







Bahasa
Halaman
Hukum


University of Calicut
Masters Thesis
Scalable Natural Language ReportManagement Using Distributed IE and
NLG from Ontology
A thesis submitted in fulfilment of the requirements
for the degree of Master of Technology
in
Computer Science and Engineering
(Computational Linguistics)
Author:
Manu Madhavan
EPALCLG007
Guide:
Dr. P. C. Reghu Raj
Professor Dept. of CSE
Dept. of Computer Science and Engineering
Government Engineering College
Palakkad - 678 633
August 2013

Declaration of Authorship
I, Manu Madhavan, declare that this thesis titled, ’Scalable Natural Language Report
Management Using Distributed IE and NLG from Ontology’ and the work presented in
it are my own. I confirm that:
� This work was done wholly or mainly while in candidature for a masters degree at
this University.
� Where any part of this thesis has previously been submitted for a degree or any
other qualification at this University or any other institution, this has been clearly
stated.
� Where I have consulted the published work of others, this is always clearly at-
tributed.
� Where I have quoted from the work of others, the source is always given. With
the exception of such quotations, this thesis is entirely my own work.
� I have acknowledged all main sources of help.
� Where the thesis is based on work done by myself jointly with others, I have made
clear exactly what was done by others and what I have contributed myself.
Signed:
Date:
i

CERTIFICATE
GOVERNMENT ENGINEERING COLLEGE
SREEKRISHNAPURAM
PALAKKAD - 678 633
MCL10 401(P) : MASTERS RESEARCH PROJECT
THESIS
This is to certify that this masters thesis entitled Scalable Natural Language
Report Management Using Distributed IE and NLG from Ontology
submitted by Manu Madhavan (EPALCLG007) to the Department of Computer
Science and Engineering, Government Engineering College, Sreekrishnapuram,
Palakkad - 678633, in partial fulfillment of the requirement for the award of M.Tech
Degree in Computer Science and Engineering (Computational Linguistics) is a
bonafide record of the work carried out by him.
Place: Sreekrishnapuram Professor
Date: Dept. of Computer Science & Engineering
Date: External Examiner


Acknowledgements
First and foremost I wish to express my wholehearted indebtedness to God Almighty
for his gracious constant care and blessings showered over me for the successful comple-
tion of the project.
I would like to gratefully acknowledge Dr. Dipti Deodhare, Scientist ‘F’, Head
of Artificial Intelligence and Neural Networks, Centre for Artificial Intelligence and
Robotics (CAIR), for her support and guidance right from selecting the project to com-
pletion of project.
I thank Ms. Jaya P. A. (Mentor), Scientist ‘C’, CAIR, for her valuable assistance,
support and guidance through discussions at each stage of the project. Her enthusiasm
and zeal towards the work motivated me to complete the project in time.
I am extremely grateful to Dr. P. C. Reghu Raj, Head of Department of CSE,
Govt Engineering College Sreekrishnapuram, for his remote guidance, inspiration and
right direction throughout the project.
This project work is a part of combined work with my friend Mr. Robert Jesuraj,
who worked on the topic, “Semantic Framework using Distributed Information Extrac-
tion and Scalable Ontology Processing ”. I appreciate his ideas, co–operation and con-
tributions in completion of the project as an effective team work.
Gratitude is extended to the scientists of CAIR, Ms.Priyanka, Mr. Lovenneeth,
Mr. Lakshmi Narasimh, Mr. Nithin, Ms.Ashika, and Mrs. Bhavani, and Mr. Sagar
(CSTEP) for their sincere directions imparted with the project.
Last but not the least I would like to thank my parents, friends and all well-wishers
without whose support and co-operation the completion of this project would not have
been possible.
iv

Contents
Declaration of Authorship i
Acknowledgements iv
Contents v
List of Figures viii
List of Tables ix
Abbreviations x
Preface xi
Abstract xii
1 Introduction 1
1.1 Knowledge Management Systems . . . . . . . . . . . . . . . . . . . . . . . 2
1.2 Semantic Web Technology . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
1.3 Big Data Problem . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
1.4 Thesis Outline . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
2 Related Work 4
3 Theoretical Background 7
3.1 Information Extraction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
3.2 Map Reduce Paradigm . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
3.3 Ontology . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
3.3.1 Representing Ontology: RDF, RDFS, OWL . . . . . . . . . . . . . 9
3.3.1.1 Basic elements of RDF . . . . . . . . . . . . . . . . . . . 10
3.3.1.2 RDFS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
3.3.1.3 OWL . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
3.4 Natural Language Generation . . . . . . . . . . . . . . . . . . . . . . . . . 12
4 Natural Language Report Management System 14
4.1 Problem Definition . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
4.2 System Architecture . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
v

Contents vi
5 Tools and Specification Standards 17
5.1 Pattern Specification Standards . . . . . . . . . . . . . . . . . . . . . . . . 17
5.1.1 CPSL . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
5.1.2 JAPE . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
5.2 ANTLR . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
5.3 Statistical IE Tools . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
5.4 Hadoop . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
5.5 APIs for Ontology Processing . . . . . . . . . . . . . . . . . . . . . . . . . 21
5.5.1 JenaTM . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
5.5.2 SESAME . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
5.6 Ontology Editors . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
5.6.1 Protege . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
5.6.2 Swoop . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
5.7 NaturalOWL . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
5.8 Pellet: Ontology Reasoner . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
5.9 Neo4j Graph Database . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
6 Distributed Information Extraction 24
6.1 Traditional IE . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
6.2 Dividing IE steps into MapReduce Task . . . . . . . . . . . . . . . . . . . 28
6.3 Notion of Statistical IE . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30
7 Ontology Processing 32
7.1 Building Base Ontology . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32
7.2 Populating base ontology . . . . . . . . . . . . . . . . . . . . . . . . . . . 34
7.3 Persistent Ontology Storage . . . . . . . . . . . . . . . . . . . . . . . . . . 35
7.4 Reusing Existing ontology . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
7.4.1 DBpedia . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
7.4.2 GeoNames Ontology . . . . . . . . . . . . . . . . . . . . . . . . . . 37
7.4.3 Freebase . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 38
7.4.4 BabelNet . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 38
8 Natural Language Generation 39
8.1 NLG from Ontology . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39
8.1.1 Analyzing Query . . . . . . . . . . . . . . . . . . . . . . . . . . . . 40
8.1.2 Extracting the knowledge from Ontology . . . . . . . . . . . . . . 41
8.1.3 Document Planning . . . . . . . . . . . . . . . . . . . . . . . . . . 42
8.1.4 Micro Planning . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 42
8.1.5 Reasoning . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 42
8.2 Other Applications of NLG . . . . . . . . . . . . . . . . . . . . . . . . . . 43
8.3 NLIDB . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 44
9 Results and Observations 45
9.1 Experimental Settings . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 45
9.2 Distributed IE . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 45
10 Conclusion and Future Works 48

Contents vii
A Setting up Hadoop Cluster 49
A.1 Prerequisites . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 49
B Taxonomy of OWL features 54
C Publications out of the Thesis 57
Bibliography 58

List of Figures
3.1 A simple camera vocabulary . . . . . . . . . . . . . . . . . . . . . . . . . . 11
3.2 Steps in NLG . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
4.1 System Architecture . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
5.1 Hadoop Cluster Architecture . . . . . . . . . . . . . . . . . . . . . . . . . 20
6.1 Steps in IE . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25
6.2 XML base structure . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25
6.3 Tokenization . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26
6.4 CPSL rule for Date . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
6.5 Annotation for Date . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
6.6 Architecture of Distributed IE . . . . . . . . . . . . . . . . . . . . . . . . . 29
7.1 Base Ontology. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33
7.2 Overview of the DBpedia components. . . . . . . . . . . . . . . . . . . . . 34
7.3 OWL Representation of Properties. . . . . . . . . . . . . . . . . . . . . . . 34
7.4 OWL Representation of Populated ontology. . . . . . . . . . . . . . . . . . 35
7.5 Overview of the DBpedia components. . . . . . . . . . . . . . . . . . . . . 37
8.1 NaturalOWL’s Protege plug-in . . . . . . . . . . . . . . . . . . . . . . . . 43
9.1 Progress in MapReduce . . . . . . . . . . . . . . . . . . . . . . . . . . . . 46
viii

List of Tables
6.1 Summary of Map Reduce Jobs . . . . . . . . . . . . . . . . . . . . . . . . 31
8.1 Classification of Questions and Answers . . . . . . . . . . . . . . . . . . . 41
9.1 Running time for diffent documents in fully distributed mode . . . . . . . 46
B.1 Taxonomy of OWL features . . . . . . . . . . . . . . . . . . . . . . . . . . 54
ix
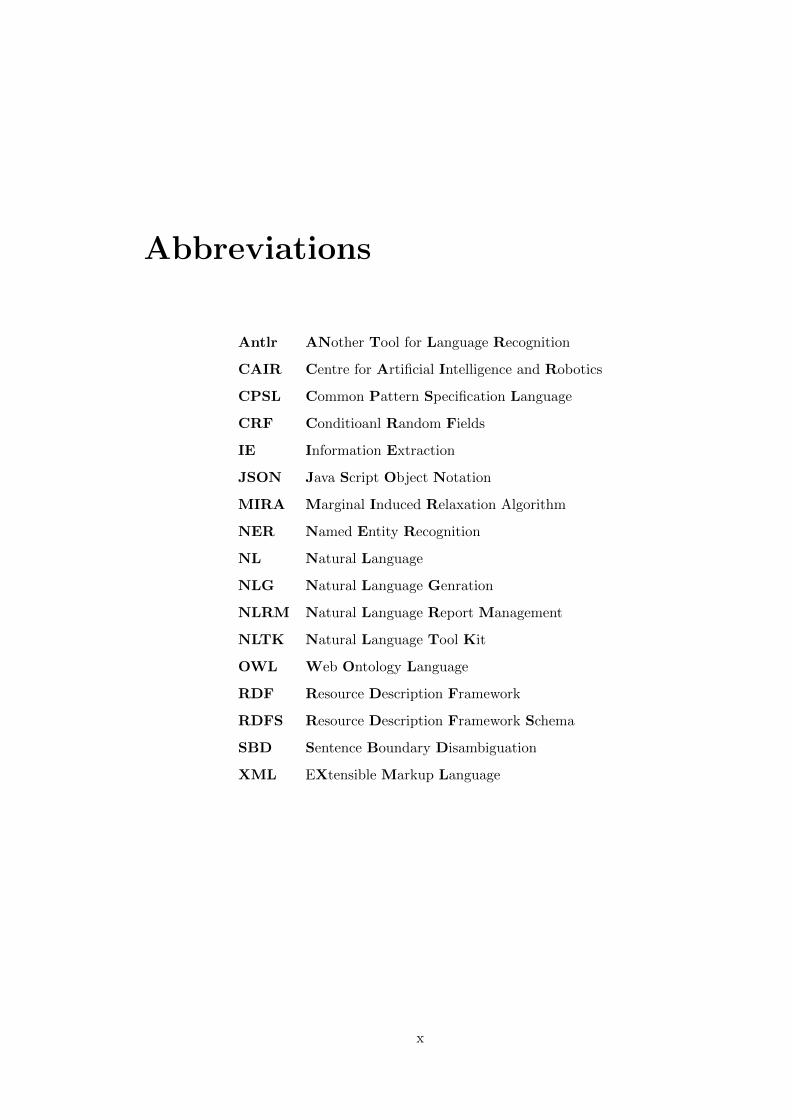
Abbreviations
Antlr ANother Tool for Language Recognition
CAIR Centre for Artificial Intelligence and Robotics
CPSL Common Pattern Specification Language
CRF Conditioanl Random Fields
IE Information Extraction
JSON Java Script Object Notation
MIRA Marginal Induced Relaxation Algorithm
NER Named Entity Recognition
NL Natural Language
NLG Natural Language Genration
NLRM Natural Language Report Management
NLTK Natural Language Tool Kit
OWL Web Ontology Language
RDF Resource Description Framework
RDFS Resource Description Framework Schema
SBD Sentence Boundary Disambiguation
XML EXtensible Markup Language
x

Preface
This thesis is built from the results of project work in the area of Natural Language
Report Management, done at Centre for Artificial Intelligence and Robotics (CAIR),
Bangalore. The goal of the project was to develop a scalable report management system
using semantic web technologies for the log reports in defence domain. As part of the
work, a distributed framework for rule based information extraction is developed and
a scalable storage for ontology is modeled. My individual contribution in this work is
the development of a natural language interface to the knowledge base using, NLG from
ontology.
As mentioned earlier, the work uses defence log reports to process. Since the reports
are confidential and publication of such information is against the rules and regulations
of CAIR, nature of reports and examples cannot be disclosed. Wherever required, this
thesis takes similar examples from the open domain.
xi

Abstract
Scalable Natural Language Report Management Using Distributed IE and
NLG from Ontology
by Manu Madhavan
The automatic text analysis and creation of Knowledge base from the natural language
reports are the key ideas in the field of semantic web. The two wide-raging challenges
to meet this ’semantic vision’ is processing of large-scale text documents and well struc-
tured knowledge representation. In the age of information explosion, performing these
tasks of big data become tedious and impractical. MapReduce, a programming paradigm
proposed by Google, gives us a new approach to solve problems related to big-data anal-
ysis, by making use of the power of multi-machines. Ontology, provides the conceptual
representation of domain information, which can be a solution for knowledge represen-
tation in semantic web. This thesis aims to develop a knowledge management system,
for large-scale natural language text reports, using Semantic web approaches .
The main step in development of any semantic web application is representation of
domain knowledge in the form of base Ontology. Then, the system has to extract the
entities related to the ontology classes and added it into the knowledge base as class
instances. The extraction of information from raw text will undergo the stages like
tokenization, gazetteer lookup, named entity recognition and relation extraction. The
entities to be extracted are represented by domain specific grammar rules. Developing a
natural language interface, with capability to understand and generate natural language
is another dimension of this work.
This project make use Hadoop - an open source implementation of MapReduce to model
a Scalable information extraction form natural language reports(of a specific domain).
The ontology is created and instantiated with Jena ontology API. Instead of traditional
relational databases, the persistent storage of ontology is done using open source graph
database - Neo4j. Antlr an open source tool for generating domain specific grammar is
used for rule-based information extraction. Ontology processing unit also have reason-
ers, which can infer the implicit knowledge from the knowledge base.
Keywords: Distributed IE, NLG, Graph Database, Ontology, Knowledge Represen-
tation

Chapter 1
Introduction
The renaissance in the modern digital age comes up with information explosion. Most
of the information available is coded in Natural Language text. The complexities of
processing and managing this bulk amount of information obliged the researchers to
think about mechanizing these processes. Natural language processing (NLP) is the
area based on the science called computational linguistics, which aims to design compu-
tational models for language processing.
Extracting information, even from a single line of text by a machine is challenging job.
The process becomes tedious when the NLP has to dealt with Big Data. The necessity for
intelligent automatic text processing arises mainly from the following two circumstances,
both being connected with the quantity of the texts produced and used nowadays in the
world:
• Millions and millions of persons dealing with texts throughout the world do not
have enough knowledge and education, or just time and a wish, to meet the modern
standards of document processing. It is just cheaper to teach the machine once
to do this work, rather than repeatedly teach every new generation of computer
users to do it by themselves.
• In many cases, to make a well–informed decision or to find information, one needs
to read, understand, and take into consideration a quantity of texts thousands
times larger than one person is physically able to read in a lifetime. For example,
to find information in the Internet on, let us say, the expected demand for a
specific product in the next month, a lot of secretaries would have to read texts
for a hundred years without eating and sleeping, looking through all the documents
where this information might appear.
1

Chapter 1. Introduction 2
The above situations show the necessity of effective knowledge management systems and
efficient handling of big data. The two broad areas, which enable a solution for the above
problems are Knowledge Management and Semantic Web Technologies. The remaining
sections introduce and discuss these areas of research.
1.1 Knowledge Management Systems
A Knowledge Management System (KMS) is a computerized system designed to support
the creation, storage, and dissemination of information. Such a system contains a central
repository of information that is well structured and employs a variety of effective and
easy to use search tools that users can use to find answers to questions quickly.
KMS are used in one specific domain acts as a data center where users can ask questions
for which it can produce intelligent answers. One of the greatest challenges of running
a contact center is making sure that users are getting consistent, accurate, and timely
information. KMS are developed to help contact center operators meet this challenge.
By having answers to frequently asked questions in a central repository, agents and/or
users can search and retrieve the correct answers quickly and consistently. The concept
of “create once, use by many ” employed in the knowledge management process greatly
increases the operating efficiency of contact centers and reduces overall costs. Other
tangible benefits include:
• Greater consistency and accuracy of information to users
• Improved handling and response times
• Increased user satisfaction
• More effective feedback from users on the quality and usefulness of the knowledge.
1.2 Semantic Web Technology
The solution for knowledge management has come up with the advent of the “ Semantic
Web Vision ”. The World Wide Web (WWW) has lots of information available and has
grown to become the single largest repository, estimated to be of the tune of a few billion
pages of information in digital format. But the WWW as of today describes only the
syntax of the information and not the semantics. Since a computer cannot understand
this information, this huge repository is effectively cut off from the immense processing

Chapter 1. Introduction 3
power offered by these machines. The Semantic Web has been proposed as an exten-
sion to the World Wide Web, and aims to make the information on the web, machine
understandable [5]. In this third generation of web technology, ontologies have become
the formalism of choice for knowledge representation and reasoning. While ontologies
are well suited for computational reasoning, it may also be equally less intuitive and less
insightful for a human user to grasp all the concepts and relationships that exist in the
given domain[21].
1.3 Big Data Problem
Today, just thinking of storing all the web information on one machine is pure science
fiction. The resources of one machine are way too small to handle even a small fraction
of the information in the web. Semantic Web is probably in the same situation than
the former web at its beginning. It is necessary to move from a single environment
perspective to a distributed settings in order to exploit the Semantic Web on a global
scale. Hadoop fills these requirements with effective storage and distributed computing
frame work.
This thesis is an attempt to solve the Knowledge Management problems with big data
analysis, using semantic web approach. Here, the work proposes framework for designing
an end to end system for Knowledge extraction from natural language reports. The
author discusses and presents a system architecture which cover distributed information
extraction, ontology processing and NLG from ontology graphs. These encompassing a
generic approaches for retrieving, processing and expressing contents from ontologies so
as to express them as answers in natural language to the questions posed. The work aims
to build a semantic framework which will try to understand the information contents
stored in natural language texts which are given as inputs.
1.4 Thesis Outline
The remaining chapters of this thesis is arranged as follows. Chapter 2 explains the
necessary theoretical background, on which the thesis is built. Some of the related
works in NLRM, information extraction and ontology based KM are given in Chapter 3.
Chapter 4 defines the problem under consideration and the proposed solution strategy.
The Chapter 5 gives the details of different tools used for the implementation. Chapters ,
6, 7, and 8 explains the details of different modules - Distributed IE, Ontology processing
and NLG - of the project. Chapter 9 presents the observations, results and discussions.

Chapter 2
Related Work
Information Extraction is an active research area in Natural Language Community.
Both the knowledge based and machine learning approaches were attempted to make
the IE process efficiently. Rule based systems are based on specifying patterns with
regular expressions. Numerous rule-based extraction systems were built by the NLP
community in the 80’s and early 90’s, based on the formalism of cascading grammars
and the theory of finite-state automata. These systems primarily targeted two classes
of extraction tasks: entity extraction (identifying instances of persons, organizations,
locations, etc.) and relationship/link extraction (identifying relationships between pairs
of such entities). The Common Pattern Specification Language (CPSL) developed in
the context of the TIPSTER project emerged as a popular language for expressing such
extraction rules [14].
The survey report [28], on Information Extraction, compared the different approaches
including statistical, rule based IE. It stated that statistical methods can be useful when
the training set is available. For developing rules in rule based IE require creating rules
which may require a domain expert to find such rules. Also, the rule based systems are
faster and more amenable to optimizations.
Manual building and customizing rules is a complex and laborious. For a closed do-
main, it correctly predicts the classes. The idea used in paper [6] use a simple IE
system that implements a pipeline architecture: entity mention extraction followed by
relation mention extraction. The corpus used in this paper was developed by LDC for
the DARPA Machine Reading project. The corpus contains 110 newswire articles on
National Football League (NFL) games [11].
The performance of supervised information extraction systems with a pipeline archi-
tecture, for a customized domain is described in [8]. It specifies a combination of a
4

Chapter 2. Related Work 5
sequence tagger with a rule-based approach for entity extraction yields better perfor-
mance for both entity and relation extraction.
At IBM Almaden Research Center, SystemT [20] was developed, an IE system that ad-
dresses the limitations of scalability by adopting an algebraic approach. By leveraging
well-understood database concepts such as declarative queries and cost-based optimiza-
tion, SystemT enabled scalable execution of complex information extraction tasks [31].
A high-level language NER rule Language (NERL) on top of SystemT, a general–
purpose algebraic information extraction system was designed and implemented at IBM
[8]. NERL is tuned to the needs of NER tasks and simplifies the process of building,
understanding, and customizing complex rule-based named-entity annotators. Laura
Chiticariu et. al. showed that these customized annotators match or outperform the
best published results achieved with machine learning techniques.
It was observed that information extraction is particularly amenable to parallelization, as
the main information extraction steps, (e.g., part-of-speech tagging and shallow syntactic
parsing) operate over each document independently . Hence, most parallel data mining
and distributed processing architectures (e.g., Google’s MapReduce) might be easily
adapted for information extraction over large collections. Approaches to distribute the
machine learning task for automated semantic annotation is discussed in [8]. It also
observed that Google’s MapReduce architecture seems to be a good choice for several
reasons: like most of information retrieval and information extraction tasks can be
ported into MapReduce architecture, similar to pattern based annotation algorithms.
Issues to scale NLP tasks to terabytes of document collection are discussed in [27].
Google Map Reduce paradigm technique is used in Hadoop [7]. It is used nowadays
widely by people ranging from academia to industries. It is used so popularly because
of its simplicity in usage and support. Building a local cluster can be done very easily.
The inefficiency when dealing with large-scale data, and the problems related to the
accuracy in extracting the massive data set is explained in [26].
In paper [3] describe an approach to populate an existing ontology with instance infor-
mation present in the natural language text provided as input. This approach starts
with a list of relevant domain ontologies created by human experts, and techniques
for identifying the most appropriate ontology to be extended with information from a
given text. Then the authors demonstrate heuristics to extract information from the
unstructured text and for adding it as structured information to the selected ontology.
This identification of the relevant ontology is critical, as it is used in identifying relevant
information in the text. Authors extract information in the form of semantic triples
from the text, guided by the concepts in the ontology. They then convert the extracted

Chapter 2. Related Work 6
information about the semantic class instances into Resource Description Framework
(RDF) and append it to the existing domain ontology. This enabled to perform more
precise semantic queries over the semantic triple store thus created. They have achieved
95% accuracy of information extraction, using this approach.
The system called RitaWN presented a new representation for Wordnet ontology using
Neo4j graph storage. This work analyzed that the graph databases yield much better re-
sults than traditional relational databases in terms of response time even under extreme
workloads thus speaking for their promised scalability [22].
The details of designing domain specific ontology is explained in [24]. The various
approaches for ontology guided question answering is discussed by Gyawali. This also
describe a generalized architecture for the same. Paper [16] identifies a set of factoid
questions, that can be asked using a domain ontology.
IBM designed IBM Watson [39], which well understands the medical records. Watson
uses IBM Content Analytics to perform critical NLP functions. Unstructured Informa-
tion Management Architecture (UIMA) is an open framework for processing text and
building analytic solutions.
The paper [5] explained a system for summarizing text inputs, and reasoning on them
is of crucial importance to many applications. attempts at multi-agent coordination,
leading to hybrid reasoning and knowledge improvement. The core system will provide
a set of reasoner libraries, to query and reason on the knowledge base. The final system
will provide a set of reasoners, text processors, and other relevant agents, along with a
framework for distributed application development [5].

Chapter 3
Theoretical Background
This chapter we will describe the technologies that are used in this work with the purpose
of providing a basic and common background to ease the understanding of the rest of
the document. Section 3.1 explains information extraction process. The basics of Map
Reduce paradigm is explained in Section 3.2 and fundamentals of ontology is given in
3.3. Section 3.4 explains the theory of NLG.
3.1 Information Extraction
Information extraction (IE) is the task of automatically extracting structured informa-
tion from unstructured and/or semi-structured machine–readable documents [28]. In
most of the cases this activity concerns processing human language texts by means of
NLP. Recent activities in multimedia document processing like automatic annotation and
content extraction out of images/audio/video could be seen as information extraction.
Applying information extraction on text, is linked to the problem of text simplification
in order to create a structured view of the information present in free text. The over-
all goal being to create a more easily machine-readable text to process the sentences.
Typical subtasks of IE include [6]:
• Named entity extraction which could include:
– Named entity recognition: recognition of known entity names (for people and
organizations), place names, temporal expressions, and certain types of nu-
merical expressions, employing existing knowledge of the domain or informa-
tion extracted from other sentences. Typically the recognition task involves
assigning a unique identifier to the extracted entity. A simpler task is named
entity detection, which aims to detect entities without having any existing
7

Chapter 3. Theoretical Background 8
knowledge about the entity instances. For example, in processing the sentence
“M. Smith likes fishing”, named entity detection would denote detecting that
the phrase “M. Smith” does refer to a person, but without necessarily having
(or using) any knowledge about a certain M. Smith who is (/or, “might be”)
the specific person whom that sentence is talking about.
– Co-reference resolution: detection of co-reference and anaphoric links between
text entities. In IE tasks, this is typically restricted to finding links between
previously-extracted named entities. For example, “International Business
Machines” and “IBM” refer to the same real-world entity. If we take the two
sentences “M. Smith likes fishing. But he doesn’t like biking”, it would be
beneficial to detect that “he” is referring to the previously detected person
“M. Smith”.
– Relationship extraction: identification of relations between entities, such as:
1. PERSON works for ORGANIZATION (extracted from the sentence “Bill
works for IBM.”)
2. PERSON located in LOCATION (extracted from the sentence “Bill is in
France.”)
• Semi–structured information extraction which may refer to any IE that tries to
restore some kind information structure that has been lost through publication
such as:
– Table extraction: finding and extracting tables from documents.
– Comments extraction : extracting comments from actual content of article in
order to restore the link between author of each sentence
• Language and vocabulary analysis:
– Terminology extraction: finding the relevant terms for a given corpus
• Audio extraction
– Template-based music extraction: finding relevant characteristic in an audio
signal taken from a given repertoire; for instance time indexes of occurrences
of percussive sounds can be extracted in order to represent the essential rhyth-
mic component of a music piece.
3.2 Map Reduce Paradigm
MapReduce is a distributed programming model originally designed and implemented
by Google for processing and generating large data sets [7]. The Google MapReduce

Chapter 3. Theoretical Background 9
programming model [11] has proved to be performant since the simple principle of “map-
ping and reduce” allows a high degree of parallelism with little costs of overhead. Today
the Google’s MapReduce framework is used inside Google to process data on the order
of petabytes on a network of few thousand of computers. In this programming model
all the information is encoded as tuples of the form 〈key, value〉. The work-flow of a
MapReduce job is like this: first, the map function processes the input tuples return-
ing some other intermediary tuple 〈key2, value2〉. Then the intermediary tuples are
grouped together according to their key. After, each group will be processed by the
reduce function which will output some new tuples of the form 〈key3, value3〉 [32].
3.3 Ontology
An ontology defines a common vocabulary for researchers who need to share informa-
tion in a domain. It includes machine-interpretable definitions of basic concepts in the
domain and relations among them. Formally an ontology is defined by a seven tuple as
follows [16]:
O = (C, HC, RC, HR, I, RI, A)
An ontology O consists of the following. The concepts C of the schema are arranged in
a subsumption hierarchy HC . Relations RC exist between concepts. Relations (Prop-
erties) can also be arranged in a hierarchy HR . Instances I of a specific concept are
interconnected by property instances RI . Additionally, one can define axioms A which
can be used to infer knowledge from already existing one.
Why would someone want to develop an ontology? Some of the reasons are [24]:
• To share common understanding of the structure of information among people or
software agents
• To enable reuse of domain knowledge
• To make domain assumptions explicit
• To separate domain knowledge from the operational knowledge
• To analyze domain knowledge
3.3.1 Representing Ontology: RDF, RDFS, OWL
RDF is the basic building block for supporting the Semantic Web. RDF is to the Se-
mantic Web what HTML has been to the Web. RDF is a language recommended by

Chapter 3. Theoretical Background 10
W3C, and it is all about metadata. RDF is capable of describing any fact (resource)
independent of any domain. RDF provides a basis for coding, exchanging, and reusing
structured metadata. RDF is structured; i.e., it is machine-understandable. Machines
can do useful operations with the knowledge expressed in RDF. RDF allows interoper-
ability among applications exchanging machine understandable information on the Web
[21].
3.3.1.1 Basic elements of RDF
RESOURCE: The first key element is the resource. RDF is a standard for metadata;
i.e., it offers a standard way of specifying data about something. This something can
be anything, and in the RDF world we call this something, resource. A resource is
identified by a uniform resource identifier (URI), and this URI is used as the name of
the resource.
Here is an example [21]. The following URI uniquely identifies a resource:
http://www.simplegroups.in/photography/SLR#Nikon-D70
1. This resource is a real-world object, i.e., a Nikon D70 camera; it is a single lens
reflex (SLR) camera.
2. URL “ http://www.simplegroups.in/photography/SLR ” is used as the first part of
the URI. More precisely, it is used as a namespace to guarantee that the underlying
resource is uniquely identified; this URL may or may not exist.
3. At the end of the namespace, “#” is used as the fragment identifier symbol to
separate the namespace from the local resource name, i.e., Nikon-D70.
4. Now the namespace + “#” + localResourceName gives us the final URI for the
resource; it is globally named.
PROPERTY: Property is a resource that has a name and can be used as a property;
i.e., it can be used to describe some specific aspect, characteristic, attribute, or relation
of the given resource. The following is an example of a property:
http://www.simplegroups.in/photography/SLR#weight
This property describes the weight of the D70 camera. STATEMENT: An RDF state-
ment is used to describe properties of resources. It has the following format:
resource (subject) + property (predicate) + property value (object) The prop-
erty value can be a string literal or a resource. Therefore, in general, an RDF statement
indicates that a resource (the subject) is linked to another resource (the object) via an
arc labeled by a relation (the predicate). It can be interpreted as follows:

Chapter 3. Theoretical Background 11
<subject> has a property <predicate>, whose value is <object>
For example:
http://www.simplegroups.in/photography/SLR#Nikon-D70 has a
http://www.simplegroups.in/photography/SLR#weight whose value
is 1.4 lb.
3.3.1.2 RDFS
RDFS is written in RDF. RDFS stands for RDF Schema. RDFS is a language one
can use to create a vocabulary for describing classes, subclasses, and properties of RDF
resources; it is a recommendation from W3C. The RDFS language also associates the
properties with the classes it defines. RDFS can add semantics to RDF predicates and
resources: it defines the meaning of a given term by specifying its properties and what
kinds of objects can be the values of these properties. RDFS is all about vocabulary.
Figure 3.1: A simple camera vocabulary.
For example, Fig 3.1 [21]. shows a simple vocabulary. This simple vocabulary tells us

Chapter 3. Theoretical Background 12
the following fact:
We have a resource called Camera, and Digital and Film are its two
sub-resources. Also, resource Digital has two sub-resources, SLR and
Point-and-Shoot. Resource SLR has a property called has-spec, whose value
is the resource called Specifications. Also, SLR has another property
called owned-by, whose value is the resource Photographer, which is a
sub-resource of Person.
3.3.1.3 OWL
OWL (Web Ontology Language) is the latest recommendation of W3C and is probably
the most popular language for creating ontologies today.
OWL = RDF schema + new constructs for expressiveness [21]
With RDF Schema it is possible to define only relations between the hierarchy of the
classes and property, or define the domain and range of these properties. The scientific
community needed a language that could be used for more complex ontologies and
therefore they started to work on a richer language that would be later released as the
OWL language [32]. OWL is built upon RDF and therefore the two languages share
the same syntax. An OWL document can be seen as a RDF document with some
specific OWL constructs. The expressiveness in achieved by adding more constrains on
properties.
OWL come up in 3 different forms: OWL-Lite, OWL-DL and OWL-Full. A comparison
of features in RDFS, and different flavours of OWL are tabulated in appendix B.
3.4 Natural Language Generation
A NLG System involves pipeline of activities like Content selection, Document planning,
Micro Planning and and reasoning, as shown in fig 3.2. In this architecture, the first step
is document planning. This involves content determination and text planning. Content
determination is the process of deciding what information should be communicated in
the text. This is described as one of the process creating a set of messages from the
systems inputs or underlying data sources. Text plan is a a non-linguistic representation
of concepts in the input message. text is not just a random collection of pieces of
information: the information is presented in some particular order, and there is usually
an underlying structure to the presentation [15].
The micro-plan module select the lexical item, that can be used to represent the message
in natural language. The activities in micro planning module involve lexical selection,

Chapter 3. Theoretical Background 13
Figure 3.2: Steps in NLG
sentence aggregation, and referring expressions. The system must choose the lexical
item most appropriate for expressing particular concepts. Aggregation is not always
necessary. Each message can be expressed in a separate sentences, but in many cases
good aggregation can significantly enhance the fluency and readability of a text. It
also perform necessary pronominalization, to improve the readability. The final step is
reasoning, which apply grammar rules on micro plan and produce syntactically, mor-
phologically, and orthographically valid output sentence.

Chapter 4
Natural Language Report
Management System
4.1 Problem Definition
Natural language reports are a major information source in almost all domains. The
people ranges from individuals to big organizations come up with large amount of reports
as part of their daily operations. Since the reports are unstructured natural language
expressions, information extraction become challenging. For example, in the defence
domain, a large collection of log data are available. More information could be extracted
by parsing these data. This log data are created by each duty soldier working at different
part of the country. These log data,which is in unstructured form, will have no value
until information in it are collected and processed to store into database. Conversion of
these unstructured data to structured data is necessary. As the size of source is increases
with the plethora of web documents, this process become convoluted.
In the above context, this thesis focuses on three major problems to design a Natural
Language Management System. The first problem is the extraction of information from
the unstructured natural language documents, specific to a domain. Extracting relevant
information from a simple sentence is a difficult task. Here the system has to deal
with big data problem. The thesis seeks a solution through proposing a distributed
computing paradigm. The second problem, is efficient representation of this information
in a structured way. To meet developing semantic web standards, ontology are used for
the knowledge management. Scalable storage and efficient retrieval of these information
is the third and most important problem under consideration.
14

Chapter 4. Natural Language Report Management System 15
4.2 System Architecture
The architecture of the proposed system is shown in figure 4.1. The entire system design
is divided into three modules:
1. Distributed IE
2. Ontology Processing
3. Interfacing Knowledge base
The first and foremost important step in system design is the creation of knowledge
base schema. The knowledge is represented as ontologies. The system takes a collection
of documents (specific to a domain) as input. The documents are characterized by
unstructured nature. The distributed IE system, works on these documents in parallel
and extract the information corresponding the KB schema. The IE system used in this
design is rule based. The IE module process the input documents and represents it in a
XML structure.
Figure 4.1: System Architecture
The ontology processing module will update the knowledge base with extracted infor-
mation. The populating instances of ontology is the functionality of this module. It

Chapter 4. Natural Language Report Management System 16
also maintain a graph database for persistent storage of ontology. The implementation
with graph database will allow the use of graph algorithms to reason the new relations
existing between the individuals. The third module is a natural language interface to
the knowledge base. This design effectively uses Natural Language Generation from
ontologies for the interface. The interface can be used in two ways: one to generate NL
results for NL queries and other to generates summary reports from the knowledge base.
The system is implemented in Java. The design and instantiation of ontology uses Jena,
an open source ontology API. The rules for IE process are written in Common Pattern
Specification Language (CPSL), and implemented using ANTLR. Neo4j, a popular open-
source graph database is used for ontology storage. To query the ontology, SPARQL
query language is used. Details of tools used in this project are given in Chapter 5.

Chapter 5
Tools and Specification Standards
This chapter gives the details of tools and specification standards used for implementing
the project.
5.1 Pattern Specification Standards
In a rule based IE system, the patterns for chunking should be specified as grammar
rules. The simplest method for pattern specification is the use of regular expressions.
More advanced methods use context free grammars and shallow parsing. There are some
sophisticated methods for pattern specification, which include programing features like
macro definitions, lexer and parser generators. Following are some of widely used pattern
specification standards.
5.1.1 CPSL
The expressions for pattern recognition are specified by context free grammars and
represented by specification called Common Pattern Specification Language (CPSL)[14].
The CPSL was designed by a committee consisting of a number of researchers from the
Government and all of the TIPSTER research sites involved in Information Extraction
that are represented in this volume.
The CPSL system maintains an interpreter, which performs the pattern matching. The
interpreter implements cascaded finite-state transducers. Each transducer accepts as
input a sequence of annotations conforming to the Annotation object specification of the
TIPSTER Architecture. Each transducer produces as output a sequence of annotations
conforming to the Annotation object specification of the TIPSTER Architecture.
17

Chapter 5. Tools and Specification Standards 18
A CPSL grammar consists of three parts: a macro definition part, a declarations part,
and a rule definition part. The declaration section allows the user to declare the name
of the grammar, since most extraction systems will employ multiple grammars to oper-
ate on the input in sequential phases. The grammar name is declared with the statement
Phase : 〈grammar name〉
The Input declaration follows Phase declaration, and tells the interpreter which annota-
tions are relevant for consideration in this phase. A typical input declaration would be:
Input : Word, NamedEntity
The rules section is the core of the grammar. It consists of a sequence of rules, each
with a name and an optional priority. The general syntax of a rule definition is
Rule : 〈rule name〉Priority : 〈integer〉〈rule pattern part〉 → 〈rule action part〉
The detailed specification of CPSL Grammar syntax is available on [14].
5.1.2 JAPE
Java Annotation Pattern Engine (JAPE) provides finite state transducers over anno-
tations based on regular expressions. Thus it is useful for pattern-matching, semantic
extraction, and many other operations over syntactic trees such as those produced by
natural language parsers. JAPE is a version of CPSL and is available as part of General
Architecture for Text Engineering (GATE)1 platform. A JAPE grammar consists of a
set of phases, each of which consists of a set of pattern/action rules. The phases run
sequentially and constitute a cascade of finite state transducers over annotations. The
left-hand-side (LHS) of the rules consist of an annotation pattern description. The right-
hand-side (RHS) consists of annotation manipulation statements. Annotations matched
on the LHS of a rule may be referred to on the RHS by means of labels that are attached
to pattern elements [10].
In comparison with CPSL, JAPE provides following features. It allows arbitrary Java
codes on the RHS. JAPE grammar can compiled and stored as serialized Java objects.
1http://www.gate.ac.uk

Chapter 5. Tools and Specification Standards 19
Apart from these differences, the language processing and recognition power of JAPE
and CPSL are the same.
5.2 ANTLR
ANTLR (ANother Tool for Language Recognition) is a powerful parser generator for
reading, processing, executing, or translating structured text or binary files. It’s widely
used to build languages, tools, and frameworks. As a translator, ANTLR executes some
codes (grammar rules, specified in a .g file) on input character stream and produce an
output. The first translation phase is called lexical analysis and operates on the incom-
ing character stream. The second phase is called parsing and operates on a stream of
vocabulary symbols, called tokens, emanating from the lexical analyzer. ANTLR auto-
matically generates the lexical analyzer and parser by analyzing the input grammar[25].
ANTLRWorks is a GUI development environment that sits on top of ANTLR and helps
the programmer edit, navigate, and debug grammars. ANTLRWorks currently has the
following main features [25]:
• Grammar-aware editor and Syntax diagram grammar view
• Interpreter for rapid prototyping
• Language-agnostic debugger for isolating grammar errors
• Nondeterministic path highlighter for the syntax diagram view
• Refactoring patterns for many common operations such as “remove left-recursion”
and “in-line rule”
• Decision lookahead (DFA) visualization, dynamic parse tree view and dynamic
AST view
5.3 Statistical IE Tools
The two popular algorithms used for statistical IE are Conditional Random Fields (CRF)
and Marginal Induced Relaxed Algorithm( MIRA). The approaches using both CRF and
MIRA for NER use a multi-class classification. In implementation using CRF or MIRA,
there are two stages[9]. In training stage, IE system learns the weights from the input,
a labeled training set along with a template structure. In testing stage, it predict the

Chapter 5. Tools and Specification Standards 20
label from weights learned in last stage. CRF++2 is a C++ implementation of CRF.
CoreNLP [44], a Standford NLP tool uses CRF for POS tagging. Miralium3 is a Java
implementation of MIRA.
5.4 Hadoop
Hadoop is an open source framework for writing and running distributed applications
that process large amounts of data. The Hadoop framework handles the processing
details, leaving developers free to focus on application logic [18]. The accessibility and
simplicity of Hadoop give it an edge over writing and running large distributed programs.
Its most widely used in student research projects in academia and the robustness and
scalability make it suitable for even the most demanding jobs at Yahoo and Facebook.
These features make Hadoop popular in both academia and industry.
Figure 5.1: Hadoop Cluster Architecture
The two fundamental pieces of Hadoop Core [33] are the MapReduce framework, and he
Hadoop Distributed File System (HDFS) (see fig. 5.1 4). Hadoop MapReduce framework
is an the distributed data processing model (refer section 3.2) execution environment
that runs on large clusters of commodity machines. HDFS is a subproject of the Apache
Hadoop which is a distributed, highly fault-tolerant file system designed to run on low-
cost commodity hardware. Hadoop cluster is a set of commodity machines networked
together in one location. Data storage and processing all occur within this cloud of
machines. Different users can submit computing “jobs” to Hadoop from individual
2http://crfpp.googlecode.com3http://code.google.com/p/miralium/4http://www.infoq.com/resource/articles/data-mine-cloud-hadoop

Chapter 5. Tools and Specification Standards 21
clients, which can be their own desktop machines in remote locations from the Hadoop
cluster[7].
5.5 APIs for Ontology Processing
The two important Java APIs available for ontology processing are Jena and Sesame.
Jena is used in the implementation of this work, but the use of Sesame is tried to compare
the performance.
5.5.1 JenaTM
Apache JenaTM is a Java framework for building Semantic Web applications. Jena
provides a collection of tools and Java libraries to help you to develop semantic web and
linked-data apps, tools and servers. The Jena Framework includes [34]:
• an API for reading, processing and writing RDF data in XML, N-triples and Turtle
formats
• an ontology API for handling OWL and RDFS ontologies
• a rulebased inference engine for reasoning with RDF and OWL data sources
• stores to allow large numbers of RDF triples to be efficiently stored on disk
• a query engine compliant with the latest SPARQL specification
• servers to allow RDF data to be published to other applications using a variety of
protocols, including SPARQL
Jena has object classes to represent graphs, resources, properties and literals. The
interfaces representing resources, properties and literals are called Resource, Property
and Literal respectively. In Jena, a graph is called a model and is represented by the
Model interface. It provides methods to read and write RDF as XML or N-Triples. Jena
also maintains relational tables for persistent storage of Ontology.
5.5.2 SESAME
Sesame is an open source Java framework for storing, querying and reasoning with RDF
and RDF Schema. It can be used as a database for RDF and RDF Schema, or as a
Java library for applications that need to work with RDF internally . Sesame can be

Chapter 5. Tools and Specification Standards 22
deployed as a Java Servlet Application in Apache Tomcat, a webserver that supports
Java Servlets and JSP technology. A central concept in the Sesame framework is the
repository. A repository is a storage container for RDF. This can simply mean a Java
object (or set of Java objects) in memory, or it can mean a relational database [42].
5.6 Ontology Editors
Ontology editors are applications designed to assist in the creation or manipulation of
ontologies. The two popular editors used in implementation of this project are Protege
and Swoop.
5.6.1 Protege
Protg is a free, open-source platform that provides a growing user community with a
suite of tools to construct domain models and knowledge-based applications with on-
tologies. Protege’s model is based on a simple yet flexible metamodel, which is complete
parable to object-oriented and frame-based systems. It basically can represent ontologies
consisting of classes, properties (slots), property characteristics (facets and constraints),
and instances. Protege provides an open Java API to query and manipulate models.
An important strength of Protege is that the Protege metamodel itself is a Protege on-
tology, with classes that represent classes, properties, and so on. Protege have plug-ins
for visualizing ontology graphs, reasoning (using Fact++ and HermiT) and modifying
existing ontology [41].
5.6.2 Swoop
SWOOP is a tool for creating, editing, and debugging OWL ontologies. It was produced
by the MIND lab at University of Maryland, College Park, but is now an open source
project with contributers from all over. Swoop provides features like web ontology editor,
importing other OWL ontologies, and OWL reasoning using Pellet [1].
5.7 NaturalOWL
NaturalOWL is an opensource natural language generation engine written in Java. It
produces English and Greek descriptions of individuals (e.g., items for sale or museum
exhibits) and classes (e.g., types of exhibits) from OWL DL ontologies. The ontologies

Chapter 5. Tools and Specification Standards 23
must have been annotated in RDF with suitable linguistic and user modeling information
[13]. NaturalOWL’s plug-in for Protege can be used to specify all the linguistic and user
modeling annotations of the ontologies that NaturalOWL requires. The annotations in
effect establish a domain-dependent lexicon, whose entries are associated with classes
or entities of the ontology; micro-plans, which are associated with properties of the
ontology; a partial order of properties, which is used in document planning; interest
scores, indicating how interesting the various facts of the ontology are to each user type;
parameters that control, for example, the desired length of the generated texts [12].
5.8 Pellet: Ontology Reasoner
Pellet is an OWL DL reasoner based on the tableaux algorithms developed for expressive
Description Logics. It supports the full expressivity OWL DL including reasoning about
nominals (enumerated classes). Pellet can also used for OWL consistency checker, which
takes a document as input, and returns one word being Consistent, Inconsistent, or
Unknown[29]. Pellet is available with both Swoop and Protege editors. The pellet
provides two kinds of querying: ABox and TBox. An ABox query is a query about
individuals and their relationship to data and other individuals through (datatype or
object) properties.
5.9 Neo4j Graph Database
The problems regarding he persistent storage of Ontology is optimized by adopting
graph databases. Neo4j is the graph database used in this work. Neo4j is an open-
source, high-performance, enterprise-grade NOSQL graph database. It is a robust (fully
ACID) transactional property graph database. Due to its graph data model, Neo4j is
highly agile and blazing fast. For connected data operations, Neo4j runs a thousand
times faster than relational databases. The storage of ontology in Neo4j like database
will facilitate analysis using graph algorithms along with scalability. This will also help
to infer FOAF relations in social network analysis [17].

Chapter 6
Distributed Information
Extraction
Information Extraction (IE) can be regarded as a subfield of NLP that focuses upon
finding specific facts in relatively unstructured documents. The aim of IE is to identify
the named entities and their relation in the domain. It ranges from identifying keywords
in a domain to extracting linguistic patterns. Some systems can use statistics collected
over the whole collection to assign confidence scores to extracted objects. Either after or
during the extraction, information can be merged for multiple occurrences of the same
object (and different objects with shared attribute values can be disambiguated).
6.1 Traditional IE
A traditional IE approach involves pipeline of activities shown in figure 6.1 [28]. In
general, a document is broken up into chunks (e.g., sentences or paragraphs), and rules
or patterns applied to identify entities. While implementing the processes, a XML
structure is defined to store the extracted information in a machine understandable
form. Each step updates the XML document with new annotations, which is important
for further processing in knowledge level. The structure of the XML document is shown
Figure 6.2.
The process starts with identifying sentence boundaries from the input text. Sentence
boundary disambiguation (SBD), also known as sentence breaking, is the problem in
natural language processing of deciding where sentences begin and end. Since the punc-
tuation marks are often ambiguous,identifying the sentence boundary by orthographic
terms become complex. A simple heuristic method for SBD is based on the following
24

Chapter 5. Distributed Information Extraction 25
Figure 6.1: Steps in IE
observation. In more formal English writing, sentence boundaries are often signaled by
terminal punctuation from the set: {., !, ?} followed by white spaces and an upper case
initial word. Among these, . is heavily overloaded. Other than a sentence boundary,
. can be a separator in abbreviations (eg. B.C.), or a separator in numerical expres-
sion(12.45). The algorithm qualify a ’.’ as an end marker through two passes. During
the first pass it mark all appearance of ’.’ as end-marker. The next pass will disqualify
the ’.’ in abbreviations and numerical expression as end-marker [19].
In the second step, each sentence is divided into tokens, the smallest unit of information.
Generally, tokens are identified by space. Depending on the domain, punctuations and
special characters, are considered as separate tokens. For example consider the sentence
in Example 6.1
Figure 6.2: XML base structure

Chapter 5. Distributed Information Extraction 26
Example 6.1. Tendulkar was born at Nirmal Nursing Home on 24 April 1974.
The tokenizer will split the sentence into different tokens as
[’Tendulkar’:word, ’was’:word, ’born’:word, ’at’:word, ’Nirmal’:word,
’Nursing’:word, ’Home’:word, ’on’:word, ’24’:number, ’April’:word,
’1973’:number, ’.’:punc]
This information is added to XML structure as given in Figure 6.3
Figure 6.3: Tokenization
Gazetteer lookup is the dictionary based identification of domain entities. For each
tokens in the input text, it will check the database and check whether there exist any
lookup for the token. The lookup information involve identification of named entities
like place, person, etc. The new information is added in XML as annotation type lookup.
In Example 6.1, a lookup can identifies ’Tendulkar’ as a person, ’April’ as month and
’Nirmal Nursing Home’ as location.
The NER involves identification of domain specific entities from patterns. The pat-
terns are specified as rules. It works essentially as a set of cascaded, nondeterministic
finitestate transducers (FST). Successive stages of processing are applied to the input,
patterns are matched, and corresponding composite structures are built. The composite
structures built in each stage provides the input to the next stage. Common Pattern
Specification Language (CPSL) is a standard for representing the rules for NER. In this
FST based approach, the pattern matching is performed in different phases. Each phase
consist of one or more rules, for pattern extraction. For example, a CPSL specification

Chapter 5. Distributed Information Extraction 27
of rule for identifying date and the annotation structure are given in Figure 6.4 and Fig-
ure 6.5 respectively. By a detailed analysis on the above rule, it will be clear how the
Figure 6.4: CPSL rule for Date
Figure 6.5: Annotation for Date
look up and token information, from the previous steps are used in NER. The pattern
matched by the rule is bounded to a name (related to the domain) which is used as
annotation type in XML structure. Some kind of Named Entities (NE) can be identified
from context information. Consider the example 6.2
Example 6.2. John went to New Delhi on his birthday.
Here, even though the date is not specified explicitly, birthday is a clue for the date of
event. Such information identified from linguistic expressions can be tagged with special
annotation context and further inferences are applied at knowledge level to extract the
actual information.

Chapter 5. Distributed Information Extraction 28
The final step is pattern identification. A pattern, generally represents an event or
concept in the domain. The pattern extraction take all the information in above steps.
In example 6.1, birth is an event, which have date, place, and person as entities. The
specification of pattern is given to the system as CPSL rules, as discussed in NER. Thus
pttern extraction can be considered as shallow parsing with CPSL grammar. These
information is also added to XML as annotation type extract pattern. The final XML
contain all extracted information with necessary computational information (such as
span, length of pattern, etc.) .
The number of phases and and the rules depends on the domain. When a phase is
selected for execution, all rules has to be checked for patterns. In our work, there are 30
phases and each phase contain around 45 rules. This entire processes have to repeat for
all the sentences in the input. The process become time consuming as the number and
size of input texts increase. In this context (of big data problem), the solution is exploring
the scope of parallel computing, by distributing the job into different computing nodes.
6.2 Dividing IE steps into MapReduce Task
The pipeline dependency of IE steps (as discussed in section 6.1), makes the parallel
computation challenging. This problem is solved by dividing the entire process into
different MapReduce jobs. The division is based on the dependency of rules and levels
of chunk. The proposed architecture achieves linewise parallelism, by processing each
sentence in parallel. The complete architecture with 5 MapReduce jobs is shown in fig.
6.6.
In short, the IE steps are divided into map jobs and finally the reduce job will collect the
results in each document and outputs the final annotated XML. The jobs are connected
by Hadoop ChainMapper method [7]. The distributed IE system takes bulk of text
documents (from a domain) as input and produce corresponding XML structure as
output. The important thing in design of MapReduce task is to correctly identify key–
value pairs.
• Map1-Sentence Splitting: The task of first mapper is performing sentence
wise splitting. We use < Key, V alue > format for mapper output. The key is
a combined string of filename and line number, separated by a special delimiter.
Value is the initial XML structure with line as the content.
• Map 2- Tokenization and Gazetteer Lookup: This mapper job is designed
to perform the next two steps of IE Tokenization and Gazetteer Lookup. Since
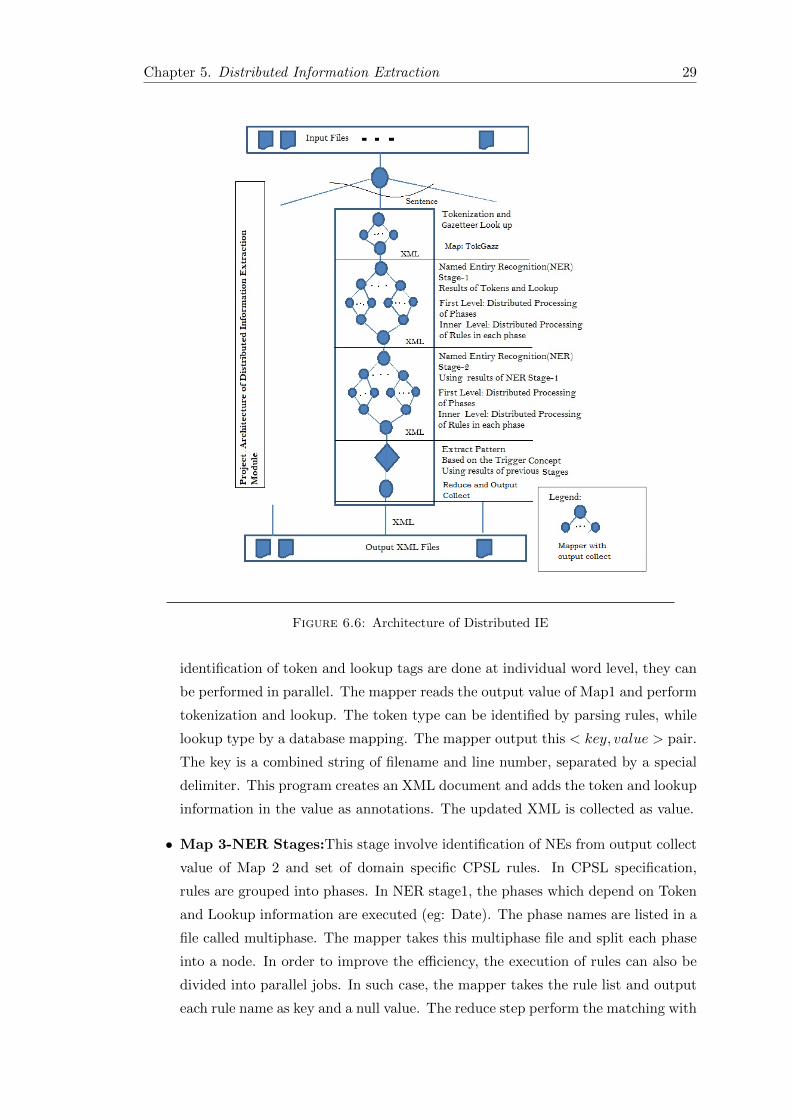
Chapter 5. Distributed Information Extraction 29
Figure 6.6: Architecture of Distributed IE
identification of token and lookup tags are done at individual word level, they can
be performed in parallel. The mapper reads the output value of Map1 and perform
tokenization and lookup. The token type can be identified by parsing rules, while
lookup type by a database mapping. The mapper output this < key, value > pair.
The key is a combined string of filename and line number, separated by a special
delimiter. This program creates an XML document and adds the token and lookup
information in the value as annotations. The updated XML is collected as value.
• Map 3-NER Stages:This stage involve identification of NEs from output collect
value of Map 2 and set of domain specific CPSL rules. In CPSL specification,
rules are grouped into phases. In NER stage1, the phases which depend on Token
and Lookup information are executed (eg: Date). The phase names are listed in a
file called multiphase. The mapper takes this multiphase file and split each phase
into a node. In order to improve the efficiency, the execution of rules can also be
divided into parallel jobs. In such case, the mapper takes the rule list and output
each rule name as key and a null value. The reduce step perform the matching with

Chapter 5. Distributed Information Extraction 30
lhs terms and if a match occur, add the pattern into the XML file as annotation.
The output collector maintains the key of previous mapper and value is the XML
file with NE chunks as additional information. The stage 1 identifies NEs which
depends on token and lookup information. NER stage 2 can be added as similar
to stage 1, with rules which take token, lookup and NER stage1 information . The
number of stages in NER can be further added, based on the dependency among
rules.
• Map 4-Short Circuiting Pattern Extraction: The final mapper in this archi-
tecture, will do the extraction of pattern relations from the input. The patterns
are represented in CPSL, and matching is performed as in NER. In most cases,
the pattern extraction involve the identification of an event, and the entities re-
lationship with that event. The preparation of pattern extraction rules need the
knowledge of the domain. It has to be represented as an hierarchical structure.
Since all rules have to be checked to find the longest matching pattern, rule based
extraction may become time consuming. In order to overcome this circumspec-
tion, the current architecture uses a short circuiting method. The adoption of such
heuristic method is based on the observation that, in most cases an event can be
identified by some clue words called trigger. The short circuiting method fires the
rule which contain the trigger. The use of heuristic approach results in significant
improvement over time complexity, by avoiding unnecessary rule firing. The final
XML structure is written as output value of this mapper class.
• Reduce: The reduce step combine values of same key into a single document.
This step combines the the XML of different lines of same file. The file name will
be the key and combined XML structure will be the value for this job.
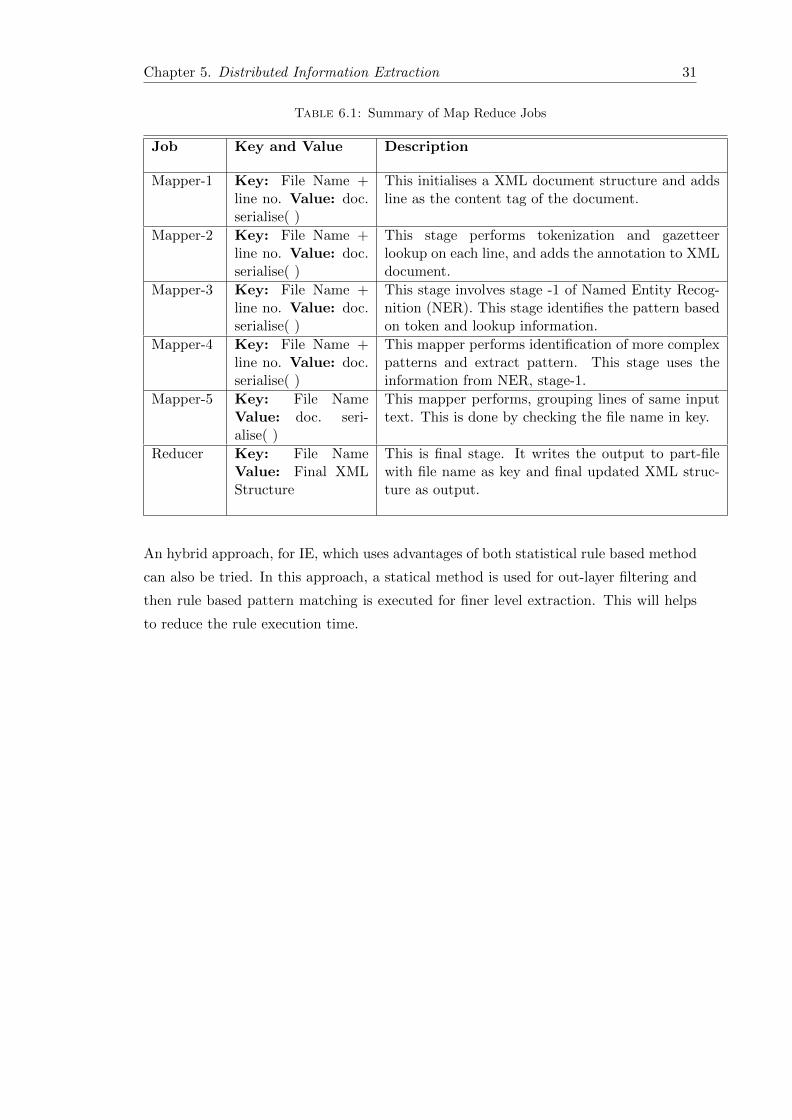
The design of Map Reduce architecture is summarized in Table 6.1.
6.3 Notion of Statistical IE
Statistical IE [28] modules are prepared by many organizations, viz. StanfordCoreNLP[44],
NLTK [6]. For preparing such a module, large collections of tagged corpus is required
These large amount of raw data could be extracted from open source domains like
newspaper archives, web snapshots, biomedical literature archives, Wall Street Jour-
nals, Brown Corpus etc. In some domains (eg. defence) its very difficult to get large
corpus, as there are no standard way of writing it. In that case, getting into statistical
approach will result in decrease in efficiency. For domain specific IE, if there are no
corpus available then rule based IE can outperform statistical IE.
Chapter 5. Distributed Information Extraction 31
Table 6.1: Summary of Map Reduce Jobs
Job Key and Value Description
Mapper-1 Key: File Name +line no. Value: doc.serialise( )
This initialises a XML document structure and addsline as the content tag of the document.
Mapper-2 Key: File Name +line no. Value: doc.serialise( )
This stage performs tokenization and gazetteerlookup on each line, and adds the annotation to XMLdocument.
Mapper-3 Key: File Name +line no. Value: doc.serialise( )
This stage involves stage -1 of Named Entity Recog-nition (NER). This stage identifies the pattern basedon token and lookup information.
Mapper-4 Key: File Name +line no. Value: doc.serialise( )
This mapper performs identification of more complexpatterns and extract pattern. This stage uses theinformation from NER, stage-1.
Mapper-5 Key: File NameValue: doc. seri-alise( )
This mapper performs, grouping lines of same inputtext. This is done by checking the file name in key.
Reducer Key: File NameValue: Final XMLStructure
This is final stage. It writes the output to part-filewith file name as key and final updated XML struc-ture as output.
An hybrid approach, for IE, which uses advantages of both statistical rule based method
can also be tried. In this approach, a statical method is used for out-layer filtering and
then rule based pattern matching is executed for finer level extraction. This will helps
to reduce the rule execution time.

Chapter 7
Ontology Processing
This chapter describes about ontology processing techniques. In computer science and
information science, an ontology formally represents knowledge as a set of concepts
within a domain, and the relationships between pairs of concepts. It can be used to
model a domain and support reasoning about concepts. Section 7.1 helps to understand
how to build a base ontology for specific domains. Section 7.2 suggests ways to populate
the base ontology, the extracted information from IE module are populated to the base
ontology and finally Section 7.4 tries to connect locally made ontology with globally
available ontologies.
7.1 Building Base Ontology
Building base Ontology requires complete understanding of the domain for which ontol-
ogy has to be made. This process can be explained with Example 7.1, an extract from
Wikipedia article about Sachin Tendulkar.
Example 7.1. Tendulkar was born at Nirmal Nursing Home on 24 April 1973.
His father Ramesh Tendulkar was a reputed Marathi novelist and his mother
Rajni worked in the insurance industry. On 14 November 1987, Tendulkar was
selected to represent Mumbai in the Ranji Trophy. A year later, on 11
December 1988, aged just 15 years and 232 days, Tendulkar made his debut for
Mumbai against Gujarat at home and scored 100 not out in that matchmaking
him the youngest Indian to score a century on first-class debut.
In this example, birth, debut, and match are three events. The birth event has, per-
son, date and location as entities and are related to the event by relations hasPerson,
32

Chapter 7. Ontology Processing 33
hasDateOfBirth and hasLocation respectively. The ontology is represented in web on-
tology language (OWL)[45], a world wide web consortium (W3C) standard for semantic
web representation. In OWL, the events and entities are represented as classes and the
relations are called properties. OWL provide many features to add semantics to the
ontology. For example, a property can be defined as inverse of another property. In
our running example, we can define a property hasPerson, which relate an event to the
person with hasperson property. Then a property hasEvent can be defined as inverse
of hasPerson, which relates the person to event class. The classes and properties can
be arranged in hierarchy, by adding sub-class, super-class relations. When a reasoner is
enabled, it can infer the implicit relations existing between the entities. A sample base
ontology structure is shown in fig 7.1.
Figure 7.1: Base Ontology.
While implementing this base structure using Jena , the ontology graph is referred as
model object[34]. Then there have methods which create ontology classes (OWL Classes)
and add to the the ontology. A sample code snippet is given below:
Model model=ModelFactory.createDefaultModel();
OntClass Person=model.addClass(“PERSON”);
OntClass Event=model.addClass(“EVENT”);
OntClass Birth=model.addClass(“BIRTH”);

Chapter 7. Ontology Processing 34
Event.addSubClass(Birth);
ObjectProperty hasBirthDate =
model.addObjectTypeProperty(“hasBirthDate”);
hasBirthDate.addDomain(Event);
hasBirthDate.addRange(Date);
The corresponding OWL representation will is given in figure 7.2 and 7.3.
Figure 7.2: OWL Representation of Base Ontology.
Figure 7.3: OWL Representation of Properties.
7.2 Populating base ontology
When the information extraction is completed, the next step is storing the information
into knowledge base. The information is added as instance of ontology classes. The Jena
provides the methods to add individuals to ontology. The labels given to the chunks
will help to identify the base class and the value is added as the individual to that class.

Chapter 7. Ontology Processing 35
For example, consider the first line in our running example, ”Tendulkar was born at
Nirmal Nursing Home on 24 April 1973”. IE step will identify this as a birth event,
with Nirmal Nursing Home as location and 24 April 1973 as date. Then class birth is
selected from ontology and the properties hasPerson, hasLocaion and hasBirthDate will
be populated with Tendulkar, Nirmal Nursing Home, 24 April 1973 respectively. So the
resulting triples after populating to base ontology will have triples like:
< Tendulkar was born at Nirmal Nursing Home on 24 April 1973
hasBirthDate 24 April 1973 >
< Tendulkar was born at Nirmal Nursing Home on 24 April 1973
hasPerson Tendulkar >
< Tendulkar was born at Nirmal Nursing Home on 24 April 1973
hasLocation Nirmal Nursing Home >
The OWL representation of populated ontology is shown in figure 7.4
Figure 7.4: OWL Representation of Populated ontology.
7.3 Persistent Ontology Storage
The challenge in the ontology based data model is to provide a scalable and efficient
persistent storage scheme. The simplest way to store RDF triples comprises of a rela-
tion/table consisting of three columns (one each for subjects, predicates and objects).
However, this approach suffers from lack of scalability and abridged query performance,
as the single table becomes long and narrow with increase in the number of RDF triples.
The recent increase in the NoSQL (eg. graph) database is a positive move regarding this
issue. In our work, Neo4j [40], a popular open source NoSQL graph database is used
for scalable persistent ontology storage. Since social networks can be easily modeled
as one large graph of interconnected users, they can be the killer application for graph
databases.

Chapter 7. Ontology Processing 36
In Neo4j, both nodes and relationships can contain properties. A relationship connects
two nodes, and is guaranteed to have valid start and end nodes. Traversing a graph
means visiting its nodes, following relationships according to some rules. As ontology
itself a graph, mapping it into a graph database will be an added benefit. In this storage
schema, both subject and object of a triplet is represented as nodes. The predicate
in this triplet is represented by relation. Since each node and relation have unique
ids, the inter relations between the nodes can be easily infer [22]. Friend of A Friend
(FOAF) relations can easily infer from this representation. The Neo4j implementation
also supports usage of graph algorithms like shortest path detection, berth first search,
etc [17].
7.4 Reusing Existing ontology
It is almost always worth considering what someone else has done and checking if we
can refine and extend existing sources for our particular domain and task. Reusing
existing ontologies may be a requirement if our system needs to interact with other
applications that have already committed to particular ontologies or controlled vocabu-
laries [30]. Many ontologies are already available in electronic form and can be imported
into an ontology-development environment that you are using. The formalism in which
an ontology is expressed often does not matter, since many knowledge-representation
systems can import and export ontologies. Even if a knowledge-representation system
cannot work directly with a particular formalism, the task of translating an ontology
from one formalism to another is usually not a difficult one. There are libraries of
reusable ontologies on the Web and in the literature. For example, we can use the
Ontolingua ontology library http://www.ksl.stanford.edu/software/ontolingua/ or the
DAML ontology library http://www.daml.org/ontologies/. There are also a number of
publicly available commercial ontologies (e.g., UNSPSC www.unspsc.org, RosettaNet
www.rosettanet.org, DMOZ www.dmoz.org.
7.4.1 DBpedia
DBpedia [36] is a community efort to extract structured information from Wikipedia and
to make this information available on the Web. DBpedia allows you to ask sophisticated
queries against datasets derived from Wikipedia and to link other datasets on the Web to
Wikipedia data. Extraction of the DBpedia datasets, and how the resulting information
is published on the Web for human and machine consumption are described in paper
[4].

Chapter 7. Ontology Processing 37
Figure 7.5: Overview of the DBpedia components.
The DBpedia dataset currently provides information about more than 1.95 million
“things”, including at least 80,000 persons, 70,000 places, 35,000 music albums, 12,000
lms. It contains 657,000 links to images, 1,600,000 links to relevant external web pages,
180,000 external links into other RDF datasets, 207,000 Wikipedia categories and 75,000
YAGO categories. DBpedia concepts are described by short and long abstracts in 13
diferent languages. These abstracts have been extracted from the English, German,
French, Spanish, Italian, Portuguese, Polish, Swedish, Dutch, Japanese, Chinese, Rus-
sian, Finnish and Norwegian versions of Wikipedia. Altogether the DBpedia dataset
consists of around 103 million RDF triples. The dataset is provided for download as a
set of smaller RDF files.
7.4.2 GeoNames Ontology
The GeoNames [38] Ontology makes it possible to add geospatial semantic information to
the Word Wide Web. All over 8.3 million geonames toponyms now have a unique URL
with a corresponding RDF web service. Other services describe the relation between
toponyms. The Ontology for GeoNames is available in OWL:
http://www.geonames.org/ontology/ontology v3.1.rdf.

Chapter 7. Ontology Processing 38
In http://www.w3.org/2005/Incubator/geo/XGR-geo-ont-20071023/ an overview and
description of geospatial foundation ontologies to represent geospatial concepts and
properties for use on the Worldwide Web. Geospatial Feature ontology provide
formal representation of ISO and OGC standards for feature discernment (General Fea-
ture Model or GFM). The GFM is the general model of which the geo vocabulary has
been developed as a very restricted subset. While the latter can adequately represent a
large proportion of Web resource, many important applications such as routing, earth
observation, and imagery interpretation require a more complete representation. Sub-
ontologies of the Feature Ontology included cover geometries, coverages (primarily
rasters and grids), and observations. Several draft translations of relevant ISO and
OGC standards into OWL ontologies are found at http://loki.cae.drexel.edu/ wbs/on-
tology/list.htm
7.4.3 Freebase
Freebase [37] is a large collaborative knowledge base consisting of metadata composed
mainly by its community members. It is an online collection of structured data harvested
from many sources, including individual ‘wiki’ contributions. Freebase aims to create a
global resource which allows people (and machines) to access common information more
effectively. It was developed by the American software company Metaweb and has been
running publicly since March 2007. Metaweb was later acquired by Google.
7.4.4 BabelNet
BabelNet[35] is a multilingual lexicalized semantic network and ontology. BabelNet
was automatically created by linking the largest multilingual Web encyclopedia i.e.
Wikipedia to the most popular computational lexicon of the English language i.e.
WordNet. The integration is performed by means of an automatic mapping and by filling
in lexical gaps in resource-poor languages with the aid of statistical machine translation.
The result is an “encyclopedic dictionary” that provides concepts and named entities
lexicalized in many languages and connected with large amounts of semantic relations.
Similarly to WordNet, BabelNet groups words in different languages into sets of syn-
onyms, called Babel synsets. For each Babel synset, BabelNet provides short definitions
(called glosses) in many languages harvested from both WordNet and Wikipedia.
Other ontologies like wikidata, YAGO are also widely used.

Chapter 8
Natural Language Generation
The storage of extracted information in the form of ontology is discussed in Chapter 7.
The representation of the knowledge in OWL/RDF makes it readable to machine. A
user and even a domain expert find it difficult to handle this kind of domain descriptions,
due to the lack of good interface. The use of graphical interfaces are a solution, which
is too domain specific and less flexible to adapt in different domain. A more intelligent
solution is the use of Natural Language interface. The NL interface will allow the users
to access the knowledge base using queries in NL. The system will use natural language
understanding (NLU) techniques to analyze the query and produce answers on NL using
natural language generation (NLG).
NLG as described in Section 3.4, takes structured data in a knowledge base as input and
produces natural language text, tailored to the presentational context and the target
reader as output. In the context of knowledge management, NLG can be applied to
provide automated documentation of ontologies and knowledge bases. It has been argued
that ontologies contain linguistically interesting patterns in choice of the words they use
for representing knowledge and this in itself makes the task of mapping from ontologies
to natural language easier. There are many approaches are used in NLG research. One
generalized method is explained here. Use of more thematic informations like Panini’s
Karaka relations will give more linguistically intelligent system performances.
8.1 NLG from Ontology
NLG from ontology is a less attempted field in Computational Linguistics. In this task,
the ontology acts as a source of information to the NLG system. The conceptualization
of domain in the form of ontology In this approach, an ontology is considered as a formal
39

Chapter 8. NLG from Ontology 40
knowledge repository which can be utilized as a resource for NLG tasks. The objective,
then, is to generate a linguistically interesting and relevant descriptive text summarizing
parts or all of the concisely encoded knowledge within the given ontology. The logically
structured manner of knowledge organization within an ontology enables to perform
reasoning tasks like Consistency checking, Concept Satisfiability, Concept Subsumption
and Instance Checking. These types of logical inferencing actions will motivate us in
proposing a set of Natural Language based questions which can be asked. NLG, in turn,
will be applied to derive descriptive texts as answers to such queries. This will eventually
help us in implementing a simple natural language based Question Answering system
guided by robust NLG techniques that act upon ontologies [16].
In this work, the NLG is used to query the knowledge base and prepare the answers
in natural language. The input is a natural language query, seeking information from
ontology. The query is analyzed to identify the key terms, which maps to the concepts
in the ontology. In order to perform query analysis, the query is processed with IE
pipeline activities and the extracted entities are represented in XML structure. The
NLG system prepare the answer and produce the answers. The NLG can also used to
generate summary reports for the query event.
Similar to the architecture discussed in previous section, NLG from ontology involves
the following steps:
1. Analyzing Query
2. Extracting the knowledge from Ontology
3. Document Planning
4. Micro Planning
5. Reasoning
8.1.1 Analyzing Query
The query will be a sentence is natural language. In query analysis, the input query
undergoes different stages in IE, as detailed in chapter 4, and possible entities and rela-
tions are recognized. The important step in query analysis is identification of question
type, which decide the nature of answer to be generated. This identification use some
empirical results, from human experience. For example. a query containing question
term where will expect a location name as answer. Some of the observation on question
term is collected in Table 8.1. Consider a sentence Tendulkar was born at Nirmal Nurs-

Chapter 8. NLG from Ontology 41
Table 8.1: Classification of Questions and Answers
Question Term Answer Type
What did you buy? [THING]Where is my coat? [PLACE]Where did they go? [PLACE]What happened next? [EVENT]How did you cook the eggs? [MANNER]
ing Home on 24 Aug 1974. This sentence is stored in ontology, as properties of birth
event, with Tendulkar–Person, Nirmal Nursing Home–Place and 24 Aug 1974–date of
event. when a query, where was Tendulkar born? is asked to knowledge base, it perform
IE steps on the question sentence, and following details will be identified.
Tendulkar : Person
born =⇒ birth : Event
where =⇒ Type: Location
8.1.2 Extracting the knowledge from Ontology
The input to the NLG system comes from the knowledge base, stored in the form of
ontology. The purpose in this stage is to extract axioms from the OWL representation.
The query analysis will identify the entities and related concepts. The selection of axioms
corresponding to the extracted concepts is achieved by executing a SPARQL query [43].
SPARQL can be used to express queries across diverse data sources, whether the data is
stored natively as RDF or viewed as RDF via middleware. t was made a standard by the
RDF Data Access Working Group (DAWG) of the World Wide Web Consortium (W3C),
and is recognized as one of the key technologies of the semantic web. For example, the
NL query in the current sentence can be represented in SPARQL specification as:
SELECT ?loc
WHERE {?x hasEvent Birth
?x hasPerson Tendulkar
?x hasLocation ?loc }The results of SPARQL queries can be results sets. In this example, the query engine
extract the list of locations, associated with birth event, where Tendulkar related to that
event by hasPerson relation. This result give Nirmal Nursing Home as result.

Chapter 8. NLG from Ontology 42
8.1.3 Document Planning
The task of document planner is to determine what to say and how to say. These are
achieved through two subtasks- content determination and document structuring. The
input to this stage is set of axioms from the ontology, and output will be a text (doc-
ument) plan. Generally, the message creation process largely consists of filtering and
summarizing input data, and the messages created are expressed in some formal lan-
guage that labels and distinguishes the entities, concepts and relations in the domain.
The text plan for answering the example question can be represented as follows [16]:
[ Subject : Tendulkar
Event : Birth
Location : Niramal Nursing Home]
The text plan should consider the rhetoric relations between the message units, thematic
roles and pragmatic and discourse structure.
8.1.4 Micro Planning
This step involves lexical selection, sentence aggregation and referring expressions. Dur-
ing the lexicalization phase, identify the lexical items that will help us in mapping the
factual knowledge within each category of OWL axioms to natural language text. In this
approach lexicalization is carried out in two phases- pre-lexicalization and lexicalization
proper. In the Pre-Lexicalization stage,an initial plan of sentence structure is prepared.
It also made a preliminary choice of lexical items for each category of the statements.
Aggregation is the task of grouping two or more simple structures to generate a single
sentence, a frequent phenomenon in natural languages. There has been lot of works in
aggregation, which concentrate on syntactic level.
8.1.5 Reasoning
Realization is the task of generating actual natural language sentences from the inter-
mediary (syntactic) representations obtained during the Micro Planning phase. For a
NLG developer, a number of general purpose realization modules are available to achieve
such functionality. SimpleNLG [2] has java classes which allow a programmer to specify
the content (such as Subject, Verb, Object, Modifiers, Tense, Preposition phrase etc) of
a sentence by setting values to the attributes in the classes. Once such attributes are
set, methods can be executed to generate output sentences; the package takes care of
the linguistic transformations and ensures grammatically well formed sentences. In our

Chapter 8. NLG from Ontology 43
current example, the reasoned output will be Tendulkar was born on Nirmal Nursing
Home.
8.2 Other Applications of NLG
Besides question answering, some other application of NLG have been tried by NLG
communities. One such application is generation of natural language description of OWL
statements. The goal of such systems are to generate natural language texts from class
definitions in an OWL ontology that serve as a description of the class. NaturalOWL[12]
an open-source natural language generation engine that produces descriptions of entities
and classes in English and Greek from OWL ontologies that have been annotated with
linguistic and user modeling information expressed in RDF . An accompanying plug-in
for the well known Protege ontology editor is available, which can be used to create the
linguistic and user modeling annotations while editing an ontology, as well as to generate
previews of the resulting texts by invoking the generation engine. An example is shown
fig. 8.1 [13].
Figure 8.1: NaturalOWL’s Protege plug-in
Another application of NLG is ontology based summarization. In this application, NLG
is used to generate the textual summaries from ontology. This also involves the steps
discussed in section 3.4.

Chapter 8. NLG from Ontology 44
8.3 NLIDB
In the systems, which are running on traditional databases can still modified with NL
interfaces. The purpose of Natural language Interface to Database System is to accept
requests in English or any other natural language and attempts to understand them
or we can say that Natural language interfaces to databases (NLIDB) are systems that
translate a natural language sentence into a database query [23]. Anyone can gather
information from the database by using such systems .Additionally, it may change our
perception about the information in a database. Traditionally, people are used to work-
ing with a form; their expectations depend heavily on the capabilities of the form.
NLIDB makes the entire approach more flexible, therefore will maximize the use of a
database.

Chapter 9
Results and Observations
This chapter reports an analysis of the performances of the proposed system. Section
9.1 reports some technical characteristics of the environment in which we conducted the
tests. Section 9.2 reports the performances obtained and an evaluation of them.
9.1 Experimental Settings
For the evaluation of the program, a cluster is setted up in CAIR, with one master node
(Intel Core2 duo )and two slave nodes (Pentium 4) . The programs that were developed
are written in Java 1.6 and they use the 0.20.0 version of Hadoop. The experiment is
carried out by running the program for different size of documents, ranges from 400 to
25000. Preparation of data set is purely random and unbiased. As mentioned earlier,
the testing was was done on a confidential business information, and so the features on
the contents cannot be disclosed.
9.2 Distributed IE
The calculation of running time of distributed IE is dome by running the program for
different datasets. The total time taken to prepare the final XML document is taken
as the running time for that datasets. The results obtained by running the program on
three node clusters is shown in Table 9.1.
In Table 9.1, the ratio of input to output size, shows the amount of information added
by the system. The rate of increase of the running time is linear for the small data
sets, but behaves non-linearly for large data sets. While the experiment calculated
the running time in undistributed IE (in native java), the running time is better than
45
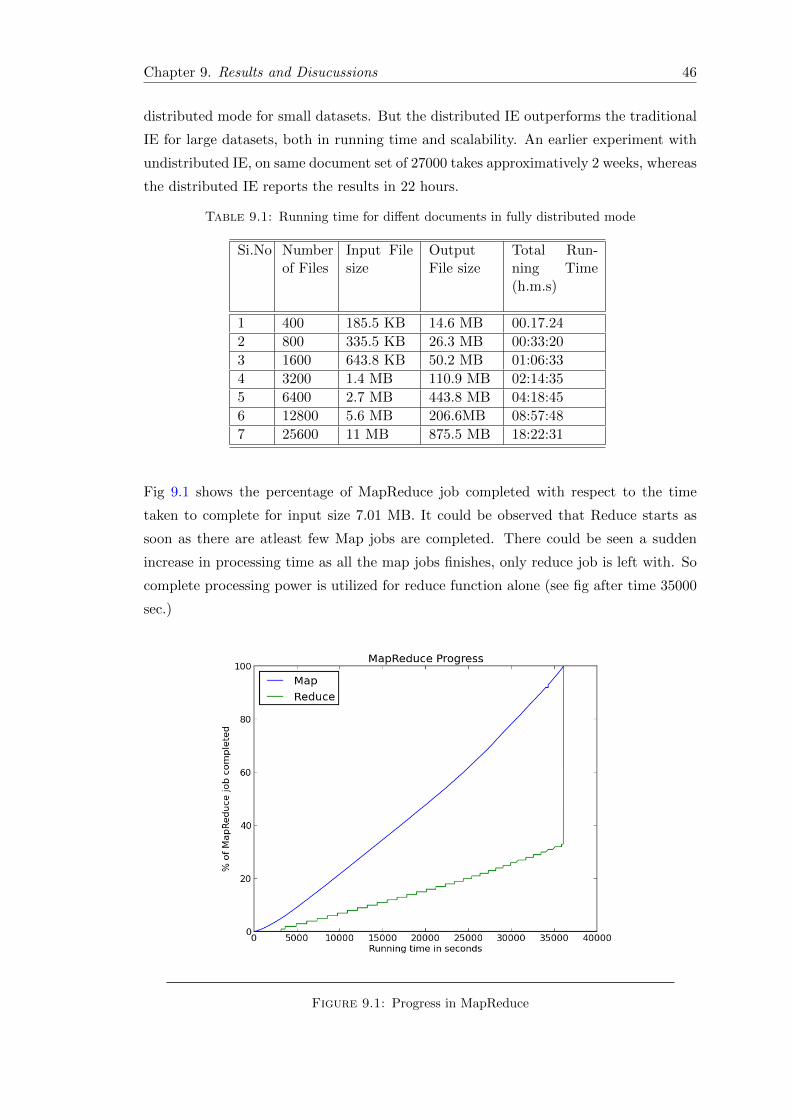
Chapter 9. Results and Disucussions 46
distributed mode for small datasets. But the distributed IE outperforms the traditional
IE for large datasets, both in running time and scalability. An earlier experiment with
undistributed IE, on same document set of 27000 takes approximatively 2 weeks, whereas
the distributed IE reports the results in 22 hours.
Table 9.1: Running time for diffent documents in fully distributed mode
Si.No Numberof Files
Input Filesize
OutputFile size
Total Run-ning Time(h.m.s)
1 400 185.5 KB 14.6 MB 00.17.24
2 800 335.5 KB 26.3 MB 00:33:20
3 1600 643.8 KB 50.2 MB 01:06:33
4 3200 1.4 MB 110.9 MB 02:14:35
5 6400 2.7 MB 443.8 MB 04:18:45
6 12800 5.6 MB 206.6MB 08:57:48
7 25600 11 MB 875.5 MB 18:22:31
Fig 9.1 shows the percentage of MapReduce job completed with respect to the time
taken to complete for input size 7.01 MB. It could be observed that Reduce starts as
soon as there are atleast few Map jobs are completed. There could be seen a sudden
increase in processing time as all the map jobs finishes, only reduce job is left with. So
complete processing power is utilized for reduce function alone (see fig after time 35000
sec.)
Figure 9.1: Progress in MapReduce

Chapter 9. Results and Disucussions 47
The scope of statistical IE is tried to reduce the dependency on rules. But, the results
were poor compared to the rule based IE. This findings leads an important observation
that, for a closed domain (like defence, where the documents are unstructured and
significantly varies from each other), rule based systems are best suit to define the
named entities.
The short circuiting method for rule execution (in sentence extraction step), is effective
in reducing the time complexity by avoiding execution of unnecessary rules.

Chapter 10
Conclusion and Future Works
This thesis is an attempt to designing an end to end system for natural language report
management. The three problems, this thesis addresses are, information extraction,
knowledge management and scalability with big data analysis. The solutions proposed
in this work are use of distributed computing power for information extraction and
scalable storage schemas. This include the works in three major areas Information
extraction, Ontology based Knowledge management and Natural Language Genearation.
Its impractical to do information extraction of large collection of natural language texts
in a single machine. Based on the result it could be seen that while using Hadoop itself
the time required to process is more. Hadoop does this job by Map/Reduce paradigm.
Ordinary Native implementation with out using distribution will take huge time. Usage
of distributed computing is really useful for processing Natural Language Texts.
The Jena API is used for Ontology creation and processng. The resultant triples are
stored in Neo4j. Use of Neo4j really makes the storage scalable. Graph Databases have
other features like finding shortest path between one node and another, finding relations
between nodes could be analysed. A template based NLG, for a small set of concept
is attempted in this project. This have to be extended in future with dynamic query
processing and better Natural Language interface. The use of tools like NaturalOwl,
will be another addition in this work.
The work can be further extended with hybrid approach for IE. Statistical methods like
Conditional Random Field (CRF) and Marginal Induced Relaxed Algorithm (MIRA)
can be used along with domain rules, to accelerate the performance of IE. The XML
structure can be replaced with lightweight JSON objects, which are widely used in
current technologies.
48

Appendix A
Setting up Hadoop Cluster
A.1 Prerequisites
• Hadoop requires Java 1.6 or above.
• Download latest version of Hadoop from http://hadoop.apache.org/
user@ubuntu:# java -version
java version ‘‘1.6.0 20’’
Java(TM) SE Runtime Environment (build 1.6.0 20-b02)
Java HotSpot(TM) Client VM (build 16.3-b01, mixed mode, sharing)
Use a dedicated Hadoop user account for running Hadoop.
$ sudo addgroup hadoop
$ sudo adduser --ingroup hadoop hduser
Configure SSH
Hadoop requires SSH access to manage its nodes, i.e. remote machines plus your local
machine if you want to use Hadoop on it (which is what we want to do in this short
tutorial).
user@ubuntu:$ su - hduser
hduser@ubuntu: $ ssh-keygen -t rsa -P ‘‘’’
Generating public/private rsa key pair.
Enter file in which to save the key (/home/hduser/.ssh/id rsa):
Created directory ‘/home/hduser/.ssh’.
Your identification has been saved in /home/hduser/.ssh/id rsa.
Your public key has been saved in /home/hduser/.ssh/id rsa.pub.
The key fingerprint is:
9b:82:ea:58:b4:e0:35:d7:ff:19:66:a6:ef:ae:0e:d2 hduser@ubuntu
49

Appendix A. Setting up Hadoop Cluster 50
The key’s randomart image is:
hduser@ubuntu:$
hduser@ubuntu:$ cat $HOME/.ssh/id rsa.pub >> $HOME/.ssh/authorized keys
hduser@ubuntu:$ ssh localhost
The authenticity of host ‘localhost (::1)’ can’t be established.
RSA key fingerprint is d7:87:25:47:ae:02:00:eb:1d:75:4f:bb:44:f9:36:26.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added ‘localhost’ (RSA) to the list of known hosts.
Linux ubuntu 2.6.32-22-generic #33-Ubuntu SMP Wed Apr 28 13:27:30 UTC 2010
i686 GNU/Linux
Ubuntu 10.04 LTS
hduser@ubuntu:$
Disabling IPv6
One problem with IPv6 on Ubuntu is that using 0.0.0.0 for the various networking-related
Hadoop configuration options will result in Hadoop binding to the IPv6 addresses of my
Ubuntu box.
To disable IPv6 on Ubuntu 10.04 LTS, open /etc/sysctl.conf in the editor of your
choice and add the following lines to the end of the file:
# disable ipv6
net.ipv6.conf.all.disable ipv6 = 1
net.ipv6.conf.default.disable ipv6 = 1
net.ipv6.conf.lo.disable ipv6 = 1
You can check whether IPv6 is enabled on your machine with the following command:
$ cat /proc/sys/net/ipv6/conf/all/disable ipv6
A return value of 0 means IPv6 is enabled, a value of 1 means disabled (thats what we
want).
Extract the contents of the Hadoop package to a location of your choice. I picked
/usr/local/hadoop.
$ cd /usr/local
$ sudo tar xzf hadoop-1.0.3.tar.gz
$ sudo mv hadoop-1.0.3 hadoop
$ sudo chown -R hduser:hadoop hadoop
Single-node setup of Hadoop Configuration
The only required environment variable we have to configure for Hadoop in is JAVA HOME.
Open conf/hadoop-env.sh in the editor of your choice (if you used the installation path
in this tutorial, the full path is /usr/local/hadoop/conf/hadoop-env.sh) and set the
JAVA HOME environment variable to the Sun JDK/JRE 6 directory.

Appendix A. Setting up Hadoop Cluster 51
export JAVA HOME=/usr/lib/jvm/java-6-sun
conf/*-site.xml
In this section, we will configure the directory where Hadoop will store its data files, the
network ports it listens to, etc. Our setup will use Hadoops Distributed File System,
HDFS, even though our little “cluster” only contains our single local machine.
$ sudo mkdir -p /app/hadoop/tmp
$ sudo chown hduser:hadoop /app/hadoop/tmp
# ...and if you want to tighten up security, chmod from 755 to 750 ...
$ sudo chmod 750 /app/hadoop/tmp
• In file conf/core-site.xml:
<property>
<name>hadoop.tmp.dir</name>
<value>/app/hadoop/tmp</value>
<description>A base for other temporary directories.</description>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:54310</value>
<description>The name of the default file system. A URI whose scheme
and authority determine the FileSystem implementation. The uri’s scheme
determines the config property (fs.SCHEME.impl) naming the FileSystem
implementation class. The uri’s authority is
used to determine the host, port, etc. for a filesystem.</description>
</property>
• In file conf/mapred-site.xml:
<property>
<name>mapred.job.tracker</name>
<value>localhost:54311</value>
<description>The host and port that the MapReduce job tracker runs
at. If ‘‘local’’, then jobs are run in-process as a single map
and reduce task.
</description>

Appendix A. Setting up Hadoop Cluster 52
</property>
• In file conf/hdfs-site.xml:
<property>
<name>dfs.replication</name>
<value>1</value>
<description>Default block replication.
The actual number of replications can be specified when the file
is created.
The default is used if replication is not specified in create time.
</description>
</property>
Formatting the HDFS filesystem via the NameNode: The first step to starting up your
Hadoop installation is formatting the Hadoop filesystem which is implemented on top
of the local filesystem of your “cluster”.
hduser@ubuntu:$ /usr/local/hadoop/bin/hadoop namenode -format
hduser@ubuntu:/usr/local/hadoop$ bin/hadoop namenode -format
10/05/08 16:59:56 INFO namenode.NameNode: STARTUP MSG:
/************************************************************
STARTUP MSG: Starting NameNode
STARTUP MSG: host = ubuntu/
127.0.1.1
STARTUP MSG: args = [-format]
STARTUP MSG: version = 0.20.2
STARTUP MSG: build = https:
//svn.apache.org/repos/asf/hadoop/common/
branches/branch-0.20 -r 911707; compiled by ‘chrisdo’ on Fri Feb 19 08:07:34
UTC 2010 ************************************************************/
10/05/08 16:59:56 INFO namenode.FSNamesystem: fsOwner=hduser,hadoop
10/05/08 16:59:56 INFO namenode.FSNamesystem: supergroup=supergroup
10/05/08 16:59:56 INFO namenode.FSNamesystem: isPermissionEnabled=true
10/05/08 16:59:56 INFO common.Storage: Image file of size 96 saved in 0
seconds.
10/05/08 16:59:57 INFO common.Storage: Storage directory .../
hadoop-hduser/dfs/name has been successfully formatted.
10/05/08 16:59:57 INFO namenode.NameNode: SHUTDOWN MSG:

Appendix A. Setting up Hadoop Cluster 53
/************************************************************
SHUTDOWN MSG: Shutting down NameNode at ubuntu/127.0.1.1
************************************************************/
hduser@ubuntu:/usr/local/hadoop$
Run the command:
hduser@ubuntu:$ /usr/local/hadoop/bin/start-all.sh
hduser@ubuntu:/usr/local/hadoop$ bin/start-all.sh
hduser@ubuntu:/usr/local/hadoop$
hduser@ubuntu:/usr/local/hadoop$ jps
2287 TaskTracker
2149 JobTracker
1938 DataNode
2085 SecondaryNameNode
2349 Jps
1788 NameNode
Running Hadoop in Multinode Cluster can be done by following this link Setup Hadoop
Multinode Cluster .
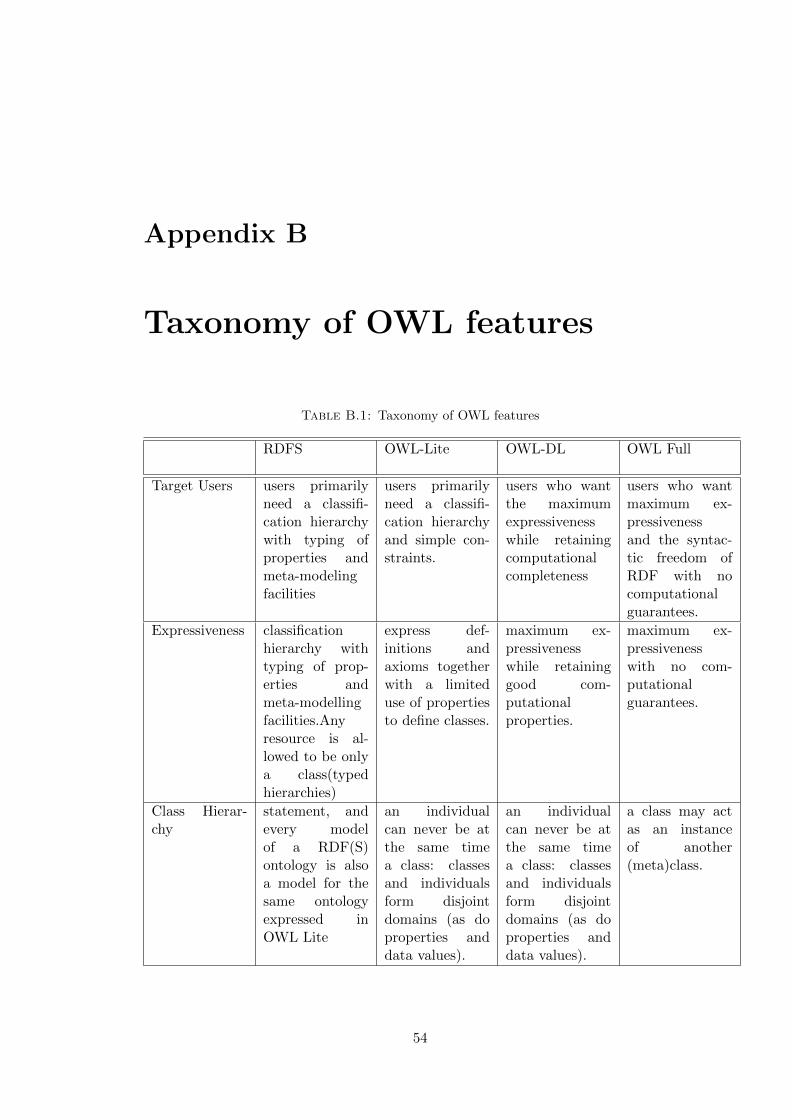
Appendix B
Taxonomy of OWL features
Table B.1: Taxonomy of OWL features
RDFS OWL-Lite OWL-DL OWL Full
Target Users users primarilyneed a classifi-cation hierarchywith typing ofproperties andmeta-modelingfacilities
users primarilyneed a classifi-cation hierarchyand simple con-straints.
users who wantthe maximumexpressivenesswhile retainingcomputationalcompleteness
users who wantmaximum ex-pressivenessand the syntac-tic freedom ofRDF with nocomputationalguarantees.
Expressiveness classificationhierarchy withtyping of prop-erties andmeta-modellingfacilities.Anyresource is al-lowed to be onlya class(typedhierarchies)
express def-initions andaxioms togetherwith a limiteduse of propertiesto define classes.
maximum ex-pressivenesswhile retaininggood com-putationalproperties.
maximum ex-pressivenesswith no com-putationalguarantees.
Class Hierar-chy
statement, andevery modelof a RDF(S)ontology is alsoa model for thesame ontologyexpressed inOWL Lite
an individualcan never be atthe same timea class: classesand individualsform disjointdomains (as doproperties anddata values).
an individualcan never be atthe same timea class: classesand individualsform disjointdomains (as doproperties anddata values).
a class may actas an instanceof another(meta)class.
54
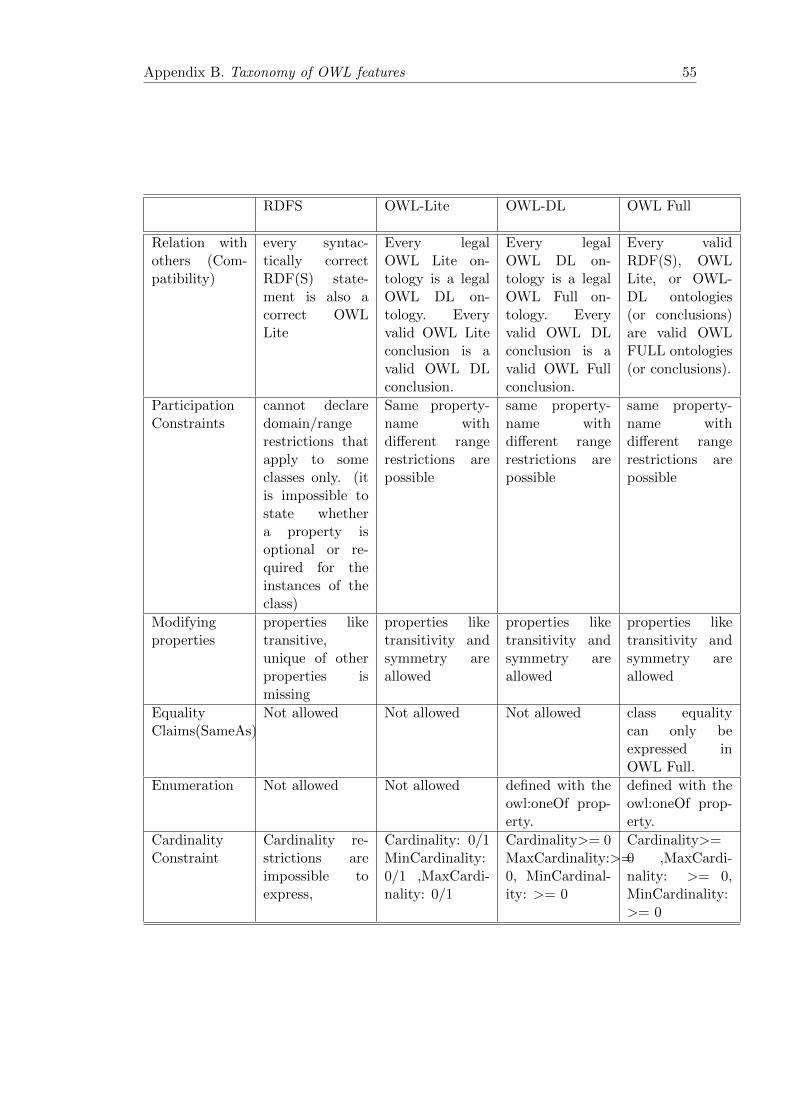
Appendix B. Taxonomy of OWL features 55
RDFS OWL-Lite OWL-DL OWL Full
Relation withothers (Com-patibility)
every syntac-tically correctRDF(S) state-ment is also acorrect OWLLite
Every legalOWL Lite on-tology is a legalOWL DL on-tology. Everyvalid OWL Liteconclusion is avalid OWL DLconclusion.
Every legalOWL DL on-tology is a legalOWL Full on-tology. Everyvalid OWL DLconclusion is avalid OWL Fullconclusion.
Every validRDF(S), OWLLite, or OWL-DL ontologies(or conclusions)are valid OWLFULL ontologies(or conclusions).
ParticipationConstraints
cannot declaredomain/rangerestrictions thatapply to someclasses only. (itis impossible tostate whethera property isoptional or re-quired for theinstances of theclass)
Same property-name withdifferent rangerestrictions arepossible
same property-name withdifferent rangerestrictions arepossible
same property-name withdifferent rangerestrictions arepossible
Modifyingproperties
properties liketransitive,unique of otherproperties ismissing
properties liketransitivity andsymmetry areallowed
properties liketransitivity andsymmetry areallowed
properties liketransitivity andsymmetry areallowed
EqualityClaims(SameAs)
Not allowed Not allowed Not allowed class equalitycan only beexpressed inOWL Full.
Enumeration Not allowed Not allowed defined with theowl:oneOf prop-erty.
defined with theowl:oneOf prop-erty.
CardinalityConstraint
Cardinality re-strictions areimpossible toexpress,
Cardinality: 0/1MinCardinality:0/1 ,MaxCardi-nality: 0/1
Cardinality>= 0MaxCardinality:>=0, MinCardinal-ity: >= 0
Cardinality>=0 ,MaxCardi-nality: >= 0,MinCardinality:>= 0

Appendix B. Taxonomy of OWL features 56
RDFS OWL-Lite OWL-DL OWL Full
Complement Not allowed Not allowed owl:complementOf owl:complementOf
rdfs:subPropertyOfSubpropertyaxioms can beapplied to bothdatatype prop-erties and objectproperties.
Subpropertyaxioms can beapplied to bothdatatype prop-erties and objectproperties.
the subjectand object ofa subprop-erty statementmust be eitherboth datatypeproperties orboth objectproperties.
Subpropertyaxioms can beapplied to bothdatatype prop-erties and objectproperties.
Transitivity NA No Restrictions for a transitiveproperty nolocal or globalcardinality con-straints shouldbe declared onthe propertyitself or its superproperties, noron the inverseof the propertyor its superproperties.
No restrictions
Symmetry NA Allowed Allowed Allowed

Appendix C
Publications out of the Thesis
1. Manu Madhavan, Robert Jesuraj, P. C. Reghu Raj, Jaya P, Dipti D, “Distributed
Information Extraction: A Map Reduce Approach”1.
2. Manu Madhavan, Robert Jesuraj, P. C. Reghu Raj, “Designing of an End to End
System for Scalable Natural Language Report Management”2.
3. Manu Madhavan, P. C. Reghu Raj, “Application of Karaka Relations in Natural
Language Generation ”, in National Conference on Indian Language Computing,
CUSAT, Kerala, 2011.
1Communicated to Applied Artificial Intelligence An International Journal. “Taylor & Francis”2Communicated to International Conference on Natural Language Processing. (ICON2013)
57

Bibliography
[1] Aditya K, Bijan P, et. al, “Swoop: A Web Ontology Editing Browser”, Int. National
Journal of Web Semantics: Science, Services and Agents on the World Wide Web,
Vol 4, issue 2, pp 144–153, 2006.
[2] Albert G and Ehud R, “SimpleNLG: A realization engine for practical applications”,
in Proceedings of the 12th European Workshop on Natural Language Generation.
2009.
[3] Anantharangachar R, Ramani S, Rajagopalan S, “Ontology Guided Information
Extraction from Unstructured Text ”, Int. Jr. of Web & Semantic Technology
(IJWesT), Vol.4, No.1, January 2013.
[4] Auer S et. al, “DBpedia: A Nucleus for a Web of Open Data ” In 6th Int. Semantic
Web Conference, Busan, Korea, 2007
[5] Banerjee S, Pallab D, Dipti D, “A System Architecture for Reasoning and Summa-
rizing hybrid text inputs using Semantic Web ”, International Journal of Lateral
Computing, vol.2, No.1, December 2005.
[6] Bird S, Klein E, and Loper E, Natural Language Processing with Python. O’Reilly
Media, 2009.
[7] Chuk L, Hadoop in Action. Manning Publication Co. Stamford, 2011.
[8] Chiticariu L, Krishnamurthy R, et.al, “Domain Adaptation of Rule-based Annota-
tors for Named-Entity Recognition Tasks” in Proc. of Empirical Methods on Natural
Language Processing (EMNLP), 2010.
[9] Crammer, K., Singer, Y., ” Ultraconservative Online Algorithms for Multiclass
Problems ”. In Journal of Machine Learning Research 3, 951–991, 2003. URL
http://jmlr.csail.mit.edu/papers/volume3/crammer03a/crammer03a.pdf.
[10] Cunningham H, Maynard D and Tablan V, JAPE: a Java Annotation Patterns
Engine, 2nd edition, Research Memorandum CS0010, Department of Computer Sci-
ence, University of Sheffield, 2000.
58

Bibliography 59
[11] Dean J and Ghemawat S, “MapReduce: Simplified Data Processing on Large Clus-
ters”, OSDI’04: Sixth Symposium on Operating System Design and Implementation,
SanFrancisco, CA, 2004.
[12] Dimitrios G, George K, Gerasimos Lampouras and Ion A, “An Open-Source Natural
Language Generator for OWL Ontologies and its Use in Protege and Second Life”,
in Proc. of 12th Conference of EACL (Demos),pp 17–20, 2009.
[13] Dimitris G, George K and Ion A ”How to install and use Natural OWL”, Athens
University of Economics and Business, Greece, 2007
[14] Douglas E A, “The Common Pattern Specification Language,” Artificial Intelli-
gence Centre,. Meno Park, CA, 1998.
[15] Ehud R, “ Building Applied Natural Language Generation Systems,” in Proc. of
Applied Natural Language Processing Conference in Washington dc, 1997.
[16] Gyawali B, “Answering Factoid Questions via Ontologies : A Natural Language
Generation Approach, M.Sc. Dissertation, Dept of Intelligent Computer Systems,
University of Malta, 2011.
[17] Ian R, Jim W, Graph Databases. First Edition, O’Reilly Media, 2013.
[18] Jason V, Pro Hadoop. Apress Media LLC, New York, 2009.
[19] Jurafsky D.,and Martin J. H., Speech and Language Processing, Pearson Education,
Inc. 2008.
[20] Krishnamurthy R, et. al, “SystemT: A System for Declarative Information Extrac-
tion”, Special Interest Group on Management of Data (SIGMOD), Vol. 37, No. 4,
December 2008.
[21] Liyang Lu, Introduction to Semantic Web and Semantic Web Technologies. Champ-
man and Hall/CRC, 2007.
[22] Nagi K, “A New Representation of WordNet using Graph Databases”, in The
Fifth International Conference on Advances in Databases, Knowledge, and Data
Applications, 2013.
[23] Neelu N, Sanjay S et al, “Natural language Interface for Database: A Brief review”,
in International Journal of Computer Science Issues, Vol. 8, Issue 2, March 2011.
[24] Noy N. F and McGuinness L. D, “Ontology Development 101: A Guide to Creating
Your First Ontology,” Stanford University, Stanford,2005.

Bibliography 60
[25] Parr T, The Definitive ANTLR Reference: Building Domain-Specific Languages.
The Pragmatic Bookshelf, Texas, 2007.
[26] Ren Z, Yan J, et. al, “Effective and Efficient Web Reviews Extraction Based on
Hadoop ”, in Proc. of Int. Conf. on Service Oriented Computing Workshops, pp
107-118, China, 2012.
[27] Ravichandran D, Pantel P and Hovy E, “The terascale challenge ”, In KDD
Workshop on Mining for and from the Semantic Web, 2004.
[28] Sarawagi S, Information extraction. Foundations and trends in databases 1(3),
261–377, 2007.
[29] Sirin E, Parsia B, and Y. Katz, “Pellet: A practical OWL-DL reasoner Web Seman-
tics”, Science, Services and Agents on the World Wide Web In Software Engineering
and the Semantic Web, Vol. 5, No. 2., pp. 51–53, 2007.
[30] Sofia H, Martins J. P. , “Reusing Ontologies,” In AAAI 2000 Spring Symposium
on Bringing Knowledge to Business Processes, 2000.
[31] Surdeanu M, Mclosky D , et. al, “Customizing an information extraction system to
a new domain”, in Proc. of the ACL Workshop on Relational Models of Semantics,
2011.
[32] Urbani J, “ RDFS/OWL reasoning using the MapReduce framework”, M.S. thesis,
Dept. of Comp. Sc., Vrije University, Amsterdam, 2009.
[33] Apche Hadoop Project, www.apache.hadoop.org, Last visited on June 2013.
[34] Apache Jena Project, www.jena.apache.org, Last visited on June 2013.
[35] BabelNet, http://www.babelfor.net/ Last visited on June 2013.
[36] DBPedia Project, http://dbpedia.org Last visited on June 2013.
[37] Freebase, www.freebase.com Last visited on June 2013.
[38] GeoNames, http://geonames.org/ Last visited on June 2013.
[39] IBM Watson Engagement Advisor, http://www-03.ibm.com/innovation/us/
watson Last visited on June 2013.
[40] Neo4j, www.neo4j.org Last visited on June 2013.
[41] Protege Project, http://protege.stanford.edu, Last visited on June 2013.
[42] Sesame, http://www.openrdf.org/doc/sesame/users/ch01.html, Last visited
on June 2013.

Bibliography 61
[43] SPARQL Tutorial, www.w3.org/TR/rdf-sparql-query/, Last visited on June
2013.
[44] Standford CoreNLP, http://nlp.stanford.edu:8080/corenlp/ visited on June
2013.
[45] Web Ontology Language, http://www.w3.org/2004/OWL/ visited on June 2013.
Top Related
Copyright © 2022 FDOKUMEN

