
Two languages, one effect: structural priming in spontaneous code-switching
28
Two languages, one effect: structural priming in spontaneous codeswitching * Rena Torres Cacoullos, Penn State University Catherine E. Travis, The Australian National University Abstract In this work, we investigate the contribution of code-switching and structural priming to variable expression of the Spanish first-person singular subject pronoun (yo ‘I’) in the New Mexico Spanish-English Bilingual corpus. Comparisons of the linguistic conditioning of variant selection in the bilingual community and in monolingual benchmark varieties indicate no alteration of Spanish grammar. Nor do we find a substantial increase in the rate of yo with maximally proximate code-switching. We do, however, find both language-internal and cross- language priming effects, such that unexpressed subjects tend to be followed by unexpressed subjects, while preceding (Spanish and English) pronouns favor subsequent pronouns. Given the rarity of unexpressed subjects in English, with code-switching more tokens occur in an environment favorable to expressed subjects—that of a preceding expressed subject. We submit that what scholars have construed as code-switching effects may be the result of associated structural priming and shifts in contexts of occurrence. Keywords: code-switching, structural priming, variation, subject expression, Spanish, English 1 Assessing codeswitching as a mechanism of change Is code-switching in and of itself a mechanism of language change? At least since Gumperz and Wilson (1971), many would answer “yes” (e.g., Backus, 2005, p. 334; Thomason, 2001, p. 136; Winford, 2005, p. 86). One of the most trumpeted loci of grammatical alteration impelled by language contact is the variable use of Spanish subject pronouns in the United States (cf. Silva-Corvalán, 1994, inter alia). This is considered a candidate for grammatical convergence because Spanish and English subject pronouns are thought to be strongly associated for bilinguals due to the overlap in their deictic meaning and person-number categories, such that the overwhelming preference for expressed subjects in English is predicted to boost the rate of expressed subject pronouns in contact Spanish varieties. We report here on the patterns of variable Spanish first person singular (1sg) subject expression in a new community-based corpus of everyday bilingual speech, the New Mexico Spanish-English Bilingual (NMSEB) corpus (Torres Cacoullos & Travis, In preparation) (Section 2). Contextual predictors of yo expression in NMSEB, as revealed in multivariate analysis, are found to be parallel to those established in variationist studies of subject * The order of authors is alphabetical; both contributed equally to this work, funded by the National Science Foundation (1019112/1019122). The research would have been impossible without a team of workers, and we gratefully acknowledge the contributions of Jenny Dumont (as UNM project manager, 2010-2011) and Colleen Balukas (at Penn State), as well as the research assistants from UNM (Daniel Abeyta, Rubel Aguilar, Raúl Aragón, Cheryl Conway, Jason Gonzales, Aubrey Healey, Leah Houle, Rebeca Martínez, Ana Medina Murillo, Amanda Ortiz, Andrés Sábogal, Lillian Sanchez, Lizeth Trevizo, Kamie Ulibarrí, Víctor Valdivia Ruiz), and from Penn State (Nicole Benevento, Yolanda Gordillo, Everardo Tapia). We also thank Garland Bills and Neddy Vigil, for their own inspiring work on New Mexican Spanish, and other colleagues for their collaboration (Sonia Balasch, Evan Kidd, Chris Koops, Enrique Lamadrid and Damian Vergara Wilson).
Transcript of Two languages, one effect: structural priming in spontaneous code-switching

Two languages, one effect: structural priming in spontaneous code-‐switching*
Rena Torres Cacoullos, Penn State University Catherine E. Travis, The Australian National University Abstract In this work, we investigate the contribution of code-switching and structural priming to variable expression of the Spanish first-person singular subject pronoun (yo ‘I’) in the New Mexico Spanish-English Bilingual corpus. Comparisons of the linguistic conditioning of variant selection in the bilingual community and in monolingual benchmark varieties indicate no alteration of Spanish grammar. Nor do we find a substantial increase in the rate of yo with maximally proximate code-switching. We do, however, find both language-internal and cross-language priming effects, such that unexpressed subjects tend to be followed by unexpressed subjects, while preceding (Spanish and English) pronouns favor subsequent pronouns. Given the rarity of unexpressed subjects in English, with code-switching more tokens occur in an environment favorable to expressed subjects—that of a preceding expressed subject. We submit that what scholars have construed as code-switching effects may be the result of associated structural priming and shifts in contexts of occurrence. Keywords: code-switching, structural priming, variation, subject expression, Spanish, English
1 Assessing code-‐switching as a mechanism of change Is code-switching in and of itself a mechanism of language change? At least since Gumperz and Wilson (1971), many would answer “yes” (e.g., Backus, 2005, p. 334; Thomason, 2001, p. 136; Winford, 2005, p. 86). One of the most trumpeted loci of grammatical alteration impelled by language contact is the variable use of Spanish subject pronouns in the United States (cf. Silva-Corvalán, 1994, inter alia). This is considered a candidate for grammatical convergence because Spanish and English subject pronouns are thought to be strongly associated for bilinguals due to the overlap in their deictic meaning and person-number categories, such that the overwhelming preference for expressed subjects in English is predicted to boost the rate of expressed subject pronouns in contact Spanish varieties.
We report here on the patterns of variable Spanish first person singular (1sg) subject expression in a new community-based corpus of everyday bilingual speech, the New Mexico Spanish-English Bilingual (NMSEB) corpus (Torres Cacoullos & Travis, In preparation) (Section 2). Contextual predictors of yo expression in NMSEB, as revealed in multivariate analysis, are found to be parallel to those established in variationist studies of subject
* The order of authors is alphabetical; both contributed equally to this work, funded by the National Science Foundation (1019112/1019122). The research would have been impossible without a team of workers, and we gratefully acknowledge the contributions of Jenny Dumont (as UNM project manager, 2010-2011) and Colleen Balukas (at Penn State), as well as the research assistants from UNM (Daniel Abeyta, Rubel Aguilar, Raúl Aragón, Cheryl Conway, Jason Gonzales, Aubrey Healey, Leah Houle, Rebeca Martínez, Ana Medina Murillo, Amanda Ortiz, Andrés Sábogal, Lillian Sanchez, Lizeth Trevizo, Kamie Ulibarrí, Víctor Valdivia Ruiz), and from Penn State (Nicole Benevento, Yolanda Gordillo, Everardo Tapia). We also thank Garland Bills and Neddy Vigil, for their own inspiring work on New Mexican Spanish, and other colleagues for their collaboration (Sonia Balasch, Evan Kidd, Chris Koops, Enrique Lamadrid and Damian Vergara Wilson).

2
expression in Latin American and Peninsular Spanish varieties (Sections 3 and 4). At the same time, New Mexico bilinguals’ Spanish does not exhibit the language-specific factors relevant to first singular subject pronoun realization in English (Section 5). In testing for a global effect of code-switching, we fail to find a substantially higher rate of the subject pronoun yo ‘I’ when there is a switch to English in the same or immediately preceding clause (as in (1)) than in Spanish-only contexts (Section 6).
(1)
Molly ... (H) .. yo creo que puede drive into my yard, ‘I think he can drive into my yard,’ [09 La salvia, 0:25:08-0:25:11] 1
We do however find a considerably higher yo rate when a preceding subject is pronominal
(whether English or Spanish), than when it is unexpressed, that is, structural priming: unexpressed subjects tend to be followed by unexpressed subjects, while preceding pronouns favor subsequent pronouns (Section 7). We submit that, rather than code-switching intrinsically inducing grammatical alteration, what is at work is the associated priming of parallel structures and shifts in the frequency of contextual features contributing to variant choice.
2 Good data for the study of code-‐switching: bilingual community and corpus
Evaluating code-switching as an impetus of language change in progress requires a corpus of unreflecting speech amenable to systematic quantitative analysis, drawn from a well-defined speech community of bilinguals who code-switch in their spontaneous discourse.
The first imperative follows from the empirical observation that the vernacular, the mode of speech that is used with friends and family and in which minimum attention is paid to speech, is highly regular and thus provides the most systematic data for linguistic analysis (Labov, 1972b, p. 112). Because of the formality and self-monitoring that controlled elicitation and experimental procedures impose, such methods are particularly unsuitable for the collection of production data of nonstandard varieties (cf. Sankoff, 1988a, p. 145-146), nor do studies that depend on anecdotal observations or haphazardly collected examples allow for a reliable accounting of actual usage. The second imperative is a consequence of the observation that individuals may exhibit idiosyncratic behavior, not constrained by community norms, and that the ways in which bilinguals combine their languages differ from community to community, even for typologically similar language pairs (cf. Poplack, 1998, for an illustration).
In this section we delineate the community and corpus in which the present study is grounded.
2.1 The contact site: Spanish and English in New Mexico Northern New Mexico is home to “arguably the oldest continually spoken variety of Spanish anywhere in the Americas that has not been updated by more recent immigration” (Lipski, 2008, p. 193). Following settlement in 1598 from New Spain (what today is Mexico), Spanish speakers in the northern section of the state had minimal contact with speakers of other varieties of Spanish (Gonzales Berry & Maciel, 2000, p. 4; Lipski, 2008, p. 195, 202), developing over time their own distinct variety which we refer to here as “Traditional New Mexican Spanish”, following Bills and Vigil (2008, p. 8). Traditional New Mexican Spanish is said to be generally Mexican grammatically but distinguishable lexically (Bills & Vigil, 2008).

3
New Mexico became a Territory of the United States in 1850, however English speakers were in the minority for longer than in the surrounding region: in 1890, 70% of the population of New Mexico could not speak English, a figure which dropped to 33% in 1910 (Fernández-Gibert, 2010, p. 48). New Mexico was awarded statehood in 1912, and English increasingly displaced Spanish in the educational system (cf. Gonzales-Berry, 2000). Children were punished for speaking Spanish in schools, as recounted in
(2). (2) Punishment at school
Pedro ... usaban la jarita or you had to go out and get a load of wood.
‘... they would use the cane or you had to go out and get a load of wood.’
[10 El timbre portátil, 0:11:16-0:11:19]
From the 1900s (with the Mexican Revolution, 1910-1920), immigration from Mexico has led to increasing contact with contemporary varieties of Mexican Spanish. While this augments the presence of Spanish overall, Traditional New Mexican Spanish is stigmatized in comparison with monolingual varieties, and thus the northward spread of Mexican Spanish also threatens the maintenance of Traditional New Mexican Spanish (Bills & Vigil, 1999, p. 56), as does the teaching of educated standard Spanish as a foreign or second language (Gonzales-Berry, 2000). This disparagement of the local variety is displayed in example (3), about the speaker’s granddaughter getting her homework—which the
speaker had helped her with—marked as wrong. In this way, contact with English as well as contact with Mexican Spanish and the educated standard are all said to endanger Traditional New Mexican Spanish (Bills & Vigil, 2008, p. 313; see also discussion in Travis and Villa, 2011). (3) Prestige of Educated Standard
Inmaculada .. they c- called it proper Spanish. Lucy mhm. Inmaculada o=r, whatever, it was called, (H) but it wasn't our Spanish. Lucy hm. Inmaculada so she got everything wrong.
[14 Calcetines, medias y mallas, 0:26:25-0:26:32] For students of language contact, the locus of which, as stressed by Weinreich (1968), is
the bilingual speaker, the remaining speakers of Traditional New Mexican Spanish and English provide a precious window into bilingual speech phenomena. Their speech allows us to examine any long-term grammatical repercussions of contact in a native, non-immigrant, community, rather than a community undergoing loss or shift within three generations (as is the case for most immigrant communities, cf. Silva-Corvalán, 1994, inter alia).
2.2 The community-‐based corpus Because our “primary object of interest [is] the speech community” (Labov, 2001, p. 34), we leave behind not only studies based on one or two individuals but also generalizations from larger numbers consisting of assorted participants of unknown social characteristics (including heterogeneous groups of university students). Speakers comprising NMSEB are bona fide New Mexicans, minimally third-generation Nuevomexicanos ‘New Mexicans’, who are bilingual and regularly use both languages with the same interlocutor in the same domain, “the appropriate code for the Hispano community” in New Mexico (Gonzales Velásquez, 1995, p. 29). That is, rather than administering tests of proficiency, we rely on the criterion of

4
regular use of both languages, as observed by the fieldworkers (and subsequently confirmed in the course of the sociolinguistic interviews) (cf. Poplack, 1993, p. 254).
In order to best approximate observation of everyday vernacular speech, we adopted the sociolinguistic interview, which includes narratives of personal experience for which participants, not the researcher, are the indisputable experts and during which monitoring of speech is minimized (Labov, 1984, p. 32-42). For NMSEB, sociolinguistic interviews were conducted by in-group members (cf. Clyne et al., 2001, p. 235-236; Poplack, 1993: 260), eight Nuevomexicano students of the University of New Mexico who recorded family and acquaintances.
A corpus that, beyond the cherry-picked example, can be used for accountable quantitative analysis requires complete transcription of the audio data. Transcriptions were done in ELAN, a software program that aligns the audio file to the transcription (Lausberg & Sloetjes, 2009). The transcription is prosodically based (cf. Du Bois et al., 1993), relying on the notion of the Intonation Unit (henceforth, IU), “a stretch of speech uttered under a single coherent intonation contour” (1993, p. 47). Each IU is represented on a distinct line in the transcription, followed by punctuation which represents its prosodic contour. Material that is realized in a single IU often shows a tighter syntactic relationship than material that is
spread across IUs (cf. Chafe, 1994, Ch. 9). As an illustration, consider (4) below, not transcribed in IUs. Without an indication of the prosody it is impossible to know if the
yo (in bold) is a post-verbal subject on dije (‘said I’), or a preverbal subject on no puedo (‘I cannot’). However, once IUs are marked, as in
(5), it becomes clear that yo is a post-‐verbal subject on dije, while puedo has an unexpressed subject. (4)
Ivette: dije yo no no puedo estar yendo pa' atrás y pa' adelante. ‘.. I said I can’t be going backwards and forwards.’
(5)
Ivette .. dije yo, No. Ø no puedo estar yendo pa' atrás y pa' adelante.
‘.. I said, No. (I) can’t be going backwards and forwards.’
[05 Las Tortillas, 0:43:54-0:49:11] Selected for transcription, and thus comprising the NMSEB corpus, were 31 recordings
with copious switching, for a total of 30 hours of speech from 41 speakers. This adds up to approximately 97,000 Intonation Units and 320,000 words. Though the amount of Spanish and English varies in the recordings and the quantification of language contact phenomena awaits a series of studies, this makes NMSEB a unique bilingual corpus, with a roughly even distribution of speech produced in Spanish and English by the same speakers, and smooth multi-word code-switching throughout. The 41 NMSEB participants are all from northern New Mexico, were born between 1923 and 1989, and comprise 23 women and 18 men, including miners, ranchers, schoolteachers (for an overview of NMSEB and a sociolinguistic profile of participants, see Travis & Torres Cacoullos, To appear). The following report is based on 14 interviews involving 18 participants, constituting 14 hours of speech, or 39,450 IUs and 136,000 words.
Having met the extralinguistic requirements for testing convergence impelled by code-switching—an appropriate contact site and speaker sample—in the following section we delimit a linguistic variable that is an appropriate candidate for grammatical convergence (see Poplack (2012a, p. 203-204) and Poplack & Levey (2010) for hard tests for convergence).

5
3 Variationist comparative method to ascertain convergence
3.1 Subject expression as a linguistic variable to gauge convergence Any pronouncement of convergence based on departures from an idealized monolingual norm as perceived by the analyst rests shakily not only on unverifiable characterizations of what the “monolingual norm” is, but also on the precarious equation of variation with change. But we know that, while all change involves variability, “not all variability and heterogeneity in language structure involves change” (Weinreich et al., 1968, p. 188). Linguistic variability is conditioned by contextual features, which contribute to speakers’ choices from the set of variants constituting a linguistic variable (Labov, 1969)—here, speakers’ choice of pronoun yo vs. an unexpressed 1sg subject, both of which broadly function to index the speaker.
Spanish subject expression has been enlisted as a candidate for grammatical convergence under the assumption that Spanish and English subject pronouns are similar enough that bilinguals may use the former at a higher rate in tandem with the overwhelming rate of use of the latter. But an issue with confining tests of convergence to comparisons of overall rates of variable occurrence is the question of the threshold for qualifying as a “high(er)” rate, given wide disparities between dialects (see Figure 1 in Section 4.1 below) and susceptibility to genre, topic or other extragrammatical situational considerations. It is through statistical modeling of conditioning factors that we can obtain “a more penetrating characterization of grammatical structure” (Erker & Guy, 2012, p. 546) (cf. Poplack et al., 2012b, p. 250).
Linguistic structure is evinced in the linguistic conditioning of variation, or the configuration of linguistic constraints—direction, magnitude and significance of effect—on the variants of a linguistic variable. The constraints are probabilistic statements about the co-occurrence of variant expressions and elements of the linguistic context in which they appear (Labov, 1969; Sankoff, 1988a). A factor (level of a predictor variable, in regression analysis) favors a variant when its frequency relative to other variants is higher in the presence of the contextual feature represented by the factor, which itself operationalizes a hypothesis about speaker choices.
For variable subject expression in Spanish, the same linguistic conditioning has been widely reported both across dialects (e.g., Cameron, 1993, 1994) and genres (Travis, 2007). Broadly replicated are effects of subject continuity (subject pronouns are favored in non-coreferential (switch reference) contexts) and structural priming (subject pronouns are favored in the context of a preceding subject pronoun). Both constraints may apply to subject realization cross-linguistically, as manifestations, respectively, of the tendency to use more coding material (e.g., stressed vs. unstressed pronoun) for less accessible referents (Givón, 1983a) and the tendency to repeat the same structure (Cameron, 1994).
Alongside these hypothesized cross-linguistic tendencies, there are also language specific effects, as we will show below. What makes Spanish subject expression in Spanish-English bilingual speech an appropriate linguistic variable to ascertain convergence is that the linguistic conditioning of English I realization presents clear differences from that of yo expression. These differences between the languages in contact, or “conflict sites” (Poplack & Meechan, 1998, p. 132), enable us to rule out cross-linguistic tendencies when making comparisons. Beyond higher or lower overall rates, then, we set ourselves the test of linguistic conditioning, and the question becomes: when bilinguals use yo as opposed to an unexpressed 1sg subject, do they adhere to Spanish constraints or has there been some accommodation to English patterns of variable 1sg subject realization?

6
3.2 Data: circumscribing the variable context It is only by accounting for occurrences as well as non-occurrences of the phenomenon of interest (Labov, 1972a, p. 69) that we can identify the factors influencing variant selection. The first step, then, in stating the linguistic conditioning of yo involves defining the variable context, the broadest domain in which speakers have a choice between variants, here expression or non-expression (Labov, 2005).
We began by extracting all tokens of finite Spanish verbs with (expressed and unexpressed) 1sg subjects produced by our participants (N=1,483), except for prosodically truncated tokens where the speaker cut off before completing the verb, and did not produce a subject pronoun (and therefore there was the potential for a truncated postverbal subject) (N=31); tokens where there was a 1sg verb, but the speech was not clear enough to definitively identify the realization of the subject (N=25); and tokens that occurred in word play or in speech produced with marked voice quality (N=5).
We then excluded all post-verbal tokens of yo (N=81, 18% of expressed subjects in the data, 81/440), as post-verbal subject pronouns are unlikely to be subject to the same constraints as preverbal ones (cf., Silva-Corvalán, 2001, p. 165). Also excluded were cases where the verb appeared in a distinct IU from the pronoun (N=19) (illustrated in (6), where both verbs were excluded, and (7)) as it is not always possible to tell in such cases whether this pronoun should be considered the subject of the verb (see Otheguy and Zentella (2012, p. 236)). Other cases of expressed subjects in rare configurations (N=4) were excluded, for example, the occurrence of a verb with two tokens of yo (y yo comencé a huellar yo al oso, ‘and I started to track the bear’ [16 Trip to Africa pt.1, 0:17:45 - 0:17:47]).
(6)
Bartolomé ...(1.2) sí pues yo cuando com- -- ... principié la escuela no sabía nada en
inglés.
‘…(1.2) yes well when I beg- -- … (I) started school (I) didn't know anything in
English’ [02 La marina, 0:37:46-0:37:53]
(7) Victoria ... pero yo no -- I don't -- no sé.
‘.. but I don’t -- I don’t -- (I) don’t know.’
[12 Juego de scrabble, 0:29:33-0:29:34]
Several non-variable contexts were identified, and also excluded for this reason. In identifying such contexts, we do not ask whether variability is theoretically possible with any given verb, but rather “we formulate … broad definitions of clausal and lexical types where variability is low enough to disqualify them from the study, and apply those definitions to each specific finite verb in order to decide whether it is to be coded and counted in the study, or passed over and neither coded nor counted” (Otheguy et al., 2007, p. 776). The non-variable contexts we identified for these data are wh-questions, as in (8), an environment where preverbal subjects do not occur in this variety (N=9); fixed expressions (N=6, e.g. ahí voy. ‘coming’ [13 La acequia, 0:00:19]) and contexts of apposition (N=1; y yo la pendeja lo hacía. ‘and I the stupid one would do it’ [12 Juego de Scrabble, 0:33:55-0:33:56]). There were no subject relatives, oft-mentioned as non-variable contexts (e.g., Otheguy & Zentella, 2012, p. 245-247), in the data.
(8)
Betty ...(0.9) (TSK) qué te puedo contar? ‘…(0.9) (TSK) what can (I) tell you?’ [13 La acequia, 0:01:27-0:01:29]

7
We included tokens where the pronoun was separated from the verb by intervening material, provided they occurred in the same IU (N=23). Intervening material in these data was always an adverb such as también ‘also’, nunca ‘never’, quizás ‘maybe’, nomás ‘only, just’ and one token of sí, which despite being apparently emphatic is a variable context in these data, as seen in (9) where it occurs with an unexpressed subject.
(9)
Fabiola por qué tú no vas pa' Taos nunca? Molly .. Ø sí voy, el otro día Ø fui con la Fabricia y, (H) .. Ø me gané un abrejarros no?
‘why don’t you ever go to Taos?’ ‘.. (I) do go, the other day (I) went with Fabricia, (H) and (I) won a jar opener you know?’
[09 La salvia, 0:23:21- 0:23:26]
Cases of unmarked contrast have similarly been excluded in past studies as presumed obligatory contexts (e.g., Silva-Corvalán, 2003, p. 850), but it has also been noted that both expressed and unexpressed subjects occur in such environments (Amaral & Schwenter, 2005; Otheguy et al., 2007, p. 775-776). Further, without a clear operationalization of contrast, there is a great risk of circularity, whereby tokens are interpreted as contrastive because of the presence of yo, and then yo is described as a marker of that contrast. The following example illustrates a potentially contrastive context, but only one of the clauses occurs with an expressed yo.
(10)
Inmaculada y luego nos peleábanos por el tuétano. Anita [@@@@@@@@@@@] Inmaculada [@@@@@@@@@@@@@@@] Lucy [@@@@@@] Lucy [2@@2] Anita [2y Ø era mayor2] so yo ga<@naba @>.
and we’d fight over the bone marrow And (I) was the oldest so I would win.’
[14 Calcetines, medias y mallas, 0:40:14-0:40:21]
Finally, we excluded the handful of tokens that were contextually ambiguous. Despite the large amount of literature on the disambiguating function of expressed pronouns, ambiguous tokens are vanishingly rare in the data, accounting for just 6 out of 1002 unexpressed tokens. Such a low rate of ambiguity is not unique to these data: Ranson (1991, p. 148) finds that when contextual elements are considered, grammatical person is relevant but unmarked linguistically in just 2% (21/1035) of verbs (all person-numbers).
Of the six “ambiguous tokens”, only two can be considered genuinely ambiguous. Of the remaining four, in one case, the ambiguity arises because they speaker doesn’t complete the utterance (though without prosodic truncation); and there are three tokens where the identity of the subject makes no difference to the interpretation of the event (what Ranson (1991, p. 145) refers to as “person irrelevant” and Ono and Thompson (1997, p. 488) describe as the “referent” being left “open”). The following is one such example, where the subject of tenía que meter el dedo could mean ‘I had to stick in my finger’, but similarly it could mean that ‘one had to’.

8
(11) Inmaculada (H) y ella me decía ándale lava los trastes
y yo te doy lipstick. Lucy <@ oh= @>. Inmaculada so Ø lavaba los trastes y yo muy contenta
con lipstick. (H) !pero ya= estaba bien gastado, Ø tenía que meter el dedo <@ pa' adentro
pa' agarrar el lipstick @>.
‘(H) and she would say to me go and wash the dishes and I’ll give you lipstick.’
‘<@ oh= @>.’ ‘so (I) would wash the dishes and I’d be all happy
with lipstick. (H) but it was already really used up, (I/she/one) had to stick a finger <@ inside to grab
the lipstick @>.’ [14 Calcetines, medias y mallas, 0:41:02-0:41:12]
These protocols leave us with 1,357 tokens for analysis. We first consider the overall rate
of expression in these tokens to then employ comparisons of the structure of variability.
4 Comparing bilingual and monolingual Spanish subject expression
4.1 Overall rates Figure 1 depicts the disparity of rates of subject expression across dialects and studies. We can see here that, at 27%, the overall rate of yo in the NMSEB sample is comparatively low and is higher in semi-directed conversations with an interviewer in Caracas (Bentivoglio, 1987, p. 36) and in conversations among friends in Cali, Colombia (Travis, 2007, p. 113) (at 46%, 329/721 and 48%, 421/878, respectively). Even discounting dialect and genre, the lower yo rate in the NMSEB sample seen in Figure 1 is dissonant with convergence in terms of the prediction that the overall rate of yo would be pulled up by virtue of bilinguals associating it with English I. It could, however, be seen as consonant with convergence, if convergence takes the form of bilinguals’ loss of constraints on subject expression, as Silva-Corvalán (1994, p. 153-162) finds for ambiguity of person-number verb morphology among third-generation Mexican-Americans in Los Angeles). The comparison of overall rates of use across dialects and studies is, as anticipated, unrevealing as to change, contact-induced or otherwise.
Figure 1 Comparison of overall rates of occurrence of Spanish 1sg subject pronoun yo
across studies*

9
* Madrid, Spain (Enríquez, 1984) and Santiago, Chile (Cifuentes, 1980-1) as reported in Silva Corvalán (1994, p. 153); Castañer, Puerto Rico (Holmquist, 2012, p. 211); Caracas, Venezuela (Bentivoglio, 1987, p. 36); Cali, Colombia (Travis, 2007, p. 113); Puente Genil, Andalucia (Ranson, 1991, p. 135, 138).
We therefore turn to the linguistic conditioning of yo, and compare the constraints on
subject expression in bilingual New Mexicans and non-contact varieties, in order to corroborate grammatical similarities or differences. If the constraints on subject expression in the data of NMSEB display differences with non-contact varieties of Spanish, on the one hand, and similarities with non-contact English, on the other, we can make an initial inference of convergence in progress.2
4.2 Linguistic conditioning of yo among bilinguals In order to determine how contextual features favor or disfavor expressed yo, we submit the data to multivariate analysis. Seven factor groups (independent variables, or predictors) were considered together in Variable-rule analysis (Sankoff, 1988b), using Goldvarb Lion (Sankoff et al., 2012). Variable-rule analysis uses logistic regression to perform binomial multivariate analysis for a choice of the “1” variant (here, yo) vs. the “0” variant (unexpressed 1sg); the procedure determines the factor groups that together account for the largest amount of variation, in terms of stepwise increase of log likelihood, such that the addition of any of the remaining factor groups does not significantly increase the fit to the model.
Table 1 Multivariate analysis of factors contributing to choice of subject pronoun yo
(vs. unexpressed subject) in New Mexico Spanish English Bilingual corpus (non-significant factors within [ ])
N=1,357; Input: .16* (Overall rate: 27%) Prob % yo N % data
Semantic class of verb Cognitive (creo ‘I believe’, no sé ‘I don’t know’, (no) me acuerdo ‘I (can’t) remember’)
.75 55% 274 20%
Other (motion, copula, speech, perception, other) .43 19% 1068 80% Realization of previous coreferential 1sg subject** Pronoun (yo or I) .67 33% 243 35% Unexpressed (Spanish 1sg verb) .40 10% 441 65% Reflexive clitic me Absent .53 28% 1204 89% Present .25 14% 153 11% Subject continuity***
Presence of Intervening Human Subjects between coreferential mentions (“switch reference”)
.62 44% 356 32%
No Intervening Human Subjects (“same reference”) .44 17% 771 68% Tense-aspect-mood Imperfective (Present and Imperfect) .54 32% 884 71% Perfective (Preterit) .40 14% 362 29% Realization of subject of immed. preceding clause
Personal pronoun (Spanish or English) [.56] 33% 230 32% Unexpressed (Spanish verb) [.47] 16% 485 68%
Polarity Negative [.51] 34% 285 21% Positive [.45] 24% 1072 79%

10
* The relationship between the Input (corrected mean) and the overall rate of variant selection (which generally it closely reflects) appears distorted because Realization of previous coreferential 1sg subject applies to only 50% (684/1,357) of the data. ** Considered up to a distance of four intervening clauses and excluding tokens without a previous mention within the preceding four clauses (N=203, yo rate 50%), with a previous non-1sg coreferential mention (N= 199), or involving quotation (N=179, yo rate 32%). *** Excluding all tokens involving quotation (N=180); tokens without a previous mention within the preceding four clauses (N= 203) are counted as “switch reference”.
In Table 1 we see that five constraints are significant: Semantic class of verb, Realization
of previous coreferential 1sg subject, Reflexive clitic me, Subject continuity, and Tense-aspect-mood. Probabilities, or factor weights, shown in the first column, are such that the closer to 1, the greater the favoring effect, or the greater the likelihood of yo occurrence in each of the contexts (factors, or levels of the predictor variables) listed on the left; the closer to 0, the greater the disfavoring effect on yo (or conversely, the favoring of unexpressed 1sg).
For semantic class of verb, replicated is the strong favoring effect of cognitive verbs reported in numerous previous studies across different varieties of Spanish (e.g., Bentivoglio, 1987, p. 60; Enríquez, 1984, p. 240; Silva-Corvalán, 1994, p. 162; Travis, 2007, p. 116-117). Frequent among cognitive verb tokens is the 1sg Present-tense prefab yo creo, with a notably high yo rate of 89% (73/82) as also reported elsewhere (Erker & Guy, 2012, p. 536, 539; Travis & Torres Cacoullos, 2012, p. 739-741) and the particular construction (yo) no sé ‘I don’t know’ with a yo rate of 43% (40/94).
Also significant is the effect of coreferential priming. This takes into account the realization of the speaker’s last reference to themselves as subject, counted within four clauses from the previous coreferential mention (see below). This effect is illustrated in the following two examples: in (12), the previous coreferential 1sg subject and the target token are both realized pronominally and in (13), both are unexpressed. As shown in Table 1, previous realization as a pronoun, yo (N=135) or I (N=108), favors occurrence of yo. We return to priming effects in Section 7.
(12) Coreferential priming: yo to yo
Javier (H) <F Yo no sé quien será, Yo no lo conozco F>.
‘(H) <F I don’t know who that is, I don’t know F>.’
[17 La comadreja, 1:10:50-1:10:53]
(13) Coreferential priming: unexpressed to unexpressed Miguel ya Ø no quería. ... it was too hard. ...(1.5) pero Ø lo hice.
‘(I) didn’t want to. … it was too hard. …(1.5) but (I) did it.’
[04 Piedras y gallinas, 12:54:44-12:54:46]
On the other hand, reflexive-marked verbs such as casarse ‘get married’, irse ‘go, leave’, quedarse ‘remain’, which make up approximately 10% of the data, strongly disfavor yo expression. Whether this has to do with the preverbal presence of any object pronoun clitic or specifically person marking on reflexive me is unknown. Most frequent is the cognitive verb acordarse (accounting for one third (54/153) of the reflexive verbs), usually appearing as (no) me acuerdo ‘I (don’t) remember’, and which shows a higher than reflexive-verb average yo rate of 20% (11/54) (vs. 14% overall, see Table 1).
As for the Tense-aspect mood constraint, yo is also disfavored with Preterit (past perfective) verb forms. This is as predicted, whether the effect is one of ambiguity of person-number morphology (Preterit suffixes distinguish grammatical persons) or follows from the

11
discourse function of tense-aspect-mood forms, such that pronominal subjects are less likely with foregrounded events (coded by perfectives) (Silva-Corvalán, 1997, 2001).
Subject continuity effects As an operationalization of subject continuity, the familiar measure of Switch Reference (see Cameron 1994) considers whether the subject of the target clause is coreferential with that of the preceding clause. It turns out that the alternative measure of Intervening Human Subjects provides a more discerning account than clause-based switch reference.
In order to replicably test these two measures, we first need to determine what to count as the previous coreferential mention, and what to count as a clause. We consider the previous coreferential mention up to a distance of four intervening clauses, and include coreferential 1sg subjects produced by the same speaker (N=686), as well as coreferential 1pl (N=93), coreferential 2nd person produced by a different speaker (N=104), and the rare cases, where there are more than three participants, of a coreferential 3sg (N=2). We operationalized the clause as any finite verb, in a main or subordinate clause, with a referential or non-referential subject, produced by any speaker, setting aside fixed expressions that are not fully clausal, which had to be determined for both Spanish and English in this bilingual corpus.
In English, not counted as clauses were discourse formulae such as you know (except where it occurs with a complement clause), you know what (on its own in an IU), let’s see, you bet, it’s like, go figure, look. Also skipped over in the clause count were 1sg subject-present tense cognitive verb collocations I mean, I guess, I think, I remember, I'm sure, I know, I don't know, identified as formulaic when they occur as parentheticals in the clause, as for I guess in (14) or on their own in an IU (as prosodically independent), as for I don’t know in the second line in (15), as opposed to when they occur introducing clausal material in the same IU (as in the first token of I don’t know in (15) (Travis & Torres Cacoullos, Submitted).3
(14)
Aurora when he finally .. decided to, .. (TSK) I guess get a house.
[15 Las cosas viejas, 0:05:50-0:05:53]
(15) Marta .. I don't know who [taught them]. Victoria [I don't know]. Marta probably Odelia,
[12 Juego de scrabble, 0:19:32-0:19:34]
In Spanish, non-clauses include fixed impersonal expressions such as es que, será que, dizque, así es, donde quiera, lo que venga, quién sabe, as well as discourse markers, such as non-literal uses of mira (as in (16)), ves ‘look’ or oye ‘listen’ (to mean something like ‘hey’), sabes (‘you know’) without a direct object, fíjate ‘look’ or ¿sabes qué? ‘you know what’. We did, however, count as clauses instances of (yo) no sé ‘I don’t know’ and yo creo ‘I think’ (as do Otheguy & Zentella, 2012, p. 234-235), because although they qualify as prefabs on frequency measures, they are not entirely autonomous of other yo + (cognitive) verb constructions by the measure of shared constraints, indicating that they do still behave as clauses (Travis & Torres Cacoullos, 2012, p. 738-741; cf. Torres Cacoullos & Walker, 2009).
(16)
Sandra y mira que Ø me hallé un dolar. ‘and look I found a dollar.’ [03 Dos comadres, 0:44:04-0:44:06]
As an alternative operationalization of subject continuity (or accessibility), Intervening
Human Subjects considers the presence of subjects with specific human referents intervening

12
between coreferential mentions as subjects. This is a reconfiguration of Givon’s (1983a, p. 14) Potential Referential Interference measure of accessibility (which counts semantically compatible referents in any syntactic role within the preceding three clauses). The following examples illustrate. In (17), between the target token in line 7, and the previous coreferential mention as subject in line 1, there are three intervening clauses, and two intervening human subjects, “she” and “Bobbie”. In (18), there is one intervening clause, but no intervening human subjects between the target in line 5 and the previous mention in line 1; the inanimate subject of the intervening clause does not count as disrupting subject continuity.
(17) Intervening Human Subject present (switch reference)
1. Betty ... Ø le fajé una nalgada. ((CLAPS)) 2. Carrie .. @@@ 3. Betty (TSK) .. she was starting to walk, 4. ... and she wanted to go to the fireplace, 5. sit on the mantel, 6. .. (TSK) ... y no la dejaba la Bobbie. 7. yo no sé qué estarían haciendo allá.
‘… (I) gave her a slap on the bottom.’ .. @@@ (TSK) .. she was starting to walk, ... and she wanted to go to the fireplace, sit on the mantel, .. (TSK) … and Bobbie wouldn’t let her. I don’t know what she was doing there.’
[13 La acequia, 0:18:16- 0:18:28]
(18) Intervening Human Subject absent (same reference) 1. Miguel ... and I used to get chile quite a bit. 2. .. y salía todo. 3. ... carrots, 4. unas carrots grandotas. 5. así ya= Ø sacaba.
‘… and I used to get chile quite a bit. .. and everything would grow. … carrots, big carrots, and (I) would pull them out like this.’
[04 Piedras y gallinas, 0:47:11-0:47:18]
At a distance of one intervening clause between the target verb and previous coreferential mention, which by definition is Switch Reference (as in (12) and (13)), an intervening human subject is present only 40% (63/156) of the time. This is what makes a difference: the rate of yo is 33% (21/63) in the presence of an intervening human subject, but 13% (12/93) in the absence of an intervening human subject. That is, what matters is that the “switch” vis-à-vis the immediately preceding clause be from a subject referring to a specific human, precisely as Travis and Torres Cacoullos (2012, p. 726-729) found for conversational monolingual Colombian Spanish. At distances of two or more intervening clauses (as in (17)) the difference between the two measures is less (between two and four intervening clauses, an intervening human subject is present two-thirds of the time (64%, 90/140) and the yo rate in the absence and presence of intervening human subjects is comparable (30%, 15/50 vs. 37%, 33/90, respectively).
As configured for the multivariate analysis, counted together were tokens with at least one intervening human subject within four clauses from the previous mention and tokens whose previous mention was at a distance of more than four clauses. As seen in Table 1, subject continuity operationalized as Intervening Human Subjects makes a significant contribution to the selection of yo.
4.3 Shared constraints The linguistic conditioning of variable yo expression shown in Table 1 for New Mexican Spanish-English bilingual speakers is parallel to that reported in numerous studies across Spanish varieties, as indicated in Table 2. Structuring the variability are constraints that we may characterize as discourse-cognitive (accessibility), mechanical (priming), and constructional ((classes of) verbs) (cf. Travis & Torres Cacoullos, 2012). As indicated by the arrows in Table 2, across the studies, pronominal subjects are favored in contexts of lower subject continuity (intervening human subjects, or switch reference), by preceding pronouns
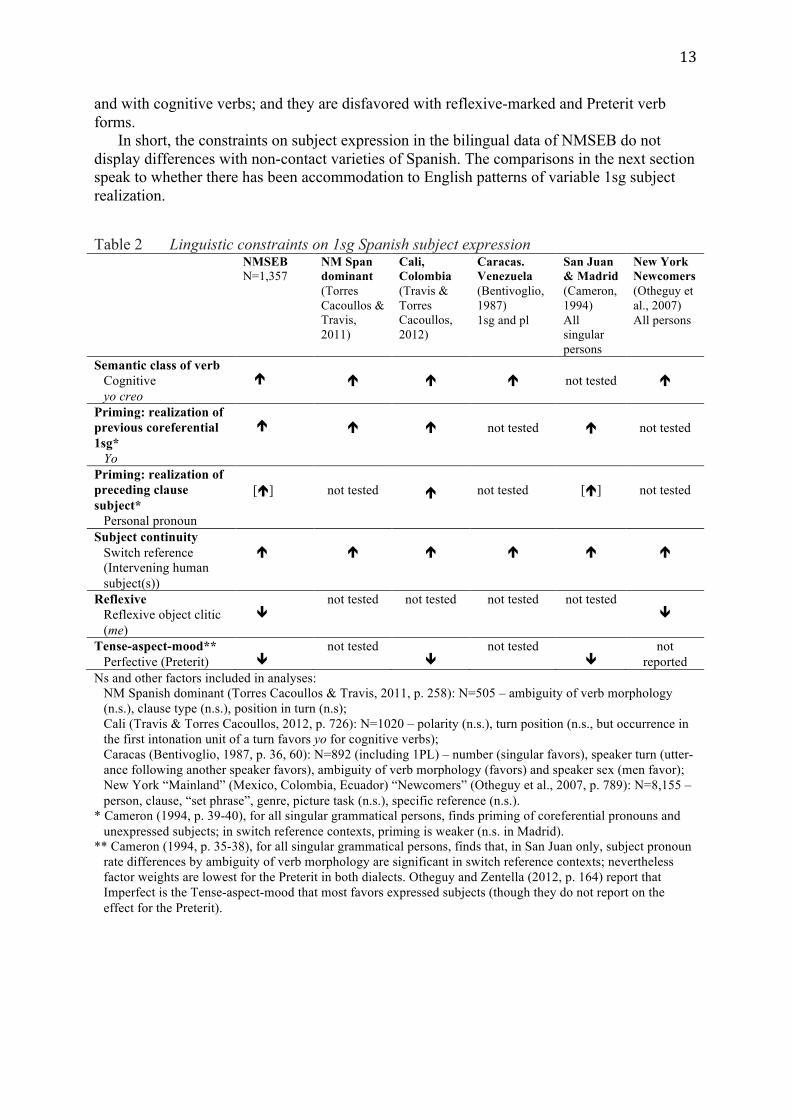
13
and with cognitive verbs; and they are disfavored with reflexive-marked and Preterit verb forms.
In short, the constraints on subject expression in the bilingual data of NMSEB do not display differences with non-contact varieties of Spanish. The comparisons in the next section speak to whether there has been accommodation to English patterns of variable 1sg subject realization.
Table 2 Linguistic constraints on 1sg Spanish subject expression NMSEB
N=1,357 NM Span dominant (Torres Cacoullos & Travis, 2011)
Cali, Colombia (Travis & Torres Cacoullos, 2012)
Caracas. Venezuela (Bentivoglio, 1987) 1sg and pl
San Juan & Madrid (Cameron, 1994) All singular persons
New York Newcomers (Otheguy et al., 2007) All persons
Semantic class of verb Cognitive yo creo
not tested
Priming: realization of previous coreferential 1sg*
Yo
not tested
not tested
Priming: realization of preceding clause subject*
Personal pronoun
[]
not tested
not tested
[]
not tested
Subject continuity Switch reference (Intervening human subject(s))
Reflexive Reflexive object clitic (me)
not tested not tested not tested not tested
Tense-aspect-mood** Perfective (Preterit)
not tested
not tested
not reported
Ns and other factors included in analyses: NM Spanish dominant (Torres Cacoullos & Travis, 2011, p. 258): N=505 – ambiguity of verb morphology (n.s.), clause type (n.s.), position in turn (n.s); Cali (Travis & Torres Cacoullos, 2012, p. 726): N=1020 – polarity (n.s.), turn position (n.s., but occurrence in the first intonation unit of a turn favors yo for cognitive verbs); Caracas (Bentivoglio, 1987, p. 36, 60): N=892 (including 1PL) – number (singular favors), speaker turn (utter-ance following another speaker favors), ambiguity of verb morphology (favors) and speaker sex (men favor); New York “Mainland” (Mexico, Colombia, Ecuador) “Newcomers” (Otheguy et al., 2007, p. 789): N=8,155 – person, clause, “set phrase”, genre, picture task (n.s.), specific reference (n.s.).
* Cameron (1994, p. 39-40), for all singular grammatical persons, finds priming of coreferential pronouns and unexpressed subjects; in switch reference contexts, priming is weaker (n.s. in Madrid).
** Cameron (1994, p. 35-38), for all singular grammatical persons, finds that, in San Juan only, subject pronoun rate differences by ambiguity of verb morphology are significant in switch reference contexts; nevertheless factor weights are lowest for the Preterit in both dialects. Otheguy and Zentella (2012, p. 164) report that Imperfect is the Tense-aspect-mood that most favors expressed subjects (though they do not report on the effect for the Preterit).

14
5 Comparing variables: bilingual Spanish subject expression vs. English subject realization
A “prerequisite” to analyzing contact-induced change, as Weinreich (1953, p. 2) states at the beginning of Languages in contact, is that “the differences and similarities between the languages in contact […] be exhaustively stated [...]”. For Spanish subject expression to serve as a diagnosable locus of convergence with English, cross-linguistic tendencies in subject realization must be ruled out.
5.1 Unexpressed subjects in Spanish and English The overall rate of subject pronoun I in spoken English is considerably higher than that of yo in any Spanish variety, with unexpressed 1sg subjects in the vicinity of under 2% (151/~9,000) (Torres Cacoullos & Travis, Submitted) to 5% (387/8401) (Wagner, 2012). A more telling difference between the two languages lies in the variable context. For I expression, variability is only found in declarative main clauses. In a sample of (expressed and unexpressed) 1sg subjects from the Santa Barbara Corpus of Spoken American English (SBCSAE), Torres Cacoullos and Travis (Submitted) find no cases of unexpressed I in interrogatives, relative clauses or subordinate (complement, adverbial, or if) clauses, other than ones involving coordination, as in if I go out and Ø ask for it (SBCSAE 17, Jim, line 7). Within declarative main clauses, variation between expressed and unexpressed I is characterized as two linguistic variables: non-coordinated verbs and verbs conjoined with and, which are subject to different prosodic constraints.
For non-coordinated verbs, unexpressed 1sg subjects occur only in absolute initial position of the Intonation Unit, as in (19), a constraint that has been intuited by a number of scholars (e.g., Napoli, 1982) as an application of a more general phonological process of (variable) “left-edge deletion” (Weir, 2012). For coordinated verbs, the variability is more robust when the conjoined clauses occur in different IUs, as in (20) (I is rare with the second conjunct on the same IU).
(19) Miles: (H) But it was like I went [to] Bahia, Jamie: [What's] -- ... last Sunday, (H) ... Ø got there at eight, (Hx) .. Ø left a te=n, ... Ø dropped this person off at home, in Foster City,
(SBCSAE – 02 Lambada, 848-854) (20) 1. Mary: .. then I, 2. ... shut the hood, 3. and Ø got back in, 4. and I started up the engine and,
(SBCSAE – 07 A Tree’s Life, 546-549)
Priming has strong parallel effects in both contexts, such that unexpressed subjects are favored when they are preceded by another unexpressed coreferential subject. That is, unexpressed I is rare, but when it does occur, it tends to do so in clusters. Switch reference appears to be of limited scope. For non-coordinated verbs, the appearance of an effect for switch reference is bound to unexpressed-to-unexpressed priming, which tends to occur with coreferential subjects, thus raising the rate of unexpressed 1sg subjects in this context. For

15
coordinated verbs, most instances occur in coreferential contexts even when in a different IU from the first conjunct.
No such prosodic constraints have been reported for Spanish subject expression, and thus prosodic position qualifies as a “conflict site” (Poplack & Meechan, 1998, p. 132), according to which the structure of variability is clearly different for Spanish 1sg subject expression and English 1sg subject expression, beyond patent overall rate differences.
If Spanish 1sg subject expression in NMSEB has been influenced by the prosodic constraints operative in English, with non-coordinated verbs we should see higher rates of unexpressed subjects where unexpressed occurs in English, namely in IU-initial position (as in line 1 in (17) (noting that preceding object clitic pronouns and/or no are considered as part of the verb). Instead, as depicted in Table 3, yo expression is highest in IU-initial position. Considering now coordinated verbs (where the conjunction y ‘and’ immediately precedes the verb), we see that the yo rate is not substantially higher than for other instances in non-IU initial position (which includes verbs preceded by adverbs such as ya ‘already’ (as in (13), line 1, though the position of expressed yo varies in such a context), the conjunction pero (as in (13), line 3), fillers, or other (more substantial) material (as in (16)). Thus, the NMSEB data demonstrate no convergence with English in relation to this constraint.
Table 3 Rate of subject pronoun yo (vs. unexpressed subject) in New Mexico Spanish
English Bilingual corpus by position of 1sg verb in Intonation Unit, and y ‘and’ coordination (N=1,352)*
% yo IU-initial 37% (245/671) Non-IU-initial 16% (87/540) Conjoined with y 18% (25/141)
* Five cases of o ‘or’ are excluded from total N.
5.2 Expressed yo vs. stressed I It could be countered, nevertheless, that subject expression may not be a pertinent English variable enticing bilinguals to convergence. What about subject pronoun stress? Givón’s (1983b, p. 17) topic accessibility continuum places unstressed pronouns in a language such as English at the same level as person-number agreement in a language such as Spanish, both coding more continuous participants, and places stressed and independent pronouns at the same level, both coding discontinuous or less accessible participants. The assumption behind this is made explicit by Payne (1997, p. 43), when he states that “[…] Spanish pronouns correspond [functionally] to English stressed pronouns (roughly speaking)”. Another reason why subject pronoun stress may be more appropriate to test convergences is because here we do observe more robust variability in English: the rate of stressed I is 13% (346/1,1861) in data from the Santa Barbara Corpus of Spoken American English, where the strongest cue for the perception of stress on I was found to be duration (Travis & Torres Cacoullos, Submitted).
However, as with subject expression, we find no evidence for convergence with patterns of stressed I, with multivariate analysis revealing differences in the linguistic conditioning between the two variables. In particular the strong cognitive verb class effect on yo is absent for stressed I, with respect to which verbs that might otherwise be classified as cognitive show disparate behavior. I think (the putative translation counterpart of yo creo), displays a stressed I rate identical to the average, and in its formulaic use (parenthetical or prosodically independent) I is stressed one half as often as in its more clausal use. On the other hand, I don’t know (CLAUSE) shows a significantly higher rate of stress, even compared with other cases of negation. In Spanish, on the other hand, cognitive verbs tend to behave as

16
a class which is centered around prefab yo creo ‘I think’ (Travis & Torres Cacoullos, 2012, p. 734-742) and NMSEB adheres to this, with a yo rate that is twice as high for yo creo (89%, 73/82) than for (yo) no sé (43%, 40/94), thus demonstrating also distinct particular constructions in the two languages.
In terms of hypothesized cross-linguistic tendencies, we find that the subject continuity constraint, though congruent with referent accessibility, is configured differently in English and Spanish, with stressed I being subject to a distance effect as opposed to a local switch-reference effect (whether in terms of the presence of an intervening human subject or in terms of a non-coreferential subject in the immediately preceding clause): stress on I is favored only when the previous mention is at a distance of at least three clauses. A shared constraint is priming: stressed I to stressed I priming is operative, such that stressed I is favored in coreferential contexts when the preceding subject was stressed, just as we observe for unexpressed I in English and for Spanish 1sg (yo to yo and unexpressed to unexpressed) priming.
In sum, if code-switching shapes bilingual grammar(s), this should have been discernable in this study, given the variable under study (1sg subject expression, which we established is an appropriate linguistic variable by which to measure convergence), the contact site (one of prolonged contact), and the corpus (one with copious spontaneous code-switching). Nevertheless, the bilinguals in NMSEB evince no alteration of Spanish constraints on subject expression. As characterized by the linguistic conditioning of variant choice, yo in NMSEB is grammatically similar to expressed yo in other varieties of Spanish, and different from candidate English counterparts expressed I and stressed I.
In case a narrower measure of code-switching would reveal an effect, in the following we zero in on code-switching at the closest possible point to speakers’ choice, within the same or immediately preceding clause.
6 Maximally proximate code-switching Though ways have been devised to elicit and measure language switching in experiments, we know of only two precedents to do so for natural code-switching: Poplack, Zentz and Dion (2012a, p. 212-213), who compare the linguistic conditioning of variant selection in “copious” vs. “sparse” code-switchers to test the contribution of code-switching to change in a speech community in Quebec, and Torres Cacoullos and Travis (2011), who, examining another sample of bilingual New Mexican speakers, compare the linguistic conditioning of variants in the presence vs. absence of code-switching by “frequent” code-switchers (defined as those who produced over 20% of their 1sg tokens in the presence of multi-word English strings within ten IUs). Torres Cacoullos and Travis (2011) find no effect using the measure of ten IUs (corresponding roughly to three clauses), but it may be that this is sufficiently large for any effect to dissipate. Here, we therefore take a maximally close measure, namely the same or the preceding clause.
6.1 Coding maximally proximate English To register the maximally proximate presence of English with respect to instances of variable Spanish subject expression, we take into account material that is both preverbal (back to the immediately preceding clause) and postverbal (up to when the clause is minimally complete), defining clauses as outlined above (Section 4.2). Preverbally, we include material that lies between the preceding verb and the target verb, as in (21), where me acuerdo is coded as being preceded by multi-word English produced by the same speaker.

17
(21) Preverbal presence of English, up to and including the preceding clause Aurora ... y luego sin su familia, y ella y su familia eran muy juntos. Ricardo ... sh= X. Aurora y luego all of a sudden, ...(0.9) no sister to talk to, no? Ricardo (H) yeah. Aurora (TSK) oh=, otra cosa, Ø me acuerdo,
‘… and then without her family, and she and her family were very close.’ ‘… sh= X.’ ‘and then all of a sudden, …(0.9) no sister to talk to, right?’ ‘(H) yeah.’ ‘(TSK) oh=, another thing, (I) remember,’
[15 Las cosas viejas, 0:34:19-0:34:29] Postverbally, we count material up to when the clause is minimally complete, regardless
of IU break with continuing (comma) intonation. This includes material on the same IU, as in (22) and in the subsequent IU, as in (23), in both of which English appears in the complement clause of the target verb. We do not count material in the next IU that is beyond minimal completion of the clause, as in (24), where con mi flashlight ‘with my flashlight’ is an adjunct and not a complement (cf. Ford et al., 2002 on the related notion of “increments”).
(22) Postverbal presence of English in the same clause, same IU
Miguel ... pues Ø le dije que I was gonna go= y, ‘… well (I) told him that I was gonna go= and,’ [04 Piedras y gallinas, 1:07:02-1:07:04]
(23) Postverbal presence of English in the same clause, following IU Monica .. yo creo que tendríanos, .. maybe twelve or thirteen years.
‘… I think that (we) would have been, .. maybe twelve or thirteen years.
[11 El trabajo, 10:43:56-0:43:59] (24)
Manuel ... (H) áhi donde Ø iba mirando, ... con mi flashlight,
‘… (H) there where (I) was looking, ... with my flashlight,’
[16 Trip to Africa pt.1, 0:24:19-0:24:22]
We distinguished multi-word English strings by the speaker who produced the target token, as in (21), (22) and (23) above (N=251), from material produced by the interlocutor— both multi-word English strings (N=76) and (possibly) English-origin single words (N=30)). Single-word English-origin items by the speaker, such as flashlight in (24) (N = 271), were also coded separately pending close analysis, since at least nouns and verbs are likely to be borrowings (Torres Cacoullos & Aaron, 2003) (see discussion in Poplack & Dion, 2012; Stammers & Deuchar, 2012); such items with at least five tokens from at least two different speakers include daddy and grandma, lonche-lonchar ‘lunch-to have lunch’, names of years, and the conjunction so. Also set aside for present purposes were proper nouns such as Albuquerque, Navy and names of persons (pseudonymized in the transcripts to protect participant anonymity) (N=75). A final conservative move was to exclude fillers in their own IU (e.g. ah, eh, oh, uh, um, which may be language-neutral), unclear speech (even when transcriber’s guess indicates language), and truncated words to the extent that the language cannot be identified (N=132).
Following these protocols, of the 1sg Spanish verbs considered, 24% (N = 251) appear maximally proximate to a same-speaker, multi-word English code-switch and 50% (N = 522) in the absence of any even possible English (and 26% maximally proximate to a same-speaker English-origin single word (N= 271)).
6.2 Proximate code-‐switching and yo expression If code-switching is a mechanism of change, intrinsically promoting grammatical convergence through raising the rate of yo (according to the received premise that convergence would be displayed by an elevated rate of expressed subject pronouns), we

18
should observe a higher yo rate precisely in maximal proximity to an English code-switch. But, as seen in Table 4, though in the predicted direction, the yo rate when multi-word English is present is a meager three percentage points higher than in the absence of any English and two percentage points higher than in the presence of a single-word English item.
Table 4 Rate of expressed Spanish 1sg subject yo proximate to a multi-word code-switch to English by the speaker vs. in the absence of any English within the same or immediately preceding clause (N=1,044)*
% yo N % data Multi-word English present 27% 68/251 24% Single-word English present 25% 68/271 26% English absent 24% 127/522 50%
*Excluding interlocutor speech, proper nouns, fillers and unclear speech. More striking is that, in two separate multivariate analyses, the direction of effect in
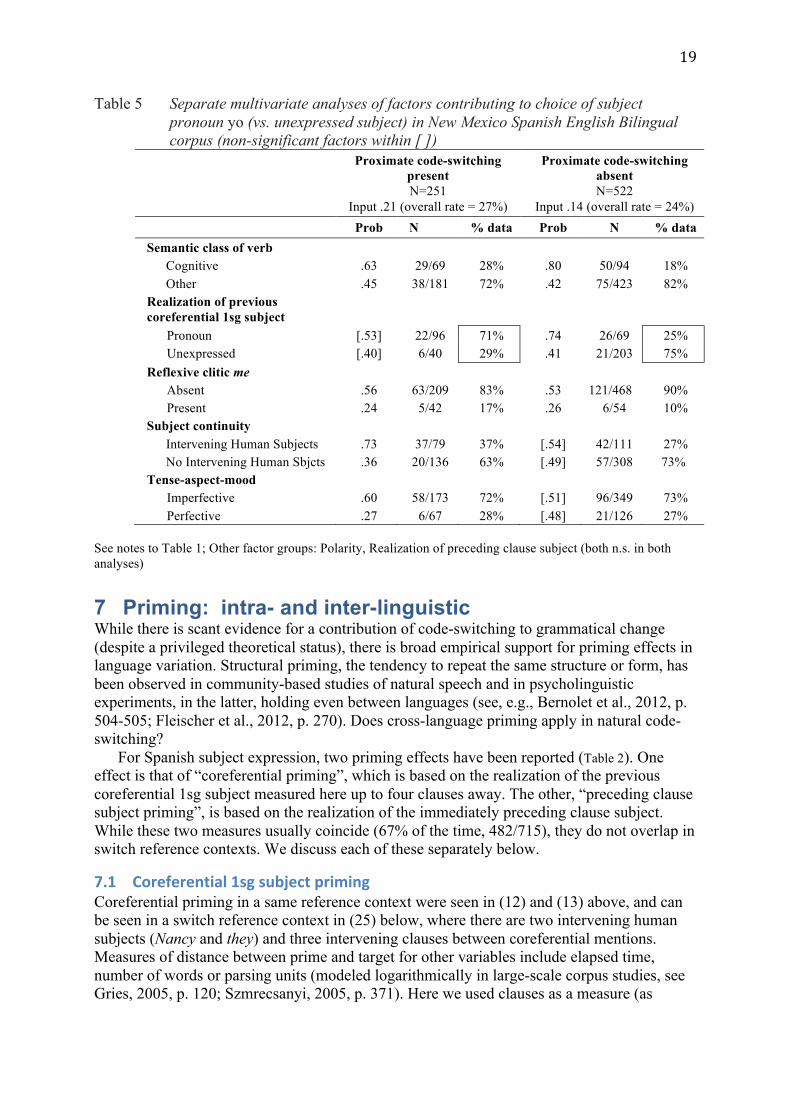
maximal proximity to an English string and in the absence of any English element is the same (Table 5). Speakers are behaving—grammatically—the same way when they are code-switching as when they are not. However, it is worthy of note that Realization of previous coreferential 1sg subject is weaker under code-switching, not selected as making a significant contribution. Further, it displays a reversal of the relative frequencies of the factors, or contextual features, where, under proximate code-switching, close to three quarters of the data occur in the context of a previous pronoun (71% of the data), while when English is absent, just one quarter of the data occur in this context (25%). Let us look more closely at priming, in the following section.
19
Table 5 Separate multivariate analyses of factors contributing to choice of subject pronoun yo (vs. unexpressed subject) in New Mexico Spanish English Bilingual corpus (non-significant factors within [ ])
Proximate code-switching present N=251
Input .21 (overall rate = 27%)
Proximate code-switching absent N=522
Input .14 (overall rate = 24%) Prob N % data Prob N % data
Semantic class of verb Cognitive .63 29/69 28% .80 50/94 18% Other .45 38/181 72% .42 75/423 82%
Realization of previous coreferential 1sg subject
Pronoun [.53] 22/96 71% .74 26/69 25% Unexpressed [.40] 6/40 29% .41 21/203 75% Reflexive clitic me Absent .56 63/209 83% .53 121/468 90% Present .24 5/42 17% .26 6/54 10% Subject continuity
Intervening Human Subjects .73 37/79 37% [.54] 42/111 27% No Intervening Human Sbjcts .36 20/136 63% [.49] 57/308 73%
Tense-aspect-mood Imperfective .60 58/173 72% [.51] 96/349 73% Perfective .27 6/67 28% [.48] 21/126 27%
See notes to Table 1; Other factor groups: Polarity, Realization of preceding clause subject (both n.s. in both analyses)
7 Priming: intra- and inter-linguistic While there is scant evidence for a contribution of code-switching to grammatical change (despite a privileged theoretical status), there is broad empirical support for priming effects in language variation. Structural priming, the tendency to repeat the same structure or form, has been observed in community-based studies of natural speech and in psycholinguistic experiments, in the latter, holding even between languages (see, e.g., Bernolet et al., 2012, p. 504-505; Fleischer et al., 2012, p. 270). Does cross-language priming apply in natural code-switching?
For Spanish subject expression, two priming effects have been reported (Table 2). One effect is that of “coreferential priming”, which is based on the realization of the previous coreferential 1sg subject measured here up to four clauses away. The other, “preceding clause subject priming”, is based on the realization of the immediately preceding clause subject. While these two measures usually coincide (67% of the time, 482/715), they do not overlap in switch reference contexts. We discuss each of these separately below.
7.1 Coreferential 1sg subject priming Coreferential priming in a same reference context were seen in (12) and (13) above, and can be seen in a switch reference context in (25) below, where there are two intervening human subjects (Nancy and they) and three intervening clauses between coreferential mentions. Measures of distance between prime and target for other variables include elapsed time, number of words or parsing units (modeled logarithmically in large-scale corpus studies, see Gries, 2005, p. 120; Szmrecsanyi, 2005, p. 371). Here we used clauses as a measure (as

20
outlined in Section 4.2), reasoning that finite verbs ‘interfere’ more than random material in the strength of a previous subject prime.
(25) Fabiola ... las cuatro vinieron? yo [creí que la N]ancy no había venido. Jake [no=]. ... they have four. Fabiola ... vino también la Nancy? ...(1.3) yo creía que no más tres muchitas.
‘.. all four came? I thought that Nancy hadn’t come.’ ‘no=. … they have four.’ ‘… did Nancy also come? …(1.3) I thought that there were only three girls.’
[09 La salvia, 0:43:09-0:43:17] Because priming is stronger “production-to-production” than “comprehension-to-
production” (Gries, 2005, p. 374, and references therein), we consider here only coreferential 1sg mentions, and exclude from this analysis of priming any cases where there is an intervening coreferential plural subject or a second person subject produced by the interlocutor (discussed in 4.2) (N=199). Further, coreferential mentions across quotative contexts, as in line 2 in (26) were coded separately as such, since we do not know how quotation may affect priming (N=179).4
(26)
Manuel ...(0.9) y Ø dije, Ø voy a chequear ese, .. y luego Ø me voy a revolver .. pa'trás.
‘…(0.9) and (I) said, (I)’m going to check on that, .. and then (I)’m going to go back.’
[16 Trip to Africa pt.1, 0:24:29-0:24:34]
To determine whether coreferential English I as well as Spanish yo (which were combined in the multivariate analyses in Table 1 and Table 5) primes yo, we make two further decisions here. First, as in Table 1 and Table 5, we compare the rate of yo when the previous coreferential 1sg was I or yo with that when it was unexpressed (instead of to the rate of yo overall). This is because priming effects for Spanish subject expression have been identified only for triggers that are pronominal or unexpressed (Cameron, 1994, p. 38-39).
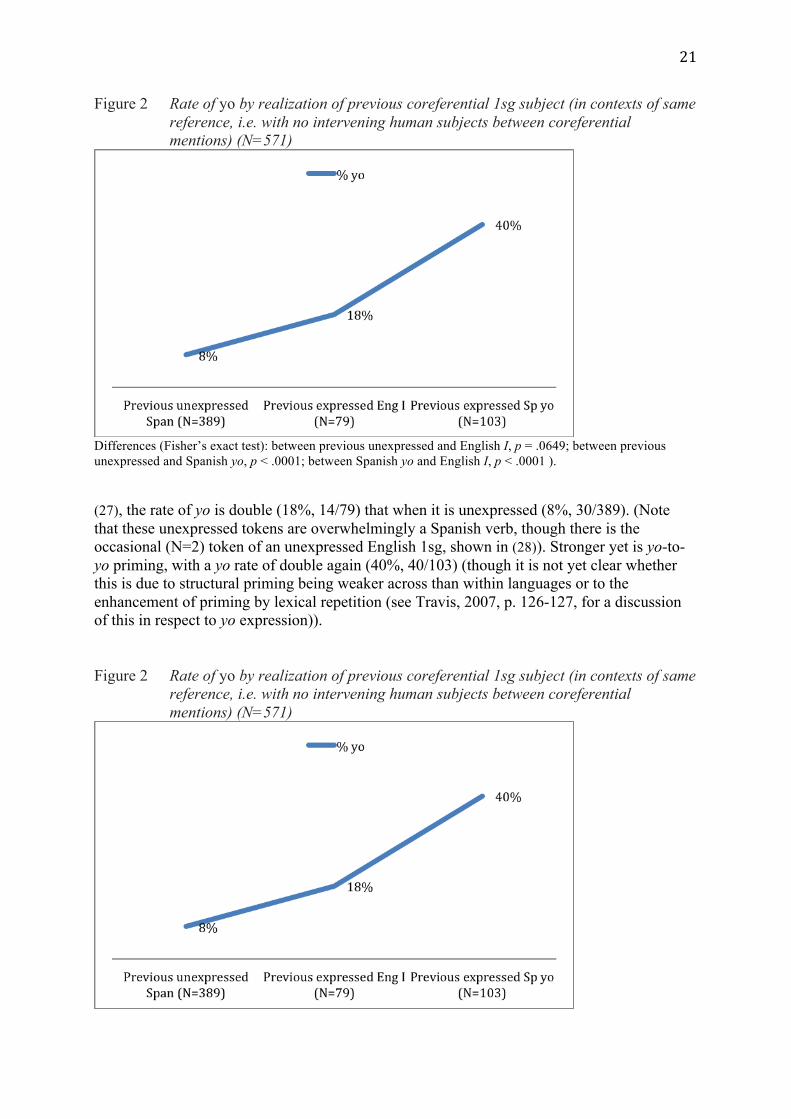
Second, we restrict the comparison to contexts of same reference (where there are no intervening human subjects, as in (12) and (13), but not (25)), because this is where priming has been found to be strongest in prior studies. There is an interplay between priming and coreferentiality, which sometimes work synergistically (namely, in same reference contexts with a previous unexpressed subject, two factors which independently disfavor subject expression) and sometimes antagonistically, such that priming operates in coreferential contexts but is neutralized or tempered by switch reference, while switch reference operates when the preceding subject is unexpressed but is overridden by pronoun-to-pronoun priming (Cameron, 1994, p. 40-41; Travis & Torres Cacoullos, 2012, p. 731-732). This is reflected in a marked genre difference in the duration of priming, which lasts longer in monologic narrative than in interactive conversation, because of greater subject and Tense-aspect-mood continuity (Travis, 2007, p. 127). Figure 2, which shows the rate of yo according to realization of the previous coreferential mention as Spanish unexpressed, English I, or Spanish yo, shows a clear effect for English I: when the realization of the previous coreferential 1sg subject is English I, as in
21
Figure 2 Rate of yo by realization of previous coreferential 1sg subject (in contexts of same reference, i.e. with no intervening human subjects between coreferential mentions) (N=571)
Differences (Fisher’s exact test): between previous unexpressed and English I, p = .0649; between previous unexpressed and Spanish yo, p < .0001; between Spanish yo and English I, p < .0001 ). (27), the rate of yo is double (18%, 14/79) that when it is unexpressed (8%, 30/389). (Note that these unexpressed tokens are overwhelmingly a Spanish verb, though there is the occasional (N=2) token of an unexpressed English 1sg, shown in (28)). Stronger yet is yo-to-yo priming, with a yo rate of double again (40%, 40/103) (though it is not yet clear whether this is due to structural priming being weaker across than within languages or to the enhancement of priming by lexical repetition (see Travis, 2007, p. 126-127, for a discussion of this in respect to yo expression)). Figure 2 Rate of yo by realization of previous coreferential 1sg subject (in contexts of same
reference, i.e. with no intervening human subjects between coreferential mentions) (N=571)

22
Differences (Fisher’s exact test): between previous unexpressed and English I, p = .0649; between previous unexpressed and Spanish yo, p < .0001; between Spanish yo and English I, p < .0001 ). (27) Cross-language coreferential priming: English I to Spanish yo
Miguel ...(1.5) I was like nineteen. ... years old. .. pero yo me acordaba.
‘I was like nineteen. … years old. .. but I remembered.’
[04 Piedras y gallinas, 0:20:08-0:20:13] (28) Cross-language coreferential priming: English unexpressed to Spanish unexpressed
Manuel ... I ... closed the cylinder and, ... Ø put it in my pocket. .. and, ... Ø proceeded to go into the cave. (H) .. áhi cuando Ø me iba metiendo a la
.. cueva,
‘... I ... closed the cylinder and, ... Ø put it in my pocket. .. and, ... Ø proceeded to go into the cave. (H) .. then when (I) was going into the cave,’
[16 Trip to Africa pt.1, 0:21:30-0:21:38]
7.2 Preceding clause subject priming The “preceding clause subject priming” is such that preceding pronouns (other personal pronouns, in addition to coreferential Spanish yo and English I) favor yo expression more than preceding unexpressed subjects. As with the coreferential priming measure, we set aside tokens involving quotation (N=141) and coreferential tokens produced by the interlocutor (N=167). We also disregard lexical (full NP) subjects (N=66), non-specific human referents (N=51), imperatives (N=24), unexpressed subjects of English 1sg verbs (N=3), and all cases of non-human subjects (.. está demasiado muy frío. ‘it is too cold’), subject relative and interrogative pronouns (quién/who), unclear speech, fixed expressions (ahi voy ‘there I go’), and truncated Spanish verbs (with potential postverbal subjects) (combined N=190).
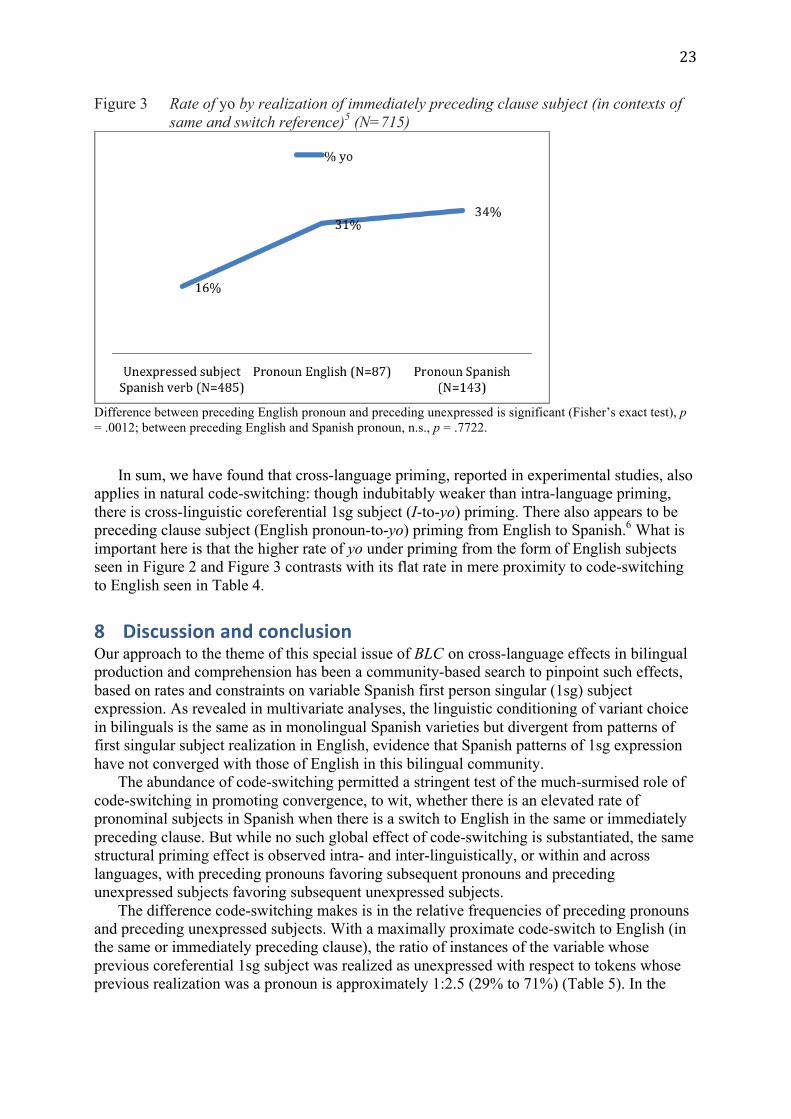
In Figure 3, we compare the rate of expressed yo when the subject of the immediately preceding clause is an unexpressed subject of a Spanish verb as in (29), an English pronoun (30), or a Spanish pronoun (31). Note that just as we saw in Figure 2, the yo rate with a preceding English pronoun (31%, 27/87) is higher than with an unexpressed subject of a Spanish verb (16%, 75/485); and in this case, it is close to that with a preceding Spanish personal pronoun (34%, 48/143).
(29) Language internal preceding subject priming: Spanish unexpressed to unexpressed
Susan Ø me preguntó si Ø quería bailar y le dije, ‘(he) asked me if (I) wanted to dance and (I) said,
[01 El abuelo, 0:36:58-0:37:00] (30) Cross-language preceding subject priming: English pronoun to yo
Betty you were all so, in a hurry to have lunch, ... yo no sé por qué.
‘you were all so, in a hurry to have lunch, … I don’t know why.’
[13 La acequia, 0:03:36-0:03:41] (31) Language internal preceding subject priming: Spanish pronun to yo
Francisco él llevaba gente fishing y=, (H) ice fishing y=, Gabriel sh=, Francisco .. yo iba con él en veces y me traiban de
runner,
‘he would take people fishing and, (H) ice fishing and, sh=, .. I would go with him sometimes and (they) would
bring me as a runner,’ [18 Las minas, 0:19:14-0:19:21]
23
Figure 3 Rate of yo by realization of immediately preceding clause subject (in contexts of same and switch reference)5 (N=715)
Difference between preceding English pronoun and preceding unexpressed is significant (Fisher’s exact test), p = .0012; between preceding English and Spanish pronoun, n.s., p = .7722.
In sum, we have found that cross-language priming, reported in experimental studies, also
applies in natural code-switching: though indubitably weaker than intra-language priming, there is cross-linguistic coreferential 1sg subject (I-to-yo) priming. There also appears to be preceding clause subject (English pronoun-to-yo) priming from English to Spanish.6 What is important here is that the higher rate of yo under priming from the form of English subjects seen in Figure 2 and Figure 3 contrasts with its flat rate in mere proximity to code-switching to English seen in Table 4.
8 Discussion and conclusion Our approach to the theme of this special issue of BLC on cross-language effects in bilingual production and comprehension has been a community-based search to pinpoint such effects, based on rates and constraints on variable Spanish first person singular (1sg) subject expression. As revealed in multivariate analyses, the linguistic conditioning of variant choice in bilinguals is the same as in monolingual Spanish varieties but divergent from patterns of first singular subject realization in English, evidence that Spanish patterns of 1sg expression have not converged with those of English in this bilingual community.
The abundance of code-switching permitted a stringent test of the much-surmised role of code-switching in promoting convergence, to wit, whether there is an elevated rate of pronominal subjects in Spanish when there is a switch to English in the same or immediately preceding clause. But while no such global effect of code-switching is substantiated, the same structural priming effect is observed intra- and inter-linguistically, or within and across languages, with preceding pronouns favoring subsequent pronouns and preceding unexpressed subjects favoring subsequent unexpressed subjects.
The difference code-switching makes is in the relative frequencies of preceding pronouns and preceding unexpressed subjects. With a maximally proximate code-switch to English (in the same or immediately preceding clause), the ratio of instances of the variable whose previous coreferential 1sg subject was realized as unexpressed with respect to tokens whose previous realization was a pronoun is approximately 1:2.5 (29% to 71%) (Table 5). In the

24
absence of any English within the same or preceding clause, the ratio is reversed, 3:1 (75 to 25%)!
The direct (cross-language) effect in operation is thus one of structural priming. Indirectly, code-switching is accompanied by altered distributions of contexts of occurrence that correlate with subject expression. Given the rarity of unexpressed subjects in English, when speakers are code-switching, more instances of variable Spanish subject expression occur in an environment favorable to expressed subjects—that of a previous expressed subject—than is the case in the absence of code-switching. Rather than intrinsically inducing grammatical alteration, as measured by comparisons of the linguistic conditioning of variant selection in bilingual and monolingual communities, code-switching makes a difference to the relative frequencies of relevant contextual features.
Appendix: Transcription Conventions (Du Bois et al., 1993) Carriage return new Intonation Unit . final intonation contour , continuing intonation contour ? appeal intonation contour -- truncated intonation contour - truncated word = lengthened syllable .. short pause (0.5 secs) ... medium pause (0.5-0.7 secs) …( ) timed pause (over 0.7 secs)
[ ] overlapped speech [2 2] consecutive overlaps X unclear syllable @ one syllable of laughter <@ @> speech produced while laughing <F F> forte (TSK) click (H) in breath (Hx) out breath (( )) researcher’s comment
References Amaral, P.M. & Schwenter, S.A. (2005). Contrast and the (non-) occurrence of subject
pronouns. In D. Eddington (ed.), Selected proceedings of the 7th Hispanic Linguistics Symposium, pp. 116-127. Somerville, MA: Cascadilla Press.
Backus, A. (2005). Codeswitching and language change: One thing leads to another? International Journal of Bilingualism, 9(3-4), pp. 307-340.
Bentivoglio, P. (1987). Los sujetos pronominales de primera persona en el habla de Caracas, Caracas: Universidad Central de Venezuela.
Bernolet, S., Hartsuiker, R.J. & Pickering, M.J. (2012). Effects of phonological feedback on the selection of syntax: Evidence from between-language syntactic priming. Bilingualism: Language and Cognition, 15(3), pp. 503-516.
Bills, G.D. & Vigil, N.A. (1999). Ashes to ashes: The historical basis for dialect variation in New Mexican Spanish. Romance Philology, 53(1), pp. 43-66.
Bills, G.D. & Vigil, N.A. (2008). The Spanish language of New Mexico and southern Colorado: A linguistic atlas, Albuquerque, NM: University of New Mexico Press.
Cameron, R. (1993). Ambiguous agreement, functional compensation, and nonspecific tú in the Spanish of San Juan, Puerto Rico, and Madrid, Spain. Language Variation and Change, 5(3), pp. 305-334.
Cameron, R. (1994). Switch reference, verb class and priming in a variable syntax. Papers from the Regional Meeting of the Chicago Linguistic Society: Parasession on variation in linguistic theory, 30(2), pp. 27-45.
Chafe, W. (1994). Discourse, consciousness and time: The flow and displacement of conscious experience in speaking and writing, Chicago: University of Chicago Press.
Cifuentes, H. (1980-1). Presencia y ausencia del pronombre personal sujeto en el habla culta de Santiago de Chile. Homenaje a Ambrosio Rabanales: Boletín de Filología de la Universidad de Chile, 31, pp. 743-752.

25
Clyne, M., Eisikovits, E. & Tollfree, L. (2001). Ethnic varieties of Australian English. In D. Blair & P. Collins (eds.), English in Australia, pp. 223-238. Amsterdam: John Benjamins.
Du Bois, J.W., Schuetze-Coburn, S., Cumming, S. & Paolino, D. (1993). Outline of discourse transcription. In J. Edwards & M. Lampert (eds.), Talking data: Transcription and coding in discourse, pp. 45-89. Hillsdale, NJ: Lawrence Erlbaum Associates.
Enríquez, E.V. (1984). El pronombre personal sujeto en la lengua española hablada en Madrid, Madrid: Consejo Superior de Investigaciones Científicas, Instituto Miguel de Cervantes.
Erker, D. & Guy, G.R. (2012). The role of lexical frequency in syntactic variability: Variation subject personal pronoun expression in Spanish. Language, 88(3), pp. 526-557.
Fernández-Gibert, A. (2010). From voice to print: Language and social change in New Mexico, 1880-1912. In S. Rivera-Mills & D. J. Villa (eds.), Spanish of the U.S. Southwest: A language in transition, pp. 45-62. Madrid: Iberoamericana.
Fleischer, Z., Pickering, M.J. & McLean, J.F. (2012). Shared information structure: Evidence from cross-linguistic priming. Bilingualism: Language and Cognition, 15(3), pp. 568-579.
Ford, C.E., Fox, B.A. & Thompson, S.A. (2002). Constituency and the grammar of turn increments. In C. E. Ford, B. A. Fox & S. A. Thompson (eds.), The language of turn and sequence, pp. 14-38. Oxford: Oxford University Press.
Givón, T. (1983a). Topic continuity in discourse: An introduction. In T. Givón (ed.), Topic continuity in discourse: A quantitative cross-linguistic study, pp. 1-41. Amsterdam: John Benjamins.
Givón, T. (1983b). Topic continuity in spoken English. In T. Givón (ed.), Topic continuity in discourse: A quantitative cross-linguistic study, pp. 343-363. Amsterdam: John Benjamins.
Gonzales Berry, E. & Maciel, D.R. (eds) (2000). The contested homeland: A Chicano history of New Mexico, Albuquerque, University of New Mexico Press.
Gonzales Velásquez, M.D. (1995). Sometimes Spanish, sometimes English: Language use among rural New Mexican Chicanas. In K. Hall & M. Bucholtz (eds.), Gender articulated: Language and the socially constructed self, pp. 421-446. New York: Routledge.
Gonzales-Berry, E. (2000). Which language will our children speak? The Spanish language and public education policy in New Mexico, 1890-1930. In E. Gonzales Berry & D. R. Maciel (eds.), The contested homeland: A Chicano history of New Mexico, pp. 169-189. Albuquerque: University of New Mexico Press.
Gries, S.T. (2005). Syntactic priming: A corpus-based approach. Journal of Psycholinguistic Research, 34(4), pp. 365-399.
Gumperz, J. & Wilson, R. (1971). Convergence and creolization: A case from the Indo-Aryan / Dravidian border in India. In D. Hymes (ed.), Pidginization and creolization of languages, pp. 151-167. Cambridge: Cambridge University Press.
Holmquist, J. (2012). Frequency rates and constraints on subject personal pronoun expression: Findings from the Puerto Rican highlands. Language Variation and Change, 24(2), pp. 203-220.
Labov, W. (1969). Contraction, deletion, and inherent variability of the English copula. Language, 45(4), pp. 715-762.
Labov, W. (1972a). Sociolinguistic patterns, Oxford: Basil Blackwell. Labov, W. (1972b). Some principles of linguistic methodology. Language in Society, 1(1),
pp. 97-120. Labov, W. (1984). Field methods of the project on linguistic change and variation. In J.
Baugh & J. Sherzer (eds.), Language in use: Readings in sociolinguistics, pp. 28-53. Englewood Cliffs, NJ: Prentice Hall.
Labov, W. (2001). Principles of linguistic change: Social factors, vol. 2, 2 vols, Oxford: Blackwell.

26
Labov, W. (2005). Quantitative reasoning in linguistics. In U. Ammon, N. Dittmar, K. J. Mattheier & P. Trudgill (eds.), Sociolinguistics/Soziolinguistik: An international handbook of the science of language and society, vol. 1 (2nd ed.), pp. 6-22. Berlin: Mouton de Gruyter.
Lausberg, H. & Sloetjes, H. (2009). Coding gestural behavior with the NEUROGES-ELAN system. Behavior Research Methods, Instruments, & Computers, 41(3), pp. 841-849 (Max Planck Institute for Psycholinguistics, The Language Archive, Nijmegen, The Netherlands. http://tla.mpi.nl/tools/tla-tools/elan/).
Lipski, J.M. (2008). Varieties of Spanish in the United States, Washington, DC: Georgetown University Press.
Napoli, D.J. (1982). Initial material deletion in English. Glossa, 16, pp. 85-111. Ono, T. & Thompson, S.A. (1997). Deconstructing 'zero anaphora' in Japanese. Berkeley
Linguistics Society, 23, pp. 481-491. Otheguy, R. & Zentella, A.C. (2012). Spanish in New York: Language contact, dialectal
leveling, and structural continuity Oxford: Oxford University Press. Otheguy, R., Zentella, A.C. & Livert, D. (2007). Language and dialect contact in Spanish of
New York: Toward the formation of a speech community. Language, 83(4), pp. 770-802. Payne, T.E. (1997). Describing morphosyntax: A guide to field linguists, Cambridge:
Cambridge University Press. Poplack, S. (1993). Variation theory and language contact: Concepts, methods and data. In D.
R. Preston (ed.), American dialect research, pp. 251-286. Amsterdam: John Benjamins. Poplack, S. (1998). Contrasting patterns of code-switching in two communities. In P. Trudgill
& J. Cheshire (eds.), The sociolinguistics reader: Multilingualism and variation, vol. 1, pp. 44-65. London: Arnold Publishers.
Poplack, S. & Dion, N. (2012). Myths and facts about loanword development. Language Variation and Change, 24(3), pp. 279-315.
Poplack, S. & Levey, S. (2010). Contact-induced grammatical change: A cautionary tale. In P. Auer & J. E. Schmidt (eds.), Language and Space: An international handbook of linguistic variation, vol. 1: Theories and methods, pp. 391-419. Berlin: Mouton de Gruyter.
Poplack, S. & Meechan, M. (1998). Introduction: How languages fit together in codemixing. International Journal of Bilingualism, 2(2), pp. 127-138.
Poplack, S., Zentz, L. & Dion, N. (2012a). Phrase-final prepositions in Quebec French: An empirical study of contact, code-switching and resistance to convergence. Bilingualism: Language and Cognition, 15(2), pp. 203-225.
Poplack, S., Zentz, L. & Dion, N. (2012b). What counts as (contact-induced) change. Bilingualism: Language and Cognition, 15(2), pp. 247-254.
Ranson, D.L. (1991). Person marking in the wake of /s/ deletion in Andalusian Spanish. Language Variation and Change, 3(2), pp. 133-152.
Sankoff, D. (1988a). Sociolinguistics and syntactic variation. In F. Newmeyer (ed.), Linguistics: The Cambridge survey (Vol. 4, Language: The socio-cultural context), pp. 140-161. Cambridge: Cambridge University Press.
Sankoff, D. (1988b). Variable rules. In U. Ammon, N. Dittmar & K. J. Mattheier (eds.), Sociolinguistics: An international handbook of the science of language and society, vol. 2, pp. 984-997. Berlin / New York: Walter de Gruyter.
Sankoff, D., Tagliamonte, S. & Smith, E. (2012), Goldvarb LION: A variable rule application for Macintosh, University of Toronto, URL http://individual.utoronto.ca/tagliamonte/goldvarb.htm.
Silva-Corvalán, C. (1994). Language contact and change: Spanish in Los Angeles, Oxford: Clarendon Press.

27
Silva-Corvalán, C. (1997). Avances en el estudio de la variación sintáctica: La expresión del sujeto. Cuaderno del Sur: Letras, Homenaje a Beatriz Fontanella de Weinberg, 27, pp. 35-49.
Silva-Corvalán, C. (2001). Sociolingüística y pragmática del español (Georgetown Studies in Spanish Linguistics), Washington, DC: Georgetown University Press.
Silva-Corvalán, C. (2003). Otra mirada a la expresión del sujeto como variable sintáctica. In F. Moreno Fernández, F. G. Menéndez, J. A. Samper, M. L. Gutiérrez Araua, M. Vaquero & C. Hernández (eds.), Lengua, Variación y contexto: Estudios dedicados a Humberto López Morales, vol. 2, pp. 849-860. Madrid: Arco Libros.
Stammers, J.R. & Deuchar, M. (2012). Testing the nonce borrowing hypothesis: Counter-evidence from English-origin verbs in Welsh. Bilingualism: Language and Cognition, 15(3), pp. 630-643.
Szmrecsanyi, B. (2005). Language users as creatures of habit: A corpus-based analysis of persistence in spoken English. Corpus Linguistics and Linguistic Theory, 1(1), pp. 113-149.
Thomason, S.G. (2001). Language contact: An introduction, Washington DC: Georgetown University Press.
Torres Cacoullos, R. & Aaron, J.E. (2003). Bare English-origin nouns in Spanish: Rates, constraints and discourse functions. Language Variation and Change, 15(3), pp. 289-328.
Torres Cacoullos, R. & Travis, C.E. (2011). Using structural variability to evaluate convergence via code-switching. International Journal of Bilingualism, 15(3), pp. 241-267.
Torres Cacoullos, R. & Travis, C.E. (In preparation). New Mexico Spanish / English Bilingual (NMSEB) corpus, National Science Foundation 1019112/1019122. http://nmcode-switching.la.psu.edu/.
Torres Cacoullos, R. & Travis, C.E. (Submitted). Prosody, priming and particular constructions: The patterning of English first-person singular subject expression in conversation. pp.
Torres Cacoullos, R. & Walker, J.A. (2009). On the persistence of grammar in discourse formulas: a variationist study of that. Linguistics, 47(1), pp. 1-‐43.
Travis, C.E. (2007). Genre effects on subject expression in Spanish: Priming in narrative and conversation. Language Variation and Change, 19(2), pp. 101-135.
Travis, C.E. & Torres Cacoullos, R. (2012). What do subject pronouns do in discourse? Cognitive, mechanical and constructional factors in variation. Cognitive Linguistics, 23(4), pp. 711-748.
Travis, C.E. & Torres Cacoullos, R. (Submitted). On the patterning of stressed I in conversation. Studies in Language, pp.
Travis, C.E. & Torres Cacoullos, R. (To appear). Making voices count: Corpus compilation in bilingual communities. Australian Journal of Linguistics, pp.
Travis, C.E. & Villa, D.J. (2011). Language policy and language contact in New Mexico: The case of Spanish. In C. Norrby & J. Hajek (eds.), Uniformity and diversity in language policy: Global perspectives, pp. 126-140. Bristol, UK: Multilingual Matters.
Wagner, S. (2012). Frequency effects in English null subjects – don’t ignore the underdog!, Paper presented at the Sociolinguistics Symposium 19, Berlin.
Weinreich, U. (1953). Languages in contact: Findings and problems, The Hague: Mouton. Weinreich, U. (1968). Languages in contact, The Hague: Mouton. Weinreich, U., Labov, W. & Herzog, M.I. (1968). Empirical foundations for a theory of
language change. In W. P. Lehmann & Y. Malkiel (eds.), Directions for historical linguistics: A symposium, pp. 95-188. Austin, TX: University of Texas Press.

28
Weir, A. (2012). Left-edge deletion in English and subject omission in diaries. English Language and Linguistics, 16(1), pp. 105-129.
Winford, D. (2005). Contact-induced change: classification and processes. Diachronica, 22(2), pp. 373-427.
1 All examples given are from NMSEB (Torres Cacoullos & Travis, In preparation). Examples are
reproduced verbatim from the transcripts (transcription conventions are presented in the Appendix). Within brackets is the recording number, name and time stamp. In the translation (which appears to the left of the original), speech that was originally produced in English appears in grey.
2 Similarities or differences in linguistic conditioning between the Spanish and English of the same bilinguals’ will provide the strongest evidence for or against convergence between their two language varieties; we leave this for future work.
3 We still consider to be alone in an IU (and therefore not clausal) cases where the only other element in the IU is a conjunction (e.g., so I don’t know). We do code as clausal I don’t know in its own IU when it is an answer to a question.
4 This includes cases where the target token is the first in a quote, and the previous mention was the quotative itself (as in line 2 in (26)), as well as when the target token is the quotative itself, and the previous mention was part of the quote (as in ... se acuerda, Ø le dije, ‘you remember, I told her’ [03 Dos comadres, 0:26:50-0:26:52]. When both the preceding and the target token were part of the quote, as for the second token in (26), however, it was counted.
5 Though most of the preceding subject clause data is found in contexts of subject continuity (same reference) (554/684), in the presence of intervening human subject(s), the yo rate still tends (n.s.) to be higher with a preceding Spanish pronoun (41%, 9/22) and an English pronoun (54%, 14/26) than with a preceding unexpressed subject of a Spanish. verb (34%, 28/82).
6 More data are needed to disentangle the contribution of I; two-thirds (59/87) of the cases of preceding clause English pronoun subjects are also ones where the previous coreferential 1sg subject was I.




















