
V i M d iliği Veri Madenciliği Veri-Nesne-Nitelik Tid Refund Marital Status Taxable Income Cheat 1...
30
1 V iM d iliği Veri Madenciliği Bölüm 2. Veri Önişleme Doç. Dr. Suat Özdemir http://ceng.gazi.edu.tr/~ozdemir Veri-Nesne-Nitelik Veri: Nesneler ve nesnelerin niteliklerinden oluşan küme – Nesne terimi yerine kayıt (record), varlık (entity), örnek (sample, instance) kullanılabilir Nitelik (Attributes) Tid Refund Marital Taxable Nitelik (attribute) bir nesnenin (object) bir özelliğidir bir insanın yaşı, ortamın sıcaklığı.. – Nitelik yerine boyut (dimension), özellik (feature, characteristic) kullanılabilir – Nitelikler ve bu niteliklere ait Nesne (Objects) Tid Refund Marital Status Taxable Income Cheat 1 Yes Single 125K No 2 No Married 100K No 3 No Single 70K No 4 Yes Married 120K No 5 No Divorced 95K Yes 6 No Married 60K No Veri Madenciliği Doç. Dr. Suat Özdemir Nitelikler ve bu niteliklere ait değerler bir nesneyi oluşturur. Nesneler grubu veriyi oluşturur –Öğrenci kayıt listesi 7 Yes Divorced 220K No 8 No Single 85K Yes 9 No Married 75K No 10 No Single 90K Yes VERİ
Transcript of V i M d iliği Veri Madenciliği Veri-Nesne-Nitelik Tid Refund Marital Status Taxable Income Cheat 1...

1
V i M d iliğiVeri Madenciliği
Bölüm 2. Veri Önişleme
Doç. Dr. Suat Özdemir http://ceng.gazi.edu.tr/~ozdemir
Veri-Nesne-Nitelik
Veri: Nesneler ve nesnelerin niteliklerinden oluşan küme– Nesne terimi yerine kayıt
(record), varlık (entity), örnek (sample, instance) kullanılabilir
Nitelik (Attributes)
Tid Refund Marital Taxable( p , )
Nitelik (attribute) bir nesnenin (object) bir özelliğidir bir insanın yaşı, ortamın sıcaklığı..– Nitelik yerine boyut
(dimension), özellik (feature, characteristic) kullanılabilir
– Nitelikler ve bu niteliklere ait
Nesne (Objects)
Tid Refund MaritalStatus
Taxable Income Cheat
1 Yes Single 125K No
2 No Married 100K No
3 No Single 70K No
4 Yes Married 120K No
5 No Divorced 95K Yes
6 No Married 60K No
Veri MadenciliğiDoç. Dr. Suat Özdemir
Nitelikler ve bu niteliklere ait değerler bir nesneyi oluşturur.
Nesneler grubu veriyi oluşturur– Öğrenci kayıt listesi
7 Yes Divorced 220K No
8 No Single 85K Yes
9 No Married 75K No
10 No Single 90K Yes 10
VERİ

2
Ayrık ve sürekli nitelikler
Ayrık Nitelik / Discrete Attribute– Sonlu sayıda değerden oluşan nitelikler
• E.g., posta kodu, meslek, ya da doküman seti içerisindeki kelimeleriçerisindeki kelimeler
– Tamsayı değerler olarak ifade edilebilir – İkili / binary nitelikler de ayrık niteliklerin özel bir
türüdür Sürekli Nitelik / Continuous Attribute
– Değeri gerçek sayılar olan niteliklerE kl k ük klik d ğ l k
Veri MadenciliğiDoç. Dr. Suat Özdemir
• E.g., sıcaklık, yükseklik, ya da ağırlık– Floating-point değerler olarak ifade edilebilir
Neden veri önişleme?
Gerçek hayatta karşılaştığımız veriler genelde eksik (missing or incomplete), hatalı (noisy), ve tutarsız (inconsistent) olma eğilimindedir.– Düşük kaliteli veriş
Veri kalitesini düşüren sorunlar: – Noise / Gürültü– Outliers / Sapan veri– Missing values / Eksik veri– Duplicate data / Tekrarlı veri
Veri MadenciliğiDoç. Dr. Suat Özdemir
p /– Veri iletim hataları– Teknolojik sınırlamalar– Veri isimlendirmede veya yapısında uyumsuzluk
3
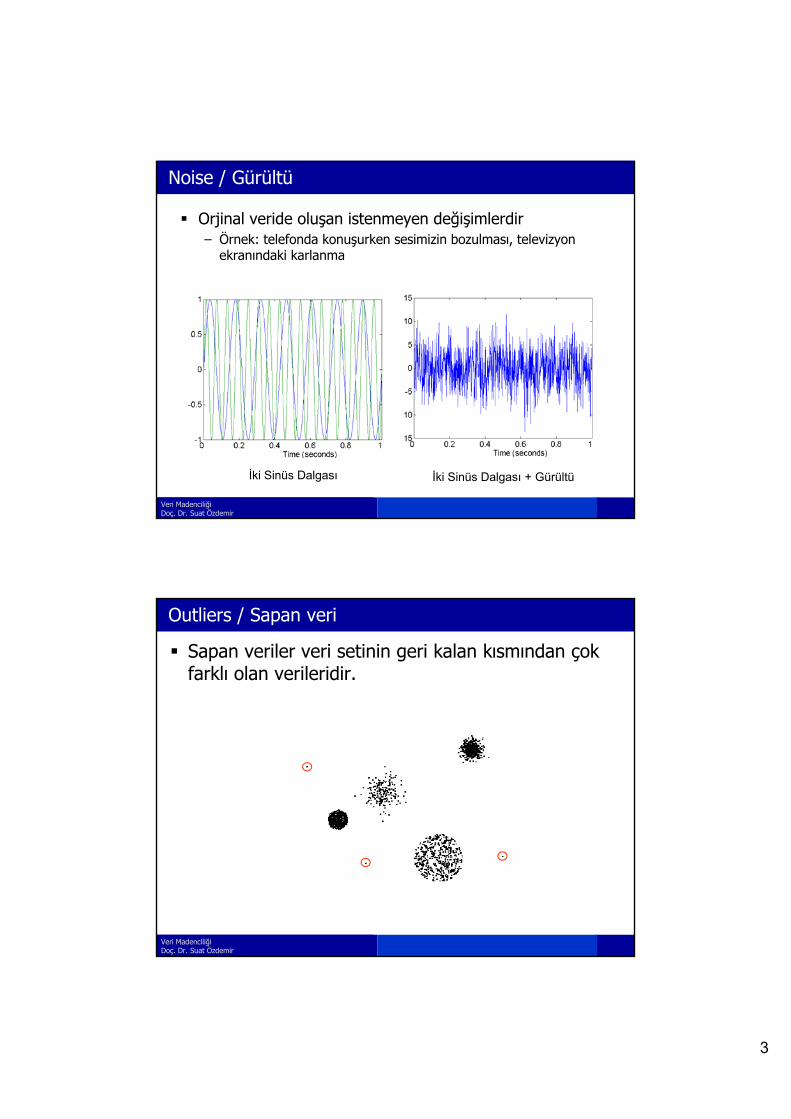
Noise / Gürültü
Orjinal veride oluşan istenmeyen değişimlerdir– Örnek: telefonda konuşurken sesimizin bozulması, televizyon
ekranındaki karlanma
Veri MadenciliğiDoç. Dr. Suat Özdemir
İki Sinüs Dalgası İki Sinüs Dalgası + Gürültü
Outliers / Sapan veri
Sapan veriler veri setinin geri kalan kısmından çok farklı olan verileridir.
Veri MadenciliğiDoç. Dr. Suat Özdemir

4
Missing Values / Eksik veri
Nedenler– Bilginin toplanamaması
• Yaşını, kilosunu ya da gelirini belirtmek istemeyen insanlar– Uygun olmayan nitelikleryg y
• Çocuklar için gelir niteliği uygulanamaz
Çözümler– Eksik verileri dikkate alma– Eksik veriyi tahmin et (ortalama vs.)
Veri MadenciliğiDoç. Dr. Suat Özdemir
Duplicate Data / Tekrarlı veri
Birbirinin aynısı olan veriler– Değişik veritabanlarının birleştirilmesi sırasında ortaya
çıkar – Birden çok eposta adresine sahip insan– Birden çok eposta adresine sahip insan
Çözüm– Veri temizleme
Veri MadenciliğiDoç. Dr. Suat Özdemir

5
Neden veri önişleme?
Düşük kaliteli veri düşük kaliteli veri madenciliği sonuçlarına yol açar
Veri önişleme?– Veri madenciliği kalitesini artırmakVeri madenciliği kalitesini artırmak – Veri madenciliğini kolaylaştırmak– Verimliliği artırmak hedeflenir
Veri MadenciliğiDoç. Dr. Suat Özdemir
Tanımlayıcı veri özetleme
Veri önişlemenin temeli Veriyi daha iyi anlamak ve anlatmak
– Verinin merkezi eğilimil ( d ) d• Ortalama, ortanca (median), mode
– Verinin dağılımı• Çeyreklikler (quartiles), IQR, variance, boxplots
Veri MadenciliğiDoç. Dr. Suat Özdemir

6
Ortalama (Mean)
Ortalama (mean)
– Örnekleme
n
iix
nx
1
1
– Popülasyon
– Ağırlıklı ortalama
i 1
N
x
n
iii xw
1
Veri MadenciliğiDoç. Dr. Suat Özdemir
– Ağırlıklı ortalama
n
ii
i
wx
1
1
Ortanca (Median)
Veri setinde ortadaki verinin değeri– Çift sayıda veri varsa ortadaki iki verinin ortalaması
Gruplanmış veriler için interpolation yolu ile Gruplanmış veriler için interpolation yolu ile bulunur
cf
lfnLmedian )
)(2/(1
Ortanca aralığın genişliği
Yaş Frekans
5‐10 120
11‐15 50
16 20 160
Ortanca aralıktan aşağıdaki aralıklardaki eleman sayılarının toplamı
Veri MadenciliğiDoç. Dr. Suat Özdemir
fmedian
Ortanca aralığın ilk elemanı
16‐20 160
21‐25 70
26‐30 200
9.165)160
)270(2/600(16
median
Ortanca aralığın frekansı
7
Mod (Mode)
Veri seti içinde en çok tekrarlanan veri– Unimodal– Bimodal
T i d l– Trimodal
Deneysel (empirical) formül
)(3 medianmeanmodemean
Veri MadenciliğiDoç. Dr. Suat Özdemir
Simetrik ve Çarpık Veri
Ortalama, ortanca ve mod değerleri Mean
MedianMode
Veri MadenciliğiDoç. Dr. Suat Özdemir

8
Verinin dağılımı
Quartiles, outliers and boxplots
– Çeyrek (Quartile): Q1 (25th percentile), Q3 (75th
percentile)p )
– Inter-quartile range: IQR = Q3 – Q1
– Five number summary: min, Q1, M, Q3, max
– Boxplot: ends of the box are the quartiles, median is marked, whiskers, and plot outlier individually
Veri MadenciliğiDoç. Dr. Suat Özdemir
, , p y
– Sapan veri (Outlier):
• usually, a value higher/lower than 1.5 x IQR
Verinin dağılımı
Varyans ve standart sapma (örnekleme: s, populasyon: σ)– Varyans:Varyans:
– Standart sapma s (ya da σ) varyansın kare kökü
n
i
n
iii
n
ii x
nx
nxx
ns
1 1
22
1
22 ])(1
[1
1)(
1
1
Veri MadenciliğiDoç. Dr. Suat Özdemir
n
ii
n
ii x
Nx
N 1
22
1
22 1)(
1

9
Normal dağılım eğrisinin özellikleri
Normal dağılım eğrisi– (μ–σ) ile (μ+σ) arasında verilerin yaklaşık %68i
bulunur (μ: ortalama, σ: standart sapma)– (μ–2σ) ile (μ+2σ) arasında %95i– (μ–3σ) ile (μ+3σ) arasında %99.7si
Veri MadenciliğiDoç. Dr. Suat Özdemir
95%
−3 −2 −1 0 +1 +2 +3
68%
−3 −2 −1 0 +1 +2 +3
99.7%
−3 −2 −1 0 +1 +2 +3
Görsel tanımlayıcı veri özetleme
Veriyi daha iyi ifade edebilmek için kullandığımız yöntemler– Boxplotp– Histogram, sıklık histogramı, bar chart– Eşit bölen (Quantile) grafikleri – Q-Q grafikleri– Serpme (scatter) grafikleri
Veri MadenciliğiDoç. Dr. Suat Özdemir

10
Boxplot analizi
Five number summary nin grafik olarak gösterimi– Minimum, Q1, M, Q3, Maximum
Boxplot
– Veri bir kutu olarak gösterilir
– Kutunun alt ve üst çizgileri 1. ve 3. çeyreklerdir
– Ortanca bir çizgi ile belirtilir
– Max ve min değerleri kutunun dışında iki çizgi (Whiskers) ile belirtilir
Veri MadenciliğiDoç. Dr. Suat Özdemir
( )
Histogram analizi
Basit istatistiksel sınıfları gösteren grafik– Veri setindeki çeşitli sınıflara ait verilerin sayısını ya da frekansını
veren dikdörtgenlerden oluşur
Veri MadenciliğiDoç. Dr. Suat Özdemir
11
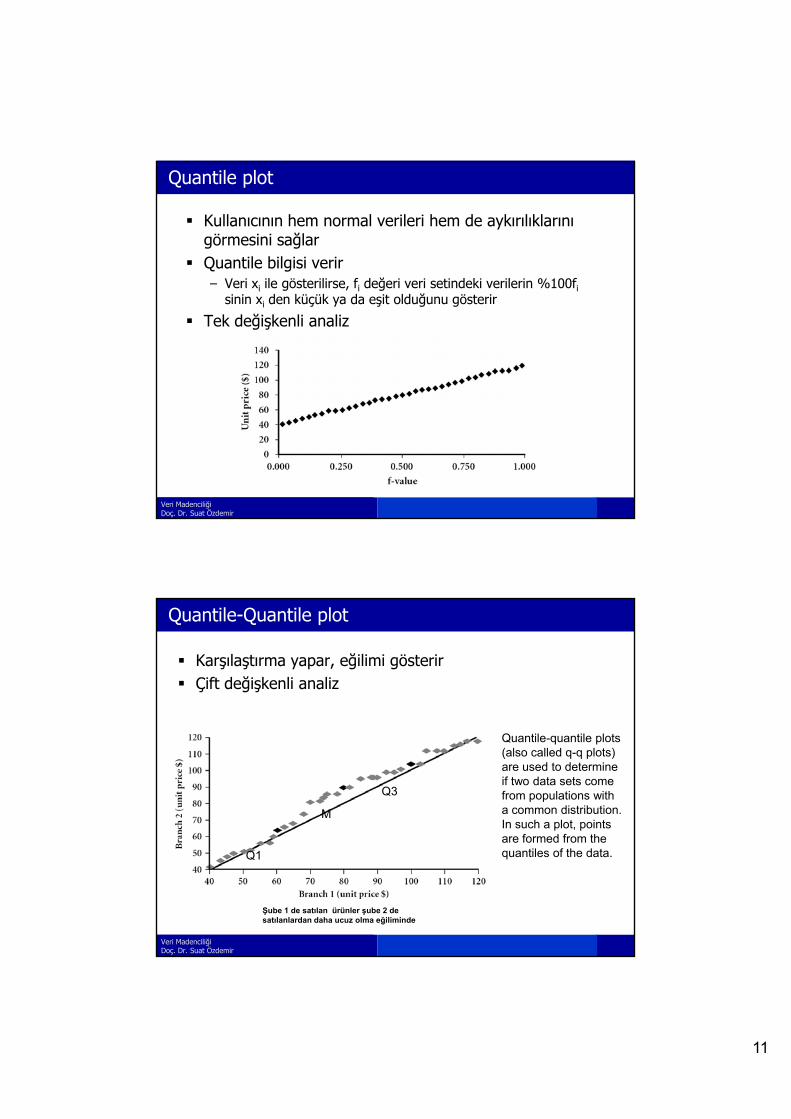
Quantile plot
Kullanıcının hem normal verileri hem de aykırılıklarını görmesini sağlar
Quantile bilgisi verirV i il ö t ili f d ğ i i ti d ki il i %100f– Veri xi ile gösterilirse, fi değeri veri setindeki verilerin %100fisinin xi den küçük ya da eşit olduğunu gösterir
Tek değişkenli analiz
Veri MadenciliğiDoç. Dr. Suat Özdemir
Quantile-Quantile plot
Karşılaştırma yapar, eğilimi gösterir Çift değişkenli analiz
Quantile-quantile plots (also called q-q plots) are used to determine if two data sets come from populations with a common distribution. In such a plot, points are formed from the
Q3
M
Veri MadenciliğiDoç. Dr. Suat Özdemir
are formed from the quantiles of the data.Q1
Şube 1 de satılan ürünler şube 2 desatılanlardan daha ucuz olma eğiliminde
12
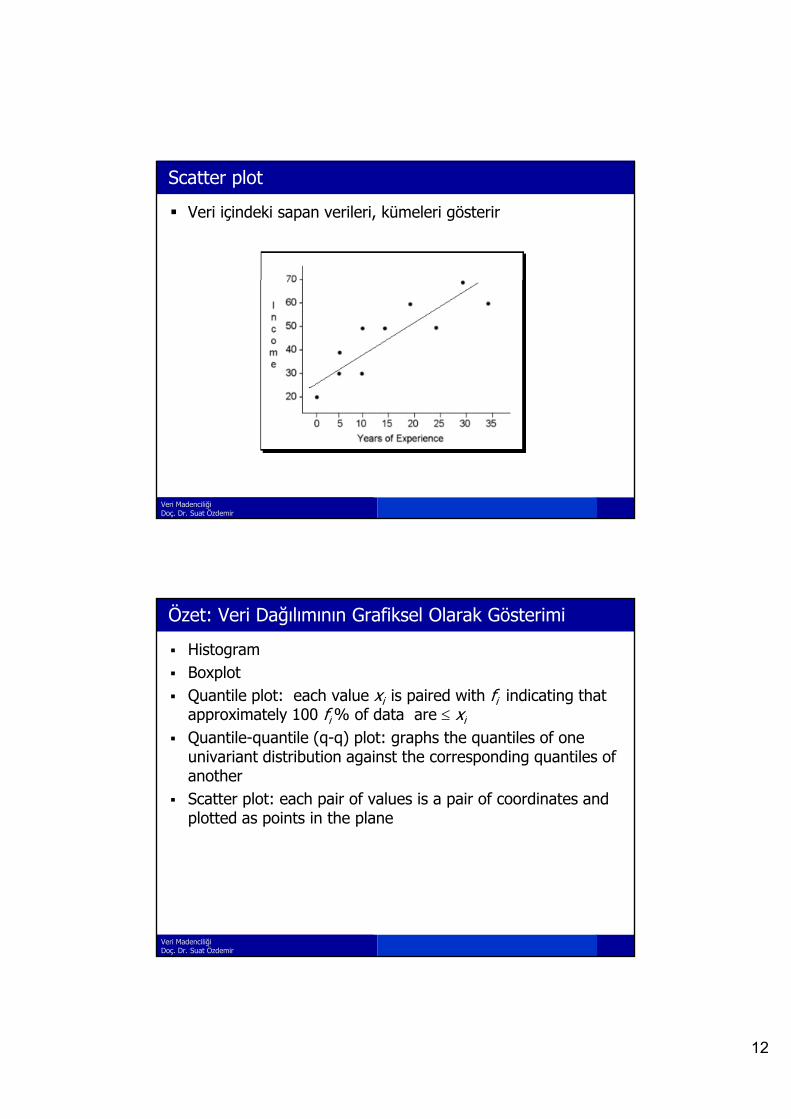
Scatter plot
Veri içindeki sapan verileri, kümeleri gösterir
Veri MadenciliğiDoç. Dr. Suat Özdemir
Özet: Veri Dağılımının Grafiksel Olarak Gösterimi
Histogram Boxplot Quantile plot: each value xi is paired with fi indicating that
approximately 100 fi % of data are xiapproximately 100 fi % of data are xi
Quantile-quantile (q-q) plot: graphs the quantiles of one univariant distribution against the corresponding quantiles of another
Scatter plot: each pair of values is a pair of coordinates and plotted as points in the plane
Veri MadenciliğiDoç. Dr. Suat Özdemir

13
Veri önişleme
Veri temizlemeVeri temizleme– Eksik veri tamamlama, hatalı verileri düzeltme, tutarsız
verileri kaldırma Veri bütünleştirmeVeri bütünleştirme
k l d k ld b l b l– Artık verileri ortadan kaldırma, veritabanlarını birleştirme Veri değiştirme Veri değiştirme
– Veriyi daha anlaşılabilir bir halde ifade etme, normalizasyon
Veri azaltmaVeri azaltma– Veri bütünleştirme, nitelik alt kümesi seçme, boyut
küçültme vb
Veri MadenciliğiDoç. Dr. Suat Özdemir
küçültme, vb.
Veri önişleme
Veri MadenciliğiDoç. Dr. Suat Özdemir

14
Veri önişleme
Veri temizlemeVeri temizleme– Eksik veri tamamlama, hatalı verileri düzeltme, tutarsız
verileri kaldırma Veri bütünleştirmeVeri bütünleştirme
k l d k ld b l b l– Artık verileri ortadan kaldırma, veritabanlarını birleştirme Veri değiştirme Veri değiştirme
– Veriyi daha anlaşılabilir bir halde ifade etme, normalizasyon
Veri azaltmaVeri azaltma– Veri bütünleştirme, nitelik alt kümesi seçme, boyut
küçültme vb
Veri MadenciliğiDoç. Dr. Suat Özdemir
küçültme, vb.
Veri temizleme
Eksik veri tamamlama, hatalı verileri düzeltme, tutarsız verileri kaldırma
Eksik veri tamamlama (missing values)– Kaydı yok sayKaydı yok say – Elle doldurma – Global bir değerle doldurma– Nitelik ortalamasıyla doldurma– Eksik verinin ait olduğu grubun nitelik ortalamasıyla
doldurma En olası değerle doldurma (regression Bayesian
Veri MadenciliğiDoç. Dr. Suat Özdemir
– En olası değerle doldurma (regression, Bayesianinference)

15
Veri temizleme
Hatalı verileri düzeltme (gürültülü-noisy data)– hatalı veri toplama gereçleri– veri giriş problemleri
i i i i d k ll l h t l l– veri girişi sırasında kullanıcıların hatalı yorumları– veri iletim hataları– teknolojik sınırlamalar– veri isimlendirmede veya yapısında uyumsuzluk
Hatalı verinin tespiti?Sapan veriler
Veri MadenciliğiDoç. Dr. Suat Özdemir
– Sapan veriler
Veri temizleme
Çözüm yöntemleri– Kova metodu (Binning): Veriyi düzleştirme, lokal çözüm
• Kova ortalaması ile düzleştirme K t il dü l ti• Kova ortancası ile düzleştirme
• Kova sınırları ile düzleştirme – Eğri uydurma (Regression)– Demetleme (Clustering)– İnsan-bilgisayar incelemesi
Veri MadenciliğiDoç. Dr. Suat Özdemir

16
Kova metodu (Binning)
Eşit genişlik (Equal-width (distance) partitioning)– Veri setini N eşit aralığa böler: uniform grid
– Eğer A ve B veri setindeki en büyük ve en küçük değerler
ise her bir aralığın genişliği: W = (B –A)/N.
– Basit ancak sapan verilerden etkilenir
– Çarpık (skewed) veri iyi ifade edilemez
Veri MadenciliğiDoç. Dr. Suat Özdemir
Kova metodu (Binning)
Eşit derinlik (Equal-depth (frequency) partitioning)
– Her bir veri aralığı yaklaşık olarak aynı sayıda veri içerir
– Ölçeklenebilir
Veri MadenciliğiDoç. Dr. Suat Özdemir

17
Binning - Örnek
Sorted data for price (in dollars): 4, 8, 9, 15, 21, 21, 24, 25, 26, 28, 29, 34
Partition into equal-frequency (equi-depth) bins:Bi 1 4 8 9 15- Bin 1: 4, 8, 9, 15
- Bin 2: 21, 21, 24, 25- Bin 3: 26, 28, 29, 34
Smoothing by bin means:- Bin 1: 9, 9, 9, 9- Bin 2: 23, 23, 23, 23- Bin 3: 29, 29, 29, 29
Veri MadenciliğiDoç. Dr. Suat Özdemir
, , ,
Smoothing by bin boundaries:- Bin 1: 4, 4, 4, 15- Bin 2: 21, 21, 25, 25- Bin 3: 26, 26, 26, 34
Regresyon
Y1
x
y = x + 1
X1
Y1’
Veri MadenciliğiDoç. Dr. Suat Özdemir

18
Demetleme / Kümeleme
Veri MadenciliğiDoç. Dr. Suat Özdemir
Veri önişleme
Veri temizlemeVeri temizleme– Eksik veri tamamlama, hatalı verileri düzeltme, tutarsız
verileri kaldırma Veri bütünleştirmeVeri bütünleştirme
k l d k ld b l b l– Artık verileri ortadan kaldırma, veritabanlarını birleştirme Veri değiştirme Veri değiştirme
– Veriyi daha anlaşılabilir bir halde ifade etme, normalizasyon
Veri azaltmaVeri azaltma– Veri bütünleştirme, nitelik alt kümesi seçme, boyut
küçültme vb
Veri MadenciliğiDoç. Dr. Suat Özdemir
küçültme, vb.

19
Veri bütünleştirme
Artık verileri ortadan kaldırma, veritabanlarını birleştirme– Schema bütünleştirme
• Varlık tanımlama (entity identification) problemVarlık tanımlama (entity identification) problem– Veritabanı 1 -> Cust_id– Veritabanı 2 -> Cust_number
• Metadata kullanımı – Her niteliği tanımla
– Artık/tekrarlı veri temizleme• Korelasyon analizi
Veri MadenciliğiDoç. Dr. Suat Özdemir
• Korelasyon analizi• Chi-square test
Korelasyon Analizi
Correlation coefficient (also called Pearson’s product moment coefficient)
BANABBBAA )())((
where n is the number of tuples, A and B are the respective means of A and B, σA and σB are the respective standard deviation of A and B, and Σ(AB) is the sum of the AB cross-product.
If 0 A d B iti l l t d (A’ l
BABA N
N
Nr BA
)())((
,
Veri MadenciliğiDoç. Dr. Suat Özdemir
If rA,B > 0, A and B are positively correlated (A’s values increase as B’s). The higher, the stronger correlation.
rA,B = 0: independent; rA,B < 0: negatively correlated
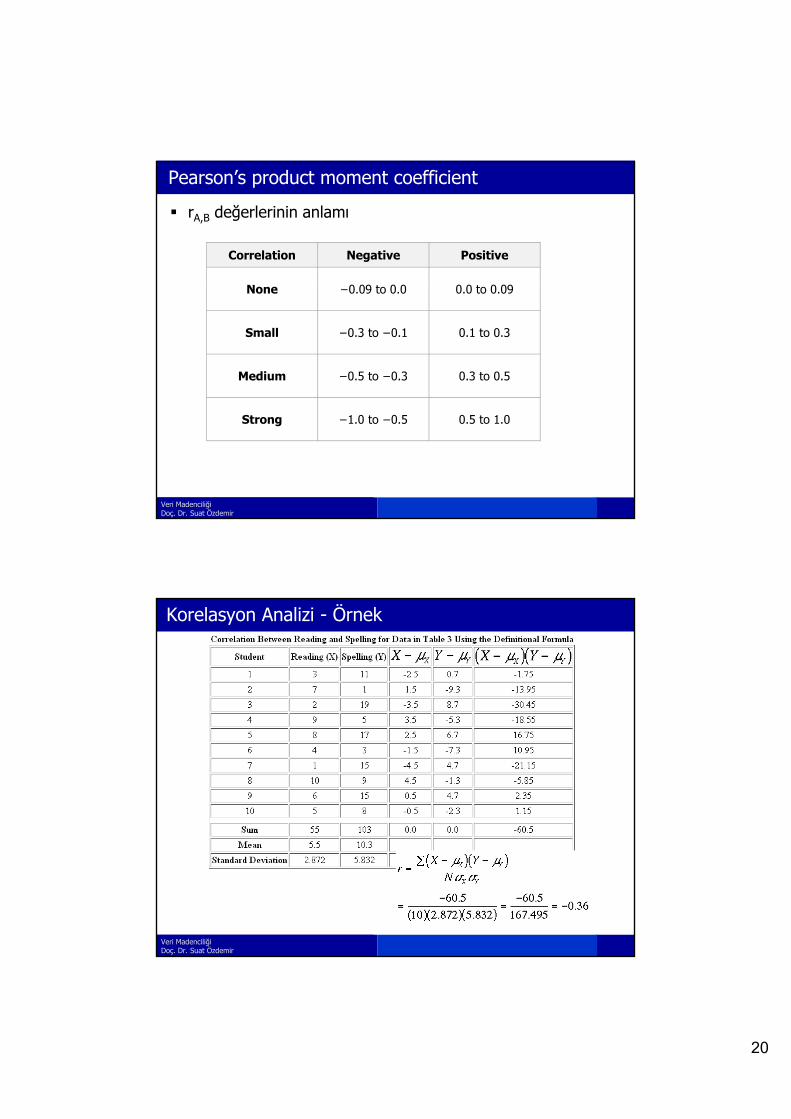
20
Pearson’s product moment coefficient
rA,B değerlerinin anlamı
Correlation Negative Positive
None −0.09 to 0.0 0.0 to 0.09
Small −0.3 to −0.1 0.1 to 0.3
Medium −0.5 to −0.3 0.3 to 0.5
Veri MadenciliğiDoç. Dr. Suat Özdemir
Strong −1.0 to −0.5 0.5 to 1.0
Korelasyon Analizi - Örnek
Veri MadenciliğiDoç. Dr. Suat Özdemir

21
Chi-square Test
Ayrık / kategorik veri için korelasyon Χ2 (chi-square) test
ExpectedObserved 22 )(
The larger the Χ2 value, the more likely the variables are related
The cells that contribute the most to the Χ2 value are those h t l t i diff t f th t d t
Expected
ExpectedObserved2 )(
Veri MadenciliğiDoç. Dr. Suat Özdemir
whose actual count is very different from the expected count Correlation does not imply causality
– # of hospitals and # of car-theft in a city are correlated– Both are causally linked to the third variable: population
Chi-square Test - Örnek
male female Sum (row)
fiction 250(90) 200(360) 450
non-fiction 50(210) 1000(840) 1050
Sum(col.) 300 1200 1500
Χ2 (chi-square) calculation (numbers in parenthesis are expected counts calculated based on the data distribution in the two categories)
Bu hipotezin yanlış olduğunu red etmek içinBağımsızlık derecesi = (r-1)(c-1)=(2-1)(2-1)=1 ve belli bir önem derecesi için chi-
Sum(col.) 300 1200 1500
93.507840
)8401000(
360
)360200(
210
)21050(
90
)90250( 22222
Veri MadenciliğiDoç. Dr. Suat Özdemir
– Bağımsızlık derecesi = (r-1)(c-1)=(2-1)(2-1)=1 ve belli bir önem derecesi için chi-square dağılımının kritik değer tablosuna bakılır
– 0.001 önem değeri için 10.828
10.828 < 507.93 olduğundan Cinsiyet ve okuma tercihi birbirlerinden bağımsız değil denir (çok kuvvetli bir ilişki vardır).

22
Kritik değer tablosu
Veri MadenciliğiDoç. Dr. Suat Özdemir
Veri önişleme
Veri temizlemeVeri temizleme– Eksik veri tamamlama, hatalı verileri düzeltme, tutarsız
verileri kaldırma Veri bütünleştirmeVeri bütünleştirme
k l d k ld b l b l– Artık verileri ortadan kaldırma, veritabanlarını birleştirme Veri değiştirme Veri değiştirme
– Veriyi daha anlaşılabilir bir halde ifade etme, normalizasyon
Veri azaltmaVeri azaltma– Veri bütünleştirme, nitelik alt kümesi seçme, boyut
küçültme vb
Veri MadenciliğiDoç. Dr. Suat Özdemir
küçültme, vb.

23
Veri değiştirme
Veriyi daha anlaşılabilir bir halde ifade etme, normalizasyon– Düzeltme (smoothing)– Birleştirme (aggregation)Birleştirme (aggregation)– Genelleme– Normalizasyon
• Max-min normalizasyon• Z-score normalizasyon• Normalizasyon by decimal scaling
Nitelik oluşturma
Veri MadenciliğiDoç. Dr. Suat Özdemir
– Nitelik oluşturma
Veri değiştirme
Min-max normalization: to [new_minA, new_maxA]
– Ex. Let income range $12,000 to $98,000 normalized to [0.0, 1.0].
AAA
AA
A
minnewminnewmaxnewminmax
minvv _)__('
– Then $73,600 is mapped to
Z-score normalization (μ: mean, σ: standard deviation):
– Ex. Let μ = 54,000, σ = 16,000. Then
Normalization by decimal scaling
716.00)00.1(000,12000,98
000,12600,73
A
Avv
'
225.1000,16
000,54600,73
Veri MadenciliğiDoç. Dr. Suat Özdemir
Normalization by decimal scaling
j
vv
10'
Where j is the smallest integer such that Max(|ν’|) < 1
v’<1 olacak şekilde v’ değerini en büyük yapacak j değeri

24
Veri önişleme
Veri temizlemeVeri temizleme– Eksik veri tamamlama, hatalı verileri düzeltme, tutarsız
verileri kaldırma Veri bütünleştirmeVeri bütünleştirme
k l d k ld b l b l– Artık verileri ortadan kaldırma, veritabanlarını birleştirme Veri değiştirme Veri değiştirme
– Veriyi daha anlaşılabilir bir halde ifade etme, normalizasyon
Veri azaltmaVeri azaltma– Veri bütünleştirme, nitelik alt kümesi seçme, boyut
küçültme vb
Veri MadenciliğiDoç. Dr. Suat Özdemir
küçültme, vb.
Veri azaltma
Veri boyutunu düşür Orijinal verinin özelliklerini koru Boyut küçültmek için harcanan zaman veri
madenciliği yaparken kazanacağımız zamanı ğ y p ğgeçmemelidir
Bazı metotlar– Veri küpü birleştirme– Nitelik altkümesi seçme– Boyut azaltma– Numerosity reduction (Veriyi modellerle yada görsel
l k if d t )
Veri MadenciliğiDoç. Dr. Suat Özdemir
olarak ifade etme)– Ayrıştırma ve konsept hiyerarşisi geliştirme

25
Nitelik altkümesi seçme
Veriye ait tüm nitelikler yapılacak iş için önemli olmayabilir– Alışveriş eğiliminin belirlenmesi/müşterilerin telefon
numaralarıT k l / d d t it likl– Tekrarlı/redundant nitelikler
Verinin dağılım özelliğini bozmadan veriyi ifade edebilecek en küçük nitelik altkümesinin seçilmesi
Sonuçta ortaya çıkan örüntü sayısı azaltılarak veri anlaşılması daha kolay hale getirilirV i i “i i” kild if d d k it lik ltkü i
Veri MadenciliğiDoç. Dr. Suat Özdemir
Veriyi “iyi” şekilde ifade edecek nitelik altkümesi nasıl bulunacak?
Nitelik altkümesi seçme
• “İyi” ve “kötü” nitelikler bağımsızlık testleri, karar ağaçları gibi yöntemlerle belirlenir• Bilgi kazancı vb.
n nitelik için 2n altküme (exponential)S i l (h i i ) l Sezgisel (heuristic) metotlar :– İleri adım adım seçme (Step-wise forward selection)
• Boş küme ile başlayıp en iyi nitelikler kümeye dahil edilir
– Geri adım adım eleme (Step-wise backward elimination)• Tüm nitelikler ile başlanıp, her basamakta en kötü
olan(lar) elenir
Veri MadenciliğiDoç. Dr. Suat Özdemir
olan(lar) elenir– İleri seçme ve geri elemenin birleştirilmesi– Karar ağacı çıkarma (Decision-tree induction)
• Ağaç ortaya çıkarılır ağaç üzerinde görülmeyen nitelikler kötü/önemsiz olarak nitelendirilir ve elenir

26
Boyut azaltma (Dimentionality Reduction)
Kodlama (encoding) ve değiştirmeyle veriyi sıkıştırma – Wavelet transforms– Principle Component Analysis (PCA)
Veri MadenciliğiDoç. Dr. Suat Özdemir
Numerosity reduction
Veriyi modellerle yada görsel olarak daha küçük formlarda ifade etme– Eğri uydurma modelleri
Histog amla– Histogramlar– Demetleme– Örnekleme
Veri MadenciliğiDoç. Dr. Suat Özdemir
27
Regresyon Analizi
Bağımlı değişken ile bir veya daha çok bağımsız değişken arasındaki
y
Y1
ilişkiyi incelemek amacıyla kullanılan bir analiz yöntemidir.
Regresyon analizi ile bağımlı ve bağımsız değişkenler arasında bir ilişki var mıdır? Eğer bir ilişki varsa
x
y = x + 1
X1
Y1’
Veri MadenciliğiDoç. Dr. Suat Özdemir
ilişki var mıdır? Eğer bir ilişki varsa bu ilişkinin gücü nedir? Değişkenler arasında ne tür bir ilişki vardır? gibi sorulara cevap aranmaya çalışılır.
Histogramlar
25
30
35
40•Equ-width/Eşit genişlik•Equ-depth/Eşit derinlik•V optimal
•(Barlar arasında en düşük varyans)
0
5
10
15
20
25
10000 30000 50000 70000 90000
(Barlar arasında en düşük varyans)•Olası bütün histogramlardan barlar arasından en düşük varyansa sahip olanı seç
•MaxDiff•(Veriler arasındaki en fazla fark edendeğer çiftleri sınırları belirler)•B kova sayısı
Veri MadenciliğiDoç. Dr. Suat Özdemir
y•En yüksek B-1 tane farkı belirle ve kovaları ayır

28
Demetleme / Kümeleme
Veri setini benzerliklerine göre demetlere ayırma Sadece demeti ifade eden bilgiyi sakla
– Merkez ve çap Gruplu yapıya sahip veri setinde daha iyi sonuç verir Hiyeraşik demetleme yapılabilir ve indeks ağaçları olarak
ifade edilebilir
Veri MadenciliğiDoç. Dr. Suat Özdemir
Örnekleme
Tüm veri seti N’i temsil edecek küçük veri seti s’i seçmek Basit metotların performansı iyi değil Uyarlanabilir metotlar
– Strafied örneklemeStrafied örnekleme– Belli bir kurala göre sınıfla her sınıftan eşit sayıda örnek al
Veri MadenciliğiDoç. Dr. Suat Özdemir

29
Örnekleme çeşitleri
Simple random sampling– There is an equal probability of selecting any particular
item Sampling without replacementSampling without replacement
– Once an object is selected, it is removed from the population
Sampling with replacement– A selected object is not removed from the population
Stratified sampling: – Partition the data set and draw samples from each
Veri MadenciliğiDoç. Dr. Suat Özdemir
– Partition the data set, and draw samples from each partition (proportionally, i.e., approximately the same percentage of the data)
– Used in conjunction with skewed data
Sampling: With or without Replacement
Veri MadenciliğiDoç. Dr. Suat Özdemir
Raw Data

30
Sampling: Cluster or Stratified Sampling
Raw Data Cluster/Stratified Sample
Veri MadenciliğiDoç. Dr. Suat Özdemir
Ayrıştırma ve konsept hiyerarşisi geliştirme
Sayısal veri– Binning– Histogram analizi
Kategorik veri– Şema seviyesinde (kullanıcılar tarafından)
• Cadde<semt<şehir<ülke– Gruplama
• {ankara,kayseri,konya}-> içanadolu– Anlamsal bağlantılar
• Bazen adres olarak sadece şehir bilgisi yetebilir. Cadde sokak numara nitelikleri atılır.
Veri MadenciliğiDoç. Dr. Suat Özdemir




















