
Combining case-based reasoning with tabu search for personnel rostering problems
21
School of Computer Science and Information Technology University of Nottingham Jubilee Campus NOTTINGHAM NG8 1BB, UK Computer Science Technical Report No. NOTTCS-TR-2004-5 Combining case-based reasoning with tabu search for personnel rostering problems Gareth R Beddoe and Sanja Petrovic First released: January 2004 © Copyright 2004 Gareth R Beddoe and Sanja Petrovic In an attempt to ensure good-quality printouts of our technical reports, from the supplied PDF files, we process to PDF using Acrobat Distiller. We encourage our authors to use outline fonts coupled with embedding of the used subset of all fonts (in either Truetype or Type 1 formats) except for the standard Acrobat typeface families of Times, Helvetica (Arial), Courier and Symbol. In the case of papers prepared using TEX or LATEX we endeavour to use subsetted Type 1 fonts, supplied by Y&Y Inc., for the Computer Modern, Lucida Bright and Mathtime families, rather than the public-domain Computer Modern bitmapped fonts. Note that the Y&Y font subsets are embedded under a site license issued by Y&Y Inc. For further details of site licensing and purchase of these fonts visit http://www.yandy.com
-
Upload
independent -
Category
Documents
-
view
3 -
download
0
Transcript of Combining case-based reasoning with tabu search for personnel rostering problems

School of Computer Science and Information TechnologyUniversity of Nottingham
Jubilee CampusNOTTINGHAM NG8 1BB, UK
Computer Science Technical Report No. NOTTCS-TR-2004-5
Combining case-based reasoning with tabu search for personnel rostering problems
Gareth R Beddoe and Sanja Petrovic
First released: January 2004
© Copyright 2004 Gareth R Beddoe and Sanja Petrovic
In an attempt to ensure good-quality printouts of our technical reports, from the supplied PDF files, we
process to PDF using Acrobat Distiller. We encourage our authors to use outline fonts coupled with
embedding of the used subset of all fonts (in either Truetype or Type 1 formats) except for the standard
Acrobat typeface families of Times, Helvetica (Arial), Courier and Symbol. In the case of papers prepared
using TEX or LATEX we endeavour to use subsetted Type 1 fonts, supplied by Y&Y Inc., for the
Computer Modern, Lucida Bright and Mathtime families, rather than the public-domain Computer Modern
bitmapped fonts. Note that the Y&Y font subsets are embedded under a site license issued by Y&Y Inc.
For further details of site licensing and purchase of these fonts visit http://www.yandy.com

Combining case-based reasoning with tabu search forpersonnel rostering problems
Gareth Beddoe and Sanja Petrovic
Automated Scheduling, Optimisation, and Planning Research Group,School of Computer Science and Information Technology, University of Nottingham,
Jubilee Campus, Nottingham NG8 1BB, United Kingdom{ grb | sxp }@cs.nott.ac.uk
Abstract. In this paper we investigate the advantages of using Case-Based Reasoning(CBR) to solve personnel rostering problems. Constraints for personnel rostering prob-lems are commonly categorised as either ‘hard’ or ‘soft’. Hard constraints are those whichmust be satisfied and a roster which violates none of these constraints is considered to be‘feasible’. Soft constraints are more flexible and are often used to measure roster quality interms of staff satisfaction. We introduce a method for repairing hard constraint violationsusing CBR. CBR is an artificial intelligence paradigm whereby new problems are solvedby considering the solutions to previous similar problems. We store a history of hard con-straint violations and their corresponding repairs, which is captured from human rosteringexperts, and use this to solve similar violations in new rosters. The soft constraints arenot defined explicitly. Their treatment is captured implicitly during the repair of hardconstraint violations. The knowledge in the case-base is combined with tabu search con-cepts in a hybrid meta-heuristic algorithm. Experiments on real world data from a UKhospital are presented. The results show that CBR can guide a meta-heuristic algorithmtowards feasible solutions with high staff satisfaction, without the need to explicitly definesoft constraint objectives.
1 Introduction
Personnel rostering problems are often highly constrained and difficult to solve manually [13].Legal, management, and staff requirements are often conflicting and must be taken into accountwhen making rostering decisions. For example, management requirements for the cover and skillmix needed for a particular task may conflict with the maximum working hours allowed (by lawand contract) as well as with individual staff preferences. Nevertheless, rostering experts developstrategies for balancing these conflicts and are able to solve most problems to their satisfaction.This paper describes an approach to automated rostering that draws on experience learned fromhuman rostering experts.
A number of different operational research approaches have been explored for solving em-ployee rostering problems. Bailey [3], Bailey and Field [4], Beaumont [6], Miller et.al. [26], andWarner [29] use mathematical programming techniques to generate nurse rosters (mostly) opti-mised with respect to measures such as staffing costs (e.g. salaries), under-staffing costs, and shiftpattern penalties (for less desirable shift patterns). Constructive algorithms have been devel-oped to address particular rostering requirements (e.g. Burns and Carter [12]). Multi-objectiveapproaches based on goal programming have been investigated by Berrada et. al. [7] and Arthurand Ravindran [2] for scheduling nurses’ on/off shift patterns by modeling the soft constraints asgoals to be reached. More recently, constraint satisfaction techniques have been used by Abden-nadher and Schlenker [1], Cheng et. al. [13], and Meyer auf’m Hofe [19] to provide a more naturalway of expressing complex constraint information. The recognition that most real life rosteringproblems are NP-hard [5] has lead researchers to explore meta-heuristic approaches. Duenas et.

al. [16] describe a genetic algorithm for a multi-objective nurse rostering model incorporatingindividual nurse preferences and an emphasis on the role of the decision maker. Bailey et. al.[5] use simulated annealing and genetic algorithms to solve a nurse rostering problem involvingnurses of different types. A hyper-heuristic approach has been developed by Burke et.al. [9] thatiteratively chooses low-level heuristics according to their on-going performance.
Tabu search is an enhancement of the basic local search concept that employs memory toavoid getting trapped in local optima [20]. The memory contains a list of recent moves withinthe search space (e.g. swapping the assignments of two nurses) that may not be performed againfor a set number of iterations. This concept of tabu moves gives the potential for short termdegradation of solution quality allowing algorithms to explore new areas of the search space.Dowsland [15] has developed a nurse rostering method based on tabu search which strategicallychooses neighbourhoods depending on the current characteristics of the search. Roster quality isdetermined by the satisfaction of coverage constraints and shift pattern penalties which are basedon notions of pattern quality and individual nurse preference. A hybrid tabu search approachwas developed by Burke et. al. [8] for highly constrained real life rostering problems. A modularevaluation function is used to determine roster quality based on a large variety of optionalconstraint types.
The quantity and representation of domain knowledge in different automated problem solv-ing techniques varies considerably. For example, in mathematical programming models thisknowledge is almost entirely stored in the form of constraints and the objective function. Theknowledge is rigidly embedded within the problem solving structure making the methods inflex-ible. Classical meta-heuristic methods incorporate domain knowledge in a more relaxed fashion,through the definition of neighbourhood structures that help the search explore promising re-gions of the solution space. These neighbourhoods can be defined as natural alterations to asolution similar to those employed by a human problem solver. Nevertheless, this knowledgemust still be hard-coded into the algorithm making it more difficult to adapt to new problemsand new circumstances. The knowledge capturing technique described in this paper providesa means by which neighbourhoods can be tailored dynamically to address specific constraintviolations in individual problems, based on human rostering experience.
Case-Based Reasoning (CBR) [18] is an artificial intelligence methodology that imitateshuman decision making by solving new problems using knowledge about the solutions to similarproblems. CBR methodology operates under the premise that similar problems will requiresimilar solutions. Previous problems and solutions are stored in a case-base and accessed duringreasoning by processes of identification, retrieval, adaptation, and storage. The identificationand retrieval phases search the case-base for cases containing problems that are most similarto the current problem in terms of a set of characteristic indices. The solutions from retrievedcases must be adapted to the context of the current problem. If a new solution might be usefulfor solving problems in the future then it is stored as a new case in the case-base.
CBR has been used for various scheduling problems. Scott and Simpson [28] combined case-based reasoning and constraint logic programming by storing shift patterns used for the con-struction of nurse rosters. CBR has been successfully applied to machine scheduling problems byMiyashita et.al. [21–24] to repair and improve schedules in a dynamic environment. Schmidt [27]used CBR to store machine scheduling problems and solution techniques according to a com-plex classification system. Burke et.al. [10] solved university course timetabling problems using acase-base of previous partial solutions. In another approach, Burke et.al. [11] developed a CBRsystem to choose appropriate heuristics for solving both course and examination timetablingproblems. Cunningham and Smyth [14] employed CBR to quickly build good quality solutionsto the traveling salesman problem and a single machine scheduling problem.
In this paper we present a novel CBR approach to the rostering problem which capturesthe rostering knowledge of human experts by storing a history of constraint violations and theircorresponding repairs. This is an extension of a previous investigation of this concept by the
2

authors in [25]. The rostering problem is presented as a type of constraint satisfaction problemwhereby a roster is defined as feasible if it does not violate any constraints. The constraintviolation that is most similar to the one that has to be repaired is retrieved from the case-baseand must then be adapted to the context of the current roster. Various meta-heuristic approacheshave been developed for nurse rostering with some success. Our aim is to investigate possiblehybridisations of CBR and meta-heuristic concepts, especially tabu search. All of the algorithmspresented here attempt to find feasible rosters by direct repair of individual constraint violations.
The research work described in this paper was guided by the real world nurse rosteringproblem in the Ophthalmological Ward at the Queen’s Medical Centre University HospitalTrust (QMC) Nottingham, United Kingdom. All cases that are stored in the case-base areacquired during the course of actual scheduling/rescheduling actions of the head nurse of theward. The paper is organised as follows. In Section 2 the rostering problem at the QMC isformulated. Section 3 gives an overview of the case-based reasoning framework. The hybridconstraint satisfaction algorithms are described in Section 4 incorporating case-based repairgeneration and tabu list concepts. In Section 5 the performance of these algorithms is comparedusing a number of problem instances from the QMC. A discussion of the benefits of the methodsproposed is given in Section 6.
2 Problem Formulation
We define the nurse rostering problem as the ordered pair:
R = 〈N,C〉, (1)
where N = {nursei : 0 ≤ i < n} is the set of n nurses to be rostered and C is a set of constraints.Nurses in the QMC ward have one of four possible qualification levels. These are, in de-
scending order of seniority: registered (RN), enrolled (EN), auxiliary (AN), and student (SN).Registered nurses are the most qualified and have had extensive practical and managementtraining whereas enrolled nurses are mainly trained in the practical aspects of nursing. Auxil-iary nurses are unqualified nurses who can perform basic duties and student nurses are currentlytraining to be either registered or enrolled nurses. These real nurse types are grouped here usingthree additional qualification types. The classification XN denotes a nurse of any type. RNs,ENs, and ANs can be classified as ‘employed’ (PN), while RNs and ENs are ‘qualified’ (QN). Inaddition to these basic qualifications, nurses can also receive ward-specific training (in this caseeye training - denoted by ET) and a grade, ranging from A to I, is determined by a combinationof qualification, specialty training, and the amount of practical experience they have. The gender(male (M) or female (F)) and international status (international(I) or home (H)) of nurses isalso taken into account when making rostering decisions.
A nurse is denoted by the 4-tuple:
nursei = 〈NurseTypei, hoursi, NRi, NPi〉 (0 ≤ i < n), (2)
where NurseTypei = {fi,1 . . . fi,5} is an array of descriptive features whose first element
fi,1 ∈ {RN,EN,AN,SN,QN,PN,XN} (3)
is the nurse’s qualification. The QN, PN, and XN qualifications are included because theNurseType array is also used to describe general skill requirements within constraints andviolations (e.g. to describe the need for a qualified nurse to cover a particular shift which couldbe filled by either a registered or an enrolled nurse). The remaining elements, fi,2 . . . fi,5, de-scribe the gender, international status, specialty training, and grade of the nurse. The numberof hours that nursei is contracted to work in a week (normally 37.5) is denoted by hoursi ∈ R
+.
3

The set of assignment variables,
NRi = {si,j : 0 ≤ j < period} (0 ≤ i < n), (4)
represents the shift assignments for nursei on day j over the number of days for which the rosterhas been constructed, denoted by period.
The set of preference assignments,
NPi = {pi,j : 0 ≤ j < period} (0 ≤ i < n), (5)
represents the preferred shift assignments of nursei over the rostering period. Preferred as-signments are established by a process of pre-rostering consultation and are used as the initialinstantiation of the shift assignment variables (i.e. initially NRi = PRi ∀i). The variables si,j
and pi,j can take values from the set {UNASSIGNED, EARLY, LATE, NIGHT, OFF}.The set C consists of a number of constraints of the following types:
Cover constraints define the skill mixes required for different shifts. A minimum number ofnurses of a particular feature set (represented by the NurseType variable) must be assignedto particular shifts. For example, the early shift requires 4 qualified nurses;
MaxDaysOn constraints limit the number of days that nurses may work in a row. For theQMC ward this is generally 5 for all nurses;
MinDaysOn constraints define the minimum number of days that nurses may work succes-sively;
Succession constraints define illegal shift combinations for nurses. A NIGHT shift followedby an EARLY shift is one such illegal combination;
Totals constraints define the maximum number of hours a nurse may work over a set timeperiod. For example, no nurse may work more than 75 hours in a fortnight.
In the literature ‘constraints’ are often divided into two categories. ‘Hard’ constraints arethose which must not be violated and are used to define roster feasibility. In our model the con-straints that are defined explicitly in the set C are hard constraints. ‘Soft’ constraints however,are flexible constraints which do not have to be satisfied. They are often used to describe rosterquality by adding a penalty to an objective function proportional to the degree of their viola-tion. In this paper we do not define soft constraints explicitly - their treatment will be capturedimplicitly by the cases in the case-base. For the remainder of this paper the word ‘constraints’refers to those hard constraints in the set C.
When constraints are applied to the set of nurses N , they generate a set of violations, eachviolation having a type determined by the corresponding constraint type. We define the probleminstance spaces PR
v and PRr as the set of constraint violations in R and the possible repairs to
the current roster R, respectively. An element violationα ∈ PRv describes the type of violation
and the parameters relevant to it. Violations are denoted as follows:
CoverViolation(NurseType, day, shift): There are insufficient nurses of feature set NurseTypeassigned to shift on day;
MaxDaysOnViolation(nursei, startDay, numDays): nursei is working too many shifts in arow starting on startDay for numDays days;
MinDaysOnViolation(nursei, startDay, numDays): nursei is working too few shifts in arow starting on startDay for numDays days;
SuccessionViolation(nursei, day): nursei has an illegal shift combination on days day andday + 1;
TotalsViolation(nursei, startDay, endDay): nursei is working too many hours between daysstartDay and endDay.
4

Fig. 1. A graphical presentation of the repair generation technique.
An element repairβ ∈ PRr describes the type of repair and the nurses, days, and shift assign-
ments involved. They can be one of the following types:
Reassign(nursei, day, shift): Assign shift to nursei on day;Swap(nursei, nursej , day): Interchange the shift assignments of nursei and nursej on day;Switch(nursei, day1, day2): Interchange the shift assignments of nursei between days day1
and day2.
The sets PRv and PR
r represent information relevant to a specific instance, R, of a rosteringproblem. The nurses, days, and shifts they describe refer directly to those within a particularroster. In order to store and reuse examples of previous violation/repair experiences we needto define a generalised structure - one that is independent of any individual rostering probleminstance. We define the case-base CB as a set of previously encountered violations and theircorresponding repairs. Figure 1 gives a graphical representation of the CBR repair generationtechnique described in Section 3. Here we will emphasise the difference between variables thatpertain to the current rostering problem and those variables which represent historical informa-tion stored in the case-base.
The case-base CB = Wv × Wr where Wv and Wr are the spaces of stored violations (theproblem history) and repairs (the solution history) respectively. Therefore a case cγ = (vγ , rγ) ∈CB where γ ∈ Γ . We define vγ and rγ as follows:
vγ = 〈V iolationTypeγ , V iolationIndicesγ〉 ; (6)
rγ = 〈RepairTypeγ , RepairIndicesγ〉 . (7)
5

Here V iolationTypeγ and RepairTypeγ contain the type and necessary parameters describ-ing violations and repairs, respectively. These are stored in their generalised forms so that theyare independent of any individual problem instance. V iolationIndicesγ and RepairIndicesγ
store the feature information needed to identify similar problem instances during case retrieval,and to generate repairs during case adaptation. The index sets are arrays of statistical featurevalues. They are the characteristics of the problem identified as having an influence on the de-cision making process. The violation indices depend on the specific type of the violation andinclude measures of roster infeasibility, nurse utilisation and satisfaction, shift pattern statistics,and shift coverage. The repair indices are statistical information about the parameters of therepair - the cover of shifts before and after the repair and the utilisation and satisfaction of thenurses involved. For a detailed description of the violation and repair indices see [25].
A generalisation of a violation in a given roster, R, is a mapping from the set of violations inthe roster, PR
v , to the set of violations, Wv, stored in the case-base. Similarly, a generalisationof a repair is a mapping from the set PR
r of possible repairs of a given roster, R, to the setof repairs, Wr, in the case-base. Violations and repairs are generalised by removing all of theirinstance-specific information and keeping only the general ‘type’ information. For example, a‘succession’ violation where nurse10 = 〈NurseType10, 37.5, NR10, NP10〉 has been assigned anight shift on day 12 followed by an early shift on day 13 is described using our notation asSUCCESSION(nurse10, 12). To store this violation in the case-base it is generalised to theform succession(NurseType,NIGHT,EARLY ) which describes the type of nurse involved inthe violation (where NurseType := NurseType10) and the illegal combination of shift assign-ments. The process of generalisation also includes calculating statistical characteristics storedas violation or repair indices.
3 Case-based Repair Generation
The method described in this section generates repairs of constraint violations within a rosterusing the generalised experience stored in the case-base. Key to the success of this method is thenotion of problem similarity. The method must first find the most similar problems in the case-base to the current problem (i.e. the violation within the current roster). Having identified themost similar violations the corresponding repairs must be adapted to the context of the currentroster. Using the notion of solution similarity and a set of simple rules, repairs are generated thatare as similar to the retrieved solution as possible given the current set of nurses and their shiftassignments. Following are the descriptions of the retrieval process, whereby similar violationsare identified, and the adaptation process for generating repairs.
The retrieval process is split into two distinct searches of the case-base. The first search filtersthe case-base to obtain cases containing violations that match the current problem in terms ofviolation type and parameters. The second search ranks the restricted set of cases using thesimilarity function Sim defined as follows.
Given generalised violations,
va = 〈V iolationTypea, V iolationIndicesa〉, and (8)
vb = 〈V iolationTypeb, V iolationIndicesb〉, (9)
Sim(IndexSeta, IndexSetb) =
(1I
I∑i=1
wi × dist(indexai, indexbi
)
)−1
, (10)
6

where IndexSeta, IndexSetb are the violation index sets V iolationIndicesa and V iolationIndicesb
respectively, I is the number of elements in the index sets, wi are the index weights, and
dist(indexai, indexbi
) =∣∣∣∣ indexbi
− indexai
indexmaxi− indexmini
∣∣∣∣, (11)
where indexmaxiand indexmini
are the maximum and minimum values of index i over the wholecase-base.
This function assigns higher values to more similar cases. Identical cases are deemed to beinfinitely similar and for computational reasons they are assigned the largest number that canbe stored in a C++ double type.
Hence, given a problem violationα, the retrieval algorithm consists of these steps:
1. Generalise violationα to get vα = 〈V iolationTypeα, V iolationIndicesα〉 by generalising theviolation parameters and calculating the violation indices with respect to the current roster;
2. Choose cases caseγ = (vγ , rγ) ∈ CB such that:
V iolationTypeα = V iolationTypeγ ; (12)
3. Rank these cases according to Sim(V iolationIndicesα, V iolationIndicesγ) .
This sorted set of cases is then passed to the adaptation process which is also separated intotwo phases. Initially, the method generates a set of candidate repairs of the same type as therepair in the retrieved case, using the data from the current roster. The second phase involvesranking these candidate repairs according to their similarity to the repair in the retrieved case.Here the set of repair indices from the retrieved case is compared with the indices of the candidaterepairs using the Sim function (Equation 10 with the repair index sets used for IndexSeta andIndexSetb).
The adaptation algorithm can be summarised as follows:
1. Consider the top ranking case case0 = (v0, r0), where r0 = 〈RepairType0, RepairIndices0〉;2. Generate a set of repairs of type RepairType0 using all possible relevant combinations of
nurses and shifts from the roster. If no repairs can be generated then remove the top caseand goto step 1;
3. Generalise the repairs in the set by calculating the RepairIndicesβ for each repairβ ;4. Rank the repairs according to Sim(RepairIndicesβ , RepairIndices0) .
To illustrate both these processes we shall describe a simple example (see the Appendixfor additional details). Consider the roster in Table 1 where E = EARLY, L = LATE, andU = UNASSIGNED. Here nurse0 and nurse1 are registered, female, non-international, eye-trained, E-grade nurses and nurse2 is an enrolled, female, non-international, eye-trained, D-grade nurse. Hence, NurseType0 = NurseType1 = {RN,F,H,ET,E} and NurseType2 ={EN,F,H,ET,D}.
0 1 2 3 4 5 6
nurse0 E U U U L E E
nurse1 L L L U U L U
nurse2 U E E L E U L
Table 1. A simple example of a nurse roster
7

A single constraint is applied to the roster, requiring that a minimum of 1 qualified nurse isassigned to every early shift. It can be seen that on day 3 there is no nurse assigned to the earlyshift. Therefore the violation that needs to be repaired is
violationα = COV ER({QN, ∗, ∗, ∗, ∗}, 3, EARLY ), (13)
where ‘*’ in the feature set indicates that a feature can take any value. The violation is passedto the retrieval process where all the examples of cover violations involving qualified nurses areidentified in the case-base. The retrieval process first converts the violation into its generalisedform:
V iolationTypeα = cover({QN, ∗, ∗, ∗, ∗}, EARLY ), (14)
and then calculates the values of the violation indices. The case-base is searched for casescontaining violations that match V iolationTypeα. Suppose, for this example, that three suchcases are found. These cases are ranked according to the similarity measure (Equation 10), asshown in the Appendix, and the case with the highest similarity is retrieved from the case-base,case0 = (v0, r0), where
v0 = 〈cover({QN, ∗, ∗, ∗, ∗}, EARLY ), {1, 92.3, 89.2, 78.3, 1, 93, 82.3, 78.1}〉 , and (15)
r0 = 〈reassign({RN,F,H,ET,E}, UNASSIGNED,EARLY ), {0, 0, 3, 2, 85.0, 0}〉 . (16)
The repair information stored in case0 must now be adapted to create a repair of the currentviolation. In this example case0 contains a (generalised) repair of type reassign that uses anurse with NurseType = {RN,F,H,ET,E} who was originally assigned an UNASSIGNEDshift on the day of the repair. The adaptation process generates a set of reassign repairs usingnurses with the correct feature set and who are currently assigned UNASSIGNED on day 3. Inour roster (Table 1) we have two nurses with such characteristics and therefore two repairs aregenerated:
repaira = REASSIGN(nurse0, 3, EARLY ); (17)
repairb = REASSIGN(nurse1, 3, EARLY ). (18)
We generalise these repairs by calculating index sets and compare them to the repair fromcase0, as shown in the Appendix. Therefore the first repair, REASSIGN(nurse0, 3, EARLY ),is returned as a solution. The case containing the constraint violation and the applied repair isthen added to the case-base by generalising both the violation and repair, thus increasing thecase-base’s experience.
4 Hybridisation of CBR and Tabu Search Concepts
Meta-heuristic approaches to rostering problems search through the solution space by iterativelyselecting solutions and exploring their neighbourhoods. The neighbourhood is defined by gener-ating a number of new solutions around the selected one. An objective function is used to choosewhich solution in the neighbourhood to move to next. The traditional tabu search approach isa meta-heuristic which keeps a memory of recently visited solutions which may not be revisitedwithin a certain time period (or tenure). This diversifying feature helps the search to avoid localoptima by forcing it to explore new areas of the search space.
In this section we will describe seven different meta-heuristic algorithms. These algorithmswill not define the neighbourhood around a solution in the same way as ‘classical’ meta-heuristics.Instead of applying an operator to an entire solution, these algorithms will choose a violation
8

within a solution and attempt to repair it. The goal of the search is to find a feasible solution,or at least to minimise the number of constraint violations in the roster. In addition, the nurses’shift preferences should be satisfied wherever possible. The hard constraints defined within theset C are used to define roster feasibility and the nurse preference information, which is usuallymodeled as one or more soft constraints, is used as a measure of roster quality. The differencewith these algorithms is that we do not represent levels of nurse satisfaction quantitativelyduring the search, or indeed when generating repairs.
A number of different mechanisms are available that can help such a local search algorithmfind good quality, feasible solutions. The seven algorithms described here are composed of dif-ferent combinations of these mechanisms. The mechanisms are:
Case-based repair generation: Repairs for constraint violations are generated using the ex-pert knowledge in the case-base. In particular, whilst addressing the hard constraint viola-tions, these repairs also imitate the expert’s handling of the nurses’ shift preferences.
Tabu Lists: Repairs are not repeated within a certain number of iterations by placing themon a tabu list of forbidden repairs. This reduces the chance that the search will get trappedin a ‘loop’ of repeating violations and repairs;
Objective function: The search is guided by an objective function which counts the numberof violated constraints in the roster and must be minimised. Repairs are chosen based ontheir ability to reduce the total number of violations in the roster.
The motivation for defining these algorithms is to determine what effect each mechanism hason search quality. We shall use them to show that knowledge from a case-base can be successfullycombined with traditional meta-heuristic search concepts thus reducing the knowledge acquisi-tion overhead required to model problem domains. All of the algorithms search for new solutionsby iteratively repairing constraint violations. In each instance the initial roster consists solely ofthe nurses’ individual shift preferences. This roster violates a large number of constraints and thegoal of the algorithms presented here is to repair all of these violations. It must be emphasisedthat the algorithms without an objective function have no explicit representation of this goal.In these algorithms the burden is placed on the mechanism which generates the repairs to guidethe search in the ‘correct’ direction.
The seven algorithms are described below. The first three algorithms generate repairs ran-domly and utilise the tabu lists (RRG-TL), the objective function (RRG-OBJ), and both mech-anisms combined (RRG-OBJ-TL). The last four methods use the case-base retrieval and adapta-tion methods described in the previous section to generate repairs - the ‘pure’ case-based repairgeneration (CBRG), with the tabu lists (CBRG-TL), with the objective function (CBRG-OBJ),and the final algorithm (CBRG-OBJ-TL) uses all three mechanisms. All of the algorithms arebased on the following iterative repair structure:
1. While (true) Do2. Generate PR
v by applying the constraints in C to N
3. If |PRv | = 0 Then exit
4. Pick random element violationα ∈ PRv
5. Perform repair generation for violationα and apply repair to N
6. Repeat
Each algorithm described in the remainder of this section implements a different version ofStep 5. Steps 2 and 3 generate the set of constraint violations in the roster at each iteration andStep 4 chooses a violation to be repaired. After a repair has been generated and applied to theroster the entire process is repeated.
9

4.1 Random Repair Generation with Tabu List (RRG-TL)
This algorithm uses no problem solving knowledge to generate repairs but uses the idea oftabu search proposed by Glover in [17]. A tabu list of repairs is used to help the algorithm toavoid local optima in the number of constraint violations and a tenure is specified which setsthe length of the list (and therefore the number of iterations for which a stored repair will beconsidered ‘tabu’). This tenure must be enforced whenever a repair is added to the tabu list byremoving the oldest repair. Some help is given to the algorithm by ensuring that the parametersof the violations, including the nurses, days, and shifts involved, are also included as parametersof the repairs. Otherwise the choice of repair type (Reassign, Swap, or Switch) and the otherparameters involved is entirely random. No evaluation of the quality of repairs or the degree ofviolation of the roster is used when deciding on repairs.
Given roster R = 〈N,C〉 and tabu list T = ∅ with tenure t :
5.1. Randomly create repairβ ∈ PRr using the parameters of violationα as ap-
propriate5.2. If repairβ ∈ T Then goto 5.15.3. Apply repairβ to N5.4. Add repairβ to T and update T
4.2 Random Repair Generation with Objective Function (RRG-OBJ)
This algorithm generates a set of repairs for a given violation and chooses the repair that willcause the largest decrease (or smallest increase) in the number of constraint violations in theroster. The algorithm is a basic local search [20] and includes no mechanism for avoiding localoptima. The method for randomly generating the repairs is the same as used for RRG-TL. Givenroster R and repairβ , the objective function fR(repairβ) is defined:
fR(repairβ) = (|PRv | before applying repairβ) − (|PR
v | after applying repairβ) . (19)
Given roster R = 〈N,C〉 and objective function fR:
5.1. Randomly generate the set of all possible repairs from PRr using the param-
eters of violationα
5.2. Choose the element repairβ from the set of repairs with highest fR(repairβ)5.3. Apply repairβ to N
4.3 Random Repair Generation with Tabu List and Objective Function(RRG-OBJ-TL)
The tabu list and objective function mechanisms are combined in this algorithm. It is essen-tially a tabu search algorithm for the constraint satisfaction problem which operates on specificconstraint violations in the roster.
Given roster R = 〈N,C〉, objective function fR, and tabu list T = ∅ with tenure t :
5.1. Randomly generate the set of all possible repairs from PRr using the param-
eters of violationα
5.2. Choose the element repairβ from the set of repairs with highest fR(repairβ)5.3. If repairβ ∈ T Then remove repairβ from the set of repairs and goto 5.25.4. Apply repairβ to N5.5. Add repairβ to T and update T
10

4.4 Case-Based Repair Generation (CBRG)
Here the experience stored in the case-base is used to generate repairs. It is assumed, for theexperiments that follow, that the case-base has been well trained and contains sufficient examplesof a variety of different problem solving episodes. There is no objective function used to chooserepairs - the similarity to the retrieved repairs from the case-base drives the search. The mostsimilar repair from the most similar case is used at every iteration. There is no method fordiversification of the search in this algorithm. This algorithm is performing a ‘blind’ search forfeasibility relying on the quality of repairs stored in the case-base.
Given roster R = 〈N,C〉 :
5.1. Generate repairβ ∈ PRr using the case-based retrieval and adaptation meth-
ods5.2. Apply repairβ to N
4.5 Case-Based Repair Generation with Tabu List (CBRG-TL)
The RRG-TL algorithm described in Section 4.1 is not guided by any rostering knowledge as therepairs for each violation are randomly generated. CBRG guides the search using the knowledgein the case-base but is unable to cope when violations are repeatedly created - it will createthe same repair for the violation each time it is encountered. The diversification provided bythe tabu lists and the rostering knowledge stored in the case-base are combined in the CBRG-TL algorithm. The tabu lists can store either repairs, cases, or a combination of both. If thenearest case found in the case-base is currently on the tabu list then the next nearest case willbe retrieved. Similarly, if a repair generated is on the tabu list then the next nearest repairgenerated from the retrieved case is used.
Given roster R = 〈N,C〉 and tabu lists TRepair = ∅ and TCase = ∅ with tenures tr and tcrespectively:
5.1. Retrieve the most similar case case0 ∈ CB5.2. If case0 ∈ TCase Then discard case0 and goto 5.15.3. Generate repairβ ∈ PR
r from case0 such that repairβ /∈ TRepair5.4. Add case0 to TCase and repairβ to TRepair and update tabu lists5.5. Apply repairβ to N
4.6 Case-Based Repair Generation with Objective Function (CBRG-OBJ)
This algorithm combines the explicit representation of the search goal using the objective func-tion with the case-base repair generation method. Each repair generated is scored according toa combination of its similarity to the repair from the retrieved case and the reduction in thenumber of hard constraints it causes in the roster. Given the objective function fR (Equation19), candidate repair repairβ , retrieved repair r0 = 〈RepairType0, RepairIndices0〉, and rosterR, the function Score is defined
Score(repairβ) = a × Sim(RepairIndicesβ , RepairIndices0) + b × fR(repairβ), (20)
where RepairIndicesβ is the feature information generalised from repairβ (see Section 2). Thesummation weights a and b have been found through experimentation to work well when theyare equal - although this may not be the case for all problems.
Given roster R = 〈N,C〉 and score function weights a and b:
5.1. Retrieve the most similar case case0 = (v0, r0)5.2. Generate a set of repairs based on r0 from case0
5.3. Choose the repairβ with the highest value according to Score(repairβ)5.4. Apply repairβ to N
11

4.7 Case-Based Repair Generation with Tabu List and Objective Function(CBRG-OBJ-TL)
This final algorithm combines all of the mechanisms. It can be described as a tabu search forthe constraint satisfaction problem with neighbourhoods determined by the case-base repairgeneration method for each constraint violation (i.e. at each iteration).
Given roster R = 〈N,C〉 and tabu lists TRepair = ∅ and TCase = ∅ with tenures tr and tcrespectively:
5.1. Retrieve the most similar case case0 = (v0, r0)5.2. If case0 ∈ TCase Then discard case0 and goto 5.15.3. Generate a set of repairs based on r0 from case0
5.4. Choose the repairβ with the highest value according to Score(repairβ)5.5. If repairβ ∈ TRepair Then remove repairβ from the set of repairs and goto
5.45.6. Add case0 to TCase and repairβ to TRepair and update tabu lists5.7. Apply repairβ to N
5 Comparison of Algorithms
The algorithms were tested on real world data from the QMC using eleven different variants:
– Case-based repair generation (CBRG);– Case-based repair generation with tabu lists of cases with tenure 5 (CBRG-TL-C5), of repairs
with tenure 10 (CBRG-TL-R10), and with both tabu lists (CBRG-TL-C5R10);– Case-based repair generation with objective function (CBRG-OBJ);– Case-based repair generation with objective function and tabu lists of cases (CBRG-OBJ-
TL-C5), repairs (CBRG-OBJ-TL-R10), and both cases and repairs (CBRG-OBJ-TL-C5R10)– Random repair generation with tabu list of repairs with tenure 10 (RRG-TL-R10);– Random repair generation with objective function (RRG-OBJ);– Random repair generation with objective function and tabu list of repairs with tenure 10
(RRG-OBJ-TL-R10);
The tenures for the tabu lists were chosen during preliminary experimentation and theyshowed good performance over a number of problems. It was noticed that an increase in repairtenure causes little change in algorithm performance. However, case tenure is very sensitive andsetting this value too high can decrease the performance of the case-based repair generationsignificantly. Some of the cases in the case-base are used with higher frequency due to a higherthan average occurrence of the violation that they represent in the roster. Consequently, whencase tenure is increased it is more likely that the case retrieved from the case-base for a givenviolation is insufficiently similar, which could lead to the generation of an inappropriate repair.
A case-base was trained using 300 examples of violations and repairs derived from preferenceand final rosters acquired from the QMC. The types of violations represented in the case-basewere not evenly spread, with cover violations making up the majority of cases. This reflectsboth the proportion of violations found in the rosters and the variety of repairs used for coverviolations involving different types of nurses and shifts. The technique used to train the case-basewill not be described here in detail. An efficient and robust training method is the subject ofon-going research.
The algorithms were run on two test problems in which preference rosters from the fourweek periods in March and April 2001 were used as initial solutions. Each algorithm was run 10times on each problem with a maximum of 500 iterations. The solution with the least number
12

|P Rv | #Feas #Iterations Speed NSat (%)
MARCH 2001
CBRG 1.4 (1.07) 2 195.4 (24.25) 0.402 (0.05) 88.5 (0.90)
CBRG-TL-C5 0.0 (0.00) 10 205.5 (59.41) 0.410 (0.11) 87.2 (1.81)
CBRG-TL-R10 0.7 (0.67) 4 181.1 (26.44) 0.440 (0.06) 88.7 (1.00)
CBRG-TL-C5R10 0.2 (0.42) 8 189.0 (56.13) 0.442 (0.10) 88.5 (1.81)
CBRG-OBJ 0.3 (0.48) 7 119.4 (26.37) 0.681 (0.11) 90.3 (1.26)
CBRG-OBJ-TL-C5 0.2 (0.42) 8 117.7 (12.29) 0.676 (0.07) 90.4 (1.34)
CBRG-OBJ-TL-R10 0.1 (0.32) 9 110.4 (10.20) 0.720 (0.06) 90.1 (2.19)
CBRG-OBJ-TL-C5R10 0.1 (0.32) 9 117.6 (14.56) 0.680 (0.08) 90.3 (1.28)
RRG-TL-R10 43.2 (5.83) 0 435.4 (57.66) 0.084 (0.02) 61.2 (5.74)
RRG-OBJ 19.6 (0.84) 0 220.9 (70.99) 0.292 (0.08) 44.8 (1.90)
RRG-OBJ-TL-R10 20.0 (1.49) 0 218.6 (95.77) 0.315 (0.12) 46.4 (2.41)
APRIL 2001
CBRG 1.0 (0.94) 3 151.0 (19.38) 0.591 (0.07) 88.1 (1.74)
CBRG-TL-C5 0.3 (0.48) 7 153.7 (21.20) 0.587 (0.08) 87.6 (2.28)
CBRG-TL-R10 0.0 (0.00) 10 142.2 (11.07) 0.629 (0.05) 88.0 (1.57)
CBRG-TL-C5R10 0.0 (0.00) 10 156.2 (22.35) 0.581 (0.08) 87.3 (0.91)
CBRG-OBJ 0.1 (0.32) 9 114.5 (29.83) 0.812 (0.15) 88.7 (1.80)
CBRG-OBJ-TL-C5 0.1 (0.32) 9 106.1 (14.35) 0.850 (0.10) 90.6 (1.95)
CBRG-OBJ-TL-R10 0.0 (0.00) 10 104.5 (11.89) 0.861 (0.09) 90.7 (2.36)
CBRG-OBJ-TL-C5R10 0.1 (0.32) 9 105.7 (11.01) 0.850 (0.09) 90.4 (1.82)
RRG-TL-R10 37.9 (8.88) 0 436.0 (64.46) 0.118 (0.02) 59.2 (4.52)
RRG-OBJ 18.9 (0.88) 0 265.4 (114.94) 0.326 (0.17) 49.9 (2.10)
RRG-OBJ-TL-R10 19.5 (0.97) 0 314.4 (99.71) 0.244 (0.08) 48.1 (1.76)
Table 2. Algorithm Performance.
of constraint violations found in each run was kept and the results summarised in Table 2. Thefirst column of results shows the mean (and standard deviation in brackets) of the number ofconstraint violations in the solutions found over each of the 10 runs of each algorithm. A valueof 0 indicates that feasibility was found on every run. The total number of feasible solutionsfound by each algorithm (out of 10) is shown in the second column. The mean (and standarddeviation) of the number of iterations needed to get the solution and the speed (average numberof violations solved per iteration) are shown in the third and fourth columns. The final columncontains the percentage of nurse shift preferences satisfied.
It is clear from the results in Table 2 that all of the algorithms that employed case-basedrepair generation were able to find solutions with fewer constraint violations than those that usedrandomly generated repairs. Figure 2 compares the mean, minimum, and maximum number ofconstraint violations in the solutions found by each algorithm. The CBRG algorithms are alsoable to reach these better solutions much faster than their RRG counterparts. In fact, prolongingthe run times of the RRG algorithms did not help them find significantly better solutions.
The nurse preference satisfaction results shown in Figure 3 also show that the CBRG algo-rithms outperform their RRG counterparts. It should be emphasised that the RRG algorithmswere not given any information about nurse preference and so they are expected to performbadly. However, these experiments do show that repairs generated using the nurse preferenceinformation implicitly stored in the case-base are able to guide the search in the direction ofbetter solutions.
Tabu lists should help the algorithms to avoid local optima by reducing the occurrenceof repeating loops of repairs and violations. Indeed, the experiments show that the CBRG
13

Fig. 2. Mean, maximum, and minimum number of constraint violations
Fig. 3. Mean, maximum, and minimum nurse satisfaction
14

algorithms without tabu lists are more likely to get ‘stuck’ in such loops. The improvementsin the number of violations in the best solutions obtained by the CBRG algorithms with tabulists for both problems are statistically significant at the 0.01 confidence level1. However, theRRG results do not show this behaviour. In fact the RRG-OBJ-TL-R10 algorithm performsslightly worse than RRG-OBJ, though this difference is not significant. The lack of improvementis possibly due to the fact that the neighbourhoods defined by the random repair generationmethod are too large for such a small tabu tenure. The tabu lists are then unable to help movethe search away from local optima. The average progress of the CBRG, CBRG-TL-C5R10,RRG-OBJ, and RRG-OBJ-TL-R10 for the MARCH 2001 problem can be seen in Figure 4.
These experiments do not show clearly which type of tabu list works best for the CBRG algo-rithms. The TL-C5, TL-R10, and TL-C5R10 variants of the CBRG and CBRG-OBJ algorithmsshow similar improvements. It is almost certainly true that the choice of tabu list is dependenton the problem being solved and on the content of the case-base. We suggest that the combinedtabu list (TL-C5R10) would be the best option for most problems because it incorporates bothtypes of diversification.
Nurse preference satisfaction is not adversely affected by the use of tabu lists with theCBRG algorithms (see Figure 5). This issue should be approached with caution however. It isconceivable that keeping repairs and cases on tabu lists could increase the probability that newrepairs violate nurse preference. In particular, the use of tabu cases may force the case-baseto retrieve less similar cases and therefore generate less suitable repairs. This can be avoidedby including sufficient cases in the case-base and by keeping the tenure of the case tabu listrelatively low.
Both the CBRG and RRG algorithms were significantly improved by the use of an objectivefunction (at the 0.05 confidence level). However the improvement to the RRG algorithms byusing an objective function was not as great as that gained by using CBRG alone. For theCBRG algorithms, the objective function introduced a trade-off between repair similarity andrepair quality which guided the search towards feasibility in fewer iterations. The scoring functionensures that when very similar repairs are generated from the case-base they will be used, butwhen it is not possible to generate similar repairs the objective function has a larger influence.Figure 6 shows the average progress of the CBRG, CBRG-OBJ, RRG-TL-R10, and RRG-OBJ-TL-R10 algorithms. A statistically significant improvement in nurse satisfaction can also beseen in the experimental results. This can be explained by the increased speed in which theOBJ algorithms arrived at their best solutions (see Figure 7). In general, faster convergence tofeasible solutions reduces the chance of unnecessary damage to the nurse preferences.
These results show very clearly the benefits of a hybrid approach. CBRG guides the searchtowards solutions with very few constraint violations and high nurse preference satisfaction butis unable to reliably find feasible solutions. The addition of tabu lists helps the search out of these‘good quality’ local optima and increases the chance of finding feasible solutions. The objectivefunction increases the rate of convergence by placing more weight on those repairs that cause adecrease in the number of constraint violations whilst still taking advantage of the knowledgein the case-base.
The results presented here are not intended to show that the case-based approach can out-perform methods that employ a tabu search strategy per se. The RRG methods shown here are byno means tailored to the problem - any sensible implementation would at least include explicitrules for avoiding violation of nurse preference under specific conditions and would probablychoose repairs by minimising the number of new violations created. However, the results doshow that when combined with a simple meta-heuristic algorithm, case-based repair generationcan increase performance significantly.
1 Using a two-sample t-test for statistical significance assuming equal population variance
15
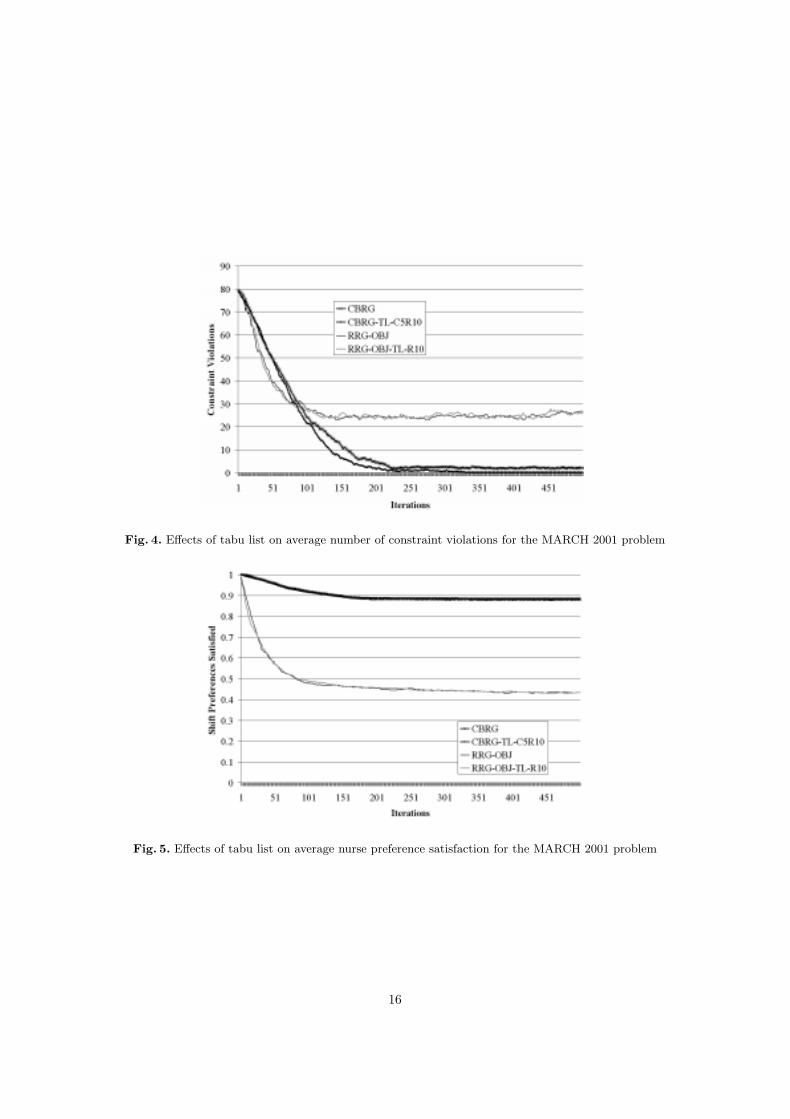
Fig. 4. Effects of tabu list on average number of constraint violations for the MARCH 2001 problem
Fig. 5. Effects of tabu list on average nurse preference satisfaction for the MARCH 2001 problem
16
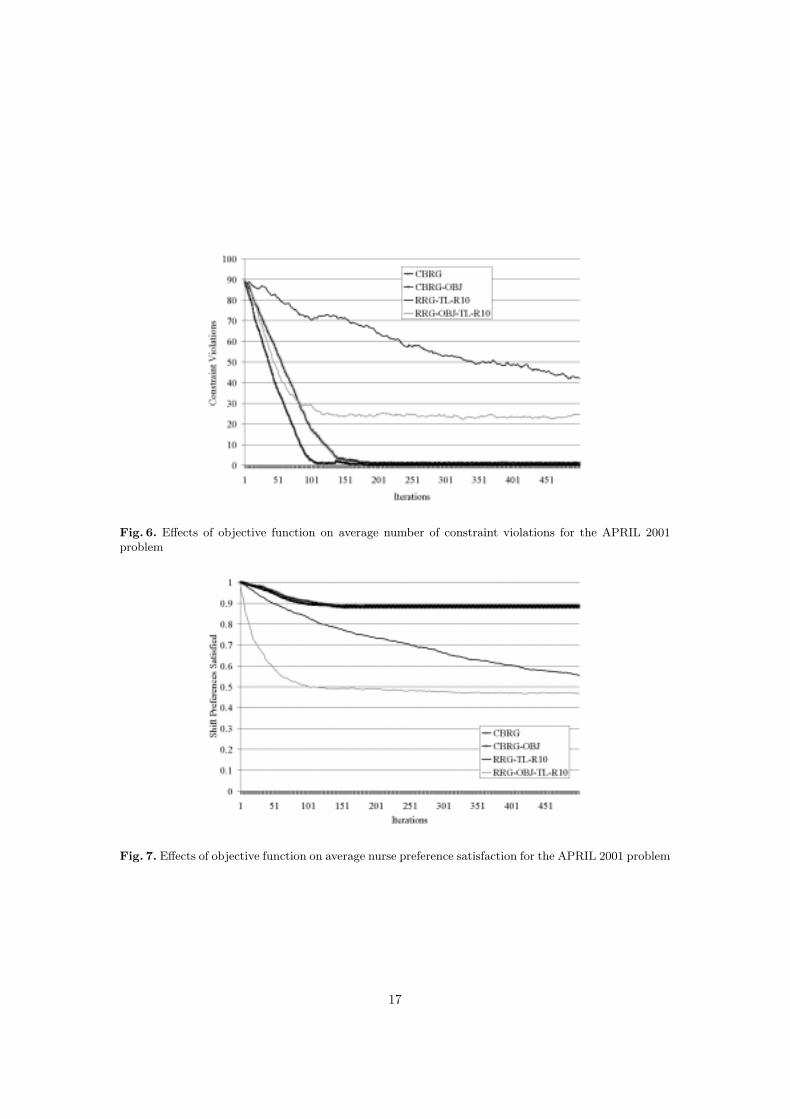
Fig. 6. Effects of objective function on average number of constraint violations for the APRIL 2001problem
Fig. 7. Effects of objective function on average nurse preference satisfaction for the APRIL 2001 problem
17
6 Conclusion
In this paper we demonstrate that a case-base can capture expert rostering knowledge by storingexamples of constraint violations and their corresponding repairs. This knowledge can then beused to generate repairs to constraint violations in new problems. Our experiments show thata simple iterative algorithm employing only the case-based repair generation mechanism cansuccessfully find good quality (albeit usually sub-optimal) solutions. We have shown that thecase-based repair generation methodology not only imitates repairs which lead to feasible ornear-feasible rosters, but that the repairs are also good at preserving the nurses’ shift preferencerequests in the final roster.
The benefits of such a case-based guided search approach are threefold. The expert-qualityrepair examples stored in the case-base help the search find feasibility much faster because theyguide the search in sensible directions. They help to guide the search away from areas of thesearch space containing ‘bad’ local optima (solutions which are locally optimal but contain manyconstraint violations). The repairs stored in the case-base avoid violating nurse shift preferenceswherever possible and so guide the search towards feasible solutions with high nurse satisfaction.Finally, all of this information is stored implicitly in the case-base and therefore does not needto be hard-coded into an algorithm using explicit rostering rules.
We have shown that the quality of rosters produced using the case-based repair methodologyalone are better than those produced using two standard meta-heuristic mechanisms, namelyan objective function and tabu lists. A hybrid approach incorporating the case-based repairgeneration with tabu lists and an objective function quickly produces good quality solutionswith high levels of nurse shift preference satisfaction.
Future research will focus on improving the knowledge capturing ability of the case-base.Methods to maintain the consistency of the knowledge and to identify erroneous or bad qualitydata must be developed. The incorporation of the case-based repair generation methodologyinto other constraint satisfaction techniques will also be considered.
7 Acknowledgements
This research is supported by the Engineering and Physical Sciences Research Council (EP-SRC) in the UK (grant number GR/N35205/01) and by the Queen’s Medical Centre UniversityHospital Trust, Nottingham.
8 Appendix
Following are the details of the similarity calculations for the example in Section 3. Cases fromthe case-base containing violations of the same type must be ranked according to the similarityfunction (Equation 10):
Index Values Sim (score)|PR
v | GSat GUO GUW Mag LSat LUO LUWα 1 100.0 86.7 86.7 1 100.0 86.7 86.7 NA
case0 1 92.3 89.2 78.3 1 93.0 82.3 78.1 2.53case1 2 86.2 73.9 68.9 1 44.0 80.2 80.1 1.36case2 15 60.8 58.3 45.6 2 70.1 80.1 60.2 0.77
The case with the highest similarity, case0 is retrieved from the case-base. The violation indicesare:
– |PRv | - The number of constraint violations in R;
18

– GSat - The percentage of shift preferences satisfied for all nurses;– GUO - The percentage of contract working hours assigned for all nurses over the whole
roster;– GUW - The percentage of contract working hours assigned for all nurses over the week
containing the violation;– Mag - The magnitude of the violation (in this case this is the cover shortage);– LSat - The percentage of shift preferences satisfied for nurses with the NurseType described
in the violation;– LUO - The percentage of contract working hours assigned for nurses with the NurseType
described in the violation over the whole roster;– LUW - The percentage of contract working hours assigned for nurses with the NurseType
described in the violation over the week containing the violation.
This case contains a repair which must be adapted to the current roster (see Equations 15and 16). New repairs are generated which are of the same type as the repair in the retrievedcase. These repairs must then be ranked according to their statistical similarity to the repair inthe case-base:
repair Index Values (see Appendix) Sim (score)SCOA SCOT SCNA SCNT Util SP
RepairIndices0 0 0 3 2 85.0 0 NArepaira 0 0 2 2 80.0 1 6.00repairb 0 0 2 2 100.0 4 2.67
The most similar repair is therefore repaira. The repair indices are:
– SCOA - The number of nurses of all types assigned to the original shift on the day of therepair;
– SCOT - The number of nurses of the NurseType described in the repair assigned to theoriginal shift on the day of the repair;
– SCNA - The number of nurses of all types assigned to the new shift on the day of the repair;– SCNT - The number of nurses of the NurseType described in the repair assigned to the
new shift on the day of the repair;– Util - The percentage of contract hours assigned to the nurse in the repair;– SP - A shift pattern distance score (described in detail in [25]).
The original shift is the shift assigned to the nurse before the repair was applied whilst thenew shift was the shift assigned by the repair.
References
1. S Abdennadher and H Schlenker. INTERDIP – an interactive constraint based nurse scheduler. InProceedings of The First International Conference and Exhibition on The Practical Application ofConstraint Technologies and Logic Programming, PACLP, 1999.
2. J L Arthur and A Ravindran. A multiple objective nurse scheduling model. AIIE Transactions,13(1):55–60, 1981.
3. J Bailey. Integrated days off and shift personnel scheduling. Computing and Industrial Engineering,9(4):395–404, 1985.
4. J Bailey and J Field. Personnel scheduling with flexshift models. Journal of Operations Management,5(3):327–338, 1985.
5. R N Bailey, K M Garner, and M F Hobbs. Using simulated annealing and genetic algorithms tosolve staff scheduling problems. Asia-Pacific Journal of Operational Research, 14:27–43, 1997.
19

6. N Beaumont. Scheduling staff using mixed integer programming. European Journal of OperationalResearch, 98:473–484, 1997.
7. I Berrada, J A Ferland, and P Michelon. A multi-objective approach to nurse scheduling with bothhard and soft constraints. Socio-Economic Planning Sciences, 30/3:183–193, 1996.
8. E K Burke, P De Causmaecker, and G Vanden Berghe. A hybrid tabu search algorithm for thenurse rostering problem. In Selected Papers from the 2nd Asia Pacific Conference on SimulatedEvolution and Learning Volume, volume 1585 of LNAI, pages 187–194. Springer Verlag, 1998.
9. E K Burke, G Kendall, and E Soubeiga. A tabu-search hyperheuristic for timetabling and rostering.accepted for publication in Journal of Heuristics, 2003/4.
10. E K Burke, B MacCarthy, S Petrovic, and R Qu. Structured cases in case-based reasoning - re-usingand adapting cases for time-tabling problems. Knowledge-Based Systems, 13:159–165, 2000.
11. E K Burke, S Petrovic, and R Qu. Case-based heuristic selection for timetabling problems. acceptedfor publication in Journal of Scheduling, 2003/04.
12. R N Burns and M W Carter. Work force size and single shift schedules with variable demands.Management Science, 31(5):599–607, 1985.
13. B M W Cheng, J H M Lee, and J C K Wu. A constriant-based nurse rostering system using aredundant modeling approach. Technical report, Department of Computer Science and Engineeringat The Chinese University of Hong Kong, 1996.
14. P Cunningham and B Smyth. Case-based reasoning in scheduling: reusing solution components.International Journal of Production Research, 35(11):2947–2961, 1997.
15. Kathryn Dowsland. Nurse scheduling with tabu search and strategic oscillation. European Journalof Operational Research, 106:393–407, 1998.
16. A Duenas, N Mort, C Reeves, and D Petrovic. Handling preferences using genetic algroithms for thenurse scheduling problem. In Proceedings of The First Multidisciplinary International Conferenceon Scheduling: Theory and Applications (MISTA), volume 1, pages 180–196, 2003.
17. F Glover. Tabu search - part I. ORSA Journal of Computing, 1:190–206, 1989.18. J L Kolodner. Case-Based Reasoning. Morgan Kaufmann Publishers Inc., 1993.19. H Meyer auf’m Hofe. Solving rostering tasks as constraint optimization. In Selected Papers from the
3rd international conference on Practice and Theory of Automated Timetabling (PATAT), LectureNotes on Computer Science, pages 280–297. Springer-Verlag, 2000.
20. Z Michalewicz and D B Fogel. How to Solve It: Modern Heuristics. Springer, 2000.21. K Miyashita and K Sycara. CABINS: A framework of knowledge aquisition and iterative revision
for schedule improvement and reactive repair. Artificial Intelligence Journal, 76:377–426, 1995.22. K Miyashita and K Sycara. Improving system performance in case-based iterative optimization
through knowledge filtering. In Proceedings of the Internation Joint Conference on Artificial Intel-ligence IJCAI’95, pages 371–376, 1995.
23. K Miyashita, K Sycara, and R Mizoguchi. Modeling ill-structured optimization tasks through cases.Decision Support Systems, 17(4):345–364, 1996.
24. K Miyashita, K Sycaras, and R Mizoguchi. Capturing scheduling knowledge from repair experiences.International Journal of Human-Computer Studies, 41:751–773, 1994.
25. S Petrovic, G R Beddoe, and G Vanden Berghe. Storing and adapting repair experiences in employeerostering. In Practice and Theory of Automated Timetabling IV - Selected Papers from PATAT’2002,volume LNCS2740 of Lecture Notes in Computer Science, pages 149–166. Springer Verlag, 2003.
26. W P Pierskalla and G J Rath. Nurse scheduling using mathematical programming. OperationsResearch, 24(5):857–870, 1976.
27. G Schmidt. Case-based reasoning for production scheduling. International Journal of ProductionEconomics, 56-57:537–546, 1998.
28. S Scott and R Simpson. Case-bases incorporating scheduling constraint dimensions - experiencesin nurse rostering. In Advances in Case-Based Reasoning - EWCBR98, Lecture Notes in ArtificialIntelligence. Springer Verlag.
29. M Warner. Scheduling nursing personnel according to nurse preference: A mathematical program-ming approach. Operations Research, 24:842–856, 1976.
20




















