
Neologia de importação no português europeu: desafios e medidas a tomar Organizadoras

• EL RANGO• LA DEVIACIÓN MEDIA• LA VARIANZA, DESVIACIÓN ESTÁNDAR• COEFICIENTE DE VARIACIÓN
*MEDIDAS DE DISPERSIÓNMEDIDAS DE DISPERSIÓN
Expositores:Yaglimir HernándezÁngel Herrera
San Nicolás de los Garza 30 de Enero 2015
• EL RANGO• LA DESVIACIÓN MEDIA• LA VARIANZA, DESVIACIÓN ESTÁNDAR• COEFICIENTE DE VARIACIÓN

1.- Conocer las diferentes medidas de dispersión, su uso y aplicaciones en estadística. Parte fundamental en el conocimiento de la variabilidad de los datos
2. - Cálculo de la desviación media
3. - Cálculo de la varianza y su medida correlativa, la desviación estándar
4. - El coeficiente de variación
5. - Diagramas de puntos y gráficos de tallo y hoja
6. - Cuartiles y percentiles
7. - Diagramas de caja
8. - Sesgo
OBJETIVOS

•También llamadas medidas de variabilidad, muestran la variabilidad de una distribución, indicando por medio de un número, si las diferentes puntuaciones de una variable están muy alejadas de la media.
•Cuanto mayor sea ese valor, mayor será la variabilidad, cuanto menor sea, más homogénea será a la media. •Así se sabe si todos los casos son parecidos o varían mucho entre ellos.
MEDIDAS DE DISPERSIÓN

Existen 3 medidas de la variabilidad utilizadas comúnmente en las ciencias del comportamiento:•Rango•Desviación estándar•Varianza

El Rango•Es la diferencia entre los datos máximo y mínimo de una distribución.
•Se emplea mucho en aplicaciones de control de procesos estadísticos (CPE), debido a que resulta fácil de calcular y entender.


Baton Rouge
R= 52 – 48
R= 4
Tucson
R= 60 – 40
R= 20

La varianza y la desviación estándar también se fundamentan en las desviaciones de
la media.
Sin embargo, en lugar de trabajar con el valor absoluto de las desviaciones,
la varianza y la desviación estándar lo hacen con el cuadrado de las desviaciones.

•La varianza •Es la media aritmética de las desviaciones de la media, elevadas al cuadrado.•Es no negativa y es cero sólo si todas las observaciones son las mismas.
•Las fórmulas de la varianza poblacional y la varianza de la muestra son ligeramente diferentes.
Varianza de la población
=Donde:• es la varianza de la población ( es la letra minúscula griega sigma); cuadrado.•X es el valor de una observación de la población.• es la media aritmética de la población.•N es el número de observaciones de la población.

•El proceso de cálculo de la varianza:•1. Comience por determinar la media.•2. Calcule la diferencia entre cada observación y la media, y eleve al cuadrado dicha diferencia.•3. Sume todas las diferencias elevadas al cuadrado.•4. Divida la suma de las diferencias elevadas al cuadrado entre el número de elementos de la población.

1. Para comenzar, es necesario determinar la media aritmética de la población.
= =
2. En seguida se calcula la diferencia entre la media y cada observación. Ésta se muestra en la tercera columna de la tabla.

3. El siguiente paso es elevar al cuadrado la diferencia entre cada valor mensual.
4. Se suman las diferencias elevadas al cuadrado. Es 1 488.
5. Finalmente, dividimos las diferencias elevadas al cuadrado por N, el número de observaciones que se realizaron.
=
Así, la variación de la población con respecto al número de multas es de 124.
•Se calculó que la varianza del número de multas levantadas en Beaufort County fue de 124. Si la varianza del número de multas aplicadas en Marlboro County, Carolina del Sur, es de 342.9, se concluye que: 1)Hay menos dispersión en la distribución del número de multas levantadas en
Beaufort (ya que 124 es menor que 342.9); 2)El número de infracciones en Beaufort County se encuentra más apiñado en torno
a la media de 29 que el número de multas levantadas en Marlboro County.
Por consiguiente, la media de multas aplicadas en Beaufort County constituye una medida de ubicación más representativa que la media de multas en Marlboro County.
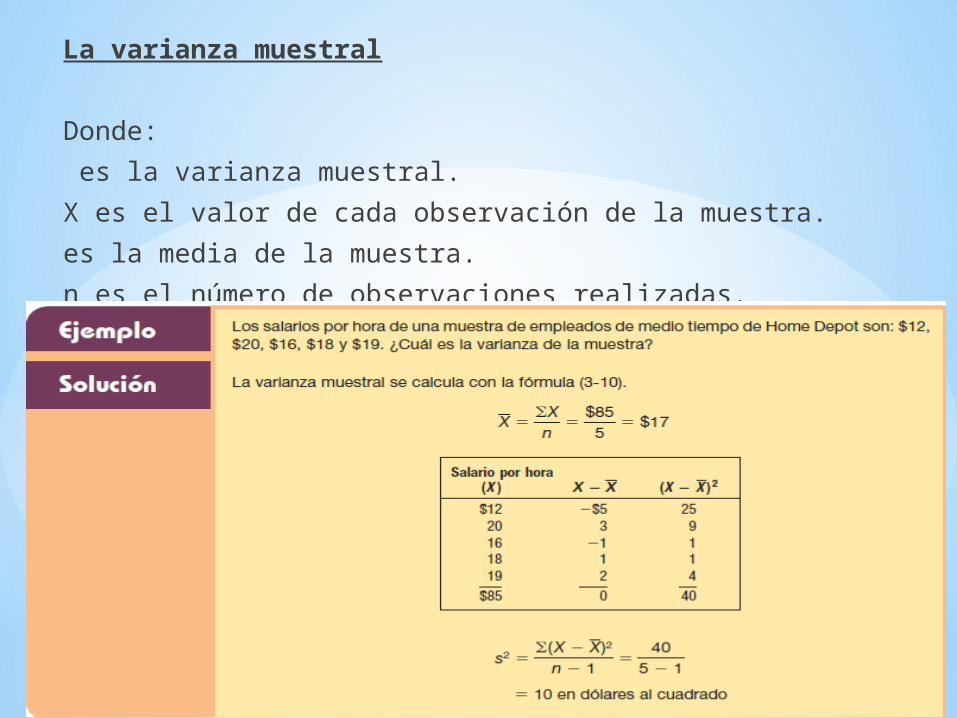
La varianza muestral
Donde: es la varianza muestral.X es el valor de cada observación de la muestra.es la media de la muestra.n es el número de observaciones realizadas.

Desviación estándarIndica que tan lejos esta el dato en bruto con respecto ala media de su distribución.
•La raíz cuadrada de la varianza de la población es la desviación estándar de la población. Y se expresa en las mismas unidades que los datos.

•La desviación estándar de la muestra es la raíz cuadrada de la varianza de la muestra.

Datos no agrupados
Varianza muestral

Propiedades de la desviación estándar.
Nos da una medida de la dispersión con respecto a la media.
La desviación estándar es sensible a cada dato de la distribución.
Al igual que la media, la desviación estándar es estable con respecto a las variaciones debidas al muestreo.

Mide la cantidad media respecto de la cual los valores de una población o muestra varían.
Donde:X es el valor de cada observación.es la media aritmética de los valores.n es el número de observaciones en la muestra.||indica el valor absoluto.
Cálculo de la desviación media
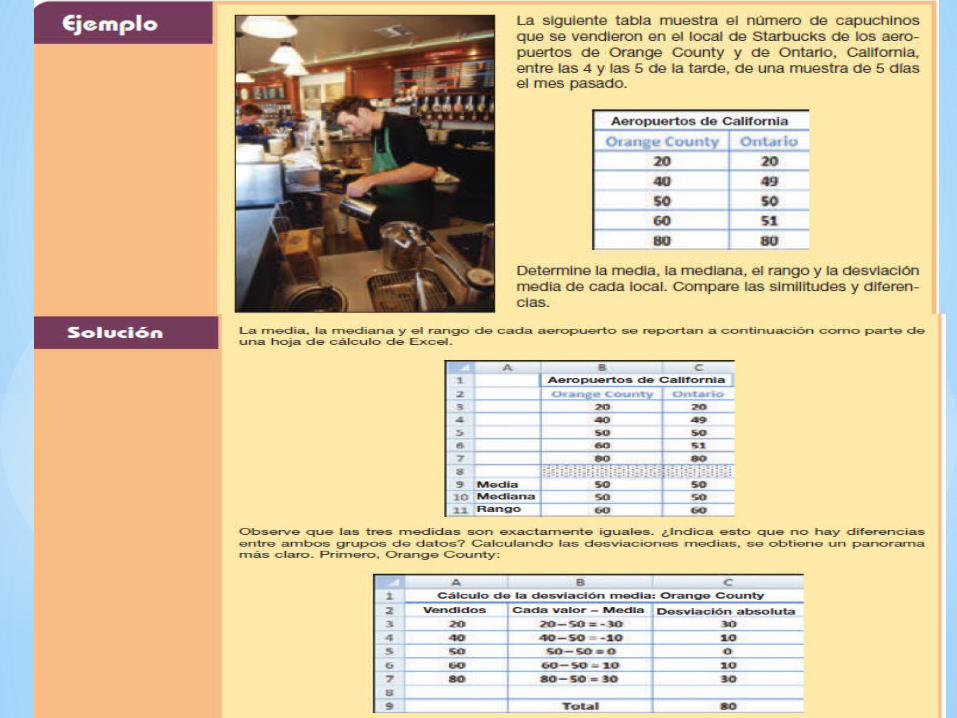


La suma de los cuadrados de las desviaciones respecto de la media = 256 Por tanto, siendo n 1 4, la varianza muestral es
Cálculo de la varianza y la desviación estándar


El teorema de Chebyshev establece lo siguiente:

•El coeficiente de variación es una medida relativa de la variabilidad; mide la desviación estándar en relación con la media.
CV=
El coeficiente de variación

Diagramas de Puntos
Programa Total de Estudiantes
Economía 12Sociología Rural 9
Estadística 5
Psicología 7
Presentan gráficamente tablas en las cuales se consideran 2 variables y una cantidad asociada a cada valor de las mismas.
Se presentan en el eje horizontal los valores de la variable y en el eje vertical los valores asociados a ésta.

Se ponen en el eje horizontal los valores de la variable y sobre cada valor se colocan tantos puntos como aparecen en éstos,
88 77 49 38 100 95 60 75 100 80
63 69 50 90 82 65 75 100 95 50
80 70 60 100 75 80 100 90 85 75

Diagrama de Tallo y Hoja
Es una herramienta que permite obtener una representación visual informativa de un conjunto de datos, para su elaboración es necesario separar para cada uno de los datos el último dígito de la derecha (hoja) del bloque de cifras restantes (tallo).
125 12 - 5 Tallo HojaLa tabla siguiente muestra
la resistencia a la compresión de 80 ejemplares de prueba de una aleación aluminio-litio.
105 221 183 186 121 181 180 14397 154 153 174 120 168 167 141245 228 174 199 181 158 176 110163 131 154 115 160 208 158 133207 180 190 193 194 133 156 123134 178 76 167 184 135 229 146218 157 101 171 165 172 158 169199 151 142 163 145 171 148 158160 175 149 87 160 237 150 135196 201 200 176 150 170 118 149

76 123 145 154 163 172 181 20087 131 146 156 163 174 183 20197 133 148 157 165 174 184 207101 133 149 158 167 175 186 208105 134 149 158 167 176 190 218110 135 150 158 168 176 193 221115 135 150 158 169 178 194 228118 141 151 160 170 180 196 229120 142 153 160 171 180 199 237121 143 154 160 171 181 199 245
Ordena de forma ascendente (de menor a mayor) los datos.
Se separa el último dígito de cada celda para identificar los tallos y las hojas.
7 6 12 3 14 5 15 4 16 3 17 2 18 1 20 08 7 13 1 14 6 15 6 16 3 17 4 18 3 20 19 7 13 3 14 8 15 7 16 5 17 4 18 4 20 710 1 13 3 14 9 15 8 16 7 17 5 18 6 20 810 5 13 4 14 9 15 8 16 7 17 6 19 0 21 811 0 13 5 15 0 15 8 16 8 17 6 19 3 22 111 5 13 5 15 0 15 8 16 9 17 8 19 4 22 811 8 14 1 15 1 16 0 17 0 18 0 19 6 22 912 0 14 2 15 3 16 0 17 1 18 0 19 9 23 712 1 14 3 15 4 16 0 17 1 18 1 19 9 24 5

Se separa el último dígito de cada celda para identificar los tallos y las hojas.
Tallo Hoja Frecuencia7 6 18 7 19 7 110 1 5 211 0 5 8 312 0 1 3 313 1 3 3 4 5 5 614 1 2 3 5 6 8 9 9 8
15 0 0 1 3 4 4 6 7 8 8 8 8 12
16 0 0 0 3 3 5 7 7 8 9 10
17 0 1 1 2 4 4 5 6 6 8 10
18 0 0 1 1 3 4 6 719 0 3 4 6 9 0 620 0 1 7 8 421 8 122 1 8 9 323 7 124 5 1

Cuartiles y Percentiles•Los cuartiles son los tres valores que dividen al conjunto de datos ordenados en cuatro partes
porcentualmente iguales.
- El primer cuartil Q 1 es el menor valor que es mayor que una cuarta parte de los datos (25%)- El segundo cuartil Q 2 (la mediana), es el menor valor que es mayor que la mitad de los datos- El tercer cuartil Q 3 es el menor valor que es mayor que tres cuartas partes de los datos (75%)
Donde:Li = limite inferior de la clase que lo contieneP = valor que representa la posición de la medidaf1 = la frecuencia de la clase que contiene el percentil solicitado.Fa-1 = frecuencia acumulada anterior a la que contiene la medida solicitada.I = intervalo de clase
= Li *I P = n/4

(I. de Clases) No. De Empleados
Salarios (f1) fa200-299 85 85300-399 90 175400-499 120 295500-599 70 365600-699 62 427700-800 36 463
= Li *I
Donde:Li = limite inferior de la clase que lo contieneP = valor que representa la posición de la medidaf1 = la frecuencia de la clase que contiene el percentil solicitado.Faa = frecuencia acumulada anterior a la que contiene la medida solicitada.I = intervalo de clase
P = n/4

(I. de Clases) No. De Empleados
Salarios (f1) fa200-299 85 85300-399 90 175400-499 120 295500-599 70 365600-699 62 427700-800 36 463
Para Datos No Agrupados:El primer cuartil: Cuando n es par: 1*n / 4 Cuando n es impar: 1(n+1) / 4
Para el tercer cuartil Cuando n es par: 3*n / 4 Cuando n es impar: 3(n+1) / 4
= Li *I
= Li *I P = 3n/4
P = 2n/4

Percentiles•Los percentiles son ciertos números que dividen la sucesión de datos ordenados en cien partes porcentualmente iguales. Estos son los 99 valores que dividen en cien partes iguales el conjunto de datos ordenados.
•Primer percentil, que supera al uno por ciento de los valores y es superado por el noventa y nueve por ciento restante
•Primer percentil, que supera al uno por ciento de los valores y es superado por el noventa y nueve por ciento restante
Donde:
Li = Límite real inferior de la clase del percentil kn = Número de datosFa = Frecuencia acumulada de la clase que antecede a la clase del percentil .fp = Frecuencia de la clase del decil kI = Longitud del intervalo de la clase del percentil.
= Li *I

Percentiles para Datos No Agrupados:
Si n es par: A * n / 10
Si n es impar: A (n+1) / 100
(A = al número de percentil que se desea buscar)

Diagramas de Caja•Los diagramas de Caja son una presentación visual que describe varias características importantes, al mismo tiempo, tales como la dispersión y simetría.•Se representan los tres cuartiles y los valores mínimo y máximo de los datos, sobre un rectángulo, alineado horizontal o verticalmente.•Una gráfica de este tipo consiste en una caja rectangular, donde los lados más largos muestran el recorrido intercuartílico. Este rectángulo está dividido por un segmento vertical que indica donde se posiciona la mediana y por lo tanto su relación con los cuartiles primero y tercero.•Esta caja se ubica a escala sobre un segmento que tiene como extremos los valores mínimo y máximo de la variable. Las líneas que sobresalen de la caja se llaman bigotes. Estos bigotes tienen tienen un límite de prolongación, de modo que cualquier dato o caso que no se encuentre dentro de este rango es marcado e identificado individualmente

Q1, el cuartil Primero es el valor mayor que el 25% de los valores de la distribución. Como N = 20 resulta que N/4 = 5; el primer cuartil es la media aritmética de dicho valor y el siguiente:
Q3 , el Tercer Cuartil, es el valor que sobrepasa al 75% de los valores de la distribución. En nuestro caso, como 3N / 4 = 15, resulta
Q2, el Segundo Cuartil es, evidentemente, la mediana de la distribución, es el valor de la variable que ocupa el lugar central en un conjunto de datos ordenados. Como N/2 =10 ; la mediana es la media aritmética de dicho valor y el siguiente:
Q2=(39 + 39) / 2 = 39
Q1=(24 + 25) / 2 = 24,5
me= Q2 = (33 + 34)/ 2 =33,5

-El bigote de la izquierda representa al colectivo de edades ( Xmín, Q1)-La primera parte de la caja a (Q1, Q2),-La segunda parte de la caja a (Q2, Q3) -El bigote de la derecha viene dado por (Q3, Xmáx).
•La parte izquierda de la caja es mayor que la de la derecha; ello quiere decir que las edades comprendidas entre el 25% y el 50% de la población está más dispersa que entre el 50% y el 75%.•El bigote de la izquierda (Xmín, Q1) es más corto que el de la derecha; por ello el 25% de los más jóvenes están más concentrados que el 25% de los mayores.•El rango intercuartílico = Q3 - Q1 = 14,5; es decir, el 50% de la población está comprendido en 14,5 años.

Una característica de un conjunto de datos es la forma. -Simétrica: simétrico de observaciones la media y la mediana son iguales, y los valores de datos se dispersan uniformemente en torno a estos valores. -Sesgo Positivo: si existe un solo pico y los valores se extienden mucho más allá a la derecha del pico que a la izquierda de éste. -Sesgo Negativo: “ derecha de éste. -Bimodal : Dos o más picos.
*Coeficiente de sesgo de Pearson:
Sesgo

Esto indica que existe un sesgo positivo moderado en los datos de las utilidades por acción. Cuando se utiliza el método del software resulta un valor similar, aunque no exactamente el mismo.

La conclusión es que los valores de las utilidades por acción se encuentran un tanto sesgadas positivamente.

•Estadística para las ciencias del comportamiento 5° Edición Robert R. Pagano
•Estadistica aplicada a los negocios y la economia 15° Edicion Lind, Marchal, Wathen
•Texto Estadística para las Ciencias Administrativas .Martinez, Ciro. Estadística y Muestreo. Ecoe Ediciones. Bogotá. 11ª. Edición
BIBLIOGRAFIA
Copyright © 2022 FDOKUMEN




















