
Just in Time Information Retrieval Agent to support text creation based on the Mixed Initiative User...
92
Just in Time Information Retrieval Agent to support Text Creation, based on the Mixed Initiative User Interface Design Lorena Recalde 1 Supervisor: Dr. Denis Lalanne April 23, 2014 Department of Informatics - Master Project Report D´ epartement d’Informatique - Departement f¨ ur Informatik • Universit´ e de Fribourg - Universit¨ at Freiburg • Boulevard de P´ erolles 90 • 1700 Fribourg • Switzerland phone +41 (26) 300 84 65 fax +41 (26) 300 97 31 [email protected] http://diuf.unifr.ch 1 [email protected], University of Fribourg
-
Upload
independent -
Category
Documents
-
view
2 -
download
0
Transcript of Just in Time Information Retrieval Agent to support text creation based on the Mixed Initiative User...

Just in Time Information RetrievalAgent to support Text Creation, basedon the Mixed Initiative User Interface
Design
Lorena Recalde1
Supervisor: Dr. Denis Lalanne
April 23, 2014
Department of Informatics - Master Project Report
Departement d’Informatique - Departement fur Informatik • Universite de Fribourg -Universitat Freiburg • Boulevard de Perolles 90 • 1700 Fribourg • Switzerland
phone +41 (26) 300 84 65 fax +41 (26) 300 97 31 [email protected] http://diuf.unifr.ch
[email protected], University of Fribourg

Abstract
Information is seen as a valuable resource, but the quality and quantity of informationretrieved at the moment of web information searching depend on both: the user’s query andthe search engine’s features. This master thesis presents a just in time information retrieval(JITIR) agent that is based on the Google Search API to implement a web application.The thesis consists of the implementation and evaluation of the Pandora Editor1 which hasas part of its main functionality an information search and retrieval agent. The motivationis to provide a new interaction paradigm to support documents writing. The interactionis oriented to enhance the text creation activity by having automated query formulationand reducing the user’s memory overload. The writer can use those queries to get relevantweb results from Google search and improve his document content and quality.
For the project, three search scopes were defined: document level, thematic segmentslevel and noun phrases level. For every scope, there is one methodology to extract wordsand phrases from the user’s current text. After being evaluated, those words will becomeinto search queries. Once having the queries, the agent interacts with the Google SearchAPI to retrieve web information that may be useful for the writer. These search levelswill allow the user to choose the best web and images results provided by Google.
The application was tested following a controlled evaluation. The goal was to show ifthe new interaction paradigm implemented in the present project and the queries extractedthanks to the JITIR agent let the writers be more efficient than by formulating their ownexplicit queries and using a common text editor plus Google running in a browser. Thequantitative results did not present a significant difference in terms of users efficiency whilethey were working with the Pandora Editor or a common editor plus a search engine.The tests applied showed that they were able to handle more information from the webby using the Pandora Editor though. The qualitative measures presented good resultsshowing that the users found the Pandora Editor easier and more useful at the momentof creating documents or retrieving images compared with a common text editor.
Keywords: Just in time information retrieval agent, direct manipulation, mixedinitiative interfaces, keywords extraction
1Pandora Editor is the name given to the web application presented in this Master Thesis
1

2

Acknowledgements
Thanks God! You are my strength... The friend who walks with me.
Thanks mom, dad, Cristy, Carito and my ’chiquitico’ Jhoel. I am happy because ofyou. I could get it just because of you.
Thanks Ale, my love! You have made my dreams part of your life. I have to say thankyou for your unconditional love and support. Te amo.
Thanks little grandmothers, God listened to your prays.
Thanks my families: Jara and Leon. Thank you my Ecuadorian friends and Cristobal, allof you are just great.
Thanks Paty Grijalva and thanks to your family. God bless you always.
Thank you my friends I met in Switzerland!! You showed me another side of friend-ship.
Thanks my teachers in the Eugenio Espejo School, Fernandez Madrid, Manuela Canizares,EPN, University of Fribourg and University of Neuchatel, you are part of my academicsteps.
Thanks to all who were my students, you pushed me to be better.
Thanks to the Ecuadorians who are contributing to have a better education and makethe SENESCYT scholarships come true.
Thanks my teacher and thesis supervisor Dr. Denis Lalanne for your constant help inall the theoretical and technical issues related to the project. Thank you for letting melearn from your knowledge and experience.
3

4

Contents
1 Introduction 131.1 Background and motivation . . . . . . . . . . . . . . . . . . . . . . . . . . . 141.2 Project aim . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 141.3 Report Content and Structure . . . . . . . . . . . . . . . . . . . . . . . . . . 15
2 Mixed Initiative Just in Time Information Retrieval Agent 172.1 Just in Time Information Retrieval Agents . . . . . . . . . . . . . . . . . . . 18
2.1.1 JITIR agent’s characteristics . . . . . . . . . . . . . . . . . . . . . . 182.1.2 Related work . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
2.2 The Mixed Initiative User Interface . . . . . . . . . . . . . . . . . . . . . . . 202.2.1 Autonomous Interface Agents work . . . . . . . . . . . . . . . . . . . 202.2.2 User Decision Making and direct manipulation . . . . . . . . . . . . 202.2.3 Collaborative work Advantages: the Mixed Initiative proposal . . . . 21
2.3 Problem statement . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 212.4 The Pandora Editor proposal . . . . . . . . . . . . . . . . . . . . . . . . . . 26
3 Languages, Technologies and Tools 293.1 Programming languages, technologies and tools that support web applica-
tion development . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 303.1.1 Commercial Search Engines and their APIs . . . . . . . . . . . . . . 303.1.2 The Programming Languages and frameworks . . . . . . . . . . . . . 31
3.2 Programming languages, technologies and tools selection . . . . . . . . . . . 313.2.1 Web Application Framework . . . . . . . . . . . . . . . . . . . . . . 313.2.2 Google AJAX Search API . . . . . . . . . . . . . . . . . . . . . . . . 323.2.3 Integrated Development Environment (IDE) . . . . . . . . . . . . . . 32
4 The Pandora Editor 354.1 The Pandora Editor Architecture . . . . . . . . . . . . . . . . . . . . . . . . 364.2 Interface Design . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
4.2.1 Feedback in the interaction . . . . . . . . . . . . . . . . . . . . . . . 394.3 Implemented Modules . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 40
4.3.1 Document Scope . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 404.3.1.1 Libraries . . . . . . . . . . . . . . . . . . . . . . . . . . . . 404.3.1.2 Text Preprocessing . . . . . . . . . . . . . . . . . . . . . . . 404.3.1.3 Descriptive Keywords Extraction . . . . . . . . . . . . . . . 414.3.1.4 Example . . . . . . . . . . . . . . . . . . . . . . . . . . . . 424.3.1.5 Limitations . . . . . . . . . . . . . . . . . . . . . . . . . . . 43
4.3.2 Thematic Segmentation Scope . . . . . . . . . . . . . . . . . . . . . 434.3.2.1 Libraries . . . . . . . . . . . . . . . . . . . . . . . . . . . . 43
5

4.3.2.2 Text Preprocessing . . . . . . . . . . . . . . . . . . . . . . . 434.3.2.3 Descriptive Keywords Extraction . . . . . . . . . . . . . . . 444.3.2.4 Example . . . . . . . . . . . . . . . . . . . . . . . . . . . . 454.3.2.5 Limitations . . . . . . . . . . . . . . . . . . . . . . . . . . . 46
4.3.3 Noun-Phrases Scope . . . . . . . . . . . . . . . . . . . . . . . . . . . 464.3.3.1 Libraries . . . . . . . . . . . . . . . . . . . . . . . . . . . . 464.3.3.2 Text Preprocessing . . . . . . . . . . . . . . . . . . . . . . . 464.3.3.3 Descriptive Keywords Extraction . . . . . . . . . . . . . . . 464.3.3.4 Example . . . . . . . . . . . . . . . . . . . . . . . . . . . . 474.3.3.5 Limitations . . . . . . . . . . . . . . . . . . . . . . . . . . . 48
5 User Evaluation 515.1 User Evaluation Goal . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 525.2 Evaluation Planning . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 52
5.2.1 Hypothesis to test . . . . . . . . . . . . . . . . . . . . . . . . . . . . 525.2.2 Independent variables . . . . . . . . . . . . . . . . . . . . . . . . . . 525.2.3 Dependent variables . . . . . . . . . . . . . . . . . . . . . . . . . . . 525.2.4 Subject selection and assignment . . . . . . . . . . . . . . . . . . . . 535.2.5 Forms and documents required . . . . . . . . . . . . . . . . . . . . . 535.2.6 Final step for the evaluation: Quality Tests . . . . . . . . . . . . . . 55
5.3 Results Obtained . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 555.3.1 Results in Document Creation Experiments . . . . . . . . . . . . . . 565.3.2 Results in Image Finding Experiments . . . . . . . . . . . . . . . . . 585.3.3 Results obtained in the Questionnaire for qualitative measures . . . 60
5.4 Result Analysis . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 62
6 Conclusions 656.1 Limitations . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 666.2 Conclusions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 666.3 Future work . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 67References . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 69
A Sports in the World Task 1.A 71A.1 Text provided . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 71A.2 Instructions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 71
B Party Planning Task 1.B 73B.1 Text provided . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 73B.2 Instructions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 73
C Natural disasters: causes and effects Task 2.A 75C.1 Text provided . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 75C.2 Instructions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 76
D Advances in medicine to improve health Task 2.B 77D.1 Text provided . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 77D.2 Instructions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 78
6

E Training Script 79E.1 Pandora Editor Goal . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 79E.2 Pandora Editor Search Scopes . . . . . . . . . . . . . . . . . . . . . . . . . . 79E.3 Pandora Editor Interface Views . . . . . . . . . . . . . . . . . . . . . . . . . 79
F Data Collection Forms 81F.1 Form to collect data: Text Editor + Google . . . . . . . . . . . . . . . . . . 81F.2 Pandora Editor Evaluation Version to collect data . . . . . . . . . . . . . . 81
G Evaluator Instructions Script 83G.1 Before the Evaluation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 83G.2 During the Evaluation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 83G.3 After the Evaluation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 83
H Qualitative Measure Questionnaire 85
I Example of the Evaluation to measure the Quality 89I.1 Measure the Quality of a Text . . . . . . . . . . . . . . . . . . . . . . . . . . 89I.2 Measure the Quality of a the Images that represent the text . . . . . . . . . 89
J Digital content 91J.1 Digital media attached . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 91J.2 Access to the Pandora Editor . . . . . . . . . . . . . . . . . . . . . . . . . . 91
7

8

List of Figures
2.1 Remembrance Agent User Interface . . . . . . . . . . . . . . . . . . . . . . . 232.2 Margin Notes User Interface . . . . . . . . . . . . . . . . . . . . . . . . . . . 232.3 Jimminy User Interface . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 232.4 Watson customized for Motorola User Interface . . . . . . . . . . . . . . . . 242.5 Calvin web based User Interface . . . . . . . . . . . . . . . . . . . . . . . . 242.6 Blogoduct User Interface . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 252.7 JITIR Agent integrated with Windows Desktop Search User Interface . . . 25
4.1 The Pandora Editor Architecture . . . . . . . . . . . . . . . . . . . . . . . . 364.2 The Pandora Editor - Main interface, full text view mode . . . . . . . . . . 374.3 The Pandora Editor - Results interface . . . . . . . . . . . . . . . . . . . . . 384.4 The Pandora Editor - Option to cancel the Noun Phrases search . . . . . . 394.5 The Pandora Editor - Feedback message about the current search state . . 394.6 Example of words with their frequencies in the document and in the paragraph 424.7 Example of results retrieved for a Document Level Search . . . . . . . . . . 434.8 Example of words with their frequencies in the document and in the segment 444.9 Example of results retrieved for a Thematic Segmentation Level Search . . 464.10 Example of results retrieved for a Noun Phrases Level Search . . . . . . . . 484.11 Example of a sentence Tagged and Parsed with NLP Stanford libraries,
using the online parser service . . . . . . . . . . . . . . . . . . . . . . . . . . 494.12 Example of results retrieved for a Noun Phrases Level Search . . . . . . . . 49
5.1 Interfaces rate (Document creation task) . . . . . . . . . . . . . . . . . . . . 605.2 Interfaces rate (Images Finding) . . . . . . . . . . . . . . . . . . . . . . . . 615.3 Pandora Editor Results Rate . . . . . . . . . . . . . . . . . . . . . . . . . . 62
F.1 Form to collect data: Text Editor + Google . . . . . . . . . . . . . . . . . . 81F.2 The Pandora Editor Evaluation Results Example (Document creation task) 82
9

10

List of Tables
2.1 JITIIR Agents and their interaction design choice . . . . . . . . . . . . . . . 22
3.1 Commercial Search Engine APIs . . . . . . . . . . . . . . . . . . . . . . . . 303.2 Web Application Programming Languages . . . . . . . . . . . . . . . . . . . 31
4.1 Stopwords Examples . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 414.2 Grammar rules or Phrase Structure Grammar example (Context-Free Gram-
mar) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 50
5.1 Controlled Evaluation Document Improvement Task 1 and Images AdditionTask 2 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 54
5.2 Quality Measure for the Task 1 and Task 2 . . . . . . . . . . . . . . . . . . 555.3 Document Length Test . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 565.4 Number of Queries Produced Test . . . . . . . . . . . . . . . . . . . . . . . 575.5 Number of Links Visited Test . . . . . . . . . . . . . . . . . . . . . . . . . . 575.6 Document Produced Quality Test . . . . . . . . . . . . . . . . . . . . . . . . 585.7 Number of Images Added Test . . . . . . . . . . . . . . . . . . . . . . . . . 585.8 Number of Queries Produced Test . . . . . . . . . . . . . . . . . . . . . . . 595.9 Images Added Quality Test . . . . . . . . . . . . . . . . . . . . . . . . . . . 605.10 Document writing task: how useful were the interfaces? . . . . . . . . . . . 615.11 Image Illustration task: how useful were the interfaces? . . . . . . . . . . . 61
11

12

Chapter 1
Introduction
Contents
1.1 Background and motivation . . . . . . . . . . . . . . . . . . . . . 14
1.2 Project aim . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
1.3 Report Content and Structure . . . . . . . . . . . . . . . . . . . 15
This chapter contains a preliminary presentation about the Pandora Editor project,the background and motivation is detailed first; later, the main objective is explained;finally, the last section consists of the structure of the present report.
13

1.1 Background and motivation
At the moment a user has the need of specific information, the process of automaticsearching and retrieving is done by an Information Retrieval (IR) system. An IR systemuses technology tools in order to storage, organize and index a collection of documents orweb pages before the search process starts. The IR system satisfies the user informationrequest by matching his query with the indexed documents in order to retrieve the onesthat are relevant for that query. While searching the Internet, the IR system uses searchengines and web crawlers to cross the web and index the information.
In order to find any kind of information most people uses web search engines, sothat search engines have a very high impact in the society and in the way informationis found and used. Current web systems and technologies are not enough to support theprocessing needs for the quantity of dynamic, unstructured and distributed information[9]. By working with a search engine the users could find some disadvantages [1]:
• The information retrieved by a search engine generally differs from the others’ results(at least the retrieved order among search engines is different).
• Depending on the kind of query and user’s needs, it is the user who has to filter theretrieved information.
• The results retrieved for a query are extracted from the web and sometimes the webinformation is noisy.
• Few search engines are able to retrieve personalized information after monitoringthe user’s search behaviour and preferences, but most of them does not.
• The quality of the results depends on the quality of the query and the imprecisekeywords formulated by novice users could affect the entire search process.
A just in time Information Retrieval system (JITIR) accesses to the user’s currentinformation in order to use it as input and finds, retrieves and evaluates new generatedinformation that could be valuable for the user’s main task. The queries that are formu-lated by the JITIR agent are implicit in the user’s current context, so the work of theagent is proactive and as non-intrusive as possible [18].
A JITIR agent is an IR system where the query is generated from the user’s monitoredenvironment, and it tries to deal with the Search and Retrieve process disadvantagesmentioned before.
1.2 Project aim
The main goal of the Pandora Editor project is to implement and evaluate a documenteditor which includes an Information Search and Retrieval Agent as part of the userinterface.
In detail, the agent extracts keywords from the user’s document, prepares the queriesand by communicating with a web search engine, it retrieves relevant web and imageresults from the internet. The whole process that involves the user’s text preprocessing,query formulation and results retrieval is transparent for the writers. The Pandora Editorand the JITIR agent implemented make that the relevant web information related to theuser’s document can be accessed easily and at the right time by presenting a simple userinterface.
14

1.3 Report Content and Structure
The report details the theoretical basement of the project and presents the process followeduntil achieving the goal that was mentioned before. In the second chapter, the featuresof a JITIR agent and related work are explained. The chapter number three details thedifferent technologies, tools and languages that supported the application development.The fourth chapter shows in detail the Pandora Editor: its architecture, the influence ofthe mixed initiative user interface for the design and the implemented modules togetherwith the libraries used; the algorithms and some examples are also showed. The fifthchapter describes the user evaluation procedure: the testing plan, the results obtainedand their analysis. Finally, the last chapter presents the limitations for the whole project,the conclusions and the future work that could be done.
15

16

Chapter 2
Mixed Initiative Just in TimeInformation Retrieval Agent
Contents
2.1 Just in Time Information Retrieval Agents . . . . . . . . . . . . 18
2.1.1 JITIR agent’s characteristics . . . . . . . . . . . . . . . . . . . . 18
2.1.2 Related work . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
2.2 The Mixed Initiative User Interface . . . . . . . . . . . . . . . . 20
2.2.1 Autonomous Interface Agents work . . . . . . . . . . . . . . . . . 20
2.2.2 User Decision Making and direct manipulation . . . . . . . . . . 20
2.2.3 Collaborative work Advantages: the Mixed Initiative proposal . . 21
2.3 Problem statement . . . . . . . . . . . . . . . . . . . . . . . . . . 21
2.4 The Pandora Editor proposal . . . . . . . . . . . . . . . . . . . . 26
In this chapter, the domain of Information Retrieval agents is discussed. The theoreti-cal basements about the Mixed Initiative User Interface design is also treated. The chapterstarts with IR agents in section 2.1, where the fundamentals, necessity and related workin this kind of systems are reviewed. The section 2.2 explains the comparison betweenboth interaction design approaches: automated agents and direct manipulation. Section2.3 discusses some issues about the work of JITIR Agents and the ways users interact withsuch type of applications depending on the interface design. To conclude, in section 2.4 Iprovide one alternative approach oriented to set a new interaction paradigm between thedocument writer and a JITIR agent.
17

2.1 Just in Time Information Retrieval Agents
While creating a document, the author will need some information to support the writingactivity. This extra information or resources could be: recent news, images, historicalreferences, specific knowledge, previous researches, etc. Therefore, one important taskthat the writer has to do in addition to the main document writing activity, is findingthe extra information required. It is very sure that the document’s author will use aweb search engine to get the knowledge needed. In this process, he will formulate andreformulate some queries, once he has some web results, he will try to get and evaluatethe relevant ones to finally organize the main ideas, synthesize them and go on with thedocument creation.
The activities previously described show the diverse tasks done by the user and theinterruptions are part of the work. Writing and searching are two different activities andalso the technology provided presents two separated and multitasking interfaces: texteditors and web search engines running on browsers. Consequently, the current designsdo not help to the user in the interaction.
Concerning the user’s expertise, if he is not novice and knows exactly what he is lookingfor, it would be easy to formulate his query and get some relevant results from the searchengine. On the other hand, a novice user could get lost with the quantity of informationthat there is in the web, and somehow it could get worse if he is not familiarized with theuse of a search engine. Maybe he is not an expert in the topic he wants to write, so it ispossible that he has no clue to start his search. As result, the fact of producing his queriesagain and again would be time and energy consuming. His goal is to write a document,and it is not spending most of the time being distracted by the search engines results.
The task of the JITIR agent is extracting keywords from the user’s text keeping theeffects of interruptions as low as possible. The agent works as an assistant, so the user hasno need to formulate queries because they are extracted directly from his own text. Later,the user can decide which of the results suggested by the JITIR agent will be helpful tosupport his writing process.
2.1.1 JITIR agent’s characteristics
A JITIR agent has some characteristics [19] [1] which differentiates it from other kinds ofagents:
• It is autonomous: A software agent works in an independent way, and while it mon-itors the user’s environment it is able to make decisions without direct manipulationor intervention of the user.
• It is proactive: the query that is formulated by the agent is the result of the state ofthe user’s environment. At certain moment of time, the sensed situation limits thequery, it means that it is not proposed by the user.
• It is not intrusive: some alarm systems used in devices make alert sounds or displaysmall notification boxes. The goal is to let know the user about the activity to do,but also it has to be able to be ignored depending on the user’s cognitive load or hiscurrent task. The JITIR system interface design presents the resulted informationin a way that warns the user, but he can still decide to ignored it, see it or postponeto review it when he has the need.
18

• It works within the user’s context: the JITIR agent will not take the user out ofhis current activity as any other notification system. The agent works by providinginformation that is useful for that activity, so the user must not change his contextor work environment.
2.1.2 Related work
The design and development of a JITIR agent is based on the requirements it has toimplement: the kind of user’s work environment to be sensed, the scope of informationsearched (user’s local documents, the web, user’s e-mails), the type of system (desktop, webor mobile application) and the way of displaying the results. Next, I am presenting briefdescriptions of some JITIR systems1, what they do and the query formulation methodsthey apply.
One of the oldest works done in JITIR agents was developed at the MassachusettsInstitute of Technology. It presents three agents [19]: the Remembrance Agent that isa system which presents a list of documents related to the current one that is beingwritten or read by the user. It can be customized: the search could be done in the e-mails list for example, or it could take as input information the last 20 written words orthe last 500. The second agent is Margin Notes that automatically add annotations tothe web pages at the moment they are being loaded. The annotations show a list of theuser’s documents related to that web page[18]. The last agent is Jimminy that presentsinformation depending on the user’s physical environment: place, who he is talking to,the time of day. The results are shown via a head-mounted display attached to a wearablecomputer (off the desktop). The three systems use a back-end called Savant that worksas an IR system providing ranked results by using documents similarity measures.
Watson is one JITIR system that retrieves information taking into consideration thedocuments that the user is manipulating. It computes term weights to choose what toinclude in a query [13]. The weighting method is to give higher weights to terms thatappear more frequently in the document and to those that appear earlier or are emphasizedin italics, in a section heading, etc.
Calvin, a personal learner information agent, monitors user’s documents accesses topresent suggestions for other resources that were consulted in similar prior contexts. Thealgorithm used is WordSieve, that performs document indexing and retrieval. It generatescontext descriptions by using information about the sequence of accessed documents toidentify words which indicate a shift in context [3]. The algorithm builds access profileswhere the goal is to identify keywords that appear frequently in defined sequences orgroups of documents that were accessed for a specific context.
In [11], the description of a JITIR agent for bloggers is presented. The Blogoductsystem uses some heuristics in order to extract implicit queries from the document thatthe user is creating. In this research they compare and test lightweight NLP techniquesand propose their heuristics for creating the queries.
Some other related works are described in [1] (SAIRE, ACQUIRE, PIA, IIRM) whichare compared with Ubiquitous Web Information Retrieval Solution Agents. The goal ofthe agents (mobile and multi-agents) is to solve problems like security and privacy issuesand associated restrictions related to the use of web information.
1The examples of JITIR agents presented where chosen according to the scope of the master thesis
19

2.2 The Mixed Initiative User Interface
The Microsoft Research Labs presented some principles to develop user interfaces mak-ing automated services and direct manipulation work together [12]. In this section bothstrategies: automated agents and user direct manipulation are explained. Later, the ad-vantages of coupling these two strategies to enhance user’s abilities at the moment of theinteraction and the influences in the Pandora Editor design are shown.
2.2.1 Autonomous Interface Agents work
In the 90’s, some computer scientists started to develop specific programs called agents,which could be seen as end user assistants. The agent work is characterized for actingwith certain level of intelligence by operating concurrently[15]. They may learn, adapt,make decisions, be independent, etc.
In summary, they are not direct manipulated interfaces, so that the user does not needto command any execution. Most of the autonomous agents interact with the user bypresenting results or showing suggestions, in a way that its work can be visualized in theinterface. In other words, some agent functionality is not only limited to be executed inthe background. An intelligent agent interacts with the application as the same as theuser does.
The problem that could appear in such applications is that not always the actionstaken by the agent are expected. This design issue might rely on user anxiety and lack ofpredictability.
Some years ago, the idea of having conversational agents to let some kind of control tothe user was considered. A conversational agent takes the shape of a person and the inter-action with the user is direct, allowing him to make decisions about future actions. Theanthropomorphic or conversational agents changed two relevant aspects: the agent’s designand the user interaction. Nowadays, the developed agents do not have anthropomorphicrepresentations because it was seen that they degrade the user’s sense of responsibility andaccomplishment. The interaction among humans is not a good reference in user interfacesdesign and ”the users want to have the feeling they did the job”2 [20].
2.2.2 User Decision Making and direct manipulation
The goal of the directly manipulated interfaces is to present comprehensive and predictabledisplays to the users. The user is who has the responsibility of his actions and as a resulthe feels a complete control over the application [20]. The most important thing for thisstrategy of design is to know who the users are going to be and which tasks they are goingto do. The features to be implemented in the interface are: reversible actions, immediatefeedback, selection by pointing, visual ways of searching, visual presentation of results andrapid access items.
One drawback of this strategy is the strong dependence on visual representations. Ifthe visual design is not good enough some gaps between the user’s goals and how toachieve them could be generated. In addition, direct manipulation stalls automation oftasks and prevents the user’s capabilities to increase while it is generally known that moreautomation implies more productivity.
2Ben Shneiderman. Intelligent User Interfaces Conference, Atlanta 1997
20

2.2.3 Collaborative work Advantages: the Mixed Initiative proposal
The employment of the mixed initiative user interface allows a collaborative work betweenthe intelligent agent, which is able to provide automated services, and the user, who is thecentre of the application goals.
The Pandora Editor design implements an agent that takes care of the informationretrieval processes in the background (value added automation) meanwhile its results aredisplayed in a simple interface that is directly manipulated by the user.
The user has the control about the moment he wants the agent starts its work, so thathe is not distracted at any time by the agent. The design promotes rapid learning of theuser and it attenuates the complexity of navigation. User productivity arises while he iscreating the document3 because of the automated tasks done by the JITIR agent whichminimizes the number of interactions. The agent work is invisible to the user. At the end,the user will see some links to the websites suggested plus relevant images related to thedocument context, which could help him to improve his writing.
2.3 Problem statement
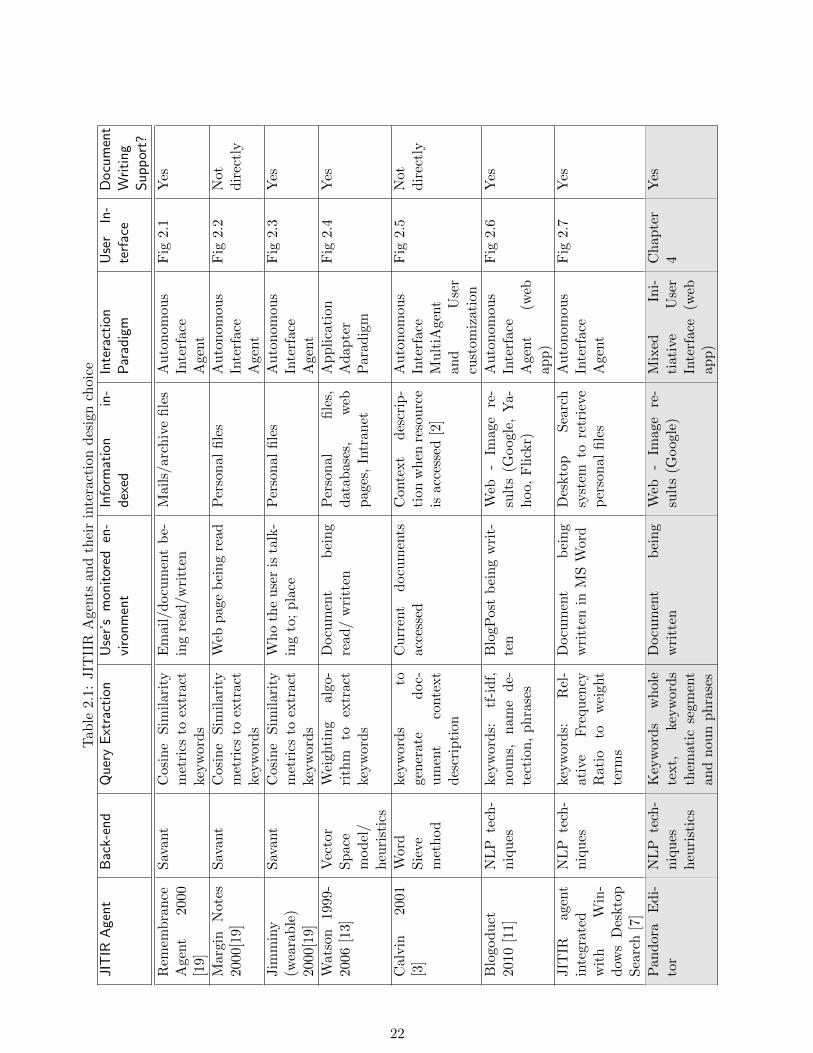
Once that the related work (2.1.2) and also the Mixed Initiative User Interface proposalwere presented (2.2.3), this section shows the Table 2.1 where a summary of the differentJITIR applications seen, together with the interaction paradigms implemented for eachare exposed.
As the table shows, the intention of those IR agents is to avoid the user to be over-whelmed with irrelevant retrieved information. With the use of a JITIR agent the timeto integrate the result data with the main task is lower and the documents, data or webpages indexed can be found at the searching moment with less noisy information.
Each example presented has its own goal and indexation process. They have their wayto extract the queries, present the results and monitor the context. Their main goals arefocused on the functionality and the tasks the agents must do. They implement interactiondesigns that seem to be efficient to reach the Agent aim and somehow are less focused ondifferent needs of information or customization that the user could require.
The section 2.4 shows a quick overview of the Pandora Editor. In this way, I amdescribing the differences among the related work reviewed and the JITIR agent done forthe present master thesis in the Table 2.1.
3See the results of the evaluation in the chapter 5
21
Tab
le2.1
:JIT
IIR
Age
nts
and
thei
rin
tera
ctio
nd
esig
nch
oice
JITIR
Agent
Back-end
QueryExtraction
User’smon
itored
en-
vironment
Inform
ation
in-
dexed
Interaction
Paradigm
User
In-
terface
Document
Writing
Support?
Rem
emb
ran
ceA
gent
2000
[19]
Sav
ant
Cos
ine
Sim
ilar
ity
met
rics
toex
tract
keyw
ord
s
Em
ail/
docu
men
tb
e-in
gre
ad/w
ritt
enM
ails
/arc
hiv
efi
les
Au
ton
om
ous
Inte
rface
Age
nt
Fig
2.1
Yes
Marg
inN
otes
200
0[1
9]
Sav
ant
Cos
ine
Sim
ilar
ity
met
rics
toex
tract
keyw
ord
s
Web
pag
eb
ein
gre
adP
erso
nal
file
sA
uto
nom
ous
Inte
rface
Age
nt
Fig
2.2
Not
dir
ectl
y
Jim
min
y(w
eara
ble
)200
0[1
9]
Sav
ant
Cos
ine
Sim
ilar
ity
met
rics
toex
tract
keyw
ord
s
Wh
oth
eu
ser
ista
lk-
ing
to;
pla
ceP
erso
nal
file
sA
uto
nom
ous
Inte
rface
Age
nt
Fig
2.3
Yes
Wats
on1999
-200
6[1
3]
Vec
tor
Sp
ace
mod
el/
heu
rist
ics
Wei
ghti
ng
algo-
rith
mto
extr
act
keyw
ord
s
Docu
men
tb
ein
gre
ad/
wri
tten
Per
son
alfi
les,
dat
abas
es,
web
pag
es,
Intr
anet
Ap
pli
cati
on
Ad
ap
ter
Para
dig
m
Fig
2.4
Yes
Calv
in20
01
[3]
Word
Sie
vem
eth
od
keyw
ord
sto
gen
erat
ed
oc-
um
ent
conte
xt
des
crip
tion
Cu
rren
td
ocu
men
tsac
cess
edC
onte
xt
des
crip
-ti
onw
hen
reso
urc
eis
acce
ssed
[2]
Au
ton
om
ous
Inte
rface
Mu
ltiA
gen
tan
dU
ser
cust
om
izat
ion
Fig
2.5
Not
dir
ectl
y
Blo
god
uct
201
0[1
1]
NL
Pte
ch-
niq
ues
keyw
ord
s:tf
-id
f,n
ou
ns,
nam
ed
e-te
ctio
n,
ph
rase
s
Blo
gPos
tb
ein
gw
rit-
ten
Web
-Im
age
re-
sult
s(G
oog
le,
Ya-
hoo,
Fli
ckr)
Au
ton
om
ous
Inte
rface
Age
nt
(web
app
)
Fig
2.6
Yes
JIT
IRage
nt
inte
gra
ted
wit
hW
in-
dow
sD
eskto
pS
earc
h[7
]
NL
Pte
ch-
niq
ues
keyw
ord
s:R
el-
ativ
eF
requ
ency
Rat
ioto
wei
ght
term
s
Docu
men
tb
ein
gw
ritt
enin
MS
Wor
dD
eskto
pS
earc
hsy
stem
tore
trie
vep
erso
nal
file
s
Au
ton
om
ous
Inte
rface
Age
nt
Fig
2.7
Yes
Pan
dora
Ed
i-to
rN
LP
tech
-n
iqu
esh
euri
stic
s
Key
word
sw
hole
text,
keyw
ord
sth
emat
icse
gm
ent
and
nou
np
hra
ses
Docu
men
tb
ein
gw
ritt
enW
eb-
Imag
ere
-su
lts
(Goog
le)
Mix
edIn
i-ti
ati
veU
ser
Inte
rface
(web
app
)
Ch
ap
ter
4Y
es
22

Figure 2.1: The Remembrance Agent User Interface [19], it presents a list of documentsrelated to the current one that is being written or read.
Figure 2.2: Margin Notes User Interface [19], it shows a list of the user’s documents relatedto the web page being load.
Figure 2.3: Jimminy User Interface [19], it retrieves information depending on the user’sphysical environment.
23

Figure 2.4: Watson customized for Motorola User Interface [13], it retrieves informationfrom the web, intranet, or personal data taking into consideration the documents that theuser is manipulating.
Figure 2.5: Calvin web based User Interface [4], it monitors user’s documents accessesto present suggestions according to other resources that were consulted in similar priorcontexts.
24
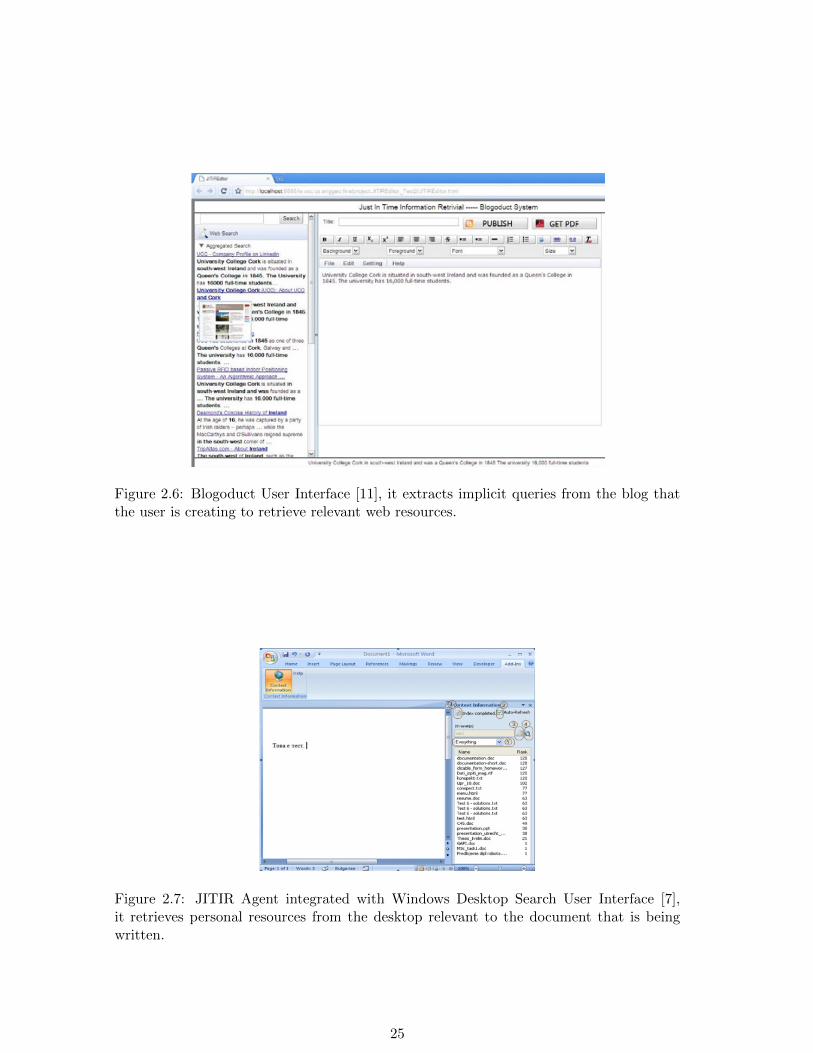
Figure 2.6: Blogoduct User Interface [11], it extracts implicit queries from the blog thatthe user is creating to retrieve relevant web resources.
Figure 2.7: JITIR Agent integrated with Windows Desktop Search User Interface [7],it retrieves personal resources from the desktop relevant to the document that is beingwritten.
25

2.4 The Pandora Editor proposal
Searching and writing are two activities that most of the time are done together. Bothactivities complement each other as the same as tools like search engines complement texteditors [11]. Switching from information seek to document writing represents the use of alot of time and user’s cognitive overload.
The need of tools that can solve those problems has motivated the development ofweb IR new generation systems and IR agents as it was detailed before. The intentionof the new search engines generation is the implementation of context driven informationsuppliers instead of having query based IR systems [5].
The implementation of intelligent agents in the IR field has proved that the usersare able to retrieve, handle and use more relevant information [7] and somehow the searchengines drawbacks are reduced. This project is oriented to find the correct way to combinea JITIR agent and the mixed initiative interface design so that the writers could be ableto create documents in less time and with a good quality through a simple interaction.The chapter 4 provides a complete description of the Pandora Editor.
26

27

28

Chapter 3
Languages, Technologies and Tools
Contents
3.1 Programming languages, technologies and tools that supportweb application development . . . . . . . . . . . . . . . . . . . . 30
3.1.1 Commercial Search Engines and their APIs . . . . . . . . . . . . 30
3.1.2 The Programming Languages and frameworks . . . . . . . . . . . 31
3.2 Programming languages, technologies and tools selection . . . 31
3.2.1 Web Application Framework . . . . . . . . . . . . . . . . . . . . 31
3.2.2 Google AJAX Search API . . . . . . . . . . . . . . . . . . . . . . 32
3.2.3 Integrated Development Environment (IDE) . . . . . . . . . . . . 32
The chapter number three presents the different technologies that were chosen to sup-port the development process of the Pandora Editor. The first section compares someprogramming languages, technologies and tools showing the advantages and disadvan-tages oriented to the development of a Web application; and the second section presentsa summary of the technologies chosen as a result of the previous analysis done.
29
3.1 Programming languages, technologies and tools that sup-port web application development
In the previous chapter some JITIR agents were presented and as it was seen, most ofthem indexes and retrieves personal data that is stored in an intra-net or in the computerof the user. The propose of the Pandora Editor is to find information and images that existin the web. In order to do this, there are APIs1 provided by commercial search enginesand let the software developers to integrate the search engine in their applications. Next,three of the Search Engines APIs are analyzed.
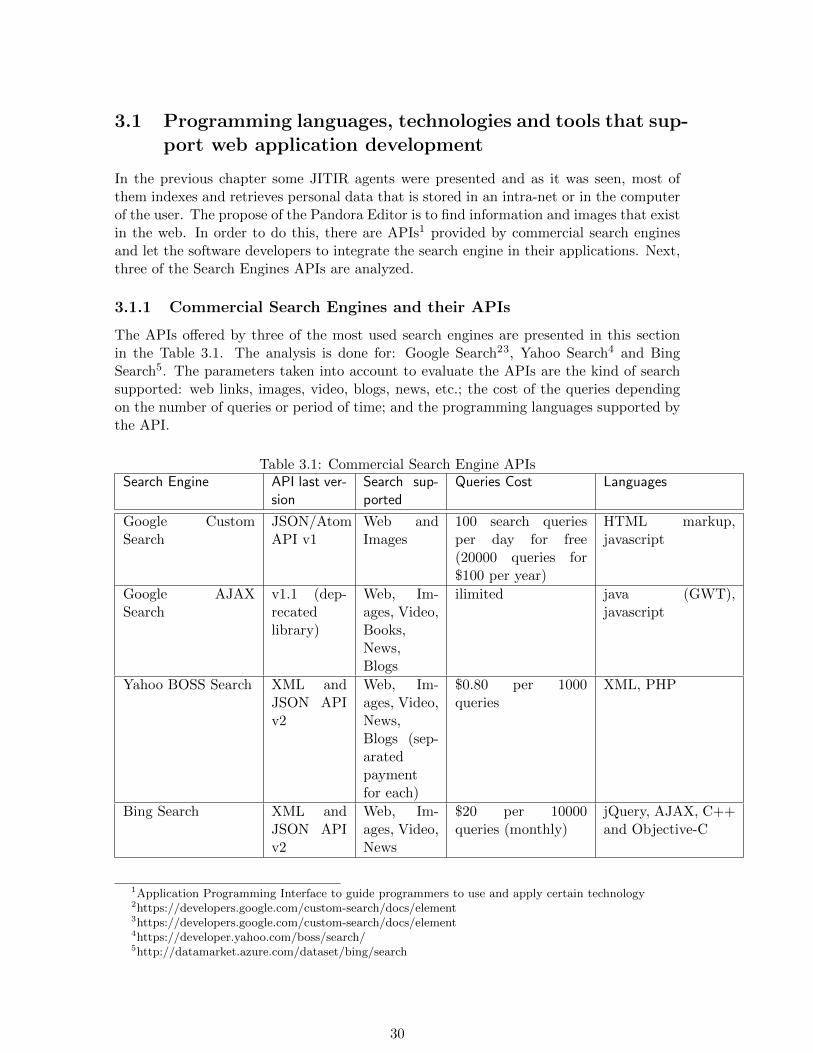
3.1.1 Commercial Search Engines and their APIs
The APIs offered by three of the most used search engines are presented in this sectionin the Table 3.1. The analysis is done for: Google Search23, Yahoo Search4 and BingSearch5. The parameters taken into account to evaluate the APIs are the kind of searchsupported: web links, images, video, blogs, news, etc.; the cost of the queries dependingon the number of queries or period of time; and the programming languages supported bythe API.
Table 3.1: Commercial Search Engine APIsSearch Engine API last ver-
sionSearch sup-ported
Queries Cost Languages
Google CustomSearch
JSON/AtomAPI v1
Web andImages
100 search queriesper day for free(20000 queries for$100 per year)
HTML markup,javascript
Google AJAXSearch
v1.1 (dep-recatedlibrary)
Web, Im-ages, Video,Books,News,Blogs
ilimited java (GWT),javascript
Yahoo BOSS Search XML andJSON APIv2
Web, Im-ages, Video,News,Blogs (sep-aratedpaymentfor each)
$0.80 per 1000queries
XML, PHP
Bing Search XML andJSON APIv2
Web, Im-ages, Video,News
$20 per 10000queries (monthly)
jQuery, AJAX, C++and Objective-C
1Application Programming Interface to guide programmers to use and apply certain technology2https://developers.google.com/custom-search/docs/element3https://developers.google.com/custom-search/docs/element4https://developer.yahoo.com/boss/search/5http://datamarket.azure.com/dataset/bing/search
30

3.1.2 The Programming Languages and frameworks
The list of programming languages which support web application development is quitebig. There are some tools and frameworks that together with the languages help thedevelopers during the whole development process. The most popular languages are: PHP,Java (Java Servlets and JavaServer Pages), Javascript, Ruby, Python, C#, Visual Basic(ASP/ASP.NET). HTML and XML are not programming languages but are also used tocreate web applications. The Table 3.2 presents some languages and their characteristics.
Table 3.2: Web Application Programming LanguagesJava PHP .Net Phyton Ruby
Maturity High High High High Medium
Multiplatform Yes Yes No Yes Yes
Hosting Availability Wide Wide Costly Medium Medium
Learning complexity High Low Medium High Low
Active community High High Medium Medium Medium
Third party libraries Very High High High Medium Low
Development Frame-works
more than30
more than20
less than 10 more than10
less than 10
Once that the Search Engines APIs and the programming languages were analysed,the decision about the technologies that are going to be used can be made. The nextsection presents the tools and technologies chosen.
3.2 Programming languages, technologies and tools selec-tion
The Pandora Editor requires to process a considerable quantity of queries per user. As itwas shown, the characteristics of Google AJAX search are adequate for the developmentof a project which is not going to be commercialized. The number of queries that canbe processed are not limited and it supports web and image search together. It has notbeen a hard decision to make because Google provides a Google Developer site wherethe community and examples are provided. The Google AJAX Search API can be nicelyembedded in Java projects through the use of Google Web Toolkit. This tools are explainednext.
3.2.1 Web Application Framework
As it was mentioned before, the language chosen was Java but the application is composedby the client and server parts. Google Web toolkit (GWT) is a technology that helps thedevelopers to program the client in java and later, the toolkit optimizes and compiles thecode to JavaScript to finally have the browser-based application6. GWT allows to embedJavaScript code into Java (JSNI) or implement the GWT query language GQuery7.
The communication between the client and the server is done through GWT RemoteProcedure Calls (asynchronously), and the server is the one that processes the text of theuser to extract the keywords and formulate the queries. The plugin added to Eclipse wasthe GWT SDK 2.5.1.
6http://www.gwtproject.org/7http://code.google.com/p/gwtquery/
31

3.2.2 Google AJAX Search API
In 2010 some Google API Libraries were created specifically to run with GWT. Oneof those Libraries is the Google AJAX Search API8. Sadly, at the moment, the API isdeprecated. However, the Google AJAX Search API version 1.1.0 worked correctly duringprevious tests done before the starting of the Pandora Editor project.
The API allows the creation of some search objects like Web, Image, Blog, Video, Newsand Books. For the Pandora Editor, only the search options of Web and Image are needed.The Google AJAX Search API permits the customization of the way the query is treated,the addition of search restrictions and the way of handle the results programmatically.The data structure that keep the results retrieved (SearchResultsHandler) just gives thepossibility to access to the first four results.
3.2.3 Integrated Development Environment (IDE)
The IDE widely used that supports the development process in Java is Eclipse. Theversion to be used is Kepler for Java EE Developers together with the JDK9 version 7.
8https://code.google.com/p/gwt-google-apis/wiki/AJAXSearchGettingStarted9Java Development Kit for Enterprise Edition
32

33

34

Chapter 4
The Pandora Editor
Contents
4.1 The Pandora Editor Architecture . . . . . . . . . . . . . . . . . . 36
4.2 Interface Design . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
4.2.1 Feedback in the interaction . . . . . . . . . . . . . . . . . . . . . 39
4.3 Implemented Modules . . . . . . . . . . . . . . . . . . . . . . . . 40
4.3.1 Document Scope . . . . . . . . . . . . . . . . . . . . . . . . . . . 40
4.3.2 Thematic Segmentation Scope . . . . . . . . . . . . . . . . . . . 43
4.3.3 Noun-Phrases Scope . . . . . . . . . . . . . . . . . . . . . . . . . 46
In this chapter the description of the Pandora Editor is detailed. The first sectionpresents the architecture of the system; the second section shows the interface design forthe user interaction; and the final section exposes the Pandora Editor functionality andthe different modules developed.
35

4.1 The Pandora Editor Architecture
The Pandora Editor is a Client - Server web application. Every time that the user requiresweb information to support the document creation he may use the Pandora Agent.
The agent will check the current state of the text by taking the entire editor envi-ronment content. This content has to be preprocessed and once that it is ready, thekeywords extraction can be done by calculating weights and evaluating them dependingon the search scope.
The chosen keywords are going to be sent as queries to Google. One query maycontain more than one word, so the Google API could help to make a final query wordsrefinement (it adds scores to the words that conforms the query). Then, when the queriesare processed by the Google Search Engine, the API will create a data structure per queryand per kind of result (web or image). This data structure contains the retrieved resultsso they can be accessed by the agent. Finally, the agent will display the relevant web andimage links.
The architecture of the agent is described next and the steps are enumerated accordingto the Figure 4.1.
Figure 4.1: The Pandora Editor Architecture
Any time that the user has the need to get some useful information from the web, theJITIR agent will apply the next steps for each search scope1:
1. The user asks the search request to the Pandora Agent.
2. The Pandora Agent will take the content of the editor and will send it to the serverto be pre-processed.
3. The Preprocessing Service will receive the current user’s text and will pre-process
1Document level, Thematic Segments level and Noun phrases level
36

it2.
4. The Query Extraction Services will find the keywords by applying the correspondingalgorithms. Formulation of the queries stage.
5. The Query or group of Queries is sent to the Pandora Agent.
6. The Agent will set the communication step with the Google AJAX Search API tosend to it the queries formulated before.
7. Google will retrieve the results corresponding to each query.
8. The Agent will present the web and image results in the corresponding interface.
4.2 Interface Design
The design of the interface is based on the Mixed-Initiative User Interface which purposeis achieving the user’s needs and goals by implementing automated actions3 in unison withdifferent metaphors or design conventions of direct manipulation interfaces.
The web application developed presents a simple text editor where the user can createhis document. The Figure 4.2 shows a screen-shot of the welcome screen. In this view theuser will have the Editor space where he can type to write the document. It also containsa table that will allow him to add some result images if there is the need. The user couldchoose among the 3 search scopes depending on the information results required. Thefinal element is the Search button that will start the work of the Pandora agent search.
Figure 4.2: The Pandora Editor - Main interface, full text view mode
2Application of Natural Language Techniques such as the use of regular expressions, removing of stop-words, sentences or paragraph extraction, POS, etc.
3The implementation usually consists on the use of Artificial Intelligence learning techniques [10], usersenvironment sensing and/or timing of services.
37

The second interface is the results view that is showed in the Figure 4.3 and has someelements:
• The Editor where the user can type and go on with the text creation.
• The table where he can add images by a drag and drop functionality.
• The panel that will display the different kinds of results from the web. The resultscan be web pages or images. If the result contains ’*’ and the representative colour isorange, it means that the results are for the Document Level. If the results are listedby numbers ’1’ ’2’ with a green colour it means that the results are for the ThematicSegments Level. If the results are listed by numbers in blue colour it means thatthe results are for the Noun Phrases Level. The user has also the option to select aword or a phrase in his text in order to start his own search. The results panel willpresent the results for user search showing a ’-’.
• The Search button that depending on the Search Scope levels chosen will process andextracts the queries. The Search button also processes the user query if it detectsthat he selected a word or phrase in his text.
• There is the Text Processed button that will present a view of the text according tothe previous search done: it will show the number of segments and also it will putin bold the noun phrases extracted.
• The full view button that will take the user to the Full or initial view of the appli-cation.
Figure 4.3: The Pandora Editor - Results interface
38

4.2.1 Feedback in the interaction
The Noun Phrases level search requires parsing the whole document in order to constructand identify the noun phrases in the user’s text. This functionality takes some time to becompleted depending on the document length. The time is around 1 second per sentencedetected. More detail about the library and algorithm is shown in the next section.
To let the user know about the time that the Noun phrases search will take, a messagewill be shown, allowing the user to cancel this search or to go on. The Figure 4.4 presentsa screen shot of this message.
Figure 4.4: The Pandora Editor - Option to cancel the Noun Phrases search
The Figure 4.5 presents the feedback information related to the state of the currentsearch. With this message, the user may realize that the Pandora Agent is working onfinding the web and image results.
Figure 4.5: The Pandora Editor - Feedback message about the current search state
39

4.3 Implemented Modules
The functionality in the web application is focused on extracting the keywords from theuser’s text. The keywords extracted should be meaningful according to the search scope.The main technique used was weighting the words that are part of the text by applying thetf-idf formula (Term Frequency-Inverse Document Frequency). This approach evaluateshow representative or important is a word for a document in a collection. The importanceof the word increases proportionally according to the number of times the word appearsin the document but is offset by the frequency of the word in the corpus [16].
tf: number of times the word appears in the document.idf = log(N/df), where N is the total number of documents and df is the total number ofdocuments where the word was found.The weight for the word will be obtained by: tf * idf.
For instance, the agent’s work in the Document Level is to give a global vision of thewhole document through the words extracted. More detail about the methods applied isexplained in the next sections.
4.3.1 Document Scope
Indexing process, document classification, document summarization, web page retrieval,etc. need to find descriptive keywords for one document. In order to extract keywords orphrases that are meaningful for the document the IR techniques take the document andevaluate its content respect a collection of documents [17]. In the present project, theinformation analysis is done for a single document and there is no a group of documentsbehind that supports the methods for keywords extraction. The evaluation of a relativelyshort text is a little more complicated than having a corpus or collection of documents.
The details about the Document Scope Search are presented next.
4.3.1.1 Libraries
The main libraries used in this scope were from the java util package: the regex packagein order to handle some regular expressions and the StringTokenizer class to separate thetext into words.
4.3.1.2 Text Preprocessing
As the whole text is seen as a String, the first thing to do is to separate it in words. Theclass StringTokenizer will build an array of words found after tokenize the text accordingto the characters: ”.;:, ’¡¿()[]?!0123456789.
The technique of Stemming 4 was not applied to preprocess the text, but a classthat identifies stopwords was developed. Therefore, to pre-process the text the Englishstopwords (it, the, an, so, etc.) were subtracted to not being considered as part of theuser’s text and all the other words were handled all with low-case form.
Here an example is shown:
4Stemming helps to keep the basic form of the words: computer, computation, computing have thesame base: comput
40

Table 4.1: Stopwords Examplesthe Stopword
alps
mountain
range
that Stopword
lies
within Stopword
switzerland
4.3.1.3 Descriptive Keywords Extraction
One technique that is used to extract keywords from the text when we do not have a cor-pus is to separate the text in segments or paragraphs and see the document as a collectionof ”documents”. In this way we could apply the tf-idf formula to find the weight that thewords have in each paragraph:
tf: number of times the word appears in the paragraph.idf = log(N/df), where N is the total number of paragraphs and df is the total number ofparagraphs where the word was found.The weight for the word will be obtained by: tf * idf.
To extract the keywords the next steps were followed:
• Separate the text into paragraphs.
• Pre-process the text per paragraph to have a list of words without stopwords.
• Find the frequency or the number of times that each word appears in the document(count setting the word in lower-case).
• Find the frequency or the number of times that the word appears in the paragraph(count setting the word in lower-case).
• Apply the tf-idf formula to find the weight for each word. The Figure 4.6 shows anexample with a small list of words with the respective frequencies in the documentand in the paragraph and their weights.
• Extract the keywords that would be part of the Query for the Document Level Searchtaking into account the next principles:
- weight equal to 0 OR weight bigger than 3.5 AND- length of the word bigger than 4 AND- the word appears in more than half of the number of paragraphs OR the wordappears more than 2 times in the paragraph.OR- the word starts with capital letter AND- the word appears in more than half of the number of paragraphs.
41
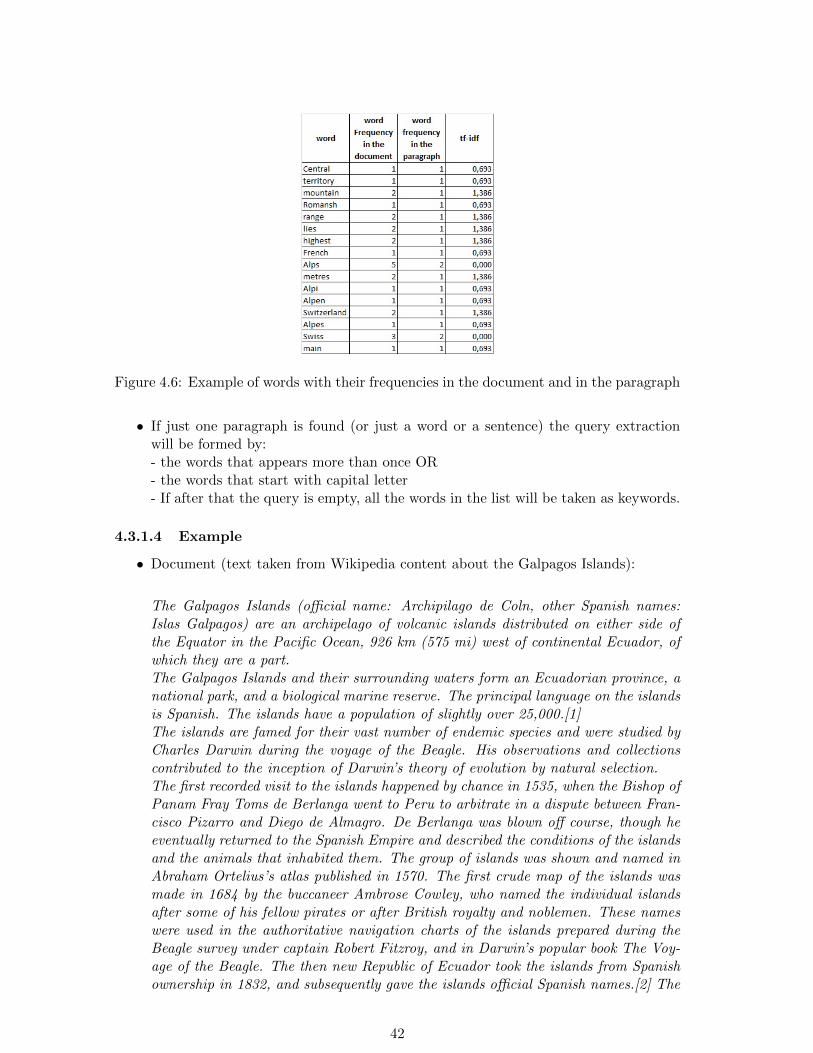
Figure 4.6: Example of words with their frequencies in the document and in the paragraph
• If just one paragraph is found (or just a word or a sentence) the query extractionwill be formed by:- the words that appears more than once OR- the words that start with capital letter- If after that the query is empty, all the words in the list will be taken as keywords.
4.3.1.4 Example
• Document (text taken from Wikipedia content about the Galpagos Islands):
The Galpagos Islands (official name: Archipilago de Coln, other Spanish names:Islas Galpagos) are an archipelago of volcanic islands distributed on either side ofthe Equator in the Pacific Ocean, 926 km (575 mi) west of continental Ecuador, ofwhich they are a part.The Galpagos Islands and their surrounding waters form an Ecuadorian province, anational park, and a biological marine reserve. The principal language on the islandsis Spanish. The islands have a population of slightly over 25,000.[1]The islands are famed for their vast number of endemic species and were studied byCharles Darwin during the voyage of the Beagle. His observations and collectionscontributed to the inception of Darwin’s theory of evolution by natural selection.The first recorded visit to the islands happened by chance in 1535, when the Bishop ofPanam Fray Toms de Berlanga went to Peru to arbitrate in a dispute between Fran-cisco Pizarro and Diego de Almagro. De Berlanga was blown off course, though heeventually returned to the Spanish Empire and described the conditions of the islandsand the animals that inhabited them. The group of islands was shown and named inAbraham Ortelius’s atlas published in 1570. The first crude map of the islands wasmade in 1684 by the buccaneer Ambrose Cowley, who named the individual islandsafter some of his fellow pirates or after British royalty and noblemen. These nameswere used in the authoritative navigation charts of the islands prepared during theBeagle survey under captain Robert Fitzroy, and in Darwin’s popular book The Voy-age of the Beagle. The then new Republic of Ecuador took the islands from Spanishownership in 1832, and subsequently gave the islands official Spanish names.[2] The
42

older names remained in use in English language publications, including HermanMelville’s The Encantadas of 1854.
• Keywords extracted:Ecuador Galapagos Spanish islands Darwin Beagle
• Results retrieved in Figure 4.7
Figure 4.7: Example of results retrieved for a Document Level Search
4.3.1.5 Limitations
The content of the text editor written by the user must be as clean as possible. Thisis the reason that technically, the widget used as element to insert the text works withplain-text. For instance, it does not handle HTML content. It means that the sentencesand paragraphs should be well defined.
Some sentences could be: 1. This is an easy example of sentence. 2. Am I writing asentence? 3. This is only the beginning... 4. We need to show more examples! 5. As hesaid: ”Everything changes”.
The configuration the user has for his browser influences the kind of the results retrievedfor a search. Therefore, it is necessary to have a browser which usage language and webresults language is English.
4.3.2 Thematic Segmentation Scope
Normally, a document shows diverse subtopics expressed in the different segments orparagraphs. If we want to write about a musician, we could start with his biography;then we may mention his main works; later, his success around the world; etc. Withthe Thematic Segmentation level Search, the Pandora agent extracts a Query per eachsegment found in the user’s text. So, the results retrieved will be specific for each of thesegments.
The details about the Thematic Segmentation Scope Search are presented next.
4.3.2.1 Libraries
Packages provided by the java libraries to process Strings are also used in this module.One external library was aggregated though. The name is UIMA Text Segmenter andallows the developer to divide the text in thematic segments.
4.3.2.2 Text Preprocessing
A text preprocessing was also done for this scope: tokenize the text according to thecharacters: ”.;:, ’¡¿()[]?!0123456789; and separate the English stopwords from the list ofwords found. The library to segment the text has its own approaches to preprocess thetext: Stemming with the use of Porter Stemmer; the elimination of stopwords and also
43

the normalization of the sentences so that the size of a sentence does not influences in thewhole text analysis.
4.3.2.3 Descriptive Keywords Extraction
To extract the keywords for each segment the next steps were followed:
• Apply the Text Segmenter library classes to separate the text into thematic segments.
• Pre-process the text to have a list of words per segment without the stopwords.
• Find the frequency or the number of times that each word appears in the wholedocument.
• Find the frequency or the number of times that the word appears in the segment.
• Apply the tf-idf formula to find the weight for each word. The Figure 4.8 shows anexample with a small list of words with the respective frequencies in the documentand in the segment and their weights.
Figure 4.8: Example of words with their frequencies in the document and in the segment
• Extract the keywords that would be part of the Query for that Thematic SegmentSearch taking into account the next principles:- weight equal to 0 AND- length of the word bigger than 4 AND- the word appears more than once in the segment.OR- length of the word bigger than 4 AND- the word appears more than once in the segment AND
44

- the word appears in LESS than half + 1 segmentsOR - the word starts with capital letter AND- the word appears more than once in the segment
4.3.2.4 Example
• Document (text taken from Wikipedia content about Coffee production in Colom-bia):The crisis that affected the large estates brought with it one of the most significantchanges of the Colombian coffee industry. Since 1875 the number of small coffeeproducers had begun to grow in Santander as well as in some regions of Antioquiaand in the region referred to as Viejo or Old Caldas. In the first decades of the20th century a new model to develop coffee exports based on the rural economy hadalready been consolidated, supported by internal migration and the colonization ofnew territories in the center and western regions of the country, principally in thedepartments of Antioquia, Caldas, Valle, and in the northern part of Tolima. Boththe expansion of this new coffee model and the crisis that affected the large estatesallowed the western regions of Colombia to take the lead in the development of thecoffee industry in the country.This transformation was very favorable for the owners of the small coffee estates thatwere entering the coffee market. The cultivation of coffee was a very attractive optionfor local farmers, as it offered the possibility of making permanent and intensive useof the land. Under this productive model of the traditional agriculture, based on theslash and burn method, the land remained unproductive for long periods of time. Incontrast, coffee offered the possibility of having an intense agriculture, without majortechnical requirements and without sacrificing the cultivation of subsistence crops,thus generating the conditions for the expansion of a new coffee culture, dominatedby small farms. Although this new breed of coffee made of country farmers demon-strated a significant capacity to grow at the margin of current international prices,Colombia did not have a relatively important dynamism in the global market of thisproduct. During the period between 1905 and 1935 the coffee industry in Colombiagrew dynamically thanks to the vision and long term politics derived from the cre-ation of the Federacin Nacional de Cafeteros de Colombia (National Federation ofCoffee Growers of Colombia) in 1927.The union of local farmers and small producers around the Federation has permittedthem to confront logistical and commercial difficulties that would not have been pos-sible individually. With time and through the research made at Cenicaf, founded in1938, and the Federation’s agricultural Extension Service, improved cultivation sys-tems. More efficient spatial patterns were developed that permitted the differentiationof the product and supported its quality. Currently the Land of Coffee in Colombiaincludes all of the mountain ranges and other mountainous regions of the country,and generates income for over 500,000 coffee farming families.
• 4 segments were found and for each the Keywords extracted were:- Document Level: coffee country small Colombia farmers- 1st. segment: model coffee Antioquia regions country Caldas estates western crisisindustry large Colombia- 2nd. segment: coffee agriculture possibility cultivation small Colombia- 3rd. segment: coffee Colombia- 4th. segment: Colombia
45

• Results retrieved in Figure 4.9
Figure 4.9: Example of results retrieved for a Thematic Segmentation Level Search
4.3.2.5 Limitations
The Thematic Segment Level Search will be able to work only if more than 1 segments werefound. If this is not the case, the Pandora editor will limit the search for the DocumentLevel search.
4.3.3 Noun-Phrases Scope
Through this scope the user will obtain results for some noun phrases extracted by thePandora agent. For example, it would be helpful if he wants to have some informationabout phrases composed by proper nouns. Some examples will be shown later.
4.3.3.1 Libraries
To make this functionality work, one of the libraries that was used is the Stanford fullparser5, with its release of January 2014. The package provides some options to thedevelopers to work with different languages, some ways for training the algorithms andpapers and examples to support the programming process.
The other library is the English Sentence Detector provided by the OpenNLP project6
of Apache, version 1.5. This library allows separating a plain text into well defined sen-tences.
4.3.3.2 Text Preprocessing
To use the library mentioned before, it is not necessary to make changes in the text.However, it must be separated into sentences. The parameter that the Stanford fullparser receives is an English sentence for the scope of this project.
4.3.3.3 Descriptive Keywords Extraction
To extract the key - noun phrases from the user’s text the next steps were followed:
5http://nlp.stanford.edu/software/lex-parser.shtml6https://opennlp.apache.org
46

• Apply the Sentence Detector library to separate the text into sentences.
• Apply the Stanford parser library for each sentence found.
• Extract the noun phrases detected by the Parser following the next principles:- noun phrase that contains two proper nouns OR- noun phrase that contains more than two words AND one of the words is a propernoun- do not choose the noun phrases extracted with the principles explained before if itcontains a verb gerund or participle, a conjunction, a possessive pronoun, an adverbor an adjective.
4.3.3.4 Example
• Document (text taken from Wikipedia content about Walt Disney):Walter Elias ”Walt” Disney was an American business magnate, animator, cartoon-ist, producer, director, screenwriter, philanthropist and voice actor. A major figurewithin the American animation industry and throughout the world, he is regarded asan international icon,[3] well known for his influence and contributions to the fieldof entertainment during the 20th century. As a Hollywood business mogul, he, alongwith his brother Roy O. Disney, co-founded Walt Disney Productions, which laterbecame one of the best-known motion picture production companies in the world. Thecorporation is now known as The Walt Disney Company and had an annual revenueof approximately US$45 billion in the 2013 financial year.As an animator and entrepreneur, Disney was particularly noted as a film producerand a popular showman, as well as an innovator in animation and theme park de-sign. He and his staff created some of the world’s most well-known fictional charac-ters including Mickey Mouse, for whom Disney himself provided the original voice.During his lifetime he received four honorary Academy Awards and won 22 AcademyAwards from a total of 59 nominations, including a record four in one year,[5] givinghim more awards and nominations than any other individual in history.[6] Disneyalso won seven Emmy Awards and gave his name to the Disneyland and Walt DisneyWorld Resort theme parks in the U.S., as well as the international resorts like TokyoDisney Resort, Disneyland Paris, and Hong Kong Disneyland.He died on December 15, 1966, from lung cancer in Burbank, California. A yearlater, construction of the Walt Disney World Resort began in Florida. His brother,Roy Disney, inaugurated the Magic Kingdom on October 1, 1971.
• The list of the noun phrases extracted were:1. Walter Elias ” Walt ” Disney2. a Hollywood business mogul3. Roy O. Disney4. Walt Disney Productions5. The Walt Disney Company6. Walt Disney World Resort7. the Walt Disney World Resort8. Roy Disney9. the Magic Kingdom
47

Figure 4.10: Example of results retrieved for a Noun Phrases Level Search
• Results retrieved in Figure 4.10
4.3.3.5 Limitations
A parser algorithm as the one that is implemented in the Stanford Parser library requiressome processing time to present the results [6]. Depending on the needs of the developer,the supporting NLP Stanford group suggests to use the Stanford Tagger instead of theParser to avoid the processing cost to be high. Basically, the work of the Tagger is to labeleach word of a sentence assigning the corresponding Part Of Speech (POS) tag: This/DT,is/VBZ, an/DT, easy/JJ, sentence/NN, ./.; in that way, we could know if the word is anoun, a verb, a preposition, etc. For the Pandora Editor, the full Parser was required; sothe main limitation is the time it takes to extract the noun phrases from each sentence.An example of a sentence Tagged and Parsed processed with the Stanford on-line parserservice is shown in the Figure 4.117.
The lexicalized probabilistic parser implemented in the Stanford Parser uses a Proba-bilistic Context-Free Grammar (PCFG) phrase structure and lexical dependency expertsto have efficient exact inference. The lexicalized PCFG Parser algorithm can be studiedin [8]. And the A* algoritm applied in the Stanford Parser can be seen in [14]
Basically in order to apply a PCFG parser, we need to have a set of rules that definethe grammar, for example:
With those rules and the addition of conditional Probabilities (assigned by a function)for each the Parser will know how to find the structure of a sentence after tagging thewords. With Lexicalization not only the rules mentioned before define the Parser, but also
7http://nlp.stanford.edu:8080/parser/index.jsp
48

Figure 4.11: Example of a sentence Tagged and Parsed with NLP Stanford libraries, usingthe online parser service
Rules of attachment, for example if we have the rule NP → NP(.) PP, the attachmentwill be through NP(.) or for the rule VP → VBD NP PP, the attachment will be thoughVBD. In the next image we can see an example:
Figure 4.12: Example of results retrieved for a Noun Phrases Level Search [8]
49
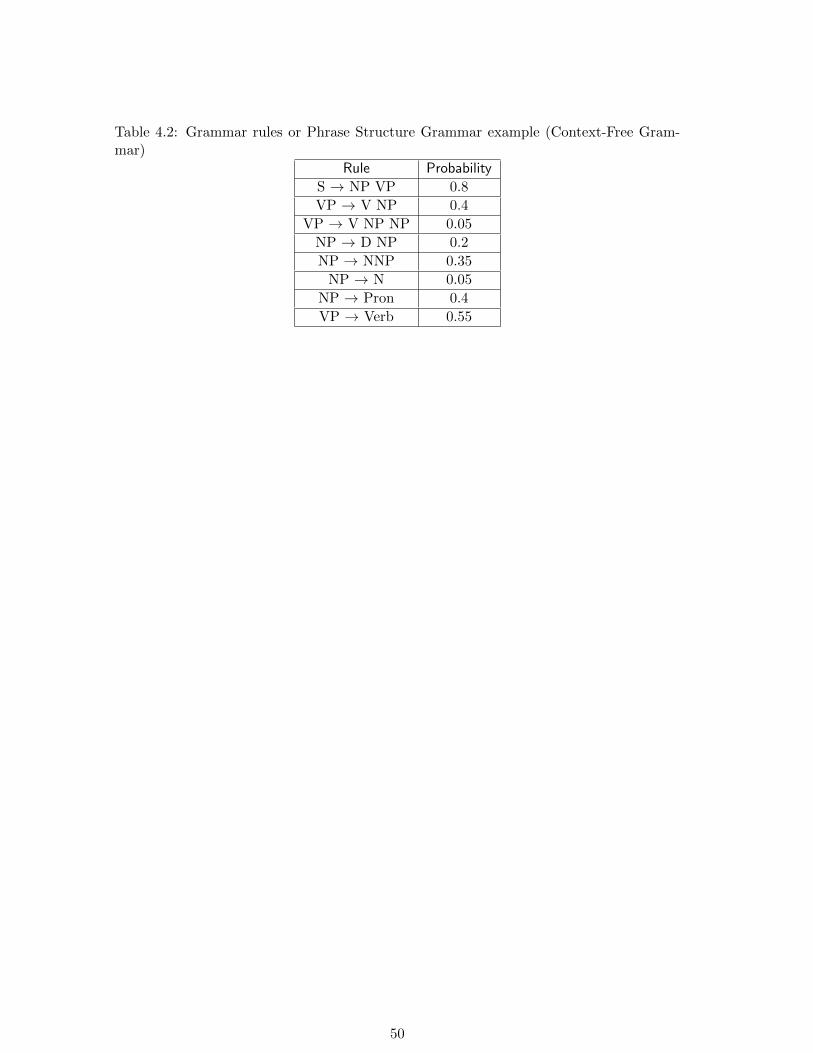
Table 4.2: Grammar rules or Phrase Structure Grammar example (Context-Free Gram-mar)
Rule Probability
S → NP VP 0.8
VP → V NP 0.4
VP → V NP NP 0.05
NP → D NP 0.2
NP → NNP 0.35
NP → N 0.05
NP → Pron 0.4
VP → Verb 0.55
50

Chapter 5
User Evaluation
Contents
5.1 User Evaluation Goal . . . . . . . . . . . . . . . . . . . . . . . . . 52
5.2 Evaluation Planning . . . . . . . . . . . . . . . . . . . . . . . . . . 52
5.2.1 Hypothesis to test . . . . . . . . . . . . . . . . . . . . . . . . . . 52
5.2.2 Independent variables . . . . . . . . . . . . . . . . . . . . . . . . 52
5.2.3 Dependent variables . . . . . . . . . . . . . . . . . . . . . . . . . 52
5.2.4 Subject selection and assignment . . . . . . . . . . . . . . . . . . 53
5.2.5 Forms and documents required . . . . . . . . . . . . . . . . . . . 53
5.2.6 Final step for the evaluation: Quality Tests . . . . . . . . . . . . 55
5.3 Results Obtained . . . . . . . . . . . . . . . . . . . . . . . . . . . . 55
5.3.1 Results in Document Creation Experiments . . . . . . . . . . . . 56
5.3.2 Results in Image Finding Experiments . . . . . . . . . . . . . . . 58
5.3.3 Results obtained in the Questionnaire for qualitative measures . 60
5.4 Result Analysis . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 62
In this chapter I present the details about the User Evaluation for the Pandora Editorapplication. First, the main aim of the tests is detailed. The next section explains theplanning stage with all the steps descriptions. The section number three details the resultsobtained, and finally, the last section shows the analysis and conclusions for the evaluation.
51

5.1 User Evaluation Goal
The objective of the evaluation is to see if the results retrieved by the JITIR agent throughGoogle by the use of auto-formulated queries are relevant for the user context. A secondimportant point to measure is the user productivity in terms of time spent to create adocument or find images and/or interruptions while doing the main activity.
The kind of evaluation applied is a Controlled Evaluation. It permits to test differentdesign conditions and it is a scientific method which involves a hypothesis approach andstatistical measures. All the steps followed during the user evaluation are described in thissection.
5.2 Evaluation Planning
The next guide lines conforms the evaluation plan and state the phases needed beforestarting the user evaluation execution.
5.2.1 Hypothesis to test
Through the User Evaluation I want to test if there is a significant difference in the usersproductivity (efficiency and quality production) while using a text editor plus Google orby using the Pandora Editor. With the tests, the results will let us know if the usersperformance changes while doing a document writing task and a illustration throughimages task.
5.2.2 Independent variables
The independent variable to be analysed is the Interface to create a document and to findimages with the support of web information results. This independent variable sets thetwo conditions that are part of the evaluation:C1 or condition 1: Text Editor + Google search in browserC2 or condition 2: The Pandora Editor
5.2.3 Dependent variables
The variables that are going to be measured are:
• For text creation:i. Number of links visited in Google vs number of links visited in the Pandora re-sults.ii. Number of times the user formulated a query in Google vs queries proposed bythe user in the Pandora Editor.iii. Length of the text produced.iv. Quality of the text produced.
• For finding images to represent a text:i. Number of images added.ii. Number of times the user formulated a query in Google vs queries proposed bythe user in the Pandora Editor.
52

iii. Quality of the images added to represent the text.
5.2.4 Subject selection and assignment
The number of users to do the evaluation will be eight. Each user will test both conditions(within group test) and will do the Tasks 1.A, 1.B and the Tasks 2.A, 2.B according tothe description in the Table 5.1.
The two tasks are divided in two groups. Each group has similar complexity tasks inorder to keep a balance between both conditions. The time to complete the tasks is fixed.The tasks are:
• T1. Complete the text given.For this task the user will have to complete or improve a text provided.Time to complete the task: 8 minutes.Minimum length: 2 paragraphs (4 to 5 lines each).
i. T1.A Sports in the world.The Appendix A contains the text provided and the instructions for the user.ii. T1.B Party organization.The Appendix B contains the text provided and the instructions for the user.
• T2. Illustrate the given text by adding images.For this task the user will have to represent the text given by using 10 pictures.Time to complete the task: 6 minutes.
i. T2.1 Natural disasters: causes and effects.The Appendix C contains the text provided and the instructions for the user.ii. T2.2 Advances in medicine to improve health.The Appendix D contains the text provided and the instructions for the user.
5.2.5 Forms and documents required
• Training script. Appendix E contains the training script which allows the user to befamiliarized with the Pandora Editor.
• Data Collection Forms. Appendix F contains the forms required at the moment ofthe evaluation, the 4 forms will be filled in per user. Some data need to be collectedwhile the evaluation and other fields will be completed after the user test. (ThePandora Editor keeps a log file from where the information will be extracted).
• Evaluator Instructions script. Appendix G describes the steps that the evaluatormust follow in order to succeed at the moment of the evaluation. Some steps needto be done first and some instructions to the user need to be explained.
• Qualitative measure questionnaire. Appendix H has a list of questions that are goingto be filled in by the user after the execution of the tasks. This questionnaire has asmain goal to measure subjective information about the user opinion and experiencewhile using the Pandora Editor vs a Text Editor and Google.
53

Tab
le5.
1:C
ontr
olled
Eva
luat
ion
Docu
men
tIm
pro
vem
ent
Tas
k1
and
Imag
esA
dd
itio
nT
ask
2T
AS
K1
(8m
inu
tes)
TA
SK
2(6
min
ute
s)
Rou
nd
1R
oun
d2
Qu
esti
onn
aire
Rou
nd
1R
oun
d2
Qu
esti
onn
air
e
User
Con
dition
Task
Con
dition
Task
Q1
Con
dition
Task
Con
dition
Task
Q2
1C
1T
1.A
C2
T1.
B1
C1
T2.
AC
2T
2.B
2
2C
1T
1.A
C2
T1.
B1
C1
T2.
AC
2T
2.B
2
3C
1T
1.B
C2
T1.
A1
C1
T2.
BC
2T
2.A
2
4C
1T
1.B
C2
T1.
A1
C1
T2.
BC
2T
2.A
2
5C
2T
1.A
C1
T1.
B1
C2
T2.
AC
1T
2.B
2
6C
2T
1.A
C1
T1.
B1
C2
T2.
AC
1T
2.B
2
7C
2T
1.B
C1
T1.
A1
C2
T2.
BC
1T
2.A
2
8C
2T
1.B
C1
T1.
A1
C2
T2.
BC
1T
2.A
2
54

Table 5.2: Quality Measure for the Task 1 and Task 2Quality Evaluation
Annotator Document Creation Images Illustration For the Users
1 T1.A and T1.B T2.A and T2.B 1 to 8
2 T1.A and T1.B T2.A and T2.B 1 to 8
3 T1.A and T1.B T2.A and T2.B 1 to 8
4 T1.A and T1.B T2.A and T2.B 1 to 8
5.2.6 Final step for the evaluation: Quality Tests
In order to measure the Quality of the images added in the Task 2, 4 extra users that aregoing to be identified as Annotators will be required. Every annotator will evaluate if thedocuments produced and if images added to the text are good. For this the Appendix Ishows an example of what the annotators will evaluate.
Every annotator will evaluate all the documents and images produced by the 8 users.
5.3 Results Obtained
As it was said before, there is one general hypothesis to be tested. To do this, we need todo one test per dependent variable. The type of test applied will be Pared-samples t test1
for each dependent variable formulated.In a t-test the independent variable help us to identify two mutually exclusive con-
ditions: Text Editor + Google and The Pandora Editor, while the dependent variableidentifies a quantitative dimension: number of words, number of images, quality rate,number of queries, etc.
With this kind of evaluation we will know whether the mean value of the dependentvariable for one condition (Text Editor + Google) differs significantly from the mean valueof the dependent variable for the second condition (The Pandora Editor).
To apply the t-test we have to set a Null Hypothesis (Ho.) and the data that will beuseful is:n = 8 for the number of users.α = 0,05 for 95 % of confidence intervaldof = n - 1 = 7 for the degree of freedom in a Pared Sample t-testThe critical value for t at α = 0,05, two-tailed test, dof = 7 is ρ = (+-)2,365 for the valueextracted from the distribution table Student.
The formula to calculate the t value is:
t =XS√n
(5.1)
Were:X = mean of the difference of the data between Condition 1 and Condition 2S = the Standard Deviation of the difference of the data between Condition 1 and Condi-tion 2
1The type of test chosen agrees with the evaluation context: 1 independent variable with 2 Conditionsfor a Experiment Within-group
55

Having ρ = 2,365, if the value t is out of the range -2,365 and +2,365 the null hypothesiswill be rejected so there is significant difference. If the evaluator prefers the use of Proba-bilities, he can work with P(t) and if the probability P(t) ¡ 5% the null hypothesis will berejected so there is significant difference.
5.3.1 Results in Document Creation Experiments
1. Ho. There is no difference in the document length of a text produced in a text editor+ Google or a text produced in the Pandora Editor.
Table 5.3: Document Length TestNumber of words produced in 8 minutes
User Condition 1 Condition 2
1 207 177
2 153 305
3 148 212
4 221 204
5 170 184
6 231 221
7 176 162
8 239 270
X C1 = 193,125 X C2 = 216,875
S2 C1 = 1283,268 S2 C2 = 2353,839
t = -1,116720064P(t) = 0,300973476
Results: The t value of -1.117 does not fall within the critical region defined bythe critical value of 2.365, and the p-value of 0.30 is greater than alpha of 0.05.Therefore the null hypothesis is accepted. The average length of a text producedin the Pandora Editor (X = 216,875, S = 2353,839)is not statistically greater thanaverage length of a text produced in a text editor + Google (X = 193,125, S =1283,268).
2. Ho. There is no difference in the number of queries formulated by the user in Googlewith the number of user queries (text selection by the user to make his own search)formulated in Pandora.
t = -1,667P(t) = 0,139
Results: The t value of -1.667 does not fall within the critical region defined bythe critical value of 2.365, and the p-value of 0.139 is greater than alpha of 0.05.Therefore the null hypothesis is accepted. The average number of queries producedby the user in the Pandora Editor (X = 4,625, S = 15,982)is not statistically greaterthan average number of queries formulated by the user in a text editor + Google (X= 2,75, S = 1,643).
56
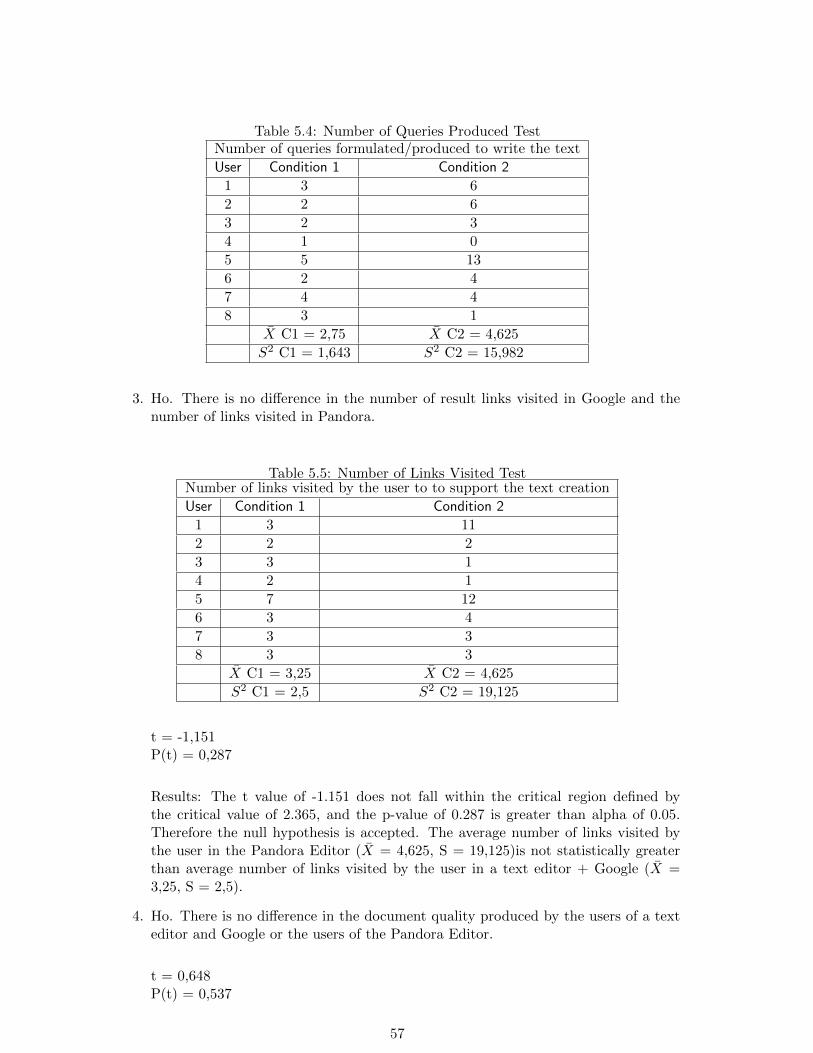
Table 5.4: Number of Queries Produced TestNumber of queries formulated/produced to write the text
User Condition 1 Condition 2
1 3 6
2 2 6
3 2 3
4 1 0
5 5 13
6 2 4
7 4 4
8 3 1
X C1 = 2,75 X C2 = 4,625
S2 C1 = 1,643 S2 C2 = 15,982
3. Ho. There is no difference in the number of result links visited in Google and thenumber of links visited in Pandora.
Table 5.5: Number of Links Visited TestNumber of links visited by the user to to support the text creation
User Condition 1 Condition 2
1 3 11
2 2 2
3 3 1
4 2 1
5 7 12
6 3 4
7 3 3
8 3 3
X C1 = 3,25 X C2 = 4,625
S2 C1 = 2,5 S2 C2 = 19,125
t = -1,151P(t) = 0,287
Results: The t value of -1.151 does not fall within the critical region defined bythe critical value of 2.365, and the p-value of 0.287 is greater than alpha of 0.05.Therefore the null hypothesis is accepted. The average number of links visited bythe user in the Pandora Editor (X = 4,625, S = 19,125)is not statistically greaterthan average number of links visited by the user in a text editor + Google (X =3,25, S = 2,5).
4. Ho. There is no difference in the document quality produced by the users of a texteditor and Google or the users of the Pandora Editor.
t = 0,648P(t) = 0,537
57
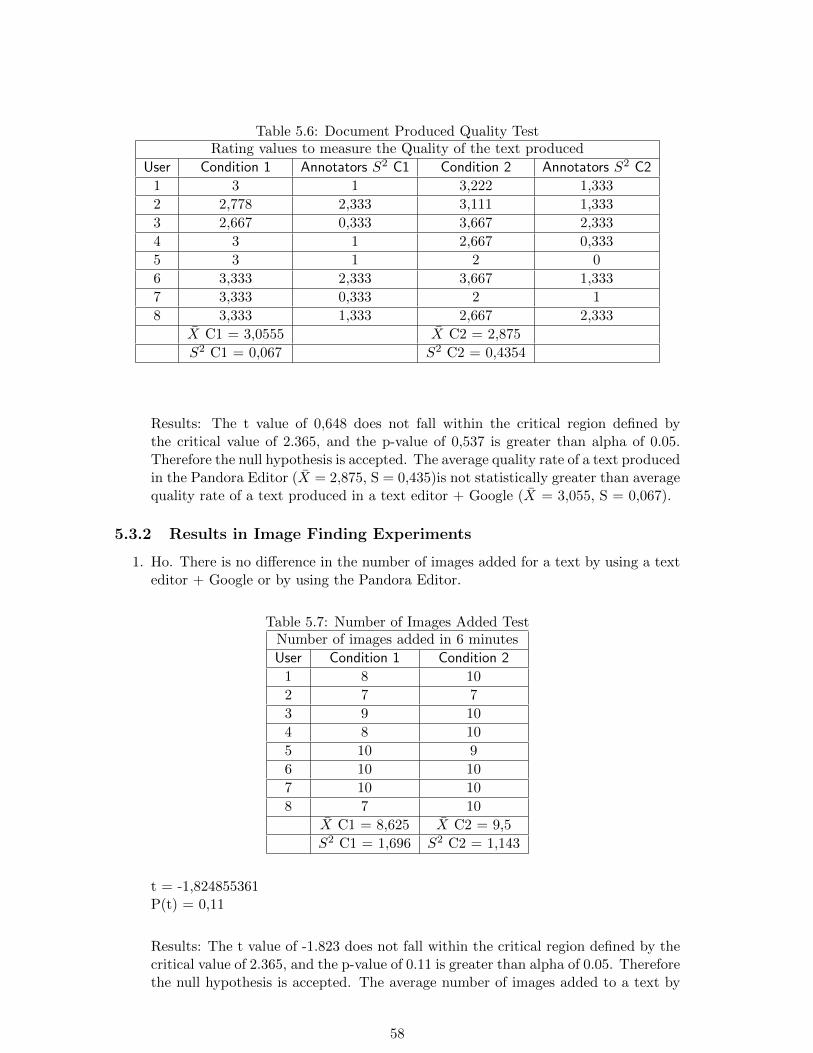
Table 5.6: Document Produced Quality TestRating values to measure the Quality of the text produced
User Condition 1 Annotators S2 C1 Condition 2 Annotators S2 C2
1 3 1 3,222 1,333
2 2,778 2,333 3,111 1,333
3 2,667 0,333 3,667 2,333
4 3 1 2,667 0,333
5 3 1 2 0
6 3,333 2,333 3,667 1,333
7 3,333 0,333 2 1
8 3,333 1,333 2,667 2,333
X C1 = 3,0555 X C2 = 2,875
S2 C1 = 0,067 S2 C2 = 0,4354
Results: The t value of 0,648 does not fall within the critical region defined bythe critical value of 2.365, and the p-value of 0,537 is greater than alpha of 0.05.Therefore the null hypothesis is accepted. The average quality rate of a text producedin the Pandora Editor (X = 2,875, S = 0,435)is not statistically greater than averagequality rate of a text produced in a text editor + Google (X = 3,055, S = 0,067).
5.3.2 Results in Image Finding Experiments
1. Ho. There is no difference in the number of images added for a text by using a texteditor + Google or by using the Pandora Editor.
Table 5.7: Number of Images Added TestNumber of images added in 6 minutes
User Condition 1 Condition 2
1 8 10
2 7 7
3 9 10
4 8 10
5 10 9
6 10 10
7 10 10
8 7 10
X C1 = 8,625 X C2 = 9,5
S2 C1 = 1,696 S2 C2 = 1,143
t = -1,824855361P(t) = 0,11
Results: The t value of -1.823 does not fall within the critical region defined by thecritical value of 2.365, and the p-value of 0.11 is greater than alpha of 0.05. Thereforethe null hypothesis is accepted. The average number of images added to a text by
58

the user in the Pandora Editor (X = 9,5, S = 1,143)is not statistically greater thanaverage number of images added to a text by the user in a text editor + Google (X= 8,625, S = 1,696).
2. Ho. There is no difference in the number of queries formulated by the user in Googleto find the images with the number of user queries (text selection by the user tomake his own search) formulated in Pandora to find images.
Table 5.8: Number of Queries Produced TestNumber of queries formulated/produced to find representative images
User Condition 1 Condition 2
1 10 7
2 9 9
3 10 14
4 13 5
5 12 15
6 6 8
7 8 9
8 9 17
X C1 = 9,625 X C2 = 10,5
S2 C1 = 4,839 S2 C2 = 18,286
t = -0,516247292P(t) = 0,622
Results: The t value of -0,516 does not fall within the critical region defined by thecritical value of 2.365, and the p-value of 0.622 is greater than alpha of 0.05. There-fore the null hypothesis is accepted. The average number of queries that the userformulated in order to find representative images for a text in the Pandora Editor(X = 10,5, S = 18,286)is not statistically greater than average number of queriesthat the user formulated in order to find representative images for a text in a texteditor + Google (X = 9,625, S = 4,839).
3. Ho. There is no difference in the quality of the images added by the users for aspecific text by the use of Google or by the use of the Pandora Editor.
t = 0,91712P(t) = 0,39
Results: The t value of 0,917 does not fall within the critical region defined by thecritical value of 2.365, and the p-value of 0,39 is greater than alpha of 0.05. Thereforethe null hypothesis is accepted. The average quality rate of the added images for atext by using the Pandora Editor (X = 2,817, S = 0,493)is not statistically greaterthan average quality rate of the added images for a text by using a text editor +Google (X = 3,0417, S = 0,3529).
59
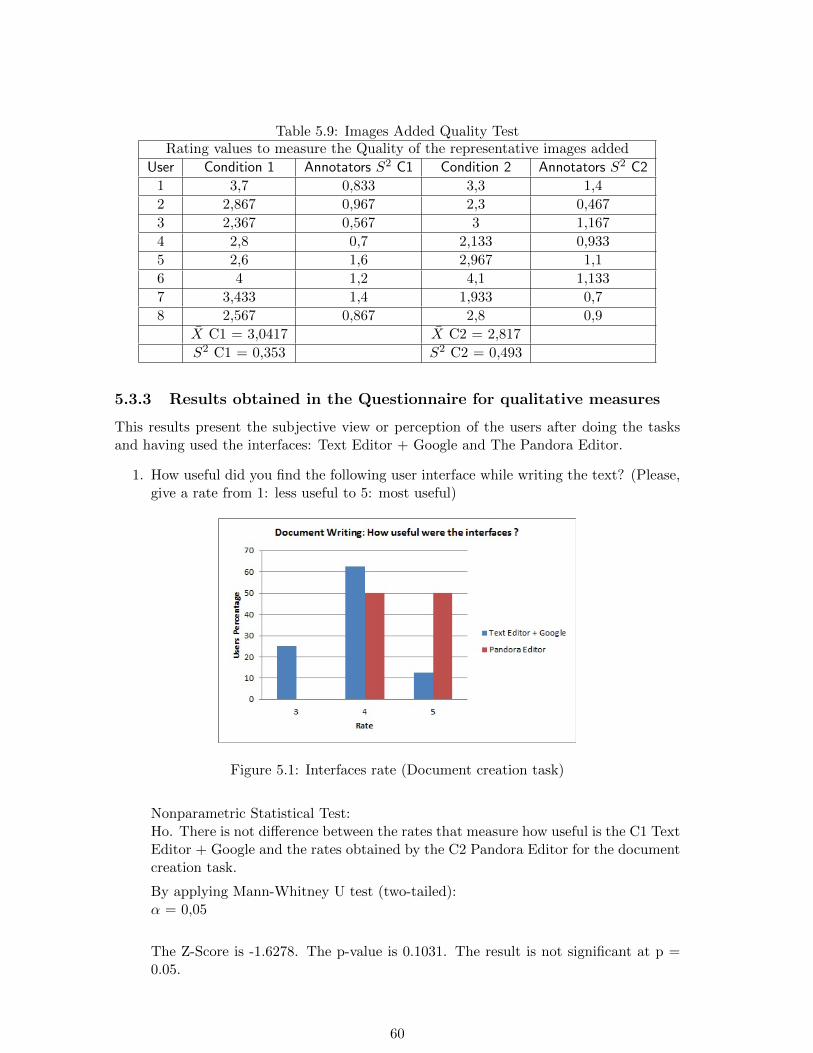
Table 5.9: Images Added Quality TestRating values to measure the Quality of the representative images added
User Condition 1 Annotators S2 C1 Condition 2 Annotators S2 C2
1 3,7 0,833 3,3 1,4
2 2,867 0,967 2,3 0,467
3 2,367 0,567 3 1,167
4 2,8 0,7 2,133 0,933
5 2,6 1,6 2,967 1,1
6 4 1,2 4,1 1,133
7 3,433 1,4 1,933 0,7
8 2,567 0,867 2,8 0,9
X C1 = 3,0417 X C2 = 2,817
S2 C1 = 0,353 S2 C2 = 0,493
5.3.3 Results obtained in the Questionnaire for qualitative measures
This results present the subjective view or perception of the users after doing the tasksand having used the interfaces: Text Editor + Google and The Pandora Editor.
1. How useful did you find the following user interface while writing the text? (Please,give a rate from 1: less useful to 5: most useful)
Figure 5.1: Interfaces rate (Document creation task)
Nonparametric Statistical Test:Ho. There is not difference between the rates that measure how useful is the C1 TextEditor + Google and the rates obtained by the C2 Pandora Editor for the documentcreation task.
By applying Mann-Whitney U test (two-tailed):α = 0,05
The Z-Score is -1.6278. The p-value is 0.1031. The result is not significant at p =0.05.
60
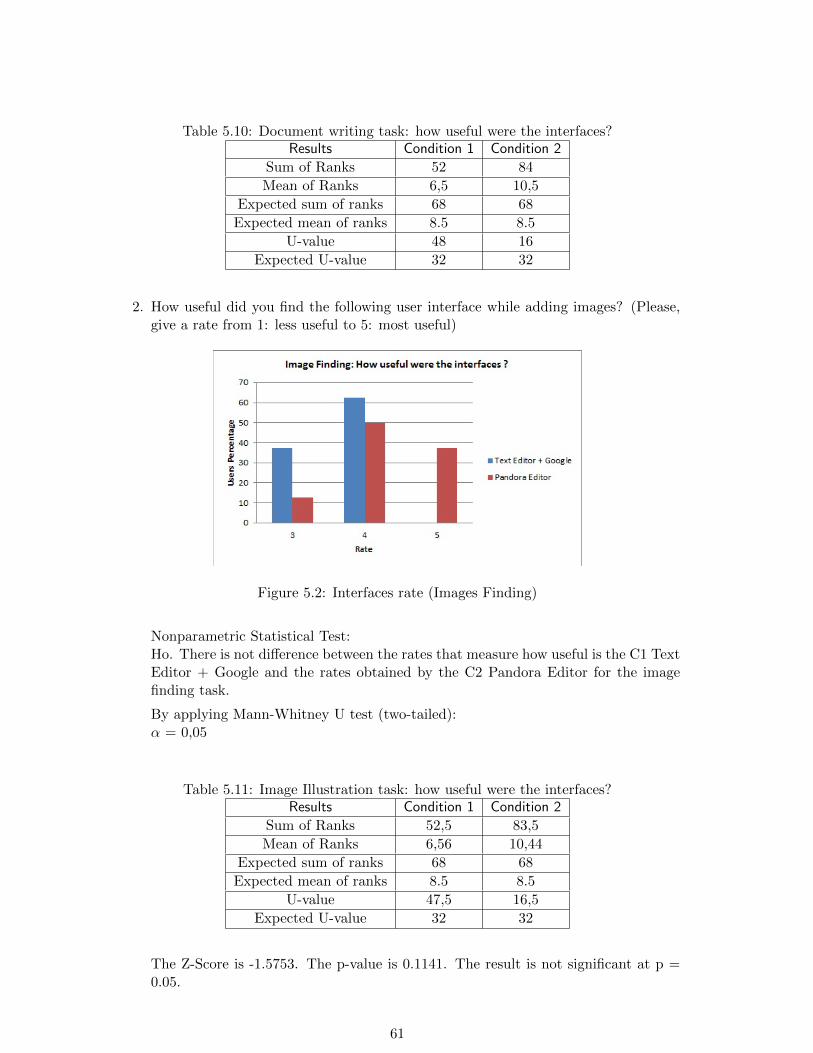
Table 5.10: Document writing task: how useful were the interfaces?Results Condition 1 Condition 2
Sum of Ranks 52 84
Mean of Ranks 6,5 10,5
Expected sum of ranks 68 68
Expected mean of ranks 8.5 8.5
U-value 48 16
Expected U-value 32 32
2. How useful did you find the following user interface while adding images? (Please,give a rate from 1: less useful to 5: most useful)
Figure 5.2: Interfaces rate (Images Finding)
Nonparametric Statistical Test:Ho. There is not difference between the rates that measure how useful is the C1 TextEditor + Google and the rates obtained by the C2 Pandora Editor for the imagefinding task.
By applying Mann-Whitney U test (two-tailed):α = 0,05
Table 5.11: Image Illustration task: how useful were the interfaces?Results Condition 1 Condition 2
Sum of Ranks 52,5 83,5
Mean of Ranks 6,56 10,44
Expected sum of ranks 68 68
Expected mean of ranks 8.5 8.5
U-value 47,5 16,5
Expected U-value 32 32
The Z-Score is -1.5753. The p-value is 0.1141. The result is not significant at p =0.05.
61

3. The Pandora Editor search results were useful at the moment to do the tasks?(Please, give a rate from 1: less useful to 5: most useful)
Figure 5.3: Pandora Editor Results Rate
4. What would you find useful to support you in document creation? - To have a listof topics related to the subject of my text- The information that a result link presents should be more specific to know if theweb page is going to be useful or not for me- To add the references in my text every time that I am using this information- To have all the useful information in one single page
5. Do you have suggestions about the Pandora Editor application? - It would be usefulto have links about the meaning of some vocabulary found in the text, as the sameas places or people mentioned- Save the important links- I would like to have a search box to do my own search- A zoom option to see the images better- I would like to have more image results- I would like to choose only web results or only images- The icons assigned to the search levels are not so intuitive- The resize of the images in the table should be automatic- I would like to add the images directly in the text- To have shortcuts to avoid the use of the mouse
5.4 Result Analysis
According to the results there is no significant difference in the users productivity (ef-ficiency and quality production) while using a text editor plus Google or by using thePandora Editor. The users performance is similar for the two tasks done, document writ-ing and images addition. However, the results show that the values obtained for thePandora Editor are higher than those for the first condition: by using Pandora the usersvisited more links, generated more queries, added more images and wrote more words.
62

While measuring the quality, there is no significant difference for the document qualityand images finding quality by the use of both conditions.
It is necessary to say that the results obtained for the Number of images added toillustrate a text given has a very low probability(t) = 0,11; which is so close to the minimalvalue accepted P(T) = 0.05 and it favours the Pandora Editor.
The subjective measures test done through the Questionnaire shows that 50% of theusers rated the user interface of Pandora Editor with a value of 4 and the other half gavea value of 5; being 5 the highest value as ’ very useful ’ for the document writing task.For the same task, the use of the Text Editor and Google got a rate of 4 from 62% of theusers, but 25% of them rated this condition with a value of 3 while 1 (13%) user rated itwith 5.
For the images addition task, the Pandora Editor interface was rated with 4 by half ofthe users, 38% of them valued it with 5 and 13% gave a rate of 3. For Google, 62,5% ofthe users rated its useful feature with 4 and 37,5% of them gave a value of 3.
The information to measure how useful both interfaces were shows that between 4 and5 users evaluated them with a value of 4. This rate is high but it is not the maximumvalue of users satisfaction about utility of the tools. However, an average measure showsthat the Pandora Editor reach 4,4 in interface useful rating while the text editor + Googlegot 3,8 in average. The statistical tests presented that the difference between the ’useful’rates for the two conditions is not significant.
The evaluation about how useful the Pandora Editor results were showed that 75% ofthe users rated them with a value of 4; the other 25% gave a rate of 5. It lets us know thatin general, the results retrieved by the JITIR agent were enough to support both tasksdone.
The results obtained for the questions 4 and 5 of the questionnaire about the user’sneeds at the moment of writing a document and suggestions show that they have infor-mation requirements while doing a web search like: they would like to have easy access tothe other links related to the topic they write, more relevant summary information of thelink2, the automatic addition of references, links with the definition of important keywordsin the text and more relevant images.
2This information is called Snipped and generally underlines de keywords the user inserted in the Query
63

64

Chapter 6
Conclusions
Contents
6.1 Limitations . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 66
6.2 Conclusions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 66
6.3 Future work . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 67
References . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 69
The final chapter describes the limitations for this version of the Pandora Editor. Theconclusions and future work will be also detailed.
65

6.1 Limitations
The main limitation that the Pandora Editor has is that it cannot run off-line. It is a webapplication that sets a connection with Google Search, so for the version developed theuser must have internet access.
The performance of the JITIR agent will be affected if the browser language or webpages results language configuration are not English. The NLP techniques applied areoriented to work with a user’s text written in English, so the browser configuration isimportant.
It is recommended the Pandora Editor runs in the browsers: Mozilla Firefox or GoogleChrome. Despite the fact that a GWT web project is optimized to run correctly in most ofthe commercial browsers, some drawbacks were found by using the application in InternetExplorer.
As the JITIR Agent must monitor the user’s text to extract the queries, if the lengthof the text is too short, unusual sentences are detected or the content is not clear (plaintext required) the results will not be relevant for that context.
6.2 Conclusions
This master thesis presents a research work on Just in Time Information Retrieval Agentsthat help or assist the user while he is creating a text. The agent is in charge of analyzingthe user’s text and presenting some web and image link suggestions that are relevant to thetopic that the user is writing. The Pandora Editor is a web application which implementedan agent that is going to extract keywords from the text and display links always thatthe user starts the search in any of the three scopes proposed: Document Level Search,Thematic Segments Level Search and Noun Phrases Level Search. The user is who has thecontrol about the search scope choice and the moment of searching, based on the MixedInitiative User Interface design.
The queries formulated by the agent are a combination of keywords and depending onthe Search Scope, the algorithms to pre-process the text and give a weight to the wordsare specific. The Pandora Editor prototype works with English texts and the results foundfor each query send are retrieved thanks to the implementation of methods provided bythe Google AJAX API.
The proposal of this project wanted to define an interaction paradigm to verify ifthe users of the Pandora JITIR agent were able to be more productive while creating adocument or finding images than by using a text editor plus a search engine. The userevaluation showed that there is not a significant difference in terms of users’ efficiencywhile they were working with the Pandora Editor or a common editor. However the testsshowed that they were able to handle more information from the web by using the PandoraEditor. The qualitative measures or subjective evaluation presented that the users foundthe interaction with the Pandora Editor more useful for both tasks done but the statisticaltests presented that the difference between the ’useful’ rates for the two conditions is notsignificant.
I could say that the results obtained did not present variation in the users’ performanceand quality production tasks because they are used to work with Google daily, so it meansa high degree of expertise working with a search engine and self-queries formulation. Myfinal conclusion and recommendation for IR Agents evaluation is to choose a bigger groupof users, let them to be well trained in the JITIR Agent (if the interface is simple, theydo not need days to get familiar with it, but the process of knowing the application and
66

all the services it provides during certain period of time is very important); and preparetasks that allow the users work more time under both test conditions.
The future work presented next is generally based on the suggestions given by theusers who had the opportunity to participate in the User Evaluation stage of the PandoraEditor project. Pandora shows to be a friendly application that required around 5 minutesof training to be understood. If the future work ideas could be implemented there wouldbe people using the tool in order to support them while they write a document.
6.3 Future work
There are useful proposals for the future work that can be done with the Pandora Editoridea. The implementation of more images retrieval seems to be a must, for example. Dur-ing the evaluations, the users found that having a text editor together with web results inthe same work environment is very useful but they still have information needs. There-fore, the implementation of more Search Scopes (Entity Search, recent related documentsSearch and similar topics Search) will be good to add.
Some field studies or careers depend a lot on document creation, so specific PandoraEditors could be developed. For example, a journalist writing about the latest news wouldlike to have an editor and web results about news in the world, news in the country, articlesfrom blogs, image, video or audio resources, maps to locate certain event and go for aninterview, etc.
In the area of Collaborative IR the future work in Pandora could let the users interacteach other if they have written or are writing about the same topic. Some networks couldbe developed around writers-topics.
Incorporate the references or citations automatically each time the writer uses others’content (text or images) is one feature that would be appreciated by document authors asthe same as the extension of more languages handling.
67

68

Bibliography
[1] Andrea Paola Barraza and Angela Carrillo-Ramos. Basic requirements to keep inmind for an ideal agent-based web information retrieval system in ubiquitous envi-ronments. In Proceedings of the 12th International Conference on Information Inte-gration and Web-based Applications & Services, iiWAS ’10, pages 550–557, NewYork, NY, USA, 2010. ACM.
[2] Travis Bauer and David Leake. A research agent architecture for real time datacollection and analysis. In In Proceedings of the Workshop on Infrastructure forAgents, MAS, and Scalable MAS, pages 61–66, 2001.
[3] Travis Bauer and David B. Leake. Real time user context modeling for informationretrieval agents. In CIKM, pages 568–570. ACM, 2001.
[4] Travis Bauer and David B. Leake. Exploiting information access patterns for context-based retrieval. In Proceedings of the 7th International Conference on Intelligent UserInterfaces, IUI ’02, pages 176–177, New York, NY, USA, 2002. ACM.
[5] Andrei Broder. The future of web search: From information retrieval to informationsupply. Fellow and VP Emerging Search Technologies, Yahoo! Research, 2006.
[6] Daniel Cer, Marie catherine De Marneffe, Daniel Jurafsky, and Christopher D. Man-ning. Parsing to stanford dependencies: Trade-offs between speed and accuracy. InIn LREC 2010, 2010.
[7] Elitza Chenkova and Ivan Koychev. A just-in-time information retrieval agent thatprovides context aware support of text creation. In Proceedings of International Con-ference on SOFTWARE, SERVICES AND SEMANTIC TECHNOLOGIES, pages44–51, 2009.
[8] Michael Collins. Lexicalized probabilistic context-free grammars. 1998.
[9] Vandana Dhingra and Komal Kumar Bhatia. Towards intelligent information re-trieval on web. International Journal on Computer Science and Engineering (IJCSE),3:1721–1726, 2011.
[10] Andrew Faulring, Brad Myers, Ken Mohnkern, Bradley Schmerl, Aaron Steinfeld,John Zimmerman, Asim Smailagic, Jeffery Hansen, and Daniel Siewiorek. Agent-assisted task management that reduces email overload. In Proceedings of the 15thInternational Conference on Intelligent User Interfaces, IUI ’10, pages 61–70, NewYork, NY, USA, 2010. ACM.
[11] Ang Gao and Derek Bridge. Using shallow natural language processing in a just-in-time information retrieval assistant for bloggers. In Proceedings of the 20th Irish
69

Conference on Artificial Intelligence and Cognitive Science, AICS’09, pages 103–113,Berlin, Heidelberg, 2010. Springer-Verlag.
[12] Eric Horvitz. Principles of mixed-initiative user interfaces. In Proceedings of theSIGCHI Conference on Human Factors in Computing Systems, CHI ’99, pages 159–166, New York, NY, USA, 1999. ACM.
[13] Kristian Hammond Sanjay Sood Jay Budzik and Larry Birnbaum. Context transfor-mations for just-in-time retrieval: Adapting the watson system to user needs. Tech-nical report, Northwestern University, (3.4), 2006.
[14] Dan Klein and Christopher D. Manning. A* parsing: Fast exact viterbi parse se-lection. In IN PROCEEDINGS OF THE HUMAN LANGUAGE TECHNOLOGYCONFERENCE AND THE NORTH AMERICAN ASSOCIATION FOR COMPU-TATIONAL LINGUISTICS (HLT-NAACL), pages 119–126, 2003.
[15] Henry Lieberman. Autonomous interface agents. In Proceedings of the ACM SIGCHIConference on Human Factors in Computing Systems, CHI ’97, pages 67–74, NewYork, NY, USA, 1997. ACM.
[16] Feifan Liu, Deana Pennell, Fei Liu, and Yang Liu. Unsupervised approaches forautomatic keyword extraction using meeting transcripts. In Proceedings of HumanLanguage Technologies: The 2009 Annual Conference of the North American Chap-ter of the Association for Computational Linguistics, NAACL ’09, pages 620–628,Stroudsburg, PA, USA, 2009. Association for Computational Linguistics.
[17] Y. Matsuo and M. Ishizuka. Keyword extraction from a single document using wordco-occurrence statistical information. International Journal on Artificial IntelligenceTools, 13:392–396, 2004.
[18] B.J. Rhodes and P. Maes. Just-in-time information retrieval agents. IBM SystemsJournal, 39(3.4):685–704, 2000.
[19] Bradley James Rhodes. Just-in-time Information Retrieval. PhD thesis, 2000.AAI0802535.
[20] Ben Shneiderman and Pattie Maes. Direct manipulation vs. interface agents. inter-actions, 4(6):42–61, November 1997.
70

Appendix A
Sports in the World Task 1.A
A.1 Text provided
So many people find that by practising any physical activity they can keep healthy andentertained. There is no a unique aim, one can do sports because of competition, for agood mental and physical condition, to increase the social relationships, to learn to bedisciplined and reach a goal, to reduce stress, to enjoy, etc. Every sport has a group ofnorms which define it. These rules allow the sport to be recognized internationally. Sportsare part of the people’s lives and practising a sportive activity is considered a human right.Generally, the propitious environmental conditions influence the way a sport is practised.According to the geographical situation and even cultural issues, one can see that a sportis practised in a country but not in others ...
A.2 Instructions
You are writing about different kinds of sports and some of them are practised in specificcountries in the world. Some sports are very popular and of course there are famoussportsmen/women and sport teams.
Time to complete the task: 8 minutes.
Minimum length: 2 paragraphs (4 - 5 lines each).
1. For this task an initial text is provided. It will be shown when you start the task.Please, read it well.2. The task is to improve or complete the text given by producing at least 2 paragraphs.3. You should NOT add images for this task.4. If you finish before the time given, please notify to the evaluator and do not close yourText Editor.
Remember: Assume that you are writing ’Wikipedia Content’, so that your documentcould be published in the web.
71

72

Appendix B
Party Planning Task 1.B
B.1 Text provided
It is supposed that a party is something enjoyable. Why does it need to be planned?Depending on the kind of party one would like to have, there are always previous thingsto verify before the important event. The first thing to think about is the number ofpeople who are going to be invited. It is better to have a list with their names, phonenumbers and addresses, so that the organizer can think in the party place according tothe number of guests. The next step is to choose an hour and date and reserve the place...
B.2 Instructions
What are the main steps to follow to organize a party? What should be considered tosucceed in the organization? What would the guests like the most?
Time to complete the task: 8 minutes.
Minimum length: 2 paragraphs (4 - 5 lines each).
1. For this task an initial text is provided. It will be shown when you start the task.Please, read it well.2. The task is to improve or complete the text given by producing at least 2 paragraphs.3. You should NOT add images for this task.4. If you finish before the time given, please notify to the evaluator and do not close yourText Editor.
Remember: Assume that you are writing ’a Magazine Content’, so that your documentcould be published.
73

74

Appendix C
Natural disasters: causes andeffects Task 2.A
C.1 Text provided
The Earth is dynamic and as a consequence, some natural phenomena occur. Thesephenomena are known as natural disasters and have their origin because of normal orabnormal behaviour in the interaction of the Earth Layers (lithosphere, biosphere, hy-drosphere, atmosphere and exosphere). Phenomena like geological, biological, physical orchemical are produced normally by natural processes in the Earth. Natural Phenomenathat occur in the lithosphere are earthquakes and volcanic eruptions; in the hydrospherewe have tsunamis and floods; in the atmosphere the disasters are hurricanes, tornadoes,electric shocks, thunders and lightning; in the biosphere: species extinction, changes inbiodiversity, and forest fires and in the exosphere we have meteors and asteroids fall.
For example, earthquakes are a result of tectonic plate activity; they occur when thegrinding or collision of plates along a fault line releases seismic energy that shakes thesurrounding ground. While areas near major fault lines such as the San Andreas Fault areprone to Earth’s most frequent and intense seismic activity, earthquakes can affect nearlyevery location on the planet. A quake may last from several seconds to a few minutes,posing its greatest threat in its ability to collapse man-made structures. When disasterstruck in Haiti on 12 January, 2010, it was the lithosphere that shook with a category 7earthquake, resulting in the deaths of approximately 230 000 people, 300 000 injured andone million rendered homeless.
While certain geographic areas are particularly susceptible to specific natural disasters,no region on Earth is free from the risk of a cataclysmic event. Earth normal behaviour isalso affected because of human activities. Human intervention and settlements can increasethe frequency and severity of natural hazards and disasters. For instance, water andair pollution, waste increase, natural resources improper exploitation (forests, minerals),industrial activities and human population exponential increase, influence in the behaviourof the environment producing Earth phenomena.
In summary, the three components of a natural disaster are: the cause (the naturalprocesses and interactions in the Earth Layers), the resultant phenomenon of their inter-action (hurricane, tsunami, earthquake, flood, etc.) and the effects (kinds and level ofdamages that could be measure as calamity or catastrophe). An example could be: Thecause: Ocean water warming plus atmospheric disturbances, the phenomenon: hurricane,and the effect: social and economic catastrophe.
75

C.2 Instructions
Add images to the text.
Time to complete the task: 5 minutes.
1. For this task a text is provided. It will be shown when you start the task. Please, readit well.2. The task is to illustrate or represent the text given by adding 10 pictures.3. You should NOT modify the text.4. If you finish before the time given, please notify to the evaluator and do not close yourText Editor.
Remember: The images added should be the most adequate for the given text.
76

Appendix D
Advances in medicine to improvehealth Task 2.B
D.1 Text provided
Throughout the health care community, small groups of individuals work together asteams. Physicians, nurses, pharmacists, technicians, and other health professionals mustcoordinate their activities to make safe and efficient patient care a priority. But theirtraining and experience must be complemented by medical equipment and technology. Theinvestment in medical research and technology has big benefits and impact in diagnostics,procedures, prostheses, devices and medicines.
General practitioners and specialists prescribe drugs and order diagnostic tests. Sur-geons and other specialists select appropriate procedures, prostheses and devices, whilehospitals purchase large diagnostic and surgical equipment and administrative supportsystems. All of these decisions are influenced by a range of factors, some of which havepromoted demand for new technologies and some of which have constrained it. Recentstudies have shown the benefits of some advances in medicine: New cancer drugs accountfor 50 to 60 per cent of the gains in US cancer survival rates (which have increased from 50to 63 per cent) since 1975. New and innovative medications for asthma have resulted in a28 per cent decline in mortality from the condition in Australia over the 1990s. Cataractsurgery results in an average gain of 1.25 quality-adjusted life-years. Insulin pumps fordiabetes patients improve patient quality of life and prolong life by an average of five yearsby reducing diabetes-related complications.
There are some broad themes emerging from current research and development in-cluding: genomics research has the potential to provide a revolutionary set of tools fortackling disease, such as the development of biological treatments; increased targeting orpersonalization of medicine linked to the development of biological therapies; convergenceof technologies such as drugs and devices, and blurring of the distinction between tech-niques traditionally used for diagnosis and for delivering treatment will continue; and theprospect of significant developments in the treatment of the major diseases of ageing (can-cers, diabetes, dementia and arthritis), which are expected to impose the greatest diseaseburdens in future.
77

D.2 Instructions
Add images to the text.
Time to complete the task: 5 minutes.
1. For this task a text is provided. It will be shown when you start the task. Please, readit well.2. The task is to illustrate or represent the text given by adding 10 pictures.3. You should NOT modify the text.4. If you finish before the time given, please notify to the evaluator and do not close yourText Editor.
Remember: The images added should be the most adequate for the given text.
78

Appendix E
Training Script
E.1 Pandora Editor Goal
The Pandora Editor is a web application that supports document creation. The main goalis to assist the writer with web and image information from the internet without havingthe need the user formulates search queries because the Pandora Agent will do this for theuser by extracting the queries from his text.
E.2 Pandora Editor Search Scopes
While you are writing a document you can select the Pandora Search scopes to do a weband image search.
The three scopes are:- Document Level: The Pandora Agent extracts a query from your document and sends
it to Google. The query represents your whole document.- Thematic Segment Level: The Pandora Agent extracts a query from each thematic
segment. For example, if Pandora defined 3 segments in your text, 3 queries (one persegment) are going to be extracted and send to Google. The query is represents onesegment.
- Noun Phrases Level: The Pandora Agent extracts some noun phrases which couldbe interesting to support your text creation. Every noun phrase extracted is going to besent to Google.
Depending on the size of the text, the display of the search results could take sometime, so you need to be a little patient.
Some Dialog boxes will be shown during the text processing and query searching. Theaim is to let you know the current state of the Pandora Search.
E.3 Pandora Editor Interface Views
The application presents two different views to the user:
1. The full view has the Editor space where you can type to write the document. Italso contains a table that will allow you to add some images if you want. You couldchoose among the 3 search scopes depending on your need. The final element is theSearch button that will start the work of the Pandora agent search.
79

2. The results view which has some elements:
• The Editor where you can type and go on with your text.
• The table where you can add images by drag and drop functionality.
• The panel that will show you the different kind of results from the web. The resultscan be web pages or images. If the result contains ’*’ it means that the results arefor the Document Level. (Orange colour)If the results are listed by numbers ’1’ ’2’ it means that the results are for theThematic Segments Level. (Green colour)If the results are listed by numbers in blue colour it means that the results are forthe Noun Phrases Level. (Blue colour)NOTE: at any time you can select a word or a phrase in your text in order to startyour own search. The results panel will present the results for your own searchshowing a ’-’.
• The Search button that depending on the Search Scope levels chosen will process andextract the queries. The Search button also processes your own query if it detectsthat you selected a word in your text.
• There is the Text Processed button that will present a view of your text accordingto the previous search done: it will show the number of segments and also it willput in bold the noun phrases extracted.
• The full view button that will take you to the Full or initial view of the application.
80

Appendix F
Data Collection Forms
F.1 Form to collect data: Text Editor + Google
The necessary data to collect for this condition are: number of queries formulated by theuser, number of links visited from the search page and number of images the user added.The next figure F.1 shows the example form.
Figure F.1: Form to collect data: Text Editor + Google
F.2 Pandora Editor Evaluation Version to collect data
If the tasks are done by using the Condition 2 which is the Pandora Editor, there is noneed of a form because one Pandora Editor Evaluation Version was implemented.
With this version the Data collected is: User ID, Name of the Task, Number of round,Document Length, Number of results clicked for each search scope, Number of resultsclicked for User Queries done and Number of User Queries generated. The figure F.2shows an example.
81

Figure F.2: The Pandora Editor Evaluation Results Example (Document creation task)
82

Appendix G
Evaluator Instructions Script
G.1 Before the Evaluation
Before each test with the users, the evaluator should:1. Delete the browser’s historial of websites previously visited.2. Prepare the browsers links to maintain the Text Editor + Google environment andPandora Editor environment opened.3. Prepare the forms corresponding to the User ID.4. Prepare a folder where to save the User results.
G.2 During the Evaluation
1. Apply the Pandora Editor Training script detailed in Appendix E.2. Explain to the User the goal of the Evaluation.3. Give to the User the Instructions per Task corresponding to the Tables 5.1 ans 5.2.The instructions are in the Appendixes A, B, C and D.4. Save the User Evaluation results.5. Ask the User to fill the Questionnaire of the Appendix H once that the tasks werecompleted.
G.3 After the Evaluation
Verify that all the previous steps were done correctly.
83

84

Appendix H
Qualitative Measure Questionnaire
1. How useful did you find the following user interface while writing the text? (Please,give a rate from 1: less useful to 5: most useful)
1. Text Editor + Google
2. The Pandora Editor
85

2. How useful did you find the following user interface while adding images to thetext? (Please, give a rate from 1: less useful to 5: most useful)
1. Text Editor + Google
2. The Pandora Editor
86

3. The Pandora Editor search results were useful at the moment to do the tasks?(Please, give a rate from 1: less useful to 5: most useful)
4. What would you find useful to support you in document creation?..................................................................................................................................................................................................................................................................................
5. Do you have suggestions about the Pandora Editor?...........................................................................................................................................................................................................................................................................................................................................................................................................................
87

88

Appendix I
Example of the Evaluation tomeasure the Quality
I.1 Measure the Quality of a Text
Is the content of the next text good to be published in Wikipedia or in a Magazine? Please,give a rate from 1 as very bad to 5 as very good.
I.2 Measure the Quality of a the Images that represent thetext
Please, read the next document:1
Throughout the health care community, small groups of individuals work together asteams. Physicians, nurses, pharmacists, technicians, and other health professionals mustcoordinate their activities to make safe and efficient patient care a priority. But theirtraining and experience must be complemented by medical equipment and technology. Theinvestment in medical research and technology has big benefits and impact in diagnostics,procedures, prostheses, devices and medicines.General practitioners and specialists prescribe drugs and order diagnostic tests. Surgeonsand other specialists select appropriate procedures, prostheses and devices, while hospitalspurchase large diagnostic and surgical equipment and administrative support systems. All
1The extracts were taken from Impacts of Advances in Medical Technology in Australia, ProductivityCommission Research Report, 2005
89

of these decisions are influenced by a range of factors, some of which have promoted de-mand for new technologies and some of which have constrained it.Recent studies have shown the benefits of some advances in medicine: New cancer drugsaccount for 50 to 60 per cent of the gains in US cancer survival rates (which have in-creased from 50 to 63 per cent) since 1975. New and innovative medications for asthmahave resulted in a 28 per cent decline in mortality from the condition in Australia overthe 1990s. Cataract surgery results in an average gain of 1.25 quality-adjusted life-years.Insulin pumps for diabetes patients improve patient quality of life and prolong life by anaverage of five years by reducing diabetes-related complications.There are some broad themes emerging from current research and development includ-ing: genomics research has the potential to provide a revolutionary set of tools for tack-ling disease, such as the development of biological treatments; increased targeting or per-sonalization of medicine linked to the development of biological therapies; convergence oftechnologies such as drugs and devices, and blurring of the distinction between techniquestraditionally used for diagnosis and for delivering treatment will continue; and the prospectof significant developments in the treatment of the major diseases of ageing (cancers, di-abetes, dementia and arthritis), which are expected to impose the greatest disease burdensin future.
Are the next images good/adequate to represent the text previously read? Please,give a rate for each image from 1 as very bad representing the text to 5 as very goodrepresenting the text.
90

Appendix J
Digital content
J.1 Digital media attached
The DVD attached to the Master Thesis Report contains:
• The PDF file with the Master Project Report: Just in Time Information RetrievalAgent to support Text Creation, based on the Mixed Initiative User Interface Design.
• A folder with the source code of the Pandora Editor web application. To import andrun the project it will be needed to add the GWT plugin to the Eclipse IDE anduse ’Import App Engine Sample Apps’ to choose the project folder in the DVD.
J.2 Access to the Pandora Editor
The Pandora Editor is running in the Google App Engine. The link for the users whowould like to see the application is http://pandoraeditor.appspot.com/
91




















