







Bahasa
Halaman
Hukum


An Efficient way to Find Frequent
Pattern with Dynamic
Programming Approach
An Efficient way to Find Frequent
Pattern with Dynamic
Programming Approach
Paper ID: 850
Prepared by: Bhalodiya Dharmesh J.
Paper ID: 850
Prepared by: Bhalodiya Dharmesh J.

Frequent Pattern Mining: An ExampleFrequent Pattern Mining: An Example
Given a transaction database DB and a minimum support threshold ξ, find all
frequent patterns (item sets) with support no less than ξ.
INPUT Minimum support: ξ =2 and DB:
OUTPUT All frequent patterns, i.e.,
{I1}, {I2}, {I4}, {I5}, {I1, I2}…,{I4, I5}
Problem Statement: How to efficiently find all frequent patterns?
Given a transaction database DB and a minimum support threshold ξ, find all
frequent patterns (item sets) with support no less than ξ.
INPUT Minimum support: ξ =2 and DB:
OUTPUT All frequent patterns, i.e.,
{I1}, {I2}, {I4}, {I5}, {I1, I2}…,{I4, I5}
Problem Statement: How to efficiently find all frequent patterns?
TID Item set
T1
T2
T3
T4
T5
T6
I1, I2, I5
I2, I3
I1, I5
I2, I4, I5
I1, I2, I4
I4, I5

Apriori StepsApriori Steps
Step 1: Candidate Generation :- Use frequent (k – 1)-itemsets (Lk-1) to
generate candidates of frequent k-itemsets Ck
Step 2: Candidate Test :- Scan database and count each pattern in Ck , get
frequent k-itemsets ( Lk )
E.G. ,
Step 1: Candidate Generation :- Use frequent (k – 1)-itemsets (Lk-1) to
generate candidates of frequent k-itemsets Ck
Step 2: Candidate Test :- Scan database and count each pattern in Ck , get
frequent k-itemsets ( Lk )
E.G. , Apriori iteration
C1 {I1}, {I2}, {I3}, {I4}, {I5}L1 {I1}, {I2}, {I4}, {I5}
C2 {I1,I2},{I1,I3},{I1,I4},{I1,I5},{I2,I3}...,{I4,I5}
L2 {I1, I2},{I1, I5},{I2, I4},{I2, I5},{I4, I5}

Performance Bottlenecks of AprioriPerformance Bottlenecks of Apriori
Candidate Generation :- Generate huge candidate sets
104 frequent 1-itemset will generate 107 candidate 2-itemsets.
To discover a frequent pattern of size 100, e.g., {I1, I2, …, I100}, one needs to generate
2100 1030 candidates.
Candidate Test :- incur multiple scans of database for each candidate.
Candidate Generation :- Generate huge candidate sets
104 frequent 1-itemset will generate 107 candidate 2-itemsets.
To discover a frequent pattern of size 100, e.g., {I1, I2, …, I100}, one needs to generate
2100 1030 candidates.
Candidate Test :- incur multiple scans of database for each candidate.

AprioriDPAprioriDP
Ideas, Construction and DesignIdeas, Construction and Design

AprioriDP: IdeasAprioriDP: Ideas
Use the dynamic table to store 1-itemset and 2-itemset candidate count.
Highly compacted, but complete for frequent pattern mining.
Avoid costly one database scan.
Directly map 2-itemset candidate.
Efficient mapping technique to find frequent itemsets.
Avoid candidate generation
Use the dynamic table to store 1-itemset and 2-itemset candidate count.
Highly compacted, but complete for frequent pattern mining.
Avoid costly one database scan.
Directly map 2-itemset candidate.
Efficient mapping technique to find frequent itemsets.
Avoid candidate generation
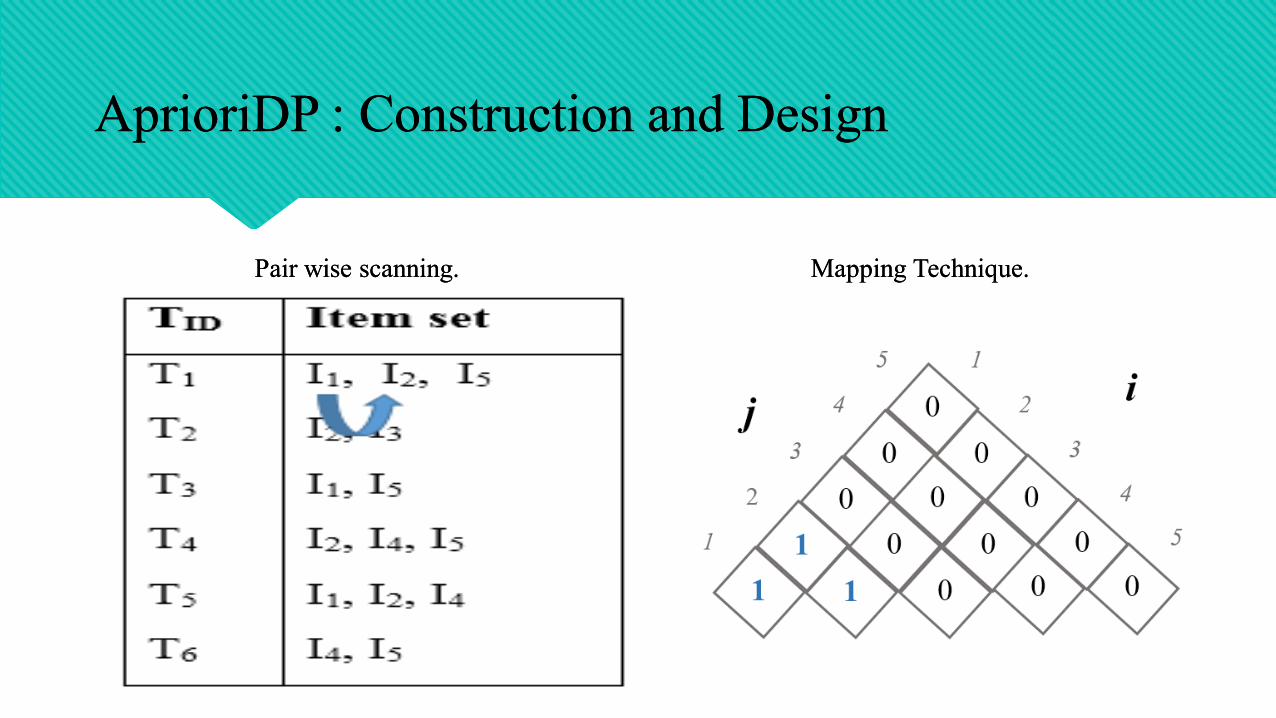
AprioriDP : Construction and DesignAprioriDP : Construction and Design
Pair wise scanning.Pair wise scanning. Mapping Technique. Mapping Technique.

AprioriDP : Construction and DesignAprioriDP : Construction and Design
Pair wise scanningPair wise scanning Mapping Technique. Mapping Technique.
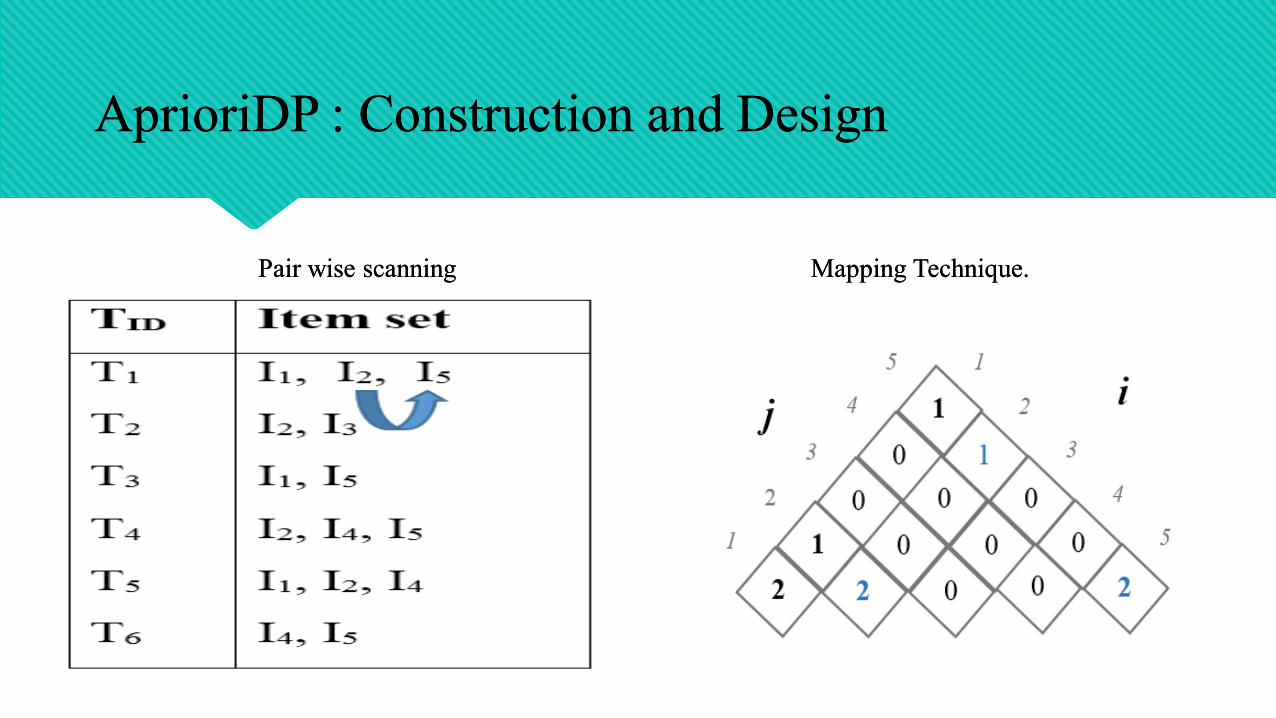
AprioriDP : Construction and DesignAprioriDP : Construction and Design
Pair wise scanningPair wise scanning Mapping Technique. Mapping Technique.

AprioriDP : Construction and Design- Final stage.AprioriDP : Construction and Design- Final stage.

Advantages of Dynamic Table structure Advantages of Dynamic Table structure
The most significant advantage of the AprioriDP
Scan the DB only once only.
Bottom-Up approach.
Completeness:
the AprioriDP contains all the information related to mining frequent patterns (2-itemset).
Compactness:
The size of the Table is bounded by the Total No. of items.
Reusable:
Once Dynamic Table fill with occurrence count, we can test candidates at different min_sup.
The most significant advantage of the AprioriDP
Scan the DB only once only.
Bottom-Up approach.
Completeness:
the AprioriDP contains all the information related to mining frequent patterns (2-itemset).
Compactness:
The size of the Table is bounded by the Total No. of items.
Reusable:
Once Dynamic Table fill with occurrence count, we can test candidates at different min_sup.

AprioriDPAprioriDP
Performance EvaluationPerformance Evaluation

Experiment SetupExperiment Setup
Compare the runtime of AprioriDP with Traditional Apriori .
Runtime vs. min_sup.
Runtime per itemset vs. min_sup.
Synthetic data sets : T25.I10.D10K
250 items
avg(transaction size)=25
avg(max/potential frequent item size)=10
10K transactions
Compare the runtime of AprioriDP with Traditional Apriori .
Runtime vs. min_sup.
Runtime per itemset vs. min_sup.
Synthetic data sets : T25.I10.D10K
250 items
avg(transaction size)=25
avg(max/potential frequent item size)=10
10K transactions

Runtime vs. min_sup.Runtime vs. min_sup.
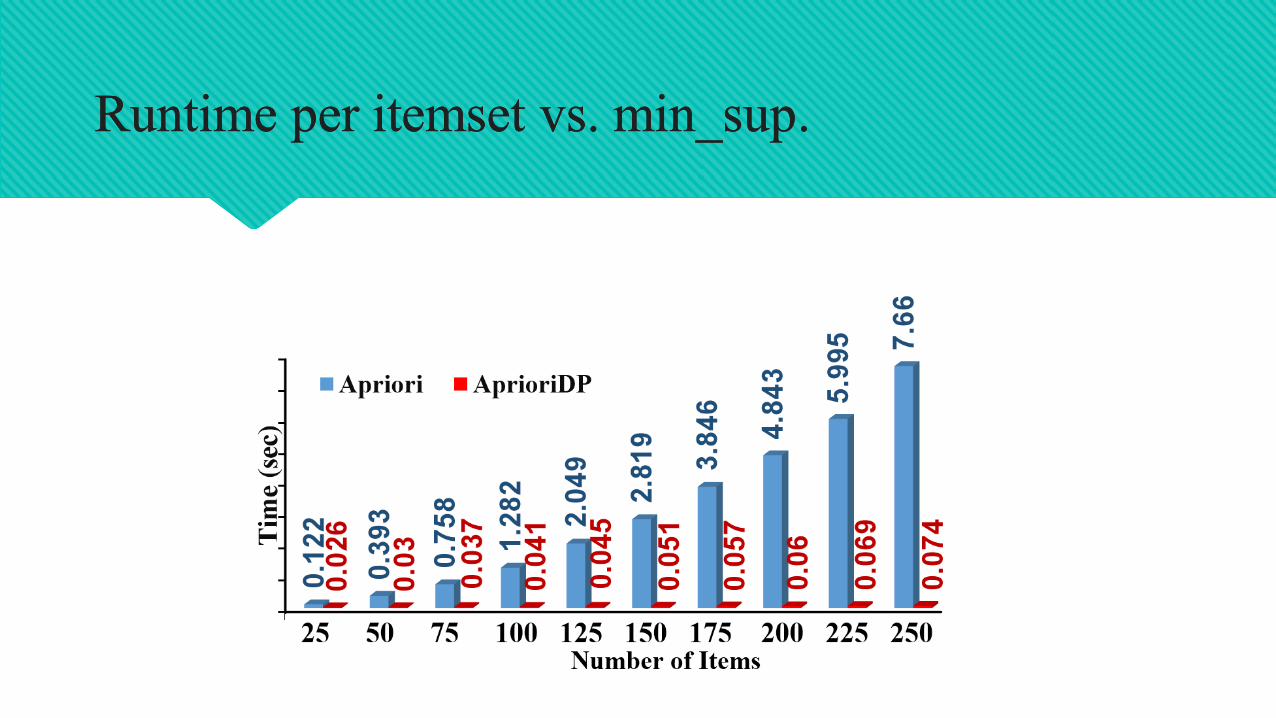
Runtime per itemset vs. min_sup.Runtime per itemset vs. min_sup.
Top Related
Copyright © 2022 FDOKUMEN

