
BAB II TINJAUAN PUSTAKA DAN LANDASAN...
41
6 BAB II TINJAUAN PUSTAKA DAN LANDASAN TEORI 2.1 Tinjauan Pustaka Penelitian mengenai algoritma apriori yang dilakukan oleh Robi Yanto dan Riri Khoiriyah (2015) yang berjudul “ Implementasi Data Mining dengan Metode Algoritma Apriori dalam Menentukan Pola Pembelian Obat”. Pada penelitian ini data yang digunakan berupa data transaksi pembelian obat periode Januari dan Februari 2014 dengan sampel 20 data transaksi yang berisi nama obat saja bukan taksonomi obat. Hal ini bertujuan agar memudahkan tetap tersedianya berbagai obat yang cenderung sering dibutuhkan oleh konsumen. Bahasa pemrograman yang digunakan adalah Visual Basic 6.0 dan database Mysql. Dengan menggunakan minimum support 40%, diperoleh 6 nama obat yang terpenuhi. Kemudian dilanjutkan dengan pembentukan kombinasi 2 itemset dan minimum support yang sama, diperoleh 2 kombinasi itemset saja. Namun ketika dilakukan kombinasi 3 itemset tidak ada kombinasi yang terpenuhi. Setelah pola frekuensi tinggi ditemukan, barulah dicari aturan asosisi yang memenuhi syarat minimum dengan menghitung confidence aturan asosiasi. Sehingga dapat disimpulkan hanya terdapat 2 kombinasi 2 itemset dengan confidence 75% dan 77,77%. Penelitian selanjutnya dilakukan oleh Arif Ismail Husin dan Farida Mulyaningsih (2015) yang berjudul “Penerapan Metode Data Mining Analisis terhadap Data Penjualan Pakaian dengan Algoritma Apriori”. Pada penelitian ini data yang digunakan adalah data penjualan pakaian pada tahun 2013 dengan tujuan untuk menemukan hubungan antar produk yang dibeli secara bersamaan. Universitas Islam Negeri Sunan Kalijaga (11.12.2019)
Transcript of BAB II TINJAUAN PUSTAKA DAN LANDASAN...

6
BAB II
TINJAUAN PUSTAKA DAN LANDASAN TEORI
2.1 Tinjauan Pustaka
Penelitian mengenai algoritma apriori yang dilakukan oleh Robi Yanto dan
Riri Khoiriyah (2015) yang berjudul “Implementasi Data Mining dengan Metode
Algoritma Apriori dalam Menentukan Pola Pembelian Obat”. Pada penelitian ini
data yang digunakan berupa data transaksi pembelian obat periode Januari dan
Februari 2014 dengan sampel 20 data transaksi yang berisi nama obat saja bukan
taksonomi obat. Hal ini bertujuan agar memudahkan tetap tersedianya berbagai
obat yang cenderung sering dibutuhkan oleh konsumen. Bahasa pemrograman
yang digunakan adalah Visual Basic 6.0 dan database Mysql. Dengan
menggunakan minimum support 40%, diperoleh 6 nama obat yang terpenuhi.
Kemudian dilanjutkan dengan pembentukan kombinasi 2 itemset dan minimum
support yang sama, diperoleh 2 kombinasi itemset saja. Namun ketika dilakukan
kombinasi 3 itemset tidak ada kombinasi yang terpenuhi. Setelah pola frekuensi
tinggi ditemukan, barulah dicari aturan asosisi yang memenuhi syarat minimum
dengan menghitung confidence aturan asosiasi. Sehingga dapat disimpulkan hanya
terdapat 2 kombinasi 2 itemset dengan confidence 75% dan 77,77%.
Penelitian selanjutnya dilakukan oleh Arif Ismail Husin dan Farida
Mulyaningsih (2015) yang berjudul “Penerapan Metode Data Mining Analisis
terhadap Data Penjualan Pakaian dengan Algoritma Apriori”. Pada penelitian ini
data yang digunakan adalah data penjualan pakaian pada tahun 2013 dengan
tujuan untuk menemukan hubungan antar produk yang dibeli secara bersamaan.
Universitas Islam Negeri Sunan Kalijaga (11.12.2019)

7
Tools yang digunakan pada algoritma apriori ini adalah tools Tanagra. Dari data
yang diperoleh selama 1 tahun tersebut dilakukan normalisasi sehingga terlihat
merk pakaian apa saja yang mendapatkan nilai penjualan paling banyak. Dengan
mengelompokkan 3 merk pakaian paling diminati per-bulan-nya, diperoleh 12
pola kombinasi merk pakaian tersebut. Menggunakan nilai minimum support
30% pada kombinasi 2 itemset, hanya menghasilkan 2 kombinasi yang terpenuhi.
Namun setelah dicoba dengan kombinasi 3 itemset tidak ada kombinasi yang
terpenuhi. Kemudian dilakukan pembentukan aturan asosiasi dari 2 kombinasi
yang terpenuhi pada 2 itemset tersebut. Menggunakan minimum confidence 66%,
2 kombinasi tersebut terpenuhi dengan nilai confidence 66,67% dan 80%.
Penelitian selanjutnya dilakukan oleh Heroe Santoso, I Putu Hariyadi dan
Prayitno (2016) yang berjudul “Data Mining Analisa Pola Pembelian Produk
dengan Menggunakan Metode Algoritma Apriori”. Penelitian ini dilakukan
dengan tujuan untuk mengelompokkan data agar dapat mengetahui
kecenderungan transaksi yang muncul bersamaan sehingga menemukan pola
pembeliannya serta bisa dijadikan acuan untuk merancang kupon diskon pada
produk tertentu untuk menarik daya beli konsumen. Data yang digunakan pada
penelitian ini adalah data transakasi pada sebuah swalayan. Tahap pertama yang
dilakukan adalah melakukan normalisasi data transaksi tersebut menjadi 1 item.
Kemudian membuat data transaksi yang telah di normalisasi tersebut dibuat dalam
bentuk tabular. Dengan menggunakan nilai minimum support 2, calon 2 itemset
pada setiap data transaksi dihitung sesuai data tabular sebelumnya dan
menghasilkan 5 k-item. Menggabungkan calon 2 itemset menjadi 3 itemset, hanya
terdapat 1 itemset yang memenuhi minimum support. Kemudian melakukan
Universitas Islam Negeri Sunan Kalijaga (11.12.2019)

8
pembentukan aturan asosiasi dengan menetapkan minimum confidence 60%,
kombinasi 2 itemset yang terpenuhi adalah 7 kombinasi dan kombinasi 3 itemset
yang terpenuhi tidak ada.
Penelitian selanjutnya yang dilakukan Margi Cahyanti, Maulana Mujahidin,
dan Ericks Rachmat Swedi (2017) yang berjudul “Penerapan Algoritma Apriori
Association Rule Untuk Analisa Nilai Mahasiswa Di Universitas Gunadarma”.
Penelitian dilakukan dengan tujuan mencari aturan asosiasi untuk nilai yang
mengulang pada 75 mata kuliah yang telah diambil. Dengan menggunakan
algoritma apriori dan bahasa pemrograman C#, peneliti berhasil membuat aplikasi
yang terkoneksi dengan server akademik Universitas Gunadarma. Hasil dari
penelitian ini adalah dengan confidence sebesar 83,84% dan minimum support
100, sehingga dapat disimpulkan bahwa dengan tingkat kepercayaan ±80%
mahasiswa yang mengulang matakuliah ”Praktikum Algoritma dan
Pemrograman” juga akan mengulang matakuliah "Pengantar Sistem Komputer”.
Penelitian selanjutnya dilkukan oleh Rahmawati Ulfa (2018) yang berjudul
“Implementasi Data Mining Menggunakan Algoritma Apriori untuk Mengetahui
Pola Pembelian Konsumen pada Data Transaksi Penjualan di KPRI UIN Sunan
Kalijaga Yogyakarta”. Tujuan dari penelitian ini adalah untuk mengetahui pola
pembelian produk oleh konsumen pada bulan Januari dan Februari 2018. Data
yang tersedia di normaliasasi agar dapat diolah dengan algoritma apriori. Dengan
menggunakan minimum support = 1, diperoleh data kandidat 1 itemset dan
kandidat 2 itemset. Namun, untuk kandidat 3 itemset tidak ada kandidat data yang
terpenuhi. Setelah mendapatkan kandidat data 2 itemset kemudian melakukan
pembangkitan aturan asosiasi dengan menetapkan minimal confidence 25%. Hasil
Universitas Islam Negeri Sunan Kalijaga (11.12.2019)
9
dari penelitian ini algoritma apriori berhasil diimplementasikan untuk mengetahui
pola pembelian konsumen dari data yang tersedia.
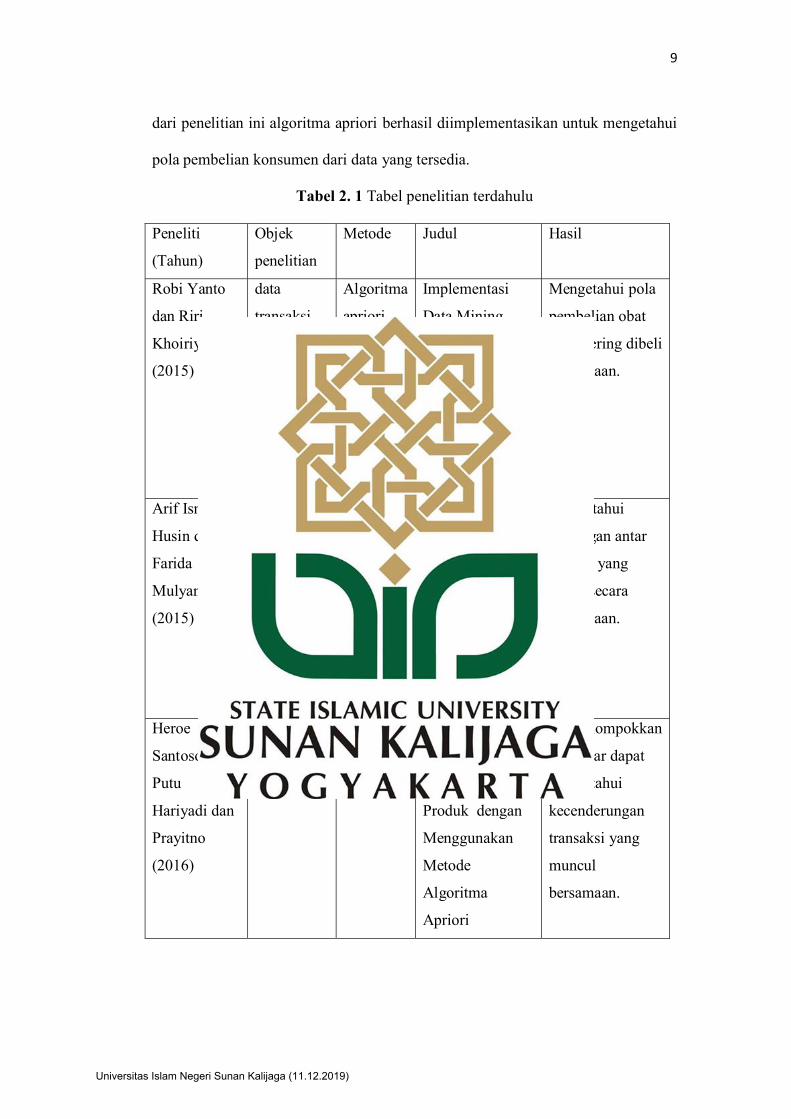
Tabel 2. 1 Tabel penelitian terdahulu
Peneliti
(Tahun)
Objek
penelitian
Metode Judul Hasil
Robi Yanto
dan Riri
Khoiriyah
(2015)
data
transaksi
pembelian
obat
periode
Januari dan
Februari
2014
Algoritma
apriori
Implementasi
Data Mining
dengan Metode
Algoritma
Apriori dalam
Menentukan Pola
Pembelian Obat
Mengetahui pola
pembelian obat
yang sering dibeli
bersamaan.
Arif Ismail
Husin dan
Farida
Mulyaningsih
(2015)
Data
transaksi
pembelian
pakaian
tahun 2013
Algoritma
apriori
Penerapan
Metode Data
Mining Analisis
terhadap Data
Penjualan
Pakaian dengan
Algoritma
Apriori
Mengetahui
hubungan antar
produk yang
dibeli secara
bersamaan.
Heroe
Santoso, I
Putu
Hariyadi dan
Prayitno
(2016)
Data
transaksi
swalayan
Algoritma
apriori
Data Mining
Analisa Pola
Pembelian
Produk dengan
Menggunakan
Metode
Algoritma
Apriori
mengelompokkan
data agar dapat
mengetahui
kecenderungan
transaksi yang
muncul
bersamaan.
Universitas Islam Negeri Sunan Kalijaga (11.12.2019)
10
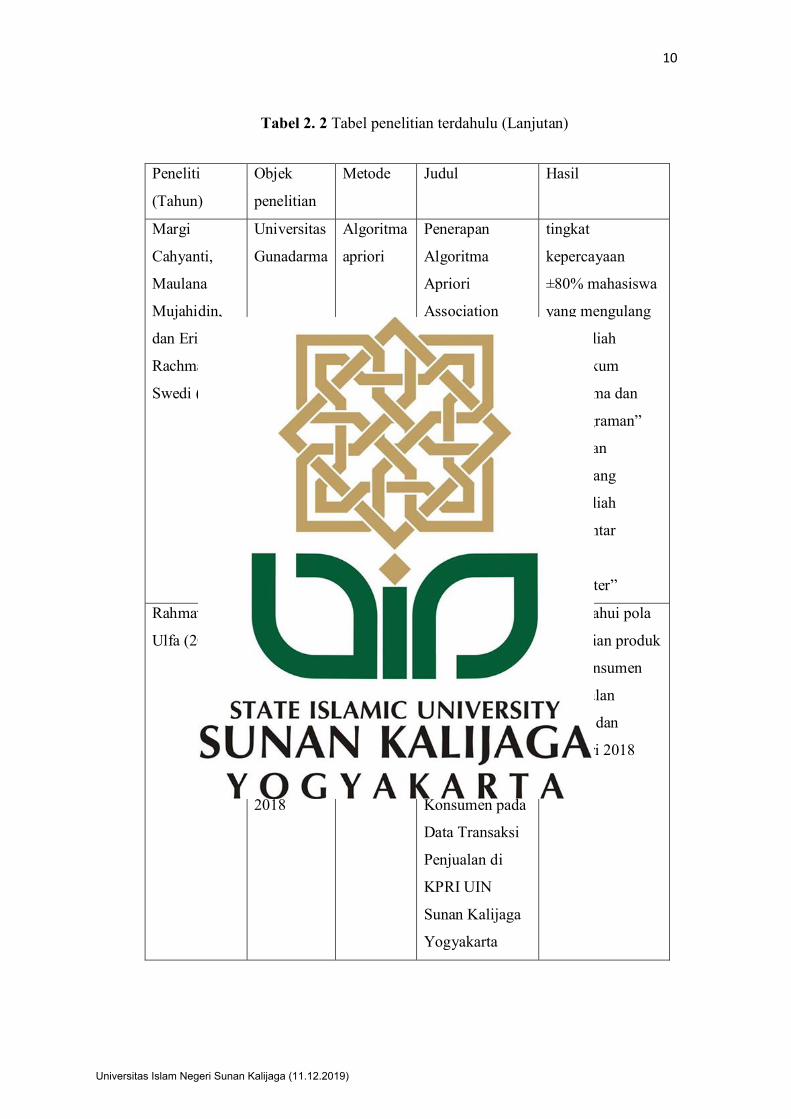
Tabel 2. 2 Tabel penelitian terdahulu (Lanjutan)
Peneliti
(Tahun)
Objek
penelitian
Metode Judul Hasil
Margi
Cahyanti,
Maulana
Mujahidin,
dan Ericks
Rachmat
Swedi (2017)
Universitas
Gunadarma
Algoritma
apriori
Penerapan
Algoritma
Apriori
Association
Rule Untuk
Analisa Nilai
Mahasiswa Di
Universitas
Gunadarma
tingkat
kepercayaan
±80% mahasiswa
yang mengulang
matakuliah
”Praktikum
Algoritma dan
Pemrograman”
juga akan
mengulang
matakuliah
"Pengantar
Sistem
Komputer”
Rahmawati
Ulfa (2018)
KPRI UIN
Sunan
Kalijaga
Yogyakarta
bulan
Januari dan
Februari
2018
Algoritma
apriori
Implementasi
Data Mining
Menggunakan
Algoritma
Apriori untuk
Mengetahui
Pola Pembelian
Konsumen pada
Data Transaksi
Penjualan di
KPRI UIN
Sunan Kalijaga
Yogyakarta
mengetahui pola
pembelian produk
oleh konsumen
pada bulan
Januari dan
Februari 2018
Universitas Islam Negeri Sunan Kalijaga (11.12.2019)

11
2.2 Landasan Teori
2.2.1 Data Mining
Data mining adalah suatu istilah yang dibuat untuk menguraikan
penemuan pengetahuan didalam database. Data mining adalah proses yang
menggunakan teknik statistik, matematika, kecerdasan buatan, dan machine
learning untuk mengekstraksi dan mengidentifikasikan informasi yang bermanfaat
dan pengetahuan yang terkait dari berbagai database besar. (Turban, dkk. 2005:
Kusrini & Luthfi, 2009).
Menurut Gartner Group data mining adalah suatu proses menemukan
hubungan yang berarti, pola, dan kecenderungan dengan memeriksa dalam
sekumpulan besar data yang tersimpan dalam penyimpanan dengan menggunakan
teknik pengenalan pola seperti teknik statistik dan matematika (Larose, 2005:
Kusrini & Luthfi, 2009).
Data mining merupakan bidang dari beberapa bidang keilmuan yang
menyatukan teknik dari pembelajaran mesin, pengenalan pola, statistik, database,
dan visualisasi untuk penanganan permasalahan pengambilan informasi dari
database besar. (Larose, 2005: Kusrini & Luthfi, 2009).
Data mining juga dapat diartikan sebagai pengekstrakan informasi baru
yang diambil dari bongkahan data besar yang membantu dalam pengambilan
keputusan (Kusrini & Luthfi, 2009).
Istilah data mining dan knowledge discovery in database (KDD) seringkali
digunakan secara bergantian untuk menjelaskan proses penggalian informasi
tersembunyi dalam suatu basis data yang besar. Sebenarnya kedua istilah tersebut
Universitas Islam Negeri Sunan Kalijaga (11.12.2019)

12
memiliki konsep yang berbeda, tetapi berkaitan satu sama lain. Dan salah satu
tahapan dalam keseluruhan proses KDD adalah data mining (Kusrini & Luthfi,
2009).
Gambar 2. 1 Proses Data Mining
Berdasarkan gambar 2.1. proses KDD secara garis besar dapat menjelaskan
sebagai berikut (Fayyad, 1996; Kusrini & Luthfi, 2009).
1. Data Selection
Pemilihan (seleksi) data dari sekumpulan data operasional perlu
dilakukan sebelum tahap penggalian informasi dalam KDD dimulai. Data hasil
seleksi yang akan digunakan untuk proses data mining, disimpan dalam suatu
berkas, terpisah dari basis data operasionalPreprocessing/ Cleaning
2. Pre-processing/ Cleaning
Sebelum proses data mining dapak dilaksanakan, perlu dilakukan
proses cleaning pada data yang menjadi fokus KDD. Proses Cleaning
mencakup antara lain membuang duplikasi data, memeriksa kesalahan pada
data, seperti kesalahan cetak (tipografi). Juga dilakukan proses enrichment,
Universitas Islam Negeri Sunan Kalijaga (11.12.2019)

13
yaitu proses “memperkaya” data yang sudah ada dengan data atau informasi
lain yang relevan dan diperlukan untuk KDD, seperti data atau informasi
eksternal.
3. Transformation
Coding adalah proses transformasi pada data yang telah dipilih
sehingga data tersebut sesuai untuk proses data mining. Proses coding dalam
KDD merupakan proses kreatif dan sangat tergantung pada jenis atau pola
informasi yang akan dicari dalam basis data.
4. Data Mining
Data mining adalah proses mencari pola atau informasi menarik dalam
data terpilih dengan menggunakan teknik atau metode tertentu. Teknik,
metode, atau algoritma dalam data mining sangat bervariasi. Pemilihan metode
atau algoritma yang tepat sangat bergantung pada tujuan dan proses KDD
secara keseluruhan.
5. Interpretation atau Evaluation
Pola informasi yang dihasilkan dari proses data mining perlu
ditampilkan dalam bentuk yang mudah dimengerti oleh pihak yang
berkepentingan. Tahap ini merupakan bagian dari proses KDD yang disebut
interpretation. Tahap ini mencakup pemeriksaan apakah pola atau informasi
yang ditemukan bertentanga dengan fakta atau hipotesis yang ada sebelumnya..
Data mining dibagi menjadi beberapa kelompok berdasarkan tugas yang dapat
dilakukan, yaitu (Larose, 2005: Kusrini & Luthfi, 2009):
Universitas Islam Negeri Sunan Kalijaga (11.12.2019)

14
1. Deskripsi
Terkadang peneliti dan analisis secara sederhana ingin mencoba
mencari cara untuk menggambarkan pola dan kecenderungan yang terdapat
dalam data. Sebagai contoh, petugas pengumpulan suara mungkin tidak dapat
menemukan keterangan atau fakta bahwa siapa yang tidak cukup profesional
akan sedikit didukung dalam pemilihan presiden. Deskripsi dari pola dan
kecenderungan sering memberikan kemungkinan penjelasan untuk suatu pola
atau kecenderungan.
2. Estimasi
Estimasi hampir sama dengan klasifikasi, kecuali variable target
estimasi lebih ke arah numerik daripada ke arah kategori. Model dibangun
menggunakan record lengkap yang menyediakan nilai dari variabel target
dibuat berdasarkan nilai prediksi. Sebagai contoh, estimasi nilai indeks prestasi
kumulatif mahasiswa program pascasarjana dengan melihat nilai indeks
prestasi mahasiswa tersebut pada saat mengikuti program sarjana.
3. Prediksi
Prediksi hampir sama dengan klasifikasi dan estimasi, kecuali bahwa
dalam prediksi nilai dari hasil akan ada di masa mendatang.
Contoh prediksi dalam bisnis dan penelitian adalah:
· Prediksi harga beras dalam tiga bulan yang akan datang.
· Prediksi presentase kenaikan kecelakaan lalu lintas tahun depan jika batas
bawah kecepatan dinaikan.
Universitas Islam Negeri Sunan Kalijaga (11.12.2019)

15
4. Klasifikasi
Dalam klasifikasi, terdapat target variabel kategori. Sebagai contoh,
penggolongan pendapatan dapat dipisahkan dalam tiga kategori, yaitu
pendapat tinggi, pendapatan sedang, dan pendapatan rendah. Contoh lain
klasifikasi dalam bisnis dan penelitian adalah:
· Menentukan apakah suatu transaksi kartu kredit merupakan transaksi yang
curang atau bukan.
· Memperkirakan apakah suatu pengajuan hipotek oleh nasabah merupakan
suatu kredit yang baik atau buruk.
· Mendiagnosis penyakit seorang pasien untuk mendapatkan termasuk
kategori penyakit apa.
5. Pengklusteran
Pengklusteran merupakan pengelompokan record, pengamatan, atau
memperhatikan dan membentuk kelas objek-objek yang memiliki kemiripan.
Kluster adalah kumpulan record yang memiliki kemiripan satu dengan yang
lainnya dan memiliki ketidakmiripan dengan record-record dalam kluster lain.
6. Asosiasi
Tugas asosiasi dalam data mining adalah menemukan atribut yang
muncul dalam satu waktu. Dalam dunia bisnis lebih umum disebut analisis
keranjang belanja.
Contoh asosiasi dalam bisnis dan penelitian adalah:
· Meneliti jumlah pelanggan dari perusahaan telekomunikasi seluler yang
diharapkan untuk memberikan respon positif terhadap penawaran upgrade
layanan yang diberikan.
Universitas Islam Negeri Sunan Kalijaga (11.12.2019)

16
· Menemukan barang dalam supermarket yan dibeli secara bersamaan dan
barang yang tidak pernah dibeli secara bersamaan.
2.2.2 Konsep Analisis Asosiasi
Analisis asosiasi atau association rule mining adalah teknik data mining untuk
menemukan aturan asosiatif antara suatu kombinasi item. Analisis asosiasi dikenal
juga sebagai teknik data mining yang menjadi dasar dari berbagai teknik data
mining lainnya. Secara khusus, salah satu tahap analisis asosisasi yang menarik
perhatian banyak peneliti untuk menghasilkan algoritma yang efisien adalah
analisis pola frekuensi tinggi (frequent pattern mining). Penting tidaknya suatu
aturan asosiasi dapat diketahui dengan dua parameter (Nofiansyah, 2014):
a. Support :
Suatu ukuran yang menunjukkan seberapa besar tingkat dominasi suatu
item/itemset dari keseluruhan transaksi. Ukuran ini menentukan apakah suatu
item/itemset layak untuk dicari confidence tersebut (missal, dari keseluruhan
transaksi yang ada, seberapa tingkat dominasi yang menunjukkan item A dan B
dibeli bersamaan).
b. Confidence :
Suatu ukuran yang menunjukkan hubungan antar 2 item secara
conditional (misal, seberapa sering item B dibeli jika orang membeli item A)
(Kusrini dan Emha, 2009).
Aturan asosiasi biasanya dinyatakan dalam bentuk :
{roti,mentega}->{susu}(support = 40%, confidence = 50%)
Aturan tersebut berarti “50% dari transaksi di database yang memuat item
roti dan mentega juga memuat item susu. Sedangkan 40% dari seluruh
Universitas Islam Negeri Sunan Kalijaga (11.12.2019)

17
transaksi yang ada di database memuat ketiga item itu.” dapat juga diartikan:
“Seorang konsumen yang membeli roti dan mentega punya kemungkinan 50%
untuk juga membeli susu. Aturan ini cukup signifikan karena mewakili 40%
dari catatan transaksi selama ini.”
Aturan sosiasi didefinisikan suatu proses yang menemukan semua
aturan asosiasi yang memenuhi syarat minimum untuk support (minimum
support) dan syarat minimum untuk confidence (minimum confidence).
(Kusrini dan Emha, 2019). Adapun langkah-langkah penyelesaiannya adalah
dengan Assosiant:
1. Analisis pola frekuensi tinggi
Tahap ini mencari kombinasi item yang memenuhi syarat minimum dari
nilai support dalam database. Nilai support sebuah item ditunjukkan pada
rumus (2,1).
��pport(�) = ∑��������� ���������� �
��������� x 100% (2,1)
Sementara itu, nilai support dari 2 itemset diperoleh dari rumus (2,2).
Support (A,B) = P(A � B)
Support(A,B) = ∑��������� ���������� ���
��������� x 100% (2,2)
2. Pembentukan aturan asosiasi
Setelah semua pola frekuensi tinggi ditemukan, barulah dicari aturan
asosiasi yang memenuhi syarat minimum untuk confidence dengan menghitung
confidence aturan asosiatif A � B.
Nilai confidence dari aturan A � B ditunjukkan pada rumus (2,3) berikut.
Confidence(A,B) = ∑��������� ���������� ���
��������� ���������� � x 100% (2,3)
Universitas Islam Negeri Sunan Kalijaga (11.12.2019)

18
2.2.3 Apriori
Algoritma apriori merupakan salah satu algoritma klasik data mining.
Algoritma apriori digunakan agar komputer dapat mempelajari aturan
asosiasi, mencari pola hubungan antar satu atau lebih item dalam suatu dataset.
Langkah atau cara kerja Apriori dapat digambarkan dalam bentuk flowchart
berikut:
Gambar 2. 2 Flowchart Apriori
Dari penggambaran pada flowchart diatas, langkah-langkah algoritma apriori
dapat dijabarkan sebagai berikut :
Universitas Islam Negeri Sunan Kalijaga (11.12.2019)

19
1. Menghitung jumlah transaksi yang akan di proses dengan algoritma apriori
2. Menghitung support kandidat 1-itemset
3. Menentukan minimum support
4. Menyeleksi item yang tidak memenuhi minimum support
5. Mengulangi langkah 2 sampai 4 (jika tidak ada yang memenuhi minimum
support, maka berhenti sampa x-itemset sebelumnya)
6. Menentukan minimum confidence
7. Melakukan aturan asosiasi, yaitu dengan membandingkan nilai confidence
masing-masing itemset dengan minimum confidence.
8. Rule terkuat adalah rule yang memenuhi batas minimum confidence
2.2.4 Python
Python merupakan bahasa pemrograman beraras tinggi yang diciptakan
oleh Guido van Rossum pada tahun 1989 di Amsterdam, Belanda. Meskipun
beraras tinggi namun Python memiliki bahasa yang sederhana yang mudah
dipahami oleh pemula. Kosakata yang terdapat pada Python sangatlah mudah
untuk diingat-ingat. Namun, dibalik kesederhanaan ini, Python mendukung
banyak pustaka yang tersimpan dalam modul-modul. Modul atau disebut juga
pustaka adalah suatu berkas yang bisa berisi kumpulan kelas, fungsi, dan
prosedur, yang bisa diakses dalam mode interaktif atau suatu skrip. Agar suatu
modul bisa digunakan dalam mode interaktif atau suatu skrip, modul harus
diimpor terlebih dahulu. Python juga menyediakan mekanisme untuk mengimpor
sejumlah modul dengan hanya menggunakan sebuah pernyataan import dengan
antarmodul dipisahkan dengan tanda koma. Sejumlah pustaka tersedia antara lain
mendukung jaringan, antarmuka grafis, pencitraan, analisis dan komputasi
Universitas Islam Negeri Sunan Kalijaga (11.12.2019)

20
numeric, hypertext (HTML, XML, dll) akses database, dan berbagai
lainnya.(Kadir, 2015).
Bahasa pemrograman Python adalah pemrograman berorientasi objek yang
memiliki keistimewaan tentang pewarisan dan instansiasi yang ditawarkan pada
bahasa berorientasi objek juga dapat diwujudkan pada Python.
Universitas Islam Negeri Sunan Kalijaga (11.12.2019)

21
BAB III
METODE PENELITIAN
3.1 Objek dan Lokasi Penelitian
Dalam melakukan penelitian tugas akhir ini, dilakukan dengan mengambil
objek penelitian berupa data penjualan pada bulan November dan Desember 2018
Toko Buku Social Agency Baru Ambarukmo yang terletak di Jl. Laksda
Adisucipto No. 22, Papringan, Caturtunggal, Yogyakarta. Toko ini tidak hanya
menjual buku, ada berbagai macam alat tulis yang disediakan.
3.2 Metode Penelitian
Metode yang digunakan pada penelitian tugas akhir ini adalah dengan
metode penelitian terapan. Yaitu menera pkan algoritma apriori pada bahasa
pemrograman python dengan tujuan untuk menganalisa pola pembelian pada Toko
Buku Social Agency Ambarukmo, dimana data yang digunakan adalah data pada
bulan November dan Desember 2018 yang telah dioalah pada tahapan
preprocessing. Dari data tersebut, untuk mendapatkan hasil yang diinginkan harus
melalui dua tahapan. Yaitu pembentukan itemset dengan minimum support yang
telah ditentukan. Selanjutnya menentukan minimum confidence untuk melakukan
pembentukan aturan asosiasi.
Universitas Islam Negeri Sunan Kalijaga (11.12.2019)

22
3.3 Tahap-tahap Penelitian
Tahap-tahap yang dilakukan dalam penelitian ini adalah
1. Pengambilan Data
Pada tahapan ini, penulis mendatangi langsung lokasi penelitian untuk
bertemu pemilik toko dengan agenda meminta izin terkait dengan
pengambilan data. Setelah mendapatkan izin, penulis kemudian
menemui admin yang mengelola data untuk meminta dan menjelaskan
data-data yang dibutuhkan pada penelitian ini.
2. Seleksi Data
Setelah memperoleh data, seleksi data adalah tahapan yang dilakukan
untuk memilih atribut-atribut yang digunakan pada data mentah
transaksi penjualan yang diperoleh dari Toko Buku Social Agency
Ambarukmo.
3. Preprocessing/ Cleaning Data
Dari atribut-atribut data yang telah dipilih pada tahapan sebelumnya,
pada tahap ini duplikasi data dan field yang tidak diperlukan dibuang
untuk mendapatkan hasil data yang dapat diolah pada metode
penelitian ini.
4. Transformation
Pada tahap ini, data siap olah yang dihasilkan pada tahap
preprocessing/cleaning dijadikan satu folder dengan data python yang
kemudian akan dilakukan pemrosesan kedalam tahapan coding.
Universitas Islam Negeri Sunan Kalijaga (11.12.2019)

23
5. Data Mining
Setelah proses transformation, tahapan Data Mining adalah tahapan
inti pada algoritma ini. Pada tahapan ini, penulis melakukan proses
coding dengan bahasa pemrograman python untuk menerapkan metode
apriori pada library yang ada. Tahap ini menghasilkan pola pembelian
konsumen yang akan menjadi acuan untuk prose
interpretation/evaluation.
6. Interpretation/Evaluation
Pola yang dihasilkan dari proses data mining selanjutnya akan
dinterpretasikan menjadi sebuah informasi atau pengetahuan
(knowledge).
Universitas Islam Negeri Sunan Kalijaga (11.12.2019)

24
BAB IV
HASIL DAN PEMBAHASAN
4.1 Pembahasan
Alur penelitian yang telah dibahas pada bab sebelumnya, dapat
diilustrasikan sebagai berikut:
Gambar 4. 1 Alur Penelitian (Ulfa, 2018)
Dari gambar 4.1. diatas, alur penelitian ini dapat diuraikan sebegai berikut:
4.1.1. Seleksi Data
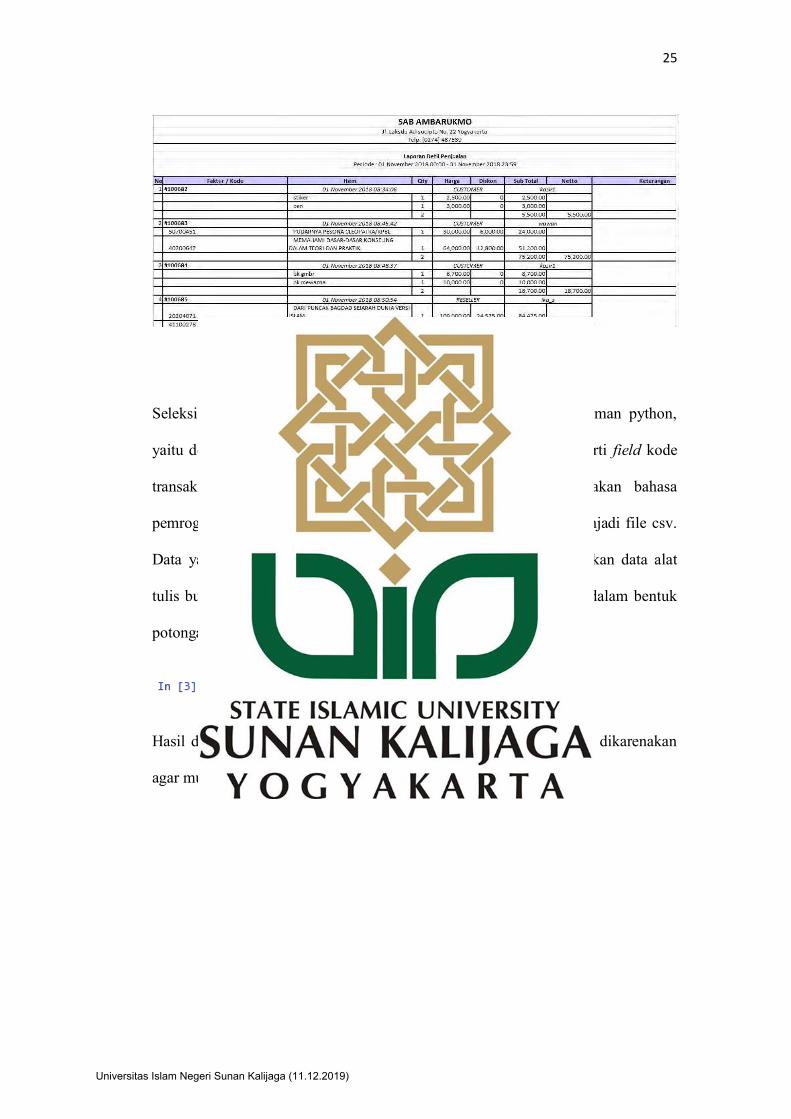
Data transaksi penjualan yang diperoleh dari toko buku Social Agency
Baru Ambarukmo yang berupa data mentah dalam format excel tersebut
dilakukan seleksi data apa saja yang akan dibutuhkan saat proses data mining.
Data tersebut diseleksi karena data yang diperoleh adalah data-data yang belum
beraturan. Berikut adalah contoh data tersebut.
Universitas Islam Negeri Sunan Kalijaga (11.12.2019)
25
Gambar 4. 2 Data Mentah
Seleksi tersebut dilakukan dengan menggunakan bahasa pemrograman python,
yaitu dengan melakukan pemilihan field-field yang dibutuhkan seperti field kode
transaksi dan faktur/ kode barang. Sebelum diolah menggunakan bahasa
pemrograman python, file excel tersebut diubah terlebih dahulu menjadi file csv.
Data yang tidak memiliki faktur/ kode dihilangkan karena merupakan data alat
tulis bukan termasuk data buku. Adapun prosesnya akan disajikan dalam bentuk
potongan kode berikut:
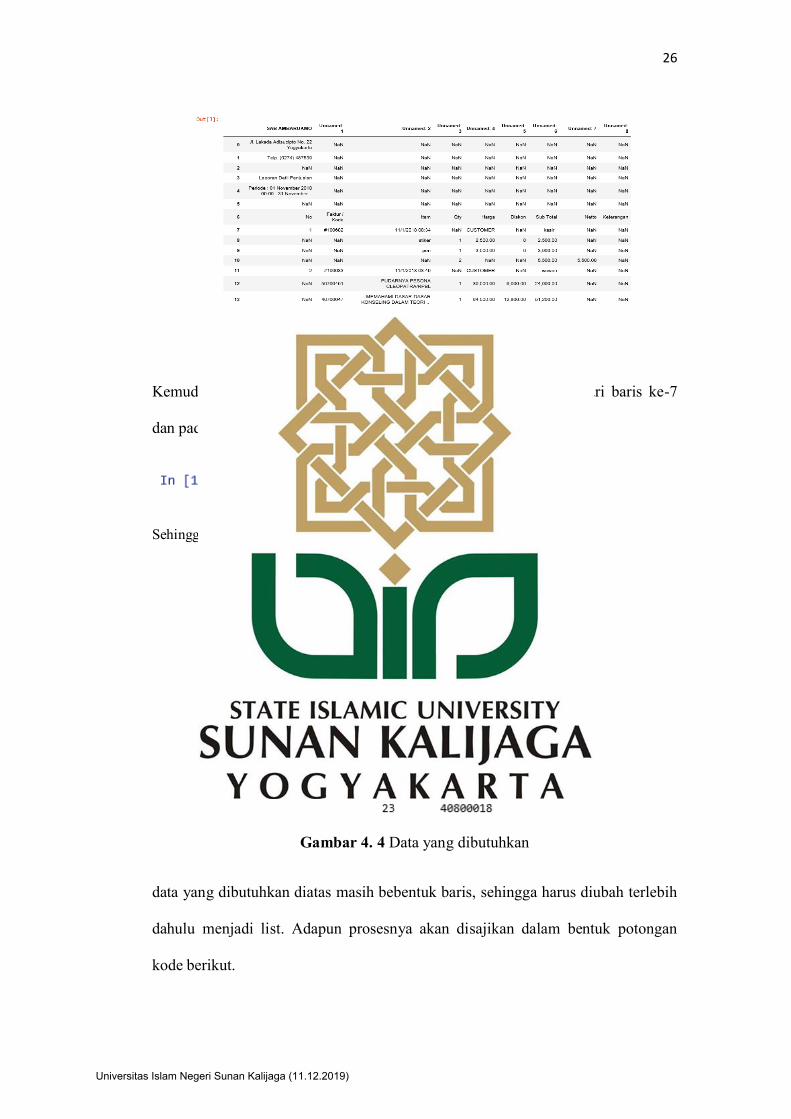
Hasil dari code diatas adalah data asli dengan tanpa header. Hal ini dikarenakan
agar mudah terbaca pada python.
Universitas Islam Negeri Sunan Kalijaga (11.12.2019)
26
Gambar 4. 3 Data awal tanpa header
Kemudian mengambil data yang dibutuhkan saja, yaitu dimulai dari baris ke-7
dan pada kolom ‘Unnamed: 1’.
Sehingga akan menampilkan data sepert pada gambar 4.4 tersebut.
Gambar 4. 4 Data yang dibutuhkan
data yang dibutuhkan diatas masih bebentuk baris, sehingga harus diubah terlebih
dahulu menjadi list. Adapun prosesnya akan disajikan dalam bentuk potongan
kode berikut.
Universitas Islam Negeri Sunan Kalijaga (11.12.2019)

27
Hasil dari proses diatas seperti pada gambar 4.5 berikut.
Gambar 4. 5 Data list
4.1.2. Pre-Processing
Tahap pertama pada tahap pre-processing adalah Labelling. Labelling
adalah proses pelabelan pada data yang sudah terseleksi. Berdasarkan penelitian di
toko buku Social Agency Baru Ambarukmo, buku-buku tersebut di bedakan
menjadi 56 jenis/ kategori. Adapun prosesnya akan disajikan dalam bentuk
potongan kode berikut.
Universitas Islam Negeri Sunan Kalijaga (11.12.2019)

28
Data hasil labelling tersebuta akan ditampilkan seperti pada gambar 4.6 berikut.
Gambar 4. 6 Data labelling
Data labelling diatas masih berbentuk data keseluruhan, sehingga harus
dibedakan antar keranjang agar bisa ditemukan association rule-nya. Adapun
prosesnya akan disajikan dalam bentuk potongan kode berikut.
Universitas Islam Negeri Sunan Kalijaga (11.12.2019)

29
Hasil dari proses data keranjang diatas adalah seperti pada gambar 4.7 berikut.
Gambar 4. 7 Data antar keranjang
Pada algoritma apriori, ketika dalam satu keranjang memiliki dua item yang sama
maka akan dianggap menjadi satu item saja. Sehingga pada preprocessing ini
akan menghapus data duplikat atau data yang serupa dalam satu keranjang.
Adapun prosesnya akan disajikan dalam potongan code berikut.
Hasil dari proses penghilangan data duplikat atau data yang sama pada satu
keranjang akan ditampilkan pada gambar 4.8 berikut.
Universitas Islam Negeri Sunan Kalijaga (11.12.2019)
30
Gambar 4. 8 Data tanpa duplikat
4.1.3. Transformation
Setelah dilakukan pre-processing, langkah selanjutnya adalah
transformation. Pada proses ini adalah dengan memastikan data tersebut sudah
dapat diolah dengan menggunakan algoritma apriori.
4.1.4. Proses Data Mining
Data hasil pre-processing tersebut, kemudian diolah dengan algoritma
apriori pada bahasa pemrograman python. Output dari proses data mining ini
adalah rule atau aturan asosiasi pada data transaksi yang diolah. Berikut adalah
contoh perhitungan manual dengan algoritma apriori yang ditunjukkan pada tabel
4.2.
Tabel 4. 1 Contoh data transaksi penjualan
No.
1. SMP Pelajaran Buku Agama
2. Psikologi Pelajaran Psikotes SMP Buku Agama
3. Pelajaran Peta SMP
4. Peta Gender Novel
5. Pelajaran Peta
Universitas Islam Negeri Sunan Kalijaga (11.12.2019)

31
Pada algoritma apriori, langkah pertama yang dilakukan adalah
menghitung jumlah transaksi yang akan dirproses. Dari tabel 4.2. diketahui
jumlah transaksi pada data tersebut adalah 5 transaksi. Setelah diketahui jumlah
transaksi, langkah selanjutnya adalah menghitung nilai support pada masing-
masing kandidat 1-itemset. Perhitungan nilai support akan ditunjukkan pada tabel
4.3.
Tabel 4. 2 Perhitungan nilai support kandidat 1-itemset
Jenis Buku Support
SMP 3/5 x 100% = 60%
Pelajaran 4/5 x 100% = 80%
Buku Agama 2/5 x 100% = 40%
Psikologi 1/5 x 100% = 20%
Psikotes 1/5 x 100% = 20%
Peta 2/5 x 100% = 40%
Gender 1/5 x 100% = 20%
Novel 1/5 x 100% = 20%
Selanjutnya menentukan minimum support dan menyeleksi item yang
tidak memenuhi. Misal dalam contoh ini, minimum support yang diambil adalah
40%. maka diperoleh item yang masuk dalam frequent itemset untuk k-1 adalah
sebagai berikut:
Tabel 4. 3 Frequent itemset k-1
Jenis Buku Support
SMP 60%
Pelajaran 80%
Buku Agama 40%
Peta 40%
Universitas Islam Negeri Sunan Kalijaga (11.12.2019)

32
Item yang telah terseleksi seperti pada tabel 4.4. tersebut dimasukkan
dalam kandidat k-itemset. Jenis buku Psikologi, Psikotes, Gender dan Novel tidak
memenuhi batas minimum support yang ditentukan, maka dihapus dari himpunan
kandidat itemset. Selanjutnya yaitu melakukan seleksi dan mencari nilai support
untuk kandidat 2 itemset dengan melakukan penggabungan pada kandidat 1
itemset yang sudah terseleksi sebelumnya. Tabel 4.5. menunjukkan perhitungan
nilai support kandidat 2-itemset.
Tabel 4. 4 Perhitungan nilai support kandidat 2-itemset
Jenis Buku Support
{SMP, Pelajaran} 3/5 x 100% = 60%
{SMP, Buku Agama} 2/5 x 100% = 40%
{SMP, Peta} 1/5 x 100% = 20%
{Pelajaran, Buku Agama} 2/5 x 100% = 40%
{Pelajaran, Peta} 2/5 x 100% = 40%
{Buku Agama, Peta} 0/5 x 100% = 0%
Perhitungan nilai support untuk 2-itemset sama dengan perhitungan nilai
support untuk 1-itemset, yaitu berpacu pada data transaksi awal. Selanjutnya
adalah proses pemangkasan atau penghapusan itemset yang tidak memenuhi
minimum support yang telah ditentukan sebelumnya. Sehingga diperoleh:
Tabel 4. 5 Frequent 2-itemset
Jenis Buku Support
{SMP, Pelajaran} 60%
{SMP, Buku Agama} 40%
{Pelajaran, Buku Agama} 40%
{Pelajaran, Peta} 40%
Universitas Islam Negeri Sunan Kalijaga (11.12.2019)

33
Selanjutnya adalah mencari support dan menggabungkan kandidat itemset
pada tabel 4.6. dengan dirinya sendiri, sehingga membentuk k-3 seperti pada tabel
4.7.
Tabel 4. 6 Perhitungan nilai support kandidat 3-itemset
Jenis Buku Support
{SMP, Pelajaran, Buku Agama} 2/5 x 100% = 40%
{SMP, Pelajaran, Peta} 1/5 x 100% = 20%
{SMP, Buku Agama, Peta} 0/5 x 100% = 0%
Berdasarkan tabel 4.7. tersebut, kandidat 3-itemset yang memenuhi nilai
minimum support hanya {SMP, Pelajaran, Buku Agama}. Sehingga diperoleh:
Tabel 4. 7 Frequent 3-itemset
Jenis Buku Support
{SMP, Pelajaran, Buku Agama} 40%
Setelah semua pola frekuensi tinggi ditemukan, kemudian melakukan
pembentukan aturan asosiasi yang memenuhi syarat minimum confidence dengan
menghitung nilai confidence pada tabel 4.7.
Berdasarkan Tabel 4.2. besarnya nilai confidence dari aturan asosiasi dapat
ditunjukkan pada tabel 4.8. berikut:
Tabel 4. 8 Aturan Asosisasi 3-itemset
Aturan Confidence
{SMP, Pelajaran -> Buku Agama} 2/3 x 100% = 67%
{SMP, Buku Agama -> Pelajaran} 2/2 x 100% = 100%
{Buku Agama, Pelajaran -> SMP} 2/2 x 100% = 100%
Universitas Islam Negeri Sunan Kalijaga (11.12.2019)

34
Selanjutnya adalah menetapkan nilai minimum confidence, misalkan dalam
contoh ini nilai minimum confidence adalah 70%, maka aturan yang terbentuk
adalah dua aturan berikut:
· Jika membeli jenis buku SMP dan Buku Agama, maka akan membeli
Pelajaran
· Jika membeli jenis buku Buku Agama dan Pelajaran, maka akan membeli
SMP
Calon aturan asosiasi dari kandidat 2-itemset dapat dilihat pada tabel 4.9.
Tabel 4. 9 Aturan Asosiasi 2-itemset
Jenis Buku Confidence
{SMP -> Pelajaran} 3/3 x 100% = 100%
{Pelajaran -> SMP} 3/4 x 100% = 75%
{SMP -> Buku Agama} 2/3 x 100% = 67%
{Buku Agama -> SMP} 2/2 x 100% = 100%
{Pelajaran -> Buku Agama} 2/4 x 100% = 50%
{Buku Agama -> Pelajaran} 2/2 x 100% = 100%
{Pelajaran -> Peta} 2/4 x 100% = 50%
{Peta -> Pelajaran} 2/3 x 100% = 67%
Setelah 2 aturan asosiasi tersebut terbentuk, selanjutnya adalah
pembentukan aturan asosiasi final, yaitu penggabungan antara 2 aturan asosiasi
dengan menambahkan nilai support dan confidence.
Tabel 4. 10 Aturan Asosiasi Final
Jenis Buku Support Confidence
{SMP -> Pelajaran} 60% 100%
{Pelajaran -> SMP} 60% 75%
{SMP -> Buku Agama} 40% 67%
Universitas Islam Negeri Sunan Kalijaga (11.12.2019)
35
Tabel 4. 11 Aturan Asosiasi Final (Lanjutan)
Jenis Buku Support Confidence
{Buku Agama -> SMP} 40% 100%
{Pelajaran -> Buku Agama} 40% 50%
{Buku Agama -> Pelajaran} 40% 100%
{Pelajaran -> Peta} 40% 50%
{Peta -> Pelajaran} 40% 67%
{SMP, Buku Agama -> Pelajaran} 40% 100%
{Buku Agama, Pelajaran -> SMP} 40% 100%
Rule terkuat adalah rule yang memenuhi batas minimum confidence.
Berdasarkan tabel 4.10. rule terkuat untuk 2-itemset terdapat pada {SMP ->
Pelajaran} dengan nilai support 60% dan nilai confidence 100%, yang artinya
bahwa 60% dari semua transaksi mengandung itemset {SMP dan Pelajaran} dan
100% transaksi yang mengandung SMP juga mengandung Pelajaran. Sedangkan
untuk 3-itemset ada 2 rule yang sama kuat, yaitu {SMP, Buku Agama ->
Pelajaran} dan {Buku Agama, Pelajaran -> SMP} dengan nilai support 40% dan
nilai confidence 100%.
4.1.5. Iterpretation/ Evaluation
Tahap ini adalah tahap dimana mengubah pola-pola yang dihasilkan oleh
proses data mining menjadi sebuah informasi atau knowledge. Pada contoh kasus
diatas, maka interpretasi yang dapat diambil untuk pola SMP -> Pelajaran
adalah: karena nilai confidence dari aturan tersebut 100%, maka knowledge yang
didapat adalah bahwa setiap pembelian jenis buku SMP, seseorang pasti akan
membeli jenis buku Pelajaran. Sehingga dapat disimpulkan persediaan buku jenis
SMP dan Pelajaran dapat diseimbangkan.
Universitas Islam Negeri Sunan Kalijaga (11.12.2019)

36
4.2. Hasil Penelitian
4.2.1. Penerapan Data Mining pada Python
Langkah pertama dalam penerapan data mining pada bahasa pemrograman
python adalah mendefinisikan variabel batasan dengan beberapa parameter
algoritma apriori yaitu min_support, min_confidence dan min_lift. Min_support
adalah batas minimal dari seberapa sering item tersebut terbeli. Min_confidence
adalah batas minimal kemungkinan kedua item tersebut terbeli secara bersamaan.
Sedangkan min_lift adalah batas minimal kemungkinan pembelian (A->B) lebih
besar daripada pembelian B. Jika lift adalah 1 artinya tidak ada hubungan antara A
dan B, namun jika lift kurang dari 1 artinya produk A dan B tidak mungkin dibeli
secara bersamaan. Pada perhitungan manual, nilai lift diperoleh dari hasil bagi
antara confidence (A->B) dan support B. Isi dari parameter tersebut dapat diubah
sesuai keinginan. Adapun prosesnya akan disajikan dalam bentuk potongan kode
berikut:
Output yang dihasilkan seperti pada gambar 4.9.
Gambar 4. 9 Output hasil awal
Universitas Islam Negeri Sunan Kalijaga (11.12.2019)

37
Selanjutnya melakukan looping dari baris pertama, sehingga dapat terbaca
jelas isi dari hasil tersebut, seperti rule, support, confidence dan lift. Adapun
prosesnya akan disajikan dalam bentuk potongan kode berikut:
Output yang dihasilkan seperti pada gambar 4.10.
Gambar 4. 10 Hasil Akhir
4.2.2. Hasil Pengolahan Data
Hasil dari pengolahan data dengan algoritma apriori pada bahasa
pemrograman python tersebut adalah sebagai berikut:
Universitas Islam Negeri Sunan Kalijaga (11.12.2019)

38
Gambar 4. 11 Hasil November
Gambar 4. 12 Hasil November (Lanjutan)
Universitas Islam Negeri Sunan Kalijaga (11.12.2019)

39
Gambar 4. 13 Hasil November (Lanjutan)
Gambar 4. 14 Hasil November (Lanjutan)
Universitas Islam Negeri Sunan Kalijaga (11.12.2019)

40
Gambar 4. 15 Hasil November (Lanjutan)
Gambar 4. 16 Hasil November (Lanjutan)
Universitas Islam Negeri Sunan Kalijaga (11.12.2019)

41
Gambar 4. 17 Hasil Desember
Gambar 4. 18 Hasil Desember (Lanjutan)
Universitas Islam Negeri Sunan Kalijaga (11.12.2019)

42
Gambar 4. 19 Hasil Desember (Lanjutan)
Gambar 4. 20 Hasil Desember (Lanjutan)
Universitas Islam Negeri Sunan Kalijaga (11.12.2019)

43
Gambar 4. 21 Hasil Desember (Lanjutan)
Gambar 4. 22 Hasil Desember (Lanjutan)
Universitas Islam Negeri Sunan Kalijaga (11.12.2019)

44
Gambar 4. 23 Hasil Desember (Lanjutan)
Gambar 4. 24 Hasil Desember (Lanjutan)
Berdasarkan gambar hasil pengolahan tersebut, dapat dibuat perbandingan
masing-masing bulan dengan menggunakan Flask, sehingga tampilan akan
berbentuk web sebagai berikut:
Universitas Islam Negeri Sunan Kalijaga (11.12.2019)
45
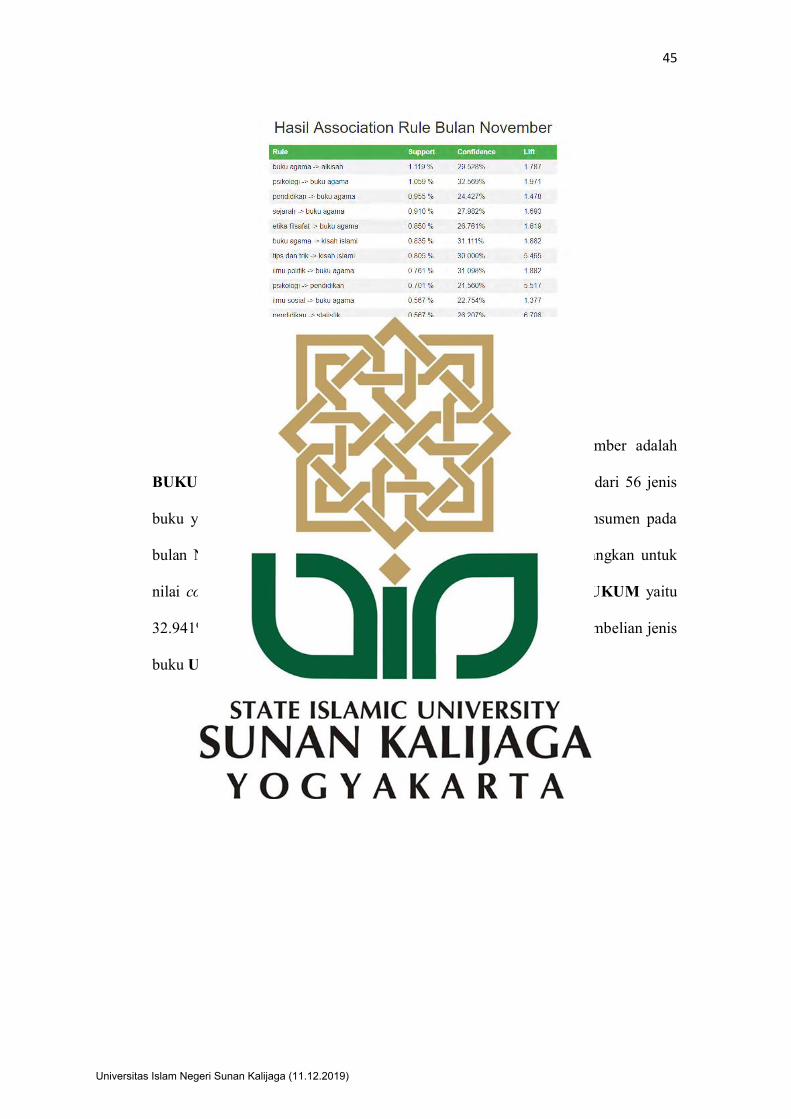
Gambar 4. 25 Association Rule Final Bulan November
Berdasarkan Gambar 4.25 rule terlaris pada bulan November adalah
BUKU AGAMA => ALKISAH dengan support 1.119%. Artinya dari 56 jenis
buku yang terdapat pada toko buku tersebut sebanyak 1.119% konsumen pada
bulan November membeli BUKU AGAMA => ALKISAH. Sedangkan untuk
nilai confidence tertinggi pada bulan November adalah UU => HUKUM yaitu
32.941%. Hal ini menunjukkan tingkat kepercayaan bahwa setiap pembelian jenis
buku UU maka 32.941% akan diikuti membeli jenis buku HUKUM.
Universitas Islam Negeri Sunan Kalijaga (11.12.2019)

46
Gambar 4. 26 Association Rule Final Bulan Desember
Berdasarkan Gambar 4.26 rule terlaris pada bulan Desember adalah
BUKU AGAMA => AL-QURAN dengan support 1.778%. Artinya dari 56 jenis
buku yang terdapat pada toko buku tersebut sebanyak 1.778% konsumen pada
bulan Desember membeli BUKU AGAMA => AL-QURAN. Sedangkan untuk
nilai confidence tertinggi pada bulan Desember adalah CERGAM => TIPS
DAN TRIK yaitu 74.286%. Hal ini menunjukkan tingkat kepercayaan bahwa
setiap pembelian jenis buku CERGAM maka 74.286% akan diikuti membeli
jenis buku TIPS DAN TRIK.
Universitas Islam Negeri Sunan Kalijaga (11.12.2019)




















