
Observation and Estimation in Linear Descriptor Systems With ...

bi-SIFT: Towards a semantically relevant local descriptor
Ignazio Infantino, Filippo VellaConsiglio Nazionale delle Ricerche
ICARViale delle Scienze ed. 11,
Palermo, ITALYEmail: [email protected]
Giovanni Spoto, Salvatore GaglioUniversita degli Studi di Palermo,
DINFOViale delle Scienze ed. 9,
Palermo, ITALYEmail: [email protected]
Abstract—Local features are widely adopted to de-scribe visual information in tasks for image registrationand matching. Nowadays the most used and studied localfeature is SIFT (Scale Invariant Feature Transform)[1]since it assures a powerful local description and theinvariance when little changes in the viewpoint occur.We propose a feature that is based on SIFT features andtends to capture larger image areas in images and can beused for semantic based task. These features are calledbi-SIFT for their resemblance with textual bigrams.We tested the capability of the proposed representationwith Corel data-set and publicly available image data-set. In particular we calculated the most representativesfeatures through a clusterization process and used thesevalue according to the visual terms paradigm. Experi-ments on the representation of sets of images with theproposed representation are shown. Results appear to beencouraging.
Keywords-Image Retrieval, Image analysis, Image rep-resentation, SIFT
I. INTRODUCTION
A growing trend in image classification andobject recognition has focused attention in findingspecific and particular objects instead to address therecognition of classes of objects. For this reason muchattention has been raised by the possibility to describeobjects and portion of an image with features able tocapture the appearance of particular point of interest[2] [3] [4] [5]. Among them SIFT (Scale InvariantFeature Transform) features [1] are widely adoptedto represent visual information for tasks involvingobject identification, image registration [6][7] andimage matching. These features have the properties tobe invariant to variation of scale, image rotation and
affine variation of viewpoint.Being local descriptors these features take into accountthe values of the pixels in a region around the keypoint but lack to capture a global information boundto the higher level semantic of a visual scene.On the other side, a descriptor aimed at capturingsemantic content - related to objects and “largescale” pattern - should represent characteristics thatare invariant for a great gamma of transformationand should capture values that are less affected bydifferent views and acquisition parameters.SIFT are a good starting point since they are invariantto rotation and scale variation and these propertiestend to preserve the objects characteristics in differentscenes.Changes of luminance are compensated by the SIFTrepresentation as gradient histogram that is invariantto variation in luminance, changes of scale arecompensated by the point selection, and changesof rotation are compensated by the orientationnormalization. Unfortunately local features, as SIFT,are bound to local regions and do not cover relevantportion of images. We propose a technique to composeSIFT features to create more abstract features relatedto wider areas in images. A more global informationis captured from values related to local features.The idea is similar to what is done in linguisticcomputation when couples of single words arecomposed in bigrams, creating a new symbolicrepresentation that is able to cover a larger languagesemantics than a single word [8] [9].In literature other works employ local descriptors todescribe image content and have been proposed byCsurka [10], Sivic and Zisserman [11] and Hare[12].

Csurka et al. [10] evaluate all the SIFT features for thedata-set, they build a cluster distribution with k-meansand represent the new images counting how manyfeatures fall in a chosen clusters. These new featuresare used as representation to classify test objects.Authors show promising results for the classificationof 7 objects.Similarly Sivic and Zisserman[11] use SIFT descriptorto form a set of values clustered and used as wordsto apply text retrieval techniques to matching objectsin keyframe of video sequences. To validate thematching among SIFT features a property of spatialconsistency is checked. In particular, a search areaformed considering the 15 nearest spatial neighborsis defined. A match between two regions centeredon a key point is validated if a key point, amongthe nearest 15 of the starting point, matches witha key point among the 15 nearest point around thetarget one. Matches that fall outside this frame are notconsidered as matching score.Hare et al. [12] applied a cross language latentsemantic indexing technique from computationallinguistic when the visual portion of information isdescribed by SIFT features.Ke and Sukthankar[13] adopt SIFT local descriptorsto create a more general descriptor. The proposeddescriptor is built considering the Principal ComponentAnalysis to linearly project high-dimensional data,given by the SIFT descriptors, to a low-dimensionaldata in the principal component space. Eachrepresentation deals with a single images keypoint.As further reference in literature, attempts to describeobjects with affine invariant descriptors can be found in[14][15]. Lazebnik et al. [14] propose descriptors thatshow invariance to affine transformation identifyingmatches among couple of images depicting the samesubject (authors concentrated their test on a set of sixhundreds butterflies), the initialized descriptors arematched against a larger validation set. Affine regionsare spotted with a Laplacian blob detector based onLindberg descriptors[4].The found regions are represented with multiple typesof image information as spin images[16] and RIFTdescriptors[17].Brown et al. [15] propose a family of features whichuse groups of interest points to form geometricallyinvariant descriptors. Interest point in the scenes are
located at the extrema of the Laplacian of the imagein scale-space and are described with a family of 2Dtransformation invariant features. In particular groupsof interest point which have in the nearest neighborsamong 2 and 4. The 2xn parameters transformationto a canonical frame are computed. The descriptoris formed resampling the region local to the interestpoints in the canonical frame. Hough Transform isused to find a cluster of features in 2D transformationspace. RANSAC is adopted to improve the 2Dtransformation estimate.
We considered that SIFT is a transformation veryuseful to capture local information generating hundredsor thousands of key points in a generic image and itis particularly suitable for tasks as image registrationor image matching. In this work, we propose a novelrepresentation achieved composing, in a suitable way,SIFT descriptors to create a reduced number of pointsin an image and that, at the same time, conveysa more abstract representation. The new descriptorscover a larger region instead of single point and thatturn out to be semantically more relevant than theoriginal patch of keypoint covered by SIFT descriptors.The representation generates features that tend to besemantically nearer to scene objects and image tags.The new feature maintains the property of keypointsin robustness against variations in illumination andchanges of scale and, for the particular way SIFTfeatures are composed and still holds the invarianceagainst rotations.We show in the experiments that this composite fea-ture, called bi-SIFT, generated from SIFTs allowsto have a reliable representation improving solutionsbased on SIFT. The paper is organized as follows:Section II describes the identification of keypointsand creation of SIFT features, Section III shows howfeatures are computed and how images are representedwith the proposed feature. In Section IV the results ofexperiment setup are shown. Finally in the section Vconclusions are drawn.
II. SIFT FEATURES
SIFT features have been proposed by Lowe [1]for detecting points that are invariant against changesin illumination, image scaling, image rotation. Thesefeatures follow the research of local features such ascorner detectors by Harris[2] and Lucas [3], scale-

space theory by Lindberg [4] and edge density byShi[5] . In particular, Lowe created local features aim-ing at identifying features less affected by geometric(as rotation, translation, scale change) and intensityvariation (linear variation).To automatically detect points that are more robustagainst these deformations, SIFTs are extracted cre-ating a pyramid of Gaussian image transformation atdifferent scales, finding in the pyramids the peaks thatare independent from variation in scale and normaliz-ing features according image dimension and rotation.In particular, the Gaussian Pyramid is calculated forthe sample image and from each layer of pyramidthe difference is calculated to obtain the Difference ofGaussian (DOG) pyramid. To get the local extrema inthe images, the neighbor points in the same scale and indifferent scales are considered and points are retainedwhen they are the greatest values among the neighborpoint in the same image and in all the other scales.Similarly are retained points that are the smallest. Thisstep is called keypoint localization.For each candidate point the location and orientationare evaluated. Considering that points with low contrastare difficult to detect and points along edges are veryunstable when noise is present, these points are dis-carded. Once the point is selected, an orientation his-togram formed with the gradient orientations of samplepoints within a region around the keypoint is formed.The orientation histogram has 36 bins covering the 360degree range of orientations. Each sample added tothe histogram is weighted by its gradient magnitudeand by a Gaussian-weighted circular window with aσ that is 1.5 times that of the scale of the keypoint.The modes of the histograms are considered as the
Figure 1: SIFT feature descriptor
dominant orientation for the given keypoints. All theorientation within the 80% of the maximum values areretained while the other values are discarded.The detected keypoints are represented forming a
descriptor with an orientation histogram on a regionformed by 4x4 neighbor pixels. Since the histogramsare populated considering orientation referred to thelargest gradient magnitude, the feature is invariantagainst rotations. Each histogram contains 8 bins eachand a descriptor contains 4 histograms around thekeypoint. The SIFT feature is then composed by 4x4x8= 128 elements. The normalization of histogram allowsa further degree of robustness against illuminationchanges. A schematic representation of SIFT featureis shown in figure 1.
III. PROPOSED FEATURE AND IMAGE
REPRESENTATION
SIFTs are reliable features and are robust againsttypical variation in picture viewpoint position.Notwithstanding they are local features and cover localproperties of objects and scenes. To create a feature asrobust as SIFT and able to describe wider areas ofimages and scenes we consider a suitable compositionof a set of keypoints in a region of image. The newfeature is composed taking into account the keypointsfalling in a circular region centered in a keypointand delimited by a fixed radius. The new feature willrepresent in a more abstract way a larger piece ofimage or a complex pattern allowing to capture largeportion of objects or scene invariant characteristics.The size of regions described by this novel feature (bi-SIFT) is driven by an empirically fixed parameter. Thisparameter is called spatial bandwidth b as it is coherentwith a spatial clustering in Mean Shift theory[18].The feature is built considering the keypoints fallingin a region centered on a keypoint. Inside this imageportion one or more keypoints can be found. If only apoint is falling in the region, meaning that the selectedpart of image captures a region with a reduced texturedinformation, the bi-SIFT feature is not generated. Inthe other case when more points fall in the regionaround the keypoint, a composite description of regionis considered. Not all the keypoints are taken intoaccount as, in this case, a variable size descriptor wouldbe created. A selection is made instead preserving themost relevant and stable information in the coveredareas. The property in SIFT descriptors that most of allmatches with stability and robustness of SIFT featuresagainst image transformation is the highest gradientmagnitude that can be evaluated as the module of themain orientation in the represented image patch. The

Figure 2: bi-SIFT composition
SIFT descriptors are then ordered according to theirhighest gradient magnitude and SIFT descriptors withhighest values are retained (in this case we set thisvalue to two but could be extended).The selected points are the most stable against variationin capture condition and are able to characterize sceneinvariant values. The new feature is formed by thejuxtaposition of the SIFT representation of the selectedpoints. A schematic representation of the new featureis shown in figure 2.This feature represents a wider area than SIFT de-
scriptors, maintaining invariance against change ofviewpoint.The value of the spatial bandwidth affects the stabilityand the representation capability of the bi-SIFT. If thevalue of spatial bandwidth is set to zero on the couplesof SIFT having the same keypoint would be chosen,if the value of the spatial bandwidth is set to a highervalue the covered area is larger but the feature is lessstable. In figure 3 it is plotted the number of bi-SIFTfor a generic image versus the value of the spatialbandwidth b between 1 and 25. The value chosen forthe parameter b is 6 because it is a good trade-offbetween the number of features and the stability of thedescriptors and if not otherwise indicated it is the valuethat is applied for the experimental setup.
The variation of luminance does not affect SIFTfor the normalization adopted and therefore will notaffect the bi-SIFT.Single SIFT features are also invariant againstvariation in scale. If a change of scale occurs the sameregion will be described by similar SIFT descriptorsin the scaled images. If two keypoints are selected toform a bi-SIFT feature in the original image, giventhat change of scale maintains the two points inside
Figure 3: Number of bi-SIFT vs spatial bandwidth
the spatial bandwidth, the same two keypoints willbe selected to form the bi-SIFT feature for the sameregion in the scaled image, providing invariance ofbi-SIFT against change of scale.If the image is rotated or the viewpoint is changed,a given region will produce an approximation of theoriginal bi-SIFT descriptor. Single points describedwith SIFT features are invariant, for SIFT properties,to rotation. A couple of keypoints forming a bi-SIFTfeature is mapped by rotation in two different positionbut since the gradient magnitude is not affected byrotation, the sort of feature will produce the samekeypoints order inside the given region and the samebi-SIFT will be formed thus assuring invarianceagainst rotations.For these properties, bi-SIFT descriptors are reliable indescribing portion of objects and relevant patterns inscenes. SIFT descriptors are related to relatively smallareas and if a couple of points that are accidentallynear in an images (e.g. a point from object anda point from background) will be greatly affectedby change of viewpoint and they will be retrievedin images depicting the same object in a differentscene with low probability. So the recurrence ofbi-SIFT feature asserts the presence of a given objector a characteristic pattern for a given scene. Some
Figure 4: Example of bi-SIFT in indoor scenes

examples of bi-SIFT are shown in 4 for two images ofthe indoor class of the Corel data-set. The distributionof bi-SIFT in the images shows how these featuresare typically placed along object edges and corners.
The proposed features, for their properties, can bealso profitably used to find reliable points for matchingbetween images. Some experiments about the matchingproperties of bi-SIFT are shown in figure 5d and figure5e.The images1 in figure 5 have been scaled with a factorfrom 0.75 to 1.25 and rotated. For each row in figure5d the performance with image 5a, 5b and 5c is shown.The x axis depicts the angle of rotation in degrees and yaxis the percentage of matching features. The trianglesare referred to bi-SIFT while the circle are referred toSIFT. The number of SIFT is much higher than thenumber of bi-SIFT and it happens in some case thatno match among bi-SIFT is found. In this case themarker is missing. On the other side when a match isdetected there is a very high probability that the matchis correct.The image 5e shows the experiment of the same imageset when data are aggregated according to the rotationangle. The x axis shows the change of scale between0.75 and 1.25 and the y axis shows the percentage ofcorrect matches.This tests have been lead using the SIFT implementa-tion by Vedaldi and Fulkerson[19].A further example of matching between images of theGraffiti data set is shown in figure 6. Images havebeen acquired with different points and the quality ofmatched points shows the good performance of the bi-SIFT also in image registration tasks. 2
Figure 6: Matching example with bi-SIFT
1Images are available at http://http://comminfo.rutgers.edu/conferences/mmchallenge/2010/02/10/nokia-challenge
2Images are available at http://www.robots.ox.ac.uk/∼vgg/data/data-aff.html
Given two images of the Graffiti data-set the match-ing among the two set of bi-SIFT are shown in figure.The plots show the values of Recall versus 1-Precisionin a similar way to what is done in [13].
Figure 7: Recall vs 1-Precision in matching task withGraffiti data-set
The two values are defined accordingly as:
recall =number of correct positive
number of total positive(1)
and
1− precision =number of false positivetotal number of matches
(2)
The plot shows as the bi-SIFT features allow ahigher precision with an equal recall compared to SIFTand how the performance is better when the spatialbandwidth, used to build the composition of SIFTdecreases. The tested values of b are among 3 and12.
A. Bag of bi-SIFT
Due to the invariance properties and descriptioncapability the proposed feature can be successfullyused to represent images in large data set. A typicalproblem in the description of large set of images canraise when the number of features extracted fromeach image can make the problem cumbersome. SIFT
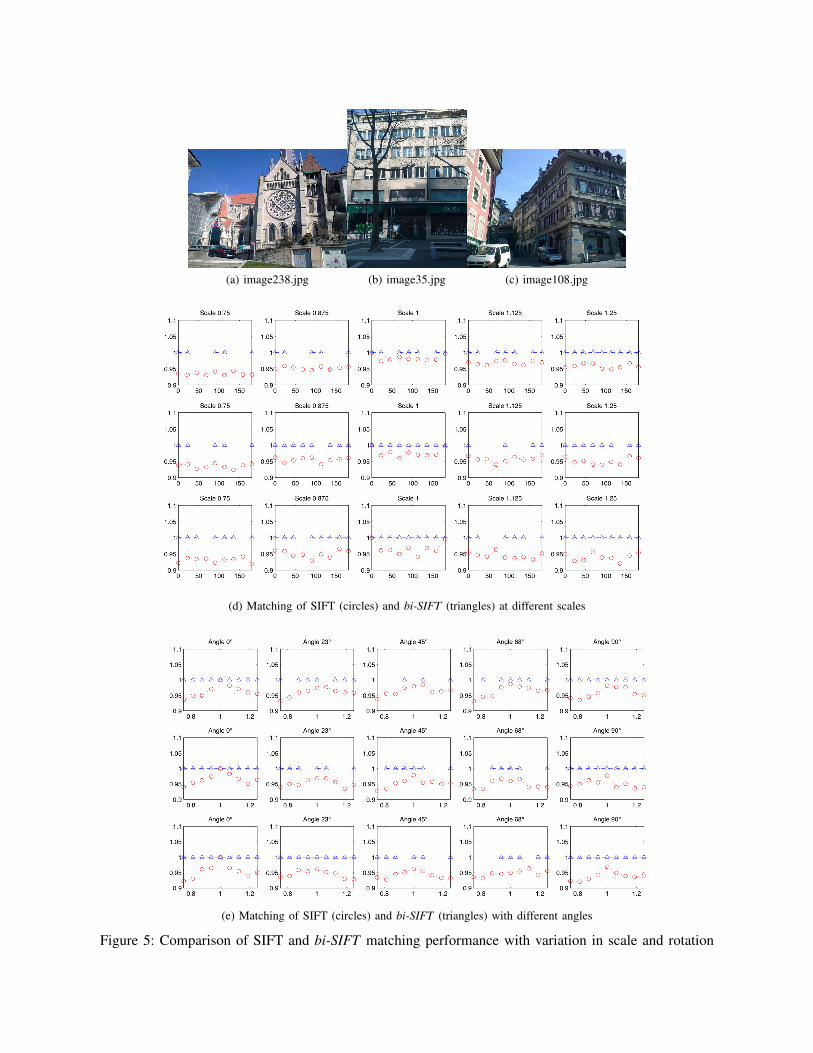
(a) image238.jpg (b) image35.jpg (c) image108.jpg
(d) Matching of SIFT (circles) and bi-SIFT (triangles) at different scales
(e) Matching of SIFT (circles) and bi-SIFT (triangles) with different angles
Figure 5: Comparison of SIFT and bi-SIFT matching performance with variation in scale and rotation

features are affected by this problem for the highnumber of features extracted from each image.Although the number of bi-SIFT is a reduced numberif compared with the number of SIFT, we choose toadopt and test the representation based on visual terms[20]. The main advantage of this technique is that toconsider the most relevant features and to representvalues according to the more frequent and intrinsicallymore significant points in the representation space.Here we propose the application of a techniquebased on visual terms where the feature to cluster isgiven by the above described bi-SIFT feature. Theunderlying hypothesis is that couples, or bigrams, ofSIFT are suitable to describe areas larger than thesingle local features expressed by SIFT and thesefeatures, collecting information at a level betweenobjects and pixels, are good candidates in the attemptfor the reduction of the semantic gap.
The conceived features are used to find reliablepoints in images for matching of local part of imagesand furthermore to represent the visual content ofimages. The set of local features is used to create adictionary of features for the description of a genericvisual content. The set of values used as symbolicdescriptor is evaluated clustering the bi-SIFT, repre-sented as vectors of 256 real numbers, and extractingthe centroids as fundamental values. For each categorythe corresponding set of bi-SIFT is considered and thevisual terms for each category is added to the globalset.A generic image is therefore represented as a bag ofvisual terms and different images will be representedby vectors considering the distribution of these valuesin the image.The process that extracts visual terms as centroidsof feature clusters allows to reduce the presence ofnoise in the features reducing the irrelevant informationin representation. Extracted visual terms are collectedforming a dictionary used to represent any visualcontent. Some examples of visual term obtained fromthe set of the bi-SIFT are shown in figure 8. For eachimage in the data-set the SIFT features are extracted,the points are coupled to form bigram of SIFT asdescribed above. For each bi-SIFT the nearest featurein the dictionary is found. For each image a vector witha cardinality equal to the size of visual dictionary, isfilled with the visual terms found in it.
Figure 8: Example of bi-SIFT visual terms for animage depicting a computer
The visual dictionary is evaluated considering all thebi-SIFT inside a given set of images and clusteringvalues for the bi-SIFT elaborated with the above de-scribed approach. In particular, clustering of featuresis accomplished through a technique based on thefeature density estimation. This technique is calledMean Shift since the algorithm iteratively follows themean vector along the gradient of density[18]. Thealgorithm is based on bandwidth parameter that drivesthe clusterization process and creates a number ofclusters according to the density estimation.For higher data dimension an improved version ofMean Shift has been proposed by the same authorscalled Adaptive Mean Shift. According this secondalgorithm data are partitioned with Local SensitiveHashing (LSH) to get a reduced dimension represen-tation of data. On the hashed data the Mean Shiftalgorithm is applied [21]. The clusterization parametersare picked empirically.The set of all the visual terms got from any category,through the clusterization process, is added to theglobal dictionary and will be used to describe animage in the data-set and a generic image too. Therepresentation of an image is achieved with a set ofvalues filled with tij values defined below:
tij =nij
nilog
N
Nj(3)
where nij is the number of occurrence of j − thvisual term in the i − th image, ni is the number ofterms in the i− th image, N is the number of imagesin the data set and Nj is the number of occurrenceof the j − th visual term. This processing multipliesthe term frequency nij/ni for the inverse documentfrequency log(N/Nj) giving an higher value to termsthat are present in shorter visual document and to lessfrequent visual terms.An advantage using bi-SIFT is the possibility to store

stable composition of SIFT keypoints. For example iftwo SIFT keypoints are near and related to the sameobject or the same pattern in the scene, when the viewchanges or the object is slightly moved in the scene,the bi-SIFT will not change considerably. On theother side, if the SIFT keypoints forming the bi-SIFTcome from different objects or came from an objectand background, there is a low probability that theywill be near in an other scene. In particular, duringthe clustering process, if no similar feature is found,feature will not contribute in forming clusters, sincethey are rare in images representation and definitelywill not affect global representation.
IV. EXPERIMENTAL RESULTS
The representation with bag of bi-SIFT has beentested with images from the Corel data set. It has beenwidely used as benchmark in image classification andannotation tasks (e.g.[20] [22]). It consists of 5000images divided in a set of CD containing images withhomogenous categories. Some images from category”computer” and ”tiger” are shown in the figure 9.
Figure 9: Example of Corel Images from categoryComputer and category Tiger
To reduce the experiments time and produce asubsampled test, a subset of 765 images has beenextracted from the Corel data-set. SIFT features havebeen calculated and have been coupled to form thecorresponding bi-SIFT features.Each image in the data-set has been processed todiscard the color information and to extract the SIFTfeatures. Although color channel conveys a relevantportion of information in this case we considerfeatures that involve just luminance information withthe possibility to add chroma information as anadditional information channel in a second moment.To evaluate the value of spatial bandwidth (see sectionIII), related to the image area covered by a bi-SIFTfeature, a clusterization process has been tested withdifferent values of spatial bandwidth. Results of
Figure 10: Number of Clusters versus the spatial band-width with Adaptive Mean Shift Clustering
experiments are shown in figure 10. The number ofcentroids versus the value of kernel bandwidth adoptedwith Adaptive Mean Shift is shown. In particular thevalues are plotted when the bi-SIFT spatial bandwidthis among 2 and 14. The graph shows that the largernumber of different centroids is produced when thevalue for the Adaptive Mean Shift kernel bandwidthis set to 0.065.
Figure 11: Number of not zero values versus thedistance
Features extracted are clustered with Adaptive MeanShift algorithm using a kernel bandwidth of 0.065 andvarying the spatial bandwidth in the feature creation.The centroids generated by the clustering process areused as visual terms allowing to describe images with aset of symbolic features. The process, as described in

Figure 12: Recall versus Precision
section III-A, creates a representation with each rowcorresponding to an image represented according tothe extracted set of visual terms. The representationof images with the tf-idf is function of the number ofvisual terms, of the chosen features and of the distanceused to match feature with visual terms.Figure 11 shows how the population of the matrix,having with rows referred to images and columnsreferred to visual terms, depends on the value ofdistance threshold used to match a given feature witha visual term. If distance threshold is too low, thereare few matches among image bi-SIFT and the visualterms; on the other side if threshold is too high manymatches are found and all these values are cut by theentropic filtering (see eq. 3). The plot is a gaussiancurve as shown in figure 11. For different value of bi-SIFT spatial bandwidth the gaussian curve is slightlyshifted. When the spatial bandwidth is set to 7, thedistance threshold that allows the least number of notzero value is 0.6.In figure 12 the Recall versus Precision is shown fortwo values of spatial bandwidth compared with SIFTcurve. The bi-SIFT curve corresponds to values ofspatial bandwidth equal to 2 and 12. The curves forthe other value of bandwidth are among these two onesand the SIFT curve is very near to the curve with valueequal to 2.
A further experiment, employing visual terms, hasbeen considered using the data set lausanne. Selectingimages of the set have been created 20 classes con-taining visually similar images. Each class contains 3
photos that are shot in the same place and with anintersection among the three figures. Images have beendescribed with SIFT and bi-SIFT visual terms and aretrieval experiment has been run.One image has been used as test image and a matchwith all the other images in the data-set has beencalculated. Images matched with the test image havebeen ordered according the number of found visualterms. A score has been assigned to the test if theimages in the same class have been retrieved amongthe first three images or not. If a single image of theclass has been found in the first three positions a scoreof 1 has been given, if two images have been found inthe first three positions, a score of 2 has been given.This experiment is analogous to the experiment of Keand Sukthankar in [13].The best average score when images are described withSIFT visual terms is 0.40 while the best average scorewith bi-SIFT is 0.5. For these experiments the visualterms have been generated employing Adaptive MeanShift clustering algorithm with a kernel bandwidthof 0.065. According to the kernel bandwidth and theclustering parameters the population of the matrix ofimages vs visual terms can be considerably changed.A plot of how these parameters affect retrieval andmatching performance is shown in figure 13.The best value when images are described with SIFTvisual terms (circles in the figure) is 0.40 when thematrix tf-idf has 227 not zero elements, while the bestscore with bi-SIFT (triangles in the figure) is 0.5 whenthe number of not zero elements is 591.
Figure 13: Score matching comparison between SIFT(circles) and bi-SIFT (triangles)

V. CONCLUSIONS
An approach aiming at creating a semantically rel-evant feature has been presented. The feature calledbi-SIFT is based on the well-know SIFT feature. Tocreate a more abstract representation features SIFTkeypoint descriptors are composed to form a featurethat resembles the text bigrams and that tends tocapture a larger part of image and can be used tosemantic oriented tasks. The feature has the invarianceproperties of SIFT and
Experiments show promising results and futureworks will include the application in task of sceneunderstanding and automatic image annotation.
REFERENCES
[1] D.G. Lowe, “Distinctive image features from scale-invariant keypoints,” International Journal of Com-puter Vision, vol. 60, pp. 91–110, 2004.
[2] C. Harris and M. Stephens, “A combined corner andedge detection,” in Proceedings of The Fourth AlveyVision Conference, 1988, pp. 147–151.
[3] B. D. Lucas and T. Kanade, “An iterative imageregistration technique with an application to stereovision,” 1981.
[4] T. Lindberg, “Effective scale: A natural unit formeasuring scale-space lifetime,” IEEE Transactionson Pattern Analysis and Machine Intelligence, vol. 15,no. 10, pp. 1068–1074, 1993.
[5] J. Shi and C. Tomasi, “Good features to track,” inProceedings of the Conference on Computer Vision andPattern Recognition, June 1994, pp. 593–600.
[6] S Cheng, V. Stankovic, and L. Stankovic, “Improvedsift-based image registration using belief propagation,”Acoustics, Speech, and Signal Processing, IEEE Inter-national Conference on, vol. 0, pp. 2909–2912, 2009.
[7] Y. Fan, M. Ding, Z. Liu, and D. Wang, “Novelremote sensing image registration method based onan improved SIFT descriptor,” in Society of Photo-Optical Instrumentation Engineers (SPIE) ConferenceSeries, Nov. 2007, vol. 6790 of Society of Photo-Optical Instrumentation Engineers (SPIE) ConferenceSeries.
[8] I. Infantino, G. Spoto, F. Vella, and S. Gaglio, “Com-position of SIFT features for robust image representa-tion,” in Multimedia Content Access: Algorithms andSystems IV, Proceedings of Society of PhotographicInstrumentation Engineers (SPIE), 2010, vol. 6540B.
[9] I. Infantino, G. Spoto, F. Vella, and S. Gaglio, “Imagerepresentation with bag-of-biSIFT,” in Proceedingsof the 5th International Conference on Signal-ImageTechnology and Internet-Based Systems (SITIS’09),2009.
[10] G. Csurka, C. Dance, L. Fan, J. Willamowski, andC. Bray, “Visual categorization with bags of key-points,” in In ECCV International Workshop on Sta-tistical Learning in Computer Vision, 2004.
[11] J. Sivic and A. Zisserman, “Video google: A textretrieval approach to object matching in videos,” inProceedings of the International Conference on Com-puter Vision, 2003, vol. 2, pp. 1470–1477.
[12] J. Hare, P. Lewis, P. Enser, and C. Sandom, “A linear-algebraic technique with an application in semanticimage retrieval,” in Proceedings of the InternationalConference on Image and Video Retrieval, 2006, pp.31–40.
[13] Y. Ke and R. Sukthankar, “Pca-sift: A more distinctiverepresentation for local image descriptors,” in Proc. ofComputer Vision and Pattern Recognition (CVPR) 04,2004, pp. 506–513.
[14] S. Lazebnik, C. Schmid, and J. Ponce, “Semi-localaffine parts for object recognition,” in Proceedings ofBMVC, 2004.
[15] M. Brown and D. Lowe, “Invariant features frominterest point groups,” in Proceedings of BMVC 2002,2002.
[16] A. Johnson, “Using spin images for efficient objectrecognition in cluttered 3d scenes,” IEEE Transactionon Pattern Analysis and Machine Intelligence, vol.21(5), pp. 433–449, 1999.
[17] S. Lazebnik, C. Schmid, and J. Ponce, “A sparsetexture representation using local affine regions,” 2004,Technical Report, CVR-TR-2004-01, Beckam Institute,University of Illinois.
[18] D. Comaniciu and P. Meer, “Mean shift: A robustapproach toward feature space analysis,” IEEE Trans-actions on Pattern Analysis and Machine Intelligence,vol. 24, pp. 603–619, 2002.

[19] A. Vedaldi and B. Fulkerson, “VLFeat: An openand portable library of computer vision algorithms,”http://www.vlfeat.org/, 2008.
[20] K. Barnard, P. Duygulu, D. Forsyth, N. de Freitas,D. M. Blei, and M.I. Jordan, “Matching words andpictures,” Journal of Machine Learning Research, vol.3, pp. 1107–1135, 2003.
[21] B. Georgescu, I. Shimshoni, and P. Meer, “Mean shiftbased clustering in high dimensions: A texture classifi-cation example,” in Proceedings of IEEE InternationalConference on Computer Vision, 2003.
[22] F. Vella, C.-H. Lee, and S. Gaglio, “Boosting ofmaximal figure of merit classifiers for automatic imageannotation,” in Proc. of Internation Conference onImage Processing, 2007.
Copyright © 2022 FDOKUMEN




















