
Necessary Roughness: Plato's "Phaedrus" and Apuleius' "Metamorphoses"
Upload
independentCategory
view
4download
0
Bryn Mawr Classical Review 03.01.12
Leonard Brandwood, The Chronology of Plato's Dialogues.Cambridge: Cambridge University Press, 1990. Pp. x + 256. ISBN0-521-39000-1.
Reviewed by Paul Keyser, University of Alberta.
Pythagoras said that the nature of all things is number (fr. 58 B 4, 8 DK6 = Arist. Metaph. 1.5[985b23–6a15, 987a9–10]), but Aristotle cautions that we must not expect more precision thanthe subject warrants (NE 1.3.1 [1094b12–4]). It is between these pillars that stylometry hasfallen; Brandwood hopes to set it right, for Plato at least, by dint of greater breadth. Alas, hefounders on a methodological rock, rarely perceived.
Although there is some evidence that the notions of measurement uncertainty (Thuc. 3.23, e.g.)and of combinatorics (Xenokrates apud Plut. QC 733a, Stoic Repugn. 1047c) had crossed theminds of Greek thinkers,1 and although the assigning of numerical values to letters and words(isopsephy) was a standard feature of Greek thought,2 it was apparently left for mid-XVIII cent.A.D. Swedish theological debates to prompt the analytic application of number to texts, first bya clergyman named Kumblaeus.3 With the development some decades later of modern statisticalmethods (by Gauss in 1801–9 in connection with the orbit of an asteroid4), the way was openedfor stylometry (though that name was coined much later). The theologian FriedrichSchleiermacher (1768–1834) in 1807 seems to have been the first to attempt the way, with theincidence of ‘hapax legomena’ in [Paul] I Timothy.5 As works on stylometry often wrongly citethe mathematician Augustus de Morgan as the pioneer, it is best to set the record straight here:6he suggested (in a letter of 18 Aug 1851 to the Rev. W. Heald) that measuring average word-length would enable one to determine which of the Pauline letters are authentic. Beginning in1867 with the work of Lewis Campbell (see below) stylometry was applied to Plato’s works,mostly with a view to establishing their chronology (for a few works, most infamously Letter 7,authorship is a question).
Brandwood’s book is a revision of his 1958 London U. doctoral dissertation, “The dating ofPlato's works by the stylistic method,” apparently delayed by the production of his great WordIndex to Plato (1976), and his recovery from a brain hemorrhage (p. x). In fact the revisions arenot great and some chapters reappear almost uerbatim (e.g., c. 2 on Campbell). Portions havebeen published elsewhere: the last chapter of the thesis (pp. 407–25), somewhat revised,appeared as “Analysing Plato’s style with an Electronic Computer,” BICS 3 (1956) 45–54, and,with further revisions, as c. 4 (pp. 50–65) of Mechanical Resolution of Linguistic Problems,Andrew D. Booth, L. Brandwood (still B.A.), and J. P. Cleave (New York/London 1958). On theother hand, some material has been added, notably cc. 21 and 22 (pp. 228–48), analysingstudies that appeared after the thesis (p. ix).
[He omits a number of studies which “seemed to be of slight significance” (p. ix, n. 3) — weought to have been given more than some of the authors’ surnames, and a sentence each (withprecise reference) would not have added much to the bulk. They are: P. Droste, De adjectivorumin -ειδής et in -ώδης desinentium apud Platonem usu (Diss. Marburg 1886) = pp. 60–7 of thesis;T. Lina, De praepositionum usu Platonico (Diss. Marburg 1889) = pp. 170–9 thesis; H.Kallenberg, “ὅτι und ὡς bei Plato als Hilfsmittel zur Bestimmung der Zeitfolge seinerSchriften,” RhM 68 (1913) 465–76 = pp. 373–6 thesis; and Andrew Fossum, “Hapax Legomenain Plato,” AJPhilol 52 (1931) 205–31 = pp. 377–81 thesis. In addition, from the appendix (pp.426–33), K. F. Nelz, De faciendi verborum usu Platonico (Diss. Bonn 1911), on πράττειv,πoιεῖv, δρᾶv, ἐργάζεσθαι, and ἀπoτελεῖv; A. Nolte, Sprachstatistische Beispiele aus denfrüheren Platonische Schriften (und aus Ariosts Orlando Furioso) (Göttingen 1914), not thejoke B. took it to be; and Yvonne Vanachter, “Un aspect du Style de Platon,” AntiquitéClassique 15 (1946) 83–95, on parts of speech (cited with approval by B. in BICS 3 (1956) 54 n.

12).]
The book takes the form of a brief introduction (2 pp.) on the external evidence and the statusquo ante, followed by 21 cc. summarizing various studies, arranged (in all but one case, c. 18)chronologically, and fitted with a brief conclusion (4 pp.) and a set of 4 brief indices (4 pp.). Thelack of a bibliography is mitigated by the treatment of the 22 studies in the individual chapters.Because the book is essentially a review of previous work, it must be covered in detail toappreciate B.’s accomplishment. In many cases the impression a reader would gain (that there isevidence for some particular view of the chronology or other) is wrong, and it is important totake the opportunity to correct these.
Lewis Campbell, The Sophistes and Politicus of Plato (Oxford 1867) was concerned with thedates of the two dialogues, and made six observations tending to date them late, of which B.suscepts two only (# 5 – ‘rhythmical cadence’ and # 6 – ‘unusual words’) to statistical treatmentor discussion (pp. 3–8).7 Why not # 4 ‘word order’?8 Campbell only grouped the Politicus andSophistes with other late works, and despite “errors of judgment” (p. 8) is praised for moderationin not overusing his figures. Campbell’s figures for vocabulary – still difficult to analysenumerically, though B. fails to explain this (cf. below on Dittenberger and μήv) – are computedas the number of words a given dialogue had in common exclusively with Tim., Crit., and Laws(considered as a set). Campbell conservatively noted the effect of subject matter andopportunity, and refrained from drawing detailed conclusions. As to rhythm, Campbell onlynoted and exampled the ‘peculiar, stately rhythm’ – here B. checks Campbell more carefully(relevant is B.’s own work on clausulae – see below) and concludes “Campbell had a flair forrecognizing important stylistic phenomena without drawing up anything like completestatistics for them” (p. 6). Friedrich Blass, in Die attische Beredsamkeit (Leipzig 1874) 2.426, remarked that Plato latertended more to avoid hiatus, and supported this with figures that are computed as number ofincidences of hiatus per Teubner-page. This gives an order: Laws I (29), Phil. (20), Tim. (6),Soph. (2), Pol. (1), where I have given the average number per ten Teubner-pages inparentheses. This is not the correct computation, for it takes no account of opportunity forhiatus (which will depend on the number of words in the text ending and beginning withvowels). B. sees the importance of Blass’ work in its confirmation of Campbell’s based on“entirely different methods” (well, at least a different measure). In fact Campbell’s onenumerical result gives for these works the order: Phil., Soph., Pol., Tim.-Crit.-Laws (the last threeassumed late and like), with others intervening – hardly “exactly the same conclusion” (pp. 9–10). Ignoring for the moment the problem of allowed or forbidden hiatus (and other details; cf.on Janell below), the proper way to count hiatus, taking opportunity into account, is as follows. Imagine, for the sake of simplicity, the case of only two vowels, say ε and o, which may be eitherfinal or initial, and let hiatus be the case where a word ends with ε/o and the following wordbegins with ε/o. Count all instances of each of the four possibilities, and we have the following‘contingency table’ (the counts are from Herodotos, done on the Ibycus computer from the TLGtext, which is that of the Budé edition):
Initial Final ε Final ο Totalε 2675 1104 28860ο 1384 542 13565
Total 17387 9422 In order to calculate how many cases of ε#ε (where I use # to indicate a word-boundary = space)we could expect, assume word-placement is uncorrelated with (i.e., independent of) whether ornot the word ends in or begins with ε (i.e., assume it is random), and then the chance of an ε-initial word would be E/N, where E (here = 28860) is the number of ε-initial words in the text,and N (here = 185578) is the total number of words in the text. The chance that an ε-initial wordwould follow an ε-final word would then be just the number of ε-final words times the chance ofan ε-initial word, or (eE / N), where e (here e = 17387) is the number of ε-final words in the text. When this is done for all the entries, we find for the contingency table:
Initial Final ε Final οε 2675 / 2704 1104 / 1465ο 1384 / 1271 542 / 689
where I have written the ratios as “Observed / Expected” (= n/N). These ratios can be evaluated

for significance in a number of ways; the simplest which can be readily justified is to computethe decimal value of the ratio n/N, and its uncertainty σ in the usual way (σ2 = [1/n + 1/N][n2/N2]),9 and then to evaluate the deviation from a decimal ratio of 1.000 (“no avoidance”) inthe usual way.10 This gives:
Initial Final ε (‰) Final ο (‰)ε 989 ± 27 754 ± 30ο 1089 ± 42 787 ± 45
where the figures are promill (‰, that is, the decimal ratio of observed to expected number ofcases of ε#ε is 0.989 ± 0.027). The deviation of ε#ο (1089 ± 42) from 1000 is not verysignificant: the z-score is (1089 – 1000)/42 = 2.1, or a P = 96 % probability of significance(which is considered marginal by most statisticians). Similarly, the deviation of ε#ε has z = -0.4(usually the sign, negative or positive, of z is not meaningful), or P = 31 % of significance (i.e.,surely not significant). But for o#ε and o#o the z-scores are 8.2 and 4.7 (suppressing as usualhereinafter the sign), or the probability of insignificance (often written P') is respectively about 1in a trillion and 3 in a million. In fact, when I examined the complete 7 x 7 contingency table,11 it appeared that mostcombinations were not significantly different from a unit ratio, but that 12 cases (α#α, α#o,α#ω, ι#ω, o#α, o#ε, o#η, o#o, υ#ε, υ#o, υ#ω, and ω#α) were ‘avoided’. Overall, collectingobserveds and expecteds, we find a decimal ratio of 932 ± 46 ‰ (promill12), with a z-score of1.5 (P = 87 %). It is probably fair to conclude that if Herodotos avoided hiatus he did so weaklyand erratically (and was it conscious?). Doing the same thing for six prose authors gave(promill):
Herodotos 932 ± 46Thucydides 880 ± 52Xenophon 758 ± 29
Plato 689 ± 20Aristotle 719 ± 17Polybios 79 ± 11
This shows a steady but not monotone decrease, though it is doubtful if this alone coulddistinguish even between Herodotos and Thucydides or between Plato and Aristotle(Thucydides and Aristotle are different at z = 2.9 or P = 99.6%, Polybios quite different fromanyone). For Xenophon, some further special tests were made. First, with “A” = Anab. and Hell., and “B”= Mem., Oec., Symp., and Apol. (to test for genre-dependence), we find Xen.(A) = 865 ± 46 andXen.(B) = 817 ± 69, with almost no chance of the difference being significant. Second, it wasnoted that hiatus with like vowels (α#α, ε#ε, etc. – the diagonal entries of the 7 x 7 matrix) wasmore strongly avoided (much more so in the B subset than in the A subset): Xen.(mixed vowels)= 782 ± 29, Xen.(like vowels) = 596 ± 24, with a z = 4.9, or P' the probability of insignificance isabout 1 in a million (such an effect was not observed in the other authors).13
Finally, for Plato, one pair of works was compared, Laws and Rep., and we find:
Plato, Rep. = 768 ± 54Plato, Laws = 519 ± 45
where the rates of hiatus are significantly different (z = 3.5, P' about 5 in a ten thousand). Sothere is a decrease (assuming Laws is after Rep.), but is it monotone, or some more complicatedfunction of time, subject, and even style sensu latiore? This (and a great deal more work likethis) is how it should be done. W. Dittenberger, “Sprachliche Kriterien für die Chronologie der platonischen Dialoge,”Hermes 16 (1881) 321–45, investigated the occurrences of various uses of μήv (pp. 11–22). Inparticular τί μήv; (as an affirmative reply), γε μήv and ἀλλὰ … μήv appear only in Symp., Lys.,Phdr., Rep., Parm., Phil., Soph., Pol., Laws, Tim., and Crit. (Ritter later noted that oὐ μήv appearsalso only in this group).14 Ritter noted a difficulty (which inheres in any vocabulary-based

measure) – in essence, with respect to what does one count? Dittenberger counted with respectto pages of text, but this does not take into account the opportunities (equivalently, theexpected rate), and Ritter preferred to find the total number of occurrences of replies anddetermine what fraction of these were γε μήv or whichever (p. 17 – and see below). Dittenbergertried to confirm his result with a study of the use of μήv in other Attic authors (pp. 13–14). Frederking (and Kugler) noted that the distribution of the various uses of μήv appeared to varywithin works (p. 17). Dittenberger then examined Plato's use of comparative particles (ὥσπερand καθάπερ), but the results are fuzzy at best (pp. 19–20). B. tries (p. 19) to make them more precise by noting a decreasing rate, counted as uses per page,in going from Euthd., Meno, Gorg., Crat., Phdo., Symp., Lysis (0.80) to Phdr., Rep., Theaet.(0.61), and thence to Parm., Phil., Soph., Pol., Tim., Crit., and Laws (0.40). In forming thesegroups, B. has begged the question (he uses a presumed approximate chronological order), hehas counted not with respect to total number of replies (cf. above), and in comparing the threenumbers he claims a clear trend – but he fails to determine whether it is in fact statisticallysignificant. Briefly the uncertainty σ for each ratio would be respectively 0.80 ± 0.15, 0.61 ±0.08, and 0.40 ± 0.07, and the level of significance of the pairwise differences would be z = 1.1(73 %) and z = 2.0 (95 %).15 That is, those are the probabilities that the difference is significant– and most statisticians would consider anything less than 95 % (I and most physicists prefer 99%) as insignificant. B. calculates (pp. 21–22) various ratios, which suffer from the same defect. Still, it is fair to say that Dittenberger showed that something was going on, as revealed by therelative rates of the use of certain particles. A. Frederking, “Sprachliche Kriterien für die Chronologie der platonischen Dialoge,” NeueJahrbücher für Philologie 125 (1882) 534–41, attempted to limit Dittenberger’s work bynoting that particle use varies for many reasons, and does so within a work (pp. 23–7). That is,he was concerned about what a statistician would call the stability of the tests being used: a veryimportant but usually neglected issue (cf. the Conclusion). He examined the use of γε μήvwithin the Laws, and τί μήv; in the Laws and Rep. (above), as well as δέ γε, unaccompanied τε(i.e., without corresponding καί, τε, or oὐτε), μῶv, and even εἶπov. When B. analyses earlierwork carefully he generally includes helpful tables (such as for Dittenberger’s μήv-statistics) –here he includes none, which obscures Frederking’s point. But the point is stated clearly (p. 27)– “the danger of making hasty deductions from insufficient material.” F. X. Kugler, De particulae τoι eiusque compositorum apud Platonem usu (Diss. Basel 1886),showed in a similar way that the use of τoι varied considerably even within a work (pp. 28–33). Here again the problem of with respect to what to count arises. Kugler considered the ratio ofμέvτoι to τoίvυv (but both are absent from Tim. and Crit., and οὖν appears instead of the latter),but (though B. does not say so) the numbers are too small to give statistically significantdifferences in many cases. E.g., to pick clearer cases, Crat. gives 0.72 ± 0.20 and Phdo. 1.80 ±0.50, which has just a 95 % probability of significance (i.e., by the usual test, just barely);16
Theaet. has 1.03 ± 0.23, not significantly different from either; Phil. and the Pol. have each 0.15± 0.06, and the Soph. 0.24 ± 0.07. Lumping all books of Laws and of Rep. each together givesrespectively 0.14 ± 0.04 and 0.77 ± 0.10 (none of these figures are given by B. nor is hisdiscussion clear).17 Now if we assume that the Laws is late and order these results accordingly,we get:18
Phdo. = 1.80 ± 0.50Theaet. = 1.03 ± 0.23Rep. = 0.77 ± 0.10Crat. = 0.72 ± 0.20Soph. = 0.24 ± 0.07Phil. = 0.15 ± 0.06Laws = 0.14 ± 0.04
A trend is clear (and even significant, overall),19 but is it meaningful? (Kugler also counted thetotal number of τoι-compounds per Stephanus-page, less correctly, as that does not takeopportunity into account: cf. B., p. 32). Is it correct here to examine ratios rather than simpledifferences? And is it correct to consider these two τoι-compounds as effective synonyms? ButKugler’s point, which B. unnecessarily disparages (it is more than “a Frederking-inspired joke atthe expense of Dittenberger and all prospective ‘stylometricians’”), is correct – “no one shoulddraw such important conclusions as Dittenberger has done on the evidence of one or two

particles” (p. 32). Morris Schanz, “Zur Entwicklung des platonischen Stils,” Hermes 21 (1886) 439–59, studiedPlato’s use of several synonyms to express ‘really’ or ‘truly’ (in contrast to ‘seemingly’ uel sim.):τῷ ὄvτι and ὄvτως as well as ὡς ἀληθῶς, τῇ ἀληθείᾳ, ἀληθῶς, and ἀληθείᾳ (pp. 34–40). Herethe difficulty is again: with respect to what to count? To take a few clearer cases, Gorg. has 17τῷ ὄvτι and no ὄvτως, Phdr. has 8 to 6, and Phil. has no τῷ ὄvτι and 15 ὄvτως – if we assume itis correct to take simple differences, the trend is quite significant. Given the Laws with 52ὄvτως and no τῷ ὄvτι, it may be meaningful as well. One could add the Gorg. with 9 τῷ ὄvτιand no ὄvτως, the Rep. with 41 to 9, the Soph. with 1 to 22, and the Phil. and Pol. with none to11 and none to 8 respectively. (The figures for ἀληθ- are less clear.) In summary, given theassumption the Laws are late, a probable order Gorg. and Phdo.; then Rep.; then Phdr.; thenTim., Pol., Phil., Soph., and Laws (where the groups separated by semicola could be defendedstatistically). Schanz himself attempted much finer distinctions, which cannot be supported bythe statistics, though B. discusses a number of them. E. Walbe, Syntaxis Platonicae Specimen (Diss. Bonn 1888), investigated πᾶς and compounds(pp. 41–7). He found that Plato’s use of σύμπας / συvάπας increased over time (much largernumber in Soph., Pol., Phil., Tim., Crit., and Laws), but that πᾶς was irregular. B. notes (p. 44)that various other factors (subject, hiatus, rhythm) play a role. B. following Lutosławskicalculates the number of πᾶς, etc. per standard page of text (which as noted above is notcorrect), and does so also for individual books of Laws and Rep. Although B. does not explorethis, it is relatively clear that, in so far as such a number is accurate, the data can be naturallygrouped into two sets (all the others versus the six dialogues listed just above) with averagevalues of 2.16 ± 0.37 uses of πᾶς per Stephanus page and 4.14 ± 0.47 per Stephanus pagerespectively (giving a z = 3.3, or P = 99.9 % probability of significance).20 The variationbetween books of the Rep. and between books of the Laws is large but stays within the limitsexpected based on the above averages: 2.12 ± 0.49 for Rep. and 3.97 ± 0.86 for Laws. That thevariation should be so much larger (given that the Rep. and Laws are the two largest works andso should have the smallest merely statistical variation) suggests either that both works werewritten over a long period (as Siebeck, Janell and others have suggested, at least for Rep. I – seebelow – which indeed is rather lower), or that the measure is not a stable one. B. correctly notesthat one can only draw “the broadest conclusions” from these data (p. 44), but then tries tocanvass various details (pp. 46–7). H. Siebeck, Untersuchungen zur Philosophie der Griechen (Halle 1888), in an appendix,examined Plato’s use of question and reply formulae (pp. 48–54). B. found that Siebeck’sfigures for the number of simple direct questions introduced with ἆρα were often wrong (totalnumber of simple direct questions was not checked); but he does not note that the percentagegives an order rather different than B.’s table would suggest (the table is B.’s arrangement – p.49, n. 2). We find (with B.’s corrected percentages, and omitting a few dialogues for which thepercentage would have a large σ):21
Meno = 11 ± 3Gorg. = 13 ± 2Euthd. = 16 ± 3Theaet. = 18 ± 3Prot. = 19 ± 4Rep. = 21 ± 2Phdo. = 22 ± 4Crat. = 24 ± 4Lysis = 25 ± 6Soph. = 29 ± 5Parm. = 29 ± 4Laws = 39 ± 4Phil. = 35 ± 5Pol. = 36 ± 7
B. has failed to analyze these data statistically, and so misses a number of points. First, none ofthe sections of the Rep. is statistically significantly different from any other (Rep. I = 16 ± 4,Rep. V–VIIII = 20 ± 2, Rep. X = 23 ± 7, Rep. II–IIII = 24 ± 3) so there is no reason to enter themseparately here. Second, no statistically significant grouping of dialogues can be made from the

results. But third, the smooth trend is itself significant. Siebeck collected numerous types ofassent and divided them into three (rather fuzzy) classes, and claimed to be able to see a weaktrend away from problematic affirmatives (such as oἶμαι) toward apodictic affirmatives (such asδῆλov). Siebeck acknowledged that other factors would influence this (p. 52) and B. notes thatthe classification itself is a problem (p. 53). Again B. canvasses various details none of whichcan be supported from the data (p. 54). Conrad Ritter, Untersuchungen über Platon (Stuttgart 1888), “was the first to write a book onthe stylistic method” as applied to Platonic chronology, and B. rightly devotes over 30 pages toit (pp. 55–86). Ritter investigated the use of reply formulae and other expressions, which B.summarizes in two dense tables (also included are Dittenberger’s work on ὥσπερ etc. andSchanz on ὄvτ- and ἀληθ-). B. notes the difficulty of counting such formulae (ἀληθῆ λέγειςappears also as ἀ. μέvτoι λ., τoῦτo μὲv ἀ. λ., πάvυ μὲv oὖv ἀ. λ., etc.), and it is not always clearwhich variants to include; at any rate B. notes that Ritter apparently did not include all formsand counted those he did include erratically (pp. 55–6). Now the numbers are all relativelysmall (the largest single entry is 220 “Answers by means of a repetition” in Rep., and most are 5to 10 times smaller), but neither Ritter nor B. listed all passages cited (say in an appendix) –which would allow later workers to check and improve the results. As it is, all the work must bedone anew; even B. only checked some results (p. 56). Ritter recognized the need to countoccurrences with respect to the number of opportunities, but for reply formulae there is thedifficulty that not every occurrence of some reply is an opportunity for any other reply (p. 57). So instead Ritter took as the base not the number of opportunities for a reply of similar meaning,rather all “reply formulae which are repeated with some frequency, together with a few which aresporadic but closely related to the former.” Ritter sought to confirm the conclusions of Dittenberger and Schanz that Soph., Pol., Phil., Tim.,Crit., and Laws form a late group, and came up with 45 results that seemed to show this. Someare clearer than others. For example (# 1) “ἔγωγε, ἔμoιγε δoκεῖ” is rarer,22 while (# 2) “ὀρθῶς,ὀρθότατα (λέγεις), ἀληθέστατα” are commoner (p. 57). True enough but putting it so obscuresthe facts. From B.’s figures (Table 10.1, p. 58) we find that “ἔγωγε, etc.” averages 16 ± 4 % ofthe total of reply formulae in Lach., Charm., Euthd., Crat., Euph., Gorg., and Meno (results forProt., Apol., Crito, and Symp. show larger σ’s and are hence excluded),23 while for Soph., Pol.,Phil., Tim., and Laws the average is 0.5 ± 0.4 %, effectively zero (Crit. figures are not given byB.). But for the Phdr. we find 1.4 ± 1.4 %, consistent with the late group (z = 0.6 or P = 46 % ofdifference), and very different from the ‘early’ group (z = 3.4 or P' = 1 in a thousand); while forPhdo., Theaet., and Rep. we find 6.3 ± 1.1 %, very different from the ‘early’ group (P' = 2 %), andfar more different from the late group (P' about 1 in a trillion); and the Phdr. is far less likely tobelong to this ‘middle’ group (P' about 1 in a thousand) than to the ‘late’ group. Thus we findthe proper grouping based on ἔγωγε, etc.24
16 ± 4 %: ‘Early’ (Lach., Charm., Euthd., Crat., Euph., Gorg., Meno) 6.3 ± 1.1 %: ‘Middle’ (Phdo., Theaet., Rep.)0.52 ± 0.45 %: ‘Late’ (Phdr., Soph., Pol., Phil., Tim., Laws) This is rather different than what one would gather from B.’s discussion (p. 57) and Table (10.1,p. 58). Similar remarks could be made for results #7, #8 (p. 63 + Table 10.1 = p. 58: vαί andπάvυ uel sim. – again B.’s labels are inconsistent, nor does he provide ratios), #13 (p. 63 + Table10.1 = p. 59: answer by repetition with γάρ or γὰρ oὖv – no ratios), #25 (p. 65 + Table 10.2 = p.60: δῆλov ὡς versus δῆλov ὅτι – no ratios) perhaps, #34–5 (p. 65 + Table 10.2 = p. 60: εἴρηταιuel sim. in referential relatives – no ratios), possibly #42 (p. 66 + table 10.2 = p. 61: πότερα/ov –no ratios), and #45 (p. 66 + Table 10.2 = p. 61: χάριv/ἕvεκα – no ratios). For some of these onecould readily figure the required ratios, for others it would be rather harder; for the remainder ofthe tests, the numbers are too small to yield much. Now comes the difficulty, faced but not solved already by Campbell, but far more acute forRitter – how to combine many different results which may not precisely agree? That is, whatrelative weight do we give to, say, the decreasing tendency to use ἔγωγε, etc., and, say, the shiftfrom πάvυ γε to πάvυ μὲv oὖv ?25 Ritter simply counts each feature as found or not found, andcomputes thereby a number that varies from 1 (Euph.) to 42 (Laws), except for Tim. and Crit.which are computed differently (pp. 66–7). In 1888, this may have been reasonable – a century

later B. ought to have told us that such things could be properly done by any of a number oftechniques of multivariate analysis (as in c. 22 – see below). Ritter was also concerned toestablish the unity of the Rep. (pp. 67–74, 79–81), and the chronological order of dialogueswithin his three groups (pp. 74–8, 82–3), and the question of the suspected works (pp. 83–6). Authenticity is for us here a separate question; while B. notes (p. 77) Ritter’s figures aregenerally not adequate to make such fine distinctions.26 Ritter concluded that, so far as hisnumber of characteristic expressions method could tell, the ten books of the Rep. are more orless identical (B. confirms this by taking pairwise averages to reduce variation due to varyingbook-length – effectively a moving average) – both Ritter and B. allow for the possibility thatBook I may differ (i.e., be earlier). J. Tiemann, “Zum Sprachgebrauch Platos,” Wochenschrift für klassische Philologie 6 (1889)248–53, 362–6, 556–9, “Einige formelhafte Wendungen bei Plato” idem 586–9, and a reviewof Ritter, idem 791–7, 839–42, wrote primarily to correct and clarify Ritter (pp. 87–91). Mostof his results are details depending on small numbers (as B. notes p. 89), though the use ofsuperlatives in reply formulae seems pretty clearly higher in Phdo., Theaet., Rep., Soph., Pol.,Phil., and Laws than in other works (so the Table 11.1, p. 88, though Tiemann and B. put itdifferently and not quite rightly). G. B. Hussey, “On the Use of Certain Verbs of Saying in Plato,” American Journal ofPhilology 10 (1889) 437–444, examined certain forms of verbs which Plato used to refer tosomething already said (in an argument) in the dialogue (pp. 92–5). He noted an increasingpercentage of the use of (ἐρ)ρήθ- and (ἐ)λεχθ-, though again the actual figures suggest an orderrather different than he (or B.) saw. Percentages from B.’s table (p. 92), using all the forms (asHussey intended and as seems reasonable from the consistency of the different numbers), are asfollows:
Gorg. = 2.6 ± 1.9Theaet. = 13 ± 6 Rep. = 14 ± 3 Symp. = 14 ± 7 Phdo. = 18 ± 7 Phdr. = 21 ± 8 Soph. = 23 ± 7 Laws = 25 ± 3 Phil. = 27 ± 6
Tim. = 46 ± 13 Pol. = 48 ± 9
where the first (Gorg.) and the last two (Tim. and Pol.) are the two groups one could validlyseparate from the others (B.’s own figures would give for the last seven the order Soph., Phdr.,Theaet., Phil., Laws; then Tim., Pol. – only roughly the same). Hans von Arnim, De Platonis Dialogis Quaestiones Chronologicae (Vorlesungsverzeichnisder U. Rostock für das Winter-Semester 1896), investigated reply formulae, apparentlyunaware of Ritter’s work (pp. 96–114). He divided reply formulae into five classes: 1) emphaticadverbs with particle, 2) expressing agreement and admitting truth, 3) adverb with ellipsis ofverb, 4) verbs expressing seeming or supposing, with adverb, 5) rhetorical questions. But theresults fluctuated in a way inconsistent with the then-agreed order of groups of dialogues. Onecould make an important point (which B. fails to note): even granting that the Laws was Plato’slast work (itself perhaps dubious – recall Ledger’s claim), how are we sure that Plato’s style, inso far as it is measurable by stylometry, changed monotonically over time till he attained thestyle of the Laws? Yet Arnim and B. here reject the apparent ups and downs (themselves onlyapparent given a previously-assumed or established order) in favor of the monotone hypothesis. Warning bells ought to have rung (as they should have, albeit more faintly, on the comparisonof almost any pair of previous results), for Arnim and for B. But B. only notes that “as regardsthe dialogues of the first period Arnim picks and chooses his evidence” (p. 108) – important butnot sufficient. For the percentage of rhetorical-question replies (pp. 102–3) and for thepercentage of πoῖov-uel sim. replies (p. 104) B. gives figures: although without uncertainties;but his Tables 13.1 (pp. 110–1) and 13.2 (pp. 112–4) allow us to compute the very necessaryσ’s. We find for rhetorical-question replies:27
5.2 ± 2.2 %: ‘Early’ (Charm., Lach., Hipp.Mi., Euthd., Meno, Gorg., Crat., Phdo.)

13.0 ± 2.4 %: ‘Middle’ (Crito, Euph., Lysis, Theaet., Parm., Rep.) 23.1 ± 3.5 %: ‘Late’ (Phdr., Phil., Soph., Pol., Laws)The dialogues grouped together are statistically indistinguishable; the pairs ‘Early’ / ‘Middle’and ‘Middle’ / ‘Late’ have a 98% probability of being significantly different. In the secondcase, for πoῖov-uel sim., we find similar results (but fewer dialogues give figures at all). There isno particular reason to believe that any of these differences necessarily correspond tochronology. Within the Rep. and the Laws we can do likewise and compare percentage ofrhetorical-question replies for each book (B. gives figures, p. 114 in Table 13.2, but notpercentages: pp. 105–7). Even the two most different books of the Rep. (V with 8 ± 3 % and VIwith 19 ± 6 %) have only a 90 % probability of being different (as noted above regardingDittenberger, 95 % or even 99 % is usually considered the minimum for significance), and whenthe other books falling between these two are considered, there is no reason, on the basis ofrhetorical-question replies, to separate the Rep. Similarly, in the Laws the two most differentbooks (VI with 39 ± 14 % and X with 12 ± 5 %)28 have only a 92 % probability of beingdifferent, and again the intermediate books militate against any separation on this basis. Thushave Rep. and Laws been included in their respective groups above (Rep. alone has 13.5 ± 1.3%, Laws alone 25.5 ± 2.8 %, the highest in its group, but not significantly so). C. Baron, “Contributions à la chronologie des dialogues de Platon,” RÉG 10 (1897) 264–78,examined anastrophe of περί (pp. 115–22). Baron wisely sought to calculate ratios of πέρι toπερί (equivalently, ratios of ΠΕΡI after to ΠΕΡI before its object), and eliminate fromconsideration phrases in which anastrophe was thought to be impossible or rare (περὶ πoλλoῦ[uel sim.] πoιεῖσθαι and περί in a prepositional phrase qualifying a substantive or substantivalarticle). B. corrects Baron’s figures at many points and agrees with Baron that Plato used πέριmore with passing time, but “several works have been placed in a group to which they do notbelong on a mechanical interpretation of their frequency figures” (pp. 116–7). But B. places thedialogues in order as determined from the corrected percentages (of πέρι/περι-total), deductingonly π. π. π. – again without σ’s. When we compute these we find that the apparent smoothincrease (Table 14.2, p. 121) is so smooth and the σ’s sufficiently large that even the Rep. andthe Laws are not certainly distinguishable. One could make some use of the results (by, say,one-dimensional cluster analysis – a technique familiar to B. from his work on Wishart andLeach, see below), and could one combine these results with independent measures (replyformulae, e.g.) by means of multivariate analysis they could add to the evidence, but as theystand it is probably going too far to say as B. does “the works which exhibit the highestincidence of anastrophe are precisely those placed by earlier investigators in the middle and latechronological groups.” Wincenty Lutosławski, The Origin and Growth of Plato’s Logic (London 1897), c. 3 (pp. 64–193), a most unusual man, 29 investigated 500 (sic) stylistic features, on the assumption that allof Soph., Pol., Phil., Tim., Crit., and Laws were late, in order to establish incontrovertibly aframework of Platonic chronology (pp. 123–35). B. wisely does not review every feature. Lutosławski’s approach is, as B. notes, flawed by his very peculiar mathematical treatment. Lutosławski computes units of stylistic affinity, where a characteristic of the later style is givena value for a particular dialogue depending on how often it is found therein (once evaluates as 1,a few times depending on length of dialogue evaluates as 2, a few more times as 3, more thanonce every two Didot-pages as 4). E.g., to borrow from von Arnim, when a rhetorical question asa response to a direct question occurs twice in Crito it has a value of 2, but it evaluates as 3 inGorg. where it occurs 16 times (but had it occurred only 5 times in Gorg. it would still have hada value of 3). Then the dialogues closest in ‘value’ to the Laws (etc.) are assumed closest theretoin time. There are other rules, but B. has made it clear that the procedure is arbitrary, and henceunreliable. What B. does not do is evaluate adequately the features suggested by Lutosławski. B.’s evaluation (pp. 132–5) does indicate a number of important and valid criticisms – but heleaves us with 161 “acceptable” characteristics, without telling us anything positive about them(only that they are not to be ignored). It is Lutosławski who seems to have coined the term“stylometry” (p. 130), so one at least of his contributions has endured. I suspect many (B. wouldallow “less than a hundred”) of Lutosławski’s proposed characteristics are worth reinvestigating. P. Natorp, “Untersuchungen über Plato’s Phaedrus und Theaetet,” Archiv für Geschichte derPhilosophie 12 (1899) 1–49, 159–86, and 13 (1900) 1–22, attempted to refute the roughconsensus on Plato’s chronology that had emerged via stylometry (because it conflicted with his

view of Plato’s philosophical development; pp. 136–52). Natorp made use, as had earlierworkers, of vocabulary figures – which (as B. notes, p. 152) depend heavily on subject. Hiscalculations, like those of Campbell, indicated ‘lexical affinity’ to the Laws, Tim., and Crit. bycomputing the number of words a given dialogue had in common with that set of assumed latedialogues, and computing a ratio per page (Didot, see Table 16.2). He also computed similar‘affinities’ for all dialogues with each of them (thus approaching the idea of numericaltaxonomy – see below). I would not spend so much time on Natorp as B. has done, since(however one proceeds numerically) there is a fundamental flaw in the procedure – vocabulary(so difficult to count in any case) is very context-dependent unless the stylometer choosescarefully indeed. Natorp did not publish the 1,949 words on which he based his work (p. 152). There is a better way, related to the problem of the unseen species in biological trappingproblems, which has been applied to Shakespeare.30
Walter Janell, “Quaestiones Platonicae,” Jahrbücher für classische Philologie S. 26 (1901)263–336, returned to hiatus in greater detail (pp. 153–66). His first task was to differentiatebetween permissible and impermissible hiatus, which he did primarily in a somewhat intuitivefashion (e.g., αὕτη ἡ is permissible since their separation “would be somewhat harsh”) and in adefinitely circular fashion – those types of hiatus found considerably more often than the rest inSoph., Pol., Tim., Crit., and Laws are permissible (but is not that what Janell was trying tomeasure: Plato’s changing avoidance of hiatus?). What he found, as B. makes clear, was thatPlato considered hiatus within a phrase or at a pause objectionable, but not with καί, the article,περί, μή, δή, ἤ with following, τί or τι, ἄv with preceding relative, εἰ with following, ὦ withfollowing, πρό, and εὖ in combination with the following verb. What he failed to do, which B.fails to note, is to count cases of hiatus with respect to opportunities for hiatus. For example,there are 130 instances of hiatus with καί in the Soph., but 222 in the Pol. – should we divide bythe number of (Didot) pages (as Janell and B. do), giving respectively 39.6 and 43.2, and soconclude that hiatus with καί is less frequent in the Soph. (3.28) than in the Pol. (5.14)? Orshould we count all forms of “allowable” hiatus in Soph. (347) and in Pol. (308), divide by(Didot) pages and conclude that allowable hiatus is more frequent in the Soph. (8.76) than in thePol. (7.13)? In fact Janell and B. count instances of objectionable hiatus and note that thenumber per page ranges from 46 (Laches) smoothly down to 28 (Menex.), but is much lower forLaws, Phil., Epin., Tim., Crit., Soph., and Pol. (8 or 9 down to less than 1). Since the distinction between objectionable (within a phrase or at a pause) and allowable (withthe words listed above) seems clear (whether or not Plato would have conceived it this way), andalthough the method of counting is flawed, the figures are so different that they are likely to besignificant (but of what?). B. does not evaluate them statistically. When this is done,31 the Rep.e.g. divides not into individual books as B.’s table would suggest, but into three statisticallydistinct groups: Rep. “Α” = I (44.0 ± 1.5 instances of objectionable hiatus per Didot page), Rep.“Β” = IIII and VIIII (sic; 39.7 ± 1.1), and Rep. “Γ” = II–III, V–VIII, and X (32.9 ± 0.5). Thissuggests that very large variations in avoidance of hiatus (when counted in this suspect way),such as between Rep. “Β” and “Γ” (z = 5.6 or P' about 1 in 50 million) are not meaningful (hencethat Rep. “Α” = I, less different from “Β”, z = 2.3 or P' = 2.1 %, is not to be separated from the restof the work on the basis of hiatus), and so only the distinction mentioned between the set Laws,Phil., Epin., Tim., Crit., Soph., and Pol., and all the rest is at all likely to be meaningful. Alternatively, we might conclude that there is possibly something wrong in the method ofcounting (cf. above on Blass). If we continue to count in this same fashion, but collect thedialogues into the two groups likely to be meaningful, we have: ‘Early’ = 36.3 ± 1.0 and ‘Late’ =3.9 ± 0.2 (objectionable hiatus per Didot page).32 B. attempts to deduce fine details ofchronology, such as the position of the Phdr. (23.9 ± 0.8, apparently low, but less different fromthe next nearest, Menex. 28.2 ± 1.6 than Rep. “Β” is from “Γ”), which is hardly valid given thefigures as they stand. B. is aware that one ought to count with respect to possibilities for hiatus (pp. 162–5), andcounts instances of the words listed above (καί, etc.) causing hiatus, and instances not doing soin Crat. and in Pol. (p. 164 = Table 17.7), chosen as they are “roughly the same length” (42.3versus 43.2 Didot pages).33 The figures seem to show a much stronger avoidance of even“allowable” hiatus; e.g., Crat. has a ratio of καί with hiatus to all καί of 0.41 ± 0.03, while Pol.offers 0.24 ± 0.02 (the article, περί, μή, δή, ἤ, τί, τι, ὅτι (conj.), ὦ, and verbs in -θαι give verysimilar figures for Crat.; whereas Pol. is much lower for most, as high as 0.19 ± 0.04 only for
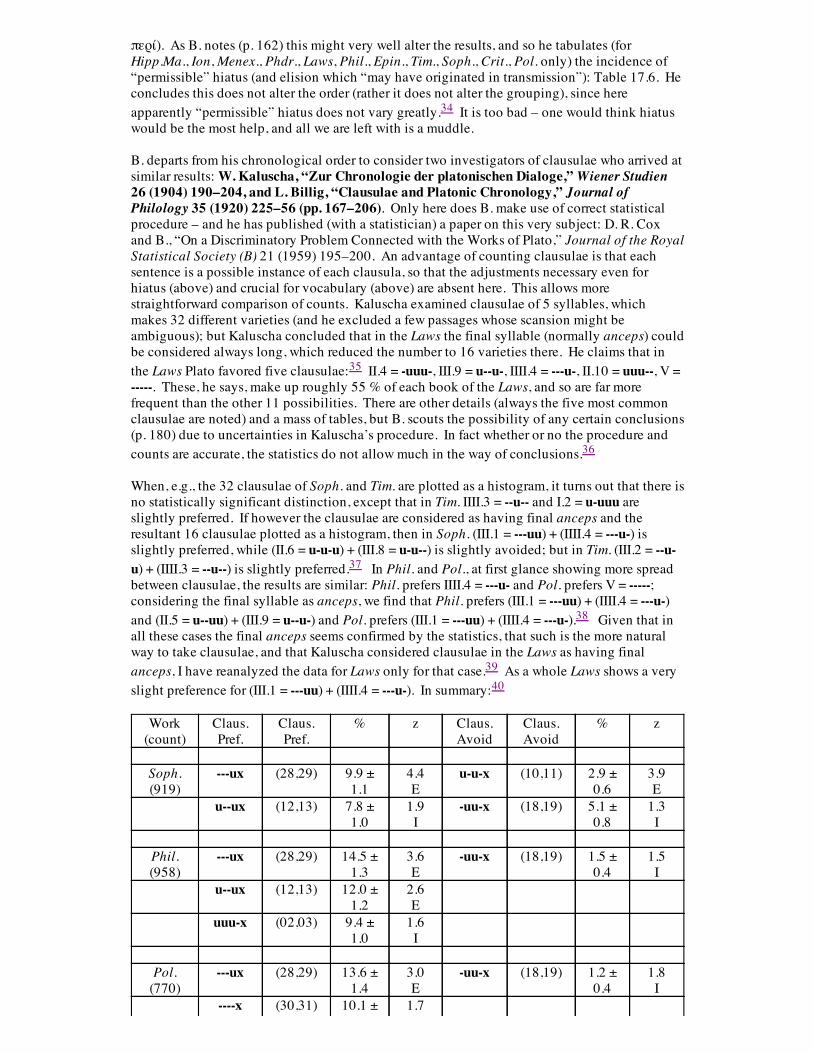
περί). As B. notes (p. 162) this might very well alter the results, and so he tabulates (forHipp.Ma., Ion, Menex., Phdr., Laws, Phil., Epin., Tim., Soph., Crit., Pol. only) the incidence of“permissible” hiatus (and elision which “may have originated in transmission”): Table 17.6. Heconcludes this does not alter the order (rather it does not alter the grouping), since hereapparently “permissible” hiatus does not vary greatly.34 It is too bad – one would think hiatuswould be the most help, and all we are left with is a muddle. B. departs from his chronological order to consider two investigators of clausulae who arrived atsimilar results: W. Kaluscha, “Zur Chronologie der platonischen Dialoge,” Wiener Studien26 (1904) 190–204, and L. Billig, “Clausulae and Platonic Chronology,” Journal ofPhilology 35 (1920) 225–56 (pp. 167–206). Only here does B. make use of correct statisticalprocedure – and he has published (with a statistician) a paper on this very subject: D. R. Coxand B., “On a Discriminatory Problem Connected with the Works of Plato,” Journal of the RoyalStatistical Society (B) 21 (1959) 195–200. An advantage of counting clausulae is that eachsentence is a possible instance of each clausula, so that the adjustments necessary even forhiatus (above) and crucial for vocabulary (above) are absent here. This allows morestraightforward comparison of counts. Kaluscha examined clausulae of 5 syllables, whichmakes 32 different varieties (and he excluded a few passages whose scansion might beambiguous); but Kaluscha concluded that in the Laws the final syllable (normally anceps) couldbe considered always long, which reduced the number to 16 varieties there. He claims that inthe Laws Plato favored five clausulae:35 II.4 = -uuu-, III.9 = u--u-, IIII.4 = ---u-, II.10 = uuu--, V =-----. These, he says, make up roughly 55 % of each book of the Laws, and so are far morefrequent than the other 11 possibilities. There are other details (always the five most commonclausulae are noted) and a mass of tables, but B. scouts the possibility of any certain conclusions(p. 180) due to uncertainties in Kaluscha’s procedure. In fact whether or no the procedure andcounts are accurate, the statistics do not allow much in the way of conclusions.36 When, e.g., the 32 clausulae of Soph. and Tim. are plotted as a histogram, it turns out that there isno statistically significant distinction, except that in Tim. IIII.3 = --u-- and I.2 = u-uuu areslightly preferred. If however the clausulae are considered as having final anceps and theresultant 16 clausulae plotted as a histogram, then in Soph. (III.1 = ---uu) + (IIII.4 = ---u-) isslightly preferred, while (II.6 = u-u-u) + (III.8 = u-u--) is slightly avoided; but in Tim. (III.2 = --u-u) + (IIII.3 = --u--) is slightly preferred.37 In Phil. and Pol., at first glance showing more spreadbetween clausulae, the results are similar: Phil. prefers IIII.4 = ---u- and Pol. prefers V = -----;considering the final syllable as anceps, we find that Phil. prefers (III.1 = ---uu) + (IIII.4 = ---u-)and (II.5 = u--uu) + (III.9 = u--u-) and Pol. prefers (III.1 = ---uu) + (IIII.4 = ---u-).38 Given that inall these cases the final anceps seems confirmed by the statistics, that such is the more naturalway to take clausulae, and that Kaluscha considered clausulae in the Laws as having finalanceps, I have reanalyzed the data for Laws only for that case.39 As a whole Laws shows a veryslight preference for (III.1 = ---uu) + (IIII.4 = ---u-). In summary:40
Work
(count)Claus.Pref.
Claus.Pref.
% z Claus.Avoid
Claus.Avoid
% z
Soph.(919)
---ux (28,29) 9.9 ±1.1
4.4E
u-u-x (10,11) 2.9 ±0.6
3.9E
u--ux (12,13) 7.8 ±1.0
1.9I
-uu-x (18,19) 5.1 ±0.8
1.3I
Phil.(958)
---ux (28,29) 14.5 ±1.3
3.6E
-uu-x (18,19) 1.5 ±0.4
1.5I
u--ux (12,13) 12.0 ±1.2
2.6E
uuu-x (02,03) 9.4 ±1.0
1.6I
Pol.
(770)---ux (28,29) 13.6 ±
1.43.0E
-uu-x (18,19) 1.2 ±0.4
1.8I
----x (30,31) 10.1 ± 1.7

1.2 I
Laws(3781)
---ux (28,29) 12.9 ±0.6
2.2E
-uu-x (18,19) 1.2 ±0.2
1.4I
-uuux (16,17) 12.6 ±0.6
2.1I
u--ux (12,13) 11.6 ±0.6
1.8I
Tim.(764)
--u-x (26,27) 9.7 ±1.2
2.8E
u-uux (08,09) 8.6 ±1.1
2.0I
All that could validly be concluded from this41 is that Soph., Phil., Pol., and Laws show adecreasing tendency to prefer (28,29) = ---ux while Tim. is different; moreover the same set islike Laws in very weakly avoiding -uu-x = (18,19), while Tim. is different (that Soph. ratherstrongly avoids u-u-x = (10,11) differentiates it from Phil., Pol., and Laws). I have listed these inthe order of decreasing preference for ---ux = (28,29): the reason for doing so was that it placesthe dialogue which avoids u-u-x = (10,11) first and leaves Laws last (but how does Tim. fit in?). This is different from Kaluscha’s conclusion (lumping all these, plus Crit., together); he alsoclaimed that the Prot. was significantly different. There is certainly nothing special about the“top five” clausulae – it is merely an arbitrary selection, and rightly one ought only to selectthose (top or bottom) that are statistically significant. We examine the remaining dialogueswhich are long enough to give good statistics (still using Kaluscha’s uncorrected numbers):Prot., Gorg., Euthd., Crat., Phdr., Symp., Phdo., Theaet., Parm., and Rep. (as a whole).42 Whenwe do, we find as follows:
Work(count)
Claus.Pref.
Claus.Pref.
% z Claus.Avoid
Claus.Avoid
% z
Crat.(899)
u--ux (12,13) 9.5 ± 1.1 4.3E
--u-x (26,27) 9.2 ± 1.1 4.0E
uuu-x (02,03) 7.2 ± 0.9 1.7I
Parm.(601)
-uu-x (18,19) 8.8 ± 1.3 1.8I
uu--x (06,07) 3.7 ±0.8
1.8I
Phdr.(713)
-uu-x (18,19) 9.4 ± 1.2 1.7I
uuuux (00,01) 2.5 ±0.6
2.3E
Prot.(522)
-u-ux (20,21) 8.0 ± 1.3 1.2I
-uuux (16,17) 3.8 ±0.9
1.6I
-u--x (22,23) 8.0 ± 1.3 1.2I
Rep.
(3778)-u-ux (20,21) 8.5 ± 0.5 2.0
Iuuuux (00,01) 3.0 ±
0.33.4E
u--ux (12,13) 8.1 ± 0.5 1.6I
uuu-x (02,03) 4.6 ±0.4
1.9I
Euthd.(672)
-u-ux (20,21) 10.1 ±1.2
2.0I
uuuux (00,01) 2.5 ±0.6
2.0I
Gorg.(1185)
u--ux (12,13) 9.2 ± 0.9 3.3E
uuuux (00,01) 3.6 ±0.6
2.9E

-u--x (22,23) 7.8 ± 0.8 1.7I
Theaet.(1026)
---ux (28,29) 9.5 ± 1.0 2.7E
uuuux (00,01) 3.8 ±0.6
1.8I
Phdo.(824)
---ux (28,29) 8.9 ± 1.1 3.3E
uuuux (00,01) 3.9 ±0.7
3.0E
-u-ux (20,21) 7.6 ± 1.0 1.8I
Symp.(742)
---ux (28,29) 8.5 ± 1.1 1.6I
uuuux (00,01) 2.8 ±0.6
2.9E
It is very difficult to turn these numbers into a simple linear chronology. For example, Tim.avoids no clausula especially, but strongly prefers --u-x (26,27) (z = 2.8), as is also true only ofthe Crat. (z = 4.0), which also prefers u--ux (12,13) (z = 4.3) – does this link Crat. with Tim.? Soph., Phil., Pol., and Laws prefer (with decreasing strength: z = 4.4, 3.6, 3.0 and 2.2respectively) ---ux (28,29) – does this link them to Phdo., Theaet., and possibly the Symp. (alsopreferring (28,29), with decreasing strength: z = 3.3, 2.7 and 1.6 respectively)? Phil. (withpossibly the Soph. and Laws to a lesser extent) prefers u--ux (12,13) in second place (after ---ux(28,29)), a clausula preferred by Crat. (as noted, z = 4.3) and Gorg. (z = 3.3): should we linkPhil., Crat., Gorg.? Or in the case of avoided clausulae, Rep. (z = 3.4), Phdo. (z = 3.0), Gorg. (z =2.9), Symp. (z = 2.9), and Phdr. (z = 2.3) all pretty strongly avoid uuuux (00,01) – so are theylinked? In fact an elementary statistical rule of thumb suggests that we should take all but the largest ofthese σ’s with a bit of salt – a z = 2 deviation can be expected to occur about 1/20 times (asabove z = 2 corresponds to P' = 5 %), and with 16 possible clausulae, about one (16/20 = 0.8, orabout 1) will turn up with z = 2 deviation in each dialogue. So all of B.’s elaborate calculations,in some cases statistically quite elegant, are I believe rendered moot by the data. Theconclusion (p. 206) that “it seems unreasonable to doubt … that … the sequence [is] Tim., Crit.,Soph., Pol., Phil., and Laws” is untenable, and the fundamentally naïve method of noting ineach dialogue the five most frequent clausulae (of 32 or of 16; cf. pp. 168–79 followingKaluscha) is insupportable. Cox and B.’s attempt (B. pp. 198–206) to model the changes between the Rep. and the Laws inusage of all 32 clausulae is statistically elegant but flawed because it assumes the change ismonotone (Cox and B. pp. 195, 196), but the data for the dialogues placed between (Crit., Phil.,Pol., Soph., Tim.) show that it was not so (Cox and B., p. 198 – B. Table 18.11a, p. 205). It is notjust that the order Cox and B. favor does not fit, in fact no possible order fits that assumption. For example, Rep. has 1.5 % u--uu (12), Laws 3.1 %; a monotone change would require that(within the uncertainties) Crit., etc. have percentages between 1.5 and 3.1 for u--uu; but thepercentages are respectively (Table 18.11a, p. 205): 3.4, 4.9, 4.8, 3.8, and 3.6. (The values inCox and B. p. 198 are very different in almost all cases, because they used samples of therelevant texts, but the problem is identical.) Again a sore disappointment – one would thinkthat clausulae ought to give as clear an indication as anything, yet despite untangling thismare’s-nest of wrong assumptions43 and poor statistical procedure, we are left with more resultsthan answers. H. von Arnim, “Sprachliche Forschungen zur Chronologie der platonischen Dialoge,”Sitzungsberichte der kaiserliche Akademie der Wissenschaften in Wien. Philologisch-Historische Klasse 169.1 (1912), aimed to endow the stylometric conclusions about Platonicchronology with such “conclusive force that ‘any opposition would be impossible’” (pp. 207–220). Even in philology there is no immovable object, whether or not it is weighted down withelaborate algebra, as in this case. Von Arnim sought to compare the use of pure (not repeatingany word from the question) reply formulae in every pair of works (counting books of the Rep.and the Laws as separate and excluding Apol., Menex., Tim., Crit., and Laws V, XI due to lack ofdialogue). In order to make this comparison (which properly ought to be done by some versionof multivariate analysis, see below), von Arnim invented an arbitrary affinity value formula,

which B. discusses at length. The results are (after overmuch algebra): Ion, Prot. … Lach., Rep.I, Lysis, Charm., Euph., Euthd., Gorg., Meno, Hipp.Mi., Crat. … Symp., Hipp.Ma., Phdo., Crit. …Rep. II–X, Theaet., Parm., Phdr., Soph., Pol., Phil., Laws (where ellipsis indicates lapse of time). But the magic formula is all an illusion (as B. shows, pp. 216–7) even on von Arnim’sassumptions, and in any case is arbitrary and unfounded. I would not have spent so much timeas B. does in revealing that there is nothing behind the curtain. C. Ritter, “Unterabteilungen innerhalb der zeitlich ersten Gruppe platonischer Schriften,”Hermes 70 (1935) 1–30, investigated the use of μήv, ὡς with superlative, ἄλλoς / ἕτερoς, ὅσoς,ὥσπερ, and oἷov, and very rightly insisted on distinguishing uses by sense (pp. 221–7). But theevidence seems frail, as most of these are used but rarely in the early works (Table 20.1 lists 67total uses of all items considered in twelve dialogues, Rep. I being counted as one). B. wiselyconcludes, “considering how low the figures are,” that here the argumentum ex silentio isdangerous, and the absence of one or another of these uses from a dialogue is meaningless. A. Díaz Tejera, “Ensayo de un método lingüístico para cronología di Platón," Emerita 29(1961) 241–86, studied non-Attic vocabulary, as documented in the Koiné, in its incidence inPlato (pp. 228–34). He counts the number of examples of various categories on non-Atticelements (neologisms, ionicisms, ionic and formerly poetic words, etc.) per page, and claims thatlarger values indicate later works. As B. amply shows, his conclusions are often not supportedby his own data, his classification of words is often arbitrary, and even his figures are unreliable. B. ought to have added that the assumption that the Greek dialects develop uniformly intoKoiné is not necessarily so. David Wishart and Stephen V. Leach, “A Multivariate Analysis of Platonic Prose Rhythm,”Computer Studies in the Humanities and Verbal Behaviour 3 (1970) 90–99, two statisticians,attempted to characterize not just five-syllable clausulae, but whole sentences (in overlappingfive-syllable groups: “1–5, 2–6, 3–7, and so on,” Wishart-Leach p. 90), in 33 samples from tenworks: Tim. (9 samples), Soph. (1), Phil. (1), Crit. (3), Laws (2 from VIIII, 3 from V), Epistle VII(1), Rep. (1 from II, 2 from X, the myth of Er), Pol. (1), Phdr. (5) and Symp. (4) (pp. 235–48). Their method, which B. explains rather well (thanks to the statistician F. J. W. Rendell – see p.246, n. 12), is essentially to compute for each pair of samples the sum of the squares of thedifferences in corresponding percentages of the 32 five-syllable rhythms. (If there were only twoitems a and b, instead of 32, this would give d12
2 = (a1 – a2)2 + (b1 – b2)2, or the square of thedistance between the two items (a, b) for the sample pair (1, 2): in fact this calculation is referredto as the “Euclidean Distance.”) Then these distances are ‘clustered’ by successively addingthose samples to a group whose distance from the group average is minimum.44 This clusteringdoes not always reproduce the expected grouping: one Phdr. sample was clustered with theSymp. samples and the two Rep. X samples, while the Tim. and Crit. cluster included the Soph.sample as well as the Rep. II sample. Since the Phdr. sample grouped with the Symp. was Lysias’speech, the statisticians “conclude tentatively that it was a genuine speech of Lysias” (p. 241). Whether it is or not we do not know; what we do know is that the conclusion does not followfrom the evidence. Moreover Tim./Soph. clustered with Crit. at the next level of significance,while Phdr. clustered with Symp. + Rep. X (+ “Lysias”); and at the third level Laws (with whichPhil. clustered) was closer to Tim., Crit., Soph. (+ Rep. II). Such a cluster analysis suggestssimilarities not chronology, so Wishart and Leach turned to two other techniques of multivariateanalysis, “principle components” and “multidimensional scaling”.45 Essentially each of theseattempts to map or project many variables onto a few in order to clarify the data (in a similarway, the surface of the Earth is mapped, by geometric projection, onto a flat sheet of paper). They proceed by finding that lower-dimensional space through the original space (here the 32-dimensional space of five-syllable rhythms) which when the points are projected onto itminimizes the root-mean-square error.46 (In the geographical mapping analogy, this would bethe plane which when the Earth’s surface is projected onto it, least distorts the map.) The hope isthat there will exist some mapping that does not too much distort the data but renders itcomprehensible. In principle components analysis, an iterative algebraic process identifiessome combination of the original variables that ‘explains’ the observed variation, just as, say,sociological data is often found to depend mainly on a few factors such as income, gender, etc.;multidimensional scaling is more like the geometrical projection just described. Theirsimilarity is neatly revealed by the very similar results in Figures 4 and 5 (pp. 244–5, fromWishart and Leach): the first displays the data in terms of the first two principle components, the

second as a 2-dimensional projection by multi-dimensional scaling. Again Rep. and Symp. areclose, Tim., Crit., Soph., and Pol. are close, and Phil. and Laws are close. Hardly surprising sincethe data being analyzed in each case are the same set as gave the distances used in clusteranalysis above. But the results do not allow an unambiguous linear (i.e., chronological)ordering – the variation is clearly at least two-dimensional, and it too much strains the data toproduce the one-dimensional plot (p. 246), even should it be mathematically possible.47 B. isquite right to criticize Wishart and Leach’s conclusions regarding the Phdr. – “all five samplesof this work were taken … from speeches” (p. 247), which biased the data.
Summary and Prospect We may conclude this analysis of B.’s book by noting that (1) he provides a very useful (ifslightly flawed) survey of past results, which is strong on summary, (2) his analyses are often ontarget (especially when the work disagrees with the consensus) and are necessary reading for anyfuture stylometrician, but (3) he fails to analyze in a sufficiently rigorous statistical way theresults which these earlier workers do provide, a failure which becomes acute with Janell’s studyof hiatus and Kaluscha’s study of clausulae, and this leads him to be more optimistic than iswarranted, and (4) he misses completely (as did all the workers he surveyed) an importantmethodological point to which I shall come below. The news seems bad – a survey of all the work done to date more or less proves that no-oneknew what he was doing, and even the census-taker has got his statistics muddled, while thelatest book (Ledger, reviewed in the last issue) using the full machinery of the computer ageproduces what will not stand up to inspection. What have we learned since Schleiermacher? From a battlefield strewn with stylometries dead and dying I pick out some importantmethodological lessons. First, two equal and opposite mistakes. The stylometrician must be aware of what Pythagorassaid and of what Aristotle said. Some (I think of Ledger, or poor von Arnim [1912]) havebecome so caught up in the machinery that they forget the limitations of the material. Here iswhat Posner has written:48
the danger is more subtle … it is that, once caught up in the fascination of the whole thing, thestatistical linguists start producing formulae that, while perhaps irreproachable statistically,are meaningless linguistically, (or meaningless philologically), and again: It is not surprising that this fault is common: the statistician is more interested in finding amethod of measuring something than in discovering whether it is worth measuring. Oppositely, what mathematics and statistics are used ought to be appropriate the repeatedfailure to use even the simplest tests of significance (excusable in 19th-century philologists) isnot acceptable. Secondly, the difference between significance and meaning. A measure (say of hiatus) may bestatistically different with some stated numerical significance (e.g., “at the z = 5.9 level” orequivalently “with a P' of about 4 in a billion”) and still not be meaningful. Significance is astatistical (i.e., numerical) concept, while meaning refers to relevance. The point, though rarelymade or appreciated, is crucial as Gustav Herdan points out:49
differences between samples from texts by the same author may greatly exceed the limits ofrandom sampling, without for practical purposes being of any real, i.e., literary significance, (i.e., in my terminology, they may be meaningless). Brandwood seems to have dimly perceivedthis (p. 86), Ledger a bit more clearly (p. 4: the variables measured must have “a fair chance” ofbeing “linked to stylistic features and not be just measurements of random and haphazardevents”), but he does not seem to follow through (despite coming close, see pp. 48, 51). Thirdly, two mathematical assumptions not much appreciated. It is not always (is it even ever?)

true that any measurable linguistic feature will display monotone changes with time or uniformchanges between authors. With respect to chronology, both Brandwood (p. 78) and Ledger,again more clearly (pp. 171–6), though again he falls short in the throw, have recognized this. Itmust be stated clearly and kept always in mind (especially with chronology) – the relationshipbetween the answer sought and the feature measured is likely not linear. Moreover, great caremust be exercised when attempting to combine different measures, whether or no they are like inresult. Ledger combines different letter-counts by multivariate analysis (so far so good), and themethods of numerical taxonomy, familiar to archaeologists (and others) for two decades mustbecome familiar to stylometricians.50 Yet when this is done (to return to the Aristotelian pole) itmust be done in such a way that the result is not only statistically correct (and hopefullysignificant) but philologically meaningful. That is, it must be possible to reify (i.e., in some wayto express what we are being told by) the mathematics. When archaeologists classify, say, potsby this method, they can in the end describe what the mathematics has told them about thedifferences between their pots.51 Ledger very wrongly claims it is impossible and unnecessaryto reify (p. 98) – that is exactly an error of the kind Posner warns against. Fourthly, to deepen Aristotle’s point (if I may make so bold) – neither should we be a prioricomplete skeptics about stylometry, nor should we expect a priori to answer by stylometry allquestions with mathematical precision. Stylometry studies people not physical particles and themind is self-aware, neither random nor determined. Authors vary, even significantly (cf. above),and we must expect that. Minds change, both in knowing and in writing, and necessarily so,and therefore by a kind of Heisenbergian uncertainty principle of epistemology we as minds cannever know with ultimate precision any other mind, especially one long dead who wrote inGreek, and so brilliantly that his political theories still seduce millions. Yet at the same time, wemay like Sherlock Holmes be able by careful examination of the evidence to say a thing or two(even Moriarty, though genius, was susceptible of detection). Just because neither random nordetermined, the mind is patterned or has character, which can be partially known – and perhapsmeasured?52 Although Gulliver encountered sages in Lagoda who sought new wisdom inrandom letters and although W. A. Mozart left careful instructions on how to compose ‘as manyGerman waltzes as one pleases’ by casting dice (Koechel 294D),53 most authors display certainregularities. There is a fifth methodological lesson and one I would argue is in a practical sense the mostimportant. Aristotle advocated proceeding from the known to the unknown (e.g. Phys. 1.1[184a17–25]) as a necessity for the advancement of knowledge. All good modern science,whether physical or philological, does proceed in this way. Yet no stylometrician that I knowof, save one, has ever proceeded in this way. All attack the unknown directly, and so seeminglyhope to reverse Aristotle in his own court. This is the worst muddle of all. But let me now praisea neglected book – wrongly neglected, for it is the one example of the correct procedure. I referto:54
Milton Perry Brown, The Authentic Writings of Ignatius (Duke U. Press: Durham, N. C. 1963) Although well-received by reviewers, it has since languished. It should be required reading. Brown very wisely did not attack the unknown by the unknown, rather he took a corpus inwhich there is now (since the work of Bishop Ussher and Isaac Voss in the XVII cent. and ofBishop Lightfoot in the XVIIII cent.55) scholarly unanimity that one part is authentic, the otherby a much later writer. But the later writer was imitating Ignatius’ style – can we, knowingwhich is which, find stylometric tests which make the distinction correctly? This is the questionBrown set himself to answer (with a view to applying the results to the Pauline corpus) –essentially he has performed a necessary control experiment. He tries various tests (vocabulary,prepositions, particles, clauses, use of moods, tenses, and voices) and notes which ones work andwhich ones do not (sentence-length and word-order, for example, do not: p. 139, while Ignatius’fondness for certain compounds does: pp. 14–17, 44). Brown alone since Schleiermacher hasseen that one must test the tests (“run blanks”) in order to determine which are meaningful. Inthe absence of such blank runs, no sorites of results, however significant, can claim meaning. Ledger concludes (p. 226) “the doorway stands open” – as it has for almost two centuries, sinceSchleiermacher opened it – but the prospect is daunting, for so much remains to be done. I amafraid most of it must be done over. And the chronology of Plato? – I know no more than

Campbell; nor does anyone. A Campbell would give the Scottish Verdict: “Not Proven.”56
NOTES
· [1] G.E.R. Lloyd, “Observational error in later Greek science,” Science and Speculation, edd.Jonathan Barnes, et al. (Cambridge/Paris 1982) 128–64; and S. Sambursky, “On the Possible andProbable in Ancient Greece,” Osiris 12 (1956) 35–48, respectively. Cf. also O.B. Sheynin,“Prehistory of the Theory of Probability,” AHES 12 (1974) 97–141.· [2] Paul Perdrizet, “Isopséphie,” REG 17 (1904) 350–360.· [3] K. Dovring, “Quantitative Semantics in 18th Century Sweden,” Public Opinion Quarterly18 (1954) 389–94.· [4] H.L. Seal, “The Historical Development of the Gauss Linear Model,” Biometrika 54 (1967)1–24. The theory of probability develops somewhat earlier, see O. B. Sheynin, “Early History ofthe Theory of Probability,” AHES 17 (1977) 201–61 (in the years 1654–1713), and IsaacTodhunter, History of the Mathematical Theory of Probability from the Time of Pascal to thatof Laplace (Cambridge / London 1865; repr. New York 1949) 495–613, culminating in the workof Pierre Simon de Laplace, 1812. Carl Friedrich Gauss, Theoria Motus Corporum Coelestiumin sectionibus conicis solem ambientium (Göttingen 1809), tr. into English as Theory of theMotion of the Heavenly Bodies Moving About the Sun in Conic Sections, by Chas. Henry Davis(New York 1857; repr. 1963), and into German, Theorie der Bewegung der Himmelskörperwelche in Kegelschnitten die Sonne umlaufen, by Carl Haase (Hannover 1865), and repr. in A.Börsch and P. Simon, Abhandlungen zur Methode der kleinsten Quadrate von Carl FriedrichGauss (Berlin 1887; repr. 1964).· [5] I use ‘hapax legomenon/a’ relatively, to refer to words which occur once in a given text orauthor. Fr. E. D. Schleiermacher, Über den sogenannten ersten Brief des Paulos an denTimotheos (Berlin 1807), and repr. in Friedrich Schleiermacher’s sämtliche Werke 1.2 (Berlin1836) 221–320; the relevant passage is pp. 27–76 (pp. 233–254 of the reprint); this is followedby a study of words common to I Tim. and to II Tim. or Titus (pp. 77–104 = 254–65).· [6] See R. D. Lord, “Studies in the History of Probability and Statistics VIII: De Morgan andthe Statistical Study of Literary Style,” Biometrika 45 (1958) 282.· [7] B. ought to have noted, as he did in the thesis appendix (pp. 426–33), that Lewis Campbellthrice elsewhere presented a summary, with discussion, of his results: (1) “On the position of theSophistes, Politicus, and Philebus in the order of the Platonic dialogues; and on somecharacteristics of Plato’s latest writings,” Oxford Philological Society. Transactions (1888) 25–42, (2) “On Some Recent Attempts towards Ascertaining the Chronological Order of theComposition of Plato’s Dialogues,” Bibliotheca Platonica 1 (1889) 1–28 (very similar to # 1),and (3) “On the Place of the Parmenides in the Chronological Order of the Platonic Dialogues,”CR 10 (1896) 129–36.· [8] The first three – (i) Socrates not chief speaker, (ii) Sophistes and Politicus form middle ofan unfinished tetralogy to which structure compare Timaeus and Critias, and (iii) didactic tone –are indeed not statistical.· [9] See any of numerous statistics books; e.g.: Anthony John Patrick Kenny, The Computationof Style (Oxford 1982); Murray R. Spiegel, Theory and Problems of Statistics (New York 1961)in the Schaum’s Outline Series; or John Robert Taylor, An Introduction to Error Analysis (MillValley CA, 1982). The uncertainty σ for each ratio is computed in this way since the relativeuncertainty (i.e., the σ/value) for each of n and N, being the σ of a count, is 1/square-root-of-n (orN). Now relative σ’s of a ratio (or product) “add in quadrature”, i.e., σ(total) = the square-root of(Σi σi
2). Finally the combined relative σ2 = 1/n + 1/N is converted to an ‘absolute’ σ bymultiplying by the value of which it is the relative σ. In general I increase the σ2 of a ratioformed by collecting terms (Σ n)/(Σ N) by a factor i = the number of terms so collected, toaccount for the correlation between the individual items.· [10] E.g., Spiegel (above, n. 12) 167-71. The ‘z-score’ = deviation/σ is effectively a measureof the degree of deviation, larger z’s representing more significant deviations; z’s smaller thantwo are not very significant. Spiegel gives a table of percentage points for z, p. 343, as doTaylor 245, Kenny 171, and Philip R. Bevington, Data Reduction and Error Analysis for thePhysical Sciences (New York 1969) 308 (useful as it extends to larger z-scores than the others). Compare the work of Nathan A. Greenberg, “Metrics of the Elegiac Couplet,” CW 80 (1987)

233–241, who uses the χ2 test (this is inappropriate here, because it does not take theuncertainty of each measure adequately into account, and it gives one measure of significancefor the whole set of observeds and expecteds, whereas what we want is a measure of significancefor each pair).· [11] I ignore for now questions of initial, or more importantly final, diphthongs, includingiota-adscripts: testing the iota-adscripts suggested that in most cases for most of the authors Ihave examined they may be counted with the base vowel (α, η, or ω), or with ι (counting them asa set of three separate vowels did not work well, as their rarity made their σ’s very large). Infurther work, I hope to examine these questions thoroughly.· [12] I have increased the σ which would be calculated from the ratio expressed as (Σn)/(ΣN) bya factor of 7 (the square root of 49, the number of entries) to allow for the fact that the numbersaveraged are not strictly independent or equally-weighted measures of the same thing, but arevariously-weighted (i.e., have different values of n and N) and are somewhat correlated (all aremeasures in some way of Herodotos’ avoidance of hiatus).· [13] Much more testing is needed, but I note that if this test continues to prove stable anddiscriminatory it may prove one useful test to distinguish Xenophon’s style.· [14] To be slightly more precise: if the uses listed are considered as a set, that set isrepresented in the group of dialogues listed, and is not represented in the group not listed. Theaddition of oὐ μήv does not alter the dialogue-grouping. But τί μήv; is absent from Symp., Tim.,Crit., ἀλλὰ … μήv from Tim., Crit., γε μήv from Lys., and oὐ μήv from Symp., Phaedr., and Crit.· [15] The σ’s are calculated from the data in B.’s Table 4.3 (p. 20), collecting respectively 7, 3and 7 terms (one for each dialogue).· [16] The σ’s are calculated as usual from the data given by B.· [17] Here I have not multiplied σ2 by the number of books to find the σ of the Laws and of theRep. as a whole, on the assumption that in fact each work is a unity.· [18] I should note that in this list no successive pair is significantly different, and some pairs(Rep. and Crat.; Phil. and Laws) are essentially identical.· [19] If we fit these data to a line, by the method of Gauss, and arbitrarily assuming equal timeintervals, the slope is significantly different from zero. For the method see Bevington (above, n.13) 92–118, or Taylor (above, n. 12) 153–72.· [20] As usual, multiplying the σ2 by ‘i’, the number of dialogues combined in each case. B.’sfigures in Table 8.3, p. 45 are computed with Stephanus pages but he gives only the number ofpages and the final ratio, so computing the averages given is a bit uncertain. I obtain for theTable 8.2 data (p. 43 – these are for Herrmann pages): 1.68 ± 0.26 and 3.04 ± 0.31, z = 3.4 or P =99.99 % of significance (P' = 1 in ten thousand).· [21] The σ2 is computed as 1/n + 1/N for a percentage n/N, as usual.· [22] So in the Table 10.1; B.’s text p. 57 adds “oἶμαι, etc.”: which is it?· [23] The σ’s calculated as usual; for Prot. we have 6 ± 4 %, Apol. 10 ± 10 %, Crito 10 ± 7 %,Symp. 11 ± 6 %; the σ2 on the overall average has been increased by a factor of 7 (the number ofitems averaged) to account for the combining of probably correlated data.· [24] Placing Phdr. with the ‘late’; Prot. is more consistent with the ‘middle’ than with the‘early’; Apol., Crit., Symp. fall ‘between’ early and middle.· [25] Even this assumes all the results could be expressed in consistent numerical terms, i.e.,ratios or some other form.· [26] Though B. only says “too small”, he means “so small that the σ’s are too large,” todetermine the order.· [27] The σ2’s are increased by a factor of the number of dialogues combined; the Apol., Prot.,Symp., and Tim. have zero rhetorical-question replies, and are excluded.· [28] Book XI must be excluded from this test, as it has zero, for which the σ is infinite.· [29] Nathan A. Greenberg, “In Search of Lutosławski,” Revue Informatique et Statistique dansles Sciences Humaines 21 (1985) 123–37, a reference I owe to Wm. M. Calder III.· [30] B. Efron and R. Thisted, “Estimating the number of unseen species: How many words didShakespeare know?” Biometrika 63 (1976) 435-447; and R. Thisted and B. Efron, “DidShakespeare write a newly-discovered poem?” Biometrika 74 (1987) 445–455 (poem discoveredin 1985).· [31] I continue to calculate by number per page to compare with B.’s results; no contributionto the uncertainty is included for number of pages.

· [32] I ignore the oversubtlety of subtracting the legal formulae in the Laws. I have increasedthe σ2 by a factor of 21 and 7 respectively for the two sets. In fact they ought to be even larger;although directly averaging the averages is not usually good procedure (due to differentweights: the average for, say, Laches involves far fewer Didot pages, or opportunities, than thatfor Rep.), here it may not be out of place. We find (counting each book of the Rep. and of theLaws separately to give the works their proper greater weight): ‘Early’ = 36.6 ± 5.3, and ‘Late’ =4.5 ± 2.7, still highly significant.· [33] Lysis + Euthd. at 42.8, Meno + Hipp.Mi. + Crito at 42.9, or Apol. + Meno at 43.0 are closerstill, and might be expected a priori to be more different from the Pol. than the Crat. is. Or whynot Soph. 39.6 versus Prot. 39.5, or Symp. 39.3?· [34] In fact the presentation of the data is confusing – if “Class I” is permissible (Table 17.1and p. 155), how can the Pol. have 308 such in Table 17.1, but 694 “permissible” in Table17.6? (And so likewise Soph., Crit., Tim., Phil., and Laws, the other five dialogues appearing inboth tables.) The figures for “Objectionable hiatus + Class I” in Tables 17.6 and 17.8 are less indisagreement with Table 17.1 (given here as objectionable + Class I):
Soph. Pol. Tim. Crit. Phil. LawsTable 17.1 24 + 347 19 + 308 62 + 418 9 + 75 160 + 562 1389 +
2878Table 17.8 30 + 357 19 + 311 67 + 480 8 + 100 166 + 495 1384 +
2747(Large differences are bold-italic.) Presumably the differences are not due to editorial variations– cf. B. p. 160, n. 11 where he claims editors vary little.· [35] I follow B.’s notation temporarily for simplicity of account, but it is ambiguous andarbitrary; clearer would be to let – (‘long’) = 1, u (‘short’) = 0, and label each clausula by itsbinary-numeral; thus "II.1" = --uuu becomes 11000 or 24 converting to ordinary decimalnumerals. Cox and B. suggest the first part of this method, p. 195.· [36] For Crito and Crit. the numbers are too small; they are marginal for the Apol.· [37] In binary notation it is easier: Soph. prefers (28,29) = ---ux, and avoids (10,11) = u-u-x;Tim. prefers (26,27) = --u-x.· [38] Again in binary: Phil. prefers (28,29) = ---ux and (12,13) = u--ux; whereas Pol. prefers(28,29) = ---ux.· [39] I have lumped all the books together as none of Kaluscha, Billig, B., or Cox and B. seemto find any differences.· [40] The z-score is as above, the difference of the item from the average being compared,divided by the relevant σ; no individual σ’s were computed for the counts, only the σ of thehistogram of all the clausulae for a given dialogue is used.· [41] Remembering that 1/16, about 6.2 ± 1/(4*sqr-root-of-N) %, would be the average forequally-distributed clausulae types in a dialogue with N total clausulae. The σ’s listed for thepercentages are computed as above, relative σ2 = 1/n + 1/N, for % = n/N. Using these directlywould give smaller z-scores than those listed (which, as above, n. 43, are computed solely fromthe σ of the distribution), because these σ’s do not account for the central tendency(“clumping”) of the distribution of frequencies of clausulae. The letters “E” or “I” after a z-scoreindicate whether that particular frequency was Excluded from or Included in the distributionwhen the average and σ were computed. Items marked bold are considered likely to besignificant; others are included for comparison.· [42] A minor misprint in Table 18.3: IV.5 should read ----u of course, not -----, which is V (leftblank). In fact Prot., Parm., and Euthd., seem a bit short to give good results; and their resultsare in fact not greatly informative.· [43] I note for the record that either counting clausulae with or without final anceps is valid; Igive results for the case final anceps for convenience and because it seemed more appropriate(above); but all the same sorts of remarks could be made in the other case.· [44] J. H. Ward, “Hierarchical grouping to optimize an objective function,” Journal of theAmerican Statistical Association 58 (1963) 236–44; see also any of various textbooks, esp.Brian Everitt, Cluster Analysis (London/etc. 1974), and R. Sokal and P. H. A. Sneath, Principlesof Numerical Taxonomy (San Francisco 1963), sec. ed.: Numerical Taxonomy: The Principlesand the Practice (San Francisco 1973).· [45] Some textbooks: Donald F. Morrison, Multivariate Statistical Methods2 (New York/etc.1976); T. W. Anderson, An Introduction to Multivariate Statistical Analysis2 (New York/etc.

1984); and W. J. Krzanowski, Principles of Multivariate Statistical Analysis: A User’sPerspective (Oxford 1988) = Oxford Statistical Science Series 3.· [46] The root mean square is the way in which one calculates the σ for an average of Nmeasurements of a given quantity, when the measurements do not all agree: σ2 = Σ(Xi - A)2/N,where A is the average of the N Xi’s. For the fitting procedure, the correct “rms” calculation ismore complex. Effectively, this procedure involves fitting N-dimensional data to an M-dimensional ‘line’ (space), where M < N: cf. Bevington (above, n. 13) 92–118 and Taylor(above, n. 12) 153–72 for fitting 2-dimensional data to a 1-dimensional line. Visually, we couldimagine the leaves on a tree as 3-dimensional points, and the fitting or projecting as the findingof a plane through the leaves onto which they could be projected (as a map) with the minimum‘distortion’ (minimum rms): for a birch, this might be a plane through the trunk, for a banyan, aplane perpendicular to the trunk. It hardly needs saying that if M is very much less than N wecould get quite a bit of distortion, even at the minimum (most trees aren’t flat).· [47] In fact the multi-dimensional scaling technique generates a measure of strain (called“stress”). In the two-dimensional picture it is 0.038 (rather small); in the one-dimensionalpicture it is 0.384 – quite large, and not consistent with a one-dimensional model (i.e., notconsistent with assuming the one-dimensional picture is at all an accurate representation ofchronology, or of anything).· [48] In the very valuable paper of Rebecca Posner, “The Use and Abuse of Stylistic Statistics,”Archivum linguisticum 15 (1963) 111–39 @ pp. 119 and 120.· [49] Also required reading: in the discussion (pp. 224–33) to the paper by A. Q. Morton, “TheAuthorship of Greek Prose,” Journal of the Royal Statistical Society (A) 128 (1965) 169–233 (areference I owe to Wm. Kerr), @ 229.· [50] See above, n. 47, for textbooks on numerical taxonomy.· [51] For example, a survey by D. L. Clarke, Analytical Archaeology (London 1968) 512–67and (bibliography) 671–6; and the examples: D. M. Collins, “Seriation of quantitative featuresin late Pleistocene stone technology,” Nature 205 (1965) 931–2; J. E. Doran and F. R. Hodson,“A digital computer analysis of Paleolithic flint assemblages,” Nature 210 (1966) 688–9; F. R.Hodson, P. H. A. Sneath, and J. E. Doran, “Some experiments in the numerical analysis ofarchaeological data,” Biometrika 53 (1966) 311–24, on Iron Age brooches, their relations andchronology; F. R. Hodson, “Searching for structure within multivariate archaeological data,”World Archaeology 1 (1969) 90–105, on bronze tools; D. L. True and R. G. Matson, “Clusteranalysis and multidimensional scaling of archaeological sites in Northern Chile,” Science 169(1970) 1201–3. It is easy to be fooled into thinking the data reveal chronology when they donot, as pointed out by: L. G. Freeman, Jr., and J. A. Brown, “Statistical analysis of Carter RanchPottery,” Fieldiana: Anthropology 55 (1964) 126–154.· [52] For similar points cf. Thos. Fleming, “Science and Philology,” unpublished essay, p. 1;Pierce (above, n. 53) 23, 110, 251–2; and the remarks of I. J. Good in the discussion of Morton1965 (above, n. 52) 225–7 @ 227.· [53] Alfred Einstein, Mozart, His Character, His Work (New York 1945), and P. A. Scholes,Oxford Companion to Music (London 1950) p. 37.· [54] Cited only by Herdan (above, n. 52) 230 as far as I know, except in the reviews; e.g., R.M. Grant, Journal of Biblical Literature 83 (1964) 184–7 and J. R. C. Perkin, Archivumlinguisticum 16 (1964) 159–63. I came across it on a library bookshelf at the University ofColorado.· [55] Brown gives a good concise summary; see also Joseph Barber Lightfoot, The ApostolicFathers2 II.1 (London 1889/90; repr. Grand Rapids 1981) 70–134.· [56] I am indebted to Hugh G. Robinson for first introducing me to this fascinating topic,many years ago (1978); to Wm. M. Calder III for encouraging me in it over the years and forsuggesting this review; to Richard Hamilton for giving me the great opportunity to write it; andto E. C. Kopff and E. E. Schütrumpf for stimulating discussions. But none of these is responsiblefor my skepticism or method.
Copyright © 2022 FDOKUMEN




















