columbia
Yu Yue, Baruch College, CUNY
Song Zhang, University of Texas, Southwestern Medical Center
Abstract
It is important for research journals to minimize bias and delay. This study, au-
thorized by the American Statistical Association Committee on Publications, analyzes
data on review times and decisions for the Journal of the American Statistical Asso-
ciation. The results show moderate effects that are attributable to both editors and
associate editors; furthermore, there is interpretable structure in the time to first deci-
sion, and evidence of association between the duration of the review and the ultimate
decision. Finally, an effort to examine institutional bias (i.e., whether the prestige of
the contact author’s institutional affiliation is related to acceptance probability) finds
a positive relationship, but this could easily be explained by confounding factors.
Keywords: Ordinal probit model, publication bias, refereeing.
1

1 Introduction
Authors and editors have longstanding concerns about the fairness and efficiency of editorial
processes. Further, the statistical profession has a duty to assess the consistency of its review
process, to ensure that good work is quickly reviewed and published. This paper provides an
exploratory analysis of data from Journal of the American Statistical Association (JASA),
in order to study how well its systems work.
The data for this research were gathered from the on-line Allentrack manuscript han-
dling systemwhich was used to process JASA submissions beginning in 2005. We captured
information on decisions made by the six editors whose terms began after the institution of
Allentrack, and we analyzed data from all three JASA sections (Applications & Case Stud-
ies, Theory & Methods, and Reviews). Section 2 describes the data, Section 3 describes the
analysis, and Section 4 summarizes the results.
Our analyses focus upon bias and speed. In terms of bias, one motivation for this work
is the persistent debate on JASA’s use of double-blind refereeing. In discussions within the
Committee on Publications of the American Statistical Association (ASA), some members
maintain that the review process could be improved if referees knew the identities of the
authors—and there are sound (Bayesian) reasons for thinking this is true. But other members
point to historical evidence, among other journals, that single-blinding invites bias. A third
opinion holds that even if double-blinding increases noise and delay, it is still valuable for the
ASA send a clear signal that gender, nationality, and institution are irrelevant in evaluating
the quality of work. And some iconoclasts argue for no-blind refereeing, in which the authors
are known to the referees and the referees are known to the authors. They claim such a no-
blind system would promote higher-quality reviews, greater courtesy, and allow referees to
be publicly recognized for good work.
As background on the bias discussion, Snodgrass (2006) reviews several kinds of bias in
single-blind systems (i.e., reviews in which the identity of the author is not concealed from
2

the referees). One early study (Goldberg, 1968) gave readers two versions of the same article,
except that one listed the author as John McKay and the other as Joan McKay. John got
significantly better ratings. Similarly, Blank (1991) found that for The American Economic
Review, borderline papers by men were more likely to be accepted than borderline papers
by women. A different kind of bias was shown by Gordon (1980); reviewers from second-tier
schools tended to favor papers by authors at second-tier schools. And Peters and Ceci (1982)
resubmitted 12 papers from top schools to journals that had previously published them, but
with the affiliation of the author changed to a second-tier school. Three were detected, eight
were rejected for “serious methodological flaws,” and one was accepted.
In response to these documented biases, many journals adopted double-blind refereeing,
so that neither the author nor the referees know each other’s identities (but, of necessity,
the editor and associate editor must know both). JASA was among these, prompted in part
by reports from the IMS New Researchers Committee (Altman et al., 1991) and Cox et al.
(1993). One goal in this study is to decide whether there is evidence that the ASA policy
has been successful.
The second issue investigated in this study was the time to publication. There is a
widespread perception that editorial decisions are made more rapidly in computer science
and bioinformatics than in statistics. Additionally, there can be long lags between final
acceptance and the appearance of an article. To the extent this is true, then our journals
are disadvantaging statisticians. And even if the perception is false, it still does damage to
the field—our best new researchers, facing the time pressure of tenure, will avoid statistics
journals and seek to publish in strong domain science journals. Of course, senior researchers
also want their work to appear quickly and to have influence.
The editors of JASA have a duty to minimize the possibility of bias and delay, while at
the same time ensuring the accurate decisions are made. To that purpose, they obtained
permission from the ASA Committee on Publications to harvest anonymized data from Al-
3

lentrack, JASA’s on-line manuscript handling system. Those data were provided to the 2009
Psychometrics Program sponsored by the Statistical and Applied Mathematical Sciences In-
stitute. A working group in that program analyzed that data, looking for problems with the
publication process.
2 The Review Process and the Data
The JASA review system typically works as follows, although there are many exceptions.
First, an author submits the paper on-line through the Allentrack manuscript handling
system. The author provides two copies of the paper, one of which is anonymized, and
indicates which of several submission categories is pertinent (usually the category is one of the
three sections of JASA: Applications & Case Studies, Theory & Methods, and Reviews, but
other categories include corrections, letters, discussions, and the ASA presidential address).
At this time the author also makes several commitments: that the paper is original work,
that it is not under consideration by another journal, and that the co-authors will be apprised
of the outcome.
Once the paper is submitted, the editorial administrator does a quality control check,
confirming the anoymization and that all of the figures and tables are readable. That usually
takes a day or so. Then the paper is given (electronically) to the appropriate editor.
The editor reviews the paper. In some cases there is a quick decision to reject. In
others, the paper is sent to an associate editor. Sometimes it takes several days or weeks
to secure an associate editor. The associate editor is usually asked to complete the review
process expeditiously so that a first decision can be sent to the authors within two months
of submission. The associate editor may make a recommendation without further review, or
may decide to contact referees (usually two or three) and ask them to assess the paper.
It can take days or weeks to secure referees. Many decline to review, which means the
search process must be restarted. (And it is entirely professional to decline to review—a
4

person may be too busy, or conflicted, or may not feel competent to handle the manuscript.)
Usually, the referees are asked to respond within six weeks, but sometimes it is necessary to
negotiate extensions or to ask for a faster turnaround.
The Allentrack system automatically sends the referee a reminder a week before the
review is due. It sends another on the day it is due, and (if necessary) several more over
the following weeks. Unfortunately, Allentrack does not automatically notify the associate
editor when a review runs late—this must be tracked actively rather than passively, and so it
is possible to overlook slow referees. Similarly, Allentrack does not notify the editor when an
associate editor is being slow—the editor must regularly review the roster of papers, looking
for problems.
Once all the referee reports have been submitted to Allentrack, the associate editor is
notified and asked to write a report. That report is based on their own reading of the
manuscript, as informed by the opinions of the referees. The associate editor submits the
report, along with confidential comments and a recommendation, to the editor through
Allentrack.
When the editor receives the reports from the referees and the associate editor, the editor
reviews the manuscript (usually this is a very careful reading, especially if the reports disagree
or if they raise a substantive issue). Then the editor writes a decision letter and sends it
to the contact author electronically, again through Allentrack. Before the letter is sent, the
editorial administrator checks that there has been no accidental breach of the anonymity of
the referees or the associate editor; this check can take a day or two to complete.
Depending upon the editor’s decision, the authors may revise and resubmit the manuscript
for further consideration. The second review process usually returns the manuscript to the
original associate editor and often the original referees, but this varies according to circum-
stance. It is possible for the revision process to iterate several times before termination, at
which time the editor renders a final decision.
5

In the course of managing the back-and-forth in the review process, Allentrack automat-
ically records data on when the manuscript changes hands, when specific review tasks are
completed, and who has responsibility for those tasks. The ASA Committee on Publication
allowed David Banks, the 2007-2009 JASA Coordinating Editor, to compile and anonymize
the data on all JASA submissions to editors whose terms started after April 1, 2006 (i.e.,
those editors who handled all of their manuscripts within the Allentrack system, which came
on-line in 2005). The ending date for the data collection was March 18, 2009; this date
allowed time for cleaning and anonymization before the start of the SAMSI Psychometrics
Program. These data were given to a SAMSI working group for analysis, and have also been
posted on www.amstat.org/publications/tas.cfm for public use.
The data consist of the following fields:
Manuscript Type. This indicates whether the manuscript was submitted to the Applica-
tions & Case Studies section, the Theory & Method section, the Reviews section, or
(much more rarely) was an invited discussion, rejoinder, comment, letter, or correction
note. The classifications in the latter categories are inconsistent, and depend on how
the authors labeled their contribution at the time of submission; for example, some
discussions are classified as regular submissions to one of the three JASA sections.
Total Number of Days. This is the total time from the initial submission to the final
decision. It includes the time that the authors spent doing revisions. Some entries
are blank, corresponding to manuscripts for which the final decision has not yet been
made.
Editor. This is an anonymized code for the editor. There are six editors represented in the
data. In nearly all cases an editor handles manuscripts for just one of the three JASA
sections, but, very rarely, an editor may handle a manuscript for a different section
(e.g., when the usual editor has a conflict of interest).
6

Final Decision. This is the final decision on the manuscript. The possible values are “ac-
cept”, “reject”, and “withdrawn without prejudice”. The last designation is probably
used by different editors in different ways, but it often indicates a manuscript that
the authors wish to withdraw, or which has been submitted to the incorrect section
of JASA , or which needs substantial rework before a review process can be begun.
In some cases it may be a politic rejection. In rare instances, the First Decision is
“reject” and the Final Decision is “accept”—this can happen when, for example, an
author challenges the initial decision and the editor is persuaded to reverse it.
AE. This is an anonymized code for the associate editor. There are 154 associate editors
in the data set. The associate editors are nested within editors; each editor has his or
her own set of associate editors, and this set often changes a little during their term.
Sometimes an editor acts as an associate editor. For many manuscripts this entry
blank, because the editor made a decision without involving an associate editor.
First Decision. The possible values for the first decision are “reject”, “acceptable with
major revision”, “acceptable with moderate revision”, “acceptable with minor revi-
sion”, “accept in present form”, and “withdrawn without prejudice”. Essentially all
research papers are rejected or require major revision after the first round of review.
The papers that are accepted or accepted with minor revision at the first decision are
typically letters, corrections, and the annual ASA presidential address. Other possible
exceptions are cases in which the paper was initially reviewed before the Allentrack
system was adopted, but the revision was submitted after, or other cases in which—
for reasons of error or convenience—a revision was handled as if it were an a new
manuscript. Many of the entries are blank, corresponding to papers that were still
under first review as of March 18, 2009.
Days to First AE Request. This variable is the time between the submission of the
7

manuscript and the time at which the editor decides to seek an associate editor, if one
is wanted. It includes the time needed for the quality control check by the editorial
administrator, and the editor’s time to make an initial assessment.
Days to AE Secured. This is the time from submission to the agreement by an associate
editor to handle the manuscript. Usually the associate editor accepts quickly, but
sometimes an associate editor is too busy or conflicted, and in that case there can be
additional delay.
Days to First Referee Assigned. This is the time from submission to the request for
the first referee, if one is selected. It provides a measure of how quickly the associate
editor is working. Of course, the first referee may decline, requiring the associate editor
to seek several referees, which lengthens the assignment process.
Days to First Referee Secured. This is the time from submission until the first referee
agrees to handle the manuscript.
Days to Final Referee Secured. This is the time from submission until the final referee
agrees to handle the manuscript. Usually there are at least two referees.
Days to Final Referee Comments Secured. This is the time until the last referee re-
port is received. In rare cases, this appears to be inconsistent with other measures,
such as the time of the editor’s decision. Such inconsistency could arise if, for example,
a referee was very slow and the associate editor decided to proceed without their input,
only later to receive a report from the referee.
Days to AE Recommendation. This is the time at which the associate editor sends their
recommendation to the editor.
Days to First Decision. This is the time required for the editor to submit the first de-
cision.
8

Days to First Decision Sent to Author. After the editor submits the first decision,
the editorial administrator reviews it to ensure there has been no accidental compromise
of anonymity. This variable indicates the time required to complete that check. Usually
this takes only a day or less.
Institution Rank. This is a binary variable. A “1” indicates that the contact author is at
one of the universities whose graduate program in statistics is ranked among the top
twenty.
Allentrack records additional information, but these are the fields that seemed most pertinent
to our concerns, and the ones contained in the posted dataset. Some of these fields are not
used in the analyses detailed in this paper, even though the SAMSI working group did
exploratory analysis on all of them.
Unfortunately, it was not practical to include gender information. In many cases it was
difficult to determine the gender of the contact author (the problem of foreign names). Also,
most papers have multiple authors, and it was unclear how to code these. The same issue
arose when classifying Institution Rank; in that case we decided to use the institution of the
contact author (but sometimes the contact author is not the first author).
3 Statistical Analysis
We study the effects due to editors and associate editors (AEs), and the effect of the rank of
the contact author’s institution, relating these to both review time and the editorial decision
that is made. We also provide general summary statistics about the process.
Overall, 27.2% of the manuscripts were sent to the Applications & Case Studies section
(A&CS), 70.9% were sent to Theory & Methods (T&M), and 2.0% were sent to the Review
section (Rev). Figure 1 shows the numbers that went to each of the six editors in the
database, broken out by their first decision categories. We have excluded the “accept”
9

category from this plot, because it is essentially unused as a first decision—the rare exceptions
include some discussions, rejoinders, letters, corrections, the ASA presidential address, and
manuscripts whose initial submission occurred before the Allentrack system was started, but
whose revision came in after (and thus the first decision in Allentrack was actually a second
or third decision in terms of the editorial process).
As Fig. 1 shows, Editors E2 and E4 handled relatively few manuscripts. These two were
the editors of the JASA Reviews section. Since there was little data, and since the editorial
decision-making for a review paper may be different from that used in a research paper,
editors E2 and E4 were omitted from the mathematical modeling described later.
Figure 2 shows the days to first decision, separated into cases in which the first decision
was made solely by an editor, and cases in which an AE was involved. The data are pooled
for all six editors, including E2 and E4. The most notable feature is the bimodality, which is
clearly attributable to the involvement of an AE. We believe (and this is supported by Fig.
3) that decisions to reject are made relatively quickly, either by an editor or by an AE who
does not feel that the paper should be sent to referees. But when an AE chooses to seek
referee input, then the process takes longer, with the first decision typically occuring about
90 days (3 months) after submission.
Figure 3 displays the time to decision, broken out in two ways. The left panel distinguishes
the four kinds of decisions: reject, acceptable with major, moderate, or minor revisions—but
it excludes the rare accept decision. The right panel shows the time to first decision according
to the JASA section that handled the paper. The left panel corroborates the impression that
rejections happen relatively quickly; the right panel shows large apparent differences in the
distributions of review times among the sections.
As a final summary, Fig. 4 shows a loess estimate of the acceptance rate as a function
of review time, pooled across all six editors. In this plot, “acceptance” means that the
first decision was not a rejection (i.e., either a straight acceptance, or a request for major,
10

moderate, or minor revision). The interpretation is that rejections happen quickly, and that
after the first month, the probability of some kind of acceptance increases steadily, with a
notable trend-change at about 90 days. This accords with the common editorial practice
of allowing referees two months for review, after which reminders are sent; these reminders
often prompt quick responses.
The following subsections fit three models that provide a more detailed understanding of
editorial and AE differences, as well as possible bias associated with institutional rank. The
analyses are based on the data for the 1971 manuscripts that were handled by editors E1,
E3, E5 and E6 (now indexed by j = 1, 2, 3, 4, respectively).
3.1 Editorial Rejection
Model 1 fits a probit model to the probability of editorial rejection without AE review. The
four editors are treated as random effects, and the institutional rank (top-tier or not), is
treated as a fixed effect.
We used the binary variable yi = 1/0 (i = 1, . . . , n1; n1 = 799) to indicate whether the ith
manuscript was directly rejected by an editor or not. We defined the indicator variable Eij
to be 1 if the ith manuscript is handled by the jth editor, and 0 otherwise. The institution
rank for the author of manuscript i was denoted by Ii. With the introduction of the latent
variable xi, Model 1 can be written as
xi = β +J∑
j=1
ηjEij + γIi + ei, ei ∼ N(0, 1), (1)
where the decision corresponds to
yi = I(xi > 0).
Here β is the intercept, ηj denotes the random effect of the jth editor, γ is the fixed institution
effect, and ei is assumed to follow a standard normal distribution to anchor the scale of
measurement for the latent variables {xi} (cf. Johnson and Albert, 1999). A locally uniform
11

prior is assigned for β and γ. We assume a two-stage prior for random effects ηj ,
ηj | σ2
η ∼ N(0, σ2
η),
σ2
η ∼ C+(0, 1), (2)
where C+(0, 1) denotes the half-Cauchy distribution with density 2/[π(1 + x2)] for x > 0.
To obtain the marginal posterior distribution on parameters of interest, we implemented a
MCMC algorithm coded in R. We ran multiple chains with different starting points to monitor
the convergence of the MCMC updates. In addition, quantile-quantile plots (cf. Johnson,
2007) were constructed to assess model fit. After a burn-in period of 20,000 updates, 30,000
subsequent updates were used for model inference. The same MCMC procedures were also
performed for the two models discussed in the following subsections.
Table 1 provides a summary of the posterior mean and standard deviation of the parame-
ters in Model 1. The posterior mean of the variance of the random effect for editor was 0.19,
while the posterior mean of the standard deviation was 0.35. The posterior interquartile
range for ση was 0.17− 0.44. These figures suggest that the (root mean square) editor effect
on the assessment of manuscript quality was approximately 35% of the standard deviation
of true manuscript quality, which in this model is (by definition) equal to 1. We regard
the magnitude of the editor effect to be well within reasonable bounds of human judgment,
although it is by no means negligible. The estimate of the institution effect, γ, is negative,
suggesting that manuscripts by authors from top-tier institutions have a better chance of
being sent to an AE for full review. Of course, the institution effect may be confounded with
a number of different factors, ranging from the possibility that top-tier institutions attract
more capable researchers who produce high-quality papers, to the possibility that editors
have an implicit bias in favor of authors from top-tier institutions. Without additional in-
formation, the cause of the institution effect estimated in Model 1 cannot be unambiguously
identified.
12

Table 1: Summary statistics for Model 1
σ2η γ
post. mean 0.19 -0.62
post. std. 0.43 0.10
3.2 Decision Conditional on AE Review
Model 2 considers only manuscripts that were sent for AE review (which often, but by no
means always, entails referee input). We fit an ordinal probit model in which the three ranked
responses are the decisions to reject, to require major revision, and to require moderate or
minor revision. (The last two decisions were combined into a single category because there
is no clear guidance to distinguish them and AEs may have used them exchangeably.)
The explanatory variables are AE (a random effect), institutional rank (a fixed effect),
and review time. Review time is expressed in the form of a linear spline with a knot at 90
days, allowing nonlinearity and respecting the information seen in Fig. 2.
For the 1172 manuscripts that were handled by AEs (with or without input from referees),
we let yi = 1, 2, 3 (i = 1, . . . , n2; n2 = 1172) code the first decision on manuscript i. A
value of 1 indicates that the manuscript was “rejected”, a 2 that it was “acceptable with
major revision”, and a 3 that it was “acceptable with moderate or minor revision”. We
defined an indicator variable Aik to be 1 if the ith manuscript was handled by the kth AE
(k = 1, . . . , K; K = 152), and 0 otherwise. Variable Ti denotes the number of days to the
first decision. We used an ordinal probit model with latent variable xi,
xi = β +
K∑
k=1
αkAik + γIi + θ1Ti + θ2(Ti − 90)+ + ei, ei ∼ N(0, 1), (3)
where
yi = l ⇐⇒ cl−1 < xi ≤ cl
13

to model the effects of AE, institution, and decision times in determining the decision reached
for a manuscript.
The quantities cl (l = 0, · · · , 3) denote ordinal category cutoffs, where c0 = −∞, c1 = 0,
and c3 = +∞. We assume c2 to be uniform on the real line subject to the constraint
c1 < c2 < c3. As in Model 1, β is the intercept and γ is the fixed institution effect. We use
αk to denote the random effect of the kth AE. In addition, (Ti−90)+ = max(0, Ti−90), and
θ1 and θ2 are the regression slopes for the linear spline of Ti. The spline knot at 90 days was
based on an exploratory analysis of the data. A locally uniform prior was assigned for the
intercept and the fixed effects, β2, γ2, θ1, and θ2. The normal-Cauchy prior (2) was again
assumed for the random effects αk, i.e., αk | σ2α ∼ N(0, σ2
α) and σ2α ∼ C+(0, 1).
Table 2 summarizes the MCMC estimates of the parameters in Model 2. Interestingly, the
estimated variance of the random AE effects σ2α is much smaller than the estimate of variance
of the editor effects σ2η from Model 1. A possible explanation for this fact is that editors
have done a good job in the early screening stage, and manuscripts handed down to AEs are
more homogeneous in quality. In addition, AE decisions usually combine their own reading
of a manuscript with input from one or more referees. This explanation is corroborated by
the insignificant institution effect, which indicates that manuscripts handled by AEs were of
similar quality despite difference in institution ranks.
We also note that the estimate of θ1 is positive, which suggests that the first decision
tends to be more positive as the time to that decision (before 90 days) becomes longer. An
explanation of this trend is that manuscripts of relatively lower quality are easier to evaluate,
and manuscripts of relatively higher quality or of borderline quality may receive conflicting
referee reports and thus require longer decision times. Alternatively, editors may more closely
scrutinize manuscripts that are potentially publishable. The estimates of θ2 and θ1 + θ2 are
negative and positive, respectively, which suggests that the association between decision and
time-to-decision decreases with time. One interpretation is that when a decision runs longer
14

than the JASA target timeline, the delay has less to do with the quality of the manuscript
and more to do with process failure.
Table 2: Summary statistics for Model 2
σ2α γ θ1 θ2 θ1 + θ2
post. mean 0.083 0.090 0.014 -0.013 0.0013
post. std. 0.038 0.10 0.00093 0.0015 0.0008
3.3 First Decision
Model 3 examines the first decision as a function of editor and institutional rank, using all of
the manuscripts handled by E1, E3, E5 and E6. The ordinal probit response has four levels:
reject, then major, moderate, or minor revision. (It is believed that editors may use the last
two categories more consistently than do AEs, and so we abandon the previous aggregation
of the last two groups). As before, editors are random effects and institutional rank is a
fixed effect. We note that in this model, the editor effect conflates editor effects with AE
effects, unlike the first model. However, it offers a more faithful picture of what an author
might expect when first submitting a paper, since at that time it is not clear whether the
paper will be assigned to AEs.
We define yi = 1, 2, 3 (i = 1, . . . , n3; n3 = 1971) as in Model 2, but now for all of the
manuscripts handled by the four CS&A and T&M editors. The other variables, xi, Eij , and
Ii are defined as in Model 1. Our model for the three-level ordinal response yi is
xi = β +
J∑
j=1
ηjEij + γIi + ei, ei ∼ N(0, 1), (4)
where
yi = l ⇐⇒ cl−1 < xi ≤ cl.
15

The category cutoffs cl (l = 0, · · · , 3) are specified in the same way as in Model 2. The
parameters β, ηj and γ are the intercept, the random editor effect, and the fixed institution
effect, respectively, and their priors are the same as those used in Model 1.
Table 3 provides a summary of the estimates of the parameters in Model 3. For this
model, the posterior mean of the variance of the random effect for editors was 0.14, while
the posterior mean of the standard deviation was 0.29. The posterior interquartile range
for ση was 0.13 − 0.36. These values suggest that the (root mean square) editor effect on
the assessment of manuscript quality was only about 30% of the standard deviation of true
manuscript quality, which is equal to 1. In our opinion, the magnitude of the editor effect
for these manuscripts was moderate, although not ignorable. The estimate of the institution
effect, γ, is positive in this model, suggesting that manuscripts by authors from top-tier
institutions have a better chance of receiving a favorable first decision. Once again, the
institution effect might be confounded by the same factors mentioned in the discussion of
Model 1.
Table 3: Summary statistics for Model 1
σ2η γ
post. mean 0.14 0.27
post. std. 0.36 0.087
4 Recommendations for the Future
Our analysis of the JASA review process suggest that the editorial decisions are subject to
non-negligible random error. Although most individuals familiar with the editorial process
believe that the best papers are almost always accepted and the worst are almost always
rejected, there may be considerable variability in decisions reached for papers between these
16

extremes; there are certainly cases where rejected manuscripts might have been accepted if
reviewed by different editors or AEs.
Our analyses found that manuscripts whose contact authors were from institutions with
statistics departments that were ranked in the top 20 fared slightly better in the review
process. It is doubtful that all or much of this is due to bias; those institutions aggressively
recruit excellent researchers. Some research (Gordon, 1980) suggests that in the past institu-
tional bias has worked in the opposite direction, tending to favor papers from less prestigious
schools.
There is also the possibility of systematic biases in the review of articles that would not
be detectable with the data from Allentrack; for example, it is likely that some decisions
were influenced by reports from referees who had broken the blinding and identified the
manuscript authors (with Internet search engines, this relatively easy to do). More subtle
biases could occur as a consequence of editors assigning manuscripts to AEs whom they
know to be particularly lenient or stringent. Also, from these data it was not easy to assess
the important possibility of gender bias; however, since recent issues of JASA suggest that
female researchers are relatively well-represented, this may not be as pressing an issue as it
was 20 years ago.
Of more concern than editorial bias and error may be the lengthy period of time required
for accepted papers to appear in print. One goal of publishing research is to quickly spark
new theories and force change in existing practice. Consider, however, the current flow
of academic publication in statistics. First, an investigator develops an idea and typically
spends months or years researching, testing, and preparing the findings for publication. The
resulting manuscript is then submitted for publication to a peer-review journal, where it
wends its way through the editor, and the AE, and referees. After some period of time, most
papers are either returned to their authors for revision, or possibly the author is advised
to submit to a “lesser” journal. The author then spends more time revising the paper and
17

obtaining additional results. Then the manuscript is resubmitted, and perhaps subjected to
additional criticism and further revision. At the end of this process, the manuscript may be
accepted. But even then publication is not an immediate result; there is another lag of six
to twelve months before the paper appears in print. As a consequence, time to publication
after first review by a journal may easily be two or three years. Thus, cutting edge and
groundbreaking ideas are generally several years stale by the time they are shared with the
general research community.
In our age of instantaneous communication, a better system for disseminating research is
clearly required. The authors of this paper are divided on the best method for reform, and
opinions range from simply establishing a preprint webpage for manuscripts (such as arXiv)
and reducing the time that referees are allowed, to the development of novel review systems.
As one example of a fresh approach, one could implement a tiered review system. At the
lowest level, anyone could upload a paper or report to a manuscript depository. Uploaded
files would be visible to the statistical community; interested readers could comment upon
them (either anonymously or not) and rate them. Manuscripts that received sufficiently
positive reviews would be elevated for more formal peer review and placed at increasingly
higher levels in the depository. After some time, those papers that had been rigorously and
favorably reviewed would by selected by the editor for “publication” in the hierarchy’s most
prestigious “journal.” Besides providing immediate dissemination of ideas, such a system
would foster the discussion of ideas within the community and reduce errors and biases
associated with the editorial process by making the process more open. The statistical
theory that underlies modern recommender systems provides a theoretical foundation for
both rating papers and for assessing reviewers.
The statistics profession deserves excellence from its publications. That obligation implies
that journals should regularly review their process data for evidence of bias or unreasonable
delay. This paper attempts to do that; to further support that goal, the data are publicly
18

available at www.amstat.org/publications/tas.cfm, so interested readers may undertake
further analysis.
More generally, the ASA has a duty to regularly question the adequacy of the service it
provides. Our present editorial processes were essentially invented by Henry Oldenburg, the
first secretary of the Royal Society, in response to the expense of paper and the limitations
of his expertise. New technology has changed that equation, and we encourage the ASA to
revisit those decisions.
Acknowledgments
This research was supported in part by NSF grant SES-0720229, NIH grant R01-MH071418,
and University of Missouri research board grant. The authors thank the Statistical and Ap-
plied Mathematical Sciences Institute for organizing the psychometrics program that made
this work possible.
REFERENCES
Altman, N., Banks, D., Chen, P., Duffy, D., Hardwick, J., Leger, C., Owen, A., and Stukel,
T. (1991). “Meeting the Needs of New Statistical Researchers,” Statistical Science, 6,
163-174. Rejoinder in Statistical Science, 7, 265-266.
Blank, R. M. (1991). “The Effects of Double-Blind Versus Single-Blind Reviewing: Experi-
mental Evidence from The American Economic Review”, American Economic Review,
81, 1041–1067.
Cox, D. R., Gleser, L., Perlman, M., Reid, N., and Roeder, K. (1993). “Report of the Ad
19

Hoc Committee of Double-Blind Refereeing,” Statistical Science, 8, 310–317.
Goldberg, P. (1968). “Are Some Women Prejudiced Against Women?” Transaction, 5,
28–30.
Gordon, M. D. (1980). “The Role of Referees in Scientific Communication,” in The Psychol-
ogy of Written Communication, J. Hartley (ed.), London, England: Kogan Page, pp.
263–275.
Johnson, V. E. (2007). “Bayesian Model Assessment Using Pivotal Quantities.” Bayesian
Analysis, 2, 1–15.
Johnson, V. E. and Albert, J.A. (1999). Ordinal Data Modeling. New York: Springer.
Peters, D. P., and Ceci, S. J. (1982). “Peer Review Practices of Psychological Journals:
The Fate of Published Articles, Submitted Again,” Behavioral and Brain Sciences, 5,
187–195.
Snodgrass, R. T. (2006). “Single- Versus Double-Blind Reviewing: An Analysis of the
Literature,” ACM SIGMOD Record, 35, 8–21.
20

Figure 1: Decisions by editor: Bar chart showing submissions of each of the six editors
together with disposition: reject, acceptable with major revisions, acceptable with moderate
revisions, or acceptable with minor revisions.
21

Figure 2: Days to first decision: Top panel displays a histogram of the days to first decision
for all submissions. The vertical axis plots density per day, the raw fraction of decisions on
each day. (Two outliers are omitted for clarity.) The lower left panel displays a frequency
histogram of days to first decision for manuscripts handled solely by the Editor. The lower
right panel displays a frequency histogram of the days to first decision for manuscripts
handled by an Associate Editor.
22

Figure 3: Days to first decision: The left panel shows days to first decision by manuscript
decision: reject, acceptable with major revision (label not shown), acceptable with moderate
revision, acceptable with minor revision (label not shown). The right panel shows days to
first decision broken out by the JASA section to which the article was submitted.
23

Figure 4: The loess estimate of acceptance rate on first decision versus the number of days to
first decision. The acceptance includes manuscripts acceptable with major/moderate/minor
revision. The dashed lines indicate the confidence interval with 2 standard errors.
24

Current Research and Practices for Cognitive Diagnosis Models 1
Running head: CURRENT RESEARCH AND PRACTICES FOR COGNITIVE DIAGNOSIS MODELS
Current Research and Practices for Cognitive Diagnosis Models:
A White Paper from Cognitive Diagnosis Models Working Group at the
2009 SAMSI Summer Program on Psychometrics
Prepared by:
André A. Rupp University of Maryland
Jimmy de la Torre Rutgers, The State University of New Jersey
With Contributions from:
Alicia Alonzo Michigan State University
Ying Cheng Notre Dame University
Jere Confrey North Carolina State University
Benjamin Cooke Duke University
Ying Cui University of Alberta
Matthew Finkelman Tufts University
Neil Heffernan Worcester Polytechnic Institute
Robert Henson University of North Carolina at Greensboro
Kristen Huff College Board
Eunice Jang University of Toronto
Tzur Karelitz Education Development Center
Roy Levy Arizona State University
Nathalie Loye Université de Montreal
James Madden Louisiana State University
Rebecca Nugent Carnegie Mellon University
Curtis Tatsuoka Case Western Reserve University

Current Research and Practices for Cognitive Diagnosis Models 2
Abstract
In this white paper we describe future directions for research and practice for cognitive diagnosis models
(CDMs) based on the work presented at the Cognitive Diagnosis Models Working Group (CDMWG),
which was assembled as part of the Summer Program in Psychometrics held at the Statistical and
Applied Mathematical Sciences Institute (SAMSI) in Raleigh, NC, from July 13-16, 2009. The
CDMWG served three aligned purposes. One, it served to take a representative survey of the current
state-of-the-art by having the invited participants describe their current line of work along with future
directions of their own work. Two, it served to develop a consensus among the participants about what
they view as the most promising directions for future research in the area of diagnostic assessments and
CDMs. Third, it served to establish collaborative relationships among the participants that are the
foundation for pursuing some of these promising research avenues. In alignment with these purposes, we
synthesize the key ideas and future research directions that were presented and discussed at the
CDMWG in this white paper.

Current Research and Practices for Cognitive Diagnosis Models 3
White Paper from the Cognitive Diagnosis Models Working Group at SAMSI 2009:
Current Research and Practices for Cognitive Diagnosis Models
In this white paper we describe future directions for research and practice for cognitive diagnosis
models (CDMs) based on the work presented at the Cognitive Diagnosis Models Working Group
(CDMWG), which was assembled as part of the Summer Program in Psychometrics held at the
Statistical and Applied Mathematical Sciences Institute (SAMSI) in Raleigh, NC, from July 13-16,
2009.
SAMSI is a partnership of Duke University, North Carolina State University, the University of North
Carolina at Chapel Hill, and the National Institute of Statistical Sciences, in collaboration with the
William R. Kenan, Jr. Institute for Engineering, Technology and Science.
SAMSI is part of the Mathematical Sciences Institutes program of the Division of Mathematical
Sciences at the National Science Foundation. It is a national institute whose vision is to forge a new
synthesis of the statistical sciences and the applied mathematical sciences with disciplinary science to
confront the very challenging and most important data- and model-driven scientific challenges. SAMSI
achieves profound impact on both research and people by bringing together researchers who would not
otherwise interact, and focusing the people, intellectual power and resources necessary for simultaneous
advances in the statistical sciences and applied mathematical sciences that lead to ultimate resolution of
the scientific challenges.
The CDMWG was supported in part through grant 0934106 in the REESE program of the National
Science Foundation. It was organized and hosted jointly by Jimmy de la Torre, Assistant Professor in the
Graduate School of Education at Rutgers, The State University of New Jersey, and André A. Rupp,
Assistant Professor in the Department of Measurement, Statistics, and Evaluation (EDMS) at the
University of Maryland. The CDMWG brought together a diverse array of emerging and established
scholars (i.e., university professors, graduate students, and measurement specialists in the private
industry) in the area of CDMs. All participants had in common that they were involved in some of the
core areas of research surrounding the design, implementation, and analysis of diagnostic assessments
that are scaled with CDMs; for a list of bios please see the Appendix A.
The CDMWG served three aligned purposes. One, it served to take a representative survey of the
current state-of-the-art by having the invited participants describe their current line of work along with
future directions of their own work. Two, it served to develop a consensus among the invited

Current Research and Practices for Cognitive Diagnosis Models 4
participants about what they view as the most promising directions for future research in the area of
diagnostic assessments and CDMs. Third, it served to establish collaborative relationships among the
participants that are the foundation for pursuing some of these promising research avenues. In alignment
with these purposes we synthesize the main ideas, research directions, and empirical findings that were
presented at the CDMWG in the following.
It is not our intention in this white paper to comprehensively review the current state-of-the-art of
diagnostic assessments and CDMs because several excellent review papers or reference volumes already
exist for that purpose. As generally accessible resources we specifically recommend the book entitled
Cognitive diagnostic assessment for education: Theory and applications by Jacqueline Leighton and
Mark Gierl (2007), which covers a range of topics similar in scope to the CDMWG. We also
recommend the book Diagnostic measurement: Theory, methods, and applications by André A. Rupp,
Jonathan Templin, and Robert Henson (in press), which contains a comprehensive and coherent didactic
introduction to CDMs. The Winter 2007 special issue of the Journal of Educational Measurement is also
a good resource for investigating some models and methodologies for cognitive diagnosis. For readers
interested in delving into the more technical literature directly, we recommend the review articles by Fu
and Li (2007), Roussos, DiBello and Stout (2007), or Rupp and Templin (2008) as well as the articles on
unified estimation frameworks for CDMs by de la Torre (2008, 2009a, 2009c), Henson, Templin, and
Willse (2009), Templin and Rupp (in press), and von Davier (2005).
Terminology
Before we begin it seems appropriate to define the basic terminology that is needed for this white
paper. As is typically the case with terminology, the choice of words and phrases is partially grounded in
disciplinary traditions, partially grounded in communicative objectives for a particular piece of writing,
and partially grounded in subtle nuanced differentiations of meaning. In the end, though, it remains a
choice that is made somewhat idiosyncratically by authors.
In this white paper, we will refer to the people who provide the observable response data as
respondents, the stimuli to which they respond as items or tasks, the instruments that collect the items or
tasks as diagnostic assessments, and the latent (i.e., unobservable) characteristics of the respondents as
attributes. As we have already done above, we will call the statistical or psychometric models of
primary interest as cognitive diagnosis models (e.g., de la Torre, 2008; Nichols, Chipman, & Brennan,
1995; Leighton & Gierl, 2007) even though recent publications also refer to them as diagnostic
classification models (e.g., Rupp and Templin, 2008; Rupp, Templin, & Henson, 2010).

Current Research and Practices for Cognitive Diagnosis Models 5
Statistically speaking, CDMs contain multiple latent variables (i.e., not directly observable
variables), which are discrete (i.e., dichotomous or polytomous) and yield statistically-driven
classifications of respondents into distinct latent classes. Hence, CDMs are also known as restricted
latent class models, because the models can be characterized as general latent class models that contain
a predetermined number of latent classes with parameter restrictions across the latent classes. The
parameter restrictions are driven by the Q-matrix, which is a table that shows which attributes are
measured by each item – if entries are dichotomous – or, alternatively, the degree to which items
measure attributes – if entries are polytomous or real-numbered (e.g., K. Tatsuoka, 1983, 2009; von
Davier, 2005). Therefore, the resulting multivariate classification of the respondents into a latent class
yields a vector of attribute-mastery states for each respondent, which is also known as an attribute
profile in the literature. With this terminology at hand we are now ready to discuss the key processes,
discussions, and outcomes of the CDMWG.
Current Challenges for Research and Practice for Diagnostic Assessments and CDMs
During the first three days of the week, the CDMWG was organized into thematic blocks that
represented the key stages of the design, implementation, and data analysis for diagnostic assessments in
various disciplines, specifically educational and psychological measurement. (The presenters for the
different blocks are given in Appendix B.)The following list summarizes these key stages:
1. The selection of a diagnostic assessment framework and clarification of the targeted decision-
making and reporting purposes of the assessment
2. The specification of a developmental theory for the measured attributes
3. The development of tasks and the specification of their relationship to the measured attributes via
a table-of-specification for the assessment and the Q-matrix
4. The selection of statistical models for calibrating the tasks and scaling the respondents, which
include parametric, nonparametric, and semi-parametric approaches
5. The estimation of these models using modern programming environments
6. The assessment of model-data fit at different levels
7. The subsequent refinement of the diagnostic assessment and/or the statistical models to improve
model-data fit at different levels
8. The provision of feedback to various groups of stakeholders using diagnostic score reports along
with associated decision-making about the targets of the assessment

Current Research and Practices for Cognitive Diagnosis Models 6
9. The collection of evidence for a comprehensive validation of all resulting inferences and
decisions that are drawn from the diagnostic assessment.
10. Potentially, the development of statistically optimal systems for computerized adaptive
assessment contexts and automated test assembly
These stages are common to the development of most standardized large-scale assessments, independent
of whether these provide information about single or multiple latent characteristics of the respondents
and independent of whether models from classical test theory (e.g., Thissen & Wainer, 2001, chapters 1-
2), item response theory (e.g., de Ayala, 2009; Embretson & Reise, 2000), factor analysis (e.g.,
McDonald, 1999; Thissen & Wainer, 2001, chapters 3-6) or CDMs are used (see Rupp, 2009a). They
are certainly not as clear-cut and linear in practice as the above list might suggest as most assessment
systems require numerous iterations of refinement and revision.
During the fourth day of the SAMSI meeting, we asked the participants of the CDMWG to
brainstorm a variety of issues that they believed researchers and applied specialists are currently
struggling with. Their key ideas can be organized into the following seven themes:
1. Integrating qualitative and quantitative evidence for analyses with CDMs
2. Creating meaningful and feasible informational richness with CDMs
3. Supporting cultural changes for teaching, learning, and diagnostic assessment with CDMs
4. Articulating common standards for diagnostic assessments and CDMs
5. Finding a balance between model sophistication and model parsimony in CDMs
6. Capitalizing on the information contained in model-data fit statistics for CDMs
7. Fostering professional development for diagnostic assessments and CDMs
We describe the key ideas articulated by the participants on these themes in the subsequent sections but
note that there are tightly interconnected and not as distinct as the list above might suggest.
Integrating Qualitative and Quantitative Evidence for Analyses with CDMs
Participants noted that it is often rather challenging to align evidence from qualitative and
quantitative data-collection for diagnostic assessments and subsequent analyses of these data with
CDMs. For example, think-aloud studies and concurrent interviews are frequently cited as valuable
sources of information into the cognitive and meta-cognitive processes (Leighton, 2004; Leighton &
Gierl, 2007). Such processes can include, for example, the response processes of respondents to the
diagnostic assessment or the decision-making processes of experts when they develop Q-matrices (Loye,
2008; Loye, Caron, Burney-Vincent, & Gagnon, 2009). Yet, this information is typically only used

Current Research and Practices for Cognitive Diagnosis Models 7
procedurally as a means of quality-control for the development process of diagnostic assessments (i.e.,
for data triangulation) but is not further integrated into explanatory modeling approaches (de Boeck &
Wilson, 2004). Speaking more generally, it is paramount that explanatory information about task or
respondent characteristics is included into CDMs to enrich the evidentiary narrative. Within unified
estimation frameworks for these models (e.g., de la Torre, 2008, 2009a, 2009c; Henson, 2009a, 2009b;
Henson, Templin, & Willse, 2009; C. Tatsuoka, 2002, 2009; von Davier, 2005), this is nowadays
possible with relative ease.
Challenges surrounding the integration of qualitative and quantitative information concern both the
quantification of qualitatively collected narratives and the narrative translation of qualitative and
quantitative data patterns. They also stem from the different methodological repertoires of researchers
working predominantly with either type of data and the lack of acceptance of qualitative data sources by
quantitatively oriented researchers. Reframing the informational value of qualitative data for a
predominantly quantitative process of scaling response data with CDMs also has implications for the
role of assessment design experts. For example, it is typically unclear what constitutes relevant
“expertise” for such experts when they are selected into panels and how their understanding of response
processes and theoretical frameworks can be most effectively used to refine the design of diagnostic
assessments. In other words, it would seem desirable to view a broader range of experts trained in
qualitative, quantitative, and mixed methods as complementary partners in the construction of a
diagnostic assessment rather than merely as functional participants who have to fulfill basic assessment
development tasks (see Rupp, 2009a).
This certainly implies a higher degree of collaboration between learning scientists, content experts,
and assessment specialists (Alonzo, 2009; Huff, 2009). Specifically, teachers with suitable levels of
experience in teaching, learning, and assessment are indispensable for the development of diagnostic
assessment systems. Teachers are particularly important because their “diagnostic” needs on a day-to-
day basis, when formative interpretations of low-stakes assessments are most frequently made, may
differ strikingly from their “diagnostic” needs as perceived by external experts. The views of experts
with background and experience in large-scale assessments are typically colored by such experiences
and understanding the needs of stakeholders like teachers or clinicians may require concerted efforts of
re-educating them with respect to these uncommon situations. Thus, it is important to interview teachers
about their needs repeatedly, at the outset, during the development, and during different implementation
phases of diagnostic assessments. This could also lead to the development of a taxonomy of inferences

Current Research and Practices for Cognitive Diagnosis Models 8
and associated decisions that need to be supported via CDMs for different stakeholder groups. For
example, in the area of evidence-centered design (e.g., Mislevy, Steinberg, Almond, & Lucas, 2006;
Huff, 2009; Rupp, 2009b) such work is translated into the development of design patterns for tasks,
which link observable task characteristics to specific evidentiary narratives via appropriate building
blocks of statistical models (e.g., Mislevy et al., 2009).
Creating Meaningful and Feasible Informational Richness with CDMs
Participants noted that there exists a certain loss of descriptive richness about learning and reasoning
processes in a domain when those fluid processes are oprationalized and translated into static Q-matrices
for a diagnostic assessment. An important factor that influences the degree of informational loss in this
translation is the grainsize of the attributes and the developmental theory within which the diagnostic
assessment design is embedded. It is clearly challenging to manage the trade-off between in-depth fine-
grained diagnostic analyses and more cursory coarse-grained proficiency profiles despite the fact that
CDMs for different attribute gradations exist (Karelitz, 2009). Furthermore, it appears that some tasks in
some domains lend themselves more easily to designs of diagnostic assessments because the space of
possible solution paths is more clearly delineable and the constituent components of these paths are
more easily enumerable and operationalizable.
For example, as demonstrated in the area of expertise research, solution paths for tasks that require
lower levels of expertise are much more linear whereas solution paths for tasks that require high levels
of expertise are much more nonlinear and mediated by metacognitive strategies. As a case in point, the
work by Confrey and Maloney (2009) demonstrates the complex manner in which concepts related to
rational number reasoning are acquired by children between elementary and middle school. Attempting
to represent this complexity with a particular diagnostic assessment of CDM always bears the risk of
significantly oversimplifying and, thus, misrepresenting the actual reasoning processes of the children.
As Rupp (2009c) discusses, diagnostic assessments are typically designed to provide information
about a particular domain that is described as “rich” in some way, but obtaining deeper information
about a few processes requires sacrificing the breadth that large-scale standardized assessments afford.
Put differently, developing rich narratives in a more restricted domain can also be seen as impoverishing
the narratives about a broader domain, which is why it is important to design, implement, and analyze
diagnostic assessments only when the specificity of the decisions they support is really needed by
stakeholders. In certain cases, feedback for individuals and groups may be desirable. When this is the
case, it is statistically easier to aggregate up reliable individual diagnostic information to create reliable

Current Research and Practices for Cognitive Diagnosis Models 9
group-level information, rather than attempt to disaggregate reliable group-level information, which may
be unreliable for individuals.
Careful task design can ensure that there is a solid alignment between the observable evidence
available through scored responses and the condensation of this evidence through CDMs. Research and
experience in various projects has taught us how this alignment becomes increasingly challenging as the
complexity of the learning environment increases. However, it is precisely in these contexts that the
potential richness of evidentiary narratives is greatest, which is what CDMs are designed to statistically
support. Importantly, this requires diagnostic assessment designers to utilize task formats that do not
distort the desired richness of the observable evidence by unnecessarily constraining respondents’
actions in these environments. While they certainly cannot be unconstrained, a rich history on
performance assessment has taught us useful lessons about how to achieve a balance between allowing
for and suitably constraining respondent behavior to support evidentiary narratives about complex skill
sets.
In short, there is a dire need of research in different domains that explicates the degree to which
response processes to different types of tasks can be decomposed in such a way that potentially rich
narratives for diagnostic assessments can be meaningfully constructed. One of the future challenges for
the field is to investigate the degree to which CDMs can be used to analyze complex response data from
more open-ended task environments with more ill-defined tasks. This will certainly prove challenging
because the successful application of related latent-variable models like multidimensional IRT models,
multidimensional FA models, and multidimensional Bayes nets requires a great deal of care. We will
discuss a selection of successful diagnostic assessment systems where the trade-off between fine-grained
and coarse-grained informational feedback has been managed well in the last section of this paper.
Supporting Cultural Changes for Teaching, Learning, and Diagnostic Assessment with CDMs
Large-scale standards-based assessment and comparative educational surveys have led to important
sea changes in the teaching, assessment, and accountability cultures of many countries around the world.
It is not the focus of this white paper to debate the relative benefits and merits of such systems, but
participants highlighted that the successful implementation of diagnostic assessment systems requires an
adjustment or change of the culture of teaching, learning, and assessment. Well-integrated diagnostic
assessment systems are frequently viewed as providing fine-grained feedback in low-stakes contexts
(Roussos, DiBello & Stout, 2007; Leighton & Gierl, 2007) and powerful worked examples exist. These
include, for example, the Cisco Networking Academy (West et al., 2009) and the Cognitive Tutors at

Current Research and Practices for Cognitive Diagnosis Models 10
Carnegie Mellon University (Heffernan, 2009), which both require an emphasis on supporting student
learning with assessment being integral yet incidental to the process. Such trends are also reflected in the
work on games- and simulation-based assessment, which include diagnostic stealth assessments (Shute
et al., 2009).
As part of such successful diagnostic assessment systems, different diagnostic score reports that
provide actionable evidence for different stakeholders are required, which often requires various design
iterations. Recent research on such reports (Jang, 2005, 2009; Huff, 2009) has demonstrated the utility
of presenting the same information in various ways, especially using modern high-resolution
visualization tools. Successfully implementing diagnostic assessment systems requires much more than
the putting all the right tools in place. It requires a commitment of school districts to continual
professional development of teachers that fosters the development of a shared mindset, value
framework, and methodological repertoire for diagnosing multiple attributes of learners.
Articulating Common Standards for Diagnostic Assessments and CDMs
The disciplines of educational and psychological measurement have developed a rich set of
standards, most notably the Standards for Educational and Psychological Testing (American
Psychological Association, American Educational Research Association, National Council of
Measurement in Education, 1999) and the Code of Fair Testing Practices in Education (Joint
Committee on Testing Practices, 2004). These standards, in alignment with shared expertise captured in
technical reports, provide guidance for principled assessment design, implementation, and analysis. On
the one hand, participants agreed that it is necessary for practitioners to adopt and adhere to existing
standards and practices that are equally applicable to diagnostic assessments. On the other hand, it is
also necessary to augment existing standards and practices to suit the inferential validity needs of
diagnostic assessments.
For example, there are no specific standards that focus on the development of Q-matrices or the
cross-validation of respondent classifications and few descriptions of best practices that provide
guidance for practitioners in the form of do’s and don’ts, for example. Even though one can infer such
information from some documents or conversations with colleagues in the field, there is far too much
distributed expertise possessed by a chosen few currently available, rather than shared expertise
available to everyone. At the same time, participants agreed that it is important not to engage in a
process of “reinventing the wheels” of sound assessment practices that already exist; rather, it is about

Current Research and Practices for Cognitive Diagnosis Models 11
giving those practices a “tune-up” that serves the unique needs of developers and users of diagnostic
assessments. Such “updates” can also be seen in related fields to which CDMs can be applied.
For example, the field of clinical psychology is currently in the process of creating a new fifth
version and associated research agenda for their key diagnostic manual, the Diagnostic and Statistical
Manual of Mental Disorders (DSM-V). Key contributions to this process focus on the dimensional
assessment of psychiatric diagnosis (Helzer et al., 2008), which aligns well with the multidimensional
nature of CDMs. The utility of these models for clinical psychology has already been illustrated by
Templin and Henson (2006) and Jaeger, Tatsuoka, & Berns (2003), and a fertile area for cross-
disciplinary research and practice exists there. If CDMs could be successfully applied to diagnostic
assessments in this area, the professional standards from clinical psychology research and practice could
certainly help sharpen and shape the thinking and acting of professionals in educational assessment.
Finding a Balance between Model Sophistication and Parsimony in CDMs
Several participants were trained quite rigorously in various statistical and psychometric models.
Yet, in alignment with established statistical practices in other disciplines, there was a strong consensus
that the key function of a suitable statistical model is to support the evidentiary narrative for the purpose
of the decision-making in the context in which the diagnostic assessment system is embedded. That is,
tailored parsimony of statistical models such as CDMs for a particular purpose is the key to any
successful application of these models. If statistical models become the driving force during certain
phases of diagnostic assessment design, they may unnecessarily constrain the structure of the
assessment. Similarly, several successful intelligent tutoring environments, which can provide useful
diagnostic information for formative purposes – albeit in typically highly constrained task domains – do
not rely on complex parametric statistical models at all but can be well accepted and perceived as highly
useful by practitioners.
This argument is not meant to suggest that there is no need to refine the development of CDMs.
Quite to the contrary, such technical developments are necessary to ensure that the methodological
toolbox contains reliable tools that measurement specialists can judiciously select from when needed.
Moreover, the structure of more complex statistical models can provide important insight into core
modeling principles that apply to simpler statistical models as well. For example, a Bayesian estimation
framework has the advantage of allowing for the inclusion of prior information about task properties and
respondent profiles into the CDM. This can be beneficial when small sample sizes and reasonably

Current Research and Practices for Cognitive Diagnosis Models 12
reliable information about plausible ranges of parameter values are available in preoperational stages of
a diagnostic assessment as well-specified prior information effectively acts as additional data.
In recent years there has also been a noticeable reorientation in the literature on educational
measurement that has led to a rediscovery and subsequent refinement of traditional classification
algorithms in lieu of complex CDMs. Work on such algorithms had gotten more prominent visibility
through conferences like the International Conference on Educational Data Mining, which will be held
for only the third time in 2010. Such a shift is healthy for the disciplines of educational and
psychological assessment, because it allows researchers and practitioners to “take a step back”. It allows
them to refocus their attention on solving classification problems in the most effective and efficient way
possible, rather than imposing unnecessarily complex classification mechanism onto systems or contexts
that are not designed to support them. However, successful systemic effects for the discipline also
require that researchers interested in diagnostic assessment and CDMs embrace more fully current and
past research in related fields such as general multivariate statistics and educational data mining.

Current Research and Practices for Cognitive Diagnosis Models 13
Capitalizing on Information Contained in Model-data Misfit Statistics for CDMs
Related to model complexity is the issue that model-data fit information is frequently either not
investigated comprehensively, or, if it is investigated in more detail, is not used to its full potential
despite some useful available tools (e.g., de la Torre, 2009b; Cui, 2009; Levy, 2009b). As reported by
West et al. (2009), information about model-data fit at various levels (i.e., absolute model fit, relative
model fit, item fit, and person fit) within a Bayesian estimation framework (Almond, Williamson,
Mislevy, & Yan, in press; Levy, 2009a) has been used successfully to refine the design of the Cisco
Networking Academy assessment system. Rather than just helping researchers identify a best-fitting
statistical model at one point in time, the information was used to iteratively refine hypotheses about
student cognition and meta-cognitive strategies. This, in turn, had implications for the refinement of the
design of the diagnostic assessment system, including specifically the feedback that was provided to the
respondents and the decisions that were made about them.
Such worked examples suggest a much richer benefit of such analyses than is often suggested from a
purely statistical perspective. In addition, they help to illustrate the decision-making processes that
assessment specialists employ to improve their assessment design and model calibration. A systematic
description of such processes in the professional literature would help to understand the underlying
value systems of assessment specialists for different types of diagnostic assessment uses. There are other
signs that fit assessment is slowly becoming more comprehensively debated in public forums. For
example, the 15th International Objective Measurement Workshop, held just before the AERA and
NCME conferences in 2010 in Denver, has as its theme “using model fit to evaluate hypotheses about
learning”.
Fostering Professional Education for Diagnostic Assessment and CDMs
As much as participants viewed the professional development of teachers as a critical key to the
future success of diagnostic assessment, the training of measurement specialists in diagnostic assessment
methods was identified as equally important. Such training involves the inclusion of topics relevant to
diagnostic assessment design, implementation, and analysis in educational and psychological
measurement courses as well as the development of novel courses dedicated to CDMs specifically.
Naturally, this requires the creation of textbooks and reference books that focus specifically on such
kinds of assessment systems; the books by Rupp, Templin, and Henson (2010), K. Tatsuoka (2009), and
Almond, Williamson, Mislevy, and Yan (in press) are important steps in this regard. Conferences in
educational and psychological measurement have seen CDMs and diagnostic assessment design become

Current Research and Practices for Cognitive Diagnosis Models 14
a core part of their training session repertoire. Several prominent scholars in the field, some of whom
attended the CDMWG, have become actively involved in the training of practitioners and professionals
alike and so one can be reasonably hopeful about the dissemination of didactic information and
associated training for the years to come. Until more successful case studies or worked exemplars are
available that show some form of an “added value” for certain diagnostic assessment systems in general
and CDM applications in particular, the “bottom-up” demand for such training will be driven mostly by
large-scale assessment agendas. This may not be advantageous overall, because there is typically a
strong gap between the desire for fine-grained diagnostic information and the understanding of the
complexity of the assessment systems that are required to collect and aggregate such information
reliably.
Three Integrative Strands for Future Research on Diagnostic Assessments and CDMs
During the fourth day of the CDMWG, we also asked participants to identify the three most critical
issues that researchers and practitioners in the fields of diagnostic assessment and CDMs should address
in the future to increase the breadth, depth, and methodological rigor of their work. These are the issues
that they identified:
1. Developing an integrated web portal that serves as a common information warehouse and virtual
meeting/exchange point for researchers and practitioners interested in diagnostic assessments and
CDMs
2. Developing an integrated software environment that is user-friendly, expandable, and statistically
powerful
3. Developing an integrated diagnostic assessment system that is optimized for providing fine-
grained diagnostic feedback based on multivariate attribute profiles from CDMs
As these three issues underscore, participants saw a clear need for a concerted effort for creating
evidentiary and practical coherence for the field of diagnostic assessment and CDMs.
Developing an Integrated Web Portal
To foster an interdisciplinary exchange and growth in the fields of diagnostic assessment and CDMs,
participants suggested the development of an integrated web portal. For the portal to have relevance,
they argued that it should be the definitive comprehensive resource for these topics, rather than just a
relatively unstructured hodgepodge of discussions, examples, and resources. Thus, it should include at
least the following pieces of information/sections/facilities:

Current Research and Practices for Cognitive Diagnosis Models 15
1. A section with an introduction to the design, implementation, and data analysis of diagnostic
assessments
2. A section with an introduction to various statistical diagnostic modeling approaches including
CDMs
3. A section with an overview of different skill domains that have been successfully modeled with
CDMs and the associated Q-matrices for these applications
4. A repository with sample data files or complete data files from diagnostic assessments that have
been successfully scaled using multiple dimensions
5. A list of available software programs for estimating CDMs and associated measurement
models/algorithms for similar purposes and contact information for acquiring them
6. Worked examples of successful diagnostic assessment systems with a public commenting facility
to create critical metatext
7. A comprehensive annotated bibliography for the different content areas represented on the
portal, including unpublished research reports or related documents
8. A section with frequently asked questions (FAQs)
9. A section with guidelines for best practices/standards/do’s and don’ts
10. A listserv for interested members of the community that the web portal addresses
11. Hyperlinks to different members of the community that the web portal addresses
12. Rich Site Summary feed
Given the scope of the web portal as sketched here, participants deemed it necessary to acquire
external funding to hire graduate students or professionals trained in data-mining and/or computer-
human interaction to design and maintain the portal. Moreover, it was viewed as important to
differentiate the needs for logistical management for creation and management, which such students
could provide, and the need for an intellectual management of the portal, which professionals in the field
should provide. They suggested that the portal could perhaps be linked to professional organizations
such as the Special Interest Group for Cognition and Assessment at AERA. The intellectual
management is critical, because decisions need to be made about what information constitutes “core”
information and how the family resemblance of new information is judged so that sufficient space on the
portal can be allocated in the right location.
Developing an Integrated Software Environment

Current Research and Practices for Cognitive Diagnosis Models 16
To foster the cross-disciplinary application of CDMs and related classification methods for
calibrating data from diagnostic assessments, participants at the CDMWG identified the need of a
common software suite. The price of such an environment would need to be competitive even though a
commercial version would generally be preferable over a freeware version given that sales would allow
for the hiring of personnel to improve the software. Alternatively, of course, one could acquire grant
money for such a development but it may be challenging, if not impossible, to acquire money for the
maintenance of the software as well as technical support. The first version of the software suite should
be targeted toward the most frequent potential users to allow for maximum market penetration while
later versions can include more advanced features that will make it attractive to secondary users as well.
Similar software suites are currently in development for related measurement modeling frameworks.
For example, a new software suite called IRTPRO (Cai, du Toit, & Thissen, forthcoming, personal
communication) will be released in 2010 to serve similar purposes for IRT analyses. Similarly, the
REMP program at the University of Massachusetts at Amherst has devoted resources, predominantly via
graduate student funding, to the development of several freeware IRT programs.
Since the acceptability and use of estimation algorithms is, in part, driven by how accessible these
algorithms are for users, expanding such efforts to the area of CDMs seems indispensable. Some efforts
are already underway in this regard. For example, Matthias von Davier will release a more flexible
software program for his family of general diagnostic models in 2010 (von Davier, personal
communication). In a similar vein, Rupp, Templin, and Henson (2010) have described how to estimate a
variety of DCMs within Mplus but the approach is not user-friendly enough at this point to be of
practical appeal for anyone but specialists interested in CDMs.
Thus, the participants identified the following desirable features of such a software suite. It should
include…
1. calibration, model-fit, and reporting engines for a variety of CDMs within a broad model
family
2. a variety of acceptable data-model fit statistics at the relative, absolute, item, and person
level
3. a variety of useful descriptive statistics for multidimensional assessments such as
discrimination indices for items and attributes, difficulty indices for items and attributes,
reliability statistics for scale scores, and standard error estimates for these scores

Current Research and Practices for Cognitive Diagnosis Models 17
4. a variety of visual representations for the attribute profile structures, both at the level of
the profile and marginally for each attribute
5. a flexible importing interface for key model elements (e.g., data file, Q-matrix, starting
values, scoring key) with capabilities to read in files from a variety of foreign file formats
6. point-and-click and graphical interfaces that are cross-generative such that one can create
Q-matrices from specifications, specifications from Q-matrices, visual representations
from Q-matrices, etc.
7. example data sets based on simulated and real data with accurate labeling of variables
and comprehensive documentation similar to international large-scale assessments such
as PISA, TIMSS, or NAEP
8. simulation capabilities with enough flexibility that various statistics can be computed on
the simulated data
9. flexible control of the output structure and format
10. a detailed, comprehensive, and clearly written user manual that includes decision
flowcharts and FAQ sections
11. a comprehensive help section
Given the current state of the market at the time of this writing, such a software suite would compete
with the following current special-purpose software programs/estimation routines for CDMs:
1. Arpeggio software by Lou DiBello et al. (Windows, DOS; commercial program)
2. Mplus code by Jon Templin (Mplus; freeware plus required commercial program)
3. MDLTM software by Matthias von Davier (Windows, DOS; free research license)
4. BUGLIB software by Curtis Tatsuoka (Linux; paid research license)
5. G-DINA code by Jimmy de la Torre (Ox; freeware)
6. LCDM software by Bob Henson (Windows, DOS; freeware)
7. AHM software by Hunka et al. (Mathematica; freeware)
8. DINA, DINO code by Alexander Robitzsch (R; freeware)
Moreover, the software suite needs to include a sufficient number of specialized features to compete
meaningfully with the following general-purpose software programs that can be used to estimate some
CDMs: Winbugs, R/S-PLUS, Mplus, Latent Gold, LEM, MLSSA, GLAMM/STATA, SAS, Fortran,
C/C++, variety of programs for Bayesian inference network, Mathematica and Ox.

Current Research and Practices for Cognitive Diagnosis Models 18
Incentives for the development of such software programs can also be given via awards, even though
they are rather minor. Nevertheless, the Bradley Hanson Award for Contributions to Educational
Measurement, for example, which is annually awarded by NCME, recognizes research efforts toward
the development of user-friendly software programs in the spirit of Bradley Hanson’s work.
Developing an Integrated Diagnostic Assessment System
The third issue that was identified by participants was the development of an integrated diagnostic
assessment system that takes a long-term perspective on diagnostic assessment and fluidly combines
formative feedback, summative evaluation, and targeted remediation. Participants noted that such a
system does not require the successful application of CDMs as several existing systems have
demonstrated. For example, the Cisco Networking Academy uses methods from CTT, IRT, and Bayes
net (Levy, 2009a; West et al., 2009), the Cognitive Tutors system uses data-mining techniques grounded
in modern cluster analysis techniques (Heffernan, 2009; see Nugent, 2009), the IMMEX system at the
University of California at Los Angeles uses IRT and neural network analysis coupled with hidden
Markov models (Soller & Stevens, 2007), and a new computerized adaptive test system that is currently
pilot-tested in China uses IRT in combination with a higher-order CDM (Chang, 2010; for similar ideas
see Cheng, 2009, and Finkelman, 2009).
The key to any successful diagnostic assessment system is not to lose sight of the targeted inferences
and decisions that are made by the associated stakeholder groups. Moreover, experience in the above
projects has shown that the development of a well-functioning fine-tuned diagnostic assessment system
requires typically numerous iterations that stretch over multiple years and cost millions of dollars in
person time and physical resources. Moreover, the most successful of these systems are designed to
monitor the development of respondents over time by mapping their learning progressions and learning
trajectories in multidimensional spaces. Rather than providing a merely efficient measurement solution
to a large-scale assessment that is given at a single point in time such as the Graduate Record
Examination or the Test of English as a Foreign Language, the best of these systems are designed to
support and foster learning within effectively structured learning environments. The resulting
assessments and feedback mechanisms are what Valerie Shute would call “stealth assessments” because
they are fluidly and unobtrusively integrated into a larger aligned repertoire of learning experiences
(Shute et al., 2009). Of course, CDMs can also be used for assessments that provide high-stakes
summative interpretations but the rhetoric surrounding their theory and use in the educational

Current Research and Practices for Cognitive Diagnosis Models 19
measurement literature suggests that researchers would like to see them more frequently applied in the
learning contexts just described.
Closing Comments
Many or the participants felt that we are currently at somewhat of a sea change in the field of
diagnostic assessment in general and CDMs in particular. While the demand for fine-grained diagnostic
information is constantly growing in various areas of educational and psychological assessment, the role
that CDMs can play in this area is not as clear. Theoretically, these models seem to respond well to a
call for such diagnostic information but applications that show their “added value” over simpler methods
or alternative complex latent-variable methods are essentially non-existent. Still, as methodological
research on CDMs is ongoing and fueled by the desire of a new cadre of researchers in the field, many
opportunities that lie at the intersection of work in different disciplines can be harvested.
The participants in the CDMWG were overall highly excited and hopeful to work with each other
and others in the field to push the methodological and application boundaries in fields that are touched
by diagnostic assessment and CDMs. Although they reflect the ideas of a selected few, we believe that
the key ideas laid out in this white paper represent some of the current thinking in these fields more
broadly. We are encouraged by the interactions of the CDMWG and the current developments in the
field that a more comprehensive, integrated, and coherent picture surrounding diagnostic assessments
and CDMs will develop in the next decade.

Current Research and Practices for Cognitive Diagnosis Models 20
References
References with a (*) are presentations given during the CDMWG meeting at SAMSI 2009. Almond, R. G., Williamson, D. M., Mislevy, R. J., & Yan, D. (in press). Bayes nets in educational
assessment. New York: Springer.
*Alonzo, A. (2009, July). Learning progressions: A cognitive diagnosis model? Paper presented at the
CDMWG at SAMSI Summer Program on Psychometrics, Raleigh, NC.
American Educational Research Association, American Psychological Association, National Council of
Measurement in Education (1999). The standards for educational and psychological testing.
Washington, DC: AERA Publications.
Cai, L., du Toit, M., & Thissen, D. (forthcoming). IRTPRO [software program].
Chang, H.-H. (2010, February). Advanced in computer-based internet testing. Presented at the MSMS
seminar in the EDMS department at the University of Maryland, College Park, MD.
*Cheng, Y. (2009, July). Computerized adaptive testing for cognitive diagnosis. Paper presented at the
CDMWG at SAMSI Summer Program on Psychometrics, Raleigh, NC.
Code of Fair Testing Practices in Education. (2004). Washington, DC: Joint Committee on Testing
Practices.
*Confrey, J., & Maloney, A. (2009, July). Developing learning trajectories and diagnostic assessments
based on student reasoning on rational number over time. Paper presented at the CDMWG at
SAMSI Summer Program on Psychometrics, Raleigh, NC.
*Cui, Y. (2009, July). Evaluating person fit for cognitive diagnostic assessment with the hierarchy
consistency index. Paper presented at the CDMWG at SAMSI Summer Program on Psychometrics,
Raleigh, NC.
de Ayala, R. J. (2009). The theory and practice of item response theory. New York: Guilford Press.
de Boeck, P., & Wilson, M. (2004). Explanatory item response theory models: A generalized linear and
nonlinear approach. New York: Springer.
de la Torre, J. (2008, July). The generalized DINA model. Paper presented at the annual International
Meeting of the Psychometric Society (IMPS), Durham, NH.
*de la Torre, J. (2009a, July). Estimation and DINA-based models. Paper presented at the CDMWG at
SAMSI Summer Program on Psychometrics, Raleigh, NC.

Current Research and Practices for Cognitive Diagnosis Models 21
*de la Torre, J. (2009b, July). Model evaluation and comparison. Paper presented at the CDMWG at
SAMSI Summer Program on Psychometrics, Raleigh, NC.
*de la Torre, J. (2009c, July). The generalized DINA model framework. Paper presented at the CDMWG
at SAMSI Summer Program on Psychometrics, Raleigh, NC.
Embretson, S. E., & Reise, S. P. (2000). Item response theory for psychologists. Mahwah, NJ: Erlbaum.
*Finkelman, M. (2009, July). Computerized adaptive testing to predict an observable outcome. Paper
presented at the CDMWG at SAMSI Summer Program on Psychometrics, Raleigh, NC.
*Heffernan, N. (2009, July). TITLE TBA. Paper presented at the CDMWG at SAMSI Summer Program
on Psychometrics, Raleigh, NC.
Helzer, J. E., Kraemer, H. C., Krueger, R. F., Wittchen, H.-U., Sirovatka, P. J., & Regier, D. A. (Eds.).
(2008). Dimensional approaches in diagnostic classification: Refining the research agenda for
DSM-V. Arlington, VA: American Psychiatric Association.
*Henson, R. (2009a, July). The LCDM. Paper presented at the CDMWG at SAMSI Summer Program on
Psychometrics, Raleigh, NC.
*Henson, R. (2009b, July). Some challenges in estimation, programming, and implementation: What
should we work on? Paper presented at the CDMWG at SAMSI Summer Program on Psychometrics,
Raleigh, NC.
Henson, R., Templin, J., & Willse, J. (2009). Defining a family of cognitive diagnosis models.
Psychometrika, 74, 191-210.
*Huff, K. (2009, July). Educational diagnostic assessment design: Interdisciplinary pathways to
progress. Paper presented at the CDMWG at SAMSI Summer Program on Psychometrics, Raleigh,
NC.
Jang, E. E. (2005). A validity narrative: Effects of reading skills diagnosis on teaching and learning in
the context of NG TOEFL. Unpublished doctoral dissertation, University of Illinois at Urbana-
Champaign, Urbana-Champaign, IL.
*Jang, E. (2009, July). Score reporting and subsequent actions. Paper presented at the CDMWG at
SAMSI Summer Program on Psychometrics, Raleigh, NC.
Jaeger, J., Tatsuoka, C., & Berns, S. (2003). Innovative methods for extracting valid cognitive deficit
profiles from NP test data in schizophrenia. Schizophrenia Research, 60, 140-140.
*Karelitz, T. (2009, July). Between dichotomy and continuity: Ordered categories in diagnostic models.
Paper presented at the CDMWG at SAMSI Summer Program on Psychometrics, Raleigh, NC.

Current Research and Practices for Cognitive Diagnosis Models 22
Leighton, J. P. (2004). Avoiding misconception, misuse, and missed opportunities: The collection of
verbal reports in educational achievement testing. Educational Measurement: Issues and Practice,
23(4), 6-15.
Leighton, J., & Gierl, M. (2007). Cognitive diagnostic assessment for education: Theory and
applications. Cambridge, UK: Cambridge University Press.
*Levy, R. (2009a, July). Markov-chain Monte Carlo (MCMC) estimation for diagnostic classification
models. Paper presented at the CDMWG at SAMSI Summer Program on Psychometrics, Raleigh,
NC.
*Levy, R. (2009b, July). Posterior predictive model checking for diagnostic classification models. Paper
presented at the CDMWG at SAMSI Summer Program on Psychometrics, Raleigh, NC.
Loye, N. (2008). Élaborer la matrice Q des modèles cognitifs dans diverses conditions et définir leur
impact sur sa validité et sa fidélité [Developing Q-matrices for cognitive models under a variety
conditions and evaluating their impact on the validity and fidelity of assessments]. Unpublished
doctoral dissertation, University of Ottawa, Ottawa, ON.
*Loye, N., Caron, F., Burney-Vincent, C., & Gagnon, M. (2009, July). Validity of diagnostic results
arising from a marriage between didactics and measurement. Paper presented at the CDMWG at
SAMSI Summer Program on Psychometrics, Raleigh, NC.
McDonald, R. P. (1999). Test theory: A unified treatment. Mahwah, NJ: Erlbaum.
Mislevy, R. J., Rioscente, M. M., & Rutstein, D. W. (2009). Design patterns for assessing model-based
reasoning. Manuscript submitted for publication.
Mislevy, R. J., Steinberg, L. S., Almond, R. G., & Lukas, J. F. (2006). Concepts, terminology, and basic
models of evidence-centered design. In D. M. Williamson, I. I. Bejar, & R. J. Mislevy (Eds.),
Automated scoring of complex tasks in computer-based testing (pp. 15-48). Mahwah, NJ: Erlbaum.
Nichols, P. D., Chipman, S. F., & Brennan, R. L. (1995). Cognitively diagnostic assessment. Mahwah,
NJ: Erlbaum.
*Nugent, R. (2009, July). Clustering in cognitive diagnosis: Some recent work and open questions.
Paper presented at the CDMWG at SAMSI Summer Program on Psychometrics, Raleigh, NC.
*Rupp, A. A. (2009a). An overview of the space of parametric CDMs. Paper presented at the CDMWG
at SAMSI Summer Program on Psychometrics, Raleigh, NC.

Current Research and Practices for Cognitive Diagnosis Models 23
*Rupp, A. A. (2009b). Frameworks for the validation of interpretations from diagnostic assessments.
Paper presented at the CDMWG at SAMSI Summer Program on Psychometrics, Raleigh, NC.
*Rupp, A. A. (2009c). Lessons learned from diagnostic task construction in various assessment
contexts. Paper presented at the CDMWG at SAMSI Summer Program on Psychometrics, Raleigh,
NC.
Rupp, A. A., & Templin, J. (2008). Unique characteristics of cognitive diagnosis models: A
comprehensive review of the current state-of-the-art. Measurement: Interdisciplinary Research &
Perspectives, 6, 219-262.
Rupp, A. A., Templin, J., & Henson, R. J. (2010). Diagnostic measurement: Theory, methods, and
applications. New York: Guilford Press.
Shute, V. J., Masduki, I., Donmez, O., Dennen, V. P., Kim, Y.-J., Jeong, A. C., & Wang, C.-Y. (2009).
Assessing 21st century knowledge and skills in game environments. Manuscript submitted for
publication.
Soller, A., & Stevens, R. (2007). Applications of stochastic analyses for collaborative learning and
cognitive assessment (IDA Document D-3421). Arlington, VA: Institute for Defense Analysis.
Tatsuoka, C. (2002). Data-analytic methods for latent partially ordered classification models. Journal of
the Royal Statistical Society (Series C, Applied Statistics), 51, 337-350.
*Tatsuoka, C. (2009, July). Partially ordered models of cognition. Paper presented at the CDMWG at
SAMSI Summer Program on Psychometrics, Raleigh, NC.
Tatsuoka, K. K. (1983). Rule-space: An approach for dealing with misconceptions based on item
response theory. Journal of Educational Measurement, 20, 345-354.
Tatsuoka, K. K. (2009). Cognitive assessment: An introduction to the rule-space method. Florence, KY:
Routledge.
Templin, J. L., & Henson, R. A. (2006). Measurement of psychological disorders using cognitive
diagnosis models. Psychological Methods, 11, 287-305.
Templin, J., & Rupp, A. A. (in press). On the origins of a statistical species: The evolution of diagnostic
classification models within the psychometric taxonomy. In G. Macready & G. Hancock (Eds.), A
Festschrift in Honor of C. Mitchell Dayton. Publisher to be determined.
Thissen, D, & Wainer, H. (Eds.). (2001). Test scoring. Mahwah, NJ: Erlbaum.
von Davier, M. (2005). A general diagnostic model applied to language testing data (RR-05-16).
Princeton, NJ: Educational Testing Service.

Current Research and Practices for Cognitive Diagnosis Models 24
West, P., Rutstein, D. W., Mislevy, R. J., Liu, J., Levy, R., DiCerbo, K. E., Crawford, A., Choi, Y., &
Behrens, J. T. (2009, June). A Bayes net approach to modeling learning progressions and task
performances. Presented at the Learning Progressions in Science (LeaPS) conference, Iowa City, IO.

Current Research and Practices for Cognitive Diagnosis Models 25
Appendix A: Presenter Biographies
(Alphabetical Listing by Last Name)
Alicia Alonzo. Alicia is an assistant professor at the University of Iowa where she specializes in formative classroom assessment for science, specifically the modeling of learning progressions for multiple skill sets. She was one of the co-organizers of the recent Learning Progressions in Science (LeaPS) conference at the University of Iowa, which brought together researchers from such diverse disciplines as cognitive science, learning sciences, science teaching, and educational measurement to discuss the state-of-the-art of conceptualizing, operationalizing, and measuring learning progressions in the field. Ying Cheng. Ying is currently an assistant professor in the Department of Psychology at Notre Dame University. Her research focuses the theoretical development and applications of item response theory (IRT), including computerized adaptive testing (CAT), test equity across different ethnicity/gender groups, classification accuracy and consistency with licensure/certification exams, such as state graduation exams. Recently she is working on cognitive diagnostic models and their applications to CAT. For her past work and proposed work in this area, Ying recently received the prestigious Bradley Hanson Award for Contributions to Educational Measurement from NCME. Jere Confrey. Jere is the Joseph D. Moore Distinguished Professor for mathematics education at the Friday Institute for Educational Innovation here in Raleigh. She is the director of the NSF-funded Generating Increased Mathematics and Science Opportunities (GISMO) project, which is a research lab whose work focuses on the design innovative approaches to learning and teaching mathematics and science. One of her areas of specialization in this regard is rational number reasoning, for which the GISMO project has released a database with relevant peer-reviewed research. Similarly, her DELTA: Diagnostic E-Learning Trajectories Approach project focuses on the design, implementation, and analysis of diagnostic assessments in this area for K-8. Ying Cui. Ying is currently an assistant professor in the Department of Educational Psychology at the University of Alberta. She received her Ph.D. in measurement, evaluation, and cognition from the University of Alberta. Her M.S. and B.S. are in statistics. Her research interests include educational measurement and evaluation, cognitive diagnostic assessment, research design and applied statistical methods, and statistical education. She is particularly interested in evaluating the construct validity of achievement tests, investigating cognitive factors underlying student test performance, and using cognitive models to interpret student test performance. She is currently pursuing ways of applying cognitive diagnostic assessments to classroom settings and evaluating their effectiveness in promoting student learning.

Current Research and Practices for Cognitive Diagnosis Models 26
Jimmy de la Torre (co-organizer). Jimmy received his Ph.D. in quantitative psychology from the University of Illinois at Urbana-Champaign. He is currently an assistant professor of educational psychology at Rutgers University. His primary research interests are in the field of psychological and educational testing and measurement, with a specific emphasis on IRT and latent variable modeling. As a researcher, his main objective is to develop and apply state-of-the-art psychometric models and methodologies to address theoretically challenging issues that have important practical consequences. Moreover, his goal as a researcher includes the distillation and dissemination of the findings and implications of his work to an audience with diverse backgrounds and needs. His work on cognitive diagnosis modeling has been published in some of the top journals in the field. In addition, he has received funding support from institutions such as the NSF, Institute of Education Sciences, National Academy of Education, and Spencer Foundation to pursue this line of work. Matthew Finkelman: Matthew received his Ph.D. in statistics from Stanford University in 2004. His dissertation, “Statistical Issues in Computerized Adaptive Testing,” explored the use of modern sequential analysis techniques to improve the efficiency of diagnosis in pass/fail tests. After graduating, he worked as a psychometrician for CTB/McGraw-Hill and Measured Progress, where he conducted research in computerized adaptive testing, cognitive diagnosis modeling, and multidimensional IRT. In 2007, he switched his focus from educational assessment to biostatistics. He served as a research fellow at the Harvard School of Public Health from August 2007 to October 2008, where he helped develop a new mixture IRT model for psychiatric diagnosis. He is now an assistant professor at the Tufts University School of Dental Medicine. His current research interests include the application of computerized adaptive testing to medical diagnosis, the automated selection of test items for cognitive diagnosis, and the development of new statistical methods to analyze dental and other medical data. Neil Heffernan. Neil received his Ph.D. in computer science in 2001 from Carnegie Mellon University. He currently is an associate professor at the Worcester Polytechnic Institute where his research interests center around cognitive modelling and intelligent tutoring systems, specifically web-based systems. He has received numerous NSF-funded grants centered around learning in mathematics and science, including a prestigious CAREER grant for early scholars. His most recent grant strives to test a computer instructional math program that will help Worcester middle school students prepare for the MCAS math exams by giving them fine-grained diagnostic feedback. The program is developed in collaboration with Carnegie Mellon University and Carnegie Learning Inc. and will be implemented within an experimental design setting to study its effectiveness for improving student learning.

Current Research and Practices for Cognitive Diagnosis Models 27
Robert Henson. Robert received his Ph.D. in quantitative psychology from the University of Illinoisis. He is now an assistant professor of Educational Research Methodology at the University of North Carolina at Greensboro. The primary focus of his research is latent variable modeling with an emphasis on cognitive diagnosis models. He is one of the foremost authorities in cognitive diagnosis modelling and has pursued a variety of research avenues related to model estimation, model fit assessment, and model application. He is also interested in the potential use of CDMs in identifying differential item functioning, and applications of CDMs outside the educational context (e.g., diagnosis of psychological disorders). He has developed a log-linear estimation approach for cognitive diagnosis models as part of an NSF grant, and is co-authoring a book on these models. His other research interests include multivariate statistics, hierarchical linear models, structural equation models, and mathematical statistics. Kristen Huff. Kristen Huff is Senior Director of Advance Placement Research and Assessment Design at the College Board. She received both her Masters of Education (University of North Carolina Greensboro) and doctorate (University of Massachusetts Amherst) in educational measurement. Before joining the College Board, Ms. Huff worked at Educational Testing Service on the development of TOEFL iBT using evidence-centered design. Her research areas of interest are assessment design, diagnostic score reporting methodology, and item difficulty modeling. She is one of the key voices in the area of diagnostic assessment design and modeling in our field and always a critical disseminator and generator of knowledge. She is also the director of the Northeastern Educational Research Association (NERA), whose annual meeting is from October 21-23 in Rocky Hill, Connecticut. Eunice Jang. Eunice is an Assistant Professor in the Department of Curriculum, Teaching and Learning at the Ontario Institute for Studies in Education (OISE) at the University of Toronto. She is interested in validity issues in cognitive diagnostic assessment, fairness and equity issues in testing, achievement gaps among students from diverse backgrounds, and literacy assessment practice. She is also keen on epistemological issues surrounding human inquiry approaches in social sciences and education. Eunice is recipient of the 2006 Jacqueline Ross TOEFL Dissertation Award, the Education Alumni Association Outstanding Student Medal, the Tatsuoka Measurement Award, the 2003 IELTS Best MA Dissertation Award, and the Katharine Aston Award for Outstanding Thesis. In recent years, she examined literacy and numeracy skill profiles for Grade 9 and 10 students based on their performance on Canadian assessments. She also collaborates with Dr. Jim Cummins on the validity project for “Steps toward English Proficiency” with over 50 ESL teachers across Ontario. STEP is intended to serve teachers to assess and track all English language learners’ literacy development in Ontario schools.

Current Research and Practices for Cognitive Diagnosis Models 28
Tzur Karelitz. Tzur received his Ph.D. in 2004 at the University of Illinois at Urbana Champaign with a thesis that focused specifically on modeling skills polytomously in a multidimensional modeling framework, for which he has argued repeatedly in the literature. During his time at the PACE center at Tufts University, he furthermore conducted applied research on wisdom, creativity, and practical and analytical thinking. He collaborated on evaluating and improving the university’s admission process and developing assessments of student outcomes, specifically, assessments of wise leadership qualities, all important so-called 21st century skills. Tzur is currently a senior research associate at the Center for Science Education in the Education Development Center in Newton, MA. Roy Levy. Roy received a Ph.D. in measurement, statistics and evaluation from the University of Maryland in 2006. He is currently an assistant professor of measurement, statistics, and methodological studies at Arizona State University. His work primarily concerns the use of statistical and psychometric models in assessment, education, and the social sciences more broadly. His interests include methodological investigations and applications in psychometrics and statistical modeling, focusing on models and procedures associated with IRT, structural equation modeling, cognitive diagnosis models, Bayesian networks, and Bayesian approaches to inference. Representative projects that he is currently involved in include dimensionality assessment for multidimensional IRT, Bayesian networks for skills diagnosis and learning progressions, model comparison strategies in mean and covariance structure models, and advances in Markov chain Monte Carlo estimation of psychometric models. Nathalie Loye. Nathalie is currently an assistant professor at the Université de Montréal in Montréal, Canada. She received her Ph.D. from the University of Ottawa where she developed a keen interest in how experts use various empirical and theoretical sources of information to construct Q-matrices for diagnostic assessment. She currently continues this work within the Canadian measurement community to foster the development of an international community of researchers in this area. Rebecca Nugent. Rebecca is currently a visiting assistant professor in the Department of Statistics at Carnegie Mellon University. She received her Ph.D. in statistics from the University of Washington, and her master's in statistics from Stanford University. She has a Bachelor's degree in mathematics, statistics, and Spanish from Rice University. Her research is primarily focused on non-parametric clustering and visualization of the (possibly) hierarchical cluster structure in data. She is also interested in assessing stability of cluster solutions by assigning measures of significance to estimated clusters. More recently, she has focused on educational data mining and, more specifically, the development of methodology (with a clustering framework) as alternatives to cognitive diagnosis models. Her recent work includes conditional subspace clustering with skill mastery information, a generalized single linkage method for estimating the cluster tree of a density, and skill set profile clustering based on student capability vectors computed from online tutoring data.

Current Research and Practices for Cognitive Diagnosis Models 29
André A. Rupp (co-organizer). Andre is an assistant professor of measurement, evaluation, and statistics at the University of Maryland. He received his Ph.D. in measurement, evaluation, and research methodology from the University of British Columbia. Until recently, he worked at the Institute for Educational Progress in Berlin, Germany. His current research interests center around cognitively-grounded assessment approaches and associated statistical models. He is interested in investigating the theoretical potential and practical limitations of diagnostic classification models, researching the robustness of such models to model misspecification, and developing principled diagnostic assessment approaches for modeling learning progressions of complex skill sets using innovative digital technologies such as games- and simulation-based learning environments. Curtis Tatsuoka. Curtis received his Ph.D. in statistics from Cornell University. He is currently an associate professor of neurology and director of biostatistics at the Neurological Institute and Neurological Outcomes Center of Case Western Reserve University. He has been working the area of cognitive diagnosis since his dissertation, in particular developing theories and methods for adaptive testing. He currently works on using lattices, a subclass of partially ordered sets, as cognitively diagnostic models in neuropsychological assessment. Applications of his work include determining differential cognitive deficits in schizophrenics, detecting early cognitive-based markers for Alzheimer’s disease, and measuring cognitive change in clinical drug trials.

Current Research and Practices for Cognitive Diagnosis Models 30
Appendix B: Schedule of the Thematic Sessions
Day Time Time Presenters 7:30 – 9:00 Breakfast
9:00 – 10:00 Introduction de la Torre
Rupp
10:00 – 11:30 Diagnostic Assessment Approaches Finkelman
Huff Tatsuoka
11:30 – 12:30 Joint Session with Other Working Groups David Banks 12:30 – 2:00 Lunch
2:00 – 3:30 Developmental Theories for
Diagnostic Assessment
Alonzo Confrey Karelitz
Monday
3:30 – 5:00 Task & Q-matrix Construction Cui
Loye Rupp
7:30 – 8:30 Breakfast
8:30 – 10:00 Fully Parametric Models for Classification de la Torre
Henson Rupp
10:00 – 11:30 Non-parametric and Semi-parametric Models
for Classification
Cui Nugent
Tatsuoka 11:30 – 12:30 Joint Session with Other Working Groups Valen Johnson 12:30 – 2:00 Lunch
2:00 – 3:30 Challenges in Estimation, Programming, and
Implementation
de la Torre Henson Levy
Tuesday
3:30 – 5:00 Model Fit Assessment & Refinement de la Torre
Levy Cui
7:30 – 8:30 Breakfast
8:30 – 10:30 Optimal Test Design and Computerized
Adaptive Testing
Cheng Finkelman Tatsuoka
10:30 – 12:00 Score Reporting & Subsequent Action Heffernan
Huff Jang
12:00 – 1:30 Lunch
1:30 – 3:00 Validation Rupp
Heffernan
Wednesday
3:00 – 5:00 Future Challenges for Diagnostic Assessment
& Cognitive Diagnosis Models Moderated
Panel Session

1
The King’s Foot of Patient Reported Outcomes: Current Practices
and New Developments for the Measurement of Change.
Richard J. Swartz*, Ph.D. The University of Texas M. D. Anderson Cancer Center
Li Cai, Ph.D., University of California, Los Angeles
Diane Fairclough, Dr.P.H., University of Colorado
Lori McLeod, Ph.D., RTI Health Solutions
Tito Mendoza, Ph.D., The University of Texas M. D. Anderson Cancer Center
Bruce Rapkin, Ph.D., Albert Einstein College of Medicine
Carolyn Schwartz, Sc.D., Deltaquest Foundation, Inc and Tufts University Medical School
And the SAMSI Psychometric Program Longitudinal Assessment of Patient Reported Outcomes
Working Group1
* all listed authors contributed equally. First listed author coordinated the final document, and others are listed
alphabetically. 1. Other working group members: Bryce Reeve, Ph.D., Charles Cleeland, Ph.D., Betsy Feldman, Ph.D., Carmen
Rivera-Medina, Ph.D., Cheryl Hill, Ph.D., Ethan Basche, M.D., Herle McGowan, Ph.D., Ken Bollen, Ph.D., Knashawn Morales, Sc.D., Lauren Nelson,Ph.D., Mark Price, M.A., M.Ed. Rochelle Tractenberg, Ph.D., MPH, Quiling Shi, Ph.D., Theresa Gilligan, M.S., Thomas Atkinson, Ph.D., Valerie Williams,Ph.D., Xiaojing Wang, Jun Wang,

2
Patient- or person-reported outcome (PRO) data is increasingly collected and recognized
as being valuable in clinical research, regulatory review, and disease management. Barriers to
longitudinal collection of PRO data which have historically been raised no longer seem
insurmountable:
There is substantial regulatory support to collect PRO data capturing patient subjective
experiences directly from patients.
Clinical investigators, NIH institutes, and industry sponsors increasingly recognize the
importance of gathering PRO data to supplement other information in clinical research. .
Consensus has developed around standards for development processes, measurement
properties, and implementation strategies for PRO measures, and these standards have
recently been encoded in documents such as the FDA’s ―Guidance for Industry: Patient-
Reported Outcome Measures Use in Medical Product Development to Support Labeling
Claims.‖ 74
A critical mass of publications demonstrate methods to gather patient-reported
information for routine medical management, and the predictive significance of patient-
reported information.
An increasing number of well-developed instruments is available.
Low-cost technologies are available for data collection; patients and staff are widely
familiar with these data collection strategies, and respondent burden can be minimized
through electronic data capture strategies like skip patterns and computerized adaptive
testing.

3
Recently PRO data has expanded from the commonly used measures of health-related
quality of life and health status measures to also include symptom-specific measures and multi-
symptom questionnaires. The formation of the PRO Consortium within the Critical Path
Institute has encouraged collaborations between academics, sponsors, and the FDA to develop
robust, publicly available symptom-specific instruments for use towards labeling claims. Single
symptom items and item banks (such as being developed through the PROMIS [Patient-Reported
Outcomes Measurement System] initiative), and multi-item questionnaires (Such as the MDASI
[M.D. Anderson Symptom Inventory]) have advanced the ability to understand the patient
experience around specific symptoms and symptom clusters with greater precision. And
sponsors increasingly consider broadening the use of PROs beyond efficacy evaluation to assess
safety and adverse events. In response to this new interest, the National Cancer Institute’s PRO-
CTCAE (Patient-Reported Outcomes version of the Common Terminology Criteria for Adverse
Events) initiative has emerged.
Any use of PROs in the study of illness and treatment obviously requires the
measurement of change. Understanding the patient experience at multiple time points and how
that experience may change provides investigators and clinicians with a more comprehensive
picture of the impact of disease and treatment. In the routine care setting, real-time collection of
PROs over time can assist with supportive care and treatment decisions, and flag concerning
trends. Systematic collection of PROs across patients in this context may be used to support
comparative effectiveness research (CER), which is of increasing interest for informing health
policy decisions. In the clinical trial setting, multiple repeat PRO measures as secondary
endpoints can increase confidence that the impact of an intervention is being appropriately
quantified.

4
Far less obvious are the complex issues that arise in conceptualizing and operationalizing
―change‖ in PRO measures and related constructs. PROs are an important aspect of the patient
experience, and further research is necessary to increase our measurement and understanding of
such outcomes and how they change. This paper outlines issues associated with
operationalizing change in PRO measures, summarizes methods to address these issues,
illuminates gaps in the current state of science, and identifies new developments rich in potential
to fill those gaps. Section 1 outlines the major issues in conceptualizing and operationalizing
change in PRO scores. Once operationalized, change can be modeled. Current methods to
model change in PRO scores over time are discussed in section 2. Recognizing that to
understand change requires identifying what constitutes a meaningful change, methods to
identify meaningful change are described in section 3. Section 4 identifies some of the major
impediments to detecting true change, and section 5 identifies new developments that show
potential for dealing with the challenges, as well as important gaps that are fertile ground for
future researchers.
1. CONCEPTUALIZING MEASUREMENT OF TRUE CHANGE IN PRO SCORES
The paradigm that dominates the concept of change in psychometric research derives
from classical test theory. In this perspective, observed measures of change (based on
subtraction of posttest from pretest scores on a given repeated measure) can be decomposed into
components: change in an attribute’s latent true score plus differences due to random error of
measurement that occur at each observation. Cronbach and colleagues20
recognized that this
error could distort true change, and so devised an approach to regress individuals’ observed
change scores toward the grand mean of sample change, in accord with the unreliability of the
measure. Regression approaches have also been used to adjust for measurement ceiling and

5
floor effects that necessarily attenuate change (i.e., initial scores close to a measure’s maximum
value simply cannot increase as much as other scores). These classical corrections to change
scores are problematic because they are highly dependent upon the characteristics of a given
sample. An individual may give exactly identical responses at each of the repeated assessment
times, yet paradoxically be assigned a non-zero change score because others in the sample have
changed.
Item response theory (IRT) offers a conceptual model and methodology that helps to
overcome some of the shortcomings of classical test theory. In IRT, the estimation of an
individual’s latent true score is based on the pattern of their responses to items with well-defined
parameters of difficulty and discrimination. These item parameters may be derived separately
and applied independent of the characteristics of any given sample. IRT item parameters map
items onto the same unidimensional latent trait continuum as the person scores, and this
facilitates instrument construction making it easier to identify and deal with ceiling and floor
problems. If we assume that item characteristics are invariant and universally applicable, then
estimates of change are not subject to sample-specific effects.
Unfortunately, IRT’s strength in measuring change also contributes to its major
weakness. To be included in a measure, item response probabilities must fit a specified model
(usually a logistic function), as a function of the given latent true score of interest. Standard IRT
models have an underlying assumption that the understanding and meaning of a given attribute
must be universally applicable to all people in all situations; that is that the underlying model
describes how the PRO being measured drives the item responses in the same way for all people.
So far, many of the mainstream IRT models do not allow for large effects of individual
differences other than influences from the person’s PRO or trait level. Item responses that do not

6
fit the probabilistic model and its assumptions simply do not follow the theory and typically are
discarded because their response mechanism cannot be accounted for. Such an approach is
potentially problematic for PROs.
In order to understand the special problems of measuring change in patient-reported
outcomes, it is important to distinguish among several broad classes of measurement. Both
classical test theory and IRT were initially developed to deal with measures of performance,
particularly in educational and intelligence testing. In the health domain, tests of mobility, grip
strength, or completion of neurocognitive tasks are all performance measures. All of these
measures require the individual to demonstrate ability, and all have an objective ―right‖ answer.
Although performance measures may involve observational, verbal, or written assessment of
individuals, they are NOT properly understood as PROs any more than measurements of viral
load or blood pressure would be PROs.
A second category of measurement involves individual perceptions. In this domain,
patients are asked to report on the occurrence, frequency, or magnitude of some event of interest.
Perceptual measures such as the number of missed doses, the number of days spent in bed or the
frequency of unprotected sexual intercourse may be considered as legitimate PROs. The most
important aspect of these perceptual measures is that they necessarily refer to an overt activity
that could in principle be observed, if not for practical or ethical constraints. Perceptual
measures ask individuals to report on some objective behavior as accurately as possible from
their personal recollection of events and experiences. To be sure, factors extrinsic to the attribute
of interest such as accuracy of recall, social desirability or cueing effects can enter into the error
of measurement, but in each case there is an externally verifiable ―right‖ answer.

7
Many PROs represent a third broad category, evaluative measures. Evaluative measures
include ratings by patients of how good or bad they feel in respect to a given set of experiences.
Questions asking individuals to judge their overall health status, quality of care, symptom
distress, and performance difficulty are all evaluative in nature. There are no external
validations for the responses to evaluative measures; an individual may visibly experience
shortness of breath when he climbs one flight of stairs, but if he reports little difficulty, than the
researcher or clinican must accept that answer. Again, extrinsic factors such as desirability or
cueing may affect evaluation, but even more important for measurement purposes are intrinsic
factors related to the process individuals use to appraise the PRO being evaluated. An individual
may say that he had little difficulty going up the stairs compared to last month or compared to
what he was told to expect at cardiac rehab sessions or compared to what he expected after
reading about his condition on the Internet. Each of these standards of comparison is valid, and
an individual’s response might be apparent if we were to elicit the standard they were using. If
measurement operations were to impose a standard of comparison (i.e., compared to a 25 year
old individual in good health), we might get the answer that we expect, but it might bear no
relationship to the individual’s subjective experience. Note that some overtly perceptual
measures have evaluative components. For example, how often an individual received emotional
support from neighbors depends on the individual’s interpretation of ―emotional support.‖ In all
these situations where the individual has their own subjective appraisal, difficulty in the
measurement of change is compounded, because it cannot be assumed that an evaluative item’s
meaning or its relationship to underlying latent variables are constant over time. Identifying true
change in a PRO score involves not only assessing a change, but also attributing the change to an
appropriate mechanism. It is of use to know if the actual condition (pain experienced by the

8
patient) has changed, or if the patient’s appraisal of the condition changed. Both will affect the
experience for the patient, but can have very different implications.
Responsiveness
Responsiveness has emerged in PRO and quality of life (QOL) measurement literature as a
PRO instrument’s sensitivity to detect a true difference or a true change (in a longitudinal setting).
Simply stated, a PRO instrument is responsive if it shows change when there is true or known
change. However, demonstrating evidence of an instrument’s responsiveness is difficult.
Often evidence of responsiveness requires identifying a responder using a measure other than
the PRO scale, such as a related clinical measure. Then, using this external measure to classify
patients into responders and non-responders, several statistics such as Cohen’s effect size or Guyatt’s
responsiveness statistics are available to provide effect size estimates of how responsive the PRO
scale is to changes in the external measure.33 Although no consensus standard for a responsiveness
statistic exists, a recent review and comparison of the available responsiveness statistics identified
one index, Cohen’s effect size, as most appropriate. Cohen’s effect size was selected because it
anchors observed change against variability at baseline, it is less vulnerable to extreme values and is
more readily interpretable.51 Good overviews of responsiveness can be found in papers by Norman
et al 51 and Fayers and Hayes.26
It is important to note that responsiveness is a contextualized attribute of an instrument5
rather than an unvarying characteristic—it is specific to and will vary as a function of who is being
analyzed (individuals or groups), which scores are being contrasted (cross-sectional versus
longitudinal), and what type of change is being quantified (observed change vs. important change).

9
As such, it is a characteristic of the performance of the instrument in a given setting with a given
population.
2. MODELING CHANGE
Once instruments are available that validly measure a change, we can model that change
over time. Only after first selecting a sensible statistical model can researchers maximize the
precision of estimates, enhance the power to detect effects, and improve the overall validity of
results drawn from data analysis. Traditional statistical approaches in longitudinal studies have
relied on the use of some form of the general linear model (GLM). Hedeker and Gibbons35
present accessible summaries of these GLM-based methods, and Muller and Stewart47
offer a
systematic and updated treatment of the underlying GLM theory.
In general, GLM-based methods have a number of deficiencies that preclude them from
being routinely applied to analyze longitudinal data. Basically, GLM-based methods make
simplying assumptions about the longitudinal data that rarely are met in practice. In addition, at
the core of GLM-based methods is a comparison of mean differences; thus GLM-based methods
do not provide information about individual differences in the longitudinal trajectories.
Although GLM-based methods have application, newer methods more suited for
longitudinal analyses are now available and widely used. There are two general model
formulations that developed somewhat independently within two different research areas. The
first modeling framework is multi-level modeling (MLM). Such models are also referred to as
hierarchical linear models in educational and behavioral sciences55
, and mixed-effects models or
mixed models in biometrics and medical statistics.21
The second modeling framework is

10
structural equation modeling (SEqM), particularly the so-called latent curve models for repeated
measures data.11
(In the literature, structural equation modeling is typically abbreviated as SEM;
however in this manuscript SEM will abbreviate standard error of measurement). SEqM
represents the culmination of econometric/sociometric simultaneous equations (path) analysis
and the psychometric factor analytic measurement models.10
In both MLM and SEqM, we specify a model directly on the repeated observations for
each individual. MLM and SEqM also offer more flexibility than GLM-based methods to more
accurately model the functional forms of the change over time. Specifically, both MLM and
SEqM allow for individual differences in the initial status and rate of change, which are
represented as (co)variance components. Both time-varying and time-invariant covariates can be
included in the models to help researchers better understand the causes and patterns of change
for individuals as well as groups. Through the use of full-information maximum likelihood,
MLM and SEqM require only the relatively weak missing at random (MAR) assumption for
missing data43
(discussed in more detail in a section on missing data). Thus these models can
handle unbalanced designs with ease. Importantly, MLM or SEqM analyses provide estimates of
individual characteristics of growth and how these individual characteristics relate to the
covariates.
For a large class of models, MLM and SEqM lead to equivalent model formulations.
MacCallum, Kim, Malarkey, and Kiecolt-Glaser44
discuss these similarities in detail. The
essence of the similarities is that the random effects in MLM are specified as latent variables in
SEqM. If the two frameworks produce equivalent models, it can be shown that the two
frameworks lead to the same parameter estimates.4 MLM is more advantageous when subjects
are clustered (e.g., subjects nested within clinics) because accounting for and modeling

11
additional levels of nesting in MLM is straightforward. SEqM is more flexible when some of the
covariates are latent constructs that are measured by fallible observed indicators because SEqM
easily accounts for measurement error.
3. ASSESSING CHANGE: IDENTIFYING MEANINGFUL CHANGE
Identifying true change in PROs over time is only one important facet of analyzing
change. A second important aspect is identifying when a change in a PRO score is meaningful.
Because PRO scales are typically without meaningful units, it is difficult to make clinical and
regulatory decisions based on PRO assessments. In an effort to provide guidance to decision-
makers, researchers have proposed various methods for estimating minimal important
differences (MIDs) or minimal clinically important differences (MCIDs) for PRO scales. An
MID is defined as the ―smallest difference in a score in the domain of interest which patients
perceive as beneficial and which would mandate, in the absence of troublesome side effects and
excessive cost, a change in the patient’s management.‖38
Basically an MID is the smallest PRO
score difference that can be judged as meaningful.
The FDA draft guidance for industry, Patient-Reported Outcome Measures: Use in
Medical Product Development to Support Labeling Claims.74
extends the responsiveness property
to include some definition or benchmark for change on the PRO scale which characterizes the
meaningfulness of an individual patient’s response to active treatment rather than a group’s response
to treatment. This indicates the importance of identifying meaningful change in order to interpret
and use PRO scores in clinical trials. Patients achieving the benchmark amount of response are
considered treatment ―responders,‖ whereas patients not achieving that amount of response are
considered ―non-responders.‖ The draft guidance provides examples of definitions, such as a 2-point
change on an 8-point scale or a prespecified percent change from baseline. These prespecified values

12
are defined using external measures and should be at least as large as an MID because minimal
change although important to the patient, and dictating some change in treatment strategy may not be
sufficient to classify a patient as a responder.
At this time, there is no consensus on the best methodology for defining the values for a
MID. Consequently, common practice is to calculate multiple estimates of MIDs and compare
both the values and the results when each estimate is applied to judge the meaningfulness of a
reported change.57,67
The FDA’s draft guidance also refers to the practice of using multiple
methods to compare MID estimates and describes this approach as ―generally helpful‖ when an
MID is applied to clinical study results. The FDA guidance further commented on the need for
optimal approaches and standards for MID definitions to be set for the interpretation of clinical
study results, presumably with the goal of providing clear recommendations in a final version of
the guidance.
After the MID or a range of MIDs has been defined, comparisons at the patient level or at
the group level may be made using the MID(s) as a discriminating guideline. For example, the
mean difference between treatment groups may be compared to the MID to supplement
statistical findings and provide information regarding the clinical meaningfulness of the
difference. At the patient level, the percentage of patients achieving change of at least one MID
for each domain can be compared across treatment groups as a criterion for the amount of
improvement. Specifically, percentages of patients achieving at least one MID of change versus
those not achieving an MID often will be compared overall and for each treatment group across
the entire treatment period. Additionally, the percentage in each group can be compared
statistically as a test of greater improvement for one treatment over another (e.g., comparing the
treatment versus placebo). There are three common categories of MID estimation techniques

13
1. Anchor-based methods: compare changes in PRO scores over time with patient-
or clinician-reported global ratings of overall change in disease severity on a
balanced Likert-type scale. For more detail see the study by Juniper et al. 39
The
name of the class of method derives from the PRO results being ―anchored‖ or
defined by differences in ratings of change (either self-reported or clinician-
reported ratings). More recent adaptations include methods to optimize
classification of the ―achieved‖ vs. ―not achieved‖ minimum change on the
anchor using ROC curves.
2. Distribution-based methods rely on the distribution of the empirical data from an
administration of the PRO measure. Most commonly the distribution based MIDs
are some function of the standard deviation of the baseline scores (this includes
methods based on the Standard Error of Measurement; or SEM). For more details
see Norman et al.49
and Wyrwich et al.77
3. Statistical Rules of Thumb MID estimation methods are, as the name implies,
based on statistical rules of thumb. For example, across numerous studies a 0.5-
unit change or greater per response on a 7-point graded-response question has
been applied to define an MID.32,50
This method is straightforward in application
and reasonably consistent across quality of life domains for various conditions
such as heart failure, chronic respiratory disease, and asthma.39
4. MAJOR IMPEDIMENTS TO DETECTING CHANGE
We have identified what constitutes a true change in a PRO score is, as well as how to
model this change and how to interpret the meaningfulness of the change. Next, we delve into
some of the impediments we encounter when measuring change in practice. There are a number

14
of threats to the measurement of true change. We focus on three particular threats relevant to
longitudinal PRO data: 1) response shift, 2) instruments with varying sensitivity across the trait
of interest, and 3) non-ignorable dropout during a trial. The estimates of change are more
sensitive to these factors when the objective is to estimate the magnitude of change within a
specific population than when the objective is to estimate the differences in change between
groups.
Response shift
As mentioned previously, individuals employ subjectivity to appraise their quality of life
and other PRO variables; in fact no measurement of quality of life or related evaluative
constructs is possible without subjective appraisal. It is perfectly understandable that an
individual’s criteria for these PROs can change during (and even be changed by) a course of
illness and treatment. In the area of quality of life research, Schwartz and Sprangers64,68
refer to
these changes as ―response shift‖ phenomena. Many studies over the past decade have
unequivocally demonstrated the ubiquity of response shifts in all manner of PRO measures.2
Sprangers and Schwartz identified three types of response shift: recalibration, a change in the
person’s internal standards used to make comparisons; reprioritization, a change in the
respondent’s values; and reconceptualization, a change in the respondent’s view or definition of
the construct.68
Upon first inspection the subjective aspects of a ―response shift‖ may seem to contribute
to measurement ―error‖ in that many current PRO measurement instruments do not account for
the subjective aspects that influence the score. However, labeling the effects of subjectivity as
error is a misnomer. In practice, the error term represents deviations in the score that are not
explained by the measure. In the case of a misspecified model, where systematic variability

15
exists but is unaccounted for, the variance of the error term absorbs that variability. Perhaps a
paradigm shift is required: In this example of subjective appraisal factors, the model is more
succinctly considered to be misspecified.
It is clear that in order to have more precise and meaningful measures of PROs, we must
know when and how to account for the subjectivity in our measurement of the PROs. This
differs from asking an individual to simply recount an activity or event, because we are asking
about their own judgment. In order to more fully address the nature of change in evaluative
measures, Schwartz and Rapkin introduced the notion of the ―contingent true score.‖ They argue
that any evaluative measure must be interpreted contingent on a cognitive-affective process of
appraisal that underlies an individual’s response.54
They formulate that the true score depends
upon four parameters of appraisal: the individual’s frame of reference or interpretation of an
item, a sampling of experiences, the standards of comparison, and the algorithm for combining
or reconciling discrepant experiences. Rapkin and Schwartz discussed how the three types of
response shift, reconceptualization, reprioritization, and recalibration, could be understood in
terms of changes in appraisal parameters that in turn account for discrepancies in the observed
versus expected changes in a patient’s response to evaluative measures.54
Subsequent research
using cognitive interviewing by Bloem and colleagues9 and ethnographic methods by Wyrwich
and colleagues76
have helped to validate this model by showing that these four domains of
appraisal substantially account for individuals’ introspective statements about their quality of
life.
It follows that any measurement of change in evaluative measures (and in certain
perceptual measures) would be contingent upon change in the underlying parameters of the
appraisal. To explain we revisit the example from section 1 of an individual rating his ability to

16
climb stairs without experience shortness of breath. If we re-evaluate that individual six months
later, he may climb the stairs in 30 seconds with little shortness of breath, but rates his difficulty
as high. This seemingly inconsistent measurement (indicating more difficulty when physically
exhibiting more ease with the situation) occurs because of a change in his subjective appraisal.
At the six-month follow up perhaps the patient researched his condition and expected his
recovery to be faster or the post-surgical pain he was previously experiencing is now gone or
because he has been working so hard in rehabilitation. Again, all of these underlying reasons are
perfectly understandable and valid; therefore the patient’s appraisal is part of their experience of
QOL. All of these underlying reasons for his response shift are perfectly understandable and
valid; therefore the patient’s appraisal is part of their experience of QOL. Expected changes
may be based on clinical judgment, a comparison with performance measures, or statistical
norms in a given sample. Accounting for appraisal parameters will essentially reduce the
measurement error (as estimated by the residuals).
It follows from the contingent true score model that response shifts in PROs induce bias
or measurement error only because in reality they are an un-specified aspect of the classical
model. In fact, evaluative outcomes necessarily require individuals to judge their experiences in
order to make their ratings. How individuals judge their experiences will largely determine their
response to items. Because appraisal processes are highly subject to change over time, we
contend that a measurement of ―true change‖ in evaluative measures requires a direct
measurement of the appraisal. Put differently, change in many PROs of interest cannot be
adequately understood in terms of movement along a single latent variable, representing better
versus worse experiences. Rather, change in several of these PROs can be adequately
understood only in the context of the appraisal.

17
Sensitivity Changes Across the PRO Continuum
It is challenging to develop items to measure across the entire range of may PROs, and
instruments tend to be adequately sensitive for only subsets of the range of the construct rather
than for the entire range. Even the newly developed PROMIS instruments – The item banks of
which underwent extensive qualitative and quantitative development – tend to be more sensitive
and reliable at certain values for the construct.29,58,71
For example, the Pain Impact bank from the
PROMIS instruments has very little reliability at the lower end of the range. These qualitative
issues affect the measurement of PROs, and therefore affect the ability to longitudinally measure
PROs; instruments that are sensitive to a particular change at a particular level in the PRO may
not be sensitive to changes at other levels in the PRO.
Missing Data
Any researcher involved with longitudinal studies using PRO measures knows the
problems that arise in the analysis of change due to missing data. Quite often the data are missing
because the subject’s quality of life has dramatically declined, or the symptoms have become so
severe that they stopped reporting their data. Therefore, the missingness of the data depends on
the outcome being measured, and such missingness cannot be ignored. Statistically speaking
these are non-ignorable missing data, or missing not at random (MNAR). These data are
problematic because selection of the appropriate analytic models depends on untestable
assumptions.25,37,46
Most classical statistical models depend on the missing at random (MAR) assumption.
When the data are MAR, the probability of missingness depends only on the observed data
( )obsY and the covariates ( X ). Appropriate analytic models in this case include well-known and
widely available methods such as maximum likelihood estimation using mixed effects models.

18
When missing data are non-ignorable, the probability of missingness depends also on the
unobserved values. In such an instance, the use of analytic methods such as maximum
likelihood estimation may generate biased estimates.
As most statistical methods assume that missing data are MAR, the typical approach for
non-ignorable missing data is to collect or determine ancillary data that capture the relationship
between missingness and the unobserved data. This ancillary information is generally other
measures of change or response ( ancY ) and not baseline covariates ( X ). Ancillary information
may include other measures of disease progression or response to treatment or concurrent
assessments by caregivers that continue when the subject cannot provide the assessment. The
assumption is that when the ancillary data is included in the analysis, the missing data are MAR
(that is, with the ancillary data, the missing data can be ignored). 24,43
Methods that have been
considered for non-ignorable missing data are multiple imputation using ancillary data, pattern
mixture models, and shared parameter (joint) models.
A classical method for handling missing data is multiple imputation, which assumes that
the missing data are MAR (independent of the value of the missing scores given observed scores
( obsY ) and covariates ( X )). However, if the information used in the imputation procedure is
limited to the information that would be used in the ultimate analysis (i.e. no ancillary data), the
results of multiple imputation will be the same as if one estimated the longitudinal change using
standard longitudinal methods (such as mixed effects models). The use of multiple imputation
will result in improved estimates of change only if ancillary information ( ancY ) is incorporated
into the imputation, and the data are then deemed MAR conditional on the observed data,
covariates and the ancillary information that has been incorporated.24

19
Pattern mixture models assume that there are subgroups of patients defined by an
indicator for a pattern of missing data, and the data are MAR within the subgroup given the
model for change over time.37,46
The overall results are based on weighted averages of the
parameter estimates within these subgroups. The ancillary data enters into the process by
defining the subgroups. Although this method initially appears to be easy to impliment, the
typical analyses requires that either patterns are pooled until there is sufficient information to
estimate all the parameters within the subgroup or assumptions are made to
extrapolate/interpolate across missing assessments.
Joint (shared parameter) models simultaneously estimate the longitudinal trajectory of the
outcome of interest ( obsY ) and the ancillary information ( ancY ) usually linking the models
through the random effects.60,61
The assumption is that conditional on the observed data ( obsY
and ancY ), the data are MAR.
5. NEW DEVELOPMENTS
New developments on the cutting edge of patient-reported outcome measurements can
address some of the previously mentioned pitfalls. New modeling techniques can enhance the
PRO measures and address other issues related to change, such as identifying an MID or MCID.
Assessing appraisal variables and accounting for their effects can increase the sensitivity to
detecting true change. Furthermore, taking advantage of technological advances to administer
PRO measures can overcome some missing data issues, and possibly facilitate standardization of
some of the appraisal variables.
The Quality of Life Appraisal Battery:

20
A complete and adequate understanding in changes of PRO scores requires direct
assessment of changes of appraisal to account for response shifts. Toward this end, Rapkin and
Schwartz introduced a Quality of Life Appraisal Battery that can elicit multiple measures of each
of the four appraisal parameters.54
The Quality of Life Appraisal Battery includes separate
sections to assess each of the four components identified by Rapkin and Schwartz: persons’
frame of reference for considering quality of life, how persons sample experiences within that
frame, how persons evaluate experiences, and how persons summarize and combine evaluations
to describe HRQOL.54
Li and Rapkin42
have demonstrated that this Quality of Life Appraisal
Battery can successfully account for changes in quality of life measures that are due to changes
in appraisal. Theefore a rich area of future research involves how to incorporate appraisal
information into PRO measurement. For purposes of this report, it will be useful to briefly
summarize the four sections of the battery: Frame of Reference, Sampling Experiences,
Standards of Comparisons, and the individual’s combinatory algorithm. Detailed information on
the scoring and psychometric properties of the Quality of Life Appraisal Battery is available
from the authors.
Frame of Reference: Rapkin introduced a measure to probe patients about their life
goals.53
The responses to this instrument facilitated construction of a component of the battery to
measure a person’s frame of reference for PRO assessment. Substantively it captures the
individuals status in broadly areas of concern that are common to most people. Then it also
captures more particular concerns that nonetheless have an important influence on an
individual’s appraisal of a PRO.
Sampling Experiences: Rapkin and Schwartz asked participants to reflect on what they
were thinking about during a PRO measure that they had just completed. Five dimensions were

21
identified: Thinking about Implications of Illness and Impact on Others; Reacting to Recent
Flare Ups; Trying to Focus on Positive Experiences; Managing Communications in the
Interview; and Thinking of Things that were Raised by the Interview.
Standards of Comparison: The battery assessed individuals’ standard of comparison by
asking them to indicate the kinds of situations or people they were thinking about in rating
quality of life questions. Three components were identified: Comparing Oneself to Other
People; Social Norms and Expectations; and One’s Ideal.
Combinatory Algorithm: In order to determine how people formulated their responses
to HRQOL questions, patients are asked to consider a series of 16 items, presented as paired
contrasts. For example, we asked people to indicate whether they were thinking about ―how well
you’ve been doing, how hard it has been, both or neither?‖ when they responded to HRQOL
questions. Principal components analysis of these items yielded seven summary dimensions,
including a focus on Negative Experiences and Feelings; Positive Feelings and Successes;
Change versus Stability; Unfinished versus Finished concerns; Others’ Concerns versus Your
Own; Recent versus Long Standing Concerns; and Independence versus Dependence on Others.
Multidimensional IRT
The advantages of item response theory (IRT) over classical test theory (CTT) in health
outcomes measurement have been demonstrated by a recent wave of applications.22
However, it
is evident that if response shift occurs, or if appraisal information is to somehow be included in
QOL or PRO measures, the construct is no longer unidimensinal (that is, having one latent trait).
As mentioned earlier, in unidimensional IRT, a single latent trait is presumed to be the
underlying construct that the observed items are measuring. Multidimensional IRT relaxes this

22
restriction so that the observed items are influenced by multiple latent variables.23
In
longitudinal settings, multidimensional IRT models are particularly useful to explore the stability
of the measurement structure over time; specifically multidimensional IRT models can detect
response shift occurrences.
For example, consider a PRO construct such as depression that is being assessed at two
time points (perhaps before and after treatment) for a group of respondents. For a variety of the
reasons mentioned above, the relationship between the items and the latent construct may change
over time. From a psychometric perspective, this is a classical longitudinal measurement
invariance issue. To model and test invariance, we require an IRT equivalent of the longitudinal
factor analysis model.72
In this model, the unidimensional construct at the two time points are
represented as two correlated factors, each measured by the time-specific item responses. The
fact that the same items are used twice leads to residual dependence that can be modeled by
including additional latent variables that are defined by item doublets across time.
Figure 1 uses path diagramming conventions to show the general structure of this model
for three items and two occasions. The observed items are represented as rectangles and the
1 2
Figure 1: Path diagram for multidimensional longitudinal IRT model

23
latent variables are circles. A longitudinal multidimensional IRT model was considered, for
example, by Hill (2006) for dichotomous responses, and by te Marvelde, Glas, & van Damme
(2006), with some restrictions, for ordinal responses.36,70
These multidimensional IRT models
can be used to test a variety of longitudinal measurement invariance hypotheses by manipulating
the constraints on the item parameters. Under appropriate circumstances, this model allows the
researcher to tease apart the observed change into two components: change due to response shift
and true change in the level and variability of the latent construct.
However, in the above scenario, response shift is still seen as a type of nuisance, and not
as an intrinsic part of measurement for PROs. A strong possibility for future research is to
incorporate appraisal information into multidimensional IRT models to control for and limit the
effects of response shift. This could enhance longitudinal measurement of PROs and facilitate
the understanding of true change. Other possible modeling techniques to incorporate appraisal
information and adjust for any effects from the appraisal variables may exist as well.
Incorporating the appraisal information as part of a PRO assessment is a challenging but
important task.
While the basic principles of multidimensional IRT are straightforward, their application
has been hampered by challenging computational issues in parameter estimation. For instance,
in the model depicted above, the number of latent variables is equal to the number of time-points
(two) plus the number of items (three). Fitting a 5-dimensional IRT model to data requires a
non-trivial amount of computation. In particular, obtaining maximum likelihood estimates of the
model parameters requires the numerical approximation of high-dimensional integrals, which
leads to an exponentially increasing computational burden. Recent computational advances in
adaptive quadrature,59
Markov chain Monte Carlo methods,6 and stochastic approximation
13,14

24
are poised to resolve the computational challenges and make multidimensional IRT practical for
health outcomes research.
Emerging Methods for Defining MIDs
New methods have been developed to define MID or CMID values. Emerging methods
include approaches incorporating clinical or patient-based judgment. For example, one approach
requires that a panel of healthcare professionals determine a ―consensus‖ value for MID based on
a series of appraisals using their clinical experience and standard-setting techniques.34
This
approach can also be applied using patient panelists as the experts on, for example, the amount of
change needed to impact daily activities or health-related quality of life. (Patient queries of this
nature can be included during the cognitive interview stage of instrument development.) Another
approach combines clinical judgment and ROC curves to identify the unit of change on the PRO
that best predicts clinical judgment of the minimal important change.73
Finally, a more recent
idea, still in the early stages of development, uses item response theory to compute change in the
PRO measure on the standardized latent construct scale and builds upon the anchor-based
methods by identifying the minimal value in terms of the minimally identified change on the
latent construct or theta.45
The Role of Gadgets
Interactive Voice Response: In addition to methodological developments that can
enhance measuring and detecting change in PRO scores, new technological developments can
also facilitate the measurement of change in PROs. Collecting PRO data such as symptom data
from patients is an ongoing challenge for both clinicians and researchers. A major problem is
tracking PROs in general and symptoms in particular between clinic visits when patients are at

25
home and may be reluctant to report that symptoms are getting worse. Given that memory of
pain and other symptoms is often poor, the real time assessment of symptoms can provide
accurate data regarding symptom patterns and changes over time.
Developments in computer and communications technology offer new opportunities for
the assessment of PROs, allowing great flexibility in the collection of data regardless of time or
venue. However, not all patients are comfortable using hand-held computers or other small
automated devices. In addition, patients have to remember to carry and use the devices every day
and to bring or transmit the symptom data to their health care providers.
The development of telephone interactive voice response (IVR) technology provides an
exciting option for two-way communication with the provider that is acceptable to most patients.
Telephone systems have been widely used in outpatient health care settings for communicating
with patients, identifying symptoms that need medical attention, and following patients after
treatment.41
However, traditional telephone communication requires considerable staff time and
is not feasible for assessing PROs on a regular basis. Using IVR technology that combines touch
tone telephones with computers and the internet is an effective way to follow patients who have
PROs such as pain that need to be monitored closely while away from the clinic or hospital. A
patient can respond to spoken instructions by using the keypad of a touch tone phone. For
example, a patient might be asked to rate his/her pain at its worst in the past day from 0 (no pain)
to 10 (pain as bad as can be imagine). Information obtained in this way can be used to update a
patient file on an Internet or Intranet site. In addition, the system can be configured to alert
physicians and other health care providers as necessary.
IVR systems have been shown to be successful tools for assessment and for clinical
interventions. Studies show success assessing depression40
and also facilitating the treatment of

26
other chronic health problems.48,52
The computer versions of scales provide data that are
equivalent to interview scales or self-administered scales.1 Patients have been able to accurately
and reliably use an IVR system designed to assess the special needs of cancer patients receiving
chemotherapy.65
In summary, an IVR system provides reliable and valid data. Accurate and regular
symptom assessment, with data provided to the patients’ physicians, facilitates symptom
management and as a consequence results in the patients’ accepting its use and being motivated
to respond. When coupled with the flexibility of the system for data collection, tie IVR system
should also minimize missing data, especially in longitudinal studies.
Computerized Testing: The widespread use of computers in clinics, and the
development of portable computing systems have introduced computerized testing for PROs.
These developments allow us to administer PRO instruments onl a local computer or over the
Internet, but and have also allowed us to develop and employ adaptive versions of PRO
instruments, known as computerized adaptive testing instruments (CATs).3,7,8,16,18,19,27,28,56,62
CATs reduce the respondent burden of questionnaires and maintain the precision of the
PRO score because they adaptively select items targeted for the individual’s current experience.
CATs work because they are associated with large item banks that cover a range of the PRO of
interest. Modern item response theory models are used to characterize the items in the bank and
mathematical algorithms dictate how to select items from the bank based on these models. For
example, a person experiencing no depressive symptoms might be administered an item such as
―I feel sad‖ but then would likely not be administered a more extreme item such as ―I feel so sad

27
I have thought of harming myself.‖ Furthermore, the patient interface is flexible; for example, a
CAT can be administered using an IVR system. By reducing respondent burden, CATs have the
potential to increase adherence and reduce missing data.
Creative Item Types: Computer-based administration of questionnaires and tests
supports the use of creative multimedia formats such as video and electronic graphics and games.
Although still relatively untapped for the assessment of PROs, such creative formats are in use as
teaching aids, and are being introduced into computer based educational assessments.3,17
An
early study involving health states found that subjects better understood the conditions being
described when multimedia formats were used rather than traditional paper-and-pencil formats.30
As a result of that study, a computer-based program to elicit preferences for a particular PRO
(activities in daily living) has been developed. The program uses videos, pictures and other
multimedia presentations via computer to familiarize respondents with health states that may be
unfamiliar to them. That program has found some success, but this program does not measure
PROs directly31,66
. Using multimedia formats in an attempt to anchor PRO assessment in a
similar way may have similar results, reducing some response shift and other phenomenon that
interfere with longitudinal measurement of change for PROs.
6. FUTURE DIRECTIONS
Identifying true change in PROs is challenging because measuring PROs is intrinsically
difficult. The process of self-report is complex and there are many factors such as the subjective
appraisal variables mentioned above that can influence self-report scores.54,63,69
Furthermore,

28
some of the PRO constructs, such as quality of life are also highly complex, and to some extent
subjective to an individual’s values and experiences.
Although substantial advancement has been made to create reliable, valid and responsive
instruments for measuring PROs, determining how to best measure PROs is a process that is still
under development. This is natural; all measures develop. Historically, even well-defined
physical measures such as length had their developmental periods. For example, what is now
the standard ―foot‖ in the US and English metric system was not once a variable and uncertain
measure. In ancient times, measures of length were based on body parts;12
the traditional belief
being that a ―foot‖ of length derived from humans measuring distance by the equivalent number
of their own feet that would cover the length in question. Of course individual feet vary in
length, and traditional accounts relay that as a first attempt to standardize the measure of length
in medieval times, the length of the King’s foot was declared the standard ―foot.‖ However, this
was still problematic because the measure changed with every new king. Finally, a unified, non-
changing standard was applied and we have the foot defined as it is today.
The historical accuracy of the details of this process is questionable; nevertheless there
are documented cases in which the definition of a measure changed as it progressed to what we
understand it to be today. As another example, an early version of a ―mile‖ measured 5000 feet
rather than the current standard of 5280 feet.
The same process of working toward a unified standard is underway among researchers
who assess PROs. Several measures for PROs exist that are widely used, valid and reliable. For
example, measures used to assess quality of life (QOL) include the Functional Assessment of
Chronic Illnesses Therapy suite of measures, ( http://www.facit.org) and general health outcome
measures such as the short-form 36 health survey questionnaire (SF-36).75
Furthermore, new

29
measures are still being developed such as the Patient Reported Outcome Measurement
Information System (PROMIS) tools (http://www.nihpromis.org). In many cases there is
substantial overlap between the measures (i.e. more than one measure targets a specific PRO
such as depression). However with the recent efforts of the PROMIS initiative and heavy
reliance on modern IRT methods researchers are attempting large-scale standardization across
the different PRO measurement scales. ―Crosswalks‖ and other methods of transforming one
instrument’s scale onto the PROMIS measurement scales are currently being developed15
.
Most PRO measures do not yet account for the appraisal factors that continue to affect
how people report their experience. Developing measures to incorporate appraisal parameters
can greatly reduce the obfuscating effect of a response shift and concomitantly increase
measurement precision. However, despite the conceptual advantages offered by the appraisal
model, incorporating appraisal data presents problems. Thus far, approaches to assess appraisal
involve qualitative data that require considerable coding to use in a quantitative analysis. Indeed,
Bloem suggests that appraisal parameters are best assessed for each individual item. Although
reliable, coding schemes have yielded dozens of variables which complicate the analysis. A
more parsimonious system to describe appraisal parameters or the identification of overarching
response states would be most valuable.
Further, it is as yet unclear how to reconcile these different approaches to the
measurement of change in PROs. Appraisal parameters necessarily come into play when
individuals respond to items. Item evaluation and selection according to item response theory
assumptions must then account for and reflect appraisal processes. It may be that current IRT
item selection in some way constrains appraisal; for example, perhaps only the items that invoke
a consistent frame of reference across people demonstrate the necessary properties for inclusion.

30
If so, it is necessary to ask what frame of reference we are unintentionally imposing by excluding
conceptually-relevant items with unacceptable item performance curves or high differential item
functioning across diverse groups.
A second possibility is that the evaluation of items may be relatively independent of
appraisal. For example, at a given time of measurement, individuals may respond to items such
as ―I feel healthy,‖ ―I am physically fit‖, and ―I am able to perform all of my activities without
difficulty‖ using a common (enough) set of appraisal criteria that these items will almost always
correlate highly with one another. That would likely be sufficient for such items to hang
together in IRT analysis to jointly estimate latent traits and item characteristics. However, the
fact that these items tend to co-vary because responses reflect similar underlying appraisal
parameters may not mean that the appraisal is ignorable at all times for these items. Different
individuals may still appraise these items differently, and an individual’s appraisal may still
change from time to time. The score on the latent variable may provide an accurate estimate of
the individual’s level on a PRO variable, but it provides no information concerning the different
cognitive pathways the individual followed at each assessment to make his or her ratings.
In order to capture true change in PROs, it will be necessary to carry out research that
brings together concepts from IRT and the contingent true score model. For example, as
previously mentioned, it may be that appraisal parameters can be more adequately captured in
models that permit multidimensional latent variables, such as with multidimensional IRT
models. Removing ambiguous or volatile items identified through IRT may help to reduce
response shifts. Furthermore, using IRT and related computer adaptive testing approaches to
assess appraisal itself may be useful in better quantifying and minimizing the burden associated
with the assessment of appraisal parameters. Incorporating appraisal information into a purely

31
psychometric treatment of items in IRT might guide decisions about item selection and about the
underlying dimensionality of the latent traits.
Another possible approach might be to adapt PRO measures to include new items or new
collection techniques that can anchor some of the important appraisal variables. Perhaps in
specific settings such as during a chemotherapy treatment regimen, there are ways to develop
items that fix the appraisal variables at specific levels such that they remain consistent for
patients across the treatment period.
In addition to developing methods and tools to control and account for response shift,
additional work in interpreting change values is required. Despite notable developments in our
understanding of minimal important change, MID/MCID, and responsiveness, there are many
issues that require further investigation. First, in current practice, units that have been defined at
the patient level are used to make both patient-level and group-level judgments. However,
smaller group-level changes or smaller differences in means between groups may equate to
similar treatment impacts as indicated by patient-level classifications based on an MID. Using
Fisher’s exact test to compare the classifications of patients into groups who ―achieved MID‖
versus those who ―did not achieve MID‖ by treatment is not equivalent to testing whether the
means of the treatment groups are statistically different and the amount of difference is at least
one MID unit.
Second, most anchor-based approaches use only a portion of the available data (e.g., data
for patients who respond ―slightly better‖ or ―slightly better/slightly worse‖ on an anchor). Data
from this sometimes very small subset are used to estimate the MID, while the remaining data
are ignored or simply checked to ensure that the pattern of change based on response to the
anchor matches the expected change on the PRO scale. Future research could identify ways to

32
incorporate all the data from anchor-based methods to define MIDs or ways of interpreting
change.
Third, MIDs or CMIDs are applied uniformly along the entire score range. This may not
be reasonable for all settings. Under certain circumstances it may be reasonable that MIDs vary
according to disease severity or some other characteristic—minimal important changes may
depend on where a patient begins on the concept measured (similar to an ANCOVA-type
argument). In addition, the measurement precision of the instrument should also be taken into
account when defining an MID. For example, an MID should not be identified and then applied
at the patient level if it is less than the standard error of measurement.
Finally, very little work has been done related to the contingent true score model and the
effect adopting this model has on developing MID estimates. How to define or interpret MID
under the contingent true score model, how this can influence a response shift, and the effect a
response shift might or might not have on a MID developed using the contingent true score
model are still open areas of research.
Much progress has been made in measuring and analyzing PROs longitudinally, and new
cutting-edge methods are being developed; nevertheless, there is plenty of room for
improvement. Interestingly, the problems of non-ignorable missing data and response shift have
some underlying similarities. Both are situations in which ancillary data improve the likelihood
that the estimation of change is closer to the true change. The challenge in both areas is to
identify the ancillary variables through research and to prospectively incorporate them into
clinical investigations. Rich areas of future research involve continued investigation of appraisal
variables, new methods to identify MID or CMID values, ways to determine the responsiveness

33
of PRO measures, methods incorporating ancillary data to improve estimates in the presence of
non-ignorable missing data, and ways to reduce missing data.

34
References
1. Agel, J., Rockwood, T., Mundt, J. C., Greist, J. H., & Swiontkowski, M. (2001). Comparison of interactive voice response and written self-administered patient surveys for clinical research. Orthopedics, 24(12), 1155-1157.
2. Ahmed, S., & Schwartz, C. E. (2009 in press). Quality of life assessments and response shift. In A. Steptoe (Ed.), Handbook of Behaviioral Medicine: Methods and Applications. New York, NY: Springer Science
3. Basu, A., Cheng, I., Prasad, M., & Rao, G. (2007). Multimedia Adaptive Computer based Testing: An Overview. Paper presented at the IEEE International Conference on Multimedia and Expo (ICME).
4. Bauer, D. J. (2003). Estimating multilevel linear models as structural equation models. Journal of Educational and Behavioral Statistics, 28, 135-167.
5. Beaton, D. E., Bombardier, C., Katz, J. N., & Wright, J. G. (2001). A taxonomy for responsiveness. Journal of Clinical Epidemilology, 54(12), 1204-1217.
6. Béguin, A. A., & Glas, C. A. W. (2001). MCMC estimation and some model-fit analysis of multidimensional IRT models. Psychometrika, 66, 541-561.
7. Bergstrom, B. A. (1996). Computerized adaptive testing for the national certification examination. Aana J, 64(2), 119-124.
8. Bjorner, J. B., Chang, C. H., Thissen, D., & Reeve, B. B. (2007). Developing tailored instruments: item banking and computerized adaptive assessment. Quality of Life Research, 16 Suppl 1, 95-108.
9. Bloem, E. F., van Zuuren, F. J., Koeneman, M. A., Rapkin, B. D., Visser, M. R. M., Koning, C. C. E., et al. (2008). Clarifying quality of life assessment: do theoretical models capture the underlying cognitive processes? Quality of life research : an international journal of quality of life aspects of treatment, care and rehabilitation, 17(8), 1093-1102.
10. Bollen, K. A. (1989). Structural equations with latent variables. New York: Wiley. 11. Bollen, K. A., & Curran, P. J. (2006). Latent curve models: A structural equation approach.
Hoboken, NJ: John Wiley & Sons. 12. . Brief History of Measurement Systems with a Chart of the Modernized Metric System (1974).
from NBS Special Publication 304A. 13. Cai, L. (in press a). High-dimensional exploratory item factor analysis by a Metropolis-Hastings
Robbins-Monro algorithm. Psychometrika. 14. Cai, L. (in press b). Metropolis-Hastings Robbins-Monro algorithm for confirmatory item factor
analysis. Journal of Educational and Behavioral Statistics. 15. Cella, D., Lai, J. S., Garcia, S. F., Reeve, B. B., Weinfurt, K. P., George, J., et al. (2008). The patient
reported outcomes measurement information system-Cancer (PROMIS-Ca): Cancer -specific appplication of a generic fatigue measure. Journal of Clinical Oncology, 26(15S), 6537.
16. Chang, C.-H. (2007). Patient-reported outcomes measurement and management with innovative methodologies and technologies. Quality of Life Research, 16, 157-166.
17. Cheng, I., & Bischof, W. F. (2007). Multimedia Item Type Design for Assessing Humawn Cognitive Skills. Paper presented at the IEEE International Conference on Multimedia and Expo (ICME)

35
18. Chien, T. W., Wu, H. M., Wang, W. C., Castillo, R. V., & Chou, W. (2009). Reduction in patient burdens with graphical computerized adaptive testing on the ADL scale: Tool development and simulation. Health and Quality of Life Outcomes, 7, 1-6. Retrieved from <Go to ISI>://000266421700001. doi:10.1186/1477-7525-7-39
19. Choi, S. W., & Swartz, R. J. (2009). Comparison of CAT item selection criteria for polytomous items. Applied Psychological Measurement, 33(6), 419-440.
20. Cronbach, L. I., & Furby, L. (1970). How we should measure "change" - or should we? Psychological Bulletin, 74(1), 68-80.
21. Demidenko, E. (2004). Mixed models: Theory and applications. Hoboken, NJ: John Wiley & Sons. 22. Edelen, M. O., Reeve, B. B., Edelen, M. O., & Reeve, B. B. (2007). Applying item response theory
(IRT) modeling to questionnaire development, evaluation, and refinement. [Validation Studies]. Quality of Life Research, 16 Suppl 1, 5-18.
23. Edwards, M. C., & Edelen, M. O. (2009). Speical topics in item response theory. In R. E. Millsap & A. Maydeu-Olivares (Eds.), Handbook of quantitative methods in psychology (pp. 178-198). New York, NY: Sage.
24. Fairclough, D. L. (2010). Design and analysis of quality of life studies in clinical trials : interdisciplinary statistics (2nd ed.). Boca Raton, FL: Chapman & Hall/CRC Press.
25. Fairclough, D. L., Thijs, H., Huang, I. C., Finnern, H. W., & Wu, A. W. (2008). Handling missing quality of life data in HIV clinical trials: what is practical? Quality of life research : an international journal of quality of life aspects of treatment, care and rehabilitation, 17(1), 61-73.
26. Fayers, P. M., & Hays, R. D. (2005). Assessing quality of life in clinical trials : methods and practice (2nd ed.). Oxford: Oxford University Press.
27. Fields, F. A. (1992). Computerized adaptive testing for NCLEX-PN. J Pract Nurs, 42(2), 8-10. 28. Fliege, H., Becker, J., Walter, O. B., Bjorner, J. B., Klapp, B. F., & Rose, M. (2005). Development of
a computer-adaptive test for depression (D-CAT). Quality of Life Research, 14(10), 2277-2291. 29. Garcia, S. F., Cella, D., Clauser, S. B., Flynn, K. E., Lad, T., Lai, J. S., et al. (2007). Standardizing
patient-reported outcomes assessment in cancer clinical trials: a patient-reported outcomes measurement information system initiative.[erratum appears in J Clin Oncol. 2008 Feb 20;26(6):1018 Note: Lad, Thomas [added]]. Journal of Clinical Oncology, 25(32), 5106-5112.
30. Goldstein, M. K., Clarke, A. E., Michelson, D., Garber, A. M., Bergen, M. R., & Lenert, L. A. (1994). Developing and Testing a Multimedia Presentation of a Health-State Description. Medical Decision Making, 14(4), 336-344.
31. Goldstein, M. K., Miller, D. E., Davies, S., & Garber, A. M. (2002). Quality of Life Assessment Software for Computer-Inexperienced Older Adults: Multimedia Utility Elicitation for Activities of Daily Living. Paper presented at the American Medical Informatics Association Annual Symposia.
32. Guyatt, G. H., Juniper, E. F., Walter, S. D., Griffith, L. E., & Goldstein, R. S. (1998). Interpreting treatment effects in randomised trials. British Medical Journal, 316, 690-693.
33. Guyatt, G. H., Walter, S. D., & Norman, G. R. (1987). Measuring change over time: Assessing the usefulness of evaluative instruments. Journal of Chronic Diseases, 40, 171-178.
34. Harding, G., Leidy, N. K., Meddis, D., Kleinman, L., Wagner, S., & O'Brien, C. (2009). Interpreting clinical trial results of patient-perceived onset of effect in asthma: methods and results of a Delphi panel. Current Medical Research and Opinion, 25(6), 1563-1571.
35. Hedeker, D. R., & Gibbons, R. D. (2006). Longitudinal data analysis. Hoboken, NJ: John Wiley & Sons.
36. Hill, C. D. (2006). Two models for longitudinal item response data. Unpublished Unpublished doctoral dissertation, University of North Carolina - Chapel Hill.
37. Hogan, J. W., Roy, J., & Korkontzelou, C. (2004). Handling drop-out in longitudinal studies. Statistics in Medicine, 23(9), 1455-1497.

36
38. Jaeschke, R., Singer, J. D., & Guyatt, G. H. (1989). Measurement of health status: Ascertaining the minimal clinically important difference Controlled Clinical Trials, 10, 407-415.
39. Juniper, E. F., Guyatt, G. H., Willan, A., & Griffith, L. E. (1994). Determining a minimal important change in a disease-specific quality of life questionnaire. Journal of Clinical Epidemilology, 47(1), 81-87.
40. Kobak, K. A., Greist, J. H., Jefferson, J. W., Mundt, J. C., & Katzelnick, D. J. (1999). Computerized assessment of depression and anxiety over the telephone using interactive voice response. MD Computing, 16(3), 64-68.
41. Korcz, I. R., & Moreland, S. (1998). Telephone prescreening enhancing a model for proactive healthcare practice. Cancer Practice, 6(5), 270-275.
42. Li, Y., & Rapkin, B. (2009). Classification and regression tree uncovered hierarchy of psychosocial determinants underlying quality-of-life response shift in HIV/AIDS. Journal of clinical epidemiology, 62(11), 1138-1147.
43. Little, R. J., & Rubin, D. B. (2002). Statistical anaalysis with missing data (2nd ed.). New York, NY: Wiley.
44. MacCallum, R. C., Kim, C., Marlarkey, W. B., & Kiecolt-Glaser, J. K. (1997). Studying multivariate change using multilevel models and latent curve models. Multivariate Behavioral Research, 32, 215-253.
45. McLeod, L. D., Nelson, L., & Lewis, C. Personal Communication July 1, 2009. 46. Michiels, B., Molenberghs, G., Bijnens, L., Vangeneugden, T., & Thijs, H. (2002). Selection models
and pattern-mixture models to analyse longitudinal quality of life data subject to drop-out. Statistics in Medicine, 21(8), 1023-1041.
47. Muller, K. E., & Stewart, P. W. (2006). Linear model theory: Univariate, multivariate, and mixed models. Hoboken, NJ: John WIley & Sons.
48. Mundt, J. C., Kaplan, D. A., & Greist, J. H. (2001). Meeting the need for public education about dementia. Alzheimer Disease & Associated Disorders, 15(1), 26-30.
49. Norman, G. R., Sloan, J., & Wyrwich, K. W. (2003). Interpretation of changes in health-related quality-of-life. Medical Care, 4, 582-592.
50. Norman, G. R., Sridhar, F. G., Guyatt, G. H., & Walter, S. D. (2001). Relation of distribution- and anchor-based approaches in interpretation of changes in helath related quality of life. Medical Care, 29, 1039-1047.
51. Norman, G. R., Wyrwich, K. W., & Patrick, D. L. (2007). The mathematical relationship among different forms of responsiveness coefficients. Quality of life research: an international journal of quality of life aspects of treatment, care and rehabilitation, 16(5), 815-822.
52. Piette, J. D. (2000). Interactive voice reponse systems in the diagnosis and management of chronic disease. American Journal of Managed Care, 6(7), 817-827.
53. Rapkin, B. D. (2000). Personal goals and response shifts: Understanding the impact of illness and events on the quality of life of people living with AIDS. In C. E. Schwartz & M. A. G. Sprangers (Eds.), Adaptation to changing health: Response shift in quality-of-life research (1st ed.). Washington, DC: American Psychological Association.
54. Rapkin, B. D., & Schwartz, C. E. (2004). Toward a theoretical model of quality-of-life appraisal: Implications of findings from studies of response shift. Health and Quality of Life Outcomes, 2, 14.
55. Raudenbush, S. W., & Byrk, A. S. (2002). Heirarchical linear models: Applications and data analysis methods (2nd ed.). Thousand Oaks, CA: Sage.
56. Reeve, B. B., Burke, L. B., Chiang, Y. P., Clauser, S. B., Colpe, L. J., Elias, J. W., et al. (2007). Enhancing measurement in health outcomes research supported by Agencies within the US Department of Health and Human Services. Quality of Life Research, 16 Suppl 1, 175-186.

37
57. Revicki, D., Hays, R. D., Cella, D., & Sloan, J. (2008). Recommended methods for determining responsiveness and minimally important differences for patient-reported outcomes. Journal of Clinical Epidemilology, 61(2), 102-109.
58. Rose, M., Bjorner, J. B., Becker, J., Fries, J. F., & Ware, J. E. (2008). Evaluation of a preliminary physical function item bank supported the expected advantages of the Patient-Reported Outcomes Measurement Information System (PROMIS). J Clin Epidemiol, 61(1), 17-33.
59. Schilling, S., & Bock, R. D. (2005). High-dimensional maximum marginal likelihood item factor analysis by adaptive quadrature. Psychometrika, 70, 533-555.
60. Schluchter, M. D. (1992). Methods for the analysis of informatively censored longitudinal data. Statistics in Medicine, 11(14-15), 1861-1870.
61. Schluchter, M. D., Greene, T., & Beck, G. J. (2001). Analysis of change in the presence of informative censoring: application to a longitudinal clinical trial of progressive renal disease. Statistics in Medicine, 20(7), 989-1007.
62. Schmitz, N., Hartkamp, N., Brinschwitz, C., & Michalek, S. (1999). Computerized administration of the Symptom Checklist (SCL-90-R) and the Inventory of Interpersonal Problems (IIP-C) in psychosomatic outpatients. Psychiatry Research, 87(2-3), 217-221.
63. Schwartz, C. E., & Rapkin, B. D. (2004). Reconsidering the psychometrics of quality of life assessment in light of response shift and appraisal. Health and Quality of Life Outcomes, 2, 16.
64. Schwartz, C. E., & Sprangers, M. A. (1999). Methodological approaches for assessing response shift in longitudinal health-related quality-of-life research. Social science & medicine (1982), 48(11), 1531-1548.
65. Siegel, K., Mesagno, F. P., Chen, J. Y., Klein, L., Bowles, M. E., McKenna, M., et al. (1988). Computerized telephone assessment of the "concrete" needs of chemotherapy outpatients: a feasibility study. Journal of Clinical Oncology, 6(11), 1760-1767.
66. Sims, T. L., Garber, A. M., Miller, D. E., Mahlow, P. T., Bravata, D. M., & Goldstein, M. K. (2005). Multimedia Quality of Life Assessment: Advances with FLAIR. Paper presented at the American Medical Informatics Association Annual Symposia.
67. Sloan, J., Cella, D., & Hays, R. D. (2005). Clinical significance of patient-reported questionnaire data: another step towards consensus. Journal of Clinical Epidemilology, 58, 1217-1219.
68. Sprangers, M. A., & Schwartz, C. E. (1999). Integrating response shift into health-related quality of life research: a theoretical model. Social science & medicine (1982), 48(11), 1507-1515.
69. Stone, A. A., Turkkan, J. S., Bachrach, C. A., Jobe, J. B., Kurtzman, H. S., & Cain, V. S. (Eds.). (2000). The Science of Self-Report: Implications for Research and Practice. Mahwah, NJ: Lawrence Erlbaum.
70. te Marvelde, J., Glas, C. A. W., Landeghem, G., & van Damme, J. (2006). Application of multidimensional item repsonse theory models to longitudinal data. Educational and Psychological Measurement 66(1), 5-34.
71. Thissen, D., Reeve, B. B., Bjorner, J. B., & Chang, C. H. (2007). Methodological issues for building item banks and computerized adaptive scales. Qual Life Res, 16 Suppl 1, 109-119.
72. Tisak, J., & Meredith, W. (1989). Exploratory longitudinal factoranalysis in multiple populations. Psychometrika, 54, 261 - 281.
73. Turner, D., H.J., S., Griffith, L. E., Beaton, D. E., M., G. A., Critch, J. N., et al. (2009). Using the entire cohort in the receiver operating characteristic analysis maximizes preicison of the minimal important difference. Journal of Clinical Epidemilology, 62(4), 374-379.
74. US Department of Health and Human Services. Food and Drug Administration (2006). Guidance for industry patient-reported outcome measures: use in mdeical product development to support labeling claims draft guidance. Retrieved February 12, 2009. from http://www.fda.gov/cder/guidance/5460dft.pdf.

38
75. Ware, J. E., Snow, K. K., Kosinski, M., & Gandek, B. (1997). SF-36 Health Survey: Manual and Interpretation Guide. Boston, MA: The Health Institute, New England Medical Center.
76. Wyrwich, K. W., & Tardino, V. M. (2006). Understanding global transition assessments. Quality of life research : an international journal of quality of life aspects of treatment, care and rehabilitation, 15(6), 995-1004.
77. Wyrwich, K. W., Tierney, W. M., & Wolinsky, F. D. (1999). Further evidence supporting an SEM-based criterion for identifying meaningful intra-individual changes in health-related quality of life. Journal of Clinical Epidemiology, 52(9), 861-873.

APPENDIX E – Workshop Participants Lists
For most of the SAMSI workshops, the participants will be summarized in three tables
below. The first table is a summary of all participants by gender, status, field of
work/study, affiliation, and location. The second table lists only the participants who
received support. The third table lists all workshop participants. The minority status of
each participant is available, but we do not include the information here because of
privacy issues; the summaries in Section H: Diversity Efforts were compiled from this
data.
The key top Status entry is as follows:
NRG – New Researcher or Graduate Student S – Students (Education & Outreach)
FP – Faculty or Professional A – Faculty (Education & Outreach)
2008-09 PROGRAM EVENTS AFTER AUGUST 1, 2009
Sequential Monte Carlo Methods
Participants Male Female Unspec-
ified Faculty/
Professional
New Researcher/
Student Stat Math Other
Supported 11 1 0 6 6 9 0 3
Unsuppted 19 7 0 10 16 24 1 1
SAMSI 3 0 0 1 2 2 0 1
Last Name First Name Gender Affiliation Major/Department Status
Airoldi Edoardo M Harvard University Statistics NRG
Bhadra Anindya M University of Michigan Statistics NRG
Carvalho Carlos M University of Chicago Statistics NRG
Doucet Arnaud M University British Columbia Stats & CS FP
Lin Xiaodong M Rutgers University Statistics FP
Lopes Hedibert M University of Chicago Other FP
Lynch Jim M University of South Carolina Statistics FP
Lyubimov Konstantin M University of Georgia Socl FP
Peters Gareth M University of New South Wales Stats & Math NRG

Petris Giovanni M University of Arkansas Statistics FP
Septier Francois M University of Lille Engg NRG
Wang Xiaopei F University of Cinncinati Statistics NRG
Sequential Monte Carlo Methods Transition Workshop
Workshop Participants
November 9-10, 2009
Last Name First Name Gender Affiliation Major/Department Status
Airoldi Edoardo M Harvard University Statistics NRG
Berger Jim M SAMSI Statistics FP
Bhadra Anindya M University of Michigan Statistics NRG
Carvalho Carlos M University of Chicago Statistics NRG
Chen Hao M Duke University Statistics NRG
Clyde Merlise F Duke University Statistics FP
Cornebise Julien M SAMSI Comp Sci NRG
Das Sourish M SAMSI Statistics NRG
Doucet Arnaud M University British Columbia Stats & CS FP
Dunson David M Duke University Statistics FP
Feng Xingdong M NISS Math NRG
Gerstoft Peter M
University of California, San Diego Phys FP
Godsill Simon M Cambridge University Statisitcs FP
Hannig Jan M University of North Carolina Statistics FP

Lenarcic Alan M Harvard University Statistics NRG
Lin Xiaodong M Rutgers University Statistics FP
Liu Bin M Duke University Statistics NRG
Lopes Hedibert M University of Chicago Other FP
Lynch Jim M University of South Carolina Statistics FP
Lyubimov Konstantin M University of Georgia Socl FP
Macaro Christian M Duke University Statistics NRG
Manolopoulou Ioanna F Duke University Statistics NRG
Mukherjee Chiranjit M Duke University Statistics NRG
Muthukumarana Saman M Simon Fraser University Statistics NRG
Pena Edsel M University of South Carolina Statistics FP
Peters Gareth M University of New South Wales Stats & Math NRG
Petralia Francesca F Duke University Statistics NRG
Petris Giovanni M University of Arkansas Statistics FP
Ratmann Oliver M Duke University Bio NRG
Rocha Guilherme M Indiana University Statistics NRG
Schott Sarah F Duke University Statisitcs NRG
Septier Francois M University of Lille Engg NRG
Shi Minghui F Duke University Statistics NRG
Tendick Patrick M Avaya Labs Research Statistics FP
Vidyashankar Anand M Cornell University Statistics FP

Wang Xia F NISS Statistics NRG
Wang Xiaopei F University of Cinncinati Statistics NRG
West Mike M Duke University Statistics FP
Wolpert Robert M Duke University Statistics FP
Wu Wensong F University of South Carolina Statistics NRG
Zou Jian M NISS Statistics NRG
2009-10 PROGRAM EVENTS THROUGH JULY 2010
Stochastic Dynamics
Stochastic Dynamics Opening Workshop
Participant Summary
August 30 – September 2, 2009
Participants Male Female Unspec-
ified Faculty/
Professional
New Researcher/
Student Stat Math Other
Number of Institutions
Represented
Number of States
Represented
Supported 27 7 0 17 17 6 27 1 26 13
Unsuppted 25 12 0 12 25 10 25 1 12 6
SAMSI 0 0 0 0 0 0 0 0 0 0
Last Name First Name Gender Affiliation Major/Department Status
Alber Mark M Notre Dame University Math FP
Amirdjanova Anna F University of Michigan Statistics FP
Anderson David M University of Wisconsin Math NRG
Baxendale Peter M
University of Southern California Math FP
Cai David M New York University Math FP
Capobianco Enrico M Polaris Science and Tech Park Statistics FP

Carreon Fernando M Unversity of Michigan Math NRG
Cerrai Sandra F Maryland Math FP
Denker Manfred M Pennsylvania State University Math FP
Elgart Vlad M Virginia Tech Statistics NRG
Forger Danny M University of Michigan Math NRG
Gentz Barbara F University of Bielefeld Math FP
Gordillo Luis M University of Puerto Rico Math NRG
Hooker Giles M Cornell University Statistics NRG
Karimi Mona F Texas A&M University Engg NRG
Katsoulakis Markos M Umass/Amherst Math NRG
Kim Eunjung F University of Notre Dame Math NRG
Kim Kunwoo M University of Illinois Math NRG
Koralov Leonid M University of Maryland Math FP
Kotelenez Peter M Case Western University Math FP
Kurtz Thomas G. M University of Wisconsin Math FP
Kuske Rachel F University of British Columbia Math FP
Lord Gabriel M Heriot Watt University Math FP
Lythe Grant M University of Leeds Math FP
Mubayi Anuj M University of Texas, Arlington Math NRG
Owhadi Houman M Cal Tech Math NRG
Popovic Lea F Concordia University Math NRG

Seadler Bradley M
Case Western Reserve University Math NRG
Stuart Andrew M Warwick University Math FP
Timofeyev Ilya M University of Houston Math FP
Wilkinson Darren M Newcastle Statistics FP
Zhang Zhigang M University of Houston Math NRG
Zhou Xiang M Princeton University Math NRG
Zhu Bin M University of Michigan Statistics NRG
Last Name First Name Gender Affiliation Major/Department
Alber Mark M Notre Dame University Math
Amirdjanova Anna F University of Michigan Statistics
Anderson David M University of Wisconsin Math
Bakhtin Yuri M Georgia Tech Math
Balachandran Prakash M Duke University Math
Banks H. Thomas M North Carolina State University Statistics
Bessaih Hakima F University of Wyoming Math
Bhamidi S Shankar M University of North Carolina Statistics
Baxendale Peter M University of Southern California Math
Cai David M New York University Math
Capobianco Enrico M Polaris Science and Tech Park Statistics
Carreon Fernando M Unversity of Michigan Math
Cerrai Sandra F Maryland Math

Chen Jing F Duke University Math
Deng Shaozhong M University of North Carolina, Charlotte Math
Denker Manfred M Pennsylvania State University Math
DeVille Lee M University of Illinois Math
Doucette Cheri F
Virginia Commonwealth University Math
Duan Jinqiao M Illinois Institute of Technology Math
Dukic Vanja F University of Chicago Statistics
Elgart Vlad M Virginia Tech Statistics
Forger Danny M University of Michigan Math
Gentz Barbara F University of Bielefeld Math
Gordillo Luis M University of Puerto Rico Math
Heller Martin M North Carolina State University Statistics
Herrera-Valdez Marco M
Arizona State University Life
Hoefer Mark M North Carolina State University Math
Hooker Giles M Cornell University Statistics
Hu Dan M New York University Math
Ji Chunlin M Duke University Statistics
Joshi Badal M Duke University Math
Kan Xingye F Illinois Institute of Technology Math
Karimi Mona F Texas A&M University Engg
Katsoulakis Markos M Umass/Amherst Math

Kim Eunjung F University of Notre Dame Math
Kim Kunwoo M University of Illinois Math
King Sarah F North Carolina State University Math
Koralov Leonid M University of Maryland Math
Kotelenez Peter M Case Western University Math
Kurtz Thomas G. M University of Wisconsin Math
Kuske Rachel F University of British Columbia Math
Layton Anita F Duke University Math
Lord Gabriel M Heriot Watt University Math
Lythe Grant M University of Leeds Math
Maggioni Mauro M Duke University Math
Mubayi Anuj M University of Texas, Arlington Math
Mucha Peter M University of North Carolina Math
Ng Hon Keung Tony M Southern Methodist University Statistics
Nolen James M Duke University Math
Owhadi Houman M Cal Tech Math
Pahlajani Chetan M
University of California, Santa Barbara Math
Popovic Lea F Concordia University Math
Reinhold Dominik M University of North Carolina Statistics
Schott Sarah F Duke University Statistics
Seadler Bradley M Case Western Reserve University Math

Sikorski Kajetan F Rensselaer Polytechnic Institute Math
Stuart Andrew M Warwick University Math
Thomas Rachel F Duke University Math
Timofeyev Ilya M University of Houston Math
Towne Warren M Rensselaer Polytechnic Institute Math
Vanden-Eijnden Eric M
Courant Institute, New York University Math
Wilkinson Darren M Newcastle Statistics
Xu Meng M University of Wyoming Math
Xu Xiaohua M Virginia Tech Bioinfo
Yang Hongxia F Duke University Statistics
Yang Yushu F University of Maryland Math
Zhang Zhigang M University of Houston Math
Zhou Douglas M New York University Math
Zhou Xiang M Princeton University Math
Zhu Bin M University of Michigan Statistics
Zhu Hongtu M University of North Carolina Biostats
Self Organization Workshop Participant Summary October 26-28, 2009
Participants Male Female Unspec-
ified Faculty/
Professional
New Researcher/
Student Stat Math Other
Number of Institutions
Represented
Number of States
Represented
Supported 11 8 0 14 5 1 14 4 16 9
Unsuppted 15 8 0 14 9 1 2 2 10 3

SAMSI 6 2 0 0 8 4 4 0 1 1
Self Organization Workshop Workshop Participant Support
October 26-28, 2009
Last Name First Name
Gender Affiliation Major/Department Status
Alber Mark M Notre Dame University Math FP
Balazs Anna F University of Pittsburgh
Chemical and Petroleum Engineering FP
Bearon Rachel F University of Liverpool
Mathematical Sciences FP
Berlyand Leonid M
Pennsylvania State University Mathematics FP
Bertozzi Andrea F
University of California, Los Angeles Mathematics FP
Canic Suncica F University of Houston Mathematics FP
Gollub Jerry M Haverford College Statistics FP
Gorb Yulia F Texas A&M University Math NRG
Graham Michael M
University of Wisconsin-Madison
Chemical and Biological Engineering FP
Gyrya Vitaliy M
Pennsylvania State University
Department of Mathematics NRG
Hilhorst Danielle F University of Paris Sud Math FP
Huang Yanghong M
University of California, Los Angeles Mathematics NRG
Laurent Thomas M
University of California, Los Angeles Math NRG
Mancini Simona F University of Orleans Math FP
Mao Yi F University of Tennessee
National Institute for Mathematical and Biological Synthesis FP
Pedley Tim M University of Cambridge DAMTP FP

Pertahme Benoit M University P. et M. Curie Laboratoire J.-L. Lions FP
Shelley Michael M New York University Math FP
Yamada Richard M University of Michigan Mathematics NRG
Self Organization Workshop Workshop Participants October 26-28, 2009
Last Name First Name Gender Affiliation Major/Department Status
Alber Mark M Notre Dame University Math FP
Aronson Igor M Argonne National Laboratory Eng & Math FP
Athreya Avanti F SAMSI/Duke University Mathematics NRG
Baker Ruth F University of Oxford Mathematical Institute NRG
Balazs Anna F University of Pittsburgh
Chemical and Petroleum Engineering FP
Bearon Rachel F University of Liverpool
Mathematical Sciences FP
Berlyand Leonid M Pennsylvania State University Mathematics FP
Bertozzi Andrea F
University of California, Los Angeles Mathematics FP
Budhiraja Amarjit M University of North Carolina Stat-OR FP
Canic Suncica F University of Houston Mathematics FP
Chertock Alina F North Carolina State University Mathematics FP
Decoene Astrid F University Paris Sud - 11
Département de Mathématiques d'Orsay NRG
Deng Shaozhong M University of North Carolina, Charlotte Math NRG
Diaz Oliver M SAMSI Math NRG

Gollub Jerry M Haverford College Statistics FP
González Carlos Manuel Mora M
Universidad de Concepción Math NRG
Gorb Yulia F Texas A&M University Math NRG
Graham Michael M University of Wisconsin-Madison
Chemical and Biological Engineering FP
Greenwood Priscilla F Arizona State Univ, SAMSI
Mathematics and Statistica FP
Gremaud Pierre M
SAMSI / North Carolina State University Math FP
Gyrya Vitaliy M Pennsylvania State University
Department of Mathematics NRG
Haider Mansoor M North Carolina State University Mathematics FP
Haines Brian M Pennsylvania State University Mathematics NRG
Hilhorst Danielle F University of Paris Sud Math FP
Horn Mary Ann F National Science Foundation Math FP
Huang Yanghong M
University of California, Los Angeles Mathematics NRG
Karpeev Dmitry M Argonne National Laboratory
Mathemacs and Computer Science FP
Kolba Tiffany F Duke University Mathematics NRG
Kramer Peter M Rensselaer Polytechnic Institute
Mathematical Sciences FP
Laurent Thomas M
University of California, Los Angeles Math NRG
Lubkin Sharon F North Carolina State University Math FP
Liu Jian-Guo M Duke University Physics and Mathematics FP
Mancini Simona F University of Orleans Math FP
Mao Yi F University of Tennessee
National Institute for Mathematical and Biological Synthesis FP

McSweeney John M SAMSI Statistics NRG
Minion Michael M SAMSI Math FP
Mucha Peter M University of North Carolina Mathematics FP
Nolen James M Duke University Mathematics NRG
Pedley Tim M University of Cambridge DAMTP FP
Pertahme Benoit M University P. et M. Curie
Laboratoire J.-L. Lions FP
Prost Jacques M ESPCI ParisTech/ Institut Curie General Direction FP
Rogers Bruce M SAMSI Math NRG
Shelley Michael M New York University Math FP
Sokolov Andrey M Princeton University
Ecology and Evolutionary Biology NRG
Srinivasan Ravi M SAMSI Statistics NRG
Sun Yi M SAMSI Statistics NRG
Thomas Rachel F Duke University Mathematics NRG
Wang Xueying F SAMSI Statistics NRG
Yamada Richard M University of Michigan Mathematics NRG
Zhang Lei M University of Bonn Mathematics NRG
Theory and Qualitative Behavior of Stochastic Dynamics Workshop Participant Summary February 8-10, 2010
Participants Male Female Unspec-
ified Faculty/
Professional
New Researcher/
Student Stat Math Other
Number of Institutions
Represented
Number of States
Represented
Supported 13 3 0 4 12 2 14 0 12 9
Unsuppted 16 6 0 14 8 2 19 0 25 3

SAMSI 6 1 0 0 7 1 6 0 1 1
Theory and Qualitative Behavior of Stochastic Dynamics Workshop
Workshop Participants Support February 8-10, 2010
Last Name First Name Gender Affiliation Major/Department Status
Bakhtin Yuri M Georgia Tech Math NRG
Baxendale Peter M
University of Southern California Math FP
Bou-Rabee Nawaf M New York University Math NRG
Elgart Vlad M Virginia Tech Statistics NRG
Gentz Barbara F University of Bielefeld Math FP
Kashan Nowrouzi Fariba F
Kentucky State University Statistics NRG
Kim Kunwoo M
University of Illinois, Urbana Champaign Math NRG
Li Xiao M
University of Illinois, Urbana Champaign Math NRG
Lu Jianfeng M New York University Math NRG
Molchanov Stas M
University of North Carolina, Charlotte Math & Stats FP
Mubayi Anuj M University of Texas Math NRG
Scheutzow Michael M
Technische Universitaet Berlin Math FP
Sowers Rich M
University of Illinois, Urbana Champaign Math NRG
Sun Xu M Illinois Institute of Technology Math NRG
Yin Mei F University of Arizona Math NRG
Zheng Zhi M University of Illinois Math NRG

Theory and Qualitative Behavior of Stochastic Dynamics Workshop Workshop Participants February 8-10, 2010
Last Name First Name Gender Affiliation Major/Department Status
Athreya Avanti F SAMSI / Duke University Math NRG
Bakhtin Yuri M Georgia Tech Math NRG
Balachandran Prakash M Duke University Mathematics NRG
Baxendale Peter M University of Southern California Math FP
Bogachev Leonid M Leeds Univeristy Math FP
Bou-Rabee Nawaf M New York University Math NRG
Budhiraja Amarjit M University of North Carolina Statistics FP
Cerrai Sandra F University of Maryland Math FP
Deshpande Amogh M North Carolina State University Math NRG
Diaz Espinosa Oliver M SAMSI Math NRG
Dolgopyat Dmitry M University of Maryland Math FP
Elgart Vlad M Virginia Tech Statistics NRG
Gentz Barbara F University of Bielefeld Math FP
Greenwood Priscilla F Arizona State University, SAMSI Math FP
Hamzi Boumediene M Duke University Mathematics FP
Kang Min F North Carolina State University Math FP
Kashan Nowrouzi Fariba F
Kentucky State University Statistics NRG
Kim Kunwoo M University of Illinois, Urbana Champaign Math NRG

Kolba Tiffany F Duke University Math NRG
Li Xiao M University of Illinois, Urbana Champaign Math NRG
Liu Jian-Guo M Duke University Physics and Mathematics FP
Liu Xin F University of North Carolina, Chapel Hill Statistics NRG
Lu Jianfeng M New York University Math NRG
Mattingly Jonathan M Duke University Math FP
McKinley Scott M SAMSI Math NRG
McSweeney John M SAMSI Statistics NRG
Molchanov Stas M University of North Carolina, Charlotte Math & Stats FP
Mora Carlos M Universidad de Concepción / SAMSI Math NRG
Mubayi Anuj M University of Texas, Arlington Math NRG
Nolen Jim M Duke University Math NRG
Novikov Alexei M Pennsylvania State Univerisity Math FP
Nualart David M University of Kansas Math FP
Pavliotis Greg M Imperial College, London Math FP
Pistone Giovanni M Politecnico di Torino Math FP
Ray-Bellet Luc M
University of Massachusetts, Amherst Math FP
Rios-Doria Daniel M SAMSI / University of Arizona Math NRG
Rogers Bruce M SAMSI Math NRG
Scheutzow Michael M Technische Universitaet Berlin Math FP
Sowers Rich M University of Illinois, Urbana Champaign Math NRG

Sun Xu M Illinois Institute of Technology Math NRG
Sun Yi M SAMSI / North Carolina State Univ Math NRG
Wang Xuan M University of North Carolina
Statistics & Operations Research NRG
Watkins Andrea F Duke University Math NRG
Yin Mei F University of Arizona Math NRG
Zheng Zhi M University of Illinois Math NRG
Molecular Workshop Participant Summary
April 15-17, 2010
Participants Male Female Unspec-
ified Faculty/
Professional
New Researcher/
Student Stat Math Other
Number of Institutions
Represented
Number of States
Represented
Supported 8 6 0 8 6 2 11 1 13 9
Unsuppted 15 4 0 8 11 8 11 0 11 3
SAMSI 4 2 0 0 6 2 4 0 1 1
Molecular Workshop
Workshop Participants Support April 15-17, 2010
Last Name First Name
Gender Affiliation Major/Department Status
Barreiro Andrea F University of Washington Math NRG
Betterton Meredith F
University of Colorado, Boulder Physics FP
Ditlevsen Susanne F University of Copenhagen Statistics NRG
Fuller Pamela F
Rensselaer Polytechnic Institute Math NRG
Hunter David M Penn State University Stats FP

Kinderleher David M
Carnegie Mellon University Math FP
Mubayi Anuj M
University of Texas, Arlington Math NRG
Nykamp Duane M University of Minnesota Math FP
Popovic Lea F Concordia University Math & Stats FP
Sacerdote Laura F University of Torino Math FP
Timofeyev Ilya M University of Houston Math FP
Volz Erik M University of Michigan Math NRG
Wang Hongyun M UC, Santa Cruz Math FP
Yamada Richard M University of Michigan Math NRG
Molecular Workshop Workshop Participants
April 15-17, 2010
Last Name First Name Gender Affiliation Major/Department Status
Arunajadai Srikesh M Columbia University Biostats NRG
Athreya Avanti F SAMSI/Duke University Math NRG
Barreiro Andrea F University of Washington Math NRG
Betterton Meredith F University of Colorado, Boulder Physics FP
Diaz Espinosa Oliver M SAMSI Math NRG
Ditlevsen Susanne F University of Copenhagen Statistics NRG
Falk Raymond M OptInference LLC Statistics FP
Fricks John M Penn State University Math FP
Fuller Pamela F Rensselaer Polytechnic Institute Math NRG
Greenwood Priscilla F Arizona State University, SAMSI Math FP
Hunter David M Penn State University Stats FP
Joshi Badal M Duke University Math NRG
Kinderleher David M Carnegie Mellon University Math FP
Kolba Tiffany F Duke University Math NRG
Kramer Peter M Rensselaer Polytechnic Institute Math FP
Lin Kevin M University of Arizona Math FP
Liu Xin F University of North Carolina Statistics NRG
Mattingly Jonathan M Duke University Math FP
McKinley Scott M Duke University Math NRG
McSweeney John M SAMSI Statistics NRG
Mora Gonzalez Carlos Manuel M SAMSI - Universidad de Concepcion Math NRG
Mubayi Anuj M University of Texas, Arlington Math NRG
Ng Hon Keung Tony M
Southern Methodist University Statistics FP
Nykamp Duane M University of Minnesota Math FP
Popovic Lea F Concordia University Math & Stats FP
Reinhold Dominik M University of North Carolina Statistics NRG
Rogers Bruce M SAMSI Math NRG
Sacerdote Laura F University of Torino Math FP
Schmindler Scott M Duke University Statistics NRG

Sikorski Kajetan M Rensselaer Polytechnic Institute Math NRG
Smith Charlie M North Carolina State University Statistics FP
Sun Yi M SAMSI & NCSU Math NRG
Timofeyev Ilya M University of Houston Math FP
Traud Amanda F UNC Math NRG
Volz Erik M University of Michigan Math NRG
Wang Hongyun M University of California, Santa Cruz Math FP
Wang Xueying F SAMSI Statistics NRG
Yamada Richard M University of Michigan Math NRG
Zhang Kurt M University of North Dakota Statistics NRG
Space-time Analysis for Environmental Mapping, Epidemiology and
Climate Change
Participants Male Female Unspec-
ified Faculty/
Professional
New Researcher/
Student Stat Math Other
Number of Institutions
Represented
Supported 21 19 0 21 19 37 0 3 29
Unsuppted 59 33 1 54 39 84 8 1 30
SAMSI 7 3 0 0 10 10 0 0 1
Last Name First Name Gender Affiliation Major/Department Status
Anderes Ethan M University of California Statistics NRG
Bandyopadhyay Soutir M Texas A&M University Statistics NRG
Barber Jarrett M University of Wyoming Statistics FP
Behrens Clifford M Telcordia Technologies, Inc. Socl NRG
Bell Michelle F Yale University Statistics NRG

Beltran Francisco M M
University of California, Santa Cruz Statistics NRG
Berhane Kiros M University of Southern California Statistics FP
Carlin Brad M University of Minnesota Statistics FP
Cooley Dan M Colorado State University Statistics FP
Cressie Noel M Ohio State University Statistics FP
Dean Charmaine F Simon Fraser University Statistics FP
Guindani Michele M University of New Mexico Statistics FP
He Zhuoqiong F University of Missouri Statistics FP
Herbei Radu M Ohio State University Statistics NRG
Hurtado Rua Sandra F University of Connecticut Statistics NRG
Jun Mikyoung F Texas A & M University Statistics FP
Kang Emily F Ohio State University Statistics NRG
Katzfuss Matthias M Ohio State University Statistics NRG
Keller Cherie F University of Florida Life FP
Konomi Bledar M Texas A&M University Statistics NRG
Lee Jaeyong M Duke University Statistics FP
Li Bo F Purdue University Statistics NRG
Liang Ye M University of Missouri Statistics NRG
Linkletter Crystal F Brown University Statistics NRG
Liu Ran F University of Connecticut Statistics NRG
Liu Desheng M Ohio State University Statistics NRG

López Quílez Antonio M Universitat de Valencia Statistics FP
Michalak Anna F University of Michigan Phys FP
Reyes Perla F
University of Wisconsin-Madison Statistics NRG
Richardson Sylvia F Imperial College London Statistics FP
Rue Havard M
Norwegian University of Science and Technology Statistics FP
Sang Huiyan F Texas A&M University Statistics NRG
Sanso Bruno M
University of California, Santa Cruz Statistics FP
Schmidt Alexandra F
Universidade Federal do Rio de Janeiro Statistics FP
Sheppard Lianne F University of Washington Statistics FP
Stein Michael M University of Chicago Statistics FP
Tuglus Catherine F
University of California, Berkeley Statistics NRG
van Lieshout Marie-Colette F
CWI & Eindhoven University of Technology Statistics FP
Wikle Chris M University of Missouri Statistics FP
Zhang Jing F Miami University Statistics NRG
Last Name First Name Gender Affiliation Major/Department
Anderes Ethan M University of California, Berkeley Statistics
Assuncao Renato M
Universidade Federal de Minas Gerais Statistics
Aune Erlend M
Norwegian University of Science & Technology Statistics
Bandyopadhyay Soutir M Texas A&M University Statistics

Banerjee Sudipto M University of Minnesota Statistics
Barber Jarrett M University of Wyoming Statistics
Bayarri Susie F University of Valencia Statistics
Behrens Clifford M Telcordia Technologies, Inc. Socl
Bell Michelle F Yale University Statistics
Beltran Francisco M M
University of California, Santa Cruz Statistics
Berger James M SAMSI Statistics
Berhane Kiros M University of Southern California Statistics
Berliner Mark M Ohio State University Statistics
Berrett Candace F Ohio State University Statistics
Berrocal Veronica F SAMSI Statistics
Bhat K Sham M Pennsylvania State University Statistics
Boehm Laura F North Carolina State University Statistics
Braverman Amy F NASA Statistics
Calder Kate F Ohio State University Statistics
Carlin Brad M University of Minnesota Statistics
Chakraborty Avishek M Duke University Statistics
Chang Howard M Johns Hopkins University Statistics
Chen Lisha F Yale University Statistics
Cheng Guang M Purdue University Statistics
Conesa David M Universitat De Valencia Statistics

Cooley Dan M Colorado State University Statistics
Cornebise Julien M SAMSI Statistics
Cressie Noel M Ohio State University Statistics
Crooks James M US Environmental Protection Agency Statistics
Das Sourish M SAMSI and Duke University Statistics
Dean Charmaine F Simon Fraser University Statistics
Dey Dipak M University of Connecticut Statistics
Dominici Francesca F Johns Hopkins Biostats
Dunson David M Duke University Statistics
Eidsvik Jo M
Norwegian University of Science & Technology Math
Erhardt Robert M University of North Carolina Statistics
Feng Xingdong M NISS Math
Ferreira Marco M University of Missouri, Columbia Statistics
Finley Andrew M Michigan State University Phys
Forte Deltell Anabel F Universitat de Valencia Statistics
Fox Emily F Duke University Statistics
Fuentes Montserrat F North Carolina State University Statistics
Gelfand Alan M Duke University Statistics
Ghosh Souprano M Duke University Statistics
Ghosh Sujit M North Carolina State University Statistics

Gieseke Morgan F North Carolina State University Statistics
Gomez-Rubio Virgilio M Universidad de Castilla-La Mancha Math
Greenwood Priscilla (Cindy) F SAMSI and Arizona State University Math
Guindani Michele M University of New Mexico Statistics
Haran Murali M Pennsylvania State University Statistics
Harlim John M North Carolina State University Math
He Zhuoqiong F University of Missouri Statistics
Held Leo M University of Zurich Statistics
Herbei Radu M Ohio State University Statistics
Herring Amy F University of North Carolina Biostats
Higdon Dave M LANL Statistics
Holan Scott M
University of Missouri
Statistics
Holland David M US EPA Statistics
Hooten Mevin M Utah State University Statistics
Hua Zhaowei F University of North Carolina Biostats
Huerta Gabriel M University of New Mexico Statistics
Hurtado Rua Sandra F University of Connecticut Statistics
Illian Janine F University of St. Andrews Statistics
Jackson Monica F American University Statistics
Jeon Soyoung F University of North Carolina Statistics
Johannesson Gardar M
Lawrence Livermore National Laboratory Statistics

Jun Mikyoung F Texas A & M University Statistics
Kafadar Karen F Indiana University Statistics
Kang Emily F Ohio State University Statistics
Katzfuss Matthias M Ohio State University Statistics
Kaufman Cari F University of California, Berkeley Statistics
Keller Cherie F University of Florida Life
Konomi Bledar M Texas A&M University Statistics
Kramer Peter M Rensselaer Polytechnic Institute Math
Lawson Andrew M Medical University of South Carolina Biostats
Lee Jaeyong M Duke University Statistics
Levine Michael M Purdue University Statistics
Li Bo F Purdue University Statistics
Li Linyuan M University of New Hampshire Statistics
Liang Ye M University of Missouri Statistics
Linder Ernst M University of New Hampshire Statistics
Linkletter Crystal F Brown University Statistics
Liu Ran F University of Connecticut Statistics
Liu Yajun F University of Missouri Statistics
Liu Desheng M Ohio State University Statistics
Lopes Danilo M Duke University Statistics
López Quílez Antonio M Universitat de Valencia Statistics

Mannshardt-Shamseldin Elizabeth F
SAMSI/Duke University Statistics
Martinez-Beneito Miguel A. M
Centro Superior de Investigación en Salud Pública Statistics
Matteson David M Cornell University Statistics
Michalak Anna F University of Michigan Phys
Micheas Athanasios M University of Missouri Statistics
Moller Jesper M Aalborg University Math
Nail Amy F U.S. Environmental Protection Agency Statistics
Nychka Doug M
National Center for Atmospheric Research Statistics
Paciorek Chris M University of California, Berkeley Statistics
Page Garritt M Duke University Statistics
Peng Roger M Johns Hopkins University Biostats
Pilz Juergen M University of Klagenfurt Statistics
Pomann Gina-Maria F North Carolina State University Statistics
Puggioni Gavino M University of North Carolina Statistics
Rajaratnam Balakanapathy M Stanford University Math
Rappold Ana F Environmental Protection Agency Statistics
Reich Brian M North Carolina State University Statistics
Reyes Perla F University of Wisconsin-Madison Statistics
Richardson Sylvia F Imperial College London Statistics
Rue Havard M
Norwegian University of Science and Technology Statistics
Sang Huiyan F Texas A&M University Statistics
Sanso Bruno M
University of California, Santa Cruz Statistics
Schmaltz Chester M University of Missouri Statistics
Schmidt Alexandra F
Universidade Federal do Rio de Janeiro Statistics
Scott Marian F University of Glasgow Statistics
Shaby Benjamin M SAMSI Statistics
Sheppard Lianne F University of Washington Statistics
Smith Leonard M London School of Economics Statistics
Smith Ron M Centre for Ecology and Hydrology Statistics
Smith Richard M University of North Carolina Statistics
Stein Michael M University of Chicago Statistics
Steinsland Ingelin F
Norwegian University of Science and Technology Statistics
Sun Dongchu M University of Missouri Statistics
Swall Jenise F U.S. Environmental Protection Agency Statistics
Tchumtchoua Sylvie F University of Connecticut Statistics
Tebaldi Claudia F UBC-Vancouver and Climate Central Statistics
Tingley Martin M SAMSI Statistics
Tuglus Catherine F University of California, Berkeley Statistics
van Lieshout Marie-Colette F
CWI & Eindhoven University of Technology Statistics
Waller Lance M Emory University Statistics

Wang Xia F NISS Statistics
Wang Xueying F SAMSI Statistics
Wikle Chris M University of Missouri Statistics
Wolpert Robert M Duke University Statistics
Xia Jessie F NISS Statistics
Xu Chang M University of Missouri - Columbia Statistics
Yang Hongxia F Duke University Statistics
Yasamin Saed M SAMSI Statistics
Young Linda F University of Florida Statistcs
Yuan Chengwei University of New Hampshire Statistics
Zhang Jun M SAMSI Statistics
Zhang Jing F Miami University Statistics
Zhao Yingqi F UNC Biostats
Zhu Zhengyuan M Iowa State University Statistics
Zidek James M University of British Columbia Satistics
Zou Jian (Frank) M NISS Satistics
GEOMED Workshop Participant Summary
November 14-16, 2009
Participants Male Female Unspec-
ified Faculty/
Professional
New Researcher/
Student Stat Math Other
Number of Institutions
Represented
Number of States
Represented
Supported 7 9 0 7 9 16 0 0 12 5
Unsuppted 1 1 0 1 1 2 0 0 2 1
SAMSI 1 1 0 0 2 2 0 0

GEOMED Workshop Workshop Participant Support
November 14-16, 2009
Last Name First Name
Gender Affiliation Major/Department Status
Bayarri Susie Female University of Valencia Stat FP
Berrocal Veronica Female SAMSI Stat NRG
Calder Kate Female Ohio State Stat NRG
Chakaborty Avishek Male Duke University Stat NRG
Chang Howard Male SAMSI Biostats NRG
Fortes Anabel Female University of Valencia Stat NRG
Gomez-rubio Viriglio Male
Universidad de Castilla-La Mancha Stat FP
Haran Murali Male Penn State U Stat FP
Lopes Danilo Male Duke U Stat NRG
Martinez-beneito Miguel Male
Centro Superior de Investigación en Salud Pública Stat FP
Nicolis Orietta Female U Bergamo Stat NRG
Yang Hongxia Female Duke U Stat NRG
Barrett Candace Female Ohio State Stat NRG
Liu Yajun Female U Missouri Stat NRG

Nail Amy Female US EPA Stat FP
Sun Dongchu Male U Missouri Stat FP
Reich Brian Male NCSU Biostats FP
GEOMED Workshop Workshop Participants November 14-16, 2009
Last Name First Name Gender Affiliation Major/Department Status
Banerjee Sudipto Male University of Minnesota Biostats FP
Bayarri Susie Female University of Valencia Stat FP
Berrocal Veronica Female SAMSI Stat NRG
Blangiardo Marta Female Imperial College Biostats NRG
Calder Kate Female Ohio State Stat NRG
Chakaborty Avishek Male Duke University Stat NRG
Chang Howard Male SAMSI Biostats NRG
Fortes Anabel Female University of Valencia Stat NRG
Gieseke Morgan Female NCSU Stat NRG
Gomez-rubio Viriglio Male Universidad de Castilla-La Mancha Stat FP
Haran Murali Male Penn State U Stat FP
Lopes Danilo Male Duke U Stat NRG
Martinez-
beneito Miguel Male
Centro Superior de Investigación en Salud Pública Stat FP
Nicolis Orietta Female U of Bergamo Stat FP

Yang Hongxia Female Duke U Stat NRG
Barrett Candace Female Ohio State Stat NRG
Liu Yajun Female U Missouri Stat NRG
Nail Amy Female US EPA Stat NRG
Sun Dongchu Male U Missouri Stat FP
Reich Brian Male NCSU Stat FP
Climate Change Workshop Participant Summary February 17-19, 2010
Participants Male Female Unspec-
ified Faculty/
Professional
New Researcher/
Student Stat Math Other
Number of Institutions
Represented
Number of States
Represented
Supported 17 5 0 13 9 11 5 6 16 9
Unsuppted 27 12 0 22 17 27 7 5 23 6
SAMSI 9 6 0 5 10 12 2 1 1 1
Climate Change Workshop Workshop Participant Support
February 17-19, 2010
Last Name First Name
Gender Affiliation Major/Department Status
Ammann Caspar M NCAR Geoscience FP
Beltran Francisco M
University of California, Santa Cruz Stats NRG
Bhat K Sham M
Pennsylvania State University Stats NRG
Buchman Susan F
Carnegie Mellon University Stats NRG
Drignei Dorin M Oakland University Stats FP
Forest Chris M
Pennsylvania State University Meteorology FP

Haran Murali M
Pennsylvania State University Stats FP
Hu Juegang M Stanford University Stats NRG
Jun Mikyoung F Texas A&M University Stats FP
Katzfuss Matthias M Ohio State University Stats NRG
Li Bo F Purdue University Stats NRG
Mearns Linda F NCAR Phys FP
Pistone Giovanni M Politecnico di Torino Math FP
Rajaratnam Bala M Stanford University Math NRG
Rowlands Dan M Oxford University Physical Sci NRG
Sain Stephan M
National Center for Atmospheric Research Math & Stats FP
Schneider Tapio M
California Institute of Technology Geosciences FP
Stainforth David M Oxford University Physical Sci FP
Timofeyev Ilya M University of Houston Math FP
Tolwinski-Ward Suz F
University of Arizona Math NRG
Wehner Michael M
Lawrence Berkeley National Laboratory Stats FP
Zhang Zepu M University of Alaska Stats FP
Climate Change Workshop
Workshop Participants February 17-19, 2010
Last Name First Name Gender Affiliation Major/Department Status

Ammann Caspar M NCAR Geoscience FP
Baines Paul M Harvard University Stats NRG
Beltran Francisco M M University of California, Santa Cruz App Math & Stats NRG
Berrocal Veronica F SAMSI Stats NRG
Bhat K Sham M Pennsylvania State University Stats NRG
Bramer Lisa F Iowa State University Stats NRG
Branstator Grant M NCAR Geosciences FP
Buchman Susan F Carnegie Mellon University Stats NRG
Buckley Lauren F University of North Carolina Biology NRG
Chang Howard M SAMSI Math NRG
Clark James M Duke University Eviron FP
Conesa David M U Valencia Stats FP
Craigmile Peter M Ohio State University Stats FP
Cressie Noel M Ohio State University Stats FP
Davison Anthony M EPFL Math FP
Drignei Dorin M Oakland University Stats FP
Dupuis Debbie F HEC Montreal Mgmt Sci FP
Eidsvik Jo M SAMSI Math FP
Erhardt Robert M University of North Carolina, Chapel Hill Stats NRG
Ferreira Marco M University of Missouri Stats FP
Forest Chris M Pennsylvania State University Meteorology FP

Genton Marc M Texas A&M University Stats FP
Goodman Dougal M
The Foundation for Science and Technology Stats FP
Greenwood Priscilla F Arizona State University, SAMSI Math FP
Hall Diana F University of North Carolina Stats NRG
Haran Murali M Pennsylvania State University Stats FP
Holt Ashley F National Geospatial-Intelligence Agency Other NRG
Hu Juegang M Stanford University Stats NRG
Jeon Soyoung F University of North Carolina Stats NRG
Jones Christopher M University of North Carolina Math FP
Jun Mikyoung F Texas A&M University Stats FP
Kang Emily F SAMSI Stats NRG
Kaper Hans M Georgetown University Math FP
Katzfuss Matthias M Ohio State University Stats NRG
Kaufman Cari F University of California, Berkeley Stats NRG
Kramer Peter M Rensselaer Polytechnic Institute Math FP
Kuensch Hans M ETHZ Stats FP
Levins Mihails M SAMSI Stats FP
Li Bo F Purdue University Stats NRG
Li Xuan F University of North Carolina Stats NRG
Li Linyuan M SAMSI Stats FP
Linder Ernst M University of New Hampshire Stats FP

Liu Yajun F SAMSI / University of Missouri Stats NRG
Mannshardt-Shamseldin Elizabeth F SAMSI Stats NRG
Martinelli Gabrielle F SAMSI Stats NRG
Martins Assuncao Renato M SAMSI Stats FP
Mearns Linda F NCAR Phys FP
Minion Michael M University of North Carolina Math FP
Modlin Danny M North Carolina State University Stats NRG
Ng Hon Keung Tony M
Southern Methodist University Stats NRG
Paul Rajib M Western Michigan University Stats NRG
Pistone Giovanni M Politecnico di Torino Math FP
Rajaratnam Bala M Stanford University Math NRG
Rios Daniel M SAMSI Stats NRG
Roberts Steven M Australian National University Stats FP
Rowlands Dan M Oxford University Physical Sci NRG
Sain Stephan M
National Center for Atmospheric Research Math & Stats FP
Salazar Esther F SAMSI Stats NRG
Sanso Bruno M University of California, Santa Cruz Stats FP
Schneider Tapio M California Institute of Technology Geosciences FP
Schwartzman Armin M Harvard School of Public Health Stats NRG
Shaby Ben M SAMSI Stats NRG
Smith Richard M University of North Carolina Stats FP

Stainforth David M Oxford University Physical Sci FP
Steinsland Ingelin F SAMSI Stats FP
Timofeyev Ilya M University of Houston Math FP
Tingley Martin M SAMSI Geosciences NRG
Tolwinski-Ward Suz F University of Arizona Math NRG
Wang Xia F NISS Stats NRG
Wang Jianqiang F National Institute of Statiatical Sciences Stats NRG
Wehner Michael M Lawrence Berkeley National Laboratory Stats FP
Wolpert Robert M Duke University Stats FP
Zhang Zepu M University of Alaska Stats FP
Zhang Jun M SAMSI Stats NRG
Zidek Jim M University of British Columbia Stats FP
Zou Jian (Frank) M NISS Stats NRG
Environmental Workshop
Participant Summary April 7-9, 2010
Participants Male Female Unspec-
ified Faculty/
Professional
New Researcher/
Student Stat Math Other
Number of Institutions
Represented
Number of States
Represented
Supported 3 4 0 2 5 6 0 1 7 5
Unsuppted 22 15 1 21 17 33 2 3 20 4
SAMSI 5 5 0 1 9 9 1 0 1 1
Environmental Workshop Workshop Participant Support
April 7-9, 2010
Last Name First Name
Gender Affiliation Major/Department Status
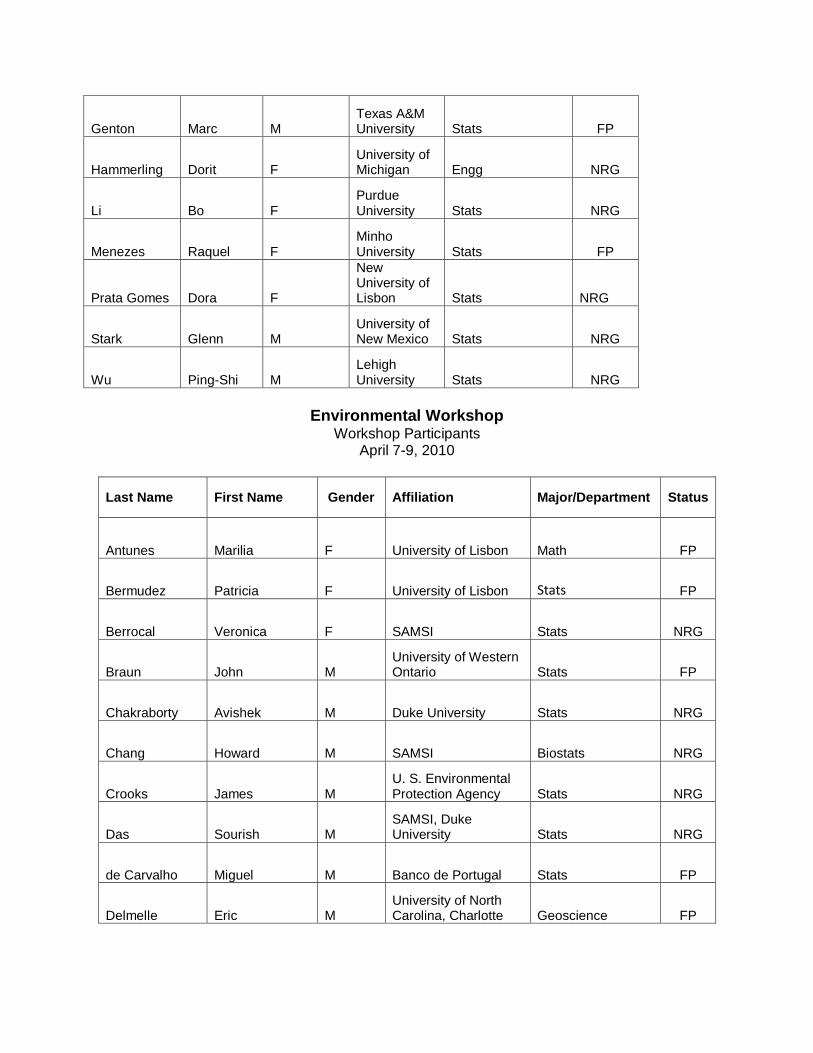
Genton Marc M Texas A&M University Stats FP
Hammerling Dorit F University of Michigan Engg NRG
Li Bo F Purdue University Stats NRG
Menezes Raquel F Minho University Stats FP
Prata Gomes Dora F
New University of Lisbon Stats NRG
Stark Glenn M University of New Mexico Stats NRG
Wu Ping-Shi M Lehigh University Stats NRG
Environmental Workshop Workshop Participants
April 7-9, 2010
Last Name First Name Gender Affiliation Major/Department Status
Antunes Marilia F University of Lisbon Math FP
Bermudez Patricia F University of Lisbon Stats FP
Berrocal Veronica F SAMSI Stats NRG
Braun John M University of Western Ontario Stats FP
Chakraborty Avishek M Duke University Stats NRG
Chang Howard M SAMSI Biostats NRG
Crooks James M U. S. Environmental Protection Agency Stats NRG
Das Sourish M SAMSI, Duke University Stats NRG
de Carvalho Miguel M Banco de Portugal Stats FP
Delmelle Eric M University of North Carolina, Charlotte Geoscience FP

Eidsvik Jo M SAMSI Math FP
Ferguson Claire F University of Glasgow Stats NRG
Finley Andrew M Michigan State University Phys NRG
Franco Villoria Maria F University of Glasgow Stats NRG
Fuentes Montse F North Carolina State University Stats FP
Genton Marc M Texas A&M University Stats FP
Green Peter M University of Bristol / SAMSI Stats FP
Hammerling Dorit F University of Michigan Engg NRG
Held Leonhard M University of Zurich Biostats FP
Holland David M U.S. Environmental Protection Agency Stats FP
Jeon Soyoung F University of North Carolina Stats NRG
Kalendra Eric M North Carolina State University Stats NRG
Kang Emily F SAMSI Stats NRG
Khan Diba F NCHS Stats NRG
Lahiri Soumen M Texas A & M University Stats FP
Li Bo F Purdue University Stats NRG
Liu Yajun F SAMSI / University of Missouri Stats NRG
Lopes Danilo M Duke University Stats NRG
Lopiano Kenneth M University of Florida Stats NRG
Mannshardt-Shamseldin Elizabeth F SAMSI / Duke Stats NRG
Maze Alena F Georgetown University Stats NRG

McDonald Claire F Centre for Ecology & Hydrology (CEH) Biosci NRG
Menezes Raquel F Minho University Stats FP
Ng Hon Keung Tony M
Southern Methodist University Stats NRG
Peng Roger M Johns Hopkins University Stats FP
Prata Gomes Dora F New University of Lisbon Stats NRG
Rappold Ana F U.S. Environmental Protection Agency Stats FP
Reich Brian M North Carolina State University Stats FP
Rue Havard M
Norwegian University of Science and Technology Stats FP
Salazar Esther F SAMSI Stats NRG
Scott Marian F University of Glasgow Stats FP
Shaby Ben M SAMSI Stats NRG
Silva Giovani M University of Lisbon Math FP
Smith Richard M University of North Carolina Stats FP
Stark Glenn M University of New Mexico Stats NRG
Steinsland Ingelin F NTNU / SAMSI Stats FP
Turkman Kamil Feridun M University of Lisbon Stats FP
Turkman Antonia Amaral F University of Lisbon Stats FP
Wang Xia F NISS Stats NRG
Wang Jianyu Duke University Stats NRG
Wu Ping-Shi M Lehigh University Stats NRG
Yajima Masanao M
University of California, Los Angeles Stats NRG

Young Linda F University of Florida Stats FP
Zhang Jun M SAMSI Stats NRG
Zou Jian M NISS Stats NRG
Education and Outreach Program
Undergraduate Two-Day Workshop
Participant Summary
October 30-31, 2009
Participants Male Female Unspecified Faculty Student
Stat/Math Majors
Other/Unspecified
Number of Institutions
Represented
Number of States
Represented
Supported 16 16 0 0 32 29 3 23 18
Unsuppted 7 7 0 10 4 13 1 6 2
SAMSI 4 1 0 5 0 5 0 1 1
Last Name First Name Gender Affiliation Major/ Department
Status
Archambault Heather F
U of North Carolina, Wilmington Mathematics S
Bayo Haddijatou F
Kentucky State University
civil/environmental engineering S
Belanus Danica F
University of North Dakota Mathematics S
Brooks Billy M
University of North Carolina, Asheville
Statisics/ Environmental Studies S
Cheng Howard M University of Arizona Mathematics S

Coles Adrian M
University of North Carolina, Wilmington Math S
Costain Ethan M
Colorado State University Biology S
Cubas-Casana Jorge M
New Jersey Institute of Technology
Mathematics of Finance and Actuarial Science S
Culiuc Amalia F
Mount Holyoke College Mathematics S
Decowski Jonathan M
University of New Hampshire Statistics S
Deis Jennifer F Florida State University Statistics S
Donoven Casey M
Montana State University, Bozeman Mathematics S
Drendel Jesse M
Colorado State University Mathematics S
Emanuel George M
University of Colorado, Boulder
Applied Math and Biology S
Gansel Allison F University of Dayton Biology S
Hom Matthew M University of Arizona
Mathematics, Economics S
Johnson Taylor F University of Arizona mathematics S
Keller Joshua M Emory University
Applied Mathematics S
Lau Shing Yan M
Carnegie Mellon University
Economics & Statistics S
Lee Elaine F
Carnegie Mellon University
Mathematical Sciences S
Li Vicky F
University of Colorado, Boulder
applied math S
McNamara Amelia F Macalester College Mathematics S
Megretskaia Dina F
Carnegie Mellon University
Economics and Mathematical Sciences S
Nolan Connor M Iowa State University
Matematics and Biology S
Parks Martin M University of Florida
Mathematics and Statistics S
Patterson Sally F
Montana State University, Bozeman
Applied Mathematics S
Puelz David M Wesleyan University
Math and Physics S
Rooker Kelly F Bridgewater College
Double majoring in Mathematics and Biology S
Schmidt Roger M Florida State University
Statistics/Philosophy S

Wamunyu Esther F Meredith College
Mathematics and civil engineering S
Woo Kaitlin F Georgetown University Mathematics S
Zhou Yan F
University of illinois, Urbana-Champaign Math S
Last Name First Name Gender Affiliation Major/Department
Archambault Heather F UNC Wilmington Mathematics
Bayarri Susie F U Valencia Stats
Bayo Haddijatou F
Kentucky State University
civil/environmental engineering
Belanus Danica F
University of North Dakota Mathematics
Berrocal Veronica F SAMSI Statistics
Boehm Laura F NCSU Statistics
Brooks Billy M
University of North Carolina, Asheville
Statisics/ Environmental Studies
Butter Eric M
University of North Carolina Biostatistics
Chakraborty Avishek M Duke Statistics
Chang Howard M SAMSI Statistics
Cheng Howard M University of Arizona Mathematics
Coles Adrian M
University of North Carolina, Wilmington Math
Costain Ethan M
Colorado State University Biology

Cubas-Casana Jorge M
New Jersey Institute of Technology
Mathematics of Finance and Actuarial Science
Culiuc Amalia F
Mount Holyoke College Mathematics
Decowski Jonathan M
University of New Hampshire Statistics
Deis Jennifer F
Florida State University Statistics
Donoven Casey M
Montana State University, Bozeman Mathematics
Drendel Jesse M Colorado State U Mathematics
Emanuel George M
U of Colorado, Boulder
Applied Math and Biology
Gansel Allison F University of Dayton Biology
Gieseke Morgan F NCSU Statistics
Gremaud Pierre M NCSU and SAMSI Math
Haran Murali M Penn State Statistics
Hom Matthew M University of Arizona
Mathematics, Economics
Hua Zhaowei F UNC Biostats
Jeon Soyoung F UNC Statistics
Johnson Taylor F University of Arizona mathematics
Keller Joshua M Emory University
Applied Mathematics
Larose Chantal F U CT Statistics
Lau Shing Yan M
Carnegie Mellon University
Economics & Statistics
Lee Elaine F
Carnegie Mellon University
Mathematical Sciences

Li Vicky F
University of Colorado, Boulder applied math
Lopes Danilo M Duke Statistics
McNamara Amelia F Macalester College Mathematics
Megretskaia Dina F
Carnegie Mellon University
Economics and Mathematical Sciences
Nolan Connor M Iowa State University
Matematics and Biology
Parks Martin M University of Florida
Mathematics and Statistics
Patterson Sally F
Montana State University, Bozeman
Applied Mathematics
Puelz David M Wesleyan University Math and Physics
Robel Alexander M Duke University
Earth/Ocean Sciences, Physics, Math (minor)
Rodriguez Terry M
University of North Carolina, Chapel Hill
Mathematical Decisions Sciences
Rooker Kelly F Bridgewater College
Double majoring in Mathematics and Biology
Schmidt Roger M
Florida State University Stats/Philosophy
Shaby Ben M SAMSI Statistics
Tingley Martin M SAMSI Statistics
Wamunyu Esther F Meredith College
Mathematics and civil engineering
Woo Kaitlin F
Georgetown University Mathematics
Yang Hongxia F Duke Stats
Zhang Jun M SAMSI Statistics

Zhou Yan F
University of illinois, Urbana-Champaign Math
Undergraduate Two-Day Workshop Participant Summary
February 26-27, 2010
Participants Male Female Unspec-
ified Faculty Student Stat/Math
Majors Other/Unspecified
Number of Institutions
Represented
Number of States
Represented
Supported 13 12 0 0 25 24 1 18 13
Unsuppted 2 2 0 4 0 4 0 3 2
SAMSI 4 2 0 6 0 6 0 1 1
Last Name First Name Gender Affiliation Major/Department Status
Abdul Hamidah F University of Michigan, Ann Arbor
Actuarial Mathematics, Statistics S
Baer Kerstin F Bryn Mawr College Mathematics S
Bartsch Jennifer F College of New Jersey Mathematics S
Blythe Rachel F
Harriet L. Wilkes Honors College of Florida Atlantic Univ.
Interdisciplinary Biology and Mathematics S
Bostwick Michael M University of Connecticut Statistics S
Cochran Jeff M Georgetown University Mathematics S
Colbert Cory M
Virginia Commonwealth University Mathematics S
Feng Tao M University of Illinois, Urbana Champaign
Applied Mathematics S
Huynh My M Arizona State University Mathematics S
Kamta Eric M Marymount University Mathematics S
Kent Meghan F Meredith College Mathematics S

Last Name First Name Gender Affiliation
Abdul Hamidah F University of Michigan, Ann Arbor
Athreya Avanti F SAMSI
Baer Kerstin F Bryn Mawr College
Bartsch Jennifer F College of New Jersey
Blythe Rachel F Harriet L. Wilkes Honors College of Florida
Liang Xuan F University of Michigan, Ann Arbor
Honors Math/Honors Economics S
Meisner Michele F College of New Jersey
Mathematics Statistics S
Ngo Thao F Arizona State University
Chemical Engineering S
Regh Todd M Southern Oregon University Mathematics S
Shepherd William M Florida State University
Pure Mathematics and Statistics S
Skowron Robert M University of Illinois, Urbana Champaign Mathematics S
Strong Homer M Reed College Mathematics S
Surber Wesley M East Tennessee State University Mathematics S
Wang Jiayin F Purdue University Actuarial Science & Applied Statistics S
Welter Amanda F University of Wisconsin, La Crosse
Mathematics (Statistics Emphasis) and Music S
Withey Catherine F Purdue University Mathematical Statistics S
Yeung Melissa F University of Chicago Mathematics S
Yu Kicho M Purdue University Statistics and Actuarial Science S
Zeng Yi M University of Illinois, Urbana-Champaign Mathematics S

Atlantic Univ.
Bostwick Michael M University of Connecticut
Cochran Jeff M Georgetown University
Cohen Sean M SAMSI
Colbert Cory M Virginia Commonwealth University
Diaz Oliver M SAMSI
Feng Tao M University of Illinois, Urbana Champaign
Greenwood Cindy F Arizona State
Gremaud Pierre M NCSU / SAMSI
Huynh My M Arizona State University
Kamta Eric M Marymount University
Kent Meghan F Meredith College
Kolba Tiffany F Duke
Liang Xuan F University of Michigan, Ann Arbor
McSweeney John M SAMSI
Meisner Michele F College of New Jersey
Ngo Thao F Arizona State University
Regh Todd M Southern Oregon University
Rogers Bruce M SAMSI
Schmidler Scott M Duke
Shepherd William M Florida State University

Skowron Robert M University of Illinois, Urbana Champaign
Strong Homer M Reed College
Surber Wesley M East Tennessee State University
Wang Jiayin F Purdue University
Wang Xieying F SAMSI
Welter Amanda F University of Wisconsin, La Crosse
Withey Catherine F Purdue University
Yeung Melissa F University of Chicago
Yu Kicho M Purdue University
Zeng Yi M University of Illinois, Urbana-Champaign
Last Name First Name Gender Affiliation
Abuzzahab Omar M University of Pennsylvania
Al Matar Najeeb M Florida Institute of Technology
Al-sharadqah Ali M University of Alabama - Birmingham
Andoniaina Rarivoarimanana University of Cincinnati
Athreya Avanti F Duke University
Auffinger Antonio M New York University
Baek Changryong M UNC - Chapel Hill
Balachandran Prakash M Duke University
Bessonov Mariya F Cornell University
Bhamidi Shankar M UNC - Chapel Hill

Bourque Matthew M University of Illinois - Chicago
Budhiraja Amarjit M UNC - Chapel Hill
Burr Meredith F Tufts University
Canepa Cristina F Carnegie Mellon University
Chandra Ajay M University of Virginia
Chaudhuri Ritwik M UNC - Chapel Hill
Chavez Esteban M Duke University
Chen Guangliang M Duke University
Chen Jiang F UNC - Chapel Hill
Chen Li F Oregon State University
Cisewski Jessi F UNC - Chapel Hill
Corwin Ivan M New York University
Crosskey Miles M Duke University
Ding Shanshan F University of Pennsylvania
Drenning Shawn M University of Chicago
Duarte Mauricio M University of Washington
Eden Richard M Purdue University
Eldredge Nathaniel M Cornell University
Ernst Philip M University of Pennsylvania
Esunge Julius M University of Mary Washington
Fang Ming M University of Minnesota

Feng Yaqin UNC - Charlotte
Ghosh Subhankar M University of Southern California
Gillespie Jr. Perry M UNC - Charlotte
Graber Jameson M University of Virginia
Guo Jing F University of Virginia
Guo Xiaoqin M University of Minnesota
Hamzi Boumediene M Duke University
Hannig Jan M UNC - Chapel Hill
Hening Alexandru M University of California - Berkeley
Hoffmeyer Allen M Georgia Institute of Technology
Holmes-Cerfon Miranda F New York University
Hu Yilei University of Paris VI and X
Huang Qizhuo University of Alabama - Birmingham
Huynh Huy M Georgia Institute of Technology
Ichiba Tomoyuki M University of California - Santa Barbara
Jackson Aaron M Duke University
Jafri Syeda Rabab University of Nottingham
Jairo Fuquene M University of Puerto Rico
Jay Parker M University of Illinois - Chicago
Jiang Duo F University of Chicago
Jiang Yunjiang M Stanford University

Jinwoo Hwang Purdue University
Kai Zhang M Duke University
Kaligotla Sivaditya M University of Southern California
Kang Hye-Won University of Minnesota
Karabash Dmytro M New York University
Kemajou Elisabeth F Southern Illinois University
Keutel Martin M University of Virginia
Kobayashi Kei Tufts University
Kolba Tiffany F Duke University
Kolba Mark M Signal Innovations Group
Kumar Ashish M SUNY - Buffalo
Lai Tri Indiana University
Leadbetter Ross M UNC - Chapel Hill
Lee Seonjoo F UNC - Chapel Hill
Lei Pedro M University of Kansas
Li Junchi M Duke University
Li Zhongyang Brown University
Lierl Janna F Cornell University
Lin Hao M University of Wisconsin
Little Anna F Duke University
Liu Xin F UNC - Chapel Hill

Liu Yufei F Brown University
Lou Shuwen F University of Washington
Lu Fei F University of Kansas
Lu Lu F University of Connecticut
Luo Shishi F Duke University
Luo Zhixiang F UNC - Chapel Hill
Ma Hui University of Alabama - Birmingham
Ma Jinyong M Georgia Institute of Technology
Ma Wei University of Virginia
Maggioni Mauro M Duke University
Mattingly Jonathan M Duke University
McGoff Kevin M University of Maryland
McKinley Scott M Duke University
McSweeney John M Concordia University
Mehrdad Behzad M New York University
Miller Jason M Stanford University
Minion Michael M UNC - Chapel Hill
Ngufor Nancy F University of Hasselt
Nguyen Tuan M Rutgers University
Nobel Andrew M UNC - Chapel Hill
Nolen James M Duke University

Pankaj Kumar M IGIDR
Pemantle Robin M University of Pennsylvania
Peng Yisha F Stanford University
Perkins William M New York University
Pipiras Vladas M UNC - Chapel Hill
Rastegar Reza M Iowa State University
Reinhold Dominik M UNC - Chapel Hill
Revzin Ella F University of Illinois - Chicago
Restrepo Ricardo M Georgia Institute of Technology
Rogers Bruce M Duke University
Ryu Hwa Yeon M Duke University
Ryvkina Jelena F Tufts University
Schott Sarah F Duke University
Setayeshgar Leila F Brown University
Shao Yuan M University of Chicago
Song Rui F University of Illinois - Urbana-Champaign
Srinivasan Ravi M University of Texas
Su Wei M University of Chicago
Su Zhe M University of Pittsburgh
Tang Xiaoxiao F University of Virginia
Thomas Rachel F Duke University

Tone Cristina F Indiana University
Vandenberg-Rodes Alexander M
University of California - Los Angeles
Varadhan S. R. Srinivasa M New York University
Varkey Paul M University of Illinois - Chicago
Vedantha Sowrirajan Lakshmi
Institute of Actuaries of India
Verella J. Tipan M University of Virginia
Viquez Juan M Purdue University
Wang Ruodu M Georgia Institute of Technology
Wang Xuan M UNC - Chapel Hill
Wang Yizao M University of Michigan
Wayman Eric M University of California - Berkeley
Webster Justin M University of Virginia
Windle Jesse M University of Texas
Xu Hangjun M Duke University
Xu Meng M University of Wyoming
Yang Xiangfeng Tulane University
Yang Yushu University of Maryland
Zhang Guanlin M University of Kansas
Zhang Xiaojing Kansas State University
Participants Male Female Unspec-
ified Faculty Student Stat/Math
Majors Other/Unspecified
Supported 10 14 0 0 24 21 3

Unsuppted 7 9 0 13 3 16 0
SAMSI 8 5 0 13 0 13 0
Last Name First Name Gender Affiliation Major/Department Status
Agattas Bailey F Aquinas College Mathematics S
Agrawal Mohit M Prinston University Mathematics S
Bayo Haddijatou F Kentucky State Mathematics S
Bender Kristina F University of North Carolina at Asheville
Pure Mathematics and Literature S
Erwin Samantha F Murray State University Mathematics S
Faircloth Vanessa F Norfolk State University
Applied Mathematics S
Geyer Kelly F
Virginia Polytechnic Institute and State University
Statistics, Mathematics S
Horn Corinne F Duke University
Electrical and Computer Engineering, Mathematics S
Huckaba Aron M Murray State University
Chemistry and Mathematics with a minor in Biology S
Huynh My M Arizona State University Mathematics S
Jones Asya F Spelman College Mathematics S
Kim Junghi F Universitiy of Connecticut
Mathematics/Statistics S
Kissler Stephen M University of Colorado, Boulder
Applied Mathematics S
Klopfenstein Toni F University of Colorado at Boulder
Applied Mathematics S
Lalla Chris M University of Illinois, Urbana-Champaign Statistics S
Lirette Seth M Mississippi State University Mathematics S
McCowan Nigel M Norfolk State University
Applied Mathematics S
Morrison Leigh F Georgetown University Mathematics S
Neavin Drew M Colorado State University Biological Sciences S
Roland Byron M East Tennessee State University Computer Science S
Shaw Candace F Spelman College Mathematics S
Tomasek Bradley M University of Illinois, Urbana-Champaign Statistics S
Wang Jiayin (Vivian) F
Purdue University, West Lafayette
Actuarial Science & Mathematical Statistics S
Yuan Lo-Hua F University of Michigan, Ann Arbor
Life Science Informatics, B.S. S
Last Name First Name Gender Affiliation Major/Department
Agattas Bailey F Aquinas College Mathematics
Agrawal Mohit M Princeton University Mathematics
Athreya Avanti F SAMSI Mathematics
Bayo Haddijatou F Kentucky State Mathematics
Bender Kristina F University of North Carolina at Asheville
Pure Mathematics and Literature
Berrocal Veronica F SAMSI Statistics
Boehm Laura F NCSU Stats
Chakraborty Avishek M Duke U Stats
Chang Howard M SAMSI Stats
Cohen Sean M NCSU Mathematics
Cole-Manning Cammey F Meredith College Mathematics
Das Sourish M SAMSI Stats
Despandhe Amogh M NCSU Mathematics
Diaz Oliver M SAMSI Mathematics

Emanuel George M University of Colorado
Applied Math and Molecular Biology
Erwin Samantha F Murray State University Mathematics
Faircloth Vanessa F Norfolk State University Applied Mathematics
Fovargue Dan M UNC Mathematics
Geyer Kelly F
Virginia Polytechnic Institute and State University
Statistics, Mathematics
Gieske Morgan F NCSU Stats
Gremaud Pierre M SAMSI/NCSU Mathematics
Horn Corinne F Duke University
Electrical and Computer Engineering, Mathematics
Hua Zhaowei F UNC Biostats
Huckaba Aron M Murray State University
Chemistry and Mathematics with a minor in Biology
Huynh My M Arizona State University Mathematics
Jeon Soyoung F UNC Stats
Jones Asya F Spelman College Mathematics
Kang Emily F SAMSI Stats
Kim Junghi F Universitiy of Connecticut
Mathematics/Statistics
Kissler Stephen M University of Colorado, Boulder Applied Mathematics
Klopfenstein Toni F University of Colorado at Boulder Applied Mathematics
Kolba Tiffany F Duke U Mathematics
Kuznetsova Anna F Duke University Mathematics AB
Lalla Chris M University of Illinois, Urbana-Champaign Statistics

Lirette Seth M Mississippi State University Mathematics
Liu Xin F UNC Stats
Lopes Danilo M Duke U Stats
McCowan Nigel M Norfolk State University Applied Mathematics
Morrison Leigh F Georgetown University Mathematics
Neavin Drew M Colorado State University Biological Sciences
Ning Yuxiao (Shawn) M New York University Mathematics
Roland Byron M East Tennessee State University Computer Science
Rogers Bruce M SAMSI Mathematics
Salazar Esther F SAMSI Stats
Shaby Ben M SAMSI Stats
Shaw Candace F Spelman College Mathematics
Tingley Martin M SAMSI Stats
Tomasek Bradley M University of Illinois, Urbana-Champaign Statistics
Wang Jiayin (Vivian) F Purdue University, West Lafayette
Actuarial Science & Mathematical Statistics
Wang Xueying F SAMSI Stats
Yang Hongxia F Duke U Stats
Yuan Lo-Hua F University of Michigan, Ann Arbor
Life Science Informatics, B.S.
Zhang Jun M SAMSI Stats
Participants Male Female Unspec-
ified Faculty Student Stat/Math
Majors Other/Unspecified
Supported 26 11 0 0 37 30 7
Unsuppted 11 1 0 12 0 8 4
SAMSI 0 2 0 2 0 2 0
Last Name First Name Gender Affiliation Major/Department Status
Brown Aaron Male Tufts University MATH S
Byrne Erin Female University of Colorado Boulder MATH S
Choi Heejun Male Purdue University MATH S
Ding Lili Female University of Cincinnati STAT S
Gabrys Robertas Male Utah State University STAT S
Griep Chad Male University of Rhode Island MATH S
Heaton Matthew Male Duke University STAT S
Jayaram Magathi Female Utah State University ENGG S
Katzfuss Matthias Male Ohio State University ENGG S
Kim Noory Male Towson University STAT S
Kirshtein Jenya Female University of Denver STAT S
Kumar Nitesh Male University of California Merced MATH S
Laungrungrong Busaba Female Arizona State University ENGG S
Li Yi Male Duke University STAT S
Lomuscio Michael Male Western Carolina University MATH S
Morales Mario Male Hunter College MATH S
Pearson Dale Male Texas Tech University MATH S

Pedings Kathryn Female College of Charleston MATH S
Porter Jacob Male University of California Davis MATH S
Proctor William Male North Carolina State University MATH S
Raghuram Karthik Male
University of California Santa Barbara ENGG S
Ramachandar Shahla Female University of Texas STAT S
Richards Gregory Male Kent State University STAT S
Samarakoon Nishantha Male Kansas State University STAT S
Shafahi Maryam Female University of California Riverside ENGG S
Shen Chongyi Male University of Iowa ENGG S
Skorczewski Tyler Male University of California Davis STAT S
Soodhalter Kirk Male Temple University MATH S
Sun Jie (Rena) Female University of Michigan MATH S
Vu Duy Male Penn State University STAT S
Wang Min Male Northern Illinois University STAT S
Wiltshire Jelani Male FSU MATH S
Yang Hongxia Female Duke University STAT S
Zhang Jingyan Female Penn State University MATH S
Zhong Peng Male University of Tennessee MATH S
Zhou Kun Male Penn State University MATH S
Zou James Male Harvard ENG S

Last Name First Name Gender Affiliation Major/Department
Bouton Chad Male Battelle Inst. ENGG
Brooks Harold Male National Severe Storm Lab PHYSICS
Brown Aaron Male Tufts University MATH
Byrne Erin Female University of Colorado Boulder MATH
Cole-Manning Cammey Female Meredith College MATH
Choi Heejun Male Purdue University MATH
Ding Lili Female University of Cincinnati STAT
Gabrys Robertas Male Utah State University STAT
Gate Brian Male
Gilleland Eric Male NCAR STAT
Griep Chad Male University of Rhode Island MATH
Heaton Matthew Male Duke University STAT
Hopping Albert Male Progress Energy PHYSICS
Ito Kazi Male NCSU MATH
Jayaram Magathi Female Utah State University ENGG
Kang Emily Female SAMSI STAT
Katzfuss Matthias Male Ohio State University ENGG
Kim Noory Male Towson University STAT
Kirshtein Jenya Female University of Denver STAT
Kumar Nitesh Male University of California Merced MATH

Laungrungrong Busaba Female Arizona State University ENGG
Li Yi Male Duke University STAT
Lomuscio Michael Male Western Carolina University MATH
Mannshardt-Shamseldin Elizabeth Female SAMSI STAT
Massad Jordan Male Sandia MATH
Morales Mario Male Hunter College MATH
Peach John Male Lincoln Laboratory MATH
Pearson Dale Male Texas Tech University MATH
Pedings Kathryn Female College of Charleston MATH
Porter Jacob Male University of California Davis MATH
Proctor William Male North Carolina State University MATH
Raghuram Karthik Male
University of California Santa Barbara ENGG
Ramachandar Shahla Female University of Texas STAT
Richards Gregory Male Kent State University STAT
Samarakoon Nishantha Male Kansas State University STAT
Scroggs Jeff Male NCSU MATH
Shafahi Maryam Female University of California Riverside ENGG
Shen Chongyi Male University of Iowa ENGG
Skorczewski Tyler Male University of California Davis STAT
Smith Ralph Male NCSU MATH

Smith Richard Male UNC STAT
Soodhalter Kirk Male Temple University MATH
Sun Jie (Rena) Female University of Michigan MATH
Vu Duy Male Penn State University STAT
Wang Min Male Northern Illinois University STAT
Wiltshire Jelani Male FSU MATH
Yang Hongxia Female Duke University STAT
Zhang Jingyan Female Penn State University MATH
Zhong Peng Male University of Tennessee MATH
Zhou Kun Male Penn State University MATH
Zou James Male Harvard ENG
2010 SUMMER PROGRAM
Semiparametric Bayesian Inference: Applications in Pharmokinetics and
Pharmacodynamics (PKPD)
PKPD Program
Participant Summary
July 12 – July 23, 2010
Participants Male Female Unspec-
ified Faculty/
Professional
New Researcher/
Student Stat Math Other
Number of Institutions
Represented
Number of States
Represented
Supported 25 9 1 18 17 29 2 4 28 15
Unsuppted 18 8 1 10 17 26 0 1 12 5
SAMSI 0 0 0 0 0 0 0 0
Last Name First Name Gender Affiliation Major/Department Status
Bayarri M.J. Female University of Valencia STAT FP
Boonstra Philip Male
University of Michigan Department of Biostatistics STAT NRG
Choi Leena Female Vanderbilt University STAT FP
Cornebise Julien Male U British Columbia STAT NRG
Dahl David Male Texas A&M University STAT FP
Ding Lili Female
Cincinnati Children's Hospital Medical Center STAT NRG
Dutta Ritabrata Male Purdue University STAT NRG
Escobar Michael Male University of Toronto STAT FP
Fronczyk Kassie Female University of California STAT NRG
Ghosh Kaushik Male
University of Nevada - Las Vegas STAT FP
Guindani Michele Male University of New Mexico STAT FP
Johnson Wes Male University of CA, Irvine STAT FP
Kottas Athanasios Male U of California, Santa Cruz STAT FP
Lewandowski Andrew Male Purdue University STAT NRG
Li Lang Male Indiana U LIFE FP
MacEachern Steven Male Ohio State STAT FP
Mueller Peter Male MD Anderson Cancer Center STAT FP
Oluyede Broderick Male
Georgia Southern University STAT FP
Pararai Mavis Female Inidiana U of Penn. STAT NRG

Quispe Vargas Walter Male
University of Puerto Rico STAT NRG
Rodriguez Abel Male University of California STAT NRG
Rosner Gary Male Johns Hopkins University STAT FP
Roura Jaime Male
University of Puerto Rico, Rio Piedras STAT NRG
Tadesse Mahlet Female Georgetown University STAT FP
Telesca Donatello Male UCLA STAT NRG
Thomas Duncan Male University of So. CA LIFE FP
Tomasetti Cristian Male University of Maryland MATH NRG
Torres David Male University of Puerto Rico MATH NRG
Vicini Paolo Male
Pfizer Global Research and Development LIFE FP
Wahed Abdus Male University of Pittsburgh STAT FP
Wang Yanpin Female U Florida STAT NRG
Wu Meihua Male University of Michigan STAT NRG
Xu Xinyi Female Ohio State University STAT FP
Yao Ping Northern Ill U LIFE NRG
Zou Yuanshu Female University of Cincinnati STAT NRG
Last Name First Name Gender Affiliation Major/Department
Armagan Artin Male Duke University STAT
Banks David Male Duke University STAT
Barbare Ralph Male Gad Consulting Services STAT

Bayarri M.J. Female University of Valencia STAT
Bhattacharya Anirban Male Duke University STAT
Bonate Peter Male GlaxoSmithKline OTHR
Boonstra Philip Male
University of Michigan Department of Biostatistics STAT
Burgette Lane Male Duke University STAT
Chen Shuguang Male GlaxoSmithKline STAT
Choi Leena Female Vanderbilt University STAT
Cornebise Julien Male U British Columbia STAT
Cui Kai Male Duke Unviersity STAT
Dahl David Male Texas A&M University STAT
Davidian Marie Female North Carolina State University STAT
De Iorio Maria Female Imperial College STAT
Ding Lili Female
Cincinnati Children's Hospital Medical Center STAT
Dunson David Male Duke University STAT
Dutta Ritabrata Male Purdue University STAT
Escobar Michael Male University of Toronto STAT
Fronczyk Kassie Female University of California STAT
Gan Kevin Male GlaxosmithKline STAT
Ghosh Jayanta Male Purdue University STAT
Ghosh Joyee Female UNC Chapel Hill STAT

Ghosh Kaushik Male University of Nevada - Las Vegas STAT
Guha Subharup Male University of Missouri STAT
Guindani Michele Male University of New Mexico STAT
Johnson Brendan Male GlaxoSmithKline LIFE
Johnson Wes Male University of CA, Irvine STAT
Korman Alexander Male Duke University STAT
Kottas Athanasios Male
University of California, Santa Cruz STAT
Kundu Suprateek Male UNC STAT
Lee Ju Hee Female Ohio State University STAT
Lewandowski Andrew Male Purdue University STAT
Li Lang Male Indiana U LIFE
MacEachern Steven Male Ohio State STAT
Mueller Peter Male MD Anderson Cancer Center STAT
Oluyede Broderick Male Georgia Southern University STAT
Omolo Bernard Male UNC Chapel Hill STAT
Pang Herbert Male Duke University STAT
Pararai Mavis Female Inidiana U of Penn. STAT
Pati Debdeep Male Duke University STAT
Quispe Vargas Walter Male
University of Puerto Rico STAT
Rizwan Ahsan Male UNC LIFE
Rodriguez Abel Male University of California STAT

Rosner Gary Male Johns Hopkins University STAT
Roura Jaime Male University of Puerto Rico, Rio Piedras STAT
Tadesse Mahlet Female Georgetown University STAT
Telesca Donatello Male UCLA STAT
Thomas Duncan Male University of So CA LIFE
Tokdar Surya Male Duke University STAT
Tomasetti Cristian Male University of Maryland MATH
Torres David Male University of Puerto Rico MATH
Vicini Paolo Male
Pfizer Global Research and Development LIFE
Wahed Abdus Male University of Pittsburgh STAT
Wang Yanpin Female UNIVERSITY OF FLORIDA STAT
Wolpert Robert Decline Duke University STAT
Wu Meihua Male University of Michigan STAT
Xiaojing Wang Female Duke University STAT
Xing Chuanhua Female Duke University STAT
Xu Xinyi Female Ohio State University STAT
Yang Mingan Saint Louis University STAT
Yao Ping Northern Ill LIFE
Yu Li Female Medimmune STAT
Zhu Hongxiao Female
University of Texas MD Anderson Cancer Center STAT

Zou Yuanshu Female University of Cincinnati STAT
2011-12 PROGRAM EVENTS THROUGH APRIL 2010
Uncertainty Quantification Workshop Participant Summary
April 6, 2010
Participants Male Female Unspec-
ified Faculty/
Professional
New Researcher/
Student Stat Math Other
Number of Institutions
Represented
Number of States
Represented
Supported 22 2 0 22 2 6 10 8 21 12
Unsuppted 23 5 0 27 1 16 9 3 19 8
SAMSI 1 1 0 2 0 2 0 0 1 1
Uncertainty Quantification Workshop Workshop Participant Support
April 6, 2010
Last Name First Name
Gender Affiliation Major/Department Status
Archibald Rick M Oak Ridge Nat'l Lab Comp Sci / Math FP
Bal Guillaume M Columbia University Applied Math FP
Berlyand Leonid M Pennsylvania State University Applied Math FP
Braverman Amy F
Jet Propulsion
Lab, Caltech Stat FP
Efendiev Yalchin M Texas A&M University Applied Math FP
Estep Don M Colorado State University Math FP
Ghanem Roger M
University of Southern California Engineering FP
Hesthaven Jan M Brown University Applied Math FP
Higdon David M LANL Statistics FP
Iaccarino Gianluca M Stanford University Engineering/Science NRG

Johannesson Gardar M LLNL Math and CS FP
Lermusiaux Pierre M MIT Engineering/Science NRG
Marzouk Youssef M MIT Engineering/Science FP
Nychka Doug M NCAR Stats FP
Owhadi Houman M Cal Tech Applied Math FP
Patra Abani M University at Buffalo Engineering/Science FP
Pitman Bruce M University at Buffalo Applied Math FP
Red-Horse John M SANDIA Probabilist? FP
Santner Tom M Ohio State University Stats FP
Shoemaker Christine F Cornell University Engineering/Science FP
Spiegelman Cliff M Texas A&M University Stats FP
Tartakovsky Daniel M
University of California, San Diego Engineering/Science FP
Wu Jeff M Georgia Tech Stats FP
Xiu Dongbin M Purdue University Applied Math FP
Uncertainty Quantification Workshop Workshop Participants
April 6, 2010
Last Name First Name Gender Affiliation Major/Department Status
Anitescu Mihai M ANL Math and CS FP
Archibald Rick M Oak Ridge Nat'l Lab Comp Sci / Math FP
Bal Guillaume M Columbia University Applied Math FP

Bayarri Susie F University of Valencia Stats FP
Berger Jim M SAMSI Stats FP
Berlyand Leonid M Pennsylvania State University Applied Math FP
Bingham Derek M Simon Fraser University Stats FP
Braverman Amy F
Jet Propulsion Lab,
Caltech Stat FP
Casella George M University of Florida Stats FP
Crowley Jim M SIAM Math FP
Deodatis George M Columbia University Engineering/Science FP
Efendiev Yalchin M Texas A&M University Applied Math FP
Estep Don M Colorado State University Math FP
Fuentes Montse F North Carolina State University Stats FP
Ghanem Roger M University of Southern California Engineering FP
Gremaud Pierre M North Carolina State University/SAMSI Math FP
Hannig Jan M University of North Carolina Stats FP
Hesthaven Jan M Brown University Applied Math FP
Higdon David M LANL Statistics FP
Iaccarino Gianluca M Stanford University Engineering/Science NRG
Johannesson Gardar M LLNL Math and CS FP
Kass Rob M CMU Stats FP
Lee Herbie M UCSC Math/Stats FP
Lermusiaux Pierre M MIT Engineering/Science NRG

Liu Fei F University of Missouri Stats NRG
Marzouk Youssef M MIT Engineering/Science FP
McKeague Ian M Columbia Biostats FP
Miller Robert M Oregon State Engineering/Science FP
Morris Max M Iowa State Stats FP
Nolen Jim M Duke University Math FP
Nychka Doug M NCAR Stats FP
Owhadi Houman M Cal Tech Applied Math FP
Pantula Sastry M North Carolina State University Stats FP
Papanicolaou George M Stanford University Applied Math FP
Patra Abani M University at Buffalo Engineering/Science FP
Petzold Linda F UCSB Applied Math FP
Pitman Bruce M University at Buffalo Applied Math FP
Raftery Adrian M U Washington Stats FP
Red-Horse John M SANDIA Probabilist? FP
Santner Tom M Ohio State University Stats FP
Sedransk Nell F SAMSI Stats FP
Shoemaker Christine F Cornell University Engineering/Science FP
Smith Ralph M North Carolina State University Math FP
Smith Richard M University of North Carolina/SAMSI Math FP
Spiegelman Cliff M Texas A&M University Stats FP

Stein Michael M U Chicago Stats FP
Tartakovsky Daniel M University of California, San Diego Engineering/Science FP
Tebaldi Claudia F UBC Stats FP
Wasserstein Ron M AMSTAT Stats FP
Welch William M UBC Stats FP
Wolpert Robert M Duke University Stats FP
Wu Jeff M Georgia Tech Stats FP
Xiu Dongbin M Purdue University Applied Math FP
Zhang Thomas M NASA FP

486
APPENDIX F – Workshop Programs and Abstracts
1. Psychometrics Summer Program
Schedule
Tuesday, July 7, 2009
(Radisson, RTP)
8:15-8:45 Registration and Continental Breakfast
8:45-9:00 Welcome
9:00-12:00 Yanyan Sheng, Southern Illinois University
“Bayesian Analysis of Item Response Theory Models”
10:00-10:30 Break
12:00-2:00 Lunch
2:00-3:00 David Thissen, University of North Carolina
“IRTPRO Demonstration”
3:00-3:15 Break
3:15-4:15 Richard Swartz, University of Texas, MD Anderson Cancer Center
“Bayesian and Classical Computerized Adaptive Testing Item Selection
Algorithms”
Wednesday, July 8, 2009
(Radisson, RTP)
8:30-9:00 Registration and Continental Breakfast
9:00-12:00 Sun-Joo Cho, University of California, Berkeley
Frank Rijmen, Educational Testing Service
Mark Wilson, University of California, Berkeley
“A Nonlinear Mixed Models Approach to IRT”
10:00-10:30 Break
12:00-2:00 Lunch
2:00-4:00 Mario Peruggia, Ohio State University
“Hierarchical Bayes Models for Response Time Data”
Trish Van Zandt, Ohio State University
“An Overview of Response Time Models in Psychology”

487
3:00-3:15 Break
4:00-5:00 Poster Advertisements (2 minute ads each)
5:00–7:00 Poster Session and Reception
SAMSI will provide poster presentation boards and tape. The board dimensions
are 4 ft. wide by 3 ft. high. They are tri-fold with each side being 1 ft. wide and
the center 2 ft. wide. Please make sure your poster fits the board. The boards can
accommodate up to 16 pages of paper measuring 8.5 inches by 11 inches.
Thursday, July 9, 2009
(Radisson, RTP)
8:30-9:00 Continental Breakfast
9:00-12:00 Mathias von Davier, Educational Testing Service
“Notes on Models for Cognitive Diagnosis”
10:00-10:30 Break
12:00-1:30 Lunch
1:30-2:30 Sandip Sinharay, Educational Testing Service
“A Critical Evaluation of Diagnostic Score Reporting: Some Theory and
Applications”
2:30-2:45 Break
2:45-4:00 Dongchu Sun, University of Missouri
“Bayesian Hierarchical Models for Recognition-Memory Experiments”
Jun Lu, American University
“A Bayesian Approach for Assessing Human Memory Using Process-
Dissociation Procedure”
Friday, July 10, 2009
(Radisson, RTP)
8:30-9:00 Continental Breakfast
9:00-12:00 Matthew Johnson, Columbia University
“An Introduction to Rater Models”

488
10:00-10:30 Break
12:00-2:00 Lunch
2:00-4:00 Paul Speckman, Dongchu Sun, and Jeff Rouder, University of Missouri
“Item-Response Models for Measuring Thresholds in Performance”
3:00-3:15 Break
Monday July, 13 – Friday July, 17
(SAMSI)
9:00-12:00 Working Group Meetings:
Peer Review Working Group (Room 104)
Cognitive Diagnostic Models Working Group (Room 150)
Longitudinal Assessment of PRO Working Group (Room 203)
12:00-1:00 Lunch
1:00-5:00 Working Group Meetings:
Peer Review Working Group (Room 104)
Cognitive Diagnostic Models Working Group (Room 150)
Longitudinal Assessment of PRO Working Group (Room 203)

489
Program on Psychometrics: Peer Review Working Group
The PRWG will meet spontaneously during the second week of the program. Currently scheduled talks
are listed below. Contributed talks will be added to the schedule during the course of the Psychometric
Program. A white paper will be prepared by the working group and summarized at a joint meeting at
the end of the week. Non-meeting time will be devoted to group collaboration on topics related to peer
review.
SCHEDULE Monday July 13, 2009 – Friday July 17, 2009
Monday July 13, 2009
11:30-12:30 David Banks, Duke University
“Judgement in JASA”
12:30-2:00 Lunch
Tuesday July 14, 2009
11:30-12:30 Valen E. Johnson, University of Texas, MD Anderson Cancer Center
“An Overview of NIH R01 Peer Review Scores”
12:30-2:00 Lunch
Wednesday July 15, 2009
11:00-12:00 Jing Cao, Southern Methodist University
“A Bayesian Approach to Ranking and Rater Evaluation: An Application to
Grant Reviews”
12:00-1:30 Lunch
Thursday July 16, 2009
11:00-12:00 Song Zhang, University of Texas, Southwestern Medical Center
“A Baysian Hierarchical Model for Multi-rater Data with Fine Scales”
12:00-1:30 Lunch
Friday July 17, 2009
11:00-12:00 Discuss Draft of White Paper
12:00-1:00 Lunch
1:00 Adjourn

490
Cognitive Diagnostic Models Working Group (CDMWG)
The CDMWG will meet during the second week of the program. The program will be more
structured during the beginning of the week, and more open during the end of the week. Talks
currently scheduled during this week are listed below. Additional talks will be added to the schedule
during the course of the Psychometric Program. A white paper will be prepared by the working group
and summarized at a joint meeting at the end of the week.
SCHEDULE Monday July 13, 2009 – Friday July 17, 2009
Monday July 13, 2009
9:00-10:00 Introduction
10:00-11:30 Matthew Finkelman, Tufts University
Kristin Huff, College Board
Curtis Tatsuoka, Case Western University
“Diagnostic Assessment Approaches”
11:30-12:30 David Banks, Duke University
12:30-2:00 Lunch
2:00-3:30 Tzur Karelitz, Education Development Center
Jere Confrey, North Carolina State University
Alicia Alonzo, University of Iowa
“Developmental Theories for Diagnostic Assessment”
3:30-5:00 Andre Rupp, University of Maryland
Ying Cui, University of Alberta
Nathalie Loye, University of Montreal
“Task & Q-matrix Construction”
Tuesday July 14, 2009
8:30-10:00 Andre Rupp, University of Maryland
Jimmy de la Torre, Rutgers University
Robert Henson, University of North Carolina, Greensboro
“Fully Parametric Models for Classification”
10:00-11:30 Curtis Tatsuoka, Case Western University
Ying Cui, University of Alberta
Rebecca Nugent, Carnegie Mellon University
“Non-parametric and Semi-parametric Models for Classification”
11:30-12:30 Valen Johnson, University of Texas, MD Anderson Cancer Center
12:30-2:00 Lunch

491
2:00-3:30 Roy Levy, Arizona State University
Robert Henson, University of North Carolina, Greensboro
Jimmy de la Torre, Rutgers University
“Challenges in Estimation, Programming, and Implementation”
3:30-5:00 Ying Cui, University of Alberta
Roy Levy, Arizona State University
Jimmy de la Torre, Rutgers University
“Model Fit Assessment & Refinement”
Wednesday July 15, 2009
8:30-10:30 Curtis Tatsuoka, Case Western University
Ying Cheng, University of Notre Dame
Matthew Finkelman, Tufts University
“Optimal Test Design and Computerized Adaptive Testing”
10:30-12:00 Eunice Jang, University of Tornoto
Neil Heffernan, Worcester Polytechnic Institute
Kristin Huff, College Board
“Score Reporting & Subsequent Action”
12:00-1:30 Lunch
1:30-3:00 Andre Rupp, University of Maryland
Tiffany Barnes, University of North Carolina, Charlotte
Neil Heffernan, Worcester Polytechnic Institute
“Validation”
3:00-5:00 Moderated Panel Session
“Future Challenges for Diagnostic Assessment”
The morning of the fourth day will be devoted to identifying the cutting-edge methods in cognitive
diagnosis modeling, and three to five important gaps that must be filled to advance the field forward.
The cutting-edge methods and research gaps will constitute the research agenda of the working group.
The topics in these research agenda will be distributed into three 90-minute time blocks that will
extend from Thursday afternoon and the first part of Friday morning. Participants will be asked to
select a research topic in each time block. The 1.5 hour-block will be used to discuss potential research
projects that can be done in specific topics, sign-up participants who can collaborate on these projects,
and outline strategies and time frame for completing these projects. Starting the latter part of Friday
morning (10:30-12:30), participants will report the summary of the discussion of potential projects to
all the participants of the working group. The working group will adjourn after a lunch.

492
Longitudinal Assessment of PRO Working Group (LAPROWG)
The LAPROWG will meet during the second week of the program. The program will be more
structured during the beginning of the week, and with more spontaneous meetings during the end
of the week. Talks currently scheduled during this week are listed below. Additional talks may
be added to the schedule during the course of the Psychometric Program. A white paper will be
prepared by the working group and summarized at a joint meeting at the end of the week.
SCHEDULE Monday July 13, 2009 – Friday July 17, 2009
Monday July 13, 2009
9:00-9:30 Richard Swartz, University of Texas M. D. Anderson Cancer Center
Introductions, Purpose of Working Group
9:30-10:20 Carolyn Schwartz, DeltaQuest
“Importance of Responsiveness to Change and Mediators to the Measurement of
Change in Health Outcomes”
10:30-Noon Ken Bollen, University of North Carolina
“Longitudinal Measurement of Patient Reported Outcomes: Latent Curve Models
Using Structural Equation Models”
1:00-3:15 Ethan Basch, Memorial Sloan Kettering Cancer Center
Charles Cleeland, University of Texas M. D. Anderson Cancer Center
“Practical Needs in Trial Design and Detecting True Change Over Time -
Clinicians’ Perspective”
Diane Fairclough, University of Colorado, Denver
“Practical Needs in Trial Design and Detecting True Change Over Time - Patient
Perspective of the Patient Experience”
3:30-5:00 Carolyn Schwartz, DeltaQuest
“Methods to Detect Response Shift and Responsiveness to Change ”
Tuesday, July 14
9:00-10:30 Bruce Rapkin, Albert Einstein College of Medicine
“Cognitive Factors in the Quality of Life Rating Response Scales and How to
Include/model This Information”
10:45-Noon Diane Fairclough, University of Denver, Colorado
“Impact of Missing Data When Evaluating Change Over Time”
1:00- 2:30 Li Cai, University of California, Los Angeles
“Multidimensional IRT and Potential Applications to Assessing PROs Over Time
and Detecting Response Shift”

493
3:00-5:15 Jeff Sloan, Mayo Clinic
“Precision, Validity and Sensitivity vs. Response Burden in PRO Endpoints –
Facilitating Detection of True Change: Using Single-item vs. Multi-item Scales
to Monitor Change”
Richard Swartz, The University of Texas M. D. Anderson Cancer Center
“Precision, Validity and Sensitivity vs. Response Burden in PRO Endpoints –
Facilitating Detection of True Change: Considering the Precision vs. Burden
Tradeoff within CAT”
Wednesday, July 15
9:00-10:30 Jeff Sloan, Mayo Clinic
“Interpreting Minimally Important Differences While Accounting for
Measurement Variability/response Shift”
10:45-Noon Brainstorming Next Steps / Outline White Papers
1:00-3:00 Outline White Paper / Discuss Datasets
Thursday, July 16
12:00-1:00 Lunch
3:00-5:00 Updates
Friday, July 17
9:00-Noon Revise Outline for White Papers/ Delegate Duties / Develop Timeline to
Complete White Paper.
12:00-1:00 Lunch
The white paper to be produced in the LAPROWG has two main goals:
1) to discuss the state of the art and recommend policy and procedures for analyzing
longitudinal PRO data
2) to identify areas needing methodological improvement when considering
longitudinal PRO data
SPEAKER ABSTRACTS
David Banks
Duke University

494
The editorial process is noisy, which affects the quality of the decision to reject or to accept a manuscript.
This talk describes some of the factors that may influence the process, and introduces a data set for analysis
that may cast light on unconscious prejudices in the management of the _Journal of the American Statistical
Association_. Additionally, the talk indicates some alternative models for publication that have the potential
to diminish the noise or bias in the review of research papers.
Jing Cao
Southern Methodist University
“A Bayesian Approach to Ranking and Rater Evaluation: Application to Grant Reviews”
We develop a Bayesian hierarchical model for the analysis of ordinal data from multirater ranking studies.
The model for a rater's score includes four latent factors: one is a latent item trait determining the true order of
items and the other three are the rater's performance characteristics, including bias, discrimination, and
measurement error in the ratings. The proposed approach aims at three goals. First, a Bayesian estimator is
introduced to estimate the ranks of items. It shows a substantial improvement over the widely used score-
average ranking estimator by utilizing the information on rater-specific scoring patterns. Second, rater
performance can be compared based on rater bias, discrimination, and measurement error. Third, a
simulation-based decision-theoretic approach is described to determine the number of raters to employ. A
simulation study and an analysis based on a grant review dataset are presented.
Ying Cheng University of Notre Dame
“Cognitive Diagnostic Computerized Adaptive Testing”
Invited Abstract: Computerized adaptive testing has seen tremendous growth in the last three decades. At the
same time, cognitive diagnosis has taken off, especially since the No Child Left Behind Act (2000) mandated
that diagnostic feedback be provided to students. Researchers have been trying to bring together the two
wonderful inventions in educational and psychological measurement. In this talk, we will summarize recent
findings and discuss future directions of cognitive diagnostic CAT research.
Jere Confrey North Carolina State University
“Developing Learning Trajectories and Diagnostic Assessments Based Student Reasoning on Rational
Number over Time”
The DELTA project (Diagnostic E-Learning Trajectories Approach) is designed to synthesize the
research on rational number and identify underlying learning trajectories. Additional interviews are
conducted to fully develop the constructs in the learning trajectories. From these, we are building items
to create diagnostic measures in mathematics and conducting pilot studies to define outcome spaces and
larger field tests to validate the items. The presentation will show how we have used the literature to
show the interconnections among concepts via a concept map and then used it to develop and refine
individual learning trajectories by refining the map and conducting additional research. An example
using equipartitioning will be provided.
Matthew Finkelman
Tufts University

495
“A Zero- and K-Inflated Mixture Model for Health Questionnaire Data”
In psychiatric assessment, Item Response Theory (IRT) is a popular tool to formalize the relation between the
severity of a disorder and associated responses to questionnaire items. Practitioners of IRT sometimes make
the assumption of normally distributed severities within a population; while convenient, this assumption is
often violated when measuring psychiatric disorders. Specifically, there may be a sizable group of
respondents whose answers place them at an extreme of the latent trait spectrum. In this article, a zero- and K-
inflated mixture model is developed to account for the presence of such respondents. The model is fitted using
an expectation-maximization (E-M) algorithm to estimate the percentage of the population at each end of the
continuum, concurrently analyzing the remaining “graded component” via IRT. A method to perform factor
analysis for only the graded component is introduced. In assessments of oppositional defiant disorder and
conduct disorder, the zero- and K-inflated model exhibited significantly better fit than the standard IRT
model.
Matthew Johnson Columbia University
“An Introduction to Rater Models”
In large-scale educational assessments, the use of open-ended items has become increasingly popular over the
past several years. Many argue that open-ended, or constructed response, items are required in order to tap
higher-level reasoning on assessments. Furthermore, certain academic abilities can, such as writing, can only
be assessed with constructed response items. The use of constructed
response items comes at a cost, however. Unlike multiple choice items, constructed-response items must be
graded by human raters. When multiple raters are utilized, the question of fairness comes to
the forefront. In an ideal world all raters would give the same score to the same student. However, when
partial credit is involved this is rarely the case. Raters often differ in terms of their severity and
in terms of the precision of their scores. In this tutorial I will discuss statistical models for
detecting/estimating rater severity and precision, and discuss methods for accounting for differences across
raters. Three approaches that will be discussed in detail are the FACETS model, the generalizability theory
approach, and the hierarchical rater model. Time permitting I will demonstrate the use of WinBUGs for
estimating the rater models.
Valen Johnson University of Texas MD Anderson Cancer Center
“Statistical Analysis of the National Institutes of Health Peer Review System”
A statistical model is proposed for the analysis of peer-review ratings of R01 grant applications submitted to
the National Institutes of Health. Innovations of this model include parameters that reflect differences in
reviewer scoring patterns, a mechanism to account for the transfer of information from an application‟s
preliminary ratings and group discussion to final ratings provided by all panel members and posterior
estimates of the uncertainty associated with proposal ratings. Application of this model to recent R01 rating
data suggests that statistical adjustments to panel rating data would lead to a 25% change in the pool of
funded proposals. Viewed more broadly, the methodology proposed in this article provides a general
framework for the analysis of data collected interactively from expert panels through the use of the Delphi
method and related procedures.
Nathalie Loye University of Montreal

496
“Validity of Diagnostic Resulting from Marriage Between Didactics and Measurement”
With CDM, diagnostic of cognitive processes used to answer items in a test is based on a Q-matrix. The
DINA model includes two items parameters that can be used to examine quality of Q-matrix, and thus validity
of diagnostic, as proposed by de la Torre (2008). This study presents some results related to the validity of the
diagnosis when Q-matrix is based on classification of items according to ontology of mathematics and
according to competences, as established by specialists in teaching. The data come from the test of
mathematics proposed in June 2008 at the École Polytechnique de Montreal.
Jun Lu American University
“A Bayesian Approach for Assessing Human Memory Using Process-Dissociation Procedure”
Modern theories of human memory postulate separate systems for conscious recollection and unconscious,
automatic recall. Psychologists have proposed experimental setups, such as the Process Dissociation
Procedure (PDP), to separate the contributions from these systems to overall memory. To analyze the PDP
data, however, researchers often aggregate outcomes across participants, items, or both. This can lead to
biased estimates due to the correlated random effects. To achieve better statistical inference, we propose a
Bayesian hierarchical model for PDP experiments. The model employs latent variables to model the
conscious and unconscious components of human memory. It features two probit models and priors with
possibly correlated random effects in situations where these correlations have theoretical interest. Three types
of priors are examined, and their efficacies are compared in a simulation study. The Bayesian approach is
also illustrated with data from a memory experiment and can be applied to signal detection problems.
Rebecca Nugent Carnegie Mellon University
“Clustering in Cognitive Diagnosis: Some Recent Work and Open Questions”
One primary objective in educational research is the development of methodology to characterize
students' ability on a set of skills. Ability could be defined as a binary response (either you have a skill or
you don't) or a continuous response on a spectrum of mastery (none to partial to complete). Traditionally,
estimation approaches have used latent class cognitive diagnosis models to fit (parametrically formulated)
item response functions. These models can quickly grow in complexity and estimation difficulty as the
number of examinees, items, and skills increase. More recently, cluster analysis has been suggested as an
alternative to identify groups of students with different latent ability. Preliminary work has shown this
potentially computationally advantageous approach can give comparable results with fewer constraints.
In this talk, we will review some parametric and nonparametric clustering approaches (and their
strengths/weaknesses) and summarize recent work using clustering in cognitive diagnosis. The
remainder of the talk will be devoted to discussing some open research problems including choosing a
method, labeling the clusters, visualization of high dimensional results, variable/skill selection (dimension
reduction; clustering in a reduced subspace), and, time permitting, clustering student learning trajectories.
Mario Peruggia
Ohio State University
“Hierarchical Bayes Models for Response Time Data”

497
Human response time data are widely used in cognitive psychology to evaluate theories of mental processing.
Typically, the data constitute the times taken by a subject to react to a succession of stimuli under varying
experimental conditions. A careful analysis of these data must distinguish and account for both local
dependencies and overall trends. Local dependencies might be directly related to the mental process
generating the response times. For example, a subject might perceive that her last few responses were slow
and try to compensate by speeding up the next few ones or vice versa. Local dependencies might also be due
to sudden distractions or attention gathering events. Overall trends might be due to learning. i.e. the fact that,
over time, a subject becomes better acquainted with the task he must perform, leading to shorter response
times. Or they might be due to fatigue, i.e. the fact that a subject tires to perform the same repetitive task,
leading to longer response times. Distinguishing between local dependencies and overall trends is difficult.
We consider a hierarchical Bayes approach that lets us handle the various modeling choices concerning local
dependencies and overall trends concurrently and lets us incorporate, in a unified fashion, the effects of
experimental covariates and of extreme observations. We use data from several experiments to illustrate and
compare the performance of the two modeling strategies. This talk is based on joint work with Peter
Craigmile and Trisha Van Zandt
Jeff Rouder University of Missouri
“Item-Response Models for Measuring Thresholds in Performance”
Human abilities in perceptual domains have historically been conceptualized with reference to a threshold.
Observers are consciously aware of a stimulus if and only if it is above a threshold intensity. One of the
critical questions in modern psychology is whether there is a subliminal effect of stimuli; that is, do stimuli
below threshold nonetheless affect subsequent behavior. Current statistical approaches to measuring
thresholds, however, define them as corresponding to an arbitrary level of performance, say .75 or .707, rather
than as the minimum amount of intensity corresponding to above-baseline performance. To fill this
measurement lacuna and assess the existence of subliminal perception, my colleagues and I developed a set of
item-response models for measuring thresholds. Traditional psychometric links, such as the probit, logit, and
t, are incompatible with thresholds as there are no true scores corresponding to baseline performance. We
introduce a truncated probit link for modeling thresholds and develop a two-parameter IRT model based on
this link. The model is Bayesian and analysis is performed with MCMC sampling. Based on model analysis,
my colleagues and I fail to find evidence for subliminal perception. The measurement of threshold is broadly
applicable in many domains outside of subliminal perception. Example include measuring the maximum
length of time a driver can drive without fatigue effects, or measuring the maximum amount of ambient noise
an air-traffic controller can tolerate without raising the chance for a mistake.
Yanyan Sheng
Southern Illinois University
“Bayesian Analysis of Item Response Theory Models”
Item response theory (IRT) provides a collection of models that describe how items and persons interact to
yield probabilistic correct/incorrect responses. The influence of items and persons on the responses is
modeled by distinct sets of parameters, and simultaneous estimation of these parameters calls for complex
statistical procedures. The unidimensional model where one latent trait is assumed will be reviewed from a
theoretical viewpoint with an emphasis on the Bayesian estimation techniques of the model parameters. As
Markov chain Monte Carlo simulation techniques offer promise for parameter estimation with complex
models, multidimensional IRT models appropriate in situations where items measure multiple traits will be
introduced in the fully Bayesian framework.

498
Sandip Sinharay Educational Testing Service
“A Critical Evaluation of Diagnostic Score Reporting: Some Theory and Applications”
Diagnostic scores are of increasing interest due to their potential remedial and instructional benefit. Naturally,
the number of testing programs that report diagnostic scores is on the rise, as are the number of research
works on cognitive diagnostic models that can be used to report diagnostic scores. This presentation will raise
the question whether the existing educational tests are ready to report high-quality diagnostic scores. A brief
review will be provided of a recent method (Haberman, 2008; Sinharay, Haberman, & Puhan, 2007) that can
be used to determine whether there is enough justification behind reporting the subscores (that are the
simplest form of diagnostic scores and are reported by several testing programs) for a test. The presentation
will also discuss the recent method of Haberman, Sinharay, and Puhan (2009) that extends the method of
Haberman (2008) to aggegate-level subscores, and of the method of Haberman and Sinharay (2009) that
extends the method of Haberman (2008) to diagnostic scores based on multidimensional item response theory
(MIRT) models. Using results from several operational and simulated data sets, it will be demonstrated that
diagnostic scores are likely to provide any benefits for only a handful of existing educational tests. Some
recommendations are made for those interested in reporting diagnostic scores.
Dongchu Sun University of Missouri
“Bayesian Hierarchical Models for Recognition-Memory Experiments”
Bayesian hierarchical probit models are developed for analyzing the data from the recognition-memory
experiment in Psychology. Both informative priors and noninformative priors are reviewed.
For the informative priors, two latent variable structure priors are proposed. One is a generalization of the
share-component prior in Lu et al. (2007). The other is based on a structure from factor analysis. The latent
variable structure priors model the correlation across participant effects and item effects flexibly by not
requiring the predetermination of the correlation sign.
Meanwhile, three options for objective Bayesian analysis are studied. The first option is to assign the constant
prior for all of the effect parameters. The second option is to use shrinkage priors by assigning bivariate
normal priors on participant effect parameters and item effect parameters at the first level, and objective priors
such as a constant prior on the covariance matrices.
The third option is to apply the constant prior to the two mean effects and hierarchical priors to the participant
and item effects with a class of noninformative priors on the variance components. The propriety of posteriors
are examined underthese options.
Simulation studies and real data analyses are conducted for comparing proposed and some existing methods.
Richard Swartz University of Texas, MD Anderson Cancer Center
“Bayesian and Classical Computerized Adaptive Testing Item Selection Algorithms”
Computerized Adaptive Testing (CAT) is one of the important applications of item response theory.
CAT algorithms adaptively select and sequentially administer items to estimate a person‟s latent trait.

499
CAT has been applied in educational and vocational tests and more recently patient-reported outcomes
questionnaires. It has been shown that applications of CAT obtain better measurement precision and test
efficiency than the standard paper-and-pencil format. A variety of item selection procedures have been
proposed for CAT and are in use. This presentation will discuss some of the classical and Bayesian
methods for item selection and trait estimation. A recent study comparing several of the different
selection methods will then be briefly discussed. In the study it was found that many of the item selection
procedures performed very similarly.
Curtis Tatsuoka
Case Western Reserve University
“Partially Ordered Classification Models: a General Framework for Cognitive Diagnosis and Adaptive
Testing”
Partially ordered sets (posets) are natural models for cognitive functioning. A statistical framework will
be described for the problem when there exists a "true" state among a partially ordered collection of
states, and observations from sequentially selected experiments (test items, measures) are used to identify
it. An advantage of adaptive testing is that testing burdens can be greatly reduced. Results on
asymptotically optimal sequential selection of experiments will be described in the context of Bayesian
classification problems when the parameter space is a finite lattice. Experiment selection rules and the
attainment of optimal rates of convergence will be discussed.
Finally, an analysis of neuropsychological testing data will be presented. This approach is used to detect
differential cognitive profiles in neurological diseases, and to link classification results to clinical course
variables.
David Thissen University of North Carolina
“IRTPRO Demonstration”
The IRTPRO (Item Response Theory for Patient-Reported Outcomes) component of the MEDPRO Project is
an entirely new application for item calibration and test scoring using IRT. Fall, 2009 release of this software
is anticipated; this presentation briefly describes its features, user interface, and output. IRTPRO provides
maximum likelihood calibration of items fitted with the 1PL, 2PL, 3PL, Graded, Generalized Partial Credit,
and Nominal IRT models in any combination, using one of three estimation algorithms: 1) Bock-Aitkin EM,
2) adaptive quadrature, or 3) Metropolis-Hastings Robbins-Monro (MHRM). Unidimensional or
multidimensional IRT models may be used; among multidimensional models, the implementation performs
full-information estimation for exploratory and confirmatory models, including the special-case treatment
appropriate for bi-factor models. Analysis of differential item functioning (DIF) is also provided, using the
Wald test, with accurate item parameter error variance-covariance matrices computed using the Supplemented
EM (SEM) algorithm. Several goodness of fit and diagnostic statistics are reported. Standard maximum a
posteriori (MAP) and expected a posteriori (EAP) estimates of the latent variable(s) for item response patterns
may be computed, as well as (weighted) summed-score to scale score translation tables.
Trisha Van Zandt Ohio State University
“An Overview of Response Time Models in Psychology”

500
Models of cognition focus on the speed and accuracy of simple choices. For example, a memory task may
ask a subject to discriminate between old (studied) and new (not studied) objects. The choice between old
and new is modeled as a process of information accumulation over time. When the evidence for one of the
choice options reaches a threshold or criterion level, a response indicating that option is made. These models
are implemented as stochastic processes such as Poisson and Wiener processes.
This talk is a tutorial that provides an overview of the different kinds of stochastic processes used in the
modeling of simple choice. I will present some historical background and motivation for how different tasks
have been modeled. My talk provides
the background for Mario Peruggia's presentation, which presents a hierarchical treatment of response time
data motivated by these types of processes.
Matthias von Davier ETS
mvondavier@ets
“Notes on Models for Cognitive Diagnosis”
Models for cognitive diagnosis - as they are called in their current incarnation - have been around for some
time now. Multidimensional latent structure models, constrained latent class models, or multiple classification
latent class models are other terms that may be more descriptive with respect to the the target of inference
(von Davier & Yamamoto, 2004, von Davier, 2005). Cognitive diagnosis describes one type of application
where a model with multidimensional latent variable is utilized to assess respondents with respect to multiple
cognitive skills. The idea of extracting more from test data than a single ability parameter or person score
has also been around for some time now, but is not without pitfalls in cases where the test instrument was not
designed for this purpose (Haberman & von Davier, 2006, von Davier, 2009). This presentation will give an
overview of the field from the perspective of what can be gained from these models, and discuss some recent
findings on models for cognitive diagnosis and their relationship to other models. The presentation will
provide information about exemplary applications of models for cognitive diagnosis, and on the estimation of
these models.
Mark Wilson University of California, Berkeley
“A Nonlinear Mixed Models Approach to IRT”
The central message of the workshop is that it is beneficial to see IRT models as extensions of generalized
linear regression models that seek to model facets of the measurement situation: These facets are most
typically persons and items, but the set may be extended to incorporate other facets such as raters, and may
also be re-labelled to suit particular applications. While the link function and the random component of the
regression model remain the same, the most interesting part of the extension concerns the structural part of the
model: (1) the kind of predictive function (linear or nonlinear, e.g. bilinear), (2) the effects (weights) of the
predictors (fixed effects or random effects).
Starting from some well-known IRT models, other and less well-known models will be framed in this
approach, based on a volume published by Springer: “Explanatory Item Response Models: A generalized
linear and nonlinear mixed approach” (De Boeck & Wilson, 2004). We will illustrate how the models can be
estimated with the SAS procedure NLMIXED.
The workshop will consist of two parts. In the first part, the explanatory item response framework will be
presented, and it will be explained how the framework fits within the family of generalized linear and

501
nonlinear mixed models. Specific attention will be devoted to the distinction between descriptive and
explanatory item response models, and the distinction between fixed and random effects. It will be shown
how well-known item response models fit within this framework. In addition, the framework naturally leads
to new item response models, such as models with both random item and random person
effects.
In the second part, an in-depth account will be given of multidimensional item response models, and models
for polytomous data. Again, both families of models can be conceptualized as generalized linear and
nonlinear mixed models, and doing so naturally leads to model extensions that may be of interest to the
applied researcher. In this part, some attention will be devoted to model estimation as well.
Throughout, the models are illustrated with datasets on anger and verbal aggression. We will also emphasize
random item concepts and models.
Song Zhang University of Texas Southwestern Medical Center
“A Bayesian Hierarchical Model for Multi-rater Data with Fine Scales”
During a peer review process, reviewers are often instructed to assign scores on a fine scale. For example, the
National Institutes of Health adopts a scoring scale of 1.0 to 5.0 with an incremental unit of 0.1. Despite the
instruction, raters often assign scores with dual scales, i.e., a rater might assign scores in the increment of 0.1
(1.1, 1.2, 1.3,...) in a certain range while assign scores in the increment of 0.5 in another (4, 4.5, ...).
Furthermore, some half-integer scores (such as 1.5, 2.0,..) are assigned more often than the others. Most of the
current ranking methods are based on ordinal models which only utilize the ordinal information of the scores.
The numerical difference between two scores is considered irrelevant as long as the order remains unchanged.
We propose a Bayesian multinomial logistic model where the numerical (besides ordinal) information of the
scores is utilized in inference. The model includes parameters of rater bias, discrimination and measurement
error. Particularly, the measurement error is allowed to have different magnitudes over the scoring range
which naturally accounts for dual scales and different frequencies of the scores. A simulation study and a real
data example are presented.

502
2. Stochastic Dynamics
Schedule Sunday, August 30, 2009
Radisson Hotel RTP
Overview Tutorials
8:00-8:55 Registration and Continental Breakfast
8:55- 9:00 Welcome
9:00-10:30 Tutorial Lecture
Peter Baxendale, University of Southern California
“Equilibrium, Bifurcation and Averaging for a Nonlinear Oscillator Perturbed by White
Noise”
10:30-11:00 Coffee Break
11:00-12:30 Tutorial Lecture
Mark Alber, Notre Dame
“Stochastic Modeling and Applications to Biology and the Medical Sciences”
12:30 –1:45 Lunch
1:45- 3:15 Tutorial Lecture
Grant Lythe, University of Leeds
“Numerical Methods for Stochastic Dynamics”
3:15-3:45 Coffee Break
3:45-5:15 Tutorial Lecture
Andrew Stuart, Warwick University
“Limit Theorems for MCMC”

503
Monday, August 31, 2009
Radisson Hotel RTP
8:00-8:45 Registration and Continental Breakfast
8:45-9:00 Welcome
9:00-12:15 Theme 1: Qualitative Behavior of Stochastic Dynamical Systems and Stochastic
Modeling
9:00-9:45 Barbara Gentz, University of Bielefeld
“Metastable Lifetimes in Coupled Random Dynamical Systems”
9:45-10:30 Rachel Kuske, University of British Columbia
“Noise Driven Order in Biological Models”
10:30-11:00 Coffee Break
11:00-11:30 Lee DeVille, University of Illinois
“Synchrony-breaking and Rare Events in Stochastic Neuronal
Networks”
11:30-12:15 Panel Discussion:
Cindy Greenwood (Moderator), Arizona State University
Peter Baxendale, University of Southern California
Leonid Koralov, University of Maryland
12:15-1:30 Lunch
1:30-4:45 Theme 2: Stochastic Dynamics Across Many Scales
1:30-2:15 Peter Kotelenez, Case Western University
“From Microscopic to Mesoscopic and Macroscopic Equations”
2:15-3:00 Sandra Cerrai, University of Maryland
"Fast Transport Asymptotics for SPDE's with Noise Acting on the Boundary"
3:00-3:30 Coffee Break
3:30-4:00 Houman Owhadi, California Institute of Technology
“Non-intrusive and Structure Preserving Multiscale Integration of Stiff
SDEs and Stochastic Hamiltonian Systems with Hidden Slow Dynamics
via Flow Averaging”

504
4:00-4:45 Panel Discussion:
Markos Katsoulakis, (Moderator) University of Massachusetts
Hakima Bessaih, University of Wyoming
Anna Amirdjanova, University of Michigan
4:45-5:15 Five Minute Madness (6 talks)
5:15-5:45 Poster Advertisement Session (2 minute ads each)
6:00-8:00 Poster Session and Reception SAMSI will provide poster presentation boards and tape. The board dimensions are 4 ft. wide by 3 ft.
high. They are tri-fold with each side being 1 ft. wide and the center 2 ft. wide. Please make sure your
poster fits the board. The boards can accommodate up to 16 pages of paper measuring 8.5 inches by 11
inches.
Tuesday, September 1, 2009
Radisson Hotel RTP
8:00-9:00 Registration and Continental Breakfast
9:00-12:15 Theme 3: Challenges in Numerical Methods for Stochastic Systems
9:00-9:45 Eric Vanden-Eijnden, Courant Institute, New York University
“Some Issues in the Long-time Simulation of Complex Systems”
9:45-10:30 Gabriel Lord, Heriot Watt University
“Numerics for SPDEs”
10:30-11:00 Coffee Break
11:00-11:30 David Anderson, University of Wisconsin
“Error Analysis of Approximation Methods for Stochastically Modeled
Chemical Reaction Systems”
11:30-12:15 Panel Discussion:
Thomas Kurtz, (Moderator) University of Wisconsin
Grant Lythe, University of Leeds
Kevin Lin, University of Arizona
12:15-1:30 Lunch
1:30-4:45 Theme 4: Estimation and Data Assimilations in Stochastic Dynamics
1:30-2:15 Darren Wilkinson, Newcastle University
“Bayesian Inference for Markov Process Models, with Applications to
Systems Biology”
2:15-3:00 Christof Schuette, Free University, Berlin
3:00-3:30 Coffee Break
3:30-4:00 John Harlim, North Carolina State University
“Stochastic Parameterization Extended Kalman Filter for Turbulent
Signal with Model Errors”

505
4:00-4:45 Panel Discussion:
Andrew Stuart (Moderator), Warwick University
John Fricks, Pennsylvania State University
Scott Schmidler, Duke University
4:45-5:30 5-Minute Madness

506
Wednesday, September 2, 2009
Radisson Hotel RTP
8:00-9:00 Registration and Continental Breakfast
9:00-12:15 Theme 5: Dynamics of Biological Networks
9:00-9:45 Lea Popovic, Concordia University
"Stochastic Modeling of Cellular Reaction Networks"
9:45-10:30 David Cai, New York University
“Mathematical Analysis of Neuronal Network Dynamics”
10:30-11:00 Coffee Break
11:00-11:30 Katie Newhall, Rensselaer Polytechnic Institute
“Synchrony in Stochastic Pulse-coupled Neuronal Network
Models”
11:30-12:15 Panel Discussion:
Mike Reed (Moderator), Duke University
Danny Forger, University of Michigan
Tim Elston, University of North Carolina
12:15-1:30 Lunch
1:30–2:30 Working Group Formation and Initial Meeting
2:30-3:30 Working Group Reports and Scheduling for Thursday and Friday
Thursday and Friday: Individual working group meetings at SAMSI.
SPEAKER ABSTRACTS
David Anderson University of Wisconsin
“Error Analysis of Approximation Methods for Stochastically Modeled Chemical Reaction
Systems”
We perform an error analysis for numerical approximation methods of continuous time Markov
chain models commonly found in the chemistry and biochemistry literature. The motivation for
the analysis is to be able to compare the accuracy of approximation methods and, specifically,
standard tau-leaping and a midpoint method. We perform our analysis under a scaling in which
the size of the time discretization is inversely proportional to some (bounded) power of the norm
of the state of the system. This is unlike previous error analyses that assumed the size of the time
discretization goes to zero independently from the abundances of the constituent molecules. Our
scaling is a natural choice because of the existence of statistically exact algorithms that can be
employed in the case of extremely small time-steps and which make approximate methods

507
unnecessary in such a scaling regime. Under the present scaling we show that the midpoint
method achieves a higher order of accuracy, in both a weak and a strong sense, than standard
tau-leaping; this result is in contrast to previous analyses. We present examples that demonstrate
our findings.
References: [1] David F. Anderson, Arnab Ganguly, Thomas G. Kurtz, Error Analysis of
Approximation Methods for Stochastically Modeled Chemical Reaction Systems. in preparation.
Peter Baxendale University of Southern California
“Equilibrium, Bifurcation and Averaging for a Nonlinear Oscillator Perturbed by White Noise”
This talk will demonstrate how a number of techniques of stochastic dynamics can be applied to
a particular two-dimensional system. Topics will include: Lyapunov exponents for linear
stochastic dynamical systems; the interplay between nonlinear systems and their linearisation;
applications of Dynkin's formula (equivalently local martingale techniques) to issues of non-
explosion, recurrence and stationary measures; behavior of stationary measures near a stochastic
bifurcation point; and stochastic averaging.
David Cai New York University
“Mathematical Analysis of Neuronal Network Dynamics”
From the perspective of nonlinear dynamical systems, nonequilibrium statistical physics, and
scientific modeling, we will briefly describe some recent developments of mathematical methods
used in analysis of the dynamics of neuronal networks arising from the brain. We will outline
some mathematical difficulties in characterization of neuronal network dynamics for the
understanding of information processing in the brain.
Sandra Cerrai University of Maryland
"Fast Transport Asymptotics for SPDE's with Noise Acting on the Boundary"
We consider a class of stochastic reaction-diffusion equations having also a stochastic
perturbation on the boundary and we show that when the diffusion rate is much larger than the
rate of reaction it is possible to replace the SPDE's by a suitable one-dimensional stochastic
differential equation. This replacement is possible under the assumption of spectral gap for the
diffusion and is a result of {\em averaging} in the fast spatial transport. We also study the
fluctuations around the averaged motion.

508
Lee DeVille University of Illinois
“Synchrony-breaking and Rare Events in Stochastic Neuronal Networks”
We consider a stochastic model for a network of discretized pulse-coupled oscillators containing
randomness both in input and in network architecture. We analyze the scalings which arise in
certain limits and various finite-size effects as perturbations of these limits. Most notably, for
certain parameters this network supports both synchronous and asynchronous modes of behavior
and will switch stochastically between these modes due to rare events. We also relate the
analysis of this network to classical results in random graph theory --- in particular, those
involving the size of the giant component in the Erdos-Renyi random graph. Finally, we study
the effect of network topology on certain mean observables. This work is joint with Charles
Peskin and Joel Spencer.
Barbara Gentz University of Bielefeld
“Metastable Lifetimes in Coupled Random Dynamical Systems”
For a system of coupled Brownian particles in a potential landscape, we will discuss the
dependence of metastable transition times on coupling strength and noise intensity. For weak
coupling, the system behaves like a stochastic particle system, while for strong coupling the
system synchronizes and transitions between metastable states occur almost simultaneously for
all particles. The transition between these extremal regimes involves a sequence of symmetry-
breaking bifurcations.
Away from bifurcation points, the small-noise asymptotics of the transition times is given by the
Eyring-Kramers formula. However, this formula breaks down in the presence of degenerate
(non-quadratic) saddles or wells as present in our system. We will show how results by Bovier,
Eckhoff, Gayrard and Klein, providing the first rigorous proof of the Eyring-Kramers formula,
can be extended to such degenerate landscapes.
This is joint work with Nils Berglund (Orléans) and Bastien Fernandez (CPT-CNRS, Marseille).
John Harlim North Carolina State University
“Stochastic Parameterization Extended Kalman Filter for Turbulent Signal with Model Errors”
An important emerging scientific issue in many practical problems ranging from climate and
weather prediction to biological science involves the real time filtering and prediction through
partial observations of noisy turbulent signals for complex dynamical systems with many degrees

509
of freedom. Model errors are often unavoidable due to our inability to justify the physical
processes and/or to even numerically resolve some physical processes with current super-
computers even if they are well understood. In this talk, I will present a novel reduced filtering
strategy, the ``Stochastic Parameterization Extended Kalman Filter" (SPEKF) algorithm that
systematically corrects both multiplicative and additive bias in an imperfect model, by blending
ideas from classical stability analysis for PDE's, Kalman filter, and stochastic models from
turbulence theory.
Peter Kotelenez Case Western Reserve University
“From Microscopic to Mesoscopic and Macroscopic Equations”
In the first part of the talk we sketch the derivation of a system of stochastic ordinary differential
equations (SODEs) from systems of microscopic deterministic equations in space dimension
$d\geq 2$ via a mesoscopic scaling limit. This scaling limit preserves a spatial correlation
length, $\varepsilon$, between Brownian motions. In a continuum limit (mass of a particle tends
to $0$, the number of particles to $\infty$) the empirical distribution of the system of SODEs
defines a class of quasi-linear stochastic partial differential equations (SPDEs). As the
correlation length $\varepsilon$ tends to $0$ the solutions of the SPDEs tend to the solutions of
quasi-linear (deterministic) PDEs, provided the initial conditions converge appropriately.
In the second part of the talk we will analyze in detail the qualitative behavior of correlated
Brownian motions. We show that at close distance correlated Brownian motions show attractive
behavior which is consistent with the depletion phenomena in colloids.
At the end we will focus on a possible numerical scheme for the time evolution of a finite
number of solute molecules, based on the mesoscopic limit theorem.
Rachel Kuske University of British Columbia
“Noise Driven Order in Biological Models”
Noise-stabilized transients in biological models: This talk covers a few biological models where
the noise-sensitivity is due to the intrinsic multiple time scales, sometimes hidden in the
dynamics. We focus on oscillations sustained by stochastic effects in otherwise quiescent
systems, and show how ideas from unrelated applications can be transfered to these new areas.
The fact that these oscillations have a strongly deterministic behavior, even though they are
purely noise-induced, obscures their stochastic sensitivity. The types of phenomenon include
amplification through coherence resonance, as well as synchronization and mix-mode
oscillations. We show how different stochastic multiple scales analyses illustrate the
mechanisms responsible for the phenomena and the conditions for their appearance.

510
Gabriel Lord
Heriot Watt University
“Numerics for SPDEs”
This talk will introduce some numerical methods for approximating stochastic PDEs and review
results on using an exponential type integrator and a multiscale type approach. We will examine
more recent results on the path-wise convergence analysis. We will motivate the talk with
practical examples drawn from areas such as computational neuroscience and porous media flow
and give an indication of open areas of interest. (draft)
Will discuss joint work with P. Kloeden, A. Neunkirch and T. Shardlow; S. Geiger and A.
Tambue as well as E. Coutts and I. Bello.
Katie Newhall
Rensselaer Polytechnic Institute
“Synchrony in Stochastic Pulse-coupled Neuronal Network Models”
Many pulse-coupled dynamical systems possess synchronous attracting states. Even
stochastically driven model networks of Integrate and Fire neurons demonstrate synchrony over
a large range of parameters. We study the interplay between fluctuations which de-synchronize
and synaptic coupling which synchronizes the network by calculating the probability to see
repeated {\em total firing events}, during which all the neurons in the network fire at once. The
mean time between total firing events characterizes the perfectly synchronous state, and is
computed from a first-passage time problem in terms of a Fokker-Planck equation for a single
neuron.
Houman Owhadi California Institute of Technology
“Non-intrusive and Structure Preserving Multiscale Integration of Stiff SDEs and Stochastic
Hamiltonian Systems with Hidden Slow Dynamics via Flow Averaging”
We introduce a new class of integrators for stiff ODEs as well as SDEs. An example of subclass
of systems that we treat are ODEs and SDEs that are sums of two terms one of which has large
coefficients. These integrators are (i) {\it Multiscale}: they are based on flow averaging and so
do not resolve the fast variables but rather employ step-sizes determined by slow variables (ii)
{\it Basis}: the method is based on averaging the flow of the given dynamical system (which
may have hidden slow and fast processes) instead of averaging the instantaneous drift of

511
assumed separated slow and fast processes. This bypasses the need for identifying explicitly (or
numerically) the slow or fast variables. (iii) {\it Non intrusive}: A pre-existing numerical scheme
resolving the microscopic time scale can be used as a black box and turned into one of the
integrators in this paper by simply turning the large coefficients on over a microscopic timescale
and off during a mesoscopic timescale. (iv) {\it Convergent over two scales}: strongly over slow
processes and in the sense of measures over fast ones. We introduce the related notion of two
scale flow convergence and analyze the convergence of these integrators under the induced
topology. (v) {\it Structure preserving}: For stiff Hamiltonian systems (possibly on manifolds),
they are symplectic, time-reversible, and symmetric (under the group action leaving the
Hamiltonian invariant) in all variables. They are explicit and apply to arbitrary stiff potentials
(that need not be quadratic). Their application to the Fermi-Pasta-Ulam problems shows
accuracy and stability over 4 orders of magnitude of time scales. For stiff Langevin equations,
they are symmetric (under a group action), time-reversible and Boltzmann-Gibbs reversible,
quasi-symplectic on all variables and conformally symplectic with isotropic friction. This is a
joint work with Molei Tao and Jerry Marsden.
Lea Popovic Concordia University
"Stochastic Modeling of Cellular Reaction Networks"
A cellular network can be modeled mathematically using principles of chemical kinetics. These
are particularly useful for studying the dynamic aspects of cells such as gene transcription,
translation, regulation, and protein-protein interactions. At the cellular level, chemical dynamics
are often dominated by the action of regulatory molecules present at levels of only a few copies
per cell. This implies that an adequate description of cellular dynamics requires analysis of
stochastic models on multiple scales. One can exploit the multiscale nature to reduce the
analytical and computational complexity of such models using approximate asymptotic models.
In general, approximations will be "hybrid" in the sense that some components will be discrete,
some diffusive, and some absolutely continuous. We give fluid and diffusion approximation
results for a subset of chemical species when the rest of the chemical species follow faster
ergodic dynamics.
Andrew Stuart Warwick University
“Limit Theorems for MCMC”
I will describe various results concerning the limiting behaviour of MCMC methods in high
dimensions. I will study Random Walk and Langevin based Metropolis-Hastings methods, as
well as Hybrid Monte Carlo. In all cases the key idea is to choose proposal scalings which ensure
an acceptance probability of order one, uniformly in dimension. Limit theorems may then be
proved and used to extract information about the computational complexity of MCMC methods.
The limiting process will be an S(P)DE, or a piecewise deterministic Markov process.

512
I will start by working with product measures and then demonstrate how this analysis may be
generalized to study the sampling of non-product measures. In particular I will highlight the
importance in applications of measures which are absolutely continuous with respect to a product
measure on a Hilbert space and show how the foregoing theory applies in this situation.
Applications will be indicated including data assimilation in oceanography, atmospheric
sciences and the geosciences, as well as problems from molecular dynamics and signal
processing.
Eric Vanden-Eijnden
Courant Institute
“Some Issues in the Long-time Simulation of Complex Systems”
The dynamics of many systems of interest in physics, chemistry and biology span many spatio-
temporal scales, making their analysis by numerical simulations difficult. Indeed, while we are
bound to simulate the dynamics at the smallest and fastest scales, we are often interested in the
system's behavior in the largest and slowest scales. These are typically not accessible to brute
force simulations, both because of the computational cost involved but also because these time
scales are way beyond the time at which we lose pathwise accuracy with standard numerical
integrators. These difficulties force us to change perspective and look at the systems from a
probabilistic viewpoint. Indeed, besides being unreliable, long time numerical trajectories are
also irreproducible due to sensitivity to initial conditions and/or small perturbations, and they are
typically uninformative per se. By identifying the right statistical descriptors for the systems that
characterize their behavior, like e.g. their invariant measure, the time-correlation functions of
suitable observable, or several statistical objects describing rare reactive, we can build algorithms
that are tailor-made to calculate these descriptors accurately and efficiently. This strategy will be
elucidated in this talk and illustrated via examples.
Darren Wilkinson Newcastle University
“Bayesian Inference for Markov Process Models, with Applications to Systems Biology”
This talk will provide an overview of the problem of conducting Bayesian inference for the fixed
parameters of nonlinear multivariate Markov processes observed partially, discretely, and
possibly with error. A sequential strategy based on either SIR or MCMC-based filtering will be
presented. For models based on stochastic differential equations, a method exploiting non-linear
diffusion bridges will be discussed, and a "global" MCMC algorithm that does not degenerate as
the degree of data augmentation increases will be elucidated. The relationship of these
techniques to methods of approximate Bayesian computation will be highlighted, and
applications to problems in systems biology will be explored.

513
#3. Tutorials and Workshop on Space-time Analysis for Environmental Mapping,
Epidemiology and Climate Change
Schedule Sunday, September 13
Radisson Hotel RTP
Overview Tutorials
8:00-8:55 Registration and Continental Breakfast
8:55- 9:00 Welcome
9:00-10:30 Tutorial Lecture 1: Alan Gelfand, Duke University
“Hierarchical Modeling for the Analysis of Spatial Data”
10:30-11:00 Coffee Break
11:00-12:30 Tutorial Lecture 2: Jim Zidek, University of British Columbia
“Designing Monitoring Networks”
12:30 –1:45 Lunch
1:45- 3:15 Tutorial Lecture 3: Michael Stein, University of Chicago
“Asymptotics for Spatial and Spatial-temporal Data”
3:15-3:45 Coffee Break
3:45-5:15 Tutorial Lecture 4: Sylvia Richardson, Imperial College London
“Introduction to Spatial Epidemiology”
Monday, September 14
Radisson Hotel RTP
8:15-9:00 Registration and Continental Breakfast
9:00-9:15 Welcome
9:15-12:00 Session on Climate Change
Chair: Michael Stein, University of Chicago
Claudia Tebaldi, Climate Central/UBC
“Ensemble of Climate Models”
Lenny Smith, London School of Economics

514
“The Science of Impacts and the Impacts of Science: Bayesian Climate Forecasts and
Adaptation in the United Kingdom”
Coffee Break (30 minutes)
Discussion Session
Amy Braverman, California Institute of Technology
Montse Fuentes, North Carolina State University
Richard Smith, University of North Carolina
12:00-1:15 Lunch
1:15-3:30 Session on Random Fields and Applications
Chair: Dongchu Sun, University of Missouri
Chris Wikle, University of Missouri
“Don't Forget the Process!: Using Scientific Process Knowledge to Motivate Spatio-
Temporal Models”
Håvard Rue, Norwegian University of Science and Technology
“Spatial Modeling and Inference using SPDEs”
Discussion Session
Noel Cressie, Ohio State University
Leo Held, University of Zurich
Alexandra Schmidt, Universidade Federal do Rio de Janeiro
3:30-4:00 Coffee Break
4:00-5:00 New Researcher Session
Chair: Alan Gelfand, Duke University
Cari Kaufman, University of California, Berkeley
“Calibration and Prediction Problems in Catchment Scale Hydrology”
Mikyoung Jun, Texas A&M University
“Nonstationary Cross-covariance Models for Multivariate Processes on a Globe”
Anna Michalak, University of Michigan
“Geostatistical Inverse Modeling for Characterizing the Global Carbon Cycle”
5:00-5:40 Poster Advertisement Session (2 minute ads each)
6:30–8:30 Poster Session and Reception
SAMSI will provide poster presentation boards and tape. The board dimensions are 4 ft.
wide by 3 ft. high. They are tri-fold with each side being 1 ft. wide and the center 2 ft.
wide. Please make sure your poster fits the board. The boards can accommodate up to
16 pages of paper measuring 8.5 inches by 11 inches.
Tuesday, September 15

515
Radisson Hotel RTP
8:15-9:00 Registration and Continental Breakfast
9:00-12:00 Session on Spatial Epidemiology
Chair: Richard Smith, University of North Carolina
Michelle Bell, Yale University
“Critical Issues of Exposure Assessment for Human Health Studies of Air Pollution”
Lianne Sheppard, University of Washington
“Linking Exposures to Health: Exposure Effects and Measurement Error in Cohort Studies”
Coffee Break
Discussion Session
Kiros Berhane, University of Southern California
Francesca Dominici, Harvard University
Dongchu Sun, University of Missouri
12:00-1:15 Lunch
1:15-3:30 Session on Spatial and Time-space Point Processes
Chair: Noel Cressie, Ohio State University
Jesper Møller, University of Aalborg
"Spatial and Space-time Point Processes: Theory"
Lance Waller, Emory University
"Spatial and Space-time Point Processes: Applications"
Discussion Session
Marie-Colette van Lieshout, CWI & Eindhoven University of Technology
Charmaine Dean, Simon Fraser University
Janine Illian, University of St. Andrews
3:30 -4:00 Coffee Break
4:00-5:40 New Researcher Session
Chair: Jim Zidek, University of British Columbia
Ethan Anderes, University of California, Davis
“Estimating Nonstationarity using Local Likelihoods”
Dan Cooley, Colorado State University
“Modeling Precipitation Extremes from a Regional Climate Model Simulations”
Crystal Linkletter, Brown University
“Latent Socio-Spatial Process Model for Social Networks”
Chris Paciorek, University of California, Berkeley
“The Importance of Scale for Spatial-confounding Bias and Precision of Spatial
Regression Estimators”

516
Huiyan Sang, Texas A&M University
"Bayesian Modeling of Spatial Extreme Values"
Wednesday, September 16
Radisson Hotel RTP
8:15-9:00 Registration and Continental Breakfast
9:00-12:00 Session on Interface of Deterministic Modeling and Space-time Statistics
Chair: Montse Fuentes, North Carolina State University
Mark Berliner, Ohio State University
“Combining Models and Observations: Bayesian Approaches”
Doug Nychka, NCAR
“Interpreting Geophysical Numerical Models using Spatial Statistics”
Coffee Break
Discussion Session
Susie Bayarri, University of Valencia
Dave Higdon, Los Alamos National Laboratory
Gardar Johannesson, Lawrence Livermore National Laboratory
12:00-1:15 Lunch
1:15–2:45 Working Group Formation and Initial Meeting
2:45 Break
2:45-3:30 Working Group Reports and Scheduling for Thursday and Friday
Thursday, September 17, and Friday, September 18
SAMSI: Individual working group meetings
SPEAKER ABSTRACTS
Ethan Anderes University of California, Davis
“Estimating Nonstationarity using Local Likelihoods”
This talk will present work on using local stationary approximations to estimate the covariance
structure in nonstationary random fields. We will begin the talk by discussing general approaches
to modeling nonstationarity and current estimation techniques for some particular examples. For
the remainder of the talk we will discuss our version of local likelihood estimation and some
practical issues that arise.

517
Mark Berliner Ohio State University
“Combining Models and Observations: Bayesian Approaches”
Advances in computational and observational assets offer both new opportunities and new
challenges in analyzing and predicting the behavior of complex systems. The challenge of
combining information is my main topic. Relevant information sources include observations,
theory, computer model output, past experience, etc. Modern datasets and computer model
output may be extremely large, so extracting their crucial information contents can be difficult.
Further, the enterprise is difficult due to uncertainties present in virtually all information sources,
mandating the need for uncertainty management. I suggest Bayesian hierarchical modeling as a
framework for approaching these issues. The presentation is organized around two classes of
approaches and focuses on examples arising in climate science, ocean forecasting, and glacial
dynamics.
Dan Cooley Colorado State University
“Modeling Precipitation Extremes from a Regional Climate Model Simulations”
Regional climate models (RCMs) are tools which allow scientists to begin to understand how
different forcings may affect climate. In this presentation we summarize two projects each
which build a spatial hierarchical model for RCM precipitation data. In the first project, we
compare extreme precipitation from a control and future simulation of a single RCM. In the
second, we compare extreme precipitation from six different RCMs all being driven by the same
reanalysis data.
Mikyoung Jun Texas A&M University
“Nonstationary Cross-covariance Models for Multivariate Processes on a Globe”
In geophysical and environmental problems, it is common to have multiple variables of interest
measured in the same location and time. As a consequence, there is a growing interest in
developing models for multivariate spatial processes, in particular, the cross covariance models.
We present a class of parametric covariance models for multivariate processes on a globe. The
covariance models are flexible in capturing nonstationarity in the data yet computationally
feasible requiring moderate number of parameters. We apply our covariance model to surface
temperature and precipitation data from an NCAR climate model to estimate the cross
correlations between the surface temperature and precipitation. We comopare the fitted results
from our model to those from the Mat´ern cross-covariance function by Gneiting, Kleiber, and
Schlather (2009) and various versions of the linear model of coregionalization. We also give a
comparison between our
fitted cross correlations and the estimated cross correlation in Trenberth and Shea (2005).

518
Cari Kaufman
University of California, Berkeley
“Calibration and Prediction Problems in Catchment Scale Hydrology”
Statistical models in environmental applications are making increasing use of the scientific
knowledge represented in systems of differential equations describing the evolution of
environmental processes. I will discuss the use of such a model in predicting changes in the
spatial-temporal distribution of soil moisture for a particular catchment under possible climate
change scenarios. One challenge has been to bridge the gap between observations, which are
spatially sparse and temporally dense, and the desired resolution of predictions, which is
spatially dense but aggregated in time. I will discuss how we can achieve this using a
hierarchical model in which the temporal evolution is driven by a catchment-level model, while
observations are modeled according to a stochastic redistribution of total water.
Crystal Linkletter
Brown University
“Latent Socio-Spatial Process Model for Social Networks”
With concerns of bioterrorism, the advent of new epidemics that spread with person-to-person
contact, such as SARS, and the rapid growth of on-line social networking websites, there is
currently great interest in building statistical models that emulate social networks. Stochastic
network models can provide insight into social interactions and increase understanding of
dynamic processes that evolve through society. A major challenge in developing any stochastic
social network model is the fact that social connections tend to exhibit unique inherent
dependencies. For example, they tend to show a lot of clustering and transitive behavior,
heuristically described as “a friend of a friend is a friend.” It might be reasonable to expect that
covariate similarities, or “closeness” in social space, should somehow be related to the
probability of connection for some social network data. The relationship between covariates and
relations is likely to be complex, however, and may in fact be different in different regions of the
covariate space. Here, we present a new socio-spatial process model that smoothes the
relationship between covariates and connections in a sample network using relatively few
parameters, so the probabilities of connection for a population can be inferred and likely social
network structures generated. Having a predictive social network model is an important step
toward the exploration of disease transmission models that depend on an underlying social
network.
Anna Michalak
University of Michigan
“Geostatistical Inverse Modeling for Characterizing the Global Carbon Cycle”

519
Increasing atmospheric concentrations of carbon dioxide are responsible for the largest
component of the rise in radiative forcing since the start of the industrial era. Currently,
approximately 8 Gt of carbon are emitted globally on an annual basis. Only approximately half
of this carbon remains in the atmosphere, however, with the other half being absorbed by global
oceans, plants, and soils, known collectively as carbon “sinks.” The prediction of future climate
change rests on our ability to predict the future behavior of these carbon sinks, with uncertainties
in model predictions caused by poor understanding of carbon sink dynamics being as large as
uncertainties associated with future anthropogenic emissions. This uncertainty can only be
reduced by understanding the spatiotemporal distribution, and processes controlling the
magnitude, of current natural and anthropogenic carbon fluxes. The use of the global network of
atmospheric carbon dioxide monitoring sites to quantify key aspects of the carbon balance at the
earth‟s surface constitutes an inverse problem. Traditionally, these inverse problems have been
addressed in a classical Bayesian framework, with a priori information provided by inventories
of activities related to carbon flux (e.g. fossil fuel emissions) or process-based models that aim to
predict the natural carbon balance in terrestrial ecosystems. Given the sparseness of the
atmospheric monitoring network, and the strong spatiotemporal variability in carbon fluxes, this
inverse problem is highly underdetermined and ill-posed. As a result, poor a priori assumptions
can bias a posteriori estimates, and inverse modeling results have been found to be very sensitive
to a priori assumptions. This presentation will discuss an alternative approach to the solution of
this inverse problem, based on a framework that can leverage multiple spatiotemporal data
sources (including in situ and remote sensing data) while quantifying and accounting for the
covariance structure of the unsampled carbon flux signal. The approach builds on geostatistical
inverse modeling tools developed in the geology and hydrology fields, coupled with formal
model selection tools for identifying key drivers of carbon flux variability. Examples from
recent work at the global and continental scale will be used to illustrate the approach, and
highlight opportunities for future developments at the interface of statistical and earth system
science.
Jesper Møller
Aalborg University
“Spatial and Space-time Point Processes: Theory”
We discuss the theory of modelling and making statistical inference for spatial and space-time
point processes. We start by defining spatial point processes, including marked point processes,
and consider their moment properties and various other useful summaries. Next we study
Poisson, Cox and Markov point process models. We continue with quick and simple simulation
free procedures as well as more comprehensive methods based on a maximum likelihood or
Bayesian approach combined with Markov chain Monte Carlo (MCMC) techniques. Then we
see how all this extend to space-time point processes. Finally, space-time point processes
specified by a conditional intensity are discussed.
Douglas Nychka
National Center for Atmospheric Research
“Interpreting Geophysical Numerical Models using Spatial Statistics”

520
Geophysical models are large numerical computer codes based on physics that can simulate the
motions, thermodynamics and electromagnetic dynamics of the Earth's atmosphere and ocean.
State-of-the-art numerical models typically have high dimensional inputs, produce
numerous spatio-temporal fields as output and require statistics simply to
summarize model results. This talk will discuss applications to regional climate and to the upper
atmosphere. The North American Regional Climate Change and Assessment Program
(NARCCAP) is the most extensive series of simulation undertaken to characterize the
uncertainty in regional climate due to different models and due to different global
conditions. Here the spatial data are averaged meteorological fields from the model output or
fields of derived statistics and the challenge is to make comparisons among models or to
irregular observations. These problems are illustrated by a functional ANOVA decomposition
among different models and also with an investigation of simulated climate extremes.
The Lyon-Fedder-Mobarry (LFM) global magnetospheric model and has the potential for
forecasting the effect of magnetic storms on the Earth's upper atmosphere. LFM is still being
actively developed and can benefit from the deliberate exploration of model parameter space
from statistical methodology for computer experiments. The spatial problem is to estimate the
response of the model to untried parameter combinations in order to find values that improve fit.
As an example, results are given for matching the model parameters to an observed magnetic
storm.
In either of these cases there are common issues of handling large data sets and exploiting
regularly gridded locations to make the statistical computations feasible. Also, these problems
motivate the need for better descriptions of the statistical uncertainty in an estimated field.
Chris Paciorek
University of California, Berkeley
“The Importance of Scale for Spatial-confounding Bias and Precision of Spatial Regression
Estimators”
Spatially correlated residuals are common in regression modeling. I consider the effects of
residual spatial structure on the bias and precision of regression coefficients, developing a simple
framework in which to understand the key issues and derive informative analytic results. When
the spatial residual is induced by an unmeasured confounder, regression models with spatial
random effects and closely-related models such as kriging and penalized splines are biased, even
when the residual variance components are known. Analytic and simulation results show how the
bias depends on the spatial scales of the covariate and the residual: bias is reduced only when
there is variation in the covariate at a scale smaller than the scale of the unmeasured
confounding. I also discuss how the scales of the residual and the covariate affect efficiency and
uncertainty estimation when the residuals are independent of the covariate, with implications for
the use of proxy information such as obtained from deterministic models and satellite retrievals.
In an application on the association between black carbon particulate matter air pollution and
birth weight, controlling for large-scale spatial variation appears to reduce bias from unmeasured
confounders, while increasing uncertainty in the estimated pollution effect.

521
Sylvia Richardson Centre for Biostatistics, Imperial College London
“Introduction to Spatial Epidemiology”
Spatial analyses abound in the epidemiological literature. Geographical variations of chronic
diseases have long been recognised as being able to suggest important aetiological clues.
Recently, the availability of geographically indexed health and population data at a small scale,
with advances in GIS, have opened the way for serious exploration of small area health statistics.
In this tutorial, we will review the main types of studies used in spatial epidemiology, in
particular disease mapping, geographical correlation studies and point source studies. We will
discuss levels of spatial modelling for disease outcomes (point data or aggregated data) and
introduce models for small area disease mapping. We will briefly review issues associated with
cluster and hot spot detection. Extension of disease mapping to space time models and models
for multiple disease will also be presented. Finally, ecological studies and issues related to
ecological bias will be reviewed, with extension to semi-ecologic designs that combine
information at different levels (individual and group). Throughout, the models will be illustrated
by numerous spatial epidemiology case studies.
Håvard Rue
Norwegian University of Science and Technology
“Spatial Modeling and Inference using SPDEs”
In this talk, I will discuss the use of stochastic partial differential equations (SPDEs) for spatial
modeling and inference. The results are highly surprising and powerful, as if we treat the SPDE's
``correct'', we obtain very sparse and explicite Markov representations of the Gaussian field even
on irregular triangulated manifolds. These representations can then be used in a structured
additive regression framework for which Bayesian inference about the marginals can be done
both faster and more accurate using integrated nested Laplace approximations (INLA) instead of
using MCMC.
Huiyan Sang Texas A&M University
"Bayesian Modeling of Spatial Extreme Values"
We propose a hierarchical modeling approach for explaining a collection of point-referenced
extreme values. In particular, annual maxima over space and time are assumed to follow
Generalized Extreme Value (GEV) distributions, with the GEV parameters specified in the latent
stage to reflect underlying spatio-temporal structure. The novelty here is that we relax the
conditionally independence assumption in the first stage of the hierarchial model which has been
adopted in previous work. We offer a spatial process model for extreme values where the

522
behavior of the surface is driven by the spatial dependence which is unexplained under the latent
spatio-temporal specification for the GEV parameters.
Lianne Sheppard University of Washington
“Linking Exposures to Health: Exposure Effects and Measurement Error in Cohort Studies”
An important application of disease models in environmental epidemiology is to provide
estimates (with appropriate uncertainty) of the effects of exposures on health outcomes. The
biggest challenges to accuracy and precision of these effects are the presence of confounders and
exposure measurement error. Epidemiological study design also influences the nature and
quality of inferences possible about health effects. In this talk I focus on the cohort study design
and discuss my perspective on important research topics. I present a basic model framework for
assessing longitudinal change for the effect of environmental exposure and discuss different
parameterizations based on scientific understanding. I review the concept of partitioning
exposure information between and within areas and discuss its scientific value for environmental
epidemiology. I present a two-stage approach to exposure measurement error and discuss the
rationale for not jointly modeling exposure and disease. I present our group‟s emerging research
understanding of the importance of exposure network design, the underlying exposure
distribution, the exposure estimation approach, and the spatial dependence structure in the
disease model in the context of health effects estimation.
Lianne Sheppard, with Adam A. Szpiro, Sun-Young Kim, Paul D. Sampson and the MESA Air
team
Michael Stein University of Chicago
“Asymptotics for Spatial and Spatial-temporal Data”
An overview of different ways of taking limits with spatial and spatial-temporal data and why it
matters.
Claudia Tebaldi University of British Columbia
“Ensemble of Climate Models”
With international efforts like the IPCC assessment as a strong motivation, modeling centers
around the world coordinate their experiments choosing a common set of forcing scenarios, and
contribute their respective output to publicly accessible archives, which host - among other
experiment results - large datasets of projections of future climate for various scenarios. Those
multi-model ensembles sample initial condition, as well as structural uncertainties in the model
design, and their availability has spurred a variety of

523
approaches to quantifying uncertainty in future climate change in a probabilistic way, while the
official reports like IPCC's rely mainly on equal-weighted averages as best guess results, and
models' ranges as a measure of the uncertainty. I am going to discuss the motivation for using
multi-model ensembles and the main challenges in interpreting them. The motivation resides in
the need of characterizing model uncertainties at the structural level. The challenges are
incapsulated in the idiosyncratic nature of this sample
of climate models, which has been called an ensemble of opportunity. It is small, it is not random
nor systematic, it is a sample of best guesses which does not fully explore the range of possible
model behaviors. In addition, model skill in simulating present day climate conditions is shown
to relate only weakly to the magnitude of predicted change. It is thus unclear by how much our
confidence in future projections should increase based on improvements in simulating present
day conditions, a reduction of intermodel spread or a larger number of models.
Lance Waller Emory University
“Spatial and Space-time Point Processes: Applications”
Spatial and spatio-temporal point process models provide a framework for describing,
evaluating, and predicting patterns in observed data. Drawing from the set of theoretical tools
presented in the preceding presentation, we explore their application and performance within a
variety of application areas including the spatial epidemiology of and screening for neglected
tropical diseases, the evaluation of environmental impacts on endangered species, the impact of
disease on the growth and patterning of epidermal nerve fibers, and the modelling of spatial-
temporal patterns in locations of forest fires. Each application provides a unique focus of
inference, and we illustrate the framing of the questions of interest, the selection of appropriate
analytic tools, and the interpretation and effective presentation of results.
Christopher Wikle
University of Missouri
“Don't Forget the Process!: Using Scientific Process Knowledge to Motivate Spatio-Temporal
Models”
Historically, spatio-temporal random processes have been motivated by science-based dynamical
processes. Indeed, classes of dependence structures have been derived from such processes. The
recognition that spatio-temporal processes are typically dynamic in nature, and are associated
with error, has led to the common use of a state-space modeling framework, as developed in the
engineering and statistical time-series literatures. However, it has often been the case that these
methods have been applied without the explicit recognition that there is a spatio-temporal
process involved. That is, these models are fit using unrealistic assumptions (i.e., dynamic does
not just mean time-varying!). Furthermore, in many spatio-temporal settings, the modeling of

524
the process is complicated by high-dimensional state vectors and unreasonably large numbers of
parameters. The point of this talk is that process based knowledge can be used to help motivate
efficient spatio-temporal dynamical parameterizations (and, or state-dimension reduction) for
linear and nonlinear processes. In addition, the talk will emphasize that the hierarchical modeling
framework allows one to build complexity in these formulations by modeling these parameters
(often using random processes as well) explicitly. The talk will include motivating examples
from the atmospheric, ocean, and ecological sciences.
#4: Self-Organization and Multi-Scale Mathematical Modeling of Active Biological Systems
October 26 – 28, 2009
Schedule
Monday, October 26, 2009
(SAMSI)
8:30 – 9:00 Registration, Continental Breakfast
9:00 – 9:15 Welcome
9:15 – 10:00 Mike Shelley, Courant Institute, New York University
“Modeling the Large-scale Hydrodynamics of Living Suspensions”
10:00 – 10:45 Simona Mancini, University of Orleans
“A Fokker-Planck Model for Two Interacting Populations of Neurons”
10:45 – 11:15 Coffee Break
11:15 – 12:00 Suncica Canic, University of Houston
“Some Multi-scale Issues in Blood Flow”
12:00 – 1:15 Lunch
1:15 - 2:00 Danielle Hilhorst, Université de Paris-Sud 11
“On the Fast Reaction Limit of a Competition-diffusion System”
2:00 – 2:45 Anna Balazs, University of Pittsburgh
“Self-sustained Motion of a Train of Haptotactic Microcapsules”
2:45 – 3:15 Coffee Break

525
3:15 – 4:00 Jacques Prost, ESPCI ParisTech/ Institut Curie
“Simple Examples of Tissue Dynamics”
4:00 – 4:15 Poster Advertisement Session (2 minute ads each)
4:15 - 5:15 Informal Discussions
5:15 –7:15 Poster Session and Reception
SAMSI will provide poster presentation boards and tape. The board
dimensions are 4 ft. wide by 3 ft. high. They are tri-fold with each side
being 1 ft. wide and the center 2 ft. wide. Please make sure your poster
fits the board. The boards can accommodate up to 16 pages of paper
measuring 8.5 inches by 11 inches.
Tuesday , October 27, 2009
(SAMSI)
8:30 - 9:00 Registration, Continental Breakfast
9:00 - 9:45 Benoit Perthame, University P. et M. Curie
“Analysis of PDE Models for Molecular Motors”
9:45 - 10:30 Jerry Gollub, Haverford College
“Swimming Dynamics of Algae Cells and the Fluid Motion They
Produce”
10:30 – 11:00 Coffee Break
11:00 - 11:45 Andrea Bertozzi, University of California, Los Angeles
“Swarming by Nature and by Design”
11:45-12:30 Yuliya Gorb, University of Houston
“Impact of the Residual Stress on the Vibrational Frequency Spectrum of
a Nonlinear Elastic Body”
12:30 - 1:45 Lunch
1:45- 2:30 Tim Pedley, University of Cambridge
“Collective Behavior of Swimming Micro-organisms”
2:30- 3:15 Rachel Bearon, University of Liverpool
“Individual to Population Models of Swimming Micro-organisms in Fluid
Flow”
3:15- 3:45 Coffee Break

526
3:45 – 4:30 Mark Alber, University of Notre Dame
“Connection between Discrete Stochastic and Continuous Models with
Applications to Biology”
4:30 - 5:30 Discussions
Wednesday, October 28, 2009
(SAMSI)
8:30 – 9:00 Registration, Continental Breakfast
9:00 - 9:45 Michael Graham, University of Wisconsin-Madison
“Transport and Collective Dynamics in Suspensions of Swimming Particles”
9:45 - 10:15 Andrey Sokolov, Princeton University
“Swimming Bacteria at Work: Reduction of Effective Viscosity and
Bacterial Machines”
10:15 - 10:45 Coffee Break
10:45 – 11:15 Lei Zhang, University of Bonn
“An Atomistic to Continuum Model for Self-assemblying Biopolymer
Aggregates”
11:15 - 12:00 Dmitry Karpeev, Argonne National Laboratory
“Effective Viscosity of Suspensions of Swimming Bacteria”
12:00-12:15 Concluding Remarks
12:15 – 1:15 Lunch
1:15 Adjourn
SPEAKER TITLES/ABSTRACTS
Mark Alber
University of Notre Dame
“Connection between Discrete Stochastic and Continuous Models with Applications to Biology”
Swarming, a collective motion of many thousands of cells, produces colonies that rapidly spread over
surfaces. A detailed cell- and behavior-based computational model of M. xanthus swarming [1] will
be used in this talk to show that reversals of gliding direction are essential for swarming and that the
reversal period predicted to maximize the swarming rate is the same as the period observed in
experiments. This suggests that the circuit regulating reversals evolved to its current sensitivity under
selection for growth achieved by swarming. Also, an orientation correlation function will be used to
show that microscopic social interactions help to form the ordered collective motion observed in
swarms [2]. Then a continuous limit will be described of a two-dimensional stochastic discrete model

527
describing cells moving in a medium and reacting to each other through direct contact, cell-cell
adhesion, and long range chemotaxis [3]. Contrary to classical Keller- Segel model, solutions of the
obtained nonlinear diffusion equation do not collapse in finite time and can be used even when
relative volume occupied by cells is ruther large. A very good agreement was demonstrated between
Monte Carlo simulations and numerical solutions of the obtained macroscopic nonlinear diffusion
equation. Combination of microscopic and macroscopic models was used to simulate growth of
Structures similar to early vascular networks.
1. Wu, Y., Jiang, Y., Kaiser, D., and M. Alber [2007], Social Interactions in Myxobacterial
Swarming, PLoS Computational Biology 3 12, e253.
2. Wu, Y., Jiang, Y., Kaiser, D., and M. Alber [2009], Periodic reversal of direction allows
Myxobacteria to swarm, Proc. Natl. Acad. Sci. USA 106 4 1222-1227 (featured in the Nature
News, January 20th, 2009, doi:10.1038/news.2009.43).
3. Lushnikov, P.P., Chen, N., and M.S. Alber [2008], Macroscopic dynamics of biological cells
interacting via chemotaxis and direct contact, Phys. Rev. E. 78, 061904.
Anna Balazs
University of Pittsburgh
“Self-sustained Motion of a Train of Haptotactic Microcapsules”
Using theory and simulation, we design a “train” of N microcapsules that undergoes self-sustained,
directed motion along an adhesive surface in solution. The motion is initiated by the release of
nanoparticles from a single “signaling” capsule at one end of the train. The released nanoparticles
can bind to the underlying surface and thereby induce an adhesion gradient on the substrate. Through
the combined effects of the self-imposed adhesion gradient and hydrodynamic interactions, the N
microcapsules autonomously move in a single file toward the region of greatest adhesion. At late
times, this train reaches a steady-state velocity U , which decreases with train length as N −1/ 2 . We
calculate the maximum length for which the train maintains this cooperative, autonomous motion.
Rachel Bearon
University of Liverpool
“Individual to Population Models of Swimming Micro-organisms in Fluid Flow”
Swimming micro-organisms in fluid environments are ubiquitous and diverse. Such micro-organisms
frequently undergo movement patterns which can be modeled as random walks. The presence of
external cues such as light, chemical gradients, or gravity can modify individual-level behaviour
resulting in the random walk being biased towards a preferred direction. In still fluid, at the
population level, this can mathematically described as a diffusion process with drift. In many natural
environments, swimming occurs in fluid environments undergoing motion. The fluid flow will

528
interact with the swimming behaviour in several ways and alter the spatial distribution of a
population, leading to such phenomena as bioconvection and gyrotactic focussing. Here I present the
derivation of a population-level advection-diffusion model for gyrotactic algae which is based on
extensive experimental observations of individual swimming cells in still fluid. I will then present
theoretical predictions and experimental data describing the behaviour of gyrotactic micro-organisms
in 3D flow. Finally I will discuss the effect of flow on the population-level spatial distribution.
Andrea Bertozzi
University of California, Los Angeles
“Swarming by Nature and by Design”
The cohesive movement of a biological population is a commonly observed natural phenomenon.
With the advent of platforms of unmanned vehicles, such phenomena has attracted a renewed interest
from the engineering community. This talk will cover a survey of the speaker's research and related
work in this area ranging from aggregation models in nonlinear PDE to control algorithms and
robotic testbed experiments. We conclude with a discussion of some interesting problems for the
applied mathematics community.
Suncica Canic University of Houston
“Some Multi-scale Issues in Blood Flow”
The speaker will talk about some multi-scale issues related to the derivation of the effective, 3D
axially symmetric equations of Biot type describing blood flow in compliant arteries with thick and
thin walls. The resulting equations form a nonlinear, hyperbolic-parabolic moving boundary problem
in two spatial and one time variables. A tricky choice of the correct time scale which will capture
both the fast waves in the arterial walls, and the relatively slow bulk velocity of blood will be
discussed. The resulting effective equations uncover many interesting physics features of the problem
otherwise hidden in the full problem coupling the incompressible, Navier-Stokes equations modeling
the fluid flow, with the structure equations (3D elasticity or viscoelasticity) modeling the arterial wall
behavior.
Jerry Gollub
Haverford College
“Swimming Dynamics of Algae Cells and the Fluid Motion They Produce”
Many cells have two flagella that behave like coupled oscillators: they can be either synchronous or
asynchronous. When synchronized (due apparently to stresses transmitted through the fluid), the cell
swims relatively straight. When asynchronous, the cell undergoes a sharp turn, which is can affect
nutrient gain or help to avoid predators. The cell is apparently able to switch between these two states
[1]. The origin of cell diffusion has thus been determined for algae cell swimmers for the first time.

529
We also consider the mixing of the background fluid produced by a cloud of swimming cells [2].
Tracers in the fluid undergo an enhancement in their Brownian motion that gives a surprising self-
similar probability distribution of displacements consisting of a Gaussian core and also exponential
tails resulting from the nearby passage of swimmers. The effects of oscillatory flagellar beating are
emphasized [3].
[1] Marco Polin, Idan Tuval, Knut Drescher, J.P. Gollub, and Raymond E. Goldstein,
"Chlamydomonas swims with two "gears" in a eukaryotic version of run-and-tumble locomotion",
Science 24 July 2009. Accompanied by a Perspective by Roman Stocker and William M. Durham:
"Eukaryotic flaggelar synchronization: tumbling for stealth?"
[2] Kyriacos C. Leptos, Jeffrey S. Guasto, J.P. Gollub, Adriana I. Pesci, and Raymond E. Goldstein,
"Dynamics of enhanced tracer diffusion in suspensions of swimming microorganisms", submitted to
Physical Review Letters.
[3] Work supported by the BBSRC (REG), a Leverhulme Trust Visiting Professorship (JPG), and
NSF Grant DMR0803153 (JPG).

530
Yuliya Gorb
University of Houston
“Impact of the Residual Stress on the Vibrational Frequency Spectrum of a Nonlinear Elastic Body”
Our work is on the modeling and analysis of the high frequency vibrational response of nonlinear
elastic bodies subjected to large deformations and residual stresses. The problem derives from
modeling the use of an ultrasound catheter to interrogate in-vivo atherosclerotic plaques in large
arteries. Given the theoretical and practical difficulties of determining the residual stress in healthy
arteries, it is even more daunting to model and measure it in arteries with a significant atherosclerotic
plaque burden. The difficulty in determining the residual stress is a central motivation for an aspect
of the study that addresses the question of how much detail of the residual stress is necessary in order
to distinguish key tissue types via ultrasound techniques.
Michael Graham
University of Wisconsin-Madison
“Transport and Collective Dynamics in Suspensions of Swimming Particles”
A suspension of swimming organisms is an example of an “active” complex fluid. At the
environmental scale, it has been suggested that swimming organisms such as krill can alter mixing in
the oceans. At the laboratory scale, experiments with suspensions of swimming cells have revealed
characteristic swirls and jets much larger than a single cell, as well as causing increased diffusivity of
tracer particles. This enhanced diffusivity may have important consequences for how cells reach
nutrients, as it indicates that the very act of swimming toward nutrients alters their distribution. The
enhanced diffusivity has also been proposed as a scheme to improve transport in microfluidic devices
and might be exploited in microfluidic cell culture of motile organisms or cells.
The feedback between the motion of swimming particles and the fluid flow generated by that motion
is thus very important, but is as yet poorly understood. In this presentation we describe theory and
simulations of hydrodynamically interacting microorganisms that shed some light on the
observations. In the dilute limit, simple arguments reveal the dependence of swimmer and tracer
velocities and diffusivities on concentration. As concentration increases, we show that cases exist in
which the swimming motion generates dramatically enhanced transport in the fluid. This transport is
coupled to the existence of long-range correlations of the fluid motion. Furthermore, the mode of
swimming matters in a qualitative way: microorganisms pushed from behind by their flagella are
predicted to exhibit enhanced transport and long-range correlations, while those pulled from the front
are not. A physical argument supported by a mean field theory sheds light on the origin of these
effects. These results imply that different types of swimmers have very different effects on the
transport of nutrients or chemoattractants in their environment.

531
Danielle Hilhorst
Université de Paris-Sud 11
“On the Fast Reaction Limit of a Competition-diffusion System”
We consider a competition-diffusion system for two competing species; the density of the first specie
satisfies a parabolic equation whereas the second one either satisfies a parabolic equation or an
ordinary differential equation. We show that the two species spatially segregate as the interspecific
competition rate becomes large; the limit problem turns out to be a free boundary problem, which
may have the form of a Stefan problem. We first present a convergence result as well as an error
estimate. We then focus on the singular limit of the interspecific reaction term, which involves a
measure located on the free boundary. This is joint work with S. Martin, M. Mimura and H.
Ninomiya.
Dmitry Karpeev
Argonne National Laboratory
“Effective Viscosity of Suspensions of Swimming Bacteria”
We present a model for dilute suspensions of swimming bacteria in a Stokesian fluid and use it to
calculate the effective viscosity of the suspension. A bacterium rotates its flagella to propel itself
forward or to reorient itself randomly in a process called tumbling. Due to a bacterium's asymmetric
shape, interactions with a prescribed generic background flow, such as a purely straining or a planar
shear flow, cause the bacterium to preferentially align in certain directions. In these aligned
configurations, self-propulsion produces a reduction in the effective viscosity. For sufficiently weak
back- ground flows, the effect of self-propulsion on the effective viscosity dominates all other
contributions, leading to an effective viscosity of the suspension that is lower than the viscosity of the
ambient fluid and, potentially, even a locally negative effective viscosity. This is in agreement with
recent experiments on suspensions of Bacillus subtilis. We present a number of asymptotic results for
the dilute limit, in which the effective viscosity can be explicitly quantified in terms of the geometry
of the bacteria, the parameters of self-propulsion and the characteristics of the background flow.
This is joint work with Leonid Berlyand, Brian Haines, Vitaliy Gyrya (Penn State) and Igor Aronson
(Argonne/U.Chicago).
Simona Mancini
University of Orleans
“A Fokker-Planck Model for Two Interacting Populations of Neurons”
We consider a kinetic equation (Fokker-Planck equation) describing the evolution in time of the
distribution function of the firing rates for two interacting population of neurons. This equation is
deduced from a Wilson-Cowan type model (see [1]), consisting on a system of stochastics
differential equations describing the evolution in time of the firing rates of neurons of various

532
interacting populations. This kind of model is applied, for example, in the study of the neuronal
response to various visual stimuli.
The specificity of the Fokker-Planck equation is that the flux term doesn't derive from a potential.
We shall prove, applying the Krein-Rutman theorem, the existence and uniqueness of a positive
solution to the stationary problem. Moreover, we show, by standard analysis, the existence and
uniqueness of the solution for the time dependent problem. Finally, the positivity of this last one and
its convergence towards the stationnary solution will be justified applying genereal relative entropy
methods.
Concerning numerical simulations, and their comparisons with known results, our results are in
agreement with those find in [1] by means of moments analysis on the stochastic system. Moreover,
we remark the slow-fast behaviour for the evolution of the distribution function, and we will then
briefly investigate the reduction of the stochastic system to one stochastic differential equation,
yielding to one-dimesional Fokker-Planck model.
[1] G. Deco, D. Marti, Biological Cybernetics, (2007).
Tim Pedley
University of Cambridge
“Collective Behaviour of Swimming Micro-organisms”
Bioconvection patterns are observed in shallow suspensions of randomly, but on average upwardly,
swimming micro-organisms which are a little denser than water. The basic mechanism is that an
overturning instability develops when the upper regions of fluid become denser than the lower
regions. The reason for the upswimming depends on the species of micro-organism: certain algae are
bottom-heavy, and therefore experience a gravitational torque when they are not vertical; certain
oxytactic bacteria swim up oxygen gradients that they generate by consuming oxygen. Rational
continuum models can be formulated and analysed in each of these cases, as long as the cell volume
fraction is low enough for cell-cell interactions to be neglected. An important aspect of the theory is
the stress distribution associated with the cells‟ active swimming motions, and the effect depends on
whether they are „pullers‟ (like algae) or „pushers‟ (like bacteria.
Another sort of pattern-formation ("whorls and jets") is observed in very concentrated cultures of
swimming bacteria where cell-cell interactions are crucial. Here we examine the deterministic
swimming of model organisms which interact hydrodynamically but do not exhibit intrinsic
randomness except in their initial positions and orientations. A micro-organism is modelled as a
squirming, inertia-free sphere with prescribed tangential surface velocity. Pairwise interactions have
been computed using the boundary element method, and the results stored in a database. The
movement of a number of identical squirmers is computed by the Stokesian Dynamics method, with
the help of the database of interactions. It is found that the spreading in three dimensions is correctly
described as a diffusive process after a sufficiently long time. Scaling arguments are used to estimate
this time-scale and the diffusivities. These depend strongly on volume fraction and mode of
squirming. However, in two dimensions the squirmers show a definite tendency to aggregation.

533
Benoit Perthame
University P. et M. Curie
“Analysis of PDE Models of Molecular Motors”
The question to explain how motion is produced within the cells (and thus in muscls and living
organisms) is fundamental in biology. In the early 90's, experimental devices have permitted to
observ the processes involved in this mechanism and to produce its biophysical understanding. It is
one of the domains where new mathematical models in biology are now available after the input of
several groups of physicists.
The purpose of this talk is to develop a mathematical theory along PDE formulations proposed and
anamyzed by D. Kinderlehrer and his co-authors. The motors we consider here are:
-) flashing rachets with asymmetric potentials,
-) conformation changes in molecules moving along a filament with an 'asymmetric'
potential.
We give different statements, in some asymptotic regimes or not, proving that the density
concentrates on one end of the filament determined by the asymmetry of the potential. The question
is to determine if 'asymmetry' just means 'non-symmetric'?
Jacques Prost
ESPCI ParisTech/ Institut Curie
“Simple Examples of Tissue Dynamics”
I will discuss tissue growth dynamics in simple geometries, introducing the notion of homeostatic
pressure. I will first show that when two tissues compete for space, in the absence of chemical
signaling, the one, which has the largest homeostatic pressure, always win. I will subsequently show
that in order for a micro-tumor to grow it must exceed a critical radius and calculate the probability
for a tumor to exceed that radius. Boundary effects and orders of magnitudes will also be discussed.
M. Basan, T. Risler , JF Joanny, X Sastre-Garau, J Prost, Homeostatic competition drives tumor
growth and metastasis nucleation Arxiv preprint arXiv:0902.1730, accepted HFSP Journal (2009).
Michael Shelley
Courant Institute, New York University
“Modeling the Large-scale Hydrodynamics of Living Suspensions”
Locomotion of an organism through a fluid is one of the most fascinating instances of fluid-structure
interaction. Just as fascinating are the large-scale flows that result when there are not one but many
locomoting bodies moving and interacting with each other through the fluid. Aside from their
intrinsic importance to biology, such systems offer new approaches to micro-scale mixing and

534
transport, as well as extraction of mechanical work, from active fluids. I will overview recent
mathematical and simulational work in describing "active suspensions" here composed of many self-
locomoting particles moving through a Stokesian fluid. This work ranges from using large-scale
particle-based simulations of hydrodynamically interacting swimmers, to the development and
application of continuum kinetic theories. Our analyses and simulations of these models demonstrate
the existence of large-scale mixing and transport, dependent upon micro-mechanical swimming
mechanisms. I will also discuss recent work on how such dynamics is modified by chemo-sensing
and taxis.
Andrey Sokolov
Princeton University
“Swimming Bacteria at Work: Reduction of Effective Viscosity and Bacterial Machines”
Measurements of the shear viscosity in suspensions of swimming Bacillus subtilis in free standing
liquid films have revealed that the viscosity can decrease by up to a factor of seven compared to the
viscosity of the same liquid without bacteria or with non-motile bacteria. The reduction in viscosity
is observed in two complimentary experiments: one studying the decay of a large vortex induced by a
moving probe and another measuring the viscous torque on a rotating magnetic particle immersed in
the film. In other series of experiments we showed that in the regime of collective swimming bacteria
can power submillimeter gears and primitive systems of gears with asymmetric teeth. The speed of
rotation depends on and is controlled by amount of oxygen available to the bacteria.
Lei Zhang
University of Bonn
“An Atomistic to Continuum Model for Self-assemblying Biopolymer Aggregates”
Self-assemblying aggregates are formed by single monomers such as peptides. They have a hierarchy
of secondary structures and can be used to model the development of pathological situations such as
Alzheimer's, prions and Huntington's diseases. In this talk, we present a multiscale approach to
model the structural properties of biopolymer aggregates. We developed a theoretical framework
which relates the microscale molecular properties of the monomers to the mesoscopic mechanical
and geometrical properties of the biopolymer aggregates. In particular, one can link the elastic
bending modulus and spontaneous curvature of the self-assembled tapes with the side chain
interactions and the backbone twists of the peptide monomers. The curved nature of the self-
assembled tapes has important biological meaning when they are used as the building block of
higher-order structures. We provide a set of numerical tests to justify our continuum elastic model for
tapes. The results suggests that it should be applicable for higher-order self-assembled structures.

535
#5: Education and Outreach Program Two-Day Workshop October 30 – 31, 2009
Schedule:
Friday, October 30, 2009
8:15 Shuttle from Radisson to SAMSI (Group #1)
8:35 Shuttle from Radisson to SAMSI (Group #2)
8:55 Shuttle from Radisson to SAMSI (Group #3)
9:15-9:30 Welcome and Introductions, Pierre Gremaud (NCSU / SAMSI)
9:30-10:20 “Statistical Models for Environmental Science and Climate Change Research”
Murali Haran (Penn State)
10:20-10:50 R Demonstration, Benjamin Shaby (SAMSI)
10:50-11:10 Break
11:10-12:00 "Downscaling Outputs from Computer Models”
Veronica Berrocal (SAMSI)
12:00-1:00 Lunch
1:00-2:00 R Lab Related to Berrocal's Application
2:00-2:50 "Paleoclimate! Reconstructing Past Temperatures using Natural
Thermometers", Martin Tingley (SAMSI)
2:50-3:20 Break
3:20-3:50 MATLAB Demonstration, Jun Zhang (SAMSI)
3:50-4:30 MATLAB Lab Related to Tingley's Application
4:30-5:00 Graduate School and Career Options, Pierre Gremaud (NCSU / SAMSI)
5:00 Shuttle to Radisson (Group #1)
5:20 Shuttle to Radisson (Group #2)
5:40 Shuttle to Radisson (Group #3)
6:00 Dinner @ Radisson
Saturday, October 31, 2009
8:00 Shuttle from Radisson to SAMSI (Group #1)
8:20 Shuttle from Radisson to SAMSI (Group #2)
8:40 Shuttle from Radisson to SAMSI (Group #3)

536
9:00-9:50 "Where to go When the Volcano Blows"
Susie Bayarri (U. Valencia, Spain)
9:50-10:40 "Multi-site Time Series Analysis of Air Pollution and
Mortality", Howard Chang (SAMSI)
10:40-11:00 Break
11:00-12:00 R Lab Related to Chang's Application
Noon Adjournment and Departure
#6: Program on Sequential Monte Carlo Methods Transition Workshop November 9 – 10, 2009
Schedule:
Monday, November 9, 2009
8.30-8:50 Registration and Continental Breakfast
8.50-9:00 Welcome
9.00-9.30 Chiranjit Mukherjee, Duke University
“Sequential Monte Carlo in Model Comparison: Example in Cellular Dynamics
in Systems Biology”
9.30-10.00 Ioanna Manolopoulou, Duke University
“Adaptive Sequential Re-Sampling from Very Large Datasets in Mixture
Modeling”
10.00-10.30 Sarah Schott, Duke University
“Speeding Up the Product Estimator Using Random Temperatures”
10.30-11:00 Break
11:00-11:30 Simon Godsill, Cambridge University
“Particles, Points and groups - Bayesian Tracking Methods”
11:30-12:00 Francois Septier, TELECOM Lille 1
“Multi-Target Tracking using MCMC-Based Particle Algorithm”
12:00-12:30 Chunjin Ji, Duke University
“Bayesian Nonparametric Modelling for Dynamic Spatial Point Processes”
12.30-1:45 Lunch
1:45 – 2:15 David Dunson, Duke University and Sourish Das, Duke and SAMSI
“Gaussian Process Latent Variable Models: Theoretical Properties and Efficient
Computation”

537
2:15 – 2:45 Minghui Shi, Duke University
“Bayesian Variable Selection via Particle Stochastic Search”
2:45-3:15 Carlos Carvalho, Chicago Business School
"Model Assessment and Sequential Design"
3:15-3.45 Break
3.45 - 4.15 Hedibert Lopes, Chicago Business School
“Particle Learning for Sequential Bayesian Computation”
4:15 – 5:00 Second Chances and Discussion
Tuesday, November 10, 2009
8.30-9:00 Registration and Continental Breakfast
9.00-9.30 Julien Cornebise, SAMSI
“Auxiliary SMC Samplers and Applications to ABC”
9:30 – 10:00 Gareth Peters, University of New South Wales
“Bayesian Alpha Stable Models via SMC Samplers PRC-ABC”
10:00-10.30 Jan Hannig, University of North Carolina Chapel Hill
"An Account of Approaches for SMC in Generalized Fiducial Inference"
10.30-11.00 Break
11.00-11.30 Arnaud Doucet , Institute of Statistical Mathematics / University British Columbia
“Forward Smoothing using Sequential Monte Carlo”
11.30-12:00 Jim Lynch, University of South Carolina
“Some Issues Regarding the Reliability of Load-sharing Systems”
12:00-12:30 Anand Vidyashankar , Cornell University
“State Space Models for Branching Processes”
12.30-1:45 Lunch
1:45-2:15 Giovanni Petris, University of Arkansas
“SMC for Transdimensional Bayesian Inference”
2:15-2:45 Konstantin Lyubimov, University of Georgia
“Sequential Monte Carlo Analysis of a Dynamic Model of Mortgage Termination”
2:45-3.15 Edsel Pena, University of South Carolina
“Bayes Multiple Decision Functions”

538
3.15-3.45 Break
3:45 – 4:15 Bin Liu, Duke University and SAMSI
“Adaptive T-mixture Importance Sampling Method”
4:15 – 5:00 Second Chances and Closing Discussion
SPEAKER ABSTRACTS
Carlos Carvalho University of Chicago
"Model Assessment and Sequential Design"
I will provide an update on the activities of the MAAD working group. I will follow with a
presentation of the working paper "Dynamic Financial Index Models" (joint work with Hao
Wang and Craig Reeson).
Julien Cornebise SAMSI
“Auxiliary SMC Samplers and Applications to ABC”
SMC Samplers, as introduced by DelMoral et al. (2006, JRSSB), are a cornerstone extending
SMC methodology to arbitrary sequences of distributions, not necessary linked by recurrence
relations -- on the contrary to the originally motivating problem of filtering state space models.
In this talk, we present an auxiliary variable approach to those new algorithms, introducing
adjustment weights in the resampling step, in a similar way to those brought to SMC filters by
Pitt and Shephard (1999, JASA). Based upon this, we provide new insights and interpretation of
the most recent Approximate Bayesian Computation (ABC)-SMC likelihood-free algorithms.
Arnaud Doucet University of British Columbia
“Forward Smoothing using Sequential Monte Carlo”
We propose a new SMC algorithm to compute the expectation of additive functionals
recursively. Whereas the standard path-based SMC estimator has an asymptotic variance
increasing quadratically with time even under favourable mixing assumptions, the variance of
the proposed SMC estimator only increases linearly with time. This allows us to derive several
new recursive parameter estimation procedures which do not suffer from the particle path
degeneracy problem.
This is joint work with Pierre Del Moral (INRIA & University Bordeaux

539
I) and Sumeetpal S. Singh (Cambridge University).
David Dunson Duke University
“Gaussian Process Latent Variable Models and SMC Computation”
Many interesting models for nonparametric density estimation, dimensionality reduction, flexible
regression, functional data analysis, and spatio-temporal data can be characterized using latent
Gaussian processes. A broad class of such models are described and an SMC approach related to
particle learning is described for posterior computation.
Simon Godsill University of Cambridge
“Particles, Points and groups - Bayesian Tracking Methods”
Authors: Simon Godsill, Francois Septier, Avishy Carmi and Sze Kim Pang.
In this talk I will describe continuous time dynamical models for groups of interacting objects,
such as vehicles, cells, etc. moving in a spatial scene. The models allow for changes in
groupings over time and interactions are captured in a behavioural fashion - objects react to the
behaviour of their neighbours by including a multivariate interaction term in the drift component
of a diffusion process. Inference is carried out
on-line using MCMC adaptations of standard sequential updating.
Jan Hannig
North Carolina State University
We explore the use of Sequential Monte Carlo for generating samples from a generalized fiducial
distribution. We report on both failures and successes of various approaches we undertook.
Chunlin Ji Duke University
“Bayesian Nonparametric Modelling for Dynamic Spatial Point Processes”
We discuss flexible Bayesian nonparametric modelling for inhomogeneous spatio-temporal
processes. This involves nonparametric spatial process mixture models of intensity functions, in
which time variation is introduced via dynamic models for underlying parameters. These models

540
characterize smooth dynamics in time in what may be quite complicated spatial patterns of
spatial inhomogeneity in intensity functions. The framework is based on a time-varying Dirichlet
process partition scheme, and physically attractive time propagation models for parameters of
nonparametric mixture models for intensities. Bayesian inference and model-fitting is addressed
involves novel particle filtering ideas and methods. Illustrative simulation examples in extended
target tracking, and substantive data analysis in applications in cell fluorescent microscopic
imaging tracking demonstrate analysis with these models.
Bin Liu Duke University
“Adaptive T-mixture Importance Sampling Method”
We propose an adaptive importance sampling (IS) method aiming to sample from a static target
distribution, which can be multimodal and also be defined in a high-dimensional parameter
space. This method mainly consists of a mixture training procedure that dynamically adapts a
mixture of Student‟s t distributions to approximate the target, as measured by an entropy
criterion. In particular, both the mixture parameters and the components allocation are updated in
a sequential manner. Taking the refined mixture as importance density, we can obtain accurate IS
estimates to the quantities we desire. A multivariate t-mixture approximation to the target comes
as a natural by-product, relying on which, we can estimate normalizing constants. Relying on
this property, we are using this method in the context of adaptive extra-solar planets detection.
Results from both simulation study and the real astronomers' data analysis are revealed.
Hedibert Lopes
University of Chicago
“Particle Learning for Sequential Bayesian Computation”
Authors: Hedibert Lopes, Carlos Carvalho, Michael Johannes and Nicholas Polson
In this paper we develop a simulation-based approach to sequential Bayesian computation.
Particle learning provides a simple yet powerful framework for efficient sequential posterior
sampling strategies. The key aspect of PL is its ability to effectively deal with the problem of
sequentially inference of fixed parameters defining general state space models. We illustrate our
methodology in a range of models and applications. We start by working in a wide class of
conditionally Gaussian state space models and generalized dynamic linear models. We further
demonstrate the generality of PL by deriving sequential algorithms for nonparametric Bayesian
and general mixture models. In addition, we extensively study issues related to convergence
diagnostics and provide simulation-based evidence of the efficiency of our particle learning
methodology. We emphasize that sequential updating offers posterior and predictive inferences
together with marginal likelihoods for model assessment as a direct by-product of our analysis so
that, in many cases, particle learning provides a natural alternative to MCMC based strategies.
Jim Lynch University of South Carolina

541
“Some Issues Regarding the Reliability of Load-sharing Systems”
These include natural censoring that occurs in such systems as well as the development of
reliability functions for systems of dependent components where the dependencies are based on
load-sharing considerations.
Konstantin Lyubimov
University of Georgia
“Sequential Monte Carlo Analysis of a Dynamic Model of Mortgage Termination”
This paper a deals with the estimation of the parameters of the latent intensity of mortgage
default and prepayment. Mortgage termination is modeled via doubly stochastic Poisson process
intensity of which depends on observable loan characteristics, dynamic macroeconomic factors
such as interest rates and house prices, and a latent factor capturing duration dependence. This
latter is assumed to be of a diffusion type. Parameters of the latent processes (one for
prepayment and one for default) are estimated using auxiliary particle filter using payment
histories of a large sample of U.S. residential mortgages. Authors calibrate model to market
prices and test different specifications of the latent intensity process.
Ioanna Manolopoulou Duke University
“Adaptive Sequential Re-Sampling from Very Large Datasets in Mixture Modeling”
One of the challenges of Markov Chain Monte Carlo in large data sets is the need to scan
through the whole data at each iteration of the sampler, which can be computationally
prohibitive. Here we consider the case where we focus inferences on observations in a (not
necessarily known) region in sample space. The motivating application arises in flow cytometry,
where interest lies in identifying specific rare cell subtypes and characterizing them according to
their corresponding markers. We develop a Sequential Monte Carlo approach whereby a targeted
sample from the region of interest is sequentially augmented, while the estimates for the
parameters evolve. We implement our procedure on an assessment of the immune response to
cytomegalovirus (CMV)-peptide stimulation using 4-color flow cytometry.
Chiranjit Mukherjee
Duke University
“Sequential Monte Carlo in Model Comparison: Example in Cellular Dynamics in Systems
Biology”
Sequential Monte Carlo analysis of time series provides a direct approach to evaluating
approximate model marginal likelihoods for model comparison. We exemplify this in studies of
dynamic bacterial communication in systems biology, where a long sequence of state vectors

542
follow a complicated nonlinear dynamic model with several dening biochemical parameters.
MCMC methods do not mix well in these contexts, and do not lead easily to reliable estimates of
model marginal likelihood. We develop an auxiliary particle ltering algorithm that
simultaneously updates latent states and fixed parameters. Our algorithm takes advantage of
distributed computing to carry forward a huge number of particles to ensure accuracy of the
estimates. Marginal likelihood computation is developed and illustrated in evaluation of
relevance of selected model components.
Edsel Pena University of South Carolina
The proliferation of high-throughput technology, epitomized by the microarray, has made high-
dimensional decision-making of central and critical importance in many scientific disciplines.
Particular examples of this multiple decision problem is that of simultaneously testing a large
number of pairs of hypotheses, as well as that of multiple classifications or more generally
multiple predictions. When assessing the consequences of actions in such multiple decision
problems, there is usually a need to utilize different measures of errors. In this talk we focus on
the false discovery (classification) and the missed discovery (classification) rates. We provide a
Bayesian solution to the problem
and pinpoint the two major computational aspects that arise: that of posterior computation where
SMC methods is of relevance and that of choosing the specific action among the 2M possible
actions, where M is the dimension of multiple decision problem. We provide an efficient
algorithm for doing the latter computational problem.
Gareth Peters
University of New South Wales
“Bayesian Alpha Stable Models via SMC Samplers PRC-ABC”
This talk focuses on a recent paper in which I develop a novel Bayesian modelling framework
based on likelihood-free inference for both univariate and multivariate alpha-stable distributions.
The multivariate setting is of particular interest as it involves formulating a Bayesian model for
the spectral mass and then utilizing likelihood-free methodology to work efficiently with such a
model.
In addition the new likelihood-free methodology for the alpha-stable setting involves
development of the SMC Samplers PRC-ABC algorithm for this context. The methodology is
then assessed and compared to alternative approaches.
Giovanni Petris University of Arkansas
“SMC for Transdimensional Bayesian Inference”

543
We present a new approach that simplifies the application of SMC to transdimensional Bayesian
inference. The proposed method is based on a simple geometric argument that has already been
applied successfully in transdimensional MCMC settings. Applications to variable selection and
to mixture densities with an unknown number of components will be used to illustrate the
method.
Sarah Schott Duke University
“Speeding Up the Product Estimator Using Random Temperatures”
Many problems consist of finding the ratio between the measure of B and the measure of B‟
where B‟ʗB. Typically, one of these measures is relatively easy to compue, and in finding the
ratio, we can approximate the other. In standard Monte Carlo methods, this ratio is approximated
by drawing samples from B, and couning the number that lie in subset B‟. But such methods
require the number of samples to be of the same order as the ratio itself, which is problematic
when B‟ is exponentially small in the size of B. To overcome this difficulty, the product
estimator introduces a sequence of nested subsets between B and B‟, indexed by a parameter β.
In the product estimator, the number of subsets is fixed. In the new approach presented here, the
sequence of subsets is adaptive. The resulting algorithm is nearly optimal and much easier to
analyze. Moreover, the new
method allows for the simultaneous estimation of the size of the set for all values of β.
Francois Septier TELECOM Lille 1
“Multi-Target Tracking using MCMC-Based Particle Algorithm”
Detection and tracking of multiple targets are essential components of modern sensor systems.
The purpose of multiple target tracking algorithms is to determine the number of targets and their
respective kinematic parameters from sequences of noisy observations. The difficulty of this
problem has increased as sensor systems in the modern battlefield are required to detect and
track targets in very low probability of detection and in hostile environments with heavy clutter.
In this talk, I will present an overview of Markov chain Monte Carlo (MCMC) methods for
sequential simulation from posterior distributions, which represent alternatives to SMC methods.
Then, an implementation of this MCMC-Based particle algorithm to perform the sequential
inference for multitarget tracking will be described and compared with other particle methods by
using a novel evaluation metric.
Minghui Shi Duke University
“Bayesian Variable Selection via Particle Stochastic Search”

544
It has become routine in many application areas to collect high-dimensional sets of candidate
predictors, and there is a need for new methods for searching the massive dimensional model
space for promising subsets. Although a number of sparse estimation methods have been
proposed, such as the Lasso and elastic net, such methods do not allow for uncertainty in variable
selection. An alternative is to use Markov chain Monte Carlo (MCMC) to conduct a stochastic
search of the model space, but such methods face major computational challenges as the number
of candidate predictors increase. This article proposes a new computational approach based on
sequential Monte Carlo, which we refer to as particle stochastic search (PSS). We illustrate PSS
through applications to linear regression and probit models.
Anand Vidyashankar
George Mason University
“State Space Models for Branching Processes”
Branching processes and their variants are extensively used to model data arising in several
investigations in contemporary science: PCR, Clinical trials, Ecology, and Finance among
others. A common theme, in several of these applications, is that the state space of the branching
process is unobservable while some information concerning the relationship between the state
space and the observable space can be obtained from various scientific sources. In this talk, I will
develop the notion of state space models for branching processes and describe a Bayesian
approach to inference that is facilitated by sequential monte carlo methods. Simulation results
and illustration with real data will also be provided.
#7: GEOMED: Spatial Epidemiology 2009 Workshop November 14 – 16, 2009
Charleston, SC
Note to self: Schedule needs to be converted to Word
#8: Program on Stochastic Dynamics Theory and Qualitative Behavior of Stochastic
Dynamics Workshop February 8 – 10, 2010
Schedule:
Monday, February 8, 2010
(SAMSI)
8:15-8:45 Registration and Continental Breakfast
8:45-9:00 Welcome
9:00 - 9:45 Luc Ray-Bellet, University of Massachusetts
“Billiards, Large Deviations, and Non-equilibrium Statistical Mechanics”
9:45- 10:30 Michael Scheutzow, Technische Universitaet Berlin
“Attractors and Expansion for Random Dynamical Systems on a Euclidean Space”
10:30 - 10:45 Break

545
10:45- 11:30 Peter Baxendale, University of Southern California
“Sustained Oscillations and Density Dependent Markov Chains”
11:30 - 12:00 Discussion of Morning talks
12:00 -1:00 Lunch
1:00 - 1:45 Stanislov Molchanov, University of North Carolina, Charlotte
“Stochastic Dynamics of Some Critical Ecosystems”
1:45 - 2:30 Alexei Novikov, Pennsylvania State University
“A Stochastic Particle System for the Burgers' Equation”
2:30 - 3:30 Break/ informal discussions
3:30- 4:00 Avanti Athreya, SAMSI / Duke University
“Metastability in a Nearly-Hamiltonian System”
4:00 - 4:30 Discussion of Afternoon talks
4:30 - 5:30 Short presentations / 5 min madness/ open problem discussion
5:30 -7:30 Poster Session and Reception
SAMSI will provide poster presentation boards and tape. The board dimensions are 4 ft.
wide by 3 ft. high. They are tri-fold with each side being 1 ft. wide and the center 2 ft.
wide. Please make sure your poster fits the board. The boards can accommodate up to
16 pages of paper measuring 8.5 inches by 11 inches.
Tuesday, February 9, 2010
(SAMSI)
8:30-9:00 Registration and Continental Breakfast
9:00 - 9:45 David Nualart, University of Kansas
“Feynman-Kac Formula for the Heat Equation Driven by Fractional Noise”
9:45- 10:30 Dmitry Dolgopyat, University of Maryland
“Quenched Limit Theorem for 1D Random Walk in Random Environment”
10:30 - 10:45 Break
10:45- 11:30 Grigorios Pavliotis, Imperial College, London
“Asymptotic Analysis for the Generalized Langevin Equation”
11:30 - 12:00 Discussion of Morning talks
12:00 -1:00 Lunch

546
1:00 - 1:45 Richard Sowers, University of Illinois
“A Stochastic Moving Boundary Value Problem”
1:45 - 2:30 Amarjit Budhiraja, University of North Carolina
“Some Large Deviation Problems for Infinite Dimensional Stochastic
Dynamical Systems”
2:30 - 3:30 Break/ informal discussions
3:30- 4:00 Scott McKinley, SAMSI / Duke University
“Anomalous Diffusion of Distinguished Particles in Bead-spring Networks”
4:00 - 4:30 Nawaf Bou-Rabee, New York University
“Nonasymptotic Behavior of MALA”
4:30 - 5:00 Discussion of Afternoon talks
Wednesday, February 10, 2010
(SAMSI)
8:30-9:00 Registration and Continental Breakfast
9:00 - 9:45 Barbara Gentz, University of Bielefeld
“Metastability for the Ginzburg-Landau Equation with Space--time White Noise”
9:45- 10:30 Yuri Bakhtin, Georgia Tech
“Diffusion Models of Sequential Decision Making”
10:30 - 10:45 Break
10:45- 11:30 TBD
11:30 - 12:30 Discussion of Morning talks
12:30 - 1:30 Lunch
1:30 Adjournment
SPEAKER TITLES/ABSTRACTS
Avanti Athreya SAMSI / Duke University

547
“Metastability in a Nearly-Hamiltonian System”
The abstract: In physics, metastability often refers to the existence of long-lived but ultimately
unstable states of a physical system, such as a supersaturated solution. Mathematically,
metastability can be understood in the context of large deviations for dynamical systems with
random perturbations. We summarize some of the background (i.e. the Freidlin-Wentzell
theory) and describe how metastability can be interpreted
for a nearly-Hamiltonian system with one degree of freedom.
Yuri Bakhtin Georgia Tech
“Diffusion Models of Sequential Decision Making”
I will consider a class of mathematical models of decision making. These models are based on
dynamics in the neighborhood of unstable equilibria and involve random perturbations due to
small noise. I will report results on the vanishing noise limit for these systems, providing precise
predictions about the statistics of decision making times and sequences of unstable equilibria
visited by the process. Mathematically, the results are based on the analysis of random Poincare
maps in the neighborhood of each equilibrium point. I will also discuss some experimental data.
Peter Baxendale University of Southern California
“Sustained Oscillations and Density Dependent Markov Chains”
A number of recent papers have considered the phenomenon of sustained oscillations in density
dependent Markov models of processes in areas such as interacting populations, epidemics, and
chemical kinetics. This talk will consist of three parts. One part will describe a recent stochastic
averaging result which explains the existence of sustained oscillations for a class of 2-
dimensional diffusion processes. A second part will survey the transition from the original
density dependent Markov chain to a diffusion approximation. (For mathematicians this is work
of Kurtz from the 1970s; for physicists,
chemists and biologists this is the Van Kampen expansion). The last part will bring these ideas
together to provide both qualitative and quantitative results on sustained oscillations for density
dependent Markov chains.
Nawaf Bou-Rabee New York University
“Nonasymptotic Behavior of MALA”

548
MALA, a Monte-Carlo method for sampling from a high-dimensional probability distribution,
can now be used to solve SDEs. I will briefly review this recent result and show why MALA is
suited for computations of quantities like equilibrium correlation functions of molecular systems.
The remainder (and majority) of my talk answers a question of Martin Hairer on the rate of
convergence of MALA to equilibrium, i.e., how long does it take for MALA to be oblivious
about where it started?
Sandra Cerrai University of Maryland
“On the Approximation of Quasipotentials”
By using arguments of $\Gamma$-convergence, we show that the quasi potential $V_\delta$,
corresponding to a class of reaction-diffusion equations in space dimension $d>1$ perturbed by
a Gaussian noise $\partial w^\delta/\partial t$ which is white in time and colored in space,
converges to the quasi-potential $V$, corresponding to space-time white noise, when the noise
has a small correlation radius $\delta$, so that it converges to the white noise $\partial w/\partial
t$, as $\delta\downarrow 0$.
We show how these results apply to the asymptotic estimate of the mean of the exit time of the
solution of the stochastic problem from a domain of attraction for the unperturbed system.
Dmitry Dolgopyat
University of Maryland
“Quenched Limit Theorem for 1D Random Walk in Random Environment”
1D random walk in random environment spends most of the time at the traps. We consider the
transient case and show that with the proper definition of traps the times spent at different traps
are independent exponential random variables (with random means). This is a joint work with
Ilya Goldsheid.
Barbara Gentz
University of Bielefeld
“Metastability for the Ginzburg-Landau Equation with Space--time White Noise”
We consider a Ginzburg--Landau partial differential equation in a bounded interval, perturbed by
weak space--time white noise. As the length of the interval increases, a transition between
activation regimes occurs. Consequently, the classical Kramers formula for the expected
transition time between metastable states breaks down. We will show how recent results by
Bovier, Eckhoff, Gayrard and Klein, providing the first rigorous proof of the Eyring--Kramers

549
formula, can be extended to this degenerate and infinite-dimensional setting in order to derive
the subexponential asymptotics of the transition time at the critical interval length.
This is joint work with Florent Barret (Palaiseau) and Nils Berglund (Orl\'eans).
Scott McKinley SAMSI / Duke University
“Anomalous Diffusion of Distinguished Particles in Bead-spring Networks”
We consider the dynamics of a distinguished particle in a network of thermally fluctuating beads
that interact with each other through linear springs. Such processes can be expressed as the sum
of a Brownian motion with a large number of Ornstein-Uhlenbeck processes. We introduce a
single parameter which can be tuned to produce a wide variety of sub-diffusive behavior -- a
long-term mean-squared displacement satisfying $\E{x2(t)} \sim t^\nu$ where $\nu \leq 1$ -- for
the generic sum-of-OU structure and demonstrate the relationship between this parameter and the
geometric structure of the bead-spring connection network in which the distinguished particle
resides. This development provides a basis to prove a conjecture from the physics community
that the Rouse exponent $\nu = 1/2$ is universal among a wide class of models.
Stanislov Molchanov
University of North Carolina, Charlotte
“Stochastic Dynamics of Some Critical Ecosystems”
Co-authors: Professor Leonid Bogachev (University of Leeds, UK), Professor Gregory Derfel
(Ben-Gurion University, Israel), Yakin Fang (UNCC), Joseph Whitmayer (UNCC)
The talk will present several results on the limiting behavior of the reaction – diffusion equations
in ,1, dZ d i.e. branching processes with diffusion (or more complicated underlying random
motion). The most interesting is the case of the critical populations where mortality and birth
rates are equal and one can expect the existence of the stationary in time and space limiting
distribution for the particle field dZxxtn ),,( .
The non-linear equation for the generating functions (of the Fisher-Kolmogorov-Petrovskii-
Piskunov type, FKPP) provides the infinite system of the equations for the correlation functions.
The analysis of these equations provides the desirable limit theorem
on 3, dZ d and (under special assumptions) on 2Z . In the 2D case we can also include the
immigration into our model. The limiting point field demonstrates many features of the real
biosystems (“patches” in the space distribution, deviations from the Poisonnian statistics etc.).
Alexei Novikov
Pennsylvania State University
“A Stochastic Particle System for the Burgers' Equation”

550
We study the dissipation mechanism of a stochastic particle system for the Burgers‟ equation.
Recently, P.Constantin and G.Iyer formulated and studied velocity field of the viscous Burgers‟
equations as an expected value of a certain stochastic process based on noisy particle
trajectories. However, a Monte-Carlo version of the above does not have a viscous dissipation
mechanism. I particular, this Monte-Carlo system develops shocks in finite time. We consider a
resetting procedure, that regularizes this Monte-Carlo system by adding more `Markovianity' to
it. This is a joint work with G.Iyer.
David Nualart University of Kansas
“Feynman-Kac Formula for the Heat Equation Driven by Fractional Noise”
We will present a Feyman-Kac formula for the stochastic heat equation driven by a
multiplicative fractional Brownian sheet. We will discuss the smoothness of the density of the
solution, and the Holder regularity in space and time variables. This is a joint work with
Yaozhong Hu and Jian Song.
Grigorios Pavliotis Imperial College, London
“Asymptotic Analysis for the Generalized Langevin Equation”
I will present some recent results on the qualitative properties of solutions to the generalized
(non-Markovian) Langevin equation (GLE). After writing the GLE as a Markov processes in an
extended phase space, I will present results on a) estimates on the (exponential) rate of
convergence to equilibrium b) bounds on derivatives of the associated Markov semigroup c) a
homogenization theorem d) convergence to the (Markovian) Langevin equation. Some
applications of our results will also be discussed.
Luc Ray-Bellet University of Massachusetts, Amherst
“Billiards, Large Deviations, and Non-equilibrium Statistical Mechanics”
We present results (joint with L.-S. Young (NUY)) on large deviation estimates for chaotic
billiards and non-uniformly hyperbolic dynamical systems. We also discuss applications of
theses results to the study of non-equilibrium steady states in statistical
mechanics.
Michael Scheutzow
Technische Universitaet Berlin

551
“Attractors and Expansion for Random Dynamical Systems on a Euclidean Space”
We provide sufficient conditions on the coefficients of a stochastic differential equation on a
Euclidean space in order that the associated random dynamical system (rds) admits a random
attractor. Roughly speaking, the drift vector field has to point towards the origin in order for an
attractor to exist. For the proof, we use chaining techniques in order to control the growth of
small balls under the rds. We also provide an example of an rds generated by a stochastic
differential equation which does not possess an attractor even though its Markov semigroup
admits a (unique) invariant probability measure.
This is joint work with Georgi Dimitroff (Kaiserslautern).
Richard Sowers University of Illinois
“A Stochastic Moving Boundary Value Problem”
We consider a stochastic perturbation of a two-phase moving boundary problem proposed by
Ludford and Stewart and studied by Caffarelli and Vazquez. There have been a number of fairly
recent works on the effects of perturbations of Stefan-like problems by Wiener fields. Our
contribution is the effect of a multiplicative term modifying the noise. This ensures that there is
only a single boundary. We understand the existence and uniqueness of the SPDE, and its
boundary regularity. This work is joint with Kunwoo Kim and Carl Mueller.
#9: Program on Space-Time Analysis for Environmental Mapping, Epidemiology and
Climate Change February 17 – 19, 2010
Schedule:
Wednesday, February 17
Radisson Hotel RTP
8:15-8:50 Registration and Continental Breakfast
8:50 -9:00 Welcome
9:00 – 12:00 Session 1: Paleoclimate Analysis
Chair, Murali Haran, Pennsylvania State University
Tapio Schneider, California Institute of Technology
“Reconstructing Past Climates from Proxies: Statistical Challenges”
Caspar Ammann, National Center for Atmospheric Research

552
Break (30 min)
Working Group Session
Paleoclimate: Bala Rajaratnam, Stanford University
Discussion Session
Bo Li, Purdue University
12:00-1:00 Lunch
1:00 – 4:30 Session 2: Extremes
Chair: Peter Craigmile, Ohio State University
Anthony Davison, EPFL
“Geostatistics of Extremes”
Debbie Dupuis, HEC Montréal
“On Modelling (Seasonally Adjusted) Extreme Daily Average Temperatures”
Mike Wehner, Lawrence Berkeley National Laboratory
"Application of Generalized Extreme Value Theory to Coupled General
Circulation Models"
Break (30 min.)
Working Group Session
Spatial Extremes: Richard Smith, University of North Carolina
Discussion Session
Richard Smith, University of North Carolina
4:30-5:30 Tutorial: “S-T Model for Oceanic and Climatological Variables”
Bruno Sanso, University of California, Santa Cruz
5:30-6:00 Poster Advertisements (2 minute ads each)
6:00-8:00 Poster Session and Reception
SAMSI will provide poster presentation boards and tape. The board
dimensions are 4 ft. wide by 3 ft. high. They are tri-fold with each side
being 1 ft. wide and the center 2 ft. wide. Please make sure your poster fits
the board. The boards can accommodate up to 16 pages of paper
measuring 8.5 inches by 11 inches.
Thursday, February 18
Radisson Hotel RTP
8:15-9:00 Registration and Continental Breakfast

553
9:00 – 12:30 Session 3: Climate Models
Chair: Hans Künsch, ETH Zurich
Ilya Timofeyev, University of Houston
“Parametric Estimation of Effective Stochastic Models from Discrete Data”
Grant Branstator, National Center for Atmospheric Research “Climate
Response and the Fluctuation-Dissipation Theorem”
David Stainforth, London School of Economics
“Challenges in the Extraction of Decision Relevant Information from
Multi-Decadal Ensembles of GCMs”
Break (30 min)
Working Group Session
Stochastic vs Deterministic Models: Peter Kramer. RPI
Discussion Session
Marc Genton, Texas A&M University
12:30-1:45 Lunch
1:45 -5:15 Session 4: Regional Climate Modeling and Downscaling
Chair: Marco Ferreira, University of Missouri
Linda Mearns, National Center for Atmospheric Research
“The North American Regional Climate Change Assessment Program
(NARCCAP): An Overview”
Cari Kaufman, University of California, Berkeley
“Functional ANOVA Models for Regional Climate Model Experiments”
Ernst Linder, University of New Hampshire
“Analyzing Regional Climate Model Outputs Using an Extended Model
for Large Spatio-Temporal Lattices”
Break (30 min.)
Working Group Session
Spatio-temporal Computation: Noel Cressie, Ohio State University
Geostats: Veronica Berrocal, Duke University & SAMSI

554
Discussion Session
Steve Sain, UCAR
Friday, February 19
Radisson Hotel RTP
8:15-9:00 Registration and Continental Breakfast
9:00 – 12:30 Session 5: Uncertainty Quantification
Chair: Paul Baines, Harvard University
Chris Forest, Pennsylvania State University
“Statistical Calibration of Climate System Properties”
Hans Künsch, ETH Zurich
“Biases and Interannual Variability of Climate Projections”
Break (30 min.)
Dan Rowlands, Oxford University
“An Objective Bayesian Approach to Climate Forecasting”
Discussion Leader
Mark Berliner, Ohio State University
12:30 – 1:45 Lunch
SPEAKER TITLES/ABSTRACTS
Grant Branstator NCAR
“Climate Response and the Fluctuation-Dissipation Theorem”
One of the most common uses of climate models is for estimation of how the climate system will
react to changes in externally imposed system forcing. The physical processes involved are
complex and involve multiple scales so only comprehensive models give accurate estimates.
Such models are difficult to use for systematic studies or for answering optimization questions.
In this presentation we discuss how the fluctuation-dissipation theorem can be used to generate
response operators that give solutions that are very similar to the response that a comprehensive
model would give for
any imposed (weak) forcing. And because of the simple form of the operator it can be used for
systematic investigations and for optimization problems. Furthermore, these response operators
are calculated using only lag-correlation statistics of the undisturbed system; neither knowledge
of the governing equations nor observations of its response to external forcing is required. Not

555
only can the response of mean state variables be estimated in this way but also estimates of
functionals of state, including variances and eddy fluxes of bandpass fields.
After verifying the accuracy of FDT based response operators we use them to address optimum
excitation questions. For example, we find heating distributions that most efficiently change a)
regional mean surface temperature, b) the amplitude of circulation features like the North
Atlantic Oscillation, and c) stormtrack characteristics including precipitation and eddy variances.
We also use FDT operators to systematically study how moving heat sources in the tropics affect
midlatitude weather statistics, a subject of interest for extending the traditional limit of
predictability.
Anthony Davison EPFL
“Geostatistics of Extremes”
Statistical methods for the analysis of independent extremes are now well-developed and widely
used. However methods for the analysis of extremes of spatial and spatio-temporal data are
much less well-developed. One approach that has been proposed is based on the application of
Bayesian computational tools to extremal models, but this seems unsatisfactory because the
usual formulation involves independence assumptions that contradict obvious properties of
spatial extremes. It seems more natural to attempt to fit max-stable processes, which extend the
classical extreme-value distributions in a natural way, but progress on this approach has been
blocked until recently because of a lack of flexible models for spatial max-stable processes and
because of difficulties in fitting the available models. In this talk I shall describe several families
of models and outline how they may be fitted, with applications to a dataset on temperature
extremes in the Alps. The work is joint with Mehdi Gholamrezaee.
Debbie Dupuis HEC Montreal
“On Modelling (Seasonally Adjusted) Extreme Daily Average Temperatures”
Various extreme value analysis techniques have been used to estimate the potential impact of
climate change on extreme phenomena. Some may be criticized for their inefficient use of
historical data, and our subsequent inability to validate estimates using adequate testing. In this
talk, we propose a model that can be validated using an out-of-sample analysis. We model the
time dynamics of daily average temperatures as a regression between daily detrended and
deseasonalized temperatures, including a seasonal error component to represent the observed
seasonal volatility. We estimate extreme daily average temperatures, normalized by the level of
volatility, using a generalized Pareto distribution after having reduced the extremal dependence
by declustering. The model is fitted to 50 years of daily observations recorded in New York City
and out-of-sample testing shows that the model performs well.
Chris Forest
Pennsylvania State University

556
“Statistical Calibration of Climate System Properties”
The behavior of modern climate system simulators is controlled by numerous parameters. By
matching model outputs with observed data we can perform inference on such parameters. This
is a calibration problem that usually requires the ability to evaluate the computer code at any
given configuration of the parameters. As the climate system simulator attempts to describe very
complex physical phenomena, the task of running the model is very computationally demanding.
Thus, a statistical model is required to approximate the model output. In this work, we use output
from the Massachusetts Institute of Technology two-dimensional climate model (climate system
component of the MIT IGSM2.2), historical records and output from a three-dimensional climate
model, to obtain estimates of the climate sensitivity, the effective thermal diffusivity in the deep
ocean and the net aerosol forcing that control the MIT IGSM2.2. We use a Bayesian approach
that allows for the use of scientifically based information on the climate parameters to be used in
the calibration process. The model tackles the problem of dealing with multivariate computer
model output and incorporates all estimation uncertainties into the posterior distributions of the
climate parameters. Additionally we obtain estimates of the correlation structure of the unforced
variability of temperature change patterns. These results are critical for understanding
uncertainty in future climate change and provide an independent check that the information that
is contained in recent climate change is robust to statistical treatment. These results include
uncertainties in the estimation of the multivariate covariance matrices.
Cari Kaufman University of California, Berkeley
“Functional ANOVA Models for Regional Climate Model Experiments”
Functional analysis of variance (ANOVA) models partition a functional response according to
the main effects and interactions of various factors. Motivated by the question of how to compare
the sources of variability in climate models run under various conditions, we develop a general
framework for functional ANOVA modeling from a Bayesian viewpoint, assigning Gaussian
process prior distributions to each batch of functional effects. We discuss computationally
efficient strategies for posterior sampling using Markov Chain Monte Carlo algorithms, and we
emphasize useful graphical summaries based on the posterior distribution of model-based
analogues of the traditional
ANOVA decompositions of variance. We present a case study using these methods to analyze
data from the Prudence Project, a climate model inter-comparison study providing ensembles of
climate projections over Europe.
Hans Künsch
ETH Zurich
“Biases and Interannual Variability of Climate Projections”

557
We study not only averages, but also interannual variability of multi-model climate projections.
We introduce two different assumptions -- called constant bias and constant
relation, respectively -- for extrapolating the substantial additive and multiplicative biases
present during the control period to the scenario period. There are also strong indications that the
biases in the scenario period are different from the extrapolations from the control period.
Including such changes in the statistical models leads to an identifiability
problem that we solve in a frequentist analysis by a zero sum side condition and in a Bayesian
analysis by informative priors. We illustrate the methods by analysing outputs from regional
climate models from the ENSEMBLES and the PRUDENCE project.
Ernst Linder University of New Hampshire
“Analyzing Regional Climate Model Outputs Using an Extended Model for Large Spatio-
Temporal Lattices”
Keywords: Gaussian random fields ; spatio-temporal analysis ; large data ; approximate
inference ; regional climate model outputs.
We propose an extension of the usual CAR model for spatial lattice data that contains a
smoothness parameter similar to the Matern class. This model is defined via the spectral
decomposition of the precision matrix of the data. For regular rectangular lattices, assuming a
circulant structure, the Fast Fourier transform (FFT) can be used thus this provides a
computationally feasible method for very large data. In addition we suggest additional dimension
reduction techniques. We examine the application of this method to spatio-temporal regional
climate model outputs of the NARCCAP program. We consider spatially varying trend models
as well as functional ANOVA type models. We also discuss connections of our methodology to
other current approaches to analyzing large spatio-temporal data such as dimension reduction
methods and approximations, triangulation and finite element approximation such as in INLA,
and others.
Linda Mearns
National Center for Atmospheric Research
“The North American Regional Climate Change Assessment Program (NARCCAP):
An Overview”
NARCCAP is an international program that is systematically investigating the uncertainties in
regional scale projections of future climate and producing high resolution climate change
scenarios using multiple regional climate models (RCMs) by nesting the RCMs within
atmosphere ocean general circulation models (AOGCMs) forced with the A2 SRES emissions
scenario, over a domain covering the conterminous US, northern Mexico, and most of Canada.
The program also includes an evaluation component through nesting the participating RCMs
within NCEP reanalyses. The spatial resolution of the RCM simulations is 50 km. This program
includes RCMs that participated in the European PRUDENCE program (HadRM3 and RegCM),
the Canadian regional climate model (CRCM) as well as the NCEP regional spectral model

558
(RSM), the NCAR/PSU MM5, and NCAR WRF. AOGCMs being used include the Hadley
Centre HadCM3, NCAR CCSM, the Canadian CGCM3 and the GFDL model. The resulting
climate model runs form the basis for multiple high resolution climate scenarios that can be used
in climate change impacts assessments over North America. High resolution (50 km) global
time-slice experiments based on the GFDL atmospheric model and the NCAR atmospheric
model (CAM3) have also been produced and will be compared with the simulations of the
regional models. There also will be opportunities for double nesting over key regions through
which additional modelers in the regional modeling community will be able to participate in
NARCCAP. Additional key science issues are being investigated such as the importance of
compatible physics in the nested and nesting models. Measures of uncertainty across the
multiple runs are being developed by geophysical statisticians. In this overview talk, evaluation
of the regional model performance and results of and the RCM simulations using boundary
conditions from the current and future runs of the AOGCMs will be presented.
Dan Rowlands University of Oxford
“An Objective Bayesian Approach to Climate Forecasting”
Bayesian Approaches have often being used in making Climate Forecasts for the coming
century. However, most are based on untestable prior assumptions on climate model parameters,
which cannot be verified in the real world. Hence, we suggest that applying ideas from Objective
Bayesian Statistics, where Objective simply means that the prior is chosen using a rule rather
than subjective judgement, may help. We illustrate these ideas using a simple Energy Balance
Model of the climate, and discuss the practicalities in extending this to larger and more complex
models
Tapio Schneider California Institute of Technology
“Reconstructing Past Climates from Proxies: Statistical Challenges”
The problem of reconstructing past climates from proxies can be viewed as a missing-data
problem. The problem is to estimate missing values of climate variables in the past from
available proxy data and statistical relations between climate variables and proxies estimable
from periods of overlap between the two. Because proxy data are sparse, the estimation problems
are usually rank-deficient or at least ill-conditioned, so additional (spatial and/or temporal)
information needs to be used to regularize the estimation problems. I will review statistical
methods currently used in these estimation problems and will discuss ways of improving them.
David Stainforth London School of Economics

559
“Challenges in the Extraction of Decision Relevant Information from Multi-Decadal Ensembles
of GCMs”
Debates over how to effectively stimulate greenhouse gas emission reductions rage on. At the
same time increasing effort is being invested in climate change adaptation. Nations and
industries are focusing on the issue and much of the $100B annual fund which has been proposed
as support from the developed world to the developing world from 2020 onwards, is likely to be
focused on adaptation efforts. This is leading to an increasing demand for climate predictions;
predictions not just of global mean temperature but of a wide range of variables at regional and
local scales. Complex climate models are the principle tools used to provide this information.
Uncertainty analysis is of course critical in such endeavours and consequently an increasing
number of climate ensembles have been generated. These have explored different aspects of
uncertainty and sources of error. They range in size from O(10-100) in activities such as the
CMIP III multi-model ensemble, to O(10,000-100,000) in the climateprediction.net project. We
now have far more data regarding GCM model error than we have ever had before but the key
questions of model interpretation remain; supplemented by ones relating to ensemble
interpretation. How do we relate model output and real world behaviour in extrapolatory
problems in complex non-linear systems? How do we combine model output with physical
understanding to provide robust guidance for societal decisions? How do we relate model
diversity and real world behaviour?
Much effort is currently being expended on the production of regional, even local, scale
probability distributions. Here I will discuss the fundamental challenges in the production of
model based probability forecasts on multi-decadal timescales and at spatial scales which could
be potentially relevant for practical decisions. These include (i) the extrapolatory nature of the
problem combined with (ii) model deficiencies and how they can be characterised, while
focusing on (iii) issues related to the lack of independence in multi-model ensembles and (iv) the
difficulties in creating relevant model metrics given the non-linear nature of the system. As part
of (iii), I will discuss the ad hoc shape of model parameter space; an issue which has significant
implications for the role of emulators in these problem.
Ilya Timofeyev University of Houston
“Parametric Estimation of Effective Stochastic Models from Discrete Data”
It is often desirable to derive an effective stochastic model for the physical process from
observational and/or numerical data. Various techniques exist for performing estimation of drift
and diffusion in stochastic differential equations from discrete datasets. In this talk we discuss
the question of sub-sampling of the data when it is desirable to approximate statistical features of
a smooth chaotic trajectory by a stochastic differential equation.
In this case estimation of stochastic differential equations would yield incorrect results if the
dataset is too dense in time. Therefore, the dataset has to sub-sampled (i.e. rarefied).
Michael Wehner

560
Lawrence Berkeley National Laboratory
"Application of Generalized Extreme Value Theory to Coupled General Circulation Models"
I will begin the presentation by highlighting some examples of Generalized Extreme Value
theory applications used in climate change assessments. This will be followed by a discussion of
the sources of uncertainty in estimating return values of daily averaged temperature and
precipitation. These include model fidelity, parent distribution sample size, robustness of the
fitted statistical model and multi-model variance. Some issues to lead us into the discussion
session will be mentioned at the end of the talk.
#10: Education and Outreach Program Two-Day Undergraduate Workshop February 26-
27, 2010
Schedule:
Friday
8:20 Shuttle from Radisson to SAMSI (Group #1)
8:40 Shuttle from Radisson to SAMSI (Group #2)
9:00 Shuttle from Radisson to SAMSI (Group #3)
9:15-9:30 Pierre Gremaud (NCSU/SAMSI) Welcome and Introduction
9:30-10:20 Scott Schmidler (Duke University, Statistics)
"Markov Chains, Networks, and Molecules"
10:20-10:50 Xueying Wang (SAMSI) R demo
10:50-11:10 Break
11:10-12:00 John McSweeney (SAMSI)
“Epidemics on Graphs”
12:00-1:00 Lunch
1:00-2:00 R lab related to McSweeney's application
2:00-2:50 Avanti Athreya (SAMSI)
“Random Walks and Brownian Motion”
2:50-3:20 Break
3:20-4:10 Oliver Diaz (SAMSI)
“Small Random Perturbation of Chaotic Maps of the Interval
and the Central Limit Theorem”
4:10-4:40 Xueying Wang (SAMSI) MATLAB demo
4:40-5:00 Pierre Gremaud (NCSU/SAMSI) Career options

561
5:00 Shuttle to Radisson (Group #1)
5:20 Shuttle to Radisson (Group #2)
5:40 Shuttle to Radisson (Group #3)
6:00 Dinner @ Radisson
Saturday
8:00 Shuttle from Radisson to SAMSI (Group #1)
8:20 Shuttle from Radisson to SAMSI (Group #2)
8:40 Shuttle from Radisson to SAMSI (Group #3)
9:00-9:50 Cindy Greenwood (Arizona State University)
“Why Stochastic Dynamics?”
9:50-10:40 Bruce Rogers (SAMSI)
“Random Graphs and Linear Algebra”
10:40-11:00 Break
11:00-12:00 MATLAB lab related to Rogers‟ application
Noon Adjournment and Departure
12:00 Shuttle from SAMSI to RDU (Group #1)
12:30 Shuttle from SAMSI to RDU (Group #2)
1:00 Shuttle from SAMSI to RDU (Group #3)
#11: Program on Space-time Analysis for Environmental Mapping, Epidemiology and
Climate Change – Fundamentals of Spatial Modeling Working Group: One-day Workshop
on Objective Bayesian for Spatial and Temporal Models March 20 – 21, 2010
San Antonio, TX
The main theme during the second half of the year for the Fundamental Working Group of the
2009-2010 SAMSI Spatial Program is to explore appropriate prior distributions for parameters of
spatial and temporal models. In the absence of sufficiently quantifiable subjective knowledge
concerning the unknown parameters, it is typical to resort to noninformative or objective priors;
these priors allow most of the benefits of Bayesian analysis to be achieved, while avoiding the
difficulty of obtaining a subjective prior. Formal objective priors were introduced for AR (1)
models by Berger and Yang (1994), and for geo-statistical models by Berger, De Oleveira and
Sanso (2001, JASA) and Paulo (2005, Annals of Statistics). However, the current results are
mainly for situations in which there is no nugget effect and no measurement errors; in practice,
both are ubiquitous.
The purpose of this one day workshop at San Antonio is to discuss the state of the art concerning
objective priors for inference with AR models and spatial processes, and to discuss the way
forward in terms of dealing with nuggets effects and measurements errors There will be three
sessions: Auto-regressive Models, Matching Priors and Fiducial Distributions, and Objective

562
Priors for Spatial Models and Space-Time Models. This will set the stage for further work by the
Working Group on these problems.
Schedule:
Saturday, March 20, 2010
Double Tree Hotel
1:50-2:00 Welcome
2:00-4:00 Session 1: Auto-regressive Models
Chair: Judith Rousseau (Universite Paris Dauphine)
2:00-2:40 Shawn Ni, University of Missouri
Objective Bayesian Analysis for AR(p) Models
2:40-3:20 Brunero Liseo, University of Missouri
Objective Priors for AR(p) Models
3:20-3:30 Maria Maddalena Barbieri Universita Roma, Discussion
3:30-3:40 Floor discussion
3:40-4:10 Coffee Break
4:10-6:00 Session 2: Matching Priors and Fiducial Distributions
Chair: Susie Bayarri (Universitat de Valencia)
4:10-4:50 Stefano Cabras (University of Cagliari) and Maria Eugenia Castellanos (Rey Carlos
University, Spain)
A Matching Prior for the Shape Parameter of the Skew-normal Distribution
4:50-5:00 Gauri Datta (University of Georgia), Discussion
5:00-5:40 Jan Hannig (University of North Carolina-Chapel Hill)
On Generalized Fiducial Inference
5:40-5:50 Jose M. Bernardo (Universitat de Valencia), Discussion
5:50-6:00 Floor discussion
Sunday, March 21, 2010
9:00-Noon Session 3: Objective Priors for Spatial Models and Space-Time Models
Chair: Christian Robert, (Universite Paris-Dauphine)
9:00-9:45 Victor De Oliveira (University of Texas at San Antonio):
Bayesian Default Analysis for Gaussian Random Fields

563
9:45-10:30 Cuirong Ren (South Dakota State University)
Objective Bayesian Analysis for a Spatial Model with Nugget Effects
10:30-11:00 Coffee Break
11:00-11:15 Rui Paulo (Technical University of Lisbon), Discussion
11:15-11:30 Bruno Sanso (University of California at Santa Cruz), Discussion
11:30-12:00 Floor discussions.
#12: Uncertainty Quantification Electronic Townhall Meeting April 6, 2010
Background Mathematical models intended for computational simulation of complex real-world processes are
a crucial ingredient in virtually every field of science, engineering, medicine, and business. Two
related but independent phenomena have led to the near-ubiquity of models: the remarkable
growth in computing power and the matching gains in algorithmic speed and accuracy. Together,
these factors have vastly increased the applicability and reliability of simulation---not only by
drastically reducing simulation time, thus permitting solution of larger and larger problems, but
also by allowing simulation of previously intractable problems.
Utilization of such computer models of processes requires addressing UQ. Issues studied in this
fast expanding field include uncertainties in the initial conditions for the models, models with
unknown parameters and/or stochastic features, combination of model outputs and noisy data
(data assimilation), inaccuracies in the models, limited availability of model outputs due to
simulation costs.
The intellectual content of computational modeling comes from a variety of disciplines,
including mathematics, statistics, operations research, and computer science, and the application
areas are remarkably diverse. Despite this diversity of methodology and application, there are a
variety of common challenges in developing, evaluating and using complex computer models of
processes, which directly relate to the mission of SAMSI.
During the academic year 2011-2012, SAMSI will host a unique year long program on both the
methodological and practical aspects of Uncertainty Quantification. Numerous interactions
between the SAMSI program and the new activity group(s) are expected.
The following participants will be present at SAMSI on April 6 to lead the above discussions:
Mihai Anitescu (ANL), Guillaume Bal (Columbia), Susie Bayarri (University of Valencia), Jim
Berger (SAMSI), Leonid Berlyand (Penn State), Amy Braverman (Jet Propulsion Laboratory,
California Institute of Technology, and UCLA), Dennis Cox (Rice), Jim Crowley (SIAM
Executive Director), George Deodatis (Columbia), Yalchin Efendiev (Texas A&M), Don Estep
(Colorado State), Montse Fuentes (N.C. State), Xavier Garaizar (LLNL), Roger Ghanem (USC),
Pierre Gremaud (N.C. State/SAMSI), Max Gunzburger (Florida State), Jan Hannig (UNC-CH),
Jan Hesthaven (Brown), David Higdon (LANL), Gianluca Iaccarino (Stanford), Pierre
Lermusiaux (MIT), Youssef Marzouk (MIT), Jim Nolen (Duke), Doug Nychka (NCAR),
Houman Owhadi (Cal Tech), Sastry Pantula (N.C. State, ASA President), Abani Patra (U.
Buffalo), Bruce Pitman (U. Buffalo), John Red-Horse (Sandia), Tom Santner (Ohio State), Nell

564
Sedransk (SAMSI), Christine Shoemaker (Cornell), Ralph Smith (N.C. State), Richard Smith
(UNC-CH/SAMSI), Daniel Tartakovsky (UCSD), Ron Wasserstein (ASA Executive Director),
Robert Wolpert (Duke), Jeff Wu (Georgia Tech), Dongbin Xiu (Purdue)
Schedule:
April 6, 2010
SAMSI
8:00-8:45 Shuttles from Radisson Hotel to SAMSI
(Provided by Charlene‟s Safe Ride)
8:30-9:00 Registration and Continental Breakfast
9:00-9:20 Welcome, presentation of SAMSI and structure of UQ program
9:20-9:40 Methodology: mathematical issues
9:40-10:00 Methodology: statistical issues
10:00-10:20 Methodology: engineering issues
10:20-10:40 General methodology discussion
10:40-11:10 Break
11:10-11:30 Applications: climate change
11:30-11:50 Applications: sustainability/energy
11:50-12:10 Applications: geosciences
12:10-12:30 General application discussion
12:30-12:45 Discussion of collaboration with the labs
12:45-1:00 List of action items
1:00-2:00 Lunch
Town Hall meeting
2:00-3:00 Discussion of new SIAM activity group
3:00-4:00 Discussion of new ASA interest group
4:00-4:45 Shuttles from SAMSI to RDU Airport
Both discussions will roughly follow the schedule:
Description of the focus-area of the proposed group
Identification of the target community that the group will serve
Description of how the focus-area overlaps or complements that of existing groups
Description the activities proposed by the group
Description of how the group will enhance the goals of the society at large (SIAM and/or ASA)

565
Description of how the group will assess its success at the close of its first charter period
Discussion of Rules of Procedure
Suggestion of names of officers for the group
Discussion of initial petitioners (20 for SIAM, 25 for ASA)
#13: Program on Space-Time Analysis for Environmental Mapping, Epidemiology and
Climate Change Statistical Aspects of Environmental Risk Workshop April 7 -9, 2010
Schedule:
Wednesday, April 7
Radisson Hotel RTP
8:15-8:50 Registration and Continental Breakfast
8:50 -9:00 Welcome: Jim Berger, SAMSI
Feridun Turkman, SPRUCE
9:00 – 12:45 Session 1: Wildfires
Chair: Richard Smith, University of North Carolina / SAMSI
John Braun, University of Western Ontario (9:00-9:45)
“Using Fire Management Tools to Assess Wildfire Risk”
Feridun Turkman, University of Lisbon, Portugal (9:45-10:30)
“Wildfires: Some Statistical Issues”
Break (30 min)
Jose Gomez-Dans, University College, London (11:00-11:45)
Giovani Silva, University of Lisbon, Portugal (11:45-12:15)
“Modelling and Analysis of Forest Fire Data in Portugal”
Discussion (12:15-12:45)
12:45-2:00 Lunch
2:00 – 2:45 Session 2: Ecological Modeling
Chair: Marian Scott, University of Glasgow
Claire Ferguson, University of Glasgow
“Lake Ecosystems: Quality, Risk and Change”
2:45-3:15 Break (30 min.)
3:15-4:30 Poster Advertisements (2 minute ads each)

566
4:30-7:00 Marian Scott, University of Glasgow
Graduate course presentation:
“What Can the Past Climate Reconstructions Inform us About Future
Climates?”
7:00-9:00 Poster Session and Reception
SAMSI will provide poster presentation boards and tape. The board
dimensions are 4 ft. wide by 3 ft. high. They are tri-fold with each side
being 1 ft. wide and the center 2 ft. wide. Please make sure your poster fits
the board. The boards can accommodate up to 16 pages of paper
measuring 8.5 inches by 11 inches.
Thursday, April 8
Radisson Hotel RTP
8:15-9:00 Registration and Continental Breakfast
9:00 – 12:30 Session 3: Preferential Sampling and Point Process Models
Chair: Leonhard Held, University of Zurich
Raquel Menezes, Minho University (9:00-9:45)
“Geostatistics, Preferential Sampling and Environmental Monitoring”
Håvard Rue, Norwegian U. of Science and Technology (9:45-10:30)
“Log Gaussian Cox Process”
Break (30 min)
Working Group Session
Brian Reich, North Carolina State University (11:00-11:30)
Avishek Chakraborty, Duke University (11:30-12:00)
“Point Pattern Modeling for Degraded Presence-Only Data over Large
Regions”
Jo Eidsvik, NTNU, Norway (12:00-12:30)
“Combining Predictive Process Models and Laplace Approximations for
Fast Bayesian Analysis of Spatial Data”
Discussion
1:00-2:30 Lunch
2:30 -5:15 Session 4: Computation and Visualization
Chair: Jo Eidsvik, NTNU, Norway

567
Andrew Finley, Michigan State University (2:30-3:15)
“Modeling and Mapping Non-Stationary Multivariate Processes for Large
Spatial Datasets”
Emily Kang, SAMSI (3:15-4:00)
"Spatio-Temporal Random Effects Models for Very Large Datasets"
Break (30 min.)
Working Group Session
Frank Zou, NISS (4:30-5:00)
"Spatio-Temporal Modeling: Computation, Visualization, and Dimension
Reduction”
Discussion Session (5:00-5:15)
Friday, April 9
Radisson Hotel RTP
8:15-9:00 Registration and Continental Breakfast
9:00 – 1:00 Session 5: Health Effects
Chair: Montse Fuentes, North Carolina State University
Roger Peng, Johns Hopkins University (9:00-9:45)
“Spatial Misalignment in Studies of the Acute Effects of Ambient Air
Pollution”
Bo Li, Purdue University (9:45-10:30)
“The Impact of Heat Waves on Morbidity in Milwaukee, Wisconsin”
Break (30 min.)
Working Group Session
Eric Kalendra, North Carolina State University (11:00-11:30)
“Spatial-temporal Association Between Daily Mortality and Exposure to
Particulate Matter”
Veronica J. Berrocal, SAMSI (11:30-12:00)
“On the Use of a PM2.5 Exposure Simulator to Explain Birthweight”
Howard Chang, SAMSI (12:00-12:30)
"Impact of Climate Change on Ambient Ozone Level and
Mortality in Southeastern United States”
Ana Rappold, USEPA (12:30-1:00)
”Respiratory and Cardiovascular Effects from the 2008 Wildlife Near NC
Pocosin National Wildlife Range”

568
1:00 – 2:00 Lunch
SPEAKER TITLES/ABSTRACTS
Veronica J. Berrocal SAMSI
Co Authors: Alan E. Gelfand, David M. Holland, Janet Burke, Marie Lynn Miranda
“On the Use of a PM2.5 Exposure Simulator to Explain Birthweight”
In relating pollution to birth outcomes, maternal exposure has usually been described using
monitoring data. Such characterization provides a misrepresentation of exposure as (i) it does not
take into account the spatial misalignment between an individual's residence and monitoring
sites, and (ii) it ignores the fact that individuals spend most of their time indoors and typically in
more than one location. In this paper, we break with previous studies by using a stochastic
simulator to describe personal exposure (to particulate matter) and then relate simulated
exposures at the individual level to the health outcome (birthweight) rather than aggregating to a
selected spatial unit.
We propose a hierarchical model that, at the first stage, specifies a linear relationship between
birthweight and personal exposure, adjusting for individual risk factors and introduces random
spatial effects for the census tract of maternal residence. At the second
stage, we specify the distribution of each individual's personal exposure using the empirical
distribution yielded by the stochastic simulator as well as a model for the spatial random effects.
We have applied our framework to analyze birthweight data from 14 counties in North Carolina
in years 2001 and 2002. We investigate whether there are certain aspects and time windows of
exposure that are more detrimental to birthweight by building different exposure metrics which
we incorporate, one by one, in our hierarchical model. To assess the difference in relating
ambient exposure (i.e. exposure to ambient concentration) to birthweight versus personal
exposure to birthweight, we compare estimates of the effect of air pollution obtained from
hierarchical models that linearly relate ambient exposure and birthweight to those obtained from
our modeling framework.
John Braun
University of Western Ontario
“Using Fire Management Tools to Assess Wildfire Risk”
Ignition risk and burn risk due to wildfire have been studied in a region of Ontario, Canada. Our
goal is to establish a methodology which could be used across the boreal forest region of Canada.
A generalized additive model was employed to obtain ignition risk probabilities and a burn
probability map using only historic ignition and fire area data. The Burn-P3 implementation of

569
the Prometheus fire growth simulation model was also used with the goal of obtaining a more
accurate burn probability map, in the absence of data on the actual regions burned by particular
fires. This approach takes into account fuel types and weather to construct realistic fire shapes.
The map of the vegetation in the region was verified and corrected, based on a field study. Burn-
P3 simulations were run under the settings recommended in the software documentation, and
were found to be fairly robust to errors in the fuel map, but simulated fire sizes appear to be
substantially larger than what is indicated in the historic record. By adjusting the input
parameters in ways that might reflect suppression effects, we conclude with a model which gives
more appropriate fire sizes. Based on the resulting burn probability map, we conclude that the
risk of fire in the study area is much lower than what Burn-P3 predicts under the recommended
settings.
Avishek Chakraborty Duke University
“Hierarchical Modeling of Presence-only Data over Large Regions”
Explaining the distribution of a species using local environmental features is a long standing
ecological problem. Often, available data is collected as a set of presence locations only thus
precluding the possibility of a desired presence-absence analysis. We propose that it is natural
to view presence-only data as a point pattern over a region and to use local environmental
features to explain the intensity driving this point pattern. We use a hierarchical model to treat
the presence data as a realization of a spatial point process, whose intensity is governed by the
set of environmental covariates. Spatial dependence in the intensity levels is modeled with
random effects involving a zero mean Gaussian process. We augment the model to capture
highly variable and typically sparse sampling effort as well as land transformation, both of which
degrade the point pattern. The Cape Floristic Region (CFR) in South Africa provides an
extensive class of such species data. The potential (i.e., nondegraded) presence surfaces over the
entire area are of interest from a conservation and policy perspective. The region is divided into
~37,000 grid cells. To work with a Gaussian process over a very large number of cells we use
predictive spatial process approximation. Bias correction by adding a heteroscedastic error
component has also been implemented. We illustrate with modeling for six of different species.
Also, comparison is made with the now popular Maxent approach though the latter is limited
with regard to inference. The resultant patterns are important on their own but also enable a
comparative view, for example, to investigate whether a pair of species are potentially competing
in the same area. An additional feature of our modeling is the opportunity to infer about
biodiversity through species richness, i.e., the number of distinct species in an areal unit. such
investigation immediately follows within our modeling framework.
Howard Chang SAMSI / Duke University
“Impact of Climate Change on Ambient Ozone Level and Mortality in Southeastern United
States”
Co-Authors: Jingwen Zhou, and Montserrat Fuentes

570
There is a growing interest in quantifying the health impacts of climate change. This paper
examines the risks of future ozone level on non-accidental mortality across 17 urban
communities in Southeastern United States. We present a modeling framework that integrates
data from climate model outputs, historical meteorology and ozone observations, and a health
surveillance database. We first modeled present-day relationships between observed maximum
daily 8-hour average ozone concentrations and meteorology measured during the year 2000.
Future ozone concentrations for the period 2040 to 2050 were then predicted using calibrated
climate model output data from the North American Regional Climate Change Assessment
Program. Daily community-level mortality counts for the period 1987 to 2000 were obtained
from the National Mortality, Morbidity and Air Pollution Study. Controlling for temperature,
dew-point temperature, and seasonality, relative risks associated with short-term exposure to
ambient ozone during the summer months were estimated using a multi-site time series design.
We estimated an increase of 0.61 pbb (95% PI: 0.51-0.71) in average ozone concentration for
2040 to 2050 compared to 2000. This corresponds to 67 (95% PI: 28-107) premature deaths in
the study communities attributable to the increase in future ozone level.
Jo Eidsvik
NTNU, Norway
“Combining Predictive Process Models and Laplace Approximations for
Fast Bayesian Analysis of Spatial Data”
The common hierarchical geostatistical model has statistical model parameters at the bottom
level, a Gaussian random field at the intermediate level, and noisy / indirect data at the top level.
One challenge for fast analysis in such models is the big-n problem driven by the O(n^3) cost of
matrix inversion. A second challenge is fast inference and prediction because there are no closed
form solutions.
We illustrate how predictive process modeling is one solution to the first challenge. This
dimension reduction technique projects the n dimensional data to m <<n knot sites. We next
present Laplace approximations and numerical routines as a fast alternative to the second
challenge. The combination of the two approaches means that modeling and inference can be
done in seconds, for large datasets. This makes higher level inference (model choice, design or
analysing preferential sampling) more available. Examples of acidification of lakes in Norway
and forest data in Michigan are presented.
Claire Ferguson University of Glasgow
“Lake Ecosystems: Quality, Risk and Change”
Establishing historical and current water quality in lake ecosystems is important in terms of
assessing risks to both the environment and human health. Eutrophication (as a result of
increased algae) impacts on plant and animal life within the ecosystem, and cyanobacterial

571
blooms (blue-green algae), of which freshwater environments are susceptible, frequently produce
potent toxins which can have adverse health effects.
Nonparametric statistical approaches will be presented to model the complex interrelated nature
of such systems. Initially, water quality will be investigated for individual lakes, with the
environmental drivers that favour cyanobacterial abundance then investigated for lake
ecosystems more generally. Relationships within the ecosystem can change throughout the year
and are potentially impacted by climate change. Therefore, varying-coefficient models and
smooth principal components analysis will then be used to model changes throughout time in
relationships and covariance structures, respectively.
The modelling with be illustrated using data from Loch Leven (Scotland), for which there exists
an excellent long-term monthly data series from the late 1960‟s, and summer phytoplankton data
from 134 lakes across the UK.
Andrew Finley
Michigan State University
“Modeling and Mapping Non-Stationary Multivariate Processes for Large Spatial Datasets”
Here we extend earlier work on hierarchical multivariate spatial models to accommodate non-
stationarity in the correlations among the outcomes as well as capturing the underlying spatial
associations. In particular, we address the computationally challenging setting where the
observations arise from a large number of locations. Direct application of such multivariate
models to large spatial datasets is often computationally infeasible because of cubic order matrix
algorithms involved in estimation. The situation is even worse in Markov chain Monte Carlo
(MCMC) contexts where such computations are performed for several thousand iterations. Here,
we discuss approaches that help overcome these hurdles without sacrificing richness in
modeling. Specifically, we work with linear models of coregionalization but employ a
dimension-reducing spatial process to model the association between the outcomes. We
illustrate the proposed methods using a synthetic and real dataset. Here, interest lies in visual and
statistical inference in the spatially-varying relationship among the outcome variables residual
spatial processes.
Eric Kalendra
North Carolina State University
“Spatial-temporal Association Between Daily Mortality and Exposure to Particulate Matter”
Fine particulate matter (PM2.5) is a mixture of pollutants that has been linked to serious health
problems, including premature mortality. Since the chemical composition of PM2.5 varies across
space and time, the association between PM2.5 and mortality might also be expected to vary
with space and season. This study uses a unique spatial data architecture consisting of geocoded
North Carolina mortality data for 2001-2002, combined with US Census 2000 data. We study
the association between mortality and air pollution exposure using different metrics (monitoring

572
data and air quality numerical models) to characterize the pollution exposure. We develop and
implement a novel statistical multi-stage Bayesian framework that provides a very broad,
flexible approach to studying the spatiotemporal associations between mortality and population
exposure to daily PM2.5 mass, while accounting for different sources of uncertainty. Most of the
pollution-mortality risk assessment has been done using aggregated mortality and pollution data
(e.g., at the county level), and that can lead to significant ecological bias and error in the
estimated risk. In this work, we study and estimate this bias and error. We also provide a
mathematical adjustment for analysis that uses aggregated data to reduce the error in the risk
assessment due to ecological bias. We present results for the State of North Carolina.
Emily Kang SAMSI
"Spatio-Temporal Random Effects Models for Very Large Datasets"
Datasets from remote-sensing platforms and sensor networks are often spatial, temporal, and
very large. Processing massive amounts of data to provide current estimates of the (hidden) state
from current and past data is challenging, and a large number of spatial locations observed
through time can quickly lead to an overwhelmingly high-dimensional statistical model. We will
demonstrate how a Spatio-Temporal Random Effects (STRE) component of a statistical model
reduces the problem to one of fixed dimension with a very fast statistical solution, a
methodology we call Fixed Rank Filtering (FRF). This is compared in a simulation experiment
to successive, spatial-only predictions based on an analogous Spatial Random Effects (SRE)
model, and the value of incorporating temporal dependence is quantified. The resulting fixed-
rank filter is scalable, in that it can handle very large datasets, and the FRF predictions provide
estimates of missing values and filter out unwanted noise. We illustrate the methods with a
remote-sensing dataset of aerosol optical depth (AOD), from the Multi-angle Imaging
SpectroRadiometer (MISR) instrument on the Terra satellite, yielding an optimal statistical
predictor of AOD on the log scale along with its prediction standard error.
Bo Li
Purdue University
“The Impact of Heat Waves on Morbidity in Milwaukee, Wisconsin”
BACKGROUND: Given the predictions of increased intensity and frequency of heat waves, it is
important to study the effect of high temperatures on human mortality and morbidity. Many
studies focus on heat wave-related mortality; however, heat-related morbidity is often
overlooked.
OBJECTIVES: The goals of this study were to examine how hot weather has affected morbidity
in Milwaukee, Wisconsin and how it is predicted to affect morbidity in the future based on
climate change projections.
METHODS: We collected meteorological, air pollution, and hospital admissions data in
Milwaukee, Wisconsin for the years 1989-2005. We estimated temperature threshold values for

573
different causes of hospital admissions and then quantified the associated percent increase of
admissions per degree above the threshold. We also estimated the future impact of higher
temperatures on admissions for the years 2059-2075.
RESULTS: Five causes of admission (endocrine, genitourinary, renal, accidents, and self-harm)
and three age groups (15-64, 75-84, >85 years) were significant factors as related to high
temperature. The estimations for future scenarios indicate a larger number of days above the
temperature threshold and an excess number of admissions.
CONCLUSIONS: High temperatures had a significant effect on several causes of hospital
admissions and age groups in Milwaukee, Wisconsin for the 1989-2005 time period. Our
predictions of increased number of heat-related hospital admissions are consistent with other
climate projections and have implications for public health interventions.
Raquel Menezes
Minho University – Azurém, Portugal
“Geostatistics, Preferential Sampling and Environmental Monitoring”
Geostatistics involves the fitting of spatially continuous models to spatially discrete data.
Preferential sampling arises when the process which determines the data-locations and the
process being modelled are stochastically dependent. Conventional geostatistical methods
assume, if only implicitly, that sampling is non-preferential. In environmental monitoring
networks, preferential sampling is likely to happen as there is a natural inclination to place more
monitors in areas classified as high risk for pollution. In this talk, we describe a model-based
approach, which considers log-Gaussian Cox processes to model the stochastic dependence of
sampling locations on spatial variable under study (Diggle, Menezes and Su, 2009). We
demonstrate through simulated examples that ignoring preferential sampling can lead to
seriously misleading inferences.We then present an application to biomonitoring data from
eastern Iberian Peninsula, where since the 90's moss has been used as biomonitor for air
pollution to measure heavy metals concentration, with intensified sampling in large urban or
industrial areas.
Roger Peng Johns Hopkins University
“Spatial Misalignment in Studies of the Acute Effects of Ambient Air Pollution”
Time series analyses of ambient air pollution often involve comparing a pollutant measured at a
point in space with an aggregate measure of health. Spatial misalignment of the exposure and
response variables can induce error, the magnitude of which depends on the spatial variation of
the exposure of interest. In air pollution epidemiology, there is an increasing focus on estimating
the health effects of the chemical components of particulate matter. One issue that is raised by
this new focus is the spatial misalignment error introduced by the lack of spatial homogeneity in
many of the particulate matter components. Current approaches to time series modeling do not
take into account the spatial properties of components and therefore could result in biased

574
estimation of health risks. We present a spatial-temporal statistical model for quantifying spatial
misalignment error and show how adjusted heath risk estimates can be obtained using a plug-in
approach and a two-stage Bayesian model. We apply our methods to a database containing
information on hospital admissions, air pollution, and weather for 20 large urban counties in the
United States.
Ana Rappold Environmental Protection Agency
“Respiratory and Cardiovascular Effects from the 2008 Wildfire Near NC Pocosin National
Wildlife Refuge”
The association of mortality and morbidity with exposure to urban air pollution is well
established, however the health effects associated with exposure to wildfire emissions are less
understood. Over the past several decades, there has been an increase in the frequency and
duration of wildfires in the United States. Wildfires are major emitters of aerosol and air
pollution, and pose an important concern to human and ecological welfare. There are substantial
public health concerns that climate change related warming trends will exacerbate these risks.
On June 1st, 2008, a lightning strike initiated a deep, smoldering fire in peat soil in eastern planes
of North Carolina. Prolonged drought and unusually low humidity allowed for rapid progression
of the fire which produced air pollution concentrations ten fold in excess of normal levels. For
duration of the wildfire, smoke affecting mostly the low populated neighboring counties.
However, during a single three day window of predominantly westerly winds, smoke plume
moved inland, exposing a large portion of the state.
Health studies on wildfires are difficult to assess due to their episodic and brief nature. In this
study, we examined emergency department (ED) visits from the state‟s comprehensive
surveillance program to establish the total burden on cardio-respiratory health posed by the
wildfire. We considered daily cardiovascular and respiratory related visits and applied standard
time series analysis to estimate the cumulative risk of exposure. Satellite data products were used
to track the location of the smoke plume and approximate county level exposure to smoke plume.
The goal of the analysis was to use health and exposure information data readily available to the
county, state and federal authorities for timely correspondence to public.
We found that for all respiratory outcomes, ED visits increased, including those for acute
conditions of bronchitis and pneumonia (cRR=1.59%, 95%CI= (1.07, 2.34)), as well as those
with chronic respiratory conditions of asthma (1.65, (1.25-2.17)) and chronic obstructive
pulmonary disease (1.73, (1.05-2.83)). We also observed an increase in hospital ED visits for
heart failure, as well as the trend towards a positive association with the combination of acute
coronary syndrome. No association was found between smoke exposure and cardiac arrhythmias.
Furthermore, none of the outcomes showed change in referent counties. In conclusion, the
findings show that even moderate exposure to wildfire smoke produces significant impact on
human welfare particularly in socio – economically depressed communities.
Håvard Rue
Norwegian University of Science and Technology

575
“Log Gaussian Cox Process”
In this talk I will discuss various issues about Log Gaussian Cox processes, which I think has a
much larger potential for applications than its status is today.
Giovani Silva University of Lisbon
“Modelling and Analysis of Forest Fire Data in Portugal”
In the last decade forest fires became a serious problem in Portugal due to different issues such
as climatic characteristics and nature of Portuguese forest. In order to analyze forest fire data, we
use generalized linear models for modelling the proportion of burned forest area. Our goal is to
find out fire risk factors that influence that proportion of burned area and what may make a forest
type susceptible or resistant to fire. Then, we analyze forest fire data in Portugal during 1990-
1994 from a Bayesian approach.
Keywords: Fire management, Burned area proportion, Forest fire data, Generalized linear model.
K.F. Turkman / M.A. Amaral Turkman
CEAUL- FCUL, University of Lisbon
“Wildfires: Some Statistical Issues”
Wildfires cause extensive loss of property and life and inflict heavy damage on ecosystems.
Policy responses of local and global fire management depend on the proper understanding of the
temporal fire extend as well as on its spatial variation across any given study area. In many fire
regimes, a small number of very large fires are responsible for the vast majority of the area
burned. Therefore, the study of spatial and temporal patterns of incidence of large fires is an
important issue. In this talk, we look at some of the statistical issues that we encountered while
modeling some data sets on wildfires. In particular, modeling extremes of wildfires is quite
challenging, raising some interesting questions.
Frank Zou
NISS
“Spatio-Temporal Modeling: Computation, Visualization and Dimension Reduction”

576
Co-Authors: Scott Holan, and Noel Cressie
Computation, visualization and dimension reduction are critical to proper modeling of high-
dimensional spatio-temporal data that are frequently encountered in substantive scientific
applications. This presentation details the year-long activities of the Computation, Visualization,
and Dimension Reduction in Spatio-Temporal Modeling working group (WG) which is part of
the current SAMSI Program on Space-time Analysis for Environmental Mapping, Epidemiology
and Climate Change. Specifically, we highlight the contributions of WG members that have
added to the success of the group and provide a brief description of research presentations that
have aided in the development of four cohesive sub-working groups (SG) whose purpose is to
investigate open research problems. Finally, we describe the four SGs and the research problems
they are exploring.
#14: Program on Stochastic Dynamics Workshop on Molecular Motors, Neuron Models,
and Epidemics on Networks April 15 -17, 2010
Schedule:
Thursday April 15, 2010
(SAMSI)
8:15-8:45 Charlene‟s Safe Ride Shuttle to SAMSI
8:15-8:45 Registration and Continental Breakfast
8:45-9:00 Welcome
9:00 - 9:55 Susanne Ditlevsen, University of Copenhagen
“The Morris Lecar Neuron Model Gives Rise to the Ornstein-Uhlenbeck
Leaky
Integrate-and-Fire Model”
9:55- 10:50 David Kinderlehrer, Carnegie Mellon University
“Aspects of Modeling Transport in Small Systems with a Look at Motor
Proteins”
10:50 - 11:05 Break
11:05- Noon Motors Group
Noon -1:00 Lunch
1:00 - 1:55 Neurons Group
1:55 - 2:50 Networks Group
2:50 - 3:05 Break
3:05- 4:45 Working Sessions

577
(Rooms 150, 201, 259)
4:45 - 5:30 Working Session Reports and Poster Advertisements
5:30 -7:30 Poster Session and Reception
SAMSI will provide poster presentation boards and tape. The board
dimensions
are 4 ft. wide by 3 ft. high. They are tri-fold with each side being 1 ft. wide
and
the center 2 ft. wide. Please make sure your poster fits the board. The boards
can accommodate up to 16 pages of paper measuring 8.5 inches by 11 inches.
7:00-7:45 Charlene‟s Safe Ride Shuttle from SAMSI to Radisson
Friday April 16, 2010
(SAMSI)
8:15-8:45 Charlene‟s Safe Ride Shuttle to SAMSI
8:30-9:00 Registration and Continental Breakfast
9:00 - 9:55 Laura Sacerdote, University of Torino
“Copulae in Neural Networks Modeling”
9:55- 10:50 Erik Volz, University of Michigan
“Mathematical Modeling of Sexually Transmitted Infections in Dynamic
Contact Networks”
10:50 - 11:05 Break
11:05- Noon Andrea Barriero, University of Washington
“Dynamics and Impact of Spike-time Correlations”
Noon -1:00 Lunch
1:00 - 1:55 Hongyun Wang, University of California, Santa Cruz
“Potential Profile of Molecular Motors”
1:55 - 4:45 Working Sessions
(Rooms 150, 201, 259)
2:30 Break
4:45 - 5:30 Working Session Reports
5:30 – 6:00 Charlene‟s Safe Ride Shuttle from SAMSI to Radisson
SPEAKER TITLES/ABSTRACTS

578
Andrea Barreiro University of Washington
“Dynamics and Impact of Spike-time Correlations”
Correlations among neural spike times can be found widely in the brain, and open the possibility
for cooperative coding of sensory inputs across neural populations. The structure of the
correlations that emerge across cells, however, can depend strongly on spike generation
mechanisms in the individual neurons. In joint work, we investigate the interplay among these
mechanisms, network architecture, and the coding of simple classes of inputs.
Meredith Betterton University of Colorado, Boulder
“Molecular Motors That Change the Length of Their Tracks”
Motor proteins in biological systems typically move with directional bias along a one-
dimensional track. Some types of motors are able to change the length of the track on which they
move, by promoting lengthening or shortening of the track. I will discuss some biological
examples of such motors (helicase proteins and kinesin-8 family proteins) and present
mathematical modeling work to describe the coupled problem of motion and track length change.
In some cases crowding and collective effects due to motion of multiple motors are important.
Susanne Ditlevsen University of Copenhagen
“The Morris Lecar Neuron Model Gives Rise to the Ornstein-Uhlenbeck Leaky Integrate-and-
Fire Model”
We analyse the stochastic-dynamical process produced by the Morris Lecar neuron model, where
the randomness arises from channel noise. Using multi-scale analysis, we show that in a
neighborhood of the stable point, representing quiescence of the neuron, this two-dimensional
stochastic process can be approximated by an Ornstein-Uhlenbeck modulation of a constant
circular motion. The firing of the Morris Lecar neuron corresponds to the Ornstein-Uhlenbeck
process crossing a boundary. This result motivates the large amount of attention paid to the
Ornstein-Uhlenbeck leaky integrate-and-fire model. A more detailed picture emerges from
simulation studies.
David Hunter Penn State University

579
“Bayesian Inference for Contact Networks Given Epidemic Data”
We estimate the parameters of a simple random network and a stochastic epidemic on that
network using data consisting of recovery times of infected hosts. The SEIR epidemic model we
fit has exponentially distributed transmission times with gamma distributed latent (exposed) and
infective periods on a network where every tie exists with the same probability, independent of
other ties. We employ a Bayesian framework and MCMC integration to make estimates of the
joint posterior distribution of the model parameters. We demonstrate some of the important
aspects of our approach by studying a measles outbreak in Hagelloch, Germany in 1861
consisting of 188 affected individuals. We provide an R package to carry out these analyses,
which is available publicly on the
Comprehensive R Archive Network (CRAN).
David Kinderlehrer Carnegie Mellon University
“Aspects of Modeling Transport in Small Systems with a Look at Motor Proteins”
We are all aware that motion in small systems presents many challenges: it is difficult to move
and maintain a course compromised by immersion in a highly fluctuating bath. We discuss some
possibilities for molecular motors, for example, kinesin-1. Our approach is to formulate a
dissipation principle connected to the Monge-Kantorovich mass transfer problem. We show how
this leads to a system of evolution equations. We then discuss how various elements of the
system must be related in order that transport actually occur. Does detailed balance play a role?
Finally, what opportunities do these ideas offer? We examine some 'hybrid variational problems'
and discuss unresolved issues, time permitting.
Duane Nykamp
University of Minnesota
“Toward a Second Order Description of Neuronal Networks”
The complexity of the activity of large numbers of neurons and their interconnectivity creates a
challenge for understanding computations within the brain. The high dimensionality of the
activity patterns and connectivity patterns is a formidable obstacle to an analysis of the
relationships between the connectivity and the behavior of the
network. If one is interested in understanding aspects of a particular behavior of a network, a
fundamental problem is determining which details (or dimensions) of the network are important.
I present an approach to developing low-dimensional network models that capture basic features
of neuronal networks. The approach is based a set of second-order statistics that represent
deviations from random networks and capture interactions among edges. Ensembles of neuronal
networks parametrized by those statistics are a simplified description of aspects of complex
networks. These parametrized classes of networks may capture in just a few dimensions key
changes in network structure as well as influences of the network structure on the dynamics of
interacting neurons.

580
Laura Sacerdote University of Torino
“Copulae in Neural Networks Modeling”
Mathematical models for neuron activity help our understanding of neural code. Different types
of models may be used depending upon the level of detail necessary for the studied problem.
Leaky integrate and Fire models due their popularity to their relatively simple mathematical
structure furthermore, despite their simplicity, they can fit experimental data. Their use has
allowed to improve our comprehension of mechanisms involved in signal transmission. Typical
examples are the studies on the role of the noise in the neuronal code or the properties of
responses to periodic stimula. These models have been used also to apply information theory to
the study of input output relationships.
The possibility to record simultaneously from two or more neurons has shown the arising of
specific patterns in observed raster displays. The existence of patterns is the result of the
presence of dependencies between spike times of different neurons. An attempt to model
networks request to switch from one-dimensional models to multivariate ones. Various attempts
in this direction have been proposed in the literature, making use of multiparticle models or
object oriented networks. The main lack of these approaches is their inability to relate single
units and network features.
Here we propose to use the copula notion to get multivariate models. Copulae are the
mathematical object allowing to join marginal distributions to get the multivariate one. Their use
has been recently proposed for statistical purposes of counts of spikes in a network. Here we
focus on their use for modeling purpose. We limit ourselves to simple models involving a few
neurons but the proposed idea could then be applied to larger networks.
Erik Volz University of Michigan
“Mathematical Modeling of Sexually Transmitted Infections in Dynamic
Contact Networks”
Mathematical epidemiology has progressed in the direction of combining increasingly realistic
models of disease progression with increasingly complex host population structure. Contact
networks have become a popular model of population structure for hosts embedded in long-term
relationships. Concurrent advances in mathematical theory have made these models more
tractable, which decreases the need to compromise between realism and mathematical analysis. I
review several special cases of epidemics spreading through complex populations which reduce
to simple solutions based on ordinary differential equations. This reveals a link between
traditional mass action models of epidemics in which contacts are instantaneous and
uncorrelated, and networks which have dynamically rearranging ties. I then investigate several
applications. A simple

581
modification to our equations allows us to model sero-sorting of HIV positive individuals, which
is the tendency to rearrange relationships to those with similar HIV status. These models are
tested using data from a high-risk cohort from Atlanta, Georgia.
Hongyun Wang University of California, Santa Cruz
“Potential Profile of Molecular Motors”
In molecular motors, the mechanical motion is coupled to the chemical reaction. In the
mathematical framework of stochastic differential equations, a motor is subject to the Brownian
diffusion and is driven by the motor potential that changes with the chemical state. For a motor
with N chemical states, there are N motor potentials, one for each chemical state. The effect of
the chemical reaction is to switch the motor among this set of N potentials. It is desirable to
reconstruct these motor potentials from single molecule experimental data. However, it is still
very difficult to measure both the position and the chemical state in single molecule experiments.
As a result, it is not realistic to reconstruct potentials for individual chemical state. Here we use
an effective potential, called motor potential profile, to characterize the motor operation. The
best advantage of using motor potential profile is that it can be reconstructed from time series of
measured position. We will also discuss the Stokes efficiency of a molecular motor and the
using the motor potential profile to decompose the Stokes efficiency into mechanical efficiency
and chemical efficiency.
#15: 4th
Annual Graduate Student Probability Conference April 30 – May 2, 2010
Duke University
Schedule:
#16: 2010 Summer Program on Semiparametric Bayesian Inference: Applications in
Pharmacokinetics and Pharmacodynamics. July 12-23, 2010
Schedule:
Monday, July 12, 2010
Radisson Hotel RTP

582
Tutorials
8:00-8:45 Registration and Continental Breakfast
8:45-9:00 Welcome & Overview
9:00-10:45 Tutorial 1
Wes Johnson, U. of California, Irvine and David Dunson, Duke University
“Bayesian Nonparametrics: An Overview”
10:45-11:15 Break
11:15-12:30 Tutorial 1, continued
12:30-1:30 Lunch
1:30-3:00 Tutorial 2
David D’Argenio, University of Southern California and Paolo Vicini, Pfizer
“Pharmacokinetics (PK) and Parmacodynamics (PD)”
3:00-3:30 Break
3:30-5:00 Tutorial 2, continued
Tuesday, July 13, 2010
Radisson Hotel RTP
Opening Workshop
8:00-9:00 Registration and Continental Breakfast
Prior Elicitation and Construction:
9:00-9:45 Wes Johnson, University of California, Irvine
“On the Value of Incorporating Scientific Input in Modeling and Data Analysis,
and How to Do it Without Pain”
9:45-10:30 Peter Thall, MDACC
“Prior Elicitation in Bayesian Clinical Trial Design”
10:30-11:00 Break
11:00-11:45 Siva Sivaganesan, University of Cincinnati
“Sample Size: How Many Subjects”
11:45-Noon Discussion
Noon-1:00 Lunch

583
1:00-2:30 Lang Li, Indiana University and Paolo Vicini, Pfizer
"Identifiability and Prior Regularization: A PK-PD Modeling View"
2:30 – 3:00 Break
3:00 – 3:45 Robert Leary, Pharsight
“Computational Challenges of Nonlinear Mixed Effects Analysis for PK/PD
Modeling”
3:45-4:30 Sujit Ghosh, North Carolina State University
“Application of Nonlinear Mixed Models Involving ODEs”
4:30-5:00 Discussion
Wednesday, July 14, 2010
Radisson Hotel RTP
8:00-9:00 Registration and Continental Breakfast
Joint PK and PD:
9:00-9:45 Wojciech Krzyzanski, State University of New York
“PK/PD Modeling of Therapeutic Effects of Erythropoietin”
9:45-10:30 Michele Guidani, University of New Mexico
“NP Bayes Functional Regression for a PK/PD Semi-Mechanistic Model”
10:30-11:00 Break
11:00-11:45 Thanasis Kottas, University of California, Santa Cruz
“A Bayesian Nonparametric Modeling Approach for Developmental Toxicology Data”
11:45-Noon Discussion
Noon-1:00 Lunch
1:00-2:30 David Conti, U. of Southern California; Duncan Thomas, U. of Southern California
“Bayesian Hierarchical and PD/PK Modeling for Complex Pathways in Molecular
Epidemiology”
2:30-3:00 Mike Reed, Duke University
“Why Metabolism is a Challenge for Statistical Analysis: the Case of
Substrate Inhibition”
3:00-3:30 Break
3:30- 4:15 Peter Mueller, MD Anderson
“Nonparametric Bayesian Models for Population PK/PD.”

584
4:15-5:00 Donatello Telesca, University of California, Los Angeles
“Modeling Pk/PGx Data”
5:00-5:30 Discussion
Thursday, July 15, 2010
Radisson Hotel RTP
8:00-9:00 Registration and Continental Breakfast
DDP, Mixture Models and Related Models:
9:00–9:45 Subharup Guha, University of Missouri
“Posterior Simulation in Countable Mixture Models for Large Data Sets”
9:45 – 10:30 Steve MacEachern, Ohio State University
“Nonparametric Bayesian Models for Related Subpopulations”
10:30-11:00 Break
11:00-11:45 Maria de Iorio, Imperial College
“Nonparametric Approaches for Heterogeneous Longitudinal Data”
11:45-12:30 Tatiana Tatarinova, University of Glamorgan
“Analysis of Biological Time Series Data in Data-Rich Situations”
12:30-1:30 Lunch
1:30-2:10 Roger Jelliffe, University of Southern California
"Tools for Individualizing Drug Dosage Regimens for Patients"
2:10-2:50 William Gillespie, Metrum Inst.
“Examples of Decison-Focused Modeling and Simulation in Clinical Drug
Development and Some Methodology R&D Opportunities They Suggest”
2:50-3:30 Gary Rosner, Johns Hopkins University
“Optimal Design with Bayesian Nonparametric Priors”
3:30-4:00 Break
4:00-5:00 David D’Argenio, University of Southern California; William Gillespie, Metrum Inst.;
Roger Jelliffe, University of Southern California; Bob Leary, Pharsight
“Implementation and Available Software”
5:00-5:30 Poster Advertisement Session: 2 minute ads by each poster presenter
6:00–8:00 Poster Session and Reception

585
SAMSI will provide poster presentation boards and tape. The board dimensions
are 4 ft. wide by 3 ft. high. They are tri-fold with each side being 1 ft. wide and
the center 2 ft. wide. Please make sure your poster fits the board. The boards can
accommodate up to 16 pages of paper measuring 8.5 inches by 11 inches.
8:00- Informal Debate: “Parametric PD Models vs. Nonparametric PD Models
Friday, July 16, 2010
Radisson Hotel RTP
8:00-9:00 Registration and Continental Breakfast
Nonparametric Bayes and Clustering for Random Effects Distributions:
9:00-9:45 David Dahl, Texas A&M University
“Strategies for Incorporating Prior Information in Random Partition Models with
Examples”
9:45-10:30 Mahlet Tadesse, Georgetown University
“Stochastic Partitioning and Model-based Clustering with Variable Selection”
10:30–11:00 Break
11:00 –11:45 Julien Cornebise, University of British Columbia
"Inference for Mixed Effects Stochastic Differential PKPD Models
with Particle MCMC"
11:45-12:15 Gary Rosner, Johns Hopkins University, and Peter Mueller, University of Texas
Summary & Discussion
12:15-1:30 Lunch
1:30–2:30 Formation of Working Groups
2:30-3:00 Break
3:00-4:00 Initial discussions
Monday, July 19 – Thursday, July 22, 2010
SAMSI, RTP,
Rooms 104, 150, 201, 203, 259
9:00 – 5:00 Working Groups - TBA
Possible Themes:
1. Identifiability and Prior Regularization
2. Joint PK and PD Modeling

586
3. PK/PD Simulation for Design and Dose Individualization
4. Pharmacogenomics and Networks
5. Nonparametric Bayes and Clustering for PK and PD Population Analysis
12:00-1:30 Lunch
Friday, July 23, 2010
SAMSI, RTP,
Room 150
9:30-12:00 Presentations by Working Groups and Discussion about Future Projects
12:00-1:30 Lunch
1:30 Adjourn
SPEAKER TITLES/ABSTRACTS
David Conti Duncan Thomas
University of Southern California University of Southern California
[email protected] [email protected]
“Bayesian Hierarchical and PD/PK Modeling for Complex Pathways in Molecular
Epidemiology”
Molecular epidemiology is concerned with the study of the joint role of genetic and
environmental influences in disease causation. Despite the current enthusiasm for “agnostic”
(hypothesis-free) genome-wide association approaches, there is still a place for biologically-
based analyses driven by our current understanding of specific pathways implicated in disease.
This talk will focus on statistical approaches to incorporating biological knowledge into the
analysis of gene-environment interactions in disease etiology. Two broad frameworks will be
introduced, one based on hierarchical modeling, the other based on physiologically-based
pharmacokinetic (PBPK) modeling (Thomas et al. 2010). In the former, a standard regression
model (such as multiple logistic for a binary disease trait) forms the first level for the study
subject‟s data, with regression coefficients for main effects of various genes, environmental
factors, and their interactions; these coefficients are in turn regressed on external “meta-data”
about these risk factors, such as indicators for specific pathways involving the various factors,
functional data, or expert knowledge organized in formal ontologies. In the PBPK approach, a
mechanistic model for the disease process is constructed, typically involving one or more latent
variables representing intermediate metabolite concentrations or other unobserved biological
processes, each related to each other and to the input variables through a system of ordinary or
stochastic differential equations. Both approaches will be illustrated on various epidemiologic
studies, such as folate metabolism in colorectal cancer, nicotine dependence, and DNA repair
following ionizing radiation exposure in second breast cancers. Either approach typically
requires one to deal with the problem of model uncertainty, such as the selection of variables to

587
include in a hierarchical model. We will discuss approaches such as stochastic search variable
selection and shrinkage using lasso or ridge priors, as well as novel methods based on Markov
chain Monte Carlo searching over the space of all possible pathway models. We will conclude
with some thoughts on the prospects for extending these approaches to genome-wide scale.
Reference: Thomas DC, Conti DV, Baurley J, Nijhout F, Reed M, Ulrich CM. Use of pathway
information in molecular epidemiology. Hum Genomics, 2010;4:21-42.
David Dahl Texas A&M University
"Strategies for Incorporating Prior Information in Random Partition Models with Examples"
Many Bayesian semiparametric and nonparametric models are based on random partitioning of
items (e.g., experimental units) into clusters, where items in the same cluster share a common
value for a model parameter. Often there is good prior information about the clustering of items,
yet traditional random partition models cannot incorporate this information. In this talk, I will
review several recently-proposed strategies for incorporating prior clustering information in
random partition models. After surveying methods for which the prior clustering information
comes in the form of
item-specific covariates, I will discuss methods that instead utilize pairwise distances between
items to inform the prior clustering distribution. Applying these methods to a model for protein
structure prediction, it is shown that the methods incorporating distance
information substantially improve predictive accuracy.
David Dunson
Duke University
“Bayesian Nonparametrics: An Overview”
Tutorial Part II: In the second part of this tutorial we provide a brief review and motivation for
the use of nonparametric Bayes methods in biostatistical applications. The focus is on methods
utilizing random probability measures, with the emphasis on a few approaches that seem
particularly useful in addressing the considerable challenges faced in modern biostatistical
research. In addition, the emphasis will be entirely on practical applications-motivated
considerations, with the goal of encouraging participants to consider related approaches for their
own data.
The discussion includes methods for functional data analysis using DP-based methods,
approaches for local shrinkage and clustering, methods for hierarchical borrowing of information
across studies, centers or exchangeable groups of data, flexible modeling of
conditional distributions using priors for collections of random probability measures that evolve
with predictors, time and spatial location, some recent applications in bioinformatics, and
methods for nonparametric Bayes hypothesis testing.
Maria de Iorio Imperial College

588
"Nonparametric Approaches for Heterogeneous Longitudinal Data"
We discuss a method for combining different but related longitudinal studies to improve
predictive precision. The motivation is to borrow strength across clinical studies in which the
same measurements are collected at different frequencies. Key features of the data are
heterogeneous populations and an unbalanced design across three studies of interest. The first
two studies are phase I studies with very detailed observations on a relatively small number of
patients. The third study is a large phase III study with over 1500 enrolled patients, but with
relatively few measurements on each patient. Patients receive different doses of several drugs in
the studies, with the phase III study containing significantly less toxic treatments. Thus, the main
challenges for the analysis are to accommodate heterogeneous population distributions and to
formalize borrowing strength across the studies and across the various treatment levels.
We describe a hierarchical extension over suitable semiparametric longitudinal data models to
achieve the inferential goal. A nonparametric random-effects model accommodates the
heterogeneity of the population of patients. A hierarchical extension allows borrowing strength
across different studies and different levels of treatment by introducing dependence across these
nonparametric random-effects distributions. Dependence is introduced by building an analysis of
variance (ANOVA) like structure over the random-effects distributions for different studies and
treatment combinations. Model structure and parameter interpretation are similar to standard
ANOVA models. Instead of the unknown normal means as in standard ANOVA models,
however, the basic objects of inference are random distributions, namely the unknown
population distributions under each study. The analysis is based on a mixture of Dirichlet
processes model as the underlying semiparametric model.
Sujit Ghosh North Carolina State University
“Application of Nonlinear Mixed Models Involving ODEs in Biomedical Sciences”
In the field of biomedical applications, data usually consists of repeated measurements on
individuals observed under varying experimental conditions. For example, in pharmacokinetics,
several blood samples are taken on participating individuals over a period of time, following
administration of a drug. The within subject relationships between the measured response and the
varying experimental conditions are often nonlinear represented by a system of nonlinear
ordinary differential equations (ODEs) and involve unknown subject-specific parameters of
interest. These models are useful because they offer a flexible framework where parameters for
both individuals and population can be estimated by combining information across all subjects.
More often such a system of ODEs does not have any analytical closed form solution, making
parameter estimation for these models quite challenging and computationally very demanding. A
method based on Euler's approximation is proposed to obtain an approximate likelihood that is
analytically tractable and thus making parameter estimation computationally less demanding
than other competing methods. These methods will be illustrated using a real data set and
simulation studies will be presented to compare the performances of these new methods to other
established methods in the literature.

589
William Gillespie
Metrum Institute
“Examples of Decision-Focused Modeling and Simulation in Clinical Drug Development
and Some Methodology R&D Opportunities They Suggest”
Modeling and simulation are increasingly used to support decision-making in clinical drug
development. Simulations are used to infer the probable range of outcomes for different
treatment regimens, patient populations and clinical trials. Simulated results are then used to
optimize decisions regarding patient treatment, clinical trial design and analysis, and
development strategy, e.g., whether to continue a development program. The modeling and
simulation approaches used for such applications vary depending on a variety of factors
including the intended purpose, amount and type of prior information, and, of course, the skills
and philosophical preferences of the modeler(s).
Two examples will be presented that use very different modeling strategies for different
purposes. Example 1 involved the use of a largely empirical Bayesian hierarchical model for
efficacy- and safety-related responses as a function of drug exposure and time constructed via
model-based meta-analysis of clinical and preclinical data. Simulations based on the resulting
model were used to optimize the design of a Phase II clinical trial. Design features explored
included adaptive stopping, adapting pruning, and use of informative prior distributions in the
trial analyses. In example 2 a multi-scale mechanistic model for calcium homeostasis and bone
remodeling was developed. The model was used to explore the impacts of chronic renal failure,
parathyroid disorders and discontinuation of denosumab treatment on biomarkers and bone
mineral density. It was also used to investigate potential causal mechanisms for long-term bone
remodeling effects of estrogen in menopausal and postmenopausal women. The current model is
deterministic. An effort is underway to implement the model in a Bayesian framework that
incorporates uncertainty in parameter values and inter-individual variation is selected
parameters. This will permit probabilistic inference and model updating via MCMC analysis of
new data as it becomes available.
Example 1 suggests the following opportunities for method development:
Modeling relationships between biomarkers and therapeutic outcomes including
approaches for integrating models for multiple biomarkers.
Use of decision analysis to optimize trial design and for analysis of adaptive trials.
Model-based meta-analysis, particularly the combined analysis of summary and
individual data
Example 2 suggests the potential for predictive inferences about clinical response to a drug
candidate even before that candidate has been administered to humans. However few such
models have been developed and fewer still provide useful probabilistic inference. This suggests
the following areas for R&D:
Development of multi-scale mechanistic models for disease progression and drug effects
relevant to other therapeutic areas.
Bayesian implementation of such models.

590
Development of Bayesian modeling methods and software better suited to such complex
mechanistic models.
William Gillespie
Metrum Institute
“Computational Tools for Bayesian PKPD Modeling”
Markov chain Monte Carlo (MCMC) simulation methods for Bayesian modeling have been
recently added to some existing pharmacometric tools, e.g., NONMEM 7 and S-Adapt.
Advantages of these programs are the inclusion of built-in PKPD model libraries and model-
specification languages, and MCMC and less computationally-demanding algorithms within a
single platform. On the other hand those tools are limited to models with two levels of random
variation (plus the prior distributions), normally-distributed inter-individual variation and a
normal-Wishart prior distribution.
More general-purpose software tools implementing MCMC for Bayesian modeling include the
BUGS language programs (WinBUGS, OpenBUGS and JAGS), the SAS MCMC procedure and
Microsoft Infer.Net. Some Bayesian modeling packages are also available for R and MatLab
though most are limited to specific classes of models. The BUGS language tools have the
advantage of being very flexible w.r.t. stochastic model structure, e.g., no limit on levels of
variability, choice of many built-in distributions, and one can easily combine sub-models with
very different stochastic structures. Their main disadvantages are the lack of specialized support
for pharmacometrics applications, less flexible specification of deterministic model components,
and the absence of less computationally-demanding algorithms within the same platform.
BUGSModelLibrary is a prototype PKPD model library for use with WinBUGS 1.4.3. The
current version includes built-in 1 and 2 compartment models with or without first order
absorption, and the ability to specify more general compartmental models in terms of first order
ODE's. The models and data format are based on NONMEM conventions. Several test cases
were analyzed using both the NONMEM 7 BAYES method and WinBUGS with
BUGSModelLibrary. For the classes of models studied:
MCMC simulations using NONMEM 7 and WinBUGS produced results with
comparable accuracy.
NONMEM 7 more often produced less auto-correlated MCMC samples.
WinBUGS required much less computation time to produce comparable MCMC results
for a mixture model, and about half the computation time for 4 test cases.
WinBUGS required more time to produce less precise results for 4 other test cases.
For _ 1=2 of the scenarios NONMEM 7 outperformed WinBUGS w.r.t. computation time
adjusted for autocorrelation.
Those results led to the following recommendations:
NONMEM 7 is a recommended platform for Bayesian modeling when suitable models
can be implemented within the limits imposed by NONMEM.
WinBUGS is a recommended platform when greater flexibility is required w.r.t.
stochastic aspects of models.

591
Based on the limited testing presented here, WinBUGS appears to perform better with
mixture models and models with inter-occasion variability and is the preferred platform
for those cases.
Subharap Guha University of Missouri
"Posterior Simulation in Countable Mixture Models for Large Datasets"
Mixture models, or convex combinations of a countable number of probability distributions,
offer an elegant framework for inference when the population of interest can be subdivided into
latent clusters having random characteristics that are heterogeneous between, but homogenous
within, the clusters. Traditionally, the different kinds of mixture models have been motivated and
analyzed from very different perspectives, and their common characteristics have not been fully
appreciated. The inferential techniques developed for these models usually necessitate heavy
computational burdens that make them difficult, if not impossible, to apply to the massive data
sets increasingly encountered in real world studies.
This talk introduces a flexible class of models called generalized Polya urn (GPU) models. Many
common mixture models, such as finite mixtures, hidden Markov models, and Dirichlet
processes are obtained as special cases of GPU models. Other important special cases include
finite dimensional Dirichlet priors, infinite hidden Markov models, analysis of densities models,
nested Chinese restaurant processes, hierarchical DP models, nonparametric density models,
spatial Dirichlet processes, weighted mixtures of DP priors, and nested Dirichlet processes.
An investigation of the theoretical properties of GPU models offers new insight into asymptotics
that form the basis of cost-effective MCMC strategies for large datasets. These MCMC
techniques have the advantage that they provide inferences from the exact posterior of interest
and are applicable to different mixture models. The versatility and impressive gains of the
methodology are demonstrated by simulation studies and by a semiparametric Bayesian analysis
of high-resolution comparative genomic hybridization data on lung cancer.
Michele Guindani University of New Mexico
“NP Bayes Functional Regression for a PK/PD Semi-Mechanistic Model”
In Clinical pharmacology, a major goal is to study the quantitative prediction of drug effects.
Complex pharmacokinetic-pharmacodynamic (PK/PD) models with feedback and transition
effects have been recently developed, for example to estimate the time course of
myelosupression. These models typically involve the presence of covariate dependent
parameters. We propose a coherent NP Bayes probabilistic framework for the analysis of these
models. Our goal is to use the information from the individuals' time courses and covariates to
provide a clustering of patients according to their PK/PD profiles. This information could then be
used to predict the PD time course for a patient on the basis of the observed PK profile, as well
as deal with missing data. In the talk I will try to outline the features as well as the challenges

592
connected with such implementation. This is a joint project with Peter Mueller, Gary L. Rosner
and Lena Friberg.
Roger Jelliffe University of Southern California
"Tools for Individualizing Drug Dosage Regimens for Patients"
The clinical tools we currently advocate are:
1. Set specific Target Goals (not windows) - Hit them most Precisely. Simply setting a
window is not enough, except for knowing a general range of serum concentrations
within which most patients, but certainly not all, do well. It does not consider each
patient's need for the drug and the risk of toxicity it appears realistic to accept in order to
obtain the hoped – for benefits of the drug. It also does not consider the patient's
sensitivity to the drug. Using the same clinical judgment, one can set a specific target
value for a serum concentration, for example, and then attempt to hit it as precisely as
possible. This target may well be outside the so-called therapeutic range, not only below
it, but also above it.
2. Describe Assay Errors by the reciprocal of the variance with which each measurement
was made. Both for population modeling and for clinical care, the laboratory can do a
much better job if it gives up using CV% as a measure of error (they are the only group in
the world who do this!) and use instead the reciprocal of the assay variance for each
measurement. This is as easy to do as CV%. One can fit a polynomial to the data and
store it in the software. Then one has a reliable measure of credibility with which to fit
each measurement. In addition, there is no need to censor low data any more. One can
drive the HIV PCR down to zero, and document it, and not just report <50 copies, for
example. This greatly increases the usefulness of the lab to the community.
3. Determine the remaining Environmental Noise. Having determined the assay error, one
can determine the remaining environmental error either as an additive or a multiplicative
term. Then one can KNOW how much error is due to the assay the how much to the
clinical environment in which the study or the patient's care has taken place. This is
important information, which is usually not obtained.
4. Evaluate CHANGING Renal Function. Most methods to estimate creatinine clearance
or GFR are based only on a single sample. We much favor a longstanding method based
on 2 serum creatinine samples which estimates the creatinine clearance in unstable
patients which makes serum creatinine rise or fall from the first to the second sample
over a stated time, in a patient of stated age, gender, height and weight.
5. Nonparametric (NP) Population PK/PD Models. We greatly favor the use on
nonparametric population models, as they make no assumptions at all about the often
genetically polymorphic shape of the parameter distributions. What you see is what
you've got. It also leads directly to...

593
6. "Multiple Model" (MM) Design of Doses. Here the multiple support points of the NP
model parameter distributions, when given a candidate dosage regimen, provide many
predictions, each weighted by the probability of that support point. It then is easy to
compute the weighted squared error of failure of those predictions to hit the target, and
then to find the specific regimen which minimizes that error.
7. MM, MAP, Hybrid, and IMM Bayesian analysis and individual models. These four
Bayesian methods provide tools to obtain useful Bayesian posterior joint densities for
patients, even when the patient's parameter densities may lie quite a distance outside the
stated ranges of the population model parameters, and also in very unstable patients
whose parameter distributions may be changing significantly during the period of data
analysis.
Wes Johnson
University of California, Irvine
“Bayesian Nonparametrics: An Overview”
Tutorial Part I: Nonparametric statistics is a misnomer. The goal of nonparametrics is
to provide flexible modeling that does not overly rely on assumptions. In order to accomplish
that goal, it is often necessary to expand a parametric family of models to include many more
models. A parametric family is indexed by a finite parameter vector. A nonparametric family is
indexed by an infinite dimensional parameter. Of course in the real world, we can't quite get to
infinity, so we truncate to obtain a family that is manageable. But in this finite approximation to
an infinite dimensional index, we are left with what are called richly parametric models, that still
allow for much flexibility in modeling. The goal of this talk is to present a few methods of
handling the complexity. We discuss the Dirichlet Process Mixture prior, which is used to model
data as theoretically infinite random mixtures of parametric distributions like the normal. We
also discuss Mixtures of Polya Tree priors that allow the user to embed a parametric family, like
the normal, in a broader class of distributions. We also briefly discuss a different kind of
nonparametrics that models a regression function in a flexible way. All methods are
implemented using Markov chain Monte Carlo methods and thus require some finesse in their
implementation. However, they do not require large sample theory for either their development
or their implementation. Moreover, once the basic machinery is set in place, virtually any
inference is achievable virtually by request through a few lines of code rather than by additional
mathematics.
Wes Johnson
University of California, Irvine
“On the Value of Incorporating Scientific Input in Modeling and Data Analysis, and How To Do
It Without Pain”
We discuss the value of incorporating scientific information that is converted into a prior
distribution for a Bayesian analysis of data. Most of the talk will focus on examples from
parametric modeling. For example, imagine a simple binomial example where n individuals

594
have been tested for HIV using an ELISA test. The probability of a test
positive outcome is the prevalence of HIV in the population sampled times that sensitivity of the
ELISA test plus the prevalence on non-HIV infected individuals times the one minus the
specificity of the test. There are three parameters and there is only one data point, the proportion
of test positives in the sample. Additional scientific input
is required to make further progress in this non-identifiable problem. Moreover, many might
place uniform priors on some of these inputs in a misguided effort to be non-informative. But it
would be impossible to believe that the accuracies of the ELISA test, or indeed the prevalence,
were equally likely to be 0 or 1. I will conclude the talk with a
discussion of how to extend informative prior information into non and semiparametric models.
Thanasis Kottas
University of California, Santa Cruz
“A Bayesian Nonparametric Modeling Approach for Developmental Toxicology Data”
We present a Bayesian nonparametric mixture modeling framework for replicated count
responses in dose-response settings. We explore the methodology for modeling and risk
assessment in developmental toxicity studies, where the primary objective is to determine the
relationship between the level of exposure to a toxic chemical and the probability of a
physiological or biochemical response, or death. Data from these experiments typically involve
features that can not be captured by standard parametric approaches. To provide flexibility in the
functional form of both the response distribution and the probability of positive response, the
proposed mixture model is built from a dependent Dirichlet process prior, with the dependence
of the mixing distributions governed by the dose level. The methodology is tested with a
simulation study, which involves comparison with semiparametric Bayesian approaches to
highlight the practical utility of the dependent Dirichlet process nonparametric mixture model.
Further illustration will be provided through the analysis of data from two developmental
toxicity studies.
Joint work with Kassandra Fronczyk, Department of Applied Mathematics and Statistics,
University of California, Santa Cruz
Wojciech Krzyzanski
University at Buffalo
“PK/PD Modeling of the Therapeutic Effects of Erythropoietin”
Pharmacokinetics describes a relationship between drug dose and drug concentrations at various
body sites such as blood and urine. Pharmacodynamics aims at establishing a relationship
between drug concentrations and pharmacological effects and links these responses to a clinical
outcome. PK/PD modeling relates drug exposure to effect by means of mathematical models.
Hematopietic cell populations that include white blood cells, red blood cells, and platelets
constitute important therapeutic targets and are used as measures of pharmacodynamic response.
Erythropoietin is a major hormone that regulates production of RBCs. Recombinant human
erythropoietin (rHuEPO) is a therapeutic agent for treatment of anemia.

595
This talk will briefly introduce a basic concept of mechanistic PK/PD modeling. The
physiology of EPO regulated erythopoietic system will be presented. A PK/PD model addressing
receptor mediated disposition of rHuEPO in rats will be described. Lifespan based indirect
response models will be exemplified by a PD model of rHuEPO effect on reticulocyte, RBC, and
hemoglobin levels.. The talk will conclude with discussion of numerical challenges associated
with the stiffness of the PK/PD model, difficulties of implementation of delay differential
equations in PK/PD software, and estimability of parameters in high dimension PK/PD systems.
Robert Leary Pharsight, Corp.
“Computational Challenges of Nonlinear Mixed Effects Analysis for PK/PD Modeling”
NLME analysis of PK/PD models poses a variety of computational challenges in terms of
algorithms, models, data handling, software, and hardware. For example, general purpose
NLME software such as the NLME package in R and S+, the PROC NLMIXED procedure in
SAS, and the BUGS Bayesian inference package are often not well suited for PK/PD analyses
due to lack of domain-specific features for handling the complex dosing, data structures, and
models often encountered. In this talk I will give an overview of the current state-of-the-art in
computational approaches to NLME analysis for PK/PD models as practiced within the
commercial and academic pharmacometric communities. Both parametric and nonparametric
methods will be discussed in terms of fundamental algorithmic approaches, specific software
implementations, and current limitations.
Lang Li
Indiana University
“PK Parameter Prior Distribution Construction from the Literature”
In this talk, we will talk about a text mining approach to extract PK parameter numerical data
from the literature automatically. The extracted data will then be transformed into compartment
models. Both linear and non-linear mixed effect models are used for these analyses.
Steve MacEachern
Ohio State University
“Nonparametric Bayesian Models for Related Subpopulations”

596
One of the fundamental questions that we face when attempting to analyze data is how to model
a collection of related subpopulations. Through time, many approaches have been developed. In
this talk, I will describe a natural progression from very simple models to
more complex models. The progression takes us from parametric models to nonparametric
Bayesian models, with a focus on dependent Dirichlet processes. Attention will be drawn to
differences between parametric and nonparametric approaches, both for modeling and for
inference.
Peter Mueller MD Anderson
“Nonparametric Bayesian Models for Population PK/PD”
We will review some nonparametric Bayesian models and approaches that are useful to model
random effects distributions in population PK/PD. We will discuss in particular alternative
approaches to incorporating regression on baseline covariates, focusing on
approaches based on random partition models.
Bhramar Mukherjee
University of Michigan
“Bayesian Analysis of Two-phase Studies of Gene-environment Interaction with an Application
to Drug-gene Interaction”
In this talk we consider Bayesian semiparametric analysis of two-phase studies of gene-
environment interaction. Phase I data is available on case-control status, basic demographic
covariates and medication use (environmental factor, say). Phase II genotype data is collected by
stratified sampling on case-control status and enriched for use of medication. The genes are
selected on the same pathway of the metabolism of the drug. We propose a Bayesian approach
based on a retrospective likelihood that data- adaptively uses the gene-environment
independence assumption and can accommodate multiple genetic factors and their interactions
through a variable selection procedure. The retrospective likelihood requires flexible modeling of
the joint distribution of multiple covariates where we adopt Bayesian nonparametric techniques.
The methods are illustrated by analyzing interaction of statins with polymorphisms in the
cholesterol synthesis and lipid metabolism pathway in a population-based case-control study of
colorectal cancer.
Michael Reed Duke University
“Why Metabolism is a Challenge for Statistical Analysis: the Case of
Substrate Inhibition”

597
Cell metabolism is a complicated network of biochemical reactions that
includes many feedback and feedforward interactions that are crucial for
regulation and adaptation to the cell‟s external environment. In addition, the
special properties of enzymes give rise to unusual nonlinear kinetics. It is serious
and important challenge to construct statistical procedures that can infer such
regulatory mechanisms and unusual kinetics from network input-output maps. A
simple example, substrate inhibition, will be discussed.
Gary Rosner Johns Hopkins University
“Optimal Design with Bayesian Nonparametric Priors”
In this talk, I review an application that concerned finding an individual‟s optimal dose of an
anticancer drug. Since there were multiple studies, we used a hierarchical model based on linked
Dirichlet processes. We also incorporated patient-specific covariates to help determine the
optimal dose. I will review several ways to incorporate covariates and point out how these
methods differ. This is joint work with Alejandro Cruz-Marcelo and Peter Mueller.
Co-Presenters: William Gillespie, Metrum Inst.; Roger Jelliffe, University of Southern California
Siva Sivaganesan University of Cincinnati
“Sample Size: How Many Subjects”
Sampling design is an important aspect of a PK study. It includes specification of the number of
sample per subject, sampling times, and the number of subjects or sample size, among other. In
this talk we given an overview of this topic focusing, specifically, on the sample size, and the
role of Bayesian approach in this context.
Mahlet Tadesse Georgetown University
“Stochastic Partitioning and Model-based Clustering with Variable Selection”
In the analysis of high-dimensional data there is often interest in uncovering cluster structure and
identifying discriminating variables. For example, the goal may be to use gene expression data
to discover new disease subtypes and to determine genes with different expression levels
between classes. Another research question that is receiving increased attention is the problem
of relating genomic data sets from various sources. For instance, the goal may be to uncover
cluster structures in the data sets and identify groups of associated markers across data sets. I
will present some Bayesian methods we have proposed to address these problems in a unified
manner.

598
Tatiana Tatarinova Alan Schumitzky
University of Glamorgan University of Southern California
[email protected] [email protected]
“Analysis of Biological Time Series Data in Data-Rich Situations”
In this talk we present two clustering methods: 1) The Kullback-Leibler Markov Chain Monte
Carlo (KLMCMC) method, and 2) The Multiple Collapse Clustering (MCC) method for the
treatment of biological time series data in a data-rich situation. Assuming a continuous nature of
most biological processes, we suggest computing parameters of nonlinear, piecewise continuous
functions approximating each cluster. Our approach is based on a combination of methods
including Gibbs sampling, Random Permutation Sampling, birth-death MCMC, and Kullback-
Leibler distance.
Donatello Telesca
University of California, Los Angeles
“Modeling Pk/PGx Data”
We describe a general framework for the exploration of the relationships between
pharmacokinetic pathways and plymorphisms in genes associated with the metabolism of a
compound of interest. We integrate a population pharmacokinetics model with a simple sampling
model of genetic mutation via a conditional dependence prior. Significant interactions are
selected allowing the pharmacokinetic parameters to depend on gene sets of variable dimension.
We discuss posterior inference and prediction based on MCMC simulation. Our model finds
motivation in the study of a chemotherapeutic agent used in the treatment of various solid
tumors.
Peter Thall MD Anderson Cancer Center
“Prior Elicitation in Bayesian Clinical Trial Design”
The impact of one‟s prior on adaptive decisions in a Bayesian clinical trial design can be
profound. For example, the prior may have a substantive effect on treatment assignments
involving life-and-death outcomes in trials of treatments for rapidly fatal diseases. This issue is
at the heart of what may be considered the strongest frequentist criticism of Bayesian methods.
Despite this, little attention has been paid to the problem of eliciting and calibrating priors in
such settings. In this talk, I will discuss how priors were established in a variety of different
Bayesian clinical trials in which I have been involved. As time permits, topics will include
Dirichlet priors for discrete 2x2 (response, toxicity) outcomes, the notion of prior effective
sample size, logistic regression and generalized logistic regression models for toxicity as a
function of either the dose of a single agent or the doses of two agents in phase I trials, using
penalized least squares to establish a prior for bivariate (efficacy, toxicity) probabilities as a
function of dose, eliciting a hyperprior for a hierarchical model in a phase II activity trial, and
eliciting priors for event-free survival time and toxicity as functions of patient covariates in a
pediatric brain tumor trial.

599
Paolo Vicini
Pfizer
“Identifiability and Prior Regularization: A PK-PD Modeling View”
Biomedical modeling practitioners have always been aware of the need to
characterize their models’ identifiability properties. This is because in
many instances the models’structure and parameters are indirectly estimated
from measurements gathered in one or more accessible compartments (e.g. blood
plasma). The remainder (inaccessible portion, e.g. peripheral organs) of the
model needs to be reconstructed or inferred from such estimation procedures.
This presentation will address various concepts relating to identifiability,
including clarification of the diverse terms used in the literature.
Procedures to avoid common pitfalls when choosing appropriate
parameterizations for PK-PD models will be described. These ideas will be
also developed in the context of sparse data population analysis with mixed
effects models. Examples from the published literature will be used to
reinforce these concepts.

600
Appendix G – Workshop Evaluations
G.1 Overview of Workshop Evaluation
At each workshop, the participants are asked to complete the SAMSI Workshop
Evaluation, which asks the participants to rank the Workshop in terms of scientific quality, staff,
helpfulness, meeting facilities, lodging, and local transportation and then asks a series of
questions. A sample evaluation is included for review.
The following results are summaries of the evaluations completed after a total of eleven
Workshops during the year broken into two categories: Program Workshops and Education and
Outreach (E&O) Workshops. The Program Workshops include the nine workshops held during
the 2009-2010 fiscal year. The E&O Workshops include the two undergraduate workshops.
The evaluation form is as follows:
SAMSI Evaluation
Your feedback on this workshop is requested by SAMSI’s funding agencies, who view it as
important for assessing and improving our performance. Your feedback is also gratefully
appreciated by SAMSI’s directors, because it will enable us to immediately improve SAMSI
activities. Please fill out this form and hand it to a SAMSI Staff Member, or return it by mail.
1. Personal Information: We are required by our funding agencies to obtain information –
in a standard format – about all participants in SAMSI activities. If you have not already done so,
please go to http://legacy.samsi.info/PartInfo/200910/participantinformationform09101.html to
provide this information. Note that if you have participated in a SAMSI activity since last July 1
and completed this webform, you need not do so again, unless your personal information has
changed.
2. General Ratings: Poor Fair Good Very Excellent
Good .
a. Scientific Quality 1 2 3 4 5
b. Staff Helpfulness 1 2 3 4 5
c. Meeting Room/AV Facilities 1 2 3 4 5
d. Lodging 1 2 3 4 5
e. Local Transportation 1 2 3 4 5
2a. What were the positive aspects of the organization and running of this workshop?
2b. What parts of the organization and running need improvement?
3. Please comment on the Scientific Quality:

601
4. Additional comments on any other aspects of the workshop
5. An important goal of SAMSI is to create synergies between disciplines. How well
did this workshop further this goal?
6. How did you learn of this workshop?
7. Please suggest ideas / contacts for future SAMSI activities
G.2 Evaluation of Scientific Content
Greater than 90% of the respondents rated the scientific content as Very Good or
Excellent for the Program Workshops. The outcomes for the E&O Workshops were similar.
G.2.1 Program Workshops (11 events)
2009 Program on Psychometrics
Summer School on Spatial Statistics
Stochastic Dynamics Opening Workshop & Tutorials
Space-time Analysis for Environmental Mapping, Epidemiology & Climate Change Opening
Workshop & tutorials
Stochastic Dynamics: Self-Organization & Multi-Scale mathematical Modeling of Active
Biological Systems
Sequential Monte Carlo Methods Transition Workshop
Climate Change Workshop
Statistical Aspects of Environmental Risk
Molecular Motors, neuron Models & Epidemics on Networks
G.2.2 Education and Outreach Workshops
UG: Two Day Undergraduate Workshop October 2009
UG: Two Day Undergraduate Workshop February 2010

602
0%
20%
40%
60%
80%
100%
excellent
very good
good
fair
poor
Summary of Science at 2009-2010 at all Workshops
0%
20%
40%
60%
80%
100%
excellent
very good
good
fair
poor
Evaluations of Staff at all Workshops

603
0%
10%
20%
30%
40%
50%
60%
70%
80%
90%
100%
excellent
very good
good
fair
poor
Evaluations of Facilities at all Workshops
0%
20%
40%
60%
80%
100%
Excellent
Very Good
Good
Fair
Poor
Evaluations of Lodgings at all Workshops

604
0%
10%
20%
30%
40%
50%
60%
70%
80%
90%
100%
Excellent
Very Good
Good
Fair
Poor
Evaluations of Transportation at all Workshops
Top Related
Copyright © 2022 FDOKUMEN

