
Social networks and interest similarity: the case of CiteULike
10
Social Networks and Interest Similarity: The Case of CiteULike Danielle H. Lee School of Information Sciences, University of Pittsburgh 135 N. Bellefield Ave., Pittsburgh, 15213 PA [email protected] Peter Brusilovsky School of Information Sciences, University of Pittsburgh 135 N. Bellefield Ave., Pittsburgh, 15213 PA [email protected] ABSTRACT In collaborative filtering recommender systems, there is little room for users to get involved in the choice of their peer group. It leaves users defenseless against various spamming or “shilling” attacks. Other social Web-based systems, however, allow users to self-select peers and build a social network. We argue that users’ self-defined social networks could be valuable to increase the quality of recommendation in CF systems. To prove the feasibility of this idea we examined how similar are interests of users connected by self-defined relationships in a collaborative tagging systems Citeulike. Interest similarity was measured by similarity of items and meta-data they share and tags they use. Our study shows that users connected by social networks exhibit significantly higher similarity on all explored levels (items, meta- data, and tags) than non-connected users. This similarity is the highest for directly connected users and decreases with the increase of distance between users. Among other interesting properties of information sharing is the finding that between-user similarity in social connections on the level of metadata and tags is much larger than similarity on the level of items. Overall, our findings support the feasibility of social network based recommender systems and offer some good hints to the prospective authors of these systems. Categories and Subject Descriptors H.1.2 [User/Machine Systems]: Human Factors; Software Psychology; J.4 [Social and Behavioral Sciences]: Sociology General Terms Measurement, Human Factors Keywords Social Networks, Information Sharing, Citeulike 1. INTRODUCTION Recommender systems powered by collaborative filtering (CF) technology have become a feature of our life. Such popular systems as Amazon.com, Netflix, Last.fm, and Google News use CF to recommend products to buy, movies to watch, music to listen to and news to read. The power of this technology is based on a relatively simple idea: starting with a target user’s rating, find a neighborhood of users who have interests similar to the target user and recommend items favored by this cohort to the target user. While CF has powered a number of successful recommender systems, recent research discovered a number of limitations to this technology. Three of these limitations are cold start, new user and sparsity; these problems have a similar cause: if the overlap between user ratings is too small, the CF approach can’t define a reliable neighborhood in order to generate recommendations. This typically happens when the system is too new (cold start), when the target user has too few ratings (new user) or when the number of total items is much larger than the number of items rated by each user (sparsity). Another problem is lack of control over the selection of peer neighborhood. Unlike first generation “push” and “pull” CF systems (Maltz and Ehrlich 1995; Schaefer, Frankowski et al. 2007), which connected people directly, modern CF systems automatically select the neighborhood and do not even expose information about the people whose rankings were used to generate the recommendations. Target users can neither add specific known persons (someone they trust in real life) to the neighborhood, nor can they exclude some strange or suspicious “peers” picked by the system. The latter leaves users defenseless against various spamming or “shilling” attacks in CF recommenders (Lam and Riedl 2004; Massa and Avesani 2004). The problems mentioned above encouraged a number of researchers to explore social recommender technologies, which seek to improve the quality of CF systems by using various kinds of self-defined social connections to form the neighborhood of similar users instead of (or in combination with) co-rating (Maltz and Ehrlich 1995; Massa and Avesani 2004; O'Donovan and Smyth 2005; Massa and Avesani 2007; Ziegler and Golbeck 2007; DuBois 2009; Jamali and Ester 2009). Our work on social recommender systems was motivated by the success of the new wave of social systems, such as LinkedIn, Flickr, Delicious, Citeulike etc., which support various kinds of social linking. The self-defined links between users in these systems establish a rich source of information, which is, in turn, used to propagate various kinds of information. Explicitly or implicitly, the users in these social networks recommend groups to joint to each other, events to attend, bookmarks to explore, or research papers to read. Beyond the word-of-mouth phenomenon for acquiring conventional information, they are also critical to find professional knowledge and seek possible collaborations (Granovetter 1983; Kautz, Selman et al. 1997; Wellman 2001). Both social linking and social tagging systems with their readily available links served as a platform for several pioneering social recommender systems. It is important to note that the promise of the social recommender systems is based on at least two assumptions. First, it is assumed that the presence of social connections defines the similarity of user interests. Second, it is assumed that the source of the recommendation is an important criterion for judging the quality Permission to make digital or hard copies of all or part of this work for personal or classroom use is granted without fee provided that copies are not made or distributed for profit or commercial advantage and that copies bear this notice and the full citation on the first page. To copy otherwise, or republish, to post on servers or to redistribute to lists, requires prior specific permission and/or a fee. Conference’04, Month 1–2, 2004, City, State, Country. Copyright 2004 ACM 1-58113-000-0/00/0004…$5.00.
Transcript of Social networks and interest similarity: the case of CiteULike

Social Networks and Interest Similarity: The Case of CiteULike
Danielle H. Lee
School of Information Sciences, University of Pittsburgh
135 N. Bellefield Ave., Pittsburgh, 15213 PA
Peter Brusilovsky
School of Information Sciences, University of Pittsburgh
135 N. Bellefield Ave., Pittsburgh, 15213 PA
ABSTRACT
In collaborative filtering recommender systems, there is little room for users to get involved in the choice of their peer group. It leaves users defenseless against various spamming or “shilling” attacks. Other social Web-based systems, however, allow users to self-select peers and build a social network. We argue that users’ self-defined social networks could be valuable to increase the quality of recommendation in CF systems. To prove the feasibility of this idea we examined how similar are interests of users connected by self-defined relationships in a collaborative tagging systems Citeulike. Interest similarity was measured by similarity of items and meta-data they share and tags they use. Our study shows that users connected by social networks exhibit significantly higher similarity on all explored levels (items, meta-data, and tags) than non-connected users. This similarity is the highest for directly connected users and decreases with the increase of distance between users. Among other interesting properties of information sharing is the finding that between-user similarity in social connections on the level of metadata and tags is much larger than similarity on the level of items. Overall, our findings support the feasibility of social network based recommender systems and offer some good hints to the prospective authors of these systems.
Categories and Subject Descriptors
H.1.2 [User/Machine Systems]: Human Factors; Software Psychology; J.4 [Social and Behavioral Sciences]: Sociology
General Terms
Measurement, Human Factors
Keywords
Social Networks, Information Sharing, Citeulike
1. INTRODUCTION Recommender systems powered by collaborative filtering (CF) technology have become a feature of our life. Such popular systems as Amazon.com, Netflix, Last.fm, and Google News use CF to recommend products to buy, movies to watch, music to listen to and news to read. The power of this technology is based on a relatively simple idea: starting with a target user’s rating, find a neighborhood of users who have interests similar to the target
user and recommend items favored by this cohort to the target user. While CF has powered a number of successful recommender systems, recent research discovered a number of limitations to this technology. Three of these limitations are cold start, new user and sparsity; these problems have a similar cause: if the overlap between user ratings is too small, the CF approach can’t define a reliable neighborhood in order to generate recommendations. This typically happens when the system is too new (cold start), when the target user has too few ratings (new user) or when the number of total items is much larger than the number of items rated by each user (sparsity). Another problem is lack of control over the selection of peer neighborhood. Unlike first generation “push” and “pull” CF systems (Maltz and Ehrlich 1995; Schaefer, Frankowski et al. 2007), which connected people directly, modern CF systems automatically select the neighborhood and do not even expose information about the people whose rankings were used to generate the recommendations. Target users can neither add specific known persons (someone they trust in real life) to the neighborhood, nor can they exclude some strange or suspicious “peers” picked by the system. The latter leaves users defenseless against various spamming or “shilling” attacks in CF recommenders (Lam and Riedl 2004; Massa and Avesani 2004).
The problems mentioned above encouraged a number of researchers to explore social recommender technologies, which seek to improve the quality of CF systems by using various kinds of self-defined social connections to form the neighborhood of similar users instead of (or in combination with) co-rating (Maltz and Ehrlich 1995; Massa and Avesani 2004; O'Donovan and Smyth 2005; Massa and Avesani 2007; Ziegler and Golbeck 2007; DuBois 2009; Jamali and Ester 2009). Our work on social recommender systems was motivated by the success of the new wave of social systems, such as LinkedIn, Flickr, Delicious, Citeulike etc., which support various kinds of social linking. The self-defined links between users in these systems establish a rich source of information, which is, in turn, used to propagate various kinds of information. Explicitly or implicitly, the users in these social networks recommend groups to joint to each other, events to attend, bookmarks to explore, or research papers to read. Beyond the word-of-mouth phenomenon for acquiring conventional information, they are also critical to find professional knowledge and seek possible collaborations (Granovetter 1983; Kautz, Selman et al. 1997; Wellman 2001). Both social linking and social tagging systems with their readily available links served as a platform for several pioneering social recommender systems.
It is important to note that the promise of the social recommender systems is based on at least two assumptions. First, it is assumed that the presence of social connections defines the similarity of user interests. Second, it is assumed that the source of the recommendation is an important criterion for judging the quality
Permission to make digital or hard copies of all or part of this work for
personal or classroom use is granted without fee provided that copies are not made or distributed for profit or commercial advantage and that copies bear this notice and the full citation on the first page. To copy
otherwise, or republish, to post on servers or to redistribute to lists, requires prior specific permission and/or a fee. Conference’04, Month 1–2, 2004, City, State, Country.
Copyright 2004 ACM 1-58113-000-0/00/0004…$5.00.

of recommendations. While the second assumption has been proven by some recent research (Bonhard and Sasse 2006; Tintarev and Masthoff 2007), the first assumption remains to be confirmed in the context of social linking and tagging systems. Is it true that connected users in the social networks share common interests? Is it likely that information collected in user libraries could be useful for users who are connected with them? If these assumptions appear to be invalid, then such networks will be useless for CF mechanisms.
The goal of this paper is to explore the relationships between similarities in user interest and their self-defined connections in social tagging system. While this exploration was motivated by the need to test the assumptions behind social recommender systems, it is also important in the context of broader research on social systems. Using real life data collected from a social Web system – Citeulike – we examined several important properties of self-defined social networks. We investigated whether a social connection might indicate user interest similarity, to what extent user interest similarity depends on the strength of their connection, and ultimately, how feasible it may be to use a social network as a source of personalized recommendation.
This paper especially focuses on a relatively new social relationship – the unilateral watching relationship. Compared with the era when the computer users stayed in isolation, users on the Web 2.0 have found it easier to know who knows what through social networks in virtual space (Wellman 2001). It is a burden, however, to contact the person who knows the desired knowledge through their personal ties (McDonald 2003). A watching relationship is a unilateral relationship where one user is interested to be connected to another. It does not require mutual agreement for being connected and getting information. Systems support information sharing mechanically on the user interface level. Therefore, it is convenient and purely based on the utility of information usefulness. In addition, it can compensate for privacy concerns because the watched users can decide what to expose or hide to the strangers by themselves.
Since unilateral relationships are mechanically connected for the purpose of getting information, it would be intuitively assumed that information of uses in unilateral relationships is similar to each other. The empirical evidence has, however, never been tested. Put differently, whether the information shared by two users in unilateral relationships are similar and what patterns in the shared information is unknown. Studies about information similarity in social networks have been mainly centered on friendship-based networks. In the Web 2.0 era, when various new relationships are emerging and the networks are “less bounded
(Wellman 2001)”, the unilateral relationship is one kind of the relationships and this study is focusing on the information similarity of this new social network.
This paper is organized as follows. In Section 2, we review the literature surrounding CF recommendation and social networks existing on the Web. The way to collect data, the description of data and the kinds of relationship are explained in Section 3. Section 4 concerns the variables and the hypotheses we tested and Section 5 presents the results. We conclude with a discussion of this study and suggestions for future research.
2. RELATED WORK
2.1 CF Technology and its Problems The CF technology emerged as an attempt to automate the word-of-mouth in the age of Internet. The technology proved its worth
in recommending taste-based items such as movies, jokes, music, etc. where the preference is hard to be appreciated by the content. It became popular for its ability to recommend serendipitous and diverse information. The popularity, however, revealed some problems associated with CF approach. CF appeared to be not well-protected against malicious users who try to harm the system or to make a profit by gamming the system. For example, by copying the whole user profile, a malicious user is perceived by the system to be a perfect peer user and the products added by him are therefore recommended to the target user (Lam and Riedl 2004; Massa and Avesani 2007; Mehta, Hofmann et al. 2007). Even without malicious users the quality of recommendation can be affected by peculiar users with unusual interests (Schaefer, Frankowski et al. 2007). Moreover, since recommenders have to compare all other users in order to find the peer group, the computation requires substantial off-line process (Massa and Avesani 2004). Finally, users who do not have sufficient ratings are not able to receive reliable recommendations (Schaefer, Frankowski et al. 2007). These CF-related problems occur in part because the recommender systems make a choice of peer group purely by similarity computation, with no way for the target users to affect the recommendation process.
2.2 Social Relationships and Interest
Similarity In early CF-related research, social networking was an important part of recommendation process. The early CF system, Tapestry was based on explicit social connections and allowed users to retrieve personalized contents, using annotations added by their friends or colleagues (Schaefer, Frankowski et al. 2007). Another pioneering CF project (Maltz and Ehrlich 1995) combined explicit social connections with active “push” approach: users could directly send interesting research papers to other colleagues. However, these pioneer systems relied on exchange of information within a “small world” and found it difficult to retain users and to keep them actively contributing to the recommendation process. As the CF-related algorithms became mature, automatic recommendations by computations became dominant.
More recently, however, the problems of CF technology caused some researchers to re-asses the value of explicit social connections as a source of information for reliable recommendation. Since users are able to know where the information came from, recommendations based on users’ own trusted social networks could increase the satisfaction of recommendation (Schenkel, Crecelius et al. 2008). The recommendations made by friends were known to be frequently better and more useful than the recommendations made by systems (Sinha and Swearingen 2001). To prove the feasibility of this approach, several research teams started with checking the main assumption: do users linked by self-defined social networks have similar interests?
Homophily and social influence are the two theories which are widely explored in sociology regarding the similarity in social networks. Homophily is defined as ‘people with similar characteristics tend to be connected (Wellman 2007)’. Social Influence means that ‘people adopt behaviors based on the behaviors of those they interact with (Crandall, Cosley et al. 2008).’ Even though it is hard to distinguish these theories and to investigate the interplay, a few studies on the similarity of social networks (based on these theories) have been undertaken by researchers in the information-science discipline.

Singla and Richardson (2008) tested the relationship between instant messenger logs and the similarity of search queries. They were able to demonstrate that search interests of people who exchanged instant messages frequently were more similar than interests of random pairs. Moreover, the longer they talked, the more similar they were(Singla and Richardson 2008).
Another social network-related research (Adamic and Adar 2003) explored word terms on the Stanford and MIT personal home pages and users’ social connections. The terms in homepages, in-links, out-links and mailing lists were analyzed to see how the information similarity predicts the friendship connections. All these four kinds of information appeared to be similar for socially connected users. There was also proportional relationship between information dissimilarity and the relationship distance (Adamic and Adar 2003).
Ziegler and Golbeck compared interest similarity between people in a social network in traditional CF context. They used user information and the user’s trust ratings in the book and movie recommendation domain. For the book data set, to lessen the data sparsity problem, they grouped the items by topics using an existing taxonomy, rather than using each information item. Since this study focused on the similarity of users’ topics of interests derived from the taxonomy, not from the items per se, it was hard to see a clear picture of information similarity on the item level. As the authors pointed, the similarity is highly dependent on the taxonomy’s design. Yet, in the second study with movie data set, they compared user similarity on the level of individual items and found that the average ratings of each movie became more similar as two users trusted each other more (Ziegler and Golbeck 2007).
Referral Web (Kautz, Selman et al. 1997) was a information retrieval application utilizing social influence. In this system, the social network was used as a way to disambiguate search queries and to reorder the search results. The system chose a certain term familiar to direct or indirect social networks of the searcher; the system gave a higher priority to the results related to the social networks. The authors extracted social network information automatically through publicly available Web information such as co-authorships of papers, organizational charts, or message exchanges in newsgroups (Kautz, Selman et al. 1997).
Yang and Chen’s research was also based on social influence. In an educational P2P system, knowledge and social networks were combined to suggest items to download. First, the system selected the most knowledgeable and most preferred users; then it suggested that the target user interacts with the selected users using instant messenger. As time goes by, the more often a user interacted with the target user, the more likely that his information was recommended to the target user. The authors considered social networks not only through the strength of a tie at a certain time point, but also through measurement of the evolution of the tie. Even with the thoughtful design of the recommendation structure, the study requires too much human intervention. In order to choose the most knowledgeable user for a query term, the system needed to have an evaluation of human experts. The users’ preferences about other users were also based on the explicit ratings. As compared to this educational domain, in a general system it is impossible for human experts to evaluate the knowledge of every individual and to allow users to provide ratings for all of the other users (Yang and Chen 2008).
Guy and his colleagues compared familiarity-based with similarity-based recommendations. Given that a typical CF recommendation utilizes a similarity-based approach, the
familiarity-based approach suggested items in which the people in the same social networks were interested. They utilized users’ self-defined social networks (connections on enterprise social networks sites) and inferred from other social networks (organizational chart relationship, co-authorship of one paper or patent, etc.). In the survey study, users preferred familiarity-based recommendation to the similarity-based recommendation (Guy, Zwerdling et al. 2009).
There are also some social interactions-based games such as Dogear and ESP game. Using knowledge about ‘what interests who’ among the social connections, they are able to guess who owns the suggested information among a user’s social connections. When a user’s guess is incorrect, the system queries whether the friend they chose could also be interested in the information in question and recommend it to the friend (von Ahn 2006; Dugan, Muller et al. 2007).
Our work presented below was motivated mainly by homophily: interest similarity between users connected by social relationships. Expanding the research cited above, we attempted to explore this topic in a very different context and with a different kind of social network: unilateral relationships in a collaborative tagging system.
2.3 Tags as User Interest Indicators Tags are descriptive words selected by users to describe items in collaborative information sharing systems. Tags were found to be helpful for organizing, retrieving and sharing information. The collection of the tags is often called ‘folksonomy’ (which is a compound word of ‘folk’ and ‘taxonomy’(Hotho, Jäschke et al. 2006)) equaling it to a collection of conceptual and structured knowledge created by people. According to the analysis of tags sharing in Connotea, around 23% of tags out of 3359 unique tags were shared between users (Lund, Hammond et al. 2005). Although it was preliminary result based on initial usage of the system, it shows that tags are being utilized not only as a way to organize information for personal goods, but as a good way to help discover useful information shared by others.
User tagging behavior can serve as rich evidence about user interests and in this capacity was applied to construct user profiles for personalized information access. Compared with item ratings, item tags not only indicate user interest, but also show from which aspects the tagged item is interesting for the user (Hung, Huang et al. 2008; Zhao, Du et al. 2008). A study using Delicious data set (Hung, Huang et al. 2008)explored the correlation between users’ tags and content tags. The authors also investigated how well personal tag sets and social contacts’ tag sets represent their preferences. As expected, personal tags were more effective to express user preferences. However, user profiles based solely on tag sets were not good enough to generate recommendation (the best precision was 21%). Another study in the domain of music recommendation using Last.fm data set, demonstrated that correlating tags semantically with query terms can significantly improve the precision of recommendation for tag-based profiles (Firan, Nejdl et al. 2007).
3. THE DATA SET
3.1 The Data Source and the Relationships As a source of data for our study we selected a collaborative tagging system Citeulike (http://www.citeulike.org/). Along with Bibsonomy (Hotho, Jäschke et al. 2006) and Connotea (Hotho,
Jäschke et al. 2006), Citeulike is one of the leading systems for sharing bibliographic references. As many other collaborative tagging systems, Citeulike supports a special kind of social

relationships between users known as watching. If a user considers a collection of references (library) assembled by another user as a good source of information, she can start “watching” this user. As a result, all items (i.e., references) assembled by the “watched” user will be automatically shown to the “watching” user as a part of her watchlist. A user can choose to watch many users, however the nature of the “watching mechanism” in collaborative tagging systems causes the users to be very careful when selecting users to watch since watching many users cause rapid growth and potential dilution of the watchlist. Thus watching in Citeulike could be considered as evidence that watched users are sources of useful information. In this sense, the relationship of watching could provide better information than the connection between friends in social networking systems.
The watching relationship was the primary target of investigation in our study. In our analysis, we distinguished two kinds of social connections – unidirectional and reciprocal. Similarly to other collaborative tagging systems, the act of adding another user to the ‘watch list’ in Citeulike is unilateral (which is different from “friends” or “connections” in social networking systems). If user A watches user B, it does not imply that user B watches user A. Each user makes watching decisions independently. It could be that user B does not watch user A. In this case, we call the watching relationship between A and B as ‘unidirectional’. Another user C watched by A may decide to watch A as well (Figure 1). We call the relationship between A and C as ‘reciprocal’.
Figure 1. Directions of relation in the center of user A
We also distinguish direct and indirect connection and use them to investigate the transitivity of common interests in the social networks. In our study, we explored three distances between users in social networks: direct, one hop and two hops. In the above example, user A and user B are in ‘direct’ relationship. If user B watches user D, user A and user D are in one hop distance unidirectional relationship (Figure 2). If user D watches user E, users A and E are in two hops distance unidirectional relationship. This distance can be applied to the reciprocal relationship as well.
Figure 2. Relation distance in the center of user A
3.2 Data Collection The information for our study was collected using snowball sampling. To choose initial set of Citeulike users, we randomly visited Citeulike in September and October of 2008 and July and August of 2009. 1365 users of Citeulike who posted new articles
at the time of visit were picked as initial seed. The information collected for each user included the bibliography (article title, list of authors, journal name, publication year, etc.), the tags and the watch list.
After collecting a group of initial users, we collected data of their watching users through breadth-first search. This snowball sampling is known to be better than other approaches such as node or link sampling, since latter two sampling techniques are likely to find many isolated pairs and smaller than the original network (Ahn, Han et al. 2007). To diversify data collection, all of the other users who have the same articles were chosen; accordingly, their information and the tags were crawled. Social connections of these users were crawled as well (i.e., we crawled two steps away from the original sets). Table 1 and Figure 3 show the descriptive statistics of the data set and the distribution of user items respectively.
Table 1. Data Summary of Citeulike
Total no. of users 19959
Total no. of distinct items (papers) 1070389
Average no. of items per user 64.75
Total no. of distinct tags 233816
Average no. of tags per user 190.75
Total no. of unidirectional relations 11295
Total no. of reciprocal relations 93
Figure 3. Distribution of the User Information Collection
Figure 4. Distribution of Relations
Out of 19959 users, 1918 users have connections (i.e., watched other users). Among these users, the average number of connections per user is 6.11. Figure 4 shows the distribution of watching relationships (showing how many users watch each
1
4
16
64
256
1024
4096
1 8 64 512 4096
No
. o
f U
se
rs
No. of Items
1
4
16
64
256
1024
1 2 4 8 16 32 64
No
. o
f U
ser
No. of Relations

specific number of users). As the figure shows, the majority of users watch just one another user and the number of users with a particular size of watching list fall rapidly following common power law pattern of collaborative tagging systems.
4. DATA ANALYSIS The goal of our study was to examine whether unilateral social connections between users may be an indicator of their interests similarity. In collaborative tagging systems, the similarity of interests can be assessed in two ways: the similarity of shared information and the similarity of used tags. In this study we explored both aspects.
The similarity of shared information was assessed using item-
based and metadata-based approaches. The traditionally used
item-based similarity can be measured as the number of shared information items (references). However, due to the irregular opportunistic nature of the bookmarking process, users with similar interests may not necessarily end up with very similar collections. In this case, similarity of interest might be more reliably measured by agreement on the level of item’s meta-data. For example, in Citeulike domain, bookmarking papers from the same authors or same journals (conferences) can be considered as an indicator of similarity. In our study, to measure metadata-based similarity we counted the number of shared authors (since it was the easiest and most reliable kind of metadata to track).
Tag similarity was assessed by counting the number of shared tags on two levels: micro level and macro level. On micro-level a tag was counted as shared if it was used by both users to tag the same common information item. On macro level any tag used by two users (regardless of the tagged item) was counted as shared.
4.1 Dependent Variables Since sizes of item and tag collections varied dramatically from user to user, we had to examine measure information similarity between users, using absolute numbers (i.e., number of common items or tags) and relative (normalized) numbers: proportion of shared items in the collections of connected users. Most meaningfully, the number of shared items can be measured in respect to the collection of the watching user. Since the relationship of watching facilitates citation borrowing from watched user, this measure can indicate to what extent the collection of watching user was influenced by the presence of the connection. However, it is also meaningful to check the fraction of shared information in the collection of the watched user and in the joint collection of both users. As a result, we used three relative similarity measures as dependent variables: inlink, outlink and overall fractions.
Figure 5. Information Overlap
Inlink Power � A � B�/A eq. 1�
Outlink Power � A � B�/B eq. 2�
Overall/Jaccard Power � A � B�/ A � B� eq. 3�
If user A watches B, the inlink measure (impact) is the fraction of shared information in A’s collection. The outlink measure is the fraction of shared information in B’s collection. The overall measure is fraction of shared information in the joint information space of both users (in other words, Jaccard similarity) Figure 5 and the following equations explain these measures more formally.
4.2 Hypotheses The main target of this study was to assess the following four hypotheses:
H1. Users connected by direct or indirect relationships share more information (information items and the metadata) than non-connected pairs. H2. Users connected by reciprocal relationships share more information (information items and the metadata) than users in unidirectional relationships. H3. Users connected by direct or indirect relationships have more similar tags on macro- and micro-level than non-connected users. H4. Users connected by reciprocal relationships have more similar tags on macro- and micro-level than users in unidirectional relations relationships.
In addition to the four main hypotheses, we expected to examine other aspects related with information sharing and interest similarity in social networks.
5. THE RESULTS
5.1 Information Sharing Patterns We started our analysis with examining global information sharing patterns in our dataset. First, we separated users who have social connections (i.e., users who watch other users or/and are watched by other users) with other users who have no incoming or outgoing watching connections and compared properties of these two sets. As we found, non-connected users who form the majority in our data set (15,409 users) are quite different from connected users. The average numbers of items collected by a users with connections (M = 173.57, n = 4549) is significantly higher than the average numbers of items collected to the users without any network (M = 32.63, n = 15409, Mann-Whitney U = 1.466E7, p < .001). Connected users also have significantly more tags (M = 510.65) than the users without connections (M = 99.11, Mann-Whitney U = 1.337E7, p < .001). In some sense, connected and not connected users form two quite different cohorts which have different distributions of collection sizes as shown on Figure 6.
Figure 6. Distribution of Item Numbers of Users with Networks vs. Users without Networks
1
4
16
64
256
1024
4096
1 8 64 512 4096
No
. o
f U
se
rs
No. of ItemsWith Networks
Without Networks

Among 4550 users with connections, 1,826 users watch other users as their networks and among them (for only unidirectional relations), 631 users are watched by other users and 1,195 users are not watched by anyone else. Regardless of whether they watch other users or not, 3,296 users are being watched by at least one user (for only unidirectional relations). Out of these users, as described, 631 users watch other users as their networks and 2,665 users are not watching anyone else.
Figure 7. Distribution of Shared Items and Meta-data (Direct Unidirectional Relationships)
Figure 8. Distribution of Shared Micro Tags and Macro Tags (Direct Unidirectional Relationships)
As we found out, despite a relatively large number of connected pairs, the overall level of information sharing was quite low. Out of 11,295 direct unidirectional pairs, 8,502 pairs did not have any common reference, 9,870 pairs did not use the same tag on the same item (micro level tag similarity), and 2,503 have no common tags at all (macro level tag similarity). The remaining users shared one or more items or tags. Thus Figure 7 and Figure 8 show how the amount of shared information is distributed over the users for direct unidirectional relations (after excluding the pairs with zero overlap). As some other distributions in collaborative tagging systems, it exhibits features of exponential distribution (appearing as straight line in log-log coordinates).
5.2 Information Similarity for Socially
Connected Pairs To test whether users connected by direct or distant social links share more information than non-connected pairs (H1), firstly we compared both absolute numbers of shared information items and metadata (Table 2). Secondly, we explored differences in relative similarity measures – fractions of shared items and meta-data for
unidirectional relationships (inlink, outlink, and overall fractions - Table 3). In all four cases, the differences for all absolute and relative measures were significant among the network distances. Directly related users have the largest fraction of shared items and meta-data and this fraction decreases with the increase of the distance between users and reaches its minimal level for not connected users (infinite distance). This data supports our H1.
Table 2. Average Numbers of the Common Information Items
Reci. Direct 1hop 2hops No Rel.
Items 15.84 1.59 .36 .21 .00
Kruskal-Wallis H = 115155.66, df = 3, p > .001
Meta-data
155.33 31.85 26.48 25.08 1.24
Kruskal-Wallis H = 7979.55, df = 3, p > .001
To check H2, we examined the number of shared items and metadata, for 93 reciprocal connections in our dataset. As we discovered, the information similarity for the users involved in a reciprocal relationship was much larger than similarity for unidirectional pairs (Table 4). An independent sample t-test demonstrated that the number of shared information items in reciprocal relationships (M = 15.84) was significantly larger than in unidirectional relationships (M = 1.59, t = -22.39, p < .001). The difference between reciprocal (M = 155.33) and unidirectional (M = 31.85) relations in the amount of shared meta-data was also significant (t = -11.06, p < .001).
Table 3. Similarity Powers in Citeulike (Unidirectional Relations)
Direct 1hop 2hop No Rel.
Items Inlink 2.35% 0.62% 0.46% 0.02%
Kruskal-Wallis H = 18894.70, df = 3, p > .001
Outlink 0.85% 0.14% 0.09% 0.02%
Kruskal-Wallis H = 2311.79, df = 3, p > .001
Overall 0.33% 0.06% 0.03% 0.00%
Kruskal-Wallis H = 5907.18, df = 3, p > .001
Meta-data
Inlink 6.09% 3.43% 3.16% 0.17%
Kruskal-Wallis H = 21847.14, df = 3, p > .001
Outlink 2.93% 1.71% 1.49% 0.17%
Kruskal-Wallis H = 5862.95, df = 3, p > .001
Overall 1.49% 1.08% 0.98% 0.07%
Kruskal-Wallis H = 4939.14, df = 3, p > .001
Table 4. Difference of Relative Similarity
Recipro. Unidir. Diff (Sig.)
Items Inlink 6.35% 2.35% t = -5.55 (p < .001)
Outlink 6.35% 0.85% t = -18.86 (p < .001)
Overall 2.16% 0.33% t = -16.60 (p < .001)
Meta-data
Inlink 13.78% 6.09% t = -6.58 (p <.001)
Outlink 13.78% 2.93% t = -14.49 (p <.001)
Overall 6.09% 1.49% t = -9.32 (p <.001)
For all relative similarity measures (inlink, outlink and overall fractions) for reciprocal relationships was also larger than for unidirectional relationships. While the differences was less remarkable in relative measures than in absolute numbers, all differences appeared to be significant as well, i.e., users connected by a reciprocal relation shared significantly larger fractions of information items than users connected by unidirectional relation (Table 4). Note that since reciprocal connections are symmetric, the inlink and outlink values are same.
1
4
16
64
256
1024
4096
16384
1 4 16 64 256
No
. o
f N
etw
ork
No. of Shared Informationitems
Meta-data
1
4
16
64
256
1024
4096
16384
1 4 16 64 256
No
. o
f N
etw
ork
No. of Shared Informationmicro tag
macro tag
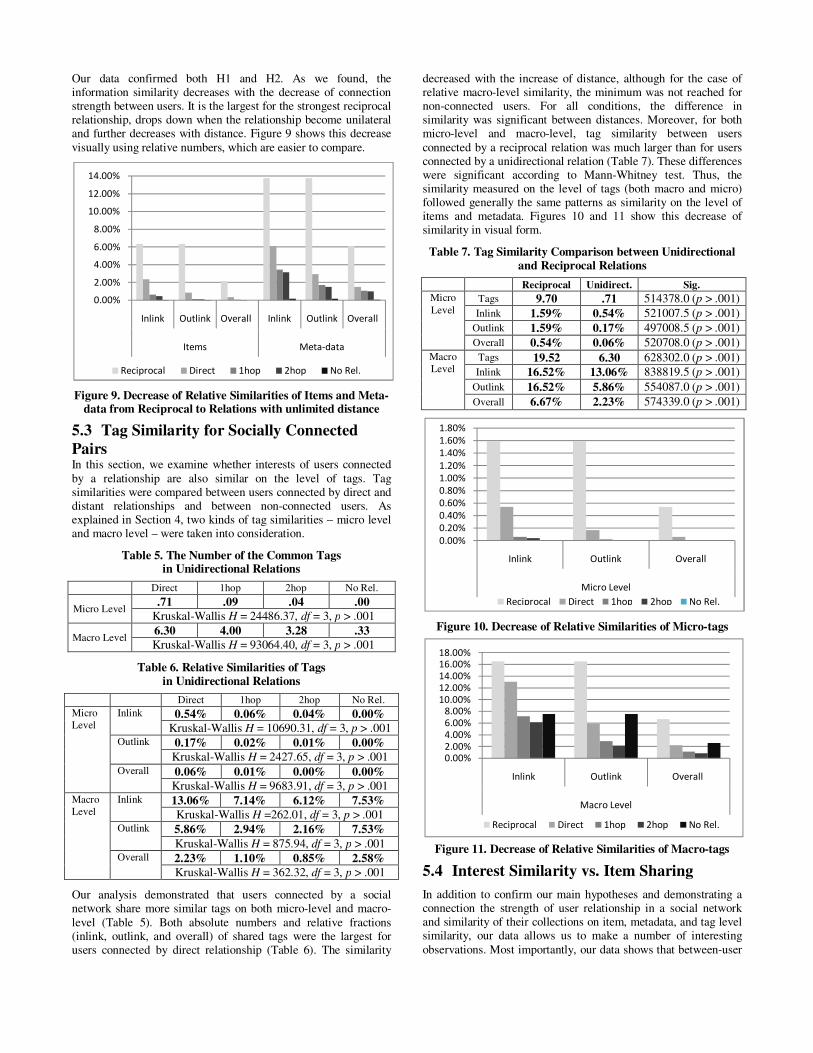
Our data confirmed both H1 and H2. As we found, the information similarity decreases with the decrease of connection strength between users. It is the largest for the strongest reciprocal relationship, drops down when the relationship become unilateral and further decreases with distance. Figure 9 shows this decrease visually using relative numbers, which are easier to compare.
Figure 9. Decrease of Relative Similarities of Items and Meta-data from Reciprocal to Relations with unlimited distance
5.3 Tag Similarity for Socially Connected
Pairs In this section, we examine whether interests of users connected by a relationship are also similar on the level of tags. Tag similarities were compared between users connected by direct and distant relationships and between non-connected users. As explained in Section 4, two kinds of tag similarities – micro level and macro level – were taken into consideration.
Table 5. The Number of the Common Tags in Unidirectional Relations
Direct 1hop 2hop No Rel.
Micro Level .71 .09 .04 .00
Kruskal-Wallis H = 24486.37, df = 3, p > .001
Macro Level 6.30 4.00 3.28 .33
Kruskal-Wallis H = 93064.40, df = 3, p > .001
Table 6. Relative Similarities of Tags
in Unidirectional Relations
Direct 1hop 2hop No Rel.
Micro Level
Inlink 0.54% 0.06% 0.04% 0.00%
Kruskal-Wallis H = 10690.31, df = 3, p > .001
Outlink 0.17% 0.02% 0.01% 0.00%
Kruskal-Wallis H = 2427.65, df = 3, p > .001
Overall 0.06% 0.01% 0.00% 0.00%
Kruskal-Wallis H = 9683.91, df = 3, p > .001
Macro Level
Inlink 13.06% 7.14% 6.12% 7.53%
Kruskal-Wallis H =262.01, df = 3, p > .001
Outlink 5.86% 2.94% 2.16% 7.53%
Kruskal-Wallis H = 875.94, df = 3, p > .001
Overall 2.23% 1.10% 0.85% 2.58%
Kruskal-Wallis H = 362.32, df = 3, p > .001
Our analysis demonstrated that users connected by a social network share more similar tags on both micro-level and macro-level (Table 5). Both absolute numbers and relative fractions (inlink, outlink, and overall) of shared tags were the largest for users connected by direct relationship (Table 6). The similarity
decreased with the increase of distance, although for the case of relative macro-level similarity, the minimum was not reached for non-connected users. For all conditions, the difference in similarity was significant between distances. Moreover, for both micro-level and macro-level, tag similarity between users connected by a reciprocal relation was much larger than for users connected by a unidirectional relation (Table 7). These differences were significant according to Mann-Whitney test. Thus, the similarity measured on the level of tags (both macro and micro) followed generally the same patterns as similarity on the level of items and metadata. Figures 10 and 11 show this decrease of similarity in visual form.
Table 7. Tag Similarity Comparison between Unidirectional
and Reciprocal Relations
Reciprocal Unidirect. Sig.
Micro
Level Tags 9.70 .71 514378.0 (p > .001)
Inlink 1.59% 0.54% 521007.5 (p > .001)
Outlink 1.59% 0.17% 497008.5 (p > .001)
Overall 0.54% 0.06% 520708.0 (p > .001) Macro Level
Tags 19.52 6.30 628302.0 (p > .001) Inlink 16.52% 13.06% 838819.5 (p > .001)
Outlink 16.52% 5.86% 554087.0 (p > .001)
Overall 6.67% 2.23% 574339.0 (p > .001)
Figure 10. Decrease of Relative Similarities of Micro-tags
Figure 11. Decrease of Relative Similarities of Macro-tags
5.4 Interest Similarity vs. Item Sharing
In addition to confirm our main hypotheses and demonstrating a connection the strength of user relationship in a social network and similarity of their collections on item, metadata, and tag level similarity, our data allows us to make a number of interesting observations. Most importantly, our data shows that between-user
0.00%
2.00%
4.00%
6.00%
8.00%
10.00%
12.00%
14.00%
Inlink Outlink Overall Inlink Outlink Overall
Items Meta-data
Reciprocal Direct 1hop 2hop No Rel.
0.00%
0.20%
0.40%
0.60%
0.80%
1.00%
1.20%
1.40%
1.60%
1.80%
Inlink Outlink Overall
Micro Level
Reciprocal Direct 1hop 2hop No Rel.
0.00%
2.00%
4.00%
6.00%
8.00%
10.00%
12.00%
14.00%
16.00%
18.00%
Inlink Outlink Overall
Macro Level
Reciprocal Direct 1hop 2hop No Rel.

similarity on the level of metadata and macro-tags is much larger than similarity on the level of items. In other words, connected users have many more common authors and tags than they have items. This difference is most easily noticeable in absolute numbers (Table 2 and Table 5), but is still remarkable even in relative numbers. For example, the inlink similarity of items in direct relation is 2.35% while inlink similarity of meta-data in the same direct relation is 6.09% and inlink similarity of tags is 13.06%. Since both tagging papers of the same authors and usage of same tags are good indicators of interest similarity, we can interpret this result as a confirmation of our hypothesis that in social tagging systems interest similarity of two users might be closer than is indicated by simply counting the number of shared items. In other words, the users undershare items.
5.5 Watching vs. Watched Users
Another interesting observation, which could be derived from data tables is that inlink similarity is typically much larger than outlink similarity in unidirectional relationships. It hints that the size of item collection of an average watching user is much smaller than a size of the collection of an average user watched by other users. This trend can be easily confirmed by plotting traditional collection size distribution separately for watching and watched users (Figure 12). While both distributions follow the common exponential pattern of social tagging systems, the distribution for watched users is shifted to the right towards larger collection sizes. In other words, in Citeulike users who watch others tend to be more information-poor than those they watch.
Table 8 examines average collection sizes for different subsets of users more closely. The number of items is significantly the largest for the users in reciprocal relationship and the smallest for the users with no relations (Kruskal-Wallis H = 4627.69, df = 3, p < .001). Average watching users have significantly less items (M=175.11) then average watched users (M = 209.55, Mann-Whitney U = 2665596.0, p < .001). Clearly, being watched by others is a signal of information richness. Moreover, as it appears, being watched by many users is even more reliable signal. We found a significant correlation between the number of watchers and several indicators of richness: the number of items in a collection (r = .355, p < .001), the number of macro tags (r = .319, p < .001), and the number of micro tags (r = .263, p < .001).
Figure 12. Distribution of Item Numbers of Watching Users vs. Watched Users
At the same time, the fact that a user watches other user could be considered as a secondary signal of information richness. As Table 8 shows, even those watching users who are not watched by others have more than twice as many items in average than users
with no social connections. Among users being watched, those who watch others are also twice more rich than those who do not watch others. Some reason to consider this indicator as secondary is the surprising lack of correlation between the number of users watched by a user and the number of items, macro tags, and micro tags assembled by that user.
Table 8. Users in Different User Groups and the Number of Items They Have
Kind of user groups No. of Users No. of Items Users unidirectionally watching 1826 175.11 Users being watched among the users watching / Users watching
others among the users being watched
631 357.01
Users not being watched among the users watching
1195 79.00
Users unidirectionally being watched 3296 209.55 Users not watching others among the
users being watched 2665 172.90
Users watching each other
(reciprocal relations) 172 423.03
Users neither watching others nor being watched
15409 32.63
5.6 Propagation or Interest Similarity?
The overlap between item collections of two connected users can be explained by two factors. First, it can be a direct outcome of shared interest of these two users – i.e., both of them can find this item interesting and bookmark it independently. At the same time, it can be also a result of information propagation, i.e., borrowing items by a watching user from the watched user, which also indicates the commonality of interests, but to a lesser extent. While the mechanism of watching encourages such propagation, a remarkably low number of shared items discovered in our study caused us to consider propagation to be a less likely cause of similarity. The lack of correlation between the number of watched users and the collection size also contradicts the idea that the propagation is the leading cause of similarity.
To answer this question more reliably, we compared the time difference between item bookmarking by the watching users and the watched user. Specifically, among all shared items, the time the items are saved by the watching and the watched users. Out of 11295 unidirectional relations, 2793 pairs have at least one item in common. 50.07% of the common items was saved by the watched users first and later by the watching users. Naturally, for the remaining 49.93% of items the reverse is true, i.e., both users are equally likely to discover the item first. All these data supports our main assumption that overlap of item collection is a sign of common interests rather than information borrowing.
5.7 Item Sharing and Item Popularity Another issue to explore was the connection between, the item popularity and item sharing. For this test, we select all items, which were stored by more than one user. Out of total 22,800 items, 14,421 items (63.25%) were stored by at least one pair of social network. The other 8,379 items (36.75%) are not shared by anyone in the social connections and only by people having no connection.
While it is natural to expect that more popular items are shared by connected users more frequently, the reverse appeared to be true. In order to normalize the data distribution (the more users store items, the more pairs share the items) we computed the percentage
1
2
4
8
16
32
64
128
256
1 4 16 64 256 1024 4096 16384
No
. o
f U
se
rs
No. of Items Watching Users
Watched Users

of the unidirectional or reciprocal relations among all the people who store the information item. There was a significant negative relationship between the item popularity and the percentage of networks, r = -.026, p < .001. Namely, less popular items were shared more by socially connected pairs, even the size of correlation was small (r < .3). Thus, more unique and rare information has a higher chance to be shared by users in social connections. This fact reveals deeper-level interest similarity between users in social networks.
Remarkably, the reverse is true for tag sharing. We found the significant positive correlation between tag popularity and the percentage of social networks in the group of users who used the tags, r = .241, p < .001.
5.8 Comparison between Social Networks and
Traditional CF-based Peer Cohorts
As explained in the introduction, the ultimate goal of our study is to embed information of users’ social network into traditional collaborative filtering algorithm. Therefore, we tested how many peer cohorts who are automatically chosen by CF approach are socially connected. In order to compare social networks and CF based peer cohorts, as target users, we selected the 1826 users who have at least one watching user. Using item-based Jaccard similarity, their peer group was selected among all other users regardless they are socially connected or not. Out of the 1826 target users, 1755 users have their peer cohorts but we failed to find any cohort for other 71 users. This result could be caused by the difference of the numbers of items. The users having peer cohorts have 180.89 items on average and the others without any cohort have 32.27 items.
Figure 13. Percentage of Social Networks in Peer Cohorts
We chose the top N peers of each target user and examined how many peer cohorts are socially connected with the target user. For top 5 peers, 0.75 peer user (14.95%) was watched by the target users. Among top 10 users and top 20 users, 1.31 peers (13.14%) and 2.40 peers (12.01%) were watched, respectively. Among top 5 peer users, 0.86 user (17.14%) is socially connected (i.e. the one who a target user watches or who watches a target user). For top 10 peer users, 1.48 users (14.76%) and 2.65 users (13.25%) are socially connected for top 10 and top 20 peer users respectively. When we include 1 hop distance relations as the social connections, 0.95 peer user (19.09%) was in social connection for
top 5 users. 1.70 peers (16.96%) and 3.09 peers (15.47%) were socially connected in top 10 and top 20 peers. Finally, we test how many peer users are in social networks of at most 2 hop distance, 0.99 users (19.80%), 1.79 users (17.88%), and 3.30 users (16.51%) are in social networks for top 5, top 10, and top 20 peers. Figure 13 displays the increased portion of social connections along with the expansion of social networks.
6. CONCLUSION AND DISCUSSION The paper argued that users’ self-defined social relations could be valuable to increase the quality of recommendation in CF systems. To prove the feasibility of this idea we examined how similar are interests of users connected by a self-defined social networks. Interest similarity was measured by similarity of items and sources they share and tags they use. For the future application, we explored the information sharing patterns, as well.
Using dataset collected from Citeulike system, we found that user connected by a self-defined social networks have more common information items, metadata, and tags than non-connected users. The similarity was largest for direct connections and decreased with the increase of distance between users in the social networks. Users involved in a reciprocal relationship exhibited significantly larger similarity than users in a unidirectional relationship on all levels. We also found some evidence that item similarity discovered in our study was really caused by similarity of interests rather than simple information propagation.
In addition, we discovered similarity on the level of metadata (authors) and tags was larger than similarity on the level of individual items (references). That is to say, due to irregular nature of bookmarking process, item-level similarity may lag behind “true” interest similarity between connected users and in some sense the users undershare items. This finding provides some additional messages for the authors of CF systems. First, it indicates that traditional item-level similarity may be less reliable way to find similar users in social bookmarking systems. At the same time, it hints that items collections of peers connected by self-defined social connections could be a useful source for cross-recommendation. Of course, with all information in favor of social network-based recommenders discovered in our study, it is still a challenge to build useful the recommendation algorithms.
Granovetter (Granovetter 1983) asked the same question in job search context. He compared the flow of information about job openings between weakly tied and strongly tied relations. He insisted that the influence of strongly connected people, such as friends, family, or relatives was not important regarding the dissemination of information. This is because the same information is circulated only inside of their network circle and hardly gets outside of the social network; therefore, it is difficult for new information to get inside of the network. Because of this, the information delivered from the weakly tied network is more useful than information from the strongly tied network.
The paper also showed that the job opening information is much easier to obtain from an acquaintance than from people close to the individual. This trend grows stronger when the people have a higher education background and the information is more professional in nature (Granovetter 1983). As Grannovetter suggested through empirical analysis in another study, the strength of the relationship is proportional to their similarity (Granovetter 1973). In this knowledge-driven era, nevertheless, if a person wants to acquire new professional information it is more useful to take advantage of information available outside of their own limited social network (Granovetter 1983). This study
0.00%2.00%4.00%6.00%8.00%
10.00%12.00%14.00%16.00%18.00%20.00%
Wa
tch
ing
Wa
tch
ing
& W
atc
he
d
1 h
op
dis
tan
ce
2 h
op
dis
tan
ce
Wa
tch
ing
Wa
tch
ing
& W
atc
he
d
1 h
op
dis
tan
ce
2 h
op
dis
tan
ce
Wa
tch
ing
Wa
tch
ing
& W
atc
he
d
1 h
op
dis
tan
ce
2 h
op
dis
tan
ce
Top 5 peers Top 10 peers Top 20 peers

implies two points worth pondering. Firstly, personal interactions are not essential elements in acquiring useful information. Weakly tied networks which have no or few personal contacts are quite common on the Web. Secondly, the question of how to compromise between information similarity and usefulness is arisen. To cope with questions about the usefulness of the shared information in a social network, in future, we plan to examine the recommendation quality, using our data sets. How the information propagates within the social network and the influence of information authorities who play a leading role in disseminating the information will both be investigated. In later studies, we plan to expand our target domains by adding different data sets.
7. REFERENCES [1] Adamic, L. A. and E. Adar (2003). "Friends and neighbors on
the Web." Social Networks 25(3): 211-230. [2] Ahn, Y.-Y., S. Han, et al. (2007). Analysis of topological
characteristics of huge online social networking services. Proceedings of the 16th international conference on World Wide Web. Banff, Alberta, Canada, ACM: 835-844.
[3] Bonhard, P. and M. A. Sasse (2006). "'Knowing me, knowing you' -- Using profiles and social networking to improve recommender systems." BT Technology Journal 24(3): 84-98.
[4] Crandall, D., D. Cosley, et al. (2008). Feedback effects between similarity and social influence in online communities. Proceeding of the 14th ACM SIGKDD international conference on Knowledge discovery and data mining. Las Vegas, Nevada, USA, ACM: 160-168.
[5] DuBois, J., Golbeck, J. Kleint, J. & Srinivasan (2009). Improving Recommendation Accuracy by Clustering Social Networks with Trust. Proc. Of ACM RecSys 2009 Workshop on Recommender Systems and the Social Web, New York, New York.
[6] Dugan, C., M. Muller, et al. (2007). The dogear game: a social bookmark recommender system. Proceedings of the 2007 international ACM conference on Supporting group work. Sanibel Island, Florida, USA, ACM: 387-390.
[7] Firan, C. S., W. Nejdl, et al. (2007). The Benefit of Using Tag-Based Profiles. Proceedings of the 2007 Latin American Web Conference, IEEE Computer Society: 32-41.
[8] Granovetter, M. (1973). "The Strength of Weak Ties." American Journal of Sociology 78(6): 1361 ~ 1380.
[9] Granovetter, M. (1983). "The Strength of Weak Ties: A Network Theory Revised." Sociological Theory 1: 201 ~ 233.
[10] Guy, I., N. Zwerdling, et al. (2009). Personalized recommendation of social software items based on social relations. Proceedings of the third ACM conference on Recommender systems. New York, New York, USA, ACM: 53-60.
[11] Hotho, A., R. Jäschke, et al. (2006). Information Retrieval in Folksonomies: Search and Ranking: 411-426.
[12] Hotho, A., R. Jäschke, et al. (2006). Trend Detection in Folksonomies: 56-70.
[13] Hung, C.-C., Y.-C. Huang, et al. (2008). Tag-based User Profiling for Social Media Recommendation. Workshop on Intelligent Techniques for Web Personalization and Recommender Systems, AAAI 2008.
[14] Jamali, M. and M. Ester (2009). Using a trust network to improve top-N recommendation. Proceedings of the third ACM conference on Recommender systems. New York, New York, USA, ACM: 181-188.
[15] Kautz, H., B. Selman, et al. (1997). "Referral Web: combining social networks and collaborative filtering." Commun. ACM 40(3): 63-65.
[16] Lam, S. K. and J. Riedl (2004). Shilling recommender systems for fun and profit. Proceedings of the 13th international
conference on World Wide Web. New York, NY, USA, ACM: 393-402.
[17] Lund, B., T. Hammond, et al. (2005). "Social Bookmarking Tools (II)." D-Lib Magazine 11(4): 1-1.
[18] Maltz, D. and K. Ehrlich (1995). Pointing the way: active collaborative filtering. Proceedings of the SIGCHI conference on Human factors in computing systems. Denver, Colorado, United States, ACM Press/Addison-Wesley Publishing Co.: 202-209.
[19] Massa, P. and P. Avesani (2004). Trust-Aware Collaborative Filtering for Recommender Systems.
[20] Massa, P. and P. Avesani (2007). Trust-aware recommender systems. Proceedings of the 2007 ACM conference on Recommender systems. Minneapolis, MN, USA, ACM: 17-24.
[21] McDonald, D. W. (2003). Recommending collaboration with social networks: a comparative evaluation. Proceedings of the SIGCHI conference on Human factors in computing systems. Ft. Lauderdale, Florida, USA, ACM: 593-600.
[22] Mehta, B., T. Hofmann, et al. (2007). Robust collaborative filtering. Proceedings of the 2007 ACM conference on Recommender systems. Minneapolis, MN, USA, ACM: 49-56.
[23] O'Donovan, J. and B. Smyth (2005). Trust in recommender systems. Proceedings of the 10th international conference on Intelligent user interfaces. San Diego, California, USA, ACM: 167-174.
[24] Schaefer, J. B., D. Frankowski, et al. (2007). Collaborative Filtering Recommender Systems. The Adaptive Web: Methods and Strateiges of Web Personalization. P. Brusilovsky, A. Kobsa and W. Nejdl. Berlin, Germany, Springer: 291-324.
[25] Schenkel, R., T. Crecelius, et al. (2008). "Social Wisdom for Search and Recommendation." IEEE Data Eng. Bull. 31(2): 40-49.
[26] Singla, P. and M. Richardson (2008). Yes, there is a correlation: - from social networks to personal behavior on the web. Proceeding of the 17th international conference on World Wide Web. Beijing, China, ACM: 655-664.
[27] Sinha, R. and K. Swearingen (2001). Comparing Recommendations Made by Online Systems and Friends. In Proceedings of the DELOS-NSF Workshop on Personalization and Recommender Systems in Digital Libraries.
[28] Tintarev, N. and J. Masthoff (2007). Effective explanations of recommendations: user-centered design. Proceedings of the 2007 ACM conference on Recommender systems. Minneapolis, MN, USA, ACM: 153-156.
[29] von Ahn, L. (2006). "Games with a Purpose." IEEE Computer Magazine June 2006: 96 - 98.
[30] Wellman, B. (2001). "Computer Networks As Social Networks." Science 293(5537): 2031-2034.
[31] Wellman, B. (2007). "The network is personal: Introduction to a special issue of Social Networks." Social Networks 29(3): 349-356.
[32] Yang, S. J. H. and I. Y. L. Chen (2008). "A social network-based system for supporting interactive collaboration in knowledge sharing over peer-to-peer network." Int. J. Hum.-Comput. Stud. 66(1): 36-50.
[33] Zhao, S., N. Du, et al. (2008). Improved recommendation based on collaborative tagging behaviors. Proceedings of the 13th international conference on Intelligent user interfaces. Gran Canaria, Spain, ACM: 413-416.
[34] Ziegler, C.-N. and J. Golbeck (2007). "Investigating interactions of trust and interest similarity." Decis. Support Syst. 43(2): 460-475.




















