



![[BG] Đường lối Cách mạng của ĐCSVN](https://static.fdokumen.com/doc/165x107/6331b0bd4e01430403004f7b/bg-duong-loi-cach-mang-cua-dcsvn.jpg)



Bahasa
Halaman
Hukum



Mục lục 1
PGS.TS. TRẦN XUÂN TÚ
MẠNG TRÊN CHIP
NHÀ XUẤT BẢN ĐẠI HỌC QUỐC GIA HÀ NỘI

2 Mạng trên chip

Mục lục 3
MỤC LỤC
DANH MỤC HÌNH VẼ ........................................................................................ 8
DANH MỤC BẢNG .......................................................................................... 13
DANH MỤC TỪ VIẾT TẮT ................................................................................ 14
LỜI NÓI ĐẦU .................................................................................................. 17
LỜI CẢM ƠN ................................................................................................... 20
Chương 1
HỆ THỐNG TRÊN CHIP VÀ KIẾN TRÚC TRUYỀN THÔNG TRUYỀN THỐNG
1.1. Hệ thống trên chip ................................................................................ 21
1.2. Kiến trúc truyền thông truyền thống vĖ những hạn chế .......................... 24
1.3. Phương phėp thiết kế hệ thống trên chip ............................................... 27
1.4. Mạng trên chip – một kiến trúc truyền thông mới .................................. 29
1.5. Kết luận chương ................................................................................... 31
Chương 2
MẠNG TRÊN CHIP: CÁC KHÁI NIỆM CƠ BÂN
2.1. Tô-pô hay cấu trúc liên kết cûa mạng trên chip ..................................... 33
2.2. Kỹ thuật truyền thông ........................................................................... 35
2.3. Cơ chế truyền thông ............................................................................. 37
2.4. Chiến lược lưu trữ ................................................................................. 39
2.5. Thuật toėn đðnh tuyến ........................................................................... 40
2.6. Tắc nghẽn vĖ kỹ thuật điều khiển luồng dữ liệu ..................................... 42
2.7. Chất lượng dðch vụ mạng ...................................................................... 45
2.8. Giao thức truyền thông ......................................................................... 47
2.9. Kết luận chương ................................................................................... 48

4 Mạng trên chip
Chương 3
THIẾT KẾ, MÔ HÌNH HÓA VÀ KIỂM CHỨNG BỘ ĐỊNH TUYẾN MẠNG
3.1. Bài toėn thiết kế ................................................................................... 50
3.2. Mô hình bộ đðnh tuyến .......................................................................... 52
3.3. Thiết kế chi tiết kiến trúc bộ đðnh tuyến ................................................. 55
3.3.1. Khối phân luồng dữ liệu cûa mô-đun lối vĖo ......................................... 56
3.3.2. Khối điều khiển cûa mô-đun lối vĖo ...................................................... 56
3.4. Khối phân luồng dữ liệu cûa mô-đun lối ra ............................................ 57
3.4.1. Khối điều khiển cûa mô-đun lối ra ........................................................ 58
3.4.2. Crossbar .............................................................................................. 58
3.5. Mô hình hòa, kiểm chứng vĖ thực thi thiết kế ........................................ 59
3.5.1. Phương phėp mô hình hòa, kiểm chứng ................................................ 59
3.5.2. Kết quĘ mô phóng vĖ kiểm chứng ........................................................ 61
3.5.3. Kết quĘ thực thi phần cứng bộ đðnh tuyến ............................................. 65
3.6. Kết luận chương ................................................................................... 66
Chương 4
THIẾT KẾ, MÔ HÌNH HÓA VÀ KIỂM CHỨNG BỘ GIAO TIẾP MẠNG
4.1. Giới thiệu ............................................................................................. 67
4.2. Kiến trúc NoC sử dụng ......................................................................... 71
4.2.1. Tô-pô mạng ......................................................................................... 71
5.2.2. Thuật toėn đðnh tuyến vĖ đðnh dạng dữ liệu ........................................... 72
4.2.3. Vi kiến trúc cûa bộ đðnh tuyến mạng ..................................................... 73
4.3. Thiết kế bộ phối ghép mạng AXI-NoC ................................................... 74
4.3.1. Đðnh dạng gòi tin .................................................................................. 76
4.3.2. Bộ phối ghép mạng Master ................................................................... 78
4.4. Phương phėp mux-selection ................................................................. 86
4.4.1. Ưu vĖ nhược điểm cûa phương phėp bắt tay truyền thống dựa vĖo FSM ...... 86
4.4.2. Phương phėp mux-selection vĖ thực thi trong MNA ............................... 87
4.5. Thực thi vĖ kiểm chứng phần cứng ....................................................... 89
4.6. Kết luận chương ................................................................................... 93

Mục lục 5
Chương 5
TỐI ƯU NĂNG LƯỢNG TIÊU THỤ CHO MẠNG TRÊN CHIP
5.1. Công suất tiêu thụ trên mạch tích hợp .................................................. 94
5.1.1. Công suất tiêu thụ động ....................................................................... 95
5.1.2. Công suất tiêu thụ tïnh ......................................................................... 98
5.2. Một số phương phėp thiết kế vi mạch công suất thấp ......................... 100
5.2.1. Phương phėp chặn cấp xung nhðp ....................................................... 101
5.2.2. Phương phėp thiết kế đa điện ėp nguồn .............................................. 102
5.2.3. Phương phėp thiết kế đa điện ėp ngưỡng ............................................ 103
5.3. Phương phėp thiết kế đa điện ėp nguồn .............................................. 104
5.3.1. Phương phėp điều khiển tỷ lệ điện ėp vĖ tần số động .......................... 105
5.3.2. Một số thėch thức trong thiết kế đa điện ėp nguồn .............................. 112
5.4. Một số giĘi phėp thiết kế mạng trên chip theo hướng giĘm thiểu
công suất tiêu thụ .............................................................................. 112
5.4.1. Kiến trúc mạng trên chip công suất thấp ALPIN .................................. 114
5.4.2. Mô hình điều khiển tần số vĖ điện ėp dựa trên kỹ thuật PSTR .................. 119
5.4.3. Kiến trúc Producer-Consumer FIFO ..................................................... 121
5.4.4. Bộ phối ghép mạng công suất thấp theo chuẩn OCP ........................... 124
5.5. Kết luận chương ................................................................................. 127
Chương 6
ỨNG DỤNG LÔ-GIC MỜ
TRONG THIẾT KẾ MẠNG TRÊN CHIP CÔNG SUẤT THẤP
6.1. Giới thiệu về thuật toėn lô-gic mờ ....................................................... 128
6.1.1. Lý thuyết mờ ...................................................................................... 130
6.1.2. Thiết kế hệ thống mờ .......................................................................... 135
6.1.3. Mô hình thuật toėn Sugeno ................................................................. 137
6.2. Bộ điều khiển tần số - điện ėp dùng cho bộ đðnh tuyến mạng trên chip ..... 138
6.2.1. Đề xuất mô hình bộ điều khiển tần số - điện ėp cho bộ đðnh tuyến ........... 138
6.2.2. Thiết kế vĖ mô hình hòa bộ điều khiển tần số - điện ėp ....................... 143

6 Mạng trên chip
6.3. Kiểm chứng hoạt động cûa bộ điều khiển tần số - điện ėp .................. 154
6.3.1. Kiểm chứng hoạt động cûa khối đo lưu lượng ..................................... 154
6.3.2. Kiểm chứng hoạt động cûa khối xėc đðnh lưu lượng cực đại .................... 155
6.3.3. Kiểm chứng hoạt động cûa khối xėc đðnh biến thiên lưu lượng ................... 155
6.3.4. Kiểm chứng hoạt động cûa bộ xử lý lô-gic mờ .................................... 156
6.3.5. Kiểm chứng hoạt động cûa bộ điều khiển tần số - điện ėp .................. 157
6.4. Mô phóng vĖ đėnh giė hiệu quĘ cûa bộ điều khiển tần số - điện ėp ..... 158
6.4.1. Ước lượng công suất tiêu thụ cûa một mạng trên chip ......................... 159
4.4.2. Đėnh giė hiệu quĘ cûa bộ điều khiển tần số - điện ėp ......................... 166
6.4.3. Đėnh giė hiệu năng với dạng truyền thông UNIFORM........................... 168
6.4.4. Đėnh giė hiệu năng với dạng truyền thông SELF-SIMILAR ................... 171
6.5. Kết luận chương ................................................................................. 178
Chương 7
THIẾT KẾ KIỂM TRA CHO MẠNG TRÊN CHIP
7.1. Giới thiệu ........................................................................................... 180
7.2. Kiểm tra cėc hệ thống trên chip dựa trên NoC ..................................... 181
7.2.1. Sử dụng kiến trúc mạng để kiểm tra cėc tài nguyên tính toán .................. 181
7.2.2. Kiểm tra kiến trúc kết nối .................................................................... 182
7.3. Giới thiệu về kiến trúc NoC không đồng bộ ......................................... 184
7.4. Phương phėp kiểm tra đề xuất cho ANOC ........................................... 185
7.5. Thiết kế vĖ thực thi ............................................................................. 188
7.5.1. Kiến trúc test wrapper ........................................................................ 188
7.5.2. Kiến trúc test cells .............................................................................. 190
7.5.3. Các test cell với chức năng bypass ..................................................... 192
7.5.4. Mô-đun điều khiển wrapper ................................................................ 194
7.6. Tạo dữ liệu kiểm tra ............................................................................ 199
7.6.1. Mô hình lỗi cho mạch không đồng bộ QDI .......................................... 199
7.6.2. Dữ liệu kiểm tra cho cėc liên kết mạng ............................................... 201
7.6.3. Dữ liệu kiểm tra cho cėc bộ đðnh tuyến mạng ..................................... 202

Mục lục 7
7.7. Chiến lược kiểm tra ............................................................................ 205
7.8. Kết quĘ thực nghiệm .......................................................................... 208
7.8.1. Chi phí không gian thực thi ................................................................. 208
7.8.2. Độ trễ tăng thêm ................................................................................ 209
7.8.3. Thời gian thực thi kiểm tra .................................................................. 210
7.8.4. Độ bao phû lỗi .................................................................................... 210
7.8.5. Chẩn đoėn lỗi vĖ đðnh vð điểm khiếm khuyết ....................................... 212
7.8.6. Tėi cấu hình bộ đðnh tuyến trong trường hợp cò lỗi đơn ....................... 213
7.9. Kết luận chương ................................................................................. 213
TÀI LIỆU THAM KHẢO .................................................................................. 215
INDEX .......................................................................................................... 233

Mục lục 8
DANH MỤC HÌNH VẼ
Hình 1-1: Mô hình hệ thống trên chip điển hình. ........................................... 22
Hình 1-2: Kiến trúc kết nối trong các hệ thống trên chip:
Kết nối điểm-tới-điểm (a); Chia sẻ bus (b). ................................... 25
Hình 1-3: Mô hình bus phân tầng. ................................................................ 26
Hình 1-4: Phương phėp thiết kế top-down. ................................................... 27
Hình 1-5: Phương phėp thiết kế bottom-up. .................................................. 28
Hình 1-6: Một ví dụ về mô hình mạng trên chip. ........................................... 30
Hình 2-1: Những tô-pô thông dụng dùng cho mạng trên chip: ring hay chordal
ring (a); fat-tree (b); butterfly fat-tree (c); 2D-mesh (d);
2D torus (e); 2D folded torus (f). .................................................. 33
Hình 2-2: Cėc cơ chế đðnh tuyến: Lưu trữ và chuyển tiếp (a); Virtual Cut
Through (b); Wormhole (c). .......................................................... 37
Hình 2-3: Chiến lược lưu trữ trên bộ đðnh tuyến: hĖng đợi lối vào (a);
hĖng đợi lối ra (b); hĖng đợi lối ra Ęo (c); hĖng đợi lối vĖo ưu tiên
kênh Ęo (d). .................................................................................. 39
Hình 2-4: Ví dụ về một trường hợp khóa chết. .............................................. 43
Hình 2-5: Tránh khóa chết bằng kênh Ęo. ..................................................... 44
Hình 2-6: Ví dụ về khòa động. ...................................................................... 44
Hình 2-7: Mô hình tham chiếu kết nối các hệ thống mở OSI. ........................ 47
Hình 3-1: Mô hình mạng trên chip đề xuất. ................................................... 50
Hình 3-2: Đðnh dạng cûa các flit. .................................................................. 51
Hình 3-3: Kiến trúc cûa bộ đðnh tuyến. ......................................................... 53
Hình 3-4: Giao thức bắt tay Ĕsend-acceptĕ. .................................................. 54
Hình 3-5: Một cặp mô-đun vĖo/ra cûa bộ đðnh tuyến. ................................... 55

Danh mục hình vẽ 9
Hình 3-6: Khối phân luồng dữ liệu cûa mô-đun lối vào. ................................. 56
Hình 3-7: Khối điều khiển cûa mô-đun lối vào. ............................................. 57
Hình 3-8: Khối phân luồng dữ liệu cûa mô-đun lối ra. ................................... 57
Hình 3-9: Khối điều khiển cûa mô-đun lối ra. ................................................ 58
Hình 3-10: Crossbar sử dụng trong thiết kế. ................................................... 59
Hình 3-11: Quy trình mô hình hóa, kiểm chứng và thực thi phần cứng. ............ 60
Hình 3-12: Mô hình kiểm chứng bộ đðnh tuyến. .............................................. 61
Hình 3-13: Kết quĘ mô phóng với mô-đun lối vào cûa bộ đðnh tuyến. ............. 62
Hình 3-14: Kết quĘ mô phóng với mô-đun lối ra cûa bộ đðnh tuyến. ................ 63
Hình 3-15: Kết quĘ mô phóng cûa bộ đðnh tuyến thiết kế. ............................... 64
Hình 3-16: Layout cûa bộ đðnh tuyến với công nghệ FPGA cûa hãng Xilinx
(thực thi trên chip XC2V1000-5ff896). .......................................... 65
Hình 4-1: Kiến trúc mạng trên chip dạng lưới hai chiều kích thước 3×3. ........ 72
Hình 4-2: Phân chia dữ liệu thành gói tin tại nguồn phát. .............................. 72
Hình 4-3: Đðnh dạng flit cûa mạng trên chip.................................................. 73
Hình 4-4: Kiến trúc chi tiết cûa một bộ đðnh tuyến mạng............................... 74
Hình 4-5: Bộ phối ghép mạng chû và bộ phối ghép mạng tớ. ........................ 75
Hình 4-6: Đðnh dạng gói tin yêu cầu: gói tin yêu cầu ghi (a);
và gói tin yêu cầu đọc (b). ............................................................ 76
Hình 4-7: Đðnh dạng gói tin phĘn hồi: gói tin phĘn hồi đọc (a);
gói tin phĘn hồi ghi. ...................................................................... 77
Hình 4-8: Kiến trúc MNA [45]. ..................................................................... 78
Hình 4-9: Kiến trúc luồng yêu cầu MNA [45]. ............................................... 79
Hình 4-10: Mô-đun MNA Transmitter: Vi kiến trúc tối ưu (a);
Máy trạng thái hữu hạn FSM (b) [45]. ........................................... 80
Hình 4-11: Mô-đun MNA Response Flow: Vi kiến trúc tối ưu (a);
Máy trạng thái hữu hạn (b) [45]. ................................................... 84
Hình 4-12: GiĘn đồ thời gian tại MNA Transmitter khi sử dụng phương phėp
bắt tay truyền thống dựa vào FSM [45]. ........................................ 86

10 Mạng trên chip
Hình 4-13: GiĘn đồ thời gian tại MNA Transmitter khi sử dụng phương phėp
mux-selection đề xuất [45]. .......................................................... 88
Hình 4-14: GiĘn đồ thời gian tại MNA Response Flow
khi sử dụng phương phėp mux-selection đề xuất [45]. .................. 88
Hình 4-15: Môi trường kiểm chứng với 9 bộ đðnh tuyến mạng. ........................ 89
Hình 4-16: Hình Ęnh layout cuối cùng cûa thiết kế [45]. ................................. 90
Hình 4-17: Công suất tiêu thụ và chi phí thực thi phần cứng ước lượng
tại các tần số hoạt động khác nhau [45]. ...................................... 91
Hình 5-1: Quá trình phóng nạp trên tụ điện ký sinh trong trường hợp
công suất chuyển mạch. .............................................................. 95
Hình 5-2: Dñng điện ngắn mạch trên cổng NOT trong trường hợp
công suất ngắn mạch. .................................................................. 96
Hình 5-3: Phân loại công suất tiêu thụ trên vi mạch tích hợp. ..................... 100
Hình 5-4: Phương phėp chặn cấp xung nhðp: không thực hiện chặn xung nhðp (a);
có thực hiện chặn xung nhðp (b). ................................................ 102
Hình 5-5: Một ví dụ về phương phėp thiết kế đa điện áp nguồn. .................. 102
Hình 5-6: Mối quan hệ giữa thời gian trễ vĖ dñng rñ đối với quy trình 90nm [51]. . 103
Hình 5-7: Mô hình hệ thống sử dụng phương phėp điều khiển tỷ lệ tần số và
điện ėp động. ............................................................................. 106
Hình 5-8: Kiến trúc ALPIN [94]. ................................................................. 114
Hình 5-9: BĘn layout vĖ đòng vó cûa vi mạch ALPIN [96]. ......................... 116
Hình 5-10: Một đơn vð mạng hoàn chînh trong ALPIN [97]. .......................... 117
Hình 5-11: Kiến trúc PSTR quĘn lý năng lượng/hiệu năng
cho mỗi vùng điện áp/tần số [99]. .............................................. 119
Hình 5-12: Thuật toėn để xėc đðnh cėc vùng điện áp/tần số độc lập VFI [57]. ..... 122
Hình 5-13: Cấu trúc cûa Producer-Consumer FIFO. ...................................... 122
Hình 5-14: Kiến trúc DFS cho VFI. ................................................................ 123
Hình 5-15: Tích hợp bộ điều khiển PI trong nền tĘng hệ thống VENGME. ...... 124
Hình 5-16: Kiến trúc cûa bộ MNI [91]. .......................................................... 125

Danh mục hình vẽ 11
Hình 6-1: Hàm liên thuộc cûa tập kinh điển . ................................... 130
Hình 6-2: Hàm phụ thuộc cûa tập Ĕmờĕ . ...................................... 132
Hình 6-3: Hàm liên thuộc tuyến tính từng đoạn. .......................................... 132
Hình 6-4: Các thông số đặc trưng cûa tập mờ. ........................................... 133
Hình 6-5: Mô hình cơ bĘn cûa một hệ thống mờ. ....................................... 136
Hình 6-6: Thuật toán lô-gic mờ theo mô hình Sugeno. ................................ 138
Hình 6-7: Tín hiệu bắt tay giữa các bộ đðnh tuyến và lõi IP. ......................... 139
Hình 6-8: Mô hình giĘi phėp điều khiển tần số điện ėp được đề xuất
cho các nốt mạng cûa một mạng trên chip [101]. ...................... 140
Hình 6-9: Mô hình khối điều khiển tần số - điện áp cho bộ đðnh tuyến mạng
trên chip [101]. .......................................................................... 141
Hình 6-10: Sơ đồ chi tiết cûa bộ điều khiển tần số - điện áp [101]. .............. 143
Hình 6-11: Sơ đồ mô tĘ khối đo lưu lượng [101]. ......................................... 144
Hình 6-12: Sơ đồ máy trạng thái mô tĘ khối đo lưu lượng [101].................... 145
Hình 6-13: Mô hình khối tính toán giá trð lưu lượng trung bình cực đại [101]. 146
Hình 6-14: Mô hình khối tính toán biến thiên giá trð lưu lượng DER. ............... 146
Hình 6-15: Sơ đồ cûa khối xử lý lô-gic mờ FLP. ............................................ 147
Hình 6-16: Mô hình hóa ở mức RTL cho bộ xử lý lô-gic mờ [111]. ............... 148
Hình 6-17: Mô tĘ cho hàm liên thuộc dạng hình thang. ................................. 148
Hình 6-18: Mô tĘ các hàm liên thuộc cho đầu vào input_1. .......................... 150
Hình 6-19: Mô tĘ các hàm liên thuộc cho đầu vào input_2. .......................... 150
Hình 6-20: Mô tĘ các hàm liên thuộc cho đầu ra output. .............................. 151
Hình 6-21: Kết quĘ mô phóng hoạt động lô-gic cûa khối đo lưu lượng. ......... 154
Hình 6-22: GiĘn đồ dạng sóng thể hiện kết quĘ mô phóng hoạt động lô-gic
cûa khối xėc đðnh lưu lượng cực đại. ........................................... 155
Hình 6-23: GiĘn đồ dạng sóng thể hiện kết quĘ mô phóng hoạt động lô-gic
cûa khối xėc đðnh biến thiên lưu lượng. ........................................ 156
Hình 6-24: GiĘn đồ sóng thể hiện kết quĘ mô phóng hoạt động
cûa khối xử lý lô-gic. .................................................................. 156

12 Mạng trên chip
Hình 6-25: Kết quĘ mô phóng khĘ năng đėp ứng cûa bộ điều khiển
tần số điện áp theo sự thay đổi cûa lưu lượng truyền thông [101]. .... 157
Hình 6-26: Mô hình cấu trúc từng khối thành phần cûa một bộ đðnh tuyến
trong mô hình ORION 3 [114]. .................................................... 161
Hình 6-27: Công suất tiêu thụ đối với kiểu truyền thông UNIFORM. ............... 169
Hình 6-28: Độ trễ truyền đối với kiểu truyền thông UNIFORM. ....................... 170
Hình 6-29: Công suất tiêu thụ đối với kiểu truyền thông SELF-SIMILAR. ....... 172
Hình 6-30: Độ trễ truyền đối với kiểu truyền thông SELF-SIMILAR. ............... 173
Hình 7-1: Mô hình thiết kế kiểm tra cho hệ thống trên chip. ........................ 179
Hình 7-2: Kiến trúc mạng trên chip không đồng bộ ANOC. .......................... 185
Hình 7-3: Kiến trúc thiết kế kiểm tra đề xuất [141]. ..................................... 186
Hình 7-4: Test wrapper cùng với bộ đðnh tuyến [141]. ................................ 189
Hình 7-5: Cấu trúc cûa một liên kết mạng [141]. ........................................ 190
Hình 7-6: Vi kiến trúc cûa các test cell vào/ra (ITC và OTC) [96]. ............... 191
Hình 7-7: Vi kiến trúc cûa các test cell với chức năng bypass:
(a) khối kiểm tra lối vào ITC; (b) khối kiểm tra lối ra OTC [141]. .. 193
Hình 7-8: Khung cấu hình kiểm tra. ............................................................ 194
Hình 7-9: Mô-đun điều khiển wrapper (WCM) [141]. .................................. 196
Hình 7-10: Wrapper được cấu hình để kiểm tra đường đðnh tuyến
NORTH SOUTH [96]. ............................................................. 197
Hình 7-11: Hoạt động cûa các mạch không đồng bộ QDI mã hóa
1-of-2 return-to-zero. .................................................................. 200
Hình 7-12: Mạch bð chặn (ngừng hoạt động) bởi một stuck-at net ĒReq1ē. .... 200
Hình 7-13: Phân tích cấu trúc cûa một bộ đðnh tuyến ANOC [141]. .............. 203
Hình 7-14: Đðnh dạng cûa một gói dữ liệu kiểm tra. ...................................... 204
Hình 7-15: Luồng kiểm tra cho mạng ANOC [141]. ...................................... 206
Hình 7-16: Các cấu hình kiểm tra: Chế độ kiểm tra (a); Chế độ bypass (b);
Chế độ transfer (c); Chế độ loop-back (d). .................................. 207
Hình 7-17: Độ trễ tăng thêm. ........................................................................ 209

Mục lục 13
DANH MỤC BÂNG
BĘng 3-1: Không gian thực thi phần cứng bộ đðnh tuyến thiết kế trên chip
XC2V1000-5ff896 ........................................................................ 65
BĘng 3-2: Năng lượng tiêu thụ cûa thiết kế .................................................... 66
BĘng 4-1: Mô tĘ trạng thái cûa máy trạng thái hữu hạn cûa MNA Transmitter ..... 81
BĘng 4-2: Mô tĘ trạng thái cûa máy trạng thái hữu hạn
cûa MNA Response Flow .............................................................. 85
BĘng 4-3: So sánh kết quĘ thực thi với một số công trình liên quan [45]. ...... 92
BĘng 5-1: So sėnh đėnh giė giữa cėc phương phėp điều khiển tỷ lệ điện áp
và tần số động ........................................................................... 111
BĘng 5-2: So sánh giữa các kỹ thuật thiết kế nhằm giĘm công suất tiêu thụ
cho mạng trên chip .................................................................... 126
BĘng 6-1: Các quy luật hợp thành cûa khối xử lý lô-gic mờ ......................... 152
BĘng 6-2: Công suất tiêu thụ đối với kiểu truyền thông UNIFORM ................ 169
BĘng 6-3: Độ trễ truyền đối với kiểu truyền thông UNIFORM ........................ 170
BĘng 6-4: Công suất tiêu thụ đối với kiểu truyền thông SELF-SIMILAR ........ 171
BĘng 6-5: Độ trễ truyền đối với kiểu truyền thông SELF-SIMILAR ................ 173
BĘng 6-6: So sėnh, đėnh giė kết quĘ đạt được với một số kỹ thuật thiết kế
nhằm giĘm công suất tiêu thụ cho mạng trên chip ...................... 176
BĘng 7-1: Mô tĘ hoạt động cûa các test cell ............................................... 194
BĘng 7-2: GiĘi thích về khung cấu hình kiểm tra .......................................... 195
BĘng 7-3: Mối liên hệ giữa TCF vĖ cėc kênh điều khiển ............................... 197
BĘng 7-4: TCF dùng để kiểm tra đường đðnh tuyến NORTH-SOUTH ................. 198
BĘng 7-5: Bộ dữ liệu kiểm tra cho từng liên kết mạng .................................. 202
BĘng 7-6: Gói tin kiểm tra đa flit dùng để kiểm tra lối vào, lối ra và kênh Ęo
cûa bộ đðnh tuyển ....................................................................... 204
BĘng 7-7: Ba gói dữ liệu kiểm tra đơn flit bổ sung dùng để kiểm tra lối vào,
lối ra và kênh Ęo cûa bộ đðnh tuyến ............................................. 205
BĘng 7-8: Báo cáo về độ bao phû lỗi Single Stuck-At (SSA) khi kiểm tra
bộ đðnh tuyến ............................................................................. 211

Mục lục 14
DANH MỤC TỪ VIẾT TẮT
ASIC Application-Specific Integrated Circuit (Mạch tích hợp ứng dụng riêng)
ATPG Automatic Test Pattern Generation (Tạo dữ liệu kiểm tra tự động)
AVS Adaptive Voltage Scaling (Điều khiển tỷ lệ điện áp thích nghi)
BU Buffer Utilization (Mức độ sử dụng bộ đệm)
CPU Central Processing Unit (Đơn vị xử lý trung tâm)
DFT Design-for-Test/Testability (Thiết kế kiểm tra)
DOR Dimesion Ordered Routing (Định tuyến thứ tự kích thước)
DSM Deep submicron (Kích thước siêu micro)
DSP Digital Signal Processor (Bộ xử lý tín hiệu số)
DVS Dynamic Voltage Scaling (Điều khiển tỷ lệ điện áp động)
DVFS Dynamic Voltage and Frequency Scaling (Điều khiển tỷ lệ điện áp
và tần số động)
FHT Fast Hartley Transform (Biến đổi Hartley nhanh)
FIFO First-In First-Out (Vào trước, ra trước)
FLP Fuzzy Logic Processing (Xử lý lô-gic mờ)
GALS Globally Asynchronous - Locally Synchronous (dị bộ toàn cầu -
đồng bộ cục bộ)
HFS Header Flit Shift (Dịch flit tiêu đề)
IP Intellectual Property
LAVFS Locally Adaptive Voltage and Frequency Scaling
LMS Least Mean Square (Bình phương trung bình tối thiểu)
LPM Local Power Manager (Khối quản lý nguồn cục bộ)
LU Link Utilization (Mức độ sử dụng liên kết)
LUT Look-Up Table (Bảng tra cứu)
MEMS Microelectronics and Microsystems (Vi cơ điện tử và vi hệ thống)
MIPS Microprocessor without Interlocked Pipeline Stages
MPSoC Multi-Processor SoC (SoC đa lõi xử lý)

Danh mục từ viết tắt 15
MSF Membership Function (Hàm liên thuộc)
MVS Multi-level Voltage Scaling (Tỷ lệ điện áp đa mức)
NA Network Adapter (Bộ phối ghép mạng)
NI Network Interface (Giao diện mạng)
NoC Network-on-Chip (Mạng trên chip)
OFDM Orthogonal Frequency-Division Multiplexing (Ghép kênh phân
chia theo tần số trực giao)
OSI Open Systems Interconnection Reference Model (Mô hình tham
chiếu kết nối các hệ thống mở)
PID Proportional Integral Derivative (Vi tích phân tỷ lệ)
RAM Random Access Memory (Bộ nhớ truy cập ngẫu nhiên)
RF Radio Frequency (Tần số radio)
RTL Register Transfer Level (Mức truyền thanh ghi)
OCP Open Core Protocol (Giao thức lõi mở)
SAF Store-and-Forward (Lưu và chuyển tiếp)
SoC System-on-Chip (Hệ thống trên chip)
TAM Test Access Mechanism (Cơ chế truy cập kiểm tra)
TCF Test Configuration Frame (Khung cấu hình kiểm tra)
TDM Time Division Multiplexing (Ghép kênh phân chia theo thời gian)
VCO Voltage-Controlled Oscillator (Bộ dao động điều khiển bằng điện áp)
VCPIQ Vital Channel Priority Input Queuing (Hàng đợi lối vào ưu tiên
kênh ảo)
VCT Virtual Cut-Through
VFC Voltage-Frequency Controller (Bộ điều khiển tần số - điện áp)
VHSIC Very High-Speed Integrated Circuit (Mạch tích hợp tốc độ rất cao)
VHDL VHSIC Hardware Description Language (Ngôn ngữ mô tả phần
cứng VHDL)
VOQ Virtual Output Queuing (Hàng đợi lối ra ảo)
WCET Worst-Case Execution Time (Thời gian xử lý trong trường hợp xấu nhất)
WCM Wrapper Control Module (Mô-đun điều khiển wrapper)

Mục lục 16

Mục lục 17
LỜI NÓI ĐẦU
Ngày nay, vi mạch tích hợp có mặt trong hầu hết các ứng dụng,
từ các ứng dụng thông thường như các thiết bị điện tử gia dụng cho
đến các ứng dụng phức tạp trong viễn thông, vũ trụ, an ninh quốc
phòng... Nghiên cứu và làm chủ công nghệ thiết kế và chế tạo vi mạch
tích hợp đóng vai trò hết sức quan trọng trong việc phát triển các
ngành điện tử, viễn thông, công nghệ thông tin và tự động hóa. Công
nghệ thiết kế, chế tạo vi mạch đã và đang phát triển một cách nhanh
chóng, cho phép người thiết kế tích hợp cả một hệ thống hoàn chỉnh
trên một phiến silicon có kích thước 1 inch2 (tương đương 6,452 cm
2)
và thường được gọi là hệ thống trên chip (SoC: System-on-Chip). Với
những hệ thống SoC ngày càng phức tạp, xu hướng tất yếu đặt ra là
chia thiết kế tổng thể thành những khối chức năng riêng biệt, thường
gọi là các lõi IP (Intellectual Property), để có thể tái sử dụng các khối
chức năng đó trong những thiết kế tiếp theo nhằm rút ngắn thời gian
thiết kế và giảm đầu tư về nhân lực. Bài toán thiết kế hệ thống do vậy
trở thành bài toán tối ưu truyền thông giữa các khối chức năng trong
vi mạch. Những kiến trúc truyền thông truyền thống như liên kết điểm
tới điểm hay chia sẻ bus không thể đáp ứng được tốc độ xử lý cũng
như mật độ tích hợp ngày càng lớn của vi mạch. Giải pháp đặt ra là sử
dụng kiến trúc truyền thông phân đoạn và định tuyến.
Chính vì vậy, trong những năm gần đây các nhà nghiên cứu thuộc
nhiều trường đại học và viện nghiên cứu trên thế giới đã bắt tay vào
việc nghiên cứu xây dựng một “mô hình vi mạng” và mong muốn tích
hợp mô hình này lên trên vi mạch nhằm đáp ứng nhu cầu truyền thông
giữa các lõi IP trong một hệ thống trên chip. Kiến trúc truyền thông
này được gọi là mạng trên vi mạch hay mạng trên chip, thuật ngữ
tiếng Anh gọi là Network-on-Chip (NoC). Những nhóm nghiên cứu
tiên phong về mạng trên chip có thể kể đến như Đại học Berkeley

18 Mạng trên chip
(Hoa Kỳ), Đại học Manchester, Công ty Silistix (Vương quốc Anh),
Học viện Công nghệ Massachussetts, Đại học Standford, Đại học
Princeton, Hãng Intel (Hoa Kỳ), Trung tâm Nghiên cứu IMEC
(Vương quốc Bỉ), Trung tâm Nghiên cứu CEA-Leti, Minatec, Công ty
Arteris (Cộng hòa Pháp), Phòng thí nghiệm của hãng Philips (Hà
Lan), Viện Tiên tiến về Khoa học và Công nghệ Hàn Quốc – KAIST
(Hàn Quốc)... Mạng trên chip được xem như là một sự lựa chọn hứa
hẹn cho các hệ thống trên chip trong tương lai. Hay nói cách khác, đây
là một mô hình truyền thông mới, hứa hẹn cung cấp các giải pháp tối
ưu nhằm khắc phục các hạn chế của các mô hình truyền thông truyền
thống trong các hệ thống trên chip có độ phức tạp cao.
Cuốn sách chuyên khảo này sẽ giới thiệu với bạn đọc các nghiên
cứu của chúng tôi liên quan đến mô hình mạng trên chip, từ những
khái niệm cơ bản đến các vấn đề liên quan đến phương pháp thiết kế,
mô phỏng, kiểm chứng và thực thi phần cứng từng cấu phần của mạng
trên chip cũng như các phương pháp tối ưu, kiểm tra giúp cho mô hình
mạng trên chip ngày càng trở nên khả thi, có thể phát triển thành các
sản phẩm ứng dụng có tính thương mại cao. Nội dung cuốn sách là
tổng hợp kinh nghiệm, kết quả nghiên cứu của tác giả với đồng
nghiệp, các nghiên cứu sinh, học viên cao học, sinh viên trong nhóm
nghiên cứu; trong đó, tác giả đóng vai trò là người triển khai nghiên
cứu trực tiếp, hướng dẫn nghiên cứu và/hoặc chịu trách nhiệm định
hướng, tổ chức triển khai nghiên cứu trong hơn một thập kỷ qua.
Bố cục của cuốn sách gồm 7 chương:
Chương 1 bàn luận về hệ thống trên chip và kiến trúc truyền
thông truyền thống. Tiếp theo, mạng trên chip được giới thiệu như là
giải pháp truyền thông mới với nhiều ưu điểm nổi trội đối với các hệ
thống trên chip có độ tích hợp cao.
Chương 2 giới thiệu các khái niệm cơ bản và tổng quan tình
hình nghiên cứu trên thế giới về mạng trên chip.
Chương 3 trình bày về thiết kế, mô hình hóa và kiểm chứng bộ
định tuyến mạng – một trong những thành phần căn bản nhất cấu
thành mạng trên chip.

Lời nòi đầu 19
Chương 4 trình bày về thiết kế, mô hình hóa và kiểm chứng bộ
giao tiếp mạng, giúp cho hạ tầng mạng có thể giao tiếp với các lõi IP
truyền thống.
Chương 5 tập trung vào các giải pháp tối ưu năng lượng trong
thiết kế mạng trên chip. Một số giải pháp thiết kế công suất thấp được
áp dụng cho các mạng trên chip sẽ được thảo luận, phân tích trong
chương này. Nội dung chương này do tác giả và Phan Hải Phong cùng
biên soạn.
Chương 6 giới thiệu giải pháp ứng dụng lô-gic mờ trong thiết
kế mạng trên chip công suất thấp. Kết quả thực thi, mô phỏng và đánh
giá hiệu quả giải pháp sẽ lần lượt được trình bày trong chương này.
Nội dung chương này do tác giả và Phan Hải Phong cùng biên soạn.
Chương 7 giới thiệu giải pháp thiết kế kiểm tra cho kiến trúc
mạng trên chip – một trong những điểm then chốt nhằm đảm bảo các
hệ thống được xây dựng trên cơ sở mạng trên chip có thể được áp
dụng vào các sản phẩm thương mại thực tiễn.
Mặc dù cuốn sách được biên soạn một cách công phu, tuy nhiên,
do giới hạn về thời gian và khuôn khổ của một cuốn sách, chắc chắn
rằng nội dung của cuốn sách chưa thể làm hài lòng tất cả bạn đọc và
cũng có thể còn sót lại một số lỗi. Tác giả rất mong nhận được sự chia
sẻ và đóng góp xây dựng của các nhà khoa học, chuyên gia công nghệ,
nghiên cứu sinh, học viên, sinh viên và tất cả bạn đọc quan tâm.
Tác giả

20 Mạng trên chip
LỜI CÂM ƠN
Tác giả xin chân thành cảm ơn các đồng nghiệp và học trò
(nghiên cứu sinh, học viên cao học, sinh viên) đã cùng làm việc, trao
đổi, hợp tác nghiên cứu với tác giả trong hơn một thập kỷ qua liên
quan đến thiết kế mạch điện tử số, cụ thể hơn là về mạng trên chip. Sự
động viên, đóng góp của các đồng nghiệp và học trò trong các hoạt
động nghiên cứu khoa học đã đem lại nhiều kết quả và động lực để tác
giả viết cuốn sách này, tổng hợp lại một chặng đường nghiên cứu về
mạng trên chip. Xin chân thành cảm ơn những người bạn đồng hành
trong chặng đường hơn một thập kỷ qua: Herve Fanet, François
Bertrand, Chantal Robach, Jean Durupt, Pascal Vivet, Yvain Thonart,
Vincent Beroulle, Edith Beigne, Suzanne Lesecq, Nguyễn Ngọc Mai,
Bùi Duy Hiếu, Đặng Nam Khánh, Phan Hải Phong, Lê Văn Thanh
Vũ, Nguyễn Tùng, Nguyễn Thị Thủy…
Tác giả cũng xin gửi lời cảm ơn sâu sắc tới Hội đồng khoa học
(GS.TS. Bạch Gia Dương, PGS.TS. Hoàng Văn Phúc, TS. Lê Quang
Minh, PGS.TS. Nguyễn Nam Hoàng, TS. Hoàng Văn Xiêm) đã có
nhiều phản biện, góp ý bổ ích, giúp cho tác giả hoàn thiện cuốn sách
với chất lượng tốt nhất. Cảm ơn em gái Phương Thảo, mặc dù không
hoạt động trong lĩnh vực công nghệ kỹ thuật nhưng đã dành nhiều thời
gian đọc và hiệu đính rất kỹ các lỗi hành văn, chế bản, chính tả… còn
tồn tại trong bản thảo, giúp cuốn sách được hoàn thiện một cách chỉn
chu, dễ hiểu đối với người đọc. Cảm ơn chị Nguyễn Thủy và Nhà xuất
bản Đại học Quốc gia Hà Nội đã dày công biên tập và thiết kế để có
được cuốn sách đẹp.
Cuối cùng, cảm ơn gia đình, vợ và các con yêu quý đã dành thời
gian quan tâm, động viên tác giả trong suốt khoảng thời gian biên
soạn cuốn sách này.
Hà Nội, tháng 3 năm 2020.
Trần Xuân Tú

Mục lục 21
Chương 1
HỆ THỐNG TRÊN CHIP
VÀ KIẾN TRÚC TRUYỀN THÔNG TRUYỀN THỐNG
Cùng với sự tiến bộ của công nghệ bán dẫn, người ta tích hợp
ngày càng nhiều khối tính toán, thường được gọi là lõi IP (Intellectual
Property), lên cùng một vi mạch (chip) nhằm đáp ứng các yêu cầu của
ứng dụng. Một hệ thống mà trước kia phải xây dựng trên một hay
thậm chí nhiều bo mạch thì giờ đây có thể được tích hợp lên trên một
phiến silicon (chip) có kích thước không quá 1 inch2 (tương đương
6,452 cm2) và do đó, hình thành thuật ngữ “hệ thống trên một vi
mạch” hay “hệ thống trên chip”1 (tiếng Anh gọi là System-on-Chip
hay viết tắt là SoC). Hệ thống trên chip được biết đến như là một
phương pháp thiết kế gần đây nhất cho phép tích hợp trên hệ thống
khoảng từ vài chục đến vài trăm lõi IP như đã kể trên. Việc tích hợp
ngày càng nhiều lõi IP lên trên một vi mạch dẫn đến việc tăng nhu cầu
truyền thông trên chip (truyền thông giữa các lõi IP với nhau). Các
phương thức truyền thông truyền thống như kết nối điểm-tới-điểm, kết
nối bus dùng chung không còn đáp ứng được nhu cầu truyền thông
trên các vi mạch. Bài toán thiết kế các hệ thống trên chip chuyển
thành bài toán thiết kế kiến trúc truyền thông trên chip [1].
1.1. Hệ thống trên chip
Hệ thống trên chip là mô hình thiết kế gần đây nhất cho phép tích
hợp một máy tính hay một hệ thống điện tử hoàn chỉnh gồm nhiều lõi
IP lên trên một chip đơn. Lõi IP có thể là vi xử lý nhúng (µP), bộ xử
lý tín hiệu số (DSP: Digital Signal Procesor), các bộ nhớ như RAM và
1 Trong cuốn sách này, để ngắn gọn thuật ngữ “hệ thống trên chip” sẽ được sử dụng.

22 Mạng trên chip
ROM, các khối vào/ra như Ethernet hay Bluetooth, các khối thu/phát
tần số radio (RF), các khối MEMS và các khối tính toán khác [2]. Ứng
dụng điển hình của các hệ thống trên chip là các ứng dụng trong lĩnh
vực hệ thống nhúng.
Hình 1-1 mô tả một hệ thống trên chip điển hình bao gồm các lõi
IP liên kết với nhau sử dụng các kết nối điểm-điểm hay các bus dùng
chung. Trước xu thế tích hợp ngày càng nhiều lõi IP lên trên cùng một
chip, hiệu suất truyền thông trên các hệ thống đang giảm đi đáng kể vì
các lõi IP này phải chia sẻ với nhau một băng thông có hạn. Để tăng
hiệu suất truyền thông, chúng ta có thể sử dụng nhiều bus dùng chung
trong cùng một hệ thống, mỗi bus được dùng để kết nối một số lõi IP
nhất định nào đó (thường là các lõi IP thường xuyên có sự trao đổi
thông tin với nhau). Để cho phép thực hiện việc truyền thông giữa các
lõi IP ở các bus khác nhau, chúng ta nối các bus này với nhau bằng
một cầu nối bus (bus bridge).
Hình 1-1: Mô hình hệ thống trên chip điển hình.
Hệ thống trên chip mở ra những ứng dụng khả thi về các quá
trình xử lý song song và độc lập, nghĩa là một hệ thống có thể chia
thành nhiều mô-đun nhỏ hơn và các mô-đun ấy có khả năng làm việc
độc lập với nhau. Khi đó, truyền thông giữa các mô-đun đóng vai trò
rất quan trọng, quyết định hiệu năng hoạt động của toàn hệ thống. Bên
cạnh đó, trong một số ứng dụng, yêu cầu về thời gian thực khiến cho
các vấn đề truyền thông trở nên phức tạp hơn. Cùng với sự phát triển
của công nghệ bán dẫn, hệ thống trên chip với các kiến trúc truyền
thông truyền thống đã bộc lộ một số vấn đề liên quan đến hiệu năng

Chương 1. Hệ thống trên chip vĖ kiến trúc hệ thống truyền thông 23
hoạt động, năng lượng tiêu hao, thời gian trễ đáp ứng trên các kết nối,
trên các cổng logic, vấn đề truyền thông cục bộ và toàn cầu… hay các
vấn đề liên quan đến quá trình sản xuất.
Vấn đề về độ trễ: Công nghệ thiết kế vi mạch ngày càng phát
triển, kích thước transistor ngày càng nhỏ, dẫn đến độ tích hợp trên
một vi mạch ngày càng cao. Khi thiết kế với công nghệ nhỏ hơn micro
(DSM: deep submicron) thì vấn đề độ trễ đặc biệt quan trọng [3]. Khi
đó, người thiết kế cần phải giải quyết các vấn đề liên quan đến độ trễ
đáp ứng của dây dẫn cục bộ, dây dẫn toàn cầu và độ trễ đáp ứng của
các cổng logic. Với các công nghệ mới, độ trễ đáp ứng giữa đầu ra và
đầu vào của cổng lô-gic rất nhỏ, đặc biệt khi so với độ trễ dây dẫn (vì
tiết diện dây dẫn rất nhỏ với các công nghệ tiên tiến). Ngoài ra, độ trễ
trên dây dẫn cục bộ trong các lõi IP cũng có sự chênh lệch khá lớn đối
với độ trễ trên các dây dẫn nối giữa các lõi IP với nhau. Ngay cả độ trễ
trên các dây dẫn toàn cầu cũng có sự khác nhau; đó là sự khác nhau
giữa các dây nối các lõi IP ở gần với các dây nối các lõi IP ở xa.
Vấn đề đồng bộ toàn cầu: Việc đạt được sự đồng bộ toàn cầu
càng trở nên khó khăn khi mật độ tích hợp và tốc độ chip càng tăng.
Các quá trình xử lý trong chip được chia nhỏ thành các xử lý bên
trong các lõi IP. Khi đó mỗi lõi IP sẽ có một xung nhịp đồng hồ
(clock) riêng nên có sự đồng bộ cục bộ riêng. Chính vì thế, rất khó để
đạt được sự đồng bộ toàn cầu giữa các xung nhịp đồng hồ của các lõi
IP với nhau. Từ đó, người ta nghĩ ra một giải pháp mới gọi là hệ thống
dị bộ toàn cầu - đồng bộ cục bộ (GALS: Globally Asynchronous -
Locally Synchronous) [4]. Mỗi lõi IP trong hệ thống GALS làm việc
với một xung nhịp đồng hồ riêng, đồng bộ cục bộ trong lõi; khi ra
ngoài, các lõi IP trao đổi với nhau thông qua các phương thức hỏi-đáp
hay bắt tay (handshaking). Việc xây dựng các hệ thống lớn từ các lõi
IP riêng, có đặc trưng thời gian khác nhau trở nên dễ dàng hơn nhờ
giải pháp GALS.
Hiệu suất thiết kế: Sự phát triển không ngừng của công nghệ
dẫn đến yêu cầu giảm thời gian thiết kế; ví dụ từ năm 1997 đến năm
2002 chu kỳ thiết kế giảm tới 50%. Thêm nữa, số lượng transistor của

24 Mạng trên chip
vi mạch ngày càng tăng, việc thu gọn hình dạng và tăng số lớp kim
loại khiến độ phức tạp của thiết kế tăng tới 50 lần trong cùng một chu
kỳ. Do đó, việc tái sử dụng các lõi IP trong thiết kế là cần thiết. Việc
sẵn có tài nguyên giúp các nhà thiết kế có thể thiết kế ở mức trừu
tượng cao hơn, không cần thiết kế ở mức transistor hay mức cổng lô-
gic nữa mà có thể thiết kế ở mức chuyển giao thanh ghi (RTL:
Register Transfer Level), thậm chí ở mức hành xử (behavior) [2].
Những lý do trên tạo nên xu hướng thiết kế hướng tới việc chia
nhỏ các khối xử lý nhằm giảm chu kỳ thiết kế, chia quá trình thiết kế
lớn thành các vấn đề con độc lập. Điều này cũng cho phép áp dụng
các phương pháp kiểm tra mô-đun, kiểm tra ở mức trừu tượng thấp
của các lõi IP, ở mức trừu tượng cao của cả hệ thống hay kết hợp cả
hai. Làm việc ở mức trừu tượng cao sẽ cho phép người thiết kế thực
hiện các thao tác linh hoạt hơn ở các mức trừu tượng thấp. Điều này
cũng dẫn tới sự khác nhau về truyền thông cục bộ và toàn cầu. Vì lý
do đó, trong thiết kế hệ thống trên chip gồm nhiều lõi IP, người thiết
kế không chỉ quan tâm đến vấn đề truyền thông bên trong từng lõi IP
mà còn phải quan tâm phát triển cả truyền thông toàn cầu, dẫn tới
phương pháp thiết kế hệ thống trên chip chuyển từ thiết kế xử lý tập
trung truyền thống sang thiết kế xử lý đồng thời tại các lõi IP. Khi đó,
việc thiết kế một hệ thống được chia nhỏ thành thiết kế các mô-đun
riêng rẽ và được chuyên môn hóa cao. Vấn đề còn lại của thiết kế hệ
thống chỉ là việc xây dựng kết nối giữa các mô-đun đó, tạo nên sự
truyền thông giữa chúng.
1.2. Kiến trúc truyền thông truyền thống và những hạn chế
Trong các mạch tích hợp, kết nối truyền thống giữa các khối chức
năng chủ yếu dựa vào mạng kết nối ad-hoc và các kiến trúc bus dùng
chung như mô tả trong Hình 1-2. Khi hệ thống trở nên phức tạp hơn,
các kiểu kiến trúc này bộc lộ nhiều hạn chế như thông lượng truyền
thông bị giới hạn, công suất tiêu thụ năng lượng lớn, tính toàn vẹn của
tín hiệu không được đảm bảo, trễ đáp ứng trong quá trình truyền tín
hiệu, vấn đề đồng bộ toàn hệ thống… Nếu chúng ta không cải thiện

Chương 1. Hệ thống trên chip vĖ kiến trúc hệ thống truyền thông 25
các phương pháp kết nối truyền thống thì những hạn chế này sẽ tạo
nên nút thắt cổ chai, hạn chế việc thiết kế và xây dựng các hệ thống
tích hợp cỡ lớn [5, 6, 7, 8].
Hình 1-2: Kiến trúc kết nối trong các hệ thống trên chip:
Kết nối điểm-tới-điểm (a); Chia sẻ bus (b).
Với kiểu kết nối ad-hoc, truyền thông giữa các lõi IP được thực
hiện thông qua các liên kết vật lý trực tiếp (liên kết điểm-tới-điểm) từ
lõi IP nguồn đến lõi IP đích, Hình 1-2(a). Ưu điểm của kiểu kết nối
này là chúng ta có được hiệu suất truyền thông tối đa giữa các đơn vị
tham gia truyền thông (có thể sử dụng tối đa tài nguyên băng thông).
Tuy nhiên, các cấu trúc truyền thông kiểu này đòi hỏi một lượng lớn
liên kết trực tiếp giữa các lõi IP trong khi hiệu quả sử dụng các liên
kết này không lớn, tần suất sử dụng vào khoảng 10% theo nghiên cứu
của Dally và cộng sự [5]. Số lượng liên kết lớn sẽ làm cho không gian
thực thi phần cứng tăng và tạo nên sự phức tạp trong quá trình đặt chỗ
và định tuyến (Place & Route). Chính vì vậy, cấu trúc truyền thông
này sẽ trở nên phức tạp cho việc thiết kế các hệ thống trên chip trong
tương lai do số lượng các lõi IP ngày càng nhiều hơn (số lượng các
liên kết sẽ tăng theo cấp số mũ khi số lượng các lõi tăng).
Để khắc phục các nhược điểm của truyền thông điểm-tới-điểm,
người ta nghĩ ra giải pháp truyền thông bus như mô tả trong Hình 1-2(b).
Ngày nay, với các hệ thống trên chip phức tạp, truyền thông chia sẻ
bus là loại cấu trúc truyền thông được sử dụng phổ biến nhất trong các
ứng dụng thương mại. Bus cung cấp giải pháp kết nối đơn giản, hiệu
quả mà qua đó các lõi IP có thể giao tiếp với nhau thông qua một giao
IP
IP
IP IP
IP
IP IP IP
IP IP
Bộ phân
xử bus
(a) (b)

26 Mạng trên chip
thức truyền thông. Nếu so sánh với kết nối điểm-tới-điểm thì cấu trúc
bus tỏ ra ưu việt hơn nhiều, kết nối bus khá mềm dẻo và dễ dàng tái sử
dụng. Tuy nhiên, cấu trúc bus chỉ cho phép thực hiện mỗi một quá
trình truyền thông giữa các lõi IP tại một thời điểm nhất định. Băng
thông của bus do đó được chia cho các IP và hiệu suất truyền thông
giảm đáng kể khi số lượng các lõi IP tăng. Chúng ta cần phải xây
dựng cơ chế phân xử để quản lý quyền truy cập của các IP khi xuất
hiện các yêu cầu đồng thời. Hơn nữa, vì bus dùng cho cả hệ thống nên
các liên kết hình thành bus có độ dài đáng kể. Điều này làm tăng công
suất tiêu thụ chung của hệ thống vì dữ liệu được truyền trên toàn bus
cho dù truyền thông chỉ thực hiện giữa vài lõi IP. Khi chúng ta tăng số
lượng lõi IP thì độ dài của bus cũng tăng và kết quả là trễ truyền dẫn
dữ liệu sẽ vượt quá chu kỳ của xung nhịp đồng hồ [9]. Qua những vấn
đề trên cho thấy về bản chất mô hình kết nối kiểu bus có những hạn
chế nhất định về khả năng kết nối khi hệ thống tích hợp một số lượng
lớn lõi IP.
Để vượt qua một vài vấn đề gặp phải nêu ở trên, các nhà nghiên
cứu đã đề xuất cấu trúc bus phân tầng như IBM Core Connect của
hãng IBM [10] hay ARM AMBA của hãng ARM [1]. Ý tưởng của
giải pháp này là sử dụng nhiều bus trong cùng một hệ thống và kết nối
chúng với nhau thông qua các cầu nối bus (bus bridge), xem Hình 1-3.
Hình 1-3: Mô hình bus phân tầng.
Với ý tưởng này, chúng ta có thể giảm số lượng lõi IP kết nối trên
cùng một bus, chiều dài của các liên kết do đó cũng được giảm đi
đáng kể. Mỗi bus sẽ có một bộ phân xử bus riêng. Tuy nhiên, giải
pháp này gặp phải một vấn đề là việc quản lý địa chỉ các lõi IP sẽ trở
nên khó khăn hơn khi truyền dữ liệu qua các cầu nối bus (dữ liệu được
truyền từ bus này qua bus khác thông qua cầu nối bus). Ngoài ra, giải
IP IP IP
Cầu nối bus IP
Bộ phân
xử bus
IPIPIP
IPIP
Bộ phân
xử bus
IP

Chương 1. Hệ thống trên chip vĖ kiến trúc hệ thống truyền thông 27
pháp này vẫn không thể loại bỏ được các vấn đề cố hữu thuộc về bản
chất của cấu trúc truyền thông dạng bus. Trước tình hình đó, mô hình
mạng trên chip đã được đề xuất và được xem như là một giải pháp đột
phá cho vấn đề truyền thông trên chip.
1.3. Phương pháp thiết kế hệ thống trên chip
Để thiết kế hệ thống mạch tích hợp, chúng ta có thể thực hiện
theo phương pháp thiết kế top-down (thiết kế từ trên xuống) hoặc
phương pháp thiết kế bottom-up (thiết kế từ dưới lên). Theo phương
pháp thiết kế top-down, hệ thống sẽ được phân chia nhỏ thành các
khối chức năng nhỏ hơn, dễ hiểu hơn. Nếu tiếp cận theo phương pháp
thiết kế này, người thiết kế sẽ thiết kế tổng quan, xây dựng các đặc tả
chung của hệ thống nhưng không nêu chi tiết bất kỳ hệ thống con nào.
Sau đó, các hệ thống con sẽ được tinh chỉnh chỉ tiết hơn, thậm chí đôi
khi được chia nhỏ thành các khối chức năng nhỏ hơn ở các cấp độ
khác nhau. Do đó, toàn bộ đặc tả của hệ thống được phân tách thành
các yếu tố cơ bản. Ngay khi các yếu tố cơ sở này được xác định thì
việc xây dựng kiến trúc thực thi các yếu tố này sẽ được triển khai dễ
dàng hơn. Sau khi các mô-đun được xây dựng, chúng ta có thể kết nối
chúng lại với nhau để xây dựng toàn bộ hệ thống từ các yếu tố riêng rẽ
này. Hình 1-4 mô tả phương pháp thiết kế top-down.
Hình 1-4: Phương pháp thiết kế top-down.
Ngược lại với phương pháp thiết kế top-down là phương pháp
thiết kế bottom-up. Đây là phương pháp thiết kế cổ điển, dựa trên việc

28 Mạng trên chip
ghép nối các khối chức năng nhỏ để hình thành hệ thống phức tạp hơn.
Với phương pháp thiết kế bottom-up, người thiết kế sẽ xác định chức
năng của từng khối chức năng nhỏ và bắt tay vào hoàn thiện thiết kế
của khối chức năng đó mà chưa quan tâm đầy đủ đến thiết kế tổng thể.
Tiếp đó, người thiết kế sẽ ghép nối các khối chức năng để xây dựng
nên hệ thống phức tạp hơn. Việc tiếp cận theo phương pháp thiết kế
này dựa trên kinh nghiệm và khả năng của người thiết kế và do đó
người thiết kế có sự bắt đầu thuận lợi hơn. Tuy nhiên, nhược điểm của
phương pháp thiết kế bottom-up là người thiết kế không hình dung
đầy đủ đặc tả kỹ thuật của hệ thống tổng thể ngay từ đầu. Do đó, thiết
kế có thể không tối ưu và người thiết kế mất nhiều thời gian để điều
chỉnh thiết kế.
Hình 1-5: Phương pháp thiết kế bottom-up.
Với các hệ thống trên chip có độ phức hợp cao, các phương pháp
thiết kế top-down và bottom-up thuần túy không còn phù hợp, đòi hỏi
người thiết kế phải xây dựng phương pháp thiết kế kết hợp cả hai
phương pháp trên. Lý do chính là khi thiết kế các hệ thống trên chip,
trong giai đoạn thiết kế lõi IP chúng ta không thể hình dung được các
chức năng cũng như việc ứng dụng nó trong hệ thống. Ngoài ra, thông
thường việc thiết kế một hệ thống trên chip sẽ bao gồm cả nhiệm vụ
thiết kế phần cứng và nhiệm vụ thiết kế phần mềm. Hai nhiệm vụ thiết
kế này có sự liên quan mật thiết với nhau và có sự tác động qua lại lẫn
nhau. Do đó, thiết kế hệ thống trên chip ngày nay còn phải áp dụng cả
phương pháp đồng thiết kế phần cứng - phần mềm.

Chương 1. Hệ thống trên chip vĖ kiến trúc hệ thống truyền thông 29
1.4. Mạng trên chip – một kiến trúc truyền thông mới
Sự phát triển của công nghệ tích hợp, sự hội tụ của các ứng dụng,
yêu cầu giảm thời gian đưa sản phẩm ra thị trường (time-to-market) đã
kéo theo những thay đổi lớn về các phương pháp thiết kế các hệ thống
trên chip. Các hệ thống trên chip tích hợp ngày càng nhiều lõi IP. Do
đó, phương pháp thiết kế tái sử dụng các lõi IP (IP reuse) càng trở nên
quan trọng trong việc thiết kế hệ thống trên chip. Các lõi IP đã được
phát triển từ các dự án trước có thể được tái sử dụng trong các ứng
dụng khác với mục đích giảm thời gian thiết kế, giảm số lượng kỹ sư
thiết kế và nhờ đó giảm giá thành thiết kế. Như đã đề cập trong
chương trước, kiến trúc bus không hoàn toàn thích nghi với các
phương pháp thiết kế mới này vì các giao thức truyền thông bus không
cho phép tạo ra sự phân cấp (phân tầng) các dịch vụ truyền thông.
Cũng vậy, việc bổ sung thêm các chức năng mới cho hệ thống cũng
làm thay đổi đáng kể kiến trúc hệ thống, tác động đến cả tầng giao
diện giữa bus và lõi IP [7].
Trong lĩnh vực truyền thông, mạng máy tính đã vượt qua được
những vấn đề trên nhờ sử dụng các cấu trúc kết nối phân tán và phân
cấp. Những vấn đề này đã được nghiên cứu hàng chục năm trước đây
khi triển khai các mạng cục bộ trong kết nối truyền thông giữa các
máy tính song song. Mạng máy tính đã phát triển rất nhiều ở mức vật
lý (Ethernet, ADSL, sợi quang, không dây) và ở mức truyền vận
(Internet, truyền tải tín hiệu âm thanh, hình ảnh), tất cả nhằm đảm bảo
tính tương thích giữa các hệ thống.
Tương tự như vậy, ý tưởng tích hợp một mạng truyền thông trên
silicon đã được đề xuất. Mục tiêu là đưa ra một kiến trúc hoàn toàn
mới, có tính cạnh tranh với các kiến trúc truyền thông truyền thống về
hiệu năng, công suất tiêu thụ và không gian thực thi. Nhiều nơi trên
thế giới đã bắt tay vào việc nghiên cứu vấn đề này khi ITRS1 khẳng
định sự cần thiết phải đưa ra một kiến trúc truyền thông mới trên chip
để vượt qua các vấn đề gặp phải khi tăng mật độ tích hợp trên các vi
1 International Technology Roadmap for Semiconductors (ITRS).

30 Mạng trên chip
mạch [4]. Những nghiên cứu đầu tiên đã đề cập đến các vấn đề về quan
điểm thiết kế ở mức hệ thống như [11, 12] hay các vấn đề quan điểm
thiết kế ở mức vật lý như [5, 13]. Không lâu sau đó, một số đóng góp
liên quan đến kiến trúc cụ thể về mạng trên chip đã được công bố như
[14, 15, 16, 17]. Hình 1-6 mô tả một ví dụ về mô hình mạng trên chip.
Hình 1-6: Một ví dụ về mô hình mạng trên chip.
Với mô hình này, các lõi IP được kết nối với nhau thông qua một
mô hình vi mạng cấu thành từ các bộ định tuyến và liên kết mạng. Các
lõi IP trong hệ thống có thể hoạt động ở các miền tần số khác nhau.
Hệ thống trên chip với mô hình vi mạng này sử hữu một số ưu điểm
nội bật so với mô hình hệ thống trên chip truyền thống như: hiệu năng
xử lý cao; quá trình xử lý tính toán được tách ra khỏi quá trình truyền
thông; cho phép quản lý năng lượng hiệu quả; năng suất thiết kế cao
(khả năng tái sử dụng các lõi IP, bộ định tuyến và khả năng mở rộng
thiết kế); tính mô-đun hóa cao; dễ dàng thực thi thiết kế hệ thống với
nhiều miền tần số khác nhau; khắc phục vấn đề lệch xung nhịp đồng
hồ (clock skew), v.v…
Nghiên cứu về mạng trên chip là một nghiên cứu tổng hợp, đa
ngành, một sự kết hợp giữa tính toán phân tán, truyền thông mạng,
truyền thông trên chip, phương pháp thiết kế hệ thống, áp dụng các
giải pháp thiết kế mạng máy tính vào thiết kế hệ thống trên chip. Hiện
IP
IPIP
IPIP
IP
RR
RR
Bộ định tuyến
Lõi IP
Liên kết mạng
RR
IP
IP
Các miền tần số khác nhau

Chương 1. Hệ thống trên chip vĖ kiến trúc hệ thống truyền thông 31
tại, trên thế giới có khoảng 40 nhóm nghiên cứu (trung tâm nghiên
cứu, trường đại học, doanh nghiệp) đang triển khai các nghiên cứu
liên quan đến mạng trên chip nhưng vẫn còn rất nhiều vấn đề cần
được giải quyết. Một số sản phẩm thử nghiệm ban đầu đã được công
bố như Intel Polaris [18] của hãng Intel, CHAIN [19] của Silistix, hay
FAUST [20] của Trung tâm Nghiên cứu CEA-Leti, Minatec. Tuy
nhiên, việc đưa ra các sản phẩm thương mại thực sự vẫn đòi hỏi nhiều
nỗ lực hơn nữa của các nhà nghiên cứu trong việc phát triển, hoàn
thiện mô hình và các phương pháp thiết kế. Chúng ta còn phải giải
quyết tối ưu hơn về kiến trúc và các bài toán liên quan như chất lượng
dịch vụ, khả năng tái cấu hình, công suất tiêu thụ, phương pháp kiểm
tra, kiểm chứng… Mặc dù đã có một vài sản phẩm thương mại nhưng
có thể nói rằng mô hình mạng trên chip vẫn còn trong giai đoạn tiếp
tục nghiên cứu thử nghiệm và hoàn thiện phương pháp luận tại các
trường đại học và các trung tâm nghiên cứu công nghiệp.
1.5. Kết luận chương
Mặc dù liên tục được cải tiến, hệ thống trên chip với kiến trúc truyền
thông truyền thống đã bộc lộ nhiều hạn chế. Trước tình thế đó, mô hình
mạng trên chip ra đời như là một giải pháp hứa hẹn cho vấn đề truyền
thông của các hệ thống trên chip, cho phép người thiết kế xây dựng các
hệ thống trên chip có độ phức tạp cao hơn, khả năng tính toán cao hơn
trong khi có kiến trúc mềm dẻo và linh hoạt hơn. Trong chương tiếp theo,
chúng ta sẽ tìm hiểu về mô hình truyền thông mới này.

Mục lục 32
Chương 2
MẠNG TRÊN CHIP: CÁC KHÁI NIỆM CƠ BÂN
Mạng trên chip (NoC: Network-on-Chip) được đề xuất lần đầu
tiên vào những năm đầu thế kỷ XXI và nhanh chóng được xem như là
một giải pháp thay thế cho mô hình truyền thông cổ điển trong các hệ
thống trên chip. Chương này sẽ tập trung làm rõ các khái niệm liên
quan đến mô hình mạng trên chip nhằm làm nổi bật các ưu việt của
mô hình này, tiếp đó trình bày tổng quan tình hình nghiên cứu về mô
hình mạng trên chip trên thế giới. Việc làm rõ các khái niệm cũng như
tổng quan tình hình nghiên cứu giúp chúng ta dễ dàng nắm bắt được
nội dung sẽ được trình bày trong các chương tiếp theo.
Ngay cả khái niệm về mạng trên chip (NoC) thì trong cộng đồng
nghiên cứu đã tồn tại hai nhận thức khác nhau: một số nhà nghiên cứu
cho rằng NoC là một tập con của SoC; số khác lại cho rằng NoC là sự
mở rộng của SoC. Trong nhận thức đầu thì NoC được định nghĩa chặt
chẽ như là cấu trúc truyền thông chuyển tiếp dữ liệu tức là mạng và
các phương thức truy nhập vào mạng. Trong cách nhận thức thứ hai,
NoC được định nghĩa rộng hơn, nó được xem như là bao quanh các
vấn đề liên quan tới ứng dụng, cấu trúc hệ thống và ảnh hưởng của
truyền thông hay ngược lại. Trong cuốn sách này, chúng ta thiên về
nhận thức thứ hai khi bàn luận về NoC. Đây cũng là xu thế chung của
các nhóm nghiên cứu về NoC trên thế giới. Để dễ phân biệt, trong
cuốn sách này chúng tôi sẽ gọi các hệ thống trên chip dựa trên mô
hình mạng trên chip là hệ thống mạng trên chip.1
1 “Hệ thống mạng trên chip” là hệ thống trên chip dựa trên mô hình mạng trên
chip, còn được gọi ngắn gọn hơn là “Hệ thống NoC”.

Chương 2. Mạng trên chip: cėc khėi niệm cơ bĘn 33
2.1. Tô-pô hay cấu trúc liên kết của mạng trên chip
Tô-pô (topology) hay cấu trúc liên kết của mạng định nghĩa cách
thức các bộ định tuyến (router) mạng kết nối với nhau sử dụng các
liên kết mạng (network link). Nó quy định tổ chức vật lý của mạng và
do đó thường được mô hình hóa bằng đồ thị. Tương tự như mạng máy
tính, có nhiều loại tô-pô khác nhau có thể được sử dụng để xây dựng
các mạng trên chip. Hình 2-1 giới thiệu một số tô-pô thường được
chọn khi xây dựng các mạng trên chip.
(a) (b) (c)
(d) (e) (f)
Hình 2-1: Những tô-pô thông dụng dùng cho mạng trên chip:
ring hay chordal ring (a); fat-tree (b); butterfly fat-tree (c); 2D-mesh (d);
2D torus (e); 2D folded torus (f).
Mỗi tô-pô có những ưu nhược điểm riêng. Để so sánh tính ưu việt
của các tô-pô, chúng ta thường sử dụng một số tiêu chí vật lý như sau:
cấp bậc của bộ định tuyến (router degree), đường kính mạng (network
diameter), tính quy tắc (regularity), tính đối xứng (symmetry), tính đa
dạng của các đường định tuyến (diversity of routing paths), độ rộng
điểm chia đôi mạng (bisection wide).

34 Mạng trên chip
Cấp bậc của bộ định tuyến được định nghĩa là số liên kết dùng để
kết nối chính bộ định tuyến đó với các bộ định tuyến lân cận. Đường
kính của mạng chính là khoảng cách lớn nhất giữa hai bộ định tuyến
trong mạng (tính theo đường định tuyến ngắn nhất). Một mạng được
gọi là có quy tắc khi các bộ định tuyến có cùng một cấp bậc. Mạng
được gọi là đối xứng nếu tô-pô mạng không thay đổi khi thay đổi vị trí
quan sát (từ các bộ định tuyến khác nhau). Một mạng có sự đa dạng về
các đường định tuyến khi hầu hết các cặp bộ định tuyến có nhiều
đường định tuyến giữa chúng. Tính đa dạng về các đường định tuyến
quyết định sức mạnh (robustness) của mạng. Độ rộng điểm chia đôi
mạng chính là số liên kết tối thiểu mà chúng ta phải cắt để chia mạng
đó thành hai phần khác nhau. Băng thông tổng cộng của các liên kết
này được gọi là băng thông của điểm chia đôi mạng (bisection
bandwidth), cho phép đo hiệu năng của một tô-pô mạng.
Theo các đề xuất kiến trúc mạng trên chip, tô-pô mạng chiếm ưu
thế nhất là tô-pô dạng lưới hai chiều (2D-mesh), Hình 2-1(a). Lý do là
vì tô-pô này có những ưu điểm vượt trội như dễ dàng thực thi trên các
công nghệ bán dẫn hiện tại, đơn giản trong chiến lược định tuyến, dễ
dàng phát triển/mở rộng mô hình mạng. Ngoài tô-pô dạng lưới hai
chiều, tô-pô 2D torus (Hình 2-1(e)) cũng thường được sử dụng với
mục đích giảm đường kính và tăng băng thông của mạng. Tuy nhiên,
tô-pô này có một số hạn chế như: việc thực thi cấu trúc tô-pô này phức
tạp hơn; các liên kết dùng để nối vòng các bộ định tuyến ở bên rìa dài
(dẫn tới suy giảm hiệu năng truyền thông). Để giảm độ dài của các liên
kết nối vòng này, ta có thể sử dụng tô-pô 2D folded torus (Hình 2-1 (f)).
Tuy nhiên, tô-pô 2D folded torus đòi hỏi thuật toán định tuyến phức
tạp hơn nhiều so với các tô-pô nêu trên. Có thể thấy rằng cả ba tô-pô
này đều có một điểm yếu chung đó là độ trễ đáp ứng cao.
Ngoài những tô-pô vừa nêu ở trên, các tô-pô fat-tree, butterfly
fat-tree và chordal ring cũng là những tô-pô được các nhà thiết kế
quan tâm. Tô-pô fat-tree và tô-pô butterfly fat-tree có đường kính
mạng rất nhỏ; do đó, độ trễ đáp ứng của các tô-pô cũng giảm đi đáng
kể. Nhược điểm của hai tô-pô này chính là cấp bậc của bộ định tuyến
và độ phức tạp của kết nối. Tô-pô butterfly fat-tree có cấp bậc của bộ

Chương 2. Mạng trên chip: cėc khėi niệm cơ bĘn 35
định tuyến bé hơn tô-pô fat-tree. Tuy nhiên, cấu trúc kết nối trong tô-
pô này phức tạp hơn nhiều; do đó, không gian thực thi phần cứng cũng
tăng lên đáng kể. Tô-pô chordal ring được sử dụng nhằm đạt được
hiệu năng truyền thông cao hơn so với tô-pô hình vòng (ring) nhưng
kết nối trong tô-pô này cũng phức tạp hơn và việc định tuyến do đó
cũng phức tạp hơn.
Một số nghiên cứu thực thi việc lai ghép các tô-pô hay việc lai
ghép giữa tô-pô mạng với cấu trúc bus nhằm tận dụng các ưu việt sẵn
có của từng loại cấu trúc truyền thông. Ví dụ như lai ghép nhằm tăng
băng thông và giảm khoảng cách giữa các bộ định tuyến [21].
Có thể kết luận rằng có nhiều tô-pô có thể sử dụng trong xây
dựng các kiến trúc mạng trên chip. Mỗi tô-pô có ưu điểm, nhược điểm
riêng. Việc chọn tô-pô cho một kiến trúc mạng trên chip là tương đối
phức tạp và liên quan đến nhiều ràng buộc đến từ ứng dụng và lưu
lượng truyền thông của mạng. Bên cạnh đó, chúng ta cũng cần phải
quan tâm đến việc cân đối giữa hiệu năng và giá thành thực thi.
2.2. Kỹ thuật truyền thông
Kỹ thuật truyền thông định nghĩa chiến lược, cách thức vận
chuyển dữ liệu trên các NoC. Thực vậy, truyền thông trên một mạng
dựa vào kỹ thuật chuyển mạch (còn được gọi là kỹ thuật nối-chuyển
trong một số tài liệu tiếng Việt gần đây). Sự chuyển mạch được định
nghĩa là sự thiết lập đường nối tạm thời giữa hai hay nhiều điểm (nút
mạng) trong mạng để truyền dữ liệu hay một bộ phận của dữ liệu.
Trong khi đó, sự định tuyến được hiểu là những chỉ thị thông minh để
quyết định đường truyền dữ liệu. Có hai kỹ thuật chuyển mạch cơ bản
được sử dụng [22, 4]: kỹ thuật chuyển mạch kênh (circuit-switching)
và kỹ thuật chuyển mạch gói (packet switching).
Kỹ thuật chuyển mạch kênh: Đây là kỹ thuật chuyển mạch đầu
tiên, được sử dụng trong các mạng điện thoại. Trong kỹ thuật này, kết
nối truyền thông giữa hai đơn vị có nhu cầu trao đổi thông tin phải
được thiết lập trước khi trao đổi thông tin. Do đó, trong quá trình
truyền thông sẽ luôn tồn tại một kết nối vật lý giữa hai đơn vị truyền

36 Mạng trên chip
thông. Thông tin điều khiển (để thiết lập và huỷ bỏ kết nối) được tách
rời khỏi dữ liệu truyền thông.
Ưu điểm của kỹ thuật chuyển mạch kênh là độ tin cậy cao (khi kết
nối đã được thiết lập thì hầu như không có thất thoát tín hiệu), băng
thông tối đa và độ trễ đáp ứng của tín hiệu thấp (do đó, thường được
dùng cho những ứng dụng thời gian thực). Tuy nhiên, kỹ thuật này có
nhược điểm là tiêu tốn tài nguyên mạng (tài nguyên bị chiếm giữ cho
đường kết nối trong suốt quá trình truyền tin và chỉ được giải phóng khi
việc truyền dữ liệu hoàn tất). Một điểm hạn chế khác là độ mềm dẻo
của kiến trúc truyền thông. Nếu chúng ta muốn thêm bớt một bộ định
tuyến thì chúng ta phải sửa đổi lại bộ điều khiển trung tâm.
Kỹ thuật chuyển mạch gói: Trong kỹ thuật chuyển mạch gói, dữ
liệu được chia thành nhiều gói tin tại nguồn trước khi gửi đến đích.
Mỗi gói tin bao gồm thông tin định tuyến và dữ liệu. Các gói tin có thể
được truyền đi đồng thời theo các đường kết nối khác nhau. Tại đích
đến, các gói tin sẽ được tái sắp xếp và hợp thành dữ liệu ban đầu.
Ưu điểm của kỹ thuật chuyển mạch gói là cho phép khai thác tối
đa hiệu suất mạng, các đơn vị có nhu cầu truyền thông có thể chia sẻ
tài nguyên mạng (bộ định tuyến, liên kết mạng). Khi đó, kết nối truyền
thông được thực hiện một cách cục bộ giữa các nút mạng chứ không
phải giữa các đơn vị truyền thông. Các tài nguyên mạng do đó có thể
được sử dụng cho các truyền thông khác.
Một ưu điểm khác nữa của kỹ thuật chuyển mạch gói là ta không
cần bộ điều khiển trung tâm bởi vì các gói tin được định tuyến một
cách riêng rẽ trong mạng. Ngược lại, các gói tin phải chứa đựng các
thông tin định tuyến: các thông tin điều khiển này được gửi cùng thời
điểm với dữ liệu truyền thông. Các bộ định tuyến do đó thường phức
tạp vì phải xử lý các thông tin điều khiển và định tuyến dữ liệu truyền
thông. Một nhược điểm nữa là độ trễ đáp ứng tín hiệu cũng lớn hơn.
Ví dụ, thi thoảng bộ định tuyến phải sửa đổi nội dung của các gói tin
để cập nhật thông tin định tuyến. Hơn nữa, các vấn đề quản lý tắc
nghẽn và quản lý thứ tự các gói tin là những trở ngại lớn trong kỹ
thuật chuyển mạch này.

Chương 2. Mạng trên chip: cėc khėi niệm cơ bĘn 37
2.3. Cơ chế truyền thông
Vì lý do kỹ thuật chuyển mạch gói khá phức tạp, các gói tin được
chia thành các đơn vị nhỏ hơn, có kích thước cố định, gọi là flit1. Đây
là một đơn vị đồng thời chứa dữ liệu và thông tin điều khiển, có thể
được truyền trong mạng. Do đó, ta phải định nghĩa cơ chế truyền
thông, có nghĩa là định nghĩa cách thức các gói tin đi từ bộ định tuyến
này sang bộ định tuyến tiếp theo trong mạng. Có ba cơ chế truyền
thông hay dùng là: Lưu trữ và chuyển tiếp (SAF: Store-And-Forward),
Virtual-Cut-Through (VCT) và Wormhole (WH).
(a) (b)
(c)
Hình 2-2: Các cơ chế định tuyến: Lưu trữ và chuyển tiếp (a);
Virtual Cut Through (b); Wormhole (c).
Lưu trữ và chuyển tiếp (SAF: Store-And-Forward): Lưu
trữ và chuyển tiếp là cơ chế truyền thông mà theo đó toàn bộ gói tin
được truyền từ nút mạng này đến nút mạng tiếp theo (Hình 2-2(a)).
Do vậy, cơ chế này đòi hỏi bộ định tuyến phải có một bộ đệm đủ lớn
để lưu trữ toàn bộ gói tin. Khi kích thước gói tin lớn thì không gian bộ
đệm cần thiết sẽ phải tăng theo. Chúng ta biết rằng không gian thực thi
bộ nhớ trên vi mạch cũng như công suất tiêu thụ của bộ nhớ là rất lớn,
do đó kích thước của các bộ đệm phải là con số giới hạn. Ngoài ra, trễ
đáp ứng của các gói tin tăng lên tại các nút mạng và các flit của gói tin
1 Flit (Flow Control Unit) – một đơn vị điều khiển luồng dữ liệu trong mạng.

38 Mạng trên chip
phải được nhận bởi nút mạng hiện tại trước khi được gửi tới nút mạng
tiếp theo. Độ trễ đáp ứng toàn bộ của một kênh truyền thông sẽ là tích
của thời gian truyền một gói tin giữa hai nút mạng với số lượng nút
mạng mà gói tin ấy đi qua khi được truyền từ nguồn tới đích.
Virtual-Cut-Through (VCT): Cơ chế truyền thông Virtual-Cut-
Through được đề xuất với mục đích giảm độ trễ đáp ứng của các gói
tin tại từng nút mạng. Với cơ chế này, ta có thể bắt đầu việc truyền gói
tin đến nút mạng tiếp theo trước khi nhận đầy đủ gói tin tại nút mạng
hiện tại như mô tả trong Hình 2-2(b).
Nhược điểm chính của cơ chế này là nút mạng hiện tại phải có
khả năng lưu trữ toàn bộ gói tin khi nút mạng tiếp theo không sẵn sàng
tiếp nhận gói tin này. Do đó, các bộ đệm sử dụng trong cơ chế này
cũng có dung lượng giống như các bộ đệm sử dụng trong cơ chế SAF
nhưng độ trễ đáp ứng giảm đi đáng kể.
Wormhole (WH): Với cơ chế truyền thông Wormhole, một flit
được truyền từ nút mạng này sang nút mạng tiếp theo khi nút mạng
tiếp theo có khả năng lưu trữ flit đó chứ không nhất thiết phải truyền
cả gói tin đầy đủ, xem Hình 2-2(c). Thông thường, mỗi gói tin bao
gồm một flit tiêu đề (header flit) và theo sau bởi nhiều flit dữ liệu (data
flit). Flit tiêu đề chứa thông tin định tuyến, chuỗi các flit theo sau
được truyền đi theo kết nối đã được thiết lập bởi flit tiêu đề. Cơ chế
này có ưu điểm là tốn rất ít không gian bộ đệm so với hai cơ chế trên
nhờ việc một gói tin có thể được truyền đi một cách dàn trải trên các
bộ định tuyến (kích thước bộ đệm được giảm thiểu tối đa). Độ trễ đáp
ứng do đó cũng được cải thiện đáng kể. Nhược điểm của cơ chế này là
nếu một flit bị chặn thì các flit theo sau cũng sẽ bị chặn, dẫn tới ảnh
hưởng đến tất cả các nút mạng trong kết nối. Khi đó, các kết nối khác
không thể sử dụng bất kỳ nút mạng nào trên đường truyền.
Mạng máy tính thường sử dụng cơ chế truyền thông SAF vì
trong mạng máy tính người ta không quan tâm đến kích thước bộ
nhớ/bộ đệm. Trong khi đó, mạng trên chip thường sử dụng cơ chế
truyền thông Wormhole do có độ trễ đáp ứng thấp và tốn ít không
gian bộ đệm.

Chương 2. Mạng trên chip: cėc khėi niệm cơ bĘn 39
2.4. Chiến lược lưu trữ
Mục trước cho thấy trong kỹ thuật chuyển mạch gói các bộ định
tuyến phải chứa các phần tử nhớ (các bộ đệm dữ liệu). Việc bố trí các
bộ đệm này tại các lối vào hay lối ra của bộ định tuyến phụ thuộc vào
các chiến lược khác nhau [23]. Trong mục này, chúng ta sẽ phân biệt
bốn chiến lược cơ bản hay được dùng khi thiết kế, xây dựng các mạng
trên chip, đó là hàng đợi lối vào (input queuing), hàng đợi lối ra
(output queuing), hàng đợi lối ra ảo (virtual output queuing), hàng đợi
lối vào ưu tiên kênh ảo (virtual channel priority input queuing).
(a) (b)
(c) (d)
Hình 2-3: Chiến lược lưu trữ trên bộ định tuyến: hàng đợi lối vào (a);
hàng đợi lối ra (b); hàng đợi lối ra ảo (c); hàng đợi lối vào ưu tiên kênh ảo (d).
Hàng đợi lối vào (input queuing): Với chiến lược hàng đợi lối
vào, N hàng đợi sẽ được thiết lập tại N lối vào của bộ định tuyến, như
mô tả trong Hình 2-3(a). Bộ phân xử tuần tự sẽ xác định tại thời điểm
nào thì lối vào nào được nối với lối ra nào nhằm đảm bảo không có
xung đột xảy ra. Tuy nhiên, lưu thông dữ liệu của bộ định tuyến sẽ
bão hòa vào khoảng 59% [24] do xảy ra tình trạng tắc nghẽn ở mỗi
đầu hàng đợi (head-of-line blocking) khi số lối vào N lớn. Hiện tượng

40 Mạng trên chip
này xảy ra khi một dữ liệu đầu hàng đợi không thể truy cập tới lối ra
và cản trở các dữ liệu phía sau nó trong cùng hàng đợi.
Hàng đợi lối ra (output queuing): Ở chiến lược hàng đợi lối ra, N
hàng đợi sẽ được thiết lập tại N lối ra của bộ định tuyến (Hình 2-3(b)).
Tất cả các flit đến cùng trong một khe thời gian sẽ được định tuyến
trước khe thời gian tiếp theo. Do vậy, ma trận chuyển mạch (crossbar)
phải có tốc độ làm việc nhanh hơn N lần so với tốc độ làm việc của
các lối vào và lối ra, kể cả khi N lối vào cùng được định tuyến đến
cùng một lối ra.
Hàng đợi lối ra ảo (VOQ: virtual output queuing): Với chiến
lược hàng đợi lối ra ảo, N2 hàng đợi được thiết lập tại N lối vào của bộ
định tuyến như mô tả trong Hình 2-3(c). Ý tưởng của chiến lược này
là kết hợp ưu điểm của hai chiến lược trên. Về nguyên tắc, chiến lược
VOQ là một phiên bản của chiến lược hàng đợi lối vào với các hàng
đợi lối ra ảo nhằm loại bỏ hiện tượng tắc nghẽn ở các đầu hàng đợi lối
vào và bắt chước hoạt động của chiến lược hàng đợi lối ra. Tất cả lối
vào đều có thể được chuyển đến lối ra trong cùng một thời điểm. Nhờ
vậy, chiến lược VOQ cho ta một hiệu suất lưu trữ cao hơn. Tuy nhiên,
chiến lược này đòi hỏi một số lượng lớn hàng đợi và do đó giá thành
thực thi phần cứng khá đắt.
Hàng đợi lối vào ưu tiên kênh ảo (VCPIQ: virtual channel
priority input queuing): Chiến lược này được đề xuất nhằm tăng
hiệu năng nối-chuyển và giảm nhược điểm của chiến lược VOQ. Với
một kênh vật lý, chúng ta thiết lập P hàng đợi (P < N) tương ứng với P
kênh ảo cùng chia sẻ băng thông của kênh vật lý (xem Hình 2-3(d)).
Việc sử dụng dung lượng kết nối tăng lên đáng kể nhờ giảm khả năng
tắc nghẽn đầu hàng đợi. Mặt khác, độ trễ đáp ứng và độ phức tạp của
bộ định tuyến tăng cùng với số lượng kênh ảo. Nghiên cứu của Pande
và đồng nghiệp [25] chỉ ra rằng số lượng kênh ảo bằng 4 (P = 4) cho
ta một thoả hiệp tốt nhất giữa tốc độ truyền dữ liệu và độ trễ đáp ứng.
2.5. Thuật toán định tuyến
Thuật toán định tuyến xác định đường đi từ nguồn về đích của một
gói tin. Trong một kiến trúc truyền thông, thuật toán định tuyến đóng

Chương 2. Mạng trên chip: cėc khėi niệm cơ bĘn 41
một vai trò hết sức quan trọng: thuật toán định tuyến tối ưu nhất sẽ đem
lại hiệu năng truyền thông cao nhất. Chính vì vậy, việc nghiên cứu về
thuật toán truyền thông được các nhà thiết kế hết sức quan tâm. Chúng
ta cần phải phân tích, cân đối các yêu cầu của bài toán để lựa chọn, xây
dựng một thuật toán vừa cho phép sử dụng tối ưu các liên kết truyền
thông, vừa tương đối đơn giản trong việc thực hiện trên chip.
Hiện có nhiều thuật toán định tuyến được sử dụng trong thiết kế
các mạng trên chip. Việc lựa chọn thuật toán phụ thuộc vào bài toán
và định hướng của các nhóm nghiên cứu khác nhau. Tuy nhiên, chúng
ta có thể tạm phân thành hai loại lớn: thuật toán định tuyến xác định
(deterministic routing algorithm) và thuật toán định tuyến thích ứng
(adaptive routing algorithm).
Với thuật toán định tuyến xác định (còn được gọi là thuật toán
định tuyến tĩnh – static routing algorithm), đường dẫn giữa nguồn và
đích được xác định và sử dụng một cách độc lập với tình trạng hiện tại
của mạng. Thuật toán này không quan tâm đến tải hiện tại của các bộ
định tuyến và các liên kết mạng khi đưa ra quyết định định tuyến.
Trong khi đó, với thuật toán định tuyến thích ứng (còn được gọi là
thuật toán định tuyến động – dynamic routing algorithm), việc quyết
định đưa ra đường định tuyến cho gói tin liên quan chặt chẽ đến trạng
thái của mạng tại thời điểm đó (tải của mạng, sự sẵn sàng của các liên
kết mạng). Kết quả là đường truyền thông giữa nguồn và đích của một
gói tin thay đổi theo thời gian.
Thuật toán định tuyến xác định đơn giản hơn so với thuật toán
định tuyến thích ứng khi thực hiện xét về khía cạnh lô-gic và sự tương
tác qua lại giữa các bộ định tuyến [6]. Thuật toán này thích hợp cho
các ứng dụng mà ta có thể dự kiến được các quá trình trao đổi dữ liệu
trong mạng và các quá trình trao đổi này tương đối ổn định. Do đó, nó
thường được dùng cho các mạng trong các hệ thống ứng dụng riêng
(ASIC). Ngược lại, thuật toán định tuyến thích ứng thường được dùng
cho các ứng dụng có lưu lượng mạng không có quy tắc và thường
không đoán trước được. Ví dụ trong trường hợp các hệ thống đa xử lý
như MPSoC (Multi-Processor SoC).

42 Mạng trên chip
Thuật toán định tuyến (kể cả xác định hay thích ứng) có thể được
phân loại cụ thể hơn tùy theo nơi lưu giữ thông tin định tuyến hay nơi
đưa ra quyết định định tuyến. Một thuật toán được gọi là thuật toán
định tuyến tại nguồn (source routing) nếu đơn vị phát dữ liệu (đơn vị
nguồn) xác định đường định tuyến. Trong trường hợp này các thông tin
về đường định tuyến được tính toán và lưu trữ trong một bảng định
tuyến của đơn vị phát dữ liệu. Khi đơn vị phát muốn gửi đi một gói tin,
nó sẽ tìm kiếm các thông tin định tuyến tương ứng với đích đến trên
bảng định tuyến và chèn các thông tin này vào flit tiêu đề của gói tin.
Ngược lại, nếu mỗi bộ định tuyến chọn đích đến của gói tin theo
hàm của địa chỉ đến (hoặc các tiêu chí khác), thì trường hợp này gọi là
thuật toán định tuyến phân tán. Quyết định định tuyến được đưa ra tại
từng bộ định tuyến bằng cách quan sát các địa chỉ đích đến trong một
bảng định tuyến hoặc thực hiện một hàm định tuyến bằng phần cứng
[26]. Với thuật toán này, mỗi bộ định tuyến sẽ phải chứa một bảng
định tuyến được xác định trước hoặc một mạch lô-gic với đầu vào là
địa chỉ đích đến của gói tin và đầu ra là quyết định về hướng định
tuyến. Khi có một gói tin được đưa đến lối vào bộ định tuyến, dựa vào
thông tin về đích đến, lối ra định tuyến sẽ được tìm thấy thông qua
việc tra bảng định tuyến hoặc được tính toán thông qua mạch lô-gic
nói trên.
2.6. Tắc nghẽn và kỹ thuật điều khiển luồng dữ liệu
Vì không có điều khiển toàn cầu khi truyền các gói tin giữa các
bộ định tuyến nên việc xảy ra hiện tượng tắc nghẽn là điều hoàn toàn
có thể. Với mạng trên chip, có hai hiện tượng tắc nghẽn điển hình là
khóa chết/tắc nghẽn tĩnh (deadlock) và khóa động/tắc nghẽn động
(livelock).
Khóa chết (deadlock) xảy ra khi một hoặc nhiều gói tin bị treo
trong một khoảng thời gian không xác định do chờ một sự kiện không
có khả năng xảy ra. Hình 2-4 là một ví dụ minh họa về một trạng thái
mà hai gói tin được định tuyến quay vòng trong một mạng dạng lưới
vuông gồm bốn bộ định tuyến. Gói tin đang chiếm giữ các liên kết

Chương 2. Mạng trên chip: cėc khėi niệm cơ bĘn 43
mạng L1 và L2 chờ liên kết L3 trong khi gói tin chiếm giữ các liên kết
mạng L3 và L4 thì lại chờ liên kết L1. Không gói tin nào có thể dịch
chuyển được vì thiếu tài nguyên mạng cần thiết cho việc định tuyến:
các liên kết đang bị chiếm giữ không bao giờ được giải phóng.
Hình 2-4: Ví dụ về một trường hợp khóa chết.
Với cơ chế định tuyến Wormhole, flit tiêu đề chứa đựng các
thông tin định tuyến và các flit dữ liệu theo sau phải được đặt gần kề,
không bao giờ được đan xen với các flit của gói tin khác [27]. Nếu flit
tiêu đề bị chặn bởi một sự tắc nghẽn do thiếu tài nguyên thì tất cả các
flit dữ liệu của gói tin cũng sẽ bị dừng lại. Điều này có nghĩa là chúng
sẽ chiếm giữ tất cả tài nguyên mạng trên đường truyền như các liên
kết mạng và bộ đệm. Kết quả là cơ chế định tuyến Wormhole rất nhạy
cảm với hiện tượng khóa chết.
Để tránh tắc nghẽn này, ta phải chọn một thuật toán định tuyến
đặc biệt có thể loại bỏ sự phụ thuộc lẫn nhau giữa các gói tin như thuật
toán XY khi sử dụng tô-pô mạng dạng 2D mesh [28]. Thuật toán XY
là một thuật toán định tuyến theo đó dữ liệu được định tuyến theo
phương X (giữa Tây và Đông), sau đó theo phương Y (giữa Bắc và
Nam). Mặt khác, ta cũng có thể sử dụng các kênh ảo để loại bỏ sự phụ
thuộc nêu trên. Với cách thức này, trong khi một gói tin bị chặn một
cách tạm thời và được lưu trữ trên các bộ định tuyến nhưng nhờ có
nhiều kênh ảo nên gói tin khác vẫn có thể được truyền qua cùng một
kênh vật lý nhưng với kênh ảo khác, xem Hình 2-5.
L1
L4 L2
L3
Gói tin 2
Gói tin 1

44 Mạng trên chip
Hình 2-5: Tránh khóa chết bằng kênh ảo.
Khóa động (livelock) là những trạng thái tắc nghẽn mà một số
gói tin không thể đến đích ngay cả khi không bị chặn một cách hoàn
toàn. Hiện tượng này thường xảy ra khi nguồn tài nguyên thay đổi
trạng thái liên tục để chờ cho những truyền thông khác kết thúc. Một
chuỗi dữ liệu muốn truyền từ nút nguồn là một trong bốn nút mạng ở
vòng ngoài tới nút đích là một trong bốn nút mạng ở trong nhưng do
bốn nút phía trong bị khóa chết nên dữ liệu cứ truyền quay vòng ở bốn
nút mạng ngoài mà không sao vào tới nút đích. Hình 2-6 mô tả một ví
dụ về hiện tượng khóa động.
Hình 2-6: Ví dụ về khóa động.
Các phương pháp để tránh khóa chết và khóa động có thể áp dụng
một cách cục bộ tại các nút mạng để hỗ trợ những dịch vụ ban đầu như
thực thi phần cứng, hoặc áp dụng toàn cầu đảm bảo điều khiển lô-gic
luồng dữ liệu bằng việc ứng dụng cơ cấu điều khiển luồng đầu-cuối
(end-to-end flow control).
Bộ định tuyến
đang trong tình
trạng khóa động
Bộ định tuyến
đang trong tình
trạng khóa chết

Chương 2. Mạng trên chip: cėc khėi niệm cơ bĘn 45
Kỹ thuật điều khiển luồng dữ liệu là cơ chế quyết định cách gói
tin di chuyển trong mạng. Vì vậy, nó gồm cả vấn đề toàn cầu và cục
bộ. Việc lựa chọn kỹ thuật điều khiển luồng dữ liệu tối ưu sẽ không
những giúp ta đạt được hiệu năng truyền thông tối đa mà còn giúp ta
hạn chế được các vấn đề tắc nghẽn nêu trên. Có ba kỹ thuật sau
thường được sử dụng:
Kỹ thuật cửa sổ (window technique): Kỹ thuật này sử dụng một
cửa sổ trượt để xác định gói tin nào được lưu thông trên mạng trong
một khoảng thời gian xác định.
Kỹ thuật điều khiển thông lượng (throughput control technique):
Tốc độ gửi dữ liệu của bên truyền được điều khiển và giới hạn.
Kỹ thuật credit (credit technique): Bên truyền phải nhận được
các credit từ bên nhận trước khi gửi một gói dữ liệu. Bên nhận gửi các
credit theo khả năng lưu trữ thông tin mới của nó. Mỗi khi một gói tin
được gửi đi thì bên truyền phải giảm giá trị bộ đếm credit.
2.7. Chất lượng dịch vụ mạng
Chất lượng dịch vụ (QoS: Quality of Service) là một khái niệm
dùng để ám chỉ các thông số hay đặc tả của các dịch vụ được cung cấp
bởi mạng dành cho một lớp đối tượng truyền thông nào đó. Các đặc tả
của QoS có thể là các thông số chỉ hiệu năng của mạng như tỷ lệ mất
mát thông tin, thông lượng, độ trễ đáp ứng trung bình, sự biến đổi của
độ trễ đáp ứng (jitter)… liên quan đến chất lượng truyền tin và sự sẵn
sàng của dịch vụ. Trong thiết kế mạng trên chip, một số khái niệm về
dịch vụ sau đây được đề cập đến [8, 23, 29]:
Tính toàn vẹn dữ liệu: dữ liệu được truyền đi không bị sai
lệch. Hay nói cách khác là dữ liệu tại nơi nhận được phải đảm bảo đầy
đủ, nguyên vẹn như lúc nó ở nơi phát.
Không xảy ra mất mát dữ liệu: đảm bảo không có gói tin hay
flit nào bị mất mát trong quá trình truyền dữ liệu trên NoC. Việc quản
lý không tốt các luồng dữ liệu hoặc các không gian nhớ trong bộ định
tuyến có thể gây nên sự mất mát dữ liệu trong quá trình truyền thông.

46 Mạng trên chip
Thứ tự dữ liệu: trong mạng trên chip, dữ liệu nhận được phải
có thứ tự sắp xếp giống như ở nguồn phát. Với các thuật toán xác
định, ta chỉ cần xây dựng cơ chế đảm bảo các gói tin không tự nhân
đôi. Ngược lại, với các thuật toán thích ứng ta cần phải xây dựng cơ
chế tái sắp xếp dữ liệu tại đích đến.
Thông lượng: lượng dữ liệu được truyền từ nguồn tới đích
trong một khoảng thời gian xác định.
Độ trễ đáp ứng: đây là một dịch vụ quan trọng trong truyền
thông mạng, được định nghĩa là thời gian kể từ khi phát dữ liệu tại
nguồn cho đến khi thu được dữ liệu tại đích.
Để đảm bảo được chất lượng dịch vụ, ta phải tìm được thoả hiệp
tối ưu nhất giữa các thông số dịch vụ cho từng ứng dụng cụ thể. Với
mạng trên chip, ta có thể chia chất lượng dịch vụ thành hai loại cơ
bản: khả năng hỗ trợ tốt nhất (BE: Best-Effort) và dịch vụ được bảo
đảm (GS: Guaranteed Service).
Các mạng có dịch vụ được đảm bảo: với các mạng trên chip
thuộc loại này, người ta xây dựng các kỹ thuật cho phép đặt chỗ trước
các tài nguyên truyền thông nhằm đảm bảo thông lượng truyền thông
và/hoặc độ trễ đáp ứng ở một mức nào đó, không liên quan đến tải
mạng. Loại dịch vụ này đòi hỏi ta phải trang bị cho mạng nhiều tài
nguyên hơn.
Các mạng với khả năng hỗ trợ tốt nhất: mạng được xác định
kích thước sao cho có được một hiệu suất trung bình tốt nhất nhưng
không đảm bảo thông lượng truyền thông và độ trễ đáp ứng trong các
trường hợp không thuận lợi. Các tài nguyên mạng có cùng mức ưu
tiên và chia sẻ dung lượng truyền thông của mạng.
Nói một cách khác, dịch vụ BE đề cập tới sự truyền thông không
cam kết trong khi dịch vụ GS thì có. Hầu hết các mạng NoC cung cấp
dịch vụ GS đều sử dụng hợp kênh phân chia theo thời gian (TDM:
Time Division Multiplexing) để thực hiện định tuyến gói tin có định
hướng kết nối nên đảm bảo được băng thông cho kết nối. Ví dụ, mạng
trên chip MANGO sử dụng chuỗi các kênh ảo để thực hiện kết nối

Chương 2. Mạng trên chip: cėc khėi niệm cơ bĘn 47
đầu-cuối ảo [30]. Các giới hạn của TDM như băng thông và đảm bảo
độ trễ có thể được giải quyết bằng việc lập thời biểu xấp xỉ. Trong khi
đó, Bjerregaard và Sparso đưa ra một hệ thống đảm bảo độ trễ và có
sự độc lập về băng thông [14].
2.8. Giao thức truyền thông
Trong một hệ thống truyền thông, giao thức truyền thông xác
định nguyên tắc truyền dữ liệu. Đó là một loạt các quy định và
phương pháp cần thiết để truyền một thông tin từ nơi phát đến nơi
nhận. Để đơn giản việc thực hiện giao thức truyền thông, người ta chia
giao thức thành các tầng khác nhau với các chức năng xác định.
Vì khái niệm mạng trên chip bắt nguồn từ mạng máy tính nên ta
có thể sử dụng các giao thức truyền thông hay dùng trong các mạng
máy tính. Tuy nhiên, các giao thức truyền thông trong mạng máy tính
khá phức tạp vì được sử dụng cho các tô-pô không xác định. Do đó,
trong khái niệm mạng trên chip ta phải đơn giản hóa các giao thức này
nhằm đạt được thoả hiệp tốt nhất giữa hiệu năng và giá thành thực thi.
Một số giao thức truyền thông cho mạng trên chip đã được đề xuất
trong các công trình [6, 31, 22, 32] khá tương đồng với mô hình tham
chiếu kết nối các hệ thống mở OSI (Open Systems Interconnection
Reference Model) như được trình bày trong Hình 2-7.
Hình 2-7: Mô hình tham chiếu kết nối các hệ thống mở OSI.

48 Mạng trên chip
Theo các đề xuất này, bốn tầng thấp nhất được thực thi trên NoC.
Những tầng cao hơn thường được dùng cho các ứng dụng và được
thực thi trên các lõi xử lý (IP, CPU) kết nối với NoC. Phần còn lại của
mục này sẽ trình bày sơ lược về chức năng của bốn tầng thấp nhất.
Tầng vật lý (physical level): tương ứng với mức thấp nhất
trong mô hình OSI. Tầng này mô tả các điều kiện phần cứng phục vụ
cho việc truyền dữ liệu: các đặc tính về điện áp và thời gian của các
tín hiệu, số lượng và chiều dài của dây dẫn kết nối giữa các bộ định
tuyến. Tầng vật lý hỗ trợ việc truyền thông tin ở mức bit hoặc mức từ
giữa hai bộ định tuyến.
Tầng liên kết dữ liệu (data link level): thực hiện một kết nối
lô-gic giữa các bộ định tuyến hoặc giữa bộ định tuyến với giao diện
mạng (NI: Network Interface), còn được gọi là kết nối hop-to-hop. Tầng
này định nghĩa cách truyền thông tin giữa các bộ định tuyến và đảm bảo
độ tin cậy của truyền thông trên các kết nối vật lý. Do vậy, tầng này có
thể bao gồm các kỹ thuật đồng bộ, điều khiển luồng và sửa lỗi.
Tầng mạng (network level): liên quan đến việc trao đổi thông
tin ở mức gói trong mạng. Tầng này định nghĩa cách thức gửi một gói
tin trong mạng từ nơi phát đến nơi nhận. Do vậy, tầng mạng chịu trách
nhiệm về các kỹ thuật truyền thông và các thuật toán định tuyến.
Trong trường hợp truyền thông Wormhole, tầng mạng đảm bảo việc
phân chia gói tin thành các flit.
Tầng giao vận (transport level): liên quan đến việc trao đổi
thông tin giữa hai đơn vị xử lý dữ liệu. Tầng này phân chia các khối
dữ liệu từ tầng phiên (session level) thành các gói tin với kích thước
phù hợp cho mạng. Tầng này chịu trách nhiệm điều khiển luồng dữ
liệu đầu-cuối và cung cấp các kỹ thuật nhằm tránh hiện tượng quá tải
và điều tiết lưu lượng truyền thông trên mạng.
2.9. Kết luận chương
Trên đây là các khái niệm cơ bản về mô hình mạng trên chip. Nội
dung của chương này đã cung cấp cho người đọc các khái niệm ban

Chương 2. Mạng trên chip: cėc khėi niệm cơ bĘn 49
đầu về mô hình mạng trên chip cho đến các khái niệm cụ thể như cấu
trúc liên kết, các kỹ thuật, cơ chế truyền thông được sử dụng, chiến
lược lưu trữ dữ liệu hay các thuật toán truyền thông có thể triển khai
với mô hình mạng trên chip cũng như ưu nhược điểm của từng chiến
lược, thuật toán truyền thông. Bên cạnh đó, nội dung chương cũng đã
đề cập, bàn luận về các vấn đề chất lượng dịch vụ mạng, khả năng xảy
ra tắc nghẽn trong quá trình truyền thông cũng như một số giải pháp
cơ bản để giải quyết các tắc nghẽn có thể xảy ra này.
Trong các chương tiếp theo, chúng ta sẽ tìm hiểu cụ thể các hoạt
động nghiên cứu liên quan trực tiếp đến các thành phần của mạng trên
chip cũng như các giải pháp, đề xuất nhằm nâng cao hiệu quả hoạt
động của mạng trên chip.

Mục lục 50
Chương 3
THIẾT KẾ, MÔ HÌNH HÓA
VÀ KIỂM CHỨNG BỘ ĐỊNH TUYẾN MẠNG
Chương trước đã đưa ra một cái nhìn tổng quan về mạng trên
chip, từ khái niệm đến tình hình nghiên cứu trên thế giới trong thời
gian qua. Trong chương này, chúng tôi sẽ tập trung trình bày về thiết
kế, mô hình hóa và phương pháp kiểm chứng bộ định tuyến mạng –
thành phần căn bản dùng để xây dựng các mô hình mạng trên chip.
Các vấn đề tối ưu thiết kế cũng sẽ được trình bày trong chương này.
3.1. Bài toán thiết kế
Với định hướng phát triển các hệ thống trên chip có độ phức tạp
cao, phục vụ cho các ứng dụng đa phương tiện và truyền thông, việc
phát triển một nền tảng hệ thống trên chip là cần thiết vì những ưu
điểm vượt bậc của mô hình. Để xây dựng nền tảng mạng trên chip,
chúng tôi đã lựa chọn cấu trúc liên kết 2D-mesh với thuật toán định
tuyến xác định, thông tin định tuyến được cung cấp tại nguồn. Như đã
trình bày ở Mục 2.1, cấu trúc liên kết này có ưu điểm là dễ dàng thực
thi phần cứng theo phương pháp truyền thống. Mô hình mạng trên
chip được đề xuất như trong Hình 3-1.
Hình 3-1: Mô hình mạng trên chip đề xuất.

Chương 3. Thiết kế, mô hình hòa vĖ kiểm chứng bộ đðnh tuyến mạng 51
Với mô hình này, ngoại trừ các bộ định tuyến ở rìa ngoài, mỗi bộ
định tuyến đều được kết nối với bốn bộ định tuyến bên cạnh thông qua
các liên kết mạng và một lõi IP. Kỹ thuật truyền thông được sử dụng ở
đây là kỹ thuật chuyển mạch gói với cơ chế truyền thông Wormhole
nhằm tối ưu việc sử dụng tài nguyên mạng và tiết kiệm bộ nhớ (tiết
kiệm không gian thực thi phần cứng). Mỗi thông điệp (message) sẽ
được chia nhỏ thành các gói tin (packet) ngay tại nguồn trước khi
truyền lên mạng. Mỗi gói tin lại được chia nhỏ thành các flit với kích
thước là 34 bit (32 bit thông tin và 2 bit điều khiển). Flit đầu tiên của
gói tin gọi là flit tiêu đề, chứa thông tin điều khiển và định tuyến của
gói tin. Các flit theo sau được gọi là flit dữ liệu (data flit hay body
flit). Hình 3-2 mô tả định dạng của các flit này.
Hình 3-2: Định dạng của các flit.
Flit tiêu đề gồm hai bit đầu tiên (BoP = „1‟, EoP = „0‟), trường 18 bit
mang các thông tin về đường định tuyến (Path-to-Target) và trường
14 bit còn lại (payload) mang các thông tin điều khiển hoặc dữ liệu,
như mô tả trong Hình 3-2(a). Tại mỗi bộ định tuyến, hai bit cuối cùng
của trường thông tin định tuyến được sử dụng nhằm xác định hướng đi
tiếp theo của gói tin: hướng Bắc (“00”), hướng Đông (“01”), hướng
Nam (“10”) và hướng Tây (“11”). Để không xảy ra tình trạng tắc
nghẽn trong quá trình truyền tin, chúng ta phải đảm bảo dữ liệu không
được định tuyến theo hướng ngược lại với hướng nó tới. Ở đây, chúng
ta quy định rằng gói tin không được gửi lại hướng đến nhằm tránh tắc
nghẽn trong định tuyến; ví dụ, gói tin đến từ hướng Tây thì không
được gửi lại hướng Tây. Với đặc điểm này, để tiết kiệm số bit thông
tin của đường định tuyến ta có thể sử dụng thông tin định tuyến về
trùng với hướng tin xuất phát để gửi gói tin đến lõi IP. Có nghĩa là,

52 Mạng trên chip
nếu gói tin xuất phát từ phía Tây, muốn gửi đến lõi IP thì giá trị hai bit
định tuyến cuối cùng sẽ là “11” (đi về lõi IP).
Với độ dài 18 bit, trường thông tin định tuyến có thể xác định
đường đi của gói tin qua 9 bước hay 9 bộ định tuyến (quãng đường đi
và về dài nhất cho mô hình mạng trên chip với 9 bộ định tuyến như
mô tả trong Hình 3-1). Trong trường hợp với mạng có kích thước lớn
hơn thì ta cần mở rộng kích thước của trường thông tin định tuyến. Cơ
chế truyền thông được thực hiện theo cơ chế Wormhole. Do đó, flit
tiêu đề thiết lập đường đi, các flit còn lại của gói tin chỉ việc đi theo
đường đi đã được thiết lập. Trường điều khiển có nhiệm vụ thiết lập
các cơ chế điều khiển thông điệp hay mã hóa loại gói tin: gói tin đọc,
gói tin viết, hay gói tin yêu cầu ngắt.
Hình 3-2(b) biểu diễn một flit dữ liệu 34 bit gồm hai bit điều
khiển (BoP = 0 và EoP). Khi EoP mang giá trị „1‟ đó là flit kết thúc
gói tin (tail flit), nếu không thì flit đó đơn thuần chỉ là flit dữ liệu,
không phải là flit kết thúc gói tin. 32 bit còn lại là thông tin dữ liệu.
Trong trường hợp đặc biệt gói tin chỉ có một flit duy nhất thì khi đó
gói tin chỉ có flit tiêu đề với BoP = EoP = „1‟. Ngoài ra, mô hình đề
xuất cũng nhắm tới việc sử dụng hai kênh ảo (VC0 và VC1) nhằm hạn
chế các hiện tượng khóa chết, khóa động (xem Mục 2.6) và nâng cao
chất lượng dịch vụ (QoS) của hệ thống. Trong đó, kênh ảo VC0 có
mức ưu tiên cao hơn.
Giao thức truyền thông của mạng đề xuất được thực hiện theo mô
hình tham chiếu OSI như mô tả trong Mục 2.8. Ở tầng liên kết dữ liệu,
ngoài tín hiệu dữ liệu, ta sử dụng thêm các tín hiệu điều khiển thực
hiện giao thức bắt tay cho mỗi kênh ảo, đó là tín hiệu truyền (send) và
tín hiệu chấp nhận (accept). Giao thức bắt tay này được gọi là giao
thức bắt tay “send-accept”. Nhờ giao thức này, tại mỗi thời điểm chỉ
có một kênh ảo hoạt động trên kênh vật lý (chiếm kênh vật lý).
3.2. Mô hình bộ định tuyến
Từ những yêu cầu đặt ra ở trên, mô hình bộ định tuyến được đề
xuất như mô tả trong Hình 3-3 với 5 cổng vào/ra [33]. Trong đó,

Chương 3. Thiết kế, mô hình hòa vĖ kiểm chứng bộ đðnh tuyến mạng 53
4 cổng vào/ra kết nối với 4 bộ định tuyến bên cạnh và một cổng vào/ra
kết nối với lõi IP. Mỗi kênh vật lý của bộ định tuyến được phân chia
thành hai kênh ảo, mỗi kênh ảo có một bộ đệm độc lập. Do sử dụng cơ
chế định tuyến Wormhole nên kích thước của bộ đệm ở các kênh ảo
này rất nhỏ, chỉ đủ chứa một flit.
Hình 3-3: Kiến trúc của bộ định tuyến.
Truyền thông giữa các bộ định tuyến hay giữa bộ định tuyến và
lõi IP được thiết lập thông qua giao thức bắt tay “send-accept” như
mô tả trên Hình 3-4. Theo đó, tín hiệu truyền (send) luôn được gửi đi
đồng thời với tín hiệu dữ liệu để xác định thông tin về kênh ảo. Còn
tín hiệu chấp nhận (accept) được gửi từ bộ định tuyến nhận ngược về
bộ định tuyến phía trước nó (bộ định tuyến truyền dữ liệu) để thông
báo trạng thái rỗi/bận của bộ đệm kênh ảo lối vào. Nếu bộ đệm lối vào
của bộ định tuyến nhận đang bận thì nó sẽ không cho phép dữ liệu từ
bộ định tuyến phía trước truyền tới, còn nếu rỗi thì dữ liệu được
truyền tới và ghi vào bộ đệm lối vào của bộ định tuyến nhận. Giao
thức bắt tay “send-accept” cũng đảm bảo tại mỗi thời điểm chỉ có một
kênh ảo chiếm kênh vật lý. Với hai kênh ảo được thiết lập trong thiết
kế đề xuất, giao diện kết nối sẽ bao gồm hai tín hiệu truyền („send0‟
và „send1‟), hai tín hiệu chấp nhận („accept0‟ và „accept1‟) dành cho
hai kênh ảo và 34 bit dữ liệu cho mỗi hướng truyền thông.

54 Mạng trên chip
Hình 3-4: Giao thức bắt tay “send-accept”.
Quá trình phân xử định tuyến của bộ định tuyến được quy ước
như sau: gói tin đến trước sẽ được xử lý trước, gói tin đến sau sẽ được
xử lý sau; trong trường hợp các gói tin đến cùng một lúc và cùng có
yêu cầu được định tuyến đến cùng một lối ra thì kênh ảo VC0 luôn có
mức ưu tiên cao hơn kênh ảo VC1 và nếu các gói tin có cùng mức ưu
tiên thì bộ định tuyến sẽ thực hiện việc định tuyến theo hướng đến của
gói tin với thứ tự ưu tiên là Bắc, Đông, Nam, Tây.
Thông qua thực nghiệm đánh giá hiệu năng của mạng trên chip
sử dụng kỹ thuật chuyển mạch kênh [34], chúng ta dễ dàng nhận ra
rằng tốc độ chuyển mạch của các crossbar là một yếu tố rất quan
trọng, quyết định hiệu năng của bộ định tuyến. Chính vì thế, trong mô
hình này chúng tôi sử dụng hai bộ crossbar (liên kết giữa các khối
vào/ra của bộ định tuyến) nhằm tăng hiệu năng định tuyến của bộ định
tuyến. Việc sử dụng hai crossbar có thể làm tăng giá thành thực thi
phần cứng bộ định tuyến nhưng không đáng kể (chủ yếu là các bộ
phân-nhập kênh thông thường).
Như vậy, bộ định tuyến đề xuất sẽ có 5 cổng vào/ra, mỗi cổng
vào/ra được trang bị hai kênh ảo riêng biệt là VC0 và VC1. Các kênh
ảo của các cổng vào/ra được kết mối với nhau thông qua hai crossbar,
X0 và X1. Trong đó, X0 dùng để kết nối các kênh ảo VC0, X1 dùng

Chương 3. Thiết kế, mô hình hòa vĖ kiểm chứng bộ đðnh tuyến mạng 55
để kết nối các kênh ảo VC1. Trong các mục tiếp theo, chúng ta sẽ tìm
hiểu sâu hơn về thiết kế chi tiết các mô-đun vào/ra của bộ định tuyến.
3.3. Thiết kế chi tiết kiến trúc bộ định tuyến
Theo như mô tả ở mục trước, các mô-đun vào/ra của bộ định
tuyến cần trang bị khả năng thiết lập hai luồng dữ liệu riêng biệt (thực
thi hai kênh ảo). Bên cạnh đó, để thực hiện quá trình truyền nhận thông
tin, trong các mô-đun này cũng cần được trang bị các mạch lô-gic điều
khiển nhằm thực thi việc định tuyến, thiết lập giao thức bắt tay “send-
accept”, điều khiển luồng dữ liệu.
Hình 3-5 minh họa kết nối của một cặp mô-đun vào/ra của bộ
định tuyến. Theo đó, mỗi mô-đun lối vào sẽ bao gồm hai thành phần
chính là khối phân luồng dữ liệu (datapath) và khối điều khiển. Trong
đó, khối phân luồng dữ liệu có nhiệm vụ phân luồng dữ liệu cho các
kênh ảo và đường định tuyến. Khối điều khiển có nhiệm vụ tạo ra các
tín hiệu điều khiển đường định tuyến, điều khiển luồng dữ liệu sử
dụng kỹ thuật credit và xây dựng giao thức bắt tay nhằm đồng bộ quá
trình truyền dữ liệu. Cấu trúc ở mô-đun lối ra cũng bao gồm khối phân
luồng dữ liệu và khối điều khiển định tuyến và quản lý credit.
Hình 3-5: Một cặp mô-đun vào/ra của bộ định tuyến.
Mô tả chi tiết của các khối chức năng trong các mô-đun vào ra sẽ
được trình bày trong các mục tiếp theo.

56 Mạng trên chip
3.3.1. Khối phân luồng dữ liệu của mô-đun lối vào
Từ yêu cầu thiết kế, mô hình khối phân luồng dữ liệu của mô-đun
lối vào được đề xuất như trong Hình 3-6.
Hình 3-6: Khối phân luồng dữ liệu của mô-đun lối vào.
Khối phân luồng dữ liệu có nhiệm vụ phân luồng các đơn vị dữ
liệu lối vào đến các bộ đệm kênh ảo tương ứng tuỳ thuộc vào tín hiệu
điều khiển phân luồng kênh ảo vc_allocation. Sau đó, dữ liệu tại các bộ
đệm này sẽ được gửi tới các crossbar tương ứng khi hội tụ đủ các điều
kiện về định tuyến. Trong khi gửi tới crossbar, phụ thuộc vào giá trị của
tín hiệu dịch flit tiêu đề HFS (Header Flit Shift), nếu đơn vị dữ liệu là
một flit tiêu đề thì nó sẽ được phân luồng đi qua một bộ dịch bit (dịch 2
bit) nhằm xoá hai bit định tuyến sử dụng cho bộ định tuyến hiện tại, còn
nếu là flit dữ liệu thông thường thì sẽ được gửi thẳng tới crossbar. Việc
dịch bit trường định tuyến này cho phép bộ định tuyến tiếp theo có thể
sử dụng hai bit định tuyến mới trong trường định tuyến.
3.3.2. Khối điều khiển của mô-đun lối vào
Khối điều khiển có nhiệm vụ tạo ra các tín hiệu điều khiển khối
phân luồng dữ liệu như tín hiệu điều khiển phân luồng kênh ảo, tín
hiệu điều khiển đường định tuyến. Ngoài ra, khối này còn có nhiệm vụ
quản lý credit luồng dữ liệu và thực thi giao thức bắt tay (đóng vai trò
quan trọng trong việc đồng bộ dữ liệu và điều khiển luồng dữ liệu đầu
cuối). Trong kỹ thuật định tuyến nguồn, dữ liệu định tuyến cần được
loại bỏ sau khi đã sử dụng và dữ liệu mới sẽ thay thế vị trí dữ liệu định
tuyến hiện tại. Chính vì vậy, khối điều khiển cũng được trang bị chức

Chương 3. Thiết kế, mô hình hòa vĖ kiểm chứng bộ đðnh tuyến mạng 57
năng nhận biết flit tiêu đề và tạo ra tín hiệu điều khiển dịch bit trường
dữ liệu định tuyến của flit tiêu đề. Theo đó, hai bit có trọng số thấp
nhất của trường định tuyến sẽ bị loại bỏ. Khối điều khiển của mô-đun
lối vào được mô tả như trong Hình 3-7.
Hình 3-7: Khối điều khiển của mô-đun lối vào.
Trong đó, tín hiệu điều khiển phân luồng kênh ảo là VC và tín hiệu
điều khiển dịch bit trường định tuyến của flit tiêu đề là HFS. Các tín
hiệu lối vào gồm: các tín hiệu bắt tay send-accept, tín hiệu báo bắt đầu
và kết thúc một gói tin (BoP, EoP), thông tin hướng định tuyến dir.
3.4. Khối phân luồng dữ liệu của mô-đun lối ra
Khối phân luồng dữ liệu ở mô-đun lối ra tương đối đơn giản, có
nhiệm vụ hợp các luồng dữ liệu từ các kênh ảo và đưa ra lối ra. Hình 3-8
mô tả kiến trúc khối phân luồng dữ liệu này. Việc điều khiển các
luồng dữ liệu phụ thuộc vào tín hiệu điều khiển VC.
Hình 3-8: Khối phân luồng dữ liệu của mô-đun lối ra.

58 Mạng trên chip
3.4.1. Khối điều khiển của mô-đun lối ra
Tương tự như khối điều khiển của mô-đun lối vào, khối điều
khiển của mô-đun lối ra cũng có nhiệm vụ tạo ra các tín hiệu điều
khiển khối phân luồng dữ liệu như tín hiệu điều khiển kênh ảo, tín
hiệu điều khiển đường định tuyến. Ngoài ra, khối này cũng có nhiệm
vụ phối hợp với khối điều khiển của mô-đun lối vào để quản lý credit
luồng dữ liệu và thực thi giao thức bắt tay. Vì rằng, tại lối ra ta không
quan tâm đến loại flit dữ liệu nên khối điều khiển của mô-đun lối ra
đơn giản hơn so với khối điều khiển của mô-đun lối vào, được mô tả
như trong Hình 3-9.
Hình 3-9: Khối điều khiển của mô-đun lối ra.
3.4.2. Crossbar
Như đã trình bày trong Mục 3.2, trong thiết kế này chúng ta sử
dụng hai crossbars, X0 và X1, cho hai kênh ảo VC0 và VC1 nhằm
tăng hiệu năng định tuyến của bộ định tuyến. Hình 3-10 mô tả sơ đồ
thực thi một crossbar sử dụng trong thiết kế này. Về bản chất, crossbar
ở đây được thực hiện tương đối đơn giản thông qua các bộ phân kênh
1:4 và hợp kênh 4:1 để truyền tải dữ liệu từ lối vào đến lối ra. Các bộ
phân/hợp kênh được điều khiển thông qua các tín hiệu tổ hợp từ các
khối lô-gic định tuyến (ở mô-đun lối vào và mô-đun lối ra).

Chương 3. Thiết kế, mô hình hòa vĖ kiểm chứng bộ đðnh tuyến mạng 59
Hình 3-10: Crossbar sử dụng trong thiết kế.
Tiếp đến, thiết kế của bộ định tuyến được mô hình hóa sử dụng
các ngôn ngữ mô tả phần cứng (ở đây, chúng tôi sử dụng ngôn ngữ
mô tả phần cứng VHDL). Để chứng minh hoạt động của thiết kế đáp
ứng đặc tả thiết kế, các bước mô phỏng và kiểm chứng sẽ được triển
khai một cách cẩn thận, tỉ mỉ. Phần còn lại của chương này sẽ trình
bày phương pháp mô hình hóa, mô phỏng và kiểm chứng thiết kế này.
3.5. Mô hình hóa, kiểm chứng và thực thi thiết kế
Tiếp theo phần thiết kế ở trên, phương pháp mô hình hóa, kiểm
chứng cũng như một số kết quả mô phỏng kiểm chứng sẽ được trình
bày trong mục này. Mô hình thiết kế sau khi đã được kiểm chứng
thành công, được thực thi trên công nghệ FPGA thông qua bộ công cụ
hỗ trợ thiết kế phần cứng ISE Foundation Suite và Vivado của hãng
Xilinx. Một số kết quả thực thi phần cứng cũng sẽ được trình bày
trong chương này.
3.5.1. Phương pháp mô hình hóa, kiểm chứng
Việc mô hình hóa, kiểm chứng và thực thi phần cứng thiết kế
được thực hiện theo quy trình mạch VLSI dựa trên công nghệ FPGA,
như mô tả trong Hình 3-11. Theo đó, quy trình này bao gồm 5 bước cơ
bản: (i) xây dựng đặc tả và phân tích thiết kế; (ii) mô hình hóa thiết kế
và xây dựng mô hình kiểm tra; (iii) tổng hợp lô-gic; (iv) thực thi định
tuyến và đặt chỗ (P&R); và cuối cùng là (v) nạp thiết kế lên chip
FPGA.

60 Mạng trên chip
Với công nghệ FPGA, hai công đoạn đầu đòi hỏi người thiết kế
đầu tư nhiều thời gian và chất xám. Trong khi đó, các công đoạn sau
gần như được thực hiện hoàn toàn tự động bởi các công cụ thiết kế.
Người thiết kế chỉ cần xây dựng các ràng buộc về mặt vật lý cho thiết
kế nhằm thu được kết quả mong muốn, đáp ứng được các đặc tả thiết
kế đề ra. Các công đoạn này đòi hỏi kinh nghiệm của người thiết kế.
Hình 3-11: Quy trình mô hình hóa, kiểm chứng và thực thi phần cứng.
Trong quá trình thực hiện thiết kế, chúng tôi cũng áp dụng phương
pháp thiết kế TOP-DOWN nhằm đơn giản hóa thiết kế và từ đó giảm thời
gian thiết kế. Ngoài hai công đoạn xây dựng đặc tả và nạp thiết kế lên
chip FPGA, các công đoạn còn lại đều được thực hiện mô phỏng nhằm
kiểm chứng chức năng hoạt động của thiết kế sau khi thực thi.
Để thực hiện việc kiểm chứng nhanh mô hình bộ định tuyến (ở các
mức RTL, netlist và layout), chúng tôi xây dựng một mô hình mạng 2×2
đơn giản có kết nối với hai lõi IP, như mô tả trong Hình 3-12. Trong mô

Chương 3. Thiết kế, mô hình hòa vĖ kiểm chứng bộ đðnh tuyến mạng 61
hình này, các bộ định tuyến R00, R01, R10 và R11 là các bộ định tuyến
thiết kế, còn các lõi xử lý “IP core 0” và “IP core 1” là các lõi xử lý đơn
giản được xây dựng với mục đích tạo ra các gói dữ liệu để truyền trên
mạng và tiêu thụ các gói dữ liệu nếu nhận được. Quá trình mô phỏng
nhằm kiểm tra chức năng của các bộ định tuyến được thực hiện thông
qua việc truyền nhận dữ liệu giữa các lõi IP với các đường định tuyến
khác nhau: “IP core 0” truyền dữ liệu cho “IP core 1” và ngược lại, hoặc
ngay chính từng IP tự truyền và nhận dữ liệu của chính mình.
Hình 3-12: Mô hình kiểm chứng bộ định tuyến.
Mô hình này cho phép ta thực hiện kiểm chứng hầu hết các vấn
đề liên quan đến quy luật định tuyến đề ra của bộ định tuyến. Tuy vậy,
mô hình này chưa cho phép ta kiểm tra quy luật xử lý định tuyến ưu
tiên khi xảy ra hiện tượng nhiều gói tin cùng xuất hiện và cùng có nhu
cầu định tuyến tới cùng một lối ra của bộ định tuyến. Việc kiểm chứng
các quy luật xử lý định tuyến ưu tiên này được thực hiện bằng mô
hình kiểm chứng đối với chỉ một bộ định tuyến (thông qua việc cấp
các gói dữ liệu đồng thời cho các lối vào của bộ định tuyến).
Mục tiếp theo sẽ trình bày một số kết quả mô phỏng kiểm chứng
nhằm minh chứng sự hoạt động theo đúng chức năng đề ra của bộ
định tuyến.
3.5.2. Kết quả mô phỏng và kiểm chứng
Việc chứng minh chức năng hoạt động của bộ định tuyến thiết kế
so với đặc tả đề ra được thực hiện nhờ mô hình mô phỏng và kiểm
chứng nêu ở Mục 3.4.1. Quá trình này được thực hiện ở các mức mô
hình hóa khác nhau (RTL, netlist, layout). Phần này sẽ trình bày một

62 Mạng trên chip
vài kết quả mô phỏng nhằm minh họa phương pháp và chứng tỏ sự
hoạt động của thiết kế.
Hình 3-3 trình bày kết quả mô phỏng tại các lối vào/ra của mô-đun
lối vào bộ định tuyến với:
Một gói tin đơn flit (gói tin chỉ bao gồm một flit) được truyền từ
lối vào dữ liệu với kênh ảo VC1 tới lối ra phía Tây (hoặc tới lõi IP nếu
mô-đun lối vào này là mô-đun lối vào phía Tây), xem Mục 3.2.
Một gói tin đa flit (gói tin bao gồm nhiều flit, trong đó có flit
tiêu đề và flit kết thúc) được truyền từ lối vào dữ liệu với kênh ảo VC0
tới lối ra phía Tây (hoặc tới lõi IP nếu mô-đun lối vào này là mô-đun
lối vào phía Tây), tương tự như gói tin thứ nhất.
Thực tế quá trình mô phỏng đã thực hiện truyền nhiều gói tin
với các hướng định tuyến khác nhau với các kênh ảo khác nhau nhằm
kiểm tra tất cả các khả năng định tuyến.
Hình 3-13: Kết quả mô phỏng với mô-đun lối vào của bộ định tuyến.
Kết quả mô phỏng cho thấy dữ liệu tại lối ra „q13‟ ta thu được gói
tin thứ nhất kèm với tín hiệu „send13‟ = „1‟ (chỉ thị kênh ảo VC1) và
tại lối ra „q03‟ ta thu được gói tin thứ hai kèm với tín hiệu „send03‟ = „1‟
(chỉ thị kênh ảo VC0). Một điểm đáng lưu ý là đối với các flit tiêu đề,
trường thông tin định tuyến được dịch phải hai bit để sẵn sàng cho quá

Chương 3. Thiết kế, mô hình hòa vĖ kiểm chứng bộ đðnh tuyến mạng 63
trình định tuyến ở bộ định tuyến tiếp theo. Do đó, hai bit có giá trị
“00” được chèn vào bên trái trường thông tin định tuyến.
Tương tự như vậy, việc kiểm chứng hoạt động của mô-đun lối ra
của bộ định tuyến cũng được tiến hành một cách độc lập trước khi
thực hiện mô phỏng toàn bộ bộ định tuyến. Hình 3-14 cho ta thấy kết
quả mô phỏng tại các lối vào/ra của mô-đun lối ra bộ định tuyến với:
Một gói tin đơn flit được truyền từ kênh ảo VC0 của mô-đun lối
vào 0 (lối vào „q00‟) tới lối ra dữ liệu „data‟.
Một gói tin đơn flit được truyền từ kênh ảo VC0 của mô-đun lối
vào 1 (lối vào „q01‟) tới lối ra dữ liệu „data‟.
Thực tế quá trình mô phỏng đã thực hiện truyền nhiều gói tin
với các mô-đun lối vào khác nhau với các kênh ảo khác nhau nhằm
kiểm tra tất cả các khả năng định tuyến.
Hình 3-14: Kết quả mô phỏng với mô-đun lối ra của bộ định tuyến.
Kết quả mô phỏng cho thấy, các gói tin lối vào được truyền tới lối ra
„data‟ theo đúng thứ tự ưu tiên trong quy luật phân xử định tuyến. Ở đây,
cả hai gói tin cùng đến một lúc từ kênh ảo VC0 của hai mô-đun vào

64 Mạng trên chip
khác nhau. Theo thứ tự, gói tin đến từ mô-đun 0 (lối vào „q00‟) được xử
lý trước và gói tin đến từ mô-đun 1 (lối vào „q01‟) được xử lý sau.
Từng mô-đun lối vào, lối ra của bộ định tuyến sau khi được kiểm
chứng độc lập sẽ được ghép lại thành bộ định tuyến hoàn chỉnh. Việc
tiến hành mô phỏng kiểm chứng toàn bộ bộ định tuyến cho phép kiểm
tra các hoạt động của bộ định tuyến một cách đầy đủ so với các đặc tả
đề ra. Hình 3-15 trình bày kết quả mô phỏng tại lối vào/lối ra của bộ
định tuyến với:
Một gói tin đơn flit đến từ hướng Bắc (lối vào „in0_data‟), kênh
ảo VC1 có đường định tuyến dự kiến tới hướng Đông (hai bit cuối
trường thông tin định tuyến có giá trị là “01”).
Một gói tin đơn flit đến từ hướng Đông (lối vào „in1_data‟),
kênh ảo VC0 có đường định tuyến dự kiến tới hướng Tây (hai bit cuối
trường thông tin định tuyến có giá trị là “11”).
Một gói tin đơn flit đến từ hướng Đông (lối vào „in1_data‟),
kênh ảo VC1 có đường định tuyến dự kiến tới hướng Tây (hai bit cuối
trường thông tin định tuyến có giá trị là “11”).
Thực tế quá trình mô phỏng đã thực hiện truyền nhiều gói tin với
các hướng vào khác nhau có đường định tuyến tới các hướng ra khác
nhau nhằm kiểm tra tất cả các khả năng định tuyến của bộ định tuyến.
Hình 3-15: Kết quả mô phỏng của bộ định tuyến thiết kế.

Chương 3. Thiết kế, mô hình hòa vĖ kiểm chứng bộ đðnh tuyến mạng 65
Kết quả cho thấy, gói tin thứ nhất đã được truyền đến lối ra
hướng Đông (lối ra „out1_data‟), kênh ảo VC1. Các gói tin thứ hai và
thứ ba lần lượt được truyền ra lối ra hướng Tây với kênh ảo VC0 (đối
với gói tin thứ hai) và kênh ảo VC1 (đối với gói tin thứ ba).
3.5.3. Kết quả thực thi phần cứng bộ định tuyến
Sau khi thực hiện mô phỏng, kiểm chứng ở mức RTL, thiết kế của
bộ định tuyến được tổng hợp lô-gic, thực thi đặt chỗ và định tuyến (P&R)
thông qua các công cụ hỗ trợ thiết kế của hãng Xilinx (ISE Foundation
Suite). Bảng 3-1 trình bày một số thông tin về kết quả thực thi phần cứng.
Theo đó, tài nguyên sử dụng để thực hiện bộ định tuyến bao gồm: 2143
thanh ghi, 1492 LUT 4 lối vào, 1969 slice và 383 bộ đệm cổng vào/ra.
Bảng 3-1: Không gian thực thi phần cứng bộ định tuyến thiết kế
trên chip XC2V1000-5ff896
Tài nguyên sử dụng Đã sử dụng Sẵn có trên chip Tỷ lệ (%)
Thanh ghi 2.143 10.240 20%
LUT 4 lối vào 1.492 10.240 14%
Slice 1.969 5.120 38%
Bộ đệm cổng vào/ra 383 432 88%
Hình 3-16 cho thấy layout của bộ định tuyến trên chip FPGA
XC2V1000-5ff896 (Xilinx).
Hình 3-16: Layout của bộ định tuyến với công nghệ FPGA của hãng Xilinx
(thực thi trên chip XC2V1000-5ff896).

66 Mạng trên chip
Sau khi tiến hành mô phỏng, kiểm chứng và đánh giá thiết kế ở
mức layout, chúng ta thu được một số thông tin về năng lượng tiêu thụ
tĩnh và năng lượng tiêu thụ động của bộ định tuyến như trình bày
trong Bảng 3-2. Trong đó, đáng chú ý là năng lượng tiêu thụ động của
thiết kế khi thực hiện các quá trình truyền thông. Thiết kế làm việc với
tần số tối đa là .
Bảng 3-2: Năng lượng tiêu thụ của thiết kế
Thành phần Năng lượng tiêu thụ (µW)
Xung đồng hồ 0,0200
Các cổng lô-gic 0,0150
Các đường tín hiệu 0,0910
Các bộ đệm cổng vào/ra 0,2900
Tổng năng lượng tĩnh 0,0378
Tổng năng lượng động 0,4529
Tổng năng lượng tiêu thụ 0,4907
3.6. Kết luận chương
Trong chương này chúng ta đã tìm hiểu về thiết kế chi tiết một bộ
định tuyến mạng trên chip – là thành phần cơ bản cấu thành kiến trúc
mạng trên chip. Các vấn đề về phương pháp mô hình hóa, kiểm chứng
hoạt động, thực thi thiết kế cũng được đề cập cụ thể, giúp người đọc
hình dung được một quy trình thiết kế đầy đủ. Một số kết quả thực
nghiệm, đánh giá trên cơ sở công nghệ FPGA cũng được đề cập và
phân tích làm cơ sở tham chiếu cho các nghiên cứu tiếp theo trong
lĩnh vực này.

Mục lục 67
Chương 4
THIẾT KẾ, MÔ HÌNH HÓA
VÀ KIỂM CHỨNG BỘ GIAO TIẾP MẠNG
Trong các hệ thống NoC, các tài nguyên tính toán (lõi IP) giao tiếp
với nhau thông qua hạ tầng mạng. Nhiều nhóm nghiên cứu quan tâm
đến việc phát triển các kiến trúc NoC và cơ chế định tuyến, trong khi đó
giao diện ghép nối giữa mạng và các lõi IP cũng cần được quan tâm
nghiên cứu. Trong chương này, chúng ta sẽ đề cập đến việc thiết kế và
thực thi một bộ phối ghép mạng tương thích với chuẩn AXI (AMBA
eXtensible Interface), được đặt tên là bộ phối ghép AXI-NoC.
4.1. Giới thiệu
Với sự tăng nhanh về độ phức tạp của các hệ thống điện tử, các
yêu cầu về thiết kế như là thời gian đưa sản phẩm ra thị trường (time-to-
market), độ tin cậy, khả năng kiểm tra, khả năng tái sử dụng… cùng với
các ràng buộc về thiết kế ngày càng khó khăn liên quan đến hiệu suất,
công suất tiêu thụ và sự biến thiên (variation)1 đã làm nảy sinh các
phương pháp thiết kế mới. Như đã đề cập, mô hình mạng trên chip gần
đây trở thành một giải pháp hứa hẹn có thể thỏa mãn các nhu cầu thiết
kế hiệu năng cao cho các hệ thống trên chip trong tương lai [5].
Ngày nay, các hệ thống có thể tích hợp đến hàng trăm lõi IP trên
một chip đơn với tốc độ hoạt động và truyền thông ở tần số GHz. Việc
kết nối giữa các lõi IP trở thành một thách thức cấp bách đối với thiết
kế các hệ thống trên chip. Do đó, việc triển khai mô hình truyền thông
1 Process variation là sự thay đổi xảy ra trong quá trình sản xuất, đặc biệt là các công
nghệ từ 90nm trở về sau, có những ảnh hưởng tới hoạt động của các transistor.

68 Mạng trên chip
dựa vào mạng là cần thiết nhằm đáp ứng các yêu cầu về truyền thông
và đảm bảo chất lượng dịch vụ.
Trong các kiến trúc mạng trên chip, các thành phần cơ bản bao
gồm các bộ định tuyến, các liên kết mạng và các bộ giao tiếp mạng. Lõi
IP được nối với mạng thông qua các giao tiếp mạng (các bộ phối ghép
mạng). Không giống như bus, mạng truyền thông trong các NoC thực
thi truyền thông chuyển mạch gói giữa các lõi IP dựa vào bộ định tuyến.
Tại mỗi nút mạng, trước khi được truyền trên mạng, các bản tin được
chia nhỏ thành nhiều gói tin liên tiếp. Mỗi gói tin bao gồm một số các
đơn vị điều khiển/dữ liệu (gọi là flit). Mỗi gói tin được bắt đầu bởi một
flit tiêu đề (lưu trữ thông tin định tuyến) và theo sau bởi các gói tin điều
khiển/dữ liệu khác. Các kiến trúc mạng kiểu này cho phép tái sử dụng
các lõi IP và hạ tầng truyền thông một cách dễ dàng. Các lõi IP khác
nhau có thể không được phát triển để có thể tương thích với các mô
hình mạng trên chip; do đó, cần có một bộ phối ghép mạng để cung cấp
một giao diện giữa các lõi IP và các bộ định tuyến mà chúng sẽ kết nối.
Việc phát triển các bộ phối ghép mạng cho phép các lõi IP và hạ tầng
mạng được phát triển một cách độc lập, giúp phân tách giữa hoạt động
tính toán và hoạt động truyền thông. Tuy nhiên, thách thức của việc
triển khai bộ phối ghép mạng là sự gia tăng độ phức tạp, không gian
thực thi, độ trễ và giảm tần số hoạt động tối đa của hệ thống [35].
Các nhà nghiên cứu đã đề xuất nhiều kiến trúc NoC trong thập kỷ
vừa qua, kể cả cấu trúc tô-pô hai chiều và ba chiều. Hầu hết các
nghiên cứu này tập trung vào kiến trúc mạng và thuật toán định tuyến.
Tuy nhiên, các giao diện giữa mạng và các lõi xử lý cũng cần được
quan tâm nghiên cứu một cách nghiêm túc để cải thiện hiệu năng tổng
thể của hệ thống. Bjerregaard và đồng nghiệp [30] đề xuất một bộ
phối ghép mạng như là giao diện giữa giao thức bus OCP và kiến trúc
mạng MANGO không đồng bộ. Bộ phối ghép mạng không chỉ đóng
vai trò như là một giao diện giữa hạ tầng mạng với các lõi IP mà còn
là giao diện đặc biệt giữa các miền đồng bộ và không đồng bộ. Trong
một công trình nghiên cứu khác, Attia và đồng nghiệp [36] đề xuất
một bộ phối ghép mạng tương thích với chuẩn OCP dành cho các
mạng trên chip hai chiều dạng lưới. Thiết kế này khá hiệu quả về mặt

Chương 4. Thiết kế, mô hình hòa vĖ kiểm chứng bộ giao tiếp mạng 69
chi phí không gian thực thi. Stergious và đồng nghiệp [37] cũng đề
xuất một bộ phối ghép mạng tương thích chuẩn OCP dành cho mạng
trên chip Xpipes. Tuy nhiên, những bộ phối ghép mạng này chỉ giúp
cho việc tích hợp các lõi IP tương thích với chuẩn giao thức lõi mở
(OCP: Open Core Protocol) với các kiến trúc mạng NoC. Trong khi
đó, gần đây rất nhiều sản phẩm thương mại sử dụng các lõi xử lý
ARM để đạt được các yêu cầu của ứng dụng về mặt hiệu năng. Việc
tích hợp các vi xử lý ARM vào các kiến trúc NoC là thực sự cần thiết
và chúng ta cần xây dựng giải pháp cho phép ghép nối các vi xử lý
ARM với các kiến trúc mạng NoC. Hiển nhiên, với các hệ thống
không đồng nhất về chuẩn thì việc xây dựng các bộ phối ghép mạng
đa giao thức là cần thiết nhằm đáp ứng các yêu cầu của các lõi IP khác
nhau. Bộ phối ghép mạng được đề xuất bởi Radulescu và đồng nghiệp
[38] cho mạng trên chip AEthereal là một ví dụ. Bộ phối ghép mạng
này có thể hỗ trợ bốn giao diện socket chuẩn (OCP, DTL, AXI based,
chủ hoặc tớ). Tuy nhiên, độ trễ chuyển tiếp của bộ phối ghép mạng
này tương đối cao. Công ty Arteris đã phát triển một giải pháp mạng
trên chip nhắm tới các vấn đề hiệu năng, công suất tiêu thụ, định thời
và tắc nghẽn trong các hệ thống trên chip phức hợp, gọi là FlexNoC.
Công nghệ mạng trên chip Arteris này có thể hỗ trợ một loạt giao thức
như AMBA AXI, AHB, APB, ACE-Lite, OCP, PIF và BVCI [39, 40].
Giao diện mạng ARM CoreLink là một giải pháp tương tự nhưng tập
trung vào các giao thức ARM. Giao diện này cung cấp cấu trúc liên
kết có khả năng cấu hình cao với các đặc tính như cho phép các nhà
thiết kế xây dựng kết nối SoC tương thích chuẩn giao thức AMBA tối
ưu và có hiệu năng cao [41]. Với các giải pháp này, người dùng phải
cấu hình đơn vị giao diện mạng tại giai đoạn xây dựng đặc tả để phù
hợp với các giao thức cần thiết của họ. Điều này có thể dẫn đến việc
tăng thêm chi phí vì các trường hợp xấu nhất cần phải được quan tâm
để hỗ trợ các biến động về yêu cầu truyền thông. El Mrabti và đồng
nghiệp [42] đưa ra các phương pháp và công cụ để triển khai ứng
dụng dễ dàng và hiệu quả trên nền tảng dựa trên IP và NoC với bộ
phối ghép mạng có thể cấu hình. Bộ phối ghép mạng có thể cấu hình
này cung cấp các công cụ để đồng bộ hóa và lập lịch cho truyền thông

70 Mạng trên chip
và cách hành xử của các lõi IP. [43] đưa ra một khối giao diện NoC hỗ
trợ các chức năng mạng tiên tiến. Bộ phối ghép mạng này hỗ trợ các
chức năng mạng khác nhau nhằm đáp ứng các yêu cầu của các hệ
thống nhắm tới. Tuy nhiên, bộ phối ghép mạng này không hỗ trợ các
giao thức giao tiếp mạng chuẩn của các lõi IP. Ruaro và đồng nghiệp
[44] đề xuất một giao diện mạng chuyên dụng cho các hệ thống trên
chip đa vi xử lý (MPSoC) dựa trên NoC, được gọi là DMNI (Direct
Memory Network Interface). Giao diện này được kết nối tới mô-đun
truy cập bộ nhớ ngẫu nhiên (DMA: Direct Memory Access) để cho
phép truyền thông giữa các vi xử lý thông qua hạ tầng mạng trên chip.
Thật không may, các bộ phối ghép mạng đề cập ở trên quá phức tạp để
có thể tham số hóa và lập trình.
Với các lý do nêu trên, chúng tôi thiết kế và thực thi một bộ phối
ghép mạng tương thích với chuẩn AXI (AXI-compliant) cho các mạng
trên chip 2D/3D có cơ chế chuyển mạnh Wormhole. Chuẩn giao tiếp
AXI (Advanced eXtensible Interface) là một trong những chuẩn giao
tiếp truyền thông hiệu quả nhất hiện nay được đề xuất bởi hãng ARM.
Đó là một bus tối ưu đọc/ghi (không còn là chia sẻ bus nữa) hỗ trợ
giao tiếp đa kênh với mức tiêu thụ điện năng thấp hơn. Bộ phối ghép
mạng AXI-NoC của chúng tôi hoạt động như là một cầu nối hai chiều
trong quá trình trao đổi dữ liệu giữa vi xử lý ARM và cấu trúc chuyển
mạch NoC. Bộ phối ghép mạng AXI-NoC được thực thi để hỗ trợ cả
hai giao dịch burst1 đọc và ghi theo chuẩn AXI với các cấu hình như
chiều dài burst, kích thước burst và loại burst. Bộ phối ghép mạng này
cũng hỗ trợ các thuật toán định tuyến tại nguồn và chuyển mạch gói
với chế độ truyền thông Wormhole. Đóng góp chủ yếu trong nghiên
cứu này của chúng tôi là một kiến trúc hiệu quả dành cho bộ phối ghép
mạng với không gian thực thi nhỏ và hiệu năng cao. Tính mô-đun hóa
của thiết kế cũng được quan tâm trong nghiên cứu này nhằm cho phép
bảo trì một cách đơn giản và/hoặc cho phép phát triển thêm để có thể
1 Giao dịch burst là một loại giao dịch truyền thông được hỗ trợ trong giao thức
truyền thông AHB/AXI. Một burst là toàn bộ các lần truyền dữ liệu trong một
giao dịch.

Chương 4. Thiết kế, mô hình hòa vĖ kiểm chứng bộ giao tiếp mạng 71
hỗ trợ các giao thức ghép nối khác. Ngoài ra, để tối đa thông lượng
truyền thông và giảm độ trễ của bộ phối ghép mạng, chúng tôi đề xuất
một phương pháp mux-selection. Đây là một phương pháp kết hợp
giữa việc sử dụng kỹ thuật máy trạng thái hữu hạn (FSM: Finite State
Machine) và thực thi thêm các bộ hợp kênh MUX để điều khiển các
tín hiệu bắt tay ở cả hai phía của giao diện ghép nối. Điều này sẽ tạo
nên một mô hình lai (kết hợp phương pháp dựa trên FSM và phương
pháp mux-selection). Trong quá trình truyền dữ liệu, bộ phối ghép
mạng trở nên trong suốt đối với hệ thống và nhờ đó giảm thiểu độ trễ.
Bộ phối ghép mạng đề xuất được thiết kế và thực thi với công nghệ
CMOS 45nm và được kiểm chứng với một nền tảng NoC kích thước
cùng với vi xử lý ARM [45].
Trong chương này, trước hết chúng ta sẽ đề cập đến các kiến trúc
NoC được sử dụng trong quá trình nghiên cứu. Tiếp theo đó, chương
này sẽ trình bày kiến trúc của bộ phối ghép mạng cũng như giải pháp
mux-selection đề xuất. Sau đó là các kết quả thiết kế, thực thi và kiểm
chứng. Một số so sánh và trao đổi cũng sẽ được đề cập trong chương
nhằm làm rõ hơn các đóng góp của công trình nghiên cứu của chúng
tôi về các bộ giao tiếp mạng.
4.2. Kiến trúc NoC sử dụng
4.2.1. Tô-pô mạng
Như đề cập ở Chương 2, Mục 2.1, có nhiều loại tô-pô có thể được
sử dụng trong các kiến trúc mạng trên chip như là fat-tree, butterfly,
ring, mesh, torus hoặc folded torus. Trong số các cấu trúc liên kết này
thì 2-D mesh và 2-D torus/folded torus được sử dụng nhiều nhất nhờ
vào các ưu điểm của chúng khi thực thi phần cứng [46]. Trong nghiên
cứu về bộ giao tiếp mạng này, chúng tôi sử dụng cấu trúc liên kết
dạng lưới hai chiều (2-D mesh). Tuy nhiên, các cấu trúc liên kết mạng
khác như 2-D torus/folded torus hoàn toàn có thể được sử dụng.
Hình 4-1 mô tả một kiến trúc mạng trên chip dạng lưới hai chiều kích
thước 3×3 được sử dụng trong nghiên cứu này.

72 Mạng trên chip
Hình 4-1: Kiến trúc mạng trên chip dạng lưới hai chiều kích thước 3×3.
Kiến trúc mạng bao gồm các bộ định tuyến, các liên kết mạng và
giao diện kết nối giữa mạng và các lõi xử lý (gọi là bộ phối ghép
mạng). Mỗi bộ định tuyến có 5 cổng hai hướng, kết nối với 4 bộ định
tuyến bên cạnh và một lõi IP gần nhất.
5.2.2. Thuật toán định tuyến và định dạng dữ liệu
Kỹ thuật truyền thông sử dụng trong kiến trúc mạng trên chip
được nêu ở đây là chuyển mạch gói với thuật toán định tuyến xác định
tại nguồn DOR (dimesion ordered routing). Cụ thể, các thuật toán XY,
West-First, North-Lase và Negative-First được sử dụng trong mạng
trên chip này với mục đính tránh hiện tượng khóa chết (deadlock). Dữ
liệu (message) được chia và đóng gói thành các gói tin tại nguồn phát
và được đưa vào mạng, xem Hình 4-2.
Hình 4-2: Phân chia dữ liệu thành gói tin tại nguồn phát.
Mỗi gói tin bao gồm một flit tiêu đề (header flit), theo sau bởi
một số flit dữ liệu (body flit) và một flit đuôi (tail flit). Kích thước của
Dữ liệu
Gói tin (kích thước thay đổi)
Flit (kích thước cố định: 34 bits)

Chương 4. Thiết kế, mô hình hòa vĖ kiểm chứng bộ giao tiếp mạng 73
mỗi flit là 34 bit; trong đó, 32 bit được sử dụng cho dữ liệu và hai bit
có trọng số cao nhất được sử dụng với mục đích điều khiển (“BoP” và
“EoP”). BoP và EoP chứa thông tin quyết định flit hiện tại là flit tiêu
đề (BoP = „1‟, EoP = „0‟), flit thân (BoP = „0‟, EoP = „0), hay flit đuôi
(BoP = „0‟, EoP = „1‟). Ngoài ra, cấu trúc này cho phép hình thành gói
tin chỉ một flit (với BoP = EoP = „1‟). Định dạng của các flit này được
trình bày ở Hình 4-3.
Theo định dạng này, flit tiêu đề có BoP = „1‟ và flit đuôi có
EoP = „1‟. Nếu cả BoP và EoP đều có giá trị „1‟ thì gói tin chỉ có duy
nhất một flit. Nếu cả hai giá trị BoP và EoP đều bằng „0‟ thì đây là
một flit body. Nhờ vào các bit điều khiển này, bộ định tuyến mạng có
thể dễ dàng nhận ra loại flit và đưa ra quyết định định tuyến. Để định
tuyến một gói tin trên mạng, thông tin định tuyến cần được đưa vào
flit tiêu đề (tại trường thông tin định tuyến “path-to-target”). Trường
thông tin này sẽ được dịch sang phải hai bit tại mỗi bộ định tuyến sau
khi hai bit có trọng số thấp nhất được sử dụng.
Hình 4-3: Định dạng flit của mạng trên chip.
4.2.3. Vi kiến trúc của bộ định tuyến mạng
Kiến trúc bộ định tuyến bao gồm 5 cổng vào, 5 cổng ra và hai
crossbar (sử dụng cho hai kênh ảo) như mô tả ở Hình 4-4. Với kiến
trúc này, mỗi cặp cổng vào/ra đều có khối lô-gic điều khiển và
datapath riêng. Datapath được chia thành hai kênh truyền thông để
thực thi hai kênh ảo: VC0 và VC1. Trong đó, VC0 có mức độ ưu tiên
cao hơn và thường được sử dụng để truyền tải các thông tin điều khiển
BoP EoP
BoP EoP
BoP EoP
Flit tiêu đề (BoP = „1‟, EoP = „0‟)
Flit thân (BoP = „0‟, EoP= „0‟)
Flit đuôi (BoP = „0‟, EoP= „1‟)
33 32 0
33 32 0
33 32 0
path-to-targetpayload
payload
payload
31
31
31

74 Mạng trên chip
quan trọng trong mạng hoặc dùng cho các dịch vụ có yêu cầu yếu tố
thời gian thực. Bên cạnh datapath, khối điều khiển lô-gic bao gồm một
bộ cấp phát kênh ảo (VC allocator), một khối lô-gic định tuyến và một
đơn vị quản lý credit. Bộ cấp phát kênh ảo sẽ phân bổ flit đến vào
kênh ảo tương ứng của nó; trong khi đó đơn vị lô-gic định tuyến phân
tích thông tin định tuyến và sinh ra các tín hiệu điều khiển cần thiết tới
crossbar để thực thi các đường định tuyến. Tín hiệu dịch chuyển flit
tiêu đề HFS cũng được gửi tới datapath để dịch trường định tuyến
path-to-target sang phải hai bit sao cho thông tin định tuyến mới sẽ
luôn sẵn sàng cho bộ định tuyến tiếp theo. Để đồng bộ với các mô-đun
lối ra, đơn vị lô-gic định tuyến cũng sinh ra các tín hiệu bắt tay gửi tới
các mô-đun lối ra. Khối quản lý credit (Credit MU) quản lý điều khiển
luồng flit. Nó sẽ thực thi giao thức bắt tay giữa các bộ định tuyến ở
mức flit. Chi tiết hơn về kiến trúc NoC và cách thực thi kiến trúc NoC
này có thể xem tại công trình [47].
Hình 4-4: Kiến trúc chi tiết của một bộ định tuyến mạng.
4.3. Thiết kế bộ phối ghép mạng AXI-NoC
Để ghép nối các vi xử lý ARM vào các kiến trúc mạng trên chip,
chúng tôi đã thiết kế hai loại bộ phối ghép mạng để đồng bộ giữa các

Chương 4. Thiết kế, mô hình hòa vĖ kiểm chứng bộ giao tiếp mạng 75
giao diện AXI và kiến trúc mạng trên chip, gọi là Bộ phối ghép mạng
chủ (MNA: Master Network Adapter) và Bộ phối ghép mạng tớ
(SNA: Slave Network Adapter) [45], như mô tả trong Hình 4-5. MNA
được sử dụng để tạo nên kết nối giữa một lõi IP chủ có giao diện
tương thích AXI và bộ định tuyến mạng trong khi lõi IP tớ kết nối với
bộ định tuyến mạng thông qua SNA. Mỗi bộ phối ghép mạng bao gồm
hai mô-đun: đơn vị luồng dữ liệu yêu cầu (Request Flow) và đơn vị
luồng dữ liệu phản hồi (Response Flow).
Hình 4-5: Bộ phối ghép mạng chủ và bộ phối ghép mạng tớ.
Với giao thức AXI, thao tác quan trọng nhất là giao dịch burst
(burst transaction). Ưu điểm của giao dịch burst là cho phép sử dụng
băng thông hiệu quả. Chúng tôi thiết kế một bộ phối ghép mạng hỗ trợ
ba loại giao dịch burst: burst cố định (fixed), burst tăng dần
(incremental) và wrapped burst. Với giao dịch burst cố định, địa chỉ của
các lần truyền tải dữ liệu là giống nhau. Loại giao dịch burst này rất hữu
ích đối với trường hợp truy cập các bộ nhớ được xây dựng trên cơ sở
các FIFO. Khác với giao dịch burst cố định, địa chỉ truy cập dữ liệu ở
giao dịch burst tăng dần sẽ tăng sau mỗi giao dịch, dựa vào địa chỉ giao
dịch trước đó. Giao dịch burst tăng dần phù hợp với việc ghi/đọc vào/từ
mảng lớn các bộ nhớ. Thao tác truy xuất bộ nhớ ở giao dịch wrapped
burst cũng tương tự cách thức ở giao dịch burst tăng dần. Chỉ khác là
khi địa chỉ truy xuất bộ nhớ tiệm cận một giá trị giới hạn thì địa chỉ đó
sẽ được đặt lại ở địa chỉ thấp hơn. Bộ phối ghép mạng đề xuất cũng hỗ
trợ các giao dịch với độ dài burst thay đổi từ 1 đến 16 và kích thước
thay đổi từ 1 đến 4 bytes. Về phía NoC, bộ phối ghép mạng AXI-NoC

76 Mạng trên chip
của chúng tôi hỗ trợ các thuật toán định tuyến tại nguồn với cơ chế
truyền thông Wormhole. Theo đó, đường định tuyến từ nút nguồn tới
nút đích được định nghĩa và cố định ngay từ đầu.
4.3.1. Định dạng gói tin
Có hai loại gói tin: gói tin yêu cầu (request packet) và gói tin
phản hồi (response packet). Gói tin yêu cầu được gửi từ nguồn tới đích
đến. Đích đến sẽ trả lời gói tin yêu cầu bằng cách phát ra một gói tin
phản hồi. Các phần sau đây sẽ mô tả định dạng của các gói tin được sử
dụng trong thiết kế của chúng tôi.
a) Định dạng của gói tin yêu cầu
Thông thường, các gói tin yêu cầu là các gói tin được gửi từ một
lõi IP chủ tới một lõi IP tớ. Chúng thường bao gồm các gói tin yêu cầu
ghi (writing request packet) và các gói tin yêu cầu đọc (reading
request packet). Định dạng các gói tin ghi và đọc được mô tả trong
trình Hình 4-6.
Hình 4-6: Định dạng gói tin yêu cầu: gói tin yêu cầu ghi (a);
và gói tin yêu cầu đọc (b).

Chương 4. Thiết kế, mô hình hòa vĖ kiểm chứng bộ giao tiếp mạng 77
Flit tiêu đề của gói tin yêu cầu bao gồm độ dài burst (LEN), kích
thước burst (Size), loại burst (BURST), thông tin node nguồn và
trường định tuyến (path-to-target). Thông tin node nguồn trong flit
tiêu đề chứa địa chỉ của bộ định tuyến hiện tại mà lõi IP chủ được nối
vào. Thông tin này được lõi IP tớ sử dụng để tính toán đường trở về
(return path) cho gói tin phản hồi. Khi lõi IP chủ đưa ra một yêu cầu đọc
hoặc ghi tới lõi IP tớ, bộ phối ghép mạng sẽ tính toán “path-to-target”
dựa vào địa chỉ đích đến và sau đó nạp thông tin này vào flit tiêu đề
của gói tin yêu cầu. Gói tin dữ liệu đầu tiên được sử dụng để chuyển
tải địa chỉ đích đến của gói tin yêu cầu. Hệ thống sử dụng địa chỉ 32
bit. Địa chỉ này sau đó được chia thành địa chỉ global và địa chỉ cục
bộ. Bốn bit có trọng số lớn nhất trong địa chỉ được sử dụng cho địa chỉ
global (dùng để xác định bộ định tuyến mà IP được kết nối). Các bit
còn lại là địa chỉ cục bộ của lõi IP đó.
Đối với gói tin yêu cầu đọc, dữ liệu không cần thiết; do đó, nó chỉ
cần hai flit. Khi đó, flit đuôi chứa địa chỉ đích đến của gói tin.
b) Định dạng của gói tin phản hồi
Định dạng của gói tin phản hồi đọc và gói tin phản hồi ghi được
mô tả trong Hình 4-7.
Hình 4-7: Định dạng gói tin phản hồi:
gói tin phản hồi đọc (a); gói tin phản hồi ghi.

78 Mạng trên chip
Khi một lõi IP tớ nhận một yêu cầu đọc, bộ phối ghép mạng sử
dụng trường thông tin nút nguồn trong gói tin yêu cầu đọc để xác định
trường định tuyến “path-to-target” và đưa trường thông tin này vào flit
tiêu đề của gói tin phản hồi đọc. Trong khi đó, gói tin phản hồi ghi chỉ
có một flit duy nhất (BoP = „1‟ và EoP = „1‟), không yêu cầu dữ liệu.
4.3.2. Bộ phối ghép mạng Master
Một mặt bộ phối ghép mạng chủ (MNA: Master Network
Adapter) đóng gói các yêu cầu từ lõi IP chủ thành các gói tin mạng để
có thể gửi vào mạng. Mặt khác, MNA cũng có chức năng giải mã các
phản hồi từ bộ định tuyến và truyền tải chúng tới lõi IP chủ. MNA chủ
yếu bao gồm hai luồng dữ liệu sau: luồng yêu cầu MNA và luồng
phản hồi MNA, tương ứng với quá trình đóng gói dữ liệu và quá trình
giải mã dữ liệu (xem Hình 4-8).
Hình 4-8: Kiến trúc MNA [45].
a) Luồng yêu cầu MNA
Luồng yêu cầu (Request Flow) MNA bao gồm hai mô-đun chính:
MNA Flit Builder và MNA Transmitter, như mô tả trong Hình 4-9.
Các tín hiệu bên trái là giao diện kết nối với lõi IP chủ còn các tín hiệu
bên phải là giao diện kết nối với bộ định tuyến mạng.

Chương 4. Thiết kế, mô hình hòa vĖ kiểm chứng bộ giao tiếp mạng 79
Hình 4-9: Kiến trúc luồng yêu cầu MNA [45].
Mô-đun MNA Flit Builder có nhiệm vụ hình thành các flit cho
các gói dữ liệu yêu cầu từ các giao dịch burst (burst transaction) của
AIX chủ. Các giá trị BoP và EoP được thêm vào các flit này một cách
tự động. Mô-đun này thực thi một bảng tra (look-up table) để tính toán
thông tin cho trường định tuyến “path-to-target”. Các lối vào của bảng
tra là bốn bit có trọng số cao nhất của bus địa chỉ. Các lối ra của mô-đun
Flit Builder là header 34 bit (flit tiêu đề của gói tin yêu cầu),
„sub_header‟ và „wdata_i‟. Với một giao dịch burst ghi, „sub_header‟
là flit dữ liệu đầu tiên và „wdata_i‟ chứa các flit còn lại của gói tin yêu
cầu ghi. Với một giao dịch burst đọc, „sub_header‟ là flit đuôi.
Mô-đun MNA Transmitter (Hình 4-10(a)) quản lý chuỗi các flit
được tạo ra bởi mô-đun MNA Flit Builder để gửi vào mạng (flit tiêu
đề flit dữ liệu flit đuôi) và để điều khiển các tín hiệu bắt tay với
kênh địa chỉ AXI chủ và kênh dữ liệu ghi. Hoạt động của MNA
Transmitter dựa vào máy trạng thái (FSM: Finite State Machine) được
mô tả trong Hình 4-10(b). Tùy thuộc vào trạng thái hiện tại, lối ra dữ
liệu của mạng „pdata_to_noc‟ (gói tin được gửi tới NoC) sẽ là
„header‟, „sub_header‟, hoặc „wdata_i‟ có nguồn gốc từ mô-đun
MNA Flit Builder. Mô-đun MNA Transmitter sẽ lựa chọn các flit phù
hợp để gửi tới mạng. Do đó, số lượng các trạng thái được giảm và
máy trạng thái FSM sẽ đơn giản hơn nhiều.

80 Mạng trên chip
Hình 4-10: Mô-đun MNA Transmitter:
Vi kiến trúc tối ưu (a); Máy trạng thái hữu hạn FSM (b) [45].
Để tăng hiệu năng của bộ phối ghép mạng (thông lượng và độ trễ),
chúng tôi đề xuất một phương pháp mux-selection nhằm tối ưu thiết kế.
Phương pháp mux-selection là một phương pháp kết hợp giữa kỹ thuật

Chương 4. Thiết kế, mô hình hòa vĖ kiểm chứng bộ giao tiếp mạng 81
máy trạng thái hữu hạn FSM và việc thực thi các bộ hợp kênh bổ trợ để
điều khiển các tín hiệu bắt tay ở cả hai phía của các giao diện mạng. Chi
tiết về phương pháp mux-selection được trình bày tại Mục 4.4. Trong
Hình 4-10, hai bộ hợp kênh được thêm nhằm điều khiển các tín hiệu lối
ra của bộ phối ghép mạng; đó là, tín hiệu yêu cầu („pvalid_to_noc‟) để
gửi dữ liệu tới giao tiếp nơi nhận/nơi đến và tín hiệu trả lời („wready‟)
để chấp nhận dữ liệu từ giao tiếp nguồn (AXI). Nhờ vào cách bố trí này,
các tín hiệu „wready‟ và „pvalid_to_noc‟ được điều khiển bởi máy trạng
thái hữu hạn FSM hoặc chúng sẽ đưa ra giá trị tín hiệu „wvalid‟ một
cách trực tiếp dựa vào giá trị của tín hiệu „hs_sel‟ (lựa chọn bắt tay).
Hình 4-10(b) trình bày sơ đồ trạng thái của máy trạng thái hữu hạn của
mô-đun MNA Transmitter. Hoạt động của máy trạng thái hữu hạn này
được mô tả trong Bảng 4-1.
Bảng 4-1: Mô tả trạng thái của máy trạng thái hữu hạn của MNA Transmitter
Trạng thái Mô tả
IDLE Trạng thái Idle. Nếu có một yêu cầu trên kênh địa chỉ chủ
AXI, tín hiệu „avalid‟ trở nên tích cực. Máy trạng thái hữu
hạn FSM sẽ chuyển sang trạng thái tiếp theo – Send
Header. Nếu không, nó sẽ chờ một yêu cầu AXI.
Send
Header
Gửi một flit tiêu đề. Nếu yêu cầu từ giao diện AXI là một
yêu cầu đọc và mạng chấp nhận flit tiêu đề thì máy trạng
thái sẽ chuyển sang trạng thái Send Sub Header 2. Nếu
yêu cầu từ giao diện AXI là một yêu cầu ghi và mạng
chấp nhận flit tiêu đề thì máy trạng thái sẽ chuyển sang
trạng thái Send Sub Header 1. Nếu mạng không ghi nhận
flit tiêu đề, máy trạng thái sẽ chờ một phản hồi từ mạng.
Send Sub
Header 1
Gửi flit dữ liệu đầu tiên. Nếu flit dữ liệu đầu tiên được
gửi, máy trạng thái sẽ chuyển sang trạng thái Send
DATA. Nếu flit dữ liệu đầu tiên chưa được gửi, máy trạng
thái chờ phản hồi từ mạng.
Send Sub
Header 2
Gửi flit đuôi tới mạng. Nếu flit đuôi của gói tin yêu cầu
đọc được gửi, máy trạng thái chuyển sang trạng thái
IDLE và chờ một “yêu cầu AXI” mới. Nếu flit đuôi của
gói tin yêu cầu đọc chưa được gửi, máy trạng thái chờ một
phản hồi từ mạng.

82 Mạng trên chip
Send DATA Gửi các flit dữ liệu. Nếu flit đuôi của một gói tin yêu cầu
ghi được gửi, máy trạng thái chuyển sang trạng thái IDLE
và chờ một “yêu cầu AXI” mới từ giao diện chủ AXI. Nếu
một dữ liệu ghi mới hợp lệ tại giao diện AXI trong khi
mạng không sẵn sàng nhận flit mới, máy trạng thái chuyển
sang trạng thái Wait for NI ready. Nếu dữ liệu ghi hợp lệ
tại giao diện AXI và đó là dữ liệu ghi cuối cùng nhưng
mạng không sẵn sàng chấp nhận flit mới, máy trạng thái
chuyển sang trạng thái Wait for tail flit finished. Nếu flit
được gửi, gửi flit tiếp theo tới NoC.
Wait for NI
ready
Chờ phản hồi từ mạng. Nếu mạng đã thừa nhận và sẵn
sàng chuyển dữ liệu ghi mới vào mạng, máy trạng thái
chuyển sang trạng thái Send DATA. Nếu không, máy
trạng thái chờ một đáp ứng từ mạng.
Wait for tail
flit finished
Chờ phản hồi từ mạng. Nếu flit đuôi được gửi, máy trạng
thái chuyển sang trạng thái IDLE và chờ một yêu cầu
AXI mới. Nếu flit đuôi chưa được gửi, máy trạng thái hữu
hạn sẽ chờ đáp ứng từ mạng.
Do các tín hiệu bắt tay được điều khiển bởi máy trạng thái hữu
hạn FSM, phương pháp này có ưu điểm của phương pháp bắt tay dựa
vào FSM truyền thống. Việc chuyển đổi trạng thái được quản lý bởi
FSM nhằm đảm bảo hoạt động đúng. Phương pháp mux-selection
cung cấp cách điều khiển trực tiếp các tín hiệu lối ra của bộ phối
ghép mạng. Cấu trúc này cho phép dữ liệu tại giao diện AXI xuất
hiện tại giao diện NoC ngay lập tức, dẫn đến độ trễ bằng không khi
truyền dữ liệu.
Khi mô-đun MNA Transmitter sẵn sàng chấp nhận dữ liệu từ giao
diện AXI và NoC sẵn sàng nhận một gói tin mới, dữ liệu được gửi tới
mạng truyền thông tại cùng chu kỳ xung đồng hồ mà dữ liệu trên giao
diện AXI sẵn sàng. Nếu mạng NoC chưa sẵn sàng, dữ liệu tại giao
diện AXI được lưu tại bộ đệm cho đến khi có phản hồi từ mạng (có
nghĩa là tín hiệu „resp_syn‟ có giá trị bằng „1‟).

Chương 4. Thiết kế, mô hình hòa vĖ kiểm chứng bộ giao tiếp mạng 83
b) Luồng phản hồi MNA
Kiến trúc của mô-đun luồng phản hồi MNA (MNA Response
Flow) đơn giản hơn nhiều so với kiến trúc của mô-đun MNA Request
Flow. Dữ liệu được chuyển từ mạng tới lõi IP chủ AXI thông qua
mô-đun MNA Response. Do đó, các gói tin từ mạng phải được giải mã
(decapsulated) tại giao diện AXI.
Mô-đun MNA Response Flow quản lý dữ liệu được chuyển tới
kênh thích hợp. Khi một gói tin hợp lệ tại bộ định tuyến
(„pvalid_fr_noc‟ nhận giá trị lô-gic cao), mô-đun MNA Response
Flow đọc flit tiêu đề để xác định liệu gói tin là gói tin phản hồi đọc
(reading response packet) hay là gói tin phản hồi ghi (writing response
packet). Trong trường hợp là gói tin phản hồi ghi (gói tin chỉ có một
flit), mô-đun MNA Response Flow trích xuất thông tin của gói tin tiêu
đề và gửi nó tới kênh phản hồi ghi AXI của lõi IP chủ. Nếu nó là một
gói tin phản hồi đọc (flit tiêu đề flit dữ liệu (1) … flit dữ liệu
(n-1) flit đuôi (flit dữ liệu thứ n), thì dữ liệu sẽ được chuyển tới
kênh dữ liệu đọc AXI. Tín hiệu „rlast‟ có giá trị lô-gic cao khi nhận
được flit đuôi của gói tin phản hồi đọc.
Tín hiệu „rlast‟ có giá trị lô-gic cao khi nhận được flit đuôi của
gói tin phản hồi đọc. Điều này có nghĩa là vận chuyển dữ liệu cuối
cùng. Tương tự như MNA Request Flow, phương pháp mux-selection
đề xuất cũng được áp dụng cho MNA Response Flow nhằm cải thiện
hiệu năng. Sơ đồ khối tối ưu của MNA Response Flow và máy trạng
thái hữu hạn của nó được trình bày trong Hình 4-11. Bảng 4-2 giải
thích hoạt động của máy trạng thái hữu hạn của MNA Response Flow.

84 Mạng trên chip
Hình 4-11: Mô-đun MNA Response Flow:
Vi kiến trúc tối ưu (a); Máy trạng thái hữu hạn (b) [45].

Chương 4. Thiết kế, mô hình hòa vĖ kiểm chứng bộ giao tiếp mạng 85
Bảng 4-2: Mô tả trạng thái của máy trạng thái hữu hạn của MNA Response Flow
Trạng thái Mô tả
IDLE Trạng thái Idle, chờ một gói tin từ NoC. Nếu phát
hiện có một gói tin phản hồi ghi xuất hiện, máy
trạng thái hữu hạn sẽ chuyển sang trạng thái Write
Response. Nếu phát hiện có một gói tin phản hồi
đọc, máy trạng thái hữu hạn sẽ chuyển sang trạng
thái Read Response.
Write Response Giải mã gói tin thành thời gian trên kênh phản hồi
ghi AXI. Nếu kênh phản hồi ghi AXI chấp nhận dữ
liệu, máy trạng thái hữu hạn sẽ chuyển sang trạng
thái IDLE và chờ một gói tin mới. Nếu thông tin
phản hồi ghi chưa được gửi, máy trạng thái tiếp tục
chờ một phản hồi từ lõi IP chủ.
Read Response Sẵn sàng để gửi dữ liệu tới kênh dữ liệu đọc AXI.
Nếu dữ liệu cuối cùng được gửi, máy trạng thái hữu
hạn sẽ chuyển sang trạng thái IDLE và chờ một gói
tin mới. Nếu dữ liệu được gửi, máy trạng thái sẽ
giải mã flit đến tiếp theo và gửi nó tới lõi IP chủ.
Nếu flit trên mạng là flit cuối cùng trong khi lõi IP
chủ không sẵn sàng chấp nhận dữ liệu mới thì máy
trạng thái hữu hạn sẽ chuyển sang trạng thái Wait
for tail flit finished. Nếu flit hợp lệ ở NoC trong
khi lõi IP chủ không sẵn sàng chấp nhận dữ liệu
mới thì máy trạng thái sẽ chuyển sang trạng thái
Wait for NI ready.
Wait for NI ready Chờ một phản hồi từ NI. Nếu dữ liệu được gửi tới
giao diện chủ, máy trạng thái sẽ giải mã flit đến tiếp
theo và gửi nó tới lõi IP chủ.
Wait for tail flit
finished
Chờ một phản hồi từ lõi IP chủ. Nếu dữ liệu đọc cuối
cùng được gửi, máy trạng thái hữu hạn sẽ chuyển sang
trạng thái IDLE và chờ một gói tin mới.

86 Mạng trên chip
4.4. Phương pháp mux-selection
Để thực hiện cơ chế bắt tay giữa các giao diện khác nhau, giao
diện AXI và giao diện NoC, một trong những phương pháp truyền
thống là sử dụng máy trạng thái hữu hạn FSM. Trong phần này, trước
hết chúng ta sẽ đề cập đến ưu điểm và nhược điểm của phương pháp
bắt tay dựa vào máy trạng thái hữu hạn. Tiếp đó, phương pháp bắt tay
mới gọi là mux-selection sẽ được giới thiệu.
4.4.1. Ưu và nhược điểm của phương pháp bắt tay truyền thống
dựa vào FSM
Phương pháp bắt tay dựa trên FSM đảm bảo việc đồng bộ thời gian
giữa các giao diện hoạt động đúng. Việc thực thi phương pháp này khá
dễ dàng và do đó phương pháp này được sử dụng rộng rãi. Trong thiết
kế của chúng tôi, việc định thời của cơ chế bắt tay được minh họa trong
Hình 4-12. Theo giản đồ thời gian này, chúng ta có thể thấy bộ phối
ghép mạng đòi hỏi hai chu kỳ đồng hồ cho mỗi giao dịch dữ liệu.
Hình 4-12: Giản đồ thời gian tại MNA Transmitter khi sử dụng phương pháp
bắt tay truyền thống dựa vào FSM [45].
Thực tế, tại thời điểm T0, giao diện nguồn (AXI) xác nhận tín
hiệu „wvalid‟ chỉ ra rằng dữ liệu hợp lệ. Tại thời điểm T1 (sườn lên
của tín hiệu xung đồng hồ), hệ thống nhận ra tính hợp lệ của dữ liệu
tại giao diện nguồn và phản hồi yêu cầu bằng cách xác nhận tín hiệu

Chương 4. Thiết kế, mô hình hòa vĖ kiểm chứng bộ giao tiếp mạng 87
„wready‟ để chấp nhận dữ liệu. Trong khi đó, hệ thống cũng nâng tín
hiệu „pvalid_to_noc‟ lên cao để yêu cầu gửi dữ liệu đến đích (mạng
NoC). Trong trường hợp tốt nhất khi đích đến (NoC) sẵn sàng chấp
nhận một giao dịch dữ liệu mới, giao dịch này sẽ được hoàn thành ở
sườn lên của xung đồng hồ T2. Phương pháp này tương đối hiệu quả
trong việc thực hiện giao diện giữa kiến trúc AXI và NoC. Tuy nhiên,
cần có hai chu kỳ xung nhịp đồng hồ cho mỗi dữ liệu được truyền từ
giao diện AXI sang NoC. Rõ ràng là nếu giao diện nguồn có thể
truyền dữ liệu theo từng nhịp tín hiệu xung nhịp đồng hồ thì bộ phối
ghép mạng dựa trên phương pháp bắt tay FSM sẽ trở thành nút thắt cổ
chai vì rằng mạng cũng chỉ cần một chu kỳ xung nhịp để truyền một
đơn vị dữ liệu. Vấn đề của phương pháp bắt tay dựa trên FSM truyền
thống có thể được giải quyết bằng cách áp dụng phương pháp mới, gọi
tên là phương pháp mux-selection. Trong mục tiếp theo, chúng ta sẽ
tìm hiểu về phương pháp mux-selection đề xuất, được áp dụng cho bộ
phối ghép mạng AXI-NoC.
4.4.2. Phương pháp mux-selection và thực thi trong MNA
Phương pháp mux-selection là một phương pháp kết hợp giữa kỹ
thuật FSM và thực thi thêm các bộ hợp kênh MUX để điều khiển các
tín hiệu bắt tay ở cả hai phía giao diện ghép nối. Như mô tả trong
Hình 4-10, hai bộ hợp kênh MUX được thêm vào để điều khiển các tín
hiệu lối ra của bộ phối ghép mạng; đó là tín hiệu yêu cầu
(„pvalid_to_noc‟) để gửi dữ liệu tới giao diện đích đến và tín hiệu
phản hồi („wready‟) để chấp nhận dữ liệu từ giao diện nguồn (AXI).
Nhờ sự sắp xếp này, các tín hiệu „wready‟ và „pvalid_to_noc‟ được
điều khiển bởi FSM hoặc chúng xuất ra giá trị „wvalid‟ dựa vào giá trị
của tín hiệu „hs_sel‟ (lựa chọn bắt tay).
Với phương pháp mux-selection đề xuất, quá trình chuyển đổi
trạng thái được FSM quản lý dễ dàng nhằm đảm bảo hoạt động đúng
trong khi nó cũng cung cấp cách điều khiển trực tiếp các tín hiệu lối ra
của bộ phối ghép mạng nhằm cho phép dữ liệu tại giao diện AXI xuất
hiện tại giao diện NoC ngay lập tức, dẫn đến độ trễ truyền dữ liệu
bằng 0 (không có trễ). Giản đồ thời gian của cơ chế bắt tay này được

88 Mạng trên chip
minh họa trong Hình 4-13. Việc truyền dữ liệu xảy ra ở sườn lên của
tín hiệu xung đồng hồ dẫn đến độ trễ truyền dữ liệu bằng không và tối
đa hóa thông lượng truyền thông.
Hình 4-13: Giản đồ thời gian tại MNA Transmitter khi sử dụng
phương pháp mux-selection đề xuất [45].
Liên quan đến MNA Response Flow, việc triển khai phương pháp
mux-selection để chọn giá trị được xuất ra trên „rvalid‟ và
„pready_to_noc‟ (Hình 4-11) làm cho độ trễ của MNA Response Flow
bằng không. Tín hiệu „hs_sel‟ (lựa chọn bắt tay) là tín hiệu điều khiển
cho các bộ hợp kênh MUX. Cơ chế bắt tay này được giải thích trong
Hình 4-14.
Hình 4-14: Giản đồ thời gian tại MNA Response Flow khi sử dụng phương
pháp mux-selection đề xuất [45].

Chương 4. Thiết kế, mô hình hòa vĖ kiểm chứng bộ giao tiếp mạng 89
4.5. Thực thi và kiểm chứng phần cứng
Để kiểm chứng kiến trúc bộ phối ghép mạng AXI-NoC đề xuất,
chúng tôi đã phát triển một môi trường kiểm tra với NoC có cấu trúc
hai chiều dạng lưới như mô tả trong Hình 4-15. Môi trường kiểm tra
này bao gồm 9 bộ định tuyến mạng, 8 lõi IP, một mô hình vi xử lý
ARM được kết nối với một bộ định tuyến mạng sử dụng bộ phối ghép
mạng chủ (Master Network Adapter). Môi trường kiểm tra NoC sử
dụng kỹ thuật truyền thông chuyển mạch gói với thuật toán định tuyến
tại nguồn Wormhole.
Hình 4-15: Môi trường kiểm chứng với 9 bộ định tuyến mạng.
Các mô hình IP giả (IP0 đến IP7) là các IP đơn giản có thể tạo ra
các gói tin gửi vào NoC và phản hồi các gói tin đến từ NoC. Các IP
giả lập này hoạt động như là các mô hình bộ nhớ đơn giản. Khi nhận
được một gói tin yêu cầu ghi, các mô-đun giả sẽ lưu trữ dữ liệu vào bộ
nhớ trong của nó. Khi nhận được yêu cầu đọc, nó trích xuất thông tin
của gói tin yêu cầu để tính toán đường dẫn trả về cho gói tin phản hồi;
sau đó, IP giả gửi dữ liệu được lưu trữ đến nút mạng nơi gói tin yêu
cầu được phát ra.
Mô hình vi xử lý ARM được cấu hình để tạo ra cả giao dịch burst
đọc và ghi với các thông số khác nhau về loại, độ dài và kích thước
của burst. Vấn đề định thời ở cả hai phía của bộ phối ghép mạng chủ
được quan sát. Dữ liệu phản hồi tới mô hình ARM được so sánh với
các kết quả mong muốn.

90 Mạng trên chip
Mỗi trường hợp kiểm tra diễn ra trong một số bước. Trước hết,
dữ liệu ngẫu nhiên được tạo ra. Thứ hai, mô hình vi xử lý ARM đưa ra
yêu cầu burst ghi tới một IP giả lập với dữ liệu được tạo ra từ bước 1.
Sau đó, một burst đọc được đưa ra cho cùng một vị trí trong bước 2.
Cuối cùng, dữ liệu đọc được so sánh với dữ liệu được ghi trước đó.
Nói tóm lại, chúng ta ghi tới và đọc về cùng một vị trí. Dữ liệu ghi và
dữ liệu đọc phải giống nhau. Hình 4-16 trình bày bố cục (layout) của
thiết kế MNA.
Hình 4-16: Hình ảnh layout cuối cùng của thiết kế [45].
Thiết kế bộ phối ghép AXI-NoC được mô hình hóa ở mức
chuyển dịch thanh ghi RTL sử dụng ngôn ngữ VHDL và sau đó được
thực thi với công nghệ CMOS 45nm. Thiết kế yêu cầu chi phí không
gian thực thi khá thấp so với các bộ định tuyến NoC (thấp hơn 10%
không gian thực thi của một bộ định tuyến mạng trong trường hợp của
chúng tôi). Hình 4-17 trình bày mối liên hệ giữa công suất tiêu thụ
(mW), không gian thực thi ( ) với tần số hoạt động của thiết kế.
Thiết kế này có thể hoạt động ở tần số cao nhất là . Tại tần
số này, thiết kế cần tới 952 cổng lô-gic và không gian thực thi tổng
cộng là . Thông lượng truyền thông của thiết kế có thể đạt
và bộ phối ghép mạng tiêu thụ khoảng .

Chương 4. Thiết kế, mô hình hòa vĖ kiểm chứng bộ giao tiếp mạng 91
Hình 4-17: Công suất tiêu thụ và chi phí thực thi phần cứng ước lượng
tại các tần số hoạt động khác nhau [45].
Bảng 4-3 trình bày một so sánh ngắn gọn giữa kết quả nghiên cứu
của chúng tôi với một số công trình nghiên cứu liên quan [38, 48, 39,
40, 49, 50]. Theo đó, thiết kế của chúng tôi có hiệu năng cao nhất về
mặt tần số hoạt động, độ trễ xử lý và thông lượng truyền thông nhờ
vào các cơ chế hoạt động lai (hybrid-operation schemes) bằng cách sử
dụng phương pháp mux-selection đề xuất. Thiết kế của chúng tôi có
thể hoạt động với tần số trong khi các thiết kế khác hoạt
động ở dải tần số từ đến . Không gian thực thi đối
với thiết kế của chúng tôi bé hơn từ 7 đến 8 lần khi so sánh với các
công trình nghiên cứu khác như [44, 50]. Công suất tiêu thụ cũng thấp
hơn các thiết kế khác, chỉ ở tần số hoạt động . Các
kết quả đáng chú ý trong nghiên cứu của chúng tôi là độ trễ xử lý và
thông lượng truyền thông. Chúng tôi loại bỏ được các bước xử lý
không cần thiết trong quá trình truyền dữ liệu. Với các kỹ thuật áp
dụng, thiết kế của chúng tôi không có độ trễ xử lý (hoặc chỉ cần một
xung nhịp đồng hồ cho việc đóng gói dữ liệu) và thông lượng truyền
thông lớn nhất khi so sánh với [38].

92
M
ạn
g t
rê
n c
hip
92 Mạng trên chip
B
ản
g 4
-3:
So
sán
h k
ết
qu
ả t
hự
c t
hi
vớ
i m
ột
số
cô
ng
trì
nh
liê
n q
uan
[45].
Des
ign
[3
8]
[48]
[39, 40]
[49]
[50]
[44]
Côn
g t
rìn
h
đề
xu
ất
Gia
o d
iện
bu
s
mụ
c ti
êu
OC
P/A
XI/
DT
L
OC
P
AX
I/A
HB
/OC
P/P
IF
N/A
O
CP
/AX
I/
Wis
hbone
DM
A
AX
I
Côn
g n
gh
ệ 0
,13
0
,13
N
/A
0,1
8
90
nm
6
5 n
m
45
nm
Tầ
n s
ố h
oạ
t đ
ộn
g
tối
đa (
MH
z)
500
400
N/A
457
-490
N/A
N
/A
650
Kh
ôn
g g
ian
th
ực
thi
(
)
143
.000
20
.000
-
64
.000
N/A
5
5.0
00
-
103
.000
24
.000
21
.371
2.7
93
Côn
g s
uất
tiêu
thụ
(m
W)
N/A
N
/A
N/A
1
9,5
-44,0
N
/A
N/A
4,1
4
Độ t
rễ (
vớ
i cả
đó
ng g
ói)
4-1
0 c
hu k
ỳ
3-8
chu k
ỳ
2-8
chu k
ỳ
N/A
N
/A
2 c
hu
kỳ
1 c
hu
kỳ
Th
ôn
g l
ượ
ng
1
6 G
bit
/s
N/A
5.3
Gbit
/s
N/A
N
/A
N/A
2
0,8
Gbit
/s

Chương 4. Thiết kế, mô hình hòa vĖ kiểm chứng bộ giao tiếp mạng 93
Giới hạn của công trình nghiên cứu của chúng tôi [45] đó là bộ
phối ghép mạng đề xuất chỉ hỗ trợ các giao diện AXI trong khi các
công trình khác [38, 39, 40, 50] hỗ trợ nhiều giao thức bus khác nhau.
Tuy nhiên, nếu hệ thống ứng dụng cần được tối ưu về mặt hiệu năng
thì bộ phối ghép mạng chuyên biệt của chúng tôi là lựa chọn tốt nhất.
Ngoài ra, phương pháp mux-selection cũng có một nhược điểm thông
thường. Đó là, phương pháp này làm tăng độ trễ đường dẫn quan trọng
(critical path) thêm hai lần độ trễ của MUX. Tuy nhiên, độ trễ đường
dẫn quan trọng này vẫn nhỏ hơn độ trễ đường dẫn quan trọng của các
kiến trúc bộ định tuyến. Do các bộ phối ghép mạng này được đặt giữa
và khá gần giao tiếp AXI và bộ định tuyến nên nó không ảnh hưởng
tới hiệu năng chung của hệ thống.
4.6. Kết luận chương
Trong chương này, chúng tôi đã trình bày thiết kế và thực thi một
bộ phối ghép mạng AXI-NoC hiệu quả, được sử dụng để ghép nối các
lõi ARM với các kiến trúc mạng trên chip. Bộ phối ghép mạng hoạt
động như là một cầu nối hai hướng giữa giao diện AXI và các kiến trúc
NoC. Nó hỗ trợ các thuật toán định tuyến tại nguồn với cơ chế truyền
thông chuyển mạch gói Wormhole trong các mạng trên chip 2D/3D với
các cấu trúc liên kết khác nhau. Một trong những ưu điểm của bộ phối
ghép mạng AXI-NoC đó là kiến trúc đơn giản, đòi hỏi không gian thực
thi nhỏ (khoảng 2.793 µm2), trong khi có thể đạt được thông lượng
truyền thông cao 20,8 Gbits/s và chỉ tiêu thụ 4,14 mW tại tần số hoạt
động 650 MHz. Một ưu điểm khác của thiết kế này đó là việc sử dụng
phương pháp mux-selection để quyết định liệu các lối ra của giao diện
được điều khiển bởi máy trạng thái hữu hạn hay trực tiếp bởi các tín
hiệu bắt tay từ giao diện kia. Phương pháp này giúp giảm độ trễ về 0 và
do đó cải thiện hiệu năng tổng thể của hệ thống. Bộ phối ghép mạng
AXI-NoC có thể được sử dụng để kết nối các IP khác tương thích với
các đặc tả của chuẩn AXI với các kiến trúc mạng NoC.

Chương 4. Thiết kế, mô hình hòa vĖ kiểm chứng bộ giao tiếp mạng 94
Chương 5
TỐI ƯU NĂNG LƯỢNG TIÊU THỤ CHO MẠNG TRÊN CHIP
Công suất tiêu thụ luôn là vấn đề được các nhà thiết kế mạch tích
hợp quan tâm hàng đầu, đặc biệt đối với các ứng dụng di động sử
dụng nguồn nuôi bằng pin. Mạng trên chip với các ưu điểm vượt trội
cho phép chúng ta tích hợp nhiều chức năng, nhiều lõi xử lý khác
nhau trên cùng một vi mạch nhằm đáp ứng yêu cầu ngày càng cao của
các ứng dụng mới. Tuy nhiên, điều này cũng đồng nghĩa với việc gia
tăng công suất và năng lượng tiêu thụ của hệ thống. Do đó, người thiết
kế mạng trên chip cần phải nghiên cứu, đề xuất các phương pháp mới
để giảm thiểu công suất tiêu thụ của hệ thống NoC nhằm đảm bảo
rằng các hệ thống này đáp ứng được các yêu cầu cao của ứng dụng
(vừa tăng hiệu năng hoạt động nhưng lại tiêu thụ ít năng lượng nhất).
Trong chương này, chúng ta sẽ lần lượt tìm hiểu các vấn đề về công
suất tiêu thụ trên mạch tích hợp, các giải pháp hiện tại giúp chúng ta
giảm thiểu công suất, năng lượng tiêu thụ của hệ thống trên chip. Cuối
cùng, chương này cũng đề cập đến một số giải pháp thiết kế mạng trên
chip theo hướng giảm thiểu công suất tiêu thụ gần đây với các ví dụ
điển hình.
5.1. Công suất tiêu thụ trên mạch tích hợp
Với công nghệ CMOS, công suất tiêu thụ của một vi mạch thông
thường bao gồm hai thành phần chính: công suất tiêu thụ động
(dynamic power) và công suất tiêu thụ tĩnh (static power) [51, 52].
Trong đó, công suất tiêu thụ động là công suất mà vi mạch đó tiêu thụ
khi các tín hiệu trong mạch có sự thay đổi về giá trị (thay đổi mức lô-gic)
- có nghĩa là khi mạch hoạt động. Công suất tiêu thụ tĩnh là công suất
mà một vi mạch tiêu thụ khi nó được cấp nguồn nhưng các tín hiệu

Chương 5. Tối ưu năng lượng tiêu thụ cho mạng trên chip 95
trong mạch không có sự thay đổi về giá trị - mạch không hoạt động.
Với các vi mạch được chế tạo dựa trên công nghệ CMOS, nguyên
nhân gây ra công suất tiêu thụ tĩnh trên vi mạch là do các dòng điện rò
trên các transistor.
5.1.1. Công suất tiêu thụ động
Công suất tiêu thụ động của một vi mạch có thể bắt nguồn từ
nhiều nguyên nhân khác nhau. Nguyên nhân đầu tiên và cũng là
nguyên nhân chính đó là do sự phóng nạp trên tụ điện ký sinh ở đầu ra
của một cổng lô-gic CMOS gây ra khi có sự thay đổi mức lô-gic của
tín hiệu trong mạch; do đó, tạo ra công suất tiêu thụ. Công suất này
được gọi là công suất chuyển mạch. Hình 5-1 mô tả quá trình phóng
nạp trên tụ điện ký sinh ở đầu ra của cổng NOT khi hoạt động.
Hình 5-1: Quá trình phóng nạp trên tụ điện ký sinh
trong trường hợp công suất chuyển mạch.
Công thức tính năng lượng tiêu thụ cho mỗi một lần chuyển trạng
thái (chuyển mạch) trên một cổng được tính bằng công thức sau:
(5-1)
Trong đó, là điện dung của tụ ký sinh và là điện áp nguồn
cung cấp. Do đó, công suất tiêu thụ động của một cổng lô-gic có thể
được biểu diễn theo công thức sau:
(5-2)
Ở công thức (5-2) này, là tần số chuyển trạng thái, là xác
suất chuyển trạng thái ở đầu ra, là tần số hoạt động của hệ
thống. Nếu điện dung hiệu dụng được định nghĩa theo công thức:

96 Mạng trên chip
(5-3)
thì ta có công thức tính công suất tiêu thụ động như sau:
(5-4)
Từ phương trình (5-4), chúng ta có thể thấy rằng công suất
chuyển mạch của một cổng lô-gic không phụ thuộc vào kích thước của
transistor mà chỉ phụ thuộc vào hoạt động chuyển mạch và độ lớn của
điện dung ký sinh ở lối ra của cổng lô-gic đó.
Bên cạnh công suất chuyển mạch thì có một nguyên nhân khác
ảnh hưởng đến công suất tiêu thụ động trên vi mạch đó là công suất
ngắn mạch, xuất hiện khi mạch chuyển trạng thái. Công suất ngắn
mạch là công suất tiêu thụ của cổng lô-gic khi xuất hiện dòng điện
ngắn mạch trên cổng đó tại thời điểm cả hai loại transistor PMOS và
NMOS đồng thời mở (Hình 5-2).
Hình 5-2: Dòng điện ngắn mạch trên cổng NOT
trong trường hợp công suất ngắn mạch.
Nếu bổ sung thêm công suất ngắn mạch vào trong phương trình
(5-4), chúng ta có công thức tổng quát để tính công suất tiêu thụ động
cho một cổng lô-gic như sau:
( ) (5-5)
Trong đó, là thời gian xuất hiện dòng ngắn mạch và là
dòng điện chuyển mạch (bao gồm dòng điện ngắn mạch và dòng điện
nạp cho tụ điện bên trong của cổng lô-gic đó). Tuy nhiên, trong một
chu kỳ chuyển trạng thái thì thời gian xuất hiện dòng điện ngắn mạch
thường rất nhỏ, đặc biệt với các công nghệ CMOS tiên tiến. Do đó, để

Chương 5. Tối ưu năng lượng tiêu thụ cho mạng trên chip 97
đơn giản quá trình tính toán, chúng ta thường sử dụng công thức (5-4)
để tính toán công suất tiêu thụ động cho một cổng lô-gic [51].
Từ công thức này, các nhà thiết kế đã đề xuất một số kỹ thuật
giảm công suất tiêu thụ động cho một mạch tích hợp với nhiều mức
tiếp cận khác nhau. Các nhà thiết kế có thể đề xuất các kỹ thuật giảm
công suất tiêu thụ ở tầng kiến trúc, cũng có thể đề xuất các kỹ thuật
giảm công suất tiêu thụ ở mức thiết kế lô-gic, thậm chí là ở mức thiết
kế mạch điện transistor. Phần lớn các kỹ thuật này tập trung vào việc
giảm tần số hoạt động và điện áp cung cấp cho hệ thống, cũng như
giảm các hoạt động có thể làm thay đổi trạng thái của dữ liệu để giảm
thiểu công suất tiêu thụ của vi mạch đó. Do sự phụ thuộc bậc hai của
công suất tiêu thụ động vào điện áp cung cấp, nên việc giảm điện áp
nguồn là một phương thức hiệu quả để giảm công suất tiêu thụ cho vi
mạch. Tuy nhiên, nếu giảm điện áp cung cấp thì tốc độ hoạt động của
cổng lô-gic cũng giảm theo. Điều này ảnh hưởng đến hiệu năng hoạt
động tổng thể của mạch. Vì thế, cách tiếp cận này cần phải được thực
hiện một cách cẩn trọng. Thông thường, các nhà thiết kế sử dụng
phương pháp này theo các cách tiếp cận sau:
Đối với các thành phần trong hệ thống mà không cần hoạt động
ở tốc độ cao (chẳng hạn như các thiết bị ngoại vi), chúng ta có thể cấp
điện áp nguồn thấp hơn so với các khối chức năng cần hoạt động ở tốc
độ cao hơn. Hướng tiếp cận này được gọi là thiết kế đa điện áp nguồn
(multi-voltage). Theo đó, mỗi khối chức năng hoặc một nhóm khối
chức năng trong hệ thống sẽ được cung cấp một nguồn nuôi khác
nhau, tùy thuộc vào yêu cầu về tốc độ hoạt động và kịch bản giảm
công suất tiêu thụ.
Đối với các vi xử lý, chúng ta có thể cấp một điện áp nguồn với
giá trị biến thiên tùy thuộc vào tác vụ mà vi xử lý đó đang thực hiện.
Với các tác vụ yêu cầu hiệu năng xử lý cao, chúng ta sẽ cấp một điện
áp nguồn và tần số hoạt động cao cho vi xử lý. Với các tác vụ yêu cầu
hiệu năng thấp, chúng ta có thể giảm điện áp và tần số hoạt động của
vi xử lý để tiết kiệm công suất tiêu thụ. Hướng tiếp cận này được gọi
là thay đổi tỷ lệ điện áp (voltage-scaling). Thách thức của phương pháp

98 Mạng trên chip
này là xác định thời điểm thay đổi điện áp. Ngoài ra, tần suất thay đổi
điện áp quá nhanh cũng sẽ làm giảm hiệu quả của phương pháp tiếp
cận này.
Một hướng tiếp cận khác nữa để giảm công suất tiêu thụ động
đó là phương pháp chặn cấp xung nhịp đồng hồ (clock gating) đối với
các khối không hoạt động. Bằng cách đưa tần số hoạt động của các
khối này về không, thì công suất tiêu thụ của các khối đó cũng giảm
về không một cách tương ứng. Đây cũng là một hướng tiếp cận hay
được sử dụng khi thiết kế các hệ thống trên chip. Hiện nay, các công
cụ hỗ trợ thiết kế hiện đại đều trang bị khả năng triển khai phương
pháp chặn cấp xung nhịp một cách tự động. Công cụ hỗ trợ thiết kế sẽ
phân tích thiết kế và đưa ra giải pháp. Tuy nhiên, để triển khai phương
pháp này thì thư viện thiết kế phải hỗ trợ các flip-flop cho phép thực
hiện kỹ thuật chặn cấp xung nhịp.
5.1.2. Công suất tiêu thụ tĩnh
Với một mạch tích hợp, công suất tiêu thụ tĩnh là công suất mà
mạch tích hợp đó tiêu thụ khi được cấp nguồn mặc dù các tín hiệu trong
mạch không có sự thay đổi về mặt giá trị. Nguyên nhân chính gây ra
công suất tiêu thụ tĩnh là do sự xuất hiện các dòng điện rò ở các
transistor. Cùng với sự phát triển của công nghệ bán dẫn, kích thước của
transistor ngày càng được thu nhỏ lại. Tuy nhiên, điều này lại làm cho
dòng rò trên transistor tăng lên và đồng nghĩa với việc công suất tiêu thụ
tĩnh ngày càng tăng. Đối với một cổng lô-gic loại CMOS, có bốn nguyên
nhân chính gây ra dòng điện rò trên cổng lô-gic đó là [51, 52]:
Dòng rò dưới ngưỡng ( ): là dòng điện chạy từ cực máng
qua cực nguồn khi transistor đó hoạt động ở vùng nghịch đảo yếu.
Dòng rò cổng ( ): là dòng điện chạy từ cực cổng thông qua
lớp oxit để đến bề mặt. Nguyên nhân gây ra dòng điện này là do hiệu
ứng đường hầm và hiện tượng bơm hạt tải nóng (hot carrier injection).
Dòng rò máng gây ra bởi cực cổng ( ): là dòng điện chạy từ
cực máng đến bề mặt do hiệu ứng trường mạnh (high field effect) ở
cực máng của MOSFET khi ta áp một điện áp lớn.

Chương 5. Tối ưu năng lượng tiêu thụ cho mạng trên chip 99
Dòng rò tiếp giáp ( ): là dòng điện gây ra bởi sự trôi của các
hạt tải thiểu số tạo nên các cặp điện tử-lỗ trống trong vùng tiếp giáp.
Dòng rò dưới ngưỡng phát sinh khi cực cổng của CMOS chưa
thực sự hoàn toàn đóng. Giá trị gần đúng của dòng rò dưới ngưỡng
được tính theo công thức sau:
( )
(5-6)
Trong đó, và là các kích thước của transistor, là điện thế
nhiệt (được tính bằng công thức và bằng 25,9 mV ở nhiệt độ
phòng), là một tham số của quá trình chế tạo và có giá trị nằm trong
khoảng từ 1,0 đến 2,5.
Phương trình (5-6) cho thấy dòng rò dưới ngưỡng phụ thuộc vào
sự chênh lệch điện áp và theo hàm mũ. Do vậy, nếu chúng ta
giảm điện áp nguồn và (để giảm công suất tiêu thụ động) thì
lại làm tăng công suất tiêu thụ tĩnh của hệ thống theo hàm số mũ.
Nguyên nhân gây ra dòng rò cổng là do hiệu ứng đường hầm ở
lớp oxit cực cổng. Với quy trình công nghệ 90nm, độ dày của lớp oxit
( ) này chỉ bằng kích cỡ của vài nguyên tử. Điều này làm cho hiệu
ứng đường hầm càng trở nên lớn hơn đối với các transistor sản xuất
bằng những quy trình công nghệ tiên tiến hơn. Với các quy trình công
nghệ lớn hơn 90nm, dòng rò trên CMOS chủ yếu là gây bởi dòng rò
dưới ngưỡng . Bắt đầu từ công nghệ 90nm trở đi, dòng rò cổng
gần như bằng 1/3 dòng rò dưới ngưỡng và thậm chí có thể bằng với
giá trị của dòng trong một vài trường hợp ở quy trình công nghệ
65nm. Đối với các quy trình công nghệ tiên tiến hơn (kích thước
transistor nhỏ hơn), các vật liệu có hằng số điện môi cao sẽ được áp
dụng vào quy trình sản xuất để nhằm giảm dòng rò cổng. Đây cũng là
phương pháp duy nhất để làm giảm dòng rò cổng trên mạch.
Theo công thức (5-6), dòng rò dưới ngưỡng cũng phụ thuộc nhiệt
độ theo hàm số mũ. Điều này ảnh hưởng lớn đến quy trình thiết kế
công suất thấp vì cho dù giá trị dòng rò ngưỡng là chấp nhận được ở
nhiệt độ phòng thì khi nhiệt độ của mạch tích hợp thay đổi cũng làm

100 Mạng trên chip
cho dòng rò ngưỡng trở nên không thể kiểm soát được. Thậm chí,
dòng rò ngưỡng của các transistor ở các vị trí khác nhau trên cùng một
vi mạch cũng có thể khác nhau.
Để giảm công suất tiêu thụ tĩnh của các mạch CMOS, các nhà
thiết kế đã đề xuất nhiều phương pháp khác nhau. Trong đó, có hai
phương pháp phổ biến nhất thường được sử dụng là:
Phương pháp đa điện áp ngưỡng (Multi - ): trong quá trình
thiết kế, chúng ta có thể áp dụng các thư viện tế bào với điện áp cao
cho những khối cần hiệu năng cao và các tế bào với điện áp thấp
cho các khối chỉ cần hoạt động ở tốc độ chuyển trạng thái thấp hơn.
Phương pháp chặn cấp nguồn (Power Gating): phương pháp
này cho phép giảm công suất tiêu thụ tĩnh của hệ thống bằng cách
ngừng cấp nguồn cho những khối lô-gic không hoạt động. Đây là
phương pháp giảm thiểu công suất tĩnh một cách tối đa nhưng lại khó
triển khai khi mạch không ngừng hoạt động một cách hoàn toàn.
Tổng hợp về công suất tiêu thụ trên một vi mạch tích hợp được
miêu tả trên Hình 5-3.
Hình 5-3: Phân loại công suất tiêu thụ trên vi mạch tích hợp.
5.2. Một số phương pháp thiết kế vi mạch công suất thấp
Từ các thảo luận về mặt lý thuyết ở Mục 5.1.1 và Mục 5.1.2, các
nhà thiết kế đã đề xuất ra nhiều phương pháp khác nhau để giảm công
Công suất tiêuthụ
Công suất tiêu thụ động
Công suất tiêu thụ do chuyển mạch:
Psw = CeffVdd2f
Công suất tiêu thụdo ngắn mạch:
Psc = tscVddIpeakf
Công suất tiêu thụ tĩnh
Công suất tiêu thụ do dòng rò:
Pleak=tactIleakVdd

Chương 5. Tối ưu năng lượng tiêu thụ cho mạng trên chip 101
suất tiêu thụ tĩnh và công suất tiêu thụ động trên một vi mạch. Mặc dù
vậy, chúng ta không thể áp dụng cùng lúc tất cả các phương pháp này
trong một thiết kế. Tuỳ theo yêu cầu, mục đích của ứng dụng khi thiết
kế một mạch tích hợp cũng như tuỳ thuộc vào công nghệ bán dẫn
dùng để sản xuất vi mạch mà người thiết kế có thể áp dụng một hoặc
nhiều phương pháp khác nhau để giảm công suất tiêu thụ cho thiết kế
của mình. Hiện nay, một số phương pháp thiết kế theo hướng giảm
công suất tiêu thụ đang được nhiều nhà thiết kế áp dụng có thể kể đến
là: (i) Phương pháp chặn cấp xung nhịp đồng hồ (Clock Gating);
(ii) Thiết kế đa điện áp nguồn (Multi - ); (iii) Thiết kế đa điện áp
ngưỡng (Multi - ).
5.2.1. Phương pháp chặn cấp xung nhịp
Trong một vi mạch, một phần lớn công suất tiêu thụ động được
phân bố trên mạng lưới các đường cấp xung nhịp đồng hồ. Theo
nghiên cứu ở [53], trên 50% công suất tiêu thụ động bị tiêu thụ ở các
bộ đệm xung nhịp. Các bộ đệm xung nhịp là một trong những thành
phần có tốc độ chuyển trạng thái nhanh nhất trong hệ thống. Thêm vào
đó, các mạch flip-flop luôn nhận tín hiệu cấp xung nhịp; do đó, nó
luôn tiêu thụ công suất cho dù các tín hiệu ở đầu vào và đầu ra không
hề thay đổi. Vì vậy, để giảm công suất tiêu thụ của vi mạch, chúng ta
có thể đưa ra giải pháp ngừng cấp xung nhịp cho các mạch flip-flop
khi nó không cần phải thực hiện việc chuyển trạng thái. Phương pháp
này được gọi là phương pháp chặn cấp xung nhịp.
Hiện nay, các công cụ thiết kế hiện đại đều có khả năng phân tích
thiết kế và nhận diện các vị trí trong mạch có thể áp dụng được
phương pháp chặn cấp xung nhịp một cách hoàn toàn tự động mà
không làm thay đổi chức năng của mạch lô-gic. Hình 5-4 minh họa
hình ảnh khi biên dịch một flip-flop D trong cả hai trường hợp, không
áp dụng phương pháp chặn cấp xung nhịp và có áp dụng phương pháp
chặn cấp xung nhịp. Trong trường hợp khi tiến hành biên dịch mà
không áp dụng phương pháp chặn cấp xung nhịp, tín hiệu xung nhịp
sẽ gửi trực tiếp đến các mạch flip-flop kể cả khi nó không hoạt động
(tín hiệu cho phép EN ở mức thấp). Với việc biên dịch có áp dụng kỹ

102 Mạng trên chip
thuật chặn cấp xung nhịp, tín hiệu xung nhịp chỉ được gửi tới các
mạch flip-flop khi tín hiệu cho phép EN ở mức cao và các flip-flop có
hoạt động chuyển mức trạng thái đầu vào và đầu ra.
Hình 5-4: Phương pháp chặn cấp xung nhịp:
không thực hiện chặn xung nhịp (a); có thực hiện chặn xung nhịp (b).
5.2.2. Phương pháp thiết kế đa điện áp nguồn
Như đã trình bày ở Mục 5.1.1, công suất tiêu thụ động tỷ lệ với
bình phương điện áp nguồn cung cấp ( ). Do vậy, chúng ta có thể
giảm công suất tiêu thụ động của toàn hệ thống bằng cách giảm điện
áp nguồn cho từng thành phần trong vi mạch (đối với những thành
phần không yêu cầu hoạt động ở tốc độ cao). Phương pháp này gọi là
phương pháp thiết kế đa điện áp nguồn. Một ví dụ về phương pháp
thiết kế đa điện áp nguồn được trình bày ở Hình 5-5.
Hình 5-5: Một ví dụ về phương pháp thiết kế đa điện áp nguồn.
Trong hệ thống trên chip này, bộ nhớ đệm hoạt động ở mức điện
áp cao nhất để đảm bảo tốc độ trao đổi dữ liệu nhanh nhất có thể. Bộ
vi xử lý CPU hoạt động ở mức điện áp cao vì hiệu năng của CPU sẽ
D
EN
Q
Clk
D
EN
Q
Clk Latch
(a) (b)
flip-flop
flip-flop
Bộ nhớ đệm(1,2 volt)
CPU(1,1 volt)
Các khối còn lại(1,0 volt)
Hệ thống trên chip

Chương 5. Tối ưu năng lượng tiêu thụ cho mạng trên chip 103
quyết định hiệu năng của toàn hệ thống. Các khối chức năng còn lại
của hệ thống sẽ hoạt động ở mức điện áp thấp hơn để giảm công suất
tiêu thụ. Tương tự vậy, những khối chức năng này cũng có thể hoạt
động ở tần số thấp hơn tần số của CPU để tiết kiệm năng lượng.
Tuy nhiên, việc áp dụng nhiều mức điện áp khác nhau cho từng
phần của hệ thống cũng sẽ làm quá trình thiết kế trở nên phức tạp hơn.
Bên cạnh việc cấp thêm các chân nguồn khác nhau, người thiết kế còn
phải bổ sung các mạng lưới cấp nguồn và các bộ chuyển mức điện áp
cho những tín hiệu truyền giữa các khối chức năng có điện áp khác
nhau. Những vấn đề này sẽ được thảo luận kỹ hơn trong Mục 5.3.
5.2.3. Phương pháp thiết kế đa điện áp ngưỡng
Nhờ vào những tiến bộ của công nghệ bán dẫn, cùng với sự thu
nhỏ kích thước của transistor, thì việc sử dụng các thư viện hỗ trợ đa
điện áp ngưỡng đã trở thành một cách thức phổ biến để giảm dòng
điện rò trong mạch. Điều này hình thành phương pháp thiết kế đa điện
áp ngưỡng.
Như đề cập trong Mục 5.1.2, dòng điện rò dưới ngưỡng ( )
phụ thuộc vào điện áp ngưỡng theo hàm mũ. Trong khi đó, thời
gian trễ của transistor sẽ ít phụ thuộc hơn vào điện áp ngưỡng. Mối
quan hệ giữa dòng rò dưới ngưỡng và thời gian trễ đối với quy trình
sản xuất vi mạch 90nm được biểu diễn như ở Hình 5-6.
Hình 5-6: Mối quan hệ giữa thời gian trễ và dòng rò đối với quy trình 90nm [51].

104 Mạng trên chip
Với những thư viện hiện đại, thông thường mỗi thư viện sẽ bao
gồm từ hai đến ba phiên bản thư viện tế bào tương ứng với các mức
điện áp ngưỡng khác nhau: điện áp ngưỡng thấp , điện áp ngưỡng
tiêu chuẩn và điện áp ngưỡng cao . Công cụ hỗ trợ thiết kế sẽ
tự động lựa chọn thư viện phù hợp để tiến hành tổng hợp nhằm tối ưu
về cả thời gian và công suất tiêu thụ. Người thiết kế cũng có thể can
thiệp việc lựa chọn thư viện cho từng khối chức năng bên trong mạch
thông qua việc đưa ra các ràng buộc thiết kế cụ thể.
5.3. Phương pháp thiết kế đa điện áp nguồn
Để giảm sâu công suất tiêu thụ trên vi mạch, gần đây các nhà
thiết kế đã đề xuất nhiều phương pháp cho phép giảm cả công suất
tiêu thụ tĩnh và công suất tiêu thụ động trên mạch. Trong các phương
pháp này, có hai phương pháp hiện được sử dụng nhiều và tương đối
phổ biến đó là: chặn cấp nguồn (power gating) và thay đổi điện áp
thích nghi (adaptive voltage scaling).
Giải pháp chính của hai phương pháp này chính là phân vùng hệ
thống thành từng khối khác nhau, cấp nguồn nuôi riêng cho từng mỗi
khối hoặc sử dụng các mức điện áp nguồn khác nhau cho từng khối
khác nhau. Cách tiếp cận này được gọi là thiết kế đa điện áp nguồn.
Phương pháp thiết kế này bắt nguồn từ việc thay đổi trong mô hình
thiết kế vi mạch gần đây, khi mà vi mạch chủ yếu được thiết kế dưới
dạng các hệ thống trên chip có tính mô-đun hóa cao, đặc biệt là các hệ
thống GALS. Với các hệ thống này, mỗi khối chức năng trong hệ
thống sẽ hoạt động dưới các điều kiện và hiệu năng khác nhau. Ví dụ,
trong một hệ thống trên chip thì CPU thường sẽ phải hoạt động với tốc
độ nhanh nhất mà kỹ thuật chế tạo bán dẫn cho phép để tăng hiệu
năng hoạt động của hệ thống. Trong khi đó, một khối giao tiếp USB
thì không cần phải hoạt động ở tốc độ cao nhưng phải đảm bảo được
mức điện áp được đặt ra bởi giao diện truyền thông. Một ví dụ khác về
việc thay đổi mức điện áp cần cung cấp đó là điện áp nguồn cấp cho
các vi mạch nhớ truy cập ngẫu nhiên (RAM). Thông thường, chúng ta
chỉ cần cấp mức điện áp nguồn nhỏ để duy trì dữ liệu lưu trên RAM,

Chương 5. Tối ưu năng lượng tiêu thụ cho mạng trên chip 105
nhưng khi cần đọc hoặc ghi dữ liệu thì điện áp nguồn cần phải được
đưa lên mức cao hơn.
Từ yêu cầu cấp nguồn của hệ thống, trong hơn một thập kỷ qua,
các nhà thiết kế đã đề xuất một số chiến lược cấp nguồn trong phương
pháp thiết kế đa điện áp nguồn như sau:
Cấp nguồn với tỷ lệ điện áp cố định (SVS: Static Voltage
Scaling): các khối hoặc các hệ thống con khác nhau được cấp các mức
điện áp cố định khác nhau. Việc xác định mức điện áp phụ thuộc vào
yêu cầu về hiệu năng và tốc độ hoạt động của khối chức năng đó.
Cấp nguồn với tỷ lệ điện áp đa mức (MVS: Multi-level Voltage
Scaling): phương pháp này là một sự mở rộng của phương pháp SVS;
theo đó, điện áp cấp cho các khối khác nhau trên vi mạch sẽ được
chuyển đổi giữa nhiều mức khác nhau. Tuy nhiên, hệ thống chỉ cho
phép chuyển giữa vài mức giá trị điện áp cố định đối với từng hoạt
động khác nhau của các hệ thống con.
Phương pháp điều khiển tỷ lệ điện áp và tần số động (DVFS:
Dynamic Voltage and Frequency Scaling): phương pháp này là một sự
mở rộng của phương pháp MVS. Tùy thuộc vào sự thay đổi của tải hệ
thống, hệ thống sẽ thay đổi tần số và điện áp nguồn một cách tự động
theo một tập hợp các giá trị điện áp và tần số hoạt động định nghĩa trước.
Phương pháp điều khiển tỷ lệ điện áp thích nghi (AVS: Adaptive
Voltage Scaling): phương pháp này là sự mở rộng của phương pháp
DVFS. Với phương pháp AVS, chúng ta sử dụng các vòng lặp phản hồi
để điều chỉnh điện áp và tần số hoạt động nhằm tối giản công suất tiêu
thụ tùy theo nhu cầu của hệ thống tại từng thời điểm.
5.3.1. Phương pháp điều khiển tỷ lệ điện áp và tần số động
Phương pháp điều khiển tỷ lệ điện áp và tần số động (DVFS)
được biết đến như là một kỹ thuật phổ biến để quản lý công suất tiêu
thụ ở mức hệ thống [51, 54, 55]. Một hệ thống khi được áp dụng
phương pháp DVFS có thể được xem như là một hệ thống điều khiển
vòng kín vì tần số hoạt động và điện áp cung cấp sẽ được điều chỉnh

106 Mạng trên chip
phụ thuộc vào tải của hệ thống. Việc thay đổi điện áp nguồn cho hệ
thống là không thể xảy ra ngay lập tức mà sẽ bị trễ một khoảng thời
gian do ảnh hưởng của điện dung ký sinh trên các đường cấp nguồn.
Chính vì vậy, thách thức lớn nhất khi thiết kế một hệ thống có áp dụng
kỹ thuật điều khiển tỷ lệ điện áp và tần số động DVFS đó là làm sao
để có thể đo và dự đoán chính xác sự thay đổi về tải của hệ thống
nhằm có thể điều chỉnh tần số, điện áp cung cấp một cách kịp thời và
chính xác. Một hệ thống sử dụng phương pháp điều khiển tỷ lệ điện áp
và tần số động để quản lý năng lượng thường gồm các khối cơ bản
được mô tả như ở Hình 5-7.
Hình 5-7: Mô hình hệ thống sử dụng phương pháp điều khiển tỷ lệ tần số
và điện áp động.
Sơ đồ khối của một hệ thống có áp dụng kỹ thuật điều khiển tỷ lệ
điện áp và tần số động DVFS thường có ba khối chính với chức năng
được mô tả như sau:
Khối cảm biến sẽ xác định các tham số chính của hệ thống như
điện áp, dòng điện trung bình hay nhiệt độ để làm cơ sở cho việc xác
định tải hoạt động của hệ thống.
Bộ điều khiển sẽ dựa trên các dữ liệu đo được từ cảm biến và so
sánh nó với hiệu năng tham chiếu được quy định trong khối quản lý
nguồn chung hoặc từ phần mềm để đưa ra các quyết định về việc
tăng/giảm điện áp và tần số cung cấp cho hệ thống.
Cuối cùng là Khối cấp nguồn và tần số có nhiệm vụ cung cấp
nguồn nuôi và tần số hoạt động cho hệ thống. Khối này thường gồm
HỆ THỐNG TRÊN CHIP
áp dụng kỹ thuật DVFS
Cảm biến
Bộ điều khiểnKhối cấp nguồn
và tần số
Dữ liệu lối vào Dữ liệu lối ra
Hiệu năngtham chiếu

Chương 5. Tối ưu năng lượng tiêu thụ cho mạng trên chip 107
các bộ cấp điện áp như bộ chuyển đổi nguồn DC-DC và các bộ cấp
xung nhịp như các bộ dao động sử dụng vòng lặp khóa pha (PLL:
Phase Locked Loop).
Trong những nghiên cứu đầu tiên về phương pháp điều khiển tỷ
lệ điện áp và tần số động DVFS, các hệ thống DVFS thường sử dụng
các bộ điều khiển dạng ngoại tuyến để giám sát tải hệ thống và từ đó
đưa ra quyết định tăng/giảm điện áp và tần số hoạt động. Với các bộ
điều khiển ngoại tuyến, chúng ta cần điều chỉnh và xác định các thông
số cần thiết của bộ điều khiển tùy thuộc vào đặc thù hệ thống trước
khi sử dụng. Các bộ điều khiển này thường dựa trên các thuật toán
điều khiển PID hoặc các biến thể của nó như các bộ điều khiển PI
hoặc điều khiển I. Tuy nhiên, nhược điểm của các bộ điều khiển kiểu
này là cần phải điều chỉnh các thông số của nó để có thể đo và dự
đoán chính xác sự thay đổi của tải hệ thống. Điều này làm cho khả
năng ứng dụng và mở rộng của hệ thống bị hạn chế nếu sử dụng các
bộ điều khiển dạng ngoại tuyến. Một vài phương pháp khác (chẳng
hạn sử dụng các bộ lọc Kalman [56, 57]) cũng đã được đề xuất để
thực hiện việc dự đoán tải hệ thống cũng như để điều khiển việc cấp
điện áp và tần số. Tuy vậy, phần lớn các phương pháp này vẫn cần
thực hiện việc thay đổi các tham số của bộ lọc khi áp dụng cho một
trạng thái mới của tải hệ thống hoặc là quá phức tạp về thuật toán để
có thể thực thi bằng phần cứng.
Cho đến nay, đã có rất nhiều hướng tiếp cận khác nhau để có thể
áp dụng phương pháp điều khiển tỷ lệ điện áp và tần số động DVFS
trong các hệ thống khác nhau. Trong những hệ thống điều khiển tỷ lệ
điện áp và tần số động DVFS đầu tiên, các thuật toán thường đánh giá
tải hệ thống dựa trên thời gian thực hiện công việc trung bình (ACET:
Average-Case Execution Time) hoặc dựa trên thời gian xử lý trong
trường hợp xấu nhất (WCET: Worst-Case Execution Time). Công
trình [58] được xem là một trong những công trình sớm nhất về
phương pháp điều khiển tỷ lệ điện áp và tần số động DVFS được công
bố. Theo đó, các tác giả đánh giá về tải hệ thống của CPU thông qua
thời gian thực hiện một tác vụ và xem rằng công suất tiêu thụ P trong
một chu kỳ xung nhịp CPU chỉ phụ thuộc vào tần số hoạt động. Từ đó,

108 Mạng trên chip
các tác giả đã đề xuất một thuật toán để xếp lịch cho các tác vụ nhằm
tối thiểu công suất tiêu thụ của CPU. Trong công trình [59], các tác
giả cũng đã đưa ra một kỹ thuật xác định thời gian xử lý WCET của
hệ thống dựa trên việc sử dụng bộ đệm và từ đó áp dụng phương pháp
điều khiển tỷ lệ điện áp và tần số động DVFS để giảm công suất tiêu
thụ. Kỹ thuật điều khiển tỷ lệ điện áp và tần số động DVFS dựa trên
thời gian xử lý WCET của các tác vụ đồng bộ trong hệ thống đa lõi xử
lý cũng được các tác giả trong công trình [60] đề xuất nhằm giảm
thiểu năng lượng hoạt động của hệ thống. Một số công trình khác [61,
62, 63] cũng áp dụng cách tiếp cận tương tự để có thể ứng dụng
phương pháp điều khiển tỷ lệ điện áp và tần số động DVFS cho hệ
thống. Tuy nhiên, nhược điểm chính của các cách tiếp cận này vẫn là
việc các thông số của thuật toán phải được thay đổi lại mỗi khi tài
nguyên hệ thống có sự biến đổi lớn.
Để khắc phục nhược điểm này, các phương pháp điều khiển tỷ lệ
điện áp và tần số động tự thích nghi đã bắt đầu được các nhóm nghiên
cứu đề xuất [64, 65]. Nielsen và đồng nghiệp [65] đã đưa ra một kiến
trúc hệ thống sử dụng vòng lặp đóng, có khả năng tự định thời để điều
chỉnh điện áp và tần số thích nghi với tải hệ thống. Bằng cách sử dụng
các bộ đệm FIFO ở đầu vào và đầu ra của vi xử lý, các tác giả thực
hiện việc đánh giá tải hệ thống dựa trên tính toán mức độ sử dụng bộ
đệm FIFO và đưa phản hồi này về để điều khiển một bộ chuyển đổi
DC-DC nhằm cung cấp điện áp một cách phù hợp với tải của CPU.
Gutnik và đồng nghiệp [64] cũng đề xuất một kiến trúc dựa trên việc
đánh giá mức độ sử dụng bộ đệm FIFO tương tự như công trình của
Nielsen. Tuy nhiên, Gutnik và đồng nghiệp đã đưa thêm vào một bộ
tạo dao động riêng để có thể thay đổi cả tần số cung cấp cho hệ thống.
Bằng việc so sánh tải hệ thống tại từng thời điểm với các giá trị tham
chiếu được lập trình sẵn trong một bảng tìm kiếm (LUT: Look-Up
Table) khả trình, bộ điều khiển sẽ điều chỉnh điện áp và tần số một
cách tương ứng với tải hoạt động. Những phương pháp điều khiển tỷ
lệ điện áp và tần số động mới được đề xuất đã giải quyết phần nào
những nhược điểm của các phương pháp cũ. Tuy nhiên, do phần lớn
những phương pháp này chỉ mới sử dụng một đại lượng, đó là mức độ

Chương 5. Tối ưu năng lượng tiêu thụ cho mạng trên chip 109
sử dụng bộ đệm (BU: Buffer Ultilization), để đánh giá tải hoạt động
của hệ thống nên chưa thể dự đoán được việc thay đổi giá trị của tải
trong tương lai gần. Do đó, khả năng đáp ứng của bộ điều khiển vẫn
còn chậm dẫn đến độ trễ của hệ thống còn lớn.
Vì vậy, để phát triển các bộ điều khiển tỷ lệ điện áp và tần số
động DVFS hiệu quả hơn thì việc đưa ra những kiến trúc mới cho các
thuật toán cho phép dự đoán tải hệ thống cũng như các phương pháp
điều khiển tự thích nghi mới đã trở thành một thách thức lớn khi thiết
kế các hệ thống điều khiển tỷ lệ điện áp và tần số động DVFS. Những
kỹ thuật này thường hướng đến việc dự đoán sự biến thiên của tải hệ
thống theo thời gian dựa trên các bộ lọc thích nghi. Phần lớn các bộ
điều khiển dạng này đều sử dụng thuật toán điều khiển PID và một số
biến thể của chúng. Một trong những kiến trúc được đưa ra đầu tiên
cho các bộ điều khiển dạng này là nghiên cứu của Wei và đồng nghiệp
[66]. Tại công trình này, các điện áp mẫu sẽ được sử dụng để điều
khiển một bộ dao động điều khiển bằng điện áp (VCO: Voltage-
Controlled Oscillator) nhằm thay đổi tần số hoạt động của hệ thống
theo sự phản hồi điện áp từ bộ chuyển đổi nâng điện áp (boost
converter). Các tín hiệu tham chiếu và tín hiệu phản hồi của bộ điều
khiển đều là sự biến đổi của tần số xung nhịp hệ thống. Bộ điều khiển
PID sẽ dựa trên việc tính toán các sai số giữa những tín hiệu này để
điều chỉnh lại điện áp và tần số của toàn mạch. Một vài kiến trúc điều
khiển tỷ lệ điện áp và tần số động dựa trên các bộ điều khiển PID cũng
được đề xuất như ở các công trình [67, 68, 55]. Hughes và đồng
nghiệp [67] đã sử dụng một bộ điều khiển PID để ước lượng thời gian
giải mã một khung hình trong các ứng dụng đa phương tiện để từ đó
điều chỉnh lại điện áp và tần số cung cấp cho CPU một cách phù hợp.
Trong các công trình [68, 55], bộ điều khiển PI đã được áp dụng để
ước lượng mức độ sử dụng bộ đệm trong một hệ thống sử dụng kỹ
thuật điều khiển tỷ lệ điện áp và tần số động DVFS để điều khiển tỷ lệ
điện áp và tần số trong các hệ thống đó. Các bộ điều khiển PID là các
bộ lọc tự thích nghi nên có khả năng dự đoán về tải của hệ thống.
Nhưng đối với các bộ điều khiển PID thì đáp ứng của bộ điều khiển
vẫn phụ thuộc vào các hệ số P, I và D được lựa chọn khi thiết lập ban

110 Mạng trên chip
đầu tương ứng với một dạng tải hệ thống nhất định. Chính vì vậy, mỗi
bộ hệ số PID chỉ phù hợp với một dạng tải nhất định của hệ thống và
người thiết kế cũng cần phải thay đổi lại các hệ số này nếu tải hệ
thống có sự thay đổi lớn. Việc thay đổi các hệ số này cũng sẽ ảnh
hưởng đến độ chính xác của quá trình dự đoán trong hệ thống.
Bên cạnh các bộ điều khiển dựa trên thuật toán PID, một vài
phương pháp ước lượng cũng như một số bộ lọc tự thích nghi khác
nhau cũng đã được đưa ra để cho phép hệ thống dự đoán về sự thay
đổi của tải và đưa ra quyết định điều chỉnh tần số và điện áp. Sinha và
đồng nghiệp [69] đã khảo sát một số bộ lọc để dự đoán tải dựa trên
các giá trị tải trong quá khứ và từ đó cho phép thiết lập điện áp động
cho bộ xử lý một cách phù hợp nhằm giảm công suất tiêu thụ. Các
khảo sát đã chỉ ra bộ lọc thích nghi LMS là một trong những bộ lọc tốt
nhất để dự đoán sự thay đổi của tải hệ thống và có thể áp dụng được
với nhiều dạng tải khác nhau mà không cần thay đổi lại các hệ số của
bộ lọc. Bang và đồng nghiệp [56] cũng đã đưa ra một bộ ước lượng tải
dựa trên bộ lọc Kalman cho phép dự đoán và bám theo sự thay đổi của
tải theo thời gian thực. Tại công trình [70], chúng tôi thực hiện việc
giám sát thời gian thực mức độ sử dụng của các FIFO trên đường
truyền thông giữa các khối xử lý để đưa ra quyết định điều khiển tần
số hoạt động của các khối xử lý này nhằm tối ưu công suất tiêu thụ.
So với những hướng tiếp cận trước đây, các bộ điều khiển ứng
dụng thuật toán lô-gic mờ đã mở ra một hướng mới cho việc áp dụng
phương pháp điều khiển tỷ lệ điện áp và tần số động DVFS trong các
mạch điện. Các bộ điều khiển lô-gic mờ có khả năng hoạt động tương
tự như với các bộ lọc tự thích nghi khi cho phép bộ điều khiển có thể
dự đoán được sự thay đổi của tải hệ thống trong tương lai gần bằng
việc dựa trên các giá trị đầu vào của tải hệ thống ở thời điểm hiện tại.
Bên cạnh đó, một ưu điểm của các bộ điều khiển lô-gic mờ so với các
bộ điều khiển PID đó là ta không cần phải thay đổi các tham số của bộ
điều khiển khi tải hệ thống thay đổi. Pourshaghaghi và đồng nghiệp
[71] đã đề xuất một kiến trúc điều khiển sử dụng thuật toán lô-gic mờ
để cho phép dự đoán sự thay đổi của tải hệ thống dựa trên biến đổi của
dòng điện tiêu thụ trong mạch. Kết quả nghiên cứu trong công trình

Chương 5. Tối ưu năng lượng tiêu thụ cho mạng trên chip 111
này đã chỉ ra rằng bộ điều khiển sử dụng thuật toán lô-gic mờ có khả
năng dự đoán và bám theo sự thay đổi của tải hệ thống với độ chính
xác cao. Hơn nữa, so với các bộ lọc tự thích nghi thì các bộ điều khiển
lô-gic mờ có thuật toán đơn giản hơn rất nhiều. Chính vì vậy, việc
cứng hóa một bộ điều khiển lô-gic mờ sẽ đơn giản hơn và cũng sẽ
chiếm ít tài nguyên hệ thống hơn so với các kiến trúc khác. Việc so
sánh giữa những công trình đã thực thi các bộ điều khiển PID [72, 73,
74, 75, 76] và Kalman [77, 78, 79] trên kiến trúc FPGA so với các bộ
điều khiển lô-gic mờ [80, 81, 82, 71] cũng đã chỉ ra được sự chênh
lệch về tài nguyên phần cứng bị chiếm dụng.
Để có thể đánh giá, lựa chọn một phương pháp điều khiển tỷ lệ
điện áp và tần số động phù hợp, một tổng hợp so sánh, đánh giá hiệu
quả giữa các phương pháp nói trên được thể hiện như trong Bảng 5-1.
Bảng 5-1: So sánh đánh giá giữa các phương pháp điều khiển tỷ lệ điện áp
và tần số động
Phương pháp
điều khiển Ưu điểm Nhược điểm
Bộ điều
khiển
ngoại
tuyến
- Sử dụng
thuật toán PID.
- Sử dụng các
biến thể của
PID: PI, PD.
Điều khiển tần số -
điện áp bám theo sự
thay đổi của tải hệ
thống khá chính
xác.
- Cần thay đổi
tham số của bộ
điều khiển khi tải
hệ thống có sự thay
đổi lớn.
- Thuật toán khá
phức tạp.
- Chiếm tài nguyên
thực thi phần cứng.
Bộ điều
khiển tự
thích nghi
Sử dụng các
bộ lọc thích
nghi (LMS,
Kalman...).
- Dự đoán và bám
theo sự thay đổi của
tải theo thời gian
thực với độ chính
xác cao.
- Không cần thay
đổi tham số khi tải
hệ thống thay đổi.
- Thuật toán điều
khiển rất phức tạp.
- Chiếm nhiều tài
nguyên thực thi
phần cứng.

112 Mạng trên chip
Bộ điều
khiển áp
dụng thuật
toán lô-gic
mờ
Sử dụng thuật
toán lô-gic
mờ.
- Hoạt động tương
tự với các bộ lọc
thích nghi.
Độ chính xác của
việc dự đoán sự
thay đổi của tải hệ
thống không bằng
các bộ lọc thích
nghi.
5.3.2. Một số thách thức trong thiết kế đa điện áp nguồn
Khi áp dụng các phương pháp thiết kế đa điện áp nguồn (cho dù
áp dụng chiến lược nào) thì người thiết kế phải luôn sẵn sàng đối mặt
với những thách thức sau:
Bộ chuyển mức: mục đích của bộ đệm chuyển mức đó là cho
phép tín hiệu có thể chuyển qua các khối sử dụng những mức điện áp
nguồn khác nhau trên vi mạch. Để người thiết kế có thể áp dụng các
phương pháp thiết kế đa điện áp nguồn thì các thư viện thiết kế (cell
library) phải hỗ trợ những bộ chuyển mức này.
Vấn đề tiếp đất, đặt điện áp nguồn và lưới dẫn nguồn: việc cung
cấp nhiều miền điện áp sẽ yêu cầu thêm nhiều chi tiết trong việc tiếp
đất (sử dụng chung tiếp đất hay bố trí tiếp đất riêng biệt) và mạng lưới
các đường dẫn cung cấp nguồn cũng phức tạp hơn.
Các vấn đề về bo mạch: thiết kế đa điện áp cũng yêu cầu bổ
sung thêm nguồn cung cấp điện áp trên bo mạch. Chúng ta phải thiết
kế bo mạch có khả năng cung cấp nhiều nguồn điện áp khác nhau.
Thứ tự thay đổi việc cấp nguồn (tăng hoặc giảm mức điện áp):
Để tránh tình trạng khóa chết (deadlock) thì việc thay đổi nguồn cung
cấp trong hệ thống phải được thực hiện theo một thứ tự nhất định.
5.4. Một số giải pháp thiết kế mạng trên chip theo hướng giảm thiểu
công suất tiêu thụ
Việc tích hợp nhiều lõi IP trong cùng một hệ thống mạng trên
chip làm cho vấn đề tiêu thụ năng lượng của toàn hệ thống trở nên rất
quan trọng. Năng lượng tiêu thụ không chỉ cung cấp cho các lõi IP mà
còn phải cung cấp cho cả kiến trúc truyền thông trên vi mạch.

Chương 5. Tối ưu năng lượng tiêu thụ cho mạng trên chip 113
Trong một số trường hợp, năng lượng dành cho kiến trúc truyền thông
có thể chiếm đến hơn 20% năng lượng tiêu thụ của toàn hệ thống (ví
dụ, đối với chip MIT Raw là 36% và đối với vi xử lý Alpha 21364 là
20%) [83]. Điều này ảnh hưởng đến hoạt động của toàn hệ thống, đặc
biệt là đối với các thiết bị di động sử dụng nguồn nuôi bằng pin. Chính
vì vậy, việc nghiên cứu và xây dựng các kiến trúc truyền thông, đặc
biệt là kiến trúc mạng trên chip, theo hướng tối ưu năng lượng tiêu thụ
đang là một vấn đề thu hút được nhiều quan tâm từ cộng đồng nghiên
cứu trong thời gian qua. Có nhiều hướng tiếp cận khác nhau khi thiết
kế mạng trên chip theo hướng tối ưu năng lượng tiêu thụ, được phân
thành ba nhóm kỹ thuật chính sau:
Áp dụng các kỹ thuật thiết kế tối ưu về năng lượng tiêu thụ cho
toàn kiến trúc mạng trên chip để đạt hiệu quả cao và tạo ra sự thống
nhất trên toàn mạng [84, 85, 86, 87]. Một số kỹ thuật thường hay được
áp dụng là kỹ thuật chặn cấp nguồn, kỹ thuật chặn cấp xung nhịp đồng
hồ, kỹ thuật điều khiển tỷ lệ tần số và điện áp động (DVFS), hay là kỹ
thuật điều khiển điện áp thích nghi (AVS)…
Thiết kế lại kiến trúc của từng mô-đun cơ bản trong mạng theo
hướng giảm thiểu năng lượng tiêu thụ. Một số nhóm nghiên cứu đã
thực hiện việc thiết kế các bộ định tuyến công suất thấp [88, 89], hay
các khối phối ghép mạng công suất thấp [90, 91]… Thường với xu
hướng này, người thiết kế sẽ tối giản kiến trúc cũng như hoạt động của
các mô-đun thiết kế nhằm giảm năng lượng tiêu thụ, đặc biệt là giảm
các phần tử nhớ trong thiết kế như thanh ghi hay bộ đệm.
Nghiên cứu, đề xuất các thuật toán định tuyến hoặc các thuật
toán nén dữ liệu trên mạng nhằm giảm thiểu thông tin truyền đi trong
mạng, từ đó giảm được năng lượng tiêu thụ của toàn mạng [92, 93].
Với hướng tiếp cận này, người thiết kế sẽ tập trung phân tích các đặc
tính trao đổi dữ liệu của ứng dụng và xây dựng phương án định tuyến
dữ liệu tối ưu.
Sau đây chúng ta sẽ tìm hiểu cụ thể một số giải pháp tối giản
công suất tiêu thụ điển hình trong thiết kế mạng trên chip được đề xuất
trong thời gian qua.

114 Mạng trên chip
5.4.1. Kiến trúc mạng trên chip công suất thấp ALPIN
Trong công trình [94], nhóm nghiên cứu tại Trung tâm Nghiên
cứu CEA-Leti, Minatec, Cộng hòa Pháp đã đưa ra nhiều giải pháp
khác nhau, áp dụng trên cùng một kiến trúc mạng trên chip bất đồng
bộ để giảm thiểu năng lượng tiêu thụ cho toàn hệ thống mạng trên
chip. Kiến trúc này được gọi là ALPIN (Asynchronous Low Power
Innovative NoC). Bằng cách áp dụng kỹ thuật thiết kế GALS (dị bộ
toàn cầu - đồng bộ cục bộ), kiến trúc mạng trên chip này được thiết kế
với nhiều vùng tần số và điện áp khác nhau. Từ đó, Edith và đồng
nghiệp đã áp dụng nhiều kỹ thuật khác nhau để làm giảm năng lượng
tiêu thụ của hệ thống cả về năng lượng tiêu thụ tĩnh và năng lượng tiêu
thụ động.
a) Kiến trúc tổng thể của mạng trên chip ALPIN
Trong kiến trúc mạng trên chip ALPIN (Hình 5-8), mỗi lõi IP
hoạt động nhờ vào một bộ tạo xung nhịp đồng hồ cục bộ. Bộ tạo xung
nhịp này có khả năng lập trình được để cho phép tạo ra một xung nhịp
có tần số thuộc một dải tần số định sẵn. Với việc hoạt động ở các vùng
tần số độc lập, mỗi lõi IP cũng được cấp nguồn bởi một khối nguồn
riêng, cho phép cung cấp hai mức điện áp hoạt động là và
cho lõi IP.
Hình 5-8: Kiến trúc ALPIN [94].

Chương 5. Tối ưu năng lượng tiêu thụ cho mạng trên chip 115
Kiến trúc ALPIN có tổng cộng sáu lõi IP và chín bộ định tuyến
đã được triển khai để tạo ra một ứng dụng cho truyền thông di động.
Các lõi IP trên hệ thống này bao gồm: một lõi TRX-OFDM, hai lõi
biến đổi Hartley nhanh (FHT: Fast Hartley Transform), một lõi MEM
(hoạt động như một bộ nhớ truy nhập trực tiếp), một lõi vi xử lý họ
80c51 và một lõi IP được sử dụng để đánh giá hiệu năng hoạt động
của mạng (NOC-pref). Mục đích triển khai hai lõi FHT trên hệ thống
là để đánh giá hai giải pháp điều khiển điện áp nguồn nhằm thay đổi
năng lượng động được áp dụng trên chip này. Một mặt, một bộ chuyển
đổi điện áp DC-DC cảm ứng tích hợp kiểu buck-boost tiên tiến được
sử dụng để thay đổi điện áp và tần số cấp cho khối FHT2 (được lập
trình thông qua 80c51). Mặt khác, kỹ thuật điều khiển điện áp và tần
số thích nghi cục bộ (LAVFS: Locally Adaptive Voltage and
Frequency Scaling) được áp dụng cho các lõi TRX-OFDM, MEM,
FHT1 để cho phép chuyển điện áp nguồn cấp cho các lõi này theo
những chế độ điện áp khác nhau ( và ). Ngoài ra, để giảm
mức tiêu thụ năng lượng tĩnh của hệ thống, kỹ thuật siêu cắt (UCO:
ultra-cut-off) [95] cũng được áp dụng. Kỹ thuật siêu cắt UCO cho
phép điều khiển các bộ chuyển mạch công suất PMOS nhằm duy trì
dòng rò tối thiểu khi lõi IP ở chế độ tạm ngừng hoạt động (stand-by).
Bên cạnh đó, để giảm tối đa năng lượng tiêu thụ tĩnh gây ra bởi các
dòng rò, các bộ định tuyến trong mạng cũng được thiết kế để tự động
chuyển về chế độ ngừng cấp nguồn nếu như không có dữ liệu được
chuyển qua nó.
Chiến lược quản lý năng lượng của hệ thống ALPIN được lập
trình bởi CPU 80c51. Vi xử lý này sẽ điều khiển các hoạt động thay
đổi điện áp thông qua một khối quản lý nguồn cục bộ (Local Power
Manager) được tích hợp vào trong bộ phối ghép mạng. Tùy thuộc vào
sự tương quan giữa hiệu năng hoạt động và năng lượng tiêu thụ mà
quá trình điều khiển điện áp và tần số diễn ra trong suốt quá trình hoạt
động tính toán và truyền thông của từng lõi IP. Một vấn đề đặt ra là
làm thế nào để đưa các lõi IP cũng như bộ định tuyến mạng quay lại
chế độ hoạt động bình thường sau khi được đặt vào chế độ ngừng hoạt
động hay bị ngắt nguồn nuôi. Để thực hiện điều đó, trong thiết kế hệ

116 Mạng trên chip
thống ALPIN có hai tín hiệu điều khiển chung toàn hệ thống. Bộ vi xử
lý sẽ điều khiển, tác động để đưa các lõi IP cũng như bộ định tuyến
mạng quay lại chế độ hoạt động bình thường thông qua hai tín hiệu
này. Lúc này, bộ vi xử lý sẽ nắm quyền điều khiển trực tiếp việc ngắt
nguồn, cũng như quá trình tái khởi động các đơn vị trên hệ thống.
Để đảm bảo kỹ thuật DVS hiệu quả trong từng vùng điện áp riêng
biệt, các quá trình điều khiển đều được triển khai thực thi ở mức phần
cứng với độ trễ giảm thiểu (so với việc triển khai các quá trình điều
khiển bằng phần mềm ở mức thấp). Nhờ việc áp dụng phương pháp
điều khiển sử dụng điều chế độ rộng xung (PWM: Pulse-Width
Modulation) vào trong quá trình chuyển mức điện áp và ,
hoạt động của các lõi IP vẫn diễn ra bình thường trong suốt quá trình
chuyển mức điện áp theo kỹ thuật DVS.
Hình 5-9: Bản layout và đóng vỏ của vi mạch ALPIN [96].
Sau đây là một số thông số kỹ thuật chính của vi mạch ALPIN
được chế tạo:
Công nghệ chế tạo: công nghệ CMOS 65nm của hãng
STMicroelectronics.
Chín bộ định tuyến mạng (trong đó, sáu bộ định tuyến được
trang bị kỹ thuật Power-Down và ba bộ định tuyến trang bị kỹ thuật
thiết kế kiểm tra [96]).
Độ phức tạp của vi mạch ALPIN: 800 kGEs, 150 pads, 4
(phần lõi), 7 (bao gồm pads), 9 miền nguồn nuôi, 6 miền tần số.
OFDMFHT1
FHT2
DC-
DC
MEM
80c51
RTW RTW RTW
RPD RPD RPD
RPD
RPD
RPD

Chương 5. Tối ưu năng lượng tiêu thụ cho mạng trên chip 117
Các kết quả chính của mạng trên chip ALPIN: thông lượng của
các bộ định tuyến là 550 MFlit/s, xung nhịp đồng hồ trong dải 120 MHz
÷ 320 MHz, thông lượng giao tiếp SAS là 200 MFlit/s.
b) Kiến trúc điều khiển tần số và điện áp tự thích nghi trong
mạng trên chip ALPIN
Để có thể tích hợp quá trình điều khiển tần số và điện áp động
DVFS trong các lõi IP, Beigne và đồng nghiệp bổ sung một số khối
chức năng bổ trợ trong mỗi lõi IP. Hình 5-10 mô tả một đơn vị mạng
hoàn chỉnh gồm lõi IP, bộ định tuyến và các khối chức năng bổ trợ [97].
Hình 5-10: Một đơn vị mạng hoàn chỉnh trong ALPIN [97].
Các khối chức năng bổ trợ này bao gồm:
Khối giao tiếp mạng (NI: Network Interface) kết hợp với khối
quản lý nguồn cục bộ (LPM: Local Power Manager). Nhiệm vụ của
khối NI là cung cấp các cơ chế truyền thông cho phép gửi và nhận các
gói tin của mạng. Khối quản lý nguồn cục bộ LPM kiểm soát các chế
độ cung cấp nguồn cục bộ để điều khiển khối cấp nguồn (PSU: Power
Supply Unit) và khối tạo tín hiệu xung nhịp đồng hồ cục bộ (LCG:
Local Clock Generation).

118 Mạng trên chip
Khối điều khiển xung nhịp bao gồm một giao tiếp SAS
(Synchronous - Asynchronous - Synchronous), một bộ tạo tín hiệu
xung đồng hồ cục bộ và một giao diện lập trình dòng trễ (delay line
programming interface) sử dụng trong kỹ thuật tạm dừng xung nhịp
đồng hồ (Pausable Clock) [97]. Khối giao tiếp SAS cho phép thực
hiện giao tiếp truyền thông dữ liệu giữa lõi IP (được thiết kế bởi lô-gic
đồng bộ) và bộ định tuyến (được thiết kế bởi lô-gic không đồng bộ).
Khối cấp nguồn (PSU) bao gồm một khối UCO (Ultra-Cut-Off)
kết hợp với các chuyển mạch công suất và một khối cung cấp điện áp
nguồn Hopping. Các bộ UCO kết hợp với các SCCMOS (Super-
Cut-Off CMOS) được sử dụng để đóng ngắt nhanh những lõi IP
không cần hoạt động. Mục đích là để ngăn dòng rò qua các transistor,
từ đó giảm được năng lượng tiêu thụ tĩnh trên lõi IP. Khối
Hopping được sử dụng để cung cấp điện áp cho quá trình điều
khiển tần số và điện áp động DVFS. Ngoài ra, khối cấp nguồn PSU
này cũng bao gồm cả một số bộ chuyển đổi mức điện áp.
Trong mỗi bộ định tuyến cũng sẽ được tích hợp một kiến trúc tự
động kiểm tra mức độ hoạt động truyền thông tại nút mạng đó theo
phương pháp đề xuất ở [98]. Kiến trúc này cho phép xác định thời
điểm nào bộ định tuyến đó không cần phải hoạt động và tự động ngắt
nguồn để giảm năng lượng tiêu thụ tĩnh ở bộ định tuyến đó.
Nhờ việc sử dụng khối UCO để điều khiển các SCCMOS, dòng
rò qua các lõi IP (ở chế độ OFF) giảm khoảng 8 lần so với khi sử dụng
các bộ chuyển mạch công suất CMOS đa ngưỡng điện áp MTCMOS
(Multiple Threshold CMOS). Năng lượng tiêu thụ động của lõi IP ở
chế độ LOW cũng giảm khoảng 10 lần so với năng lượng tiêu thụ của
lõi IP đó ở chế độ HIGH. Hiệu quả về mặt tiêu thụ năng lượng khi
hoạt động ở chế độ HOPPING là 97% nếu tỷ lệ giữa và là
50%. Việc tích hợp nhiều kỹ thuật thiết kế công suất thấp trên hệ
thống ALPIN cho phép các tác giả thử nghiệm nhiều phương án, chiến
lược giảm công suất tiêu thụ khác nhau để đánh giá hiệu quả của các
phương án.

Chương 5. Tối ưu năng lượng tiêu thụ cho mạng trên chip 119
5.4.2. Mô hình điều khiển tần số và điện áp dựa trên kỹ thuật PSTR
Zakaria và đồng nghiệp [99] đã thiết kế một mạng trên chip sử
dụng kỹ thuật GALS để phân chia các vùng điện áp và tần số hoạt
động khác nhau. Bằng cách đưa ra một phương pháp mới để tự động
điều chỉnh tần số và điện áp dựa vào các quá trình biến thiên trong
mỗi miền điện áp, các tác giả hướng đến việc đảm bảo được hiệu năng
hoạt động nhưng đồng thời giảm được năng lượng tiêu thụ của hệ
thống. Kỹ thuật điều khiển chính được đề xuất trong công trình này là
một thiết kế được gọi là PSTR (Programmable Self-Timed Ring);
trong đó, một bộ điều khiển chính sẽ giám sát lưu lượng tải trên hệ
thống cũng như các quá trình biến đổi của một số tham số trong hệ
thống để tự động điều chỉnh các giá trị tần số và điện áp cung cấp. Kỹ
thuật này được áp dụng cho mỗi miền điện áp/tần số trong hệ thống
GALS-NoC để giám sát, quản lý về mặt hiệu năng, đồng thời thực
hiện quá trình điều khiển DVFS. Hình 5-11 mô tả kiến trúc mô hình
điều khiển tần số và điện áp PSTR nêu trên.
Hình 5-11: Kiến trúc PSTR quản lý năng lượng/hiệu năng
cho mỗi vùng điện áp/tần số [99].
Chức năng của từng khối trong kiến trúc này được mô tả cụ thể
như sau:
Khối cảm biến đo tốc độ (Speed Sensor) thực hiện việc giám sát
tốc độ của vi xử lý MIPS ở chế độ thời gian thực. Việc giám sát tốc độ

120 Mạng trên chip
này là cơ sở để bộ điều khiển số đưa ra quyết định thay đổi tần số
xung nhịp đồng hồ cung cấp cho vi xử lý.
Khối giám sát hoạt động (Activity Node) thực hiện việc giám
sát hoạt động truyền thông của hệ thống mạng. Nó sẽ cung cấp kết quả
cho bộ điều khiển số để điều khiển điện áp/tần số nhằm đánh giá ước
lượng về hiệu năng của một số tham số cục bộ so với các khối xử lý
khác (ví dụ, tần số cục bộ). Giá trị ước lượng của các tham số sẽ được
xem như là giới hạn trên của tham số đó trong quá trình hoạt động.
Khối mạch vòng không đồng bộ khả trình (Programmable
Asynchronous Ring) về bản chất là mạch tạo dao động khả trình, có
nhiệm vụ tạo ra các tần số theo yêu cầu cho từng khối xử lý.
Khối chuyển đổi điện áp DC-DC chịu trách nhiệm cung cấp
điện áp hoạt động phù hợp theo tín hiệu điều khiển từ bộ điều khiển số
(Digital Controller). Lối ra của khối chuyển đổi điện áp là giá trị điện
áp cung cấp cho vi xử lý hoạt động.
Bộ điều khiển số Digital Controller sẽ thực hiện việc quản lý
chuyển đổi điện áp/tần số dựa trên các tham số từ Speed Sensor và từ
yêu cầu của phần mềm điều khiển (hệ điều hành). Sau khi so sánh giá
trị của tham số, bộ Digital Controller sẽ gửi tín hiệu điều khiển điện áp
đến khối DC-DC Converter và tín hiệu điều khiển tần số đến PSTR để
thay đổi điện áp và tần số hoạt động một cách phù hợp.
Với phương pháp điều khiển DVFS, Zakaria và đồng nghiệp sử
dụng thuật toán điều khiển như trình bày ở tài liệu [100]. Theo đó, họ
sử dụng hai mức điện áp { } và ba mức tần số
để thay đổi tùy thuộc vào đánh giá hiệu
quả năng lượng tiêu thụ của thuật toán này. Một tiến trình khởi chạy
thông thường của hệ thống được chia làm hai quá trình. Trong quá
trình đầu tiên, hệ thống sẽ hoạt động ở mức điện áp và với tần số
cực đại để đạt tốc độ hoạt động tối đa (hiệu năng cao nhất). Sau
đó, hệ thống sẽ chuyển sang hoạt động ở mức điện áp thấp và tần
số hoạt động thấp hơn . Thông qua việc dự đoán các hoạt động
tiếp theo của hệ thống, Zakaria và đồng nghiệp đã xây dựng một quy

Chương 5. Tối ưu năng lượng tiêu thụ cho mạng trên chip 121
luật điều khiển để tính toán thời gian chuyển từ điện áp xuống
điện áp và ngược lại.
Zakaria và đồng nghiệp đã thực thi kỹ thuật đề xuất trên với lõi vi
xử lý MIPS R2000 trên công nghệ CMOS 45nm của hãng
STMicroelectronics để kiểm chứng hoạt động và hiệu quả của nó. Với
hệ thống mạng trên chip có 8 phân khu GALS, kỹ thuật đề xuất có thể
tiết kiệm được khoảng 50,7% công suất tiêu thụ động, 19,92% năng
lượng tiêu thụ với chi phí phần cứng tăng 4,15%. Với các hệ thống có
nhiều lõi IP trong một phân khu GALS thì kỹ thuật này sẽ phát huy
hiệu quả cao hơn.
5.4.3. Kiến trúc Producer - Consumer FIFO
Pillamari và đồng nghiệp đề xuất một phương pháp phân chia
vùng điện áp/tần số dựa trên việc kết hợp các lõi IP lân cận, cùng sử
dụng một giá trị điện áp nguồn và xung nhịp hoạt động [57]. Các lõi
IP này được liên kết cùng với nhau để tạo thành một vùng điện áp/tần
số độc lập (VFI: Voltage Frequency Island). Việc liên kết các lõi IP
được dựa trên một thuật toán để ước lượng lưu lượng tải của lõi IP khi
làm việc để từ đó tính toán ra các giá trị điện áp và tần số cần thiết.
Mục đích của phương pháp này là để có thể áp dụng kỹ thuật điều
khiển điện áp và tần số động DVFS vào trong cấu trúc mạng nhưng
không làm tăng độ phức tạp của hệ thống lên quá nhiều.
Pillamari và đồng nghiệp đã áp dụng kỹ thuật tiên đoán dựa vào
bộ lọc Kalman để dự đoán được lưu lượng tải của lõi IP. Họ đã đề
xuất một kiến trúc FIFO mới có tích hợp bộ lọc Kalman để dự đoán
lưu lượng tải của từng vùng điện áp/tần số độc lập VFI. Kiến trúc
FIFO này được gọi là Producer – Consumer FIFO. Bên cạnh đó,
Pillamari và đồng nghiệp cũng đã đưa ra một thuật toán để cho phép
tính toán và gán các lõi IP có cùng điện áp, tần số và trong cùng một
VFI. Lưu đồ thuật toán này được mô tả như trong Hình 5-12. Nhờ
phân chia thiết kế thành các vùng điện áp/tần số độc lập VFI, kỹ thuật
điều khiển điện áp và tần số động DVFS được áp dụng cho từng vùng
VFI nhằm giảm công suất tiêu thụ của mạch.

122 Mạng trên chip
Hình 5-12: Thuật toán để xác định các vùng điện áp/tần số độc lập VFI [57].
Để các vùng điện áp/tần số độc lập VFI có thể trao đổi dữ liệu
với nhau, mô hình Producer – Consumer FIFO được thiết kế như mô
tả trong Hình 5-13 [57]. Trong đó, vùng điện áp/tần số độc lập VFI1
(được gọi là Producer VFI hay P-VFI) sẽ thực hiện việc ghi dữ liệu
vào FIFO và vùng điện áp/tần số độc lập VFI2 (được gọi là Consumer
VFI hay C-VFI) sẽ đọc dữ liệu đó từ FIFO. Tại mỗi thời điểm, chỉ có
một hoạt động đọc hoặc ghi là được thực hiện. Vùng điện áp/tần số
độc lập P-VFI chỉ có thể ghi dữ liệu nếu FIFO chưa đầy và vùng điện
áp/tần số độc lập C-VFI chỉ có thể đọc dữ liệu khi FIFO không trống.
Hình 5-13: Cấu trúc của Producer-Consumer FIFO.
ProducerPart
clk_put
Multi clockFirst-in First-out
ConsumerPart
data_put
req_put
data_get
req_get
full empty
Thao tác ghi Thao tác đọc
clk_get

Chương 5. Tối ưu năng lượng tiêu thụ cho mạng trên chip 123
Để có thể giám sát và thay đổi tần số trong từng VFI, Pillamari và
đồng nghiệp đã giới thiệu một kiến trúc điều khiển tần số động DFS
như mô tả trông Hình 5-14 [57].
Hình 5-14: Kiến trúc DFS cho VFI.
Với kiến trúc này, một khối giám sát được sử dụng để đếm số
lượng xung nhịp cần cho mỗi hoạt động đọc/ghi dữ liệu trong một
khoảng thời gian lấy mẫu . Hệ số bước nhảy tần số của từng
vùng điện áp/tần số độc lập VFI được tính thông qua giá trị xung nhịp
thu được ở vùng điện áp/tần số độc lập P-VFI và ở vùng điện áp/tần số
độc lập C-VFI. Đây cũng chính là các giá trị được sử dụng trong thuật
toán dự đoán tải hoạt động để xác định tần số hoạt động cực đại của
hệ thống.
Một giải pháp khác cũng có cơ chế điều khiển tần số và điện áp
động dựa vào FIFO được chúng tôi đề xuất và áp dụng cho bộ mã hóa
H.264/VENGME1 [70]. Điểm khác biệt ở đây là chúng tôi giám sát
mức độ sử dụng của các FIFO trên đường truyền thông giữa các khối
xử lý để đưa ra quyết định điều khiển tần số hoạt động của các khối xử
lý này nhằm tối ưu công suất tiêu thụ (thông qua bộ điều khiển PI,
xem Hình 5-15). Kỹ thuật quản lý công suất tiêu thụ dựa vào mức sử
dụng FIFO (FIFO-level based Power Management) đề xuất được tổng
1 VENGME (Video Encoder for Next Generation Equipment): Vi mạch mã hóa
video theo chuẩn H.264/AVC được phát triển bởi Phòng thí nghiệm trọng điểm
Hệ thống tích hợp thông minh, Trường Đại học Công nghệ, Đại học Quốc gia Hà
Nội. Sản phẩm đoạt Giải thưởng Nhân tài Đất Việt năm 2015.

124 Mạng trên chip
hợp và thực thi với công nghệ 28nm của hãng STMicroelectronics.
Giải pháp đề xuất có thể giảm công suất tiêu thụ của khối NAL
(Network Abstraction Layer) tới 59,3%. Nếu áp dụng phương pháp
điều khiển này với nhiều miền điện áp khác nhau thì hiệu quả tối giản
công suất tiêu thụ còn khả quan hơn nữa.
Hình 5-15: Tích hợp bộ điều khiển PI trong nền tảng hệ thống VENGME.
5.4.4. Bộ phối ghép mạng công suất thấp theo chuẩn OCP
Chouchene và đồng nghiệp [91] đã giới thiệu một cấu trúc phần
cứng giao diện mạng sử dụng chuẩn giao tiếp lõi mở (OCP: Open
Core Protocol) để giảm năng lượng tiêu thụ trong một mạng NoC
dạng 2D-mesh bằng cách sử dụng phương pháp chặn cấp xung nhịp
đối với các đơn vị mạng không hoạt động. Bộ giao diện mạng NI được
thiết kế như một cầu nối giữa giao tiếp OCP với kết cấu chuyển mạch
của NoC. Nó sẽ đóng vai trò đồng bộ về mặt thời gian giữa lõi IP có
giao tiếp OCP với NoC, đóng gói dữ liệu truyền từ OCP thành các flit
của NoC và ngược lại. Đồng thời, bộ giao diện mạng cũng đảm nhận
vai trò tính toán các thông tin về định tuyến và là bộ đệm cho các flit
trong một số trường hợp. Bộ giao diện mạng NI được thiết kế theo đặc
tả kỹ thuật của giao thức giao tiếp lõi mở OCP phiên bản 2.2 và hỗ trợ
các quá trình truyền: đọc/ghi đơn và đọc/ghi theo khối.
VENGME platform
EC-NAL module
NALSRAM
Intra prediction
Inter prediction
Transformation-Quantization
Async. FIFO
Data Data
Producer P(EC)
Consumer C(NAL)
fP = 50MHz
fC
Write enable
Full
Read enable
Empty
Write clock Read clock
Main clock
Control signalsSynchronizer
SynchronizerStatus signals
PI controller
Frequencydivider
Clockgating
fMax = 100MHz
Max clock
FIFO level
fsel
Clock generator

Chương 5. Tối ưu năng lượng tiêu thụ cho mạng trên chip 125
Với giải pháp đề xuất, các tác giả đã thiết kế bốn bộ giao diện
mạng chủ (MNI: Master Network Interface). Trong đó, mỗi bộ giao
diện mạng chủ MNI lại được phân chia thành hai khối con: một cho
kênh yêu cầu và một cho kênh phản hồi, xem Hình 5-16. Nhiệm vụ
chính của bộ giao diện mạng chủ MNI là nhận yêu cầu từ lõi IP chủ và
đóng gói yêu cầu này để truyền lên mạng, đồng thời nó cũng đảm
nhận việc nhận gói dữ liệu từ mạng, giải mã gói và chuyển dữ liệu cho
lõi IP chủ. Do đó, kiến trúc của MNI được thiết kế với hai luồng dữ
liệu, một cho quá trình yêu cầu và một cho quá trình phản hồi.
Hình 5-16: Kiến trúc của bộ MNI [91].
Với thiết kế luồng dữ liệu cho MNI như trên, Chouchene và đồng
nghiệp chia kiến trúc của MNI thành bốn khối chức năng: bộ điều
khiển FIFO, bộ tạo tiêu đề (Header Builder), khối giao tiếp mạng,
khối tạm ngừng cấp xung nhịp đồng hồ (Stoppable Clock). Đây cũng
chính là các khối cơ bản để các tác giả có thể áp dụng kỹ thuật tạm
ngừng cấp xung nhịp nhằm tiết kiệm năng lượng tiêu thụ. Việc giảm
năng lượng tiêu thụ của bộ giao diện mạng chủ MNI được thực hiện

126 Mạng trên chip
thông qua khối tạm ngừng cấp xung nhịp đồng hồ (Stoppable Clock).
Khối tạm ngừng cung cấp xung nhịp đồng hồ sẽ chịu trách nhiệm
cung cấp hoặc ngừng cung cấp xung nhịp đồng hồ cho các khối điều
khiển FIFO và Header Builder trong trường hợp những khối này tạm
ngừng hoạt động.
Kết quả thực nghiệm cho thấy giải pháp đề xuất của Chouchene
và đồng nghiệp có thể giảm được 63% công suất tiêu tán so với khối
MNI ban đầu đối với luồng dữ liệu điều khiển dựa vào cơ chế bắt tay
với chi phí phần cứng là 19%. Còn đối với luồng dữ liệu điều khiển
dựa vào credit thì công suất tiêu tán giảm được là 37% trong khi chi
phí phần cứng tăng lên chỉ 2%. Một vấn đề khác là tần số hoạt động
của hệ thống bị giảm khoảng 21% khi thực hiện giải pháp này.
Bảng 5-2 trình bày so sánh giữa các kỹ thuật thiết kế nhằm giảm
năng lượng cho một mạng trên chip đề cập trong phần trên.
Bảng 5-2: So sánh giữa các kỹ thuật thiết kế nhằm giảm công suất tiêu thụ
cho mạng trên chip
Kỹ thuật
thiết kế được
áp dụng
Khối kiến trúc
trên NoC được áp
dụng kỹ thuật
giảm công suất
tiêu thụ
Công nghệ
thực thi,
đánh giá
Hiệu quả
đạt được
Kiến trúc
ALPIN
[94]
Điều khiển tỷ
lệ điện áp
động (DVS).
Ultra-Cut-Off
Toàn bộ NoC bao
gồm: các lõi IP và
bộ định tuyến đi
kèm.
CMOS
65nm,
ST
Microelectr
onics.
- Công suất
tiêu thụ động
ở chế độ LOW
giảm 10 lần so
với chế độ
HIGH
- Công suất
tiêu thụ tĩnh
giảm 8 lần khi
sử dụng loại
transistor công
suất SC-
CMOS

Chương 5. Tối ưu năng lượng tiêu thụ cho mạng trên chip 127
Kỹ thuật
PSTR [99]
Điều khiển tỷ
lệ điện áp và
tần số động
(DVFS)
Từng phân vùng
của NoC (gồm
một số lõi IP và
bộ định tuyến hoạt
động ở cùng một
mức điện áp).
CMOS
45nm,
ST
Microelectr
onics
Công suất tiêu
thụ động của
một NoC giảm
được tối đa
51,42%.
Kiến trúc
Producer -
Consumer
FIFO [57]
Điều khiển tỷ
lệ điện áp và
tần số động
(DVFS)
Từng phân vùng
của NoC (gồm một
số lõi IP và bộ
định tuyến hoạt
động ở cùng một
mức điện áp).
CMOS
90nm,
TSMC.
Giảm được tối
đa 32,2%
công suất tiêu
thụ động của
một NoC.
Bộ phối
ghép
mạng công
suất thấp
chuẩn
OCP [91]
Chặn cấp
xung nhịp
Bộ phối ghép mạng
(NI).
FPGA
Xilinx
Virtex5
Giảm được từ
37% đến 63%
công suất tiêu
thụ của một
bộ NI
5.5. Kết luận chương
Công suất tiêu thụ của hệ thống trên chip luôn là một thách thức
vô cùng khó khăn đối với các nhà thiết kế, quyết định sự thành bại của
một sản phẩm khi đưa ra thị trường. Điều này đặc biệt đúng đối với
các hệ thống có độ tích hợp cao, được sử dụng trong các ứng dụng di
động với nguồn nuôi là pin hay ắc quy có giới hạn về công suất. Việc
tìm kiếm một giải pháp tối ưu công suất tiêu thụ luôn là điều mà các
nhà thiết kế hệ thống trên chip phải nghĩ tới. Trong chương này, chúng
ta đã tìm hiểu về các phương pháp tối ưu công suất tiêu thụ cho các hệ
thống trên chip, điển hình là các hệ thống trên chip dựa trên mô hình
mạng (mạng trên chip). Chương tiếp theo sẽ giới thiệu việc ứng dụng
lô-gic mờ trong phát triển một giải pháp thiết kế mạng trên chip công
suất thấp.

Chương 4. Thiết kế, mô hình hòa vĖ kiểm chứng bộ giao tiếp mạng 128
Chương 6
ỨNG DỤNG LÔ-GIC MỜ
TRONG THIẾT KẾ MẠNG TRÊN CHIP CÔNG SUẤT THẤP
Như đã trình bày ở chương trước, có nhiều kỹ thuật được áp dụng
để giảm công suất tiêu thụ của một hệ thống trên chip. Với hệ thống
trên chip được xây dựng dựa trên mô hình vi mạng thì việc triển khai
các kỹ thuật thay đổi mức điện áp, tần số hoạt động có phần thuận lợi
hơn nhờ tính mô-đun hóa của hệ thống dạng mạng trên chip. Một trong
những vấn đề cần quan tâm khi áp dụng các kỹ thuật thay đổi mức điện
áp và tần số hoạt động đó là việc đưa ra quyết định thay đổi vừa làm sao
có thể tối thiểu công suất tiêu thụ của hệ thống nhưng đồng thời vẫn
phải đảm bảo hiệu năng hoạt động của hệ thống ở mức đáp ứng yêu cầu
của ứng dụng. Một trong những phương pháp mà chúng tôi đã nghiên
cứu, triển khai đó là ứng dụng lô-gic mờ trong thiết kế mạng trên chip
công suất thấp. Chương này sẽ đề cập trước hết đến thuật toán lô-gic
mờ và một số mô hình cơ bản có thể triển khai trong thiết kế vi mạch
công suất thấp. Tiếp đó, các phần còn lại của chương sẽ trình bày việc
thực thi thuật toán lô-gic mờ trong thiết kế mạng trên chip có công suất
tiêu thụ thấp. Kết quả nghiên cứu này được công bố trong luận án tiến
sỹ của Phan Hải Phong, thực hiện tại Phòng thí nghiệm trọng điểm Hệ
thống tích hợp thông minh, Trường Đại học Công nghệ, Đại học Quốc
gia Hà Nội [101] dưới sự hướng dẫn của tác giả. Phần nội dung chương
này được biên tập lại từ Luận án.
6.1. Giới thiệu về thuật toán lô-gic mờ
Năm 1965, giáo sư Lotfi Aliasker Zadeh, Đại học California tại
Berkeley (Hoa Kỳ) đã đề xuất lý thuyết tập mờ [102]. Tiếp đó, năm 1973,
ông công bố lý thuyết về lô-gic mờ. Tại thời điểm lý thuyết tập mờ

Chương 6. Ứng dụng lô-gic mờ trong thiết kế mạng trên chip… 129
được công bố, hầu hết các nhà toán học cũng như các kỹ sư điều khiển
tự động chưa hoàn toàn đón nhận khái niệm này. Tuy nhiên, cùng với
sự phát triển của công nghiệp, lý thuyết này đã có những ứng dụng
ngày càng quan trọng trong nhiều lĩnh vực khác nhau, từ lý thuyết
điều khiển cho đến trí tuệ nhân tạo (Artificial Intelligence).
Đặc biệt, vào thập niên 80, khi các kỹ sư Nhật Bản áp dụng thành
công lô-gic mờ vào các hệ thống điều khiển tự động (hệ thống xử lý
nước của Fuji Electric hay hệ thống xe điện ngầm của Hitachi...) thì
lô-gic mờ càng có vị trí quan trọng trong lĩnh vực này. Đến nay,
những lĩnh vực mà lý thuyết lô-gic mờ đã được áp dụng thành công có
thể kể đến là: điều khiển tự động, tiết kiệm năng lượng, xử lý dữ liệu,
xử lý tín hiệu… và đặc biệt là lĩnh vực thiết kế rô-bốt. Hiện nay, rất
nhiều nghiên cứu đang tập trung vào việc thiết kế các rô-bốt có
phương thức hành xử tương tự con người dựa trên các thuật toán về
lô-gic mờ. Nhờ đó, các rô-bốt thế hệ mới có thể có các “suy nghĩ” và
hoạt động giống với con người hơn so với các thế hệ rô-bốt trước đó
[103, 104].
Trước đây, các hệ thống xử lý lô-gic mờ thường được triển khai
dưới dạng các phần mềm. Ưu điểm của hướng tiếp cận này là cho
phép việc triển khai hệ thống nhanh hơn, dễ dàng sửa đổi hệ thống khi
cần thiết, giảm được thời gian phát triển và đặc biệt là chi phí phát
triển thấp. Mặc dù vậy, một trong những nhược điểm của các hệ thống
phần mềm đó chính là tốc độ xử lý và tính toán bị giới hạn. Điều này
đã ảnh hưởng đến việc triển khai các thuật toán lô-gic mờ lên những
hệ thống thời gian thực. Chính điều này đã thúc đẩy các nhà nghiên
cứu phát triển thêm những hệ lô-gic mờ có tốc độ xử lý và tính toán
nhanh hơn. Một trong những hướng phát triển hiện nay cho hệ thống
lô-gic mờ đó chính là thực thi chúng ở dạng các lõi xử lý cứng để tăng
tốc độ của hệ thống [105, 80, 106, 107]. Với hướng tiếp cận này, các
hệ thống xử lý lô-gic mờ có thể đạt đến hàng triệu phép tính toán/suy
luận lô-gic mờ trong một giây (FLIPS: Fuzzy Logical Inference per
Second) [108]. Nakamura và các cộng sự [109] cũng đã xây dựng
được một lõi xử lý lô-gic mờ với 12 đầu vào có độ phân giải 16 bit và
tốc độ tính toán cũng đạt đến FLIPS.

130 Mạng trên chip
6.1.1. Lý thuyết mờ
a) Tập mờ
Tập kinh điển
Khái niệm tập hợp dựa trên nền tảng lô-gic được định nghĩa như
là sự sắp xếp chung các đối tượng có cùng tính chất và được gọi là
phần tử của tập hợp đó. Cho một tập hợp , một phần tử thuộc
được ký hiệu là: . Thông thường ta dùng hai cách để biểu diễn
tập kinh điển, đó là:
Liệt kê các phần tử của tập hợp. Ví dụ, tập {xe đạp, xe
máy, xe khách, xe tải}.
Biểu diễn tập hợp thông qua đặc điểm và tính chất tổng quát
của các phần tử. Ví dụ, tập các số thực ( ), tập các số tự nhiên ( ).
Để biểu diễn một tập hợp trên tập nền , ta sử dụng hàm liên
thuộc , với:
{
(6-1)
Ký hiệu thỏa mãn một số tính chất nào đó . Ta nói,
tập được định nghĩa trên nền tập . Ví dụ, việc mô tả hàm liên
thuộc của tập số thực từ -7 đến 7 ( ) được
thể hiện như ở Hình 6-1.
Hình 6-1: Hàm liên thuộc của tập kinh điển .
Định nghĩa tập mờ
Các tập mờ hay tập hợp mờ là sự mở rộng của lý thuyết tập hợp
cổ điển và được dùng trong lô-gic mờ. Trong lý thuyết tập hợp cổ
điển, quan hệ thành viên của các phần tử trong một tập hợp được đánh

Chương 6. Ứng dụng lô-gic mờ trong thiết kế mạng trên chip… 131
giá theo kiểu nhị phân với điều kiện rõ ràng: “một phần tử hoặc thuộc
hoặc không thuộc về tập hợp”. Trái lại, lý thuyết tập mờ cho phép
đánh giá từ từ về quan hệ thành viên giữa một phần tử và một tập hợp.
Quan hệ thành viên này được mô tả bằng một hàm liên thuộc
(membership function) .
Tập hợp mờ là tập hợp mà mỗi thành phần là một bộ số. Như vậy,
ta nói là tập mờ nếu có biểu diễn:
( ) (6-2)
trong đó, là tập mờ trên không gian nền nếu được xác định
bởi hàm:
: (6-3)
Trong đó:
: là tập nền hay được gọi là tập vũ trụ của tập mờ .
là hàm liên thuộc.
là độ liên thuộc của vào tập mờ .
Các tập mờ được coi là một mở rộng của lý thuyết tập hợp cổ
điển là vì với một không gian tham chiếu (không gian nền) nhất định,
một hàm liên thuộc có thể giữ vai trò của một hàm đặc trưng, ánh xạ
mỗi phần tử tới một giá trị 0 hoặc 1 như trong khái niệm cổ điển.
Trong khái niệm tập hợp kinh điển hàm liên thuộc của tập , chỉ có
một trong hai giá trị là “1” nếu hoặc “0” nếu .
Tuy nhiên, cách biểu diễn hàm liên thuộc như trên sẽ không phù
hợp với những tập được mô tả “mờ”. Ví dụ, ta cần mô tả tập gồm
các số thực gần bằng 5:
(6-4)
Khi đó, ta không thể khẳng định chắc chắn số 4 có thuộc tập
hay không mà ta chỉ có thể nói nó thuộc tập bao nhiêu phần trăm.
Lúc này, ta phải coi hàm liên thuộc có giá trị trong khoảng từ 0
đến 1 tức là: (Hình 6-2).

132 Mạng trên chip
Hình 6-2: Hàm phụ thuộc của tập “mờ” .
Từ phân tích trên ta có định nghĩa như sau: Tập mờ A xác định
trên tập kinh điển M là một tập mà mỗi phần tử của nó được biểu diễn
bởi một cặp giá trị . Trong đó, và là ánh xạ. Ánh
xạ được gọi là hàm liên thuộc của tập mờ . Tập kinh điển
được gọi là cơ sở của tập mờ .
Các hàm liên thuộc của tập ( ) được sử dụng để tính độ phụ
thuộc của một phần tử nào đó theo hai cách: tính trực tiếp (nếu
có công thức ở dạng tường minh) hoặc tra bảng (nếu ở dạng bảng).
Các hàm liên thuộc có dạng “trơn tru” được gọi là hàm liên
thuộc kiểu . Đối với hàm liên thuộc kiểu , do các công thức biểu
diễn có độ phức tạp lớn nên thời gian tính độ phụ thuộc cho một
phần tử lâu hơn. Trong kỹ thuật điều khiển mờ thông thường, các hàm
liên thuộc kiểu thường được thay gần đúng bằng một hàm tuyến tính
từng đoạn. Một hàm liên thuộc có dạng tuyến tính từng đoạn được gọi
là hàm liên thuộc có mức chuyển đổi tuyến tính (Hình 6-3).
Hình 6-3: Hàm liên thuộc tuyến tính từng đoạn.
Hàm liên thuộc ở trên với và chính là
hàm liên thuộc của một tập nền.

Chương 6. Ứng dụng lô-gic mờ trong thiết kế mạng trên chip… 133
Các thông số đặc trưng cho tập mờ
Trong một tập mờ, các thông số đặc trưng cho tập mờ đó bao
gồm: độ cao, miền xác định và miền tin cậy (như được mô tả như
trong Hình 6-4).
Hình 6-4: Các thông số đặc trưng của tập mờ.
Độ cao của một tập mờ (định nghĩa trên cơ sở tập ) là giá
trị lớn nhất trong các giá trị của hàm liên thuộc.
s (6-5)
Một tập mờ có ít nhất một phần tử có độ phụ thuộc bằng 1 được
gọi là tập mờ chính tắc ( ). Ngược lại, một tập mờ với
gọi là tập mờ không chính tắc.
Miền tin cậy của tập mờ trên nền là một tập là tập con
của thỏa mãn.
(6-6)
Miền xác định của tập mờ trên nền là một tập là tập con
của thỏa mãn.
(6-7)
b) Lô-gic mờ
Khái niệm
Lô-gic mờ (fuzzy logic) được phát triển từ lý thuyết tập mờ để
thực hiện lập luận một cách xấp xỉ thay vì lập luận chính xác theo
lô-gic cổ điển. Người ta hay nhầm lẫn mức độ đúng với xác suất.

134 Mạng trên chip
Tuy nhiên, hai khái niệm này hoàn toàn khác nhau. Độ đúng đắn của
lô-gic mờ biểu diễn độ liên thuộc với các tập được định nghĩa không rõ
ràng, chứ không phải khả năng xảy ra một biến cố hay điều kiện nào đó.
Để minh họa sự khác biệt, xét tình huống sau: A đang đứng trong
một ngôi nhà có hai phòng thông nhau: phòng bếp và phòng ăn. Trong
nhiều trường hợp, trạng thái của A là một tập hợp gồm hai biến cố:
hoặc là anh ta “trong bếp” hoặc “không ở trong bếp”. Nhưng vấn đề gì
sẽ xảy ra nếu A đứng tại cửa nối giữa hai phòng? Lúc này, anh ta có
thể được coi là “có phần ở trong bếp”. Việc định lượng trạng thái
“một phần” này cho ra một quan hệ liên thuộc đối với một tập mờ.
Chẳng hạn, nếu A chỉ thò một ngón chân cái vào phòng ăn, ta có thể
nói rằng A ở “trong bếp” đến 99% và ở trong phòng ăn là 1%. Một khi
anh ta còn đứng ở cửa thì không có một biến cố nào quyết định rằng A
hoàn toàn “ở trong bếp” hay hoàn toàn “không ở trong bếp”.
Lô-gic mờ cho phép độ liên thuộc có giá trị trong khoảng đóng 0
và 1. Nếu ở hình thức ngôn từ, các khái niệm không chính xác như
“hơi hơi”, “gần như”, “khá là” và “rất” là được chấp nhận. Cụ thể, nó
cho phép quan hệ thành viên không đầy đủ giữa thành viên và tập hợp.
Tính chất này có liên quan đến tập mờ và lý thuyết xác suất.
Biến ngôn ngữ
Biến ngôn ngữ có thể xem là một thành phần chính trong các hệ
thống lô-gic mờ. Một biến ngôn ngữ có thể xem như là sự kết hợp các
thành phần ngôn ngữ mô tả cùng một ngữ cảnh.
Ví dụ, trong trường hợp mô tả nhiệt độ, ta không chỉ có hai trạng
thái là “nóng” và “lạnh” mà còn có các trạng thái như “rất nóng”, “hơi
nóng”, “trung bình”, “hơi lạnh” và “rất lạnh”. Tất cả các trạng thái này
đều được dùng để mô tả nhiệt độ. Chúng được gọi là các tập ngôn
ngữ, mang một khoảng giá trị nào đó của biến ngôn ngữ và được vẽ
trên cùng một đồ thị. Các luật trong hệ lô-gic mờ sẽ mô tả hoạt động
của hệ thống. Các luật này sẽ dùng biến ngôn ngữ như là những từ
vựng để mô tả các tầng điều khiển trong hệ.

Chương 6. Ứng dụng lô-gic mờ trong thiết kế mạng trên chip… 135
Khái niệm biến ngôn ngữ đã được Zadeh đưa ra như sau [102]:
Một biến ngôn ngữ được xác định bởi bộ ( , , , ) trong đó:
là tên biến. Ví dụ: “nhiệt độ”, “tốc độ”, “độ ẩm”…
là tập các từ là các giá trị ngôn ngữ tự nhiên mà có thể nhận.
Ví dụ: là “tốc độ” thì có thể là {“chậm”, “trung bình”, “nhanh”}.
là miền các giá trị vật lý mà có thể nhận. Ví dụ: là “tốc
độ” thì có thể là {0 km/h, 1 km/h, …, 150 km/h}.
là luật ngữ nghĩa, ứng mỗi từ trong với một tập mờ
trong . Từ định nghĩa trên chúng ta có thể nói rằng biến ngôn ngữ là
biến có thể nhận giá trị là các tập mờ trên một vũ trụ nào đó.
6.1.2. Thiết kế hệ thống mờ
Một mô hình hệ thống lô-gic mờ sẽ bao gồm các yếu tố chính
sau: dữ liệu (đầu vào và đầu ra), các hàm chuyển đổi, các phép toán
lô-gic và các biến ngôn ngữ.
Dữ liệu cho hệ thống mờ được chia làm hai nhóm chính: dữ liệu
đầu vào và dữ liệu đầu ra. Mỗi nhóm lại chia ra dữ liệu rõ và dữ liệu mờ.
Các hàm liên thuộc thực hiện việc chuyển đổi từ dữ liệu rõ sang
dữ liệu mờ. Người thiết kế cần phải lựa chọn các hàm phục vụ cho
việc chuyển đổi phù hợp với mục tiêu của hệ thống. Thông thường có
bốn loại hàm thường được sử dụng trong các hệ thống mờ: hình tam
giác, hình thang, hình chuông và hình que.
Các phép toán của lô-gic mờ: lô-gic mờ cũng giống lô-gic thông
thường đều quy định về các phép toán như giao, hợp, loại trừ, cộng,
phủ định… Tuy nhiên, cách tính giá trị của mỗi phép toán lại khác so
với lô-gic thông thường. Các phép toán này ảnh hưởng rất nhiều đến
một thành phần quan trọng của hệ mờ đó là việc định khoảng giá trị.
Đây cũng là cơ sở cho việc thiết lập các luật trong hệ lô-gic mờ.
Biến ngôn ngữ: một biến ngôn ngữ sẽ quy định giá trị của một
trường cụ thể trong hệ thống. Giá trị của biến ngôn ngữ sẽ là dạng từ
ngữ. Thông thường, người ta gắn các khoảng giá trị số cho một từ ngữ
nào đó thể hiện được bản chất của biến.

136 Mạng trên chip
Các luật trong mô hình lô-gic mờ: đây là thành phần điều khiển
của một hệ thống lô-gic mờ. Các luật được thực hiện dựa trên câu lệnh
IF - THEN và một số phép toán lô-gic khác như AND, OR, NOT…
Trong một hệ thống, nếu tập luật càng chính xác thì hiệu quả của hệ
thống càng cao.
Để thiết lập một hệ thống mờ hoàn chỉnh, chúng ta cần xây dựng
các thành phần con của hệ thống như ở Hình 6-5.
Hình 6-5: Mô hình cơ bản của một hệ thống mờ.
Quá trình hoạt động của một hệ thống mờ có thể được mô tả như
sau: Đầu tiên các dữ liệu thực tế (dữ liệu rõ) sẽ được đưa vào đầu vào
của hệ thống. Qua bước mờ hóa (Fuzzification) ta sẽ thu được dữ liệu
“mờ” và kết quả này sẽ được sử dụng làm đầu vào cho quá trình xử lý
tiếp theo (Quá trình hợp thành - Fuzzy Engine). Dựa vào tập luật hợp
thành mà quá trình hợp thành sẽ tính toán và cho ra dữ liệu cần thiết cho
quá trình giải mờ (De–Fuzzification). Sau bước cuối cùng này ta sẽ có
kết quả là các dữ liệu rõ để dành cho quá trình điều khiển. Như vậy, về
cơ bản thì một hệ thống lô-gic mờ thường gồm ba quá trình chính:
Quá trình mờ hóa: thực hiện biến đổi các giá trị rõ đầu vào thành
một miền giá trị mờ với hàm liên thuộc và biến ngôn ngữ tương ứng.
Quá trình hợp thành: biến đổi các giá trị mờ của biến ngôn ngữ
đầu vào thành các giá trị mờ của biến ngôn ngữ đầu ra dựa trên các
luật hợp thành đã xây dựng.
Quá trình giải mờ: biến đổi các giá trị mờ của biến ngôn ngữ
đầu ra thành các giá trị rõ để thực hiện điều khiển đối tượng.
HỆ THỐNG MỜ
Quá trình
mờ hóa
Quá trình
hợp thành
Luật điều khiển
Quá trình
giải mờDữ liệu vào Dữ liệu ra

Chương 6. Ứng dụng lô-gic mờ trong thiết kế mạng trên chip… 137
6.1.3. Mô hình thuật toán Sugeno
Mô hình thuật toán Sugeno (hay còn được gọi là mô hình Takagi-
Sugeno-Kang) là một mô hình lô-gic mờ được đề xuất vào năm 1985
bởi Sugeno [110]. Mô hình này cũng hoàn toàn tương tự với mô hình
chung đã được đề cập đến trong Mục 6.1.2. Hai quá trình đầu tiên là
quá trình mờ hóa và quá trình hợp thành đều giống nhau ở các mô
hình. Chỉ riêng với mô hình Sugeno thì các hàm liên thuộc ở đầu ra là
ở dạng hàm tuyến tính hoặc là một hằng số. Vì vậy, quá trình giải mờ
và luật điều khiển sẽ khác với các mô hình khác.
Đối với mô hình Sugeno, về cơ bản luật điều khiển sẽ được phát
biểu dưới dạng quy luật IF-THEN như sau:
“IF AND THEN ”
Trong trường hợp và đầu ra là một hằng số thì ta gọi
mô hình này là mô hình Sugeno bậc 0.
Với mô hình này, mỗi giá trị đầu ra của từng quy luật hợp
thành sẽ được đặc trưng bởi một giá trị trọng số . Giá trị trọng số
này sẽ phụ thuộc vào quy luật hợp thành mà ta đặt ra khi tổ hợp các
biến ngôn ngữ tự nhiên. Giả sử, nếu ta áp dụng quy tắc AND với đầu
vào và thì giá trị này sẽ là:
Với mô hình Sugeno, quá trình giải mờ sẽ sử dụng phương pháp
xác định giá trị trọng tâm để tính ra giá trị đầu ra . Với các giá trị
đầu ra của từng quy luật hợp thành và giá trị trọng số của nó thì
đầu ra của thuật toán này sẽ được tính theo công thức sau:
∑
∑
Trong đó, là tổng số các quy tắc hợp thành đã được thiết lập.
Hình 6-6 mô tả hoạt động của thuật toán lô-gic mờ theo mô hình
Sugeno với hai lối vào là input_1 và input_2.

138 Mạng trên chip
Hình 6-6: Thuật toán lô-gic mờ theo mô hình Sugeno.
6.2. Bộ điều khiển tần số - điện áp dùng cho bộ định tuyến mạng
trên chip
Nhằm giảm năng lượng tiêu thụ ở các nốt mạng trong một mô
hình mạng trên chip, trong các công trình nghiên cứu của nhóm [111,
101], chúng tôi đã đề xuất việc ứng dụng lô-gic mờ để xây dựng bộ
điều khiển tần số - điện áp cho các bộ định tuyến mạng. Trong mục
này, chúng ta sẽ lần lượt tìm hiểu cụ thể về mô hình đề xuất và cách
thức thực thi mô hình này.
6.2.1. Đề xuất mô hình bộ điều khiển tần số - điện áp cho bộ
định tuyến
Như đã đề cập trong phần trước, trong nhiều nghiên cứu về các
thuật toán điều khiển tần số và điện áp động DVFS cho mạng trên
chip, thông số về mức độ sử dụng bộ đệm thường được sử dụng để đo
mức độ hoạt động của mạng. Tuy nhiên, việc đánh giá hoạt động của
mạng dựa trên mức độ sử dụng bộ đệm có thể chưa được chính xác
trong một số trường hợp. Ví dụ, khi xuất hiện lỗi tại một bộ định tuyến
nào đó, giá trị mức độ sử dụng bộ đệm của bộ định tuyến đó có thể
tăng lên nhưng tải mạng tại thời điểm đó có thể vẫn ở mức thấp.
Chính vì vậy, các nhà thiết kế đề xuất một thông số khác cho phép
đánh giá lưu lượng truyền thông trên mạng một cách chính xác hơn,
đó là xác định lưu lượng truyền thông dựa vào mức độ sử dụng liên
kết giữa hai bộ định tuyến (LU: Link Ultilization) [112, 113]. Trên cơ
sở giám sát sự thay đổi về lưu lượng truyền thông trên mạng được
phản ánh qua hai thông số BU và LU, các nhà thiết kế đưa ra những
thuật toán điều chỉnh điện áp và tần số cho hệ thống một cách phù hợp
để giảm năng lượng tiêu thụ trên hệ thống nhưng vẫn duy trì được
hiệu năng truyền thông của hệ thống theo yêu cầu của ứng dụng.

Chương 6. Ứng dụng lô-gic mờ trong thiết kế mạng trên chip… 139
Trong nghiên cứu này, chúng tôi xác định rằng lưu lượng truyền
thông qua một bộ định tuyến chính là đại lượng phản ánh mức độ hoạt
động của bộ định tuyến đó. Từ đó, chúng tôi đề xuất mô hình cho bộ
điều khiển tần số - điện áp (VFC: Voltage Frequency Controller) cho bộ
định tuyến của mạng trên chip thông qua việc giám sát lưu lượng truyền
thông trên bộ định tuyến. Nếu lưu lượng truyền thông lớn, bộ định
tuyến cần phải được cấp tần số cũng như điện áp hoạt động cao hơn để
đáp ứng yêu cầu về tốc độ truyền dữ liệu cao và ngược lại. Để đánh giá
chính xác tình trạng hoạt động của mạng tại mỗi bộ định tuyến, chúng
tôi cũng sử dụng thông số sử dụng liên kết mạng LU như một đại lượng
đánh giá lưu lượng truyền thông qua mỗi bộ định tuyến. Ở đây, thông
số sử dụng liên kết mạng sẽ được tính toán dựa trên số lượng flit truyền
qua liên kết mạng ngay tại cổng tương ứng của bộ định tuyến.
Với bộ định tuyến được thiết kế tại Phòng thí nghiệm trọng điểm
Hệ thống tích hợp thông minh (SISLAB) cho một nền tảng mạng trên
chip dạng lưới hai chiều [47], quá trình truyền một flit giữa bộ định
tuyến với một bộ định tuyến khác (hoặc lõi IP) được thực hiện thông
qua các tín hiệu bắt tay như ở Hình 6-7. Quá trình truyền được bắt đầu
khi có một tín hiệu yêu cầu truyền („req0‟ hoặc „req1‟) gửi đến bộ
định tuyến (hoặc lõi IP) đích. Sau khi quá trình truyền nhận hoàn tất,
một tín hiệu phản hồi là „resp0‟ hoặc „resp1‟ sẽ được gửi lại để xác
nhận. Do đó, để có thể đo được số flit đã được truyền qua một cổng
nào đó trên bộ định tuyến, chúng ta chỉ cần đếm số lần tín hiệu „resp0‟
hoặc „resp1‟ phát sinh sự kiện và lấy đó để xác định số flit truyền.
Hình 6-7: Tín hiệu bắt tay giữa các bộ định tuyến và lõi IP.
Bộ định tuyến
req0, req1
Data
Bộ định tuyến
Hoặc Lõi IP
resp0, resp1
Data
req0, req1
resp0, resp1
Bộ đếm

140 Mạng trên chip
Để giảm thiểu năng lượng tiêu thụ của các bộ định tuyến được sử
dụng tại các nốt mạng trong một hệ thống mạng trên chip, chúng tôi
đề xuất sử dụng một khối điều khiển tần số - điện áp để thay đổi tần số
và điện áp hoạt động của bộ định tuyến theo mức độ hoạt động của
chính bộ định tuyến đó. Khối điều khiển này có nhiệm vụ giám sát lưu
lượng truyền thông qua bộ định tuyến; từ đó, dự đoán lưu lượng
truyền thông qua bộ định tuyến trong tương lai gần để đưa ra quyết
định tăng hoặc giảm tần số hoạt động một cách phù hợp với hoạt động
của bộ định tuyến. Đồng thời với việc thay đổi tần số, các mức điện áp
cung cấp cho bộ định tuyến cũng được khối điều khiển thiết lập phù
hợp với tần số hoạt động của bộ định tuyến này để có thể giảm tối đa
công suất tiêu thụ của bộ định tuyến (Hình 6-8).
Hình 6-8: Mô hình giải pháp điều khiển tần số điện áp được đề xuất
cho các nốt mạng của một mạng trên chip [101].
Để đơn giản hóa cấu trúc của bộ giám sát lưu lượng, đồng thời để
giảm thiểu được tài nguyên thực thi hệ thống, chúng tôi đề xuất áp

Chương 6. Ứng dụng lô-gic mờ trong thiết kế mạng trên chip… 141
dụng thuật toán lô-gic mờ cho quá trình dự đoán lưu lượng và từ đó
đưa ra quyết định điều khiển tần số - điện áp. Mô hình của hệ thống
được đề xuất sẽ bao gồm các khối chính sau: các khối đo lưu lượng
Counter, khối tính toán giá trị lưu lượng trung bình cực đại (MA: Max
Average), khối tính toán biến thiên lưu lượng (DER: Derivative), bộ
xử lý lô-gic mờ (FLP: Fuzzy Logic Processing) và khối điều chỉnh tần
số - điện áp (VFA: Voltage Frequency Adjusting). Hình 6-9 mô tả sơ
đồ khối tổng thể của hệ thống.
Hình 6-9: Mô hình khối điều khiển tần số - điện áp
cho bộ định tuyến mạng trên chip [101].
Chức năng cụ thể của từng khối trong sơ đồ này được mô tả như sau:
Khối đo lưu lượng Counter sẽ thực hiện việc đo giá trị lưu
lượng truyền thông qua mỗi cổng của bộ định tuyến. Các giá trị lưu
lượng này sẽ được dùng để so sánh tại khối tính toán giá trị lưu lượng
trung bình cực đại MA nhằm xác định được giá trị lưu lượng truyền
thông cực đại truyền qua bộ định tuyến đó.
Khối tính toán giá trị lưu lượng trung bình cực đại MA sẽ xử lý
các giá trị lưu lượng truyền thông từ các cổng của bộ định tuyến gửi
đến. Khối này sẽ thực hiện việc so sánh các giá trị để chọn ra giá trị
Vdd – Fclk
Adjusting
Max Average Derivative
FZ
FE
DFZ
Input_1
Input_2
Counter_S
Counter_E
Counter_W
Counter_IP
Counter_N
Bộ xử lý lô-gic mờ
Bộ định tuyến

142 Mạng trên chip
lưu lượng lớn nhất đã được truyền qua bộ định tuyến và chuyển giá trị
này đến đầu vào thứ nhất của bộ xử lý lô-gic mờ FLP. Mục đích của
quá trình này chính là để cho bộ xử lý lô-gic mờ FLP có cơ sở để đưa
ra quyết định điều chỉnh tần số, điện áp của bộ định tuyến phù hợp với
yêu cầu về lưu lượng truyền thông cao nhất qua bộ định tuyến đó.
Khối tính toán biến thiên lưu lượng DER được thiết kế để có
thể xác định sự biến thiên về lưu lượng truyền thông của một cổng.
Các giá trị lưu lượng qua mỗi cổng sẽ được gửi đến các bộ tính toán
biến thiên lưu lượng DER tương ứng với cổng đó. Các khối tính toán
biến thiên lưu lượng DER sẽ thực hiện việc lưu hai giá trị lưu lượng:
một giá trị của thời điểm hiện tại và một giá trị của thời điểm trước đó
một “khung thời gian”. Từ đó, khối tính toán biến thiên lưu lượng
DER sẽ xác định được sự biến thiên về mặt lưu lượng truyền thông
qua từng cổng. Kết hợp với thông tin về lưu lượng cực đại từ khối tính
toán giá trị lưu lượng trung bình cực đại MA, khối tính toán biến thiên
lưu lượng DER sẽ đưa ra giá trị biến thiên của lưu lượng để làm đầu
vào cho thông số biến thiên lưu lượng của bộ xử lý lô-gic mờ.
Khối xử lý lô-gic mờ (FLP) được xây dựng từ ba khối con, đó
là: khối mờ hóa (FZ: Fuzzification), khối hợp thành (FE: Fuzzy
Engine) và khối giải mờ (DFZ: Defuzzification). Như đã đề cập ở
trên, hoạt động của khối xử lý lô-gic mờ FLP dựa trên mô hình
Sugeno nhằm đơn giản quá trình mô hình hóa và các quá trình tính
toán, từ đó giảm thiểu tài nguyên phần cứng cần sử dụng.
- Khối mờ hóa FZ nhận dữ liệu từ hai đầu vào đó là dữ liệu về lưu
lượng truyền thông lớn nhất đi qua bộ định tuyến và dữ liệu về sự biến
thiên của lưu lượng đó trong một đơn vị thời gian. Nhiệm vụ của khối
này là làm mờ hóa dữ liệu dựa trên các hàm liên thuộc đã được đề
xuất. Kết quả ở đầu ra của khối này là ta thu được các giá trị về độ phụ
thuộc của các hàm liên thuộc gọi là giá trị hay cấp độ liên thuộc).
- Khối hợp thành FE sẽ dựa trên bảng quy tắc hợp thành (quy tắc
IF-THEN) được đề xuất để xác định ra các giá trị trọng số của các quy
tắc hợp thành này. Ngoài ra, vì được xây dựng trên mô hình

Chương 6. Ứng dụng lô-gic mờ trong thiết kế mạng trên chip… 143
Sugeno nên khối hợp thành FE cũng có nhiệm vụ tính toán giá trị ra
cho từng quy tắc hợp thành đã được đề xuất.
- Khối giải mờ DFZ sẽ dựa trên giá trị liên thuộc của các hàm liên
thuộc , giá trị trọng số của các quy tắc hợp thành và giá trị ra
của mỗi quy tắc để xác định giá trị đầu ra của bộ điều khiển. Giá trị
này chính là giá trị cần thiết để điều chỉnh tần số hoạt động của bộ
định tuyến phù hợp với lưu lượng và sự biến thiên của lưu lượng qua
bộ định tuyến đó.
Khối điều chỉnh tần số - điện áp VFA thực hiện việc điều khiển
điện áp và tần số hoạt động của bộ định tuyến. Trong mô hình được đề
xuất, bộ định tuyến sẽ sử dụng ba cặp giá trị của tần số - điện áp. Sự
thay đổi của tần số hoạt động đồng thời cũng sẽ điều chỉnh điện áp
hoạt động về mức tương ứng với tần số mới. Sự thay đổi tần số hoạt
động sẽ được xác định thông qua giá trị điều khiển ở đầu ra của bộ xử
lý lô-gic mờ.
Hình 6-10 mô tả mô hình cụ thể của bộ điều khiển tần số - điện
áp sử dụng cho bộ định tuyến mạng trên chip nêu trên.
Hình 6-10: Sơ đồ chi tiết của bộ điều khiển tần số - điện áp [101].
6.2.2. Thiết kế và mô hình hóa bộ điều khiển tần số - điện áp
Mô hình của khối điều khiển tần số - điện áp đã được đề xuất ở
mục trên được mô hình hóa bằng cách sử dụng ngôn ngữ mô tả phần

144 Mạng trên chip
cứng VHDL. Các khối thành phần của bộ điều khiển tần số - điện áp
sẽ được mô hình hóa ở mức truyền thanh ghi (RTL) và được mô
phỏng, kiểm chứng về mặt lô-gic bằng phần mềm mô phỏng
ModelSim của hãng Mentor Graphics.
a) Khối đo lưu lượng
Hình 6-11 mô tả mô hình của khối đo lưu lượng. Khối đo lưu
lượng Counter sẽ nhận tín hiệu bắt tay từ bộ định tuyến để xác định
thời điểm một flit đã được truyền hoàn tất. Tín hiệu bắt tay này sẽ
được đưa đến cổng vào „res_in‟ để thực hiện việc đo số lượng flit.
Khối đo lưu lượng được mô hình hóa với hai khối con: Signal_counter
và Clock_counter. Trong mô hình đề xuất, khối Clock_counter được
sử dụng để đếm số lượng xung nhịp từ tín hiệu xung nhịp đồng hồ
„clk‟. Khối Signal_counter sẽ đếm các sự kiện từ tín hiệu „resp_in‟.
Khi tín hiệu „resp_in‟ thay đổi giá trị từ „0‟ lên „1‟ là báo hiệu một flit
truyền đã hoàn thành và giá trị đếm trong khối Signal_counter sẽ tăng
thêm một đơn vị. Khi khối Clock_counter đếm đủ một số lượng xung
nhịp nhất định (trong mô hình này, giá trị được lựa chọn là 100 xung
nhịp), một tín hiệu chốt được sẽ được gửi đến khối Signal_counter.
Khối Signal_counter sau khi nhận được tín hiệu chốt từ Clock_counter
sẽ gửi số lượng xung tín hiệu „resp_in‟ mà nó đếm được ra cổng
„val_count_out‟. Sau đó, giá trị đếm sẽ được khởi tạo lại từ đầu để
chuẩn bị cho lần đo tiếp theo.
Hình 6-11: Sơ đồ mô tả khối đo lưu lượng [101].
Để có thể mô hình hóa các hoạt động của khối đo lưu lượng
Counter, chúng tôi sử dụng mô hình máy trạng thái hữu hạn (FSM:
Finite State Machine) với ba trạng thái để mô tả các hoạt động này. Ba

Chương 6. Ứng dụng lô-gic mờ trong thiết kế mạng trên chip… 145
trạng thái được sử dụng để mô tả toàn bộ hoạt động của khối đo lưu
lượng Counter là: init, count và count_full (Hình 6-12).
Hình 6-12: Sơ đồ máy trạng thái mô tả khối đo lưu lượng [101].
Ở trạng thái init, các tín hiệu sẽ được khởi tạo về giá trị ban
đầu. Trạng thái tiếp theo sau trạng thái này sẽ là trang thái count và sẽ
được chuyển ngay ở xung nhịp tiếp theo của hệ thống.
Trạng thái count sẽ thực hiện việc đếm và lưu giá trị đếm vào
các thanh ghi „val_count‟, „clk_count‟ khi có các sự kiện từ tín hiệu
„resp_in‟ và tín hiệu xung nhịp đồng hồ „clk‟. Khi giá trị đếm của
thanh ghi „clk_count‟ đạt đến giá trị 100, máy trạng thái sẽ chuyển
sang trạng thái cuối cùng là count_full.
Trong trạng thái count_full, số sự kiện được lưu trong thanh
ghi val_count sẽ được chốt và gửi ra cổng „val_count_out‟. Trong
trạng thái này, một tín hiệu („end_count‟) cũng sẽ được gửi đến khối
tính toán biến thiên lưu lượng DER để thông báo một quá trình đếm
đã kết thúc. Tiếp theo, máy trạng thái sẽ chuyển về trạng thái init để
chuẩn bị cho quá trình đếm tiếp theo.
b) Khối tính toán giá trị lưu lượng trung bình cực đại
Khối tính toán giá trị lưu lượng trung bình cực đại MA sẽ nhận giá
trị lưu lượng truyền qua các cổng của bộ định tuyến từ những khối đo lưu
lượng Counter gắn vào từng cổng. Bằng cách so sánh các giá trị lưu
lượng truyền thông nhận được, khối tính toán giá trị lưu lượng trung bình
cực đại này sẽ xác định được giá trị lưu lượng trung bình lớn nhất truyền
qua bộ định tuyến và giá trị này thuộc về cổng truyền nào. Giá trị lưu

146 Mạng trên chip
lượng trung bình cực đại sẽ được gửi đến lối vào „input_1‟ của khối xử lý
lô-gic mờ để làm thông số đầu vào cho khối xử lý. Về mặt mô hình, khối
tính toán giá trị lưu lượng trung bình cực đại MA được thực thi như là tập
hợp của các khối so sánh 8-bit (Hình 6-13). Mỗi khối sẽ thực hiện việc so
sánh hai giá trị lưu lượng và chọn ra giá trị lớn hơn để gửi đến khối so
sánh tiếp theo. Sau khi lựa chọn được giá trị lớn nhất giữa năm đầu vào,
tín hiệu „port_sel(2:0)‟ sẽ thông báo đến khối tiếp theo địa chỉ của cổng
có giá trị lưu lượng lớn nhất này.
Hình 6-13: Mô hình khối tính toán giá trị lưu lượng trung bình cực đại [101].
c) Khối tính toán biến thiên lưu lượng
Để thực hiện việc tính toán biến thiên lưu lượng qua từng cổng
của bộ định tuyến, khối tính toán biến thiên lưu lượng DER được triển
khai với mô hình như mô tả trong Hình 6-14. Hai thanh ghi 8-bit:
nw_reg và pr_reg được sử dụng để lưu hai giá trị của lưu lượng. Một
giá trị là lưu lượng truyền thông hiện tại truyền qua mỗi cổng, một giá
trị là lưu lượng truyền thông chuyển qua cổng đó trước đó một khung
thời gian. Biến thiên của lưu lượng được tính là hiệu giá trị tuyệt đối
giữa hai giá trị này của lưu lượng.
Hình 6-14: Mô hình khối tính toán biến thiên giá trị lưu lượng DER.

Chương 6. Ứng dụng lô-gic mờ trong thiết kế mạng trên chip… 147
d) Khối xử lý lô-gic mờ
Để xử lý hai dữ liệu vào là lưu lượng và biến thiên của lưu lượng,
chúng tôi đề xuất sử dụng mô hình bộ xử lý lô-gic mờ FLP với hai đầu
vào. Do quá trình thay đổi tần số và điện áp phải hoạt động theo từng
cặp V-F, nên đầu ra bộ xử lý lô-gic mờ FLP chỉ cần có tín hiệu điều
khiển sự thay đổi về tần số. Vì vậy, bộ xử lý lô-gic mờ FLP được thiết
kế chỉ có một đầu ra và là các hàm đơn giá theo giá trị của tần số.
Cũng vì các hàm liên thuộc ở đầu ra của bộ xử lý lô-gic mờ FLP
là các giá trị đơn giá của tần số (là các giá trị hằng số) nên trong
trường hợp này quá trình điều khiển sẽ được áp dụng mô hình Sugeno
bậc 0 như đã trình bày ở Mục 6.1.3. Mô hình này được thực thi với
từng khối con như sau (Hình 6-15):
Hình 6-15: Sơ đồ của khối xử lý lô-gic mờ FLP.
Khối mờ hóa FZ được thực thi với hai khối con input_MSF.
Mỗi khối con là một quá trình tính toán giá trị liên thuộc của các đầu
vào „input_1‟ và „input_2‟ dựa trên các hàm liên thuộc được đề xuất.
Khối hợp thành FE bao gồm hai khối con: khối AND–rule xác
định giá trị trọng số cho từng quy luật hợp thành và khối được dùng
để tính toán giá trị đầu ra của mỗi quy luật hợp thành tương ứng.
Khối giải mờ DFZ được thực thi như một quá trình tính toán giá
trị đầu ra cuối cùng của bộ xử lý lô-gic mờ dựa trên các giá trị trọng
số và giá trị đầu ra của từng quy luật hợp thành .

148 Mạng trên chip
Toàn bộ các khối này sau đó được mô hình hóa bằng ngôn ngữ
mô tả phần cứng VHDL dưới dạng các tiến trình (Process). Các thanh
ghi được chèn vào sau mỗi Process để đảm bảo luồng dữ liệu được
thực hiện đúng. Việc mô hình hóa bộ xử lý lô-gic mờ FLP bằng ngôn
ngữ VHDL ở mức RTL như được mô tả trong Hình 6-16.
Hình 6-16: Mô hình hóa ở mức RTL cho bộ xử lý lô-gic mờ [111].
e) Quá trình mờ hóa
Quá trình mờ hóa là quá trình chuyển đổi từ một giá trị rõ của đầu
vào, thành một giá trị liên thuộc đối với từng hàm liên thuộc. Giá trị
liên thuộc này sẽ phụ thuộc vào hình dạng của hàm liên thuộc và tập
xác định của nó. Thông thường, các hàm liên thuộc thường có dạng
hình tam giác, hình thang, hoặc hình chuông (phân bố Gauss)… Tuy
nhiên, để việc mô hình hóa hệ thống được đơn giản thì dạng hình của
hàm liên thuộc được lựa chọn là hình tam giác.
Để mô hình hóa quá trình mờ hóa, một hàm liên thuộc dạng hình
thang sẽ được mô tả với một bộ các tham số như ở Hình 6-17 [107].
Hàm liên thuộc dạng tam giác sẽ là sự đơn giản hóa của hàm dạng
hình thang với tham số trùng với điểm . Bộ tham số cần mô
tả khi xây dựng một hàm liên thuộc dạng tam giác sẽ bao gồm:
, , , .
Hình 6-17: Mô tả cho hàm liên thuộc dạng hình thang.

Chương 6. Ứng dụng lô-gic mờ trong thiết kế mạng trên chip… 149
Giá trị liên thuộc của đầu vào theo hàm liên thuộc sẽ được
tính toán dựa trên ba phân đoạn chính:
Nếu hoặc thì .
Nếu thì
Nếu hoặc
{
Giá trị liên thuộc sẽ nằm trong khoảng . Tuy nhiên, để
thuận tiện trong việc tính toán thì khoảng xác định này sẽ được rời rạc
hóa thành khoảng nhỏ có giá trị rời rạc, bắt đầu từ 0x00 (tương ứng
với giá trị 0) đến 0xFF (tương ứng với giá trị 1). Với việc mô tả một
hàm liên thuộc bằng bộ bốn thông số như trên thì trong ngôn ngữ
VHDL, các hàm liên thuộc sẽ được mô tả dưới dạng một tập dữ liệu
dạng bản ghi.
Quá trình mờ hóa giá trị lưu lượng ở đầu vào sẽ được
thực hiện thông qua năm hàm liên thuộc, tương ứng với các biến ngôn
ngữ tự nhiên là “vlow, low, medium, high, vhigh”. Các hàm liên thuộc
được sử dụng trong mô hình này là các hàm dạng tam giác với các giá
trị của tập dữ liệu được mô tả như trong Hình 6-18. Theo đó, giá trị
cực đại của hàm liên thuộc vhigh là 0xC0, tương ứng với giá trị lưu
lượng cực đại là 192 Mflits/s. Giá trị này được lựa chọn phù hợp với
tốc độ truyền thông cực đại của bộ định tuyến đã được thiết kế tại
Phòng thí nghiệm trọng điểm Hệ thống tích hợp thông minh
(SISLAB), vào khoảng 180 Mflits/s [47]. Hệ số và
được chọn là 0x08 cho cả hai sườn của hàm liên thuộc, mục đích là
đảm bảo việc tính toán sẽ được thực hiện với sai số ít nhất có thể. Quá
trình mờ hóa giá trị lưu lượng sẽ tương ứng với một khối Input_MSF
trong mô hình được đề xuất và được thực thi như một Process trong
ngôn ngữ VHDL.

150 Mạng trên chip
Hình 6-18: Mô tả các hàm liên thuộc cho đầu vào input_1.
Đầu vào là giá trị của biến thiên lưu lượng cực đại qua bộ
định tuyến. Giá trị của biến thiên lưu lượng được xác định là lượng thay
đổi về lưu lượng, mà không phụ thuộc vào giá trị đó là tăng hay giảm.
Với đầu vào , quá trình mờ hóa sẽ được thực hiện thông qua ba
hàm liên thuộc với các biến ngôn ngữ tương ứng là “slow, normal,
fast”. Các hàm liên thuộc này cũng là các hàm tam giác với các giá trị
của tập xác định được mô tả như trong Hình 6-19. Giá trị cực đại của
hàm liên thuộc ứng với biến ngôn ngữ “fast” là 0x3C tương ứng với lưu
lượng biến thiên 60 Mflits/s. Giá trị và của các hàm
liên thuộc đều bằng nhau và được chọn bằng 0x11.
Hình 6-19: Mô tả các hàm liên thuộc cho đầu vào input_2.
Đầu ra của bộ xử lý lô-gic mờ FLP là một giá trị hằng số,
tương ứng với tần số hoạt động của bộ định tuyến. Vì vậy hàm liên
thuộc của đầu ra sẽ là các hàm đơn trị. Đầu ra sẽ được mô tả bằng ba hàm

Chương 6. Ứng dụng lô-gic mờ trong thiết kế mạng trên chip… 151
liên thuộc với các biến ngôn ngữ là “low, normal và high” (Hình 6-20).
Trong ngôn ngữ VHDL, chúng ta mô tả các hàm liên thuộc ở đầu ra
như là các hằng số 8-bit.
Hình 6-20: Mô tả các hàm liên thuộc cho đầu ra output.
f) Quá trình xác định quy luật hợp thành
Bằng việc áp dụng mô hình Sugeno, một quy luật hợp thành trong
mô hình sẽ bị tác động bởi luật điều khiển được phát biểu dưới dạng
quy luật IF-THEN như sau:
IF AND THEN
Trong trường hợp và đầu ra là một hằng số thì ta gọi
mô hình này là mô hình Sugeno bậc 0. Ở mô hình này, với mỗi giá trị
đầu ra của từng quy luật hợp thành sẽ được đặc trưng bởi một giá trị
trọng số . Giá trị trọng số này sẽ phụ thuộc vào quy luật hợp thành
mà chúng ta đặt ra khi tổ hợp các biến ngôn ngữ tự nhiên. Giả sử, nếu
chúng ta áp dụng quy tắc AND với đầu vào và
thì giá trị này sẽ là:
Quá trình tính toán giá trị trọng số sẽ tương ứng với khối
AND-rule trong mô hình được đề xuất. Quá trình này sẽ được thực thi
như là một Process và được thực hiện thông qua đoạn mã tìm kiếm giá
trị cực tiểu như sau:

152 Mạng trên chip
begin{lstlisting}[frame=single]
rule_weight: process (u_x, u_y) is
variable i, j: integer;
begin -- Đoạn chương trình tìm giá trị cực tiểu
for i in 1 to n loop
for j in 1 to m loop
if (u_x(i) < u_y(j)) then
rule_w(i,j) <= u_x(i);
else
rule_w(i,j) <= u_y(j);
end if;
end loop;
end loop;
end process rule_weight;
end{lstlisting}
Trong đó, và chính là các giá trị liên thuộc của các đầu
vào và .
Với các hàm liên thuộc được mô tả ở Mục 6.1.1, chúng ta sẽ có
tất cả quy luật hợp thành. Thông thường, chúng ta có thể bỏ qua
những quy luật ít phổ biến hoặc ít xuất hiện trong tổng số các quy luật
hợp thành được đề xuất. Tuy nhiên, trong mô hình thực nghiệm của
chúng tôi, nên toàn bộ 15 quy luật này đều được thực thi vì số lượng
quy luật hợp thành không lớn. Bảng 6-1 mô tả chi tiết các quy luật
hợp thành.
Bảng 6-1: Các quy luật hợp thành của khối xử lý lô-gic mờ
Lưu lượng Biến thiên lưu lượng Tần số
vlow
low
medium
high
vhigh
slow
slow
slow
slow
slow
low
low
low
normal
normal
vlow normal low

Chương 6. Ứng dụng lô-gic mờ trong thiết kế mạng trên chip… 153
low
medium
high
vhigh
normal
normal
normal
normal
low
normal
high
high
vlow
low
medium
high
vhigh
fast
fast
fast
fast
fast
normal
normal
high
high
high
g) Quá trình giải mờ
Quá trình giải mờ là quá trình tính toán lại giá trị chính xác ở đầu
ra của bộ xử lý lô-gic mờ FLP. Với các giá trị đầu ra của từng quy luật
hợp thành và giá trị trọng số của nó, quá trình giải mờ sẽ sử
dụng phương pháp xác định giá trị trọng tâm để tính ra giá trị đầu ra
. Giá trị này sẽ được tính theo công thức sau:
∑
∑
Trong đó, là tổng số các quy tắc hợp thành đã được thiết lập. Đoạn
mã nguồn VHDL sau được dùng để mô tả quá trình tính toán này:
for i in 1 to n loop
for j in 1 to m loop
w_t:= unsigned(w(i,j));
z_t:= unsigned(z(i,j));
upper:= upper + (w_t*z_t);
lower:= lower + w_t;
end loop;
end loop;
z_out:= divide(upper,lower);
Trong đó, và là số hàm liên thuộc của các đầu vào
và . Các giá trị và chính là các giá trị trọng số
và giá trị đầu ra của các quy tắc hợp thành được tính ra trong những
khối trước đó.

154 Mạng trên chip
6.3. Kiểm chứng hoạt động của bộ điều khiển tần số - điện áp
Để kiểm chứng hoạt động của bộ điều khiển tần số - điện áp
VFC, từng khối chức năng trong bộ điều khiển tần số - điện áp sẽ
được mô phỏng các hoạt động ở mức lô-gic bằng phần mềm
ModelSim. Đối với mỗi khối chức năng, chúng tôi tạo một môi trường
kiểm tra (testbench) bằng VHDL cho phép sinh ra các tín hiệu đầu vào
ngẫu nhiên cho khối chức năng đó. Sau khi chạy mô phỏng bằng phần
mềm ModelSim của hãng Mentor Graphics, kết quả ở đầu ra sẽ được
so sánh với dữ liệu tạo ra từ đặc tả kỹ thuật của từng khối để xác định
hoạt động của khối đó đã đúng với thiết kế hay chưa.
Để tạo các tín hiệu ngẫu nhiên, chúng tôi sử dụng thư viện OSVVM;
đây là một thư viện cho phép tạo ra các biến ngẫu nhiên trong ngôn ngữ
VHDL. Do đó, trong testbench chúng ta cần thêm vào gói RandomPkg
để có thể dùng các hàm tạo biến ngẫu nhiên của thư viện này.
6.3.1. Kiểm chứng hoạt động của khối đo lưu lượng
Sau khi chạy mô phỏng trên phần mềm ModelSim, kết quả mô
phỏng hoạt động của khối đo lưu lượng Counter được thể hiện dưới
dạng giản đồ sóng như ở Hình 6-21. Ở giản đồ sóng này, chúngta thấy
rằng khi thanh ghi count_num đếm đến giá trị 100 thì trạng thái của
máy trạng thái FSM sẽ chuyển sang trạng thái count_full để kết thúc
một lượt đếm. Giá trị đếm được lúc này là 0x78 sẽ được gửi từ thanh
ghi val_count_temp ra cổng ra „val_count_out‟. Giá trị này là phù hợp
với số sự kiện phát sinh từ xung „resp_in‟ trong thời gian 100 chu kỳ
xung nhịp. Đồng thời khi quá trình đếm kết thúc, xung
„end_count_out‟ cũng được đưa lên cao trong một chu kỳ xung nhịp
để thông báo quá trình đếm tại bộ đo lưu lượng đã kết thúc.
Hình 6-21: Kết quả mô phỏng hoạt động lô-gic của khối đo lưu lượng.

Chương 6. Ứng dụng lô-gic mờ trong thiết kế mạng trên chip… 155
6.3.2. Kiểm chứng hoạt động của khối xác định lưu lượng cực đại
Để thực hiện việc mô phỏng hoạt động của khối xác định lưu
lượng cực đại MA, chương trình testbench sẽ tạo ra năm giá trị ngẫu
nhiên để đưa vào năm đầu vào của khối xác định lưu lượng cực đại
MA. Sau đó, giá trị ở đầu ra của khối này sẽ được lấy và kiểm tra xem
có đúng với giá trị đầu vào lớn nhất trong năm đầu vào tại thời điểm
đó hay không.
Một đoạn giản đồ dạng sóng cho kết quả mô phỏng hoạt động của
khối xác định lưu lượng cực đại MA được thể hiện như ở Hình 6-22.
Với đoạn giản đồ sóng này, ta thấy tại thời điểm đang xét có năm giá
trị đầu vào là: 0xD6, 0xCB, 0x98, 0xF1 và 0x11. Khối xác định lưu
lượng cực đại MA đã lựa chọn giá trị lớn nhất trong năm giá trị này là
0xF1 và chuyển giá trị này ra đầu ra „max_traff_out‟ ngay khi đầu vào
tương ứng có sự thay đổi về giá trị. Đồng thời tín hiệu „port_sel_out‟
cũng xuất ra giá trị 0x00 để thông báo là giá trị lưu lượng lớn nhất
đang thuộc về cổng SOUTH (phía Nam).
Hình 6-22: Giản đồ dạng sóng thể hiện kết quả mô phỏng hoạt động lô-gic
của khối xác định lưu lượng cực đại.
6.3.3. Kiểm chứng hoạt động của khối xác định biến thiên lưu lượng
Giản đồ dạng sóng biểu diễn kết quả mô phỏng hoạt động của khối
xác định biến thiên lưu lượng DER được chỉ ra như trong Hình 6-23.
Như trong giản đồ sóng thể hiện, tại thời điểm đang xét thì giá trị lưu
lượng đầu vào là 0x4161 và giá trị lưu lượng truyền qua cổng này
trước đó một khung thời gian là 0x8449. Vì vậy giá trị của biến thiên

156 Mạng trên chip
lưu lượng qua cổng này là 0x4288. Giá trị này được cập nhật sau một
chu kỳ xung nhịp đồng hồ.
Hình 6-23: Giản đồ dạng sóng thể hiện kết quả mô phỏng hoạt động lô-gic
của khối xác định biến thiên lưu lượng.
6.3.4. Kiểm chứng hoạt động của bộ xử lý lô-gic mờ
Chương trình kiểm tra (testbench) sẽ tạo ra các dữ liệu đầu vào
với giá trị ngẫu nhiên và đưa vào các đầu vào và của
bộ xử lý lô-gic mờ FLP (tương ứng với các đầu vào „traffic_val_in‟ và
„dev_traffic_in‟ trong mã nguồn). Giá trị của dữ liệu vào sẽ được giới
hạn trong khoảng giá trị cực đại của các hàm liên thuộc. Bằng cách
quan sát dạng sóng của các tín hiệu ra và giá trị của đầu ra cuối cùng
(tương ứng với đầu ra z_out trong chương trình), ta sẽ xác định
được hoạt động của bộ xử lý lô-gic mờ FLP là đúng hay không.
Một đoạn kết quả ở dạng giản đồ dạng sóng của quá trình mô phỏng
được trình bày như ở Hình 6-24. Các kết quả từ đầu ra đều được so sánh
với những kết quả tính toán độc lập. Như ta thấy ở trong phần được đánh
dấu, sau khi có tín hiệu reset, bộ xử lý lô-gic mờ FLP bắt đầu hoạt động.
Khi các đầu vào có thay đổi về giá trị lần lượt là 0x4E (cho tín hiệu
„traffic_val_in‟) và 0x0F (cho tín hiệu „dev_traffic_in‟) thì kết quả ở đầu
ra là 0x30. Kết quả này là đúng với các tính toán như ở phần lý
thuyết. Ta cũng thấy được là kết quả tính toán sẽ thu được sau hai chu kỳ
xung nhịp đồng hồ. Điều này là hoàn toàn đúng đắn với thiết kế phần
cứng của khối xử lý lô-gic mờ FLP như trong Mục 6.2.2.
Hình 6-24: Giản đồ sóng thể hiện kết quả mô phỏng hoạt động
của khối xử lý lô-gic.

Chương 6. Ứng dụng lô-gic mờ trong thiết kế mạng trên chip… 157
Tiếp tục phân tích, ta thấy khi giá trị của đầu vào „traffic_val_in‟
thay đổi thành 0x73 trong khi giá trị của „dev_traffic_in‟ vẫn là 0x0F
thì đầu ra sẽ có giá trị là 0x4C. Tiếp theo, khi giá trị ở đầu vào
„dev_traffic_in‟ thay đổi thành 0x05 thì bộ xử lý lô-gic mờ FLP cũng
tính toán được ra giá trị của đầu ra là 0x48. Các kết quả tính toán thu
được ở đầu ra đều được thực hiện trong vòng hai chu kỳ xung nhịp kể
từ khi một trong hai đầu vào có sự thay đổi về mặt giá trị.
6.3.5. Kiểm chứng hoạt động của bộ điều khiển tần số - điện áp
Sau khi thực hiện mô phỏng và kiểm chứng chức năng hoạt động
của từng khối chức năng riêng rẽ, chúng tôi đã tích hợp các khối chức
năng này thành bộ điều khiển tần số - điện áp hoàn chỉnh. Để kiểm
chứng, đánh giá hoạt động của bộ điều khiển này, chúng tôi đã xây
dựng một chương trình kiểm tra để sinh ra các tín hiệu vào ngẫu nhiên
và đồng thời ghi lại giá trị lưu lượng truyền thông tương ứng với các
tín hiệu vào này. Bằng cách khảo sát sự thay đổi ở đầu ra của tín hiệu
điều khiển tần số theo giá trị lớn nhất của lưu lượng truyền thông
chuyển qua bộ định tuyến, chúng ta đánh giá được khả năng đáp ứng
của bộ điều khiển đã được thiết kế. Kết quả mô phỏng bộ điều khiển
tần số - điện áp hoàn chỉnh được thể hiện như ở trong Hình 6-25.
Hình 6-25: Kết quả mô phỏng khả năng đáp ứng của bộ điều khiển tần số điện áp
theo sự thay đổi của lưu lượng truyền thông [101].
Qua đồ thị phản ánh sự thay đổi của lưu lượng truyền thông và
đáp ứng thay đổi của tín hiệu điều khiển tần số, chúng ta có thể thấy

158 Mạng trên chip
bộ điều khiển tần số - điện áp đã hoạt động đúng với mục đích và đặc
tả đề ra của thiết kế. Sự thay đổi của tín hiệu điều khiển tần số đã bám
theo sát với sự thay đổi của lưu lượng truyền thông. Điều này cho thấy
khả năng giám sát và dự đoán sự thay đổi lưu lượng truyền thông của
bộ điều khiển tần số - điện áp là khá chính xác, đáp ứng được yêu cầu
thay đổi tần số và điện áp cho bộ định tuyến theo sự biến đổi của lưu
lượng truyền thông.
Cụ thể hơn, chúng ta xét sự thay đổi của tín hiệu điều khiển tần số
đối với lưu lượng truyền thông tại bà vùng trong đồ thị là V1, V2 và
V3. Ta thấy, tại vùng V1 của đồ thị khi lưu lượng truyền thông tăng
lên đến giá trị 150 Mflits/s - 160 Mflits/s (ở tại các đỉnh số 1 và số 2)
thì tín hiệu điều khiển tần số cũng thay đổi tương ứng (ứng với tần số
cao nhất). Sau đó, lưu lượng giảm xuống chỉ còn khoảng 50 Mflits/s
tại đỉnh số 3 vùng V1 thì tần số được điều chỉnh lại ở mức thấp nhất
để giảm công suất tiêu thụ cho hệ thống. Tiếp theo, tần số hoạt động
lại được tăng lên giá trị cao nhất để đáp ứng với giá trị lưu lượng
truyền qua tăng lên đến 130 Mflits/s (tại đỉnh 4 của vùng V1).
Tương tự đối với vùng V2, khi lưu lượng truyền thông khoảng
150 Mflits/s thì tần số hoạt động cũng được điều chỉnh ở mức cao nhất
(đỉnh số 5 của vùng V2). Sau đó, khi lưu lượng truyền thông giảm
xuống ở các đỉnh số 6 và số 7 (còn khoảng 70 Mflits/s) thì tần số cũng
được điều chỉnh tương ứng ở mức thấp nhất. Ở trong vùng V3, ta cũng
thấy rõ sự đáp ứng một cách tức thời của tín hiệu điều khiển tần số
tương ứng với sự thay đổi của lưu lượng truyền thông.
6.4. Mô phỏng và đánh giá hiệu quả của bộ điều khiển tần số -
điện áp
Tiếp theo phần thiết kế và mô hình hóa khối điều khiển tần số -
điện áp cho bộ định tuyến trong mạng trên chip, phần này sẽ trình bày
phương pháp mô phỏng và đánh giá hiệu quả của mô hình đề xuất.
Theo đó, chúng ta sẽ lần lượt đề cập đến mô hình ORION - một mô
hình cho phép ước lượng, đánh giá năng lượng tiêu thụ của mạng trên
chip với độ chính xác gần bằng với các kết quả tổng hợp phần cứng.

Chương 6. Ứng dụng lô-gic mờ trong thiết kế mạng trên chip… 159
Tiếp theo, chúng ta sẽ tìm hiểu việc sử dụng phần mềm mô phỏng
VNOC 2.0 và trao đổi về một số chiến lược đánh giá hiệu năng tiêu
thụ năng lượng của bộ điều khiển tần số - điện áp.
6.4.1. Ước lượng công suất tiêu thụ của một mạng trên chip
Mạng trên chip đã và đang chứng tỏ là một kiến trúc truyền thông
trên chip phù hợp với các hệ thống đa lõi nhờ những đặc tính như độ trễ
truyền thấp và khả năng mở rộng cao. Tuy nhiên, do tích hợp ngày càng
nhiều các lõi IP lên cùng một hệ thống nên việc triển khai hệ thống
mạng trên chip phải đối mặt với vấn đề tối ưu về độ trễ truyền và công
suất tiêu thụ. Để có thể hỗ trợ các nhà thiết kế lựa chọn được một mô
hình tốt ở thời điểm bắt đầu thiết kế một hệ thống, những mô hình hỗ
trợ mô phỏng và ước lượng năng lượng tiêu thụ cũng như độ trễ truyền
trên một mạng trên chip ngày càng yêu cầu phải có độ chính xác cao.
Với một mô hình tốt thì độ chính xác của quá trình mô phỏng, ước
lượng về mặt công suất tiêu thụ trên hệ thống có thể đạt đến sai số
không quá 10% so với thực tế triển khai hệ thống thực [114].
a) ORION 3 - một mô hình hiệu quả để đánh giá năng lượng tiêu
thụ cho mạng trên chip
Để có thể mô phỏng và ước lượng được công suất tiêu thụ của
một mạng trên chip ở mức kiến trúc, các mô hình ước lượng thường
được xây dựng dựa trên hai hướng tiếp cận chính sau:
Mô hình được xây dựng dựa trên các mô hình mẫu có sẵn ở
mức kiến trúc (chẳng hạn như mô hình ORION 2 [115, 116]). Với
hướng tiếp cận này, một tập các mô hình mẫu về công suất tiêu thụ và
diện tích thực thi của từng khối thành phần trong bộ định tuyến sẽ
được đề xuất. Các khối chính của bộ định tuyến mà các mô hình này
thường dùng để xây dựng tập mẫu là: bộ đệm cổng vào/ra, các
crossbar, các chuyển mạch (switch), bộ phân chia kênh ảo (VC
arbiter). Tuỳ thuộc vào kiến trúc cụ thể của bộ định tuyến cần thiết kế
mà mô hình mẫu phù hợp với từng khối thành phần sẽ được lựa chọn
để cho phép mô phỏng và ước lượng được công suất tiêu thụ và diện
tích thực thi của hệ thống mạng trên chip.

160 Mạng trên chip
Cách tiếp cận thứ hai là các mô hình mô phỏng được xây dựng
dựa trên việc phân tích hồi quy các dữ liệu thu được từ sau khi thực
hiện quá trình đặt chỗ và định tuyến (post Place & Route) [117, 118].
Bên cạnh hai hướng tiếp cận trên, một số mô hình khác cũng đã
được đề xuất dựa trên dữ liệu của quá trình tiền layout (tổng hợp mức
RTL hoặc mức cổng lô-gic) [119, 120, 121, 122, 123] hoặc là của quá
trình sau layout (post layout) [124, 125, 126, 127]. Trong [123], các
tác giả đã đề xuất mô hình xác định công suất tiêu thụ cho mạng trên
chip dựa vào việc xác định số lượng transistor mà kiến trúc đó sử
dụng. Tuy nhiên, mô hình này có nhược điểm là sai số rất lớn vì nó
không xác định được các tham số đặc trưng cho việc tiêu thụ năng
lượng của từng khối riêng rẽ trong một kiến trúc mạng trên chip.
Chang và đồng nghiệp [119] cũng phát triển một mô hình mô phỏng
khác cho phép ước lượng công suất tiêu thụ theo từng chu kỳ. Tuy
vậy, sai số của mô hình này cũng vẫn lên đến 20%. Với hướng tiếp
cận bằng việc xác định các tham số hồi quy, nhóm nghiên cứu của
Meloni [126] và nhóm nghiên cứu của Lee [121] đã đề xuất mô hình
phân tích hồi quy dựa trên dữ liệu của quá trình mô phỏng sau layout
và mô phỏng lô-gic ở mức RTL. Tuy vậy, các mô hình này vẫn còn
khá thô và chưa giải thích được sự phân bổ năng lượng tiêu thụ trong
từng khối thành phần của mạng trên chip khi tải mạng thay đổi.
Tương tự như các mô hình trên, ORION 3 cũng sử dụng mô hình
các tham số với độ chính xác cao bằng cách phân tích hồi quy các
tham số với phương pháp bình phương tối thiểu để tăng độ chính xác
của những tham số này. Bằng việc tính toán hồi quy cho các tham số
dựa trên các công nghệ chế tạo 65nm và 45nm, mô hình ORION 3 có
thể đạt được sai số không quá 9,8% [114] so với quá trình thực thi
thực tế. Bên cạnh đó, mô hình này còn được mở rộng để cho phép
tăng tính chính xác của việc mô phỏng bằng cách thêm vào quá trình
tính toán ước lượng năng lượng tiêu thụ của hệ thống ở mức truyền
từng flit. Đây chính là lý do chúng tôi lựa chọn mô hình ORION 3 để
đánh giá nhanh hiệu quả của giải pháp thiết kế mạng trên chip công
suất thấp đề xuất ở trên.

Chương 6. Ứng dụng lô-gic mờ trong thiết kế mạng trên chip… 161
Cấu trúc của mô hình ORION 3
Mô hình ORION 3 được mô hình hóa dưới dạng từng khối thành
phần của một bộ định tuyến. Mô hình của từng khối thành phần được
các tác giả phát triển dựa trên việc phân tích quá trình sau tổng hợp
(post-synthesis) và netlists được sinh ra từ quá trình đặt chỗ và định
tuyến (P&R) của hai bộ định tuyến là Net Maker (được phát triển bởi
Đại học Cambridge) và Open Source NoC router (được phát triển bởi
Đại học Standford). Các khối thành phần của bộ định tuyến được mô
hình hóa trong mô hình này bao gồm: bộ đệm vào, các chuyển mạch
và bộ phân chia kênh ảo (VC arbiter), bộ chuyển mạch chéo (crossbar)
và bộ đệm đầu ra (Hình 6-26). Dựa vào việc phân chia các khối thành
phần của bộ định tuyến, mô hình ORION dùng các tham số sau để đặc
trưng cho từng khối thành phần: P: các cổng vào ra; V: bộ phân chia
kênh ảo; B: các bộ đệm; F: chiều dài của flit. Ngoài ra, để nâng cao độ
chính xác của mô hình so với các phiên bản trước, một số yếu tố sau
đã được bổ sung thêm vào trong mô hình ORION 3:
Các tài nguyên điều khiển: chẳng hạn như các tín hiệu lựa chọn
FIFO và giải mã lô-gic ở các bộ đệm vào/ra.
Mô hình hóa bộ chuyển mạch chéo dưới dạng mạch ba trạng thái.
Bổ sung thêm tài nguyên của bộ đệm vào để tối ưu độ trễ cho
các bộ phân xử.
Các bộ đệm đầu ra được mô hình hóa để chỉ lưu trữ flit tiêu đề.
Hình 6-26: Mô hình cấu trúc từng khối thành phần của một bộ định tuyến
trong mô hình ORION 3 [114].

162 Mạng trên chip
Các khối thành phần được mô hình hóa với độ ảnh hưởng theo
từng tham số đến công suất tiêu thụ của bộ định tuyến như sau:
Mô hình của khối chuyển mạch chéo: khối chuyển mạch chéo
này làm nhiệm vụ đấu nối giữa hai đầu vào và đầu ra bất kỳ trên bộ
định tuyến với nhau để cho phép các flit truyền qua bộ định tuyến từ
các cổng tương ứng. Trong mô hình ORION 3, bộ chuyển mạch chéo
được mô hình hóa với tham số là .
Mô hình khối chuyển mạch và bộ phân chia kênh ảo: đây là
khối đưa ra các tín hiệu điều khiển cho bộ chuyển mạch chéo nhằm có
thể thiết lập một kết nối từ cổng vào đến cổng ra theo yêu cầu truyền
thông. Trong mô hình ORION 3, khối khối chuyển mạch và bộ phân
chia kênh ảo này được mô hình hóa với tham số là:
.
Mô hình khối đệm đầu vào: khối đệm đầu vào làm nhiệm vụ
chứa các flit đến ở từng cổng lối vào nhằm chuẩn bị cho việc giải mã
để xác định được cổng ra tương ứng của flit đó. Số bộ đệm FIFO trong
khối đệm đầu vào được mô hình hóa với tham số là
. Sau khi phân tích quá trình tổng hợp và quá trình đặt chỗ và định
tuyến (P&R), các tín hiệu điều khiển của khối đệm đầu vào được mô
hình hóa theo công thức:
.
Mô hình bộ đệm đầu ra: bộ đệm đầu ra có nhiệm vụ lưu trữ các
flit tiêu đề khi những flit này chuyển từ các chuyển mạch ra các kênh
truyền tiếp theo. Mục đích của bộ đệm đầu ra là để có thể đồng bộ
được tốc độ truyền của flit giữa các chuyển mạch và kênh truyền
tương ứng. Bộ đệm ra được mô hình hóa với tham số là . Tuy
nhiên, do mỗi cổng lại có thêm nhiều tín hiệu điều khiển khác và cả
các bộ kênh ảo cho riêng từng cổng, nên tham số mô hình cho bộ đệm
phải bổ sung thêm một lượng là .
b) Phần mềm mô phỏng VNOC 2.0
Phần mềm VNOC 2.0 được tác giả Cristinel Ababei (Đại học
Marquette, Cộng hòa Ý) phát triển để mô phỏng các hoạt động của

Chương 6. Ứng dụng lô-gic mờ trong thiết kế mạng trên chip… 163
mạng trên chip [112]. Phần mềm này được phát triển bằng ngôn ngữ
C++ và cho phép người dùng thay đổi mã nguồn để tuỳ biến phù hợp
với mục đích sử dụng của mình. Bên cạnh việc hỗ trợ mô phỏng các
hoạt động thông thường của một mạng trên chip, VNOC 2.0 còn được
tích hợp hai mô hình ORION 2 và ORION 3 cho phép ước lượng năng
lượng tiêu thụ của mạng trên chip đó trong quá trình mô phỏng. Vì
vậy, người dùng có thể áp dụng các thuật toán về điều khiển tần số -
điện áp dựa trên phương pháp DVFS trên mạng trên chip và nhận
được các kết quả mô phỏng về năng lượng mà hệ thống đã tiêu thụ.
Có thể nói, đây là một trong những phần mềm hiếm hoi cho phép
người thiết kế có thể mô phỏng những thuật toán DVFS trên các mạng
trên chip ở mức hệ thống nhằm có thể kiểm tra những thuật toán này
tại thời điểm bắt đầu một thiết kế.
Một số ưu điểm của phần mềm VNOC 2.0 so với những công cụ
mô phỏng mạng trên chip khác là:
Được phát triển bằng C++, dễ dàng sửa đổi và tích hợp thêm
các thuật toán điều khiển DVFS. VNOC 2.0 hỗ trợ sẵn các hàm điều
khiển điện áp, tần số của các bộ định tuyến trong mạng.
Hỗ trợ mô phỏng nhiều mô hình truyền thông khác nhau trên
mạng trên chip như: uniform, transpose, hotspot và selfsimilar.
Được tích hợp mô hình mô phỏng ORION 2 và ORION 3.
VNOC 2.0 hỗ trợ mô phỏng tính toán năng lượng tiêu thụ cho mạng
trên chip.
Phần mềm VNOC 2.0 được tác giả phát triển trên nền tảng hệ
điều hành Linux Ubuntu 12.04 LTS (64bit). Để chạy được VNOC 2.0,
người dùng cần cài thêm một số gói thư viện cần thiết. Nếu biên dịch
thành công, file thực thi vnoc sẽ được tạo ra. Sau đó, chúng ta có thể
chạy lệnh vnoc để xem hướng dẫn về các tham số của phần mềm. Các
tham số cần thiết để chạy một quá trình mô phỏng trong VNOC 2.0
được mô tả như sau:
trace_file: tên của trace file (sử dụng trong trường hợp mô
phỏng truyền thông thực).

164 Mạng trên chip
traffic: kiểu mô hình truyền thông (kiểu mô hình truyền thông
phải thuộc một trong những dạng sau: Uniform, Hotspot, Transpose1,
Transpose2, Selfsimilar và Tracefile). Theo đó, UNIFORM là truyền
thông theo mô hình phân bố chuẩn. HOTSPOT là truyền thông theo mô
hình chỉ phát ở một số nút mạng. TRANSPOSE1 và TRANSPOSE2 là
truyền thông theo mô hình chuyển vị. SELFSIMILAR là truyền thông
theo mô hình tự ánh xạ. TRACEFILE là truyền thông theo kịch bản có
sẵn (lấy từ tập tin ghi lại một quá trình truyền thông trên mạng thật).
hotspots: danh sách của nút hotspot trong mạng nếu ta mô
phỏng với kiểu HOTSPOT.
hotspot_percentage: xác suất các gói gửi qua nút hotspot.
injection_rate: tỷ lệ gói tin gửi vào mạng.
ary_size: kích thước mạng.
packet_size: kích thước gói tin.
flit_size: kích thước của flit.
inp_buf: kích thước bộ đệm input-port.
out_buf: kích thước bộ đệm output-port.
routing: dạng thuật toán định tuyến (XY hoặc TXY - Torus XY).
vc_n: số lượng kênh ảo.
link_bw: băng thông của các liên kết (link).
cycles: số chu kỳ xung cần chạy mô phỏng.
warmup: số lượng xung cần chạy “Warmup”.
hist_window: khung thời gian lấy mẫu cho một dự đoán.
do_dvfs: có áp dụng điều khiển DVFS hoặc không.
dvfs_mode: chế độ điều khiển DVFS (phải thuộc hai dạng:
SYNC or ASYNC).

Chương 6. Ứng dụng lô-gic mờ trong thiết kế mạng trên chip… 165
use_link_pred: có sử dụng dự đoán về mức độ sử dụng liên kết
(Link Utilization) hay không.
Để có thể sử dụng VNOC 2.0 mô phỏng và đánh giá hiệu năng
của bộ điều khiển tần số - điện áp, chúng ta cần chỉnh sửa mã nguồn
của VNOC 2.0 cho phù hợp với bộ điều khiển tần số - điện áp VFC đã
thiết kế. Thuật toán phân phối DVFS của chương trình sẽ được thay
bởi thuật toán dựa trên lô-gic mờ. Chương trình VNOC 2.0 hỗ trợ sẵn
thuật toán phân phối DVFS dựa trên dữ liệu của tải mạng trong quá
khứ để dự đoán sự thay đổi của tải. Thuật toán này hoạt động với hai
phương thức là đồng bộ (tham số SYNC) và bất đồng bộ (tham số
ASYNC). Trong nghiên cứu của chúng tôi, đoạn chương trình
ASYNC đã được thay bằng đoạn chương trình thực hiện thuật toán
FUZZY. Vì vậy, tham số để sử dụng bộ FUZZY như là khối điều
khiển DVFS khi mô phỏng sẽ là dvfs_mode: ASYNC.
Phần mềm VNOC 2.0 cũng cung cấp hai thông số cho người sử
dụng có thể dùng để dự đoán mức độ hoạt động của mạng đó là: mức
độ sử dụng bộ đệm trên mỗi cổng BU và mức độ sử dụng liên kết trên
mỗi cổng LU. Trong đó, thông số LU được xác định chính là số lượng
flit truyền qua liên kết đó trong một khung thời gian lấy mẫu (được
gọi là: history window – hist_window). Giá trị của LU sẽ nhận được
thông qua hàm: counter_flits_sent_during_hw(int i)}. Để triển khai
thuật toán lô-gic mờ, thông số LU và giá trị biến thiên của nó qua một
khung thời gian (hist_window) sẽ được sử dụng để làm đầu vào cho
khối lô-gic mờ của bộ điều khiển tần số - điện áp VFC. Việc sử dụng
tham số nào để đánh giá tải mạng sẽ phụ thuộc tham số use_link_pred.
Nếu tham số này có giá trị „0‟ thì thông số BU sẽ được sử dụng và nếu
nó có giá trị là „1‟ thì thông số LU sẽ được sử dụng. Vì sử dụng thông
số LU là đầu vào của khối điều khiển tần số - điện áp nên chương
trình mô phỏng phải thiết lập với tham số use_link_pred = 1. Đoạn mã
chương trình mô tả quá trình thay thế thuật toán phân phối DVFS
bằng khối lô-gic mờ được thể hiện như ở dưới đây.

166 Mạng trên chip
if (use_link_pred() = true) {
for (i = 1; i < 4; i++) {
if (_LU_predicted_out_i[i] < _LU_predicted_out_i[i+1])
{
_LU_predicted_max = int(_LU_predicted_out_i[i+1]);
_LU_predicted_der_max=int(_LU_predicted_out_i_der[i+1]);
} else
{
_LU_predicted_max = int(_LU_predicted_out_i[i]);
_LU_predicted_der_max = int(_LU_predicted_out_i_der[i]);
}
}
flp_out = flp(_LU_predicted_max,_LU_predicted_der_max);
Giá trị ở đầu ra của bộ điều khiển tần số - điện áp VFC sẽ được
sử dụng để điều khiển giá trị điện áp – tần số một cách phù hợp. Phần
mềm VNOC 2.0 cung cấp sẵn hàm cho phép thay đổi tần số và điện áp
của bộ định tuyến: set_frequencies_and_vdd(int DVFS_LEVEL).
4.4.2. Đánh giá hiệu quả của bộ điều khiển tần số - điện áp
Để mô phỏng hoạt động của mạng trên chip sau khi đã tích hợp
bộ điều khiển tần số - điện áp sử dụng thuật toán lô-gic mờ được,
chúng tôi sử dụng các cấu hình và tham số chính tham khảo từ bộ
thông số mô phỏng chuẩn ở các công trình [128, 112, 129] như sau:
NoC được cấu hình với mô hình mạng có cấu trúc liên kết dạng
lưới hai chiều (2D mesh) với kích thước mạng 8×8. NoC gồm 64 bộ
định tuyến với kích thước bộ đệm vào ở mỗi bộ là 18 flit (có độ rộng
64 bit) trên mỗi kênh ảo. Mỗi bộ định tuyến có bốn kênh ảo.
Các bộ định tuyến sẽ được nối với nhau thông qua các liên kết
với tổng độ dài là 2 mm và độ rộng bus là 64 bit. Tổng độ dài liên kết
được ước lượng dựa trên công nghệ và độ rộng bus đã chọn, đồng thời
tham khảo từ [112, 129].

Chương 6. Ứng dụng lô-gic mờ trong thiết kế mạng trên chip… 167
Mô hình truyền thông sử dụng trong các kịch bản mô phỏng
gồm hai dạng: UNIFORM và SELF-SIMILAR. Trong đó, mô hình
truyền thông UNIFORM là mô hình truyền thông chuẩn, được nhiều
nghiên cứu sử dụng để đánh giá hiệu năng hoạt động của mạng trên
chip. Riêng với mô hình truyền thông SELF-SIMILAR, đây được cho
là một mô hình truyền thông phản ánh gần đúng nhất quá trình truyền
thông trên mạng máy tính.
Các gói tin được đưa vào mạng với kích thước cố định là
6 flit/gói tin.
Tất cả các mô phỏng đều được chạy trong 100.000 chu kỳ xung
nhịp, trong đó 1.000 xung nhịp đầu tiên là để chạy khởi động (warmup).
Chế độ DVFS được áp dụng với ba cặp tần số - điện áp như sau:
, , .
Tần số được chọn phù hợp với lưu lượng truyền
thông cực đại mà bộ xử lý lô-gic mờ FLP có thể xử lý được. Các
mức điện áp được chọn phù hợp với công nghệ 65nm mà mô hình
ORION sử dụng.
Để có cơ sở đánh giá về hiệu quả tiết kiệm năng lượng của bộ
điều khiển tần số - điện áp đã thiết kế, các mô phỏng đối với các kiểu
truyền thông khác nhau đều được thiết lập để chạy với hai trường hợp
là: không áp dụng quá trình điều khiển DVFS và áp dụng quá trình
điều khiển DVFS. Với mỗi mô hình truyền thông khi áp dụng thuật
toán điều khiển DVFS, kịch bản mô phỏng sẽ được chạy với ba giá trị
khác nhau của khung thời gian lấy mẫu đó là: hist_window = 100,
hist_window = 150 và hist_window = 200. Tỷ lệ gói tin gửi vào mạng
sẽ được thay đổi trong từng kịch bản mô phỏng tùy thuộc vào kiểu
truyền thông được sử dụng để đảm bảo mạng không bị tắc nghẽn.
Để thu được các giá trị về công suất tiêu thụ và độ trễ truyền của
mạng khi chưa áp dụng quá trình điều khiển DVFS ta chạy lệnh mô
phỏng hoạt động của NoC với tham số do_dvfs = 0. Ví dụ:
vnoc traffic: UNIFORM injection_rate: 0.001 cycles:10000 do_dvfs:0

168 Mạng trên chip
Để thu được các giá trị về công suất tiêu thụ và độ trễ truyền của
mạng khi áp dụng quá trình điều khiển DVFS ta chạy lệnh mô phỏng
hoạt động của NoC với tham số do_dvfs1 = 1 và dvfs_mode =
ASYNC. Ví dụ:
vnoc traffic: UNIFORM injection_rate: 0.001 cycles: 10000 do_dvfs: 1
dvfs_mode: ASYNC use_link_pred: 1
6.4.3. Đánh giá hiệu năng với dạng truyền thông UNIFORM
Để đánh giá hiệu quả của bộ điều khiển tần số - điện áp đối với dạng
truyền thông UNIFORM, chúng tôi tiến hành chạy mô phỏng với thông
số lưu lượng dữ liệu truyền thông traffic được thiết lập là UNIFORM. Tỷ
lệ gói tin gửi vào mạng (thông số injection_rate) được thiết lập với giá trị
khởi đầu là 0,01 gói/chu kỳ và được tăng dần với bước giá trị là 0,005
gói/chu kỳ theo từng kịch bản mô phỏng. Qua khảo sát, khi hệ thống
được thiết lập để hoạt động ở chế độ điều khiển tỷ lệ điện áp và tần số
động DVFS và tỷ lệ gói tin gửi vào mạng lớn hơn 0,05 gói/chu kỳ thì
mạng sẽ bị tắc nghẽn. Vì vậy, các kịch bản mô phỏng sẽ thực hiện với tỷ
lệ gói tin gửi vào mạng không quá 0,05 gói/chu kỳ.
Kết quả mô phỏng thu được về năng lượng tiêu thụ của hệ thống
đối với dạng truyền thông UNIFORM được trình bày ở trong Bảng 6-2.
Đồ thị biểu diễn sự phụ thuộc của năng lượng tiêu thụ với tỷ lệ gói tin
gửi vào mạng trong trường hợp này được thể hiện như ở Hình 6-27.
Từ đồ thị, ta có thể thấy với trường hợp khung thời gian lấy mẫu nhỏ
(hist_window = 100) thì năng lượng tiêu thụ của hệ thống chỉ giảm rất
ít so với trường hợp khi chưa áp dụng kỹ thuật điều khiển tỷ lệ điện áp
và tần số động DVFS. Hiệu quả tiết kiệm năng lượng chỉ đạt khoảng
5,2% tương ứng với tỷ lệ gói tin gửi vào mạng là 0,05 gói/chu kỳ.
Điều này có thể giải thích là với thời gian lấy mẫu ngắn thì bộ xử lý
lô-gic mờ sẽ không kịp thu đủ dữ liệu để có thể đưa ra quyết định về
thay đổi tần số - điện áp cho hệ thống. Với kết quả thu được, ta có thể
thấy đối với mô hình truyền thông kiểu UNIFORM thì bộ điều khiển
tần số - điện áp đã được đề xuất có thể đạt hiệu quả tiết kiệm năng

Chương 6. Ứng dụng lô-gic mờ trong thiết kế mạng trên chip… 169
lượng lên đến 43% tương ứng với tỷ lệ gói tin gửi vào mạng là 0,05
gói/chu kỳ và thông số hist_window = 200.
Bảng 6-2: Công suất tiêu thụ đối với kiểu truyền thông UNIFORM
Tỷ lệ đưa gói
tin vào mạng Công suất tiêu thụ (W)
(gói/chu kỳ) No_DVFS DVFS_100 DVFS_150 DVFS_200
0,010 1,4361 1,4359 1,4355 1,4345
0,015 1,7062 1,706 1,7056 1,7012
0,020 1,9756 1,9753 1,9713 1,9424
0,025 2,2441 2,2425 2,2201 2,1049
0,030 2,5147 2,51 2,432 2,1811
0,035 2,7845 2,7712 2,5713 2,2087
0,040 3,0464 3,0075 2,6515 2,2391
0,045 3,3191 3,2248 2,7074 2,2618
0,050 3,5855 3,3992 2,7394 2,3029
Hình 6-27: Công suất tiêu thụ đối với kiểu truyền thông UNIFORM.
1
1,5
2
2,5
3
3,5
4
0 0,01 0,02 0,03 0,04 0,05
CÔ
NG
SU
ẤT
(W
)
TỶ LỆ GÓI TIN ĐƯA VÀO MẠNG (GÓI/CHU KỲ)
No_DVFS DVFS_100 DVFS_150 DVFS_200

170 Mạng trên chip
Các kết quả mô phỏng về độ trễ truyền được trình bày như ở
trong Bảng 6-3. Đồ thị biểu diễn sự phụ thuộc của độ trễ truyền với tỷ
lệ gói tin gửi vào mạng được thể hiện như trong Hình 6-28. Kết quả
thu được cho thấy trong trường hợp tỷ lệ gói tin là 0,05 gói/chu kỳ thì
độ trễ truyền cũng chỉ tăng thêm tối đa khoảng 80% so với trường hợp
không áp dụng kỹ thuật điều khiển tỷ lệ điện áp và tần số động DVFS.
Bảng 6-3: Độ trễ truyền đối với kiểu truyền thông UNIFORM
Tỷ lệ đưa gói
tin vào mạng Độ trễ truyền (chu kỳ)
(gói/chu kỳ) No_DVFS DVFS_100 DVFS_150 DVFS_200
0,010 35,3127 35,3127 35,3127 35,3194
0,015 36,0762 36,0762 36,1397 36,3049
0,020 36,941 36,9424 37,1928 37,5584
0,025 37,9287 37,9944 38,4316 39,4467
0,030 39,2962 39,4951 40,3443 42,4035
0,035 40,9304 41,3328 43,1801 46,3998
0,040 42,9702 43,7516 47,2628 54,2017
0,045 46,0000 47,5315 53,7371 65,1928
0,050 49,7726 53,2126 65,6165 92,0129
Hình 6-28: Độ trễ truyền đối với kiểu truyền thông UNIFORM.
30
40
50
60
70
80
90
100
0 0,01 0,02 0,03 0,04 0,05
ĐỘ
TR
Ễ (
CH
U K
Ỳ)
TỶ LỆ ĐƯA GÓI TIN VÀO MẠNG (GÓI/CHU KỲ)
No_DVFS DVFS_100 DVFS_150 DVFS_200

Chương 6. Ứng dụng lô-gic mờ trong thiết kế mạng trên chip… 171
6.4.4. Đánh giá hiệu năng với dạng truyền thông SELF-SIMILAR
Đối với mô hình truyền thông dạng SELF-SIMILAR, chúng tôi
tiến hành chạy các kịch bản mô phỏng tương tự như ở Mục 6.4.3
nhưng với thông số traffic được thiết lập là SELF-SIMILAR. Tỷ lệ gói
tin gửi vào mạng được thiết lập với giá trị khởi đầu là 0,001 gói/chu
kỳ và sẽ được thay đổi qua từng kịch bản với bước giá trị là 0,001
gói/chu kỳ. Với tỷ lệ gói tin vào khoảng 0,019 gói/chu kỳ, mạng cũng
sẽ bị tắc nghẽn; do đó, các kịch bản mô phỏng sẽ không được thiết lập
giá trị injection_rate vượt quá ngưỡng này. Kết quả mô phỏng về công
suất tiêu thụ của mạng đối với kiểu truyền thông này được trình bày
chi tiết ở Bảng 6-4. Đồ thị biểu diễn sự phụ thuộc của công suất tiêu
thụ với tỷ lệ gói tin gửi vào mạng trong các trường hợp khác nhau của
thông số hist_window cũng được thể hiện như ở Hình 6-29.
Bảng 6-4: Công suất tiêu thụ đối với kiểu truyền thông SELF-SIMILAR
Tỷ lệ đưa gói
tin vào mạng Công suất tiêu thụ (W)
(gói/chu kỳ) No_DVFS DVFS_100 DVFS_150 DVFS_200
0,0010 0,9501 0,9506 0,9475 0,9475
0,0021 1,0038 1,0082 1,0065 1,0026
0,0033 1,0721 1,0690 1,0606 1,0526
0,0044 1,1324 1,1255 1,1168 1,1055
0,0055 1,1914 1,1825 1,1698 1,1566
0,0065 1,2445 1,2410 1,2281 1,2019
0,0077 1,3124 1,3007 1,2807 1,2486
0,0089 1,3751 1,3597 1,3281 1,2930
0,0100 1,4295 1,4120 1,3845 1,3394
0,0111 1,4895 1,4792 1,4312 1,3679
0,0122 1,5449 1,5236 1,4834 1,4081
0,0134 1,6126 1,5961 1,5273 1,4395
0,0142 1,6491 1,6490 1,5799 1,4765
0,0155 1,7191 1,7098 1,6390 1,5146
0,0166 1,7869 1,7669 1,6903 1,5468
0,0177 1,8415 1,8427 1,7285 1,5857
0,0188 1,9015 1,9012 1,7894 1,6103

172 Mạng trên chip
Hình 6-29: Công suất tiêu thụ đối với kiểu truyền thông SELF-SIMILAR.
Cũng tương tự như với kiểu truyền thông UNIFORM, đối với
trường hợp hist_window = 100 ta thấy công suất tiêu thụ trong hai
trường hợp áp dụng kỹ thuật điều khiển tỷ lệ điện áp và tần số động
DVFS và không áp dụng kỹ thuật này là gần như không thay đổi. Tỷ lệ
hiệu quả về mặt tiêu thụ năng lượng đối với dạng truyền thông này cũng
chỉ đạt tối đa khoảng 15% (trong trường hợp hist_window = 200). Có
thể thấy rằng đối với mô hình truyền thông dạng SELF-SIMILAR thì
hiệu quả tiết kiệm năng lượng của bộ điều khiển được đề xuất là không
cao. Điều này có thể lý giải là do mô hình SELF-SIMILAR tuy được
đánh giá là dạng truyền thông phản ánh khá đúng với quá trình truyền
thông trên mạng [130] nhưng nó chỉ phù hợp với các mạng có độ phức
tạp cao như mạng máy tính. Trong những mô hình mạng đơn giản như
mô hình mạng trên chip thì dạng truyền thông này chưa thể phản ánh
sát với khả năng truyền thông thực tế của mạng.
Các kết quả mô phỏng về độ trễ truyền của kiểu truyền thông
SELF-SIMILAR cũng được trình bày như ở Bảng 6-5. Đồ thị biểu
diễn sự thay đổi về giá trị của độ trễ truyền theo tỷ lệ gói tin gửi vào
mạng trong từng trường hợp thông số hist_window khác nhau cũng
được thể hiện như trong Hình 6-30. Từ kết quả ta thấy độ trễ truyền
tăng thêm khoảng 88% với trường hợp hist_window = 200 và tỷ lệ gói
tin gửi vào mạng ở mức 0,019 gói/chu kỳ. Tuy nhiên, trong trường
hợp này ta thấy độ trễ truyền đã bắt đầu tăng đột biến nên sẽ làm tắc
nghẽn mạng nếu tỷ lệ gói tin gửi vào lớn hơn giá trị 0,019 gói/chu kỳ.
0,80
1,00
1,20
1,40
1,60
1,80
2,00
0,0000 0,0050 0,0100 0,0150 0,0200
CÔ
NG
SU
ẤT
(W
)
TỶ LỆ ĐƯA GÓI TIN VÀO MẠNG (GÓI/CHU KỲ)
No_DVFS DVFS_100 DVFS_150 DVFS_200

Chương 6. Ứng dụng lô-gic mờ trong thiết kế mạng trên chip… 173
Bảng 6-5: Độ trễ truyền đối với kiểu truyền thông SELF-SIMILAR
Tỷ lệ đưa gói
tin vào mạng Độ trễ truyền (cycles)
(gói/chu kỳ) No_DVFS DVFS_100 DVFS_150 DVFS_200
0,0010 62,4448 63,7469 63,1168 64,4616
0,0021 66,0308 67,1209 68,3670 68,0480
0,0033 70,2799 69,7621 70,5225 69,6866
0,0044 72,3271 72,4358 73,6598 75,0464
0,0055 75,4287 74,4464 75,4435 77,4675
0,0065 76,8289 78,2567 80,2838 79,8564
0,0077 81,5980 82,1508 84,7751 85,6886
0,0089 85,7357 87,7644 89,1817 97,0321
0,0100 88,4889 90,0644 95,6485 101,4250
0,0111 96,7212 96,0298 102,4270 105,9849
0,0122 100,2125 98,5326 109,5057 119,0150
0,0134 110,0215 111,0377 118,0791 126,4432
0,0142 117,6606 119,6319 133,1088 136,2806
0,0155 126,6277 128,9624 140,6516 159,5778
0,0166 139,0773 135,2421 154,3833 183,3667
0,0177 148,3676 156,9831 171,8460 246,2747
0,0188 168,5772 190,7613 204,7842 317,1215
Hình 6-30: Độ trễ truyền đối với kiểu truyền thông SELF-SIMILAR.
50
100
150
200
250
300
350
0,0000 0,0050 0,0100 0,0150 0,0200
ĐỘ
TR
Ẽ T
RU
YỀ
N (
CH
U K
Ỳ)
TỶ LỆ ĐƯA GÓI TIN VÀO MẠNG (GÓI/CHU KỲ)
No_DVFS DVFS_100 DVFS_150 DVFS_200

174 Mạng trên chip
Kết quả thực nghiệm được so sánh với một số công trình nghiên
cứu liên quan như ở trong Bảng 6-6. Với cùng công nghệ CMOS
65nm (như đối với mô hình ORION đã áp dụng), ta thấy kiến trúc
ALPIN [94] có khả năng tiết kiệm năng lượng tiêu thụ rất cao (từ 80%
đến 100% so với mức HIGH). Tuy nhiên, để đạt được điều này thì
Beigné và đồng nghiệp đã áp dụng rất nhiều kỹ thuật tiết kiệm năng
lượng khác nhau (DVS, Ultra-Cut-Off) trên nhiều phần khác nhau của
kiến trúc ALPIN nhằm tiết kiệm cả công suất tiêu thụ động và công
suất tiêu thụ tĩnh. Trong khi đó, trong nghiên cứu này chúng tôi chỉ
tập trung tiết kiệm công suất tiêu thụ động cho một thành phần nhỏ
của một NoC đó là các bộ định tuyến.
Công trình của nhóm Pillamari [57] và Zakaria [99] cũng áp dụng
kỹ thuật điều khiển tỷ lệ điện áp và tần số động DVFS để thay đổi
điện áp - tần số cho từng phân vùng trên NoC (mỗi phân vùng là bao
gồm cả lõi IP và bộ định tuyến). Do đó, khả năng tiết kiệm năng lượng
của những hệ thống này khá cao. Với công trình [99] thì có thể tiết
kiệm tới hơn 50% công suất tiêu thụ. Tuy nhiên, công trình [99] được
tổng hợp trên công nghệ CMOS 45nm là công nghệ tiên tiến hơn
nhiều so với công nghệ CMOS 65nm mà nhóm chúng tôi sử dụng.
Công trình [57] chỉ đạt được hiệu suất tiết kiệm khoảng 30% do phải
thực thi trên công nghệ CMOS 90nm. Tuy vậy, công trình này lại áp
dụng kỹ thuật điều khiển tỷ lệ điện áp và tần số động DVFS cho
những phân vùng lớn của NoC nên nếu so sánh với kết quả của chúng
tôi thì hiệu quả đạt được vẫn thấp hơn.
Công trình do Ababei và đồng nghiệp đề xuất [112] là một công
trình có hướng tiếp cận khá gần với nghiên cứu của chúng tôi khi đều
hướng đến việc áp dụng kỹ thuật điều khiển tỷ lệ điện áp và tần số
động DVFS cho bộ định tuyến để giảm được công suất tiêu thụ cho hệ
thống. Cả hai nghiên cứu đều được mô phỏng trong cùng điều kiện khi
cùng sử dụng mô hình ORION với công nghệ CMOS 65nm của hãng
TSMC. Trong công trình [112], các tác giả đã đề xuất một thuật toán
cho phép giảm công suất tiêu thụ của bộ định tuyến trong hệ thống lên

Chương 6. Ứng dụng lô-gic mờ trong thiết kế mạng trên chip… 175
tới 50% với độ trễ truyền tăng thêm khoảng gần 150%. Trong khi đó,
với kết quả mô phỏng của chúng tôi cho thấy bộ điều khiển lô-gic mờ
được đề xuất cho phép giảm công suất của bộ định tuyến trong hệ
thống khoảng 43% và độ trễ truyền chỉ tăng tối đa khoảng 80%.
Việc so sánh kết quả nghiên cứu từ những công trình trên cho
thấy trong điều kiện sử dụng cùng một công nghệ và đều áp dụng kỹ
thuật điều khiển tỷ lệ điện áp và tần số động DVFS thì kết quả mà
chúng tôi thu được cũng tương đương với các kết quả của những công
trình khác trên thế giới.
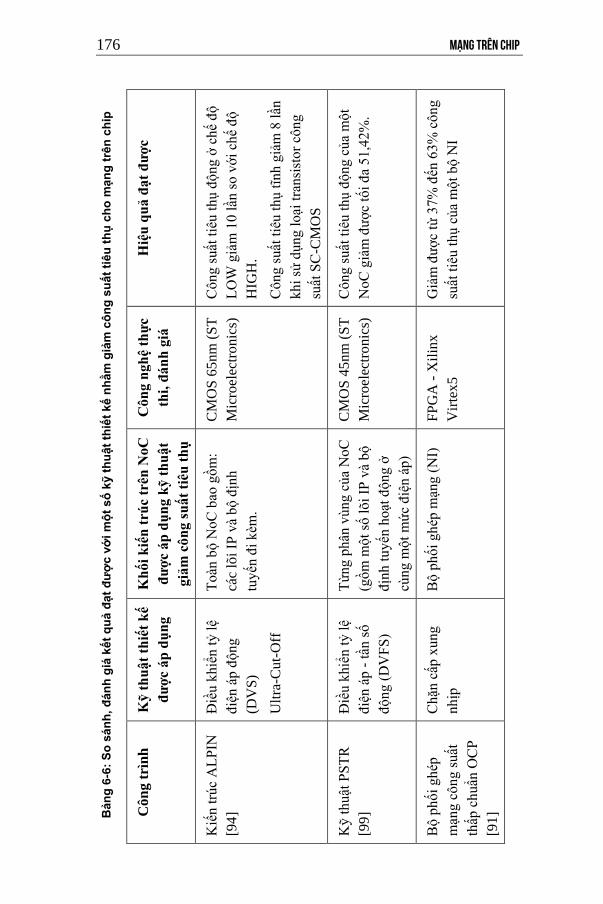
17
6
Mạ
ng
tr
ên
ch
ip
176 Mạng trên chip
Bản
g 6
-6:
So
sán
h,
đán
h g
iá k
ết
qu
ả đ
ạt
đư
ợc v
ới
mộ
t số
kỹ t
hu
ật
thiế
t kế n
hằm
giả
m c
ôn
g s
uất
tiêu
th
ụ c
ho
mạ
ng
trê
n c
hip
Côn
g t
rìn
h
Kỹ
th
uậ
t th
iết
kế
đư
ợc
áp
dụ
ng
Kh
ối
kiế
n t
rúc
trên
NoC
đư
ợc
áp
dụ
ng
kỹ
th
uậ
t
giả
m c
ôn
g s
uấ
t ti
êu t
hụ
Côn
g n
gh
ệ th
ực
thi,
đá
nh
giá
Hiệ
u q
uả
đạ
t đ
ượ
c
Kiế
n t
rúc
AL
PIN
[94
]
Điề
u k
hiể
n t
ỷ l
ệ
điệ
n á
p đ
ộn
g
(DV
S)
Ult
ra-C
ut-
Off
To
àn b
ộ N
oC
bao
gồm
:
các
lõi
IP v
à b
ộ đ
ịnh
tuy
ến đ
i kèm
.
CM
OS
65
nm
(S
T
Mic
roel
ectr
onic
s)
Côn
g s
uất
tiê
u t
hụ đ
ộng ở
chế
độ
LO
W g
iảm
10 l
ần s
o v
ới
chế
độ
HIG
H.
Côn
g s
uất
tiê
u t
hụ t
ĩnh g
iảm
8 l
ần
kh
i sử
dụng l
oại
tra
nsi
sto
r cô
ng
suất
SC
-CM
OS
Kỹ
thu
ật P
ST
R
[99
]
Điề
u k
hiể
n t
ỷ l
ệ
điệ
n á
p -
tần
số
độ
ng
(D
VF
S)
Từ
ng
phân
vùng
của
No
C
(gồ
m m
ột
số l
õi
IP v
à bộ
địn
h t
uy
ến h
oạt
độn
g ở
cùn
g m
ột
mứ
c điệ
n á
p)
CM
OS
45
nm
(S
T
Mic
roel
ectr
onic
s)
Côn
g s
uất
tiê
u t
hụ đ
ộng c
ủa
một
NoC
giả
m đ
ượ
c tố
i đ
a 51
,42%
.
Bộ p
hối
gh
ép
mạn
g c
ôn
g s
uất
thấp
ch
uẩn
OC
P
[91
]
Ch
ặn c
ấp x
un
g
nh
ịp
Bộ
ph
ối
gh
ép m
ạng
(N
I)
FP
GA
- X
ilin
x
Vir
tex5
Giả
m đ
ượ
c từ
37%
đến
63%
côn
g
suất
tiê
u t
hụ c
ủa
một
bộ N
I

Chương 6
. Ứ
ng d
ụng lô
-gic
mờ tro
ng thiế
t kế
mạn
g trê
n ch
ip…
177
Chương 6. Ứng dụng lô-gic mờ trong thiết kế mạng trên chip… 177
Kiế
n t
rúc
Pro
du
cer
-
Con
sum
er F
IFO
[57
]
Điề
u k
hiể
n t
ỷ l
ệ
điệ
n á
p -
tần
số
độ
ng
(D
VF
S)
Từ
ng
phân
vùng
của
No
C
(gồ
m m
ột
số l
õi
IP v
à bộ
địn
h t
uy
ến h
oạt
độn
g ở
cùn
g m
ột
mứ
c điệ
n á
p)
CM
OS
90
nm
(TS
MC
)
Giả
m đ
ượ
c tố
i đ
a 32
,2%
cô
ng
suất
tiê
u t
hụ đ
ộng
của
một
No
C.
Th
uật
to
án p
hân
ph
ối
DV
FS
[11
2]
Điề
u k
hiể
n t
ỷ l
ệ
điệ
n á
p -
tần
số
độ
ng
(D
VF
S)
Bộ
địn
h t
uy
ến m
ạng
(ro
ute
r)
CM
OS
65
nm
(TS
MC
)
Giả
m đ
ượ
c tố
i đ
a 50
% c
ông s
uất
tiêu
th
ụ đ
ộng
của
toàn
bộ c
ác b
ộ
địn
h t
uy
ến t
ron
g m
ột
No
C.
Bộ đ
iều k
hiể
n
lô-g
ic m
ờ đ
ượ
c đ
ề
xu
ất [
11
1,
131,
10
1]
Điề
u k
hiể
n t
ỷ l
ệ
điệ
n á
p -
tần
số
độ
ng
(D
VF
S)
Bộ
địn
h t
uy
ến m
ạng
(ro
ute
r)
CM
OS
65
nm
(TS
MC
)
Giả
m đ
ượ
c tố
i đ
a 43
% c
ông s
uất
tiêu
th
ụ đ
ộng
của
toàn
bộ c
ác b
ộ
địn
h t
uy
ến t
ron
g m
ột
No
C.

Chương 6. Ứng dụng lô-gic mờ trong thiết kế mạng trên chip… 178
6.5. Kết luận chương
Trong chương này, chúng tôi đã trình bày mô hình của một bộ
điều khiển tần số - điện áp dựa vào xử lý lô-gic mờ cho các bộ định
tuyến để nhằm giảm năng lượng tiêu thụ ở các nốt mạng trong một mô
hình mạng trên chip. Mô hình của bộ điều khiển tần số - điện áp cũng
đã được tiến hành mô hình hóa bằng ngôn ngữ mô tả phần cứng
VHDL ở mức chuyển dịch thanh ghi để có thể xây dựng phương án
đánh giá, ước lượng được hiệu quả của mô hình này. Các mô phỏng
hoạt động lô-gic của từng khối trong mô hình và toàn bộ khối điều
khiển cũng đã được thực hiện trên phần mềm ModelSim. Các kết quả
thu được đã chứng tỏ bộ điều khiển tần số - điện áp hoạt động hoàn
toàn đúng với các yêu cầu đặt ra khi xây dựng mô hình.
Sau khi đã thiết kế và mô hình hóa bộ điều khiển tần số - điện áp
cho bộ định tuyến trong mạng trên chip, việc ước lượng, đánh giá và
kiểm chứng hiệu năng của mô hình đề xuất đã được thực hiện nhờ áp
dụng mô hình ORION 3 kết hợp với phần mềm mô phỏng VNOC 2.0.
Kết quả cho thấy giải pháp đề xuất hoạt động hiệu quả, cho phép hệ
thống giảm tới 43% công suất tiêu thụ trong khi độ trễ truyền của hệ
thống chỉ tăng nhẹ.

Chương 7. Thiết kế kiểm tra cho mạng trên chip… 179
Chương 7
THIẾT KẾ KIỂM TRA CHO MẠNG TRÊN CHIP
Các vi mạch trước khi đưa vào sử dụng trong các thiết bị đều cần
được kiểm tra nhằm phát hiện các lỗi có thể xảy ra trong quá trình sản
xuất. Việc kiểm tra phát hiện lỗi càng được thực hiện càng sớm càng
tốt, giúp giảm chi phí sản xuất sản phẩm cuối cùng. Với các hệ thống
trên chip, việc kiểm tra tìm kiếm lỗi sau khi vi mạch đã được đóng gói
hoàn toàn không dễ dàng. Chính vì vậy, người thiết kế cần phải tính
đến việc thực hiện kiểm tra trong quá trình thiết kế vi mạch nhằm giúp
cho quá trình kiểm tra sau khi đóng gói trở nên dễ dàng hơn. Từ đó,
hình thành khái niệm thiết kế kiểm tra1. Hình 7-1 mô tả một mô hình
thiết kế kiểm tra thông dụng cho hệ thống trên chip. Dữ liệu kiểm tra
sẽ được đưa vào hệ thống để kiểm tra lõi IP nhúng nhờ vào cơ chế
truy cập kiểm tra (TAM: Test Access Mechanism) và một mạch điện
đặc biệt bao quanh lõi IP gọi là test wrapper – thường được thiết kế
theo chuẩn IEEE 1500 [132].
Hình 7-1: Mô hình thiết kế kiểm tra cho hệ thống trên chip.
1 Thiết kế kiểm tra (DFT: Design-for-Test/Testability)
IP cầnkiểm tra
IP
CPU
I/OInterface
ROM
UserDefined
Logic
IP
IP
Wrapper
SRAM
TAM TAM
IP
Phân tíchkết quảBộ tạo dữ
liệu kiểm tra
TAM: Test Access Mechanism

180 Mạng trên chip
Mô hình mạng trên chip có nhiều ưu điểm, hứa hẹn được ứng
dụng rộng rãi trong các thiết bị điện tử trong tương lai gần. Tuy nhiên,
để đưa mô hình NoC vào các sản phẩm thương mại trên thị trường thì
việc kiểm tra các hệ thống mạng trên chip là một thách thức. Trong
các hệ thống mạng trên chip, các tài nguyên tính toán nhúng có thể
được kiểm tra bằng các phương pháp truyền thống (được phát triển
cho hệ thống trên chip) trong khi chúng ta cần các phương pháp kiểm
tra hiệu quả cho các kiến trúc mạng vì chúng có cấu trúc khá quy tắc.
Chương này sẽ giới thiệu và bàn luận về việc thiết kế kiểm tra cho
mạng trên chip, từ các nghiên cứu của các nhóm trên thế giới cho đến
giải pháp đề xuất của chúng tôi đối với mô hình mạng trên chip.
7.1. Giới thiệu
Nhằm giải quyết các vấn đề gặp phải khi thiết kế các hệ thống
trên chip như các ràng buộc về mặt thời gian, các nhà thiết kế đã đề
xuất mô hình hệ thống dị bộ toàn cầu - đồng bộ cục bộ (GALS:
Globally Asynchronous - Locally Synchronous) [133]. Với một hệ
thống GALS, các lõi IP giao tiếp một cách không đồng bộ với nhau
thông qua một môi trường truyền thông không đồng bộ. Chúng ta sẽ
dễ dàng nhận thấy rằng kiến trúc mạng trên chip hoàn toàn phù hợp
với nền tảng GALS khi kiến trúc mạng (các bộ định tuyến và các liên
kết mạng) được thực thi hoàn toàn bằng lô-gic không đồng bộ trong
khi các tài nguyên tính toán (các lõi IP) được thực thi với các phương
pháp thiết kế đồng bộ truyền thống [134].
Những nghiên cứu gần đây đề xuất một số kiến trúc mạng trên
chip không đồng bộ [19], [135], [46], [136]. Những ưu điểm chính của
mạng trên chip không đồng bộ là robustness (ít bị ảnh hưởng bởi sự
biến thiên về độ trễ do các tính chất vật lý, nhiệt độ hay điện áp gây
nên), dễ dàng thực hiện việc định tuyến, việc quản lý công suất tiêu
thụ một cách hiệu quả [96].
Để đưa mô hình mạng trên chip vào các sản phẩm thương mại
trên thị trường thì việc kiểm tra các hệ thống mạng trên chip là một

Chương 7. Thiết kế kiểm tra cho mạng trên chip… 181
thách thức. Ngày nay, trong các hệ thống NoC, các tài nguyên tính
toán nhúng có thể được kiểm tra bằng các phương pháp truyền thống
trong khi chúng ta cần các phương pháp kiểm tra hiệu quả cho các
kiến trúc NoC vì chúng có cấu trúc khá quy tắc.
Trong khoảng hơn một thập kỷ qua, một số giải pháp thiết kế
kiểm tra đã được đề xuất. Tuy nhiên, hầu hết các giải pháp đề xuất tập
trung vào thiết kế kiểm tra cho các NoC đồng bộ [133], [137], [138],
[139]. Bên cạnh một vài giải pháp thiết kế kiểm tra đề xuất cho các
kiến trúc NoC không đồng bộ [140], thì tại công trình [141] chúng tôi
đã đề xuất một kiến trúc thiết kế kiểm tra sử dụng các mạch lô-gic
QDI (Quasi-Delay-Insensitive) cho các kiến trúc NoC không đồng bộ.
Kiến trúc thiết kế kiểm tra này sau đó được thực thi bằng công nghệ
CMOS 65nm của hãng STMicroelectronics. Tiếp đó, để triển khai
việc kiểm tra, Trần Xuân Tú và đồng nghiệp cũng đưa ra một phương
pháp tạo các dữ liệu kiểm tra cho các bộ định tuyến và liên kết mạng.
7.2. Kiểm tra các hệ thống trên chip dựa trên NoC
Cũng giống như các hệ thống trên chip truyền thống, các hệ thống
trên chip dựa trên mô hình NoC cũng cần được kiểm tra để đảm bảo
không chứa các lỗi trong quá trình sản xuất. Do cấu trúc của NoC có
tính nguyên tắc, chiến lược kiểm tra cho các hệ thống NoC cần phải
quan tâm đến các vấn đề sau: (1) kiểm tra các tài nguyên tính toán
nhúng (lõi IP) và các giao diện mạng đi kèm; (2) kiểm tra hạ tầng kết
nối bao gồm các bộ định tuyến và các liên kết mạng giữa các bộ định
tuyến này.
7.2.1. Sử dụng kiến trúc mạng để kiểm tra các tài nguyên tính toán
Để kiểm tra các lõi IP nhúng trong các hệ thống NoC, chúng ta có
thể sử dụng test wrapper được định nghĩa trong chuẩn IEEE 1500
[132] để kiểm tra từng lõi IP nhúng và kiến trúc mạng có thể được sử
dụng như là cơ chế truy cập kiểm tra (TAM: Test Access Mechanism)
băng thông cao. Theo đó, dữ liệu kiểm tra sẽ được đóng gói thành các

182 Mạng trên chip
gói tin được truyền trên mạng nhờ giao thức mạng (network protocol).
Ý tưởng sử dụng kiến trúc mạng như là một TAM được đề xuất lần
đầu bởi Mohsen Nahvi và André Ivanov, Đại học British Columbia,
Canada với mạng NIMA (Novel Indirect and Module Architecture)
[142]. Kiến trúc mạng này được phát triển cho mục đích kiểm tra,
không phải cho mục đích truyền thông trên hệ thống. Không lâu sau
đó, một số giải pháp kiểm tra lõi IP sử dụng NoC như là các TAM
băng thông cao cũng được đề xuất [143], [144]. Sự khác nhau căn bản
giữa các đề xuất này là việc thiết kế các test wrapper và sự thích ứng
của chúng đối với cách thức vận hành của mạng trên chip.
Những ưu điểm chính của hướng tiếp cận này là chúng ta không
cần thêm chi phí phần cứng để thực thi các TAM bổ sung và có thể
triển khai việc kiểm tra lõi xử lý từ nhiều đường khác nhau (multi-path
core test). Hơn nữa, việc xử lý dữ liệu kiểm tra cũng được tách ra khỏi
quá trình truyền thông và kiến trúc kiểm tra hoàn toàn có thể mở rộng
quy mô theo yêu cầu của hệ thống. Tuy nhiên, chúng ta cần lưu ý một
điều là kiến trúc NoC cần được kiểm tra một cách kỹ lưỡng trước khi
được sử dụng.
7.2.2. Kiểm tra kiến trúc kết nối
Việc kiểm tra kiến trúc kết nối là một trong những thách thức mới
ở mạng trên chip. Trong các công trình nghiên cứu trước đây về các
hệ thống GALS, giao diện giữa các lõi IP đồng bộ cục bộ đã được
giảm xuống thành các kết nối điểm-điểm, sử dụng các kỹ thuật đồng
bộ ở cả hai đầu. Các giải pháp kiểm tra liên quan là các phần mở rộng
kiểm tra để áp đặt một xung nhịp đồng hồ đơn cho cả hai đầu kết nối
và sử dụng phương pháp scan chain truyền thống trên miền xung nhịp
đồng hồ mới này. Phương pháp kiểm tra này được sử dụng tại công
trình [145]. Theo đó, lô-gic không đồng bộ bổ sung được kiểm tra
thông qua các mẫu kiểm tra chức năng cụ thể. Tuy nhiên, trong mô
hình mạng trên chip, kiến trúc kết nối không còn là một tập các kết nối
điểm-điểm mà toàn bộ kiến trúc định tuyến cần phải được kiểm tra.

Chương 7. Thiết kế kiểm tra cho mạng trên chip… 183
Có một cách đơn giản để kiểm tra mạng truyền thông đó là định
tuyến dữ liệu kiểm tra đi qua các đường truyền thông khác nhau sử
dụng giao thức mạng. Nếu các đáp ứng kiểm tra (test response) khác
với kết quả mong muốn hoặc bị thất lạc thì chúng ta có thể khẳng định
là mạng truyền thông bị lỗi. Ưu điểm của phương án tiếp cận này là sự
đơn giản của nó và không đòi hỏi chi phí phần cứng để triển khai. Tuy
nhiên, phương pháp tiếp cận này có một số hạn chế. Mặc dù các bộ
định tuyến mạng có thể được cấu hình để truyền các dữ liệu kiểm tra
đi bất kỳ nơi đâu trong mạng, tuy nhiên khả năng kiểm tra (testability)
của mạng vẫn không được giải quyết. Chúng ta không thể truy cập
một cách trực tiếp tới các cổng vào của bộ định tuyến cần kiểm tra
(router-under-test) để có thể điều khiển và chúng ta cũng không thể
truy cập trực tiếp tới tất cả cổng ra của bộ định tuyến cần kiểm tra để
đọc kết quả.
Có một vài đề xuất thiết kế kiểm tra cụ thể dùng để kiểm tra các
kiến trúc NoC. Với các NoC đồng bộ thì chúng ta có thể sử dụng một
xung nhịp đồng hồ kiểm tra riêng cho toàn bộ vi mạch vì chúng ta có
thể xem NoC là tập hợp các lõi xử lý đồng bộ được kết nối với nhau
bằng kết nối điểm-điểm. Tuy nhiên, cách thức này không thực sự tối
ưu về mặt thời gian thực thi kiểm tra. Do đó, một số giải pháp cụ thể
cho từng thành phần của NoC đã được nghiên cứu trong thời gian qua.
Vì rằng các bộ định tuyến bao gồm các bộ đệm FIFO và các phần
mạch lô-gic định tuyến cho nên hầu hết các trao đổi trong [133], [137]
đều cho rằng việc kiểm tra bộ định tuyến mạng cần được thực hiện
thành từng phần tách biệt: sử dụng một bộ BIST (Built-In Self-Test)
cho các FIFO và các phương pháp truyền thống cho phần lô-gic định
tuyến. Tuy nhiên, các FIFO lại được phân bố trên toàn vi mạch và trở
thành một thử thách lớn đối với phương pháp tiếp cận này.
Một số đề xuất [138], [139] sử dụng kỹ thuật quét nối tiếp (serial
scan). Đây là phương pháp rất tốn kém về mặt không gian phần cứng
và thời gian thực thi đối với việc kiểm tra các NoC không đồng bộ.
Bên cạnh đó, các đề xuất này chỉ tập trung vào việc kiểm tra các bộ

184 Mạng trên chip
định tuyến mạng mà không quan tâm đến việc kiểm tra các kết nối
giữa các miền xung nhịp đồng hồ khác nhau.
NoC không đồng bộ được thiết kế và thực thi bằng các lô-gic
không đồng bộ, không sử dụng tín hiệu xung nhịp đồng hồ chung.
Việc kiểm tra các NoC không đồng bộ thường khó hơn kiểm tra các
NoC đồng bộ vì có nhiều vòng lặp phản hồi trong các mạch không
đồng bộ và thiếu sự hỗ trợ của các công cụ thiết kế điện tử EDA
(Electronics Design Automation) cho kiểm tra [145]. Có một vài
phương pháp tiếp cận thiết kế kiểm tra cho các mạch không đồng bộ
nhưng chi phí phần cứng quá lớn. Công trình nghiên cứu [140] trình
bày một kiến trúc kiểm tra cho NoC không đồng bộ dựa trên việc chèn
các scan-latches để ngắt các vòng lặp phản hồi của các thành phần
Muller-C1. Nhược điểm của đề xuất này là không gian thực thi kiến
trúc này chiếm tới 43% tổng không gian thực thi của cả thiết kế, cho
dù kích thước thiết kế nào.
7.3. Giới thiệu về kiến trúc NoC không đồng bộ
Phần này trình bày về kiến trúc NoC không đồng bộ được sử dụng
làm mục tiêu thử nghiệm khi xây dựng giải pháp thiết kế kiểm tra. Chi
tiết hơn về kiến trúc NoC không đồng bộ này được trình bày bởi Edith
Beigné và đồng nghiệp tại [46]. Kiến trúc NoC không đồng bộ này
được đặt tên là ANOC. Hình 7-2 mô tả mô hình của mạng trên chip
ANOC. Theo đó, kiến trúc mạng ANOC bao gồm các bộ định tuyến
mạng, các liên kết mạng, các giao diện đồng bộ không đồng bộ SAS
(asynchronoussynchronous) và các giao tiếp mạng. ANOC được sử
dụng như là kiến trúc truyền thông trong hệ thống trên chip GALS có
tên gọi là FAUST (Flexible Architecture Unified System for Telecoms
– Hệ thống hợp nhất có kiến trúc linh hoạt cho viễn thông) [20].
1 Muller element là một linh kiện cơ bản trong thiết kế số không đồng bộ self-
timed. Nó thực thi một sự kết hợp của các signal transitions (sự kiện/events).

Chương 7. Thiết kế kiểm tra cho mạng trên chip… 185
Hình 7-2: Kiến trúc mạng trên chip không đồng bộ ANOC.
Các bộ định tuyến mạng không đồng bộ là các thành phần cơ bản
của kiến trúc mạng. Chúng có năm cổng vào/ra hai hướng để nối với
bốn bộ định tuyến lân cận (NORTH, EAST, SOUTH, WEST) và tài
nguyên tính toán đồng bộ gần nhất thông qua một bộ giao tiếp mạng
(NI: network interface) và một bộ giao diện SAS. Các bộ định tuyến
và liên kết mạng được thiết kế và thực thi sử dụng kiểu lô-gic không
đồng bộ QDI như trong [146]. Truyền thông giữa các bộ định tuyến
mạng được thiết lập bằng một giao thức bắt tay (giao thức “send-
accept” ở mức flit) với hai kênh ảo nhằm cải thiện chất lượng dịch vụ
(QoS: Quality of Service) của hệ thống. Các liên kết mạng là các kênh
hai hướng 34 bit. Trong đó, 32 bit được sử dụng cho dữ liệu và 2 bit
được sử dụng để mã hóa thông tin về gói tin: bắt đầu gói tin BoP
(Begin-of-Packet) và kết thúc gói tin EoP (End-of-Packet). Thông tin
định tuyến được chứa trong flit tiêu đề, cụ thể là ở trường thông tin
định tuyến “Path-to-Target”. Trường thông tin định tuyến này sẽ được
dịch sang phải hai bit tại mỗi bộ định tuyến sau khi hai bit có trọng số
thấp được sử dụng để xác định hướng đi tiếp theo (định tuyến nguồn).
7.4. Phương pháp kiểm tra đề xuất cho ANOC
Như đề cập trong Mục 7.2, các phương pháp tiếp cận có cấu trúc,
ứng dụng cho các mạch không đồng bộ, có chi phí không gian thực thi
NI
SAS
NI
SAS
NI
SAS
NI
SAS
NI
SAS
NI
SAS
NI
SAS
NI
SAS
NI
SAS
IP IP IP
IP IP IP
IP IP IP
R R R
R R R
R R R

186 Mạng trên chip
phần cứng khá lớn cũng như thời gian thực hiện kiểm tra khá dài. Hơn
nữa, việc thiếu vắng các công cụ EDA hỗ trợ kiểm tra từ các công ty
cung cấp công cụ hỗ trợ thiết kế cũng làm cho việc tạo ra các dữ liệu
kiểm tra một cách tự động ATPG (Automatic Test Pattern Generation)
cho các mạch lô-gic không đồng bộ trở nên rất khó khăn. Do đó,
phương pháp tiếp cận của chúng tôi là dựa vào tính nguyên tắc và các
đặc tính của kiến trúc mạng. Thách thức chủ yếu ở đây là làm thế nào
để tách rời các thành phần mạng (bộ định tuyến và các liên kết mạng)
để sau đó áp đặt trực tiếp các mẫu dữ liệu kiểm tra lên các thành phần
mạng cần kiểm tra (element-under-test) và thu về các kết quả kiểm tra.
Để việc kiểm tra trở nên dễ dàng đối với ANOC, chúng tôi đã đề
xuất kiến trúc thiết kế kiểm tra DFT như trong Hình 7-3. Trong kiến
trúc này, mỗi bộ định tuyến mạng không đồng bộ sẽ được bao quanh
bởi một test wrapper không đồng bộ để cải thiện khả năng điều khiển
(controllability) và khả năng quan sát (observability) của các bộ định
tuyến. Các liên kết mạng được tái sử dụng để thiết lập các cơ chế truy
cập kiểm tra TAM băng thông cao.
Hình 7-3: Kiến trúc thiết kế kiểm tra đề xuất [141].
Như vậy, test wrapper được sử dụng với các mục đích sau: (a) để
chèn các véc-tơ kiểm tra (test vector) vào các thành phần mạng cần
kiểm tra và lấy kết quả kiểm tra ra; (b) cùng với các liên kết mạng, để
cfg_in
cfg_out
data_in
data_out
GAC unit
Test Wrapper
kênh cấu hình kiểm traWCM
Lõi IP Lõi IP Lõi IP
Lõi IP Lõi IP Lõi IP

Chương 7. Thiết kế kiểm tra cho mạng trên chip… 187
thiết lập các cơ chế truy cập kiểm tra TAM không đồng bộ có băng
thông cao để vận chuyển dữ liệu kiểm tra. Để kiểm tra một liên kết
mạng giữa các bộ định tuyến, chúng ta có thể sử dụng hai test wrapper
để chèn các véc-tơ kiểm tra và thu nhận kết quả kiểm tra.
Tất cả các hoạt động của test wrapper được điều khiển bởi mô-đun
điều khiển gọi là mô-đun điều khiển wrapper (WCM: Wrapper
Control Module). Để thiết lập một luồng kiểm tra (test flow)1 cho toàn
bộ kiến trúc mạng trên chip, trong đề xuất này chúng tôi thiết lập một
kênh cấu hình 2-bit dùng riêng cho mục đích kiểm tra bằng cách nối
các mô-đun WCM nối tiếp với nhau. Các luồng kiểm tra của toàn bộ
kiến trúc mạng trên chip được định nghĩa bởi một bộ điều khiển bên
ngoài. Bộ điều khiển này được tích hợp vào trong một thiết bị gọi là
thiết bị Cung cấp – Điều khiển – Phân tích dữ liệu kiểm tra (GAC:
Generator-Analyzer-Controller). Vai trò của thiết bị GAC là tạo ra các
dữ liệu kiểm tra, tạo ra cấu hình kiểm tra và phân tích kết quả kiểm
tra. Khối GAC này có thể được thực thi trên chip như là một khối
BIST hoặc thực thi bên ngoài chip như là một chương trình máy tính.
Trong quá trình nghiên cứu của chúng tôi, khối GAC này được thực
thi trên một kit phát triển FPGA để có thể dễ dàng kết nối với vi mạch
hệ thống mạng trên chip.
Giao tiếp truyền thông giữa khối GAC và kiến trúc ANOC bao
gồm các kênh vào/ra 34 bit „data_in‟ và „data_out‟) và kênh cấu hình
kiểm tra vào/ra hai bit („cfg_in‟ và „cfg_out‟).
Kiến trúc DFT đề xuất này được thiết kế và thực thi bằng lô-gic
không đồng bộ QDI vì một số lý do sau: hoàn toàn phù hợp với kiến
trúc mạng ANOC (cũng được thực thi với lô-gic không đồng bộ QDI);
không cần tín hiệu xung nhịp đồng hồ dành riêng cho kiểm tra; và
không thêm chi phí thực thi giao diện kết nối đồng bộ không đồng
bộ SAS. Hơn nữa, thường thì chúng ta dễ dàng kiểm tra thiết kế QDI
hơn vì trong hoạt động của mạch QDI yêu cầu sự dịch chuyển tín
hiệu; nếu xuất hiện bất kỳ một lỗi stuck-at tại lối ra linh kiện nào thì
1 Luồng kiểm tra (test flow) được hiểu là trình tự kiểm tra.

188 Mạng trên chip
cũng có thể làm mạch QDI bị treo [147]. Việc treo mạch này dễ dàng
nhận biết tại khối GAC vì nó không thể tiếp tục thực thi các giao thức
bắt tay 4 pha của lô-gic không đồng bộ. Sử dụng một watchdog, chúng
ta thực sự có thể nhận biết được liệu một ghi nhận (acknowledgement)
không bao giờ được trả về tại lối vào hoặc đầu ra dự kiến sẽ không
bao giờ đến hoặc không bao giờ kết thúc.
Việc tái sử dụng các liên kết mạng giữa các bộ định tuyến không
chỉ cho phép thiết lập được cơ chế truy cập kiểm tra TAM băng thông
cao mà còn giúp chúng ta tránh được các vấn đề liên quan đến tắc
nghẽn dây dẫn khi thực hiện layout cho toàn bộ vi mạch. Kiến trúc
DFT đề xuất được thiết kế cho mạng trên chip ANOC nhưng hoàn
toàn có thể được sử dụng cho tất cả các kiến trúc mạng trên chip
không đồng bộ khác được xây dựng bởi lô-gic QDI.
7.5. Thiết kế và thực thi
Mục này sẽ trình bày việc thiết kế và thực thi test wrapper – một
thành phần quan trọng của kiến trúc DFT đề xuất. Việc xây dựng kiến
trúc DFT tổng thể được thực hiện một cách đơn giản bằng việc lắp
ghép các test wrapper lại với nhau.
7.5.1. Kiến trúc test wrapper
Vai trò của test wrapper là vận chuyển dữ liệu kiểm tra (test
vector) tới các bộ định tuyến cần kiểm tra và lấy ra các kết quả kiểm
tra. Tương ứng với số cổng vào/ra của bộ định tuyến ANOC, test
wrapper được thiết kế bao gồm 5 khối kiểm tra lối vào (ITC: input test
cell), 5 khối kiểm tra lối ra (OTC: output test cell) và một mô-đun
điều khiển wrapper (WCM), như mô tả ở Hình 7-4. Các ITC và OTC
được kết nối luân phiên với nhau, tạo nên một đường boundary-scan
bao quanh bộ định tuyến. Lý do kết nối luân phiên các ITC và OTC là
nhằm tối ưu chi phí phần cứng thực thi test wrapper cũng như tối ưu
dây nối. Vai trò của WCM là điều khiển tất cả các khối kiểm tra (test
cell) để thực thi các chức năng của test wrapper.

Chương 7. Thiết kế kiểm tra cho mạng trên chip… 189
Hơn nữa, để giảm thời gian kiểm tra và tối thiểu hóa độ phức tạp
của kiểm tra, trong các kiến trúc DFT luôn có chức năng bypass (vượt
qua). Chức năng này sẽ cho phép giảm độ dài của đường kiểm tra (test
path) bằng cách sử dụng các ngắn mạch (short-circuit) giữa đầu vào
và đầu ra của test wrapper. Với chức năng bypass, chỉ những bộ định
tuyến cần kiểm tra mới được đặt trong chế độ kiểm tra. Do đó, bộ định
tuyến cần kiểm tra dường như được kết nối trực tiếp với khối GAC,
trong khi các bộ định tuyến khác được đặt ở chế độ không hoạt động.
Hình 7-4 mô tả đường bypass hai hướng (đường đậm đứt nét) giữa các
cổng vào/ra EAST và các cổng và/ra WEST. Dữ liệu kiểm tra từ cổng
vào EAST của test wrapper được vận chuyển trực tiếp đến cổng ra
WEST của test wrapper và dữ liệu từ cổng vào WEST của test wrapper
được vận chuyển trực tiếp đến cổng ra EAST của test wrapper mà
không cần phải đi qua bộ định tuyến cũng như các test cell khác.
Hình 7-4: Test wrapper cùng với bộ định tuyến [141].
Bởi vì giao diện bên ngoài của test wrapper tương tự với giao
diện bên ngoài của bộ định tuyến, kiến trúc mạng trên chip gần như
không thay đổi ngoại trừ bổ sung thêm kênh cấu hình kiểm tra 2-bit.
Cũng giống kiến trúc ANOC, test wrapper này được thiết kế và
thực thi với lô-gic không đồng bộ QDI. Tại công trình nghiên cứu này,
WCM
OTC
ITC
ITC
OTC
ITC OTC
ITC
OTC
OTC ITC
Test wrapper
ANOC
router
WEST
RES
EAST
SOUTH
NORTH
cfg_in
cfg_out
2
2
34

190 Mạng trên chip
chúng tôi đã sử dụng giao thức trao đổi tín hiệu RTZ (return-to-zero)
4 pha cho các kênh không đồng bộ cùng với sử dụng bộ đệm WCHB
(Weak-Condition Half Buffer) cho các tầng đường ống. Để giảm thiểu
công suất tiêu thụ, đường truyền dữ liệu (32 bits + BoP + EoP) được
thiết kế hoàn toàn với dữ liệu mã hóa 1-of-4 (MR4) [148]; do đó, cần
kết nối 17 MR4 QDI (mỗi kết nối MR4 bao gồm 4 rails và một tín
hiệu acknowledge). Kênh cấu hình kiểm tra 2 bit cũng được thiết kế
với dữ liệu mã hóa 1-of-4 và do đó cần một kết nối MR4. Các kênh
điều khiển khác được thiết kế với dữ liệu mã hóa 1-of-2 (DR: Dual-
Rail) hoặc Single-Rail (SR) (mỗi kết nối DR bao gồm 2 rails và một
tín hiệu acknowledge và mỗi kết nối SR bao gồm 1 rail và một tín
hiệu acknowledge). Hình 7-5 mô tả cấu trúc của liên kết mạng.
Hình 7-5: Cấu trúc của một liên kết mạng [141].
7.5.2. Kiến trúc test cells
Trong kiến trúc test wrapper, các thành phần chính là các test cell
(ITC và OTC). Chức năng của các test cells có thể được mô tả như sau:
Ở chế độ bình thường (normal mode), dữ liệu truyền thông được
vận chuyển từ mạng đến bộ định tuyến thông qua các ITC và từ bộ
định tuyến trở về mạng thông qua các OTC mà không cần các tín hiệu
điều khiển kiểm tra (test control), nhờ tín hiệu vô hiệu hóa chế độ
kiểm tra chung.
Ở chế độ kiểm tra (test mode), hoạt động của các ITC được giải
thích như sau: dữ liệu kiểm tra từ mạng hoặc từ test cell trước đó được
một liên kết mạng
1 kênh DR
17 kênh MR4
2 kênh SR
Req. 1
Ack.
Req. 2
Req.
từ 1 đến 4
Ack.
Req.
Ack.

Chương 7. Thiết kế kiểm tra cho mạng trên chip… 191
lưu trữ trong test cell hiện tại, sau đó dữ liệu được lưu trữ này sẽ được
vận chuyển tới bộ định tuyến cần kiểm tra hoặc test cell tiếp theo.
Điều này cũng hoàn toàn tương tự đối với OTC: dữ liệu kiểm tra từ bộ
định tuyến cần kiểm tra hoặc từ test cell trước đó được lưu trữ tại test
cell hiện tại; sau đó, dữ liệu được lưu trữ này sẽ được vận chuyển tới
mạng hoặc test cell tiếp theo. Tất cả các thao tác này được điều khiển
bởi các kênh điều khiển có nguồn gốc từ mô-đun WCM của wrapper.
Để thực thi các chức năng trên, chúng tôi đã phát triển một vi kiến
trúc của các test cell (cho cả ITC lẫn OTC) như mô tả trong Hình 7-6.
Hình 7-6: Vi kiến trúc của các test cell vào/ra (ITC và OTC) [96].
Vi kiến trúc này bao gồm hai bộ hợp kênh không đồng bộ (MUX
và MODE) và hai khối phân chia (splitting blocks) không đồng bộ (S1
và S2). Với kiến trúc này, dữ liệu truyền trông được vận chuyển từ lối
vào „noc-in‟ tới lối ra „noc-out‟ thông qua MODE trong chế độ hoạt
động bình thường. Trong chế độ kiểm tra, dữ liệu kiểm tra hoặc từ lối
vào „noc-in‟ hoặc từ lối vào „cell-in‟ được lưu trữ trên kênh không
đồng bộ „LOCAL‟ giữa MUX và MODE/cell tiếp theo nhờ vào các
đặc tính lưu trữ của thiết kế kênh không đồng bộ; sau đó, dữ liệu được
lưu trữ này sẽ được vận chuyển đến hoặc là lối ra „noc-out‟ hoặc lối ra
„cell-out‟. Các thao tác này được điều khiển bởi hai kênh điều khiển
không đồng bộ, „ctrl-mux‟ và „ctrl-mode‟, cung cấp bởi WCM.
Ở chế độ hoạt động bình thường (normal mode), „ctrl-mode‟ chỉ
được thăm dò và không cần xác nhận (sử dụng một C-element bất đối
xứng) để giảm thiểu độ trễ và tín hiệu điều khiển.
S2noc-in
noc-out
cell-in
cell-out
ctrl-mux
ctrl-mode
0
1
10
S1
MODE
MUX
LO CAL
A
B

192 Mạng trên chip
Để gửi dữ liệu tới một trong hai linh kiện tiếp theo, chúng ta sử
dụng một khối phân chia không điều khiển. Do đó, kênh lối vào „noc-in‟
được phân chia bởi S1 thành hai kênh (A và B) được nối với MODE
và MUX. Tương tự, kênh lưu trữ tại chỗ/cục bộ „LOCAL‟ được phân
chia bởi S2 thành hai kênh nối với MODE và „cell-out‟. Các bộ phân
chia không điều khiển này hoàn toàn là mạch tổ hợp và có thể dễ dàng
được thực thi bằng cách kết hợp các tín hiệu acknowledge (các tín
hiệu acknowledge từ MUX và MODE cho S1, các tín hiệu
acknowledge từ MODE và „cell-out‟ cho S2) nhằm giảm thiểu trễ và
chi phí không gian thực thi. Việc thực thi chi tiết các khối lô-gic này
được trình bày tại [96].
Ngoài ra, kiến trúc này sử dụng hai tín hiệu „accept0‟ và
„accept1‟ để điều khiển các luồng dữ liệu của hai kênh ảo. Mỗi bộ hợp
kênh (MUX và MODE) tạo ra một cặp tín hiệu accept. Nhờ vào điều
kiện loại trừ, các tín hiệu accept ra tại „noc-in‟ được tạo ra bằng cách
hợp các tín hiệu accept từ các bộ nhập kênh này. Việc này có thể được
thực hiện một cách dễ dàng bởi một khối lô-gic tổ hợp nhỏ. Để đơn
giản, vi kiến trúc của các test cell trong Hình 7-6 không bao gồm các
tín hiệu send/accept này.
Kích thước của các kênh kiểm tra cơ bản giống như kích thước
của các liên kết mạng bởi vì các khối hợp kênh và phân chia được
thực thi với các kênh có độ rộng 34 bit. Do đó, mỗi kênh kiểm tra có
17 kết nối MR4 QDI đối với đường truyền dữ liệu, một kết nối DR
dành cho tín hiệu „send‟ và hai kết nối SR dành cho hai tín hiệu
„accept0‟ và „accept1‟.
7.5.3. Các test cell với chức năng bypass
Như đề cập ở trên, chức năng bypass thường hay được sử dụng
trong các kiến trúc thiết kế kiểm tra. Trong trường hợp của chúng tôi,
để thực thi chức năng bypass cho test wrapper, chúng tôi đã sửa đổi
kiến trúc test cell như mô tả trong Hình 7-7.

Chương 7. Thiết kế kiểm tra cho mạng trên chip… 193
Hình 7-7: Vi kiến trúc của các test cell với chức năng bypass:
(a) khối kiểm tra lối vào ITC; (b) khối kiểm tra lối ra OTC [141].
Phần thay đổi quan trọng ở đây chính là bộ hợp kênh MODE. Với
các khối kiểm tra lối vào ITC, chúng tôi thêm một kênh lối ra bypass
(„bp-out‟), xem Hình 7-7(a). Với các test cell lối ra OTC, chúng tôi
thêm một kênh bypass lối vào („bp-in‟), xem Hình 7-7(b). Lúc này,
kênh điều khiển „ctrl-mode‟ được mã hóa bằng dữ liệu mã hóa MR3
để có thể mã hóa giá trị ba chế độ hoạt động khác nhau (bình thường,
kiểm trat và bypass). Ở chế độ bypass, dữ liệu từ „noc-in‟ sẽ được vận
chuyển tới lối ra „bp-out‟ của các ITC và dữ liệu từ lối vào „bp-in‟ sẽ
được vận chuyển tới „noc-out‟ của các OTC. Bảng 7-1 tổng hợp các
hoạt động của test cell theo các giá trị của các kênh điều khiển.
S2noc-in
noc-out
cell-in
cell-out
ctrl-mux
ctrl-mode
10
S1
MODE
MUX
LO CAL
bp-out
(a)
S2noc-in
noc-out
cell-in
cell-out
ctrl-mux
ctrl-mode
10
S1
MODE
MUX
LO CAL
bp-in
(b)

194 Mạng trên chip
Bảng 7-1: Mô tả hoạt động của các test cell
ctrl-
mode
ctrl-
mux Mô tả hoạt động của các test cell
0 - Chế độ hoạt động bình thường (normal), luôn được
cho phép để giảm số lần điều khiển.
- 0 Nhận dữ liệu từ „noc-in‟ và lưu trữ.
- 1 Nhận dữ liệu từ „cell-in‟, sau đó lưu trữ dữ liệu hoặc
vận chuyển dữ liệu tới „cell-out‟ nếu có một yêu cầu
từ cell tiếp theo.
1 - Vận chuyển dữ liệu đang lưu trữ tới „noc-out‟.
2 - Chế độ bypass (luôn được cho phép để giảm số lần
điều khiển).
Chú ý: dấu (-) có nghĩa là không có giá trị nào được viết lên kênh điều khiển.
Để nhận một dữ liệu từ „noc-in‟, lưu trữ dữ liệu này trên kênh
„LOCAL‟ và sau đó gửi nó tới „noc-out‟, kênh điều khiển „ctrl-mux‟
cần được viết với giá trị „0‟ và kênh điều khiển „ctrl-mode‟ cần được
viết với giá trị „1‟.
7.5.4. Mô-đun điều khiển wrapper
Hoạt động của test wrapper được quyết định bởi các khung cấu
hình kiểm tra (TCF: Test Configuration Frame), tạo ra bởi khối GAC.
Để giảm số kênh điều khiển được cung cấp bởi khối GAC, toàn bộ
khung cấu hình kiểm tra được phân chia ra thành hai mẩu 2-bit, được
gửi lần lượt tới mô-đun điều khiển wrapper (WCM: Wrapper Control
Module). Với kiến trúc của chúng tôi, mỗi khung cấu hình kiểm tra
gồm 25 mẩu cấu hình 2 bit (được mã hóa bởi mã 1-of-4), minh họa
trong Hình 7-8.
Hình 7-8: Khung cấu hình kiểm tra.
EoF ID [2:0] EMO4 MMCO4 EMI4 MCI4 EMO0 MCI0 EMO0 MCI0
24 23 : 21 RO – RI 0NO – NIW…S…E

Chương 7. Thiết kế kiểm tra cho mạng trên chip… 195
Ý nghĩa của khung cấu hình kiểm tra được giải thích trong Bảng 7-2.
Bảng 7-2: Giải thích về khung cấu hình kiểm tra
EoF Thông báo kết thúc khung cấu hình (End of Frame)
ID[2:0] Mã số test wrapper
EMO[i] Cho phép kênh „ctrl-mode‟ của OTC i
MCO[i] Giá trị của kênh „ctrl-mux‟ của OTC i
EMI[i] Cho phép kênh „ctrl-mode‟ của ITC i
MCI[i] Giá trị của kênh „ctrl-mux‟ của ITC i
M Chế độ làm việc của test wrapper
Mỗi vị trí cấu hình được mã hóa bởi một dữ liệu MR4 (2 bit); do
đó, giá trị của mỗi vị trí cấu hình có thể là “0”, “1”, “2” và “3” [MR4]
(tương ứng với các giá trị {00}, {01}, {10} và {11} trong mã nhị phân).
Giá trị “3” [MR4] thông báo kết thúc khung cấu hình EoF; do đó, các vị
trí cấu hình khác có thể sử dụng nhiều nhất ba giá trị. Với ba vị trí cấu
hình cho phần nhận diện test wrapper, khung cấu hình kiểm tra TCF có
thể được sử dụng cho các kiến trúc NoC có tới 27 bộ định tuyến. Với
các kiến trúc NoC lớn hơn, chúng ta cần thêm vị trí nhận diện.
Vai trò của mô-đun điều khiển WCM là gom các giá trị cấu hình
liên tiếp từ kênh cấu hình cho đến khi chúng tạo nên khung cấu hình
kiểm tra TCF cho test wrapper. Khi mô-đun điều khiển WCM nhận
được khung cấu hình đầy đủ bằng cách nhận biết thông tin EoF như là
mảnh cuối cùng của cấu hình, nó phải xác định xem khung cấu hình
nhận được dành cho test wrapper này hay không. Việc này được thực
hiện một cách dễ dàng bằng trường ID (“Indentifier‟). Nếu ID của
khung cấu hình tương ứng với test wrapper này thì WCM của test
wrapper đó sẽ tạo ra các kênh điều khiển (tương ứng với các giá trị
của khung cấu hình) để điều khiển các test cell.
Để thực thi chức năng trên, mô-đun điều khiển WCM được cấu
tạo gồm bộ dịch khung (frame shifter), khối “EoF Detector” (phát hiện
kết thúc khung), khối “ID Verifier” (kiểm tra mã số của wrapper) và
khối truyền tín hiệu kiểm tra, như minh họa ở Hình 7-9.

196 Mạng trên chip
Hình 7-9: Mô-đun điều khiển wrapper (WCM) [141].
Mục đích của bộ dịch khung là đọc cấu hình mới từ khối GAC
thông qua lối vào „cfg-in‟, dịch khung cấu hình kiểm tra một vị trí
(mẩu cấu hình 2 bit) sang phải và viết ra vị trí cấu hình có trọng số
thấp nhất lên kênh cấu hình thông qua lối ra „cfg-out‟. Khối kiểm tra
kết thúc khung “EoF Detector” sẽ nhận biết việc một khung cấu hình
kiểm tra đã được nhận đầy đủ và khối kiểm tra mã số “ID Verifier” sẽ
xác minh mã số nhận dạng của khung cấu hình kiểm tra nhận được.
Khối truyền tín hiệu kiểm tra được sử dụng để điều khiển các test cell.
Nó nhận các giá trị điều khiển từ bộ dịch khung khi xuất hiện tín hiệu
EoF và mã số ID trùng hợp với test wrapper. Các lối ra của Bộ dịch
khung này bao gồm 20 kênh điều khiển „ctrl-mode[i]‟ và „ctrl-mux[i]‟,
với i nhận giá trị từ 0 đến 4 tương ứng với các hướng NORTH, EAST,
SOUTH, WEST, RES) được sử dụng để điều khiển 10 test cell.
Giá trị của Mode (M) có thể là “0”[MR4] (chế độ hoạt động
thông thường), “1”[MR4] (chế độ kiểm tra), hoặc “2”[MR4] (chế độ
bypass). Giá trị được viết lên kênh điều khiển „ctrl-mode[i]‟ của các
ITC hoặc của các OTC là giá trị của vị trí Mode. Tuy nhiên, trong chế
độ kiểm tra kênh „ctrl-mode[i]‟ của ITC i chỉ được viết khi EMI[i]
bằng “1”[MR4] và kênh điều khiển „ctrl-mode[i]‟ của OTC i chỉ được
viết khi EMO[i] bằng “1”[MR4]. Giá trị được viết trên mỗi kênh „ctrl-
mux[i]‟ của các ITC hoặc các OTC phụ thuộc vào giá trị của MCI[i]
hoặc MCO[i] một cách tương ứng: kênh „ctrl-mux[i]‟ của ITC i nhận
giá trị „0‟ khi MCI[i] bằng “1”[MR4], nó nhận giá trị „1‟ khi MCI[i]
bằng “2”[MR4]; tương tự, kênh „ctrl-mux[i]‟ của OTC i nhận „0‟ khi
MCO[i] bằng “1”[MR4], nó nhận giá trị „1‟ khi MCO[i] bằng “2”[MR4].
Bộ dịch khung
EoF
Detector
ID
Verifier
Truyền tín hiệu kiểm tra
MR[4] MR[4]cfg-in cfg-out
ctrl-mode[i] &
with i = 0..4
ctrl-mux[i]
EoFID ok

Chương 7. Thiết kế kiểm tra cho mạng trên chip… 197
Chúng ta có thể tổng hợp các mối liên hệ giữa TCF và các kênh điều
khiển ở trên như trong Bảng 7-3.
Bảng 7-3: Mối liên hệ giữa TCF và các kênh điều khiển
For direction i OTC i ITC i
M EMO MCO EMI MCI ctrl-mode ctrl-mux ctrl-mode ctrl-mux
0 X X X X 0 - 0 -
2 X X X X 2 - 2 -
1 0 0 0 0 - - - -
1 1 0 1 0 1 - 1 -
1 0 1 0 1 - 0 - 0
1 0 2 0 2 - 1 - 1
Chú ý: dấu (-) có nghĩa là không có giá trị nào được viết lên kênh điều khiển.
Để hiểu rõ hơn, bây giờ chúng ta lấy một ví dụ về việc kiểm tra
đường định tuyến NORTH SOUTH của một bộ định tuyến, như minh
họa trong Hình 7-10. Trong ví dụ này, chúng ta giả thiết rằng cổng
phía Đông (EAST) của bộ định tuyến được kết nối với cơ chế truy cập
kiểm tra TAM.
Hình7-10: Wrapper được cấu hình để kiểm tra đường định tuyến
NORTH SOUTH [96].
WCM
OTC-3
ITC-3
ITC-1
OTC-1
ITC-0 OTC-0
ITC-4
OTC
-4
OTC-2 ITC-2
Test wrapper
ANOC
router
WEST
RES
EAST
SOUTH
NORTH
cfg_in
cfg_out
2
2
34
Input
Output
Routing path
Under test

198 Mạng trên chip
Chúng ta có thể dễ dàng tạo ra khung cấu hình kiểm tra TCF cho
quá trình kiểm tra này, xem Bảng 7-4.
Bảng 7-4: TCF dùng để kiểm tra đường định tuyến NORTH-SOUTH
EoF ID RO-RI WO-WI SO-SI EO-EI NO-NI M
3 001 00-00 00-00 01-02 12-01 02-12 1
Khung cấu hình kiểm tra này có thể được giải thích như sau: Giá
trị có trọng số lớn nhất EoF = “3”[MR4] cho biết kết thúc khung cấu
hình. Ba giá trị tiếp theo ID = “001”[MR4]) có nghĩa là khung cấu
hình này được dùng cho test wrapper có mã số là 1. Giá trị có trọng số
bé nhất Mode = “1”[MR4] đặt test wrapper vào chế độ kiểm tra. EI = “01”
(cũng như EMI[1] = „0‟ và MCI[1] = „1‟) có nghĩa là ITC-1 (EAST)
nhận dữ liệu kiểm tra từ TAM và dịch chuyển chúng tới OTC-0
(NORTH). NO = “02”[MR4] có nghĩa là OTC-0 hoạt động ở chế độ
dịch chuyển (shifting mode); do đó, dữ liệu kiểm tra được dịch tới
ITC-0 (NORTH). Dữ liệu kiểm tra sau đó được đưa vào bộ định tuyến
cần kiểm tra bởi ITC-0 vì rằng NI = “12”[MR4].
Sau các hoạt động của bộ định tuyến, với SO = “01”[MR4], OTC-2
(SOUTH) nhận các kết quả kiểm tra từ bộ định tuyến cần kiểm tra và
vận chuyển chúng tới ITC-2 (SOUTH). ITC-2 đang hoạt động ở chế độ
dịch chuyển vì SI = “02”[MR4]. Do đó, kết quả kiểm tra được dịch
chuyển tới OTC-1 (EAST). Với EO = “12”[MR4], OTC-1 nhận các kết
quả kiểm tra và gửi chúng tới bộ phân tích kiểm tra được tích hợp
trong khối GAC thông qua cơ chế truy cập kiểm tra TAM.
Chú ý rằng, cơ chế truy cập kiểm tra TAM được thiết lập bởi các
test wrapper khác và các liên kết mạng. Các vị trí cấu hình kiểm tra
khác như RO, RI, WO, WI nhận giá trị “00”[MR4] có nghĩa là các test
cell sau đây không liên quan và không bị điều khiển: OTC-4 (RES),
ITC-4 (RES), OTC-3 (WEST) và ITC-3 (WEST).
Mục tiêu của ví dụ trên là chỉ ra cách thức xây dựng một khung
cấu hình kiểm tra. Về thực tiễn, các khung cấu hình kiểm tra này được

Chương 7. Thiết kế kiểm tra cho mạng trên chip… 199
tạo ra một cách tự động bằng một chương trình kiểm tra riêng, phụ
thuộc vào chiến lược kiểm tra.
7.6. Tạo dữ liệu kiểm tra
7.6.1. Mô hình lỗi cho mạch không đồng bộ QDI
Thao tác của mạch đồng bộ dựa vào các giá trị lô-gic quan sát
được trên các net1 tại từng chu kỳ xung nhịp đồng hồ. Do đó, kiểm tra
mạch đồng bộ dựa vào việc điều khiển và quan sát các mức lô-gic của
các net. Các phương pháp ATPG đồng bộ truyền thống sử dụng đặc
tính này để áp đặt các giá trị lối ra flip-flop với các giá trị lô-gic khác
nhau và quan sát mức lô-gic tại các lối vào flip-flop để nhận biết các
lỗi stuck-at đơn (SSA) của mạch cần kiểm tra. Công cụ ATPG xác
định các tổ hợp giá trị trên tất cả các flip-flop để nhận biết lỗi.
Tuy nhiên, hoạt động của mạch không đồng bộ QDI dựa trên các
mã thông báo (token) chạy bên trong lô-gic. Mã hóa 1-of-N return-to-
zero được sử dụng để truyền bá các mã thông báo: tất cả các net nhận
giá trị giữa lô-gic „1‟ (có dữ liệu) và lô-gic „0‟ (không có dữ liệu)
trong quá trình hoạt động. Hình 7-11 mô tả hành vi này trong trường
hợp các mạch không đồng bộ QDI mã hóa 1-of-2 return-to-zero.
Chúng ta có thể thấy rằng một net bị mắc kẹt (stuck-at net) sẽ cản trở
sự thay đổi xen luân phiên nói trên và chặn một trong các vòng bắt tay
cũng như tất cả các quá trình tiếp của mạch, như minh họa trong
Hình 7-12. Khi đó, tại lối ra chúng ta không quan sát thấy dữ liệu.
Hơn nữa, nếu nhiều net bị mắt kẹt ở các vòng lặp bắt tay khác nhau thì
thiết kế đang kiểm tra sẽ bị ngừng hoạt động. Nhờ đó, chúng ta dễ
dàng phát hiện thiết kế bị lỗi.
1 Cách gọi đường tín hiệu trong mạch.

200 Mạng trên chip
Hình 7-11: Hoạt động của các mạch không đồng bộ QDI
mã hóa 1-of-2 return-to-zero.
Hình 7-12: Mạch bị chặn (ngừng hoạt động) bởi một stuck-at net „Req1‟.
Do đó, để quan sát các lỗi stuck-at trên các net của mạch không
đồng bộ QDI, chúng ta chỉ cần gán ép (force) một tín hiệu bắt tay trên
mỗi net và kiểm tra sự sống của mạch. Nhờ vậy, việc tạo dữ liệu kiểm tra
cũng đơn giản hơn. Tuy nhiên, do không có công cụ tự động để tạo dữ
liệu kiểm tra, trong trường hợp này chúng tôi phải phân tích chức năng
Bên gửi Bên nhận
Req0
Req1
Ack
0 1
Req0
Req1
Ack
lần truyền thứ nhất lần truyền thứ hai
Pha 1 Pha 2 Pha 3 Pha 4Pha 1 Pha 2 Pha 3 Pha 4
Req0
Req1
Ack
Bên gửi Bên nhận
Req0
Req1
Ack
0 1
Req0
Req1
Ack
Req0
Req1
Ack
lần truyền thứ nhất lần truyền thứ hai
Pha 1 Pha 2 Pha 3 Pha 4Pha 1 Pha 2 Pha 3 Pha 4

Chương 7. Thiết kế kiểm tra cho mạng trên chip… 201
của mạch để xây dựng dữ liệu kiểm tra. Vì rằng, mạng trên chip là các
cấu trúc kết nối, không phải là cấu trúc xử lý, nên chỉ có một vài phần
điều khiển cần phải kích thích tất cả các net và test wrapper chỉ cần được
cấu hình để đưa các véc-tơ kiểm tra vào lối vào và lấy kết quả ở lối ra.
7.6.2. Dữ liệu kiểm tra cho các liên kết mạng
Trong ANOC, các liên kết mạng được thực thi bằng lô-gic QDI
không đồng bộ. Mỗi liên kết mạng được cấu thành gồm 17 kênh MR4,
một kênh DR và hai kênh SR, như minh họa trong Hình 7-5. Các kênh
MR4 được sử dụng để vận chuyển dữ liệu truyền thông, kênh DR
„send‟ được sử dụng để chỉ ra kênh ảo nào được sử dụng để truyền dữ
liệu và các kênh SR („accept0‟ và „accept1‟) được sử dụng để biểu thị
sự sẵn sàng của các kênh ảo tương ứng. Mỗi kênh MR4 bao gồm bốn
đường (rail) yêu cầu và một đường xác nhận. Mỗi kênh DR bao gồm
hai đường yêu cầu và một đường xác nhận và mỗi kênh SR gồm một
đường yêu cầu và một đường xác nhận.
Xem xét chức năng của mạng, các liên kết mạng không cần điều
khiển mà chỉ truyền các giá trị từ lối vào của liên kết mạng tới lối ra
của liên kết mạng. Việc kiểm tra một liên kết mạng tương đương với
việc kiểm tra 17 kênh MR4 độc lập và kiểm tra các kênh DR và SR.
Các véc-tơ kiểm tra toàn diện cho 17 kênh MR4 được xây dựng dựa
trên 4 giá trị có thể xảy ra đối với mỗi một chữ số mã 1-of-4 của các
tín hiệu dữ liệu, đó là “0.0.0….0”, “1.1.1….1”, “2.2.2….2”;
“3.3.3….3”. Các véc-tơ này được gửi từ test wrapper của một bộ định
tuyến tới test wrapper của bộ định tuyến bên cạnh. Bên cạnh đó, để
kiểm tra tín hiệu biểu thị kênh ảo (tín hiệu „send‟), hay kênh DR, thì
chúng ta cần chữ số mã 1-of-2 với hai giá trị có thể xảy ra (“0” và “1”)
đi kèm với các véc-tơ kiểm tra ở trên. Các kênh SR „accept‟ sẽ được
kiểm tra một cách tự nhiên khi test wrapper của bộ định tuyến bên
cạnh phản hồi việc chấp nhận một flit trên các tín hiệu „data+send‟.
Bảng 7-5 trình bày bộ véc-tơ kiểm tra dành cho một liên kết mạng.
Cuối cùng, chúng ta chỉ cần bốn véc-tơ để kiểm tra một liên kết mạng.
Bởi vì tất cả các liên kết mạng giống nhau nên các véc-tơ này được sử
dụng để kiểm tra tất cả các liên kết mạng.

202 Mạng trên chip
Bảng 7-5: Bộ dữ liệu kiểm tra cho từng liên kết mạng
Data (tất cả 17 chữ số mã “1-of-4”) Send (chữ số mã 1-of-2)
“0.0.0…………………0” “0”
“0.0.0…………………0” “1”
“0.0.0…………………0” “0”
“0.0.0…………………0” “1”
7.6.3. Dữ liệu kiểm tra cho các bộ định tuyến mạng
Chức năng của bộ định tuyến ANOC có thể được giải thích như
sau: các tài nguyên tính toán chia sẻ các gói dữ liệu (các gói dữ liệu
này có thể được định tuyến một cách riêng rẽ trên mạng). Một gói tin
bao gồm các flit nối tiếp nhau (mỗi một flit bao gồm 32 bit dữ liệu và
hai bit điều khiển). Mỗi gói tin luôn bao gồm một flit tiêu đề, theo sau
bởi các flit dữ liệu và flit đuôi như được đề cập trong Mục 7.3. Flit
tiêu đề sẽ cung cấp thông tin định tuyến, chứa tại trường thông tin
định tuyến “Path-to-Target”, là một véc-tơ gồm các hướng định tuyến
mà gói tin cần đi theo. Mỗi bộ định tuyến sử dụng hai bit có trọng số
thấp nhất của véc-tơ định tuyến đó để định tuyến toàn bộ gói tin đến
hướng được xác định sẵn và dịch trường định tuyến “Path-to-Target”
sao cho nó có thể được sử dụng bởi bộ định tuyến tiếp theo. Các flit
dữ liệu chứa các dữ liệu truyền thông và flit đuôi thông báo với bộ
định tuyến sự kết thúc của gói tin.
Theo Hình 7-13, mỗi một đơn vị cổng vào bao gồm một khối vào
IN nhận dữ liệu từ lối vào. Dữ liệu này sau đó được phân kênh tới hai
khối kênh ảo (VC0 và VC1). Tương tự, mỗi đơn vị cổng ra bao gồm
các khối kênh ảo (VC0 và VC1) và một khối lối ra OUT cho phép
nhập kênh dữ liệu từ hai kênh ảo và chuyển chúng tới lối ra.
Việc kiểm tra một bộ định tuyến có thể được thực hiện theo cách
sau: các véc-tơ kiểm tra được chèn vào một trong các cổng vào của bộ
định tuyến và kết quả kiểm tra được đọc tại các cổng ra. Để đưa được
các véc-tơ kiểm tra này tới bộ định tuyến cần kiểm tra, các véc-tơ kiểm
tra này phải được đóng gói như các gói dữ liệu kiểm tra và phải tuân thủ

Chương 7. Thiết kế kiểm tra cho mạng trên chip… 203
định dạng của các gói tin thông thường được sử dụng trong mạng trên
chip. Với cấu trúc được trình bày trong Hình 7-13, các đường định
tuyến thông thường trong bộ định tuyến được xác định bởi:
- Thông tin BoP/EoP thông báo sự hiện diện của trường định
tuyến và sự cần thiết để dịch chuyển nó hay không.
- Thông tin hướng định tuyến chỉ báo nơi mà dữ liệu được định
tuyến đến.
- Thông tin kênh ảo VC chỉ báo nơi mà các flit được lưu trữ.
Việc chèn các gói dữ liệu kiểm tra vào trong các đơn vị lối vào
khác nhau được thực hiện bằng cách cấu hình test wrapper như đã đề
cập ở trên.
Hình 7-13: Phân tích cấu trúc của một bộ định tuyến ANOC [141].
Để có thể có được độ bao phủ kiểm tra đầy đủ cho bộ định tuyến
cần kiểm tra, dữ liệu kiểm tra cần được đóng gói theo định dạng mô tả
trong Hình 7-14.
IN
(Kết
nốichuyển
mạch)
Đơn vị cổng vào 0
IN_0 OUT_0
VC0
VC1
IN_4
VC0
VC1
OUT
Đơn vị cổng ra 0
OUT_4
Ctrl Ctrl
IN
VC0
VC1
VC0
VC1
OUT
Ctrl CtrlĐơn vị cổng vào 4
Đơn vị cổng vào 1
Đơn vị cổng vào 2
Đơn vị cổng vào 3
Đơn vị cổng ra 1
Đơn vị cổng ra 2
Đơn vị cổng ra 3
Đơn vị cổng ra 4

204 Mạng trên chip
Hình 7-14: Định dạng của một gói dữ liệu kiểm tra.
Cấu trúc của một cổng vào/ra của bộ định tuyến bao gồm 17 kênh
MR4 không đồng bộ dành cho dữ liệu, một kênh DR và hai kênh SR
dành cho các tín hiệu điều khiển “send-accept”, tương tự như đối với
cấu trúc liên kết mạng (như trình bày ở Mục 7.6.2). Do đó, chúng ta
sử dụng cách tương tự để tạo nên các véc-tơ kiểm tra như chúng ta đã
thực hiện đối với các liên kết mạng. Tất cả các chữ số mã “1-of-4” của
flit kiểm tra không liên quan đến thông tin điều khiển nên được gán ép
một cách độc lập với tất cả các giá trị có thể (“0”, “1”, “2” và “3”), đó
là 15 chữ số mã “1-of-4” như được trình bày trong Bảng 7-6.
Bảng 7-6: Gói tin kiểm tra đa flit dùng để kiểm tra lối vào, lối ra
và kênh ảo của bộ định tuyển
Dữ liệu (data) Send
BoP/EoP 15 chữ số mã “1-of-4” Hướng Kênh ảo
2 “0.0.0……………0” “dir.” “vc.”
0 “0.0.0……………0” “0” “vc.”
0 “1.1.1……………1” “1” “vc.”
0 “2.2.2……………2” “2” “vc.”
1 “3.3.3……………3” “3” “vc.”
Chúng ta có thể thấy rằng các véc-tơ kiểm tra này cho phép kiểm
tra phần “dữ liệu” của các khối khác nhau (IN, VCvc.) của đơn vị lối
vào được xác định bởi test wrapper và các khối khác nhau (VCvc.,
1 0
(a) Flit tiêu đề
(b) Flit thân
(c) Flit đuôi
dir.dữ liệu kiểm tra
dữ liệu kiểm tra
BoP EoP
0 0
0 1
path-to-target
dữ liệu kiểm tra
dữ liệu kiểm tra

Chương 7. Thiết kế kiểm tra cho mạng trên chip… 205
OUT) của đơn vị lối ra được xác định bởi hướng định tuyến (“dir.”).
Tuy nhiên, để bao phủ được phần “điều khiển” của mỗi đơn vị vào/ra,
chúng ta phải quan tâm đến tất cả các tổ hợp của các giá trị điều khiển.
Do đó, các chữ số mã “1-of-4” chứa thông tin BoP/EoP, tất cả các chữ
số mã “1-of-4” trong trường định tuyến “Path-to-Target” và chữ số mã
“1-of-2” biểu thị kênh ảo được sử dụng phải được gán với các tổ hợp
có thể xảy ra để kiểm tra tất cả các tín hiệu của từng cặp vào-ra. Để
thực hiện điều đó, chúng tôi đã định nghĩa ba gói tin 1-flit bổ sung
như mô tả trong Bảng 7-7.
Bảng 7-7: Ba gói dữ liệu kiểm tra đơn flit bổ sung dùng để kiểm tra lối vào,
lối ra và kênh ảo của bộ định tuyến
Dữ liệu (data) Send
BoP/EoP 15 chữ số mã “1-of-4” Hướng Kênh ảo
3 “1.1.1……………1” “dir.” “vc.”
3 “2.2.2……………2” “dir.” “vc.”
3 “3.3.3……………3” “dir.” “vc.”
Cuối cùng, chúng ta cần tới 8 véc-tơ kiểm tra để bao phủ các
chức năng hoạt động của một cụm gồm một lối vào, một lối ra và một
kênh ảo. Do mỗi bộ định tuyến có 5 lối vào, 4 lối ra kết nối với mỗi
lối vào và hai kênh ảo, để kiểm tra toàn bộ bộ định tuyến chúng ta cần
tổng cộng 320 véc-tơ kiểm tra. Những véc-tơ kiểm tra này được chèn
vào bộ định tuyến cần kiểm tra thông qua việc cấu hình test wrapper.
Các cấu hình kiểm tra tương ứng có thể được tính toán bằng một
chương trình máy tính riêng và đưa ra tổng cộng là 640 khung cấu
hình kiểm tra do việc đưa véc-tơ kiểm tra vào và đọc kết quả ra là tách
biệt. Mục 7.8.4 sẽ đề cập đến độ bao phủ các lỗi stuck-at khi sử dụng
các véc-tơ chức năng trên. Trong mục tiếp theo chúng ta sẽ trình bày
cách thức kiểm tra toàn bộ mạng ANOC.
7.7. Chiến lược kiểm tra
Mục này sẽ trình bày một chiến lược kiểm tra đơn giản, cho phép
kiểm tra tất cả các thành phần của mạng ANOC. Với chiến lược này,

206 Mạng trên chip
tại mỗi thời điểm chỉ có một bộ định tuyến mạng được kiểm tra. Sau
đó, chúng ta sẽ kiểm tra tất cả các liên kết mạng kết nối với bộ định
tuyến đó. Sau khi bộ định tuyến hiện tại và các liên kết mạng của nó
được kiểm tra xong, chúng ta sẽ cấu hình test wrapper để đưa bộ định
tuyến này vào hoạt động ở chế độ bypass và chuyển sang kiểm tra bộ
định tuyến tiếp theo và các liên kết mạng của bộ định tuyến tiếp theo
đó. Luồng kiểm tra được thiết lập bởi kênh cấu hình kiểm tra, được
minh họa bằng đường mũi tên nét đậm như trong Hình 7-15.
Hình 7-15: Luồng kiểm tra cho mạng ANOC [141].
Với luồng kiểm tra này, thuật toán kiểm tra được mô tả như sau:
THUẬT TOÁN KIỂM TRA CHO MẠNG TRÊN CHIP ANOC
Set current-router = 1; /* Bắt đầu từ bộ định tuyến thứ nhất */
While current-router ≤ N do /* N là số bộ định tuyến trong mạng */
/***** Kiểm tra bộ định tuyến *****/
Set current-router in test mode;
Apply all router test vectors (320) to the router-under-test;
/* Một véc-tơ kiểm tra cần 2 khung cấu hình kiểm tra TCF */
/***** Kiểm tra liên kết mạng *****/
If current-router is not in the last row of the network then
Set current-router in transfer mode;
/* Hướng định tuyến hướng tới cổng South (V-next router) */
links-under-test
current-routerH-next
router
V-next
router
12345
106
1115
2016
Kênh cấu hình
kiểm tra
cfg-in
cfg-out

Chương 7. Thiết kế kiểm tra cho mạng trên chip… 207
Set V-next-router in loop-back mode;
/* nhờ vòng định tuyến lặp, mỗi véc-tơ kiểm tra có thể kiểm tra cả hai
hướng của liên kết mạng */
Apply all link test vectors (4) to the vertical links-under-test;
/* links-under-test là các liên kết theo chiều dọc giữa bộ định tuyến hiện
tại và bộ định tuyến V-next */
End if;
If the current-router is not the last router of the row-under-test then
Set current-router in transfer mode;
/* Hướng định tuyến tới H-next router */
Set H-next-router in loop-back mode;
Apply all link test vectors (4) to the horizontal links-under-test;
/* links-under-test là các liên kết mạng giữa bộ định tuyến hiện tại và
bộ định tuyến H-next */
End if;
/***** Chuẩn bị lặp lại các bước kiểm tra tiếp theo *****/
Set current-router in bypass mode;
/* Đặt current-router (bộ định tuyến hiện tại) ở chế độ bypass và chuyển
sang next-router (bộ định tuyến tiếp theo). Chú ý rằng, hướng bypass được
xác định bởi luồng kiểm tra */
current-router = current-router + 1;
End while;
Hình 7-16: Các cấu hình kiểm tra: Chế độ kiểm tra (a);
Chế độ bypass (b); Chế độ transfer (c); Chế độ loop-back (d).
Router Router
Router Router
(a) (b)
(c) (d)

208 Mạng trên chip
Chiến lược kiểm tra trình bày ở trên đòi hỏi kiến trúc DFT phải
hoạt động một cách chính xác. Do đó, kiến trúc DFT này cũng cần
được kiểm tra trước khi thực hiện việc kiểm tra các bộ định tuyến và
liên kết mạng. Việc kiểm tra kiến trúc DFT này được thực hiện bằng
cách đặt tất cả các test wrapper sang chế độ truyền dữ liệu và khi đó
việc tạo các dữ liệu kiểm tra tương ứng được thực hiện như nguyên
tắc tạo dữ liệu kiểm tra cho các liên kết mạng.
Mặc dù kiến trúc DFT nêu trên được thiết kế để kiểm tra kiến trúc
mạng NoC (các bộ định tuyến và liên kết mạng), tuy nhiên kiến trúc
này cũng có thể được sử dụng để kiểm tra các tài nguyên tính toán
(các lõi IP) và các giao tiếp mạng của chúng. Có nghĩa là kiến trúc
DFT này có thể được sử dụng để kiểm tra toàn bộ hệ thống mạng trên
chip. Cụ thể về vấn đề này được trình bày chi tiết ở [96]. Nhờ vào việc
tái sử dụng các liên kết mạng như là các cơ chế truy cập kiểm tra
TAM thông lượng cao để vận chuyển dữ liệu kiểm tra nên kiến trúc
DFT này không sử dụng thêm bất kỳ bus kiểm tra riêng nào.
7.8. Kết quả thực nghiệm
7.8.1. Chi phí không gian thực thi
Kiến trúc DFT không đồng bộ đề xuất được thực thi bằng công
nghệ CMOS 65nm của hãng STMicroelectronics (cùng với thư viện
công nghệ lô-gic không đồng bộ 65nm của Phòng thí nghiệm TIMA
thuộc Trung tâm Khoa học và Công nghệ Quốc gia (CNRS), Cộng
hòa Pháp [149]). Không gian thực thi của một test cell là 8.560 µm2 và
không gian thực thi của mô-đun điều khiển WCM là 10.400 µm2. Kết
quả là một test wrapper gồm 5 khối kiểm tra lối vào, 5 khối kiểm tra
lối ra và một mô-đun điều khiển WCM sẽ cần một không gian thực thi
khoảng 96.000 µm2; tương đương 32,7% không gian thực thi của một
bộ định tuyến mạng không đồng bộ có thể kiểm tra. Để có thể hình
dung dễ dàng hơn về không gian thực thi test wrapper, chúng ta so
sánh test wrapper với một khối biến đổi Fourier nhanh (FFT) trong hệ
thống được thực thi với một chi phí khoảng 1.600.000 µm2 (tương
đương 250 kGates).

Chương 7. Thiết kế kiểm tra cho mạng trên chip… 209
Tuy nhiên, kiến trúc DFT đề xuất không chỉ được sử dụng cho
mỗi việc kiểm tra kiến trúc mạng mà còn có thể được sử dụng như là
cơ chế truy cập kiểm tra TAM để kiểm tra các thành phần khác của hệ
thống ANOC (bao gồm cả các lõi IP và giao tiếp mạng khác). Do đó,
chi phí không gian thực thi kiến trúc DFT này nên được chia sẻ cho
toàn bộ các tài nguyên tính toán trên vi mạch. Kết quả là chi phí này
chỉ chiếm vào khoảng 3% đến 5% tổng chi phí toàn vi mạch, phụ
thuộc vào kích thước của vi mạch. Với trường hợp dự án FAUST [20],
không gian thực thi của kiến trúc DFT này chiếm 4,8% tổng không
gian thực thi cả vi mạch FAUST).
7.8.2. Độ trễ tăng thêm
Test wrapper được sử dụng để cải thiện khả năng truy cập và khả
năng kiểm tra của kiến trúc mạng ANOC nhưng chúng cũng làm tăng
độ trễ truyền thông của mạng ANOC ở chế độ hoạt động thông
thường. Với thực thi của chúng tôi, độ trễ tăng thêm này là 0,34 ns đối
với một cặp cổng lối vào và lối ra, so với độ trễ truyền của bộ định
tuyến là 2 ns (kết quả đo đạc sau layout), xem Hình 7-17.
Hình 7-17: Độ trễ tăng thêm.
Điều này tương ứng với độ trễ của hai C-elements bất đối xứng
và hai cổng AND. Tuy nhiên, do các vòng lặp tín hiệu bắt tay tại các
lối vào/lối ra của bộ định tuyến không phải là vấn đề lớn (trong các
OTC
ITC
ITC
OTC
ITC OTC
ITC
OTC
ANOC
router
WEST
RES
EAST
NORTH
0.17ns 0.17ns2.00ns

210 Mạng trên chip
mạch không đồng bộ QDI, hiệu suất được xác định bằng chiều dài của
các vòng lặp tín hiệu bắt tay) nên hầu như thông lượng truyền thông
của NoC không bị giảm đi, nghĩa là vẫn 500 Mflits/s ở chế độ hoạt
động thông thường.
7.8.3. Thời gian thực thi kiểm tra
Bằng cách sử dụng các liên kết mạng như là cơ chế truy cập kiểm
tra TAM, kiến trúc DFT đề xuất sở hữu các đường kiểm tra băng thông
cao. Tuy nhiên, chúng ta cần gửi dữ liệu cấu hình kiểm tra để điều
khiển việc chèn dữ liệu kiểm tra và thu thập kết quả kiểm tra. Thông
lượng của kênh cấu hình vào khoảng 2 ns cho từng mẩu cấu hình,
khoảng 50 ns cho một khung dữ liệu cấu hình kiểm tra hoàn chỉnh.
Khi kiểm tra các liên kết mạng, chúng ta cần hai khung cấu hình
cho từng véc-tơ kiểm tra, cho cả quá trình chèn dữ liệu kiểm tra và
quá trình quan sát kết quả kiểm tra bởi vì lúc đó có hai test wrapper
được sử dụng. Để kiểm tra các bộ định tuyến, trong hầu hết các trường
hợp chúng ta chỉ cần một khung cấu hình kiểm tra đơn là đủ để chèn
dữ liệu kiểm tra và quan sát kết quả kiểm tra. Do đó, tốc độ kiểm tra
vào khoảng 20 Mtest-vectors/s. Tuy nhiên, để đơn giản việc tạo các
khung cấu hình kiểm tra, chúng ta sử dụng hai khung cấu hình kiểm
tra cho mỗi véc-tơ kiểm tra khi kiểm tra các bộ định tuyến: một khung
cấu hình dùng để chèn véc-tơ kiểm tra và một khung cấu hình dùng để
quan sát kết quả kiểm tra. Theo đó, tốc độ kiểm tra vào khoảng 10
Mtest-vectors/s. Với các véc-tơ kiểm tra được tạo ra, thời gian kiểm
tra cần thiết cho mỗi bộ định tuyến mạng là 32 µs và thời gian kiểm
tra cần thiết cho mỗi liên kết mạng hai hướng là 0,4 µs.
Kết quả là tổng thời gian thực thi việc kiểm tra cho một mạng
ANOC gồm 20 bộ định tuyến là 0,7 ms (trong khi đó, thời gian thực
thi kiểm tra đối với một khối FFT trong hệ thống là 7,114 ms).
7.8.4. Độ bao phủ lỗi
Để đánh giá, ước lượng hiệu quả của phương pháp tiếp cận này,
chúng ta sử dụng mô hình lỗi stuck-at đơn khá nổi tiếng trên cả các lối

Chương 7. Thiết kế kiểm tra cho mạng trên chip… 211
vào và lối ra của các tế bào mạch (circuit cells). Vì không có công cụ
hỗ trợ để tính toán độ bao phủ lỗi (fault coverage) cho các thiết kế
không đồng bộ nên chúng tôi đã xây dựng một chương trình phần
mềm dựa trên các kịch bản (scripts) để chèn một cách tự động các lỗi
lên tất cả các chân của tế bào mạch tiêu (standard cell) chuẩn của bộ
định tuyến cần kiểm tra (mỗi lần chèn một lỗi đơn), mô phỏng và tính
toán các lỗi được phát hiện. Một lỗi được phát hiện nếu mạch kiểm tra
bị treo (không có sự thay đổi giá trị tại các lối ra hoặc không xuất hiện
tín hiệu acknowledge) trước khi kết thúc quá trình kiểm tra. Với các
véc-tơ kiểm tra được tạo ra, phương pháp kiểm tra đề xuất đạt độ bao
phủ lỗi lên tới 99,86% đối với các bộ định tuyến, 100% đối với các
liên kết mạng. Độ bao phủ lỗi của việc kiểm tra chính kiến trúc DFT
đạt 99,75% sử dụng tất cả các véc-tơ kiểm tra có thể. Sở dĩ chúng ta
đạt được độ bao phủ rất cao này là nhờ vào đặc tính kiến trúc luồng dữ
liệu (dataflow) của các bộ định tuyến mạng, chủ yếu được xây dựng
dựa trên các bộ hợp kênh và phân kênh trên một cấu trúc giống đường
ống và kiểu thiết kế dựa vào mã thông báo (token-base design style)
sử dụng trong mạng ANOC: các lỗi duy nhất không được phát hiện
trong bộ định tuyến đã được định vị trước khi các lối vào của một số ít
C-elements bất đối xứng sử dụng trong thiết kế để kiểm tra các điều
kiện chạy đua (race conditions – là tình huống không mong muốn khi
nhiều yêu cầu xảy ra cùng một lúc) trên các mã thông báo điều khiển
sử dụng cho một số mã thông báo dữ liệu.
Bảng 7-8: Báo cáo về độ bao phủ lỗi Single Stuck-At (SSA)
khi kiểm tra bộ định tuyến
Mạch cần kiểm tra Lỗi SSA
ở lối ra
Lỗi SSA
ở lối vào
Lỗi SSA ở cả lối ra
và lối vào
Bộ điều khiển
cổng vào
3.178/3.178
(100%)
6.016/6.016
(100%)
9.194/9.194 (100%)
Bộ điều khiển
cổng ra
5.185/5.198
(99,74%)
8.925/8.944
(99,78%)
14.110/14.142
(99,77%)
Toàn bộ bộ
định tuyến
41.815/41.880
(99,84%)
74.705/74.800
(99,87%)
116.520/116.680
(99,86%)

212 Mạng trên chip
Bảng 7-8 trình bày một báo cáo ngắn gọn về số lượng các lỗi
được đưa vào, số lượng các lỗi nhận biết được và độ bao phủ lỗi của
từng phần của bộ định tuyến cũng như của cả toàn bộ bộ định tuyến.
Mô hình lỗi stuck-at đơn dựa vào chân (pin-based) được sử dụng ở
đây mang lại kết quả tốt vì hiệu ứng lô-gic của lỗi stuck-at là để ngăn
chặn sự xuất hiện quá trình chuyển dịch mức lô-gic và do đó hầu hết
các trường hợp hấp thụ mã thông báo trong hệ thống mạch không
đồng bộ. Các loại lỗi khác có thể làm xuất hiện một quá trình chuyển
dịch mức lô-gic mới, nghĩa là tạo ra một mã thông báo mới trong một
phần khác của hệ thống (ngắn mạch, nhiễu chéo tín hiệu – crosstalk,
v.v…). Những lỗi này không làm cho mạch bị treo ngay lập tức và
không thể phát hiện được khi sử dụng các véc-tơ kiểm tra nêu ở trên.
Dù vậy, với việc lặp đi lặp lại quá trình kiểm tra, các mã thông báo bổ
sung được tạo ra bởi loại lỗi này có thể lấp đầy toàn bộ chuỗi mã
thông báo và làm cho hệ thống bị treo. Giả sử rằng lỗi xảy ra ở mỗi
lần kiểm tra, hệ thống sẽ bị treo sau một số lần kiểm tra, bằng với độ
sâu đường ống của bộ định tuyến, ví dụ bằng 9 trong trường hợp mạng
ANOC. Điều này có thể dẫn tới việc chúng ta cần khoảng thời gian
kiểm tra tổng thể khoảng 7 ms cho toàn bộ mạng ANOC để bắt được
loại lỗi này.
7.8.5. Chẩn đoán lỗi và định vị điểm khiếm khuyết
Kiến trúc DFT đề xuất không chỉ cho phép chúng ta phát hiện các
lỗi stuck-at mà còn cho phép chúng ta xác định được vị trí của các
điểm khiếm khuyết - là nguyên nhân tạo nên các lỗi stuck-at. Ưu điểm
là chúng ta có thể định vị được các lỗi đã phát hiện trong các mạch
cần kiểm tra và sau đó tìm kiếm các nguyên nhân trong quá trình sản
xuất sinh ra các lỗi này. Kết quả, việc chẩn đoán giúp chúng ta cải
thiện quy trình sản xuất để tránh các khiếm khuyết đó xảy ra trong
tương lai.
Thực vậy, bằng việc phân tích cấu trúc của bộ định tuyến chúng
ta có thể thấy rằng phần điều khiển của bộ định tuyến chiếm khoảng
10% số cổng lô-gic của bộ định tuyến và số lượng các cổng lô-gic của
một khối lối vào tương đương với số lượng cổng lô-gic của một khối

Chương 7. Thiết kế kiểm tra cho mạng trên chip… 213
lối ra. Ngoài phần điều khiển, mỗi khối lối vào và lối ra có thể được
chia nhỏ thành ba phần con với số cổng lô-gic khá tương đồng, xem
Hình 7-13.
Trong trường hợp lỗi stuck-at đơn, tập hợp 320 véc-tơ trên cho
phép cách ly ngay phần chứa lỗi; đó là một phần trong 40 phần con.
Nếu lỗi nằm ở phần dữ liệu, sự độc lập của các kênh MR4 cho phép
cách ly lỗi ở không gian 1/600 của bộ định tuyến khi sử dụng thêm 15
véc-tơ tính toán trong quá trình phân tích. Hơn nữa, nếu tất cả 4 giá trị
của mã số 1-of-4 bị loại bỏ, chúng ta có thể kết luận rằng lỗi nằm trên
đường ghi nhận (acknowledgement). Còn nếu chỉ một trong 4 giá trị
bị loại bỏ thì lỗi nằm trên một trong các đường (rail) 1-of-4. Do đó,
một khiếm khuyết có thể được định vị trên một không gian 1/3000 của
bộ định tuyến. Với bộ định tuyến gồm khoảng 20.000 cổng lô-gic, có
thể nói là phương pháp này cho phép chúng ta định vị lỗi với độ chính
xác trong cụm khoảng 7 cổng lô-gic.
7.8.6. Tái cấu hình bộ định tuyến trong trường hợp có lỗi đơn
Nhờ vào việc thêm các kênh bypass cho mục đích kiểm tra,
chúng ta có thể sử dụng các kênh bypass này để duy trì kết nối trong
mạng khi bộ định tuyến bị lỗi bằng cách cấu hình bộ định tuyến
chuyển sang sử dụng chế độ bypass, thay vì để dữ liệu di chuyển qua
bộ định tuyến bị lỗi. Khi đó, thông tin trường định tuyến cũng được
chỉnh sửa bằng cách loại bỏ các hướng định tuyến không sử dụng.
Điều này cho phép tiếp tục sử dụng vi mạch bị lỗi (với hiệu năng thấp
hơn) hoặc sử dụng vi mạch này cho các ứng dụng khác để giảm chi
phí sản xuất hoặc có thể được sử dụng để kiểm tra kỹ hơn nhằm tìm
kiếm các lỗi khác trong quá trình thử nghiệm/gỡ lỗi.
7.9. Kết luận chương
Việc xây dựng giải pháp thiết kế kiểm tra luôn là một trong
những vấn đề quan trọng, góp phần đảm bảo sản phẩm vi mạch cuối
cùng không có lỗi và có thể được đưa vào ứng dụng thực tiễn. Mô
hình mạng trên chip có nhiều điểm ưu việt khi triển khai các hệ thống

214 Mạng trên chip
lớn nhưng cũng cho thấy nhiều thách thức, đặc biệt là vấn đề kiểm tra
tìm kiếm và phát hiện các lỗi có thể xảy ra trong quá trình sản xuất vì
chúng có độ tích hợp cao.
Với mạng trên chip, các kiến trúc mạng trên chip không đồng bộ
dường như đang là lựa chọn tốt cho truyền thông trên chip của các hệ
thống GALS, chúng cũng có những vấn đề hết sức quan trọng liên
quan đến khả năng kiểm tra cần được quan tâm. Trong quá trình
nghiên cứu về mạng trên chip, chương này đã trình bày một hướng
tiếp cận đầy đủ của chúng tôi về thiết kế kiểm tra cho các kiến trúc
mạng trên chip không đồng bộ. Cụ thể, chúng tôi đã đề xuất, thiết kế
và thực thi một kiến trúc DFT hoàn toàn không đồng bộ cho kiến trúc
mạng ANOC [141]. Kiến trúc DFT này có thể được cấu hình để có thể
thích nghi với các mạng trên chip không đồng bộ khác với các tô-pô
mạng khác nhau. Kiến trúc DFT này được thực thi với công nghệ
CMOS 65nm của STMicroelectronics, sử dụng thư viện tế bào chuẩn
từ Phòng thí nghiệm TIMA, Đại học Bách khoa Grenoble, Cộng hòa
Pháp [149]. Việc kiểm thực được triển khai thông qua một nền tảng
đồng mô phỏng SystemC/Verilog netlist. Kiến trúc DFT này sau đó
được tích hợp trên một hệ thống NoC được sản xuất thử nghiệm có tên
gọi là ALPIN [94, 96].
Liên quan đến dữ liệu kiểm tra, chúng tôi cũng đề xuất một
phương pháp tạo dữ liệu kiểm tra đơn giản, hiệu quả. Việc tạo dữ liệu
kiểm tra và các thông tin cấu hình kiểm tra tương ứng được thực hiện
thông qua một chương trình phần mềm. Với dữ liệu kiểm tra này,
hướng tiếp cận của chúng tôi đạt được độ bao phủ lên tới 99,86% (sử
dụng các mô hình lỗi stuck-at đơn).

Chương 6. Ứng dụng lô-gic mờ trong thiết kế mạng trên chip… 215
TÀI LIỆU THAM KHÂO
[1] ARM, AMBA Advanced eXtensible Interface (AXI) Protocol
Specification (Version 1.0), 2003.
[2] R. Rajsuman, System-on-a-Chip: Design and Test, Artech
House Publishers, 2000.
[3] D. Sylvester and K. Keutzer, "A Global Wiring Paradigm for
Deep Submicron Design," IEEE Transactions on Computer
Aided Design Integrated Circuits, vol. 19, pp. 242-252, 2000.
[4] A. Jantsch and H. Tenhunen, Networks on Chip, Kluwer
Academic Publisher, 2003.
[5] W. Dally and B. Towles, "Route Packets, Not Wires: On-chip
Interconnection," in Proceedings of the Design Automation
Conference (DAC), Las Vegas, 2001.
[6] L. Benini and G. D. Michel, "Networks on Chips: A New SoC
Paradigm," IEEE Computer Journal, vol. 35, no. 1, pp. 70-78, 2002.
[7] C. A. Zeferino, M. Kreutz, L. Carro and A. A. Susin, "A Study
on Communication Issues for Systems-on-Chip," in
Proceedings of the 15th Symposium on Integrated Circuits and
System Design, 2002.
[8] A. Radulescu and K. Goossens, "Communication Services for
Network on Chip," in Domain-Specific Processors: Systems,
Architectures, Modeling, and Simulation, 2003, pp. 275-299.
[9] C. Grecu, P. P. Pande, A. Ivanov and R. Saleh, "Structured
Interconnect Architecture: A Solution for the Non-Scalability of
Bus-based SoCs," in Proceedings of the Great Lakes
Symposium VLSI, 2004.

216 Mạng trên chip
[10] IBM CoreConnect, "CoreConect Bus Archiecture," [Online].
Available: www-03.ibm.com/chips/products/coreconnect/index.
html. [Accessed 01 10 2019].
[11] L. Benini and G. De Michel, "Powering Networks on Chips," in
Proceedings of the 14th IEEE/ACM Int'l Symposium on Systems
Synthesis (ISSS), 2001.
[12] A. Hemani, A. Jantsch, S. Kumar, A. Postula, J. Oberg, M.
Millberg and D. Lindqvist, "Network on Chip: An Architecture
for Billion Transistor Era," in Proceedings on the IEEE
NorChip Conference, Turku, Finland, 2000.
[13] R. Ho, K. W. Mai and M. A. Horowitz, "The Future of Wires,"
Proceedings of the IEEE, vol. 89, no. 4, pp. 490-504, 2001.
[14] P. Guerrier and A. Greiner, "A Generic Architecture for On-chip
Packet-Switch Interconnections," in Proceedings of the Design,
Automation and Test in Europe Conference (DATE), 2000.
[15] J. Liang, S. Swaminathan and R. Tessier, "aSOC: A Scalable,
Single-Chip Communications Architecture," in Proceedings of
the IEEE Int'l Conference on Parallel Architectures and
Compilation Techniques, 2000.
[16] E. Rijpkema, K. Goossens and P. Wielage, "A Router
Architecture for Networks on Silicon," in Proceedings of 2nd
Workshop on Embedded Systems, 2001.
[17] F. Karim, A. Nguyen, S. Dey and R. Rao, "On-Chip
Communication Architecture for 0C-768 Network Processors,"
in Proceedings of the 38th Design Automation Conference
(DAC), Las Vegas, NV, USA, 2001.
[18] S. Vangal and e. al., "An 80-Tile 1.28TFLOPS Network-on-
Chip in 65nm," in the IEEE Int'l Solid-State Circuits
Conference (ISSCC), San Francisco, USA, 2007.

TĖi liệu tham khĘo 217
[19] J. Bainbridge and S. Fuber, "CHAIN: a Delay-Insensitive Chip
Area Interconnect," IEEE Micro, vol. 22, no. 5, pp. 16-23, 2002.
[20] D. Lattard, E. Beigne, C. Bernard, C. Bour, F. Clermidy, Y.
Durand, J. Durupt, D. Varreau, P. Vivet, P. Penard, A. Bouttier
and F. Berens, "A Telecom Baseband Circuit based on an
Asynchronous Network-on-Chip," in International Solid-State
Circuits Conference (ISSCC), San Francisco, 2007.
[21] S. Wielage and K. Gossens, "Networks on Silicon: Blessing or
Nightmare?," in The Euromicro Symposium on Digital System
Design (DSD), Dortmund, 2002.
[22] F. Moraes, N. Calazans, A. Mello and L. O. L. Moller,
"HERMES: an Infrastructure for Low Area Overhead Packet-
Switching Networks on Chip.," Integration, the VLSI Journal,
pp. 69-93, October 2004.
[23] E. Rijpkema, K. Goossen, A. Radulescu, J. Dielissen and P. v.
Meerbergen, "Trade Offs in the Design of a Router with both
Guaranteed and Best-Effort Services for Networks on Chip,"
IEE Proceedings on Computers and Digital Techniques, vol.
150, no. 5, pp. 294-302, September 2003.
[24] M. Karol, H. M and S. Morgan, "Input versus Output Queuing on
a Space-Division Packet Switch," IEEE Transactions on
Communications, vol. 35, no. 12, pp. 1347-1356, December 1987.
[25] P. Pande, C. Grecu, M. Jones, A. Ivanov and R. Saleh,
"Performance Evaluation and Design Trade-offs for Network-
on-Chip Interconnect Architectures," IEEE Transactions on
Computers, vol. 54, no. 8, pp. 1025-1040, August 2005.
[26] E. Bolotin, I. Cidon, R. Ginosar and A. Kolodny, "Efficient Routing
in Irregular Topology NoCs," CCIT Technical Report, 2005.
[27] W. Dally and C. Seitz, "Deadlock-Free Message Routing in
Multiprocessor Interconnection Networks," IEEE Transactions
on Computers, vol. 36, no. 5, pp. 547-553, May 1987.

218 Mạng trên chip
[28] C. Glass and L. Ni, "The Turn Model for Adaptive Routing,"
vol. 41, pp. 875-902, 1994.
[29] K. Goosens, J. Dielissen and e. al., "Guaranteeing The Quality
of Services in Networks on Chip.," in Networks on Chip,
Kluwer Academic Publisher, 2003, pp. 61-82.
[30] T. Bjerregaard and J. Sparso, "A Router Architecture for
Connection-Oriented Service Guarantees in the MANGO
Clockless Network-on-Chip.," in the Design, Automation and
Test in Europe Conference (DATE), Munich, 2005.
[31] S. Kumar and e. al., "Network on Chip Architecture and Design
Methodology," in the IEEE Computer Society Annual
Symposium on VLSI (ISVLSI), Pittsburgh, 2002.
[32] M. Millberg, E. Nilsson, R. Thid, S. Kumar and A. Jantsch,
"The Nostrum Backbone - a Communication Protocol Stack for
Networks on Chip.," in the 17th Int'l Conference on VLSI
Design (VLSID), 2004.
[33] X.-T. Tran, "Project report (QC.08.18) "Design and Modeling
of a Network Router for On-chip Communication"," Vietnam
National University, Hanoi, Hanoi, 2009.
[34] T. H. Pham, P. H. Pham, X.-T. Tran and C. Kim, "Analysis and
Evaluation of Traffic-Performance in a Backtracked Routing
Network-on-Chip.," in The 2nd International Conference on
Communications and Electronics (ICCE), Hoi An, 2008.
[35] B. Attia, W. Chouchene, A. Zitouni and R. Tourki, "Network
Interface Sharing for SoCs based NoC," in 2011 International
Conference on Communications, Computing and Control
Applications, 2011.
[36] B. Attia, A. Zitouni, N. Abid and R. Tourki, "A Modular Network
Interface Adapter Design for OCP Compatibles NoCs,"
International Journal of Computer and Network Security, 2009.

TĖi liệu tham khĘo 219
[37] S. Stergiou, F. Angiolini, S. Carta, L. Raffo, D. Bertozzi and G.
De Micheli, "Xpipes Lite: a Synthesis Oriented Design Library
for Networks on Chips," in 2005 Design, Automation Test in
Europe Conference Exhibition (DATE), 2005.
[38] A. Radulescu, J. Dielissen, K. Goossens, E. Rijpkema and P.
Wielage, "An Efficient On-Chip Network Interface Offering
Guaranteed Services, Shared-Memory Abstraction, and Flexible
Network Configuration," in 2004 Design, Automation Test in
Europe Conference Exhibition (DATE), 2004.
[39] J.-J. Lecler and G. Baillieu, "Application driven network-on-
chip architecture exploration & refinement for a complex SoC,"
Design Automation for Embedded Systems, vol. 15, no. 2, pp.
133-158, 2011.
[40] Arteris, "ARM AMBA ACE, AXI, OCP, or Any Transaction
Protocols," Arteris, 2019. [Online]. Available:
http://www.arteris.com/axi-protocol-arm-ace-ahb-apb.
[Accessed 5 November 2019].
[41] ARM, "CoreLink Network Interconnect Family," 2019. [Online].
Available: https://www.arm.com/products/system-ip/interconnect/
corelink-nic-family.php. [Accessed 10 November 2019].
[42] A. El Mrabti, F. Rousseau, F. Petrot, J. Martin, R. Lemaire and
E. Vaumorin, "Design Environment for the Support of
Configurable Network Interfaces in NoC-based Platforms," in
2010 International Conference on Embedded Computer Systems
(SAMOS), 2010.
[43] S. Saponara, T. Bacchillone, E. Petri, L. Fanucci, R. Locatelli
and M. Coppola, "Design of a NoC Interface Macrocell with
Hardware Support of Advanced Networking Functionalities,"
IEEE Transactions on Computers, vol. 99, 2012.
[44] M. Ruaro, F. B. Lazzarotto, C. A. Marcon and F. G. Moraes,
"DMNI: A specialized network interface for NoC-based

220 Mạng trên chip
MPSoCs," in 2016 IEEE International Symposium on Circuits
and Systems (ISCAS), 2016.
[45] X.-T. Tran, T. Nguyen, H.-P. Phan and D.-H. Bui, "AXI-NoC:
High-Performance Adaptation Unit for ARM Processors in
Network-on-Chip Architectures," IEICE Transactions on
Fundamentals of Electronics, Communications and Computer
Sciences, Vols. E100-A, no. 8, pp. 1650-1660, 2017.
[46] E. Beigné, F. Clemidy, P. Vivet, A. Clouard and M. Renaudin,
"An Asynchronous NoC Architecture Providing Low Latency
Service and its Multi-level Design Framework," in The 11th
IEEE Int. Symposium on Asynchronous Circuits and Systems
(ASYNC), 2005.
[47] N.-K. Dang, T.-V. Le-Van and X.-T. Tran, "FPGA
Implementation of a Low Latency and High Throughput
Network-on-Chip Router Architecture," in 2011 International
Conference on Integrated Circuits and Devices in Vietnam
(ICDV), 2011.
[48] T. Bjerregaard, S. Mahadevan, R. Olsen and J. Sparsoe, "An
{OCP} Compliant Network Adapter for GALS-based SoC," in
2005 International Symposium on System-on-Chip, 2005.
[49] D. Matos, M. Costa, L. Carro and A. Susin, "Network interface
to synchronize multiple packets on NoC-based Systems-on-
Chip," in 18th IEEE/IFIP VLSI System on Chip Conference
(VLSI-SoC), 2010.
[50] J. Sparso, E. Kasapaki and M. Schoeberl, "An Area-Efficient
Network Interface for a TDM-based Network-on-Chip," in 2012
Design, Automation Test in Europe Conference Exhibition
(DATE), 2013.
[51] R. Aitken, A. Gibbons, K. Shi, M. Keating and D. Flynn, Low
Power Methodology Manual for System-on-Chip Design,
Springer, 2008.

TĖi liệu tham khĘo 221
[52] C. Piguet, Low-Power Electronics Design, CRC Press, 2005.
[53] K. Pokhrel, "Physical and Silicon Measures of Low Power
Clock Gating Success: An Apple to Apple Case Study," in
Synopsys Users Group Conference, 2007.
[54] J. Rabaey, Low Power Design Essentials, Springer, 2009.
[55] Q. Wu, P. Juang, M. Martonosi, L. S. Peh and D. W. Clark,
"Formal Control Techniques for Power-Performance
Management," IEEE Micro, vol. 25, no. 5, pp. 52-62,
September 2005.
[56] S. Y. Bang, K. Bang, S. Yoon and E. Y. Chung, "Run-Time
Adaptive Workload Estimation for Dynamic Voltage Scaling,"
IEEE Transactions on Computer-Aided Design of Integrated
Circuits and Systems, vol. 28, no. 9, pp. 1334-1347, September
2009.
[57] P. Pillamari, K. J. Naidu and H. M. Kittur, "Power reduction
using DVFS with a producer-consumer FIFO," in International
Conference on Signal Processing, Communication, Computing
and Networking Technologies (ICSCCN), 2011.
[58] F. Yao, A. Demers and S. Shenker, "A scheduling model for
reduced CPU energy," 1995.
[59] C. Im, H. Kim and S. Ha, "Dynamic Voltage Scheduling
Technique for Low-Power Multimedia Applications Using
Buffers," in International Symposium on Low Power
Electronics and Design (ISLPED), 2001.
[60] R. Jejurikar and R. Gupta, "Energy-aware Task Scheduling with
Task Synchronization for Embedded Real-time Systems," IEEE
Transactions on Computer-Aided Design of Integrated Circuits
and Systems, vol. 25, no. 6, pp. 1024-1037, June 2006.
[61] A. Azevedo, I. Issenin, R. Cornea, R. Gupta, N. Dutt, A.
Veidenbaum and A. Nicolau, "Profile-based Dynamic Voltage

222 Mạng trên chip
Scheduling using Program Checkpoints," in 2002 Design,
Automation and Test in Europe Conference and Exhibition,
2002, 2002.
[62] E.-Y. Chung, L. Benini and G. De Micheli, "Contents Provider-
assisted Dynamic Voltage Scaling for Low Energy Multimedia
Applications," in International Symposium on Low Power
Electronics and Design, 2002.
[63] P. Yang, C. Wong, P. Marchal, F. Catthoor, D. Desmet, D.
Verkest and R. Lauwereins, "Energy-aware runtime scheduling
for embedded-multiprocessor SOCs," IEEE Design Test of
Computers, vol. 18, no. 5, pp. 46-58, September 2001.
[64] V. Gutnik and A. P. Chandrakasan, "Embedded power supply
for low-power DSP," IEEE Transactions on Very Large Scale
Integration (VLSI) Systems, vol. 5, no. 4, pp. 425-435,
December 1997.
[65] L. S. Nielsen, C. Niessen, J. Sparso and K. van Berkel, "Low-
Power Operation Using Self-timed Circuits and Adaptive
Scaling of the Supply Voltage," IEEE Transactions on Very
Large Scale Integration (VLSI) Systems, vol. 2, no. 4, pp. 391-
397, December 1994.
[66] G.-Y. Wei and M. Horowitz, "A Fully Digital, Energy-efficient,
Adaptive Power-supply Regulator," IEEE Journal of Solid-State
Circuits, vol. 34, no. 4, pp. 520-580, April 1999.
[67] C. J. Hughes and S. V. Adve, "A Formal Approach to Frequent
Energy Adaptations for Multimedia Applications," in 31st Annual
International Symposium on Computer Architecture, 2004.
[68] Z. Lu, J. Lach, M. Stan and K. Skadron, "Reducing multimedia
decode power using feedback control," in 21st International
Conference on Computer Design, 2003.
[69] A. Sinha and A. P. Chandrakasan, "Dynamic Voltage
Scheduling using Adaptive Filtering of Workload Traces," in
14th International Conference on VLSI Design, 2001.

TĖi liệu tham khĘo 223
[70] N.-M. Nguyen, W. Lombardi, E. Beigné, S. Lesecq and X.-T.
Tran, "FIFO-level-based Power Management and its Application
to a H.264 encoder," in the 40th Annual Conference of IEEE
Industrial Electronics Society (IECON), Dallas, TX, USA, 2014.
[71] H. Pourshaghaghi, J. Escobar and J. Gyvez, Synthesis and
VHDL Implementation of Fuzzy Logic Controller for Dynamic
Voltage and Frequency Scaling (DVFS) Goals in Digital
Processors, E. Dadios, Ed., InTech, 2012.
[72] F. Brunno, R. Caponetto, L. Fortuna and D. Porto, "Parameter
Tuning and Hardware Implementation of a Non Integer Order
PID Controller," in 14th Mediterranean Conference on Control
and Automation, 2006.
[73] F. Zhang and Z. Li, "Design of fractional PID control system for
BLDC motor based on FPGA," in The Chinese Control And
Decision Conference (CCDC), 2018.
[74] P. Das, P. J. Edavoor, S. Raveendran and A. D. Rahulkar,
"Design and implementation of computationally efficient
architecture of PID based motion controller for robotic land
navigation system in FPGA," in Conference on Information and
Communication Technology (CICT), 2017.
[75] J.-S. Kim, H.-W. Jeon and S. Jung, "Hardware implementation of
nonlinear PID controller with FPGA based on floating point
operation for 6-DOF manipulator robot arm," in the Inernational
Conference on Control, Automation and Systems, 2007.
[76] I. Masngut, G. N. P. Pratama, A. I. Cahyadi, S. Herdjunanto and
J. F. J. Pakpahan, "Design of fractional-order proportional-
integral-derivative controller: Hardware realization," in the
International Conference on Information and Communications
Technology (ICOIACT), 2018.
[77] B. Xue, W. De-ming, T. Jun-jun and Z. Bu-hui, "The Hardware
Design and Simulation of Kalman Filter Based on IP Core and

224 Mạng trên chip
Time-sharing Multiplex," in 2011 Fourth International Conference
on Intelligent Computation Technology and Automation, 2011.
[78] I. Zbierska, T. Talapmka and R. Dlugosz, "Parallel matrix
multiplication in 2-gain Kalman filter realized in hardware," in
2017 IEEE 30th International Conference on Microelectronics
(MIEL), 2017.
[79] C. R. Lee and Z. Salcic, "A fully-hardware-type maximum-
parallel architecture for Kalman tracking filter in FPGAs," in
International Conference on Information, Communications and
Signal Processing, 1997.
[80] K. M. Deliparaschos, F. I. Nenedakis and S. G. Tzafestas,
"Design and Implementation of a Fast Digital Fuzzy Logic
Controller Using FPGA Technology," Journal of Intelligent and
Robotic Systems, vol. 45, no. 1, pp. 77-96, 2006.
[81] D. N. Oliveira, A. P. de Souza Braga and O. da Mota Almeida,
"Fuzzy Logic Controller Implementation on a FPGA Using
VHDL," in the Annual Meeting of the North American on Fuzzy
Information Processing Society (NAFIPS), 2010.
[82] Y.-H. Liu, Z.-Z. Yang, S.-Q. Huang and J.-F. Wei, "Design and
Implementation of an FPGA-based Fuzzy Controller for
Switched-Mode Power Supplies," in the World Congress on
Intelligent Control and Automation (WCICA), 2011.
[83] M. Sharma and M. Ayoub Khan, "Investigation of Low-Power
Techniques in Network-on-Chip," in World Applied Sciences
Journal 16 (Special Issue on Recent Trends in VLSI Design), 2012.
[84] W. Zong and Q. Xu, "DOART: A Low-Power and Low-Latency
Network-on-Chip," in 34th IEEE International Conference on
Computer Design (ICCD), 2016.
[85] A. Psarras, J. Lee, P. Mattheakis, C. Nicopoulos and G.
Dimitrakopoulos, "A Low-Power Network-on-Chip Architecture
for Tile-Based Chip Multi-Processors," in the International Great
Lakes Symposium on VLSI (GLSVLSI), 2016.

TĖi liệu tham khĘo 225
[86] M. Yadav, M. Casu and M. Zamboni, "LAURA-NoC: Local
Automatic Rate Adjustment in Network-on-Chips With a
Simple DVFS," IEEE Transactions on Circuits and Systems II,
no. 60, pp. 647-651, 2013.
[87] I. Vaisband and E. G. Friedman, "Dynamic Power Management
with Power Network-on-Chip," in the 12th International New
Circuits and Systems Conference (NEWCAS), 2014.
[88] A. Bhanwala, M. Kumar and Y. Kumar, "FPGA Based Design
of Low Power Reconfigurable Router for Network on Chip
(NoC)," in International Conference on Computing,
Communication Automation, 2015.
[89] F. Mohammadian, "FALP: A Fault Adaptive and Low Power
Method for Network on Chip Router," in Wokshop Proceedings
on Architecture of Computing Systems(ARCS), 2014, 2014.
[90] K. Swaminathan, G. Lakshminarayanan, F. Lang, M. Fahmi and
S. B. Ko, "Design of A Low Power Network Interface for
Network on chip," in 26th IEEE Canadian Conference on
Electrical and Computer Engineering (CCECE), 2013.
[91] W. Chouchene, B. Attia, A. Zitouni, N. Abid and R. Tourki, "A
Low Power Network Interface For Network on Chip," in 8th
International Multi-Conference on Systems, Signals & Devices,
2011.
[92] G. Sravya and M. Sailaja, "VLSI Design of Low Power Data
Encoding Techniques for Network-on-Chip," in the International
Conference on Signal Processing, Communication, Power and
Embedded System (SCOPES), 2016.
[93] D. Sarma, G. Lakshminarayanan and K. Chavali, "A Novel
Encoding Scheme for Low Power in Network on Chip Links," in
25th International Conference on VLSI Design (VLSID), 2012.
[94] E. Beigne, F. Clermidy, H. Lhermet, S. Miermont, Y. Thonnart,
X.-T. Tran, A. Valentian, D. Varreau, P. Vivet, X. Popon and H.

226 Mạng trên chip
Lebreton, "An Asynchronous Power Aware and Adaptive NoC
Based Circuit," IEEE Journal of Solid-State Circuits, vol. 44,
no. 4, pp. 1167-1177, 2009.
[95] E. Beigne, F. Clermidy, S. Miermont, Y. Thonnart, A. Valentian
and P. Vivet, "A Localized Power Control mixing hopping and
Super Cut-Off techniques within a GALS NoC," in IEEE
International Conference on Integrated Circuit Design and
Technology and Tutorial (ICICDT), 2008.
[96] X.-T. Tran, Méthode de Test et Conception en Vue du Test pour
les Réseaux sur Puce Asynchrones: Application au Réseau
ANOC, Grenoble, France: Grenoble INP, 2008.
[97] E. Beigne, F. Clermidy, S. Miermont and P. Vivet, "Dynamic
Voltage and Frequency Scaling Architecture for Units
Integration within a GALS NoC," in 2nd ACM/IEEE
International Symposium on Networks-on-Chip (NoCS), 2008.
[98] Y. Thonnart, E. Beigne, A. Valentian and P. Vivet, "Power
Reduction of Asynchronous Logic Circuits Using Activity
Detection," IEEE Transactions on Very Large Scale Integration
(VLSI) Systems, vol. 17, no. 7, pp. 893-906, 2009.
[99] H. Zakaria and L. Fesquet, "Process Variability Robust Energy-
Efficient Control for Nano-scaled Complex SoCs," in Faible
Tension Faible Consommation (FTFC), 2011.
[100] E. Yahya, O. Elissati, H. Zakaria, L. Fesquet and M. Renaudin,
"Programmable/Stoppable Oscillator Based on Self-Timed
Rings," in 15th IEEE Symposium on Asynchronous Circuits and
Systems (ASYNC), 2009.
[101] H. P. Phan, Power consumption optimization for network-on-
chip architectures, Vietnam National University, Hanoi, 2019.
[102] L. A. Zadeh, "Fuzzy Sets," Information and Control, vol. 8, no.
3, pp. 338-353, 1965.

TĖi liệu tham khĘo 227
[103] D. Song and S. Jung, "Neural Compensation Technique for
Fuzzy Controlled Humanoid Robot Arms : Experimental
Studies," in IEEE 22nd International Symposium on Intelligent
Control (ISIC), 2007.
[104] D. H. Song and S. Jung, "Geometrical Analysis of Inverse
Kinematics Solutions and Fuzzy Control of Humanoid Robot
Arm under Kinematics Constraints," in International
Conference on Mechatronics and Automation, 2007.
[105] K. Deliparaschos, F. Nenedakis and S. Tzafestas, "A fast digital
fuzzy logic controller: FPGA design and implementation," in
10th IEEE Conference onEmerging Technologies and Factory
Automation (ETFA), 2005.
[106] S. Uppalapati and D. Kaur, "Design and Implementation of a
Mamdani Fuzzy Inference System on an FPGA," in Annual
Meeting of the North American on Fuzzy Information
Processing Society (NAFIPS), 2009.
[107] P. Vuong, A. Madni and J. Vuong, "VHDL Implementation For
a Fuzzy Logic Controller," in World Automation Congress
(WAC), 2006.
[108] S. Guo, L. Peters and H. Surmann, "Design and Application of
an Analog Fuzzy Logic Controller," vol. 4, no. 4, 1996.
[109] K. Nakamura, N. Sakashita, Y. Nitta, K. Shimomura and T.
Tokuda, "Fuzzy Inference and Fuzzy Inference Processor,"
IEEE Micro, vol. 13, no. 5, pp. 37-48, 1993.
[110] M. Sugeno, "An Introductory Survey of Fuzzy Control,"
Information Sciences, vol. 36, no. 1, pp. 59-83, 1985.
[111] H. P. Phan and X.-T. Tran, "Design and Modeling of a Voltage-
Frequency Controller for Network-on-Chip Routers based on Fuzzy-
Logic," VNU Journal of Computer Science and Communication
Engineering (JCSCE), vol. 31, no. 2, pp. 56-65, 2015.

228 Mạng trên chip
[112] C. Ababei and N. Mastronarde, "Benefits and Costs of
Prediction Based DVFS for NoCs at Router Level," in 27th
IEEE International System-on-Chip Conference (SOCC), 2014.
[113] L. Shang, L.-S. Peh and N. K. Jha, "Dynamic Voltage Scaling
with Links for Power Optimization of Interconnection
Networks," in Ninth International Symposium on High-
Performance Computer Architecture (HPCA-9), 2003.
[114] A. B. Kahng, B. Lin and S. Nath, "Explicit Modeling of Control
and Data for Improved NoC Router Estimation," in Design
Automation Conference (DAC), 2012, 2012.
[115] A. B. Kahng, B. Li, L.-S. Peh and K. Samadi, "ORION 2.0: A
Fast and Accurate NoC Power and Area Model for Early-stage
Design Space Exploration," in Design, Automation and Test in
Europe (DATE), Nice, France, 2009.
[116] A. B. Kahng, B. Li, L. S. Peh and K. Samadi, "ORION 2.0: A
Power-Area Simulator for Interconnection Networks," IEEE
Transactions on Very Large Scale Integration (VLSI) Systems,
vol. 20, no. 1, pp. 191-196, 2012.
[117] A. B. Kahng, B. Lin and K. Samadi, "Improved On-chip Router
Analytical Power and Area Modeling," in 15th Asia and South
Pacific Design Automation Conference (ASP-DAC), 2010.
[118] K. Jeong, A. B. Kahng, B. Lin and K. Samadi, "Accurate
Machine-Learning-Based On-Chip Router Modeling," IEEE
Embedded Systems Letters, vol. 2, no. 3, Septembers 2010.
[119] J. Chan and S. Parameswaran, "NoCEE: Energy Macro-model
Extraction Methodology for Network on Chip Routers," in
IEEE/ACM International Conference on Computer-Aided
Design (ICCAD), 2005.
[120] G. Guindani, C. Reinbrecht, T. Raupp, N. Calazans and F. G.
Moraes, "NoC Power Estimation at the RTL Abstraction Level," in
IEEE Computer Society Annual Symposium on VLSI, 2008.

TĖi liệu tham khĘo 229
[121] S. E. Lee and N. Bagherzadeh, "A High Level Power Model for
Network-on-Chip (NoC) Router," Journal Computers and
Electrical Engineering, vol. 35, no. 6, pp. 837-845, 2009.
[122] G. Palermo and C. Silvano, "PIRATE: A Framework for
Power/Performance Exploration of Network-on-Chip
Architectures," in Integrated Circuit and System Design. Power
and Timing Modeling, Optimization and Simulation: 14th
International Workshop, PATMOS 2004, Santorini, Greece,
September 15-17, 2004. Proceedings, Springer Berlin Heidelberg.
[123] C. S. Patel, S. M. Chai, S. Yalamanchili and D. E. Schimmel,
"Power Constrained Design of Multiprocessor Interconnection
Networks," in International Conference on Computer Design
VLSI in Computers and Processors, 1997.
[124] N. Banerjee, P. Vellanki and K. S. Chatha, "A Power and
Performance Model for Network-on-Chip Architectures," in
Design, Automation and Test in Europe Conference and
Exhibition (DATE), 2004.
[125] A. Banerjee, R. Mullins and S. Moore, "A Power and Energy
Exploration of Network-on-Chip Architectures," in First
International Symposium on Networks-on-Chip (NoCS), 2007.
[126] P. Meloni, I. Loi, F. Angiolini, S. Carta, M. Barbaro, L. Raffo
and L. Benini, "Area and Power Modeling for Networks-on-
Chip with Layout Awareness," in IEEE VLSI Design, 2007.
[127] S. Penolazzi and A. Jantsch, "A High Level Power Model for
the Nostrum NoC," in 9th EUROMICRO Conference on Digital
System Design (DSD), 2006.
[128] D. A. K. Mishra, A. Yanamandra, R. Das, S. Eachempati, R.
Iyer, N. Vijaykrishnan and R. Chita, "RAFT: A router
architecture with frequency tuning for on-chip networks,"
Journal of Parallel and Distributed Computing, vol. 71, no. 5,
pp. 625 - 640, 2011.

230 Mạng trên chip
[129] A. K. Coskun, T. S. Rosing and K. C. Gross, "Utilizing
Predictors for Efficient Thermal Management in Multiprocessor
SoCs," IEEE Transactions on Computer-Aided Design of
Integrated Circuits and Systems, vol. 10, pp. 1503-1516,
October 2009.
[130] K. Park and W. Willinger, Self-Similar Network Traffic and
Performance Evaluation, John Wiley & Sons, Inc., 2000.
[131] H. P. Phan, X. T. Tran and T. Yoneda, "Power Consumption
Estimation using VNOC2.0 Simulator for a Fuzzy-Logic based
Low Power Network-on-Chip," in 2017 IEEE International
Conference on Integrated Circuit Design and Technology (IEEE
ICICDT), 2017, 2017.
[132] IEEE 1500, "IEEE 1500 Standard for Embedded Core Test,"
[Online].
[133] D. Chapiro, Globally Asynchronous Locally Synchronous
Systems, Standford University, 1984.
[134] A. Jantsch and H. Tenhunen, Networks on Chip, (Kluwer
Academic Publisher, 2003.
[135] A. Lines, "Asynchronous Interconnect for Synchronous SoC
Design," IEEE Micro, vol. 24, no. 1, pp. 32-41, 2004.
[136] R. Dobkin, V. Vishnyakov, E. Friedman and R. Ginosar, "An
Asynchronous Router for Multiple Service Levels Networks on
Chip," in The 11th IEEE Int. Symposium on Asynchronous
Circuits and Systems (ASYNC), New York, 2005.
[137] B. Vermeulent, J. Dielissen, K. Goossens and C. Ciordas,
"Bringing Communication Networks on a Chip: Test and
Verification Implications," IEEE Communication Magazine, pp.
74-86, September 2003.
[138] A. Amory, E. Briao, E. Cota, M. Lubaszewski and F. and Moraes,
"A Scalable Test Strategy for Network-on-Chip Routers," in
International Test Conference (ITC), Texas, USA, 2005.

TĖi liệu tham khĘo 231
[139] M. Hosseinabady, A. Banaiyan, M. Nazm and Z. Navabi, "A
Concurrent Testing Method for NoC Switches," in Design
Automation and Test in Europe (DATE), Munich, Germany, 2006.
[140] A. Efthymiou, J. Bainbridge and D. Edwards, "Test Pattern
Generation and Partial-Scan Methodology for an Asynchronous
SoC Interconnect," IEEE Transactions on VLSI Systems, p.
1384–1392, December 2005.
[141] X.-T. Tran, Y. Thonnart, J. Durupt, V. Beroulle and C. Robach,
"Design-for-Test Approach of an Asynchronous Network-on-
Chip Architecture and its Associated Test Pattern Generation
and Application," IET Computers & Digital Techniques, vol. 3,
no. 5, pp. 487-500, 2009.
[142] M. Nahvi and A. Ivanov, "Indirect Test Architecture for SoC
Testing," IEEE Transactions on CAD of Integrated Circuits and
Systems, vol. 23, no. 7, pp. 1128-1142, July 2004.
[143] E. Cota, L. Carro and M. Lubaszewski, "Reusing an On-Chip
Network for the Test of Core-Based Systems," vol. 9, no. 4, pp.
471-499, October 2004.
[144] A. Amory, K. Goossens, E. Marinissen, M. Lubaszewski and F.
Moraes, "Wrapper Design for the Reuse of Networks-on-Chip
as Test Access Mechanism," in The IEEE European Test
Symposium (ETS), Southampton, UK, 2006.
[145] F. Gürkaynak, T. Villiger, S. Oetiker, N. Felber, H. Kaeslin and
W. Fichtner, "A Functional Test Methodology for Globally
Asynchronous Locally Synchronous Systems," in The
International Symposium on Advanced Research in
Asynchronous Circuits and Systems (ASYNC), 2002.
[146] A. Martin, "Programming in VLSI: From Communicating
Processes to Delay-Insensitive Circuits," in Developments in
Concurrency and Communication, Addison-Wesley, 1990.

232 Mạng trên chip
[147] P. Hazewindus, Testing Delay-Insensitive Circuits, PhD thesis,
California Institute of Technology, 1992.
[148] J. Bainbridge, W. Toms, D. Edwards and S. Furber, "Delay-
Insensitive, Point-to-Point Interconnect using m-of-n Codes," in
The 9th IEEE International Symposium on Asynchronous
Circuits and Systems (ASYNC), Canada, 2003.
[149] P. Maurine, J. Rigaud, F. Bouesse, G. Sicard and M. Renaudin,
"Static Implementation of QDI Asynchronous Primitives," in
The 13th Int. Workshop on Power and Timing Modeling,
Optimization and Simulation (PATMOS), 2003.

Index 233
INDEX
A
ad-hoc, 24, 25
B
Best-Effort, 46
biến ngôn ngữ, 134, 135
bộ điều khiển tần số - điện áp, 139
bộ định tuyến, 30, 33, 42, 43, 51, 52, 55,
68, 74, 113, 138, 180, 185
bộ định tuyến cần kiểm tra, 183, 188,
189, 191, 198, 202, 203, 205, 211
bộ phối ghép mạng, 68
bus phân tầng, 26
C
cấp bậc của bộ định tuyến, 33
cấp độ liên thuộc, 142
cầu nối bus, 22, 26
chặn cấp nguồn, 104
chất lượng dịch vụ, 45
cơ chế truy cập kiểm tra, 181, 186, 187,
188, 197, 198, 208, 209, 210
cơ chế truyền thông, 37
công suất chuyển mạch, 95
công suất ngắn mạch, 96
công suất tiêu thụ động, 94, 95, 96, 97,
98, 99, 101, 102, 104, 121, 127, 174,
177
công suất tiêu thụ tĩnh, 94, 98, 99, 100,
101, 104, 174
D
deadlock, 42
deep submicron, 23
dị bộ toàn cầu - đồng bộ cục bộ, 14, 23,
114, 180
dịch vụ được đảm bảo (GS), 46
điểm-tới-điểm, 21, 25, 26
điều khiển luồng đầu-cuối, 44
độ bao phủ lỗi, 211, 212
độ rộng điểm chia đôi mạng, 33
độ trễ đáp ứng, 23, 34, 36, 38, 40, 45, 46
đổi điện áp thích nghi, 104
dòng điện rò, 95
dòng rò cổng, 98
dòng rò dưới ngưỡng, 98, 99
dòng rò máng gây ra bởi cực cổng, 98
dòng rò tiếp giáp, 99
dữ liệu kiểm tra, 181, 188
đường kính mạng, 33
F
flit, 37, 68
flit dữ liệu, 38
flit đuôi, 73
flit thân, 73
flit tiêu đề, 14, 38, 42, 43, 51, 52, 56, 57,
62, 68, 73, 74, 77, 78, 79, 81, 83,
161, 162, 185, 202
G
GALS, 14, 23, 114, 119, 121, 180, 182,
184, 214
giao thức bắt tay “send-accept”, 52, 53,
55
giao thức lõi mở (OCP: Open Core
Protocol), 69
giao thức truyền thông, 47
giao tiếp mạng, 68
gói tin (packet), 51
gói tin phản hồi, 76
gói tin phản hồi đọc, 83
gói tin phản hồi ghi, 83

234 Mạng trên chip
gói tin yêu cầu, 76
gói tin yêu cầu đọc, 76
gói tin yêu cầu ghi, 76
Guaranteed Service, 46
H
hàm liên thuộc, 130, 131, 132, 133, 135,
136, 137, 142, 143, 147, 148, 149,
150, 151, 152, 153, 156
hàng đợi lối ra, 39, 40
hàng đợi lối ra ảo, 39, 40
hàng đợi lối vào, 39
hàng đợi lối vào ưu tiên kênh ảo, 39, 40
hệ thống lô-gic mờ, 129, 134, 135, 136
hệ thống mờ, 136
hệ thống trên chip, 17, 21, 22, 29, 67,
94, 104, 128, 179
head-of-line blocking, 39
I
IP reuse, 29
K
kênh vật lý, 52
kết nối điểm-điểm, 22
khả năng điều khiển, 186
khả năng hỗ trợ tốt nhất (BE), 46
khả năng kiểm tra, 67, 183, 209, 214
khả năng quan sát, 186
khái niệm tập hợp, 130
khóa chết, 42, 43, 44, 52, 72, 112
khóa động, 42, 44, 52
khung cấu hình kiểm tra, 194, 195, 196,
198, 205, 206, 210
kỹ thuật chuyển mạch gói, 35, 36, 37,
39, 51
kỹ thuật chuyển mạch kênh, 35, 36, 54
kỹ thuật credit, 45, 55
kỹ thuật cửa sổ, 45
kỹ thuật điều khiển luồng dữ liệu, 45
kỹ thuật điều khiển thông lượng, 45
Kỹ thuật truyền thông, 35
L
liên kết mạng, 33
livelock, 42, 44
lô-gic mờ, 133
lõi IP, 17, 19, 21, 22, 23, 24, 25, 26, 29,
30, 51, 53, 60, 62, 67, 68, 72, 75, 76,
77, 78, 83, 85, 89, 112, 114, 115,
116, 117, 118, 121, 124, 125, 126,
127, 139, 159, 174, 176, 177, 180,
181, 182, 208, 209
lỗi stuck-at đơn, 199, 210, 212, 213, 214
luồng kiểm tra, 187, 206, 207
lưu trữ và chuyển tiếp, 37
lý thuyết tập mờ, 128, 131, 133
M
mạng trên chip, 17, 18, 19, 27, 30, 31,
32, 33, 34, 35, 38, 39, 41, 42, 45, 46,
47, 48, 49, 50, 52, 54, 66, 67, 68, 70,
71, 72, 73, 74, 93, 94, 112, 113, 114,
117, 119, 121, 126, 127, 128, 138,
139, 140, 141, 158, 159, 160, 163,
166, 167, 172, 176, 178, 179, 180,
182, 184, 185, 187, 188, 189, 201,
203, 206, 208, 213, 214
mẩu cấu hình, 194, 196, 210
máy trạng thái hữu hạn, 71, 81, 82, 83,
85, 86, 93, 144
mô hình Sugeno, 137
mô-đun điều khiển wrapper, 187, 194
mức chuyển giao thanh ghi, 24
P
phương pháp chặn cấp nguồn, 100
phương pháp chặn cấp xung nhịp, 98,
101, 124
phương pháp đa điện áp ngưỡng, 100
phương pháp điều khiển tỷ lệ điện áp
thích nghi, 105
phương pháp điều khiển tỷ lệ điện áp và
tần số động, 105, 106, 107, 108, 109,
110, 111
phương pháp mux-selection, 71, 80, 87

Index 235
phương pháp thiết kế đa điện áp nguồn,
102
phương pháp thiết kế đa điện áp
ngưỡng, 103
Q
quá trình giải mờ, 136, 153
quá trình hợp thành, 136
quá trình mờ hóa, 136, 148, 149
R
RTL, 24
S
sự biến thiên (variation), 67
T
tắc nghẽn động, 42
tắc nghẽn tĩnh, 42
tầng giao vận, 48
tầng liên kết dữ liệu, 48
tầng mạng, 48
tầng vật lý, 48
tập kinh điển, 130
tập mờ, 130
thiết kế kiểm tra, 19, 116, 179, 180, 181,
183, 184, 186, 192, 213, 214
thiết kế tái sử dụng các lõi IP, 29
thời gian đưa sản phẩm ra thị trường, 67
thời gian đưa sản phẩm ra thị trường
(time-to-market), 29
thời gian xử lý trung bình, 107
thông lượng, 24, 45, 46, 71, 80, 88, 91,
93, 117, 208, 210
thứ tự dữ liệu, 46
thuật toán định tuyến, 40
thuật toán định tuyến động, 41
thuật toán định tuyến phân tán, 42
thuật toán định tuyến tại nguồn, 42
thuật toán định tuyến thích ứng, 41
thuật toán định tuyến tĩnh, 41
thuật toán định tuyến xác định, 41, 50,
72
thuật toán Sugeno, 137
tính đa dạng của các đường định tuyến,
33
tính đối xứng, 33
tính quy tắc, 33
tính toàn vẹn dữ liệu, 45
tô-pô, 33, 34, 35, 71
tỷ lệ điện áp cố định, 105
tỷ lệ điện áp đa mức, 105
V
véc-tơ kiểm tra, 186, 201, 202, 204, 205,
206, 207, 210, 211, 212
Virtual-Cut-Through, 37, 38
W
Wormhole, 37, 38

Top Related
Copyright © 2022 FDOKUMEN

