
CI-Miner: semantically enhancing scientific processes
21
Earth Sci Inform (2009) 2:249–269 DOI 10.1007/s12145-009-0038-3 RESEARCH ARTICLE CI-Miner: semantically enhancing scientific processes Paulo Pinheiro da Silva · Leonardo Salayandía · Aída Gándara · Ann Q. Gates Received: 12 September 2009 / Accepted: 5 October 2009 / Published online: 10 December 2009 © Springer-Verlag 2009 Abstract The realization of an international cyberin- frastructure of shared resources to overcome time and space limitations is challenging scientists to rethink how to document their processes. Many known scientific process requirements that would normally be consid- ered impossible to implement a few years ago are close to becoming a reality for scientists, such as large scale integration and data reuse, data sharing across distinct scientific domains, comprehensive support for explain- ing process results, and full search capability for sci- entific products across domains. This article introduces the CI-Miner approach that can be used to aggregate knowledge about scientific processes and their products through the use of semantic annotations. The article shows how this aggregated knowledge is used to benefit scientists during the development of their research ac- tivities. The discussion is grounded on lessons learned through the use of CI-Miner to semantically anno- tate scientific processes in the areas of geo-sciences, Communicated by: H.A. Babaie P. Pinheiro da Silva (B ) · L. Salayandía · A. Gándara · A. Q. Gates Department of Computer Science, University of Texas at El Paso, 500 W. University Ave., El Paso, TX 79968, USA e-mail: [email protected] L. Salayandía e-mail: [email protected] A. Gándara e-mail: [email protected] A. Q. Gates e-mail: [email protected] environmental sciences and solar physics: A use case in the field of geo-science illustrates the CI-Miner ap- proach in action. Keywords Abstract workflow · Cyberinfrastructure · Distributed provenance · Ontology · Scientific process · Scientific workflow Introduction Cyberinfrastructure (CI) is “the set of organizational practices, technical infrastructure and social norms that collectively provide for the smooth operation of sci- entific work at a distance” (Edwards et al. 2007). A goal of CI is to enable novel scientific discover- ies through the provision of data with high levels of availability, as well as the complex processing capa- bilities required for data analysis. As a result of an increasing use of CI in scientific activities, we anticipate that most existing and future scientific systems (i.e., software systems that carry out a process to obtain a result of scientific significance) will need to handle the use of multiple data sources. Different data sources typically will be created through different methods, and they will have different quality assessment prac- tices (Jösang and Knapskog 1998; Kamvar et al. 2003; Zaihrayeu et al. 2005), as well as different format encodings (Bray et al. 2008; NASA/Science Office of Standards and Technology 1999). There have been im- portant advances in CI toward solving the problem of integrating data from multiple sources, as supported by the creation of data centers and virtual observato- ries such as GEON (Aldouri et al. 2004) and Earth- Scope (http://www.seis.sc.edu/ears/) that serve as data
Transcript of CI-Miner: semantically enhancing scientific processes

Earth Sci Inform (2009) 2:249–269DOI 10.1007/s12145-009-0038-3
RESEARCH ARTICLE
CI-Miner: semantically enhancing scientific processes
Paulo Pinheiro da Silva · Leonardo Salayandía ·Aída Gándara · Ann Q. Gates
Received: 12 September 2009 / Accepted: 5 October 2009 / Published online: 10 December 2009© Springer-Verlag 2009
Abstract The realization of an international cyberin-frastructure of shared resources to overcome time andspace limitations is challenging scientists to rethink howto document their processes. Many known scientificprocess requirements that would normally be consid-ered impossible to implement a few years ago are closeto becoming a reality for scientists, such as large scaleintegration and data reuse, data sharing across distinctscientific domains, comprehensive support for explain-ing process results, and full search capability for sci-entific products across domains. This article introducesthe CI-Miner approach that can be used to aggregateknowledge about scientific processes and their productsthrough the use of semantic annotations. The articleshows how this aggregated knowledge is used to benefitscientists during the development of their research ac-tivities. The discussion is grounded on lessons learnedthrough the use of CI-Miner to semantically anno-tate scientific processes in the areas of geo-sciences,
Communicated by: H.A. Babaie
P. Pinheiro da Silva (B) · L. Salayandía ·A. Gándara · A. Q. GatesDepartment of Computer Science,University of Texas at El Paso, 500 W. University Ave.,El Paso, TX 79968, USAe-mail: [email protected]
L. Salayandíae-mail: [email protected]
A. Gándarae-mail: [email protected]
A. Q. Gatese-mail: [email protected]
environmental sciences and solar physics: A use casein the field of geo-science illustrates the CI-Miner ap-proach in action.
Keywords Abstract workflow · Cyberinfrastructure ·Distributed provenance · Ontology · Scientificprocess · Scientific workflow
Introduction
Cyberinfrastructure (CI) is “the set of organizationalpractices, technical infrastructure and social norms thatcollectively provide for the smooth operation of sci-entific work at a distance” (Edwards et al. 2007).A goal of CI is to enable novel scientific discover-ies through the provision of data with high levels ofavailability, as well as the complex processing capa-bilities required for data analysis. As a result of anincreasing use of CI in scientific activities, we anticipatethat most existing and future scientific systems (i.e.,software systems that carry out a process to obtain aresult of scientific significance) will need to handle theuse of multiple data sources. Different data sourcestypically will be created through different methods,and they will have different quality assessment prac-tices (Jösang and Knapskog 1998; Kamvar et al. 2003;Zaihrayeu et al. 2005), as well as different formatencodings (Bray et al. 2008; NASA/Science Office ofStandards and Technology 1999). There have been im-portant advances in CI toward solving the problem ofintegrating data from multiple sources, as supportedby the creation of data centers and virtual observato-ries such as GEON (Aldouri et al. 2004) and Earth-Scope (http://www.seis.sc.edu/ears/) that serve as data

250 Earth Sci Inform (2009) 2:249–269
warehouses and that provide standardized tooling andprotocols for data retrieval and analysis. As scientificteams continue to adopt CI in their practices, however,alternate ways of collaboration are surfacing that re-quire a decentralized approach to multiple-source dataintegration (Kushmerick 1997; Ashish and Knoblock1997; Fonseca et al. 2003). As a result of a new gen-eration of research activities that are more collabo-rative and multi-disciplinary in nature, scientists willneed novel ways of collecting data to facilitate sharing,searching, and explaining data and data-derived arti-facts.
In general, machines are not always successful atintegrating data. For example, it is difficult for a ma-chine to identify that “Benjamin Franklin, Politician” isthe same “Benjamin Franklin, Inventor,” which may bedocumented separately in some pages on the Web. Hu-mans may conclude that the different “Franklin” refer-ences relate to the same object. A machine, however,without further information, may be unable to deter-mine that relation. Semantic annotations are metadata(i.e., data about data) that allow software applicationsto identify, for example, that an object in an annotateddataset is the same object that has been semanticallyannotated in another dataset. In the example above,through the use of semantic annotations, a softwareapplication could verify that the two “Franklin” refer-ences relate to the same object in the following manner:they are both semantically annotated to be of the typeperson; the “Franklin” part of the term refers to a lastname; “Politician” and “Inventor” are position titles;and the “Franklin, politician in Philadelphia” was alsothe inventor. In general terms, we see that the needfor “semantics” is an immediate consequence of thecollaborative nature of most scientific processes and thefoundation upon which CI-Miner rests.
One challenge that scientists face when working col-laboratively is the need to agree on a common and con-sistent terminology, especially when accessing datasetsfor scientific analysis. For example, the term “altitude”used in two datasets may be the height in referenceto the terrain or in reference to the sea level. Scien-tists often interpret the meaning through inspection.In other situations, the interpretation of terminologyis less obvious. For example, scientists coming fromdifferent organizations or fields of expertise may usedifferent data formats and standards to describe similaror related observations. Semantic annotations may beused to describe dataset contents providing a system-atic way for machines to verify semantic relationshipsbetween dataset attributes, e.g., two attributes are thesame, one attribute subsumes another, two attributesare distinct.
Understanding the scientific process used when col-laboratively working on scientific analysis is anotherchallenge to consider. To address this challenge, seman-tic annotations can be used to document the steps takento perform scientific analysis, as well as to identify thetools and people involved in the creation and executionof the process. These are especially significant in ascientific setting where reliability and traceability ofprocess results is crucial.
This article introduces the CI-Miner methodologyfor semantically enhancing scientific processes. Themethodology, which uses specific notations and is car-ried out through the use of software tools, is intendedfor scientists who are not necessarily computer scien-tists or experts in semantic technologies. Furthermore,scientists who use the CI-Miner methodology recognizethat machines and automation should be involved inthe process of sharing, searching and explaining sci-entific artifacts. The methodology considers that sci-entists have a comprehensive understanding about theprocesses that they are interested in designing andimplementing.
This article describes the methodology by explain-ing how the semantic annotations added to a sci-entific process are used to generate explanations onhow processes can be executed, how scientific artifactsare derived from experimental data, and how scien-tists can search, visualize, and ask questions aboutprocess results. Section “Background” presents in-formation about how tools, languages, and otherapproaches are being used to manage and use knowl-edge about scientific processes. Section “Use case:collaboration challenges for the creation of geophysi-cal studies of crustal structure” introduces a use caseto illustrate the challenges of capturing, preserving,and using knowledge about scientific processes. Theuse case and related challenges are used throughoutthe article to demonstrate the CI-Miner methodologyin action. Section “CI-Miner” describes the method-ology along with supporting notations and tools.Section “CI-Miner benefits and discussion” revisits thechallenges presented in Section “Use case: collabora-tion challenges for the creation of geophysical studiesof crustal structure” to highlight the benefits of usingCI-Miner. Other case studies are also reported in thissection. Conclusions and future developments are pre-sented in Section “Conclusions and future work”.
Background
The CI-Miner semantic enhancements described in thisarticle are comparable to several ongoing efforts in the

Earth Sci Inform (2009) 2:249–269 251
research areas of ontologies, workflow specifications,and provenance. This section describes efforts in theseareas, including other comprehensive efforts that cap-ture process and provenance knowledge of scientificprocesses.
Ontologies to support shared knowledge
Ontologies support a key function of establishing ashared body of knowledge in the form of vocabularyand relationships. A benefit of using ontologies to de-scribe knowledge is that they can be used for a widerange of purposes. For example, the application of on-tologies can range from establishing knowledge aboutgeneral content on the Web, to establishing knowledgeabout very specialized scientific processes.
Several advances in Semantic Web technology havemade using ontologies more feasible. The Ontol-ogy Web Language (OWL) (McGuiness and vanHarmelen 2004), a standardized web language fordefining ontologies, allows for more interoperabilitybetween distinct scientific communities, and hence,ontology development has become a popular activityamong scientific communities.
The purpose for developing ontologies, however,varies widely among scientific communities. The TAM-BIS ontology (Baker et al. 1999) and the myGrid on-tology (Wroe et al. 2003) are examples of ontologiesthat are intended to create categorizations of conceptsand relationships. For example, TAMBIS categorizesrepresentations of biological structures into “physical”and “abstract.” Additionally, TAMBIS has separateconcept divisions for biological processes and biologicalfunctions. This notion of distinguishing between thepossible representations of a concept helps reinforcethe idea that separating concepts into categorizationsis beneficial.
The Gene Ontology (GO) (http://www.geneontology.org/) is a controlled vocabulary aboutgene information. It is split up into three maincategories, the cellular component ontology, molecularfunction ontology, and the biological process ontology.In addition to documenting a controlled vocabulary,the purpose of the GO ontology is to documentscientific processes.
The Semantic Web for Earth and Environmen-tal Terminology (SWEET) ontologies (http://sweet.jpl.nasa.gov) were developed to capture knowledge aboutEarth System science. A group of scientists have beencapturing several thousand Earth System science termsusing the OWL ontology language. There are twomain types of ontologies in SWEET: facet and uni-fier ontologies. Facet ontologies deal with a particu-
lar area of Earth System science (earth realm, non-living substances, living substances, physical processes,physical properties, units, time, space, numeric, anddata). Unifier ontologies were created to piece to-gether and create relationships that exist among thefacet ontologies. Facet ontologies use a hierarchi-cal methodology in which children are specializationsof their parent nodes. The SWEET ontologies arecurrently being used in GEON (The GeosciencesNetwork: building cyberinfrastructure for the geo-sciences) (http://www.geongrid.org/) to capture geo-logic processes and terms.
Tools that leverage ontologies must facilitate thecreation and reuse of ontologies allowing scientists towork together using an agreed upon vocabulary in sup-port of scientific research activities, e.g., creating crustalmodels of the Earth.
Workflow tools to capture process knowledge
Many scientific workflow tools are available and in usefor modeling scientific processes. Taylor et al. (2006)discusses various implementations using such toolswithin the scientific community, as well as the chal-lenges and benefits of using scientific workflow toolsin general. One benefit of workflow tools in general isthat they support the capture and preserving of processknowledge by allowing users to build graphical repre-sentations of a scientific process. Typically, workflowsare built in a systematic way via a user interface and theresults are reproducible artifacts that can be reused andmodified.
Wings (Gil et al. 2006) is a workflow tool that allowsscientists to specify the steps in a scientific process usingsemantic annotations in building the workflow. Becausethe ultimate goal for Wings workflows is to build anexecutable representation of the scientific process, pre-liminary work must be done to define the semanticcharacteristics of the workflow, including dataset andexecutable components. Having semantic descriptionsavailable during the design phase allows Wings to sug-gest and verify interoperable components while theworkflow is being developed. However, understandingsemantic and executable details of components maynot be something a group of scientists are preparedto discuss when designing a scientific workflow. In thiscase, requiring semantically annotated workflow com-ponents is an added challenge at an initial stage ofworkflow design. Allowing workflows to be designedat an abstract level, where scientists are focused onthe scientific process without consideration for imple-mentation details until a workflow has been agreedupon can avoid this distraction. Furthermore, it would

252 Earth Sci Inform (2009) 2:249–269
be helpful to leverage existing knowledge about dataand components over the Web as opposed to having tobuild them locally.
Taverna (Zhao et al. 2008) allows life scientists tobuild executable workflows over a portal that managesa pre-defined set of data and service components. Onerestriction of this portal is that, in order to build aworkflow, the portal only gives access to componentsfor which it has descriptions. This, similar to Wings,means that scientists need to build a working set ofcomponent descriptions before they build a workflow.Given that this portal is focused on life sciences, thereis a variety of existing knowledge already built into theportal, but this is not the case for all scientific domainsor for scientific teams that choose not to use the portal.Another issue is that the Taverna portal is focused onone scientific domain. There are cases where scientistswant access to datasets available from different sources,not just from one scientific domain, i.e., life sciences.
Furthermore, there are additional challenges to us-ing current workflow tools. For example, there areimplementations that require modeling of steps thatthe scientist performs, like instrument calibration orartifact evaluations. Most scientific workflow tools donot support modeling human intervention within scien-tific processes. Another challenge is that most scientificworkflow tools lack an overall methodology for sup-porting scientists in understanding an abstract scientificprocess and for refining the information to supportsharing and reuse of knowledge and scientific results.
Tools to capture provenance knowledge
Scientific processes, as defined in this paper, are notnecessarily captured by scientific workflows that haveexecutable specifications; however, there is a signif-icant effort of using provenance in scientific work-flows that needs to be considered. For example, weobserve the use of provenance models in differ-ent workflow systems such as REDUX (Barga andDigiampietri 2008), Taverna, Pegasus (Kim et al. 2008)and Karma (Simmhan et al. 2008). These systems arebased on two layers of provenance named retrospectivelayer—information about workflow executions—andprospective layer—information about workflow specifi-cations (Clifford et al. 2008). These retrospective layerstend to have very general concepts for representingprocess execution traces at the same time that theyincorporate domain-specific concepts. Domain-specific
concepts can be incorporated in multiple ways; forexample, they can be provided by domain-specific on-tologies or hard-coded in the systems. In the case ofTaverna, which is dedicated to supporting workflows inthe Bioinformatics domain, the approach is to includerelated domain ontologies.
We observe a tendency of provenance systems todevelop into comprehensive frameworks for captur-ing and collecting process and provenance knowledge.The Zoom*UserViews project (Davidson et al. 2007)and the PrIMe methodology to develop provenance-aware applications (Miles et al. 2009) are examplesof such frameworks. Zoom*UserViews is a collabo-ration among several projects being integrated into acomprehensive solution. Zoom*UserViews focuses oncapturing process knowledge in an executable work-flow environment. The level of details required forworkflow specifications to be executable tends to bedistracting for scientists to understand and thus shareprocess knowledge. Many are the benefits of using suchframework although captured process knowledge maynot be at a level of abstraction that is more convenientfor scientists.
The PrIMe methodology uses software engineeringpractices to elicit “provenance questions” from users,analyze data-generation applications to build data-dependency models that are useful to answer the prove-nance questions, and instrument the applications withwrappers to capture provenance that can be used toanswer the provenance questions. PrIMe centers on thedevelopment/instrumentation of software applicationsfrom a common understanding to capture provenance.The documentation of scientific processes to promoteunderstanding among a scientific community is not anecessary goal of the methodology.
Use case: collaboration challenges for the creationof geophysical studies of crustal structure
This section presents a use case in which scientists col-laborate to create crustal models of the Earth and sharethem with others. Crustal models are used to identifythe geological structure of the Earth, e.g., the Amazonbasin. The identification of such structures is impor-tant for several reasons, including to identify mineralreserves and to predict the degree of erosion a regioncan experience when it loses vegetation coverage, i.e.,forest deforestation. Related challenges are describedto motivate the need for CI-Miner.

Earth Sci Inform (2009) 2:249–269 253
Use case description
Figure 1 depicts a collaboration in which scientists aredefining a process to create a crustal model that will beused by another scientist. In this scenario, Scientist1 and Scientist 2 work toward gaining a commonunderstanding about the scientific process CM used tocreate a model of a particular region of Earth. Initially,the understanding of Scientist 1 about the CrustalModel process (CM′) varies from that of Scientist2 (CM′′). As the development phase of the processprogresses, it is expected that the scientists will even-tually reach consensus and document CM by describingthe main steps of the process along with the flow ofinformation, where the final version of CM is based onthe original versions CM′ and CM′′. The documentationof CM is useful to preserve the collaborative effort toreach consensus and to share this knowledge with otherscientists. For instance, Fig. 1 shows that Scientist3 was not involved in the development of process CMand the subsequent creation of the crustal model. How-ever, Scientist 3 wants to understand what is beingrepresented by the crustal model to reuse it in her ownwork. Depending on the availability of the authoringscientists or supporting documentation about processCM, Scientist 3 may have a difficult time evaluatingthe scientific result.
The scenario depicted in Fig. 1 is a simplificationof many scientific collaborations. Complicating factorsmay include, among many others, scientists collabo-rating remotely with limited real-time communication,and scientists with different fields of expertise thatmay use different terminologies to describe scientificprocesses.
Use case challenges
Regardless of the complicating factors involved in sci-entific collaborations, scientists often succeed in devel-oping and using scientific processes to derive productslike crustal models. These successes are often hindered,however, when scaling scientific processes for use by awider community. Lack of mechanisms to capture, pre-serve, and reuse knowledge about scientific processesare often the cause of the scalability problem. What ismore, scientists must share research results and docu-ment the processes used to generate research results ina manner that supports their reproduction in order tobe successful. The challenges described below are criti-cal because the task of documenting processes requiresa significant amount of effort from scientists.
Figure 2 shows the main steps and data flow of theCM process of creating a crustal model, which is usedas an example to present the challenges. The processbegins with the ProfileLineDecision step at whichthe scientist determines the profile line of the model.Digital Elevation Maps (DEMs) and gravity data aretwo cost-effective sources of data that can be used todetermine a profile line. The right side of Fig. 2 showsadditional details about the ProfileLineDecisionstep of the process. As shown, gravity data has tobe treated by the computation of a Bouguer anomalyto create a BouguerAnomalyMap where input fromthe geoscientist is required in addition to the gravitydata. The Bouguer anomaly is a computed value re-moving the attraction of the terrain above sea level,i.e., the terrain effect, from gravity readings. The stepof analyzing DEMs and Bourguer Anomaly Maps toultimately determine the location of the profile line
Fig. 1 Creating and reusinga scientific result
ScientificResult
Scientist 1
Scientist 3
Analyze
How was this model created?
colla
bora
te
Scientist 2
Scientific Process
CM'
Scientific Process
CM''
Create based onCM

254 Earth Sci Inform (2009) 2:249–269
Fig. 2 Process to create a crustal model
(DrawProfileLine) is a manual step driven by thegeoscientist.
The initial steps of the CM process describe the se-lection of specific data sources that scientists decidedto include as part of this process. Furthermore, theprocess describes the need for humans to enter inputparameters, as well as the need for humans to analyzedata to make decisions.
Challenge 1. Capturing and preserving processknowledge. Capturing and preserving human activityin support of scientific processes in a way that offersreliable interpretation by others is difficult. Even forparts of the process that include systematic activities, i.e.,machine activity or machine-assisted human activity,differences in scientific terminology across fields ofexpertise complicates the problem.
Continuing with the description of the CM process,the next step after determining the profile line is tocreate a cross section about the crustal structure ofEarth along the profile line (CreateCrossSectionin Fig. 2). The cross section is comprised of tectonicbodies represented by polygons, where each tectonicbody is assigned a density value. In order to construct acredible cross section, the geoscientist needs to researchthe area of interest to find data that can shed light into
the properties of the tectonic bodies. The sources ofdata used in the process discussed here include: welldata, receiver function data, and possibly previouslycreated crustal models that can serve as a basis towardscreating a refined model. Because of the diversity ofdata sources involved, as well as possibly conflictingresults obtained from different sources, constructing across section requires expert interpretation of the data.
This part of the process involves expert interpreta-tion of various types of data to make decisions aboutthe model to be created. Once a scientific result hasbeen produced, the decisions made at this step maybe required to assess its quality. Furthermore, scientistswanting to verify the reproducibility of a scientific resultrequire access to this knowledge.
Challenge 2. Capturing and preserving provenanceknowledge. The challenge is to capture and preserveprovenance knowledge about a scientific result in a waythat it can be effectively accessed and used by others.
The next step in the CM process consists of using thecross section created as the basis to construct a forwardmodel of gravity and magnetic data along the pro-file line. The forward model yields theoretical gravityand magnetic values based on the geometric structuresand densities of the tectonic bodies conforming the

Earth Sci Inform (2009) 2:249–269 255
cross section. The cross section along with the theo-retical gravity and magnetic profiles are denominateda CrustalModel-Draft.
This part of the process involves the use of a processcomponent that takes some input and systematicallyconstructs a model as output. There may be severalsystems that can be used to satisfy the requirementsof this process component. The scientist may need tomake a decision as to which process component is moreappropriate.
Challenge 3. Supporting the integration and interop-eration of process components. The challenge involvescapturing and preserving the process-related knowledgerequired to assess the appropriateness of the system to beused regarding its capability of sharing data with otherprocess components.
The last step in the process is to compare the re-sulting crustal model draft against a profile of gravityand magnetic field data observations to determine thefitness level of the theoretical values of the forwardmodel. Based on the criteria of the geoscientist, if thefitness level of the crustal model is good enough, theprocess ends by having a geoscientist-endorsed crustalmodel. Otherwise, the process continues by using thecrustal model draft as the basis to conduct a refinementiteration.
Challenge 4. Supporting comprehensive query capa-bilities for process components and products. Oncea scientific result has been obtained, a challenge is toleverage the scientific process knowledge mentioned inChallenge 1, as well as the provenance knowledge aboutthe result mentioned in Challenge 2 to support advancedquery capabilities.
For example, consider the case where a scientistwants to search for crustal models created specificallywith the use of the PACES data source illustrated inFig. 2 and where the profile line was determined byScientist 1. Support for comprehensive query ca-pabilities for process and products could address thisproblem.
Challenge 5. Supporting comprehensive visualizationcapabilities for process components and products. Thechallenge is to have access to intermediate results alongthe execution of the scientific process and be able tovisualize them in a way that can shed light into the innerworkings of the process.
Defining scientific processes may involve an iterativeprocess of trial and error, where scientists experimentwith different components or steps in the process todetermine an optimal choice. Visualization of interme-diate results may be a critical capability for scientists todefine scientific processes. Similarly, understanding theprocess inner workings through visualization of inter-mediate results may also be valuable for other scientistswanting to reuse the scientific process or the productscreated with it.
CI-Miner
CI-Miner offers an approach to help scientists docu-ment the knowledge behind their research activitiesin the form of semantic annotations so that softwareapplications can use this knowledge to better supportscientists’ research activities. With the use of CI-Miner,scientists can focus on solving scientific problems with-out worrying about technical nuances of developingand reusing scientific systems. This section presents themethodology behind CI-Miner and the technology usedto carry out such methodology.
Methodology
There are different types of scientific systems thatrange from legacy to state-of-the-art, well-establishedto under-development, non-documented to well-documented. In addition, the development of newscientific systems may be required to support novelscientific processes. In order to support scientificprocesses that leverage these wide ranges of scientificsystems, scientists need to understand and be ableto communicate the essential functionalities of thesesystems. In addition, they must be able to communicatethe dependencies between these systems and thescientific processes of interest.
The CI-Miner methodology can be applied followingan a posteriori or an a priori approach to documenta-tion. In an a posteriori approach (i.e., from system todocumentation) the intention is to analyze the innerworkings of an existing scientific system in order tocreate systematic documentation that can be used tounderstand its appropriateness to a particular scientificprocess, and that can be used to enhance the existingscientific system with features that show (from the per-spective of the scientist) the steps that are carried outby the scientific system to produce a scientific result.
In an a priori approach (i.e., from documentation tosystem) the intention is to systematically document thescientific process from the perspective of the scientist in

256 Earth Sci Inform (2009) 2:249–269
order to support the development of a correspondingscientific system, or to identify existing systems thatcan be reused. As in the a posteriori, the systematicdocumentation produced can be used to enhance thesystem to be developed or reused with features thatshow (from the perspective of the scientist) how scien-tific results are produced using the system.
It is assumed that scientists adopting CI-Miner arecapable of capturing common knowledge about thescientific process at hand. It is also assumed that oncescientists reach a common understanding about theprocess, that they can establish the fundamental con-cerns of carrying out the scientific process, and that theycan evaluate whether a scientific system (or parts ofit) appropriately support the concerns. For example, ageoscientist that is adopting CI-Miner and that is taskedwith the scientific endeavor of creating a crustal model(i.e., the case study of Section “Use case: collabora-tion challenges for the creation of geophysical studiesof crustal structure”) should be able to establish thatcreating a forward model of theoretical gravity valuesfrom a cross section is a necessary step. Furthermore,the geoscientist should be able to evaluate whethera given forward modeling software provides adequatefunctionality for that step.
The methodology is presented as a series of stepsthat a scientist needs to accomplish in order to sys-tematically document a scientific process, as well as toenhance scientific systems that are used to support thescientific process. The order of the steps may vary, forexample, depending on whether an a posteriori or an apriori approach is used.
Figure 3 shows the scenario presented in Sec-tion “Use case: collaboration challenges for the cre-ation of geophysical studies of crustal structure”, alongwith the semantic annotation resulting from using theCI-Miner methodology (the annotations are repre-sented by the boxes around the scientific product in thecenter of the figure). The scientific result is presentedalong with provenance semantic annotation (i.e., theProvenance box around the scientific product) thatencodes the knowledge about how that result was cre-ated, which data sources where used in its creation, andwhat human decisions where made towards creatingit. Furthermore, the provenance about the scientificproduct is grounded upon a documented process CMthat is encoded in the form of an abstract workflow. InCI-Miner, a scientific product of interest is called theSubject of Discourse (SOD) of the methodology. Fur-ther, the scientific process responsible for the derivationof a SOD is the Process of Discourse (POD) of the
methodology. Scientists may use the methodology todocument multiple SODs and corresponding PODsincluding PODs that can derive multiple SODs each.An assumption, however, is that a scientist may onlyfocus on one SOD and one POD at a time while usingthe CI-Miner methodology.
In Fig. 3, the fact that the Abstract Workflowbox is around the Provenance box means that thereis a mapping between the provenance knowledge con-cepts and the abstract workflow concepts, and that thismapping is encoded in the provenance allowing one toreach the corresponding abstract workflow by inspect-ing the provenance. Lastly, both the abstract workflowof CM and the provenance of the scientific result aregrounded on common terminology that is described inthe form of an Ontology. The ontology and abstractworkflows are useful in the collaborative phases be-tween Scientist 1 and Scientist 2 to definingprocess P to create the scientific result. The provenanceabout the scientific result is useful to Scientist 3because the scientific result is accompanied with ad-ditional information that describes how that scientificresult was created.
Step A: Establish a vocabulary of terms about theprocess of discourse. The vocabulary definedin this step is the knowledge represented bythe Ontology box in Fig. 3.1
1. Identify and name the kinds of datathat are used in the POD. These includethings such as datasets, input parame-ters, field observations, and data logs. Itis important to emphasize that the goalof this step is to identify kinds of datarather than proper data. For example, ascientific process about the creation ofa gravity contour map may use multi-ple gravity datasets, where each datasetcontains gravity readings about a distinctregion. In the case of these datasets, onlyone kind of data needs to be identifiedand named—“gravity data.” The kinds ofdata identified in this step are the dataconcepts of the POD;
2. Identify and name the SOD that is themain outcome of the POD. The SOD
1The vocabulary defined in this step may build upon other exist-ing vocabularies documented as ontologies. This is referred to asontology harvesting.

Earth Sci Inform (2009) 2:249–269 257
Fig. 3 Scenario aboutcreating and reusing scientificresults with CI-Miner
ScientificResult
Scientist 1
Scientist 3
Analyze
How was this model created?
Scientific Process
CM'
Scientific Process
CM''
colla
bora
teScientist 2
Ontology
AbstractWorkflow
Provenance
Create based onCM
with CI-Miner
CM
is considered also a data concept of thePOD. A POD may derive other productsin addition to the SOD. The scientist maychoose to include or disregard these addi-tional data concepts;
3. Identify and name the kinds of meth-ods that are used in the process. Thesemethods are process components such assoftware tools and human activities thattake some data as input and transformit. Similarly as before, the goal of thisstep is to identify kinds of methods. Forexample, there may be several tools capa-ble of computing the standard deviationof a dataset attribute. In this case, onlya generic method needs to be identifiedand named—“standard deviation.” Thekinds of methods identified in this stepare the method concepts of the POD;
4. When appropriate, compare the data andmethod concepts identified thus far toother established vocabularies in the fieldof study to refine the process vocabu-lary, i.e., change an identified conceptname for a concept name that is moreestablished in the scientific community,or identify synonyms. For the case of dataconcepts, harvesting concepts from otherestablished vocabularies is useful for pur-poses of data integration. For example, adata concept initially identified by a sci-entist as Corrected Gravity Data may becompatible to the definition of ProcessedGravity Data used in the vocabulary
endorsed by an established organizationthat maintains a data repository of grav-ity datasets; hence, those datasets couldbe used in the execution of the POD.
5. Identify the input and output relationsbetween the data and method conceptsof the POD. In other words, for eachmethod concept identified in A.3, iden-tify the data concepts that the methodconcept consumes, i.e., input data, andeach data concept that the method con-cept produces, i.e., output data.
Step B: Specify an abstract workflow specification forthe process of discourse. The specificationdefined in this step is represented by theAbstract Workflow box in Fig. 3.
1. Model the POD as an abstract work-flow in terms of the vocabulary estab-lished in Step A. By using the data andmethod concepts previously established,the scientist models his or her under-standing of the scientific process as a setof steps, each of which is represented bya method, and each of which requiresa set of input data and results in a setof output data. The set of steps is in-terconnected through data interdepen-dencies. For example, Fig. 4 shows anabstract workflow specification wheredata is represented by directed edges, andmethods are represented by rectangles.The ProfileLineDecision methodhas the data SouthwestGravityData
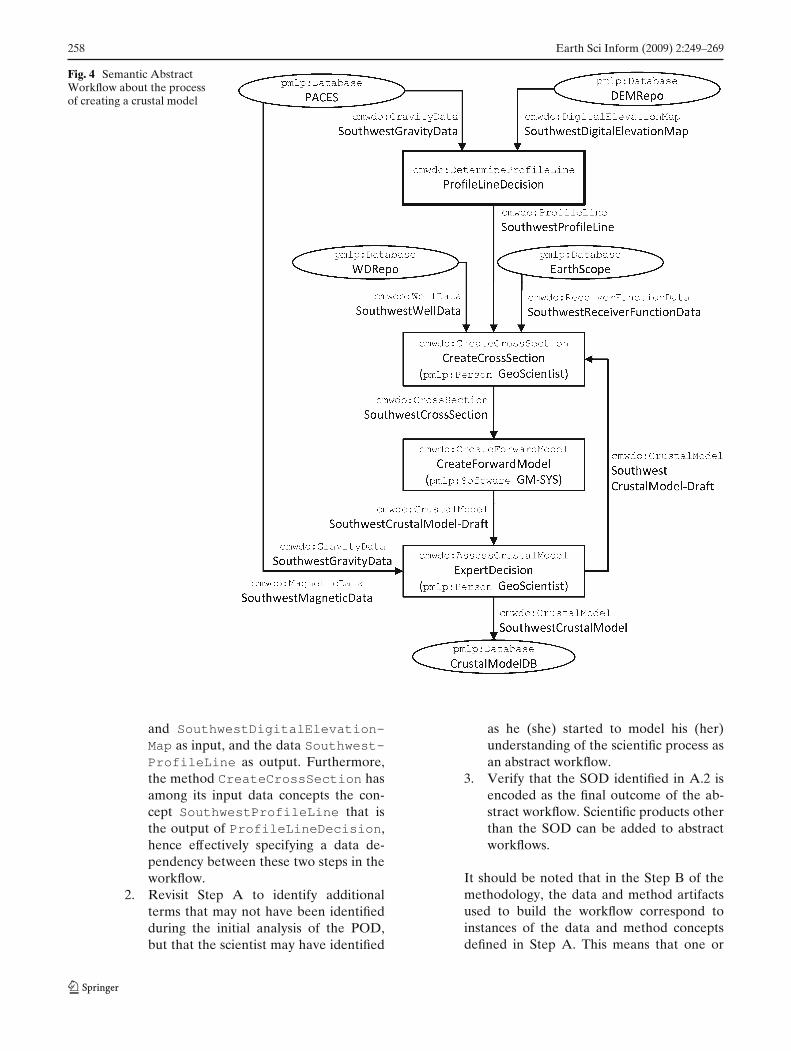
258 Earth Sci Inform (2009) 2:249–269
Fig. 4 Semantic AbstractWorkflow about the processof creating a crustal model
and SouthwestDigitalElevation-Map as input, and the data Southwest-ProfileLine as output. Furthermore,the method CreateCrossSection hasamong its input data concepts the con-cept SouthwestProfileLine that isthe output of ProfileLineDecision,hence effectively specifying a data de-pendency between these two steps in theworkflow.
2. Revisit Step A to identify additionalterms that may not have been identifiedduring the initial analysis of the POD,but that the scientist may have identified
as he (she) started to model his (her)understanding of the scientific process asan abstract workflow.
3. Verify that the SOD identified in A.2 isencoded as the final outcome of the ab-stract workflow. Scientific products otherthan the SOD can be added to abstractworkflows.
It should be noted that in the Step B of themethodology, the data and method artifactsused to build the workflow correspond toinstances of the data and method conceptsdefined in Step A. This means that one or

Earth Sci Inform (2009) 2:249–269 259
more instances of a concept can be employedin the abstract workflow. For example, Fig. 4shows two instances of the GravityDataconcept, one is used as an input to Profile-LineDecision, while the other is used as aninput to ExpertDecision.The design of abstract workflow specifica-tions can require more elaborated abstractionmechanisms. For example, the workflow dia-gram illustrated in Fig. 2 shows an expansionof the ProfileLineDecision rectangle,which provides additional details about thatstep. The supported mechanisms to modelworkflows at multiple levels of abstractionare described in Gates et al. (2009).
Step C: Instrument scientific system to capture prove-nance about the subject of discourse. Theknowledge about process executions cap-tured in this step are represented by theProvenance box in Fig. 3.
1. Map the methods (or steps) identified inthe abstract workflow to scientific sys-tems or parts of scientific systems thatcorrespond to such steps. In the case ofusing the methodology with an a poste-riori approach, this mapping should befairly straight forward, since the termi-nology and abstract workflows definedin the previous steps are modeled basedon the analysis of the scientific system.In an a priori, however, the mappingmay be more challenging since it mayinvolve cases where a scientific systemdoes not exist for a corresponding step.For example, these steps may be due tohuman interventions to the process thatare important to be recognized as stepsin scientific processes;
2. Identify metadata to describe theprocessing of each step of the abstractworkflow, as well as the metadatato describe the data consumed andthe data produced by each step. Forexample, the CreateForwardModelstep presented in Fig. 4 couldinclude metadata such as the nameof the scientific system used toperform the step, e.g., GM-SYS.The SouthwestCrossSection dataconsumed by that step could includemetadata such as the name of theregion, e.g., Southwest;
3. For steps that are not classified as hu-man interventions, use data annotatorsto capture provenance. Data annota-tors use the metadata identified in StepC.2 to annotate the provenance for thestep execution. With the use of the in-put/output data contained in the ab-stract workflow for each step of thePOD, data annotator modules are auto-matically generated for each step in theform of template code that captures theinputs used when a step is initiated, aswell as the outputs resulting when a stepis finished;
4. [Optional] For steps that are humaninterventions, consider the creation oftools that would enable scientists to doc-ument their interventions;
5. Inspect the abstract workflow specifi-cation for properties that dictate whenprovenance should be logged. For ex-ample, when intermediate artifacts donot persist during execution of theworkflow, an in-processing approachmust be used to capture the prove-nance for intermediate artifacts and, ifneeded, to capture the artifacts them-selves before they are expunged fromthe process;
6. Modify the system coordinating agentto invoke data annotators. This impliesthat the invocation of data annotatorsneed to occur at precise moments inexecution, thus the coordinating agentof the data annotators is also the co-ordinating agent of the concrete work-flow. Deciding where to add these callsto a workflow requires that a user un-derstands specifics of a concrete work-flow, such as which parts correspond tothe coordination of process (i.e., controlflow) and which parts correspond to theexecution of workflow activities; for it isthis knowledge that is needed to instru-ment the workflow;
7. Execute the scientific process;8. If a workflow does not delete interme-
diate results, or if users are unable tomodify a workflow, then a non-invasivepost-processing annotation can be used.In this case, knowing about work-flow how/when/where workflow activi-ties are invoked is less important than

260 Earth Sci Inform (2009) 2:249–269
knowing specific properties of data out-put from the activities. This is be-cause post-processing annotators searchfor the existence of certain types andproperties of data to clue in that aparticular workflow activity was exe-cuted. For example, if an annotatorwas configured to capture provenanceassociated with the crustal model ac-tivity CreateForwardModel it wouldsearch the file system for the exis-tence of a SouthwestCrossSection,which would provide evidence that theCreateCrossSection was executed;
9. [Optional] In the absence of a com-prehensive search capability for seman-tic annotations published on the Web,i.e., a search engine that can locateand index semantic annotations, iden-tify the location where provenance doc-uments are initially stored. This stepmay be also required if standard searchcapabilities are insufficient for selectingprovenance-related search criteria;
10. [Optional] In the absence of a compre-hensive search capability for semanticannotations published on the Web, cre-ate a routine for crawling the prove-nance documents and for storing themin a triple-store database.
Figure 5 shows the outcomes that a scientist obtainsafter each of the phases of the methodology. After StepA the scientist has established a basic vocabulary to talkabout the POD. This vocabulary is documented in theform of an ontology, i.e., a workflow-driven ontology.After Step B the scientist has created an abstract de-scription of the POD in terms of the vocabulary definedin the previous step. After Step C the scientist has a col-lection of provenance documents for each execution ofthe POD, where each of these provenance documentsis linked to its corresponding SOD.
The next section describes how these steps are ac-complished with the use of ontology encoding, abstractworkflow specification, and provenance, as well as withthe use of tools for managing these encodings.
Implementation—supporting tools and notations
This section explains how CI-Miner is implementedthrough the use of a collection of tools and notations.
Ontology support
In computer science, ontologies have gained a lot ofattention since the Semantic Web initiative was re-vealed in 2001 (Berners-Lee et al. 2001). Ontologies areartifacts used for capturing knowledge about a givendomain in terms of concepts and relationships amongconcepts. The way ontologies are created and used isdriven by their purpose of use. In particular, Guarino(1997) suggested the classification of ontologies accord-ing to their level of dependence to a particular task orpoint of view.
In the CI-Miner case, the focus is on the use oftask ontologies for capturing knowledge about a sci-entific discipline through the use of process-relatedconcepts. This approach is called workflow-driven on-tologies (WDOs) (Salayandia et al. 2006). The twomain classes of WDO upper-level ontology2 are Dataand Method. The Data class is representative of thedata components of a scientific process. These can bethings such datasets, documents, instrument readings,input parameters, maps, and graphs. The Method classis representative of discrete activities involved in thescientific process that transform the data components.The intention of WDOs is to allow scientists to captureprocess-related concepts by extending the hierarchiesof Data and Method (Steps A.1 and A.3 of the method-ology). Furthermore, Data and Method classes can berelated through isInputTo and isOutputOf relations tocapture their data-flow interdependencies with respectto a scientific process (Step 5 of the methodology).
Figure 6 shows a taxonomic representation frag-ment of the Crustal Modeling Workflow-Driven On-tology (cmwdo). As shown, cmwdo is a WDO be-cause the taxonomy is grounded on the wdo:Dataand wdo:Method classes. According to cmwdo,both DigitalElevationMap and GravityData areFieldData that may be used in a scientific process(because FieldData is of type wdo:Data). More-over, in terms of process functionalities, cmwdo showsthat a scientific process used to develop crustal models,i.e., CM, may have a step called CreateForward-Model, since it is a subclass of wdo:Method. As cmwdoshows us, these are the terms that geoscientists mayuse to describe the process of building crustal mod-els. It is important to note that the description of acrustal modeling scientific process is not in cmwdo: theontology does not know how many data instances and
2http://trust.utep.edu/1.0/wdo.owl

Earth Sci Inform (2009) 2:249–269 261
Fig. 5 Outcomes after eachstep of the methodology. aAfter Step A the outcome is aworkflow-driven ontologythat captures concepts relatedto the process of discourse(POD). b After Step B theoutcome is an abstractworkflow of the POD tocreate the subject ofdiscourse (SOD), where theabstract workflow isgrounded on the conceptsdefined in the ontology ofStep A. c After Step C theoutcome is a searchableprovenance artifact that islinked to the SOD
method instances are needed to implement the processand how these data instances and method instancesare connected to produce crustal models. WDO-It!3
(Pinheiro da Silva et al. 2007) is a tool that enablesscientists to create workflow-driven ontologies for theirarea of interest.
Workflow support
From a scientist’s perspective, processes can be gen-eralized as graphical structures containing the follow-ing: nodes representing discrete activities, and directededges representing data flow between those activities.Activities connected through edges effectively deter-mine data dependencies between the activities. In-formation fed into the process is provided by datasources, and information generated by the process maybe stored in a data sink. Traversing the graph from itsinitial data sources to its final data sinks simulates theaction of carrying out a complex process conformed ofsimpler activities. To deploy such a representation ofa process as an automated or semi-automated system,additional control flow information is necessary to de-termine the rules that guide the graph traversal.
According to the CI-Miner approach, scientificprocess specifications can be captured by semantic ab-stract workflows (SAWs). SAWs are artifacts capableof describing the process at a level of detail that isadequate for scientists. The term “semantic” refers to
3WDO-It! tool available at http://trust.utep.edu/wdo/downloads/.
the fact that nodes and edges of the workflow corre-spond to instances of concepts defined in an ontology,i.e., a WDO. “Abstract” refers to the fact that thecaptured process lacks additional constructs necessaryto produce automated systems that, for example, wouldimplement the modeled process as a scientific work-flow. In this sense, SAWs are not committed to beexecutable workflow specifications.
Figure 4 shows an example of the graphical notationof SAWs for our use case. Instances of wdo:Dataare represented by directed edges and instances ofwdo:Method are represented by rectangles. Data andmethods instances are labeled with a name given bythe scientist and prefixed with the name of their corre-sponding user-defined WDO class. SAW’s Sources andSinks are introduced in the graphical notation of SAWsas a bootstrapping mechanism to indicate the startingand ending points of a process, and these are repre-sented by ovals. Sources and Sinks are also labeled withthe name of their corresponding class defined in theprovenance component of the Proof Markup Language(PML-P) ontology discussed below.
WDO-It! can be used to build SAWs from WDOs(Step B.1 of the methodology). By dragging anddropping WDO data and methods inside a graphi-cal workspace, scientists can instantiate methods anduse data to connect methods. SAWs do not have thecapability to model control flow. This may be ben-eficial in that it removes a layer of complexity forthe scientist. For scientists who are more engaged inthe design process, however, this restriction may in-troduce a level of frustration, for instance, to include

262 Earth Sci Inform (2009) 2:249–269
Fig. 6 Crustal Modeling Workflow-Driven Ontology
information such as the number of times a methoditerates or the conditions for the execution of methods.Despite these limitations, the benefits of SAWs lay intheir simplicity to describe scientific processes, as wellas to include additional information related to prove-nance as described in the following section.
Provenance support
Once a SAW has been authored, e.g., using the WDO-It! tool, it can be used to drive the generation of“data annotators” that are modules designed to captureprovenance associated with workflow activities (StepC.3 of the methodology). Executing a set of data anno-tators corresponding to a single SAW is similar to exe-cuting a workflow in the sense that some coordinatingagent is needed for both the synchronized invocationof each data annotator and for the message passingfacilities needed for communicating between them.
Data annotators are built for the main purpose oflogging provenance; they do not transform data belong-ing to the scientific process of interest. Therefore, dataannotators use provenance as the exclusive languagefor communication (i.e., the inputs and outputs of dataannotators are provenance elements). When using dataannotators, provenance is transformed by each anno-tator by always enhancing the input provenance tracewith more information.
The provenance captured in CI-Miner is encoded inthe Proof Markup Language (PML) (McGuinness andPinheiro da Silva 2004; Pinheiro da Silva et al. 2008),which is designed to support distributed provenance;thus, data annotators can too be distributed along withany remote services that are invoked by a workflow.This is possible because the inputs to data annotators,which are PML node sets associated with executions
of the dependent workflow activities, are referenced byURIs. This is convenient because often times complexscientific processes are modularized and controlled bya master script that in turn makes calls to serviceswhich may or may not be located remotely. In thesecases, the agent coordinating the data annotators doesnot need to know about provenance as a whole, butonly encounters the URIs of intermediate provenanceelements.
The goal of capturing provenance about data is tosupport the explanation of how data is created or de-rived, e.g., which sources were used, who encoded thedata, and more. As shown in Fig. 7, the PML ontologydefines primitive concepts and relations for represent-ing provenance about data. PML is divided into twomodules McGuinness et al. (2007):4
– The justification module5 (PML-J) defines conceptsand relations to represent dependencies betweenidentifiable things;
– The provenance module6 (PML-P) defines conceptsto represent identifiable things from the real worldthat are useful to determine data lineage. For ex-ample, sources such as organization, person, agent,service, and others are included in PML-P.
The goal of the justification ontology is to providethe concepts and relations used to encode the infor-mation manipulation steps used to derive a conclu-sion. A justification requires concepts for representingconclusions, conclusion antecedents, and the informa-tion manipulation steps used to transform/derive con-clusions from antecedents. Although the terms in thejustification ontology stem from the theorem provingcommunity, they can be mapped into terms used todescribe worflow components; for example, conclusionsrefer to intermediate data and antecedents refer tothe inputs of some processing step. The justificationvocabulary has two main concepts: pmlj:NodeSetand pmlj:InferenceStep. A pmlj:NodeSet in-cludes structure for representing a conclusion and a setof alternative pmlj:InferenceSteps each of whichprovides a distinct justification for the conclusion. Theterm pmlj:NodeSet is chosen because it captures thenotion of a set of nodes (with inference steps) fromone or many proof trees deriving the same conclusion.Every pmlj:NodeSet has exactly one unique identi-fier that is web-addressable, i.e., a URI.
4The ontology includes a trust relation module that is not used byCI-Miner.5http://inference-web.org/2.0/pml-justification.owl6http://inference-web.org/2.0/pml-provenance.owl

Earth Sci Inform (2009) 2:249–269 263
IdentifiedThing
InformationSource
Agent
DocumentOrganizationPersonSensorSoftware
Inference EngineWeb Service
DatabaseData SetOntologyPublicationWebsite
Thing
PML Ontology
NodeSet (hasConclusion, isConsequentOf)
InferenceStep (hasAntecedent)
Thing
PMLJ ModulePMLP Module
Fig. 7 A simplified view of the PML Ontology
Figure 8 outlines a PML node set capturingthe processing step implemented by an instanceof cmwdo:CreateForwardModel in Fig. 4. Theoutput of cmwdo:CreateForwardModel is an
instance of cmwdo:CrustalModel calledSouthwestCrustalModel-Draft, and thisdata is captured in the Conclusion element as aninstance of pmlp:Information, as described below.
<rdf:RDF> <NodeSet rdf:about="http://.../CrustalModeling.owl#answer"> <hasConclusion> <pmlp:Information> <pmlp:hasURL rdf:datatype="http://www.w3.org/2001/XMLSchema#anyURI"> http://.../CrustalModel.dat </pmlp:hasURL> <pmlp:hasFormat rdf:resource="http://.../registry/FMT/CrustalModel.owl#model"/> </pmlp:Information> </hasConclusion> <isConsequentOf> <InferenceStep> <hasInferenceEngine rdf:resource="http://.../pmlp/FwdModelSoftware.owl#GM_SYS"/> <hasInferenceRule rdf:resource="http://.../pmlp/CrustalModeling.owl#CreateForwardModel"/> <hasAntecedentList> <NodeSetList> <ds:first rdf:resource="http://.../proof/CrossSection.owl#answer"/> <ds:next rdf:resource="http://.../proof/GravityData.owl#answer"/> <ds:last rdf:resource="http://.../proof/MagneticData.owl#answer"/> </NodeSetList> </hasAntecedentList> </InferenceStep> </isConsequentOf> </NodeSet></rdf:RDF>
Fig. 8 Example of a provenance encoding in PML

264 Earth Sci Inform (2009) 2:249–269
Additionally, the inputs consumed by cmwdo:-CreateForwardModel are captured as Antecedentsof the node set’s inference step.
Figure 7 shows that the foundational concept inPML-P is pmlp:IdentifiedThing, which refers toan entity in the real world. These entities have at-tributes that are useful for provenance such as name,description, create date-time, authors, and owner. Forexample, in Fig. 8 the node set is adorned with PML-P instances that effectively convey that this nodeset corresponds to an execution of cmwdo:Create-ForwardModel. The PML-P inference engine instanceis named GM-SYS to indicate that this captured step isin fact an execution of a software system called “GM-SYS”. Furthermore, the PML-P inference rule instancedescribes the specific step, (e.g., CreateForward-Model) in terms of what the step does and what organi-zation is responsible for this particular implementationof the algorithm. PML includes two key subclasses ofpmlp:IdentifiedThing motivated by provenancerepresentational concerns: pmlp:Information andpmlp:Source. The concept pmlp:Informationsupports references to information at various levels ofgranularity and structure. The concept pmlp:Sourcerefers to an information container, and it is oftenused to refer to all the information from the con-tainer. A pmlp:Source is further specialized into apmlp:Agent or a pmlp:Document, and a documentcan be a database, a dataset, and a publication amongothers. PML-P provides a simple, but extensible taxon-omy of sources.
CI-Miner benefits and discussion
To demonstrate some of the benefits of our method-ology, we discuss the use of CI-Miner in a collection ofcase studies. To facilitate this discussion, we use the fivechallenges identified in our use case.
Process knowledge preservation
The main goal for steps A and B of the CI-Minerprocess is to generate documentation of a scientificprocess in a form that can be understood by a di-verse group of scientists. We have implemented theCI-Miner process in various projects and, as a result,have created accompanying ontologies and abstractworkflows representing process knowledge. Many ofthese implementations involve legacy systems, i.e., soft-ware systems already implemented to perform the au-tomated steps of scientific research activities. Initially,we found that many of the discussions of the processes
behind legacy-based systems focused on source code.These discussions occurred between a scientific teamof non-programmers and a few programmers and thediscussions would often break down. At times, therewas little understanding as to what the code was do-ing, regardless of a scientists exposure to the over-all process. Discussing abstract workflows built fromcommon terminology avoided the distractions resultingfrom discussions of variables, source code and pro-gram syntax. One interesting observation was when twoscientists, who had been working together for years,had fundamental disagreements as to how a processworked. By creating reproducible representations ofscientific activities, we were able to facilitate agree-ment with respect to the scientific process, addressingChallenge 1 in the use case. In this case, the ben-efit of creating abstract workflows was a consistentunderstanding of a single process understood in twodifferent ways. In many scientific processes, it wasnecessary to document both the steps performed bysoftware and those performed by a scientist. Someworkflow tools will not allow for such differentiation,e.g., all steps must be machine executable. Working atan abstract level within a workflow allowed the captureof scientific process knowledge, regardless of imple-mentation details. One final benefit of the CI-Minerstep to capture process knowledge comes from us-ing semantically annotated technology. Many projects,with which we worked, needed to integrate datasetsavailable over the Web. For example, the Virtual Solar-Terrestrial Observatory (VSTO) ontology7 is beingused by one project to describe a process for capturingimages of the sun. By using ontologies to describe in-puts, we were able to harvest the terminology within theVSTO ontology and use it in the project’s workflows.In this way, the workflows reuse terminology from atrusted and accepted source.
Provenance knowledge preservation
An important benefit to building abstract workflowsis the direction workflows give to provenance preser-vation. Using the technologies available to CI-Miner,in particular PML, we were able to build deposits ofprovenance information at data sources. For example,PML-P nodes were made to annotate the characteris-tics of data reading instruments and the nodes werepublished for access over the Web. Whenever data isaccessed from these instruments, the related PML-Pnode provides an explanation. Within the semantically
7http://dataportal.ucar.edu/schemas/vsto.owl

Earth Sci Inform (2009) 2:249–269 265
annotated abstract workflows of CI-Miner, source in-formation can be shown as inputs and outputs of com-ponents. With specific characteristics about the source,we are able to understand workflow components withinthe context of the workflow, not just at the distributedweb location. Given that the workflow captures thesteps within the process and has access to knowledgeabout that process, it can automatically generate ascript that would direct the provenance capture frominputs and outputs and to build data annotators. Theannotators facilitate the collection of source informa-tion when the scientific process is actually executed.By following the CI-Miner methodology and using thecombination of tools available, e.g., abstract workflows,source information and data annotators, a significantamount of provenance has been built into the real-time collection of data for a scientific process involvingsolar physics. In an environmental study, we neededto annotate data that was produced days, weeks, andeven years ago. As a result, there were thousands ofdata files so a manual approach to annotating them wasunrealistic. To help with this challenge, the workflowwas used to understand the overall process of capturingthe data, and post-processing annotators were built toannotate the data. The overall result, whether usingdata annotators or post-processing annotators, is theaggregation of provenance to the scientific artifacts.Moreover, the preserved provenance is in a structuredformat, machine readable and available for access overthe Web, resulting in searchable descriptions of datathat can be used by other scientists to understand theresults. The accomplishments described above addressChallenge 2 in the use case.
Data integration and interoperability capabilities
Data integration is facilitated by WDOs, SAWs, andontologies harvested by WDOs. The data hierarchy ina WDO provides an explicit way of annotating whetherthe content of two data sets have the same kind of mea-surements, and SAWs identify where these datasetsare used in the process. For example, Fig. 4 shows theCM use of a dataset called SouthwestGravityData,which is of type cmwdo:GravityData. This meansthat the CM process can be repeated for other re-gions of the planet as long as the dataset used in thisstep of the process is about gravity measurements inthe new region of interest and the dataset is of typecmwdo:GravityData. Furthermore, lets say that ascientist decides to produce crustal models for an ex-tensive area of the U.S., e.g., the western part of theU.S. In this case, the ProfileLineDecision stepin the CM process could be based on a new dataset
of type cmwdo:GravityData derived from the merg-ing of the content of SouthwestGravityData andNorthwestGravityData datasets.
A more complex data integration scenario iswhen datasets are not of the same type, but stillneed to be integrated. For instance, according toFig. 6, cmwdo:GravityData is a specializationof cmwdo:FieldData. To execute the Profile-LineDecision step for the western part of theU.S., let’s assume that the NorthwestGravity-Data is of type cmwdo:FieldData, but not of typecmwdo:GravityData. This means that some of theattributes in the two datasets are the same, which iswhy both datasets are of type cmwdo:FieldData),and others are different. In this case, data integrationmay be accomplished by inspecting the hierarchicalstructure provided by the ontology and the specifica-tions of the fields of these datasets. These specificationsmay be available in the ontologies describing thesedatasets and the ontologies harvested by WDO. Thus,through these inspections, tools can perform semanticmatching (Giunchiglia and Shvaiko 2003) to verify howterms are pair-wise related and if the datasets can becombined. If such a description is unavailable, scientistswould need to analyze the datasets manually and de-termine how their concepts match semantically. Evenin this situation, there is still benefit in using WDOsand SAWs to document scientists’ findings that wouldenable future data integration efforts. The semantic en-hancements described above are essential steps towardsa systematic data integration approach based on CI-Miner. These enhancements address Challenge 3 in theuse case.
In terms of interoperability, WDOs, SAWs and PMLare encoded as OWL documents. Using OWL termi-nology, WDOs are OWL documents describing onto-logical classes and relations, while SAWs are OWLdocuments describing instances of the classes and prop-erties defined in WDOs.
Search and query capabilities
Many computationally expensive processes are oftenrepeated multiple times because of the difficulty sci-entists may have to search for process results whetherthey are published on the Web or stored in a localfile-system. For instance, the scientist using the crustalmodeling SAW needs to decide a profile line for thesouthwest part of the United States. To make thisdecision, according to Fig. 2, the scientist may needto use a BouguerAnomalyMap about the southwestregion of the U.S. However, if Bouguer Anomaly maps

266 Earth Sci Inform (2009) 2:249–269
are published on the Web, chances are that no searchengines can locate them just with the use of keywords.
Without the use of semantic annotation, searchengines are limited on how much knowledge theyare capable of extracting out of ordinary Web con-tent (McGuinness 1998), i.e., non-annotated web con-tent. If Bouguer Anomaly maps are semanticallyannotated, for example, with the use of CI-Miner,and published in a place that can be indexed by asemantic-aware search engine such as IWSearch (Pin-heiro da Silva et al. 2008) and Swoogle (Ding et al.2004), then the scientist may be able to locate theappropriate map.
The characteristics of the request in the above ex-ample are: The object is a Bouguer Anomaly map; itis derived from gravity data; and the gravity data isfrom the southwest region of the U.S. These are allproperties that can be verified against the map prove-nance. To explain how they are verified, we need tounderstand the difference between how IWSearch andgeneral-purpose search engines work.
– Looking for PML documents. Like other searchengines, IWSearch crawls the Web, i.e., follows thehyper-links in the URL to identify new URLs re-cursively, creating this way a list of URLs. Differentthan most search engines, IWSearch can identifyPML documents from a list of URLs. For the URLsthat are PML documents, IWSearch can get theircontent and use to populate a database that isthen used to answer queries, e.g., SPARQL queriesPrud’hommeaux and Seaborne (2008). This meansthat internally, IWSearch can import the knowl-edge encoded in PML documents and use queriesto retrieve specific properties about selected PMLdocuments. For example, in a trivial way, we canuse queries to list the known responses for eachexecution of the CreateContourMap method inCM. In terms of queries, a database managementsystem would retrieve all the objects in the databaseof type NodeSet and from these node sets it wouldretrieve the InferenceSteps that execute themethod CreateContourMap.
– Select PML documents about Bouguer Anomalymaps. A first SPARQL query would ask for PMLdocuments that are node sets which have conclu-sions of the type BouguerAnomalyMap, e.g., thedocument in Fig. 8). This would reduce drasticallythe number of PML documents that have the po-tential to answer the scientist’s request.
– Select Bouguer Anomaly maps derived from gravitydata. From this pool of Bouguer Anomaly maps,IWSearch performs a more complex and expen-
sive combination of SPARQL queries that woulduse the relationships between node sets (the has-Antecedents property inside of inference steps)to traverse down the PML proof trace of each mapand identify those maps that were derived fromdatasets of type GravityData. In this case, thesegravity datasets are also the conclusions of othernode sets reached in the process of traversing downthe derivation paths of each Bouguer Anomalymap. This is a step that can be pre-processed foreach PML node set added to the triple-store data-base.
– Select gravity data from the southwest region of theU.S. Finally, by inspecting the node sets holdingthe datasets of type GravityData, IWSearch canverify which ones are from the southwest region ofthe U.S. by verifying the parameter values used toretrieve the gravity data from the PACES database.
As one can see, semantic annotation enables thetask of searching for scientific data and other products.Without the use of semantic annotations in the BouguerAnomaly map example, it would be much harder ifeven possible for a scientist to locate the map of in-terest. This query capability addresses the Challenge4 in the use case. We claim that CI-Miner addressesChallenge 4 because the semantic annotations usedto represent abstract workflows and provenance, i.e.,WDOs, SAWs, and PML documents, are encoded inOWL and based on Web technologies that includeURLs and namespaces. Further, CI-Miner uses novelapproaches for searching and querying the content ofthese semantic annotations, e.g., triple-store technolo-gies may be used to query WDOs, SAWs, and PML. Inaddition to the query capabilities mentioned above, itis worth mentioning that the queries considered in theCM use case are defined in terms of scientists’ terminol-ogy: the BouguerAnomalyMap was originally definedin a workflow-driven ontology like the one presentedin Fig. 6 and developed by the scientists (Keller et al.2004).
Visualization capabilities
The capability of visualizing process components andresults (Challenge 5 in our use case), whether the re-sults are intermediate or final, is as important as thecapability of searching for these results. For example,for the gravity datasets provided by PACES in Fig. 2,we can consider the use of three visualizations: textualview, plot view, and XMDV view. The default textualview is a table; the raw ASCII result from gravitydatabase. The location plot viewer provides a 2D plot

Earth Sci Inform (2009) 2:249–269 267
Fig. 9 Different viewers forgravity data sets
of the gravity reading in terms of latitude and longitude.XMDV, on the other hand, provides a parallel coordi-nates view, a technique pioneered in the 1970’s, whichhas been applied to a diverse set of multidimensionalproblems (Xie 2007). Figure 9 shows a pop-up of the2D plot and XMDV visualizations in their respectiveviewer windows. Upon selecting a node set in a gravitydata derivation trace, provenance visualization toolslike ProbeIt!8 (Del Rio and Pinheiro 2007) are ableto determine, based on a semantic description of theoutput data, which viewers are appropriate. This issimilar to a Web browser scenario in which transmitteddata is tagged with a MIME-TYPE that is associatedwith a particular browser plug-in. These visualizationtools should be flexible enough to support a wide arrayof scientific conclusion formats just as Web browserscan be configured to handle any kind of data, butalso leverage any semantic descriptions of the data.For example, XMDV is a viewer suited to any n-dimensional data; the data rendered by XMDV needonly be in a basic ASCII tabular format, as shown onthe left hand side of Fig. 9. Because gravity datasets areretrieved in an ASCII tabular format, XMDV can beused to visualize them. However, this kind of data isalso semantically defined as being of type Gravity-Data, in which case provenance visualization toolsneed to be configured to invoke a 2D spatial viewer, asshown in Fig. 9. The semantic capabilities provided bythese tools need to complement the MIME tables usedin typical Web browsers, which only indicate the formator syntax of the data.
8ProbeIt! tool available at http://trust.utep.edu/probeit/applet/
Semantic annotations captured by CI-Miner enablethe task of visualizing scientific data and other products.Without the use of semantic annotations to identifythe kind of data available in the gravity datasets inthe example above, it would be difficult for scientists1) to have access to these intermediate results and 2) toknow which tool to use to visualize these results. Thisvisualization capability corresponds to the Challenge5 in our use case. We claim that CI-Miner addressesChallenge 5 because of the following: the SAW spe-cification includes a visual notation used to presentabstract workflows to scientists; tools like Probe-It pro-vide browsing capabilities for PML at the same timethat it reuses conventional and state-of-the-art visual-ization capabilities to support the visualization and dataanalysis of scientific data and their provenance.
Conclusions and future work
This article introduces CI-Miner methodology for se-mantically enhancing scientific processes. The steps inthe methodology take into consideration the need forscientists to be fully involved in semantic enhancementsof scientific processes, whether processes are entirelyperformed by humans, executed by machines, or acombination of both. In CI-Miner, scientists can createdomain-specific terminologies encoded as workflow-driven ontologies and can use these ontologies to sup-port the specification of both abstract workflows aboutscientific processes and provenance about the outcomeof scientific process executions. One of the goals ofCI-Miner is to capture and preserve knowledge aboutscientific processes.
The use of both abstract workflows and provenanceto annotate scientific data and products allow semantic-

268 Earth Sci Inform (2009) 2:249–269
aware tools to support complex tasks, which has beenidentified as a challenge for conventional scientificprocesses. Semantic data integration allows scientistsand semantic-enabled tools to figure out whether twodatasets have the same type and, if not, whether twoattributes in distinct datasets are of the same type. Dataintegration processing leverages knowledge encoded inontologies (including workflow-driven ontologies) andabstract workflows. Semantic search leverages theknowledge encode in provenance allowing scientiststo look for specific components of scientific processes.Semantic visualization allows scientists to visually an-alyze and understand many components of scien-tific processes, including diagrams representing theprocess specifications. The approach supports multiplevisualization strategies for each process result. Themethodology has the potential of enabling scientificcommunities to take advantage of an entire new gen-eration of semantically-enabled tools and services thatare under development by industry and academic orga-nizations.
CI-Miner was originally designed to enhance scien-tific processes to support interdisciplinary projects atUTEP’s CyberShARE Center9 that required dealingwith multiple scientific processes that are at differentmaturity levels, that are applied to a distinct scien-tific field, i.e., geo-science, environmental sciences andcomputational mathematics, and that are supported bya distinct community. CI-Miner has been a collectiveeffort among the communities directly involved withCyberShARE and with members of the Mauna Loa So-lar Observatory at the National Center of AtmosphericResearch. One of the most important results of CI-Miner to date is that its development has brought dis-tinct communities closer, making possible for them tocollaborate and share resources.
Acknowledgements This work was supported in part by NSFgrants HRD-0734825 and EAR-0225670.
References
Aldouri R, Keller G, Gates A, Rasillo J, Salayandia L,Kreinovich V, Seeley J, Taylor P, Holloway S (2004) GEON:geophysical data add the 3rd dimension in geospatial studies.In: Proceedings of the ESRI international user conference2004. San Diego, CA, p 1898
Ashish N, Knoblock C (1997) Wrapper generation for semi-structured internet sources. ACM SIGMOD Rec 26(4):8–15
Baker PG, Goble CA, Bechhofer S, Paton NW, Stevens R, BrassA (1999) An ontology for bioinformatics applications. Bioin-formatics 15(6):510–520. doi:10.1093/bioinformatics/15.6.510
9http://cybershare.utep.edu/
Barga RS, Digiampietri LA (2008) Automatic capture and effi-cient storage of e-science experiment provenance. ConcurrComput: Pract Experience 20(5):419–429
Berners-Lee T, Hendler J, Lassila O (2001) The semantic web.Sci Am 284:34–43
Bray T, Paoli J, Sperberg-McQueen CM, Maler E, Franc oY(2008) Extensible Markup Language (XML) 1.0 (fifth edi-tion) W3C recommendation
Clifford B, Foster IT, Vöckler JS, Wilde M, Zhao Y (2008) Track-ing provenance in a virtual data grid. Concurr Comput: PractExperience 20(5):565–575
Davidson SB, Cohen-Boulakia S, Eyal A, Ludascher B,McPhillips TM, Bowers S, Anand MK, Freire J (2007)Provenance in scientific workflow systems. IEEE Data EngBull 30(4):44–50
Del Rio N, Pinheiro da Silva P (2007) Probe-it! visualizationsupport for provenance. In: Bebis G, Boyle RD, Parvin B,Koracin D, Paragios N, Syeda-Mahmood TF, Ju T, LiuZ, Coquillart S, Cruz-Neira C, Müller T, Malzbender T(eds) ISVC (2), lecture notes in computer science, vol 4842.Springer, New York, pp 732–741
Ding L, Finin T, Joshi A, Pan R, Cost RS, Peng Y, ReddivariP, Doshi V, Sachs J (2004) Swoogle: a search and metadataengine for the semantic web. In: CIKM ’04: proceedings ofthe thirteenth ACM international conference on informa-tion and knowledge management. ACM, New York, pp 652–659. doi:10.1145/1031171.1031289
Edwards PN, Jackson SJ, Bowker GC, Knobel CP (2007) Un-derstanding infrastructure: dynamics, tensions, and design.Technical Report, School of Information, University ofMichigan. (Final report of the workshop, “History and the-ory of infrastructure: lessons for new scientific cyberin-frastructures”)
Fonseca FT, Davis CA, Câmara G (2003) Bridging ontologiesand conceptual schemas in geographic information integra-tion. Geoinformatica 7(4):355–378
Gates AQ, Pinheiro da Silva P, Salayandia L, Ochoa O, GandaraA, Del Rio N (2009) Use of abstraction to support geoscien-tistsúnderstanding and production of scientific artifacts. In:Keller G, Baru C (eds) Geoinformatics: cyberinfrastructurefor the solid earth sciences. Cambridge University Press,Cambridge (in press)
Gil Y, Ratnakar V, Deelman E, Spraragen M, Kim J (2006)Wings for pegasus: a semantic approach to creating verylarge scientific workflows. In: Proceedings of the OWL: ex-periences and directions (OWLED-06), Athens, 10–11 No-vember 2006
Giunchiglia F, Shvaiko P (2003) Semantic matching.Technical Report, vol 71, CEUR - WS. http://sunsite.informatik.rwth-aachen.de/Publications/CEUR-WS/Vol-71/Giunchiglia.pdf
Guarino N (1997) Semantic matching: formal ontological distinc-tions for information organization, extraction, and integra-tion. In: Proceedings of SCIE, pp 139–170
Jösang A, Knapskog S (1998) A metric for trusted systems. In:Proceedings of the 21st NIST-NCSC national informationsystems security conference, pp 16–29
Kamvar S, Schlosser M, Garcia-Molina H (2003) The Eigentrustalgorithm for reputation management in P2P networks. In:Proceedings of the 12th international conference on WorldWide Web, pp 640–651
Keller G, Hildenbrand T, Kucks R, Webring M, Briesacher A,Rujawitz K, Torres R, Gates A, Kreinovich V (2004) A com-munity effort to construct a gravity database for the UnitedStates and an associated Web portal. In: Special paper ongeoinformatics, Geological Society of America

Earth Sci Inform (2009) 2:249–269 269
Kim J, Deelman E, Gil Y, Mehta G, Ratnakar V (2008) Prove-nance trails in the wings/pegasus system. Concurr Comput:Pract Experience 20(5):587–597
Kushmerick N (1997) Wrapper induction for information extrac-tion. PhD thesis, University of Washington
McGuinness DL (1998) Ontological issues for knowledge-enhanced search. In: Guarino N (ed) Proc of the 1st interna-tional conference on formal ontology in information systems(FOIS’98). IOS Press, Trento, Italy, pp 302–316
McGuinness DL, Pinheiro da Silva P (2004) Explaining answersfrom the semantic web. J Web Semant 1(4):397–413
McGuinness DL, van Harmelen F (2004) OWL Web ontol-ogy language overview. Technical Report, World WideWeb Consortium (W3C). Recommendation, http://www.w3.org/TR/owl-features/
McGuinness D, Ding L, Pinheiro da Silva P, Chang C (2007)PML2: a modular explanation interlingua. In: Proceedings ofthe AAAI 2007 workshop on explanation-aware computing.Vancouver, British Columbia, Canada
Miles S, Groth P, Munroe S, Moreau L (2009) Prime: amethodology for developing provenance-aware applica-tions. ACM Trans Softw Eng Methodol. http://eprints.ecs.soton.ac.uk/17450/
NASA/Science Office of Standards and Technology (1999) Defi-nition of the Flexible Image Transport System (FITS), Stan-dard NOST 100-2.0
Pinheiro da Silva P, Salayandia L, Gates A (2007) Wdo-it! a toolfor building scientific workflows from ontologies. TechnicalReport UTEP-CS-07-50, University of Texas at El Paso, ElPaso, TX
Pinheiro da Silva P, McGuinness DL, Del Rio N, Ding L (2008)Inference web in action: lightweight use of the proof markuplanguage. In: International semantic web conference
Pinheiro da Silva P, Sutcliffe G, Chang C, Ding L, Del RioN, McGuinness D (2008) Presenting TSTP proofs with in-ference Web tools. In: Schmidt R, Konev B, Schulz S(eds) Proceedings of the workshop on practical aspectsof automated reasoning, 4th international joint confer-ence on automated reasoning. Sydney, Australia, Accep-ted
Prud’hommeaux E, Seaborne A (2008) Sparql query language forrdf. W3C Recommendation
Salayandia L, Pinheiro da Silva P, Gates AQ, Salcedo F (2006)Workflow-driven ontologies: an earth sciences case study. In:Proceedings of the 2nd IEEE international conference on e-science and grid computing. Amsterdam, Netherlands
Simmhan YL, Plale B, Gannon D (2008) Karma2: provenancemanagement for data-driven workflows. Int J Web ServiceRes 5(2):1–22
Taylor IJ, Deelman E, Gannon DB, Shields M (2006) Workflowsfor e-science: scientific workflows for grids. Springer, NewYork
Wroe C, Stevens R, Goble C, Roberts A, Greenwood M (2003) Asuite of daml+oil ontologies to describe bioinformatics webservices and data. Int J Coop Inf Syst 12(2):597–624 (specialissue on Bioinformatics)
Xie Z (2007) Towards exploratory visualization of multivariatestreaming data. http://davis.wpi.edu/
Zaihrayeu I, Pinheiro da Silva P, McGuinness DL (2005)IWTrust: improving user trust in answers from the Web.In: Proceedings of 3rd international conference on trustmanagement (iTrust2005). Spring, Paris, France, pp 384–392
Zhao J, Goble CA, Stevens R, Turi D (2008) Mining taverna’ssemantic web of provenance. Concurr Comput: Pract Expe-rience 20(5):463–472




















