
BAB III METODOLOGI PENELITIAN 3.1. Ruang Lingkup...
17
31 BAB III METODOLOGI PENELITIAN 3.1. Ruang Lingkup Penelitian Penelitian ini dilakukan untuk menganalisis daya saing ekspor dan faktor- faktor yang memengaruhi ekspor ban mobil Indonesia ke enam negara tujuan utama, yakni Amerika Serikat, Jepang, Malaysia, Australia, Filipina, dan Arab Saudi. Jenis data yang digunakan penulis dalam penelitian ini berupa data sekunder yang didapatkan dari World Bank, UN Comtrade, Badan Pusat Statistik, Kementerian Perdagangan, Kementerian Perindustrian, Trade Map, dan beberapa sumber yang lain yang didapatkan dari buku-buku literatur dan media elektronik. Data yang digunakan mencakup enam negara tujuan utama untuk ekspor ban mobil dari Indonesia, yakni Gross Domestic Product (GDP) setiap negara, jarak geografis ke Indonesia sebagai negara pengekspor, dan populasi masing-masing negara. Data berupa nilai dan volume ekspor ban mobil ke enam negara tujuan utama didapatkan dari United Nation Comtrade, data berupa jarak geografis didapat dari timeanddate.com, dan data berupa populasi keenam negara tujuan didapatkan dari World Bank. Enam negara tersebut dipilih penulis sebagai objek observasi dikarenakan keenam negara tersebut merupakan negara pengimpor ban mobil Indonesia terbesar (top six countries) selama periode lima tahun terakhir, yakni tahun 2012-2017 Adapun tahun yang penulis jadikan sebagai observasi penelitian ialah tahun 2004 hingga 2017 (14 tahun penelitian).
Transcript of BAB III METODOLOGI PENELITIAN 3.1. Ruang Lingkup...

31
BAB III
METODOLOGI PENELITIAN
3.1. Ruang Lingkup Penelitian
Penelitian ini dilakukan untuk menganalisis daya saing ekspor dan faktor-
faktor yang memengaruhi ekspor ban mobil Indonesia ke enam negara tujuan
utama, yakni Amerika Serikat, Jepang, Malaysia, Australia, Filipina, dan Arab
Saudi. Jenis data yang digunakan penulis dalam penelitian ini berupa data sekunder
yang didapatkan dari World Bank, UN Comtrade, Badan Pusat Statistik,
Kementerian Perdagangan, Kementerian Perindustrian, Trade Map, dan beberapa
sumber yang lain yang didapatkan dari buku-buku literatur dan media elektronik.
Data yang digunakan mencakup enam negara tujuan utama untuk ekspor ban mobil
dari Indonesia, yakni Gross Domestic Product (GDP) setiap negara, jarak geografis
ke Indonesia sebagai negara pengekspor, dan populasi masing-masing negara. Data
berupa nilai dan volume ekspor ban mobil ke enam negara tujuan utama didapatkan
dari United Nation Comtrade, data berupa jarak geografis didapat dari
timeanddate.com, dan data berupa populasi keenam negara tujuan didapatkan dari
World Bank. Enam negara tersebut dipilih penulis sebagai objek observasi
dikarenakan keenam negara tersebut merupakan negara pengimpor ban mobil
Indonesia terbesar (top six countries) selama periode lima tahun terakhir, yakni
tahun 2012-2017 Adapun tahun yang penulis jadikan sebagai observasi penelitian
ialah tahun 2004 hingga 2017 (14 tahun penelitian).

32
3.2. Metode Analisis
Metode analisis yang digunakan penulis dalam penelitian ini adalah metode
penghitungan RCA (Revealed Comparative Advantage) untuk mengukur daya
saing komparatif ekspor. RCA merupakan suatu metode untuk mengukur
keunggulan komparatif pada suatu kawasan atau wilayah. Metode RCA dalam
mengukur keunggulan komparatif ban mobil Indonesia dibandingkan dengan
negara pesaingnya menggunakan rumus sebagai berikut:
RCA = xij/Xj
Xiw/Xw
dimana:
Xij = nilai ekspor ban mobil Indonesia ke negara tujuan (US$)
Xj = nilai total ekspor Indonesia ke negara tujuan (US$)
Xiw = nilai ekspor ban mobil dunia ke negara tujuan (US$)
Xw = nilai total ekspor dunia ke negara tujuan (US$)
i = ban mobil
j = negara Indonesia
w = dunia
Jika nilai RCA melebihi angka satu (RCA>1), maka komoditas tersebut
memiliki keunggulan komparatif atau berdaya saing tinggi. Dan sebaliknya, jika
nilai RCA lebih kecil dari satu (RCA<1), maka komoditas tersebut tidak memiliki
keunggulan komparatif atau berdaya saing rendah. Penulis menyarankan penelitian
menganalisis Revealed Comparative Advantage (RCA) selanjutnya dapat

33
disempurnakan dengan formula Revealed Symmetric Comparative Advantage
(RSCA), secara sistematis RSCA dirumuskan sebagai berikut:
𝑅𝑆𝐶𝐴 = (𝑅𝐶𝐴 − 1)
(𝑅𝐶𝐴 + 1)
Analisis dengan menggunakan metode penghitungan RSCA bertujuan
untuk membandingkan daya saing suatu komoditas dengan berbagai negara. Nilai
RSCA berkisar antara -1 sampai 1 (-1 ≤ RSCA ≤ 1). Jika nilai RSCA kurang dari
0, maka komoditas di negara tersebut tidak memiliki keunggulan komparatif.
Sebaliknya, jika nilai RSCA lebih dari 0, maka komoditas di negara tersebut
memiliki keunggulan komparatif. Penghitungan ini menggunakan data tahunan
untuk memudahkan dalam mengetahui perkembangan jenis komoditas yang daya
saingnya mengalami peningkatan ataupun penurunan.
Indeks RCA juga dapat digunakan untuk mendapatkan wawasan lebih lanjut
untuk menargetkan industri-industri yang saat ini menunjukkan kerugian
komparatif tetapi memiliki potensi untuk mencapai daya saing ekspor dari waktu
ke waktu. Hal ini dapat dicapai dengan mengklasifikasikan struktur ekspor suatu
negara, berdasarkan pada 4 digit kode HS menjadi enam kelompok produk yang
lebih luas berdasarkan pada perbandingan relatifnya.
Selain itu, untuk menganalisis faktor-faktor yang memengaruhi nilai ekspor
ban mobil digunakan metode kuantitatif berbasis data panel cross-section yang
didasarkan pada pendekatan Random Effect Model yang merupakan model terbaik
untuk digunakan dalam penelitian ini. Pengolahan data dilakukan dengan
menggunakan software Microsoft Excel dan Stata-13.

34
3.3. Model Penelitian
Model analisis yang digunakan dalam penelitian ini adalah model Ordinary
Least Square (OLS), dengan bentuk panel data dari tahun 2004 hingga 2017.
Variabel terikatnya adalah nilai ekspor ban mobil Indonesia ke negara tujuan
(EXPijt). Variabel bebasnya terdiri dari GDP riil Indonesia (GDPit), GDP riil negara
tujuan (GDPjt), nilai tukar (ERit), jarak geografis (DISTit), dan populasi negara
tujuan (POPit). Kemudian untuk menganalisis data, persamaan diubah untuk
melinearkan dalam bentuk logaritma yang dikenal dengan istilah log-log. Maka, dapat
ditulis model persamaannya sebagai berikut:
𝐥𝐨𝐠𝐄𝐗𝐏𝐢𝐣𝐭 = 𝛃𝟎 + 𝛃𝟏𝐥𝐨𝐠𝐆𝐃𝐏𝐑𝐈𝐢𝐭 + 𝛃𝟐𝐥𝐨𝐠𝐆𝐃𝐏𝐍𝐓𝐢𝐭 + 𝛃𝟑𝐥𝐨𝐠𝐄𝐑𝐢𝐭
+ 𝛃𝟒𝐥𝐨𝐠𝐃𝐈𝐒𝐓𝐢𝐭 + 𝛃𝟓𝐥𝐨𝐠𝐏𝐎𝐏𝐢𝐭 + 𝛆𝐢𝐭
Keterangan:
EXP = total nilai ekspor ban mobil Indonesia ke negara tujuan (US$)
β0 = konstanta
β1, β2, … , β5 = koefisien regresi
GDPRI = GDP riil Indonesia (US$)
GDPNT = GDP riil negara tujuan (US$)
ER = nilai tukar dollar AS terhadap rupiah (US$/Rp)
DIST = jarak geografis antara ibukota Indonesia dengan ibukota negara
tujuan (km)
POP = jumlah penduduk/populasi negara tujuan (jiwa)
ε = error

35
i = Indonesia
j = enam negara tujuan ekspor ban mobil Indonesia (AS, Jepang,
Malaysia, Australia, Filipina, Arab Saudi)
t = tahun 2004 hingga 2017
3.4. Metode Pengumpulan Data
Penulis menggunakan data sekunder dengan data panel periode waktu 14
tahun yakni dari tahun 2004 hingga 2017 dengan unit cross-section. Data diperoleh
dari website dan publikasi United Nation Comtrade, World Bank, dan institusi
lainnya yang berkaitan dengan penelitian ini. Adapun data yang dikumpulkan
dalam penelitian ini ialah data total nilai ekspor Indonesia, data nilai ekspor
Indonesia dengan komoditas ban mobil, data luas lahan perkebunan karet
Indonesia, data GDP negara Indonesia, data GDP enam negara tujuan utama ekspor
ban mobil Indonesia (Amerika Serikat, Jepang, Malaysia, Australia, Filipina, dan
Arab Saudi), data nilai tukar rupiah terhadap dollar AS, data jarak geografis antar
negara, serta data populasi negara tujuan selama tahun 2004 hingga 2017.
Data-data tersebut bersumber dari:
1. United Nation Comtrade (UN Comtrade)
2. World Bank
3. Trade Map
4. Badan Pusat Statistik
5. Kementerian Perindustrian
6. Kementerian Perdagangan
36
7. timeanddate.com
8. World Integrated Trade Solution (WITS)
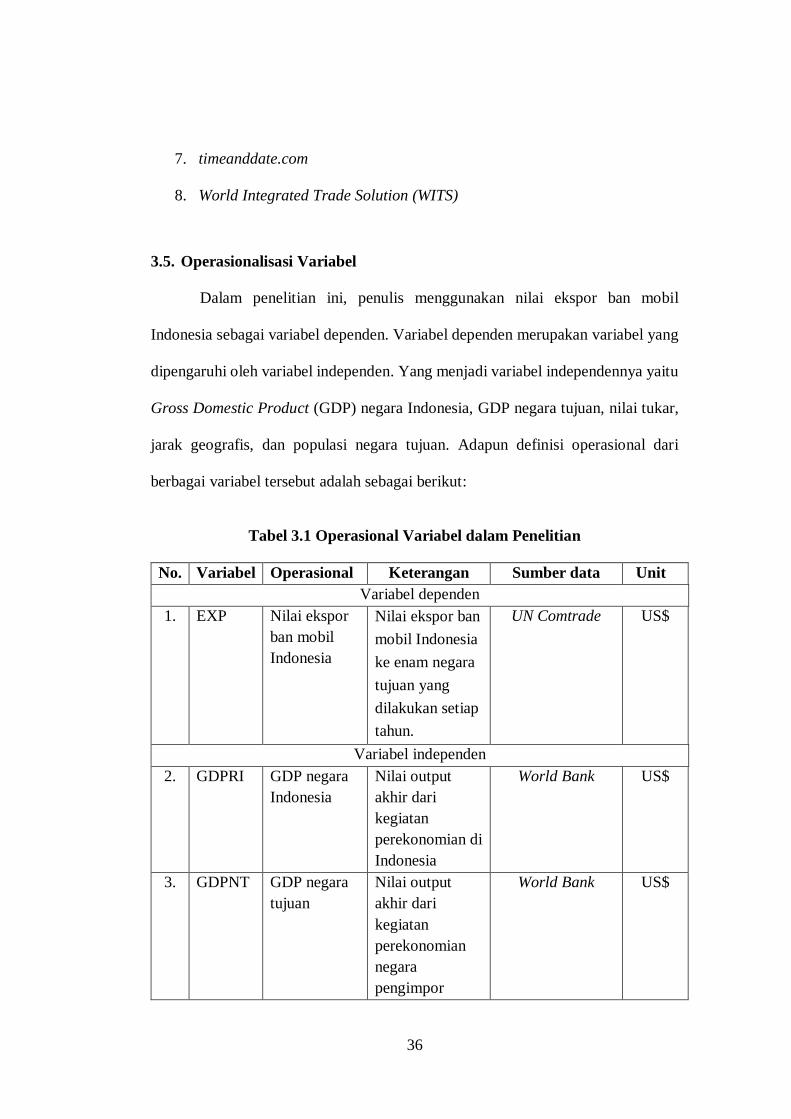
3.5. Operasionalisasi Variabel
Dalam penelitian ini, penulis menggunakan nilai ekspor ban mobil
Indonesia sebagai variabel dependen. Variabel dependen merupakan variabel yang
dipengaruhi oleh variabel independen. Yang menjadi variabel independennya yaitu
Gross Domestic Product (GDP) negara Indonesia, GDP negara tujuan, nilai tukar,
jarak geografis, dan populasi negara tujuan. Adapun definisi operasional dari
berbagai variabel tersebut adalah sebagai berikut:
Tabel 3.1 Operasional Variabel dalam Penelitian
No. Variabel Operasional Keterangan Sumber data Unit
Variabel dependen
1. EXP Nilai ekspor
ban mobil
Indonesia
Nilai ekspor ban
mobil Indonesia
ke enam negara
tujuan yang
dilakukan setiap
tahun.
UN Comtrade US$
Variabel independen
2. GDPRI GDP negara
Indonesia
Nilai output
akhir dari
kegiatan
perekonomian di
Indonesia
World Bank US$
3. GDPNT GDP negara
tujuan
Nilai output
akhir dari
kegiatan
perekonomian
negara
pengimpor
World Bank US$

37
4. ER Kurs Nilai tukar
dollar AS
terhadap rupiah
World Bank US$/Rp
5. DIST Jarak
geografis
Jarak antara
ibukota negara
Indonesia
dengan ibukota
negara tujuan
secara geografis
timeanddate.com Km
6. POP Populasi Jumlah
penduduk di
negara tujuan
ekspor
World Bank Jiwa
3.6. Teknik Pengolahan Data
Pengolahan data dalam penelitian ini menggunakan pendekatan kuantitatif
dengan metode data panel. Metode ini menggabungkan dua jenis data, yakni data
berupa deret waktu (time series) dan data individu (cross section). Menurut Baltagi
(2001), terdapat beberapa kelebihan dalam menggunakan data panel untuk
penelitian, yakni sebagai berikut:
1. Heterogenitas dalam setiap individu dapat ditunjukkan dari estimasi data panel.
2. Data panel mampu mendeteksi dan mengukur dampak yang tidak dapat dilihat
oleh data time series dan cross section.
3. Data panel dapat membantu dalam analisis studi yang lebih kompleks.
4. Data panel lebih efisien dalam memberikan informasi dan degree of freedom,
namun dengan kolinearitas yang sedikit antar variabel.
Sumber: website dan publikasi setiap data.

38
5. Metode panel lebih baik untuk menentukan perubahan dinamis dibandingkan
cross section dan mampu meminimalisir bias.
Menurut Gujarati & Porter (2009), data panel yang digunakan untuk
mengestimasi model regresi dapat dilakukan melalui tiga pendekatan dimana
selanjutnya akan dianalisa untuk menentukan metode regresi yang tepat, yakni:
1) Pooled Least Square Model
Model ini mengasumsikan perilaku data antar negara adalah konstan dalam
berbagai kurun waktu karena model ini tidak memperhatikan dimensi waktu
maupun individu. Model estimasinya dituliskan dalam bentuk persamaan
berikut:
𝑌𝑖𝑡 = 𝛼0 + 𝛽1𝑋1𝑖𝑡 + 𝛽2𝑋2𝑖𝑡 + ⋯ + 𝛽𝑛𝑋𝑖𝑡 + µ𝑖𝑡
2) Fixed Effect Model
Model ini mengasumsikan bahwa koefisien slope adalah konstan, sedangkan
intercept antar individu diasumsikan berbeda. Akan tetapi, intercept antar
waktu diasumsikan sama (fixed effect). Untuk melakukan estimasi pada model
ini sering digunakan dummy karena sulitnya memenuhi asumsi pada model
pooled least square. Model estimasinya dituliskan dalam bentuk persamaan
berikut:
𝑌𝑖𝑡 = 𝛼1 + 𝛼2𝐷2 + ⋯ + 𝛼𝑛𝐷𝑛 + 𝛽2𝑋2𝑖𝑡 + ⋯ + 𝛽𝑛𝑋𝑖𝑡 + µ𝑖𝑡
3) Random Effect Model
Model ini mengasumsikan bahwa nilai koefisien slope adalah konstan, tetapi
nilai intercept-nya memiliki perbedaan antar individu dan antar waktu. Pada
model ini, perbedaan intercept dimasukkan ke dalam error masing-masing

39
negara. Keuntungan menggunakan model ini ialah menghilangkan
heteroskedastisitas. Model estimasinya dituliskan dalam bentuk persamaan
berikut:
𝑌𝑖𝑡 = 𝛽1 + 𝛽2𝑋2𝑖𝑡 + ⋯ + 𝛽𝑛𝑋𝑖𝑡 + е𝑖𝑡 + µ𝑖𝑡
Dimana е𝑖𝑡 + µ𝑖𝑡 ialah faktor kesalahan yang acak dan diasumsikan tidak
memiliki hubungan dengan 𝑋𝑖𝑡. Faktor kesalahan tersebut terdiri dari
komponen spesifik dari individu yang konstan sepanjang waktu (е𝑖𝑡) dan
variasi komponen kesalahan oleh antar individu dan waktu.
Langkah selanjutnya ialah melakukan tahap pengujian. Adapun pada
penelitian ini terdapat tiga tahap pengujian dalam penggunaan model panel,
diantaranya:
a. Uji Chow
Pengujian ini dilakukan untuk mengetahui model mana yang lebih baik
digunakan dalam penelitian, antara model pooled least square atau
fixed effect model. Hipotesis yang digunakan dalam Uji Chow ialah
sebagai berikut: 𝐻0: Model pooled least square lebih baik
𝐻𝐴: Fixed effect model lebih baik
Uji Chow harus memenuhi kriteria sebagai berikut:
1. Apabila (Prob > F) < α maka 𝐻0 ditolak, berarti lebih baik
menggunakan fixed effect model.
2. Apabila (Prob > F) ≥ α maka 𝐻0 tidak dapat ditolak, berarti lebih
baik menggunakan model pooled least square.

40
b. Uji Hausman
Pengujian ini dilakukan untuk mengetahui apakah lebih baik
menggunakan fixed effect model atau random effect. Hipotesis dalam
uji Hausman ialah sebagai berikut:
𝐻0: Random effect model lebih baik
𝐻𝐴: Fixed effect model lebih baik
Uji Hausman harus memenuhi kriteria sebagai berikut:
1. Apabila (Prob > χ2) < α maka 𝐻0 ditolak, berarti lebih baik
menggunakan fixed effect model.
2. Apabila (Prob > χ2) ≥ α maka 𝐻0 tidak dapat ditolak, berarti lebih
baik menggunakan random effect model.
c. Uji Breusch – Pagan Langrangian Multiplier
Pengujian ini dilakukan untuk mengetahui model mana yang lebih baik
digunakan antara random effect model atau pooled least square.
Hipotesis dalam Uji Breusch ialah sebagai berikut:
𝐻0: Pooled least square lebih baik
𝐻𝐴: Random effect model lebih baik
Uji Breusch harus memenuhi kriteria sebagai berikut:
1. Apabila (Prob > x̄2) < α maka 𝐻0 ditolak, yang berarti lebih baik
menggunakan random effect model.

41
2. Apabila (Prob > x̄2) ≥ α maka 𝐻0 tidak dapat ditolak, yang berarti
lebih baik menggunakan pooled least square.
3.7. Pengujian Masalah dalam Analisis Regresi Linear
Salah satu metode pendugaaan parameter dalam model regresi linear ialah
Ordinary Least Square (OLS) yang berlandaskan pada sejumlah asumsi tertentu.
Pada prinsipnya, model regresi linear yang dibangun harus memenuhi beberapa
asumsi yakni Best, Linear, Unbiased Estimator (BLUE).
3.7.1. Uji Multikolinearitas
Multikolinearitas adalah permasalahan pada suatu model regresi jika
terdapat hubungan yang kuat antar variabel independen. Yang menjadi salah satu
penyebab terjadinya multikolinearitas yakni terdapat pengambilan data yang tidak
baik ataupun penggunaan variabel yang lebih banyak dibandingkan jumlah
observasinya.
Tanda multikolinearitas dapat diketahui dengan melihat nilai R2. Jika
terdapat sedikit variabel independen yang signifikan mempengaruhi variabel
dependen, maka bisa dikatakan terdapat masalah multikolinearitas dalam model.
Selain itu, untuk mengetahui ada atau tidaknya masalah multikolinearitas ialah
dengan melihat korelasi antar variabel independen dimana ketika terdapat korelasi
yang lebih dari 0,8 maka dapat dikatakan terjadi masalah multikolinearitas (Gujarati
& Porter, 2009).

42
Masalah multikolinearitas dapat diperbaiki atau dihilangkan dengan
melakukan beberapa hal, yakni:
- Menghilangkan variabel yang menyebabkan bias
- Penambahan data baru
- Mengkombinasikan data time series dan data cross section.
3.7.2. Uji Heteroskedastisitas
Masalah heteroskedastisitas terjadi karena varian dari error terms yang
tidak lagi konstan. Konsekuensi dari adanya heteroskedastisitas ialah proses
estimasi menjadi tidak efisien yang menyebabkan hasil uji T-statistik dan uji F-
statistik menjadi tidak berguna. Hipotesis yang digunakan dalam uji
Heteroskedastisitas adalah:
𝐻0: tidak adanya masalah heteroskedastisitas
𝐻𝐴 adanya masalah heteroskedastisitas
Kriteria dan kesimpulan:
(Prob>Chi2) < α = 𝐻0 ditolak, berarti ada masalah heteroskedastisitas dalam
regresi.
(Prob>Chi2) > α = 𝐻0 tidak dapat ditolak, berarti tidak ada masalah
heteroskedastisitas dalam regresi.

43
3.7.3. Uji Autokorelasi
Masalah autokorelasi merupakan masalah berupa korelasi antara residual
pada suatu variabel dengan residual variabel lainnya. Konsekuensinya adalah dapat
menimbulkan adanya regresi palsu sebab nilai varian untuk masing-masing variabel
tidak lagi minimum (Gujarati & Porter, 2009).
Hipotesis yang digunakan pada uji Autokorelasi ialah:
𝐻0: tidak adanya masalah autokorelasi
𝐻𝐴 adanya masalah autokorelasi
Kriteria dan kesimpulan:
(Prob>Chi2) < α = 𝐻0 ditolak, berarti ada masalah autokorelasi
(Prob>Chi2) > α = 𝐻0 tidak dapat ditolak, berarti tidak ada masalah
autokorelasi
3.8. Pengujian Statistik
Pengujian statistik dilakukan untuk memperkuat hasil estimasi dari sebuah
penelitian. Adapun pengujian statistik yang dilakukan meliputi koefisien
determinasi (R2), uji signifikansi simultan, dan uji signifikansi parsial.
3.8.1. Koefisien Determinasi (R2)
Koefisien determinasi atau R2 (R-squares) merupakan ukuran yang
memberikan informasi mengenai seberapa besar kemampuan variabel independen
dalam menjelaskan variabel dependen di dalam sebuah model. Apabila nilai
koefisien determinasi semakin mendekati 0, maka variabel independen kurang

44
mampu dalam menjelaskan variabel dependen sehingga dapat dinyatakan bahwa
model persamaan yang dipakai kurang sempurna. Begitupun sebaliknya, apabila
nilai koefisien determinasi semakin mendekati 1 maka variabel dependen mampu
dijelaskan secara keseluruhan oleh variabel independen.
3.8.2. Uji Signifikansi Simultan
Uji ini dilakukan untuk melihat dan mengetahui adanya pengaruh variabel
independen secara keseluruhan terhadap variabel dependen dalam model pada
tingkat signifikansi tertentu. Hipotesis yang digunakan adalah sebagai berikut:
𝐻0: 𝛽1 = 𝛽2 = .... = 𝛽𝑛 = 0 (semua variabel independen dalam model secara
bersama-sama tidak mempengaruhi variabel dependen)
𝐻𝐴: paling tidak ada satu 𝛽𝑛≠ 0 (semua variabel independen dalam model
secara bersama-sama mempengaruhi variabel dependen)
Dengan statistik uji:
𝐹 = 𝑅2/(𝑘 − 1 )
(1 − 𝑅2)/(𝑛 − 𝑘)
dimana:
𝑅2 = koefisien determinasi
k = jumlah variabel independen
n = jumlah sampel

45
Dengan kriteria sebagai berikut:
Jika Fstat > Ftable atau Prob F < α maka 𝐻0 ditolak. Berarti dapat dikatakan
bahwa semua variabel independen dalam model mempengaruhi variabel
dependen.
Jika Fstat ≤ Ftable atau Prob F ≥ α maka 𝐻0 tidak dapat ditolak. Berarti semua
variabel independen dalam model tidak mempengaruhi variabel dependen.
Namun, apabila hasil estimasi regresi menggunakan pendekatan random
effect model, maka perlu melakukan uji Wald Chi-Square untuk melihat apakah
seluruh variabel independen memiliki pengaruh terhadap variabel dependen secara
signifikan (StataCorp, 2013), dengan hipotesis yang sama serta kriteria sebagai
berikut:
Jika Prob χ2 < α maka 𝐻0 ditolak, yang berarti bahwa variabel independen
dalam model secara bersama-sama mempengaruhi variabel dependen.
Jika Prob χ2 ≥ α maka 𝐻0 tidak dapat ditolak, yang berarti bahwa semua
variabel independen dalam model secara bersama-sama tidak mempengaruhi
variabel dependen.
3.8.3. Uji Signifikansi Parsial
Penggunaan ini dilakukan untuk melihat dan mengetahui adanya pengaruh
antara variabel independen dengan variabel independen secara individu terhadap
variabel dependen dalam model pada tingkat signifikansi tertentu, dengan hipotesis
sebagai berikut:

46
𝐻0: 𝛽𝑛 = 0 dimana variabel independen tidak mempengaruhi variabel
dependen secara signifikan.
𝐻𝐴: 𝛽𝑛 ≠ 0 dimana variabel independen mempengaruhi variabel dependen
secara signifikan.
Dengan statistik uji:
𝑡 = 𝛽^𝑛 − 𝛽𝑛
𝑠𝑒(𝛽^𝑛)
dimana:
𝛽^𝑛 = koefisien variabel independen ke-n
𝛽𝑛 = nilai dari hipotesis nol
𝑠𝑒(𝛽^𝑛) = simpangan baku dari variabel independen ke-n
Dengan hipotesis sebagai berikut:
𝐻0: β=0, berarti variabel independen tidak mempengaruhi variabel dependen
𝐻𝐴: β ≠ 0, berarti variabel independen mempengaruhi variabel dependen
Kriteria dan kesimpulan:
Jika tstat > ttable atau -tstat < -ttabel (Prob t < α) maka 𝐻0 ditolak. Artinya variabel
independen mempengaruhi variabel dependen secara signifikan.
Jika -ttable ≤ tstat ≤ -ttabel (Prob t ≥ α) maka 𝐻0 tidak dapat ditolak. Artinya
variabel independen tidak mempengaruhi variabel dependen secara
signifikan.

47
Menurut StataCorp (2013), jika hasil regresi menggunakan pendekatan
random effect model, maka dapat dilakukan uji z untuk melihat pengaruh dari
masing-masing variabel independen terhadap variabel dependen dengan hipotesis
yang sama serta kriteria sebagai berikut:
Jika Prob z < α maka 𝐻0 ditolak. Artinya variabel independen mempengaruhi
variabel dependen secara signifikan.
Jika Prob z ≥ α maka 𝐻0 tidak dapat ditolak. Artinya variabel independen tidak
mempengaruhi variabel dependen secara signifikan.




















