
Compiling object-oriented data intensive applications
11
-
Upload
independent -
Category
Documents
-
view
1 -
download
0
Transcript of Compiling object-oriented data intensive applications

Compiling Object-Oriented Data Intensive Applications �
Renato Ferreira� Gagan Agrawaly Joel Saltz�
�Department of Computer Science
University of Maryland, College Park MD 20742
frenato,[email protected] of Computer and Information Sciences
University of Delaware, Newark DE 19716
Abstract
Processing and analyzing large volumes of data plays an in-creasingly important role in many domains of scienti�c re-search. High-level language and compiler support for devel-oping applications that analyze and process such datasetshas, however, been lacking so far.
In this paper, we present a set of language extensionsand a prototype compiler for supporting high-level object-oriented programming of data intensive reduction operationsover multidimensional data. We have chosen a dialect ofJava with data-parallel extensions for specifying collectionof objects, a parallel for loop, and reduction variables asour source high-level language. Our compiler analyzes par-allel loops and optimizes the processing of datasets throughthe use of an existing run-time system, called Active DataRepository (ADR). We show how loop �ssion followed byinterprocedural static program slicing can be used by thecompiler to extract required information for the run-timesystem. We present the design of a compiler/run-time in-terface which allows the compiler to e�ectively utilize theexisting run-time system.
A prototype compiler incorporating these techniques hasbeen developed using the Titanium front-end from Berke-ley. We have evaluated this compiler by comparing the per-formance of compiler generated code with hand customizedADR code for three templates, from the areas of digital mi-croscopy and scienti�c simulations. Our experimental re-sults show that the performance of compiler generated ver-sions is, on the average 21% lower, and in all cases within afactor of two, of the performance of hand coded versions.
1 Introduction
Analysis and processing of very large multi-dimensional sci-enti�c datasets (i.e. where data items are associated withpoints in a multidimensional attribute space) is an impor-tant component of science and engineering. Examples of
�This research was supported by NSF Grant ACR-9982087 and
NSF CAREER award ACI-9733520.
these datasets include raw and processed sensor data fromsatellites, output from hydrodynamics and chemical trans-port simulations, and archives of medical images. Thesedatasets are also very large, for example, in medical imag-ing, the size of a single digitized composite slide image athigh power from a light microscope is over 7GB (uncom-pressed), and a single large hospital can process thousandsof slides per day.
Applications that make use of multidimensional datasetsare becoming increasingly important and share several im-portant characteristics. Both the input and the output areoften disk-resident. Applications may use only a subset ofall the data available in the datasets. Access to data itemsis described by a range query, namely a multidimensionalbounding box in the underlying multidimensional attributespace of the dataset. Only the data items whose associ-ated coordinates fall within the multidimensional box are re-trieved. The processing structures of these applications alsoshare common characteristics. However, no high-level lan-guage support currently exists for developing applicationsthat process such datasets.
In this paper, we present our solution towards allowinghigh-level, yet e�cient, programming of data intensive re-duction operations on multidimensional datasets. Our ap-proach is to use a data parallel language to specify compu-tations that are to be applied to a portion of disk-residentdatasets. Our solution is based upon designing a prototypecompiler using the titanium infrastructure which incorpo-rates loop �ssion and slicing based techniques, and utiliz-ing an existing run-time system called Active Data Reposi-tory [5].
We have chosen a dialect of Java for expressing this classof computations. Our chosen dialect of Java includes data-parallel extensions for specifying collection of objects, a par-allel for loop, and reduction variables. However, the ap-proach and the techniques developed are not intended to belanguage speci�c. Our overall thesis is that a data-parallelframework will provide a convenient interface to large mul-tidimensional datasets resident on a persistent storage.
Conceptually, our compiler design has two major newideas. First, we have shown how loop �ssion followed byinterprocedural program slicing can be used for extractingimportant information from general object-oriented data-parallel loops. This technique can be used by other com-pilers that use a run-time system to optimize for locality orcommunication. Second, we have shown how the compilerand the run-time system can use such information to e�-

ciently execute data intensive reduction computations.Our compiler extensively uses the existing run-time sys-
tem ADR for optimizing the resource usage during execu-tion of data intensive applications. ADR integrates storage,retrieval and processing of multidimensional datasets on aparallel machine. While a number of applications have beendeveloped using ADR's low-level API and high performancehas been demonstrated [5], developing applications in thisstyle requires detailed knowledge of the design of ADR andis not suitable for application programmers. In comparison,our proposed data-parallel extensions to Java enable pro-gramming of data intensive applications at a much higherlevel. It is now the responsibility of the compiler to utilizethe services of ADR for memory management, data retrievaland scheduling of processes.
Our prototype compiler has been implemented using thetitanium infrastructure from Berkeley [20]. We have per-formed experiments using three di�erent data intensive ap-plications templates, two of which are based upon the Vir-tual Microscope application [9] and the third is based on wa-ter contamination studies [14]. For each of these templateswe have compared the performance of compiler generatedversions with hand customized versions. Our experimentsshow that the performance of compiler generated versionsis, on average 21% lower, and in all cases within a factor oftwo of the performance of hand coded versions. We presentan analysis of the factors behind the lower performance ofthe current compiler and suggest optimizations that can beperformed by our compiler in the future.
The rest of the paper is organized as follows. In Section 2,we further describe the charactestics of the class of data in-tensive applications we target. Background information onthe run-time system is provided in Section 3. Our chosenlanguage extensions are described in Section 4. We presentour compiler processing of the loops and slicing based anal-ysis in Section 5. The combined compiler and run-time pro-cessing for execution of loops is presented in Section 6. Ex-perimental results from our current prototype are presentedin Section 7. We compare our work with existing relatedresearch e�orts in Section 8 and conclude in Section 9.
2 Data Intensive Applications
In this section, we �rst describe some of the scienti�c do-mains which involve applications that process large datasets.Then, we describe some of the common characteristics of theapplications we target.
Data intensive applications from three scienti�c areas arebeing studied currently as part of our project.
Analysis of Microscopy Data: The Virtual Microscope [9]is an application to support the need to interactively viewand process digitized data arising from tissue specimens.The Virtual Microscope provides a realistic digital emula-tion of a high power light microscope. The raw data for sucha system can be captured by digitally scanning collections offull microscope slides under high power. At the basic level,it can emulate the usual behavior of a physical microscopeincluding continuously moving the stage and changing mag-ni�cation and focus.
Water contamination studies: Environmental scientists studythe water quality of bays and estuaries using long runninghydrodynamics and chemical transport simulations [14]. The
chemical transport simulation models reactions and trans-port of contaminants, using the uid velocity data gener-ated by the hydrodynamics simulation. This simulation isperformed on a di�erent spatial grid, and often uses sig-ni�cantly coarser time steps. This is achieved by mappingthe uid velocity information from the circulation grid, av-eraged over multiple �ne-grain time steps, to the chemicaltransport grid and computing smoothed uid velocities forthe points in the chemical transport grid.
Satellite data processing: Earth scientists study the earthby processing remotely-sensed data continuously acquiredfrom satellite-based sensors, since a signi�cant amount ofearth science research is devoted to developing correlationsbetween sensor radiometry and various properties of the sur-face of the earth [5]. A typical analysis processes satellitedata for ten days to a year and generates one or more com-posite images of the area under study. Generating a com-posite image requires projection of the globe onto a two di-mensional grid; each pixel in the composite image is com-puted by selecting the \best" sensor value that maps to theassociated grid point.
Data intensive applications in these and related scien-ti�c areas share many common characteristics. Access todata items is described by a range query, namely a multidi-mensional bounding box in the underlying multidimensionalspace of the dataset. Only the data items whose associ-ated coordinates fall within the multidimensional box areretrieved. The basic computation consists of (1) mappingthe coordinates of the retrieved input items to the corre-sponding output items, and (2) aggregating, in some way, allthe retrieved input items mapped to the same output dataitems. The computation of a particular output element is areduction operation, i.e. the correctness of the output usu-ally does not depend on the order in which the input dataitems are aggregated.
3 Overview of the Runtime System
Our compiler e�ort targets an existing run-time infrastruc-ture, called the Active Data Repository (ADR) [5] that inte-grates storage, retrieval and processing of multidimensionaldatasets on a parallel machine. We give a brief overview ofthis run-time system in this section.
Processing of a data intensive data-parallel loop is car-ried out by ADR in two phases: loop planning and loop ex-ecution. The objective of loop planning is to determine aschedule to e�ciently process a range query based on theamount of available resources in the parallel machine. Aloop plan speci�es how parts of the �nal output are com-puted. The loop execution service manages all the resourcesin the system and carries out the loop plan generated bythe loop planning service. The primary feature of the loopexecution service is its ability to integrate data retrievaland processing for a wide variety of applications. This isachieved by pushing processing operations into the storagemanager and allowing processing operations to access thebu�er used to hold data arriving from disk. As a result, thesystem avoids one or more levels of copying that would beneeded in a layered architecture where the storage managerand the processing belong in di�erent layers.
A dataset in ADR is partitioned into a set of (logical)disk blocks to achieve high bandwidth data retrieval. Thesize of a logical disk block is a multiple of the size of a phys-

ical disk block on the system and is chosen as a trade-o� be-tween reducing disk seek time and minimizing unnecessarydata transfers. A disk block consists of one or more objects,and is the unit of I/O and communication. The processingof a loop on a processor progresses through the followingthree phases: (1) Initialization { output disk blocks (possi-bly replicated on all processors) are allocated space in mem-ory and initialized, (2) Local Reduction { input disk blockson the local disks of each processor are retrieved and aggre-gated into the output disk blocks, (3) Global Combine { ifnecessary, results computed in each processor in phase 2 arecombined across all processors to compute �nal results forthe output disk blocks.
ADR run-time support has been developed as a set ofmodular services implemented in C++. ADR allows cus-tomization for application speci�c processing (i.e., mappingand aggregation functions), while leveraging the commonali-ties between the applications to provide support for commonoperations such as memory management, data retrieval, andscheduling of processing across a parallel machine. Cus-tomization in ADR is currently achieved through class in-heritance. That is, for each of the customizable services,ADR provides a base class with virtual functions that areexpected to be implemented by derived classes. Adding anapplication-speci�c entry into a modular service requires thede�nition of a class derived from an ADR base class for thatservice and providing the appropriate implementations ofthe virtual functions. Current examples of data intensiveapplications implemented with ADR include Titan [5], forsatellite data processing, the Virtual Microscope [9], for vi-sualization and analysis of microscopy data, and coupling ofmultiple simulations for water contamination studies [14].
4 Java Extensions for Data Intensive Computing
In this section we describe a dialect of Java that we havechosen for expressing data intensive computations. Thoughwe propose to use a dialect of Java as the source languagefor the compiler, the techniques we will be developing willbe largely independent of Java and will also be applicableto suitable extensions of other languages, such as C, C++,or Fortran 90.
4.1 Data-Parallel Constructs
We borrow two concepts from object-oriented parallel sys-tems like Titanium [20], HPC++ [2], and Concurrent Ag-gregates [6].
� Domains and Rectdomains are collections of objects ofthe same type. Rectdomains have a stricter de�nition,in the sense that each object belonging to such a col-lection has a coordinate associated with it that belongsto a pre-speci�ed rectilinear section of the domain.
� The foreach loop, which iterates over objects in a do-main or rectdomain, and has the property that theorder of iterations does not in uence the result of theassociated computations. We further extend the se-mantics of foreach to include the possibility of updatesto reduction variables, as we explain later.
We introduce a Java interface called Reducinterface. Anyobject of any class implementing this interface acts as a re-duction variable [10]. The semantics of a reduction variableis analogous to that used in version 2.0 of High PerformanceFortran (HPF-2) [10] and in HPC++ [2]. A reduction vari-able has the property that it can only be updated inside a
foreach loop by a series of operations that are associativeand commutative. Furthermore, the intermediate value ofthe reduction variable may not be used within the loop, ex-cept for self-updates.
4.2 Example Code
Figure 1 outlines an example code with our chosen exten-sions. This code shows the essential computation in thevirtual microscope application [9]. A large digital image isstored in disks. This image can be thought of as a two di-mensional array or collection of objects. Each element inthis collection denotes a pixel in the image. Each pixel com-prises of three characters, which denote the color at thatpoint in the image. The interactive user supplies two im-portant pieces of information. The �rst is a bounding boxwithin this two dimensional box, this implies the area withinthe original image that the user is interested in scanning.We assume that the bounding box is rectangular, and can bespeci�ed by providing the x and y coordinates of two points.The �rst 4 arguments provided by the user are integers andtogether, they specify the points lowend and hiend. Thesecond information provided by the user is the subsamplingfactor, an integer denoted by subsamp. The subsamplingfactor tells the granularity at which the user is interested inviewing the image. A subsampling factor of 1 means thatall pixels of the original image must be displayed. A sub-sampling factor of n means that n2 pixels are averaged tocompute each output pixel.
The computation in this kernel is very simple. First,a querybox is created using speci�ed points lowend andhiend. Each pixel in the original image which falls withinthe querybox is read and then used to increment the valueof the corresponding output pixel.
4.3 Restrictions on the Loops
The primary goal of our compiler will be to analyze andoptimize (by performing both compile-time transformationsand generating code for ADR run-time system) foreach loopsthat satisfy certain properties. We assume standard seman-tics of parallel for loops and reductions in languages likeHigh Performance Fortran (HPF) [10] and HPC++ [2]. Fur-ther, we require that no Java threads be spawned withinsuch loop nests, and no memory locations read or written toinside the loop nests may be touched by another concurrentthread. Our compiler will also assume that no Java excep-tions are raised in the loop nest and the iterations of theloop can be reordered without changing any of the languagesemantics. One potential way of enabling this can be to usebound checking optimizations [15].
5 Compiler Analysis
In this section, we �rst describe how the compiler processesthe given data-parallel data intensive loop to a canonicalform. We then describe how interprocedural program slicingcan be used for extracting a number of functions which arepassed to the run-time system.
5.1 Initial Processing of the Loop
Consider any data-parallel loop in our dialect of Java, aspresented in Section 4. The memory locations modi�ed inthis loop are only the elements of collection of objects, ortemporary variables whose values are not used in other it-erations of the loop or any subsequent computations. Thememory locations accessed in this loop are either elements

Interface Reducinterface f*Any object of any class implementingthis interface is a reduction variable*
gpublic class VMPixel fchar colors[3];void Initialize() fcolors[0] = 0 ;colors[1] = 0 ;colors[2] = 0 ;g*Aggregation Function*void Accum(VMPixel Apixel, int avgf) fcolors[0] += Apixel.colors[0]/avgf ;colors[1] += Apixel.colors[1]/avgf ;colors[2] += Apixel.colors[2]/avgf ;ggpublic class VMPixelOut extends VMPixel
implements Reducinterface;public class VMScope fstatic int Xdimen = ... ;static int Ydimen = ... ;static Point[2] lowpoint = [0,0];
*Data Declarations*static Point[2] hipoint = [Xdimen-1,Ydimen-1];static RectDomain[2] VMSlide = [lowpoint : hipoint];static VMPixel[2d] VScope = new VMPixel[VMSlide];public static void main(String[] args) fPoint[2] lowend = [args[0],args[1]];Point[2] hiend = [args[2],args[3 ]];int subsamp = args[4];RectDomain[2] Outputdomain = [[0,0]:(hiend -
lowend)/subsamp];VMPixelOut[2d] Output = new VMPixelOut[Outputdomain] ;RectDomain[2] querybox ;Point[2] p;foreach(p in Outputdomain) fOutput[p].Initialize();gquerybox = [lowend : hiend] ;*Main Computational Loop*foreach(p in querybox) fPoint[2] q = (p - lowend)/subsamp ;Output[q].Accum(VScope[p],subsamp*subsamp) ;ggg
Figure 1: Example Code
of collections or values which may be replicated on all pro-cessors before the start of the execution of the loop.
For the purpose of our discussion, collections of objectswhose elements are modi�ed in the loop are referred to asleft hand side or lhs collections, and the collections whoseelements are only read in the loop are considered as righthand side or rhs collections.
The functions used to access elements of collections ofobjects in the loop are referred to as the subscript functions.
De�nition 1 Consider any two lhs collections or any tworhs collections. These two collections are called congruenti�
� The subscript functions used to access these two col-lections in the loop are identical.
� The layout and partitioning of these two collections areidentical. By identical layout we mean that elementswith the same indices are put together in the same diskblock for both the collections. By identical partitioningwe mean that the disk blocks containing elements withidentical indices from these collections reside on thesame processor.
Consider any loop. If multiple distinct subscript func-tions are used to access rhs collections and lhs collectionsand these subscript functions are not known at compile-time,tiling output and managing disk accesses while maintaininghigh reuse and locality is going to be a very di�cult taskfor the run-time system. In particular, the current imple-mentation of ADR does not support such cases. Therefore,we perform loop �ssion to divide the original loop into a setof loops, such that all lhs collections in any new loop arecongruent and all rhs collections are congruent. We nowdescribe how such loop �ssion is performed.
Initially, we focus on lhs collections which are updatedin di�erent statements of the same loop. We perform loop
�ssion, so that all lhs collections accessed in any new loopare congruent. Since we are focusing on loops with no loop-carried dependencies, performing loop �ssion is straight-forward. An example of such transformation is shown inFigure 2, part (a).
We now focus on such a new loop in which all lhs col-lections are congruent, but not all rhs collections may becongruent. For any two rhs accesses in a loop that are notcongruent, there are three possibilities:1. These two collections are used for calculating values ofelements of di�erent lhs collections. In this case, loop �ssioncan be performed trivially.2. These two collections Y and Z are used for calculatingvalues of elements of the same lhs collection. Such lhs
collection X is, however, computed as follows:
X(f(i)) opi = Y (g(i)) opj Z(h(i))
such that, opi � opj . In such a case, loop �ssion canbe performed, so that the element X(f(i)) is updated usingthe operation opi with the values of Y (g(i)) and Z(h(i)) indi�erent loops. An example of such transformation is shownin Figure 2, part (b).3. These two collections Y and Z are used for calculatingvalues of the elements of the same lhs collection and unlikethe case above, the operations used are not identical. Anexample of such a case is
X(f(i)) + = Y (g(i)) � Z(h(i))
In this case, we need to introduce temporary collection ofobjects to copy the collection Z. Then, the collection Y andthe temporary collection can be accessed using the samesubscript function. An example of such transformation isshown in Figure 2, part (c).
After such a series of loop �ssion transformations, theoriginal loop is replaced by a series of loops. The property

foreach(r 2 R) fO1[SL(r)] op1 = A1(I1[SR(r)]; : : : ; In[SR(r)]): : :
Om[SL(r)] opm = Am(I1[SR(r)]; : : : ; In[SR(r)])g
Figure 3: A Loop In Canonical Form
of each loop is that all lhs collections are accessed withthe same subscript function and all rhs collections are alsoaccessed with the same subscript function. However, thesubscript function for accessing the lhs collections may bedi�erent from the one used to access rhs collections.
5.1.1 Terminology
After loop �ssion, we focus on an individual loop at atime. We introduce some notation about this loop which isused for presenting our solution. The terminology presentedhere is illustrated by the example loop in Figure 3.
The range (domain) over which the iterator iterates isdenoted by the function R. Let there be n rhs collection ofobjects read in this loop, which are denoted by I1; : : : ; In.Similarly, let the lhs collections written in the loop be de-noted byO1; : : : ; Om. Further, we denote the subscript func-tion used for accessing right hand side collections by SR andthe subscript function used for accessing left hand side col-lections by SL.
Given a point r in the range for the loop, elements SL(r)of the output collections are updated using one or more ofthe values I1[SR(r)]; : : : ; In[SR(r)], and other scalar valuesin the program. We denote by Ai the function used for cre-ating the value which is used later for updating the elementof the output collection Oi. The operator used for perform-ing this update is opi.
5.2 Slicing Based Interprocedural Analysis
We are primarily concerned with extracting three sets offunctions, the range function R, the subscript functions SRand SL, and the aggregation functions A1; : : : ;Am. Simi-lar information is often extracted by various data-parallelFortran compilers. One important di�erence is that weare working with an object-oriented language (Java), whichis signi�cantly more di�cult to analyze. This is mainlybecause the object-oriented programming methodology fre-quently leads to small procedures and frequent procedurecalls. As a result, analysis across multiple procedures maybe required in order to extract range, subscript and aggre-gation functions.
We use the technique of interprocedural program slicingfor extracting these three sets of functions. Initially, wegive background information on program slicing and givereferences to show that program slicing can be performedacross procedure boundaries, and in the presence of languagefeatures like polymorphism, aliases, and exceptions.
5.2.1 Background: Program Slicing
The basic de�nition of a program slice is as follows. Givena slicing criterion (s; x), where s is a program point in theprogram and x is a variable, the program slice is a subsetof statements in the programs such that these statements,when executed on any input, will produce the same value ofthe variable x at the program point s as the original pro-gram.
The basic idea behind any algorithm for computing pro-gram slices is as follows. Starting from the statement p inthe program, we trace any statements on which p is data orcontrol dependent and add them to the slice. The same isrepeated for any statement which has already been includedin the slice, till no more statements can be added in the slice.
Slicing has been very frequently used in software develop-ment environments, for debugging, program analysis, merg-ing two di�erent versions of the code, and software mainte-nance and testing. A number of techniques have been pre-sented for accurate program slicing across procedure bound-aries [18].
5.2.2 Extracting Range Function
We need to determine the rhs and lhs collection of objectsfor this loop. We also need to provide the range function R.
The rhs and lhs collection of objects can be computedeasily by inspecting the assignment statements inside theloop and in any functions called inside the loop. Any col-lection which is modi�ed in the loop is considered a lhs
collection, and any other collection touched in the loop isconsidered a rhs collection.
For computing the domain, we inspect the foreach loopand look at the domain over which the loop iterates. Then,we compute a slice of the program using the entry of theloop as the program point and the domain as the variable.
5.2.3 Extracting Subscript Functions
The subscript functions SR and SL are particularly impor-tant for the run-time system, as it determines the size of lhscollections written in the loop and the rhs disk blocks fromeach collection that contribute to the lhs collections.
The function SL can be extracted using slicing as follows.Consider any statement in the loop which modi�es any lhs
collection. We focus on the variable or expression used toaccess an element in the lhs collection. The slicing crite-rion we choose is the value of this variable or expression atthe beginning of the statement where the lhs collection ismodi�ed.
The function SR can be extracted similarly. Considerany statement in the loop which reads from any rhs collec-tion. The slicing criterion we use is the value of the expres-sion used to access the collection, at the beginning of sucha statement.
Typically, this value of the iterator will be included insuch slices. Suppose the iterator is p. After �rst encounter-ing p in the slice, we do not follow data-dependencies for pany further. Instead, the functions returned by the slice usesuch iterator as the input parameter.
For the virtual microscope template presented in Fig-ure 1, the slice computed for the subscript function SL isshown at the left hand side of Figure 4 and the code gen-erated by the compiler is shown on the left hand side ofFigure 5. In the original source code, the rhs collection isaccessed with just the iterator p, therefore, the subscriptfunction SR is the identity function. The function SL re-ceives the coordinates of an element in the rhs collection asparameter (iterpt) from the run-time system and returnsthe coordinates of the corresponding lhs element. Titaniummultidimensional points are supported by ADR as a classnamed ADR Pt. Also, in practice, the command line param-eters passed to the program are extracted and stored in adata-structure, so that the run-time system does not needto explicitly read args array.

(a) foreach (p in box) fA[f(p)] += C[p]B[g(p)] += C[p]
g
#
foreach (p in box) fA[f(p)] += C[p]
gforeach (p in box) f
B[g(p)] += C[p]g
(b) foreach (p in box) fA[f(p)] += B[g(p)] + C[h(p)]
g
#
foreach (p in box) fA[f(p)] += B[g(p)]
gforeach (p in box) f
A[f(p)] += C[h(p)]g
(c) foreach (p in box) fA[f(p)] += B[p] � C[g(p)]
g
#
foreach (p in box) fT[p] = C[g(p)]
gforeach (p in box) f
A[f(p)] += B[p] � T[p]g
Figure 2: Examples of Loop Fission Transformations
Point[2] lowend = [args[0],args[1]];int subsamp = args[4];Point[2] q = (p - lowend)/subsamp ;
foreach(p in querybox) fPoint[2] q = (p - lowend)/subsamp ;Output[q].Accum(VScope[p],subsamp*subsamp) ;
g
Figure 4: Slice for Subscript Function (left) and for Aggregation Function (right)
5.2.4 Extracting Aggregation Functions
For extracting the aggregation function Ai, we look at thestatement in the loop where the lhs collection Oi is modi-�ed. The slicing criterion we choose is the value of the ele-ment from the collection which is modi�ed in this statement,at the beginning of this statement.
For the virtual microscope template presented in Fig-ure 1 has only one aggregation function. This slice for thisaggregation function is shown in Figure 4 and the actualcode generated by the compiler is shown in Figure 5. Thefunction Accum accessed in this code is obviously part ofthe slice, but is not shown here. The generated functioniterates over the elements of a disk block and applies ag-gregation functions on each element, if that element inter-sects with the range of the loop and the current tile. Thefunction is presented as a parameter of current block (thedisk block being processed), the current tile (the portionof lhs collection which is currently allocated in memory),and querybox which is the iteration range for the loop. Ti-tanium rectangular domains are supported by the run-timeas ADR Box. Further details of this aggregation function areexplained after presenting the combined compiler/run-timeloop processing.
6 Combined Compiler and Run-time Processing
In this section we explain how the compiler and run-timesystem can work jointly towards performing data intensivecomputations.
6.1 Initial Processing of the Input
The system stores information about how each of the rhs
collection of objects Ii is stored across disks. Note thatafter we apply loop �ssion, all rhs collections accessed inthe same loop have identical layout and partitioning. The
compiler generates appropriate ADR functions to analyzethe meta-data about collections Ii, the range function R,and the subscripting function SR, and compute the list ofdisk blocks of Ii that are accessed in the loop. The domainof each rhs collection accessed in the loop is SR � R. Notethat if a disk block is included in this list, it is not necessarythat all elements in this disk block are accessed during theloop. However, for the initial planning phase, we focus onthe list of disk blocks.
We assume a model of parallel data intensive computa-tion in which a set of disks is associated with each node ofthe parallel machine. This is consistent with systems likeIBM SP and cluster of workstations. Let the set
P = fp1; p2; : : : ; pqg
denote the list of processors in the system. Then, the in-formation computed by the run-time system after analyzingthe range function, the input subscripting function and themeta-data about each of the collections of objects Ii is thesets Bij . For a given input collection Ii and a processor j,Bij is the set of disk blocks b that contain data for collec-tion Ii, is resident on a disk connected to processor pj , andintersections with SR � R.
Further, for each disk block bijk belonging to the setBij , we compute the information D(bijk), which denotes thesubset of the domain SR � R which is resident on the diskblock b. Clearly the union of the domains covered by allselected disk blocks will cover the entire area of interest, orin formal terms,
8i[
8 j; 8 k
D(bijk) � SR � R

ADR Pt Subscript out( ADR Pt iterpt ) fADR Pt outpoint(2);ADR Pt lowend(2);lowend[0] = args[0];lowend[1] = args[1];int subsamp = args[4];outpoint[0] = (iterpt[0] - lowend[0])/subsamp;outpoint[1] = (iterpt[1] - lowend[1])/subsamp;return outpoint ;
g
void Accumulate(ADR Box current block, ADR Boxcurrent tile, ADR Box querybox) f
ADR Box box = current block.intersect(querybox);ADR Pt lowpt = box.getLow();ADR Pt highpt = box.getHigh();ADR Pt inputpt(2);ADR Pt outputpt(2);int subsamp = args[4];for (i0 = lowpt[0]; i0 < highpt[0]; i0++) ffor (i1 = lowpt[1]; i1 < highpt[1]; i1++) finputpt[0] = i0;inputpt[1] = i1;if (project(inputpt, outputpt, current tile)) fOutput[outputpt].Accum(VScope[inputpt],
subsamp*subsamp);g
gg
g
Figure 5: Compiler Generated Subscript and Aggregation Functions
6.2 Work Partitioning
One of the issues in processing any loop in parallel is workor iteration partitioning, i.e., deciding which iterations areexecuted on which processor.
The work distribution policy we use is that each itera-tion is performed on the owner of the element read in thatiteration. This policy is opposite to the owner computes pol-icy [11] which has been commonly used in distributed mem-ory compilers, in which the owner of the lhs element workson the iteration. The rationale behind the approach is thatthe system will not have to communicate blocks of the rhscollections. Instead, only replicated elements of the lhs col-lections need to be communicated to complete the compu-tation. Note that the assumptions on the nature of loops wehave placed requires replacing an initial loop by a sequenceof canonical loops, which may also increase net communica-tion between processors. However, we do not consider it tobe a problem for the set of applications we target.
6.3 Allocating Output Bu�ers and Strip Mining
The distribution of rhs collections is decided before per-forming the processing, and we have decided to partition theiterations accordingly. We now need to allocate bu�ers toaccumulate the local contributions to the �nal lhs objects.
We use run-time analysis to determine the elements ofoutput collections which are updated by the iterations per-formed on a given processor. This run-time analysis is sim-ilar to the one performed by run-time libraries for execut-ing irregular applications on distributed memory machines.Any element which is updated by more than one processor isinitially replicated on all processors by which it is updates.Several di�erent strategies for allocation of bu�ers have beenstudies in the context of the run-time system [5]. Selectingamong these di�erent strategies for the compiler generatedcode is a topic for future research.
The memory requirements of the replicated output spaceis typically higher than the available memory on each pro-cessor. Therefore, we need to divide the replicated outputbu�er into chunks that can be allocated on each processor'smain memory. This is the same issue as strip mining or tiling
used for improving cache performance. We have so far usedonly a very simple strip mining strategy. We query the run-time system to determine the available memory that can beallocated on a given processor. Then, we divide the lhs
space into blocks of that size. Formally, we divide the lhs
domain SL � R into a set of smaller domains (called strips)fS1; S2; : : : ; Srg. Since each of the lhs collection of objectsin the loop is accessed through the same subscripting func-tion, same strip mining is done for each of them.
In performing the computations on each processor, wewill iterate over the set of strips, allocate that strip for eachof the n output collections, and compute local contributionsto each strip, before allocating the next strip. To facilitatethis, we compute the set of rhs disk blocks that will con-tribute to each strip of the lhs.
6.4 Mapping Input to the Output
We use subscripting functions SR and SL for computing theset of rhs disk blocks that will contribute to each strip ofthe lhs as indicated above. To do this we apply the func-tion SL � (S
�1
R ) to each D(bijk) to obtain the correspondingdomain in the lhs region. These output domains that eachdisk block can contribute towards are denoted as OD(bijk).If D(bijk) is a rectangular domain and if the subscriptingfunctions are monotonic, OD(bijk) will be a rectangular do-main and can easily be computed by applying the subscript-ing function to the two extreme corners. If this is not thecase, the subscripting function needs to be applied on eachelement of D(bijk) and the resulting OD(bijk) will just bea domain and not a rectangular domain. Formally, we com-pute the sets Ljl, for each processor j and each output stripl, such that
Ljl = fj j 8 i (OD(bijk) \ Sl) 6= �g
6.5 Actual Execution
The computation of sets Lil marks the end of the loop plan-ning phase of the run-time system. Using this information,now the actual computations are performed on each proces-sor. The structure of the computation is shown in Figure 6.In practice, the computation associated with each rhs disk
For each output strip Sl:Execute on each Processor Pj :
Allocate and initialize strip Sl for O1; : : : ;Om
Foreach k 2 LjlRead blocks bijk; i = 1; : : : ; n from disksForeach element e of D(bijk)
If the output pt. intersects with SlEvaluate functions A1; : : : ;Am
Global reduction to �nalize the values for Sl
Figure 6: Loop Execution on Each Processor
block and retrieval of disk blocks is overlapped, by usingasynchronous I/O operations.
We now explain the aggregation function generated bythe compiler for the virtual microscope template presentedin Figure 1, shown in Figure 5, right hand side. The ac-cumulation function output by the compiler captures theForeach element part of the loop execution model shownin Figure 6. The run-time system computes the sets Ljl asexplained previously and invokes the aggregation functionin a loop that iterates over each disk block in such a set.The current compiler generated code computes the rectan-gular domain D(bijk) in each invocation of aggregation func-tion, by doing an intersection of the current block and queryblock. The resulting rectangular domain is denoted by box.
The aggregation function iterates over the elements ofbox. The conditional if project() achieves two goals. First,it applies subscript functions to determine the lhs elementoutputpt corresponding to the rhs element inputpt. Sec-ond, it checks if outputpt belongs to current tile. Theactual aggregation is applied only if outputpt belongs tocurrent tile. This test represents a signi�cant source ofine�ciency in the compiler generated code. If the tile orstrip being currently processed represents a rectangular rhsregion and the subscript functions are monotonic, then theintersection of the box and the tile can be performed beforethe inner loop. This is in fact done in the hand customiza-tion of ADR for virtual microscope [9]. Performing such anoptimization automatically is a topic for future research andbeyond the scope of our current work.
7 Current Implementation and Experimental Results
In this section, we describe some of the features of the cur-rent compiler and then present experimental results compar-ing the performance of compiler generated customization forthree codes with hand customized versions.
Our compiler has been implemented using the publiclyavailable Titanium infrastructure from Berkeley [20]. Ourcurrent compiler and run-time system only implements asubset of the analysis and processing techniques describedin this paper. Two key limitations are as follows. We canonly process codes in which the rhs subscript function isthe identity function. It also requires that the domain overwhich the loop iterates is a rectangular domain and all sub-script functions are monotonic.
We have used three templates for our experiments.
� VMScope1 is identical to the code presented in Figure 1.It models a virtual microscope, which provides a real-istic digital emulation of a microscope, by allowing theusers to specify a rectangular window and a subsam-pling factor. The version VMScope1 averages the colors
of neighboring pixels to create a pixel in the outputimage.
� VMScope2 is similar to VMScope1, except for one impor-tant di�erence. Instead of taking average of the pixels,it only picks every subsampth element along each di-mension to create the �nal output image. Thus, onlymemory accesses and copying is involved in this tem-plate, no computations are performed.
� Bess models computations associated with water con-tamination studies over bays and estuaries. The com-putation performed in this application determines thetransport of contaminants, and accesses large uid ve-locity data-sets generated by a previous simulation.
Virtual Microscope (averaging)
01020304050607080
1 2 4 8
# of processors
Execut
ionTim
e(s)
Compiled
Original
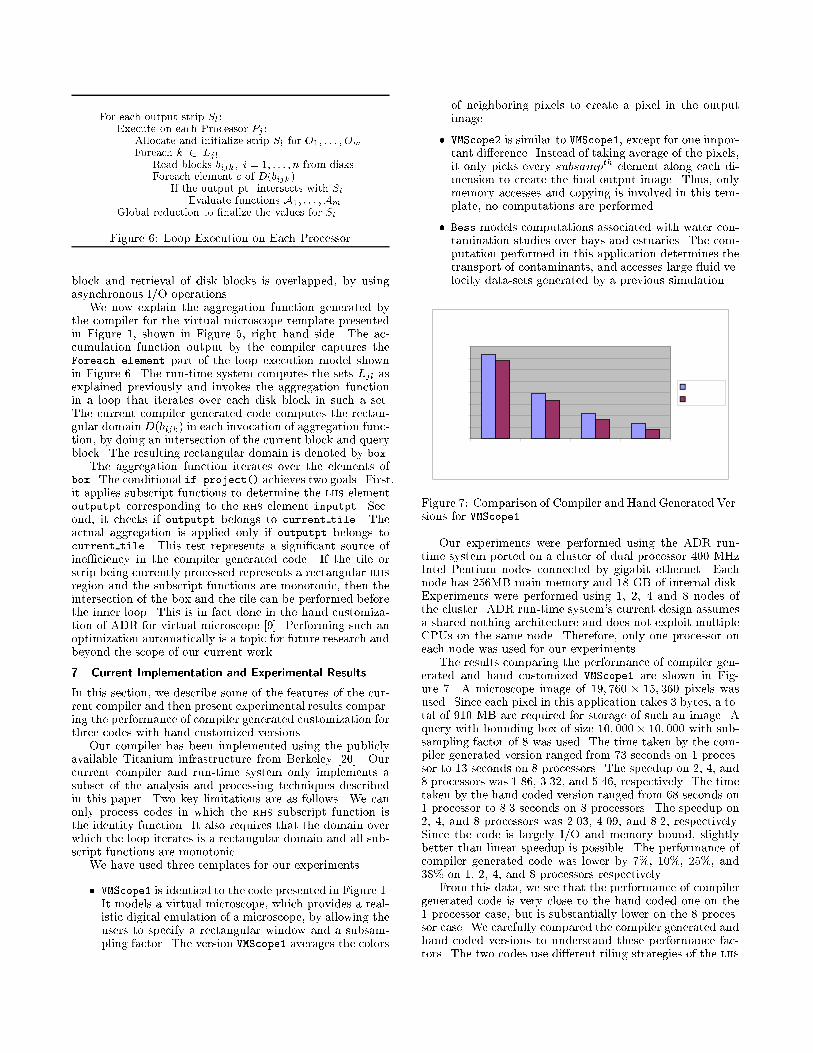
Figure 7: Comparison of Compiler and Hand Generated Ver-sions for VMScope1
Our experiments were performed using the ADR run-time system ported on a cluster of dual processor 400 MHzIntel Pentium nodes connected by gigabit ethernet. Eachnode has 256MB main memory and 18 GB of internal disk.Experiments were performed using 1, 2, 4 and 8 nodes ofthe cluster. ADR run-time system's current design assumesa shared nothing architecture and does not exploit multipleCPUs on the same node. Therefore, only one processor oneach node was used for our experiments.
The results comparing the performance of compiler gen-erated and hand customized VMScope1 are shown in Fig-ure 7. A microscope image of 19; 760 � 15; 360 pixels wasused. Since each pixel in this application takes 3 bytes, a to-tal of 910 MB are required for storage of such an image. Aquery with bounding box of size 10; 000� 10; 000 with sub-sampling factor of 8 was used. The time taken by the com-piler generated version ranged from 73 seconds on 1 proces-sor to 13 seconds on 8 processors. The speedup on 2, 4, and8 processors was 1.86, 3.32, and 5.46, respectively. The timetaken by the hand coded version ranged from 68 seconds on1 processor to 8.3 seconds on 8 processors. The speedup on2, 4, and 8 processors was 2.03, 4.09, and 8.2, respectively.Since the code is largely I/O and memory bound, slightlybetter than linear speedup is possible. The performance ofcompiler generated code was lower by 7%, 10%, 25%, and38% on 1, 2, 4, and 8 processors respectively.
From this data, we see that the performance of compilergenerated code is very close to the hand coded one on the1 processor case, but is substantially lower on the 8 proces-sor case. We carefully compared the compiler generated andhand coded versions to understand these performance fac-tors. The two codes use di�erent tiling strategies of the lhs

collections. In the hand coded version, an irregular strat-egy is used which ensures that each input disk block mapsentirely into a single tile. In the compiler version, a simpleregular tiling is used, in which each input disk block can mapto multiple tiles. As shown in Figure 5, the compiler gen-erated code performs an additional check in each iteration,to determine if the lhs element intersect with the tile cur-rently being processed. In comparison, the tiling strategyused for hand coded version ensures that this check alwaysreturns true, and therefore does not need to be inserted inthe code. But, because of the irregular tiling strategy, anirregular mapping is required between the bounding box as-sociated with each disk block and the actual coordinates onthe allocated output tile. This mapping needs to be carriedout after each rhs disk block is read from the memory. Thetime required for performing such mapping is proportionalto the number of rhs disk blocks processed by each proces-sor for each tile. Since the output dataset is actually quitesmall in our experiments, the number of rhs disk blocks pro-cessed by each processor per tile decreases as we go to largercon�gurations. As a result, the time required for this extraprocessing reduces. In comparison, the percentage overheadassociated with extra check in each iteration performed bythe compiler generated version remains unchanged. This dif-ference explains why the compiler generated code is slowerthan the hand coded one, and why the di�erence in perfor-mance increases as we go to larger number of processors.
Virtual Microscope (subsampling)
0
10
20
30
40
50
1 2 4 8
# of processors
Execut
ionTim
e(s)
Compiled
Original
Figure 8: Comparison of Compiler and Hand Generated Ver-sions for VMScope2
The results comparing the performance of compiler gen-erated and hand coded VMScope2 are shown in Figure 8.This code was executed on same dataset and query as usedfor VMScope1. The time taken by the compiler generatedversion ranged from 44 seconds on 1 processor to 9 secondson 1 processor. The hand coded version took 47 secondson 1 processor and nearly 5 seconds on 8 processors. Thespeedup of compiler generated version was 2.03, 3.31, and4.88 on 2, 4, and 8 processors respectively. The speedup ofhand coded version was 2.38, 4.98, 10.0 on 2, 4, and 8 pro-cessors respectively.
A number of important observations can be made. First,though the same query is executed for VMScope1 and VMScope2templates, the execution times are lower for VMScope2. Thisis clearly because no computations are performed in VMScope2.However, a factor of less than two di�erence in executiontimes shows that both the codes are memory and I/O boundand even in VMScope1, the computation time does not dom-inate. The speedups for hand coded version of VMScope2 are
higher. This again is clearly because this code is I/O andmemory bound.
The performance of compiler generated version was bet-ter by 6% on 1 processor, and was lower by 10% on 2 pro-cessors, 29% on 4 processors, and 48% on 8 processors. Thisdi�erence in performance is again because of the di�erencein tiling strategies used, as explain previously. Since thistemplate does not perform any computations, the di�erencein the conditionals and extra processing for each disk blockhas more signi�cant e�ect on the overall performance. Inthe 1 processor case, the additional processing required foreach disk block becomes so high that the compiler generatedversion is slightly faster. Note that the hand coded versionwas developed for optimized execution on parallel systemsand therefore, is not highly tuned for sequential case. Forthe 8 processor case, the extra cost of conditional in each it-eration becomes dominant for the compiler generated cost,and therefore, it is almost factor of 2 slower than the handcoded one.
Bays and Estuaries Simulation System
0
20
40
60
80
100
120
140
1 2 4 8
# of processors
Execut
ionTim
e(s)
Compiled
Original
Figure 9: Comparison of Compiler and Hand Generated Ver-sions for Bess
The results comparing performance of compiler gener-ated and hand coded version for Bess are shown in Fig-ure 9. The dataset comprises of a grid with 2113 elementsand 46,080 time-steps. Each time-step has 4 4-byte oatingpoint numbers per grid element, denoting simulated hydro-dynamics parameters previously computed. Therefore, thememory requirements of the dataset are 1.6 GB. The Besstemplate we experimented with performed weighted averag-ing of each of the 4 values for each column, over a speci�ednumber of time-steps. The number of time-steps used forour experiments was 30,000.
The execution times for compiler generated version rangedfrom 131 seconds on 1 processor to 11 seconds on 8 proces-sors. The speedup on 2, 4, and 8 processors was 1.98, 5.53,and 11.75 respectively. The execution times for hand codedversion ranged from 97 seconds on 1 processor to 9 secondson 8 processors. The speedup on 2, 4, and 8 processors was1.8, 5.4, and 10.7 respectively. The compiler generated ver-sion was slower by a factor of 25%, 19%, 24%, and 19% on1, 2, 4, and 8 processors respectively.
We now discuss the factors behind the di�erence in per-formance of compiler generated and hand coded Bess ver-sions. As with both the VMScope versions, the compiler gen-erated Bess performs checks for intersecting with the tile foreach pixel. The output for this applications is very small,and as a result, the hand coded version explicitly assumesa single output tile. The compiler generated version can-not make this assumption and still inserts the conditionals.

The amount of computation associated with each iterationis much higher for this application. Therefore, the percent-age overhead of the extra test is not as large as the VMScopetemplates. The second important di�erence between thecompiler generated and hand coded versions is how aver-aging is done. In the compiler generated code, each valueto be added is �rst divided by the total number of valueswhich are being added. In comparison, the hand coded ver-sion performs the summation of all values �rst, and thenperforms a single division. The percentage overhead of thisis independent of the number of processors used. We believethat the second factor is the dominant reason for the di�er-ence in performance of two versions. This also explain whythe percentage di�erence in performance remains unchangedas the number of processors in increased. The performanceof compiler generated code can be improved by performingthe standard strength reduction optimization. However, thecompiler needs to perform this optimization interprocedu-rally, which is a topic for future work.
As an average over these three templates and 1, 2, 4,and 8 processor con�gurations, the compiler generated ver-sions are 21% slower than hand coded ones. Considering thehigh programming e�ort involved in managing and optimiz-ing disk accesses and computation on a parallel machine, webelieve that a 21% slow-down from automatically generatedcode will be more than acceptable to the application devel-opers. It should also be noted that the previous work in thearea of out-of-core and data intensive compilation has fo-cused only on evaluating the e�ectiveness of optimizations,and not on any comparisons against hand coded versions.
Our analysis of performance di�erences between compilergenerated and hand coded versions has pointed us to a num-ber of directions for future research. First, we need to con-sider more sophisticated tiling strategies to avoid large per-formance penalties associated with performing extra testsduring loop execution. Second, we need to consider more ad-vanced optimizations like interprocedural code motion andinterprocedural strength reduction to improve the perfor-mance of compiler generated code.
8 Related Work
Our work on providing high-level support for data inten-sive computing can be considered as developing an out-of-core Java compiler. Compiler optimizations for improvingI/O accesses have been considered by several projects. ThePASSION project at Northwestern University has consid-ered several di�erent optimizations for improving locality inout-of-core applications [3, 12]. Some of these optimizationshave also been implemented as part of the Fortran D com-pilation system's support for out-of-core applications [17].Mowry et al. have shown how a compiler can generateprefetching hints for improving the performance of a vir-tual memory system [16]. These projects have concentratedon relatively simple stencil computations written in Fortran.Besides the use of an object-oriented language, our work issigni�cantly di�erent in the class of applications we focuson. Our techniques for loop execution are particularly tar-geted towards reduction operations, whereas previous workhas concentrated on stencil computations. Our slicing basedinformation extraction for the run-time system allows usto handle applications which require complex data distri-butions across processors and disks and for which only alimited information about access patterns may be known atcompile-time.
Many researchers have developed aggressive optimization
techniques for Java, targeted at parallel and scienti�c com-putations. javar and javab are compilation systems target-ing parallel computing using Java [1]. Data-parallel exten-sions to Java have been considered by at least two otherprojects: Titanium [20] and HP Java [4]. Our e�ort is alsounique in considering persistent storage, complex distribu-tions of data on processors and disks, and the use of a so-phisticated run-time system for optimizing resources.
Several run-time support libraries and �le systems havebeen developed to support e�cient I/O in a parallel envi-ronment [7, 8, 13, 19]. They also usually provide a collec-tive I/O interface, in which all processing nodes cooperateto make a single large I/O request. Our work is di�erent intwo important ways. First, we are supporting a much higherlevel of programming by involving a compiler. Second, ourtarget run-time system, ADR also di�ers from these systemsin several ways. The computation is an integral part of theADR framework. With the collective I/O interfaces pro-vided by many parallel I/O systems, data processing usuallycannot begin until the entire collective I/O operation com-pletes. Also, data placement algorithms optimized for rangequeries are also integrated as part of the ADR framework.
9 Conclusions
In this paper we have addressed the problem of expressingdata intensive computations in a high-level language andthen compiling such codes to e�ciently manage data re-trieval and processing on a parallel machine. We have de-veloped data-parallel extensions to Java for expressing thisimportant class of applications. Using our extensions, theprogrammers can specify the computations assuming thatthere is a single processor and at memory.
Conceptually, our compiler design has two major newideas. First, we have shown how loop �ssion followed byinterprocedural program slicing can be used for extractingimportant information from general object-oriented data-parallel loops. This technique can be used by other com-pilers that use a run-time system to optimize for locality orcommunication. Second, we have shown how the compilerand run-time system can use such information to e�cientlyexecute data intensive reduction computations. This tech-nique for processing such loops is independent of the sourcelanguage.
These techniques have been implemented in a prototypecompiler built using the Titanium front-end. We have usedthree templates, from the areas of digital microscopy andscienti�c simulations, for evaluating the performance of thiscompiler. We have compared the performance of compilergenerated code with the performance of codes developed bycustomization the run-time system ADR manually. Our ex-periments have shown that the performance of compiler gen-erated codes is, on the average 21% slower than the handcoded ones, and in all cases within a factor of 2. We believethat these results establish that our approach can be verye�ective.
Acknowledgments
We are grateful to Chialin Chang, Anurag Acharya, TahsinKurc, Alan Sussman and other members of the ADR teamfor developing the run-time system, developing hand cus-tomized versions of applications, helping us with the exper-iments, and for many fruitful discussions we had with themduring the course of this work.

References
[1] A. Bik, J. Villacis, and D. Gannon. javar: A prototype Javarestructing compiler. Concurrency Practice and Experience,9(11):1181{91, November 1997.
[2] Francois Bodin, Peter Beckman, Dennis Gannon, SrinivasNarayana, and Shelby X. Yang. Distributed pC++: Basicideas for an object parallel language. Scienti�c Program-ming, 2(3), Fall 1993.
[3] R. Bordawekar, A. Choudhary, K. Kennedy, C. Koelbel, andM. Paleczny. A model and compilation strategy for out-of-core data parallel programs. In Proceedings of the Fifth ACMSIGPLAN Symposium on Principles & Practice of ParallelProgramming (PPOPP), pages 1{10. ACM Press, July 1995.ACM SIGPLAN Notices, Vol. 30, No. 8.
[4] Bryan Carpenter,Guansong Zhan, Geo�rey Fox, Yuhong Wen, and Xinyng Li.HPJava: Data-parallel extensions to Java. Available fromhttp://www.npac.syr.edu/projects/pcrc/July97/doc.html,December 1997.
[5] Chialin Chang, Renato Ferreira, Alan Sussman, and JoelSaltz. Infrastructure for building parallel database systemsfor multi-dimensional data. In Proceedings of the SecondMerged IPPS/SPDP (13th International Parallel ProcessingSymposium & 10th Symposium on Parallel and DistributedProcessing). IEEE Computer Society Press, April 1999.
[6] A.A. Chien and W.J. Dally. Concurrent aggregates (CA). InProceedings of the Second ACM SIGPLAN Symposium onPrinciples & Practice of Parallel Programming (PPOPP),pages 187{196. ACM Press, March 1990.
[7] Peter F. Corbett and Dror G. Feitelson. The Vesta paral-lel �le system. ACM Transactions on Computer Systems,14(3):225{264, August 1996.
[8] P. E. Crandall, R. A. Aydt, A. C. Chien, and D. A. Reed. In-put/Output characteristics of Scalable Parallel Applications.In Proceedings Supercomputing '95, December 1995.
[9] R. Ferreira, B. Moon, J. Humphries, A. Sussman, J. Saltz,R. Miller, and A. Demarzo. The Virtual Microscope. In Pro-ceedings of the 1997 AMIA Annual Fall Symposium, pages449{453. American Medical Informatics Association, Hanleyand Belfus, Inc., October 1997. Also available as Universityof Maryland Technical Report CS-TR-3777 and UMIACS-TR-97-35.
[10] High Performance Fortran Forum. Hpf language speci�ca-tion, version 2.0. Available fromhttp://www.crpc.rice.edu/HPFF/versions/hpf2/�les/hpf-v20.ps.gz, January 1997.
[11] Seema Hiranandani, Ken Kennedy, and Chau-Wen Tseng.Compiling Fortran D for MIMD distributed-memory ma-chines. Communications of the ACM, 35(8):66{80, August1992.
[12] M. Kandemir, J. Ramanujam, and A. Choudhary. Improvingthe performance of out-of-core computations. In Proceedingsof International Conference on Parallel Processing, August1997.
[13] David Kotz. Disk-directed I/O for MIMD multiprocessors.In Proceedings of the 1994 Symposium on Operating Sys-tems Design and Implementation, pages 61{74. ACM Press,November 1994.
[14] Tahsin M. Kurc, Alan Sussman, and Joel Saltz. Couplingmultiple simulations via a high performance customizabledatabase system. In Proceedings of the Ninth SIAM Confer-ence on Parallel Processing for Scienti�c Computing. SIAM,March 1999.
[15] S. P. Midki�, J. E. Moreira, and M. Snir. Optimizing boundschecking in Java programs. IBM Systems Journal, August1998.
[16] Todd C. Mowry, Angela K. Demke, and Orran Krieger. Au-tomatic compiler-inserted i/o prefetching for out-of-core ap-plications. In Proceedings of the Second Symposium on Op-erating Systems Design and plementation (OSDI '96), Nov1996.
[17] M. Paleczny, K. Kennedy, and C. Koelbel. Compiler supportfor out-of-core arrays on parallel machines. In Proceedings ofthe Fifth Symposium on the Frontiers of Massively ParallelComputation, pages 110{118. IEEE Computer Society Press,February 1995.
[18] T. Reps, S. Horwitz, M. Sagiv, and G. Rosay. Speeding upslicing. In Proceedings of the Conference on Foundations ofSoftware Engineering, 1994.
[19] R. Thakur, A. Choudhary, R. Bordawekar, S. More, andS. Kutipudi. Passion: Optimized I/O for parallel applica-tions. IEEE Computer, 29(6):70{78, June 1996.
[20] K. Yelick, L. Semenzato, G. Pike, C. Miyamoto, B. Li-bit, A. Krishnamurthy, P. Hil�nger, S. Graham, D. Gay,P. Colella, and A. Aiken. Titanium: A high-performanceJava dialect. Concurrency Practice and Experience, 9(11),November 1998.




















