
Distillation Column Internals/Configurations for Process ... - FKIT

Human Pose Estimation using Partial Configurationsand Probabilistic Regions
Timothy J. Roberts∗, Stephen J. McKenna†and Ian W. Ricketts‡
April 4, 2006
Abstract
A method for recovering a part-based descriptionof human pose from single images of people is de-scribed. It is able to perform estimation efficientlyin the presence significant background clutter, largeforeground variation, self-occlusion and occlusionby other objects. This is achieved through two keydevelopments. Firstly, a new formulation is pro-posed that allows partial configurations, hypothe-ses with differing numbers of parts, to be madeand compared. This permits efficient global sam-pling in the presence of self and other object occlu-sions without prior knowledge of body part visibil-ity. Secondly, a highly discriminatory likelihoodmodel is proposed comprising two complemen-tary components. A boundary component improvesupon previous appearance distribution divergencemethods by incorporating high-level shape and ap-pearance information and hence better discrimi-nates textured, overlapping body parts. An inter-part component uses appearance similarity of bodyparts to reduce the number of false-positive, multi-part hypotheses, hence increasing estimation effi-ciency. Results are presented for challenging im-ages with unknown subject and large variations insubject appearance, scale and pose.
1 Introduction and Motivation
Human pose estimation, if reliable and efficient,could form the basis of many important applica-tions. In addition to being necessary for automatedanalysis when only images are available as input,
∗[email protected]†[email protected]‡[email protected]
computer vision also provides a compelling alter-native to other sensing modalities in terms of cost,intrusiveness, accuracy and reliability. These of-ten competing requirements make it unlikely thata ‘one size fits all’ approach will be successful.Here we focus upon the largely ignored problemof automatic estimation of the transformation andvisibility of a set of body parts from highly un-constrainedsingle images. In particular, we intro-duce the partial configuration formulation that al-lows pose hypotheses with varying numbers of visi-ble parts to be made and compared. This part-basedapproach can be contrasted with lower detail poseparametrisations such as global position and scaleor a body contour, which are popular for highly un-constrained applications such as surveillance andsmart environments. The advantage of a part basedapproach is that occlusion can be explicitly mod-elled and efficient part based global search tech-niques can be employed. The partial configurationapproach is also applicable to scenes containing oc-clusion of people by other objects. It can also becontrasted with highly detailed pose descriptions,such as 3D surface structure, which occur in cer-tain medical and professional sports analysis appli-cations where the emphasis on accuracy and detailusually results in a more costly, intrusive systemthat requires highly constrained environments andoff-line operation in order to be beneficial. Thisfocus on a medium level of detail and highly un-constrained images is arguably the most promis-ing in terms of future, large scale applications suchas computer games, virtual reality and high band-width human computer interfaces and would al-low more detailed automated interpretation of posefrom pre-existing images.
The majority of current pose estimation methods
1

make strong assumptions regarding the backgroundscene, subject’s appearance (clothing), viewpoints,temporal dynamics, self-occlusion and occlusionby other objects [40, 38, 16]. Indeed, in spite ofconsiderable research into human tracking, mosttracking systems remain limited to constrainedscenes and rely upon strong temporal pose con-straints and therefore manual (re)initialisation. Incontrast, this paper focuses on the task of estimat-ing human pose fromsingle real-world images ofpoorly constrained scenes. This is clearly a morechallenging task since temporal information is ab-sent. Furthermore, given images containing restric-tive, partial information due to occlusion, the aim isto estimate the body pose of the visible portion. It isassumed that the system is not required to recoverpersonal metric details such as body sizes.
Most existing pose estimation systems followan analysis by synthesisparadigm in which posemodels are hypothesised and compared to images.Bayesian probability often forms the basis of suchsystems for a number of reasons. Firstly, the prob-abilistic logic provides a coherent framework formodelling the inherent uncertainty in the image andsystem. Secondly, Bayes rule allows the depen-dency between model and data to be reversed andthus the principled use of this paradigm. Thirdly,probability theory allows the construction of an ef-ficient system since decision making can proceed inthe presence of limited data and assumptions. Fi-nally, Bayesian statistics allows additional, perhapssubjective, prior information such as pose con-straints to be incorporated in a principled manner,something which is particularly important in lightof the complex appearance of people in images.Many human tracking systems build upon this spa-tial framework by assuming a Markov relation-ship between frames and thereby obtain a temporalprior. Taken together these approaches are essen-tially the probabilistic manifestation of the model-based architecture proposed early on by O’Rourkeand Badler [45].
In this Bayesian framework, components thatmust be developed in order to construct such a sys-tem are (i) a pose model that, by incorporating priorknowledge, describes the variation of human shape,(ii) a likelihood model that discriminates incorrectpose hypotheses from correct ones (i.e. those thatcorrespond to people) based upon image measure-
ments, and (iii) a computationally feasible estima-tion scheme that searches for probable pose hy-potheses. The aims of the work described here are:
1. Efficient discrimination of a single personwith a complex, unknown appearance froma cluttered, unknown scene that possibly oc-cludes body parts.
2. The development of a formulation that allowsefficient, accurate global estimation in suchconditions.
This emphasis on the formulation and likelihoodis central to the spirit of this and previous work [50]and distinguishes it from other research that usu-ally concentrates on prior constraints and efficientsearch techniques.
The paper is organized as follows. Section 2reviews the most relevant previous work. Sec-tion 3 describes the pose estimation problem to beaddressed, making explicit certain operational as-sumptions. Sections 4 and 5 describe the over-all formulation and the likelihood model. An em-pirical investigation of the likelihood is presentedin Section 6. Section 7 describes a pose estimationscheme and applies it to real-world images. Finally,Section 8 discusses the system as a whole, sum-marises its advantages and limitations and suggestssome directions for future research.
2 Previous work
A sizeable literature exists that is concerned, insome way or another, with the estimation of hu-man pose from images. Exhaustive coverage wouldbe inappropriate here. Instead, work most relevantto the formulation of pose estimation systems andlikelihood models is reviewed. Much of the litera-ture is concerned with human tracking rather thanestimation from a single image but certain compo-nents, such as likelihood models, are still relevanthere.
2.1 Formulation
Body modelling for pose estimation has been for-mulated using a variety of approaches. Some con-centrate on modelling the appearance in the im-age whilst others explicitly model the physical 3D
2

structure and acquisition system. Some model thebody as a whole whilst others decompose the bodyinto component parts.
Image contour models and silhouettes are par-ticularly relevant in applications where the back-ground is known or can be estimated. For exam-ple, silhouettes have been used to recover bodyparts from walking sequences [20]. An active con-tour model with interactive correction has beenused to recover a 3D body model [64]. Baumbergand Hogg [3] used contour modes of variation totrack pedestrians. Contour shape models have alsobeen combined with 2D part models to estimate 3Dpose [4] and over multiple viewpoints [44]. Suchhybrid models help disambiguate self-occludingposes such as the hands moving over the bodyand thereby resolve a key disadvantage of the con-tour representation. Rosaleset al. [52, 53] inferredpossible 2D joint locations from Hu moments ofsilhouettes using a learning architecture that im-plicitly represented the part-based nature of thehuman body. Given multiple views, expectation-maximisation was used to find the most consistent3D pose and the associated views.
In order to tackle the problem of contourdetec-tion, MacCormick and Blake [31] proposed a prob-abilistic discriminant based upon a likelihood ra-tio of edge measurements due to foreground andbackground clutter. This approach has similaritiesto the one adopted in this paper. When combinedwith importance sampling it allowed global sam-pling of an image containing low-dimensional tar-gets (head and shoulders). This partially addressedthe problem of automatically initialising contourmodels but was not practical for more varied ob-jects. The approach was extended to discriminateocclusion events from weak measurements [32].
The structure of the human body is well under-stood and anthropometric data are readily avail-able [18]. A part-based description is natural sinceit corresponds to our rigid bone structure. Theshapes of individual parts are commonly mod-elled using geometric primitives. Cardboard peo-ple models use 2D rectangular patches [25, 6].Others have used 2D ribbons [30] or 2D ellipti-cal blobs [65]. Early work by Hogg [21] used 3Dcylindrical primitives. Others have subsequentlyused cones with elliptical cross-sections [63],super-quadrics [36] or tapered super-quadrics [26,
17]. The shape parameters of these geometric partprimitives are often fitted manually or to specificcases using multiple views (e.g. [26]). Inter-subjectvariability is usually ignored. A notable exceptionis [59] whose detailed, high-dimensional, humanmodel used anthropometric data to specify a prioron part sizes. However, intra-scene variation due tonon-rigid deformation and clothing motion was notaddressed.
It is common to consider the body as a tree struc-ture, with the torso as the root, and to chain themodel-to-image transforms hierarchically, therebycapturing the kinematic structure of the humanbody. Various parameterisations of 3D part trans-formations have been proposed. Hierarchical 3Dtransformations with rotations parameterised usingEuler angles have been used [63] but suffer fromsingularity problems which arise when changes instate become unobservable. A 2D scaled prismaticparameterisation avoids such problems [6, 43]. The3D twists and exponential map formulation used inrobotics linearises the kinematics and removes thesingularity problems [5]. Such problems can alsobe avoided by using a random sample estimationscheme such as particle filtering that does not relyupon local derivatives [11].
More flexible joint representations than simplerelative orientation have been used with a resultingincrease in state dimensionality. Relative transla-tion of parts constrained by spring forces has beenused for the shoulder. Alternative ball and socketjoint parameterisations have been investigated [1].A phase space representation was considered forthe arm [39]. Finally, part-based transformationsalso allow existing inverse kinematics techniquesto be applied [66].
Three-dimensional part models account for self-occlusion by representing depth and using hiddensurface removal. In order to account for self-occlusion with 2D part models, depth ordering canbe used [49]. It is possible to track through self-occlusions without predicting them explicitly bypropagating multiple hypotheses [6]. Furthermore,even with a detailed 3D model it can be difficultto describe the appearance of partially occludedparts. This prompted work on actively choosingviewpoints from which to compute the likelihoodbased upon part visibility [26]. One significant ad-vantage of physically motivated 3D models is that
3

hypotheses can easily be related between multi-ple views [17]. However, the focus of this paperis on monocular estimation. There are problemsinherent in uncalibrated monocular estimation of3D pose even when 2D joint point locations areknown[62, 2, 41].
Part-based models allow constraints on the body,such as joint angle limits to be encoded. Beyondsimple joint angle limits, priors over whole posecan be defined [27]. Physically motivated 3D mod-els also allow constraints based upon part inter-penetration to be expressed [59].
In conclusion, a part-based representation is nat-ural given our prior knowledge of human bodystructure. In comparison to contour-based models,using this prior knowledge on the form of the bodyremoves much of the burden of learning highlyvaried shape models, implicitly accounts for non-linear changes resulting from self-occlusion and al-lows easier encoding of pose constraints. Further-more, a part-based parameter space is easier to in-terpret and allows constraints to be encoded moreeasily than contour descriptions. In comparisonto 3D physical models, view-oriented models aremore compact since (absolute) depth is not param-eterised. The 3D models allow multiple views tobe related and self-occlusion and perspective ef-fects to be modelled explicitly but these advantagescome at the expense of increased dimensionalityand problems with ambiguities.
2.2 Likelihood
Due to the complexity and variation of humanappearance, building a general but discriminatorylikelihood model is difficult and still a topic of ac-tive research. Various likelihood models have beenproposed. Those based on cues such as optical flowand background models are not mentioned becausetheir use is excluded by the problem characteris-tics outlined in Section 3. It should be noted thatstrongly discriminatory likelihood models are notas important for trackers using temporal constraintson typically short, manually initialised sequencesas they are for the global pose estimation problemconsidered here.
Any likelihood model should be evaluatedwithin the context of the entire pose estimation sys-tem. Nevertheless two desiderata can be identified:
(i) it should be highly discriminatory, especiallysince the number of incorrect instances is muchlarger than the number of correct instances, and (ii)it should allow efficient sampling and search tech-niques to be applied. These goals can be compet-ing. From the point of view of discrimination theideal likelihood model would be a delta function onthe correct model configuration. In reality, the like-lihood is usually multi-modal and complex. Fur-thermore, there is a tradeoff between model gener-ality and discrimination. For example, better dis-crimination becomes possible when prior knowl-edge of foreground appearance is available. How-ever, a key problem in human pose estimation isthat there is in general limited information avail-able regarding the foreground and background ap-pearance.
Two categories of likelihood model can be iden-tified: (i) those that are based upon differencesin appearance of the foreground and backgroundaround the boundary, and (ii) those that model theappearance of object foreground.
2.2.1 Boundary Models
Likelihood models based upon appearance differ-ences across the model boundary are popular forhuman tracking since they can exhibit a good de-gree of invariance to changes in foreground andbackground appearance. Early work by Hogg [21]used a threshold on the magnitudes of Sobel fil-ter responses to detect edges and projected modelboundary segments were then inspected to findedges within a specified distance and relative ori-entation. Gavrila and Davis [17] used a similar ap-proach but employed a robust variant of a chamferdistance transform computed from detected edgesin order to provide a smooth, broad search func-tion. Wachter and Nagel improved on this ap-proach by matching model edges directly to filterresponses and actively selecting strong model can-didates based on the overlap with similar parts [63].Furthermore, due to the limitations of intensityedge cues in real world images, a foreground tem-plate was also employed to stabilise tracking.
A different approach to boundary modelling in-volves casting model normals and inspecting gra-dients along these ‘measurement lines’. Mac-Cormick and Blake [31] developed a probabilis-
4

tic formulation of this approach based on mod-elling distributions of features on the foregroundand background. In order to deal with occlusion,which is manifested as groups of weak boundarymeasurements, this scheme was extended to incor-porate a Markov random field learnt from previousocclusion instances [32].
Konishiet al.[28] emphasised the importance ofboth principled statistical modelling and describ-ing filter responses from the non-boundary edges.To accomplish this, ground truth segmentationswere used to learn the probability density func-tions (PDFs) of multi-scale filter responses both onand off object boundaries. Then a ratio betweenthese PDFs, the likelihood ratio, was used to pro-vide a nonlinear mapping from edge features to ameasure of the edge strength. In comparison withstandard model-based techniques excellent resultswere reported and this represents the state-of-the-art in ‘bottom up’ intensity edge detection. Siden-bladh and Black [57] applied this approach to hu-mans by learning PDFs of intensity edge featuresfor points around human boundaries and for pointson the background. Likelihood ratios were thencombined by assuming independence. However, incontrast to previous work, it was reasoned that theimportant edge information is contained in the ori-entation and scale of the edges rather than in themagnitude and therefore the image should be con-trast normalised. A conclusion of their work that isrelevant here is that statistical models of colour andtexture would improve results.
In contrast to the above approaches that comparemodel projections to simple local filters, Ronfardetal. [51] trained support vector classifiers for wholeparts (and one for the whole body) based upon ori-entation and scale specific Gaussian derivative fil-ters (a 2016 dimensional feature vector per imagelocation). However, this system was unable to ac-count for self-occlusion. The false part detectionrate (in contrast to person detection which makesuse of grouping) was reported to be approximately80% (although this does not include confusion be-tween parts).
Much of the work relating to boundary detectionrelates to the gradient of intensity images. Humanclothing however is usually colourful and makinguse of this information should improve discrimi-nation. Furthermore, clothing is usually textured
which requires more complex models of bound-aries. A generic approach to colour edge detectionis provided by the compass operator (Ruzon andTomasi [54]). Here the divergence between colourdistributions either side of a circle’s oriented bisec-tor is mapped, heuristically, to edge strength. Mar-tin et al. [34] improved on this approach by com-bining intensity, colour and texture features and bylearning the mapping from ground truth segmen-tations in a similar manner to the work of Kon-ishi et al. described above. In particular, colourand texture gradients were formulated using theχ2 measure between colour and texton [33] dis-tributions either side of the boundary. Althoughthis approach, whereby the image is filtered be-fore fitting the high level geometric model, pro-vided good performance in a statistically soundformulation it is unable to account for large scaletexture changes often present in human clothing.The author comments the performance of localisedbottom-up boundary models at finding boundariesin real-world images is significantly lower than hu-man performance. This is not surprising giventhat texture can occur over large scales and thatthe high human performance depends upon havinglarge regions either side of the boundary. Morietal [42] combined these statistical boundary detec-tion methods with a normalised cuts segmentationscheme. Some of the resulting regions correspondto salient parts that ‘pop out’ and can drive poseestimation. When assembling poses from thesesalient parts inter region appearance is also used.
Research pertaining to ‘top down’ colour andtexture boundary models has been surprisinglylimited, especially for human pose estimation.Shahrokni et al. [56] used zero and first orderMarkov processes along measurement lines tomodel texture and determine the most likely po-sition of a texture boundary (assuming the linecrossed the boundary). Their results on trackingrigid, textured objects in cluttered scenes empha-sised the limitations of intensity edge cues. Theformulation allowed fast local tracking. However,using texture on measurement lines assumes thatthe texture can be described by this line, which canbe violated when the surface undergoes non-rigiddeformation, for example. In this paper, a bound-ary likelihood model is introduced at the level ofbody parts, along with a model of inter-part simi-
5

larity in order to improve localisation of large scaletextures
2.2.2 Foreground Models
A description of the absolute appearance is usu-ally unavailable, primarily due to the variability inclothing. In tracking scenarios, foreground appear-ance can be assumed to be known from either man-ual initialisation [6, 63] or previous frames but willvary due to lighting changes and clothing motion.
One case when absolute appearance is knownwith some certainty is skin although this is sensitiveto illumination and is often only applicable to thehead and hands. In relation to human pose estima-tion, template matching and texture distributionslearnt off-line have been used to detect naked peo-ple, their limbs and torsos [14, 22]. Parket al. [46]used a segmentation scheme and then applied acolour classifier to detect skin coloured body parts.Pfinder used clusters in colour-position space tofind the head and hands in a real-time implemen-tation [65]. However, foreground regions were firstsegmented using a background model. Face detec-tion methods have been combined with other likeli-hood modules to improve performance. For exam-ple, [37] represented the face and upper body usinglocal gradient orientation features.
In the case when clothing appearance informa-tion is available, Sidenbladhet al. [58] proposedlearning a linear subspace representation of the sur-face texture for a particular subject from a set ofviews. Ground truth for a 3D cylindrical shapemodel was provided by a motion capture systemwhich was in turn used to project the image ontothe model surface. Regions on the surface wereweighted by visibility. This model allowed rotationabout the limb’s major axis to be recovered if thelimb’s surface had distinguishing non-symmetricfeatures such as an emblem. However, the appear-ance had to be learned off-line and was subject-specific. In contrast to this off-line appearance es-timation, Ramanan and Forsyth [48] used motion,appearance consistency and kinematic constraintsto find a colour representation of the foreground ap-pearance of individual limbs automatically beforetracking.
Human appearance has other properties that canbe used to discriminate it from the background.
Sidenbladhet al. [57] learnt the distributions forcorrect and incorrect poses of ridge features for-mulated in terms of second derivative filters at thescale of the body part. A clear example of the dis-criminatory power of larger scale foreground struc-ture is provided by similarity templates, concate-nations of relationships between pairs of pixels inan image window [61]. These have been used forpedestrian detection but relied upon limited vari-ation in pose and were slow to evaluate. Relation-ships between pairs of foreground features have notbeen used for more detailed, part-based pose es-timation. In particular, the relationship betweenbody parts which usually have a similar appear-ance, has not been used to enhance discrimination.In this paper, the similarity between the appearanceof opposing body parts is used to improve discrim-ination of larger configurations and thereby con-strain the estimation.
Finally it is important to note that foregroundappearance models are of independent interest fortracking specific people through occlusions andgroup interactions [35, 19].
2.3 Estimation
Current human pose estimation methods can bebroadly categorised as either combinatorial or fullstate space search. The combinatorial approach isadopted in most single image pose estimation sys-tems and consists of finding candidate body partsand then grouping these as determined by inter-partconstraints. This approach usually makes assump-tions regarding the form of the optimisation func-tion in order to efficiently combine the parts. Incontrast, full state space search approaches attemptto find all possible body parts simultaneously andmake no such assumptions. However, they are usu-ally only applicable when strong prior informationregarding pose is available, such as a motion esti-mate in a tracking scenario. Another point of dif-ferentiation is that of solution representation, somepose estimation systems estimate a single pose anda local estimate of uncertainty (e.g. [63, 22]) whilstothers estimate multiple solutions, modelled eithersemi-parametrically [6] or non-parametrically asparticle sets [59, 10].
A good general example of the combinatorial ap-proach is pictorial structures [13] which have been
6

applied to human pose estimation in indoor scenes.Pose estimation is formulated as a global energyminimisation problem with energy comprised of aper part term and an interaction term. By assumingthat the interactions between parts can be modelledas a tree, the problem can be solved in time linearwith the number of assemblies using dynamic pro-gramming. The solution is a MAP estimation ofpose.
The combinatorial approach to human pose esti-mation has since been most actively developed byForsythet al. Early work described the use of a hi-erarchical grouping scheme, called a body plan, fordetecting of naked humans and animals [14, 15].These body plans employ a sequential classifica-tion approach based upon cylindrical algebraic de-composition in which a decision surface in highdimensions (e.g. corresponding to a whole hu-man) can be projected to multiple lower dimen-sional spaces (e.g. corresponding to single partsand pairs) to improve efficiency. For example, in-dividual part detections with many false positiveswere fed into a pair-wise classifier which in turn fedinto a three-part classifier, each stage further prun-ing the candidates. The topology of the classifica-tion network is fixed prior to learning the individ-ual classifiers. A sequential classification approachwas also described by Ioffe and Forsyth [23] butrelied on binary classification of limbs rather thanestimating likelihoods. A new approach to estima-tion was then proposed based upon drawing assem-blies proportional to a likelihood of the full (fixedsize) assembly. In order to efficiently draw samplesfrom this likelihood, a set of marginal likelihoodswas proposed and assumed to be independent ofother parts (an important limitation). Assemblieswere then built in a fixed order (torso, upper limbs,lower limbs) by re-sampling the marginal likeli-hoods. Due to inter-part constraints, such as therequirement of parts to be distinct, this model nolonger has a tree structure and cannot be inferredusing dynamic programming. In later work the sin-gle tree model was criticised as a representationdue to the inability to represent self-occlusion (afrequent, significant phenomenon in human poseestimation). A mixture of trees representation wasproposed to address these deficiencies without re-sort to full state space search [22].
[37] learnt a set of classifiers for combinations
of frontal and profile upper body views and frontalleg views. As expected using joint classificationof parts greatly improved performance. Morietal [42] used salient parts identified from a bottomup segmentation scheme to drive a combinatorialpose estimation method. Whilst this system pro-vided good results on the cropped sports test im-ages it is not clear how successful the approach willbe with larger uncertainty in scale.
The second estimation approach, that of search-ing the full dimensional state space makes no as-sumptions regarding inter-part relations such asself-occlusion and is the most popular approach forhuman tracking where a temporal prior is available.However, this approach usually requires manualinitialisation and re-initialisation upon failure to becomputationally feasible. It is therefore only con-sidered briefly. One set of approaches uses eitherlocal gradient (e.g. [63]) or hierarchical-best-firstsearch schemes (e.g. [17]). Whilst efficient, suchlocal approaches are not feasible when significantocclusion occur, fast irregular motions are presentor large amount of background clutter is present.Furthermore, such models can have problems withsingularities [43, 11]. Cham and Rehg [6] over-come these problems by recovering the multiplehypotheses and tracking these using local Gauss-Newton search. An alternative approach is thatof sampling importance resampling and a non-parametric particle representation such as Conden-sation [24], whereby samples are drawn from thetemporal prior for diffusion and resampling. How-ever, blind application of such methods requires alarge number of particles for good results. There-fore, many techniques have been proposed to in-crease efficiency by taking advantage of the struc-ture of the human form. For example, Deutscheretal [9] used ideas from simulated annealing to morereliably estimate the global structure of the poste-rior distribution. The formulation resulted in an au-tomatic soft partitioning of the search space andused genetic algorithm-style cross-over operatorsto take advantage of the (semi-) hierarchical natureof the problem [10]. Choo and Fleet [7] appliedthe hybrid Markov Chain Monte Carlo (MCMC)scheme whereby a local potential is defined thatspeeds acceptance without biasing the sampling be-haviour. In addition, multiple Markov chains wereused to efficiently explore the multi-modal poste-
7

rior. [29] used a data driven MCMC scheme to es-timate the pose of the upper body. Sminchisescuetaldeveloped a set of novel sampling schemes thatexplicitly model characteristics of the distributionsfound in monocular human tracking. One suchtechnique, Covariance Scaled Sampling [59], sam-ples deeply along the directions of largest uncer-tainty since in monocular tracking, the authors rea-son, it is in these directions that alternative maximaare likely to be found. Another algorithm, Kine-matic Jumping [60], was proposed to flip the orien-tation of parts in order to escape local maxima thatoccur in monocular estimation. Such local maximaare related to poses that cannot be reliably discrim-inated even when joint positions are known [62].
3 Image and Scene Characteristics
To begin the discussion of the work presented inthis paper the assumptions regarding the image andscene are made explicit.Subject. A single per-son is assumed to be present in an unknown posethat is to be recovered. The appearance (e.g. cloth-ing) of this person is unknown. Clothing can beloose fitting and therefore have a complex outline.Furthermore, clothing can be textured in complexways and at many scales.Scene. Images are ofindoor or outdoor scenes. These scenes have un-known structure and can contain clutter at similarscales to the human body. Different types of scenelead to differences in the shape of typical objectsthat are visible (and presumably also differences inthe pose of the person). Objects in the scene canhave a textured appearance.Occlusion. In additionto self-occlusion, the person might be partially oc-cluded by other objects in the scene, a key difficultyin visual pose estimation.Viewpoint. It is assumedthat the scale of the person is known only approx-imately. Furthermore, it is assumed that the classof viewpoint (e.g. overhead, profile) is known, al-though the system should be able to be retrained towork with another viewpoint.Perspective.It is as-sumed that perspective effects are weak. In partic-ular, it is assumed that these effects are small whencompared to intra- and inter-person shape variabil-ity. Perspective effects could be modelled if theintrinsic camera parameters were known.Modal-ity. Since the majority of existing images are in
colour the focus is upon this modality (instead ofmonochromatic, range or infrared modalities). Thecolour signal can be noisy.Illumination. The im-ages can have complex illumination from multiplesources. Illumination might be so poor that certainbody parts cannot be distinguished based on localvisual appearance. Strong cast shadows and self-shadowing can occur.
4 Formulation
A central thesis of this work is that the limitationsof current pose estimation systems when applied toreal world images are symptomatic of a poor poserepresentation and that these limitations cannot beresolved efficiently, if at all, by simply improvingthe likelihood model and estimation scheme. Asdiscussed in the review, the structure of the humanbody can be naturally described using part-baseddecomposition. The part parameters used here cor-respond to a level of detail suitable for many appli-cations where the input is monocular, cluttered andlow quality. In common with previous part basedapproaches our formulation has an easy to interpretparameter space, models self-occlusion and allowsconstraints on the body to be encoded. However, incontrast to previous part-based approaches the ap-proach described here does not constrain the num-ber of parts or rely upon knowledge of the part visi-bility prior to estimation. The key point here is thatalthough using a fixed number of body parts seemsa sensible physical model given that the majority ofpeople have a known fixed number of body parts,considering the number of body parts as variableleads to a bettervisual modelandgreater efficiency.Since a 3D model of the scene is usually unavail-able, and requiring one would limit the applicabil-ity of the system, other object-occlusion cannot bepredicted in the same manner as self-occlusion.
4.1 Partial Configurations
A key element of the formulation developed here,coined partial configurations, is that the number ofhypothesised body parts can vary. Possible par-tial configurations include single part hypotheses,full body hypotheses and everything in between.A partial configuration includes pose hypotheses
8

for some non-empty subset of the set of a per-son’s body parts. Its parameter space dimensional-ity varies with the number of parts in the configura-tion. It should be emphasised that the posterior dis-tribution of partial configurations does not treat theparts independently (both the likelihood and priorconstraints use pairwise part potentials). A config-uration will be denotedC and its parts indexed byi or j.
Clearly, for this approach to be useful it must bepossible to compare partial configurations of dif-fering dimensionality. Moreover, larger correct hy-potheses should be preferred to smaller correct hy-potheses. Consider how hypotheses in a fixed sizestate space are usually compared. The most popu-lar approach is to find the maxima of the posteriorp(C|I) whereI denotes the image. It usually suf-fices to compute the likelihood and prior, ignoringthe evidence. This assumes however that the imagecontains (at least) one subject, since if such a tar-get did not exist a maximum would still be foundand the system would have no idea if this was cor-rect. This approach is not applicable in the caseof partial configurations since essentially multiplemodels exist (some of which may not have a cor-responding instance). Computing the normalisingfactor, the evidence, for each combination of partsand thereby computing posterior probabilities thatcan be compared is not computationally feasible.
Instead, the problem is treated as one of discrim-inating between people and backgroundat eachpoint in the state space. The state space is there-fore augmented by a class labelv ∈ {0, 1} thatlabels the hypothesis as either for a person (v = 1)or for a background process (v = 0). An opti-mum classification for a particular pose is foundby choosing the class with the highest probability(assuming uniform risk) [12]. This is equivalentto forming the logarithm of the posterior ratio,ρ,given in Equation (1) and classifying hypotheses aspeople whenρ > 0 and as background otherwise.
ρ = lnp(C, v = 1|I)
p(C, v = 0|I)
= lnp(I|C, v = 1)
p(I|C, v = 0)+ ln
p(C, v = 1)
p(C, v = 0)(1)
Posterior ratios allow hypotheses from multiplemodels to be compared based upon how different
each hypothesis is to a statistical process describ-ing the background class. From the point of view ofestimation efficiency, the key point is that whilst al-lowing the number of parts to vary greatly increasesthe number of possible pose hypotheses, the rela-tionship between configurations can be used to dis-proportionately increase sampling efficiency andperform global estimation. In general, configura-tions with large numbers of parts are more stronglydiscriminated from the background than configura-tions with small numbers of parts (although find-ing larger configurations can be more difficult).Therefore, large correct configurations tend to havehigher posterior ratios than small correct configura-tions. This is due to the structured form of appear-ance and pose of people which is modelled usinginter-part pose and appearance constraints.
4.2 Modelling Part Pose
Partial configurations can be applied to 2D or 3Dpart parameterisations. A depth-ordered 2D modelis adopted here since the application is to monoc-ular data and this avoids the genuine ambiguitiesthat exist with 3D monocular estimation and gives amore compact state space, both of which ease esti-mation. As mentioned previously it is assumed thatthe uncertainty in 2D shape due to limited perspec-tive effects and 3D shape variation is comparable tothe uncertainty due to clothing and intra-personalvariability.
We first emphasise that the partial configurationsformulation is non-hierarchical: there is no singleroot body part and parts in a kinematic chain are of-ten missing. Although this removes the automatickinematic behaviour, it is not clear whether this be-haviour eases estimation anyway. Whilst it mightbe argued that a non-hierarchical representation re-sults in a higher dimensional state space it is worthnoting that complex joints like the shoulder cannotbe adequately modelled using relative orientationalone and pose models often use relative transla-tion to allow a better fit.
The transformation of the 2D body part modelinto image space is a restricted affine transforma-tion and is similar to the scaled prismatic parame-terisation [6, 43]. However, in this system the partsshare a common scale parameter. Equation (2)gives the transformation,Ti(x), for a point on the
9

ith part. The interpretation of this transformation isstraightforward: a part model is translated so thatits centre is at(ai, bi) and then rotated byθi in theimage plane. An extension, denoted byei, is ap-plied to model rotation out of the image plane andthe part is scaled by a common scale factors.
Ti(x) = s
[
cos θi ei sin θi
− sin θi ei cos θi
]
x +
(
ai
bi
)
(2)
4.3 Probabilistic Region Templates forParts
The use ofad hoc geometric primitives as partmodels limits generality and does not addressuncertainty due to inter-person variability, intra-person variability, clothing and non-rigid deforma-tion. However, modelling such variation explic-itly is not necessary in order to solve for the de-sired pose description.Probabilistic region tem-platesare proposed here as an alternative. They en-code shape uncertainty explicitly and do not makehard distinctions between the foreground and back-ground of hypothesised parts. In addition to thevariations identified above, part shape uncertaintyis also introduced by un-modelled perspective ef-fects and 3D shape variation. In general, shapemodel uncertainty is due to un-parameterised vari-ation (in contrast to pose uncertainty which is in-herent in the problem).
A part’s shape is represented as a probabilis-tic region template, denotedMi, computed fromaligned training data by estimating a mean imagefrom manually specified binary segmentation im-ages (see Fig. 2). Each point inMi representsthe probability of that point being on the part.These non-parametric templates thus encode shapeuncertainty based upon marginalisation over un-parameterised shape variation. Opting not to pa-rameterise a degree of freedom, and marginalisingover it, reduces the size of the state space. For con-venience, probabilistic region templates are treatedas having infinite extent although they are illus-trated and implemented as finite masks that includeall the non-zero probabilities.
Specifically, probabilistic region templates wereestimated from manually specified part segmenta-tions aligned using the 2D transformation of Equa-
Figure 1: Examples of manually segmented partforeground. The rows correspond to torsos, heads,upper arms, lower arms, upper legs and lower legs.
tion (2). Limb training examples were extractedfrom fully extended parts (i.e. with the majoraxis of the part approximately parallel to the im-age plane). Fig. 1 illustrates typical segmentations.Twenty training examples were used for each limbpart (making a total of160) along with20 for thetorso and40 for the head. Note that training seg-mentations were deliberately not re-scaled to nor-malise for changes in the physical size of the sub-ject, in order to account for this variability.
The rotation about each limb part’s majoraxis was not parameterised since these rotationschanged the shape and appearance very little. Fur-thermore, the limb part templates were constrainedto be symmetric about their major axis. This wasachieved by flipping the training segmentations andusing the flipped versions for learning as well.
4.4 Probabilistic Self-occlusion
Depth ordering is used to account for self-occlusion. Since the depth ordering is not knownprior to estimation in most cases, the ordering must
10

Figure 2: The probabilistic region templates, all atthe same scale, that result from marginalising overthe foreground segmentations and enforcing sym-metry around the vertical axis.
be included as part of the pose hypothesis. Sinceshape is modelled using probabilistic region tem-plates, a hypothesised configuration gives rise to aprobabilistic assignment of part labels to points inimage space. More specifically, letPi denote theset of image points at which theith part is visible.Furthermore, letj ↑ i denote that thejth part iscloser to the camera than theith part according tothe hypothesised depth ordering. The probabilitythat theith part will be visible at a pointx in theimage plane (i.e. the part’s foreground probabil-ity at that point) is determined by the inverse parttransform, as shown in Equation (3).
P (x ∈ Pi|C) =Mi(T−1i (x))
×∏
j:j↑i
(1 − Mj(T−1j (x)) (3)
The probability that no part will be visible at apoint x given the hypothesised configuration canbe computed using Equation (4) wherei indexesthe parts in the configuration.
P (∄i : x ∈ Pi|C) = 1 −∑
i
P (x ∈ Pi|C) (4)
These equations will be used to form likelihoodmeasurements. In particular, the probability of apart being visible at a point in the image can beused to determine a weight that is used to forma distribution that describes the appearance of thebody part.
4.5 Pose Prior
A simple hard constraint prior can be based on up-per and lower bounds on the relative pose of anchorpoints defined on pairs of body parts. Such a priorcan be learned from data. This prior embodies scaleand translational invariance. It does not directly in-corporate constraints upon the absolute or relativeorientation of body parts. A more specific model,defined in terms of global pose, would improve dis-crimination but such models require more data toestimate and are not the focus of this work.
For each part, a set of anchor points is definedthat corresponds to the position of idealised jointsin the body. These anchor points are specified man-ually. The limb has an anchor point at each end, thehead has a single anchor point at the neck and thetorso has anchor points at the neck and limb jointpoints. Let the vector (specified in Cartesian co-ordinates) that connects the anchor points betweenparts i and j be (mi,j, ni,j). The prior probabil-ity that the pair is correct is considered to be a tophat function over the relative position of these an-chor points. The prior over background poses isalso considered to be uniform, but over the entireimage. The prior probabilities of being a person orbackground,P (v), are unimportant because onlya single maximum is sought. They would becomeimportant for detection and scenes containing mul-tiple people. The prior on the pose as a wholeis formed by assuming part independence and isgiven by Equation (5):
p(C, v = 1) ∝∏
i,j:j>i
p(mi,j|v = 1)p(ni,j|v = 1)
(5)wherei andj index the parts in the configuration,C. Body parts are also constrained to lie within theimage.
The parameters of the prior, namely the mini-mum and maximum relative horizontal and verticaldisplacements, were determined from150 images
11

of standing, walking, pointing, waving and sittingposes from various viewpoints (i.e. not always faceon). People were always upright in these images.Part elongation was constrained such thatei ≥ 0.7for any hypothesised part.
5 Likelihood
In this section the probabilistic part based shapemodel is used to inspect the image and deter-mine support for the partial configuration hypoth-esis. Clearly, it is not feasible to learn the jointPDF of measurements conditioned upon model pa-rameters,p(I|C, v), due to the large number ofparameters. In the interests of generalisation ahighly parameterised model must be establishedthat encodes conditional independencies, repre-senting, for example, invariance to position andforeground appearance. This Section develops twosuch models. The boundary model discriminatespeople using short range appearance differencesthat occur along the model boundary. In contrast,the inter-part model discriminates people basedupon long range appearance similarities betweenbody parts. Both likelihood models are formulatedin terms of the divergence of appearance distribu-tions formed from regions in the image induced bythe high-level shape model.
5.1 Foreground Appearance
Let f(I,x) denote a local image feature computedat locationx in imageI. A foreground appearancemodel for a part is based upon marginalising fea-tures over its foreground region, weighted by visi-bility:
Fi(z) =∑
x:f(I,x)=z
P (x ∈ Pi|C) (6)
The appearance distributions are represented usingjoint intensity-chromaticity histograms (3D distri-butions). A histogram representation is used forspeed of computation and because the distributionsare often multi-modal. For scenes in which thebody parts appear small, semi-parametric densityestimation methods such as Gaussian mixture mod-els would be more appropriate. In general, localfilter responses could also be used to represent theappearance, e.g. [55].
5.2 Part Boundary Model
As remarked in the review section, the majorityof boundary based object localisation methods relyupon bottom up boundary detection (i.e. edge orlocalised filter ). Furthermore, much considerationhas been given to how to compare feature distri-butions and what features to use. In contrast, thefocus here is on using the high-level model to cap-ture large scale texture and predicting where strongcontrasting boundaries are likely to occur. This canbe seen as a natural progression of the feature di-vergence approaches to larger scales by condition-ing upon the high level model. This difference inemphasis is particularly important for human ap-pearance modelling where large scale textures of-ten occur and where there is often weak boundariesbetween body parts (i.e. there is a the discrepancybetween the structural part model and the visualboundaries in the image). For example, whilst thekinematic structure is described by boundaries atthe neck, elbow, shoulders, hips and knees the vi-sual boundaries often occur on a part (e.g. a T-shirtending midway along the upper arm) or not at all(e.g. the usual lack of a boundary between the up-per arm and torso).
In order to account for the difference betweena kinematic and visual boundary the notion of spa-tially dependent contrast is introduced. Many mod-els of contrast are possible, here a straightforwardmodel based upon the expected contrast betweenbody parts is developed. This model assumes allpoints on two body parts are equally contrasting(ignoring visibility). The extent to which a pixelx is expected to contrast in appearance with theith
part is given by Equation (7):
Γi(x) = P (∄j : x ∈ Pj|C)+∑
j
αijP (x ∈ Pj |C)
(7)whereαij are weights that encode prior expecta-tion of part contrast with other parts. Note thatαij = αji andαii = 0. These weights could be es-timated from representative data or, as in the caseof experiments reported in Section 7, subjectively(specifically,αij = 0.1 wheni andj were adjoin-ing limb segments,αij = 0.5 between other com-binations). It is important to understand that usingmore discriminatory features, such as orientation
12

dependent texture features, will result in higher ex-pected contrast between points.
As one might expect, varying the size of thecontrasting region gives a tradeoff between shapespecificity and obtaining a good estimate of thecontrasting appearance. For the results presentedhere the contrasting appearance distribution is ex-tracted from a region of approximately equal area(in the probabilistic sense) to the foreground re-gion. This choice is supported by the fact thatthe discrimination (as determined by the inducedlikelihood ratio described below) is weaker whenlarger and smaller regions are used (although bet-ter weighting schemes could exist). In particu-lar, this region is formed for each part by findingthe Euclidean distanced such that all points withP (x ∈ Pi|C) = 0 that are within a distanced of apoint with P (x ∈ Pi|C) > 0, in addition to thosewith P (x ∈ Pi|C) < 1, give an equal (probabilis-tic) area to the foreground. For example, in the caseof the lower arm this is all those points in the maskwithin 3 pixels of a foreground point.
Bi(z) =∑
x:f(I,x)=z
Γi(x) (8)
Finally, to complete the model of a contrastingregion, consideration must be given to the evalua-tion of partial configurations that do not describeall possible body parts. In such cases theexpectedpose of the missing body parts can be used to ob-tain contrasting regions. For example, when de-tecting single body parts, performance can be im-proved by distinguishing positions where the back-ground appearance is most likely to differ from theforeground appearance. For example, a region atthe top of the lower arm where it usually joins theupper arm can be identified as an adjoining regionand would be expected to have similar appearanceto the part. It is important to note that this is onlyimportant, and thus used for, better bottom-up iden-tification of body parts. When the adjoining partis specified using a multiple part configuration, thestandard model of contrast described above is em-ployed.
Once the foreground and contrasting appearancedistributions (histograms) are formed there aremany measures that could be used to compare themincludingχ2, the Kullback Leibler divergence, the
Jeffrey distance, the Bhattacharyya measure andthe Minkowski metric. Alternatives have been pro-posed specifically for comparing histograms in-cluding histogram intersection, the quadratic formand the Earth mover’s distance, the latter two be-ing global measures of histogram similarity. (SeePuzichaet al. [47] for a comparison of distribu-tion similarity measures in the context of textureregions.) Based on its success in colour basedtracking [8], the Bhattacharyya measure is adoptedhere. The divergence measure between theith
part’s foreground and background appearance isgiven by Equation (9).
Di =∑
z
√
Fi(z) × Bi(z) (9)
The Bhattacharyya measure is related to the like-lihood non-linearly. Therefore, the distributionsof divergence between foreground and backgroundappearance are learned for correct (v = 1) andincorrect (v = 0) configurations in a supervisedfashion. In particular, av = 1 distribution is esti-mated from data obtained by manually specifyingthe transformation parameters to align the proba-bilistic region template to be on parts that are nei-ther occluded nor overlapping. Thev = 0 distri-bution, which encodes the likelihood of observinga part-shaped object in the class of scenes underconsideration, is estimated by generating randomalignments elsewhere. The ratio of these two dis-tributions, Equation (10), defines a log-likelihoodratio, l1, for a partial configuration based on the re-gion divergence measures for its parts.
l1 =∑
i
(ln p(Di|v = 1) − ln p(Di|v = 0)) (10)
Any single-part hypothesis that results in a his-togram divergence with log-likelihood above zerois morelikely (i.e. not taking into account the prior)to be a body part than not be a body part.
In order to obtain a smooth log likelihood func-tion, l1, and interpolate/extrapolate the learnt data,a parametric function was fitted to the data. In par-ticular, it was expected, and confirmed empirically,that a Boltzmann sigmoid function, with a func-tional form given in Equation (11), would providea good fit for the boundary ratio (correlation coef-ficient 0.96). This is the function used to ‘score’
13

a single body part configuration and is plotted inFig. 3. This learnt sigmoid function acts as a softclassifier for body parts based upon the divergencemeasure.
S(x) = a+b − a
1 + ec−x
d
(11)
5.3 Inter-Part Model
Since the part boundary likelihood ratio will usu-ally result in many false positives, it is useful to en-code relationshipsbetweenthe appearance of bodyparts to improve discrimination. For example, aperson’s upper left arm will often have a similarcolour and texture to the upper right arm. Longrange structure provides a mechanism for discrim-inating large correct configurations from large in-correct configurations and thereby pruning incor-rect hypotheses.
The model of inter-part similarity encodes dis-similarity using the divergence between pairs ofparts. Since rotation about a limb’s major axis isnot parameterised (since it cannot usually be ac-curately recovered) and clothing can move relativeto the part’s surface, image texture on two limbscan be very different. Matching texture featuresis further complicated by the rotation of texturefeatures on the surface of the limb relative to theimage plane. Therefore, in the same way as thepart boundary model, colour histograms are used torepresent appearance and divergence between twoparts’ foregrounds as given by Equation (12). Fu-ture work might investigate texture features in ad-dition to colour to enhance discrimination of bodyparts, especially overlapping parts with orientedtexture.
Fij =∑
z
√
Fi(z) × Fj(z) (12)
PDFs of the divergence measure were learnt simi-larly to the part boundary case. Equation (13) givesthe inter-part log likelihood ratio,l2, that resultsfrom these two distributions.
l2 =∑
(i,j)
(ln p(Fij |v = 1)−ln p(Fij |v = 0)) (13)
Specifically, inter-part divergence PDFs for pairsof opposing limb parts expected to have similar ap-pearance were learned from examples with correctand incorrect pose. In particular,20 pairs of upperand lower arms and legs were used. Their correctpose was manually specified and incorrect poseswere generated by drawing from the pose prior ofEquation (5). Fig. 4 shows plots of these two PDFsmodelled as Gaussians. The resulting likelihood ra-tio function is also shown. It can be seen that thismodel strongly penalises opposing part pairs thatare not similar in appearance.
5.4 Combining the Models
The log-likelihood ratios,l1 and l2, are combinedassuming conditional independence. Notice thatthe relative importance of the models is implicit inthe likelihood ratio which allows principled fusionof the different models. The overall log-likelihoodratio is the sum of the boundary and inter-part com-ponents.
6 Empirical Investigation of Like-lihood
Before considering full pose estimation it is use-ful to investigate the likelihood models by comput-ing projections resulting from the variation of partsfrom interesting configurations. This allows an un-derstanding of the sensitivity to different types ofclutter. Furthermore, an intensity edge model toallow a more quantitative evaluation of the newboundary likelihood model.
For these tests and the pose estimation resultsthat follow the images were obtained using a rangeof still and video cameras. It was assumed thatthe intrinsic camera parameters were unknown andconstant (between scenes and cameras). The typi-cal resolution of the input images was640 × 480pixels. The colour appearance histograms had83
bins.
6.1 Comparison to Intensity Edge Model
The proposed part boundary likelihood ratio wascompared to an intensity edge-based model for
14

0.0 0.2 0.4 0.6 0.8 1.0
0.00
0.05
0.10
0.15
0.20
0.25
0.30
0.35
0.40
0.45
0.50
Pro
ba
bil
ity
Den
sity
Similarity of Foreground Appearance to
Adjacent Background Appearance
On
Off
0.0 0.2 0.4 0.6 0.8 1.0
-4
-3
-2
-1
0
1
2
3
4
Lo
g L
ikeli
ho
od
Ra
tio
Similarity of Foreground Appearance to
Adjacent Background Appearance
Head
Lower Arm
Lower Leg
Figure 3: Left: A plot of the learnt PDFs of foreground to background appearance similarity for thev = 1 andv = 0 part configurations of a head template. Right: A plot of a Boltzmann sigmoid functionfit to the log of the likelihood ratio data for head, lower arm and lower leg parts. It can be seen that thedistributions are well separated.
0
0.1
0.2
0.3
0.4
0.5
0.6
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
Paired Appearance Similairy
Pro
ba
bil
ity
Den
sity
Off Pair
On Pair
-30
-25
-20
-15
-10
-5
0
5
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
Paired Appearance Similarity
Lo
g L
ikeli
ho
od
Ra
tio
Figure 4: Left: A plot of the learnt PDFs of foreground appearance similarity for paired and non-pairedconfigurations. Right: The log of the resulting likelihood ratio. It can be seen, as would be expected, thatmore similar regions are more likely to be a pair.
single body parts. Rather than make assump-tions about the form of the model boundary to bematched to image edges (for example, a fixed vari-ance Gaussian [63]), the learned probabilistic re-gion templates were used. The spatial gradientof a probabilistic region template provides an es-timate of the mean spatial gradient for a part (sincethe derivative is a linear operator). A response isformed by convolving the derivative of the prob-abilistic mask with the image. Image edge mag-nitude and orientation were computed using3 × 3Sobel filters.
The magnitudes of edge responses correspond-ing to a body part boundary will vary in a structured
and partly predictable way. For example, bound-ary segments around the joints neighbouring sim-ilarly clothed parts will have low magnitudes. Amodel of this structure can be used to improve dis-crimination. The single part response was inves-tigated here using manually selected segments ofexpected high magnitude, similarly to some othersystems (e.g. [57]). Part-specific response distri-butions were learned in a supervised fashion frombody part training data for correct (v = 1) and in-correct (v = 0) part pose. Only the magnitude ofthe component of the filter response orthogonal tothe model was used for discrimination. The likeli-hood ratio for the part as a whole was computed by
15

assuming independence of the individual measure-ments.
6.2 Single Part Likelihood Ratios
Fig. 5 shows the projections of log-likelihood ratiosfor single part configurations onto typical imagescontaining significant clutter. Results are shownfor both the part boundary model (computed us-ing Equation (10)) and the comparative edge-basedmodel. The first image shows the response for ahead while the other two images show the responseto a vertically-oriented limb filter. It can be seenthat, in comparison to the intensity edge model, theproposed part boundary method is highly discrim-inatory and produces relatively few false maxima.Fig. 6 illustrates the typical spatial variations of thepart boundary and the edge-based likelihood ratios.The edge-based response, whilst indicative of thecorrect position, has significant false, positive log-likelihood ratios.
Although the part boundary ratio is more expen-sive to compute than the edge-based ratio (approxi-mately an order of magnitude slower in the currentimplementation), it is far more discriminatory andas a result, fewer samples are needed when per-forming pose search, leading to an overall perfor-mance benefit. The edge-based method did not usecontrast normalisation or a multi-scale approach asexpounded in Ref. [57] and this may partly explainits relatively poor performance.
6.3 Inter-part Likelihood Ratios
Fig. 7 shows the projection of the inter-part like-lihood ratio for a typical image and shows it tobe highly discriminatory. It limits the possiblepose configurations if one limb part can be foundreliably and helps reduce the likelihood of incor-rect large assemblies. This enables larger incorrectconfigurations to be pruned, making deterministic,combinatorial search more feasible.
7 Pose Estimation
A central thesis of this work is that by improvingthe formulation and likelihood models, the estima-tion problem can be eased. In particular, by bet-ter discriminating individual parts and using rela-
tions between parts to prune larger incorrect config-urations, relatively simple estimation schemes canyield useful pose estimation results. The partialconfiguration formulation allows bottom-up sam-pling to focus pose search, making global estima-tion feasible whilst still allowing for self-occlusion(and inter-part appearance relations). Since thestructure of the model does not allow exact infer-ence due to inter-part relations, techniques suchas dynamic programming cannot be applied. In-stead an iterative combinatorial search with localoptimisation is employed. This approach, althoughless efficient than methods such as pictorial struc-tures [51] and mixtures of trees [22], is more flex-ible and it is feasible because of the strong like-lihood model developed. The search scheme pre-sented here is relatively straightforward. Neverthe-less it succeeds in obtaining interesting pose esti-mation results thus demonstrating the strength ofthe formulation and likelihood model.
Recall that it is assumed that exactly one per-son is present in the image. The pose estimationproblem can thus be treated as one of global max-imisation. It is also assumed, as is common withother pose estimation systems, that the scale pa-rameter is known to a good approximation. Themodel based approach makes incorporate this in-formation straightforward.
The most important body parts, in terms of infor-mation content and for human computer interfacecontrol, for example, are the outer limbs and thehead. Furthermore, the torso and upper limbs areusually harder to identify due to a lack of contrastwith neighbouring regions. Therefore, the searchscheme used here aims to identify the head andouter limbs (i.e. the lower arms and lower legs).This also makes labelling of parts simpler. Futurework could improve the search scheme to find theremaining parts.
7.1 Search Algorithm
7.1.1 Coarse sampling
First, the parameter spaces of single part pose con-figurations was uniformly sampled. Specifically,translation parameters were sampled every3 pixelsand part orientations everyπ/4 radians (which wassufficient because limb part templates were sym-
16
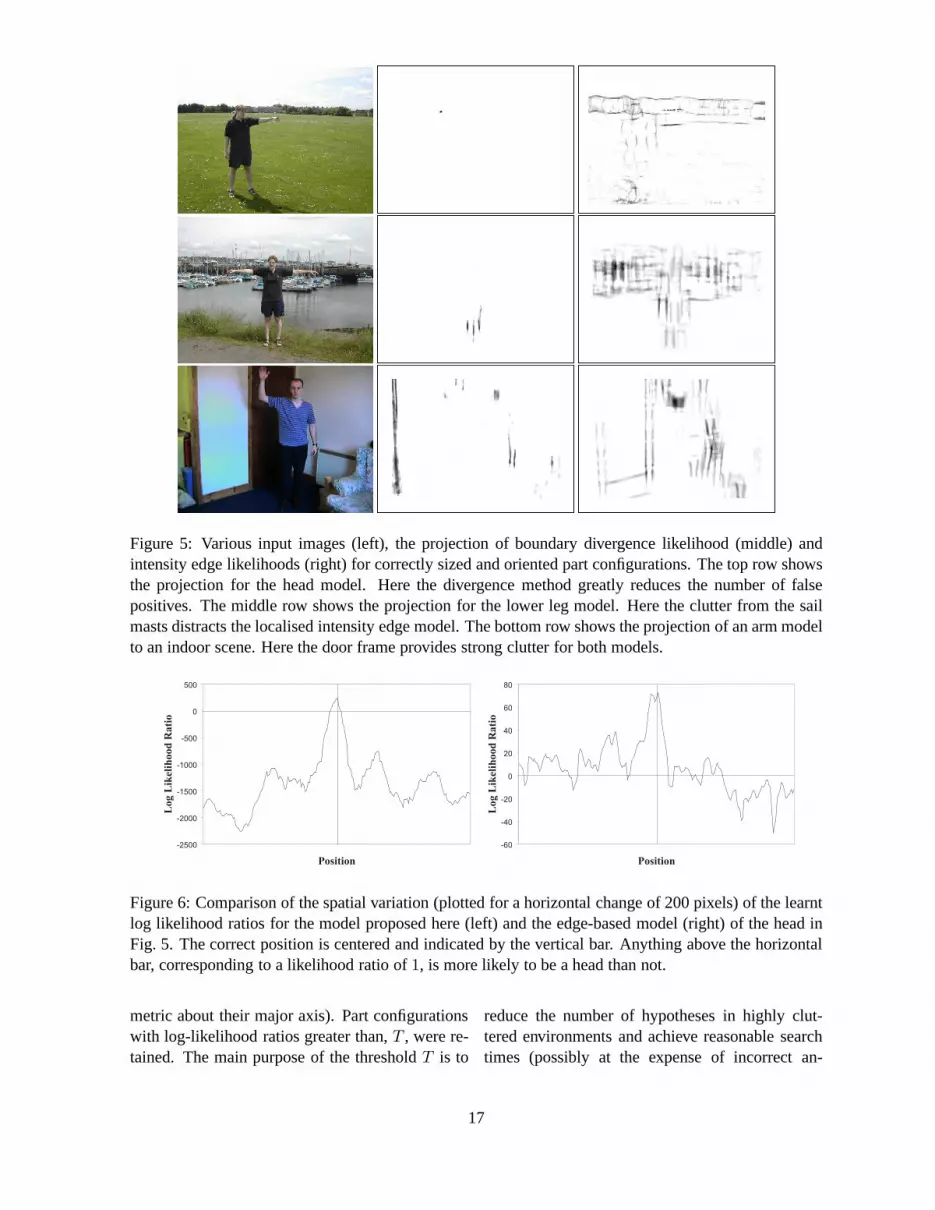
Figure 5: Various input images (left), the projection of boundary divergence likelihood (middle) andintensity edge likelihoods (right) for correctly sized andoriented part configurations. The top row showsthe projection for the head model. Here the divergence method greatly reduces the number of falsepositives. The middle row shows the projection for the lowerleg model. Here the clutter from the sailmasts distracts the localised intensity edge model. The bottom row shows the projection of an arm modelto an indoor scene. Here the door frame provides strong clutter for both models.
-2500
-2000
-1500
-1000
-500
0
500
Position
Lo
g L
ikel
iho
od
Ra
tio
-60
-40
-20
0
20
40
60
80
Position
Lo
g L
ikel
iho
od
Ra
tio
Figure 6: Comparison of the spatial variation (plotted for ahorizontal change of 200 pixels) of the learntlog likelihood ratios for the model proposed here (left) andthe edge-based model (right) of the head inFig. 5. The correct position is centered and indicated by thevertical bar. Anything above the horizontalbar, corresponding to a likelihood ratio of1, is more likely to be a head than not.
metric about their major axis). Part configurationswith log-likelihood ratios greater than,T , were re-tained. The main purpose of the thresholdT is to
reduce the number of hypotheses in highly clut-tered environments and achieve reasonable searchtimes (possibly at the expense of incorrect an-
17

Figure 7: Investigation of a paired part response. Left: an image for which significant limb candidatesare found in the background. Right: the projection of the loglikelihood ratio for the paired response tothe person’s lower right leg in the image.
swers). For most experiments it was kept constantat a conservative value. Parts were allocated ini-tial labels based upon the division of the imageinto quadrants. However, this initial labelling isunimportant because as subsequent search identi-fies larger configurations labels are re-hypothesisedand better constrained. At this stage the head andsome outer limbs were often found (if unoccludedand not camouflaged) along with false positivesdue to background clutter.
7.1.2 Local Optimisation
Each part configuration was locally optimised byiteratively proposing random perturbations and ac-cepting them when the posterior ratio increased(this was found to perform better than a numeri-cal gradient based local search). Translation wasperturbed by up to2 pixels in each direction, ori-entation by up to12◦ and elongation by up to10%.Depth order was also searched in order to accountfor self-occlusion by proposing part movements upand down a layer. Part configurations with similarpose were merged.
7.1.3 Combinatorial Search
Part candidates are then iteratively grouped to buildlarger pose configurations. This began with eval-uation of all possible pairs of (locally optimised)parts. Those pairs with likelihood ratio lower thanT were discarded. Triples were then formed fromall the parts in the retained pairs. This continued
to some maximum configuration size,5 parts in theresults reported here. Evaluation of a configurationat any stage in this combinatorial search involvedpart labelling, evaluation of the prior and, for thoseconfigurations with non-zero prior, evaluation ofthe likelihood ratio,l. Part labelling was performedby first selecting an anchor part, the head if presentand otherwise the upper left part . Other parts werelabelled based on their position relative to this an-chor part. Parts are labelled as left or right accord-ing to their relative positions in the image frame.The search was elitist in that the best configura-tion was kept irrespective of whether it passed latergrouping stages. At each stage of grouping, theinter-part pose and appearance relations reducedthe number of possible parts under consideration.After each grouping stage local optimisation wasperformed. After the final grouping stage the bestconfiguration was locally optimised for200 itera-tions prior to output, including the global scale fac-tor which was perturbed by up to5%. Every stagein the search involves a rehypothesising of part la-bels. For very small configurations (e.g. an up-per arm) the labelling is highly unconstrained andprone to error. However, for larger configurationsthe prior constraints make the labelling more likelyto be correct. The labels at any stage (e.g. sin-gle part stage) in the search are only important forthat stage to be able to return a MAP estimate ofpose. Representing distributions over part labels(and pose) is deferred for future work.
A limitation of this ’feed-forward’ inferencescheme is that parts that are significantly occluded
18

by other part(s), and therefore have weak likeli-hood responses, are never hypothesised later inthe search. Future work could develop samplingschemes that, given the pose of a set of body parts,form larger configurations that account for the lackof contrast and self-occlusion.
7.2 Empirical Evaluation
Pose estimation was evaluated on a set of im-ages with characteristics described in Section 3 (i.e.cluttered indoor and outdoor scenes, various un-known subjects in various poses without constrain-ing either clothing or lighting). Figures 8 and 9show the pose configurations with highest posteriorratio found within a fixed maximum run-time. Al-though inter-part links are not visualised here, weemphasises that these results represent estimates ofpose configurations with inter-part relationships interms of appearance and pose. Closer inspectionof the input images reveals the presence of JPEGencoding artifacts.
Histograms were built efficiently by projectingscan-line segments and iteratively computing themask co-ordinates inside these segments. Thecolours in the image were preprocessed into his-togram bins. The implementation sampled singlepart configurations with scales = 1 at approxi-mately3KHz from an typical image with resolu-tion 640×480 on a2GHz PC. Run-time for a com-plete pose estimation ranged from2 minutes, whenlimited part candidates were identified, to the max-imum 2 hours, when many part candidates wereidentified in heavily cluttered scenes.
7.3 Discussion of Pose Estimation Results
The results support the hypothesis that it is possi-ble to efficiently find highly informative partial so-lutions in real-world images using a strong single-part and inter-part likelihood model. Furthermore,the system was able to recover pose in the pres-ence of other-object occlusion. The largest con-figurations presented in the results happen to havefour parts. Although five part configurations werehypothesised they gave lower responses. For allthe test images the head, arms and legs were cor-rectly labelled. It was difficult to identify a single‘correct’ scale for some images however, the sys-
tem was not overly sensitive to the correct choice.In particular, baggy clothing and perspective ef-fects cause changes in relative scale between bodyparts (breaking the assumption of a common singlescale). The model showed good generalisation overchanges in scale (600% variation). It was observedfrom these results that pose estimation in indoorscenes was more problematic due to clutter fromman-made objects such as door frames. Sceneswith large amounts of clutter caused long run-timesdue to combinatorial explosion in the number oflarger configurations.
Since much of the information about pose is con-tained in the smaller sub-configurations, especiallyin the outer limbs, finding small numbers of parts isnot as significant a drawback as one might initiallyassume. Moreover, these results compare favorablywith other state-of-the-art pose estimation systemsthat require more restricted scenes and assume thatmore is known about the appearance (e.g. [22, 23]).In particular, these other systems also often onlyfind three to five body parts.
8 Conclusions
Two fundamental problems of visual human poseestimation were focussed upon: (i) discriminatinga subject with complex, unknown appearance froma cluttered, unknown scene that possibly occludesparts of the subject using a single image, and (ii)formulating the pose estimation problem such thatefficient, accurate global estimation is possible insuch conditions. This is in contrast to the majorityof published research on human tracking and hu-man pose estimation which has focused upon theestimation problem. The strategy adopted here wasto ease the estimation problem by improving theformulation and likelihood model.
The first main contribution was the partial con-figuration formulation that allows pose configura-tions with variable numbers of parts to be comparedin a principled manner. Adopting such an approachhas two key advantages. Firstly, it allows other-object occlusion to be modelled when the structureof the scene is unavailable (which is the case in thegreat majority of applications). Other-object occlu-sion is common in real world images of people buthas been largely ignored in previous work. Sec-
19

Figure 8: Pose estimation results. Notice the large variation in clothing appearance, the loose fit ofsome clothing and degree of background clutter. Also noticethe presence of other object occlusion. Theonly complete failure was the final image where a reflection inthe background provided a strong partresponse.
ondly, encoding pose using partial configurationsallows more efficient and flexible search schemesto be implemented. In particular, it allows bottom-up part hypotheses to be used to focus the searchfor larger configurations without making restrictiveassumptions about self-occlusion, other-object oc-clusion or inter-part relations. This was combinedwith a novel shape model that, when transformedinto the image using the pose parameters, encodesthe uncertainty in visibility of parts at points in theimage and forms the basis of the measurement pro-cess. This probabilistic approach is important forefficient pose estimation where there is significantun-parameterised variation due to factors such asclothing and inter-person variability. Moreover, ad-ditional gains in efficiency can be made by com-bining similar part models and removing degrees
of freedom that have little effect on the appear-ance. This probabilistic region formulation wasfurther developed to model self-occlusion and ex-pected contrast.
The second main contribution was an efficient,highly discriminatory, spatial likelihood modelcomposed of two complementary components. Theboundary component allowed good discriminationof body parts based upon divergence between fea-ture distributions in regions induced by the high-level shape model encoded using probabilistic re-gion templates and taking into account inter-partcontrast. The use of high-level shape allowed bet-ter discrimination in the presence of complex, tex-tured appearance than models based upon bottom-up boundary measurements. The inter-part compo-nent enabled efficient discrimination of larger con-
20

Figure 9: Pose estimation results. Notice the large scale changes that are present as well as the variationin pose (sitting, standing, jumping). Also notice the presence of other object occlusion. Two of theimages show partially incorrect results and one is completely incorrect (due to strong clutter from thebookcase).
figurations by exploiting the long range appearancesimilarity between parts.
It was demonstrated that by building upon thisfoundation a straightforward search scheme is able
21

to recover a large amount of information about thepose efficiently and globally. Such an approachcould be used to automatically initialise and re-cover human trackers without relying upon ad-hocmodels or assumptions of visibility.
References
[1] P. Baerlocher and R. Boulic. DeformableAvatars, chapter Parametrization and rangeof motion of the ball-and-socket joint, pages180–190. Kluwer Academic, 2001.
[2] C. Barron and I. A. Kakadiaris. Estimatinganthropometry and pose from a single uncal-ibrated image. Computer Vision and ImageUnderstanding, 81(3):269–284, March 2001.
[3] A. Baumberg and D. Hogg. An efficientmethod for contour tracking using activeshape models. InProc. of IEEE Workshop onMotion of Non-Rigid and Articulated Objects,pages 194–199, 1994.
[4] R. Bowden, T. A. Mitchell, and M. Sarhadi.Non-linear statistical models for the 3D re-construction of human pose and motion frommonocular image sequences.Image and Vi-sion Computing, 18(9):729–737, June 2000.
[5] C. Bregler and J. Malik. Tracking people withtwists and exponential maps. InIEEE Confer-ence on Computer Vision and Pattern Recog-nition, pages 8–15, Santa Barbara, CA, 1998.
[6] T. J. Cham and J. M. Rehg. A multiple hy-pothesis approach to figure tracking. InIEEEConference on Computer Vision and PatternRecognition, volume 2, pages 239–245, FortCollins, Colorado, USA, 1999.
[7] K. Choo and D. J. Fleet. People tracking us-ing hybrid Monte Carlo filtering. InIEEE In-ternational Conference on Computer Vision,pages 321–328, Vancouver, 2001.
[8] D. Comaniciu, V. Ramesh, and P. Meer. Real-time tracking of nonrigid objects using meanshift. IEEE Conference on Computer Vi-sion and Pattern Recognition, pages 673–678,2000.
[9] J. Deutscher, A. Blake, and I. Reid. Artic-ulated body motion capture by annealed par-ticle filtering. In IEEE Conference on Com-puter Vision and Pattern Recognition, vol-ume 2, pages 126–133, South Carolina, USA,2000.
[10] J. Deutscher, A. Davison, and I. Reid. Auto-matic partitioning of high dimensional searchspaces associated with articulated body mo-tion capture. InIEEE Conference on Com-puter Vision and Pattern Recognition, vol-ume 2, pages 669–676, Hawaii, 2001.
[11] J. Deutscher, B. North, B. Bascle, andA. Blake. Tracking through singularities anddiscontinuities by random sampling. InIEEEInternational Conference on Computer Vi-sion, pages 1144–1149, September 1999.
[12] R. Duda, P. Hart, and D. Stork.Pattern Clas-sification. Wiley, 2nd edition, 2001.
[13] P. F. Felzenszwalb and D. P. Huttenlocher. Ef-ficient matching of pictorial structures. InIEEE Conference on Computer Vision andPattern Recognition, volume 2, pages 66–73,2000.
[14] D. A. Forsyth and M. M. Fleck. Body plans.In IEEE Conference on Computer Vision andPattern Recognition, pages 678–683, PuertoRico, 1997.
[15] D. A. Forsyth and M. M. Fleck. Auto-matic detection of human nudes.Interna-tional Journal of Computer Vision, 32(1):63–77, August 1999.
[16] D. M. Gavrila. The visual analysis of humanmovement: A survey.Computer Vision andImage Understanding, 73(1):82–98, January1999.
[17] D. M. Gavrila and L. S. Davis. 3D model-based tracking of humans in action: A multi-view approach. InIEEE Conference on Com-puter Vision and Pattern Recognition, pages73–80, San Francisco, USA, 1996.
[18] M. Grosso, R. Quach, and N. Badler. Anthro-pometry for computer animated human fig-ures. InProceedings of Computer Animation
22

Human Figures, pages 83–96. Spring Verlag,1989.
[19] I. Haritaoglu, D. Harwood, and L. S. Davis.Hydra: Multiple people detection and track-ing using silhouettes. InIEEE InternationalWorkshop on Visual Surveillance, page 613,June 1999.
[20] I. Haritaoglu, D. Harwood, and L. S. Davis.W4: Real-time surveillance of people andtheir activities. IEEE Transactions onPattern Analysis and Machine Intelligence,22(8):809–830, August 2000.
[21] D. Hogg. Model-based vision: A program tosee a walking person.Image and Vision Com-puting, 1(1):5–20, 1983.
[22] S. Ioffe and D. A. Forsyth. Human trackingwith mixtures of trees. InIEEE InternationalConference on Computer Vision, volume 1,pages 690–695, 2001.
[23] S. Ioffe and D.A. Forsyth. Probabilistic meth-ods for finding people.International Journalof Computer Vision, 43:45–68, June 2001.
[24] M. Isard and A. Blake. Contour tracking bystochastic propagation of conditional density.In European Conference on Computer Vision,volume 1, pages 343–356, Cambridge, 1996.
[25] S. Ju, M. Black, and Y. Yacoob. Cardboardpeople: a parameterized model of articulatedimage motion. InIEEE International Confer-ence on Face and Gesture Recognition, pages38–44, Killington, VT, USA, 1996.
[26] I. A. Kakadiaris and D. Metaxas. Model-based estimation of 3D human motion withocclusion based on active multi-viewpoint se-lection. InIEEE Conference on Computer Vi-sion and Pattern Recognition, pages 81–87,San Francisco, USA, 1996.
[27] I. Karaulova, P. Hall, and A. Marshall. Ahierarchical model of dynamics for trackingpeople with a single video camera. InBritishMachine Vision Conference, pages 352–361,Bristol, 2000.
[28] S. Konishi, A.L. Yuille, J.M. Coughlan, andS.C. Zhu. Statistical edge detection: learn-ing and evaluating edge cues.IEEE Transac-tions on Pattern Analysis and Machine Intel-ligence, 25(1):57–74, January 2003.
[29] M. W. Lee and Cohen I. Human upper bodypose estimation from static images. InEuro-pean Conference on Computer Vision, pages126–138, 2004.
[30] M. K. Leung and Y. H. Yang. First sight: Ahuman body outline labeling system.IEEETransactions on Pattern Analysis and Ma-chine Intelligence, pages 359–377, April1995.
[31] J. MacCormick and A. Blake. A probabilisticcontour discriminant for object localisation.In IEEE International Conference on Com-puter Vision, pages 390–395, 1998.
[32] J. MacCormick and A. Blake. Spatial depen-dence in the observation of visual contours.In European Conference on Computer Vision,1998.
[33] J. Malik, S. Belongie, T. Leung, and J. Shi.Contour and texture analysis for image seg-mentation. International Journal of Com-puter Vision, 43(1):7–27, June 2001.
[34] D.R. Martin, C.C. Fowlkes, and J. Malik.Learning to detect natural image boundariesusing local brightness, color, and texture cues.IEEE Transactions on Pattern Analysis andMachine Intelligence, 26(5):530–549, May2004.
[35] S. J. McKenna, S. Jabri, Z. Duric, A. Rosen-feld, and H. Wechsler. Tracking groups ofpeople. Computer Vision and Image Under-standing, 80(1):42–56, October 2000.
[36] D. Metaxas and D. Terzopoulos. Shape andnon rigid motion estimation through physicsbased synthesis. IEEE Transactions onPattern Analysis and Machine Intelligence,15(6):580–591, June 1993.
[37] K. Mikolajczyk, C. Schmid, and A. Zisser-man. Human detection based on a probabilis-
23

tic assembly of robust part detectors. InEu-ropean Conference on Computer Vision, vol-ume I, pages 69–81, 2004.
[38] T. B. Moeslund and F. Bajers. Summariesof 107 computer vision-based human motioncapture papers. Technical Report LIA99-01,University of Aalborg, 1999.
[39] T. B. Moeslund and E. Granum. 3D humanpose estimation using 2D-Data and an alter-native phase space representation. InIEEEWorkshop on Human Modeling, Analysis andSynthesis, 2000.
[40] T. B. Moeslund and E. Granum. A surveyof computer vision-based human motion cap-ture. Computer Vision and Image Under-standing, 81(3):231–268, March 2001.
[41] G. Mori and J. Malik. Estimating human bodyconfigurations using shape context matching.In European Conference on Computer Vision,pages 666–680, 2002.
[42] G. Mori, X. Ren, A.A. Efros, and J. Ma-lik. Recovering human body configura-tions: Combining segmentation and recogni-tion. pages II: 326–333, 2004.
[43] D. D. Morris and J. M. Rehg. Singularityanalysis for articulated object tracking. InIEEE Conference on Computer Vision andPattern Recognition, pages 289–296, 1998.
[44] E. Ong and S. Gong. A dynamic humanmodel using hybrid 2D-3D representations inhierarchical PCA space. InBritish MachineVision Conference, pages 33–42, Nottingham,1999.
[45] J. O’Rourke and N. I. Badler. Model-basedimage analysis of human motion using con-straint propagation. IEEE Transactions onPattern Analysis and Machine Intelligence,2(6):522–536, November 1980.
[46] J. Park, O. Hwang-Seok, D. Chang, andE. Lee. Human posture recognition usingcurve segments for image retrieval. InSPIEConference on Storage and Retrieval for Me-dia Databases, volume 3972, pages 2–11,2000.
[47] J. Puzicha, Y. Rubner, C. Tomasi, and J. M.Buhmann. Empirical evaluation of dissimilar-ity measures for color and texture.IEEE In-ternational Conference on Computer Vision,pages 1165–1173, 1999.
[48] D. Ramanan and D. A. Forsyth. Findingand tracking people from the bottom up. InIEEE Conference on Computer Vision andPattern Recognition, volume II, pages 467–474, Madison, Wisconsin, June 2003.
[49] J.M. Rehg and T. Kanade. Model based track-ing of self occluding articulated objects. InIEEE International Conference on ComputerVision, pages 612–617, 1995.
[50] T. J. Roberts, S. J. McKenna, and I. W. Rick-etts. Human pose estimation using learntprobabilistic region similarities and partialconfigurations. InEuropean Conference onComputer Vision, 2004.
[51] R. Ronfard, C. Schud, and B. Triggs. Learn-ing to parse pictures of people. InEuropeanConference on Computer Vision, pages 700–714, Copenhagen, 2002.
[52] R. Rosales and S. Sclaroff. Inferring bodypose without tracking body parts. InIEEEConference on Computer Vision and PatternRecognition, volume 2, pages 721–727, 2000.
[53] R. Rosales, M. Siddiqui, J. Alon, andS. Sclaroff. Estimating 3D body pose usinguncalibrated cameras. InIEEE Conferenceon Computer Vision and Pattern Recognition,volume I, pages 821–827, 2001.
[54] M.A. Ruzon and C. Tomasi. Color edge de-tection with the compass operator. InIEEEConference on Computer Vision and PatternRecognition, pages II: 160–166, 1999.
[55] B. Schiele and J. L. Crowley. Recognitionwithout correspondence using multidimen-sional receptive field histograms.Interna-tional Journal of Computer Vision, 36(1):31–50, 2000.
[56] A. Shahrokni, T. Drummond, and P. Fua. Tex-ture boundary detection for real-time track-
24

ing. In European Conference on ComputerVision, volume II, pages 566–577, 2004.
[57] H. Sidenbladh and M. J. Black. Learningimage statistics for Bayesian tracking. InIEEE International Conference on ComputerVision, volume 2, pages 709–716, Vancouver,2001.
[58] H. Sidenbladh, F. de la Torre, and M. J. Black.A framework for modeling the appearance of3D articulated figures. InIEEE InternationalConference on Face and Gesture Recognition,pages 368–375, Grenoble, 2000.
[59] C. Sminchisescu and B. Triggs. Covari-ance scaled sampling for monocular 3D bodytracking. In IEEE Conference on ComputerVision and Pattern Recognition, volume 1,pages 447–454, Hawaii, 2001.
[60] C. Sminchisescu and B. Triggs. Kinematicjump processes for monocular 3D humantracking. In IEEE Conference on ComputerVision and Pattern Recognition, pages I: 69–76, 2003.
[61] C. Stauffer and E. Grimson. Similarity tem-plates for detection and recognition. InIEEEConference on Computer Vision and PatternRecognition, volume I, pages 221–228, 2001.
[62] C. Taylor. Reconstruction of articulated ob-jects from point correspondences in a singleuncalibrated image.Computer Vision and Im-age Understanding, 80:349–363, September2000.
[63] S. Wachter and H. H. Nagel. Tracking personsin monocular image sequences.ComputerVision and Image Understanding, 74(3):174–192, June 1999.
[64] J. Wilhelms, A. van Gelder, L. Atkinson-Derman, and A. Luo. Human motion fromactive contours. InIEEE Workshop on Hu-man Motion, pages 155–160, 2000.
[65] C. R. Wren, A. Azarbayejani, T. J. Darrell,and A.P. Pentland. Pfinder: Real-time track-ing of the human body.IEEE Transactions onPattern Analysis and Machine Intelligence,19(7):780–785, July 1997.
[66] J. Zhao and N.I. Badler. Inverse kinemat-ics positioning using nonlinear programmingfor highly articulated figures. ACM Trans.Graph., 13(4):313–336, 1994.
25
Copyright © 2022 FDOKUMEN



















