
Indefinite Pronouns in ELF
19
Course Paper Indefinite Pronouns in ELF The frequency and distribution of -one/-body indefinite compounds in the English used by native Swedish-speakers Author: Emily Öhman Supervisor: Mikko Laitinen Semester: Spring 2014 Course Code: 4EN006
Transcript of Indefinite Pronouns in ELF

Course Paper
Indefinite Pronouns in ELF The frequency and distribution of -one/-body indefinite compounds in the English used by native Swedish-speakers
Author: Emily Öhman Supervisor: Mikko Laitinen Semester: Spring 2014 Course Code: 4EN006

Contents 1 Introduction _______________________________________________ 1
2 Theoretical background ______________________________________ 2
3 Data & Method _____________________________________________ 6 3.1 The corpus _____________________________________________ 6 3.2 Method _______________________________________________ 7 3.3 Genre Definitions _______________________________________ 7 3.4 Problems ______________________________________________ 8
4 Results ___________________________________________________ 9 4.1 Genre variation ________________________________________ 10 4.2 Collocates ____________________________________________ 11 4.3 Statistical Significances _________________________________ 13
5 Comparisons ______________________________________________ 13
6 Conclusions ______________________________________________ 15
7 References _______________________________________________ 16

1
1 Introduction This paper examines how native Swedish-speakers use the compound indefinite
pronouns of English. The LNU student corpus will be utilized to find data on
frequencies, distribution in different genres, and variation in the use of the indefinite
pronouns of English. The data is analyzed and discussed in the Results section, as
well as compared to previous findings that focused on native varieties of English in
the Comparisons section. The unit of analysis for this study is indefinite pronoun
compounds with a human reference: i.e. those comprising of the determiner
morphemes any-, some-, every-, and no-, and either one of the nominal morphemes -
one or -body.
Biber et al. (1999) describe an indefinite pronoun as something that refers to
"entities that the speaker/writer cannot or does not want to specify more exactly"
(351). Based on data from the LSWE1 corpus they claim that -body compounds are
more common in the genre of conversation (oral) and -one compounds in written
registers (literate) (Biber et al. 1999: 351). Nonetheless, in present-day English (PDE)
these compound forms are considered to be in free variation (cf. Quirk 1985,
Raumolin-Brunberg 1994, Svartvik 1997, Biber 1999, D'Arcy 2013). The examples2
below illustrate the interchangeability of the two different compound forms:
(1) 𝐸𝑣𝑒𝑟𝑦𝑜𝑛𝑒𝐸𝑣𝑒𝑟𝑦𝑏𝑜𝑑𝑦 over eighteen now has a vote.
(2) 𝑆𝑜𝑚𝑒𝑜𝑛𝑒𝑆𝑜𝑚𝑒𝑏𝑜𝑑𝑦 was telling me you’ve been to America.
(3) Has 𝑎𝑛𝑦𝑜𝑛𝑒𝑎𝑛𝑦𝑏𝑜𝑑𝑦 got anything to say?
(4) There was 𝑛𝑜 𝑜𝑛𝑒𝑛𝑜𝑏𝑜𝑑𝑦 at the office.
1 Longman Spoken and Written English corpus 2 Adapted from Quirk et al. (1985: 378)

2
An overwhelming trend in most varieties of PDE is a move towards compound forms
with -one at the expense of -body compounds (cf. Russell 2012, D’Arcy et al. 2013,
Öhman 2014). This trend is particularly noticeable in young speakers but is evident in
all genres, genders, and most regions. The research questions are posed keeping this
in mind:
• What is the frequency and distribution of -one/-body compounds in
ELF?
• How does the distribution compare to native varieties of English?
The following sections will discuss theoretical approaches to these questions, and
introduce the corpus and unit of analysis in detail. The final sections present and
analyze the findings.
2 Theoretical background Although the two compound forms are in free variation in PDE, this is a fairly recent
development as lexical leveling was not finalized until the end of the 19th century
(D’Arcy et al. 2013: 288). Before -one and -body compounds, indefinite pronouns in
Old English (OE) and Middle English (ME) consisted of simple forms: Raumolin-
Brunberg & Kahlas-Tarkka (1997:46) list ælc, ægwhilc, æghwa, ægþer, æghwæþer,
gehwilc, gehwa, sum, ænig, nan, nænig, (the equivalent of PDE any, some, every,
each, none), and -man compounds:
(5) Nu seið sum mann: Sceal ic luuiȝe ðane euele mann? (ME: Vices and Virtues 1 73)
Somebody says then: Do I have to love an evil man?
(6) ne mæg ænig twæm godum ðeowigan (OE: Mercian C10)
no one can serve two gods
As the examples above demonstrate, man compounds and simple forms were used in
ME and OE constructs where today -one or -body compounds are used. Example (5)
also demonstrates one of the possible reasons for the disappearance of man: with both
3
the grammaticalized form of man (as a function word) and the lexical man in
common use, there was a risk of confusion. There are different theories as to why -
one and -body compounds emerged and started to appear in constructs where
previously a man compound or simple form would have been chosen (e.g.
grammaticalization processes), however, that discussion is beyond the scope of this
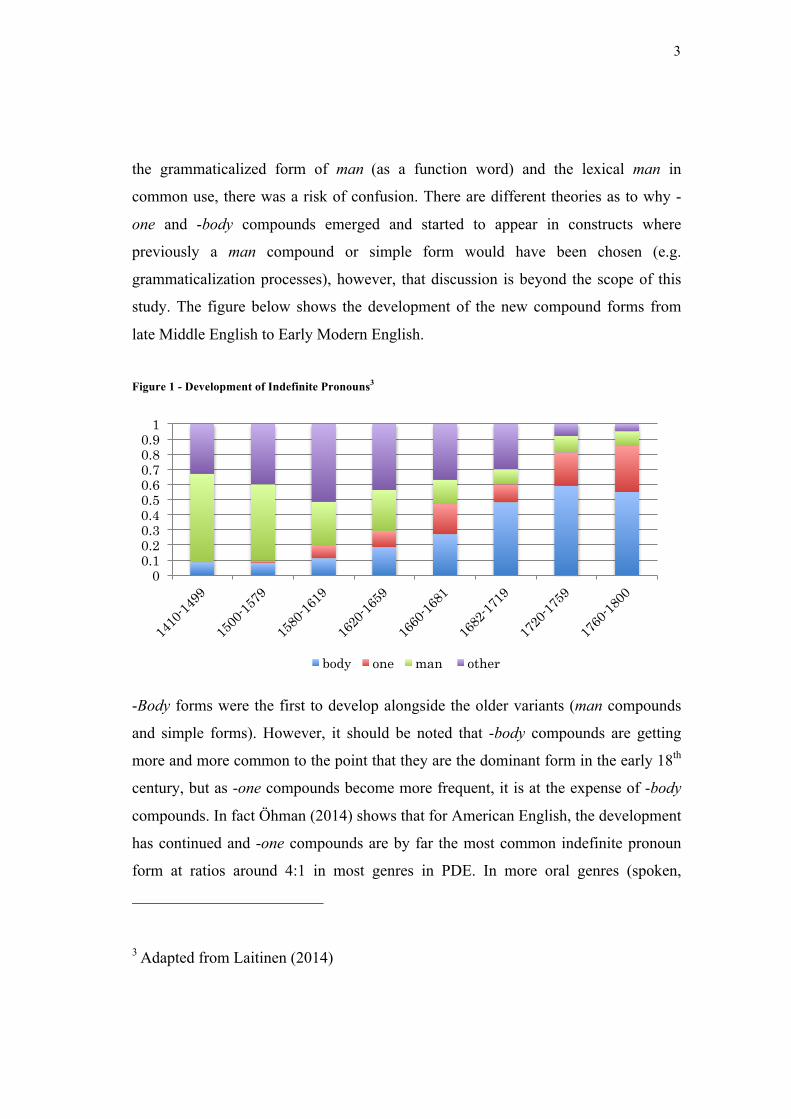
study. The figure below shows the development of the new compound forms from
late Middle English to Early Modern English.
Figure 1 - Development of Indefinite Pronouns3
-Body forms were the first to develop alongside the older variants (man compounds
and simple forms). However, it should be noted that -body compounds are getting
more and more common to the point that they are the dominant form in the early 18th
century, but as -one compounds become more frequent, it is at the expense of -body
compounds. In fact Öhman (2014) shows that for American English, the development
has continued and -one compounds are by far the most common indefinite pronoun
form at ratios around 4:1 in most genres in PDE. In more oral genres (spoken,
3 Adapted from Laitinen (2014)
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9
1
body one man other

4
fiction), the ratio is not quite as high but has increased similarly to the more formal
literate genres (magazines, non-fiction books, newspapers, academic publications).
Even for many oral genres, -one compounds are more common than -body
compounds (Öhman 2014: 37). D’Arcy et al. (2013) and Russell (2012) found similar
development in other varieties of English such as Canadian, British, and Scottish
English.
Although the two compound forms are generally considered to be in free
variation (with the exception of partitive structures that only take -one compounds),
there are dissenting voices among linguists. Kishimoto (2010) proved that there are
no syntactic constraints affecting the distribution, however, Bolinger (1976, 1977)
found semantic constraints and calls other scholars out on what he calls “assumed
free variation” (1977: 14). By presenting graduate students with surveys, he found
that -one has connotations of closeness and -body of distance. This has been
dismissed as a “tendency but not a rule” by Raumolin-Brunberg & Kahlas-Tarkka
(1997: 74), however, Svartvik and Lindquist (1997) found some evidence to support
Bolinger’s claims by examining collocations with -one and -body compounds.
Svartvik & Lindquist’s study will be further explored in the Results section.
Previous studies have found that -one is considered the more prestigious of the
two compound forms (Quirk et al. 1985, Biber et al. 1999). Similarly, people with a
high socio-economic status are more likely to use compounds with -one rather than -
body (Russell 2012, D’Arcy et al. 2013). Another strong indicator of compound
choice is age with young people far more likely to use -one compounds than older
people from the same region. This finding was reported by D’Arcy et al (2013) for
British English and Russell (2012) for both Canadian and Scottish English.
There are two main points where this study differs from other similar studies.
Firstly, nearly all studies of indefinite pronoun use in English have been conducted
based on native-speaker (NS) data. Thus to be able to link the findings from those
studies to this one, English Lingua Franca (ELF) studies and studies done on English
language textbooks need to be consulted. Secondly, a majority of corpus studies are

5
conducted using mega corpora (such as the BNC, COCA, COHA etc.). There are
many advantages to using large corpora, but perhaps most importantly, the data
gathered from such corpora is likely more accurate and more representative simply
because idiosyncrasies and other atypical language use affects the results less than
they would in a smaller corpus. Another benefit is of course the number of
occurrences, which becomes more important the less common the feature being
investigated is.
Mark Davies (2012), the creator of COHA4 and COCA5 among other mega
corpora, argues for the use of mega corpora precisely because of the reasons listed
above, but specifies that the corpus needs to be carefully assembled and tagged in
order to be truly useful; the sheer number of words is not a guarantee of quality or
accuracy (Davies 2012: 14). On the other hand Hundt & Leech (2012) give four
reasons as to why smaller corpora are still a useful tool: 1) careful genre sampling, 2)
more accurate tagging, 3) possibility of manually examining relevant instances as
they are fewer, and 4) full-text access which enables the researcher to access full
context when looking at e.g. concordance. For this study, the benefit is clearly that
the small size of the corpus enables careful examination of specific instances.
To expand on the first point, ELF studies suggest that the language of English
Second Language (ESL) and English as a Foreign Language (EFL) textbooks “does
not mirror authentic language use” (Römer 2001:1). The language in textbooks tends
to be more formal (Alcaraz n.d.: 780), which might explain some of the -one
compound dominance, as -one is the more formal variant. Another theory is that
English in the expanding circle6 might be more innovative. D’Arcy et al. (2013: 304)
4 Corpus of Historical American English 5 Corpus of Contemporary American English 6 Kachru refers to countries where English is the mother tongue of most people as the inner circle, former colonies such as India, and Singapore etc where English is widely spoken alongside the national language and plays a governmental role as the outer circle, and most other countries as the expanding circle.

6
suggests in relation to New Zealand English that a possible reason for the high ratio
of -one compounds might be an indication of innovativeness. Öhman (2014), too,
shows that -one compounds are only increasing their dominance, and thus it can be
inferred that in regions with higher ratios of -one compounds, the development has
nearly run its course with -one compounds practically the only indefinite pronoun
form.
To summarize, -one compounds are more common in nearly all genres and inner
circle regions to the point that -body is slowly disappearing from use. -One
compounds are also the more prestigious and formal variant and EFL textbook
language tends to be quite formal so it is likely that the LNU ELF corpus data will
reflect this particularly for the theses genre.
3 Data & Method In this section the corpus and the methods use to examine the data will be presented.
3.1 The corpus The corpus used for this study is the LNU student corpus which was compiled in
early 2014 from material available online. The data consists of texts from between
2010 and 2014. It consists of two genres: theses and blogs. The theses were collected
from DiVA7 and selected based on a few criteria such as the date of publication and
the “Swedishness” of the author’s name. Furthermore, care was taken to select
samples from both genders, as well as from a wide range of Swedish universities and
fields of research. The blogs were selected based on similar criteria; the texts had to
be from the 2010s and blogs by expatriates were excluded in order to better represent
English use in Sweden by native Swedish-speakers. Permission to use the blog text in
7 The “DiVA portal is a finding tool for research publications and student theses written at … 34 [Swedish] universities and colleges of higher education” http://www.diva-portal.org/smash/aboutdiva.jsf

7
the corpus was asked for in Swedish to ensure the author was indeed a native
Swedish speaker. All texts were edited to consist of a comparable word count. For
theses this generally meant removing the background section (as it typically contains
many quotes and other non-original text) and quotes where applicable. For blogs this
meant excluding some older entries.
3.2 Method The text files were loaded into the AntConc concordance software. The searches were
conducted with the keywords (anyone, anybody, someone, …) and those hits that
were not in line with the unit of analysis, -one/-body compound indefinite pronouns
with a human reference, were excluded. As the corpus is rather small in size, this was
done by examining each individual hit. The exclusions consisted mainly of a few
partitive structures as only -one compounds can be used in them:
(7) Would anyone of you buy it as it is now? (Blog)
(8) …huge hug to everyone of them. (Blog)
(9) …but no one of them have found the optimal solution… (Thesis)
(10) There is no one true form of a language. (Thesis)
No one in (9) does not refer to humans but political parties. In fact, none or not one
would have been a more grammatically correct structure, however, in this instance it
is treated as regional variation.
After the data collection, the numbers were analyzed in Excel and statistical
significances were evaluated using the chi-square method. N is always calculated per
100,000 occurrences.
3.3 Genre Definitions The genre division can vary greatly between different corpora, but typically there are
more literate and more oral genres. The LNU ELF corpus consists of two genres:
blogs and theses. The theses are an example of very formal, informative texts; a
typical example of a literary genre. The blogs are quite informal, and in this context,

8
an oral genre. In both American and British English, -body compounds are more
frequent in oral genres and -one compounds dominate the more literate genres. Figure 2 - Genre overview8
3.4 Problems The main issue regarding the results of this study relate to the low occurrence rate of
indefinite pronouns in all the data, particularly in the thesis section of the corpus; this
problem was dealt with by not only analyzing the frequencies, but also examining the
separate instances to gain a better understanding of how indefinite pronouns are used
in ELF situations.
Another issue is, as always with corpora, the representativeness of the data.
Naturally, academic theses will have been written by highly educated people, and for
the theses included in the corpus, perhaps even by an elite of the elite as except for
English studies, very few people are required to write in English. This means that
some people chose to write in a language other than their native language. The
education level of the bloggers is harder to ascertain, however, they too chose to
8 Adapted from Öhman (2014)

9
write in English rather than Swedish. The most common reason for bloggers choosing
to write in English appeared to be audience reach, but there was at least one instance
of wanting to practice English. Nonetheless, all writers felt confident enough in their
English skill to write in English, which suggests that they too, are likely to be
educated. As -one compounds are considered the more prestigious variant (Biber et
al. 1999: 351) and are linked to high SES, perhaps the choice between -one and -body
has more to do with elitism than EFL education or media influence. This is all
speculation and the data will be analyzed without any specific regard to such
hypotheses.
As already mentioned in a few instances in relation to illustrations and examples
from the corpus, a typical problem when analyzing non-native speaker (NNS) data is
grammatical mistakes. When NSs make grammatical mistakes, they are rarely
categorized as mistakes or errors. Instead, “mistakes” are simply considered
examples of language variation. However, this can hardly be claimed about NNS
mistakes, as the mistake is not one of regional or other variation but often due to a
lack of understanding of the grammatical principles or attempting to use one’s native
language grammar with English. Seidlhofer (2011) argues that NNS English is just as
valid as NS English, but true as that might be, it does not seem feasible to analyze
language variation and change from an “anything goes” perspective. Nonetheless, as
these types of mistakes have little bearing on the frequency pattern of indefinite
pronoun compounds, for this study such mistakes have been ignored and analyzed as
if they were a simple case of regional variation.
4 Results The findings are presented in the sections below. First the overall frequencies are
analyzed and discussed. Then in the later sections genre variation, collocates, and
statistical significances will be examined. A summary of the data is presented in the
table below:
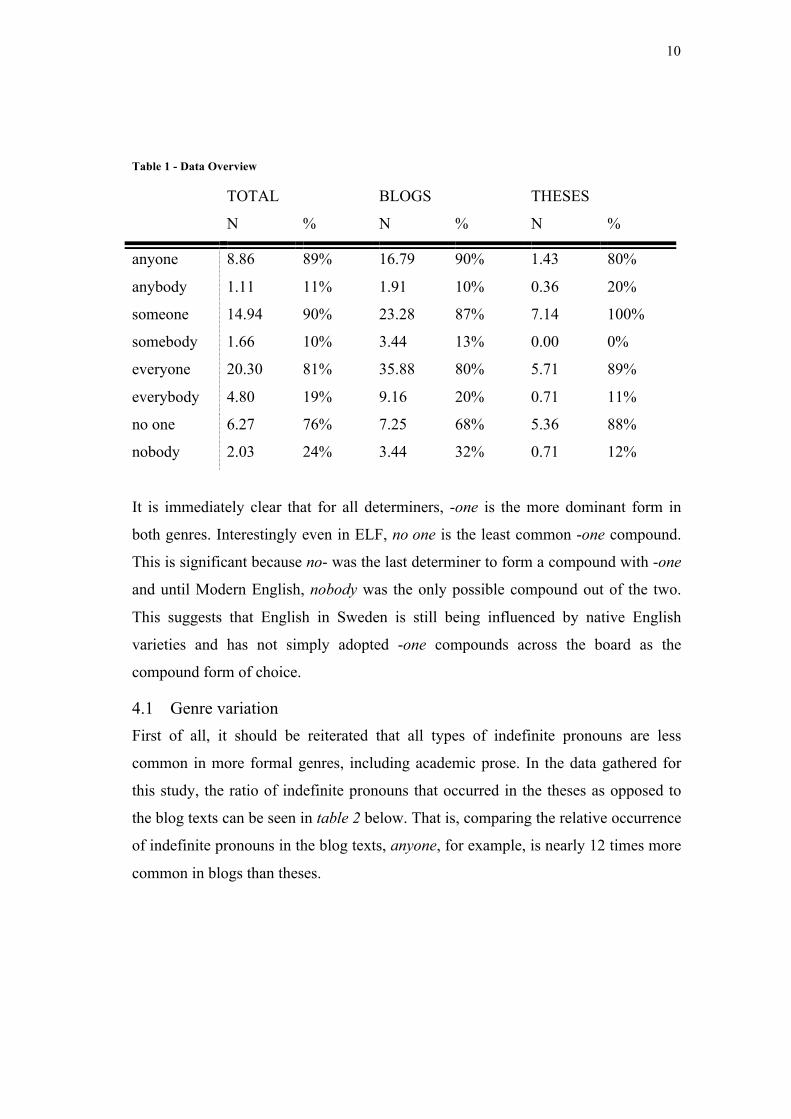
10
Table 1 - Data Overview
TOTAL BLOGS THESES
N % N % N %
anyone 8.86 89% 16.79 90% 1.43 80%
anybody 1.11 11% 1.91 10% 0.36 20%
someone 14.94 90% 23.28 87% 7.14 100%
somebody 1.66 10% 3.44 13% 0.00 0%
everyone 20.30 81% 35.88 80% 5.71 89%
everybody 4.80 19% 9.16 20% 0.71 11%
no one 6.27 76% 7.25 68% 5.36 88%
nobody 2.03 24% 3.44 32% 0.71 12%
It is immediately clear that for all determiners, -one is the more dominant form in
both genres. Interestingly even in ELF, no one is the least common -one compound.
This is significant because no- was the last determiner to form a compound with -one
and until Modern English, nobody was the only possible compound out of the two.
This suggests that English in Sweden is still being influenced by native English
varieties and has not simply adopted -one compounds across the board as the
compound form of choice.
4.1 Genre variation First of all, it should be reiterated that all types of indefinite pronouns are less
common in more formal genres, including academic prose. In the data gathered for
this study, the ratio of indefinite pronouns that occurred in the theses as opposed to
the blog texts can be seen in table 2 below. That is, comparing the relative occurrence
of indefinite pronouns in the blog texts, anyone, for example, is nearly 12 times more
common in blogs than theses.

11
Table 2 - How much more common are indefinite pronouns in blogs?
INDEFINITE PRONOUN OCCURRENCE
IN BLOGS (over theses)
anyone 11.76
anybody 5.34
someone 3.26
somebody N/A
everyone 6.28
everybody 12.82
no one 1.35
nobody 4.81
The two forms that differ most from the rest are someone and no one. Someone
appeared in the blog texts a total of 61 (N = 23.28) times and in the theses 20 (N =
7.14). No one appeared 18 (N = 7.25) times in the blog texts and 14 (N = 5.36) in the
theses.
(11) …no one ought to be held responsible… (thesis)
(12) No one wants to come home looking like a… (blog)
(13) …because everyone has different experiences. (blog)
(14) We are warranted in holding someone blameworthy…(thesis)
The examples above illustrate typical instances of indefinite pronouns in the corpus.
The main difference between the language used in theses and blogs appears to be the
level of formality of collocates. Ought (as in example (11)), for example, is a fairly
uncommon construct and appears only 16 times in the entire corpus, of which 14
instances are in the theses. Similarly, warranted (as in (14)) occurs twice in the
entire corpus, both times in theses.
4.2 Collocates As mentioned in the background section, Svartvik & Lindquist (1997: 17-18) tested
Bolinger’s (1976,1977) hypothesis of semantic constraints with some of the

12
collocates Bolinger discussed. Svartvik and Lindquist reasoned that if indeed there
are semantic differences, the collocates that appear with the different compounds
should reflect this as well. They found that the data supported Bolinger’s argument
but that it was “hardly overwhelming” proof. (Svartvik & Lindquist 1997: 18) Table 3 - Collocates and Semantic Constraints
Collocate Frequency LNU ELF
% LNU ELF anybody
% COCA anybody
Svartvik & Lindquist
(1997)
does anyone 1
0% 39% anybody much
more common anybody 0
has anyone 0
N/A 30% anybody much
more common anybody 0
anyone That
1 50% 49% 60%
anybody 1
anyone who
8 0% 25% 19%
anybody 0
Table 4 above illustrates Svartvik & Lindquist’s (1997) findings and compares them
with Öhman’s (2014) as well as the LNU ELF corpus data. Unfortunately due to the
size of the LNU ELF corpus and the overwhelming dominance of -one compounds in
the data, it is not possible to draw any conclusions based on collocates. The data do
seem to suggest that NNSs disregard the semantic constraints Bolinger claims exist;
there are 8 instances of anyone who but zero of anybody who. This ratio is 3:1 in the
COCA data presented by Öhman and 4:1 in Svartvik & Lindquist’s data compared to
0:8 in the LNU ELF data. It would have been surprising had the LNU ELF data
shown indications of semantic constraints as whether such constraints exist is still
debated and certainly not taught in Swedish EFL classrooms.
(15) …if there is anyone that wonders…
(16) Anybody that have played falldown on your iPhone?

13
The examples above show the two any- compounds that appear as pre-collocates with
that. Interestingly there are several grammatical mistakes in (11), however, it does
not seem like mistakes are more common in one genre over the other.
4.3 Statistical Significances The statistical significances of the frequencies were calculated using the chi-square
method. As the table below shows, the only statistically insignificant differences are
in the frequency of no one and nobody in blogs (5.9%), and anyone and anybody in
theses (18%). All other results are statistically significant even at α 0.1 % and
certainly at the commonly accepted 5%.
Table 4 - Statistical Significances
BLOGS &
THESES BLOGS THESES
Any- 3.47E-07 2.52E-08 1.80E-01
Some- 1.15E-12 5.11E-10 7.74E-06
Every- 2.43E-11 1.16E-10 9.67E-04
No- 3.65E-03 5.88E-02 1.62E-03
5 Comparisons Although this study shows that -one compounds are clearly the dominant variety in
both oral and literate genres in ELF spoken in Sweden, due to the small size of the
corpora, the results cannot be taken at face value. Nonetheless, the statistical
significance calculations support the notion that -one compounds are more common
than -body compounds, just as they are in most varieties of English. The table below
attempts to place the findings of this study in an international context by comparing
the results with those found in other studies.
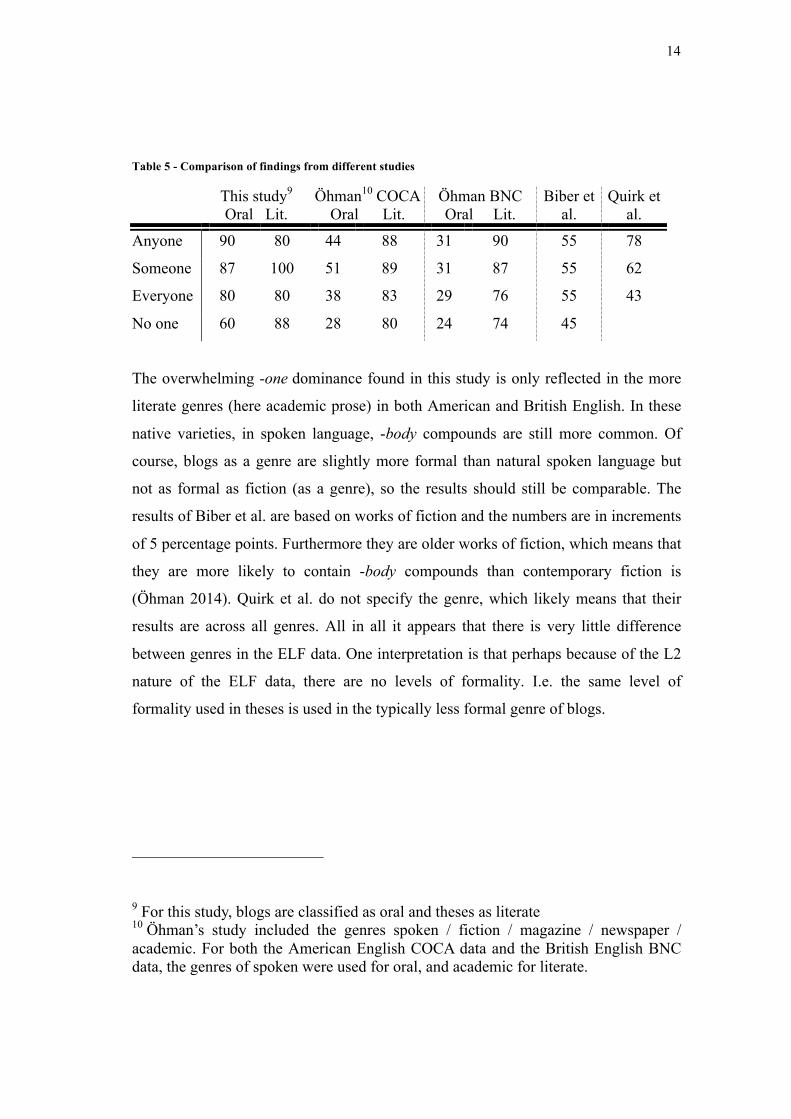
14
Table 5 - Comparison of findings from different studies
This study9 Öhman10 COCA Öhman BNC Biber et al.
Quirk et al. Oral Lit. Oral Lit. Oral Lit.
Anyone 90 80 44 88 31 90 55 78
Someone 87 100 51 89 31 87 55 62
Everyone 80 80 38 83 29 76 55 43
No one 60 88 28 80 24 74 45
The overwhelming -one dominance found in this study is only reflected in the more
literate genres (here academic prose) in both American and British English. In these
native varieties, in spoken language, -body compounds are still more common. Of
course, blogs as a genre are slightly more formal than natural spoken language but
not as formal as fiction (as a genre), so the results should still be comparable. The
results of Biber et al. are based on works of fiction and the numbers are in increments
of 5 percentage points. Furthermore they are older works of fiction, which means that
they are more likely to contain -body compounds than contemporary fiction is
(Öhman 2014). Quirk et al. do not specify the genre, which likely means that their
results are across all genres. All in all it appears that there is very little difference
between genres in the ELF data. One interpretation is that perhaps because of the L2
nature of the ELF data, there are no levels of formality. I.e. the same level of
formality used in theses is used in the typically less formal genre of blogs.
9 For this study, blogs are classified as oral and theses as literate 10 Öhman’s study included the genres spoken / fiction / magazine / newspaper / academic. For both the American English COCA data and the British English BNC data, the genres of spoken were used for oral, and academic for literate.

15
6 Conclusions The LNU ELF corpus data clearly suggests that -one compounds are by far the most
dominant variety of the English spoken in Sweden. This is true for both the more oral
genre of blogs and for the literate genre of academic theses. It is beyond the scope of
this study to investigate the reason for this overwhelming dominance, however, it is
likely a combination of different factors. Among these the formality of the English
used in language education, and the lack of a colloquial variant are likely influencers.
The lack of a more colloquial, less formal, variant means that the differences between
genres are leveled out.
The data could also be interpreted as ELF being more innovative and at the
forefront of language change as -one compounds are taking over all genres in native
Englishes as well. The high number of instances of nobody in blogs compared to any
other -body compounds suggests that this particular ELF variant at least has not
simply adopted the more formal -one compound for all determiners. Instead the
development closely follows that of native varieties in which no one was the last of
the 8 compounds examined to emerge.

16
7 References Alcaraz Marmol, G. (no date) Vocabulary Input in EFL Textbooks: Frequency Levels. A Survey of Corpus-based Research, 771-783.
Biber, G. et al. 1999.Longman Grammar of Spoken and Written English. London: Longman.
Bolinger, D. "The In-Group: One and Its Compounds," in P.A. Reich, (ed.), The Second LACUS Forum, 1975, 229-237. Columbia, S.C., Hornbeam, 1976.
Bolinger, D. 1977. Meaning and Form. New York: Longman.
Criado, R. & A. Sanchez. Vocabulary in EFL Textbooks. A Contrastive Analysis against Three Corpus-Based Word Ranges A Survey of Corpus-based Research, 862-875.
D'Arcy, A. et al. 2013. Asymmetrical Trajectories: The past and present of -body/-one. Language Variation and Change, 25: 287-310.
Davies, M. 2012. Some methodological issues related to corpus-based investigations of recent syntactic changes in English. In Nevalainen, T. & Traugott, E. (eds). The Oxford Handbook of the History of English. OUP. (Draft)
Elham, N.M. & P. Reza. 2013. Analysis of English language textbooks in the light of English as an International Language (EIL): A comparative study. International Journal of Research Studies in Language Learning, 2:2, 83-96.
Hundt, M. and G. Leech. 2012. Small is beautiful – on the value of standard reference corpora for observing recent grammatical change. In Nevalainen, T. & Traugott, E. (eds). The Oxford Handbook of the History of English. OUP. (Draft)
Kishimoto, H. 2000. Indefinite Pronouns and Overt N-Raising. Linguistic Inquiry, 31:3, 557-566.
Laitinen, M. 2014 Indefinite pronouns with singular human reference in the long 18th century. (Draft)
Quirk, R. & et al. 1985. A Comprehensive Grammar of the English Language. London: Longman
Raumolin-Brunberg, H, & L. Kahlas-Tarkka. 1997. Indefinite pronouns with singular human reference. in M. Rissanen, M. Kytö, & K. Heikkonen (eds.) Grammaticalization at work: Studies of long-term developments in English. Berlin: Mouton de Gruyter. 17-85.

17
Rissanen, M. 1997. Whatever happened to the Middle English indefinite pronouns? In J. Fisiak (ed.) Studies in Middle English linguistics. New York: Mouton de Gruyter. 513-530.
Russell, A. 2012. Why Does Everyone Say Everybody?: Compound Indefinite Pronouns in Rural Ontario. University of Toronto.
Römer, U. 2001. Comparing Real and Ideal Language Learner Input: The Use of an EFL Textbook Corpus in Corpus Linguistics and Language Teaching. Cologne, Germany.
Seidlhofer, B. 2011. Understanding English as a Lingua Franca. Oxford University Press.
Svartvik, J. & H. Lindquist. 1997. One and body language. In Udo Fries, Viviane Müller & Peter Schneider (eds.) From Ælfric to the New York Times. Studies in English Corpus Linguistics, 11–20. Amsterdam & Atlanta: Rodopi.
Öhman, E. 2014. Indefinite Pronouns in American English: A corpus study of 200 years of -one /-body indefinite pronoun compounds in American English. MA thesis, Linnaeus University, Sweden. (Draft)




















