
Fuzzy optimisation of multi-objective job shop scheduling based on inventory information

Simulation-based average case analysis for parallel job scheduling
Fabricio Alves Barbosa da Silva1;Isaac D. Scherson1;2;
[email protected], [email protected] ASIM, LIP6, Universite Pierre et Marie Curie, Paris,France.2Dept. of Information and Comp. Science, University of California, Irvine, CA92697, U.S.A
Abstract
This paper analyses the resource allocation problem inparallel jobs scheduling, with emphasis given to gang ser-vice algorithms. Gang service has been widely used asa practical solution to the dynamic parallel job schedul-ing problem. To provide a sound analysis of gang serviceperformance, a novel methodology based on the traditionalconcept of competitive ratio is introduced. Dubbed dynamiccompetitive ratio, the new method is used to do an averagecase analysis based on simulation of resource allocation al-gorithms. These resource allocation algorithms apply to thegang service scheduling of a workload generated by a sta-tistical model. Moreover, dynamic competitive ratio is thefigure of merit used to evaluate and compare packing strate-gies for job scheduling under multiple constraints. It willbeshown that for the unidimensional case there is a small dif-ference between the performance of best fit and first fit; firstfit can hence be used without significant system degrada-tion. For the multidimensional case, when memory is alsoconsidered, we concluded that the resource allocation al-gorithm must try to balance the resource utilization in alldimensions simultaneously, instead of given priority to onlyone dimension of the problem.
Keywords - Parallel Job Scheduling, Gang schedul-ing, Coscheduling, Parallel Computation, Dynamic Algo-rithm Analysis, Competitive Analysis, Resource Manage-ment, Bin-Packing.
1 Introduction
Parallel job scheduling is an important problem whosesolution may lead to better utilization of modern multipro-
cessors and/or parallel computers. The basic schedulingproblem can be stated as follows: “Given the aggregate ofall tasks of multiple jobs in a parallel system, find a spa-tial and temporal allocation to execute all tasks efficiently”.For the purposes of scheduling, we view a computer as aqueueing system. An arriving job may wait for some time,receive the required service, and depart. The time associ-ated with the waiting and service phases is a function of thescheduling algorithm and the workload. Some schedulingalgorithms may require that a job wait in a queue until allof its number of required processors become available (asin variable partitioning [9]), while in others, like time slic-ing, the arriving job receives service immediately throughaprocessor sharing discipline.
We focus on scheduling based on gang service [24],namely, a paradigm where all tasks of a job in the servicestage are grouped into a gang and concurrently scheduledin distinct processors. Given a job composed of N tasks,in gang service these N tasks compose a process workingset, and all tasks belonging to this process working set arescheduled simultaneously in different processors, i.e., gangservice algorithms is the class of algorithms that scheduleon the basis of whole process working sets [24]. Reasonsto consider gang service are responsiveness [10], efficientsharing of resources [17] and ease of programming. In gangservice the tasks of a job are supplied with an environmentthat is very similar to a dedicated machine [17]. It is usefulto any model of computation and any programming style.The use of time slicing allows performance to degrade grad-ually as load increases. Applications with fine-grain inter-actions benefit of large performance improvements over un-coordinated scheduling [13].
Gang service allows both the time sharing as well as thespace sharing of the machine, and it was originally intro-

duced by Ousterhout [24]. Performance benefits of gangservice the set of tasks of a job has been extensively ana-lyzed in [17, 10, 13, 32]. Packing schemes for gang servicewere analyzed in [8].
Some implementations of gang service have been de-scribed in the literature. Hori et al. [16] describe a gangscheduler implementation in a workstation cluster that al-lows the time sharing of a 64 processor machine inter-connected by Myrinet. Feitelson and Rudolph proposedthe distributed hierarchical control (DHC) [11, 14, 12],which defines a control structure over the parallel machineand combines time-slicing with a buddy-system partition-ing scheme. In [11] a DHC scheme for supporting gangscheduling was proposed. Gang schedulers based on thedistributed hierarchical control structure has been imple-mented for the IBM RS/6000 [15, 5], and its performancehas been analyzed from a queueing theoretic perspective[29]. Suzaki and Walsh [30] proposed a variation of gangscheduling for Fujitsu AP1000+ parallel computed dubbedModerate coscheduling. This algorithm controls the orderof priority of parallel processes managed by the local sched-uler in processors which relaxes some of the strict condi-tions of gang scheduling. Silva and Scherson [27, 26] pro-posed a improved scheduling algorithm based on gang ser-vice, dubbed concurrent gang, that allows the simultaneousscheduling of parallel jobs and solves two main problemsrelated with gang service, i.e. task blocking and I/O boundjob performance.
The efficient allocation of existing resources is funda-mental for improving the performance of scheduling algo-rithms in general, and gang service algorithms in particular.Depending on the scheduling strategy used, a number ofheuristics are available. To decide which heuristic is bet-ter for a given algorithm, two basic methodologies most areused. The first one is worst case or competitive analysis.Competitive analysis is the technique of evaluating an algo-rithm by comparing its performance to the optimal off-linealgorithm. Competitive analysis is a formal way of eval-uating algorithms that are limited in some way (e.g., lim-ited information, computational power, number of preemp-tions) [4]. This measure was first introduced in the study ofa memory management system [21, 28]. The second possi-bility is to use average case analysis. The need for an aver-age case analysis arises from the fact that in many applica-tions the worst case never seems to occur. Thus, for thesecases there is a strong need for results that tell us more abouttypical behavior. Some theoretical results for average caseanalysis are available[1], but these results are valid onlyforinputs described only by simple probability distributions. Itis increasingly more difficult to find theoretical results astheprobability distributions of the input in the average case be-come more complex. In these cases, simulation is the mosteffective way of doing an average case analysis of heuristics
associated with a given algorithm. In this paper we proposea methodology for average case analysis of algorithms us-ing simulation dubbed dynamic competitive ratio.
The architectural model we consider in this paper is adistributed memory multiprocessor with four main compo-nents: 1) Processor/memory modules (Processing Elements- PE), 2) An interconnection network that provides point topoint communication, 3) A synchronizer, that synchronizesall components at regular intervals in order to coordinatethe context switch among all processors and 4) A front end,where jobs are submitted. This architecture model is similarto the one defined in the BSP model [31].
The programming model considered in this paper is theSPMD (single program, multiple data) model. The SPMDparadigm is by far the most popular parallel programmingstyle. We adopt here the SPMD programming model as thebasis for workload generation to evaluate the efficiency ofour proposed scheduling algorithms.
In section 2 some preliminary definitions are stated. Theone dimensional resource sharing problem for gang servicealgorithms is stated and analyzed in section 3. The multidimensional resource sharing problem is the subject of sec-tion 4. Section 5 contains our final remarks.
2 Generalities and Definitions
Consider the scheduling of a set of parallel jobs. A use-ful tool to help visualize the time utilization in parallel ma-chines is a two-dimensional diagram dubbedtrace diagram.The trace diagram is also known in the literature as Ouster-hout matrix [24]. Referring to figure 1, one dimensionrepresents processors while the other dimension representstime. Through the trace diagram it is possible to visualizethe time utilization of the set of processors given a schedul-ing algorithm.
Gang Scheduling can hence be defined with respect tothe trace diagram as the concurrent scheduling of the setof tasks of a job in a slice. Finding a scheduling becomesequivalent to computing the trace diagram for a given work-load (a set of jobs). The trace diagram is first computed atpower up and updated at each workload change (task arrival,completion, etc). Gang service algorithms are preemptivealgorithms. We will be particularly interested in gang ser-vice algorithms which areperiodic and preemptive. Relatedto periodic preemptive algorithms are the concepts of cycle,slice, period and slot. AWorkload changeoccurs at the ar-rival of a new job, the termination of an existing one, orthrough the variation of the number of eligible tasks of ajob to be scheduled. The time between workload changes isdefined as acycle. Between workload changes, we may de-fine a period that is a function of the workload and the spa-tial allocation. The period is the minimum interval of timewhere all jobs are scheduled at least once. A cycle/period is
2

��������
��������
��������
��������
��������
��������
��������
��������
��������
��������
��������
��������
��������
��������
��������
J1
J1
J1
J1
Period
Workload Change Workload Change
Cycle
Period Period Period
Slot
J2
J2
J2
J2
J3
J4
J4
J4
J4
J4
J6
J6J1
J1
J3
P0
P1
P2
P3
P4
J5
J5
Slice
Idle Slots
Time
n-1P
Figure 1. Time Utilization in Parallel Machines
composed ofslices; a slice corresponds to a time slice in apartition that includes all processors of the machine. Aslotis the processors’ view of a slice. A Slice is composed of Nslots, for a machine with N processors. If a processor hasno assigned task during its slot in a slice, then we have anidle slot. The number of idle slots in a period divided by thetotal number of slots in that period defines theIdling Ratio.
Some important results can be derived from the trace di-agram:
Theorem 1 Given a workload W composed of parallelSPMD jobs, for every temporal schedule S there exists aperiodic scheduleSp such that the idling ratio ofSp is atmost that of S.
Proof 1 First, let’s give a definition that will be useful inthis proof. We define herejob happinessin an interval oftime as the number of slots allocated to a job divided by thetotal number of slots in the interval.
Define the progress of a job at a particular time as thenumber of slices granted to each of its tasks up to that time.Thus, if a job has V tasks, its progress at sliceS may berepresented by aprogress vectorof V components, whereeach component is an integer less than or equal to S. Ob-serve that no task may lag behind another task of the sameparallel SPMD job by more than a constant C number ofslices. We call this behavior aslegal execution rule. Notethat C depends on the characteristics of the program. Itcan be determined, for instance, by global synchronizationstatements. In the worst case C slices corresponds to thecompletion time of the job. Observe thatC < 1, since thedata partitions in a SPMD program are necessarily finite,so is the program itself. Therefore, no two elements in theprogress vector can differ by more than C. Define the differ-ential progress of a job at a particular time as the number of
slices by which each task leads the slowest task of the job.Thus a differential progress vector at time t is also a vec-tor of V components, where each component is an integerless than or equal to C. The differential progress vector isobtained by subtracting out the minimum component of theprogress vector from each component of the progress vector.Thesystem’s differential progress vector(SDPV) at time tis the concatenation of all job’s differential progress vectorsat time t. The key is to note that the SDPV can only assumea finite number of values. Therefore there exists an infinitesequence of timesti1 ; ti2; ::: such that the SDPVs at thesetimes are identical.
Consider any time interval[tik; ti0k]. One may constructa periodic schedule by cutting out the portion of the tracediagram betweentik ti0k and replicating it indefinitely alongthe time axis.
We claim that such a periodic schedule is legal. Fromthe equality of the SPDVs attik and ti0k it follows that alltasks belonging to the same job receive the same number ofslices during each period. In other words, at the end of eachperiod, all the tasks belonging to the same job have madeequal progress. Therefore, no two tasks lag behind anothertask of the same job by more than a constant number ofslices.
Secondly, observe that it is possible to choose a time in-terval [tik ; ti0k] such that the happiness of each job duringthis interval is at least as much as in the complete trace di-agram. This implies that the happiness of each job in theconstructed periodic schedule is larger than or equal to thehappiness of each job in the original temporal schedule.
Therefore, the idling ratio of the constructed periodicschedule must be less than or equal to the idling ratio of theoriginal temporal schedule. Since the fraction of area in thetrace diagram covered by each job increases, the fractioncovered by the idle slots must necessarily decrease. Thisconcludes the proof.
A consequence of the previous theorem is stated in thefollowing corollary:
Corollary 1 Given a WorkloadW , for the set of all feasibleperiodic schedules S, the schedule with smaller idling ratiois the one with smaller period.
Proof 2 The feasible schedule with smaller period is theone which has the smaller number of slices (resulting in asmaller number of total slots) and which packs all jobs asdefined in the gang service algorithm. The number of oc-cupied slots is the same for all feasible periodic schedules,since the workload is the same. So the ratio between thenumber of idle slots, which is the difference between the to-tal number of slots and the number of occupied slots, andthe total number of slots is minimized when we have a mini-mum number of total slots, which is the case in the minimumperiod schedule.
3

As a consequence of the previous corollary, only periodschedules will be considered for the rest of this paper.
2.1 Other Definitions
We will also considerClairvoyant scheduling algorithmsas those that may use knowledge of the jobs’ executiontimes to assign time intervals to jobs in a set of proces-sors. Non-Clairvoyant Scheduling Algorithmsassign timeinterval to jobs in a set of processors without knowing theexecution times of jobs that have not yet been completed.A scheduling problem is said to bestaticif all release timesare 0, i.e., all the jobs are available for execution at the startof the schedule. Adynamicscheduling problem allows arbi-trary (nonnegative) release jobs. A Parallel job is composedof tasks, and we definePreemptive scheduling algorithmsas those where the execution of any task can be suspendedat any time and resumed later from the point of preemption.
3 One Dimensional Resource Sharing
In the one dimensional resource sharing problem, jobsare represented by only one parameter: the number of tasks(which is equal to the number of required processors in gangservice) that compose the job. The machine is character-ized by the number of processors. We suppose that otherresources, such as memory, have infinite availability. Wewill analyze in this section the dynamic variation, wherearrival times can be different from zero. Observe that thisproblem is similar to the one dimensional dynamic (on-line)bin-packing problem as will be shown below.
3.1 Packing in Gang Service
Recall that the computation of a schedule (i.e. the com-putation of the trace diagram) can be reduced to a prob-lem similar to the bin packing problem. In the classical,one dimensional bin-packing problem, a given list of itemsL = I1; I2; I3; ::: is to be partitioned into a minimum num-ber of subsets such that the items on each subset sum to nomore than B, which is the capacity of the bins. In the stan-dard physical interpretation, we view the items of a subsetas having been packed in a bin of capacity B. This prob-lem is NP-Hard [3], so research has concentrated on algo-rithms that are merely close to optimal. For a given list L,let OPT(L) be the number of bins used in optimal packing,and define: s(L) = dP jIjjB e (1)
Note that for all lists L,s(L) � OPT (L). For a givenalgorithm A, let A(L) denote the number of bins used when
L is packed by A and define the wastewA(L) to be A(L)-S(L).
When applying bin-packing to parallel job scheduling,bins corresponds to slices in the trace diagram, and itemsrepresents SPMD jobs.
In this paper we deal with bin-packing algorithms thatare dynamic (also dubbed “on-line”). A bin packing al-gorithm is dynamic if it assigns items to bins in order(I1; I2; :::), with itemIi assigned solely on the basis of thesizes of the preceding items and the bins which they are as-signed to, without reference to the size or number of remain-ing items [25, 3]. Two of the most well known strategies fordynamic bin-packing are first fit and best fit. In first fit, thenext item to be packed is assigned to the lowest-indexed binhaving an unused capacity no less than the size of the item.In best fit the used bins are sorted according to their capac-ities. The item to be packed is assigned to the bin with thesmallest capacity that is sufficient. Best fit can be imple-mented to run in timeO(N logN ), and among online al-gorithms offers perhaps the best balance between worst andaverage case packing performance [3]. For instance, theonly known on-line algorithm with better expected wastethan best fit is the considerably more complicated algorithmof [25] that has expected waste�(N1=2 log1=2N ) (com-pared with�(N1=2 log3=4N ) for best fit) which is the bestpossible for any dynamic algorithm; this algorithm howeverhas an unbounded asymptotic worst case-ratio.
However, it should be stressed that the problem that weconsider in this paper is slightly different from the originaldynamic bin packing problem, since each item has a dura-tion associated with it. As items represent SPMD jobs, theduration represent the time it takes to run on a dedicatedmachine.
3.2 Dynamic Competitive Ratio
Competitive ratio(CR) based metrics [4, 22] are used tocompare various space sharing strategies. The reason isthat the competitive ratio is a formal way of evaluating al-gorithms that are limited in some way (e.g., limited infor-mation, computational power, number of preemptions) [4].This measure was first introduced in the study of a mem-ory management problem [21, 28]. The Competitive ra-tio [18, 4] for a scheduling algorithm A is defined as:CR(n) = supJ :jJj=n A(J)OPT (J) (2)
WhereA(J) denotes the cost of the schedule producedby algorithm A, and OPT(J) denotes the cost of an opti-mal scheduler, all under a predefined metric M. One wayto interpret the competitive ratio is as the payoff to a gameplayed between an algorithm A and an all-powerful malev-olent adversary OPT that specifies the inputJ [18].
4

We are interested in the dynamic case, where we havea sequence of jobsJ = fJ1; J2; J3; J4; ::::g, with an arrivaltimesai � 0 associated with each job, which is the thecase for jobs submitted to parallel supercomputers, as sev-eral workload studies show [8, 7]. Observe that consecutivearrival times can vary between seconds to hours, dependingon the hour of the day [8]. For instance, let’s consider amachine that implements a gang scheduler using the tracediagram (an example is [23]). Upon arrival of a new job,the front end will look for the first slice with sufficient num-ber of processors in the trace diagram (which is stored in thefront end), will allocate the incoming job on that slice, willupdate the trace diagram, and the new job will start runningin the next period. The same sequence of actions is takenfor subsequent jobs.
For the dynamic case as defined in the previous para-graph, the definition of equation 2 is not convenient. For adynamic scheduling the number of jobsn can be of order ofthousands or tens of thousands of jobs, but they arespacedin time, in a way that, at each instant of time, we would havetypically tens of jobs at most scheduled in the machine. Be-yond that, competitive analysis has been criticized becauseit often yields ratios that are unrealistic high for ”normal”inputs, since it consider the worst case workload, and as aresult it can fail to identify the class of online algorithmsthat work well [18]. These facts led us to propose a sim-ulation methodology for comparing dynamic algorithms onparallel scheduling based on the competitive ratio.
For the application of CR methodology in dynamicscheduling, let’s consider as reference (adversary) algo-rithm the optimal algorithm OPT for a predefined metric Mapplied at each new arrival time. The OPT scheduler willbe a clairvoyant dynamic adversary, with knowledge aboutall arrival times and the characteristics of all jobs. We willcall this methodology of comparing dynamic algorithms asDynamic Competitive Ratio(CRd), and the scheduler de-fined by applying OPT at arrival times asOPTd. Formallywe have: CRd(N ) = 1N NX�=1 A(� )OPTd(� ) (3)
WhereN represents the number of arrival times consid-ered. Observe thatCRd only varies at arrival times. AsWorkload we have a (possibly infinite) sequence of jobsJ= fJ1; J2; J3; J4; ::::g, with an arrival timeai � 0 asso-ciated with each job. At the time of each arrival, workloadchanges are taken into consideration in a way that only thosejobs that are still running at the arrival time are consideredby bothA andOPT algorithms.
SinceCRd is a simulation based methodology, a veryimportant question is the determination of the workload tobe used in conjunction withCRd to compare different algo-rithms. When choosing the new coming job at each arrival
time, we have two possibilities : either selecting a “worstcase” job that would maximize theCRd or considering syn-thetic workload models with arrival times and running timesbeing modeled as random variables. Since with the “worstcase” option we may create fake workloads that never hap-pen in practice and leads to the sort of criticism we cited be-fore, we believe that the best option is to use one of the syn-thetic workload models that have been recently proposed inthe literature [7, 8]. These models and its parameters havebeen abstracted through careful analysis of real workloaddata from production machines. The objective with this ap-proach is to produce an average case analysis of algorithmsbased on real distributions.
A lower bound for the packing problem under dynamiccompetitive ratio is derived in the following theorem.
Theorem 2 For the dynamic packing of SPMD jobs inthe trace diagram and for any non-clairvoyant scheduler,CRd(N ) � 1 , N > 0Proof 3 Consider N=1. In the case of a workload com-posed by one embarrassingly parallel job with a degree ofparallelism P, if we have a non clairvoyant scheduler thatschedules each task in a different processor, as would doOPTd, we haveCRd(1) = 1.
Conversely, an optimal clairvoyant scheduler will al-ways be capable of producing a scheduling at least as goodas a non-clairvoyant one, since the clairvoyant schedulerhas all the information available about the workload at anyinstant in time. SoCRd(N ) � 1
For bin-packing, the reference or optimal algorithmswill be simply the sum of item sizes s(L), sinces(L) �OPT (L), and it can be easily computed. However, in orderto useCRd to compare the performance of algorithms, wemust first define precisely the workload model we will usein theCRd computation, which is done in the next section.
3.3 Workload Model
The workload model that we consider in this paper wasproposed in [7]. This is a statistical model of the work-load observed on a 322-node partition of the Cornell The-ory Center SP2 from June 25, 1996 to September 12, 1996,and it is intended to model rigid job behavior. During thisperiod, 17440 jobs were executed.
The model is based on finding Hyper-Erlang distribu-tions of common order that match the first three momentsof the observed distributions. Such distributions are charac-terized by 4 parameters:
5
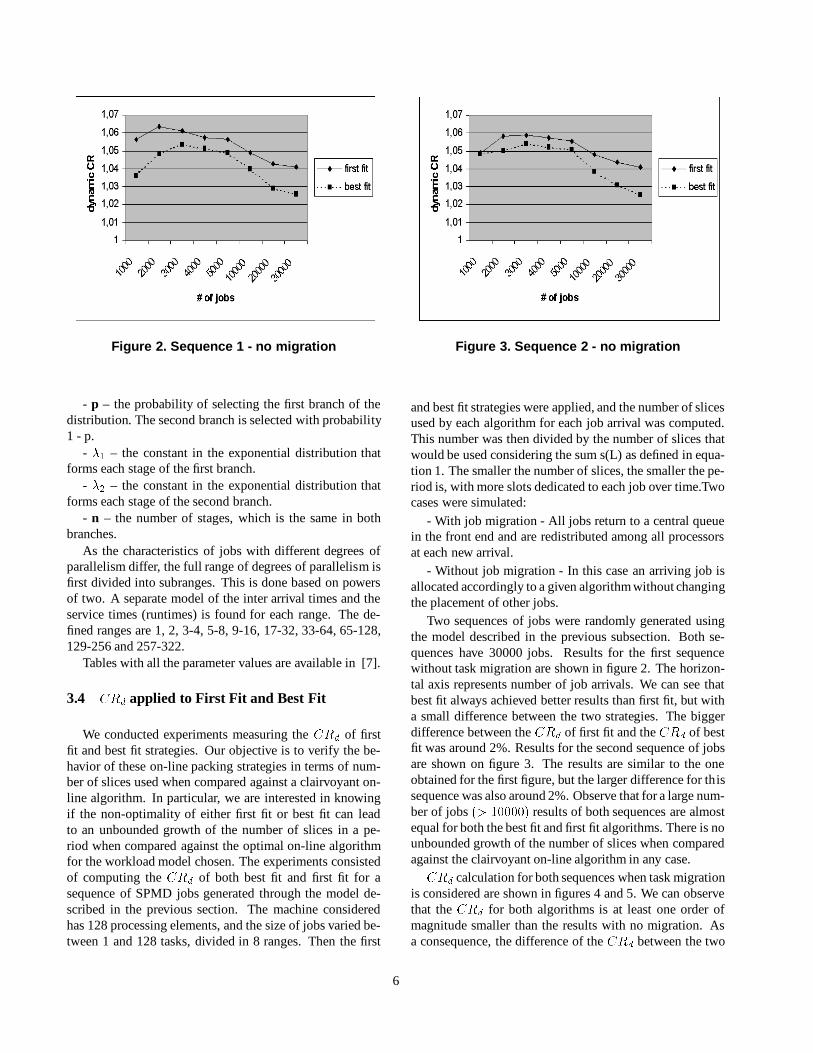
Figure 2. Sequence 1 - no migration
- p – the probability of selecting the first branch of thedistribution. The second branch is selected with probability1 - p.
- �1 – the constant in the exponential distribution thatforms each stage of the first branch.
- �2 – the constant in the exponential distribution thatforms each stage of the second branch.
- n – the number of stages, which is the same in bothbranches.
As the characteristics of jobs with different degrees ofparallelism differ, the full range of degrees of parallelism isfirst divided into subranges. This is done based on powersof two. A separate model of the inter arrival times and theservice times (runtimes) is found for each range. The de-fined ranges are 1, 2, 3-4, 5-8, 9-16, 17-32, 33-64, 65-128,129-256 and 257-322.
Tables with all the parameter values are available in [7].
3.4 CRd applied to First Fit and Best Fit
We conducted experiments measuring theCRd of firstfit and best fit strategies. Our objective is to verify the be-havior of these on-line packing strategies in terms of num-ber of slices used when compared against a clairvoyant on-line algorithm. In particular, we are interested in knowingif the non-optimality of either first fit or best fit can leadto an unbounded growth of the number of slices in a pe-riod when compared against the optimal on-line algorithmfor the workload model chosen. The experiments consistedof computing theCRd of both best fit and first fit for asequence of SPMD jobs generated through the model de-scribed in the previous section. The machine consideredhas 128 processing elements, and the size of jobs varied be-tween 1 and 128 tasks, divided in 8 ranges. Then the first
Figure 3. Sequence 2 - no migration
and best fit strategies were applied, and the number of slicesused by each algorithm for each job arrival was computed.This number was then divided by the number of slices thatwould be used considering the sum s(L) as defined in equa-tion 1. The smaller the number of slices, the smaller the pe-riod is, with more slots dedicated to each job over time.Twocases were simulated:
- With job migration - All jobs return to a central queuein the front end and are redistributed among all processorsat each new arrival.
- Without job migration - In this case an arriving job isallocated accordingly to a given algorithmwithout changingthe placement of other jobs.
Two sequences of jobs were randomly generated usingthe model described in the previous subsection. Both se-quences have 30000 jobs. Results for the first sequencewithout task migration are shown in figure 2. The horizon-tal axis represents number of job arrivals. We can see thatbest fit always achieved better results than first fit, but witha small difference between the two strategies. The biggerdifference between theCRd of first fit and theCRd of bestfit was around 2%. Results for the second sequence of jobsare shown on figure 3. The results are similar to the oneobtained for the first figure, but the larger difference for thissequence was also around 2%. Observe that for a large num-ber of jobs(> 10000) results of both sequences are almostequal for both the best fit and first fit algorithms. There is nounbounded growth of the number of slices when comparedagainst the clairvoyant on-line algorithm in any case.CRd calculation for both sequences when task migrationis considered are shown in figures 4 and 5. We can observethat theCRd for both algorithms is at least one order ofmagnitude smaller than the results with no migration. Asa consequence, the difference of theCRd between the two
6
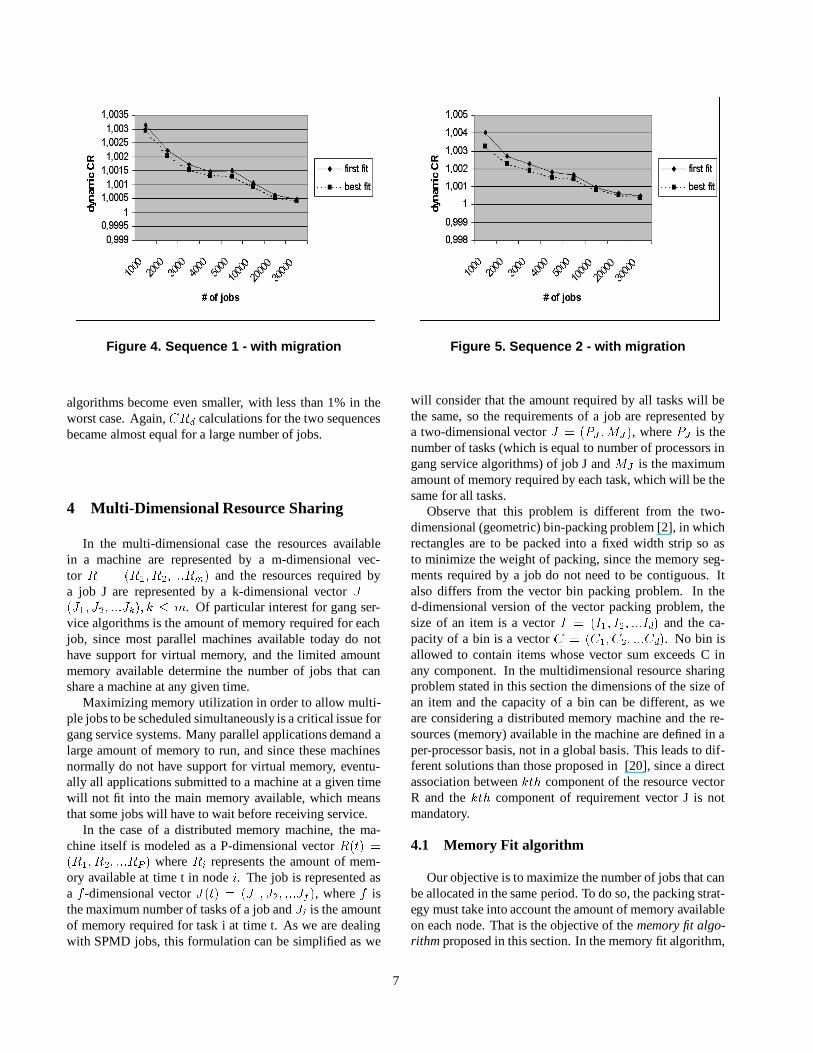
Figure 4. Sequence 1 - with migration
algorithms become even smaller, with less than 1% in theworst case. Again,CRd calculations for the two sequencesbecame almost equal for a large number of jobs.
4 Multi-Dimensional Resource Sharing
In the multi-dimensional case the resources availablein a machine are represented by a m-dimensional vec-tor R = (R1; R2; :::Rm) and the resources required bya job J are represented by a k-dimensional vectorJ =(J1; J2; :::Jk); k � m. Of particular interest for gang ser-vice algorithms is the amount of memory required for eachjob, since most parallel machines available today do nothave support for virtual memory, and the limited amountmemory available determine the number of jobs that canshare a machine at any given time.
Maximizing memory utilization in order to allow multi-ple jobs to be scheduled simultaneously is a critical issue forgang service systems. Many parallel applications demand alarge amount of memory to run, and since these machinesnormally do not have support for virtual memory, eventu-ally all applications submitted to a machine at a given timewill not fit into the main memory available, which meansthat some jobs will have to wait before receiving service.
In the case of a distributed memory machine, the ma-chine itself is modeled as a P-dimensional vectorR(t) =(R1; R2; :::RP) whereRi represents the amount of mem-ory available at time t in nodei. The job is represented asa f-dimensional vectorJ(t) = (J1; J2; :::Jf), wheref isthe maximum number of tasks of a job andJi is the amountof memory required for task i at time t. As we are dealingwith SPMD jobs, this formulation can be simplified as we
Figure 5. Sequence 2 - with migration
will consider that the amount required by all tasks will bethe same, so the requirements of a job are represented bya two-dimensional vectorJ = (PJ ;MJ ), wherePJ is thenumber of tasks (which is equal to number of processors ingang service algorithms) of job J andMJ is the maximumamount of memory required by each task, which will be thesame for all tasks.
Observe that this problem is different from the two-dimensional (geometric) bin-packing problem [2], in whichrectangles are to be packed into a fixed width strip so asto minimize the weight of packing, since the memory seg-ments required by a job do not need to be contiguous. Italso differs from the vector bin packing problem. In thed-dimensional version of the vector packing problem, thesize of an item is a vectorI = (I1; I2; :::Id) and the ca-pacity of a bin is a vectorC = (C1; C2; :::Cd). No bin isallowed to contain items whose vector sum exceeds C inany component. In the multidimensional resource sharingproblem stated in this section the dimensions of the size ofan item and the capacity of a bin can be different, as weare considering a distributed memory machine and the re-sources (memory) available in the machine are defined in aper-processor basis, not in a global basis. This leads to dif-ferent solutions than those proposed in [20], since a directassociation betweenkth component of the resource vectorR and thekth component of requirement vector J is notmandatory.
4.1 Memory Fit algorithm
Our objective is to maximize the number of jobs that canbe allocated in the same period. To do so, the packing strat-egy must take into account the amount of memory availableon each node. That is the objective of thememory fit algo-rithm proposed in this section. In the memory fit algorithm,
7

the front end at each job arrival chooses the slice and theprocessors that will receive an incoming job as a functionof the amount of memory available, in order to balance theusage of memory among the nodes of the machine. If morethan one solution is possible, the front end chooses a sliceusing the best fit strategy. If there is no set of processorsin the available slices with sufficient memory to receive thenew job, the front end can create a new slice to accommo-date the new coming job. Of course a new slice can alsobe created due to insufficient number of processors in theexisting slices, as in best fit and first fit.
If a job arrives and there is no sufficient resources avail-able for its execution, it waits in the global queue until theamount of memory required by the job becomes available.However, if another jobs arrives later and there is a suffi-cient amount of memory to schedule the job, it is scheduledimmediately, as in the backfilling strategy.
When choosing a slice for scheduling a new coming job,first the memory fit chooses the J processors in a slice wherethere is more memory available, where J is the degree ofparallelism of a job. Then computes a ”measure of balance”in order to know how much that particular allocation re-duces imbalance. The algorithm repeats this sequence forevery existing slice and also considers the possible creationof a new slice. The solution that minimizes the memoryimbalance in the machine is the chosen.
For the measure of memory imbalance, in this paper wehave chosen amax/averagebalance measure [19]. For agiven slice, the front end considers the allocation of a job inthe set of processors where there is more memory available,and then compute the following measure:B(slice) = maxiMiPPi=1Mi (4)
WhereMi is the amount of memory available in node i.A lower value of B indicates a better balance.
4.2 CRd applied to Memory fit
In this section we apply a sequence of jobs to evaluate theperformance underCRd of the memory fit packing algo-rithm and we compare with the best fit algorithm of section3, with no migration in both cases. This algorithmwas mod-ified to take into account memory requirements. The slicechosen is the one that minimizes processor waste and at thesame time has sufficient memory to accommodate the job,regardless of any memory balance. However, we must firstdefine a memory usage for each job in the sequence, sincethe workload model used did not take into account memoryrequirements. In this paper, we considered that the memoryusage of a job has a direct correlation with this size. This as-sumption is coherent with workload modeling that was used
Figure 6. Dynamic competitive ratio appliedto memory fit
as a guide line for scheduler design in parallel machines, no-tably in the Tera MTA [6]. In this work was observed thatjobs with large amounts of parallelism have large memoryrequirements and use a lot of resources. Small tasks, onthe other hand, use resources in bursts, have small mem-ory requirements and are not very parallel. Based on theseobservations we defined that for each job, the memory uti-lization of a job varied between 2 MB and 256 MB per nodein function of the size of the job and the ranges defined insubsection 3.3. For instance, we considered that 1 task jobsrequire 2 MB of memory, 2 task jobs require 4 MB per task,3-4 task jobs require 8 MB per task, and so on. Each nodehad 512 MB of main memory.
Our objective is to maximize the number of jobs that fitin one period of the machine by maximizing the memoryutilization of the machine. The reference algorithm alwayshas a memory utilization of 100%, given that enough jobshave arrived to fill in the memory, due to its clairvoyance.So the quantity that was calculated for each new arrival wasthe memory utilization of the algorithm under analysis di-vided by the memory utilization of the optimal algorithm.Simulation results are shown in figures 6 and 7. Figure 6illustrates the evolution ofCRd over time. Figure 7 showsthe throughput of both memory fit and best fit. Observe thatthe number of arrivals and arrival times submitted to bothalgorithms are the same, since the same sequence of jobswere submitted to both algorithms. In both cases the hori-zontal axis represents time in seconds. The evolution of thesystem was simulated for 10000, 20000, 30000, 40000 and50000 seconds. These values are chosen in order to verifythe evolution of the system during a working day (50000seconds represents 13.8 hours).
We can observe that the Memory Fit algorithm not only
8

Figure 7. Throughput of both best fit andmemory fit
yields better memory utilization than best fit, but it also im-proves the throughput, as illustrated by figure 7. This is adirect consequence of the capability of the memory fit algo-rithm of allocating more jobs in the same period.
5 Conclusion
In this paper we analyze questions related to resourcesharing in parallel scheduling algorithms. One conclusionderived from that analysis is that multidimensional resourcesharing analysis is necessary when defining a resource allo-cation strategy for this class of algorithms, as the compari-son between best fit and memory fit in the limited memoryanalysis demonstrated.
To provide a sound analysis of concurrent gang perfor-mance, a novel simulation-based methodology, dubbed dy-namic competitive ratio, based on the traditional concept ofcompetitive ratio is also introduced. Dynamic competitiveratio was used to compare packing algorithms submitted toa workload generated by a statistical model, and to com-pare resource allocation strategies for job scheduling un-der multiple constraints. For the unidimensional case wecan conclude that there is not a large difference betweenthe performance of best fit and first fit under the workloadmodel considered, and first fit can be used without signif-icant system degradation. For the multidimensional case,when memory is also considered, the better performance ofmemory fit over best fit under dynamic CR let us concludethat the resource allocation algorithm must try to balancethe resource utilization in all dimensions at the same time,instead of given priority to only one dimension of the prob-lem.
References
[1] E.G. Coffman, M. R. Garey, and D. S. Johnson. Ap-proximation Algorithms for Bin Packing: A Survey.Approximation Algorithms for NP-Hard Problems -Ed. Dorit Hochbaum, 1996.
[2] E.G. Coffman, M.R. Garey, and D.S. Johnson. BinPacking with Divisible Item sizes.Journal of Com-plexity, 3:406–428, 1987.
[3] E.G. Coffman, D.S. Johnson, P.W. Shor, and R.R. We-ber. Markov Chains, Computer Proofs, and AverageCase Analysis of Best Fit Bin Packing. InProceedingsof the 29th ACM Symposium on Theory of Computing,pages 412–421, 1993.
[4] J. Edmonds, D.D. Chinn, T. Brecht, and X. Deng.Non-Clairvoyant Multiprocessor Scheduling of Jobswith Changing Execution Characteristics (extendedabstract). InProceedings of the 1997 ACM Sympo-sium of Theory of Computing, pages 120–129, 1997.
[5] F. Wang et al. A Gang Scheduling Design for Multi-programmed Parallel Computing Environments.JobScheduling Strategies for Parallel Processing, LNCS1162:111–125, 1996.
[6] G. Averson et al. Scheduling on the Tera MTA.JobScheduling Strategies for Parallel Processing, LNCS949, 1995.
[7] J. Jann et al. Modeling of Workloads in MPP.JobScheduling Strategies for Parallel Processing, LNCS1291:95–116, 1997.
[8] D. Feitelson. Packing Schemes for Gang Schedul-ing.Job Scheduling Strategies for Parallel Processing,LNCS 1162:89–110, 1996.
[9] D. Feitelson. Job Scheduling in MultiprogrammedParallel Systems. Technical report, IBM T. J. WatsonResearch Center, 1997. RC 19970 - Second Revision.
[10] D. Feitelson and M. A.Jette. Improved Utilizationand Responsiveness with Gang Scheduling.JobScheduling Strategies for Parallel Processing, LNCS1291:238–261, 1997.
[11] D. Feitelson and L. Rudolph. Distributed Hierarchi-cal Control for Parallel Processing.IEEE Computer,pages 65–77, May 1990.
[12] D Feitelson and L. Rudolph. Mapping and Schedulingin a Shared Parallel Environment Using DistributedHiearchical Control. InProceedings of the 1990 In-ternational Conference on Parallel Processing, 1990.
9

[13] D. Feitelson and L. Rudolph. Gang Scheduling Perfor-mance Benefits for Fine-Grain Synchronization.Jour-nal of Parallel and Distributed Computing, 16:306–318, 1992.
[14] D. Feitelson and L. Rudolph. Evaluation of DesignChoices for Gang Scheduling Using Distributed Hier-archical Control.Journal of Parallel and DistributedComputing, 35:18–34, 1996.
[15] H. Franke, P. Pattnaik, and L. Rudolph. Gang Schedul-ing For Highly Efficient Distributed MultiprocessorSystems. InProceedings of Frontiers’96, 1996.
[16] A. Hori, H. Tezuka, and Y. Ishikawa. Overhead Anal-ysis of Preemptive Gang Scheduling.Job SchedulingStrategies for Parallel Processing, LNCS 1459:217–230, 1998.
[17] M. A. Jette. Performance Characteristics of GangScheduling In Multiprogrammed Environments. InProceedings of SC’97, 1997.
[18] B. Kalyanasundaram and K. Pruhs. Speed is as Pow-erful as Clairvoyance. InProceedings of the 36th Sym-posium on Computer Science, pages 214–221, 1995.
[19] W. Leinberger, G. Karypis, and V. Kumar. JobScheduling in the Presence of Multiple Resources Re-quirements. InProceedings of Supercomputing’ 99,1999.
[20] W. Leinberger, G. Karypis, and V. Kumar. Multi-Capacity Bin Packing Algorithms with Applicationsto Job Scheduling under Multiple Constraints. InProceedings of the 1999 International Conference OnParallel Processing, 1999.
[21] M.S. Manasse, L.A. McGeoch, and D.D. Sleator.Competitive Algorithms for On Line problems. InProceedings of the Twentieth Annual Symposium onthe theory of Computing, pages 322–333, 1988.
[22] R. Motwani, S. Phillips, and E. Torng. Non-clairvoyant scheduling. Theoretical Computer Sci-ence, 130(1):17–47, 1994.
[23] J. K. Ousterhout, D. A. Scelza, and P. S. Sindhu.Medusa: An Experiment in Distributed OperatingSystem Structure. Communications of the ACM,23(2):92–105, 1980.
[24] J.K. Ousterhout. Scheduling Techniques for Concur-rent Systems. InProceedings of the 3rd InternationalConference on Distributed Comp. Systems, pages 22–30, 1982.
[25] P.W. Shor. How to do better than best fit: Tight boundsfor average case on-line bin packing. InProceedingsof the 32th IEEE Annual Symposium on Foundationsof Computer Science, pages 752–759, 1990.
[26] F.A.B. Silva and I.D. Scherson. Towards Flexibilityand Scalability in Parallel Job Scheduling. InProceed-ings of the 1999 IASTED Conference on Parallel andDistributed Computing Systems, 1999.
[27] F.A.B. Silva and I.D. Scherson. Improving Through-put and Utilization on Parallel Machines ThroughConcurrent Gang Scheduling. InProceedings of theIEEE International Parallel and Distributed Process-ing Symposium 2000, 2000.
[28] D.D. Sleator and R.E. Tarjan. Amortized Efficiency ofList Update and Paging Rules.Communications of theACM, 28(2):202 – 208, 1985.
[29] M. S. Squillante, F. Wang, and M. Papaefthymiou. AnAnalysis of Gang Scheduling for MultiprogrammedParallel Computing Environments. InProceedings ofthe 8th Annual ACM Symposium on Parallel Algo-rithms and Architectures, pages 89–98, 1996.
[30] K. Suzaki and D. Walsh. Scheduling on AP/Linuxfor Fine and Coarse Grain Parallel Processes.JobScheduling Strategies for Parallel Processing, LNCS1659:111–128, 1999.
[31] L. G. Valiant. A bridging model for parallel computa-tions. Communications of the ACM, 33(8):103 – 111,1990.
[32] F. Wang, M. Papaefthymiou, and M. S. Squil-lante. Performance Evaluation of Gang Schedulingfor Parallel and Distributed Multiprogramming.JobScheduling Strategies for Parallel Processing, LNCS1291:277–298, 1997.
10
Copyright © 2022 FDOKUMEN




















