
Analisis Algoritma K-means Clustering Menggunakan Openmp-libre
30
LAPORAN TUGAS AKHIR ANALISIS ALGORITMA K‐MEANS CLUSTERING DENGAN MENGGUNAKAN OPENMP (Studi Kasus : Data Survei Sosial Ekonomi Nasional BPS) Disusun Dalam Rangka memenuhi Tugas Akhir Mata Kuliah EL6210 Komputasi Paralel Program Studi Pasca Sarjana Informatika Sekolah Teknik Elektro dan Informasi Institut Teknologi Bandung 2013
-
Upload
ruth-masrany-sirait -
Category
Documents
-
view
82 -
download
0
description
clustering
Transcript of Analisis Algoritma K-means Clustering Menggunakan Openmp-libre

LAPORAN TUGAS AKHIR
ANALISIS ALGORITMA K‐MEANS CLUSTERING
DENGAN MENGGUNAKAN OPENMP
(Studi Kasus : Data Survei Sosial Ekonomi Nasional BPS)
Disusun Dalam Rangka memenuhi Tugas Akhir
Mata Kuliah EL6210 Komputasi Paralel
Program Studi Pasca Sarjana Informatika
Sekolah Teknik Elektro dan Informasi
Institut Teknologi Bandung
2013


i
DAFTAR PUSTAKA
DAFTAR PUSTAKA ...................................................................................................................................... i
DAFTAR TABEL .......................................................................................................................................... ii
DAFTAR GAMBAR .................................................................................................................................... iii
1. PENDAHULUAN ................................................................................................................................ 1
1.1. K‐Means Clustering ........................................................................................................................... 1
1.2. Algoritma K‐Means Clustering .......................................................................................................... 1
1.3. Cara Kerja Algoritma K‐Mean Clustering: ......................................................................................... 3
2. STUDI KASUS K‐MEANS CLUSTERING ............................................................................................... 4
2.1. Studi Kasus ....................................................................................................................................... 4
2.2. Tahapan Iterasi K‐Means Clustering ................................................................................................. 4
3. IMPLEMENTASI ALGORITMA K‐MEANS CLUSTERING ....................................................................... 8
3.1. Spesifikasi dan Tools ......................................................................................................................... 8
3.2. Serial Programming .......................................................................................................................... 9
3.3. Paralel Programming ...................................................................................................................... 12
4. ANALISIS PROGRAM PARALEL K‐MEANS CLUSTERING ................................................................... 15
4.1. Waktu Eksekusi Program Serial ...................................................................................................... 15
4.2. Waktu Eksekusi Program Paralel .................................................................................................... 16
4.3. Sebaran Objek Data Berdasarkan Cluster ....................................................................................... 18
5. KESIMPULAN .................................................................................................................................. 21
DAFTAR PUSTAKA ................................................................................................................................... 22
LAMPIRAN .............................................................................................................................................. 23

ii
DAFTAR TABEL
Tabel 1. Struktur Objek Data .................................................................................................................... 4
Tabel 2. Hasil Pengelompokkan Group Objek Data .................................................................................. 8
Tabel 3. Waktu Eksekusi Program Serial ................................................................................................ 15
Tabel 4. Waktu Eksekusi Program Paralel .............................................................................................. 16
Tabel 5. Selisih rata‐rata waktu eksekusi antara program paralel dengan serial ................................... 18

iii
DAFTAR GAMBAR
Gambar 1. Flowchart K‐Means Clustering ................................................................................................ 2
Gambar 2. Skema 3 matrix dengan variabel‐variabelnya ........................................................................ 3
Gambar 3. Sebaran objek data ke centroid awal pada Iterasi 0 ............................................................... 4
Gambar 4. Sebaran objek data ke centroid baru pada Iterasi 1 ............................................................... 6
Gambar 5. Sebaran objek data ke centroid baru pada Iterasi 2 ............................................................... 7
Gambar 6. Kode Program Serial K‐Means Clustering ............................................................................. 11
Gambar 7. Kode Program Paralel K‐Means Clustering ........................................................................... 14
Gambar 8. Penerapan Paralel Pada Kode Program ................................................................................ 15
Gambar 9. Grafik Rata‐Rata Waktu Eksekusi Program Serial ................................................................. 16
Gambar 10. Grafik Rata‐Rata Waktu Eksekusi Program Serial dan Paralel ............................................ 17
Gambar 11. Grafik Sebaran Objek Data Berdasarkan Cluster untuk N : 10 RT ....................................... 18
Gambar 12. Grafik Sebaran Objek Data Berdasarkan Cluster untuk N : 100 RT .................................... 19
Gambar 13. Grafik Sebaran Objek Data Berdasarkan Cluster untuk N : 1.000 RT .................................. 19
Gambar 14. Grafik Sebaran Objek Data Berdasarkan Cluster untuk N : 10.000 RT ................................ 20
Gambar 15. Grafik Sebaran Objek Data Berdasarkan Cluster untuk N : 100.000 RT .............................. 20


1
ANALISIS ALGORITMA K‐MEANS CLUSTERING
DENGAN MENGGUNAKAN OPENMP
1. PENDAHULUAN
1.1. K‐Means Clustering
K‐Means Clustering merupakan metode untuk mengklasifikasikan atau mengelompokkan
objek‐objek (data) ke dalam K‐group (cluster) berdasarkan atribut tertentu. Pengelompokkan data
dilakukan dengan memperhitungkan jarak terdekat antara data‐data (objek observasi) dengan pusat
cluster (centroid). Prinsip utama dari metode ini adalah menyusun K buah centroid atau rata‐rata
(mean) dari sekumpulan data berdimensi N, dimana metode ini mensyaratkan nilai K sudah diketahui
sebelumnya (apriori). Algoritma K‐means dimulai dengan pembentukan prototipe cluster diawal
kemudian secara iteratif prototipe cluster tersebut diperbaiki sehingga tercapai kondisi konvergen,
yaitu kondisi dimana tidak terjadi perubahan yang signifikan pada prototipe cluster. Perubahan ini
diukur dengan menggunakan fungsi objektif D yang umumnya didefinisikan sebagai jumlah atau rata‐
rata jarak tiap item data dengan centroid groupnya.
1.2. Algoritma K‐Means Clustering
Algoritma K‐Means Clustering merupakan metode clustering berbasis jarak yang membagi
data‐data ke dalam sejumlah cluster dimana proses clustering tersebut dilakukan dengan
memperhatikan kumpulan dari data‐data yang akan dikelompokkan. Pada algoritma ini, pusat cluster
atau centroid dipilih pada tahap awal secara acak dari sekumpulan koleksi (populasi) data. Kemudian
K‐Means menguji masing‐masing komponen didalam populasi data dan menandai komponen
tersebut ke salah satu centroid yang telah didefinisikan sebelumnya berdasarkan jarak minimum
antara komponen (data) dengan masing‐masing centroid. Posisi centroid akan dihitung kembali
sampai semua komponen data dikelompokkan ke setiap centroid dan terakhir akan terbentuk posisi
centroid baru. Iterasi ini akan terus dilakukan sampai tercipta kondisi konvergen. Secara lebih detail,
algoritma K‐means Clustering adalah sebagai berikut :
1. Definisikan jumlah K cluster.
2. Inisialisasi K pusat cluster (centroid) sebagai seed points (prototipe cluster awal). Centroid ini
dapat diperoleh secara acak atau dipilih dari K objek data pertama.
3. Untuk setiap komponen data, hitung dan tandai jarak (distance) ke centroid awal kemudian
masukkan data tersebut ke centroid yang paling dekat jaraknya

2
4. Hitung dan ubah kembali centroid tiap cluster sebagai rata‐rata dari seluruh anggota
kelompok (group) cluster tersebut.
5. Cek semua data kembali dan taruh setiap data yang terdekat dengan centroid baru. Jika
anggota tiap cluster tidak berubah (konvergen), maka langkah berhenti dan jika masih
berubah, kembali ke langkah 2.
Berikut ini flowchart dari algoritma K‐Means :
Gambar 1. Flowchart K‐Means Clustering
Berdasarkan uraian tersebut, maka algoritma K‐Means Clustering akan melakukan proses
iterasi atau pengulangan langkah‐langkah berikut sampai terjadi kestabilan (konvergen) atau tidak
ada obyek data yang berpindah centroid :
1. Menentukan koordinat setiap centroid
2. Menentukan jarak setiap obyek data ke centroid
3. Mengelompokkan obyek‐obyek data tersebut berdasarkan pada jarak minimumnya
terhadap centroid
Begin
Definisikan Jumlah
cluster K
Tentukan centroid
Hitung jarak objek data
ke centroid
Kelompokkan objek data berdasarkan
jarak minimum ke centroid
Ada objek
yang
berpindah
kelompok ?
End

3
1.3. Cara Kerja Algoritma K‐Mean Clustering:
Jika jumlah data (N) lebih kecil dari jumlah cluster (K) maka kita masukkan setiap data
menjadi centroid dari cluster. Setiap centroid memiliki sebuah nomor cluster. Jika jumlah data lebih
besar dari jumlah cluster, maka untuk setiap data kita hitung jarak terhadap seluruh centroid hingga
mendapatkan jarak minimum (terdekat). Jika kita tidak yakin mengenai lokasi centroid, lakukan
pendekatan mengenai letak centroid berdasarkan data terkini. Lalu masukkan semua data pada
centroid baru tersebut. Proses ini berulang sampai tidak ada lagi data yang dipindahkan pada cluster
lainnya. Secara matematis perulangan ini dapat dibuktikan secara konvergen.
Data 1 2 3 .... Total Data
0 Nomor Cluster
1 X
2 Y
SumXY 1 2 3 .... Nomor Cluster
1 X
2 Y
3 Banyak data dalam cluster
Centroid
1
2
3
....
Nomor Cluster
1 X
2 Y
Gambar 2. Skema 3 matrix dengan variabel‐variabelnya
4
2. STUDI KASUS K‐MEANS CLUSTERING
2.1. Studi Kasus
Studi Kasus yang digunakan pada K‐Means Clustering ini adalah Data Survei Sosial Ekonomi
Nasional (SUSENAS) Tahun 2012 BPS Provinsi Bali. Objek data yang digunakan disini adalah Rumah
Tangga (RT) dengan atribut (komponen) objek data yang diambil sebanyak 2 (dua) variabel, yaitu X
(Pengeluaran) dan Y (Pendapatan). Berikut contoh layout sederhana dari objek data tersebut :
Tabel 1. Struktur Objek Data
Objek Data X: Pengeluaran
(ribuan)
Y : Pendapatan
(ribuan)
Rumah Tangga A 1 1
Rumah Tangga B 2 1
Rumah Tangga C 4 3
Rumah Tangga D 5 4
Untuk implementasi algoritma K‐Means Clustering, jumlah objek data yang digunakan adalah
maksimal sebanyak 100.000 Rumah Tangga, dimana koleksi objek data tersebut digunakan secara
bertahap dengan interval log n, sehingga ada 5 (lima) kali training set untuk mencapai jumlah
populasi objek data tersebut, meliputi 10, 100, 1.000, 10.000 dan 100.000 Rumah Tangga.
2.2. Tahapan Iterasi K‐Means Clustering
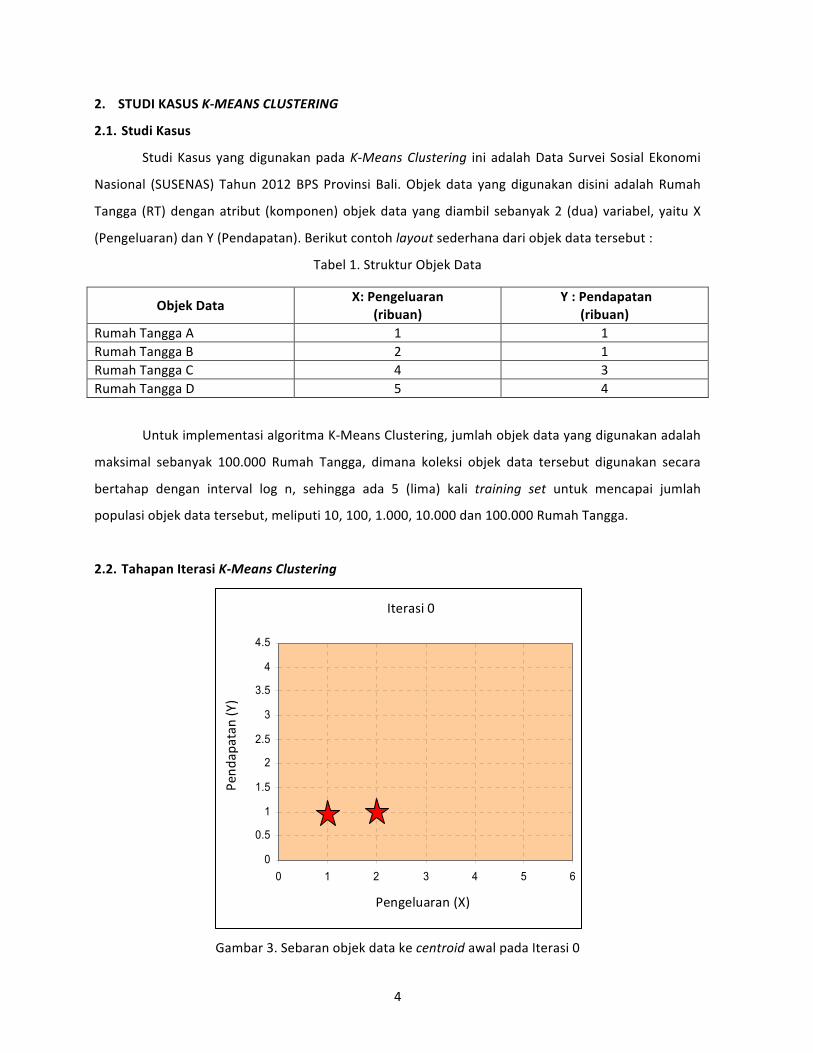
Gambar 3. Sebaran objek data ke centroid awal pada Iterasi 0
? ?
? /Ç ×? È Ù ? /É ÚÇ ×È ÙÉ Ú
? / - / ?? / - / ?
/Ç ×? È Ù /É Ú
iteration 0
0
0.5
1
1.5
2
2.5
3
3.5
4
4.5
0 1 2 3 4 5 6
attribute 1 (X): weight index
att
rib
ute
2 (
Y):
pH
Pengeluaran (X)
Pendapatan (Y)
Iterasi 0

5
Berikut ini tahapan‐tahapan iterasi algoritma K‐Means Clustering :
1. Jumlah K‐Cluster
Jumlah cluster yang diinginkan adalah sebanyak K, misalnya sebanyak 2 cluster (group), sehingga
jumlah centroid yang harus didefinisikan di awal juga sebanyak 2 (dua) centroid.
2. Iterasi 0 : Set nilai awal centroid
Misalkan nilai awal centroid adalah 2 nilai atribut pertama pada objek data : Rumah Tangga A
dan B, dinotasikan dengan C1 dan C2 , dimana C1 = (1,1) dan C2 = (2,1)
3. Iterasi 0 : Jarak dari setiap objek data ke centroid
Hitung jarak (D) setiap objek data tersebut ke centroid cluster dengan menggunakan Euclidean
Distance, sehingga didapatkan matriks jarak sebagai berikut :
Jarak objek Rumah Tangga C ke C1 : (4 − 2)! + (3 − 1)! = 3.61
Jarak objek Rumah Tangga C ke C2 : (4 − 2)! + (3 − 1)! = 2.83
4. Iterasi 0 : Clustering Objek Data
Selanjutnya melakukan pengelompokkan (G) objek data tersebut ke cluster (group 1 atau group
2) berdasarkan jarak minimum (terdekat) dengan centroid.
Dari matrik G0 tersebut, terlihat bahwa Rumah Tangga A masuk kedalam group 1, sedangkan
Rumah Tangga B, C dan D masuk kedalam group 2
5. Iterasi 1 : Tentukan centroid baru
Setelah mengetahui anggota setiap group, langkah selanjutnya adalah menghitung kembali
centroid baru untuk setiap group tersebut. Group 1 hanya mempunyai 1 (satu) anggota, yaitu
Rumah Tangga A dengan centroid baru sama dengan centroid awal C1= (1,1), sedangkan Group 2
mempunyai 3 (tiga) anggota, yaitu Rumah Tangga B, C dan D, sehingga centroid baru adalah rata‐
rata jarak dari seluruh anggota objek data yang masuk dalam kelompok (group) 2.
�! =2 + 4 + 5
3,1 + 3 + 4
3= (
11
3,10
3)
? ?use Euclidean distance, then we have distance matrix at iteration
10
2
(1,1) 10 1 3.61 5
(2,1) 21 0 2.83 4.24
1 2 4 5
1 1 3 4
group
group
A B C D
X
Y
? /Ç ×? È Ù ? /É ÚÇ ×È ÙÉ Ú
cD
c
Each column in the distance matrix symbolizes the object. The
corresponds to the distance of each object to the first centroid a
? / - / ?? / - / ?
/Ç ×? È Ù /É Ú
? ?
? /Ç ×? È Ù ? /É ÚÇ ×È ÙÉ Ú
? / - / ?? / - / ?
element of Group matrix below is 1 if and o
01 0 0 0 1
0 1 1 1 2
A B C D
group
group
/Ç ×? È Ù /É ÚG
6
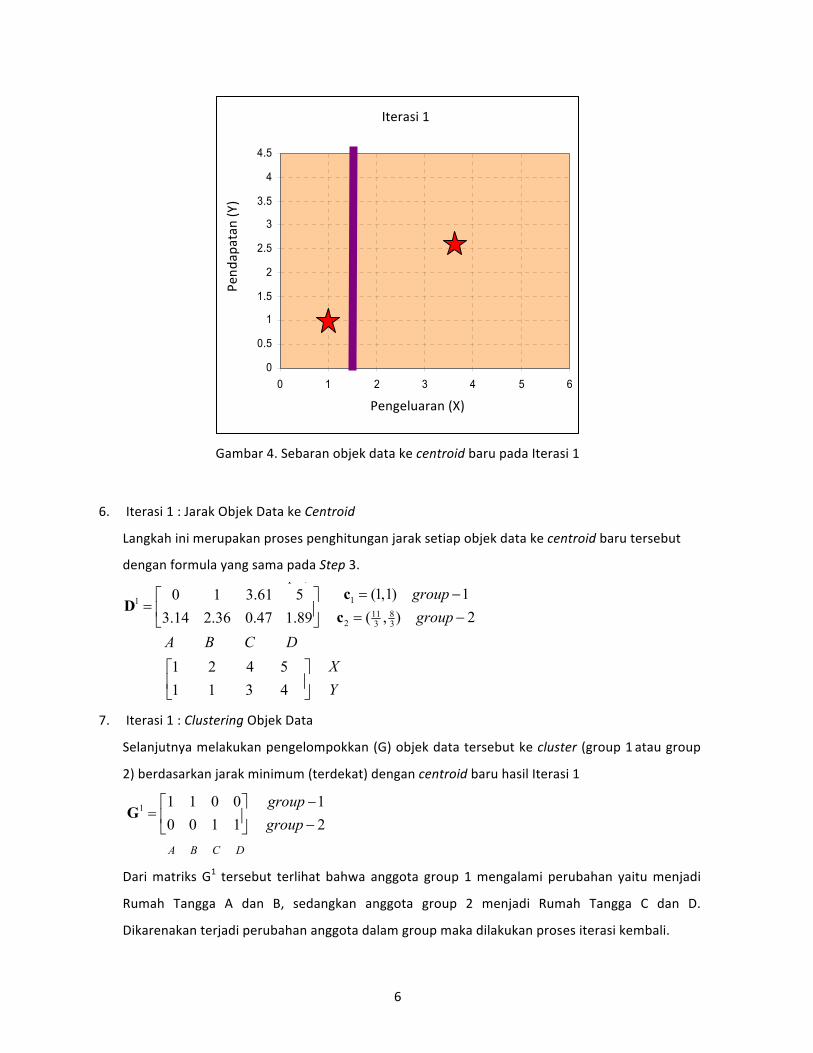
Gambar 4. Sebaran objek data ke centroid baru pada Iterasi 1
6. Iterasi 1 : Jarak Objek Data ke Centroid
Langkah ini merupakan proses penghitungan jarak setiap objek data ke centroid baru tersebut
dengan formula yang sama pada Step 3.
7. Iterasi 1 : Clustering Objek Data
Selanjutnya melakukan pengelompokkan (G) objek data tersebut ke cluster (group 1 atau group
2) berdasarkan jarak minimum (terdekat) dengan centroid baru hasil Iterasi 1
Dari matriks G1 tersebut terlihat bahwa anggota group 1 mengalami perubahan yaitu menjadi
Rumah Tangga A dan B, sedangkan anggota group 2 menjadi Rumah Tangga C dan D.
Dikarenakan terjadi perubahan anggota dalam group maka dilakukan proses iterasi kembali.
?- - - -? ?
5. Iteration-1, Objects-Centroids distances: The next step is to comp
? /Ç ×? È Ù ? /É ÚÇ ×È ÙÉ Ú
/Ç ×? È Ù /É Ú
- -? ? - -? ?
iteration 1
0
0.5
1
1.5
2
2.5
3
3.5
4
4.5
0 1 2 3 4 5 6
attribute 1 (X): weight index
att
rib
ute
2 (
Y):
pH
?- - - -? ?
the new centroids. Similar to step 2, we have distance matrix at iteration
11
8112 3 3
(1,1) 10 1 3.61 5
( , ) 23.14 2.36 0.47 1.89
1 2 4 5
1 1 3 4
group
group
A B C D
X
Y
? /Ç ×? È Ù ? /É ÚÇ ×È ÙÉ Ú
cD
c
6. Iteration-1, Objects clustering: Similar to step 3, we assign each obj
/Ç ×? È Ù /É Ú
- -? ? - -? ?
?- - - -? ?
? /Ç ×? È Ù ? /É ÚÇ ×È ÙÉ Ú
objects remain. The Group matrix is shown
11 1 0 0 1
0 0 1 1 2
A B C D
group
group
/Ç ×? È Ù /É ÚG
7. Iteration 2, determine centroids: Now we
- -? ? - -? ?
Pengeluaran (X)
Pendapatan (Y)
Iterasi 1
7
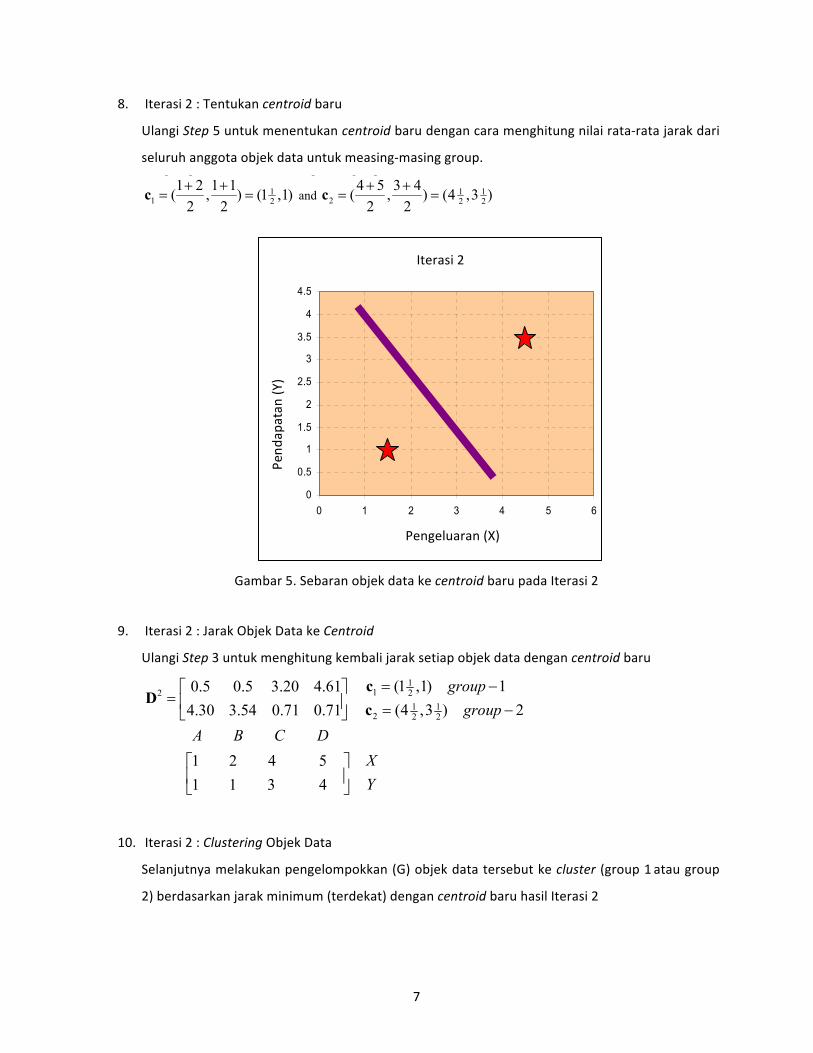
8. Iterasi 2 : Tentukan centroid baru
Ulangi Step 5 untuk menentukan centroid baru dengan cara menghitung nilai rata‐rata jarak dari
seluruh anggota objek data untuk measing‐masing group.
Gambar 5. Sebaran objek data ke centroid baru pada Iterasi 2
9. Iterasi 2 : Jarak Objek Data ke Centroid
Ulangi Step 3 untuk menghitung kembali jarak setiap objek data dengan centroid baru
10. Iterasi 2 : Clustering Objek Data
Selanjutnya melakukan pengelompokkan (G) objek data tersebut ke cluster (group 1 atau group
2) berdasarkan jarak minimum (terdekat) dengan centroid baru hasil Iterasi 2
?- - - -? ?
? /Ç ×? È Ù ? /É ÚÇ ×È ÙÉ Ú
/Ç ×? È Ù /É Ú
on the clustering of previous iteration. Group1 and group 2 both has two members
ntroids are 11 2
1 2 1 1( , ) (1 ,1)
2 2
- -? ?c and 1 12 2 2
4 5 3 4( , ) (4 ,3 )
2 2
- -? ?c
8. Iteration-2, Objects-Centroids distances: Repeat step 2 again, we
? /Ç ×? È Ù ? /É ÚÇ ×È ÙÉ Ú
/Ç ×? È Ù /É Ú?
iteration 2
0
0.5
1
1.5
2
2.5
3
3.5
4
4.5
0 1 2 3 4 5 6
attribute 1 (X): weight index
att
rib
ute
2 (
Y):
pH
iteration 2 as 1
1 22
1 12 2 2
(1 ,1) 10.5 0.5 3.20 4.61
(4 ,3 ) 24.30 3.54 0.71 0.71
1 2 4 5
1 1 3 4
group
group
A B C D
X
Y
? /Ç ×? È Ù ? /É ÚÇ ×È ÙÉ Ú
cD
c
9. Iteration-2, Objects clustering: Again, we assign each object based on the m
1 1 0 0 1roup /Ç ×? È Ù /É Ú?
Pengeluaran (X)
Pendapatan (Y)
Iterasi 2

8
Dari matriks G2 tersebut terlihat tidak ada perubahan anggota untuk group 1 dan group 2,
sehingga sudah tercapai kondisi konvergen. Proses iterasi tidak perlu dilakukan lagi dan rankaian
proses clustering selesai. Hasil akhir dari proses ini adalah koordinat centroid akhir dan identitas
group (cluster) untuk masing‐masing objek data.
Tabel 2. Hasil Pengelompokkan Group Objek Data
Objek Data (N) X: Pengeluaran
(ribuan)
Y : Pendapatan
(ribuan)
Group
(Cluster)
Rumah Tangga A 1 1 1
Rumah Tangga B 2 1 1
Rumah Tangga C 4 3 2
Rumah Tangga D 5 4 2
3. IMPLEMENTASI ALGORITMA K‐MEANS CLUSTERING
3.1. Spesifikasi dan Tools
Spesifikasi Komputer yang digunakan adalah sebagai berikut :
• Sistem Operasi : Windows 7 32 Bit
• Processor : AMD Turion X2 Dual Core 2.2 GHz
• RAM : 4 GB
Tools yang digunakan dalam pembuatan program serial dan paralel K‐Means Clustering pada laporan
ini adalah :
• Bahasa Pemrograman : C++
• IDE : Code Blocks 10.05
• Compiler : gcc
• Library : OpenMP
? /Ç ×? È Ù ? /É ÚÇ ×È ÙÉ Ú
9. Iteration-2, Objects clustering: Again, we ass
21 1 0 0 1
0 0 1 1 2
A B C D
group
group
/Ç ×? È Ù /É ÚG
We obtain result that2 1?G G . Comparing

9
3.2. Serial Programming
Berikut ini source code dari Program Serial K‐Means Clustering
//--------------------------------------------------------------------------------- //Program Serial K-Means Clustering //Aris Jayandrana (NIM. 23512180) //Maria Fransiska Sirait (NIM. 23512198) //Novianto Budi Kurniawan (NIM. 23512176) //--------------------------------------------------------------------------------- #include <stdio.h> #include <math.h> #include <string> #include <sstream> #include <iostream> #include <vector> #include <fstream> #include <stdlib.h> using namespace std; int main() { //baca file ifstream in("D:/TUgas Paralel Final/mydata10.csv"); string line, field; vector< vector<string> > array; vector<string> v; while ( getline(in,line) ) { v.clear(); stringstream ss(line); while (getline(ss,field,',')) { v.push_back(field); } array.push_back(v); } int cluster[4], count[4]; const int rows = array.size(); //jumlah titik const int columns = 2; const int crows = 2; const int ccolumns = 2; float dmin, dpoint[rows][crows]; // int point[rows][columns]={{5,5},{2,1},{1,3},{5,4}}; //int group[rows]; int point[rows][columns]; int group[rows]; //group id untuk tiap point int group_member_count[2]={0,0}; //jumlah anggota untuk tiap group double centroid [crows][ccolumns]; for(int i =0;i<rows;i++) { for(int j=0;j<columns;j++){ point[i][j]= atoi(array[i][j].c_str()); // printf("%d\n",point[i][j]);

10
} } //pilih 2 titik pertama sebagai centroid for (int i=0;i<2;i++) { for(int j=0;j<2;j++) { centroid[i][j] = point[i][j]; } // printf("Initial centroid group %d : (%f,%f)\n",i,centroid[i][0],centroid[i][1]); } //masukkan semua titik ke group 0 for (int i = 0; i < rows; i++) { group[i]=0; } int group_changing = 2; while(group_changing>0) { group_changing = 0; //ukur jarak antar titik ke centroid for (int i = 0; i < rows; i++) { for (int j = 0; j < 2; j++) { dpoint[i][j] = 0.0; dpoint[i][j] += sqrt(pow((point[i][0] - centroid[j][0]),2)+pow((point[i][1] - centroid[j][1]),2)); // printf("Jarak point %d ke centroid %d : %f\n",i+1,j+1,dpoint[i][j] ); } } //masukkan tiap titik kedalam group dengan mengukur jarak centroid yang paling dekat int temp_group; group_member_count[0]=0; group_member_count[1]=0; for (int i = 0; i < rows; i++) { if (dpoint[i][0]<dpoint[i][1]) { temp_group = group[i]; group[i] = 0; group_member_count[0]++; if(temp_group != group[i]) { group_changing++; } } else if(dpoint[i][0]>dpoint[i][1]) { temp_group = group[i]; group[i]=1; group_member_count[1]++; if(temp_group != group[i]) { group_changing++; } } else

11
{ temp_group = group[i]; group[i]=0; group_member_count[0]++; if(temp_group != group[i]) { group_changing++; } } } //hitung posisi centroid baru untuk tiap group float sumX[2]={0,0},sumY[2]={0,0}; for (int i = 0; i < rows; i++) { if(group[i] == 0){ sumX[0] += point[i][0]; sumY[0] += point[i][1]; } else{ sumX[1] += point[i][0]; sumY[1] += point[i][1]; } } double newCentroid[crows][ccolumns]; newCentroid[0][0] = sumX[0]/group_member_count[0]; newCentroid[0][1] = sumY[0]/group_member_count[0]; newCentroid[1][0] = sumX[1]/group_member_count[1]; newCentroid[1][1] = sumY[1]/group_member_count[1]; printf("Centroid baru group 0 = (%f,%f) ; dengan sumX = %f, sumY = %f, group member = %d\n",newCentroid[0][0],newCentroid[0][1],sumX[0],sumY[0],group_member_count[0]); printf("Centroid baru group 1 = (%f,%f) ; dengan sumX = %f, sumY = %f, group member = %d\n",newCentroid[1][0],newCentroid[1][1],sumX[1],sumY[1],group_member_count[1]); centroid[0][0] = newCentroid[0][0]; centroid[0][1] = newCentroid[0][1]; centroid[1][0] = newCentroid[1][0]; centroid[1][1] = newCentroid[1][1]; } ofstream myfile; myfile.open ("D:/TUgas Paralel Final/data_hasil_clustering.csv"); for(int i=0;i<rows;i++) { myfile << point[i][0]; myfile << ","; myfile << point[i][1]; myfile << ","; myfile << group[i]; myfile << "\n"; } myfile.close(); }
Gambar 6. Kode Program Serial K‐Means Clustering

12
3.3. Paralel Programming
Berikut ini source code dari Program Paralel K‐Means Clustering
//--------------------------------------------------------------------------------- //Program Paralel K-Means Clustering //Aris Jayandrana (NIM. 23512180) //Maria Fransiska Sirait (NIM. 23512198) //Novianto Budi Kurniawan (NIM. 23512176) //--------------------------------------------------------------------------------- #include <stdio.h> #include <math.h> #include <string> #include <sstream> #include <iostream> #include <vector> #include <fstream> #include <stdlib.h> #include <omp.h> using namespace std; int main() { omp_set_num_threads(2); //baca file ifstream in("D:/TUgas Paralel Final/mydata10.csv"); string line, field; vector< vector<string> > array; vector<string> v; while ( getline(in,line) ) { v.clear(); stringstream ss(line); while (getline(ss,field,',')) { v.push_back(field); } array.push_back(v); } int cluster[4], count[4]; const int rows = array.size(); //jumlah titik const int columns = 2; const int crows = 2; const int ccolumns = 2; float dpoint[rows][crows]; // int point[rows][columns]={{5,5},{2,1},{1,3},{5,4}}; //int group[rows]; int point[rows][columns]; int group[rows]; //group id untuk tiap point int group_member_count[2]={0,0}; //jumlah anggota untuk tiap group double centroid [crows][ccolumns];

13
for(int i =0;i<rows;i++) { for(int j=0;j<columns;j++){ point[i][j]= atoi(array[i][j].c_str()); // printf("%d\n",point[i][j]); } } //pilih 2 titik pertama sebagai centroid for (int i=0;i<2;i++) { for(int j=0;j<2;j++) { centroid[i][j] = point[i][j]; } // printf("Initial centroid group %d : (%f,%f)\n",i,centroid[i][0],centroid[i][1]); } //masukkan semua titik ke group 0 for (int i = 0; i < rows; i++) { group[i]=0; } int group_changing = 2; while(group_changing>0) { group_changing = 0; #pragma omp parallel { //ukur jarak antar titik ke centroid #pragma omp parallel for for (int i = 0; i < rows; i++) { for (int j = 0; j < 2; j++) { dpoint[i][j] = 0.0; dpoint[i][j] += sqrt(pow((point[i][0] - centroid[j][0]),2)+pow((point[i][1] - centroid[j][1]),2)); printf("Jarak point %d ke centroid %d : %f\n",i+1,j+1,dpoint[i][j] ); } } } //masukkan tiap titik kedalam group dengan mengukur jarak centroid yang paling dekat int temp_group; group_member_count[0]=0; group_member_count[1]=0; for (int i = 0; i < rows; i++) { if (dpoint[i][0]<dpoint[i][1]) { temp_group = group[i]; group[i] = 0; group_member_count[0]++; if(temp_group != group[i]) { group_changing++; } } else if(dpoint[i][0]>dpoint[i][1])

14
{ temp_group = group[i]; group[i]=1; group_member_count[1]++; if(temp_group != group[i]) { group_changing++; } } else { temp_group = group[i]; group[i]=0; group_member_count[0]++; if(temp_group != group[i]) { group_changing++; } } // printf("Point %d masuk ke cluster %d\n",i+1,group[i]); } //hitung posisi centroid baru untuk tiap group float sumX[2]={0,0},sumY[2]={0,0}; for (int i = 0; i < rows; i++) { if(group[i] == 0){ sumX[0] += point[i][0]; sumY[0] += point[i][1]; } else{ sumX[1] += point[i][0]; sumY[1] += point[i][1]; } } double newCentroid[crows][ccolumns]; newCentroid[0][0] = sumX[0]/group_member_count[0]; newCentroid[0][1] = sumY[0]/group_member_count[0]; newCentroid[1][0] = sumX[1]/group_member_count[1]; newCentroid[1][1] = sumY[1]/group_member_count[1]; printf("Centroid baru group 0 = (%f,%f) ; dengan sumX = %f, sumY = %f, group member = %d\n",newCentroid[0][0],newCentroid[0][1],sumX[0],sumY[0],group_member_count[0]); printf("Centroid baru group 1 = (%f,%f) ; dengan sumX = %f, sumY = %f, group member = %d\n",newCentroid[1][0],newCentroid[1][1],sumX[1],sumY[1],group_member_count[1]); centroid[0][0] = newCentroid[0][0]; centroid[0][1] = newCentroid[0][1]; centroid[1][0] = newCentroid[1][0]; centroid[1][1] = newCentroid[1][1]; } }
Gambar 7. Kode Program Paralel K‐Means Clustering

15
Berdasarkan kode program tersebut terlihat bahwa proses paralel menggunakan library OpenMP
diterapkan pada penghitungan Euclidean Distance (jarak) antara setiap objek data dengan centroid.
#pragma omp parallel { //ukur jarak antar titik ke centroid #pragma omp parallel for for (int i = 0; i < rows; i++) { for (int j = 0; j < 2; j++) { dpoint[i][j] = 0.0; dpoint[i][j] += sqrt(pow((point[i][0] - centroid[j][0]),2)+pow((point[i][1] - centroid[j][1]),2)); printf("Jarak point %d ke centroid %d : %f\n",i+1,j+1,dpoint[i][j] ); } } }
Gambar 8. Penerapan Paralel Pada Kode Program
Pada kasus ini jumlah cluster ditetapkan sebanyak 2 (dua) group (K=2), sehingga jumlah
centroid yang ditentukan juga sebanyak 2 (dua) buah. Jumlah objek data yang digunakan diambil
secara bertahap mulai dari 10, 100, 1.000, 10.000 dan 100.000 Rumah Tangga.
4. ANALISIS PROGRAM PARALEL K‐MEANS CLUSTERING
Proses analisis implementasi program K‐Means Clustering dilakukan dengan membandingkan
hasil waktu eksekusi untuk serial dan paralel dengan cara melakukan uji coba sebanyak 5 (lima) kali
terhadap masing‐masing training set. Waktu eksekusi proses yang akan dibandingkan disini adalah
rata‐rata waktu eksekusi kelima uji coba tersebut.
4.1. Waktu Eksekusi Program Serial
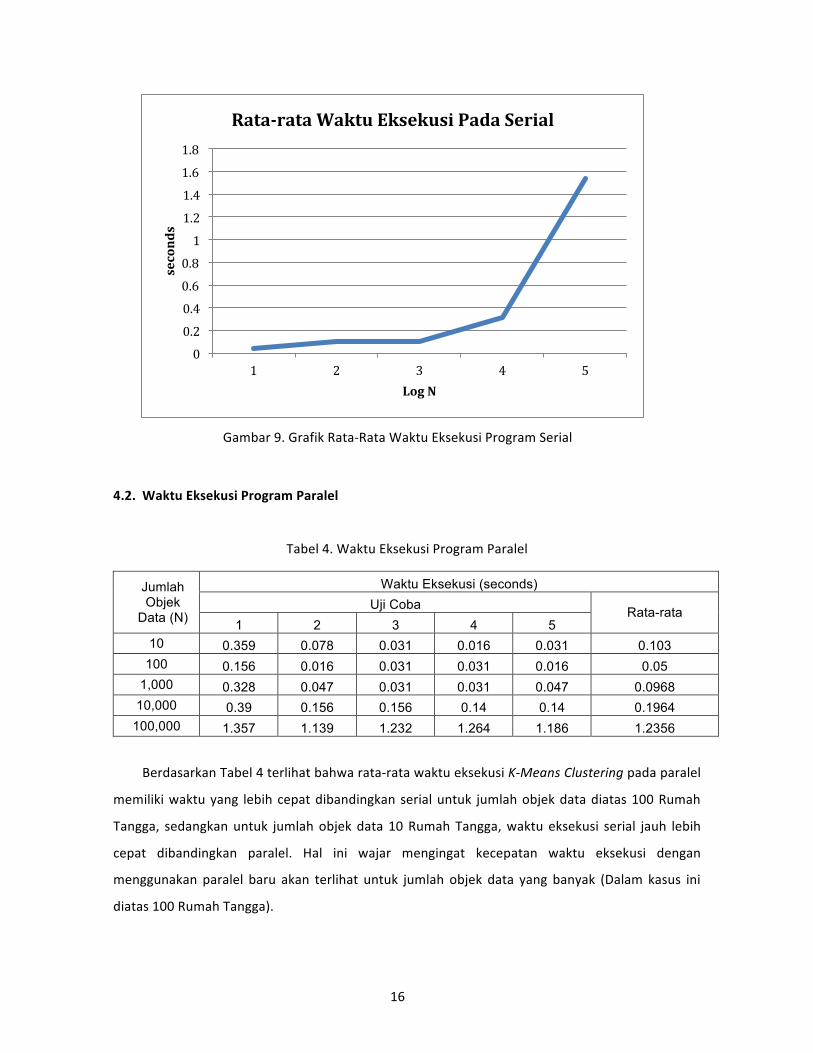
Tabel 3. Waktu Eksekusi Program Serial
Jumlah Objek Data
(N)
Waktu Eksekusi (seconds)
Uji Coba Rata-rata
1 2 3 4 5
10 0.016 0.062 0.016 0.047 0.047 0.0376
100 0.25 0.031 0.016 0.125 0.094 0.1032
1,000 0.296 0.031 0.094 0.047 0.031 0.0998
10,000 0.484 0.499 0.156 0.296 0.156 0.3182
100,000 1.763 1.404 1.451 1.591 1.482 1.5382
16
Gambar 9. Grafik Rata‐Rata Waktu Eksekusi Program Serial
4.2. Waktu Eksekusi Program Paralel
Tabel 4. Waktu Eksekusi Program Paralel
Jumlah Objek
Data (N)
Waktu Eksekusi (seconds)
Uji Coba Rata-rata
1 2 3 4 5
10 0.359 0.078 0.031 0.016 0.031 0.103
100 0.156 0.016 0.031 0.031 0.016 0.05
1,000 0.328 0.047 0.031 0.031 0.047 0.0968
10,000 0.39 0.156 0.156 0.14 0.14 0.1964
100,000 1.357 1.139 1.232 1.264 1.186 1.2356
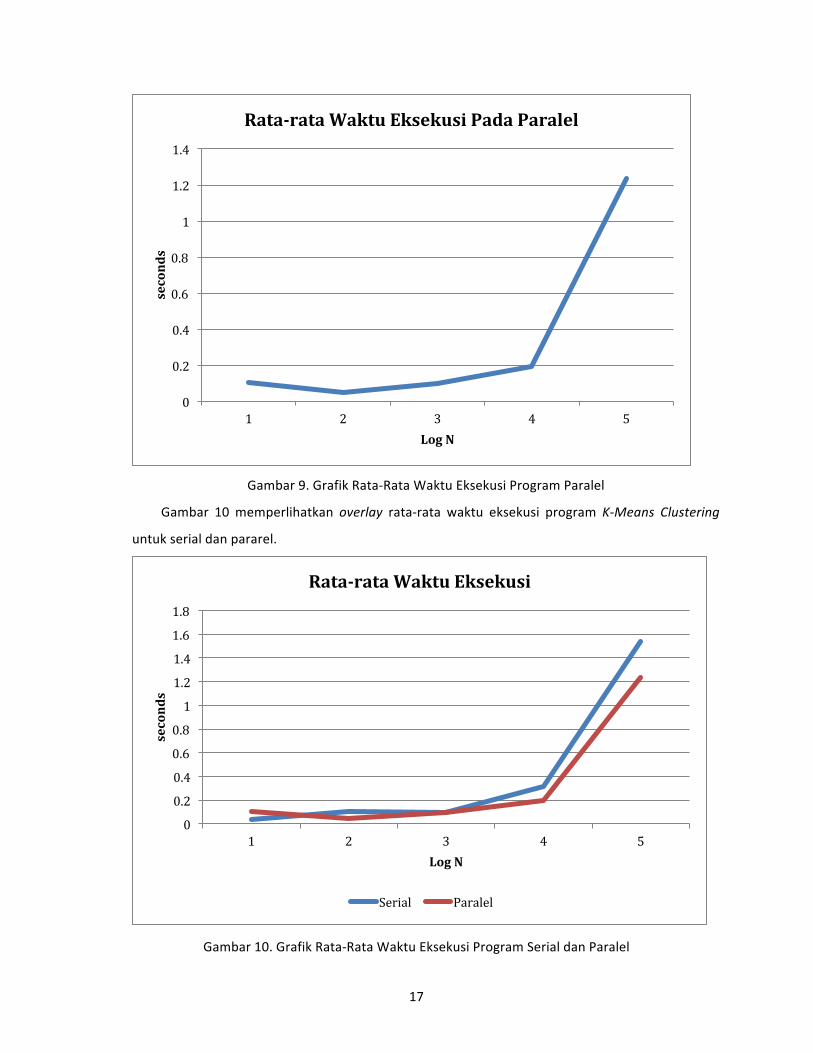
Berdasarkan Tabel 4 terlihat bahwa rata‐rata waktu eksekusi K‐Means Clustering pada paralel
memiliki waktu yang lebih cepat dibandingkan serial untuk jumlah objek data diatas 100 Rumah
Tangga, sedangkan untuk jumlah objek data 10 Rumah Tangga, waktu eksekusi serial jauh lebih
cepat dibandingkan paralel. Hal ini wajar mengingat kecepatan waktu eksekusi dengan
menggunakan paralel baru akan terlihat untuk jumlah objek data yang banyak (Dalam kasus ini
diatas 100 Rumah Tangga).
0
0.2
0.4
0.6
0.8
1
1.2
1.4
1.6
1.8
1 2 3 4 5
seconds
Log N
Rata‐rata Waktu Eksekusi Pada Serial
17
Gambar 9. Grafik Rata‐Rata Waktu Eksekusi Program Paralel
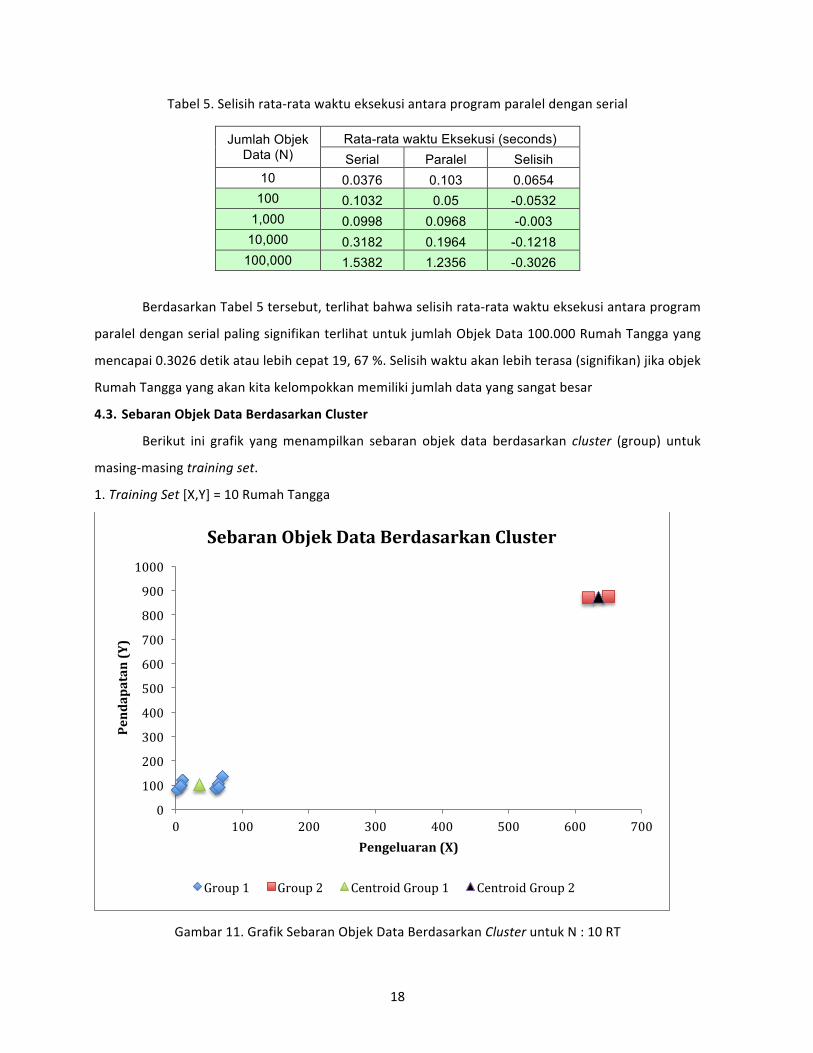
Gambar 10 memperlihatkan overlay rata‐rata waktu eksekusi program K‐Means Clustering
untuk serial dan pararel.
Gambar 10. Grafik Rata‐Rata Waktu Eksekusi Program Serial dan Paralel
0
0.2
0.4
0.6
0.8
1
1.2
1.4
1 2 3 4 5
seconds
Log N
Rata‐rata Waktu Eksekusi Pada Paralel
0
0.2
0.4
0.6
0.8
1
1.2
1.4
1.6
1.8
1 2 3 4 5
seconds
Log N
Rata‐rata Waktu Eksekusi
Serial Paralel
18
Tabel 5. Selisih rata‐rata waktu eksekusi antara program paralel dengan serial
Jumlah Objek Data (N)
Rata-rata waktu Eksekusi (seconds)
Serial Paralel Selisih
10 0.0376 0.103 0.0654
100 0.1032 0.05 -0.0532
1,000 0.0998 0.0968 -0.003
10,000 0.3182 0.1964 -0.1218
100,000 1.5382 1.2356 -0.3026
Berdasarkan Tabel 5 tersebut, terlihat bahwa selisih rata‐rata waktu eksekusi antara program
paralel dengan serial paling signifikan terlihat untuk jumlah Objek Data 100.000 Rumah Tangga yang
mencapai 0.3026 detik atau lebih cepat 19, 67 %. Selisih waktu akan lebih terasa (signifikan) jika objek
Rumah Tangga yang akan kita kelompokkan memiliki jumlah data yang sangat besar
4.3. Sebaran Objek Data Berdasarkan Cluster
Berikut ini grafik yang menampilkan sebaran objek data berdasarkan cluster (group) untuk
masing‐masing training set.
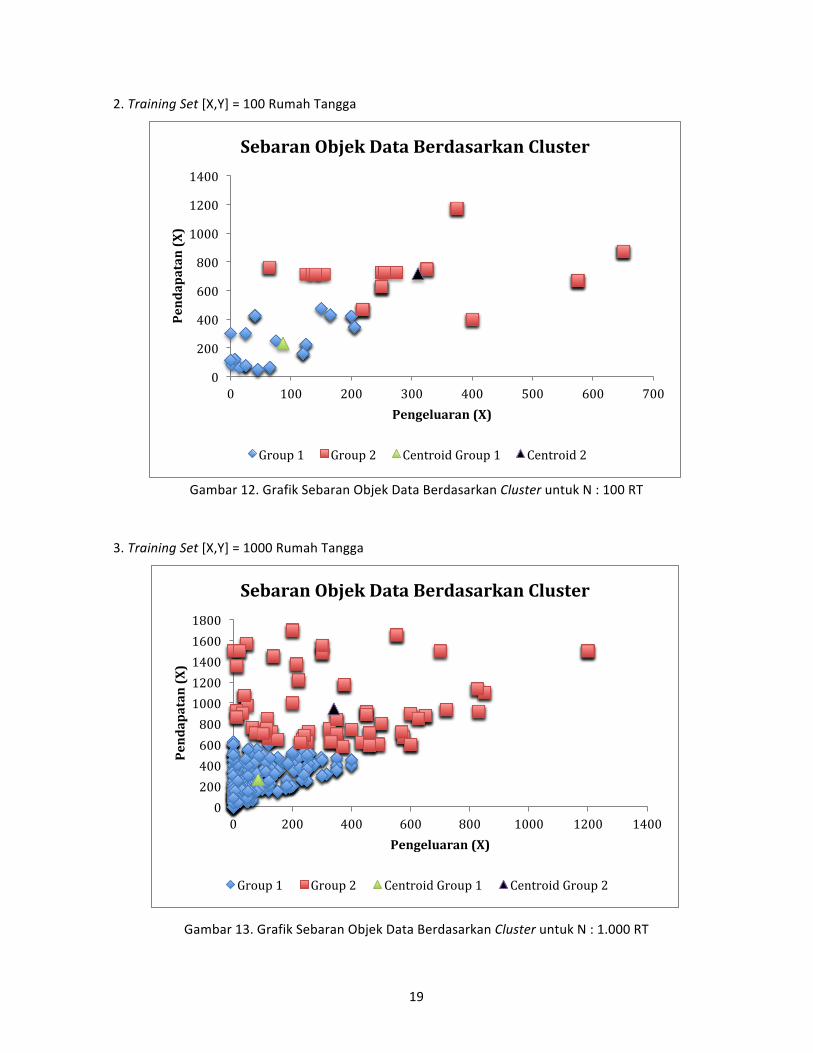
1. Training Set [X,Y] = 10 Rumah Tangga
Gambar 11. Grafik Sebaran Objek Data Berdasarkan Cluster untuk N : 10 RT
0
100
200
300
400
500
600
700
800
900
1000
0 100 200 300 400 500 600 700
Pendapatan (Y)
Pengeluaran (X)
Sebaran Objek Data Berdasarkan Cluster
Group 1 Group 2 Centroid Group 1 Centroid Group 2
19
2. Training Set [X,Y] = 100 Rumah Tangga
Gambar 12. Grafik Sebaran Objek Data Berdasarkan Cluster untuk N : 100 RT
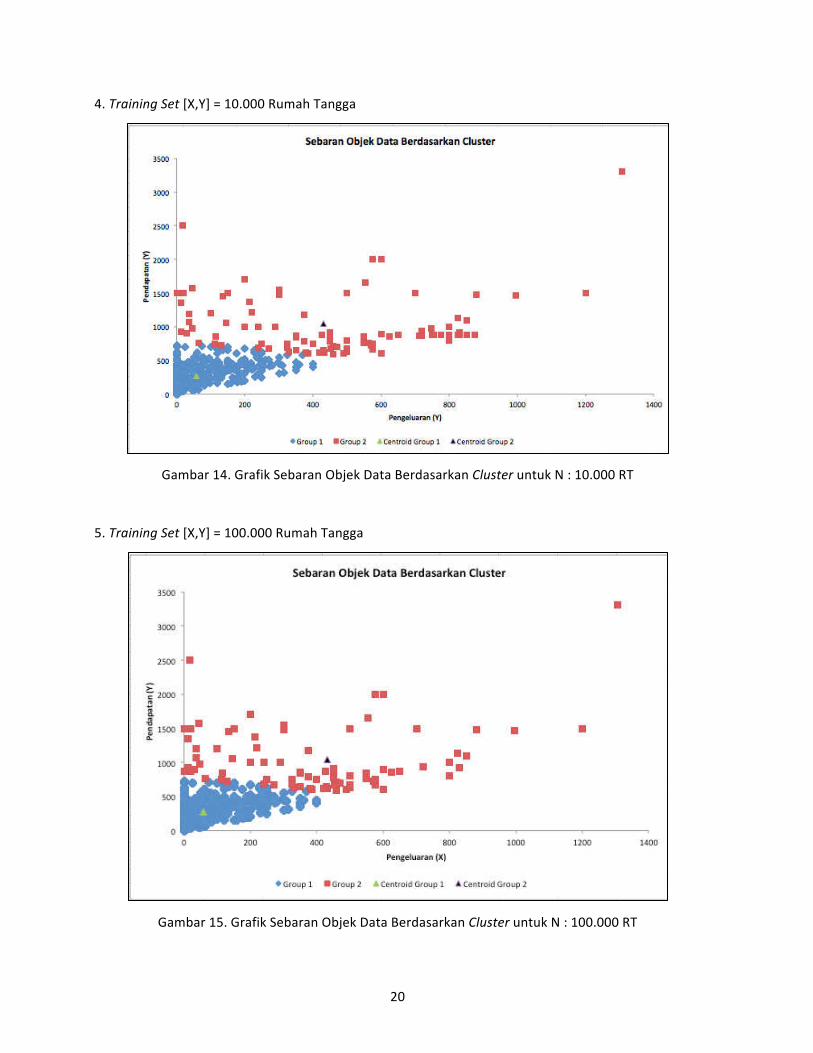
3. Training Set [X,Y] = 1000 Rumah Tangga
Gambar 13. Grafik Sebaran Objek Data Berdasarkan Cluster untuk N : 1.000 RT
0
200
400
600
800
1000
1200
1400
0 100 200 300 400 500 600 700
Pendapatan (X)
Pengeluaran (X)
Sebaran Objek Data Berdasarkan Cluster
Group 1 Group 2 Centroid Group 1 Centroid 2
0
200
400
600
800
1000
1200
1400
1600
1800
0 200 400 600 800 1000 1200 1400
Pendapatan (X)
Pengeluaran (X)
Sebaran Objek Data Berdasarkan Cluster
Group 1 Group 2 Centroid Group 1 Centroid Group 2
20
4. Training Set [X,Y] = 10.000 Rumah Tangga
Gambar 14. Grafik Sebaran Objek Data Berdasarkan Cluster untuk N : 10.000 RT
5. Training Set [X,Y] = 100.000 Rumah Tangga
Gambar 15. Grafik Sebaran Objek Data Berdasarkan Cluster untuk N : 100.000 RT

21
Berdasarkan grafik persebaran objek data untuk masing‐masing training set terlihat bahwa,
data pengeluaran dan pendapatan Susenas tersebut termasuk ke dalam kategori data yang homogen,
artinya data‐data pengeluaran dan pendapatan banyak yang sama nilainya untuk Rumah Tangga yang
menjadi observasi (objek) data. Kondisi masyarakat dan kondisi ekonomi yang homogen dengan
klasifikasi pekerjaan yang sejenis menyebabkan persebaran datanya seperti itu.
5. KESIMPULAN
Kesimpulan yang dapat diambil dari uji coba program paralel K‐Means Clustering adalah
sebagai berikut :
1. Penerapan program paralel pada K‐Means Clustering terbukti mempercepat waktu eksekusi
proses dengan jumlah objek data (pengeluaran dan pendapatan rumah tangga) diatas 100
Rumah Tangga dan akan terlihat signifikan untuk jumlah objek mencapai 100.000 Rumah Tangga.
Percepatan waktu eksekusi tersebut akan lebih signifikan terlihat jika jumlah objek data yang kita
libatkan semakin banyak.
2. Program paralel K‐Means Clustering didesain untuk menggunakan objek data (training set)
dengan jumlah yang besar, sehingga pemanfaatan parallel computation akan lebih signifikan. Jika
analisis homogenitas dan data augmentation menggunakan objek data (training set) yang kecil,
maka hasil waktu eksekusinya tidak akan terlalu berpengaruh. Hal ini berarti pada algoritma
program paralel K‐Means Clustering terdapat hubungan positif antara ukuran training set dengan
waktu eksekusi (speedup) yang ditentukan oleh arsitektur cluster.
3. Algoritma K‐Means Clustering walaupun cepat tetapi keakuratannya tidak dijamin. Seringkali
algoritma ini mengalami konvergensi prematur. Pada algoritma di atas juga tidak dijamin jarak
antara masing‐masing centroid tidak merentang sehingga jika ada dua atau lebih kelompok
dengan titik pusat massa yang berdekatan maka hasilnya terlihat kurang memuaskan.

22
DAFTAR PUSTAKA
[1]
[2]
[3]
Beddo, Vanessa, Application of Parallel Programming in Statistics, California : University of
Los Angeles, 2002.
Liao, Wei‐keng, Paralel K‐Means Data Clustering, [Online]. Available :
(http://users.eecs.northwestern.edu/~wkliao/Kmeans//). Diakses pada tanggal 22 Mei
2013.
Teknomo, Kardi, K‐Means Clustering Tutorial, [Online]. Available :
(http://people.revoledu.com/kardi/tutorial/kMean/). Diakses pada tanggal 21 Mei 2013.
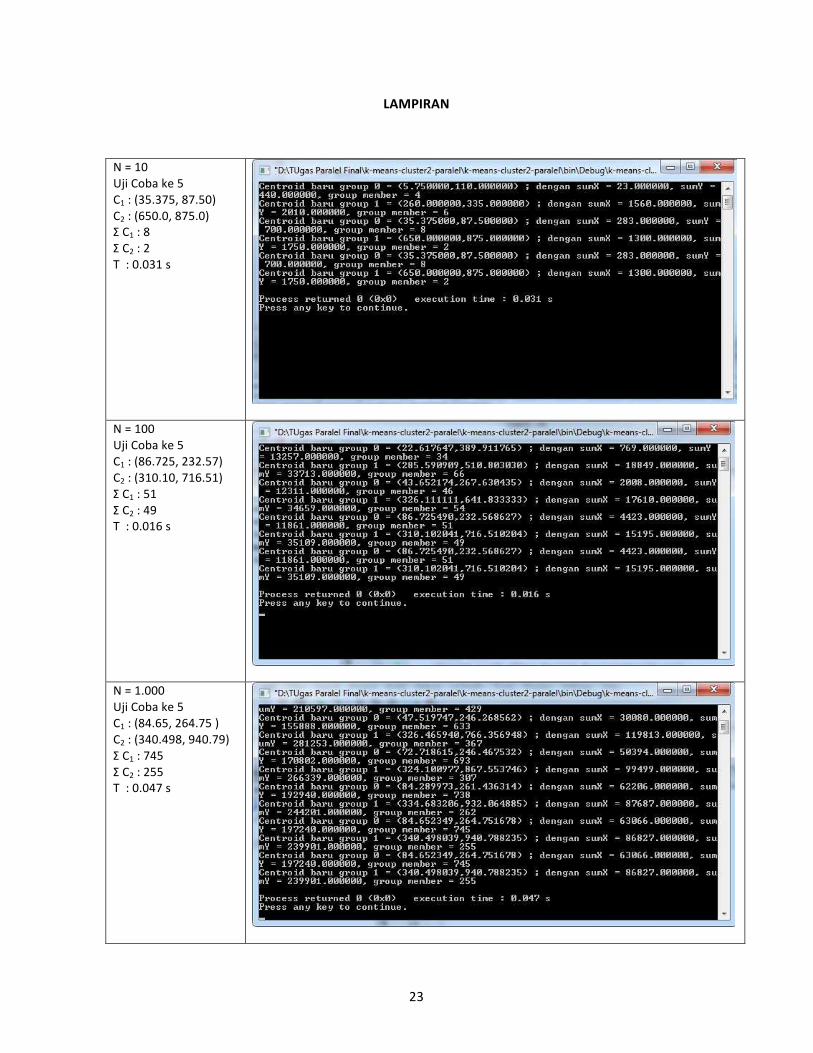
23
LAMPIRAN
N = 10
Uji Coba ke 5
C1 : (35.375, 87.50)
C2 : (650.0, 875.0)
Σ C1 : 8
Σ C2 : 2
T : 0.031 s
N = 100
Uji Coba ke 5
C1 : (86.725, 232.57)
C2 : (310.10, 716.51)
Σ C1 : 51
Σ C2 : 49
T : 0.016 s
N = 1.000
Uji Coba ke 5
C1 : (84.65, 264.75 )
C2 : (340.498, 940.79)
Σ C1 : 745
Σ C2 : 255
T : 0.047 s
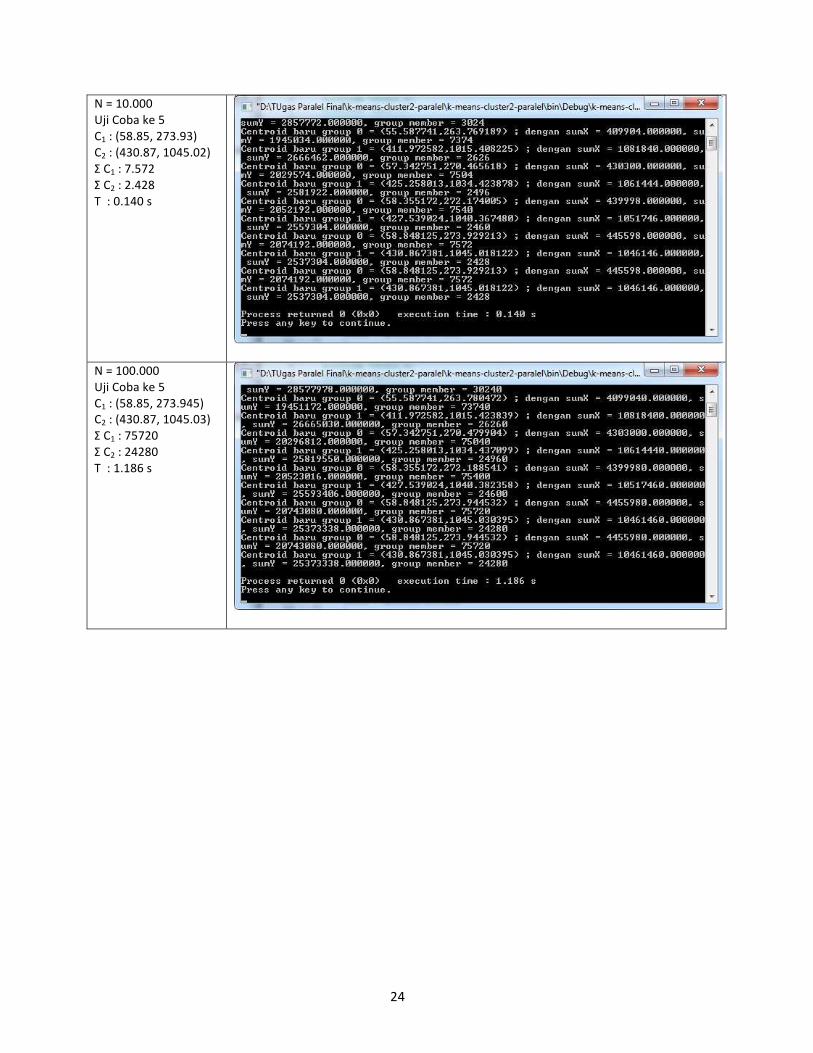
24
N = 10.000
Uji Coba ke 5
C1 : (58.85, 273.93)
C2 : (430.87, 1045.02)
Σ C1 : 7.572
Σ C2 : 2.428
T : 0.140 s
N = 100.000
Uji Coba ke 5
C1 : (58.85, 273.945)
C2 : (430.87, 1045.03)
Σ C1 : 75720
Σ C2 : 24280
T : 1.186 s




















