
How do roots and suffixes influence reading of pseudowords: A study of young Italian readers with...
18
PLEASE SCROLL DOWN FOR ARTICLE This article was downloaded by: [Burani, Cristina] On: 12 May 2011 Access details: Access Details: [subscription number 937547971] Publisher Psychology Press Informa Ltd Registered in England and Wales Registered Number: 1072954 Registered office: Mortimer House, 37- 41 Mortimer Street, London W1T 3JH, UK Language and Cognitive Processes Publication details, including instructions for authors and subscription information: http://www.informaworld.com/smpp/title~content=t713683153 How do roots and suffixes influence reading of pseudowords: A study of young Italian readers with and without dyslexia Daniela Traficante a ; Stefania Marcolini bc ; Alessandra Luci d ; Pierluigi Zoccolotti e ; Cristina Burani c a Department of Psychology, CRIdee, Catholic University of Milan, Milan, Italy b Department of Psychology and Cultural Anthropology, University of Verona, Verona, Italy c Institute for Cognitive Sciences and Technologies, Rome, Italy d Bambino Gesù Pediatric Hospital Scientific Institute - IRCCS, Rome, Italy e Department of Psychology, Sapienza University of Rome, Rome, Italy First published on: 19 July 2010 To cite this Article Traficante, Daniela , Marcolini, Stefania , Luci, Alessandra , Zoccolotti, Pierluigi and Burani, Cristina(2011) 'How do roots and suffixes influence reading of pseudowords: A study of young Italian readers with and without dyslexia', Language and Cognitive Processes, 26: 4, 777 — 793, First published on: 19 July 2010 (iFirst) To link to this Article: DOI: 10.1080/01690965.2010.496553 URL: http://dx.doi.org/10.1080/01690965.2010.496553 Full terms and conditions of use: http://www.informaworld.com/terms-and-conditions-of-access.pdf This article may be used for research, teaching and private study purposes. Any substantial or systematic reproduction, re-distribution, re-selling, loan or sub-licensing, systematic supply or distribution in any form to anyone is expressly forbidden. The publisher does not give any warranty express or implied or make any representation that the contents will be complete or accurate or up to date. The accuracy of any instructions, formulae and drug doses should be independently verified with primary sources. The publisher shall not be liable for any loss, actions, claims, proceedings, demand or costs or damages whatsoever or howsoever caused arising directly or indirectly in connection with or arising out of the use of this material.
Transcript of How do roots and suffixes influence reading of pseudowords: A study of young Italian readers with...

PLEASE SCROLL DOWN FOR ARTICLE
This article was downloaded by: [Burani, Cristina]On: 12 May 2011Access details: Access Details: [subscription number 937547971]Publisher Psychology PressInforma Ltd Registered in England and Wales Registered Number: 1072954 Registered office: Mortimer House, 37-41 Mortimer Street, London W1T 3JH, UK
Language and Cognitive ProcessesPublication details, including instructions for authors and subscription information:http://www.informaworld.com/smpp/title~content=t713683153
How do roots and suffixes influence reading of pseudowords: A study ofyoung Italian readers with and without dyslexiaDaniela Traficantea; Stefania Marcolinibc; Alessandra Lucid; Pierluigi Zoccolottie; Cristina Buranic
a Department of Psychology, CRIdee, Catholic University of Milan, Milan, Italy b Department ofPsychology and Cultural Anthropology, University of Verona, Verona, Italy c Institute for CognitiveSciences and Technologies, Rome, Italy d Bambino Gesù Pediatric Hospital Scientific Institute - IRCCS,Rome, Italy e Department of Psychology, Sapienza University of Rome, Rome, Italy
First published on: 19 July 2010
To cite this Article Traficante, Daniela , Marcolini, Stefania , Luci, Alessandra , Zoccolotti, Pierluigi and Burani,Cristina(2011) 'How do roots and suffixes influence reading of pseudowords: A study of young Italian readers with andwithout dyslexia', Language and Cognitive Processes, 26: 4, 777 — 793, First published on: 19 July 2010 (iFirst)To link to this Article: DOI: 10.1080/01690965.2010.496553URL: http://dx.doi.org/10.1080/01690965.2010.496553
Full terms and conditions of use: http://www.informaworld.com/terms-and-conditions-of-access.pdf
This article may be used for research, teaching and private study purposes. Any substantial orsystematic reproduction, re-distribution, re-selling, loan or sub-licensing, systematic supply ordistribution in any form to anyone is expressly forbidden.
The publisher does not give any warranty express or implied or make any representation that the contentswill be complete or accurate or up to date. The accuracy of any instructions, formulae and drug dosesshould be independently verified with primary sources. The publisher shall not be liable for any loss,actions, claims, proceedings, demand or costs or damages whatsoever or howsoever caused arising directlyor indirectly in connection with or arising out of the use of this material.

How do roots and suffixes influence reading
of pseudowords: A study of young Italian readers with
and without dyslexia
Daniela Traficante1, Stefania Marcolini2,5, Alessandra Luci3,Pierluigi Zoccolotti4 and Cristina Burani5
1Department of Psychology, CRIdee, Catholic University of Milan, Milan,
Italy, 2Department of Psychology and Cultural Anthropology, University of
Verona, Verona, Italy, 3Bambino Gesu Pediatric Hospital Scientific Institute �IRCCS, Rome, Italy, 4Department of Psychology, Sapienza University
of Rome, Rome, Italy, 5Institute for Cognitive Sciences and Technologies,
Rome, Italy
The study explored the different influences of roots and suffixes in reading aloudmorphemic pseudowords (e.g., vetr-ezza, ‘‘glass-ness’’). Previous work on adultsshowed a facilitating effect of both roots and suffixes on naming times. In thepresent study, pseudoword stimuli including roots and suffixes in differentcombinations were administered to sixth-grade children with dyslexia (N�22)and skilled readers (N�44), matched for chronological age. Indeed, thesequential reading strategy of less proficient readers (particularly for pseudo-words) should favour the emergence of differences between left and rightconstituents (root and suffix, respectively) in reading performance. Resultsshowed that for both children with dyslexia and skilled young readers the onset ofpronunciation depended exclusively on roots, while there was no significant effectof suffixes. However, both roots and suffixes led to higher levels of accuracy thanmatched orthographic strings of letters. Posthoc regression analyses confirmedthe morphological nature of the root and suffix effects, over and above the effectsof the frequency of their orthographic patterns. Results indicate that the positionof the reading units within the letter string, as well as their differential effects onlatencies and accuracy, should be taken into account by models of morphologicalprocessing in word recognition and reading and by applied intervention research.
Correspondence should be addressed to Daniela Traficante, Department of psychology,
Catholic University, Largo Gemelli 1, 20123 Milano, Italy. E-mail: [email protected]
The research reported in this paper was supported by MIUR-PRIN Grant 2005111248 to
Pierluigi Zoccolotti. The authors thank Dr Roberto Iozzino for making possible to examine
children at the Centre for Cognitive and Linguistic Disorders (ASL 1) in Rome.
LANGUAGE AND COGNITIVE PROCESSES
2011, 26 (4/5/6), 777�793
# 2010 Psychology Press, an imprint of the Taylor & Francis Group, an Informa business
http://www.psypress.com/lcp DOI: 10.1080/01690965.2010.496553
Downloaded By: [Burani, Cristina] At: 16:50 12 May 2011

Keywords: Morphological structure; Reading processing; Children with dyslexia;
Pseudowords.
INTRODUCTION
The present study focuses on the relative roles of roots and suffixes in
modulating reading aloud morphologically complex new words in children
with different reading expertise.
The role of morphemic constituents in word recognition has been mainly
studied in adults by means of the lexical decision task and various models of
morphological processing have been proposed. Sublexical models posit that
morphemic constituents of a stimulus are sequentially parsed and the
corresponding sublexical units feed-forward activation to the word level
(e.g., Taft, 1994). In contrast, supralexical models (Giraudo & Grainger,
2003) claim that activation of morphemes follows recognition of the full-form
representation. In dual-route models (Burani & Caramazza, 1987; Schreuder
& Baayen, 1995), visual stimuli activate in parallel both morphological
constituents (through a parsing route) and full-forms (through a direct route).
Distributional properties of both morphemes and whole words determine
who wins the race. Low frequency or new derived words, composed of high-
frequency roots and high-frequency/productivity affixes, should be the ideal
candidates to be accessed through morphological constituents.
Several studies have confirmed the role of root frequency in lexical
decision (e.g., Burani & Thornton, 2003; Cole, Beauvillan, & Segui, 1989),
while the role of the suffix is less clear. The presence of a high-frequency
derivational suffix in a pseudoword led to increased rejection times and
several false alarms in lexical decision, both in the presence and in the
absence of a real root (Burani, Dovetto, Thornton, & Laudanna, 1997;
Burani & Thornton, 2003). These results show the relevance of the right-end
constituent (the suffix) in the access to morphemes within a pseudoword
context.
On the other hand, with low-frequency words (Burani & Thornton, 2003,
exp. 3), only root frequency influenced lexical decision latencies; suffix
frequency did not exert any effect. In the case of low-frequency words, the
root (the first, left-end constituent) may provide a head start for the
morphological route, which can lead to activation of the word representation
through parsing of the constituent morphemes before the full form is
activated by the direct route (Bertram & Hyona, 2003). Activation coming
from the suffix (the second, right-end constituent) might occur too late in the
processing, in which case the suffix would be less relevant than the root in the
recognition process. These findings need to be accommodated within models
(Baayen, Schreuder, & Sproat, 2000) in which no difference is considered
among constituents occurring in different word positions.
778 TRAFICANTE ET AL.
Downloaded By: [Burani, Cristina] At: 16:50 12 May 2011

In reading aloud morphologically complex pseudowords, Burani et al.
(1997) found a facilitating effect of the presence of a derivational suffix.
Burani, Arduino, and Marcolini (2006) investigated the relative roles of roots
and suffixes in reading pseudowords. The presence of a root speeded namingirrespective of the presence of a suffix, whereas the presence of a suffix
produced weaker facilitating effects on naming times. The authors concluded
that roots provide a head start for naming. Nevertheless, the role of the
information deriving from the second constituent needs further investigation.
Some indications concerning the role of constituent position within the
word come from studies examining eye movements during silent sentence
reading. Niswander, Pollatsek, and Rayner (2000) showed that root
frequency of English derived words affected first fixation duration andthat whole-word frequency had an effect on gaze duration. Studies on Dutch
and Finnish compounds showed involvement of both the left and right
constituents (Hyona & Pollatsek, 1998; Kuperman, Bertram, & Baayen,
2008; Pollatsek, Hyona, & Bertram, 2000). They also showed that the
duration of the first fixation was influenced by the frequency of the first
morphemic constituent and frequency of the second morpheme affected gaze
duration and later processing. Bertram and Hyona (2003) claimed that
morphological effects are more likely to emerge when stimulus processingrequires more than one eye fixation.
Although sixth-grade readers may already resemble adults regarding the
size of their perceptual span in reading (Haikio, Bertram, Hyona, & Niemi,
2009; Rayner, 1986), less proficient readers have a smaller perceptual span
that may lead to difficulties in identifying most words in one piece. In order
to study the differential roles of left vs. right morphemic constituents it might
be useful to present morphologically complex words and pseudowords to
readers who have less developed decoding skills and show analytical andfractionated text scanning, like beginning readers or children with dyslexia
(De Luca, Borrelli, Judica, Spinelli, & Zoccolotti, 2002; De Luca, Di Pace,
Judica, Spinelli, & Zoccolotti, 1999; Hutzler & Wimmer, 2004). Given the
sequentiality of the reading process of less proficient children, particularly
for pseudowords (Coltheart, Rastle, Perry, Langdon, & Ziegler, 2001), left
and right constituents might affect the reading performances of these
children to different extents. First, however, it would be useful to determine
whether young readers and children with dyslexia make use of morphemicunits in reading aloud.
The use of morphemic units in typically developing readers and in
children with dyslexia emerged in several studies. In third- to sixth-graders,
younger children tended to read correctly the suffixes of phonologically
opaque derived words (e.g., ‘‘natural’’) and to mispronounce the base word
(Mann & Singson, 2003). Other studies showed that poor readers had
difficulty in reading opaque derived words (Carlisle, Stone, & Katz, 2001;
READING MORPHOLOGICAL PSEUDOWORDS 779
Downloaded By: [Burani, Cristina] At: 16:50 12 May 2011

Windsor, 2000), but benefited from the morphemic structure of transparent
words. Carlisle and Stone (2005) found that children in both the lower
(second and third) and upper (fifth and sixth) elementary grades were more
accurate in reading derived words with transparent structure, but only thelower grade students were also faster on the transparent than the opaque
items. Furthermore, they showed that middle and high school students read
phonologically transparent derived words more accurately than opaque
words, but only the younger ones read the former words more rapidly.
As for Italian, Burani, Marcolini, and Stella (2002) found an advantage in
reading pseudoword stimuli composed of morphemes (root�suffix) com-
pared to pseudowords without morphological structure (nonroot�nonsuf-
fix) in third- to fifth-graders. Similar results were reported for sixth-gradechildren with dyslexia and for second-grade readers (Burani, Marcolini, De
Luca, & Zoccolotti, 2008). Only younger readers and children with dyslexia
took advantage of morphological structure also in reading real words
(Burani et al., 2008; Marcolini, Traficante, Zoccolotti, & Burani, in press).
These findings show that morpheme-based reading is particularly useful
for children with dyslexia and for beginning readers and results in improved
reading performance on both new and real words. In fact, morphemes are
reading units of an intermediate size between graphemes, which lead toextremely slow and analytical processing, and words, which, for unskilled
readers, are too large units to be processed as a whole (Burani et al., 2008).
However, it is still unclear whether roots and suffixes differentially influence
reading aloud because of their position in the letter string. Clarification of
these issues is important for modelling reading processes.
Word morphology has been recently considered with particular interest
within the connectionist approach to reading. In connectionist models, the
units encode regularities deriving from probabilistic information aboutorthography, phonology, and semantics. Graded, nondiscrete morphological
structures emerge in the course of learning relationships among sounds,
spellings, and meanings of words (Gonnerman, Seidenberg, & Andersen,
2007). Within such framework, fluency in reading may depend on the ability
to forge links among frequently co-occuring letters and to store them as
patterns, connecting multiple systems (Wolf et al., 2009). Pagliuca and
Monaghan (2010) claimed that, for Italian, a transparent orthography with a
rich morphology, morphemes may emerge within the connections betweenorthography and phonology without the contribution of semantics (see also
Plaut & Gonnerman, 2000). In their connectionist model that successfully
simulated main results on morphological effects in reading Italian pseudo-
words aloud, no difference was made between root and suffix.
On the basis of the data available for Italian, it could be hypothesised that
the facilitation on reading performance is due to the activation of the root
only, because the left constituent is the access code to the lexicon (Taft &
780 TRAFICANTE ET AL.
Downloaded By: [Burani, Cristina] At: 16:50 12 May 2011

Forster, 1975), or because it occurs in the initial position in the stimulus
(Hyona, Bertram, & Pollatsek, 2004). In the present study, we aimed to
determine the relative influences of roots and suffixes in modulating reading
aloud of children with different rates of fluency. Children with dyslexia mightpay less attention to the suffix than to the root, because of the extremely
sequential left-to-right scanning of the stimulus. On the other hand, sixth-
grade proficient readers might be able to take more advantage from the
right-end morphemic unit (the suffix) than children with dyslexia. Proficient
readers might apply a scanning strategy aimed at isolating the suffix, in order
to get information about stress assignment (Rastle & Coltheart, 2000), as
adults are prone to do (Burani et al., 1997, 2006).
To assess these hypotheses, four types of complex pseudowords, consistingof two morphemic units (root�suffix), only one morphemic unit (root�no-
suffix or no-root�suffix), or no morphemic units (no-root�no-suffix) were
used. In a previous study on adults, which was based on the same stimuli
(Burani et al., 2006, exp. 3), roots had a strong effect on naming times,
whereas suffixes had a weaker effect. If this difference is due to the position
of the suffix in the stimulus, less skilled readers*and particularly children
with dyslexia*who typically present highly sequential scanning of the
stimulus, may show even stronger differential effects related to the positionof the morphemic units in the word than adults and reveal a prominent role
of the root. Moreover, from the developmental data on low-frequency
derived words (e.g., Carlisle & Stone, 2005), some distinction between
fluency and accuracy performance should be expected, with roots mainly
affecting reading latencies, possibly because of their role in providing
meaning (Elbro & Arnbak, 1996), and suffixes mainly affecting accuracy,
because of their effect to correct stress assignment on new stimuli (see, e.g.,
Jarmulowicz, Taran, & Hay, 2007, 2008). Finally, we will try to distinguishthe role of the morphological structure from that of the orthographical�phonological features (as assessed by bigram frequency), which represent a
critical factor in reading pseudowords.
METHOD
Participants
The reading level of 270 students, recruited from sixth-grade classes of a
junior high school in Milan, was assessed. Two groups participated to the
experiment: 14 children with dyslexia (five girls and nine boys) and 44 skilled
children (14 girls and 30 boys). Eight children (two girls and six boys),
examined at the Centre for Cognitive and Linguistic Disorders (ASL 1) in
Rome, were also included in the first group, adding up to a total of 22
children with dyslexia.
READING MORPHOLOGICAL PSEUDOWORDS 781
Downloaded By: [Burani, Cristina] At: 16:50 12 May 2011

Criteria for inclusion in the dyslexic group were scores of at least two
standard deviations below the mean score in typically developing popula-
tions for either speed or accuracy in text reading (MT Reading test,
Cornoldi, Colpo, & Gruppo, 1995) or in a single word-reading test (Subtest
No. 4 of the Battery for the Diagnosis of Developmental Dyslexia and
Dysorthographia; Sartori, Job, & Tressoldi, 1995). The MT test requires the
participant to read a passage aloud within a 4-min time limit; speed (no. of
syllables per sec) and accuracy (no. of errors) were scored. The word reading
(Subtest no. 4) requires reading a list of 112 words; speed (total time in sec),
and accuracy (no. of errors) were scored. All children with reading disorder
from the original sample were tested.
Children with dyslexia were compared to skilled children of the same
chronological age, whose performances on the MT reading test and on single
word-reading test were within one SD below the norm for both speed and
accuracy. Forty-four children falling within these criteria were available for
testing. The two groups were matched for gender, age, and nonverbal
intelligence (Raven’s Coloured Progressive Matrices) (Table 1). All children
had normal or corrected-to-normal vision.
TABLE 1Means and standard deviations (in parentheses) for age (in months), raw and
normative z scores on Raven’s Coloured Progressive Matrices test, on MT reading test,and on Subtest No. 4 of the Battery for the Diagnosis of Developmental Dyslexia andDysorthographia. Data are presented separately for children with dyslexia and skilled
readers and compared by means of Student’s t test
Children with dyslexia
(N�22)
Skilled readers
(N�44)
Student’s t
M Mean z M Mean z (on raw scores)
Chronological age 141.31 (4.0) 141.32 (4.2) �0.09
Raven’s test 28.23 (2.5) �0.03 (0.7) 29.96 (3.41) 0.31 (0.7) �1.16
Reading speed (MT test)
(no. of syllables per sec)
1.97 (0.4) 1.48 (0.5) 3.58 (0.6) 0.03 (0.4) �10.46*
Reading accuracy (MT
test) (no. of errors)
20.75 (7.7) 1.51 (1.24) 7.57 (4.5) �0.05 (0.6) 4.24*
Reading speed (Subtest 4)
(total time in sec)
170.09 (44.3) 1.88 (0.7) 83.89 (14.07) 0.02 (0.5) 8.47*
Reading accuracy
(Subtest 4) (no. of
errors)
12.38 (7.68) 5.93 (4.1) 1.96 (1.8) 0.41 (1.1) 4.89*
*pB.001.
782 TRAFICANTE ET AL.
Downloaded By: [Burani, Cristina] At: 16:50 12 May 2011

Materials and design
The materials were the same as those used by Burani et al. (2006, exp. 3).
Four sets of 16 pseudowords were generated (see Appendix A): pseudowords
in the first set (root�suffix, e.g., bagnezza) consisted of a root (bagn-,
‘‘bath’’) and a derivational suffix (-ezza, ‘‘-ness’’) in a combination not
existing in the Italian language. Pseudowords in Set 2 (root�nonsuffix, e.g.,
bagnezzo) included the same root (bagn-) used in the first set, followed by an
orthographic sequence (-ezzo*) not corresponding to a real Italian suffix.
Pseudowords in Set 3 (nonroot�suffix, e.g., bognezza) were formed of
orthographic sequences (bogn*) that did not correspond to any existing root,
but were matched to the roots of the morphological sets for orthographic
structure and bigram frequency and included the same suffixes (-ezza) used
in the first set [difference on bigram frequency between 1 and 3 Sets: t(30)�1.02, p�.32, two-tailed]. Finally, pseudowords in Set 4 (nonroot�nonsuffix,
e.g., bognezzo) were formed of the same nonmorphemic orthographic
sequences*nonsuffix and nonroots, respectively*used in Sets 2 and 3.
Nonsuffixes in Sets 2 and 4 were matched for length, CV structure, and
average frequency in word-final position to the suffixes of Sets 1 and 3 (all
Student’s tB1.5, p�.1). Frequency values for roots, suffixes, and bigrams
were drawn from the child frequency count by Marconi, Ott, Pesenti, Ratti,
and Tavella (1993).The roots included in Sets 1 and 2 had very high frequency. The suffixes
occurring in Sets 1 and 3 were among the most frequent in Italian nominal
and adjectival derivatives. The nonroot sequences in Sets 3 and 4 were
obtained from the roots included in Set 1 by substituting one letter. The
nonsuffix sequences were the same in Sets 2 and 4, with the exception of two
item pairs, in which two different final sequences (-omo in Set 2 and -ede in
Set 4) were used to avoid the accidental inclusion of real words. Nevertheless,
these two sequences had a similar frequency and a similar CV structure. In
order to avoid embedding real words in the stimuli, some suffixes and
nonsuffixes were shifted across roots and nonroots in Sets 2 and 4. Stimuli in
the four sets had the same initial phonemes. Pseudowords in the four sets
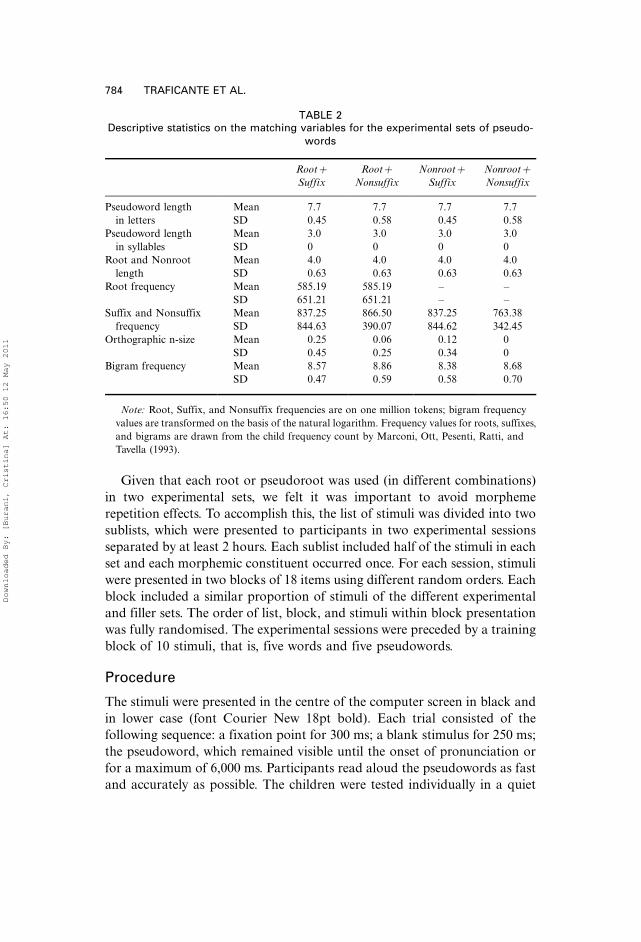
were matched for length in syllables (all three syllables) and in letters (mean
length: 7.7 letters), suffix and nonsuffix frequency, F(3, 60)�.07, p�.97,
orthographic n-size F(3, 60)�1.92, p�.13, and mean bigram frequency,
F(3, 60)�1.80, p�.15 (Table 2).
Eight pseudoword fillers were added, two with the final nonsuffix -omo,
and six with the nonsuffix -ede, i.e., the nonsuffixes that were not exactly
matched in pseudoword Sets 2 and 4. Inserting these fillers allowed the same
number of repetitions of final sequences for each of the four experimental
sets, for a total of 72 items.
READING MORPHOLOGICAL PSEUDOWORDS 783
Downloaded By: [Burani, Cristina] At: 16:50 12 May 2011
Given that each root or pseudoroot was used (in different combinations)
in two experimental sets, we felt it was important to avoid morpheme
repetition effects. To accomplish this, the list of stimuli was divided into two
sublists, which were presented to participants in two experimental sessions
separated by at least 2 hours. Each sublist included half of the stimuli in each
set and each morphemic constituent occurred once. For each session, stimuli
were presented in two blocks of 18 items using different random orders. Each
block included a similar proportion of stimuli of the different experimental
and filler sets. The order of list, block, and stimuli within block presentation
was fully randomised. The experimental sessions were preceded by a training
block of 10 stimuli, that is, five words and five pseudowords.
Procedure
The stimuli were presented in the centre of the computer screen in black and
in lower case (font Courier New 18pt bold). Each trial consisted of the
following sequence: a fixation point for 300 ms; a blank stimulus for 250 ms;
the pseudoword, which remained visible until the onset of pronunciation or
for a maximum of 6,000 ms. Participants read aloud the pseudowords as fast
and accurately as possible. The children were tested individually in a quiet
TABLE 2Descriptive statistics on the matching variables for the experimental sets of pseudo-
words
Root�Suffix
Root�Nonsuffix
Nonroot�Suffix
Nonroot�Nonsuffix
Pseudoword length Mean 7.7 7.7 7.7 7.7
in letters SD 0.45 0.58 0.45 0.58
Pseudoword length Mean 3.0 3.0 3.0 3.0
in syllables SD 0 0 0 0
Root and Nonroot Mean 4.0 4.0 4.0 4.0
length SD 0.63 0.63 0.63 0.63
Root frequency Mean 585.19 585.19 � �SD 651.21 651.21 � �
Suffix and Nonsuffix Mean 837.25 866.50 837.25 763.38
frequency SD 844.63 390.07 844.62 342.45
Orthographic n-size Mean 0.25 0.06 0.12 0
SD 0.45 0.25 0.34 0
Bigram frequency Mean 8.57 8.86 8.38 8.68
SD 0.47 0.59 0.58 0.70
Note: Root, Suffix, and Nonsuffix frequencies are on one million tokens; bigram frequency
values are transformed on the basis of the natural logarithm. Frequency values for roots, suffixes,
and bigrams are drawn from the child frequency count by Marconi, Ott, Pesenti, Ratti, and
Tavella (1993).
784 TRAFICANTE ET AL.
Downloaded By: [Burani, Cristina] At: 16:50 12 May 2011

room at their school. A microphone connected to a voice-key recorded the
responses and the E-Prime software allowed measuring naming reaction
times (RTs) in milliseconds (ms). Mispronunciation errors were noted by the
experimenter.
Data analysis
Two kinds of analyses were carried out. The first, based on the factorialdesign, aimed at investigating the different roles of roots and suffixes in
reading pseudowords. It was carried out on (natural) log-transformed RTs by
means of a mixed effect model in which participants and items were crossed
independent random effects (Baayen, Davidson, & Bates, 2008), and group
(poor readers and skilled children), roots (roots and nonroots), and suffixes
(suffixes and nonsuffixes) were fixed factors. Accuracy, in binary form (0 1),
was analysed through a logistic linear model, in which group, roots, and
suffixes (as dummy variables) were the predictors.The second analysis was a posthoc regression aimed at discriminating the
role of orthographic patterns, measured by bigram frequency, from the role
of morphemic units, such as roots and suffixes (whose frequency was
computed by summing the frequency of all derived words including a given
morpheme) on RTs and accuracy. Five predictors were considered in the
analysis: one factorial, group (skilled children vs. children with dyslexia), and
four numeric predictors, i.e., the bigram frequency of the left part of the
string (corresponding to the root or to the nonroot unit), bigram frequencyof the right part of the string (corresponding to the suffix or to the nonsuffix
unit), (natural) log-transformed frequency of the root, (natural) log-
transformed frequency of the suffix. All correlations among the four numeric
predictors were nonsignificant with the exception of left constituent bigram
frequency with root frequency, r(64)�.32, pB.05. In order to assess whether
a predictor contributes significantly to explain the variance in the dependent
variable over and above the predictors entered before it in the regression
model, a sequential analysis of variance was used in the regression analysison RTs (Baayen, 2008, p. 183). As for accuracy, a logistic regression model
was fitted and a table listing the partial effects of the predictors was
obtained.
RESULTS
Invalid trials due to technical failures and out-of-time responses (�6,000 ms)
accounted for 5.4%, and 0.8% of the responses of children with dyslexia and
skilled readers, respectively. These trials were treated as missing data and
excluded from all analyses. Pronunciation errors were excluded from the
analyses on RTs and accounted for 31% and 11% of the responses of children
READING MORPHOLOGICAL PSEUDOWORDS 785
Downloaded By: [Burani, Cristina] At: 16:50 12 May 2011

with dyslexia and skilled readers, respectively. Vocal RTs for correctly named
items and percentages of errors are presented in Table 3.
Naming was faster for skilled young readers than for children with
dyslexia. Yet, in both groups the onset of pronunciation was a function of the
root only: this led to reliable facilitatory effects of 181 ms for children with
dyslexia and of 76 ms for skilled readers, respectively. There were no
significant effects of the suffix and no significant interactions (Table 4).
The analysis on accuracy showed main effects of group, root, and suffix
(Table 5). All interactions were far from significant. Children with dyslexia
had a lower level of accuracy than skilled readers, but in both groups the
TABLE 3Descriptive statistics by groups: mean reaction times with standard deviations in
parentheses and percentages of errors
Children with dyslexia Skilled readers
Root-Suffix Rt 1,982 (191.5) 863 (68.9)
% ERR 24 5
Root-Nonsuffix Rt 1,976 (283.6) 916 (82.0)
% ERR 30 11
Nonroot-Suffix Rt 2,106 (269.8) 982 (83.8)
% ERR 34 11
Nonroot-Nonsuffix Rt 2,214 (391.5) 949 (101.7)
% ERR 41 16
Root effect Rt �181 �76
% ERR �10.5 �5.5
Suffix effect Rt �50 �10
% ERR �6.5 �5.5
TABLE 4Reaction times: mixed effect model analysis
Df Sum sq Mean sq F value Estimate St. error t value
(Intercept) 8.33526 0.16951 49.17
Group 1 5.4163 5.4163 60.4579 �0.78154 0.09727 �8.03
Root 1 1.8121 1.8121 20.2270 �0.15600 0.06440 �2.42
Suffix 1 0.1935 0.1935 2.1596 �0.11726 0.06492 �1.81
Group*Root 1 0.0790 0.0790 0.8822 0.05406 0.03417 1.58
Group*Suffix 1 0.1340 0.1340 1.4961 0.06135 0.03445 1.78
Root*Suffix 1 0.0642 0.0642 0.7164 0.07825 0.08880 0.88
Group*Root*Suffix 1 0.1524 0.1524 1.7015 �0.06151 0.04716 �1.30
Note: AIC, 1,836; BIC, 1,904; logLik, �907.2; deviance, 1,774; REMLdev, 1,814. Number of
observations: 3,376; Groups: Subject, 66; Stimuli 64.
786 TRAFICANTE ET AL.
Downloaded By: [Burani, Cristina] At: 16:50 12 May 2011

presence of morphemic units, both roots and suffixes, led to more accurate
naming performance.
Since the stimuli are pseudowords, root and suffix effects might be
interpretable as orthographic effects. The multiple linear regression model
carried out on RTs showed that, apart from the main role of the group factor,
b��.72, t��40.82, pB.001, root frequency, b��.011448, t��4.256,
pB.001, is the most reliable predictor of RTs (Table 6) (effect size computed
according to Kuperman et al., 2008, p. 1128: �38 ms). Moreover, the
relevance of this predictor was still evident after considering the role of the
bigram frequency of the same sequence of letters, F�18.11, pB.001. Bigram
frequency of the right part of the string led to a delay relative to the mean
TABLE 5Accuracy: logistic linear model analysis
Factor Df Chi-square p value
Group (factor�higher order factors) 4 334.78 B.0001
All interactions 3 0.89 .8285
Root (factor�higher order factors) 4 38.24 B.0001
All interactions 3 2.53 .4704
Suffix 4 21.81 .0002
All interactions 3 2.41 .4913
Group*Root (factor�higher order factors) 2 0.57 .7516
Group*Suffix (factor�higher order factors) 2 0.46 .7934
Root*Suffix (factor�higher order factors) 2 2.18 .3360
Group*Root*Suffix (factor�higher order factors) 1 0.10 .7465
Total interaction 4 2.73 .6036
Total 7 367.05 B.0001
TABLE 6Reaction times: linear regression model
Estimate Std. error t value Pr(�jtj) F value Pr
(Intercept) 8.131996 0.106556 76.317 B2e�16
Group �0.718598 0.017604 �40.820 B2e�16 1660.0720 B2e�16
Left part bigram
frequency
�0.006532 0.010639 �0.614 0.5393 3.3866 0.06582
Right part bigram
frequency
0.016912 0.007852 2.154 0.0313 5.3990 0.02021
Log Root frequency �0.011448 0.002690 �4.256 2.14e�05 18.1065 2.146e�05
Log Suffix frequency �0.001226 0.002481 �0.494 0.6212 0.2443 0.62117
Note: Residual standard error: 0.4506 on 3,370 degrees of freedom. Multiple R2, 0.3336;
adjusted R2, 0.3326. F-statistic, 337.4 on 5 and 3,370 DF; p-value,B2.2e�16.
READING MORPHOLOGICAL PSEUDOWORDS 787
Downloaded By: [Burani, Cristina] At: 16:50 12 May 2011
level of speed showed by the intercept (effect size:�58 ms), making the
difference between orthographic and morphemic effects stronger.
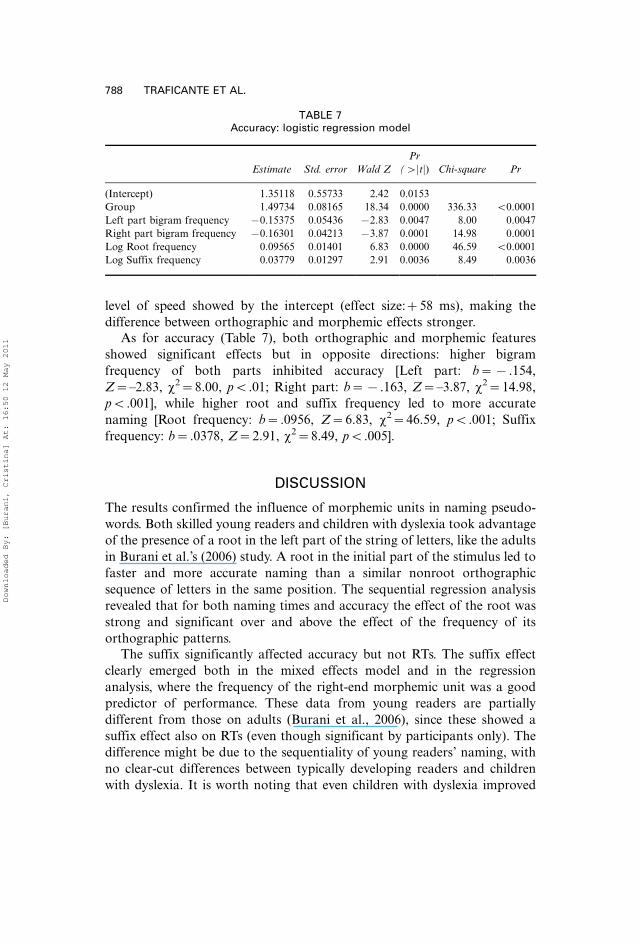
As for accuracy (Table 7), both orthographic and morphemic features
showed significant effects but in opposite directions: higher bigram
frequency of both parts inhibited accuracy [Left part: b��.154,
Z��2.83, x2�8.00, pB.01; Right part: b��.163, Z��3.87, x2�14.98,
pB.001], while higher root and suffix frequency led to more accurate
naming [Root frequency: b�.0956, Z�6.83, x2�46.59, pB.001; Suffix
frequency: b�.0378, Z�2.91, x2�8.49, pB.005].
DISCUSSION
The results confirmed the influence of morphemic units in naming pseudo-
words. Both skilled young readers and children with dyslexia took advantage
of the presence of a root in the left part of the string of letters, like the adults
in Burani et al.’s (2006) study. A root in the initial part of the stimulus led to
faster and more accurate naming than a similar nonroot orthographic
sequence of letters in the same position. The sequential regression analysis
revealed that for both naming times and accuracy the effect of the root was
strong and significant over and above the effect of the frequency of its
orthographic patterns.
The suffix significantly affected accuracy but not RTs. The suffix effect
clearly emerged both in the mixed effects model and in the regression
analysis, where the frequency of the right-end morphemic unit was a good
predictor of performance. These data from young readers are partially
different from those on adults (Burani et al., 2006), since these showed a
suffix effect also on RTs (even though significant by participants only). The
difference might be due to the sequentiality of young readers’ naming, with
no clear-cut differences between typically developing readers and children
with dyslexia. It is worth noting that even children with dyslexia improved
TABLE 7Accuracy: logistic regression model
Estimate Std. error Wald Z
Pr
(�jtj) Chi-square Pr
(Intercept) 1.35118 0.55733 2.42 0.0153
Group 1.49734 0.08165 18.34 0.0000 336.33 B0.0001
Left part bigram frequency �0.15375 0.05436 �2.83 0.0047 8.00 0.0047
Right part bigram frequency �0.16301 0.04213 �3.87 0.0001 14.98 0.0001
Log Root frequency 0.09565 0.01401 6.83 0.0000 46.59 B0.0001
Log Suffix frequency 0.03779 0.01297 2.91 0.0036 8.49 0.0036
788 TRAFICANTE ET AL.
Downloaded By: [Burani, Cristina] At: 16:50 12 May 2011

their performances in the rather difficult task of pseudoword reading by
using morphemic constituents. In a transparent orthography like Italian, the
decoding deficit seems not to reduce the chance of forging morphemic
patterns. These results indicate the relevance of training programmes (e.g.,RAVE-O, Wolf et al., 2009; Wolf, Miller, & Donnelly, 2000) developed to
explicitly teach the use of morphological information*along with phono-
logical, orthographic, semantic, and syntactic knowledge*to increase fluent
reading and comprehension.
The present pattern of results emphasises the role of the constituent
position in the stimulus, by assigning a leading role to the first unit and
reducing the effect of the second one. Considering the results in Italian, the
head start to decomposition provided by the root emerged not only in lexicaldecision (Burani & Thornton, 2003) but also in naming and more evidently
in young readers than in adults for the applied naming strategies. These data,
along with the suffix effect on accuracy, are consistent with results on eye
movements in sentence reading, indicating that both morphemic constituents
(left and right) are important (Hyona & Pollatsek, 1998; Kuperman et al.,
2008) but exert different effects: the first influences the duration of the first
fixation while the second affects later processing (Pollatsek et al., 2000).
In understanding the role of morphemic units in reading it is worth notingthat their relevance cannot be explained by considering morphemes only as
high-probability sequences of graphemes, because the frequency of roots and
suffixes was a stronger predictor of naming performance than the frequency of
their bigrams. Thus, the peculiarity of the root in improving reading fluency and
accuracy does not stem only from its orthographic familiarity but also from the
regularity of the orthography-to-semantics mapping provided by the unit.
A similar claim can be made for the suffix, although its position does not
allow it to influence the onset of pronunciation. Hyona et al. (2004)discussed which type of information (orthographic or lexical) is picked up
from the second constituent while the first one is being fixated and proposed
that the information useful for processing could be primarily orthographic in
nature. Our results, however, indicate that the morpho-lexical information
drawn from the second constituent is not reducible to pure orthographic
information for at least two reasons. First, nonmorphemic final strings (e.g.,
ezzo), which had the same orthographic frequency and CV structure as
suffixes (e.g., -ezza), did not exert any facilitation effect. Second, in the caseof accuracy, the effect of the suffix was strong and significant over and above
the effect of the frequency of its orthographic patterns.
The suffix did not influence the onset of pronunciation (presumably
because of the sequential procedure used by young readers) but had a role
similar to the root in enhancing pronunciation accuracy. This finding might
be due to the effects of the suffix on the correct phonological rendering of a
new word. In Italian, assembling the pronunciation of (bound) root and
READING MORPHOLOGICAL PSEUDOWORDS 789
Downloaded By: [Burani, Cristina] At: 16:50 12 May 2011

suffix at the production stage implies assigning a stress to the root-suffix
combination that is different than the root stress. The second constituent
(i.e., the suffix) is crucial in such a process for its strong role as stress
attractor (see Jarmulowicz et al., 2007, 2008), affecting co-articulation of the
morphemic combination.The morphemic effects found in the present study on pseudoword naming
confirm that young readers use form-meaning regularities to segment new
written words, thus improving decoding and comprehension skills (see
Jarmulowicz, Hay, Taran, & Ethington, 2008). The present results can be
explained with reference to a morphologically decomposed lexicon, in which
both roots and suffixes are stored. Accordingly, they are compatible with
both sublexical (Taft, 1994) and dual route (Burani & Caramazza, 1987;
Schreuder & Baayen, 1995) models. However, the differential pattern of root
and suffix effects shown by children underscores the need of considering the
positions of the reading units within the letter string and their differential
roles in providing a head start to morphological decomposition (Bertram &
Hyona, 2003). As the root was effective independently of the presence of a
suffix (see also Burani et al., 2006), root representations must be activated as
soon as the (left-to-right) scanning of the stimulus identifies corresponding
orthographic patterns. Accordingly, models of reading that implement
morphological information have to include root representations along with
affix representations in the early stages of processing. Rastle and Coltheart
(2000) made an interesting attempt at modelling reading processing by
including morphemic units. However, since the authors claimed that the
pronunciation of polysyllabic stimuli is obtained by deriving suffix pronun-
ciation from the affix store (while the rest of the string is read via grapheme-
to-phoneme rules), their approach cannot explain the data from Italian
readers showing the prominent role of the root. This is better fitted by PDP
models (Gonnerman et al., 2007; Plaut & Gonnerman, 2000), as they
consider morphemic units as emerging patterns from orthographic, phono-
logical, and semantic representations. However, these models do not consider
the role of constituents’ positions in the stimulus. For example, the model
developed by Pagliuca and Monaghan (2010) does account for the
morphemic effects in reading pseudowords aloud by using connections
only between orthographic and phonological patterns, but it does not yet
consider the peculiar role of morphemic position.
Further efforts are needed to build a reading model that accounts for the
relevant role of morphemic unit position, the key function of the root in
accessing meaning (see also Elbro & Arnbak, 1996), and the importance of
the suffix for stress assignment and for its semantic and syntactic
information.
790 TRAFICANTE ET AL.
Downloaded By: [Burani, Cristina] At: 16:50 12 May 2011

REFERENCES
Baayen, R. H., Schreuder, R., & Sproat, R. (2000). Morphology in the mental lexicon: A
computational model for visual word recognition. In F. van Eynde & D. Gibbon (Eds.), Lexicon
development for speech and language processing (pp. 267�291). Dordrecht: Kluwer.
Baayen, R. H. (2008). Analyzing linguistic data: A practical introduction to statistics. Cambridge,
UK: Cambridge University Press.
Baayen, R. H., Davidson, D. J., & Bates, D. M. (2008). Mixed-effects modeling with crossed
random effects for subjects and items. Journal of Memory and Language, 59, 390�412.
Bertram, R., & Hyona, J. (2003). The length of a complex word modifies the role of morphological
structure: Evidence from eye movements when reading short and long Finnish compounds.
Journal of Memory and Language, 48, 615�634.
Burani, C., Arduino, L. S., & Marcolini, S. (2006). Naming morphologically complex pseudowords:
A headstart for the root? The Mental Lexicon Journal, 1, 299�327.
Burani, C., & Caramazza, A. (1987). Representation and processing of derived words. Language
and Cognitive Processes, 3, 217�227.
Burani, C., Dovetto, F. M., Thornton, A. M., & Laudanna, A. (1997). Accessing and naming
suffixed pseudo-words. In G. E. Booij & J. van Marle (Eds.), Yearbook of morphology, 1996
(pp. 55�72). Dordrecht: Kluwer.
Burani, C., Marcolini, S., De Luca, M, & Zoccolotti, P. (2008). Morpheme-based reading aloud:
Evidence from dyslexic and skilled Italian readers. Cognition, 108, 243�262.
Burani, C., Marcolini, S., & Stella, G. (2002). How early does morpho-lexical reading develop in
readers of a shallow orthography? Brain and Language, 81, 568�586.
Burani, C., & Thornton, A. M. (2003). The interplay of root, suffix and whole-word frequency in
processing derived words. In R. H. Baayen & R. Schreuder (Eds.), Morphological structure in
language processing (pp. 157�208). Berlin: Mouton.
Carlisle, J. F., & Stone, C. A. (2005). Exploring the role of morphemes in word reading. Reading
Research Quarterly, 40, 428�449.
Carlisle, J. F., Stone, C. A., & Katz, L. A. (2001). The effects of phonological transparency on
reading derived words. Annals of Dyslexia, 51, 249�274.
Cole, P., Beauvillan, C., & Segui, J. (1989). On the representation and processing of prefixed
and suffixed derived words: A differential frequency effect. Journal of Memory and Language,
28, 1�13.
Coltheart, M., Rastle, K., Perry, C., Langdon, R., & Ziegler, J. (2001). DRC: A dual route cascaded
model of visual word recognition and reading aloud. Psychological Review, 108, 204�256.
Cornoldi, C., Colpo, G., & Gruppo, M. T. (1995). MT Reading test: Guidelines. Firenze: O. S.
De Luca, M., Borrelli, M., Judica, A., Spinelli, D., & Zoccolotti, P. (2002). Reading words and
pseudo-words: An eye movement study of developmental dyslexia. Brain and Language, 80,
617�626.
De Luca, M., Di Pace, E., Judica, A., Spinelli, D., & Zoccolotti, P. (1999). Eye-movements patterns
in linguistic and non-linguistic tasks in developmental surface dyslexia. Neuropsychologia, 37,
1407�1420.
Elbro, C., & Arnbak, E. (1996). The role of morpheme recognition and morphological awareness in
dyslexia. Annals of Dyslexia, 46, 209�240.
Giraudo, H., & Grainger, J. (2003). A supralexical model for French derivational morphology. In
E. M. H. Assink & D. Sandra (Eds.), Reading complex words: Cross-language studies (pp. 139�157). New York: Kluwer.
Gonnerman, L. M., Seidenberg, M. S., & Andersen, E. S. (2007). Graded semantic and
phonological similarity effects in priming: Evidence for a distributed connectionist approach
to morphology. Journal of Experimental Psychology: General, 136, 323�345.
READING MORPHOLOGICAL PSEUDOWORDS 791
Downloaded By: [Burani, Cristina] At: 16:50 12 May 2011

Haikio, T., Bertram, R., Hyona, J., & Niemi, P. (2009). Development of the letter identity span in
reading: Evidence from the eye movement moving window paradigm. Journal of Experimental
Child Psychology, 102, 167�181.
Hutzler, F., & Wimmer, H. (2004). Eye movements of dyslexic children when reading in a regular
orthography. Brain and Language, 89, 235�242.
Hyona, J., Bertram, R., & Pollatsek, A. (2004). Are long compound words identified serially via
their constituents? Evidence from an eye-movement-contingent display change study. Memory
and Cognition, 32, 523�532.
Hyona, J., & Pollatsek, A. (1998). Reading Finnish compound words: Eye fixations are affected by
component morphemes. Journal of Experimental Psychology: Human Perception and Perfor-
mance, 24, 1612�1627.
Jarmulowicz, L., Hay, S. E., Taran, V. L., & Ethington, C. A. (2008). Fitting derivational
morphophonology into a developmental model of reading. Reading and Writing, 21, 275�297.
Jarmulowicz, L., Taran, V. L., & Hay, S. E. (2007). Third graders’ metalinguistic skills, reading
skills, and stress production in derived English words. Journal of Speech, Language, and Hearing
Research, 50, 1�13.
Jarmulowicz, L., Taran, V. L., & Hay, S. E. (2008). Lexical Frequency and third-graders’ stress
accuracy in derived English word production. Applied Psycholinguistics, 29, 213�235.
Kuperman, V., Bertram, R., & Baayen, R. H. (2008). Morphological dynamics in compound
processing. Language and Cognitive Processes, 23, 1089�1132.
Mann, V., & Singson, M. (2003). Linking morphological knowledge to English decoding ability:
Large effects of little suffixes. In E. M. H. Assink & D. Sandra (Eds.), Reading complex words:
Cross-language studies (pp. 1�25). New York: Kluwer.
Marcolini, S., Traficante, D., Zoccolotti, P., & Burani, C. (in press). Word frequency modulates
morpheme-based reading in poor and skilled Italian readers. Applied Psycholinguistics.
Marconi, L., Ott, M., Pesenti, E., Ratti, D., & Tavella, M. (1993). Lessico Elementare. Dati statistici
sull’italiano letto e scritto dai bambini delle elementari [Elementary Lexicon: Statistical data for
Italian written and read by elementary school children]. Bologna: Zanichelli.
Niswander, E., Pollatsek, A., & Rayner, K. (2000). The processing of derived and inflected suffixed
words during reading. Language and Cognitive Processes, 15, 389�420.
Pagliuca, G., & Monaghan, P. (2010). Discovering large grain-sizes in a transparent orthography:
Insights from a connectionist model of Italian word naming. European Journal of Cognitive
Psychology. DOI: 10.1080/09541440903172158.
Plaut, D. C., & Gonnerman, L. M. (2000). Are nonsemantic morphological effects incompatible
with a distributed connectionist approach to lexical processing? Language and Cognitive
Processes, 15, 445�485.
Pollatsek, A., Hyona, J., & Bertram, R. (2000). The role of morphological constituents in reading
Finnish compound words. Journal of Experimental Psychology: Human Perception and
Performance, 26, 820�833.
Rastle, K., & Coltheart, M. (2000). Lexical and nonlexical print-to-sound translation of disyllabic
words and nonwords. Journal of Memory and Language, 42, 342�364.
Rayner, K. (1986). Eye movements and the perceptual span in beginning and skilled readers.
Journal of Experimental Child Psychology, 41, 211�236.
Sartori, G., Job, R., & Tressoldi, P. E. (1995). Batteria per la valutazione della dislessia e
disortografia evolutiva [Battery for the Diagnosis of Developmental Dyslexia and Dysortho-
graphia]. Firenze: O. S.
Schreuder, R., & Baayen, R. H. (1995). Modeling morphological processing. In L. B. Feldman
(Ed.), Morphological aspects of language processing (pp. 131�154). Hillsdale, NJ: Lawrence
Erlbaum.
Taft, M. (1994). Interactive-activation as a framework for understanding morphological proces-
sing. Language and Cognitive Processes, 9, 271�294.
792 TRAFICANTE ET AL.
Downloaded By: [Burani, Cristina] At: 16:50 12 May 2011

Taft, M., & Forster, K. (1975). Lexical storage and retrieval of prefixed words. Journal of Verbal
Learning and Verbal Behavior, 14, 638�647.
Windsor, J. (2000). The role of phonological opacity in reading achievement. Journal of Speech,
Language and Hearing Research, 43, 50�61.
Wolf, M., Barzillai, M., Gottwald, S., Miller, L., Spencer, K., Norton, E., & Morris, R. (2009). The
RAVE-O intervention: Connecting neuroscience to the classroom. Mind, Brain and Education,
3, 84�93.
Wolf, M., Miller, L., & Donnelly, K. (2000). The retrieval, automaticity, vocabulary elaboration,
orthography (RAVE-O): A comprehensive fluency-based reading intervention program. Journal
of Learning Disabilities, 33, 375�386.
APPENDIX A: PSEUDOWORD STIMULI USED IN THEEXPERIMENT
Root�Suffix Root�Nonsuffix Nonroot�Suffix Nonroot�Nonsuffix
BAGNEZZA BAGNEZZO BOGNEZZA BOGNEZZO
CARTISMO CARTOSTA CURTOSO CURTOSTA
CODISMO CODOSTA CUDEZZA CUDOSTA
CORPEZZA CORPEZZO CURPISTA CURPEZZO
CUOROSO CUOROSTO CUONEZZA CUONOSTA
DONNISTA DONNOSTO DINNISMO DINNOSTO
ERBISTA ERBOSTA ERDISMO ERDOSTO
GITISTA GITOSTO GETISTA GETOSTO
GUERROSO GUERROMO GUARROSO GUARREDE
MAMMISTA MAMMOSTA MEMMISTA MEMMOSTO
PALLISMO PALLOSTO PILLISMO PILLOSTA
SONNEZZA SONNEZZO SANNISTA SANNEZZO
STELLOSO STELLOMO STOLLOSO STOLLEDE
STRADOSO STRADOMO STRODOSO STRODEZZO
VETREZZA VETREZZO VATREZZA VATROMO
ZAMPISMO ZAMPOMO ZEMPISMO ZEMPOMO
READING MORPHOLOGICAL PSEUDOWORDS 793
Downloaded By: [Burani, Cristina] At: 16:50 12 May 2011




















