
Reinforcement Learning Models Predict Individual Differences ...
Upload
independentCategory
view
2download
0
M. Pěchouček, P. Petta, and L.Z. Varga (Eds.): CEEMAS 2005, LNAI 3690, pp. 306 – 315, 2005. © Springer-Verlag Berlin Heidelberg 2005
A Multi-agent Fuzzy-Reinforcement Learning Method for Continuous Domains
Erkan Duman, Mehmet Kaya, and Erhan Akin
Firat University, Department of Computer Engineering, 23119, Elazig, Turkey {erkanduman, kaya, eakin}@firat.edu.tr
Abstract. This paper proposes a fuzzy reinforcement learning based method for improving the learning ability of multi-agents acting in continuous domains. The previous studies in this area generally solved multi-agent learning problem by using discrete domains. However, the most of real-world problems use the continuous state spaces. Also, it is really a difficult task to handle the continuous domains for multi-agent learning systems. In this paper, proposing a novel approach, we will have two significant advantages according to the conventional multi-agent learning algorithm. One of them is that the number of state spaces of learning agents in multi-agent environment only depends on the number of fuzzy sets which were used to represent the state of an agent. Whereas, in the previous approaches, the visual area of agent or the size of domain were taken into consideration for the state space. The other advantage is that the employed environment has a continuous domain as in the real-world problems. Experimental results obtained on a well-known pursuit domain show the effectiveness of the proposed approach.
Keywords: Multi-agent Systems, Fuzzy Logic, Reinforcement Learning, Continuous Domain.
1 Introduction
Multi-agent systems form a particular type of distributed artificial intelligence systems. They are different from single agent systems in the sense that there is no global control and globally consistent knowledge. So, limitations on the processing power of a single agent are eliminated in a multi-agent environment. In other words, since data and control are distributed, multi-agent systems include the inherent advantage of distributed systems, such as scalability, fault-tolerance and parallelism, among others [1].
The realization of cooperative behavior in multi-agent systems is an interesting topic from the viewpoint of engineering and cognitive science. In particular, reinforcement learning of cooperative behaviors has attracted recent attention because of its adaptability to dynamic environments. For this purpose, reinforcement learning has been applied to multi-agent systems such as pursuit games, soccer, the prisoners’ dilemma game, and coordination games.
One approach to model multiagent learning is to augment the state of each agent with the information about other existing agents [2-4]. However, as the number of

A Multi-agent Fuzzy-Reinforcement Learning Method for Continuous Domains 307
agents in a multiagent environment increases, the state space of each agent grows exponentially. Another solution is to generalize visited states to unvisited ones as in supervised learning. In order to handle this problem, functional approximation and generalization methods seem to be more feasible solutions. Unfortunately, optimal convergence of functional approximation implementation of reinforcement learning algorithms has not been proven yet [5, 6, 10]. As the alternative approaches, we proposed some fuzzy-reinforcement learning based methods for multi-agent discrete domains [7, 8].
However, how agents acquire and maintain knowledge is an important issue in reinforcement learning. When the state space of the task is small and discrete as it is the case with the above studies, the Q-values are usually stored in a lookup table. But, this method is either impractical in case of large state-action spaces, or impossible with continuous state spaces. The main drawback of look-up tables is their scaling problem. In case of a task with a huge state space, it is difficult and unlikely to store all states in a limited memory and to visit each state in reasonable time. In order to handle the problems of large and continuous state spaces, in this paper, we present a novel multi-agent fuzzy-reinforcement learning method. It uses a fuzzy inference mechanism in continuous domain. The each learning agent in the environment acts observing its nearest partner and prey. Also, with the proposed reward mechanism, a cooperation behavior is exhibited.
The rest of the paper is organized as follows. Section 2 gives an introduction of reinforcement learning and Q-learning algorithm. Section 3 describes the proposed algorithm. Section 4 presents the experimental results of the algorithm. Section 5 includes the conclusions.
2 Reinforcement Learning
Reinforcement Learning (RL) is used to answer the questions of how an autonomous agent perceives the environment and make the optimum decision to reach its own goal. It is very interesting that such an agent does not need any previous information about the search space [9].
In the RL algorithm, an agent interacts with the environment by using its sensors and actuators as shown in Figure 1. The agent receives the information of the current state s by its sensors then it applies the making decision algorithm and determines an output action a . It gets a feedback information r from environment after acting a . If the new state of the agent is a goal state, r will be positive, otherwise, it will have a negative value.
The RL might be modeled as a Markov Decision Process and this model is the most widely mathematical model of RL. This is formalized as follows:
• S is the finite set of the states. • A is the finite set of the actions. • R is the function determining the expected reward r ):( rSxAR →
• T is the translation function between the current and the next states ( )( )SSxAT π→,

308 E. Duman, M. Kaya, and E. Akin
Environment
ControlSystem
Agent
a
Action
Reward
State
r s
Fig. 1. The model of the Reinforcement Learning
The notation of ( )IsasT ,, indicates the probability of the transition from state s to Is by acting a . As a result of Markov Decision Process, the function of ( )T does
not consider the previous states. It is only concerned with the current state and the available actions.
The Q-Learning is the most popular technique in RL applications, where the pairs of (state,action) are saved in a look-up table. The following learning equation is used to update the cells of the Q-table in the run time.
( ) ( ) ( ) ( )⎥⎦⎤
⎢⎣⎡ ++−=
∈
II
AaasQrasQasQ
I,max..,.1, γαα (1)
The notations of the α and γ indicates the learning rate and the discount factor at
the interval of the [0,1] respectively. ( )II asQ , indicates the action with the
maximum reward in the next state.
3 The Proposed Method
In this study, a new approach based on fuzzy inference system is proposed to improve the ability of the multi-agent reinforcement learning in continuous domain. Q-learning is used as learning algorithm in this method. It could be understood from the title of this study that all the hunter agents move together in order to reach a common goal. The number of the hunter agents determined arbitrary is four and their common goal is to surround the single prey agent in continuous pursuit problem. The cooperation of the hunter agents is provided by using same structure of Q-tables and the learning algorithm. However, they are not able to observe the search space entirely. Each agent can see objects at a certain distance, the radius of which is r and does not have any information about the remaining of the search space as seen in Figure 2.
So far, many researchers have proposed various methods to improve the learning ability in multi-agent systems in discrete domain. However most of them are not appropriate for continuous domain because the state space of each learning agent grows exponentially in terms of the number of partners in environment and visual

A Multi-agent Fuzzy-Reinforcement Learning Method for Continuous Domains 309
H1 r
H2 r
H3r
H4
r
P
r
Fig. 2. A Multi-agent system in the continuous pursuit problem
depth of each agent. In our method, the size of Q-tables is independent from these terms; it is only related to the number of linguistic labels of input variables in fuzzy inference system used to decide the optimal action in current state. This underlying idea causes reducing the requirements of time and memory in Q-learning algorithm. Also, the search space of the agents that has been transformed from a simple grid to a continuous environment is very important advantage for the proposed method to be able to be used in real world problems.
As you can see in Figure 3, each agent has a fuzzy inference mechanism in order to choose the optimal action in its current state. There are four fuzzy input variables representing the distances and the angles of the nearest and the prey hunters and, one output variable for an action produced by inference mechanism in this structure.
The other nearesthunter
The Prey
FUZZYINFERENCEMECHANISM
Distance
Angle
Distance
Angle
Action
Reward
Fig. 3. The fuzzy inference mechanism of each agent
First, each agent must perceive the nearest hunter and the prey available in its visual area in order to start choosing an action. If they are inside, it must measure the distance and the angle of them by crisp values as shown in above figure, which are the input variables of the fuzzy inference mechanism. Here, the first step is fuzziness of the input values as linguistic variables. So, each agent is able to determine its own state by these fuzzy sets. In such a case, the action to be done is determined by using relative rows.

310 E. Duman, M. Kaya, and E. Akin
Table 1. The structure of Q-table in the proposed method
state/action action-1 action-2 ….. …. ….. action-m state-1 Q11 Q12 …. …. …. Q1m
state-2 Q21 Q22 ….. ….. …. Q2m
: : : : : : : : : : : : : :
state-n Qn1 Qn2 ….. ….. ….. Qnm
As the rows in the Q-table indicates the states which agent can perceive, the columns shows the possible actions. The ijQ values in cells represent the amount of
the reward in the case agent chooses action j in state i . If the agent observes state i ,
it must calculate the probabilities of the actions which is able to be done in that state
according to ijQ values in relative cells by using Equation 1. This equation is known
as Boltzmann distribution in literature, where τ represents the temperature which will be decreased in the following iterations so as to reduce the probabilities of small
ijQ values. After the probabilities are calculated, the agent uses the Roulette Wheel
being a popular selection method in Genetic Algorithms to choose the action ia as
seen in figure 4 ( )mi ≤≤1 .
[ ]( )
( )∑ ∈
=Aa
asQ
asQ
i
k
k
i
e
esa τ
τπ
/,
/,
| (2)
a1
a3
a2
a4
a5
ππ
ππ
π
Fig. 4. Roulette Wheel method for choosing an action according to their probabilities
However, the following equation as the learning rule is different from the
conventional structure by adding two gains: µ and Iµ . They represent the degrees of
the memberships of the agent in state s and Is respectively.
( ) ( ) ( ) ( )⎥⎦⎤
⎢⎣⎡ ++−=
∈.,max...,.1, II
Aa
I asQrasQasQI
γαµαµ (3)
Each of the agents has a visual area whose radius is ( )51 ≤≤ iri . Through this
study, all the visual areas are defined as same and the agents cannot observe the remaining of the search space because this is generally a disadvantage if we decide to apply the proposed method to the real-world problems.

A Multi-agent Fuzzy-Reinforcement Learning Method for Continuous Domains 311
The information received from the environment by agent is about the distances and angles of the other nearest hunter agent and the prey present in its own visual area. If there is no other hunter and the prey in that area, the agent moves at random exactly.
This paper proposes a generalization method based on fuzzy sets to decrease the state spaces of the agents in the continuous domain. For this case, the membership functions representing states of each agent are given in Figure 5.
The both of the distance axes shown in Figure 5 have three uniform membership functions and the definitive intervals of them are bounded with [ ]100,0 , because the radius of the agent’s visual area is assumed to be 100. The angle linguistic variables for the other nearest hunter agent and the prey have four triangular membership
functions at interval of [ ]οο 360,0 .
After the fuzzification of hunternearest θ variable which represents the angle of the
other nearest hunter, the agent will has two linguistic labels from the set of (East[E], North[N], West[W] and South[S] ) with 1m and 2m that indicate the membership
degrees of fuzzy sets it belongs to. With hunternearest d representing the distance of the
other nearest hunter agent, it will receive two linguistic labels more from the set of
(Small[S}, Medium[M] and Large[L]) with 3m and 4m .
Similarly, preyθ and preyd representing the angle and the distance of the prey are
fuzzified as explained. The steps of observing a current state can be explained better by using a numerical
example as follows: Consider that the agent j is the nearest hunter inside the visual
area of the agent i and the agent i will measure οθ 30=ij and 60=ijd . In this case,
[ ]21, mm and [ ]43 , mm are computed by above fuzzy sets as shown in Figure 6.
In this example case, the agent j , as the other nearest hunter, is assumed to be
located at North [N] with weight of 33.01 =m and at East [E] with weight of
67.02 =m according to the agent i . Besides, it belongs to Large [L] and Medium
[M] membership functions with weight of 2.03 =m and 8.04 =m respectively.
So, the agent i will observe the following four states with 4321 ,,, µµµµ .
s1 = EM (The agent j ’s angle is East and its distance is Medium).
s2 = EL (The agent j ’s angle is East and its distance is Large).
s3 = NM (The agent j ’s angle is North and its distance is Medium).
s4 = NL (The agent j ’s angle is North and its distance is Large).
The agent i observes state s1 with weight of 421 .mm=µ . Similarly, the other three
membership degrees are computed:
s1 = EM (The agent j ’s angle is East and its distance is Medium) 421 .mm=⇒ µ
s2 = EL (The agent j ’s angle is East and its distance is Large) 322 .mm=⇒ µ
s3 = NM (The agent j ’s angle is North and its distance is Medium) 413 .mm=⇒ µ
s4 = NL (The agent j ’s angle is North and its distance is Large) 414 .mm=⇒ µ

312 E. Duman, M. Kaya, and E. Akin
0 90 180 270 360
µ (nearest hunter)
East North West South East Small Medium Large
0 50 100
90 180 270 360
North West South East Small Medium
0 50
angle distance
angle distance
East Large
1000
angle µ (nearest hunter)distance
µ (prey)angle µ (prey)
distance
Fig. 5. Membership functions representing the state of an agent
0 90 180 270 360
µ (nearest hunter)
East North West South East Small Medium Large
0 50 100
angle distance
angle µ (nearest hunter)distance
30
m =0,331
m =0,672
m =0,804
60
m =0,203
Fig. 6. The fuzzification of the οθ 30=ij and the 60=ijd
We can assume that the prey agent p is inside the visual area of the agent i at the
same time. Then, the number of the states observed by the agent i will be 4x4=16. Each of them is represented as a row in the agent’s own Q-table. However, these rows can have different membership degrees. The membership degrees of all the states are computed by minimum function using relative pairs of weights as two arguments.
In Q-table, the number of states depends on the number of the membership functions, rather than the visual area of the agent. The agent’s decision space resolution decreases if the radius of the agent’s visual area increases while the number of the membership functions is constant. However, the agent perceives a larger area. On the other hand, the agent exhibits a finer resolution if the number of membership functions increases while the radius of the agent’s visual area is constant.
In this study, the number of the states is computed as shown in equation 5. It could be thought as the number of the rows in each of the agent’s Q-tables.
1.LL states ofnumber The 43214321 +++= xLLLxLxLxL (4)
In the above equation, the iL variable indicates the number of the linguistic labels
for fuzzy input variables ( )41 ≤≤ i . The size of the Q-table depends on the number of

A Multi-agent Fuzzy-Reinforcement Learning Method for Continuous Domains 313
the other agents or the radius of the agent’s visual area. 1L indicates the number of
the agent j ’s angle variable according to the agent i . Similarly, 2L for the agent j ’s
distance, 3L for the prey’s angle and 4L for the prey’s distance are used to determine
the size of the state space. Each of iL is added with 1 because the relative input
variable is able to exceed the bounds of defined interval. As an example, if we assume 3L and 4 4231 ==== LLL as in Figure 5 and
Figure 6, then the number of states evaluates to 12x12+12+12+1, where 12×12 is the number of states in case both the prey and the other hunter are observed in the visual environment of the hunter under consideration, 12+12 is the number of states in case only one agent, either the prey or a hunter, is observed and 1 is the number of states in case no agent is perceived.. The agent i will chose an action ia from the set of
actions ( )54321 ,,,, aaaaaA = after it observed the current state according to the Q-
values in corresponding cells. The action ia can be one of the (right, up, left, down
and none).
H1
H2
H3
H4
P
AB
C D
Fig. 7. The performed pursuit problem with 4 hunters and single prey
The proposed method was applied to a continuous pursuit problem with four hunter and single prey as shown in Figure 7. If hunter 1 observes the its own current state, it will see the area of A meaning the other nearest hunter is 4 and the prey is inside the visual area. Similarly, the area of B for hunter 2, C for hunter 3 and D for hunter 4 will be drawn imaginary. The hunter 2 and 3 will chose an action at random exactly because any other agent is not inside their visual area but hunter 4 will move according to hunter 1’s location.
Hunter 1 will get a reward r computed as shown in Equation 5 from the
environment on moving a new state Is . sr represents the special reward that is
proportional with only the distance between hunter 1 and prey. It is limited to 50 because the goal is to surround the prey by all hunters, not only by one. gr indicates
the general reward according to the distances of all hunters to the prey and it is limited to 50 too. Thus, when all hunters surrounded the prey, the r will be 100.
gs rrr += (5)
314 E. Duman, M. Kaya, and E. Akin
4 Experimental Results
We used a pursuit game containing a single prey and four hunter agents in the continuous domain to evaluate the performance of the proposed method. In the experiment environment, we tested it in 10000 trials. Each trial begins with a single prey and four hunter agents placed at random positions inside the search space, and ends when either the prey is captured or at 2000 time steps.
When the all hunter agents surround the prey, they get the reward of 100 from environment. Otherwise, each hunter agent gets a special reward according to its distance to the prey and others. The size of domain is fixed as 5000x5000. Besides, we determined the parameters of the Q-learning as the following.
• The learning rate, 2.08.0 →=α • The discount factor, 9.0=γ
• The initial value of the Q-cells are 0.1
We determined that the learning rate α was 0.8 at the beginning of the experiment but when the learning process had been well advanced it begun to decrease until 0.2. Specially, having chosen the initial values of the cells in the Q-tables as 0.1 accelerated the learning processes of the agents.
We applied the practice in an environment that it was developed by using a visual object-oriented programming language. The search space and the agents were represented by a continuous toroidal grid object and geometrical shapes objects respectively.
0
200
400
600
800
1000
1200
1 8 15 22 29 36 43 50 57 64 71 78 85 92 99
Trial(x100)
Ava
rage
Tim
e S
teps
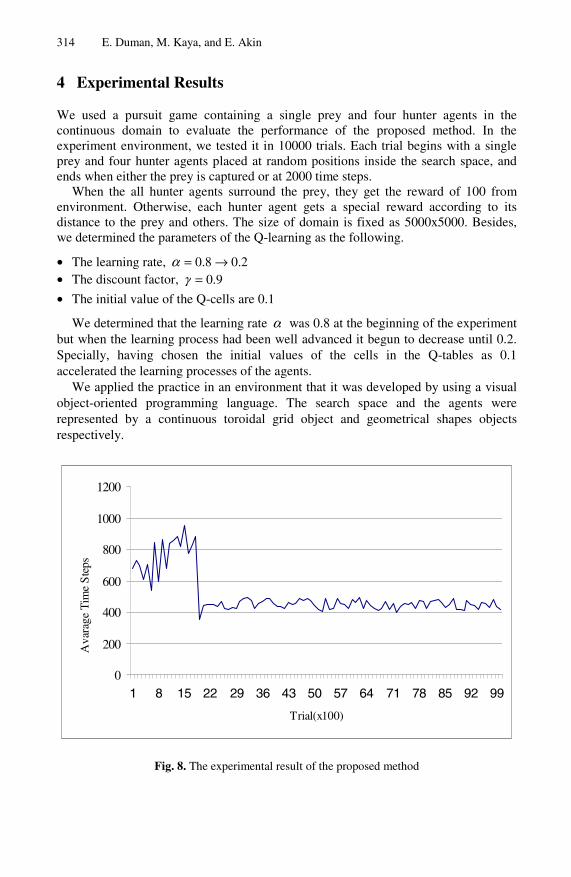
Fig. 8. The experimental result of the proposed method

A Multi-agent Fuzzy-Reinforcement Learning Method for Continuous Domains 315
The average time steps per trial were calculated for 10000 trials after a small number of tests as seen in figure 8. There was a rapid learning process between 1500 and 2000 trials then the learning curve started to converge, because the learning rate reached the minimum value after 2000 trials.
5 Conclusion
We have proposed a novel multi-agent fuzzy-reinforcement learning method for multi-agent system in continuous domain as the real world problems to improve the performance of it. There were a few disadvantages for traditional RL algorithms to be able to be used in real applications. For instance, the size of Q-tables and the time requirement would grow up exponentially for the most conventional methods so we adapted it by using fuzzy sets. Besides, in the our proposed method, we considered that an agent was not be able to see the entire of the search space and the requirements were not depend upon the visual depth and the number of the agents. There were two significant criteria for the sensitiveness of the system that the number of the linguistic labels used in fuzzy logic and the parameters of these labels in the our proposed method.
References
1. P. Stone and M. Veloso, “Multiagent systems: A Survey from a Machine Learning Perspective,” Autonomous Robots, Vol.8 No.3, 2000.
2. M.L. Littman, “Markov Games as a Framework for Multiagent Reinforcement Learning,” Proceedings of the International Conference on Machine Learning, pp.157-163. San Francisco, CA, 1994.
3. T.W. Sandholm and R. H. Crites, “Multiagent Reinforcement Learning in the Iterated Prisoner’s Dilemma,” Biosystems, Vol.37, pp.147-166, 1995.
4. M. Tan, “Multi-agent Reinforcement Learning: Independent vs. Cooperative Agents,” Proceedings of the International Conference on Machine Learning, pp.330-337, 1993.
5. R.S. Sutton, “Generalization in reinforcement learning: Successful Examples Using Sparse Coarse Coding,” Advances in Neural Information Processing Systems, 1996.
6. R.S. Sutton and A.G. Barto, Reinforcement Learning: An Introduction, Cambridge, MA: MIT Press, 1998.
7. M. Kaya and R. Alhajj, “Modular Fuzzy-Reinforcement Learning Approach with Internal Model Capabilities for Multiagent Systems”, IEEE Transactions on Systems, Man and Cybernetics-Part B, vol. 34 (2), pp. 1210-1223, April 2004.
8. M. Kaya and R. Alhajj, “Reinforcement Learning in Multiagent Systems: A Modular Fuzzy Approach with Internal Model Capabilities”, 14th IEEE International Conference on Tools with Artificial Intelligence, November 2002, Washington DC.
9. L.P. Kaelbling, M.L. Littman and A.W. Moore, “Reinforcement learning: A survey,” Artificial Intelligence Research, Vol.4, pp.237-285, 1996.
10. H. Berenji and D. Vengerov, “Advantage of Cooperation between Reinforcement Learning Agents in Difficult Stochastic Problems,” Proceedings of IEEE International Conference on Fuzzy Systems, 2000.
Copyright © 2022 FDOKUMEN




















