
Artificial Intelligence Methods Based Hierarchical ... - arXiv

Imagination, Perception and Artificial Intelligence
by Kevin Karn (1988)
Master's Thesis, New York University, Dept. of Computer Science
Thesis advisor: Martin Davis Thesis reviewed by: Ernest Davis
1

Contents
Preface ................................ ................................ ................................ ...... 2 1. Methodology ................................ ................................ ............................. 3 2. Linearity ................................ ................................ ................................ . 7 3. Hume and Kant ................................ ................................ ....................... 14 4. What the Apes Lack ................................ ................................ .................. 22 5. The Image................................ ................................ .............................. 27 6. Feature Rings................................ ................................ .......................... 43 7. Hypotheses, Formation, Application................................ ................................ 56 8. Conclusion ................................ ................................ ............................. 79 References ................................ ................................ ................................ 84
Preface My thesis is that imagination is a pivotal linchpin of human perception (and thought), and therefore
must play a role in the science of artificial intelligence. Imagination, however, is an extremely complex
phenomenon, and what I have written could easily be extended in a variety of directions. I have not
attempted to take my analysis onto the level of exhaustive detail and computer implementation. This is
because the status of imagery has been, and still is to a great extent, so confused and precarious in
philosophy and the cognitive sciences that, I feel, the topic is best served by a general and yet thorough
demonstration of its reality and importance. I have attempted to develop a sound, empirically-grounded
framework upon which more detailed theories of the imagination can be erected.
I hope the reader, like I, will be pleasantly surprised by the not insignificant coherence of the
material I have compiled here.
2

1. Methodology
Frankenstein, in a word, is the tacit and true final goal of artificial intelligence (AI). We have to
consciously remind ourselves of this embarrassing fact in today's era of inch-by-inch progress in
ever-proliferating subfields, but the founders of AI were acutely aware of it. In fact in the early days,
many of them saw the Advent just around the corner, like Minsky [34] who ominously forecast in 1961
that "... we are on the threshold of an era that will be strongly influenced, and quite possibly dominated,
by problem solving machines." Prognostications of this sort, which seem absurd in the current research
climate, are common in the early AI literature, and have in fact been catalogued and ridiculed by
Dreyfus [9,10].
But let us by-pass the ridicule and instead highlight one of Dreyfus' basic and most constructive
questions: If the success of the AI enterprise seemed so assured and imminent at the beginning, why did
the program break down? Dreyfus, to his credit, gives a detailed answer to this question, and we shall
return to it in the conclusion (P. 80). But now I would like to say a few words on the failure and
methodology of AI.
First, it is patently obvious that to date we have no Frankenstein or even anything remotely
comparable, so measuring along this standard, AI has been and remains a disappointment. This
disappointment can, of course, be tempered if you take the goal of AI to be bigger and better systems
for circumscribed industrial, commercial and military applications. But, as a point of philosophy, we
shall reject such a view in this paper.
So assuming our goal is to design and realize a true, all-purpose mechanical mind (i.e. Frankenstein),
it would seem wise to carefully choose a method. I call the default research paradigm in AI, which was
appropriated from other more successful sciences, Fragmentism. The strategy of this paradigm is to
break a complex phenomenon into well-defined fragments, model the fragments, and then somehow
eventually expand the fragments or put them back together. I believe a detailed and convincing case can
be made that the Fragmentism paradigm is, by its very nature, incapable of leading us to our goal.
I would, however, like to avoid the detail, since my main aim in this thesis is constructive not critical.
3

So here I briefly summarize my three main objections.
1) The mind is not a department store. Close inspection reveals numerous cases where one faculty
infuses another, or two faculties are symbiotic. For instance, perception of a certain visual pattern may
require action (in the form of eye movements) and a form of creativity (i.e. seeing faces in the clouds),
and so it is impossible for a perception unit to analyze the input and pass a description to action and
creativity units. It needs those latter units to make the description in the first place. The chronic failure
and frustration of trying to part out the mind may be telling us something. Maybe you cannot part it out;
maybe you have to grasp it somehow in toto.
2) "Ad hoc" is a pejorative term in the AI literature for machines which lack generality and work
only in a fixed range of situations. This is regarded as inexpedient because human thought has no
similar restrictions, and thus such machines fail as comprehensive models. But the methodology itself
of AI is ad hoc: systems are developed by circumscribing well-defined behaviors and then constructing
the machinery to perform them. So unsurprisingly no one ever attains the desired generality because no
one ever sets out to attain it. Our plan relies overly on fortune if we expect a machine designed for a
limited task to suddenly reveal itself as having total human generality.
3) AI is, almost by definition, a collection of tools, none of which does the intended job. So I
suppose it is inevitable that a common default view in AI is that "... intelligence is a kludge; people have
so many ad hoc approaches to so many different activities that no universal principles can be found."
(Sowa [45], P. 23) Patrick Winston and Michael Brady, in their Foreword for the MIT Press Series in
Artificial Intelligence (see Dyer [11], P. xii) write: "Unfortunately, a definition of intelligence seems
impossible at the moment because intelligence appears to be an amalgam of so many
information-processing and information-representation abilities." Needless to say, the disorganized tool
box nature of the field bears a suspicious similarity to the posited disorganized tool box nature of the
mind; almost as though the phenomenon is being modified to conform to the explanation rather than
vice versa.
There is something else fishy about this. If the goal of AI is to create intelligence, how do we know
whether we are succeeding or even what we are doing if we do not know what intelligence is? Actually
4

there is a widespread, parochial notion of intelligence in AI; it is something that is involved in things
like chess playing, theorem proving, IQ tests and so on, and not involved in things like spitting contests
for example. Researchers erroneously believe that they have endowed a machine with intelligence when
they have programmed it to perform some task which in the public imagination is thought to require
"brains." The problem here is that intelligence resides not in what you do but in how you do it. Playing
chess is not intelligent; playing chess intelligently is intelligent. The central problem of AI is not, as is
commonly assumed, the development of heuristics to prune mindless exponential searching. Rather it is
how to endow a computer with the ability to see into the structure of a problem, so that it need do no
mindless searching at all. Hence, insofar as we are aiming for Frankenstein, we must seek a theoretical
advance, and this in turn requires insight into the nature of intelligence.
Now we have only one conspicuous prototype for intelligence (the human being) so the task is
imitation, and man's experience with art provides an important lesson. Even a cursory examination of
the art of diverse places and times reveals the chronic tendency of man to adopt traditional stylizations
of what he sees, art which reflects a dogmatic rather than supple and open-eyed approach to the world.
The battle to see what is there, instead of what should be there or what we want to be there or what has
been authorized or passed down or codified, is an endless one, and our only weapon against blindness is
to go to the thing and look at it. (Zu den sachen! "To the things" — The rallying cry of the
phenomenologists.) A man cannot force and bludgeon his way from blindness to sight; he may only
assume the submissiveness to the object which marks a sincere observer and entreat the lightning to
strike.
This idea, that one must approach and study an object without pre-supposition before embarking on
its imitation, seems almost a truism, and yet in the existing work on artificial intelligence it is almost
entirely lacking. For to gain a comprehensive, rich and ordered view of the mind would take one into
the very bowels of philosophy and psychology, far afield from the piece-meal projects and
programming exercises which define AI. So one finds researchers breaking out their algorithms,
equations and well-defined domains on Page 1. This reflects a misguided fascination with tools over the
task itself, much like some writers whose ardor for jargon and wordplay overrides the basic task of
5

writing, i.e., to say something. I do not mean by this that formalism is misguided or inapplicable. Any
explanatory theory must be deductive; we must show how the widest possible range of phenomena
logically follow from the smallest possible set of basic principles. But mathematics and computer
programs are bewitching sirens and bottomless pits from which we must rein in our minds. We must
make it a conditioned reflex to maintain the tether to our patron saint Frankenstein and thereby avoid
entanglement in the branches of infinitely extendable knowledge. The correct path is not to spend 15
minutes gaining a fragmentary and brittle image of man and then spend 15 years exploring the formal
structure implied by that image. We must instead exercise patience and develop a lucid, whole image
from which our formal needs can be ascertained.
6

2. Linearity In approaching the mind, we would like, as with any object of study, to uncover a penetrating yet
constrictive idea of its fundamental nature; we require a framework wherein we may elaborate. The
subject of the mind in particular demands such limits, for the mind is an omnivorous, infinitely creative
thing which effortlessly leads the unwary out-of-bounds, diverting investigation away from the creative
mechanism itself and into the bottomless pit of the mechanism's products.
The mind is, in a sense, a window onto the external world, a window so clear that men took
thousands of years to even realize it was there. Primitive men as well as most modern people are so
intimately involved with the world that they feel themselves beyond the window, outside. This is the
"objective consciousness" of Merleau-Ponty [32], a devious consciousness which obscures its own
origins, and serious thinkers have been as susceptible to its allure as anyone else. And rightfully so, for
as Merleau-Ponty notes (quoting Scheler): "Nothing is more difficult than to know precisely what we
see. 'There is in natural intuition a sort of "crypto-mechanism" which we have to break in order to reach
phenomenal being' or again a dialectic whereby perception hides itself from itself." (P. 58) We can
regard the world as having two poles: objectivity and subjectivity. If I swing to the objective pole, I
view myself in the "third-person" so to speak; I see the world as expanding out arbitrarily in the spatial
and temporal dimensions, and I am just an object among objects. If, on the other hand, I swing to the
subjective pole, I stand on the cogito of Descartes' famous axiom: I am not just an object among
objects; I am, in Merleau-Ponty's phrase, "the absolute source," and I wonder how I could ever think
otherwise. Nothing is more obvious than the fact that I am always situated in a limited, egocentric
perspective. So how could it be that I not only transcend these apparent limits, but transcend them with
such paradoxical ease and have the greatest difficulty even seeing them? This difficulty is Scheler's
"crypto-mechanism," and its power is attested to by the fact that almost 2,000 years lie between the
birth of Western philosophy in the figure of Socrates, and the first true grasp of the subjective viewpoint
with Descartes. An underlying ambition of Merleau-Ponty's philosophy is to rectify the oft-distorted
relationship between subjectivity and objectivity. He writes:
"Scientific points of view, according to which my existence is a moment of the world's, are
7

always both naive and at the same time dishonest, because they take for granted, without explicitly mentioning it, the other point of view, namely that of consciousness, through which from the outset a world forms itself round me and begins to exist for me." (P. ix)
In other words, subjectivity is prior to objectivity, both conceptually and ontogenetically. For firstly,
all our knowledge of the world (including science) is derived from and refers back to the situated
perspective of consciousness. And secondly, as Piaget [38] has experimentally demonstrated, a child is
not born with fully developed notions of external objects, space and so on. Rather, an infant begins with
an egocentric, syncretic* perspective from which objective consciousness is constructed step-by-step†.
The reader may feel that here I am trading in philosophical quibbles which have nothing to do with AI,
and that we should steer toward more conventional themes. But such a move has been and would be a
grave mistake. To see this consider two examples:
1) In the area of knowledge representation, the general AI strategy is to encode knowledge into what
are known in the parlance as schemata. For example, a schema for BUS would be an elucidation, made
explicit through brain-storming, of what a bus is. A bus has four wheels, carries people, stops at bus
stops, has a driver, moves at less than the speed of sound, can plunge or wreck and kill its riders, costs
money to ride, needs fuel to run, emits exhaust... etc. This information is coded up into a data structure
which a computer can then access and operate on. The problem is that this in no way tells us how such
knowledge is constructed from, and brought to bear during direct sensual contact with the world. It is a
sort of third-person objectification of a bus—an empty symbol whose meaning ("BUS as it appears to
me in my experience") is not represented for the computer, and thus can serve no practical function in
interfacing with the world. This results from ignoring the conceptual priority of subjectivity, that is,
trying to code up the world starting from how it is in-itself, rather than how it appears to a situated
* Syncretism is a term, introduced by M. Claparède, for a well-known trait of child thought: that happenstance juxtapositions in the child1s experience are mistakenly taken to be objective. † A tremendous amount of follow-up work on this topic has confirmed Piaget's conclusion. Flavell [13] writes: "Virtually everyone now agrees with Piaget that the infant is not born with the object concept and therefore must somehow acquire it. Because it is so counterintuitive that any living creature could lack an object concept, this agreement is a very important scientific achievement." (P. 40)
8

observer ("me").
2) In robotics and other areas where a computer must deal with an environment which changes with
time there is a deep difficulty (called the "frame problem") in maintaining a data base which models the
environment. The problem is that facts in the data base may interact in complex ways, so that a change
in one fact (through, say, a robot's action) has an unpredictable effect on other facts, and the whole data
base has to be recomputed. Moreover, ridiculous numbers of so-called "frame axioms" must be
introduced to allow the computer to deduce that changing one fact has no effect on various other facts.
One tempting way to solve this problem would be to make the database more like the world. For
example we might have a robot represent its playpen as a 3-dimensional matrix, with itself, its limbs
and its toys all indicated therein. We might even adopt some mechanism whereby objects which are
dropped in the model fall to earth just as they do in real life and so on. The ideal then would be for the
robot to have a model of the world which is exactly like the world; and we might rightly call this the
ultimate spawn of the objective viewpoint. So what is wrong with this picture? As Pylyshyn [38] has
pointed out, the problem is that we are assuming what we are trying to explain. As he puts it:
"...if the representation is too similar to the world it represents, it is of no help in apprehending the
world, since it merely moves the problem in one layer..." (P. 40)
In a related connection, he notes that:
"...[mental representations must in some way be similar to real objects for] otherwise thought would be irrelevant to action, and our chances of survival would be negligible. From this one is tempted to say that representations and the objects they represent must have much in common. Beginning with this innocent remark we are irresistibly and imperceptibly drawn towards the fatal error or attributing more and more of the properties of the environment, as described in the physical sciences, to the representation itself." (P. 38)
After Quine, Pylyshyn calls this temptation "objective pull." Succumbing to this pull amounts to
putting the objective before the subjective—i.e. trying to understand the mind in terms which it is the
mind's job to construct. Merleau-Ponty shows how philosophical understanding has been historically
undermined by this mistake, and inasmuch as AI often unconsciously follows in the footsteps of old
philosophy, it too has been and is susceptible.
9

Having produced these examples (which could easily be multiplied) indicating the relevance of the
objective-subjective distinction to the AI enterprise, let us look to neglected subjectivity, and see
whether it has something to teach us.
In conversing with a friend over coffee, I have a strong tendency to feel, when I look at him, that he
is completely present before me, that he is a simultaneously given, unitary thing. If someone were to
ask me "What are you looking at?" I would unhesitatingly reply "Mike." This is the most natural reply
in the world, and reflects the sovereignty of the objective viewpoint in our common sense. But closer
scrutiny reveals that something more complex is going on. In looking at Mike, it is impossible for me to
bring him entirely within my foveal vision at one time, and so my eyes are constantly darting over him.
He makes an expressive gesture, calling my eyes to his hand, and then raises his eyebrows for sarcastic
effect, drawing my gaze back to his face. He spins to look behind him, showing me the back of his head.
His legs and hips are completely hidden from me by the table. So when I say that I see "Mike," I am
being somewhat misleading. It would be more proper to say that I see a sequence of aspects of Mike; a
complex temporal flurry of impressions more than a unitary thing. This is not a new observation. For
example, Hebb [19] stresses that: "The percept of any but the simplest object cannot be regarded as a
static pattern of activity isomorphic with the perceived object but must be a sequentially organized or
temporal pattern." (P. 469)
We began this chapter in search of a pithy characterization of mind, and with this last observation it
falls into our lap. The mind is a sequence of moments in time. That is, the mind is a strictly linear thread,
and, as much as we like to believe the contrary, we cannot have a bulge in the thread—a spatial cavity
wherein we can stop time and put the pieces of the world together into a coherent, bird's-eye view. This
thread is composed of moments, and the reader need only reflect for a moment to realize how
insubstantial and partial a single moment truly is. Beware of the "objective pull" here. I have sometimes
asked people to describe for me their idea of a moment of time. Invariably they conjure up allusions to
the continuum, with moments densely packed, always another between any given two. But this is not at
all what I have in mind. These people are stepping out of themselves and looking at time in the
third-person. What I mean by a moment is not the scientific view, but the personal subjective view for
10

which the scientific notion of a point on the continuum is mere short-hand or sign-language. These
subjective moments are difficult to describe, but perhaps we can say that they, like visual fixations,
seem to have a crisp (albeit fleeting) center, surrounded by a more nebulous and semi-conscious edge.
As noted above, the schema is the structure of choice in AI for representing knowledge and
organizing memory, and a problem with schema is that they are divorced from our concrete, sensual
existence in time. If these schema are to be an accurate model of human memory, then surely we must
specify how they get into the mind via time, and how they are applied by the mind in time. The lack of
any general, accepted specification of this type is a major defect of the schema model. But perhaps our
newfound view of the mind as a traffic or stream of moments in time can help us with this. That is, is it
possible that our memory structure is a reinstatement of our perceptual life? Could it be that perceptual
moments are somehow recorded in temporal sequence in our brains? Surprisingly, there is extremely
strong evidence for such a view. Penfield and Roberts [37] have demonstrated, through electrode
stimulation of patients undergoing brain surgery, that memories are somehow stored in strips like
motion pictures in the brain's temporal lobes. The authors characterize the elicited flashbacks as:
"...a little like the performance of a wire recorder or a strip of cinematographic film on which are registered all those things of which the individual was once aware—the things he selected for his attention in that interval of time. Absent from it are the sensations he ignored, the talk he did not heed." (P. 53)
Penfield and Roberts also note that the flashbacks were:
"...for the most part, quite unimportant moments in the patient's life; standing on a street corner, hearing a mother call her child, taking part in a conversation, listening to a little boy as he played in the yard..." (P. 53)
On this basis they speculate that perhaps very little of a person's life is omitted from the on-going
stream-of-consciousness record.
There is another important dividend of the view that the mind is a sequence of moments in time,
namely a new perspective on concepts. What is a concept? As a first approximation we might say: a
11

general idea as opposed to a particular individual. But under pressure this approximation unravels,
revealing the apparent opposition to be illusory. For consider the concept of, say, "dog." It is often said
that this concept is what allows us to see the variety of individual, particular dogs as falling under a
single type. Also, the reason we need the concept to do this is that different breeds and individual dogs
appear differently and so we cannot do template matching. But is it not true that a single particular dog
"Lassie" can appear to us, in time, in almost an infinite variety of ways? So how do we recognize all
these impressions as falling under a single type, that is as impressions of "Lassie." The point here is that
particulars are universals, just finer grained. Returning to my earlier example of conversing with my
friend Mike, we see that my various eye fixations, and the various facets of Mike which they might
reveal, must somehow be placed or interpreted as coming from Mike. We are all naive Platonists on the
level of objects, positing the existence of a realm of unitary, unchanging, and thus ideal, things as the
reality behind the shadows of our sensual spectacle. The real Mike or Mike in-himself, is such an idea,
and slightly misappropriating a term from Kant I call this thing in-itself, as opposed to its appearance, a
noumenon.
A hinted at side-effect of this view that particulars are universals is that it shows how deeply
interpretation, ambiguity and context are woven into our experience. As noted above, sometimes we
must attribute different impressions to the same noumenon. But there are also many instances in our
journey through time when we are confronted with similar moments. For example, if I reach down and
stroke a dog, and then later a cat enters the room and I reach down and stroke it, these two momentary
impressions may be virtually the same. But nevertheless, I interpret one of these impressions as from a
dog, and another as from a cat, on the basis of context. So it is a feature of our minds that we create
noumena to lie behind and account for the ever-changing fragmentary flux of the moments of time we
confront. And since sometimes these moments may resemble each other, we have to disambiguate or
interpret them in order to place them with their correct noumena.
But perhaps the pivotal question provoked by thought along these lines is this: What faculty of the
mind allows or causes us to create noumena—self-identical, ideal units beyond perception—so that
interpretation of impressions becomes possible? Or to put it another way, what faculty allows the mind
12

to construct an objective world from appearance and egocentric subjectivity?
13

3. Hume and Kant* Imagination... that is how both Hume and Kant answer the question concluding the previous chapter.
It is imagination which allows us to rise above the fragmentary and ever-changing march of our
momentary impressions, and thereby construct and inhabit an objective world of external noumena.
Further, both these philosophers believe that, in the above capacity, imagination plays an essential role
in ordinary perception itself. This last view is surprising in two ways. First, it places a heavy functional
burden on imagination, a faculty which is often considered to be rather frothy and frivolous. And
second, it entails that higher level thought is constantly being brought to bear even during simple
perception, so thought and perception cannot be rigidly demarcated and studied in isolation. Therefore,
if Hume and Kant are right, there is little hope for the AI strategy of using, say, a self-contained vision
subsystem to create structured descriptions for higher level processing. So in this chapter we will
consider the views of these two philosophers, and try to form a rough idea of how imagination could
function as an ingredient of perception.
Hume [21] has a simple view of imagination which seems to accord well with common sense. He
divides all perceptions of the mind into two classes, impressions and ideas, the difference between the
two being one of "vivacity." He writes:
"Those perceptions, which enter with the most force and violence, we may name impressions; and under this name I comprehend all our sensations, passions and emotions, as they make their first appearance in the soul. By ideas I mean the faint images of these used in thinking and reasoning..." (P. 1)
Hume, on the whole, regards an image (his "idea") as a copy (like a photograph or audio recording)
of a previous stimulus, or in Hebb's phrase, "as a static pattern of activity isomorphic to the perceived
object." This view is alluring, but in the end flawed, and since we shall be referring to it in later analysis,
I propose to call it the "Humean Image."
Hume divides the human mind into three basic faculties—sense, reason and imagination—and his
famous argument asks: To which of these faculties can we ascribe the belief in external * I am indebted to Strawson [47] and Warnock [51] for the discovery of this material.
14

mind-independent objects? His first step is to distinguish between belief in the continued existence
versus belief in the distinct or independent existence of external objects. Clearly these two forms are
equivalent:
"For if the objects of our senses continue to exist, even when they are not perceiv'd, their existence is of course independent of and distinct from the perception; and vice versa, if their existence be independent of the perception and distinct from it, they must continue to exist, even tho' they be not perceiv'd." (P. 188)
It is not really evident that this is an important distinction, but it is a part of Hume 's argument, so we
point it out.
He dismisses as ridiculous and self-contradictory the notion that the senses could engender the belief
in continued existence. For that would imply that we somehow sensed something while we were not
sensing it. He then proceeds to ask whether the senses allow us to directly perceive things as distinct.
He dismisses this possibility, for:
"When the mind looks farther than what immediately appears to it, its conclusions can never be put to the account of the senses; and it certainly looks farther, when from a single perception it infers a double existence, and supposes the relations of resemblance and causation between them." (P. 189)
We may also recount here, in further support of Hume, Piaget's [38] demonstration that very young
children (under the age of about 8 months) behave as though an object hidden under a blanket has
virtually vanished into thin air. If in fact inexperienced children see an ardently desired object as
distinct, and distinctness is equivalent to continuity, why do they immediately forget the object when it
falls from sight?
Having disposed of sense, Hume next considers reason. Unfortunately his argument is rather
confused, and perhaps marred by a lack of clarity on the precise nature and scope of what he calls
"reason." But we can isolate his main points:
1. The "vulgar" (that is, those without a philosophical cast of mind) attribute colors, sounds and the
15

like to objects themselves. This belief is so strong that "...when the contrary opinion is advanc'd by
modern philosophers, people imagine they can almost refute it from their feeling and experience, and
that their very senses contradict this philosophy." (P. 192) But this belief is false, and therefore cannot
arise from reason.
2. In Hume's view, all reasoning must rely oh the memory of sequential juxtaposition of cause and
effect in experience. Since a noumenon is not available to the senses, being by definition what is
beyond sense, such a juxtaposition can never be observed.
3. The belief in objects is so essential to our survival that nature will not allow it to depend on such a
feeble and error-prone faculty as reason. No matter what sophistical devices we use to convince
ourselves of the unreality of the external world, when we emerge from out study, we jump out of the
way of an oncoming carriage. In short, the belief in external objects is deeper than reason.
So, by the principle of elimination, we are left with imagination.
Hume's account of how imagination functions in building a world of objects is renowned for its
complexity and lingering pockets of implausibility, but parts of it are persuasive.
First of all, Hume describes two features of our experience, constancy and coherence, which
imagination preys on in constructing external objects. Constancy means that certain "pictures" in our
experience, especially of stationary unchanging objects like mountains, houses, trees and so on, tend to
recur in a uniform way. Coherence means that even those things which change tend to change in regular,
predictable ways. For example, a fire which I left burning may have burnt out when I return, thus losing
constancy. But I have seen such things happen before and may even have predicted it, so the experience
retains coherence. Hume also claims that imagination possesses a sort of inertia so that:
"...when set into any train of thinking, [it] is apt to continue, even when its object fails it, and like a galley set in motion by the oars, carries on its course without any new impulse." (P. 198)
So the imagination, when confronted with the suggestive but incomplete coherence of our experience,
moves to complete it. Also, it must be imagination which does this job because the requisite ideal
16

completeness is never encountered in our experience, and thus is "unreal." So it is as though we were
each scientists, poring over reams of data, searching for an underlying and unifying cause for the
numerical perturbations. We make various hypotheses by imagining, striving always for the simplest
and most explanatory. The best hypothesis then becomes a noumenon, the thing behind the data which
is showing us its various faces, and we believe in its reality.
This much is plausible and we shall make use of it, but for Hume it is not enough. Since he defines
belief, like just about everything else, in terms of "force" and "vivacity," he feels that the above
argument in terms of coherence is "... too weak to support alone so vast an edifice, as is that of the
continu'd existence of all bodies..." (P.198-199) So he provides a complicated additional argument,
based on constancy, which maybe précised as follows.
The notion of identity can only arise when a single object has multiple manifestations, and the only
way this can happen is through time. Hume regards the contemplation of the same, constant object over
a duration of time as the prototypical source of the notion of identity.
This notion is diffused through the agency of resemblance. The mind has a tendency to confuse
resembling things with identical things. For example, a mathematical proof involving two functions on
the same set may be difficult to understand because we keep confounding the two. So when we view the
sun again after an interval during which it has been hidden, we believe we are seeing the same thing due
to a dual resemblance. First, the current picture of the sun resembles a previous one, and second, this
experience reminds us of viewing a constant object which has been hidden. So we "feign" a belief in a
continued object, and this belief derives its requisite "vivacity" from impressions, from which it more or
less rubs off. Hume then notes that, since he has accounted for the belief in continued existence, the
belief in distinct existence falls out, and his system is complete.
Let us take stock of what we have learned from Hume.
1. The Humean Image: The Humean Image itself has problems we will discuss later. But, in this
connection, Hume's view implies* that we entertain a Humean image when we recognize two
impressions of the sun as of the same thing. But looking to our subjective experience, we see this is not
* See Warnock [51] P. 135-136 for a justification of this interpretation of Hume.
17

true. When viewing an object after an interval during which it has been hidden, I do not seem to retrieve
a memory image which I keep in the back of my mind and compare or confuse with the present
impression.
2. The Senses: Hume's argument on the senses is sound. We must look internally for the source of
the noumena.
3. Belief (cf. the "crypto-mechanism"): His notion of belief as "vivacity" is unsatisfying, but he is on
the right track when he claims that belief in objects is deep-rooted, deeper than reason. Jaspers [23], in
his text on psychopathology, stresses the emotional roots of schizophrenia, and points out that
rationality and delusional disconnection from reality can exist side by side. As he puts it: "The critical
faculty is not obliterated but put into the service of the delusion. The patient thinks, tests argument and
counterarguments in the same way as if he were well." (P. 97)
4. Explanation: There is a close affinity between positing noumena as an explanation or "theory" for
our disconnected journey of moments in time, and creating scientific concepts like gravity or quarks to
explain empirical data. (cf. Chapter 7)
5: Identity: The concept of identity requires that we see the same thing in different manifestations,
and this in turn requires some notion of objective time. For identity means "different, but the same," and
there is no way to be aware of the difference if we have no concrete idea of a time other than now. And
to have an idea of a time other than now requires imagination (memory) for we are making what is
absent present. So imagination is a prerequisite for any notion of identity, and thus of external objects.*
Let us now examine Kant's perspective on the imagination.
On this topic, Kant (true to form) owes a great deal to Hume, and yet supercedes him. Like Hume, he
claims that sense, on its own, is incapable of providing us with a world of independent objects, and sees
imagination at work in our very perception.
He writes:
"Now, since every appearance contains a manifold, and since different perceptions therefore occur in the mind separately and singly, a combination of them, such as they cannot have in
* This is an analytic argument and follows from the meaning of the terms.
18

sense itself, is demanded. There must therefore exist in us an active faculty for the synthesis of this manifold. To this faculty I give the title, imagination." (Kant [24], P.144)
And this is further reinforced in a note on the above section:
"Psychologists have hitherto failed to realise that the imagination is a necessary ingredient of perception itself. This is due partly to the fact that that faculty has been limited to reproduction, partly to the belief that the senses not only supply impressions but also combine them so as to generate images of objects. For that purpose something more than the mere receptivity of impressions is undoubtedly required, namely, a function for the synthesis of them." (P.144n)
Thus Kant regards sense as passive and unequipped to organize the welter of data which impinges on
it; and since some internal faculty must provide the organization of sense impressions which obviously
occurs (i.e. we are unitary minds living in a world of objects, not serial bombardments of dumb
impressions), he singles out imagination. This is already an advance over Hume. For Hume believed, in
rough caricature, that imagination creates for us a world of objects through a sort of deceit or confusion.
When we see the sun again in the morning, this kicks up a static Humean image of the sun we saw
yesterday, and the resemblance tricks us into believing we are seeing a self-same individual. Kant
rejects this. He sees imagination rather as an active, organizing power working internally within the
perception.
This reflects another of his innovations. Whereas Hume takes the imagination to be essentially
passive (a sort of mental photography), Kant divides the imagination into two types: a passive form,
which he calls reproductive or empirical, and an active form, which he calls productive or
transcendental. Like Hume, Kant has a three-fold division of the psyche (into sense, imagination and
understanding), and imagination, in its two forms, acts to mediate between the extremes of sense and
understanding. Imagination lends to sense the synthesizing action of the understanding, without which
sense would be chaotic and mindless, and to understanding the concrete material of sense, without
which understanding would be empty of meaning and divorced from reality. This bivalent view of the
imagination is highly original in the Western philosophical tradition, anticipated only perhaps by
19

Plotinus and Avicenna (see Casey [5] P.131-132).
The mediation of sense and understanding by imagination has two faces. On the one hand the
passive imagination is responsible for working impressions into images, a process which Kant calls
"apprehension." But this process is not simply a matter of photography:
"But it is clear that even this apprehension of the manifold would not by itself produce an image and a connection of the impressions, were it not that there exists a subjective ground which leads the mind to reinstate a preceding perception alongside a subsequent perception to which it has passed, and so to form a whole series of perceptions." (P.144)
Thus Kant anticipates our experimentally confirmed guess that impressions are recorded in
sequential strips.
The active imagination, on the other hand, is responsible for subsuming sequences of impressions
under concepts of the understanding, i.e. performing a sort of "pattern recognition." This is achieved
through what Kant calls a "schema." One might feel that we have a conflict of terminology here with
the AI schema, but in fact the two words largely refer to the same thing, and the latter use may derive
from the former.* Kant defines the schema, in contrast to the image:
"If five points be set alongside one another, thus, ..... , I have an image of the number five. But if, on the other hand, I think only of a number in general, whether it be five or a hundred, this thought is rather the representation of a method whereby a multiplicity, for instance a thousand, may be represented in an image in conformity with a certain concept, than the image itself. For with such a number as a thousand the image can hardly be surveyed and compared with the concept. This representation of a universal procedure of imagination in providing an image for a concept, I entitle the schema of this concept." (P.182)
The schema, then, is a rule or procedure by which we can, if we so desire, produce images
(originally fashioned by the passive imagination) subsumed under a certain concept. Thus the schema is
a sort of generalized image, and marks an advance over its Humean counterpart. Moreover, it is by
* The principle difference is that the AI schema is a static collection of declarative facts with no connection to imagination, while Kant's schema is the specification of a procedure which can be use to produce images. In model-theoretic terms, both schemas are theories, but Kant's schema has the additional capacity to produce appropriate models.
20

means of the schema that the active imagination organizes our sense impressions. Unfortunately Kant,
like AI, is silent on how precisely this occurs.
But we can clarify this somewhat by considering a line of thought due to Strawson [47]. Suppose
that on the street you meet a person who strikes you as familiar, but whom you cannot quite place. Then
suddenly something clicks and you recognize who it is. This is a peculiar experience if you scrutinize it
closely; it is almost as though you can see the old face in the new. Strawson struggles for words to
describe this, saying the past perception is "alive in" or "infuses" the present perception. He stresses
moreover that this is not a matter of calling up a Humean image which is compared with the present
perception. For we can very well, recognize a face as familiar without any specific memory of the
situation where we encountered it before. The memory is woven into the fiber of the present perception
as Kant suggested.
This concludes my survey of Hume and Kant. My aim here was to support a claim that imagination
is an integral part of ordinary perception, particularly insofar as it allows us to transcend subjectivity
and awaken to objectivity. As we have seen, two eminent figures of Western philosophy also
endeavored in this same vein. From them we have derived a certain disjointed picture of the
imagination (which we shall refine further below) and two good arguments for its essentiality to
perception: first, the analytic proof of its necessity for having ideas of noumena, and second, the
observation by Strawson that images from the past can "infuse" or "come alive in" present perception.
Two cardinal features of imagination are its capacity for making images, and its function in making
what is absent present. Perhaps this latter is what makes imagination such a tempting candidate for that
which gives us the idea that objects can exist beyond our perception of them. As Nietzsche says: "The
dead man lives on, because he appears to the living man in dreams."* It is this ability to make the absent
present that we shall address in the next section, albeit from a different angle.
* Human, All Too Human, 5.
21

4. What the Apes Lack Regardless of how clever the higher apes (chimpanzees, gorillas and orangutans) may be, there is a
yawning gulf between them and man which is amply summed up in the word "culture." One
conspicuous feature of culture is its explosiveness (on evolutionary time scales) and its infinite
extendibility, and so one wonders what allowed our distant ancestors to transcend the level of apes. Was
it a quick trick, a sort of "quantum leap"? Or was it a long-term construction of a complex apparatus?
As noted earlier, AI tends to regard man as a tool-box or "kludge" with no general organizing
principle, and thus would appear to favor the latter explanation. For surely it must have taken
evolutionary time to develop the myriad requisite information processing and representation techniques.
I, on the other hand, am inclined toward the former view, i.e. that the explosion of culture was triggered
by a subtle and simple trick.
Two arguments support my view. The first is that it would have taken too long to evolve a complex
tool-box of skills.
Recent techniques of DNA comparison place the split of the human and ape lineages in the range of
2.6 to 8 million years ago (Hasegawa et. al.[17], Sibley and Ahlquist [44]). If we assume,
conservatively, that the root lineage did not possess cultural abilities beyond those of apes, and that the
beginnings of culture are marked by the advent of simple stone tools in the lower Pleistocene (about 2
million years ago; see Buettner-Janusch [4]), then we are left with a window of 0.6 to 6 million years
for the development of neural structures and techniques to support culture. This is a paltry figure on the
evolutionary time scale. Evolutionary rates are difficult to gauge and vary for complex reasons, but it
remains implausible that any spectacularly complicated mechanism (like an intelligent Rube Goldberg
kludge) could evolve in 0.6 to 6 million years.
Second, we agree with Buettner-Janusch that "Culture is based upon an ability, a trait, which
appeared during the course of primate evolution, the ability to symbol."(P. 347) Perhaps I am mistaken
but it seems that this ability is not at all complicated, at least in the sense of having many inter-related
parts and mechanisms. Rather it seems, indeed, like a "quantum leap," or a simple and almost magical
new perspective or form of vision (in the broader sense). It seems like a general, all-purpose light which
22

can in principle be focused onto anything; I do not see how you could have it only part way, or build it
up piece by piece. (That is, could you have a creature which could refer to some things with symbols
and not others?)
So assuming a trick was involved here, what was it? Research by the comparative psychologist
Lorenz [27] furnishes a provocative clue. His work on jackdaws in the 1920s was the first to
demonstrate the existence of cultural traditions among animals. He found that jackdaws, reared in
isolation from their wild and experienced fellows, had not the slightest fear of man, dogs, cats and other
predators. He further determined that the jackdaw has an innate reflex stimulated by the sight of any
animal (even another jackdaw) carrying a flexible, black object (presumably a "dead jackdaw"). When
confronted with such a sight, the adult jackdaw emits "a penetrating rasping, rattling sound" which
spreads through the flock. Once a certain animal has been classed as dangerous through this response,
the flexible black object is no longer necessary; thereafter the reflex is triggered by the animal alone. So
when a young jackdaw sees a cat in the presence of older jackdaws, the older birds are aroused and
communicate their fear to the younger bird through the contagion of affect. Lorenz concluded that the
jackdaws raised in captivity had never been indoctrinated into the "tradition," and thus had never
acquired a fear of predators. Lorenz raises a telling point about such animal traditions:
"There is one vital respect in which these examples of animal tradition differ from human tradition: they are all dependent on the presence of the object with which the tradition is associated. An experienced jackdaw can only tell an inexperienced jackdaw that cats are dangerous when a cat is actually there to demonstrate the fact, and a rat can only teach its inexperienced fellows that a particular bait is poisonous when the bait is actually present. This seems to be true of all animal tradition, from the simplest transmission of conditioned responses to the most complex learning by imitation. This dependence on the presence of objects is probably the obstacle which prevents animal tradition from accumulating in the way it does in man. A specific tradition, such as that of the jackdaws' knowledge of cats, is broken once the object on which it depends fails to appear in the course of one particular generation, and the fact that all animal traditions are thus comparatively short-lived may well prevent their joining up with each other and creating a fund of common knowledge. It is only the development of abstract thought, together with the complementary development of verbal language, that enables tradition to become free of objects; for by means of independent symbols, facts and relationships can be established without the concrete presence of the objects themselves" (P.160-161)
23

If we, rightfully, define imagination as the ability to make what is absent present, then imagination is
precisely what the jackdaw lacks. And Lorenz pinpoints this lack as the barrier hindering the
development of culture. Kohler [25] came to similar conclusions in his classic study of chimpanzee
intelligence. He found that if a chimpanzee is placed in a cage, with a banana beyond arm's reach
outside the bars, and a stick long enough to draw in the banana at hand, the chimpanzee can grasp the
situation, take the stick and retrieve its prize. But this ability is governed by the following proviso:
"... if the experimenter takes care that the stick is not visible to the animal when gazing directly at the objective—and that, vice versa, a direct look at the stick excludes the whole region of the objective from the field of vision — then, generally speaking, recourse to the instrument is either prevented or at least greatly retarded, even when it has already been frequently used." (P. 37)
This is further reinforced by Kohler's observations of chimpanzee emotions. The chimpanzee's
emotional life is remarkably rich and similar to our own; for instance, they feel shame, plead for
forgiveness, and take out scoldings on weaker comrades. But they show no traces of emotions, such as
grief, which require consciousness of absent objects. Kohler once observed the collapse of an ill
chimpanzee in sight of his comrades. Immediately one of the group ran to help, crying in sympathy. But
once the sick chimpanzee had been taken back to his cage (where he died), the others forgot him and
showed no grief (P. 285-286). These results of Lorenz and Kohler make imagination a prime candidate
for the trick or "missing link" we began this section in search of. But before this hypothesis wins our
full support, it must answer two objections. First there is the case of apes who have been taught
languages using manual signs or shaped blocks. This research has conclusively shown that apes are
capable of some sort of communication about their environment. But their ability to communicate about
spatially or temporally displaced objects is highly retarded. A comprehensive survey of ape language
studies (Ristau and Robbins [41]) indicates that, despite considerable interest in the topic of
displacement, apes have been only rarely and painstakingly encouraged to refer to absent objects, and
then only in the most primitive way. Second there is the fact that apes have a prodigious recognition
memory. For example, Goodall [15] recounts the story of Washoe, a chimpanzee who recognized his
former trainer after a separation of 11 years. Also Kohler found that chimpanzees could see fruit buried,
24

い
A.
and then immediately find and dig it up the next morning, 16 hours after they had last seen it.
Such observations do not imply that the chimpanzee entertains images while an object is absent.
Even human beings perform similar feats without evoking imagery. For example, I may recognize an
old classmate after many years without having a single thought of him in the interim, or I may put a
letter in my pocket and forget it entirely until I get to the post office. Furthermore if the chimpanzee has
long-lasting imagery, why does it forget its beloved missing companion, or the stick behind it when it is
desperate for a banana?
This solves part of the problem, but we must dredge further. Recall that I, following Hume and Kant,
have claimed that imagination is an essential ingredient of ordinary perception. How then could a
chimpanzee (or even a dog for that matter) seemingly recognize an individual object given its lack of
imagination?
We can answer this question by distinguishing between three different forms of imagination:
Latent imagination: Part of the imagination's role is to create imprints or copies of experience.
Almost all animals have this kind of imagination in the form of memory. For example, even a jackdaw
must maintain a representation of a previously encountered noxious stimulus in order to recognize and
avoid it. But these passive representations are part of the classification hardware or the creature's
nervous system and cannot be liberated. They are more akin to conditioned responses and do not direct
of manifest themselves in perception. They are inaccessible to consciousness and serve only to classify
what is present, not to revive what is absent.*
Imported imagination: This form not only records, but also revives the recording so that it can
direct and appear in the present perception. It is distinguished from latent imagination by the fact that
images of absent things can now be discerned within a present thing. Perception is no longer a matter of
putting a stimulus into a black box and getting its type out the back. The content of the box is now
accessible and can play a role in directing how the stimulus is apprehended. In latent imagination each
* As we have seen earlier, child psychologists agree that the infant has no concept of independent objects. And yet even a new born quickly develops the ability to recognize its mother's face. Piaget [38] resolves this problem by appealing to latent imagination. That is, the infant recognizes pictures not independent objects.
25

stimulus has a single classification, but in imported imagination the same stimulus can be regarded in
different ways.*
Free-state imagination: We might call this form imagination proper, for it is what allows us to
conjure up images of absent objects even when we are perceiving something unrelated or not perceiving
anything at all. Among its species are dreaming and day-dreaming. Now we are in a position to deal
with our dilemma. Clearly the chimpanzee, and by extension other animals, has an extreme deficiency
of free-state images while awake (although they may dream). They also show a limited degree of
imported imagination and this, I contend, is what makes them intelligent. For example, in the stick
problem, the present perception of the situation must make the stick appear in the light of the
chimpanzees previous experience with sticks.
Finally, we see that the question whether imagination is a necessary ingredient of perception hinges
on what we mean by perception. If perception is a black box classifying stimuli, we only need latent
imagination, which is to say no real imagination at all. But our human perception is much richer than
this. We are not stimulus-response computers which, when given a bar code, recognize it in a passive
mechanical way and output the correct product specifications. We do more than react; we posit the
existence of an ideal world of noumena beyond the bar codes and actively see one bar code in many
different ways.
Now I have gone, and will go, to further lengths to implicate imagination in such processes, so at the
least we may say: imagination is a fundamental factor underlying the richness of human perception. To
this we may add the principal conclusion of this chapter: Imagination, in making the absent present,
appears to be the "missing link" in the intellectual transition from ape to man. So we may reasonably
conjecture that imagination is a linchpin and proceed to a finer analysis of its structure.
* These remarks on imported imagination may seem somewhat cryptic at this point. The phenomenon will be addressed in more detail in the next chapter.
26

5. The Image Thus far I have labored to establish a variant of the romantic view of the imagination, i.e. that
imagination is a central and essential feature of human perception and cognition. But obviously this
approach will only benefit the science of AI if we can formalize it. So in this and the following two
chapters I shall attempt to draw a much sharper picture of both the image and its dynamics.
Naively, the best approach to the image would seem to be examining it introspectively in the free
state. But that is a slippery road indeed, fraught with accidental self-deceptions and objective pull, so
we shall instead follow in the steps of Wittgenstein [52] by taking imported imagination as our point of
departure.
Recall that in imported imagination an image of an absent thing invades or directs or changes the
appearance of a present perception. What on earth does that mean? Let us consider an example.
Everyone is familiar with figures like this:
The "Necker Cube"
This cube has the peculiar property of being bi-stable; it has two mutually exclusive, consistent
interpretations. (In fact it is worse than that. Not only can we regard one of the central corners as either
hidden or occluding, we can also regard the figure as planar, with no 3-dimensionality whatsoever.)
Wittgenstein was deeply impressed by this phenomenon and devoted a long passage of the
Philosophical Investigations to its analysis. He calls this ability to fluctuate between alternate views
27

"seeing-as"—that is, you can see the Necker cube "as this" or "as that." What seems to endlessly
fascinate him is that the same, congruent figure can look entirely different. He writes: "So we interpret
it, and see it as we interpret it." (P. 193) He calls the variant interpretations of the figure "aspects," and
the sudden, startling shift from one view to another the "dawning of an aspect." He stresses the
apparent dual nature of seeing in such a dawning: "I see that it has not changed and yet I see it
differently." (P. 193) What are we to make of this paradoxical change with no change? First of all, it is
absolutely certain that what is changing is not the stimulation pattern on our retinal cells. So the
change must not lie in what we are looking at but in how we are looking at it. Wittgenstein
characterizes this "how" in the following terms:
"I suddenly see the solution of a picture-puzzle. Before, there were branches there; now there is a human shape. My visual impression has changed and now I recognize that it has not only shape and colour but also a quite particular 'organization'." (P. 196)
As Strawson [47] has noted, this harks back to Kant's view of imagination as an organizing power
working within perception. Can we get a sharper idea of this 'organization' Wittgenstein is referring to?
I have heard the tale of a polar explorer who spent hours sketching a distant mountain with two long
tapering ice floes, until the mountain moved and he realized it was a nearby walrus. What changed with
the realization was undoubtedly the way the pieces of the picture fit together and related. For instance,
two ice floes on a mountain have no particular intrinsic connection, no matter how symmetrical they
are; they are just meaningless forms which do not fit into any higher complex of inter-relationships. But
when the seed of the walrus realization begins to sprout, it lacks and needs these two white streaks and
seizes them to complete itself, injecting them with meaning and connection within an organized
complex.
At times I also experience this 'organization' when I wake up. When I was a child and my parents
moved me while I was sleeping, or even today if I go to sleep on my bed the wrong way, I may awaken
with a peculiar, almost dizzy disorientation. The sights around me violate my expectations, and there is
a brief flurry of helter-skelter confusion until I catch sight of a "landmark," so to speak, and the world
28

spins around to accommodate, everything settling in its proper place.*
Wittgenstein further indicates how our perception can lack this 'organization': "After all, how
completely ragged what we see can appear!" (P. 200) This recalls an observation of Kohler [25] on the
chimpanzee. He found that the chimpanzee has great difficulty conceptualizing a visual scene which is
obvious for human beings. For example, if the ape must unwind a rope coiled neatly on a pole to
achieve its prize, it will haphazardly jerk and thrash with the end as though it were dealing with a
hopeless tangle. Or if the ape must bring a ladder through the cage bars, it does well when the ladder is
almost aligned and the correct movement is visually evident. But when the ladder is askew, the
chimpanzee seems to look at the criss-crossing pattern of bars and rungs as hopelessly
incomprehensible, and begins to angrily thrash. This is not an unknown occurrence even among human
beings; Kohler compares it to his own experience with folding chairs.
Another example in this same vein is provided by the results of Chase and Simon [6] on chess
memory. They conducted experiments wherein both masters and novices were briefly presented with a
board position and then asked to replicate it from memory. It was found that masters were vastly more
proficient when the position was derived from actual chess play, but masters and novices were on even
ground when given a random arrangement of pieces. Chase and Simon suggest that the superior
performance of the masters can be attributed to their having a large stock of stereotypical chess patterns
from which to quickly construct an economical representation of the position. So perhaps we can say
that, to the novice, chess positions in the middle game look as "ragged" as random arrangements of
pieces look to the master. The master, on the other hand, sees more than just a happenstance
arrangement when given a significant position. The pieces cohere and fall together into larger
meaningful complexes, just like the explorer's ice floes which mutate into walrus tusks.
Examples of this type are common in mathematics and science as well. For instance, we have the
case of Godel seeing that the unique prime number decomposition of an integer could be used to encode
a string of symbols into a single number. Surely this momentous insight and its implications were not * Minsky [35] relates a similar example: "Suppose you were to leave a room, close the door, turn to reopen it, and find an entirely different room. You would be shocked. The sense of change would be almost as startling as if the world suddenly changed before your eyes." (P. 221)
29

written all over the face of the prime number decomposition. That is, where others had looked and seen
only something "ragged," Godel saw 'organization.' On a more mundane plane, suppose you have a
right triangle, with acute angles A and B, whose edges are labeled with their lengths. Consider how
your whole manner of regarding the triangle changes when you switch from calculating the sine of A to
calculating the sine of B. And what about the realization that projectiles trace out a parabolic path? I am
inclined to think that this step required the confluence of two streams of human endeavor: the perfection
of long-range artillery and the study of conic sections. The ancients developed the latter, but for some
reason, perhaps the primitivity of their siege engines or the aristocratic distance of science from military
affairs, everyone at the time apparently held a "ragged" view of hurtling rocks. It is hard indeed to
imagine a man, who has spent long hours sketching and playing with parabolas, viewing the rise and
fall of a projectile and not being struck by an aspect—that feeling "Wait a minute... I've seen that
somewhere before." And is it not a common expression in scientific circles: "To solve the problem, you
have to look at it like this." OR "Once you see it as a dynamic programming problem, the rest is trivial."
At the risk of beating this sadly neglected topic to death, I would like to point out that this
'organization' is not limited to perception; it equally asserts itself in action. Children are the most
conspicuous examples. As Wittgenstein writes:
"Here is a game played by children: they say that a chest, for example, is a house; and thereupon it is interpreted as a house in every detail. A piece of fancy is worked into it." (P. 206)
I myself have seen my daughter put a non-existent "grandma" on a toy horse, smash a picture of a
snake and use a crayon as a microphone. Adults are by no means immune to this behavior. A friend,
while telling me the story of a basketball game, may whirl and "shoot" to illustrate the dramatic final
play. Or he may mimic the voice of his mother or punch the wall as though it were a person he wants to
hit. Even the military, that great bastion of morbid seriousness, conducts "war-games" and uses sticks as
make-believe rifles. The reader has undoubtedly noticed, in the above examples a strong connection
with our ordinary notions of imagination (particularly what I call "imported imagination). The polar
30

explorer "imagined" he saw a mountain; Gödel’s work was "imaginative"; children are said to have
vivid "imaginations." This connection was not lost on Wittgenstein, who writes:
"The concept of an aspect is akin to the concept of an image. In other words: the concept 'I am now seeing it as...' is akin to 'I am now having this image'." (P. 213)
One of his primary reasons for thinking so is that "Seeing an aspect and imagining are subject to the
will." (P. 213) But he also notes:
"The colour of the visual impression corresponds to the colour of the object (this blotting paper looks pink to me, and is pink)—the shape of [the] visual impression to the shape of the object (it looks rectangular to me, and is rectangular)—but what I perceive in the dawning of an aspect is not a property of the object, but an internal relation between it and other objects." (P. 212)
This "internal relation of an object with other objects" is a common feature of all the examples I have
given. And as Strawson [47] has pointed out, this must require imagination since the "other objects" are
not present.
But to be fair we must grant that Wittgenstein hesitated to view all seeing as "seeing-as." He claims
that "...I cannot try to see a conventional picture of a lion as a lion, any more than an F as that letter.
(Though I may well try to see it as a gallows for example.)" (P. 206) But this cannot be right. For
consider the Japanese symbol "十". In Japanese this is read "juu" and means "ten," but it is also the
symbol for "plus" and bears a suspicious similarity to some versions of the small letter "T". When
reading Japanese, or a mathematical expression, it certainly would take an effort to see this mark as a
"T". In fact "conventional" is the operative word in Wittgenstein's claim. The reason I cannot try to see
a conventional lion as a lion is not that it is psychologically impossible; rather it is because this way of
looking is conventional, i.e., established as a standard by cultural convention. There is no basis for
thinking that a lion really is a lion, any more than there is a basis for thinking that "十" really is "juu."
Even if we take a 100% conventional picture of a standing male lion posed on a white background, I
can formally distort it. I might for instance view it as a bizarre creature with a long, tail-like neck, tuft
31

of hair head and a huge grotesque, but useless tail with a face on it to frighten predators. Is this a lion?
And can I not fluctuate between the conventional view (seeing the picture "as a lion") and this perverse
view just as in the Necker cube?
The indisputable fact is that anything can be regarded in myriad ways. This is the trademark that
imported imagination bestows on human perception. All seeing is "seeing-as" or interpretation, even
though some interpretations are more conventional that others. Thus all human vision involves
imagination. We fail to notice this because, for the most part, the world and our images run in tight
lock-step, and often when they do not the world is what gives. Now naive reflection would seem to
confirm that images are Humean, i.e. iconic photographs. But Kant and our look at imported
imagination suggest that the image has a peculiar sort of dynamic 'organization.' Wittgenstein points out
the conflict with the Humean image:
"If you put the 'organization' of a visual impression on a level with colour and shapes, you are proceeding from the idea of the visual impression as an inner object. Of course this makes this object into a chimera; a queerly shifting construction. For the similarity to a picture is now impaired." (P. 196)
This is not just an artifact of imported imagination not shared by free-state images. For Pylyshyn
[39,40] has compiled a wealth of evidence against the Humean image in any form. His basic point
amounts to this: Mental images are not raw and reperceived; they are already interpreted. It is tempting
to believe that an image is like a picture, so that, when someone asks me what color my mail box is, I
recall the picture, look at it with my "mind's eye" and reply "silver."
The problem is not that we are mistaken when we believe we do this. Rather the belief suggests that
the image exists independently of our interpretation of it—i.e. that I can keep probing into the image
and learning new things from it just as I can with an actual photograph.
But if the image is like a photograph, says Pylyshyn, then why when it degrades, do we lose discrete
conceptual units and relations? For example, in trying to recall an old photograph of my first grade class,
I might remember some people and have forgotten others. Among the people I do remember, I might
have forgotten where they were standing although I know they were there and remember what their
32

faces looked like. It seems that images never fade, or lose resolution or get their corners torn off like
actual photographs.
Furthermore, Pylyshyn cites a number of experiments indicating that memory images are tightly
bound to how they are encoded. For example, in the chess experiments of Chase and Simon (discussed
above), the masters are not superior to novices in their ability to "photograph" the board, as the results
with random positions demonstrate. Rather the masters have stereotypical concepts into which pieces
can fit, and when they recall a position they are recalling the concepts more than the raw "picture" they
saw. This same principle holds when we listen to someone speak. In general, we do not remember the
exact words of what was said, only the gist. Or consider the following experiment. Mark off a 3x3
matrix like a tic-tac-toe board, and fill in the cells with a random arrangement of digits. Memorize the
numbers and try to see the matrix in your mind's eye. Can you read the diagonals? The rows backwards
and from the bottom? This task nicely illustrates the difference between the two approaches to imagery
(the Humean; and Pylyshyn's approach, which I call the Kantian), as shown in the figure below:
Pylyshyn's evidence (only briefly summarized here), similar arguments by Casey [5], Hebb [19] and
33

Sartre [42], our earlier remarks on 'organization' in imported imagination, a wealth of anecdotal
evidence, and properly reflective common sense all indicate that the Humean view is incorrect and we
should opt for the Kantian.
We also note that the Humean image does not make much sense in the framework I have developed.
For we have seen that a primary function of imagination is to create noumena— ideal, self-identical
units beyond perception—so that we may interpret the flux of our sense impressions. This function
would be incapacitated if images were raw and required interpretation. We would then be trying to
interpret a welter of sense data by means of a welter of internal imagery, which in turn would require a
"mind’s eye" and "mind's eye's imagery" etc. etc.
Furthermore, Pylyshyn's view (that images are already interpreted and do not require reperception)
sits well with another frequently noticed property of images—namely, that we cannot be wrong about
them. For example, it is virtually impossible to conjure up an image of a house, and then realize, on
closer scrutiny, that it is not a house at all; it is actually a cardboard box. The image, in this sense, does
not carry with it any hidden surprises.* It is an outgrowth of the intention which brought it into
existence. As Sartre [42] writes:
"My perception can deceive me, but not my image. Our attitude towards the object of the image could be called "quasi-observation." Our attitude is, indeed, one of observation, but it is an observation which teaches nothing. If I produce an image of a page of a book, I am assuming the attitude of a reader, I look at the printed pages. But I am not reading. And, actually, I am not even looking, since I already know what is written there." (P. 13)
This property is also evident when, for instance, a child deems a scribble to be "Mommy." The child
is not wrong because it is her prerogative to say what the picture is; it is what she meant it to be. If we
assume that this is a factual property of imagery, then it would make little sense to say that the image,
like a picture, is raw and requires interpretation. For then we could very well be deceived by our
images; I might form an image of 5 apples, and then realize a moment later that there were actually six.
Such images would obviously completely undermine certainty in, among other things, mathematics.
* We shall see momentarily that there is another sense in which an image can hide things.
34

Up to this point, we have determined that the image has two basic properties: it has 'organization,'
and it is pre-interpreted. I would like now to develop a third, and final property, namely that the image
has a temporal structure. Recall that in Chapter 2 on "Linearity" (above, P. 8), we suggested that
memory is a reinstatement of our moment-by-moment perceptual experience in time, and produced
physiological evidence supporting this view. Hebb [19] has suggested that the same applies to the
image:
"If the reader will form an image of some familiar object such as a car or a rowboat he will find that its different parts are not clear all at once but successively, as if his gaze in looking at an actual car shifted from fender to trunk to windshield to rear door to windshield, and so on. This freedom in seeing any part at will may make one feel that all is simultaneously given: that the figure of speech of an image, a picture "before the mind's eye," in the old phrase, does not misrepresent the actual situation." (P. 469)
That is, the image is comprised of a sequence of partial moments which must be journeyed through. To
demonstrate that this partiality of successive imagery moments is not an artifact of his psychological
theory, Hebb cites Binet's [3] reports of imagery in his theoretically naive 14-year-old daughter:
"Asked to consider the laundress, she reported seeing only the lady's head; if she saw anything else it was very imperfect and did not include the laundress's clothing or what she was doing. For a crystalline lens, she saw not the lens but the eye of her pet dog, with little of the head or the rest of the animal; and for a handle-bar, all the front part of her bicycle but missing the seat and the rear wheel." (Binet [3], P. 126, cited in Hebb [19] P. 475)
If the image is a cluster of partial moments, what is the "glue" that holds it together? Hebb [18,19]
proposes a view that we shall examine in detail in the next chapter: that the partial moments are
integrated through correlates of eye (or more generally head and body) movements.
So let us recap the three main features of the image we have derived in this chapter:
1) The image has a peculiar dynamic 'organization' which is particularly evident in imported
imagination.
2) The image is pre-interpreted and does not require reperception.
3) The image is a temporal structure of partial moments, perhaps integrated by correlates of eye (or
35

head and body) movements).
Let us adopt the mild assumptions that: (A) the 'organization' of an image is some sort of system of
inter-relationships, and (B) anything pre-interpreted must be some kind of unambiguous, canonical
representation. Then properties 1) and 2) above imply that the image is quite like an AI schema. For
example, the image for WALRUS might be represented in a LISP schema as follows:
(WALRUS ?W (PART-OF ?B ?W) (PART-OF ?T1 ?W) (PART-OF ?T2 ?W) (INSTANCE-OF ?B BODY) (COLOR-OF ?B DARK) (INSTANCE-OF ?T1 TUSK) (INSTANCE-OF ?T2 TUSK) (COLOR-OF ?T1 WHITE) (COLOR-OF ?T2 WHITE))
All this says is that a walrus is a thing with three parts: a dark body, and two white tusks. The
variables ?W, ?B, ?T1 and ?T2 are open to be bound to an actual instance of a walrus, and its three
components (body, tusk1 and tusk2). This schema has two nice properties which make it akin to an
image. First, it inter-relates various pieces into a complex whole, thus explaining how the image can
lack something, and reach out to seize and interpret it, as happened with the "two white streaks" in the
polar explorer example. Second, its various component symbols—WALRUS, BODY/ TUSK,
PART-OF etc.—are completely unambiguous, pre-interpreted and hold no hidden surprises.
However, as we have noted earlier, a key problem with schemata is that they are non-temporal, and
thus skirt our third criterion for imagery. How schemata are built from moment-by-moment subjective
time is generally ignored; the computer has no need to build schemata because that job is relegated to
the programmer (see, for instance. Dyer [11]). How schemata are brought to bear during
moment-by-moment subjective time is often sidelined as well, because schemata are most widely used
in text processing and data base situations where the computer has essentially no contact with the world
we live in (i.e. as in Dyer [11]), and vision and robotics work tend to focus on the pre-conceptual level
36

(see Marr [31]). So temporality is one point of discontinuity between images and schema.
Still this does not strike to the heart of the matter. If our analysis is correct then images, regardless of
their temporal nature, seem to lack any of the "pictorial" character which would distinguish them from
concepts. One might feel like Pylyshyn [40], that "...the representation is so obviously selective and
conceptual in nature [that] referring to it as an image—a term that has pictorial or projective
connotations is very misleading." (P. 24) But this is an unsatisfactory viewpoint because it fails to
explain why we feel that, in thinking, images are pictorial and often more expeditious than concepts.
For example, consider the following story problem:
1. B is 1 mile due west of A
2. C is 1 mile due north of B
3. D is 1 mile due east of C
Q. How is A related to D?
Problems of this type are often solved by drawing a picture, either mentally, or on paper, or with a
finger in the air. That is, we do not blindly reason or calculate our way to the answer; we create an
image in which the answer is evident and then see it.* Granted the above problem is very simple. But it
cannot be denied that images are exploited to advantage in a variety of more complex problems. So how
do we explain this if images and concepts are the same thing?
What images and concepts share is that they are both schema-like structures of inter-relationships.
The difference between them lies in the nature of these inter-relationships. Whereas in a concept the
relations are so to speak "objective” or "intrinsic," in an image these relations are, as Hebb suggested,
correlates of eye, head or body movements. Thus, for example, a planar image is a data structure whose
main properties are that it is 2-dimensional, and the operation defined on it is free scansion in any
* Waltz [50] makes this same point, noting the combinatorially explosive deductions confronting
actual AI programs which attempt to solve complicated problems of the above type logically, without images.
37

direction.
To clarify this rather elusive point, let us consider another example. Suppose we represent a family
of individuals using a tree, like so:
If we represent this structure conceptually, we obtain something like the following (letting P(x) mean
'parent of x'):
P(A)=nil P(B)=P(C)=P(D)=A P(E)=P(F)=P(G)=B P(H)=C P(I)=H
On the other hand, if we represent the structure imagistically, we obtain (ignoring movement metrics
and simplifying the potential greatly):
LOOK_UP(A)=BLANK LOOK_UP&RIGHT(B)=A LOOK_UP(C)=A LOOK_RIGHT(C)=D LOOK_WAY_DOWN(A)=I LOOK_UP&LEFT(I)=G, etc.
Whereas in an ordinary tree data structure we are constrained to moving within the "objective"
relations (i.e. edges), if we represent the tree as a picture data structure, we achieve much greater
freedom. This is not to say that a picture data structure must contain the results of all possible eye
38

movements from all possible positions. The point is that theoretically it can, and the greater the freedom
of scansion, the closer the representation approximates a picture.
The importance of this idea is that it allows us to salvage the image as an explanatory construct, and
rationalize rather than side-step (as Pylyshyn [39, 40] does) the belief that images are pictorial and
useful in thought. But let me stress further that the image is not inherently pictorial; we are not
regressing to the Humean paradigm. An image is a subjective, concrete species of concept which only
gradually and imperfectly approximates a picture.
So in the earlier example of memorizing a 3x3 matrix, your original idea will be closer to a concept
than a picture, as is revealed by tests of free scansion like reading diagonals. But with practice, you
learn the diagonals and odd scanning paths so that instead of painstakingly working them out each time,
you can in a sense "read them off." The greater your facility in reading off odd scanning patterns, the
closer your concept approaches a picture.
This view also shows how we can learn something new from an image, despite the fact that images
are pre-interpreted. For example, many Americans of a certain era have an auditory image of the
"Pledge of Allegiance." So what is the Pledge's last word? I have asked a number of people that
question, and it generally takes them some time to answer—roughly as long as it takes to quickly recite
the pledge. So do these people know the last word of the pledge before I ask? In one sense they do not
because they must take time to work it out and produce it. In another sense, they do because they can
eventually produce it. But being able to eventually produce an answer is a rather dubious criterion of
knowledge. For example, it might be that standard algebraic facts, which any high school student knows,
can be combined in some twisted, counter-intuitive manner so as to prove Fermat's Last Theorem. If
that is true, then any high school graduate could eventually, given years of mental trauma and a little
luck, produce the desired proof. So, by the "ability to eventually produce" criterion of knowledge,
everyone who knows high school algebra also knows the proof of Fermat's Last Theorem!
The point here is that an image can contain hidden aspects, but these aspects lie in the structural
relations which bind the image together, not in an uninterpreted iconic photograph. These hidden
aspects (like the last word of the pledge) make images useful in two ways (both noted by Waltz [50]).
39

First, we can use them to implicitly and compactly store numerous propositions. For instance, there is
no need for me to store statements like: "The last word of the pledge is 'all'." or "The pledge, read
backward, turned inside out, converted to numbers and squared is such and such." The image allows us
to compute such propositions on an as-needed basis. Second, these hidden aspects are what make
images useful in solving problems like the story problem given above. We can construct an image
according to some specifications, and then process it to find out more about it.
Now I would like also to note that we can extend the planar image if we allow relations involving
bodily movements. For then we can define an analogous 3-dimensional space data structure or "spatial
image." For example, consider an elevator-like robot which moves within a 3-dimensional "shaft"
structure like the following:
At any moment of time the robot can be in any one of the structure's 7 cells A through G. When the
robot is in any cell, it receives a signal on its perceptual side indicating which cell it is in. Also, the
robot has 6 possible actions: IN(I), OUT(O), EAST(E), WEST(W), UP(U) and DOWN(D).
Then this robot's world can be captured in the schematic spatial image shown on the following page.
40

Spatial Image
The appeal of such spatial images is that they allow us to define a world in subjective (egocentric)
rather than objective terms.* That is, spatial images, like their planar analogues, are encodings of how a
situated subject's perception and action are knit together by a world, rather than how the world itself is
knit together.
This subjective character of images makes them an attractive means of mediating between sense and
concepts, just as Kant suggested. The benefit of developing this notion of mediation is two-fold. First,
as we have seen, the AI schema is a pure concept—objective and divorced from a situated subject's
perception and action, and thus of little help in interfacing with the world. But images have sensory and
motor aspects, as well as conceptual aspects, and thus may usher concepts into contact with the world.
Second, there is substantial evidence (Piaget [38], Vygotsky [49], Flavell [13]) that images are the
* We also note that Tolman [48] experimentally implicates spatial images (what he calls "cognitive maps") as the means a rat employs to represent a maze, and thus perhaps its environment.
41

cradle of pure concepts; that is, knowledge in the child is sensuous, concrete and image-based.
Sensorimotor images serve originally as surrogates for adult concepts and only gradually acquire
objectivity. So, in sum, the image shows promise of remedying the two major defects of AI schema:
how they are applied during and built from experience.
42

6. Feature Rings In the theoretical analysis of the previous chapter, we suggested, following Hebb [18,19], that the
image is a structure held together by correlates of eye, head and body movements. This claim was not
adequately addressed, so in this chapter we shall review some corroborative results from the field of eye
movement research.
In psychology, the topic of eye movements has had a long and controversial history, and the field has
generated a surprisingly ample literature—only a fraction of which shall be touched on in this chapter.
The principal focus here shall be to describe and analyze an eye movement based theory of memory and
visual recognition originally proposed by Hebb [18] and more recently explored by Hochberg [20],
Noton and Stark [36], Farley [12] and many others.
I. Feature rings
As noted, the theory to be examined here has had a number of incarnations in the work of different
authors, each of whom has developed a different terminology. For the sake of uniformity, this chapter
shall adopt the terminology of Noton and Stark [36].
It is a well known phenomenon that the fixations of a subject viewing a picture tend to occur at
points of high information content such as corners, rapidly changing contours and incongruous objects
(Mackworth and Morandi [30], Loftus [26]). Recordings of the viewing path of a picture therefore look
clustered, with certain focal points attracting the majority of fixations. In studying such recordings.
Noton and Stark [36] observed, like many previous investigators, that the transitions between various
focal points seemed somewhat regular and even appeared to form cycles. For example, in viewing a
portrait, fixations might intermittently return to a certain "beaten track" such as left eye, nose, mouth,
left eye. Noton and Stark called these regular movements "scan paths" and found evidence (albeit
contested by some for statistical reasons) of their existence in a more systematic survey of eye
movement data.
These observations on scan paths led Noton and Stark to propose that these paths play a functional
role in recognition. They claimed that the memory or mental model of an object consists of a directed
43

simple cycle (as in graph theory) whose nodes are the contents of fixations and whose arcs are labeled
with eye movements. In short, this structure encodes the particular eye movement necessary to get from
one fixation content to another in the original viewed picture. They called such a graph a "feature ring"
—the cyclic structure and term "ring" suggested by the observed cycles in scan paths. (For similar
structures, Hebb [18] uses the term "phase sequence," Hochberg [20] the term "schematic map," and
Farley [12] the term "image.") Noton and Stark further hypothesized that when a subject views
something the first time, a feature ring is laid down and this later directs eye movement during
recognition. To test this theory, he conducted an experiment with 2 phases. In the learning phase
subjects were shown 5 pictures they had never seen, each for 20 seconds. In the recognition phase, these
pictures were shuffled with 5 unseen pictures, and each picture in this randomly ordered 10 picture
sequence was presented to the subjects for 5 seconds. The subjects' goal during the recognition phase
was to class the pictures as seen or unseen. Eye movements were recorded during all viewings.
The result of this experiment was: 65% of the time, the scan path in the recognition phase largely
reiterated that of the learning phase. Noton and Stark point out that: "That is a rather strong result in
view of the many possible paths around each picture..." (P. 40) To account for the 35% of the viewings
where a scan path did not occur. Noton and Stark relaxed their feature ring model to something closer to
a general directed graph, and suggested that the scanning process dictated by the feature ring is probable
rather than deterministic.
II. Problems with feature rings
The feature ring theory is controversial, and a variety of objections have been made in the literature.
For instance, Groner et. al. [16] claim that there is no evidence suggesting that visual features are
stored with eye movement components. But that is an oversight; for dreams, which surely are built from
scraps of memory, are accompanied by eye movements. Dement and Kleitman [8] have shown
experimentally that these REM (Rapid Eye Movements which accompany dreaming) are correlated
with dream content. For instance, a subject awakened after one minute of almost purely horizontal eye
movements reported dreaming of "two people throwing tomatoes at each other," and another subject
44

awakened after a similar period of vertical eye movements "dreamed of standing at the bottom of a tall
cliff operating some sort of hoist and looking up at climbers at various levels and down at the hoist
machinery." (P. 344) It would be stretching things to claim that the dream is "projected" somewhere and
the dreamer must move his eyes to see different parts of it. For if it is "projected" anywhere, it is
projected inside the brain*, and clearly moving the eyes will not affect vision of that picture one iota. So
the pictures and eye movements of the dream must be correlated by some memory mechanism like a
feature ring.
Groner et. al. further claim that feature rings would be an inefficient form of storage. But as we have
seen earlier, Penfield and Roberts [37] have shown that memories—even very insignificant
memories—are stored in motion-picture-like strips in the brain. Unfortunately, Penfield and Roberts do
not comment on the eye movements of the patients during these episodes, but I believe my basic point
has been made. That is, we have at least one good reason for considering this prima facie inefficient
encoding.
Another difficulty has been the question of the statistical reliability of the results on scan paths, i.e.,
it is difficult to discriminate between a "bona-fide" scan path and a random artifact (Groner et. al.[16],
Stark and Ellis [46]). This is a knotty question, but I believe that the above evidence of dreams and the
considerable theoretical interest of the feature ring theory (which hopefully is apparent in light of the
previous chapters), demand that we go beyond this quibble. We must not call off the race before the
horses are even out of the chute. That is to say, we may profit by pursuing the deeper questions of the
mechanics and workability of the theory, and to this we now turn.
1. The Interpretation Problem
In the previous chapter, we marshaled a number of psychological and philosophical arguments
indicating that an image is not raw and uninterpreted. Since the appeal of feature rings lies in their
kinship to the notion of imagery we have developed, we are confronted with the problem that nodes of * It could not be projected in the eye itself (equally futilely) because the optical pathway is composed solely of afferent fibers.
45

feature rings (in the Noton and Stark model) are uninterpreted, iconic imprints of fixation contents. This
could be remedied, however, by making feature ring nodes interpretations of fixation contents.
Such a move is rendered plausible by the old and elegant eye movement based theory of visual
ambiguity (Gale and Findlay [14], Hochberg [20], Stark and Ellis [46]). To see how this theory works
consider Wittgenstein's "duck-rabbit":
The Duck-Rabbit
This figure, like the Necker cube, has two aspects—a duck and a rabbit—and we saw, in discussing
Wittgenstein, that when we alternate between the two aspects, what appears to vary is the 'organization'
of the picture elements. The eye movement theory of ambiguous figures states that this shift in
'organization' is intrinsically linked with how you scan a figure—where you look, and where you avoid
looking. One can get a sense of why this theory is so old and persistent just by viewing the duck-rabbit
for a while, alternating between the two aspects, and observing how the duck and rabbit appear to be
associated with different ways of scanning the figure. For instance, viewing the right side (the rabbit's
nose) seems more tightly bound to the rabbit interpretation, and the left side (the duck's bill) to the duck
interpretation. To account for these facts. Gale and Findlay [14] have proposed that each possible
fixation content has multiple interpretations. For example, the protrusion on the right side of the
duck-rabbit can be viewed as either "rabbit ears" or "duck bill." These interpretations are related
together into complex wholes (which constitute higher level interpretations) by eye movements, and the
46

picture element interpretations have varying probabilities of evoking complexes in which they occur.
Shifting between aspects is hypothesized to occur when the current fixation interpretation is more
tightly bound to a complex other than that currently aroused. This theory has been, to a reasonable
extent, confirmed (Gale and Findlay [14], Stark and Ellis [46]). And it offers two advantages over
exotic, anti-structural explanations like bi-stable neural nets (Marr [31], P. 25). First, it has some
grounding in empirical findings, and second it provides a probable and more refined idea of how images
can "come alive in" or "infuse" current perception—a commonplace and factual occurrence, as we have
seen.
So we shall adopt this revision of the feature ring theory which transforms feature rings into what we
have earlier called planar images. (We shall, however retain the term feature ring for the duration of this
chapter.)
2. The Parallel vs. Serial Problem
Another objection to the feature ring theory is this: If recognition requires eye movement, how do we
account for the fact that (some!) images can be recognized when presented with a tachistoscope so
quickly (on the order of a few hundred milliseconds) that eye movement is impossible? Similarly, what
about images that are so small that they can fit into the 1-2° visual angle of the fovea and thus require
no eye movement to be seen clearly and recognized?
Two basic responses have been given here but before analyzing them, I would like to briefly combat
the extreme and unsatisfactory conclusion that the feature ring theory is 100% erroneous. The main
difficulty with assuming that all recognition is parallel, instantaneous and astructural is that it is not. For
example, if I am involved in a game where I must determine whether a given car is my car, and the car
is superficially identical to mine and moreover I will be electrocuted if I misjudge, then clearly my
recognition must and will involve something more structural than a glance.* And this is not an artificial,
pathological case. The world is (and was especially in less pampered times) filled with life and death
situations dependent on a recognition. This man I am drinking with appears to be a friend—he wears
* This "car game" is analyzed in more detail on P. 59 below.
47

our uniform and speaks our language—but perhaps he is my assassin. Shall I judge by a glance?
Having noted this problem with the pure parallel view, let us now consider the two ways parallel and
serial recognition have been reconciled.
a) Hebb: Hebb [18] was deeply influenced by the work of Senden [43] concerning congenitally
blind persons who were given sight during adulthood through removal of their cataracts. It was found
that these persons have counter-intuitive difficulty learning the skills of visual recognition. He cites one
striking example given by Miner [33]: "Miner's patient, described as exceptionally intelligent despite
her congenital cataract, two years after operation had learned to recognize only 4 or 5 faces and in daily
conferences with 2 persons for a month did not learn to recognize them by vision." (Hebb [18], P.105)
Hebb stresses that at-a-glance recognition of the type exhibited in tachistoscope experiments is only
developed after a long, arduous learning process which in the normal person occurs in infancy. Hebb's
essential idea of this process is as follows. When a congenitally blind person is given sight in adulthood,
he or she has tremendous difficulty recognizing something as simple as a triangle, and must resort to
techniques like counting corners. The slightest change in the set-up—different lighting or a different
backdrop—completely disrupts a previously skillful recognition. But with practice, the counting of
corners and so on becomes more and more rapid and smooth until the person is capable of recognizing
the triangle "at-a-glance."* Hebb believes this is achieved through the formation of what he calls
"assemblies," and gives the following illustrative example:
"Let us say an infant has already developed assemblies for lines of different slope in his visual field. He is now exposed visually to a triangular object fastened to the side of his crib, so he sees it over and over again from a particular angle. Looking at it excites three primary assemblies corresponding to the three sides. As these are excited together, a secondary assembly gradually develops, whose activity is perception of the object as a whole—but in that orientation only. If now he has a triangular block to play with, and sees it again and again from various angles, he will develop several secondary assemblies, for the perception of the triangle in its different orientations. Finally, taking this to its logical conclusion, when these various secondary assemblies are active together or in close sequence, a tertiary assembly is developed, whose activity is perception of the triangle as a triangle, regardless of its orientation." (Hebb [19], P. 472)
* Compare with the remarks on pp. 41-42 on how concrete concepts gradually take on the characteristics of images with practice.
48

Thus the final result is that the infant develops what we might call a disjunctive normal form (DNF)
detector for triangles. That is, primary and secondary assemblies are template matchers which respond
to static patterns on the retina—edges and triangles respectively. The secondary assemblies, which each
respond to a particular triangle on the retina (with fixed size, shape, position and orientation), are
connected to a large OR gate (the tertiary assembly) which responds when any one of its inputs
responds. Hebb's view has two basic problems. First, if the result of the learning process is a DNF
triangle detector, we would need a separate secondary assembly for each of the immense variety of
triangles which can be inscribed in the retina. Moreover, the detector would not seem to be very useful
in allowing us to differentiate between triangles, or seeing (interpreting) one triangle in various ways
(i.e. when calculating the sine of different angles in the same triangle).
Second, it seems, as Hebb points out, that tachistoscope recognition is error prone and limited.
Hence even if his hypothesis is correct, it must have an upper limit which he does not acknowledge (cf.
the car game, above and on P. 59 below). We cannot in general expect people to classify objects of high
complexity with any precision in a tachistoscope presentation. They might be able to tell you the object
was a polygon, but it is doubtful whether they could tell you it had exactly 27 sides, etc.
So we shall reject Hebb's theory of "assemblies," and provide an information-theoretic mechanism
which I will call the "Trademark Heuristic." Recall that Gale and Findlay [14] propose that each
possible fixation content has interpretations, and these local interpretations are integrated, via eye
movements, into larger structures which in turn constitute higher level interpretations. Now what
happens if, through experience, a certain fixation content is monopolized by a certain higher level
interpretation?
Then we have a local feature which serves as a unique marker for a higher level entity. For instance,
a sequined glove on one hand is a sort of trademark for Michael Jackson, and will belong to his feature
ring and few others. So if we by chance fixate on that glove in a tachistoscope presentation, it will give
us tremendous information—in the sense that it drastically cuts down our uncertainty about which
feature ring applies. And this in turn allows us to recognize Michael Jackson at-a-glance.
49

This account is consonant with the results of Gale and Findlay [14]. They found that, when a large
ambiguous figure was painted onto a subject's retina as an after-image using a flashgun (to eliminate the
effects of eye movements), the aspect seen depended on which part of the image was painted onto the
fovea. This suggests, as the Trademark Heuristic predicts, that the "gist" obtained from brief exposure
to a picture depends on the part of the picture fixated.
There are, however, two facts which escape the Trademark Heuristic:
i) Intraub [22] has demonstrated that encoding within a single fixation need not, under certain
circumstances, be an all-or-nothing detection phenomenon. The amount of information extracted from a
single fixation can vary depending on the length of the fixation, and the attention devoted to it (i.e. we
may decide how deeply to encode a certain fixation).
ii) Shifting of ambiguous figures and illusory length distortions still occur when an illusion is
stabilized on a subject's retina (Gale and Findlay [14], Coren [7]).
So let us consider a second approach to the Parallel vs. Serial problem:
b) Noton and Stark: Noton and Stark [36] propose that the usually overt eye movements are carried
out by the practiced adult as internal shifts of attention in the case of a small picture, and describe
experiments which support this view.
In the first type of experiment, subjects are presented with an array of designs, each small enough to
be apprehended in a single fixation, and asked to find a "target" design. Such experiments reveal that
the subject requires more time to recognize the target than to reject non-targets. This suggests that some
sort of sequential checking process is involved; i.e. the subject is not equipped with a parallel "detector"
which he sweeps over the array until it signals the presence of the target. Furthermore, when the
complexity of the target design is varied, target recognition time varies proportionally. This also runs
counter to the view that the subject develops an instantaneous, astructural detector for the target. Noton
and Stark also recount an experiment wherein a subject viewed a small drawing of a cube, and indicated
50

after randomly chosen intervals where he thought he was looking. At the same time, the subject's eye
movements were recorded. It was found that the subject's eye movements deviated very little from the
center of the drawing, whereas the points at which he felt he was looking were widely dispersed over
the figure. The authors regard this as evidence that attention can be and is internally directed onto parts
of a picture small enough to fit into a single fixation. Gale and Findlay [14] also postulate internal
attention mechanisms as allowing the shift between aspects of a retinally stabilized image. They write:
"The ability to alternate the perception of stabilized images is hypothesized here to be a function of the generally small size of the stimuli, such that attention can be moved about the stimulus without the need for eye movements. When large stabilized images have been employed and eye movements recorded then movements have been found despite their futility." (P. 148)
So Gale and Findlay maintain that the process underlying the shifting of ambiguous figures is
selective attention. Eye movements are an expression of this selectivity, but may not be necessary if the
viewed figure is small (and simple) enough. Our position on the Parallel vs. Serial Problem can thus be
summarized as follows. A large number of cases of recognition (like the car game (see P. 59 below) and
large pictures) require a serial process. Tachitoscopically presented images can be roughly classified
using the Trademark Heuristic, and more precisely defined through attentional operation on the
decaying sensory icon (Hochberg [20]). Small images and retinally stabilized images (which are
generally small) are handled through a serial process involving internal shifts of attention. So we shall
contend that single perceptual moments (i.e. attention fixations, with or without eye movements) can be
interpreted in parallel, but all other recognition is either overtly or covertly structural.
To accommodate the Noton and Stark theory, we could modify the feature ring so that its nodes are
interpretations of attention fixations, and its edges are labeled with either eye or attention movements.
This, however, would not affect the main tenets of the theory, so in the rest of this chapter we shall
simplify things by retaining the language of eye movements. The extension to attention fixations and
movements is just a reinstatement of the same process on a new plane, and shall be left implicit.
Now, having digested the Parallel vs. Serial Problem, let us bring up two more problems with feature
51

rings.
3. The Serial Recognition Problem
Noton and Stark's idea of the feature ring based recognition process has the following serious flaw.
Assuming that a person has a collection of feature rings in memory and is presented with an image, the
problem of recognition amounts to finding the feature ring which best fits the data. Clearly the person
cannot apply all the feature rings at one time since they are liable to specify conflicting eye movements.
On the other hand, applying them all in round-robin fashion would be computationally expensive and
contradictory to the known facts of human performance. Moreover, we cannot select the "right" feature
ring right off the bat, because if we could do that we, paradoxically, would not need the feature ring.* In
short, Noton and Stark's hypothesis that the feature ring "directs" the scanning and recognition process
becomes vague and impossible when multiple feature rings come into play.
4. The Termination Problem
The last problem with a feature ring is the fact that it is a general directed graph. That is, we usually
regard a recognition process as having a beginning and then an end where a definite judgment is made,
i .e. "That is a guitar." So do we break up the ring, and then write the recognition algorithm so that
every single link must be checked? That would bring us back to the deterministic feature ring model
which Noton and Stark saw as contradicting experiment.
These last two problems stem from the vagueness of the theory and so we shall attempt to
approximately resolve them below.
III. Clarification
The feature ring theory says that a person's mental model of something (i.e. a car, a tree, a friend
etc.) is a feature ring, i.e., a directed graph whose nodes are interpretations of fixation contents and
whose arcs are labeled with eye movements. So in some sense, we can think of a person's intellect as
* This paradox applies to any recognition scheme using conflicting serial procedures.
52

containing numerous feature rings, all named or labeled according to what they represent. Given a
picture, the task is similar to string matching in that we must find occurrences of the feature rings
(=strings) in the picture (=text). As has been noted above ("The Serial Recognition Problem," P. 55), we
can neither try "fitting" all the feature rings at once nor apply feature rings in round-robin fashion.
So how do we apply feature rings?
#1) Fact: In a single fixation, an observer determines the "gist" of a picture (Bierderman et. al.[2],
Intraub [22], Loftus [26]). This information is sketchy (Hebb [18]) and deficient regarding the
inter-relationships of objects in the scene (Bierderman et. al. [2], Farley [12]).
#2) Consensus: This "gist" aids in determining the destination of the next saccade (Bierderman et.
al.[2], Intraub [22], Loftus [26]). These phenomena can be understood in terms of the Trademark
Heuristic. That is, when we make our initial fixation on a picture, we interpret the fixation content.
There may be many interpretations or few, and these interpretations will only be part of certain feature
ring complexes. We can rule out the feature rings which do not contain the current interpretation, and
thus avoid wasting time trying to "fit" rings which will never fit due to their gross or local
physiognomy.
This gives us a partial answer to the Serial Recognition Problem: We pare down the set of feature
rings to be applied, using the interpretation or "gist" obtained at the initial fixation. But suppose the
original "gist" does not narrow the field down to a single possibility. Then what do we do?
#3) Fact: Fixations occur at "informative" details (Loftus [26], Mackworth and Morandi [30]).
After the initial fixation, we have a set of potentially applicable feature rings, and we desire to pare
down this set as quickly as possible. So we could use the probabilities associated with fixation content
interpretations (or a measure derived from them) to choose as our next saccade destination that which
most increased our certainty about which feature ring to apply—i.e., that yielding the most information
in the information-theoretic sense.*
So far this discussion amounts a fairly satisfactory answer to both the Serial Recognition and * Loftus [26] defines "informative": "An object in a picture is informative to the extent that it has a low conditional probability of being there given the rest of the picture and the subject's past history." (p. 503)
53

Termination Problems. There is no preset algorithm for recognition which runs through branchless
stages. Rather we start off with a field of possible interpretations and whittle down that field as quickly
as we can by conducting the most informative experiment possible at each saccade. When the field has
been narrowed to one possibility, recognition is complete. So the amount of effort and time involved in
a recognition varies depending on the information yielded by each fixation, and thus on the context.
Furthermore, we note that this version of the feature ring theory can account for the statistical doubts
regarding scan paths mentioned above (P. 48) since the feature rings do not enforce an exact, previously
ordered scanning path. The path is, so to speak, determined "on the run."
The recognition process just described illustrates, in germ form, the following ubiquitous and central
principle:
#4) Consensus: Perception is a complex, multi-form, interlaced process of bottom-up and top-down
control (Farley [12], Gale and Findlay [14], Hebb [18], Hochberg [20], Loftus [26], Minsky [35], Waltz
[50]).
This holds in the recognition process because the choice of saccade destination depends on the
obtained "gist" (bottom-up), and the interpretation probabilities and feature ring inter-relationships
(top-down). But from another angle, we can view the recognition process as bottom-up control which
terminates when an unequivocal interpretation has been reached. At that point the feature ring
associated with the interpretation takes over, and control shifts to the top-down mode. And yet even
within this feature ring guided top-down process, we may saccade to the most informative point (within
the feature ring), thus modulating the top-down with some bottom-up. This would check the
characteristic flaw of top-down control—riding roughshod over the facts—and also allow us to reject
our initial hypothesis as quickly as possible if it can in fact be rejected.
IV. Conclusion
In this chapter we have presented evidence (relating to dreams) that at least some memories
inter-relate momentary impressions and eye movements, thus suggesting that the planar image data
structure proposed theoretically in the previous chapter is psychologically realistic. Moreover, we have
54

seen how feature rings (planar images) can be used to explain visual ambiguity, and have thereby
clarified our idea of how images can manifest themselves in or direct perception (i.e. by controlling eye
movements). The feature ring theory also shows us how an image can be created from experience:
through a direct recording mechanism of the type hinted at by Penfield and Roberts [37] (the main
problem being how interpretations develop and differentiate; these issues are discussed in the following
chapter).
We also must point out some inadequacies. First, the feature ring theory deals only with eye (and
attention) movements, and neglects the treatment of head and body movements which any general
account of imagery would require. Second, and more important, the theory implicitly sanctions the view
that all memories are images. This is incorrect, because some memories are pure concepts and have no
eye movement components. Since the theory downplays pure concepts, it fails to tell us how to get from
images to concepts, and thus liberate our thinking from the tyranny of the concrete.
Still, feature rings have pointed out a key aspect of the dynamic behavior of imported images—that
they must come into play within a complex ebb-and-flow of bottom-up and top-down control. This
dynamism is the concern of the next chapter.
55

7. Hypotheses, Formation, Application To begin, let us consider an example (albeit rather far-fetched) which illustrates a major theme of
this chapter. Suppose a man plays the "car game" introduced in the previous chapter; that is, he is
presented with a car, and must determine whether it is his or not. The penalty for wrong judgment is
death. How would the man approach this problem? Assuming the penalty motivated him, he would
probably proceed to the car and inspect it, principally by examining defects which another person
would be unlikely to notice. For example, he might know that his car has a broken weld on the exhaust
pipe which he noticed once when the car was jacked up for an oil change. So he gets down under the
car with a flashlight and looks at the weld, finding that it is indeed broken. So this is a confirmation, but
there is a rusty wire around the pipe which seems unfamiliar. Had the wire been there before and
escaped his notice, or was it a discrepancy? He weighs this discrepancy according to the certainty of his
memory and decides to leave it as a nagging unsettled question. He tries a whole series of
experiments—checking for the creak in the door, the sticky point on the accelerator, the chain under the
seat—and each time is confirmed. So he is leaning toward the opinion that this is his car. But then he
notices the brand name on the tire. He does not remember what the brand name on his tire was, but his
tires were from California and definitely did not have Arabic markings like this one. Moreover, the man
who proposed the game looks vaguely Middle Eastern. A light is going on here, and he rechecks the
ashtray which he only examined cursorily before, thinking the cigarette butts were his. On closer
inspection he finds a cigarette which also bears Arabic markings. His working hypothesis now is that
the car was brought from somewhere in the Middle East and doctored to look and behave like his car.
He waits until the man falls asleep and searches his wallet. He finds suggestive evidence: a duty receipt
placing a car, with a serial number matching that of the car being inspected, in Malta two days earlier
when he was driving his car to South Carolina. This would seem to confirm his new hypothesis, but
nagging questions arise. Could the man have forged the document, and tampered with the serial number
and tires of his own car? Or maybe the serial number is that of his own car; he does not remember it.
The man seemed to fall asleep suspiciously easily. Is the new hypothesis just a carefully choreographed
red herring? And so on. The man proceeds like a detective, noting discrepancies and confirmations,
56

weighing their certitude, framing new hypotheses. Then once he has digested everything to his
satisfaction, he embarks on an intensive, multi-dimensional, conscious weighing process. He leans one
way, then another, until satisfaction builds to the point where it discharges itself in a judgment: "Yes, it
is my car."
This example is contrived, but it derives some merit from the fact that it not only constitutes a case
of structured, serial recognition (i.e. a typical recognition), but also obviously exemplifies the basic
paradigm of scientific reasoning. Let us see how this "Hypothesis Paradigm" might connect to the main
themes of this thesis.
1. Hume: As noted earlier, Hume saw the world as structured by a peculiar, orderly "coherence" which
the imagination exploits to create noumena. For instance, I may leave a fire burning in the hearth, and
find it a pile of smoldering embers when I return. So I am confronted with two disparate appearances,
and yet I view them not as entirely distinct things but as manifestations of the same underlying thing (i.e.
a noumenon). Clearly this unification cannot be attributed to similarity of appearance (Hume's
"constancy"), so Hume attributes it to what he calls "coherence." That is, if I have previously seen a fire
mutate into embers, I can unite the two disparate appearances by means of this connective experience.
Thus for Hume, the ability to predict transformations of an object's appearance is the essential
component of the world's coherence. Our world is coherent because it is a tight fabric woven together
by bonds of predictability, and this, Hume contends, is in part what makes us attribute continued
existence to objects.
We can see how this might work with two examples. First, suppose that we have a coin, hidden in a
small ring box, which we check up on periodically. Then if the coin is there on two successive
inspections (involving looking, weighing, monitoring by a device etc.), we assume it was there between
the inspections. We feel certain that the coin did not blink out of existence while our back was turned,
for if coins were always disappearing like this, then surely someone somewhere would have caught one
doing so, either by accident or stealth. But then again, cannot we imagine an empirically inaccessible
demon or even mindless necessary mechanism which blinks out the coin as soon as the coast is clear
57

and rematerializes it when someone looks? Not really, for the kink in this hypothesis is the relationship
between what is "visible" (thus existing) and what is "invisible" (thus non-existing). For instance,
consider the core of the earth. If at some moment no one is monitoring or even cares about its existence
then by hypothesis it would disappear, causing a massive cataclysmic collapse of the earth's surface.
We might somehow explain the non-occurrence of this collapse by postulating a mechanism which
makes the earth's surface behave as though the core were there, even when it is not. But here we begin
to tempt Occam's razor*, and one asks: Why not let the core itself be this mechanism?
Objects do not exist in a vacuum; they are inter-connected in a web of predictable cause and effect—
i.e. they are coherent. If I enter a room and find the couch frayed, this is evidence that the cat was
existing while I did not perceive her. If I tip an hour-glass and leave it in a room where no one is
perceiving or monitoring it, I return and find it has marked time exactly as it should in my absence. If it
blinked out of existence when I turned my back, what mechanism calculated the proper distribution of
sand for reinstatement? If I am a child holding a block I can still feel it when I close my eyes, thus
showing that things can exist independently of my vision of them. Likewise, I can release the block
while viewing it, demonstrating that it can exist independently of my touch. In short, objects leave
traces of their continued existence and the most parsimonious way to account for these traces is to
complete the partial coherence by positing noumena. Another example supports Hume's line of thought.
Consider things like ghosts which are widely believed to be unreal products of the imagination. It is not
the wispiness of ghosts or the fact that they are supposed to be the souls of the dead which makes them
unreal. It is the fact that they violate the laws of coherence. For if ghosts left traces of themselves, and
there was some rationale behind their appearance so they could be conjured up in a scientific laboratory
in repeatable experiments, then they would undoubtedly be accepted as actual mind-independent
phenomena, regardless of their immateriality. So how does imagination exploit this coherence to create
noumena? It does so by creating images, which, as we have seen are complexes of interpretations held
together by correlates of movement. But more than that, each image is already a hypothesis because it is
* An axiom proposed by Occam during the backlash against medieval scholasticism: "Do not multiple explanatory entities beyond necessity."
58

comprised of experiments which predict how the world will behave. For example, in a feature ring
(planar image), the basic unit of information is: "If I am looking at x and move my eyes in direction y I
will see z." Similarly, in the car game the man exploits the spatial image of his car to classify a
particular experience under a noumenon. For instance, he knows: "If I am sitting in my front seat, and I
bend over and look under the seat, I will see a chain."
So in short we are claiming this: The world is a coherent web of predictable cause and effect
relationships. A child is born into this world and begins to form images—structures recording how the
world has been, and thus predicting how it will be, in terms of the child's own perceptions and actions.
But these structures continually collapse under the weight of their discrepancies and reform on ever
higher, more adaptive planes. Finally to achieve optimal consistency and prediction, these images
(hypotheses) must develop to the point where objects are posited as existing independently of the mind.
Furthermore (in line with our earlier analyses) the ability to conjure up images of absent objects is a key
impetus behind the formation of this objective hypothesis.
2. Piaget: The above arguments suggest that coherence is a key factor in the development of notions of
objects or noumena. But we would like empirical evidence as well, and for this we turn to Piaget [38].
This renowned child psychologist demonstrated (to the lasting satisfaction of the field, as we noted
earlier) that children are not born with and must acquire notions of objects. Let us briefly outline the
early stages of object concept development revealed by Piaget's research.
STAGES 1 and 2 (about 0 to 4 months): The child recognizes what Piaget calls "pictures"—i.e.
momentary impressions. The child learns to track a moving object with its eyes, and after it disappears
will stare at or look back to the point of disappearance as though this action would make the object
appear.
STAGE 3 (about 4 to 8 months): The child can now predict, to some extent, the itinerary of a moving
object which disappears. For instance, if a toy is dropped on the floor, the child will look to the floor for
59

it. However, this behavior is still in some sense a dumb reflex, for if Piaget drops the object behind his
own back, the child will search for it in his lap (P. 17). Furthermore, if the initial movement of the
object is not seen or the look to the floor is unsuccessful, the child will stare at the hand which dropped
it as thought it might any moment appear there. The child is also capable of uncovering an object which
has been partially hidden by a screen (such as a blanket) but completely forgets and makes no attempt to
uncover objects which are fully hidden, even though she has the motor skills to do so. Consider the
following observation from this stage:
"I then offer her the doll which is crying. Jacqueline laughs. I hide it behind the fold in the sheet; she whimpers. I make the doll cry; no search. I offer it to her again and put a handkerchief around it; no reaction. I make the doll cry in the handkerchief; nothing." (P. 40)
STAGE 4 (about 8 to 12 months): The child will now lift up or brush aside a screen to retrieve an
object which has been hidden behind it. The object, however, is still not completely constituted. For
firstly, if an object is hidden under blanket A and the child successfully recovers it a few times, and then
the object is hidden under blanket B (while the child is watching intently), the child will search for it
under A. This reaction can be extreme. For example, Piaget hides a toy parrot in his lap by covering it
with his hand, and the child removes the hand to obtain it a few times. Then he:
"... [places] it in plain view on the edge of a table, 50 centimeters away. At the first attempt Jacqueline raises my hand and obviously searches under it, always watching the parrot on the table." (P. 55)
There are also residual reactions during this period. For instance, if Piaget removes a doll hanging over
the child's hammock and hides it behind his back, she will look behind him. But if this look is
unsuccessful, she will return her gaze to the place where the doll previously hung. (P. 62)
STAGE 5 (about 12 to 18 months): The principal hallmark of this period is that objects are searched
for where they were last seen hidden. That is, the child is unable to account for what Piaget calls
60

"invisible displacements." For example, if a toy is hidden in a box, and the box is covered with a blanket
under which the toy is removed, and then the box is withdrawn from the blanket, the child will search
the box and completely neglect the blanket. The child believes that the object is somehow linked with
the screen into which he last saw it disappear.
STAGE 6 (about 18 to 24 months): The child is now capable of finding the object after invisible
displacements, and has some sense of the object's conservation, i.e. of the fact that it must be
somewhere. Yet the following bizarre reactions from stages 5, 6 and beyond clearly indicate the
lingering discrepancies between the object concepts of adults and children:*
"At 1;3 (9) Lucienne is in the garden with her mother. Then I arrive; she sees me come, smiles at me, therefore obviously recognizes me (I am at a distance of about 1 meter 50). Her mother then asks her: "Where is papa?" Curiously enough, Lucienne immediately turns toward the window of my office where she is accustomed to seeing me and points in that direction. A moment later we repeat the experiment; she has just seen me 1 meter away from her, yet, when her mother pronounces my name, Lucienne again turns toward my office. Here it may be seen that if I do not represent two archetypes to her, at least I give rise to two distinct behavior patterns not synthesized nor exclusive of one another but merely juxtaposed: "papa at his window" and "papa in the garden." At 1;6 (7) Lucienne is with Jacqueline who has just spent a week in bed in a separate room and has gotten up today. Lucienne speaks to her, plays with her, etc., but this does not prevent her, a moment later, from climbing the stairs which lead to Jacqueline's empty bed and laughing before entering the room as she does everyday; therefore she certainly expects to find Jacqueline in bed and looks surprised at her own mistake. At 2;4 (3) Lucienne, hearing a noise in my office, says to me (we are together in the garden): "That is papa up there." Finally, at 3;5 (0) after seeing her godfather off in an automobile, Lucienne comes back into the house and goes straight to the room in which he slept, saying, "I want to see if godfather has left." She enters alone and says to herself, "Yes, he has gone."" (P. 64-65)
Let us take stock of Piaget's results in our context. First we note that each of Piaget's stages is
characterized by a certain hypothesis of the object's location, and an associated motor reaction for
obtaining the object. These hypotheses and reactions are summed up in the following table:
* Note: "1;3 (9)" means "1 year, 3 months, 9 days."
61
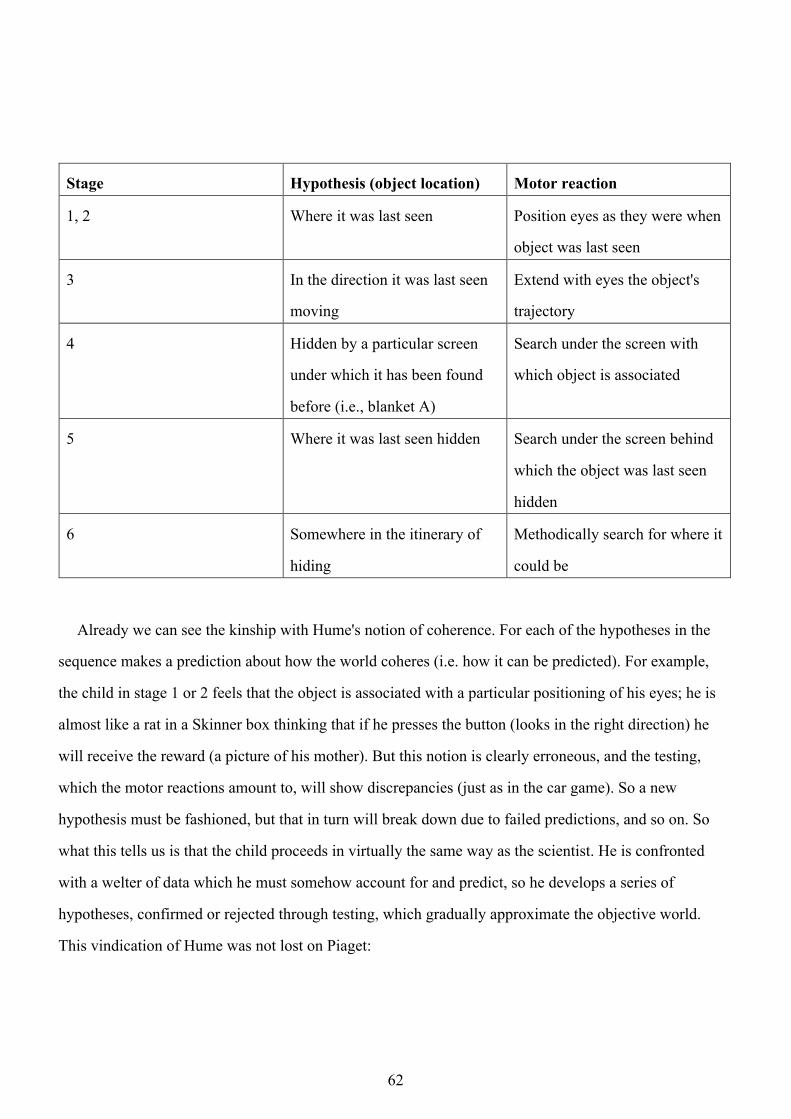
Stage Hypothesis (object location) Motor reaction
1, 2 Where it was last seen Position eyes as they were when
object was last seen
3 In the direction it was last seen
moving
Extend with eyes the object's
trajectory
4 Hidden by a particular screen
under which it has been found
before (i.e., blanket A)
Search under the screen with
which object is associated
5 Where it was last seen hidden Search under the screen behind
which the object was last seen
hidden
6 Somewhere in the itinerary of
hiding
Methodically search for where it
could be
Already we can see the kinship with Hume's notion of coherence. For each of the hypotheses in the
sequence makes a prediction about how the world coheres (i.e. how it can be predicted). For example,
the child in stage 1 or 2 feels that the object is associated with a particular positioning of his eyes; he is
almost like a rat in a Skinner box thinking that if he presses the button (looks in the right direction) he
will receive the reward (a picture of his mother). But this notion is clearly erroneous, and the testing,
which the motor reactions amount to, will show discrepancies (just as in the car game). So a new
hypothesis must be fashioned, but that in turn will break down due to failed predictions, and so on. So
what this tells us is that the child proceeds in virtually the same way as the scientist. He is confronted
with a welter of data which he must somehow account for and predict, so he develops a series of
hypotheses, confirmed or rejected through testing, which gradually approximate the objective world.
This vindication of Hume was not lost on Piaget:
62

"...three criteria seem to us to contribute to the definition of the object peculiar to the sciences: in the first place, every objective phenomenon permits anticipation, in contrast to other phenomenon whose advent, fortuitous and contrary to all anticipation, permits the hypothesis of a subjective origin. But, as subjective phenomena also can give rise to anticipation (for example, the "illusions of the senses") and moreover as unexpected events are sometimes those which mark the failure of an erroneous interpretation and thus entail progress in objectivity, a second condition must be added to the first: a phenomenon is the more objective the more it lends itself, not only to anticipation, but also to distinct experiments whose results are in accordance with it. But that is still not enough, for certain subjective qualities may be linked with constant physical characteristics, as qualitative colors with luminous waves. In this case, only a deduction of the totality succeeds in dissociating the subjective from the objective: only that phenomenon constitutes a real object which is connected in an intelligible way with the totality of a spatio-temporal and causal system (for example, luminous waves constitute objects because they have a physical explanation, whereas quality is dissociated from the objective system). These three methods are found to be the very same which the little child uses in his effort to form an objective world." (P. 97-98)
But let us notice more. A striking feature of the progression delineated by Piaget is that the
original notions of objects are given in terms of relations between movements and perceptions—
i.e., they are imagistic in the sense of the term we have developed. Indeed, Piaget calls the first 18
months of life the "sensori-motor period" (see Beard [1]) because the dominant trend is the
development of "sensori-motor schema," i.e., integrations of perception and movement into
complex wholes, i.e., images. Thus Piaget's work suggests, as we claimed earlier, that images are
the cradle of concepts.
3. Sartre: We have previously discussed the phenomenon of imported imagination, wherein, in
Wittgenstein's phrase, "an image comes into contact with a visual impression." How is this
accomplished? For we are up against the classic problem of memory which I described in the
previous chapter (the Serial Recognition Problem, see P. 55). That is, I have many memory
images, and I must select one which applies to the current experience. But I cannot compare the
current experience with all my images in parallel because each image unfolds differently in time.
Moreover, serial comparison would take an unreasonable amount of time. And I cannot magically
select the "right" image because that is precisely what I am trying to explain.
Sartre addresses this problem by describing how his own image was evoked while
63

watching the impressionist Franconay mimic the French singer Maurice Chevalier. He
suggest that the retrieval and application of images is guided by what he calls "signs."
These signs are what we earlier (in Chapter 6 "Feature Rings", P. 44) called trademarks.
That is, they are local image structures which are monopolized by larger image structures in
which they are subsumed. A certain hat, a sequined glove, a mannerism—these are all signs.
Sartre illustrates how these signs can evoke and guide an image:
"The artist appears. She wears a straw hat; she protrudes the lower lip, she bends her head forward. I cease to perceive, I read, that is, I make a significant synthesis. The straw hat is at first a simple sign, just as the cap and the silk kerchief of the real singer are signs that he is about to sing an apache song. That is to say, that at first I do not see the hat of Chevalier through the straw hat, but that the hat of the mimic refers to Chevalier, as the cap refers to the "apache sphere." To decipher the signs is to produce the concept "Chevalier." At the same time I am making the judgment: "she is imitating Chevalier." With this judgment the structure of consciousness is transformed. The theme, now, is Chevalier. By its central intention, the consciousness is imaginative, it is a question of realizing my knowledge in the intuitive material furnished me." (Sartre [42], P.36-37)
First we note that watching an impressionist is clearly a case of visual ambiguity or
"seeing-as." As Sartre puts it: "I am always free to see Maurice Chevalier as an image, or a
small woman who is making faces." (P. 36) Thus we might expect to find affinities with the
feature ring theory of visual ambiguity, and indeed we do. Sartre writes:
"An imitation is already a studied model, a simplified representation. It is into these simplified representations that consciousness wants to slip an imaginative intuition. Let us add that these very bare simplified representations—so bare, so abstract that they can be immediately read as signs—are engulfed in a mass of details which seem to oppose this intuition. How is Maurice Chevalier to be found in these fat painted cheeks, that black hair, that feminine body, those female clothes?" (P. 37)
Sartre answers this last question by noting that the discrepancies are neglected and
treated as a ground upon which the confirmations form a figure:
"That black hair we did not notice as being black; that body we did not perceive to be the body of a woman, we did not see those prominent curves... They have a sensible
64

opaqueness; otherwise they are but a setting." (P. 38)
This suggests, as the feature ring theory of ambiguity predicts, that what we see in
Franconay depends greatly on where we look at Franconay. The aspect of the small woman
is evoked by her hair, clothes and physique; the aspect of Maurice Chevalier is evoked by
the straw hat, the protrusion of the lip and the bend of her head.
We can also perceive affinities here with the car game (i.e., serial recognition, see P.
59): Franconay is the car to be inspected, and Maurice Chevalier is the man's own car. In
both cases, a hypothesis is formed on the basis of signs. The hat is a sign for Chevalier, and
the chain under the seat is a sign for the man's own car. These signs have
information-theoretic significance, as suggested in the previous chapter. That is,
P(Chevalier | hat) and P(my car | chain) are high, while P(another person | hat) and
P(another car | chain) are low, so that the hat and chain are highly-informative features that
are effective in reducing our uncertainty about which image applies. Once we have an
image, we have what amounts to a hypothesis (as we have seen) because the image is a
conglomeration of experiments. We can maintain the "seeing-as" experience by homing in
on those experiments which are confirmed, and avoiding those which reveal discrepancies.
But it may be, sometimes, that the experimentation guided by a certain image reveals
discrepancies which are in turn signs for a new image. In watching Franconay, this occurs
when we fixate on her hair. This is a violation of a prediction of the Chevalier image, but at
the same time it is a positive sign for Franconay and may lead to an evocation of her image
which will then guide the perception. Likewise, in the car game, the Arabic markings on the
tire not only disconfirm one hypothesis, they are a sign for another. And this new
hypothesis immediately reaches out and seizes the "Middle Eastern" man, reinterpreting
him and endowing him with meaning in a higher complex.
I believe I have now shown, to a reasonable extent, the ubiquity of the Hypothesis
Paradigm in human mentation. We have found evidence of it in recognition (the car game),
and have shown in the previous chapter that there is good reason to believe that the vast
65

majority of recognitions are sequential and governed by this paradigm. We have seen how
the paradigm may underly our notions of noumena and objectivity (Hume). Furthermore,
we have established a sound connection between hypotheses and images, and shown that
imagination is a prerequisite for having ideas of noumena (Chapter 3-4). We have seen the
Hypothesis Paradigm in operation in the development of the child's concepts of objects
(Piaget), and in the highest realms of scientific thought. And we have uncovered the
paradigm in imported imagination and visual ambiguity (Sartre), which in turn are closely
linked with recognition.
Even taking all this in the utmost sobriety, one is tempted to conclude that here we have
rooted out a basic, general control mechanism of thought. So let us cast the paradigm in
general form. First we have a set of hypotheses which can be applied to experience. Each of
these hypotheses contains experiments which predict how the world will behave, and these
experiments can reveal either confirmations or discrepancies. But there is more to the
picture than this, because hypotheses are not static; they rise and fall, congeal and
disintegrate. Reflecting what we have stressed about schema, there are two fundamental
questions we can ask about this dynamism:
1) Formation: How is an original, prototypical hypothesis formed or toppled through
moment-by-moment experience in time?
2) Application: How do existing hypotheses get applied to and rejected by current
moment-by-moment experience in time?
I shall call these two questions, respectively, the formation and application problems.
Now my main concern in this thesis is imagination, and the solutions I shall essay for these
two problems shall be couched in those terms. But this does not constitute a claim that
hypotheses and images are the same thing. What I do claim is that images are a form of
hypothesis, and that there may be developmental and functional continuities between
66

images and less concrete conceptual hypotheses. So with that caveat, let us proceed.
Formation: Images are structures of interpretations held together by correlates of
movement, and we have seen that the interpretation-movement-interpretation bond can be
regarded as a prediction or experiment, thus justifying the comparison with hypotheses. So
the formation problem amounts to this: How is an image formed from experience in time?
The Noton and Stark [36] theory of feature-rings furnishes a clue. In that theory, an image
is a directed graph whose nodes are the content of fixations and whose edges are labeled
with eye movements. So there is a clear algorithm for forming such images: Fixate on a part
of a picture, create a node labeled with what you see, extend an edge from that node to a
new node, label the edge with an eye movement, move your eyes according to that eye
movement, fill in the new node with what you see etc. This process is illustrated in the
following diagram:
Noton and Stark Image Formation
This is an easy and clean learning technique with two nice features. First, it is obviously
related to the Penfield and Roberts [37] results on cinematographic recording of memory,
67

and second, since the bonding is subjective, we could potentially use this technique to
explain syncretism in the child. The problem, however, is that the nodes of the feature ring
are iconic copies of fixation content rather than interpretations. So the Noton and Stark
theory cannot account for visual ambiguity, or even the recognition of the same figure of a
different color (such as a negative of the duck-rabbit). To resolve this problem, we
proposed, following Gale and Findlay [14], that the nodes of a feature ring (i.e. image) are
interpretations rather than iconic copies. But this would seem to destroy the utility of the
Noton and Stark formation principle, for we cannot record interpretations. Interpretations
are not a part of the sense data which can be recorded; they must come from an internal
source.
We can begin to extricate ourselves from this problem by considering learning in the
following light. Suppose we take a simple animal, such as a rat, and distinguish between the
"input" impressions it can receive, and the momentary "output" actions it can perform. Also
suppose that we use capital letters to designate the inputs and small letters to designate the
outputs. Then we can use alternating sequences of capital and small letters to describe the
rat's behavior in terms of what it is seeing and doing. (Note that these descriptions are
subjective, i.e. from the rat's point of view.)
We can interpret simple operant conditioning in this format. For example, imagine a rat
in a Skinner box seeing something and moving, seeing something and moving etc. This
input-output chain continues until the rat accidentally hits the button and a pellet of food
drops out. So we infer that the link between the stimulus of seeing the button and the action
of pressing it is strengthened. If we let B = sight of button, p = action of pressing button and
F = food (which is reinforcing), we can say, in our notational framework, that the
occurrence of the sequence BpF should lead the animal to do p when seeing B.
But what does the animal do in the following situation (where E represents electrical
shock)?:
Trial 1:BpF, Trial 2: BpE, Trial 3: BpF, Trial 4: BpE etc.
68

If the animal uses standard stimulus-response conditioning to learn in these
circumstances, it will go into an oscillatory fit, for after Trial 1 (BpF), p is strengthened,
just in time for the animal to be punished on the next trial and vice versa.
This alternation of reward and punishment might be just a sadistic experiment by a crazy
professor, but it can be much more interesting than that. For suppose we change the rat's
box so that there are identical buttons at either end; call them L and R. Both buttons have
food dispensers, but feed is only delivered from R, and then only in the case that L has been
pressed first. So, letting N = no food, we may imagine the rat meandering around the cage
and experiencing the following sequence:
...RpN...LpN...RpF...RpN...RpN...RpN...LpN...RpF...RpN...RpN...LpN...LpN...LpN...
If we realize that L and R look identical from the rat's perspective, we see that the
above alternating sequence has nothing to do with sadism. The environment is trying to say:
"Pushing R is partly right and partly wrong; there's more to it!"
Now the conditioned response is interesting from the standpoint of image formation,
because it is the germ of an image; images are, in a broad sense, networks of
stimulus-movement-stimulus bonds. Furthermore, the conditioned response is a hypothesis
because it makes a prediction about the world which can fail or succeed. The alternating
sequences we have described are a case in point; the response is alternately confirmed and
disconfirmed. And Piaget, among others, has suggested that disconfirmation is the engine
underlying learning.
So let us see how these ideas might be adapted to generalize the Noton and Stark image
formation process. First of all, in that process, fixation-movement-fixation bonds are always
derived from actual experience, so the recorded relationship must have held at least once.
Therefore, we can expect that many failed predictions will be of the on-again-off-again,
alternating variety indicated above. And any such alternating discrepancy will wreak havoc
69

with the Noton and Stark recording process.
For the predictive bonds then become diffuse and probabilistic rather than certain. This
situation cannot be resolved by attaching probability weights to the arcs of the feature ring.
Because then, firstly, deciding whether a result is a discrepancy or confirmation becomes a
slippery, hard to decide matter. If P(AbC)=0.5 and P(AbD)=0.5, and we obtain AbC in
experience, is that a confirmation or a discrepancy? And secondly, simply recording
probabilities will not promote structural understanding. For consider the rat in the box with
two buttons which we spoke of earlier. Then letting B = sight of button (L or R, they look
the same), the rat may compute probabilities like P(BpF)=l/20 and P(BpN)=19/20. These
probabilities obviously give the rat no structural understanding whatsoever; they make the
rat treat the situation like a slot machine, rather than what it really is—a vending machine. •
So how do we handle alternating discrepancies? To my knowledge no one has offered a
solution of this issue, so I shall here make a sketchy, partial and admittedly speculative
attempt. I believe, like Kant, that the human mental process tacitly assumes that the world is
deterministic—i.e. we are extremely inclined to attribute every effect to a cause. Thus,
when we get an alternating sequence, say AbC...AbD...AbC...AbD etc., we believe that
there is something in the context which is causing the non-determinism.* For example, if
half the time I sit on a chair and it squeaks, and the other half of the time it does not, I
attribute the squeak to some cause.
Perhaps it is the way I am sitting, or the humidity, or someone is switching the chairs on
me and so on. My contention is that this same process occurs in the child's formation of
images. The child begins by recording via the Noton and Stark scheme, but as soon as an
alternating discrepancy occurs (say AbC, AbD), the child splits the iconic A into two
interpretations A1 and A2. These interpretations are such that both can be evoked by the
sensory impression of A, and furthermore the child forms two new deterministic links
(A1bC and A2bD) from the old non-deterministic links (AbC and AbD). So the new
* This, of course, is a variant of the Principle of Sufficient Reason.
70

representation says that there are two different A's, one which leads by b to C and one
which leads by b to D. Now when the child obtains, say, XxA, both A1 and A2 are evoked.
So the child can take move b, and if, say, C is obtained, the child interprets A as A1 and
builds a link XxA1.
To take a concrete example, suppose that A = sight of an eye, b = eye movement to the
mouth, C = sight of a moustache and D = sight of no moustache. Then the child may obtain
the alternating sequence AbC, AbD when alternately viewing its mother and father. So A
will differentiate into two interpretations: A1 = dad's eye, and A2 = mom's eye. In this way
the child can maintain the predictive power of his images. For once the father image has
been applied, the child knows that AbC, even though father and mother's eyes may be very
similar.
I readily admit that this idea, which I call the splitting principle, is only an indication
and could undoubtedly benefit from a more rigorous empirical and formal treatment. But it
is an answer (at least a partial one) to the image formation problem which not only accords
with our other analyses, but also is amenable to mathematical methods and computer
implementation.
Application: Recall that the application problem concerns how images are evoked and
dismissed by moment-by-moment experience in time. We have already encountered this
problem to some extent in our discussion of imported imagination and feature rings. For
example, in the car game or Sartre's example of the impressionist, we saw that an image
could "invade" or "come alive in" the present perception. Similarly, the feature ring theory
states that the visual exploration of an object is directed by a feature ring recorded when the
object was previously encountered. What we are asking, then, is how an applicable image is
selected, applied and dismissed when it loses its applicability.
Two paradoxes make this problem difficult. One, which we have mentioned earlier (the
Serial Recognition Problem, 6.II.3, P. 55), is that the applicability of a memory image
71

cannot be determined until the image is applied, so we cannot select an applicable image
prior to the application process. Applicable images must be selected "on the run," while the
application is in progress.
The second paradox (which I shall call the "Part-Whole Paradox"*) derives from the following
situation: The currently applied image determines the perception, and the current perception
determines the applied image. So we have a sort of chicken-egg relationship between top-down and
bottom-up control.
This paradoxical relationship is essentially the same as that obtaining between the
individual and society. For there too the individual both determines and is determined by
the society.† So let us examine for a moment the structure of control within human societies,
and see whether we can, by analogy, learn something useful.
Perhaps the most obvious feature of control in human societies is its free-flowing
malleability, and the myriad forms it can assume. This is reflected in the plethora of terms
for human governmental structures: dictatorship, oligarchy, democracy, feudalism, anarchy,
representative democracy, parliamentary systems etc. But even these terms are
impoverished when one considers the baroque tableau of actual and potential control
relationships. For example, within a democracy there may be top-down hierarchies (armies,
corporations, churches), old-boy networks, executive orders, policy-setting bureaus,
informal pecking orders (i.e. in academia) and so on.
Furthermore, these structures are in a constant state of flux along two different
dimensions. First of all, the actual structure may change. For example, an unchallenged
dictator may grow senile and make increasingly grave errors, thus prompting a crisis of
confidence and coup by coalition. Secondly, the control regime within an existing structure
* I have taken this term from Mackay [29] who uses it to refer to the closely related paradox wherein context determines perception and vice versa. † In fact, Part-Whole Paradoxes of this type occur quite naturally in a variety of guises, and constitute, I believe, the central problem of top-down/bottom-up control. Surely these paradoxes deserve a much more thorough formal analysis than I shall give here.
72

may ebb and flow due to external circumstance. For example, an army platoon commander
may be making autonomous decisions in the field when his unit finds critical enemy maps
which he relays to his superior. These flow all the way back to supreme command, where a
completely different strategy is determined and passed back down the chain, resulting in a
new top down order to the platoon commander.
This flexibility and flux carries over into the domain of images. As Waltz [50] writes:
"A few perceptual clues may suffice for me to "see" that my wife is in the room of our house where I expect to find her. "Seeing" in this case involves a relatively large amount of top-down image construction with relatively little bottom-up processing. On the other hand, a task such as deciding whether I have cleaned all the food off the pot I am washing involves a much larger portion of bottom-up processing." (P. 569)
In other words, the proportions of bottom-up and top-down control in perception are not fixed
beforehand by a rigid regime; the control structure actually mutates through a wide space of possible
forms. This phenomenon is also apparent in the car game. If I go outside in the morning and see my car
where I left it, I recognize it at-a-glance through top-down expectation. But in the car game, I must pay
attention to the object so my perception is more data-driven or bottom-up. Still, as we saw in the car
game, bottom-up control may suggest a new hypothesis which results in a new top-down strategy
(shades of the platoon commander).
What these observations indicate is that images are not embedded in a fixed control regime; that is,
there is not an "executive algorithm" which, for instance, enforces a fixed schedule of bottom-up
control followed by top-down control. Rather, the images themselves should be the loci of control, each
capable of passing information up, receiving information from below, directing subordinates and
receiving direction from superiors.*
* This is an example of Vygotsky's [49] "analysis into units," wherein a complex multiform system is analyzed by breaking it into the smallest parts retaining the basic properties of the whole. This contrasts with what Vigotsky calls "analysis into elements," which in this case would involve splitting bottom-up and top-down control and trying to understand them in isolation. (See Vygotsky [49], P. 3-5.)
73

So we are maintaining, like Kant, that images are both active and passive. This is not implausible, for
as Casey [5] points out, free-state imagining has both spontaneous and controlled aspects.
On the one hand, images and sequences of images often seem to crop up and run their course
autonomously; and on the other hand, we often dominate our images and force them to conform to our will.
Likewise, when viewing an ambiguous figure like the Necker cube, a certain aspect may autonomously
crop up and defy our attempts to change it. or we may be able to bend the images to our will and shift
between aspects effortlessly.
So assuming that an image is a locus of control, both active and passive, I would like to give a
schematic, but I feel basically correct, account of the image application process which steers clear of the
Serial Recognition and Part-Whole paradoxes.
First of all, I propose that images congeal, through the formation process outlined above, into
fairly distinct units. This occurs because the bonds of predictability which hold the image together
must give way beyond a certain point. For instance, when an infant is confronted with his mother's
face, he may originally integrate the white wall behind her into his image through syncretism. But
this subjective bond will eventually disintegrate as the child begins to move and sees his mother
before different backdrops. So the child’s image of his mother's face will gradually dissociate from
the backdrop and form a local zone of predictability (i.e., an image).
I propose further (although I did not discuss this contingency in the section on formation) that these
images for local zones of predictability are each associated with a higher level interpretation (which I shall
call the image1s "label"), and the image as a whole is this label combined with the image's main body. In
this way structures of images can form recursive hierarchies. That is, an image is a structure of
interpretations held together by correlates of movement and is itself an interpretation, so the image can
have component images and can be part of larger images. This structure is illustrated on the following page.
74
75

I view the above hierarchy as essentially like the organization chart of an army, through which
bottom-up and top-down control can ebb and flow. This flux is represented by the three states an image in
this hierarchy can assume during the application process: off, on or active. When off, the image plays no
role in the perception; when on, the image has been evoked by information from below; and when active,
the image directs the perception by sequentially activating its subimages.
The application process is recursive, involving similar steps for each level of images. Here I shall
present only the first two steps; higher level steps can be extrapolated.
STEP 1: Suppose a person takes in an impression i1. This impression is matched in parallel against a
store of previously recorded impressions. The matching stored impression is associated in memory with a
number of atomic interpretations. Each of these atomic interpretations has a probability which has been
computed through experience. All things being equal, the interpretation with the highest probability (call it
a1) is selected. Now a1 may occur in only a single 1st level image. If so, that image (call it I1) is the only
one which applies, and we proceed to STEP 2. If not, then a1 is turned on in all the 1st level images in
which it occurs. At this point, the applicable image is uncertain, so the 1st level images containing a1
compete to determine the next movement. That movement is chosen which yields the most information, i.e.,
that which can optimally pare down the 1st order candidates through discrepancies. Call the selected
movement m1. m1 is executed yielding a new impression i2. At the same time, the arc labeled m1 is
followed in each 1st level image containing a1. This will yield a set of interpretations, one for each image
containing a1. i2 will not be able to be interpreted according to some of the members of this set, and the
associated 1st level images will be eliminated through discrepancies. The remaining 1st level candidates
are pared down, by iterating the above process, until only one 1st level image is left. Call this image I1.
STEP 2: At this point we have determined the applicable 1st level image I1. If there are no 2nd level
images, then we activate I1 and it begins to direct and interpret the perception. If there are 2nd level images,
turn I1 on. Now the label for I1 may occur in only one 2nd level image, I2. If so, then we have found the
2nd level image which applies. If there are no 3rd level images, then I2 is activated and directs the
perception. If there are 3rd level images, then we proceed to STEP 3 etc. Now if I1 occurs in multiple
76

images at the 2nd level, then the 2nd level image which applies is uncertain. So the 2nd level images must
compete to determine the 2nd level movement. That movement is chosen which maximizes information;
call it m2. m2 is executed, yielding a new impression i3. This input of i3 will initiate a new cycle of STEP 1
processing which yields the next applicable 1st level image, call it J1. Now the label of J1 is compared
against the results of m2 in all the candidate 2nd level images. This results in the paring down of the
candidates through discrepancies, and the 2nd level process continues until we have found a 2nd level
image which applies. Then we proceed to STEP 3 etc.
STEPS like the above are recursively iterated up the image hierarchy until the applicable image at the
highest level has been obtained. That image is then activated, and it begins to direct the perception starting
from its subimage under which the current experience falls. A high-level movement is executed to the most
informative point in the highest level image, yielding a new subimage. That subimage is then activated,
and the activation recursively descends down the hierarchy until atomic interpretations are applied to
incoming impressions.
However, if during this recursive descent of activation a discrepancy occurs, the image subsuming the
discrepancy will fail (i.e. shift from active to off), and another interpretation may be activated, causing the
bottom-up process to initiate again.
Obviously the above is only a rough sketch, but even so the underlying principle is quite conceptually
complex. To do justice to this complexity would require a thesis in itself, so here we will rest content with
pointing out two features of this control scheme which are relevant in our context.
i) Visual ambiguity: The system explains two important facets of visual ambiguity—the shifting and
mutual exclusion of interpretations. Shifting occurs when an image fails during the top-down activation
process, and the interpretation that caused the discrepancy, and thus failure, initiates a new episode of
bottom-up activity. Two interpretations must be mutually exclusive because an image can only interpret
the perception when it is active, and the rules of the algorithm ensure that an image never becomes active
until all its competitors have been eliminated.
ii) Malleability: The system accounts for the fact that different perceptions can involve varying
77

proportions of bottom-up and top-down control. When the system is confronted with an unfamiliar
situation or a situation where expectations are constantly being violated, bottom-up processing will
dominate. On the other hand, when the system is in a situation which has been classified under a
high-level image (i.e. like a man in his own house), many interpretations will be readily given by
top-down expectations.
This concludes my description of how images are applied. I am in no way prepared to claim that the
above process is psychologically accurate or even remotely close to being implementable. What I do claim
is that I am in the right ballpark and something like this must be going on during image application. My
reasons for believing this are as follows. First, there is wide-spread consensus that perception is a
multi-form process of interlaced bottom-up and top-down control, as was pointed out in the previous
chapter. Second, a number of proposed mechanisms for cognitive model control significantly resemble my
account (see Fahlman in Minsky [35], P. 264-267 and Lowe [28]). Third, my mechanism is a
generalization of the feature ring control scheme outlined in the previous chapters on the basis of
reasonably reliable experimental evidence. And fourth, it is difficult to imagine a process which does not
"ebb-and-flow" like mine avoiding the Serial Recognition Problem and Part-Whole Paradox.
In conclusion, I would like to summarize the main points we have made in this chapter.
1) The "Hypothesis Paradigm" seems to be a general feature of human mentation—intimately linked with noumena and recognition, and extending from the infant's first gropings to the highest reaches of science. Moreover, images can usefully be regarded as hypotheses, thus further connecting images with noumena and recognition. 2) The simple recording process of Noton and Stark can be modified via the splitting principle to account, at least partially, for the formation and differentiation of images through discrepancies. 3) The process of image application during perception is a complex interplay of bottom-up and top-down control guided by trademarks, discrepancies and confirmations. Also, this process must somehow overcome the Serial Recognition Problem and Part-Whole Paradox by using an ebb-and-flow principle similar to that of the mechanism we have outlined.
78

8. Conclusion Let us retrace our steps and take a larger view of the points this thesis has touched on. First
of all, we examined the methodology of AI, and adopted what might be called a "bottom-up"
design philosophy. That is, we resolved to put comprehensive understanding of the human mind
(or at least earnest steps in that direction) first, and formal computational tools second. Clearly,
in this modest exposition we have not succeeded in unraveling the entire knot. But I believe I
have succeeded in what I set out to do—namely to clarify the concept of imagination and
demonstrate its importance.
Our point of departure was "Linearity"—my shorthand for the fact that the mind is a
sequence of moments in time. Thus we challenged the tacit, alluring and all-pervasive objective
viewpoint, and swung to the opposite pole of subjectivity. (I trust that by now the reader knows
what I mean by "subjectivity.") This shift allowed us to see perception as the problem of
organizing our chaotic journey through time via ideal, mind-independent noumena—a process of
transcending subjectivity and awakening to objectivity.
We then proceeded to Hume and Kant, who both proposed that imagination is the means by
which perception is organized, and found their views to be essentially sound. For first, we saw
that the notion of identity (and hence noumena) requires imagination in that we must compare
the present perception with an absent one which has passed on, and second, images from the past
often "come alive" in present perception.
Next we asked: What do the apes lack that prevents them from accumulating culture like
human beings? We argued that they lacked a trick, and all indications, again, pointed to
imagination.
So assuming the importance of imagination, we analyzed the image in depth and found it to
have 3 basic properties:
i) Dynamic organization
ii) Pre-interpretation (i.e. the image is not raw or Humean)
iii) Integration through correlates of movement
79

With these properties in mind, we discussed the feature ring theory of perception which
originated in eye movement research. We found evidence that memories are, indeed, stored
subjectively in strips, and that these memories have eye movement components. We also found
evidence that feature rings (i.e. images) play a role in recognition, a process which we argued is
sequential in the overwhelming majority of cases.
Further, the sequential nature of recognition suggested the involvement of some sort of
hypothesis formation and evaluation mechanism. So we examined the "Hypothesis Paradigm"
and found it to be a highly general feature of human mentation, linked in particular with three
domains connected with imagery: noumena, recognition and imported imagination. And we
solidified this link by showing how the image could be viewed as a hypothesis.
Finally, we proposed tentative mechanisms to account for the two main problems of the
dynamic behavior of images—how they get into and are applied by the mind in time. In the
former case, we noted a continuity between the conditioned response and images, and described
a discrepancy-driven method of interpretation creation and differentiation. In the latter case, we
noted the malleability of the image application process (i.e. the fact that different perceptions
involve varying proportions of bottom-up and top-down control), and gave a mechanism
exemplifying this property.
Now we are left with a piece a of unsettled business. Recall that at the outset of this thesis
we reiterated Dreyfus' [9] question: If the prospects for AI seemed so rosy in the 1950's, what
happened? What unanticipated barrier did researchers come up against? Dreyfus answered this
question by describing four forms of "human information processing" which conventional AI is
at a loss to mimic, and I would like here to discuss three of these forms (the fourth being a
combination of the previous three), and consider whether their imitation might be aided through
imagistic constructs of the type we have developed.
The three forms, which we shall address in turn, are: fringe consciousness, ambiguity
tolerance and essential-inessential discrimination.
80

1. Fringe consciousness
Dreyfus describes fringe consciousness in the context of chess, and contrasts it with
heuristically-guided search—its conventional AI surrogate. It is perhaps most evident in the fact
that a human chess master, examining on the order of 100-200 potential board positions, can
select a better move than a computer program like, say, Cray Blitz, which examines as many as
10 million.
Dreyfus accounts for this discrepancy by noting that, in protocols where a chess player
thinks aloud, two distinct stages can be discerned—what he calls "zeroing-in" and
"counting-out." Zeroing-in generally occurs at the start of the protocol, and is expressed in
phrases like: "I notice his Rook is undefended." This is then followed by an episode of
counting—out, where the player examines a modest, but generally deep, tree of possibilities. So
it seems that humans have the advantageous ability to vastly trim the potential search space by
zeroing-in on the most crucial issue at any point in the game.
Dreyfus attributes this ability to fringe consciousness—a marginal awareness which shapes
our perception without being explicitly considered or excluded. And the way it does this is by
making things look different. For example, past experience, in the form of a vocabulary of
stereotypical chess patterns, makes certain zones of the board look promising or dangerous etc.
Dreyfus writes:
"In general what is needed is an account of the way the background of past experience and the history of the current game can determine what shows up as a figure and attracts a player's attention." (P. 105)
Now we have found that images account for precisely this sort of phenomenon—i.e., where
memory models recorded in the past "invade" or "direct" the present perception. And further, the
eye movement theory of visual ambiguity provides an explanation of how the look of a chess
position can change. So we may reasonably conclude that images have a role to play in fringe
consciousness.
81

2. Ambiguity tolerance
Dreyfus characterizes ambiguity tolerance as the ability to disambiguate or interpret
incoming data without explicitly considering all possible alternative meanings. He writes: "The sentence is heard in the appropriate way because the context organizes the perception; and since sentences are not perceived except in context they are always perceived with the narrow range of meaning the context confers." (P. 108)
So it seems that here again images have a role to play. For as we saw in the application
mechanism, once an image has been activated, it directs the perception and assigns
interpretations to incoming impressions, thereby eliminating the need to consider alternatives.
3. Essential-Inessential discrimination
Dreyfus equates this ability with insight, and contrasts it with trial-and-error search. Now we have
already obliquely implicated imagination in insight by our remarks on imported imagination in chapter 5
(recall in particular the scientific examples), but let us try to make this connection more explicit.
Suppose that I, like an ape, am placed in a cage with a banana outside the bars which I must obtain. A
problem has been set for me, which can be summarized in the phrase "how to get it." So what happens
when my eyes settle on the stick and I suddenly see that it is a solution to my problem? It seems that I do
not, at the point of insight, entertain images of myself picking up the stick and fishing through the bars
with it. The insight is too quick, and that stage seems to come later. Rather it seems that my mind suddenly
blossoms into an atmosphere or "set" in which the stick and banana play a central role. I have vague
intimations not only of the stick, but also what I shall do with it, why I shall do i, and what will happen.
But these are surely inchoate intimations. What I have is an insight, which like a seed is simple, yet holds
within itself the directions for development and growth.
Now my contention is that insight can be understood as imported imagination—i.e., as what
Wittgenstein calls "the dawning of an aspect." For example, in the above case, the insight essentially
amounts to an absent sensori-motor schema or image (namely that governing "stick fishing") suddenly
being evoked and "invading" the present perception.
82

Obviously I cannot prove that this interpretation of insight is correct because insight is not a
well-defined notion. But the following points make the interpretation at least reasonable. First, both insight
and shifting of aspects have a similar "magical" and startling quality. Second, it seems that almost all
scientific insights amount, in the end, to seeing one thing in terms of another; for example, light as waves,
projectiles as parabolas, space as a curved surface, biological cell components as machinery, (Z, +) as
(R, ・) etc. And third, imagination is generally conceded to play a role in breaking free of traditional
blindnesses and bias.
If this equating of insight with imported imagination is valid, then we have succeeded in implicating
imagination in all of Dreyfus' forms of human information processing. So does this mean that imagination
is the great panacea which will solve all our problems? I am hardly so bold as to go that far. What I will
say is what I have been saying all along—that the objective schemata of AI, while suitable representations
of our pure concepts, are totally out of touch with our subjective experience in time, and images seem to
occupy a desirable half-way point between subjectivity and objectivity. Unfortunately I have taken only
baby steps toward connecting these two poles, but that is to be expected. After all, the complete transition
from the sensori-motor intelligence of infancy to formal abstract adult thought takes on the order of 13
years. Nevertheless, I regard the explication of this transition as the outstanding problem which my
research has raised.
Lastly, I would like to list my remaining questions:
1. How does imagination function in thought (as opposed to perception)? How does imagination function
in action? What is the relation between imagination and affect?
2. How are free-state images controlled?
3. How are images created as models for abstract concepts, and how do these models function in thought?
4. How do the image formation and application processes relate?
5. How do noumena relate to our concepts of causality?
6. Why does the objective viewpoint dominate and hide subjectivity? That is, what is the nature of the
"crypto-mechanism"?
83

f
References 1. Beard, R. M., An Outline of Piaget's Developmental Psychology for Students and Teachers, New
York: Mentor Books, 1969. 2. Bierderman, I., Rabinowitz, J. C., Glass, A. L., and Stacy, E. W., "On the Information Extracted
from a Glance at a Scene," Journal of Experimental Psychology, 1974, 103, 597-600. 3. Binet, A., L'étude experimentale de l'intelligence, Paris: Schleicher, 1903. 4. Buettner-Janusch, J., Origins of Man: Physical Anthropology, New York: John Wiley & Sons,
1966. 5. Casey, E. S., Imagining: A Phenomenological Study, Bloomington, Indiana: Indiana University
Press, 1976. 6. Chase, E. V., & Simon, H. A., "Perception in Chess," Cognitive Psychology, 1973, 4, 55-81. 7. Coren, S., "The Interaction Between Eye Movements and Visual Illusions," in D. Fisher, R.
Monty and J. Senders (Eds.) Eye Movements: Cognition and Visual Perception, New Jersey: Lawrence Erlbaum, 1981, P. 67-81.
8. Dement, W., and Kleitman, N., "Eye Movements During Sleep," Journal of Experimental Psychology, 1957, 53, 339-346.
9. Dreyfus, H. L., What Computers Can't Do [Revised Edition],New York: Harper & Row, 1979. 10. Dreyfus, H. L., and Dreyfus, S. E., Mind over Machine, New York: Free Press, 1986. 11. Dyer, M. G., In-depth Understanding, Cambridge, Massachusetts: MIT Press, 1983. 12. Farley, A, M., "A Computer Implementation of Constructive Visual Imagery and Perception," in
R. Monty and J. Senders (Eds.) Eye Movements and Psychological Processes, New Jersey: Lawrence Erlbaum,1976, P. 499-513.
13. Flavell, J. H., Cognitive Development [2nd Edition], New Jersey: Prentice-Hall, 1985. 14. Gale, A. G., and Findlay, J. M., "Eye Movement Patterns in Viewing Ambiguous Figures,” in R.
Groner, C. Menz, D. Fisher and R. Monty (Eds.) Eye Movements and Psychological Functions: International Views, New Jersey: Lawrence Erlbaum, 1983, 145-168.
15. Goodall, J., The Chimpanzees of Gombe, Cambridge, Massachusetts: Belknap Press, 1986. 16. Groner, R., Walder F., and Groner, M., "Looking at Faces: Local and Global Aspects of
Scanpaths," in A. G. Gale and F. Johnson (Eds.) Theoretical and Applied Aspects of Eye Movement Research, Amsterdam: North-Holland, 1983, P. 522-533.
17. Hasegawa, M., Kishino, H., and Yano, T., "Dating of the Human-Ape Splitting by a Molecular Clock of Mitochondrial DNA," Journal if Molecular Evolution, 1985, 22, 160-174.
18. Hebb, D. O., The Organization of Behavior, New York: John Wiley & Sons, 1949. 19. Hebb, D. O., "Concerning Imagery," Psychological Review, 1968, 75, 466-477. 20. Hochberg, J. E., "In the Mind's Eye," in R. N. Haber (Ed.) Contemporary Theory and Research in
Visual Perception, New York: Holt, Rinehart & Winston, 1968, P. 309-331. 21. Hume, D., A Treatise of Human Nature, Oxford: Clarendon Press, 1888. 22. Intraub, H., "Identification and Processing of Briefly Glimpsed Visual Scenes," in [7], P.181-190. 23. Jaspers, K., General Psychopathology, Trans. by J. Hoenig and M. W. Hamilton, Chicago:
University of Chicago Press, 1963. 24. Kant, I., Critique of Pure Reason, Trans. by N. K. Smith, New York: St. Martin's, 1965. 25. Kohler, W., The Mentality of Apes, Trans. by E. Winter, London: Kegan Paul, Trench, Truber &
Co., 1925. 26. Loftus, G. R., "A Framework for a Theory of Picture Recognition," in [12], P. 499-513. 27. Lorenz, K., Behind the Mirror: A Search for a Natural History of Human Knowledge, Trans. by R.
84

Taylor, New York: Harcourt Brace Jovanovich, 1977. 28. Lowe, D. Perceptual Organization and Visual Recognition, Boston: Kluwer Academic, 1985. 29. Mackay, D. G., The Organization of Perception and Action, New York: Springer-Verlag, 1987. 30. Mackworth, N. H., and Morandi, A. J., "The Gaze Selects Informative Details within Pictures,"
Perception & Psychophysics, 1967, 2, 547-552. 31. Marr, D., Vision, New York: W. H. Freeman & Co., 1982. 32. Merleau-Ponty, M., The Phenomenology of Perception, Trans. by C. Smith, New Jersey:
Routledge & Kegan Paul, 1962. 33. Miner, J. B., "A Case of Vision Acquired in Adult Life," Psychological Review Monograph
Supplement, 1905, 6, no. 5, 103-118. 34. Minsky, M. "Steps toward Artificial Intelligence," Proceedings of I. R. E., 1961, 49. 35. Minsky, M., "A Framework for Representing Knowledge," in P. H. Winston (Ed.) The
Psychology of Computer Vision, New York: McGraw-Hill, 1975, P. 211-277. 36. Noton, D., and Stark, L., "Eye Movements and Visual Perception," Scientific American, 1971,
224, 35-43. 37. Penfield, W., and Roberts, L., Speech and Brain-Mechanisms, New Jersey: Princeton University
Press, 1959. 38. Piaget, J., The Construction of Reality in the Child, Trans. by M. Cook, New York: Ballantine
Books, 1954. 39. Pylyshyn, Z. W., "What the Mind's Eye Tells the Mind1s Brain: A Critique of Mental Imagery,"
Psychological Bulletin, 1973, 80, 1-24. 40. Pylyshyn, Z. W., "Imagery and Artificial Intelligence," in C. W. Savage (Ed.) Perception and
Cognition: Issues in the Foundations of Psychology, Minnesota Studies in the Philosophy of Science, Vol. 9, Minneapolis: University of Minnesota Press, 1978.
41. Ristau, C. A., and Robbins, D., "Language in the Great Apes: A Critical Review," in J. Rosenblatt, R. A. Hinde, C. Beer, and M. C. Busnel (Eds.) Advances in the Study of Behavior, Vol. 12, New York: Academic Press, 1981.
42. Sartre, J., The Psychology of Imagination, Secaucus, New Jersey: Citadel Press. 43. Senden, M. v., Raum- und Gestaltauffassung bei operierten Blidgeborenen vor und nach der
Operation, Leipzig: Barth, 1932. 44. Sibley, C. G., and Ahlquist, J. E., "The Phylogeny of the Hominid Primates, as indicated by
DNA-DNA hybridization," Journal of Molecular Evolution, 1984, 20, P. 2-15. 45. Sowa, J. F., Conceptual Structures, Reading, Massachusetts: Addison-Wesley, 1984. 46. Stark, L., and Ellis, S., "Scanpaths Revisited: Cognitive Models Direct Active Looking," in [7],
P.193-226. 47. Strawson, P. F., "Imagination and Perception," in L. Foster and J. W. Swanson (Eds.) Experience
and Theory, Massachusetts: University of Massachusetts Press, 1970, P. 31-54. 48. Tolman, E. C., "Cognitive Maps in Rats and Men," Psychological Review, 1948, 55, 189-208. 49. Vygotsky, L. V., Thought and Language, Trans. by E. Hanfmann and G. Vakar, Cambridge,
Massachusetts: MIT Press, 1962. 50. Waltz, D. L., "On the function of mental imagery," The Behavioral and Brain Sciences, 1979, 2,
569-570. 51. Warnock, M., Imagination, Berkeley and Los Angeles: University of California Press, 1976. 52. Wittgenstein, L., Philosophical Investigations, Trans. by G. E. M. Anscombe, Oxford: Basil
Blackwell,1953.
85
Copyright © 2022 FDOKUMEN




















