
Image Retrieval Using Keywords: The Machine Learning Perspective
36
1 Image Retrieval Using Keywords: The Machine Learning Perspective Zenonas Theodosiou Dept. of Communication and Internet Studies, Cyprus University of Technol- ogy, Limassol, Cyprus Nicolas Tsapatsoulis Dept. of Communication and Internet Studies, Cyprus University of Technol- ogy, Limassol, Cyprus CONTENTS 1.1 Introduction ............................................................... 3 1.2 Background ............................................................... 4 1.2.1 Key Issues in Automatic Image Annotation ...................... 7 1.3 Low-level Feature Extraction ............................................. 9 1.3.1 Local Features ..................................................... 10 1.3.2 Global or Holistic Features ........................................ 11 1.3.3 Feature Fusion ..................................................... 13 1.4 Visual Models Creation ................................................... 14 1.4.1 Dataset Creation .................................................. 15 1.4.2 Learning Approaches .............................................. 16 1.5 evaluation performance Evaluation ....................................... 19 1.6 A study on creating visual models ........................................ 21 1.6.1 Feature Extraction ................................................ 22 1.6.2 Keywords Modeling ............................................... 22 1.6.3 Experimental Results ............................................. 25 1.7 Conclusion ................................................................. 29 1.1 Introduction Given the rapid growth of available digital images, image retrieval has at- tracted a lot of research interest the last decades. Image retrieval research efforts are falling into content-based and text-based methods. Content-based methods retrieve images by analyzing and comparing the content of a given image example as a starting point. Text-based methods are similar to docu- ment retrieval and retrieve images using keywords. The latter is the approach of preference both for ordinary users and search engine engineers. Besides the fact that the majority of users are familiar with text-based queries, content- 3
-
Upload
independent -
Category
Documents
-
view
0 -
download
0
Transcript of Image Retrieval Using Keywords: The Machine Learning Perspective

1
Image Retrieval Using Keywords: TheMachine Learning Perspective
Zenonas Theodosiou
Dept. of Communication and Internet Studies, Cyprus University of Technol-ogy, Limassol, Cyprus
Nicolas Tsapatsoulis
Dept. of Communication and Internet Studies, Cyprus University of Technol-ogy, Limassol, Cyprus
CONTENTS
1.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31.2 Background . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
1.2.1 Key Issues in Automatic Image Annotation . . . . . . . . . . . . . . . . . . . . . . 71.3 Low-level Feature Extraction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
1.3.1 Local Features . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 101.3.2 Global or Holistic Features . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 111.3.3 Feature Fusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
1.4 Visual Models Creation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 141.4.1 Dataset Creation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 151.4.2 Learning Approaches . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
1.5 evaluation performance Evaluation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 191.6 A study on creating visual models . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
1.6.1 Feature Extraction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 221.6.2 Keywords Modeling . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 221.6.3 Experimental Results . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25
1.7 Conclusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29
1.1 Introduction
Given the rapid growth of available digital images, image retrieval has at-tracted a lot of research interest the last decades. Image retrieval researche!orts are falling into content-based and text-based methods. Content-basedmethods retrieve images by analyzing and comparing the content of a givenimage example as a starting point. Text-based methods are similar to docu-ment retrieval and retrieve images using keywords. The latter is the approachof preference both for ordinary users and search engine engineers. Besides thefact that the majority of users are familiar with text-based queries, content-
3

4 Book title goes here
based image retrieval lacks semantic meaning. Furthermore, image examplesthat have to be given as a query are rarely available. From the search engineperspective, text-based image retrieval methods get advantage of the well es-tablished techniques for document indexing and are integrated into a unifieddocument retrieval framework. However, for text-based image retrieval to befeasible, images must be somehow related with specific keywords or textualdescription. In contemporary search engines this kind of textual descriptionis, usually, obtained from the web page, or the document, containing the cor-responding images and includes HTML alternative text, the file names of theimages, captions, surrounding text, metadata tags or the keywords of thewhole web page [49]. Despite the fact that this type of information is not di-rectly related to the content of the images it can be utilized only in web-pageimage retrieval. As a result, image retrieval from dedicated image collectionscan be done either by content-based methods or by explicitly annotating im-ages by assigning tags to them to allow text-based search. The latter processis collectively known as ‘image annotation’ or ‘image tagging’.
Image annotation can be achieved using various approaches like free textdescriptions, keywords chosen from controlled vocabularies etc. Nevertheless,the annotation process remains a significant di"culty in image retrieval sincethe manual annotation seems to be the only way guarantying success. Thisis partially a reason explaining why the content-based image retrieval is stillconsidered an option for accessing the enormous amount of digital images.Despite the plethora of available tools, manual annotation is an extremelydi"cult and elaborate task since the keyword assignment is performed onimage basis. Furthermore, manual annotations cannot always be consideredas correct due to the visual information that always lets the possibility forcontradicting interpretation and ambiguity [32].
In recent years, much e!ort has been expended on automatic image anno-tation in order to exploit the advantages of both the text-based and content-based image retrieval methods and compromise their drawbacks mentionedabove. In any case the ultimate goal it to allow keyword searching based onthe image content [83]. Thus, automatic image annotation e!orts try to mimichumans aiming to associate the visual features that describe the image contentwith semantic labels.
This chapter focuses on image retrieval using keywords under the perspec-tive of machine learning. It covers di!erent aspects of the current research inthis area, including low-level feature extraction, creation of training sets anddevelopment of machine learning methodologies. It also presents the evalua-tion framework of automatic image annotation and discusses various methodsand metrics utilized within it. Furthermore, it proposes the idea of addressingautomatic image annotation by creating visual models, one for each availablekeyword, and presents an example of the proposed idea by comparing di!er-ent features and machine learning algorithms in creating visual models forkeywords referring to the athletics domain.

Image Retrieval Using Keywords: The Machine Learning Perspective 5
1.2 Background
Automatic image annotation has been a topic of on-going research for morethan a decade. Several interesting techniques have been proposed during thisperiod [55]. Although appears to be a particularly complex problem for re-searchers and despite the fact that annotation obtained automatically is notexpected to reach the same level of detail as the one obtained by humans,remains a research hot topic. The reason is obvious: Manual annotation of theenormous amount of images created and uploaded to the web every day is notonly impractical; it is simply impossible. Therefore, automatic assignment ofkeywords to images for retrieval purposes is highly desirable. The proposedmethods towards this direction attempted to address first, the di"culty ofrelating high-level human interpretations with low-level visual features andsecond, the lack of correspondence between the keywords and image regionsin the (training) data.
Traditionally in content-based image retrieval, images are represented andretrieval using low-level features such as color, texture and shape regions. Sim-ilarly in automatic image annotation, a manually annotated set of data is usedto train a system for the identification of joint or conditional probability of anannotation occurring together with a certain distribution of feature vectorscorresponding to image content [5]. Di!erent models and machine learningtechniques were developed to learn the correlation between image featuresand textual words based on examples of annotated images. Learned models ofthis correlation are then applied to predict keywords for unseen images [85].Although the low-level features extracted from an image cannot be automat-ically translated reliably into high-level semantics [21], the selection of visualfeatures that better describe the content of an image is an essential step forthe automatic image annotation. The interpretation inconsistency betweenimage descriptors and high-level semantics is known as ‘semantic gap’ [68] or‘perceptual gap’ [36]. Recent research focuses on new low-level feature extrac-tion algorithms to bridge the gap between the simplicity of available visualfeatures and the richness of the user semantics.
The co-occurrence model proposed by Mori et al. [57] can be assumed asthe first automatic image annotation approach. This model tries to capturethe correlations between images and keywords (assigned to them) and consistsof two main stages. In the first stage, every image is divided into sub-regionsand a global descriptor for each sub-region is calculated. In the second stage,feature vectors extracted from sub-regions are clustered using vector quantiza-tion. Finally, the probability of a label related to a cluster is estimated by theco-occurrence of the label and the sub-regions within the cluster. Duygulu etal. [22] proposed a model of object recognition as a machine translator in orderto annotate images automatically. Every image is segmented into object shaperegions, called ‘blobs’, and a visual vocabulary is created by feature quantiza-

6 Book title goes here
tion of the extracted feature vectors of the regions. Finally, the correspondencebetween blobs and words is found by utilizing the Expectation-Maximizationalgorithm. The Cross Media Relevance Model (CMRM) was introduced byJeon et al. [37] in order to improve the machine translator model. They fol-lowed the same procedure for calculating the blob representation of imagesas Duygulu et al. and then utilized the CMRM to learn the joint distributionof blobs and words in a given image. The loss of useful information duringthe quantization from continuous features into discrete blobs that occurredon the translation model and CMRM, was treated by Lavrenko et al. [46].The proposed Continuous Relevance Model (CRM) does not require an in-termediate clustering stage and associates directly continuous features withwords. Further improvement on annotation results was obtained by the Multi-ple Bernoulli Relevance Model (MBRM) [27], where the word probabilities areestimated using a multiple Bernoulli model and the image feature probabili-ties using a non-parametric kernel density estimate. The computational costof parameter estimation is probably one of the drawbacks of using statisticalmodels in automatic image annotation approaches since the learning of pa-rameters lasts several hours. Nevertheless, object recognition based methodsfor image annotation are of limited scope because object recognition itself isa very hard problem and is solved only under strict constraints.
Automatic image annotation tries to learn the behavior of humans. Thus,utilization of machine learning methods is almost natural [45]. The objectiveis to learn a set of rules from training instances (pairs of images and key-words) and the creation of a classifier that can be used to generalize to newinstances [44]. Several methods were developed within the machine learningframework. Classification and clustering based methods are among the mostpopular [45]. In classification approaches, image classifiers are constructedwith the aid of training data, and are applied to classify a given image intoone of several classes. Each class usually corresponds to a particular keyword.Several machine learning algorithms have been used for image classificationinto keywords classes. Support Vector Machine (SVM) [19], Hidden MarkovModels [30], Decision Trees [38], are some of them. An extensive review on ma-chine learning classifiers in image annotation is given in [44] while the generalprincipal of machine learning utilization is revisited in Section 1.4.
Although classification based annotation methods give promising results,they are designed for small-scale datasets and they use a small number ofkeyword classes. As a result the trained classifiers do not generalize smoothlyto allow accurate classification, of the large amount of images that are missingannotations, to the available classes. The limited number of manually anno-tated data (few positive and negative examples) that are used during traininglead to ine!ective keywords models without generalization ability. The limitednumber of classes, on the other the hand, is very restrictive to the number oftext queries that will derive results. Users, in general, are reluctant to adoptsearch interfaces that are based on predefined sets of keywords because theyare familiar with the free text searching paradigm used in web-search en-

Image Retrieval Using Keywords: The Machine Learning Perspective 7
gines. Another problem of classification based annotation is that classifiersrelate images with a single keyword while it is obvious that image content canbe associated with many keywords. The multi-instance multi-label learning(MIML) proposed in [86], [87] where each training example is described bymultiple instances and associated with multiple class labels tries to eliminatethis problem. Although this method gives a fair solution to the problem ofassigning more than one keyword to a given image, it has also several limita-tions. In order to model a valid probability of labels it is necessary to computea summation over all possible label assignments leading to high computationalcost. Furthermore, there is no provision to add new labels (keywords). Theinitial set of keywords remains unchanged while erroneous tagging is accumu-lated since the labels, that are assigned to a particular image, depend on itscontent similarity with other images that already have this label. Therefore,in case where the initial label of an image is erroneous the error is propagatedto all images having similar content.
Creating independent keyword models, separately, appears to be a realisticsolution to the drawbacks of the previous method. A given image could beassociated with more than one keyword and a new keyword model can betrained irrespectively of the existing ones. This approach provides the requiredscalability for large scale text-based image retrieval. The idea of automaticimage annotation through independent keyword visual models is illustrated inFig. 1.1. The whole procedure is divided into two main parts: the training andautomatic image annotation. In the first part, visual models for all availablekeywords are created, using the one-against-all training paradigm, while inthe second part, annotations are produced for a given image based on theoutput of these models, once they fed by a feature vector extracted from theinput image. On the other hand, whenever a training data for new keywordare available, a new visual model is created for this keyword, and added intothe unified framework. A detailed explanation of the use of keyword visualmodels for automatic image annotation is given in Section 1.4.
1.2.1 Key Issues in Automatic Image Annotation
There are some issues commonly encountered in automatic image annotationsystems either image retrieval is approached using the content-based or thetext-based paradigm.
Initially, the problem of searching the enormous number of digital imagecollections that are available through the Web or in personal repositories wastackled by e"cient and intelligent schemes for content-based image retrieval(CBIR) [68]. CBIR computes relevance based on the visual similarity of imagelow-level features such as color, texture and shape [59]. Early CBIR systemswere based on the query by-example paradigm [31], which defines image re-trieval as the search for the best database match to a user-provided queryimage. Under this framework, and in order to maximize the e!ectiveness ofCBIR systems, it was soon became necessary to mark specific regions in the

8 Book title goes here
FIGURE 1.1Automatic image annotation using visual models of keywords.
images so as to model particular objects. During automatic annotation, labelscorresponding to object classes are assigned every time a particular objectinstance is encounter in the input image. As already mentioned, this objectinstance almost always corresponds to an image region (part of the image).Therefore, region-based features must be computed and used for object mod-eling. Under this perspective, semantic labeling using object class labels isactually an object detection task. Unfortunately, object detection is a veryhard task itself and is solvable only for limited cases and under strict con-straints.
The low performance of CBIR systems along with their limited scopeled researchers to investigate alternative schemes for image retrieval. It wasquickly realized that the ultimate users were willing to search for images usingtheir familiar text-based search interface. Therefore, the design of fully func-tional image retrieval systems would require support for semantic queries [61].In such systems, images in the database are annotated with semantic labels,enabling the user to specify the query through a natural language descrip-tion of the visual concepts of interest. This realization, combined with thecost of manual image labeling, generated significant interest in the problem ofautomatically extracting semantic descriptors from images.
As already mentioned in the previous section, automatic annotation ofdigital images with semantic labels is traditionally coped by utilizing machine

Image Retrieval Using Keywords: The Machine Learning Perspective 9
learning emphasizing on classification. In that case, semantic labels may referto an abstract term, such as indoor, outdoor, athletics, or to an object classsuch as human, car, tree, foam mats, etc. The latter case reinforces the objectdetection problem encountered in CBIR systems. In order to learn a particularobject class and create a classifier to recognize it automatically you needaccurate and region specific features of the training examples. Indeed, thereexist some approaches [82] that use some kind of object detection in order toassign semantic labels to images [11]. In contrary to object classes, abstractterms cannot be related to specific image regions. In the literature of automaticsemantic image annotation, proposed approaches tend to classify images usingonly abstract terms or using holistic image features for both abstract termsand object classes. Nevertheless, extraction and selection of low-level features,either holistic or from particular image areas is of primary importance forautomatic image annotation. This is true either for the content-based or forthe text-based retrieval paradigm. In the former case the use of appropriatelow-level features leads to accurate and e!ective object class models used inobject detection while in the latter case, the better the low-level features are,the easier the learning of keyword models is. Low-level feature extraction isone of the key issues in automatic image annotation and is examined in detailin the next section.
The intent of the image classification is to categorize the content of theinput image to one of several keyword classes. A proper image annotationmay contain more than one keyword that is relevant to the image content, soa reclassification process is required in this case, as well as whenever a newkeyword class is added to the classification scheme. The creation of separatevisual models for all keyword classes adds a significant value in automaticimage annotation since several keywords can be assigned to the input image.As the number of keyword classes increases the number of keywords assignedto the images also increases too and there is no need for reclassification. How-ever, the keyword modeling incurred various issues such as the large amountof manual e!ort required in developing the training data, the di!erences ininterpretation of image contents, and the inconsistency of the keyword as-signments among di!erent annotators. These key issues are also examined indetail in subsequent sections.
1.3 Low-level Feature Extraction
Low-level feature extraction is the first crucial step in the keyword modelingprocess. Aims at capturing the important characteristics of the visual con-tent of images. The low-level features are defined to be those basic featuresthat can be extracted automatically from an image without any informationabout spatial relationships [60]. They can be broadly divided into two main

10 Book title goes here
types: (a) Local or domain-specific features, and (b) Global or holistic fea-tures. Selection of the most appropriate subset of features plays a significantrole in e"cient classification schemes as well as in visual modeling of key-words. Feature extraction and selection can be evaluated from three di!erentperspectives: First, in terms of their ability to identify relevant features, sec-ond in terms of the performance of the created classifiers and third, in termsof the reduction of the number of features. The research in feature extractionis rich and dozens of methods have been proposed for keyword modeling.
1.3.1 Local Features
Local features are image patterns that di!er from their immediate neighbor-hood. They are usually associated with a change of an image property orseveral properties simultaneously, although they are not necessarily localizedexactly on this change. Image properties commonly considered for local fea-ture derivation are intensity, colour, and texture. Local invariant features notonly allow finding correspondences in spite of large changes in viewing condi-tions, occlusions, and image clutter, but also yield an interesting descriptionof the image content. Ideal local features should have repeatability, distinc-tiveness, locality, quantity, accuracy and e"ciency [78]. Local features werefirst introduced by Schiele and Crowely [65], and Schmid and Mohr [66] andsoon became very popular especially in machine learning frameworks.
The Scale Invariant Features Transform (SIFT) [52] and Histogram of Gra-dients (HOG) [20] are two of the most successful local features categories. Theyare based on histograms of gradient orientations weighted by gradient magni-tudes. The two methods di!er slightly in the type of spatial bins that they use.The SIFT, proposed by Lowe [52], transforms image data into scale-invariantcoordinates relative to local features and computes a set of features that arenot a!ected by object scaling and rotation. Key points are detected as themaxima of an image pyramid built using di!erence-of-Gaussians. The multi-scale approach results in features that are detected across di!erent scales ofimages. For each detected keypoint, a 128 dimensional feature vector is com-puted describing the gradient orientations around the keypoint. The strongestgradient orientation is selected as reference, thus giving rotation invariance toSIFT features. On the other hand, HOG uses a more sophisticated way forbinning. The image is divided into small connected regions and a histogramof gradient directions or edge orientations within each region is compiled. Forthe implementation of HOG, each pixel within the region casts a weightedvote for an orientation-based histogram channel.
Due to the large number of SIFT keypoints contained in an image, variousapproaches have been used to reduce the dimensionality or prune the numberof detected keypoints before using them to train keyword models. Anotherdi"culty in using the original SIFT features in machine learning is that thenumber of keypoints and consequently the dimensionality of input vector isimage dependent. As a result they cannot directly employed for creating and

Image Retrieval Using Keywords: The Machine Learning Perspective 11
feeding keyword models. The PCA-SIFT is proposed in [41] by utilizing Princi-pal Component Analysis (PCA) to normalized gradient patches to achieve fastmatching and invariance to image deformations. Mikolajczyk and Schmid [56]presented an extension of the SIFT descriptor, the significance of the GradientLocation and Orientation Histogram (GLOH) which applies also the PCA fordimensionality reduction. Instead of PCA, the Linear discriminate Analysis(LDA) has also been applied to create a low-dimensional representation [6].
The e!ectiveness of SIFT and GLOH features led to several modificationsthat try to combine their advantages. Recently, the Speeded Up Robust Fea-tures (SURF) descriptor that approximates the SIFT and GLOH by usingintegral images to compute the histograms bins has been proposed [7]. Thismethod is computationally e"cient with respect to computing the descriptorvalues at every pixel and di!ers from SIFT’s spatial weighting scheme. In par-ticular, all gradients contribute equally to their respective bins, which resultsin damaging artifacts when used for dense keypoints computation. The Daisydescriptor [73], on the other hand, retains the robustness of SIFT and GLOHand can be computed quickly at every single image pixel.
Other approaches, use clustering techniques to manage the thousands oflocal descriptors produced by SIFT. Bag-Of-Features (BOF) methods repre-sent an image as orderless collection of local features [67], [84], [50]. Usually,the k-means clustering algorithm groups visual patches into one cluster andcreates a visual vocabulary. For each image the number of occurrences of eachword is counted to form a histogram representation. Besides the advantages ofthe BOF representation, these methods have important descriptive limitationbecause they disregard the spatial information of the local features. Lazeb-nik et al. [47] extended the BOF approach and proposed the Spatial PyramidMatching method which partitions the image into increasingly fine sub-regionsand computes histograms of local features found inside each sub-region.
SIFT features were originally proposed for object detection and recogni-tion tasks. In these tasks a dedicated matching scheme is used to compareimages or image regions. In keyword modeling this is not the case. The SIFTfeature vector feeds the keyword visual models to produce an output indicat-ing whether or not the corresponding keyword can be assigned to the imagecorresponding to this input vector. This di!erence, along with the dimen-sionality reduction, which is applied to produce SIFT based vectors of fixeddimensionality, lead to deteriorate performance in image retrieval comparedto other types of features, like the MPEG-7 descriptors [72].
1.3.2 Global or Holistic Features
Global features provide di!erent information than local ones since they areextracted from the entire image. Statistical properties such as histograms,moments, contour representations, texture features and features derived fromimage transforms like Fourier, Cosine and Wavelets can be considered as globalfeatures. Global features cannot separate foreground from background infor-

12 Book title goes here
mation; they combine information from both parts together [78]. These fea-tures can be used when there is interest for the overall composition of theimage, rather than a foreground object. However, in some cases, global fea-tures have been also applied for object recognition [77], [58]. The feature setin these approaches obtained from the projections to the eigenspace createdby computing the prominent eigenvectors based on the Principal ComponentAnalysis of the image training sets.
Recently, the Compact Composite Descriptors (CCDs) [16] which cap-ture more than one types of information at the same time in a very compactrepresentation have been used for image retrieval applications [4], [12]. TheFuzzy Color and Texture Histogram (FCTH) [14] and the Color and EdgeDirectivity Descriptor (CEDD) [13] are determined for natural color imagesand combine color and texture information in a single histogram. The Bright-ness and Texture Directionality Histogram (BTDH) descriptor [15] describesgrayscale images and captures both brightness and texture characteristics in a1D histogram. Finally, the Spatial Color Distribution Descriptor (SpCD) [17]combines color and spatial color distribution information and can be used forartificial images. The performance of CCDs has been evaluated using severaldatabases and experimental results indicated high accuracy in image retrievaltask achieving, in some cases, better performance than other commonly usedfeatures for image retrieval such as the MPEG-7 descriptors.
The MPEG-7 visual descriptors [1] use standardized description of imagecontent and they were especially designed for image retrieval in the content-based retrieval paradigm. Their main property is the description of global
TABLE 1.1MPEG-7 visual descriptors.
Descriptor Type #Features
Color DC coe!cient of DCT (Y channel) 1DC coe!cient of DCT (Cb channel) 1DC coe!cient of DCT (Cr channel) 1AC coe!cients of DCT (Y channel) 5AC coe!cients of DCT (Cb channel) 2AC coe!cients of DCT (Cr channel) 2
Dominant colors VariesScalable color 16
Structure 32Texture Intensity average 1
Intensity standard deviation 1Energy distribution 30
Deviation of energy’s distribution 30Regularity 1Direction 1 or 2
Scale 1 or 2Edge histogram 80
Shape Region shape 35Global curvature 2
Prototype curvature 2Highest peak 1
Curvature peaks Varies

Image Retrieval Using Keywords: The Machine Learning Perspective 13
image characteristics based on color, texture or shape distribution, amongothers. A total of 22 di!erent kinds of features (known as descriptors) areincluded: nine for color, eight for texture and five for shape. The various featuretypes are shown in Table 1.1. The number of features, shown in the thirdcolumn of this table, in most cases is not fixed and depends on user choice. Thedominant color descriptor includes color value, percentage and variance andrequires especially designed metrics for similarity matching. Furthermore, thenumber of features included in this descriptor is not known a priori since theyare image dependent (for example an image may be composed from a singlecolor whereas others vary in color distribution). The previously mentioneddi"culties cannot be easily handled in machine learning schemes and as aresult the dominant color descriptor is rarely used in keyword modeling andclassification schemes. The region shape descriptor features are computed onlyon specific image regions (and therefore they are not used in holistic imagedescription). The number of peaks values of the contour shape descriptorvaries depending on the form of an input object. Furthermore, they require aspecifically designed metric for similarity matching because they are computedbased on the HighestPeak value. The remaining of the MPEG-7 descriptorsshown in Table 1.1 can be easily employed in machine learning schemes andsince they are especially designed for image retrieval they are an obvious choicefor keyword modeling.
Global features are a natural choice for image retrieval that is based onmachine learning. Since they are extracted from the image as whole theyare also appropriate for creating visual models for keywords. This is becausetraining data can be created by defining the keywords that are related with theimages used for training and there is no need to define specific regions in theseimages (which is by far more tedious). However, the choices of global featuresfrom which one can select is unlimited and in some cases depend on thetype of features. Despite the fact that the MPEG-7 descriptors were initiallyproposed for CBIR systems they perform excellent within the machine learningparadigm used either in classification based keyword extraction or in keywordmodeling. As a result they provide a good starting point in experimentationdealing with automatic image annotation and should be used as a benchmarktest before adopting di!erent feature types.
1.3.3 Feature Fusion
Feature fusion is of primary importance in case where multiple features typesare used in training keyword models. Fusion can derive and gain the most e!ec-tive and least dimensional feature vectors that benefit final classification [81].Usually for each keyword group, various feature vectors are normalized andcombined together into a feature union-vector whose dimension is equal to thesum of the dimensions of the individual low-level feature vectors. Dimension-ality reduction methods are then applied to extract the linear features fromthe integrated union vector and reduce the dimensionality. Principle Compo-

14 Book title goes here
nent Analysis (PCA) and Linear Discriminant Analysis (LDA) are two widelyused approaches in this framework.
The PCA is a well-established technique for dimensionality reductionwhich converts a number of correlated variables into a several uncorrelatedvariables called principal components. For a set of observed d -dimensionaldata vectors Xi, i ! {1, ..., N}, the M principal components pj , j ! {1, ...,M} are given by the M eigenvectors with the largest associated eigenvalues!j of the covariance matrix:
S =1
N
!
i
(Xi " X)(Xi " X)T (1.1)
where X is the data sample mean and Spj=!jpj . The M principal com-ponents of the observed vector Xi are given by the vector:
ci = PT (Xi " X) (1.2)
where P={p1, p2, ..., pM}. The variables cj are uncorrelated because thecovariance matrix S is diagonal with elements !j . Usually cross-validationis performed to estimate the minimum number of features required to yieldthe highest classification accuracy. However, the computational cost of cross-validating is prohibitive so other approaches such as the maximum likelihoodestimator (MLE) [48] are employed to estimate the intrinsic dimensionality ofthe fused feature vector by PCA.
LDA follows a supervised method to map a set of observed d -dimensionaldata vectors Xi, i ! {1, ..., N} to a transformed space using a function Y =wX. The w is given by the maximum eigenvector of the S!1
w Sb where Sw isthe average within-class scatter matrix and Sb is the between-class covariancematrix of Xi.
The matrix w is determined such that the Fisher criterion of between-classscatter over average within-class scatter is maximized [28]. The original Fishercriterion function applied in the LDA is,
J =wSbw
T
wSwwT(1.3)
Obviously there are several fusion techniques that can be used to selectthe best feature set for training visual models for keywords. However, bothPCA and LDA are based on a strong mathematical background and shouldinvestigate before examining alternatives. Nonlinear fusion methods, on theother hand, might be proved more e"cient in some cases.

Image Retrieval Using Keywords: The Machine Learning Perspective 15
1.4 Visual Models Creation
Creating accurate visual models for keywords depends not only on the low-level feature set that is used but also on the training data. Availability oftraining data and the use of especially designed earning algorithms are twoimportant factors that must be also carefully investigate. This section sum-marizes various approaches used to deal with these factors.
1.4.1 Dataset Creation
Training examples that are used for creating visual models for keywords arepairs of images and keywords. The low-level feature vector extracted from theimage is considered as an example of the visual representation of keywordsassigned to this image. Aggregating feature vectors across many images elim-inates the case of having several keywords sharing exactly the same trainingexamples. However, collection of manually annotated images to be used forcreating the keyword visual models is a costly and tedious procedure. Fur-thermore, manual annotations are likely to contain human judgment errorsand subjectivity in interpreting the image due to di!erences in visual percep-tion and prior knowledge. As presented in [70], there are several demographicfactors that influence the way that people annotate images. As result is a com-mon practice nowadays to use multiple annotations per image obtained formdi!erent people to alleviate this subjectivity as well as for detecting outliersor erroneous annotations. In the past, manually annotated datasets were ob-tained by experts. Since the majority of tomorrow users of search engines arenon experts, the idea of modeling the knowledge of several people rather thanan expert can significantly improve the ultimate e"ciency of image retrievalsystems.
As already mentioned multiple judgments per image from several peopleimprove the annotation quality. The act of outsourcing work to a large crowdof workers is rapidly changing the way datasets are created [80]. The fact thatdi!erences between implicit and explicit relevance judgments are not so far [39]opened a new way, where implicit relevance judgments were considered astraining data for various machine learning-based improvements to informationretrieval [54], [76].
Crowdsourcing [34] is a an attractive solution to the problem of cheaplyand quickly acquiring annotations. It has the potential to improve evalua-tion of the keyword modeling by scaling up relevance assessments and creat-ing collections with more representative judgments [40]. Amazon MechanicalTurk [2] presents a practical framework to accomplish such annotation tasksby extending the interactivity of crowdsourcing using more comprehensiveuser interfaces and micro-payment mechanisms [23].
An alternative to manual annotation of training data is to explore the suc-

16 Book title goes here
cessful mechanisms of automatic keyword extraction in text-based documentsadopted by contemporary search engines. The large amount of web images lo-cated in text documents and web-pages can be used for that purpose. The textthat surrounds theses images inside the web documents provides importantsemantic information that can be used for keyword extraction. Web ImageContext Extraction (WICE) denotes the process of determining the textualcontents of web document that are semantically related to an image and as-sociates them with that image. WICE uses the associate text as a source forderiving the content of images. In text-based image retrieval, the user provideskeywords or key phrases and text retrieval techniques are used for retrieval ofthe best ranked image. Successful web image search engines like the Googleimages1 and Yahoo!Image Search2 are well known WICE examples.
Image file names, anchor texts, surrounding paragraphs or even the wholetext of the hosting web page are usually used as a textual content in WICEapplications. Several approaches have been proposed to extract the text blocksas concept sources for images. A bootstrapping approach to automaticallyannotate web images based on predefined list of concepts by fusing evidencesfrom image contents and their associated HTML text in terms of a fixed sizeof sequence is presented in [26]. The main drawback of the proposed method isthe low annotation performance since extracted text may be irrelevant to thecorresponding image. Other applications use the DOM tree structure of theweb page [25], [3] and Vision based Page Segmentation (VIPS) algorithm [33]to extract image context using the surrounding text. Recently an interestingapproach was presented in [74] where the context extraction is achieved byutilizing VIPS algorithm and semantic representation of text blocks.
Usually, the datasets created either through crowdsourcing or based on thesurrounding text principle su!er from the limited number of labelled imagesthat correspond to the keyword classes of interest. A well structured frame-work can moderate the restrictions introduced by small labelled datasets andboost the performance of the learner using co-training algorithms [8]. In such acase, the labelled images are presented by two di!erent views and two learningalgorithms are trained separately on each view and the prediction on unla-belled images of each algorithm are used to enlarge the training set of theother.
It is fair to mention here, however, that automatic extraction of keywordsfrom web-pages containing images so as to be used as training data is clearlyinferior to using manually annotated images through crowdsourcing. The co-training mechanism mentioned above provides an attractive framework forcombing crowdsourcing and automatic keyword extraction so as to get the ad-vantage of both: accuracy and ease of training data collection. Initial trainingis performed using crowdsourced data while co-training is applied on trainingdata collected automatically.
1http://images.google.com/.2http://images.search.yahoo.com/.

Image Retrieval Using Keywords: The Machine Learning Perspective 17
1.4.2 Learning Approaches
Machine learning methods play an important role in automatic image anno-tation schemes. Machine learning involves algorithms that build general hy-potheses based on supplied instances and then use them to make predictionsabout future instances. Classification algorithms are based on the assumptionthat input data belong to one of several classes that may be specified eitherby an analyst or automatically clustered. Many analysts combine supervisedand unsupervised classification processes to develop final output analysis andclassified maps.
Supervised image classification organizes instances into classes by analyz-ing the properties of the supplied image visual features where each instanceis represented by the same number of features. Training instances are splitinto training and test sets. Initially, the characteristic properties of the visualfeatures of the training instances are isolated and class learning finds the de-scription that is shared by all positives instances. The resulting classifier isthen used to assign class labels to the testing instances where the values ofthe predictor features are known, but the value of the class label is unknown.Several supervised methods based on rules, neural networks, and statisticallearning have been utilized for classifying images into class labels as well asfor keyword model creation.
Decision trees are logic-based learning algorithms that sort instances ac-cording to feature values based on the divide-and-conquer approach. They aredeveloped by algorithms that split the input set of visual features into branch-like segments (nodes). A decision tree consists of internal decision nodes wherea test function is applied and the proper branch is taken based on the out-come. The process starts at the root node and it is repeated until a leaf nodeis achieved. There is a unique path for data to enter class that is defined byeach leaf node and this path is used to classify unseen data. A variety of deci-sion trees methods have been used in classification tasks such as CART [10],ID3 decision tree [63], its extension C4.5 [64] that has shown a good balancebetween speed and error rate [51], and the newest Random Forest [9].
Although, decision trees o!er a very fast processing and training phasecomparing to other machine learning approaches, su!er from the problem ofoverfitting to the training data, resulting in some cases in excessively detailedtrees and low predictive power for previously unseen data. Furthermore, deci-sion trees were designed for classification tasks: Every input entering the tree’sroot is classified to only one of its leafs. Assuming that the leafs correspondto keywords and the input is a low-level vector extracted from an input imagethen this image is assigned at most one keyword during prediction. The key-word models, on the other hand, are based on the one-against-all paradigm.For each keyword there is a dedicated predictor which decides, based on thelow-level feature vector it fed with, whether the corresponding image must beassigned the particular keyword or not.
The rules created for each path from the root to a leaf in a decision tree can

18 Book title goes here
also be used directly for classification. Rule based algorithms aim to constructthe smallest rule-set that is consistent with the training data. In comparisonwith decision trees, rule-based learning evaluates the quality of the set ofinstances that is covered by the candidate rule while the former evaluatesthe average quality of a number of disjoint sets [44]. However, rule-basedlearning faces problems with noisy data. More e"cient learners have beenproposed such as the IPER (Incremental Reduced Error Pruning) [29] andRipper (Repeated Incremental Pruning to Produce Error Reduction) [18] toovercome these drawback.
Assuming that every keyword is modeled with a rule, then rule-based learn-ing is appropriate for creating visual models for keywords since it provides therequired scalability. That is, every time a new keyword must be modeled anew rule is constructed, based on available training data, without a!ectingthe existing keyword models (rules). Unfortunately, the case is not so sim-ple. Rule based systems perform well in cases where the dimensionality ofinput is limited. However, the low-level features that are used to capture thevisual content of an image or image region are inherently of high dimension-ality. Thus, despite their scalability rule-based systems lack in performancecompare to other keyword modeling schemes.
Neural Networks (NNs) have incredible generalization and good learningability for classification tasks. NNs use the input data and train a networkto learn a complex mapping for classification. A NN is supplied by the inputinstances and actual outputs and then compares the predicted class with theactual class and estimates the error to modify the weights. There are numer-ous NNs based algorithms with significant research interest in Radial BasisFunction (RBF) networks [35] since in comparison with the multilayer percep-trons, the RBF trains faster and their hidden layer has easier interpretation.Furthermore, in comparative study on object classification [75] for keywordextraction purposes, RBFs proved to be the more robust and with the highestpredicting performance among several state of the NN classifiers.
An RBF network consists on an input layer, a hidden layer with a RBFactivation function and a linear output layer. Tuning the activation functionto achieve the best performance is a little bit tricky, quite arbitrary and depen-dent on the training data. Thus, despite their significant abilities in predictionand generalization RBF networks are not so popular as statistical learning ap-proaches discussed next.
Support Vector Machines (SVMs), a machine learning scheme which isbased on statistical learning theory, is one of the most popular approachesto data modeling and classification [79]. SVMs, with the aid of kernel map-ping, transform input data into a high dimensional feature space and try tofind the hyperplane that separates positive from negative samples. The ker-nel can be linear, polynomial, Gaussian, Radial Basis Function (RBF), etc.The hyperplane is chosen such as it keeps the distance between the nearestpositive and negative examples as high as possible. The number of featuresencountered in the training data does not a!ect the model complexity of an

Image Retrieval Using Keywords: The Machine Learning Perspective 19
SVM, so SVMs deal perfectly with learning tasks where the dimensionalityof feature space is large with respect to the number of training instances.Training a classifier using SVM has less probability of losing important infor-mation because SVM constructs the optimal hyperplane using dot productsof the training feature vectors with the hyperplane. Sequential Minimal Op-timization (SMO) [62], [42] and LibSVM [24] are two of the state of the artimplementations of the SVMs with high classification performance.
As far as the creation of visual models from keywords is concerned, theSVMs have many desirable properties. First, they are designed to deal withbinary problems (they make decisions on whether an input instance belongsor not to a particular class) which provides the required scalability to trainnew keyword models independently of the existing ones. Second, they deale!ectively with the large dimensionality of the input space created by low-levelfeature vectors extracted from images. Finally, they do not require so manytraining examples as other machine learning methods. As we have alreadymentioned, in automatic image annotation the availability of training data isa key issue. Therefore, methods that are conservative in this requirement arehighly preferable.
1.5 evaluation performance Evaluation
Keyword visual models are created using training data but their performancemust be evaluated on unseen training examples. The experimental perfor-mance on unseen data, tests the ability of the visual models to generalize.Training models using larger datasets leads to models with better generaliza-tion ability. This is true, however, when measures against overfitting are takenduring training.
The performance of the created keyword visual models can be evaluatedusing a variety of measures. These measures are mainly taken from patternrecognition and information retrieval domains. The simplest measure used isthe accuracy of correctly classifying instances in the corresponding keywordclasses. Accuracy is defined as the percentage of correct classifications on testdata while the error rate is the percentage of incorrect ones. The relationbetween accuracy and error rate is given below:
Accuracy = 1 " ErrorRate (1.4)
Although accuracy is representative enough to test the e!ectiveness ofthe created models, it su!ers from several limitations. It assumes a relativelyuniform distribution of training samples and as well as equal cost for misclassi-fications. The information about actual and predicted classification containedin the confusion matrix [43] can be used for deriving a variety of e!ectiveness

20 Book title goes here
FIGURE 1.2Confusion Matrix.
measures. An example of a confusion matrix for two keyword classes (Positive,Negative) is shown in Fig. 1.2.
In the confusion matrix a represents the number of samples in the testdata that were correctly classified as negative (TN-True Negative) while d in-dicates the number of data classified correctly as positive (TP-True Positive).In the same way, b represents the number of samples that were negative butincorrectly classified as positive (FP-False Positive) while c shows the numberof positive samples that incorrectly classified as negative (FN-False Negative).Based on the confusion matrix the accuracy can be calculated as:
Accuracy =a + d
a + b + c + d=
TN + TP
Total number of cases(1.5)
The True Positive Rate (TPR) measure, which in the domain of informa-tion retrieval is known as Recall, indicates the proportion of positive samplesthat were correctly classified:
TPR =d
c + d=
TP
Actual positive cases(1.6)
Similarly the True Negative Rate (TNR) indicates the proportion of neg-ative samples that correctly classified as negative:
TNR =a
a + b=
TN
Actual negative cases(1.7)
The False Positive Rate (FPR) indicates the proportion of negative sam-ples that were incorrectly classified as positive while the False Negative Rate(FNR) indicates the proportion of positive samples that were incorrectly clas-sified as negative:
FPR =b
a + b(1.8)

Image Retrieval Using Keywords: The Machine Learning Perspective 21
FNR =c
c + d(1.9)
Finally, Precision, which is also a popular measure used in informationretrieval, represents the proportion of the predicted positive samples that werecorrectly classified as such. It is given by the following formula:
Precision =d
b + d(1.10)
The harmonic average of Precision and Recall gives the F-measure:
F " measure =2 # Precision # Recall
Precision + Recall(1.11)
The precision-recall curve illustrates precision as a function of recall andit is a type of ROC curve. In several cases by tuning the parameters of themodels you have the opportunity to decrease Precision in favor of Recall andvice-versa. By doing so you can create the corresponding curve and decide on‘operation point’ (pair of precision and recall performances) that meet yourrequirements.
In cases where the ranking of results is important (i.e., some keywordsare more related than others with a particular image) alternative measuresare used. The Mean Average Precision (MAP) is a popular measure used inthis case. In order for MAP to be computed the precision in several queriesis calculated and the mean score is obtained. However, in these queries thenumber of results is restricted. Examples of such queries are: “Find the bestkeyword of image X”, “Find the two better keywords for image X”, “Findthe three better keywords for image X”, and so on. The MAP is the averageprecision of these queries and is computed by:
MAP =
"Qi=1
P (i)
Q(1.12)
where Q indicates the total number of queries and P(i) is the precision ob-tained in the i-th query.
1.6 A study on creating visual models
Further to the discussion included to the previous sections, we present an ex-perimental study on the creation of visual models for crowdsourcing originatedkeywords within the athletics domain. Initially, 500 images3 were manually an-
3The images were randomly selected from a large dataset collected in the framework ofFP6 BOEMIE project.

22 Book title goes here
notated by 15 users using a predefined vocabulary of 33 keywords [72]. Manualannotation was performed with the aid of the MuLVAT annotation tool [71].
For our experiments we have selected eight representative keywords andfor each keyword, 50 images that were annotated with this keyword were cho-sen. Twelve di!erent visual models were created for each keyword class bycombining three di!erent feature types and four di!erent machine learningalgorithms. The keywords modeled are: “Discus”, “Hammer”, “High Jump”,“Hurdles”, “Javelin”, “Long Jump”, “Running”, and “Triple Jump”. The per-formance and e!ectiveness of the created models are evaluated utilizing theaccuracy of correctly classified instances.
The unified framework of creating visual models for keywords obtained viacrowdsourcing is illustrated in Fig. 1.3 while a detailed example is given inFig. 1.4 and Fig. 1.5.
1.6.1 Feature Extraction
Three di!erent low-level feature types, HOG, SIFT and MPEG-7 were ex-tracted from each image group and used to create the visual models. In thecase of HOG, the implementation proposed in [53] was used with the aid of25 rectangular cells and 9 bins histogram per cell. The 16 histograms with 9bins were then concatenated to make a 225-dimensional feature vector. In thecase of SIFT, the large number of extracted keypoints was quantized into a100-dimensional feature vector using k-means clustering. Finally, after an ex-tensive experimentation on MPEG-7 descriptors (for details see also [75]) theColor Layout(CL), Color Structure (CS), Edge Histogram (EH) and Homoge-nous Texture (HT) descriptors were chosen. The combination of the selecteddescriptors creates a 186-dimensional feature vector.
1.6.2 Keywords Modeling
As already mentioned in the previous sections, in order to ensure scalabilityand to fulfill the multiple keyword assignment per image, keyword modelsshould be developed using the one-against-all training paradigm [69]. Thus,the creation of a visual model for each keyword was treated as a binary clas-sification problem. The feature vectors of each keyword class were split intotwo groups: 80% were used for training models and the remaining 20% fortesting the performance of these models. Positive examples were chosen fromthe corresponding keyword class while the negative ones were randomly takenfrom the seven remaining classes.
For the learning process we used four di!erent algorithms: decision trees(in particular the Random Forest variation), induction rules (Ripper), NeuralNetworks (RBFNetwork) and Support Vector Machines (SMO). During train-ing some parameters were optimized via experimentation in order to obtainthe best performing model for each feature vector. The number of trees wasoptimally selected for the Random Forest models. The minimal weights of

Image Retrieval Using Keywords: The Machine Learning Perspective 23
FIGURE 1.3Automatic image annotation by modeling crowdsourcing originated keywords.

24 Book title goes here
FIGURE 1.4Example of creating visual models.

Image Retrieval Using Keywords: The Machine Learning Perspective 25
FIGURE 1.5Example of automatic image annotation using visual models.
instances within a split and the number of rounds of optimization were ex-amined for Ripper models. The number of clusters and ridge were tuned foreach one of the feature vectors for the RBFNetwork. Finally, we experimentedwith the complexity constant and type of kernel for the SMO.
1.6.3 Experimental Results
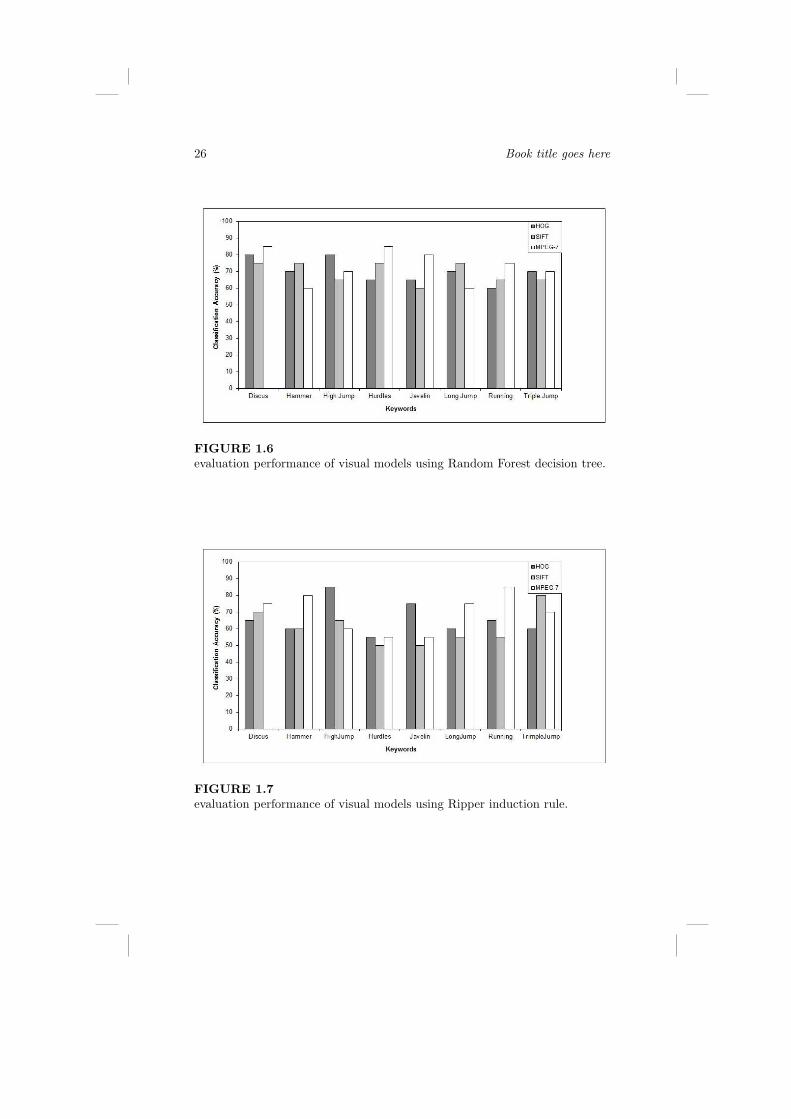
Figures 1.6, 1.7, 1.8, 1.9 show the accuracy of correctly classified instancesper keyword class using the four di!erent machine learning algorithms men-tioned earlier. The results shown in these figures can be examined under threeperspectives: First, in terms of the e"ciency and e!ectiveness of the variouslearning algorithms in modelling crowdsourced keywords, second, in terms ofthe appropriateness of the low-level features to accurately describe the visualcontent of images in distinctive manner, and third, in terms of the ability ofthe created models to classify the images into the corresponding classes andassign to them the right keywords.
TABLE 1.2Average classification accuracy(%) values.
Classifier HOG SIFT MPEG-7 Overall
Random Forest 70.0 69.38 73.13 70.83Ripper 65.63 60.63 69.38 65.21RBFNetwork 75.0 64.38 75.63 71.67SMO 72.5 69.38 81.25 74.38
26 Book title goes here
FIGURE 1.6evaluation performance of visual models using Random Forest decision tree.
FIGURE 1.7evaluation performance of visual models using Ripper induction rule.

Image Retrieval Using Keywords: The Machine Learning Perspective 27
FIGURE 1.8evaluation performance of visual models using RBFNetwork.
FIGURE 1.9evaluation performance of visual models using SMO support vector machine.

28 Book title goes here
The performance of the learning algorithms is examined through the timerequired to train the models (e"ciency), the robustness to the variation oflearning parameters and the e!ectiveness of the created models to identifythe correct keywords for unseen input images.
The learning takes no more than a few seconds for the majority of thekeyword models for all the machine learning algorithms examined. The fluc-tuation in classification performance during parameters tuning is significantlylower in Random Forest, Ripper and SMO than that of the RBFNetwork. Thisis something expected. As already discussed, tuning the activation functionlayer in RBF networks is a bit tricky and depends on the training data.
As far as the e!ectiveness is concerned, there is a significant di!erence onthe performance of the models created using the individual learners. It is evi-dent from Table 1.2 that SMO is the most reliable learner with a total averageclassification accuracy equal to 74.38%. The RBFNetwork and Random Forestobtain nearly the same average classification accuracy with both performingbetter when fed with MPEG-7 features. Random Forest performs well for theother type of features while the RBFNetwork performs fairly well when usingHOG features and quite moderately when fed with SIFT type features. TheRipper inductive rule algorithm obtains the worst average classification ac-curacy score. The overall best classification accuracy occurs when combiningthe SMO classifier with MPEG-7 features while the worst performance occurswhen combining the Ripper algorithm with the SIFT features. The majority,if not all, of the above results are in agreement with previous studies. SVMbased algorithms perform well in learning tasks where the dimensionality of in-put space is high with respect to the number of training examples. Rule-basedclassifiers, on the other hand, face di"culties whenever the dimensionality ofinput space is high.
Concerning the e!ectiveness of the various low-level feature types, the ex-perimental results indicate that the MPEG-7 features perform better thanHOG and SIFT. The classification accuracy obtained using these features isbetter than the other two independently of the training algorithm used. Thesecond more reliable low-level feature type for modeling keywords is the HOG.HOG features when combined with an RBFNetwork classifier achieve an aver-age classification accuracy of 75% which is quite high. The worst performanceis obtained by the SIFT type features. It only achieves a maximum classifica-tion accuracy of approximately 75% for specific keyword classes. In particular,when combined with Random Forest decision tree it reaches an accuracy score75% for the keyword classes “Discus” and “Hammer” (see also Fig. 1.6) whilewhen combined with SMO it reaches similar score for“Hurdles” keyword class(see also Fig. 1.9). It is interesting to note that the best performance of theSIFT features is obtained for keyword classes corresponding to objects withwell defined shape characteristics.
Once again, the results referring to the feature types are quite predictable.MPEG-7 descriptors are especially designed features to accommodate contentbased image retrieval. They were selected based on extended experimentation

Image Retrieval Using Keywords: The Machine Learning Perspective 29
and comparative studies with other feature types. SIFT features, on the otherhand, were primarily defined for object detection and object modeling tasks.Furthermore, in an attempt to fix the dimensionality of input space so asto be used in machine learning frameworks, SIFT keypoints are grouped to-gether using either histograms or clustering methods. This grouping discardsthe information about the spatial distribution of keypoints and deterioratessignificantly their visual content description power.
Nearly all models are able to assign the right keywords to unseen images.The overall accuracy scores are in the range 55%-95%. The best scores are ob-tained for keyword classes corresponding to objects with a well defined shapesuch as “Discus” and “Hurdles”. In contrary, keyword classes corresponding tomore abstract terms, such as “Running” and “Triple Jump” achieve relativelypoor scores. Thus, keywords that are related with the actual content of theimages can be more easily modeled, and as a result, automatic annotation ofinput images with such keywords is both feasible and realistic. On the otherhand, modeling keyword classes which are not clearly related with the imagecontent is by far more di"cult. This is because the content of images corre-sponding to these keywords has many similarities with the content of imagescorresponding to other keywords.
1.7 Conclusion
Although Content Based Image Retrieval (CBIR) has attracted large amountof research interest, the di"culties in querying by an example propel ultimateusers towards text queries. Searching by text queries yields more e!ectiveand accurate results that meet the needs of the users while at the same timepreserves their familiarity with the way traditional search engines operate.In recent years, much e!ort has been expended on automatic image annota-tion methods, since the manual assignment of keywords is time consuming andlabour intensive procedure. This chapter overviews the automatic image anno-tation under the perspective of machine learning and covers di!erent aspectsin this area. It discusses and presents several studies referring to: (a) low-levelfeature extraction and selection, (b) training algorithms that can be utilizedfor keyword modeling based on visual content, and (c) the creation of appro-priate and reliable training data, to be used with the training scheme, usingthe least manual e!ort. Finally, we have proposed and illustrate a new idea foraddressing the key issues in automatic keyword extraction by creating separatevisual models for all available keywords using the one-against-all paradigm toaccount for the scalability and multiple keyword assignment problems.
We believe that the prospective reader of this chapter would be equippedwith the ability to identify the key issues in automatic image annotation andwould be triggered to think ahead to propose alternative solutions. Further-

30 Book title goes here
more, the last section of the chapter can serve as a guide for researchers whowant to experiment with automatic keyword assignment to digital images.

Bibliography
[1] ISO/IEC 15938-3:2001 Information Technology - Multimedia ContentDescription Interface - Part 3: Visual, Ver. 1.
[2] Amazon Mechanical Turk - Artificial Artificial Intelligence,http://www.mturk.com.
[3] S. Alcic and S. Conrad. A clustering-based approach to web image contextextraction. In Proceedings of 3rd International Conferences on Advancesin Multimedia, pages 74–79, Budapest, Hungary, April 2011.
[4] A. Arampatzis, K. Zagoris, and S. A. Chatzichristofis. Dynamic two-stageimage retrieval from large multimedia databases. Information Processing& Management, 49(1):274–285, January 2013.
[5] K. Athanasakos, V. Stathopoulos, and J. Jose. A framework for evaluat-ing automatic image annotation algorithms. Lecture Notes in ComputerScience, 5993:217–228, 2010.
[6] B. Ayers and M. Boutell. Home interior classification using sift key-point histograms. In Proceedings of IEEE International Conference onComputer Vision and Pattern Recognition, pages 1–6, Minneapolis, Min-nesota, USA, June 2007.
[7] H. Bay, A. Ess, T. Tuytelaars, and L. V. Gool. Surf: Speeded up robustfeatures. Computer Vision and Image Understanding, 110(3):346–359,June 2008.
[8] A. Blum and T. Mitchell. Combining labeled and unlabeled data with co-training. In Proceedings of the 11th Annual Conference on ComputationalLearning Theory, pages 92–100, July 1998.
[9] L. Breiman. Random forests. Machine Learning, 45:5–32, October 2001.
[10] L. Breiman, J. Friedman, C. J. Stone, and R. A. Olshen. Classificationand regression trees. Statistics/Probability Series. Chapman & Hall, NewYork, NY, USA, January 1984.
[11] G. Carneiro, A.B. Chan, P.J. Moreno, and N. Vasconcelos. Supervisedlearning of semantic classes for image annotation and retrieval. IEEETransactions on Pattern Analysis and Machine Intelligence, 29(3):394–410, March 2007.
31

32 Book title goes here
[12] S. A. Chatzichristofis, A. Arampatzis, and Y. S. Boutalis. Investigat-ing the behavior of compact composite descriptors in early fusion, latefusion and distributed image retrieval. Radioengineering, 19(4):725–733,December 2010.
[13] S. A. Chatzichristofis and Y. S. Boutalis. Cedd: Color and edge directivitydescriptor: A compact descriptor for image indexing and retrieval. InA. Gasteratos, M. Vincze, and J. K. Tsotsos, editors, Computer VisionSystems, volume 5008 of Lecture Notes in Computer Science, pages 312–322. Springer Berlin Heidelberg, May 2008.
[14] S. A. Chatzichristofis and Y. S. Boutalis. Fcth: fuzzy color and texturehistogram - a low level feature for accurate image retrieval. In Proceedingsof 9th International Workshop on the Image Analysis for MultimediaInteractive Services, pages 191–196, Klagenfurt, Austria, May 2008.
[15] S. A. Chatzichristofis and Y. S. Boutalis. Content based radiology imageretrieval using a fuzzy rule based scalable composite descriptor. Multi-media Tools and Applications, 46:493–519, January 2010.
[16] S. A. Chatzichristofis and Y. S. Boutalis. Compact composite descriptorsfor content based image retrieval: Basics, concepts, tools. VDM Verlag,Saarbrucken, Germany, August 2011.
[17] S. A. Chatzichristofis, Y. S. Boutalis, and M. Lux. Spcd - spatial colordistributionddescriptor - a fuzzy rule based compact composite descriptorappropriate for hand drawn color sketches retrieval. In Proceedings of the2nd International Conference on Agents and Artificial Intelligence, pages58–63, Valencia, Spain, January 2010.
[18] W. W. Cohen. Fast e!ective rule induction. In 12th International Con-ference on Machine Learning, pages 115–123, Tahoe City, CA, USA, July1995.
[19] C. Cusano, G. Ciocca, and R. Schettini. Image annotation using svm.In Proceedings of Internet Imaging V, volume SPIE 5304, pages 330–338,December 2003.
[20] N. Dalal and B. Triggs. Histograms of oriented gradients for human de-tection. In Proceedings of International Conference on Computer Vision& Pattern Recognition, pages 886–893, San Diego, CA, USA, June 2005.
[21] R. Datta, D. Joshi, J. Li, and J. Z. Wang. Image retrieval: Ideas, influ-ences, and trends of the new age. ACM Computing Surveys, 40(2):5:1–5:60, April 2008.
[22] P. Duygulu, K. Barnard, J. F. G. de Freitas, and A. D. Forsyth. Objectrecognition as machine translation: learning a lexicon for a fixed imagevocabulary. In Proceedings of the 7th European Conference on ComputerVision-Part IV, pages 97–112, Copenhagen, Denmark, May 2002.

Image Retrieval Using Keywords: The Machine Learning Perspective 33
[23] C. Eickho! and A. P. De Vries. How crowdsourcable is your task? InWorkshop on Crowdsourcing for Search and Data Mining, pages 11–14,Hong Kong, February 2011.
[24] R.-E. Fan, P.-H. Chen, and C.-J. Lin. Working set selection using sec-ond order information for training support vector machines. Journal ofMachine Learning Research, 6:1889–1918, December 2005.
[25] F. Fauzi, J.-L. Hong, and M. Belkhatir. Webpage segmentation for ex-tracting images and their surrounding contextual information. In Proceed-ings of the ACM International Conference on Multimedia, pages 649–652,Vancouver, Canada, October 2009.
[26] H. Feng, R. Shi, and T.-S. Chua. A bootstrapping framework for annotat-ing and retrieving www images. In Proceedings of the 12th Annual ACMInternational Conference on Multimedia, pages 960–967, New York, NY,USA, October 2004.
[27] S. L. Feng, R. Manmatha, and V. Lavrenko. Multiple bernoulli relevancemodels for image and video annotation. In Proceedings of the IEEE Com-puter Society Conference on Computer Vision and Pattern Recognition,pages 1002–1009, Washington, DC, USA, June 2004.
[28] K. Fukunaga. Introduction to Statistical Pattern Recognition. AcademicPress Professional, Inc., San Diego, CA, USA, October 1990.
[29] J. Furnkranz and G. Widmer. Incremental reduced error pruning.In International Conference on Machine Learning, pages 70–77, NewBrunswick, NJ, USA, July 1994.
[30] A. Ghoshal, P. Ircing, and S. Khudanpur. Hidden markov models forautomatic annotation and content - based retrieval of images and video.In Proceedings of the 28th Annual International ACM SIGIR Conferenceon Research and Development in Information Retrieval, pages 544–551,Salvador, Brazil, August 2005.
[31] J. Hafner, H.S. Sawhney, W. Equitz, M. Flickner, and W. Niblack.E"cient color histogram indexing for quadratic form distance func-tions. IEEE Transactions on Pattern Analysis and Machine Intelligence,17(7):729–736, July 1995.
[32] A. Hanbury. A survey of methods for image annotation. Journal of VisualLanguages & Computing, 19(5):617–627, October 2008.
[33] X. He, D. Cai, J.-R. Wen, W.-Y. Ma, and H.-J. Zhang. Clustering andsearching www images using link and page layout analysis. ACM Trans-actions on Multimedia Computing, Communications, and Applications,3(2), May 2007.

34 Book title goes here
[34] J. Howe. Crowdsourcing: Why the power of the crowd is driving the futureof business. Crown Business, New York, NY, USA, August 2008.
[35] R. J. Howlett and Jain L. C. Radial basis function networks 2: Newadvances in design. Physica-Verlag, Heidelberg, Germany, March 2001.
[36] R. Jaimes, M. Christel, S. Gilles, R. Sarukkai, and W.-Y. Ma. Multimediainformation retrieval: What is it, and why isn’t anyone using it? In Pro-ceedings of the 7th ACM SIGMM International Workshop on MultimediaInformation Retrieval, pages 3–8, Singapore, November 2005.
[37] J. Jeon, V. Lavrenko, and R. Manmatha. Automatic image annotationand retrieval using cross-media relevance models. In Proceedings of the26th Annual international ACM SIGIR Conference on Research and De-velopment in Informaion Retrieval, pages 119–126, Toronto, ON, Canada,July 2003.
[38] L. Jiang, J. Hou, Z. Chen, and D. Zhang. Automatic image annotationbased on decision tree machine learning. In Proceedings of InternationalConference on Cyber-Enabled Distributed Computing and Knowledge Dis-covery, pages 170–175, Zhangjiajie, China, October 2009.
[39] T. Joachims, L. Granka, B. Pang, H. Hembrooke, and Gay G. Accuratelyinterpreting clickthrough data as implicit feedback. In Proceedings ofthe 28th Annual International ACM SIGIR Conference, pages 154–161,Salvador, Brazil, August 2005.
[40] G. Kazai, J. Kamps, M. Koolen, and N. Milic-Frayling. Crowdsourcing forbook search evaluation: Impact of quality on comparative system ranking.In Proceedings of the 34th Annual International ACM SIGIR Conferenceon Research and Development in Information Retrieval, pages 205–214,Beijing, China, July 2011.
[41] Y. Ke and R. Sutkthankar. Pca-sift: A more distinctive representation forlocal image descriptors. In Proceedings of IEEE International Conferenceon Computer Vision and Pattern Recognition, volume 2, pages II–506–II–513, Washington, DC, USA, June 2004.
[42] S. S. Keerthi, S. K. Shevade, C. Bhattacharyya, and K. R. K. Murthy.Improvements to platt’s smo algorithm for svm classifier design. NeuralComputation, 13(3):637–649, March 2001.
[43] R. Kohavi and F. Provost. Glossary of terms. Machine Learning, 30(2-3):271–274, January 1998.
[44] S. B. Kotsiantis. Supervised machine learning: A review of classificationtechniques. Informatica, 31:249–268, October 2007.

Image Retrieval Using Keywords: The Machine Learning Perspective 35
[45] H. Kwasnicka and M. Paradowski. Machine learning methods in auto-matic image annotation. In J. Koronacki, Z. Ra?, S. Wierzcho?, andJ. Kacprzyk, editors, Advances in Machine Learning II, volume 263 ofStudies in Computational Intelligence, pages 387–411. Springer BerlinHeidelberg, 2010.
[46] V. Lavrenko, R. Manmatha, and J. Jeon. A model for learning the se-mantics of pictures. In Proceedings of Advances in Neural InformationProcessing Systems, Lake Tahoe, NV, USA, December 2003.
[47] S. Lazebnik, C. Schmid, and J. Ponce. Beyond bags of features: Spatialpyramid matching for recognizing natural scene categories. In ProceedingsIEEE Computer Society Conference on Computer Vision and PatternRecognition, volume 2, pages 2169–2178, New York, NY, USA, June 2006.
[48] E. Levina and P. J. Bickel. Maximum likelihood estimation of intrinsicdimension. Advances in Neural Information Processing Systems, 17:777–784, December 2004.
[49] J. Li and J.Z. Wang. Real-time computerized annotation of pictures. InProceedings of the ACM Multimedia Conference, pages 911–920, SantaBarbara, CA, USA, October 2006.
[50] T. Li, T. Mei, I.-S. Kweon, and X.-S. Hua. Contextual bag-of-words forvisual categorization. IEEE Transactions on Circuits and Systems forVideo Technology, 21(4):381–392, April 2011.
[51] T. S. Lim, W.-Y. LOH, and W. Cohen. A comparison of predictionaccuracy, complexity, and training time of thirty-three old and new clas-sification algorithms. Machine Learning, 40:203–228, September 2000.
[52] D. G. Lowe. Distinctive image features from scale invariant keypoints.International Journal of Computer Vision, 60(2):91–110, November 2004.
[53] O. Ludwig, D. Delgado, V. Goncalves, and U. Nunes. Trainable classifier-fusion schemes: An application to pedestrian detection. In Proceedings of12th International IEEE Conference on Intelligent Transportation Sys-tems, pages 432–437, St.Louis, MO, USA, October 2009.
[54] C. Macdonald and I. Ounis. Usefulness of quality clickthrough data fortraining. In Proceedings of the 2009 Workshop on Web Search Click Data,pages 75–79, Barcelona, Spain, February 2009.
[55] A. Makadia, V. Pavlovic, and S. Kumar. A new baseline for image an-notation. In Proceedings of European Conference on Computer Vision,pages 316–329, Marseille, France, October 2008.
[56] K. Mikolajczyk and C. Schmid. A performance evaluation of local descrip-tors. IEEE Transactions on Pattern Analysis and Machine Intelligence,27(10):1615–1630, October 2005.

36 Book title goes here
[57] Y. Mori, H Takahashi, and R. Oka. Image-to-word transformation basedon dividing and vector quantizing images with words. In Proceedings ofInternational Workshop on Multimedia Intelligent Storage and RetrievalManagement, pages 405–409, Orlando, FL, USA, October 1999.
[58] H. Murase and S. Nayar. Visual learning and recognition of 3-d objectsfrom appearance. International Journal of Computer Vision, 14(1):5–24,January 1995.
[59] C. W. Niblack, R. Barber, W. Equitz, M. D. Flickner, E. H. Glasman,D. Petkovic, P. Yanker, C. Faloutsos, and G. Taubin. Qbic project: query-ing images by content, using color, texture, and shape. In Proceedingsof SPIE Storage and Retrieval for Image and Video Databases, pages173–187, San Jose, CA, USA, January 1993.
[60] M. Nixon and A. S. Aguado. Feature Extraction & Image Processing.Academic Press, San Diego, CA, USA, second edition, January 2008.
[61] R. W. Picard. Light-years from lena: video and image libraries of thefuture. In Proceedings of International Conference on Image Processing,pages 310–313, Washington, DC, USA, October 1995.
[62] J. C. Platt. Advances in kernel methods. chapter Fast training of supportvector machines using sequential minimal optimization, pages 185–208.MIT Press, Cambridge, MA, USA, 1999.
[63] J. R. Quinlan. Discovering rules by induction from large collections ofexamples. In D. Michie, editor, Expert systems in the micro-electronicage, pages 168–201. Edinburgh University Press, Edinburgh, UK, 1979.
[64] J. R. Quinlan. C4.5: Programs for machine learning. Morgan KaufmannPublishers Inc., San Francisco, CA, USA, October 1992.
[65] B. Schiele and J.L. Crowley. Probabilistic object recognition using mul-tidimensional receptive field histograms. In Proceedings of the 13th In-ternational Conference on Pattern Recognition, volume 2, pages 50–54,Vienna, Austria, August 1996.
[66] C. Schmid and R. Mohr. Local grayvalue invariants for image re-trieval. IEEE Transactions on Pattern Analysis and Machine Intelli-gence, 19(5):530–535, May 1997.
[67] J. Sivic and A. Zisserman. Video google: A text retrieval approach to ob-ject matching in videos. In Proceedings of IEEE International Conferenceon Computer Vision, pages 1470–1477, Nice, France, October 2003.
[68] A. W. M. Smeulders, M. Worring, S. Santini, A. Gupta, and R. Jain.Content-based image retrieval at the end of the early years. IEEE Trans-actions on Pattern Analysis and Machine Intelligence, 22(2):1349–1380,December 2000.

Image Retrieval Using Keywords: The Machine Learning Perspective 37
[69] D. M. J. Tax and R .P .W. Duin. Using two-class classifiers for multiclassclassification. In Proceedings of the of 16th International conference ofPattern Recognition, pages 124–127, Quebec, Canada, August 2002.
[70] Z. Theodosiou, C. Kasapi, and N. Tsapatsoulis. Semantic gap betweenpeople: An experimental investigation based on image annotation. In Sev-enth International Workshop on Semantic and Social Media Adaptationand Personalization, pages 73–77, Luxembourg, December 2012.
[71] Z. Theodosiou, A. Kounoudes, N. Tsapatsoulis, and M. Milis. Mulvat: Avideo annotation tool based on xml-dictionaries and shot clustering. InC. Alippi, M. Polycarpou, C. Panayiotou, and G. Ellinas, editors, Arti-ficial Neural Networks II ICANN 2009, volume 5769 of Lecture Notes inComputer Science, pages 913–922. Springer Berlin Heidelberg, September2009.
[72] Z. Theodosiou and N. Tsapatsoulis. Modelling crowdsourcing originatedkeywords within the athletics domain. In L. Iliadis, I. Maglogiannis, andH. Papadopoulos, editors, Artificial Intelligence Applications and Innova-tions, volume 381 of IFIP Advances in Information and CommunicationTechnology, pages 404–413. Springer Berlin Heidelberg, September 2012.
[73] E. Tola, V. Lepetit, and P. Fua. Daisy: An e"cient dense descriptorapplied to wide-baseline stereo. IEEE Transactions on Pattern Analysisand Machine Intelligence, 32(5):815–830, May 2010.
[74] G. Tryfou, Z. Theodosiou, and N. Tsapatsoulis. Web image context ex-traction based on semantic representation of web page visual segments.In Proceedings of the 7th Int. Workshop on Semantic and Social MediaAdaptation and Personalization, pages 63–67, Luxembourg, December2012.
[75] N. Tsapatsoulis and Z. Theodosiou. Object classification using the mpeg-7 visual descriptors: An experimental evaluation using state of the artdata classifiers. In C. Alippi, M. Polycarpou, C. Panayiotou, and G. El-linas, editors, Artificial Neural Networks II ICANN 2009, volume 5769of Lecture Notes in Computer Science, pages 905–912. Springer BerlinHeidelberg, September 2009.
[76] T. Tsikrika, C. Diou, A. P De Vries, and A. Delopoulos. Image anno-tation using clickthrough data. In Proceedings of the 8th InternationalConference on Image and Video Retrieval, pages 1–8, Santorini, Greece,July 2009.
[77] M. A. Turk and A. P. Pentland. Face recognition using eigenfaces. In Pro-ceedings of the IEEE Computer Society Conference on Computer Visionand Pattern Recognition, pages 586–591, Maui, HI, USA, June 1991.

38 Book title goes here
[78] T. Tuytelaars and K. Mikolajczyk. Local invariant feature detectors: Asurvey. Computer Graphics and Vision, 3(3):177–280, January 2008.
[79] V. Vapnik. The nature of statistical learning theory. Springer-Verlag,New York, NY, USA, 1995.
[80] P. Welinder and P. Perona. Online crowdsourcing: rating annotators andobtaining cost e!ective labels. In Proceedings of IEEE Conference onComputer Vision and Pattern Recognition, pages 25–32, San Francisco,CA, USA, June 2010.
[81] J. Yang, J.-Y. Yang, D. Zhang, and J.-F. Lu. Feature fusion: Parallelstrategy vs. serial strategy. Pattern Recognition, 33:1369–1381, June 2003.
[82] J. Yang, S, S. K. Kim, K. S. Seo, Y. M. Ro, J.-Y. Kim, and Y. S. Seo.Semantic categorization of digital home photo using photographic regiontemplates. Information Processing & Management, 43(2):503–514, March2007.
[83] D. Zhang, M. M. Islam, and G. Lu. A review on automatic image anno-tation techniques. Pattern Recognition, 45:346–362, January 2012.
[84] M. Zhang and A. A. Sawchuk. Motion primitive-based human activityrecognition using a bag-of-features approach. In Proceedings of the 2ndACM SIGHIT International Health Informatics Symposium, pages 631–640, Miami, FL, USA, January 2012.
[85] R. Zhang, Z. Zhang, M. Li, and H. J. Zhang. A probabilistic semanticmodel for image annotation and multi-modal image retrieval. MultimediaSystems, pages 27–33, August 2006.
[86] Z. H. Zhou and M. L. Zhang. Multi-instance multi-label learning withapplication to scene classification. In Advances in Neural InformationProcessing Systems 19, pages 1609–1616, December 2006.
[87] S. Zhu and X. Tan. A novel automatic image annotation method basedon multi-instance learning. Procedia Engineering, 15:3439–3444, 2011.




















