
Sustainable sequencing of N jobs on one machine: a fuzzy approach
14
44 Int. J. Services and Operations Management, Vol. 15, No. 1, 2013 Copyright © 2013 Inderscience Enterprises Ltd. Sustainable sequencing of N jobs on one machine: a fuzzy approach Sanjoy Kumar Paul Department of Industrial and Production Engineering, Bangladesh University of Engineering and Technology (BUET), Dhaka – 1000, Bangladesh E-mail: [email protected] Abstract: Sequencing of jobs on one machine is a very common problem in scheduling. Several factors have to be taken into consideration to make the sequencing more realistic. In this paper, a fuzzy inference system is developed to tackle the uncertainty of variables in a sequencing problem. Arrival order, processing time, due date, slack time remaining, critical ratio, queue ratio and slack time remaining per operation, are considered as input variables and priority of jobs is considered as output variable. Multiple objectives are fulfilled as priority is obtained from the aggregated optimised result of individual rule developed in a rule editor. A job with higher priority is given more preferences in sequencing. MATLAB fuzzy logic toolbox is used to develop the model. A numerical example is presented to explain the approach. Keywords: sequencing; scheduling; fuzzy inference system; FIS; MATLAB fuzzy logic toolbox. Reference to this paper should be made as follows: Paul, S.K. (2013) ‘Sustainable sequencing of N jobs on one machine: a fuzzy approach’, Int. J. Services and Operations Management, Vol. 15, No. 1, pp.44–57. Biographical notes: Sanjoy Kumar Paul is an Assistant Professor in the Department of Industrial and Production Engineering, Bangladesh University of Engineering and Technology (BUET), Bangladesh. His research interest includes applications of artificial intelligence in industrial engineering problems, simulation and modelling. 1 Introduction Sequencing is the order of processing of jobs on a machine to meet the objectives of scheduling. There are several objectives in real life sequencing problem which should be fulfilled. Minimisation of processing time (PT), meet the due date (DD), minimisation of slack time remaining (STR), meet the planned queue time etc. are several objectives, which have to be taken into consideration to make the sequencing more realistic. Multiple objectives should be considered to make the sequence sustainable. Typical scenario of processing of N jobs on one machine is presented in Figure 1. There are N number of jobs which to be processed on single machine to meet the objectives.
Transcript of Sustainable sequencing of N jobs on one machine: a fuzzy approach

44 Int. J. Services and Operations Management, Vol. 15, No. 1, 2013
Copyright © 2013 Inderscience Enterprises Ltd.
Sustainable sequencing of N jobs on one machine: a fuzzy approach
Sanjoy Kumar Paul Department of Industrial and Production Engineering, Bangladesh University of Engineering and Technology (BUET), Dhaka – 1000, Bangladesh E-mail: [email protected]
Abstract: Sequencing of jobs on one machine is a very common problem in scheduling. Several factors have to be taken into consideration to make the sequencing more realistic. In this paper, a fuzzy inference system is developed to tackle the uncertainty of variables in a sequencing problem. Arrival order, processing time, due date, slack time remaining, critical ratio, queue ratio and slack time remaining per operation, are considered as input variables and priority of jobs is considered as output variable. Multiple objectives are fulfilled as priority is obtained from the aggregated optimised result of individual rule developed in a rule editor. A job with higher priority is given more preferences in sequencing. MATLAB fuzzy logic toolbox is used to develop the model. A numerical example is presented to explain the approach.
Keywords: sequencing; scheduling; fuzzy inference system; FIS; MATLAB fuzzy logic toolbox.
Reference to this paper should be made as follows: Paul, S.K. (2013) ‘Sustainable sequencing of N jobs on one machine: a fuzzy approach’, Int. J. Services and Operations Management, Vol. 15, No. 1, pp.44–57.
Biographical notes: Sanjoy Kumar Paul is an Assistant Professor in the Department of Industrial and Production Engineering, Bangladesh University of Engineering and Technology (BUET), Bangladesh. His research interest includes applications of artificial intelligence in industrial engineering problems, simulation and modelling.
1 Introduction
Sequencing is the order of processing of jobs on a machine to meet the objectives of scheduling. There are several objectives in real life sequencing problem which should be fulfilled. Minimisation of processing time (PT), meet the due date (DD), minimisation of slack time remaining (STR), meet the planned queue time etc. are several objectives, which have to be taken into consideration to make the sequencing more realistic. Multiple objectives should be considered to make the sequence sustainable. Typical scenario of processing of N jobs on one machine is presented in Figure 1. There are N number of jobs which to be processed on single machine to meet the objectives.

Sustainable sequencing of N jobs on one machine 45
Figure 1 Scenario of processing of n jobs on one machine
Job 1
Job2
Job 3
Job N
Machine Completed jobs
Meet the objectives
There are several jobs which to be processed on single machine to complete finished jobs. The main problem is to determine the order of processing in sequencing. It is a really difficult task to satisfy all the objectives at one time. Previously, the expected makespan was minimised for sequencing jobs on a machine (Chakravarty and Balakrislman, 1997), the number of late jobs was minimised for sequencing of jobs on single machine (Moore, 1968; Maxwell, 1970), total penalty costs resulting from tardiness of jobs were minimised for scheduling N jobs on single machine (Shwimer, 1972). Forst (1993) minimised the sum of the total weighted job earliness and the total weighted job tardiness on one machine, when the job PTs are independent and identically distributed random variables. El-Bouri et al. (2000) presented an approach for single machine job sequencing problems that minimises a cost function exhibiting a limited exponential behaviour. Emmons (1975) considered sequencing n jobs on one machine under the multiple objectives of minimising mean flow time with the minimum number of tardy jobs. Tavakkoli-Moghaddam et al. (2006) minimised the sum of maximum earliness and tardiness to find optimal sequence. Koulamas (2005) studied and formulated as linear programming problems inverse scheduling problems with objective is to determine the minimal perturbation to the job parameters (e.g., PTs) so that the given sequence becomes optimal with respect to a pre-selected objective function. Cheng et al. (2011) considered a single-machine scheduling problem with deteriorating jobs and setup times to minimise the maximum tardiness. Lee and Kim (2012) focused on the problem of scheduling jobs on a single machine that requires periodic maintenance with the objective of minimising the number of tardy jobs. Xia et al. (2008) considered DD assignment and sequencing for multiple jobs in a single machine shop to minimise a linear combination penalty on job earliness, penalty on job tardiness and penalty associated with long DD assignment.
Fuzzy logic was applied in some other problems. Paul and Azeem (2011) applied fuzzy logic to find optimal number of shifts in production. Alvisi et al. (2006) applied fuzzy logic to solve forecasting problem. Work in process inventory was minimised in a hybrid flow shop scheduling using fuzzy logic by Paul and Azeem (2010). Ma and Ojala (2006) used fuzzy logic to quantitatively benchmark the effect of collaboration in supply chain.

46 S.K. Paul
Fuzzy logic is able to take several inputs at a time to fulfil multiple objectives and also tackle uncertainty of variables. No work has been found so far to find out a sustainable sequencing for N jobs one machine problem using fuzzy logic. This paper focuses on to determine a sustainable sequencing to meet multiple objectives with considering fuzziness of PT, DD, STR, critical ratio (CR), queue ratio (QR) and slack time remaining per operation (STRPO) as input variables and priority of job as output variable.
2 Fuzzy inference system
Fuzzy inference system (FIS) is an optimisation technique which considers different inputs and relates those inputs with output with some rules. Rules indicate the relationship between inputs and outputs. The output is optimised based on relationship between variables. The final output is obtained from the aggregated optimised result of individual rule.
Fuzzy set theory was originally presented by Zadeh (1965) in his seminal paper ‘fuzzy sets’ in Information and Control. Fuzzy logic was developed later from fuzzy set theory primary to reason with uncertain and vague information and secondary to represent knowledge in operationally powerful form (Frantti and Mähönen, 2001). Fuzzy inference is the process of formulating the mapping from a given input to an output using fuzzy logic. The mapping then provides a basis from which decisions can be made, or patterns discerned.
There are two types of FISs that can be implemented in fuzzy logic toolbox: Mamdani-type and Sugeno-type. These two types of inference systems vary somewhat in the way outputs are determined. Because of its multidisciplinary nature, FISs are associated with a number of names, such as fuzzy-rule-based systems, fuzzy expert systems, fuzzy modelling, fuzzy associative memory, fuzzy logic controllers, and simply (and ambiguously) fuzzy systems. Mamdani’s fuzzy inference method is the most commonly seen fuzzy methodology. Mamdani’s method was among the first control systems built using fuzzy set theory. It was proposed by Mamdani and Assilian (1975) as an attempt to control a steam engine and boiler combination by synthesising a set of linguistic control rules obtained from experienced human operators. Mamdani-type inference, as defined for fuzzy logic toolbox, expects the output membership functions to be fuzzy sets. After the aggregation process, there is a fuzzy set for each output variable that needs defuzzification. It is possible, and in many cases much more efficient, to use a single spike as the output membership functions rather than a distributed fuzzy set. This type of output is sometimes known as a singleton output membership function, and it can be thought of as a pre-defuzzified fuzzy set. It enhances the efficiency of the defuzzification process because it greatly simplifies the computation required by the more general Mamdani method, which finds the centroid of a two-dimensional function. Rather than integrating across the two-dimensional function to find the centroid, the weighted average of a few data points is used. Sugeno-type systems support this type of model. In general, Sugeno-type systems can be used to model any inference system in which the output membership functions are either linear or constant.
In fuzzy logic toolbox, there are five parts of the fuzzy inference process: fuzzification of the input variables, application of the fuzzy operator (AND or OR) in the antecedent, implication from the antecedent to the consequent, aggregation of the

Sustainable sequencing of N jobs on one machine 47
consequents across the rules, and defuzzification. These sometimes cryptic and odd names have very specific meaning that is defined in the following steps.
2.1 Step I: fuzzification of inputs
The first step is to take the inputs and determine the degree to which they belong to each of the appropriate fuzzy sets via membership functions. In fuzzy logic toolbox, the input is always a crisp numerical value limited to the universe of discourse of the input variable and the output is a fuzzy degree of membership in the qualifying linguistic set. Fuzzification of the input amounts to either a table lookup or a function evaluation. Each input is fuzzified over all the qualifying membership functions required by the rules.
2.2 Step II: application of fuzzy operator
After the inputs are fuzzified, the degree to which each part of the antecedent is satisfied for each rule is known. If the antecedent of a given rule has more than one part, the fuzzy operator is applied to obtain one number that represents the result of the antecedent for that rule. This number is then applied to the output function. The input to the fuzzy operator is two or more membership values from fuzzified input variables. The output is a single truth value. Any number of well-defined methods can fill in for the AND operation or the OR operation. In fuzzy logic toolbox, two built-in AND methods are supported: min (minimum) and prod (product). Two built-in OR methods are also supported: max (maximum), and probor (probabilistic OR) method.
2.3 Step III: implication method
Before applying the implication method, the rule’s weight is determined. Every rule has a weight between 0 and 1, which is applied to the number given by the antecedent. Generally, this weight is 1 and thus has no effect at all on the implication process. From time to time you may want to weight one rule relative to the others by changing its weight value to something other than 1. After proper weighting has been assigned to each rule, the implication method is implemented. A consequent is a fuzzy set represented by a membership function, which weights appropriately the linguistic characteristics that are attributed to it. The consequent is reshaped using a function associated with the antecedent (a single number). The input for the implication process is a single number given by the antecedent, and the output is a fuzzy set. Implication is implemented for each rule. Two built-in methods are supported, and they are the same functions that are used by the AND method: min (minimum), which truncates the output fuzzy set and prod (product), which scales the output fuzzy set.
2.4 Step IV: aggregation of all outputs
Because decisions are based on the testing of all of the rules in a FIS, the rules must be combined in some manner in order to make a decision. Aggregation is the process by which the fuzzy sets that represent the outputs of each rule are combined into a single fuzzy set. Aggregation only occurs once for each output variable, just prior to the fifth and final step, defuzzification. The input of the aggregation process is the list of truncated output functions returned by the implication process for each rule. The output of the

48 S.K. Paul
aggregation process is one fuzzy set for each output variable. As long as the aggregation method is commutative (which it always should be), then the order in which the rules are executed is unimportant. Three built-in methods are supported: max (maximum), probor (probabilistic OR) and sum (simply the sum of each rule’s output set).
2.5 Step V: defuzzification
The input for the defuzzification process is a fuzzy set (the aggregate output fuzzy set) and the output is a single number. As much as fuzziness helps the rule evaluation during the intermediate steps, the final desired output for each variable is generally a single number. However, the aggregate of a fuzzy set encompasses a range of output values, and so must be defuzzified in order to resolve a single output value from the set.
Perhaps the most popular defuzzification method is the centroid calculation, which returns the centre of area under the curve. There are five built-in methods supported: centroid, bisector, middle of maximum (the average of the maximum value of the output set), largest of maximum, and smallest of maximum. Figure 2 presents the description of FIS.
Figure 2 Fuzzy inference system

Sustainable sequencing of N jobs on one machine 49
The fuzzy inference diagram is the composite of all the smaller diagrams presented so far in this section. It simultaneously displays all parts of the fuzzy inference process. Information flows through the fuzzy inference diagram is shown in Figure 3. In Figure 3, the flow proceeds up from the inputs in the lower left, then across each row, or rule, and then down the rule outputs to finish in the lower right. This compact flow shows everything at once, from linguistic variable fuzzification all the way through defuzzification of the aggregate output.
Figure 3 Interpretation of fuzzy inference diagram
3 Fuzzy approach in sequencing
Fuzzy logic is applied in this research to calculate the priority of jobs to determine sequence of jobs to be processed on one machine. Arrival order (AO), PT, DD, STR, CR, QR and STRPO of jobs are taken into considerations as input variables to calculate priority of jobs which is the output of the FIS. The fuzzy approach of sequencing can be presented in Figure 4. Seven variables are considered as fuzzy inputs and one variable is considered as output of fuzzy approach.
While generating the fuzzy model’s linguistic variables, variation of each input and output is used for designing the system. AO is one of the input which linguistic variables are ‘1st’, ‘2nd’, ‘3rd’, ‘4th’ and so on. Linguistic variables for other input variables are ‘very low’, ‘low’, ‘average’, ‘high’ and ‘very high’. Linguistic variables for output are ‘very very low’, ‘very low’, ‘low’, ‘average’, ‘high’, ‘very high’ and ‘very very high’. Variation of input variables is shown in Table 1 and variation of output variable is shown in Table 2. For Gaussian membership function data is given as (standard deviation, mean) and for triangular membership function data is given as a triplet (a1, a2, a3).

50 S.K. Paul
Figure 4 Fuzzy approach for proposed sequencing of n jobs on one machine
Arrival order (AO)
Processing time (PT)
Due date (DD)
Slack time remaining
(STR)
Critical ratio (CR)
Queue ratio (QR)
Slack time remaining
per operation (STRPO)
Fuzzification of the input through the
fuzzy set and membership
function
Evaluation of pertinent rules from
the rule base Defuzzification Priority of
jobs (P)
Table 1 Variation for input linguistic variables
Input variable
Type of membership
function Very low Low Average High Very high
Processing time
Gaussian [0.7, 3] [0.7, 6.5] [0.7, 10.5] [0.7, 14] [0.7, 18]
Due date Gaussian [1.2, 4] [1.2, 9] [1.2, 14] [1.2, 20] [1.2, 26]
Slack time remaining (STR)
Gaussian [0.6, 2] [0.6, 5] [0.6, 8] [0.6, 11] [0.6, 13.5]
Critical ratio
Triangular [0, 0.2, 0.4] [0.25, 0.62, 0.9] [0.7, 1.15, 1.5] [1.2, 1.7, 2.4] [2, 2.5, 3]
Queue ratio Triangular [0, 0.5, 1.2] [1, 1.5, 2.2] [2, 2.5, 3.2] [3, 3.5, 4.2] [4, 4.5, 5]
STR per operation
Triangular [0, 0.25, 0.5] [0.4, 0.8, 1.2] [1.1, 1.7, 2.2] [2.1, 2.6, 3.2] [3, 3.5, 4]
Table 2 Variation for output linguistic variables
Output variable
Membership function
Very very low
Very low Low Average High Very
high
Very very high
Job priority
Triangular [0.0, 0.075, 0.15]
[0.11, 0.20, 0.28]
[0.24, 0.33, 0.40]
[0.37, 0.48, 0.58]
[0.54, 0.63, 0.72]
[0.6, 0.75, 0.84]
[0.8, 0.9, 1.0]

Sustainable sequencing of N jobs on one machine 51
After examining the linguistic variables, membership functions are determined and entered into MATLAB fuzzy toolbox. The FIS for input and output variables is shown in Figure 5. Inputs variables are shown in the left side and output variable is shown in the right side of Figure 5. Mamdani type FIS is considered in this research.
Figure 5 FIS model for job priority in sequencing (see online version for colours)
STRperOperation
The membership function and the linguistic variables of input and output variables are entered in MATLAB fuzzy toolbox membership function editor. Gaussian membership functions are considered for each linguistic variables of fuzzy PT, DD and STR input variables and triangular membership functions are considered for each linguistic variables of CR, QR and slack time per operation input variables and priority of job output variable. Figure 6 represents the membership function and linguistic variables for input PT. Gaussian membership function and linguistic variables are entered for other input variables DD and STR. Triangular membership function and linguistic variables are entered for input variables CR, QR, STRPO and output variable job priority. Membership functions and linguistic variables for input CR and output job priority are shown in Figure 7 and Figure 8 respectively.

52 S.K. Paul
Figure 6 Membership function for PT (see online version for colours)
Figure 7 Membership function for CR (see online version for colours)
Figure 8 Membership function for job priority (see online version for colours)

Sustainable sequencing of N jobs on one machine 53
After determination of membership functions and linguistic variables for each input and output, the rules are designated and written in MATLAB Fuzzy Toolbox for evaluation. And after the needed data are entered, inputs are solved according to changing input positions for solving of fuzzified systems. Total 152 rules are developed with the help of MATLAB Fuzzy Toolbox Rule Editor. Two examples of rules are given here.
1 if (AO is 1st) and (PT is very low) and (DD is very low) and (STR is very low) and (CR is very low) and (QR is very low) and (STRPO is very low) then (priority is very very high)
2 If (AO is 5th) and (PT is average) and (DD is average) and (STR is average) and (CR is average) and (QR is average) and (STRPO is average) then (priority is average).
In proposed fuzzy approach, ‘min’, ‘max’ and ‘min’ operator are considered as AND, OR and implication method respectively and ‘sum’ and ‘bisector’ operator are proposed for aggregation and defuzzification respectively. The properties of proposed fuzzy approach for sequencing of jobs on one machine are summarised as shown in Table 3. Table 3 Summery of proposed fuzzy approach
Object model Sequencing of jobs
Inputs [AO, PT, DD, STR, CR, QR, STRPO] Output [P] Number of inputs 7 Number of output 1 Types of FISs Mamdani-type AND method min OR method max Implication method min Aggregation Sum Defuzzification Bisector Membership function Gaussian and triangular Number of rules 152
4 Result analysis
A case study is presented to analyse the result from fuzzy approach of sequencing. In this case study, total ten jobs have to be processed on one machine. Information about jobs is given in Table 4.
Information about jobs in Table 4 is given as input in rule viewer of Fuzzy logic toolbox. For each job, AO, PT, DD, STR, CR, QR and STRPO are given as input and priority of each job is obtained as output from rule viewer. Priority is obtained from the aggregated optimised result of individual rule developed in rule editor. Table 5 shows the priority of each job obtained from FIS. As job A has obtained highest priority, it will be processed first and Job J has obtained lowest priority, it will be processed last. The position of jobs in the sequence is also presented in Table 5.
54 S.K. Paul
Table 4 Information about jobs in sequencing
Job Arrival order
Processing time (days)
Due date (days)
Slack time remaining (days)
Critical ratio
Queue ratio
STR per operation
A 1 6 7 1 0.333 0.50 0.50 B 2 7 9 2 0.571 2.00 0.40 C 3 5 8 3 0.600 1.50 1.50 D 4 9 12 3 0.778 1.00 0.75 E 5 18 26 8 1.167 4.00 1.60 F 6 12 15 3 0.833 3.00 1.00 G 7 7 14 7 1.286 3.50 3.50 H 8 15 21 6 1.067 1.50 1.50 I 9 3 8 5 1.000 2.50 2.50 J 10 17 28 11 1.353 3.667 1.833
Table 5 Priority of jobs and position in sequencing
Job Priority Position in sequencing
A 0.71 1 B 0.69 2 C 0.63 3 D 0.61 4 E 0.42 8 F 0.50 6 G 0.42 7 H 0.40 9 I 0.54 5 J 0.30 10
In this study, seven input parameters are considered to find priority of jobs. Input parameters have some relationship with output. Changes of priority with two input parameters are studied by surface analysis obtained from fuzzy surface viewer. Figure 9 shows the surface analysis which presents the changes of priority with two input parameters. From Figure 9, generally it can be said that with increasing the value of inputs, priority of jobs is decreased.
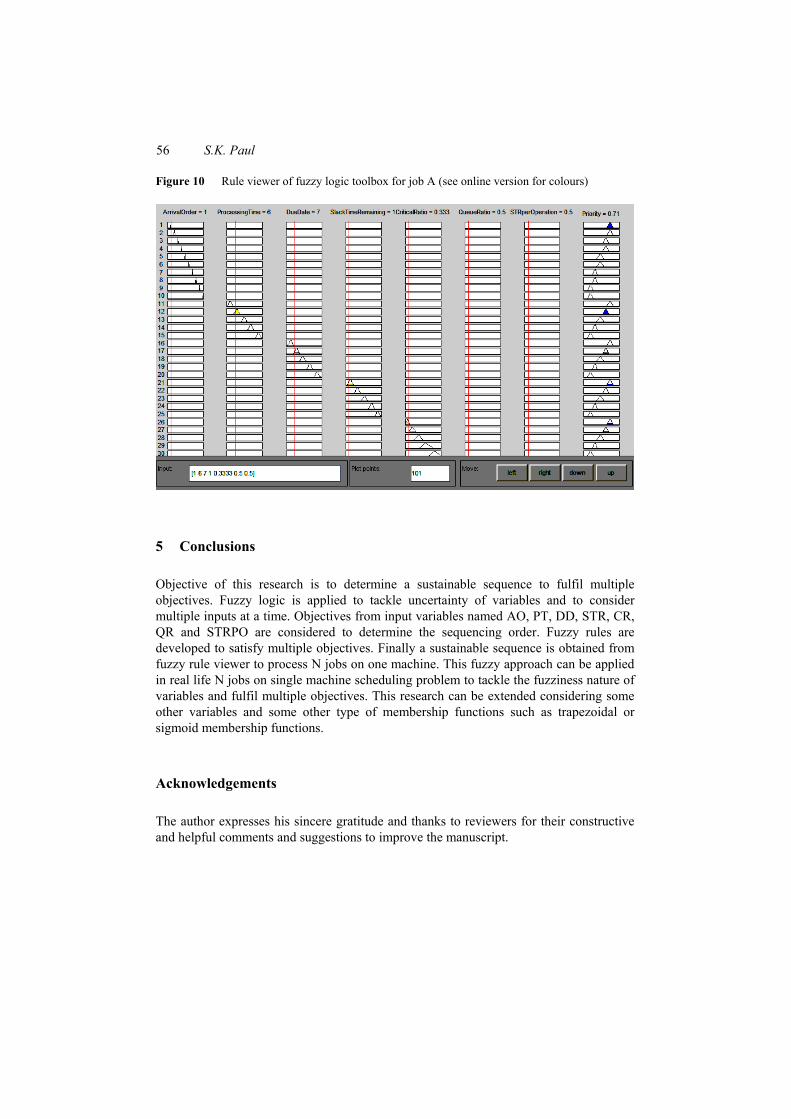
Highest priority is obtained from the information of job A and lowest priority is obtained for job J using rule viewer of Fuzzy Logic Toolbox. Position in sequencing is determined as higher value of priority is given more preferences. Rule viewer of job A is shown in Figure 10. Values of seven inputs are given in fuzzy rule viewer and priority is obtained from the aggregated optimised result of individual rule. From Figure 10, priority value of job A is obtained 0.71. Similarly priority value is obtained for other jobs which are shown in Table 5. Finally sustainable job sequence of processing obtained from result of FIS is A-B-C-D-I-F-G-E-H-J.

Sustainable sequencing of N jobs on one machine 55
Figure 9 Changes of priority of jobs with two input parameters, (a) changes of priority with PT and DD (b) changes of priority with PT and STR (c) changes of priority with PT and QR (d) changes of priority with DD and STRPO (e) changes of priority with DD and QR (f) changes of priority with STR and STRPO
(a) (b)
(c) (d)
(e) (f)
56 S.K. Paul
Figure 10 Rule viewer of fuzzy logic toolbox for job A (see online version for colours)
5 Conclusions
Objective of this research is to determine a sustainable sequence to fulfil multiple objectives. Fuzzy logic is applied to tackle uncertainty of variables and to consider multiple inputs at a time. Objectives from input variables named AO, PT, DD, STR, CR, QR and STRPO are considered to determine the sequencing order. Fuzzy rules are developed to satisfy multiple objectives. Finally a sustainable sequence is obtained from fuzzy rule viewer to process N jobs on one machine. This fuzzy approach can be applied in real life N jobs on single machine scheduling problem to tackle the fuzziness nature of variables and fulfil multiple objectives. This research can be extended considering some other variables and some other type of membership functions such as trapezoidal or sigmoid membership functions.
Acknowledgements
The author expresses his sincere gratitude and thanks to reviewers for their constructive and helpful comments and suggestions to improve the manuscript.

Sustainable sequencing of N jobs on one machine 57
References Alvisi, S., Mascellani, G., Franchini, M. and Bardossy, A. (2006) ‘Water level forecasting through
fuzzy logic and artificial neural network approaches’, Hydrology and Earth System Sciences, Vol. 10, No. 1, pp.1–17.
Chakravarty, A.K. and Balakrislman, N. (1997) ‘Job sequencing rules for minimising the expected makespan in flexible machines’, European Journal of Operational Research, Vol. 96, No. 2, pp.274–288.
Cheng, T.C.E., Hsu, C.J., Huang, Y.C. and Lee, W.C. (2011) ‘Single-machine scheduling with deteriorating jobs and setup times to minimise the maximum tardiness’, Computers and Operations Research, Vol. 38, No. 12, pp.1760–1765.
El-Bouri, A., Balakrishnan, S. and Popplewell, N. (2000) ‘Sequencing jobs on a single machine: a neural network approach’, European Journal of Operational Research, Vol. 126, No. 3, pp.474–490.
Emmons, H. (1975) ‘One machine sequencing to minimise mean flow time with minimum number tardy’, Naval Research Logistics Quarterly, Vol. 22, No. 3, pp.585–592.
Forst, F.G. (1993) ‘Stochastic sequencing on one machine with earliness and tardiness penalties’, Probability in the Engineering and Informational Sciences, Vol. 7, No. 2, pp.291–300.
Frantti, T. and Mahonen, P. (2001) ‘Fuzzy logic-based forecasting model’, Engineering Applications of Artificial Intelligence, Vol. 14, No. 2, pp.189–201.
Koulamas, C. (2005) ‘Inverse scheduling with controllable job parameters’, International Journal of Services and Operations Management, Vol. 1, No. 1, pp.35–43.
Lee, J.Y. and Kim, Y.D. (2012) ‘Minimising the number of tardy jobs in a single-machine scheduling problem with periodic maintenance’, Computers and Operations Research, Vol. 39, No. 9, pp.2196–2205.
Ma, H. and Ojala, L. (2006) ‘Benchmarking the collaboration in the supply chain’, International Journal of Services and Operations Management, Vol. 2, No. 4, pp.367–387.
Mamdani, E.H. and Assilian S. (1975) ‘An experiment in linguistic synthesis with a fuzzy logic controller’, International Journal of Man-Machine Studies, Vol. 7, No. 1, pp.1–13.
Maxwell, W.L. (1970) ‘On sequencing n jobs on one machine to minimise the number of late jobs’, Management Science, Vol. 16, No. 5, pp.295–297.
Moore, J.M. (1968) ‘An n job, one machine sequencing algorithm for minimising the number of late jobs’, Management Science, Vol. 15, No. 1, pp.102–109.
Paul, S.K. and Azeem, A. (2010) ‘Minimisation of work in process inventory in hybrid flow shop scheduling using fuzzy logic’, International Journal of Industrial Engineering: Theory, Applications and Practice, Vol.17, No. 2, pp.115–127.
Paul, S.K. and Azeem, A. (2011) ‘Selection of the optimal number of shifts in fuzzy environment: manufacturing company’s facility application’, Journal of Industrial Engineering and Management, Vol. 3, No. 1, pp.54–67.
Shwimer, J. (1972) ‘On the N-job, one-machine, sequence-independent scheduling problem with tardiness penalties: a branch-bound solution, Management Science, Vol. 18, No. 6, pp.B301–B313.
Tavakkoli-Moghaddam, R., Moslehi, G., Vasei, M. and Azaron, A. (2006) ‘A branch-and-bound algorithm for a single machine sequencing to minimise the sum of maximum earliness and tardiness with idle insert’, Applied Mathematics and Computation, Vol. 174, No. 1, pp.388–408.
Xia, Y., Chen, B. and Yue, J. (2008) ‘Job sequencing and due date assignment in a single machine shop with uncertain processing times’, European Journal of Operational Research, Vol. 184, No. 1, pp.63–75.
Zadeh, L.A. (1965) ‘Fuzzy sets’, Information and Control, Vol. 8, No. 3, pp.338–353.




















