
High-Stakes English-Language Assessments for Aviation Professionals: Supporting the Use of a Fully...
15
18 IEEE TRANSACTIONS ON PROFESSIONAL COMMUNICATION, VOL. 53, NO. 1, MARCH 2010 High-Stakes English-Language Assessments for Aviation Professionals: Supporting the Use of a Fully Automated Test of Spoken-Language Proficiency —RYAN DOWNEY,MASANORI SUZUKI, AND ALISTAIR VAN MOERE Abstract—A recent International Civil Aviation Organization initiative mandates that pilots and air-traffic controllers operating on international routes demonstrate adequate English-language proficiency for successful communication. The Versant Aviation English Test was developed to serve this purpose. It is a fully automated speaking and listening performance test, where administration of the test tasks and scoring of the candidates’ responses are computerized. We argue that not only do candidates engage in cognitively and linguistically appropriate interactions, but that computer-generated scores and human ratings are consistent , enabling valid score-based decisions to be made on the basis of automated language testing. Index Terms—Automated test, aviation English, language testing, speech-recognition technology. The assessment of spoken-language skills is crucial in professions where communication breakdowns may have catastrophic consequences. International aviation professionals, including pilots and air-traffic control personnel, are routinely engaged in communications with fellow professionals who may not share their native (or primary) languages. Connell’s analysis of the initial five-year period of the NASA Aviation Safety Reporting System reported that “over 70 per cent of the reports submitted noted problems in the transfer in information in the aviation system” [1, p. 20]. It has been claimed that miscommunications related to second-language (L2) issues contributed to at least 11% of fatal airplane crashes worldwide in the period of 1982–1991 [2, p.101]. Making effective decisions regarding the language skills of aviation professionals is thus a high-stakes endeavor and depends on valid assessment practices. The International Civil Aviation Organization (ICAO) implemented a global initiative to require international aviation professionals to demonstrate English proficiency by March 2008. (A modified deadline has been extended to March 2011.) This mandate requires the development of reliable, valid, and efficient assessment tools that will enable informed decision-making based on spoken-language skills in the aviation context. Manuscript received November 11, 2008; revised March 24, 2009. Current version published February 24, 2010. The authors are with Pearson Knowledge Technologies, Palo Alto, CA 94306 USA (email: [email protected]; masanori. [email protected]; [email protected]). Color versions of one or more of the figures in this paper are available online at http://ieeexplore.ieee.org. IEEE 10.1109/TPC.2009.2038734 Numerous assessments have been developed for the aviation context in response to ICAO’s initiative, many of which utilize interlocutors in an oral proficiency interview (OPI) format [3, p. 4]. However, the OPI format faces several challenges with regard to practicality, reliability, and standardization for widespread (global) use. This paper documents the development of a standardized, automated assessment that was created to overcome these challenges. The development of this test involved research collaboration drawing on the aviation expertise of the Federal Aviation Administration (FAA) and the test-development expertise of Ordinate Corporation, now part of the Knowledge Technologies group of Pearson. The goal was to develop a practical, reliable, automated assessment instrument that would produce scores comparable to those given by expert human raters when assigning proficiency scores to candidates speaking English in aviation and general contexts (i.e., by validating the test scores against trained aviation professionals’ ratings). The resulting test—the Versant Aviation English Test (VAET)—is claimed to provide an automated approach to placing aviation professionals on the ICAO Language Proficiency Rating scale [4]. This paper first reviews the application of speech-recognition technology in language learning and assessment (Technology in Language Assessment), followed by a description of the current status on aviation-English testing (Assessing Aviation Communication). It then describes the procedures for developing the VAET (Test Development) and constructing an automated scoring model (Scoring Technology). Finally, it presents a statistical analysis of test 0361-1434/$26.00 © 2010 IEEE Authorized licensed use limited to: Auburn University. Downloaded on March 11,2010 at 16:00:48 EST from IEEE Xplore. Restrictions apply.
-
Upload
independent -
Category
Documents
-
view
5 -
download
0
Transcript of High-Stakes English-Language Assessments for Aviation Professionals: Supporting the Use of a Fully...

18 IEEE TRANSACTIONS ON PROFESSIONAL COMMUNICATION, VOL. 53, NO. 1, MARCH 2010
High-Stakes English-Language Assessments for AviationProfessionals: Supporting the Use of a Fully Automated Testof Spoken-Language Proficiency—RYAN DOWNEY, MASANORI SUZUKI, AND ALISTAIR VAN MOERE
Abstract—A recent International Civil Aviation Organization initiative mandates that pilots and air-traffic controllersoperating on international routes demonstrate adequate English-language proficiency for successful communication.The Versant Aviation English Test was developed to serve this purpose. It is a fully automated speaking and listeningperformance test, where administration of the test tasks and scoring of the candidates’ responses are computerized.We argue that not only do candidates engage in cognitively and linguistically appropriate interactions, but thatcomputer-generated scores and human ratings are consistent �� � �����, enabling valid score-based decisions tobe made on the basis of automated language testing.
Index Terms—Automated test, aviation English, language testing, speech-recognition technology.
The assessment of spoken-language skills iscrucial in professions where communicationbreakdowns may have catastrophic consequences.International aviation professionals, includingpilots and air-traffic control personnel, areroutinely engaged in communications with fellowprofessionals who may not share their native(or primary) languages. Connell’s analysis of theinitial five-year period of the NASA Aviation SafetyReporting System reported that “over 70 per centof the reports submitted noted problems in thetransfer in information in the aviation system” [1, p.20]. It has been claimed that miscommunicationsrelated to second-language (L2) issues contributedto at least 11% of fatal airplane crashes worldwidein the period of 1982–1991 [2, p.101].
Making effective decisions regarding the languageskills of aviation professionals is thus a high-stakesendeavor and depends on valid assessmentpractices. The International Civil AviationOrganization (ICAO) implemented a global initiativeto require international aviation professionals todemonstrate English proficiency by March 2008.(A modified deadline has been extended to March2011.) This mandate requires the development ofreliable, valid, and efficient assessment tools thatwill enable informed decision-making based onspoken-language skills in the aviation context.
Manuscript received November 11, 2008; revised March 24,2009. Current version published February 24, 2010.The authors are with Pearson Knowledge Technologies, Palo Alto,CA 94306 USA (email: [email protected]; [email protected]; [email protected]).Color versions of one or more of the figures in this paper areavailable online at http://ieeexplore.ieee.org.
IEEE 10.1109/TPC.2009.2038734
Numerous assessments have been developed forthe aviation context in response to ICAO’s initiative,many of which utilize interlocutors in an oralproficiency interview (OPI) format [3, p. 4]. However,the OPI format faces several challenges with regardto practicality, reliability, and standardization forwidespread (global) use. This paper documentsthe development of a standardized, automatedassessment that was created to overcome thesechallenges.
The development of this test involved researchcollaboration drawing on the aviation expertise ofthe Federal Aviation Administration (FAA) and thetest-development expertise of Ordinate Corporation,now part of the Knowledge Technologies groupof Pearson. The goal was to develop a practical,reliable, automated assessment instrument thatwould produce scores comparable to those given byexpert human raters when assigning proficiencyscores to candidates speaking English in aviationand general contexts (i.e., by validating the testscores against trained aviation professionals’ratings). The resulting test—the Versant AviationEnglish Test (VAET)—is claimed to providean automated approach to placing aviationprofessionals on the ICAO Language ProficiencyRating scale [4].
This paper first reviews the application ofspeech-recognition technology in languagelearning and assessment (Technology in LanguageAssessment), followed by a description of thecurrent status on aviation-English testing(Assessing Aviation Communication). It thendescribes the procedures for developing theVAET (Test Development) and constructing anautomated scoring model (Scoring Technology).Finally, it presents a statistical analysis of test
0361-1434/$26.00 © 2010 IEEE
Authorized licensed use limited to: Auburn University. Downloaded on March 11,2010 at 16:00:48 EST from IEEE Xplore. Restrictions apply.

DOWNEY et al.: HIGH-STAKES ENGLISH-LANGUAGE ASSESSMENTS FOR AVIATION PROFESSIONALS 19
scores (Validation Studies). In doing so, this paperconstructs a validity argument by addressing thelinguistic, theoretical, and statistical evidencerequired to support the use of machine-generatedtest scores for decision making in the aviationdomain.
TECHNOLOGY IN LANGUAGE ASSESSMENT
The field of computer-assisted language learning(CALL) has seen an increased use of automaticspeech-recognition (ASR) technology in the lasttwo decades. Several language-learning softwareapplications are now commercially available (e.g.,DynEd, Carnegie Speech’s NativeAccent, SRI’sEduSpeak, Rosetta Stone). In the aviation context,speech-recognition technology is being used to trainaviation personnel to meet ICAO requirements.DynEd’s Aviation English for Pilots and CarnegieSpeech’s Climb Level 4 are examples of theseASR-based CALL programs. Increasingly, advancesin ASR are facilitating processes in the cockpit andcontrol tower [5], [6]. However, these applicationsare used in learning, training, or managementprograms; speech-recognition technology has yetto be successfully used for certification purposesin the high-stakes domain of assessing aviationcommunication.
The complex interaction between a pilot andan air-traffic controller during even routineradiotelephonic communication (see [7]) mightseem out of reach for these technologies [4],[8]. However, dimensions of spoken language,such as pronunciation [9]–[12] and fluency[13]–[15], can now be precisely and automaticallyquantified by speech-analysis software thatis capable of analyzing speech for temporalsubcomponents, such as pausing and phrasing,and for subphonemic events, such as voice-onsettime. Scoring algorithms then estimate thespeaker’s proficiency based on a model of howhuman raters evaluated other speakers. Forexample, the pronunciation of a nonnative speakerof English can be compared with a model ofpronunciation developed by sampling a largenumber of native speakers of English in order toproduce an objective pronunciation score.
Speech recognition and statistical modeling oflanguage have reached the stage at which fullyautomated assessments can produce reasonablecorrelations between human ratings of spokenperformances and machine scores [16]–[19] withcorrelations of overall ability ratings as high as0.97 [20]. Thus, although it might be surprising
to some, the successful automated assessment oflanguage can be achieved, provided that the test iscarefully designed.
ASSESSING AVIATION COMMUNICATION
A recent survey showed that at least 20 aviationEnglish tests have been developed in responseto ICAO’s English-proficiency requirements [21].Some of those tests were developed specifically fortesting aviation professionals domestically (e.g.,Japan’s English Proficiency Test for Airline Pilots,or Thailand’s Thai DCA Aviation Test), while otherswere developed for an international test-takerpopulation (e.g., Eurocontrol’s English LanguageProficiency for Aeronautical Communication, orRMIT’s English Language Test for Aviation). Mostof these tests consist of listening and speakingtasks, and the speaking section typically employsa traditional oral interview, which is scored byhuman raters.
To inform test design, ICAO published its Manualon the “Implementation of ICAO LanguageProficiency Requirements,” a set of guidelinesdesigned to facilitate the development ofcommunication assessment among internationalpilots and air-traffic controllers [4]. This documentcodifies international air-navigation standards,requirements, and recommended practices, aswell as layout specifications and descriptors bywhich testing organizations may develop their ownassessment tools to place aviation professionals ona six-point rating scale: Level 1 (pre-elementary),Level 2 (elementary), Level 3 (preoperational),Level 4 (operational), Level 5 (extended), andLevel 6 (expert). The ICAO guidelines also requirethe demonstration of language proficiency in thefollowing six key language skills: (1) pronunciation,(2) structure, (3) vocabulary, (4) fluency, (5)comprehension, and (6) interactions. Any pilot orair-traffic controller operating on internationalroutes should demonstrate at least Level 4 in all sixof these language skills [4].
According to the guidelines, a compliant test mustsatisfy the following ICAO requirements [4]:• The test must be a proficiency test of speaking
and listening.• The test must be based on the ICAO rating scale
and holistic descriptors.• The test must test speaking and listening
proficiency in a context appropriate to aviation.• The test must test language use in a broader
context than in the use of ICAO phraseologiesalone.
Authorized licensed use limited to: Auburn University. Downloaded on March 11,2010 at 16:00:48 EST from IEEE Xplore. Restrictions apply.

20 IEEE TRANSACTIONS ON PROFESSIONAL COMMUNICATION, VOL. 53, NO. 1, MARCH 2010
In addition, the following factors (and others) mustbe considered during test development (delineatedin greater detail in [22]):• The test must be able to assess all six
ICAO-specified language skills.• The test-development team must include
qualified specialists.• The test-development process must be validated
(i.e., all tasks and items must be reviewed byindependent experts, and test instructions mustbe reviewed by stakeholders).
• The test must be secure.• The test must be reliable, valid, and practical.• The test administration and scoring should be
standardized in all locations.• All test sessions must be recorded and stored
securely.
It is worth detailing some of these issues, suchas the need that the test be reliable, valid, andpractical, and the need for standardized testingconditions across locations [4], [22]. These issuesare crucial for the assessment to be fair to allcandidates and are important components inevaluating the usefulness of any language test [23,p. 18]. In the following descriptions, the issues arediscussed with an emphasis on how an automatedassessment can satisfy these criteria and can, insome cases, provide an advantage over traditionalinterview-style assessments.
Reliability The reliability of a test reflects theconsistency of the test scores. Reliability can bemeasured in several ways. In spoken-languagetesting, the reliability is usually based onhow consistently two different raters assess acandidate’s performance. (In principle, reliabilityshould involve how consistent raters are acrossperformances, but in practice, interrater reliabilityis more common.) Although high interraterreliability can be achieved in interview tests, humanraters do not typically agree perfectly, particularlyin borderline cases [24, p. 237]. Despite thispotential problem, other existing aviation tests stillemploy the interview format. The VAET, on the otherhand, is highly reliable, as it is always consistentin how it assigns a score to a spoken response.Further, the automated scoring is independentand objective; candidates need not be concernedabout the qualifications, training, or preferencesof their individual rater(s). Because all tests aremachine-processed and scored on the basis ofrobust statistical modeling, scores are not affectedby differences in individual rater severity or bias.(Reliability data for the automated test describedhere are given in the Validation Studies section.)
Validity Various kinds of validity evidence must begathered when determining the applicability of testscores to a particular use. Generally, test validityreflects the extent to which making inferences ordecisions on the basis of test scores is justified,and the degree of validity depends on theoreticalrationales and empirical evidence supportingthe interpretation of test scores [25], [26]. Forexample, one evidential aspect of validity involvesauthenticity [27, p. 301]. The test experience canbe said to be authentic if it allows candidates todemonstrate skills in situations very similar to thecommunicative domain they will find themselvesin, basing test items on “real-world” language andinteractions. In radiotelephony, no facial cuesor body language can aid communication, andmanaging communication in voice-only situationscan be more challenging than face-to-faceinteractions. A test using a medium that offersa closer simulation to aviation communicationwould thus simulate the real-world task demandsof radiotelephony. (An analysis of the cognitivedemands of the test tasks and their relation toinferences that can be made on the basis of testscores is given in the Test Development section.)
Practicality Most spoken-language assessmentsrequire hiring, training, and maintaininginterviewers and raters. Finding qualifiedprofessionals is often challenging and costly,especially for organizations with large volumes ofcandidates. Human raters may also experiencefatigue while conducting oral proficiency interviews,which may affect administration and scoringfrom one candidate to the next. The notion ofpracticality cannot be underestimated, particularlyin a large-scale assessment [23, p. 36]. Anassessment providing an automated delivery andscoring option—for example, over the telephone orcomputer—cuts down on the practical challengesof finding and training raters, monitoring andmaintaining the calibration of their ratingbehavior, and scheduling test sessions. Instead,an automated test can be proctored by anysuitable administrator without the need for trainedexaminers, test scoring stays calibrated, and testscan be administered and taken on demand.
Standardization Fair and standardized testingprocedures are critical qualities of any high-stakestest including certification of aviation professionals.Studies have reported inherent problems with theinterview format, showing that interviewers modifytheir language from one candidate to another wheneliciting ratable spoken performance [24], [28],[29]. Furthermore, elicitation skills and interviewer
Authorized licensed use limited to: Auburn University. Downloaded on March 11,2010 at 16:00:48 EST from IEEE Xplore. Restrictions apply.

DOWNEY et al.: HIGH-STAKES ENGLISH-LANGUAGE ASSESSMENTS FOR AVIATION PROFESSIONALS 21
variability may result in very different ratings forthe same candidate [29], [30]. For these reasons,evidence suggests that a computer-mediatedspeaking test—where all candidates receivecontrolled prompts from a common item pool andwill be scored by the same algorithms—can befairer than face-to-face interviews in appropriatecontexts [31].
Additionally, aviation professionals may be exposedto a wide variety of speech styles and accents intheir day-to-day roles [4], [32], but in interviewtests, they only hear one examiner’s voice, whichmeans interview tests lack the variety typically seenin an authentic context. Automated assessmentcan overcome this problem by using test items(i.e., recorded test questions) that are spoken bymany different voices, providing a controlled rangeof accents and speaking styles. These recordedtest items further guarantee that nuances inintonation for each test item are preserved andreproduced identically across test administrations.This standardized presentation is in contrastto human examiners, who might read out testquestions with different emphasis, clarity, orspeed. With a computer-administered test, notonly is presentation of test items standardizedin different geographic locations, but scoringis also standardized. Human raters may beinfluenced, for example, by their (un)familiaritywith certain languages or regional accents [28],[33, p. 127]. But automated scores are generatedby using data-driven scoring models and nothuman examiners in various locations with varyingopinions about what is acceptable or intelligible.
Given that an automated test can, in theory, satisfyall of these criteria and provide an advantage overtraditional assessment methods in some cases,the question remains: Can an automated testbe developed that will accurately measure thecandidate’s ability and produce scores that arecomparable to human judgments of a candidate’sEnglish-speaking ability in the aviation domain?The remainder of this paper addresses this questionby describing the development and validation ofsuch a test.
TEST DEVELOPMENT
After briefly summarizing the test-developmentprocess, this section contains the followingsubsections that describe the VAET in more detail:the test structure and tasks (Test Description),the construct or ability measured in the test (Test
Construct), and the subskills for which scores areproduced (Subscores and Relationship to Tasks).
The test-development process is summarized asfollows: First, test tasks and items were specifiedand developed with the intention of elicitingperformances that would best capture candidates’facility with spoken aviation English. Once aprototype test consisting of thousands of items wasdeveloped, a large-scale field test in 40 countrieswas conducted to collect spoken performancedata from 478 native speakers and 628 nonnativespeakers of English, all of whom were active orretired aviation professionals. A total of morethan 75,000 spoken responses to test items wascaptured as sound files and subsequently ratedby an international team of 11 raters who wereexperienced as aviation-English professionals,having been very active in aviation-Englishteaching, testing, or material/curriculumdevelopment in different parts of the world (e.g., theUS, UK, Spain, Italy, Central America, Thailand).All responses used in development were each ratedindependently by at least two raters.
During data collection, spoken responses andtheir corresponding ratings were assigned to adevelopment set and a validation set of 140 tests.Care was taken such that no validation data wereincluded in the development dataset. In otherwords, one set of test-taker performances wasused to develop the automated scoring algorithmsdevelopment set and a different, nonoverlappingset of data was used to independently validatethe accuracy of the scoring system validation set.A total of 25,890 expert ratings were assigned tospoken responses from the development set. Theseratings were used to optimize the speech-processingmodels so that the models would best predict whatscores human raters assigned. Data were subjectedto many-facet Rasch modeling using the computerprogram Facets to establish difficulty measuresfor items, which feed into test scores [34]. TheFacets program estimates rater severity, subjectability, and item difficulty [35]. The validationset consisted of 140 tests, for a total of 10,920responses, to which 20,673 expert ratings wereassigned. Analyses performed on the validationset formed the basis for determining how well theautomated system predicted human judgments (seeValidation Studies).
Test Description The VAET can be taken on thetelephone or on computer and takes approximately25 minutes to complete. Scores can be retrievedonline from a secure website several minutes after
Authorized licensed use limited to: Auburn University. Downloaded on March 11,2010 at 16:00:48 EST from IEEE Xplore. Restrictions apply.

22 IEEE TRANSACTIONS ON PROFESSIONAL COMMUNICATION, VOL. 53, NO. 1, MARCH 2010
Fig. 1. Data flow in test administration, processing, and score reporting.
the test is completed. Instructions for the testare spoken in an examiner voice and are printedverbatim on a test paper. (See Fig. 1 for a schemaof the automated system.)
Each test is uniquely constructed, with testitems drawn from a large item pool, taking intoconsideration variables such as the difficultyand content of item. Test items on the VAET arerecorded as spoken prompts that are presentedin various native and nonnative English speakervoices at a standard radiotelephony pace. Voices oftest items are distinct from the examiner’s voice.During the test, the automated administrationsystem presents the items, and the candidate thenresponds to the items. The system is interactive—forexample, the length of time for which the candidateis silent after a response signals to the systemthat the response is finished and that the nextprompt should be presented. Each test presents78 recorded items, eliciting five to seven minutesof spoken-performance data from the candidatewithin the 25-minute duration of the test. Sinceitem prompts have known difficulty values, thetesting system is able to probe a candidate’slevel in a similar manner to a human interviewerby presenting items in an order approximatingincreasing difficulty.
Each of the eight tasks in the test was designedto provide information for one or more of ICAO’srequired subskills: pronunciation, structure,vocabulary, fluency, comprehension, andinteractions. The following subsections provide
brief descriptions of the task types and theabilities required to respond to the items in eachtask; responses from the first seven tasks areautomatically scored and contribute in differentways to the generation of each ICAO subscore.The last task, open questions, is not scoredautomatically; responses from this task arerecorded and may be accessed from a securewebsite by authorized administrators wishing tohear samples of a candidate’s spontaneous speechin English.
Aviation Reading: The candidate reads aloudsentences in ICAO phraseology that are printed onthe test paper, for example:
1) World Air 891, request descent.2) World Air 891, maintain flight level 280 expect
descent shortly.
Common-English Reading: This task is the same asabove, except that the sentences consist of commonEnglish.
Repeat: The candidate listens to a sentence incommon English and then attempts to repeat thesentence aloud exactly as it was heard. The topicsused are everyday and work-related topics, forexample:
The candidate hears: I try to get there a coupleof hours before the scheduled departure.
The candidate repeats: I try to get there a coupleof hours before the scheduled departure.
Authorized licensed use limited to: Auburn University. Downloaded on March 11,2010 at 16:00:48 EST from IEEE Xplore. Restrictions apply.

DOWNEY et al.: HIGH-STAKES ENGLISH-LANGUAGE ASSESSMENTS FOR AVIATION PROFESSIONALS 23
Short-answer Questions: The candidate listensto spoken questions about common, concrete,and work-related topics in common English andresponds with a single word or short phrase. Eachquestion asks for basic information or requiressimple inferences based on time, sequence,number, lexical content, or logic. The questions donot presume any knowledge of specific cultural,geographic, or historic facts or other subject matter:
The candidate hears: I have a pair of suitcases.How many suitcases do I have?
The candidate responds: Two. or You have two.
Readback: Candidates hear a spokenradiotelephony message and are asked to givean appropriate readback to confirm theirunderstanding of the message. The call sign in themessage is printed on the test paper for support.The candidate is expected to produce a readbackusing aviation phraseology as recognized by ICAO:
On the test paper, the candidate sees:
1. Coastal Air 315
The candidate hears: Coastal Air 315, maintainflight level 210.
A correct response might be: Maintain flightlevel 210, Coastal Air 315.
Another correct response is: Coastal Air 315,maintaining flight level 210.
Corrections and Confirmations: The candidatehears a radiotelephony message, either from theair-traffic controller’s perspective or the pilot’sperspective. The candidate also sees the callsign in the message printed on the test paper.Then, the candidate hears a readback, whichmight contain the correct information, incorrectinformation, or a request for more information. Thecandidate is expected to respond to the messageappropriately, using ICAO phraseology whenpossible. For example, if the response containswrong information, the candidate is expected toprovide the correct information. Some items reflectroutine communications or situations, while otherscover less-routine material, for example:
On the test paper, the candidate sees:
1. Charlie Romeo 4013
The candidate hears:
(Speaker 1) Charlie Romeo 4013, continuedescent to flight level 110, report passing 150.
(Speaker 2) Descending to flight level 10thousand, report passing 15 thousand, CharlieRomeo 4013.
A correct response might be: Charlie Romeo4013, negative, continue descent to flight level110, report passing 150.
Another correct response is: Charlie Romeo4013, I say again, continue descent to flightlevel 110, report passing 150.
Story Retelling: Candidates listen to an aurallypresented aviation scenario and are then asked todescribe what happened in their own words. Thescenarios are several sentences long and describeone or more characters, a situation, and anoutcome. Some topics are designed to be common,concrete, and familiar, while others are less familiaror unexpected:
The candidate hears:
Most of the flight between Tokyo and Hawaiiwas calm. An hour into the flight, the pilotencountered a line of storms which she hadto fly over. The flight became bumpy, andthe passengers were nervous but the flightattendants kept everyone in their seats. After afew minutes, the plane cleared the storms andthe rest of the flight was smooth. Several hourslater, the plane arrived safely in Hawaii.
Open Questions: The candidate listens to spokenquestions on work-related, aviation topics incommon English and then describes his or heropinion, experience, or thought process for eachquestion. This task is used to collect spontaneousspeech samples from the candidate:
The candidate hears (twice before responding):
In your experience, what kinds of weather arethe most difficult for air-traffic management andwhy? Please explain In your experience,what kinds of weather are the most difficultfor air-traffic management and why? Pleaseexplain.
Test Construct As with any assessmentinstrument, it is important to specify the abilitiesthat the test is designed to measure, or the testconstruct [36]. The VAET is designed to measurefacility in spoken aviation English and commonEnglish in the aviation domain. This constructrepresents the ability to understand spokenEnglish—both within the aviation radiotelephonyphraseology and on topics related to aviation (suchas movement, position, time, duration, weather,
Authorized licensed use limited to: Auburn University. Downloaded on March 11,2010 at 16:00:48 EST from IEEE Xplore. Restrictions apply.

24 IEEE TRANSACTIONS ON PROFESSIONAL COMMUNICATION, VOL. 53, NO. 1, MARCH 2010
Fig. 2. Processing components in listening andspeaking (adapted from [37]).
and animals)—and to respond appropriately inintelligible English at a fully functional pace.
For a speaker to participate successfully in aspoken exchange, several cognitive tasks must beaccomplished in real time: The speaker needs totrack what is being said, extract meaning as speechcontinues, and then formulate and articulate arelevant response. These component processes oflistening and speaking are schematized in Fig. 2,adapted from Levelt [37].
The VAET provides a measurement of real-timelanguage processing, and effective real-timelanguage processing requires automaticity of theencoding and decoding of oral language [38]. Anexample of automaticity is when an experienceddriver is driving a car: The driver performsnumerous operations simultaneously withouthaving to consciously think about them. In thecontext of a test of aviation English, automaticityrefers to the ability to access and retrieve lexicalitems, to build phrases and clause structures, andto articulate responses without conscious attentionto the linguistic code [38]–[40]. Automaticity allowsthe speaker/listener to pay attention to the messageof the speech rather than paying attention to thegrammar or vocabulary that conveys the message.
The concept of automaticity in speaking isparticularly important in air-traffic communication.Air-traffic control is a cognitively demandingcommunicative situation made more challengingwhen pilots and air-traffic controllers arecommunicating in a second language [41]. Duringan emergency situation, pilots and air-trafficcontrollers must be able to focus on solving theproblem at hand rather than focusing on how to saywhat needs to be said. The same facility in spokenEnglish that enables an aviation professional tosatisfactorily perform the test tasks in real timealso enables that individual to successfully handlepredictable, less predictable, and unexpectedsituations with fully functional English.
Subscores and Relationship to Tasks Eachtask in the test is specifically designed to provideinformation about the candidate’s ability onone or more of the six ICAO subskills [4]. Theeffect of task on a subskill score is refined byfactoring in performance from multiple tasks inthe calculation of most subskill scores. Multipleparameters are extracted from candidate responsesin each task to generate scores that meet the ICAOlanguage-proficiency criteria. Fig. 3 illustrateswhich sections of the test contribute to whichsubscores. In the remainder of this section,each subskill is summarized with regard to theinformation extracted from performance on thetask and to the ICAO scale descriptors. (A moredetailed justification for these relations can befound in [42].)
Pronunciation: The ICAO Language ProficiencyRating Scale defines the pronunciation subskilllevels in terms of “pronunciation, stress, rhythm,and intonation” [4, p. A-10]. Aviation reading,readback, and corrections and confirmationsprovide the candidate’s pronunciation samplesin the work-related, phraseology domain (e.g.,World Air 891, request descent), whereas responsesto common-English reading and repeat itemsreflect the candidate’s pronunciation ability inthe common-English context on more common,concrete topics (e.g., I try to get there a coupleof hours before the scheduled departure). Theautomated system extracts information about thestress and segmental forms of the words in theresponses and the pronunciation of the segments inthe words within a prosodic phrasal context. Theseaspects of pronunciation are sufficient to predict alistener’s “ease of understanding” as described inthe ICAO Language Proficiency Rating Scale [4, p.A-10].
Structure: The structure subskill represents thecandidate’s ability to control basic and complexgrammatical structures in real time [4, p. A-10].The candidate’s responses from the testing repeatare used to derive scores on this subskill. This taskrequires the candidate to “correctly repeat all thepertinent forms for person, tense, register” [43, p.9]. In other words, sentence repetition requiresthe candidate to use grammatical knowledge inreal time to repeat sentences with all phrasesand clauses intact and in grammatically correctsequences. As sentences increase in length andcomplexity, the task becomes increasingly difficultfor less proficient speakers who are less familiarwith the language’s phrase structures and commonsyntactic forms [43].
Authorized licensed use limited to: Auburn University. Downloaded on March 11,2010 at 16:00:48 EST from IEEE Xplore. Restrictions apply.

DOWNEY et al.: HIGH-STAKES ENGLISH-LANGUAGE ASSESSMENTS FOR AVIATION PROFESSIONALS 25
Fig. 3. Relation of subscores to item types for the Versant Aviation English Test.
Vocabulary: The ICAO descriptors define thevocabulary subskill in terms of the range andaccuracy of vocabulary for effective communicationand for paraphrasing [4, p. A-11]. The vocabularysubscore is generated from two tasks. Responsesfrom short-answer questions indicate the range ofa candidate’s effective reception and production ofcore vocabulary. Responses from story retelling,on the other hand, measure deeper productivevocabulary knowledge and competence in retrievinglexical items for paraphrasing. Scoring of thestory-retelling responses focuses on the range ofvocabulary elicited from the candidate and theaccuracy of its use. The information obtainedfrom these two tasks provides evidence about thecandidate’s ability to use vocabulary knowledge atthe word, phrase, sentence, and discourse levels.
Fluency: The ICAO fluency subskill is characterizedin terms of the candidate’s ability and ease inmaintaining appropriate speech flow and tempoat length within a discourse, making use ofdiscourse markers and connectors for effectivecommunication [4, p. A-12]. Although the fluencysubscore is derived from the same five tasks thatare used to estimate the pronunciation subscore,different features are extracted from thoseresponses and are separately analyzed to generateICAO fluency levels. Features of fluency include therate of speaking, the position and length of pausesin each of the four tasks, as well as the rate andcontinuity of speech while accurately responding toand using discourse-level cues. The tasks used toproduce the fluency subscore require candidates
to perform in common-English structures andradiotelephony phraseology.
Comprehension: ICAO classifies the comprehensionsubskill as the degree of accuracy with whicha candidate is able to comprehend common,concrete, and work-related topics [4, p. A-13]. TheVAET instrument assesses the candidate’s abilityto understand questions and aviation messages inphraseology and common-English structures. Inshort-answer questions, the candidate needs toidentify lexical items and process their meaning inreal time for comprehension. The readback task isdesigned to measure the candidate’s comprehensionability in radiotelephony messages. The scoringsystem analyzes responses for key content. As perthe ICAO rating scale descriptors, the combinationof these two tasks provides evidence about thecandidate’s ability to comprehend spoken Englishin routine and phraseology contexts and in moregeneral contexts.
Interactions: In the ICAO Language ProficiencyRating Scale, the interactions subskill ischaracterized in terms of “immediacy andappropriateness” of responses and “informativenessof the content” conveyed in responses elicitedby routine and nonroutine situations [4, p.A-14]. Immediacy can be operationalized as thelatency (or delay) of responses. Immediacy ismeasured from repeat, readback, as well ascorrections and confirmations. Appropriatenessand informativeness can be assessed based on thecontent of the responses to short-answer questions,readback, corrections and confirmations, and
Authorized licensed use limited to: Auburn University. Downloaded on March 11,2010 at 16:00:48 EST from IEEE Xplore. Restrictions apply.
26 IEEE TRANSACTIONS ON PROFESSIONAL COMMUNICATION, VOL. 53, NO. 1, MARCH 2010
story retelling. In corrections and confirmationsand readback tasks, the amount and order of thepredefined, key information determines whether theresponse is appropriate and informative. Responsesto short-answer questions demonstrate whetherthe candidate can provide the most relevant andappropriate word(s) in the given context with ashort spoken response. Story retelling providesevidence for whether the candidate can relatekey information in the story at an extended,spontaneous discourse level.
Taken together, these tasks provide direct measuresof the candidate’s listening and speaking ability,according to the six subskills in the ICAO ratingscale. The next section describes the scoring systemin more detail.
SCORING TECHNOLOGY
The automated system underlying the VAETinstrument’s scoring employs multitrait scoring,providing multiple, independent measures from thesame response. This means that responses on onetask usually contribute to more than one subscore.For example, information on the manner of acandidate’s utterance feeds into the pronunciationor fluency score, while information on the contentof the same utterance feeds into the grammar andvocabulary score. An advantage of this aspect ofthe automated scoring system’s capability is thatsubscores are not confounded by features relatedto other language skills. After discussing relativeadvantages of the multitrait scoring approach,Fulcher warns that “frequently raters cannot makethe distinction required to assign three or fourseparate grades for one speech sample” [44, p. 90],a tendency also known as “cross-contamination”[45]. Unlike human raters, the speech processorsdo not transfer judgment across subskills. Forexample, the automated scoring system is notinfluenced by a heavy accent when evaluating thecontent of the candidate’s response.
In each section of the test, the incoming response(a spoken answer) is recognized automaticallyby a Hidden Markov Model (HMM)-based speechrecognizer developed from the HMM Tool Kit [46].The acoustic models for the speech recognizerrepresent models of each sound, or phone, in thelanguage. The speech recognizer uses a dictionary,which lists the common pronunciations for eachword that the system should recognize. For theVAET, these models were trained on data from thediverse sample of native and nonnative speakersof English during the field test. In this way, the
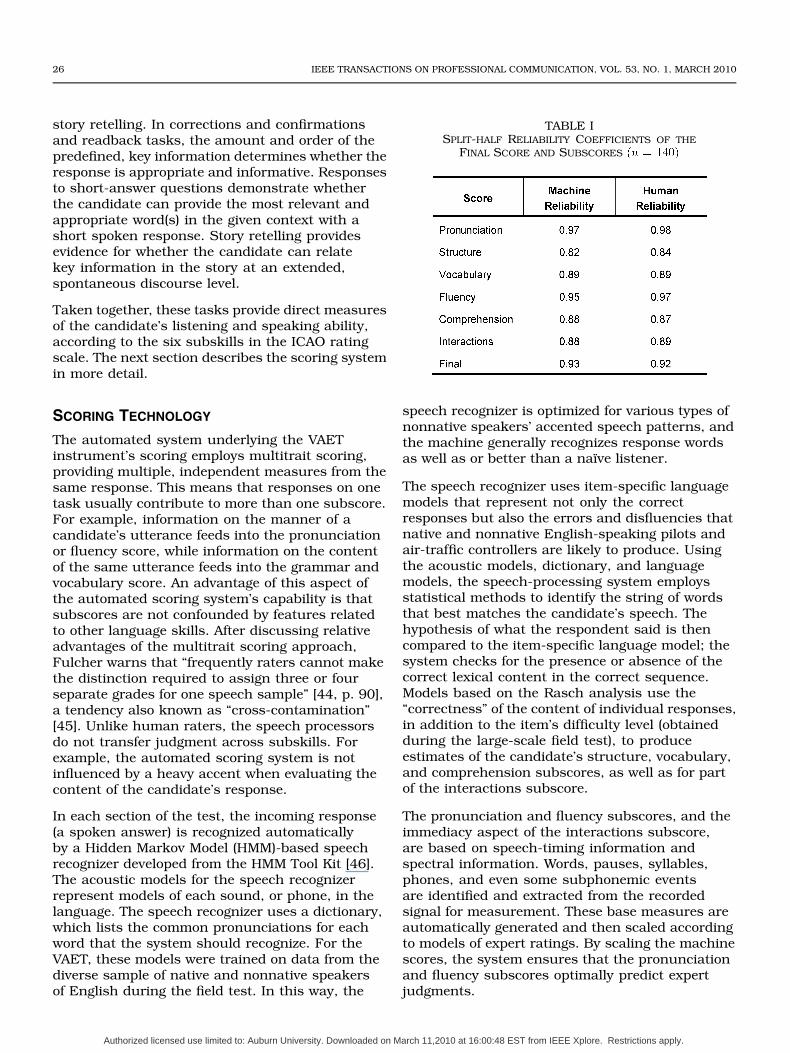
TABLE ISPLIT-HALF RELIABILITY COEFFICIENTS OF THE
FINAL SCORE AND SUBSCORES �� � ����
speech recognizer is optimized for various types ofnonnative speakers’ accented speech patterns, andthe machine generally recognizes response wordsas well as or better than a naïve listener.
The speech recognizer uses item-specific languagemodels that represent not only the correctresponses but also the errors and disfluencies thatnative and nonnative English-speaking pilots andair-traffic controllers are likely to produce. Usingthe acoustic models, dictionary, and languagemodels, the speech-processing system employsstatistical methods to identify the string of wordsthat best matches the candidate’s speech. Thehypothesis of what the respondent said is thencompared to the item-specific language model; thesystem checks for the presence or absence of thecorrect lexical content in the correct sequence.Models based on the Rasch analysis use the“correctness” of the content of individual responses,in addition to the item’s difficulty level (obtainedduring the large-scale field test), to produceestimates of the candidate’s structure, vocabulary,and comprehension subscores, as well as for partof the interactions subscore.
The pronunciation and fluency subscores, and theimmediacy aspect of the interactions subscore,are based on speech-timing information andspectral information. Words, pauses, syllables,phones, and even some subphonemic eventsare identified and extracted from the recordedsignal for measurement. These base measures areautomatically generated and then scaled accordingto models of expert ratings. By scaling the machinescores, the system ensures that the pronunciationand fluency subscores optimally predict expertjudgments.
Authorized licensed use limited to: Auburn University. Downloaded on March 11,2010 at 16:00:48 EST from IEEE Xplore. Restrictions apply.
DOWNEY et al.: HIGH-STAKES ENGLISH-LANGUAGE ASSESSMENTS FOR AVIATION PROFESSIONALS 27
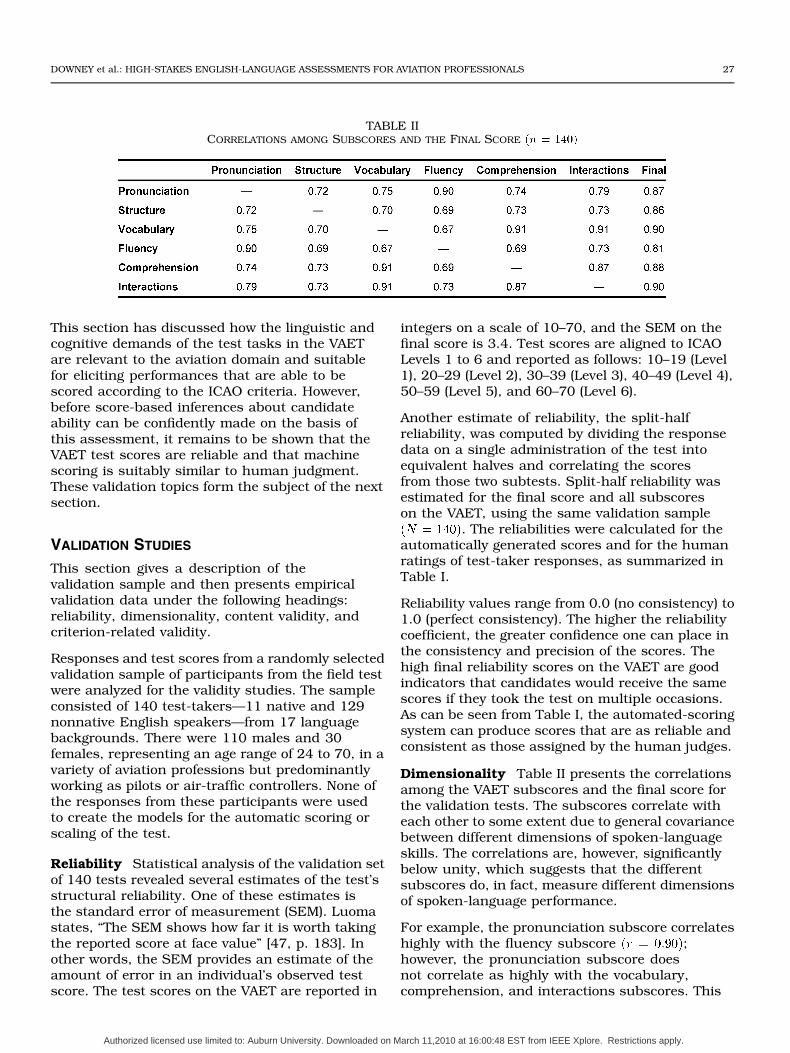
TABLE IICORRELATIONS AMONG SUBSCORES AND THE FINAL SCORE �� � ����
This section has discussed how the linguistic andcognitive demands of the test tasks in the VAETare relevant to the aviation domain and suitablefor eliciting performances that are able to bescored according to the ICAO criteria. However,before score-based inferences about candidateability can be confidently made on the basis ofthis assessment, it remains to be shown that theVAET test scores are reliable and that machinescoring is suitably similar to human judgment.These validation topics form the subject of the nextsection.
VALIDATION STUDIES
This section gives a description of thevalidation sample and then presents empiricalvalidation data under the following headings:reliability, dimensionality, content validity, andcriterion-related validity.
Responses and test scores from a randomly selectedvalidation sample of participants from the field testwere analyzed for the validity studies. The sampleconsisted of 140 test-takers—11 native and 129nonnative English speakers—from 17 languagebackgrounds. There were 110 males and 30females, representing an age range of 24 to 70, in avariety of aviation professions but predominantlyworking as pilots or air-traffic controllers. None ofthe responses from these participants were usedto create the models for the automatic scoring orscaling of the test.
Reliability Statistical analysis of the validation setof 140 tests revealed several estimates of the test’sstructural reliability. One of these estimates isthe standard error of measurement (SEM). Luomastates, “The SEM shows how far it is worth takingthe reported score at face value” [47, p. 183]. Inother words, the SEM provides an estimate of theamount of error in an individual’s observed testscore. The test scores on the VAET are reported in
integers on a scale of 10–70, and the SEM on thefinal score is 3.4. Test scores are aligned to ICAOLevels 1 to 6 and reported as follows: 10–19 (Level1), 20–29 (Level 2), 30–39 (Level 3), 40–49 (Level 4),50–59 (Level 5), and 60–70 (Level 6).
Another estimate of reliability, the split-halfreliability, was computed by dividing the responsedata on a single administration of the test intoequivalent halves and correlating the scoresfrom those two subtests. Split-half reliability wasestimated for the final score and all subscoreson the VAET, using the same validation sample
. The reliabilities were calculated for theautomatically generated scores and for the humanratings of test-taker responses, as summarized inTable I.
Reliability values range from 0.0 (no consistency) to1.0 (perfect consistency). The higher the reliabilitycoefficient, the greater confidence one can place inthe consistency and precision of the scores. Thehigh final reliability scores on the VAET are goodindicators that candidates would receive the samescores if they took the test on multiple occasions.As can be seen from Table I, the automated-scoringsystem can produce scores that are as reliable andconsistent as those assigned by the human judges.
Dimensionality Table II presents the correlationsamong the VAET subscores and the final score forthe validation tests. The subscores correlate witheach other to some extent due to general covariancebetween different dimensions of spoken-languageskills. The correlations are, however, significantlybelow unity, which suggests that the differentsubscores do, in fact, measure different dimensionsof spoken-language performance.
For example, the pronunciation subscore correlateshighly with the fluency subscore ;however, the pronunciation subscore doesnot correlate as highly with the vocabulary,comprehension, and interactions subscores. This
Authorized licensed use limited to: Auburn University. Downloaded on March 11,2010 at 16:00:48 EST from IEEE Xplore. Restrictions apply.

28 IEEE TRANSACTIONS ON PROFESSIONAL COMMUNICATION, VOL. 53, NO. 1, MARCH 2010
is because pronunciation and fluency are relatedto acoustic characteristics of the candidate’sresponses, whereas vocabulary, comprehension,and interactions are related to the content aspectof the candidate’s responses.
Content Validity Content validity is the degreeto which the language of the test items representsthe target language-use domain (i.e., the aviationdomain). It is not enough to have knowledgeableitem writers; rather, their writing should beinformed by a corpus of actual usage to ensureappropriate language coverage. The languagecontent of the VAET instrument was informed byan aviation corpus compiled by the TESOL andLinguistics program at Oklahoma State University.This corpus consisted of radiotelephony transcripts(235,000 words), aviation standards publications(338,000 words), and general aviation publications(258,000 words). Further content-related evidenceof validity was provided by expert judgment andempirical item analysis. Each item was reviewed bysubject-matter aviation experts to ensure contentrelevance and conformity to expected usage.Further, the responses elicited by items werereviewed to ensure that items elicited the intendedlanguage and that native-speaker respondentswith aviation experience were able to performsatisfactorily on all items. If an item was notrelatively easy for a native-speaker sample, or ifit was unclear whether the item was measuringspoken English or another underlying ability, theitem was removed from the test.
Criterion-Related Validity The automaticallygenerated scores in the VAET and the scores givenby expert human raters should be equivalent. Inshort, expert human judgments are the criterionagainst which we can measure the accuracy of theautomatic scores. A high correlation between thetwo scores would suggest that the machine scoringaccurately matches expert ratings.
In one study, responses from the 140 validationtests were transcribed and rated by humans,and were also run through the automaticscoring models. Fig. 4 shows a scatter plot ofthe final machine-generated scores and finalhuman-generated scores, and Table III shows thecorrelation for the final score and each subscorebetween the machine-generated scores andhuman-generated scores.
Fig. 4 shows a clear linear trend, indicating thatfor every case evaluated, the scores generated bymachine and by trained transcribers and ICAO
Fig. 4. Overall scores versus human-generated overallscores (� � ���, � � ����) from the Versant AviationEnglish Test.
TABLE IIICORRELATIONS BETWEEN THE VERSANT AVIATION
ENGLISH TEST AND HUMAN SCORES �� � ����
expert raters are closely aligned. In addition, astrong correlation was found for each subscore.These correlations and the scatter plot provideevidence that the machine-generated scoressystematically correspond with the scoresgenerated by the ICAO expert raters.
In another study, the responses on the story-retelland open-question tasks were used to estimate thecandidates’ ICAO level. These tasks elicited the mostfree, unconstrained responses from candidatesand, together, accounted for five 30-second-longturns per candidate, for a total of 2.5 minutes ofrecordings. Six ICAO expert raters listened to theselanguage samples and provided holistic estimatesof candidates’ ICAO levels. Five responses wererated independently for each candidate, and eachresponse was rated by at least two different ratersindependently, producing a total of at least 10
Authorized licensed use limited to: Auburn University. Downloaded on March 11,2010 at 16:00:48 EST from IEEE Xplore. Restrictions apply.
DOWNEY et al.: HIGH-STAKES ENGLISH-LANGUAGE ASSESSMENTS FOR AVIATION PROFESSIONALS 29
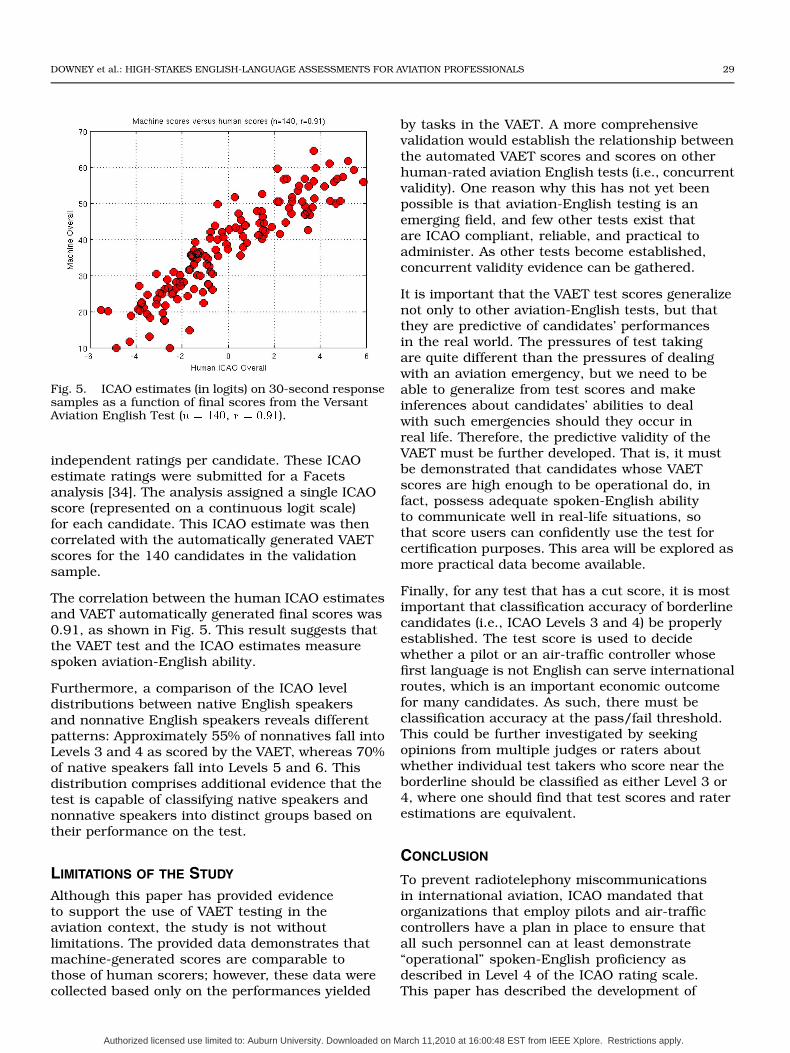
Fig. 5. ICAO estimates (in logits) on 30-second responsesamples as a function of final scores from the VersantAviation English Test (� � ���, � � ����).
independent ratings per candidate. These ICAOestimate ratings were submitted for a Facetsanalysis [34]. The analysis assigned a single ICAOscore (represented on a continuous logit scale)for each candidate. This ICAO estimate was thencorrelated with the automatically generated VAETscores for the 140 candidates in the validationsample.
The correlation between the human ICAO estimatesand VAET automatically generated final scores was0.91, as shown in Fig. 5. This result suggests thatthe VAET test and the ICAO estimates measurespoken aviation-English ability.
Furthermore, a comparison of the ICAO leveldistributions between native English speakersand nonnative English speakers reveals differentpatterns: Approximately 55% of nonnatives fall intoLevels 3 and 4 as scored by the VAET, whereas 70%of native speakers fall into Levels 5 and 6. Thisdistribution comprises additional evidence that thetest is capable of classifying native speakers andnonnative speakers into distinct groups based ontheir performance on the test.
LIMITATIONS OF THE STUDY
Although this paper has provided evidenceto support the use of VAET testing in theaviation context, the study is not withoutlimitations. The provided data demonstrates thatmachine-generated scores are comparable tothose of human scorers; however, these data werecollected based only on the performances yielded
by tasks in the VAET. A more comprehensivevalidation would establish the relationship betweenthe automated VAET scores and scores on otherhuman-rated aviation English tests (i.e., concurrentvalidity). One reason why this has not yet beenpossible is that aviation-English testing is anemerging field, and few other tests exist thatare ICAO compliant, reliable, and practical toadminister. As other tests become established,concurrent validity evidence can be gathered.
It is important that the VAET test scores generalizenot only to other aviation-English tests, but thatthey are predictive of candidates’ performancesin the real world. The pressures of test takingare quite different than the pressures of dealingwith an aviation emergency, but we need to beable to generalize from test scores and makeinferences about candidates’ abilities to dealwith such emergencies should they occur inreal life. Therefore, the predictive validity of theVAET must be further developed. That is, it mustbe demonstrated that candidates whose VAETscores are high enough to be operational do, infact, possess adequate spoken-English abilityto communicate well in real-life situations, sothat score users can confidently use the test forcertification purposes. This area will be explored asmore practical data become available.
Finally, for any test that has a cut score, it is mostimportant that classification accuracy of borderlinecandidates (i.e., ICAO Levels 3 and 4) be properlyestablished. The test score is used to decidewhether a pilot or an air-traffic controller whosefirst language is not English can serve internationalroutes, which is an important economic outcomefor many candidates. As such, there must beclassification accuracy at the pass/fail threshold.This could be further investigated by seekingopinions from multiple judges or raters aboutwhether individual test takers who score near theborderline should be classified as either Level 3 or4, where one should find that test scores and raterestimations are equivalent.
CONCLUSION
To prevent radiotelephony miscommunicationsin international aviation, ICAO mandated thatorganizations that employ pilots and air-trafficcontrollers have a plan in place to ensure thatall such personnel can at least demonstrate“operational” spoken-English proficiency asdescribed in Level 4 of the ICAO rating scale.This paper has described the development of
Authorized licensed use limited to: Auburn University. Downloaded on March 11,2010 at 16:00:48 EST from IEEE Xplore. Restrictions apply.

30 IEEE TRANSACTIONS ON PROFESSIONAL COMMUNICATION, VOL. 53, NO. 1, MARCH 2010
an automated performance test designed tomeasure listening and speaking abilities ofnonnative English-speaking aviation professionalsin their workplace. The test does not employ thetraditional means of engaging the candidate in aface-to-face interaction with a human examiner,as would occur in interview-style tests. Instead,the VAET instrument implements a voice-only testmethod, replicating an important aspect of thecommunication modality that candidates actuallyencounter in their profession.
It is commonly accepted that the validity of testscores is based on an overall evaluative argumentaccording to the available evidence [25], [26]. Thispaper has presented a variety of such evidence,including a description of the cognitive andlinguistic demands of each task, a theoretical anddata-driven rationale for scoring, and a statisticalanalysis of test scores. Further, an analysis ofICAO’s criteria in relation to the test administrationand test structure has supported the claim thatthe test is relevant, standardized, and practical,both in administration and scoring. The resultsof the study provide a validity argument for VAETthat justifies using test scores in making decisionsabout placement and training, hiring, and certifyingin the aviation profession.
This study provides further positive evidencethat speech-processing technology has reached asufficiently advanced stage for the assessment ofcommunication skills in high-stakes professionaldomains. In fact, the same underlying technologyhas already been applied to assess spoken
language for a wide variety of purposes, includingdemonstrating that US Border Patrol officers havesufficient spoken-Spanish ability for field work,and screening job applicants for spoken-Englishability in call centers in India and the Philippines[48], as well as assessing spoken-Dutch languageskills of immigrants to the Netherlands [49]. In thefuture, there are certain to be other possibilitiesand applications of this technology to promoteeffective communication in specific, professionaldomains, such as law, medicine, transportation,and interpretation/translation.
ACKNOWLEDGMENTS
The project reported in this article was a cooperativeresearch agreement between Pearson’s KnowledgeTechnologies group and the US Federal AviationAdministration (FAA). The authors acknowledgethat they are employed by the publisher of theassessment instrument described herein, that theinstrument described is a commercial product, andthat the project was funded internally. Validationdata presented here can be found in the handbookaccompanying the test [42].
The authors would like to thank the guesteditor and anonymous reviewers for their helpfulcomments on an earlier draft of this manuscript.They would also like to thank G. Elliott for hisguidance and Dr. C. Moder of Oklahoma StateUniversity for her expertise during the developmentof this test. They would also like to thank Dr. J.Balogh, Dr. J. Cheng, and Dr. J. Bernstein for theirroles in the test-development process.
REFERENCES
[1] L. Connell. (1995). Pilot and controller communications issues in Proc. Methods & Metrics of VoiceCommunication Workshop. [Online]. Available: http://www.faa.gov/library/reports/medical/oamtechreports/1990s/media/AM96-10.pdf
[2] D. Crystal, English as a Global Language. Cambridge, UK: Cambridge Univ. Press, 1997.[3] J. Mell, “Standards for test development in aviation: From placement to proficiency,” presented at the ICAO
Aviation Language Symp., Montréal, QC, Canada, Sep. 1–3, 2004.[4] International Civil Aviation Organization, “Manual on the implementation of the ICAO language proficiency
requirements,” Doc 9835 AN/453, Montréal, QC, Canada, 2004.[5] L. Dourmap and P. Truillet, “Vocal interaction and air traffic management: The VOICE project,” presented at
the Int. Conf. Human-Computer Interaction in Aeronautics, Toulouse, France, Sep. 29–Oct. 1, 2004.[6] D. Schäfer. (2001, Feb.). Context-sensitive speech recognition in the air traffic control
simulation. EUROCONTROL Experimental Centre (EEC), note no. 02/2001. [Online]. Available:mhttp://www.eurocontrol.int/eec/public/standard_page/DOC_Report_2001_004.html
[7] L. Loukopoulos, R. K. Dismukes, and I. Barshi, “Concurrent task demands in the cockpit: Challenges andvulnerabilities in routine flight operations,” in Proc. 12th Int. Symp. Aviation Psychology, 2003, pp. 737–742.
[8] H. Hering. (2001, Jan.). Technical analysis of ATC controller to pilot voice communication with regardsto automatic speech recognition systems. EUROCONTROL Experimental Centre (EEC) note No. 01/2001.[Online]. Available: http://www.eurocontrol.int/eec/public/standard_page/DOC_Report_2001_001.html
[9] H. Franco, L. Neumeyer, Y. Kim, and O. Ronen, “Automatic pronunciation scoring for language instruction,”in Proc. Int. Conf. Acoustics, Speech, and Signal Processing, 1997, pp. 1471–1474.
Authorized licensed use limited to: Auburn University. Downloaded on March 11,2010 at 16:00:48 EST from IEEE Xplore. Restrictions apply.

DOWNEY et al.: HIGH-STAKES ENGLISH-LANGUAGE ASSESSMENTS FOR AVIATION PROFESSIONALS 31
[10] N. Minematsu, “Pronunciation assessment based upon the compatibility between a learner’s pronunciationstructure and the target language’s lexical structure,” in Proc. Interspeech, 2004, pp. 1317–1320.
[11] A. Raux and T. Kawahara, “Automatic intelligibility assessment and diagnosis of critical pronunciationerrors for computer-assisted pronunciation learning,” in Proc. Int. Conf. Spoken Language Processing, 2002,pp. 737–740.
[12] C. Cucchiarini, H. Strik, D. Binnenpoorte, and L. Boves, “Pronunciation evaluation in read and spontaneousspeech: A comparison between human ratings and automatic scores,” in Proc. New Sounds, 4th Int. Symp.Acquisition of Second-Language Speech, 2000, pp. 72–79.
[13] Y. Liu, E. Shriberg, A. Stolcke, D. Hillard, M. Ostendorf, and M. Harper, “Enriching speech recognitionwith automatic detection of sentence boundaries and disfluencies,” IEEE Trans. Speech Audio Process., vol.14, no. 5, pp. 1526–1540, Sep., 2006.
[14] C. Cucchiarini, H. Strik, and L. Boves, “Quantitative assessment of second language learners’ fluency bymeans of automatic speech recognition technology,” J. Acoust. Soc. Amer., vol. 107, no. 2, pp. 989–999, 2000.
[15] O. D. Deshmukh, K. Kandhway, K. Audhkhasi, and A. Verma, “Automatic evaluation of spoken Englishfluency,” presented at the IEEE Int. Conf. Acoustics, Speech, and Signal Processing, Taipei, Taiwan, Apr.19–24, 2009.
[16] A. Chandel, A. Parate, M. Madathingal, H. Pant, N. Rajput, S. Ikbal, O. Deshmukh, and A. Verma,“Sensei: Spoken language assessment for call center agents,” in Proc. IEEE Int. Workshop on Automatic SpeechRecognition Understanding, 2007, pp. 711–716.
[17] F. de Wet, C. Van der Walt, and T. R. Niesler, “Automatic assessment of oral language proficiency andlistening comprehension,” Speech Commun., vol. 51, no. 10, pp. 864–874, 2009.
[18] J. Bernstein, J. De Jong, D. Pisoni, and B. Townshend, “Two experiments on automatic scoring of spokenlanguage proficiency,” in Proc. Integrating Speech Technology in Language Learning, 2000, pp. 57–61.
[19] Pearson. (2008). Versant Spanish test: Test description and validation summary. Pearson KnowledgeTechnologies, Palo Alto, CA. [Online]. Available: http://www.ordinate.com/technology/validation.jsp
[20] Pearson. (2008). Versant English test: Test description and validation summary. Pearson KnowledgeTechnologies, Palo Alto, CA. [Online]. Available: http://www.ordinate.com/technology/validation.jsp
[21] J. C. Alderson. (2008, Sep.). Final report on a survey of aviation English tests. [Online]. Available:http://www.ealta.eu.org/guidelines.htm
[22] International Civil Aviation Organization, “Language testing criteria for global harmonization,” Cir 318-AN/180,2009.
[23] L. F. Bachman and A. S. Palmer, Language Testing in Practice. London, UK: Oxford Univ. Press, 1996.[24] D. J. Reed and G. B. Halleck, “Probing above the ceiling in oral interviews: What’s up there?,” in Proc. LTRC,
1996, pp. 225–240.[25] L. J. Cronbach, “Five perspectives on validation argument,” in Test Validity, H. Wainer and H. Braun,
Eds. Hillsdale, NJ: Lawrence Erlbaum Associates, 1988, pp. 3–17.[26] S. Messick, “Validity,” in Educational Measurement, R. L. Linn, Ed. New York: Macmillan/American Council
on Education, 1998, pp. 13–103.[27] L. F. Bachman, Fundamental Considerations in Language Testing. London, UK: Oxford Univ. Press, 1990.[28] A. Brown and T. Lumley, “Interviewer variability in specific-purpose language performance tests,” in Proc.
LTRC, 1996, pp. 137–150.[29] A. Brown, “Interviewer variation and the co-construction of speaking proficiency,” Language Testing, vol. 20,
no. 1, pp. 1–25, 2003.[30] T. McNamara, “Language testing: A question of context,” in Language Testing Reconsidered, J. Fox, M.
Wesche, D. Bayliss, L. Cheng, C. Turner, and C. Doe, Eds. Ottawa, ON, Canada: Univ. of Ottawa Press,2007, pp. 131–137.
[31] C. W. Stansfield and D. M. Kenyon, “Research on the comparability of the oral proficiency interview and thesimulated oral proficiency interview,” System, vol. 20, no. 3, pp. 347–364, 1992.
[32] E. Mathews, “New provisions for English language proficiency are expected to improve aviation safety,”ICAO J., vol. 59, no. 1, pp. 4–6, 2004.
[33] T. McNamara, Measuring Second Language Performance. Harlow, Essex, UK: Addison-Wesley Longman, 1996.[34] J. M. Linacre. (2003). Facets Rasch Measurement Computer Program. [Online]. Available: http://winsteps.com[35] J. M. Linacre, B. B. Wright, and M. E. Lunz. (1990). A facets model for judgmental scoring, Memo 61. MESA
Psychometric Laboratory. [Online]. Available: http://www.rasch.org/memo61.htm[36] American Psychological Association, Standards for Educational and Psychological Testing. Washington, DC:
American Psychological Association, 1999.[37] W. J. M. Levelt, Speaking: From Intention to Articulation. Cambridge, MA: MIT Press, 1989.[38] A. Cutler, “Lexical access,” in Encyclopedia of Cognitive Science. Vol. 2, Epilepsy—Mental Imagery, Philosophical
Issues About, L. Nadel, Ed. London, UK: Nature Publishing Group, 2003, pp. 858–864.[39] J. D. Jescheniak, A. Hahne, and H. J. Schriefers, “Information flow in the mental lexicon during speech
planning: Evidence from event-related brain potentials,” Cognit. Brain Res., vol. 15, no. 3, pp. 261–276, 2003.[40] W. J. M. Levelt, “Spoken word production: A theory of lexical access,” in Proc. National Academy of Sciences,
2001, vol. 98, no. 23, pp. 13,464–13,471.[41] C. Farris, P. Trofimovich, N. Segalowitz, and E. Gatbonton, “Air traffic communication in a second language:
Implications of cognitive factors for training and assessment,” TESOL Quart., vol. 42, no. 3, pp. 397–410, 2008.
Authorized licensed use limited to: Auburn University. Downloaded on March 11,2010 at 16:00:48 EST from IEEE Xplore. Restrictions apply.

32 IEEE TRANSACTIONS ON PROFESSIONAL COMMUNICATION, VOL. 53, NO. 1, MARCH 2010
[42] Pearson. (2007). Versant aviation English test: Test description and validation summary. Pearson KnowledgeTechnologies, Palo Alto, CA. [Online]. Available: http://www.ordinate.com/technology/validation.jsp
[43] C. F. Radloff, Sentence Repetition Testing for Studies of Community Bilingualism. Dallas, TX: Summer Instituteof Linguistics and the University of Texas at Arlington Publications in Linguistics, 1991.
[44] G. Fulcher, Testing Second Language Speaking. London, UK: Longman/Pearson Education, 2003.[45] J. C. Alderson, “Report of the discussion on general language proficiency,” in Issues in Language Testing, J. C.
Alderson and A. Hughes, Eds. London, UK: The British Council, 1981, pp. 187–194.[46] S. Young, D. Kershaw, J. Odell, D. Ollason, V. Valtchev, and P. Woodland, The HTK Book Version
3.0. Cambridge, UK: Cambridge Univ., 2000.[47] S. Luoma, Assessing Speaking. Cambridge, UK: Cambridge Univ. Press, 2004.[48] R. Downey and A. Van Moere, “In the ear of the beholder: Dependence of comprehensibility on language
background of speaker and listener,” presented at the Language Testing Research Colloq., Denver, CO, Mar.17–20, 2009.
[49] J. H. A. L. De Jong, M. Lennig, A. Kerkhoff, and P. Poelmans, “Development of a test of spoken Dutch forprospective immigrants,” Language Assess. Quart., vol. 6, no. 1, pp. 41–60, 2009.
Ryan Downey received the Ph.D. degree in Language and Communicative Disorders from the University of California, San Diego,
and San Diego State University. He is a test developer with Pearson Knowledge Technologies, Palo Alto, CA. His research interests
include examining the cognitive and linguistic processes underlying language production and comprehension.
Masanori Suzuki received the M.A. degree in Teaching English to Speakers of Other Languages from San Francisco State
University, San Francisco. He is a senior test developer with Pearson Knowledge Technologies, Palo Alto, CA. He has been developing
automated spoken-language tests using speech-recognition technology for the past six years, including tests of spoken English,
Spanish, and Arabic. His research interests are language testing and psycholinguistics.
Alistair Van Moere received the Ph.D. degree in Applied Linguistics from Lancaster University, Lancaster, UK. He is Director of Test
Development with Pearson Knowledge Technologies, Palo Alto, CA, where he oversees various spoken-language tests used globally
in high-stakes contexts. He has worked on numerous language test development and validation projects, including Trinity College
examinations, London; Lancaster University’s validation of the English Language Proficiency for Aeronautical Communication
(ELPAC) test, Luxemburg; and the Kanda University Proficiency Test, Japan.
Authorized licensed use limited to: Auburn University. Downloaded on March 11,2010 at 16:00:48 EST from IEEE Xplore. Restrictions apply.




















