
A Pure Peer-To-Peer Desktop Grid framework with efficient fault tolerance
7
A Pure Peer-to-Peer Desktop Grid Framework with Efficient Fault Tolerance Ali E. El-Desoky Dept. of Computer Engineering Mansoura University, Egypt Hisham A. Ali Dept. of Computer Engineering Mansoura University, Egypt [email protected] Abdulrahman A. Azab Dept. of Computer Engineering Mansoura University, Egypt [email protected] Abstract- P2P computing is the sharing of computer resources by direct exchange. P2P Desktop Grid is a P2P computing environment with Desktop resources and usually built on the Internet infrastructure. The most important challenges for a P2P Desktop Grid involve: 1) minimizing reliance on central servers to achieve decentralization, 2) providing interoperability with other platforms, 3) providing interaction methodologies between grid nodes that overcome connectivity problems in the Internet environment, and 4) providing efficient fault tolerance to maintain performance with frequent faults. The main objective of this paper is to introduce a Pure P2P Desktop Grid framework that built on Microsoft's .Net technology. The proposed framework composed of the following components, 1) a communication protocol based on both FTP and HTTP, for interaction between grid nodes to provide Interoperability, 2) An efficient checkpointing approach to provide fault tolerance, and 3) Four interaction models for implementing connectivity for both serial and parallel execution. No reliance on central servers involved in the framework. Such framework will help in overcoming the problems associated to Decentralization, Interoperability, Connectivity and fault tolerance. Performance evaluation has been implemented by running an application code built on variable dimensions’ matrix multiplication on a Desktop Grid based on the proposed framework. Performed experiments have been focused on measuring the impact of failures on the execution time for different connectivity models. Experimental results show that using the proposed framework as an infrastructure for running distributed applications has a great impact on improving fault tolerance, beside achieving full decentralization, Interoperability and solving connectivity problems. I. INTRODUCTION The world’s computing power and disk space is no longer primarily concentrated in supercomputer centers and machine rooms. Instead it is distributed in hundreds of millions of personal desktop and mobile computer systems belonging to the general public [6]. A characteristic of these systems is that they are relatively resource rich (in terms of CPU power, memory, and disk capacity) but are utilized only for a fraction of the time during a day. Even during the time they are in use, their average utilization is much less than their peak capacity [1]. A Desktop Grid * is usually built on the Internet infrastructure in which resources are unreliable and frequently turned off or disconnected [2]. The idea of desktop grid is to harvest the idle time of Internet connected computers, to run very large and distributed applications [3]. The aim of the researchers in the field of Desktop Grid was that anyone could offer resources for a Grid system, and anyone can claim resources dynamically, according to the actual needs, in order to solve a computationally intensive * The usage of the concept "Desktop Grid" in this paper refers to: Computational Desktop Grid. task [4]. To achieve this twofold aim, two trends are involved in the development and research fields of Desktop Grid. Researchers and developers in the first trend consider a Desktop Grid as a Global Computing environment. The key idea of Global Computing is to harvest the idle time of Internet connected computers (e.g. Desktops) which may be widely distributed across the world, to run a very large and distributed application [3]. In a Global Computing environment, resources (i.e. Desktops) can be involved into the Grid system as working volunteer nodes for the common goal of that Grid. Nonetheless, only one or few nodes (i.e. centralized servers) can benefit from those resources for computation [4]. This model is also known as Volunteer Computing [5]. BOINK [6], SZTAKI [4], and XtremWeb [3] are popular Global Computing solutions. In the other trend, a Desktop Grid is considered as a P2P (i.e. peer-to-peer) computing environment [7], where each node acts as a peer, so that, it can act as a resource provider (i.e. Grid Worker) or as a resource consumer (i.e. Grid Client). P2P Desktop Grid can be defined as: "P2P computing environment built on Desktop resources". In P2P computing environment, execution of both simple serial and large parallel applications can be carried out. A serial application needs a single Grid thread [8] to run on a single worker. In a parallel application, the task is partitioned into multiple Grid threads to run on multiple workers in parallel fashion. To the best of our knowledge, Condor [9], Alchemi [8], Harmony [1], Entropia2000 (Internet version of Entropia) [10] and some implementations of XtremWeb [3] are the most efficient P2P Computing solutions. In this work, P2P computing trend is being focused on. Decentralization, Interoperability, Connectivity and fault tolerance are important issues to be addressed in peer-to-peer computing [2, 3]. Decentralization To achieve decentralization, reliance on central servers can be completely eliminated, what so called: "pure P2P computing" model, or minimized to performing required functions, what so called: "hybrid P2P computing" model [11]. To the best of our knowledge, all of the existing solutions implement hybrid P2P computing. Interoperability To achieve Interoperability, it must be able for a peer node in a specific P2P Desktop Grid to interact with peers in other P2P Desktop Grids which are built on different Grid platforms (i.e. cross platform integration), [8]. In Alchemi and recently, in Condor [12] Cross-platform interaction is enabled, through XML web service, to support communication with any Grid platform that supports web
Transcript of A Pure Peer-To-Peer Desktop Grid framework with efficient fault tolerance

A Pure Peer-to-Peer Desktop Grid Framework with Efficient Fault Tolerance
Ali E. El-Desoky Dept. of Computer Engineering
Mansoura University, Egypt
Hisham A. Ali Dept. of Computer Engineering
Mansoura University, Egypt [email protected]
Abdulrahman A. Azab Dept. of Computer Engineering
Mansoura University, Egypt [email protected]
Abstract- P2P computing is the sharing of computer
resources by direct exchange. P2P Desktop Grid is a P2P computing environment with Desktop resources and usually built on the Internet infrastructure. The most important challenges for a P2P Desktop Grid involve: 1) minimizing reliance on central servers to achieve decentralization, 2) providing interoperability with other platforms, 3) providing interaction methodologies between grid nodes that overcome connectivity problems in the Internet environment, and 4) providing efficient fault tolerance to maintain performance with frequent faults. The main objective of this paper is to introduce a Pure P2P Desktop Grid framework that built on Microsoft's .Net technology. The proposed framework composed of the following components, 1) a communication protocol based on both FTP and HTTP, for interaction between grid nodes to provide Interoperability, 2) An efficient checkpointing approach to provide fault tolerance, and 3) Four interaction models for implementing connectivity for both serial and parallel execution. No reliance on central servers involved in the framework. Such framework will help in overcoming the problems associated to Decentralization, Interoperability, Connectivity and fault tolerance. Performance evaluation has been implemented by running an application code built on variable dimensions’ matrix multiplication on a Desktop Grid based on the proposed framework. Performed experiments have been focused on measuring the impact of failures on the execution time for different connectivity models. Experimental results show that using the proposed framework as an infrastructure for running distributed applications has a great impact on improving fault tolerance, beside achieving full decentralization, Interoperability and solving connectivity problems.
I. INTRODUCTION
The world’s computing power and disk space is no longer primarily concentrated in supercomputer centers and machine rooms. Instead it is distributed in hundreds of millions of personal desktop and mobile computer systems belonging to the general public [6]. A characteristic of these systems is that they are relatively resource rich (in terms of CPU power, memory, and disk capacity) but are utilized only for a fraction of the time during a day. Even during the time they are in use, their average utilization is much less than their peak capacity [1].
A Desktop Grid* is usually built on the Internet infrastructure in which resources are unreliable and frequently turned off or disconnected [2]. The idea of desktop grid is to harvest the idle time of Internet connected computers, to run very large and distributed applications [3]. The aim of the researchers in the field of Desktop Grid was that anyone could offer resources for a Grid system, and anyone can claim resources dynamically, according to the actual needs, in order to solve a computationally intensive
* The usage of the concept "Desktop Grid" in this paper refers to: Computational Desktop Grid.
task [4]. To achieve this twofold aim, two trends are involved in the development and research fields of Desktop Grid.
Researchers and developers in the first trend consider a Desktop Grid as a Global Computing environment. The key idea of Global Computing is to harvest the idle time of Internet connected computers (e.g. Desktops) which may be widely distributed across the world, to run a very large and distributed application [3]. In a Global Computing environment, resources (i.e. Desktops) can be involved into the Grid system as working volunteer nodes for the common goal of that Grid. Nonetheless, only one or few nodes (i.e. centralized servers) can benefit from those resources for computation [4]. This model is also known as Volunteer Computing [5]. BOINK [6], SZTAKI [4], and XtremWeb [3] are popular Global Computing solutions.
In the other trend, a Desktop Grid is considered as a P2P (i.e. peer-to-peer) computing environment [7], where each node acts as a peer, so that, it can act as a resource provider (i.e. Grid Worker) or as a resource consumer (i.e. Grid Client). P2P Desktop Grid can be defined as: "P2P computing environment built on Desktop resources". In P2P computing environment, execution of both simple serial and large parallel applications can be carried out. A serial application needs a single Grid thread [8] to run on a single worker. In a parallel application, the task is partitioned into multiple Grid threads to run on multiple workers in parallel fashion. To the best of our knowledge, Condor [9], Alchemi [8], Harmony [1], Entropia2000 (Internet version of Entropia) [10] and some implementations of XtremWeb [3] are the most efficient P2P Computing solutions.
In this work, P2P computing trend is being focused on. Decentralization, Interoperability, Connectivity and fault tolerance are important issues to be addressed in peer-to-peer computing [2, 3]. Decentralization
To achieve decentralization, reliance on central servers can be completely eliminated, what so called: "pure P2P computing" model, or minimized to performing required functions, what so called: "hybrid P2P computing" model [11]. To the best of our knowledge, all of the existing solutions implement hybrid P2P computing. Interoperability
To achieve Interoperability, it must be able for a peer node in a specific P2P Desktop Grid to interact with peers in other P2P Desktop Grids which are built on different Grid platforms (i.e. cross platform integration), [8]. In Alchemi and recently, in Condor [12] Cross-platform interaction is enabled, through XML web service, to support communication with any Grid platform that supports web

services. In other solutions, cross-platform integration is not supported or enabled only with other specific platforms according to some contract or agreement. Connectivity
As Desktop Grids are usually built on the Internet infrastructure, firewalls may block incoming requests from a Grid client located outside of the local network of a Grid worker. This problem can be solved by selecting the suitable interaction mode between clients and workers. There are two possible modes for such interaction: Push mode, where the client can send work to the worker and Pull mode and, where the worker can ask for work from the client [2]. Pull mode can be applicable in the Internet environment where all connections are initiated by the worker. In Condor and Harmony, implement push mode. While in Entropia2000, XtremWeb implement pull mode. Alchemi implement both push and pull modes. In the three previous groups, interaction (i.e. push/pull mode) is not implemented directly between a Client and a Worker. It is done across other management nodes (e.g. servers), as all of the previous solutions are built on the hybrid P2P model. Fault tolerance
A fault-tolerant Grid model must accept very frequent faults while maintaining performance [3]. This can be implemented in P2P Desktop Grid model through providing the ability for system to continue working with frequent failures of peers. A common method for ensuring task execution progress on Worker peers is to checkpoint periodically its state, so that, in case of a failure, the application can be rolled back and restarted on another Worker from its last checkpoint [13]. If there is no support for checkpointing, the application will restart execution from scratch. There are two fundamental checkpointing approaches: (1) System-level checkpointing (SLC), (2) Application-level checkpointing (ALC) [14]. In SLC, the whole application’s system state is captured and saved, while in ALC, only the critical program variables and data structures are saved. ALC can be implemented as full or incremental checkpointing. In incremental ALC, at each checkpoint, only that part of the application’s state is saved that has changed since the previous checkpoint, instead of saving all checkpoint data (i.e. in full ALC) [16]. This would considerably reduce the checkpoint file size, so that, it can be transmitted between nodes on the Internet. In P2P Desktop Grid environment, the checkpoint data can be saved at the Client, the worker, or at a dedicated server [2]. It can also be partitioned and distributed on a number of peers [15].
Condor implements full ALC, and the checkpoint data can be saved at the worker or on a checkpoint server. Harmony implements full SLC [1] storing checkpoint data locally at the Worker. No checkpointing approach is provided by XtremWeb package, Entropia2000 or Alchemi.
From the previous discussion, it is clear that although, several techniques had been developed concerning previous issues and they are quite successful, there still remain lacks to achieve the promised performance especially in fault tolerance and decentralization. None of them implemented incremental checkpointing. This simply will prevent using
their checkpointing approaches on the Internet. None of them implemented full decentralization. Interoperability is rarely implemented. In this paper, a novel pure P2P Desktop Grid framework is proposed, where, decentralization is completely achieved. Interoperability is achieved by providing communication through XML web service. An efficient fault-tolerance technique is provided through implementing an incremental ALC approach [16].
II. SYSTEM MODEL
The proposed framework is designed for building a pure P2P Desktop Grid system for resolving both serial and parallel applications. Two major components are involved: The Worker (W), which is responsible for task execution, and the Client (C), which is responsible for task allocation and task submission to a suitable worker, in case of serial task execution, or the suitable workers, in case of parallel task execution. A Grid node (i.e. peer) will have both client and worker components installed and can act as a client or as a worker. The proposed model is presented in Fig.1.
Peer
Peer
Peer
Peer Peer
Peer
Peer
Peer Figure 1. Pure P2P Desktop Grid model
As shown in Fig. 1, the P2P model is unstructured. Any
message from a Grid node to all other nodes will be sent through broadcasting. Using broadcasting, as the number of nodes increases, network traffic will increase with a large scale. This may limit the scalability of the system. In our future work, a structured P2P model with efficient routing algorithm will be implemented to overcome this problem.
Each node periodically sends IamAlive messages to all other nodes (through broadcasting). A timeout mechanism is used to specify which nodes are failed. To register a new node in the Grid, this can be performed from any existing (i.e. registered) Grid node. Once a new node is registered, the node in which the registration has been performed sends registration information (e.g. Node ID) of the new node to all existing nodes (through broadcasting). Each node will store information about all registered nodes.
III. INTERACTION BETWEEN CLIENT AND WORKER(S)
In our recent paper, Ref. [2], a fault-tolerant remote task execution model based on incremental ALC using four approaches: FCST, FCMT, ICST, and ICMT, has been presented. The most efficient one is ICMT (Incremental Checkpointing with a Multiple Threaded Process). Two

modifications have been made to that previous model version, presented in Ref. [2]. First, this version is pure P2P, while the previous version has been built with reliance on a directory server (i.e. hybrid P2P). Second, in this version, during task execution, the worker periodically sends the checkpoint to the client, while in the previous version; the client has been responsible for periodically capturing the checkpoint file from the worker. Four interaction modes can be implemented based on the task execution model: Push mode for Serial execution (PsS), Pull mode for Serial execution (PlS), Push mode for Parallel execution (PsP), and Pull mode for Parallel execution (PlP) (see section I). These modes can be implemented through four algorithms, which steps are described in the following subsections, A - D. The aim of each algorithm is to carryout the execution of one of the two application types (i.e. serial and parallel), using one of the two interaction modes (i.e. push and pull).
A. Push mode for serial execution (PsS) Algorithm When a client (C) has a task (T) to be executed, the
following steps are included: 1. C sends a GetWorkerSpecifications request to all online
workers. 2. Each worker reply will provide a description of its
capabilities (e.g. free CPU and free Memory). 3. When replays from all online workers are received, C
performs a matchmaking* process between the resource requirements of T and the capabilities of each replied worker. Then, an efficient scheduling* algorithm is applied to generate an ordered list of online workers putting the most suitable worker for T at the top of the list.
4. C pushes task files of T to the first worker in the list (W). Once receiving files, W starts execution of T and C will start monitoring W using a separate monitoring thread (Th).
5. W periodically sends checkpoint files to C. The fault-tolerance mechanism applied to deal with unexpected failure of W is described in Ref. [2]. If W failed, C removes W from the worker list, go to step 4.
6. When task execution is completed, W sends the result file to C, then C reports end of execution to the user.
B. Pull mode for serial execution (PlS) Algorithm To enable pull mode execution, some/all workers in the
Grid must be configured to work in pull mode. The following steps are included: 1. All workers (i.e. in pull mode) in the Grid periodically
sends IsTaskAvailable request to all online clients. Each client always replies NoTaskAvailable when there is no task to be executed.
2. When a client (C) has a task (T) to execute, T is published, so that, C replies TaskIsAvailable to all requesting workers containing information about resource requirements of T.
3. Once a worker W receives that response, it performs matchmaking between the capabilities of W and the requirements of T. The matchmaking result will be:
* Description of the matchmaking and scheduling algorithms will be published in another paper because of space limitations.
SuitableTask, if W can execute T without overloading local resources, or NotSuitableTask otherwise.
4. If the matchmaking process resulted in SuitableTask, W sends another IsTaskAvailable request to C, to find out if another worker pulled the task.
5. If C replied TaskIsAvailable, W sends IamPullingTheTask message to C and starts pulling task files of T. When C receives IamPullingTheTask from a worker W, T will be reserved for W, and C will reply NoTaskAvailable to all other workers.
6. When all task files are pulled, W sends TaskCaptured message to C, and starts execution of T. Once C receives TaskCaptured from W, it starts monitoring W using a separate monitoring thread (Th).
7. Step A.5 is performed. If W failed, go to Step 2. 8. When task execution is completed, step A.6 is performed.
C. Push mode for parallel execution (PsP) Algorithm When a client (C) has a parallel task (T) to execute, T will
be executed in the following sequence: 1. Task files for each subtask (Tpi) of T are stored in a
separate directory ( ∀ i = 1, 2,…N ,N: number of subtasks), where i is the unique ID for the subtask Tpi.
2. Steps A.1 through A.3 are performed. 3. For i = 1 to N:
C pushes task files of Tpi to the first worker in the list (Wi). Once receiving files, W starts execution of Tpi and C will start monitoring Wi using a separate monitoring thread (Thi).
4. Step A.5 is performed for each Tpi ( ∀ i = 1, 2, …N). 5. When execution of a subtask Tpi is completed, Wi sends
the result file of Tpi to C, then, C stops the thread Thi. 6. When all result files are received, C combines these files
to construct the result file of T, then reports end of execution to the user.
D. Pull mode for parallel execution (PlP) Algorithm When a client (C) has a parallel task (T) to execute, T will
be executed in the following sequence: 1. Steps C.1 and B.1 are performed. 2. When T is ready for execution, T is published, so that, C
replies SubTaskIsAvailable to all requesting workers containing information about resource requirements of T, and the ID (I) of the first available subtask of T (TpI).
3. Step B.3 is performed. 4. If the matchmaking process resulted in SuitableTask, W
sends another IsSubTaskAvailable request, containing the value of I, to C, to find out if another worker pulled the subtask TpI.
5. If C replied SubTaskIsAvailable for TpI, W sends IamPullingTheSubTask message, including I, to C and starts pulling task files of TpI. When C receives IamPullingTheSubTask from a worker W for TpI, TpI will be reserved for W.
6. If I = N (all subtasks are pulled) then go to step 7. Else: C increments the value of I, to point at the next available subtask, go to step 2.
7. When all task files are pulled for a subtask Tpi by a worker Wi ( ∀ i = 1, 2, …N), Wi sends SubTaskCaptured message for Tpi to C, and starts execution of Tpi. Once C receives SubTaskCaptured from Wi, it starts monitoring Wi using a separate monitoring thread (Thi).

8. Step A.5 is performed for each Tpi ( ∀ i = 1, 2, …N). if a worker Wi failed, set I = i and go to step 2.
9. Steps C.5 and C.6 are performed.
IV. CLIENT AND WORKER ARCHITECTURE
The Worker and the Client are the major components involved in the system. Each Grid node (i.e. Peer) has both components installed. Implementation of both components is mainly based on .Net Framework. All classes, associated with the client or the worker, are included in the GridLibrary namespace. The clients user may write his/her own code for the task in any language supported by .Net framework. An abstract class, GridBase, is included in the GridLibrary namespace as a base class for any user class. A user class inherited from GridBase must override the WorkingMethod() method in which the user code is written. Methods associated with the incremental ALC are also included in GridBase and can be optionally called in the user code. The code file of a Grid task [2] is the compiled version of the user class, as a .Net DLL assembly. In this section, the architecture of each component is briefly described.
Worker Architecture The Grid worker has two main functionalities: executing
Grid tasks, periodically requesting for task from available clients, in case of pull mode.
Communication Layer
WorkerApplication
ExecutionMonitor
Computaion Layer
Monitor
Figure 2. Architecture of the Worker Fig. 2 shows the worker architecture. The Monitor is a
daemon background process which is responsible for periodically sending IamAlive and IsTaskAvailable messages to the clients and responding to GetWorkerSpecifications requests (see section III. A). The Worker Application is responsible for executing the user code included in the code file and sending checkpoint files [2] to the client. It is assumed that worker machines are not dedicated for grid tasks, so, the worker applications runs as a background process, with lowest priority in order not to affect the performance of other user applications running on the worker machine. The Execution Monitor is a daemon background process responsible for starting the Worker Application when all task files are received, monitoring the task execution and sending the execution result to the client at the end of execution.
Client Architecture The Grid client has six functionalities: requesting for
resource specifications from the workers, performing matchmaking and scheduling to generate the ordered worker list (see section III. A), pushing task files to worker(s), publishing serial/parallel tasks (in case of pull mode),
monitoring the execution of tasks on workers and implementing the fault-tolerance mechanism. Fig. 3 shows the client architecture. User GUI is a windows application, runs in the user application domain, through which the client user can generate the task/subtask files and configure the execution process [2]. The Scheduler is a background process used when working in PsS or PsP modes (see section III). It is responsible for requesting worker specifications from online workers, calling the matchmaker to perform matchmaking, and generate the ordered worker list. The Distributor is responsible for allocating subtasks to workers in the worker list, and used in PsP mode only. Task/Subtask Manager is responsible for pushing task/subtask files to the worker, monitoring task/subtask execution on the worker, receiving checkpoint files and responding to worker failure. One Task Manager is generated in a separate thread in case of serial execution, while multiple Subtask Managers are generated each in separate thread in case of parallel execution.
Communication Layer
SubtaskManagerSubtaskManagerSubtaskManager
SubtaskManagerSubtaskManagerSubtaskManager
TaskManager
SubtaskManager
SubtaskManagerSubtaskPublisher
SubtaskManager
SubtaskManagerSubtaskPublisher
TaskPublisher
Distributor Scheduler
Matchmaker Subtask pool
Grid Client Application Domain User Application Domain
PsPPsPoror
PlPPlPPlPPlP
PsPPsP
PsSPsS
PlSPlS
PsSPsS
PsPPsP
UserUserGUIGUI
Figure 3. Architecture of the Client
Task Publisher and Subtask Publisher are used when
working in PlS and PlP respectively (see section III). It is responsible for setting a flag associated with the task/subtask through which it can be detected that the task /subtask is available or not when the worker sends IsTaskAvailable request. One Task publisher is generated in a separate thread when working in PlS mode, while multiple Subtask Managers are generated each in separate thread when working in PlP mode.
Communication Layer The communication layer is responsible for providing
communication channels to perform transmission of control commands and files between the client and the worker. Fig. 4 shows the structure of the communication layer. Two alternative communication protocols can be implemented in the system: Tightly Coupled Communication Protocol (TCCP), and Loosely Coupled Communication Protocol (LCCP). TCCP is based on .Net Remoting with binary serialization [17] over TCP channel for transmitting both control commands and files. Using TCCP, all transmitted data are binary serialized, so that, a grid node which is configured as TCCP node (i.e. uses TCCP in the communication layer) can establish communication with another TCCP node only. Interoperability is not supported in TCCP. LCCP is based on standard protocols. Two communication channels are established in LCCP: HTTP channel through XML Web Service interface, in which, all

Control commands are executed through calling web methods, and FTP channel for files transmission.
HTTPHTTP(Xml web service)
FTPFTP
HTTPHTTP(Xml web service)
FTPFTP
ClientWorker
Control commands
.Net .Net RemotingRemoting
.Net .Net RemotingRemoting
FilesFiles
Control commands and files
TCCPTCCP LCCPLCCP
Figure 4. The Communication Layer Across LCCP, custom grid middleware, which supports
web services, can interoperate with any LCCP node in the system. In Alchemi, Web Service interface is enabled for cross-platform support, but no support for file transfer across FTP, as no support for checkpointing in Alchemi.
V. PERFORMANCE EVALUATION
Testbed The testbed is a LAN consisting of 13 workers and one
client. Fig. 5 shows the structure of the LAN: seven workers, PC1 - PC7, are PCs connected to an Ethernet switch (100 Mbps max) together with the client, PC8. The other six workers, TC1 - TC6, are Tablet PCs which are connected as wireless nodes to an access-point (54 Mbps max). The access-point is connected to the switch as shown. The client is Pentium 4 3.0GHz machine with 512MB physical memory running Windows Server 2003 Enterprise Edition. All PC workers are Pentium 4 3.0GHz machines with 256MB physical memory running Windows XP professional. All TC workers are Intel Pentium M 2GHz machines with 512MB physical memory running Windows XP Tablet PC Edition.
Figure 5. The Testbed for experimentations
Test Application and Methodologies Test application is the computation of multiplication of two
square matrices with variable sizes: 1500×1500, 2100×2100 and 2400 × 2400 each. The multiplication is implemented using both serial and parallel execution methodologies. In
case of parallel execution, the multiplication is partitioned into a number of subtasks and the multiplier matrix is partitioned into a set of sub-matrices so that, for multiplying two N × N matrices using M workers: M subtasks are generated, in each subtask the multiplier size is n×N and the multiplicand is N × N, where, n = N/M. The ICMT checkpointing approach (see section III) is used to provide fault-tolerance in both serial and parallel executions, with constant checkpoint interval of 30 seconds.
Results All experiments have been performed on a real P2P
Desktop Grid, based on the infrastructure in Fig.5, for evaluating the performance of both serial and parallel executions. Experimental results are basically focused on describing: 1) the impact of failures on the execution time, 2) The impact of increasing the number of parallel workers on the execution time, for parallel execution, and 3) the impact of using pull mode interaction instead of push mode on the execution time.
A. Serial Execution In serial execution, a task runs on a single worker. In case
of a worker failure, the task is restarted on another worker starting from the last checkpoint. In Fig. 6, the execution time of matrix multiplication for variable matrix size is depicted with varying numbers of failures for variable matrix size using both PsS and PlS.
(a) PsS
(b) PlS
Figure 6. Impact of failures on the execution time for Variable Matrix Size
Using: (a) PsS and (b) PlS All experiments described in Fig. 6 are implemented over
TCCP. It is clear that the impact of increasing the number of
0
200
400
600
800
1000
1200
1400
1600
1500x1500 2100x2100 2400x2400
Matrix size
Tota
l exe
cutio
n tim
e (S
econ
ds)
0 Failures1 Failure2 Failures3 Failures4 Failures5 Failures
0
200
400
600
800
1000
1200
1400
1600
1800
1500x1500 2100x2100 2400x2400
Matrix size
Tota
l exe
cutio
n tim
e (S
econ
ds)
0 Failures1 Failure2 Failures3 Failures4 Failures5 Failures
failures on execution time overhead is not considerable. Using smaller matrix size, there is a little increase in the execution time with failures. On the other hand, lager increase in the execution time is noticed for lager matrix size. This is explained by the fact that larger size of computation data results in larger increase in the transmission time of data files from the client to a new worker each time the current worker is failed. In case of using PsS, Fig. 6 (a), increasing the number of failures results in regular and smaller increase in the execution time, while for PlP, Fig. 6 (b), ruffling and larger increase in the execution time occurs with the increase in the number of failures. This is explained that, in case of failure occurrence in push mode, PsS, the client is responsible for pushing the task to the next worker in the list generated in the scheduling process, while in pull mode, PlP, the client waits for a free worker to pull the task. The time taken to start the task on a new worker depends on the time taken by the worker to detect that the client has a published task, perform matchmaking and pull the task files. This highly depends on the worker computation speed and communication speed with the client, taking into account that 6 workers are wireless.
To compare execution time in case of using TCCP with that in case of using LCCP, in Fig. 7, the execution time for 2400 × 2400 matrix size1 using PsS over both TCCP and LCCP is depicted as a function of the number of failures.
0
200
400
600
800
1000
1200
1400
1600
0 1 2 3 4 5
Number of failures
Tota
l Exe
cutio
n tim
e (S
econ
ds)
TCCPLCCP
Figure 7. Impact of Failures on the execution time using PsS over TCCP and
LCCP for 2400x2400 matrix size
From Fig. 7, it can be noticed that no considerable difference between execution time in case of using LCCP and that in case of using TCCP. It can be deduced that implementing communication over LCCP instead of TCCP will not affect the performance.
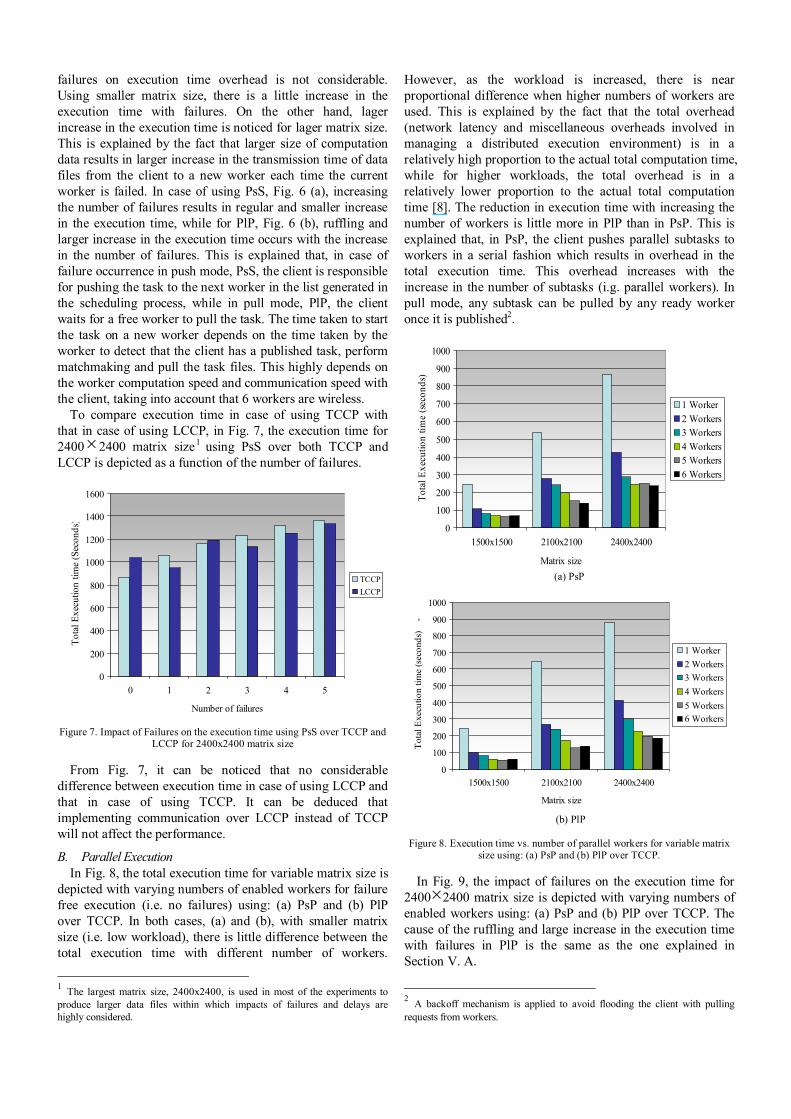
B. Parallel Execution In Fig. 8, the total execution time for variable matrix size is
depicted with varying numbers of enabled workers for failure free execution (i.e. no failures) using: (a) PsP and (b) PlP over TCCP. In both cases, (a) and (b), with smaller matrix size (i.e. low workload), there is little difference between the total execution time with different number of workers.
1 The largest matrix size, 2400x2400, is used in most of the experiments to produce larger data files within which impacts of failures and delays are highly considered.
However, as the workload is increased, there is near proportional difference when higher numbers of workers are used. This is explained by the fact that the total overhead (network latency and miscellaneous overheads involved in managing a distributed execution environment) is in a relatively high proportion to the actual total computation time, while for higher workloads, the total overhead is in a relatively lower proportion to the actual total computation time [8]. The reduction in execution time with increasing the number of workers is little more in PlP than in PsP. This is explained that, in PsP, the client pushes parallel subtasks to workers in a serial fashion which results in overhead in the total execution time. This overhead increases with the increase in the number of subtasks (i.g. parallel workers). In pull mode, any subtask can be pulled by any ready worker once it is published2.
0
100
200
300
400
500
600
700
800
900
1000
1500x1500 2100x2100 2400x2400
Matrix size
Tota
l Exe
cutio
n tim
e (s
econ
ds)
1 Worker2 Workers3 Workers4 Workers5 Workers6 Workers
(a) PsP
0
100
200
300
400
500
600
700
800
900
1000
1500x1500 2100x2100 2400x2400
Matrix size
Tota
l Exe
cutio
n tim
e (s
econ
ds)
-
1 Worker2 Workers3 Workers4 Workers5 Workers6 Workers
(b) PlP
Figure 8. Execution time vs. number of parallel workers for variable matrix
size using: (a) PsP and (b) PlP over TCCP.
In Fig. 9, the impact of failures on the execution time for 2400×2400 matrix size is depicted with varying numbers of enabled workers using: (a) PsP and (b) PlP over TCCP. The cause of the ruffling and large increase in the execution time with failures in PlP is the same as the one explained in Section V. A.
2 A backoff mechanism is applied to avoid flooding the client with pulling requests from workers.

In both cases, (a) and (b), with the largest number of workers, 6 workers, the increase in execution time with increasing the number of failure is larger than that with 5 workers. This occurred because larger memory overhead is caused at the client for larger number of parallel subtasks by monitoring execution, periodically receiving checkpoint data from workers and passing task files to new workers after failures. This results in overhead in execution time if the memory is overloaded. Increasing the physical memory of the client may well overcome the problem.
54 3
21
0 65
43 2 1
0
200
400
600
800
1000
1200
1400
1600
1800
Execution tim
e (seconds) -
Number of Failures Number of workers
(a) PsP
5 43
21
0 65
43 2 1
0
200
400
600
800
1000
1200
1400
1600
1800
Execution time (seconds)
Number of Failures Number of workers
(b) PlP
Figure 9. the impact of failures on the execution time for 2400x2400 matrix
size using: (a) PsS and (b) PlS over TCCP.
VI. CONCLUSION AND FUTURE WORK
In this paper, a pure P2P desktop Grid framework based on unstructured P2P model has been presented. The main objective of the proposed framework is to provide computing environment for running distributed applications on non-dedicated desktop machines. Incremental application level checpointing is implemented for providing fault tolerance for both serial and parallel applications. Four algorithms for providing different interaction modes between grid nodes within the framework, for improving connectivity, have been described. The LCCP communication protocol has been
implemented for providing communication between heterogeneous grid nodes. Experimental results show that implementing the framework on a real Desktop Grid improved fault tolerance in a full decentralized environment for serial and parallel applications using both push and pull mode interactions.
We are planning to include a structured P2P overlay as an additional layer over the communication layer. We are also planning to add a security layer for providing secure communication between nodes, and standboxing for securely running Grid tasks on workers. Performance evaluation experiments will be performed on grid nodes communicated via Internet.
REFERENCES [1] Vijay K. Naik, Swaminathan Sivasubramanian, David Bantz, Sriram
Krishnan, "Harmony: a desktop grid for delivering enterprise computations",4th International Workshop on Grid Computing (Grid 2003), Nov. 2003.
[2] Ali E. El-Desoky, Hisham A. Ali, Abdulrahman A. Azab, "Improving Fault Tolerance in Desktop Grids Based On Incremental Checkpointing", ICCES'06, Nov. 2006.
[4] Peter Kacsuk, Norbert Podhorszki, and Tamas Kiss, "Scalable desktop Grid system", In VECPAR 2006. 7th International meeting on high performance computing for computational science. Rio de Janeiro, 2006., Pages 1-13, 2006.
[3] Gilles Fedak, C´ecile Germain, Vincent N´eri and Franck Cappello, “XtremWeb : A Generic Global Computing System”, CCGRID ’01, 2001.
[5] David P. Anderson, Eric Korpela, Rom Walton, "High-Performance Task Distribution for Volunteer Computing". First IEEE International Conference on e-Science and Grid Technologies, Dec. 2005.
[6] David P. Anderson, “BOINC: A System for Public-Resource Computing and Storage”, CMSC714. November 22, 2005.
[7] David Barkai, "Peer-to-Peer Computing: Technologies for Sharing and Collaborating on the Net", Intel Press; 1st edition, March. 2002.
[8] Akshay Luther, Rajkumar Buyya, Rajiv Ranjan, and Srikumar Venugopal, "Peer-to-Peer Grid Computing and a .NET-based Alchemi Framework", Wiley Press, New Jersey, USA, June 2005.
[9] Douglas Thain, Todd Tannenbaum, and Miron Livny, "Distributed Computing in Practice: The Condor Experience" Concurrency and Computation: Practice and Experience, Vol. 17, No. 2-4, pages 323-356, February-April, 2005.
[10] Andrew A. Chien, Shawn Marlin, and Stephen T. Elbert, "Grid resource management: state of the art and future trends", Pages: 431 - 450, ISBN:1-4020-7575-8, 2004.
[11] David Barkai, "An Introduction to Peer-to-Peer Computing", Developer UPDATE Magazine Intel ®, Feb. 2000.
[12] Clovis Chapman, Charaka Goonatilake, Wolfgang Emmerich, Matthew Farrellee, Todd Tannenbaum, Miron Livny, Mark Calleja, and Martin Dove, "Condor BirdBath: Web Service interfaces to Condor", Proceedings of the 2005 UK e-Science All Hands Meeting, Nottingham, UK, September 2005.
[13] Anh Nguyen-Tuong and Andrew S. Grimshaw, “Using Reflection for Incorporating Fault-Tolerance Techniques into Distributed Applications”, www.ggf.org, 2002.
[14] Paul Stodghill, "Use Cases for Grid Checkpoint and Recovery", www.ggf.org, 2004.
[15] Raphael Y. de Camargo, Renato Cerqueira, Fabio Kon, “Strategies for Storage of Checkpointing Data using Non-dedicated Repositories on Grid Systems”, MGC’05, December, 2005 Grenoble, France.
[16] Roberto Gioiosa, Jos´e Carlos Sancho, Song Jiang and Fabrizio Petrini, "Transparent, Incremental Checkpointing at Kernel Level: a Foundation for Fault Tolerance for Parallel Computers", Proceedings of the 2005 ACM/IEEE SC|05 Conference (SC’05), 2005.
[17] "System.Runtime.Serialization.Formatters.Binary Namespace", http:// msdn2.microsoft.com.




















