
Learning How to Extract Rotation-Invariant and Scale-Invariant Features from Texture Images
Upload
independentCategory
view
0download
0
View-Invariant Human-Body Detection with Extension to Human ActionRecognition using Component-Wise HMM of Body Parts
Bhaskar Chakraborty, Ognjen RudovicComputer Vision Center
& Dept. Ciencies de la Computacio,Edifici O, Campus UAB,08193 Bellaterra, [email protected]
Jordi GonzalezInstitut de Robotica i Informatica Industrial
(UPC – CSIC)
Abstract
This paper presents a technique for view invariant hu-man detection and extending this idea to recognize basichuman actions like walking, jogging, hand waving and box-ing etc. To achieve this goal we detect the human in itsbody parts and then learn the changes of those body partsfor action recognition. Human-body part detection in dif-ferent views is an extremely challenging problem due todrastic change of 3D-pose of human body, self occlusionsetc while performing actions. In order to cope with theseproblems we have designed three example-based detectorsthat are trained to find separately three components of thehuman body, namely the head, legs and arms. We incorpo-rate 10 sub-classifiers for the head, arms and the leg de-tection. Each sub-classifier detects body parts under a spe-cific range of viewpoints. Then, view-invariance is fulfilledby combining the results of these sub classifiers. Subse-quently, we extend this approach to recognize actions basedon component-wise Hidden Markov Models (HMM). Thisis achieved by designing a HMM for each action, which istrained based on the detected body parts. Consequently, weare able to distinguish between similar actions by only con-sidering the body parts which has major contributions tothose actions e.g. legs for walking, running etc; hands forboxing, waving etc.
1. IntroductionHuman detection based action recognition is a constantly
expanding research area due to number of applicationsfor surveillance (behaviour analysis), security (pedestriandetection), control (human-computer interfaces), content-based video retrieval, etc. It is, however, a complex anddifficult-to-resolve problem because of the enormous dif-ferences that exist between individuals, both in the way they
Figure 1. Images from the KTH database showing some of thechallenges involved with people detection in still images wherethe 3D-pose of their body parts changes with great variety whileperforming some actions like clapping, walking, boxing, and jog-ging.
move and their physical appearance, view-point and the en-vironment where the action is carried out. Fig. 1 showssome images from the KTH’s database [12], demonstrat-ing the variation of the human poses w.r.t. different cameraviews and for different actions.
Toward this end, several approaches can be found in theliterature [7]. Some approaches are based on holistic bodyinformation where no attempt is made to identify individualbody parts. Authors like [3] use HMM and AdaBoost forrecognition of 3-D human action considering joint positionor pose angles. However, there are actions which can bebetter recognized by only considering body parts, such asthe dynamics of the legs for walking, running and jogging[2]. Consequently, action recognition can be based on aprior detection of the human body parts [9].
In this context, human body parts should be first detectedin the image: authors like [6, 11] describe human detectionalgorithms by probabilistic body part assembly. However,these approaches use motion information, explicit models,a static camera, assume a single person in the image, orimplement tracking rather than pure detection. Mohan etal. [8] used Haar-Like features and SVM for component-
978-1-4244-2154-1/08/$25.00 c©2008 IE

wise object detection. However, Haar-Like features cannotobtain certain special structural feature that can be useful todesign a view invariant human detection. Moreover, thereis no method to select the best features for the SVM so thatthe performance can be improved by minimizing the featurevector size. Lastly, these works do not cope well for thedetection of profile poses.
Due to these difficulties in the view-invariant body partsdetection, action recognition has been restricted by analyz-ing the human body as a whole from multiple views. Forexample, Mendoza and Perez de la Blanca [5] detect hu-man actions using Hidden Markov Models (HMM) basedon contour-based histogram of full body. Also, authorsin [1] combine shape information and optical flow basedon the silhouette to achieve this goal. Likewise, [14] usesthe sum of silhouette pixels. However, when knowledge ofbody part detection is applied in action recognition higherdetection rate can be achieved as demonstrated in this paper.
Our approach introduces a technique for view-invarianthuman detection and subsequently learning the stochasticchanges of the body part components to recognize differentactions. We use a hierarchy of multiple example-based clas-sifiers for each of different body part-components and viewinvariant human detection is achieved by combining the re-sult of those detectors in a meaningful way. Since humanaction is viewed as a combination of the motion of differentbody parts, action detection can be analyzed as a stochas-tic process by learning the changes of such components us-ing HMM. Moreover, in this way we can only consider fea-tures from those body part-components which actually tak-ing part into the action e.g. the legs for walking, jogging andrunning. We have compared our result with current state ofthe art [12] and [5]. Lastly, our method for action recogni-tion is also able to detect the direction of motion from thelikelihood map obtained from HMM.
This paper is organised as follows. In Section 2 we havepresented view-invariant human detection method in detail.Section 3 describes the component wise HMM method to-wards the detection of human actions. Section 4 reportson the performance of our system. Finally conclusions aredrawn in Section 5.
2. View-Invariant Human DetectionTowards human action dection our system first detects
full human by detecting body parts. To ensure the viewinvariance in human detection, for each body part more thanone detector has been designed and the knowledge of eachof those body part detectors are combined finally to increasethe robustness of the whole system.
The component-based human detection has some inher-ent advantages over existing techniques. After detectionof human body parts geometric constraints are used whichsupplements the visual information present in an image. In
contrast, a full-body person detector relies solely on visualinformation and does not take full advantage of the knowngeometric properties of the human body. Other problems infull human detection e.g. partial occlusion can be avoidedusing this approach.
2.1. Detection of Human Body Parts
The human detection system starts detecting people inimages by selecting specific size rectangular windows foreach body parts from top left corner of the image as an in-put to head, leg and arm detectors. These inputs are thenindependently classified as either a respective body parts ora non-body part and finally those are combined into a propergeometrical configuration in bigger window as a person. Allof these candidate regions are processed by the respectivecomponent detectors to find the strongest candidate compo-nents. The image itself is processed at several sizes. Thisallows the system to detect various sizes of people at anylocation in an image.
2.2. Feature Extraction and Selection
In our approach training images of each body part detec-tor are divided into several 8x8 blocks after applying So-bel mask on them. HOG features are extracted from thoseblocks dividing the gradients into 6 bins from -90o to +90o.In this way for each of this 8x8 pixel window 6 feature vec-tor can be obtained. Next step is to select the best 6 featurepacks among them. This feature selection method is basedon standard deviation (σ).
Considering we have N number of training image sam-ples of size WxH. We have divided each training image inton number of 8x8 blocks. For each of these 8x8 block wehave 6 gradient based features, gi where i = 1,2,...,6. Wedefine σ of ith block and jth gradient feature i.e. σij as fol-lows:
σij = (1N
)N∑
t=1
(g(t)ij − µij)
2(1)
where i = 1,2,...,n; j = 1,2,...,6; t = 1,2,...,N; g(t)ij is defined
as jth gradient feature of i th block of tth training image andµij is defined as the mean of jth gradient of ith block overall the training images.
Now the σ value of (1) has been sorted and those 6 fea-ture packets are taken where the σ is smaller than some pre-defined threshold. In our case we run the experiment severaltimes to obtain that threshold. In this way the feature size isminimized.
2.3. Training Body-part Detectors
To identify human into one particular scale of imageeach of the head and leg detectors are applied simultane-ously. In the present system there are four head detec-

Figure 2. Training database for each body part detectors e.g. head,arm and leg. Each body part detectors have more than one sub-classifiers e.g. head detector has four sub-classifiers frontal, back-ward, left and right profile.
tors, two leg detectors and four arm detectors. The fourhead detectors are for the view angle 45o to 135o, 135o to225o, 225o to 315o and 315o to 45o. We choose this di-vision so that consecutive ranges have smooth transition ofhead poses. For arm, there are four classifiers correspond-ing different position of arms. Detecting arms is a diffi-cult task since arms have more degree of freedom than theother components. For walking, jogging we have used ma-jor four pose of the arm with the pose symmetry the detec-tion of other pose possibilities can be achieved. For actionslike hand waving, boxing etc more than four sub-classifiershave been designed since in those cases arms pose changesrapidly. To detect the legs two sub-classifiers have beenadded, one for open legs and other for profile legs. We useSVM to classify the data vectors resulting from the featureextraction and feature selection method of the components.The SVM algorithm uses structural risk minimization tofind the hyper plane that optimally separates two classes ofobjects. This is equivalent to minimizing a bound on gen-eralization error. The optimal hyper plane is computed as adecision surface of the form:
f = sgn(g(x)) (2)
where,
g(x) = (l∗∑
i=1
K(x, xi) + b) (3)
In (3) K is many possible kernel functions, yi ∈ {-1, 1 } isthe class label of the data point {x1, x2,..., xl∗} is the setof training images and x is data point to be classified bySVM. In our method we have used polynomial kernel. Fig.2 shows few training samples of our body part component
training database. HumanEva Database1 [13] has been usedto create those training images. In our method for head, legand arm detector window sizes have been fixed to 72 x 48,184 x 108 and 124 x 64 pixels respectively. 264 x 124 pixelswindow has been applied for full human. For training eachcomponent detectors 10,000 true positives and 20,000 falsepositives have been used.
The result of those component detectors has combinedbased on geometrical configuration. Since the head is themost stable part of the body, the geometric combination hasbeen done by first considering the head. Subsequently, theleg component is taken into account and, after that, botharms are combined. We include the Leg Bounding Box(LBB) (184 x 108) after the Head Bounding Box (HBB)is computed (72 x 48) from the head detector. This is doneby checking that the x component of the center of the LBBmust be within the width of HBB and the y component mustbe greater than the y component of the centre of the FullHuman Bounding Box (FHBB) (264 x 124). After foundFHBB, Arm Bounding Box (ABB) (124 x 64) has beenincorporated within that area. It gives computational ef-ficiency since here we only use one specific window sizeinstead of whole image.
We have chosen the result from that sub classifier whichgives the best score result. When a person is moving in acircular path in some cases we can have best score for twosub classifier for arms and other cases provide us only onebest score since the arms can be occluded behind the body.Fig. 3 shows the results of the component detectors in Hu-manEva Database [13]. Full detection has been in Fig.4.These detections are strong example of view invariance de-tection since in HumanEva database the agents performingactions in a circular path and our component detectors haveshown robust performance in detecting those agents.
3. Human Action Recognition using HMMThe aforementioned component wise view invariant hu-
man detection is next extended to human action recogni-tion. Toward this end, we learn the stochastic changes ofdetected body parts using HMM to recognize human ac-tions like walking and jogging. In our system we use onlythose body part components which have major contributionon the action. From the HMM likelihood map we can detectthe direction of motion by which we can infer the view pointof the person with respect to camera for the actions whereagents moves from one place to another e.g. walking.
3.1. HMM Learning
The feature set used to learn component HMM is almostsame as that used for SVM of each body part detector. In-stead of selecting features here we take the mean of each
1http://vision.cs.brown.edu/humaneva/

Figure 3. Results of head, arm and leg detector as a validation pro-cess. Here detection of profile head and leg is shown. Arm detec-tions are shown where both arms are visible and one is occluded.
Figure 4. Validation process of full human detection. Experimentsare performed in Human Eva database.
Figure 5. Performance of full human detection in KTH’s database.Detection of profile image with difference leg, arm and leg posi-tion has been shown.
6 bin angle histogram vector. So if there are n number ofblocks (8 x 8) in a training image then we have {µ1, µ2,...,
Figure 6. Performance of full human detection in HERMES indoorsequence. Detection performance is shown when body parts aretilted. In the first image arm detector fails to detect one visiblearm.
µn} this set of features where µj can be defined as
µj = (16)
6∑i=1
gi (4)
where gi is the gradient histogram of jth bin. The signifi-cance of taking mean is to get general orientation of bodypart which intern signify one pose or, series of similar posesin a action. We fit a Gaussian Mixture Model (GMM) intothose feature values to obtain key pose alphabet for a partic-ular action. Those key poses are the center of each clusterobtained from GMM. To detect actions like walking, jog-ging and running only legs has been used and for boxing,hand waving and hand clapping we take only hands to learnour component HMM.
We have used same training set from HumanEvadatabase as of the body part detectors to train componentwise HMM. For actions like hand waving, hand clappingand running we have used sequences from KTH databasefor training and rest for testing, since HumanEva databasedo not contain those actions. We have chosen a sequenceof frames to define one cycle for every actions. After thatwe map those frame sequences into pose alphabet to obtainone sequence of states for HMM learning. We have com-puted P (Ot|st = s) i.e. the probability of an observationsequence Ot given the state s at time t using both Forwardand Baum-Welch algorithm of HMM [10]. We use Hu-manEval Database as our validation database. While testingthe performance of HMM, likelihood map has been com-puted using the probability values obtained from the HMMfor each frame of the test sequence. Maximum values oflikelihood map indicate the end of each action cycle.
4. Experimental ResultsWe have used KTH’s [12] Database2 and HERMES in-
door sequence dataset [4] to test the performance of oursystem architecture. Fig 5 shows some detection exampleof KTH database. In KTH database there are several image
2http://www.nada.kth.se/cvap/actions/

(a)
(b)
(c)
Figure 7. ROC curves of different component detectors are demon-strated. The positive detection rate is plotted as a percentageagainst the false alarm rate. The false alarm rate is the numberof false positive detections per window inspected. The obtainedresults are from (a) HumanEva database, (b) KTH database and(c) HERMES indoor sequence respectively.
sequences where it is impossible to detect arms due to dif-ferent cloths. But most of the cases we are able to detecthead and legs and when they are in proper geometrical or-der we detect full human. There are some sequences whereonly legs can be detected due to low resolution. For lowresolution image sequences much information has been lost
due to scaling and Sobel mask hardly found important edgesfrom the particular body parts. Images shown are of differ-ent sizes. Detected box has been drawn after rescaling itinto 1:1 scale.
Fig. 6 is the examples from HERMES indoor sequences.Here we have shown the detection of human where they aretilted and are of different scale. The ROC’s are shown in theFig.7 for three component detector e.g. head, legs and armsof different databases. These ROC’s are generated consider-ing the overall performance of all the sub-classifiers of eachgroup of the three classifiers. ROC analysis can reveal thathead detection and leg detection are very robust. But forarm detection the detection rate is not very high since armpose varies drastically while performing actions. In KTHdatabase ROC shows more than 90% detection rate of legand for head is it less. This is due to low resolution of headin several sequences. In Hermes ROC we have little lessdetection rate than previous two. It is because this sequencehas real background and humans are sometimes tilted, dif-ferent clothing etc. But in that sequence arm detection ratehas been more than other two.
In the KTH’s database there are different types of ac-tions: walking, jogging, boxing, hand waving etc. Theseactions were performed by 25 different people of both sexesin four different scenarios: outdoors, outdoors with scalevariation, outdoors with different clothes and indoors. Wehave applied our method for all those sequences for actiondeteciton. Table 1 shows the comparison of action detec-tion rate with two other method e.g. local feature withSVM [5] and contour histogram [12] based action deteciton.Our method performs well in walking, running, boxing andclapping. A better detection rate is achieved than full bodycontour histogram based action recognition. Table 2 showsthe confusion matrix of our approach. In this matrix wecan observe missclassification with other actions. Since ourmethod consider the stochastic change of body parts whichhas the major contribution in action so if there is some simi-larity in movement of those components in different actionsthen recognition using HMM become difficult. We havefound some of jogging sequences are misclassified as walk-ing etc. Jogging and running legs are very similar and insome cases there are problems of resolution and contrast,so it is difficult to be distinguished. Actions involving handmotion have similar problems, like some agent performingwaving similar to clapping, causing ambiguity. The advan-tage of the component-wise HMM is that the deteciton ofbody parts is very robust and in a test sequence if detectionfails in certain frames then also HMM can detect the actionsince in a long chain of sequence overall action topology ismaintained.
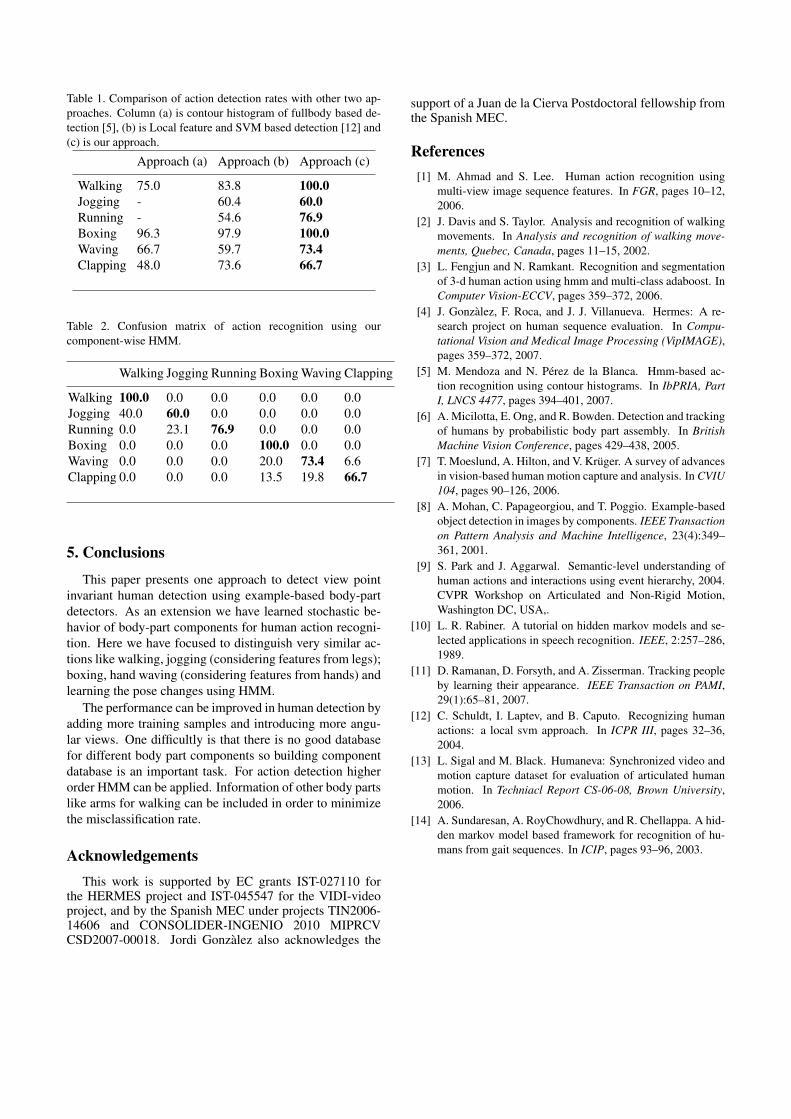
Table 1. Comparison of action detection rates with other two ap-proaches. Column (a) is contour histogram of fullbody based de-tection [5], (b) is Local feature and SVM based detection [12] and(c) is our approach.
Approach (a) Approach (b) Approach (c)
Walking 75.0 83.8 100.0Jogging - 60.4 60.0Running - 54.6 76.9Boxing 96.3 97.9 100.0Waving 66.7 59.7 73.4Clapping 48.0 73.6 66.7
Table 2. Confusion matrix of action recognition using ourcomponent-wise HMM.
Walking Jogging Running Boxing Waving Clapping
Walking 100.0 0.0 0.0 0.0 0.0 0.0Jogging 40.0 60.0 0.0 0.0 0.0 0.0Running 0.0 23.1 76.9 0.0 0.0 0.0Boxing 0.0 0.0 0.0 100.0 0.0 0.0Waving 0.0 0.0 0.0 20.0 73.4 6.6Clapping 0.0 0.0 0.0 13.5 19.8 66.7
5. Conclusions
This paper presents one approach to detect view pointinvariant human detection using example-based body-partdetectors. As an extension we have learned stochastic be-havior of body-part components for human action recogni-tion. Here we have focused to distinguish very similar ac-tions like walking, jogging (considering features from legs);boxing, hand waving (considering features from hands) andlearning the pose changes using HMM.
The performance can be improved in human detection byadding more training samples and introducing more angu-lar views. One difficultly is that there is no good databasefor different body part components so building componentdatabase is an important task. For action detection higherorder HMM can be applied. Information of other body partslike arms for walking can be included in order to minimizethe misclassification rate.
AcknowledgementsThis work is supported by EC grants IST-027110 for
the HERMES project and IST-045547 for the VIDI-videoproject, and by the Spanish MEC under projects TIN2006-14606 and CONSOLIDER-INGENIO 2010 MIPRCVCSD2007-00018. Jordi Gonzalez also acknowledges the
support of a Juan de la Cierva Postdoctoral fellowship fromthe Spanish MEC.
References[1] M. Ahmad and S. Lee. Human action recognition using
multi-view image sequence features. In FGR, pages 10–12,2006.
[2] J. Davis and S. Taylor. Analysis and recognition of walkingmovements. In Analysis and recognition of walking move-ments, Quebec, Canada, pages 11–15, 2002.
[3] L. Fengjun and N. Ramkant. Recognition and segmentationof 3-d human action using hmm and multi-class adaboost. InComputer Vision-ECCV, pages 359–372, 2006.
[4] J. Gonzalez, F. Roca, and J. J. Villanueva. Hermes: A re-search project on human sequence evaluation. In Compu-tational Vision and Medical Image Processing (VipIMAGE),pages 359–372, 2007.
[5] M. Mendoza and N. Perez de la Blanca. Hmm-based ac-tion recognition using contour histograms. In IbPRIA, PartI, LNCS 4477, pages 394–401, 2007.
[6] A. Micilotta, E. Ong, and R. Bowden. Detection and trackingof humans by probabilistic body part assembly. In BritishMachine Vision Conference, pages 429–438, 2005.
[7] T. Moeslund, A. Hilton, and V. Kruger. A survey of advancesin vision-based human motion capture and analysis. In CVIU104, pages 90–126, 2006.
[8] A. Mohan, C. Papageorgiou, and T. Poggio. Example-basedobject detection in images by components. IEEE Transactionon Pattern Analysis and Machine Intelligence, 23(4):349–361, 2001.
[9] S. Park and J. Aggarwal. Semantic-level understanding ofhuman actions and interactions using event hierarchy, 2004.CVPR Workshop on Articulated and Non-Rigid Motion,Washington DC, USA,.
[10] L. R. Rabiner. A tutorial on hidden markov models and se-lected applications in speech recognition. IEEE, 2:257–286,1989.
[11] D. Ramanan, D. Forsyth, and A. Zisserman. Tracking peopleby learning their appearance. IEEE Transaction on PAMI,29(1):65–81, 2007.
[12] C. Schuldt, I. Laptev, and B. Caputo. Recognizing humanactions: a local svm approach. In ICPR III, pages 32–36,2004.
[13] L. Sigal and M. Black. Humaneva: Synchronized video andmotion capture dataset for evaluation of articulated humanmotion. In Techniacl Report CS-06-08, Brown University,2006.
[14] A. Sundaresan, A. RoyChowdhury, and R. Chellappa. A hid-den markov model based framework for recognition of hu-mans from gait sequences. In ICIP, pages 93–96, 2003.
Copyright © 2022 FDOKUMEN




















