pengembangan modul update data pada sistem spatial data ...
27
PENGEMBANGAN MODUL UPDATE DATA PADA SISTEM SPATIAL DATA WAREHOUSE HOTSPOT BOLIVIANTO KUSUMAH DEPARTEMEN ILMU KOMPUTER FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR BOGOR 2014
Transcript of pengembangan modul update data pada sistem spatial data ...

PENGEMBANGAN MODUL UPDATE DATA PADA SISTEM SPATIAL DATA WAREHOUSE HOTSPOT
BOLIVIANTO KUSUMAH
DEPARTEMEN ILMU KOMPUTER FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR BOGOR
2014


PERNYATAAN MENGENAI SKRIPSI DAN SUMBER INFORMASI SERTA PELIMPAHAN HAK CIPTA
Dengan ini saya menyatakan bahwa skripsi berjudul Pengembangan Modul
Update Data pada Sistem Spatial Data Warehouse Hotspot adalah benar karya saya dengan arahan dari komisi pembimbing dan belum diajukan dalam bentuk apa pun kepada perguruan tinggi mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir skripsi ini.
Dengan ini saya melimpahkan hak cipta dari karya tulis saya kepada Institut Pertanian Bogor.
Bogor, Januari 2014
Bolivianto Kusumah NIM G64114047

ABSTRAK
BOLIVIANTO KUSUMAH. Pengembangan Modul Update Data pada Sistem Spatial Data Warehouse Hotspot. Dibimbing oleh HARI AGUNG ADRIANTO.
Sistem spatial on-line analytical processing (SOLAP) telah dikembangkan untuk membantu melakukan pengamatan terhadap titik panas. Sistem tersebut mampu melakukan analisis SOLAP dan menampilkan visualisasi persebaran titik panas, namun belum mampu memperbarui data titik panas ke dalam data warehouse. Penelitian ini bertujuan untuk mengembangkan modul update data. Sistem dibuat menggunakan bahasa pemrograman Java dan memiliki graphical user interface (GUI). Sumber data yang digunakan oleh sistem ini adalah hasil pencitraan satelit berupa fail teks, berisikan informasi titik panas milik Direktorat Pengendalian Kebakaran Hutan (DPKH). Ekstraksi dilakukan untuk mengambil informasi titik panas pada fail teks dan melakukan penyesuaian bentuk skema agar dapat disimpan pada data warehouse. Dengan mengacu pada konsep extraction, transformation, dan loading (ETL), sistem ini mampu memetakan data dari data source ke dalam data warehouse, dan dapat memproses beberapa fail teks sekaligus. Kata kunci: data warehouse, ETL, kebakaran hutan, SOLAP, spasial, titik panas
ABSTRACT
BOLIVIANTO KUSUMAH. Development of Data Updating Module for Hotspot Spatial Data Warehouse. Supervised by HARI AGUNG ADRIANTO.
The spatial on-line analytical processing (SOLAP) was developed to support hotspots monitoring. The system is able to perform SOLAP analysis and provide the visualization of hotspot distribution. However, this system has not been able to update the hotspots data into a data warehouse. This research aimed to develop a data updating module. This system was built in Java programming language and has a graphical user interface (GUI). The data source used by this system was the result of satellite imagery in the form of a text file, which contains information of hotspots owned by Directorate of Forest Fire Control. Extraction was done to retrieve hotspots information in the text file and make the schematic adjustments in order to be stored in the data warehouse. Refers to the concept of extraction, transformation, and loading (ETL), the system is able to map the data from the data source into the data warehouse, and can process multiple text files.
Keywords: data warehouse, ETL, forest fires, hotspot, SOLAP, spatial

Skripsi sebagai salah satu syarat untuk memperoleh gelar
Sarjana Komputer pada
Departemen Ilmu Komputer
PENGEMBANGAN MODUL UPDATE DATA PADA SISTEM SPATIAL DATA WAREHOUSE HOTSPOT
BOLIVIANTO KUSUMAH
DEPARTEMEN ILMU KOMPUTER FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR BOGOR
2014


Judul Skripsi : Pengembangan Modul Update Data pada Sistem Spatial Data Warehouse Hotspot
Nama : Bolivianto Kusumah NIM : G64114047
Disetujui oleh
Hari Agung Adrianto, SKom MSi Pembimbing
Diketahui oleh
Dr Ir Agus Buono, MSi MKom Ketua Departemen
Tanggal Lulus:

Judul SkIipsi: Pengembangan Modul Update Data pada Sistem Spatial Data Warehouse Hotspot
Nama : Bolivianto Kusumah NIM : G64114047
Disetujui oleh
Adrianto SKom MSi Pembimbing I
Tanggal Lulus: 1 Z MAR 2014

PRAKATA Puji dan syukur penulis panjatkan kepada Allah subhanahu wa ta’ala atas
segala karunia-Nya sehingga karya ilmiah ini berhasil diselesaikan. Tema yang dipilih dalam penelitian yang dilaksanakan sejak bulan Juli 2013 ini ialah titik panas, dengan judul Pengembangan Modul Update Data pada Sistem Spatial Data Warehouse Hotspot.
Terima kasih penulis ucapkan kepada Bapak Hari Agung Adrianto Skom MSi selaku pembimbing, serta teman-teman departemen ilmu komputer yang telah banyak memberi saran. Ungkapan terima kasih juga disampaikan kepada ayah, ibu, serta seluruh keluarga, atas segala doa dan kasih sayangnya.
Semoga karya ilmiah ini bermanfaat.
Bogor, Januari 2014
Bolivianto Kusumah

DAFTAR ISI
DAFTAR TABEL vi DAFTAR GAMBAR vi DAFTAR LAMPIRAN vi PENDAHULUAN 1
Latar Belakang 1
Perumusan Masalah 1
Tujuan Penelitian 2
Manfaat Penelitian 2
Ruang Lingkup Penelitian 2
METODE 2
Sumber Data 3
Ekstraksi Data 4
Data Staging Area 4
Pembersihan Data 4
Data Store 4
Transformasi Data 5
Loading 5
Pengujian 6
Lingkungan Pengembangan 6
HASIL DAN PEMBAHASAN 6
Pemilihan Berkas 7
Ekstraksi Data 7
Data Staging Area 8
Pemuatan Data 9
Pengujian 10
SIMPULAN DAN SARAN 13
Simpulan 13
Saran 13
DAFTAR PUSTAKA 13
LAMPIRAN 13 RIWAYAT HIDUP 15

DAFTAR TABEL
1 Waktu eksekusi ekstraksi data 11 2 Waktu eksekusi transformasi data 12 3 Waktu eksekusi pemuatan data 12 4 Waktu eksekusi keseluruhan (dengan 200 data valid) 12
DAFTAR GAMBAR
1 Framework umum pada proses ETL (El-Bastawissy et al. 2011) 3 2 Proses ETL modifikasi 3 3 Skema snowflake modifikasi (Imaduddin, 2012) 5 4 List view fail teks 7 5 Model class Hotspot 8 6 List view hasil ekstraksi 8 7 Model class fakta 9 8 Hasil proses transaksi pemuatan data pada console 10 9 Visualisasi hotspot pada peta 11
DAFTAR LAMPIRAN
1 Format sumber data 14 2 Antarmuka sistem 15

PENDAHULUAN
Latar Belakang
Kebakaran hutan dan lahan dapat dipantau dengan menggunakan AVHRR-NOAA (Advanced Very High Resolution Radiometer – National Oceanic and Atmospheric Administration) yaitu melalui pengamatan titik panas (Thoha, 2008). Direktorat Pengendalian Kebakaran Hutan (DPKH) menggunakan data titik panas hasil pencitraan lokasi jarak jauh oleh satelit NOAA untuk memonitor titik panas dalam upaya pengendalian kebakaran hutan dan lahan. DPKH secara rutin melakukan pengambilan data titik panas di beberapa wilayah di Indonesia, kemudian menyimpan data tersebut dalam bentuk citra dan fail teks. Menurut Imaduddin (2012) teknologi data warehouse dengan tool on-line analytical processing (OLAP) merupakan salah satu solusi permasalahan penumpukan data hasil pencitraan lokasi jarak jauh. OLAP dapat digunakan untuk mengorganisasikan data persebaran titik panas dan menampilkan informasi sehingga dapat digunakan untuk pengambilan keputusan dalam pengendalian kebakaran hutan.
Trisminingsih (2010) telah melakukan penelitian dengan judul pembangunan spatial data warehouse berbasis web untuk persebaran hotspot di wilayah Indonesia. Penelitian tersebut kemudian dilanjutkan oleh Fadli (2011) dengan menambahkan modul visualisasi kartografis. Pada tahun berikutnya Imaduddin (2012) mencoba melengkapi kekurangan penelitian Fadli (2011), yaitu dengan melakukan sinkronisasi antara query OLAP dengan peta sehingga memudahkan pengguna dalam melakukan analisis spatial dengan tool OLAP. Dari ketiga penelitian tersebut kekurangan yang dimiliki adalah tidak tersedianya modul untuk melakukan update data titik panas, dan data yang tersedia hanya pada rentang tahun 1997 – 2005 yang merupakan hasil praproses secara manual yang dilakukan Trisminingsih (2010).
Penelitian ini dilakukan dalam upaya untuk melengkapi ketiga penelitian tersebut dengan menambahkan modul update data titik panas. Dengan bersumber pada data yang dimiliki oleh DPKH yaitu berupa fail teks, modul ini memiliki fungsi membaca (parsing) data didalam fail tersebut lalu mempersiapkan data tersebut sebelum memasuki data warehouse. Dengan demikian pengguna diharapkan tidak lagi melakukan praproses data secara manual untuk menambahkan data titik panas secara langsung pada data warehouse.
Perumusan Masalah
Pengambilan data titik panas dilakukan menggunakan satelit kemudian hasil tersebut disimpan dalam bentuk citra dan fail teks. Sumber data yang digunakan dalam penelitian ini ialah data titik panas yang berupa fail teks. Untuk memasukkan data titik panas ke dalam data warehouse guna keperluan analisis, pengguna harus melakukan praproses terlebih dahulu terhadap fail teks dan menambahkannya ke dalam data warehouse. Sedangkan, setiap fail teks tersebut terdiri atas beberapa baris dan kolom informasi titik panas, dan diperbarui secara terus menerus dalam rentang waktu tertentu.

2
Penambahan titik panas dengan melakukan praproses data secara manual tidak lagi memungkinkan untuk dilakukan, mengingat jumlah data yang harus diproses sangat banyak. Oleh karena itu penelitian ini dilakukan dalam upaya membantu pengguna menangani penambahan data titik panas baru ke dalam data warehouse. Tantangan yang dihadapi adalah: 1 Bagaimana melakukan ekstraksi data pada fail teks? 2 Bagaimana mengubah hasil ekstraksi tersebut ke dalam bentuk yang sesuai
dengan kebutuhan data warehouse? 3 Bagaimana menyimpan data dengan format yang sesuai dengan skema pada
data warehouse? Berdasarkan pada kondisi tersebut pendekatan yang mungkin dilakukan
adalah menggunakan metode extraction, transformation, dan loading (ETL). ETL merupakan tahapan yang digunakan dalam praproses data. Dimulai dari pengambilan data sampai dengan penyimpanan data pada data warehouse.
Tujuan Penelitian
Tujuan penelitian ini adalah untuk menambahkan modul update data titik panas, pada sistem yang telah dikembangkan oleh Imaduddin (2012) yaitu dengan melakukan ekstraksi data titik panas baru yang didapat dari fail teks yang dimiliki oleh DPKH dan menambahkannya ke dalam data warehouse guna keperluan analisis.
Manfaat Penelitian
Hasil penelitian ini diharapkan dapat memudahkan pengguna dalam melakukan update data titik panas ke dalam data warehouse dengan melakukan praproses data secara otomatis.
Ruang Lingkup Penelitian
Ruang lingkup dalam penelitian ini adalah: 1 Penelitian dilakukan pada data milik DPKH berupa fail teks yang dapat
diunduh secara bebas pada situs resmi DPKH. 2 Data yang digunakan adalah data yang berisi informasi dan atribut - atribut
titik panas. 3 Penelitian yang dilakukan hanya sampai pada penyimpanan data ke dalam
data warehouse.
METODE
Metode yang digunakan pada penelitian ini mengacu pada konsep extraction, transformation dan loading (ETL). ETL merupakan tahapan yang digunakan untuk melakukan praproses data dalam kegiatan data warehousing. Framework

3
umum dalam proses ETL menurut El-Bastawissy et al. (2011) ditunjukkan pada Gambar 1. Data staging area (DSA) menunjukkan tempat dimana terjadinya proses transformasi sebelum dimuat ke dalam data warehouse (DW).
Selama proses ETL, data diekstraksi dari basis data OLTP, kemudian ditransformasi ke dalam bentuk yang sesuai dengan skema data warehouse, dan dimuat ke dalam data warehouse database (Berson dan Smith, 1997; Moss, 2005) di dalam El-Bastawissy et al. (2011). Sumber data bagi data warehouse juga dapat berasal dari sistem selain OLTP seperti fail teks, legacy systems, dan spreadsheets (El-Bastawissy et al. 2011).
Penelitian ini memiliki alur yang merupakan hasil modifikasi dari framework umum yang dikemukakan oleh El-Bastawissy et al. (2011), seperti ditunjukkan pada Gambar 2, dengan menambahkan data store (DS) sebagai media penyimpanan data. Data store akan menyimpan data hasil ekstraksi yang telah melalui tahap pembersihan data.
Ekstraksi data dilakukan pada sumber data dengan melakukan teknik parsing pada fail teks, kemudian hasil parsing dimasukkan ke dalam DSA untuk dilakukan proses pembersihan data dan transformasi data. Data yang telah dibersihkan akan disimpan pada data store terlebih dahulu, sebelum dilakukan transformasi data dan pemuatan data ke dalam data warehouse.
Sumber Data
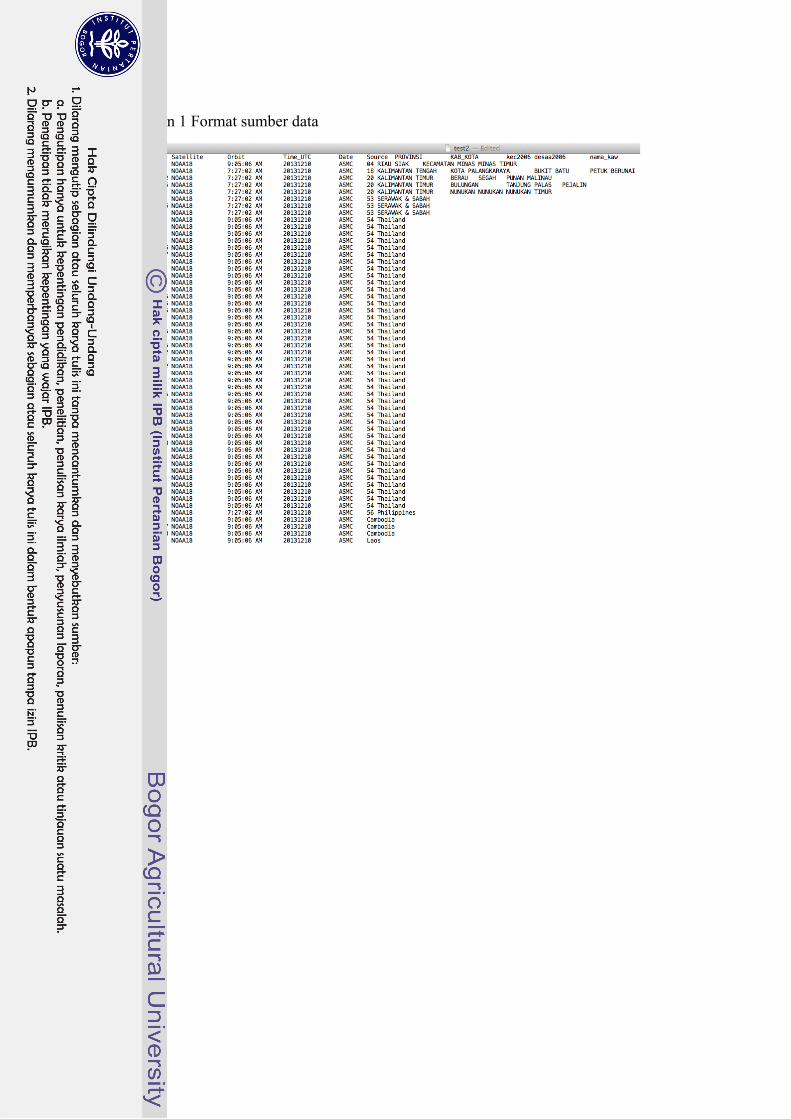
Sumber data merupakan data yang digunakan sebagai sumber masukan untuk data warehouse, data tersebut akan diambil melalui proses ekstraksi data untuk kemudian dimuat ke dalam data warehouse. Sumber data pada penelitian ini berfokus pada satu tipe format yaitu fail teks berisikan informasi titik panas milik DPKH, yang telah dipublikasikan dan bebas diunduh pada situs resmi DPKH. Format sumber data seperti ditunjukkan pada Lampiran 1.
Gambar 1 Framework umum pada proses ETL (El-
Bastawissy et al. 2011)
Gambar 2 Proses ETL modifikasi

4
Ekstraksi Data
Proses ekstraksi data bertujuan untuk mendapatkan data dari sumber data, yang diperlukan oleh data warehouse. Langkah yang dilakukan pada proses ini adalah text parsing. Text parsing merupakan proses pengambilan informasi teks pada fail berbasis teks. Proses ekstraksi data dapat dilakukan terhadap satu atau beberapa sumber data sekaligus. Hasil ekstraksi kemudian dilanjutkan kedalam tahap data staging area kemudian data yang telah bersih disimpan ke dalam data store.
Data Staging Area
Data yang telah diekstraksi dari beberapa sumber data berbeda, kemudian dipindahkan ke dalam data staging area dimana data akan ditransformasikan dan dibersihkan sebelum dipetakan ke dalam data warehouse (El-Bastawissy et al. 2011).
Proses yang terjadi pada tahapan ETL adalah melakukan ekstraksi terhadap sumber data, kemudian hasil ekstraksi akan dimuat ke dalam DSA. DSA merupakan area khusus dalam kegiatan data warehousing, yaitu merupakan tempat dimana data akan ditransformasikan, diseragamkan, dan dibersihkan (Simitsis dan Vassiliadis 2009).
Penelitian ini menggunakan ArrayList pada bahasa pemrograman Java, sebagai data staging area, yang secara fisik berada di dalam memori dan bersifat non-volatile. Masing-masing data hasil ekstraksi dimodelkan dalam bentuk objek hotspot, yang merupakan hasil bentukan dari class Hotspot pada Java, kemudian objek-objek hotspot tersebut dimasukkan kedalam list objek hotspot yang bertipe data ArrayList.
Pembersihan Data
Pembersihan data adalah proses membuang data hasil ekstraksi data yang dianggap tidak valid yang terjadi di dalam data staging area. Pada tahap ini proses yang dilakukan adalah mendeteksi missing value, mendeteksi redudansi data, dan melakukan validasi lokasi hotspot pada tiap objek yang berada di dalam data staging area. Objek hotspot dikatakan tidak valid apabila terdapat missing value pada atribut yang dibutuhkan oleh data warehouse, terjadi redundansi data hotspot, dan atau objek hotspot yang bukan merupakan hotspot yang berada di dalam wilayah Indonesia. Objek hotspot yang tidak valid akan dikeluarkan dari data staging area. Data yang telah bersih kemudian akan disimpan ke dalam data store sebelum memasuki tahap transformasi data.
Data Store
Data store merupakan media penyimpanan data, yang secara fisik adalah database yang menyimpan informasi hotspot hasil ekstraksi data dari sumber data, yang telah dibersihkan dan diseragamkan. Data yang berada di dalam data store

5
menjadi acuan untuk proses pembersihan data yaitu menghilangkan redudansi. Data yang berada pada data staging area akan dibuang apabila data tersebut telah ada di dalam data store dengan membandingkan nilai atribut-atribut seperti lat, long, dan date, sedangkan data yang belum terdapat di dalam data store akan disimpan.
Transformasi Data
Setelah melalui tahap ekstraksi data dan pembersihan data maka tahapan berikutnya adalah tahap transformasi data. Transformasi data adalah proses mengubah data hasil ekstraksi dan pembersihan data menjadi bentuk yang sesuai bagi skema data warehouse, proses ini terjadi di dalam data staging area. Skema data warehouse terdiri atas satu tabel fakta dan tiga tabel dimensi. Adapun tabel-tabel dimensi tersebut yakni dimensi titik panas, dimensi waktu, dan dimensi satelit. Bentuk skema data warehouse hasil modifikasi yang dibuat Imaduddin (2012) dari penelitian sebelumnya dapat dilihat pada Gambar 3.
Proses yang terjadi pada tahap ini adalah membaca kembali data titik panas hasil ekstraksi yang tersimpan pada data store, kemudian hasil pembacaan dari data store akan dimodelkan kedalam bentuk class pada bahasa pemrograman Java, mengikuti skema data warehouse. Atribut date mengalami perubahan bentuk menjadi dimensi waktu yang memiliki atribut yaitu tahun, kuartil, dan bulan.
Loading
Loading merupakan tahap terakhir dalam proses ETL, yaitu memuat data pada data warehouse. Data yang telah diekstraksi, dibersihkan, dan ditransformasi di dalam data staging area kemudian dipetakan ke dalam data warehouse. Data
Gambar 3 Skema snowflake modifikasi (Imaduddin,
2012)

6
warehouse harus dinonaktifkan terlebih dahulu dari kegiatan operasional sebelum proses loading, agar tidak mengganggu kegiatan operasional.
Proses insert data dilakukan menggunakan query insert dengan memetakan tabel-tabel dimensi terlebih dahulu kemudian tabel fakta, hal ini dilakukan untuk mendapatkan foreign key yang dibutuhkan oleh tabel fakta. Untuk menghindari agar tidak terjadi kesalahan dalam proses insert data, maka digunakan fitur rollback. Fitur rollback akan membatalkan transaksi insert data ketika terjadi kesalahan.
Pengujian
Pengujian terhadap modul update hasil penelitian ini dilakukan dalam dua tahap yaitu uji query dan uji performa sistem. Uji query dilakukan terhadap sistem SOLAP dengan memasukkan query MDX, kemudian melihat apakah data hotspot yang baru ditambahkan melalui modul update muncul pada peta atau tidak. Uji performa dilakukan untuk mengetahui berapa waktu yang dibutuhkan untuk melakukan praproses di masing-masing tahap ETL dan waktu keseluruhan.
Lingkungan Pengembangan
Penelitian ini diimplementasikan menggunakan bahasa pemrograman Java dan SQL serta dengan spesifikasi perangkat keras dan lunak sebagai berikut: 1 Perangkat Keras
Spesifikasi perangkat keras yang digunakan adalah: o Intel ® Core™ i5 CPU 1.8 GHz. o Memori 4 GB 1600 MHz DDR 3. o Harddisk 256 GB SSD. o Keyboard dan mouse.
2 Perangkat Lunak o Sistem operasi Mac OS X Mavericks 1.9 64 bit. o NetBeans IDE 7.2.1. o Postgres 9.3.0 dengan ekstensi PostGIS 2.0. o pgAdmin3 1.18.1.
HASIL DAN PEMBAHASAN
Hasil penelitian ini berupa sistem yang mampu melakukan praproses data terhadap sumber data dengan mengacu pada proses ETL, dan memiliki antarmuka untuk membantu pengguna dalam melakukan praproses. Sistem ini memiliki empat fitur yaitu pemilihan berkas, ekstraksi data, transformasi data, dan pemuatan data yang masing-masing direpresentasikan secara berurutan dengan tombol "Browse", "Extraction", "Staging & Transform", dan "Loading" pada antarmuka sistem. Antarmuka sistem ditunjukkan pada Lampiran 2. Masing-masing fitur saling terkait antara satu dan yang lain dengan mengikuti alur proses ETL.

7
Pemilihan Berkas
Pemilihan berkas merupakan fitur yang digunakan untuk memilih berkas sumber data yaitu fail teks berisikan informasi titik panas, yang akan diproses untuk tahap ekstraksi data. Pemilihan berkas dapat dilakukan terhadap beberapa berkas sekaligus. Berkas-berkas terpilih kemudian akan ditampilkan di dalam list view fail teks pada antarmuka seperti ditunjukkan pada Gambar 4.
Ekstraksi Data
Ekstraksi data merupakan fitur yang digunakan untuk melakukan proses pengambilan data terhadap berkas sumber data terpilih. Proses ekstraksi data dilakukan dengan menggunakan teknik parsing pada fail teks yang memiliki format data seperti pada Lampiran 1. Sumber data memiliki 12 atribut, namum tidak seluruh atribut dibutuhkan untuk kegiatan data warehousing, untuk itu perlu dilakukan seleksi atribut terlebih dahulu. Atribut-atribut yang dipilih pada sumber data adalah: 1 Latitude, merupakan informasi garis lintang. 2 Longitude, merupakan informasi garis bujur. 3 Satelit, merupakan informasi nama satelit. 4 Orbit, merupakan informasi waktu satelit mengambil titik panas. 5 Time UTC, merupakan informasi keterangan waktu siang atau malam. 6 Date, merupakan informasi tanggal titik panas tersebut diambil. 7 Source, merupakan informasi mengenai sumber.
Langkah-langkah dalam melakukan parsing yaitu membaca fail teks baris demi baris, kemudian memotong baris tersebut menjadi kolom-kolom sesuai dengan atribut terpilih, dengan pemisah yaitu “ ” (space). Baris merepresentasikan record dan kolom merepresentasikan atribut. Data hasil parsing kemudian dimodelkan dalam bentuk class, yaitu class Hotspot (Gambar 5), yang merupakan representasi dari tabel hotspot pada data store.
Pemodelan ke dalam bentuk class dimaksudkan untuk menjaga integrasi antar atribut, serta melakukan penyesuaian tipe data. Hasil ekstraksi kemudian dimasukkan ke dalam list hotspot yang bertindak sebagai data staging area. List hotspot merupakan sebuah array bertipe data class hotspot yang menampung objek-objek hasil pemodelan class. List hotspot dapat divisualisasikan ke dalam list view pada antarmuka seperti ditunjukkan pada Gambar 6.
Gambar 4 List view fail teks

8
Data Staging Area
Data staging area merupakan tempat persiapan data hasil ekstraksi, sebelum data dimuat ke dalam data warehouse. Persiapan data melibatkan proses data cleaning dan transformasi data. Setelah data dibersihkan, data yang telah bersih kemudian disimpan pada data store. Data store merupakan tempat penyimpanan data dari berbagai sumber, yang sudah terintegrasi, dari hasil ekstraksi dan telah melalui proses pembersihan data. Data Cleaning
Data cleaning merupakan proses pembersihan data titik panas yang tidak valid. Data yang termasuk kategori tidak valid adalah terdapat redudansi data, berada diluar wilayah Indonesia, atau terdapat missing value. Apabila data dikategorikan tidak valid maka data tersebut akan dikeluarkan dari staging area.
Mendeteksi redudansi data dapat dilakukan dengan menelusur apakah di dalam data store sudah tersimpan titik panas yang sama atau tidak, dengan membandingkan atribut lat, long, dan tanggal. Apabila ketiga nilai tersebut sama, maka telah terjadi redudansi, kemudian data yang redundan tersebut akan dikeluarkan dari data staging area.
Melakukan validasi terhadap lokasi titik panas dilakukan pada sisi basis data dengan melakukan query, dua buah data bertipe geometry akan dibandingkan. Basis data Postgres dengan ekstensi PostGIS, memiliki fungsi pengolahan data spatial yaitu _st_contains(geometry Kabupaten, geometry Hotspot) untuk membandingkan apakah geometry kabupaten yang bertipe polygon mengandung bagian geometry titik panas yang bertipe point. Jika point titik panas tersebut
Gambar 5 Model class Hotspot
Gambar 6 List view hasil ekstraksi

9
termasuk bagian dari salah satu polygon kabupaten, maka titik panas tersebut masuk ke dalam wilayah Indonesia, dan jika bukan merupakan bagian polygon kabupaten, titik panas tersebut akan dikeluarkan dari data staging area.
Pendeteksian missing value dilakukan dengan menelusur atribut penting yang akan digunakan dalam kegiatan data warehousing pada objek-objek hotspot di dalam data staging area. Atribut-atribut penting yang dimaksud yakni latitude, longitude, satelit, dan tanggal. Apabila salah satu nilai tersebut tidak ada atau null maka objek hotspot tersebut akan dikeluarkan dari dalam data staging area.
Transformasi Data
Transformasi data dilakukan terhadap data source yang telah diekstraksi dan telah melalui proses data cleaning. Transformasi bertujuan untuk mengubah data menjadi bentuk yang sesuai bagi skema data warehouse. Data class hotspot akan diubah menjadi model class fakta dan dimensi-dimensi mengikuti skema data warehouse. Model class terdiri atas satu model fakta dan tiga model dimensi, model dimensi terdiri atas dimensi geohotspot, dimensi waktu, dan dimensi satelit.
Proses transformasi mengubah model class hotspot (Gambar 5) menjadi model class fakta (Gambar 7) sesuai dengan skema data warehouse dengan melakukan penyesuaian tipe data. Atribut lat, long, dan idKab akan dipetakan ke dalam dimensi geohotspot, atribut tanggal akan diubah formatnya menjadi bulan, kuartil, dan tahun kemudian dipetakan ke dalam dimensi waktu, lalu atribut satelit akan dipetakan ke dalam dimensi satelit. Objek-objek fakta akan dimasukkan kedalam list fakta yang merupakan array bertipe data class fakta. List fakta ini merupakan data staging area bagi data yang telah mengalami tahap transformasi.
Pemuatan Data
Pemuatan data adalah proses memindahkan data pada data staging area ke dalam data warehouse. Proses ini dilakukan terhadap data yang berada dalam data staging area, yang telah mengalami proses transformasi data. Data-data tersebut telah siap untuk dimuat ke dalam data warehouse. Proses pemuatan data dilakukan terhadap data warehouse yang sebelumnya telah dinon-aktifkan dari kegiatan operasional.
Tabel fakta pada data warehouse membutuhkan foreign key dari dimensi-
Gambar 7 Model class fakta

10
dimensi terkait sebagai referensi. Untuk itu pemuatan data dilakukan dengan memuat model dimensi-dimensi terlebih dahulu ke dalam data warehouse, dan mengembalikan nomor id record yang baru dimasukkan, untuk mendapatkan referensi foreign key bagi model class fakta. Setelah foreign key didapatkan untuk masing-masing dimensi, kemudian dilakukan pemuatan model class fakta.
Untuk menghindari terjadinya kesalahan dalam pemuatan data ke dalam data warehouse, maka dilakukan penyatuan proses-proses pemuatan ke dalam sebuah proses transaksi, dimana didalamnya terdapat operasi-operasi query terhadap data warehouse. Setiap proses transaksi akan dinyatakan sebagai proses yang berhasil atau gagal sebagai satu kesatuan. Apabila operasi-operasi di dalam proses transaksi salah satunya mengalami kegagalan, maka pemuatan data atas transaksi tersebut dibatalkan, dan sistem akan memroses data berikutnya. Setiap transaksi pemuatan data pada data warehouse akan ditampilkan pada console seperti ditunjukkan pada Gambar 8.
Pengujian
Uji Query Uji query dilakukan untuk melihat apakah data hotspot hasil ekstraksi dari
sumber data berhasil dimuat ke dalam data warehouse dan ditampilkan pada peta atau tidak. Data uji yang digunakan adalah fail teks milik DPKH pada rentang tanggal 1-9 Januari tahun 2013 yang berjumlah 9 fail. Pengujian ini dilakukan dengan memasukkan query MDX berikut:
SELECT {[Measures].[Jumlah_Hotspot]} ON COLUMNS, {[lokasi].[Hotspot].Members} ON ROWS FROM [geohotspot] WHERE [waktu].[2013]
Query MDX tersebut akan menampilkan seluruh sebaran data hotspot yang ada pada tahun 2013 (data hotspot yang baru ditambahkan) yang berjumlah 77 titik (valid) dari 1615 informasi hotspot pada fail teks seperti ditunjukkan pada Gambar 9. Uji Performa
Uji performa dilakukan untuk melihat waktu eksekusi yang dibutuhkan pada tiap tahapan ETL dan total waktu eksekusi untuk keseluruhan proses ETL. Data uji yang digunakan adalah fail teks yang berisi record-record data hotspot. Jumlah data yang diuji berturut-turut yaitu 100, 200, 300, 400, dan 500 record data hotspot yang berada pada satu buah fail teks pada masing-masing proses. Skala pengukuran uji performa adalah waktu dalam satuan millisecond (ms) dan
Gambar 8 Hasil proses transaksi pemuatan data pada
console

11
dilakukan sebanyak tiga kali iterasi. Empat tahapan proses yang diuji sebagai berikut: 1 Ekstraksi Data
Waktu eksekusi proses ekstraksi data terhadap sumber data, cenderung lebih cepat dibandingkan dengan proses lainnya di dalam ETL. Hal ini dikarenakan proses ekstraksi hanya melibatkan proses parsing text dan tidak melibatkan kegiatan penyimpanan data seperti halnya pada penyimpanan data ke dalam data store dan pemuatan data ke dalam data warehouse. Pengujian waktu eksekusi ekstraksi data ditunjukkan oleh Tabel 1.
Tabel 1 Waktu eksekusi ekstraksi data
Jumlah Data Waktu eksekusi ekstraksi data pada iterasi ke- 1 2 3
Waktu eksekusi (ms) 100 120 133 111 200 212 209 201 300 327 333 319 400 411 401 407 500 481 477 471 2 Staging dan Transformasi Data
Proses transformasi melibatkan proses pembersihan data serta penyimpanan data yang telah dibersihkan ke dalam data store sehingga waktu eksekusi proses transformasi memakan waktu lebih lama dibandingkan dengan ekstraksi data dan pemuatan data. Setiap seratus jumlah data ditambahkan waktu eksekusi akan meningkat lebih kurang 3000 ms atau sekitar 3 detik. Pengujian waktu eksekusi transformasi data ditunjukkan oleh Tabel 2.
Gambar 9 Visualisasi hotspot pada peta
12
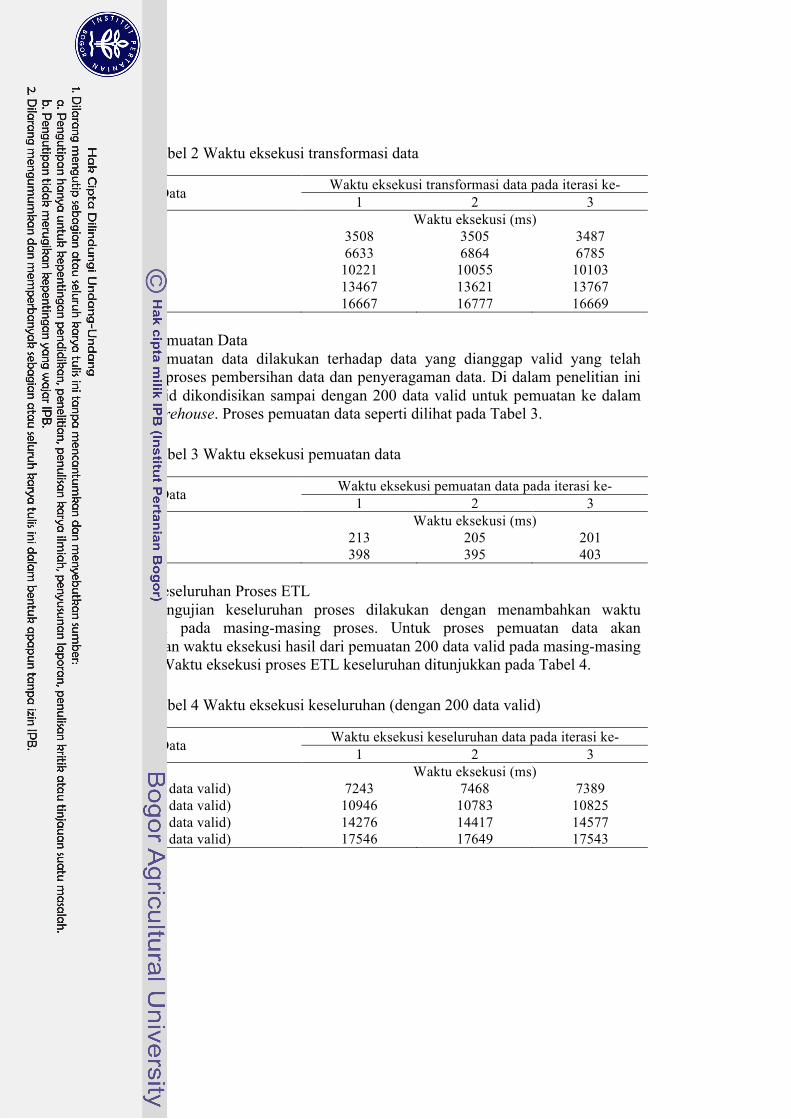
Tabel 2 Waktu eksekusi transformasi data
Jumlah Data Waktu eksekusi transformasi data pada iterasi ke- 1 2 3
Waktu eksekusi (ms) 100 3508 3505 3487 200 6633 6864 6785 300 10221 10055 10103 400 13467 13621 13767 500 16667 16777 16669
3 Pemuatan Data
Pemuatan data dilakukan terhadap data yang dianggap valid yang telah melalui proses pembersihan data dan penyeragaman data. Di dalam penelitian ini data valid dikondisikan sampai dengan 200 data valid untuk pemuatan ke dalam data warehouse. Proses pemuatan data seperti dilihat pada Tabel 3.
Tabel 3 Waktu eksekusi pemuatan data
Jumlah Data Waktu eksekusi pemuatan data pada iterasi ke- 1 2 3
Waktu eksekusi (ms) 100 213 205 201 200 398 395 403 4 Keseluruhan Proses ETL
Pengujian keseluruhan proses dilakukan dengan menambahkan waktu eksekusi pada masing-masing proses. Untuk proses pemuatan data akan digunakan waktu eksekusi hasil dari pemuatan 200 data valid pada masing-masing iterasi. Waktu eksekusi proses ETL keseluruhan ditunjukkan pada Tabel 4.
Tabel 4 Waktu eksekusi keseluruhan (dengan 200 data valid)
Jumlah Data Waktu eksekusi keseluruhan data pada iterasi ke- 1 2 3
Waktu eksekusi (ms) 200 (200 data valid) 7243 7468 7389 300 (200 data valid) 10946 10783 10825 400 (200 data valid) 14276 14417 14577 500 (200 data valid) 17546 17649 17543

13
SIMPULAN DAN SARAN
Simpulan
Praproses data titik panas yang bersumber pada fail teks milik DPKH, tidak lagi dilakukan secara manual. Dengan mengacu pada konsep ETL sistem mampu melakukan praproses terhadap data titik panas berupa fail teks. Praproses dilakukan oleh sistem dengan memilih fail teks yang akan disimpan pada data warehouse. Sistem ini mampu melakukan pembersihan data terhadap data titik panas yang tidak valid, dan mampu untuk melakukan pembatalan ketika memuat data ke dalam data warehouse, apabila terjadi kesalahan.
Saran
Sistem ini hanya dapat melakukan praproses data terhadap data titik panas pada fail teks milik DPKH, dan tidak dapat melakukan praproses data terhadap sumber yang lain. Penambahan dan pemilihan dimensi mungkin dibutuhkan seiring dengan penambahan lingkup analisis pada sistem SOLAP ataupun terjadi perubahan skema pada data warehouse.
Untuk itu pada pengembangan berikutnya diharapkan sistem mampu melakukan praproses data terhadap sumber data yang lain serta dapat menambah, dan memilih dimensi sesuai dengan kebutuhan analisis.
DAFTAR PUSTAKA
Berson A, Smith SJ. 1997. Data Warehousing, Data Mining, and OLAP. New York (US): McGraw-Hill.
El-Bastawissy AH, El-Sappagh SHA, Hendawi AMA. 2011. Journal of King Saud University. A Proposed Model for Data Warehouse ETL Processes. 23(1):91-104.
Fadli MH. 2011. Data warehouse spatio-temporal kebakaran hutan menggunakan Geomondrian dan Geoserver [skripsi]. Bogor (ID): Institut Pertanian Bogor.
Han J, Kamber M. 2006. Data Mining. Ed ke-2. San Francisco (US): Morgan Kaufmann Publishers.
Imaduddin A. 2012. Sinkronisasi antara visualisasi peta dan query OLAP pada spatial data warehouse kebakaran hutan di Indonesia [skripsi]. Bogor (ID): Institut Pertanian Bogor.
Simitsis A, Vassiliadis P. 2009. Encyclopedia of Database Systems. Extraction, Transformation, and Loading.doi:10.1007/978-0-387-39940-9_158.
Thoha AS. 2008. Penggunaan data hotspot untuk monitoring kebakaran hutan dan lahan di Indonesia [karya tulis]. Medan (ID): Universitas Sumatera Utara.
Trisminingsih R. 2010. Pembangunan spatial data warehouse berbasis web untuk persebaran hotspot di wilayah Indonesia [skripsi]. Bogor (ID): Institut Pertanian Bogor.
14
Lampiran 1 Format sumber data

15
Lampiran 2 Antarmuka sistem

16
RIWAYAT HIDUP
Penulis dilahirkan di Bogor pada tanggal 19 Januari 1990 dan memiliki nama lengkap Bolivianto Kusumah. Penulis merupakan putra pertama dari tiga bersaudara dari pasangan Wowon Trestiady dan Mimin Mintarsih.
Penulis telah menyelesaikan studi Sekolah Menengah Atas di SMA Negeri 4 Bogor pada tahun 2008. Kemudian penulis melanjutkan studi tingkat perguruan tinggi pada tahun 2008, dengan mengikuti seleksi masuk di Program Diploma Institut Pertanian Bogor dengan program keahlian Manajemen Informatika, dan dinyatakan lulus pada tahun 2011. Pada tahun yang sama penulis mengikuti proses seleksi masuk program ekstensi Ilmu Komputer di IPB dan dinyatakan diterima sebagai mahasiswa program ekstensi Ilmu Komputer pada tahun 2011.