
Reusable e-learning development: Case studies, practices ...
Upload
independentCategory
view
0download
0
SOmWARE-PRACTICE AND EXPERIENCE, VOL. 26(5), 491-530 (MAY 1996)
Retrieval of Reusable Components using Functional Similarity
s. FAUSTLE, M. G. FUGINI AND E. DAMIANI Politecnico di Milano, Dipartimento di Elettronica e Informazione, Piazza da Vinci, 32,
1-20133 Milano, Italy (email: [email protected])
SUMMARY During application development under reuse, much effort is spent in retrieving suitable components. This paper presents an approach to retrieval based on software descriptions of components, and on a mechanism for computing the functional similarity of clusters of reuse candidates. Descriptions are given in a semi-formal fashion and using fuzzy weights for keywords. Algorithms for similarity computation are presented. The experimental tool for this approach manages imprecise queries posed by developers against a software repository; results about reuse of object-oriented code based on the use of the tool are presented, giving measures of recall and precision of the proposed approach.
KEY WORDS fuzzy retrieval; reusable software components; keyword searching; information storing and retrieval; reuse support repository; empirical methods
1. INTRODUCTION The growing effort towards reusing software components and project information needs an effective underlying classification and retrieval methodology. A central difficulty in every reuse-based development environment is the identification of the most suitable reuse candidate among those stored within a project repository. User queries should be flexible to allow a degree of uncertainty in order to isolate a set of components that can be adapted to the new application.' Many of the existing software libraries or reposi- tories exhibit both the classification problem (description of components, and efficient inclusion of new clusters of components) and the retrieval problem.2 This paper addresses the issue of reuse-support retrieval models, and of tools for exploring the component base through the use of fuzzy 10gic.~-~
In the literature, most of the proposed retrieval systems and empirical studies on reuse share the following concepts:
I . The item classification (representation problem) is based on formal attributes, such as in the attribute-value, faceted, and keyword-based methods (see Reference 2 for an overview), and/or semi- or informal text bodie~."'~
2. A function exists for ranking sets of items that are relevant with respect to given requisites;8.9~'2~'3.'5 in Reference 16 this function, based on usage models, com- putes a reuse reliability value to be attached to components and to be validated against usage profiles.
CCC 0038-0644/96/050491-40 0 1996 by John Wiley & Sons, Ltd.
Received 3 March 1994 Revised 2 October 1995

492 s. FAUSTLE, M. G . FUGINI AND E. DAMIANI
3. A definition of conceptual distance/closeness and a related metric for similarity between items is given. Conceptual distance is also used to keep the repository a coherent structure of similar vs. subclass object structures, as proposed in Refer- ence 17.
4. Different representation methods tend to show similar recall and precision para- meters during the retrieval phase.I8
In the Ithaca application development environment”* the principal goal is to reduce the long-term cost of development and maintenance of standard applications in selected application domains. ‘Standard applications’ are applications that share software components as well as project related knowledge, globally called development experi- ence, described in a sofhvare infomation base (SIB).20 The target applications are assumed to be object-oriented; also the development system employs an object-oriented paradigm, thus enhancing reusability of components and their associated development information.*’ In the Ithaca environment two user roles are planned: an expert user, the application engineer, who creates reusable items and maintains the SIB, and an appli- cation developer who builds new applications by retrieving reusable components from the SIB and composing them with the active assistance of development tools.22
The SIB is an object-oriented repository, where data are organized into a layered semantic network according to the Telos knowledge representation language.23 The items and their attributes are nodes of the network and represent descriptions of software artefacts (requirements, designs, documentation, implementations) and their mutual cor- respondences. The item-attribute links and the usual object-oriented link types (specialization and instantiation links) are used to navigate the SIB.
In the Ithaca life-cycle, application development is an interleaved iteration of basic steps: requirement specification, detailed design and implementation. These steps are followed by the application engineer to obtain a running app l i~a t ion :~~ within a certain application domain, he/she is driven by the Ithaca development tools in the task of selecting useful reuse candidates from the SIB. These candidates are tailored and scripted to form a running prototype of the application, which is monitored, validated and further developed. The approach to retrieval is both parts-based and language- based:2 the application engineer integrates software parts into a new application, with the assistance of design knowledge encoded into the SIB descriptors and exploited by the Selection Tools.
The present work proposes a classification and retrieval schema, developed within the Ithaca approach. In Ithaca, reuse candidates (executable software objects, specifications, documentation, design procedures, tests, and, in general, project information) are retrieved from the SIB and evaluated on the basis of their behavioural compatibility within the context of development requirements of the application being defined. The basic goal of the retrieval system is to assist the application developer in iteratively finding useful candidates by proposing entry points into the SIB, and then guiding the developer in obtaining similarity clusters around selected focus items pertaining to previously found candidate sets. This supports bound explorative navigation. This kind of retrieval method can be classified as a hybrid between browsing and querying: the SIB is queried and the query answer set can be browsed in an interleaved manner. Tools in Ithaca are explicitly provided for these two search modes. The SIB elements
* Ithaca (Integrated Toolkit for Highly Advanced Computer Applications) is EEC-Esprit I1 Project no. 2705, started January 1989 and completed in December 1993.

RETRIEVAL OF REUSABLE COMPONENTS 493
are classes whose attributes, which can in turn be SIB classes, constitute a semantic network describing entities created or involved in the life-cycle of applications and their relationships. For this reason, the SIB classes are called descriptors (of requirements, of design, of code). Class attributes are class name, attribute names, parameter types, source language, etc. The retrieval of a SIB class can occur via its name or via its attributes’ values. However, two factors limit the expressive power of these descriptors:
1 . The SIB class names, as well as their attribute names, must be unique SIB-wise; hence, the application engineer is limited when choosing the names.
2. In the choice of attributes for the definition of a descriptor, the application engin- eer is constrained by the data schema of the SIB meta and superclasses, according to the SIB implementation system.23
As a consequence, the names of the SIB classes are often poorly expressive for the retrieval. The descriptive power is therefore enhanced using the linguistic tool described in this paper, that is, software descriptions. A software description (SD) is a combination of keywords describing the behaviour of the component associated with the SIB node. The SD is schema-free and name conflict-free, due to its informal semantics. This decoupling of a portion of the descriptor from the SIB formal data schema is useful for querying and navigating the SIB. In fact, the SIB user has to face two kinds of uncer- tainty:
(i) a vague knowledge of the internal organization of SIB class attributes, i.e. of the
(ii) a vague knowledge of the characteristics of both the available reusable compo-
Therefore, difficulties may arise in using the SIB Telos query language, whose format is RETRIEVE x,/class,, . . ., x,jclass, : WellFormedF~rmula requiring references to the class types. In a loosely-structured information space such as the SIB, it can be more effective to support queries concerning only the attribute values with no specification of their type (‘access by value’ in Reference 25). SDs are suitable for this type of search, the keywords in an SD being untyped. An SD can be seen as: (a) a collection of properties, statically associated with a SIB class; (b) a collection of requirements, that is a query dynamically associated to a user. Therefore, an SD is both a classification and a retrieval linguistic mechanism.
Combinations of keywords (namely, keyword pairs) are used in the SDs. Keyword pairs, calledfeatures, are weighted via afizzy value. The fuzzy weight in an SD rep- resents ‘how well’ a feature describes the component behaviour; the fuzzy weight in a query specifies ‘how relevant’ the feature is for the developer. Fuzzy values are a further support provided by the approach to imprecision: they express the degree of imprecision that characterizes the description, helping the application developer in retrieving reuse candidates and the application engineer in classifying reusable components. Moreover, fuzzy weights are suitable to implement an adaptive classification and retrieval system4 which, by observing the user reaction to the system-proposed candidates, slowly tunes the weights’ values to ameliorate their descriptive power. A quality function is employed to observe the user reactions to proposed candidates; it is beyond the scope of this paper to illustrate the system tuning (the interested reader can refer to Refer- ence 26).
The paper is organized as follows. The classification of reusable components based
data schema
nents and of the searched component.

494 s. FAUSTLE, M. G. FUGINI AND E. DAMIANI
on SDs in the SIB is presented in Section 2. The retrieval mechanism, based on a confidence value (CV) computed by the system on pairs of SDs is described in Section 3, evaluated using fuzzy set theory concept^.^ The retrieval system based on the pro- posed approach is presented in Section 4. Evaluation results are reported in Section 5, based on empirical studies of some object-oriented code libraries. Final remarks and a comparison with other classification and retrieval systems are given in Section 6. The Appendix reports sample repository descriptors, and some retrieval sessions.
2. ITEMS OF THE REPOSITORY: CLASSIFICATION The items of the SIB are Telos classes describing reusable components at the various stages of development and the correspondences among components during these stages. A SIB class should contain any kind of knowledge that is useful for the reuse paradigm. We distinguish between two kinds of knowledge:
1. Functional knowledge describes the functionalities of software components seen
2. Teleological knowEedge relates a component with other entities pertinent to various
Besides other attributes, the SIB classes may own a leaf-node attribute, which is a semi-formal description of the item, called a software description (SD). This is a list of properties, calledfeatures, which portray the behaviour of the item. The length of a description, i.e. the number of features, is unbound. The primitive elements of a feature are verbs, nouns, adjectives, etc., i.e. open class keywords.'*
The interpretation of keywords as verb-noun or noun-adjective pairs is an advantage of the expressive power of the proposed system. This is enhanced via two means pro- vided to assign more general or more specific keywords: (1) a thesaurus is available to enforce semantic coherence among the terms used; a mechanism for automatic deri- vation of the thesaurus from SIB descriptors is outlined; (2) the SIB descriptions are not at the same level of detail, but rather are organized at three levels, mirroring the software development phases: the requirement description (RD) level, the design description (DD) level, and the implementation description (ID) level (see Figure 1).
SDs are suitable to represent the first kind of knowledge, but may also describe non- functional properties of an item, such as hardware/software compatibility constraints. Other attributes of SIB classes are useful for both kinds of knowledge; however, SDs being keyword-based, and therefore notation independent, they can be a more useful platform for query formulation and resolution in a loosely structured information space such as the SIB, where the data schema is not necessarily well known formally by its users.27
as black-box reusable elements exhibiting a behaviour in terms of services.
stages of an application development.20
2.1 In the belief that associations of concepts are more expressive than single concepts,28
features are pairs of related keywords. A feature may be a verb-noun, noun-adjective or noun-noun pair, or any other combination of two keywords. Features are used to compute similarity links between the SIB nodes and may be edited by expert users (i.e. the application engineer in Ithaca), or automatically/interactively extracted from textual descriptions, such as source listings, manual pages, headers, comments, etc., which are
Elements of an SD: features

RETRIEVAL OF REUSABLE COMPONENTS 495
M3
Figure 1. Sketch of the SIB schema and of its predefined Tebs links
often delivered together with the items. A protocol for automatic extraction of features from object-oriented code has been defined and is illustrated in Section 4.
Various interpretations can be given to features. A feature may describe an action performed by the component, in which case it typically contains a verb and a noun (representing the object on which the action is performed), or a passive characteristic

496 s. FAUSTLE, M. G. FUGINI AND E. DAMIANI
of the component. In this second case it contains no verb, but rather nouns and adjec- tives. The two kinds of features are called active features and passive features, respect- ively. Typically, active features can be used to describe functionalities, or services, delivered by a component, passive features are used for the description of its non- functional characteristics.
An example of an active feature is ‘edit-text’, a verb-noun pair, where the ‘edit’ keyword expresses an action and the ‘text’ keyword denotes the object upon which the action is performed. The action-object pair may be a step of an algorithm or a service offered by the component. An example of a passive feature is ‘cohesion-high’, a noun- adjective pair, where the noun determines the category of a non-functional property and the adjective determines the value assumed by the property. Three possible semantic interpretations, and the relative interpretations of weights, are given in Table I. A tem- poral precedence among features is the distinguishing issue between interpretations 1 and 2.
Weights, contexts, and inheritance
The features, forming a description, may be weighted by assigning fuzzy weights to them. The weight is a relevance index of the feature within an SD. In general, the fuzzy weight in an SD represents ‘how well’ a feature describes the component behaviour; the fuzzy weight in a query specifies ‘how relevant’ the feature is for the developer. Weights are provided as a policy-free mechanism; they contribute to improving and refining the retrieval of components only if their usage is based on a coherent semantic and linguistic framework agreed between application engineers and application devel- opers. Namely, the meaning of a weight is strongly bound to the context where the description is formulated. Contexts are classification and retrieval environments used to partition the SIB to reflect the described application domains and also different reuse perspectives.20 This is formalized by considering that each SD is made by contexts c,,c2, ..., c,. Of course, some contexts might be empty in the SD of some components, and some features may appear in more than one context. The case of contextless SDs can be dealt with simply by introducing a dummy ‘SIB-wise’ context.
Table I. Interpretation of features and weights
I . Interpretation An SD contains: Every feature Relationship Meaning of weights describes: among
features
1. ‘Algorithm’ Descriptions of an algorithm temporal algorithms performed step precedence
by components
offered by an abstract data type
2. ‘ADT’ Lists of services a service/method none
3. ‘Profile’ Lists of non- a non-functional none functional properties Property
such as ‘maturity’ etc.
detail and completeness of the
performed step detail and
completeness of the servicelmethod
relevance of the aspect

RETRIEVAL OF REUSABLE COMPONENTS 497
Weights are computed automatically for features using a weighting function adapted from classical text retrieval function^.^^.^^ The original function proposed by Salton is used for the computation of relevance of terms in text documents; our adaptation takes into account the fact that, for software components, the accompanying documentation may be unfit to allow reliable statistical analysis on term distribution. So we cannot rely on the statistical approach for automatic weighting. However, the component inter- faces can be considered as a rudimentary documentation of the component behavior. The function allows us to perform a frequency analysis on the methods’ names in order to extract the relevant ones. Therefore, we employ a weighting function whose return values, in the range [0,1] can be seen as values of a characteristic function, obtaining a (possibly not disjoint) family of fuzzy sets, one for each SD. The followingfeature weighting function (FWF) is defined:
where Wik is the weight of the kth feature in the ith component and Vik is the frequency of the kth feature in that component, N is the SIB size and I t k is the number of SIB components exhibiting that feature. F is the total number of distinct features in the SIB. The value of vik is 1 when considering one SIB-wise context.
The application of this function spares the application engineer one task when coupled with automatic keyword extraction from software and software docu- mentation.I2 It can provide an effective technique for automatic derivation of SDs. The basic ideas of this FWF are extracting highly relevant terms (discarding high- frequency/low relevance ones) and enhancing differences: a not-so-important feature in an SD with a low total weight will have the same weight of a high-importance one in a SD with higher total weight. For a detailed exposition of the characteristics of this function, we refer to References 28 and 29.
Possible contexts are defined by the system manager (application engineer) and may regard functional (e.g. behaviour, services) and non-functional (e.g. hardware requirements) aspects. The context constrains the scope of a description to a certain reuse viewpoint, The definition of contexts and the definition of the exact meaning of weights within each context is supposed to be a prerequisite of the environment, but may vary in different user communities. Contexts, as well as keywords, are part of the system thesaurus.
The SIB class representing an SD may include more than one context. It is the case when different descriptions are given for different contexts. For example, the rep- resented artefact may own a description in one context enumerating its functionalities, a sort of interface specification, and a description in a different context containing hardware constraints etc. Both these descriptions belong to the item’s (multicontext) SD. A description, formulated within a certain context, can contain only keywords that are defined for that context in the thesaurus: by relating homonyms to a context, they are bound to a unique meaning. Operationally, according to the Te10s~~ attribute mech- anism, a description is bound to a context by attaching a label to it.
In accordance with the object-orientation paradigm of the underlying repository, SDs

498 S. FAUSTLE, M. G. FUGINI AND E. DAMIANI
are inherited along specialization paths. Inheritance is not elective,^' i.e. a descendant inherits all the features of a parent. This is in agreement with the hypothesis that it never occurs that a descendant has less functionalities than its parents,31 having to maintain behavioural and signature c~mpatibi l i ty .~~ Further, inheritance is context sensi- tive; within each context, the object inherits the parent’s description pertaining to the same context (if one is defined). The definition of SDs within the SIB is incremental: every item’s descriptions contain only the enrichments with respect to its parent’s, within each context.
Handling fuzzy weights Descriptions respecting the syntax of SDs may be embedded into a data definition
language (DDL): when a special character (e.g. ‘%’ using Yacc conventions) is encoun- tered during the parsing phase, the SD parser is invoked. If another special (‘%’) charac- ter is encountered, and the starting rule is satisfied (i.e. no parsing errors occurred), the control returns to the DDL parser. This way, the syntax of SDs is independent of the DDL syntax, i.e. descriptions may contain reserved words of the DDL.
Since fuzzy values can make the user interaction difficult during retrieval, discrete values are computed at the user inter$zce for fuzzy weights, returning a symbol belong- ing to a predefined symbolic set. We adopted the six-valued set { VL, L, M, H, VH) (i.e. very low, low, medium, high, very high, plus the null value used for computation). Unweighted features are supposed to be of average (M) importance.
Thesaurus The system vocabulary, called the thesaurus, lists all the terms used in the compo-
nents, and contains a synonymia relationship between terms.33 The thesaurus can be regarded as a view on the SIB, which helps users in describing components and in retrieving them, and which mediates among the various jargons of code libraries, pro- viding a uniform controlled vocabulary.
Every concept described in the SIB is represented by a unique thesaurus term, admit- ting synonyms. The stored descriptions consist of unique terms only, but synonyms may be used for their formulation; this enhances the system flexibility and user friendli- ness, but imposes normalization of the descriptions, i.e. substitution of synonyms with unique terms, before their storage in the repository. Internally, the thesaurus terms (unique terms and synonyms) are stored as w ~ r d - s t e m s . ~ ~ The normalization and stem extracting mechanism should be transparent to the users.
Fuzzy synonymia in the thesaurus is interpreted in the context of application develop- ment as follows: synonym terms mean ‘similar’ functionalities, i.e. adaptability of components. Synonymia is therefore used to compute the fuzzy similarity in the algor- ithms of Section 3, which elaborate lists of features to derive a fuzzy similarity value among components.
The definition of the unique terms of the thesaurus must be negotiated between the system manager(s) and the system users, trying to find the most expressive term for each concept. The unique term-synonym relationship validity is sensitive to user-feedback. Periodically the synonym sets for each unique term are revised by the application engin- eer, and possibly modified. The relationship between unique terms and synonyms should be one-to-many within each context, otherwise ambiguities arise during the normaliz-

RETRIEVAL OF REUSABLE COMPONENTS 499
ation process. If this is not granted, ambiguities must be resolved by defining substi- tution rules.’3
The thesaurus is available on-line to assist system managers and users in editing descriptions or queries. An on-line help to explain contexts and keywords should be available too. The thesaurus is properly initialized and managed by the application engineer, possibly with the assistance of an automatic method. An automatic construc- tion method has been proposed in Reference 26. It is beyond the purpose of the paper to illustrate the thesaurus. The interested reader is referred to Reference 26 for its auto- matic derivation from SIB descriptors. Its role in the selection tool is briefly presented in Section 4.
2.2. Examples In this section, we present some brief examples in order to clarify the concepts out-
lined so far. We refer the reader to the Section 5 for a description of experiments and their results.
As a first example, consider a possible description of a component that manages the user interface of an application using the ‘X’ window system. The Telos schema of the SIB is given in Figure 1, where RD, DD, ID stand for requirements, design, implemen- tation description, respectively. In the example, the SIB item is an implementation description of an object called ’xIM’, an instance of a generic class ’UI-Object‘. As such, it inherits a fixed set of attributes describing objects written in an object- oriented language. The item contains descriptions in two contexts: ‘algorithm’, specify- ing a sequence of steps performed by the object, and ‘profile’, containing non-functional attributes of the item.
The example is given in Figure 2 using the Telos syntax and user interface-level symbolic weights; unspecified weights stand for ‘medium’ (M). The keywords used in the algorithm description, such as ‘server’, ‘events’ and ‘context’ have unique meanings in an ‘X’ user community, but may have other meanings outside, hence the need to interpret a description within a certain setting and to have a thesaurus mechanism mediating among the different implementation library jargons.
The distribution of weights indicates that the component has a particularly rich event loop, i.e. the component is able to manage many types of events sent by the X-server to the application, although it is not particularly suitable to set contexts (e.g. the graphics context). In an algorithm description, a high weight means that the component performs the step with great accuracy, is able to deal with exceptions and handle them, and, generally, delivers a rich and reliable service to its clients.
The profile description is composed of passive features of the category-value type. ‘Maturity’, ‘cohesion’ and ‘documentation’ are categories, ‘high’, ‘very high’, ‘good’ are values, not to be confused with the weights ‘VH’, ‘H’ etc.: the keyword ‘high’ means that the component is highly mature (i.e. is well tested and stable), the ‘H’ weight means that the aspect ‘maturity’ is considered of high importance. Note that in the present case, ‘high’ and ‘good’ could be considered synonymous keywords; how- ever, this does not always hold, e.g. here, a good documentation of the component is in general not a relevant feature.
As a second example, we move to the requirement description (RD) level of the SIB. The example uses a slightly different syntax, namely the SD-method embedded into the ORM specification modelz2 used at the SIB requirement description level. The SIB

500 s. FAUSTLE, M. G. FUGINI AND E. DAMIANI
IndividualClass XUIM in UI-Object isA ID with attribute
source-language: “C ++”; source-fdename: xfile source-directory:/bin/x 1 1 project: x-project domain: interactive applications category: interfaces author: x-team releaseDate: 1/1/90 environment: ”X”; /* possibly other attributes ... *I
SoftwareDescription
algorithm:% connect - server; define - window; select - events; set - context: L; map - window; manage- events: VH %;
profile: % maturity - high : H; cohesion - high : VH; documentation - good : L %
end XUIM
/*medium*/ /*medium*/
/*medium*/ /*low*/ /*medium*/ /* very high */
/*high*/ /*very high*/ /*low*/
Figure 2. Description of a SIB implementation class
requirement description class OrderProcessing is given in Figure 3, using the syntax of the ORM model. The interpretation of the keyword assignment policies in this exam- ple is as follows. Weights are defined as ‘very high’, ‘high’, ‘medium’, ‘low’, ‘very low’, and ‘null’, where the basic criteria for assigning weights are the following:
1. ‘Very high’ is assigned to a feature describing services offered internally by the RD class.
2. ‘Medium’ is assigned to a feature describing services which are provided by other classes called by the RD class.
3. ‘Low’ corresponds to external services which can be used optionally by the RD class. It is also given for features that weakly characterize the class, but are inserted in the description to denote the possibility of reusing the class in other application contexts. For example, in Figure 3, the feature (manage, loan-request , low) denotes that management of requests related to loans is marginal in an application regarding order processing; however, the class could be reused in other contexts where loan management is requested, for example in banking applications. Three contexts are represented: (1) the ‘base’ context, regarding the basic services of the class in all the possible reuse perspectives,

RETRIEVAL OF REUSABLE COMPONENTS
SD of class OrderProcessing context base
( manage, order, veryhigh ) ( manage, loan-request, low ) ( check, order, high ) ( check, warranties, medium ) ( check, client-info, high)
( receive, order, veryhigh ) ( check, order, medium )
( execute, order, veryhigh ) ( reject, order, high ) ( compile, order, high )
( compile, invoice, low )
( receive, order-note, veryhigh )
context sales-system
I* the class activates the check procedures does not execute them, therefore weight=medium */
I* order execution *I /* executed by OrderRocessing *I
/* filling Order document with order information */
/* does not characterize strongly this class */ context public-administration
/* in Public administration contexts Order Notes are used with special bureaucratic management
procedures *f ( manage, order-note, high ) ( require-signature, order-note, high) ( check-archives, authorization-letter, veryhigh
Figure 3. Description of a SIB requirement class
50 1
(2) the ‘sales-system’ context, describing the functionalities for reuse in ‘sales’ applications, (3) the public-administration context, regarding another specific reuse area.
An example of 4uery formulation is provided in Figure 4; the application developer is designing an information system dealing with orders. Therefore, he is looking in the
retrieve SIB component where /* SD part *I condl. ( manage, order, high ), I* alternative n.1 */
( check, order, high ), ( reject, order, high ), ( archive, order, low ) I* this feature is of marginal interest */
also a class managing generic requests c o d . ( manage, request, low ) I* alternative n.2:
would fit *I and class-type = process-class’ has-property client-type=’big-client’
I* class attribute part *I
/*an application for Industrial Clients is being designed *I
incoming-memage start from OrderAdministrator /*the initiator *I
Figure 4. Example of a query on the SIB

502 s. FAUSTLE, M. G . FUGINI AND E. DAMIANI
SIB for a reusable class providing the services of an order processing procedure related to big clients and started by the OrderAdministrator class.
The candidate class should manage orders or requests and should include tasks related to order check, reject and archive. Different weights are assigned to the order and request features. Since the ‘order processing’ class is the scope of the search, a high weight is assigned to the order-related feature; however, since a request processing class is also acceptable, a feature related to a generic ‘request’ has been added to the query with lower relevance.
The query contains both the fuzzy SD part of the desired class, and the class attributes part. Weights are assigned considering the relevance of a feature for the designer. The conditions (condl . , cond2 . ) in the query correspond to alternative search criteria; conditions are processed sequentially; features within each condition are also processed sequentially according to the listing order. In the example of Figure 4, cond2. specifies that, if a ‘good’ component is not found using condl . , other components should be searched for, which can be reused with a higher adaptation effort. In Figure 4, we suppose that order Is-a request. The assumption is that SDs are inherited along the SIB Is-a chains: a component exhibits all the features owned by the ancestors and has additional features pertaining to its own behavior. Reference 22 gives an evaluation of this approach to requirement specification classification and management.
3. RETRIEVAL OF COMPONENTS: SIMILARITY
In real world, two entities are similar if there is a partial identity in their characteristics, in their appearance or in their properties. The ‘degree’ of similarity is given by the number of, and relevance of common characteristics of the two entities. In the context of building software applications by retrieving and composing reusable components, we consider the similarity of two classes as an index of how easily and efficiently with respect to the whole application a class can be substituted by another class in the process of composing the application.
Similarity between two class items item1 and item2 is therefore defined as the prob- ability that iteml can be substituted by item2 while keeping the application requirements satisfied. Similarity is evaluated in terms of a Conjidence Value (CV). The CVs are computed using the SDs of the SIB items. The CV results from the comparison of two SDs. The purpose of the comparison is to determine the number of matching properties in these descriptions. Then the degree of similarity is given by the number and relevance of common characteristics. The relevance is expressed by means of weights of features, which are normalized weights.
Given two SDs, it is possible to compute a similarity link with an associated numeri- cal fuzzy value, the CV, defined by a characteristic function which, given two item descriptions as arguments, returns a value in the range 0-1. The CV is the central measure of retrieval because it measures the similarity between the content of a query and the SDs in the SIB. Since the query is often composed of a few features compared to the number of features usually composing an SD, a corrective factor has to be intro- duced to balance the two ranges of sizes. The exact expression introduced for this factor is presented in Section 5.
As stated earlier, an SD is a set of features that characterize the behaviour of an item. Similarity may be defined as a function of the features that are common to two

RETRIEVAL OF REUSABLE COMPONENTS 503
descriptions. Syntactically, the confidence value can be expressed by a relation on the Cartesian product of two descriptions as follows:
CV : SD x SD - [0,1]
The CV defines a similarity index among information items for which the following
1 . It is possible that, given three items, the pairs iteml-item2 and item2-item3 share common features, however item1 and item3 share none. It follows that knowledge of the CV between items 1 and 2 and between items 2 and 3 does not provide any element to infer knowledge about similarity between items 1 and 3. Therefore similarity is computable only by direct comparison.
2. Since similarity between two items expresses their behavioural compatibility, a high confidence value means that little adaptation effort is needed to substitute one object for the other. If the relationship between two objects is hierarchic,6 e.g. parent-child, it is known that the child must be able to functionally substitute for its however, the inverse substitution is not granted. More generally, if two objects are bound by a syntactic relation,6 the asymmetry of the confidence value reflects the fact that it is easier to substitute a simple object exhibiting few functionalities by a complex one, than the other way around. The two properties above are characterized by the following expressions:
non-transitive (1) and asymmetric (2) properties hold:
non transitivity: CV(item1, item2) > 0 and CV(item2, item3) > 0 * CV(item1, item3) = ? asymmetry: generally CV( item 1, item2) f CV(item2, item 1)
3.1. Confidence value computation To compute the confidence value between two descriptions, the following matrices
are defined: the equivalence matrix EQ, the importance matrix IMP, the weight vector W, the satisfaction matrix SAT and the similarity vector SZM. The definition and compu- tation of these matrices depends on a six-valued fuzzy logic, derived from the three- valued Heyting logic? For this logic, the primitives shown in Table I1 have been defined.
1. The EQ matrix expresses the degree of keyword-compatibility between the ith feature of the source description and thejth feature of a stored description, con- sidering the synonym relationship between keywords. The elements of EQ are given by the following characteristic function (n and m are the cardinalities of the source and stored descriptions respectively, n is the fuzzy operator defined in Table 11.
Table 11. Primitives for a six-valued logic
intersection: A n B = min (A, B) union: A U B = max (A, B) implication: A - B = min (1 , BIA) equivalence: A - B = min (AIB, BIA) negation: not A = 1 - A

504 s. FAUSTLE. M. G. FUGINI AND E. DAMIANI
EQ[illil = syn (source-SD[i].keyl, stored-SDul.key1) n syn (source_SD[i].key2, stored-SDlj] .key2) for 0 5 i < n, 0 S j < rn
2. The IMP matrix expresses the implication of weights between thejth feature in a stored description and the ith feature of the source description, and is given by the following characteristic function:
if (EQ[i][i] > 0)
else
f o r 0 5 i < n, 0 5 j < rn
ZMPu] [i] = (source-SD[i] .imp
IMP b][i] = 0
stored-SD.Ij] .imp)
The value of weights implication in IMP is defined only for pairs of features having keyword-compatibility, and expresses the degree of satisfaction that a fea- ture of the stored description can provide to a feature of the source description, depending on the weight values. Formally, the value of satisfaction is given by fuzzy implication of the fuzzy weights.
3. The weight vector W contains normalized weights of the source description, the sum of all components of the vector yielding I:
mi] = source-SD[i].imp / C k source-SD[k].imp for 0 5 k < n
4. Given the matrices EQ, IMP and W, the satisfaction matrix SAT is computed as follows. The ‘x’ operator stands for rows by columns product:
SAT = diag [EQ x IMP]
The function ‘diag’ transforms a quadratic matrix into a diagonal matrix setting the elements not pertaining to the principal diagonal to zero. It is applied to the product of EQ and IMP because only elements on the diagonal are significant to the computation of similarity.33
5. The similarity vector SZM is defined as the matrix product of the satisfaction matrix and the weight vector. The similarity vector has dimensions [n][rn] x [rn][n] x [n][l] = [n][l], i.e. is a vector with one component for every feature of the source description. Each element of this vector expresses a weighted satisfaction index for the corresponding feature in the source description.
SIM = SAT x W
6. Finally, the confidence value CV is given by the sum of the components of the similarity vector SIM. The CV expresses the overall compatibility of the stored description with respect to the source description.
CV = CiDi SIM;, for 1 5 i I n

RETRIEVAL OF REUSABLE COMPONENTS 505
where Di are the sampled values of a defuzzijicationfunction D; the sampling in the range [0,1] is based on intervals of n parts, where the ith interval ranges from (i - l)/n to iln. For D, a triangular function has been ~e lec ted .~
3.2. Wildcard resolution Wildcards may be used in a query to allow for the specification of a ‘template’
corresponding to multiple components in the SIB. A wildcard is a special character (typically ‘*’) that can substitute for any keyword in the description. It broadens the requirements to be satisfied by relaxing the algorithm of computation of the CV, since wildcards match any keyword of the SDs in the corresponding position. On the other hand, wildcards introduce ambiguity, because a one-to-one correspondence between features is no longer granted, i.e. a feature in a stored description may meet more than one feature of the source description (or vice versa). The purpose of wildcards is to re- map 1 - m relationships between the query and the corresponding SDs into 1 - I relationships, thus bringing the computation to our matching procedure.
An example
An example is given for the computation of the CV between two descriptions (n = 3, m = 4): the matrixes EQ, IMP, SAT, the W and SIM vectors and the confidence value CV are shown (‘*’ denotes a wildcard):
Source description. % connect-server; set-attributes:H; * -event 8
%
Stored description. % select-input; set-attributes:L; manage-events:H; resize-window %
1. In this example no synonyms are supposed to exist, so the values in the EQ matrix are either 0 (i.e. two features are different) or 1 (i.e. two features match exactly). EQ[ l][ 13 has value 1 because the second feature of the source description is com- patible with the second feature of the stored description:
2. Considering the importance matrix, ZMP[2][2] has value 0-25 because the second

506 s. FAUSTLE, M. G . FUGINI AND E. DAMIANI
feature of the source description is compatible with the second feature of the stored description and H 3 L = M (0.5 * 0.125 = 0-25)
0 0.25 0 0 0
3. The second feature of the source description is more important than the first and third ones. This fact is reflected in the following weight vector W
4. The second feature of the source description has a medium satisfaction index SAql][ I] (because of the disadvantageous relation of the importance values), and the third feature is completely satisfied (SAT[2][2]):
5. Multiplying the satisfaction matrix SAT by the weight vector W, we obtain the similarity vector SIM:
6. Summing up the elements of the similarity vector we obtain the confidence value. Although two of the three features posed as requirements in the source description are met by the stored description, the resulting CV is relatively low. This is because the second feature is only partially satisfied: the requirements asked for a component where attribute setting capabilities have a high importance, whereas the component described by the stored description sets only a low importance on the same feature:
CV = 0-375 Ambiguities introduced by the use of wildcards can be resolved by imposing some
limitations on the IMP andor EQ matrices. As wildcards are introduced, the IMP and EQ matrices become more dense, i.e. the null-valued elements decrease. As a conse-

RETRIEVAL OF REUSABLE COMPONENTS 507
quence, every row of the matrices may contain more than one non-null element. Among several possible disambiguating the most restrictive alternative has been chosen. The corresponding algorithm is presented here below in C-like pseudocode. The n and m constants stand for the cardinality of the source and target description, respectively. All elements in every row of the compatibility matrix CMP, resulting from the scalar product of the IMP and EQ matrices are set to zero, except for the highest. (CMP[i]Ij] = IMP[i]Ij] *EQ[i][i] , MAX, is the highest value of the ith row of the CMP matrix).
This algorithm imposes a constraint on the CV since it re-establishes a one-to-one relationship between source and target features, i.e. every feature of the source descrip- tion may be satisfied at most by one single feature of the compared description.
Algorithm for ( i s ; i<n; i t + ) /* for each row */ {
for (i=o; j<m; j-t i-) /* for each value in the row */
if (CMP[i][j] < MAX,) I
1; CMP[i][i] = 0;
1
3.3. Order of features Up to now, no assumptions have been made concerning the order of features in
descriptions. Implicitly this order corresponds to the citation order within the descrip- tion. If no particular meaning is associated with the order of features (e.g. in an object- interface description), an enumerative comparison algorithm is applied. This was the case in the preceding sections.
For some kinds of descriptions however (e.g. the description of an algorithm), the order of features has the meaning of temporal precedence. An example of ordered features describing an algorithm has been given in Figure 2, for the ‘XUIM’ implemen- tation class.
In such cases, the user may want to be able to operate a more restrictive comparison. For this possibility an ordered comparison algorithm has been developed imposing that the subset of common features must have the same relative positions in the compared descriptions. The choice of which type of comparison the system should perform is left to the user.
An ordered comparison is granted if the following condition holds.
Condition The comparison of two descriptions is ordered if the sagittal representation4 of the
EQ matrix presents no interfering (i.e. crossed) arcs. The sagittal representation of the EQ matrix of the example shown in the previous
section is depicted in Figure 5. Possible interfering arcs may be removed by applying a reduction algorithm33 to the equivalence matrix EQ.
The decision of which arcs to remove is based on a heuristic algorithm: first, the

508 s. FAUSTLE, M. G. FUGINI AND E. DAMIANI
1
Feature1
Feature2
Feature3
Feature4
Feature1
Feature2
Feature3
source-fd stored-fd
Figure 5. Sagittal representation of the EQ matrix of the example
features of the source description are partitioned into the four disjoint sets NIL, R, R* and R+. A feature pertains to
NIL R R* R+
if no arcs depart from it if no exiting arc causes interference if some departing arcs cause interference if all the departing arcs cause interference
The arcs are directed from the source description to the stored description. The num- ber of crossings caused by an arc is called the interference factor. Then arcs are removed from the feature of R* and of R+. The arc-removing algorithm is given by the following pseudocode.
Arc reduction algorithm (Compute the sets NIL, R, R*, R+) repeat {
while not EMPTY (R*)
(Remove all interf. arcs departing from feature E R* with low- est weight)
(Recompute the sets NIL, R, R*, R+)
(Remove arc with highest interf. factor from feature E R+ with lowest weight
(Recompute the sets NIL, R, R*, R+)
I INST1:
1 INST2:
} until EMPTY (R+)
Ambiguous situations may arise during arc removal. These are resolved by the fol- lowing rules:
Rule I . If two or more arcs departing from a feature have the same interference factor, the arc ending in the feature with lower fuzzy weight is removed.

RETRIEVAL OF REUSABLE COMPONENTS 509
If the instruction labelled INST1 is applicable to two or more features, it is applied to the first feature found (the topmost in the sagittal representation). If the instruction labelled INST2 is applicable to two or more features, remove the arc with lowest satisfaction value (given by the SAT matrix elements).
The arc removal algorithm extracts a subset of common features appearing in the same order in both descriptions, discarding some of the compatibility relationships (indicated by arcs) between features. The general philosophy of the algorithm and the rules is to discard arcs conveying lower satisfaction first.
Rule 2.
Rule 3.
4. COMPONENT RETRIEVAL: THE SELECTION TOOL In this section we move from the theory of comparison given so far, to the operative usage of this theory. Given an SD-the source description representing the searched object-and starting a comparison against the descriptions stored in the SIB, it is pos- sible to obtain a cluster of items that exhibit a certain degree of similarity with the source object. The source description may be interactively edited by a user, and used as an entry point in the SIB, or pertain to a candidate found in a previous search step. The objects belonging to the answer set may be browsed or queried again. The user can select an object of the cluster to become the new seurchfocus, and ask the system to compute a new cluster which is 'centered' around it. In this way it is possible to navigate the SIB along the dynamic hyperlinks which are iteratively computed starting from the current source (i.e. focus) object (see Figure 6).
To resolve a query, the system takes the source description interactively edited by the user, or pertaining to the selected focus object, and systematically compares it with the (relevant) descriptions stored in the SIB, applying the enumerative or the ordered algorithm, according to user instructions.
The answer set is composed of all the stored descriptions returning a CV higher than
source FD "'T2
SIB IEMS cluster 2
Figure 6. Iterative selection of candidates via queries

5 10 S. FAUSTLE, M. G. FUGINI AND E. DAMIANI
zero. The re~aZZ~~ of a query may be augmented by introducing wildcards, either in the source description or in the stored descriptions. Formally the answer set A is given by
A = { stored-SD E SIB 1 CV(source-SD, stored-SD) > t )
where t is the threshold. A description of the selection mechanism is given in the format of Data Flow Diagrams in the Appendix.
4.1. Filtering The user can augment the precision34 of the query answer set by imposing a threshold
(or cut value) on the CV, as explained in the previous sections. This is a filtering mechanism for the search. If the cut value is set to 1, only perfect fitting candidates are retrieved into the cluster. The resulting set is called the alpha-cut4 A, of the original set A and expressed by the formula
A, = ( stored-SD E SIB I CV(source-SD, stored-SD) 2 a )
Another way to filter the answer set is to restrict the search to a certain context, determined by the label of the description. The resulting set A, is given by:
A, = { stored-SD E A I label(stored-SD) = “context” }
The third filtering mechanism applicable on the answer set is the reduction of the specialization dependencies. As a matter of fact, the query answer set will contain many objects that are hierarchically related to each other via Is-a relationships, due to the inheritance. The user may reject all members of a family, retaining only the roots, obtaining the resulting set A,., or retaining only the leaves, obtaining A , :
A , = { stored-SD1, stored-SD2 E A not Is-a(storedSD1, stored-SD2) ] A, = { stored-SDl, stored-SD2 E A not Is-a(stored-SD2, stored-SD1) }
The three filtering mechanisms may be applied to the answer set A either simul- taneously or independently.
4.2. The prototype tool
A prototype of the selection tool for retrieval of components from the SIB has been implemented during the Ithaca project embedding the described classification and retrieval mechanism. The purpose of the prototype has been to perform a first evaluation of the approach using the Telos knowledge representation language as a host environ- ment, and studying the interface of the mechanisms with the Ithaca tools environment. Later experimentation has been devoted to measuring the effectiveness of the classifi- cation and retrieval, obtaining recall and precision measures to be compared with other systems (this further experimentation is described in the next section).
The Telos prototype, internally, converts the symbolic values of weights at the user interface-belonging to the set { VH,H,M,L,VL}-into numeric values, corresponding

RETRIEVAL OF REUSABLE COMPONENTS 51 1
to fuzzy values, according to the data structures shown in Table 111. The C-like syntax of Table I11 is used internally by the implemented tool to represent the types and vari- ables that are necessary to compute the CV. The type fuzzy is a floating point number in the range 0-1. The source description corresponds to the searched object, the stored one is associated with a SIB item.
The Telos system provides a window user interface based on SunView in SunOS/Unix/BIM-Prolog environment. The retrieval mechanism based on SDs is usable within dedicated QUERY and VIEW windows. The comparison type and the fil- tering mechanisms described in the previous sections are settable on the control panel of the QUERY facility. Queries can be edited in a text subwindow, and the query answer set (candidates) is visualized. Queries and query answer sets can be saved and recalled at a later moment. SDs are displayed to the user and an object may be selected as a focus object, around which the system suggests a new similarity cluster. As an on-line help in editing descriptions, a THESAURUS window is provided, where the defined keywords and the allowed contexts can be visualized.
The use of the search interface has shown that the effectiveness of the described fuzzy query system increases dramatically when coupled with the SIB browser.35 The functionalities of the Ithaca Selection Tools have been experimented within the Ithaca project, particularly for the interaction with the other tools of the environment, such as the SIB and RECAST (REquirement Composition and Selection Tool) devoted to reuse of requirement specifications.22
5. EVALUATION OF THE APPROACH We undertook an empirical study to find evidence of the viability of the described classification and retrieval mechanism. For the classification of reusable components in the repository, we employed a set of symbolic functions implementing the fuzzy calcu-
Table 111. Implementation data structures for computation of the confidence value
typedef typedef typedef atruct [ String String fuzzy
} Feature:
Feature Feature fuzzy fuzzy fuzzy fuzzy
fuzzy
fuzzy fuzzy
float fuzzy; char* String;
keyl; key2 ;
;
Cv; Syn (char *, char *);
I* floating point number in the range [0,1] *I I* character string *I
I* first keyword *I I* second keyword *I I* importance value *I I* a feature is composed of two keywords and a fuzzy
I* source description : contains n features *I I* stored description : contains m features *I I* equivalence matrix: dimension n rows x rn columns *I I* importance matrix: dimension m rows x n columns *I I* satisfaction matrix: dimension n rows x n columns *I /* weight vector : one weight for every feature of the
I* similarity vector: one weight for every feature of the
/* confidence value: result of the comparison *I I* function taking two strings and returning a fuzzy value *I
weight *I
source SD *I
source-SD *I

512 s. FAUSTLE, M. G. FUGINI AND E. DAMIANI
lus described in the paper (using MathematicaTM). We examined and classified the fol- lowing object code libraries: the NIH library of extended data types,36 the Borland C t t 3.1 class library of graphical objects, a library of basic classes in the Smalltalk class library distribution kit, the University of Wisconsin ‘Linear Algebra Package Distri- bution Kit’ (rel. 2.0), and other classes extracted from References 30 and 37-39. Quanti- tative parameters regarding the obtained SIB are summarized in Table IV.
Method We defined a SIB descriptor for each class; the descriptor has the class name and
includes the class-defined methods (inherited methods are ignored, unless overridden by the class). The comments associated with the code are examined only in those cases where the method names showed scarce expressive power. Features are constructed using the pairs (method-first-parameter) and a fuzzy weight is assigned to them. We noticed that the extracted terms have a significant expressiveness. Therefore, a method for semi-automatic extraction of keywords from the descriptors and for their proper coupling into features is feasible, and has in fact been implemented. In general, key- words can be automatically extracted from object code and then manually refined by the application engineer using the accompanying documentation. We have obtained a lexicon which turns out to comprise a satisfying set of terms. The corrective factor for the query size (Section 3) has been settled to be
where N is the size of the SD, n is the query size, yn is the number of matches between the features of the query and those of the SD, and k is a constant, SIB-wise value allowing for manual tuning.
Evaluation method Let us now describe how we performed the evaluation of the retrieval mechanism.
Although we shall compare our results to those obtained from a couple of analogous
Table IV. SIB parameters
SIB parameters Values
I . Total number of components 2. Number of C t t components 3. Number of Smalltalk/Eiffel components 4. Maximum length of SD 5 . Minimum length of SD 6. Average length of SD 7. Number of features 8. Number of terms
87 70 17 34
1 9
487 379

RETRIEVAL OF REUSABLE COMPONENTS 513
systems (i.e. software components classificatiodretrieval systems), our point here is to show that our retrieval system behaves in a way satisfactorily close to a human expert performing the same tasks. Moreover, we intend to show that this can be obtained even without the support of a full-fledged thesaurus and that retrieval performs effectively thanks to the possibility of assigning relevance weights to the characteristics of the desired component. This allows the application developer to rapidly focus his search or, vice versa, to broaden the query space at will in accordance with the main purpose of the system, that is to support uncertainty both in classification and retrieval.
In addition, we want to point out that the comparison results are not conclusive, since we did not submit the same queries to all the systems under comparison. In fact, performance results for the other systems taken into account are taken from Refer- ence 12.
In order to evaluate the role of weights in the retrieval mechanism, we repeated the same queries (the same features) with different weights. Some examples are reported in the Appendix. In general, the developer has two ways to modify the queries taking into account the results of previous searches: by varying the features, and by varying the weights. By imagining these two variations as two axes, the developer will usually follow a path in the plane. We tested those strategies separately.
Query setup The experimental set of queries has been defined as follows. We have set up three blocks of five queries each. The total number of queries is
comparable to the number (30) used in Reference 12, given the size of our repository. In fact, the number of queries that should be used for a thorough testing is constrained by the size of the repository. The queries have been executed three times each, at different threshold values for the ranked returned list, thus leading to a meaningful number of runs.
It is important to remark that our 15 test queries were prepared off-line and then submitted to the system in succession. No substitution or reformulation of queries on the basis of their results was ever allowed, even when it was clearly suggested by the system’s answer. A slightly different approach was instead undertaken in the evaluation of the compared systems, where query feedback was allowed on query formulation.
Moreover, our queries are related to each other within a block, in order to reproduce the human behaviour. In fact, each block mimicks a retrieval session where the devel- oper progressively refines an initial query to search for a certain kind of component. In our model, refining means adding new features to the query. Therefore, in each block, queries are ordered by inclusion, starting with the query composed of the mini- mum number of features. We also imposed that weights assigned to progressively added features must be greater than, or equal to, the highest weight already present in the previous query. This constraint can help in rapidly focusing the search. As mentioned above, we did not use a thesaurus, but we listed and normalized all the items contained in the descriptors, and assumed a good knowledge of this vocabulary by the developer when formulating the query. Hence, the synonymia computation was not performed. Our purpose was in fact to test the effectiveness of the retrieval mechanism alone (with no sources of interference caused by further complexity in the mechanism), and to obtain numerical values for the recall and the precision. Each query was submitted to the judgment of a human expert who has consulted the SIB and countersigned the

514 S. FAUSTLE, M. G . FUGINI AND E. DAMIANI
components which, according to his opinion, should have been retrieved. The counter- signed components constitute the query control set. Later, the query was submitted to the system. The returned components were limited by a threshold to form a ranked set of candidates.
The recall and the precision have been defined as follows:
number of retrieved components belonging to the control set cardinality of the control set
recall =
number of retrieved components belonging to the control set number of retrieved components
precision =
Query execution The query blocks are reported in the Appendix. For each block Bi, i = 1, ..., 3 we
executed the queries Qi,, ..., Qi5 and computed the recall values (ril, ..., ris) and the precision values (pil, ..., pa). Each block has been executed three times, with threshold values 0.1, 0.4, and 0.5, respectively for the ranked list.
Then, we ordered the recall-precision pairs for increasing values of recall, taking the median of precisions for the same recall value. This is repeated for the three threshold values. Across query blocks, we averaged the precision values for each obtained recall value. This procedure is analogous to the procedure outlined in Reference 12.
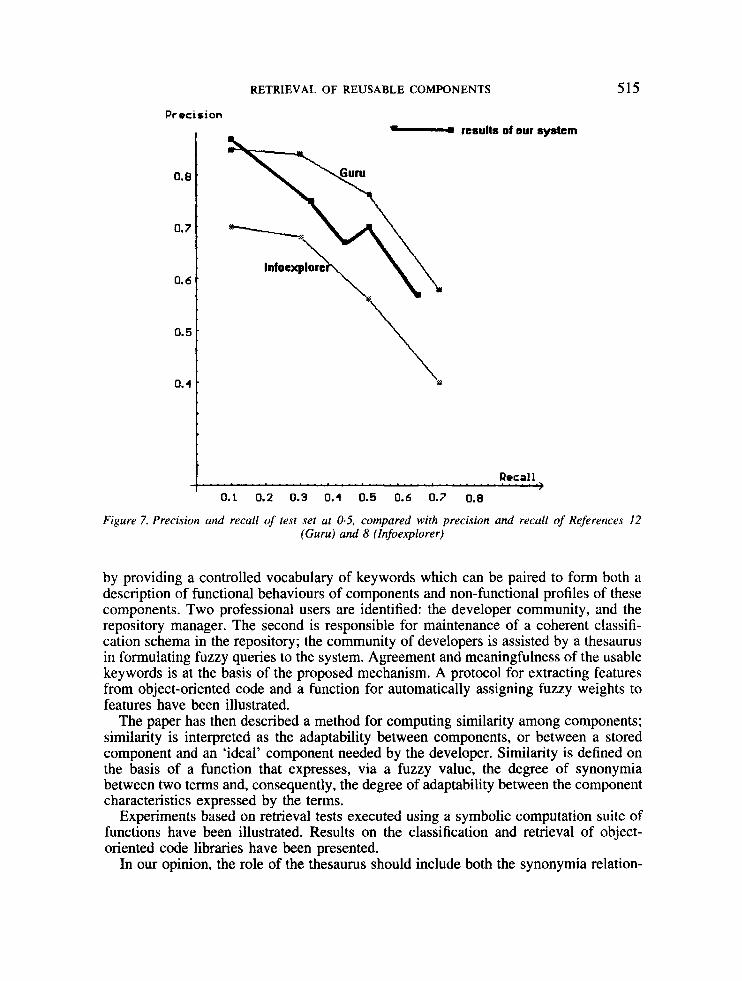
The results of precision and recall for 0.5 threshold are plotted in Figure 7. In the plot, the results of Reference 12 and of Reference 8 are also shown as a basis for comparison only, since the results of those systems have been obtained by selecting the best results out of a much wider set of queries.
We observe that the system shows a good behaviour at the lowerhpper limits of the considered range of recall values while keeping satisfactory precision values in the central portion of the range.
The precision and recall values for the various query blocks are also reported in the Appendix. Here we observe that adding features to a query often leads to an increased precision, but up to a certain point. After the break point, the risk is that features are included that are shared by a large set of components. For example, in the first block, we begin by searching a random access component by asking for an index (at()int , indexrangeoerr, and donext()lterator); later (query Q2-Q3) we focus our search by adding sorting (sort{)-) and the extraction of the maximum (max{)-). This leads to a constant high value of precision (around 1). Progressively, we added features detailing the desired method (reveree()-, and compare()-) which are shared by other components than the arrays. The rationale of this adding is that we want to see all possible relevant pieces of software and then possibly intersect the obtained result can- didate sets (arrays and components having ‘reverse’ methods). This leads to an expected drop in precision (0-5).
6 . CONCLUDING REMARKS AND FUTURE WORK This paper has described a mechanism for retrieval of reusable components in a reposi- tory storing software artefact descriptions. The repository is intended for use by cievel- opers applying a reuse oriented method. The proposed method classifies reusable items
RETRIEVAL OF REUSABLE COMPONENTS
Precision
0. a
0.7
0.6
0.5
0.4
results
515
of our system
Recall -~
0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8
Figure 7. Precision and recall of test set at 0.5, compared with precision and recall of References 12 (Guru) and 8 (Infoexplorer)
by providing a controlled vocabulary of keywords which can be paired to form both a description of functional behaviours of components and non-functional profiles of these components. Two professional users are identified: the developer community, and the repository manager. The second is responsible for maintenance of a coherent classifi- cation schema in the repository; the community of developers is assisted by a thesaurus in formulating fuzzy queries to the system. Agreement and meaningfulness of the usable keywords is at the basis of the proposed mechanism. A protocol for extracting features from object-oriented code and a function for automatically assigning fuzzy weights to features have been illustrated.
The paper has then described a method for computing similarity among components; similarity is interpreted as the adaptability between components, or between a stored component and an ‘ideal’ component needed by the developer. Similarity is defined on the basis of a function that expresses, via a fuzzy value, the degree of synonymia between two terms and, consequently, the degree of adaptability between the component characteristics expressed by the terms.
Experiments based on retrieval tests executed using a symbolic computation suite of functions have been illustrated. Results on the classification and retrieval of object- oriented code libraries have been presented.
In our opinion, the role of the thesaurus should include both the synonymia relation-

516 s. FAUSTLE, M. G. FUGINI AND E. DAMIANI
ship and all the functions usually included in a controlled vocabulary. In the illustrated experimentation, we wanted the thesaurus not to affect the retrieval study. In current work, a thesaurus is being experimented with, based on theoretical results on automatic construction presented in Reference 26.
In order to complete the presentation of our approach, we conclude by comparing the description method illustrated in this paper with some basic classification and retrieval systems that return afuzzy set of candidates related to each other by some metrics, we obtain the results shown in Table V. All the mentioned systems share the following properties:
1. The query answer set is composed of classes, called candidates, with an associated relevance index which we call conjidence value (CV).
2. The relevance of a candidate is indicated by a fuzzy value between 0 and 1. 3. The retrieval is based on descriptions formed of keywords. 4. The same description format is used for classification and retrieval.
Table V. Comparison between different classification and retrieval schemes
Altair/O, Faceted scheme xos SDs
1 . Primitive
2 . Description description item
format
Keyword Keyword Keyword Feature (keyword pair) Sequence of features
Sequence of keywords
Sequences of keywords belonging to different facets
Sequence of keywords belonging to different categories Unbound Unbound Fixed by number
of facets Facet citation order
3. Description
4. Importance of length
description items
Unbound
Weight associated with keywords
No Importance value associated with features Associated with comparison of descriptions Dynamic
5. Relevance of query answer set members
6. Relevance computation
7. Computation of query answer set
Associated with production rules
Associated with standard attributes
Associated with comparison of descriptions Dynamic Static Static
Using production rules associated with keywords
Identity between descriptions and query descriptor
Similarity between descriptions and query descriptor Behavioral compatibility Yes
Similarity between descriptions and query descriptor Context bound compatibility Yes
8. Relevance meaning
9. Controlled vocabulary
10. Wildcards admitted
11. Synonyms admitted
Behavioral compatibility Yes
Reuse effort
Yes
Yes Yes Not specified Yes
No Yes Yes Yes

RETRIEVAL OF REUSABLE COMPONENTS 517
Three selected systems are compared with the SDs method. These systems are the Altair/O, system,’ the faceted classification and the external object system (XOS).~ Analogies and differences are shown in Table V. We remark that these systems are taken into consideration from a conceptual point of view but could not be used for precision and recall comparison due to the fact that, to the best of our knowledge, these values were not available at the moment of our experimentation planning.
The issue of wildcards proves a helpful tool in query formulation at the early stages of a search, and whenever the developer wants to expand the recall of the search to explore the SIB contents. In the present status of the prototype and of the simulation algorithms, we avoid wildcards in the SIB descriptors, while allowing for wildcard use in the queries. However, since the presence of wildcards complicates the search algor- ithm, wildcards should be avoided when looking for specific components, e.g., when looking for ‘linear equation solver’ components in a mathematical library; when looking for such a component, the developer can use more precise keywords describing the solving method, the employed data, the modifications on the input data, the storage needs, etc. Instead, the function for automatic assignment of weights works in a satisfi- able manner.
We observe that, in order to progress towards an efficient system the main issues are:
(a) A semantically rich thesaurus able to mediate the various jargons of the libraries. For the thesaurus, an initialization phase and a frequent manual intervention by the application engineer will always be needed. For thesaurus construction and maintenance, contexts prove helpful, also for scanning the documentation look- ing for term relevance within contexts. The thesaurus automatic construction has been tackled in Reference 26 and is a current object of our research.
(b) A tuning mechanism of the SIB retrieval system. Monitoring the users’ reactions to the proposed candidates is needed so that the whole classification/retrieval system can be ameliorated along time. To this aim, a quality function defined in Reference 26 has been designed which, exploiting the potential of fuzzy systems, contributes substantially to the system precision in that the system is tuned to the users’ answers.
(c) The implementation of a more advanced prototype in an object-oriented system, such as the Telos system or an 0-0 DBMS. This would allow one to give a class structure to the software descriptors and therefore to fully design the query mechanism introducing computation performance parameters.
ACKNOWLEDGEMENTS
This work was partially supported by the EEC-Ithaca Project no. 2705, and by the Italian National Research Council ‘Progetto Finalizzato Informatica e Calcolo Paral- lelo’, L.R.C. ‘Infokit’. We thank all the partners in the Infokit Group and in the Ithaca Tools Group for common work and useful comments. We would also like to thank R. Bellinzona and R. Zoccali, who helped in the design and implementation of the system.

518 S. FAUSTLE, M. G. FUGINI AND E. DAMIANI
APPENDIX
Some descriptors taken from our SIB are shown below, to provide a sketch of their structure (weights are shown as they have been computed by Mathernatica, main- taining the same precision level for decimals). Then, we show a sample controlled vocabulary of terms extracted from the SIB and the three blocks of queries that have been used to test the system.
ARRAY contain contain contain addcontent contain hash capacity isequal species at resize contain sort index donext store store size compare occurrence add remove remove
ARRAYST decode ismember store element - pri n t start element-replace refers
BAG multiple equal resize add
dictionary
set cltn orderdcltn WILDCARD WILDCARD object WILDCARD int self set WILDCARD range iterator io file WILDCARD object object object object all
bag
li teral-array array io stream self collection literal
occurrence object insigned occurrence
0.87523724875661 0.87523724875661 0.6240372635325735 0.6240372635325735 0.87523724875661 0.2247335884443359 0.4152248522056913 0.18654980788091 56 0.4967443765 167542 0.4967443765 167542 0.87523724875661 0.6240372635325735 0.87523724875661 0.87523724875661 0.4967443765 167542 0.1247627512433903 0.17 10974 1021 29087 0.415224852205691 3 0.20424253467321 72 0.357021621 191 3368 0.2775646083083885 0.3 12727 1064 162543 0.2775646083083885
0.87523724875661 0.8752372487566 1 0.1247627512433903 0.87523724875661 0.87523724875661 0.87523724875661 0.8752372487566 1
0.8752372487566 1 0.87523724875661 0.8752372487566 1 0.8752372487566 1

RETRIEVAL OF REUSABLE COMPONENTS
add donext dump remove remove compare hash isequal occurrence size store
BIGINT print add check
BITBOARD initialize capacity isempty isequal print store compare hash
BITSET set use capacity hash isempty isequal print size store store compare
Controlled vocabulary A abs abstract accelerator access
object iterator stream object all self self object object self io
file self WILDCARD
class self self object stream io object self
smallinteger simpleword WILDCARD WILDCARD WILDCARD object stream WILDCARD io file object
action activate add addcon tent
0.2775646083083885 0.4967443765 167542 0.35702162 1 191 3368 0.3 12727 1064162543 0.2775646083083885 0.35702 162 1 19 13368 0.4967443765 167542 0.1865498078809 156 0.35702 1621 191 3368 0.8752372487566 1 0.1247627512433903
0.8752372487566 1 0.4967443765 167542 0.87523724875661
0.87523724875661 0.87523724875661 0.6240372635325735 0.18654980788091 56 0.12476275 12433903 0.12476275 12433903 0.20424253467321 72 0.4967443765 167542
0.87523724875661 0.87523724875661 0.4 1522485220569 13 0.2247335884443359 0.2775646083083885 0.1865498078809156 0.12476275 12433903 0.4152248522056913 0.12476275 12433903 0.17 lO974102129087 0.2042425346732172
all allocate amount and
519

520 S. FAUSTLE, M. G. FUGINI AND E. DAMIANI
answer append application apply arity arrange array arrow assign associate association at atallput B bag begin bet ween block border bound box buffer build button buttoncontroller C call capacity cascade center change channel char character characters tring check child class clear close cltn code cofac tor collect collection column combine compare
component compute concat condition cont contain content control controller COPY crack create current D date
deactivate dec decode deinitialize delete detect determinant device dialog dictionary difference directory display division do dofinish donext doreset dot double down draw dump dynamic E edit element end enumerator environment equal event
day
extent F factor file filename filter find finish first float focus forbidden fraction frame free further G gcd get go
haar handle hash head highlight hilbert horizontal hour hourgmt hypersolve I icon ide inc include index info initialize input insert insigned install int intersection inverse io

RETRIEVAL OF REUSABLE COMPONENTS 52 1
is isdst isempty isequal isleaf ismember isupper issuppertriangular i tem iterate iterator K
keyboard key value L label last layout leaf left length list literal load loc a1 time lookup
M manager manipulate mark matrix matrixsymm max mdi menu menubar menubutton meq message min minus minute minutegmt modalwindow modify mounth
key
loop
move multiple N name new newobject next nextlink norm normalize number 0 object occurrence okay on1 ysolve open operator orderdcltn origin overflow P paint parent point pointer POP position Prep previous print
process product prompt Ptr push Put R radius range read recover rectangle reduce refers release remove
Prl
removeall replace represent reset resize response reverse right root row run S save scale scan schedule scrollbar scrollwrapper search second seek segment selection self send seqcltn set setup shl shr sibling signal simpleword singly linked singular size smallin teger solution solve sort source spacing species specific sqa start state store

522
stream string sub swap switch T table tell text tile time tproduct transfer
S . FAUSTLE, M. G . FUGINI AND E. DAMIANI
translate transpose triangle U underflow union unit unorderedcollection unschedule unsigned update use V
validation value vector version vertical view w window wrapper write Y Yea
Now, the queries which have been executed against the SIB are presented.
Query block 1 In this retrieval session, the developer is looking for (a) component(s) that can be
randomly accessed. ‘-’ is used as the wildcard symbol. ‘0’ is the term separator. ‘Self’ is the auto reference.
Control set of B l (selected by a human expert)
collection array, vector, collection, matrix, arrayedcollection, sequentiablecollection, bag, set,
at()int; 0 . 8 indexrangeoerr; 0 . 5 donext()iterator; 0 . 7 storeofile; 0.2 print()- ; 0 . 2
at() int i 0 . 7 indexrangeoerr; 0 . 4 donext()iterator; 0 . 4 storeofile; 0 . 2 print()- ; 0.2 sort()- ; 0 . 8 mx()- ; 0 . 7

RETRIEVAL OF REUSABLE COMPONENTS 523 Q3 = Ql+Q2+ swap()O. 8
Q4 = Q3+ occurrencesof()-0 .7
Q5 = Q4+ reverse()- ; 0.8 compare()- ; 0.8
Query block 2
unordered elements of “set” type. In this retrieval session, the developer is looking for (a) component(s) containing
Control set of B2 (selected by a human expert)
collection, bitset, bitboard, heap, stack, dictionary array, vector, collection, matrix, arrayedcollection, sequentiablecollection, bag, set,
Ql isempty()-; 0 . 8 add()ob j ect ; 0.8 remove()obj ect ; 0.6 print()-; 0.2 store()- ; 0.2
Q2 isempty()- ; 0.8 add()(obj ect ; 0.8 remove()ob j ect ; 0.6 print()-; 0 . 2 store()-; 0.2 compare()self; 0.8 isequal()self; 0.8
isempty()- ; 0.7 add()object;0.7 remove()ob j ect ; 0.7 print()- ; 0.2 store()-;0.2 comgare()self ; 0.7 isequal()self; 0.7 includes()ob ject ; 0.8 occurrencesof()object;O.8
isempty()- ; 0.5 add()(object; 0.5 remove()ob j ect ; 0.5
Q3
Q4

524 s. FAUSTLE, M. G . FUGINI AND E. DAMIANI
print()-; 0 . 2 store()- ; 0 . 2 comgare()self; 0 . 5 isequal()self; 0 . 5 includes()object; 0 . 5 occurrencesof()object;O.5 union()self; 0.8 intersection()self; 0.8
Q5 = Q4+ hash()- ; 0.8
Query block 3
graphical windows. In this retrieval session, the developer is looking for (a) component(s) managing
Control set of B3 (selected by a human expert) tedita, twindowa, tmicli
activate()window; 0 . 8 5 rawoborder; 0 . 3 size()window; 0 . 8 setup()window; 0 . 8
activate()window; 0 . 8 5 drawoborder; 0 . 3 set()column; 0 . 7 setorow; 0.7 cascadeochild; 0 . 2 setug()window; 0 . 8 build()special-window;0.6 new-graphicodevice; 0 . 5
activate()window; 0 . 7 createomdi; 0 . 4 scrollbar()horizontal;O.6 scrollbar()vertical; 0.6 setup()window; 0 . 8 build()special-window; 0.6 new-graphicodevice; 0.5 stroked~display()graphic~context;O.5
Ql
Q2
Q3
Results of query execution In the graphs in Figures 8 and 9 we show the results of queries in terms of recall
and of precision. The precision and recall paths are obtained as the average of the three blocks of queries at three threshold values. The thresholds are labels on the curves.
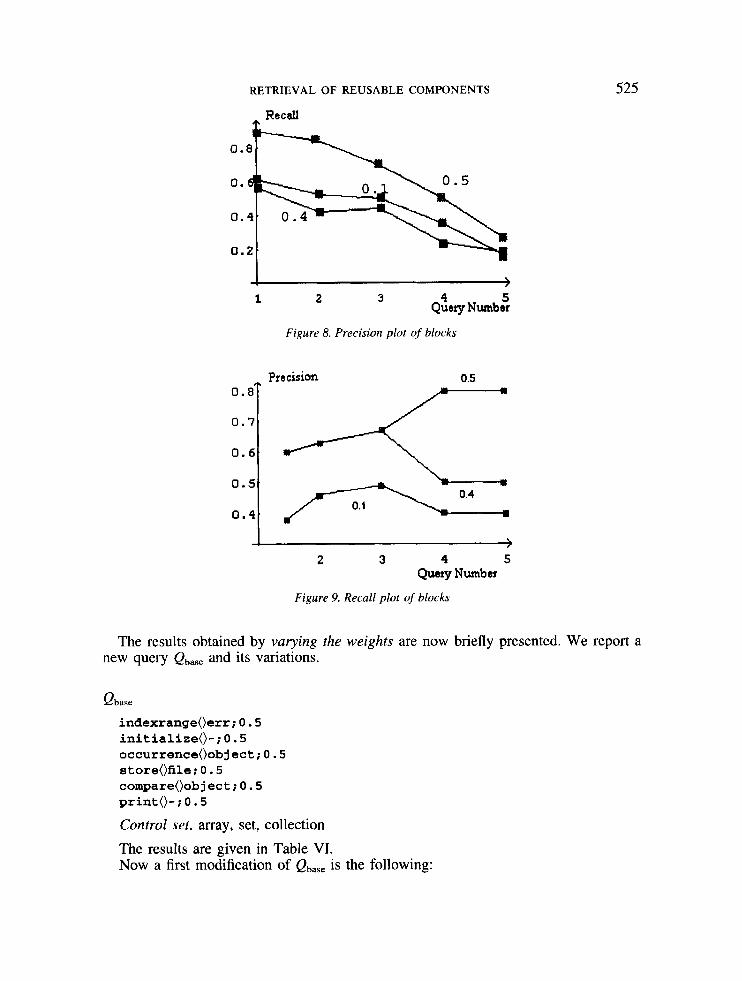
RETRIEVAL OF REUSABLE COMPONENTS
R e e d
0 . 8
0.7
0 . 6
0 . 5 ,
0.4,
0.2.
1 2 3 4 5 Query Number
Figure 8. Precision plot of blocks
525
2 3 4 5 Query Number
Figure 9. Recall plot of blocks
The results obtained by varying the weights are now briefly presented. We report a new query Qbase and its variations.
indexrangeoerr ; 0.5 initialize()-; 0 . 5 occurrence()object; 0.5 store()file; 0 . 5 comgare()obj ect ; 0.5 print()- ; 0 . 5
Control set. array, set, collection The results are given in Table VI. Now a first modification of Qbase is the following:

526 s. FAUSTLE, M. G. FUGINI AND E. DAMIANI
Table VI. Qbase
Threshold Precision Recall
0.1 0.3 0.5 0.7
0.14 0.13 0.2 0.5
1 0.4 0.2 0.2
Table VII. QueryA
Threshold Precision Recall ~~
0.1 0.19 1 0.3 0.19 0.6 0.5 0.18 0.4 0.7 0.33 0.2
QuelrA indexrangeoerr; 0 . 7 initialize()-;O.7 occurrence()ob j ect ; 0 . 7 storeofile; 0 . 4 comgare()ob j ect ; 0 . 4 print()- ; 0 . 4
and its results are given in Table VII. We observe that recall and precisi n vary independently in dependence of the
weights. The results of a query can be tuned by adjusting the weights. The idea here is to focus the search using features, and then to finally tune the retrieve set by means of the weights.
Now another variation of Qbase is:
indexrangeoerr; 0.4 initialize()- ; 0.4
Table VIII. QueryB
The shol d Precision Recall
0.1 0.18 1 0.3 0.22 0.8 0.5 0.2 0.4 0.7 0.33 0.2
RETRIEVAL OF REUSABLE COMPONENTS 527
occurrence()obj ect ; 0 . 7 store()file; 0 .4 compare()ob j ect ; 0 . 7 grinto-; 0 . 4
the results of which are given in Table VIII.
Figure 10. Context diagram (AD = developer, AE = engineer)
SIB A
ld
domain kmwl
SW oomponnt
uld Thesaurus
V
d
sd
Retrieval 2
SIB Answer Set
Figure I I . Level 0: overview diagram
528 s. FAUSTLE. M. G. FUGINI AND E. DAMIANI
M
domln knowl.
As usual, QueryB has been formulated independently of the observation of the results
Finally, we summarize the proposed approach by giving in Figures 10-13 a data obtained from QueryA.
flow diagram description of the classificatiodretrieval mechanism.
keyword.
Thesaurus SIB fd k.wrd. I
0-
candd.W c*ssos
fd
Figure 13, Level 1: ciass retrieval

RETRIEVAL OF REUSABLE COMPONENTS 529 REFERENCES
I . R. Prieto-Diaz, ‘Status report: software reusability’, IEEE Software, 10, (3), (1993). 2. W. B. Frakes and T. P. Pole, ‘An empirical study of representation methods for reusable software compo-
3. L. A. Zadeh and R. R. Yagen, (eds). Uncertainty in Knowledge Bases, Springer Verlag, Berlin, 1991. 4. G. J. Klir and T. A. Folger, Fuzzy Sets, Uncertainty, and Information, Prentice-Hall, 1988. 5 . 6. Kosko, Neural Networks and Fuzzy Systems: A Dynamical Systems Approach to Machine Intelligence,
6. R. Prieto-Diaz and P. Freeman, ‘Classifying software for reusability’, IEEE Software, 4, (1987). 7. G. Arango, R. Cazalens, et al. ‘Design of a software reusability subsystem in an object-oriented environ-
8. IBM AIX Version 3 for RISC Sysied6000. Commands Reference, IBM, Yorktown Heights, NY, 1990. 9. S. Gibbs and V. Prevelakis, ‘Xos: an overview’, in D. Tsichritzis (ed.), Object Management, Centre Univer-
sitaire d’hformatique, Universite’ de Geneve, 1990. 10. G. Spanoudakis and P. Costantopoulos, ‘Similarity for analogical software reuse: a conceptual modeling
approach’, Proc. CASE ’Y3, Paris, June 1993. 1 1 . P. G. Anick, R. A. Flynn and D. R. Hansen, ‘Addressing the requirements of a dynamic corporate textual
information base’, Proc. ACM Con5 on Info. Retrieval SIGIR ’ Y l , Chicago, Illinois, 13-16 October 1991. 12. Y. S. Maarek, D. M. Berry and G. E. Kaiser, ‘An information retrieval approach for automatically con-
structing software libraries’, IEEE Trans. Sqffwure Engineering, 17, (X), (1991 ). 13. R. Prieto-Diaz, ‘Implementing faceted classification for software reuse’, Comm. ACM, 34, (5) , (1991). 14. J. Tague, A. Salminen and C. McClellan, ‘A complete formal model for information retrieval systems’,
IS. Y. Zha, V. V. Raghavan and J. S. Deogun, ‘An object-oriented modeling of the history of optimal
16. C. Wholin and P. Runeson, ‘Certification of software components’, IEEE Trans. Software Engineering, 20,
17. J . Dvozak, ‘Conceptual entropy and its effect on class hierarchies’, IEEE Computer, 27, (6), (1994). 18. W. B. Frakes and P. Gandel, ‘Representing reusable software’, Information Sofmare Technology, 32,
( 1990). 19. M. Ader, 0. Nierstrasz, 0. McMahon, G. Mueller and A.-K. Proefrock, ‘The lthaca technology: a landscape
for object-oriented application development’, Proc. ESPRIT ’YO Conf., Kluwer Academic Publishers, Nov- ember 1990.
20. P. Constantopoulos, M. Doerr and Y. Vassiliou, ‘Repositories for software reuse: the software information base’, in N. Prakash, C. Rolland and 6. Pernici (eds), Informutir~n System Development Process, North- Holland, 1993.
2 I . M. G. Fugini. 0. Nierstrasz and B. Pernici, ‘Application development through reuse in the ITHACA tools environment’, ACM-SIGOIS Bulletin, August 1992.
22. R. Bellinzona, M. G. Fugini and B. Pernici, ‘Reusing specifications in 00 applications’ IEEE S@vure, 12, (2), (1995).
23. J . Mylopoulos, A. Borgida, et al., ‘Telos: a language for representing knowledge about information sys- tems’, ACM Trans. Information Systems, 8, (4), (1990).
24. V. De Antonellis and B. Pernici, ‘Reusing specifications through refinement levels’, Data and Knowledge Engineering, Vol. 15, North-Holland, Elsevier, 1995.
25. A. Motro, ‘BAROQUE: a browser for relational databases’, ACM Trans. Ofice Info. Systems, 4, (2), (1986). 26. E. Damiani and M. G. Fugini, ‘Automatic thesaurus construction supporting fuzzy retrieval of reusable
components’, Proc. ACM SIC-APP Con5 on Applied Computing (SAC ’95), Nashville, February 1995. 27. A. Motro, ‘FLEX: a tolerant and cooperative user interface to databases’, IEEE Trans. Knowledge and
Data Engineering, 2, 2, (1990). 28. G. Salton, Automatic Text Processing, Addison Wesley, 1989. 29. G. Salton, J. Allan and C. Buckley, ‘Automatic structuring and retrieval of large text files’, Comm. ACM,
30. B. Meyer, Object-Oriented Software Construction, Prentice-Hall, 1988. 31. B. J. Cox, Object Oriented Programming, Addison-Wesley, 1987. 32. P. Wegner, ‘Learning the language’, Byte, March 1989. 33. M. G. Fugini and S. Faustle, ‘Querying a software information base for components reuse’, IEEE 2nd
nents’, IEEE Trans. Software Engineering, 20, (8), (1994).
Prentice-Hall, Englewood Cliffs, N.J., 1991.
ment’, Rapport Technique Altuir 25-88, November 1988.
Proc. Con5 Inf). Retrieval SIGIR ’91, Chicago, Illinois, 13-16 October 1991.
retricvals’, Proc. ACM Conf on Info. Retrieval SIGIR ’91, Chicago, Illinois, 13-16 October 1991.
( 6 ) , (1994).
37, (2), (1994).
International Workshop on Software Reusability, Lucca, Italy, March 1993.

530 s. FAUSTLE, M. G. FUGINI AND E. DAMIANI
34. G. Salton, Automatic Information Organization and Retrieval, McGraw-Hill, 1968. 35. P. Constantopoulos, E. Pataki, ‘A browser for software reuse’, Proc. CAiSE ’92, Manchester, May 1992. 36. A. Gorlen, et al., Data Abstraction and Information Hiding in Ci-t, Prentice-Hall, 1986. 37. T. Cargill, C t t Programming Style, Addison-Wesley, 1992. 38. G. Buzzi-Ferraris, Scientific C+: Building Numerical Libraries the Object Oriented Way, Addison-
39. B. Stroustrup, The CU Programming Language, Addison-Wesley, 1993. Wesley, 1993.
Copyright © 2022 FDOKUMEN




















