
Enhancing web page classification through image-block importance analysis
17
Enhancing web page classification through image-block importance analysis E. Fersini a, * , E. Messina a , F. Archetti a,b a Dipartimento di Informatica Sistemistica e Comunicazione, Universita ` degli Studi di Milano-Bicocca, Italy b Consorzio Milano Ricerche, Italy Received 30 July 2007; received in revised form 8 November 2007; accepted 12 November 2007 Available online 3 January 2008 Abstract We present a term weighting approach for improving web page classification, based on the assumption that the images of a web page are those elements which mainly attract the attention of the user. This assumption implies that the text con- tained in the visual block in which an image is located, called image-block, should contain significant information about the page contents. In this paper we propose a new metric, called the Inverse Term Importance Metric, aimed at assigning higher weights to important terms contained into important image-blocks identified by performing a visual layout analysis. We propose different methods to estimate the visual image-blocks importance, to smooth the term weight according to the importance of the blocks in which the term is located. The traditional TFxIDF model is modified accordingly and used in the classification task. The effectiveness of this new metric and the proposed block evaluation methods have been validated using different classification algorithms. Ó 2007 Elsevier Ltd. All rights reserved. Keywords: Term weighting; Vector space model; Visual layout analysis; Document classification 1. Introduction Today’s search engines and document classification techniques are mostly based on textual information and do not take into account those information related to visual layout features. Actually, in the sense of human perception, it is always the case that people view a web page as a composition of semantic objects rather than as a single object. Indeed, when a web page is presented to the user, the spatial and visual cues help him to unconsciously divide the page into several semantic part containing different types of information beside its main topic, for example: navigation bar, copyright, contact information and so on. The detection of this semantic content structure may improve the performance of web information retrieval tasks such as classifi- cation or clustering. In Kovacevic, Diligenti, Gori, and Milutinovic (2002) the authors provide a mechanism 0306-4573/$ - see front matter Ó 2007 Elsevier Ltd. All rights reserved. doi:10.1016/j.ipm.2007.11.003 * Corresponding author. Tel.: +39 0264487850; fax: +39 0264487880. E-mail address: [email protected] (E. Fersini). Available online at www.sciencedirect.com Information Processing and Management 44 (2008) 1431–1447 www.elsevier.com/locate/infoproman
-
Upload
independent -
Category
Documents
-
view
1 -
download
0
Transcript of Enhancing web page classification through image-block importance analysis

Available online at www.sciencedirect.com
Information Processing and Management 44 (2008) 1431–1447
www.elsevier.com/locate/infoproman
Enhancing web page classification throughimage-block importance analysis
E. Fersini a,*, E. Messina a, F. Archetti a,b
a Dipartimento di Informatica Sistemistica e Comunicazione, Universita degli Studi di Milano-Bicocca, Italyb Consorzio Milano Ricerche, Italy
Received 30 July 2007; received in revised form 8 November 2007; accepted 12 November 2007Available online 3 January 2008
Abstract
We present a term weighting approach for improving web page classification, based on the assumption that the imagesof a web page are those elements which mainly attract the attention of the user. This assumption implies that the text con-tained in the visual block in which an image is located, called image-block, should contain significant information aboutthe page contents. In this paper we propose a new metric, called the Inverse Term Importance Metric, aimed at assigninghigher weights to important terms contained into important image-blocks identified by performing a visual layout analysis.We propose different methods to estimate the visual image-blocks importance, to smooth the term weight according to theimportance of the blocks in which the term is located. The traditional TFxIDF model is modified accordingly and used inthe classification task. The effectiveness of this new metric and the proposed block evaluation methods have been validatedusing different classification algorithms.� 2007 Elsevier Ltd. All rights reserved.
Keywords: Term weighting; Vector space model; Visual layout analysis; Document classification
1. Introduction
Today’s search engines and document classification techniques are mostly based on textual information anddo not take into account those information related to visual layout features. Actually, in the sense of humanperception, it is always the case that people view a web page as a composition of semantic objects rather thanas a single object. Indeed, when a web page is presented to the user, the spatial and visual cues help him tounconsciously divide the page into several semantic part containing different types of information beside itsmain topic, for example: navigation bar, copyright, contact information and so on. The detection of thissemantic content structure may improve the performance of web information retrieval tasks such as classifi-cation or clustering. In Kovacevic, Diligenti, Gori, and Milutinovic (2002) the authors provide a mechanism
0306-4573/$ - see front matter � 2007 Elsevier Ltd. All rights reserved.
doi:10.1016/j.ipm.2007.11.003
* Corresponding author. Tel.: +39 0264487850; fax: +39 0264487880.E-mail address: [email protected] (E. Fersini).

1432 E. Fersini et al. / Information Processing and Management 44 (2008) 1431–1447
to detect the visual layout structure of a web page through identification of different page components such asheaders, navigation bars, left and right menus, footers, and informative parts. The functional role of eachcomponent is defined through a set of heuristic rules, derived by statistical analysis on a sample of web pages,which intuitively characterize each class of common visual component.
In Cai, Yu, Wen, and Ma (2003a, 2003b) a Vision-based Page Segmentation (VIPS) algorithm has beenproposed. VIPS algorithm, based on the assumption that semantically related contents are usually groupedtogether, is able to divide the page into different regions, called blocks, using visual separators. The semanticcontent of a web page is mapped in a hierarchical structure in which each node corresponds to a block. VIPSalgorithm makes full use of page layout features: first it extracts all the suitable blocks from the html DOMtree, secondly it finds separators between extracted blocks, represented by horizontal or vertical lines, thatvisually do not cross any block. With this information the web page semantic structure is constructed.
Another important approach, presented in Mehta, Mitra, and Karnick (2005), is based on the oppositeassumption that in a web page semantically related contents are not always grouped together, but may be dis-tributed across the web page, intentionally or unintentionally. Therefore, physically distributed but semanti-cally homogeneous blocks are treated as a single unit. All these approaches consider the contents of all visualblock as equally important for the purpose of document classification.
In this paper we propose a metric for computing importance taking into account also the importance of thevisual block in which the term is located. The idea of using structural information for measuring the impor-tance of different parts in a web page has been proposed recently in Yi and Liu (2003), Huang, Yu, Li, Xue,and Zhang (2005) and Song, Liu, Wen, and Ma (2004). In particular in Yi and Liu (2003) the authors proposea feature weighting technique to deal with web page noise, i.e. information that is not part of the page maincontents. They first build a compressed structure tree to capture the common structure of a set of web pages,and then use an information gain based method to evaluate the importance of each node (block) in the tree.Based on the tree this information is used to assign a weight to each word feature. Another supervisedapproach to compute the importance of a block in a web page is proposed in Song et al. (2004), where theblock importance estimation is formulated as a learning problem. A visual segmentation approach is usedto organize a web page in a semantic hierarchical structure and, for each block, a feature vector is constructedusing spatial features (position and size) and content features (number of: links, forms, images, etc). Given aset of pre-labeled blocks represented using the feature vector and its importance, a supervised classificationalgorithm is instantiated to construct an importance model. Both this methods require to manually build atraining set of annotated data. An unsupervised method for estimating block importance and relevance withrespect to a given query has been proposed in Huang et al. (2005). The importance evaluation follows the ideaof Language Modeling proposed in Ponte and Croft (1998) which estimate it as the probability that a docu-ment generates a given set of blocks.
In this paper, we present an alternative unsupervised approach which, to improve the efficacy of informa-tion retrieval systems, not only combines textual information and visual structure but also takes into accountinformation related to important visual cues, represented by images. This approach is based on the assump-tion that images represent the page components which mainly attract the attention of the users. Therefore, thetext of a visual block containing an image is likely to be more informative with respect to other visual blocks.Of course not all images are equally important, for example banners or logos are noisy information, thereforewe need to associate and evaluate the semantic content of an image. For this purpose we can see a web page asa couple XðH;UÞ, where H ¼ fX1;X2; . . . ;Xng is a finite set of visual blocks and U is a set of horizontal andvertical separators. Each block Xi 2 H denotes a semantic part of the web page, do not overlap any otherblocks and can be recursively considered as a web page.
In our study visual blocks are detected by using spatial and visual cues as reported in Cai et al. (2003a). Animage-block is defined as a visual block which contains an image. To assign higher weights to important termscontained into image-blocks by performing a visual layout analysis, we propose a new metric, called Inverse
Term Importance.In this paper we also propose three different query independent methods to evaluate image-blocks impor-
tance. These approaches consist of three main steps: first we evaluate the importance of each term within itsimage-block, we then evaluate image-block importance within the document and use this evaluation forsmoothing the term weights accordingly. The traditional TFxIDF scoring method is modified into an Image

E. Fersini et al. / Information Processing and Management 44 (2008) 1431–1447 1433
Weighted scoring function called IWTFxIDF, which takes into account the image-block importance. The pro-posed approach has been validated with respect to different classification algorithms.
The outline of this paper is the following. In Section 2 we present our methodology along with the descrip-tion of our Information Retrieval system functionality. In Section 3 we describe the datasets and the perfor-mance measure used for validating our approach. In Section 4 experimental results are presented anddiscussed. Finally, in Section 5 conclusions are derived.
2. The information retrieval system model
2.1. Overview of the system
In this section we present the Information Retrieval system where the visual block analysis function and theproposed term and block evaluation methods have been integrated. The entire work-flow is depicted in Fig. 1.Pages are crawled from the Web and indexed into a repository. Html pages, before being indexed, are pro-cessed by the Image-Block Analysis Module to weight terms according to the importance metric describedin Section 2.3. Therefore when a query is submitted documents matching it are retrieved and classified accord-ing to this new metric. An additional evaluation module has been introduced to estimate the classification per-formance obtained by using the new metric. In the following we illustrate in details the main modules of oursystem.
2.2. Visual block analysis
During the indexing phase, a pre-processing activity is performed to make page cases insensitive, removestop words, acronyms, non-alphanumeric characters, html tags and apply stemming rules, using Porter’s suffixstripping algorithm. Since the indexing module is able to manage different document formats, for every pro-cessed document we can have two representations into the index. If the document is not an html page, then it isrepresented using only one field containing all the document terms. If the document is an html page, then it isrepresented using two fields: one for the vocabulary of terms contained into the entire document and the otherfor the important terms belonging to the important image-blocks, which is a subset of the document vocab-ulary; if the web page does not contain any image the second field is empty.
For html pages the VIPS analysis functionality is instantiated for segmenting the web page into semanticpartitions to identify every image-block, see Cai et al. (2003a, 2003b). The page segmentation algorithm needs
Fig. 1. Computational process.

Fig. 2. Semantic image-blocks on a real web page. Image-blocks 1 and 2 (red frame) are considered important, while block 3 (green frame)is not significant. (For interpretation of the references to colour in this figure legend, the reader is referred to the web version of thisarticle.)
1434 E. Fersini et al. / Information Processing and Management 44 (2008) 1431–1447
the exploration of the web page DOM tree and therefore has OðjEj � jDjÞ time complexity, where jEj is thenumber of nodes in the DOM tree, and jDj is the number of web pages in the repository. Nevertheless, thisis the complexity in the worst case, when a partitioning procedure has to consider paths to all possible nodes.In the best case, when the DOM root is not dividable at first time, this search reduces to OðDÞ since for eachweb page its complexity is Oð1Þ.
After the layout analysis has been performed, terms strictly related to an image-block are captured, eval-uated and stored into the index. As mentioned before, the term importance evaluation is based on the assump-tion that images are the components of the page which mainly attract the attention of the user. However, wemust take into account that not all images are important and that some of them are only noisy elements, as forexample banners or gifs referred to webmaster e-mail. In Fig. 2 it is possible to see an example of importantimage-blocks: image-blocks 1 and 2 (red frame) are considered meaningful for the document, while image-block 3 (green frame), which reflect noisy information, is considered not important. We identify the mostinformative image-blocks and their most important terms, by using the Inverse Term Importance Metric asdescribed in Section 2.3.
2.3. Basic term scoring procedure
When a user submits a query about a topic of interest, a set of document Q is retrieved from the documentcollection D stored into the index. To prepare the input for the classification module the document set Q ismapped into a matrix M ¼ ½mij�. Each row of M is represented by a document d, following the Vector SpaceModel presented in Salton, Wong, and Yang (1975):
dj!¼ ðw1j;w2j; . . . ;wjV jjÞ ð1Þ
where jV j is the number of terms contained in the set of document Q and wij is the weight of the ith term in thejth document. Usually this weight is computed using the TFxIDF approach, presented in Salton and Buckley(1998), as follows:
wij ¼ TFðti; djÞ � IDFðti i ¼ 1; . . . ; jV j; j ¼ 1; . . . ; jQjÞ ð2Þ
where TFðti; djÞ is the Term Frequency, i.e. the number of occurrences of term ti in dj, and IDFðtiÞ is the In-
verse Document Frequency. IDFðtiÞ is a factor which enhances the terms which appear in fewer documents,while downgrading the terms occurring in many documents and is defined as

E. Fersini et al. / Information Processing and Management 44 (2008) 1431–1447 1435
IDFðtiÞ ¼ logjQj
DFðtiÞ
� �i ¼ 1; . . . ; jV j ð3Þ
where DFðtiÞ is the number of documents containing the ith term.In our approach the weight wij is defined introducing a refined version of TFðti; djÞ, named Image Weighted
Term Frequency (IWTF), which takes into account important image-block terms which are likely to describethe document content; in particular the IWTF is defined as follows:
IWTFðti; djÞ ¼ TFðti; djÞ þ TIðti; djÞ ð4Þ
The basic idea is to augment TFðti; djÞ by a ‘‘visual sensitive” term scoring TIðti; djÞ. The IDF factor, describedin (3), is maintained to evaluate the usefulness of a word into the entire collection:
wij ¼ IWTFðti; djÞ � IDFðtiÞ ð5Þ
Note that if a document does not contain images the IWTF reduces to the traditional TF measure.To compute TIðti; djÞ, let Kj be the set of image-blocks contained in document dj 2 Q and Ik be the set of
terms contained in k 2 Kj. Given a term ti 2 Ik belonging to dj we define the Inverse Term Importance (ITI) as
ITIikj ¼�rikj
�cij � �rikjð6Þ
where �rikj represents the number of occurrences of term ti into image-block k 2 Kj, and �cij is the number ofoccurrences of term ti in document dj 2 Q.
This ITI metric is based on the assumption that if a subset of terms belongs to an image-block k and theseterms are well distributed along the entire document, then the image-block is likely to be important. If theseterms are not frequent in the rest of the document we may deduce that either the terms are not significant forthe document topic or we have a multi-topic document. An ITIikj near to zero means that term i is informativefor document j. Increasing values of ITIikj imply decreasing importance of the term ti with respect to documentdj. In this way it is possible to identify for each document the set of discriminant terms for the analyzed doc-ument regardless of their spatial location. This is one of the novelties of our approach with respect to the exist-ing ones.
Given a document dj we consider only those terms ti having ITIikj < g, where g is a threshold parameter.The value of this threshold has been studied during the experimental phase, evaluating the performance of theclassification phase by varying this parameter (more details are given in Section 4). The Term Importance mea-sure (TI) can be now defined as
TIðti; djÞ ¼ maxk2Kj
ITI�1ikj
n oð7Þ
Note that TI can be considered related to the Information Gain given by term i for identifying the documenttopic.
The Term Importance computation, which is performed during the indexing phase, is characterized by aOðjW j � jDjÞ time complexity, where W represents the set of terms contained in the whole document collectionD. Indeed, in the worst case, when V � W , it requires to estimate the Inverse Term Importance for all terms inW and for all documents in D.
2.4. Visual block importance estimation
To evaluate more precisely the terms importance according to the document topic, we need to evaluate eachimage-block importance and to smooth the terms importance taking into account the block importance inwhich each word is located, leading us to a smoothed version of the ITI metric defined in (6). If a term islocated in a important block with respect to the document topic, this term is likely to be descriptive for theweb page content, and then the value of TI must be increased accordingly. Eq. (7) is then modified into
TIðti; djÞ ¼ maxk2Kj
gITI�1ikj
n oð8Þ

1436 E. Fersini et al. / Information Processing and Management 44 (2008) 1431–1447
where gITI ikj can be computed by using three different image-block evaluation methods namely: ITI-based, Co-
sine-based and Iterative Block Importance. The idea of the proposed methods is that if a term is considered
Fig. 3. Cosine-based block importance pseudocode.
Table 1Dataset features
Category Number of document Number of images
Art and humanities 3280 31,660Science 2810 32,771Health 1740 15,449Recreation and sports 1250 8243Society and culture 960 7100
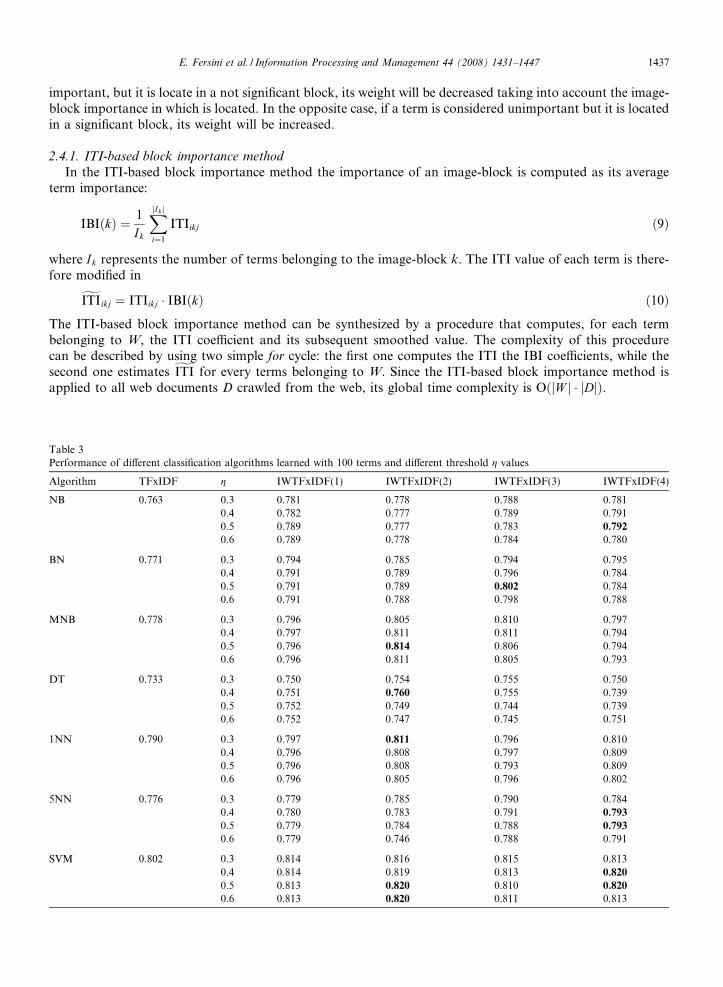
Table 2Performance of different classification algorithms learned with 50 terms and different threshold g values
Algorithm TFxIDF g IWTFxIDF(1) IWTFxIDF(2) IWTFxIDF(3) IWTFxIDF(4)
NB 0.681 0.3 0.677 0.684 0.657 0.6540.4 0.678 0.684 0.658 0.6780.5 0.677 0.683 0.659 0.6760.6 0.677 0.683 0.658 0.702
BN 0.745 0.3 0.739 0.758 0.730 0.7580.4 0.737 0.760 0.726 0.7530.5 0.731 0.759 0.727 0.7560.6 0.731 0.756 0.729 0.763
MNB 0.732 0.3 0.715 0.756 0.715 0.7540.4 0.726 0.755 0.716 0.7550.5 0.724 0.755 0.714 0.7550.6 0.724 0.753 0.714 0.762
DT 0.707 0.3 0.713 0.715 0.698 0.7070.4 0.710 0.709 0.694 0.7230.5 0.706 0.708 0.694 0.724
0.6 0.706 0.706 0.693 0.720
1NN 0.708 0.3 0.722 0.726 0.713 0.7380.4 0.718 0.723 0.714 0.7410.5 0.710 0.722 0.715 0.7410.6 0.710 0.722 0.716 0.747
5NN 0.719 0.3 0.701 0.723 0.695 0.7440.4 0.703 0.722 0.694 0.7340.5 0.703 0.722 0.692 0.7370.6 0.704 0.693 0.693 0.750
SVM 0.753 0.3 0.744 0.760 0.727 0.7600.4 0.749 0.757 0.729 0.7530.5 0.744 0.757 0.728 0.7530.6 0.744 0.755 0.729 0.763
E. Fersini et al. / Information Processing and Management 44 (2008) 1431–1447 1437
important, but it is locate in a not significant block, its weight will be decreased taking into account the image-block importance in which is located. In the opposite case, if a term is considered unimportant but it is locatedin a significant block, its weight will be increased.
2.4.1. ITI-based block importance method
In the ITI-based block importance method the importance of an image-block is computed as its averageterm importance:
TablePerfor
Algori
NB
BN
MNB
DT
1NN
5NN
SVM
IBIðkÞ ¼ 1
Ik
XjIk j
i¼1
ITIikj ð9Þ
where Ik represents the number of terms belonging to the image-block k. The ITI value of each term is there-fore modified in
gITIikj ¼ ITIikj � IBIðkÞ ð10Þ The ITI-based block importance method can be synthesized by a procedure that computes, for each termbelonging to W, the ITI coefficient and its subsequent smoothed value. The complexity of this procedurecan be described by using two simple for cycle: the first one computes the ITI the IBI coefficients, while thesecond one estimates gITI for every terms belonging to W. Since the ITI-based block importance method isapplied to all web documents D crawled from the web, its global time complexity is OðjW j � jDjÞ.3mance of different classification algorithms learned with 100 terms and different threshold g values
thm TFxIDF g IWTFxIDF(1) IWTFxIDF(2) IWTFxIDF(3) IWTFxIDF(4)
0.763 0.3 0.781 0.778 0.788 0.7810.4 0.782 0.777 0.789 0.7910.5 0.789 0.777 0.783 0.792
0.6 0.789 0.778 0.784 0.780
0.771 0.3 0.794 0.785 0.794 0.7950.4 0.791 0.789 0.796 0.7840.5 0.791 0.789 0.802 0.7840.6 0.791 0.788 0.798 0.788
0.778 0.3 0.796 0.805 0.810 0.7970.4 0.797 0.811 0.811 0.7940.5 0.796 0.814 0.806 0.7940.6 0.796 0.811 0.805 0.793
0.733 0.3 0.750 0.754 0.755 0.7500.4 0.751 0.760 0.755 0.7390.5 0.752 0.749 0.744 0.7390.6 0.752 0.747 0.745 0.751
0.790 0.3 0.797 0.811 0.796 0.8100.4 0.796 0.808 0.797 0.8090.5 0.796 0.808 0.793 0.8090.6 0.796 0.805 0.796 0.802
0.776 0.3 0.779 0.785 0.790 0.7840.4 0.780 0.783 0.791 0.793
0.5 0.779 0.784 0.788 0.793
0.6 0.779 0.746 0.788 0.791
0.802 0.3 0.814 0.816 0.815 0.8130.4 0.814 0.819 0.813 0.820
0.5 0.813 0.820 0.810 0.820
0.6 0.813 0.820 0.811 0.813

1438 E. Fersini et al. / Information Processing and Management 44 (2008) 1431–1447
2.4.2. Cosine-based block importance method
The Cosine-based block importance computes the image-block importance as the cosine between theimage-block k and the entire document dj using the Vector Space Model:
TablePerfor
Algori
NB
BN
MNB
DT
1NN
5NN
SVM
IBIðkÞ ¼ h k!; dj!i
k k!kkdj!k
ð11Þ
where k!
and dj!
are the vectors representing the image-block k and the document dj, respectively. In ourexperiments we considered k descriptive of document dj if the cosine measure is greater than a given thresholdq. In this case the ITI is modified as
gITIikj ¼ITIikj � IBIðkÞ if IBIðkÞ 6 q
ITIikj � 1IBIðkÞ otherwise
(ð12Þ
Since IBIðkÞ represents the cosine measure between an image-block and a document, 0 6 IBIðkÞ 6 1. In thisway terms belonging to an image-blocks k with IBIðkÞ < q are penalized, while terms located into an image-block with IBIðkÞP q are rewarded.
The Cosine-based block importance method can be described by the pseudo-code reported in Fig. 3. Fol-lowing this procedure, having a set of image-blocks KH ¼ maxjfKjg extracted from all the documents dj 2 D,and jW j terms, the time required by the Cosine-based block importance method is OðjW j � jKHj � jDjÞ.
4mance of different classification algorithms learned with 150 terms and different threshold g values
thm TFxIDF g IWTFxIDF(1) IWTFxIDF(2) IWTFxIDF(3) IWTFxIDF(4)
0.781 0.3 0.800 0.805 0.797 0.7880.4 0.799 0.797 0.803 0.7920.5 0.799 0.798 0.804 0.8000.6 0.799 0.802 0.807 0.803
0.782 0.3 0.805 0.798 0.810 0.8010.4 0.805 0.801 0.815 0.8070.5 0.807 0.799 0.816 0.8080.6 0.807 0.802 0.808 0.799
0.824 0.3 0.843 0.843 0.833 0.8420.4 0.845 0.838 0.844 0.8450.5 0.845 0.836 0.845 0.850
0.6 0.845 0.842 0.845 0.846
0.752 0.3 0.765 0.760 0.763 0.7650.4 0.763 0.754 0.763 0.7710.5 0.759 0.757 0.766 0.780
0.6 0.758 0.760 0.763 0.773
0.805 0.3 0.819 0.816 0.807 0.8160.4 0.815 0.821 0.815 0.8140.5 0.808 0.821 0.818 0.8160.6 0.808 0.821 0.816 0.821
0.758 0.3 0.780 0.809 0.776 0.7740.4 0.777 0.810 0.775 0.7710.5 0.776 0.813 0.778 0.7780.6 0.776 0.794 0.783 0.791
0.827 0.3 0.846 0.852 0.844 0.8400.4 0.851 0.841 0.846 0.8400.5 0.850 0.846 0.847 0.8540.6 0.850 0.845 0.845 0.855

Table 5Performance of different classification algorithms learned with 200 terms and different threshold g values
Algorithm TFxIDF g IWTFxIDF(1) IWTFxIDF(2) IWTFxIDF(3) IWTFxIDF(4)
NB 0.800 0.3 0.827 0.829 0.829 0.8110.4 0.829 0.826 0.829 0.8120.5 0.832 0.824 0.832 0.8220.6 0.832 0.820 0.832 0.823
BN 0.783 0.3 0.811 0.812 0.809 0.7920.4 0.813 0.813 0.816 0.7950.5 0.816 0.812 0.811 0.7990.6 0.816 0.806 0.804 0.802
MNB 0.849 0.3 0.865 0.861 0.859 0.8540.4 0.865 0.861 0.857 0.8550.5 0.862 0.864 0.855 0.8590.6 0.862 0.866 0.856 0.856
DT 0.758 0.3 0.788 0.794 0.783 0.7620.4 0.789 0.797 0.790 0.7760.5 0.782 0.791 0.789 0.7820.6 0.782 0.790 0.786 0.767
1NN 0.810 0.3 0.853 0.858 0.827 0.8310.4 0.850 0.860 0.836 0.8270.5 0.849 0.863 0.837 0.8310.6 0.849 0.857 0.838 0.830
5NN 0.758 0.3 0.780 0.809 0.776 0.7740.4 0.777 0.810 0.775 0.7710.5 0.776 0.813 0.778 0.7780.6 0.776 0.794 0.783 0.791
SVM 0.857 0.3 0.871 0.871 0.866 0.8660.4 0.870 0.871 0.867 0.8640.5 0.871 0.871 0.866 0.871
0.6 0.871 0.868 0.870 0.870
E. Fersini et al. / Information Processing and Management 44 (2008) 1431–1447 1439
2.4.3. Iterative block importance methodThe third proposed method is based on the idea that an image-block importance depends not only on its
terms, but also on its possible relations with other image-blocks. In fact, might be cases in which TIðti; djÞ ishigh because ti appears frequently in the document, but only in some unimportant image-blocks. If we do nottake in to account these unimportant image-blocks, the TI value may decrease. We then propose an iterativeprocedure to eliminate unimportant image-blocks and to compute the TI values using only important image-blocks.
Recalling that Kj be the set of all image-blocks contained in the document dj, the Iterative block impor-tance method can be synthesized in the following pseudocode.
Following this process we evaluate for each image-block k its IBI, and if the image-block k is consideredunimportant, we than delete k updating the remaining image-blocks. At the end we find the set of image-blocks that most probably are related to the document topic.
With respect to its computational complexity, this method can be synthesized by three nested iterative cycle
(see Fig. 4): the first one is over all documents dj 2 D, the second one is over the image-block set Kj in eachdocument dj, and the last one includes the computation of ITI and IBI coefficients for all the terms ti 2 W .Following this simple procedure, the computational cost of the Iterative Block Importance method can bedescribed by a OðjW j � jKHj � jDjÞ time complexity.
In the following table we report the time (s) taken by the Iterative Block Importance method to processa document on a Pentium M 735 processor. The minimum, maximum and average times has beencomputed on a sample of 10,000 documents with up to 35,000 terms. (More details on the dataset are givenin Section 3).

1440 E. Fersini et al. / Information Processing and Management 44 (2008) 1431–1447
Table 6Performance of different classification a
Algorithm TFxIDF g
NB 0.830 0000
BN 0.780 0000
MNB 0.869 0000
DT 0.775 0000
1NN 0.857 0000
5NN 0.842 0000
SVM 0.875 0000
Minimum
lgorithms learned with 500 terms and diffe
IWTFxIDF(1) IWTFxI
.3 0.836 0.843
.4 0.839 0.840
.5 0.844 0.838
.6 0.844 0.842
.3 0.804 0.796
.4 0.805 0.800
.5 0.804 0.801
.6 0.802 0.798
.3 0.879 0.878
.4 0.881 0.879
.5 0.885 0.879
.6 0.883 0.878
.3 0.793 0.788
.4 0.798 0.800
.5 0.789 0.802
.6 0.800 0.780
.3 0.867 0.864
.4 0.864 0.863
.5 0.859 0.865
.6 0.861 0.865
.3 0.851 0.856
.4 0.855 0.856
.5 0.854 0.853
.6 0.857 0.842
.3 0.882 0.878
.4 0.884 0.882
.5 0.880 0.880
.6 0.879 0.879
Maximum
rent threshold g values
DF(2) IWTFxIDF(3) IWT
0.840 0.840.843 0.840.847 0.840.844 0.84
0.804 0.800.810 0.800.808 0.81
0.810 0.80
0.878 0.880.880 0.880.881 0.880.882 0.88
0.768 0.790.806 0.800.788 0.800.789 0.79
0.862 0.86
0.868 0.860.864 0.860.867 0.86
0.848 0.860.858 0.87
0.854 0.860.850 0.86
0.872 0.870.876 0.870.885 0.870.882 0.87
Average
g ¼ 0:3
0.031 5.89 0.32 g ¼ 0:4 0.032 6.81 0.31 g ¼ 0:5 0.031 7.12 0.34 g ¼ 0:5 0.032 5.51 0.313. Dataset and evaluation measure
To evaluate the effectiveness of the proposed term weighting approach, we compared the performanceobtained by different classification procedures by using the classical TFxIDF scoring and the four term weight-ing techniques proposed in this paper. In this section we describe the dataset used and the performance eval-uation metric adopted. The main steps of the experimental phase performed to validate our approach aredescribed below.
Step 1. Dataset construction. We built a dataset selecting about 10,000 web pages from popular sites listedin five categories of Yahoo! Directories (http://dir.yahoo.com/). See Table 1.
Step 2. Indexing. All the collected pages have been indexed. Every html page has been pro-cessed by the”image-block analysis” module to extract image-blocks, andto compute the TI values.
FxIDF(4)
5561
592
7
3446
1002
8
442
10
81
6788

E. Fersini et al. / Information Processing and Management 44 (2008) 1431–1447 1441
Step 3. Data preparation. Before submitting the indexed document to the classification phase we per-formed a feature selection procedure based on the Term Frequency Varianceindex presented in Nicholas, Dhillon, and Kogan (2003) and given by
qðtiÞ ¼Xn1
i¼1
f 2i �
1
n1
Xn1
i¼1
fi
" #2
ð13Þ
where n1 is the number of documents in Q containing ti at least once. Duringthe experimental phase we restrict the vocabulary dimension selecting a set Tof terms with the highest Term Frequency Variance index.
Step 4. Classification. In this step we encapsulated the following learning algorithms using WekaAPI (http://www.cs.waikato.ac.nz/ml/weka/) Witten and Frank (1999):Naive Bayes (NB) John and Langely (1995), Bayesian Network (BN) Pearl(1982), Multinomial Naive Bayes (MNB) McCallum and Nigam (1998),Decision Tree (DT) Quinlan (1993), K-Nearest Neighbour (1NN and5NN) Aha, Kibler, and Albert (1991) and Support Vectors Machines(SVM) Platt (1999) with a linear kernel.
Step 5. Performance evaluation. To evaluate the classification performance, we used the widely adopted F-measure metric which combines the Precision and Recall measure typicalof Information Retrieval. Given a set of class label C, related to the Categoryin Table 1, we compute Precision and Recall for the class label a 2 C as
PrecisionðaÞ ¼ # of doc successfully classified as belonging to a# of doc classified as belonging to a
ð14Þ
RecallðaÞ ¼ # of doc successfully classified as belonging to a# of doc belonging to a
ð15Þ
The F-measure for each class a 2 C is computed as the harmonic mean ofPrecision and Recall:
F ðaÞ ¼ 2 �RecallðaÞ � PrecisionðaÞRecallðaÞ þ PrecisionðaÞ ð16Þ
The overall quality of the classification is given by a scalar F � computed asthe weighted sum of the F-measure values taken over all the class a 2 C:
F � ¼Xa2C
jajjDj F ðaÞ ð17Þ
4. Experimental results
The proposed metric and its related scoring functions have been evaluated with respect to the learning algo-rithms, performing a 10-folds Cross Validation as testing method. In Tables 2–6 we compared the F-measure
Fig. 4. Iterative block importance method pseudocode.

1442 E. Fersini et al. / Information Processing and Management 44 (2008) 1431–1447
obtained for increasing number of features, i.e. terms considered descriptive of the document. This means thatthe vocabulary is restricted to T ¼ 50; 100; 150; 200; 500. We do not report the performances comparison using
Fig. 5. Learning algorithms performance comparison.
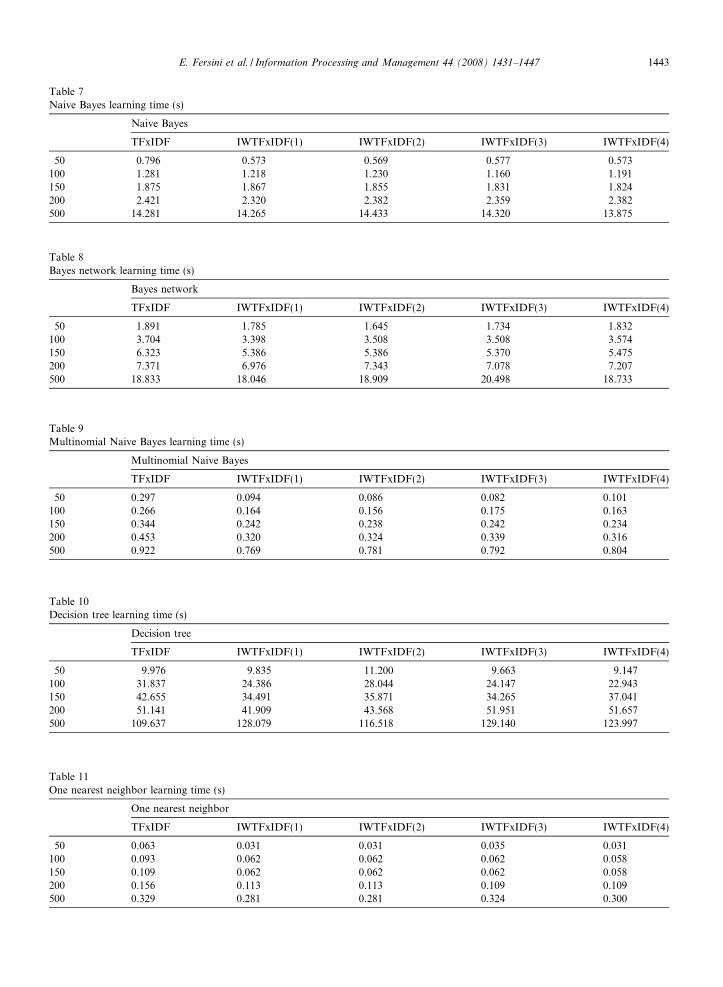
Table 7Naive Bayes learning time (s)
Naive Bayes
TFxIDF IWTFxIDF(1) IWTFxIDF(2) IWTFxIDF(3) IWTFxIDF(4)
50 0.796 0.573 0.569 0.577 0.573100 1.281 1.218 1.230 1.160 1.191150 1.875 1.867 1.855 1.831 1.824200 2.421 2.320 2.382 2.359 2.382500 14.281 14.265 14.433 14.320 13.875
Table 8Bayes network learning time (s)
Bayes network
TFxIDF IWTFxIDF(1) IWTFxIDF(2) IWTFxIDF(3) IWTFxIDF(4)
50 1.891 1.785 1.645 1.734 1.832100 3.704 3.398 3.508 3.508 3.574150 6.323 5.386 5.386 5.370 5.475200 7.371 6.976 7.343 7.078 7.207500 18.833 18.046 18.909 20.498 18.733
Table 9Multinomial Naive Bayes learning time (s)
Multinomial Naive Bayes
TFxIDF IWTFxIDF(1) IWTFxIDF(2) IWTFxIDF(3) IWTFxIDF(4)
50 0.297 0.094 0.086 0.082 0.101100 0.266 0.164 0.156 0.175 0.163150 0.344 0.242 0.238 0.242 0.234200 0.453 0.320 0.324 0.339 0.316500 0.922 0.769 0.781 0.792 0.804
Table 10Decision tree learning time (s)
Decision tree
TFxIDF IWTFxIDF(1) IWTFxIDF(2) IWTFxIDF(3) IWTFxIDF(4)
50 9.976 9.835 11.200 9.663 9.147100 31.837 24.386 28.044 24.147 22.943150 42.655 34.491 35.871 34.265 37.041200 51.141 41.909 43.568 51.951 51.657500 109.637 128.079 116.518 129.140 123.997
Table 11One nearest neighbor learning time (s)
One nearest neighbor
TFxIDF IWTFxIDF(1) IWTFxIDF(2) IWTFxIDF(3) IWTFxIDF(4)
50 0.063 0.031 0.031 0.035 0.031100 0.093 0.062 0.062 0.062 0.058150 0.109 0.062 0.062 0.062 0.058200 0.156 0.113 0.113 0.109 0.109500 0.329 0.281 0.281 0.324 0.300
E. Fersini et al. / Information Processing and Management 44 (2008) 1431–1447 1443

1444 E. Fersini et al. / Information Processing and Management 44 (2008) 1431–1447
an increasing number of terms belonging to the dataset vocabulary because the results of our approachesbecome asymptotic with respect to the standard TFxIDF scoring technique. The scoring function used duringthe performance evaluation are describe in the following:
� IWTFxIDF(1): all blocks are considered equally important; the weight wij is computed as in Eq. (5) nottaking into account any image-block evaluation method.� IWTFxIDF(2): the importance of each image-block is computed as the average importance of its terms;
this scoring technique compute wij following the ITI-based Block Importance estimation presented in Sec-tion 2.4.1.� IWTFxIDF(3): the block importance is computed as the cosine function between the block and the entire
document vector; IWTFxIDF(3) computes the weight wij taking into account the Cosine-based BlockImportance estimation presented in Section 2.4.2, considering a block k important for document dj settingq ¼ 0:7.� IWTFxIDF(4): the block importance is computed through a procedure that iterative evaluate and delete
unimportant blocks; IWTFxIDF(4) computes the weight wij following the Iterative Block importance esti-mation process presented in Section 2.4.3.
We used as benchmark the traditional TFxIDF scoring function.Table 2 shows that our scoring function, for T ¼ 50, computed according to the Iterative Block Importance
approaches (IWTFxIDF(4)) always outperforms the traditional TFxIDF scoring method, IWTFxIDF(2)works well, while IWTFxIDF(1) and (3) perform poorly. Tables 3 and 4 indicates that our scoring methods,for T ¼ 100 and 150, respectively, are better and, in the worst case, equal to the standard approach. Morespecifically, the Iterative Block Importance and ITI-based approach (IWTFxIDF(4) and (2)) methods producesignificantly better classification quality. In Table 5 ðT ¼ 200Þ it is interesting to note peaks of performanceobtained by the ITI-based approach (IWTFxIDF(2)) and decreasing F-measure values for the Iterative BlockImportance (IWTFxIDF(4)). Table 6 shows that the Iterative block importance method (IWTFxIDF(4)) pro-duces significantly better classification quality increasing T to 500.
There are some remarks which lie outside the goal of this paper, but are quite interesting. A first consid-eration regards a performance comparison between Bayesian Network and the remaining learning algorithm:Bayesian Network show a decreasing performance relative to the other algorithms as the number of featuresincreases. This behavior could be explained by the overfitting caused by a high number of terms (nodes). Asecond observation regards a performance comparison between the K-Nearest Neighbor methods: 1NN
Table 12Five nearest neighbor learning time (s)
Five nearest neighbor
TFxIDF IWTFxIDF(1) IWTFxIDF(2) IWTFxIDF(3) IWTFxIDF(4)
50 0.109 0.046 0.023 0.023 0.031100 0.079 0.050 0.050 0.047 0.051150 0.109 0.066 0.078 0.070 0.070200 0.141 0.105 0.093 0.097 0.093500 0.266 0.242 0.238 0.226 0.250
Table 13Support vector machines learning time (s)
Support vector machines
TFxIDF IWTFxIDF(1) IWTFxIDF(2) IWTFxIDF(3) IWTFxIDF(4)
50 21.616 30.237 21.781 23.492 24.641100 37.812 37.812 40.320 40.781 40.426150 60.329 63.411 56.634 60.302 58.966200 75.996 65.922 66.969 75.008 76.383500 185.726 209.668 236.116 336.479 196.566
E. Fersini et al. / Information Processing and Management 44 (2008) 1431–1447 1445
approach defines a better model compared with 5NN method because data can overlap and, with an increas-ing number of neighbors, the performance tends to decrease. A third remark is about Support VectorMachines: this linear classifier, which simultaneously minimizes the empirical classification error and maxi-mizes the geometric margin, is the learning algorithm that has the better performance. However, it is interest-ing to note that Multinomial Naive Bayes, which is characterized by the absence of parameters, has similarperformances with respect to the Support Vector Machine. This consideration lead us to consider MultinomialNaive Bayes, in our experiment, a very good learning algorithm for its performance stability and its param-eters independence.
A final remark regarding the performance is related to the influence that semantic image interpretationcould have during the terms scoring phase and consequently during the learning task. Even if we did notinclude an image interpretation approach in our framework, analyzing only the surrounding text of an image,we plan to introduce some additional models related to image understanding to improve the precision duringterms evaluation. Gao, Fan, Xue, and Jain (2006) and Li and Perona (2005) are interesting approaches able toanalyze and understand image semantic through hierarchial models. In this direction we aim at combiningimage and textual analysis, to extract a more precise and meaningful semantic related to important image-blocks.
In Fig. 5 we compared, for any learning algorithm, the F-measure values obtained varying the number ofterms between the standard technique and the scoring method which produces the more stable result in termsof averaged F-measure over the threshold g. The Iterative Block Importance method seems to be the termsscoring procedure producing the greater number of”successes”. However, if we consider the average F-mea-sure over the m threshold values, as index of performance stability, we find that some classifier although notoptimal performs very well on average. As reported in Fig. 5b, e, and g, this is the case of the Cosine methodfor Bayesian Network, the ITI-based approach for 1NN and the scoring technique that consider all blockequally important (IWTFxIDF(1)) for the Support Vector Machines. Naive Bayes, MultiNomial Naive Bayes,Decision Tree and 5NN, Fig. 5a, c, d and f, gives the best performance on average with the IWTFxIDF(4)based on the Iterative Block Importance method.
With respect to the learning task, the time complexity related to the model building depends on every singleclassification algorithm. In Tables 7–13 we compared the required computational time (in s) in the learningphase for each classification algorithm. Since the time performance obtained by using the proposed scoringmethods are stable with respect to the parameter g, we report the average time obtained g equal to 0.3,0.4, 0.5 and 0.6. The time measurements are computed on a Pentium M 400 MHz, Windows XP system.
Note that the proposed scoring technique ensures a good compromise between classification accuracy andlearning time, in particular for 1NN, 5NN and Multinomial Naive Bayes. A further interesting remark regardsthe comparison between Multinomial Naive Bayes and Support Vector Machines: the time performance val-idate the consideration that Multinomial Naive Bayes classifier obtain the same good performance in terms ofaccuracy of the Support Vector Machines, while requiring a much lower learning time.
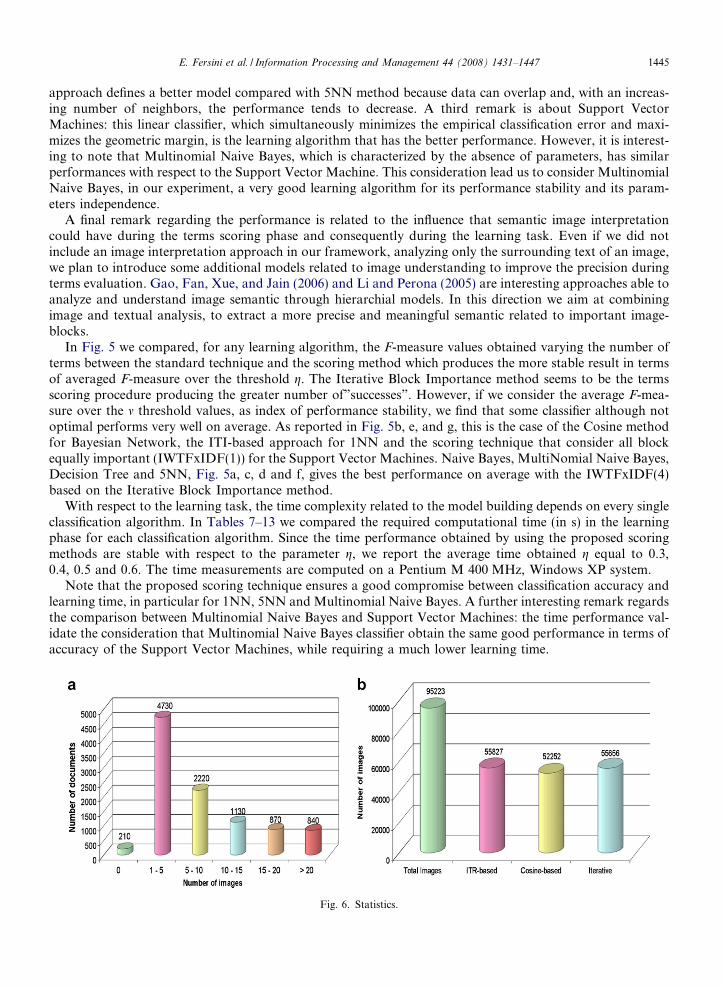
Fig. 6. Statistics.

1446 E. Fersini et al. / Information Processing and Management 44 (2008) 1431–1447
5. Why our approach works better than traditional TFxIDF
We believe that the main reason related to the success of our approaches is that images represent one of themost important elements reported in a web page. To prove our intuition at the basis of our approaches weprovide simple numerical statistics. Consider the set of documents used during the experimental phase.Fig. 6a shows how many document are structured to include different number of images. As reported only210 documents are plain text, while more than half of documents contain approximately between from 1 to5 images. One of the most interesting things that confirm our initial assumption is showed in Fig. 6b. Wereported a comparison between the number of images belonging to the original document dataset and thenumber of image-blocks that our block evaluation methods considered as important. Indicatively all of ourapproaches identify more than half of image-blocks as related to the topic of the documents in which arelocated, and then considered important. Moreover, after the identification of important image-blocks, termsbelonging to these image-blocks are manipulated to improve their importance. In this way the feature selectionpolicy is driven to select those attributes with better discriminative power.
6. Conclusions and future works
In this paper we presented a novel approach for improving the performance of document classification sys-tems. This approach is able to identify important image-blocks contained in a web page to recognize thoseterms that are more informative for the entire document. The main advantage of our approach lies in its abil-ity to distinguish the most important content from less important and noisy information. Moreover our meth-ods are query independent, unsupervised and independent from any spatial constraints related to importantcontents. Results show that our approaches outperform the standard TFxIDF model in terms of classificationaccuracy.
Acknowledgements
We thank Ilaria Giordani and Silvia Dondi, for their help in software development.
References
Aha, D. W., Kibler, D., & Albert, M. K. (1991). Instance-based learning algorithms. Machine Learning, 6(1), 37–66.Cai, D., Yu, S., Wen, J. R., & Ma, W. Y. (2003a). Extracting content structure for web pages based on visual representation. Technical
Report MSR-TR-2003-79.Cai, D., Yu, S., Wen, J. R., & Ma, W. Y. (2003b). Extracting content structure for web pages based on visual representation. In X. Zhou,
Y. Zhang, & M. E. Orlowska (Eds.), Proceedings of the Pacific Web conference (pp. 406–417).Gao, Y., Fan, J., Xue, X., & Jain, R. (2006). Automatic image annotation by incorporating feature hierarchy and boosting to scale up
SVM classifiers. In K. Nahrstedt, M. Turk, Y. Rui, W. Klas, & K. Mayer-Patel (Eds.), Proceedings of the 14th annual ACM
international conference on multimedia (pp. 901–910). New York: ACM Press.Huang, S., Yu, Y., Li, S., Xue, G.-R., & Zhang, L. (2005). A study on combination of block importance and relevance to estimate page
relevance. In A. Ellis & T. Hagino (Eds.), Proceedings of the 14th international conference on World Wide Web (Special interest tracks
and posters) (pp. 1042–1043). New York: ACM Press.John, G.-H., & Langely, P. (1995). Estimating continuous distributions in Bayesian classifiers. In P. Besnard & S. Hanks (Eds.),
Proceedings of the eleventh conference on uncertainty in artificial intelligence (pp. 338–345). San Francisco: Morgan Kauffman.Kovacevic, M., Diligenti, M., Gori, M., & Milutinovic, V. M. (2002). Recognition of common areas in a web page using visual
information: a possible application in a page classification. In Proceedings of the 2002 IEEE international conference on data mining
(pp. 250–257). Washington: IEEE Computer Society.Li, F., & Perona, P. (2005). A Bayesian hierarchical model for learning natural scene categories. In Proceeding of 2005 IEEE computer
society conference on computer vision and pattern recognition (pp. 524–531). San Diego: IEEE Computer Society.McCallum, A., & Nigam, K. (1998). A comparison of event models for naive bayes text classification. In Proceedings of the fifteenth
national conference on artificial intelligence. Menlo Park: AAAI Press.Mehta, R. R., Mitra, P., & Karnick, H. (2005). Extracting semantic structure of web documents using content and visual information. In
A. Ellis & T. Hagino (Eds.), Proceedings of the 14th international conference on World Wide Web (pp. 928–929). New York: ACMPress.
Nicholas, C., Dhillon, I., & Kogan, J. (2003). Feature selection and document clustering. In M. W. Berry (Ed.), A comprehensive survey of
text mining. Springer-Verlag.

E. Fersini et al. / Information Processing and Management 44 (2008) 1431–1447 1447
Pearl, J. (1982). Reverend bayes on inference engines: a distributed hierarchical approach. In D. L. Waltz (Ed.), Proceedings of the national
conference on artificial intelligence (pp. 133–136). Menlo Park: AAAI Press.Platt, J. C. (1999). Fast training of support vector machines using sequential minimal optimization. In B. Schlkopf, C. J. C. Burges, & A. J.
Smola (Eds.), Advances in kernel methods: support vector learning (pp. 185–208). Cambridge: MIT Press.Ponte, J. M., & Croft, W. B. (1998). A language modeling approach to information retrieval. In Proceedings of the 21st annual international
ACM SIGIR conference on research and development in information retrieval (pp. 275–281).Quinlan, J. R. (1993). C4.5: Programs for machine learning. San Francisco: Morgan Kauffman.Salton, G., & Buckley, C. (1998). Term-weighting approaches in automatic text retrieval. Information Processing and Management, 24(5),
513–523.Salton, G., Wong, A., & Yang, C. S. (1975). A vector space model for automatic indexing. Communications of the ACM, 18(11), 613–620.Song, R., Liu, H., Wen, J.-R., & Ma, W.-Y. (2004). Learning block importance models for web pages. In S. I. Feldman, M. Uretsky, M.
Najork, & C. E. Wills (Eds.), Proceedings of the 13th international conference on World Wide Web (pp. 203–211). New York: ACMPress.
Witten, I. H., & Frank, E. (1999). Data mining: practical machine learning tools and techniques with java implementations. San Francisco:Morgan Kauffman.
Yi, L., & Liu, B. (2003). Web page cleaning for web mining through feature weighting. In G. Gottlob & T. Walsh (Eds.), International joint
conference on artificial intelligence (pp. 43–50). San Francisco: Morgan Kauffman.




















