







Bahasa
Halaman
Hukum


BigBatch – An Environment for ProcessingMonochromatic Documents
Rafael Dueire Lins, Bruno Tenorio Avila, and Andrei de Araujo Formiga
Universidade Federal de Pernambuco, Recife - PE, Brazil
Abstract. BigBatch is a processing environment designed to automati-cally process batches of millions of monochromatic images of documentsgenerated by production line scanners. It removes noisy borders, checksand corrects orientation, calculates and compensates the skew angle,crops the image standardizing document sizes, and finally compressesit according to user defined file format. BigBatch encompasses the bestand recently developed algorithms for such kind of document images.BigBatch may work either in standalone or operator assisted modes. Be-sides that, BigBatch in standalone mode is able to process in clusters ofworkstations or in grids.
1 Introduction
Digitalization of large amounts of paper documents inherited from a recent pastis the way organizations use to move into the electronic document era. Thisallows bridging over the gap of past and present technologies, organizing, in-dexing, storing, retrieving directly or making accessible through networks, andkeeping the contents of documents for future generations. Although new tech-nologies such as digital cameras are becoming of widespread use with documents,production line flatbed scanners (such as [15]) are still the best technical andeconomical choice for the digitalization of batches of millions of bureaucraticdocuments.
The direct outcome of such scanning process yields poor quality images, asmay be seen in Figure 1 and 2, below. BigBatch in operator driven mode removesnoisy borders, checks and corrects orientation, calculates and compensates theskew angle, crops the image standardizing document sizes, and finally compressesit according to user defined file format. BigBatch encompasses the best and re-cently developed algorithms for such kind of document images. In batch mode,the environment works standalone on a whole batch of documents performingoperations in a pre-defined order. In general, the digitalization technology ofproduction-line scanners is used onto bureaucratic document without either his-torical or iconographic value, kept due to legal restrictions. Several thousandsimages are generated by each scanner per day. Thus, not only the efficiency ofthe algorithms used in image filtering is crucial, but the possibility of working inclusters of workstations or PC’s allows a much higher throughput. This clusterfeatures and may be tuned to handle all the scanner production batch or mayeven use the spare processing time of the local area network in the organization,working extra-office hours for instance.
A. Campilho and M. Kamel (Eds.): ICIAR 2006, LNCS 4142, pp. 886–896, 2006.c© Springer-Verlag Berlin Heidelberg 2006

BigBatch – An Environment for Processing Monochromatic Documents 887
Fig. 1. Skewed document with solidblack frame
Fig. 2. Wrongly oriented skewed docu-ment with solid black frame
Fig. 3. Standalone filtering of the doc-ument of Figure 1
Fig. 4. Standalone filtering of the docu-ment of Figure 2
The BigBatch standalone processing of the documents presented in Figure 1and 2 is presented in Figures 3 and 4, respectively.
2 BigBatch in Operator Driven Mode
The activation of BigBatch opens its initial screen which allows the four differentoperation modes: Manual, Standalone, Cluster and Grid. The three first of themare already implemented while the Grid mode is still being implemented, andwill allow the same functionality of document filtering working on a Wide AreaNetwork or internets (even in the Internet). Manual is the operator driven mode,which has now four operations implemented: Remove Noise, Remove Black Bor-der, Deskew, and Remove White Border. In Manual mode the user opens animage of his choice, an example of what the interface becomes is presented on

888 R.D. Lins, B.T. Avila, and A. de Araujo Formiga
Fig. 5. BigBatch interface working in Manual mode
Figure 5. The user may apply the filters in any order with complete freedom,even of repeating operations several times. In what follows one briefly describesthe functionality of each of the existing filters.
Remove Noise. Very often due to dust or fungi on documents, the result ofdigitalization yields small ”dots” on different areas scattered on the image. Thosedots are sometimes imperceptible by the human naked eye, but even in this casethey cause losses in image compression (as they reduce run-length) and may alsodegrade OCR performance. Such artifact is known as ”salt-and-pepper” noise[9]. BigBatch encompasses a salt-and-pepper filter, which scans the documentimage and analyzes blocks of 3x3 pixels. If the central pixel under the maskhas color different from its surroundings, it has its color inverted to match itsneighbors. Such filter is standard in most image processing environments.
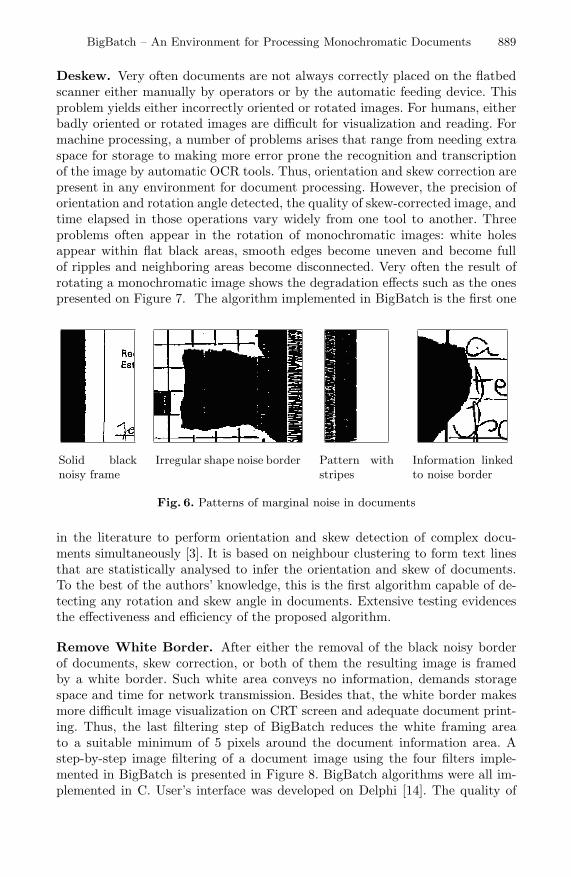
Border Removal. Depending on a number of factors such as the size of the doc-ument, its state of conservation and physical integrity, the presence or absenceof dust in the document and scanner parts, etc. very frequently the image gener-ated is framed either by a solid or stripped black border. This frame, also knownas marginal noise, not only drops the quality of the resulting image for CRTvisualization, but also consumes space for storage and large amounts of tonerfor printing. Removing such frame manually is not practical due to the need ofspecialized users and time consumed in the operation. Several production-linescanner manufacturers have developed softwares for removing those noisy bor-ders. However, the softwares tested [12][13][16][17][18] are too greedy and tendto remove essential parts of documents. (Figure 6 presents some of the mosttypical kinds of noise border).
BigBatch – An Environment for Processing Monochromatic Documents 889
Deskew. Very often documents are not always correctly placed on the flatbedscanner either manually by operators or by the automatic feeding device. Thisproblem yields either incorrectly oriented or rotated images. For humans, eitherbadly oriented or rotated images are difficult for visualization and reading. Formachine processing, a number of problems arises that range from needing extraspace for storage to making more error prone the recognition and transcriptionof the image by automatic OCR tools. Thus, orientation and skew correction arepresent in any environment for document processing. However, the precision oforientation and rotation angle detected, the quality of skew-corrected image, andtime elapsed in those operations vary widely from one tool to another. Threeproblems often appear in the rotation of monochromatic images: white holesappear within flat black areas, smooth edges become uneven and become fullof ripples and neighboring areas become disconnected. Very often the result ofrotating a monochromatic image shows the degradation effects such as the onespresented on Figure 7. The algorithm implemented in BigBatch is the first one
Solid blacknoisy frame
Irregular shape noise border Pattern withstripes
Information linkedto noise border
Fig. 6. Patterns of marginal noise in documents
in the literature to perform orientation and skew detection of complex docu-ments simultaneously [3]. It is based on neighbour clustering to form text linesthat are statistically analysed to infer the orientation and skew of documents.To the best of the authors’ knowledge, this is the first algorithm capable of de-tecting any rotation and skew angle in documents. Extensive testing evidencesthe effectiveness and efficiency of the proposed algorithm.
Remove White Border. After either the removal of the black noisy borderof documents, skew correction, or both of them the resulting image is framedby a white border. Such white area conveys no information, demands storagespace and time for network transmission. Besides that, the white border makesmore difficult image visualization on CRT screen and adequate document print-ing. Thus, the last filtering step of BigBatch reduces the white framing areato a suitable minimum of 5 pixels around the document information area. Astep-by-step image filtering of a document image using the four filters imple-mented in BigBatch is presented in Figure 8. BigBatch algorithms were all im-plemented in C. User’s interface was developed on Delphi [14]. The quality of

890 R.D. Lins, B.T. Avila, and A. de Araujo Formiga
Original image Classical algorithm
Fast Black-Run algorithm BigBatch algorithm
Fig. 7. Examples of degradation of a word rotated of 45 and -45
Noise filtering Noisy black bor-der removed
Orientation and skewcorrected image
Cropped and finalfiltered image
Fig. 8. Images obtained after each filtering step using BigBatch
images processed with BigBatch was at least as good as the best ones producedby the other commercial tools tested [12][13][16][17][18]. Sequential processingin BigBatch outperformed all the other tools whenever images of comparablequality were generated (many times some of the tested tools demanded lesstime than BigBatch for border removal, for instance, but that operation wasperformed unsatisfactorily).
3 Standalone Batch Processing
BigBatch in standalone mode processes a full batch of documents placed on adirectory sequentially. The operator assisted mode allows each tool to be usedto improve a given image. Besides that, BigBatch in standalone mode is ableto process in clusters of workstations [5], automatically dispatching documentsfrom a file server to workstations and collecting them after processing.

BigBatch – An Environment for Processing Monochromatic Documents 891
Table 1. Standalone Batch Processing results.
Dataset Number of images Original size Processed sizeCD1 6.020 252 MB 228 MBCD2 5.615 706 MB 436 MBCD3 5.097 647 MB 380 MBCD4 4.538 705 MB 417 MB
BigBatch was used to process over 21.000 monochromatic document imagesgenerated by Kodak [15] production line scanners compressed in TIFF G4 fileformat. The first set (CD1) consists of images with 200dpi and mostly blackborders and little noise. The next three sets (CD2, CD3 and CD4) consists ofimages with 300dpi resolution and noisy black borders. After 10 hours and 47minutes, BigBatch took 1,82 seconds, in average, for each image to applied allfilters. The filters applied to the images reduced over 36% the overall datasetsize (Table 1).
One of the improvements to be added to BigBatch in standalone processingmode is the collection of statistical data on the processed documents such as:
– the number of uncorrectly oriented documents in the batch, which gives anaccount of the quality of batch preparation.
– the number of pixels altered by the salt-and-pepper filter, which signals thedegree of dust in documents and scanner flatbed.
– the average and variance of the skew angle found in documents from thebatch, with may witness the care of operator in document handling or thequality and cleaness of the auto-feeding device of the scanner.
– the number of border pixels removed, which stands a degrading factor indocument storage, transmission through networks, visualization, and print-ing.
One may see those numbers as a preliminary ”measure of quality” of digitaliza-tion.
4 BigBatch in Cluster
The processing of large batches of documents is a processing intensive task thatmay run for several hours. This is even more so if automatic text transcriptionand indexing is performed. Preliminary tests show that today the transcriptionof a document takes about over a minute of cpu (using Omnipage 15.0 runningon a Intel Pentium IV, 1.6 GHz clock and 512MB RAM) per A4 page. One ofthe pioneering features of BigBatch is the possibility of using a cluster to processbatches of thousands or even millions of documents. The operations performedon documents are exactly the same as the ones performed in standalone mode.
The cluster architecture is set to a farm of processors. Most of clusters todayare implemented for Linux or Solaris and use MPI for interprocessor communica-tion. The BigBatch cluster was designed for the Windows platform and uses the

892 R.D. Lins, B.T. Avila, and A. de Araujo Formiga
TCP/IP protocol for communication. The first version supports only one mas-ter which dispatches packets to workers and waits for their reply. The masterperforms no other operation but worker supervision and feeding.
Since a document image is independent of another, the load balancing of thecluster can be simplified. The server builds packages of data containing ten imagesand sends to the workers. The packaging of several documents has two advantages:
1. reducing the TCP/IP overhead and latency and;2. balancing the work load.
The package has a reasonable amount of images to keep the client busy for fewseconds and small enough to balance the load. One must remark that ”in the realworld” most batches of documents are non-homogeneous. As one may observein the figures provided on Table 1, documents vary in size, integrity, amountof borders to be removed, etc, yielding different processing time per document.Although the number of documents in packets is the same, the processing timeellapsed by the worker may vary widely.
Currently, there is no fault-tolerance recovery strategy. If the master dies thewhole cluster stops. If a worker dies there is no task redistribution. It is plannedto make improvements to the BigBatch architecture to allow the master to keeptrack of the work sent out and time-out dead (or out of range) workers. Thissimple control strategy allows packet re-allocation.
The BigBatch cluster is not bound to a homogeous architecture. In a heteroge-nous cluster, the faster the client, more packages it receives, while the slower lesspackages. Each client maintains a queue of the packages to pipeline the clientprocess flow and keep its resources busy at maximum.
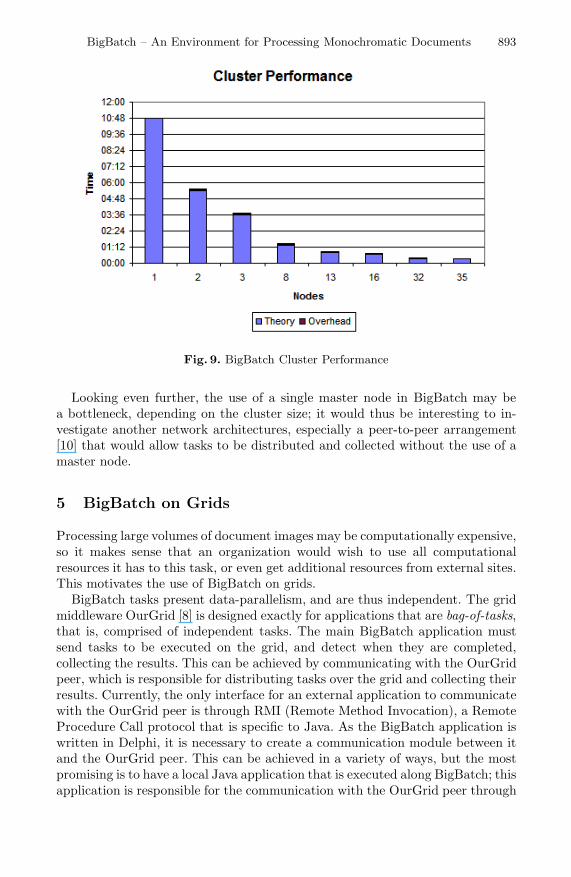
The BigBatch toolbox has been extensively tested on a homogeneous cluster ofup to 35 PCs. The net was a non-dedicated 100 Mbps Ethernet with one 3Comswitch with capacity for 48 nodes and a uplink of 1.0 GBps. Each processingnode, including the server, was an Intel Pentium IV, 1.6 GHz clock and 512MBRAM. Figure 9 shows the performance test on 2, 3, 8, 16, 32 and 35 nodes,which with one node the images were processed in 10 hours and 47 minutes. Thecluster performed nearly linear with little of overhead in task distribution andcollection. It reached, with 35 nodes, the equivalent performance of a 52GHzcomputer processing over 21.000 images in almost 20 minutes or over 1.000images per minute. For the next cluster version, it is planned to extract featuresfrom the compressed document image to estimate and classify them, in order toadopt better load balancing strategies and reduce the distribution overhead.
Besides that, a dynamic non-uniform control of the packet size sent by themaster may increase the troughput of the architecture.
Another planned addition is to develop a BigBatch cluster version on the Mes-sage Passing Interface (MPI). This would allow the use of BigBatch in dedicatedcluster installations that do not use the Windows operating system.
Also on the cluster implementation side, an interesting future analysis to bemade is the comparison of the performance of the two versions of the BigBatchclusters under Windows and Linux, with the use of Kylix [14] to compile forLinux machines.
BigBatch – An Environment for Processing Monochromatic Documents 893
Fig. 9. BigBatch Cluster Performance
Looking even further, the use of a single master node in BigBatch may bea bottleneck, depending on the cluster size; it would thus be interesting to in-vestigate another network architectures, especially a peer-to-peer arrangement[10] that would allow tasks to be distributed and collected without the use of amaster node.
5 BigBatch on Grids
Processing large volumes of document images may be computationally expensive,so it makes sense that an organization would wish to use all computationalresources it has to this task, or even get additional resources from external sites.This motivates the use of BigBatch on grids.
BigBatch tasks present data-parallelism, and are thus independent. The gridmiddleware OurGrid [8] is designed exactly for applications that are bag-of-tasks,that is, comprised of independent tasks. The main BigBatch application mustsend tasks to be executed on the grid, and detect when they are completed,collecting the results. This can be achieved by communicating with the OurGridpeer, which is responsible for distributing tasks over the grid and collecting theirresults. Currently, the only interface for an external application to communicatewith the OurGrid peer is through RMI (Remote Method Invocation), a RemoteProcedure Call protocol that is specific to Java. As the BigBatch application iswritten in Delphi, it is necessary to create a communication module between itand the OurGrid peer. This can be achieved in a variety of ways, but the mostpromising is to have a local Java application that is executed along BigBatch; thisapplication is responsible for the communication with the OurGrid peer through

894 R.D. Lins, B.T. Avila, and A. de Araujo Formiga
RMI, and to the BigBatch application through the Java Native Interface (JNI),mediating communication between the two. Then the OurGrid peer will be ableto distribute the tasks over all the grid nodes inside the organization’s site, andeven to external sites that have idle nodes available.
A question that arises in relation to running BigBatch tasks over a grid isthe scheduling of these tasks. OurGrid includes a scheduling algorithm that wasdeveloped for bag-of-tasks applications that are data-intensive [11], which is thecase with BigBatch. However, it is not entirely clear if this is the best schedulingpossible in this case. The BigBatch application has access to information aboutthe images that would allow some prediction of processing times for each, andthis extra information could be used to better schedule the tasks. The OurGridscheduling algorithm was designed to not need such information, spending morecpu cycles to compensate for this. It was further assumed for this schedulingalgorithm that the data is reused, and it is not clear if this applies to the caseof BigBatch. Some investigation about this topic is necessary in order to decidethe best approach.
Another interesting possibility for running BigBatch over a grid would be tobetter distribute its tasks over an organization, using only its internal resources.In cluster mode, BigBatch will distribute tasks to nodes in the same subnet only,and any particular subnet will have many fewer nodes than are available in thewhole organization. This is well suited to dedicated homogeneous clusters, butit is also possible to use a larger number of nodes by sending tasks for them toperform while they are idle. In this fashion, any computer in the organizationmay be used to process BigBatch tasks, if they are not being used for somethingelse. Grids are heterogeneous in nature and can deal with organizational barriersby design, so they are a natural choice in this respect. The OurGrid peer could bethus configured to consider only internal nodes and not seek nodes from externalsites. Any computer inside the organization could be turned into a grid node byinstalling a small application and doing some configuration. This would allowthe use of far more computational resources than would be possible with thecluster mode.
6 Conclusion and Further Developments
This paper presents BigBatch an efficient processing environment for monochro-matic documents. It is particularly suitable to process documents digitized byautomatically fed production line scanners. It currently works in three modes:operator driven (manual) mode, standalone and in clusters.
In the current version of BigBatch, algorithms were all implemented in C;Parallel processing capabilities as well as the user interface were developed inDelphi [14] running on Windows XP.
The BigBatch toolbox has been extensively tested on a homogeneous clus-ter of 35 PCs. Each processing node was an Intel Pentium IV, 1.6 GHz clockand 512MB RAM. Test images were generated by Kodak [15] production linescanners, with 200dpi resolution and compressed in TIFF(G4) file format. The

BigBatch – An Environment for Processing Monochromatic Documents 895
quality of images processed with BigBatch was at least as good as the best onesproduced by the other commercial tools tested [12][13][16][17][18]. Sequentialprocessing in BigBatch outperformed all the other tools whenever images of com-parable quality were generated (many times some of the tested tools demandedless time than BigBatch for border removal, for instance, but that operation wasperformed unsatisfactorily).
The possibility of integrating a commercial OCR tool with BigBatch for theautomatic indexing of documents with the help of user defined (keyword) dictio-naries is currently under investigation. At a later stage, BigBatch will be inter-faced with commercial database tools for the automatic insertion of documentimages and their attributes (such as keywords).
The extension of BigBatch to work in grids is also under development, us-ing the OurGrid middleware [8]. This will open the possibility of processingbatches of documents over WANs or internets. Besides that, it allows use thespare processing capabilities of organizations to, with little changes in their envi-ronment and in a fashion completely transparent to the end users, process theirinternal documents.
Acknowledgements
Research reported herein was partly sponsored by CNPq-Conselho Nacional dePesquisas e Desenvolvimento Tecnolgico of the Brazilian Government, to whomthe authors express their gratitude.
References
1. Avila, B.T., Lins, R.D.: A New Algorithm for Removing Noisy Borders from Mono-chromatic Documents. ACM Symposium on Applied Computing. (2004) 1219–1225
2. Avila, B.T., Lins, R.D.: Efficient Removal of Noisy Borders from MonochromaticDocuments. International Conference on Image Analysis and Recognition. 3212(2004) 249–256
3. Avila, B.T., Lins, R.D.: A New and Fast Orientation and Skew Detection Al-gorithm for Monochromatic Document Images. ACM Symposium on DocumentEngineering. (2005)
4. Avila, B.T., Lins, R.D., Augusto, L.: A New Rotation Algorithm for Monochro-matic Images. ACM Symposium on Document Engineering. (2005)
5. Buyya, R.: High Performance Cluster Computing: Architectures and Systems.Prentice Hall (1999)
6. Lins, R.D., Avila, B.T.: A New Algorithm for Skew Detection in Images of Docu-ments. International Conference on Image Analysis and Recognition. 3212 (2004)234–240
7. Lins, R.D., Alves, N.F.: A New Technique for Assessing the Performance of OCRs.International Conference on Computer Applications. 1 (2005) 51–56
8. Mowbray, M.: OurGrid: a Web-based Community Grid. In Proc. of the IADISInternational Conference on Web Based Communities. (2006)
9. O’Gorman, L. and Kasturi: R. Document Image Analysis. IEEE Computer SocietyExecutive Briefing. (1997)

896 R.D. Lins, B.T. Avila, and A. de Araujo Formiga
10. Parameswaran, M., Susarla, A., Whinston, A. B.: P2P Networking: AnInformation-Sharing Alternative, IEEE Computer, 7:34 (2001) 31–38
11. Santos-Neto, E., Cirne, W., Brasileiro, F., Lima, A.: Exploiting Replication andData Reuse to Efficiently Schedule Data-Intensive Applications on Grids. In Proc.of the 10th Workshop on Job Scheduling Strategies for Parallel Processing. (2004)
12. BlackIce Document Imaging SDK 10. BlackIce Software Inc.http://www.blackice.com/
13. ClearImage 5. Inlite Res. Inc. http://www.inliteresearch.com14. Delphi 7 and Kylix. Borland Inc. http://www.borland.com15. Kodak Digital Science Scanner 1500.
http://www.kodak.com/global/en/business/docimaging/1500002/16. Leadtools 13. Leadtools Inc. http://www.leadtools.com17. ScanFix Bitonal Image Optimizer 4.21. TMS Sequoia, http://www.tmsinc.com18. Skyline Tools Corporate Suite 7. Skyline Tools Imaging.
http://www.skylinetools.com
Copyright © 2022 FDOKUMEN

