
Lisensi ini mengizinkan setiap orang untuk menggubah ...kc.umn.ac.id/1310/3/BAB II.pdf · Berikut...
21
Team project ©2017 Dony Pratidana S. Hum | Bima Agus Setyawan S. IIP Hak cipta dan penggunaan kembali: Lisensi ini mengizinkan setiap orang untuk menggubah, memperbaiki, dan membuat ciptaan turunan bukan untuk kepentingan komersial, selama anda mencantumkan nama penulis dan melisensikan ciptaan turunan dengan syarat yang serupa dengan ciptaan asli. Copyright and reuse: This license lets you remix, tweak, and build upon work non-commercially, as long as you credit the origin creator and license it on your new creations under the identical terms.
Transcript of Lisensi ini mengizinkan setiap orang untuk menggubah ...kc.umn.ac.id/1310/3/BAB II.pdf · Berikut...

Team project ©2017 Dony Pratidana S. Hum | Bima Agus Setyawan S. IIP
Hak cipta dan penggunaan kembali:
Lisensi ini mengizinkan setiap orang untuk menggubah, memperbaiki, dan membuat ciptaan turunan bukan untuk kepentingan komersial, selama anda mencantumkan nama penulis dan melisensikan ciptaan turunan dengan syarat yang serupa dengan ciptaan asli.
Copyright and reuse:
This license lets you remix, tweak, and build upon work non-commercially, as long as you credit the origin creator and license it on your new creations under the identical terms.

20
BAB II
Landasan Teori
2.1 Image Processing
2.1.1 Citra
Citra (Image) adalah data informasi yang dapat disampaikan
berupa gambar. Pada penelitian ini citra merupakan bahan dasar yang akan
disegmentasi dengan menggunakan tiga algoritma yaitu K-Means, Mean
Shift, dan Normalizet Cut.
2.1.2 Image Processing
Image processing adalah salah satu teknik untuk mengelola sebuah
gambar untuk mendapatkan gambar yang sudah siap untuk dikelola lebih
lanjut. Image processing dilakukan untuk memperbaiki kesalahan data
sinyal gambar yang diperoleh karena adanya gangguan transmisi sinyal
selama proses akuisisi sinyal seperti peningkatan kontras, transformasi
warna, restorasi citra, dan untuk meningkatkan kualitas gambar agar lebih
mudah diinterpretasi oleh penglihatan manusia baik dilakukan dengan
manipulasi dan juga dengan analisis terhadap gambar. Input untuk
segmentasi citra adalah citra itu sendiri, sedangkan output–nya adalah citra
hasil dari segmentasi citra tersebut
Analisis segmentasi..., Jhon Hendro Panjaitan, FTI UMN, 2016

21
Image processing dapat dilakukan dengan berbagai teknik yaitu
image enhancement, color image processing, image feature extraction,
image compression dan image segmentation. Dari semua teknik di atas
tujuannya adalah untuk memperbaiki gambar supaya lebih baik.
Algoritma K-Means, Mean Shift, dan Normalized Cut merupakan
tiga algoritma yang dapat digunakan untuk mengelola sebuah gambar
untuk mendapatkan gambar yang baru yang telah di segmentasi dimana
gambar ini sudah siap untuk di proses lebih lanjut dalam hal penelitian ini
melakukan analisis terhadap gambar yang telah disegmentasi. Oleh karena
itu algoritma K-Means, Mean Shift, dan Normalized Cut akan di uji tingkat
keberhasilannya untuk mensegmentasi sebuah citra.
2.2 K- means
K-mean clustering merupakan algoritma iterative dengan
meminimalkan jumlah kuadrat error antara vektor objek dengan pusat
cluster terdekatnya dengan rumus sebagai berikut :
µk =
∑
---------------------------------(2.1)
Di mana : µk : titik centroid dari cluster ke-k
: banyaknya data pada cluster ke-k
: data ke-q pada cluster ke-k
Analisis segmentasi..., Jhon Hendro Panjaitan, FTI UMN, 2016

22
Proses segmentasi citra di mulai dengan memilih secara acak nilai
„k‟ buah dokumen sebagai pusat cluster awal, dan anggotanya akan
mengikuti jarak terdekat pada pusat cluster yang telah di bentuk.
Menentukan anggota pada setiap cluster yang telah di bentuk dapat
ditentukan dengan cara melihat jarak terdekat pada pusat centroid yang
telah di bentuk, jarak antara pusat centroid dengan anggota-anggotanya
dapat di hitung dengan tiga cara yaitu, Euclidian distance, City Block, dan
Minkowski. Pada segmentasi gambar ini persamaan yang digunakan adalah
Euclidian distance yaitu dengan cara menghitung jarak dari anggota
cluster ke pusat cluster dengan rumus sebagai berikut :
D( ) = √∑ --------------------------- (2.2)
Dimana: d = jarak
j = banyak data
c = centroid
x = data
Analisis segmentasi..., Jhon Hendro Panjaitan, FTI UMN, 2016
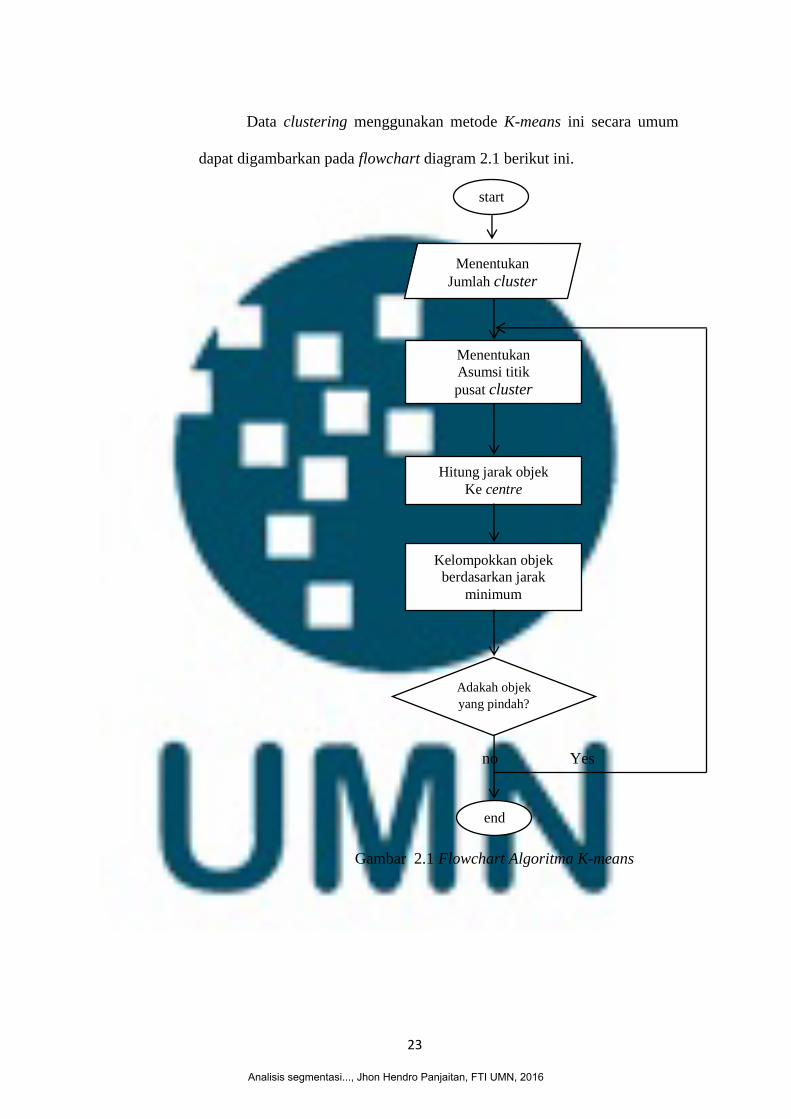
23
Data clustering menggunakan metode K-means ini secara umum
dapat digambarkan pada flowchart diagram 2.1 berikut ini.
no Yes
Gambar 2.1 Flowchart Algoritma K-means
start
Menentukan
Asumsi titik
pusat cluster
Menentukan
Jumlah cluster
Hitung jarak objek
Ke centre
Kelompokkan objek
berdasarkan jarak
minimum
Adakah objek
yang pindah?
end
Analisis segmentasi..., Jhon Hendro Panjaitan, FTI UMN, 2016

24
Berikut adalah penjelasan dari flowchart diagram 2.1 pada algoritma K-
Means.
a) Algoritma menerima jumlah cluster, dalam penelitian ini jumlah cluster di
input secara langsung oleh penelitit,
b) Menentukan jumlah cluster dengan jumlah cluster maksimal 255 karena
nilai maksimal dari warna adalah 255, pada penelitian ini jumlah cluster
dimasukkan langsung oleh peneliti. Contoh jika diberikan data 1.000 baris
di dalam dataset dan dari data yang diberikan akan di bentuk 3 cluster.
Maka peneliti memasukkan nilai k = 3 sebagai cluster awal yang akan di
buat. Cluster awal akan mengambil record secara acak dari dataset, dan
setiap cluster awal yang di bentuk hanya mempunyai satu record data,
c) Setiap cluster yang sudah terbentuk akan di hitung nilai rata-ratanya hal ini
bertujuan untuk menentukan pusat cluster. Rata-rata dari suatu cluster
adalah rata-rata dari semua record yang terdapat di dalam cluster tersebut,
d) Setelah pusat cluster ditentukan maka langkah selanjutnya adalah
mengalokasian anggota cluster ke pusat cluster dengan cara menghitung
jarak terdekat pada pusat cluster.
e) Ulangin langkah-langkah yang sebelumnya sampai terbentuk cluster-
cluster yang stabil dan prosedur k-means selesai dengan iterasi maksimal =
10 kali atau cluster akan stabil terbentuk ketika iterasi dari K-means tidak
membuat cluster baru sebagai pusat cluster atau nilai rata-rata aritmatika
dari semua cluster baru sama dengan nilai rata-rata cluster lama.
Analisis segmentasi..., Jhon Hendro Panjaitan, FTI UMN, 2016

25
2.2.1 Metode Pengalokasian Data ke Dalam Masing Masing Cluster
Ada dua cara pengalokasian data kembali ke dalam masing-masing
cluster pada saat proses pengulangan clustering yaitu Hard K-means dan
fuzzy K-means. Perbedaan kedua metode ini terletak pada asumsi yang di
pakai sebagai dasar pengalokasian.
Hard K-means
Dalam metode ini pengalokasian data ke dalam masing-masing
cluster didasarkan pada perbandingan jarak antara data dengan pusat data
pada setiap cluster yang ada. Data yang dimasukkan kedalam cluster yang
terdekat dengan pusat data. Pengalokasian ini dapat dirumuskan sebagai
berikut :
= { {( )}
------------------------------- (2.3)
Keterangan : : keanggotaan data ke – K cluster ke-i
: nilai centre cluster ke-i
Fuzzy K-means
Metode ini mengalokasikan kembali data ke dalam masing-masing
cluster dengan cara memanfaatkan teori Fuzzy yaitu memetakan suatu
ruang input kedalam ruang output dengan cara memanfaatkan himpunan
Analisis segmentasi..., Jhon Hendro Panjaitan, FTI UMN, 2016

26
fuzzy. Dalam metode fuzzy K-means dipergunakan variable membership
function, , yang merujuk pada seberapa besar kemungkinanan suatu
data bisa menjadi anggota ke dalam suatu cluster. Pada Fuzzy K-mean
diperkenalkan juga suatu variable m yang merupakan weighting exponent
dari membership function. Variable ini dapat mengubah besaran pengaruh
dari membership function, , , dalam proses clustering menggunakan
metode membership function. m mempunyai wilayah nilai m < 1. Tetapi
sekarang ini tidak ada ketentuan yang jelas seberapa besar nilai m yang
optimal dalam melakukan proses optimasi suatu permasalahan clustering.
Nilai m yang umumnya digunakan adalah 2.
2.2.2 Beberapa Permasalahan yang Terkait dengan K-Means
Beberapa permasalahan yang sering dijumpai pada saat
menggunakan metode K-means untuk melakukan pengelompokan pada K-
means adalah sebagai berikut :
a) Ditentukannya beberapa model clustering yang berbeda,
b) Pemilihan jumlah cluster yang tepat,
c) Kegagalan untuk converge,
d) Pendekatan outliers,
e) Bentuk dari masing-masing cluster,
f) Masalah overlapping.
Analisis segmentasi..., Jhon Hendro Panjaitan, FTI UMN, 2016

27
Beberapa permasalahan di atas perlu diperhatikan pada saat
menggunakan K-means. Permasalahan pertama umumnya disebabkan oleh
perbedaan proses inisialisasi dari anggota masing-masing cluster. Di mana
proses inisialisasi dilakukan secara acak. Proses inisialisasi secara acak
mempunyai kecenderungan untuk memberikan hasil yang lebih baik,
walaupun dari segi kecepatan untuk converge lebih lambat. Pada
permasalahan yang kedua merupakan masalah yang sering terjadi dalam
metode K-mean. Untuk mengatasi masalah pada pemilihan jumlah cluster
yang tepat yaitu dilakukan pendekatan untuk menentukan jumlah cluster
yang tepat untuk suatu dataset.
Permasalahan ketiga adalah kegagalan untuk converge, hal ini
secara teori terjadi pada kedua metode K-means yaitu Hard K-means dan
Fuzzy K-means. Pada Hard K-means hal ini akan lebih sering terjadi
karena setiap data di dalam dataset dialokasikan secara tegas untuk
menjadi bagian dari cluster tertentu. Perpindahan dari satu data ke satu
cluster tertentu dapat mengubah karakteristik model clustering sehingga
dapat menyebabkan data yang telah dipindahkan tersebut lebih sesuai
berada di cluster yang awal sebelum data tersebut dipindahkan. Demikian
juga dengan keadaan sebaliknya, kejadian seperti ini akan mengakibatkan
pemodelan tidak akan berhenti dan kegagalan untuk converge akan terjadi.
Namun permasalahan tersebut kecil kemungkinan untuk terjadi pada Fuzzy
K-means, karena setiap data dilengkapi dengan membership untuk menjadi
anggota cluster yang ditemukan.
Analisis segmentasi..., Jhon Hendro Panjaitan, FTI UMN, 2016

28
Permasalahan pendekatan outliers merupakan permasalahan umum
yang hampir terjadi di setiap metode yang melakukan pemodelan terhadap
data, khususnya pemodelan untuk data metode K-means. Hal ini memang
menjadi permasalahan yang sangat krusial. Beberapa hal yang perlu
diperhatikan dalam melakukan pendekatan outliers dalam pengelompokan
data termasuk bagaimana cara menentukan apakah data item tersebut
merupakan outliers dari suatu cluster tertentu dan apakah data dalam
jumlah kecil yang membentuk suatu cluster sendiri dapat dianggap sebagai
outliers. Proses ini memerlukan suatu pendekatan khusus yang berbeda
dengan proses pendeteksian outliers di dalam suatu dataset yang hanya
terdiri dari satu populasi yang homogen.
Permasalahan pembentukan dari masing-masing cluster yang
ditentukan, tidak seperti metode data clustering lainnya termasuk mixture,
K-means, umumnya tidak mengindahkan bentuk dari masing-masing
cluster yang mendasari model yang terbentuk, walaupun secara alamiah
masing-masing dari cluster umumnya berbentuk bundar. Untuk dataset
yang diperkirakan mempunyai bentuk yang tidak biasa, beberapa
pendekatan perlu diterapkan.
Masalah overlapping adalah permasalahan yang sering diabaikan
karena umumnya masalah ini sulit untuk diketahui. Hal ini terjadi pada
metode Hard K-means dan Fuzzy K-means, karena secara teori metode ini
tidak dilengkapi fitur untuk mendeteksi apakah di dalam suatu cluster ada
cluster yang lain yang kemungkinan tersebunyi atau tidak terlihat.
Analisis segmentasi..., Jhon Hendro Panjaitan, FTI UMN, 2016

29
Maka dari beberapa permasalahan dapat diketahui bahwa K-means
merupakan metode pemodelan yang besifat tanpa arah. Karena
pengkategorian metode-metodenya pengklasifikasian data didasarkan pada
adanya dataset yang item awalnya mempunyai label kelas dan dataset yang
tidak mempunyai kelas. Jika data sudah memiliki label kelas maka akan
diklasifikasikan menggunakan label kelas yang sama tersebut dalam
melakukan pengklasifikasian Klusternya. Semetara data yang belum dapat
label kelas maka akan diklasifikasikan dengan menggunakan metode tanpa
arah klasifikasi.
Selain permasalahan pengelompokan data ke masing-masing
cluster, ada beberapa hal permasalahan kecil yang harus diperhatikan yaitu
bagaimana cara menentukan jumlah cluster yang tepat dan menempatkan
sejumlah data pada cluster yang tepat supaya lebih mudah untuk
dianalisis. Untuk metode K-means dalam menentukan jumlah cluster dari
dataset yang disediakan umumnya menggunakan dua metode saja, yaitu
metode tanpa arahan (unsupervised) dan metode supervised, atau bisa juga
ditentukan dari awal oleh user sendiri.
Analisis segmentasi..., Jhon Hendro Panjaitan, FTI UMN, 2016

30
2.2.3 K-Means untuk Data yang Mempunyai Bentuk Khusus
Beberapa dataset yang mempunyai bentuk yang khusus
memerlukan metode pemecahan masalah yang khusus pula. Untuk
keperluan seperti ini beberapa peneliti telah mengusulkan pengembangan
metode K-means yang secara khusus memanfaatkan kernel trik, di mana
data space untuk data awal di-mapping ke dalam feature space yang
berdimensi tinggi.
Pengembangan metode K-means dengan kernel trik ini adalah
bahwa data pada feature space tidak lagi dapat didefinisikan secara
explisit, sehingga perhitungan nilai membership function dan central tidak
lagi dapat dilakukan secara langsung. Beberapa cara yang diusulkan untuk
menurunkan nilai variable yang diperlukan tersebut adalah objective
function yang digunakan dalam menilai suatu proses pengelompokan
apakah sudah converge atau tidak.
2.3 Mean Shift
Mean shift adalah metode untuk menentukan nilai maksimum lokal
dari suatu probabilitas kepadatan yang diberikan. Dengan menggunakan
segmentasi mean shift, suatu citra akan memiliki warna-warna yang
homogen dalam suatu wilayah, metode mean shift digunakan untuk
menemukan kepadatan mode dari suatu gambar. Dapat dirumuskan seperti
persamaan 2.4 berikut :
Analisis segmentasi..., Jhon Hendro Panjaitan, FTI UMN, 2016

31
{ } n
I = 1 C ------------------------------------ (2.4)
di mana nilai estimasi kepadatan mengarah pada nilai x
(x) =
∑
---------------------------(2.5)
Dimana D merupakan dimensi dari data, untuk lebih sederhananya
kita dapat melihat rumus di bawah ini dengan asumsi kernel lebar adalah
sama. Maka kernel tujuan dapat dirumuskan seperti persamaan 2.6 berikut
:
(x) =
∑
----------------------------- (2.6)
Maka jika mean shift vector diberikan maka dapat dirumuskan
seperti persamaan 2.7 berikut :
m(x) = ∑
∑
– x -------------------------- (2.7)
Karena setiap titik yang bersatu dengan mode yang sama, akan
dijadikan sabagai satu cluster. Sehingga proses segmentasi clustering akan
selesai jika semua mode sudah bersama dalam satu cluster yang sama.
Analisis segmentasi..., Jhon Hendro Panjaitan, FTI UMN, 2016
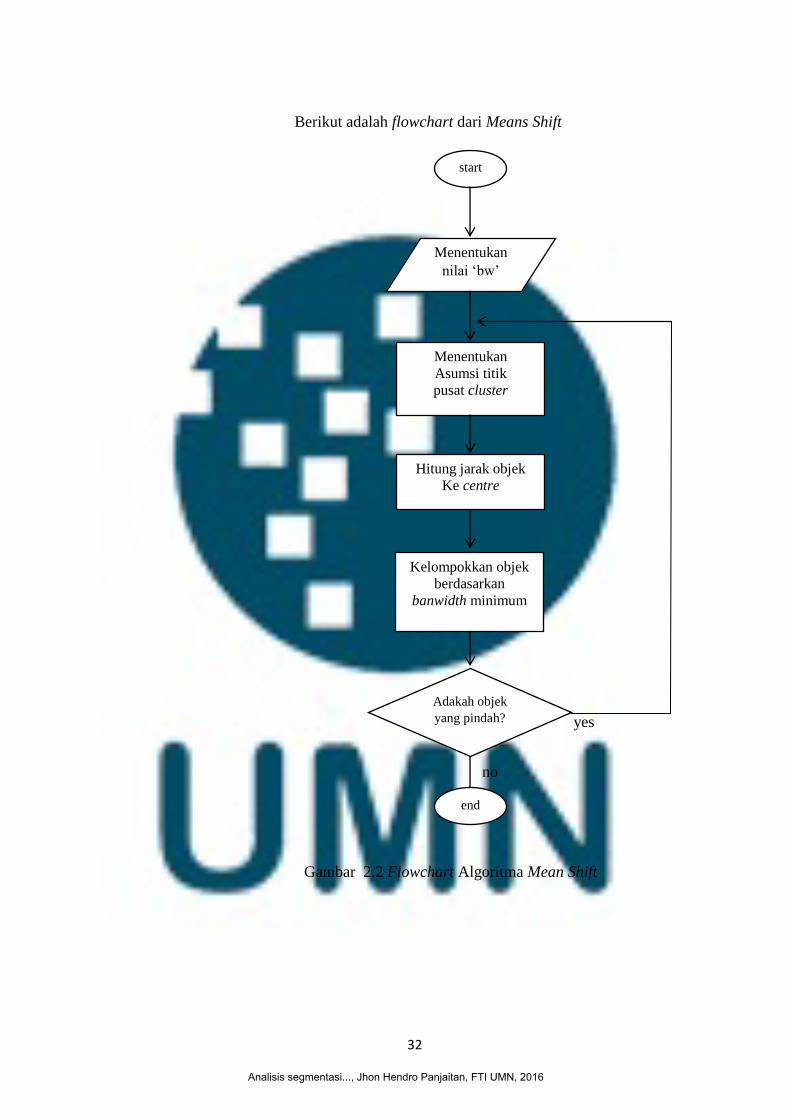
32
Berikut adalah flowchart dari Means Shift
v yes
no
Gambar 2.2 Flowchart Algoritma Mean Shift
start
Menentukan
nilai „bw‟
Menentukan
Asumsi titik
pusat cluster
Kelompokkan objek
berdasarkan
banwidth minimum
Hitung jarak objek
Ke centre
Adakah objek
yang pindah?
end
Analisis segmentasi..., Jhon Hendro Panjaitan, FTI UMN, 2016

33
Berikut adalah penjelasan dari flowchart diagram 2.2 pada algoritma K-
Means.
a) Program dijalankan,
b) Algoritma menerima jumlah „bw‟ jumlah bw pada penelitian ini
ditentukan langsung oleh peneliti,
c) Jumlah cluster akan di bentuk berdasarkan nilai bandwidth yang
dimasukkan, dimana jumalah bandwidth akan mempengaruhi
jumlah cluster yang di bentuk, jika jumalah bandwidth semakin
kecil maka jumlah cluster akan semakin besar
d) Setiap cluster yang sudah terbentuk akan dihitung nilai rata-
ratanya. Rata-rata dari suatu cluster adalah rata-rata dari semua
record yang terdapat di dalam cluster tersebut. Pengalokasian data
ke dalam cluster dilakukan berdasarkan bandwidth minimum,
dimana setiap anggota akan dihitung bandwitdth terkecil ke pusat
cluster
e) Ulangin langkah-langkah yang sebelumnya sampai terbentuk
cluster-cluster yang stabil dan prosedur k-means selesai. cluster
akan stabil terbentuk ketika iterasi dari K-means tidak membuat
cluster baru sebagai pusat cluster atau nilai rata-rata aritmatika dari
semua cluster baru sama dengan nilai rata-rata cluster lama,
f) Program selesai.
Analisis segmentasi..., Jhon Hendro Panjaitan, FTI UMN, 2016

34
2.4 Normalized Cut
Normalized cut adalah algoritma yang membagi beberapa cluster
berdasarkan satu elemen yang sama yang hanya didasarkan pada nilai-nilai
ukuran yang sama antara semua pasangan dan dari unsur-unsur yang sama
pula. Pedekatan yang dilakukan adalah dengan menggunakan metode
spectral hal ini didasarkan pada sifat-sifat vector eigen dari matriks yang
di hitung menggunakan persamaan antar setiap pasangan element.
Normalized cut membagi gambar dengan dua node yaitu node A
dan node B dengan cara menghapus titik tepi penghubung kedua node
tersebut. Tingkat ketidaksamaan antara kedua node dapat dirumuskan pada
persamaan 2.8.
Cut (A,B) = ∑ --------------------- (2.8)
Dimana u dan v adalah dua node dan w merupakan bobot masukan
pada segmentasi. Karena semua gambar yang bersifat seperti texture,
warna, dan gradient dapat digunakan untuk membangun suatu nilai
matriks, salah satu cara untuk mengurangi nilai pada gambar adalah
dengan algoritma minimum cut. Algoritma minimum cut adalah algoritma
yang memotong nilai yang lebih kecil dari dua node yang terpisah
sehingga nilai dari kedua node tersebut tidak rusak, sehingga kemungkinan
gagal untuk menentukan node sangat kecil.
Analisis segmentasi..., Jhon Hendro Panjaitan, FTI UMN, 2016

35
Unutk mendefenisikan Ncut dapat dirumuskan sebagai berikut
gambar 2.5:
Gambar 2.3 Pembagian node [4]
Dengan rumus sebagai berikut
Cut (A,B) = ∑ ------------------------(2.9)
Keeratan kedua hubungan pada kedua node yang terpisah dapat
dirumuskan seperti persamaan 2.10 berikut :
Ncut (A,B) =
=
+
= 2 –(
) +
= 2 - (A,B) ---------------------------------(2.10)
Analisis segmentasi..., Jhon Hendro Panjaitan, FTI UMN, 2016

36
Dari rumus di atas dapat disimpulkan bahwa keeratan kedua
hubungan antara node sangat erat hal ini diketahui karena nilai yang di
potong antara kedua node sangat kecil, lebih lanjut dapat disederhanakan
dengan persamaan berikut ini :
Dari persamaan di atas disimpulkan meminimalkan bahwa,
pemisahan antara node dan memaksimalkan hubungan dalam satu node
dapat memberikan nilai yang lebih bagus pada tiap-tiap node. Di sini
dibutuhkan beberapa metode pendekatan untuk menyelesaikan pemberian
nilai secara umum. Berikut adalah langkah-langkah untuk menggunakan
nilai pada algoritma yang digunakan :
a) Langkah 1
Dalam sebuah gambar, yang pertama adalah membangun sebuah
graf dengan bobot. dapat dihitung dengan menggunakan rumus
beritikut :
w(i,j) =
-----------------(2.11)
Dimana || X(i) – X(j)||2 < r, jika w(I,j) = 0, dimana X(i) adalah
lokasi spesial pada simpul dalam node I, F(i) merupakan vector
gambar. Fitur vector adalah pemisahan gambar berdasakan
warna yang dimiliki oleh objek.
b) Langkah 2
Analisis segmentasi..., Jhon Hendro Panjaitan, FTI UMN, 2016

37
Memecahkan sistem persamaan, di mana perumusan pada
langkah pertama akan diselesaikan pada tahap 2. Dapat
dirumuskan sebagai berikut :
( ----------------------------- (2.12)
Dengan memberikan nilai eigen vector y dan eigen λ
c) Langkah 3
Memberikan nilai eigen terkecil pada kedua node yang telah
dipisahkan untuk meminimalkan nilai normalized cut
d) Langkah 4
Memeriksa kembali node yang telah dipisahkan apakah node
masih harus dipartisi kembali atau tidak. Jika dipartisi kembali,
maka pengerjaan akan kembali pada langkah yang pertama,
tetapi jika tidak ada partisi lagi maka node sudah terbentuk.
Analisis segmentasi..., Jhon Hendro Panjaitan, FTI UMN, 2016
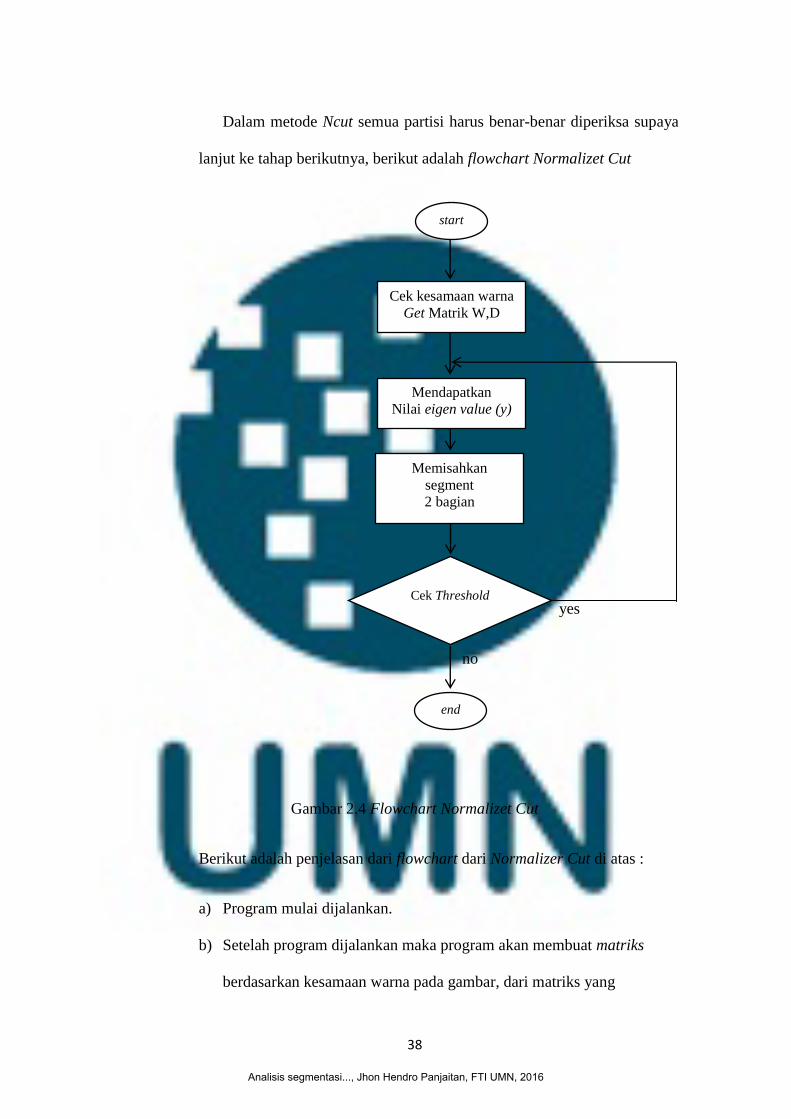
38
Dalam metode Ncut semua partisi harus benar-benar diperiksa supaya
lanjut ke tahap berikutnya, berikut adalah flowchart Normalizet Cut
Yes yes
no
Gambar 2.4 Flowchart Normalizet Cut
Berikut adalah penjelasan dari flowchart dari Normalizer Cut di atas :
a) Program mulai dijalankan.
b) Setelah program dijalankan maka program akan membuat matriks
berdasarkan kesamaan warna pada gambar, dari matriks yang
start
Cek kesamaan warna
Get Matrik W,D
Mendapatkan
Nilai eigen value (y)
Memisahkan
segment
2 bagian
Cek Threshold
end
Analisis segmentasi..., Jhon Hendro Panjaitan, FTI UMN, 2016

39
terbentuk maka setiap matriks akan memiliki bobot yang disebut „W‟
dan dari matriks yang sudah ada akan dihitung matriks diagonalnya
untuk mendapatkan nilai „D‟
c) Langkah berikutnya adalah mendapatkan nilai threshold, nilai ini
nantinya untuk memotong titik tengah dari pixel yang ada pada citra,
nilai threshold pada penelitian ini ditentukan langsung oleh peneliti.
d) Setelah pemisahan gambar berhasil dilakukan maka langkah
selanjutnya adalah mengecek kembali apakah masih ada nilai
threshold pada gambar. Jika masih ada nilai threshold maka proses
akan kembali ke langkah yang ke 2 tetapi jika nilai threshold sudah
tidak ada maka program akan berhenti dan akan menampilkan hasil
dari segmentasi gambar yang di proses.
e) Program selesai.
Analisis segmentasi..., Jhon Hendro Panjaitan, FTI UMN, 2016




















