
7 regresi
33
194 7 Regresi linier sederhana dan korelasi 7.1 Pendahuluan Di dalam bab 5 dan 6 telah kita bahas berbagai teknik pendugaan dan pengujian hipotesis tentang rata-rata populasi dan selisih rata-rata dari dua populasi. Persoalan yang kita pecahkan dalam bab-bab tersebut umumnya relatif mudah dan sederhana karena walaupun berkaitan dengan dua populasi, kedua populasi tersebut umumnya diasumsikan bersifat independen, artinya tidak ada keterkaitan antara satu populasi dengan populasi yang lainnya. Dalam kehidupan sehari-hari, sering kali kita temui bahwa nilai suatu variabel (Y) dipengaruhi oleh nilai variabel lain (X), atau berkaitan dengan nilai variabel lain. Bentuk hubungan antar kedua variabel tersebut adalah persoalan yang akan kita bahas dalam analisis regresi dan korelasi. Sebagai contoh, kita mungkin tertarik untuk meneliti hubungan antara pola konsumsi seseorang dalam suatu komunitas tertentu (Y) dengan penghasilannya per bulan (X), atau hubungan antara pendapatan suatu perusahaan (Y) dengan biaya yang dikeluarkan oleh perusahaan tersebut untuk pemasangan iklan dalam media cetak (X), atau pengaruh pemberian berbagai dosis suatu jenis pupuk tertentu (X) terhadap peningkatan produksi padi varietas tertentu (Y). Dalam setiap kasus di atas, variabel Y merupakan variabel dependen atau variabel respons yang nilai-nilainya tergantung pada nilai-nilai variabel X, yang disebut sebagai variabel independen atau variabel bebas. Analisis regresi digunakan untuk membangun suatu model matematis untuk menjelaskan bentuk hubungan antar kedua variabel tersebut (jika hubungan tersebut ada). Misalnya, jika kita beranggapan bahwa terdapat hubungan linier antara pola konsumsi seseorang dengan penghasilannya, maka untuk menguji anggapan tersebut kita akan mengambil sampel yang terdiri atas beberapa orang anggota komunitas tersebut dan memeriksa pola konsumsi dan penghasilan mereka. Jika anggapan tersebut benar, maka nilai-nilai pengamatan akan mencerminkan pola hubungan kedua variabel tersebut. Dalam bab ini konsep-konsep dasar tentang hubungan keterkaitan antar variabel tersebut akan kita bahas melalui analisis regresi dan korelasi. Namun demikian, pembahasan tersebut akan kita batasi hanya untuk kasus-kasus yang sederhana saja, yaitu kasus yang hanya melibatkan dua variabel saja. Pembahasan untuk kasus-kasus yang melibatkan hubungan keterkaitan antar lebih dari dua variabel
-
Upload
feri-prasetio -
Category
Documents
-
view
153 -
download
7
description
Perkuliahan Dasar Statistik
Transcript of 7 regresi

194
77777777 RReeggrreessii ll iinniieerr sseeddeerrhhaannaa ddaann
kkoorreellaassii
7.1 Pendahuluan
Di dalam bab 5 dan 6 telah kita bahas berbagai teknik pendugaan dan pengujian hipotesis tentang rata-rata populasi dan selisih rata-rata dari dua populasi. Persoalan yang kita pecahkan dalam bab-bab tersebut umumnya relatif mudah dan sederhana karena walaupun berkaitan dengan dua populasi, kedua populasi tersebut umumnya diasumsikan bersifat independen, artinya tidak ada keterkaitan antara satu populasi dengan populasi yang lainnya. Dalam kehidupan sehari-hari, sering kali kita temui bahwa nilai suatu variabel (Y) dipengaruhi oleh nilai variabel lain (X), atau berkaitan dengan nilai variabel lain. Bentuk hubungan antar kedua variabel tersebut adalah persoalan yang akan kita bahas dalam analisis regresi dan korelasi. Sebagai contoh, kita mungkin tertarik untuk meneliti hubungan antara pola konsumsi seseorang dalam suatu komunitas tertentu (Y) dengan penghasilannya per bulan (X), atau hubungan antara pendapatan suatu perusahaan (Y) dengan biaya yang dikeluarkan oleh perusahaan tersebut untuk pemasangan iklan dalam media cetak (X), atau pengaruh pemberian berbagai dosis suatu jenis pupuk tertentu (X) terhadap peningkatan produksi padi varietas tertentu (Y).
Dalam setiap kasus di atas, variabel Y merupakan variabel dependen atau variabel respons yang nilai-nilainya tergantung pada nilai-nilai variabel X, yang disebut sebagai variabel independen atau variabel bebas. Analisis regresi digunakan untuk membangun suatu model matematis untuk menjelaskan bentuk hubungan antar kedua variabel tersebut (jika hubungan tersebut ada). Misalnya, jika kita beranggapan bahwa terdapat hubungan linier antara pola konsumsi seseorang dengan penghasilannya, maka untuk menguji anggapan tersebut kita akan mengambil sampel yang terdiri atas beberapa orang anggota komunitas tersebut dan memeriksa pola konsumsi dan penghasilan mereka. Jika anggapan tersebut benar, maka nilai-nilai pengamatan akan mencerminkan pola hubungan kedua variabel tersebut.
Dalam bab ini konsep-konsep dasar tentang hubungan keterkaitan antar variabel tersebut akan kita bahas melalui analisis regresi dan korelasi. Namun demikian, pembahasan tersebut akan kita batasi hanya untuk kasus-kasus yang sederhana saja, yaitu kasus yang hanya melibatkan dua variabel saja. Pembahasan untuk kasus-kasus yang melibatkan hubungan keterkaitan antar lebih dari dua variabel

195
biasanya dibahas dalam topik yang khusus, yaitu dalam bahasan tentang analisis regresi berganda (multiple regression analysis), atau analisis variable ganda (multivariate analysis) yang merupakan topik bahasan dalam Ilmu Statistik tingkat lanjut. Dalam buku ini analisis regresi berganda dibahas secara singkat dalam bab 8.
7.2 Hubungan antara variabel dependen dengan variabel bebas
Untuk model regresi yang hanya melibatkan satu variabel dependen dan satu variabel bebas, bentuk hubungan antar kedua variabel tersebut biasanya dapat diperiksa dengan memetakan setiap pasangan pengamatan (x, y) dalam suatu diagram pencar (scatter diagram). Pemetaan data ke dalam suatu bentuk diagram pencar tidak saja bermanfaat dalam memeriksa bentuk hubungan antar kedua variabel, tetapi juga dalam mengeksplorasi data secara keseluruhan, misalnya dalam memeriksa kemungkinan adanya nilai pencilan, melihat bentuk distribusi data, atau memeriksa kecenderungan (trend) dalam data. Diagram pencar digunakan untuk memvisualisasikan bentuk hubungan antar ke dua variabel tersebut. Dalam diagram tersebut, variabel dependen selalu dipetakan dalam sumbu tegak dan variabel bebas dipetakan dalam sumbu mendatar. Sebagai ilustrasi, berbagai bentuk diagram pencar disajikan dalam gambar 7.1.
Data dalam gambar 7.1.a dan 7.1.b mengindikasikan bentuk hubungan antara variabel X dan Y yang cenderung linier. Data dalam kedua gambar tersebut terlihat mengelompok di sekitar suatu garis lurus. Gambar 7.1.c menunjukkan suatu bentuk hubungan antara variabel X dan Y yang mungkin dapat dijelaskan melalui suatu persamaan eksponensial atau kuadratik. Sedangkan data dalam gambar 7.1.d tidak menunjukkan adanya bentuk hubungan yang kuat antara variabel X dan Y. Hal ini terlihat betapa data dalam gambar tersebut terpencar secara sembarang, tanpa menunjukkan adanya suatu keteraturan.
Pemetaan pasangan data (x, y) ke dalam suatu diagram pencar merupakan suatu langkah awal dalam menganalisis hubungan antara kedua variabel tersebut. Beberapa informasi yang dapat kita peroleh dengan mengamati suatu diagram pencar dari pasangan data (x, y) diantaranya adalah:
� ada atau tidaknya kecenderungan bahwa data tersebut mengelompok di sekitar suatu garis lurus, atau bentuk kurva sederhana lainnya
� bagaimana kecenderungan bentuk hubungan antara variabel X dan Y; misalnya adakah kecenderungan bahwa nilai-nilai y menaik dengan bertambahnya nilai x, ataukah sebaliknya, artinya nilai-nilai y cenderung menurun dengan bertambahnya nilai x.
� bagaimana ‘kekuatan’ hubungan antara variabel X dan Y; kedua variabel tersebut dikatakan mempunyai hubungan atau keterkaitan yang erat jika data dalam diagram pencar tersebut mengelompok di sekitar suatu garis lurus atau kurva sederhana lainnya: semakin dekat jarak antara data

196
dengan garis atau kurva tersebut, maka semakin kuat hubungan kedua variabel tersebut
� kemungkinan adanya nilai pencilan dalam data
X
Y
(a)
X
Y
(b)
X
Y
(c)
X
Y
(d)
Gambar 7.1 Diagram pencar: beberapa contoh bentuk hubungan antara X dan Y
Hubungan antara variabel pengamatan X dan Y dapat dinyatakan dalam suatu model atau pernyataan matematis. Salah satu bentuk yang paling sederhana adalah model linier, yaitu:
XY 10 ββ += ............................................................................... [7.1]
Dalam model [7.1] tersebut, β0 dan β1 keduanya merupakan konstanta yang tidak diketahui nilainya. Dalam persamaan tersebut variabel X merupakan penduga bagi variabel Y. Secara grafis, persamaan [7.1] tersebut menyatakan persamaan
sebuah garis lurus yang memotong sumbu tegak Y di titik β0 dengan kemiringan
(slope) β1.

197
Koefisien kemiringan suatu garis lurus menyatakan besar kenaikan/penurunan garis tersebut dengan bertambahnya nilai X sebesar satu satuan. Artinya,
� jika β1 > 0, maka garis tersebut akan menaik sebesar β1 satuan dengan bertambahnya nilai X sebesar satu satuan, tetapi
� jika β1 < 0 maka garis tersebut akan menurun sebesar β1 satuan dengan bertambahnya nilai X sebesar satu satuan, dan
� jika β1 = 0 maka garis tersebut merupakan garis yang mendatar (horizontal).
Gambar 7.2 menyajikan contoh dua buah persamaan garis lurus. Gambar 7.2.a
menyajikan sebuah garis lurus dengan β0 = 1 dan β1 = 2 yang dinyatakan dengan persamaan Y = 1 + 2X. Perhatikan bahwa garis tersebut memotong sumbu Y di titik (0, 1) dan menaik sebesar 2 satuan setiap pertambahan nilai X sebesar 1
satuan. Gambar 7.2.b menyajikan sebuah garis lurus dengan β0 = 6 dan β1 = –1,5 yang dinyatakan dengan persamaan Y = 6 – 1,5X. Garis tersebut memotong sumbu Y di titik (0, 6) dan turun sebesar 1,5 satuan setiap pertambahan nilai X sebesar 1 satuan.
-1
1
3
5
7
-1 0 1 2 3X
Y
+2
+1
koef. kemiringan=
+2/1 = 2
titik potong
dengan sumbu Y
0
2
4
6
8
-1 0 1 2 3
X
Y
-1,5
+1
koef. kemiringan=
-1,5/1 = -1,5
titik potong
dengan sumbu Y
a. Y = 1 + 2X b. Y = 6 – 1,5X
Gambar 7.2 Persamaan garis lurus dan interpretasinya
Terdapat dua jenis hubungan antara variabel Y dan variabel X, yaitu:
� hubungan deterministik (deterministic relationship), dimana setiap nilai variabel Y bersifat konstan dan hanya tergantung pada nilai variabel X.

198
Dalam hal ini setiap nilai X berpasangan dengan hanya satu nilai Y, sehingga untuk suatu nilai X tertentu, nilai Y dapat ditentukan dengan pasti.
� hubungan stokastik (stochastic relationship), dimana variabel Y merupakan variabel acak yang nilai-nilainya tergantung pada nilai X, tetapi tidak dapat diduga dengan pasti. Dalam hal ini setiap nilai X berasosiasi dengan suatu distribusi peluang bagi nilai-nilai Y secara keseluruhan.
Contoh 7.1
Seorang tukang pisang goreng menjual dagangannya dengan harga Rp 500,- per biji. Jika X adalah jumlah pisang goreng yang terjual pada suatu hari tertentu, dan Y adalah jumlah pendapatan kotor per hari, maka hubungan antara Y dan X dapat dinyatakan melalui model berikut:
Y = 500X
Hubungan tersebut merupakan hubungan deterministik karena nilai Y dapat ditentukan dengan pasti jika nilai X diketahui besarnya, yaitu dengan cara mensubstitusikan nilai X tersebut ke dalam persamaan di atas.
Contoh 7.2
Dalam memproduksi suatu jenis barang, sebuah perusahaan harus mengeluarkan sejumlah biaya yang terdiri atas biaya tetap sebesar Rp 1.000.000,- dan biaya variabel sebesar Rp 300 per satuan hasil produksinya. Jika X adalah jumlah produksi barang tersebut, dan Y adalah total biaya produksi, maka hubungan antara Y dan X dapat dinyatakan sebagai berikut:
Y = 1.000.000 + 300X
Hubungan tersebut juga merupakan suatu bentuk hubungan deterministik.
Contoh 7.3
Pengetahuan tentang pola pengeluaran rumah tangga untuk keperluan rekreasi keluarga merupakan salah satu aspek yang menjadi bahan pertimbangan pengusaha hiburan untuk memperluas atau mempertahankan usahanya di suatu daerah. Pada umumnya, besar pengeluaran suatu keluarga untuk keperluan rekreasi cenderung meningkat dengan meningkatnya pendapatan keluarga tersebut. Akan tetapi, besar pengeluaran suatu rumah tangga untuk keperluan rekreasi tidak semata-mata dipengaruhi oleh besar pendapatan tetapi juga dipengaruhi oleh berbagai faktor lain.

199
Misalkan X adalah pendapatan per bulan suatu rumah tangga, dan Y adalah pengeluaran rumah tangga tersebut untuk keperluan rekreasi keluarga. Dalam kasus ini, untuk suatu nilai X tertentu, nilai Y tidak dapat ditentukan secara tepat karena terdapat faktor/variabel lain yang mempengaruhi nilai Y tersebut. Oleh karena itu, hubungan antara variabel X dan Y untuk kasus ini merupakan hubungan stokastik. Model probabilistik yang mengaitkan pengeluaran rumah tangga ke–i, Yi, dengan pendapatan rumah tangga ke–i, X = xi , adalah sebagai berikut:
iii xY εββ ++= 10 .......................................................................... [7.2]
dimana εi adalah nilai suatu variabel acak ε yang merepresentasikan faktor-faktor
lain yang mempengaruhi nilai Y. Variabel ε disebut sebagai galat acak (random
error variable). Dalam model tersebut varibel ε merupakan selisih antara nilai
pengamatan Yi dengan titik yang terletak pada garis β0 + β1xi.
7.3 Analisis regresi linier sederhana
Analisis regresi adalah salah satu teknik statistik yang paling populer yang biasa digunakan untuk tujuan peramalan atau pendugaan tentang nilai variabel dependen Y. Analisis regresi berkaitan dengan hubungan stokastik antara variabel dependen Y dengan variabel bebas X. Oleh karena itu, tujuan penggunaan analisis regresi adalah untuk membangun suatu model probabilistik yang dapat digunakan untuk meramalkan atau menduga nilai variabel dependen (Y), berdasarkan pada nilai-nilai variabel bebas (X). Analisis regresi merupakan suatu topik yang cakupannya sangat luas, tetapi dalam bab ini, pembahasannya akan kita batasi hanya pada teknik regresi linier sederhana, yaitu tentang pendugaan satu variabel Y oleh satu variabel X saja.
Salah satu asumsi yang digunakan dalam suatu model regresi linier sederhana adalah bahwa setiap nilai variabel X berkaitan dengan suatu distribusi dari nilai-nilai variabel Y. Kita gunakan notasi E(Yi|X = xi) atau E(Yi|xi) untuk menyatakan nilai harapan bersyarat (conditional expected value) bagi variabel acak Yi untuk nilai variabel bebas tertentu, yaitu X = xi, sedangkan fungsi kepekatan variabel acak Y tersebut dinotasikan dengan f(y|x). Asumsi lain yang digunakan dalam suatu model regresi linier sederhana adalah bahwa hubungan antara nilai harapan bagi Yi dengan nilai xi dapat dinyatakan melalui persamaan berikut:
( ) iii xxYE 10| ββ += ..................................................................... [7.3]
dimana β0 dan β1 adalah parameter regresi yang tidak diketahui nilainya. Persamaan [7.3] tersebut menyatakan bahwa nilai rata-rata bagi Yi untuk nilai xi tertentu terletak dalam suatu garis lurus (lihat gambar 7.3). Persamaan tersebut merupakan garis regresi populasi (population regression line).

200
Dalam gambar 7.3 terlihat bahwa setiap nilai xi (dalam gambar tersebut x1 dan x2) berasosiasi dengan suatu populasi dari nilai-nilai Y, dimana rata-rata setiap
populasi tersebut terletak pada garis regresi E(Y|X) = β0 + β1X. Walaupun populasi tersebut mempunyai rata-rata yang berbeda, diasumsikan bahwa populai tersebut
mempunyai varians σ2 yang sama.
Y
X
f(y|x)
x1 x2
E(Y|X) = β0 + β1X
E(Y1|x1)E(Y2|x2)
Gambar 7.3 Model probabilistik bagi hubungan stokastik antara X dan Y
Telah dikemukakan sebelumnya bahwa terdapat faktor-faktor lain selain variabel X yang mempengaruhi nilai-nilai variabel Y, sehingga menyebabkan nilai individual Yi
bervariasi di sekitar E(Yi|xi). Faktor-faktor lain tersebut dinotasikan dengan εi yang
disebut sebagai faktor galat (error term). Karena nilai-nilai εi juga bervariasi maka nilai-nilai tersebut merupakan suatu variabel acak yang disebut variabel acak galat (error random variabel):
( )( )ii
iiii
xY
xYEY
10
|
ββ
ε
+−=
−= ....................................................................... [7.4]
Dengan demikian, setiap nilai pengamatan Yi sama dengan nilai harapannya ditambah galat, yaitu
( )ii
iiii
x
xYEY
εββ
ε
++=
+=
10
| ......................................................................... [7.5]
Dalam penggunaannya, analisis regresi linier sederhana sangat tergantung pada berbagai asumsi yang berkaitan dengan variabel acak galat tersebut. Asumsi dasar dari analisis regresi linier sederhana adalah sebagai berikut:

201
1. Variabel acak galat berdistribusi Normal dengan rata-rata sama dengan
nol dan mempunyai varians yang sama untuk semua nilai X, yaitu 2eσ .
2. Nilai-nilai galat bersifat independen satu sama lainnya dan tidak berkaitan dengan variabel X.
Asumsi tentang kesamaan varians yang disebut juga asumsi homogenitas varians (homoscedasticity), mengandung arti bahwa nilai-nilai galat tersebut mempunyai varians yang sama, tidak peduli berapapun nilai X-nya. Asumsi tentang keindependenan galat berarti bahwa nilai-nilai galat tersebut tidak berkaitan satu sama lainnya. Pelanggaran terhadap asumsi-asumsi tersebut dapat mengaki-batkan nilai dugaan bagi varians menjadi bias dan pengujian hipotesis terhadap parameter regresi menjadi tidak syah.
7.4 Penduga kuadrat terkecil bagi ββββ0 dan ββββ1
Karena parameter β0 dan β1 dalam persamaan [7.3] tidak kita ketahui besarnya, maka persamaan regresinyapun tidak kita ketahui dan harus kita duga dengan menggunakan data sampel (xi, yi). Dengan demikian, untuk menduga persamaan
regresi tersebut kita cukup menduga parameter β0 dan β1. Salah satu teknik pendugaan yang sering digunakan adalah metode kuadrat terkecil (least squares
method). Misalkan b0 dan b1 masing-masing nilai dugaan bagi parameter β0 dan
β1, maka nilai dugaan bagi Yi, dinotasikan dengan iy adalah
ii xbby 10ˆ += ................................................................................. [7.6]
Karena persamaan [7.6] tersebut diperoleh berdasarkan atas data sampel, persamaan tersebut disebut sebagai garis regresi sampel (sample regression line) yang merupakan penduga bagi garis regresi populasi dalam persamaan [7.3]. Faktor galat bagi data sampel biasa disebut sebagai sisaan (residuals), dan dinotasikan dengan ei, dimana ei adalah selisih antara nilai pengamatan yi dengan
nilai dugaannya, iy , yaitu
ii
iii
xbby
yye
10
ˆ
−−=
−= .......................................................................... [7.7]
Dengan demikian, nilai sisaan merupakan simpangan dari nilai dugaan terhadap nilai pengamatannya, sehingga dapat digunakan untuk mengukur kesalahan pendugaan. Jika nilai pengamatan bagi variabel dependen lebih besar dari nilai
dugaannya ( )yy iˆ> , maka sisaan akan bernilai positif; dan jika nilai pengamatan
tersebut lebih kecil dari nilai dugaannya ( )yy iˆ< , maka sisaan akan bernilai
negatif. Suatu pendugaan yang sempurna terjadi jika yy iˆ= , dimana sisaannya
akan bernilai nol.

202
X
Y
xi
XbbY 10ˆ +=
iy
( )ii yx ,yi
iii yye ˆ−=
Gambar 7.4 Hubungan antara yi, iy dan ei
Oleh karena itu, jumlah kuadrat sisaan (residual sum of squares), disingkat JKS, yang dihitung dengan rumus berikut:
( )( )∑
∑∑−−=
−==
210
22 ˆJKS
ii
iii
xbby
yye ........................................................... [7.8]
sering digunakan sebagai ukuran ketelitian pendugaan secara umum. Pendugaan persamaan regresi dengan metode kuadrat terkecil pada dasarnya dilakukan dengan menentukan garis regresi sampel yang meminimumkan jumlah kuadrat sisaan (JKS). Dengan metode kuadrat terkecil, nilai dugaan bagi parameter
regresi β0 dan β1 masing-masing adalah b0 dan b1 dimana
xbyb 10 −= ................................................................................... [7.9]
dan
( )( )( )∑
∑−
−−=
21xx
yyxxb ................................................................... [7.10]
atau
( )221
∑∑∑∑∑
−
−=
xxn
yxxynb ................................................................ [7.11]
Penurunan rumus-rumus di atas dapat dilihat dalam boks 7.1.

203
Boks 7.1:
Nilai-nilai b0 dan b1 diperoleh dengan menentukan turunan pertama dari JKS terhadap b0 dan b1 dan kemudian menyamakannya dengan nol:
( )( )
∑∑∑∑∑∑
∑∑
+++−−=
−−=
−==
22110
2010
2
210
22
222
ˆJKS
xbxbbnbxybyby
xbby
yye
Turunan pertama dari JKS terhadap b0 adalah:
∑∑ ++−=∂
∂xbnby
b10
0
222JKS
xbybxbynbb
10100
0JKS
−=⇔−=⇔=∂
∂ ∑∑
Dengan cara yang sama, tentukan turunan dari JKS terhadap b1 dan samakan turunan tersebut dengan nol:
0222JKS 2
100
=++−=∂
∂ ∑∑∑ xbxbxyb
Substitusikan nilai n
xb
n
yb
∑∑−= 10 ke dalam persamaan di atas, maka
( )
( )
( )
( )221
2
12
1
2
12
1
21
2
1
211
02222
0222
∑∑∑∑∑
∑∑∑∑∑
∑∑∑∑∑
∑∑∑∑∑
∑∑∑∑∑
−
−=
−=−
−=−
=+−+−
=+
−+−
xxn
yxxynb
xynxyxbxnb
xyn
xy
n
xbxb
xbn
xb
n
xyxy
xbxn
xb
n
yxy
Beberapa kelebihan metode kuadrat terkecil dibandingkan dengan metode-metode pendugaan lainnya adalah:
204
� untuk satu set data yang sama, garis regresi dengan metode kuadrat terkecil memberikan JKS yang paling kecil dibandingkan dengan JKS yang dihasilkan oleh garis regresi lain
� metode kuadrat terkecil dapat dengan mudah diperluas untuk model-model dengan jumlah variabel X yang lebih banyak
Contoh 7.4
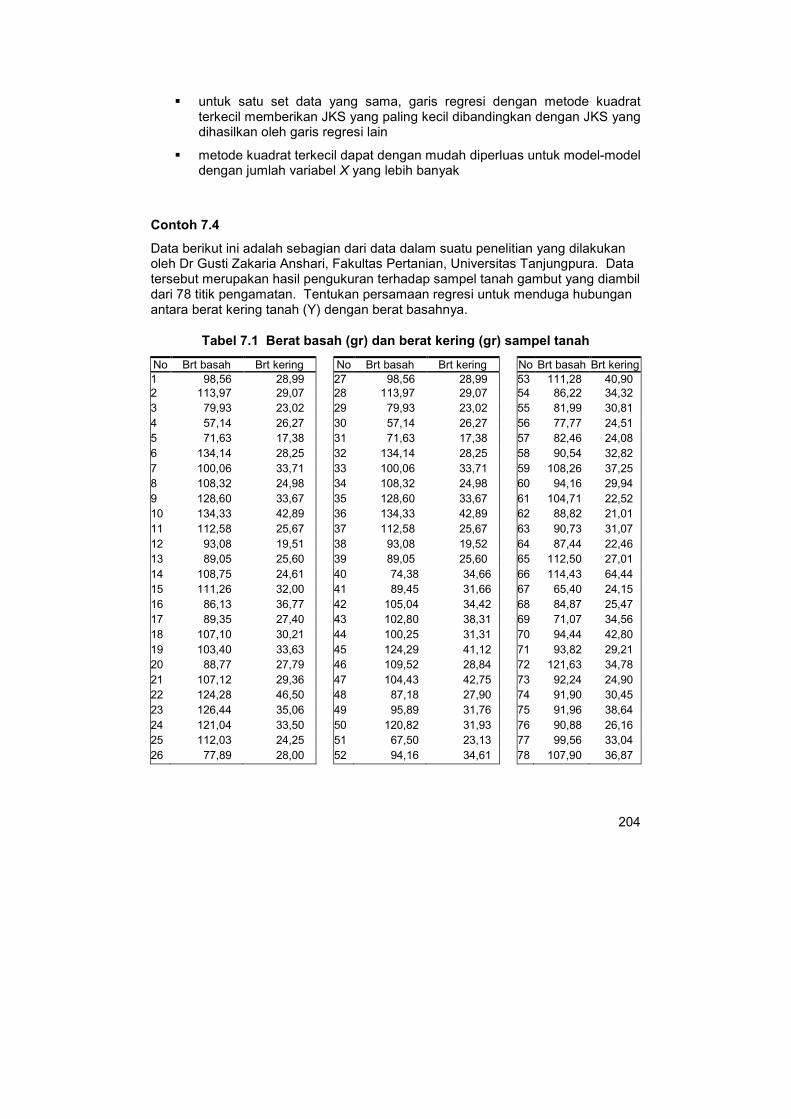
Data berikut ini adalah sebagian dari data dalam suatu penelitian yang dilakukan oleh Dr Gusti Zakaria Anshari, Fakultas Pertanian, Universitas Tanjungpura. Data tersebut merupakan hasil pengukuran terhadap sampel tanah gambut yang diambil dari 78 titik pengamatan. Tentukan persamaan regresi untuk menduga hubungan antara berat kering tanah (Y) dengan berat basahnya.
Tabel 7.1 Berat basah (gr) dan berat kering (gr) sampel tanah
No Brt basah Brt kering No Brt basah Brt kering No Brt basah Brt kering
1 98,56 28,99 27 98,56 28,99 53 111,28 40,90
2 113,97 29,07 28 113,97 29,07 54 86,22 34,32
3 79,93 23,02 29 79,93 23,02 55 81,99 30,81
4 57,14 26,27 30 57,14 26,27 56 77,77 24,51
5 71,63 17,38 31 71,63 17,38 57 82,46 24,08
6 134,14 28,25 32 134,14 28,25 58 90,54 32,82
7 100,06 33,71 33 100,06 33,71 59 108,26 37,25
8 108,32 24,98 34 108,32 24,98 60 94,16 29,94
9 128,60 33,67 35 128,60 33,67 61 104,71 22,52
10 134,33 42,89 36 134,33 42,89 62 88,82 21,01
11 112,58 25,67 37 112,58 25,67 63 90,73 31,07
12 93,08 19,51 38 93,08 19,52 64 87,44 22,46
13 89,05 25,60 39 89,05 25,60 65 112,50 27,01
14 108,75 24,61 40 74,38 34,66 66 114,43 64,44
15 111,26 32,00 41 89,45 31,66 67 65,40 24,15
16 86,13 36,77 42 105,04 34,42 68 84,87 25,47
17 89,35 27,40 43 102,80 38,31 69 71,07 34,56
18 107,10 30,21 44 100,25 31,31 70 94,44 42,80
19 103,40 33,63 45 124,29 41,12 71 93,82 29,21
20 88,77 27,79 46 109,52 28,84 72 121,63 34,78
21 107,12 29,36 47 104,43 42,75 73 92,24 24,90
22 124,28 46,50 48 87,18 27,90 74 91,90 30,45
23 126,44 35,06 49 95,89 31,76 75 91,96 38,64
24 121,04 33,50 50 120,82 31,93 76 90,88 26,16
25 112,03 24,25 51 67,50 23,13 77 99,56 33,04
26 77,89 28,00 52 94,16 34,61 78 107,90 36,87

205
Penyelesaian:
Untuk menduga nilai-nilai b0 dan b1, kita perlu menghitung i
x∑ , i
y∑ , ii yx∑
dan ∑ 2ix , dalam hal ini nilai-nilai tersebut adalah sebagai berikut:
03,7719
90,10797,11356,98
=
+++=∑ Lix
68,2383
87,3607,2999,28
=
+++=∑ Liy
( )( ) ( )( ) ( )( )2558,240412
87,3690,10707,2997,11399,2856,98
=
+++=∑ Lii yx
1937,789250
90,10797,11356,98 2222
=
+++=∑ Lix
Rata-rata sampel adalah 9619,98=x dan 56,30=y dengan n = 78. Maka,
( )221
∑∑∑∑∑
−
−=
ii
iiii
xxn
yxyxnb
( )1782,0
03,77191937,78925078
68,238303,77192558,2404127821 =
−×
×−×=b
dan
927,12
9619,981782,056,30
10
=
×−=
−= xbyb
Oleh karena itu, persamaan regresi sampelnya adalah
ii xy 1782,0927,12ˆ +=
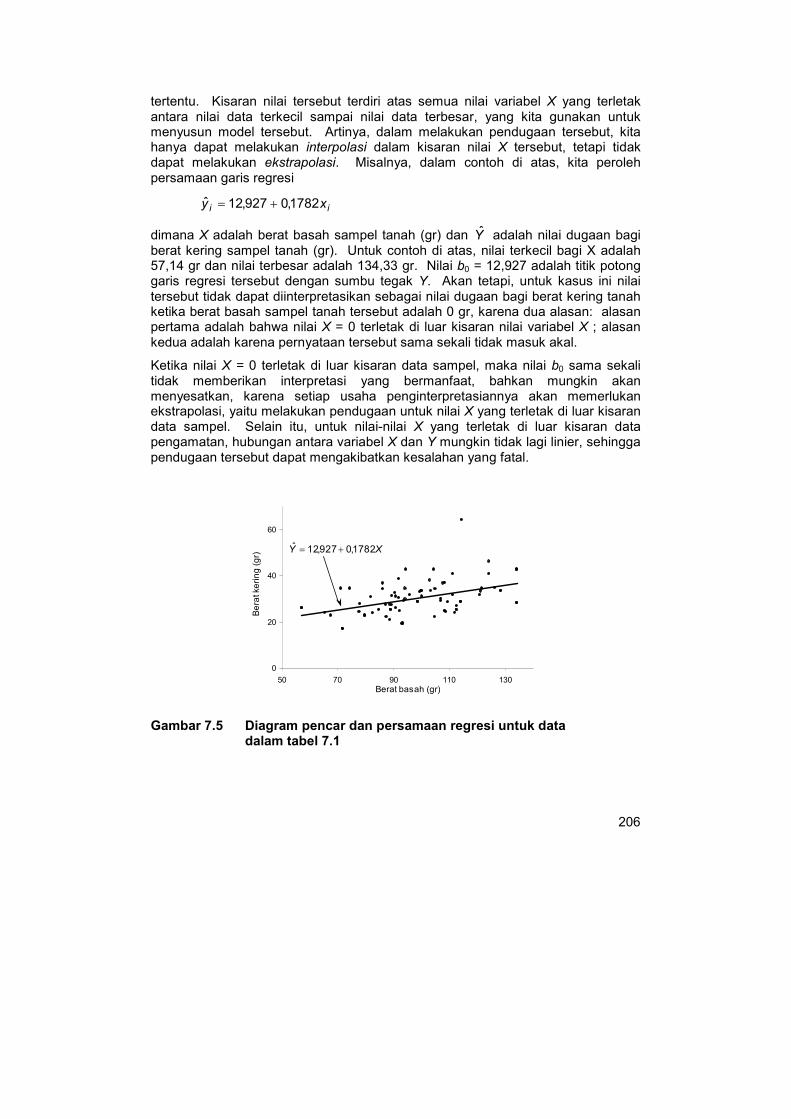
Suatu model persamaan regresi biasanya digunakan untuk tujuan pendugaan. Hal yang perlu diperhatikan dalam melakukan pendugaan tersebut adalah bahwa kita hanya bisa melakukan pendugaan dalam suatu kisaran nilai variabel bebas yang
206
tertentu. Kisaran nilai tersebut terdiri atas semua nilai variabel X yang terletak antara nilai data terkecil sampai nilai data terbesar, yang kita gunakan untuk menyusun model tersebut. Artinya, dalam melakukan pendugaan tersebut, kita hanya dapat melakukan interpolasi dalam kisaran nilai X tersebut, tetapi tidak dapat melakukan ekstrapolasi. Misalnya, dalam contoh di atas, kita peroleh persamaan garis regresi
ii xy 1782,0927,12ˆ +=
dimana X adalah berat basah sampel tanah (gr) dan Y adalah nilai dugaan bagi berat kering sampel tanah (gr). Untuk contoh di atas, nilai terkecil bagi X adalah 57,14 gr dan nilai terbesar adalah 134,33 gr. Nilai b0 = 12,927 adalah titik potong garis regresi tersebut dengan sumbu tegak Y. Akan tetapi, untuk kasus ini nilai tersebut tidak dapat diinterpretasikan sebagai nilai dugaan bagi berat kering tanah ketika berat basah sampel tanah tersebut adalah 0 gr, karena dua alasan: alasan pertama adalah bahwa nilai X = 0 terletak di luar kisaran nilai variabel X ; alasan kedua adalah karena pernyataan tersebut sama sekali tidak masuk akal.
Ketika nilai X = 0 terletak di luar kisaran data sampel, maka nilai b0 sama sekali tidak memberikan interpretasi yang bermanfaat, bahkan mungkin akan menyesatkan, karena setiap usaha penginterpretasiannya akan memerlukan ekstrapolasi, yaitu melakukan pendugaan untuk nilai X yang terletak di luar kisaran data sampel. Selain itu, untuk nilai-nilai X yang terletak di luar kisaran data pengamatan, hubungan antara variabel X dan Y mungkin tidak lagi linier, sehingga pendugaan tersebut dapat mengakibatkan kesalahan yang fatal.
0
20
40
60
50 70 90 110 130
Berat basah (gr)
Be
rat ke
rin
g (
gr)
XY 1782,0927,12ˆ +=
Gambar 7.5 Diagram pencar dan persamaan regresi untuk data dalam tabel 7.1

207
Sebaliknya, kemiringan garis regresi sering kali memberikan interpretasi yang lebih bermanfaat. Untuk contoh di atas, nilai b1 = 0,1782 menunjukkan bahwa untuk setiap kenaikan berat basah tanah sebesar satu gram, secara rata-rata akan menaikkan berat kering sampel tanah sebesar 0,1782 gr.
Persamaan regresi di atas kita peroleh dengan menggunakan metode kuadrat terkecil, sehingga garis tersebut merupakan garis lurus terbaik yang memi-nimumkan JKS. Namun demikian, hal ini bukan merupakan jaminan bahwa garis tersebut mencerminkan keadaan data dengan baik. Salah satu indikator yang dapat digunakan untuk mengetahui sampai sejauh mana persamaan suatu garis regresi mencerminkan keadaan data secara keseluruhan adalah dengan menghitung simpangan baku sisaan (residual standard deviation), se, yang dihitung dengan rumus berikut:
( )
22
JKS
210
−
−−
=−
=∑
n
xbby
ns i
ii
e ........................................... [7.12]
atau
2
102
−
−−
=∑∑∑
n
yxbyby
s i
ii
i
i
i
i
e ............................................. [7.13]
dimana n adalah jumlah pengamatan, sedangkan bilangan 2 (dalam n – 2) berasal
dari jumlah parameter yang diduga dalam persamaan regresinya (yaitu β0 dan β1). Walaupun kelihatan lebih rumit, rumus dalam persamaan [7.13] lebih mudah digunakan dalam melakukan perhitungan secara manual.
Simpangan baku sisaan, se, mengukur pencaran atau keragaman data di sekitar garis regresinya. Semakin kecil nilai se, maka nilai-nilai Y akan semakin terkon-sentrasi di sekitar garis regresi tersebut. Sebaliknya, semakin besar nilai se, maka semakin besar pula pencaran data dari garis regresinya.
Untuk contoh 7.4, simpangan baku sisaannya adalah:
6681,676
241,3379
278
2558,2404121782,068,2383927,126492,77029
==
−
×−×−=es
Perhatikan bahwa simpangan baku sisaan (se = 6,6681) tidak terlalu berbeda jauh nilainya dari simpangan baku sampel variabel Y (sy = 7,3718), hal ini menunjukkan bahwa garis regresi tersebut tidak sepenuhnya cocok mencerminkan hubungan antara X dan Y. Artinya, berat kering sampel tanah tidak dapat diduga dengan baik hanya dengan mengukur berat basah sampelnya saja.
208
7.5 Koefisien determinasi dan sumber keragaman dalam analisis regresi
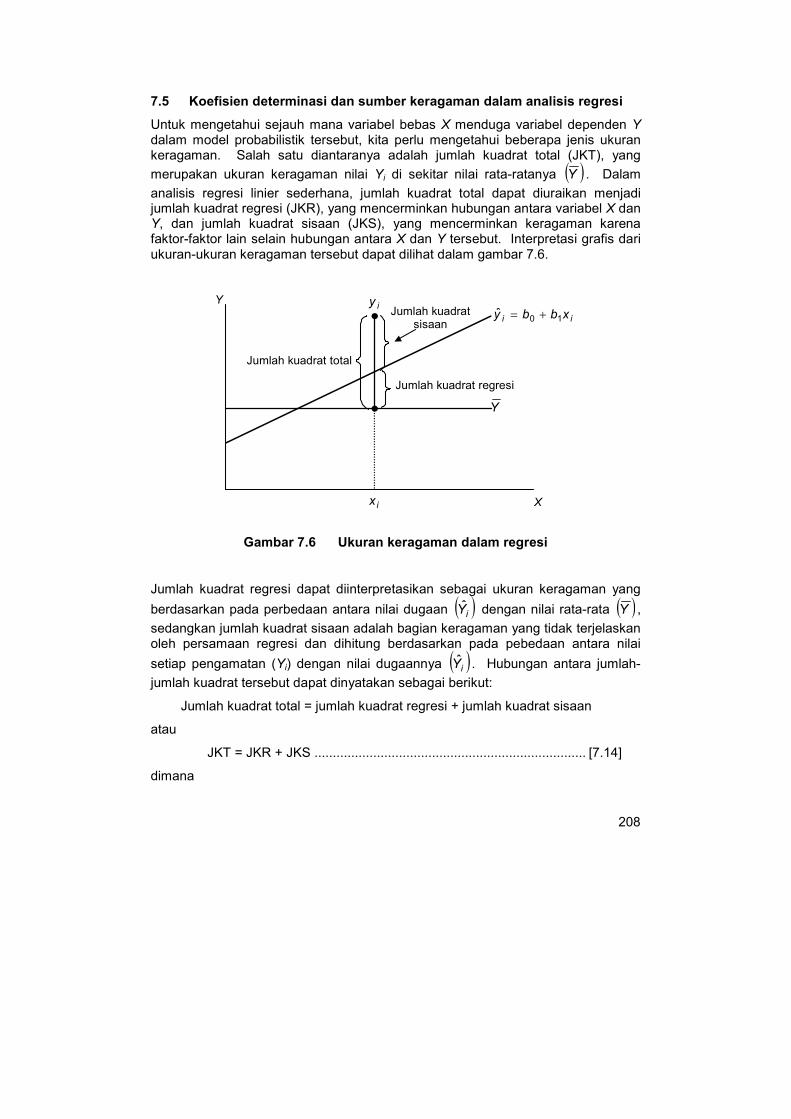
Untuk mengetahui sejauh mana variabel bebas X menduga variabel dependen Y dalam model probabilistik tersebut, kita perlu mengetahui beberapa jenis ukuran keragaman. Salah satu diantaranya adalah jumlah kuadrat total (JKT), yang
merupakan ukuran keragaman nilai Yi di sekitar nilai rata-ratanya ( )Y . Dalam
analisis regresi linier sederhana, jumlah kuadrat total dapat diuraikan menjadi jumlah kuadrat regresi (JKR), yang mencerminkan hubungan antara variabel X dan Y, dan jumlah kuadrat sisaan (JKS), yang mencerminkan keragaman karena faktor-faktor lain selain hubungan antara X dan Y tersebut. Interpretasi grafis dari ukuran-ukuran keragaman tersebut dapat dilihat dalam gambar 7.6.
Jumlah kuadrat total
Jumlah kuadrat regresi
Jumlah kuadrat sisaan
Y
iy
ix X
Y
ii xbby 10ˆ +=
Gambar 7.6 Ukuran keragaman dalam regresi
Jumlah kuadrat regresi dapat diinterpretasikan sebagai ukuran keragaman yang
berdasarkan pada perbedaan antara nilai dugaan ( )iY dengan nilai rata-rata ( )Y ,
sedangkan jumlah kuadrat sisaan adalah bagian keragaman yang tidak terjelaskan oleh persamaan regresi dan dihitung berdasarkan pada pebedaan antara nilai
setiap pengamatan (Yi) dengan nilai dugaannya ( )iY . Hubungan antara jumlah-
jumlah kuadrat tersebut dapat dinyatakan sebagai berikut:
Jumlah kuadrat total = jumlah kuadrat regresi + jumlah kuadrat sisaan
atau
JKT = JKR + JKS .......................................................................... [7.14]
dimana

209
( )
( )22
2
1
JKT
∑∑
∑
−=
−=
ii
i
i
yn
y
yy
................................................................ [7.15]
dan
( )
( )210
2
1
ˆ JKR
∑∑∑
∑
−+=
−=
iiii
i
i
yn
yxbyb
yy
......................................... [7.16]
serta
( )
∑∑∑
∑
−−=
−=
iiii
i
ii
yxbyby
yy
102
2ˆJKS
................................................ [7.17]
Untuk contoh 7.4 di atas, kita peroleh bahwa JKT = 4184,388 dan JKR = 805,147 serta JKS = 3379,241.
Ukuran keragaman yang lain adalah adalah koefisien determinasi, R2. Koefisien
determinasi merupakan bagian keragaman dari variabel Y yang dijelaskan oleh persamaan regresinya. Nilai R
2 dihitung dengan rumus berikut:
JKT
JKR2 =R ..................................................................................... [7.18]
Untuk contoh 7.4 di atas, kita peroleh bahwa
1924,0388,4184
147,8052 ==R
Nilai R2 tersebut menunjukkan bahwa persamaan garis regresi linier
ii xy 1782,0927,12ˆ += menjelaskan 19,24% dari keragaman berat kering sampel
tanah. Hal ini berarti, sekitar 81% dari keragaman tersebut tidak terjelaskan oleh persamaan regresinya.
7.6 Membaca output komputer
Setiap program statistik menyajikan hasil analisisnya dengan cara yang berbeda, akan tetapi informasi dasar yang disajikan pada umumnya sama. Pasangan data (x, y) biasanya diinput ke dalam dua kolom (variabel) yang berbeda, misalnya dalam program MINITAB kedua variabel tersebut dalam contoh 7.4 masing-masing

210
disimpan dalam kolom C1 dengan nama ‘B_basah’ dan kolom C2 dengan nama ‘B_kering’. Analisis regresi dapat dilakukan dengan memilih menu
Stat ���� Regression ���� Regression...
Perintah tersebut akan mengaktifkan jendela Regression seperti terlihat dalam
gambar 7.7.
Gambar 7.7 Jendela Regression dalam MINITAB
Isikan variabel dependen (Y) ke dalam kotak Response: (dalam hal ini ‘B_kering’)
dan variabel bebas (X) ke dalam kotak Predictors: (dalam hal ini ‘B_basah’),
lalu klik OK.
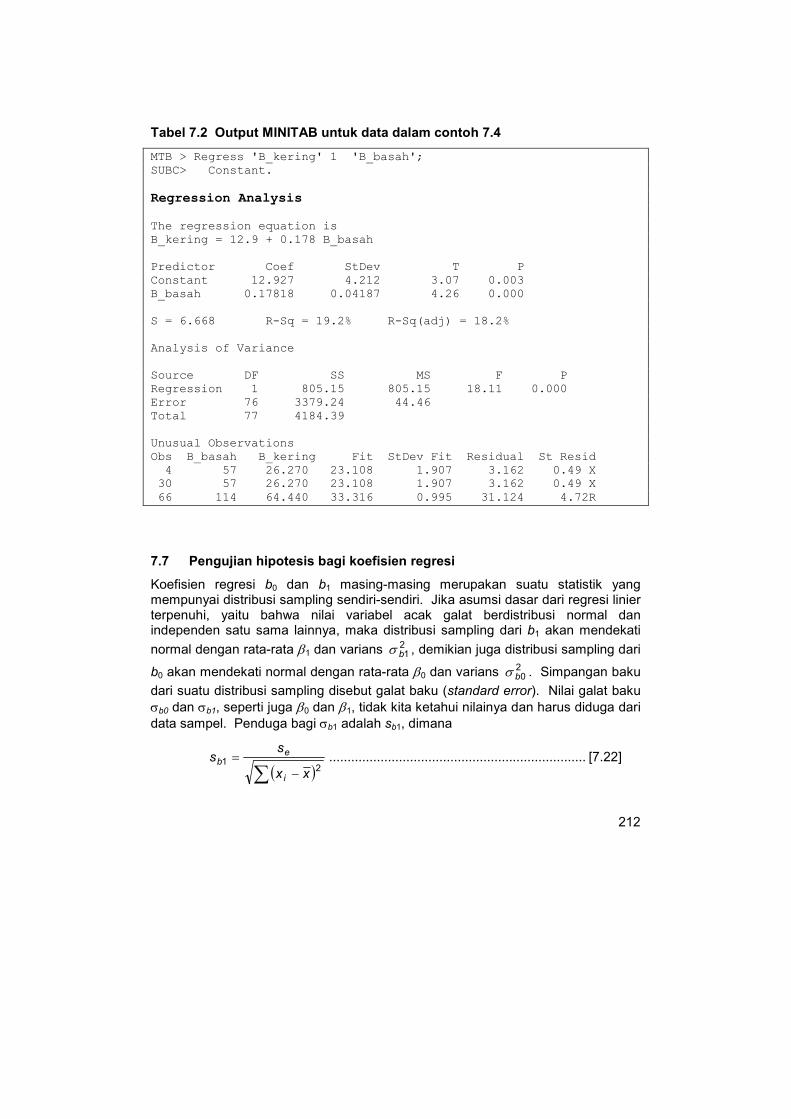
Output dari program paket statistik MINITAB untuk contoh 7.4 disajikan dalam tabel 7.2. Dalam tabel tersebut, dua baris pertama dari output MINITAB adalah perintah dalam MINITAB untuk analisis regresi. Nilai b0 = 12,297 dan b1 = 0,17818
tercantum dalam kolom “Coef“ dari output tersebut. Selain itu, output tersebut
juga menyajikan statistik lain, diantaranya adalah
S, simpangan baku sisaan: se = 0,668
R-Sq, koefisien determinasi: R2 = 19,2%
Regression SS, jumlah kuadrat regresi: JKR = 805,15
Error SS, jumlah kuadrat sisa: JKS = 3379,24
Total SS, jumlah kuadrat total, JKT = 4184,39

211
Jumlah-jumlah kuadrat tersebut biasa disusun dalam suatu tabel analisis keragaman (analysis of variance). Dalam output MINITAB, tabel analisis
keragaman disajikan di bawah judul “Analysis of Variance”. Kolom
“Source” di bawah judul tersebut mendefinisikan sumber-sumber keragaman
dalam analisis regresi, yang merupakan penguraian dari keragaman total, yaitu
keragaman karena model regresi (Regression) dan keragaman karena faktor lain
(Error). Kolom “DF” adalah derajat bebas bagi masing-masing sumber
keragaman (source of variance), sedangkan kolom “SS” adalah jumlah kuadratnya,
dan kolom “MS” adalah kuadrat tengah (Mean squares) bagi masing-masing
sumber keragaman. Nilai kuadrat tengah, biasa dinotasikan dengan KT, dihitung dengan cara membagi jumlah kuadrat dengan derajat bebas bagi sumber keragaman yang bersesuaian, yaitu
1
JKRKTR
−=k
.................................................................................. [7.18]
dan
kn −=
JKSKTS .................................................................................. [7.19]
dimana KTR dan KTS, masing-masing adalah kuadrat tengah regresi dan kuadrat tengah sisa.
Kolom F dalam tabel analisis keragaman menyajikan nilai statistik F, dimana
)(JKS
)1(JKR
kn
kF
−
−= ........................................................................... [7.20]
Statistik F tersebut berdistribusi mengikuti kaidah distribusi F dengan derajat
bebas ν1 = k – 1 dan ν2 = n – k. Dalam output tersebut nilai statistik F tercantum
dalam kolom “F” yaitu = 18,11. Nilai statistik tersebut kemudian dibandingkan nilai
teoritis distribusi F dengan derajat bebas ν1 = 1 dan ν2 = 76, yang menghasilkan nilai P = 0.000. Dalam analisis regresi linier sederhana statistik F tersebut menguji
pasangan hipotesis H0: β1 = 0 vs H1: β1 ≠ 0 (pengujian hipotesis ini dibahas secara lebih rinci pada bagian 7.7)
Output tersebut juga menampilkan nilai koefisien determinasi terkoreksi,
“R-Sq(adj)”. Nilai tersebut dihitung dengan rumus berikut:
( )222terkoreksi 1
1R
kn
kRR −
−−
−= ..................................................... [7.21]
dimana k adalah jumlah koefisien regresi (dalam hal ini adalah dua, yaitu b0 dan b1); dan n adalah jumlah pengamatan (dalam hal ini adalah 78). Nilai koefisien determinasi terkoreksi sering digunakan ketika model regresinya menjadi lebih kompleks, misalnya dalam analisis regresi berganda.
212
Tabel 7.2 Output MINITAB untuk data dalam contoh 7.4
MTB > Regress 'B_kering' 1 'B_basah';
SUBC> Constant.
Regression Analysis
The regression equation is
B_kering = 12.9 + 0.178 B_basah
Predictor Coef StDev T P
Constant 12.927 4.212 3.07 0.003
B_basah 0.17818 0.04187 4.26 0.000
S = 6.668 R-Sq = 19.2% R-Sq(adj) = 18.2%
Analysis of Variance
Source DF SS MS F P
Regression 1 805.15 805.15 18.11 0.000
Error 76 3379.24 44.46
Total 77 4184.39
Unusual Observations
Obs B_basah B_kering Fit StDev Fit Residual St Resid
4 57 26.270 23.108 1.907 3.162 0.49 X 30 57 26.270 23.108 1.907 3.162 0.49 X
66 114 64.440 33.316 0.995 31.124 4.72R
7.7 Pengujian hipotesis bagi koefisien regresi
Koefisien regresi b0 dan b1 masing-masing merupakan suatu statistik yang mempunyai distribusi sampling sendiri-sendiri. Jika asumsi dasar dari regresi linier terpenuhi, yaitu bahwa nilai variabel acak galat berdistribusi normal dan independen satu sama lainnya, maka distribusi sampling dari b1 akan mendekati
normal dengan rata-rata β1 dan varians 21bσ , demikian juga distribusi sampling dari
b0 akan mendekati normal dengan rata-rata β0 dan varians 20bσ . Simpangan baku
dari suatu distribusi sampling disebut galat baku (standard error). Nilai galat baku
σb0 dan σb1, seperti juga β0 dan β1, tidak kita ketahui nilainya dan harus diduga dari
data sampel. Penduga bagi σb1 adalah sb1, dimana
( )∑ −=
21
xx
ss
i
eb ...................................................................... [7.22]

213
dan penduga bagi σb0 adalah sb0, dimana
( )∑ −+=
2
2
0
1
xx
x
nss
i
eb .......................................................... [7.23]
Kolom “StDev” dalam output MINITAB di atas (tabel 7.2) menyajikan nilai-nilai
tersebut, yaitu sb0 = 4,212 dan sb1 = 0,04187.
Pengujian hipotesis terhadap parameter regresi, yaitu β0 dan β1 dapat dilakukan dengan menggunakan statistik uji t. Dapat ditunjukkan bahwa nilai statistik t, dimana
bs
bt
β−= ....................................................................................... [7.24]
adalah suatu variabel acak yang berdistribusi t dengan derajat bebas ν = n – k. Statistik t tersebut dapat digunakan sebagai suatu statistik uji dalam pengujian hipotesis tentang koefisien regresi.
Hipotesis tentang tidak adanya hubungan linier antara variabel X dengan variabel Y dinyatakan dalam bentuk hipotesis nol sebagai berikut:
H0: β1 = 0 ....................................................................................... [7.25]
Hipotesis alternatif bagi hipotesis nol tersebut adalah bahwa ada hubungan linier
antara kedua variabel tersebut, artinya β1 ≠ 0. Hal ini dirumuskan sebagai berikut:
H1: β1 ≠ 0 ....................................................................................... [7.26]
Jika hipotesis nol benar, artinya β1 = 0, maka nilai statistik uji t dalam persamaan [7.24] berubah menjadi
1
1
bs
bt = .......................................................................................... [7.27]
Secara konvensional, pengujian terhadap pasangan hipotesis tersebut kemudian dapat dilakukan dengan membandingkan nilai t yang diperoleh dari persamaan
[7.27] dengan nilai t dalam tabel lampiran 3 dengan derajat bebas ν = n – k. Untuk
taraf nyata α tertentu, kriteria pengujiannya adalah:
� terima H0 jika tα/2; n–k ≤ t ≤ tα/2; n–k, dan
� tolak H0 jika t < tα/2; n–k atau t > tα/2; n–k.
Kolom “T” dalam output MINITAB (tabel 7.2) menyajikan nilai statistik t tersebut,
yang dihitung dengan cara membagi koefisien regresi dengan penduga bagi galat bakunya (perhatikan bahwa 0,17818/0,04187 = 4,26).

214
Nilai statistik t tersebut kemudian dibanding dengan dengan nilai teoritis dari distribusi t dengan derajat bebas n – k. Dari distribusi t kita peroleh suatu nilai peluang yang disebut nilai P (P-value).
Nilai P adalah nilai dugaan bagi peluang diperolehnya hasil sampel tersebut dengan asumsi bahwa sampel tersebut merupakan suatu sampel acak dari suatu populasi dimana H0 benar.
Nilai P yang kecil menunjukkan bahwa sampel tersebut tidak mungkin berasal dari suatu populasi dimana H0 benar. Dalam output MINITAB P-value tercantum dalam
kolom “P”, yaitu P = 0,000 (nilai P sebenarnya tidak sama dengan nol, tetapi
merupakan suatu nilai yang sangat kecil, sehingga ketika dibulatkan menjadi 3 desimal nilainya mendekati nol). Hal ini menunjukkan sampel tersebut tidak mungkin berasal dari suatu populasi dimana H0 benar. Oleh karena itu kita
simpulkan bahwa H0 salah, konsekuensinya kita terima H1: β1 ≠ 0 yang berarti terdapat hubungan linier antara kedua variabel X dan Y.
Secara konvensional, para peneliti biasanya menggunakan kriteria pengujian sebagai berikut:
Tolak H0 (dan terima H1) jika nilai P < 0,05
Setiap koefisien dengan nilai P yang lebih kecil dari 0,05 biasa dikatakan sebagai berbeda nyata atau siginifikan (statistically significant). Salah satu kelemahan dari kriteria pengujian tersebut adalah bahwa perbedaan antara dihasilkannya P = 0,49
(signifikan pada taraf nyata α = 0,05) dengan dihasilkannya P = 0,51 (tidak
signifikan pada taraf nyata α = 0,05) sering kali tidak jauh berbeda. Dengan mencantumkan nilai P yang sebenarnya maka kelemahan tersebut dapat teratasi,
karena penentuan nilai signifikansi (taraf nyata α) sebenarnya tidak harus selalu sama dengan 0,05.
Dalam bagian 7.6 telah dikemukakan bahwa pasangan hipotesis [7.25] dan [7.26] dapat juga diuji dengan menggunakan statistik uji F. Dalam analisis regresi linier sederhana, kedua statistik uji tersebut, yaitu statistik uji t dalam [7.27] dan statistik uji F dalam [7.20], pada dasarnya menguji pasangan hipotesis yang sama, sehingga menghasilkan nilai P yang sama. Hubungan kedua statistik tersebut adalah sebagai berikut:
2tF = ........................................................................................... [7.28]
Dalam analisis regresi linier ganda F dapat digunakan untuk pengujian hipotesis tentang koefisien regresi yang lebih kompleks.
7.8 Pendugaan selang kepercayaan
Pendugaan selang kepercayaan (1–α)100% bagi koefisien regresi dapat dilakukan dengan menggunakan rumus berikut:

215
bikni stb ×± −;;2α ............................................................................ [7.29]
dimana tα/2 ; n – k adalah nilai kritis dari distribusi t dengan derajat bebas = n – k (tabel lampiran 3).
Untuk menentukan selang kepercayaan 95% bagi β1 dalam contoh 7.4, dari tabel
lampiran 3 kita lihat bahwa nilai tα/2 ; n – k = t0,025 ; 76 terletak antara t0,025 ; 60 = 2,003
dan t0,025 ; 120 = 1,9799, dengan interpolasi kita peroleh bahwa t0,025 ; 76 = 1,997,
sehingga selang kepercayaan 95% bagi β1 adalah
2618,00946,0
0836,01782,0
04187,0997,11782,0
1 ≤≤
±
×±
β
Dengan cara yang sama, kita juga dapat menentukan selang kepercayaan di sekitar nilai dugaan bagi Y. Hal ini dapat dilakukan dengan menggunakan rumus [7.30].
iykni stY ˆ;2ˆ ×± −α ............................................................................ [7.30]
Penggunaan rumus [7.30] tersebut dapat digunakan dalam dua kasus yang berbeda, yaitu
� menentukan selang kepercayaan bagi E(Yi|X = xi), yaitu nilai harapan (rata-rata) bagi Yi untuk nilai X = xi. Untuk kasus ini, gunakan
( )
( )22ˆ
1
1
∑∑ −
−+=
ii
ieiy
xn
x
xx
nss ................................................... [7.31]
� menentukan selang dugaan atau selang kepercayaan bagi suatu nilai tunggal Yi untuk X = xi. Untuk kasus ini gunakan
( )
( )1
1
1
22ˆ +
−
−+=
∑∑ ii
ieiy
xn
x
xx
nss .............................................. [7.32]
Baik selang kepercayaan maupun selang dugaan, keduanya mempunyai bentuk yang hiperbolis yang semakin menyempit dengan semakin dekatnya nilai xi
terhadap nilai rata-ratanya ( )x . dan semakin melebar ketika nilai xi semakin jauh
dari nilai x . Selang kepercayaan dan selang pendugaan bagi data dalam contoh 7.4 disajikan dalam gambar 7.8.
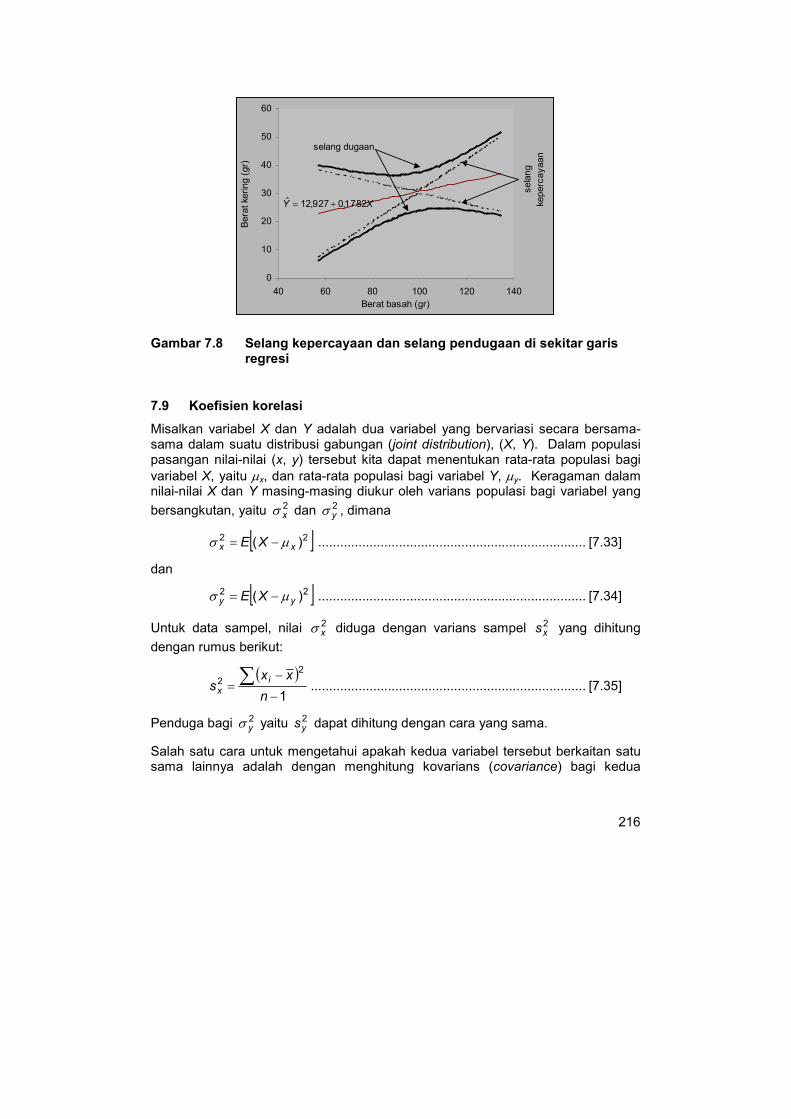
216
0
10
20
30
40
50
60
40 60 80 100 120 140
Berat basah (gr)
Bera
t ke
ring (
gr)
XY 1782,0927,12ˆ +=
se
lan
g
kep
erc
ayaan
selang dugaan
Gambar 7.8 Selang kepercayaan dan selang pendugaan di sekitar garis regresi
7.9 Koefisien korelasi
Misalkan variabel X dan Y adalah dua variabel yang bervariasi secara bersama-sama dalam suatu distribusi gabungan (joint distribution), (X, Y). Dalam populasi pasangan nilai-nilai (x, y) tersebut kita dapat menentukan rata-rata populasi bagi
variabel X, yaitu µx, dan rata-rata populasi bagi variabel Y, µy. Keragaman dalam nilai-nilai X dan Y masing-masing diukur oleh varians populasi bagi variabel yang
bersangkutan, yaitu 2xσ dan 2
yσ , dimana
[ ]22 )( xx XE µσ −= ......................................................................... [7.33]
dan
[ ]22 )( yy XE µσ −= ......................................................................... [7.34]
Untuk data sampel, nilai 2xσ diduga dengan varians sampel 2
xs yang dihitung
dengan rumus berikut:
( )1
2
2
−
−= ∑
n
xxs
i
x ........................................................................... [7.35]
Penduga bagi 2yσ yaitu 2
ys dapat dihitung dengan cara yang sama.
Salah satu cara untuk mengetahui apakah kedua variabel tersebut berkaitan satu sama lainnya adalah dengan menghitung kovarians (covariance) bagi kedua

217
variabel tersebut. Jika data yang kita miliki adalah data populasi, maka kovarians
populasi bagi variabel X dan Y dinotasikan dengan xyσ dimana
( ) ( )( )[ ]yxxy YXEYXCov µµσ −−== , ........................................... [7.36]
Untuk data sampel nilai xyσ diduga dengan kovarians sampel , sxy, yang dihitung
dengan rumus berikut:
( )( )1−
−−= ∑
n
yyxxs
ii
xy ................................................................ [7.37]
atau
−
−= ∑∑∑
n
yxxy
nsxy
1
1 ...................................................... [7.38]
Koefisien keragaman mengukur seberapa besar kedua variabel tersebut bervariasi secara bersama-sama. Kelemahan penggunaan kovarians dalam mengukur kekuatan hubungan antar variabel X dan Y diantaranya adalah bahwa besaran
xyσ dan sxy sangat tergantung pada satuan yang digunakan untuk mengukur
variabel X dan Y. Misalnya, dalam mempelajari hubungan antara diameter pohon
(X) dan tinggi pohon (Y), maka nilai xyσ (dan sxy) akan mempunyai nilai yang lebih
besar jika kedua variabel tersebut diukur dalam satuan cm daripada jika diukur dalam satuan inchi. Masalah satuan tersebut sering kali dijumpai dalam persoalan ekonomi dan bisnis, dimana nilai mata uang (misalnya rupiah) seringkali dinyatakan dalam ribuan, jutaan atau milyaran. Untuk mengatasi masalah tersebut, kovarians sering dibakukan sehingga tidak lagi tergantung pada satuan pengukuran variabelnya. Kovarians populasi yang dibakukan disebut juga koefisien korelasi populasi (population correlation coefficient) yang dinotasikan
dengan huruf Yunani ρ (dibaca rho), dimana
yx
xy
σσ
σρ = ..................................................................................... [7.39]
Dapat ditunjukkan bahwa untuk setiap populasi pasangan nilai (x, y), maka
–1 ≤ ρ ≤ 1 ....................................................................................... [7.40]
Ketika ρ = 0 maka variabel X dan Y tidak berasosiasi secara linier, dan dikatakan bahwa X dan Y tidak berkorelasi. Jika semua pasangan nilai (x, y) terletak pada
suatu garis lurus dengan koefisien kemiringan (slope) yang positif, maka ρ = 1. Jika semua pasangan nilai (x, y) terletak pada suatu garis lurus dengan koefisien
kemiringan (slope) yang negatif, maka ρ = –1. Jika pasangan nilai (x, y) terletak di sekitar suatu garis lurus dengan koefisien kemiringan (slope) yang positif, maka

218
X
Y
a. ρ = –1
X
Y
b. ρ = –1
X
Y
c. ρ = –0,7
X
Y
d. ρ = –0,7
X
Y
e. ρ = 0
X
Y
f. ρ = 0
X
Y
g. ρ = 0,7
X
Y
h. ρ = 0,7
X
Y
i. ρ = 1
X
Y
j. ρ = 1
Gambar 7.9 Ilustrasi tentang beberapa nilai koefisien korelasi

219
nilai ρ akan mendekati nilai +1, dan sebaliknya jika pasangan nilai (x, y) terletak di sekitar suatu garis lurus dengan koefisien kemiringan (slope) yang negatif, maka
nilai ρ akan mendekati nilai –1. Keadaan ini menunjukkan bahwa ρ merupakan suatu ukuran kekuatan hubungan linier antar dua variabel. Secara umum,
� Nilai ρ = –1 menunjukkan suatu hubungan linier negatif yang sempurna
� Nilai ρ = +1 menunjukkan suatu hubungan linier positif yang sempurna
� Semakin besar nilai mutlak dari ρ semakin kuat hubungan linier kedua variabel tersebut
� Nilai ρ = 0 menunjukkan tidak adanya hubungan linier antara kedua variabel, artinya, jika kedua variabel tersebut bersifat saling bebas
(independen) maka nilai ρ = 0. Akan tetapi jika nilai ρ = 0 tidak berarti bahwa kedua variabel tersebut bersifat saling bebas, karena kedua variabel tersebut dapat saja mempunyai hubungan yang tidak linier.
Gambar 7.9 menyajikan beberapa pasangan data (x, y) dengan nilai koefisien korelasi yang berbeda. Misalnya gambar 7.9.a dan 7.9.b menyajikan dua set data yang berbeda tetapi mempunyai koefisien korelasi yang sama (dalam hal ini
ρ = –1). Koefisien korelasi menunjukkan letak atau posisi sebaran data terhadap suatu garis lurus. Semakin dekat data tersebut dengan suatu garis lurus maka koefisien korelasinya akan semakin mendekati 1 atau –1 (tergantung koefisien kemiringan garis lurus tersebut).
Nilai koefisien korelasi populasi, ρ, diduga dengan menghitung koefisien korelasi sampel yang dinotasikan dengan r:
yx
xy
ss
sr = ....................................................................................... [7.41]
dimana sxy adalah kovarians sampel; sx dan sy masing-masing adalah simpangan baku sampel bagi variabel X dan Y. Nilai r dalam persamaan [7.41] biasa juga disebut sebagai koefisien korelasi Pearson (Pearson product-moment correlation coefficient).
Koefisien korelasi, baik untuk populasi maupun untuk sampel, tidak mempunyai satuan dan nilainya tidak berubah dengan berubahnya satuan pengukuran variabel X dan Y. Sebagai contoh, nilai koefisien korelasi tidak berubah walaupun variabel jarak X diukur dalam satuan cm, inci ataupun meter, atau variabel berat Y diukur dalam satuan gr, kg ataupun ton.

220
7.10 Hubungan antara koefisien korelasi dengan koefisien regresi
Koefisien korelasi r dan koefisien regresi b1 keduanya merupakan ukuran keeratan hubungan linier antar variabel X dan Y. Hubungan kedua koefisien tersebut dinyatakan sebagai berikut:
x
y
s
srb =1 ....................................................................................... [7.42]
atau
y
x
s
sbr 1= ....................................................................................... [7.43]
dimana sx dan sy masing-masing adalah simpangan baku bagi variabel X dan Y.
Karena sx dan sy keduanya selalu bernilai positif, maka r = 0 hanya terjadi jika b1 = 0. Artinya, koefisien korelasi akan bernilai nol jika dan hanya jika garis persamaan regresinya merupakan suatu garis mendatar yang koefisien kemiringannya adalah nol. Suatu persamaan garis regresi yang mendatar menunjukkan bahwa variabel X sama sekali tidak dapat digunakan untuk menduga nilai-nilai variabel Y. Oleh karena itu, pernyataan bahwa variabel X tidak berkorelasi dengan variabel Y, pada dasarnya sama saja dengan pernyataan bahwa variabel X tidak mempunyai hubungan linier dengan variabel Y.
Selain itu, karena sx dan sy keduanya selalu bernilai positif, maka koefisien korelasi r mempunyai tanda yang sama dengan koefisien regresi b1. Artinya, koefisien korelasi r akan bertanda positif jika persamaan garis regresinya mempunyai koefisien kemiringan yang positif, dan sebaliknya.
Contoh 7.5
Koefisien korelasi untuk data dalam contoh 7.4 dihitung sebagai berikut:
( )( )6844,58
78
68,238303,77192558,240412
77
1
1
1
=
−=
−
−= ∑∑∑
n
yxxy
nsxy
( ) ( )
3525,32978
03,77191937,789250
77
1
1
1
1
2
2
2
2
2
=
−=
−
−=
−
−= ∑∑∑
n
xx
nn
xxs
i
x

221
( ) ( )
3427,5478
68,23836492,77029
77
1
1
1
1
2
2
2
2
2
=
−=
−
−=
−
−= ∑∑∑
n
yy
nn
yys
i
y
sehingga
( )( )439,0
3427,543525,329
6844,58===
yx
xy
ss
sr
Perhatikan bahwa koefisien korelasi r dapat juga dihitung dengan rumus [7.43],
yaitu
439,03427,54
3525,3291782,01 =×==
y
x
s
sbr
7.11 Beberapa masalah dalam analisis regresi
Beberapa masalah yang biasa mengurangi keabsahan analisis regresi diantaranya adalah:
� Variabel lain yang diabaikan. Jika variabel X dan Y keduanya dipengaruhi oleh variabel lain, maka koefisien b1 mungkin kurang mencerminkan hubungan antara variabel X dan Y yang sebenarnya.
� Hubungan yang tidak linier. Metode kuadrat terkecil menetapkan suatu
garis lurus yang dianggap paling cocok bagi data tersebut. Garis tersebut dapat memberikan informasi yang salah jika hubungan antara variabel Y dan X sebenarnya tidak linier.
� Varians galat yang tidak konstan. Jika varians galat dapat berubah dengan berubahnya nilai X, maka nilai galat baku, hasil pengujian
hipotesis dan selang kepercayaan bagi koefisien regresi patut diragukan kebenarannya.
� Korelasi antar galat. Inferens tentang koefisien regresi yang menyangkut
pengujian hipotesis, pendugaan selang kepercayaan dan nilai galat baku berdasarkan atas asumsi bahwa nilai-nilai galat bersifat independen, artinya tidak berkorelasi. Sehingga jika asumsi tersebut tidaj dipenuhi, maka inferens tentang koefisien regresipun patut diragukan kebenarannya.
� Galat yang tidak berdistribusi normal. Prosedur pengujian hipotesis dengan statistik t dan F berdasarkan atas asumsi kenormalan nilai-nilai
222
galat. Namun demikian, analisis regresi bersifat ‘robust’ terhadap asumsi
kenormalan ini, artinya jika tidak terlalu serius menyimpang dari distribusi normal maka inferens tentang garis regresi dan koefisien regresi tidak terlalu terpengaruhi.
� Kasus influensial. Metode kuadrat terkecil sangat peka terhadap data pencilan (outlier). Satu nilai data pencilan saja dapat menarik garis regresi
ke atas atau ke bawah dan secara substansial mempengaruhi hasil secara keseluruhan.
Diagram pencar (scatter plot) antara variabel Y dan X biasanya sangat efektif
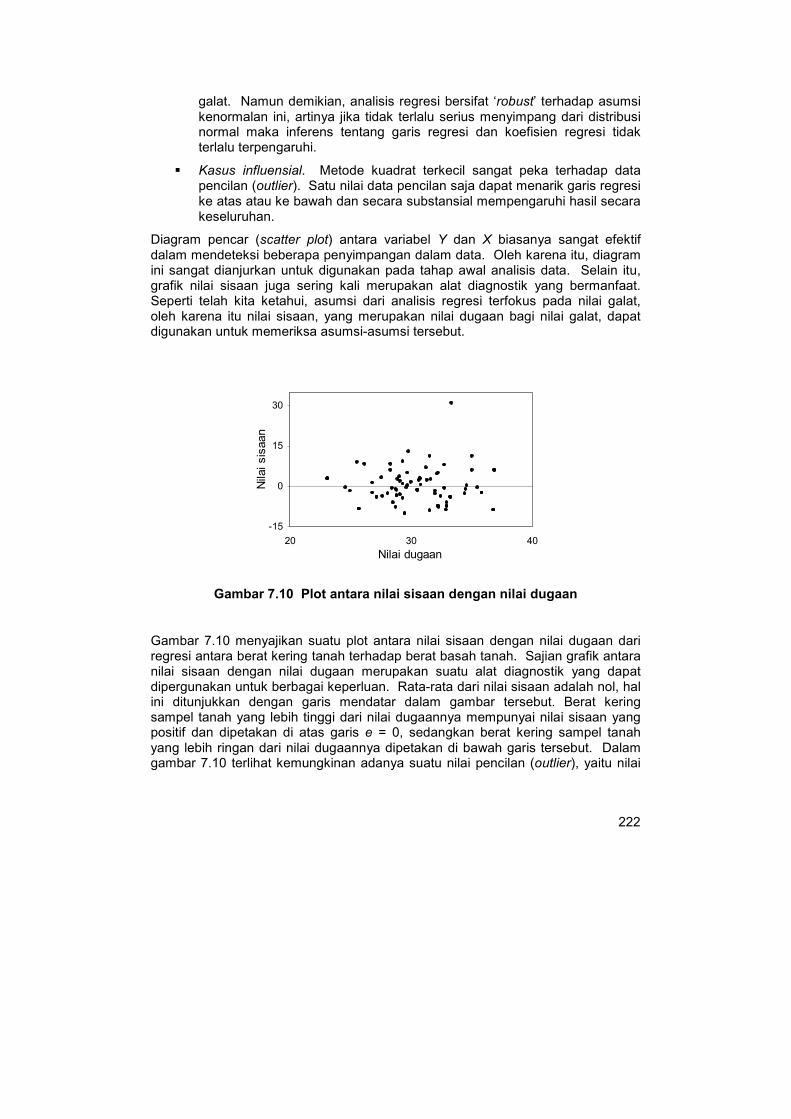
dalam mendeteksi beberapa penyimpangan dalam data. Oleh karena itu, diagram ini sangat dianjurkan untuk digunakan pada tahap awal analisis data. Selain itu, grafik nilai sisaan juga sering kali merupakan alat diagnostik yang bermanfaat. Seperti telah kita ketahui, asumsi dari analisis regresi terfokus pada nilai galat, oleh karena itu nilai sisaan, yang merupakan nilai dugaan bagi nilai galat, dapat digunakan untuk memeriksa asumsi-asumsi tersebut.
-15
0
15
30
20 30 40
Nilai dugaan
Nila
i sis
aan
Gambar 7.10 Plot antara nilai sisaan dengan nilai dugaan
Gambar 7.10 menyajikan suatu plot antara nilai sisaan dengan nilai dugaan dari regresi antara berat kering tanah terhadap berat basah tanah. Sajian grafik antara nilai sisaan dengan nilai dugaan merupakan suatu alat diagnostik yang dapat dipergunakan untuk berbagai keperluan. Rata-rata dari nilai sisaan adalah nol, hal ini ditunjukkan dengan garis mendatar dalam gambar tersebut. Berat kering sampel tanah yang lebih tinggi dari nilai dugaannya mempunyai nilai sisaan yang positif dan dipetakan di atas garis e = 0, sedangkan berat kering sampel tanah
yang lebih ringan dari nilai dugaannya dipetakan di bawah garis tersebut. Dalam gambar 7.10 terlihat kemungkinan adanya suatu nilai pencilan (outlier), yaitu nilai
223
pengamatan yang nilai sisaannya sangat besar dan jauh berbeda dengan nilai-nilai lainnya.
Dugaan(a) Plot yang ideal
0
Dugaan
(b) Kasus influensial
0
Dugaan
(c) Tidak berdistribusi normal
0
Dugaan(d) Hubungan yang tidak linier
0
Dugaan
(e) Heterogenitas varians
0
Dugaan(f) Heterogentitas varians
0
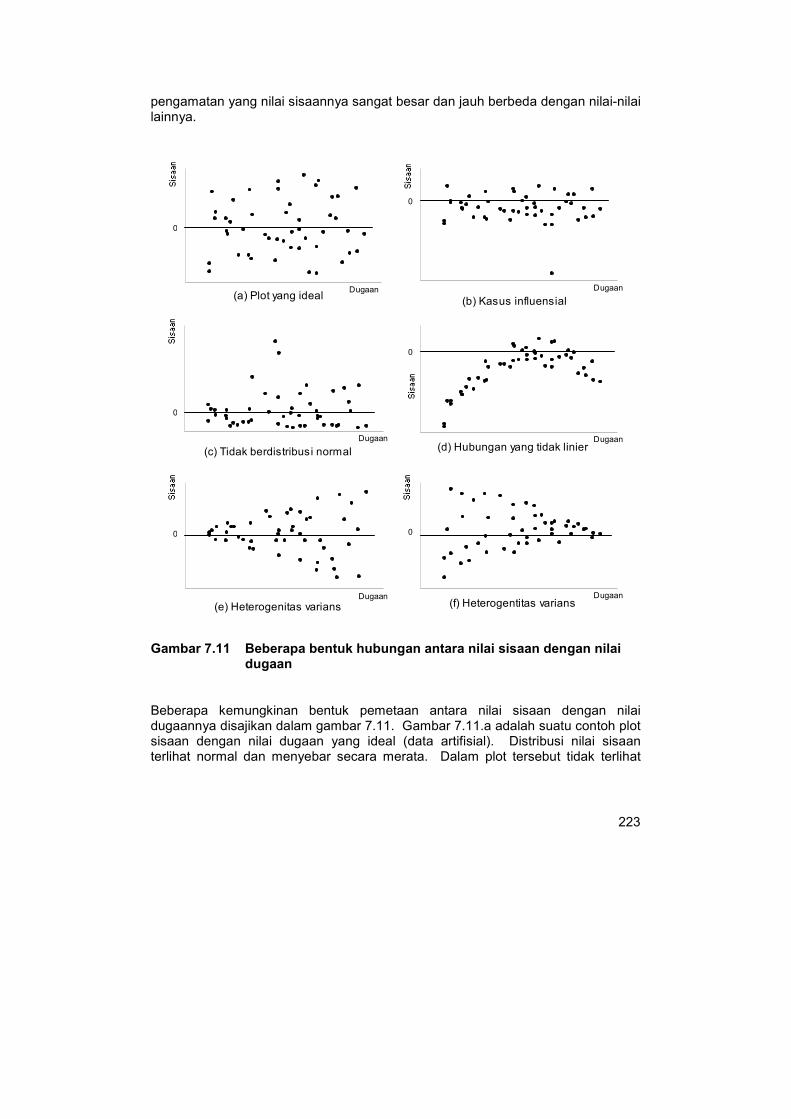
Gambar 7.11 Beberapa bentuk hubungan antara nilai sisaan dengan nilai dugaan
Beberapa kemungkinan bentuk pemetaan antara nilai sisaan dengan nilai dugaannya disajikan dalam gambar 7.11. Gambar 7.11.a adalah suatu contoh plot sisaan dengan nilai dugaan yang ideal (data artifisial). Distribusi nilai sisaan terlihat normal dan menyebar secara merata. Dalam plot tersebut tidak terlihat

224
adanya nilai pencilan atau bentuk ketidak–linieran. Gambar 7.11.b – f menyajikan kasus-kasus dimana asumsi tentang galat terlanggar.
Dalam banyak kasus, pelanggaran terhadap asumsi dalam analisis regresi sering kali dapat diatasi dengan melakukan transformasi baik terhadap variabel dependen maupun variabel independen atau keduanya. Terdapat beberapa jenis transformasi yang sering digunakan, diantaranya adalah transformasi akar kuadrat (square-root transformation), transformasi logaritma (logarithmic transformation) dan transformasi terbalik (recipcoral transformation). Namun demikian, penentuan atau pemilihan bentuk transformasi yang layak digunakan sering kali bukan merupakan hal yang mudah.
Soal-soal latihan
7.1 Jelaskan apa yang dimaksud dengan garis regresi populasi
7.2 Jelaskan apa yang dimaksud dengan garis regresi sampel
7.3 Jelaskan mengapa terjadi perbedaan antara persamaan garis regresi populasi dengan garis regresi sampel?
7.4 Jelaskan asumsi yang mendasari analisis regresi linier sederhana
7.5 Misalkan persamaan suatu garis regresi sampel adalah sebagai berikut:
ii xy 5,310ˆ +=
Tentukan nilai sisaan bagi nilai-nilai pengamatan berikut:
a. (xi = 20, yi = 75) b. (xi = 14, yi = 58) c. (xi = 10, yi = 50)
7.6 Seorang direktur bagian personalia sebuah perusahaan berpendapat bahwa terdapat suatu hubungan antara umur seorang operator komputer di perusahaannya dengan jumlah hari ketidakhadiran operator tersebut dalam tempo enam bulan. Dia kemudian mengambil sampel acak yang terdiri dari 10 orang dan diperoleh data sebagai berikut:
Operator 1 2 3 4 5 6 7 8 9 10
Jumlah hari absen (Y) 12 10 10 9 8 12 6 11 15 8 Umur (X) 25 30 42 33 45 27 55 41 22 58
a. Tentukan persamaan regresi yang menunjukkan hubungan antara umur
operator dengan jumlah ketidak-hadirannya di tempat kerja. b. Interpretasikan koefisien-koefisien regresinya c. Tentukan nilai simpangan baku sisaan dan interpretasikan nilai tersebut d. Tentukan nilai koefisien determinasi (R
2), dan interpretasikan nilai tersebut
7.7 Sebuah penelitian kecil dilaksanakan di sebuah kota di bagian timur laut benua Amerika untuk mengamati pola penggunaan listrik masyarakat di
225
daerah tersebut. Data yang dikumpulkan oleh peneliti tersebut diantaranya adalah jumlah penggunaan daya listrik bulanan per rumah tangga (dalam satuan kilowatt-jam (KWH)) dan suhu bulanan rata-rata (dalam satuan derajat Fahrenheit) yang dihitung sebagai rata-rata suhu pada siang hari dalam bulan tersebut. Hasil sampel selama 10 bulan diperoleh data sebagai berikut:
Penggunaan listrik (Y)
Suhu bulanan rata-rata (X)
1000 420 400 705 550 850
1020 670 610 560
18 50 55 30 45 25 17 35 38 42
a. Tentukan persamaan garis regresi sampelnya b. Interpretasikan koefisien-koefisien regresinya c. Tentukan nilai simpangan baku sisaan dan interpretasikan nilai tersebut d. Tentukan nilai koefisien determinasi (R
2), dan interpretasikan nilai tersebut
e. Dugalah penggunaan daya listrik per rumah tangga ketika rata-rata suhu bulanan adalah 40
o F
7.8 Untuk suatu jenis sepeda motor tertentu, hubungan antara ongkos perbaikan kendaraan (dalam ribuan rupiah) dengan umur kendaraan (tahun) mendekati suatu bentuk hubungan yang linier. Dari 9 sampel sepeda motor yang diambil secara acak, diperoleh data sebagai berikut:
Sepeda motor 1 2 3 4 5 6 7 8 9
Ongkos perbaikan (Y) 80 99 79 138 170 140 114 83 94 Umur (X) 2 3 1 7 10 8 4 1 2
a. Tentukan persamaan garis regresinya b. Interpretasikan koefisien-koefisien regresinya c. Tentukan nilai simpangan baku sisaan dan interpretasikan nilai tersebut d. Tentukan nilai koefisien determinasi (R
2), dan interpretasikan nilai tersebut
e. Dugalah ongkos perbaikan yang mungkin harus dikeluarkan untuk sepeda motor berusia 6 tahun dan 3 tahun.
7.9 Data berikut ini adalah hasil pengukuran diameter dan tinggi pohon Pinus pinaster Ait. pada umur 9 tahun:

226
Pohon 1 2 3 4 5 6 7 8 9 10 11 12
Diameter (cm) 11,2 5,55 11,05 10,45 10,1 5,25 8,6 10,65 8,95 7,6 5,45 9,35
Tingggi (m) 7,1 4,8 6,6 6,4 6,8 4,5 5,1 6,1 6,0 5,6 5,1 5,6
a. Tentukan model persamaan garis regresi untuk menduga tinggi pohon dengan menggunakan diameternya
b. Interpretasikan koefisien-koefisien regresinya c. Tentukan nilai simpangan baku sisaan dan interpretasikan nilai tersebut d. Tentukan nilai koefisien determinasi (R
2), dan interpretasikan nilai tersebut
e. Dugalah tinggi pohon pinus yang diameternya adalah 7 cm
7.10 Data berikut ini adalah hasil pengukuran terhadap diameter tujuh pohon Pinus pinaster Ait. yang diukur pada berbagai tingkat umur:
Umur (tahun)
Pohon 9 12 16
1 8,05 12,00 15,70
2 8,55 12,65 15,90
3 6,55 10,4, 13,25
4 12,00 16,2, 19,50
5 8,90 13,10 16,30
6 8,25 11,40 13,60
7 8,85 12,60 15,00
a. Tentukan model persamaan garis regresi untuk menduga diameter pohon berdasarkan umur pohon tersebut
b. Interpretasikan koefisien-koefisien regresinya c. Tentukan nilai simpangan baku sisaan dan interpretasikan nilai tersebut d. Tentukan nilai koefisien determinasi (R
2), dan interpretasikan nilai tersebut
e. Dugalah tinggi pohon pinus yang umurnya adalah 11 dan13 tahun
7.11 Untuk soal-soal 7.6, 7.7, 7.8, 7.9 dan 7.10 di atas ujilah hipotesis H0: β1 = 0, dan apakah kesimpulan anda?
7.12 Jelaskan kelemahan penggunaan kovarians sebagai salah satu ukuran keeratan hubungan antar variabel X dan Y
7.13 Tentukan nilai-nilai kovarians bagi soal-soal 7.6, 7.7, 7.8, 7.9 dan 7.10 di atas
7.14 Dalam keadaan bagaimanakah koefisien korelasi antar dua variabel akan bernilai negatif?
7.15 Tentukan nilai dugaan bagi koefisien korelasi antar kedua variabel dalam soal -soal 7.6, 7.7 , 7.8, 7.9 dan 7.10




















