
Dynamic Load Balancing for Object-Based Parallel Computations
12
Transcript of Dynamic Load Balancing for Object-Based Parallel Computations

Informatica 22 (1998) 219-230 219Dynamic Load Balancing for Object-Based Parallel Computations1Michele Di SantoUniversit�a del Sannio, Benevento, [email protected] FrattolilloUniversit�a di Salerno, Fisciano (SA), ItalyWilma RussoUniversit�a della Calabria, Rende (CS), ItalyEugenio ZimeoUniversit�a di Napoli \Federico II", Napoli, ItalyKeywords: load balancing, object-oriented programming, parallelism, actors, TransputersEdited by: Rudi MurnReceived: October 23, 1997 Revised: February 23, 1998 Accepted: March 3, 1998Object-based parallel programming allows for the expression of ideal programs, whichdo not specify the mapping of objects to machine nodes. A parallel machine can e�-ciently execute ideal programs only if a runtime tool dynamically takes the appropriateplacement decisions. This paper presents a new distributed adaptive load balancingalgorithm, called PWF (Probabilistic Wave Front). It uses simple heuristics that guidethe dynamic allocation of objects on the nodes of a parallel machine and their migrationamong the nodes. Experimental results show that PWF constantly outperforms both therandom algorithm and the ACWN (Adaptive Contracting Within Neighborhood) oneand therefore succeeds in accurately placing objects on the nodes of a parallel system.1 IntroductionWhile technological factors are making parallelcomputers more and more cost-e�ective and areimposing a common architectural organizationmade by a collection of nodes (processor-memorypairs) connected by a communication network[6], developing e�cient and portable parallel pro-grams is still hard [4]. In fact, programmers arestill forced to use rather low-level programmingmodels and languages and to explicitly managecomputational resources.In the search for a solution to these prob-lems, the use of the object-based paradigm [17]has stirred the interest of the parallel computingcommunity. In fact, it combines well with paral-lelism, since their logical autonomy makes objectsa natural unit for parallel execution [2, 11], andallows for the expression of ideal, i.e. architecture-1This research was supported in part by the Italian Or-ganization for University and for Scienti�c and Technologi-cal Research (M.U.R.S.T.) under grants \60%" and \40%".
independent, parallel algorithms.In order to automatically and e�ciently mapan ideal algorithm onto an architecture, an ap-propriate object placement policy is needed. Itmust specify both where to allocate each new ob-ject and if and how to redistribute the already al-located ones.2 Because of the extreme exibilityo�ered by dynamic creation and interconnectionof objects, it is very di�cult to statically predictthe shapes and the extents of the structures towhich the computation will give rise at runtime,and so to give an automatic, static solution to theproblem of devising an e�cient object placementpolicy aimed at minimizing the total executiontime of a parallel program. Therefore, two possi-ble approaches are:{ To explicitly program, for each group ofobjects in the application, a partition and2Generally, e�ciency depends also on the schedulingpolicy that each node adopts in selecting the next objectready to run, but we disregard this dependency here.

220 Informatica 22 (1998) 219-230 M. Di Santo et al.distribution strategy (PDS). In this case,reusability and scalability are greatly en-hanced by adopting methodologies for mod-ular speci�cation of PDSs. [12].{ To use an automatic placement tool that dy-namically decides where to allocate each newobject and if and how to redistribute the al-ready allocated ones.This paper examines the problem of the auto-matic placement of objects and proposes the PWF(Probabilistic Wave Front) algorithm, a new dis-tributed adaptive load balancing algorithm basedon some simple heuristics that guide the dynamicallocation of objects on the nodes of a parallel ma-chine and their migration among the nodes. Inorder to verify the e�ectiveness of the proposal,we included the PWF, the ACWN [14, 15] andthe random load balancing algorithms in an Ac-tor [1] programming environment running on aTransputer network. Experimental results showthat the PWF algorithm constantly outperformsthe other two and therefore succeeds in accuratelyplacing objects on the nodes of our parallel sys-tem.In the programming model adopted, objects,which unify both data and code in a local state,are dynamically created and referred throughsystem-wide identi�ers. They manifest a purereactive nature and interact with other objectsonly via message passing. The communicationmechanism is point-to-point, asynchronous andone-directional. Messages are eventually deliv-ered to their destinations, but transmission or-der is not necessarily preserved at delivery. Un-bounded queues associated to receiving objectsbu�er incoming messages, before they are seriallyprocessed. Functional interactions among objectsare modeled with the use of continuations.The structure of the article is as follows. Inthe following two sections, we describe a frame-work for dynamic placement of objects and thenpresent and discuss the PWF algorithm. In thelast three sections, we describe how to tune thealgorithm for obtaining the best performances, il-lustrate a set of experimental results that provethe e�ectiveness of our proposal and present theconclusions.
2 A framework for dynamicplacement of objectsThe study of provably e�cient on line schedulingalgorithms for parallel programs whose computa-tions are revealed only at runtime is still in itsinfancy and some theoretical results are availableonly for a few kinds of applications and for speci�ccomputational models [3].Therefore, in order to achieve good speedups,existing object-based programming environmentspragmatically adopt dynamic placement algo-rithms based on heuristics that essentially try tosatisfy the two goals of load balance and local-ity. Load balance guarantees that, at each momentduring the computation, all the nodes of the ma-chine have su�cient work to do. Instead, localityreduces network tra�c, by decreasing the distancebetween data and the node where it is needed.Unfortunately, these goals are in con ict, in thatload balance bene�ts from the uniform distribu-tion of objects across the network, while localityis favored by the concentration of objects on a fewnearby nodes.3Information collected by dynamic placement al-gorithms is very often limited to load informationand so these algorithms are generally referred toas dynamic load balancing algorithms (DLBAs),even if locality concerns are to some extent takeninto account.In general, among all the balancing algorithmscited in the literature, the distributed adaptiveones (DALBAs) give better chances of achievinggood performance and scalability [5, 10, 13, 9].These algorithms, in the context of object-basedcomputations, run on each machine node in orderto execute the following activities:1. updating local load and state;2. exchanging with other nodes load balancingmessages (LBMs) derived from local states;3. choosing the node where to allocate a newobject;4. deciding if and how to redistribute some ofthe already allocated objects.3Even if in modern interconnection networks latenciesare relatively insensitive to distance, many long distancemessages may result in link contention and consequentlydegrade network throughput.

DYNAMIC LOAD BALANCING .... Informatica 22 (1998) 219-230 221In order to set up a framework for DALBAs inthe context of object-based programming models,we spend a few words on each activity and on themain strategies that each one can adopt.Updating local load and state. The ba-sic activity performed by a DALBA running on anode is to evaluate the local load. Because mes-sages exchanged among objects are the drivingforce, a good measure of the current load may bethe number of \serviceable" messages waiting tobe processed on the node. This measure is su�-ciently accurate when all the messages in the com-putation have near equal elaboration times, as itis often the case in applications characterized byrather small-grained objects.Another DALBA activity is to handle localstate, which often includes both data derived fromreceived LBMs and some adaptive indices andthresholds. Therefore, local state allows eachDALBA to relate local load with the load of othernodes and to adapt its activities and strategies tothe changing load conditions in the system.Exchanging information. Nodes exchangeinformation in the form of LBMs which can becommunicated either periodically or when loadchanges by pre�xed amounts. The latter solutionavoids exchanging useless information, but, in anycase, the amounts should be tuned for the speci�capplication in order to realize a trade-o� betweencommunication costs and accuracy of exchangedinformation.Load in a LBM can be speci�ed either as anabsolute value or as an estimate expressed as avalue in a �nite number of alternatives, such aslight, moderate, or heavy. The latter solution isto be preferred because it lets each sending nodeevaluate its own load condition.In order to assure scalability to DALBAs, eachnode has to exchange information only with a sub-set of the other ones. In the case of multicom-puters and geographically or hierarchically dis-tributed systems, this subset can coincide withthe physical neighbors of the node, so contribut-ing to reduce network tra�c. Instead, in the caseof a fully connected distributed system, it is neces-sary to adopt a node-grouping strategy, in order todetermine for each node both a receiving set anda sending one. Each node sends LBMs only tothe members of its sending set and receives LBMsonly from the members of its receiving set. The
node-grouping strategy must satisfy some mini-mal requirements [16]:{ sets must be \reasonably" small and of sim-ilar size;{ for each pair of nodes a and b, b must be\reachable" from a, i.e. either a and b mustbelong to the same receiving set or a node xmust exist, such as x is reachable from a andb is reachable from x.This last requirement guarantees that, if neces-sary, a creation or migration request that origi-nates from a node can reach any other node.In the following, we say that node a is a \neigh-bor" of node b if either a is a physical neighbor ofb or a belongs to the receiving set of b.Taking the allocation decision. Whateverthe allocation strategy adopted, allocation mustbe guaranteed to take place in a �nite time. Thiscan be assured by limiting to some maximumvalue the number of \hops" traveled by the al-location request. In particular, a small maximumvalue promotes locality together with fast andlow-cost object creation, but may prevent quickload spreading and so cause a loss of e�ciency atthe beginning of the computation.Reducing the maximum number of hops to zerocorresponds to adopting a purely local allocationstrategy and so to using the only redistributionmechanism in order to gain load balancing. Thisis generally inappropriate, in that redistributioninduces high overheads. Instead, a strategy whichallocates objects on the basis of local state ofnodes should be adopted, in order to reduce theprobability of redistributing objects and so in-creasing the e�ciency of balancing.Taking the migration decision. Object re-distribution is necessary when, despite a good ini-tial allocation, some nodes move towards lightload conditions. In migrating objects, a DALBAcan adopt a sender initiated strategy or a receiverinitiated one or a mix of them [13, 18]. Anyway,in order to preserve locality, an object should notbe migrated many times and, in order to reducecommunication overhead, the amount of load tomove should be obtained from a small number ofobjects and by minimizing the total number oftransferred bytes.

222 Informatica 22 (1998) 219-230 M. Di Santo et al.Symbols MeaningsNS Number of nodes in the system0..NS-1 Identi�ers of nodes in the systemthisNode Identi�er of the node running the PWF algorithmN Set of identi�ers of thisNode neighbors, totally orderedN' Set N [ fthisNodeg, totally orderedload Current load value of thisNode (initialized to 0)idle, light, medium, heavy Load levels of a nodelevel Current load level of thisNode (initialized to light)IT idle level threshold (level = idle i� load � IT)LT, HT Current light and heavy level thresholds(level = light i� IT < load � LTlevel = medium i� LT < load � HTlevel = heavy i� load > HT)LT0, HT0 Initial values of LT and HT (received by PWF at the beginning of computation)�T Adaptive increase of LT and HT (received by PWF at the beginning of computation)last The node in N' where the last creation was made (initialized to anyone of N values)succ(n) 8n 2 N', returns the node immediately following n in N', if it exists;the �rst node in N', otherwiseMP Probability value for a medium load level (0 < MP < 1)(received by PWF at the beginning of computation)Pn 8n 2 N, current probability value of node n, equal to:0 if n is known to have a heavy load level;1 if n is known to have a light or idle load level;MP if n is known to have a medium load levelPthisNode Current probability value of thisNode, equal to:0 if Pn = 1, 8n 2 N; 1 otherwisef A real value in [0, 1], which determines the maximum fraction of neighborsto involve in a migration (received by PWF at the beginning of computation)M Set of neighbors to involve in a migration (M � fn : n 2 N ^ Pn 6= 1g) ^ (j M j� bf� j N jc)random() Returns a random real value in [0, 1[send msg to S Sends the message msg to all the nodes in the set Smigrate �L to n Migrates to node n a load at most equal to �LTable 1: Symbols and their meanings.3 The PWF AlgorithmThe PWF (Probabilistic Wave Front) algorithmis a new DALBA, based on the framework set upin the previous section, and applicable to object-based, parallel programming environments run-ning on systems made up of a number of nodescommunicating only by means of message pass-ing. The only assumptions about the communi-cation network are that message passing is reliableand, for each node, a set of neighboring nodes isde�ned in such a way as to satisfy the minimalrequirements stated in the previous section. Mes-sages need not arrive in the same order they aresent, but, if this happens among neighbors, theperformance of PWF improves.The name PWF has been chosen in order tomake explicit the two main characteristics of thealgorithm:{ Objects di�use through the system accordingto the simple rule that the number of hops
traveled by each request of creation or mi-gration is at most one.{ The candidate node on which to create anew object, is �rstly selected by a simpleround-robin strategy among the neighbors ofthe node where the request occurs, and thenpasses a validation step, based on a probabil-ity value that depends on its load level.The PWF algorithm is based on the followingmain assumptions:{ Each node \sees" only a subset of the othernodes (its neighbors) and so stores load infor-mation only relative to these nodes and ex-changes LBMs and requests of creation andmigration only with these nodes.{ Local load is measured as the number of ser-viceable messages waiting to be processed onthe node.{ Load in LBMs is expressed as a value in a �-nite number of alternatives, derived from the

DYNAMIC LOAD BALANCING .... Informatica 22 (1998) 219-230 223actual load value by using some appropriatethresholds.{ Some of the thresholds are adaptively modi-�ed.{ The load of a node is known to each of itsneighbors only indirectly through a proba-bility value. Moreover, on each node, a fur-ther probability value synthesizes the aggre-gate load of neighbors.updateLoad(dl):load load + dlif load > HT thenif level 6= heavy thenlevel heavysend (thisNode; heavy) to Nelsif load > LT thenif level 6= medium thenlevel mediumsend (thisNode;medium) to Nelsif load > IT thenif level > light thenlevel lightsend (thisNode; light) to Nelsif level = light thenlevel idlesend (thisNode; idle; jM j) to MFigure 1: The updateLoad component.handleLBM(sender, newLevel, m):case newLevel ofheavy: Psender 0PthisNode 1if Pn = 0 8n 2 N thenHT HT0 + �TLT LT0 + �Tmedium: Psender MPPthisNode 1HT HT0LT LT0light: Psender 1if Pn = 1 8n 2 N thenPthisNode 0HT HT0LT LT0idle: Psender 1if Pn = 1 8n 2 N thenPthisNode 0HT HT0LT LT0if load > LT0 then�L min(d(LT0- IT )=me;load-LT0)migrate �L to senderFigure 2: The handleLBM component.
selectedNode():repeatlast succ(last)until random() < Plastreturns lastFigure 3: The selectedNode component.In detail, the PWF algorithm consists of thethree components updateLoad, handleLBM, andselectedNode, which are executed on each nodeof the system. They are respectively described inFigures 1, 2, and 3. The symbols adopted andtheir meanings are described in Table 1.updateLoad(dl) runs each time the node changesits load by a quantity dl, which can be either pos-itive (a new message is received by an object re-siding on the node or an old message becomes ser-viceable) or negative (a message is processed byan object on the node or some object is migratedor a message becomes temporarily unserviceable).It is up to this component to notify each loadlevel variation to all the neighbors, by sendingthem appropriate LBMs consisting of two �elds:the identity of the sender node and its new loadlevel. Only in the case of a light to idle transition,when migrations are to be activated, the LBMsinclude, as a third �eld, the cardinality of M, tobe used by the target nodes in order to evaluatethe amount �L of load to be migrated. In thiscase, noti�cation is limited to a set M contain-ing at most a fraction f of heavy or medium loadneighbors; obviously, in formingM, heavily loadedneighbors are to be preferred.handleLBM(sender, newLevel, m) runs each timethe node receives an LBM from one of its neigh-bors. This component updates probability valuesand the thresholds LT and HT; moreover, whenrequired, it commands object migrations. As mi-grations tend to elevate the load of the idle nodeto LT0, by knowing that m neighbors are involvedin the migration, the amount of load �L to bemigrated is evaluated as the m-th part of LT0-IT.Obviously, if necessary, this amount is reducedin order to guarantee a load level on the node atleast equal to medium. Therefore, a migration cannever cause a node to move to a light or idle loadlevel.selectedNode() runs each time a request to cre-ate a new object rises on the node and consists of

224 Informatica 22 (1998) 219-230 M. Di Santo et al.two possibly repeated steps:{ a candidate node in the set N' is selected,according to a round-robin strategy;{ the candidate node is validated if a randomlygenerated real number in the range [0, 1[is lesser than the current probability of thenode.It must be noted that, according to the probabil-ity values assigned to nodes:{ a node is selected in a number of steps atmost equal to the cardinality of N';{ a heavily loaded neighbor is never validated;{ a lightly loaded neighbor is always validated;{ a medium loaded neighbor is validated withprobability MP;{ a creation is always remote, as long as all theneighbors are lightly loaded;{ a creation is always local, as long as all theneighbors are heavily loaded.The strategies adopted in the PWF algorithm areat the same time simple, and therefore e�cientlyimplementable, and e�ective in guaranteeing theaccuracy of balancing.As to simplicity, it is worth noting that:{ Measuring the load as the number of service-able messages waiting to be processed on thenode requires only counting.{ Nodes involved in communications are alwaysneighbors.{ LBMs are sent only when transitions in loadlevels occur. The many LBMs generated bythe oscillations of load around a thresholdcan be avoided by an \hysteresis mechanism"that splits each threshold into two, with thelower one to be used when load decreases andthe upper one when load increases.{ Allocation of a new object is guaranteed totake place after at most one delegation, sothat each object is created either locally oronto a neighbor of the node where the cre-ation request arises.
Instead, accuracy of balancing is assured by thefollowing algorithm behaviors:{ Both non-local allocation and redistributionof objects are pursued. The adopted alloca-tion strategy signi�cantly reduces the proba-bility of expensive migrations, which remainhowever necessary to contrast both residualload imbalances, typical of highly dynamiccomputations, and structural ones occurringin the �nal phases of computations.{ Initially, when nodes are not loaded yet, al-location is mainly controlled by the round-robin selection strategy, so guaranteeing aquick load spreading. Later, when nodestend to be more heavily loaded, allocationbecomes mainly controlled by the validationstep, so assuring a more accurate selection ofthe destination.{ Adaptively incrementing the thresholds LTand HT of a node, when all its neighbors areheavily loaded, delays the transition of thenode towards higher load levels, so enablingit to receive further work from its neighbors.4 Choosing parametersThe performance of the PWF algorithm dependson the values chosen for the parameters LT0, HT0,MP, IT, �T, and f.Load distribution is essentially controlled bythe values of the thresholds LT0 and HT0 thatshould be chosen according to the expected max-imum load per node EML. Practically, this valuecan be approximated by MMLRANDOM , the av-erage of the maximum loads measured on eachnode during a preliminary run which makes useof the random balancing strategy, chosen in or-der to eliminate any dependence from balancingparameters. Our experience shows that the bestperformances are obtained when LT0 and HT0 arerespectively set to the 40% and 80% of EML. Inparticular:{ lower LT0 values may prevent a quick loadspreading, so determining imbalances andconsequently inducing expensive load redis-tribution;{ higher values may cause objects to be spreadout even when it is not actually necessary, by

DYNAMIC LOAD BALANCING .... Informatica 22 (1998) 219-230 225giving rise to both a wasteful communicationoverhead and a loss of computation locality.Analogous considerations can be made for thethreshold HT0. In fact, lower values may induceload imbalances, because objects tend to be lo-cally created, while higher values may cause ob-ject creations on heavily loaded nodes.Even if MP may assume values in the range]0, 1[, its value should be about 12 . In fact, thechoice of an extreme value in the range corre-sponds to reduce the two thresholds LT0 and HT0to only one. In particular, MP=0 corresponds toset HT0 equal to LT0, while MP=1 correspondsto set LT0 equal to HT0. Moreover, in order tochoose an accurate value of MP, both the kindof computation and the connectivity level of thenetwork should be taken into account. In particu-lar, if the object creation activity is rather evenlydistributed among nodes and the average num-ber of neighbors in the system is high, it is likelythat a medium loaded node will move towards aheavy load condition. In this case, in order toexploit computation locality and limit the over-head due to object spreading, MP should assumea value lesser than 12 . Conversely, if the objectcreation activity is limited to a few nodes and theaverage number of neighbors in the system is low,it is likely that a medium loaded node will movetowards a light load condition. In this case, inorder to favor object spreading, MP should be setto a value higher than 12 . Anyway, our experienceshows that the best results are obtained with MPvalues ranging from 0.4 and 0.6.The value of the IT threshold determines whena node that is going to become idle requests workfrom some of its neighbors. Therefore, too lowa value could excessively delay redistribution, soas not to impede the node from becoming idle.On the contrary, too high a value could cause ananticipated and useless redistribution, so inducinga wasteful overhead.As already said, the adaptive increase of thethresholds LT and HT by the quantity �T, whenneighbors are all heavily loaded, aims at delay-ing node transition towards higher load levels, soenabling it to receive further work from its neigh-bors. Therefore, if �T is set to a too low value,the delay e�ect is negligible. On the contrary, toohigh a value may cause imbalances because of theout to date load information kept on neighbors.
The value of f determines the number of neigh-bors to involve in a migration. It should be setaccording to the kind of computation. In fact, ina highly dynamic computation, there may be loadimbalances among nodes and a node is likely tobe surrounded by neighbors in very di�erent loadconditions. In such a situation, f should be set toa low value, so that the amount of load to be mi-grated to an idle node tends to be provided onlyby the most loaded neighbors. On the contrary,in a computation characterized by rather regularload conditions, an idle node is likely to be sur-rounded by lightly loaded neighbors. Therefore, fshould be set to a high value, so that the amountof load to be migrated to an idle node tends tobe provided by a greater number of lightly loadedneighbors.5 Experimental resultsIn order to prove the e�ectiveness of our proposal,we have compared the PWF algorithm with therandom and the ACWN (Adaptive ContractingWithin Neighborhood) ones [14, 15]. These algo-rithms were chosen for the following reasons:{ The random algorithm achieves quite a uni-form load distribution with a minimum ex-ploitation of system resources, but neither itassures any locality to the computation, noris it adaptive.{ The ACWN algorithm gets a good load dis-tribution, assures a high locality to the com-putation, and is adaptive, but it inducessome communication and computing over-heads.The three load balancing algorithms have beenintegrated into ASK (Actor System Kernel), theruntime support of AL++ [7], a semantic exten-sion of C++, implemented through a class librarywhich provides an object-oriented interface forActor programming. The prototype implemen-tation of ASK has been developed in the 3L Par-allel C programming language. It runs on an IN-MOS system which consists of a network of six-teen T800 Transputers, clocked at 20 MHz, withlinks at 20 Mbits/s, and each equipped with 1Mbyte of RAM with two wait states. A PC actsas a host system and I/O server. ASK runs at
226 Informatica 22 (1998) 219-230 M. Di Santo et al.the top of a low-level network environment thatprovides node-to-node asynchronous communica-tion and routing between non-adjacent nodes, forboth ring and 2D Torus topologies.Here we show the experimental results obtainedon three sample programs, characterized by dif-ferent computation structures and communica-tion patterns, which stress in di�erent ways thedynamic properties of the balancing algorithmstested:{ Range-add, which uses a \divide-and-conquer" strategy in order to compute in par-allel the sum of all the integers in the rangebetween 0 and 10 millions. The computationis characterized by a binary tree structure,where each leaf object adds the numbers inthe received range and passes on the sum toits parent, while each internal object splitsthe received range into two, passes on themto two new created objects, receives back thetwo sums, combines them and passes on theresult to its parent.{ N-queens, which realizes a concurrent searchof all the solutions to the problem of plac-ing n queens on an n�n chessboard in sucha way that no queen may be taken by anyother queen. The computation is character-ized by a highly dynamic structure whoseshape cannot be predicted at compile-time.Each search object receives a chessboard witha partial solution, i.e. i queens safely placedon the �rst i columns, and tries to extendit by �nding all the safe positions on the(i+1)-th column. Whenever a safe positionis found, the new partial solution is passedto a new search object that tries to extend itfurther.{ Tsp, which generates a solution of thetraveling salesman problem, by �nding a\minimum-distance" route a sales represen-tative may follow in order to visit each city ina given list exactly once. The computationhas a tree structure whose size cannot be pre-dicted at compile-time. Searching starts bycreating n-1 objects and proceeds in parallelaccording to a \branch and bound" scheme.Each object receives a di�erent partial route,extends it by adding one city, evaluates thenew partial distance and, only if it is less than
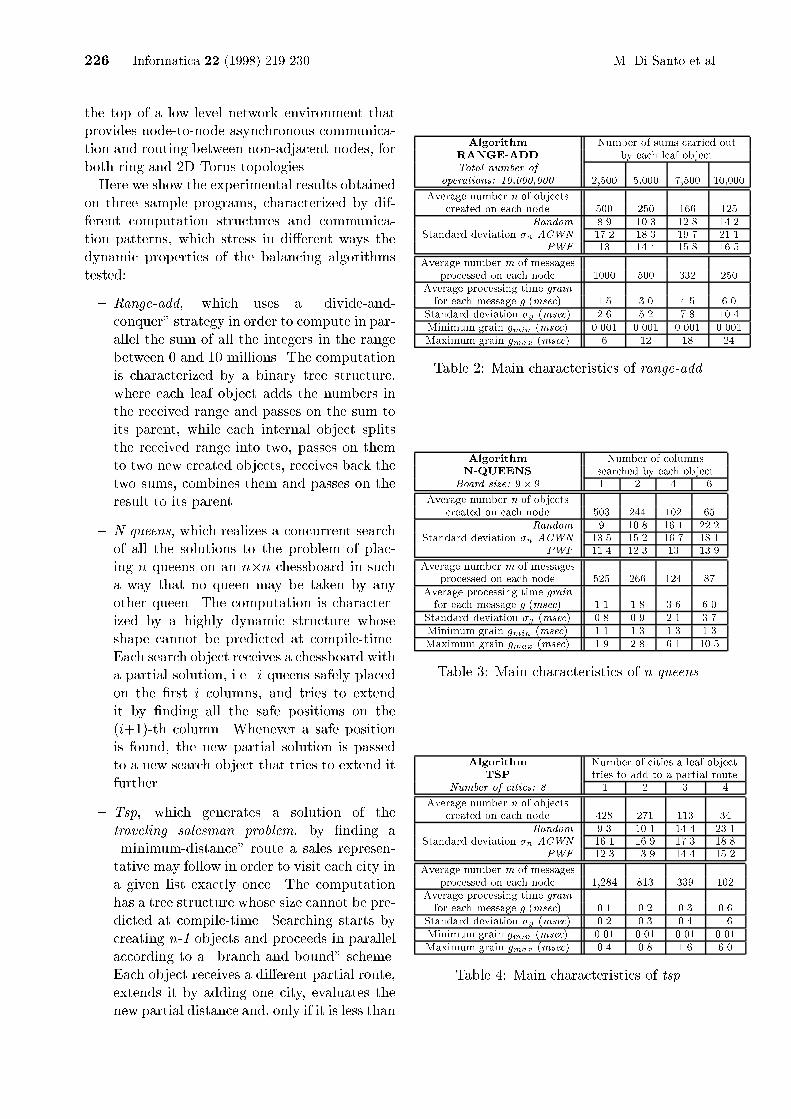
Algorithm Number of sums carried outRANGE-ADD by each leaf objectTotal number ofoperations: 10,000,000 2,500 5,000 7,500 10,000Average number n of objectscreated on each node 500 250 166 125Random 8.9 10.3 12.8 14.2Standard deviation �n ACWN 17.2 18.3 19.7 21.1PWF 13 14.4 15.8 16.5Average number m of messagesprocessed on each node 1000 500 332 250Average processing time grainfor each message g (msec) 1.5 3.0 4.5 6.0Standard deviation �g (msec) 2.6 5.2 7.8 10.4Minimum grain gmin (msec) 0.001 0.001 0.001 0.001Maximum grain gmax (msec) 6 12 18 24Table 2: Main characteristics of range-add.Algorithm Number of columnsN-QUEENS searched by each objectBoard size: 9� 9 1 2 4 6Average number n of objectscreated on each node 503 244 102 65Random 9 10.8 16.1 22.2Standard deviation �n ACWN 13.5 15.2 16.7 18.1PWF 11.4 12.3 13 13.9Average number m of messagesprocessed on each node 525 266 124 87Average processing time grainfor each message g (msec) 1.1 1.8 3.6 6.0Standard deviation �g (msec) 0.8 0.9 2.1 3.7Minimum grain gmin (msec) 1.1 1.3 1.3 1.3Maximum grain gmax (msec) 1.9 2.8 6.1 10.5Table 3: Main characteristics of n-queens.Algorithm Number of cities a leaf objectTSP tries to add to a partial routeNumber of cities: 8 1 2 3 4Average number n of objectscreated on each node 428 271 113 34Random 9.3 10.1 14.4 23.1Standard deviation �n ACWN 16.1 16.9 17.3 18.8PWF 12.3 13.9 14.4 15.2Average number m of messagesprocessed on each node 1,284 813 339 102Average processing time grainfor each message g (msec) 0.1 0.2 0.3 0.6Standard deviation �g (msec) 0.2 0.3 0.4 1.6Minimum grain gmin (msec) 0.01 0.01 0.01 0.01Maximum grain gmax (msec) 0.4 0.8 1.6 6.0Table 4: Main characteristics of tsp.
DYNAMIC LOAD BALANCING .... Informatica 22 (1998) 219-230 227
0
10
20
30
40
50
60
70
80
90
100
0 1 2 3 4 5 6 7
Effi
cien
cy (
%)
Granularity (millisec)
ACWNRandom
PWFExplicit
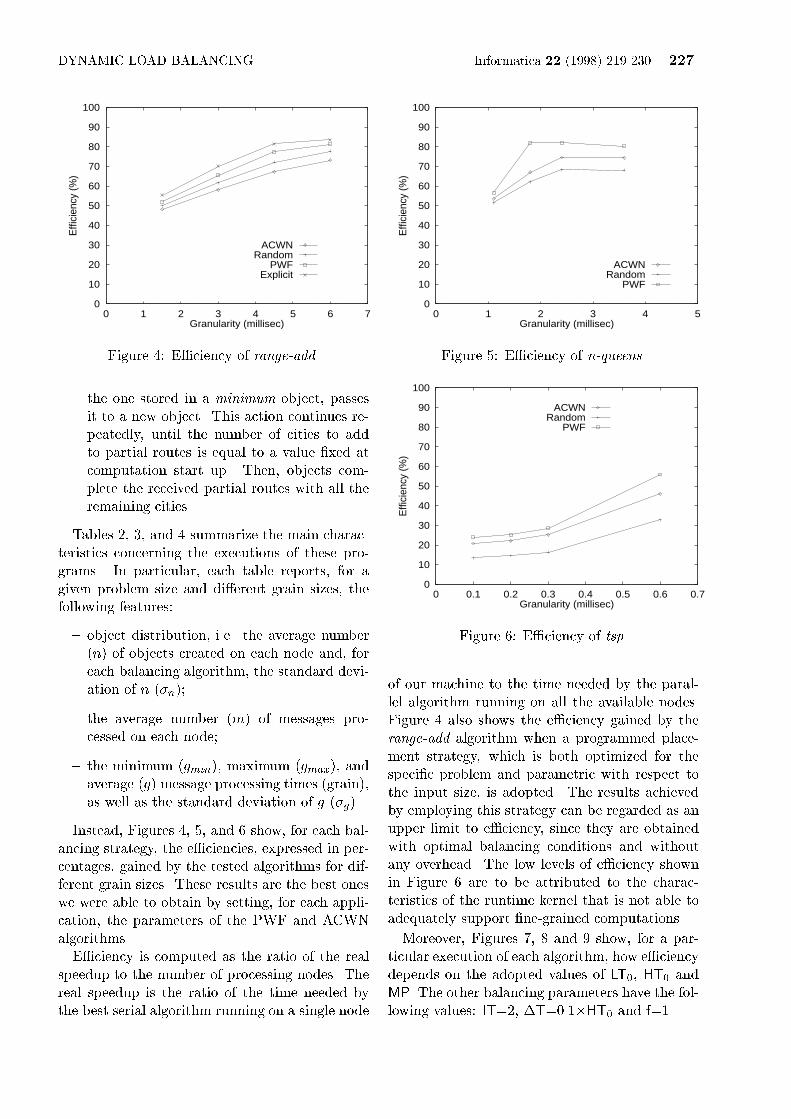
Figure 4: E�ciency of range-add.the one stored in a minimum object, passesit to a new object. This action continues re-peatedly, until the number of cities to addto partial routes is equal to a value �xed atcomputation start up. Then, objects com-plete the received partial routes with all theremaining cities.Tables 2, 3, and 4 summarize the main charac-teristics concerning the executions of these pro-grams. In particular, each table reports, for agiven problem size and di�erent grain sizes, thefollowing features:{ object distribution, i.e. the average number(n) of objects created on each node and, foreach balancing algorithm, the standard devi-ation of n (�n);{ the average number (m) of messages pro-cessed on each node;{ the minimum (gmin), maximum (gmax), andaverage (g) message processing times (grain),as well as the standard deviation of g (�g).Instead, Figures 4, 5, and 6 show, for each bal-ancing strategy, the e�ciencies, expressed in per-centages, gained by the tested algorithms for dif-ferent grain sizes. These results are the best oneswe were able to obtain by setting, for each appli-cation, the parameters of the PWF and ACWNalgorithms.E�ciency is computed as the ratio of the realspeedup to the number of processing nodes. Thereal speedup is the ratio of the time needed bythe best serial algorithm running on a single node
0
10
20
30
40
50
60
70
80
90
100
0 1 2 3 4 5
Effi
cien
cy (
%)
Granularity (millisec)
ACWNRandom
PWFFigure 5: E�ciency of n-queens.
0
10
20
30
40
50
60
70
80
90
100
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7
Effi
cien
cy (
%)
Granularity (millisec)
ACWNRandom
PWF
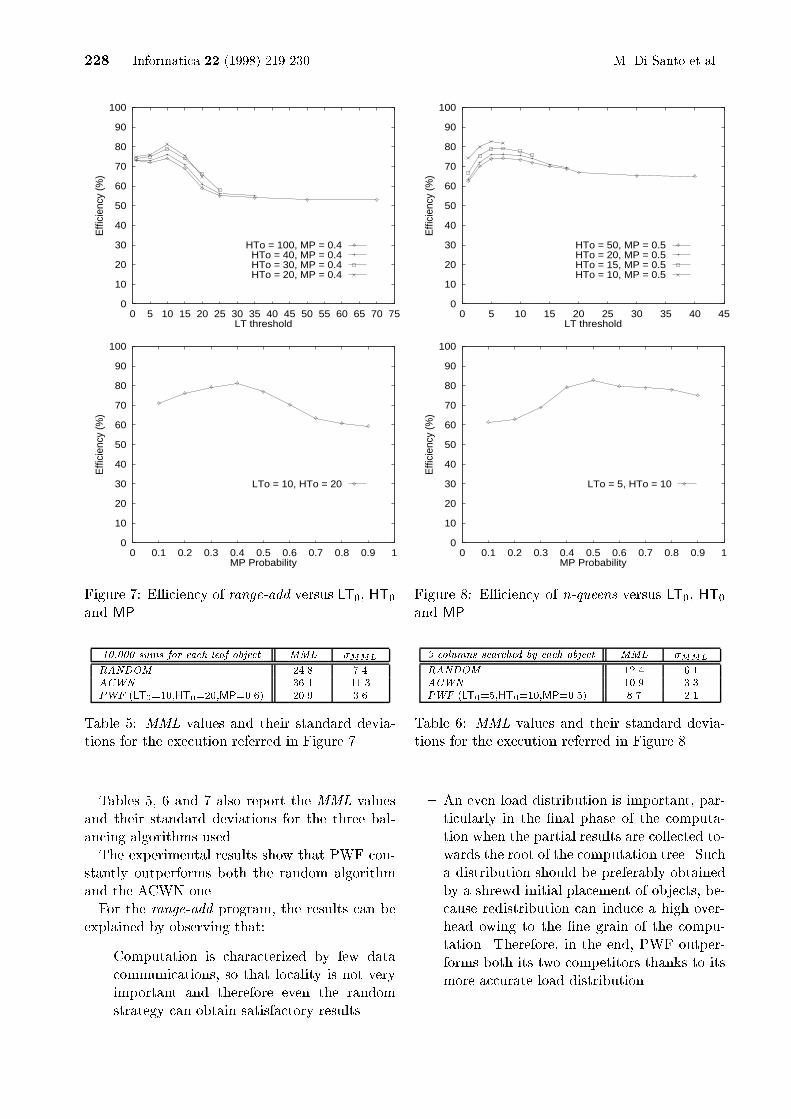
Figure 6: E�ciency of tsp.of our machine to the time needed by the paral-lel algorithm running on all the available nodes.Figure 4 also shows the e�ciency gained by therange-add algorithm when a programmed place-ment strategy, which is both optimized for thespeci�c problem and parametric with respect tothe input size, is adopted. The results achievedby employing this strategy can be regarded as anupper limit to e�ciency, since they are obtainedwith optimal balancing conditions and withoutany overhead. The low levels of e�ciency shownin Figure 6 are to be attributed to the charac-teristics of the runtime kernel that is not able toadequately support �ne-grained computations.Moreover, Figures 7, 8 and 9 show, for a par-ticular execution of each algorithm, how e�ciencydepends on the adopted values of LT0, HT0 andMP. The other balancing parameters have the fol-lowing values: IT=2, �T=0.1�HT0 and f=1.
228 Informatica 22 (1998) 219-230 M. Di Santo et al.
0
10
20
30
40
50
60
70
80
90
100
0 5 10 15 20 25 30 35 40 45 50 55 60 65 70 75
Effi
cien
cy (
%)
LT threshold
HTo = 100, MP = 0.4HTo = 40, MP = 0.4HTo = 30, MP = 0.4HTo = 20, MP = 0.4
0
10
20
30
40
50
60
70
80
90
100
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
Effi
cien
cy (
%)
MP Probability
LTo = 10, HTo = 20
Figure 7: E�ciency of range-add versus LT0, HT0and MP.10,000 sums for each leaf object MML �MMLRANDOM 24.8 7.4ACWN 36.1 11.3PWF (LT0=10,HT0=20,MP=0.6) 20.9 3.6Table 5: MML values and their standard devia-tions for the execution referred in Figure 7.Tables 5, 6 and 7 also report the MML valuesand their standard deviations for the three bal-ancing algorithms used.The experimental results show that PWF con-stantly outperforms both the random algorithmand the ACWN one.For the range-add program, the results can beexplained by observing that:{ Computation is characterized by few datacommunications, so that locality is not veryimportant and therefore even the randomstrategy can obtain satisfactory results.
0
10
20
30
40
50
60
70
80
90
100
0 5 10 15 20 25 30 35 40 45
Effi
cien
cy (
%)
LT threshold
HTo = 50, MP = 0.5 HTo = 20, MP = 0.5HTo = 15, MP = 0.5HTo = 10, MP = 0.5
0
10
20
30
40
50
60
70
80
90
100
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
Effi
cien
cy (
%)
MP Probability
LTo = 5, HTo = 10
Figure 8: E�ciency of n-queens versus LT0, HT0and MP.3 columns searched by each object MML �MMLRANDOM 12.4 6.1ACWN 10.9 3.3PWF (LT0=5,HT0=10,MP=0.5) 8.7 2.1Table 6: MML values and their standard devia-tions for the execution referred in Figure 8.{ An even load distribution is important, par-ticularly in the �nal phase of the computa-tion when the partial results are collected to-wards the root of the computation tree. Sucha distribution should be preferably obtainedby a shrewd initial placement of objects, be-cause redistribution can induce a high over-head owing to the �ne grain of the compu-tation. Therefore, in the end, PWF outper-forms both its two competitors thanks to itsmore accurate load distribution.
DYNAMIC LOAD BALANCING .... Informatica 22 (1998) 219-230 229
0
10
20
30
40
50
60
70
80
90
100
0 5 10 15 20
Effi
cien
cy (
%)
LT threshold
HTo = 20, MP = 0.6 HTo = 10, MP = 0.6 HTo = 5, MP = 0.6
0
10
20
30
40
50
60
70
80
90
100
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
Effi
cien
cy (
%)
MP Probability
LTo = 2, HTo = 5
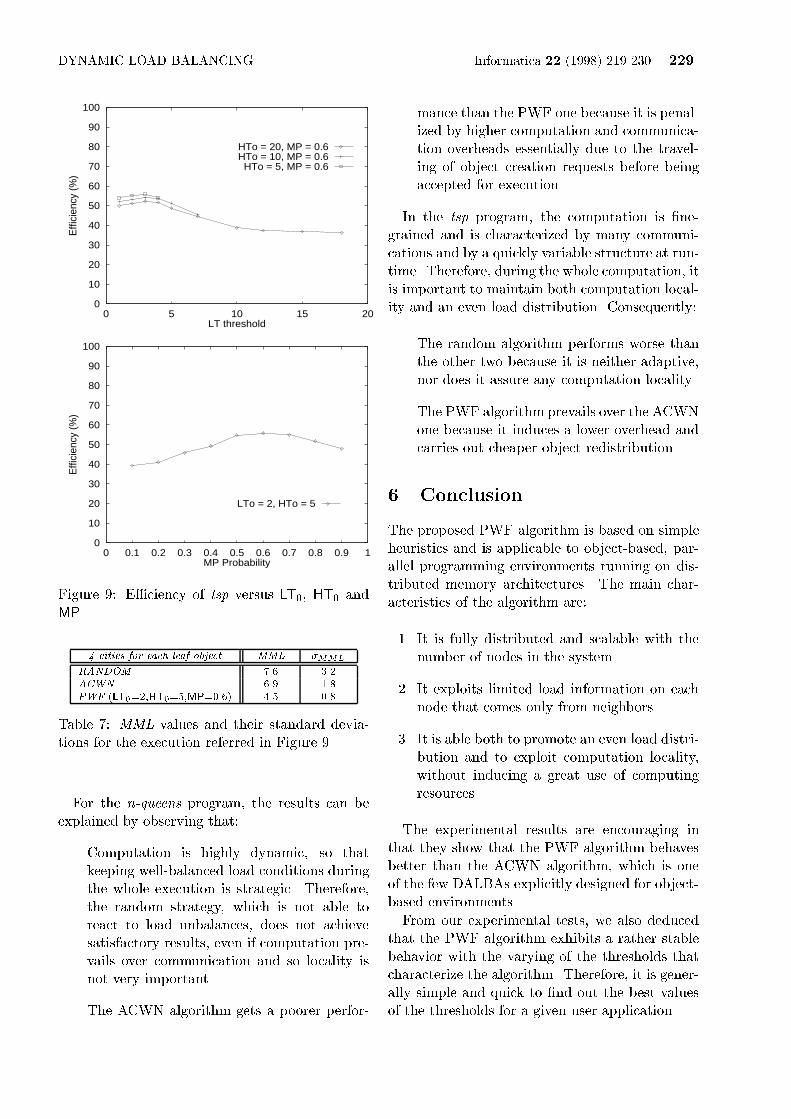
Figure 9: E�ciency of tsp versus LT0, HT0 andMP. 4 cities for each leaf object MML �MMLRANDOM 7.6 3.2ACWN 6.9 1.8PWF (LT0=2,HT0=5,MP=0.6) 4.5 0.8Table 7: MML values and their standard devia-tions for the execution referred in Figure 9.For the n-queens program, the results can beexplained by observing that:{ Computation is highly dynamic, so thatkeeping well-balanced load conditions duringthe whole execution is strategic. Therefore,the random strategy, which is not able toreact to load unbalances, does not achievesatisfactory results, even if computation pre-vails over communication and so locality isnot very important.{ The ACWN algorithm gets a poorer perfor-
mance than the PWF one because it is penal-ized by higher computation and communica-tion overheads essentially due to the travel-ing of object creation requests before beingaccepted for execution.In the tsp program, the computation is �ne-grained and is characterized by many communi-cations and by a quickly variable structure at run-time. Therefore, during the whole computation, itis important to maintain both computation local-ity and an even load distribution. Consequently:{ The random algorithm performs worse thanthe other two because it is neither adaptive,nor does it assure any computation locality.{ The PWF algorithm prevails over the ACWNone because it induces a lower overhead andcarries out cheaper object redistribution.6 ConclusionThe proposed PWF algorithm is based on simpleheuristics and is applicable to object-based, par-allel programming environments running on dis-tributed memory architectures. The main char-acteristics of the algorithm are:1. It is fully distributed and scalable with thenumber of nodes in the system.2. It exploits limited load information on eachnode that comes only from neighbors.3. It is able both to promote an even load distri-bution and to exploit computation locality,without inducing a great use of computingresources.The experimental results are encouraging inthat they show that the PWF algorithm behavesbetter than the ACWN algorithm, which is oneof the few DALBAs explicitly designed for object-based environments.From our experimental tests, we also deducedthat the PWF algorithm exhibits a rather stablebehavior with the varying of the thresholds thatcharacterize the algorithm. Therefore, it is gener-ally simple and quick to �nd out the best valuesof the thresholds for a given user application.

230 Informatica 22 (1998) 219-230 M. Di Santo et al.References[1] G. A. Agha (1986) Actors: a Model of Concur-rent Computation in Distributed Systems, TheMIT Press, Cambridge.[2] G. A. Agha (1990) Concurrent Object-Oriented Programming, Communications ofthe ACM, 33(9), p. 125-141.[3] G. E. Blelloch, P. B. Gibbons & Y. Matias(1995) Provably E�cient Scheduling for Lan-guages with Fine-Grained Parallelism, 7th An-nual ACM Symposium on Parallel Algorithmsand Architectures, ACM Press, New York, p.1-12.[4] G. E. Blelloch, (1996) Programming Paral-lel Algorithms,Communications of the ACM,39(3), p. 85-97.[5] T. L. Casavant & J. G. Kuhl (1988) A Tax-onomy of Scheduling in General-Purpose Dis-tributed Computing Systems, IEEE Transac-tions on Software Engineering 14(2), p. 141-154.[6] D. E. Culler, R. M. Karp, D. A. Patterson,A. Sahay, K. E. Schauser, E. Santos, R. Subra-monian & T. von Eicken (1993) LogP: Towardsa Realistic Model of Parallel Computation, 4thACM SIGPLAN Symposium on Principles andPractice of Parallel Programming, p. 1-12.[7] M. Di Santo, F. Frattolillo, W. Russo &E. Zimeo (1996) The AL++ Project: Object-Oriented Parallel Programming on Multicom-puters, 1st International Workshop on Paralleland Distributed Software Engineering, Chap-man & Hall, London, p. 277-282.[8] M. Di Santo, F. Frattolillo & G. Iannello(1995) Experiences in Dynamic Placement ofActors on Multicomputer Systems, 3rd Eu-romicro Workshop on Parallel and DistributedProcessing, IEEE Computer Society Press, LosAlamitos, p. 130-137.[9] A. Dubrovski, R. Friedman & A. Schuster(1997) Load Balancing in Distributed Sharedmemory Systems, to appear on InternationalJournal on Applied Software Technology.
[10] D. L. Eager, E. D. Lazowska & E. D.Zahorjan(1986) Adaptive Load Sharing in HomogeneousDistributed Systems, IEEE Transactions onSoftware Engineering, 12(5), p. 662-675.[11] D. G. Kafura & R. G. Lavender (1996) Con-current Object-Oriented Languages and the In-heritance Anomaly in Parallel Computers: The-ory and Practice (Eds. T. L. Casavant, P.Tvrd��k and F. Pl�asil), IEEE Computer SocietyPress, Los Alamitos, p. 221-264.[12] R. Panvar & G. Agha (1994) A Methodol-ogy for Programming Scalable Architectures,Journal of Parallel and Distributed Computing,22(3), p. 479-487.[13] N. G. Shivaratri, P. Krueger & M. Sing-hal (1992) Load Distributing for Locally Dis-tributed Systems, IEEE Transactions on Com-puters, 41(12), p. 33-44.[14] W. Shu & L. V. Kal�e (1989) DynamicScheduling of Medium-Grained Processes onMulticomputers, TR-89-1528, Computer Sci-ence Department, University of Illinois atUrbana-Champaign.[15] A. Sinha & L. V. Kal�e (1993)A Load Balanc-ing Strategy for Prioritized Execution of Tasks,International Parallel Processing Symposium,p. 230-237.[16] T. T. Y. Suen & J. S. K. Wong (1992) E�-cient Task Migration Algorithm for DistributedSystems, IEEE Transactions on Parallel andDistributed Systems, 3(4), p. 488-499.[17] P. Wegner (1990) Concepts and Paradigmsof Object-oriented Programming, OOPS Mes-senger, 1(1).[18] M. H. Willebeek-LeMair & A. P. Reeves(1993) Strategies for Dynamic Load Balancingon Highly Parallel Computers, IEEE Transac-tions on Parallel and Distributed Systems, 4(9),p. 979-993.




















