
MATERI PELATIHAN 2015 PENGOLAHAN DATA SPSS · PDF fileTranformasi data pada Recode merupakan...
38
2015 MATERI PELATIHAN PENGOLAHAN DATA SPSS NURRATRI KURNIA SARI, S. Pd., M. Pd
Transcript of MATERI PELATIHAN 2015 PENGOLAHAN DATA SPSS · PDF fileTranformasi data pada Recode merupakan...

2015
MATERI PELATIHAN PENGOLAHAN DATA SPSS
NURRATRI KURNIA SARI, S. Pd., M. Pd

1
MENGENAL SPSS
SPSS adalah sebuah program aplikasi yang memiliki kemampuan analisis statistik
cukup tinggi serta sistem manajemen data pada lingkungan grafis dengan menggunakan
menu-menu deskriptif dan kotak-kotak dialog yang sederhana sehingga mudah untuk
dipahami cara pengoperasiannya. Beberapa aktivitas dapat dilakukan dengan mudah dengan
menggunakan pointing dan clicking mouse.
SPSS banyak digunakan dalam berbagai riset pemasaran, pengendalian dan perbaikan
mutu (quality improvement), serta riset-riset sains. SPSS pertama kali muncul dengan versi
PC (bisa dipakai untuk komputer desktop) dengan nama SPSS/PC+ (versi DOS). Tetapi,
dengan mulai populernya system operasi windows. SPSS mulai mengeluarkan versi windows
(mulai dari versi 6.0 sampai versi terbaru sekarang).Pada awalnya SPSS dibuat untuk
keperluan pengolahan data statistik untuk ilmu-ilmu social, sehingga kepanjangan SPSS itu
sendiri adalah Statistikal Package for the Social Sciens. Sekarang kemampuan SPSS
diperluas untuk melayani berbagai jenis pengguna (user), seperti untuk proses produksi di
pabrik, riset ilmu sains dan lainnya. Dengan demikian, sekarang kepanjangan dari SPSS
Statistical Product and Service Solutions.
SPSS dapat membaca berbagai jenis data atau memasukkan data secara langsung ke
dalam SPSS Data Editor. Bagaimanapun struktur dari file data mentahnya, maka data dalam
Data Editor SPSS harus dibentuk dalam bentuk baris (cases) dan kolom (variables). Case
berisi informasi untuk satu unit analisis, sedangkan variable adalah informasi yang
dikumpulkan dari masing-masing kasus. Hasil-hasil analisis muncul dalam SPSS Output
Navigator. Kebanyakan prosedur Base System menghasilkan pivot tables, dimana kita bisa
memperbaiki tampilan dari keluaran yang diberikan oleh SPSS. Untuk memperbaiki output,
maka kita dapat mmperbaiki output sesuai dengan kebutuhan. Beberapa kemudahan yang lain
yang dimiliki SPSS dalam pengoperasiannya adalah karena SPSS menyediakan beberapa
fasilitas seperti berikut ini:
Data Editor. Merupakan jendela untuk pengolahan data. Data editor dirancang
sedemikian rupa seperti pada aplikasi-aplikasi spreadsheet untuk mendefinisikan,
memasukkan, mengedit, dan menampilkan data.
Viewer. Viewer mempermudah pemakai untuk melihat hasil pemrosesan, menunjukkan
atau menghilangkan bagian-bagian tertentu dari output, serta memudahkan distribusi
hasil pengolahan dari SPSS ke aplikasi-aplikasi yang lain.
Multidimensional Pivot Tables. Hasil pengolahan data akan ditunjukkan dengan
multidimensional pivot tables. Pemakai dapat melakukan eksplorasi terhdap tabel dengan
pengaturan baris, kolom, serta layer. Pemakai juga dapat dengan mudah melakukan
pengaturan kelompok data dengan melakukan splitting tabel sehingga hanya satu group
tertentu saja yang ditampilkan pada satu waktu.
High-Resolution Graphics. Dengan kemampuan grafikal beresolusi tinggi, baik untuk
menampilkan pie charts, bar charts, histogram, scatterplots, 3-D graphics, dan yang
lainnya, akan membuat SPSS tidak hanya mudah dioperasikan tetapi juga membuat
pemakai merasa nyaman dalam pekerjaannya.
Database Access. Pemakai program ini dapat memperoleh kembali informasi dari
sebuah database dengan menggunakan Database Wizard yang disediakannya.
Data Transformations. Transformasi data akan membantu pemakai memperoleh data
yang siap untuk dianalisis. Pemakai dapat dengan mudah melakukan subset data,
mengkombinasikan kategori, add, aggregat, merge, split, dan beberapa perintah transpose
files, serta yang lainnya.

2
Electronic Distribution. Pengguna dapat mengirimkan laporan secara elektronik
menggunakan sebuah tombol pengiriman data (e-mail) atau melakukan export tabel dan
grafik ke mode HTML sehingga mendukung distribusi melalui internet dan intranet.
Online Help. SPSS menyediakan fasilitas online help yang akan selalu siap membantu
pemakai dalam melakukan pekerjaannya. Bantuan yang diberikan dapat berupa petunjuk
pengoperasian secara detail, kemudahan pencarian prosedur yang diinginkan sampai
pada contoh-contoh kasus dalam pengoperasian program ini.
Akses Data Tanpa Tempat Penyimpanan Sementara. Analisis file-file data yang
sangat besar disimpan tanpa membutuhkan tempat penyimpanan sementara. Hal ini
berbeda dengan SPSS sebelum versi 11.5 dimana file data yang sangat besar dibuat
temporary filenya.
Interface dengan Database Relasional. Fasilitas ini akan menambah efisiensi dan
memudahkan pekerjaan untuk mengekstrak data dan menganalisnya dari database
relasional.
Analisis Distribusi. Fasilitas ini diperoleh pada pemakaian SPSS for Server atau untuk
aplikasi multiuser. Kegunaan dari analisis ini adalah apabila peneliti akan menganalisis
file-file data yang sangat besar dapat langsung me-remote dari server dan memprosesnya
sekaligus tanpa harus memindahkan ke komputer user.
Multiple Sesi. SPSS memberikan kemampuan untuk melakukan analisis lebih dari satu
file data pada waktu yang bersamaan.
Mapping. Visualisasi data dapat dibuat dengan berbagai macam tipe baik secara
konvensional atau interaktif, misalnya dengan menggunakan tipe bar, pie atau jangkauan
nilai, simbol gradual, dan chart.
Bagian Data Editor

3
Keterangan:
Name digunakan untuk memberi keterangan nama varoabel
Type untuk memmilih jenis data yang direkam
Width untuk mengatur lebar koom dalam hasil analisis
Decimal digunakan untuk menentukan jumlah angka di belakang koma
Label digunakan untuk memberikan keterangan pada variabel
Value digunakan untuk mengatur keterangan untuk data variabel
Missing digunaka untuk mengatur data hilang/ tidak lengkap
Column digunakan untuk mengatur lebar lebar kolom dalam data view
Align digunakan untuk mengatur jenis penataan
Measure digunakan untuk menentukan jenis skala pengukuran data
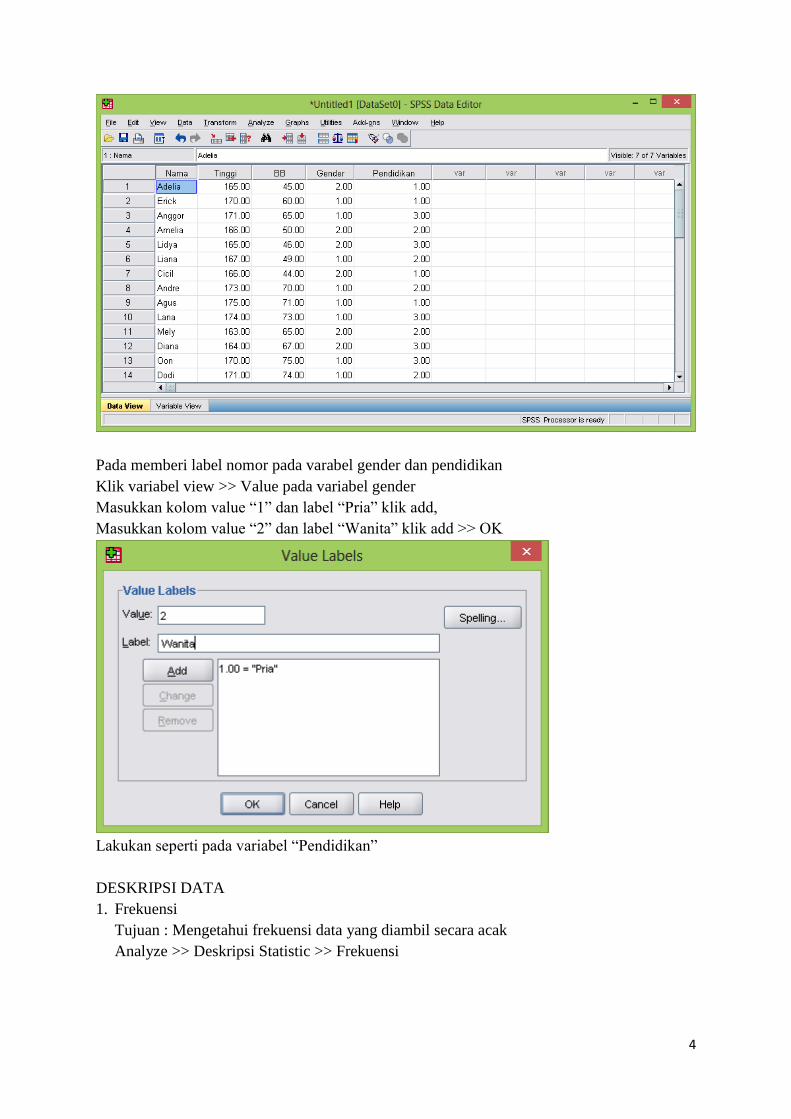
Data pasien di RS Umum kota Surakarta sebagai berikut;
No Nama Tinggi Berat Gender Pendidikan
1. Adelia 165 45 Wanita SMU
2. Erick 170 60 Pria SMU
3. Anggoro 171 65 Pria Sarjana
4. Amelia 166 50 Wanita Akademi
5. Lidya 165 46 Wanita Sarjana
6. Liana 167 49 Pria Akademi
7. Cicil 166 44 Wanita SMU
8. Andre 173 70 Pria Akademi
9. Agus 175 71 Pria SMU
10. Lana 174 73 Pria Sarjana
11. Mely 163 65 Wanita Akademi
12. Diana 164 67 Wanita Sarjana
13. Oon 170 75 Pria Sarjana
14. Dodi 171 74 Pria Akademi
15. Agung 172 70 Pria Sarjana
Masukan data di atas pada input SPSS
DESKRIPSI DATA
4
Pada memberi label nomor pada varabel gender dan pendidikan
Klik variabel view >> Value pada variabel gender
Masukkan kolom value “1” dan label “Pria” klik add,
Masukkan kolom value “2” dan label “Wanita” klik add >> OK
Lakukan seperti pada variabel “Pendidikan”
DESKRIPSI DATA
1. Frekuensi
Tujuan : Mengetahui frekuensi data yang diambil secara acak
Analyze >> Deskripsi Statistic >> Frekuensi

5
Masukkan Gender dan Pendidikan ke kolom Variabel >> OK
Hasil “OutPut”
Gender
Frequency Percent Valid Percent Cumulative Percent
Valid Pria 9 60.0 60.0 60.0
Wanita 6 40.0 40.0 100.0
Total 15 100.0 100.0
Pada hasil “Gender” diatas dapat disimpulkan bahwa Frekuesi pria sebanyak 9 dengan
presentase 60%, sedangkan Wanita sebanyak 6 dengan presentase 40%.
Pendidikan
Frequency Percent Valid Percent Cumulative Percent
Valid SMU 4 26.7 26.7 26.7
Akademi 5 33.3 33.3 60.0
Sarjana 6 40.0 40.0 100.0
Total 15 100.0 100.0
Pada hasil “Pendidikan” diatas dapat disimpulkan bahwa Frekuesi SMU sebanyak 4 dengan
presentase 26,7%, Akademi sebanyak 5 dengan presentase 33,3%, sedangkan Sarjana
sebanyak 6 dengan presentase 40%.
6
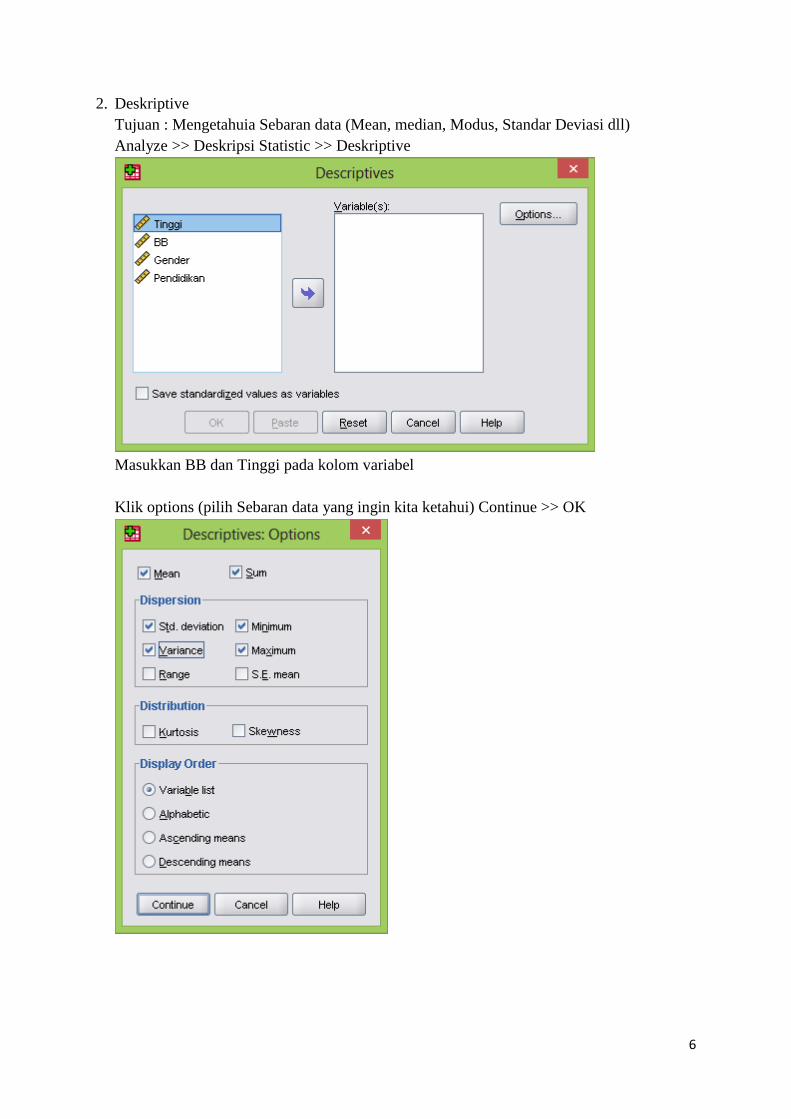
2. Deskriptive
Tujuan : Mengetahuia Sebaran data (Mean, median, Modus, Standar Deviasi dll)
Analyze >> Deskripsi Statistic >> Deskriptive
Masukkan BB dan Tinggi pada kolom variabel
Klik options (pilih Sebaran data yang ingin kita ketahui) Continue >> OK

7
Hasil “output SPSS”
Descriptive Statistics
N Minimum Maximum Sum Mean Std. Deviation Variance
Tinggi 15 163.00 175.00 2532.00 1.6880E2 3.87667 15.029
BB 15 44.00 75.00 924.00 61.6000 11.55607 133.543
Valid N (listwise) 15
3. Explore
Tujuan : Mengetahui Frekuensi dan Sebaran Data (Mean, median, Modus, Standar
Deviasi) berdasarkan per kategori
Analyze >> Deskripsi Statistic >> Explore
Masukkan “Tinggi dan BB” pada kolom Dependent List,
Masukkan “Gender dan Pendidikan” pada kolom Factor List >> OK
Hasil Output SPSS
Descriptives
Gender Statistic Std. Error
Tinggi Pria Mean 1.7144E2 .80123
95% Confidence Interval for
Mean
Lower Bound 1.6960E2
Upper Bound 1.7329E2
5% Trimmed Mean 1.7149E2
Median 1.7100E2
Variance 5.778

8
Std. Deviation 2.40370
Minimum 167.00
Maximum 175.00
Range 8.00
Interquartile Range 3.50
Skewness -.329 .717
Kurtosis .302 1.400
Wanita Mean 1.6483E2 .47726
95% Confidence Interval for
Mean
Lower Bound 1.6361E2
Upper Bound 1.6606E2
5% Trimmed Mean 1.6487E2
Median 1.6500E2
Variance 1.367
Std. Deviation 1.16905
Minimum 163.00
Maximum 166.00
Range 3.00
Interquartile Range 2.25
Skewness -.668 .845
Kurtosis -.446 1.741
BB Pria Mean 67.4444 2.78444
95% Confidence Interval for
Mean
Lower Bound 61.0235
Upper Bound 73.8654
5% Trimmed Mean 68.0494
Median 70.0000
Variance 69.778
Std. Deviation 8.35331
Minimum 49.00
Maximum 75.00
Range 26.00
Interquartile Range 11.00
Skewness -1.582 .717
Kurtosis 2.313 1.400
9
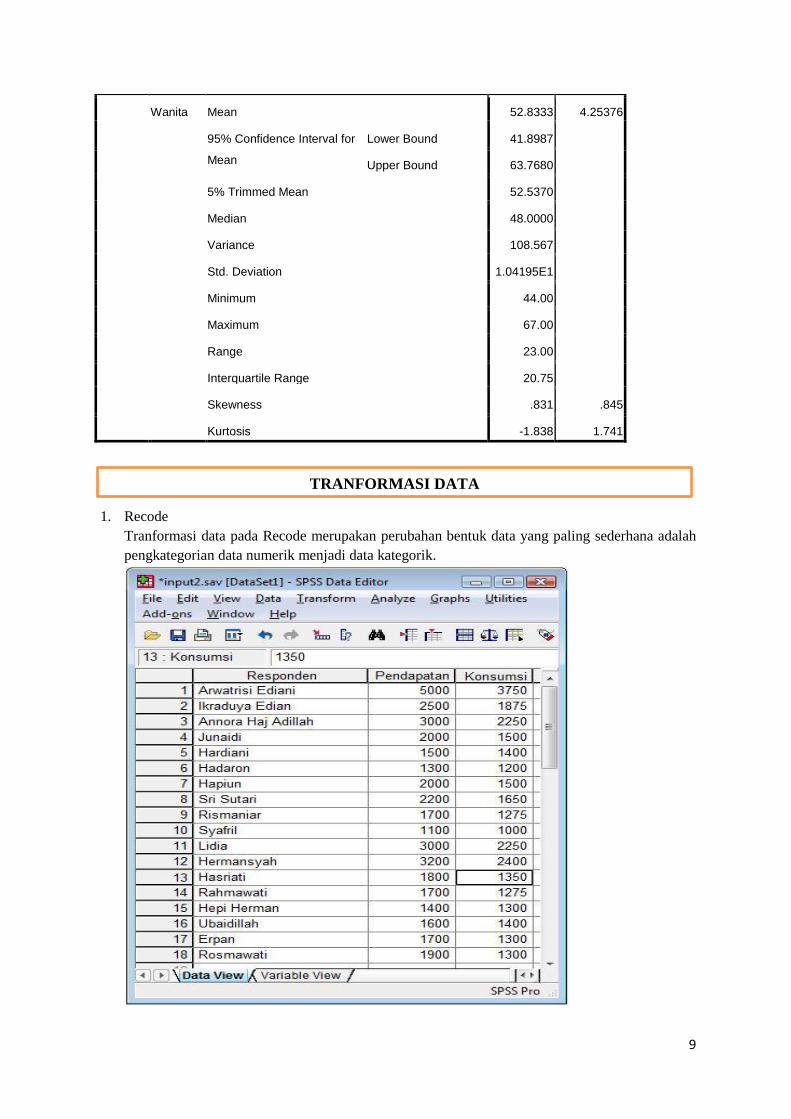
Wanita Mean 52.8333 4.25376
95% Confidence Interval for
Mean
Lower Bound 41.8987
Upper Bound 63.7680
5% Trimmed Mean 52.5370
Median 48.0000
Variance 108.567
Std. Deviation 1.04195E1
Minimum 44.00
Maximum 67.00
Range 23.00
Interquartile Range 20.75
Skewness .831 .845
Kurtosis -1.838 1.741
1. Recode
Tranformasi data pada Recode merupakan perubahan bentuk data yang paling sederhana adalah
pengkategorian data numerik menjadi data kategorik.
TRANFORMASI DATA
10
Mengelompokkan Pendapatan tinggi, sedang, rendah;
Pendapatan tinggi : di atas 4000
Pendapatan sedang : 3900-2000
Pendapatan rendah : di bawah 1900
Langkah-langkah dalam transformasi data:
Dari menu utama, pilihlah:
Transform <
Recode <
Into Different Variable….
2. Compute
Berdasarkan data tersebut, kita ingin menghitung tabungan masing-masing responden
(yang berasal dari pendapatan dikurangi konsumsi), yang akan digunakan untuk
pengolahan data lebih lanjut.
Untuk melakukan itu,
klik Transform > Compute Variable
1. UJI NORMALITAS
Tujuan:
Untuk mengetahui distribusi data, apakah berbentuk distribusi normal atau tidak.
Contoh Masalah:
1. Apakah data uang saku berdistribusi normal?
2. Apakah data motivasi belajar berdistribusi normal?
3. Apakah data prestasi belajar berdistribusi normal?
Kasus:
Berikut ini disajikan data tentang Usia, berat badan dan kadar gula darah pasien:
Usia Berat Badan
Kadar Gula
Darah
Usia Berat Badan
Kadar Gula
Darah
50 58 108 45 63 118
60 45 150 45 46 114
65 54 104 65 57 107
55 48 120 55 49 142
40 61 110 45 55 144
35 54 125 40 48 139
65 52 105 30 58 147
90 50 110 25 52 108
35 58 108 45 60 110
30 60 110 65 54 121
45 48 134 50 56 100
25 62 128 60 53 109
30 44 117 40 61 111
Ujilah apakah ketiga variabel di atas memiliki distribusi normal? Ujilah dengan menggunakan taraf
signifikansi 5%!
Langkah-langkah dalam menganalisis
UJI PRASYARAT
11
1. Rekamlah data tersebut ke dalam tiga kolom:
Kolom pertama data tentang Uang Saku
Kolom kedua data tentang Motivasi Belajar
Kolom ketiga data tentang Prestasi Belajar
2. Berilah keterangan data tersebut dengan menggunakan variable view.
Baris pertama (Name = X1, Label = Uang Saku)
Baris kedua (Name = X2, Label = Motivasi Belajar)
Baris ketiga (Name = Y, Label = Prestasi Belajar)
3. Simpanlah data tersebut dengan nama Latihan Uji Normalitas
4. Lakukan analisis dengan menggunakan menu
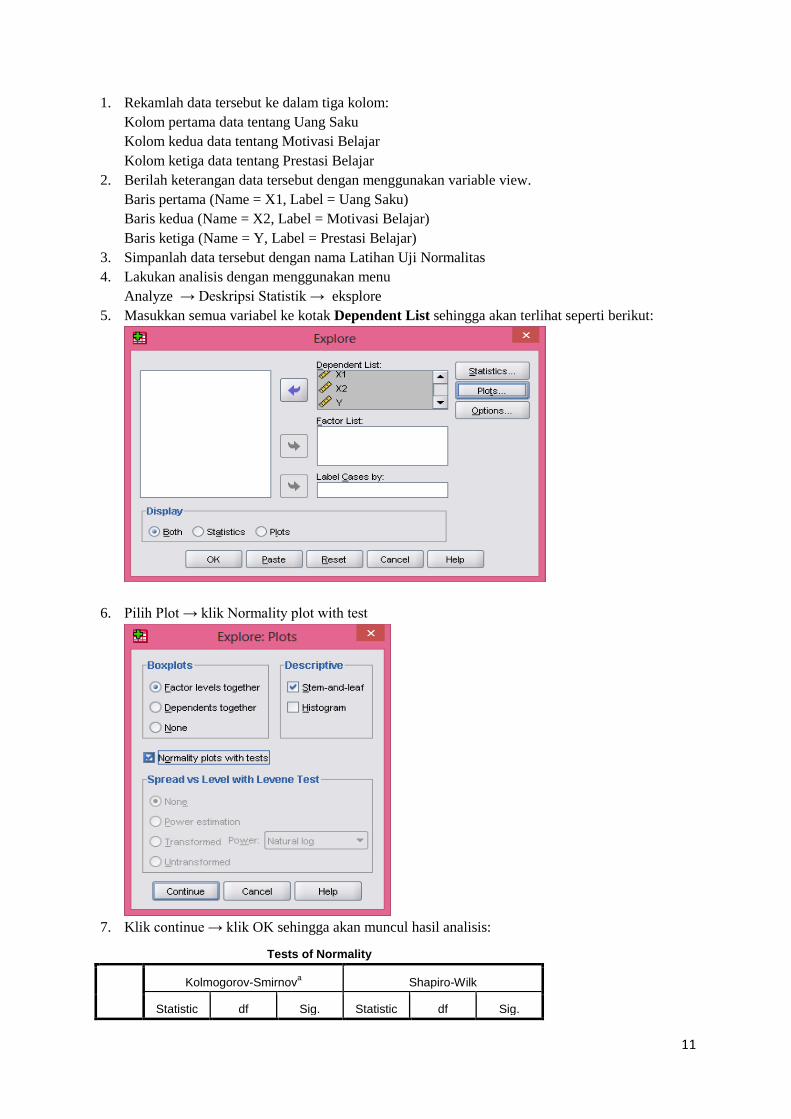
Analyze → Deskripsi Statistik → eksplore
5. Masukkan semua variabel ke kotak Dependent List sehingga akan terlihat seperti berikut:
6. Pilih Plot → klik Normality plot with test
7. Klik continue → klik OK sehingga akan muncul hasil analisis:
Tests of Normality
Kolmogorov-Smirnova Shapiro-Wilk
Statistic df Sig. Statistic df Sig.

12
X1 .141 26 .194 .943 26 .162
X2 .105 26 .200* .959 26 .364
Y .210 26 .004 .872 26 .004
a. Lilliefors Significance Correction
*. This is a lower bound of the true significance.
1. Tabel di atas menunjukkan hasil analisis uji normalitas terhadap ketiga variabel di atas.
Bagian yang perlu dilihat untuk keperluan uji normalitas adalah bagian kolom
Kolmogorov-Smirnov Z dan Sig. Dengan asumsi sebagai berikut,
a. nilai Sig ≥ 0,05 maka data berdistribusi normal,
b. Sig < 0,05 maka distribusi data tidak normal.
2. Berdasarkan hasil analisis di atas diperoleh untuk variabel X1 = usia nilai Z K-S sebesar
0,141 dengan sig 0,194. Oleh karena nilai sig tersebut lebih besar dari 0,05 maka dapat
disimpulkan bahwa data variabel usia pasien berdistribusi normal.
3. Bagaimana dengan variabel lainnya? Buatlah kesimpulannya!
2. UJI LINIERITAS
Tujuan: Untuk mengetahui linearitas hubungan antara variabel bebas dengan variabel terikat.
Contoh Masalah:
Apakah hubungan antara variabel uang saku dengan variabel prestasi belajar berbentuk garis
linear?
Apakah hubungan antara variabel motivasi belajar dengan variabel prestasi belajar berbentuk
garis linear?
Kasus:
Berikut ini disajikan data tentang Usia, berat badan dan kadar gula darah pasien:
Usia Koresterol
Tekanan darah Usia Koresterol
Tekanan darah
Sistolik Sistolik
45 238 128 65 213 138
45 195 170 90 196 134
65 240 124 35 207 127
55 198 140 30 199 162
45 211 130 45 205 164
50 204 145 25 243 159
60 202 125 30 208 167
65 200 130 25 202 128
55 208 128 45 210 130
40 210 130 65 204 141
35 198 154 50 206 120
50 212 148 60 203 129
60 194 137 40 211 131
40 230 110 80 150 115 Ujilah apakah hubungan antara variabel usia dengan variabel dalam tekanan darah berbentuk
linear?
Ujilah apakah hubungan antara variabel kadar koresterol dengan variabel tekan darah berbentuk
linear?
Gunakan taraf signifikansi 5%!

13
Langkah-langkah dalam menganalisis
1. Rekamlah data tersebut ke dalam tiga kolom:
Kolom pertama data tentang Usia
Kolom kedua data tentang Koresterol
Kolom ketiga data tentang Tekanan darah
2. Berilah keterangan data tersebut dengan menggunakan variable view.
Baris pertama (Name = X1, Label = Usia)
Baris kedua (Name = X2, Label = Koresterol)
Baris ketiga (Name = Y, Label = Tekanan darah)
3. Simpanlah data tersebut dengan nama Latihan Uji Linearitas
4. Lakukan analisis dengan menggunakan menu Analyze >> Compare Means >> Means…
5. Masukkan seluruh variabel bebas (X1 dan X2) ke dalam kotak Independent List dan masukkan
variabel terikatnya (Y) pada kotak Dependent List. Sehingga akan terlihat seperti berikut:
Klik tombol Option >> klik Test for linearity >> klik Continue
Klik OK sehingga akan muncul hasil analisis:
ANOVA Table
Sum of Squares df Mean Square F Sig.
Y * X1 Between
Groups
(Combined) 3128.264 10 312.826 1.453 .239
Linearity 973.196 1 973.196 4.521 .048
Deviation from
Linearity 2155.068 9 239.452 1.112 .405
Within Groups 3659.450 17 215.262
Total 6787.714 27
Print out yang dihasilkan dari analisis ini sebenarnya cukup banyak namun untuk
kepentingan uji linearitas yang perlu ditafsirkan hanyalah print out ANOVA Table seperti terlihat
di atas. Yang perlu dilihat adalah hasil uji F untuk baris Deviation from linearity. Kriterianya
adalah jika nila sig F tersebut kurang dari 0,05 maka hubungannya tidak linear, sedangkan jika
nilai sig F lebih dari atau sama dengan 0,05 maka hubungannya bersifat linear.

14
Berdasarkan hasil analisis di atas menunjukkan bahwa nila F yang ditemukan adalah sebesar
1,112 dengan sig 0,405. Oleh karena nilai sig tersebut lebih dari 0,05 maka dapat disimpulkan
bahwa hubungan antara variabel uang saku dan prestasi belajar bersifat linear.
1. UJI One-sample t-test
Tujuan: digunakan untuk menguji perbedaan rata satu kelompok
Kasus:
Diperoleh data dari sebuah rumah sakit JIH, jumlah pasien selama 20 hari. Bagian
administarasi menyatakan bahwa dalam 20 hari itu, terdapat rata-rata jumlah pasien
dirumah sakit JIH sebanyak 20 orang. Uji hipotesis apakah benar pernyataan diatas.
Hari Jumlah Pasien Hari Jumlah Pasien
1 15 26
2 19 22
3 21 23
4 24 23
5 23 20
6 25 19
7 20 18
8 25 28
9 26 21
10 22 22
Langkah-langkah dalam menganalisis
1. Rekamlah data tersebut ke dalam satu kolom:
Kolom data tentang Jumlah pasien
2. Simpanlah data tersebut dengan nama Latihan Uji One-samples t-test
3. Lakukan analisis dengan menggunakan menu Analyze >> Compare Means >> Means…
Klik OK sehingga akan muncul hasil analisis:
One-Sample Test
Test Value = 20
t df Sig. (2-tailed) Mean Difference
95% Confidence Interval of the
Difference
Lower Upper
Pasien 3.003 19 .007 2.10000 .6365 3.5635
Hasil uji t ditemukan nilai t sebesar 3,003 dengan sig (2-tailed) 0,007. Oleh karena nilai sig <
0,05 maka dapat disimpulkan bahwa ada perbedaan rata-rata perkiraan rata-rata jumlah
Pasien dengan jumlah pasien pada data.
UJI BEDA

15
2. UJI T-Test
Tujuan: Digunakan untuk menguji perbedaan rata dua kelompok yang saling bebas
Kasus:
Berikut ini disajikan data angket pada pengguna ruang yang dilengkapi detektor asap
rokok dengan alarm berbasis mikrokontroler dengan detektor asap rokok dengan alarm
berbasis makrokontroler
Pengguna detektor asap rokok
dengan alarm
Pengguna detektor asap rokok
dengan alarm
Mikrokontroler Makrokontroler Mikrokontroler Makrokontroler
80 79 90 88
100 112 95 94
110 100 114 100
96 86 131 78
86 86 82 81
130 125 110 93
115 121 100 110
105 99 116 104
105 111 141 77
115 98 96 122
121 88 95 78
99 98 120
121 100 99
114 88 75
111 100 78
122 93 111
Ujilah apakah ada perbedaan penggunaan detektor asap rokok dengan alarm berbasis
mikrokontroler dengan detektor asap rokok dengan alarm berbasis makrokontroler?
(Gunakan taraf signifikansi 5%)
Langkah-langkah dalam menganalisis
1.) Rekamlah data tersebut ke dalam dua kolom:
Kolom pertama data tentang jenis detektor dengan kode 1 untuk mikrokontrol, dan 2
untuk makrokontrol
Kolom kedua data tentang Responden
2.) Berilah keterangan data tersebut dengan menggunakan variable view.
3.) Simpanlah data tersebut dengan nama Latihan Independent t test
4.) Lakukan analisis dengan menggunakan menu
Analyze >> Compare Means >> Independent Samples t test
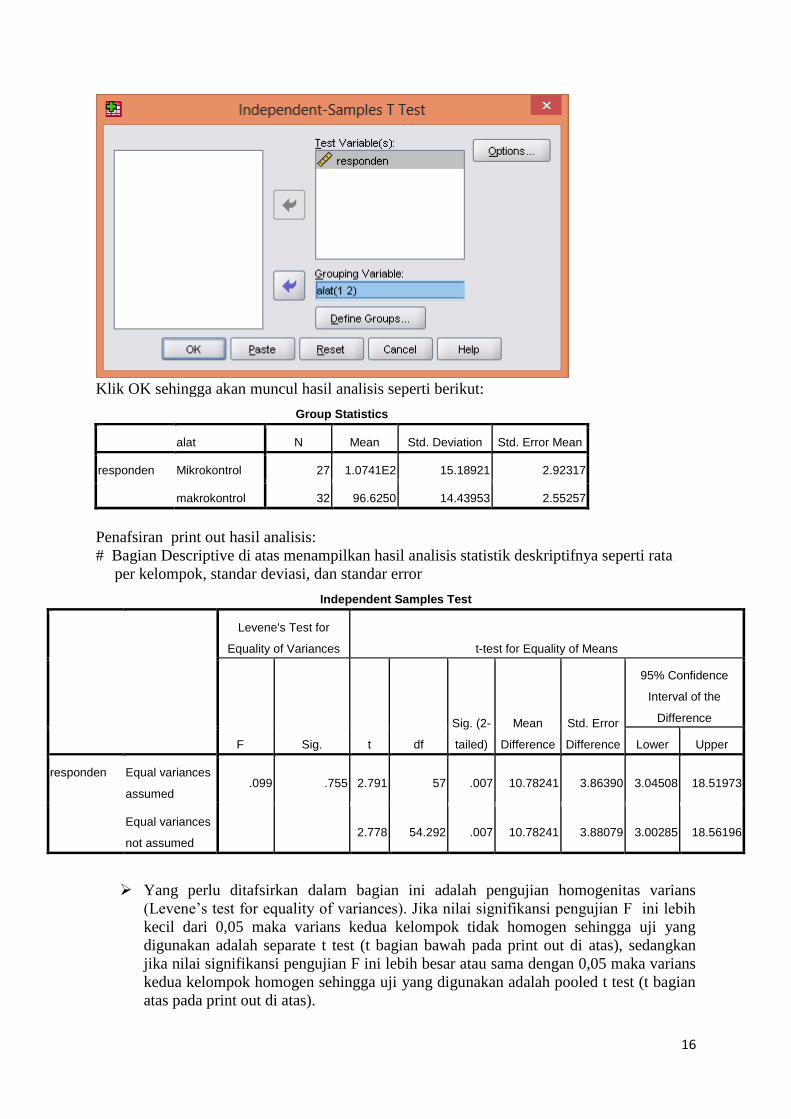
5.) Masukkan variabel Responden ke Test Variables dan alat ke Grouping Variable
6.) Klik tombol Define Groups lalu isikan 1 pada kotak Group 1 dan isikan 2 pada kotak
Group 2 lalu klik Continue, sehingga akan terlihat seperti berikut:
16
Klik OK sehingga akan muncul hasil analisis seperti berikut:
Group Statistics
alat N Mean Std. Deviation Std. Error Mean
responden Mikrokontrol 27 1.0741E2 15.18921 2.92317
makrokontrol 32 96.6250 14.43953 2.55257
Penafsiran print out hasil analisis:
# Bagian Descriptive di atas menampilkan hasil analisis statistik deskriptifnya seperti rata
per kelompok, standar deviasi, dan standar error
Independent Samples Test
Levene's Test for
Equality of Variances t-test for Equality of Means
F Sig. t df
Sig. (2-
tailed)
Mean
Difference
Std. Error
Difference
95% Confidence
Interval of the
Difference
Lower Upper
responden Equal variances
assumed .099 .755 2.791 57 .007 10.78241 3.86390 3.04508 18.51973
Equal variances
not assumed
2.778 54.292 .007 10.78241 3.88079 3.00285 18.56196
Yang perlu ditafsirkan dalam bagian ini adalah pengujian homogenitas varians
(Levene’s test for equality of variances). Jika nilai signifikansi pengujian F ini lebih
kecil dari 0,05 maka varians kedua kelompok tidak homogen sehingga uji yang
digunakan adalah separate t test (t bagian bawah pada print out di atas), sedangkan
jika nilai signifikansi pengujian F ini lebih besar atau sama dengan 0,05 maka varians
kedua kelompok homogen sehingga uji yang digunakan adalah pooled t test (t bagian
atas pada print out di atas).

17
Hasil pengujian F di atas menunjukkan bahwa nilai F sebesar 0,099 dengan sig. 0,755.
Oleh karena nilai sig > 0,05 maka varians kedua kelompok tersebut homogen. Oleh
karena uji t yang digunakan adalah t yang bagian atas (Pooled t test/equal variances
assumed).
Hasil uji t ditemukan nilai t sebesar 2,791 dengan sig (2-tailed) 0,007. Oleh karena
nilai sig < 0,05 maka dapat disimpulkan bahwa ada perbedaan rata-rata tanggaan
antara detektor mikrokontrol dan makrokontrol. Oleh karena nilai rata-rata tanggapan
pengguna detektor mikrokontrol lebih tinggi dibandingkan detektor makrokontrol
(lihat bagian print out descriptive) maka dapat disimpulkan bahwa alat detektor
mikrokontrol lebih baik daripada makrontrol.
3. PAIRED T TEST
Tujuan: Digunakan untuk menguji perbedaan rata-rata dua kelompok yang saling
berpasangan
Kasus:
Efek Suplementasi Vitamin A Terhadap Sensitivitas Kontras Penderita Defisiensi
Vitamin A. Berikut ini disajikan data nilai sebelum dan sesudah penggunaan
suplementasi vitamin A terhadap Sensitivitas Kontras Penderita defisiensi vitamin A;
Sebelum Sesudah Sebelum Sesudah
66 71 64 85
61 87 65 92
68 85 68 88
69 76 67 90
63 73 60 68
74 80 75 67
73 74 77 85
83 94 81 81
72 78 78 88
74 76 73 78
80 80 72 92
80 74 86 76
74 74 76 77
74 75 88 73
83 74 70 75
80 76 69 83
78 79 72 80
74 90 70 77
74 84 84 85
Ujilah apakah ada perbedaan antara nilai pre test dan nilai post test? Jika ada perbedaan,
manakah di antara keduanya yang nilainya lebih baik? (Gunakan taraf signifikansi 5%)
Langkah-langkah dalam menganalisis
1.) Rekamlah data tersebut ke dalam dua kolom:

18
Kolom pertama data tentang Nilai Sebelum
Kolom kedua data tentang Nilai Sesudah
2.) Berilah keterangan data tersebut dengan menggunakan variable view.
3.) Simpanlah data tersebut dengan nama Latihan Paired t test
4.) Lakukan analisis dengan menggunakan
menu Analyze >> Compare Means >> Paired-Samples t Test...
5.) Masukkan variabel sebelum dan sesudah ke Paired Variables, sehingga akan terlihat
seperti berikut:
Klik OK sehingga akan muncul hasil analisis seperti berikut:
Paired Samples Statistics
Mean N Std. Deviation Std. Error Mean
Pair 1 sebelum 73.5526 38 6.86825 1.11418
sesudah 80.0000 38 6.90476 1.12010
Penafsiran print out hasil analisis:
# Bagian di atas menampilkan hasil analisis statistik deskriptifnya seperti rata per
pasangan, standar deviasi, dan standar error
Paired Samples Correlations
N Correlation Sig.
Pair 1 sebelum & sesudah 38 -.062 .714
Bagian di atas menampilkan hasil analisis korelasi antara kedua pasangan data. Koefisien
korelasinya adalah sebesar -0,062 dengan sig 0,714. Hal ini menunjukkan bahwa kedua
pasangan data tersebut tidak berkorelasi.
19
Paired Samples Test
Paired Differences
t df
Sig. (2-
tailed)
Mean
Std.
Deviation
Std. Error
Mean
95% Confidence
Interval of the
Difference
Lower Upper
Pair 1 sebelum -
sesudah -6.44737 10.03426 1.62777 -9.74555 -3.14919 -3.961 37 .000
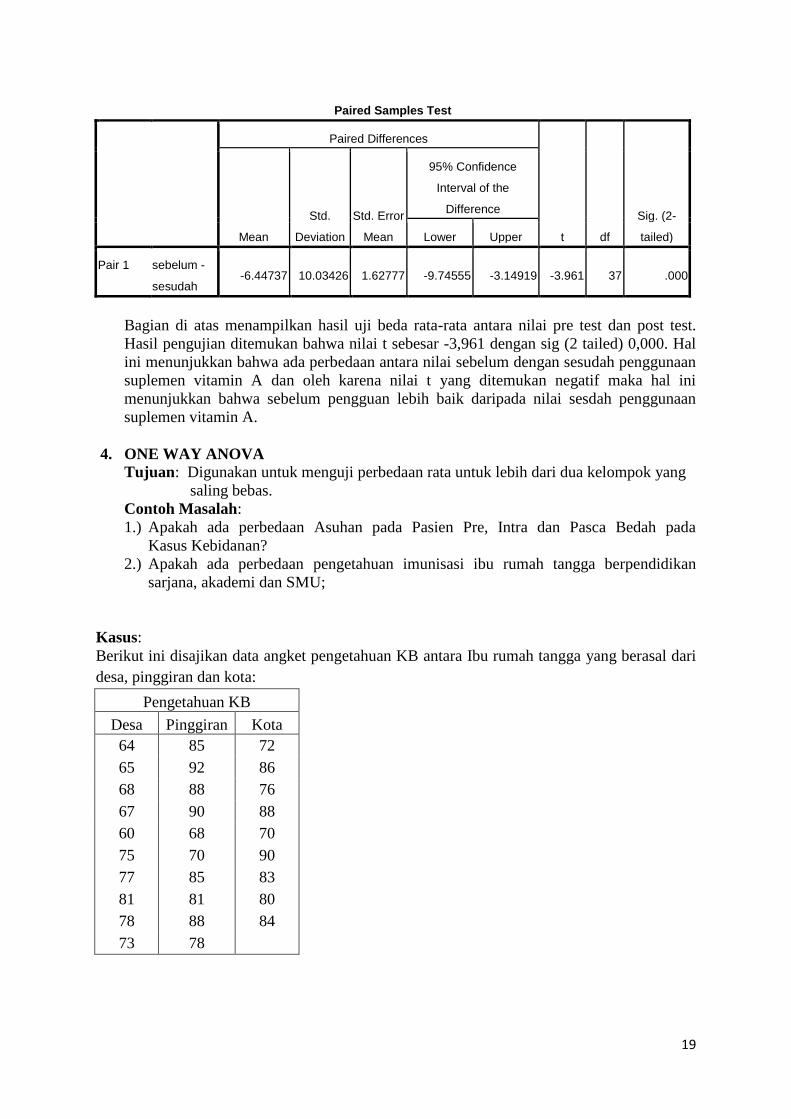
Bagian di atas menampilkan hasil uji beda rata-rata antara nilai pre test dan post test.
Hasil pengujian ditemukan bahwa nilai t sebesar -3,961 dengan sig (2 tailed) 0,000. Hal
ini menunjukkan bahwa ada perbedaan antara nilai sebelum dengan sesudah penggunaan
suplemen vitamin A dan oleh karena nilai t yang ditemukan negatif maka hal ini
menunjukkan bahwa sebelum pengguan lebih baik daripada nilai sesdah penggunaan
suplemen vitamin A.
4. ONE WAY ANOVA
Tujuan: Digunakan untuk menguji perbedaan rata untuk lebih dari dua kelompok yang
saling bebas.
Contoh Masalah:
1.) Apakah ada perbedaan Asuhan pada Pasien Pre, Intra dan Pasca Bedah pada
Kasus Kebidanan?
2.) Apakah ada perbedaan pengetahuan imunisasi ibu rumah tangga berpendidikan
sarjana, akademi dan SMU;
Kasus:
Berikut ini disajikan data angket pengetahuan KB antara Ibu rumah tangga yang berasal dari
desa, pinggiran dan kota:
Pengetahuan KB
Desa Pinggiran Kota
64 85 72
65 92 86
68 88 76
67 90 88
60 68 70
75 70 90
77 85 83
81 81 80
78 88 84
73 78
20
Ujilah apakah ada perbedaan Pengetahuan KB ibu yang berasal dari Desa, Pinggiran dan
Kota? Jika ada perbedaan, manakah di antara ketiganya yang memiliki pengetahuan paling
tinggi? (Gunakan taraf signifikansi 5%)
Langkah-langkah dalam menganalisis
1.) Rekamlah data tersebut ke dalam dua kolom:
Kolom pertama data tentang asal daerah dengan kode 1 untuk desa, 2 pinggiran dan 3
kota
Kolom kedua data tentang Nilai
2.) Berilah keterangan data tersebut dengan menggunakan variable view.
3.) Simpanlah data tersebut dengan nama Latihan One Way ANOVA
4.) Lakukan analisis dengan menggunakan menu
Analyze >> Compare Means >> One Way ANOVA
5.) Masukkan variabel X2 ke Dependent List dan X1 ke Factor sehingga akan terlihat seperti
berikut:
Klik tombol Post Hoc >> Scheffe >> Continue
Klik tombol Options >> Descriptive >> Homogeneity of Variances Test >> Continue
lalu klik OK sehingga akan muncul hasil analisis seperti berikut:
Descriptives
nilai
N Mean
Std.
Deviation Std. Error
95% Confidence Interval
for Mean
Minimum Maximum Lower Bound Upper Bound
desa 10 70.8000 6.95701 2.20000 65.8233 75.7767 60.00 81.00
pinggiran 10 82.5000 8.22260 2.60021 76.6179 88.3821 68.00 92.00
kota 9 81.0000 7.03562 2.34521 75.5919 86.4081 70.00 90.00
Total 29 78.0000 8.94826 1.66165 74.5963 81.4037 60.00 92.00
21
Penafsiran print out hasil analisis:
# Bagian Descriptive di atas menampilkan hasil analisis statistik deskriptifnya seperti rata
per kelompok, standar deviasi, standar error, minimum dan maksimum
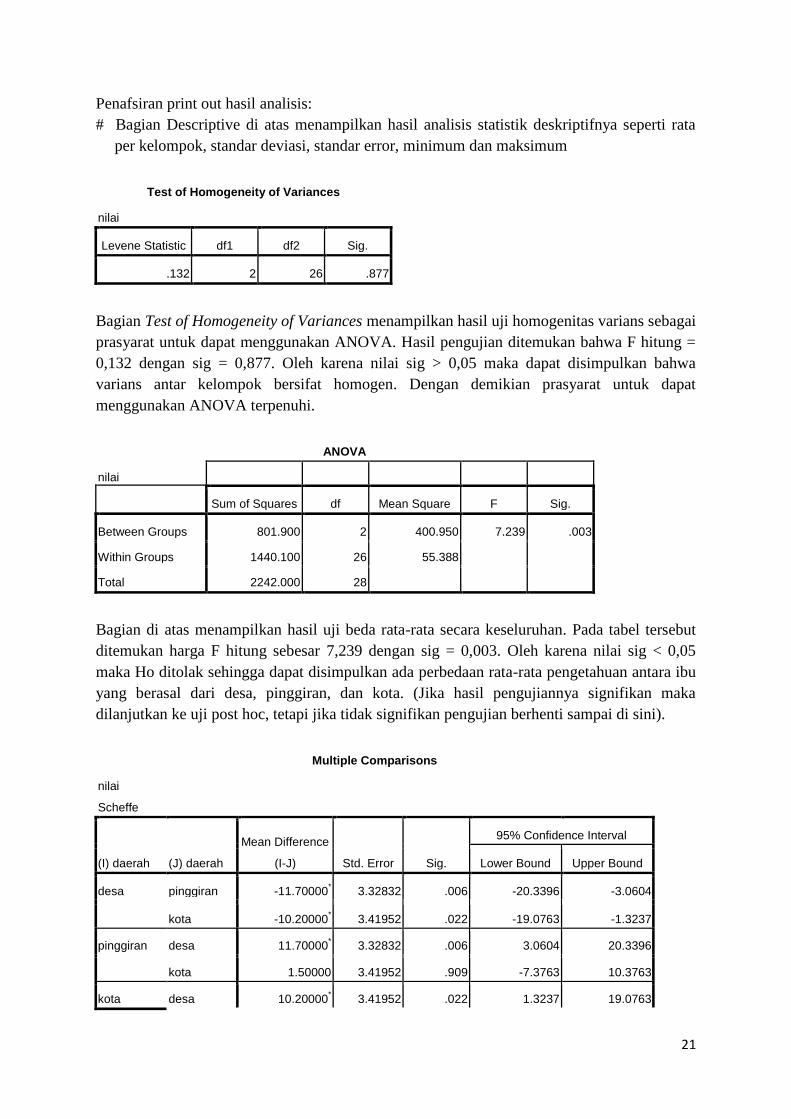
Test of Homogeneity of Variances
nilai
Levene Statistic df1 df2 Sig.
.132 2 26 .877
Bagian Test of Homogeneity of Variances menampilkan hasil uji homogenitas varians sebagai
prasyarat untuk dapat menggunakan ANOVA. Hasil pengujian ditemukan bahwa F hitung =
0,132 dengan sig = 0,877. Oleh karena nilai sig > 0,05 maka dapat disimpulkan bahwa
varians antar kelompok bersifat homogen. Dengan demikian prasyarat untuk dapat
menggunakan ANOVA terpenuhi.
ANOVA
nilai
Sum of Squares df Mean Square F Sig.
Between Groups 801.900 2 400.950 7.239 .003
Within Groups 1440.100 26 55.388
Total 2242.000 28
Bagian di atas menampilkan hasil uji beda rata-rata secara keseluruhan. Pada tabel tersebut
ditemukan harga F hitung sebesar 7,239 dengan sig = 0,003. Oleh karena nilai sig < 0,05
maka Ho ditolak sehingga dapat disimpulkan ada perbedaan rata-rata pengetahuan antara ibu
yang berasal dari desa, pinggiran, dan kota. (Jika hasil pengujiannya signifikan maka
dilanjutkan ke uji post hoc, tetapi jika tidak signifikan pengujian berhenti sampai di sini).
Multiple Comparisons
nilai
Scheffe
(I) daerah (J) daerah
Mean Difference
(I-J) Std. Error Sig.
95% Confidence Interval
Lower Bound Upper Bound
desa pinggiran -11.70000* 3.32832 .006 -20.3396 -3.0604
kota -10.20000* 3.41952 .022 -19.0763 -1.3237
pinggiran desa 11.70000* 3.32832 .006 3.0604 20.3396
kota 1.50000 3.41952 .909 -7.3763 10.3763
kota desa 10.20000* 3.41952 .022 1.3237 19.0763

22
pinggiran -1.50000 3.41952 .909 -10.3763 7.3763
*. The mean difference is significant at the 0.05 level.
Bagian ini menampilkan hasil uji lanjut untuk mengetahui perbedaan antar kelompok secara
spesifik sekaligus untuk mengetahui mana di antara ketiga kelompok tersebut yang
pengetahuan KBnya paling tinggi. Untuk melihat perbedaan antarkelompok dapat dilihat
pada kolom sig. Misalnya untuk melihat perbedaan pengetahuan KB antara ibu yang berasal
dari Desa dan Pinggiran diperoleh nilai sig = 0,006, Oleh karena nilai sig < 0,05 dapat
disimpulkan bahwa ada perbedaan pengetahuan KB antara ibu yang berasal dari Desa dan
Pinggiran. Dalam hal ini pengetahuan KB ibu yang berasal dari desa lebih rendah daripada
pengetahuan KB ibu yang berasal dari pinggiran. (Coba lakukan pembandingan IPK antara
Desa dan Kota, serta antara Pinggiran dan Kota! Buatlah kesimpulannya!)
UJI CHI KUADRAT
Tujuan : Untuk mengeahuiperbedaan proporsi antara 2 variabel atau lebih
Kasus :
RS Dr Oen 1 Solo mengamati perbedaan pengaruh tingkat perokok aktif dan pasif pada ibu
dengan berat badan bayi yang akan dilahirkan didapat data berikut;
Perokok BB bayi
Perokok BB bayi
Aktif 2.5
Aktif 2.5
Pasif 3.3
Pasif 3.1
Pasif 2.75
Pasif 3.4
Aktif 2.3
Pasif 3.2
Aktif 2.4
Pasif 3.3
Aktif 2.15
Pasif 3.4
Aktif 2.2
Pasif 2.8
Aktif 3.1
Pasif 2.1
Pasif 2.3
Aktif 1.8
Aktif 2.6
Aktif 2.0
Pasif 2.8
Aktif 1.8
Aktif 2.6
Aktif 2.4
Aktif 2.3
Pasif 1.8
Pasif 3.4
Pasif 2.7
Pasif 2.0
Pasif 2.9
Kategori bayi
UJI BEDA PROPORSI
23
BB bayi < 2,4 kg yaitu bayi prematur
BB bayi > 2,5 kg yaitu bayi normal
Ujilah apakah ada perbedaan antara variabel berat badan dengan kebiasaan merokok?
Langkah-langkah dalam menganalisis
1.) Rekamlah data tersebut ke dalam dua kolom:
Kolom pertama data tentang Perokok
Kolom ketiga data tentang BB bayi
2.) Berilah keterangan data tersebut dengan menggunakan variable view.
3.) Kategorikan BB bayi ke kategori bayi prematur atau normal
4.) Simpanlah data tersebut dengan nama Latihan Uji Beda proporsi
5.) Lakukan analisis dengan menggunakan menu
Analyze >> Deskriptive Stat >> Crosstab
6.) Pilih variabel ROKOK, kemudian klik tanda > untuk memasukkannya ke kotak Row(s)
7.) Pilih variabel Kategori bayi, kemudian klik tanda > untuk memasukkannya ke kotak
Colom(s).
Klik ststistic pilih chi square dan risk >> continue
Klik cells pilih colom >> continue >> Ok.
Hasil Ouputnya
24
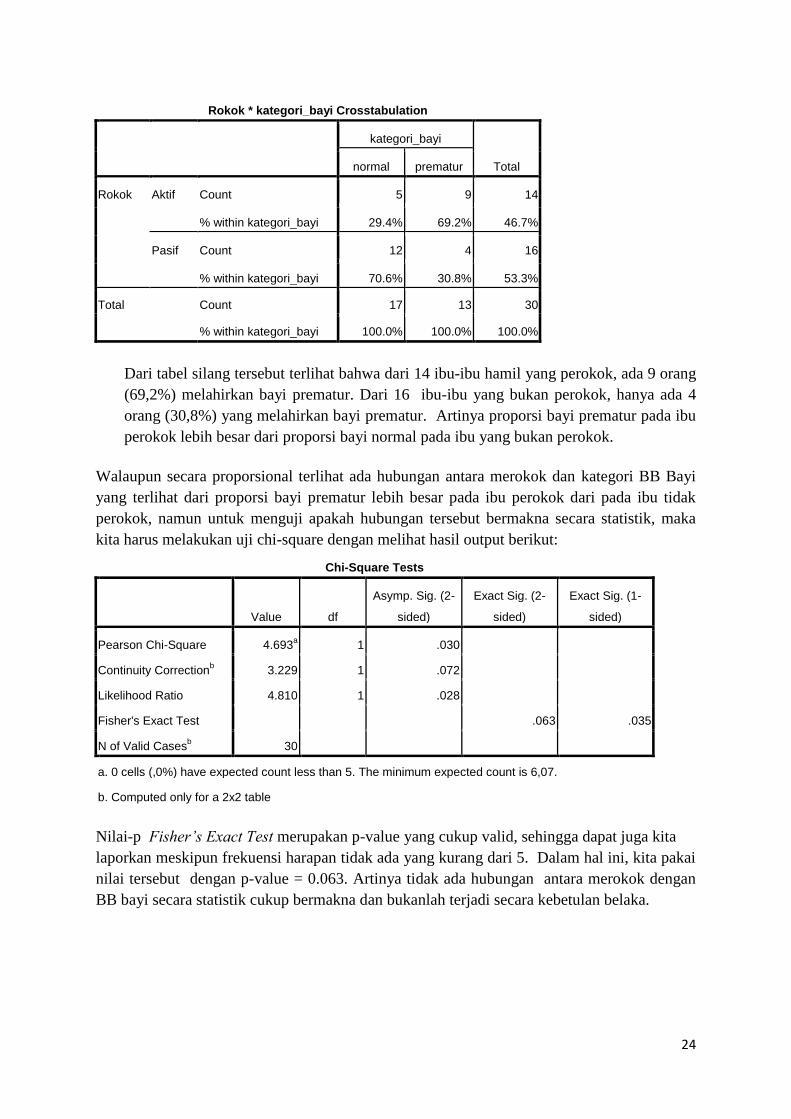
Rokok * kategori_bayi Crosstabulation
kategori_bayi
Total normal prematur
Rokok Aktif Count 5 9 14
% within kategori_bayi 29.4% 69.2% 46.7%
Pasif Count 12 4 16
% within kategori_bayi 70.6% 30.8% 53.3%
Total Count 17 13 30
% within kategori_bayi 100.0% 100.0% 100.0%
Dari tabel silang tersebut terlihat bahwa dari 14 ibu-ibu hamil yang perokok, ada 9 orang
(69,2%) melahirkan bayi prematur. Dari 16 ibu-ibu yang bukan perokok, hanya ada 4
orang (30,8%) yang melahirkan bayi prematur. Artinya proporsi bayi prematur pada ibu
perokok lebih besar dari proporsi bayi normal pada ibu yang bukan perokok.
Walaupun secara proporsional terlihat ada hubungan antara merokok dan kategori BB Bayi
yang terlihat dari proporsi bayi prematur lebih besar pada ibu perokok dari pada ibu tidak
perokok, namun untuk menguji apakah hubungan tersebut bermakna secara statistik, maka
kita harus melakukan uji chi-square dengan melihat hasil output berikut:
Chi-Square Tests
Value df
Asymp. Sig. (2-
sided)
Exact Sig. (2-
sided)
Exact Sig. (1-
sided)
Pearson Chi-Square 4.693a 1 .030
Continuity Correctionb 3.229 1 .072
Likelihood Ratio 4.810 1 .028
Fisher's Exact Test .063 .035
N of Valid Casesb 30
a. 0 cells (,0%) have expected count less than 5. The minimum expected count is 6,07.
b. Computed only for a 2x2 table
Nilai-p Fisher’s Exact Test merupakan p-value yang cukup valid, sehingga dapat juga kita
laporkan meskipun frekuensi harapan tidak ada yang kurang dari 5. Dalam hal ini, kita pakai
nilai tersebut dengan p-value = 0.063. Artinya tidak ada hubungan antara merokok dengan
BB bayi secara statistik cukup bermakna dan bukanlah terjadi secara kebetulan belaka.

25
1. KORELASI PRODUCT MOMENT
Tujuan: Digunakan untuk menguji korelasi/hubungan antara satu variabel dengan satu
variabel lainnya.
Data yang dianalisis harus berupa data yang berskala interval/rasio
Contoh Masalah:
Apakah ada korelasi yang positif antara produktifitas perawat melalui metode tim-
fungsional dan fungsional?
Apakah ada hubungan antara pengalaman kerja dengan produktivitas kerja karyawan?
Kasus:
Studi komparasi kepuasan peserta askes sosial yang. Memanfaatkan pelayanan kesehatan di
ppk tingkat i puskesmas. Berikut ini disajikan data kepuasan peserta askes sosial dan
pelayanan kesehatan, sebagai berikut;
Subjek Kepuasan pemakai
program
Kepuasan
Pelayanan
Subjek Kepuasan pemakai
program
Kepuasan
Pelayanan
1 33 58
11 36 56
2 32 52
12 21 47
3 21 48
13 21 49
4 34 49
14 33 60
5 34 52
15 35 63
6 35 57
16 21 55
7 32 55
17 32 58
8 21 50
18 33 49
9 21 48
19 34 55
10 35 54
20 35 58
Ujilah apakah ada korelasi yang positif antara motivasi belajar dengan prestasi belajar?
(Gunakan taraf signifikansi 5%)
Langkah-langkah dalam menganalisis
1.) Rekamlah data tersebut ke dalam dua kolom:
Kolom pertama data tentang pemakai program
Kolom kedua data tentang layanan
2.) Berilah keterangan data tersebut dengan menggunakan variable view.
3.) Simpanlah data tersebut dengan nama Latihan Korelasi Product Moment
4.) Lakukan analisis dengan menggunakan menu
Analyze >> Correlate >> Bivariate
5.) Masukkan variabel X dan Y ke kotak Variables sehingga akan terlihat seperti berikut:
UJI KORELASI DAN UJI REGRESI LINIER

26
6.) Klik tombol Options >> Means and Standard Deviation >> Cross Product Deviations and
Covariance >> Continue
7.) Klik OK sehingga akan muncul hasil analisis:
Descriptive Statistics
Mean Std. Deviation N
BPJS 29.9500 6.10845 20
layanan 53.6500 4.57999 20
Bagian Descriptive di atas menampilkan hasil analisis statistik deskriptifnya seperti rata-rata
per variabel, standar deviasi, dan jumlah sampel
Correlations
BPJS layanan
BPJS Pearson Correlation 1 .624**
Sig. (2-tailed) .003
N 20 20
layanan Pearson Correlation .624** 1
Sig. (2-tailed) .003
N 20 20
**. Correlation is significant at the 0.01 level (2-tailed).
Dari tabel di atas diperoleh sig. 0,008 maka keputusan uji H0 ditolak artiya Ada hubungan antara IQ
dengan Prestasi. Nilai Korelasi sebesar 0,576 berarti korelasi termasuk kategori “sedang”
2. REGRESI LINEAR SEDERHANA
Tujuan:

27
a. Digunakan untuk menguji hubungan/korelasi/pengaruh satu variabel bebas terhadap
satu variabel terikat.
b. Regresi juga dapat digunakan untuk melakukan prediksi atau estimasi variabel terikat
berdasarkan variabel bebasnya.
c. Data yang dianalisis harus berupa data yang berskala interval/rasio
Contoh Masalah:
a. Apakah ada pengaruh motivasi belajar terhadap prestasi belajar mahasiswa?
b. Apakah pengalaman kerja mempengaruhi produktivitas kerja karyawan?
Kasus:
Hubungan Pengetahuan Ibu Tentang Pemberian Nutrisi Terhadap Status Gizi Anak
Toddler Di Desa Gonilan. Berikut ini disajikan data tentang pengetahuan ibu tentang
pemberian nutrisi dan status gizi;
Pengetahuan
Pemberian Nutrisi gizi anak
Pengetahuan
Pemberian Nutrisi gizi anak
63 118
58 125
46 114
45 150
57 107
54 104
49 142
48 120
55 144
61 128
48 139
54 125
58 147
52 105
52 108
50 128
60 110
58 108
54 121
60 110
56 100
48 134
53 109
62 128
61 111
44 117
Ujilah apakah ada pengaruh motivasi belajar terhadap prestasi belajar? (Gunakan
taraf signifikansi 5%)
Hitunglah berapa besarnya kontribusi variabel bebas terhadap variabel terikatnya?
Bagaimana persamaan garis regresinya? Tafsirkan maknanya!
Langkah-langkah dalam menganalisis
1.) Rekamlah data tersebut ke dalam dua kolom:
Kolom pertama data tentang Pengetahuan
Kolom kedua data tentang gizi anak
2.) Berilah keterangan data tersebut dengan menggunakan variable view.
Baris pertama (Name = X, Label = Pengetahuan)
Baris kedua(Name = Y, Label = gizi anak)
3.) Simpanlah data tersebut dengan nama Latihan Regresi Linear Sederhana
4.) Lakukan analisis dengan menggunakan menu
28
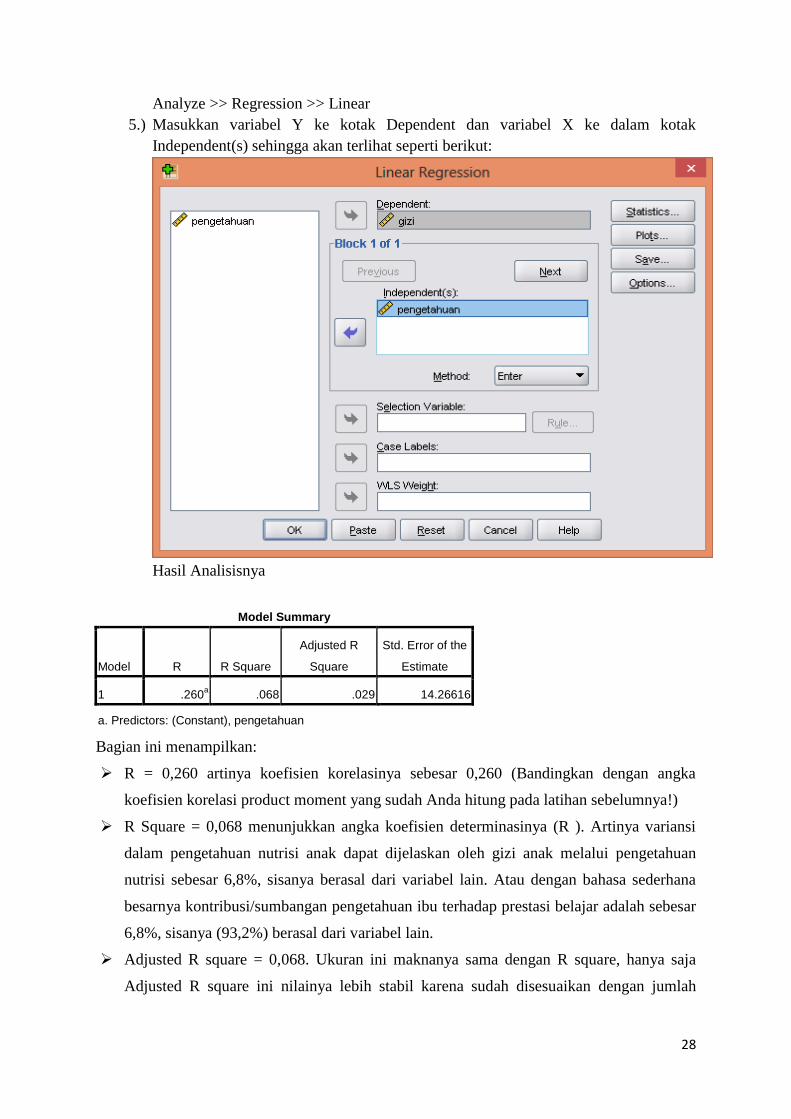
Analyze >> Regression >> Linear
5.) Masukkan variabel Y ke kotak Dependent dan variabel X ke dalam kotak
Independent(s) sehingga akan terlihat seperti berikut:
Hasil Analisisnya
Model Summary
Model R R Square
Adjusted R
Square
Std. Error of the
Estimate
1 .260a .068 .029 14.26616
a. Predictors: (Constant), pengetahuan
Bagian ini menampilkan:
R = 0,260 artinya koefisien korelasinya sebesar 0,260 (Bandingkan dengan angka
koefisien korelasi product moment yang sudah Anda hitung pada latihan sebelumnya!)
R Square = 0,068 menunjukkan angka koefisien determinasinya (R ). Artinya variansi
dalam pengetahuan nutrisi anak dapat dijelaskan oleh gizi anak melalui pengetahuan
nutrisi sebesar 6,8%, sisanya berasal dari variabel lain. Atau dengan bahasa sederhana
besarnya kontribusi/sumbangan pengetahuan ibu terhadap prestasi belajar adalah sebesar
6,8%, sisanya (93,2%) berasal dari variabel lain.
Adjusted R square = 0,068. Ukuran ini maknanya sama dengan R square, hanya saja
Adjusted R square ini nilainya lebih stabil karena sudah disesuaikan dengan jumlah

29
variabel bebasnya. Standard Error of The Estimate = 14,266 yang menunjukkan ukuran
tingkat kesalahan dalam melakukan prediksi terhadap variabel terikat.
ANOVAb
Model Sum of Squares df Mean Square F Sig.
1 Regression 354.057 1 354.057 1.740 .200a
Residual 4884.559 24 203.523
Total 5238.615 25
a. Predictors: (Constant), pengetahuan
b. Dependent Variable: gizi
Bagian ini menampilkan hasil pengujian koefisien determinasi. Hasil pengujian tersebut
ditemukan harga F hitung sebesar 1,749 dengan sig. = 0,200. Oleh karena nilai sig. > 0,05
maka Ho (ρ = 0) diterima yang artinya hubungan antara gizi anak memiliki tidak
berpengaruh yang signifikan terhadap pengetahuan nutri ibu.
Coefficientsa
Model
Unstandardized Coefficients
Standardized
Coefficients
t Sig. B Std. Error Beta
1 (Constant) 157.668 27.767 5.678 .000
pengetahuan -.674 .511 -.260 -1.319 .200
a. Dependent Variable: gizi
Bagian ini menampilkan persamaan garis regresi dan pengujiannya. Persamaan
garis regresi dapat diperoleh dari kolom Unstandardized Coefficients (B). Dengan
demikian persamaan garis regresinya adalah:
Y’ = 15,668 -0,674 X
Untuk menguji koefisen garisnya dapat dilihat pada kolom t dan sig. Hasil pengujian
ditemukan nilai t hitung sebesar 5,678 dengan sig. = 0,000 (bandingkan dengan nilai
sig. F). Oleh karena nilai sig. < 0,05 maka Ho (β = 0) ditolak yang artinya gizi
berpengaruh positif terhadap pengetahuan nutrisi.

30
3. REGRESI LINEAR GANDA
Tujuan:
Digunakan untuk menguji hubungan/korelasi/pengaruh lebih dari satu variabel bebas
terhadap satu variabel terikat.
Regresi juga dapat digunakan untuk melakukan prediksi atau estimasi variabel
terikat berdasarkan variabel bebasnya.
Data yang dianalisis harus berupa data yang berskala interval/rasio
Contoh Masalah:
Apakah ada pengaruh uang saku dan motivasi belajar terhadap prestasi belajar
mahasiswa?
Bagaimana pengaruh lingkungan kerja dan pengalaman kerja terhadap produktivitas
kerja karyawan?
Kasus:
Hubungan antara berat badan ibu hamil, tinggi badan ibu terhadap berat badan bayi.
Berikut ini disajikan data tentang berat badan ibu, tinggi badan dan berat badan bayi :
BB Ibu Hamil TB ibu hamil BB Bayi
70 168 3.10
65 150 2.83
66 156 2.50
61 153 2,91
68 159 2.74
69 160 2.61
63 169 2.70
74 163 3.50
73 161 4.00
83 164 4.10
72 148 3.73
74 153 3.30
78 155 3.40
76 164 3.61
77 165 2.83
Hitunglah berapa besarnya kontribusi bersama seluruh variabel bebas terhadap
variabel terikatnya? Ujilah apakah ada kontribusi tersebut signifikan? (Gunakan
taraf signifikansi 5%)
Bagaimana persamaan garis regresinya? Tafsirkan maknanya!
Ujilah pengaruh secara masing-masing variabel bebas secara parsial!
Langkah-langkah dalam menganalisis
1.) Rekamlah data tersebut ke dalam tiga kolom:

31
Kolom pertama data tentang BB ibu hamil
Kolom kedua data tentang TB ibu hamil
Kolom ketiga data tentang BB bayi
2.) Berilah keterangan data tersebut dengan menggunakan variable view.
Baris pertama (Name = X1, Label = BB ibu hamil)
Baris kedua (Name = X2, Label = TB ibu hamil)
Baris ketiga (Name = Y, Label = BB bayi)
3.) Simpanlah data tersebut dengan nama Latihan Regresi Ganda
4.) Lakukan analisis dengan menggunakan menu
Analyze >> Regression >> Linear
5.) Masukkan variabel Y ke kotak Dependent dan variabel X1 dan X2 ke dalam kotak
Independent(s) sehingga akan terlihat seperti berikut:
Klik OK sehingga akan muncul hasil analisis:
Model Summary
Model R R Square
Adjusted R
Square
Std. Error of the
Estimate
1 .791a .626 .564 .39413
a. Predictors: (Constant), TB_ibu, BB_ibu
Bagian ini menampilkan:
R = 0,791 artinya koefisien korelasinya sebesar 0,791 (Bandingkan dengan angka
koefisien korelasi product moment yang sudah Anda hitung pada latihan sebelumnya!)
32
R Square = 0,626 menunjukkan angka koefisien determinasinya (R ). Artinya variansi
dalam berat badan bayi dapat dijelaskan oleh berat badan ibu hamil dan tinggi badan ibu
hamil melalui berat badan ibu hamil dan tinggi badan ibu hamil sebesar 62,6%, sisanya
berasal dari variabel lain. Atau dengan bahasa sederhana besarnya kontribusi/sumbangan
berat badan ibu hamil dan tinggi badan ibu hamil terhadap berat badan bayi adalah
sebesar 62,6%, sisanya (37,4%) berasal dari variabel lain.
Adjusted R square = 0,626. Ukuran ini maknanya sama dengan R square, hanya saja
Adjusted R square ini nilainya lebih stabil karena sudah disesuaikan dengan jumlah variabel
bebasnya. Standard Error of The Estimate = 0,39413 yang menunjukkan ukuran tingkat
kesalahan dalam melakukan prediksi terhadap variabel terikat.
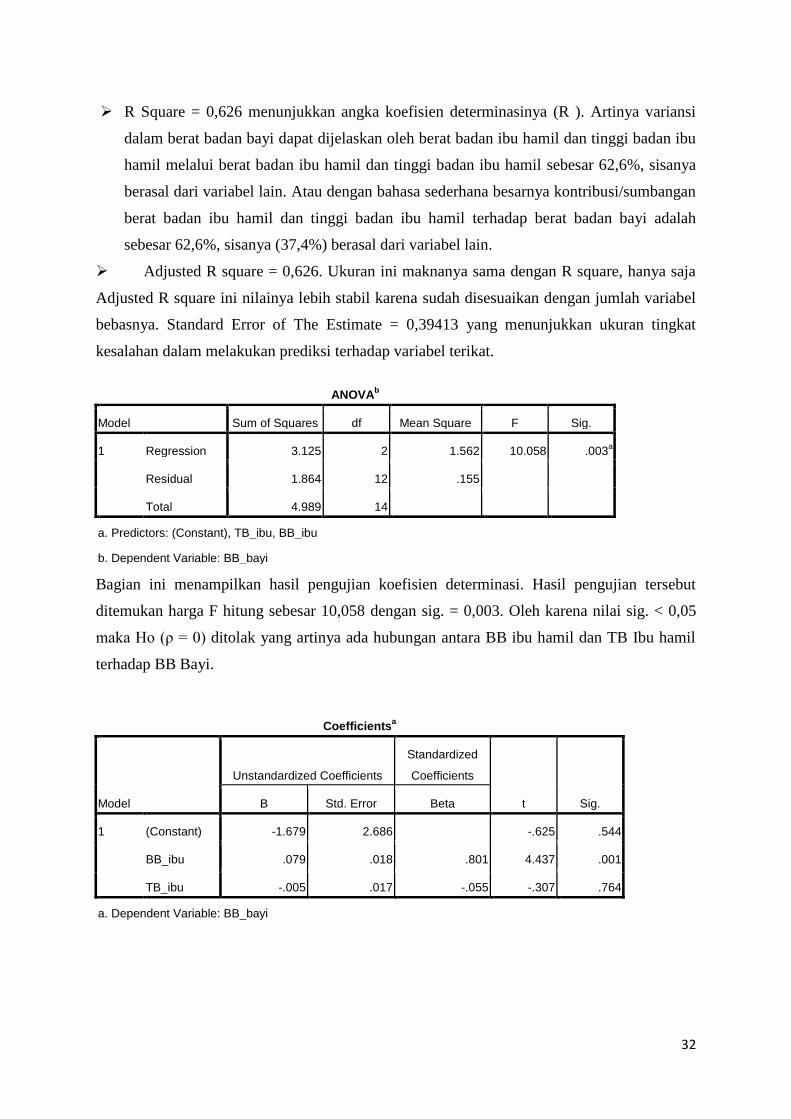
ANOVAb
Model Sum of Squares df Mean Square F Sig.
1 Regression 3.125 2 1.562 10.058 .003a
Residual 1.864 12 .155
Total 4.989 14
a. Predictors: (Constant), TB_ibu, BB_ibu
b. Dependent Variable: BB_bayi
Bagian ini menampilkan hasil pengujian koefisien determinasi. Hasil pengujian tersebut
ditemukan harga F hitung sebesar 10,058 dengan sig. = 0,003. Oleh karena nilai sig. < 0,05
maka Ho (ρ = 0) ditolak yang artinya ada hubungan antara BB ibu hamil dan TB Ibu hamil
terhadap BB Bayi.
Coefficientsa
Model
Unstandardized Coefficients
Standardized
Coefficients
t Sig. B Std. Error Beta
1 (Constant) -1.679 2.686 -.625 .544
BB_ibu .079 .018 .801 4.437 .001
TB_ibu -.005 .017 -.055 -.307 .764
a. Dependent Variable: BB_bayi

33
Bagian ini menampilkan persamaan garis regresi dan pengujiannya. Persamaan garis regresi
dapat diperoleh dari kolom Unstandardized Coefficients (B). Dengan demikian persamaan
garis regresinya adalah:
Y’ = -1,679 + 0,079 X1 – 0,05X2
Untuk menguji koefisen garisnya dapat dilihat pada kolom t dan sig. Hasil pengujian
ditemukan nilai t hitung sebesar 4,437 dengan sig. = 0,001 (bandingkan dengan nilai
sig. F). Oleh karena nilai sig. < 0,05 maka Ho (β = 0) ditolak yang artinya BB Bayi
berpengaruh positif terhadap BB ibu hamil.
Bivariate Pearson (Korelasi Produk Momen Pearson)
Analisis ini dengan cara mengkorelasikan masing-masing skor item dengan skor total. Skor total adalah penjumlahan dari keseluruhan item. Item-item pertanyaan yang berkorelasi signifikan dengan skor total menunjukkan item-item tersebut mampu memberikan dukungan dalam mengungkap apa yang ingin diungkap.
Pengujian menggunakan uji dua sisi dengan taraf signifikansi 0,05. Kriteria pengujian adalah sebagai berikut:
- Jika r hitung ≥ r tabel (uji 2 sisi dengan sig. 0,05) maka instrumen atau item-item pertanyaan berkorelasi signifikan terhadap skor total (dinyatakan valid).
- Jika r hitung < r tabel (uji 2 sisi dengan sig. 0,05) maka instrumen atau item-item pertanyaan tidak berkorelasi signifikan terhadap skor total (dinyatakan tidak valid). Contoh Kasus: Seorang mahasiswa bernama Andi melakukan penelitian dengan menggunakan skala untuk mengetahui atau mengungkap prestasi belajar seseorang. Andi membuat 10 butir pertanyaan dengan menggunakan skala Likert, yaitu angka 1 = Sangat tidak setuju, 2 = Tidak setuju, 3 = Setuju dan 4 = Sangat Setuju. Setelah membagikan skala kepada 12 responden didapatlah tabulasi data-data sebagai berikut:
Tabel 1. Tabulasi Data (Data Fiktif)
Subjek Skor Item Skor
1 2 3 4 5 6 7 8 9 10 Total
1 3 4 3 4 4 3 3 3 3 3 33
2 4 3 3 4 3 3 3 3 3 3 32
3 2 2 1 3 2 2 3 1 2 3 21
4 3 4 4 3 3 3 4 3 3 4 34
5 3 4 3 3 3 4 3 4 4 3 34
UJI VALIDITAS DAN RELIABILITAS ANGKET

34
6 3 2 4 4 3 4 4 3 4 4 35
7 2 3 3 4 4 4 3 4 3 2 32
8 1 2 2 1 2 2 1 3 4 3 21
9 4 2 3 3 4 2 1 1 4 4 28
10 3 3 3 4 4 4 4 4 3 3 35
11 4 4 3 4 4 3 4 4 4 2 36
12 3 2 1 2 3 1 1 2 3 3 21
Langkah-langkah dengan program SPSS
Masuk program SPSS
Klik variable view pada SPSS data editor Pada kolom Name ketik item1 sampai item10, kemudian terakhir ketikkan
skortot (skor total didapat dari penjumlahan item1 sampai item10)
Pada kolom Decimals angka ganti menjadi 0 untuk seluruh item
Untuk kolom-kolom lainnya boleh dihiraukan (isian default) Buka data view pada SPSS data editor Ketikkan data sesuai dengan variabelnya, untuk skortot ketikkan total
skornya. Klik Analyze - Correlate - Bivariate
Klik semua variabel dan masukkan ke kotak variables
Klik OK. Hasil output yang diperoleh dapat diringkas sebagai berikut:
Tabel. Hasil Analisis Bivariate Pearson

35
Dari hasil analisis didapat nilai korelasi antara skor item dengan skor total. Nilai ini kemudian kita bandingkan dengan nilai r tabel, r tabel dicari pada signifikansi 0,05 dengan uji 2 sisi dan jumlah data (n) = 12, maka didapat r tabel sebesar 0,576 (lihat pada lampiran tabel r).
Berdasarkan hasil analisis di dapat nilai korelasi untuk item 1, 9 dan 10 nilai kurang dari 0,576. Karena koefisien korelasi pada item 1, 9 dan 10 nilainya kurang dari 0,576 maka dapat disimpulkan bahwa item-item tersebut tidak berkorelasi signifikan dengan skor total (dinyatakan tidak valid) sehingga harus dikeluarkan atau diperbaiki. Sedangkan pada item-item lainnya nilainya lebih dari 0,576 dan dapat disimpulkan bahwa butir instrumen tersebut valid.
2. Corrected Item-Total Correlation Analisis ini dengan cara mengkorelasikan masing-masing skor item
dengan skor total dan melakukan koreksi terhadap nilai koefisien korelasi yang overestimasi. Hal ini dikarenakan agar tidak terjadi koefisien item total yang overestimasi (estimasi nilai yang lebih tinggi dari yang sebenarnya). Atau dengan cara lain, analisis ini menghitung korelasi tiap item dengan skor total (teknik bivariate pearson), tetapi skor total disini tidak termasuk skor item yang akan dihitung. Sebagai contoh pada kasus di atas kita akan menghitung item 1 dengan skor total, berarti skor total didapat dari penjumlahan skor item 2 sampai item 10. Perhitungan teknik ini cocok digunakan pada skala yang menggunakan item pertanyaan yang sedikit, karena pada item yang

36
jumlahnya banyak penggunaan korelasi bivariate (tanpa koreksi) efek overestimasi yang dihasilkan tidak terlalu besar.
Menurut Azwar (2007) agar kita memperoleh informasi yang lebih akurat mengenai korelasi antara item dengan tes diperlukan suatu rumusan koreksi terhadap efek spurious overlap.
Pengujian menggunakan uji dua sisi dengan taraf signifikansi 0,05. Kriteria pengujian adalah sebagai berikut:
- Jika r hitung ≥ r tabel (uji 2 sisi dengan sig. 0,05) maka instrumen atau item-item pertanyaan berkorelasi signifikan terhadap skor total (dinyatakan valid).
- Jika r hitung < r tabel (uji 2 sisi dengan sig. 0,05) maka instrumen atau item-item pertanyaan tidak berkorelasi signifikan terhadap skor total (dinyatakan tidak valid).
Sebagai contoh kasus kita menggunakan contoh kasus dan data-data pada analisis produk momen di atas.
Langkah-langkah pada program SPSS
Masuk program SPSS
Klik variable view pada SPSS data editor Pada kolom Name ketik item1 sampai item 10
Pada kolom Decimals angka ganti menjadi 0 untuk seluruh item
Untuk kolom-kolom lainnya boleh dihiraukan (isian default) Buka data view pada SPSS data editor Ketikkan data sesuai dengan variabelnya, Klik Analyze - Scale – Reliability Analysis
Klik semua variabel dan masukkan ke kotak items
Klik Statistics, pada Descriptives for klik scale if item deleted
Klik continue, kemudian klik OK, hasil output yang didapat adalah sebagai berikut:
Tabel. Hasil Analisis Validitas Item dengan
Teknik Corrected Item-Total Correlation
R E L I A B I L I T Y A N A L Y S I S - S C A L E (A L P H A)
Item-total Statistics
Scale Scale Corrected
Mean Variance Item- Alpha
if Item if Item Total if Item
Deleted Deleted Correlation Deleted
ITEM1 27.2500 29.8409 .4113 .8345
ITEM2 27.2500 28.0227 .6151 .8157
ITEM3 27.4167 25.7197 .8217 .7933

37
ITEM4 26.9167 26.6288 .7163 .8046
ITEM5 26.9167 29.5379 .5603 .8223
ITEM6 27.2500 25.8409 .7764 .7975
ITEM7 27.3333 25.1515 .6784 .8078
ITEM8 27.2500 27.1136 .5679 .8204
ITEM9 26.8333 32.8788 .1866 .8482
ITEM10 27.0833 35.3561 -.1391 .8683
Reliability Coefficients
N of Cases = 12.0 N of Items = 10
Alpha = .8384
Dari output di atas bisa dilihat pada Corrected Item – Total Correlation, inilah nilai korelasi yang didapat. Nilai ini kemudian kita bandingkan dengan nilai r tabel, r tabel dicari pada signifikansi 0,05 dengan uji 2 sisi dan jumlah data (n) = 12, maka didapat r tabel sebesar 0,576 (lihat pada lampiran tabel r).
Dari hasil analisis dapat dilihat bahwa untuk item 1, 5, 9 dan 10 nilai kurang dari 0,576. Karena koefisien korelasi pada item 1, 5, 9 dan 10 nilainya kurang dari 0,576 maka dapat disimpulkan bahwa butir instrumen tersebut tidak valid. Sedangkan pada item-item lainnya nilainya lebih dari 0,576 dan dapat disimpulkan bahwa butir instrumen tersebut valid.
Sebagai catatan: analisis korelasi pada contoh kasus di atas hanya dilakukan satu kali, untuk mendapatkan hasil validitas yang lebih memuaskan maka bisa dilakukan analisis kembali sampai 2 atau 3 kali, sebagai contoh pada kasus di atas setelah di dapat 6 item yang valid, maka dilakukan analisis korelasi lagi untuk menguji 6 item tersebut, jika masih ada item yang tidak signifikan maka digugurkan, kemudian dianalisis lagi sampai didapat tidak ada yang gugur lagi.




















