
BAB I - blog ship | blognya rifqi neeh · Web viewMisalnya untuk menguji pernyataan bahwa dalam...
65
1 4.1 PENDAHULUAN Pembuatan kesimpulan mengenai segala sifat populasi dilakukan menggunakan sifat-sifat atau karakteristik sampel yang diambil dari populasi yang didapat. Kesimpulan yang dibuat disebut kesimpulan statistis yang untuk singkatnya dikatakan sebagai kesimpulan. Untuk memperoleh kesimpulan, biasanya didahului oleh pengandaian atau asumsi mengenai populasi yang mungkin betul ataupun mungkin tidak betul dan disebut Hipotesis Statistis atau disingkat Hipotesis dan biasa dilambangkan dengan H 0 (baca : H nol). Hipotesis inilah yang akan diteliti menggunakan karakteristik sampel yang diambil dari populasi yang sedang ditinjau. Apabila ternyata penelitian berdasarkan sampel ini, dalam batas-batas tertentu, memperlihatkan adanya kesesuaian dengan hipotesis, maka akan dikatakan hipotesis nol diterima. Ini berarti BAB IV UJI HIPOTESIS
Transcript of BAB I - blog ship | blognya rifqi neeh · Web viewMisalnya untuk menguji pernyataan bahwa dalam...

1
4.1 PENDAHULUAN
Pembuatan kesimpulan mengenai segala sifat populasi dilakukan
menggunakan sifat-sifat atau karakteristik sampel yang diambil dari populasi
yang didapat. Kesimpulan yang dibuat disebut kesimpulan statistis yang untuk
singkatnya dikatakan sebagai kesimpulan.
Untuk memperoleh kesimpulan, biasanya didahului oleh pengandaian
atau asumsi mengenai populasi yang mungkin betul ataupun mungkin tidak betul
dan disebut Hipotesis Statistis atau disingkat Hipotesis dan biasa dilambangkan
dengan H0 (baca : H nol). Hipotesis inilah yang akan diteliti menggunakan
karakteristik sampel yang diambil dari populasi yang sedang ditinjau. Apabila
ternyata penelitian berdasarkan sampel ini, dalam batas-batas tertentu,
memperlihatkan adanya kesesuaian dengan hipotesis, maka akan dikatakan
hipotesis nol diterima. Ini berarti hipotesis nol telah dibenarkan. Apabila
penelitian itu, dalam batas-batas tertentu tidak memperlihatkan kesesuaian
dengan hipotesis nol, maka dikatakan bahwa hipotesis nol ditolak. Dengan ini
diartikan bahwa antara hasil penelitian dan hipotesis nol masih terdapat
perbedaan yang berarti.
Pengandaian lain yang berbeda / bertentangan dengan hipotesis nol
dinamakan hipotesis alternatif atau disingkat saja dengan alternatif dan
dilambangkan dengan H1 (baca : H satu). Berdasarkan penelitian yang dilakukan
itu apabila menerima hipotesis nol tentunya mengakibatkan menolak alternatif
dan menerima alternatif sama dengan menolak hipotesis nol. Cara atau langkah
yang membawa kepada penentuan untuk menerima atau menolak hipotesis nol
BAB IV
UJI HIPOTESIS

2
dinamakan pengujian hipotesis. Berdasarkan hasil pengujian inilah akhirnya
kesimpulan akan dibuat.
4.2 DUA MACAM KEKELIRUAN
Penelitian yang dilakukan kemudian bermuara pada hasil akhir untuk
menerima atau menolak hipotesis nol. Pada waktu menerima atau menolak
hipotesis nol ini, selama hipotesis yang dibuat mungkin benar atau tidak benar,
dan selama penelitian pada umumnya hanya berdasarkan pada sebuah sampel,
akan terjadi hal-hal sebagai berikut :
a. Jika H0 benar dan berdasarkan penelitian yang dilakukan akan
diterima (berarti menolak H1), maka keputusan yang diambil
merupakan langkah yang benar.
b. Demikian pula, apabila H0 tidak benar dan penelitian
menolaknya, jadi H1 diterima, maka tentulah keputusan yang
diambil merupakan langkah yang benar.
c. Jika H0 benar, tetapi berdasarkan penelitian ditolak, ini berarti
telah menentukan untuk menerima alternatif H1. Maka
kesimpulan yang telah diambil adalah suatu kekeliruan.
Kekeliruan ini, dalam statistika dikenal dengan Kekeliruan
Macam I, atau kekeliruan . Jadi kekeliruan adalah
kekeliruan yang terjadi pada waktu membuat kesimpulan
mengenai sesuatu yang seharusnya diterima tetapi kesimpulan
dari penelitian menolaknya.
d. Sebaliknya apabila H0 tidak benar sedangkan penelitian
menyatakan harus menerimanya, maka kesimpulan yang telah
diambil merupakan suatu kekeliruan. Kekeliruan ini dikenal
dengan kekeliruan macam II atau kekeliruan . Jadi kekeliruan
adalah kekeliruan yang terjadi pada waktu membuat
kesimpulan daripada sesuatu yang seharusnya ditolak, tetapi
penelitian mengatakan untuk menerimanya.

3
Itulah hal-hal yang mungkin terjadi pada waktu menyimpulkan populasi
melalui pengujian hipotesis. Bila hal-hal di atas disusun dalam daftar agar lebih
mudah untuk diingat, akan diperoleh :
KEKELIRUAN MEMBUAT KESIMPULAN
Kesimpulan Keadaan Sebenarnya
H Benar A Benar
H diterima Kesimpulan benar Kekeliruan macam II ()
A diterima Kekeliruan macam I () Kesimpulan benar
Tabel 4.1 : Tabel kesimpulan dan model kesalahan yang terjadi
Karena dalam pengambilan kesimpulan selalu diikuti dengan
kemungkinan terjadinya kesalahan baik maupun , maka setiap pengujian
harus merencanakan sedemikian rupa sehingga kekeliruan-kekeliruan dan
pada waktu membuat kesimpulan ditekan hingga sekecil mungkin. Tetapi dalam
pelaksanaannya tidaklah mudah karena untuk sebuah sampel yang diketahui,
usaha untuk memperkecil kekeliruan yang satu akan menyebabkan besarnya
kekeliruan yang lain. Sehingga berdasarkan kenyatan tersebut, dalam
prakteknya cukup diperhatikan kekeliruan atau resiko mana yang dianggap lebih
penting untuk dihindari.
Besar kecilnya resiko pada waktu membuat kekeliruan ( atau ),
biasanya dinyatakan dalam bentuk peluang. Peluang diperbuatnya kekeliruan
macam I, (peluang menerima H1 apabila sebenarnya H0 yang harus diterima),
dinamakan taraf signifikan atau taraf nyata atau disebut juga taraf arti. Peluang
ini, sering dinyatakan dengan , biasanya ditentukan lebih dahulu sebelum
penelitian terhadap sampel dilakukan. Penentuan besarnya ini mencerminkan
besarnya resiko yang akan ditanggung dalam penelitian. Berdasarkan harga yang
telah ditentukan itulah akan diketahui batas-batas untuk menentukan apakah
pengujian akan menerima H0 atau menolaknya.

4
Dalam banyak hal ternyata dengan mengambil taraf nyata , atau disebut
pula resiko , sebesar 0,01 atau 0,05 akan memberikan hasil pengujian yang
memuaskan. Tentu saja nilai yang lain boleh digunakan apabila ternyata
dengan nilai tersebut akan mengakibatkan diperoleh risiko yang lebih kecil dan
pula hasil pengujian akan dapat dianggap lebih memuaskan.
Arti mengenai besar nilai ini adalah bahwa dari tiap 100 hipotesis nol
yang seharusnya diterima kira-kira 100 ditolak. Dikatakan bahwa 100(1 - )
% kesimpulan yang dibuat benar.
Contoh :
Seorang pengusaha ingin menentukan apakah perlu atau tidak ia memasang iklan
mengenai barangnya dalam sebuah surat kabar di suatu kota. Apabila
diperkirakan akan ada faedahnya, maka jelas ia perlu memasang iklan. Tetapi
tentulah ia tidak akan melakukan jika sebaliknya. Dari uraian di atas, dapat
dirumuskan sebagai berikut :
TINDAKAN YANG DILAKUKAN PENGUSAHA
MENGENAI PEMASANGAN IKLAN
Tindakan
yang dilakukan
Sebenarnya pemasangan iklan
Berfaedah Tidak Berfaedah
Memasang iklan Tindakan benar Tindakan keliru.
Kekeliruan macam II
Tidak memasang iklan Tindakan keliru.
Kekeliruan macam I
Tindakan benar
Kesimpulan statistis yang akan dibuat adalah mengenai populasi melalui
sifat-sifatnya yang berupa parameter populasi antara lain rata-rata ,
perbandingan dan simpangan baku . Nilai-nilai inilah yang akan diuji dan
disimpulkan melalui pengujian hipotesis.
Langkah-langkah uji hipotesis dan membuat kesimpulan didahului
dengan perumusan hipotesis dan alternatifnya sebagai berikut :

5
a. Perumusan hipotesis H0 yang akan diuji disertai keterangan
seperlunya. Perumusan ini dibuat sesuai dengan persoalan yang
dihadapi. Ada tiga hal yang biasa digunakan :
1) Hipotesis mengandung pengertian sama.
Jika ingin menguji dugaan bahwa pada umumnya masa pakai
pesawat TV sekitar 10.000 jam umpamanya, maka perumusan
yang dapat digunakan adalah :
H0 : = 10.000 jam,
berarti bahwa pesawat TV itu sesuai dengan yang diperkirakan,
ialah rat-rata 10.000 jam.
Untuk menguji pikiran bahwa hanya sekitar 40% saja dari orang
yang masuk ke toko swalayan yang ternyata berbelanja, dapat
digunakan perumusan :
H0 : = 40 %
berarti hanya sekitar 40 % saja yang masuk ke toko yang
ternyata berbelanja.
2) Hipotesis mengandung pengertian maksimum.
Misalnya untuk menguji pernyataan bahwa dalam pengiriman
barang terdapat kerusakan paling besar 5%, perumusan sebagai
berikut dapat dipergunakan :
H0 : 5 %
berarti kerusakan dalam pengiriman barang maksimum 5%.
3) Hipotesis mengandung pengertian minimum.
Jika ingin menguji bahwa pakaian dapat dipakai pada umumnya
paling cepat rusak dalam tempo 180 hari, dapat dibuat
perumusan :
H0 : 180 hari
berarti paling cepat kain itu pada umumnya akan rusak dalam
tempo 180 hari.
b. Perumusan Alternatif (H1) yang sesuai dengan H0

6
Isi dari alternatif H1 itu bertentangan dengan hipotesis H0,
sehingga berdasarkan penelitian nanti dengan mudah ditentukan apakah
akan memilih H0 atau H1. Sesuai dengan adanya tiga hal mengenai H0
yang mungkin, maka untuk perumusan H1 pun akan ada tiga hal.
1) Sebagai imbangan perumusan H0 yang mengandung
pengertian sama, maka H1 harus mengandung pengetian tidak
sama. Untuk soal masa pakai pesawat TV dalam contoh di atas,
H1 menjadi :
H1 : 10.000 jam,
berarti bahwa pesawat TV itu tidak sesuai dengan 10.000 jam.
2) Sebagai imbangan perumusan H0 yang mengandung
pengertian maksimum, maka H1 harus mengandung pengertian
minimum. Untuk soal keru-sakan dalam pengiriman barang
dalam contoh di atas, H1 menjadi :
H1 : > 5 %
berarti kerusakan dalam pengiriman barang lebih besar dari 5%
(atau minimum 5%).
3) Sebagai imbangan perumusan H0 yang mengandung
pengertian minimum, maka H1 harus mengandung pengertian
maksimum. Untuk soal masa pakai pakaian dalam contoh di
atas, H1 menjadi :
H1 : < 180 hari
berarti paling lama kain itu akan rusak dalam tempo 180 hari.
4.3 UJI BEDA RATA-RATA
4.3.1 One Sample Test
a. Sampel Besar (n30)
Langkah-langkah uji hipotesis :

7
1. Menyusun H0 dan H1 (ada 3 macam hipotesis)
a.
b.
c.
2. Menentukan level of significance ()
3. Menentukan peraturan-peraturan pengujiannya / kriterianya
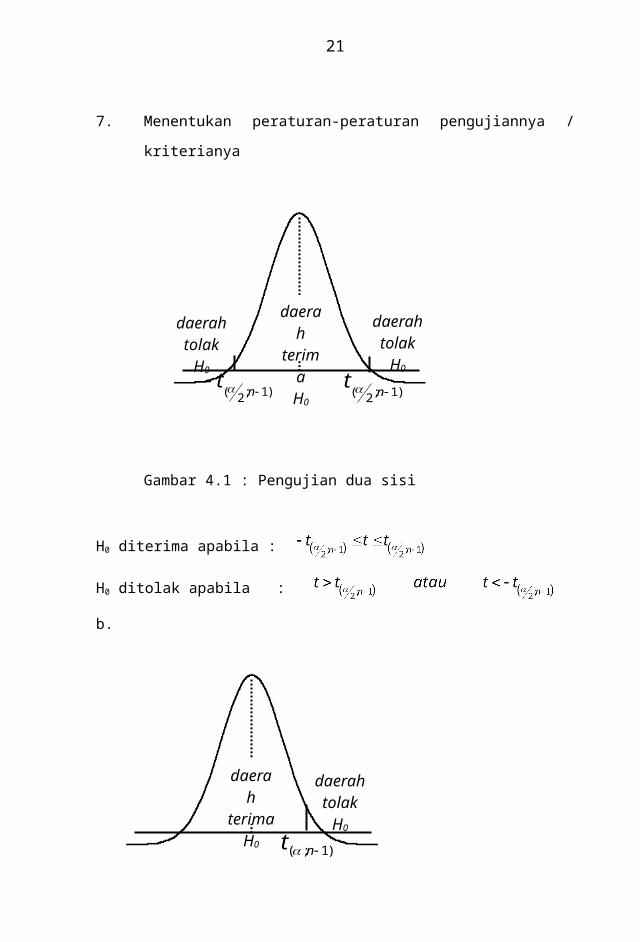
Gambar 4.1 : Pengujian dua sisi
H0 diterima apabila
H0 ditolak apabila
b.
daerahterima
H0
daerahtolakH0
daerahtolakH0
-z/2 z/2
daerahterima
H0
daerahtolakH0
z

8
Sampel Kecil (n<30)
Gambar 4.2 : Pengujian satu sisi kanan
H0 diterima apabila
H0 ditolak apabila
c.
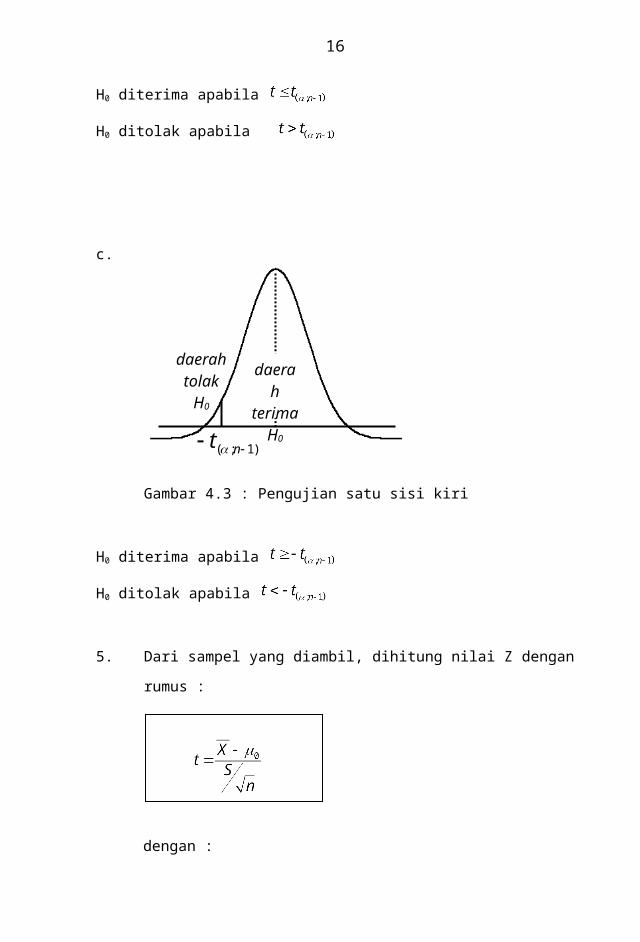
Gambar 4.3 : Pengujian satu sisi kiri
H0 diterima apabila
H0 ditolak apabila
4. Dari sampel yang diambil, dihitung nilai Z dengan rumus :
dengan :
adalah rata-rata sampel
daerahterima
H0
daerahtolakH0
-z

9
adalah rata-rata populasi sebagai pembanding
adalah standar deviasi sampel
banyaknya titik sampel
5. Bandingkan langkah ke 3 dan ke 4 untuk diambil kesimpulan.
Contoh :
Suatu pabrik dengan kapasitas produksi 880 ton perhari. Namun, semenjak ada
perbaikan mesin, diduga ada perubahan jumlah produksi setiap harinya. Untuk
pengujian, diambil sampel sebanyak 50 hari dengan rata-rata hitung=871 ton dan
standar deviasi=21 ton. Apa kesimpulan yang dapat diambil ?
Jawab :
1. ton
ton
2.
maka
Z=1,96
3. Kriteria pengujian
daerahterima
H0
daerahtolakH0
daerahtolakH0
-1,96 1,96

10
H0 diterima jika
H0 ditolak jika atau
4.
5. Karena -3,03 < -1,96 maka H0 ditolak
Kesimpulan :
Hasil produksi setiap harinya tidak sama dengan 880 ton.
b. Sampel kecil (n<30)
Langkah pengujian pada dasarnya sama dengan sampel besar, kecuali pada
kriteria pengujian dan perhitungan nilai t hitung.
1. Menyusun H0 dan H1 (ada 3 macam hipotesis)
a.
b.
c.
2. Menentukan level of significance ()
4. Menentukan peraturan-peraturan pengujiannya / kriterianya
daerah
terimaH0
daerahtolakH0
daerahtolakH0
( ; 1)2 nt
( ; 1)2 n
t

11
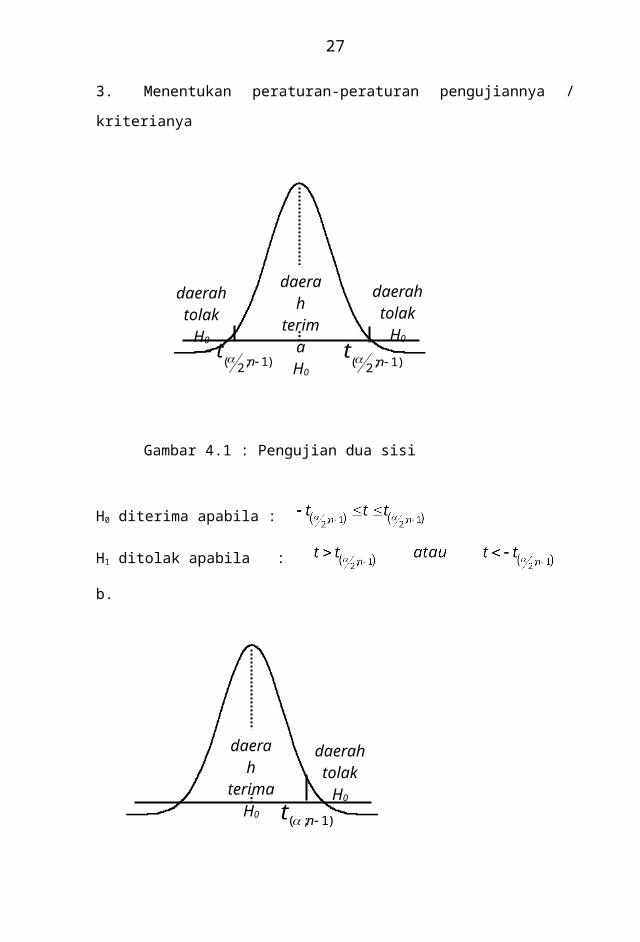
Gambar 4.1 : Pengujian dua sisi
H0 diterima apabila :
H0 ditolak apabila :
b.
Gambar 4.2 : Pengujian satu sisi kanan
H0 diterima apabila
H0 ditolak apabila
c.
daerahterima
H0
daerahtolakH0
( ; 1)nt
daerahterima
H0
daerahtolakH0
( ; 1)nt

12
Gambar 4.3 : Pengujian satu sisi kiri
H0 diterima apabila
H0 ditolak apabila
5. Dari sampel yang diambil, dihitung nilai Z dengan rumus :
dengan :
adalah rata-rata sampel
adalah rata-rata populasi sebagai pembanding
adalah standar deviasi sampel
banyaknya titik sampel
5. Bandingkan langkah ke 3 dan ke 4 untuk diambil kesimpulan.
4.3.2 Independent Sample Test
a. Sampel Besar (n30)
Langkah-langkah uji hipotesis :
1. Menyusun H0 dan H1 (ada 3 macam hipotesis)
a.
b.

13
c.
2. Menentukan level of significance ()
3. Menentukan peraturan-peraturan pengujiannya / kriterianya
a.
Gambar 4.1 : Pengujian dua sisi
H0 diterima apabila
H0 ditolak apabila
b.
daerahterima
H0
daerahtolakH0
daerahtolakH0
-z/2 z/2
daerahterima
H0
daerahtolakH0
z

14
Sampel Kecil (n<30)
Gambar 4.2 : Pengujian satu sisi kanan
H0 diterima apabila
H0 ditolak apabila
c.
Gambar 4.3 : Pengujian satu sisi kiri
H0 diterima apabila
H0 ditolak apabila
4. Dari sampel yang diambil, dihitung nilai Z dengan rumus :
daerahterima
H0
daerahtolakH0
-z

15
dengan :
adalah rata-rata sampel
adalah rata-rata populasi sebagai pembanding
adalah standar deviasi sampel
banyaknya titik sampel
6. Bandingkan langkah ke 3 dan ke 4 untuk diambil kesimpulan.
b. Sampel Kecil (n<30)
Langkah pengujian pada dasarnya sama dengan sampel besar, kecuali pada
kriteria pengujian dan perhitungan nilai t hitung.
1. Menyusun H0 dan H1 (ada 3 macam hipotesis)
a.
b.
d.
2. Menentukan level of significance ()
7. Menentukan peraturan-peraturan pengujiannya / kriterianya
daerah
terimaH0
daerahtolakH0
daerahtolakH0
( ; 1)2 nt
( ; 1)2 n
t
16
Gambar 4.1 : Pengujian dua sisi
H0 diterima apabila :
H0 ditolak apabila :
b.
Gambar 4.2 : Pengujian satu sisi kanan
H0 diterima apabila
H0 ditolak apabila
c.
daerahterima
H0
daerahtolakH0
( ; 1)nt
daerahterima
H0

17
Gambar 4.3 : Pengujian satu sisi kiri
H0 diterima apabila
H0 ditolak apabila
4. Dari sampel yang diambil, dihitung nilai t dengan rumus :
dengan :
adalah rata-rata sampel satu
adalah rata-rata sampel dua
adalah standar deviasi sampel
banyaknya titik sampel
5. Bandingkan langkah ke 3 dan ke 4 untuk diambil kesimpulan.
4.3.3 Paired Sample Test
a. Sampel Besar (n30)
Langkah-langkah uji hipotesis.
daerahtolakH0

18
1. Menyusun H0 dan H1 (ada 3 macam hipotesis)
a.
b.
a.
2. Menentukan level of significance ()
3. Menentukan peraturan-peraturan pengujiannya / kriterianya
a.
Gambar 4.1 : Pengujian dua sisi
H0 diterima apabila
H1 ditolak apabila
b.
daerahterima
H0
daerahtolakH0
daerahtolakH0
-z/2 z/2
daerahterima
H0
daerahtolakH0
z

19
Sampel Kecil (n<30)
Gambar 4.2 : Pengujian satu sisi kanan
H0 diterima apabila
H1 ditolak apabila
c.
Gambar 4.3 : Pengujian satu sisi kiri
H0 diterima apabila
H1 ditolak apabila
4. Dari sampel yang diambil, dihitung nilai Z dengan rumus :
daerahterima
H0
daerahtolakH0
-z

20
dengan :
adalah rata-rata sampel
adalah standar deviasi sampel
banyaknya titik sampel
5. Bandingkan langkah ke 3 dan ke 4 untuk diambil kesimpulan.
b. Sampel Kecil (n<30)
Langkah pengujian pada dasarnya sama dengan sampel besar, kecuali pada
kriteria pengujian dan perhitungan nilai t hitung.
1. Menyusun H0 dan H1 (ada 3 macam hipotesis)
a.
b.
e.
2. Menentukan level of significance ()
3. Menentukan peraturan-peraturan pengujiannya / kriterianya
daerah
terimaH0
daerahtolakH0
daerahtolakH0
( ; 1)2 nt
( ; 1)2 n
t
21
Gambar 4.1 : Pengujian dua sisi
H0 diterima apabila :
H1 ditolak apabila :
b.
Gambar 4.2 : Pengujian satu sisi kanan
H0 diterima apabila
H1 ditolak apabila
c.
daerahterima
H0
daerahtolakH0
( ; 1)nt
daerahterima
H0
daerahtolakH0

22
Gambar 4.3 : Pengujian satu sisi kiri
H0 diterima apabila
H1 ditolak apabila
4. Dari sampel yang diambil, dihitung nilai t dengan rumus :
dengan :
adalah rata-rata Di dengan Di = X1i - X2i
adalah standar deviasi Di
banyaknya pasangan titik sampel
5. Bandingkan langkah ke 3 dan ke 4 untuk diambil kesimpulan.
4.4 SOAL-SOAL
1. Uraikan seperlunya, apa yang dimaksud dengan :
1) Hipotesis dan Hipotesis tandingan
2) Kekeliruan macam
3) Kekeliruan macam
4) Taraf nyata
5) Risiko

23
2. Bedakan antara :
1) Alternatif sepihak dan alternatif dua pihak
2) Taksiran statistis dan kesimpulan statistik
5. Prinsip apakah yang digunakan saat membuat kesimpulan statistis ?
6. Jelaskan, apakah artinya jika ketika membuat kesimpulan telah diambil
kekeliruan = 0,01 dan kekeliruan = 0,08 !
7. Pengujian bersifat signifikan (atau nyata), apa artinya ?
8. Pembuat printer menyatakan bahwa ia telah membuat berkualitas lebih
baik. Ia menyatakan bahwa dengan printer yang baru itu, penggunaan normal
akan tahan selama 95 bulan. Dari pemakaian printer yang baru ini, telah berhasil
dikumpulkan sebanyak 86 printer bekas yang rata-rata telah dipakai selama 92
bulan dengan simpangan baku 6 bulan. Apakah cukup dapat diperlihatkan
berdasarkan kenyataan tersebut dengan resiko = 0,05, bahwa perusahaan
printer telah berhasil membuat printer baru sesuai dengan yang ia nyatakan ?
9. Seorang perwira koperasi AAL menyatakan bahwa pesanan yang ia
terima telah mengalami perubahan apabilaa dibandingkan dengan masa-masa
lalu. Pesanan masa lalu yang dipakai pedoman ternyata pukul rata berharga Rp.
50.000,-. Untuk meneliti pernyataan perwira tersebut sejumlah pesanan yang
berikut digunakan sebagai bahan.
Pesanan (ribuan) Banyak pesanan
1 - 9
10 - 24
25 - 49
246
307
893

24
50 - 99
100 - 249
419
162
Jumlah 2.027
1) Tentukan dahulu perumusan Ho dan H1 !
2) Dari daftar di samping untuk keperluan penelitian tersebut,
harga-harga apa yang perlu dicari ?
3) Apabila untuk penelitian tersebut diambil = 0,01, tentukan
bagaimana kesimpulannya ?
10. Seorang agen susu sapi mengatakan bahwa susu yang ia jual cukup baik,
oleh karena untuk setiap liter susu rata-rata berisikan 0,025 kg.lemak mentega.
Sebuah badan yang berwenang telah mengadakan penelitian, oleh karena akhir-
akhir ini ada dugaan bahwa kualitas susu itu telah mengalami penurunan. Badan
tersebut meneliti sebanyak 16 liter susu yaang diambil secara acak dari agen
susu. Dari setiap liter susu yang diteliti, diukur berat lemak mentega yang ada.
Hasilnya ternyata rata-rata 0,024 kg sedangkan simpangan bku untuk ke 16 liter
susu yang diteliti itu 0,0023 kg. Jika resiko yang diambil oleh badan itu sebesar
0,05, maka apakah kesimpulan yang dapat diambil ?
9. Pengiriman barang dinyatakan dapat diterima apabila berisikan barang
rusak sebanyak 4% atau kurang; sedangkan dalam hal lainnya pengiriman barang
harus ditolak. Dari pengiriman yang terdiri dari 50.000 barang, diambil sebuah
sampel acak terdiri atas 300 barang yang akan dipakai untuk menentukan
penerimaan dan penolakan pengiriman itu. Setelah ketiga ratus barang tadi
diperiksa, ternyata didapat sebanyak 14 buah yang rusaak. Jika dalam penentuan
ini tidak mau mengambil resiko lebih dari 0,05 untuk menolak pengiriman
apabila sebenarnya seharusnya diterima, bagaimana mengenai nasib pengiriman
tersebut ? Bagaimana kalau resikonya hanya 1% ?

25
10. Sampel acak semacam barang telah diambil dari dua kumpulan yang
masing-masing dihasilkan oleh mesin A dan mesin B. Dari produksi mesin A
diambil 200 barang dimana terdapat 19 yang rusak; sedangkan dari produksi
mesin B diambil 100 barang dimana terdapat yang rusak 5 buah. Selidiki
dengan = 0,05, apakah kualitas barang yang dihasilkan oleh mesin itu sama
atau berbeda ?
11. Berdaasarkan keterangan masa lampau diperkirakan sekitar 60% dari
konsumen telah menggunakan sabun cuci merk AWET. Hasil ini berdasarkan
penelitian sebuah sampel yang terdiri dari 1400 konsumen. Pengusaha sabun
telah mengadakan iklan besar-besaran. Kemudian diteliti bagaimana hasilnya.
Ternyata dari sebanyak 2.175 konsumen sejumlah 1.415 menyatakan
menyenangi sabun cuci itu. Dari hasil ini dengan taraf nyata = 0,05 dapatkah
disimpulkan bahwa iklan yang telah dilakukan itu bermanfaat ?
BAB VANALISIS REGRESI DAN KORELASI

26
5.1 PENGERTIAN UMUM
Banyak permasalahan yang datanya dinyatakan oleh lebih dari sebuah
variabel. Mengingat analisis kumpulan data yang terdiri atas banyak variabel
pada dasarnya merupakan perluasan dari analisis yang datanya terdiri atas dua
variabel, maka di sini terutama akan dibicarakan penelaahan kumpulan data yang
dilukiskan oleh dua variabel saja. Untuk keperluan penelaahan, kepada kedua
variabel itu digunakan simbul yang lazim dipakai, ialah X dan Y yang dapat
diberi indeks menurut keperluannya yaitu :
dan
Atau pasangan ; i = 1,2, … , n
Sehingga sampel yang berukuran n itu terdiri atas n buah pasang data.
Contoh 5.1 :
Jika menyatakan banyak pengunjung ke suatu toko swalayan dan diartikan
orang-orang diantara pengunjung itu yang berbelanja di toko tersebut misalnya,
maka akan diteliti kumpulan data seperti dalam daftar berikut :
Tabel 5.1 : Jumlah pengunjung dan belanja di suatu toko swalayan
Pengunjung ( ) Yang Berbelanja ( )300 156290 151345 175419 203378 196353 189435 241361 197394 212436 232
27
Hal-hal yang akan dipelajari mengenai kumpulan data yang terdiri atas
dua variabel yaitu :
a. Mempelajari derajat asosiasi antara kedua variabel. Bagian ini
dalam statistika dikenal dengan nama ANALISIS KORELASI.
Hubungan korelasional ini tidak menjelaskan apakah suatu variabel
menjadi penyebab dari variabel yang lainnya.
b. Mempelajari hubungan yang ada di antara variabel-variabel
sehingga dari hubungan yang diperoleh dapat menaksir variabel yang
satu apabila harga variabel lainnya diketahui. Bagian ini dikenal dengan
nama ANALISIS REGRESI.
Contoh 5.2 :
a. Dari data yang tertera dalam daftar di atas, dapat dicari
hubungan yang ada antara pengunjung dan yang belanja. Jika pada
suatu hari ada 390 pengunjung, dari hubungan yang diperoleh dapat
diperkirakan ada berapa yang akan belanja di toko itu. Selain daripada
itu, juga dapat ditentukan berapa kuat jumlah pembeli ditentukan oleh
adanya pengunjung
b. Diketahui bahwa produk nasional kotor ditentukan oleh produk-
produk. Lainnya, antara lain jasa, Jika data selama waktu-waktu tertentu
diketahui, hubungan antara produk-produk nasional kotor dan jasa dapat
dihitung. Dari hubungan ini, produk nasional kotor dapat diperkirakan
jika jasa dapat diketahui.
5.2 ANALISIS REGRESI
Untuk menjelaskan bagaimana hubungan antara dua variabel, perhatikan
data yang tercantum dalam tabel berikut :

28
Tabel 5.2 : Banyak pengunjung dan belanja di suatu toko swalayan selama 30
hari.
HARI KE
PENGUNJUNG (Xi)
BELANJA(Yi)
HARI KE
PENGUNJUNG (Xi)
BELANJA(Yi)
123456789101112131415
353934403143403034393332364043
323631382942332929363131333736
161718192021222324252627282930
404132343035363739413334363837
383730302835293435363232343734
Dalam daftar di atas merupakan banyak pengunjung (dinyatakan dengan
Xi) dan yang berbelanja (dinyatakan dengan Yi) yang telah dicatat oleh
seseorang pengusaha di tokonya.
Kebiasaan yang digunakan dalam penentuan simbul-simbul yang lazim,
ialah Xi untuk hal yang diperkirakan lebih tepat dapat digolongkan ke dalam
variabel yang sifatnya bebas, sedangkan Yi untuk variabel yang diperkirakan
akan bergantung pada Xi. Variabel Xi disebut variabel bebas sedangkan Yi
disebut variabel tak bebas.
Representasi untuk data dalam Tabel 6.2 di atas, diagram pencarnya
dapat dilihat seperti dalam gambar berikut !
. . . . . . . .

29
Gambar 5.1 : Diagram pencar dari data pada Tabel 6.2
Dengan menggunakan diagram ini dapat dilihat apakah ada sesuatu
hubungan yang berarti diantara titik-titik itu pada atau sekitar garis lurus ? Jika
demikian halnya, cukup alasan bagi kita untuk menduga bahwa antara variabel-
variabel itu ada hubungan linear. Dalam hal lainnya, antara variabel-variabel itu
diduga terdapat hubungan non linear.
Setelah diketahui bentuk hubungan antara variabel itu, tugas selanjutnya
ialah menentukan hubungan tersebut dirumuskan dalam suatu persamaan
matematis. Kemudian disusun dalam suatu persamaan garis yang
merepresentasikan persamaan matematisnya. Garis ini dikenal dengan nama garis
regresi. Jika hubungan Y = f(X) itu linear, maka garis yang didapat adalah
garis regresi linear. Dalam hal lainnya didapat regresi nonlinear.
REGRESI NON LINEAR
Gambar 5.2 : Representasi garis regresi linear dan non linear
Gambar di atas memperlihatkan diagram pencar untuk data dalam daftar
dengan garis lurus atau regresi linear yang diduga cocok dengan letak titik-titik
diagram. Gambar 5.2 melukiskan regresi non linear untuk sesuatu persoalan.

30
Oleh karena regresi linear merupakan bentuk regresi yang paling mudah
ditelaah, kecuali itu juga karena banyak regresi nonlinear yang dapat diselesaikan
dengan bantuan regresi linear, maka di sini terutama hanyalah regresi tersebut
yang akan dibicarakan.
Bagaimanakah menentukan persamaan regresi yang linear ini? Yang
paling mudah ialah dengan jalan kira-kira menurut penglihatan kita. Pada
kumpulan titik-titik itu ditarik sebuah garis lurus yang akan paling dekat titik-
titik itu berkerumun sekitar garis yang ditarik tadi. Sesudah itu ditentukan
bagaimana persamaannya.
Meskipun cara tersebut sangat mudah dilakukan namun untuk penelitian
jarang dilakukan oleh karena kecuali terlalu kasar hasilnya, juga terlalu subyektif
dan ini sedapat mungkin harus dihindarkan. Karenanya akan ditinjau cara yang
dianggap cukup baik dan sering digunakan. Cara yang dimaksud adalah
METODA KUADRAT TERKECIL. Sebelum cara ini dibicarakan, terlebih
dahulu akan ditinjau seperlunya macam-macam regresi linear yang mungkin,
sehubungan dengan variabel bebas.
Di atas dikatakan, bahwa jika variabel X yang diketahui terlebih dahulu
dan kemudian Y ditentukan berdasarkan X ini, maka ditentukan hubungan
Y=f(X). Rumusan hubungan ini lebih dikenal dengan nama Regresi Y atas X.
Jika regresi Y atas X ini linear, maka persamaannnya dapat dituliskan
dalam bentuk linear :
………(5.1)
Dengan berarti taksiran nilai X untuk harga Y yang diketahui.
Untuk menentukan koefisien-koefisien a dan b ini akan digunakan
METODA KUADRAT TERKECIL. Ternyata bahwa untuk regresi linear dalam
rumus 6.1, harga-harga a dan b dapat dihitung berdasarkan sekumpulan data
sebanyak n buah dengan menggunakan sistem persamaan :

31
.............. (5.2)
Pasangan persamaan dengan dua anu a dan b ini, bentuk rumus 6.3, disebut
persamaan-persamaan normal untuk bentuk regresi dalam rumus 6.1. Setelah
diselesaikan, akan didapat harga-harga a ddan b yang dicari, yakni:
.............. (5.3)
Untuk menjelaskan penggunaan rumus 5.3 di atas, sekarang ditinjau contoh
mengenai banyak pengunjung dan yang berbelanja ke sebuah toko yang datanya
tertera dalam Tabel 5.2. Dari diagram pencar gambar 5.1 mudah dilihat bahwa
titik-titik itu terletak sekitar garis lurus. Untuk menentukan regresi linear Y atas
X, maka sebaliknya dibuat sebuah daftar seperti Tabel 5.3 berikut ini.
Tabel 5.4 : Tabel penyelesaian persamaan regresi linear
Xi Yi Xi2 Yi2 XiYi Xi Yi Xi2 Yi2 XiYi
34 32 1156 1024 1088 40 38 1600 1444 1520

32
38
34
40
31
43
40
30
33
39
33
32
36
40
42
36
31
38
29
42
33
29
29
36
31
31
33
37
36
1444
1156
1600
961
1849
1600
900
1089
1521
1089
1024
1296
1600
1764
1296
961
1444
841
1764
1089
841
841
1296
961
961
1289
1369
1296
1368
1054
1520
899
1806
1320
870
4957
1296
1023
992
1089
1480
1512
41
32
34
30
35
36
37
39
40
33
34
36
37
37
37
30
30
28
35
29
34
35
36
32
32
34
37
34
1681
1024
1156
900
1225
841
1156
1225
1296
1024
1024
1156
1369
1156
1369
900
900
784
1225
841
1156
1225
1296
1024
1024
1156
1369
1156
1517
960
1020
840
1225
1044
1258
1365
1440
1056
1088
1224
1369
1258
545 503 20049 17073 18481 541 501 19651 16869 18184
Dari daftar di atas diperoleh :
Disubstitusikan harga-harga tersebut dengan rumus regresi linear dengan
mengambil n = 30, didapat :

33
Sehingga garis regresi linear yang dimaksud mempunyai persamaan :
Dengan menggunakan persamaan yang diperoleh ini dapat diperkirakan berapa
orang diantara pengunjung itu yang akan berbelanja, apabila jumlah pengunjung
dapat diketahui. Apabila rata-rata perjam ada 40 orang yang berkunjung ke
toko itu, maka dapat diperkirakan dari diperoleh :
Y = 1,6 + (0,88)(40)
= 36,81 orang yang berbelanja.
5.3 REGRESI NON LINEAR
Setelah dipelajari seperlunya mengenai bentuk hubungan linear antara
dua variabel X dan Y sekarang akan diperhatikan bentuk hubungan nonlinear
antar dua variabel. Tidak akan dibicarakan secara luas dan mendalam mengenai
regresi nonlinear ini, tetapi hanya merupakan suatu tinjauan singkat saja, tinjauan
yang pada umumnya dapat ditelaah berdasarkan teori regresi linear.
Meskipun terdapat banyak sekali bentuk regresi non linear yang biasa
digunakan tetapi di sini hanyalah akan ditinjau beberapa saja yang penting dan
termudah. Untuk regresi nonlinear Y atas X yang akan ditinjau di sini, antara
lain berbentuk lengkungan :
a. Parabola kuadratis dengan persamaan
b. Parabola kubis dengan persamaan
c. Logaritmis dengan persamaan :
d. Hiperbola dengan persamaan :
5.4 REGRESI LINEAR BERGANDA

34
Ada banyak kenyataan bahwa pengamatan akan terdiri atas lebih dari dua
variabel. Sehingga yang harus digunakan adalah regresi dengan variabel bebas
lebih dari satu.
Contoh :
1. Harga beras tidak saja hanya ditentukan oleh adanya persediaan, tetapi juga
oleh harga bensin, upah buruh dan sebagainya.
2. Produksi telur ayam tidak saja bergantung pada banyaknya ayam petelur
yang ada saja, tetapi juga dari banyak makanan yang diberikan, umur
ayam dan barangkali masih ada faktor lainnya.
Apabila ada satu variabel terikat Y dan k variabel bebas
sehingga terdapat hubungan semacam garis regresi Y atas .
Dalam bagian ini akan dijelaskan secara singkat bagaimana garis regresi yang
dimaksud dapat ditentukan dan yang akan ditinjau di sini hanyalah garis regresi Y
atas yang paling sederhana ialah yang dikenal dengan nama
regresi linear berganda. Persamaan umum untuk regresi linear berganda ini
adalah :
Dimana harus ditentukan dari data hasil pengamatan. Mudah
dilihat bahwa regresi di atas ini merupakan perluasan dari regresi linear
sederhana.
Pertanyaan yang timbul adalah : bagaimana koefisien-koefisien
ditentukan ? Secara sama dengan regresi linear sederhana, maka
dipergunakan metode KUADRAT TERKECIL. Oleh karena ada k+1 parameter
yang harus dicari maka diperlukan k+1 persamaan dengan k+1 anu. Dapat
dibayangkan bahwa hal itu memerlukan metode penyelesaian yang lebih baik dan

35
karenanya memerlukan matematika yang lebih tinggi lebih-lebih untuk variabel
yang cukup banyak.
Untuk regresi linear berganda yang sederhana :
Misalnya kita harus menyelesaikan 3 persamaan dengan 3 anu yang berbentuk :
Untuk persamaan regresi dengan 4 variabel bebas, maka diperlukan 4 persamaan.
Demikian seterusnya.
5.5 ANALISIS KORELASI
Dalam bagian yang lalu, telah dipelajari bagaimana hubungan antara dua
variabel X dan Y dapat ditentukan. Hubungan yang diperoleh dinyatakan dalam
bentuk persamaan matematis yang dalam statistika dikenal dengan nama garis
regresi. Jika X merupakan variabel bebas dan Y variabel tak bebas, regresi Y
atas X dapat digunakan untuk meramalkan nilai Y apabila nilai X diketahui.
Dalam banyak soal, jika nilai-nilai pengamatan terdiri atas lebih dari
sebuah variabel, bukan saja regresinya yang perlu dihitung, tetapi juga kekuatan
hubungan antara variabel-variabel itu. Ukuran yang digunakan untuk itu adalah
koefisien korelasi.
Untuk keperluan analisis tentang korelasi ini, seperti biasa akan
dibedakan antara statistik (ialah koefisien korelasi untuk data dalam sampel) dan
parameter (untuk menyatakan koefisien korelasi populasi. Koefisien korelasi

36
untuk sampel, jadi merupakan statistik, akan dinyatakan dengan r sedangkan
parameternya dengan (baca : rho).
Dalam bagian berikut ini akan diuraikan bagaimana r dihitung dan
selanjutnya akan diberikan penjelasan mengenai pengujian derajat asosiasi.
a. Koefisien Korelasi
Karena ternyata korelasi dan regresi berhubungan erat, maka
untuk menentukan ukuran asosiasi atau koefisien korelasi, perlu
terpenuhi syarat-syarat :
1) Koefisien korelasi harus besar apabila derajat asosiasi
tinggi dan harus kecil apabila derajat asosiasi rendah.
2) Koefisien korelasi harus bebas daripada satuan yang
digunakan untuk mengukur variabel.
Untuk mencapai kedua syarat di atas, maka untuk menentukan
koefisien korelasi r biasa digunakan statistik :
Inilah rumus koefisien korelasi yang pertama yang disebut KOEFISIEN
KORELASI PERSON atau PRODUCT MOMENT.
Koefisien korelasi r menunjukkan apakah cukup beralasan bagi kita
untuk menyatakan ada atau tidak adanya hubungan linear antara
variabel-variabel X dan Y. Rumus lain yang juga sering dipergunakan
adalah :

37
Dengan menggunakan perhitungan matematika, ternyata dapat
dibuktikan bahwa batas-batas koefisien korelasi itu berada dalam
daerah / interval :
-1 r 1
Tanda positif menyatakan bahwa antara variabel-variabel itu terdapat
korelasi positif atau korelasi langsung yang berarti nilai variabel X yang
kecil berpasangan dengan nilai variabel Y yang kecil serta nilai variabel
X yang besar berpasangan dengan nilai variabel Y yang besar pula.
Korelasi positif menunjukkan letak titik-titik dalam diagram
pencar berada sekitar garis lurus yang koefisien arahnya positif. Makin
dekat letak titik-titik itu pada garis lurus, makin kuatlah korelasi positif
itu dan harganya makin dekat kepada satu.
Jika titik-titik itu terletak pada garis lurus yang arahnya positif,
akan diperoleh harga r = +1.
Jika variabel X yang besar berpasangan dengan Y yang kecil dan
jika X kecil berpasangan dengan Y yang besar, akan diperoleh Korelasi
negatif atau korelasi invers.
Dilihat dari diagram pencarnya, letak titik-titik akan berada
sekitar sebuah garis lurus yang koefisien arahnya negatif. Makin dekat
letak titik-titik itu pada garis yang dimaksud, makin dekat pula nilai r
kepada -1. Dan akhirnya jika titik-titik itu terletak pada garis lurus yang
koefisien arahnya negatif didapat harga r = -1.
r = +1 r = -1

38
Dalam prakteknya jarang sekali didapatkan diagram pencar yang
letak titik-titiknya pada sebuah garis lurus seperti dalam gambar di atas
sangat jarang. Yang sering didapati adalah bentuk yang menyebabkan
nilai koefisien korelasi tidak sama dengan 1 atau -1. Makin terpencar
letak titik-titik itu dari sebuah garis lurus, makin dekatlah r kepada nol.
Setelah dikenal apa arti koefisien korelasi, masih ada ukuran lain
yang sebenarnya lebih mudah untuk ditafsirkan dalam penggunaannya.
Ukuran tersebut ialah yang dinamakan koefisien determinasi yang tiada
lain daripada kuadrat koefisien korelasi. Jadi :
Koefisien Determinasi = r2
Karena sudah diketahui bahwa koefisien korelasi berada -1 r +1,
maka tentulah koefisien determinasi mulai dari nol sampai dengan 1,
atau :
0 r2 1
Koefisien determinasi biasanya dinyatakan dengan persen. Sedangkan
penafsirannya adalah jika r = 0,94 sehingga r2 = 0,8836 atau 88,36%
maka ditafsirkan sebagai 88,36% variasi suatu variabel yang disebabkan
oleh variabel lainnya.
Koefisien determinasi banyak digunakan dalam penjelasan tambahan
untuk hasil perhitungan koefisien regresi.
b. Menghitung r Untuk Data Berkelompok
Rumus-rumus di atas adalah rumus-rumus untuk menentukan r
apabila datanya massih belum disusun dalam daftar distribusi frekuensi.
Rumus-rumus tersebut pula cukup menyenangkan untuk digunakan
apabila datanya tidak terlalu banyak. Jika data yang sedang dicari
korelasinya itu banyak sekali, dengan menggunakan rumus-rumus
tersebut akan memakan waktu yang lama dari perhitungannya. Oleh
karena itu perlu ada usaha untuk mempersingkatnya. Jalan yang lazim
ditempuh ialah terlebih dahulu menyusun data ke dalam daftar distribusi
frekuensi. Oleh karena kita sedang berhadapan dengan penelitian yang

39
terdiri atas dua variabel, maka kitapun akan memperoleh dua distribusi
frekuensi. Kedua distribusi frekuensi ini harus disajikan dalam daftar
yang berklasifikasi dua, sedemikian sehingga dampaknya banyak seperti
daftar kontingensi. Banya baris sesuai dengan banyak kelas interval
distribusi frekuensi variabel yang satu, sedangkan banyak kolom sesuai
dengan banyak kelas interval dari distribusi frekuensi variabel kedua.
Untuk variabel yang satu, yang terdapat dalam baris, kelas-kelas
intervalnya mulai dari atas ke bawah disusun seperti biasa, yakni dari
data yang kecil hingga yang paling besar. Variabel yang terdapat dalam
kolom, kelas-kelas intervalnya dari kiri ke kanan yang dimulai dari data
yang kecil hingga yang besar.
Frekuensi data dalam daftar ini akan didapati dalam tiap-tiap sel.
Jadi frekuensi dalam setiap sel merupakan banyak data yang ada dalam
kelas interval variabel yang satu dan juga yang ada dalam kelas interval
variabel yang lain.
Contoh :
Berikut data gaji tentara (data fiktif, tahun 95) beserta pengeluarannya
untuk keperluan rekreasi bersama keluarga.
Daftar gaji tentara dan pengeluaran untuk wisata
(dalam puluhan ribu rupiah)
Gaji
wisata
30-39 40-49 50-59 60-69 70-79 80-89 90-99 jumlah
0,00-0,99 1 1
1,00-1,99 2 3 1 6
2,00-2,99 1 2 10 2 15
3,00-3,99 5 6 5 1 1 1 19
4,00-4,99 2 4 3 2 1 12
5,00-5,99 1 10 6 2 19

40
6,00-6,99 2 5 2 2 11
7,00-7,99 1 1 2
Jumlah 4 10 19 14 19 12 7 85
Dari daftar dapat dilihat bahwa ada 4 tentara dengan gaji Rp. 300.000
sampai dengan Rp. 400.000 sebulannya, dengan pengeluaran untuk
wisata masing-masing 1 orang Rp. 0 sampai dengan Rp. 99.000.
Sekarang persoalannya adalah bagaimana menentukan koefisen korelasi
antara keduanya ?
Untuk itu dipergunakan rumus berikut :
dimana :
u = koding untuk variabel X
v = koding untuk variabel Y
fx = frekuensi kelas interval dari variabel X
fy = frekuensi kelas interval dari variabel Y
f = frekuensi dalam tiap sel
n = banyak data.
Sekarang dipergunakan peerumusan di atas.
Gaji tentara
x 34,5 44,5 54,5 64,5 74,5 84,5 94,5
Y u -3 -2 -1 0 1 2 3 fy fyv fyv2 Fuv
0,495 -3 1 1 -3 9 9
1,495 -2 2 3 1 6 -12 24 26
2,495 -1 1 2 10 2 15 -15 15 17

41
3,495 0 5 6 5 1 1 1 19 0 0 8
4,495 1 2 4 3 2 1 12 12 12 8
5,495 2 1 10 6 2 19 38 76 56
6,495 3 2 5 2 2 11 33 99 45
7,495 4 1 1 2 8 32 20
fx 4 10 19 14 19 12 7 85 61 267 181
fxu -12 -20 -19 0 19 24 24 21
fxu2 36 40 19 0 19 48 63 63
fuv 24 16 10 0 38 48 45 45
Untuk variabel x, telah diambil koding u = 0 yang sesuai dengn tanda
kelas 64,5 dan untuk variabel Y diambil koding v = 0 sesuai dengan
tanda kelas 3,495. Koding-koding lainnya diambil seperti biasa, yakni
untuk tanda kelas yang makin kecil berturut-turut -1, -2, -3, …..
sedangkan untuk tanda kelas yang makin besar +1, +2, +3, … Harga-
harga fxu didapat dengan mengalikan fx = 4 kali u = -3, fxu = -20 dari fx =
10 kali u = -2 dan seterusnya. Demikian pula fyv = 3 didapat dari fy = 1
kali v = -3, fyv = -12 didapat dari fy = 6 kali v = -2 dan seterusnya.
Nilai fxu2 diperoleh dengan mengalikan fxu dengan u, nilai fyv2 adalah
hasil kali fyv dengan v dan seterusnya.
Dengan demikian, nilai r adalah :
85. 181 - 13. 61
r =
{85.225 - 132} {85.267 - 612}
r = 0,77
Angka ini menyatakan kuatnya hubungan antara gaji bulanan tentara dan
pengeluaran untuk pariwisata.
c. Korelasi Rank
sama

42
Ada kalanya ingin diketahui korelasi antara dua variabel tidak
berdasarkan pada pasangan data dimana nilai sebenarnya diketahui.
Umpamanya saja, kita telah melakukan penelitian mengenai tingkatan
menyenangi merk sepatu olahraga bagi prajurit A dan prajurit B anggota
TNI AL. Hasilnya dinyatakan dalam tabel di bawah ini. Untuk sepatu
yang paling disukai, diberi nilai 1 dan yang paling tidak disukai diberi
nilai 10. Urut-urutan nilai tersebut dinamakan RANK. Berdasarkan
rank tersebut, dapatlah ditentukan hubungan / korelasi antara keddua
variabel. Ukuran yang diperoleh biasa dinamakan koefisien korelasi
rank atau biasa juga dikenal dengan koefisien korelasi spearman dan
disimbulkan dengan r' (baca : er - aksen) untuk membedakan dengan
koefisien korelasi yang sudah dikenal.
Merk sepatu Prajurit A Prajurit B
1 2 3
Adidas 1 2
Lotto 2 3
Speck 3 1
Spotex 5 4
New Era 4 5
Jet 6 6
Niel 8 9
Pioneer 9 7
Crown 7 8
Best 10 10
Rumus untuk menghitung koefisien korelasi spearman adalah:

43
dengan di = selisih tiap pasang rank
n = banyaknya pasangan data
Sehingga dengan menggunakan rumus di atas, persoalan kesukaan
terhadap sepatu merk tertentu dapat dicari koefisien korelasinya, sebagai
berikut :
Rank A 1 2 3 5 4 6 8 9 7 10
Rank B 2 3 1 4 5 6 9 7 8 10
di -1 -1 2 1 -1 0 -1 2 -1 0 Jml
di2 1 1 4 1 1 0 1 4 1 0 14
r' = 0,015
d. Korelasi Berganda
Korelasi berganda merupakan korelasi dari beberapa variabel
bebas secara serentak dengan variabel terikat
Misalkan ada k variabel bebas, dan satu variabel terikat
Y dalam suatu persamaan regresi linear
maka besarnya korelasi bergandanya adalah :
dengan

44
e. Korelasi Parsial
Korelasi parsial adalah korelasi antara sebuah variabel tak bebas
dengan sebuah variabel bebas tertentu dengan variabel-variabel bebas
lain dianggap tetap / konstan.
Koefisien korelasi parsial dinyatakan dengan perumusan :
Untuk dua variabel bebas :
Korelasi parsial Y dengan X1 dengan X2 dianggap konstan adalah :
Korelasi parsial Y dengan X2 dengan X1 dianggap konstan adalah :
5.6 SOAL-SOAL
a. Berikan contoh dimana ramalan akan diperlukan !
b. Apakah yang dimaksud dengan :
1) regresi linear
2) regresi nonlinear
3) regresi linear X atas Y
4) regresi linear Y atas X
5) metode kuadrat terkecil
6) persamaan normal suatu regresi
7) simpangan baku bersyarat
8) regresi linear berganda
c. Jelaskan mengenai perbedaan antara regresi linear dan non linear
d. Dalam uraian yang mengenai hampir seluruhnya hanya ditinjau
tentang regresi Y atas X. Untuk mendapatkan uraian tentang regresi X

45
atas Y, tinggallah menukarkan variabel-variabel X dan Y. Sejalan
dengan ini, regresi X atas Y, cobalah tuliskan rumuss yang sesuai.
e. Dalam hal yang berikut, sebutkan apakah taksiran rata-rata atau
taksiran nilai individu yang diperlukan :
1) bagaimanakah jualan tahun yang akan datang, apabila
untuk tahun itu diketahui produk nasional kotor yang
diharapkan ?
2) Orang - orang dengan pendapatan Rp 1000.000,00 tiap
bulan berapa dapat menyediakan uangnya untuk keperluan
sosial ?
f. Perhatikanlah regresi linier dalam rumus x = + X. Apakah
artinya kalau = 0 ?
g. Jelaskanlah arti dalam hal yang berikut, apabila regresi linier :
X = ongkos untuk keperluan iklan dalam ribuan rupiah
Y = hasil jualan karena iklan tersebut dalam ribuan rupiah
h. Dengan menggunakan data dalam daftar berikut, tentukanlah
regresi linier untuk memperkirakan nilai ujian statistika jika diketahui
NEM matematika SMU nya diketahui.
NO NEM Matematika SMU Nilai statistika123456789101112131415
404041424344454647474848494950
656666676972727375767778768080

46
i. Garis regresi untuk memperkirakan pengeluaran keluarga tiap
bulan guna keperluan makanan berdasarkan pendapatan keluarga tiap
bulan, dinyatakan dalam ribuan rupiah , ditentukan oleh :
^
Y = 185 + 1,46 X
1) Berapakah pukul rata pengeluaran keluarga setiap bulan
guan keperluan makanan apabila pendapatan keluarga setiap
bulannya mencapai 100.000 rupiah ?
2) Berapa ribu rupiahkah pengeluaran setiap bulan akan
bertambah, jika pendapatan naik dengan Rp. 1.000,- ?
3) Apakah keanehannya jika X = 0 rupiah ?
j. Dalam tempo delapan tahun, hubungan antara Produk Nasional
Kotor (Y) dengan hasil jualan tahunan minyak mentah dinyatakan oleh X
di suatu negara, ditentukan oleh : Y = -3,21 + 0,02453 X
Dengan X, Y dalam milyard unit uang di negara itu.
1) Apakah arti 0,02453
2) Jika hasil jualan tahunan minyak mentah mencapai harga
285 milyard unit barang, berapakah Produk Nasional Kotor di
negara itu diperkirakan untuk tahun tersebut ?
3) Jika selanjutnya diketahui sy.x. = 0,241 dan X2i =
1.089,413 sedangkan Xi = 2.927, maka dengan koefisien
kepercayaan 0,95 tentukan batas-batas pertambahan Produk
Nasional Kotor untuk setiap milyard bertambahnya hasil jualan
minyak mentah.
k. Apakah yang dimaksud dengan :
1) Korelasi
2) Koefisien korelasi
3) Korelasi parsial
4) Korelasi positif

47
5) Korelasi negatif
6) Korelasi Rank
l. Berikan contoh masing-masing sebuah, dimana diperkirakan
akan didapat korelasi :
1) Positif
2) Negatif
m. Hasil penelitian sesuatu hal menghasilkan r = 0. Apakah ini
berarti bahwa antara variabel-variabel yang diteliti itu tidak terdapat
hubungan ?
n. Tafsiran apakah yang dapat diperoleh jika dikatakan bahwa
koefisien korelasi antara banyak kecelakaan di pabrik tiap tahun dan
umur pegawai di pabrik itu sebesar r = -0,65
o. Untuk soal h di atas, carilah korelasi antara NEM matematika
SMU dengan nilai ujian statistika.
p. Dua orang ahli disuruh mencoba kecap yang dihasilkan
oleh 12 perusahaan kecap. Untuk kecap yang paling enak, oleh
setiap ahli diberi nomor satu, yang kurang enak diberi nomor dua
dan seterusnya. Hasilnya diberikan dalam daftar berikut :
Ahli A 10 3 5 4 1 8 7 6 2 9 11 12
Ahli B 8 6 1 12 3 11 2 5 7 4 10 9
1) Carilah koefisien korelasi ranknya.
2) Selidikilah, apakah ada kesesuaian rasa kedua ahli itu ?




















