Microsoft® SQL Server® 2012 Analysis Services Model ...
70
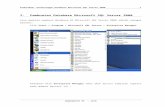
Przekład: Jakub Niedźwiedź, Witold Sikorski APN Promise, Warszawa 2012 Marco Russo Alberto Ferrari Chris Webb Microsoft ® SQL Server ® 2012 Analysis Services Model tabelaryczny BISM
-
Upload
khangminh22 -
Category
Documents
-
view
1 -
download
0
Transcript of Microsoft® SQL Server® 2012 Analysis Services Model ...

Przekład: Jakub Niedźwiedź, Witold Sikorski
APN Promise, Warszawa 2012
Marco RussoAlberto FerrariChris Webb
Microsoft® SQL Server® 2012 Analysis ServicesModel tabelaryczny BISM
##7#52#aSUZPUk1BVC1WaXJ0dWFsbw==

Microsoft® SQL Server® 2012 Analysis Services: Model tabelaryczny BISM© 2012 APN PROMISE SA
Authorized Polish translation of English edition of Microsoft® SQL Server® Analysis Services: The BISM Tabular Model ISBN: 978-0-7356-5818-9Copyright © 2012 by Marco Russo, Alberto Ferrari, Christopher WebbThis translation is published and sold by permission of O’Reilly Media, Inc., which owns or controls all rights to publish and sell the same.
APN PROMISE SA, biuro: ul. Kryniczna 2, 03-934 Warszawatel. +48 22 35 51 600, fax +48 22 35 51 699e-mail: [email protected]
Wszystkie prawa zastrzeżone. Żadna część niniejszej książki nie może być powielana ani rozpowszechniana w jakiejkolwiek formie i w jakikolwiek sposób (elektroniczny, mechaniczny), włącznie z fotokopiowaniem, nagrywaniem na taśmy lub przy użyciu innych systemów bez pisemnej zgody wydawcy.
Książka ta przedstawia poglądy i opinie autorów. Przykłady firm, produktów, osób i wydarzeń opisane w niniejszej książce są fikcyjne i nie odnoszą się do żadnych konkretnych firm, produktów, osób i wydarzeń, chyba że zostanie jednoznacznie stwierdzone, że jest inaczej. Ewentualne podobieństwo do jakiejkolwiek rzeczywistej firmy, organizacji, produktu, nazwy domeny, adresu poczty elektronicznej, logo, osoby, miejsca lub zdarzenia jest przypadkowe i niezamierzone.
Microsoft oraz znaki towarowe wymienione na stronie http://www.microsoft.com/about/legal/en/us/IntellectualProperty/Trademarks/EN-US.aspx są zastrzeżonymi znakami towarowymi grupy Microsoft. Wszystkie inne znaki towarowe są własnością ich odnośnych właścicieli.
APN PROMISE SA dołożyła wszelkich starań, aby zapewnić najwyższą jakość tej publikacji. Jednakże nikomu nie udziela się rękojmi ani gwarancji. APN PROMISE SA nie jest w żadnym wypadku odpowiedzialna za jakiekolwiek szkody będące następstwem korzystania z informacji zawartych w niniejszej publikacji, nawet jeśli APN PROMISE została powiadomiona o możliwości wystąpienia szkód.
ISBN: 978-83-7541-103-4
Przekład: Jakub Niedźwiedź, Witold SikorskiRedakcja: Marek WłodarzKorekta: Ewa SwędrowskaSkład i łamanie: MAWart Marek Włodarz
##7#52#aSUZPUk1BVC1WaXJ0dWFsbw==

iii
Skrócony spis treści
Przedmowa . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . xv
Wprowadzenie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . xvi
1 Wprowadzenie do modelu tabelarycznego . . . . . . . . . . . . . . . . . . . . . . . . . . . 1
2 Rozpoczęcie pracy w modelu tabelarycznym . . . . . . . . . . . . . . . . . . . . . . . . 21
3 Ładowanie danych w modelu tabelarycznym . . . . . . . . . . . . . . . . . . . . . . . . 77
4 Podstawy języka DAX . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 123
5 Pojęcie kontekstu wyznaczania wartości . . . . . . . . . . . . . . . . . . . . . . . . . . . . 151
6 Zapytania w modelu tabelarycznym . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 191
7 Zaawansowane funkcje DAX . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 245
8 Analiza czasowa w języku DAX . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 303
9 Narzędzia xVelocity i DirectQuery . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 345
10 Tworzenie hierarchii . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 383
11 Modelowanie danych w modelu tabelarycznym . . . . . . . . . . . . . . . . . . . . . 405
12 Korzystanie z zaawansowanych relacji w modelu tabelarycznym . . . . . . 435
13 Warstwa prezentacji w modelu tabelarycznym . . . . . . . . . . . . . . . . . . . . . . 459
14 Model tabelaryczny i narzędzie PowerPivot . . . . . . . . . . . . . . . . . . . . . . . . . 481
15 Bezpieczeństwo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 497
16 Interfejs modelu tabelarycznego . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 523
17 Wdrażanie modelu tabelarycznego . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 549
18 Optymalizacja i monitorowanie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 599
Dodatek: Opis funkcji DAX . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 631
Indeks . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 647
O autorach . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 666
##7#52#aSUZPUk1BVC1WaXJ0dWFsbw==

##7#52#aSUZPUk1BVC1WaXJ0dWFsbw==

v
Spis treściPrzedmowa . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . xv
Wprowadzenie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . xvi
1 Wprowadzenie do modelu tabelarycznego . . . . . . . . . . . . . . . . . . . . 1
Ekosystem Microsoft BI . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1Czym jest usługa Analysis Services i dlaczego należy jej używać?. . . . . . 1Krótka historia Analysis Services . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3Obecny zestaw BI firmy Microsoft . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3Samoobsługowa i korporacyjna analiza biznesowa ( BI) . . . . . . . . . . . . . . 5
Architektura Analysis Services 2012: jeden produkt, dwa modele . . . . . . . . 7Model tabelaryczny . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8Model wielowymiarowy . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10Po co są dwa modele? . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11Przyszłość Analysis Services . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
Wybór odpowiedniego modelu dla naszego projektu . . . . . . . . . . . . . . . . . 13Licencje . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14Aktualizacja poprzednich wersji Analysis Services . . . . . . . . . . . . . . . . . . 14Prostota korzystania . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14Kompatybilność z PowerPivot . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15Cechy wydajności zapytań . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15Cechy wydajności przetwarzania . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15Uwarunkowania sprzętowe . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16BI czasu rzeczywistego . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17Narzędzia klienckie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18Porównanie funkcji . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
Podsumowanie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
2 Rozpoczęcie pracy w modelu tabelarycznym . . . . . . . . . . . . . . . . . 21
Określenie środowiska deweloperskiego . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21Komponenty środowiska deweloperskiego . . . . . . . . . . . . . . . . . . . . . . . . 21Licencje . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23Proces instalacji . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
Praca z narzędziami danych SQL Server . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33Tworzenie nowego projektu . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33
##7#52#aSUZPUk1BVC1WaXJ0dWFsbw==

vi Spis treści
Konfiguracja nowego projektu. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 35Import z PowerPivot . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39Import wdrożonego projektu z Analysis Services . . . . . . . . . . . . . . . . . . . 40Zawartość projektu tabelarycznego . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 40
Budowa prostego modelu tabelarycznego . . . . . . . . . . . . . . . . . . . . . . . . . . . 42Ładowanie danych do tabeli . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 43Praca w widoku diagramu . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 51Wdrożenie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 54
Zapytania w modelu tabelarycznym w Excelu . . . . . . . . . . . . . . . . . . . . . . . . 55Połączenie z modelem tabelarycznym . . . . . . . . . . . . . . . . . . . . . . . . . . . . 56
Zapytania w modelu tabelarycznym w widoku Power View . . . . . . . . . . . . 67Tworzenie połączenia z modelem tabelarycznym . . . . . . . . . . . . . . . . . . 67Budowa podstawowego raportu Power View . . . . . . . . . . . . . . . . . . . . . . 68Dodawanie wykresów i fragmentatorów . . . . . . . . . . . . . . . . . . . . . . . . . . 70Interakcja z raportem . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 71
Praca w SQL Server Management Studio . . . . . . . . . . . . . . . . . . . . . . . . . . . . 73Podsumowanie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 76
3 Ładowanie danych w modelu tabelarycznym . . . . . . . . . . . . . . . . . 77
Dostępne źródła danych . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 77Personifikacja . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 79Poświadczenia po stronie serwera i po stronie klienta . . . . . . . . . . . . . . . . . 80Praca z dużymi plikami . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 82Ładowanie z serwera SQL Server . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 83
Ładowanie z listy tabel . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 85Ładowanie relacji . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 87Ładowanie z zapytania SQL . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 89Ładowanie z widoków . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 89
Otwieranie istniejących połączeń . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 90Ładowanie z programu Access . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 91Ładowanie z usług Analysis Services . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 93
Korzystanie z edytora MDX . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 94Ładowanie z tabelarycznej bazy danych . . . . . . . . . . . . . . . . . . . . . . . . . . 95
Ładowanie z pliku Excela . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 97Ładowanie z pliku tekstowego . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 100Ładowanie ze schowka . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 102Ładowanie z raportu usług Reporting Services . . . . . . . . . . . . . . . . . . . . . . 105
Ładowanie raportów przy użyciu strumieniowych źródeł danych . . . . 111
##7#52#aSUZPUk1BVC1WaXJ0dWFsbw==

Spis treści vii
Ładowanie ze strumieniowych źródeł danych . . . . . . . . . . . . . . . . . . . . . . . 112Ładowanie z SharePoint . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 114Ładowanie z Windows Azure DataMarket . . . . . . . . . . . . . . . . . . . . . . . . . . 115Wybór właściwej metody ładowania danych . . . . . . . . . . . . . . . . . . . . . . . . 119Dlaczego sortowanie danych jest ważne . . . . . . . . . . . . . . . . . . . . . . . . . . . 120Podsumowanie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 121
4 Podstawy języka DAX . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 123
Obliczenia w języku DAX . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 123Składnia DAX . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 123Typy danych języka DAX . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 124Operatory DAX . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 126Wartości DAX . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 127
Wyliczane kolumny i miary . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 128Wyliczane kolumny . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 128Miary . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 129
Edycja miar przy użyciu edytora DAX . . . . . . . . . . . . . . . . . . . . . . . . . . . . 131Wybór między wyliczanymi kolumnami a miarami . . . . . . . . . . . . . . . . 132
Obsługa błędów w wyrażeniach DAX . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 133Błędy konwersji . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 134Błędy działań arytmetycznych . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 135Puste lub brakujące wartości . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 136Przechwytywanie błędów . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 137
Popularne funkcje DAX . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 138Funkcje agregacji . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 138Funkcje logiczne . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 141Funkcje informacyjne . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 142Funkcje matematyczne . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 142Funkcje tekstowe . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 143Funkcje konwersji . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 143Funkcje daty i czasu . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 143Funkcje relacyjne . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 144
Stosowanie podstawowych funkcji DAX . . . . . . . . . . . . . . . . . . . . . . . . . . . . 146Podsumowanie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 149
5 Pojęcie kontekstu wyznaczania wartości . . . . . . . . . . . . . . . . . . . . . 151
Kontekst wyznaczania wartości w pojedynczej tabeli . . . . . . . . . . . . . . . . . 151Kontekst filtru w pojedynczej tabeli . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 152
##7#52#aSUZPUk1BVC1WaXJ0dWFsbw==

viii Spis treści
Kontekst wiersza w pojedynczej tabeli . . . . . . . . . . . . . . . . . . . . . . . . . . . 156Praca z kontekstem wyznaczania wartości dla pojedynczej tabeli . . . 162
Funkcja EARLIER . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 166Kontekst wyznaczania wartości w wielu tabelach . . . . . . . . . . . . . . . . . . . . 169
Kontekst wiersza z wieloma tabelami . . . . . . . . . . . . . . . . . . . . . . . . . . . . 169Kontekst wiersza i łańcuch relacji . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 172Użycie kontekstu filtru z wieloma tabelami . . . . . . . . . . . . . . . . . . . . . . . 174Interakcje kontekstów wiersza i filtru . . . . . . . . . . . . . . . . . . . . . . . . . . . . 178Modyfikowanie kontekstu filtru dla wielu tabel . . . . . . . . . . . . . . . . . . . 182Końcowe rozważania dla kontekstu wyznaczania wartości . . . . . . . . . . 188
Podsumowanie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 189
6 Zapytania w modelu tabelarycznym . . . . . . . . . . . . . . . . . . . . . . . . . 191
Narzędzia do tworzenia zapytań w modelu tabelarycznym . . . . . . . . . . . 191Składnia zapytania DAX . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 193Zastosowanie funkcji CALCULATETABLE i FILTER . . . . . . . . . . . . . . . . . . . . . 196Zastosowanie funkcji ADDCOLUMNS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 199Zastosowanie SUMMARIZE . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 201Zastosowanie CROSSJOIN, GENERATE oraz GENERATEALL . . . . . . . . . . . . 210Zastosowanie funkcji ROW . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 216Zastosowanie funkcji CONTAINS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 217Zastosowanie funkcji LOOKUPVALUE . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 219Definiowanie miar w zapytaniu . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 221
Testowanie miar za pomocą zapytania . . . . . . . . . . . . . . . . . . . . . . . . . . . 224Parametry w zapytaniu DAX . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 225
Zastosowanie zapytania DAX w SQL Server Reporting Services . . . . . 226Wykonywanie zapytań za pomocą języka MDX . . . . . . . . . . . . . . . . . . . . . 231
Zastosowanie lokalnych miar DAX w zapytaniach MDX . . . . . . . . . . . . 237Szczegółowe przeglądanie w MDX . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 239
Wybór pomiędzy DAX i MDX . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 242Podsumowanie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 244
7 Zaawansowane funkcje DAX . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 245
Funkcje CALCULATE i CALCULATETABLE . . . . . . . . . . . . . . . . . . . . . . . . . . . . 245Kontekst wyznaczania wartości w zapytaniach DAX . . . . . . . . . . . . . . . 246Modyfikowanie kontekstu filtru za pomocą funkcji CALCULATETABLE . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 249
Zastosowanie FILTER w argumentach CALCULATEi CALCULATETABLE . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 253
##7#52#aSUZPUk1BVC1WaXJ0dWFsbw==

Spis treści ix
Podsumowanie działania funkcji CALCULATE i CALCULATETABLE . . . . 261Sterowanie filtrami i wyborami . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 262
Zastosowanie funkcji ALLSELECTED do sum wizualnych . . . . . . . . . . . . 262Filtry i filtry krzyżowe . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 267Utrzymywanie złożonych filtrów za pomocą KEEPFILTERS . . . . . . . . . . 277
Funkcje sortowania . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 283Zastosowanie TOPN . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 283Stosowanie funkcji RANKX . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 287Zastosowanie funkcji RANK.EQ . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 296
Funkcje statystyczne . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 297Odchylenie standardowe i wariancja z użyciem funkcji STDEV i VAR . 297Pobieranie próbek za pomocą funkcji SAMPLE . . . . . . . . . . . . . . . . . . . 300
Podsumowanie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 302
8 Analiza czasowa w języku DAX . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 303
Modelowanie tabelaryczne z tabelą dat . . . . . . . . . . . . . . . . . . . . . . . . . . . . 303Tworzenie tabeli Date . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 304Definiowanie relacji z tabelami Date . . . . . . . . . . . . . . . . . . . . . . . . . . . . 309Dublowanie tabeli Date . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 315Ustawienie metadanych dla tabeli Date . . . . . . . . . . . . . . . . . . . . . . . . . . 319
Funkcje analizy czasowej w języku DAX . . . . . . . . . . . . . . . . . . . . . . . . . . . . 321Agregowanie i porównywanie w czasie . . . . . . . . . . . . . . . . . . . . . . . . . . 321Miary semiaddytywne . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 335
Podsumowanie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 344
9 Narzędzia xVelocity i DirectQuery . . . . . . . . . . . . . . . . . . . . . . . . . . . 345
Architektura modelu tabelarycznego w Analysis Services 2012 . . . . . . . . 346Tryb In-Memory i xVelocity . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 347
Wykonywanie zapytania w trybie In-Memory . . . . . . . . . . . . . . . . . . . . 347Bazy danych zorientowane wierszowo i kolumnowo . . . . . . . . . . . . . . . 351Magazyn xVelocity (VertiPaq) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 354Wykorzystanie pamięci w xVelocity (VertiPaq) . . . . . . . . . . . . . . . . . . . . 357Optymalizowanie wydajności przez ograniczanie
wykorzystania pamięci . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 361Zrozumienie opcji przetwarzania . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 367
Korzystanie z DirectQuery i trybów hybrydowych . . . . . . . . . . . . . . . . . . . 371Tryb DirectQuery . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 372Analizowanie zdarzeń trybu DirectQuery przy użyciu
narzędzia SQL Profiler . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 375
##7#52#aSUZPUk1BVC1WaXJ0dWFsbw==

x Spis treści
Ustawienia DirectQuery . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 376Wdrażanie przy użyciu DirectQuery . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 380
Podsumowanie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 381
10 Tworzenie hierarchii . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 383
Hierarchie podstawowe . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 383Czym są hierarchie? . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 383Kiedy budować hierarchie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 385Tworzenie hierarchii . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 386Najlepsze praktyki projektowania hierarchii . . . . . . . . . . . . . . . . . . . . . . 387Hierarchie obejmujące wiele tabel . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 387
Hierarchie pomiędzy elementami nadrzędnymi i podrzędnymi . . . . . . . . 390Czym są hierarchie pomiędzy elementami nadrzędnymi
i podrzędnymi? . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 390Konfigurowanie hierarchii pomiędzy elementami
nadrzędnymi i podrzędnymi. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 391Operatory jednoargumentowe . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 396
Podsumowanie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 404
11 Modelowanie danych w modelu tabelarycznym . . . . . . . . . . . . . 405
Zrozumienie różnych technik modelowania danych. . . . . . . . . . . . . . . . . . 405Korzystanie z bazy danych OLTP . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 408
Praca z modelami wymiarowymi . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 408Praca z powoli zmieniającymi się wymiarami . . . . . . . . . . . . . . . . . . . . . 410Praca ze zdegenerowanymi wymiarami . . . . . . . . . . . . . . . . . . . . . . . . . . 414Korzystanie z migawkowych tabel faktów . . . . . . . . . . . . . . . . . . . . . . . . 415
Obliczanie agregacji ważonych . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 419Zrozumienie zależności cyklicznych . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 422Zrozumienie możliwości kolumn obliczeniowych: analiza ABC . . . . . . . . 426Modelowanie przy włączonym silniku DirectQuery . . . . . . . . . . . . . . . . . . 430Korzystanie z widoków do odseparowania się od bazy danych . . . . . . . . 433Podsumowanie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 434
12 Korzystanie z zaawansowanych relacji w modelu tabelarycznym . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 435
Korzystanie z relacji wielokolumnowych . . . . . . . . . . . . . . . . . . . . . . . . . . . . 435Grupowanie w modelu tabelarycznym . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 438Korzystanie z relacji wiele do wielu . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 440Implementowanie analizy koszykowej . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 446
##7#52#aSUZPUk1BVC1WaXJ0dWFsbw==

Spis treści xi
Zapytania do modeli danych z zaawansowanymi relacjami . . . . . . . . . . . 450Implementowanie konwersji walut . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 454Podsumowanie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 458
13 Warstwa prezentacji w modelu tabelarycznym . . . . . . . . . . . . . . 459
Nazwy, sortowanie i formatowanie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 459Nadawanie nazw obiektom . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 459Ukrywanie kolumn . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 462Organizowanie miar . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 462Sortowanie danych w kolumnie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 462Formatowanie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 467
Perspektywy . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 469Właściwości związane z Power View . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 471
Default Field Set . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 471Właściwości Table Behavior . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 473
Zgłębianie danych . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 475Kluczowe wskaźniki wydajności (KPI) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 476Podsumowanie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 479
14 Model tabelaryczny i narzędzie PowerPivot . . . . . . . . . . . . . . . . . 481
PowerPivot for Microsoft Excel 2010 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 481Korzystanie z listy pól PowerPivot . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 484Zrozumienie tabel połączonych . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 487
PowerPivot for Microsoft SharePoint . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 488Korzystanie z odpowiedniego narzędzia do danego zadania . . . . . . . . . . 491Prototyp w PowerPivot, wdrażanie w modelu tabelarycznym . . . . . . . . . 494Podsumowanie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 495
15 Bezpieczeństwo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 497
Role . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 497Tworzenie ról bazodanowych . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 498Członkostwo w wielu rolach . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 500
Zabezpieczenia administracyjne . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 500Rola Server Administrator . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 500Role bazodanowe i uprawnienia administracyjne . . . . . . . . . . . . . . . . . 502
Zabezpieczenia danych . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 503Podstawowe zabezpieczenia danych . . . . . . . . . . . . . . . . . . . . . . . . . . . . 503Testowanie zabezpieczeń danych . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 505Zaawansowane wyrażenia filtra wierszy . . . . . . . . . . . . . . . . . . . . . . . . . . 509
##7#52#aSUZPUk1BVC1WaXJ0dWFsbw==

xii Spis treści
Zabezpieczenia dynamiczne . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 514Funkcje DAX związane z zabezpieczeniami dynamicznymi . . . . . . . . . 514Implementowanie zabezpieczeń dynamicznych przy użyciu CUSTOMDATA . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 515
Implementowanie zabezpieczeń dynamicznych przy użyciu USERNAME . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 516
Zaawansowane scenariusze uwierzytelniania . . . . . . . . . . . . . . . . . . . . . . . . 517Łączenie się z usługami Analysis Services spoza domeny . . . . . . . . . . . 517Kerberos i problem podwójnego przeskoku . . . . . . . . . . . . . . . . . . . . . . 518
Monitorowanie zabezpieczeń . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 520Podsumowanie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 522
16 Interfejs modelu tabelarycznego . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 523
Zrozumienie różnych interfejsów modelu tabelarycznego . . . . . . . . . . . . 524Zrozumienie konwersji pomiędzy modelem tabelarycznym
a wielowymiarowym . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 524Korzystanie z AMO z poziomu .NET . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 528Pisanie kompletnej aplikacji AMO . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 530
Tworzenie widoków źródeł danych . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 531Tworzenie kostki . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 531Ładowanie tabeli SQL Server . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 532Tworzenie miary . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 535Tworzenie kolumny obliczeniowej . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 536Tworzenie relacji . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 537Wyciąganie wniosków . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 542
Przeprowadzanie typowych operacji w AMO przy użyciu .NET . . . . . . . . 543Przetwarzanie obiektu . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 544Praca z partycjami . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 544
Korzystanie z AMO przy pomocy PowerShell . . . . . . . . . . . . . . . . . . . . . . . 545Korzystanie z poleceń XMLA . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 546Rozszerzenia CSDL . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 548Podsumowanie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 548
17 Wdrażanie modelu tabelarycznego . . . . . . . . . . . . . . . . . . . . . . . . . . 549
Odpowiedni rozmiar serwera . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 549Wymagania dla xVelocity . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 549Wymagania odnośnie DirectQuery . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 553
Automatyzacja wdrażania na serwerze produkcyjnym . . . . . . . . . . . . . . . . 554Partycjonowanie tabel . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 555
##7#52#aSUZPUk1BVC1WaXJ0dWFsbw==

Spis treści xiii
Definiowanie strategii partycjonowania . . . . . . . . . . . . . . . . . . . . . . . . . . 556Definiowanie partycji dla tabeli w modelu tabelarycznym . . . . . . . . . . 558Zarządzanie partycjami tabeli . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 562
Opcje przetwarzania . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 565Dostępne opcje przetwarzania . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 566Definiowanie strategii przetwarzania . . . . . . . . . . . . . . . . . . . . . . . . . . . . 570Uruchamianie przetwarzania . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 574
Automatyzacja przetwarzania . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 578Korzystanie z XMLA . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 578Korzystanie z AMO . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 584Korzystanie z PowerShell . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 585Korzystanie z usług SSIS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 585
Wdrażanie DirectQuery . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 590Definiowanie strategii partycjonowania DirectQuery . . . . . . . . . . . . . . 590Implementowanie partycji dla DirectQuery i trybów hybrydowych . . 592Zabezpieczenia i personifikacja w DirectQuery . . . . . . . . . . . . . . . . . . . 596
Podsumowanie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 598
18 Optymalizacja i monitorowanie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 599
Znajdowanie procesu usług Analysis Services . . . . . . . . . . . . . . . . . . . . . . . 599Zrozumienie konfiguracji pamięci . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 601Korzystanie z liczników wydajnościowych związanych z pamięcią . . . . . . 605Zrozumienie planów zapytań . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 610
Zrozumienie funkcji SUMX . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 616Zbieranie informacji czasowych z narzędzia Profiler . . . . . . . . . . . . . . . 618
Typowe techniki optymalizacyjne . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 619Wymiana walut . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 620Stosowanie filtrów w odpowiednim miejscu . . . . . . . . . . . . . . . . . . . . . . 622Korzystanie z relacji, kiedy to możliwe . . . . . . . . . . . . . . . . . . . . . . . . . . . 624
Monitorowanie zapytań MDX . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 626Monitorowanie DirectQuery . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 627Zbieranie informacji przy wykorzystaniu dynamicznych
widoków zarządzających . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 628Podsumowanie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 630
Dodatek Opis funkcji DAX . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 631
Funkcje statystyczne . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 631Funkcje przekształcania tabeli . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 633
##7#52#aSUZPUk1BVC1WaXJ0dWFsbw==

xiv Spis treści
Funkcje logiczne . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 634Funkcje informacyjne . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 635Funkcje matematyczne . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 636Funkcje tekstowe . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 638Funkcje daty i czasu . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 640Funkcje filtrowania i wartości . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 641Funkcje analizy czasowej . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 643
Indeks . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 647
O autorach . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 678
##7#52#aSUZPUk1BVC1WaXJ0dWFsbw==

xv
Przedmowa
Autorów, którymi są Marco Russo, Alberto Ferrari i Chris Webb, znam od lat ze względu na moją pracę w zespole produktu Analysis Services. Dość wcześnie
znaleźli się oni wśród pierwszych osób zajmujących się modelowaniem wielowymiaro-wym i zaoferowali swoje opinie i sugestie jako wartościowi partnerzy, pozwalający nam na ulepszanie produktu. Gdy w SQL Server 2012 wprowadziliśmy model tabelaryczny, autorzy od początku byli na pokładzie, uczestnicząc przy wstępnych ocenach i stosując swoje znaczące umiejętności w tej nowej technologii. Marco, Alberto i Chris zapewnili konkretną pomoc w kształtowaniu produktu i kierunku jego rozwoju, za co jesteśmy im głęboko wdzięczni.
Autorzy to naprawdę jedni z najlepszych i najbardziej błyskotliwych ludzi w tej dziedzinie. Indywidualnie i wspólnie napisali już wiele książek. Książka Expert Cube Development with Microsoft SQL Server 2008 Analysis Services wyróżnia się wśród innych i jest lekturą obowiązkową do zrozumienia modelowania wielowymiarowego w Ana-lysis Services. Prócz pisania zadziwiających książek, Marco, Alberto i Chris często pojawiają się jako mówcy na kluczowych konferencjach, prowadzą kursy szkoleniowe i są konsultantami dla fi rm, które stosują analizę biznesową do poprawy działania organizacji. Autorzy ci to czołówka w swej dziedzinie; ich blogi są na czele list wyszu-kiwania niemal każdego zapytania związanego z budową aplikacji w dziedzinie analizy biznesowej.
Książka, którą trzymacie w rękach, szczegółowo opisuje sposoby budowania apli-kacji analizy biznesowej z wykorzystaniem języka DAX oraz modeli tabelarycznych. Jednak jej największą zaletą są porady praktyczne. Jest to książka, którą mogli napi-sać tylko dojrzali praktycy analizy biznesowej (BI). To mieszanka informacji, których potrzebujemy najbardziej: pełnego przewodnika po modelowaniu tabelarycznym, zrównoważonego odpowiednimi poradami prowadzącymi nas przez podejmowanie decyzji dotyczących modelowania. Mam nadzieję, że książka ta spodoba się Wam tak jak mnie. Jestem pewien, że stanie się ważnym zasobem, który warto mieć pod ręką podczas pracy nad modelami tabelarycznymi.
Edward MelomedMenedżer programowySQL Server Analysis Services
##7#52#aSUZPUk1BVC1WaXJ0dWFsbw==

Wprowadzenie
Autorzy tej książki nie byli zbyt zadowoleni, gdy po raz pierwszy usłyszeli o pla-nach fi rmy Microsoft wobec Analysis Services w wersji SQL Server 2012. Analysis
Services nie zyskał wielu nowych funkcji od roku 2005, choć w tym czasie stał się narzędziem OLAP o najwyższej sprzedaży. Wydawało się, że fi rma Microsoft straciła zainteresowanie tym produktem. Wydanie PowerPivot oraz cały szum wokół samoob-sługowej wersji analizy biznesowej (Business Intelligence, BI) sugerował, że Microsoft nie jest już zinteresowany tradycyjną korporacyjną BI, a nawet że uważa profesjo-nalnych deweloperów za niepasujących do dzisiejszego świata, w którym końcowi użytkownicy mogą budować własne aplikacji BI bezpośrednio w Excelu. Potem fi r-ma Microsoft ogłosiła, że technologia leżąca u podstaw PowerPivot będzie włączona do Analysis Services i wydawało się, że spełniają się najgorsze obawy: najbardziej roz-budowany model wielowymiarowy został porzucony na rzecz uproszczonego podejścia opartego na tabelach. Dojrzały produkt został zastąpiony przez wersję 1.0, w której brakowało wielu użytecznych funkcji. Na szczęście, gdy autorzy zaczęli korzystać z pierwszych gotowych kopii nowej wersji, okazało się, że się mylili – ukazał się znacznie lepszy, choć skomplikowany, obraz sytuacji.
SQL Server 2012 jest bez wątpienia kamieniem milowym w rozwoju Analysis Ser-vices. Pomimo wszelkich plotek mówiących coś przeciwnego, można z całą stanow-czością stwierdzić, że Analysis Services nie umarły ani nie umierają. Przeciwnie, pod-legają metamorfozie w kierunku czegoś nowego o znacznie większych możliwościach. W miarę jak zachodzi ta zmiana, Analysis Services staje się dwugłową bestią – to dwa niemal odrębne produkty (choć mające wiele wspólnego kodu). Kostki i wymiary Analysis Services, znane wielu ludziom z poprzednich wersji, stały się „modelem wie-lowymiarowym”, natomiast część Analysis Services podobna do PowerPivot staje się znana jako „model tabelaryczny". Każdy z tych dwóch modeli ma swoje mocne i słabe strony, i są one odpowiednie dla różnego rodzaju projektów. Model tabelaryczny nie zastępuje modelu wielowymiarowego. Model tabelaryczny nie jest „lepszy” lub „gor-szy” od wielowymiarowego. Oba modele po prostu wzajemnie się uzupełniają. Pomi-mo wieloletniego przywiązania do modelu wielowymiarowego, model tabelaryczny zrobił na nas wrażenie, gdyż nie tylko jest niezwykle szybki, ale ze względu na swą prostotę przyciągnie do BI wielu nowych zwolenników.
Z dwóch powodów autorzy skupili się w tej książce wyłącznie na modelu tabe-larycznym. Po pierwsze, w modelu wielowymiarowym nie wprowadzono zbyt wie-lu zmian, więc wcześniejsze książki na temat Analysis Services są nadal aktualne.
##7#52#aSUZPUk1BVC1WaXJ0dWFsbw==

xvii
Po drugie, jeśli w naszym projekcie korzystamy z Analysis Services, wcześniej musi-my podjąć decyzję, którego modelu będziemy używać – mało prawdopodobne jest używanie obydwu. Oznacza to, że każdy, kto decyduje się na korzystanie z modelu tabelarycznego, i tak nie będzie zainteresowany modelem wielowymiarowym. Jednym z podstawowych celów tej książki jest podanie informacji potrzebnych do podjęcia decyzji o używanym modelu.
Autorzy z przyjemnością uczyli się modelu tabelarycznego i pisali na jego temat i mają nadzieję, że Czytelnicy podzielą to przekonanie.
Dla kogo przeznaczona jest ta książkaKsiążka ta jest skierowana do profesjonalnych deweloperów BI: to konsultanci lub członkowie grup deweloperskich BI, którzy mają rozpocząć projekt, korzystając z modelu tabelarycznego.
ZałożeniaChoć zaczniemy od podstaw modelu tabelarycznego, więc książkę tę można traktować jako wprowadzenie do tematu, zakładamy jednak, że Czytelnicy znają podstawowe pojęcia BI, takie jak modelowanie wymiarowe oraz projektowanie hurtowni danych. Do zrozumienia struktury modelu tabelarycznego i ładowania do niego danych oraz takich tematów, jak DirectQuery, ważna będzie wiedza o relacyjnych bazach danych, zwłaszcza o SQL Server.
Wcześniejsze doświadczenie z modelem wielowymiarowym Analysis Services nie jest konieczne, ale zakładamy, że Czytelnicy wiedzą coś na ten temat i porównujemy jego funkcje z odpowiednimi funkcjami modelu tabelarycznego.
Kto nie powinien czytać tej książkiŻadna książka nie jest odpowiednia dla każdego odbiorcy i ta nie stanowi wyjątku. Osoby bez doświadczenia w zakresie analizy biznesowej dość szybko znajdą się w kło-potach, podobnie jak menedżerowie bez wykształcenia technicznego.
##7#52#aSUZPUk1BVC1WaXJ0dWFsbw==

xviii Wprowadzenie
Organizacja książkiOrganizacja książki jest następująca: W pierwszym rozdziale znajduje się wprowa-dzenie do modelu tabelarycznego, czym on jest i kiedy należy go używać, a kiedy nie. Rozdziały 2 i 3 poświęcono podstawom budowy modelu tabelarycznego. W roz-działach od 4 do 8 omawiany jest język DAX, jego pojęcia, składnia i funkcje oraz sposób tworzenia wyliczanych kolumn, miar i zapytań. W rozdziałach od 9 do 16 jest mowa o różnych tematach związanych z projektowaniem modelu tabelarycznego, jak hierarchie, relacje, wiele-do-wielu oraz bezpieczeństwo. Wreszcie w rozdziałach 17 i 18 jest mowa o zagadnieniach operacyjnych, takich jak dostosowanie sprzętu oraz konfi guracja, optymalizacja i monitorowanie.
Stosowane konwencje i cechy książkiInformacje w książce przedstawiono, korzystając z konwencji, dzięki którym mają być one czytelne i łatwe do śledzenia:
■ Elementy w ramkach, takie jak „Uwaga” podają dodatkowe informacje lub alter-natywne metody skutecznego wykonania danego kroku.
■ Tekst do wpisania (poza blokami kodu) jest pogrubiony. ■ Znak plus (+) między nazwami klawiszy oznacza, że trzeba te klawisze nacisnąć
jednocześnie. Na przykład tekst „naciśnij Alt+Tab” oznacza, że trzeba trzymać naciśnięty klawisz Alt, a wtedy nacisnąć klawisz Tab.
■ Pionowa kreska między dwoma lub więcej elementami menu (na przykład Plik | Zamknij) oznacza, że trzeba wybrać pierwsze menu lub jego element, potem następny i tak dalej.
Wymagania względem systemuAby zainstalować przykłady kodu oraz przykładowe bazy danych z tej książki, trzeba mieć następujący sprzęt i oprogramowanie:
■ Windows Vista SP2, Windows 7, Windows Server 2008 SP2 lub nowsze. Można korzystać zarówno z wersji 32-bitowych, jak i 64-bitowych.
■ Nie mniej niż 4 GB wolnego miejsca na dysku. ■ Nie mniej niż 4 GB pamięci RAM. ■ Procesor 2,0GHz x86 lub x64, albo lepszy. ■ Instancję modelu tabelarycznego SQL Server Analysis Services 2012 Tabular plus
komponenty klienckie. Pełna instrukcja instalacji znajduje się w rozdziale 2, „Rozpoczęcie pracy w modelu tabelarycznym”.
##7#52#aSUZPUk1BVC1WaXJ0dWFsbw==

Przykłady kodu xix
Przykłady koduBaza danych wykorzystywana w przykładach tej książki została oparta na przykła-dowej bazie danych Microsoft Adventure Works 2012 DW. Ponieważ istnieje kilka różnych wersji tej bazy danych, a każda jest nieco inna, zalecamy pobranie tej bazy danych, której link podano niżej, zamiast korzystania w przykładach z własnej kopii Adventure Works.
Wszystkie przykładowe projekty oraz przykładową bazę danych można pobrać z następującej strony:
http://go.microsoft.com/FWLink/?Linkid=254183
Aby pobrać plik BismTabularSample.zip oraz przykładową bazę danych, trzeba postę-pować zgodnie ze wskazówkami.
Instalacja próbek koduInstalacja próbek kodu na swoim komputerze w celu korzystania z przykładów zawar-tych w książce, wymaga postępowania zgodnie z poniższymi krokami:
1. Rozpakowujemy plik z przykładami na nasz twardy dysk.
2. Przywracamy dwie bazy danych SQL Server z plików .bak, które można znaleźć w katalogu Databases. Pełną instrukcję postępowania można znaleźć tu: http://msdn.microsoft.com/en-us/library/ms177429.aspx.
3. Przywracamy tabelaryczną bazę danych Adventure Works do Analysis Services z pliku .abf, która także znajduje się w katalogu Databases. Pełną instrukcję postę-powania można znaleźć tu: http://technet.microsoft.com/en-us/library/ms174874.aspx.
4. Każdy rozdział ma swój katalog zawierający przykłady kodu. W wielu przy-padkach mają one formę projektu, który trzeba otworzyć za pomocą narzędzi SQL Server Data Tools. Pełną instrukcję instalacji SQL Server Data Tools podano w rozdziale 2, „Rozpoczęcie pracy w modelu tabelarycznym”.
##7#52#aSUZPUk1BVC1WaXJ0dWFsbw==

xx Wprowadzenie
Errata i wsparcie dla książkiAutorzy dołożyli wszelkich starań, aby zapewnić dokładność książki i jej kontekstu. Wszelkie błędy, które zostały zgłoszone po publikacji książki, podano na naszej witry-nie Microsoft Press w oreilly.com:
http://go.microsoft.com/FWLink/?Linkid=254181
Każdy, kto znajdzie błąd, którego nie ma na liście, może go zgłosić na tejże stronie.Ewentualną dodatkową pomoc można uzyskać, pisząc e-mail do Microsoft Press
Book Support, pod adres [email protected] powyższymi adresami nie można uzyskać wsparcia dla oprogramowania fi rmy
Microsoft.
Czekamy na kontaktW Microsoft Press satysfakcja Czytelników jest podstawowym priorytetem, a kontakty od klientów najcenniejszym zasobem. Czekamy na komentarze na temat tej książki pod adresem:
http://www.microsoft.com/learning/booksurvey
Ankieta jest krótka i czytamy każdy komentarz i pomysł. Z góry dziękujemy za Wasz wkład!
Pozostańmy w kontakcieNiech trwa wymiana poglądów. Jesteśmy też na Twitterze: http://twitter.com/MicrosoftPress
PodziękowaniaAutorzy chcą podziękować niżej wymienionym osobom za ich pomoc i radę. Są to: Akshai Mirchandani, Amir Netz, Ashvini Sharma, Brad Daniels, Cristian Petculescu, Dan English, Darren Gosbell, Dave Wickert, Denny Lee, Edward Melomed, Greg Galloway, Howie Dickerman, Hrvoje Piasevoli, Jeffrey Wang, Jen Stirrup, John Sirmon, John Welch, Kasper de Jonge, Marius Dumitru, Max Uritsky, Paul Sanders, Paul Turley, Rob Collie, Rob Kerr, TK Anand, Teo Lachev, Thierry D’Hers, Thomas Ivarsson, Thomas Kejser, Tomislav Piasevoli, Vidas Matelis, Wayne Robertson, Paul te Braak, Stacia Misner, Javier Guillen, Bobby Henningsen, Toufi q Abrahams, Christo Olivier, Eric Mamet, Cathy Dumas i Julie Strauss.
##7#52#aSUZPUk1BVC1WaXJ0dWFsbw==

1
ROZDZIAŁ 1
Wprowadzenie do modelu tabelarycznego
Celem tego rozdziału jest wprowadzenie do usług Analysis Services 2012, podanie krótkiego przeglądu idei modelu tabelarycznego (ang. Tabular model) oraz analiza
jego związków z modelem wielowymiarowym (ang. Multidimensional model), cało-ścią usług Analysis Services 2012 oraz z szerszym zakresem narzędzi fi rmy Microsoft do analizy biznesowej (BI). Rozdział ten pomoże nam także w podjęciu najważniej-szej zapewne decyzji w cyklu życia naszego projektu: czy należy korzystać z modelu tabelarycznego.
Ekosystem Microsoft BIW ekosystemie fi rmy Microsoft, BI nie jest oddzielnym produktem; jest to raczej zestaw funkcji rozdzielonych pomiędzy kilka produktów, co wyjaśnimy w kolejnych punktach.
Czym jest usługa Analysis Services i dlaczego należy jej używać?Analysis Services to baza danych OLAP (online analytical processing, przetwarza-nie analityczne online), rodzaj bazy danych w wysokim stopniu zoptymalizowanej do wykonywania zapytań i obliczeń powszechnie stosowanych w środowisku analizy biznesowej. Wykonuje wiele działań zbliżonych do relacyjnej bazy danych, ale różni się od niej w wielu elementach. W większości przypadków rozwiązanie biznesowe BI jest łatwiej uzyskać, korzystając z usługi Analysis Services w połączeniu z relacyjną bazą danych, taką jak Microsoft SQL Server, niż korzystając z samego SQL Servera. Analysis Services nie zastępuje relacyjnej bazy danych ani odpowiednio zaprojekto-wanej hurtowni danych.
Usługi Analysis Services można traktować jako dodatkową warstwę metadanych lub model semantyczny, umieszczony ponad hurtownią danych w relacyjnej bazie danych. Ta dodatkowa warstwa zawiera informacje o tym, jak powinny być połączone tabele faktów i tabele wymiarów, jak agregować miary, jakie możliwości eksploracji danych w ramach hierarchii powinni mieć użytkownicy, defi nicje podstawowych obliczeń i tak dalej. Warstwa ta obejmuje jeden lub więcej modeli zawierających logikę biznesową
##7#52#aSUZPUk1BVC1WaXJ0dWFsbw==

2 Rozdział 1: Wprowadzenie do modelu tabelarycznego
naszej hurtowni danych – zaś użytkownicy końcowi wykonują zapytania w ramach tych modeli, a nie w zawartej w nich relacyjnej bazie danych. Dzięki temu, że wszyst-kie informacje znajdują się w jednym centralnym położeniu i są współdzielone przez użytkowników, zapytania pisane przez użytkowników stają się znacznie prostsze: w większości przypadków zapytanie musi jedynie opisać, które wiersze i kolumny są potrzebne, zaś model zastosuje odpowiednią logikę biznesową, aby zwracane war-tości były sensowne. Co najważniejsze, niemożliwe staje się napisanie zapytania, któ-re zwraca „niepoprawny” wynik z powodu błędu użytkownika końcowego, takiego jak niewłaściwe powiązanie dwóch tabel lub sumowanie kolumny, której nie można sumować. To z kolei oznacza, że narzędzia raportowania i analizy po stronie użytkow-nika końcowego muszą wykonać znacznie mniejszą pracę i mogą dostarczyć prostszy grafi czny interfejs do budowania przez niego zapytań. Oznacza to także, że do tego samego modelu można dołączać różne narzędzia, nadal otrzymując spójne wyniki.
Innym sposobem myślenia o usługach Analysis Services jest traktowanie ich jako rodzaju pamięci podręcznej używanej do przyspieszenia raportowania. W większości scenariuszy, w których korzystamy z Analysis Services, ładuje się do nich kopię danych z hurtowni danych. W konsekwencji wszystkie zapytania związane z raportami i analizą są realizowane poprzez Analysis Services, a nie w ramach relacyjnej bazy danych. Choć nowoczesne relacyjne bazy danych są mocno zoptymalizowane i zawierają wiele funkcji nakierowanych konkretnie na raporty BI, Analysis Services to baza danych zaprojekto-wana specjalnie dla tego typu prac i może w większości przypadków dać znacznie lepszą efektywność wykonywania zapytań. Optymalizacja działania zapytania jest niezwykle ważna dla użytkowników końcowych, gdyż pozwala im na przeglądanie danych bez długiego oczekiwania na realizację raportów oraz bez przerw w łańcuchu rozumowania.
Największą korzyścią dla działu IT jest możliwość przeniesienia ciężaru tworzenia raportów na użytkowników końcowych. Częstym problemem projektów BI, które nie korzystają z OLAP, jest fakt, że wydział IT musi tworzyć zarówno hurtownie danych, jak i powiązane z nią raporty. Zwiększa to konieczny wysiłek i nakład czasu, często powodując frustrację biznesu w sytuacji, gdy dział IT nie potrafi zrozumieć wyma-gań związanych z tworzeniem raportów i reagować na nie tak szybko, jak się tego wymaga. Gdy używana jest baza danych OLAP, taka jak Analysis Services, dział IT może udostępniać użytkownikom końcowym używane przez nią modele, pozwalając im na samodzielne budowanie raportów za pomocą takiego narzędzia, jakie im naj-bardziej odpowiada. Najpopularniejszym narzędziem klienckim jest Microsoft Excel. Od czasu, gdy w Offi ce 2000 tabele przestawne Excela uzyskały możliwość bezpo-średniego połączenia z kostkami Analysis Services, Excel 2010 ma niezwykle silne możliwości jako klient Analysis Services.
Podsumowując, Analysis Services nie tylko ogranicza nakłady pracy działu IT, lecz także zwiększa satysfakcję użytkownika końcowego, gdyż użytkownicy mogą sami budować raporty zgodnie ze swoimi chęciami i przeglądać dane we własnym tempie bez pośredników.
##7#52#aSUZPUk1BVC1WaXJ0dWFsbw==

Ekosystem Microsoft BI 3
Krótka historia Analysis ServicesUsługi SQL Server Analysis Services – inaczej usługi OLAP, zgodnie z wcześniejszą terminologią wprowadzoną przy udostępnieniu SQL Server 7.0 – stanowiły pierw-sze wejście fi rmy Microsoft na rynek BI. Po ich wprowadzeniu wiele osób uznało, że pokazały one, iż oprogramowanie BI może wyjść z niszy i wejść na masowy rynek. Sukces Analysis Services i pozostałych produktów BI fi rmy Microsoft, jaki miał miej-sce w ostatniej dekadzie, potwierdził te przewidywania. Usługi SQL Server Analysis Services 2000 stanowiły pierwszą wersję Analysis Services, która zyskała duże znacze-nie na rynku. Analysis Services 2005 szybko stały się najlepiej sprzedającym się narzę-dziem OLAP, gdy zaś Analysis Services 2008 i 2008 R2 jeszcze poprawiły skalowalność i wydajność, coraz więcej fi rm zaczęło je przyjmować jako podstawę swojej strategii BI. Terabajtowe kostki są teraz dość częste, a słynnym przykładem jest tu kostka Yahoo! o rozmiarach 24 TB, pokazując, ile można osiągnąć. Dziś Analysis Services to dojrzały produkt, który odniósł sukces i jest używany w tysiącach wdrożeń fi rmowych, ciesząc się pełnym zaufaniem.
Obecny zestaw BI firmy MicrosoftSukces usług Analysis Services nie byłby możliwy, gdyby nie stanowiły one części szer-szego zestawu narzędzi BI, które fi rma Microsoft z sukcesem wprowadzała z upływem lat. Tych narzędzi jest bardzo wiele, dlatego warto je wymienić, dodając krótki opis działania każdego z nich.
Zestaw BI fi rmy Microsoft BI można podzielić na dwie główne grupy: produkty stanowiące część zestawu narzędzi SQL Server oraz produkty stanowiące część grupy Offi ce. Narzędzia związane z SQL Server BI w obrębie SQL Server 2012 obejmują:
■ Relacyjną bazę danych SQL Server Flagowy produkt zestawu SQL Server i platforma relacyjnej hurtowni danych.
http://www.microsoft.com/sqlserver/en/us/default.aspx ■ SQL Azure Wersja SQL Servera przygotowana przez Microsoft w oparciu
o chmurę, która obecnie nie jest powszechnie używana do celów BI, ale w przy-szłości, gdy inne produkty oparte na chmurze staną się bardziej popularne, będzie coraz więcej używana.
https://www.windowsazure.com/en-us/home/features/sql-azure ■ Równoległa hurtownia danych Wysoce specjalizowana wersja SQL Servera,
skierowana dla fi rm posiadających hurtownie danych o pojemności wielu tera-bajtów, w której obciążenie pracą można rozdzielić na wiele fi zycznych serwerów.
http://www.microsoft.com/sqlserver/en/us/solutions-technologies/data-warehousing/pdw.aspx
##7#52#aSUZPUk1BVC1WaXJ0dWFsbw==

4 Rozdział 1: Wprowadzenie do modelu tabelarycznego
■ SQL Server Integration Services Narzędzie do wybierania, transformacji i łado-wania (ETL – extract, transform, load) przeznaczone do przenoszenia danych z miejsca na miejsce. Zwykle wykorzystywane jest do ładowania danych do hur-towni danych.
http://www.microsoft.com/sqlserver/en/us/solutions-technologies/business-intelligence/integrationservices.aspx
■ Apache Hadoop Szeroko stosowane narzędzie open-source służące do agregacji i analizy dużej liczby danych. Firma Microsoft zdecydowała się na bezpośrednią jego obsługę w systemie Windows i zapewnia narzędzia pomocnicze do jego inte-gracji z resztą zestawu Microsoft BI.
http://www.microsoft.com/bigdata ■ Usługi raportowania SQL Server Reporting Services Narzędzie do tworzenia
statycznych i semistatycznych sformatowanych raportów, będące prawdopodobnie najszerzej używanym narzędziem SQL Server BI.
http://www. www.microsoft.com/sqlserver/en/us/solutions-technologies/business-intelli-gence/reportingservices.aspx
■ Raportowanie SQL Azure Wersja SQL Server Reporting Services oparta na chmurze, w czasie pisania książki dostępna jako wersja beta.
http://msdn.microsoft.com/en-us/library/windowsazure/gg430130.aspx ■ Power View Narzędzie do wizualizacji i analizy o dużych możliwościach,
dostępne za pośrednictwem Microsoft SharePoint, które działa jako zewnętrzne opakowanie Analysis Services.
http://www.microsoft.com/sqlserver/en/us/future-editions/SQL-Server-2012-breakthrough-insight.aspx
■ StreamInsight Złożona platforma przetwarzania zdarzeń służąca do analizy danych, które przychodzą za szybko i w zbyt wielkiej liczbie, aby pozostać w rela-cyjnej bazie danych.
http://www.microsoft.com/sqlserver/en/us/solutions-technologies/business-intelligence/complex-event-processing.aspx
■ Usługi Master Data Services Narzędzie do zarządzania spójnym zbiorem pod-stawowych danych w systemach BI.
http://www.microsoft.com/sqlserver/en/us/solutions-technologies/business-intelligence/master-data-services.aspx
■ Usługi jakości danych (Data Quality Services) Narzędzie zapewniające jakość i czyszczenie danych.
http://msdn.microsoft.com/en-us/library/ff877917(v=sql.110).aspx ■ PowerPivot Samoobsługowe narzędzie BI, które umożliwia użytkownikom
zbudowanie własnych rozwiązań raportowania w Excelu i publikowanie ich
##7#52#aSUZPUk1BVC1WaXJ0dWFsbw==

Ekosystem Microsoft BI 5
w SharePoint. Jest blisko związane z Analysis Services i jest dokładniej omawiane w punkcie „Samoobsługowa i korporacyjna analiza biznesowa (BI)”.
Narzędzia BI opracowane w ramach grupy Offi ce obejmują:
■ SharePoint 2010 Flagowy portal i produkt do współpracy fi rmy Microsoft. Z punktu widzenia fi rmy Microsoft wszelkie nasze raporty BI powinny znaleźć się w SharePoint, za pośrednictwem aplikacji Excel i Excel Services, Reporting Services, Power View oraz PerformancePoint. Służy także jako centrum współdzie-lenia modeli PowerPivot, dzięki zastosowaniu PowerPivot dla SharePoint.
■ Usługi PerformancePoint Services Narzędzie do tworzenia pulpitu nawigacyj-nego BI w ramach SharePoint.
■ Excel 2010 Od dawna używany arkusz kalkulacyjny i zapewne najszerzej na świecie używane narzędzie BI. Excel od dawna potrafi ł połączyć się bezpo-średnio z Analysis Services poprzez tabele przestawne i formuły kostek. Teraz, po wprowadzeniu PowerPivot, który jest dodatkiem (add-in) do Excela, stanowi on centrum samoobsługowej strategii BI fi rmy Microsoft.
Warto też wspomnieć, że fi rma Microsoft udostępnia coraz więcej eksperymentalnych narzędzi BI na swojej witrynie SQL Azure Labs (http://www.microsoft.com/en-us/sqlazu-relabs/default.aspx), które obejmują projekty określane jako „Social Analytics” (Analiza społeczna) i „Data Explorer” (Eksplorator danych). Ponadto wielu innych dostawców oprogramowania ma swój udział w ekosystemie BI fi rmy Microsoft, na przykład two-rząc narzędzia klienckie dla usług Analysis Services.
Samoobsługowa i korporacyjna analiza biznesowa ( BI)Jednym z najbardziej znaczących trendów ostatnich lat w dziedzinie BI było pojawie-nie się tak zwanych samoobsługowych narzędzi BI, takich jak QlikView oraz Tableau. Celem tych narzędzi jest wyposażenie użytkowników w możliwość tworzenia nie-wielkich rozwiązań BI bez pomocy działu IT lub z niewielką pomocą z ich strony. W pewnym sensie usługi Analysis Services zawsze były swego rodzaju narzędziem samoobsługowym BI, umożliwiającym użytkownikom końcowym budowanie włas-nych zapytań i raportów, jednak nadał wymagają specjalisty z dziedziny IT do pro-jektowania i budowania bazy danych Analysis Services oraz związanej z nią hurtowni danych. Oznacza to, że są one zwykle połączone z innymi, bardziej tradycyjnymi narzędziami korporacyjnymi BI, w których projektowanie baz danych, raportowanie i dostęp do danych są ściśle kontrolowane przez dział IT. W wielu organizacjach, zwłaszcza tych mniejszych, brakuje po prostu zasobów do realizacji większych pro-jektów BI; jeśli nawet się ich podejmują, istnieje duży procent niepowodzeń dla tego typu projektów, stąd dla pewnej grupy użytkowników samoobsługowe narzędzia IT są atrakcyjne, gdyż pozwalają im robić wszystko samodzielnie.
##7#52#aSUZPUk1BVC1WaXJ0dWFsbw==

6 Rozdział 1: Wprowadzenie do modelu tabelarycznego
Najprostszym sposobem wywołania sporu między dwoma specjalistami BI jest zadanie im pytania, co myślą o samoobsługowych BI. Z jednej strony samoobsługowe BI sprawiają, że tworzenie BI jest bardzo skoncentrowane na biznesie, zapewnia dobrą reakcję na potrzeby i jest elastyczne. Z drugiej strony może to wzmocnić problemy związane z utrzymywaniem nieaktualnych danych, marną jakością danych, brakiem integracji między wieloma systemami źródłowymi oraz różnymi interpretacjami spo-sobu modelowania danych, zwłaszcza że zwolennicy samoobsługowych BI twierdzą, że czasochłonny etap tworzenia hurtowni danych jest zbędny. Niezależnie od wad i zalet samoobsługowych BI jest to szybko rosnący rynek, którego Microsoft, jako fi rma zajmująca się oprogramowaniem, nie mogła zignorować, więc w roku 2010 wypuściła własne samoobsługowe narzędzie BI o nazwie PowerPivot.
PowerPivot to wersja Analysis Services przeznaczona na komputery osobiste, przyj-muje jednak postać dodatku do aplikacji do Excela 2010, który można bezpłatnie pobrać. (Więcej szczegółów można znaleźć na www.powerpivot.com). Sprawia ona, że użytkownicy Excela mogą łatwo importować dane z wielu źródeł, budować własne modele oraz przeszukiwać je za pomocą tabel przestawnych. Baza danych PowerPivot działa jako proces wewnętrzny Excela; wszystkie importowane dane są tam przecho-wywane i wszystkie zapytania z Excela są realizowane względem nich. Użytkownicy Excela mogą działać na znacznie większej liczbie danych niż kiedykolwiek wcześniej, gdy przechowywali je bezpośrednio w arkuszu Excela, przy szybkich jak błyskawica czasach odpowiedzi zapytań. Podczas zapisywania skoroszytu Excela, baza danych PowerPivot i wszystkie pozostałe dane są przechowywane wewnątrz skoroszytu; sko-roszyt można potem skopiować i współdzielić, tak jak inne skoroszyty Excela, jednak każdy użytkownik, który chce przeglądać dane przechowywane w PowerPivot, musi mieć PowerPivot zainstalowany na swoim komputerze. Aby bardziej efektywnie współ-dzielić modele i raporty między grupami użytkowników, potrzebna jest usługa Power-Pivot for SharePoint, która integruje się z wersją Microsoft SharePoint 2010 Enterprise.
Dzięki PowerPivot for SharePoint możliwe stało się załadowanie do aplikacji SharePoint skoroszytu zawierającego bazę danych PowerPivot, a użytkownicy uzy-skali dostęp do przeglądania przez sieć WWW raportów w skoroszytach za pomocą Excel Service. Można także wykonywać zapytania dotyczące danych przechowywa-nych w PowerPivot na serwerze, używając w tym celu Excela lub innego narzędzia klienta Analysis Services dostępnego na swoim komputerze.
Udostępnienie PowerPivot nie oznacza, że zmniejszyło się zaangażowanie formy Microsoft w narzędzia korporacyjne. Żadne narzędzie nie jest właściwe we wszyst-kich sytuacjach. Zaletą fi rmy Microsoft jest to, że nie tylko sprzedaje zarówno samo-obsługowe narzędzia BI, jak i narzędzia korporacyjne, lecz ma także spójne zasady współistnienia obu typów narzędzi w ramach jednej organizacji. Microsoft przewiduje sytuację, w której działy IT i zaawansowani użytkownicy żyją w harmonii, w której projekty prowadzone przez dział IT korzystają z korporacyjnych narzędzi BI i przeka-zują do wszystkich dane z centralnej hurtowni danych za pomocą raportów i kostek
##7#52#aSUZPUk1BVC1WaXJ0dWFsbw==

Architektura Analysis Services 2012: jeden produkt, dwa modele 7
Analysis Services. Jednocześnie zaawansowani użytkownicy mogą swobodnie budo-wać swoje własne samoobsługowe modele w PowerPivot, współdzielić je z innymi oraz, jeśli ich modele zyskają popularność, przekazywać je działowi IT, aby je dalej rozwijał, obsługiwał i ewentualnie włączał do modelu korporacyjnego. PowerPivot for SharePoint zapewnia pewną liczbę pulpitów pozwalających działowi IT na monito-rowanie wykorzystania modeli PowerPivot, które zostały załadowane do SharePoint, zaś w Analysis Services 2012 możliwe jest także importowanie modeli utworzonych w PowerPivot do Analysis Services. Kolejne wersje będą prawdopodobnie zawierać funkcje pomocne w budowaniu mostów pomiędzy światami samoobsługowych i kor-poracyjnych BI.
Architektura Analysis Services 2012: jeden produkt, dwa modeleW tej części rozdziału wyjaśniono element architektury Analysis Services, która w SQL Server 2012 jest podzielona na dwa modele.
Pierwszą i najważniejszą kwestią dotyczącą Analysis Services 2012 jest fakt, że są to w zasadzie dwa produkty w jednym. Analysis Services w wersji SQL Server 2008 R2 i wcześniejszych jest nadal dostępny, ale nazywa się teraz modelem wielowy-miarowym (Multidimensional model). Został poprawiony w zakresie wydajności, ska-lowalności i możliwości zarządzania, ale nie zawiera nowych funkcji. Natomiast nowa wersja Analysis Services, która bardzo przypomina PowerPivot, nosi nazwę modelu tabelarycznego (Tabular model). Właśnie Model tabelaryczny jest tematem tej książki.
Podczas instalacji Analysis Services trzeba wybrać, czy instalujemy instancję, która pracuje w trybie tabelarycznym, czy w trybie wielowymiarowym. Więcej szczegółów na temat instalacji podano w rozdziale 2, „Rozpoczęcie pracy w modelu tabelarycz-nym”. Instancja tabelaryczna może obsługiwać tylko bazy danych zawierające modele tabelaryczne, zaś instancja wielowymiarowa może obsługiwać bazy danych zawierające modele wielowymiarowe. Choć obie części Analysis Services mają wiele wspólnego kodu, w wielu aspektach muszą być traktowane jak oddzielne produkty. Koncepcje związane z projektem dwóch typów modeli bardzo się różnią, więc nie można prze-kształcić tabelarycznej bazy danych w bazę wielowymiarową i odwrotnie, bez prze-budowania wszystkiego do nowa. Po tym stwierdzeniu trzeba podkreślić, że z punk-tu widzenia użytkownika końcowego oba modele wykonują niemal te same zadania i wydają się identyczne, jeśli używane są z poziomu narzędzia klienckiego jak Excel.
W kolejnych podrozdziałach porównano dostępne funkcje modeli tabelarycznego i wielowymiarowego oraz zdefi niowano niektóre ważne terminy używane w dalszej części tej książki.
##7#52#aSUZPUk1BVC1WaXJ0dWFsbw==

8 Rozdział 1: Wprowadzenie do modelu tabelarycznego
Model tabelarycznyW modelu tabelarycznym obiektem najwyższego poziomu jest baza danych, co przy-pomina koncepcję bazy danych w relacyjnej bazie danych SQL Server. Instancja Analysis Services może zawierać wiele baz danych, zaś każda baza danych może być traktowana jak zawarta w niej kolekcja obiektów i danych odnoszących się do jed-nego rozwiązania biznesowego. Jeśli przy pisaniu raportów lub analizowaniu danych okazuje się, że trzeba wykonywać zapytania względem wielu baz danych, zapewne popełniliśmy gdzieś błąd, gdyż wszystko, czego potrzebujemy, powinno być zawarte w jednej bazie danych.
Modele tabelaryczne są zaprojektowane za pomocą narzędzi SQL Server Data Tools (SSDT), zaś projekt w SSDT jest odwzorowany na bazę danych w Analysis Services. Po utworzeniu projektu w SSDT, musimy go wdrożyć w instancji Analysis Services, co oznacza, że SSDT wykonuje kilka poleceń, aby utworzyć nową bazę danych w Ana-lysis Services lub zmienia strukturę istniejącej bazy danych. SQL Server Management Studio (SSMS), narzędzie używane do zarządzania już wdrożonymi bazami danych, może być także wykorzystane do pisania zapytań względem baz danych.
Bazy danych składają się z jednej lub większej liczby tabel danych. Tabela w mode-lu tabelarycznym jest bardzo podobna do tabeli w relacyjnych bazach danych. Jest ona zwykle ładowana z pojedynczej tabeli w relacyjnej bazie danych lub z wyników instrukcji SQL SELECT. Tabela ma ściśle ustaloną liczbę kolumn, które są defi niowa-ne w momencie projektowania. Może mieć zmienną liczbę wierszy, zależnie od licz-by danych do niej załadowanych. Każda kolumna ma niezmienny typ, na przykład kolumna może zawierać tylko wartości całkowite, tylko teksty lub tylko wartości dzie-siętne. Ładowanie danych do tabeli jest określane jako przetwarzanie tabeli.
Podczas projektowania można też zdefi niować relacje między tabelami. W przeci-wieństwie do SQL, nie można defi niować relacji podczas realizacji zapytań; wszystkie zapytania muszą korzystać z wcześniej istniejących relacji. Jednak relacje między tabe-lami mogą być oznaczone jako aktywne lub nieaktywne, zaś podczas zapytania można wybrać, które relacje między tabelami będą używane. Wewnątrz zapytań i obliczeń można też symulować efekt relacji, które nie istnieją. Wszystkie relacje są relacjami jeden-do-wielu i muszą obejmować tylko jedną kolumnę z każdej z dwóch tabel. Nie można zdefi niować relacji, które mają jawnie postać jeden-do-jednego albo wiele-do--wielu, choć ten sam efekt można osiągnąć, pisząc zapytania i obliczenia w określony sposób. Nie jest także możliwe zaprojektowanie relacji opartych na więcej niż jednej kolumnie z tabeli ani relacji rekurencyjnych, łączących tabelę z nią samą.
Model tabelaryczny wykorzystuje wyłącznie mechanizm oparty na pamięci i prze-chowuje na dysku tylko kopię swoich danych, tak więc żadne dane nie zostaną utra-cone, jeśli usługa zostanie zrestartowana. Podczas gdy model wielowymiarowy, jak większość relacyjnych mechanizmów baz danych, przechowuje swoje dane w for-macie opartym na wierszach, model tabelaryczny korzysta z bazy danych opartej na kolumnach, noszącej nazwę pamięciowego mechanizmu analitycznego xVelocity, który
##7#52#aSUZPUk1BVC1WaXJ0dWFsbw==

Architektura Analysis Services 2012: jeden produkt, dwa modele 9
w większości przypadków oferuje znaczące polepszenie wydajności zapytań. (Wię-cej szczegółów na temat bazy danych opartej na kolumnach można znaleźć w http://en.wikipedia.org/wiki/Column-oriented_DBMS).
UWAGA Pamięciowy mechanizm analityczny xVelocity był przed wydaniem Analysis Servi-ces 2012 znany jako mechanizm Vertipaq. W dokumentacji, postach na blogach i w innych materiałach online pozostało wiele odwołań do nazwy Vertipaq. Pozostaje ona nawet we-wnątrz samego produktu, w nazwach własnościowych oraz zdarzeniach aplikacji Profiler. Nazwa xVelocity jest używana także w odniesieniu do większej rodziny powiązanych tech-nologii, w tym do nowej funkcji indeksu pamięci kolumnowej w mechanizmie relacyjnej bazy danych SQL Server 2012. Więcej szczegółów na temat tej terminologii można znaleźć pod adresem http://blogs.msdn.com/b/analysisservices/archive/2012/03/09/xvelocity-and--analysis-services.aspx.
W modelu tabelarycznym zapytania i obliczenia są zdefi niowane w DAX (Data Analysis eXpressions), podstawowym języku modelu tabelarycznego i w PowerPivot. Narzędzia klienckie, takie jak Power View mogą generować zapytania w DAX, aby wyciągać dane z modelu tabelarycznego. Można też pisać własne zapytania w DAX i wykorzystywać je w raportach. Możliwe jest także pisanie zapytań w języku MDX używanym w mode-lu wielowymiarowym. Oznacza to, że model tabelaryczny jest wstecznie kompatybilny z wieloma istniejącymi narzędziami klienckimi Analysis Services, takimi jak Excel i SQL Server Reporting Services, oraz narzędziami innych producentów oprogramowania.
Do tabeli w modelu tabelarycznym można dodawać wyznaczane kolumny, określa-ne jako kolumny wyliczane; wykorzystuje się w nich wyrażenia DAX, aby zwracać war-tości na podstawie danych znajdujących się w innych kolumnach tej samej lub innej tabeli w obrębie tej samej bazy danych Analysis Services. Podczas przetwarzania oraz po zakończeniu przetwarzania kolumny wyliczane zachowują się dokładnie tak samo jak zwykłe kolumny. Za pomocą wyrażeń DAX na tabelach można także defi niować miary. Miarami nazywamy wyrażenia DAX, które zwracają pewną zagregowaną war-tość na podstawie danych z jednej lub wielu kolumn. Prostym przykładem miary jest wartość sumy wszystkich wartości z kolumny zawierającej wielkości sprzedaży. Klu-czowe wskaźniki wydajności (KPI) są bardzo podobne do miar, jednak stanowią kolekcję obliczeń, dzięki której można określić stosunek miary do wartości docelowej oraz to, czy w miarę upływu czasu zbliża się ona do wyznaczonego celu.
W większości narzędzi użytkowych, takich jak Excel, do zapytań w modelu tabe-larycznym stosuje się zasady podobne do tych w tabelach przestawnych: kolumny z różnych tabel można przeciągać względem osi wierszy i kolumn tabeli przestawnej, tak aby określone wartości z tych kolumn stały się poszczególnymi wierszami i kolum-nami tabeli przestawnej, a miary wewnątrz tabeli pokazywały zagregowane wartości liczbowe. Końcowy efekt przypomina nieco zapytanie Group By w SQL, ale defi nicja sposobu agregacji danych jest z góry zdefi niowana wewnątrz miar i nie musi być
##7#52#aSUZPUk1BVC1WaXJ0dWFsbw==

10 Rozdział 1: Wprowadzenie do modelu tabelarycznego
podawana wewnątrz samego zapytania. Aby poprawić wrażenia użytkownika, można także zdefi niować dla tabel hierarchię wewnątrz modelu tabelarycznego, co tworzy wie-lopoziomowe, predefi niowane ścieżki postępowania. Perspektywy mogą ukrywać nie-które części złożonego modelu, co zwiększa wartości użytkowe, zaś role zabezpieczeń mogą być wykorzystane do odmowy dostępu do określonych wierszy danych z tabeli określonego użytkownika. Jednak perspektyw nie należy mylić z zabezpieczeniami; nawet jeśli obiekt jest ukryty w perspektywie, nadal można wysłać do niego zapytanie, zaś samej perspektywy nie można zabezpieczyć.
Model wielowymiarowyNa swoim najwyższym poziomie model wielowymiarowy jest bardzo podobny do modelu tabelarycznego: dane są zorganizowane w bazy danych, zaś bazy danych są zaprojektowane w SSDT (wcześniej w BI Development Studio lub w BIDS) i zarzą-dzane przez SQL Server Management Studio.
Różnice stają się widoczne poniżej poziomu bazy danych, gdzie koncepcje wielo-wymiarowe przeważają nad relacyjnymi. W modelu wielowymiarowym dane są mode-lowane jako seria kostek i wymiarów, a nie tabel. Na każdą kostkę składa się jedna lub więcej grupa miar, zaś każda grupa miar jest kostką odwzorowaną na jedną tablicę fak-tów w hurtowni danych. Grupa miar zawiera jedną lub więcej miar, zaś miary są bar-dzo podobne do miar w modelu tabelarycznym. Kostka ma dwa lub więcej wymiarów: jeden specjalny wymiar, wymiar miar, który zawiera wszystkie miary z każdej grupy miar oraz różne inne wymiary, takie jak czas, produkt, położenie geografi czne, klient i tak dalej, które mają odwzorowanie w wymiarach logicznych w modelu wymiaro-wym. Każdy z wymiarów niebędący miarą składa się z jednego lub więcej atrybutów (na przykład w wymiarze Data mogą być to takie atrybuty, jak Dzień, Miesiąc i Rok), zaś atrybuty te mogą być z kolei używane w jednopoziomowych hierarchiach lub tworzyć wielowymiarowe hierarchie użytkownika. Hierarchię można stosować przy budowa-niu zapytań. Użytkownicy rozpoczynają od analizy danych na wysoce zagregowanym poziomie, jak poziom roku w wymiarze czasu, a potem mogą przechodzić na niższe poziomy, jak kwartały, miesiące i dni, aby zobaczyć trendy i interesujące anomalie.
Ponieważ model wielowymiarowy jest bezpośrednim następcą poprzednich wersji Analysis Services, zgodnie z oczekiwaniami obejmuje on bogaty i dojrzały zestaw funk-cji reprezentujący owoce ponad dekady rozwoju, choć niektóre z tych funkcji używane są niezbyt często. Większość funkcji dostępnych w modelu tabelarycznym istnieje tak-że w modelu wielowymiarowym, lecz model wielowymiarowy ma także wiele funkcji, które nie zostały jeszcze zaimplementowane w modelu tabelarycznym. Szczegółowe porównanie funkcji w obu modelach znajduje się w dalszej części rozdziału.
W modelu wielowymiarowym można przechowywać dane na trzy sposoby:
■ OLAP wielowymiarowy (Multidimensional OLAP, MOLAP), gdzie dane są przecho-wywane we własnym formacie Analysis Services opartym na pamięci dyskowej.
##7#52#aSUZPUk1BVC1WaXJ0dWFsbw==

Architektura Analysis Services 2012: jeden produkt, dwa modele 11
■ OLAP relacyjny (Relational OLAP, ROLAP), gdzie Analysis Services działa jak war-stwa metadanych i żadne dane nie są przechowywane w samej usłudze Analysis Services; gdy zapytania kierowane są do kostki, zapytania SQL są uruchamiane względem źródłowej relacyjnej bazy danych.
■ OLAP hybrydowy (Hybrid OLAP, HOLAP), który jest taki sam jak ROLAP, ale zawie-ra trochę wcześniej zagregowanych wartości zapisanych w MOLAP.
Pamięć MOLAP jest używana w przeważającej większości implementacji, choć czasem, gdy potrzebne jest tak zwane BI czasu rzeczywistego, używana jest pamięć ROLAP. Pamięć HOLAP prawie nigdy nie jest używana.
Obszarem, w którym modele wielowymiarowy i tabelaryczny różnią się, są obsłu-giwane języki zapytań i obliczeń. Podstawowym językiem modelu wielowymiarowego jest MDX i tylko w nim można defi niować zapytania i obliczenia. Język MDX odniósł sukces i jest obsługiwany przez wiele narzędzi klienckich Analysis Services innych producentów. Był on także promowany jako pół otwarty standard przez grono pro-ducenckie pod nazwą XMLA Council (teraz w zasadzie niedziałające), a w rezulta-cie został także przyjęty przez wiele innych narzędzi OLAP, które są bezpośrednimi konkurentami Analysis Services. Jednak problemem MDX jest to, co stanowi ogólnie problem wielu użytkowników z modelem wielowymiarowym: choć ma on wielkie możliwości, wielu specjalistów BI miało trudności z nauczeniem się go, gdyż używane w nim pojęcia, takie jak wymiary i hierarchie, znacznie różnią się od tych, do których przyzwyczaił nas język SQL.
Ponadto fi rma Microsoft publicznie zobowiązała się (w swoim poście na blogu zespołu Analysis Services i w innych ogłoszeniach publicznych, http://blogs.msdn.com/b/analysisservices/archive/2011/05/16/analysis-services-vision-amp-roadmap-update.aspx), że w modelu wielowymiarowym będzie można obsługiwać zapytania DAX po wdro-żeniu Analysis Services 2012, jako część pakietu serwisowego. Pozwoli to, aby Power View tworzył zapytania dla modeli wielowymiarowych i modeli tabelarycznych, choć prawdopodobnie będzie trzeba przyjąć pewne kompromisy, a niektóre z funkcji mode-lu wielowymiarowego mogą nie działać zgodnie z oczekiwaniami, gdy będziemy uży-wać zapytań DAX.
Po co są dwa modele?Dlaczego nastąpił ten podział? Choć fi rma Microsoft nie komentuje tej sprawy pub-licznie, istnieje wiele prawdopodobnych powodów.
■ Wielowymiarowa wersja Analysis Services starzeje się. Została zaprojektowana w erze 32-bitowych serwerów z jednym lub dwoma procesorami i pamięci RAM mniejszej od 1 GB, zaś pamięć na dyskach stanowiła dla baz danych tylko jed-ną z opcji. Czasy się zmieniły, a nowy sprzęt uległ radykalnej zmianie. Nowa generacja kolumnowych baz danych opartych na pamięci ustanowiła standard
##7#52#aSUZPUk1BVC1WaXJ0dWFsbw==

12 Rozdział 1: Wprowadzenie do modelu tabelarycznego
dla wydajności zapytań z analitycznymi zadaniami, więc Analysis Services musi się dostosować do nowej technologii. Wsteczne upakowanie nowego pamięcio-wego mechanizmu xVelocity do istniejącego modelu wielowymiarowego nie jest prostym zadaniem, więc konieczne stało się wprowadzenie nowego modelu tabe-larycznego, który w pełni wykorzysta mechanizm xVelocity.
■ Pomimo sukcesu wielowymiarowych Analysis Services, panowała opinia, że trud-no się go nauczyć. Niektórzy specjaliści od baz danych, przyzwyczajeni do relacyj-nego modelowania baz danych, mieli trudności z opanowaniem koncepcji wielo-wymiarowych, zaś ci, którzy je opanowali, stwierdzali, że droga nauki jest trudna. Jeśli więc Microsoft chce dotrzeć z BI do szerszej publiczności, musi uprościć proces tworzenia – stąd przejście od złożonego świata modelu wielowymiarowego do względnie prostych i znanych koncepcji modelu tabelarycznego.
■ Firma Microsoft postrzega samoobsługową BI jako potencjalne źródło znacznego wzrostu, zaś PowerPivot stanowi jej wejście na rynek. Jest istotne, aby zacho-wać spójność między narzędziami samoobsługowymi i korporacyjnymi fi rmy. Jeśli więc usługi Analysis Services muszą zostać zmodernizowane, powinny być kompatybilne z PowerPivot, zapewniając podobne zasady projektowania, aby modele samoobsługowe mogły być łatwo zaktualizowane do pełnych rozwiązań korporacyjnych.
■ Niektóre typy danych są modelowane w bardziej odpowiedni i prostszy sposób za pomocą podejścia tabelarycznego, a innym typom danych bardziej odpowia-da podejście wielowymiarowe. Dwa oddzielne modele dają programistom wybór takiego podejścia, które lepiej pasuje do ich potrzeb w danych okolicznościach.
Czym jest model semantyczny BI?Jednym z terminów przewijających się przy omawianiu Analysis Services 2012 jest semantyczny model BI (BISM, BI Semantic Model). Ten termin nie odnosi się ani do modelu wielowymiarowego, ani do tabelarycznego, lecz opisuje działanie Analysis Services w zestawie Microsoft BI: działa on jako warstwa semantyczna leżąca ponad relacyjną hurtownią danych, dodając bogatą warstwę metadanych obejmującą hierarchie, miary i obliczenia. W tym zakresie model ten jest bardzo podobny do modelu UDM (Unifi ed Dimensional Model), który był używany w czasach wprowadzania SQL Server 2005. W niektórych przypadkach określe-nie semantyczny model BI odnosiło się tylko do modelu tabelarycznego, ale nie jest to właściwe. Ponieważ ta książka jest poświęcona przede wszystkim modelo-wi tabelarycznemu, nie będziemy często używać tego terminu, jednak uważamy, że trzeba dokładnie rozumieć, czym on jest i jak powinien być używany.
##7#52#aSUZPUk1BVC1WaXJ0dWFsbw==

Wybór odpowiedniego modelu dla naszego projektu 13
Przyszłość Analysis ServicesFakt, że wewnątrz Analysis Services istnieją dwa modele oraz dwa języki zapytań i obliczeń, nie jest idealną sytuacją. Przede wszystkim oznacza to, że rozpoczynając projekt musimy wybrać, którego modelu będziemy używać, a wtedy możemy mieć za mało danych, aby wiedzieć, który z nich jest odpowiedni – to jest zagadnienie, które jest omawiane w następnym punkcie. Oznacza to także, że każdy, kto zdecyduje się specjalizować w Analysis Services, musi nauczyć się dwóch technologii. Taki stan rzeczy zapewne nie będzie trwał długo.
Firma Microsoft jasno twierdzi, że model wielowymiarowy nie jest deprecjonowany, zaś model tabelaryczny nie ma go zastąpić. Możliwe, że w kolejnych wersjach Analy-sis Services pojawią się nowe funkcje przeznaczone dla modelu wielowymiarowego. Fakt, że modele tabelaryczny i wielowymiarowy mają wspólną część kodu sugeruje, że niektóre funkcje mogą być z łatwością rozwijane jednocześnie dla obu modeli. Post na blogu Analysis Services sugerował wcześniej, że z czasem oba modele zbliżą się do siebie i będą oferować te same funkcje, więc decyzje co do używanego modelu będą oparte na tym, czy deweloper woli modelowanie wielowymiarowe, czy też relacyjne. Krokiem w tym kierunku będzie moment, gdy w modelu wielowymiarowym stanie się dostępna obsługa zapytań DAX.
Jeszcze jedna kwestia związana z przyszłością Analysis Services jest jasna: usługi te będą przenoszone na chmury. Wprawdzie w chwili pisania tej książki do publicznej wiadomości nie podano żadnych szczegółów, fi rma Microsoft potwierdziła, że pracuje na wersji Analysis Services opartej na chmurze, zaś wersja ta wraz z SQL Azure, SQL Azure Reporting Services oraz Offi ce 365 będą stanowić jądro strategii BI fi rmy.
Wybór odpowiedniego modelu dla naszego projektuMoże wydawać się dziwne, że w tym miejscu książki zajmujemy się tematem, czy model tabelaryczny jest odpowiedni dla naszego projektu, choć nic jeszcze nie wiemy o samym modelu, ale na takie pytanie trzeba sobie odpowiedzieć na podobnie wczes-nym etapie naszego projektu BI. Z grubsza można stwierdzić, że dla 60-70 procent projektów każdy z modeli działa podobnie, ale dla pozostałych 30-40 procent prawid-łowy wybór modelu jest bardzo ważny.
Jak wcześniej napisano, po rozpoczęciu prac z jednym modelem w ramach Analysis Services nie ma możliwości przejścia na drugi i trzeba zacząć wszystko od począt-ku, marnując wiele cennego czasu, więc dokonanie prawidłowej decyzji powinno nastąpić możliwie wcześnie. Podczas podejmowania decyzji trzeba wziąć pod uwagę wiele czynników. W tej części omawiamy wszystkie elementy na rozsądnym poziomie szczegółowości. Można mieć w pamięci te czynniki podczas czytania dalszych części książki, zaś po jej zakończeniu będziemy wiedzieć, czy mamy korzystać z modelu tabelarycznego czy wielowymiarowego.
##7#52#aSUZPUk1BVC1WaXJ0dWFsbw==

14 Rozdział 1: Wprowadzenie do modelu tabelarycznego
LicencjePakiet Analysis Services 2012 jest dostępny w następujących wersjach: SQL Server Standard, SQL Server Business Intelligence oraz SQL Server Enterprise. W wersji SQL Server Standard dostępny jest jednak tylko model wielowymiarowy, zaś dostępne funk-cje są identyczne jak w poprzednich wersjach Analysis Services. Oznacza to, że kilka ważnych funkcji potrzebnych do skalowania modelu wielowymiarowego, takich jak podział na partycje, jest niedostępnych w wersji SQL Server Standard. Wersja SQL Server Business Intelligence zawiera zarówno model wielowymiarowy, jak i tabelarycz-ny, podobnie jak wersja SQL Server Enterprise. W zakresie funkcji Analysis Services obie wersje są identyczne; jedyną różnicą między tymi wersjami jest fakt, że licencja SQL Server Business Intelligence opiera się na licencji serwerowej plus licencje klien-ckie (CAL, Client Access License), podczas gdy wersja SQL Server Enterprise jest licencjonowana oddzielnie na każdy CPU. (Nie można już uzyskać licencji dla wersji SQL Server Enterprise na serwer plus CAL, jak to było w przeszłości). W wersjach SQL Server Business Intelligence i SQL Server Enterprise oba modele, tabelaryczny i wie-lowymiarowy, zawierają wszystkie dostępne funkcje i mogą korzystać z tylu rdzeni, na ile pozwala system operacyjny.
W rezultacie czasami korzystanie z modelu tabelarycznego może być droższe niż użycie modelu wielowymiarowego, gdyż model wielowymiarowy jest dostępny w wer-sji SQL Server Standard, w przeciwieństwie do modelu tabelarycznego. Przy ograniczo-nym budżecie i znajomości modelu wielowymiarowego, gdy liczba danych nie wymaga z korzystania z takich funkcji, jak partycjonowanie, dla oszczędności sensowny jest wybór modelu wielowymiarowego i wersji SQL Server Standard. Jeśli jednak chcemy zapłacić nieco więcej za wersję SQL Server Business Intelligence lub SQL Server Enter-prise, to przy wyborze modelu nie należy kierować się kosztami licencji.
Aktualizacja poprzednich wersji Analysis ServicesJak już wspomniano, nie ma możliwości przekształcenia modelu wielowymiarowego w model tabelaryczny. Z pewnością na rynku pojawią się narzędzia, które będą obiecy-wać przekształcenie za pomocą kilku kliknięć myszą, ale takie narzędzia mogą działać tylko względem bardzo prostych modeli wielowymiarowych i nie zaoszczędzą nam wiele czasu. Dlatego, jeśli mamy zaawansowaną implementację modelu wielowymia-rowego oraz umiejętności w zakresie jego obsługi, nie ma zapewne sensu porzucania go na rzecz modelu tabelarycznego, o ile nie mamy konkretnych problemów z mode-lem wielowymiarowym, które model tabelaryczny mógłby rozwiązać.
Prostota korzystaniaJeśli z kolei zaczynamy korzystać z Analysis Services 2012 bez żadnego doświadcze-nia z modelem wielowymiarowym lub OLAP, zapewne stwierdzimy, że model tabe-laryczny jest znacznie prostszy do nauki niż model wielowymiarowy. Nie tylko sama
##7#52#aSUZPUk1BVC1WaXJ0dWFsbw==

Wybór odpowiedniego modelu dla naszego projektu 15
koncepcja jest prostsza do zrozumienia, zwłaszcza jeśli korzystaliśmy z relacyjnych baz danych, lecz także proces budowy projektu jest bardziej oczywisty, a do nauczenia się jest znacznie mniej funkcji. Budowa pierwszego modelu tabelarycznego jest znacz-nie szybsza i prostsza niż budowa pierwszego modelu wielowymiarowego. Można też stwierdzić, że łatwiej nauczyć się języka DAX niż języka MDX, zwłaszcza w zakresie podstawowych obliczeń, choć w rzeczywistości oba te języki są tak samo mylące dla osób przyzwyczajonych do SQL.
Kompatybilność z PowerPivotModel tabelaryczny oraz PowerPivot są niemal identyczne, jeśli chodzi o sposób projek-towania; interfejsy użytkownika są w obu przypadkach praktycznie jednakowe, oba też korzystają z języka DAX. Modele PowerPivot mogą być importowane do narzędzi danych SQL Server w celu wygenerowania modelu tabelarycznego, choć procesu tego nie można przeprowadzić w kierunku przeciwnym. Modelu tabelarycznego nie można przekształ-cić na model PowerPivot. Jeśli więc zależy nam na użytkowaniu samoobsługowej BI z wykorzystaniem PowerPivot, sens ma korzystanie z modelu tabelarycznego w naszych korporacyjnych modelach BI, gdyż projekty i kod można między nimi przenosić.
Cechy wydajności zapytańWprawdzie niebezpieczne jest tu generalizowanie na temat wydajności zapytań, ale można stwierdzić, że w modelu tabelarycznym będą w większości przypadków działać nie gorzej niż w wielowymiarowym, zaś przy niektórych określonych scenariuszach będą znacznie lepsze. Na przykład pewne miary obliczeniowe, które są słabością mode-lu wielowymiarowego, działają bardzo dobrze w modelu tabelarycznym. Konkretne dowody także wskazują na to, że zapytania względem szczegółowych raportów (na przykład zapytania zwracające wiele wierszy oraz dane na poziomie tabeli faktów), będą działać w modelu tabelarycznym znacznie lepiej, o ile napiszemy je w języku DAX, a nie w MDX. Niestety przy bardziej skomplikowanych obliczeniach i techni-kach modelowania, jak w relacjach wiele-do-wielu, znacznie trudniej jest stwierdzić, czy lepiej działa model wielowymiarowy, czy tabelaryczny i tylko sprawdzenie kon-cepcji może nam wskazać, czy wydajność danego modelu będzie spełniać wymagania.
Cechy wydajności przetwarzaniaTrudne jest także porównanie wydajności przetwarzania w modelach wielowymiaro-wym i tabelarycznym. W modelu tabelarycznym przetwarzanie dużej tabeli może być znacznie wolniejsze niż dla podobnej grupy miar w modelu wielowymiarowym, gdyż model tabelaryczny nie potrafi przetwarzać równolegle partycji w ramach tej samej tabeli, zaś model wielowymiarowy (pod warunkiem posiadania wersji SQL Server Business Intelligence lub SQL Server Enterprise, które tworzą partycje grup miar) może przetwarzać równolegle partycje w tej samej grupie miar. Odrzucając różne
##7#52#aSUZPUk1BVC1WaXJ0dWFsbw==

16 Rozdział 1: Wprowadzenie do modelu tabelarycznego
działania niekompatybilne, wykonywane przez każdy z modeli podczas przetwarza-nia, jak budowa agregacji i indeksów w modelu wielowymiarowym, liczba wierszy surowych danych, które można przetwarzać na sekundę w jednej partycji, zapewne będzie podobna.
Jednak w zakresie przetwarzania model tabelaryczny ma pewne znaczące zale-ty wobec modelu wielowymiarowego. Po pierwsze, w modelu tabelarycznym nie ma agregacji, co oznacza, że w czasie przetwarzania odpada jedno czasochłonne zada-nie. Po drugie, przetwarzanie jednej tabeli w modelu tabelarycznym nie ma bezpo-średniego wpływu na inne tabele modelu, zaś w modelu wielowymiarowym prze-twarzanie wymiaru ma swoje konsekwencje. Wykonanie całego procesu względem wymiaru w modelu wielowymiarowym oznacza, że trzeba wykonać całe przetwarza-nie na kostkach, w których używany jest ten wymiar, a ponadto nawet aktualizacja wymiaru wymaga procesu indeksowania na kostce, aby przebudować agregacje. Oba te elementy przyprawiają o ból głowy przy dużych wdrożeniach wielowymiarowych, zwłaszcza gdy mamy dostępne niewielkie okno przetwarzania.
Uwarunkowania sprzętoweModele wielowymiarowy i tabelaryczny mają także bardzo różne wymagania sprzęto-we. Pamięć dyskowa modelu wielowymiarowego oznacza, że ważne są dyski o dużej wydajności i o bardzo dużej pojemności. Potrzebna jest także pamięć podręczna, więc korzystne jest posiadanie odpowiedniej pamięci RAM, choć nie jest to wymóg koniecz-ny. W modelu tabelarycznym wydajność pamięci dyskowej nie jest priorytetowa, gdyż baza danych przechowywana jest w pamięci. Dlatego ważne jest posiadanie pamięci RAM wystarczającej do przechowywania bazy danych i do obsługi szczytów wykorzy-stania pamięci, które mają miejsce podczas realizacji zapytań lub przetwarzania danych.
Wymagania dyskowe modelu wielowymiarowego będą zapewne łatwiejsze do zaspo-kojenia niż zapotrzebowanie na pamięć modelu tabelarycznego. Zakup dużych pamięci dyskowych dla serwera jest stosunkowo tani i prosty dla działu IT. Wiele fi rm ma sie-ciowe obszary pamięci (SAN), które może nie dają znacznej wydajności, ale pozwalają łatwo zapewnić odpowiednią pojemność pamięci (lub zwiększać ją). Natomiast zakup dużych ilości pamięci RAM dla serwera może być trudny – wymaganie pół terabajta pamięci RAM dla serwera powoduje zdziwienie. Ponadto, jeśli okaże się, że potrze-bujemy więcej pamięci RAM niż przewidywano na początku, zwiększenie dostęp-nej ilości może być kłopotliwie. Z doświadczenia wiadomo, że można zacząć pracę z pojemnością pamięci RAM, która wydaje się rozsądna, ale wraz z rozbudową tabeli faktów, dodawaniem nowych danych do modelu i coraz bardziej skomplikowanymi zapytaniami, można zacząć napotykać błędy braku pamięci. Ponadto w przypadku niektórych bardzo wielkich, obejmujących kilka terabajtów danych implementacji Analysis Services, zakup serwera z pamięcią wystarczającą na przechowywanie mode-lu może okazać się niemożliwy, a wtedy model wielowymiarowy będzie jedyną opcją możliwą do realizacji.
##7#52#aSUZPUk1BVC1WaXJ0dWFsbw==

Wybór odpowiedniego modelu dla naszego projektu 17
BI czasu rzeczywistegoTemat nie jest już tak popularny jak kilka lat temu, ale wymagania dotyczące czasu rze-czywistego lub warunków bliskich czasowi rzeczywistemu mogą w projektach BI stać się coraz częstsze. BI czasu rzeczywistego odnosi się zwykle do potrzeby użytkowni-ków końcowych, aby zapytania i analiza danych były możliwe natychmiast po załado-waniu danych do hurtowni danych, bez długiego oczekiwania na załadowanie danych do Analysis Services.
Model wielowymiarowy może obsłużyć ten problem na jeden z dwóch sposobów: przez wykorzystanie pamięci MOLAP i podział danych tak, aby wszystkie nowe dane w hurtowni danych wędrowały do jednej, stosunkowo niewielkiej partycji, którą moż-na szybko przetwarzać, lub poprzez wykorzystanie pamięci ROLAP i wyłączenie stoso-wania pamięci podręcznej, aby model wielowymiarowy wydawał zapytania SQL przy każdym przekazaniu zapytania. Pierwsza z tych opcji jest zwykle preferowana, choć może być trudna do implementacji, zwłaszcza gdy tabele wymiarów i tabele faktów ulegają zmianie. Aktualizacja danych w wymiarze może być powolna i wymagać prze-budowy agregacji. Pamięć ROLAP w modelu wielowymiarowym może często – w przy-padku dużych ilości danych – powodować niską wydajność, więc czas na realizację zapytania w trybie ROLAP może być dłuższy niż czas do ponownego przetworzenia partycji MOLAP w pierwszej z opcji.
Model tabelaryczny oferuje w zasadzie te same dwie opcje, ale mają one mniej wad niż ich odpowiedniki w modelu wielowymiarowym. Jeśli dane są przechowywane w mechanizmie pamięci xVelocity, aktualizacja danych w jednej tabeli nie ma wpły-wu na dane w pozostałych tabelach, więc czasy przetwarzania mogą być szybsze, zaś implementacja znacznie prostsza. Jeśli dane mają pozostać w mechanizmie relacyjnym, to podstawową różnicę stanowi oczekiwanie, że odpowiednik trybu ROLAP, określany jako DirectQuery, będzie działał znacznie lepiej niż ROLAP. Jest tak dlatego, że w trybie DirectQuery usługi Analysis Services próbują przenieść całe przetwarzanie zapytań z powrotem do relacyjnej bazy danych przez translację całego otrzymanego zapytania na zapytanie SQL. (Wielowymiarowy tryb ROLAP tego nie robi; przekłada niektóre wewnętrzne działania na zapytania SQL, ale część działań, takich jak wykonywanie obliczeń, wykonuje sam). Jednak DirectQuery ma także szereg ograniczeń: w trybie DirectQuery akceptuje tylko zapytania DAX, a nie MDX, co oznacza, że na przykład użytkownicy Excela nie mogą zobaczyć danych czasu rzeczywistego, gdyż Excel gene-ruje jedynie zapytania MDX; jako źródło danych obsługiwany jest tylko SQL Server; zabezpieczenie danych musi być implementowane na serwerze SQL Server, a nie może być implementowane w Analysis Services; wreszcie ani obliczone kolumny, ani wiele popularnych funkcji DAX nie jest obsługiwanych, więc można korzystać tylko z mode-li z bardzo prostymi obliczeniami DAX. Pełny opis konfi guracji trybu DirectQuery podano w rozdziale 9, „Narzędzia xVelocity i DirectQuery”.
##7#52#aSUZPUk1BVC1WaXJ0dWFsbw==

18 Rozdział 1: Wprowadzenie do modelu tabelarycznego
Narzędzia klienckieW wielu przypadkach sukces lub porażka projektu BI zależy od jakości narzędzi uży-wanych przez użytkowników końcowych do analizy dostarczanych danych. Dlatego ważna jest odpowiedź na pytanie, jakie narzędzia klienckie obsługuje każdy z modeli.
Zarówno model tabelaryczny, jak i wielowymiarowy, obsługują zapytania MDX, więc teoretycznie narzędzia klienckie Analysis Services powinny obsługiwać oba modele. Jednak w praktyce, choć niektóre narzędzia klienckie, takie jak Excel i SQL Server Reporting Services, działają tak samo dobrze w obu przypadkach, może być konieczna aktualizacja niektórych narzędzi klienckich innych dostawców, zaś nadal stosowane niektóre starsze narzędzia mogą w ogóle nie działać poprawnie.
W czasie gdy ta książka była pisana, tylko model tabelaryczny obsługiwał zapytania DAX, choć ich obsługa przez model wielowymiarowy była obiecywana w przyszłości w modelu wielowymiarowym. Oznacza to, że przynajmniej na początku Power View – nowe promowane przez Microsoft narzędzie wizualizacji danych – będzie działać tylko w modelach tabelarycznych. Nawet gdy obsługa języka DAX w modelach wielowymia-rowych zostanie wprowadzona, zapewne funkcje Power View nie będą tam działać, podobnie jak nie wszystkie funkcje modelu wielowymiarowego będą działać zgodnie z oczekiwaniami przy obsłudze zapytań za pomocą DAX.
Porównanie funkcjiKolejną sprawą do rozważenia przy wyborze modelu są funkcje dostępne w mode-lu wielowymiarowym, które nie mają odpowiedników w modelu tabelarycznym lub są tylko w nim częściowo implementowane. Jednak nie wszystkie funkcje są waż-ne przy wszystkich projektach, więc trzeba stwierdzić, że w wielu scenariuszach w modelu tabelarycznym można przybliżyć niektóre funkcje modelu wielowymiaro-wego za pomocą sprytnego wykorzystania DAX w obliczanych kolumnach i miarach. W każdym przypadku, jeśli nie mamy doświadczenia z modelem wielowymiarowym, nie będzie nam brakować funkcji, z których nigdy nie korzystaliśmy.
Oto lista najważniejszych funkcji, których brak w modelu tabelarycznym:
■ Zapis zwrotny, możliwość zapisania przez użytkownika końcowego wartości do wielowymiarowej bazy danych. Może to być na przykład bardzo istotne w apli-kacjach fi nansowych, gdzie użytkownik wprowadza dane budżetowe.
■ Translacje, w których metadane modelu wielowymiarowego mogą pojawiać się w różnych językach u użytkowników korzystających z wersji lokalnych na swoich komputerach osobistych.
■ Bezpieczeństwo miar w wymiarze, czyli funkcjonalność pozwalająca nadawać lub odbierać prawa do dostępu do pojedynczej miary.
■ Bezpieczeństwo komórek, dzięki któremu można nadać lub odebrać prawo do dostępu do pojedynczych komórek. Nie ma możliwości implementacji takiej
##7#52#aSUZPUk1BVC1WaXJ0dWFsbw==

Wybór odpowiedniego modelu dla naszego projektu 19
funkcjonalności w modelu tabelarycznym, ale funkcja ta używana jest rzadko w modelu wielowymiarowym.
■ Zmienne hierarchie, często używana technika zapobiegająca korzystaniu z hierar-chii dziecko/rodzic. W modelu wielowymiarowym hierarchia użytkownika może się upodobnić do hierarchii rodzic/dziecko poprzez ukrycie jej elementów w razie spełnienia pewnych warunków; na przykład, gdy element ma taka samą nazwę jak jego rodzic. Jest to określane jako zmienna hierarchia. W modelu tabelarycznym nie ma niczego podobnego.
■ Wymiary pełniące rolę są raz tworzone i przetwarzane, a potem pojawiają się wiele razy w tym samym modelu pod różnymi nazwami i w różnych relacjach z grupami miar. W modelu wielowymiarowym są to wymiary pełniące rolę. Podobna konstrukcja jest możliwa w modelu tabelarycznym, dzięki czemu moż-na tworzyć wiele relacji między dwiema tabelami (patrz rozdział 3, „Ładowanie danych w modelu tabelarycznym”), ale choć funkcja jest bardzo użyteczna, nie wykonuje dokładnie tego samego zadania jak wymiar pełniący rolę. Jeśli w modelu tabelarycznym chcemy zobaczyć tę samą tabelę w dwóch miejscach jednocześnie, musimy ją dwukrotnie załadować, co wydłuża czas wykonania i utrudnia utrzy-manie bazy.
■ Przypisania w zakresach oraz działania jednoargumentowe to funkcje zaawan-sowanych obliczeń, dostępne w MDX w modelu wielowymiarowym, ale niemoż-liwe lub bardzo trudne do odtworzenia w języku DAX w modelu tabelarycznym. Te rodzaje obliczeń są często stosowane w aplikacjach fi nansowych, więc to i brak zapisu zwrotnego oraz rzeczywistej hierarchii rodzic/dziecko oznacza, że model tabelaryczny nie jest odpowiedni dla tego typu zastosowań.
Wymienione poniższej funkcje są w modelu tabelarycznym obsługiwane tylko częściowo:
■ Obsługa hierarchii rodzic/dziecko jest w modelu wielowymiarowym specjal-nym typem hierarchii zbudowanym na podstawie tabeli wymiaru z samopołącze-niem, dzięki któremu każdy wiersz tabeli reprezentuje jeden element hierarchii i ma połączenie z innym wierszem reprezentującym jego element rodzicielski w hierarchii. Hierarchie rodzic/dziecko mają w modelu wielowymiarowym wiele ograniczeń i mogą powodować problemy z wydajnością zapytań. Jednak są bardzo wygodne do modelowania hierarchii, takich jak struktury organizacyjne w przed-siębiorstwie, gdyż deweloper nie musi podczas projektowania znać maksymal-nej głębokości hierarchii. Model tabelaryczny implementuje podobną funkcję za pomocą funkcji języka DAX, takich jak PATH (patrz szczegóły w rozdziale 9), ale niestety deweloper musi zdecydować o maksymalnej głębokości hierarchii w czasie projektowania.
##7#52#aSUZPUk1BVC1WaXJ0dWFsbw==

20 Rozdział 1: Wprowadzenie do modelu tabelarycznego
■ Obsługa relacji wiele-do-wielu w modelu wielowymiarowym jest jedną z naj-ważniejszych funkcji i jest stale wykorzystywana. (Niektóre zastosowania moż-na znaleźć w materiałach w witrynie http://www.sqlbi.com/articles/many2many/). W modelu tabelarycznym można odtworzyć tę funkcję za pomocą DAX, co opi-sano w rozdziale 12, „Korzystanie z zaawansowanych relacji w modelu tabelarycz-nym”, ale choć przy tym podejściu wydajność zapytań może być tak dobra jak w modelu wielowymiarowym, powoduje to znaczną komplikację budowy wyra-żeń DAX używanych w miarach. Jeśli model zawiera wiele relacji wiele-do-wielu lub powiązane relacje wiele-do-wielu, ta dodatkowa złożoność może oznaczać, że utrzymanie wyrażeń DAX używanych w miarach jest niezwykle trudne.
■ Szczegółowe przeglądanie (drillthrough) – funkcja, dzięki której użytkownik może kliknąć komórkę, aby zobaczyć wszystkie szczegółowe dane, które zagre-gowano, aby otrzymać daną wartość. Funkcja ta jest obsługiwana w obu mode-lach, ale w modelu wielowymiarowym można określić, które kolumny z których wymiarów i grup miar są dzięki niej podawane. W modelu tabelarycznym nie ma interfejsu w narzędziach danych SQL Server, który by na to pozwolił, więc funkcja szczegółowego przeglądania podaje domyślnie każdą kolumnę z tabeli, na której się oparto. Można jednak ręcznie dokonać edycji defi nicji XMLA swego modelu, jak opisano to w poście na blogu pod adresem: http://sqlblog.com/blogs/marco_russo/archive/2011/08/18/drillthrough-for-bism-tabular-and-attribute-keys-in--ssas-denali.aspx. Interfejs użytkownika do automatyzacji procesu edycji jest także dostępny w dodatku BIDS Helper (http://bidshelper.codeplex.com/).
PodsumowanieW tym rozdziale zobaczyliśmy, czym są modele tabelaryczny i wielowymiarowy w Analysis Services 2012, jakie są ich zalety i wady oraz jak należy ich używać. Kluczowym elementem do zapamiętania jest fakt, że bardzo się one różnią – w zasadzie są to oddzielne produkty – i nie należy podejmować decyzji o korzystaniu z mode-lu tabelarycznego w projekcie bez sprawdzenia, czy dobrze pasuje on do naszych wymagań. W następnym rozdziale postawimy pierwsze kroki przy budowie modeli tabelarycznych.
##7#52#aSUZPUk1BVC1WaXJ0dWFsbw==

21
ROZDZIAŁ 2
Rozpoczęcie pracy w modelu tabelarycznym
Po wstępnym zaprezentowaniu funkcji zestawu Microsoft Business Intelligence (BI), Analysis Services 2012 i modelu tabelarycznego, w tym rozdziale pokażemy, jak
rozpocząć tworzenie projektu. Poznamy sposób instalacji Analysis Services, zasady pracy z projektami z użyciem narzędzi SQL Server Data Tools, podstawowe moduły modelu tabelarycznego oraz jak tworzyć i wdrażać bardzo prosty model tabelaryczny oraz jak wykonywać w nim zapytania.
Określenie środowiska deweloperskiegoPrzed rozpoczęciem pracy z modelem tabelarycznym trzeba określić swoje środowisko deweloperskie.
Komponenty środowiska deweloperskiegoŚrodowisko deweloperskie ma trzy komponenty logiczne: deweloperska stacja robo-cza, serwer obszaru roboczego oraz serwer deweloperski. Każdy z tych komponentów można zainstalować na jednym komputerze lub na oddzielnych jednostkach. Każdy komponent pełni swoją rolę i musimy te role dobrze zrozumieć.
Deweloperska stacja robocza
Model tabelaryczny będziemy implementować na stacji roboczej. Jak wiemy, modele tabelaryczne są projektowane przy użyciu narzędzi SQL Server Data Tools (wcześ-niej noszących nazwę BI Development Studio, czyli BIDS); jest to Visual Studio 2010 plus kilka szablonów projektów związanych z SQL Server. Nie jest potrzebna oddzielna licencja na Visual Studio, więc można w pełni zainstalować SQL Server Data Tools za pomocą instalatora SQL Server. Jeśli mamy licencję na pełną wersję Visual Studio 2010 do wykonywania prac w środowisku .NET lub innym, wtedy szablo-ny projektów SQL Server pojawią się jako dodatkowe opcje w oknie dialogowym nowego projektu.
Po zakończeniu projektowania naszego modelu tabelarycznego za pomocą SQL Ser-ver Data Tools (SSDT) trzeba zbudować i wdrożyć nasz projekt. Budowa projektu przypomina kompilację kodu: w procesie budowy następuje translacja wszystkich
##7#52#aSUZPUk1BVC1WaXJ0dWFsbw==

22 Rozdział 2: Rozpoczęcie pracy w modelu tabelarycznym
informacji zapisanych w plikach projektu na język defi nicji danych zwany XML for Ana-lysis (XMLA). Wdrożenie obejmuje wówczas wykonanie pliku XMLA w ramach tabe-larycznej instancji Analysis Services, działającej na naszym serwerze wdrożeniowym. Wynikiem będzie albo utworzenie nowej bazy danych, albo zmiana w bazie istniejącej.
Serwer deweloperski
Serwer deweloperski to serwer z zainstalowaną instancją usług Analysis Services dzia-łających w trybie tabelarycznym, którego można używać do przechowywania swoich modeli podczas ich tworzenia. Projekt wdrażamy na serwerze deweloperskim ze swojej stacji roboczej. Serwer powinien znajdować się w tej samej domenie co stacja robocza wdrażania projektu. Po wdrożeniu projektu na serwerze, my i każda osoba przez nas upoważniona możemy widzieć swój model tabelaryczny i wysyłać do niego zapytania. Jest to szczególnie ważne dla innych członków naszego zespołu, którzy tworzą raporty lub inne fragmenty naszego rozwiązania BI.
Nasza stacja robocza i serwer, związane z tworzeniem projektu, mogą znajdować się na oddzielnych komputerach lub obie funkcje może spełniać jeden komputer. Z wielu powodów jest jednak lepiej, żeby funkcję serwera deweloperskiego spełniała oddzielna, dedykowana jednostka.
■ Prawdopodobnie dedykowany serwer będzie miał znacznie lepsze parametry niż stacja robocza, zaś – jak wkrótce zobaczymy – w szczególności ilość dostępnej pamięci jest bardzo ważna podczas tworzenia modelu tabelarycznego. Wymagania dotyczące pamięci oznaczają, że istotne jest stosowanie systemu 64-bitowego, zaś stacja robocza może mieć nadal zainstalowaną 32-bitową wersję systemu Windows, choć dla serwerów wersja 64-bitowa jest dziś standardem.
■ Korzystanie z oddzielnego serwera ułatwi także przydzielanie innym dewelope-rom, testerom i użytkownikom praw dostępu do naszych modeli tabelarycznych jeszcze w trakcie pracy nad nim. Umożliwia im to uruchamianie własnych zapytań i budowanie raportów bez przeszkadzania nam; niektóre zapytania mogą wymagać wielu zasobów, a nie chcielibyśmy, aby nasza stacja robocza zaczęła się niespodzie-wanie zacinać, gdy ktoś uruchomi duże zapytanie. Ponadto oczywiście nikt nie będzie w stanie uruchomić zapytania na naszej stacji roboczej, gdy ją wyłączymy i pójdziemy do domu.
■ Dedykowany serwer umożliwi nam także zmiany modeli podczas wykonywania innej pracy. Tak jak w poprzednim punkcie, przetwarzanie dużego modelu wyma-ga wielu zasobów i może trwać kilka godzin. Próba wykonywania tego na własnej stacji roboczej może uniemożliwić nam jakąkolwiek inną pracę.
■ Dedykowany serwer deweloperski będzie miał zapewne regularnie wykonywaną kopię zapasową, co zmniejszy prawdopodobieństwo utraty wyników naszej pracy w przypadku awarii sprzętowej.
##7#52#aSUZPUk1BVC1WaXJ0dWFsbw==

Określenie środowiska deweloperskiego 23
Pracę bez dedykowanego serwera deweloperskiego można rozważać tylko w przypad-ku, jeśli brakuje nam sprzętu lub gdy nie pracujemy nad ofi cjalnym projektem, lecz sprawdzamy model tabelaryczny lub dokonujemy instalacji w celu kształcenia się.
Serwer bazy danych obszaru roboczego
Jednym ze sposobów, w jaki model tabelaryczny ułatwia nam pracę, jest podejście WYSIWYG (dostajesz to, co widzisz), więc przy każdej zmianie modelu ma ona natychmiast swoje odbicie w danych, które widzimy w SSDT, bez konieczności zapi-sywania lub wdrażania czegokolwiek. Jest to możliwe, gdyż SSDT ma swoją własną, prywatną tabelaryczną bazę danych, określaną jako baza danych obszaru roboczego, w której może automatycznie dokonać wdrożenia przy każdej wprowadzonej zmianie. Można traktować tę bazę danych jak rodzaj bazy danych na czas trwania prac.
Ważne jest, aby nie pomylić bazy danych obszaru roboczego z tworzoną bazą danych. Tworzoną bazę danych można współdzielić z całym zespołem deweloperskim i można ją aktualizować raz, dwa razy dziennie. Natomiast baza obszaru roboczego nie powinna być nigdy przeszukiwana ani zmieniania inaczej niż przez używaną przez nas instancję SSDT. Choć tworzona baza danych może nie zawierać wszystkich danych, które docelowo będą używane w wersji produkcyjnej, ale będzie miała reprezenta-tywną próbkę i tak dość sporych rozmiarów. Baza danych obszaru roboczego musi być bardzo często zmieniana i może zawierać tylko niewielką ilość danych. Wreszcie, jak już wiemy, istnieje wiele powodów, dla których tworzona baza danych powin-na znajdować się na oddzielnym serwerze; natomiast jest kilka istotnych powodów, dla których serwer bazy danych obszaru roboczego powinien być umieszczony na tej samej maszynie, na której tworzymy bazę.
LicencjeWszystkie instalacje w środowisku tworzenia projektu muszą korzystać z wersji SQL Server Developer Edition. Wersja ta ma wszystkie funkcje wersji Enterprise Edition, ale kosztuje znacznie mniej. Jedyną niedogodnością takiej licencji jest to, że nie można z niej korzystać na serwerze produkcyjnym.
Proces instalacjiNauczymy się teraz, jak instalować różne komponenty środowiska deweloperskiego.
Instalacja deweloperskiej stacji roboczej
Na deweloperskiej stacji roboczej trzeba zainstalować następujące aplikacje: SQL Server Data Tools i SQL Server Management Studio; dokumentację SQL Server; system kon-troli źródeł oraz inne użyteczne narzędzia deweloperskie, takie jak BIDS Helper.
##7#52#aSUZPUk1BVC1WaXJ0dWFsbw==

24 Rozdział 2: Rozpoczęcie pracy w modelu tabelarycznym
Deweloperskie narzędzia instalacyjne Potrzebne komponenty można zainstalować na deweloperskiej stacji roboczej z poziomu instalatora SQL Server w opisany niżej sposób:
1. Logujemy się jako użytkownik z uprawnieniami administracyjnymi.
2. Klikamy dwukrotnie SETUP.EXE, aby uruchomić SQL Server Installation Center.
3. Klikamy Installation w menu z lewej strony okna, jak pokazano na rysunku 2-1.
RYSUNEK 2-1 Strona SQL Server Installation Center
4. Klikamy pierwszą opcję po prawej stronie, New SQL Server Stand-Alone Installation Or Add Features To An Existing Installation (Nowa niezależna insta-lacja SQL Server lub dodatki do istniejącej instalacji).
Kreator sprawdza zasady SQL Server Support Rules, aby stwierdzić, czy pliki pomocnicze można bez przeszkód zainstalować.
5. Jeśli wszystkie testy zakończą się pozytywnie, klikamy OK.
Kreator sprawdza, czy są aktualizacje SQL Server, takie jak pakiety serwisowe, które chcielibyśmy zainstalować.
6. Zakładamy, że nie ma żadnych dodatków, więc klikamy Next (Dalej), a pliki kon-fi guracji zostaną zainstalowane.
##7#52#aSUZPUk1BVC1WaXJ0dWFsbw==

Określenie środowiska deweloperskiego 25
Kreator sprawdza Setup Support Rules (Zasady obsługi instalacji), jak pokazano na rysunku 2-2, aby sprawdzić, czy nie występują błędy, które mogłyby spowo-dować niepowodzenie instalacji. Problemy trzeba rozwiązać, zanim instalacja się rozpocznie. Ostrzeżenia, które widać na rysunku 2-2 jako elementy oznaczone trójkątami, można zignorować, jeśli uważamy je za bez znaczenia.
7. Klikamy Next, aby kontynuować.
RYSUNEK 2-2 Strona zasad instalacji Setup Support Rules
8. Na stronie Installation Type (Typ instalacji) wybieramy przycisk Perform A New Installation Of SQL Server 2012 (Wykonaj nową instalację SQL Server 2012), a następnie klikamy Next.
9. Na stronie Product Key (Klucz produktu), wybieramy Enter A Product Key (Wprowadź klucz produktu) i podajemy klucz do naszej licencji SQL Server Developer Edition.
10. Na stronie License Terms (Warunki licencji) zaznaczamy pole wyboru I Accept The License Terms (Akceptuję warunki licencji), a następnie klikamy Next.
11. Na stronie Setup Role (Ustawienia roli), wybieramy przycisk opcji SQL Server Feature Installation (Instalacja funkcji SQL Server), a następnie klikamy Next.
12. Na stronie Feature Selection (Wybór funkcji), zaznaczamy pola wyboru dla SSDT, Documentation Components, Management Tools – Basic oraz Management Tools – Complete, jak widać na rysunku 2-3.
##7#52#aSUZPUk1BVC1WaXJ0dWFsbw==

26 Rozdział 2: Rozpoczęcie pracy w modelu tabelarycznym
RYSUNEK 2-3 Wybór funkcji na stronie Feature Selection
WAŻNE Teraz, przy instalacji serwera bazy danych obszaru roboczego na tej samej maszynie co deweloperska stacja robocza, trzeba także wykonać kroki podane w części „Instalacja serwera bazy danych obszaru roboczego”.
13. Na stronie Installation Rules (Zasady instalacji), jeśli zasady są spełnione, klikamy Next.
14. Na stronie Disk Space Summary (Podsumowanie pamięci dyskowej), klikamy Next, jeśli mamy dość miejsca na dysku, aby kontynuować instalację.
15. Na stronie Error Reporting (Raportowanie błędów) klikamy Next.
16. Na stronie Installation Confi guration Rules (Zasady konfi guracji instalacji), jeśli zasady są spełnione, klikamy Next.
17. Na stronie Ready To Install (Gotowe do instalacji) klikamy Install (Instaluj), roz-poczynając instalację.
18. Po zakończeniu instalacji zamykamy kreator.
Instalacja dokumentacji SQL Server W tym miejscu mamy gotową instalację SSDT i SQL Server Management Studio, ale nie mamy lokalnej kopii pomocy i dokumen-tacji. Instalacja dokumentacji oznacza, że zawsze mamy dostęp do najnowszej wersji, ale nie możemy z niej korzystać, gdy nie jesteśmy połączeni z Internetem. Podczas pierwszego użycia SQL Server Documentation zobaczymy okno dialogowe, takie jak to pokazane na rysunku 2-4.
##7#52#aSUZPUk1BVC1WaXJ0dWFsbw==

Określenie środowiska deweloperskiego 27
RYSUNEK 2-4 Wybór domyślnych ustawień pomocy
Jeśli klikniemy Yes (Tak), otworzy się nasza przeglądarka i zostaniemy skierowa-ni do dokumentacji SQL Server na witrynie MSDN. Jeśli jednak spodziewamy się, że możemy w jakimś punkcie pracować offl ine, pomocne może być przełączenie się na pomoc offl ine. Można tego dokonać, klikając Manage Help Settings (Zarządzaj usta-wieniami pomocy), które znajdziemy w menu Start systemu Windows. Przechodzimy do All Programs | Microsoft SQL Server 2012 | Documentation and Community | Manage Help Settings (Wszystkie programy| Microsoft SQL Server 2012|Dokumentacja i społeczność|Zarządzaj ustawieniami pomocy). Uruchamia to aplikację Help Library (Biblioteka pomocy). Przejście na pomoc lokalną wymaga wykonania następujących kroków:
1. Klikamy Choose Online Or Local Help (Wybierz pomoc online lub pomoc lokal-ną), co widać na rysunku 2-5.
RYSUNEK 2-5 Wybór Choose Online Or Local Help na stronie Help Library Manager
2. Wybieramy przycisk opcji I Want To Use Local Help (Chcę używać pomocy lokal-nej), co widać na rysunku 2-6.
##7#52#aSUZPUk1BVC1WaXJ0dWFsbw==
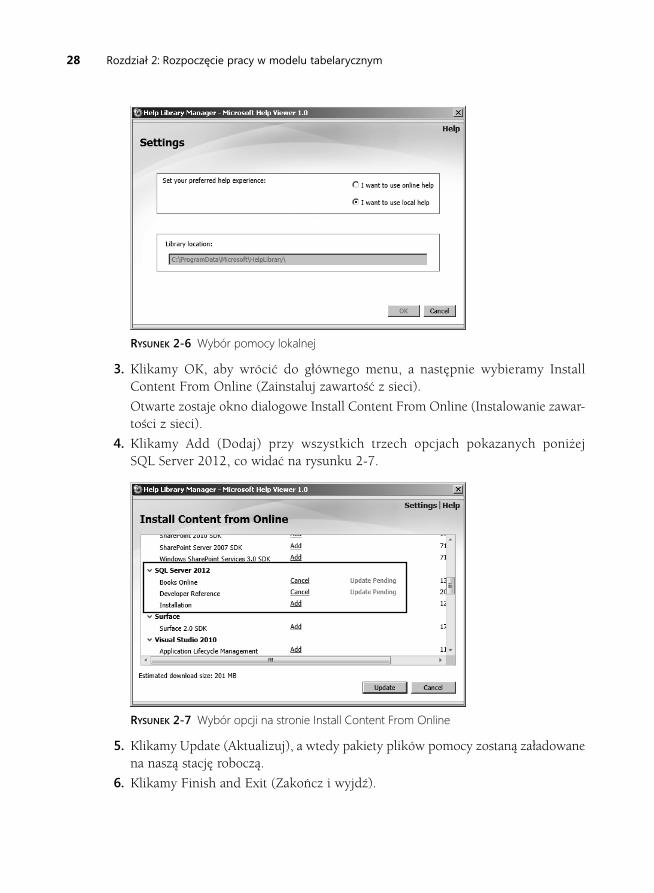
28 Rozdział 2: Rozpoczęcie pracy w modelu tabelarycznym
RYSUNEK 2-6 Wybór pomocy lokalnej
3. Klikamy OK, aby wrócić do głównego menu, a następnie wybieramy Install Content From Online (Zainstaluj zawartość z sieci).
Otwarte zostaje okno dialogowe Install Content From Online (Instalowanie zawar-tości z sieci).
4. Klikamy Add (Dodaj) przy wszystkich trzech opcjach pokazanych poniżej SQL Server 2012, co widać na rysunku 2-7.
RYSUNEK 2-7 Wybór opcji na stronie Install Content From Online
5. Klikamy Update (Aktualizuj), a wtedy pakiety plików pomocy zostaną załadowane na naszą stację roboczą.
6. Klikamy Finish and Exit (Zakończ i wyjdź).
##7#52#aSUZPUk1BVC1WaXJ0dWFsbw==

Określenie środowiska deweloperskiego 29
Kontrola kodu źródłowego W tym miejscu trzeba dysponować jakąś kontrolą kodu źródłowego, która daje się dobrze zintegrować z Visual Studio, jak Team Foundation Server, aby sprawdzać tworzone projekty za pomocą SSDT. Tworzenie rozwiązania BI dla Analysis Services nie różni się od innych form prac deweloperskich, więc jest niezwykle ważne, aby nasz kod źródłowy zawarty w projekcie SSDT był zapisany bezpiecznie, a także by dało się wrócić do wcześniejszych wersji po dokonaniu w pro-jekcie zmian.
Inne narzędzia Na swojej deweloperskiej stacji roboczej trzeba także zainstalować Offi ce 2010, aby była możliwość przeglądania modelu tabelarycznego po jego wdro-żeniu, ponieważ tego nie można robić w SSDT. W dalszej części rozdziału pokaza-no, że gdy będziemy gotowi, SSDT podejmie próbę uruchomienia aplikacji Microsoft Excel. Przeglądarka wchodząca w skład SQL Server Management Studio jest bardzo ograniczona (opiera się na sterowaniu generatorem zapytań MDX w SQL Server Reporting Services) i jest znacznie gorsza od przeglądarki kostki, która była dostępna w poprzednich wersjach SQL Server Management Studio.
Ponadto na swojej deweloperskiej stacji roboczej trzeba zainstalować wymienione poniżej bezpłatne narzędzia, które zapewniają dodatkowe użyteczne funkcje. W kolej-nych rozdziałach będziemy się do nich odwoływać.
■ BIDS Helper Nagradzany darmowy dodatek do Visual Studio opracowany przez członków społeczności Microsoft BI jako rozszerzenie SSDT. Choć większość jego funkcjonalności ma zastosowanie tylko w modelu wielowymiarowym, dodano także nowe funkcje dla modelu tabelarycznego, takie jak możliwość defi niowania działań. Można go załadować z witryny http://bidshelper.codeplex.com/.
■ Rozszerzenia OLAP PivotTable Dodatek do Excela daje dodatkowe funkcje wykorzystywane przez PivotTable w połączeniu ze źródłami danych w Analysis Services. Pozwala on między innymi na obejrzenie kodu MDX wygenerowanego przez PivotTable. Można go pobrać z witryny: http://olappivottableextend .codeplex.com/.
■ Edytor DAX dla SQL Server Dodatek do Visual Studio przygotowany przez zespół deweloperski Analysis Services, który udostępnia w SSDT pełny edytor języka DAX. Warto zauważyć, że ten dodatek, choć został opracowany przez pracowników fi rmy Microsoft, nie ma ofi cjalnego wsparcia ze strony Microsoft. Można go pobrać z witryny http://daxeditor.codeplex.com/.
■ BISM Normalizer Narzędzie służące do porównywania i scalania dwóch modeli tabelarycznych. Jest ono szczególnie użyteczne, gdy próbujemy połą-czyć ze sobą modele utworzone w PowerPivot i istniejący model tabelarycz-ny. Można go pobrać z witryny http://visualstudiogallery.msdn.microsoft .com/ 5be8704f-3412-4048-bfb9-01a78f475c64.
##7#52#aSUZPUk1BVC1WaXJ0dWFsbw==

30 Rozdział 2: Rozpoczęcie pracy w modelu tabelarycznym
Instalacja serwera deweloperskiego
Aby na swoim serwerze deweloperskim zainstalować instancję Analysis Services w try-bie tabelarycznym, trzeba wykonać wszystkie kroki do 11. włącznie, opisane w części „Instalacja deweloperskiej stacji roboczej”. Potem wykonujemy następujące działania:
1. Na stronie Feature Selection (Wybór funkcji), zaznaczamy pole wyboru Analysis Services, co widać na rysunku 2-8.
RYSUNEK 2-8 Wybór Analysis Services na stronie Feature Selection
2. Na stronie Instance Confi guration (Konfi guracja instancji) wybieramy instan-cję domyślną lub nazwaną, aby zainstalować instancję domyślną lub nazwaną, co widać na rysunku 2-9.
Zalecana jest instancja nazwana o znaczącej nazwie (na przykład tabelaryczna), gdyż przy instalacji innej instancji Analysis Services na tym samym serwerze, lecz uruchomionej w trybie wielowymiarowym, będzie znacznie łatwiej określić, z którą instancją aktualnie się łączymy.
3. Na stronie Disk Space Requirements (Wymagania dotyczące miejsca na dysku), klikamy Next, jeśli mamy dość miejsca na dysku, aby kontynuować instalację.
4. Na stronie Server Confi guration (Konfi guracja serwera), w zakładce Service Accounts (Konta usług), wprowadzamy nazwę użytkownika i hasło potrzebne potem przy uruchamianiu usługi Analysis Services Windows. Musi być to konto domeny utworzone specjalnie w tym celu.
##7#52#aSUZPUk1BVC1WaXJ0dWFsbw==
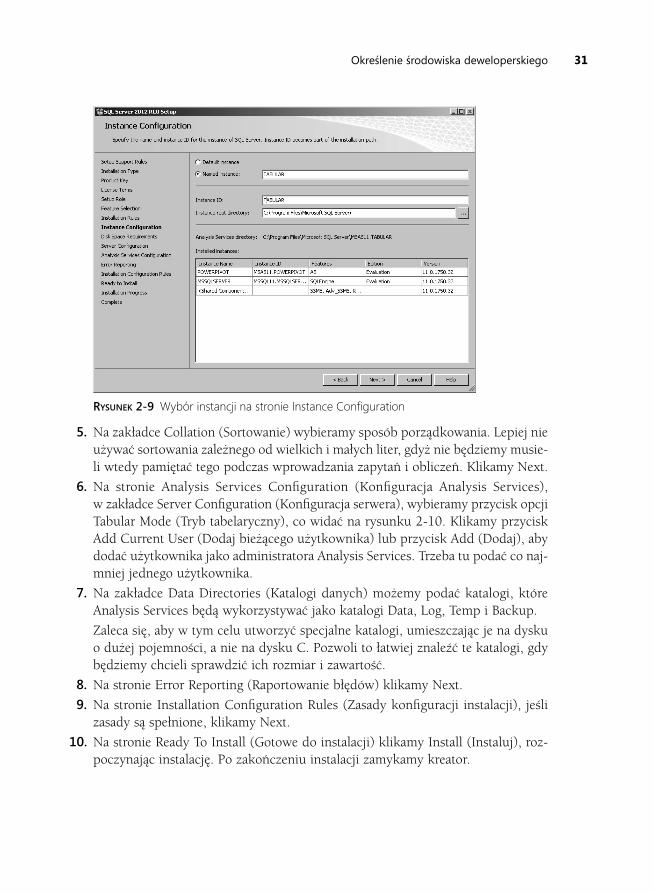
Określenie środowiska deweloperskiego 31
RYSUNEK 2-9 Wybór instancji na stronie Instance Configuration
5. Na zakładce Collation (Sortowanie) wybieramy sposób porządkowania. Lepiej nie używać sortowania zależnego od wielkich i małych liter, gdyż nie będziemy musie-li wtedy pamiętać tego podczas wprowadzania zapytań i obliczeń. Klikamy Next.
6. Na stronie Analysis Services Confi guration (Konfi guracja Analysis Services), w zakładce Server Confi guration (Konfi guracja serwera), wybieramy przycisk opcji Tabular Mode (Tryb tabelaryczny), co widać na rysunku 2-10. Klikamy przycisk Add Current User (Dodaj bieżącego użytkownika) lub przycisk Add (Dodaj), aby dodać użytkownika jako administratora Analysis Services. Trzeba tu podać co naj-mniej jednego użytkownika.
7. Na zakładce Data Directories (Katalogi danych) możemy podać katalogi, które Analysis Services będą wykorzystywać jako katalogi Data, Log, Temp i Backup.
Zaleca się, aby w tym celu utworzyć specjalne katalogi, umieszczając je na dysku o dużej pojemności, a nie na dysku C. Pozwoli to łatwiej znaleźć te katalogi, gdy będziemy chcieli sprawdzić ich rozmiar i zawartość.
8. Na stronie Error Reporting (Raportowanie błędów) klikamy Next.
9. Na stronie Installation Confi guration Rules (Zasady konfi guracji instalacji), jeśli zasady są spełnione, klikamy Next.
10. Na stronie Ready To Install (Gotowe do instalacji) klikamy Install (Instaluj), roz-poczynając instalację. Po zakończeniu instalacji zamykamy kreator.
##7#52#aSUZPUk1BVC1WaXJ0dWFsbw==

32 Rozdział 2: Rozpoczęcie pracy w modelu tabelarycznym
RYSUNEK 2-10 Wybór zakładki Tabular Mode na stronie Analysis Services Configuration
UWAGA Podczas pracy będziemy prawdopodobnie musieli mieć także dostęp do instancji mechanizmu relacyjnej bazy danych SQL Server; można rozważyć jego instalację na na-szym serwerze deweloperskim.
Instalacja serwera bazy danych obszaru roboczego
Instalacja serwera bazy danych obszaru roboczego obejmuje podobne kroki jak instala-cja serwera deweloperskiego, ale przed rozpoczęciem instalacji trzeba tu odpowiedzieć na dwa istotne pytania.
Najpierw trzeba podjąć decyzję, na jakim fi zycznym komputerze zainstalować ser-wer bazy danych obszaru roboczego. Instalacja na własnym serwerze dedykowanym byłaby marnowaniem sprzętu, ale można go zainstalować zarówno na deweloperskiej stacji roboczej, jak i na serwerze deweloperskim. Każda opcja ma swoje za i przeciw, ale na ogół zalecamy w miarę możliwości instalację na stacji roboczej. Są ku temu następujące powody:
■ SSDT ma opcję tworzenia kopii zapasowej bazy danych obszaru roboczego pod-czas zapisywania projektu (aczkolwiek nie jest to opcja domyślna).
■ Podczas tworzenia nowego projektu tabelarycznego z istniejącego skoroszytu PowerPivot można importować dane i metadane.
■ Łatwiej jest importować dane z Excela, Microsoft Access lub z plików tekstowych.
##7#52#aSUZPUk1BVC1WaXJ0dWFsbw==

Praca z narzędziami danych SQL Server 33
Drugim pytaniem jest, z jakiego konta będziemy korzystać do uruchomienia usługi Analysis Services. W poprzedniej części dla instalacji deweloperskiej bazy danych zale-cano oddzielne konto w domenie; dla bazy danych obszaru roboczego wygodniejsze może być skorzystanie z konta, na które normalnie logujemy się do usługi Analysis Services. Pozwoli to instancji bazy danych obszaru roboczego na dostęp do wszyst-kich lokalizacji plików, do których mamy dostęp, więc będzie łatwiej wykonać kopię roboczą tych baz danych z poziomu PowerPivot.
Wszystkie te możliwości są dokładnie przedstawione w poście na blogu Cathy Dumas pod adresem: http://blogs.msdn.com/b/cathyk/archive/2011/10/03/confi guring-a--workspace-database-server.aspx.
Praca z narzędziami danych SQL ServerPo skonfi gurowaniu środowiska deweloperskiego można zacząć korzystać z narzędzi danych SQL Server Data Tools, aby wykonać kilka zadań.
Tworzenie nowego projektuGdy wszystko jest gotowe, można zacząć budowę nowego modelu tabelarycznego. W tym celu musimy utworzyć nowy projekt w SSDT. Tego nauczymy się w tej części rozdziału.
Najpierw uruchamiamy SSDT. Jeśli jest to pierwsze wykonanie, pokaże się okno dialogowe wyświetlone na rysunku 2-11, pytając nas o wybór domyślnych ustawień środowiska. Trzeba wybrać ustawienia Business Intelligence Settings (Ustawienia ana-lizy biznesowej).
RYSUNEK 2-11 Wybór ustawienia Business Intelligence Settings na stronie Default Environment Settings
##7#52#aSUZPUk1BVC1WaXJ0dWFsbw==

34 Rozdział 2: Rozpoczęcie pracy w modelu tabelarycznym
Po pojawieniu się strony startowej z menu File (Plik) wybieramy New Project. Pojawi się wówczas okno dialogowe pokazane na rysunku 2-12. Na liście po lewej stronie Installed Templates (Zainstalowane szablony) klikamy Analysis Services, aby pokazać opcje tworzenia nowego projektu Analysis Services.
RYSUNEK 2-12 Okno dialogowe New Project (Nowy projekt)
Pierwsze dwie opcje z listy służą do tworzenia projektów modelu wielowymiarowego, więc je zignorujemy. Pozostają nam jeszcze trzy opcje:
■ Analysis Services Tabular Project (Projekt tabelaryczny usług Analysis Services) Tworzy nowy, pusty projekt przeznaczony do projektowania modelu tabelarycznego.
■ Import From PowerPivot (Importuj z programu PowerPivot) Umożliwia import modelu utworzonego za pomocą PowerPivot do nowego projektu SSDT.
■ Import From Server (Tabular) (Importuj z serwera) Umożliwia wskazanie modelu wdrożonego wcześniej w Analysis Services i import jego metadanych do nowego projektu.
Klikamy opcję Analysis Services Tabular Project, aby utworzyć nowy projekt; pozostałe dwie opcje poznamy w dalszej części rozdziału.
##7#52#aSUZPUk1BVC1WaXJ0dWFsbw==

Praca z narzędziami danych SQL Server 35
Edycja projektów w trybie onlineCzytelnicy, którzy mają doświadczenie z wielowymiarowymi modelami Analysis Services, wiedzą, że z modelami wielowymiarowymi można pracować w SSDT także w inny sposób: w trybie online. Dzięki temu można połączyć się z wielowymiarową bazą danych, która została wcześniej wdrożona i edytować ją na serwerze w taki spo-sób, że każdy zapis natychmiast powoduje zmiany na serwerze. Opcja ta nie jest obsłu-giwana w trybie tabelarycznym i nie działa automatycznie w zakupionej wersji pakietu.
Konfiguracja nowego projektuPo utworzeniu nowego projektu musimy skonfi gurować różne jego właściwości.
Kreator właściwości domyślnych
Jeśli po raz pierwszy tworzymy nowy projekt tabelaryczny w SSDT, kreator pomaga nam w ustawieniu jednej ważnej właściwości projektu: serwer, którego chcemy używać zarówno jako domyślny serwer bazy danych obszaru roboczego, jak i domyślny serwer deweloperski, co widać na rysunku 2-13.
RYSUNEK 2-13 Ustawianie domyślnego serwera obszaru roboczego
Jest jednak możliwe korzystanie z różnych serwerów dla bazy danych obszaru robo-czego i bazy deweloperskiej; dalej pokazany jest sposób ręcznej zmiany ustawień.
Właściwości projektu
Właściwości projektu można ustawić, klikając prawym przyciskiem myszy nazwę projektu w oknie Solution Explorer (Eksplorator rozwiązań), a następnie wybiera-jąc Properties. Pojawia się okno dialogowe Project Properties (Właściwości projektu), pokazane na rysunku 2-14.
##7#52#aSUZPUk1BVC1WaXJ0dWFsbw==

36 Rozdział 2: Rozpoczęcie pracy w modelu tabelarycznym
RYSUNEK 2-14 Okno dialogowe Project Properties
Trzeba ustawić podane poniżej właściwości. (Niektóre inne właściwości będą omawia-ne w dalszej części książki).
■ Deployment Options\Processing Option (Opcje wdrażania\Przetwarzanie opcji) Właściwość ta określa, jaki typ przetwarzania ma miejsce po wdrożeniu projektu na serwerze deweloperskim; określa, czy i w jaki sposób Analysis Services automatycznie ładuje dane do modelu po dokonaniu w nim zmian. Ustawienie domyślne, Default (Domyślny), ponownie przetwarza każdą tabelę, która nie była przetwarzana lub w której wdrożone zmiany pozostawiłyby ją w stanie nieprze-tworzonym. Można także wybrać Full (Pełne), co oznacza, że cały model będzie ponownie przetwarzany. Zalecamy jednak wybranie opcji Do Not Process (Nie przetwarzaj), aby automatycznie nie wykonywać żadnego przetwarzania. Jest to lepsze, gdyż przetwarzanie dużego modelu może zająć dużo czasu, zaś często zdarza się, że chcemy wdrożyć zmiany bez przetwarzania lub przy przetworzeniu tylko wybranych tabel.
■ Deployment Server\Server (Serwer wdrażania\Serwer) Właściwość ta zawie-ra nazwę serwera wdrażania, na którym chcemy dokonać wdrożenia. Domyślne ustawienie jest zgodne z danymi z kreatora Default Properties Wizard (Kreator właściwości domyślnych). Nawet jeśli korzystamy z lokalnego serwera, trzeba usu-nąć wartość domyślną i wstawić pełną nazwę serwera deweloperskiego (w forma-cie nazwa_serwera\nazwa_instancji), na wypadek, gdyby model był kiedykolwiek używany na innej stacji roboczej.
■ Deployment Server\Edition (Serwer wdrażania\Wersja) Właściwość ta umoż-liwia ustawienie wersji SQL Server, której będziemy używać na serwerze produk-cyjnym i zapobiega wdrożeniu z wykorzystaniem funkcji, które w danej wersji
##7#52#aSUZPUk1BVC1WaXJ0dWFsbw==

Praca z narzędziami danych SQL Server 37
nie są dostępne. Ponieważ obecnie nie ma różnicy w funkcjach między wersjami Enterprise i Business Intelligence SQL Server – jedynymi wersjami, w których dostępny jest model tabelaryczny – ustawienie tej właściwości nie ma znaczenia, ale można ją ustawić na wypadek przyszłych różnic w dostępnych funkcjach.
■ Deployment Server\Database (Serwer wdrażania\Baza danych) Tu mamy nazwę bazy danych, w której wdrażamy projekt. Domyślnie jest ona ustawiona na nazwę projektu, ale nazwa bazy danych widoczna jest dla użytkowników koń-cowych, więc trzeba uzgodnić z nimi, jakiej nazwy chcieliby używać.
■ Deployment Server\Cube Name (Serwer wdrażania\Nazwa kostki) Tu mamy nazwę kostki, wyświetlaną we wszystkich narzędziach klienckich, które będą wydawać zapytania do modelu w MDX lub w Excelu. Domyślną nazwą jest Model, ale zaleca się zmianę tej nazwy po jej skonsultowaniu z użytkownikami końcowymi.
Właściwości modelu
Są też właściwości, które trzeba ustawić dla samego modelu. Można je znaleźć po klik-nięciu prawym przyciskiem myszy pliku Model.bim w oknie Solution Explorer, a następnie trzeba wybrać Properties, aby wyświetlić panel znajdujący się w SSDT, co widać na rysunku 2-15.
RYSUNEK 2-15 Okno dialogowe Model Properties
##7#52#aSUZPUk1BVC1WaXJ0dWFsbw==

38 Rozdział 2: Rozpoczęcie pracy w modelu tabelarycznym
Właściwości trzeba ustawić według następujących zasad:
■ Data Backup (Kopia zapasowa danych) Tu określa się, co się będzie działo z bazą danych obszaru roboczego po zamknięciu naszego projektu. Domyślnym ustawieniem jest Do Not Back Up To Disk (Nie wykonuj kopii zapasowej na dys-ku), co oznacza, że przy zamykaniu projektu nie jest zachowywana żadna kopia. Jeśli jednak pracujemy z lokalnym serwerem bazy danych obszaru roboczego, instancja tego serwera bazy danych działa na koncie z wystarczającymi uprawnie-niami, aby zapisywać w katalogu projektu (jak własne konto domeny, co zalecano już w tym rozdziale), zaś ilość danych w bazie danych obszaru roboczego jest niewielka, można rozważyć zmianę tej właściwości na Back Up To Disk (Wykonaj kopię zapasową na dysku). Podczas zamykania projektu baza danych obszaru roboczego zostanie zapisana w tym samym katalogu co projekt SSDT. Powody, dla których taka sytuacja może być użyteczna, podano w poście na blogu: http://blogs.msdn.com/b/cathyk/archive/2011/09/20/working-with-backups-in-the-tabular-designer.aspx, jednak powody te nie są zbyt istotne, zaś tworzenie kopii zapasowej zwiększa czas potrzebny na zapisanie projektu.
■ File Name (Nazwa pliku) Tu określa się nazwę pliku .bim naszego projektu; dalej, w punkcie „Zawartość projektu tabelarycznego”, jest dokładny opis tego pliku. Zmiana nazwy pliku .bim może być użyteczna, jeśli w ramach jednego rozwiązania SSDT pracujemy przy kilku projektach.
■ Workspace Retention (Przechowywanie obszaru roboczego) Ta właściwość określa, co się dzieje z bazą danych obszaru roboczego (o nazwie podanej we właś-ciwości tylko do odczytu, Workspace Database) na serwerze bazy, gdy zamyka-my nasz projekt SSDT. Domyślne ustawienie to Unload From Memory (Zwolnij z pamięci). Baza danych zostaje odłączona, pozostając na dysku, ale nie zużywając pamięci. Gdy projekt jest ponownie otwierany, zostaje szybko ponownie podłączo-na. Ustawienie Keep In Memory (Zachowaj w pamięci) wskazuje, że baza danych nie zostaje odłączona i w chwili zamknięcia projektu jej stan nie ulega zmianie. Ustawienie Delete Workspace (Usuń obszar roboczy) wskazuje, że baza danych ma zostać całkowicie usunięta i przy ponownym otwarciu projektu musi zostać ponownie utworzona. Dla projektów o małym zestawie danych lub dla projektów chwilowych, tworzonych na potrzeby testowania i eksperymentalnie zaleca się ustawienie Delete Workspace, gdyż inaczej skumulujemy wiele baz danych obsza-ru roboczego, które zblokują serwer i zużyją przestrzeń dyskową. Jeśli pracujemy z jednym projektem lub korzystamy z wielkich ilości danych, użyteczne może być ustawienie Keep In Memory, gdyż zmniejsza ono czas potrzebny na otwarcie projektu.
■ Workspace Server (Serwer obszaru roboczego) Tu podajemy nazwę instancji tabelarycznej Analysis Services 2012, której chcemy używać jako serwera bazy danych obszaru roboczego.
##7#52#aSUZPUk1BVC1WaXJ0dWFsbw==

Praca z narzędziami danych SQL Server 39
Okno dialogowe opcji
Wiele z domyślnych ustawień właściwości wymienionych powyżej można także zmie-nić wewnątrz SSDT, więc nie trzeba ich rekonfi gurować dla każdego tworzonego pro-jektu. Aby wykonać to zadanie, z menu Tools (Narzędzia) wybieramy Options (Opcje), aby otworzyć okno dialogowe Options, co widać na rysunku 2-16.
Po lewej stronie wybieramy Analysis Services\Data Modeling (Analysis Services\Modelowanie danych), aby ustawić domyślne wartości właściwości modelu dla Works-pace Server, Workspace Retention i Data Backup. Strona Analysis Services\Deployment (Analysis Services\Wdrożenie) umożliwia nam wstawienie nazwy serwera wdrożenio-wego, który ma być używany domyślnie, zaś strona Business Intelligence Designers\Analysis Services Designers\General (Projektowanie BI\Projektowanie Analysis Servi-ces\Ogólne) pozwala na ustawienie domyślnej wartości dla właściwości Deployment Server Edition (Wydanie serwera wdrażania).
RYSUNEK 2-16 Okno dialogowe Options
Import z PowerPivotZamiast tworzenia pustego projektu w SSDT, można zaimportować do nowego projektu metadane, a w niektórych przypadkach także model z PowerPivot. Aby tego dokonać, tworzymy nowy projekt i w oknie dialogowym New Project (Nowy projekt) wybiera-my Import From PowerPivot (Importuj z programu PowerPivot), co widać na rysun-ku 2-12. Następnie wybieramy skoroszyt Excela zawierający model PowerPivot, któ-ry chcemy importować, a wtedy zostanie utworzony model tabelaryczny identyczny z modelem zawartym w PowerPivot.
Jeśli konto usługi, z którego uruchamiamy serwer bazy danych obszaru robo-czego, nie ma uprawnień do odczytu wybranego pliku, pojawi się okno dialogowe,
##7#52#aSUZPUk1BVC1WaXJ0dWFsbw==

40 Rozdział 2: Rozpoczęcie pracy w modelu tabelarycznym
widoczne na rysunku 2-17, wskazujące, że z modelu będą importowane tylko meta-dane, a nie dane.
RYSUNEK 2-17 Okno dialogowe importu z PowerPivot z ostrzeżeniem
Kliknięcie Yes (Tak) spowoduje utworzenie projektu baz danych. Jeśli wszystkie dane projektu PowerPivot pochodzą z zewnętrznych źródeł danych, ponowne załadowanie danych będzie względnie proste. Jeśli jednak niektóre lub wszystkie dane modelu pochodzą z samego skoroszytu, do załadowania danych trzeba wykonać większą pracę, więc może się okazać, że łatwiej będzie nadać odpowiednie uprawnienia do tego pliku kontu usługi bazy danych obszaru roboczego. Więcej informacji na ten temat można znaleźć w poście na blogu: http://blogs.msdn.com/b/cathyk/archive/2011/08/22/recovering--from-cryptic-errors-thrown-when-importing-from-powerpivot.aspx.
Informacje o tym, co się dzieje w tle, gdy importujemy model PowerPivot, można znaleźć w poście na blogu: http://blogs.msdn.com/b/cathyk/archive/2011/08/15/what-does--import-from-powerpivot-actually-do.aspx.
Import wdrożonego projektu z Analysis ServicesNowy projekt można również utworzyć z istniejącej tabelarycznej bazy danych Analysis Services, która została wcześniej wdrożona na serwerze. Może to być pomocne, jeśli musimy szybko utworzyć kopię projektu lub jeśli projekt został utracony, zmieniony lub zepsuty, a nie korzystaliśmy z kontroli źródła. Aby wykonać to zadanie w oknie dialogowym New Project, wybieramy Import From Server (Tabular) (Importuj z ser-wera (tabelarycznie)), co widać na rysunku 2-12. Otrzymamy prośbę o połączenie się z serwerem, a baza danych, którą chcemy importować, zostanie utworzona.
Zawartość projektu tabelarycznegoTrzeba znać wszystkie pliki powiązane z projektem tabelarycznym w SSDT. Pliki zwią-zane z nowym, pustym projektem można zobaczyć w okienku Solution Explorer, co widać na rysunku 2-18.
##7#52#aSUZPUk1BVC1WaXJ0dWFsbw==
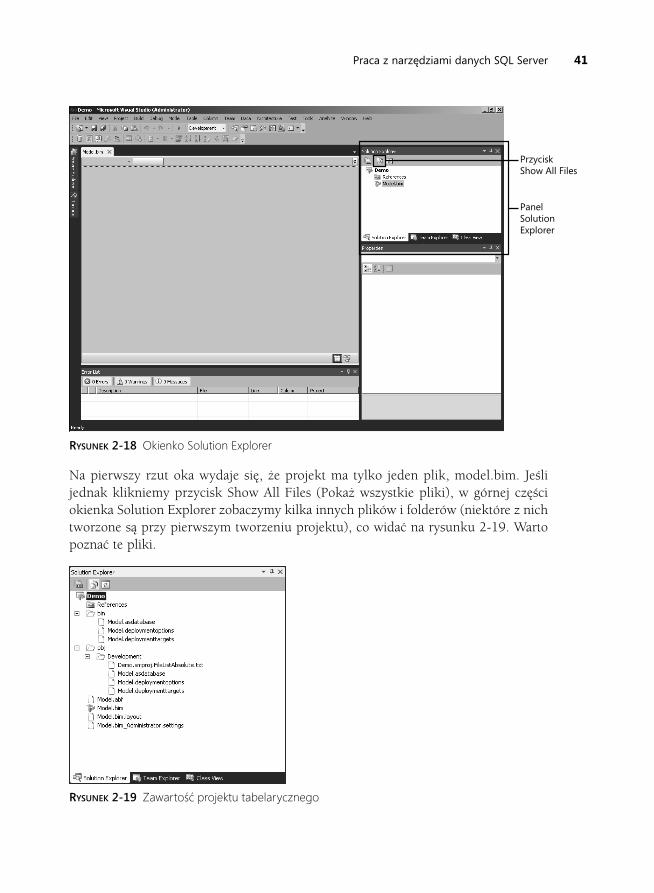
Praca z narzędziami danych SQL Server 41
PrzyciskShow All Files
PanelSolutionExplorer
RYSUNEK 2-18 Okienko Solution Explorer
Na pierwszy rzut oka wydaje się, że projekt ma tylko jeden plik, model.bim. Jeśli jednak klikniemy przycisk Show All Files (Pokaż wszystkie pliki), w górnej części okienka Solution Explorer zobaczymy kilka innych plików i folderów (niektóre z nich tworzone są przy pierwszym tworzeniu projektu), co widać na rysunku 2-19. Warto poznać te pliki.
RYSUNEK 2-19 Zawartość projektu tabelarycznego
##7#52#aSUZPUk1BVC1WaXJ0dWFsbw==

42 Rozdział 2: Rozpoczęcie pracy w modelu tabelarycznym
■ Model.bim zawiera metadane projektu oraz wszelkie dane, które zostały do obiek-tu skopiowane lub wklejone. (Więcej na ten temat napisano w rozdziale 3, „Ładowanie danych w modelu tabelarycznym”). Metadane mają postać polecenia alter XMLA alter. (XMLA jest opartym na XML językiem defi niowania danych, używanym w Analysis Services). Zwróćmy uwagę, że te same metadane były uży-wane do tworzenia bazy danych obszaru roboczego; nie muszą to być te same metadane, których używano podczas wdrażania projektu na serwerze deweloper-skim. Jeśli plik Model.bim zostanie z jakiegoś powodu uszkodzony lub nie daje się otworzyć, można go odtworzyć, wykonując kroki opisane w poście na blogu: http://blogs .msdn.com/b/cathyk/archive/2011/10/07/recovering-your-model-when-you--can-t-save-the-bim-fi le.aspx.
■ Pliki .asdatabase, .deploymentoptions i .deploymenttargets zawierają właściwości, które mogą być różne przy wdrażaniu projektu w lokalizacji, takiej jak serwer two-rzonej bazy danych, a nie na serwerze bazy danych obszaru roboczego. Zawierają one takie właściwości, jak nazwa serwera i bazy danych do wdrożenia. Można je ustawić w oknie dialogowym Project Properties – Właściwości projektu), poka-zanym na rysunku 2-14. Więcej informacji na temat tych plików można znaleźć pod adresem: http://msdn.microsoft.com/en-us/library/ms174530(v=SQL.110).aspx.
■ Plik .abf fi le zawiera kopię zapasową bazy danych obszaru roboczego, która jest tworzona, gdy właściwość Data Backup w pliku Model.bim jest ustawiona na war-tość Back Up To Disk.
■ Plik .settings zawiera kilka właściwości, które są zapisywane na dysku przy każ-dym otwarciu projektu. Więcej informacji o wykorzystaniu tego pliku można znaleźć pod adresem http://blogs.msdn.com/b/cathyk/archive/2011/09/23/where-does--data-come-from-when-you-open-a-bim-fi le.aspx/BismData. Jeśli chcemy zrobić kopię całego projektu SSDT za pomocą kopiowania i wklejenia jego folderu do nowej lokalizacji na dysku, musimy wyrzucić ten plik ręcznie, co szczegółowo opisa-no w poście na blogu: http://sqlblog.com/blogs/alberto_ferrari/archive/2011/09/27/creating-a-copy-of-a-bism-tabular-project.asp.
■ Plik .layout zawiera informacje dotyczące wielkości, położenia oraz stanu róż-nych okien i okienek z wnętrza SSDT w momencie zapisywania projektu. Więcej informacji na ten temat można znaleźć pod adresem http://blogs.msdn.com/b/cathyk/archive/2011/12/03/new-for-rc0-the-layout-fi le.aspx.
Budowa prostego modelu tabelarycznegoW tej części przechodzimy proces tworzenia i wdrażania prostego modelu, aby pomóc w opanowaniu interfejsu użytkownika SSDT i zilustrować pojęcia opisane wcześniej w tym rozdziale. Jest to bardzo podstawowe wprowadzenie do tego procesu, a w dal-szych rozdziałach książki kroki te zostaną przedstawione bardziej szczegółowo. Zanim
##7#52#aSUZPUk1BVC1WaXJ0dWFsbw==

Budowa prostego modelu tabelarycznego 43
zaczniemy, trzeba sprawdzić, czy wszystkie konta używane do uruchamiania instancji Analysis Services w obszarze roboczym i na serwerze deweloperskim mają dostęp do instancji SQL Server i przykładowej bazy danych Works DW 2012 na naszym serwerze deweloperskim. (Adventure Works DW dla SQL Server 2012 można pobrać z http://msftdbprodsamples.codeplex.com).
Ładowanie danych do tabeliNajpierw tworzymy nowy projekt tabelaryczny w SSDT; ekran powinien przypominać to, co pokazano na rysunku 2-18 po otwarciu pliku Model.bim. Mamy teraz pusty projekt i trzeba załadować dane do jego tabeli. Z menu Model (widocznego tylko wtedy, gdy otwarty jest plik Model.bim) na górze ekranu wybieramy Import From Data Source (Importuj ze źródła danych); uruchomiony zostanie kreator Table Import Wizard (Kreator importu tabeli), co pokazano na rysunku 2-20.
RYSUNEK 2-20 Pierwszy krok kreatora Table Import Wizard
Pod nagłówkiem Relational Databases (Relacyjne bazy danych) wybieramy Microsoft SQL Server i klikamy Next. Na następnej stronie łączymy się z bazą danych Adventure Works DW 2012 w SQL Server, co widać na rysunku 2-21.
Ponownie klikamy Next. W kroku Impersonation Information (Informacje o perso-nifi kacji) konfi gurujemy sposób, w jaki Analysis Services będzie łączyć się z SQL Ser-ver, aby załadować dane. W tym miejscu najłatwiej jest wybrać opcję Specifi c Win-dows User Name And Password (Określ nazwę i hasło użytkownika Windows), aby
##7#52#aSUZPUk1BVC1WaXJ0dWFsbw==
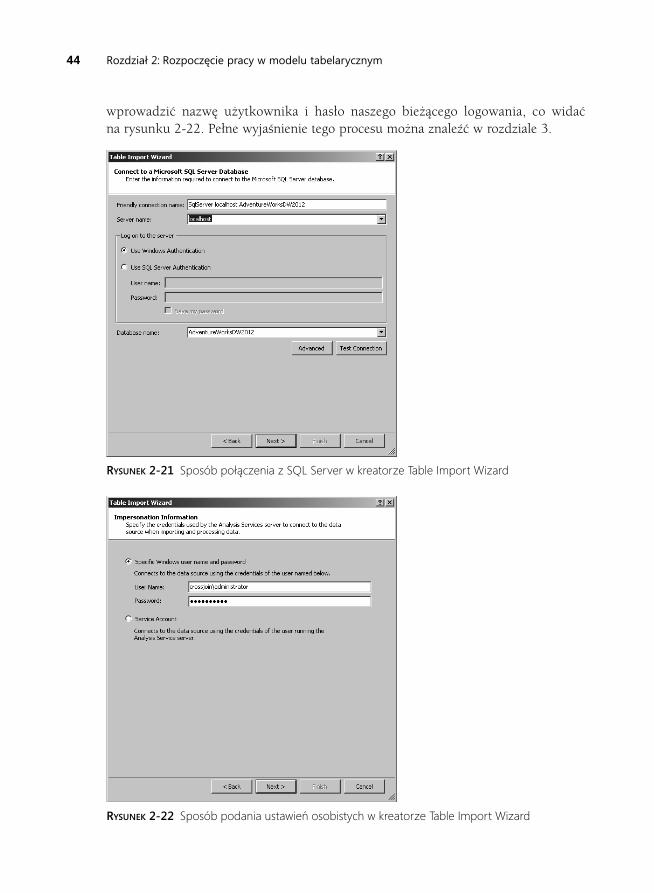
44 Rozdział 2: Rozpoczęcie pracy w modelu tabelarycznym
wprowadzić nazwę użytkownika i hasło naszego bieżącego logowania, co widać na rysunku 2-22. Pełne wyjaśnienie tego procesu można znaleźć w rozdziale 3.
RYSUNEK 2-21 Sposób połączenia z SQL Server w kreatorze Table Import Wizard
RYSUNEK 2-22 Sposób podania ustawień osobistych w kreatorze Table Import Wizard
##7#52#aSUZPUk1BVC1WaXJ0dWFsbw==

Budowa prostego modelu tabelarycznego 45
Ponownie klikamy Next i sprawdzamy, czy wybrano opcję Select From A List Of Tables And Views (Wybierz z listy tabel i widoków), a następnie znowu klikamy Next. Następnie, w Select Tables And Views (Wybierz tabele i widoki) wybieramy tabele, zgodnie z tym, co widać na rysunku 2-23: DimProduct, DimProductCategory, DimProductSubcategory oraz FactInternetSales.
RYSUNEK 2-23 Sposób wybierania tabel i widoków w kreatorze Table Import Wizard
Klikamy Finish (Zakończ) i widzimy, że dane z wybranych tabel są ładowane do naszej bazy danych obszaru roboczego. Powinno to zająć jedynie kilka sekund; jeśli napot-kamy tu błędy, powodem może być fakt, że używana instancja Analysis Services nie może połączyć się z bazą danych SQL Server. Aby naprawić ten błąd, musimy powtó-rzyć poprzednie kroki, a w kroku Impersonation Information próbujemy inną nazwę użytkownika, która ma odpowiednie uprawnienia, lub korzystamy z innego konta usług. Jeśli korzystamy z serwera obszaru roboczego na komputerze innym niż nasz komputer deweloperski, trzeba sprawdzić, czy zapory sieciowe nie blokują połącze-nia z Analysis Services do SQL Server oraz czy SQL Server może akceptować zdalne połączenia. Kończmy pracę w kreatorze, klikając Close (Zamknij).
W tym miejscu praca w Grid View (Widok siatki) daje ekran pokazany na rysunku 2-24, na którym widać dane w tabeli w widoku siatki.
##7#52#aSUZPUk1BVC1WaXJ0dWFsbw==

46 Rozdział 2: Rozpoczęcie pracy w modelu tabelarycznym
Lista rozwijanakolumn
Nagłówkikolumn
Dane tabeli
Panelwłaściwości(Properties)dla tabeli
PrzyciskDiagram View
Przycisk Grid ViewZakładki tabel Widok siatki
RYSUNEK 2-24 Okno Grid View
Dane z różnych tabel można obejrzeć, klikając zakładkę z nazwą tabeli. Wybór tabeli powoduje, że jej właściwości pojawiają się w okienku Properties. Niektóre właściwości oraz możliwość usuwania tabeli i przenoszenia jej na liście zakładek można ustawić po kliknięciu prawym przyciskiem myszy zakładki danej tabeli.
Konkretną kolumnę tabeli można znaleźć za pomocą poziomego paska przewijania, znajdującego się bezpośrednio nad zakładkami tabel lub z rozwijanej listy kolumn powyżej tabeli. Aby znaleźć dane z tabeli, klikamy strzałkę w dół obok nagłówka kolumny. Przeglądanie danych umożliwia kliknięcie strzałki przy nazwie kolumny, co widać na rysunku 2-25. Możemy posortować dane według wartości w kolumnie i fi ltrować je dzięki wybraniu lub usunięciu poszczególnych wartości lub za pomo-cą wbudowanych zasad fi ltrowania. Zwróćmy uwagę, że fi ltrowane są tylko dane wyświetlone na ekranie, a nie wszystkie dane zawarte w tabeli.
Kliknięcie prawym przyciskiem myszy na kolumnie pozwala nam ją usunąć, zmie-nić jej nazwę, zablokować ją (co oznacza, że kolumna będzie zawsze widoczna, nieza-leżnie od przewijania, podobnie jak kolumny w Excelu) oraz kopiować dane.
##7#52#aSUZPUk1BVC1WaXJ0dWFsbw==
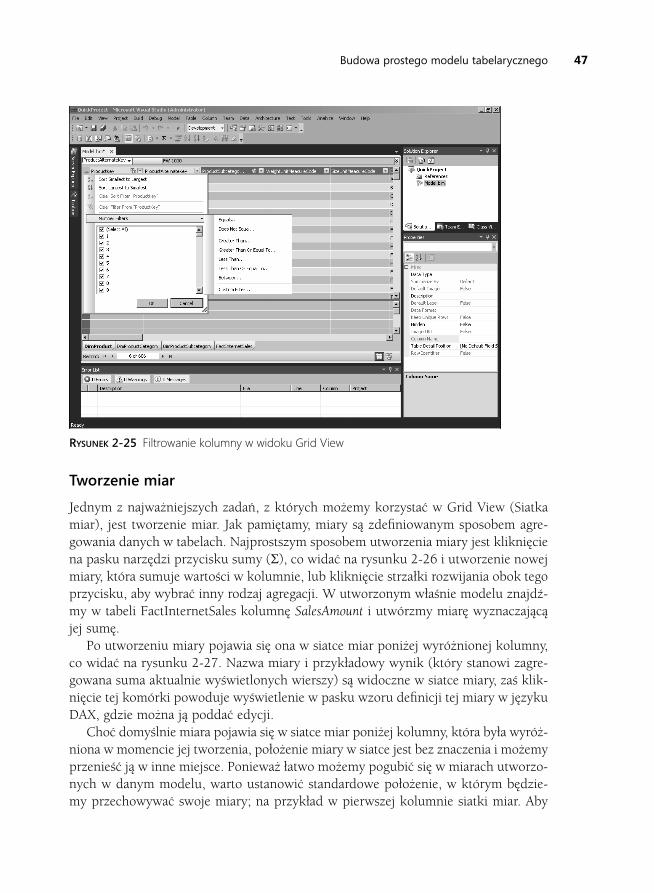
Budowa prostego modelu tabelarycznego 47
RYSUNEK 2-25 Filtrowanie kolumny w widoku Grid View
Tworzenie miar
Jednym z najważniejszych zadań, z których możemy korzystać w Grid View (Siatka miar), jest tworzenie miar. Jak pamiętamy, miary są zdefi niowanym sposobem agre-gowania danych w tabelach. Najprostszym sposobem utworzenia miary jest kliknięcie na pasku narzędzi przycisku sumy (Σ), co widać na rysunku 2-26 i utworzenie nowej miary, która sumuje wartości w kolumnie, lub kliknięcie strzałki rozwijania obok tego przycisku, aby wybrać inny rodzaj agregacji. W utworzonym właśnie modelu znajdź-my w tabeli FactInternetSales kolumnę SalesAmount i utwórzmy miarę wyznaczającą jej sumę.
Po utworzeniu miary pojawia się ona w siatce miar poniżej wyróżnionej kolumny, co widać na rysunku 2-27. Nazwa miary i przykładowy wynik (który stanowi zagre-gowana suma aktualnie wyświetlonych wierszy) są widoczne w siatce miary, zaś klik-nięcie tej komórki powoduje wyświetlenie w pasku wzoru defi nicji tej miary w języku DAX, gdzie można ją poddać edycji.
Choć domyślnie miara pojawia się w siatce miar poniżej kolumny, która była wyróż-niona w momencie jej tworzenia, położenie miary w siatce jest bez znaczenia i możemy przenieść ją w inne miejsce. Ponieważ łatwo możemy pogubić się w miarach utworzo-nych w danym modelu, warto ustanowić standardowe położenie, w którym będzie-my przechowywać swoje miary; na przykład w pierwszej kolumnie siatki miar. Aby
##7#52#aSUZPUk1BVC1WaXJ0dWFsbw==

48 Rozdział 2: Rozpoczęcie pracy w modelu tabelarycznym
RYSUNEK 2-26 Tworzenie miary w Grid View (Siatka miar)
Miaraw siatcemiar
Definicja miary w pasku formuły
RYSUNEK 2-27 Miara w siatce miar
##7#52#aSUZPUk1BVC1WaXJ0dWFsbw==
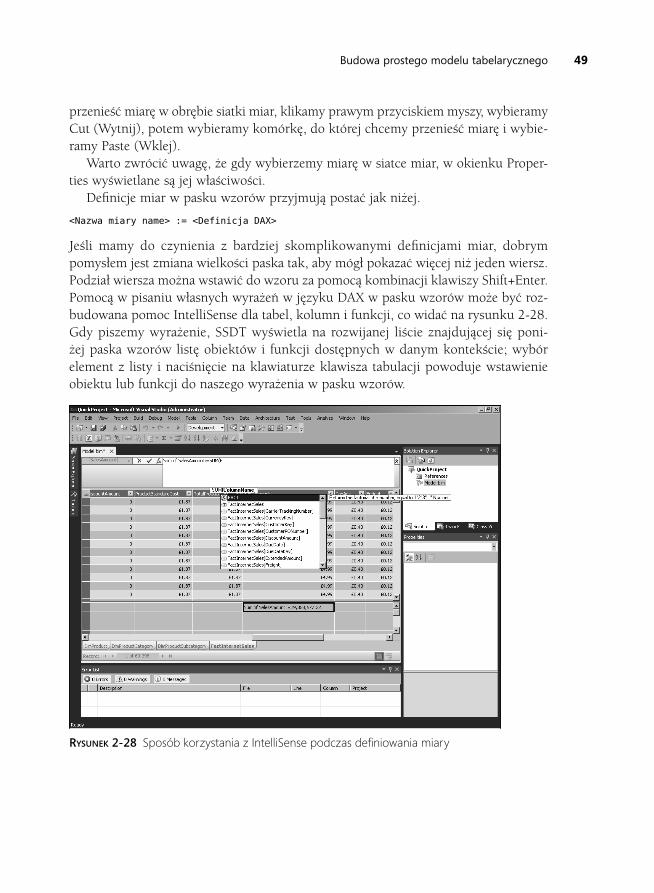
Budowa prostego modelu tabelarycznego 49
przenieść miarę w obrębie siatki miar, klikamy prawym przyciskiem myszy, wybieramy Cut (Wytnij), potem wybieramy komórkę, do której chcemy przenieść miarę i wybie-ramy Paste (Wklej).
Warto zwrócić uwagę, że gdy wybierzemy miarę w siatce miar, w okienku Proper-ties wyświetlane są jej właściwości.
Defi nicje miar w pasku wzorów przyjmują postać jak niżej.
<Nazwa miary name> := <Definicja DAX>
Jeśli mamy do czynienia z bardziej skomplikowanymi defi nicjami miar, dobrym pomysłem jest zmiana wielkości paska tak, aby mógł pokazać więcej niż jeden wiersz. Podział wiersza można wstawić do wzoru za pomocą kombinacji klawiszy Shift+Enter. Pomocą w pisaniu własnych wyrażeń w języku DAX w pasku wzorów może być roz-budowana pomoc IntelliSense dla tabel, kolumn i funkcji, co widać na rysunku 2-28. Gdy piszemy wyrażenie, SSDT wyświetla na rozwijanej liście znajdującej się poni-żej paska wzorów listę obiektów i funkcji dostępnych w danym kontekście; wybór element z listy i naciśnięcie na klawiaturze klawisza tabulacji powoduje wstawienie obiektu lub funkcji do naszego wyrażenia w pasku wzorów.
RYSUNEK 2-28 Sposób korzystania z IntelliSense podczas definiowania miary
##7#52#aSUZPUk1BVC1WaXJ0dWFsbw==
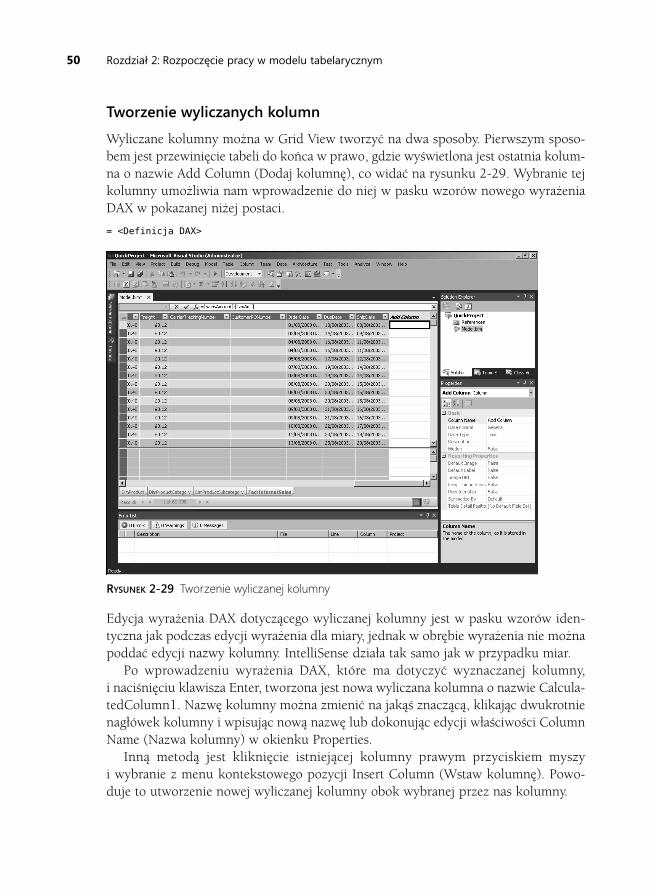
50 Rozdział 2: Rozpoczęcie pracy w modelu tabelarycznym
Tworzenie wyliczanych kolumn
Wyliczane kolumny można w Grid View tworzyć na dwa sposoby. Pierwszym sposo-bem jest przewinięcie tabeli do końca w prawo, gdzie wyświetlona jest ostatnia kolum-na o nazwie Add Column (Dodaj kolumnę), co widać na rysunku 2-29. Wybranie tej kolumny umożliwia nam wprowadzenie do niej w pasku wzorów nowego wyrażenia DAX w pokazanej niżej postaci.
= <Definicja DAX>
RYSUNEK 2-29 Tworzenie wyliczanej kolumny
Edycja wyrażenia DAX dotyczącego wyliczanej kolumny jest w pasku wzorów iden-tyczna jak podczas edycji wyrażenia dla miary, jednak w obrębie wyrażenia nie można poddać edycji nazwy kolumny. IntelliSense działa tak samo jak w przypadku miar.
Po wprowadzeniu wyrażenia DAX, które ma dotyczyć wyznaczanej kolumny, i naciśnięciu klawisza Enter, tworzona jest nowa wyliczana kolumna o nazwie Calcula-tedColumn1. Nazwę kolumny można zmienić na jakąś znaczącą, klikając dwukrotnie nagłówek kolumny i wpisując nową nazwę lub dokonując edycji właściwości Column Name (Nazwa kolumny) w okienku Properties.
Inną metodą jest kliknięcie istniejącej kolumny prawym przyciskiem myszy i wybranie z menu kontekstowego pozycji Insert Column (Wstaw kolumnę). Powo-duje to utworzenie nowej wyliczanej kolumny obok wybranej przez nas kolumny.
##7#52#aSUZPUk1BVC1WaXJ0dWFsbw==