
ANALISIS PERBANDINGAN KOMPUTASI …publication.gunadarma.ac.id/bitstream/123456789/1126/1/...2.2.3...
12
ANALISIS PERBANDINGAN KOMPUTASI SEKUENSIAL DAN KOMPUTASI PARALEL GPU MEMANFAATKAN TEKNOLOGI NVIDIA CUDA PADA APLIKASI KOMPRESI CITRA MENGGUNAKAN ALGORITMA DCT 8X8 1 Andika Januarianto (50407094) 2 Dr.-Ing.Adang Suhendra, Ssi.,SKom., Msc 1 Mahasiswa Teknik Informatika, Fakultas Teknologi Industri, Universitas Gunadarma, [email protected] 2 Dosen Tetap Universitas Gunadarma, [email protected] ABSTRAKSI Salah satu operasi pengolahan citra digital yaitu kompresi citra. Hal tersebut bertujuan untuk menghemat bandwith saat proses transmisi citra dan menghemat ruang penyimpanan harddisk. Dewasa ini, kompresi citra berkembang menjadi proses yang bisa di olah secara paralel pada GPU sejak Nvidia mengeluarkan teknologi Cuda sebagai pelopor arsitektur paralel pada dunia teknologi informasi. Dengan adanya proses paralel, maka diharapkan proses kompresi citra bisa menghasilkan waktu yang lebih cepat.Uji parameternya menggunakan cuda timer function untuk empat buah citra uji dengan menggunakan algoritma DCT yang di implementasikan ke dalam bahasa CUDA C++. Hasil perbandingan speedupnya menunjukkan bahwa proses kompresi citra pada komputasi paralel lebih cepat daripada proses kompresi citra pada komputasi sekuensial dengan rata- rata nilai sebesar 3.6. Kata Kunci : Kompresi, Citra, Cuda, GPU, DCT. ABSTRACT One of digital image processing is image compression. It aims for saving bandwith when image transmission process and for saving harddisk capacity. Nowdays, image compression has evolved to become parallel processing on GPU since nvidia release about cuda technology. It as pioneer of parallel architecture especially in the world of information and technology. The existence of parallel process, it expected from process of image compression can get the result in a faster time. Test parameters using CUDA timer function for four test images using the DCT algorithm implemented in the CUDA C + + language. The result of Speedup comparison results show that the process of image compression on parallel computing faster than the process of image compression in sequential computing with an average value of 3.6. Keywords : Compression, Image, Cuda, GPU, DCT.
Transcript of ANALISIS PERBANDINGAN KOMPUTASI …publication.gunadarma.ac.id/bitstream/123456789/1126/1/...2.2.3...

ANALISIS PERBANDINGAN KOMPUTASI SEKUENSIAL DAN KOMPUTASI PARALEL GPU MEMANFAATKAN TEKNOLOGI NVIDIA CUDA PADA
APLIKASI KOMPRESI CITRA MENGGUNAKAN ALGORITMA DCT 8X8
1Andika Januarianto (50407094)2 Dr.-Ing.Adang Suhendra, Ssi.,SKom., Msc
1Mahasiswa Teknik Informatika, Fakultas Teknologi Industri, Universitas Gunadarma, [email protected]
2Dosen Tetap Universitas Gunadarma, [email protected]
ABSTRAKSI
Salah satu operasi pengolahan citra digital yaitu kompresi citra. Hal tersebut bertujuan untuk menghemat bandwith saat proses transmisi citra dan menghemat ruang penyimpanan harddisk. Dewasa ini, kompresi citra berkembang menjadi proses yang bisadi olah secara paralel pada GPU sejak Nvidia mengeluarkan teknologi Cuda sebagai pelopor arsitektur paralel pada dunia teknologi informasi. Dengan adanya proses paralel, maka diharapkan proses kompresi citra bisa menghasilkan waktu yang lebih cepat.Uji parameternya menggunakan cuda timer function untuk empat buah citra uji dengan menggunakan algoritma DCT yang di implementasikan ke dalam bahasa CUDA C++. Hasil perbandingan speedupnya menunjukkan bahwa proses kompresi citra pada komputasi paralel lebih cepat daripada proses kompresi citra pada komputasi sekuensial dengan rata-rata nilai sebesar 3.6.
Kata Kunci : Kompresi, Citra, Cuda, GPU, DCT.
ABSTRACT
One of digital image processing is image compression. It aims for saving bandwith when image transmission process and for saving harddisk capacity. Nowdays, image compression has evolved to become parallel processing on GPU since nvidia release about cuda technology. It as pioneer of parallel architecture especially in the world of information and technology. The existence of parallel process, it expected from process of image compression can get the result in a faster time. Test parameters using CUDA timer function for four test images using the DCT algorithm implemented in the CUDA C + + language. The result of Speedup comparison results show that the process of image compression on parallel computing faster than the process of image compression in sequential computing with an average value of 3.6.
Keywords : Compression, Image, Cuda, GPU, DCT.

1. Pendahuluan
Perkembangan teknologi di bidang multimedia dewasa ini demikian pesatnya, khususnya dalam pemanfaatan aplikasi citra/gambar digital. Ironisnya, citra digital yang memiliki kandungan informasi yang sangat penting umumnya memiliki ukuran besar sehingga diperlukan kapasitas memori yang besar pula untuk penyimpanan data citra ataupun untuk penggunaan bandwith pada transmisi data citra. Namun, dalam dua dekade terakhir. Telah dikembangkan salah satu teknik pengoperasian citra digital yang berfungsi untuk menghilangkan informasi yang tidak penting pada citra sehingga dapat mengurangi ukuran data dari citra asli. Dan dengan demikian, ruang penyimpanan data bisa menjadi lebih hemat dan proses transmisi bisa menjadi lebih cepat. Operasi pengolahan citra tersebut dikenal dengan istilah kompresi citra atau Image Compression.
Tamal Bose,dalam bukunya yang berjudul “ Digital Signal dan Image Processing “ mengatakan bahwa citra digital memiliki ribuan piksel dan masing-masingnya memerlukan banyak bit untuk di representasikan, oleh karena itu citra digital harus dikompresi. Mengacu dari sumber yang telah dikemukakan oleh ilmuwan di atas, timbul suatu pertanyaan, apakah proses kompresi citra memerlukan waktu yang cukup lama untuk mendapatkan hasil yang sesuai, terlebih jika proses tersebut hanya dilakukan oleh komputasi sekuensial?. Keadaan inilah yang memicu dilakukannya berbagai algoritma yang
bekerja secara sekuensial kemudian dikonversikan ke dalam banyak algoritma paralel yang dapat berjalan pada Graphic Processing Unit ( GPU ). Beberapa algoritma yang terkait dengan proses kompresi citra pada GPU antara lain yaitu algoritma Discrete Cosine Transform ( DCT ), algoritma Fraktal, algoritma Discrete Wavelete Transform ( DWT ) .
Pada sebuah penelitian sebelumnya, yang telah dilakukan oleh dua orang berkebangsaan Indonesia dengan judul jurnal “Algoritma Kompresi Fraktal Sekuensial Dan Paralel Untuk Kompresi Citra”( Satrya N Ardhitya dan Lely Hariyanto, 2011) menyatakan bahwa proses kompresi citra pada komputasi paralel GPU menghasilkan waktu yang lebih cepat dibandingkan dengan proses kompresi citra pada komputasi sekuensial. Oleh karena itu, penulis mencoba membuktikan kebenaran dari analisa tersebut dengan menggunakan metode kompresi citra yang lain yaitu metode DCT yang beroperasi pada blok 8x8.
Sehingga tujuan dari penelitian ini tercapai yaitu membandingkan nilai speedup dari beberapa sample citra uji yang di olah dari data percobaan pada komputasi sekuensial dan pada komputasi paralel dengan memanfaatkan cuda timer function sebagai uji parameter untuk mendapatkan waktu proses kompresi citra pada setiap sampel uji .

2. Tinjauan Pustaka
2.1 Kompresi Citra
Kompresi citra adalah aplikasi kompresi data yang dilakukan terhadap citra digital dengan tujuan untuk mengurangi redudansi dari data-data yang terdapat dalam citra sehingga dapat disimpan atau ditransmisikan secara efisien.
Teknik pada kompresi terbagi menjadi 2 jenis yaitu :
1. Loseless Compression
Teknik kompresi citra dimana tidak ada satupun informasi citra yang dihilangkan, biasanya digunakan pada citra medik. Metode yang dipakai pada teknik kompresi ini antara lain : Run Length Encoding, Entropy Encoding ( Huffman, Aritmatik ) dan Adaptive Dictionary Based ( LZW ).
2. Lossy Compression
Teknik kompresi citra yang menghilangkan beberapa informasi dalam citra asli dan merubah ukuran file citra menjadi lebih kecil dari citra aslinya. Teknik ini mengubah detail dan warna pada file citra menjadi lebih sederhana tanpa terlihat perbedaan yang mencolok dalam pandangan manusia, sehingga ukurannya menjadi lebih kecil, biasanya digunakan pada citra foto atau image lain yang tidak memerlukan detail citra ,
diman kehilangan bitrate foto tidak berpengaruh pada citra. Metode yang dipakai pada teknik kompresi ini antara lain : Color Reduction, Chroma Subsampling, Transform Coding.
Hal-hal penting dalam kompresi citra antara lain :
1. Scalability
Adalah kualitas dari hasil proses pengkompresian citra karena manipulasi bitstream tanpa adanya dekompresi atau rekompresi, biasanya dikenal pada lossless codec. Contohnya pada saat preview image sementara ketika di unduh, semakin baik scalability, semakin bagus preview imagenya.
2. Region of Interest Coding
Daerah-daerah tertentu dienkode dengan kualitas yang lebih tinggi daripada yang lain
3. Meta Information: citra yang dikompres juga dapat memiliki meta information seperti statistik warna, tekstur, small preview image , dan author atau copyright information.
2.2 Algoritma DCT
Metode DCT pertama kali diperkenalkan oleh Ahmed, Natarajan dan Rao pada tahun 1974 dalam makalahnya
yang berjudul “On Image Processing and a Discrete Cosine Transform” . DCT adalah sebuah teknik untuk mengubah

sinyal ke dalam komponen frekeunsi dasar. DCT merepresentasikan sebuah citra dari penjumlahan sinusoida dari magnitude dan frekeunsi yang berubah-ubah. Sifat dari DCT adalah mengubah informasi citra yang signifikan dikonsentrasikan hanya pada beberapa koefisien DCT. DCT berhubungan erat dengan Fast Fourier Transform ( FFT ), sehingga menjadikan data direpresentasikan dalam komponen frekeunsinya. Demikian pula, dalam aplikasi pemrosesan citra, DCT dua dimensi memetakan sebuah citra atau sebuah segmen gambar ke dalam komponen frekeunsi dua dimensi ( 2D ).
DCT adalah sebuah skema lossy compression dimana NxN blok ditransformasikan dari domain spasial ke domain DCT. DCT menyusun sinyal
tersebut ke frekeunsi spasial yang disebut dengan koefisien DCT. Frekeunsi koefisien DCT yang lebih rendah muncul pada kiri atas dari sebuah matriks DCT, dan frekeunsi koefisien DCT yang lebih tinggi berada pada kanan bawah dari matriks DCT. Sistem penglihatan manusia tidak begitu sensitive dengan error yang ada pada frekenusi tinggi disbanding dengan yang ada pada frekuensi rendah. Karena itu, maka frekuensi yang lebih tinggi tersebut dapat di kuantisasi.
Berikut skema proses kompresi menggunakan algoritma DCT beroperasi blok 8x8 :
Gambar 1. Skema Algoritma DCT8x8
2.2 GPU
GPU memiliki arsitektur tertentu, hal ini disebabkan karena GPU merupakan prosesor multithread yang mampu mendukung jutaan pemrosesan data pada satu waktu [Mukhlis, Yulisdin dan Lingga Harmanto, 2007]. Arsitektur tersebut dapat digambarkan seperti dibawah ini :
Gambar 2. Arsitektur GPU
Gambar di atas menggambarkan GPU terdiri dari n thread processor dan device memory. Setiap thread processor. Terdiri
dari beberapa precision FPU (Fragement Processsing Unit ) . Device memory akan menjadi tempat pemrosesan data sementara selama proses parallel. Pada pemrosesan data, GPU menggunakan metode shared memory multiprocessor. Kelebihan shared memory ini dibandingkan dengan jenis paralel computer yang lain adalah lebih cepat dan effiisien karena kecepatan transfer data antar unit komputasi tidak mengalami degradasi. Shared memory multiprocessor juga memliki kekurangan , diantaranya :
1. Relatif lebih mahal dan rumit untuk diimplementasikan 2. Tidak tahan lama,,system jenis ini lebih sulit untuk di upgrade

3. Sulit untuk mengkoordinasikan pembagian memory yg tersedia untuk masing-masing unit komputasi
2.2.1 Hirarki Kernel GPU
CUDA menyediakan ekstensi pada bahasa C berupa fungsi yang ditandai tag khusus: __global__
Bila membaca keyword __global__, CPU akan menjalankan fungsi tersebut di dalam GPU. Setelah memulai eksekusi pada GPU, program akan segera mengeksekusi perintah berikutnya, tidak harus menunggu eksekusi GPU selesai. Hal ini memungkinkan pemrogram untuk menjalankan komputasi secara paralel antara CPU dan GPU.
Selain dengan keyword __global__ , kernel juga dapat dideklarasikan dengan keyword __device__. Bedanya, kernel __device__ini hanya dapat dipanggil oleh kernel yang lain, alias oleh fungsi yang sudah berjalan pada GPU. Kernel CUDA, baik yang didefinisikan dengan keyword __global__ maupun __device__ , mempunyai kelemahan: ia tak dapat dieksekusi secara rekursif. Artinya, suatu kernel tidak dapat memanggil dirinya sendiri. Kernel CUDA juga tak dapat memanggil fungsi selain kernel CUDA yang lain. Ini berarti fungsi host (CPU) tidak dapat dipanggil dari kernel (GPU).
Kernel sendiri dijalankan dengan banyak thread secara bersamaan pada GPU. Bisa dibilang thread adalah satuan eksekuis terkecil dalam CUDA. Thread ini dikelompokkan pada block. Jumlah thread yang dapat dijalankan pada satu block terbatasi oleh kemampuan hardware, tapi satu kernel dapat dijalankan oleh banyak block sekaligus.
Banyaknya block dan thread per block didefinisikan saat memanggil kernel dalam program. Thread yang berada dalam satu block dapat saling berbagi memori, tapi tidak dengan thread yang berada di lain block.
Gambar 3. Hirarki Kernel GPU
2.2.2 Hirarki Thread GPU
Blok Thread diperlukan untuk mengeksekusi secara mandiri. Ini mungkin untuk mengeksekusi mereka dalam urutan apapun, secara paralel atau seri. Persyaratan ini memungkinkan blok thread secara mandiri untuk dijadwalkan dalam urutan apapun di setiap jumlah core, memungkinkan programmer untuk menulis kode yang timbangan dengan jumlah core. Jumlah blok thread di grid biasanya ditentukan oleh ukuran data yang sedang diproses bukan oleh jumlah prosesor dalam sistem.
Gambar 4. Hirarki Thread GPU

2.2.3 Hirarki Memori GPU
CUDA thread mengijinkan akses data dari banyak ruang pada meori ketika sedang mengeksekusi program CUDA. Setiap thread memiliki private local memory. Masing-masing thrad block memiliki shared memory yang bisa di implementasikan untuk semua thread pada blok. Oleh karena itu, semua thread memiliki akses untuk global memori yang sama. Global, konstan dan tekstur memori di optimalkan untuk kebutuhan yang
berbeda-beda. Global, konstan dan tekstur memori diakses pada seluruh fungsi kernel pada aplikasi yang sama.
Gambar 5. Hirarki Memori GPU
2.4 Cuda
CUDA merupakan akronim dari Compute Unified Device Architecture yaitu sebuah teknologi yang dikembangkan oleh NVIDIA untuk mempermudah utilitasi GPU untuk keperluan umum (non-grafis).
Arsitektur CUDA ini memungkinkan pengembang perangkat lunak untuk membuat program yang berjalan pada GPU buatan NVIDIA dengan syntax yang mirip dengan syntax C yang sudah banyak dikenal. Pemorgraman CUDA sama seperti membuat program C biasa. Saat kompilasi, syntax2 C biasa akan diproses oleh compiler C, sedangkan syntax dengan keyword CUDA akan diproses oleh compiler CUDA (nvcc).
Arsitektur CUDA memiliki beberapa keunggulan, diantaranya adalah :
1. CUDA menggunakan bahasa “C” standar, dengan beberapa ekstensi yang simpel.2. Shared memory – CUDA menyingkapkan wilayah memory yang cepat (berukuran 16 KB) yang dapat di
bagi diantara Start Debugging.yang ada. Hal ini dapat digunakan sebagai user-managed-cache, sehingga mengaktifkan bandwitdth yang lebih besar (dari besaran bandwidth yang dimungkinkan), menggunakan texture loops.3. Support penuh terhadap operasi integer dan bitwise.
Namun dibalik beberapa kelebihan itu, CUDA juga memiliki kekurangan. Kekurangan dari arsitektur CUDA adalah :
1. CUDA tidak support texture rendering.2. Bus Bandwidth dan latensi antara CPU dengan GPU bisa jadi tidak imbang.3. CUDA hanya terdapat pada GPU Nvidia.
Untuk dapat bekerja dengan teknologi CUDA ada 3 komponen yang harus tersedia pada perangkat PC atau notebook. Komponen tersebut antara lain :

1. CUDA driver, merupakan driver yang harus sudah terinstal pada device yang akan digunakan untuk menjalankan program CUDA. Device tersebut harus menggunakan kartu grafis dari Nvidia. 2. CUDA toolkit, merupakan ruang lingkup pengembangan CUDA dari bahasa C sehingga akan menghasilkan CUDA-enabled GPU. 3. CUDA SDK, berisi sample-sample program CUDA dan header yang dapat dijalankan oleh program CUDA.
3. Metode Penelitian
Penelitian ini dilakukan untuk mencapai tujuan yang diharapkan yaitu mengukur kinerja teknologi CUDA menggunakan algoritma DCT 8x8 blok untuk melakukan proses kompresi citra dengan cara mengukur speed up atau kecepatan yang dapat dicapai oleh teknologi CUDA yang mengerjakan proses secara paralel dan kemudian membandingkan speedup yang didapat dengan algoritma DCT yang dilakukan secara sekuensial.
Penelitian ini dilakukan agar dapat menjawab beberapa masalah, antara lain :
1.Mengetahui speedup dari proses yang dikerjakan secara paralel dengan menggunakan teknologi CUDA yang berasal dari GPU Nvidia GeForce GT 540M.
2.Mengetahui speedup dari proses yag dilakukan secara sekuensial dengan menggunakan processor i3-2310M.
3.Dapat membandingan kedua speedup diatas, yaitu speed up dari proses yag dikerjakan secara sekuensial dan paralel. Untuk dapat menjawab beberapa masalah
diatas, maka ada beberapa langkah penelitian yang harus penulis lakukan terlebih dahulu. Langkah-langkah penelitian tersebut antara lain :
1. Mempersiapkan program CUDA untuk Paralel GPU
Pada bagian ini, penulis akan mempersiapkan program CUDA yang membahas tentang kompresi citra dengan menggunakan algoritma DCT 8x8. Program CUDA ini harus dapat dijalankan pada GPU Nvidia GT 540M. Pada forum nvidia, beberapa developer telah membuat program kompresi citra menggunakan metode DCT 8x8. Program ini berisi tahap-tahap dalam melakukan proses kompresi citra mulai dari tahap mengambil citra uji. sampling, DCT , Quantization, Entropy coding hingga mendapakan citra hasil kompresi .
Pada algoritma DCT8x8, di sesuaikan dengan batasan masalah bahwa Metode DCT 8x8 yag digunakan hanya dengan menggunakan pendekatan 1 kernel . Program ini akan menghasilkan output berupa waktu yang dihasilkan dari eksekusi kernel selama proses kompresi citra berlangsung berlangsung. Waktu yang dihasilkan dengan satuan waktu berupa ms (millisecond) dengan input berupa empat buah citra uji dengan masing-masing citra uji memliki dimensi yaitu 256x256px, 512x512px, 1024x1024px, 2048x2048px.
2. Mempersiapkan program C++ untuk komputasi sekuensial
Pada bagian ini, kita akan mempersiapkan program C++ yang akan dijalankan pada CPU berupa intel processor i3 2310M. Program didapat dari satu paket dengan program yang dijalankan pada proses paralel. Pada

program ini, kompresi citra memanfaatkan perkalian matriks 8x8 dengan input berupa beberapa dimensi citra uji. Program pada cpu dinamai dengan file dct8x8_Gold.cpp. dan pada program CPU ini akan di proses loading untuk memproses citra original menjadi citra yang telah dikompresi. 3. Membandingkan speed up antara GPU dan CPU Setelah program CPU dan GPU berhasil dijalankan, maka langkah selanjutnya adalah membandingkan speed up antara program yang dikerjakan oleh GPU dan CPU. 4. Menarik kesimpulan berdasarkan penelitian yang telah dilakukan.Berdasarkan proses perbandingan yang telah dilakukan sebelumnya, kita dapat menarik kesimpulan apa yang didapat dari percobaan yang telah dilakukan dan proses yang lebih cepat dikerjakan antara GPU dan CPU. Bagaimana perbandingan yang dihasilkan antara kedua program diatas.
3.1 Algoritma DCT 8x8 pada Cuda
Berdasarkan referensi dari sumber pengembang program cuda Anton Obhukov dan Alexander Kharlamov:2008 , maka diperlukan tahapan-tahapan hingga tercapai penggunaan teknologi CUDA pada algoritma DCT 8x8 untuk proses kompresi citra. Beberapa tahapan fase tersebut yaitu :
Pelaksanaan DCT8x8 menurut definisi ini dilakukan dengan menggunakan dasar perkalian mariks.Untuk mengkonversi 8x8 masukansampel ke dalam domain transform, dua perkalian dua matriks mutlak diperlukan.Namun, solusi ini prakteknya tidak pernah digunakan ketika menghitungDCT8x8 pada CPU.Karena menunjukkantinggi kompleksitas komputasi relatif
dengan beberapa metode yang terpisah.Berbeda halnya dengan CUDA, petapendekatan dijelaskan baik untuk model pemrograman CUDA dan arsitekturparallel khususnya.
Gambar dibagi menjadi satu set blok seperti yang ditunjukkan pada gambar (1). Setiap satu set blok-CUDA menjalankan 64 thread untuk melakukan penghitungan DCT. Masing-masing thread di blok-CUDA menghitung koefisien DCT tunggal. Semua bentuk persinyalan sebelum di hitung akan disimpan dalam bentuk array yang terletak pada memori.
Array pada memori konstan
tersebut ditampilkan sebagai array dua
dimensi yang berisi nilai-nilai fungsi
dasar yaitu A (x,u). Fungsi Dua dimensi
DCT ukuran NxN didefinisikan sebagai
berikut :
Gambar 6. Sampel citra yang dibagi ke dalam 8x8 blok.
Dua dimensi DCT dilakukan dalam empat langkah ( mempertimbangkan jumlah thread ):

1. Thread dengan koordinat (ThreadIdx.x, ThreadIdx.y) memuatsatu pixel dari teksturuntuk memori bersama. Untukmemastikan seluruh blok dimuatuntuk saat ini,semua thread yang melewati titik sinkronisasi.
2. Thread menghitung dot productantara dua vektor: Kolom ThreadIdx.y dari kosinus koefisien(yang sebenarnya deretan AT dengannomor yang sama) dan ThreadIdx.xkolom dari blok masukan. Untuk memastikan semua koefisien dariATX adalah dihitung, dan harus di sinkronisasikan.
3. Thread dihitung dengan formula ( ATX ) A , dengan cara yang sama seperti langkah 2
4. Seluruh blok akan disalin dari shared memory untuk hasil output dalam global memorydan setiap thread bekerja dengan single pixel.
Gambar 7. Model komputasi DCT pada Thread GPU
Model komputasi DCT pada GPU ditunjukkan pada gambar di atas. Setiap blok thread menghitung satu sub persegi untuk mendapatkan hasil perhitungan matriks ( Kotak persegi hijau ). Setiap thread dalam blok menghitung satu
elemen matriks. Blok biru menunjukkanbagaimana perhitungan dilakukan .
Elemen pada matriks asli dan transfer matriks koefisien disorot dengan warna yang berbeda. Untuk mentransfer kolom kedua, matriks akan bertukar posisi.
Gambar 8. Model komputasi DCT pada memory GPU
Setiap elemen me-load dari memori global untuk berbagi memori . Karena ukuran blok di atur menjadi 8x8, maka indeks thread akan menjadi jumlah indeks pada bank memori. Setelah menyelesaiakan perhitungan, data memori akan di-load kembali ke memori global.
Untuk menyesuaikan model perhitungan dengan ukuran piksel matriks . Maka dibuatlah padding lokasi yang di set sebagai warna biru terang agar akses memori menjadi selaras ketika mengeksekusi program.
3.2 Kompleksitas Algoritma DCT
Algoritma DCT memiliki kompleksitas waktu Total sebesar O ( N log N), dengan kompleksitas waktu yang diterapkan pada formula perkalian dua matriks sebesar O ( N3 ). Oleh karena itu, jika Algoritma DCT menggunakan blok 8x8 maka inputan n = 8, membutuhkan ( 83 ) langkah untuk menyelesaikan proses perkalian matriksnya.

3.3 Spesifikasi Hardware dan Software
Pada saat pembuatan dan menjalankan program terutama program CUDA dibutuhkan spesifikasi-spesifikasi tertentu untuk perangkat yang digunakan. Dibawah ini akan diuraikan perangkat yang digunakan baik hardware maupun software.
Spesifikasi Hardware (Perangkat Keras)o Notebook ASUS N43SLo Prosesor Intel Core i3 2310M 2.2
GHzo GPU Nvidia GeForce GT 540 M 2
GB yang mendukung teknologi CUDA
o Memori DDR3 1333 MHz SDRAM 2 GB
o Harddisk 640 GB Spesifikasi Software (Perangkat
Lunak)o Sistem Operasi Microsoft
Windows 7o Microsoft Visual Studio 2008
sebagai IDEo NVIDIA Graphics Driver 285.62o NVIDIA CUDA Toolkit v3.2o NVIDIA GPU Computing SDK
3.2 Spesifikasi GPU Nvidia Cuda
Geforce GT540Mo CUDA Cores : 96o Processor Clock ( MHz ): 1344o Memory Clock ( MHz ): 900o Memory Interface Width : 128-bito Memory Bandwidth (GB/Sec)
: 28.8o Microsoft DirectX: 11
4. Hasil Pengujian dan Analisa
Data yang digunakan berupa waktu proses kompresi yang didapat dari
beberapa kali percobaan pada program sekuensial dan parallel. Cara melakukan percobaan adalah dengan melakukan build pada project, jika tidak ditemukan error lagi atau dengan kata lain program sukses di build kemudian pada menu pilih debug lalu klik Start Debugging.
4.1 Hasil Pengujian Waktu perbandingan Kompresi citra pada komputasi sekuensial dan parallel
Gambar 9. Grafik perbandingan waktu proses kompresi citra pada komputasi sekuensial dan paralel
1. pada data pertama dengan citra uji 256 x 256 piksel, perbandingan antara komputasi sekuensial dan paralel tidak menunjukan perbedaan yang signifikan. pada komputasi sekuensial proses kompresinya membutuhkan waktu 0.674 ms sedangkan pada komputasi parallel proses kompresinya membutuhkan waktu 0.452 ms. 2. pada data kedua dengan citra uji 512 x 512 piksel, perbandingan antara komputasi sekuensial dan paralel juga tidak menunjukan perbedaan yang signifikan. pada komputasi sekuensial proses kompresinya membutuhkan waktu 4 ms sedangkan pada komputasi parallel proses kompresinya membutuhkan waktu 0.948 ms.3. pada data ketiga dengan citra uji 1024 x 1024 piksel, perbandingan antara komputasi sekuensial dan paralel menunjukan perbedaan yang cukup
terlihat. pada komputasi sekuensial proses kompresinya membutuhkan waktu 17.294 ms sedangkan pada komputasi parallel proses kompresinya membutuhkan waktu 3.508 ms.4. pada data keempat dengan citra uji 2048 x 2048 piksel, perbandingan antara komputasi sekuensial dan paralel menunjukan perbedaan yang signifikan. pada komputasi sekuensial proses kompresinya membutuhkan waktu 68.144 ms sedangkan pada komputasi parallel proses kompresinya membutuhkan waktu 13.53 ms.
4.2 Speedup
Mengacu pada rumus
S(p) =
Keterangan rumus : S (p) = nilai speedup ts = Waktu Pemrosesan Sekuensial tp =Waktu pemrosesan parallel dengan p processor
maka di dapat nilai speedup sebagai berikut :
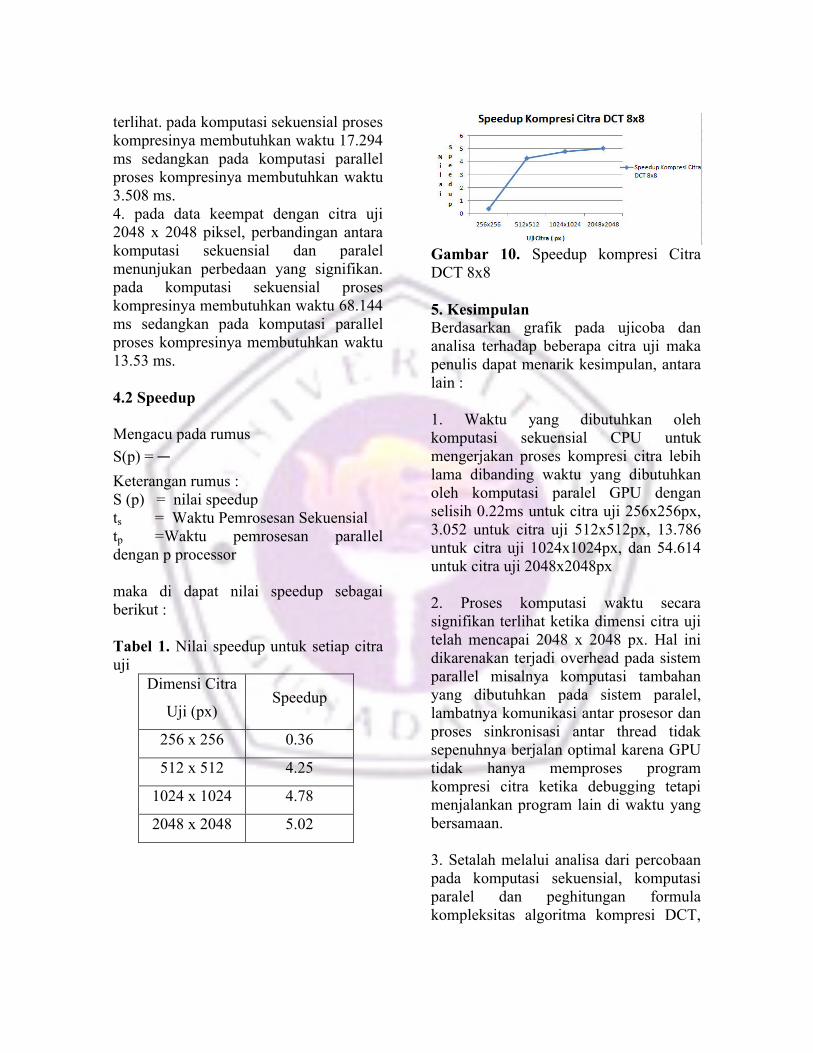
Tabel 1. Nilai speedup untuk setiap citra uji
Dimensi Citra
Uji (px)Speedup
256 x 256 0.36
512 x 512 4.25
1024 x 1024 4.78
2048 x 2048 5.02
Gambar 10. Speedup kompresi Citra DCT 8x8
5. KesimpulanBerdasarkan grafik pada ujicoba dan analisa terhadap beberapa citra uji maka penulis dapat menarik kesimpulan, antara lain :
1. Waktu yang dibutuhkan oleh komputasi sekuensial CPU untuk mengerjakan proses kompresi citra lebih lama dibanding waktu yang dibutuhkan oleh komputasi paralel GPU dengan selisih 0.22ms untuk citra uji 256x256px, 3.052 untuk citra uji 512x512px, 13.786 untuk citra uji 1024x1024px, dan 54.614 untuk citra uji 2048x2048px
2. Proses komputasi waktu secara signifikan terlihat ketika dimensi citra uji telah mencapai 2048 x 2048 px. Hal ini dikarenakan terjadi overhead pada sistem parallel misalnya komputasi tambahan yang dibutuhkan pada sistem paralel, lambatnya komunikasi antar prosesor dan proses sinkronisasi antar thread tidak sepenuhnya berjalan optimal karena GPU tidak hanya memproses program kompresi citra ketika debugging tetapi menjalankan program lain di waktu yang bersamaan.
3. Setalah melalui analisa dari percobaan pada komputasi sekuensial, komputasi paralel dan peghitungan formula kompleksitas algoritma kompresi DCT,

maka dapat disimpulkan dari penggambaran grafik pada proses komputasi melalui percobaan sesuai dengan penggambaran grafik pada penghitungan formula DCT yaitu data yang dihasilkan bersifat non-linear. Karena, semakin besar blok proses pada DCT membutuhkan perhitungan yang semakin kompleks dan bit-bit image yang direpresentasikan harus melalui beberapa tahapan perhitungan seperti kuantisasi maupun enthropy coding yang menyebabkan komputasi tidak efisien.
4. speedup bersifat terus meningkat terhadap data citra uji serta non-linear terhadap data citra uji. Karena pengaruh jumlah piksel yang semakin besar menyebabkan penghitungan bit-bit citra menjadi lebih kompleks. Hal ini sesuai dengan Hukum Gustafson yang berbunyi“Speedup akan meningkat jika ukuran data juga ditingkatkan” .
5. Hasil speedup pada uji citra 256x256 px dengan 512x512 px mengalami kenaikan yang cukup signifikan karena proses preprocessing pada penjadwalan kerja dari masing-masing prosessor tidak bisa dikerjakan secara parallel. Hal ini yang menyebabkan lambatnya proses penyalinan memori utama ke memori VGA untuk diproses oleh procesoor VGA.
Untuk penelitian selanjutnya, eksperimen yang akan dilakukan difokuskan pada beberapa hal berikut :
1. Melakukan ujicoba jika metode DCT8x8 pada CUDA di implementasikan untuk transmisi citra menggunakan kanal multipath.2. Melakukan perbandingan komputasi waktu setiap citra uji antara
metode DCT 8x8 pada CUDA dengan metode Fraktal pada CUDA.
6.Referensi
[1]Anonim.NVIDIACUDAProgrammingGuide2.3NvidiaCorporation,http://developer.download.nvidia.com, 2009.
[2] Anonim. Kompresi data menggunakan discrete cosine transform. http://repository.usu.ac.id , 2010.
[3]Antonius Rachmat Chrismanto. Kompresicitra.http://lecturer.ukdw.ac.id , 2006.
[4]Anton Obhukov and Alexander Kh armalov. Discrete Cosine Transform for 8x8 Blocks . Nvidia Corporation, 2008.
[5]Maria Kartawijaya. Analisis kinerja perkalian matriks paralel menggunakan metrik isoefisiensi. TESL A , 10, 2008.
[6] Rosni Gonindjaya. Konsep dasar citra. http://rosnigj.staff.gunadarma.ac.id/Downloads/files/15421/Konsep+Dasar+Citra.pdf , 2006.
[7]Tamal Bose. Digital Signal and Image Processing. John Willey and Sons ( ASIA ), 2004.
[8]Zainuddin Muhammad Agus Febri, Ikhsan P ratama and Tri Budi Santoso. Analisis kinerja transmisi citra menggunakan tra nsformasi dct melalui kanal multipath. http://www.eepis-its.edu , 2009.




















