
BAB II TINJAUAN PUSTAKA - sinta.unud.ac.id II.pdf · 1. Menurut Yudhoyono, soal status almarhum...
24
7 BAB II TINJAUAN PUSTAKA 2.1 Peringkasan Teks Otomatis Peringkasan teks otomatis adalah proses mengurangi teks pada dokumen dengan menggunakan program komputer untuk membuat ringkasan yang berisikan poin-poin penting dimana hasil ringkasan tidak lebih dari setengah dokumen asli (Radev et al, 2002). Terdapat dua bagian dari kriteria peringkasan teks yaitu ekstraksi dan abstraksi (Suanmali et al, 2009). Teknik ekstraksi yaitu teknik peringkasan secara lengkap yang terdiri dari urutan-urutan kalimat yang disalin dan memilih bagian-bagian kalimat penting dari dokumen asli. Sedangkan teknik abstraksi adalah teknik peringkasan dengan mengambil informasi penting dari dokumen kemudian menghasilkan ringkasan yang menggunakan kalimat baru yang tidak terdapat pada dokumen asli. 2.2 Kalimat Kalimat adalah satuan bahasa terkecil yang merupakan kesatuan pikiran. Kalimat dapat dibedakan menjadi bahasa lisan dan bahasa tulis. Dalam bahasa lisan, kalimat adalah satuan bahasa yang terbentuk atas gabungan kata dengan kata, gabungan kata dengan frasa, atau gabungan frasa dengan frasa, yang minimal berupa sebuah klausa bebas yang minimal mengandung satu subjek dan predikat. Dalam bahasa tulis, kalimat adalah satuan bahasa yang diawali oleh huruf kapital, diselingi atau tidak diselingi tanda koma (,), titik dua (:) atau titik koma (;) dan diakhiri dengan lambang intonasi final yaitu tanda titik (.), tanda tanya (?) atau tanda seru (!). Pada tugas akhir ini, tiap-tiap kalimat yang ada pada dokumen akan dihitung skornya berdasarkan fitur ekstraksi. Skor dari kalimat tersebut akan menentukan apakah kalimat tersebut penting atau tidak. Kalimat yang memiliki skor tinggi kemungkinan merupakan kalimat yang penting dari sebuah dokumen.
Transcript of BAB II TINJAUAN PUSTAKA - sinta.unud.ac.id II.pdf · 1. Menurut Yudhoyono, soal status almarhum...

7
BAB II
TINJAUAN PUSTAKA
2.1 Peringkasan Teks Otomatis
Peringkasan teks otomatis adalah proses mengurangi teks pada dokumen
dengan menggunakan program komputer untuk membuat ringkasan yang
berisikan poin-poin penting dimana hasil ringkasan tidak lebih dari setengah
dokumen asli (Radev et al, 2002). Terdapat dua bagian dari kriteria peringkasan
teks yaitu ekstraksi dan abstraksi (Suanmali et al, 2009). Teknik ekstraksi yaitu
teknik peringkasan secara lengkap yang terdiri dari urutan-urutan kalimat yang
disalin dan memilih bagian-bagian kalimat penting dari dokumen asli. Sedangkan
teknik abstraksi adalah teknik peringkasan dengan mengambil informasi penting
dari dokumen kemudian menghasilkan ringkasan yang menggunakan kalimat baru
yang tidak terdapat pada dokumen asli.
2.2 Kalimat
Kalimat adalah satuan bahasa terkecil yang merupakan kesatuan pikiran.
Kalimat dapat dibedakan menjadi bahasa lisan dan bahasa tulis. Dalam bahasa
lisan, kalimat adalah satuan bahasa yang terbentuk atas gabungan kata dengan
kata, gabungan kata dengan frasa, atau gabungan frasa dengan frasa, yang
minimal berupa sebuah klausa bebas yang minimal mengandung satu subjek dan
predikat. Dalam bahasa tulis, kalimat adalah satuan bahasa yang diawali oleh
huruf kapital, diselingi atau tidak diselingi tanda koma (,), titik dua (:) atau titik
koma (;) dan diakhiri dengan lambang intonasi final yaitu tanda titik (.), tanda
tanya (?) atau tanda seru (!).
Pada tugas akhir ini, tiap-tiap kalimat yang ada pada dokumen akan
dihitung skornya berdasarkan fitur ekstraksi. Skor dari kalimat tersebut akan
menentukan apakah kalimat tersebut penting atau tidak. Kalimat yang memiliki
skor tinggi kemungkinan merupakan kalimat yang penting dari sebuah dokumen.

8
Pada tugas akhir ini, kalimat dipisahkan berdasarkan tanda titik (.) dan
kutipan langsung diasumsikan sebagai satu kalimat yang tidak dapat dipisahkan.
Berikut ini contoh pemisahan kalimat dari sebuah dokumen:
Menurut Yudhoyono, soal status almarhum Theys itu dikesampingkan dulu saat
ini. "Yang penting, pengusutan kematiannya harus tuntas demi keadilan dan
kebenaran," papar Yudhoyono yang menyebut almarhum Theys sebagai tokoh.
"Biarkanlah proses ini berjalan dengan baik, dan nanti dengan transparan dan
penjelasan gamblang rakyat akan melihat siapa almarhum Theys itu. Maka lebih
bagus, status predikat politik siapa Pak Theys itu kita kesampingkan," tambahnya.
Berdasarkan dokumen di atas, sistem akan melakukan pemisahan kalimat
berdasarkan titik (.) dan kutipan langsung. Sehingga dokumen di atas akan
menghasilkan tiga buah kalimat. Berikut ini tiga kalimat yang telah dipisahkan:
1. Menurut Yudhoyono, soal status almarhum Theys itu dikesampingkan
dulu saat ini.
2. "Yang penting, pengusutan kematiannya harus tuntas demi keadilan dan
kebenaran," papar Yudhoyono yang menyebut almarhum Theys sebagai
tokoh.
3. "Biarkanlah proses ini berjalan dengan baik, dan nanti dengan transparan
dan penjelasan gamblang rakyat akan melihat siapa almarhum Theys itu.
Maka lebih bagus, status predikat politik siapa Pak Theys itu kita
kesampingkan," tambahnya.
2.3 Text Preprocessing
Penyimpanan data secara terstruktur dapat membantu pengolahan data
yang dilakukan oleh komputer, karena data terstruktur dapat mempermudah
penciptaan algoritma yang efisien. Oleh karena itu pada text mining, dibutuhkan
pemrosesan data terlebih dahulu untuk mengubah data tekstual yang tidak
terstruktur menjadi data yang terstruktur. Di dalam text mining proses untuk
mendapatkan representasi terstruktur dari data tekstual mentah yang tidak
terstruktur disebut text preprocessing.
Tahap text preprocessing terdiri dari beberapa tahap yaitu tokenizing,
filtering, tagging, dan stemming. Pada tugas akhir ini hanya menggunakan proses

9
tokenizing, filtering, dan stemming. Proses tagging tidak digunakan karena ketiga
proses yang telah disebutkan sebelumnya sudah cukup untuk mendapatkan data
yang terstruktur. Gambar 2.1 menunjukkan tahap preprocessing text.
Gambar 2.1 Tahap Preprocessing Text
2.3.1 Tokenizing
Pada proses tokenizing, kata-kata yang ada di dalam dokumen harus
dipecah-pecah terlebih dahulu menjadi bagian-bagian yang lebih kecil berupa kata
tunggal yang memiliki arti atau biasa disebut token (Manning et al, 2009). Proses
tokenizing pada tugas akhir ini dilakukan per kalimat. Selain itu dilakukan juga
pengubahan huruf-huruf yang ada di dalam dokumen menjadi huruf kecil (case
folding) serta dilakukan penghilangan tanda baca. Hal ini dilakukan terlebih
dahulu untuk mempermudah proses pengolahan lebih lanjut.
Contoh tokenizing :
Teks asli : Saya senang bermain sepakbola di rumah sejak kecil.
Hasil tokenizing : saya, senang, bermain, sepakbola, di, rumah, sejak, kecil
2.3.2 Filtering
Text filtering bertujuan untuk mengambil kata-kata yang dapat
mempresentasikan isi dokumen dengan cara membuang kata-kata yang dianggap
tidak penting yang biasa disebut stopwords (Manning et al, 2009). Stopwords
dapat berupa kata sambung, kata depan, dan kata seru seperti “di”, “yang”, “dan”,
“ke”, “wah”, “serta”, “wow”, dan lain-lain.
Tokenizing
Filtering
Stemming
Hasil
Preprocessing
Original
Text

10
Contoh filtering :
Hasil tokenizing : saya, senang, bermain, sepakbola, di, rumah, sejak, kecil
Hasil filtering : senang, bermain, sepakbola, rumah
2.3.3 Stemming
Stemming adalah proses yang dilakukan untuk mengambil bentuk dasar
dari suatu kata yang telah melalui proses filtering (Manning et al, 2009).
Algoritma stemming untuk bahasa yang satu berbeda dengan algoritma stemming
untuk bahasa lainnya. Sebagai contoh bahasa Inggris memiliki morfologi yang
berbeda dengan bahasa Indonesia sehingga algoritma stemming untuk kedua
bahasa tersebut juga berbeda. Proses stemming pada teks berbahasa Indonesia
lebih rumit/kompleks karena terdapat variasi imbuhan yang harus dibuang untuk
mendapatkan root word (kata dasar) dari sebuah kata.
Pada umumnya kata dasar pada bahasa Indonesia terdiri dari kombinasi
misalnya “berjalan”, “menjalani”, “perjalanan” sama-sama memiliki kata dasar
“jalan”. Banyak metode yang dapat digunakan untuk melakukan stemming pada
dokumen berbahasa Indonesia salah satunya adalah algoritma Nazief dan Adriani.
Algoritma ini berdasarkan aturan-aturan yang mengelompokkan imbuhan yang
diperbolehkan dan dilarang untuk digunakan. Pada tugas akhir ini menggunakan
algoritma Nazief dan Adriani karena algoritma Nazief dan Andriani merupakan
algoritma stemming untuk teks berbahasa Indonesia yang memiliki presentase
keakuratan lebih baik dari algoritma lainnya (Agusta, 2009). Berikut ini adalah
langkah-langkah yang dilakukan oleh algoritma Nazief dan Adriani (Agusta,
2009):
1. Cari kata yang akan distem dalam kamus. Jika ditemukan maka
diasumsikan bahwa kata tersebut adalah root word. Maka algoritma
berhenti.
2. Inflection Suffixes (“-lah”, “-kah”, “-ku”, “-mu”, atau “-nya”) dibuang.
Jika berupa particles (“-lah”, “-kah”, “-tah”, atau “-pun”) maka langkah ini
diulangi lagi untuk menghapus Possesive Pronouns (“-ku”, “-mu”, atau “-
nya”), jika ada.

11
3. Hapus Derivation Suffixes (“-i”, “-an” atau “-kan”). Jika kata ditemukan
di kamus, maka algoritma berhenti. Jika tidak maka ke langkah 3a
a. Jika “-an” telah dihapus dan huruf terakhir dari kata tersebut adalah “-
k”, maka “-k” juga ikut dihapus. Jika kata tersebut ditemukan dalam
kamus maka algoritma berhenti. Jika tidak ditemukan maka lakukan
langkah 3b.
b. Akhiran yang dihapus (“-i”, “-an” atau “-kan”) dikembalikan, lanjut ke
langkah 4.
c. Hapus Derivation Prefix. Jika pada langkah 3 ada sufiks yang dihapus
maka pergi ke langkah 4a, jika tidak pergi ke langkah 4b.
d. Periksa tabel kombinasi awalan-akhiran yang tidak diizinkan (tabel
2.1). Jika ditemukan maka algoritma berhenti, jika tidak pergi ke
langkah 4b.
e. For i=1 to 3, tentukan tipe awalan kemudian hapus awalan. Jika root
word belum juga ditemukan lakukan langkah 5, jika sudah maka
algoritma berhenti. Catatan: jika awalan kedua sama dengan awalan
pertama algoritma berhenti.
4. Melakukan Recoding.
5. Jika semua langkah telah selesai tetapi tidak juga berhasil maka kata awal
diasumsikan sebagai root word. Proses selesai.
Tipe awalan ditentukan melalui langkah-langkah berikut:
1. Jika awalannya adalah: “di-”, “ke-”, atau “se-” maka tipe awalannya
secara berturut-turut adalah “di-”, “ke-”, atau “se-”.
2. Jika awalannya adalah “te-”, “me-”, “be-”, atau “pe-” maka dibutuhkan
sebuah proses tambahan untuk menentukan tipe awalannya.
3. Jika dua karakter pertama bukan “di-”, “ke-”, “se-”, “te-”, “be-”, “me-”,
atau “pe-” maka berhenti.
4. Jika tipe awalan adalah “tidak ada” maka berhenti. Jika tipe awalan adalah
bukan “tidak ada” maka awalan dapat dilihat pada Tabel 2.2. Hapus
awalan jika ditemukan.
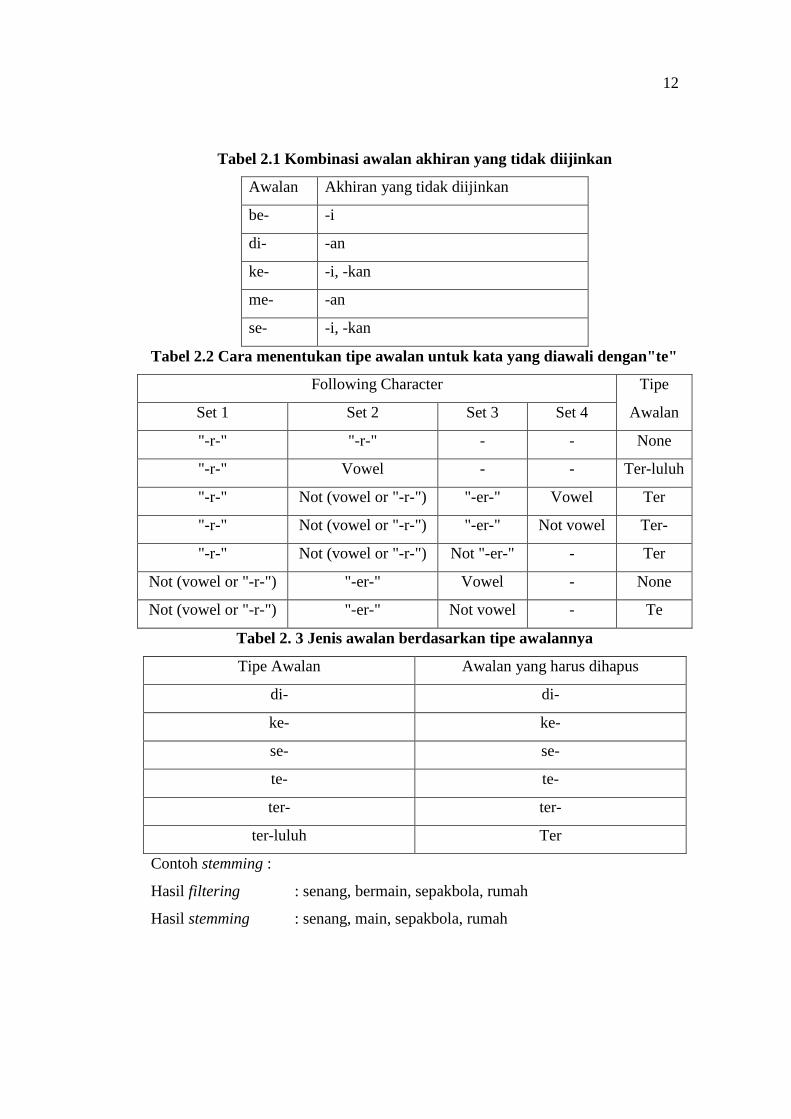
12
Tabel 2.1 Kombinasi awalan akhiran yang tidak diijinkan
Awalan Akhiran yang tidak diijinkan
be- -i
di- -an
ke- -i, -kan
me- -an
se- -i, -kan
Tabel 2.2 Cara menentukan tipe awalan untuk kata yang diawali dengan"te"
Following Character Tipe
Set 1 Set 2 Set 3 Set 4 Awalan
"-r-" "-r-" - - None
"-r-" Vowel - - Ter-luluh
"-r-" Not (vowel or "-r-") "-er-" Vowel Ter
"-r-" Not (vowel or "-r-") "-er-" Not vowel Ter-
"-r-" Not (vowel or "-r-") Not "-er-" - Ter
Not (vowel or "-r-") "-er-" Vowel - None
Not (vowel or "-r-") "-er-" Not vowel - Te
Tabel 2. 3 Jenis awalan berdasarkan tipe awalannya
Tipe Awalan Awalan yang harus dihapus
di- di-
ke- ke-
se- se-
te- te-
ter- ter-
ter-luluh Ter
Contoh stemming :
Hasil filtering : senang, bermain, sepakbola, rumah
Hasil stemming : senang, main, sepakbola, rumah

13
2.4 Fitur Ekstraksi Teks
Pada tugas akhir ini menggunakan fitur ekstraksi untuk menghitung skor
tiap-tiap kalimat dalam dokumen. Untuk setiap kalimat dalam dokumen, skor
kalimat dihitung berdasarkan fitur ekstraksi dimana nilai dari tiap-tiap fitur
dinormalisasikan sehingga nilainya berada dalam range [0,1]. Normalisasi ini
dilakukan agar nilai dari tiap-tiap fitur ekstraksi tidak memiliki gap atau selisih
yang besar.
Adapun fitur-fitur ekstraksi yang digunakan pada tugas akhir ini yaitu
positive keyword pada kalimat (f1), kemiripan antar kalimat (f2), kalimat yang
menyerupai judul (f3) dan cosine similarity (f4). Penjelasan dari tiap-tiap fitur
adalah sebagai berikut ini:
2.4.1 Fitur Keyword Positif (F1)
Positif keyword adalah kata yang sering muncul pada sebuah paragraf
(Marlina, 2012). Fitur ini dapat dihitung menggunakan rumus (2.1) :
(2.1)
Dengan si(positif keyword) adalah jumlah kata dalam suatu kalimat yang
mengandung keyword dibagi dengan jumlah kata dalam seluruh kalimat yang
mengandung keyword, dengan keyword merupakan banyaknya kata yang muncul
dalam suatu dokumen. Berikut ini contoh perhitungan keyword positif:
Ibarat tambang emas, Bangka Belitung dipandang menyimpan sejumlah potensi
yang siap gali. Tidak mengherankan bila jumlah pendatang ke provinsi ini terus
bertambah. Konfilk antara warga luar dan local sendiri mulai muncul di
beberapa tempat. Beberapa terkesan sebagai konflik etnis, namun tidak
berkembang lebih jauh karena aparat pemerintah dan keamanan tampaknya
bergerak cepat menyelesaikannya.
Hasil preprocessing :
aparat/1 bangka/1 belitung/1 kembang/1 tambah/1 cepat/1 pandang/1 emas/1
etnis/1 gali/1 aman/1 konflik/2 lokal/1 heran/1 selesai/1 simpan/1 muncul/1
perintah/1 datang/1 potensi/1 provinsi/1 tambang/1 kesan/1 warga/1.

14
Dari hasil preprocessing diatas, kata konflik adalah kata yang memilki
jumlah kemunculan paling banyak yaitu sebanyak dua kali. Oleh karena itu positif
keyword dari dokumen tersebut adalah “konflik”. Pada kalimat pertama tidak
mengandung positif keyword “konflik”, oleh karena itu skor fitur f2 untuk kalimat
pertama adalah 0. Sehingga skor fitur positf keyword untuk tiap-tiap kalimat
adalah berturu-turut 0,0, ½, ½.
2.4.2 Fitur Kemiripan Antar-Kalimat (F2)
Kemiripan antar-kalimat adalah daftar kata-kata yang dapat dicocokkan
antara kalimat yang satu dengan kalimat yang lainnya dalam dokumen atau
dengan kata lain merupakan kata yang muncul dalam kalimat sama dengan kata
yang muncul dalam kalimat lain (Aristoteles dkk, 2012). Berikut ini contoh
perhitungan kemiripan antar kalimat, diasumsikan kalimat yang dijadikan contoh
di bawah ini adalah kalimat yang telah melewati proses preprocessing:
Kalimat 1 : Kami pergi nonton dan belanja.
Kalimat 2 : Kami pergi rekreasi.
Kalimat 3 : Kami sedang nonton bola.
Berdasarkan ketiga kalimat diatas, perhitungan skor untuk fitur f4 dapat
diilustrasikan pada gambar 2.2.
Gambar 2.2 Ilustrasi fitur kemiripan antar kalimat
Berdasarkan gambar 2.2, skor f2 untuk kalimat 1 adalah 3/8. Hal ini
dikarenakan terdapat tiga buah kata pada kalimat 1 yang memiliki kesamaan
dengan kata yang ada pada kalimat 2 dan kalimat 3 yaitu “kami”, “pergi”,
nonton
pergi dan
belanja
kami
sedang
bola
rekreasi
kalimat 1 kalimat 2
kalimat 3

15
“nonton”. Skor f2 untuk kalimat 2 adalah 2/8. Hal ini dikarenakan terdapat dua
buah kata pada kalimat 2 yang memiliki kesamaan dengan kata yang ada pada
kalimat 1 dan 3 yaitu “kami”, “pergi”. Skor f2 untuk kalimat 3 adalah 2/8. Hal
ini dikarenakan terdapat dua buah kata pada kalimat 3 yang memiliki kesamaan
kata dengan kata yang ada pada kalimat 1 dan 2 yaitu “kami”, “nonton”. Fitur ini
dihitung dengan menggunakan rumus (2.2)
(2.2)
2.4.3 Fitur Kalimat yang Menyerupai Judul Dokumen (F3)
Kalimat yang menyerupai judul dokumen adalah kumpulan kata yang
dapat dicocokkan antara kalimat satu dengan judul dokumen atau dengan kata lain
merupakan kata yang muncul dalam kalimat sama dengan kata yang ada dalam
judul dokumen(Aristoteles dkk, 2012).
Berikut ini contoh perhitungan skor f3, diasumsikan kalimat yang
dijadikan contoh di bawah ini adalah kalimat yang telah melewati proses
preprocessing:
Judul : Kegiatan kami bersama
Kalimat 1 : Kami pergi nonton.
Kalimat 2 : Kami pergi belanja.
Kalimat 3 : Kegiatan kami adalah olahraga bersama.
Berdasarkan judul dan tiga kalimat diatas, perhitungan skor f5 dapat
diilustrasikan dengan gambar 2.3 berikut ini :
Gambar 2.3 Ilustrasi fitur kalimat yang menyerupai judul dokumen
olahraga
adalah kami
kegiatan
bersama
pergi
nonton kami
kami
kegiatan
bersama
pergi
belanja
judul
kegiatan
bersama
Kalimat 1 Kalimat 2 Kalimat 3 judul judul

16
Berdasarkan gambar 2.3, skor f3 untuk kalimat 1 adalah 1/5, hal ini
dikarenakan terdapat satu kata pada kalimat 1 yang sama dengan kata yang ada
pada judul dokumen yaitu kata “kami”. Skor f3 untuk kalimat 2 adalah 1/5, hal ini
dikarenakan terdapat satu kata pada kalimat 2 yang sama dengan kata yang ada
pada judul dokumen yaitu kata “kami”. Skor f3 untuk kalimat 3 adalah 3/5, hal ini
dikarenakan terdapat tiga kata pada kalimat 3 yang sama dnegna kata yang ada
pada judul dokumen yaitu kata “kami”, “kegiatan”, “bersama”. Fitur ini dapat
dihitung dengan menggunakan rumus (2.3).
(2.3)
2.4.4 Fitur Cosine Similarity (F4)
Pada penelitian ini menggunakan semua keyword yang ada dalam
dokumen kecuali kata-kata stoplist. Perhitungan cosine similarity melibatkan
pembobotan (weights) TF-IDF dimana wi,j didefinisikan pada (2.4), dan tfi adalah
banyaknya kemunculan term ke-i pada kalimat. SFi sentences frequency
merupakan banyak kalimat yang mengandung term ke-i sedangkan ISFi =
merupakan ukuran diskriminan kemunculan term ke-i dalam dokumen,
N adalah banyaknya kalimat dalam satu dokumen.
(2.4)
Pengiriman emas rusak karena kebakaran. Pengiriman perak tiba di
sebuah truk perak. Pengiriman emas tiba di truk.
Setelah mengalami text preprocessing, kalimat menjadi :
S1 : kirim emas rusak bakar
S2 : kirim perak truk perak
S3 : kirim emas truk
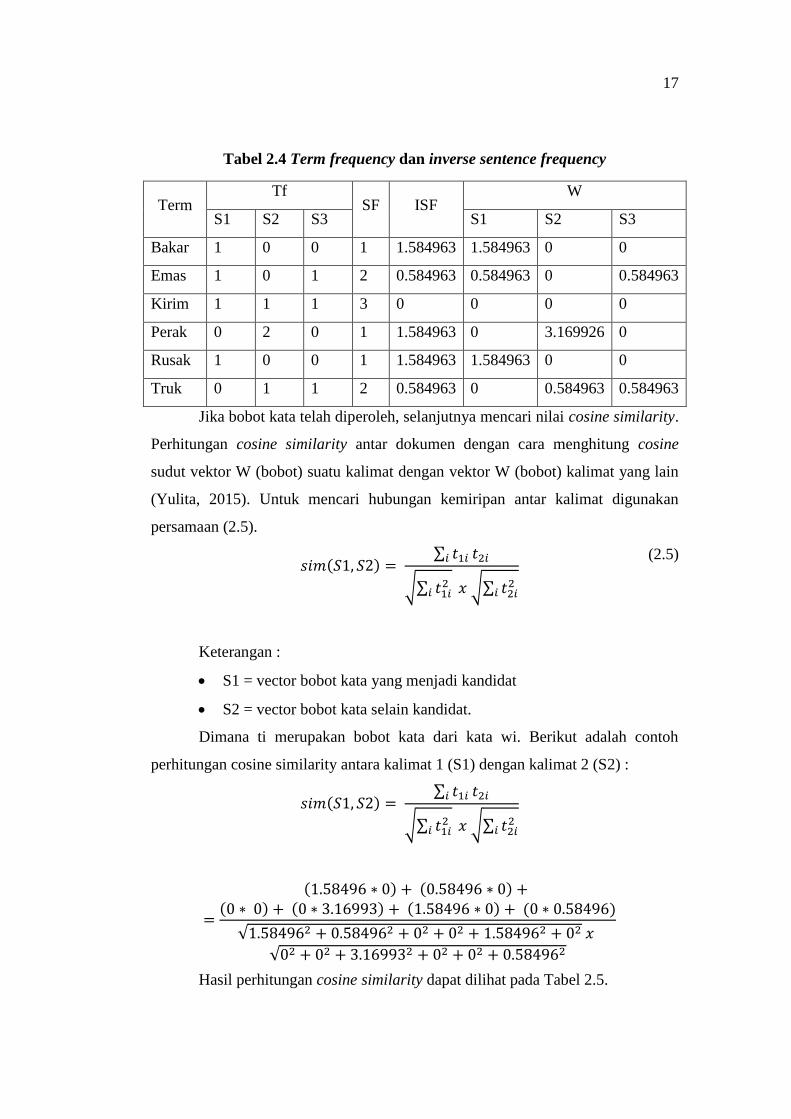
17
Tabel 2.4 Term frequency dan inverse sentence frequency
Term Tf
SF ISF W
S1 S2 S3 S1 S2 S3
Bakar 1 0 0 1 1.584963 1.584963 0 0
Emas 1 0 1 2 0.584963 0.584963 0 0.584963
Kirim 1 1 1 3 0 0 0 0
Perak 0 2 0 1 1.584963 0 3.169926 0
Rusak 1 0 0 1 1.584963 1.584963 0 0
Truk 0 1 1 2 0.584963 0 0.584963 0.584963
Jika bobot kata telah diperoleh, selanjutnya mencari nilai cosine similarity.
Perhitungan cosine similarity antar dokumen dengan cara menghitung cosine
sudut vektor W (bobot) suatu kalimat dengan vektor W (bobot) kalimat yang lain
(Yulita, 2015). Untuk mencari hubungan kemiripan antar kalimat digunakan
persamaan (2.5).
(2.5)
Keterangan :
S1 = vector bobot kata yang menjadi kandidat
S2 = vector bobot kata selain kandidat.
Dimana ti merupakan bobot kata dari kata wi. Berikut adalah contoh
perhitungan cosine similarity antara kalimat 1 (S1) dengan kalimat 2 (S2) :
Hasil perhitungan cosine similarity dapat dilihat pada Tabel 2.5.
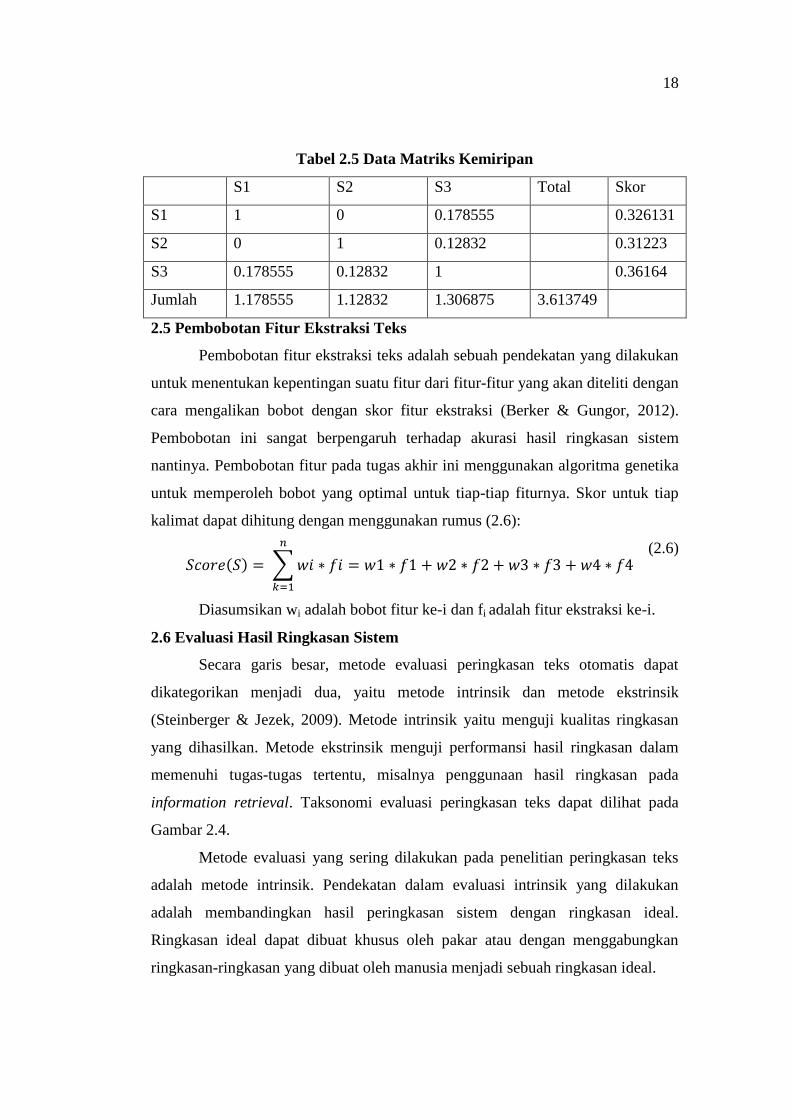
18
Tabel 2.5 Data Matriks Kemiripan
S1 S2 S3 Total Skor
S1 1 0 0.178555 0.326131
S2 0 1 0.12832 0.31223
S3 0.178555 0.12832 1 0.36164
Jumlah 1.178555 1.12832 1.306875 3.613749
2.5 Pembobotan Fitur Ekstraksi Teks
Pembobotan fitur ekstraksi teks adalah sebuah pendekatan yang dilakukan
untuk menentukan kepentingan suatu fitur dari fitur-fitur yang akan diteliti dengan
cara mengalikan bobot dengan skor fitur ekstraksi (Berker & Gungor, 2012).
Pembobotan ini sangat berpengaruh terhadap akurasi hasil ringkasan sistem
nantinya. Pembobotan fitur pada tugas akhir ini menggunakan algoritma genetika
untuk memperoleh bobot yang optimal untuk tiap-tiap fiturnya. Skor untuk tiap
kalimat dapat dihitung dengan menggunakan rumus (2.6):
(2.6)
Diasumsikan wi adalah bobot fitur ke-i dan fi adalah fitur ekstraksi ke-i.
2.6 Evaluasi Hasil Ringkasan Sistem
Secara garis besar, metode evaluasi peringkasan teks otomatis dapat
dikategorikan menjadi dua, yaitu metode intrinsik dan metode ekstrinsik
(Steinberger & Jezek, 2009). Metode intrinsik yaitu menguji kualitas ringkasan
yang dihasilkan. Metode ekstrinsik menguji performansi hasil ringkasan dalam
memenuhi tugas-tugas tertentu, misalnya penggunaan hasil ringkasan pada
information retrieval. Taksonomi evaluasi peringkasan teks dapat dilihat pada
Gambar 2.4.
Metode evaluasi yang sering dilakukan pada penelitian peringkasan teks
adalah metode intrinsik. Pendekatan dalam evaluasi intrinsik yang dilakukan
adalah membandingkan hasil peringkasan sistem dengan ringkasan ideal.
Ringkasan ideal dapat dibuat khusus oleh pakar atau dengan menggabungkan
ringkasan-ringkasan yang dibuat oleh manusia menjadi sebuah ringkasan ideal.

19
Gambar 2.4 Taksonomi pengujian peringkasan teks
Penelitian ini menggunakan metode evaluasi Recall-Oriented Understudy
for Gisting Evaluation (ROUGE). ROUGE menghitung jumlah n-gram kata yang
overlap antara ringkasan sistem dengan ringkasan referensi Adapun teknik
penghitungan ROUGE-N antara sebuah ringkasan sistem dan sekumpulan
ringkasan manual terdapat pada persamaan (2.7).
(2.7)
Dimana n adalah panjang dari n-gram, Countmatch(gramn) adalah jumlah n-
gram yang sama antara sebuah ringkasan sistem dan sebuah ringkasan referensi,
Count(gramn) adalah jumlah n-gram dalam ringkasan referensi.
Tabel 2.6 menunjukkan contoh perhitungan ROUGE-N pada Document
Understanding Conference 2003 (Lin, 2004). C1 adalah kalimat ringkasan sistem.
R1 dan R2 adalah kalimat dalam sebuah ringkasan referensi. Asumsikan bahwa
C1, R1 dan R2 sudah melewati proses text preprocessing. Ada 20 unigram, 19
bigram, 18 trigram, dan 17 4-gram token dari R1 dan R2 yang tercantum dalam
kolom total. Kolom match adalah jumlah kecocokan dari setiap ringkasan
referensi. Skor akhir adalah perbandingan antara nilai Match dengan Total.
C1 : pulses may ease schizophrenic voices
R1 : magnetic pulse series sent through brain may ease schizophrenic
voices

20
R2 : yale finds magnetic stimulation some relief to schizophrenics
imaginary voices
Tabel 2.6 Contoh Perhitungan ROUGEn
R1 R2 Match Total Score
ROUGE1 may, ease, schizophrenic, voices Voices 5 20 0.25
ROUGE2 may ease, ease schizophrenic,
schizophrenic voices
- 3 19 0.16
ROUGE3 may ease schizophrenic, ease
schizophrenic voices
- 2 18 0.11
ROUGE4 may ease schizophrenic, ease
schizophrenic voices
- 1 17 0.05
Studi awal dari Lin dan Hovy tahun 2003 (Steinberger & Jezek, 2009)
menunjukkan bahwa evaluasi otomatis menggunakan versi unigram dari dari
ROUGE-N, yaitu ROUGE-1 berkolerasi baik dengan evaluasi manusia
berdasarkan berbagai statistik. Oleh karena itu penelitian ini menggunakan
evaluasi hasil ringkasan sistem dengan ROUGE-1.
2.7 Algoritma Genetika
Algoritma genetika merupakan evaluasi atau perkembangan dunia
komputer dalam bidang kecerdasan buatan (artificial intelligence). Kemunculan
algoritma genetika ini terinspirasi oleh teori Darwin dan teori-teori dalam ilmu
biologi, sehingga banyak istilah dan konsep biologi yang digunakan dalam
algoritma genetika, karena sesuai dengan namanya, proses-proses yang terjadi
dalam algoritma genetika sama dengan apa yang terjadi pada evaluasi biologi.
Algoritma genetika adalah algoritma pencarian yang berdasarkan pada
mekanisme sistem natural yakni genetik dan seleksi alam. Pada dasarnya
algoritma genetika adalah program komputer yang mensimulasikan proses
evolusi, dengan menghasilkan kromosom-kromosom dari tiap populasi secara
random dan memungkinkan kromosom tersebut berkembang biak sesuai dengan
hukum-hukum evolusi yang nantinya diharapkan akan dapat menghasilkan
kromosom prima atau yang lebih baik. Kromosom ini merepresentasikan solusi
dari permasalahan yang diangkat, sehingga apabila kromosom yang baik tersebut

21
dihasilkan, maka diharapkan solusi yang baik dari permasalahan tersebut juga
didapatkan.
2.7.1 Istilah dalam Algoritma Genetika
Terdapat beberapa definisi penting dalam Algoritma Genetika yang perlu
diperhatikan, yaitu:
1. Genotype (Gen), sebuah nilai yang menyatakan satuan dasar yang
membentuk suatu arti tertentu dalam satu kesatuan gen yang dinamakan
kromosom. Dalam algoritma genetika, gen ini bisa berupa biner, float,
integer maupun karakter atau kombinatorial.
2. Allele, merupakan nilai dari gen.
3. Kromosom/Individu, merupakan gabungan gen-gen yang membentuk nilai
tertentu dan menyatakan solusi yang mungkin dari suatu permasalahan.
4. Populasi, merupakan sekumpulan individu yang akan diproses bersama
dalam satu siklus proses evolusi.
5. Generasi, menyatakan satu siklus proses evolusi atau satu iterasi di dalam
algoritma genetika.
6. Fitness, menyatakan seberapa baik nilai dari suatu individu yang
didapatkan.
2.7.2 Struktur Algoritma Genetika
Algoritma genetika adalah algoritma pencarian hasil yang terbaik, yang
didasarkan pada perkawinan dan seleksi gen secara alami. Kombinasi perkawinan
ini dilakukan dengan proses acak (random). Dimana struktur gen hasil proses
perkawinan ini, akan menghasilkan gen inovatif untuk diseleksi. Dalam setiap
generasi, ciptaan buatan yang baru (hasil perkawinan), diperoleh dari bit-bit dan
bagian-bagian gen induk yang terbaik. Tujuan dari algoritma genetika ini adalah
menghasilkan populasi yang terbaik dari populasi awal. Sedangkan keuntungan
dari algoritma genetika adalah sifat metode pencariannya yang lebih optimal,
tanpa terlalu memperbesar ruang pencarian.
Dalam menyusun suatu algoritma genetika menjadi program, maka
diperlukan beberapa tahapan proses, yaitu proses pembuatan generasi awal, proses
seleksi, proses crossover, proses mutasi dan pengulangan proses sebelumnya.

22
1) Pendefinisian Individu
Pendefinisian individu merupakan proses pertama yang harus dilakukan
dalam Algoritma Genetika yang menyatakan salah satu solusi yang
mungkin dari suatu permasalahan yang diangkat. Pendefinisian individu
atau yang biasa disebut juga merepresentasikan kromosom yang akan
diproses nanti, dilakukan dengan mendefinisikan jumlah dan tipe dari gen
yang digunakan dan tentunya dapat mewakili solusi permasalahan yang
diangkat.
Gen dapat direpresentasikan dalam bentuk: bit, bilangan real, string, daftar
aturan, gabungan dari beberapa kode, elemen permutasi, elemen program
atau representasi lainnya yang dapat diimplementasikan untuk operator
genetika.
2) Membangkitkan Populasi Awal dan Kromosom
Membangkitkan populasi awal adalah proses membangkitkan sejumlah
individu atau kromosom secara acak atau melalui prosedur tertentu.
Ukuran untuk populasi tergantung pada masalah yang akan diselesaikan
dan jenis operator genetika yang akan diimplementasikan. Setelah ukuran
populasi ditentukan, kemudian dilakukan pembangkitan populasi awal.
Teknik yang digunakan dalam pembangkitan populasi awal adalah
Random Generation. Dimana cara ini melibatkan pembangkitan bilangan
random untuk nilai setiap gen sesuai dengan representasi kromosom yang
digunakan.
IPOP = round{random(Nipop, Nbits)} (2.8)
Dimana IPOP adalah gen yang nantinya berisi pembulatan dari bilangan
random yang dibangkitkan sebanyak Nipop(jumlah populasi) X Nbits
(jumlah gen dalam tiap kromosom).
3) Nilai Fitness
Suatu individu dievaluasi berdasarkan suatu fungsi tertentu sebagai ukuran
performansinya. Pada masalah optimasi, solusi yang akan dicari adalah
memaksimumkan fungsi h (dikenal sebagai masalah maksimasi) sehingga
nilai fitness yang digunakan adalah nilai dari fungsi h tersebut, yakni f = h

23
(di mana f adalah nilai fitness). Tetapi jika masalahnya adalah
meminimalkan fungsi h (masalah minimasi), maka fungsi h tidak bisa
digunakan secara langsung. Hal ini disebabkan adanya aturan bahwa
individu yang memiliki nilai fitness tinggi lebih mampu bertahan hidup
pada generasi berikutnya. Oleh karena itu nilai fitness yang dapat
digunakan adalah f = 1/h, yang artinya semakin kecil nilai h, semakin
besar nilai f. Tetapi hal ini akan menjadi masalah jika h bisa bernilai 0,
yang mengakibatkan f bisa bernilai tak hingga. Untuk mengatasinya, h
perlu ditambah sebuah bilangan yang dianggap kecil [0-1] sehingga nilai
fitnessnya menjadi = 1/(h+1) dengan a adalah bilanga nyang kecil dan
bervariansi [0-1] sesuai dengan masalah yang akan diselesaikan.
4) Proses Seleksi
Operasi seleksi dilakukan dengan memperhatikan fitness dari tiap
individu, manakah yang dapat dipergunakan untuk generasi selanjutnya.
Seleksi ini digunakan untuk mendapatkan calon induk yang baik, semakin
tinggi nilai fitnessnya maka semakin besar juga kemungkinan individu
tersebut terpilih.
Terdapat beberapa macam cara seleksi untuk mendapatkan calon induk
yang baik. Metode seleksi yang umumnya digunakan adalah roulette
wheel. Cara kerja metode ini adalah sebagai berikut:
a. Hitung total fitness semua individu (fi dumana I adalah individu ke-1
sampak ke-n).
b. Hitung probabilitas seleksi masing-masing individu.
(2.9)
c. Dari probabilitas tersebut, dihitung jatah interval masing-masing
individu pada angka 0 sampai 1.
d. Bangkitkan bilangan random antara 0 sampai 1.
e. Dari bilangan random yang dihasilkan tentukan urutan untuk populasi
baru hasil proses seleksi,
(2.10)

24
Dimana C adalah nilai komulatif probabilitas, R adalah nilai random dari
roulette-wheel dan K adalah iterasi kromosom.
5) Pindah Silang (Crossover)
Sebuah kromosom yang mengarah pada solusi yang baik dapat diperoleh
dari proses memindah-silangkan dua buah kromosom. Pindah silang hanya
bisa dilakukan dengna suatu probabilitas crossover, artinya pindah silang
bisa dilakukan hanya jika suatu bilangan random yang dibangkitkan
kurang dari probabilitas crossover yang ditentukan. Pada umumnya
probabilitas tersebut diset mendekati 1.
Pindah silang yang paling sederhana adalah pindah silang satu titik potong
(one-point crossover). Suatu titik potong dipilih secara acak (random),
kemudian bagian pertama dari parent 1 digabungkan dengan bagian kedua
dari parent 2. Pada crossover satu titik, posisis crossover k (k-1,2,..N-1)
dengan N merupakan panjang kromosom yang diseleksi secara random.
Contoh:
11001011 + 11011111 = 11001111
Kromosom yang idjadikan induk dipilih secara acak dan jumlah
kromosom yang mengalami crossover dipengaruhi oleh parameter
crossover_rate (pc). Pseudo-code untuk proses crossover adalah:
begin
k ← 0;
while (k<populasi) do
R[k] ← random(0-1);
if ( R[k] < pc ) then
select Chromosome[k] as parent;
end;
k = k + 1;
end;
end;
6) Mutasi

25
Mutasi merupakan proses mengubah nilai dari satu atau beberapa gen
dalam suatu kromosom. Mutasi ini berperan untuk menggantikan gen yang
hilang dari populasi akibat seleksi yang memungkinkan munculnya
kembali gen yang tidak muncul pada inisialisasi populasi. Metode mutasi
yang digunakan adalah mutasi dalam pengkodean nilai. Proses mutasi
dalam pengkodean nilai dapat dilakukan dengan berbagai cara, salah
satunya yaitu dengan memilih sembarang posisi gen pada kromosom, nilai
yang ada tersebut kemudian dirubah dengan suatu nilai tertentu yang
diambil secara acak.
Jumlah kromsom yang mengalami mutasi dalam satu populasi ditentukan
oleh parameter mutation_rate. Untuk memilih posisi gen yagn mengalami
mutasi dilakukan dengan cara membangkitkan bilangan integer acak
antara 1 sampai total_gen. Kemudian tentukan berapa banyak mutasi yang
terjadi dengan menentukan variable mutation_rate (pm) dari total gen yang
mengalami populasi. Maka nilai gen pada posisi tersebut diganti dengan
bilangan acak.
7) Offspring
Offspring merupakan kromosom baru yang dihasilkan setelah melalui
proses-proses sebelumnya. Kemudian pada offspring tersebut dihitung
nilai fitnessnya apakah sudah optimal atau belum, jika sudah optimal
berarti offspring tersebut merupakan solusi optimal, tetapi jika belum
optimal maka akan diseleksi kembali, begitu seterusnya sampai terpenuhi
kriteria berhenti. Beberapa kriteria berhenti yang sering digunakan antara
lain :
1. Berhenti pada generasi tertentu.
2. Berhenti setelah dalam beberapa generasi berturut-turut didapatkan
nilai fitness tertinggi tidak berubah.
3. Berhenti bila dalam n generasi berikut tidak didapatkan nilai fitness
yang lebih tinggi.

26
2.8 Model Pengembangan Waterfall
Model waterfall merupakan model proses klasik yang bersifat sistematis,
berurutan dari satu tahap ke tahap lain dalam membangun software (Sommerville
2011).
Model SDLC waterfall sering disebut model sekuensial linier (sequential
linear) atau alur hidup klasik (classic life cycle). Model waterfall menyediakan
pendekatan alur hidup perangkat lunak secara terurut. Model ini mengusulkan
sebuah pendekatan kepada pengembangan software yang sistematik dan
sekuensial yang mulai dari tingkat kemajuan sistem pada seluruh analisis, desain,
pengkodean, pengujian, dan tahap penerapan atau pemeliharaan program.
Model waterfall memiliki tahapan – tahapan dalam prosesnya, setiap
tahapan tersebut harus diselesaikan sebelum berlanjut ke tahap berikutnya.
Ilustrasi model waterfall terdapat pada gambar 2.5.
Gambar 2.5 Ilustrasi Model Waterfall
Berikut merupakan tahapan-tahapan dalam model proses SDLC:
1. Analisis Kebutuhan
Proses pengumpulan kebutuhan dilakukan secara intensif untuk
mespesifikasikan kebutuhan perangkat lunak agar dapat dipahami
perangkat lunak seperti apa yang dibutuhkan user.

27
2. Desain Sistem
Desain perangkat memfokus pada desain pembuatan program perangkat
lunak termasuk struktur data, arsitektur, representasi antarmuka, dan
prosedur pengkodean. Tahap ini mentranslasi kebutuhan perangkat lunak
dari tahap analisis kebutuhan ke representasi desain agar dapat
mengimplementasikan menjadi program pada tahap selanjutnya.
3. Implementasi pada Kode Program
Selama tahap ini, perancangan perangkat lunak direalisasikan sebagai
serangkaian program atau unit program. Unit pengujian melibatkan
verifikasi bahwa setiap unit memenuhi spesifikasinya.
4. Pengujian Program
Pengujian fokus pada perangkat lunak direalisasikan sebagai serangkaian
program atau unit program. Unit pengujian melibatkan verifikasi bahwa
setiap unit memenuhi spesifikasinya.
5. Penerapan dan Pemeliharaan
Tahap penerapan sistem meliputi penerapan sistem pada dunia yang nyata,
dimana user langsung menggunakan dan menilai sistem apakah sudah
memenuhi kebutuhan. Pemeliharaan meliputi kesalahan pengujian yang
tidak ditemukan pada awal tahap siklus hidup, meningkatkan
implementasi unit sistem dan meningkatkan pelayanan sistem sebagai
kebutuhan baru ditemukan. Tahap pemeliharaan dapat mengulangii proses
pengembangan yang ada tetapi tidak untuk membuat perangkat lunak baru.
2.9 Functional Decomposition Diagram (FDD)
Functional Decomposition Diagram atau disingkat dengan istilah FDD
merupakan sebuah representasi top-down (disajikan dalam bentuk hirarki) dari
sebuah fungsi atau proses dari suatu sistem (Rosenblatt, 2013:140). Menurut
Rosenblatt dengan menggunakan FDD, suatu analis sistem dapat menunjukkan
proses bisnis dan memecahnya kembali menjadi beberapa tingkatan fungsi atau
proses yang lebih detail yang hampir mirip dengan sebuah struktur organisasi.

28
2.10 Data Flow Diagram (DFD)
Menurut Rosenblatt (2014) DFD merupakan sebuah diagram yang
merepresentasikan bagaimana suatu sistem menyimpan, memproses dan
mentransformasi suatu data. Diagram konteks adalah diagram yang terdiri dari
suatu proses dan menggambarkan ruang lingkup suatu sistem. Diagram konteks
merupakan level tertinggi dari DFD yang menggambarkan seluruh input ke sistem
atau output dari sistem. Diagram konteks akan memberi gambaran tentang
keseluruhan sistem. Sistem dibatasi oleh boundary (dapat digambarkan dengan
garis putus). Dalam diagram konteks hanya ada satu proses. Tidak boleh ada store
dalam diagram konteks.
Data Flow Diagram (DFD) adalah suatu diagram yang menggunakan
notasi-notasi untuk menggambarkan arus dari data sistem, yang penggunaannya
sangat membantu untuk memahami sistem secara logika, terstruktur dan jelas.
DFD merupakan alat bantu dalam menggambarkan atau menjelaskan proses kerja
suatu sistem.
DFD sering digunakan untuk menggambarkan suatu sistem yang telah ada
atau sistem baru yang akan dikembangkan secara logika tanpa
mempertimbangkan lingkungan fisik di mana data tersebut mengalir (misalnya
lewat telepon, surat dan sebagainya) atau lingkungan fisik di mana data tersebut
akan disimpan (misalnya file kartu, microfiche, harddisk, tape, diskette dll). DFD
merupakan alat yang digunakan pada metodologi pengembangan sistem yang
terstruktur (structured analysis and design)
2.11 Pengujian Black Box
Pengujian kotak hitam atau black box testing adalah jenis pengujian
perangkat lunak yang dapat dilakukan ketika tidak memiliki kode sumber, hanya
memiliki program hasil eksekusi kode tersebut. Situasi ini terjadi di beberapa titik
dalam proses pembangunan suatu perangkat lunak. Sekelompok penguji,
pengguna akhir, pakar bisnis dan pengembang adalah tim terbaik untuk
melakukan pengujian jenis ini. Pengguna akhir memberikan kontribusi

29
Gambar 2.6 Simbol-simbol pada DFD
pengetahuan substansial tentang perilaku yang tepat yang diharapkan dari
perankat lunak. Pengembang memberikan kontribusi pengetahuan seubstansial
tentang perilaku bisnis seperti yang diterapkan dalam perangkat lunak. Pengujian
kotak hitam dengan pengguna akhir juga disebut sebagai pengujian perilaku
karena pada pengujian ini menguji seluruh fungsi yang seharusnya dimiliki
perangkat lunak dapat berfungsi sebagaimana mestinya.
2.12 Tinjauan Studi
Ada beberapa penelitian yang pernah dilakukan mengenai peringkasan
teks otomatis, algoritma genetika antara lain:
1. Genetic Algorithm Based Sentence Extraction for Text Summarization,
(Suanmali et al, 2009). Pada penelitian ini dilakukan ekstraksi ringkasan
dengan memberikan nilai untuk setiap fitur kalimat yang dimiliki
menggunakan Genetic Algorithm (GA). Penelitian menggunakan data
dokumen berbahasa Inggris dari Document Understanding Conference
(DUC) 2002. Terdapat delapan fitur kalimat yang digunakan yaitu title
feature, sentence length, features weight, sentence position, sentence to
sentence similarity, proper noun, thematic word dan numerical data.
Genetic Algorithm untuk training dokumen demi menentukan bobot
sentence features. Penelitian ini menggunakan pengujian dengan
perhitungan ROUGE-1 dan menghasilkan akurasi sebesar 46,47%.

30
2. Sistem Peringkasan Dokumen Berita Bahasa Indonesia Menggunakan
Metode Regresi Logistik Biner (Marlina, 2012). Pada penelitian ini
dilakukan peringkasan teks dengan metode regresi logistik biner untuk
menganalisis beberapa faktor dengan sebuah variabel yang bersifat biner.
Penelitian menggunakan dokumen yang berasal dari dokumen berita
online harian Kompas yang didapat dari korpus penelitian Ridha (2002).
Penelitian menggunakan evaluasi koefisien dice menghasilkan akurasi
sebesar 42,84% pada rasio ringkasan 30%. Cara menghitung koefisien dice
ditunjukkan pada persamaan
(2.11)
Dimana x merupakan banyaknya kalimat yang dihasilkan sistem dan y
merupakan banyaknya kalimat yang diringkas secara manual.
3. Peringkas Dokumen Berbahasa Indonesia Berbasis Kata Benda
dengan BM25 (Rivaldi 2013). Penelitian ini mengembangkan peringkasan
teks berdasarkan kata benda. Penelitian menggunakan fitur cosine
similarity, content overlap, dan Okapi BM25. Data yang digunakan adalah
data dokumen penelitian Ridha (2002). Penelitian menggunakan evaluasi
koefisien dice. Hasil rata-rata pengujian ringkasan sistem menunjukkan
44%.














