
PREDICTIVE ADAPTATION FOR SERVICE LEVEL AGREEMENTS ON THE GRID
14
I.J. of SIMULATION Vol.7 No 2 29 ISSN: 1473-804x online, 1473-8031 print PREDICTIVE ADAPTATION FOR SERVICE LEVEL AGREEMENTS ON THE GRID JAMES PADGETT, KARIM DJEMAME AND PETER DEW School of Computing, University of Leeds, Leeds LS2 9JT Email: [jamesp, karim, dew]@comp.leeds.ac.uk Abstract. Users of Grid systems often need to attach Quality of Service (QoS) information such as time or performance constraints to guarantee timely execution of their application. Grid resources have varying quality and reliability and can easily be swamped by competing applications. If this coincides with the users execution their results may be delayed. In support of this we propose a Service Level Agreement (SLA) management system including resource reservation and run-time adaptation. Our system has the capability of predicting the execution time of an SLA bound application before and during runtime. A historical usage record for auditing and prediction of future execution times is also described. Through experimental analysis we show our solution is capable of predicting with some accuracy the execution time of SLA bound applications before and during runtime. Mechanisms for automated monitoring and violation capture are presented showing how performance and time constraints can be validated. Adaptation through migration is proved useful in reducing the execution time of our application when the CPU load available to that application is reduced. Keywords: Service Level Agreements, Grid, application runtime prediction and adaptation 1 INTRODUCTION Grid computing [Berman et al. 2003] provides potential users access to high performance computational resources and applications. These users may wish to attach Quality of Service (QoS) commitments to their applications in order to guarantee timely execution. An example of this is the Distributed Aircraft Maintenance Environment (DAME) Diagnostic System [Austin et al. 2004]. Users of this Grid based decision support system require timely application response in order that commitments can be maintained. The Grid comprises resources of varying type, quality and reliability perhaps from many administrative domains. These resources can be easily swamped when demand is high, leading to a drop in application performance. If this coincides with the execution of a time critical application, the results may be delayed. This has consequences in the real world and can lead to broken commitments and penalty conditions. The ability to uphold an execution commitment and assure its timely response is a goal within the Grid research community. In support of this we propose a Service Level Agreement (SLA) management system incorporating resource reservation and run- time adaptation. For this system to function, commitments and assurances are specified using Service Level Agreements (SLA). An SLA is a contract between user and provider, stating the expectations that exist between them. It is desireable to be able to reliably predict the execution time of an application. We extend support for resource selection and reservation using an external resource broker. A historical usage record is used to predict future execution times and SLA auditing. SLA management systems found in the literature [Verma et al. 2001; Leff et al. 2003; Sahai et al. 2003] focus on a limited subset of management functions such as negotiation and reservation, or reservation and monitoring. None support prediction based adaptation. Our system has the capability of predicting the execution time before and during runtime. We provide support for a historical usage record and an SLA specification including SLA provenance. Presented are the functional responsibilities for the SLA management architecture describing the implemented solution (Section 2). Taking an SLA for a compute service as a motivation, a specification for an SLA is described (Section 3). Detailed descriptions of the research topics are provided including the prediction and adaptation methodology. In support of these is a method of job monitoring using an external monitoring service. A method for resource selection and reservation is also described. (Section 4). Experiments are designed to test the prediction and adaptation methodology for an SLA bound application executing on a large distributed Grid infrastructure, the White Rose Grid J. PADGETT, K. DJEMAME and P. DEW: PREDICTIVE ADAPTATION FOR SERVICE LEVEL AGREEMENTS ON THE GRID
-
Upload
independent -
Category
Documents
-
view
1 -
download
0
Transcript of PREDICTIVE ADAPTATION FOR SERVICE LEVEL AGREEMENTS ON THE GRID

I.J. of SIMULATION Vol.7 No 2 29 ISSN: 1473-804x online, 1473-8031 print
PREDICTIVE ADAPTATION FOR SERVICE LEVEL AGREEMENTS ON THE GRID
JAMES PADGETT, KARIM DJEMAME AND PETER DEW
School of Computing, University of Leeds, Leeds LS2 9JT Email: [jamesp, karim, dew]@comp.leeds.ac.uk
Abstract. Users of Grid systems often need to attach Quality of Service (QoS) information such as time or performance constraints to guarantee timely execution of their application. Grid resources have varying quality and reliability and can easily be swamped by competing applications. If this coincides with the users execution their results may be delayed. In support of this we propose a Service Level Agreement (SLA) management system including resource reservation and run-time adaptation. Our system has the capability of predicting the execution time of an SLA bound application before and during runtime. A historical usage record for auditing and prediction of future execution times is also described. Through experimental analysis we show our solution is capable of predicting with some accuracy the execution time of SLA bound applications before and during runtime. Mechanisms for automated monitoring and violation capture are presented showing how performance and time constraints can be validated. Adaptation through migration is proved useful in reducing the execution time of our application when the CPU load available to that application is reduced.
Keywords: Service Level Agreements, Grid, application runtime prediction and adaptation
1 INTRODUCTION
Grid computing [Berman et al. 2003] provides potential users access to high performance computational resources and applications. These users may wish to attach Quality of Service (QoS) commitments to their applications in order to guarantee timely execution. An example of this is the Distributed Aircraft Maintenance Environment (DAME) Diagnostic System [Austin et al. 2004]. Users of this Grid based decision support system require timely application response in order that commitments can be maintained.
The Grid comprises resources of varying type, quality and reliability perhaps from many administrative domains. These resources can be easily swamped when demand is high, leading to a drop in application performance. If this coincides with the execution of a time critical application, the results may be delayed. This has consequences in the real world and can lead to broken commitments and penalty conditions.
The ability to uphold an execution commitment and assure its timely response is a goal within the Grid research community. In support of this we propose a Service Level Agreement (SLA) management system incorporating resource reservation and run-time adaptation.
For this system to function, commitments and assurances are specified using Service Level Agreements (SLA). An SLA is a contract between
user and provider, stating the expectations that exist between them.
It is desireable to be able to reliably predict the execution time of an application. We extend support for resource selection and reservation using an external resource broker. A historical usage record is used to predict future execution times and SLA auditing.
SLA management systems found in the literature [Verma et al. 2001; Leff et al. 2003; Sahai et al. 2003] focus on a limited subset of management functions such as negotiation and reservation, or reservation and monitoring. None support prediction based adaptation. Our system has the capability of predicting the execution time before and during runtime. We provide support for a historical usage record and an SLA specification including SLA provenance.
Presented are the functional responsibilities for the SLA management architecture describing the implemented solution (Section 2). Taking an SLA for a compute service as a motivation, a specification for an SLA is described (Section 3). Detailed descriptions of the research topics are provided including the prediction and adaptation methodology. In support of these is a method of job monitoring using an external monitoring service. A method for resource selection and reservation is also described. (Section 4). Experiments are designed to test the prediction and adaptation methodology for an SLA bound application executing on a large distributed Grid infrastructure, the White Rose Grid
J. PADGETT, K. DJEMAME and P. DEW: PREDICTIVE ADAPTATION FOR SERVICELEVEL AGREEMENTS ON THE GRID

I.J. of SIMULATION Vol.7 No 2 30 ISSN: 1473-804x online, 1473-8031 print
(WRG) (Section 5). The WRG consists of high performance Grid resources at Leeds, Sheffield and York Universities. Its resources are heterogeneous and have different administrative domains. This makes it ideally suited for testing of the proposed solution. The results confirm our solution is capable of predicting with some accuracy the execution time of our SLA bound application before and during runtime. Adaptation through migration is proved useful in reducing the execution time of our application when the CPU load available to that application is reduced. Related work is presented in Section 6, followed by a conclusion and evaluation.
2 ARCHITECTURE
Fig. 1. SLA Management Architecture
The SLA Manager provides SLA and resource management support to virtual organisations such as the Distributed Aircraft Maintenance Environment (DAME) Diagnostic System [Austin et al. 2004]. In this example the SLA Manager is supporting a Grid based decision support system where timely and reliable application provision is a requirement. Users gain access to application services with the option of attaching time and/or performance constraints. The architecture is illustrated in Fig. 1 and highlights component responsibilities. A description of these responsibilities is given in the succeeding sections.
2.1 Instantiation and Modification
The SLA Factory provides a template for SLA specification based on user identification of relevant time or performance constraints. The factory records provenance data within the SLA Instance during the policing phase. Provided is a record of warnings and violations important for auditing after the agreement has terminated. Warnings are recorded when significant events are detected which may affect the SLA in the future but no actual violation has occurred. Violations are recorded when actual breaches in time or performance constraints have occurred.
2.2 Negotiation and Reservation
To select and reserve resources onto which the SLA bound application may execute, the SLA Manager uses an external Resource Broker. The broker has responsibility for placing reservations with a resource provider. The architecture allows for a community of brokers providing reservations for resources of different types, e.g. compute, storage and even bandwidth. The example used in this research is a SNAP-based resource broker [Haji et al. 2005], which provides reservations for compute resources. During the negotiation phase the user specifies a Task Service Level Agreement (TSLA). This represents an agreement specification for a desired level of performance or time constraint for their application. At present we use a request() / agree() protocol similar to that specified within the SNAP framework [Czajkowski et al. 2002]. The SLA Manager enters into an agreement with the Resource Broker, which provides a reservation guarantee with the resource provider; this is a Resource Service Level Agreement (RSLA). Together the TSLA and RSLA form a Binding Service Level Agreement (BSLA) which binds the task to the potential resource capabilities promised within the RSLA.
2.3 Monitoring
Any Grid Monitoring Service (GMS) [Czajkowski et al. 2001] which can provide dynamic information about resource and application state may be used. This may be achieved using local Grid Monitoring Tools [Balaton et al. 2000]. Examples include Net Logger [Gunter et al. 2000] and the Network Weather Service [Wolski et al. 1999].
The use of a Grid Monitoring Tool (GMT) compliant with the Grid Monitoring Architecture (GMA) [Tierney et al. 2002] would allow a publish / subscribe mechanism to query resource and
J. PADGETT, K. DJEMAME and P. DEW: PREDICTIVE ADAPTATION FOR SERVICELEVEL AGREEMENTS ON THE GRID

I.J. of SIMULATION Vol.7 No 2 31 ISSN: 1473-804x online, 1473-8031 print
application performance information. Tools such as these can help to preserve domain autonomy whilst still allowing the SLA Engine to automatically monitor the time and/or performance constraints.
2.4 Violations
Grid infrastructures integrate heterogeneous resources with varying quality and reliability. This places importance on the ability to dynamically monitor the state of the resources and application processes. A reliable violation capture mechanism including a system of warnings and violations is important for auditing of the SLA. The information provides a historical record of the execution which may be used for debugging or extraction of data which can be used to improve the initial prediction technique. Warnings are recorded when significant events are detected which may affect the SLA in the future but no actual violation has occurred. Violations are recorded when it is beyond doubt that breaches in time or performance constraints have occurred.
2.5 Policing
The SLA Engine implements a predictive rule based decision maker. A rule based control strategy offers effective control where the control action does not have a continuous domain. The SLA manager does not have authoritative control over all applications submitted to the Grid infrastructure. The ability to effect the CPU processing potential is implemented either by migration onto a faster machine or one offering a load average which is less than that of the current resource. The adaptive process involves a prediction model, a rule based decision maker and a grid monitoring service.
Policing an SLA bound application in this way has the potential to significantly improve performance and timely response. Although not the subject of the research in this paper, this technique could be used to optimise the performance of the SLA bound application by changing its behavior depending on resource performance and availability.
3 SLA SPECIFICATION
The proposed SLA specification includes a job submission description; a provenance record; and the ability to extend an economic model. These provide the SLA with physical, historical and economic elements for describing application requirements.
Job submission elements include a job description which identifies the job, user and resource requirements; plus any data staging requirements. The SLO’s represent the active guarantees within the SLA and are quantified by a corresponding Service Level Indicator (SLI). Elements describing the parties involved in the agreement may support a listing of users or providers.
Provenance elements support historical usage and economic functions elsewhere in the SLA. Warnings and violations are recorded to allow a historical or usage record to be constructed. These include violation occurrences; prediction and migration decisions; and checkpointing actions.
3.1 Example: Specification for a Compute Service
An example SLA for a compute service is specified in Table 1. It gives an indication of the components which make up an SLA Instance.
Table 1. SLA Specification of a compute service
Component Observation
Purpose An application service with task requirements
Parties Consumer, resource broker & resource provider
Scope Compute service
Service Level Objective (SLO)
Ensure availability of resources satisfying task requirements for the duration of the Grid service task
SLO Attributes
Time and performance constraints
Service Level Indicators (SLI)
For each SLO attribute, its value is a SLI
Exclusions Adaptation / reservation may not be included
Administration SLO’s met through resource brokering / adaptation
The SLO parameter represents a qualitative guarantee such as a time or performance constraint. Time constraints may be specified in numerous ways, examples are (1) an acceptable period in which to complete the application execution or (2) an earliest start and earliest finish time.
Performance constraints may be expressed as a desired level of performance in such metrics as CPU load and amount of memory (RAM). The SLI parameter represents the quantitative level of guarantee for the SLO. An SLI value may take a number of forms: an upper and lower bound or a
J. PADGETT, K. DJEMAME and P. DEW: PREDICTIVE ADAPTATION FOR SERVICELEVEL AGREEMENTS ON THE GRID

I.J. of SIMULATION Vol.7 No 2 32 ISSN: 1473-804x online, 1473-8031 print
mean value to be maintained for the duration of the application.
4 SYSTEM IMPLEMENTATION
4.1 Resource Reservation
The SLA Manager is able to negotiate with a Resource Broker to provide resource selection and reservation for the SLA bound application. A performance evaluation of this using a SNAP-based resource broker [Haji et al. 2004] is presented in [Padgett et al. 2005].
Fig. 2 illustrates the interactions between the user, SLA manager and resource broker during resource negotiation. The TSLA is abstracted in a content tree and passed to the resource broker. If resources matching the request are available, a quote is sent back to the SLA Manager. To complete the negotiation the SLA Manager must send an agree signal back to the resource broker. The SLA document is marshaled into a persistent state (XML) using the Java Architecture for XML Binding (JAXB) API.
4.2 Job Monitoring and Violation capture
To demonstrate the concept of automated monitoring of a Grid environment - the Globus Monitoring and Discovery Service (MDS) is used [Czajkowski et al. 2001]. The MDS is packaged with the Globus Toolkit and can be configured to publish resource and application information. The MDS adequately supports our adaptive decision procedure and experiments. This does not rule out the use of a functionally equivalent system such as those mentioned in Section 2.3.
The SLA Engine matches SLOs to relevant metrics produced by the GMS – enabling validation against performance measurement data. The ability to dynamically monitor the state of the SLA-bound application is the requirement.
Policy Outcomes
1. Modify TTL2. Checkpoint3. Migrate4. Terminate
......
mdsx
M1 M2 MxViolationDateTimeValueSli
R1....R2 Rx
P1P2 Px..
Globus Information Service
Fig. 3. Monitoring and Policing Mechanism
The SLA engine launches a number of monitoring subscriptions corresponding to each SLO (Figure 3). These periodically compare the measured value taken from the GMS with the value listed in the SLI. When a violation occurs a violation object is created; a time stamp and value are logged within the SLO.
4.3 Rule Based Adaptation
The SLA Manager implements a predictive rule based decision maker, which offers an effective
Fig. 2. Resource Reservation Process
J. PADGETT, K. DJEMAME and P. DEW: PREDICTIVE ADAPTATION FOR SERVICELEVEL AGREEMENTS ON THE GRID

I.J. of SIMULATION Vol.7 No 2 33 ISSN: 1473-804x online, 1473-8031 print
control algorithm in this situation. The nature of control policy within a compute based Grid environment means the control actions available do not have a continuous domain. The SLA Manager does not have authoritative control over all applications submitted to the WRG. Therefore, a limited number of control actions are available to enforce the SLA bound application. These include: modification of the Time to Live (TTL), a checkpoint request, migration or termination.
A fuzzy based control algorithm may be of use where the control action has a continuous domain. This may be applied to optimise the applications TTL if an economic model were applied to the CPU time. Our solution does not at present include an economic model but this will be the subject of future research.
The decision maker uses an inference mechanism and rule base to determine if violation has occurred or is likely to occur. The rule base contains a series of rules based on the guarantees specified in the SLA.
Control variables are used to describe the application state during run-time. An example used in the experiments section are (1) the scheduled remaining execution time Tschedule, and (2) the predicted remaining execution time Tremaining.
The rules are represented by If premise Then consequence. The premise represents the current system state and the consequents the control action for the execution.
4.4 Adaptive decisions: An Example
Adaptive decisions involve a predictive module, a rule based decision maker and a Grid monitoring service (Figure 3). In this example, two control variables are used, each with 4 states; therefore 16 rules are possible.
The decision maker takes input from two sources, the scheduled remaining execution time, Tschedule and the predicted remaining execution time, Tremaining. The latter is generated in the prediction module using the CPU load (CPUload) available to the application and a Runtime Prediction Formula (RTP) formula presented in Section 4.6; the former is taken from the SLA (Fig. 4). The control actions within the rule base are abstracted from the SLA.
Fig. 4. Rule-based Adaptation Process
Table 2. Adaptive Decisions: An Example
1. procedure adaptive_decision (Tremaining, Tschedule, Ti)
2. if Tremaining �
Tschedule and Ti > 0.75Tschedule then
3. control_action := migrate
4. elseif Tremaining � Tschedule and 5. 0.5Tschedule < Ti � 0.75Tschedule then 6. control_action := checkpoint 7. else 8. control_action := zero 9. return(control_action) 10. end control_action
Every rule does not result in a control action; in this example only two out of the sixteen rules result in a definitive control action.
An example of the adaptive decision procedure is given in Table 2. Note that the algorithm is purely illustrative for this example. The rules are configured to reflect the users SLA requirements.
The first rule describes the situation when the predicted remaining execution time Tremaining is very-much-greater-than the scheduled remaining execution time Tschedule AND the application is more than 75% complete. Ti is the elapsed time since the start of the execution. For this situation an attempt is made to migrate the application onto a faster resource. The second rule describes the situation when the predicted remaining execution time Tremaining is much-greater-than the scheduled remaining execution time Tschedule AND the application is between 50% and 75% complete. For
Rule based Decision Maker
Prediction Module
Tschedule Tremaining
CPUload
Input
1. Modify TTL 2. Checkpoint 3. Migration 4. Termination
SLA Instance
Input
Timeconstraint
J. PADGETT, K. DJEMAME and P. DEW: PREDICTIVE ADAPTATION FOR SERVICELEVEL AGREEMENTS ON THE GRID

I.J. of SIMULATION Vol.7 No 2 34 ISSN: 1473-804x online, 1473-8031 print
this situation a signal is sent to ensure an up to date checkpoint is available for the application instance.
4.5 Initial Prediction
An initial prediction method using linear regression is used to predict the execution time of the application. The procedure is illustrated in Fig. 5 using a historical dataset of previous application executions. The points represent previous runs of our application. The response variable is the predicted CPU time of our application and the predictor variable is the size of the dataset to be processed.
Using our historical dataset with a least squares method [Weisberg 2005], our prediction would overestimate the CPU time for a predictor interval below 0.8 and above 1.2.
Using a local linear method [Loader 1999] provides a more sophisticated fit for our historical dataset. The predictions are less likely to be overestimated and become more accurate as the historical dataset is populated with more data.
Fig. 5. Dataset Size vs. Predicted CPU Time
4.6 Run-time Prediction
Our application displays a linear workload profile given no CPU shortage. To predict the remaining execution time during execution the RTP formula (1) is proposed. It provides a run-time assessment of the remaining execution time based on the CPU load available to the application during run-time. It is particularly suitable for applications which are CPU
intensive. Assessments can then be made as to whether the application will complete within a specified time through comparison with the scheduled remaining execution time. Even when the initial prediction is not 100% accurate, runtime prediction can determine with some accuracy that the execution will take significantly longer than anticipated.
estimate
n
iii
remaining F
FTT
T�
−
=
∆−=
1
0%100
(1)
�=
==n
iinestimate F
nFF
0
1 (2)
The fractional CPU load available to the application Fi is measured over n samples at time Ti. T100% is the time the application would take to execute given no shortage in CPU resource throughout the application execution. T100% is generated using the initial prediction technique. Festimate is the mean CPU load available to the application over n samples (2).
Tremaining is the predicted remaining execution time if Festimate is maintained for the remainder of the execution.
In the event that Festimate continually drops in succesive samples the estimated value will be invalid. This can be countered with a worst case value for Festimate [Othman et al. 2003].
After migration a scaling factor Y is used to adjust for the change in CPU potential. The value of Tremaining prior to migration is scaled using Eqn. 3. TM
remaining is the remaining CPU time on the new resource given its CPU potential.
Overheads due to migration, such as file transfers and time in pending queue of new resource are assumed to be negligible.
TYT remainingMremaining =
(3)
On restart, TMremaining is set to TM
100%. Up to date values of TM
remaining are calculated using Eqn. 1.
5 EXPERIMENTS AND RESULTS
Experiments are designed to test 1) prediction and adaptation, 2) monitoring and violations, for an SLA bound application executing on a large distributed Grid infrastructure, the White Rose Grid (WRG). The WRG resources are both heterogeneous and have different administrative domains; this makes it ideally suited for testing of the proposed solution. The experiments make use of a Grid cluster at the Leeds site with migrations taking place between
J. PADGETT, K. DJEMAME and P. DEW: PREDICTIVE ADAPTATION FOR SERVICELEVEL AGREEMENTS ON THE GRID
I.J. of SIMULATION Vol.7 No 2 35 ISSN: 1473-804x online, 1473-8031 print
nodes. The application used is one which exhibits similar properties to those used within the DAME system but with checkpointing support.
During execution of our SLA bound application, the SLA Manager must be able to record notifications within the SLA. Experiment 1 will investigate whether:
• the SLA engine can accurately measure changes in resource parameters;
• the violation capture mechanism records these changes.
Initial and run-time prediction of our applications CPU time is needed to support the adaptive decision procedure. Experiment 2 will:
• demonstrate the concept of initial prediction using historical information from previous runs of our application;
• determine if the RTP formula provides accurate run-time predictions.
When our application is executing and the resource is swamped by a competing application there may be a CPU resource deficit. The application may no longer meet its time constraint. Experiment 3 will investigate whether:
• migration results in a faster application execution time, given the submission of competing applications.
5.1 Experimental Scenario 1
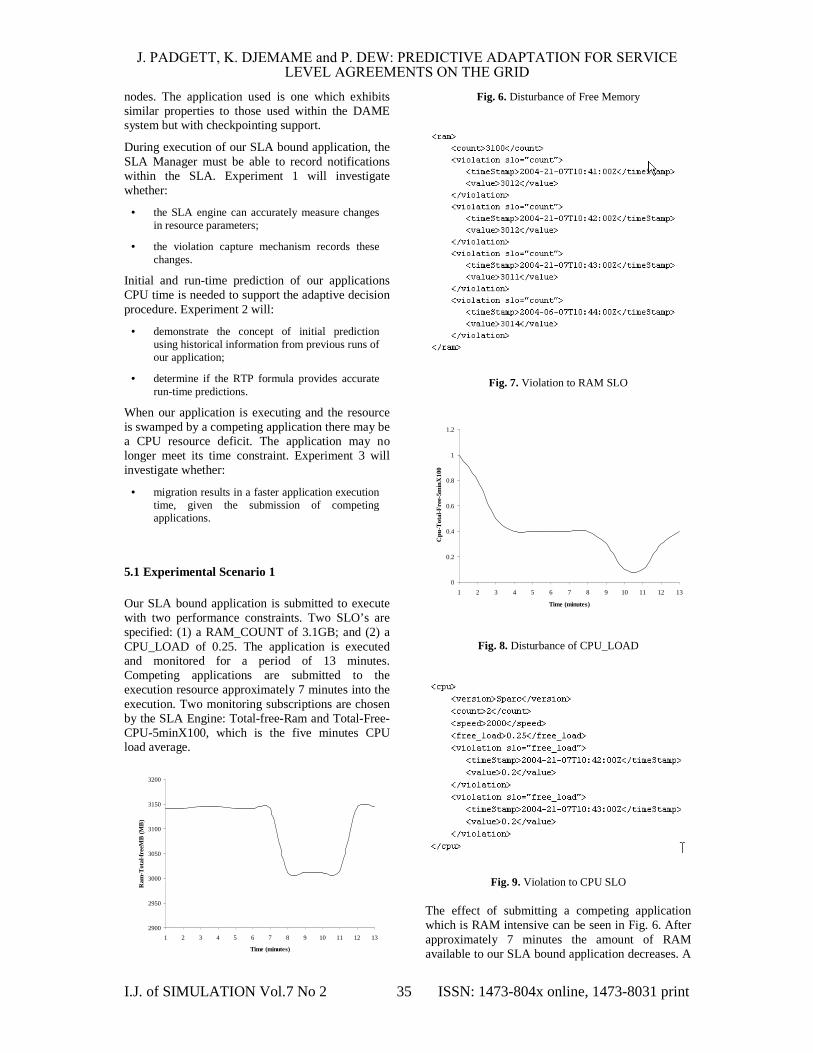
Our SLA bound application is submitted to execute with two performance constraints. Two SLO’s are specified: (1) a RAM_COUNT of 3.1GB; and (2) a CPU_LOAD of 0.25. The application is executed and monitored for a period of 13 minutes. Competing applications are submitted to the execution resource approximately 7 minutes into the execution. Two monitoring subscriptions are chosen by the SLA Engine: Total-free-Ram and Total-Free-CPU-5minX100, which is the five minutes CPU load average.
2900
2950
3000
3050
3100
3150
3200
1 2 3 4 5 6 7 8 9 10 11 12 13
Time (minutes)
Ram
-Tot
al-f
reeM
B (M
B)
Fig. 6. Disturbance of Free Memory
Fig. 7. Violation to RAM SLO
0
0.2
0.4
0.6
0.8
1
1.2
1 2 3 4 5 6 7 8 9 10 11 12 13
Time (minutes)
Cpu
-Tot
al-F
ree-
5min
X10
0
Fig. 8. Disturbance of CPU_LOAD
Fig. 9. Violation to CPU SLO
The effect of submitting a competing application which is RAM intensive can be seen in Fig. 6. After approximately 7 minutes the amount of RAM available to our SLA bound application decreases. A
J. PADGETT, K. DJEMAME and P. DEW: PREDICTIVE ADAPTATION FOR SERVICELEVEL AGREEMENTS ON THE GRID
I.J. of SIMULATION Vol.7 No 2 36 ISSN: 1473-804x online, 1473-8031 print
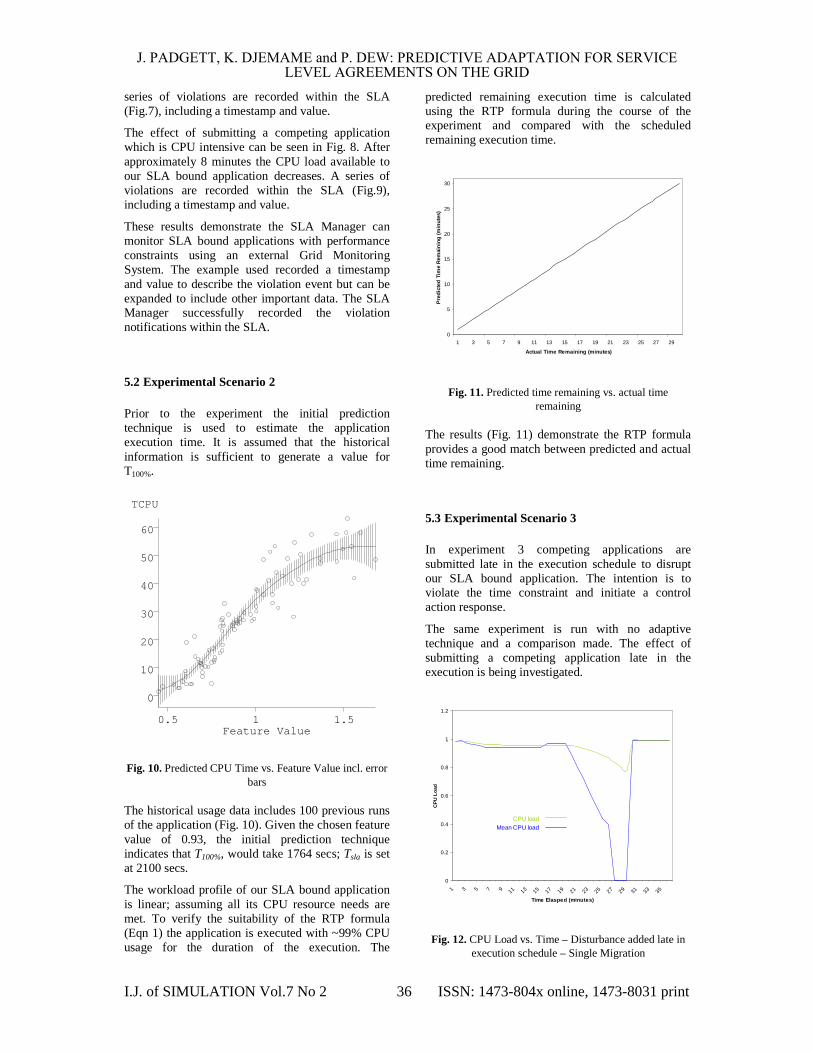
series of violations are recorded within the SLA (Fig.7), including a timestamp and value.
The effect of submitting a competing application which is CPU intensive can be seen in Fig. 8. After approximately 8 minutes the CPU load available to our SLA bound application decreases. A series of violations are recorded within the SLA (Fig.9), including a timestamp and value.
These results demonstrate the SLA Manager can monitor SLA bound applications with performance constraints using an external Grid Monitoring System. The example used recorded a timestamp and value to describe the violation event but can be expanded to include other important data. The SLA Manager successfully recorded the violation notifications within the SLA.
5.2 Experimental Scenario 2
Prior to the experiment the initial prediction technique is used to estimate the application execution time. It is assumed that the historical information is sufficient to generate a value for T100%.
Feature Value0.5 1 1.5
TCPU
0
10
20
30
40
50
60
Fig. 10. Predicted CPU Time vs. Feature Value incl. error bars
The historical usage data includes 100 previous runs of the application (Fig. 10). Given the chosen feature value of 0.93, the initial prediction technique indicates that T100%, would take 1764 secs; Tsla is set at 2100 secs.
The workload profile of our SLA bound application is linear; assuming all its CPU resource needs are met. To verify the suitability of the RTP formula (Eqn 1) the application is executed with ~99% CPU usage for the duration of the execution. The
predicted remaining execution time is calculated using the RTP formula during the course of the experiment and compared with the scheduled remaining execution time.
0
5
10
15
20
25
30
1 3 5 7 9 11 13 15 17 19 21 23 25 27 29
Actual Time Remaining (minutes)
Pre
dic
ted
Tim
e R
emai
nin
g (
min
ute
s)
Fig. 11. Predicted time remaining vs. actual time remaining
The results (Fig. 11) demonstrate the RTP formula provides a good match between predicted and actual time remaining.
5.3 Experimental Scenario 3
In experiment 3 competing applications are submitted late in the execution schedule to disrupt our SLA bound application. The intention is to violate the time constraint and initiate a control action response.
The same experiment is run with no adaptive technique and a comparison made. The effect of submitting a competing application late in the execution is being investigated.
0
0.2
0.4
0.6
0.8
1
1.2
1 3 5 7 9 11 13 15 17 19 21 23 25 27 29 31 33 35
Time Elasped (minutes)
CP
U L
oad
CPU loadMean CPU load
Fig. 12. CPU Load vs. Time – Disturbance added late in execution schedule – Single Migration
J. PADGETT, K. DJEMAME and P. DEW: PREDICTIVE ADAPTATION FOR SERVICELEVEL AGREEMENTS ON THE GRID

I.J. of SIMULATION Vol.7 No 2 37 ISSN: 1473-804x online, 1473-8031 print
0
5
10
15
20
25
30
35
40
1 3 5 7 9 11 13 15 17 19 21 23 25 27 29 31 33 35
Time Elasped (minutes)
Tim
e R
emai
ning
(m
inu
tes)
W C M W
Tremaining
Tschedule
T100%
Fig. 13. Time remaining vs. Time elapsed Disturbance added late in execution schedule – Single Migration
The results from experiment 3 are presented in Figures 12 – 15. After approximately 20 minutes a competing application is submitted; the CPU load available to the SLA bound application decreases (Fig. 12). At approximately 24 minutes, as the difference between Tremaining and Tschedule decreases, warnings are recorded within the SLA. A checkpoint and migration signal is sent shortly afterward; migration onto a faster resource takes place between 26 and 29 minutes. The CPU load available to the SLA bound application increases on the faster resource; Tremaining falls below Tschedule, the execution is completed on-time and the SLA honoured (Fig. 13).
0
0.2
0.4
0.6
0.8
1
1.2
1 3 5 7 9 11 13 15 17 19 21 23 25 27 29 31 33 35
Time Elasped (minutes)
CP
U L
oad
CPU loadMean CPU load
Fig. 14. CPU Load vs. Time – Disturbance added late in execution schedule – No Migration
0
5
10
15
20
25
30
35
40
1 3 5 7 9 11 13 15 17 19 21 23 25 27 29 31 33 35
Time Elasped (minutes)
Tim
e R
emai
ning
(m
inu
tes)
Tremaining
Tschedule
T100%
W W V
Fig. 15. Time remaining vs. Time elapsed – Disturbance added late in execution schedule – No Migration
The SLA bound application was executed again with no adaptive technique. After approximately 20 minutes a competing application is submitted; the CPU load available to the SLA bound application decreases (Fig. 14). At approximately 24 minutes a warning is recorded within the SLA as the difference between Tremaining and Tschedule decreases. The available CPU load remains low, no migration takes place resulting in a second warning at 26 minutes. The difference between Tremaining and Tschedule continues to increase resulting in a violation at 30 minutes. The execution fails to finish on-time and the SLA is violated (Fig. 15).
5.4 Experimental Scenario 4
In experiment 4 competing applications are submitted early in the execution schedule to disrupt the SLA bound application. The intention is to violate the time constraint and initiate a control action response.
0
0.2
0.4
0.6
0.8
1
1.2
1 3 5 7 9 11 13 15 17 19 21 23 25 27 29 31 33 35 37 39
Time Elasped (minutes)
CP
U L
oad
CPU loadMean CPU load
Fig. 16. CPU Load vs. Time – Disturbance added early in execution schedule – Single Migration
J. PADGETT, K. DJEMAME and P. DEW: PREDICTIVE ADAPTATION FOR SERVICELEVEL AGREEMENTS ON THE GRID

I.J. of SIMULATION Vol.7 No 2 38 ISSN: 1473-804x online, 1473-8031 print
The same experiment is run with no adaptive technique and a comparison made. The effectiveness of the rule-based decision maker to ensure timely application completion is being investigated.
-5
0
5
10
15
20
25
30
35
40
45
1 3 5 7 9 11 13 15 17 19 21 23 25 27 29 31 33 35 37 39
Time Elasped (minutes)
Tim
e R
emai
ning
(m
inu
tes)
Tremaining
Tschedule
T100%
W WW C M
Fig. 17. Time remaining vs. Time elapsed – Disturbance added early in execution schedule – Single Migration
The results from experiment 4 are presented in Figures 16 – 19. The effect of submitting a competing application early in the execution is being investigated. After approximately 2 minutes a competing application is submitted; the CPU load available to the SLA bound application decreases (Fig. 16). At approximately 3 and 6 minutes, as the difference between Tremaining and Tschedule decreases, warnings are recorded within the SLA. A checkpoint and migration signal is sent shortly afterward; migration onto a faster resource takes place between 8 and 11 minutes. The CPU load available to the application increases on the faster resource; Tremaining falls below Tschedule, the execution is completed on-time and the SLA honoured (Fig. 17).
0
0.2
0.4
0.6
0.8
1
1.2
1 3 5 7 9 14 16 18 20 22 24 26 28 30 32 34 36 38 40
Time Elasped (minutes)
CP
U L
oad
CPU loadMean CPU load
Fig. 18. CPU Load vs. Time – Disturbance added early in execution schedule – No Migration
-5
0
5
10
15
20
25
30
35
40
45
1 3 5 7 9 14 16 18 20 22 24 26 28 30 32 34 36 38 40
Time Elasped (minutes)
Tim
e R
emai
nin
g (m
inu
tes)
W VW W W
Tremaining
Tschedule
T100%
Fig. 19. Time remaining vs. Time elapsed – Disturbance added early in execution schedule – No Migration
The SLA bound application was executed again with no adaptive technique. After approximately 2 minutes a competing application is submitted; the CPU load available to the SLA bound application decreases (Fig. 18). At 3, 5 and 6 minutes warnings are recorded within the SLA as the difference between Tremaining and Tschedule decreases. The available CPU load remains low, no migration takes place resulting in a 4th warning at 8 minutes. The difference between Tremaining and Tschedule continues to increase resulting in a violation at 17 minutes. The execution fails to finish on-time and the SLA is violated (Fig. 19).
6 RELATED WORK
There have been a number of attempts at specifying a language and associated management system for SLAs on the Grid. Architectures from Sahai et al [Sahai et al. 2003], Leff et al [Leff et al. 2003] and Verma et al [Verma et al. 2001] concentrate on SLAs within commercial Grids. The SLA language used is the Web Service Level Agreement (WSLA) specification, presented by Ludwig et al [Ludwig et al. 2003]. The Global Grid Forum have defined WS-Agreement [Andrieux et al. 2004]; an agreement-based service level agreement specification designed to support Web Service Resource Framework (WSRF) services. Two other important works are automated SLA monitoring for Web services [Jin et al. 2002] and analysis of SLAs for Web services [Sahai et al. 2002]. Contract negotiation within distributed systems have been the subject of research where business-to-business (B2B) service guarantees are needed [Goodchild et al. 2000]. The mapping of natural language contracts into models suitable for contract automation [Milosevic and Dromey 2002] exist but have not been applied to a Grid environment or an SLA. An approach for formally modeling e-Contracts [Marjanovic and
J. PADGETT, K. DJEMAME and P. DEW: PREDICTIVE ADAPTATION FOR SERVICELEVEL AGREEMENTS ON THE GRID

I.J. of SIMULATION Vol.7 No 2 39 ISSN: 1473-804x online, 1473-8031 print
Milosevic 2001] exists at a higher level than the research by Ludwig et al [Ludwig et al. 2003]. Automated negotiation and authorisation systems for the Grid already exist [Lock 2004] but involve no monitoring or run-time adaptation.
A performance prediction based tool, known as PACE (Performance Analysis and Characterisation Environment) [Nudd et al. 2000] has been developed at the University of Warwick. This uses a combination of source code analysis and hardware modeling to provide an application performance prediction. In [Nudd et al. 2004], the use of PACE in the context of Grid resource scheduling is discussed. The hardware models used in this research are static, which provides the advantage of reusability but does not account for dynamic changes to resource performance.
In [Smith et al. 1998] methods are discussed for predicting execution run-time for parallel applications using historical information. Execution times of similar applications run in the past, are used to estimate the execution time. Application of this method to executions run on a Grid using a local batch queuing system are considered in [Smith 2003]. This work considers the prediction of execution start times for pending jobs in order to decrease the average job wait time. Although their results indicate that the approach is successful at reducing the average wait time it does not provide information as to the anticipated execution time of the user’s job.
Vadhiyar et. al. [Vadhiyar and Dongarra 2003], [Vadhiyar and Dongarra 2005] discuss migration and self adaptivity for the Grid. Migration decisions are based on resource load, potential performance benefits and time reached in the application execution. This technique is limited to Message Passing Interface (MPI) based programs but makes use of user specified execution times and tolerance thresholds.
Huedo et. al. [Huedo et al. 2004] present a framework for adaptive execution in Grids; adaptation actions are periodically evaluated according to a rescheduling condition based on workload parameters or a performance contract. This work does not consider prediction of remaining execution time or integration with a formal SLA specification, although performance contracts are used.
7 CONCLUSION
This work presents an SLA management system for timely application response in a Grid based decision support system. It provides resource reservation and run-time adaptation for SLA bound applications. In
addition a prediction method for estimating the applications CPU time before and during execution is presented.
Experiments are conducted in a Grid environment, the White Rose Grid. They show our solution is capable of predicting with some accuracy the execution time of SLA bound applications before and during runtime. Adaptation through migration has proved useful in reducing the execution time of an application when the CPU load available to that application is reduced.
The results demonstrate the SLA Manager can monitor SLA bound applications with performance constraints using an external Grid Monitoring System. The SLA Manager successfully records violation notifications within the SLA, capturing a timestamp and value for each violation event.
Grids consist of resources of varying type, quality and reliability perhaps from many administrative domains. In situations where these resources are swamped by competing applications, a drop in application performance is possible. If this coincides with the execution of an SLA bound application, our solution has demonstrated that it does not have to lead to a delay in time critical results.
Application migrations which take place late in the execution schedule are less likely to benefit from the adaptive decision process. A time delay due to migration represents a bigger percentage of the remaining execution time for the application. Although experiment 3 benefited from a migration, we suggest an enhancement to the adaptive decision procedure. The initial prediction technique described in Section 4.5 could be applied in such a way as to predict the delay due to migration. For our application a migration involves the movement of the remaining section of the dataset to a new resource. The dataset size and delay could be captured and used as the predictor and response variables respectively.
An extention to this research may focus the estimation of time delays due to file transfer and waiting time on new resource. An interesting solution may be a learning based technique similar to the initial prediction technique described in Section 4.5.
Further work may focus on the use of a fuzzy control algorithm and a control action in the continuous domain. One possibility is to optimise the applications TTL in the presence of an economic model applied to the CPU time of the application. This solution may be useful if the agreed deadline for the application is flexible and could be adapted through negotiation. An economic model reflecting usage and CPU time may provide a motivation.
J. PADGETT, K. DJEMAME and P. DEW: PREDICTIVE ADAPTATION FOR SERVICELEVEL AGREEMENTS ON THE GRID

I.J. of SIMULATION Vol.7 No 2 40 ISSN: 1473-804x online, 1473-8031 print
ACKNOWLEDGEMENTS
The work reported in this paper was partly supported by the DAME project under UK Engineering and Physical Sciences Research Council Grant GR/R67668/01. We are also grateful for the support of the DAME partners, including the help of staff at Rolls-Royce, Data Systems & Solutions, Cybula, and the Universities of York, Sheffield and Oxford.
REFERENCES
Andrieux, A., K. Czajkowski, A. Dan, K. Keahey, H. Ludwig, J. Pruyne, J. Rofrano, S. Tuecke and M. Xu. 2004, "Web Services Agreement Specification (WS-Agreement)". Global Grid Forum.
Austin, J., T. Jackson, M. Fletcher, M. Jessop, P. Cowley and P. Lobner. 2004, "Predictive Maintenance: Distributed Aircraft Engine Diagnostics". In. The Grid 2: Blueprint For A New Computing Infrastructure. I. Foster and C. Kesselman. Elsevier Science, Oxford, UK.
Balaton, Z., P. Kacsuk, N. Podhorszki and F. Vajda. 2000, "Comparison of Representative Grid Monitoring Tools". LPDS-2/2000. Laboratory of Parallel and Distributed Systems, Hungarian Academy of Sciences, Budapest, Hungary.
Berman, F., G. C. Fox and A. J. G. Hey. 2003, "Grid Computing: Making the Global Infrastructure a Reality". Wiley, Chichester, USA.
Czajkowski, K., S. Fitzgerald, I. Foster and C. Kesselman. 2001, "Grid Information Services for Distributed Resource Sharing". In Proc. High Performance Distributed Computing. (San Francisco, CA, August), IEEE Computer Society Press. pp181-194.
Czajkowski, K., I. Foster, C. Kesselman, V. Sander and S. Tuecke. 2002, "SNAP: A Protocol for Negotiating Service Level Agreements and Coordinating Resource Management in Distributed Systems". In Proc. Job Scheduling Strategies for Parallel Processing. (Edinburgh, UK, July) Lecture Notes in Computer Science 2537, Springer-Verlag, Berlin, Germany. pp153-183.
Goodchild, A., C. Herring and Z. Milodevic. 2000, "Business contracts for B2B". Distributed Systems Technology Center (DSTC), Austrailia.
Gunter, D., B. Tierney, B. Crowley, M. Holding and J. Lee. 2000, "NetLogger: A Toolkit for Distributed System Performance Analysis". In Proc. Modeling, Analysis and Simulation of Computer and Telecommunication
Systems. (San Francisco, CA, USA, August), IEEE Computer Society Press. pp267-273.
Haji, M., P. Dew, K. Djemame and I. Gourlay. 2004, "A SNAP-based Community Resource Broker using a Three-Phase Commit Protocol". In Proc. Proceedings of the 18th IEEE International Parallel and Distributed Processing Symposium. (Santa Fe, USA, April), IEEE Computer Society Press. pp56-67.
Haji, M., I. Gourlay, K. Djemame and P. Dew (2005). "A SNAP-based Community Resource Broker using a Three-Phase Commit Protocol: a Performance Study". Computer Journal. 48(3). pp333-346.
Huedo, E., R. S. Montero and I. M. Llorente (2004). "A Framework for Adaptive Execution in Grids". Software Practice And Experience. 34(7). pp631-652.
Jin, L., V. Machiraju and A. Sahai. 2002, "Analysis on Service Level Agreement of Web Services". HPL-2002-180. HP Laboratories.
Leff, A., J. T. Rayfield and D. M. Dias (2003). "Service-Level Agreements and Commercial Grids". IEEE Internet Computing. 7(4). pp44-50.
Loader, C. 1999, "Local regression and likelihood". Springer-Verlag, New York, USA.
Lock, R. 2004, "Automated Contract Negotiations for the Grid". In Proc. Postgraduate Research Conference in Electronics, Photonics, Communications & Networks, and Computing Science. (University of Hertfordshire, UK, April), EPSRC. pp141-142.
Ludwig, H., A. Keller, A. Dan, R. King and R. Franck (2003). "A Service Level Agreement Language for Dynamic Electronic Services". Electronic Commerce Research. 3(1/2). pp43-59.
Marjanovic, O. and Z. Milosevic. 2001, "Towards Formal Modeling of e-Contracts". In Proc. Enterprise Distributed Object Computing. (Seattle, WA, USA, September), IEEE Computer Society Press. pp59-68.
Milosevic, Z. and R. G. Dromey. 2002, "On Expressing and Monitoring Behaviour in Contracts". In Proc. Enterprise Distributed Object Computing. (Lausanne, Switzerland, September), IEEE Computer Society Press. pp3-14.
Newhouse, S. and J. MacLaren. "Grid Economic Service Architecture (GESA)". Global Grid Forum.
Nudd, G. R., C. Junwei, D. J. Kerbyson and E. Papaefstathiou. 2000, "Performance Modeling of Parallel and Distributed Computing using PACE". In Proc. 19th
J. PADGETT, K. DJEMAME and P. DEW: PREDICTIVE ADAPTATION FOR SERVICELEVEL AGREEMENTS ON THE GRID

I.J. of SIMULATION Vol.7 No 2 41 ISSN: 1473-804x online, 1473-8031 print
IEEE International Performance, Computing and Communications Conference. (Phoenix, USA, February), IEEE Computer Society Press. pp485-492.
Nudd, G. R., H. N. L. C. Keung, J. R. D. Dyson and S. A. Jarvis. 2004, "Self-adaptive and Self-optimising Resource Monitoring for Dynamic Grid Environments". In Proc. 15th International Workshop on Database and Expert Systems Applications. (Zaragoza, Spain, August), Institut Für Anwendungsorientierte Wissensverarbeitung. pp689-693.
Othman, A., P. Dew, K. Djemame and I. Gourlay. 2003, "Adaptive Grid Resource Brokering". In Proc. Cluster Computing. (Hong Kong, December), IEEE Computer Society Press. pp172-179.
Padgett, J., M. Haji and K. Djemame. 2005, "SLA Management in a Service Oriented Architecture". In Proc. International Conference on Computer Science and its Applications. (Singapore, May) Lecture Notes in Computer Science 3483, Springer-Verlag, Berlin, Germany. pp1282-1291.
Sahai, A., A. Graupner, V. Machiraju and A. van Moorsel. 2003, "Specifying and Monitoring Guarentees in Commercial Grids through SLA". In Proc. 3rd IEEE/ACM International Symposium on Cluster Computing and the Grid. (Tokyo, Japan, IEEE Computer Society Press. pp292-299.
Sahai, A., V. Machiraju, M. Sayal, L. Jin and F. Casati. 2002, "Automated SLA Monitoring for Web Services". HPL-2002-191. HP Laboratories.
Smith, W. 2003, "Improving Resource Selection and Scheduling using Predictions". In. Grid Resource Management: State of the Art and Future Trends. J. Nabrzyski, J. M. Schopf and J. Weglarz. Kluwer Academic Publishers, Boston, USA.
Smith, W., I. Foster and V. Taylor. 1998, "Predicting Application Run Times Using Historical Information". In Proc. Job Scheduling Strategies for Parallel Processing. (Amsterdam, The Netherlands, March) Lecture Notes in Computer Science 1459, Springer-Verlag, Berlin, Germany. pp122-142.
Tierney, B., R. Aydt, D. Gunter, W. Smith, M. Swany, V. Taylor and R. Wolski. 2002, "A Grid Monitoring Architecture". Global Grid Forum.
Vadhiyar, S. and J. Dongarra. 2003, "A Performance Oriented Migration Framework for The Grid". In Proc. Cluster Computing and the Grid. (Tokyo, Japan, May), IEEE Computer Society. pp130-137.
Vadhiyar, S. S. and J. J. Dongarra. 2005, "Self adaptivity in Grid computing". In. Combined Special Issues on Grid Performance and Grids and Web Services for E-Science. Wiley, Chichester, USA: pp235-258.
Verma, D., M. Beigi and R. Jennings. 2001, "Policy Based SLA Management in Enterprise Networks". In. Policies for Distributed Systems and Networks. M. Sloman, J. Lobo and E. C. Lupu. Springer-Verlag, Berlin, Germany: pp137-152.
Weisberg, S. 2005, "Applied linear regression". Wiley, Chichester, USA.
Wolski, R., N. T. Spring and J. Hayes (1999). "The network weather service: a distributed resource performance forecasting service for metacomputing". Future Generation Computer Systems. 15(5-6). pp757-768.
BIOGRAPHY
James Padgett is a PhD candidate in the School of Computing at Leeds University, UK where he has been since 2002. His current research interests include service level agreements within distributed systems, resource management including reservation, and run-time adaptation for Grid applications. Mr Padgett received his BEng(Hons) in Chemical Engineering and his MSc in Distributed Systems from Leeds University in 2000 and 2002 respectively.
Karim Djemame is a Lecturer in the School of Computing at the University of Leeds, UK where he has been since 1998. His current research interests include Grid computing, networking, performance modeling and evaluation, parallel and distributed simulation. Dr Djemame received his PhD in computer science from Glasgow University, UK in 1999 and his MSc in computer science from Constantine University, Algeria in 1991.
J. PADGETT, K. DJEMAME and P. DEW: PREDICTIVE ADAPTATION FOR SERVICELEVEL AGREEMENTS ON THE GRID

I.J. of SIMULATION Vol.7 No 2 42 ISSN: 1473-804x online, 1473-8031 print
Peter Dew is Professor of Computer Science in the School of Computing at the University of Leeds, UK, Director of Informatics Institute, a member of the White Rose Grid Executive and the e-Science TAG management committee. His research interests are performance analysis of HPC/Grid systems, Grid architectures, peer-to-peer collaborative knowledge sharing environments, and virtual environments.
J. PADGETT, K. DJEMAME and P. DEW: PREDICTIVE ADAPTATION FOR SERVICELEVEL AGREEMENTS ON THE GRID




















