







Bahasa
Halaman
Hukum


SIXTH FRAMEWORK PROGRAMME PRIORITY 1
FOCUSING AND INTEGRATING RESEARCH New and Emerging Science and Technology
Project no. 5010 CONTACT
Learning and Development of CONTextual ACTion Instrument: SPECIFIC TARGETED RESEARCH PROJECT Thematic Priority: New and Emerging Science and Technology (NEST), Adventure
Activities
Published papers
Period covered: from 01/09/2005 to 31/08/2006 Date of preparation: 9/10/2006 Start date of project: 01/09/2005 Duration: 36 months Project coordinators name: Laila Craighero, Giulio Sandini Project coordinator organisation name: University of Genova, DIST, LIRA-lab Revision 1

1. Arbib, M., Metta, G., Van der Smagt, P. Neurorobotics: From Vision to Action. In
Handbook of Robotics, Chapter 64. Submitted, July 2006.
2. Fadiga L, Craighero L, Olivier E. (2005). Human motor cortex excitability during the
perception of others' action. Current Opinion in Neurobiology, 15:213-8.
3. Fadiga L., Craighero L. (2006). Hand actions and speech representation in Broca's area.
Cortex, 42:486-90.
4. Fadiga L., Craighero L. Roy A.C. (2006). Broca's area: A speech area? In Y. Grodzinsky &
K. Amunts (Eds.), Broca's region. New York: Oxford University Press.
5. Fadiga L., Craighero L., Fabbri Destro M., Finos L., Cotillon-Williams N., Smith A.T.,
Castiello U. (in press). Language in shadow. Social Neuroscience.
6. Falck-Ytter, T., Gredebäck,G., & von Hofsten, C. (2006). Infants predict other people's
action goals. Nature Neuroscience, 9, 878 - 879.
7. Fitzpatrick, P., Needham, A., Natale, L., Metta, G. (in press) Shared Challenges in Object
Perception for Robots and Infants. Infant and Child Development, special issue 2006.
8. Gredebäck, G., Örnkloo, H, Von Hofsten, C. (2006). The development of reactive saccade
latencies. Experimental Brain Research, 173(1), 159-164.
9. Gustavsson, L., Marklund, E., Klintfors, E., Lacerda, F. (2006). Directional Hearing in a
Humanoid Robot - Evaluation of Microphones Regarding HRTF and Azimuthal
Dependence. In Fonetik 2006, pp. 45-48
10. Hörnstein, J., Lopes, M., Santos-Victor, J., Lacerda. F. (2006) Sound localization for
humanoid robots - building audio-motor maps based on the HRTF. Proceedings of The
IEEE/RSJ International Conference on Intelligent Robots and Systems, IROS, Beijing,
China, Oct. 9-15, 2006.
11. Jamone, L., Metta, G., F. Nori, F., Sandini, G. (2006) James: A Humanoid Robot Acting
over an Unstructured World. Accepted to the Humanoids 2006 conference, December 4-6th,
2006, Genoa, Italy.
12. Klintfors, E., Lacerda, F. (2006). Potential relevance of audio-visual integration in mammals
for computational modeling. In Proceedings of the Ninth International Conference on
Spoken Language Processing (Interspeech 2006 - ICSPL), pp. 1403-1406

13. Lacerda, F. (in press) Ett ekologiskt perspektiv på tidig talspråksutveckling. Proceedings of
the 10th Nordisk Barnspråkssymposium.
14. Lacerda, F., Sundberg, U. (2006). Proposing ETLA An Ecological Theory of Language
Acquisition. Revista de Estudos Linguísticos da Universidade do Porto.
15. Marklund, E., Lacerda, F. (2006). Infants' ability to extract verbs from continuous speech. In
Proceedings of the Ninth International Conference on Spoken Language Processing
(Interspeech 2006 - ICSPL), pp.1360-1362
16. Metta G., Sandini G., Natale L., Craighero L. Fadiga L. (2006). Understanding mirror
neurons: A bio-robotic approach. Interaction Studies 7:197-232.
17. Natale, L. , Metta, G. , Sandini, G. (2006). Sviluppo sensomotorio in un robot antropomorfo.
In Sistemi Intelligenti, La via italiana alla vita artificiale, special issue (1) 95-104
18. Orabona, F., Metta, G., Sandini, G. (2006). Learning Associative Fields from Natural
Images. In the 5th IEEE Computer Society Workshop on Perceptual Organization in
Computer Vision, New York City, June 22, 2006. In Conjunction With IEEE CVPR.
19. Rizzolatti G., Craighero L. (2005). Mirror neuron: a neurological approach to empathy. In
J.-P. Changeux, A.R. Damasio, W. Singer and Y. Christen (Eds.) Neurobiology of Human
Values.
20. Theuring, C., Gredebäck, G., Hauf, P. (in press) Object processing during a joint gaze
following task. European Journal of Developmental Psychology.
21. Von Hofsten, C. (in press) Action in Development. Developmental Science.
22. Von Hofsten, C., Kochukhova, O., Rosander, K. (in press) Predictive occluder tracking in 4-
month-old infants. Developmental Science.

Arbib et al. for Robotics Handbook June 21, 2006 1
1
Handbook of Robotics Chapter 64: Neurorobotics: From Vision to Action
Michael Arbib Computer Science, Neuroscience, and USC Brain Project
University of Southern California
Los Angeles, CA 90089-2520, USA
Giorgio Metta
LIRA-Lab, DIST
University of Genova
Viale Causa, 13, 16145 Genova, Italy
Patrick van der Smagt
DLR/Institute of Robotics and Mechatronics
P.O.Box 1116, 82230 Wessling, Germany
July 17, 2006 64.1. Introduction 5070 0.9 64.2. Neuroethological Inspiration 32287 5.9 64.3. The Role of the Cerebellum 24447 4.4 64.4. The Role of Mirror Systems 31702 5.8 64.5. Extroduction 2050 0.4 64.6. References 21008 4.8 Figures 9 2.25 24.45
64.1. Introduction 1 64.2. Neuroethological Inspiration 2
64.2.1 Optic Flow in Bee & Robot..................................................................................................2 64.2.2. Visually-Guided Behavior in Frog & Robot .....................................................................4 64.2.3. Navigation in Rat & Robot .................................................................................................5 64.2.4 Schemas and Coordinated Control Programs ...................................................................8 64.2.5 Salience and Visual Attention............................................................................................10
64.3. The Role of the Cerebellum 11 64.3.1 The Human Control Loop .................................................................................................12 64.3.2 Models of Cerebellar Control............................................................................................13 64.3.3 Cerebellar Models and Robotics .......................................................................................17
64.4. The Role of Mirror Systems 18 64.4.1 Mirror Neurons and the Recognition of Hand Movements ............................................19 64.4.2 A Bayesian View of the Mirror System ............................................................................22 64.4.3 Mirror Neurons and Imitation ..........................................................................................26
64.5. Extroduction 28 64.6. References 28

Arbib et al. for Robotics Handbook June 21, 2006 1
1
64.1. Introduction Neurorobotics may be defined as “the design of computational structures for robots inspired by the study of the
nervous systems of humans and other animals”. We note the success of artificial neural networks – networks of
simple computing elements whose connections change with “experience” – as providing a medium for parallel
adaptive computation that has seen application in robot vision systems and controllers but here we emphasize neural
networks derived from the study of specific neurobiological systems. Neurorobotics has a two-fold aim: creating
better machines which employ the principles of natural neural computation; and using the study of bio-inspired
robots to improve understanding of the functioning of the brain. Chapter 60, Biologically Inspired Robots,
complements our study of “brain design” with work on “body design”, the design of robotic control and actuator
systems based on careful study of the relevant biology.
Walter (1953) described two ‘biologically inspired’ robots, the electromechanical tortoises Machina speculatrix
and M. docilis (though each body has wheels not legs). M. speculatrix has a steerable photoelectric cell, which
makes it sensitive to light, and an electrical contact, which allows it to respond when it bumps into obstacles. The
photo-receptor rotates until a light of moderate intensity is registered, at which time the organism orients towards the
light and approaches it. However, very bright lights, material obstacles and steep gradients are repellent to the
“tortoise”. The latter stimuli convert the photo-amplifier into an oscillator; which causes alternating movements of
butting and withdrawal, so that the robot pushes small objects out of its way, goes around heavy ones, and avoids
slopes. The “tortoise” has a “hutch”, which contains a bright light. When the machine’s batteries are charged, this
bright light is repellent. When the batteries are low, the light becomes attractive to the machine and the light
continues to exert an attraction until the tortoise enters the hutch, where the machine’s circuitry is temporarily turned
off until the batteries are recharged, at which time the bright hutch light again exerts a negative tropism. The second
robot, M. docilis was produced by grafting onto M. speculatrix a circuit designed to form conditioned reflexes. In
one experiment, Walter connected this circuit to the obstacle avoiding device in M. speculatrix. Training consisted
in blowing a whistle just before bumping the shell.
Although Walter’s controllers are simple and not based on neural analysis, they do illustrate the attempt to gain
inspiration from seeking the simplest mechanisms that will yield an interesting class of biologically inspired robot
behaviors, and then showing how different additional mechanisms yield a variety of enriched behaviors. Valentino
Braitenberg’s (1984) book Vehicles is very much in this spirit and has entered the canon of neurorobotics. While
their work provides a historical background for the studies surveyed here, we instead emphasize studies inspired by
the computational neuroscience of the mechanisms serving vision and action in the human and animal brain. We
seek lessons from linking behavior to the analysis of the internal workings of the brain (i) at the relatively high-level
of characterizing the functional roles of specific brain regions (or the functional units of analysis called schemas,
Section 64.2.4), and the behaviors which emerge from the interactions between them, and (ii) at the more detailed
level of models of neural circuitry linked to the data of neuroanatomy and neurophysiology. There are lessons for
neurorobotics to be learned from even finer-scale analysis of the biophysics of individual neurons and the
neurochemistry of synaptic plasticity but these are beyond the scope of this chapter (see Segev & London, 2003, and
Fregnac, 2003, respectively, for entry points into the relevant computational neuroscience).

Arbib et al. for Robotics Handbook June 21, 2006 2
2
The plan of this Chapter is as follows: After some selected examples from computational neuroethology, the
computational analysis of neural mechanisms underlying animal behavior, we show how perceptual & motor
schemas and visual attention provide the framework for our action-oriented view of perception, and show the
relevance of the computational neuroscience to robotic implementations (Section 64.2). We then pay particular
attention to two systems of the mammalian brain, the cerebellum and its role in tuning and coordinating actions
(Section 64.3); and the mirror system and its roles in action recognition and imitation (Section 64.4). The
extroduction will then invite readers to explore the many other areas in which neurorobotics offers lessons from
neuroscience to the development of novel robot designs. What follows, then, can be seen as a contribution to the
continuing dialogue between robot behavior and animal and human behavior in which particular emphasis is placed
on the search for the neural underpinnings of vision, visually-guided action, and cerebellar control.
64.2. Neuroethological Inspiration Biological evolution has yielded a staggering variety of creatures each with brains and bodies adapted to specific
niches. One may thus turn to the neuroethology of specific creatures to gain inspiration for special-purpose robots.
In Section 64.2.1, we will see how researchers have studied bees and flies for inspiration for the design of flying
robots, but have also learned lessons for the visual control of terrestrial robots. In Section 64.2.2, we introduce Rana
computatrix, an evolving model of visuo-motor co-ordination in frog and toad. The name “the frog that computes”,
was inspired by Walter’s M. speculatrix and inspired in turn the names of a number of other “species”’ of
neuroethologically-inspired robots, including Beer’s (1990) computational cockroach Periplaneta computatrix and
Cliff’s (1992) hoverfly Syritta computatrix.
Moreover, we learn not only from the brains of specific creatures but also from comparative analysis of the
brains of diverse creatures, looking for homologous mechanisms as computational variants which may be related to
the different ecological niches of the creatures that contain them. A basic theme of brain evolution is that new
functions often emerge through modulation and coordination of existing structures. In other words, to the extent that
new circuitry may be identified with the new function, it need not be as a module that computes the function
autonomously, but rather as one that can deploy prior resources to achieve the novel functionality. Section 64.2.3
will introduce the role of the rat brain in navigation, while Section 64.2.4 will look at the general framework of
perceptual schemas motor schemas and coordinated control programs for a high level view of the neuroscience and
neurorobotics of vision and action. Finally, Section 64.2.5 will look at the control of visual attention in mammals as
a homologue of orienting behavior in frog and toad. All this sets the stage for our emphasis on the roles of the
cerebellum (Section 64.3) and mirror systems (Section 64.4) in the brains of mammals and their implications for
neurorobotics. We stress that the choice of these two systems is conditioned by our own expertise, and that studies
of many other brain systems also hold great importance for neurorobotics.
64.2.1 Optic Flow in Bee & Robot Before we turn to vertebrate brains for much of our inspiration for neurorobotics, we briefly sample the rich
literature on insect-inspired research. Among the founding studies in computational neuroethology were a series of
reports from the laboratory of Werner Reichardt in Tübingen which linked the delicate anatomy of the fly’s brain to
the extraction of visual data needed for flight control. More than 40 years ago, Reichardt (1961) published a model
of motion detection inspired by this work that has long been central in discussions of visual motion in both the

Arbib et al. for Robotics Handbook June 21, 2006 3
3
neuroscience and robotics literatures. Borst & Dickinson (2003) provide a recent study of continuing biological
research on visual course control in flies. Such work has inspired a large number of robot studies, including those of
van der Smagt & Groen (1997), Liu & Usseglio-Viretta (2001), Ruffier et al., 2003, and Reiser & Dickinson, 2003.
Here, however, we look in a little more detail at honeybees. Srinivasan, Zhang & Chahl (2001) continued the
tradition of studying image motion cues in insects by investigating how optic flow (the flow of pattern across the eye
induced by motion relative to the environment) is exploited by honeybees to guide locomotion and navigation. They
analyzed how bees perform a smooth landing on a flat surface: image velocity is held constant as the surface is
approached, thus automatically ensuring that flight speed is close to zero at touchdown. This obviates any need for
explicit knowledge of flight speed or height above the ground. This landing strategy was then implemented in a
robotic gantry to test its applicability to autonomous airborne vehicles. Barron & Srinivasan (2006) investigated the
extent to which ground speed is affected by headwinds. Honey bees were trained to enter a tunnel to forage at a
sucrose feeder placed at its far end (Fig. 1 left). The bees used visual cues to maintain their ground speed by
adjusting their air speed to maintain a constant rate of optic flow, even against headwinds which were, at their
strongest, 50% of a bee's maximum recorded forward velocity.
Vladusich et al. (2005) studied the effect of adding goal-defining landmarks. Bees were trained to forage in an
optic-flow-rich tunnel with a landmark positioned directly above the feeder. They searched much more accurately
when both odometric and landmark cues were available than when only odometry was available. When the two cue
sources were set in conflict, by shifting the position of the landmark in the tunnel during tests, bees overwhelmingly
used landmark cues rather than odometry. This, together with other such experiments, suggests that bees can make
use of odometric and landmark cues in a more flexible and dynamic way than previously envisaged.
Fig. 1. Observation of the trajectories of honeybees flying in visually textured tunnels has provided insights into how
bees use optic flow cues to regulate flight speed and estimate distance flown, and balance optic flow in the two eyes to

Arbib et al. for Robotics Handbook June 21, 2006 4
4
fly safely through narrow gaps. This information has been used to build autonomously navigating robots. Upper right
shows schematic illustration of a honeybee brain, carrying about a million neurons within about one cubic millimeter.
(Image credits: Left: Science Vol. 287, pp. 851-853, 2000; upper right: “Virtual Atlas of the Honeybee Brain”,
http://www.neurobiologie.fu-berlin.de/beebrain/Bee/VRML/SnapshotCosmoall.jpg and lower right: Research School of
Biological Sciences, Australian National University.)
In earlier studies of bees flying down a tunnel, Srinivasan & Zhang (1997) placed different patterns on the left
and right walls. They found that bees balance the image velocities in the left and right visual fields. This strategy
ensures that bees fly down the middle of the tunnel, without bumping into the side walls, enabling them to negotiate
narrow passages or to fly between obstacles. This strategy has been applied to a corridor-following robot (Fig. 1,
bottom right). By holding constant the average image velocity as seen by the two eyes during flight,. the bee avoids
potential collisions, slowing down when it flies through a narrow passage. The movement-sensitive mechanisms
underlying these various behaviors differ qualitatively as well as quantitatively, from those that mediate the
optomotor response (e.g., turning to track a pattern of moving stripes) that had been the initial target of investigation
of the Reichardt laboratory. The lesson for robot control is that flight appears to be coordinated by a number of
visuomotor systems acting in concert, and the same lesson can apply to a whole range of tasks which must convert
vision to action. Of course, vision is but one of the sensory systems that play a vital role in insect behavior. Webb
(2001) uses her own work on robot design inspired by the auditory control of behavior in crickets to anchor a far-
ranging assessment of the extent to which robotics can offer good models of animal behaviors.
64.2.2. Visually-Guided Behavior in Frog & Robot “What the frog’s eye tells the frog brain” (Lettvin et al., 1959) treated the frog’s visual system from an
ethological perspective, analyzing circuitry in relation to the animal’s ecological niche to show that different cells in
the retina and the visual midbrain region known as the tectum were specialized for detecting predators and prey.
However, in much visually guided behavior, the animal does not respond to a single stimulus, but rather to some
property of the overall configuration. We thus turn to the question “What does the frog’s eye tell the frog?”,
stressing the embodied nervous system or, perhaps equivalently, an action-oriented view of perception. Consider, for
example, the snapping behavior of frogs confronted with one or more fly-like stimuli. Ingle (1968) found that it is
only in a restricted region around the head of a frog that the presence of a fly-like stimulus elicits a snap, that is, the
frog turns so that its midline is pointed at the stimulus and then lunges forward and captures the prey with its tongue.
There is a larger zone in which the frog merely orients towards the target, and beyond that zone the stimulus elicits
no response at all. When confronted with two “flies” within the snapping zone, either of which is vigorous enough
that alone it could elicit a snapping response, the frog exhibits one of three reactions: it snaps at one of the flies; it
does not snap at all; or it snaps in between at the “average fly”. Didday (1976) offered a simple model of this choice
behavior which may be considered as the prototype for a winner-take-all (WTA) model which receives a variety of
inputs and (under ideal circumstances) suppresses the representation of all but one of them; the one that remains is
the “winner’” which will play the decisive role in further processing. This was the beginning of Rana computatrix
(Arbib, 1987, 1989 for overviews).
Studies on frog brains and behavior inspired the successful use of potential fields for robot navigation strategies.
Data on the strategies used by frogs to capture prey while avoiding static obstacles (Collett, 1982) grounded the

Arbib et al. for Robotics Handbook June 21, 2006 5
5
model by Arbib & House (1987) which linked systems for depth perception to the creation of spatial maps of both
prey and barriers. In one version of their model, they represented the map of prey by a potential field with long-
range attraction and the map of barriers by a potential field with short-range repulsion, and showed that summation
of these fields yielded a field that could guide the frog’s detour around the barrier to catch its prey. Corbacho &
Arbib (1995) later explored a possible role for learning in this behavior. Their model incorporated learning in the
weights between the various potential fields to enable adaptation over trials as observed in the real animals. The
success of the models indicated that frogs use reactive strategies to avoid obstacles while moving to a goal, rather
than employing a planning or cognitive system. Other work (e.g. Cobas and Arbib, 1992) studied how the frog’s
ability to catch prey and avoid obstacles was integrated with its ability to escape from predators. These models
stressed the interaction of the tectum with a variety of other brain regions such as the pretectum (for detecting
predators) and the tegmentum (for implementing motor commands for approach or avoidance).
Arkin (1989) showed how to combine a computer vision system with a frog-inspired potential field controller to
create a control system for a mobile robot that could successfully navigate in a fairly structured environment using
camera input. The resultant system thus enriched other roughly contemporaneous applications of potential fields in
path planning with obstacle avoidance for both manipulators and mobile robots (Khatib, 1986; Krogh & Thorpe,
1986). The work on Rana Computatrix proceeded at two levels – both biologically realistic neural networks, and in
terms of functional units called schemas which compete and cooperate to determine behavior. Section 64.2.4 will
show how more general behaviors can emerge from the competition and cooperation of perceptual and motor
schemas as well as more abstract coordinating schemas too. Such ideas were, of course, developed independently by
a number of authors, and so entered the robotics literature by various routes, of which the best known may be the
subsumption architecture of Brooks (1986) and the ideas of Braitenberg cited above; while Arkin’s work on
behavior-based robotics (Arkin 1998) is indeed rooted in schema theory. Arkin et al. (2003) present a recent
example of the continuing interaction between robotics and ethology, offering a novel method for creating high-
fidelity models of animal behavior for use in robotic systems based on a behavioral systems approach (i.e. based on
a schema-level model of animal behavior, rather than analysis of biological circuits in animal brains), and describe
how an ethological model of a domestic dog can be implemented with AIBO, the Sony entertainment robot.
64.2.3. Navigation in Rat & Robot
The tectum, the midbrain visual system which determines how the frog turns its whole body towards it prey or
orients it for escape from predators (Section 64.2.2), is homologous with the superior colliculus of the mammalian
midbrain. The rat superior colliculus has been shown to be “frog-like”, mediating approach and avoidance (Dean, et
al., 1989), whereas the best-studied role of the superior colliculus of cat, monkey and human is in the control of
saccades, rapid eye movements to acquire a visual target. Moreover, the superior colliculus can integrate auditory
and somatosensory information into its visual frame (Stein & Meredith, 1993) and this inspired Strosslin et al.
(2002) to use a biologically inspired approach based on the properties of neurons in the superior colliculus to learn
the relation between visual and tactile information in control of a mobile robot platform. More generally, then, the
comparative study of mammalian brains has yielded a rich variety of computational models of importance in
neurorobotics. In this section, we further introduce the study of “mammalian neurorobotics” by looking at studies of
mechanisms of the rat brain for spatial navigation.

Arbib et al. for Robotics Handbook June 21, 2006 6
6
The frog’s detour behavior is an example of what O'Keefe & Nadel (1978) called the taxon (behavioral
orientation) system (as in Braitenberg, 1965, a taxis [plural taxes] is an organism's response to a stimulus by
movement in a particular direction). They distinguished this from a system for map-based navigation, and proposed
that the latter resides in the hippocampus, though Guazzelli et al. (1998) qualified this assertion, showing how the
hippocampus may function as part of a cognitive map. The taxon versus map distinction is akin to the distinction
between reactive and deliberative control in robotics (Arkin, 2003). It will be useful to relate taxis to the notion of an
affordance (Gibson, 1966), a feature of an object or environment relevant to action. For example, in picking up an
apple or a ball, the identity of the object may be irrelevant, but the size of the object is crucial. Similarly, if we wish
to push a toy car, recognizing the make of car copied in the toy is irrelevant, whereas it is crucial to recognize the
placement of the wheels to extract the direction in which the car can be readily pushed. Just as a rat may have basic
taxes for approaching food or avoiding a bright light, say, so does it have a wider repertoire of affordances for
possible actions associated with the immediate sensing of its environment. Such affordances include "go straight
ahead" for visual sighting of a corridor, "hide" for a dark hole; "eat" for food as sensed generically; "drink"
similarly; and the various turns afforded by e.g., the sight of the end of the corridor. It also makes rich use of
olfactory cues. In the same way, a robot’s behavior will rely on a host of reactions to local conditions in fulfilling a
plan –e.g., knowing it must go to the end of a corridor it will nonetheless use local visual cues to avoid hitting
obstacles, or to determine through what angle to turn when reaching a bend in the corridor.
������������
���� ����
������������
��������������
�������������
����������������������
��� ���������
����������� ���
���!��������
�"���������#�����"������
$�����������������������
���������
$��"����
������"%��
$��&����������������
�������������
��� ���� �����
������������
Fig. 2. The TAM-WG model has at its basis a system, TAM, for exploiting affordances. This is elaborated by a system,
WG, which can use a cognitive map to plan paths to targets which are not currently visible. Note that the model
processes two different kinds of sensory inputs. At bottom right are those associated with, e.g., hypothalamic systems
for feeding and drinking, and may provide both incentives and rewards for the animal’s behavior, contributing both to
behavioral choices, and to the reinforcement of certain patterns of behavior. The nucleus accumbens and caudo-

Arbib et al. for Robotics Handbook June 21, 2006 7
7
putamen mediate an actor-critic style of reinforcement learning based on hypothalamic drive of the dopamine system.
The sensory inputs at top left are those that allow the animal to sense its relation with the external world, determining
both where it is (the hippocampal place system) as well as affordances for action (the parietal recognition of
affordances can shape the premotor selection of an action). The TAM model focuses on the parietal-premotor reaction
to immediate affordances; the WG (World Graph) model places action selection within the wider context of a cognitive
map. (Adapted from Guazzelli et al., 1998.)
Both normal and hippocampal-lesioned rats can learn to solve a simple T-maze (e.g., learning whether to turn left
or right to find food) in the absence of any consistent environmental cues other than the T-shape of the maze. If
anything, the lesioned animals learn this problem faster than normals. After criterion was reached, probe trials with
an 8-arm radial maze were interspersed with the usual T-trials. Animals from both groups consistently chose the side
to which they were trained on the T-maze. However, many did not choose the 90° arm but preferred either the 45° or
135° arm, suggesting that the rats eventually solved the T-maze by learning to rotate within an egocentric orientation
system at the choice point through approximately 90°. This leads to the hypothesis of an orientation vector being
stored in the animal's brain but does not tell us where or how the orientation vector is stored. One possible model
would employ coarse coding in a linear array of cells, coding for turns from - 180° to +180°. From the behavior, one
might expect that only the cell's close to the preferred behavioral direction are excited, and that learning "marches"
this peak from the old to the new preferred direction. To "unlearn" -90°, say, the array must reduce the peak there,
while at the same time "building" a new peak at the new direction of +90°. If the old peak has "mass" p(t) and the
new peak has "mass" q(t), then as p(t) declines toward 0 while q(t) increases steadily from 0, the center of mass will
progress from -90° to +90°, fitting the behavioral data.
The determination of movement direction was modeled by "rattification" of the Arbib & House (1987) model of
frog detour behavior. There, prey were represented by excitation coarsely coded across a population, while barriers
were encoded by inhibition whose extent closely matched the retinotopic extent of each barrier. The sum of
excitation was passed through a winner-take-all circuit to yield the choice of movement direction. As a result, the
direction of the gap closest to the prey, rather than the direction of the prey itself, was often chosen for the frog's
initial movement. The same model serves for behavioral orientation once we replace the direction of the prey (frog)
by the direction of the orientation vector (rat), while the barriers correspond to the presence of walls rather than alley
ways.
To approach the issue of how a cognitive map can extend the capability of the affordance system, Guazzelli et al.
extended the Lieblich & Arbib (1982) approach to building a cognitive map as a world graph, a set of nodes
connected by a set of edges, where the nodes represent recognized places or situations, and the links represent ways
of moving from one situation to another. A crucial notion is that a place encountered in different circumstances may
be represented by multiple nodes, but that these nodes may be merged when the similarity between these
circumstances is recognized. They model the process whereby the animal decides where to move next, on the basis
of its current drive state (hunger, thirst, fear, etc.). The emphasis is on spatial maps for guiding locomotion into
regions not necessarily current visible, rather than retinotopic representations of immediately visible space, and
yields exploration and latent learning without the introduction of an explicit exploratory drive. The model shows (i)
how a route, possibly of many steps, may be chosen that leads to the desired goal; (ii) how short cuts may be chosen,

Arbib et al. for Robotics Handbook June 21, 2006 8
8
and (iii) through its account of node-merging why, in open fields, place cell firing does not seem to depend on
direction.
The overall structure and general mode of operation of the complete model is shown in Fig. 2, which gives a
vivid sense of the lessons to be learned by studying not only specific systems of the mammalian brain but also their
patterns of large-scale interaction. This model is but one of many inspired by the data on the role of the
hippocampus and other regions in rat navigation. Here, we just mention as pointers to the wider literature the papers
by Girard et al. (2005) and Meyer et al. (2005) which are part of the Psikharpax project, which is doing for rats what
Rana computatrix did for frogs and toads.
64.2.4 Schemas and Coordinated Control Programs Schema theory complements neuroscience's well-established terminology for levels of structural analysis (brain
region, neuron, synapse) with a functional vocabulary, a framework for analysis of behavior with no necessary
commitment to hypotheses on the localization of each schema (unit of functional analysis), but which can be linked
to a structural analysis whenever appropriate. Schemas provide a high-level vocabulary which can be shared by
brain theorists, cognitive scientists, connectionists, ethologists, kinesiologists – and roboticists. In particular, schema
theory can provide a distributed programming environment for robotics (see, e.g., the RS [Robots Schemas]
language of Lyons & Arbib, 1989, and supporting architectures for distributed control as in Metta et al., 2006a).
Schema theory becomes specifically relevant to neurorobotics when the schemas are inspired by a model
constrained by data provided by, e.g., human brain mapping, studies of the effects of brain lesions, or
neurophysiology.
A perceptual schema not only determines whether an object or other "domain of interaction" is present in the
environment but can also provide important. The activity level of a perceptual schema signals the credibility of the
hypothesis that what the schema represents is indeed present; whereas other schema parameters represent relevant
properties such as size, location, and motion of the perceived object. Given a perceptual schema, we may need
several schema instances, each suitably tuned, to subserve perception of several instances of its domain, e.g., several
chairs in a room.
Motor schemas provide the control systems which can be coordinated to effect a wide variety of actions. The
activity level of a motor schema instance may signal its "degree of readiness" to control some course of action. What
distinguishes schema theory from usual control theory is the transition from emphasizing a few basic controllers
(e.g., for locomotion or arm movement) to a large variety of motor schemas for diverse skills (peeling an apple,
climbing a tree, changing a light bulb), with each motor schema depending on perceptual schemas to supply
information about objects which are targets for interaction. Note the relevance of this for robotics – the robot needs
to know not only what the object is but also how to interact with it. Modern neuroscience (Ungerleider & Mishkin,
1982; Goodale & Milner, 1992) has indeed established that the monkey and human brain each use a dorsal pathway
(via the parietal lobe) for the “how” and a ventral pathway (via inferotemporal cortex) for the “what”.
A coordinated control program, interweaves the activation of various perceptual, motor, and coordinating
schemas in accordance with the current task and sensory environment to mediate complex behaviors. Fig. 3 shows
the original coordinated control program (Arbib 1981, inspired by data of Jeannerod & Biguer, 1982). As the hand
moves to grasp a ball, it is preshaped so that when it has almost reached the ball, it is of the right shape and

Arbib et al. for Robotics Handbook June 21, 2006 9
9
orientation to enclose some part of the ball prior to gripping it firmly. The outputs of three perceptual schemas are
available for the concurrent activation of two motor schemas, one controlling the arm to transport the hand towards
the object and the other preshaping the hand. Once the hand is preshaped, it is only the completion of the fast initial
phase of hand transport that "wakes up" the final stage of the grasping schema to shape the fingers under control of
tactile feedback. (This model anticipates the much later discovery of perceptual schemas for grasping in a localized
area [AIP] of parietal cortex and motor schemas for grasping in a localized area [F5] of premotor cortex. See Fig. 4.)
The notion of schema is thus recursive – a schema may be analyzed as a coordinated control program of finer
schemas, and so on until such time as a secure foundation of neural specificity is attained.
visual ,
kinesthetic, and
tactile input
Visual
Location
Hand Reaching
Fast Phase
Movement
Hand
PreshapeHand
Rotation
Actual
Grasp
Size
RecognitionOrientation
Recognition
size
Grasping
orientation
activation of
visual search
visual and
kinesthetic input
target
location
visual
input
visual
input
Slow Phase
Movement
visual
input
recognition
criteria
activation
of reaching
Fig. 3. Hypothetical coordinated control program for reaching and grasping. The perceptual schemas (at the top)
provide parameters for the motor schemas (at the bottom) for the control of "reaching" (arm transport ≈ hand reaching)
and "grasping" (controlling the hand to conform to the object). Dashed lines indicate activation signals which establish
timing relations between schemas; solid lines indicate transfer of data. (Adapted from Arbib 1981.)
Subsequent work has refined the scheme of Fig. 3. For example, Hoff & Arbib’s (1993) model uses “time needed
for completion” of each of the movements – transporting the hand and preshaping the hand – to explain data on how
the reach to grasp responds to perturbation of target location or size. Moreover, Hoff and Arbib (1992) show how to
embed an optimality principle for arm trajectories into a controller which can use feedback to resist noise and
compensate for target perturbations, and a predictor element to compensate for delays from the periphery. The result
is a feedback system which can act like a feedforward system described by the optimality principle in "familiar"
situations, where the conditions of the desired behavior are not perturbed and accuracy requirements are such that
"normal" errors in execution may be ignored. However, when perturbations must be corrected for or when great
precision is required, feedback plays a crucial role in keeping the behavior close to that desired, taking account of

Arbib et al. for Robotics Handbook June 21, 2006 10
10
delays in putting feedback into effect. This integrated view of feedback and feedforward within a single motor
schema seems to us of value for neurorobotics as well as the neuroscience of motor control.
It is standard to distinguish a forward or direct model which represents the path from motor command to motor
output, from the inverse model which models the reverse pathway – i.e., going from a desired motor outcome to a
set of motor commands likely to achieve it. As we have just suggested, the action plan unfolds as if it were
feedforward or open-loop when the actual parameters of the situation match the stored parameters, while a feedback
component is employed to counteract disturbances (current feedback) and to learn from mistakes (learning from
feedback). This is obtained by relying on a forward model that predicts the outcome of the action as it unfolds in
real-time. The accuracy of the forward model can be evaluated by comparing the output generated by the system
with the signals derived from sensory feedback (Miall et al., 1993). Also, delays must be accounted for to address
the different propagation times of the neural pathways carrying the predicted and actual outcome of the action. Note
that the forward model in this case is relatively simple, predicting only the motor output in advance: since motor
commands are generated internally it is easy to imagine a predictor for these signals (known as an efference copy).
The inverse model, on the other hand, is much more complicated since it maps sensory feedback (e.g. vision) back
into motor terms. These concepts will prove important both in our study of the cerebellum (Section 64.3) and mirror
systems (Section 64.4).
64.2.5 Salience and Visual Attention Discussions of how an animal (or robot) grasps an object assume that the animal or robot is attending to the
relevant object. Thus, whatever the subtlety of processing in the canonical and mirror systems for grasping, its
success rests on the availability of a visual system coupled to an oculomotor control system that bring foveal vision
to bear on objects to set parameters needed for successful interaction. Indeed, directing attention appropriately is a
topic for which there is a great richness of both neurophysiological data and robotic application. In this
neuromorphic model of the bottom-up guidance of attention in primates (Itti & Koch, 2000), the input video stream
is decomposed into eight feature channels at six spatial scales. After surround suppression, only a sparse number of
locations remain active in each map, and all maps are combined into a unique saliency map. This map is scanned by
the focus of attention in order of decreasing saliency through the interaction between a winner-take-all mechanism
(which selects the most salient location) and an inhibition-of-return mechanism (which transiently suppresses
recently attended locations from the saliency map). Because it includes a detailed low-level vision front-end, the
model has been applied not only to laboratory stimuli, but also to a wide variety of natural scenes, predicting a
wealth of data from psychophysical experiments.
When specific objects are searched for, low-level visual processing can be biased not only by the gist (e.g.,
“outdoor suburban scene”) but also for the features of that object. This top-down modulation of bottom-up
processing results in an ability to guide search towards targets of interest (Wolfe, 1994). Task affects eye
movements (Yarbus, 1967), as do training and general expertise. Navalpakkam & Itti (2005) propose a
computational model which emphasizes four aspects that are important in biological vision: determining task-
relevance of an entity, biasing attention for the low-level visual features of desired targets, recognizing these targets
using the same low-level features, and incrementally building a visual map of task-relevance at every scene location.
It attends to the most salient location in the scene, and attempts to recognize the attended object through hierarchical

Arbib et al. for Robotics Handbook June 21, 2006 11
11
matching against object representations stored in long-term memory. It updates its working memory with the task-
relevance of the recognized entity and updates a topographic task-relevance map with the location and relevance of
the recognized entity. For example, in one task the model forms a map of likely locations of cars from a video clip
filmed while driving on a highway. Such work illustrates the continuing interaction between models based on visual
neurophysiology and human psychophysics with the tackling of practical robotic applications.
Orabona, Metta, Sandini (2005) implemented an extension of the Itti-Koch model on a humanoid robot with
moving eyes, using log-polar vision as in Sandini and Tagliasco (1980), and changing the feature construction
pyramid by considering proto-object elements (blob-like structures rather than edges). The inhibition of return
mechanism has to take into account a moving frame of reference, the resolution of the fovea is very different from
that at the periphery of the visual field, and head and body movements need to be stabilized. The control of
movement might thus have a relationship with the structure and development of the attention system. Rizzolatti et al.
(1987) proposed a role for the feedback projections from premotor cortex to the parietal lobe, assuming that they
form a tuning signal that dynamically changes visual perception. In practice this can be seen as an implicit attention
system which “selects” sensory information while the action is being prepared and subsequently executed. The early
responses, before action onset, of many premotor and parietal neurons suggest a premotor mechanism of attention
that deserves exploration in further work in neurorobotics.
64.3. The Role of the Cerebellum Although cerebellar involvement in muscle control was advocated long ago by the Greek gladiator surgeon
Galen of Pergamum (129-216/17 CE), it was the publication by Eccles, Ito and Szentágothai (1967) of the first
comprehensive account of the detailed neurophysiology and anatomy of the cerebellum (Ito, 2006) that provided the
inspiration for the Marr-Albus model of cerebellar plasticity (Marr, 1969; Albus, 1971) that is at the heart of most
current modeling of the role of the cerebellum in control of motion and sensing. From a robotics point of view, the
most convincing results are based on Albus’ (1975) Cerebellar Model Articulation Controller (CMAC) model and
subsequent implementations by Miller (e.g., 1994). These models, however, are only remotely based on the structure
of the biological cerebellum. More detailed models are usually only applied to 2-degree-of-freedom robotic
structures, and have not been generalized to real-world applications (Peters & van der Smagt, 2002). The problem
may lie with viewing the cerebellum as a stand-alone dynamics controller. An important observation about the brain
is that schemas are widely distributed, and different aspects of the schemas are computed in different parts of the
brain. Thus, one view is that (i) cerebral cortex has the necessary models for choosing appropriate actions and
getting the general shape of the trajectory assembled to fit the present context, whereas (ii) the cerebellum provides a
side-path which (on the basis of extensive learning of a forward motor model) provides the appropriate corrections
to compensate for control delays, muscle nonlinearities, Coriolis and centrifugal forces occasioned by joint
interactions, and subtle adjustments of motor neuron firing in simultaneously active motor pattern generators to
ensure their smooth coordination. Thus, for example, a patient with cerebellar lesions may be able to move his arm
to successfully reach a target, and to successfully adjust his hand to the size of an object. However, he lacks the
machinery to perform either action both swiftly and accurately, and further lacks the ability to coordinate the timing
of the two subactions. His behavior will thus exhibit “decomposition of movement” – he may first move the hand till
the thumb touches the object, and only then shape the hand appropriately to grasp the object. Thus analysis of how

Arbib et al. for Robotics Handbook June 21, 2006 12
12
various components of cerebral cortex interact to support forward and inverse models which determine the “overall
shape of the behavior” must be complemented by analysis of how the cerebellum handles control delays and
nonlinearities to transform a well-articulated plan into graceful, coordinated action. Within this perspective,
cerebellar structure and function will be very helpful in the control of a new class of highly antagonistic robotic
systems as well as in adaptive control.
64.3.1 The Human Control Loop Lesions and deficits of the cerebellum impair the coordination and timing of movements while introducing
excessive, undesired motion; effects which cannot be compensated by the cerebral cortex. According to mainstream
models, the cerebellum filters descending motor cortex commands to cope with timing issues and communication
delays which go up to 50ms one-way for arm control. Clearly, closed-loop control with such delays is not viable in
any reasonable setting, unless augmented with an open-loop component, predicting the behavior of the actuator
system. This is where the cerebellum comes into its own. The complexity of the vertebrate musculoskeletal system,
clearly demonstrated by the human arm using a total of 19 muscle groups for planar motion of the elbow and
shoulder alone (Nijhof & Kouwenhoven, 2002) requires a control mechanism coping with this complexity,
especially in a setting with long control delays. One cause for this complexity is that animal muscles come in
antagonistic pairs (e.g., flexing versus extending a joint). Antagonistic control of muscle groups leads to energy-
optimal (Damsgaard, Rasmussen, & Christensen, 2000) and intrinsically flexible systems. Contact with stiff or fast-
moving objects requires such flexibility to prevent breakage. In contrast, classical (industrial) robots are stiff, with
limb segments controlled by linear or rotary motors with gear boxes. Even so, most laboratory robotic systems have
passively stiff joints, with active joint flexibility obtainable only by using fast control loops and joint torque
measurement. Although it may be debatable whether such robotic systems require cerebellar-based controllers, the
steady move of robotics towards complete anthropomorphism by mimicking human (hand and arm) kinematics as
well as dynamics as closely as possible, requires the search for alternative, neuromorphic control solutions.
Figure 4. Simplified control loop relating cerebellum and cerebral motor cortex in supervising the spinal cord’s control
of the skeleto-muscular system.
Vertebrate motor control involves the cerebral motor cortex, basal ganglia, thalamus, cerebellum, brain stem and
spinal cord. Motor programs, originating in the cortex, are fed into the cerebellum. Combined with sensory
information through the spinal cord, it sends motor commands out to the muscles via the brain stem and spinal cord,
which controls muscle length and joint stiffness (Bullock & Contreras-Vidal, 1993). The full control loop is depicted
in Fig. 4 (see Schaal & Schweighofer, 2005, for an overview of robotic vs. brain control loops). The model in Fig. 4

Arbib et al. for Robotics Handbook June 21, 2006 13
13
clearly resembles the well-known computed torque model and, when the cerebellum is interpreted as a Smith model,
it serves to cope with long delays in the control loop (Miall et al, 1993; van der Smagt & Hirzinger, 2000). It is thus
understood to incorporate a forward model of the skeletomuscular system. Alternative approaches use the
cerebellum as an inverse model (e.g., Ebadzadeh et al, 2005), which however leads to increased complexity and
control loop stability problems.
64.3.2 Models of Cerebellar Control The cerebellum can be divided into two parts: the cortex and the deep nuclei. There are two systems of fibers
bringing input to the both the cortex and nuclei: the mossy fibers and the climbing fibers. The only output from the
cerebellar nucleus comes from cells called Purkinje cells, and they project only to the cerebellar nuclei, where their
effect is inhibitory. This inhibition sculpts the output of the nuclei which (the effect varies from nucleus to nucleus)
may act by modulating activity in the spinal cord, the mid-brain or the cerebral cortex. We now turn to models
which make explicit use of the cellular structure of the cerebellar cortex (Eccles et al., 1967; Ito, 1984; see Fig. 5a).
The human cerebellum has 7-14 million Purkinje cells (PCs), each receiving about 200,000 synapses. Mossy Fibers
(MFs) arise from the spinal cord and brainstem. They synapse onto granule cells and deep cerebellar nuclei. Granule
cells have axons which each project up to form a T with the bars of the Ts forming the Parallel Fibers (PFs). Each
PF synapses on about 200 PCs. The PCs, which are grouped into microzones, inhibit the deep nuclei. PCs with their
target cells in cerebellar nuclei are grouped together in microcomplexes (Ito, 1984). Microcomplexes are defined by
a variety of criteria to serve as the units of analysis of cerebellar influence on specific types of motor activity. The
Climbing Fibers (CF) arise from the inferior olive. Each PC receives synapses from only one CF, but a CF makes
about 300 excitatory synapses on each PC which it contacts. This powerful input alone is enough to fire the PC,
though most PC firing depends on subtle patterns of PF activity. The cerebellar cortex also contains a variety of
inhibitory interneurons. The Basket Cell is activated by PF afferents and makes inhibitory synapses onto PCs. Golgi
Cells receive input from PFs, MFs, and CFs and inhibit granule cells.
(a)
(b)

Arbib et al. for Robotics Handbook June 21, 2006 14
14
(c)
(d)
Figure 5. (a) Major cells in the cerebellum. (b) Cells in the Marr-Albus model. The granule cells are state encoders,
feeding system state and sensor data into the PC. PC/PF synapses are adjusted using the Widrow-Hoff rule. The output
of the PC are steering signals for the robotic system. (c) The APG model, using the same state encoder as b. (d) The
MPFIM model. A single module corresponds to a group of Purkinje cells: predictor, controller, and responsibility
estimator. The granule cells generate the necessary basis functions of the original information.
The Marr-Albus Model: In the Marr-Albus model (Marr, 1969; Albus, 1971) the cerebellum functions as a
classifier of sensory and motor patterns received through the MFs. Only a small fraction of the parallel fibers (PF)
are active when a Purkinje cells (PC) fires and thus influence the motor neurons. Both Marr and Albus hypothesized
that the error signals for improving PC firing in response to PF, and thus MF input, were provided by the climbing
fibers (CF), since only one CF affects a given PC. However, Marr hypothesized that CF activity would strengthen
the active PF/PC synapses using a Widrow-Hoff learning rule, whereas Albus hypothesized they would weaken
them. This is an important example of a case where computational modeling inspired important experimentation.
Eventually, Masao Ito was able to demonstrate that Albus was correct – the weakening of active synapses is now
known to involve a process called long-term depression (Ito, 1984). However, the rule with weakening of synapses
still known as the Marr-Albus model, and remains the reference model for studies of synaptic plasticity of cerebellar
cortex. However, both Marr and Albus viewed each PC as functioning as a perceptron whose job it was to control an
elemental movement, contrasting with more plausible models in which PCs serve to modulate the involvement of
microcomplexes (which include cells of the deep nuclei) in motor pattern generators (e.g., the APG model described
below).
Since the development of the Marr-Albus model several cerebellar models have been introduced in which
cerebellar plasticity plays a key role. Limiting our overview to computational models, we will describe (1) the
Cerebellar Model Articulation Controller CMAC, (2) the Adjustable Pattern Generator APG, (3) the Schweighofer-
Arbib model, and (4) the Multiple Paired Forward-Inverse Models (van der Smagt, 1998, 2000).
The Cerebellar Model Articulation Controller CMAC: One of the first well-known computational models of
the cerebellum is the Cerebellar Model Arithmetic Controller CMAC (Albus, 1975; see Fig. 5b). The algorithm was
based on Albus’ understanding of the cerebellum, but it was not proposed as a biologically plausible model. The
idea has its origins in the BOXES approach, in which for n variables an n-dimensional hypercube stores function

Arbib et al. for Robotics Handbook June 21, 2006 15
15
values in a lookup-table. BOXES su��ers from the curse of dimensionality: if each variable can be discretized into D
di��erent steps, the hypercube has to store Dn function values in memory. Albus assumed that the mossy fibers
provided discretized function values. If the signal on a mossy fiber is in the receptive field of a particular granule
cell, it fires onto a parallel fiber. This mapping of inputs onto binary output variables is often considered to be the
generalization mechanism in CMAC. The learning signals are provided by the climbing fibers.
Albus’ CMAC can be described in terms of a large set of overlapping, multi-dimensional receptive fields with
finite boundaries. Every input vector falls within the range of some local receptive fields. The response of CMAC to
a given input is determined by the average of the responses of the receptive fields excited by that input. Similarly,
the training for a given input vector a��ects only the parameters of the excited receptive fields.
The organization of the receptive fields of a typical Albus CMAC with a two-dimensional input space can be
described as follows: The set of overlapping receptive fields is divided into C subsets, commonly referred to as
“layers”. Any input vector excites one receptive field from each layer, for a total of C excited receptive fields for
any input. The overlap of the receptive fields produces input generalization, while the o��set of the adjacent layers of
receptive fields produces input quantization. The ratio of the width of each receptive field (input generalization) to
the o��set between adjacent layers of receptive fields (input quantization) must be equal to C for all dimensions of
the input space. This organization of the receptive fields guarantees that only a fixed number, C, of receptive fields
is excited by any input.
If a receptive field is excited, its response equals the magnitude of a single adjustable weight specific to that
receptive field. The CMAC output is the average of the weights of the excited receptive fields. If nearby points in
the input space excite the same receptive fields, they produce the same output value. The output only changes when
the input crosses one of the receptive field boundaries. The Albus CMAC thus produces piece-wise constant outputs.
Learning takes place as described above.
CMAC neural networks have been applied in various control situations (see Miller, 1994, for a review), starting
from adaptation of PID control parameters for an industrial robot arm and hand-eye-systems up to biped walking
(Sabourin & Bruneau, 2005).
The Adjustable Pattern Generator APG: The APG model (Houk et al., 1996) got its name because the model
can generate a burst command with adjustable intensity and duration. The APG is based on the same understanding
of the mossy fiber-granule cell-parallel fiber structure as CMAC, using the same state encoder, but has the crucial
difference (Fig. 2c) that the role of the nuclei is crucial. In the APG model, each nucleus cell is connected to a motor
cell in a feedback circuit. Activity in the loop is then modulated by Purkinje cell inhibition, a modeling idea
introduced by Arbib et al. (1974).
The learning algorithm determines which of the PF-PC synapses will be updated in order to improve movement
generation performance. This is the traditional credit assignment problem: which synapse (the structural credit
assignment) must be updated based on a response issued when (temporal credit assignment). While the former is
solved by the CFs, which are considered binary signals, for the latter eligibility traces on the synapses are introduced
serving as memory for recent activity to determine which synapses are eligible for updates. The motivation for the
eligibility signal is this: Each firing of a PC cell will take some time to affect the animal’s movement, and an even

Arbib et al. for Robotics Handbook June 21, 2006 16
16
further delay will occur before the CF can signal an error in the movement in which the PC is involved. Thus the
error signal should not affect those PF-PC synapses which are currently active, but should instead act upon those
synapses which affected the activity whose error is now being registered – and this the eligibility is timed to signal.
The APG has been applied in a few control situations, e.g., a single muscle-mass system and a simulated two-link
robot arm. Unfortunately these applications do not allow us judge the performance of the APG scheme itself due to
the fact that the control task itself was hidden within spinal cord and muscle models.
The Schweighofer-Arbib Model: The Schweighofer-Arbib model was introduced in Schweighofer (1995). It
does not use the CMAC state encoder but tries to copy the anatomy of the cerebellum. All cells, fibers and axons in
Fig. 2a are included. Several assumptions are made: (1) there are two types of mossy fibers, one type reflecting the
desired state of the controlled plant and another which carries information on the current state. A mossy fiber
diverges into approximately 16 branches. (2) Granule cells have an average of four dendrites each of which receive
input from di��erent mossy fibers through a synaptic structure called the glomerulus. (3) Three Golgi cells synapse
on a granule cell through the glomerulus and the strength of their influence depends on the simulated geometric
distance between the glomerulus and the Golgi cell. (4) The climbing fiber connection on nuclear cells as well as
deep nuclei is neglected.
Learning in this model depends on directed error information given by the climbing fibers from the inferior olive
(IO). Here, long term depression is performed when the IO firing rate provides an error signal for an eligible
synapse, while compensatory but slower increases in synaptic strength can occur when no error signal is present.
Schweighofer applied the model to explain several acknowledged cerebellar system functions: (1) saccadic eye
movements, (2) two-link limb movement control (Schweighofer et al., 1998a,b), and (3) prism adaptation (Arbib et
al., 1995). Furthermore, control of a simulated human arm was demonstrated.
Multiple Paired Forward-Inverse Models (MPFIM): Building on a long history of cerebellar modeling by
Kawato, Wolpert and Kawato (1998) proposed a novel functional model of the cerebellum which uses multiple
coupled predictors and controllers which are trained for control, each being responsible for a small state space
region. The MPFIM model is based on the indirect/direct model approach by Kawato, and is also based on the
microcomplex theory. We noted earlier that a microzone is a group of PCs, while a microcomplex combines the PCs
of a microzone with their target cells in cerebellar nuclei. In MPFIM, a microzone consists of a set of modules
controlling the same degree of freedom and is learned by only one particular climbing fiber. The modules in this
microzone compete to control this particular synergy. Inside such a module there are three types of PC which
perform the computations of a forward model, an inverse model or a responsibility predictor, but all receiving the
same input. A single internal model i is considered to be a controller which generates a motor command �i and a
predictor which predicts the current acceleration. Each predictor is a forward model of the controlled system, while
each controller contains an inverse model of the system in a region of specialization. The responsibility signal
weights the contribution which this model will make to the overall output of the microzone. Indeed, MPFIM further
assumes that each microzone contains n internal models of situations occurring in the control task. Model i generates
motor command �i, and estimates its own responsibility ri. The feedforward motor command �ff consists only of the
output of the single models adjusted by the sum of responsibility signals: ��= iii rr /ff ττ .

Arbib et al. for Robotics Handbook June 21, 2006 17
17
The PCs are considered to be roughly linear. The MF inputs carry all necessary information including state
information, e��erence copies of the last motor commands as well as desired states. Granule cells, and eventually the
inhibitory interneurons as well, nonlinearly transform the state information to provide a rich set of basis functions
through the PFs. A climbing fiber carries a scalar error signal while each Purkinje cell encodes a scalar output –
responsibilities, predictions and controller outputs are all one-dimensional values. MPFIM has been introduced with
di��erent learning methods: its first implementations were done using gradient descent methods; subsequently, EM
batch-learning and hidden Markov chain EM learning have been applied.
Comparison of the Models: Summing up, we can categorize the cerebellar models CMAC, APG,
Schweighofer-Arbib, and MPFIM as follows:
(a) State-encoder driven models: This kind of model assumes that the granule cells are on-o�� types of entities
which split up the state-space. This kind of model is best suited for, e.g., simple function approximation, and su��ers
strongly from the curse of dimensionality.
(b) Cellular-level models: Obviously, the most realistic simulations would be at the cellular level. Unfortunately,
modeling only a few Purkinje cells at realistic conditions is an immense computational challenge, and other relevant
neurons are even less well understood. Still, from the biological point of view this kind of model is the most
important since it allows obtaining insight into cerebellar function on cellular level. The first steps into this direction
were taken by the Schweighofer-Arbib model.
(c) Functional models: From the computer science point of view, the most interesting models are based on
functional understanding of the cells. In this case, we obtain only a basic insight of the functions of the parts and
apply it as a crude approximation. This kind of approach is very promising and MPFIM, with its emphasis on the
use of responsibility signals to combine models appropriately, provides an interesting example of this approach..
64.3.3 Cerebellar Models and Robotics From the previous discussions, it is clear that a popular view is that the function of the cerebellum within the
motor control loop is to represent a forward model of the skeletomuscular system. As such it predicts the movements
of the body, or rather the perceptually coded (e.g. through muscle spindles, skin-based positional information, and
visual feedback) representation of the movements of the body. With this prediction a fast control loop between
motor cortex and cerebellum can be realized, and motor programs are played before being sent to the spinal cord (cf.
Fig. 4). Proprioceptive feedback is used for adaptation of the motor programs as well as for updating the forward
model stored in the cerebellum. However, the Schweighofer-Arbib model is based on the view that the cerebellum
offers not so much a total forward model of the skeletomuscular system so much as a forward model of the
difference between the crude model of the skeletomuscular system available to the motor planning circuits of the
cerebral cortex, and the more intricately parameterized forward model of the skeletomuscular system needed to
support fast, graceful movements with minimal use of feedback. This hypothesis is reinforced by the fact that
cerebellar lesions do not prohibit motion but substantially reduces its quality, since the forward model of the
skeletomuscular system is of lesser quality.
As robotic systems move towards their biological counterparts, the control approaches can or must do the same.
There are many lines of research investigating the former part; cf. Chapter 13 “Flexible Arms” and Chapter 60

Arbib et al. for Robotics Handbook June 21, 2006 18
18
“Biologically-Inspired Robots”. It be noted that the drive principle that is used to move the joints does not
necessarily have a major impact on the outer control loop. Whether McKibben muscles, which are intrinsically
flexible but bulky (van der Smagt et al, 1996), low-dynamics polymer linear actuators, or dc motors with spindles
and added elastic components are used does not affect the control approach at the cerebellar level, but rather at the
motor control level (cf. spinal cord level). Of key importance, however, are the resulting dynamical properties of the
system, which are of course influenced by its actuators.
Passive flexibility at the joints, which is a key feature of muscle systems, is essential for reasons of safety,
stability during contact with the environment, and storage of kinetic energy. As mentioned before, however,
biological systems are immensely complex, requiring large groups of muscles for comparatively simple movements.
A reason for this complexity is the resulting nearly linear behavior, which has been noted for, e.g., muscle activation
with respect to joint stiffness (Osu & Gomi, 1999). By this regularization of the complexity of the skeletomuscular
system, the complexity of the forward model stored in the cerebellum is correspondingly reduced. The whole picture
therefore seems to be that the cerebellum, controlling a piecewise linear skeletomuscular system, incorporates a
forward model thereof to cope with delays in the peripheral nervous system. Consequently, although the
applicability of cerebellar systems to highly nonlinear dynamics control of traditional robots is questionable, the use
of cerebellar systems as forward models appears to be useful in the control of more complex and flexible robotic
systems. The control challenge posed by the currently emerging generation of robots employing antagonistic motor
control therefore opens a new wealth of applications of cerebellar systems.
64.4. The Role of Mirror Systems Mirror neurons were first discovered in the brain of the macaque monkey – neurons that fire both when the
monkey exhibits a particular grasping action, and when the monkey observes another (monkey or human) perform a
similar grasp (Rizzolatti et al. 1995; Gallese et al., 1996). Since then, human studies have revealed a mirror system
for grasping in the human brain – a mirror system for a class X of actions being a set of regions that are active both
when the human performs some action from X and when the human observes someone else performing an action
from X (see, e.g., Grafton et al., 1996; Rizzolatti et al., 1996; Fadiga, et al., 1999). We have no single neuron studies
proving the reasonable hypothesis that the human mirror system for grasping contains mirror neurons for specific
actions, but most models of the human mirror system for grasping assume that it contains circuitry analogous to the
mirror neuron circuitry of the macaque brain. However, the current consensus is that monkeys have little or no
ability for imitation, whereas the human mirror system plays a key role in our capability for imitation (Iacoboni, et
al., 1999), pantomime, and even language (Arbib & Rizzolatti, 1997; Arbib, 2005). Indeed, it has been suggested
that mirror neurons underlie the motor theory of speech perception of Alvin Liberman et al. (1967) which holds that
speech perception rests on the ability to recognize the motor acts that produce speech sounds.
Section 64.4.1 reviews basic neurophysiological data on mirror neurons in the macaque, and presents both the
FARS model of canonical neurons (unlike mirror neurons, these are active when the monkey executes an action but
not when he observes it) and the MNS model of mirror neurons and their supporting brain regions. Section 64.4.2
then use Bayes rule to offer a new, probabilistic view of the mirror system’s role in action recognition, and
demonstrates the operation of the new model in the context of studies with two robots. Finally, Section 64.4.3

Arbib et al. for Robotics Handbook June 21, 2006 19
19
briefly shifts the emphasis of our study of mirror neurons to imitation, which in fact is the area that has most
captured the imagination of roboticists. 64.4.1 Mirror Neurons and the Recognition of Hand Movements
Area F5 in premotor cortex of the macaque contains, among others, neurons which fire when the monkey
executes a specific manual action: e.g., one neuron might fire when the monkey performs a precision pinch, another
when it executes a power grasp. (In discussing neurorobotics, it seems unnecessary to explain in any detail the areas
like F5, AIP and STS described here – they will function as labels for components of functional systems. To fill in
the missing details see, e.g., Rizzolatti et al., 1998, 2001.) A subset of these neurons, the so-called mirror neurons,
also discharge when the monkey observes meaningful hand movements made by the experimenter which are similar
to those whose execution is associated with the firing of the neuron. By contrast, the canonical neurons are those
belonging to the complementary, anatomically segregated subset of grasp-related F5 neurons which fire when the
monkey performs a specific action and also when it sees an object as a possible target of such an action – but do not
fire when the monkey sees another monkey or human perform the action. Finally, F5 contains a large population of
motor neurons which are active when the monkey grasps an object (either with the hand or mouth) but do not
possess any visual response. F5 is clearly a motor area although the details of the muscular activation are abstracted
out – F5 neurons can be effector-independent. By contrast, primary motor cortex (F1) formulates the neural
instructions for lower motor areas and motor neurons.
Moreover, macaque mirror neurons encode transitive actions and do not fire when the monkey sees the hand
movement unless it can also see the object or, more subtly, if the object is not visible but is appropriately “located”
in working memory because it has recently been placed on a surface and has then been obscured behind a screen
behind which the experimenter is seen to be reaching (Umiltà et al., 2001). All mirror neurons show visual
generalization. They fire when the instrument of the observed action (usually a hand) is large or small, far from or
close to the monkey. They may also fire even when the action instrument has shapes as different as those of a human
or monkey hand. Some neurons respond even when the object is grasped by the mouth. When naive monkeys first
see small objects grasped with a pair of pliers, mirror neurons do not respond, but after extensive training some
precision pinch mirror neurons do show activity also to this new grasp type (Ferrari et al., 2005).
Mirror neurons for grasping have also been found in parietal areas of the macaque brain and, recently, it has been
shown that parietal mirror neurons are sensitive to the context of the observed action being predictive of the
outcome as a function of contextual cues – e.g., some grasp related parietal mirror neurons may fire for a grasp that
precedes eating the grasped object while others fire for a grasp that precedes placing the object in a container (see
Fogassi, et al., 2005). In practice the parieto-frontal circuitry seems to encode action execution and simultaneously
action recognition by taking into account a large set of potential candidate actions which are selected on the basis of
a range of cues such as vision of the relation of the effector to the object and certain sounds (when relevant for the
task). Further, feedback connections (frontal to parietal) are thought to be part of a stimulus selection process which
refines the sensory processing by “attending” to stimuli relevant for the ongoing action (Rizzolatti et al., 1987;
recall discussion in Section 64.2.5). Recognition is then supported by the activation of the same circuitry in the
absence of overt movement.

Arbib et al. for Robotics Handbook June 21, 2006 20
20
Fig. 6. The original FARS diagram (Fagg & Arbib, 1998) is here modified to show PFC acting on AIP rather than F5.
The idea is that prefrontal cortex uses the IT identification of the object, in concert with task analysis and working
memory, to help AIP select the appropriate affordance from its “menu”.
We clarify these ideas by briefly presenting the FARS model of the canonical F5 neurons and the MNS model of
the F5 mirror neurons. In each case, the F5 neurons function effectively only because of the interaction of F5 with a
wide range of other regions. We have stressed (Section 64.2.3) the distinction between recognition of the category of
an object and recognition of its affordances. The parietal area AIP processes visual information to extract
affordances, in this case properties of the object relevant to grasping it (Taira et al., 1990). AIP and F5 are
reciprocally connected with AIP being more visual and F5 more motoric.
The FARS (Fagg-Arbib-Rizzolatti-Sakata) model (Fagg and Arbib 1998; Fig. 6) embeds F5 canonical neurons in
a larger system. The dorsal stream (which passes through AIP) can only analyze the object as a set of possible
affordances; whereas the ventral stream (via inferotemporal cortex, IT) is able to recognize what the object is. The
latter information is passed to prefrontal cortex (PFC) which can then, on the basis of the current goals of the
organism, bias the choice of affordances appropriate to the task at hand. Neuroanatomical data (as analyzed by
Rizzolatti and Luppino, 2003) suggest that PFC and IT may modulate action selection at the level of parietal cortex.
Fig. 6 gives a partial view of FARS updated to show this modified pathway. The affordance selected by AIP
activates F5 neurons to command the appropriate grip once it receive a “go signal” from another region, F6, of
prefrontal cortex. F5 also accepts signals from other PFC areas to respond to working memory and instruction
stimuli in choosing among the available affordances. Note that this same pathway could be implicated in tool use,
bringing in semantic knowledge as well as perceptual attributes to guide the dorsal system (Johnson-Frey, 2004).
With this, we turn to the mirror system. Since grasping a complex object require careful attention to motion of,
e.g., fingertips relative to the object we hold that the primary evolutionary impetus for the mirror system was to
facilitate feedback control of dexterous movement. We now show how parameters relevant to such feedback could
be crucial in enabling the monkey to associate the visual appearance of what it is doing with the task at hand. The
key “side effect” will be that this feedback-serving self-recognition is so structured as to also support recognition of

Arbib et al. for Robotics Handbook June 21, 2006 21
21
the action when performed by others – and it is this “recognition of the actions of others” that has created the
greatest interest in mirror neurons and systems.
Figure 7. The MNS (Mirror Neuron System) model (Oztop and Arbib, 2002). Note that this basic mirror system for
grasping crucially links the visual process of the superior temporal sulcus (STS) to the parietal regions (7b) and
premotor regions (F5) which have been shown to contain mirror neurons for manual actions.
The MNS model of Oztop & Arbib (2002) provides some insight into the anatomy while focusing on the learning
capacities of mirror neurons. Here, the task is to determine whether the shape of the hand and its trajectory are "on
track" to grasp an observed affordance of an object using a known action. The model is organized around the idea
that the AIP → F5canonical pathway emphasized in the FARS model (Fig. 6) is complemented by another pathway
7b → F5mirror. As shown in Fig. 7 (middle diagonal), object features are processed by AIP to extract grasp
affordances, these are sent on to the canonical neurons of F5 that choose a particular grasp. Top diagonal.
Recognizing the location of the object (top diagonal) provides parameters to the motor programming area F4 which
computes the reach. The information about the reach and the grasp is taken by the motor cortex M1 (=F1) to control
the hand and the arm. The rest of the figure provides components that can learn and apply key criteria for activating
a mirror neuron, recognizing that the preshape of the observed hand corresponds to the grasp that the mirror neuron
encodes and is appropriate to the object, and that the hand is moving on an appropriate trajectory. Making crucial
use of input from the superior temporal sulcus (STSa; Perrett et al., 1990; Carey et al., 1997), schemas at bottom left
recognize the shape of the observed hand, and how that hand is moving. Other schemas implement hand-object
spatial relation analysis and check how object affordances relate to hand state. Together with F5 canonical neurons,
this last schema (in parietal area 7b) provides the input to the F5 mirror neurons.
In the MNS model, the hand state was defined as a vector whose components represented the movement of the
wrist relative to the location of the object and of the hand shape relative to the affordances of the object. Oztop and
Arbib showed that an artificial neural network corresponding to PF and F5mirror could be trained to recognize the
grasp type from the hand state trajectory, with correct classification often being achieved well before the hand

Arbib et al. for Robotics Handbook June 21, 2006 22
22
reached the object, using activity in the F5 canonical neurons that commands a grasp as training signal for
recognizing it visually. Crucially, this training prepares the F5 mirror neurons to respond to hand-object relational
trajectories even when the hand is of the "other" rather than the "self” because the hand state is based on the view of
movement of a hand relative to the object, and thus only indirectly on the retinal input of seeing hand and object
which can differ greatly between observation of self and other. Bonaiuto et al (2006) have developed MNS2, a new
version of the MNS model to address data on audio-visual mirror neurons that respond to the sight and sound of
actions with characteristic sounds such as paper tearing and nut cracking (Kohler et al., 2002), and on response of
mirror neurons when the target object was recently visible but is currently hidden (Umiltà et al., 2001). Such
learning models, and the data they address, make clear that mirror neurons are not restricted to recognition of an
innate set of actions but can be recruited to recognize and encode an expanding repertoire of novel actions.
The discussion of this section avoided any reference to imitation (see Section 64.4.5. On the other hand, even
without considering imitation, mirror neurons provide a new perspective for tackling the problem of robotic
perception by incorporating action (and motor information) into a plausible recognition process. In role of the
fronto-parietal system in relating affordances, plans and actions shows the crucial role motor information and
embodiment. We argue that this holds lessons for neurorobotics: the richness of the “motor” system should strongly
influences what the robot can learn, proceeding autonomously via a process of exploration of the environment rather
than relying overmuch on the intermediary of logic-like formalisms. When recognition exploits the ability to act,
then the breadth of the action space becomes crucially related to the precision, quality, and robustness of the robot’s
perception.
64.4.2 A Bayesian View of the Mirror System We now show how to cast much that is known about the mirror system into a controller-predictor model (Miall et
al, 1993; Wolpert et al., 2001) and analyze the system in Bayesian terms. As shown by the FARS model, the
decision to initiate a particular grasping action is attained by the convergence in area F5 of several factors including
contextual and object-related information; similarly many factors affect the recognition of an action. All this
depends on learning both direct (from decision to executed action) and inverse models (from observation of an
action to activation of a motor command that could yield it). Similar procedures are well known in the
computational motor control literature (Jordan & Rumelhart, 1992; Kawato et al., 1987). Learning of the affordances
of objects with respect to grasping can also be achieved autonomously by learning from the consequences of
applying many different actions to different parts of different objects.
But how is the decision made to classify an observed behavior as an instance of one action or another? Many
comparisons could be performed in parallel with the model for one action becoming predominantly activated. There
are plausible implementations of this mechanism using a gating network (Demiris & Johnson, 2003; Haruno et al.,
2001). A gating network learns to partition an input space into regions; for each region a different model can be
applied or a set of models can be combined through an appropriate weight function. The design of the gating
network can encourage collaboration between models (e.g. linear combination of models) or competition (choosing
only one model rather than a combination). Oztop et al. (2005) offer a similar approach to the estimation of the
mental states of the observed actor, using some additional circuitry involving the frontal cortex.

Arbib et al. for Robotics Handbook June 21, 2006 23
23
We now offer a Bayesian approach to using the predictor-controller formulation approach to the mirror system.
This Bayesian approach views affordances as priors in the action recognition process where the evidence is
conveyed by the visual information of the hand, providing the data for finding the posterior probabilities as mirror
neurons-like responses which automatically activate for the most probable observed action. Recalling that the
presence of a goal (at least in working memory) is needed to elicit mirror neuron responses in the macaque. We
believe it is also particularly important during the ontogenesis of the human mirror system. For example, Woodward
(1998) has shown that even at nine months of age, infants recognized an action as being novel if it was directed
toward a novel object rather than just having a different kinematics – showing that the goal is more fundamental
than the enacted trajectory. Similarly, if one sees someone drinking from a coffee mug then one can hypothesize that
a particular action (that one already knows in motor terms) is used to obtain that particular effect. The association
between the canonical response (object-action) and the mirror one (including vision) is made when the observed
consequences (or goal) are recognized as similar in the two cases. Similarity can be evaluated following criteria
ranging from kinematic to social consequences.
Many formulations of recognition tasks are available in the literature (Duda, Hart, & Stork, 2000) besides those
keyed to the study of mirror neurons. Here, however, we focus on the Metta et al. (2006b) Bayesian interpretation of
the recognition of actions. We equate the prior probabilities for actions with the object affordances, that is:
( | )i kp A O (1)
where Ai is the ith action from a motor repertoire of I actions, and Ok is the target object of the grasping action out of
a set of K possible objects. The affordances of an object identify the set of actions that are most likely to be executed
upon it, and consequently the mirror activation of F5 can be thought as:
( | , )i kp A F O (2)
where F are the features obtained by observation of the trajectory of the temporal evolution of the observed action.
This probability can be computed from Bayes rule as:
( | , ) ( | , ) ( | )i k i k i kp A F O p F A O p A O= (3)
(An irrelevant normalization factor has been neglected so that, strictly speaking, the posterior in (3) is no longer a
probability.) With this, a classifier is constructed by taking the maximum over the possible actions:
ˆ max ( | , )i ki
A p A F O= (5)
Following Lopes & Santos-Victor (2005), Metta et al. assume that the features F along the trajectories are
independent. This is clearly not true for a smooth trajectory linking the movement of the hand and fingers to the
observed action. However, this approximation simplified the estimation of the likelihoods in equation, though later
implementations should take into account the dependence across time.
The object recognition stage (i.e., finding Ok ) requires as much vision as is needed to determine the probability
of the various grasp types being effective, the hand features F correspond to the STS response, and the response of
the mirror neurons determines the most probable observed action Ai. We can identify certain circuits in the brain
with the quantities described above:
( | , )i kp A F O Mirror neuron responses, obtained by a combination of the information as in (3)

Arbib et al. for Robotics Handbook June 21, 2006 24
24
( | , )i kp F A O The activity of the F5 motor neurons generating certain motor patterns given the selected action
and the target object
( | )i kp A O Object affordances: the response of the circuit linking AIP and the F5 canonical neurons
AIP�F5
Visuomotor map Transformation of the hand-related visual information into motor data: identified with the
response of STS � PF/PFG � F5, this is represented in F5 by ( | , )i kp F A O
However this table does not exhaust the various computations required in the model: In the learning phase, the
visuo-motor map is learned by a sigmoidal feedforward neural network trained with the backpropagation algorithm
(both visual and motor signals are available); affordances are learned simply by counting the number of occurrences
of actions given the object (visual processing of object features was assumed); and the likelihood was approximated
by a mixture of Gaussians and the parameters learned by the expectation maximization (EM) algorithm. During the
recognition phase, motor information is not available, but is recovered from the visuo-motor map. Fig. 8 shows a
block diagram of the operation of the classifier.
Figure 8:block diagram of the recognition process. Recognition (mirror neurons activation) is due to the
convergence in F5 of two main contributions: signals from the AIP-F5canonical connections and signals from the
STS-PF/PFG-F5 circuit. In this model, activations are thought of as probabilities and combined using Bayes’ rule.
A comparison (Lopes & Santos-Victor, 2005) was made of system performance (a) when using the output of the
inverse model and thus employing motor features to aid classification during the training phase; and (b) when only
visual data were available for classification. Overall, their interpretation of their results is that by mapping in motor
space they allow the classifier to choose features that are much better suited for performing optimally, which in turn
facilitates generalization. The same is not true in visual space, since a given action may be viewed from different
viewpoints. One may compare this to the viewpoint-invariant of hand state adopted in the MNS model – which has
the weakness there of being built in rather than emerging from training.
Another set of experiments was performed on a humanoid robot upper-torso called Cog (Brooks et al, 1999). Cog
has a head, arms, and a moving waist for a total of 22 degrees of freedom but does not have hands. It has instead
simple flippers that could be used to push and prod objects. Fitzpatrick & Metta (2003; Metta, et al., 2006b) were

Arbib et al. for Robotics Handbook June 21, 2006 25
25
interested in starting from minimal initial hypotheses yet yielding units with responses similar to mirror neurons.
The robot was programmed to identify suitable cues to start the interaction with the environment and direct its
attention towards potential objects, using an attention system similar to that (Itti & Koch, 2000) described in section
64.2.5. Although the robot could not grasp objects, it could generate useful cues from touch, push and prod actions.
The problem of defining objects reflects the problem of segmenting the visual scene. Criteria such as contrast,
binocular disparity and motion can be applied, but any of them can fail in a given situation. In the present system,
optic flow was used to detect and segment an object after impact with the arm end-point, and from segmentation
based on shape, color, and behavior data. Depending on the available motor repertoire, the robot could explore a
range of possible object behaviors (affordances) and form an object model which combines both sensorial and motor
properties of the object the robot had the chance to interact with.
In a typical experiment, the human operator waves an object in front of the robot which reacts by looking at it. If
the object is dropped on the table in front of the robot, a reaching action is initiated, and the robot possibly makes
contact with the object. Vision is used during the reaching and touching movement to guide the robot’s flipper
toward the object, to segment the hand from the object upon contact, and to collect information about the behavior
of the object caused by the application of a certain action (Fitzpatrick, 2003). Unfortunately, interaction of the
robot’s flipper with objects does not result in a wide class of different affordances and so this study focused on the
rolling affordances of a toy car, an orange juice bottle, a ball, and a colored toy cube.
Besides reaching, the robot’s motor repertoire consists of four different stereotyped approach movements covering a
range of directions of about 180° around the object. For each successful trial, the robot “stored” the result of the
segmentation, the object’s principal axis which was selected as representative shape parameter, the action – initially
selected randomly from the set of four approach directions – and the movement of the center of mass of the object
for some hundreds of milliseconds after impact with the flipper was detected. This gives information about the
rolling properties (affordances) of the different objects: e.g., the car tends to roll along its principal axis, the bottle at
right angle with respect to the axis. Figure 9 shows the result of collecting about 700 samples of generic poking
actions and estimating the average direction of displacement of the object. Note, for example, that the action labeled
as “backslap” (moving the object with the flipper outward from the robot) gives consistently a visual object motion
upward in the image plane (corresponding to the peak at –100°, 0° being the direction parallel to the image x axis;
the y axis pointing downward). A similar consideration applies to the other actions. Although crude, this
implementation shows that with little pre-existing structure the robot could acquire the crucial elements for building
knowledge of objects in terms of their affordances. Given a sufficient level of abstraction, this implementation is
close to the response of canonical neurons in F5 and their interaction with neurons observed in AIP that respond to
object orientation (Sakata et al., 1997).

Arbib et al. for Robotics Handbook June 21, 2006 26
26
Figure 9. Top panels: the affordances of two objects: a toy car and a bottle represented as the probability of moving
along a given direction measured with respect to the object principal axis (visual). It is evident that the toy car tends to
move mostly along the direction identified with the principal axis and the orange juice bottle at right angle with respect
to its principal axis. Bottom: the probability of a given action generating a certain object movement. The reference
frame is anchored to the image plane in this case.
64.4.3 Mirror Neurons and Imitation Fitzpatrick & Metta (2003) also addressed the question of what is further required for interpreting observed
actions. Where in the previous section, the robot identified the motion of the object because of a specific action
applied to it, here it could backtrack and derive the type of action from the observed motion of the object. It can
further explore what is causing motion and learn about the concept of manipulator in a more general setting. In fact,
the same segmentation procedure mentioned earlier could visually interpret poking actions generated by a human as
well as those generated by the robot. One might argue that observation could be exploited for learning about object
affordances. This is possibly true to the extent passive vision is reliable and action is not required. The advantage of
the active approach, at least for the robot, is that it allows controlling the amount of information impinging on the
visual sensors by, for instance, controlling the speed and type of action. This strategy might be especially useful
given the limitations of artificial perceptual systems. Thus, observations can be converted into interpreted actions.
The action whose effects are closest to the observed consequences on the object (which we might translate into the
goal of the action) is selected as the most plausible interpretation given the observation. Most importantly, the
interpretation reduces to the interpretation of the “simple” kinematics of the goal and consequences of the action
rather than to understanding the “complex” kinematics of the human manipulator. The robot understands only to the
extent it has learned to act. One might note that a more refined model should probably include visual cues from the

Arbib et al. for Robotics Handbook June 21, 2006 27
27
appearance of the manipulator into the interpretation process. Indeed, the hand state that was central to the Oztop-
Arbib model was based on an object-centered view of the hand’s trajectory in a coordinate frame based on the
object’s affordances. The last question to address is whether the robot can imitate the “goal” of a poking action. The
step is indeed small since most of the work is actually in interpreting observations. Imitation was generated in the
following by replicating the latest observed human movement with respect to the object and irrespective of its
orientation. For example, in case the experimenter poked the toy car sideways, the robot imitated him/her by
pushing the car sideways. Starting from this simple experiment, we need to formalize what is required for a system
that has to acquire and deliver imitation.
Roboticists have been fascinated by the discovery of mirror neurons and the purported link to imitation that
exists in the human nervous system. The literature on the topic extends from models of the monkey’s (non-imitative)
action recognition system (Oztop & Arbib, 2002) to models of the putative role of the mirror system in imitation
(Demiris & Johnson, 2003; Arbib et al., 2000), and in real and virtual robots (Schaal, Ijspeert, & Billard, 2003).
Oztop, Kawato, Arbib (2006) propose a taxonomy of the models of the mirror system for recognition and imitation,
and it is interesting to note how different are the computational approaches that have been now framed as mirror
system models, including recurrent neural networks with parametric bias (Tani et al., 2004), behavior-based modular
networks (Demiris & Johnson, 2003), associative memory based methods (Kuniyoshi et al., 2003), and the use of
multiple direct-inverse models as in the MOSAIC architecture (Wolpert et al., 2003; cf. the Multiple Paired
Forward-Inverse Models of Section 64.3.2).
Following the work of Schaal et al. (2003) and Oztop et al. (2006), we can propose a set of schemas required to
produce imitation:
• determine what to imitate, inferring the goal of the demonstrator
• establish a metric for imitation (correspondence; Nehaniv, 2006)
• map between dissimilar bodies (mapping)
• imitate behavior formation
which are also discussed also in greater detail by Nehaniv & Dautenhahn (1998). In practice, computational and
robotic implementations have tackled these problems with different approaches and emphasizing different parts or
specific subproblems of the whole. For example, in the work of Demiris and Hayes (2002), the rehearsal of the
various actions (akin to the aforementioned theory of motor perception) was used to generate hypotheses to be
compared with the actual sensory input. It is then remarkable how more recently a modified approach of this
paradigm has been used in comparison with real human transcranial magnetic stimulation (TMS) data.
Ito et al. (2006) (not the Masao Ito of cerebellar fame) take a dynamical systems approach using a recurrent
neural network with parametric bias (RNNPB) and teach a humanoid robot to manipulate certain objects. In this
approach the parametric bias (PB) encodes (tags) certain sensorimotor trajectories. Once learning is complete the
neural network can be used either to recall a given trajectory by setting the PB externally or provide input for the
sensory data only and observe the PB vector that would represent in that case the recognition of the situation on the
basis of the sensory input only (not motor information available). It is relatively easy to interpret these two situations
as the motor generation and the observation in a mirror neurons model.

Arbib et al. for Robotics Handbook June 21, 2006 28
28
The problem of building useful mappings between dissimilar bodies (consider a human imitating a bird’s
flapping wings) was tackled by Nehaniv and Dautenhahn (1998) where an algebraic framework for imitation is
described and the correspondence problem formally addressed. Any system implementing imitation should clearly
provide a mapping between either dissimilar bodies or even in the case of similar bodies when either the kinematics
or dynamics is different depending on the context of the imitative action.
Sauser & Billard (2006) modeled the ideomotor principle, according to which, observing the behavior of others
influences our own performances. The ideomotor principle points directly to one of the core issues of the mirror
system, that is, the fact that watching somebody else’s actions changes something in the activation of the observer,
thus facilitating certain neural pathways. The work in question gives also a model implemented in terms of neural
fields (see Sauser & Billard, 2006 for details) and tries to explain the imitative cortical pathways and the behavior
formation.
64.5. Extroduction As the foregoing makes clear, robotics has much to learn from neuroscience and much to teach neuroscience.
Neurorobotics can learn from the ways in which the brains and bodies of different creatures adapt to diverse
ecological niches – as computational neuroethology helps us undertand how the brain of a creature has evolved to
serve “action-oriented perception”, and the attendant ptrocesses of learning, memory, planning and social
interaction.
We have sampled the “design” of just a few subsystems (both functional and structural) in just a few animals –
optic flow in the bee, approach, escape and barrier avoidance in frog & toad, and navigation in the rat, as well as the
control of eye movements in visual attention, the role of mammalian cerebellum in handling the nonlinearities and
time delays of flexible motor systems, and the mirror systems of primates in action recognition and of humans in
imitation. And there are many more creatures with lessons to offer the roboticist than we can sample here.
Moreover, if we just confine attention to the brains of humans, this Chapter has mention at least 7a, 7b, AIP,
Area 46, caudo-putamen, cerebellum, cIPS, F2, F4, F5, hippocampus, hypothalamus, inferotemporal cortex, LIP,
MIP, motor cortex, nucleus accumbens, parietal cortex, prefrontal cortex, premotor cortex, pre-SMA (F6), spinal
cord, STS, and VIP – and it is clear that there are many more details to be understood for each region, and many
more regions whose interactions hold lessons for roboticists. We say this not to depress the reader, but rather to
encourage further exploration of the literature of computational neuroscience and to note that the exchange with
neurorobotics proceeds both ways: neuroscience can inspire novel robotic designs; conversely, robots can be used to
test whether brain models still work when they make the transition from disembodied computer simulation to
meeting the challenge of guiding the interactions of a physically embodied system with the complexities of its
environment.
64.6. References Albus, J. S., 1971, A theory of cerebellar function, Mathematical Biosciences 10: 25-61.
Albus, J. S., 1975, Data Storage in the Cerebellar Model Articulation Controller (CMAC), Journal of Dynamic
Systems, Measurement and Control, ASME, pp. 228-233.

Arbib et al. for Robotics Handbook June 21, 2006 29
29
Arbib, M. A., 1981, Perceptual structures and distributed motor control, in Handbook of Physiology – The Nervous
System II. Motor Control (V. B. Brooks, Ed.), Bethesda, MD: American Physiological Society, pp.1449-1480.
Arbib, M. A. (1987). Levels of modeling of visually guided behavior. Behavioral and Brain Science, 10:407-465.
Arbib, M. A., 1989, Visuomotor Coordination: Neural Models and Perceptual Robotics, in Visuomotor
Coordination: Amphibians, Comparisons, Models, and Robots, (J. -P. Ewert and M. A. Arbib, Eds.), Plenum
Press, pp. 121-171.
Arbib, M.A. (2005). From Monkey-like Action Recognition to Human Language: An Evolutionary Framework for
Neurolinguistics (with commentaries and author’s response), Behavioral and Brain Sciences, 28, 105-167.
Arbib, M. A., & House, D. H. (1987). Depth and detours: An essay on visually guided behavior. in M.A. Arbib &
A.R. Hanson (Eds.), Vision, Brain and Cooperative Computation, Bradford Books/ The MIT Press, pp.129-163.
Arbib, M., and Rizzolatti, G., 1997, Neural expectations: a possible evolutionary path from manual skills to
language, Communication and Cognition, 29, 393-424.
Arbib, M. A., Billard, A., Iacoboni, M., & Oztop, E. (2000). Synthetic brain imaging: grasping, mirror neurons and
imitation. Neural Networks, 13(8-9), 975-997.
Arbib, M. A., Boylls, C. C., and Dev, P., 1974, Neural Models of Spatial Perception and the Control of Movement,
in Kybernetik und Bionik/Cybernetics R. Oldenbourg, pp. 216-231.
Arbib, M.A., Schweighofer, N., and Thach, W. T., 1995, Modeling the Cerebellum: From Adaptation to
Coordination, in Motor Control and Sensory-Motor Integration: Issues and Directions, (D. J. Glencross and J. P.
Piek, Eds. ), Amsterdam: North-Holland Elsevier Science, pp. 11-36.
Arkin, R. C. (1998). Behavior-Based Robotics, Cambridge, MA: The MIT Press.
Arkin, R. C. (1989). Motor schema-based mobile robot navigation. International Journal of Robotics Research,
8:92-112.
Arkin, R., Fujita, M., Takagi, T., and Hasegawa, R., 2003, An Ethological and Emotional Basis for Human-Robot
Interaction, Robotics and Autonomous Systems, 42(3-4).
Barron A, Srinivasan MV., 2006, Visual regulation of ground speed and headwind compensation in freely flying
honey bees (Apis mellifera L.). J Exp Biol. 209(Pt 5):978-84.
Beer, R. D., 1990, Intelligence as Adaptive Behavior: An Experiment in Computational Neuroethology, Academic
Press.
Bonaiuto, B., Rosta, E., & Arbib, M.A., 2006, Extending the Mirror Neuron System Model, I. Audible Actions and
Invisible Grasps, Biological Cybernetics (in press).
Borst, A., & Dickinson, M., 2003, Visual Course Control in Flies, in The Handbook of Brain Theory and Neural
Networks, Second Edition, (M.A. Arbib, Ed.), Cambridge, MA: Bradford Books/The MIT Press, pp.1205-1210.
Braitenberg, V., 1965, Taxis, kinesis, decussation, Progress in Brain Research, 17:210-222.
Braitenberg, V., 1984, Vehicles: Experiments in Synthetic Psychology, Bradford Books/The MIT Press.
Brooks, R. A., Breazeal, C. L., Marjanovi�, M., & Scassellati, B. (1999). The COG project: Building a Humanoid
Robot. In C. L. Nehaniv (Ed.), Computation for Metaphor, Analogy and Agents (Vol. 1562, pp. 52-87):
Springer-Verlag.

Arbib et al. for Robotics Handbook June 21, 2006 30
30
Bullock, D., & Contreras-Vidal, J. (1993). How spinal neural networks reduce discrepancies between motor
intention and motor realization. In K. Newell & D. Corcos (Eds.), Variability and motor control (pp. 183–221).
Champaign, Illinois: Human Kinetics Press.
Cliff, D., 2002, Neuroethology, Computational, in The Handbook of Brain Theory and Neural Networks, Second
Edition, (M.A. Arbib, Ed.), Cambridge, MA: Bradford Books/The MIT Press.
Cobas, A., and Arbib, M., 1992, Prey-Catching and Predator-Avoidance in Frog and Toad: Defining the Schemas. J.
Theor. Biol, 157:271-304.
Collett, T. (1982). Do toads plan routes? A study of detour behavior of B. viridis. Journal of Comparative
Physiology [A], 146:261-271.
Corbacho, F.J., and Arbib, M.A., 1995, Learning to Detour, Adaptive Behavior, 4:419-468.
Damsgaard, M., Rasmussen, J., & Christensen, S.T. (2000): Numerical simulation and justification of antagonists in
isometric squatting. In: Prendergast, P.J., Lee, T.C., Carr, A.J.: Proceedings of the 12th Conference of the
European Society of Biomechanics, Royal Academy of Medicine in Ireland.
Dean, P., Redgrave, P. & Westby, G. W. M. 1989 Event or emergency? Two response systems in the mammalian
superior colliculus. Trends Neurosci. 12: 138–147.
Demiris, Y., Hayes, G. (2002). Imitation as a dual-route process featuring predictive and learning components: a
biologically-plausible computational model. In K. Dautenhahn and C. Nehaniv (Eds.), Imitation in Animals and
Artifacts. MIT Press.
Demiris, Y., & Johnson, M. H. (2003). Distributed, predictive perception of actions: a biologically inspired robotics
architecture for imitation and learning. Connection Science, 15(4), 231-243.
Didday, R. L., 1976, A model of visuomotor mechanisms in the frog optic tectum, Mathematical Biosciences,
30:169-180.
Duda, R. O., Hart, P. E., & Stork, D. G. (2001). Pattern Classification (2nd. ed.). New York: John Wiley and Sons
Inc.
Ebadzadeh, M., Tondu, B., and Darlot, C., 2005, Computation of inverse functions in a model of cerebellar and
reflex pathways allow to control a mobile mechanical segment, Neuroscience 133: 29-49.
Eccles, J. C., Ito, M., and Szentágothai, J., 1967, The Cerebellum as a Neuronal Machine, Springer-Verlag.
Fadiga, L., Buccino, G., Craighero, L., Fogassi, L., Gallese, V., & Pavesi, G. (1999). Corticospinal excitability is
specifically modulated by motor imagery: a magnetic stimulation study. Neuropsychologia, 37, 147-158.
Fagg, A. H., and Arbib, M. A., 1998, Modeling Parietal-Premotor Interactions in Primate Control of Grasping,
Neural Networks, 11:1277-1303.
Ferrari, P. F., Rozzi, S., & Fogassi, L. (2005). Mirror Neurons Responding to Observation of Actions Made with
Tools in Monkey Ventral Premotor Cortex. Journal of Cognitive Neuroscience, 17: 212-226.
Fitzpatrick, P. (2003). First Contact: an active vision approach to segmentation. Paper presented at the IEEE/RSJ
International Conference on Intelligent Robots and Systems (IROS), October 27-31, Las Vegas, Nevada, USA.
Fitzpatrick, P., & Metta, G. (2003). Grounding vision through experimental manipulation. Philosophical
Transactions of the Royal Society: Mathematical, Physical, and Engineering Sciences, 361(1811), 2165-2185.

Arbib et al. for Robotics Handbook June 21, 2006 31
31
Fogassi, L., Ferrari, P. F., Gesierich, B., Rozzi, S., Chersi, F., & Rizzolatti, G. (2005). Parietal Lobe: From Action
Organization to Intention Understanding. Science, 308(4), 662-667.
Fregnac, Y., 2003, Hebbian Synaptic Plasticity, in The Handbook of Brain Theory and Neural Networks, Second
Edition, (M.A. Arbib, Ed.), Cambridge, MA: Bradford Books/The MIT Press, pp.5125-522.
Gallese, V., Fadiga, L., Fogassi, L., & Rizzolatti, G. (1996). Action recognition in the premotor cortex. Brain, 119,
593-609.
Gibson, J. J. 1966 The senses considered as perceptual systems. London: Allen & Unwin.
Girard B, Filliat D, Meyer JA, et al., 2005, Integration of navigation and action selection functionalities in a
computational model of cortico-basal-ganglia-thalamo-cortical loops, Adaptive Behavior 13(2):115-130.
Goodale, M. A., and Milner, A. D., 1992, Separate visual pathways for perception and action, Trends in
Neuroscience, 15:20-25.
Guazzelli, A., Corbacho, F. J., Bota, M., and Arbib, M. A., 1998, Affordances, Motivation, and the World Graph
Theory, Adaptive Behavior, 6:435-471.
Grafton, S. T., Arbib, M. A., Fadiga, L., and Rizzolatti, G., 1996, Localization of grasp representations in humans by
PET: 2. Observation compared with imagination. Exp Brain Res. 112:103-111.
Haruno, M., Wolpert, D. M., & Kawato, M. (2001). MOSAIC Model for sensorimotor learning and control. Neural
Computation, 13, 2201-2220.
Hoff, B., and Arbib, M.A., 1992, A model of the effects of speed, accuracy, and perturbation on visually guided
reaching, in Control of Arm Movement in Space: Neurophysiological and Computational Approaches, (R.
Caminiti, P.B. Johnson, and Y. Burnod, Eds.), Experimental Brain Research Series 22, pp.285-306.
Hoff, B. and Arbib, M.A., 1993, Simulation of Interaction of Hand Transport and Preshape During Visually Guided
Reaching to Perturbed Targets, J .Motor Behav. 25: 175-192.
Houk, J. C., Buckingham, J. T., & Barto, A. G., 1996, Models of the cerebellum and motor learning, Behavioral and
Brain Sciences 19(3): 368-383.
Iacoboni, M., Woods, R. P., Brass, M., Bekkering, H., Mazziotta, J. C., & Rizzolatti, G. (1999). Cortical
Mechanisms of Human Imitation. Science, 286, 2526-2528.
Ingle, D., 1968, Visual releasers of prey catching behavior in frogs and toads Brain, Behav., Evol. 1: 500-518.
Ito, M., 1984, The cerebellum and neural control, New York: Raven Press.
Ito, M., 2006, Cerebellar circuitry as a neuronal machine, Progress in Neurobiology 78 (5): 272-303
Ito, M., Noda, K., Hoshino, Y., & Tani, J. (2006). Dynamic and interactive generation of object handling behaviors
by a small humanoid robot using a dynamic neural network model. Neural Networks, 19(2), 323-337.
Itti, L., and Koch, C., 2000 A saliency-based search mechanism for overt and covert shifts of visual attention, Vision
Research, 40:1489-1506.
Jeannerod M., and Biguer, B., 1982, Visuomotor mechanisms in reaching within extra-personal space. In: Advances
in the Analysis of Visual Behavior (D.J. Ingle, R.J.W. Mansfield and M.A. Goodale, Eds.), The MIT Press,
pp.387-409.
Johnson-Frey SH. 2004 The neural bases of complex tool use in humans. Trends in Cognitive Sciences 8:71-78.

Arbib et al. for Robotics Handbook June 21, 2006 32
32
Jordan, M. I., & Rumelhart, D. E. (1992). Forward models: Supervised learning with a distal teacher. Cognitive
Science, 16(3), 307-354.
Kawato, M., Furukawa, K., & Suzuki, R. (1987). A hierarchical neural network model for control and learning of
voluntary movement. Biological Cybernetics, 57, 169-185.
Khatib, O. (1986). Real-time obstacle avoidance for manipulators and mobile robots. The International Journal of
Robotics Research, 5:90-98.
Kuniyoshi, Y., Yorozu, Y., Inaba, M., & Inoue, H. (2003). From visuomotor self learning to visual imitation - a
neural architecture for humanoid learning. Paper presented at the International conference on Robotics and
Automation, Taipei, Taiwan.
Lettvin, J. Y., Maturana, H., McCulloch, W. S., and Pitts, W. H., 1959, What the frog's eye tells the frog brain,
Proceedings of the IRE, 47:1940-1951.
Liberman, A. M., Cooper, F. S., Shankweiler, D. P., & Studdert-Kennedy, M. (1967). Perception of the speech code.
Psychological Review, 74, 431-461.
Lieblich, I., and Arbib, M.A., 1982, Multiple Representations of Space Underlying Behavior, The Behavioral and
Brain Sciences, 5: 627-659.
Liu, SC, & Usseglio-Viretta, A., 2001, Fly-like visuomotor responses of a robot using aVLSI motion-sensitive
chips. Biol Cybern. 85(6):449-57.
Lopes, M., & Santos-Victor, J. (2005). Visual learning by imitation with motor representations. IEEE Transactions
on Systems, Man, and Cybernetics, Part B Cybernetics, 35(3):438-449.
Lyons, D.M., and Arbib, M.A., 1989, A Formal Model of Computation for Sensory-Based Robotics, IEEE Trans. on
Robotics and Automation, 5:280-293.
Marr, D. A., 1969, A theory of cerebellar cortex, Journal of Physiology 202: 437-470.
Metta, G., Fitzpatrick, P., & Natale, L. (2006a). YARP: yet another robot platform. International Journal on
Advanced Robotics Systems, 3(1):43-48.
Metta, G., Sandini, G., Natale, L., Craighero, L., & Fadiga, L. (2006a). Understanding mirror neurons: a bio-robotic
approach. Interaction Studies, special issue on Epigenetic Robotics, 7(2):197–232.
Meyer JA, Guillot A, Girard B, et al., 2005, The Psikharpax project: towards building an artificial rat, Robotics and
Autonomous Systems 50(4):211-223.
Miall, R.C., Weir, D.J., Wolpert, D.M. and Stein, J.F., 1993, Is the cerebellum a Smith predictor?, Journal of Motor
Behavior 25: 203-216
Miller, W. T., 1994, Real-time application of neural networks for sensor-based control of robots with vision. IEEE
Transactions on Systems, Man, and Cybernetics, vol. 19, pp. 825-831.
Navalpakkam, V., & Itti, L., 2005, Modeling the influence of task on attention, Vision Research 45:205–231
Nehaniv, C.L., 2006, Nine billion correspondence problems, in Imitation and Social Learning in Robots, Humans,
and Animals: Behavioural, Social and Communicative Dimensions (C.L. Nehaniv and K. Dautenhahn, Eds.),
Cambridge: Cambridge University Press.

Arbib et al. for Robotics Handbook June 21, 2006 33
33
Nehaniv, C.L., & Dautenhahn, K. (1998). Mapping between dissimilar bodies: Affordances and the algebraic
foundations of imitation. Paper presented at the European Workshop on Learning Robots (EWRL-7), Edinburgh,
UK.
Nijhof, E.-J., Kouwenhoven, E., 2002: Simulation of multijoint arm movements. In: Biomechanics and Neural
Control of Posture and Movement (Winters, J.M., Crago, P.E., Eds.). New York : Springer-Verlag, pp. 363-372.
O'Keefe, J. and Nadel, L., 1978, The Hippocampus as a Cognitive Map, Oxford: Clarendon Press.
Orabona, F., Metta, G., & Sandini, G. (2005, June 25th). Object-based Visual Attention: a Model for a Behaving
Robot. Paper presented at the 3rd International Workshop on Attention and Performance in Computational
Vision, CVPR, San Diego, CA, USA
Osu, R. and Gomi, H., 1999, Multijoint muscle regulation mechanisms examined by measured human arm stiffness
and EMG signals, Journal of Neurophysiology, 81 (4), 1458-1468.
Oztop, E., and Arbib, M.A., 2002, Schema Design and Implementation of the Grasp-Related Mirror Neuron System,
Biological Cybernetics, in press.
Oztop, E., Kawato, M., & Arbib, M. A. (2006). Mirror neurons and imitation: A computationally guided review.
Neural Networks, 19(3), 254-271.
Oztop, E., Wolpert, D. M., & Kawato, M. (2005). Mental state inference using visual control parameters. Cognitive
Brain Research, 22, 129-151.
Perrett, D.I., Hietanen, J.K., Oram, M.W. and Benson, P.J. (1992) Organization and functions of cells in the
macaque temporal cortex. Philosophical Transactions of the Royal Society of London, B, 335: 23-50.
Perrett. D.M. & Puce, A. (2003) Electrophysiology and brain imaging of biological motion. Phil. Trans. R. Soc.
Lond. B 358, 435–445.
Peters, J. and van der Smagt, P., 2002, Searching a scalable approach to cerebellar based control, Applied
Intelligence 17: 11-33.
Reichardt, W. (1961) Autocorrelation, a principle for the evaluation of sensory information by the central nervous
system. In W.A. Rosenblith (ed): Sensory Communication. New York, London: The M.I.T. Press and John Wiley
& Sons, pp. 303-317.
Reiser MB, Dickinson MH, 2003, A test bed for insect-inspired robotic control., Philos Transact A Math Phys Eng
Sci. Oct 15;361(1811):2267-85.
Rizzolatti, G., & Luppino, G. (2003). Grasping movements: visuomotor transformations. In M. A. Arbib (Ed.), The
handbook of brain theory and neural networks (2nd ed). Cambridge, MA: The MIT Press, pp. 501–504.
Rizzolatti, G., Fadiga L., Gallese, V., and Fogassi, L., 1995, Premotor cortex and the recognition of motor actions.
Cogn Brain Res., 3: 131-141.
Rizzolatti, G., Fadiga, L., Matelli, M., Bettinardi, V., Perani, D., and Fazio, F., 1996, Localization of grasp
representations in humans by positron emission tomography: 1. Observation versus execution. Exp Brain Res.,
111:246-252.
Rizzolatti, G., Fogassi L., & Gallese, V. (2001) Neurophysiological mechanisms underlying the understanding and
imitation of action. Nat. Rev. Neurosc. 2, 661-670.

Arbib et al. for Robotics Handbook June 21, 2006 34
34
Rizzolatti, G., G. Luppino, & M. Matelli (1998) The organization of the cortical motor system: new concepts.
Electroencephalography and Clinical Neurophysiology (106:283-296.
Rizzolatti, G., Riggio, L., Dascola, I., & Umiltà, C. (1987). Reorienting attention across the horizontal and vertical
meridians: evidence in favor of a premotor theory of attention. Neuropsychologia, 25, 31-40.
Ruffier, F. Viollet, S. Amic, S. Franceschini, N., 2003, Bio-inspired optical flow circuits for the visual guidance of
micro air vehicles, in: Proceedings of the 2003 International Symposium Circuits and Systems, 2003. ISCAS '03.,
Volume: 3, pp. III-846-III-849.
Sabourin, C. and Bruneau, O., 2005, Robustness of the dynamic walk of a biped robot subjected to disturbing
external forces by using CMAC neural networks, Robotics and Autonomous Systems 51: 81-99
Sakata, H., Taira, M., Kusunoki, M., Murata, A., & Tanaka, Y. (1997). The TINS lecture - The parietal association
cortex in depth perception and visual control of action. Trends in Neurosciences, 20(8), 350-358.
Sandini, G., & Tagliasco, V. (1980). An Anthropomorphic Retina-like Structure for Scene Analysis. Computer
Vision, Graphics and Image Processing, 14(3), 365-372.
Sauser, E.L., & Billard, A. (2006). Parallel and distributed neural models of the ideomotor principle: An
investigation of imitative cortical pathways. Neural Networks, 19:285-298.
Schaal, S. and Schweighofer, N., 2005, Computational motor control in humans and robots, Current Opinion in
Neurobiology 15: 675-682.
Schaal, S., Ijspeert, A. J., & Billard, A. (2003). Computational approaches to motor learning by imitation.
Philosophical Transaction of the Royal Society: Biological Sciences, 358(1431), 537–547.
Schweighofer, N., 1995, Computational models of the cerebellum in the adaptive control of movements, Ph.D.
thesis, University of Southern California.
Schweighofer, N., Arbib, M. A., and Kawato, M., 1998a, Role of the Cerebellum in Reaching Quickly and
Accurately: I. A Functional Anatomical Model of Dynamics Control, European Journal of Neuroscience, 10: 86-
94.
Schweighofer, N., Spoelstra, J., Arbib, M. A., and Kawato, M., 1998b, Role of the Cerebellum in Reaching Quickly
and Accurately: II. A Neural Model of the Intermediate Cerebellum, European Journal of Neuroscience, 10:95-
105.
Segev, I., & London, M., 2003, Dendritic Processing, in The Handbook of Brain Theory and Neural Networks,
Second Edition, (M.A. Arbib, Ed.), Cambridge, MA: Bradford Books/The MIT Press, pp.324-332.
Srinivasan MV & Zhang SW 1997, Visual control of honeybee flight. EXS, 84:95-113.
Srinivasan MV, Zhang S, Chahl JS., 2001, Landing strategies in honeybees, and possible applications to
autonomous airborne vehicles. Biol Bull. 200(2):216-21.
Stein, B.E., and Meredith, M.A., 1993, The Merging of the Senses, Cambridge, MA: The MIT Press.
Strosslin T, Krebser C, Arleo A, Gerstner W, 2002, Combining multimodal sensory input for spatial learning, in
Artificial Neural Networks - ICANN 2002, Lecture Notes In Computer Science, 2415:87-92.
Taira, M., Mine, S., Georgopoulos, A.P., Murata, A., and Sakata, H., 1990, Parietal cortex neurons of the monkey
related to the visual guidance of hand movement, Exp. Brain Res. 83:29-36.

Arbib et al. for Robotics Handbook June 21, 2006 35
35
Tani, J., Ito, M., & Sugita, Y. (2004). Self-organization of distributedly represented multiple behavior schemata in a
mirror system: Reviews of robot experiments using RNNPB. Neural Networks, 17(8-9), 1273-1289.
Umiltà MA, Kohler E, Gallese V, Fogassi L, Fadiga L, Keysers C, Rizzolatti G. (2001) I know what you are doing.
a neurophysiological study, Neuron 31(1):155-65.
Ungerleider, L. G., and Mishkin, M., 1982, Two cortical visual systems, in Analysis of Visual Behavior (D. J. Ingle,
M. A. Goodale, and R. J. W. Mansfield, Ed.), Cambridge, MA: The MIT Press, pp.549-586.
van der Smagt, P., 1997, Teaching a robot to see how it moves, Neural Network Perspectives on Cognition and
Adaptive Robotics, (Browne, A, Ed.) pp. 195-219. Institute of Physics Publishing.
van der Smagt, P., 1998, Cerebellar control of robot arms, Connection Science, 10:301-320.
van der Smagt, P., 2000, Benchmarking cerebellar control, Robotics and Autonomous Systems, 32:237-251.
van der Smagt, P. and Groen, F., 1997, Visual feedback in motion, Neural Systems for Robotics, (Omidvar, O. and
van der Smagt, P., Eds.), Academic Press, pp.37-73
van der Smagt, P., Groen, F. and Schulten, K., 1996, Analysis and control of a rubbertuator robot arm, Biological
Cybernetics 75(5): 433-440.
Walter, W.G., 1953, The Living Brain, London Duckworth (reprinted by Pelican Books, Harmondsworth, 1961).
Wolfe, J M, 1994, Guided search 2.0: a revised model of visual search, Psychonomic Bull Rev, 1:202-238.
Wolpert, D. and Kawato, M., 1998, Multiple paired forward and inverse models for motor control, Neural Networks
11: 1317-1329.
Wolpert, D. M., Doya, K., & Kawato, M. (2003). A unifying computational framework for motor control and social
interaction. Philosophical Transaction of the Royal Society: series B, Biological Sciences, 358(1431), 593-602.
Wolpert, D. M., Ghahramani, Z., & Flanagan, R. J. (2001). Perspectives and problems in motor learning. Trends in
Cognitive Sciences, 5(11), 487-494.
Woodward, A. L. (1998). Infant selectively encode the goal object of an actor's reach. Cognition, 69, 1-34.
Yarbus, A, 1967, Eye Movements and Vision, New York: Plenum Press.

Human motor cortex excitability during the perception ofothers’ actionLuciano Fadiga1, Laila Craighero1 and Etienne Olivier2
Neuroscience research during the past ten years has
fundamentally changed the traditional view of the motor
system. In monkeys, the finding that premotor neurons also
discharge during visual stimulation (visuomotor neurons) raises
new hypotheses about the putative role played by motor
representations in perceptual functions. Among visuomotor
neurons, mirror neurons might be involved in understanding
the actions of others and might, therefore, be crucial in
interindividual communication. Functional brain imaging
studies enabled us to localize the human mirror system, but the
demonstration that the motor cortex dynamically replicates the
observed actions, as if they were executed by the observer, can
only be given by fast and focal measurements of cortical
activity. Transcranial magnetic stimulation enables us to
instantaneously estimate corticospinal excitability, and has
been used to study the human mirror system at work during the
perception of actions performed by other individuals. In the
past ten years several TMS experiments have been performed
investigating the involvement of motor system during others’
action observation. Results suggest that when we observe
another individual acting we strongly ‘resonate’ with his or
her action. In other words, our motor system simulates
underthreshold the observed action in a strictly congruent
fashion. The involved muscles are the same as those used in
the observed action and their activation is temporally strictly
coupled with the dynamics of the observed action.
Addresses1 Section of Human Physiology, Universita di Ferrara, Ferrara, Italy2 Laboratory of Neurophysiology, Universite Catholique de Louvain,
Brussels, Belgium
Corresponding author: Fadiga, Luciano ([email protected])
Current Opinion in Neurobiology 2005, 15:213–218
This review comes from a themed issue on
Cognitive neuroscience
Edited by Angela D Friederici and Leslie G Ungerleider
Available online 17th March 2005
0959-4388/$ – see front matter
# 2005 Elsevier Ltd. All rights reserved.
DOI 10.1016/j.conb.2005.03.013
IntroductionA large amount of evidence suggests that actions are
represented in the brain in a similar way to words in a
vocabulary [1]. Neurophysiological studies of monkey
premotor cortex have established that hand and mouth
goal directed actions are represented in area F5. This
www.sciencedirect.com
goal-directed encoding is demonstrated by the discrimi-
native behavior of F5 neurons when an action that is
motorically similar to the one effective in triggering
neuronal response is executed in a different context.
For instance, a F5 neuron that responds during hand
grasping will not respond when similar finger movements
are performed with a different purpose, for example,
scratching [2]. Several F5 neurons, in addition to their
motor properties, also respond to visual stimuli. Mirror
neurons form a class of visuomotor neurons that respond
both when the monkey performs goal-directed hand
actions and when it observes other individuals performing
similar actions [3–5].
Prompted by the discovery of monkey mirror neurons
and stimulated by their possible involvement in high-
level cognitive functions, such as understanding others’
behavior and interindividual communication, several
functional brain imaging studies were performed to inves-
tigate whether or not a mirror-neuron system is also
present in the human brain. Results showed that observa-
tion of an action recruits a consistent network of cortical
areas, including the ventral premotor cortex (which
extends posteriorly to the primary motor cortex), the
inferior frontal gyrus, the inferior parietal lobule and
the superior temporal cortex (for recent literature see
Rizzolatti and Craighero [6]). However, brain imaging
studies give us a static picture of the activated areas and
do not enable us to conclude that the observer’s motor
system is dynamically (on-line) replicating the observed
movements. Transcranial magnetic stimulation (TMS)
can be used to measure the corticospinal (CS) excitability
with a relatively high temporal resolution, and has been
used extensively to address this issue.
Here, we review the most recent studies that investigate
using TMS how the human motor cortex reacts to other’s
action observation.
Transcranial magnetic stimulation: a tool tomeasure motor activation during observationof others’ actionsAlthough TMS was originally designed to test the integ-
rity of the CS system by recording a motor evoked
potential (MEP) from a given muscle in response to
primary motor cortex (M1) stimulation, the potential of
TMS to investigate brain functions has proved much
greater. TMS can be used either to inactivate specific
brain regions, by repetitively stimulating the brain to
obtain long lasting inhibition, or to interfere transiently
with its neural activity, by applying a single TMS pulse
Current Opinion in Neurobiology 2005, 15:213–218

214 Cognitive neuroscience
[7,8]. This approach enables us to infer the contribution
of the ‘perturbed’ area to the investigated function,
similar to the situation in animal experiments in which
muscimol injections enable us to deduce the role of the
inactivated structure by quantifying the induced beha-
vioral deficit [9,10]. The precision of localization of the
TMS target has also been recently greatly improved by
using frameless stereotaxic methods (for recent literature,
see Noirhomme et al. [11�]), enabling us to target more
precisely those ‘motorically silent’ cortical regions lying
outside M1. In addition to its use in inactivation studies,
TMS can also be used to monitor changes in CS excit-
ability that specifically accompany motor performance
[12], or that are induced by the activity of various brain
regions connected with M1. This can be done by measur-
ing the amplitude of MEPs elicited by TMS under
various experimental conditions (see Figure 1).
The first evidence that CS excitability is modulated
during observation of an action was given by our group
ten years ago [13]. TMS was applied to the area of motor
cortex that represents the hand and MEPs were recorded
from contralateral hand muscles (extensor digitorum com-
munis [EDC], flexor digitorum superficialis [FDS], first
dorsal interosseus [FDI], and opponens pollicis [OP])
during observation of transitive (grasping of different
objects) and intransitive (arm elevation) arm–hand move-
ments. During observation of grasping action, the ampli-
tude of MEPs recorded from OP and FDI increased
compared with those observed in the control conditions.
During observation of arm movement the increase was
present in all muscles except OP (Figure 2c).
This experimental outcome raised the question of
whether the muscles that were facilitated during the
Figure 1
~ 3000 V~ 5500 A~ 2.5 T (Field intensity)
~ 2 cm (Activated region)~ 100 µs (Pulse total time)~ 2 µs (Pulse rising time)
Transcranial magnetic stimulation. The fast circulation of a strong electrical
in the brain. If the induced current is large enough, underlying cortical neuro
spinal motoneurons, evoking a MEP detectable by standard electromyograp
Current Opinion in Neurobiology 2005, 15:213–218
observation of a given action were the same as those
active during its execution. To answer this question,
EMG from hand muscles was recorded during rest, object
grasping and arm lifting movements, and the pattern of
EMG activation replicated exactly that of MEPs elicited
by TMS during action observation. These results have
been successfully replicated and extended by other
groups. Brighina et al. [14] investigated the effect of
the observation of simple intransitive thumb movements
(abduction) and of sequential thumb–finger opposition
movements on left and right motor cortex excitability.
Although some methodological details are absent from
the paper (e.g. whether the presented action was per-
formed by a right or a left hand), the results show an
increase of the CS excitability in both hemispheres that
depended on the complexity of the observed task. More
recently, Gangitano et al. [15] showed the presence of a
strict temporal coupling between the changes in CS
excitability and the dynamics of the observed action.
Indeed, MEPs recorded from the FDI muscle at different
time intervals during passive observation of a pincer
grasping action matched in time the dynamics of the
kinematics of the pinch that characterized the actual
movements. Clark et al. [16�] have recently assessed
the specificity of the CS facilitation induced by action
observation. They recorded MEPs from FDI muscle of
the dominant hand during TMS of contralateral M1 while
participants first, merely observed, second, imagined, or
third, observed to subsequently imitate simple hand
actions. They did not find any statistically significant
difference among the three conditions. However, MEPs
recorded during these three conditions were strongly
facilitated when compared with those recorded during
highly demanding non-motor cognitive tasks (i.e. MEPS
collected during a backwards mental counting task).
MEP
Current Opinion in Neurobiology
current in the coil positioned on the skull induces an electric current
ns are brought over threshold and the descending volley reaches the
hy techniques.
www.sciencedirect.com

Human motor cortex excitability during the perception of others’ action Fadiga, Craighero and Olivier 215
Glossary
H-reflex: Hoffmann reflex, its amplitude (as recorded by EMG,
electromyography) depends upon spinal motoneuron excitability, and
it is evoked by stimulating the afferent fibers in peripheral nerves.
F-wave: Centrifugal discharge recorded by EMG and evoked in
motoneurons by antidromic excitation of the motoneuron axon–soma.
Figure 2
*
*
*
OPFDI-0.50
-0.25
0.00
0.25
0.50
ME
P to
tal a
reas
(z-
scor
e)TMS
(a)
(c)
(b)
Transcranial magnetic stimulation can be used to instantaneously
measure the excitability of the CS system. Schematic depiction of the
effect of a same intensity TMS on (a) resting and (b) underthreshold
depolarized (note the yellow soma) CS neurons. In (c) typical changes
of corticospinal excitability during action observation are shown. Bar
histograms describe the effect of hand grasping observation (black
bars), arm movement observation (white bars) and control condition
(shaded bars) on the TMS-induced MEPs recorded from first dorsal
interosseus (FDI) and opponens pollicis (OP) muscles (modified with
permission from Fadiga et al. [13]).
There are at least two possible explanations for the
origin of the MEP facilitation induced by action obser-
vation. The first one is that the facilitation of MEPs is
due to the enhancement of M1 excitability produced
through excitatory cortico–cortical connections. Consid-
ering that monkey area F5, where mirror neurons are
located, is premotor cortex that is strongly connected
with M1 [17], one could explain the facilitation of MEPs
induced by action observation as the consequence of a
facilitatory cortico–cortical effect arising from the
human homolog of monkey area F5. The second possi-
ble explanation is that TMS reveals, through the CS
www.sciencedirect.com
descending volley, a facilitation of motoneurons (MNs)
mediated by parallel pathways (e.g. from the premotor
cortex to the brainstem). Indeed, when MEP amplitude
variation is used as an end-point measure, a change in
M1 excitability cannot be firmly established unless any
modification in MN excitability is ruled out. Further-
more, changes in MEP amplitude caused by a variation
of M1 or MN excitability are undistinguishable and,
unfortunately, techniques that enable us to address this
issue are uncomfortable for subjects (transcranial elec-
trical stimulation, brainstem electrical stimulation),
inapplicable (as in the case of H-reflex for intrinsic hand
muscles), or unreliable because they assess only a small
fraction of the whole MN population (as in the case of
F-wave).
To assess the spinal involvement in action observation-
related MEP facilitation, Baldissera et al. [18] investi-
gated spinal cord excitability during action viewing. To
do this, they measured the amplitude of H-reflex (see
glossary) in finger flexor forearm muscles while subjects
were looking at goal-directed hand actions. Results
showed that although there was a significant modulation
of the H-reflex specifically related to the different phases
of the observed movement, the modulation pattern was
opposite to that occurring at the cortical level. Whereas
modulation of cortical excitability strictly mimics the
seen movements, as if they were performed by the
observer, the spinal cord excitability appears to be reci-
procally modulated. Indeed, the spinal MNs of finger
flexors were facilitated during observation of hand open-
ing (finger extension) but inhibited during observation of
hand closure (finger flexion). This effect was interpreted
as the expression of a mechanism serving to block overt
execution of seen actions. However, other authors failed
in showing specific changes in H-reflex amplitude during
observation of simple finger movements (see below;
[19]).
The more recently developed paired-pulse TMS might
help to determine the cortical or spinal origin of CS
facilitation (see [20]). The rationale of this technique is
the use of a subthreshold conditioning TMS pulse
followed, at various delays, by a supra-threshold TMS
test pulse. Depending on the delay between these two
pulses, it is possible to investigate changes in the excit-
ability of excitatory or inhibitory interneurons within M1
itself. Intracortical inhibition (ICI) is usually observed
for short (1–5 ms) or long (50–200 ms) intervals between
conditioning and test TMS, whereas intracortical
Current Opinion in Neurobiology 2005, 15:213–218

216 Cognitive neuroscience
facilitation (ICF) was maximal for 8–20 ms intervals.
Strafella and Paus [21] used this approach to examine
changes in cortical excitability during action observa-
tion. They stimulated the left M1 during rest, observa-
tion of handwriting and observation of arm movements.
MEPs were recorded from the FDI and biceps brachialis
muscles. Results showed that action observation
induced a facilitation of MEP amplitude evoked by
the single test stimulus and led to a decreased ICI at
3 ms interstimulus interval. The authors, therefore,
came to the conclusion that CS facilitation induced by
action observation was attributable to cortico–cortical
facilitating connections.
A series of experiments was set up with the aim of
clarifying the modulation of CS excitability induced
by some peculiar characteristics of the observed action.
In a recent experiment aiming to investigate whether
human mirror neurons are somehow tuned for one’s own
actions or not, Patuzzo et al. [19] showed an increase in
right FDS MEP amplitude associated with a reduction in
ICI, during the observation of both self (pre-recorded
videos representing subjects’ own motor performance)
and non-self finger flexion, as compared with those at
rest. Moreover, these authors failed to observe significant
changes in spinal excitability as tested with H-reflex or
F-wave (see glossary). Maeda et al. [22] investigated the
self–others issue extensively, by using TMS to measure
CS excitability during observation of actions of various
degrees of familiarity. In two conditions, subjects were
watching their own previously recorded hand actions. In
the ‘frequently observed configuration’ the acting fingers
were directed away from the body, and in the ‘not
frequently observed configuration’ the fingers were
directed toward the body. In the remaining two condi-
tions, subjects were watching the previously recorded
hand actions of unknown people both in the frequently
(fingers toward the body) and in the not frequently
(fingers away from the body) configuration. Results
showed that the frequently observed hand actions pro-
duced greater CS excitability with respect to the control
condition, whereas this was not the case for the less
frequently observed hand actions. In a subsequent
experiment, Maeda et al. [23] further investigated the
issue of the orientation of the observed hand. Results
showed that MEP facilitation was greater during obser-
vation of natural hand orientations. Aziz-Zadeh et al. [24]
investigated whether CS facilitation during action obser-
vation is modulated by the laterality of the observed body
part or not, and they found that when TMS was applied
over the left M1, MEPs were larger while observing right
hand actions. Likewise, when TMS was applied over the
right M1, MEPs were larger while observing left hand
actions.
Finally, in a very recent experiment, Gangitano et al.[25��] investigated the reason behind the presence of a
Current Opinion in Neurobiology 2005, 15:213–218
strict temporal coupling between the CS excitability
modulation and the dynamics of an observed reaching–
grasping movement (see Gangitano et al. [15]). Two sets
of visual stimuli were presented in two distinct exper-
iments. The first stimulus was a video-clip showing a
natural reaching–grasping movement. The second video-
clip represented an anomalous movement, in which the
temporal coupling between reaching and grasping com-
ponents was disrupted by changing the time of occur-
rence of the maximal finger aperture. This effect was
realized either by keeping the hand closed throughout the
whole reaching and opening it just in proximity to the
target (Experiment 1) or by substituting part of the
natural finger opening with a sudden movement of clo-
sure (Experiment 2). Whereas in Experiment 1 MEP
modulation was generally absent, the observation of
video-clip presented in Experiment 2 induced a clear,
significant modulation of CS excitability. This modula-
tion, however, was limited to the part of the observed
action preceding the visual perturbation (the sudden
finger closure). These results suggest that any modification
of the canonical plan of an observed action induces a reset
of the mirror system, which therefore stops its activity. It
can be deduced that the mirror system works online to
predict the goal and the outcome of the observed action.
Motor facilitation induced by ‘listening’ toothers’ actions: a link with speechperception?Others’ actions do not generate only visually perceivable
signals. Action-generated sounds and noises are also very
common in nature. One might expect, therefore, that also
this sensory information, related to a particular action,
could determine motor activation specific for that same
action. Very recently, it has been reported that a fraction
of monkey mirror neurons, in addition to their visual
response, also become active when the monkey listens
to an action-related sound (e.g. breaking of a peanut)
[26��]. It is tempting, therefore, to conclude that mirror
neurons might form a multimodal representation of goal
directed actions involved in action recognition. Experi-
mental evidence shows similar results in humans. Aziz-
Zadeh et al. [27] used TMS to explore whether or not CS
excitability is modulated by listening to action-related
sounds. In their experiment, left and right M1 were
studied. MEPs were recorded from the contralateral
FDI muscle while subjects listened to one of two kinds
of bimanual hand action sounds (typing or tearing paper),
to a bipedal leg action sound (walking) and to a control
sound (thunder). Results showed that sounds associated
with bimanual actions produced greater CS excitability
than sounds associated with leg movements or control
sounds. Moreover, this facilitation was exclusively later-
alized to the left hemisphere.
Sundara et al. [28] tested the possibility that a mirror
mechanism, similar to that found during observation of
www.sciencedirect.com

Human motor cortex excitability during the perception of others’ action Fadiga, Craighero and Olivier 217
actions, would also be present during presentation of
speech gestures both in the visual and in the auditory
modalities. The authors found that visual observation of
speech movement enhanced MEP amplitude specif-
ically in facial muscles involved in production of the
observed speech. By contrast, listening to the sound did
not produce MEP enhancement. This negative result,
as far as speech sounds are concerned, might be
explained by the fact that they recorded MEPs from
muscles (facial) not directly involved in speech sound
production. Indeed, our group [29] demonstrated that
during speech listening there is an increase of MEP
recorded from the listeners’ tongue muscles when the
presented words would strongly involve, when pro-
nounced, tongue movements. Furthermore, the effect
was stronger in the case of words than in the case of
pseudowords, suggesting a possible unspecific facilita-
tion of the motor speech center due to recognition that
the presented material belongs to an extant word. As
suggested by the ‘motor theory of speech perception’
originally proposed by A. Liberman [30], the presence
of a phonetic resonance in the motor speech centers
might subserve speech perception. This theory main-
tains that the ultimate constituents of speech are not
sounds but articulatory gestures that have evolved
exclusively at the service of language. According to
Liberman’s theory, the listener understands the
speaker when his or her articulatory gesture representa-
tions are activated by the listening to verbal sounds.
Also in this line is the study by Watkins et al. [31]
demonstrating that speech perception, either by listen-
ing to speech or by observing speech-related lip move-
ments, enhanced MEPs recorded from the orbicularis
oris muscle of the lips. This increase in motor excit-
ability during speech perception was, however, evident
for left hemisphere stimulation only. In a subsequent
experiment, Watkins and Paus [32��] combined TMS
with positron emission tomography to identify the brain
regions mediating the changes in motor excitability
during speech perception. Results showed that during
auditory perception of speech, the increased size of the
MEP obtained by stimulation over the face representa-
tion of the primary motor cortex correlated with regio-
nal increase of blood flow in the posterior part of the left
inferior frontal gyrus (Broca’s area). To verify the pre-
sence of an evolutionary link between the hand motor
and the language system, as proposed by an influential
theory of the evolution of communication [33], Floel
et al. [34�] examined if, and to what extent, language
activates the hand motor system. They recorded MEPs
from the FDI muscle while subjects underwent three
consecutive experiments attempting to isolate the com-
ponents (articulatory linguistic, auditory, cognitive and
visuospatial attentional) more crucial in activating the
motor system. Results showed that productive and
receptive linguistic tasks only excite the motor cortices
for both hands.
www.sciencedirect.com
ConclusionsA large body of evidence supports the view that percep-
tion of others’ actions is constantly accompanied by motor
facilitation of the observer’s CS system. This facilitation
is not only present during action observation but also
while listening to action-related sounds and, more inter-
estingly, while listening to speech. Further research is,
however, necessary to investigate if the cytoarchitectonic
homologies linking Broca’s area — and particularly Brod-
mann’s area 44 — to monkey’s area F5, where mirror
neurons have been found [35], might reflect the evolu-
tionary continuity of a communicative system originally
developed in our ancestors.
When considering TMS experiments, one should be
aware of the fact that any change in CS excitability,
even if a spinal contribution is firmly excluded, does
not tell us much about the actual brain structures
underlying the facilitation. Indeed, given the large
number of non-primary motor areas that establish exci-
tatory connections with M1, a change in M1 excitability
could originate from any of these areas. However, the
combination of TMS experiments with brain imaging
studies represents a new powerful method of analysis.
This new potential, together with the technical
improvements of TMS technique (i.e. paired pulse
stimulation, enhanced focalization and use of frameless
stereotaxic systems), is expected to increase our working
knowledge of the complex functions of the human
motor system.
AcknowledgementsThis work has been supported by European Commission grantsMIRROR and NEUROBOTICS to L Fadiga and L Craighero and byEuropean Science Foundation Origin of Man, Language and Languages,Eurocores and Italian Ministry of Education grants to L Fadiga.
References and recommended readingPapers of particular interest, published within the annual period ofreview, have been highlighted as:
� of special interest�� of outstanding interest
1. Rizzolatti G, Fadiga L: Grasping objects and grasping actionmeanings: the dual role of monkey rostroventral premotorcortex (area F5). In Sensory Guidance of Movement, NovartisFoundation Symposium. Edited by GR Bock, JA Goode. JohnWiley and Sons; 1988:81-95.
2. Rizzolatti G, Camarda R, Fogassi L, Gentilucci M, Luppino G,Matelli M: Functional organization of inferior area 6 in themacaque monkey: II. Area F5 and the control of distalmovements. Exp Brain Res 1988, 71:491-507.
3. Di Pellegrino G, Fadiga L, Fogassi L, Gallese V, Rizzolatti G:Understanding motor events: a neurophysiological study.Exp Brain Res 1992, 91:176-180.
4. Gallese V, Fadiga L, Fogassi L, Rizzolatti G: Action recognition inthe premotor cortex. Brain 1996, 119:593-609.
5. Rizzolatti G, Fadiga L, Gallese V, Fogassi L: Premotor cortex andthe recognition of motor actions. Brain Res Cogn Brain Res1996, 3:131-141.
6. Rizzolatti G, Craighero L: The mirror-neuron system. Annu RevNeurosci 2004, 27:169-192.
Current Opinion in Neurobiology 2005, 15:213–218

218 Cognitive neuroscience
7. Walsh V, Cowey A: Transcranial magnetic stimulation andcognitive neuroscience. Nat Rev Neurosci 2000, 1:73-79.
8. Rafal R: Virtual neurology. Nat Neurosci 2001, 4:862-864.
9. Wardak C, Olivier E, Duhamel JR: Saccadic target selectiondeficits after lateral intraparietal area inactivation in monkeys.J Neurosci 2002, 22:9877-9884.
10. Wardak C, Olivier E, Duhamel JR: A deficit in covert attentionafter parietal cortex inactivation in the monkey. Neuron 2004,42:501-508.
11.�
Noirhomme Q, Ferrant M, Vandermeeren Y, Olivier E, Macq B,Cuisenaire O: Registration and real-time visualization oftranscranial magnetic stimulation with 3-D MR images.IEEE Trans Biomed Eng 2004, 51:1994-2005.
A methodological study presenting a new system that maps the TMStarget directly onto the individual anatomy of the subject. The approachfollowed by the authors enables accurate and fast processing that makesthe method suitable for on-line applications.
12. Lemon RN, Johansson RS, Westling G: Corticospinal controlduring reach, grasp, and precision lift in man. J Neurosci 1995,15:6145-6156.
13. Fadiga L, Fogassi L, Pavesi G, Rizzolatti G: Motor facilitationduring action observation: a magnetic stimulation study.J Neurophysiol 1995, 73:2608-2611.
14. Brighina F, La Bua V, Oliveri M, Piazza A, Fierro B: Magneticstimulation study during observation of motor tasks. J NeurolSci 2000, 174:122-126.
15. Gangitano M, Mottaghy FM, Pascual-Leone A: Phase-specificmodulation of cortical motor output during movementobservation. Neuroreport 2001, 12:1489-1492.
16.�
Clark S, Tremblay F, Ste-Marie D: Differential modulation ofcorticospinal excitability during observation, mental imageryand imitation of hand actions. Neuropsychologia 2004,42:105-112.
A TMS study that directly compares various conditions known to activatemotor representations in humans.
17. Shimazu H, Maier MA, Cerri G, Kirkwood PA, Lemon RN:Macaque ventral premotor cortex exerts powerful facilitationof motor cortex outputs to upper limb motoneurons. J Neurosci2004, 24:1200-1211.
18. Baldissera F, Cavallari P, Craighero L, Fadiga L: Modulation ofspinal excitability during observation of hand actions inhumans. Eur J Neurosci 2001, 13:190-194.
19. Patuzzo S, Fiaschi A, Manganotti P: Modulation of motor cortexexcitability in the left hemisphere during action observation: asingle- and paired-pulse transcranial magnetic stimulationstudy of self- and non-self-action observation.Neuropsychologia 2003, 41:1272-1278.
20. Di Lazzaro V, Oliviero A, Pilato F, Saturno E, Dileone M, Mazzone P,Insola A, Tonali PA, Rothwell JC: The physiological basis oftranscranial motor cortex stimulation in conscious humans.Clin Neurophysiol 2004, 115:255-266.
21. Strafella AP, Paus T: Modulation of cortical excitability duringaction observation: a transcranial magnetic stimulation study.Neuroreport 2000, 11:2289-2292.
Current Opinion in Neurobiology 2005, 15:213–218
22. Maeda F, Chang VY, Mazziotta J, Iacoboni M: Experience-dependent modulation of motor corticospinal excitabilityduring action observation. Exp Brain Res 2001, 140:241-244.
23. Maeda F, Kleiner-Fisman G, Pascual-Leone A: Motor facilitationwhile observing hand actions: specificity of the effect androle of observer’s orientation. J Neurophysiol 2002,87:1329-1335.
24. Aziz-Zadeh L, Maeda F, Zaidel E, Mazziotta J, Iacoboni M:Lateralization in motor facilitation during action observation:a TMS study. Exp Brain Res 2002, 144:127-131.
25.��
Gangitano M, Mottaghy FM, Pascual-Leone A: Modulation ofpremotor mirror neuron activity during observation ofunpredictable grasping movements. Eur J Neurosci 2004,20:2193-2202.
This is the first investigation of the effects of visual perturbations on themirror-neuron system in humans. The authors found that an unexpectedfinger closure during the execution of a grasping movement resets theobserver’s mirror system and zeroes the previously induced corticospinalfacilitation.
26. Kohler E, Keysers CM, Umilta A, Fogassi L, Gallese V,Rizzolatti G: Hearing sounds, understanding actions:Action representation in mirror neurons. Science 2002,297:846-848.
27. Aziz-Zadeh L, Iacoboni M, Zaidel E, Wilson S, Mazziotta J: Lefthemisphere motor facilitation in response to manual actionsounds. Eur J Neurosci 2004, 19:2609-2612.
28. Sundara M, Namasivayam AK, Chen R: Observation-executionmatching system for speech: a magnetic stimulation study.Neuroreport 2001, 12:1341-1344.
29. Fadiga L, Craighero L, Buccino G, Rizzolatti G: Speech listeningspecifically modulates the excitability of tongue muscles: aTMS study. Eur J Neurosci 2002, 15:399-402.
30. Liberman AM, Mattingly IG: The motor theory of speechperception revised. Cognition 1985, 21:1-36.
31. Watkins KE, Strafella AP, Paus T: Seeing and hearing speechexcites the motor system involved in speech production.Neuropsychologia 2003, 41:989-994.
32.��
Watkins K, Paus T: Modulation of motor excitability duringspeech perception: the role of Broca’s area. J Cogn Neurosci2004, 16:978-987.
By using the association of TMS and positron emission tomography theauthors investigate the homology of frontal cortex and demonstrate therole of Broca’s area in the speech listening-induced motor facilitation.
33. Rizzolatti G, Arbib MA: Language within our grasp.Trends Neurosci 1998, 21:188-194.
34.�
Floel A, Ellger T, Breitenstein C, Knecht S: Language perceptionactivates the hand motor cortex: implications for motortheories of speech perception. Eur J Neurosci 2003,18:704-708.
Here, the authors show the existence of a lexical link between speech andhand movement representation.
35. Petrides M, Pandya DN: Comparative architectonic analysis ofthe human and the macaque frontal cortex. In Handbook ofNeuropsychology Vol. IX. Edited by F Boller, J Grafman. Elsevier;1994:17-58.
www.sciencedirect.com

A series of studies on the brain correlates of theverbal function demonstrate the involvement ofBroca’s region (Brodmann’s area – BA 44) duringboth speech generation (see Liotti et al., 1994 forreview) and speech perception (see Papathanassiouet al., 2000 for a review of recent papers). Recently,however, several experiments have shown thatBroca’s area is involved also in very differentcognitive and perceptual tasks, not necessarilyrelated to speech. Brain imaging experiments havehighlighted the possible contribution of BA 44 in“pure” memory processes (Mecklinger et al., 2002;Ranganath et al., 2003), in calculation tasks (Gruberet al., 2001), in harmonic incongruity perception(Maess et al., 2001), in tonal frequencydiscrimination (Muller et al., 2001) and in binoculardisparity (Negawa et al., 2002). Another importantcontribution of BA 44 is certainly found in themotor domain and motor-related processes. Gerlachet al. (2002) found an activation of BA 44 during acategorization task only if performed on artifacts.Kellenbach et al. (2003) found a similar activationwhen subjects were required to answer a questionconcerning the action evoked by manipulableobjects. Several studies reported a significantactivation of BA 44 during execution of graspingand manipulation (Binkofski et al., 1999a, 1999b;Gerardin et al., 2000; Grèzes et al., 2003; Hamzei etal., 2003; Lacquaniti et al., 1997; Matsumura et al.,1996; Nishitani and Hari, 2000). Moreover, theactivation of BA 44 is not restricted to motorexecution but spreads over to motor imagery(Binkofski et al., 2000; Geradin et al., 2000; Grèzesand Decety, 2002).
From a cytoarchitectonical point of view(Petrides and Pandya, 1997), the monkey’s frontalarea which closely resembles human Broca’s regionis a premotor area (area F5 as defined by Matelli et
al., 1985). Single neuron studies (see Rizzolatti etal., 1988) showed that hand and mouth movementsare represented in area F5. The specificity of thegoal seems to be an essential prerequisite inactivating these neurons. The same neurons thatdischarge during grasping, holding, tearing,manipulating, are silent when the monkey performsactions that involve a similar muscular pattern butwith a different goal (i.e., grasping to put away,scratching, grooming, etc.). All F5 neurons sharesimilar motor properties. In addition to their motordischarge, however, a particular class of F5neurons discharges also when the monkey observesanother individual making an action in front of it(‘mirror neurons’; Di Pellegrino et al., 1992;Gallese et al., 1996; Rizzolatti et al., 1996a). Thereis a strict congruence between visual and motorproperties of F5 mirror neurons: e.g., mirrorneurons motorically coding whole hand prehensiondischarge during observation of whole handprehension performed by the experimenter but notduring observation of precision grasp. The mostlikely interpretation for the visual response of thesevisuomotor neurons is that, at least in adultindividuals, there is a close link between action-related visual stimuli and the corresponding actionsthat pertain to monkey’s motor repertoire. Thus,every time the monkey observes the execution ofan action, the related F5 neurons are addressed andthe specific action representation is “automatically”evoked. Under certain circumstances it guides theexecution of the movement, under others, itremains an unexecuted representation of it, thatmight be used to understand what others are doing.
Transcranial magnetic stimulation (TMS)(Fadiga et al., 1995; Strafella and Paus, 2000) andbrain imaging experiments demonstrated that amirror-neuron system is present also in humans:
Cortex, (2006) 42, 486-490
SPECIAL ISSUE: POSITION PAPER
HAND ACTIONS AND SPEECH REPRESENTATION IN BROCA’S AREA
Luciano Fadiga and Laila Craighero
(Department of Biomedical Sciences, Faculty of Medicine, Section of Human Physiology,University of Ferrara, Ferrara, Italy)
ABSTRACT
This paper presents data and theoretical framework supporting a new interpretation of the role played by Broca’s area.Recent brain imaging studies report that, in addition to speech-related activation, Broca’s area is also significantly involvedduring tasks devoid of verbal content. In consideration of the large variety of experimental paradigms inducing Broca’sactivation, here we present some neurophysiological data from the monkey homologue of Brodmann’s areas (BA) 44 and45 aiming to integrate on a common ground these apparently different functions. Finally, we will report electrophysiologicaldata on humans which connect speech perception to the more general framework of other’s action understanding.
Key words: hand action, speech, Broca’s area, mirror neurons, neurophysiology, transcranial magnetic stimulation

when the participants observe actions made byhuman arms or hands, motor cortex becomesfacilitated (this is shown by TMS studies) andcortical activations are present in the ventralpremotor/inferior frontal cortex (Rizzolatti et al.,1996b; Grafton et al., 1996; Decety et al., 1997;Grèzes et al., 1998, 2003; Iacoboni et al., 1999;Decety and Chaminade, 2003). Grèzes et al. (1998)showed that the observation of meaningful but notthat of meaningless hand actions activates the leftinferior frontal gyrus (Broca’s region). Two furtherstudies have shown that observation of meaningfulhand-object interaction is more effective inactivating Broca’s area than observation of nongoal-directed movements (Hamzei et al., 2003;Johnson-Frey et al., 2003). Similar conclusionshave been reached also for mouth movementobservation (Campbell et al., 2001). In addition,direct evidence for an observation/executionmatching system has been recently provided bytwo experiments, one employing functionalmagnetic resonance imaging (fMRI) technique(Iacoboni et al., 1999), the other using event-related magnetoencephalography (MEG) (Nishitaniand Hari, 2000), that directly compared in the samesubjects action observation and action execution.
The evidence that Broca’s area is activatedduring time perception (Schubotz et al., 2000),calculation tasks (Gruber et al., 2001), harmonicincongruity perception (Maess et al., 2001), tonalfrequency discrimination (Muller et al., 2001),prediction of sequential patterns (Schubotz and vonCramon, 2002a) as well as during prediction ofincreasingly complex target motion (Schubotz andvon Cramon, 2002b), suggest that this area couldhave a central role in human representation ofsequential information in several different domains(Lieberman, 1991). This could be crucial for actionunderstanding, allowing the parsing of observedactions on the basis of the predictions of theiroutcomes. Others’ actions do not generate onlyvisually perceivable signals. Action-generatedsounds and noises are also very common in nature.In a very recent experiment Kohler et al. (2002)have found that 13% of the investigated F5neurons discharge both when the monkeyperformed a hand action and when it heard theaction-related sound. Moreover, most of theseneurons discharge also when the monkey observedthe same action demonstrating that these ‘audio-visual mirror neurons’ represent actions,independently of whether they are performed,heard or seen. The presence of an audio-motorresonance in a region that, in humans, is classicallyconsidered a speech-related area, prompts theLiberman’s hypothesis on the mechanism at thebasis of speech perception (motor theory of speechperception; Liberman et al., 1967; Liberman andMattingly, 1985; Liberman and Wahlen, 2000).This theory maintains that the ultimate constituentsof speech are not sounds but articulatory gestures
Hand and speech in Broca’s area 487
that have evolved exclusively at the service oflanguage. Speech perception and speech productionprocesses could thus use a common repertoire ofmotor primitives that, during speech production,are at the basis of articulatory gesture generation,and during speech perception are activated in thelistener as the result of an acoustically evokedmotor “resonance”. According to Liberman’s theory(Liberman et al., 1967; Liberman and Mattingly,1985; Liberman and Wahlen, 2000), the listenerunderstands the speaker when his/her articulatorygestures representations are activated by thelistening to verbal sounds. Although this theory isnot unanimously accepted, it offers a plausiblemodel of an action/perception cycle in the frame ofspeech processing.
To investigate if speech listening activateslistener’s motor representations, Fadiga et al.(2002) administered TMS on cortical tongue motorrepresentation, while subjects were listening tovarious verbal and non-verbal stimuli. Motorevoked potentials (MEPs) were recorded fromsubjects’ tongue muscles. Results showed thatduring listening of words formed by consonantsimplying tongue mobilization (i.e., Italian ‘R’ vs.‘F’) MEPs significantly increased. This indicatesthat when an individual listens to verbal stimuli,his/her speech related motor centers are specificallyactivated. Moreover, words-related facilitation wassignificantly larger than pseudo-words related one.
The presence of “audio-visual” mirror neuronsin the monkey and the presence of “speech-relatedacoustic motor resonance” in humans, suggeststhat, independently of the sensory nature of theperceived stimulus, the mirror-neuron resonantsystem retrieves from the action vocabulary (storedin the frontal cortex) the stimulus-related motorrepresentations. It is however unclear if theactivation of the motor system during speechlistening is causally related to speech perception, orif it is a mere epiphenomenon due, for example, toan automatic compulsion to repeat without any rolein speech processing. One experimental approachto answer this question could be to interfere withspeech perception by applying TMS on speech-related motor areas. Although classical theoriesconsider the inferior frontal gyrus as the “motorcenter” for speech production, cytoarchitectonicalhomologies with monkey area F5, and brainimaging and patients studies (among more recentpublications see Watkins and Paus, 2004; Dronkerset al., 2004, Wilson et al., 2004) suggest that thisregion may play a fundamental role in perceivedspeech processing. Broca’s area was thereforeselected as the best candidate for our study.
In order to investigate a possible role of Broca’sarea in speech perception, both at the lexical and atthe phonological level (Fadiga et al., 2002 showedthat both these speech-related properties influencemotor resonance) we selected a priming paradigm.Priming experiments, in general, demonstrate that

whenever a word (target) is preceded by a somehowrelated word (prime) it is processed faster than whenit is preceded by an unrelated word. The prime cantherefore have either a semantic or phonologicrelation with the target. Our starting aim was to testthe possibility to modulate this facilitation byinterfering on Broca’s activity with TMS. Amagnetic stimulus delivered immediately after thelistening of the prime, on a functionally-related brainregion, should impair prime processing, resulting ina modification in the priming effect. In ourexperiment we used the paradigm by Emmorey et al.(1989) in which subjects are requested to perform alexical decision on a target preceded by a rhyming ornot rhyming prime. By manipulating the lexicalcontent of both the prime and the target stimuli(Emmorey et al., 1989, used only word prime), inaddition to the rhyming effect we tested also the roleof Broca’s area at the lexical level. Single pulseTMS was administered to Broca’s region in 50% ofthe trials while subjects were submitted to a lexicaldecision task on the target. Subjects had to respondby pressing one of two keys with their left indexfinger. TMS was administered during the 20 msecpause between prime and target acousticpresentation (interstimulus interval – ISI). The click
488 Luciano Fadiga and Laila Craighero
of the stimulator never overlapped with the acousticstimuli. The pairs of verbal stimuli could pertain tofour categories which differed for presence of lexicalcontent (words vs. pseudo-words) in the prime andin the target (Table I).
From data analysis on trials without TMS (seeFigure 1) an interesting (and unexpected) findingemerged: lexical content of the stimuli modulatesthe phonological priming effect. No priming effectwas found in the pseudo-word/pseudo-wordcondition in which neither the target nor the primewas an element of the lexicon. In other words, inorder to have a phonological effect it is necessaryto have the access to the lexicon. In trials duringwhich TMS was delivered, a TMS-dependent effectwas found only in pairs where the prime was aword and the target was a pseudo-word, andconsisted in the abolition of the phonologicalpriming effect. Thus, TMS on Broca’s area madethe pairs word/pseudo-word similar to the pseudo-word/pseudo-word ones.
This finding suggests that the stimulation of theBroca’s region might have affected the primingeffect not because it interferes with phonologicalprocessing but because it interferes with lexicalcategorization of the prime. In support to this
TABLE I
Example of the stimuli used in the experiment
Rhyming Not-rhyming
Word/word zucca (pumpkin) – mucca (cow) fiume (river) – scuola (school)Word/pseudo-word freno (brake) – preno strada (street) – tertoPseudo-word/word losse – tosse (cough) stali – letto (bed)Pseudo-word/pseudo-word polta – solta brona – dasta
Fig. 1 – Reaction times (RTs ± standard error of mean – SEM – in msec) for the lexical decision during the phonological primingtask without (left panel) and with (right panel) transcranial magnetic stimulation (TMS) administration. White bars: conditions in whichprime and target share a rhyme. Black bars: no rhyme. Asterisk on the black bar means the presence (p > .05, Newman-Keuls test) of aphonological priming effect (response to rhyming target faster than response to not-rhyming target) in the relative condition. TMSadministration did not influence the accuracy of the participants that was always close to 100%. W-W: prime-word/target-word; W-PW:prime-word/target-pseudo-word; PW-W: prime-pseudo-word/target-word; PW-PW: prime-pseudo-word/target-pseudo-word.

interpretation are recent results from Blumstein etal. (2000) who have found that Broca’s aphasicsdisplay deficits in the facilitation of lexicaldecision targets by prime words that rhyme withthe target. In contrast, Wernicke’s aphasics showeda pattern of results similar to that of normalsubjects. Moreover, Milberg et al. (1988), in aphonological distortion study, showed that Broca’saphasics failed to show semantic priming when thephonological form of the prime stimulus wasdistorted. The authors interpreted this finding in theframework of the hypothesis that Broca’s aphasicshave reduced lexical activation levels (Utman etal., 2001). As a result, while in normal subjects anacoustically degraded input is able to activate thelexical representation, in aphasics it fails to reach asufficient level of activation. However, there isevidence that Broca’s aphasics have impairedlexical access even in response to intact acousticinputs (Milberg et al., 1988).
The results of our TMS experiment onphonological priming, together with the data onpatients reported above, lead to the conclusion thatBroca’s region is not the main responsible for theacoustic motor resonance effect shown by Fadigaet al. (2002). This effect was in fact present duringlistening of both words and pseudo-words and wasonly partially related to lexical properties of theheard stimuli. The localization of the premotor areainvolved in such a “low level” motor resonancewill be the argument of our future experimentalwork.
CONCLUSIONS
In the present paper we discuss the possibilitythat the activation of Broca’s region during speechprocessing, more than indicating a specific role ofthis area, may reflect its general involvement inmeaningful action recognition. This possibilityfounds its basis on the observation that in additionto speech-related activation, this area is activatedduring observation of meaningful hand or mouthactions. Speech represents a particular case of thisgeneral framework: among meaningful actions,phonoarticulatory gestures are meaningful actionsconveying words. This hypothesis is moreoversupported by the observation that Broca’s aphasics,in addition to speech production deficits, show animpaired access to the lexicon (although for somecategory of verbal stimuli). The consideration thatBroca’s area is the human homologue of monkeymirror neurons area, opens the possibility thathuman language may have evolved from an ancientability to recognize actions performed by others,visually or acoustically perceived. The Liberman’sintuition (Liberman et al., 1967; Liberman andMattingly, 1985; Liberman and Wahlen, 2000) thatthe ultimate constituents of speech are not soundsbut articulatory gestures that have evolved
Hand and speech in Broca’s area 489
exclusively at the service of language, seems to usa good way to consider speech processing in themore general context of action recognition.
Acknowledgements. The research presented in thispaper is supported within the framework of the EuropeanScience Foundation EUROCORES program “The Originof Man, Language and Languages”, by EC “MIRROR”Contract and by Italian Ministry of Education Grants.
REFERENCES
BINKOFSKI F, AMUNTS K, STEPHAN KM, POSSE S, SCHORMANN T,FREUND HJ, ZILLES K and SEITZ RJ. Broca’s region subservesimagery of motion: A combined cytoarchitectonic and fMRIstudy. Human Brain Mapping, 11: 273-285, 2000.
BINKOFSKI F, BUCCINO G, POSSE S, SEITZ RJ, RIZZOLATTI G andFREUND H-J. A fronto-parietal circuit for object manipulationin man: Evidence from an fMRI study. European Journal ofNeuroscience, 11: 3276-3286, 1999a.
BINKOFSKI F, BUCCINO G, STEPHAN KM, RIZZOLATTI G, SEITZ RJand FREUND H-J. A parieto-premotor network for objectmanipulation: Evidence from neuroimaging. ExperimentalBrain Research, 128: 21-31, 1999b.
BLUMSTEIN SE, MILBERG W, BROWN T, HUTCHINSON A, KUROWSKIK and BURTON MW. The mapping from sound structure to thelexicon in aphasia: Evidence from rhyme and repetitionpriming. Brain and Language, 72: 75-99, 2000.
CAMPBELL R, MACSWEENEY M, SURGULADZE S, CALVERT G,MCGUIRE P, SUCKLING J, BRAMMER MJ and DAVID AS.Cortical substrates for the perception of face actions: An fMRIstudy of the specificity of activation for seen speech and formeaningless lower-face acts (gurning). Cognitive BrainResearch, 12: 233-243, 2001.
DECETY J and CHAMINADE T. Neural correlates of feelingsympathy. Neuropsychologia, 41: 127-138, 2003.
DECETY J, GREZES J, COSTES N, PERANI D, JEANNEROD M, PROCYKE, GRASSI F and FAZIO F. Brain activity during observation ofactions: Influence of action content and subject’s strategy.Brain, 120: 1763-1777, 1997.
DI PELLEGRINO G, FADIGA L, FOGASSI L, GALLESE V andRIZZOLATTI G. Understanding motor events: Aneurophysiological study. Experimental Brain Research, 91:176-180, 1992.
DRONKERS NF, WILKINS DP, VAN VALIN RD JR, REDFERN BB andJAEGER JJ. Lesion analysis of the brain areas involved inlanguage comprehension. Cognition, 92: 145-77, 2004.
EMMOREY KD. Auditory morphological priming in the lexicon.Language and Cognitive Processes, 4: 73-92, 1989.
FADIGA L, CRAIGHERO L, BUCCINO G and RIZZOLATTI G. Speechlistening specifically modulates the excitability of tonguemuscles: A TMS study. European Journal of Neuroscience,15: 399-402, 2002.
FADIGA L, FOGASSI L, PAVESI G and RIZZOLATTI G. Motorfacilitation during action observation: A magnetic stimulationstudy. Journal of Neurophysiology, 73: 2608-2611, 1995.
GALLESE V, FADIGA L, FOGASSI L and RIZZOLATTI G. Actionrecognition in the premotor cortex. Brain, 119: 593-609,1996.
GERARDIN E, SIRIGU A, LEHÉRICY S, POLINE J-B, GAYMARD B,MARSAULT C and AGID Y Partially overlapping neuralnetworks for real and imagined hand movements. CerebralCortex, 10: 1093-1104, 2000.
GERLACH C, LAW I, GADE A and PAULSON OB. The role of actionknowledge in the comprehension of artefacts: A PET study.NeuroImage, 15: 143-152, 2002.
GRAFTON ST, ARBIB MA, FADIGA L and RIZZOLATTI G.Localization of grasp representations in humans by PET: 2.Observation compared with imagination. Experimental BrainResearch, 112: 103-111, 1996.
GRÈZES J, ARMONY JL, ROWE J and PASSINGHAM RE. Activationsrelated to “mirror” and “canonical” neurones in the humanbrain: An fMRI study. NeuroImage, 18: 928-937, 2003.
GRÈZES J, COSTES N and DECETY J. Top-down effect of strategy onthe perception of human biological motion: A PETinvestigation. Cognitive Neuropsychology, 15: 553-582, 1998.
GRÈZES J and DECETY J. Does visual perception of object affordaction? Evidence from a neuroimaging study.Neuropsychologia, 40: 212-222, 2002.

490 Luciano Fadiga and Laila Craighero
GRUBER O, INDERFEY P, STEINMEIZ H and KLEINSCHMIDT A.Dissociating neural correlates of cognitive components inmental calculation. Cerebral Cortex, 11: 350-359, 2001.
HAMZEI F, RIJNTJES M, DETTMERS C, GLAUCHE V, WEILLER C andBUCHEL C. The human action recognition system and itsrelationship to Broca’s area: An fMRI study. NeuroImage, 19:637-644, 2003.
IACOBONI M, WOODS R, BRASS M, BEKKERING H, MAZZIOTTA JCand RIZZOLATTI G. Cortical mechanisms of human imitation.Science, 286: 2526-2528, 1999.
JOHNSON-FREY SH, MALOOF FR, NEWMAN-NORLUND R, FARRER C,INATI S and GRAFTON ST. Actions or hand-object interactions?Human inferior frontal cortex and action observation. Neuron,39: 1053-1058, 2003.
KELLENBACH ML, BRETT M and PATTERSON K. Actions speaklouder than functions: The importance of manipulability andaction in tool representation. Journal of CognitiveNeuroscience, 15: 30-45, 2003.
KOHLER E, KEYSERS CM, UMILTÀ A, FOGASSI L, GALLESE V andRIZZOLATTI G. Hearing sounds, understanding actions: Actionrepresentation in mirror neurons. Science, 297: 846-848,2002.
LACQUANITI F, PERANI D, GUIGNON E, BETTINARDI V, CARROZZOM, GRASSI F, ROSSETTI Y and FAZIO F. Visuomotortransformations for reaching to memorized targets: A PETstudy. NeuroImage, 5: 129-146, 1997.
LIBERMAN AM, COOPER FS, SHANKWEILER DP and STUDDERT-KENNEDY M. Perception of the speech code. PsychologicalReview, 74: 431-461, 1967.
LIBERMAN AM and MATTINGLY IG. The motor theory of speechperception revised. Cognition, 21: 1-36, 1985.
LIBERMAN AM and WAHLEN DH. On the relation of speech tolanguage. Trends in Cognitive Neuroscience, 4: 187-196,2000.
LIEBERMAN P. Speech and brain evolution. Behavioral and BrainSciences, 14: 566-568, 1991.
LIOTTI M, GAY CT and FOX PT. Functional imaging and language:Evidence from positron emission tomography. Journal ofClinical Neurophysiology, 11: 175-90, 1994.
MAESS B, KOELSCH S, GUNTER TC and FRIEDERICI AD. Musicalsyntax is processed in Broca’s area: An MEG study. NatureNeuroscience, 4: 540-545, 2001.
MATELLI M, LUPPINO G and RIZZOLATTI G. Patterns of cytochromeoxidase activity in the frontal agranular cortex of macaquemonkey. Behavioral Brain Research, 18: 125-137, 1985.
MATSUMURA M, KAWASHIMA R, NAITO E, SATOH K, TAKAHASHI T,YANAGISAWA T and FUKUDA H. Changes in rCBF duringgrasping in humans examined by PET. NeuroReport, 7: 749-752, 1996.
MECKLINGER A, GRUENEWALD C, BESSON M, MAGNIÉ M-N andVON CRAMON Y. Separable neuronal circuitries formanipulable and non-manipualble objects in workingmemory. Cerebral Cortex, 12: 1115-1123, 2002.
MILBERG W, BLUMSTEIN S and DWORETZKY B. Phonologicalprocessing and lexical access in aphasia. Brain and Language,34: 279-293, 1988.
MULLER R-A, KLEINHANS N and COURCHESNE E. Broca’s area and
the discrimination of frequency transitions: A functional MRIstudy. Brain and Language, 76: 70-76, 2001.
NEGAWA T, MIZUNO S, HAHASHI T, KUWATA H, TOMIDA M, HOSHIH, ERA S and KUWATA K. M pathway and areas 44 and 45 areinvolved in stereoscopic recognition based on binoculardisparity. Japanese Journal of Physiology, 52: 191-198, 2002.
NISHITANI N and HARI R. Temporal dynamics of corticalrepresentation for action. Proceedings of the NationalAcademy of Sciences, 97: 913-918, 2000.
PAPATHANASSIOU D, ETARD O, MELLET E, ZAGO L, MAZOYER B andTZOURIO MAZOYER N. A common language network forcomprehension and production: A contribution to thedefinition of language epicenters with PET. NeuroImage, 11:347-57, 2000.
PETRIDES M and PANDYA DN. Comparative architectonic analysisof the human and the macaque frontal cortex. In Boller F andGrafman J (Eds), Handbook of Neuropsychology (vol. IX).New York: Elsevier, 1997.
RANGANATH C, JOHNSON MK and D’ESPOSITO M. Prefrontalactivity associated with working memory and episodic long-term memory. Neuropsychologia, 41: 378-389, 2003.
RIZZOLATTI G, CAMARDA R, FOGASSI L, GENTILUCCI M, LUPPINO Gand MATELLI M. Functional organization of inferior area 6 inthe macaque monkey: II. Area F5 and the control of distalmovements. Experimental Brain Research, 71: 491-507, 1988.
RIZZOLATTI G, FADIGA L, GALLESE V and FOGASSI L. Premotorcortex and the recognition of motor actions. Cognitive BrainResearch, 3: 131-141, 1996a.
RIZZOLATTI G, FADIGA L, MATELLI M, BETTINARDI V, PAULESU E,PERANI D and FAZIO F. Localization of grasp representation inhumans by PET: 1. Observation versus execution.Experimental Brain Research, 111: 246-252, 1996b.
SCHUBOTZ RI, FRIEDERICI AD and VON CRAMON DY. Timeperception and motor timing: A common cortical andsubcortical basis revealed by fMRI. NeuroImage, 11: 1-12,2000.
SCHUBOTZ RI and VON CRAMON DY. Predicting perceptual eventsactivates corresponding motor schemes in lateral premotorcortex: An fMRI study. NeuroImage, 15: 787-96, 2002a.
SCHUBOTZ RI and VON CRAMON DY. A blueprint for target motion:fMRI reveals perceived sequential complexity to modulatepremotor cortex. NeuroImage, 16: 920-35, 2002b.
STRAFELLA AP and PAUS T. Modulation of cortical excitabilityduring action observation: A transcranial magnetic stimulationstudy. NeuroReport, 11: 2289-2292, 2000.
UTMAN JA, BLUMSTEIN SE and SULLIVAN K. Mapping from soundto meaning: Reduced lexical activation in Broca’s aphasics.Brain and Language, 79: 444-472, 2001
WATKINS K and PAUS T. Modulation of motor excitability duringspeech perception: The role of Broca’s area. Journal ofCognitive Neuroscience, 16: 978-87, 2004.
WILSON SM, SAYGIN AP, SERENO MI and IACOBONI M. Listening tospeech activates motor areas involved in speech production.Nature Neuroscience, 7: 701-2, 2004.
Luciano Fadiga, Faculty of Medecine, Department of Biomedical Sciences, Section ofHuman Physiology, University of Ferrara, via Fossato di Mortara 17/19, 44100 Ferrara,Italy. e-mail: [email protected]

1
This chapter is dedicated in memory of Massimo Matelli.
Broca’s region: a speech area?
Luciano Fadiga, Laila Craighero, Alice Roy
Department of Biomedical Sciences, Section of Human Physiology
University of Ferrara - Italy
Introduction
Since its first description in the 19th Century, Broca’s area, largely coincident with
Brodmann areas 44/45 (pars opercularis and pars triangularis of the inferior frontal gyrus
(IFG), see Amunts et al., 1999) has represented one of the most challenging areas of the
human brain. Its discoverer, the French neurologist Paul Broca (1861), strongly claimed that
a normal function of this area is fundamental for the correct functioning of verbal
communication. In his view this area, which he considered a motor area, contains a
“memory” of the movements necessary to articulate words. Several Broca’s colleagues,
however, argued against his interpretation (i.e. Henry C. Bastian, who considered Broca’s
area a sensory area deputed to tongue proprioception), and perhaps the most famous
among them, Paul Flechsig, postulated for Broca’s area a role neither motor nor sensory
(see Mingazzini, 1913). According to his schema, drawn to explain the paraphasic
expression of sensory aphasia, Broca’s region is driven by Wernicke’s area and, due to its
strong connections to the inferior part of the precentral gyrus (gyrus frontalis ascendens), it
recruits and coordinates the motor elements necessary to produce words articulation. It is
important to stress here that the whole set of knowledge on the function of Broca’s area
possessed by the neurologists of the 19th Century, derived from the study of the correlation
between functional impairment and brain lesions, as assessed post-mortem by
neuropathological investigations.
The neurosurgeon Wilder Penfield was the first who experimentally demonstrated the
involvement of Broca’s region in speech production. By electrically stimulating the frontal
lobe in awake patients undergoing brain surgery for intractable epilepsy, he collected dozens
of cases and firstly reported that the stimulation of the inferior frontal gyrus evoked the arrest
of ongoing speech, although with some individual variability. The coincidence between the
focus of the Penfield effect and the location of the Broca’s area, was a strongly convincing
argument in favour of the motor role of this region (Penfield and Roberts, 1959).

2
Apart from some pioneeristic investigation of speech-related evoked potentials (Ertl
and Schafer, 1967; Lelord et al., 1973), the true scientific revolution in the study of verbal
communication was represented by the discovery of brain imaging techniques, such as
positron emission tomography (PET), functional magnetic resonance (fMRI) and
magnetoencephalography (MEG). This mainly because evoked potential technique, although
very fast in detecting neuronal responses, was definitely unable to localize brain activation
with enough spatial resolution (the situation has changed now with high-resolution EEG). As
soon as positron emission tomography became available, a series of independent studies on
the brain correlates of the verbal function demonstrated the involvement of Broca’s region
during generation of speech (for a review of early studies see Liotti et al., 1994). At the same
time, however, the finding that Broca’s region was activated also during speech perception
became more and more accepted (see Papathanassiou et al., 2000 for review). This finding
represents in our view the second revolution in the neuroscience of speech. Data coming
from cortical stimulation of collaborating patients undergoing neurosurgery confirmed these
observations. According to Schaffler et al. (1993) the electrical stimulation of the Broca’s
area in addition to the speech production interference originally shown by Penfield, produced
also comprehension deficits, particularly evident in the case of “complex auditory verbal
instructions and visual semantic material”. According to the same group, while Broca’s region
is specifically involved in speech production, Wernicke’s AND Broca’s areas both participate
to speech comprehension (Schaffler et al., 1993). This double-faced role of Broca’s area is
now widely accepted, although with different functional interpretations. The discussion in
deep of this debate is however outside the scope of the present chapter but readers will find
details on it in other contributions to the present book.
The perceptual involvement of Broca’s area seems not restricted to speech perception.
Since early ‘70s several groups have shown a strict correlation between frontal aphasia and
impairment in gestures/pantomimes recognition (Gainotti and Lemmo, 1976; Duffy and Duffy,
1975; Daniloff et al., 1982; Glosser et al., 1986; Duffy and Duffy, 1981; Bell, 1994). It is often
unclear, however, whether this relationship between aphasia and gestures recognition
deficits is due to Broca’s area lesion only or if it depends on the involvement of other,
possibly parietal, areas. In fact, it is a common observation that aphasic patients are
frequently affected by ideomotor apraxia too (see Goldenberg, 1996).
This chapter will present data and theoretical framework supporting a new
interpretation of the role played by Broca’s area. In a first part we will briefly review a series
of recent brain imaging studies which report, among others, the activation of area 44/45. In
consideration of the large variety of experimental paradigms inducing such activation, we will
make an interpretative effort by presenting neurophysiological data from the monkey

3
homologue of BA44/BA45. Finally we will report electrophysiological data on humans which
connect speech perception to the more general framework of other’s action understanding.
Does only speech activate Broca’s area?
In this section we will present recent brain imaging experiments reporting Broca’s area
activation. Experiments will be grouped according to the general cognitive function they
explore.
Memory and attention.
Brain imaging studies aiming at identifying the neuronal substrate of the working
memory have repeatedly observed activations of Broca’s area. However, these results
should be taken cautiously as most of the experimental tasks used verbal stimuli and do not
allowed to clearly disambiguate the role of BA44 in the memory processes from the well-
known one in language processes. Considered as the neuronal substrate of the phonological
loop, a component of the working memory system, few memory studies have highlighted the
possible contribution of Broca’s area in “pure” memory processes. Mecklinger and
colleagues (2002) recently reported the activation of BA44 during a delay match-to-sample
task in which subjects were required to match the orientation of non-manipulable objects.
When tested with pictures of manipulable objects the activation shifted caudally to the left
ventral premotor cortex. While in this study BA44 was mainly associated with the encoding
delay, Ranganath and co-workers (2003) failed to demonstrate any preferential activation of
Broca’s area for the encoding or, conversely, the retrieval phases. Furthermore the authors
found the activation of Broca’s area both during a long-term memory task and a working
memory task, questioning thus a specific involvement in the working memory system.
Interestingly, the stimuli used in this experiment were pictures of face and, as we will review
later, Broca’s area seems particularly responsive to facial stimuli. Moreover, there is a series
of papers by Ricarda Schubotz and Yves von Cramon in which they investigate non-motor
and non-language functions of the premotor cortex (for review see Schubotz and von
Cramon, 2003). According to this work the premotor cortex is also involved in prospective
attention to sensory events and in processing serial prediction tasks.
Arithmetics and calculation.
If the role of Broca’s area in non-verbal memory remains to be confirmed, its potential
participation in calculation tasks is equally confusing. Arithmetic studies face with two
problems that could both account for the activation of BA44, the working memory sub-
processes and the presence of covert speech (Delazer et al, 2003; Menon et al, 2000;

4
Rickard et al, 2000). To this respect, the study of Gruber et al (2001) is interesting as they
carefully controlled for the covert-speech but still found an activation of Broca’s area.
Moreover they compared a simple calculation task to a compound one and once again
observed an activation of Broca’s area. If the hypothesis of the verbal working memory
cannot be ruled out, these authors nevertheless strengthened the potential involvement of
Broca’s area in processing symbolic meaningful operations and applying calculation rules.
Music.
Playing with rules seems to be part of the cognitive attributions of BA44, as repeatedly
observed during tasks manipulating syntactic rules. In an elegant study, Maess and
colleagues (2001) have further extended these observations to musical syntax. Indeed, the
predictability of harmonics and the rules underlying music organization has been compared
to language syntax (Patel et al, 1998; Bharucha et Krumhansl, 1983). By inserting
unexpected harmonics Maess and co-workers (2001) created a sort of musical syntactic
violation. Using magnetoencephalography (MEG) they studied the neuronal counterpart of
hearing harmonic incongruity, as expected basing on a previous experiment, they found an
early right anterior negativity, a parameter that has already been associated with harmonics
violation (Koelsch et al, 2000). The source of the activity pointed out BA44, bilaterally.
However the story is not that simple, and in addition to a participation in high order processes
Broca’s area takes part to lower order processes such as tonal frequency discrimination
(Muller et al, 2001) or binocular disparity (Negawa et al, 2002).
Motor-related functions.
Excluding the linguistic field, another important contribution of BA44 is certainly found
in the motor domain and motor-related processes. Gerlach et al (2002) asked subjects to
perform a categorization task between natural and man-made objects and found an
activation of BA44 extending caudally to BA6 for artefacts only. The authors proposed that
categorization might rely on motor-based knowledge, artefacts being more closely linked with
hand actions than natural objects. Distinguishing between manipulable and non-manipulable
objects, Kellenbach and colleagues (2003) found a stronger activation of BA44 when
subjects were required to answer a question concerning the action evoked by manipulable
objects. However, performing a categorization task or answering a question even by the way
of a button press are likely to evoked covert speech. Against this criticism are several studies
reporting a significant activation of BA44 during execution of distal movements such as
grasping (Binkofski et al, 1999ab; Gerardin et al, 2000; Grezes et al, 2003; Hamzei et al,
2003; Lacquaniti et al, 1997; Matsumura et al, 1996; Nishitani et Hari, 2000). Moreover, the

5
activation of BA44 is not restricted to motor execution but spreads over motor imagery
(Binkofski et al, 2000; Geradin et al, 2000; Grezes et Decety, 2002).
How can we solve the puzzle?
In order to understand how the human brain works, usually neuroscientists try to define
which human areas are morphologically closer to electrophysiologically characterized
monkey ones. In our case, to navigate through this impressive amount of experimental data,
we will perform the reversal operation by stepping down the evolutionary scale in order to
examine the functional properties of the homologue of BA44 in our “progenitors”. From a
cytoarchitectonical point of view (Petrides and Pandya, 1997), the monkey’s frontal area
which closely resembles human Broca’s region is an agranular/disgranular premotor area
(area F5 as defined by Matelli et al. 1985) (see Rizzolatti et al., 2002). We will therefore
examine the functional properties of this area by reporting the results of experiments aiming
to find a behavioral correlate to single neuron responses.
Motor properties of the monkey homologue of human Broca’s area
Area F5 forms the rostral part of inferior area 6 (Fig. 1).
Figure 1. Lateral view of monkey left hemisphere. Area F5 is buried inside the arcuate sulcus (posterior bank)
and emerges on the convexity immediately posterior to it. Area F5 is bidirectionally connected with the inferior
parietal lobule (areas AIP, anterior intraparietal, PF and PFG) and represents the monkey homologue of human
Broca’s area (Petrides and Pandya, 1997). Areas F5 sends some direct connections also to hand/mouth

6
representations of primary motor cortex (area F1) and to the cervical enlargement of the spinal cord. This last
evidence definitely demonstrates its motor nature.
Microstimulation (Hepp-Reymond et al., 1994) and single neuron studies (see Rizzolatti
et al. 1988) show that in area F5 are represented hand and mouth movements. The two
representations tend to be spatially segregated: while hand movements are mostly
represented in the dorsal part of area F5, mouth movements are mostly located in its ventral
part. Although not much is known about the functional properties of “mouth” neurons, the
properties of “hand” neurons have been extensively investigated. Rizzolatti et al. (1988)
recorded single neuron activity in monkeys trained to grasp objects of different size and
shape. The specificity of the goal seems to be an essential prerequisite in activating these
neurons. The same neurons that discharge during grasping, holding, tearing, manipulating,
are silent when the monkey performs actions that involve a similar muscular pattern but with
a different goal (i.e. grasping to put away, scratching, grooming, etc.). Further evidence in
favor of such a goal representation is given by F5 neurons that discharge when the monkey
grasps an object with its right hand or with its left hand (Figure 2). This observation suggests
that some F5 premotor neurons are capable to generalize the goal, independently from the
acting effector. Using the action effective in triggering neuron’s discharge as classification
criterion, F5 neurons can be subdivided into several classes. Among them, the most
common are "grasping", "holding", "tearing", and "manipulating" neurons. Grasping neurons
form the most represented class in area F5. Many of them are selective for a particular type
of prehension such as precision grip, finger prehension, or whole hand prehension. In
addition, some neurons show specificity for different fingers configuration, even within the
same grip type. Thus, the prehension of a large spherical object (whole hand prehension,
requiring the opposition of all fingers) is coded by neurons different from those coding the
prehension of a cylinder (still whole hand prehension but performed with the opposition of the
four last fingers and the palm of the hand). The temporal relation between grasping
movement and neuron discharge varies from neuron to neuron. Some neurons become
active during the initial phase of the movement (opening of the hand), some discharge during
hand closure, and others discharge during the entire grasping movement from the beginning
of fingers opening until their contact with the object.

7
Figure 2. Example of F5 motor neuron. In each panel eight trials are represented (rasters in the uppermost part)
together with the sum histogram (lowermost part). Trials are aligned with the moment at which the monkey
touches the target (vertical line across rasters and histograms). Ordinates: spikes/second; Abscissae: 20 ms bins.
.
Taken together, the functional properties of F5 neurons suggest that this area stores a
set of motor schemata (Arbib, 1997) or, as it was previously proposed (Rizzolatti and
Gentilucci, 1988), contains a "vocabulary" of motor acts. The "words" composing this
vocabulary are constituted by populations of neurons. Some of them indicate the general
category of an action (hold, grasp, tear, manipulate). Others specify the effectors that are
appropriate for that action. Finally, a third group is concerned with the temporal segmentation
of the actions. What differentiates F5 from the primary motor cortex (M1, BA4) is that while
F5 motor schemata code for goal-directed actions (or fragments of specific actions), in the
primary motor cortex are represented movements, which are independent from the action
context in which they are used. In comparison with F5, M1 could therefore be defined as a
"vocabulary of movements".
Visuomotor properties of the monkey homologue of human Broca’s area
All F5 neurons share similar motor properties. In addition to their motor discharge,
however, several F5 neurons discharge also to the presentation of visual stimuli (visuomotor
neurons). Two radically different categories of visuomotor neurons are present in area F5:
Neurons of the first category discharge when the monkey observes graspable objects
(“canonical” F5 neurons, Rizzolatti et al., 1988; Rizzolatti and Fadiga, 1998). Neurons of the
second category discharge when the monkey observes another individual making an action
in front of it (di Pellegrino et al., 1992, Gallese et al., 1996; Rizzolatti et al., 1996a). For this

8
peculiar “resonant” properties, neurons belonging to the second category have been named
“mirror” neurons (Gallese et al., 1996). The two categories of F5 neurons are located in two
different sub-regions of area F5: canonical neurons are mainly found in that sector of area F5
buried inside the arcuate sulcus, whereas mirror neurons are almost exclusively located in
the cortical convexity of F5.
Recently, the visual responses of canonical neurons have been re-examined using a
formal behavioral paradigm, which allowed to separately test the response related to object
observation, during the waiting phase between object presentation and movements onset,
and during movement execution (Murata et al., 1997). The results showed that among the
canonical neurons recorded in area F5, two thirds were selective to one or few specific
objects. When visual and motor properties of F5 object observation neurons are compared, it
becomes clear that there is a strict congruence between the two types of responses.
Neurons that become active when the monkey observes small size objects, discharge also
during precision grip. On the contrary, neurons selectively active when the monkey looks at a
large object, discharge also during actions directed towards large objects (e.g. whole hand
prehension). The most likely interpretation for visual discharge in these visuomotor neurons
is that, at least in adult individuals, there is a close link between the most common 3D stimuli
and the actions necessary to interact with them. Thus, every time a graspable object is
visually presented, the related F5 neurons are addressed and the action is "automatically"
evoked. Under certain circumstances, it guides the execution of the movement, under others,
it remains an unexecuted representation of it, that might be used also for semantic
knowledge.
Mirror neurons, that become active when the monkey acts on an object and when it
observes another monkey or the experimenter making a similar goal-directed action, appear
to be identical to canonical neurons in terms of motor properties, but they radically differ from
them as far as visual properties are concerned (Rizzolatti and Fadiga, 1998). In order to be
triggered by visual stimuli, mirror neurons require an interaction between a biological effector
(hand or mouth) and an object. The sights of an object alone, of an agent mimicking an
action, or of an individual making intransitive (non-object directed) gestures are all
ineffective. The object significance for the monkey has no obvious influence on mirror neuron
response. Grasping a piece of food or a geometric solid produces responses of the same
intensity.
Mirror neurons show a large degree of generalization. Largely different visual stimuli,
but representing the same action, are equally effective. For example, the same grasping
mirror neuron that responds to a human hand grasping an object, responds also when the
grasping hand is that of a monkey. Similarly, the response is, typically, not affected if the
action is done near or far from the monkey, in spite of the fact that the size of the observed

9
hand is obviously different in the two conditions. It is also of little importance for neuron
activation if the observed action is eventually rewarded. The discharge is of the same
intensity if the experimenter grasps the food and gives it to the recorded monkey or to
another monkey, introduced in the experimental room. The observed actions which most
commonly activate mirror neurons are grasping, placing, manipulating, holding.
Most mirror neurons respond selectively to only one type of action (e.g. grasping).
Some are highly specific, coding not only the type of action, but also how that action is
executed. They fire, for example, during observation of grasping movements, but only when
the object is grasped with the index finger and the thumb. Typically, mirror neurons show
congruence between the observed and executed action. According to the type of congruence
they exhibit, mirror neurons have been subdivided into “strictly congruent” and “broadly
congruent” neurons (Gallese et al. 1996). Mirror neurons in which the effective observed and
effective executed actions correspond in terms of goal (e.g. grasping) and means for
reaching the goal (e.g. precision grip) have been classed as “strictly congruent”. They
represent about one third of F5 mirror neurons. Mirror neurons that, in order to be triggered,
do not require the observation of exactly the same action that they code motorically, have
been classed as “broadly congruent”. They represent about two-third of F5 mirror neurons.
The early studies of mirror neurons concerned essentially the upper sector of F5 where
hand actions are mostly represented. Recently, a study was carried on the properties of
neurons located in the lateral part of F5 (Ferrari et al. 2003), where, in contrast, most
neurons are related to mouth actions. The results showed that about 25% of studied neurons
have mirror properties. According to the visual stimuli effective in triggering the neurons, two
classes of mouth mirror neurons were distinguished: ingestive and communicative mirror
neurons. Ingestive mirror neurons respond to the observation of actions related to ingestive
functions, such as grasping food with the mouth, breaking it, or sucking. Neurons of this
class form about 80% of the total amount of the recorded mouth mirror neurons. Virtually, all
ingestive mirror neurons show a good correspondence between the effective observed and
the effective executed action. In about one third of them, the effective observed and
executed actions are virtually identical (strictly congruent neurons), in the remaining the
effective observed and executed actions are similar or functionally related (broadly congruent
neurons). More intriguing are the properties of the communicative mirror neurons. The most
effective observed action is for them a communicative gesture such as, for example, lip
smacking. However, as the ingestive mirror neurons, they strongly discharge when the
monkey actively performs an ingestive action.
It seems plausible that the visual response of both canonical and mirror neurons
address the same motor vocabulary, the words of which constitute the monkey motor
repertoire. What is different is the way in which “motor words” are selected: in the case of

10
canonical neurons they are selected by object observation, in the case of mirror neurons by
the sight of an action. Thus, in the case of canonical neurons, vision of graspable objects
activates the motor representations more appropriate to interact with those objects. In the
case of mirror neurons, objects alone are no more sufficient to evoke a premotor discharge:
what is necessary is a visual stimulus describing a goal-directed hand action in which both,
an acting hand and a target must be present.
Summarizing the evidence presented above, the monkey precursor of human Broca’s
area is a premotor area, representing hand and mouth goal-directed actions, provided with
strong visual inputs coming from the inferior parietal lobule. These visual inputs originate in
distinct parietal areas and convey distinct visual information: 1) object-related information,
used by canonical neurons to motorically categorize objects and to organize the hand-object
interaction; 2) action-related information driving the response of mirror neurons during
observation of action made by others.
Which are the human areas activated by action observation?
The existence of a mirror-neuron system in humans has been first demonstrated by
electrophysiological experiments. The first pioneer demonstration of a “visuomotor
resonance” has been reported by Gastaut and Bert (1954) and Cohen-Seat et al. (1954).
These authors showed that the observation of actions made by humans exerts a
desynchronizing effect on the EEG recorded over motor areas, similar to that exerted by
actual movements. Recently, more specific evidence in favor of the existence of a human
mirror system arose from transcranial magnetic stimulation (TMS) studies of cortical
excitability. Fadiga et al. (1995) stimulated the left motor cortex of normal subjects using
TMS while they were observing meaningless intransitive arm movements as well as hand
grasping movements performed by an experimenter. Motor evoked potentials (MEPs) were
recorded from various arm and hand muscles. The rationale of the experiment was the
following: if the mere observation of the hand and arm movements facilitates the motor
system, this facilitation should determine an increase of MEPs recorded from hand and arm
muscles. The results confirmed the hypothesis. A selective increase of motor evoked
potentials was found in those muscles that the subjects would have used for producing the
observed movements. Additionally, this experiment demonstrated that both goal-directed and
intransitive arm movements were capable to evoke the motor facilitation. More recently
Strafella and Paus (2000) supported these findings and demonstrated the cortical nature of
the facilitation.
The electrophysiological experiments described above, while fundamental in showing
that action observation elicits a specific, coherent activation of motor system, do not allow the

11
localization of the areas involved in the phenomenon. The first data on the anatomical
localization of the human mirror-neuron system have been therefore obtained using brain-
imaging techniques. PET and fMRI experiments, carried out by various groups,
demonstrated that when the participants observed actions made by human arms or hands,
activations were present in the ventral premotor/inferior frontal cortex (Rizzolatti et al. 1996b;
Grafton et al. 1996; Decety et al. 1997; Grèzes et al. 1998; Iacoboni et al. 1999, Decety and
Chaminade; 2003; Grèzes et al. 2003). As already mentioned for TMS experiments by
Fadiga et al. (1995) both transitive (goal directed) and intransitive meaningless gestures
activate the mirror-neuron system in humans. Grèzes et al. (1998) investigated whether the
same areas became active in the two conditions. Normal human volunteers were instructed
to observe meaningful or meaningless actions. The results confirmed that the observation of
meaningful hand actions activates the left inferior frontal gyrus (Broca’s region), the left
inferior parietal lobule plus various occipital and inferotemporal areas. An activation of the left
precentral gyrus was also found. During meaningless gesture observation there was no
Broca’s region activation. Furthermore, in comparison with meaningful action observations,
an increase was found in activation of the right posterior parietal lobule. More recently, two
further studies have shown that a meaningful hand-object interaction more than pure
movement observation, is effective in triggering Broca’s area activation (Hamzei et al, 2003;
Johnson-Frey et al, 2003). Similar conclusions have been reached also for mouth movement
observation (Campbell et al, 2001).
In all early brain imaging experiments, the participants observed actions made by
hands or arms. Recently, experiments were carried out to learn whether mirror system coded
actions made by other effectors. Buccino et al. (2001) instructed participants to observe
actions made by mouth, foot as well as by hand. The observed actions were: biting an apple,
reaching and grasping a ball or a small cup, and kicking a ball or pushing a brake (object-
related actions). Similar actions but non object-related (such as chewing) were also tested.
The results showed that: (1) During observation of non object-related mouth actions
(chewing), activation was present in areas 6 and in Broca’s area on both sides, with a more
anterior activation (BA45) in the right hemisphere. During object-related action (biting), the
pattern of premotor activation was similar to that found during non object-related action. In
addition, two activation foci were found in the parietal lobe. (2) During the observation of non
object-related hand/arm actions there was a bilateral activation of area 6 that was located
dorsally to that found during mouth movement observations. During the observation of
object-related arm/hand actions (reaching-to-grasp-movements) there was a bilateral
activation of premotor cortex plus an activation site in Broca’s area. As in the case of
observation of mouth movements, two activation foci were present in the parietal lobe. (3)
During the observation of non object-related foot actions there was an activation of a dorsal

12
sector of area 6. During the observation of object-related actions, there was as in the
condition without object, an activation of a dorsal sector of area 6. In addition, there was an
activation of the posterior part of the parietal lobe. Two are the main conclusions that can be
drawn from these data. Fist, the mirror system is not limited to hand movements, Second,
actions performed with different effectors are represented in different regions of the premotor
cortex (somatotopy). Third, in agreement with previous data by Grèzes et al. (1998) and
Iacoboni et al. (1999), the parietal lobe is part of the human mirror systems, and that it is
strongly involved when an individual observes object-directed actions.
The experiments reviewed in this section, tested subjects during action observation
only. Therefore, the conclusion that frontal activated areas such as Broca’s region have
mirror properties was an indirect conclusion based on their premotor nature and, in the case
of Broca’s area, by its homology with monkey’s premotor area F5. However, if one looks at
the results of the brain imaging experiments reviewed in the second section of this chapter
(Motor-related functions of Broca’s area), it appears clearly that Broca’s area is an area
becoming active not only during speech generation, but also during real and imagined hand
movements. If one combines these two observations it appears that Broca’s area might be
the highest-order motor region where an observation/execution matching occurs. Direct
evidence for an observation/execution matching system was recently provided by two
experiments, one employing fMRI technique (Iacoboni et al 1999), the other using event-
related MEG (Nishitani and Hari, 2000).
Iacoboni et al. (1999) instructed normal human volunteers to observe and imitate a
finger movement and to perform the same movement after a spatial or a symbolic cue
(observation/execution tasks). In another series of trials, the same participants were asked to
observe the same stimuli presented in the observation/execution tasks, but without giving
any response to them (observation tasks). The results showed that activation during imitation
was significantly stronger than in the other two observation/execution tasks in three cortical
areas: left inferior frontal cortex, right anterior parietal region, and right parietal operculum.
The first two areas were active also during observation tasks, while the parietal operculum
became active during observation/execution conditions only.
Nishitani and Hari (2000) addressed the same issue using event-related
neuromagnetic recordings. In their experiments, normal human participants were requested,
in different conditions, to grasp a manipulandum, to observe the same movement performed
by an experimenter, and, finally, to observe and simultaneously replicate the observed
action. Their results showed that during execution, there was an early activation in the left
inferior frontal cortex (Broca’s area) with a response peak appearing approximately 250 ms
before the touch of the target. This activation was followed within 100-200 ms by activation of
the left precentral motor area and 150-250 ms later by activation of the right one. During

13
observation and during imitation, pattern and sequence of frontal activations were similar to
those found during execution, but the frontal activations were preceded by an occipital
activation due to visual stimulation occurring in the former conditions.
More recently, two studies of Koski and colleagues (2002, 2003) have made further
steps toward the comprehension of imitation mechanism and its relation to BA44. First,
(Koski et al., 2002) they compared the activity evoked by imitation and observation of finger
movements in the presence or conversely the absence of an explicit goal. They found that
the presence of goal increases the activity observed in BA44 for the imitation task only. They
concluded that imitation may represent a behavior tuned to replicate the goal of an action.
Later, the same authors (Koski et al., 2003) investigated the potential difference between
anatomical (actor and imitator both move the right hand) and specular imitation (the actor
moves the left hand, the imitator moves the right hand as in a mirror). They demonstrated
that the activation of Broca’s area was present only during specular imitation. In sum a
growing amount of studies established the determinant role of Broca’s area in distal and
facial motor functions such as movement execution, observation, simulation and imitation,
emphasizing further the fundamental aspect of the goal of the action.
What links hand actions with speech?
Others’ actions do not generate only visually perceivable signals. Action-generated
sounds and noises are also very common in nature. One could expect, therefore, that also
this sensory information, related to a particular action, could determine a motor activation
specific for that same action. A very recent neurophysiological experiment addressed this
point. Kohler and colleagues (2002) investigated whether there are neurons in area F5 that
discharge when the monkey makes a specific hand action and also when it hears the
corresponding action-related sounds. The experimental hypothesis started from the remark
that a large number of object-related actions (e.g. breaking a peanut) can be recognized by a
particular sound. The authors found that 13% of the investigated neurons discharge both
when the monkey performed a hand action and when it heard the action-related sound.
Moreover, most of these neurons discharge also when the monkey observed the same
action demonstrating that these ‘audio-visual mirror neurons’ represent actions
independently of whether them are performed, heard or seen.
The presence of an audio-motor resonance in a region that, in humans, is classically
considered a speech-related area, evokes the Liberman’s hypothesis on the mechanism at
the basis of speech perception (motor theory of speech perception, Liberman et al., 1967;
Liberman and Mattingly, 1985; Liberman and Wahlen, 2000). The motor theory of speech
perception maintains that the ultimate constituents of speech are not sounds, but articulatory

14
gestures that have evolved exclusively at the service of language. A cognitive translation into
phonology is not necessary because the articulatory gestures are phonologic in nature.
Furthermore, speech perception and speech production processes use a common repertoire
of motor primitives that, during speech production, are at the basis of articulatory gesture
generation, while during speech perception, are activated in the listener as the result of an
acoustically evoked motor “resonance”. Thus, sounds conveying verbal communication are
the vehicle of motor representations (articulatory gestures) shared by both the speaker and
the listener, on which speech perception could be based upon. In other terms, the listener
understands the speaker when his/her articulatory gestures representations are activated by
verbal sounds.
Fadiga et al. (2002), in a TMS experiment based on the paradigm used in 1995 (Fadiga
et al. 1995), tested for the presence in humans of a system that motorically “resonates” when
the individuals listen to verbal stimuli. Normal subjects were requested to attend to an
acoustically presented randomized sequence of disyllabic words, disyllabic pseudo-words
and bitonal sounds of equivalent intensity and duration. Words and pseudo-words were
selected according to a consonant-vowel-consonant-consonant-vowel (cvccv) scheme. The
embedded consonants in the middle of words and of pseudo-words were either a double ‘f’
(labiodental fricative consonant that, when pronounced, requires slight tongue tip
mobilization) or a double ‘r’ (lingua-palatal fricative consonant that, when pronounced,
requires strong tongue tip mobilization). Bitonal sounds, lasting about the same time as
verbal stimuli and replicating their intonation pattern, were used as a control. The excitability
of motor cortex in correspondence of tongue movements representation was assessed by
using single pulse TMS and by recording MEPs from the anterior tongue muscles. The TMS
stimuli were applied synchronously with the double consonant of presented verbal stimuli
(words and pseudo-words) and in the middle of the bitonal sounds. Results (see Figure 3)
showed that during speech listening there is an increase of motor evoked potentials recorded
from the listeners’ tongue muscles when the listened word strongly involves tongue
movements, indicating that when an individual listens to verbal stimuli his/her speech related
motor centers are specifically activated. Moreover, words-related facilitation was significantly
larger than pseudo-words related one.
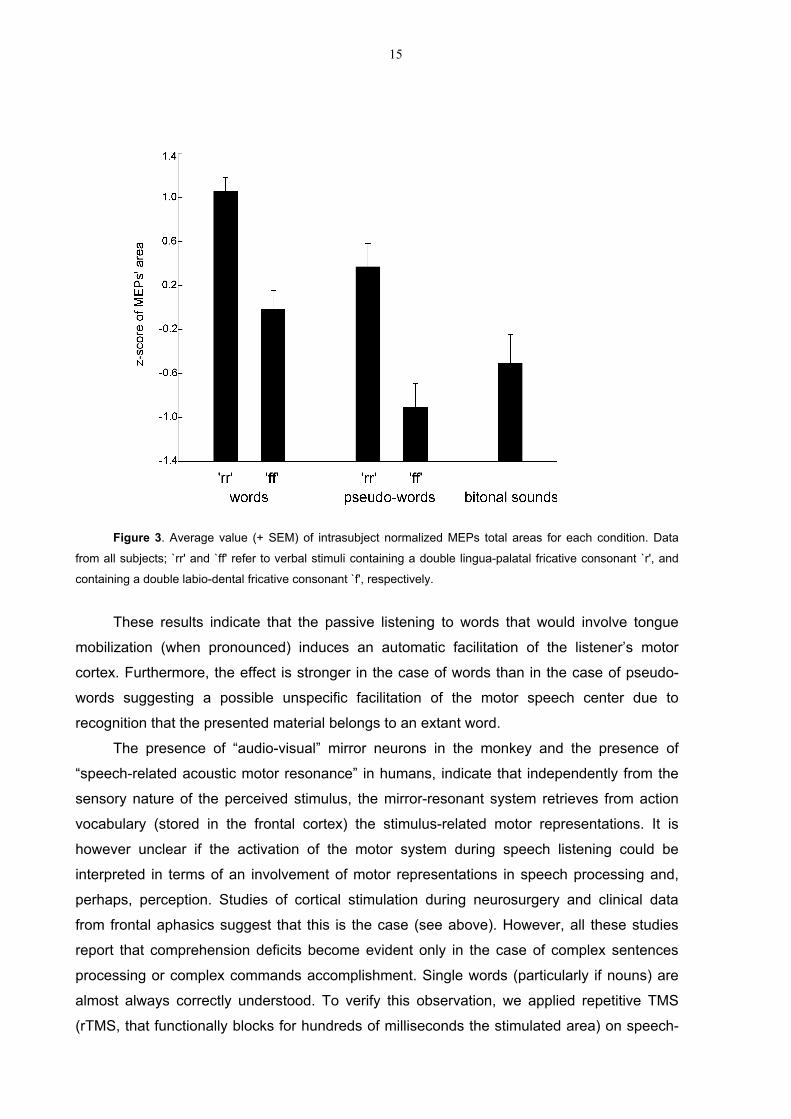
15
Figure 3. Average value (+ SEM) of intrasubject normalized MEPs total areas for each condition. Data
from all subjects; `rr' and `ff' refer to verbal stimuli containing a double lingua-palatal fricative consonant `r', and
containing a double labio-dental fricative consonant `f', respectively.
These results indicate that the passive listening to words that would involve tongue
mobilization (when pronounced) induces an automatic facilitation of the listener’s motor
cortex. Furthermore, the effect is stronger in the case of words than in the case of pseudo-
words suggesting a possible unspecific facilitation of the motor speech center due to
recognition that the presented material belongs to an extant word.
The presence of “audio-visual” mirror neurons in the monkey and the presence of
“speech-related acoustic motor resonance” in humans, indicate that independently from the
sensory nature of the perceived stimulus, the mirror-resonant system retrieves from action
vocabulary (stored in the frontal cortex) the stimulus-related motor representations. It is
however unclear if the activation of the motor system during speech listening could be
interpreted in terms of an involvement of motor representations in speech processing and,
perhaps, perception. Studies of cortical stimulation during neurosurgery and clinical data
from frontal aphasics suggest that this is the case (see above). However, all these studies
report that comprehension deficits become evident only in the case of complex sentences
processing or complex commands accomplishment. Single words (particularly if nouns) are
almost always correctly understood. To verify this observation, we applied repetitive TMS
(rTMS, that functionally blocks for hundreds of milliseconds the stimulated area) on speech-

16
related premotor centers during single word listening (Fadiga et al., unpublished
observation). TMS was delivered on a site 2 cm anterior to the hot-spot of the hand motor
representation, as assessed during mapping sessions performed on individual subjects. At
the end of each trial, participants were required to identify the listened word in a list
presented on a computer screen. Data analysis showed that rTMS was ineffective in
perturbing subject’s performance. As expected, subjects were perfectly able to report the
listened word independently from the presence or the absence of the stimulation, from the
duration of stimulation itself and from the moment at which the stimulus was delivered with
respect to the beginning of the presented word. If one accepts that Broca’s region is not
concerned with single word perception but at the same time considers that this area has
been classically considered the brain center more involved in phonological processing (at
least in production), a possible contradiction emerges. In order to investigate more rigorously
the perceptual role of Broca’s area we decided therefore to use an experimental paradigm
very sensitive in detecting a possible phonological impairment following Broca’s area
inactivation. It should be noted however that although phonology, among various speech
attributes, is strictly related to the more motor aspects of speech (phono-articulatory), this
doesn’t mean that other speech attributes, such as lexicon and syntax, are totally unrelated
to motor representations. It is well known, in fact, that several Broca’s aphasic patients
present differential deficits in understanding nouns (less impaired) and verbs (more impaired,
particularly in the case of action verbs) (see Bak et al. 2001).
With this aim we applied rTMS on Broca’s region during a phoneme discrimination task
in order to see if rTMS-induced inhibition was able to produce a specific “deafness“ for the
phonologic characteristics of the presented stimuli. Subjects were instructed to carefully
listen to a sequence of acoustically presented pseudo-words and to categorize the stimuli
according to their phonological characteristics by pressing one among four different switches
(Craighero, Fadiga and Haggard, unpublished data). Stimuli consisted of 80 pseudo-words
subdivided into four different categories. Categories were formed according to the phonetic
sequence of the middle part of the stimulus which could be “dada”, “data”, “tada” or “tata”
(e.g.: pipedadali, pelemodatalu, mamipotadame, pimatatape). Subjects had to press as soon
as possible the button corresponding to stimulus category. Participants’ left hemisphere was
magnetically stimulated in three different regions by using rTMS: a) the focus of the tongue
motor representation, b) a region 2 centimeters more anterior (ventral premotor/inferior
frontal cortex), c) a region 2 centimeters more posterior (somatosensory cortex). Repetitive
transcranial magnetic stimulation was delivered at a frequency of 20 Hz in correspondence of
the 2nd critical formant, in correspondence of the 1st and of the 2nd critical formants, and also
during the whole critical portion of the presented word. The hypothesis was that rTMS
delivered in correspondence of the speech-related premotor cortex, by determining the

17
temporary inhibition of the resonance system, should induce slower reaction times and a
significant higher amount of errors in the discrimination task with respect to the sessions in
which other cortical regions were stimulated. Results, however, showed no difference
between the performances obtained during the different experimental conditions (which
included also a control without rTMS).
A possible interpretation of the absence of any effect of interference on phonologic
perception could be that the discrimination task we used doesn’t, indeed, involve a
phonologic perception. The task could be considered a mere discrimination task of the serial
order of two different (not necessarily phonological) elements: the sound “TA” and the sound
“DA”. It is possible that the way in which the subjects solve the task is the same he/she
would use also in the case of two different tones and, possibly, involving structures different
from the Broca’s area. Another possible interpretation is that the used stimuli (pseudo-words)
are treated by the brain as non-speech stimuli, because they are semantically meaningless.
In order to be sure to investigate subjects with a task necessarily involving phonologic
perception, we decided to use a paradigm classically considered a phonological one: the
“phonological priming” task. Phonological priming effect refers to the fact that a target word is
recognized faster when it is preceded by a prime word sharing with it the last syllable
(rhyming effect, Emmorey, 1989).
In a single pulse TMS experiment we therefore stimulated participants’ inferior frontal
cortex while they were performing a phonological priming task. Subjects were instructed to
carefully listen to a sequence of acoustically presented pairs of verbal stimuli (dysillabic
‘cvcv’ or ‘cvccv’ words and pseudo-words) in which final phonological overlap was present
(rhyme prime) or, conversely, not present. Subjects were requested to make a lexical
decision on the second stimulus (target) by pressing with index finger or middle finger one
button if the target was a word and another button if the target was a pseudo-word.
The pairs of verbal stimuli could pertain to four categories which differed for presence
of lexical content in the prime and in the target:
- prime-word/target-word (W-W)
- prime-word/target-pseudoword (W-PW)
- prime-pseudoword/target-word (PW-W)
- prime-pseudoword/target-pseudoword (PW-PW).
Each category contained both rhyming and non-rhyming pairs. In some randomly
selected trials, we administered single pulse TMS in correspondence of left BA44 (Broca’s
region, localized by using “Neurocompass”, a frameless stereotactic system built in our
laboratory) during the interval (20 ms) between prime and target stimuli.

18
In trials without TMS, three are the main results: (i) strong and statistically significant
facilitation (phonological priming effect) when W-W, W-PW, PW-W pairs are presented; (ii)
no phonological priming effect when the PW-PW pair is presented; (iii) faster responses
when the target is a word rather than a pseudoword (both in W-W and PW-W).
Figure 4. Reaction times (RTs) in milliseconds (+ SEM) relative to the lexical decision during a
phonological priming task. Dotted line: phonological overlap present. Solid line: phonological overlap absent. W-
W, prime-word/target-word; W-PW, prime-word/target-pseudoword; PW-W, prime-pseudoword/target-word; PW-
PW, prime-pseudoword/target-pseudoword.
An interesting finding emerges from the analysis of these results: the presence or
absence of lexical content modulates the presence of the phonological priming effect. When
neither the target nor the prime has the access to the lexicon (PW-PW pair), the presence of
the rhyme does not facilitate the recognition of the target. In other words, in order to have a
phonological effect it is necessary to have the access to the lexicon.
In trials during which TMS was delivered, only W-PW pairs were affected by brain
stimulation: the W-PW pair behaving exactly as the PW-PW one. This finding suggests
that the stimulation of the Broca’s region might have affected the lexical property of the
prime. As consequence, the impossibility to have access to the lexicon determines the
absence of the phonological effect. According to our interpretation, the TMS-related effect is
absent in the W-W and PW-W pairs because of the presence of a meaningful (W) target.
950
1000
1050
1100
1150
1200
w-w w-pw pw-w pw-pw
priming
non priming
RTs

19
Being aware that a possible criticism to our data is that the task was implying a lexical
decision, we replicated the experiment by asking subjects to detect if the final vowel of the
target stimulus was ‘A’ or ‘O’. Despite the absence of any lexicon-directed attention, the
results were exactly the same as in the case of the lexical decision paradigm. Further
experiments are now carried out in order to reinforce this observation. In particular, brain
regions other that Broca’s area will be stimulated in order to test the specificity of the
observed effect.
Conclusions
The present chapter reviews some literature data and presents some experimental
results showing that, in addition to speech-related tasks, Broca’s area is significantly involved
also during tasks devoid of verbal content. If in some cases one could advance the criticism
that internal speech might have been at the origin of this activation, in other cases such
possibility is ruled out by appropriate controls. As frequently happens in Biology, when too
much interpretations are proposed for an anatomic-functional correlate, one should strongly
doubt about each of them. We started from this skeptic point of view by making an attempt to
correlate what was found with brain imaging in humans with what is known in monkeys at
single neuron level. The behavioral conditions triggering the response of neurons recorded in
the monkey area which is more closely related to human Broca’s (ventral premotor area F5)
are: 1) Grasping with the hand and grasping with the mouth actions. 2) Observation of
graspable objects. 3) Observation of hand/mouth actions performed by other individuals. 4)
Hearing sounds produced during manipulative actions. The experimental evidence suggests
that, in order to activate F5 neurons, executed/observed/heard actions must be all goal-
directed. Does the cytoarchitectonical homology, linking monkey area F5 with Broca’s area,
correspond to some functional homology? Does human Broca’s area discharge during
hand/mouth action execution/observation/hearing too? Does make difference, in terms of
Broca’s activation, if observed actions are meaningful (goal-directed) or meaningless? A
positive answer to these questions comes from fMRI experiments in which human subjects
are requested to execute goal-directed actions and are presented with the same visual
stimuli effective in triggering F5 neurons’ response (graspable objects or tools and actions
performed by other individuals). Results show that in both cases, Broca’s area become
significantly active. Finally, it is interesting to note that observation of meaningless
movements, while strongly activates human area 6 (bilaterally) is definitely less effective in
activating Broca’s region.
It has been suggested that a motor resonant system, such as that formed by mirror-
neurons, might have given a neural substrate to interindividual communication (see Rizzolatti

20
and Arbib, 1998). According to this view, speech may have evolved from a hand/mouth
gestural communicative system. A complete theory on the origin of speech is however well
beyond the scope of this chapter. Our aim in writing was to suggest to the readers some
stimulating starting points and to make an attempt to conciliate two streams of research,
which start from very different positions: the study of speech representation in humans and
the study of hand action representation in monkeys. These two approaches reach a common
target: the premotor region of the inferior frontal gyrus where Paul Broca first localized its
“frontal speech area”. The data presented in the last section of this chapter go in this
direction and although they represent only an experimental starting point, we think that they
already could allow some preliminary considerations and speculations.
The first important point is that the temporary inactivation of Broca’s region during
phonological tasks is ineffective in perturbing subjects’ performance. This result is definitely
against a “pure” phonological role of Broca’s region. The interpretation we favor is that it is
impossible to dissociate phonology from lexicon at Broca’s level because there “exist” only
words. In other terms, phonologically relevant stimuli are matched on a repertoire of words
and not on individually meaningless, “phonemes assembly”. Consequently, the motor
resonance of tongue representation revealed by TMS during speech listening (Fadiga et al.
2002) is probably a mixed phenomenon which should involve cortical regions others than
Broca’s area (possibly BA6) being this “acoustically-evoked mirror effect” independent from
the meaning of the presented stimuli. The motor representation of hand/mouth actions
present in Broca’s area derives from an ancient execution/observation (hearing) matching
system, already present in monkeys. As a consequence forms of communication other than
the verbal one, although expressions of a residual ancient mechanism, should exert a
significant effect on Broca’s area benefiting of its twofold involvement with motor goals:
during execution of own actions and during perception of others’ ones. We will investigate
this topic in the near future by using brain-imaging techniques.
The intimate motor nature of Broca’s region cannot be neglected when interpreting the
results of experiments testing hypotheses apparently far from pure motor tasks. The
hypothesis we suggest here (being aware of its purely speculative nature) is that the original
role played by this region in generating/extracting action meanings (by organizing/interpreting
motor sequences of individually meaningless movements) might have been generalized
during evolution giving to this area a new capability. The capability to deal with meanings
(and rules) which share with the motor system similar hierarchical and sequential structures
harmonized by a general, supramodal “syntax”.

21
Acknowledgements
The research presented in this chapter is supported in the framework of the European Science
Foundation EUROCORES program “The Origin of Man, Language and Languages”, by EC
“MIRROR” Contract and by Italian Ministry of Education Grants. We deeply thank G. Spidalieri for
his fruitful comments on early versions of the manuscript.
References
Amunts K, Schleicher A, Burgel U, Mohlberg H, Uylings HB, Zilles K (1999) Broca's
region revisited: cytoarchitecture and intersubject variability. Journal of Comparative
Neurology;412:319-341.
Arbib MA (1997) From visual affordances in monkey parietal cortex to hippocampo-
parietal interactions underlying rat navigation. Philos Trans R Soc Lond B Biol Sci;352:1429-
1436.
Bak TH, O'Donovan DG, Xuereb JH, Boniface S, Hodges JR. (2001) Selective
impairment of verb processing associated with pathological changes in Brodmann areas 44
and 45 in the motor neurone disease-dementia-aphasia syndrome. Brain;124:103-120.
Bell BD (1994) Pantomime recognition impairment in aphasia: an analysis of error
types. Brain Lang.;47:269-278.
Bharucha J and Krumhansl C (1983) The representation of harmonic structure in
music: hierarchies of stability as a function of context. Cognition;13:63-102.
Binkofski F, Amunts K, Stephan KM, Posse S, Schormann T, Freund HJ, Zilles K, Seitz
RJ (2000) Broca's region subserves imagery of motion: a combined cytoarchitectonic and
fMRI study. Human Brain Mapping;11:273-285.
Binkofski F, Buccino G, Posse S, Seitz RJ, Rizzolatti G, Freund H-J (1999a) A fronto-
parietal circuit for object manipulation in man: evidence from an fMRI study. European
Journal of Neuroscience;11:3276-3286.
Binkofski F, Buccino G, Stephan KM, Rizzolatti G, Seitz RJ, Freund H-J (1999b) A
parieto-premotor network for object manipulation: evidence from neuroimaging. Experimental
Brain Research;128:21-31.
Broca PP (1861) Loss of Speech, Chronic Softening and Partial Destruction of the
Anterior Left Lobe of the Brain. Bulletin de la Société Anthropologique;2:235-238.
Buccino G, Binkofski F, Fink GR, Fadiga L, Fogassi L, Gallese V, Seitz RJ, Zilles K,
Rizzolatti G, Freund HJ (2001). Action observation activates premotor and parietal areas in a
somatotopic manner: an fMRI study. European Journal of Neuroscience;13:400-404.

22
Campbell R, MacSweeney M, Surguladze S, Calvert G, McGuire P, Suckling J,
Brammer MJ, David AS (2001) Cortical substrates for the perception of face actions: an fMRI
study of the specificity of activation for seen speech and for meaningless lower-face acts
(gurning). Cognitive Brain Research;12:233-243.
Cohen-Seat G, Gastaut H, Faure J and Heuyer G. (1954) Etudes expérimentales de
l'activité nerveuse pendant la projection cinématographique. Revue Internationale de
Filmologie;5:7-64.
Daniloff JK, Noll JD, Fristoe M, Lloyd LL (1982) Gesture recognition in patients with
aphasia. Journal of Speech and Hearing Disorders;47:43-49.
Decety J, Chaminade T (2003) Neural correlates of feeling sympathy.
Neuropsychologia;41:127-138.
Decety J, Grezes J, Costes N, Perani D, Jeannerod M, Procyk E, Grassi F, Fazio F
(1997) Brain activity during observation of actions: Influence of action content and subject's
strategy. Brain;120:1763-1777.
Delazer M, Dohmas F, Bartha L, Brenneis A, Lochy A, Trieb T, Benke T (2003)
Learning complex arithmetic: an fMRI study. Cognitive Brain Research;18:76-88.
Di Pellegrino G, Fadiga L, Fogassi L, Gallese V, Rizzolatti G (1992) Understanding
motor events: a neurophysiological study. Experimental Brain Research;91:176-180.
Duffy RJ and Duffy JR (1975) Pantomime recognition in aphasics. Journal of Speech
and Hearing Research;18:115-132.
Duffy RJ and Duffy JR (1981) Three studies of deficits in pantomimic expression and
pantomimic recognition in aphasia. Journal of Speech and Hearing Research;24:70-84.
Emmorey KD (1989) Auditory morphological priming in the lexicon. Language and
Cognitive Processes;4:73-92.
Ertl J and Schafer EW (1967) Cortical activity preceding speech. Life Sciences;6:473-
479.
Fadiga L, Craighero L, Buccino G, Rizzolatti G (2002) Speech listening specifically
modulates the excitability of tongue muscles: a TMS study. European Journal of
Neuroscience;15:399-402.
Fadiga L, Fogassi L, Pavesi G, Rizzolatti G (1995). Motor facilitation during action
observation: A magnetic stimulation study. Journal of Neurophysiology;73:2608-2611.
Ferrari PF, Gallese V, Rizzolatti G, Fogassi L (2003) Mirror neurons responding to the
observation of ingestive and communicative mouth actions in the monkey ventral premotor
cortex. European Journal of Neuroscience;17:1703-1714.
Gainotti G, Lemmo MS (1976) Comprehension of symbolic gestures in aphasia. Brain
and Language;3:451-460.

23
Gallese V, Fadiga L, Fogassi L, Rizzolatti G (1996) Action recognition in the premotor
cortex. Brain;119:593-609.
Gastaut HJ and Bert J. (1954) EEG changes during cinematographic presentation.
Electroencephalography and Clinical Neurophysiology;6:433-444.
Gerardin E, Sirigu A, Lehéricy S, Poline J-B, Gaymard B, Marsault C, Agid Y (2000)
Partially overlapping neural networks for real and imagined hand movements. Cerebral
Cortex;10:1093-1104.
Gerlach C, Law I, Gade A, Paulson OB (2002) The role of action knowledge in the
comprehension of artefacts: a PETstudy. Neuroimage;15:143-152.
Glosser G, Wiener M, Kaplan E (1986) Communicative gestures in aphasia. Brain and
Language;27:345-359.
Goldenberg G (1996) Defective imitation of gestures in patients with damage in the left
or right hemispheres. Journal of Neurology, Neurosurgery and Psychiatry;61:176-180.
Grafton ST, Arbib MA, Fadiga L, Rizzolatti G (1996) Localization of grasp
representations in humans by PET: 2. Observation compared with imagination. Experimental
Brain Research;112:103-111.
Grezes J, Armony JL, Rowe J, Passingham RE (2003) Activations related to "mirror"
and "canonical" neurones in the human brain: an fMRI study. Neuroimage;18:928-937.
Grezes J, Costes N, Decety J (1998) Top-down effect of strategy on the perception of
human bioogical motion: a PET investigation. Cognitive Neuropsychology;15:553-582.
Grezes J, Decety J (2002) Does visual perception of object afford action? Evidence
from a neuroimaging study. Neuropsychologia;40:212-222.
Gruber O, Inderfey P, Steinmeiz H, Kleinschmidt A (2001) Dissociating neural
correlates of cognitive components in mental calculation. Cerebral Cortex;11:350-359.
Hamzei F, Rijntjes M, Dettmers C, Glauche V, Weiller C, Buchel C (2003) The human
action recognition system and its relationship to Broca's area: an fMRI study.
Neuroimage;19:637-644.
Hepp-Reymond MC, Husler EJ, Maier MA, Ql HX (1994) Force-related neuronal
activity in two regions of the primate ventral premotor cortex. Canadian Journal of Physiology
and Pharmacology;72:571-579.
Iacoboni M, Woods R, Brass M, Bekkering H, Mazziotta JC, Rizzolatti G (1999) Cortical
mechanisms of human imitation. Science;286:2526-2528.
Johnson-Frey SH, Maloof FR, Newman-Norlund R, Farrer C, Inati S, Grafton ST (2003)
Actions or hand-object interactions? Human inferior frontal cortex and action observation.
Neuron;39:1053-1058.

24
Kellenbach ML, Brett M, Patterson K (2003) Actions speak louder than functions: the
importance of manipulability and action in tool representation. Journal of Cognitive
Neuroscience;15:30-45.
Koelsch S, Gunter T, Friederici AD, Schroger E (2000) Brain indices of music
processing: "non-musicians" are musical. Journal of Cognitive Neuroscience;12:520-541.
Kohler E, Keysers CM, Umiltà A, Fogassi L, Gallese V, Rizzolatti G (2002) Hearing
sounds, understanding actions: Action representation in mirror neurons. Science;297:846-
848.
Koski L, Iacoboni M, Dubeau M-C, Woods RP, Mazziotta JC (2003) Modulation of
cortical activity during different imitative behaviors. Journal of Neurophysiology;89:460-471.
Koski L, Wohlschlager A, Bekkering H, Woods RP, Dubeau M-C, Mazziotta JC,
Iacoboni M (2002) Modulation of motor and premotor activity during imitation of target-
directed actions. Cerebral Cortex;12:847-855.
Lacquaniti F, Perani D, Guignon E, Bettinardi V, Carrozzo M, Grassi F, Rossetti Y,
Fazio F (1997) Visuomotor transformations for reaching to memorized targets: a PET study.
Neuroimage;5:129-146.
Lelord G, Laffont F, Sauvage D, Jusseaume P (1973) Evoked slow activities in man
following voluntary movement and articulated speech. Electroencephalography Clinical
Neurophysiology;35:113-124.
Liberman AM and Mattingly IG (1985) The motor theory of speech perception revised.
Cognition;21:1-36.
Liberman AM and Wahlen DH (2000) On the relation of speech to language. Trends in
Cognitive Neuroscience;4:187-196.
Liberman AM, Cooper FS, Shankweiler DP, Studdert-Kennedy M (1967) Perception of
the speech code. Psychological Review;74:431-461.
Liotti M, Gay CT, Fox PT (1994) Functional imaging and language: evidence from
positron emission tomography. Journal of Clinical Neurophysiology;11:175-190.
Maess B, Koelsch S, Gunter TC, Friederici AD (2001) Musical syntax is processed in
Broca's area: an MEG study. Nature Neuroscience;4:540-545.
Matelli M, Luppino G, Rizzolatti G. (1985) Patterns of cytochrome oxidase activity in the
frontal agranular cortex of macaque monkey. Behavioral Brain Research, 18:125-137.
Matsumura M, Kawashima R, Naito E, Satoh K, Takahashi T, Yanagisawa T, Fukuda H
(1996) Changes in rCBF during grasping in humans examined by PET. NeuroReport;7:749-
752.
Mecklinger A, Gruenewald C, Besson M, Magnié M-N, Von Cramon Y (2002)
Separable neuronal circuitries for manipulable and non-manipualble objects in working
memory. Cerebral Cortex;12:1115-1123.

25
Menon V, Rivera SM, White CD, Glover GH, Reiss AL (2000) Dissociating prefrontal
and parietal cortex activation during arithmetic processing. Neuroimage;12:357-365.
Mingazzini G (1913) Lezioni di Anatomia neurologica. Roma.
Muller R-A, Kleinhans N, Courchesne E (2001) Broca's area and the discrimination of
frequency transitions: a functional MRI study. Brain and Language;76:70-76.
Murata A, Fadiga L, Fogassi L, Gallese V, Raos V, Rizzolatti G (1997) Object
representation in the ventral premotor cortex (area F5) of the monkey. Journal of
Neurophysiology;78:2226-2230.
Negawa T, Mizuno S, Hahashi T, Kuwata H, Tomida M, Hoshi H, Era S, Kuwata K
(2002) M pathway and areas 44 and 45 are involved in stereoscopic recognition based on
binocular disparity. Japanese Journal of Physiology;52:191-198.
Nishitani N, Hari R (2000) Temporal dynamics of cortical representation for action.
Proceedings of the National Academy of Sciences;97:913-918.
Papathanassiou D, Etard O, Mellet E, Zago L, Mazoyer B, and Tzourio-Mazoyer N.
(2000) A common language network for comprehension and production: a contribution to the
definition of language epicenters with PET. Neuroimage;11:347-357.
Patel AD, Gibson E, Ratner J, Besson M, Holcomg P (1998) Processing syntactic
relations in language and music: an event-related potential study. Journal of Cognitive
Neuroscience;10:717-733.
Penfield W and Roberts L (1959) Speech and brain mechanisms. Princeton, NJ:
Princeton University Press.
Petrides M and Pandya DN. (1997) Comparative architectonic analysis of the human
and the macaque frontal cortex. In Handbook of Neuropsychology, ed. F Boller, J Grafman,
pp. 17–58. New York: Elsevier. Vol. IX.
Ranganath C, Johnson M, D'esposito M (2003) Prefrontal activity associated with
working memory and episodic long-term memory. Neuropsychologia;41:378-389.
Rickard TC, Romero SG, Basso G, Wharton C, Flitman S, Grafman J (2000) The
calculating brain:an fMRI study. Neuropsychologia;38:325-335.
Rizzolatti G and Arbib MA (1998) Language within our grasp. Trends in
Neuroscience;21:188-194.
Rizzolatti G and Fadiga L (1998) Grasping objects and grasping action meanings: the
dual role of monkey rostroventral premotor cortex (area F5). In: G. R. Bock & J. A. Goode
(Eds.), Sensory Guidance of Movement, Novartis Foundation Symposium (pp. 81-103).
Chichester: John Wiley and Sons.
Rizzolatti G and Gentilucci M (1988) Motor and visual-motor functions of the premotor
cortex. In: P. Rakic & W. Singer (Eds.), Neurobiology of Neocortex (pp.269-284). Chichester:
John Wiley and Sons.

26
Rizzolatti G, Camarda R, Fogassi L, Gentilucci M, Luppino G, Matelli M (1988).
Functional organization of inferior area 6 in the macaque monkey: II. Area F5 and the control
of distal movements. Experimental Brain Research;71:491–507.
Rizzolatti G, Fadiga L, Gallese V, Fogassi L (1996a) Premotor cortex and the
recognition of motor actions. Cognitive Brain Research;3:131-141.
Rizzolatti G, Fadiga L, Matelli M, Bettinardi V, Paulesu E, Perani D, Fazio F (1996b)
Localization of grasp representation in humans by PET: 1. Observation versus execution.
Experimental Brain Research;111:246-252.
Rizzolatti G, Fogassi L and Gallese V (2003) Motor and cognitive functions of the
ventral premotor cortex. Current Opinion in Neurobiology;12:149-154.
Schaffler L, Luders HO, Dinner DS, Lesser RP and Chelune GJ. (1993)
Comprehension deficits elicited by electrical stimulation of Broca’s area. Brain;116:695–715.
Schubotz RI and von Cramon DY (2003) Functional-anatomical concepts of human
premotor cortex: evidence from fMRI and PET studies. Neuroimage;20, Suppl 1:120-131.
Strafella AP and Paus T (2000) Modulation of cortical excitability during action
observation: a transcranial magnetic stimulation study. NeuroReport;11:2289-2292.

UNCORRECTED PROOF
AUTHOR’S QUERY SHEET
Author(s): Fadiga et al. PSNS 197544Article title:Article no:
Dear Author
Some questions have arisen during the preparation of your manuscript fortypesetting. Please consider each of the following points below and make anycorrections required in the proofs.
Please do not give answers to the questions on this sheet. All correctionsshould be made directly in the printed proofs.
AQ1 What does (27) represent here?
AQ2 Chapter title?

UNCORRECTED PROOF
Language in shadow
Luciano Fadiga
University of Ferrara, Ferrara, Italy and Italian Institute of Technology, Genova, Italy
Laila Craighero, Maddalena Fabbri Destro, and Livio Finos
University of Ferrara, Ferrara, Italy
Nathalie Cotillon-Williams and Andrew T. Smith
University of London, London, UK
Umberto Castiello
University of London, London, UK and University of Padova, Padova, Italy
The recent finding that Broca’s area, the motor center for speech, is activated during action observationlends support to the idea that human language may have evolved from neural substrates already involvedin gesture recognition. Although fascinating, this hypothesis has sparse demonstration because whileobserving actions of others we may evoke some internal, verbal description of the observed scene. Herewe present fMRI evidence that the involvement of Broca’s area during action observation is genuine.Observation of meaningful hand shadows resembling moving animals induces a bilateral activation offrontal language areas. This activation survives the subtraction of activation by semantically equivalentstimuli, as well as by meaningless hand movements. Our results demonstrate that Broca’s area plays arole in interpreting actions of others. It might act as a motor-assembly system, which links and interpretsmotor sequences for both speech and hand gestures.
INTRODUCTION
Several theories have been proposed to explain
the origins of human language. They can be
grouped into two main categories. According to
‘‘classical’’ theories, language is a peculiarly hu-
man ability based on a neural substrate newly
developed for the purpose (Chomsky, 1966;
Pinker, 1994). Theories of the second ‘‘evolu-
tionary’’ category consider human language as
the evolutionary refinement of an implicit com-
munication system, already present in lower
primates, based on a set of hand/mouth goal-
directed action representations (Armstrong,
Stokoe, & Wilcox, 1995; Corballis, 2002; Rizzo-
latti & Arbib, 1998). The classical view is sup-
ported by the existence in humans of a cortical
network of areas that become active during
verbal communication. This network includes
the temporal�parietal junction (Wernicke’s
area), commonly thought to be involved in
sensory processing of speech, and the inferior
frontal gyrus (Broca’s area) classically considered
to be the speech motor center.
Correspondence should be addressed to: Luciano Fadiga, Department of Biomedical Sciences and Advanced Therapies, Section
of Human Physiology, University of Ferrara, via Fossato di Mortara 17/19, I-44100 Ferrara, Italy. E-mail: [email protected]
This work was supported by EC grants ROBOT-CUB, NEUROBOTICS and CONTACT to LF and LC by European Science
Foundation (OMLL Eurocores) and by Italian Ministry of Education grants to LF, and by a Research Strategy Fund to UC.
We thank Attilio Mina for helpful bibliographic suggestions on animal hand shadows, Carlo Truzzi for creating the hand shadows
stimuli, and Rosario Canto for technical support.
# 2006 Psychology Press, an imprint of the Taylor & Francis Group, an informa business
SOCIAL NEUROSCIENCE, 2006, 00 (00), 1�13
C:/3B2WIN/temp files/PSNS197544_S100.3d[x] Tuesday, 5th September 2006 15:25:2
www.psypress.com/socialneuroscience DOI:10.1080/17470910600976430

UNCORRECTED PROOF
However, the existence of areas exclusivelydevoted to language has increasingly been chal-lenged by experimental evidence showing thatBroca’s area and its homologue in the righthemisphere also become active during the ob-servation of hand/mouth actions performed byother individuals (Aziz-Zadeh, Koski, Zaidel,Mazziotta, & Iacoboni, 2006; Decety et al., 1997;Decety & Chaminade, 2003; Grafton, Arbib,Fadiga, & Rizzolatti, 1996; Grezes, Costes, &Decety, 1998; Grezes, Armony, Rowe, & Passing-ham, 2003; Iacoboni, Woods, Brass, Bekkering,Mazziotta, & Rizzolatti, 1999; Rizzolatti et al.,1996). This finding seems to favor the evolution-ary hypothesis, supporting the idea that thelinguistic processing that characterizes Broca’sarea may be closely related to gesture processing.Moreover, comparative cytoarchitectonic studieshave shown a similarity between human Broca’sarea and monkey area F5 (Matelli, Luppino, &Rizzolatti, 1985; Petrides, 2006; Petrides & Pan-dya, 1997; von Bonin & Bailey, 1947), a premotorcortical region that contains neurons dischargingboth when the monkey acts on objects andwhen it sees similar actions being made byother individuals (Di Pellegrino, Fadiga, Fogassi,Gallese, & Rizzolatti, 1992; Gallese, Fadiga,Fogassi, & Rizzolatti, 1996; Rizzolatti, Fadiga,Gallese, & Fogassi, 1996). These neurons, called‘‘mirror neurons,’’ may allow the understandingof actions made by others and might provide aneural substrate for an implicit communicationsystem in animals. It has been proposed that thisprimitive ‘‘gestural’’ communication may be atthe root of the evolution of human language(Rizzolatti & Arbib, 1998). Although fascinating,this theoretical framework can be challenged byinvoking an alternative interpretation, more con-servative and fitting with classical theories of theorigin of language. According to this view, hu-mans are automatically compelled to covertlyverbalize what they observe. The involvement ofBroca’s area during action observation maytherefore reflect inner, sub-vocal speech genera-tion (Grezes & Decety, 2001). Clearly, anexperiment determining which of these twointerpretations is correct, could provide a funda-mental insight into the origins of language.
We investigated here the possibility that Bro-ca’s area and its homologue in the right hemi-sphere become specifically active during theobservation of a particular category of handgestures: hand shadows representing animalsopening their mouths. These stimuli have been
selected for two main reasons. First, by usingthese stimuli it was possible to design an fMRIexperiment in which any activation due to covertverbalization could be removed by subtraction:the activation evoked while observing videosrepresenting stimuli belonging to the same se-mantic set (i.e., real animals opening theirmouths), and expected to elicit similar covertverbalization, could be subtracted from activityelicited by hand shadows of animals opening theirmouths. Residual activation in Broca’s area afterthis critical subtraction would demonstrate theinvolvement of ‘‘speech-related’’ frontal areas inprocessing meaningful hand gestures. Second,hand shadows only implicitly ‘‘contain’’ thehand creating them. Thus they are interestingstimuli that might be used to answer the questionof how detailed a hand gesture must be in orderto activate the mirror-neuron system. The resultswe present here support the idea that Broca’sarea is specifically involved during meaningfulaction observation and that this activation isindependent of any internal verbal descriptionof the seen scene. Moreover, they demonstratethat the mirror-neuron system becomes activeeven if the pictorial details of the moving handare not explicitly visible. In the case of ourstimuli, the brain ‘‘sees’’ the performing handalso behind the appearance.
METHODS
Participants were 10 healthy volunteers (6 fe-males and 4 males; age range 19�32, mean 23).All had normal or corrected vision, no pastneurological or psychiatric history and no struc-tural brain abnormality. Informed consent wasobtained according to procedures approved bythe Royal Holloway Ethics Committee. Through-out the experiment, subjects performed the sametask, which was to carefully observe the stimuli,which were back projected onto a screen visiblethrough a mirror mounted on the MRI head coil(visual angle, 158�/208 approximately). Stimuliwere of six types: (1) movies of actual humanhands performing meaningless movements; (2)movies of the shadows of human hands represent-ing animals opening their mouths; (3) movies ofreal animals opening their mouths, plus threefurther movies representing a sequence of stillimages taken from the previously described threevideos. Hand movements were performed by aprofessional shadow artist. All stimuli were
C:/3B2WIN/temp files/PSNS197544_S100.3d[x] Tuesday, 5th September 2006 15:25:3
2 FADIGA ET AL.

UNCORRECTED PROOF
enclosed in a rectangular frame (Figure 1), in a640�/480 pixel array and were shown in greyscale. Each movie lasted 15 seconds, and con-tained a sequence of 7 different moving/staticstimuli (e.g., dog, cow, pig, bird, etc., all openingtheir mouths). The experiment was conducted asa series of scanning sessions, each lasting 4minutes. Each session contained eight blocks. Ineach session two different movie types werepresented in an alternated order (see Figure 1,bottom). Each subject completed six sessions. Theorder of sessions was varied randomly acrosssubjects. The six sessions contrasted the followingpairs of movie types: (1) C1�/moving animalhand shadows, C2�/static animal hand shadows;(2) C1�/moving real hands, C2�/static realhands; (3) C1�/moving real animals, C2�/staticreal animals; (4) C1�/moving animal hand sha-dows, C2�/moving real animals; (5) C1�/movinganimal hand shadows, C2�/moving real hands;(6) C1�/moving real hands, C2�/moving realanimals. Whole-brain fMRI data were acquiredon a 3T scanner (Siemens Trio) equipped with anRF volume headcoil. Functional images wereobtained with a gradient echo-planar T2* se-quence using blood oxygenation level-dependent(BOLD) contrast, each comprising a full-brainvolume of 48 contiguous axial slices (3 mmthickness, 3�/3 mm in-plane voxel size). Volumeswere acquired continuously with a repetition time(TR) of 3 seconds. A total of 80 scans wereacquired for each participant in a single session (4minutes), with the first 2 volumes subsequentlydiscarded to allow for T1 equilibration effects.Functional MRI data were analyzed using statis-tical parametric mapping software (SPM2, Well-come Department of Cognitive Neurology,London). Individual scans were realigned, spa-tially normalized and transformed into a standardstereotaxic space, and spatially smoothed by a6 mm FWHM Gaussian kernel, using standardSPM methods. A high-pass temporal filter (cut-off 120 seconds) was applied to the time series.Considering the relatively low number of partici-pants, a high-threshold, corrected, fixed effectsanalysis, was first performed by each experimen-tal condition. Pixels were identified as signifi-cantly activated if PB/.001 (FDR corrected formultiple comparisons) and the cluster size ex-ceeded 20 voxels. The activated voxels survivingthis procedure were superimposed on the stan-dard SPM2 inflated brain (Figure 1). Clusters ofactivation were anatomically characterized ac-cording to their centers of mass activity with the
aid of Talairach co-ordinates (Talairach & Tour-noux, 1988), of the Muenster T2T converter(http://neurologie.uni-muenster.de/T2T/t2tconv/conv3d.html) and by taking into account theprominent sulcal landmarks. Furthermore, as faras Broca’s region is concerned, a hypothesis-driven analysis was performed for sessions (3)�(6). In this analysis, a more restrictive statisticalcriterion was used (group analysis on individualsubjects analysis, small volume correction ap-proach, cluster size �/20 voxels). Only significantvoxels (PB/.005) within the most permissiveborder of cytoarchitectonically defined probabil-ity maps (Amunts, Schleicher, Burgel, Mohlberg,Uylings, & Zilles, 1999) were considered. This lastanalysis was performed with the aid of theAnatomy SPM toolbox (Eickhoff et al., 2005).Subjects’ lips were video-monitored during thewhole scanning procedure. No speech-relatedmuscle activity was detectable during video pre-sentation. The absence of speech-related motoractivity during video presentation was assessed ina pilot experiment, on a set of different subjects,looking at the same videos presented in thescanner while electromyography of tongue mus-cles was recorded according to the technique usedby Fadiga, Craighero, Buccino, and Rizzolatti(2002).
RESULTS
During the fMRI scanning volunteers observedvideos representing: (1) the shadows of humanhands depicting animals opening and closing theirmouths; (2) human hands executing sequences ofmeaningless finger movements; or (3) real ani-mals opening their mouths. Brain activations werecompared between pairs of conditions in a blockdesign. In addition (4, 5, 6), each condition wascontrasted with a ‘‘static’’ condition, in which thesame stimuli presented in the movie were shownas static pictures (e.g., stills of animals presentedfor the same time as the corresponding videos).The comparison between the first three ‘‘moving’’conditions with each corresponding ‘‘static’’ one,controls for nonspecific activations and empha-sizes the action component of the gesture.Figure 1 shows, superimposed, the results of themoving vs. static contrasts for animal handshadows and real animals conditions (red andgreen spots, respectively). In addition to largelyoverlapping occipito-parietal activations, a speci-fic differential activation emerged in the anterior
LANGUAGE AREAS ACTIVATED BY HAND SHADOWS 3
C:/3B2WIN/temp files/PSNS197544_S100.3d[x] Tuesday, 5th September 2006 15:25:3

UNCORRECTED PROOF
Figure 1 (Continued)
C:/3B2WIN/temp files/PSNS197544_S100.3d[x] Tuesday, 5th September 2006 15:25:4
4 FADIGA ET AL.

UNCORRECTED PROOF
part of the brain. Animal hand shadows stronglyactivated left parietal cortex, pre- and post-central gyri (bilaterally), and, more interestinglyfor the purpose of the present study, bilateralinferior frontal gyrus (BA 44 and 45). Conversely,the only frontal activation reaching significance inthe moving vs. static contrast for real animals waslocated in bilateral BA 6, close to the premotoractivation shown in an fMRI experiment byBuccino et al. (2004) when subjects observedmouth actions performed by monkeys and dogs.This location may therefore correspond to apremotor region where a species-independentmirror-neuron system for mouth actions is presentin humans. A discussion of non-frontal activationsis beyond the scope of the present paper, howeverthe above threshold activation foci are listed inTable 1. The results shown in Figure 1 on one sideseem to rule out the possibility that the inferiorfrontal activity induced by action viewing is dueto covert speech, on the other side indicate thatthe shadows of animals opening their mouths,although clearly depicting animals and not hands,convey implicit information about the humanbeing moving her hand in creating them. Indeed,they evoke an activation pattern superimposableon that evoked by hand action observation(Buccino et al., 2001; Grafton et al., 1996; Grezeset al., 2003; see Figure 1 and Table 1). To interpretthis result, it may be important to stress thepeculiar nature of hand shadows: although theyare created by moving hands, the professionalismof the artist creating them is such that the hand isnever obvious. Nevertheless, the mirror-neuronsystem is activated. The possibility we favor isthat the brain ‘‘sees’’ the hand behind theshadow. This possibility is supported by recentdata demonstrating that monkey mirror neuronsbecome active even if the final part of thegrasping movement is performed behind a screen(Umilta et al., 2001). Consequently, the humanmirror system (or at least part of it) seems to actmore as an active interpreter than as a passiveperceiver.
The bilateral activation of inferior frontalgyrus shown in Figure 1 during observation ofanimal hand shadows cannot yet be attributed to
covert verbalization. This is because it survivesthe subtraction of still images representing thesame stimuli presented in the moving condition,which might also evoke internal naming. It couldbe argued, however, that videos of movinganimals and animal shadows are dynamic andricher in details than their static controls, andmight more powerfully evoke a semantic repre-sentation of the observed scene, but this cannotbe stated with confidence. We therefore made adirect comparison between moving animal handshadows and moving real animals. We narrowedthe region of interest from the whole brain (as inFigure 1) to bilateral BA 44, the main target ofour study. This hypothesis-driven analysis wasperformed by looking at voxels within the mostpermissive borders of the probabilistic map of thisarea provided by Amunts et al. (1999) by takingas significance threshold the p value of .005(random effect analysis). The results of thiscomparison are shown in Figure 2B. As alreadysuggested by Figure 1 and Table 1, right and(more interestingly) left frontal clusters survivedthis subtraction. The first one was located in rightBA 44 (X�/58, Y�/12, Z�/24), an area known tobe involved during observation of biologicalaction, either meaningful or meaningless (Grezeset al., 1998; Iacoboni et al., 1999). The second oneis symmetrically positioned on the left side (X�/
�/50, Y�/4, Z�/22). Finally, two additionalclusters were present in Broca’s region. One wasmore posterior, in that part of the inferior frontalgyrus classically considered as speech related(X�/�/58, Y�/12, Z�/14; pars opercularis) andone more anterior, within area 45 according tothe Talairach and Tournoux atlas (1988), (X�/
�/45, Y�/32, Z�/14; pars triangularis). Thisfinding agrees with our hypothesis and demon-strates that the activation of Broca’s area duringaction understanding is independent of internalverbalization: if an individual is compelled toverbalize internally when a hand-shadow repre-senting an animal is presented, the same indivi-dual should also verbalize during the observationof real animals.
The finding that Broca’s area involvementduring observation of hand shadows is not
Figure 1. Cortical activation pattern during observation of animal hand shadows and real animals. Significantly activated voxels
(P B/.001, fixed effects analysis) in the moving animal shadows and moving real animals conditions after subtraction of the static
controls. Activity related to animal shadows (red clusters) is superimposed on that from real animals (green clusters). Those brain
regions activated during both tasks are depicted in yellow. In the lowermost part of the figure the experimental time-course for each
contrast is shown (i.e., C1, moving; C2, static). Note the almost complete absence of frontal activation for real animals in comparison
to animal shadows, which bilaterally activate the inferior frontal gyrus (arrows).
LANGUAGE AREAS ACTIVATED BY HAND SHADOWS 5
C:/3B2WIN/temp files/PSNS197544_S100.3d[x] Tuesday, 5th September 2006 15:25:5

UNCORRECTED PROOF
TABLE 1
Montreal Neurological Institute (MNI) and Talairach (TAL) co-ordinates and T-values of the foci activated during observation of
moving animal hand shadows, real hands, and real animals, after subtraction of static conditions
MNI TAL
x y z x y z T-value
Animal hand shadows
Inferior frontal gyrus
BA 44
R 62 8 24 61 9 22 4.71
L �/62 8 24 �/61 9 22 4.58
BA 45
R 58 22 14 57 22 12 3.37
Precentral gyrus
BA 6
R 54 0 36 53 2 33 5.29
60 2 34 59 4 31 4.90
L �/60 �/2 36 �/59 0 33 5.09
�/60 0 18 �/59 1 17 3.56
�/60 �/12 38 �/59 �/10 36 5.24
BA 4
R 54 �/18 36 53 �/16 34 7.97
Postcentral gyrus
BA 40
L �/58 �/22 16 �/57 �/21 16 5.92
BA 3
L �/32 �/38 52 �/32 �/34 50 6.53
BA 2
R 32 �/40 66 32 �/36 63 5.18
Superior parietal lobule
BA 7
R 26 �/48 64 26 �/44 61 6.24
Cuneus
BA 18
R 16 �/100 6 16 �/97 10 10.43
20 �/96 8 20 �/93 12 12.36
L �/16 �/104 2 �/16 �/101 7 5.09
Middle occipital gyrus
BA 18
R 42 �/90 8 42 �/87 12 7.78
L �/28 �/96 2 �/28 �/93 6 6.95
BA 19
L �/40 �/86 0 �/40 �/83 4 7.28
Insula
BA 13
R 54 �/40 20 54 �/38 20 6.35
Middle temporal gyrus
BA 37
R 54 �/70 2 53 �/68 5 10.95
Temporal fusiform gyrus
BA 37
R 42 �/44 �/16 42 �/43 �/11 7.52
L �/44 �/44 �/16 �/44 �/43 �/11 6.44
Cerebellum
R 10 �/80 �/44 8 �/80 �/42 6.53
L �/8 �/78 �/44 �/8 �/77 �/33 5.61
Amygdala
R 22 �/2 �/22 22 �/3 �/18 3.85
L �/18 �/2 �/22 �/18 �/3 �/18 4.15
C:/3B2WIN/temp files/PSNS197544_S100.3d[x] Tuesday, 5th September 2006 15:25:6
6 FADIGA ET AL.

UNCORRECTED PROOF
TABLE 1 (Continued )
MNI TAL
x y z x y z T-value
Real hands
Inferior frontal gyrus
BA 44
R 62 16 28 61 17 25 5.67
L �/60 10 26 �/60 12 23 3.64
Middle frontal gyrus
BA 6
R 34 �/6 62 34 �/3 57 5.30
L �/24 �/8 52 �/24 �/5 48 4.18
Superior frontal gyrus
BA 10
R 4 58 28 4 58 23 6.22
L �/26 54 �/2 �/27 52 �/4 4.14
Postcentral gyrus
BA 3
R 52 �/20 40 51 �/18 38 4.71
BA 7
R 28 �/50 66 28 �/46 63 12.50
BA 40
R 46 �/32 54 46 �/29 51 4.58
L �/66 �/22 14 �/65 �/21 14 3.37
Inferior parietal lobule
BA 40
R 62 �/30 28 61 �/28 27 4.02
32 �/42 58 32 �/38 55 8.23
L �/50 �/30 32 �/50 �/28 31 5.09
�/34 �/42 58 �/34 �/38 55 6.51
Superior parietal lobule
BA 7
L �/32 �/56 62 �/33 �/51 60 4.94
Cuneus
BA 18
L �/20 �/94 6 �/20 �/91 10 7.13
Middle occipital gyrus
BA 19
L �/54 �/76 2 �/53 �/74 6 7.42
�/36 �/62 14 �/36 �/59 16 7.60
Lingual gyrus
BA 17
R 10 �/96 �/8 10 �/93 �/2 5.74
Inferior occipital gyrus
BA 18
R 30 �/94 �/12 30 �/92 �/6 6.10
L �/26 �/96 �/8 �/26 �/93 �/2 6.69
Middle temporal gyrus
BA 37
R 52 �/68 2 51 �/66 5 7.78
Temporal fusiform gyrus
BA 37
R 46 �/42 �/18 46 �/41 �/13 5.45
L �/46 �/44 �/16 �/46 �/43 �/11 4.59
Cerebellum
R 20 �/82 �/28 20 �/81 �/20 4.11
L �/28 �/56 �/50 �/28 �/56 �/39 5.10
Parahippocampal gyrus
BA 34
R 30 6 �/18 30 5 �/15 6.75
Insula
R 52 �/22 18 51 �/20 18 6.05
LANGUAGE AREAS ACTIVATED BY HAND SHADOWS 7
C:/3B2WIN/temp files/PSNS197544_S100.3d[x] Tuesday, 5th September 2006 15:25:7

UNCORRECTED PROOF
TABLE 1 (Continued )
MNI TAL
x y z x y z T-value
Globus pallidus
R 16 2 2 16 2 2 4.10
L �/16 0 �/2 �/16 0 �/2 3.59
Real animals
Precentral gyrus
BA 4
L �/62 �/14 38 �/61 �/12 36 6.61
BA 6
R 36 �/2 34 36 0 31 5.93
32 �/12 52 32 �/9 48 4.48
L �/30 0 38 �/30 2 35 10.43
Middle frontal gyrus
BA 47
L �/46 48 �/2 �/46 46 �/4 3.92
Superior frontal gyrus
BA 6
R 30 �/8 72 30 �/4 67 3.66
BA 8
R 20 30 56 20 32 50 6.13
Postcentral gyrus
BA 2
L �/38 �/40 70 �/38 �/36 66 4.56
BA 3
R 34 �/36 54 34 �/32 51 3.26
L �/18 �/44 76 �/18 �/39 72 3.35
Precuneus
BA 7
L �/8 �/54 46 �/8 �/50 45 6.08
Middle occipital gyrus
BA 18
R 20 �/98 14 20 �/94 18 11.75
L �/20 �/94 10 �/20 �/91 14 14.91
BA 19
R 38 �/80 2 38 �/77 6 7.21
L �/40 �/86 �/2 �/40 �/83 2 9.88
�/54 �/76 2 �/53 �/74 6 8.43
Lingual gyrus
BA 18
R 14 �/86 �/14 14 �/84 �/8 5.40
L �/6 �/88 �/10 �/6 �/86 �/4 5.24
Limbic lobe-uncus
BA 28
L �/28 8 �/24 �/28 7 �/21 7.00
Superior temporal gyrus
BA 41
L �/46 �/40 12 �/46 �/38 13 3.77
Middle temporal gyrus
BA 21
L �/54 �/24 �/8 �/53 �/24 �/6 3.54
BA 37
R 52 �/70 4 51 �/68 7 8.03
Temporal fusiform gyrus
BA 37
R 44 �/42 �/20 44 �/41 �/15 6.50
L �/46 �/50 �/20 �/46 �/49 �/14 4.66
Cerebellum
R 46 �/58 �/32 46 �/58 �/24 3.55
L �/48 �/58 �/32 �/48 �/58 �/24 3.78
C:/3B2WIN/temp files/PSNS197544_S100.3d[x] Tuesday, 5th September 2006 15:25:7
8 FADIGA ET AL.

UNCORRECTED PROOF
explainable in terms of internal speech suggeststhat, in agreement with other data in the litera-ture, this area may play a crucial role in actionunderstanding. However, it remains the fact thatBroca’s area is known as a speech area and itsinvolvement during overt and covert speechproduction has clearly been demonstrated re-cently (Palmer, Rosen, Ojemann, Buckner, Kel-ley, & Petersen, 2001). The hypothesis we favor isthat this area participates in verbal communica-tion because it represents the product of theevolutionary development of a precursor alreadypresent in monkeys: the mirror neurons area F5,that portion of the ventral premotor cortex wherehand/mouth actions are represented (see Petrides,2006). Accordingly, in agreement with the char-acteristics of area F5 neurons, Broca’s area shouldrespond much better to goal-directed action thanto simple, meaningless movements. To test thispossibility, we performed two further compari-sons: (1) The observation of human hands per-forming meaningless finger movements versus theobservation of moving real animals opening theirmouths, to determine how much of the parsopercularis activation was due to the observationof meaningless hand movements; (2) The obser-vation of animal hand shadows versus the ob-servation of meaningless finger movements, to pitthe presence of hands against the presence ofmeaning. The results are shown in Figure 2, C andD, respectively. After comparison (1), althoughthe more dorsal, bilateral, BA 44 activation wasstill present (Figure 2C, left: X�/�/56, Y�/10,Z�/26; right: X�/58, Y�/10, Z�/24), no voxelsabove significance were located in the parsopercularis of Broca’s area. This demonstratesthat finger movements per se do not activatespecifically that part of Broca’s area. In contrast,after comparison (2) a significant activation waspresent in the left pars opercularis (Figure 2D;
X�/�/58, Y�/6, Z�/4), demonstrating the invol-vement of Broca’s area pars opercularis in pro-cessing actions of others, particularly whenmeaningful and thus, implicitly, communicative.
DISCUSSION
The finding that animal hand shadows but notreal animals or meaningless finger movementsactivate that part of Broca’s region most inti-mately involved in verbal communication supporta similarity between these stimuli and spokenwords. Animal hand shadows are formed bymeaningless finger movements combined toevoke a meaning in the observer through theshape appearing on a screen. Thus, when onelooks at them, the representation of an animalopening its mouth is evoked. Words that formsentences are formed by individually meaninglessmovements (phonoarticulatory acts), which ap-propriately combined and segmented conveymeanings and representations. Does this twofoldinvolvement of Broca’s area reflect a specific roleplayed by it in decoding actions and particularlycommunicative ones? A positive answer to thisquestion arises, in our view, from the finding thatwhen observation of meaningless finger move-ments is subtracted from observation of animalhand-shadows, an activation of the left parsopercularis persists.
The activation of Broca’s area during gesturalcommunication has already been shown indeaf signers, both during production and percep-tion. This was interpreted as a vicariant involve-ment of Broca’s area because of its verbalspecialization (Horwitz et al., 2003). In otherterms, according to this interpretation, Broca’sarea is activated because, by signing, deafpeople express linguistic concepts. In our study
TABLE 1 (Continued )
MNI TAL
x y z x y z T-value
Amygdala
L �/34 �/6 �/16 �/34 �/6 �/13 3.70
Globus Pallidus
L �/24 �/10 �/4 �/24 �/10 �/3 4.93
Anterior Cingulate
BA 24
L �/4 36 8 �/4 35 6 4.70
Note : BA�/Brodmann area; R�/right hemisphere; L�/left hemisphere; x, y, z�/co-ordinates.
LANGUAGE AREAS ACTIVATED BY HAND SHADOWS 9
C:/3B2WIN/temp files/PSNS197544_S100.3d[x] Tuesday, 5th September 2006 15:25:7

UNCORRECTED PROOF
participants were presented with communicative
hand gestures but, in contrast to studies investi-
gating deaf people, the gestures were non-sym-
bolic even if able to address in an unambiguous
way a specific concept (e.g., a barking dog). Thus,
we show here, the involvement of Broca’s region
can not be explained in terms of linguistic
decoding of the gesture meaning. Conversely,
the results indicate that Broca’s region is involved
in the understanding of communicative gestures.
Figure 2 (Continued)
C:/3B2WIN/temp files/PSNS197544_S100.3d[x] Tuesday, 5th September 2006 15:25:8
10 FADIGA ET AL.

UNCORRECTED PROOF
How can this ‘‘perceptual’’ function be recon-ciled with the universally accepted motor role ofBroca’s area for speech? One possible interpreta-tion is that Broca’s area, due to its premotororigin, is involved in the assembly of meaninglesssequence of action units (whether finger orphonoarticulatory movements) into meaningfulrepresentations. This elaboration process mayproceed in two directions. In production, Broca’sarea recruits movement units to generate words/hand actions. In perception, Broca’s area, beingthe human homologue of monkey area F5,addresses the vocabulary of speech/hand actions,which form the template for action recognition.Our hypothesis is that, in origin, Broca’s areaprecursor was involved in generating/extractingaction meanings by organizing/interpreting motorsequences in terms of goal. Subsequently, thisability might have been generalized during theevolution that gave this area the capability to dealwith meanings (and rules), which share similarhierarchical and sequential structures with themotor system (Fadiga, Craighero, & Roy, 2006).
This proposal is in agreement with fMRIinvestigations that indicate that Broca’s area isnot always activated during speech listening. In arecent experiment Wilson, Saygin, Sereno, andIacoboni (2004) carried out an fMRI study inwhich subjects (1) passively listened to mono-syllables and (2) produced the same speechsounds. Results showed a substantial bilateraloverlap between regions activated during thetwo conditions, mainly in the superior part ofventral premotor cortex. Conversely, the activa-tion of Broca’s region was present only in some ofthe studied subjects, in our view because the taskdid not require any meaning extraction. Thisinterpretation is in line with brain imaging studiesindicating that, in speech comprehension, Broca’sarea is mainly activated during processing ofsyntactic aspects (Bookheimer, 2002). Luria(1966) had already noticed that Broca’s areapatients made comprehension errors in syntacti-cally complex sentences such as passive construc-
tions. Finally, data coming from corticalstimulation of collaborating patients undergoingneurosurgery, showed that the electrical stimula-tion of the Broca’s area produced comprehensiondeficits, particularly evident in the case of ‘‘com-plex auditory verbal instructions and visual se-mantic material’’ (Schaffler, Luders, Dinner,Lesser, & Chelune, 1993). The data of the presentexperiment, together with the series of evidencepresented above, are in agreement with thosetheories on the origins of human language thatconsider it as the evolutionary refinement of animplicit communication system based on hand/mouth goal-directed action representations(Armstrong et al., 1995; Corballis, 2002; Rizzolatti& Arbib, 1998). This possibility finds furthersupport from a recent experiment based on theanalysis of brain MRIs of three great ape species(Pan troglodytes, Pan paniscus and Gorilla gor-illa) showing that the extension of BA 44 is largerin the left hemisphere than in the right. While asimilar asymmetry in humans has been correlatedwith language dominance (Cantalupo & Hopkins,2001), this hypothesis does not fit in the case ofapes. It might be, however, indicative of an initialspecialization of BA 44 for communication. Infact, in captive great apes manual gestures areboth referential and intentional, and are prefer-entially produced by the right hand. Moreover,this right-hand bias is consistently greaterwhen gesturing is accompanied by vocalization(Hopkins & Leavens, 1998).
In conclusion, our results support a commonorigin for human speech and gestural commu-nication in non-human primates. It has beenproposed that the development of human speechis a consequence of the fact that the precursor ofBroca’s area was endowed, before the emergenceof speech, with a gestural recognition system(Rizzolatti & Arbib, 1998). Here we have takena step forward, empirically showing for thefirst time that human Broca’s area is not anexclusive ‘‘speech’’ center but, most probably, amotor assembly center in which communicative
Figure 2. Results of the analysis focused on bilateral area 44. (A) Cytoarchitectonically defined probability map of the location of
left and right area 44, drawn on the Colin27T1 standard brain on the basis of Juelich-MNI database (27 ). The white cross
superimposed on each brain indicates the origin of the co-ordinates system (x�/y�/z�/0). The correspondence between colors and
percent probability is given by the upper color bar. (B), (C) and (D), significant voxels (P B/.005, random effects analysis) falling
inside area 44, as defined by the probability map shown in (A), in the three contrasts indicated in the Figure. Color bar: T-values.
Note the similar pattern of right hemisphere activation in (B) and (C), the similar location of the posterior-dorsal activation of the
left hemisphere in (B) and (C), and the two additional foci in the pars opercularis and pars triangularis of Broca’s area in (B). Note,
in (D), the survival of the activation in pars opercularis, after subtraction of real hands from animal hand shadows. When the reverse
contrasts were tested (real animals vs. either animal shadows or real hands), the results failed to show any significant activation
within area 44.
AQ1
LANGUAGE AREAS ACTIVATED BY HAND SHADOWS 11
C:/3B2WIN/temp files/PSNS197544_S100.3d[x] Tuesday, 5th September 2006 15:25:10

UNCORRECTED PROOF
gestures, whether linguistic or otherwise, areassembled and decoded (Fadiga et al., 2006). Itstill remains unclear whether hand/speech motorrepresentations are mapped in this area accordingto a somatotopic organization, or if Broca’s areaworks in a supramodal way, by dealing witheffector-independent motor rules.
Manuscript received 000
Manuscript accepted 000
First published online day/month/year
REFERENCES
Amunts, K., Schleicher, A., Burgel, U., Mohlberg, H.,Uylings, H. B., & Zilles, K. (1999). Broca’s regionrevisited: Cytoarchitecture and intersubject varia-bility. Journal of Comparative Neurology, 412, 319�341.
Armstrong, A. C., Stokoe, W. C., & Wilcox, S. E.(1995). Gesture and the nature of language. Cam-bridge, UK: Cambridge University Press.
Aziz-Zadeh, L., Koski, L., Zaidel, E., Mazziotta, J., &Iacoboni, M. (2006). Lateralization of the humanmirror neuron system. Journal of Neuroscience,26(11), 2964�2970.
Bookheimer, S. (2002). Functional MRI of language:New approaches to understanding the corticalorganization of semantic processing. Annual Reviewof Neuroscience, 25, 151�188.
Buccino, G., Binkofski, F., Fink, G. R., Fadiga, L.,Fogassi, L., Gallese, V., et al. (2001). Actionobservation activates premotor and parietal areasin a somatotopic manner: An fMRI study. EuropeanJournal of Neuroscience, 13, 400�404.
Buccino, G., Lui, F., Canessa, N., Patteri, I., Lagravi-nese, G., Benuzzi, F., et al. (2004). Neural circuitsinvolved in the recognition of actions performed bynonconspecifics: An fMRI study. Journal of Cogni-tive Neuroscience, 16, 114�126.
Cantalupo, C., & Hopkins, W. D. (2001). AsymmetricBroca’s area in great apes. Nature, 414(6863), 505.
Chomsky, N. (1966). Cartesian linguistics. New York:Harper & Row.
Corballis, M. C. (2002). From hand to mouth. Theorigins of language. Princeton, NJ: Princeton Uni-versity Press.
Decety, J., & Chaminade, T. (2003). Neural correlatesof feeling sympathy. Neuropsychologia, 41, 127�138.
Decety, J., Grezes, J., Costes, N., Perani, D., Jeannerod,M., Procyk, E., et al. (1997). Brain activity duringobservation of actions: Influence of action contentand subject’s strategy. Brain, 120, 1763�1777.
Di Pellegrino, G., Fadiga, L., Fogassi, L., Gallese, V., &Rizzolatti, G. (1992). Understanding motor events:A neurophysiological study. Experimental BrainResearch, 91, 176�180.
Eickhoff, S. B., Stephan, K. E., Mohlberg, H., Grefkes,C., Fink, G. R., Amunts, K., et al. (2005). A newSPM toolbox for combining probabilistic cytoarch-
itectonic maps and functional imaging data. Neuro-image, 25, 1325�1335.
Fadiga, L., Craighero, L., & Roy, A. C. (2006). Broca’sarea: A speech area? In Y. Grodzinsky & K. Amunts(Eds.), Broca’s region. New York: Oxford UniversityPress.
Fadiga, L., Craighero, L., Buccino, G., & Rizzolatti, G.(2002). Speech listening specifically modulates theexcitability of tongue muscles: A TMS study. Eur-opean Journal of Neuroscience, 15, 399�402.
Gallese, V., Fadiga, L., Fogassi, L., & Rizzolatti, G.(1996). Action recognition in the premotor cortex.Brain, 119, 593�609.
Grafton, S. T., Arbib, M. A., Fadiga, L., & Rizzolatti, G.(1996). Localization of grasp representations inhumans by PET: 2. Observation compared withimagination. Experimental Brain Research, 112,103�111.
Grezes, J., & Decety, J. (2001). Functional anatomy ofexecution, mental simulation, observation, and verbgeneration of actions: A meta-analysis. HumanBrain Mapping, 12, 1�19.
Grezes, J., Armony, J. L., Rowe, J., & Passingham, R. E.(2003). Activations related to ‘‘mirror’’ and ‘‘cano-nical’’ neurones in the human brain: An fMRI study.Neuroimage, 18, 928�937.
Grezes, J., Costes, N., & Decety, J. (1998). Top-downeffect of strategy on the perception of humanbiological motion: A PET investigation. CognitiveNeuropsychology, 15, 553�582.
Hopkins, W. D., & Leavens, D. A. (1998). Hand use andgestural communication in chimpanzees (Pan tro-glodytes). Journal of Comparative Psychology,112(1), 95�99.
Horwitz, B., Amunts, K., Bhattacharyya, R., Patkin, D.,Jeffries, K., Zilles, K., et al. (2003). Activation ofBroca’s area during the production of spoken andsigned language: A combined cytoarchitectonicmapping and PET analysis. Neuropsychologia, 41,1868�1876.
Iacoboni, M., Woods, R. P., Brass, M., Bekkering, H.,Mazziotta, J. C., & Rizzolatti, G. (1999). Corticalmechanisms of human imitation. Science, 286, 2526�2528.
Luria, A. (1966). The higher cortical function in man.New York: Basic Books.
Matelli, M., Luppino, G., & Rizzolatti, G. (1985).Patterns of cytochrome oxidase activity in thefrontal agranular cortex of macaque monkey. Beha-vioral Brain Research, 18, 125�137.
Palmer, E. D., Rosen, H. J., Ojemann, J. G., Buckner,R. L., Kelley, W. M., & Petersen, S. E. (2001). Anevent-related fMRI study of overt and covert wordstem completion. Neuroimage, 14, 182�193.
Petrides, M. (2006). Broca’s area in the human andnonhuman primate brain. In Y. Grodzinsky & K.Amunts (Eds.), Broca’s region. New York: OxfordUniversity Press.
Petrides, M., & Pandya, D. N. (1997). In F. Boller & J.Grafman (Eds.), Handbook of neuropsychology(Vol. IX, pp. 17�58). New York: Elsevier.
Pinker, S. (1994). The language instinct: How the mindcreates language. New York: William Morrow.
AQ2
C:/3B2WIN/temp files/PSNS197544_S100.3d[x] Tuesday, 5th September 2006 15:25:12
12 FADIGA ET AL.

UNCORRECTED PROOF
Rizzolatti, G., & Arbib, M. A. (1998). Language withinour grasp. Trends in Neuroscience, 21, 188�194.
Rizzolatti, G., Fadiga, L., Gallese, V., & Fogassi, L.(1996). Premotor cortex and the recognition ofmotor actions. Cognitive Brain Research, 3, 131�141.
Rizzolatti, G., Fadiga, L., Matelli, M., Bettinardi, V.,Paulesu, E., Perani, D., et al. (1996). Localization ofgrasp representations in human by PET: 1. Observa-tion versus execution. Experimental Brain Research,111, 246�252.
Schaffler, L., Luders, H. O., Dinner, D. S., Lesser, R. P.,& Chelune, G. J. (1993). Comprehension deficitselicited by electrical stimulation of Broca’s area.Brain, 116, 695�715.
Talairach, J., & Tournoux, P. (1988). Co-planar stereo-tactic atlas of the human brain. New York: GeorgThieme Verlag.
Umilta, M. A., Kohler, E., Gallese, V., Fogassi, L.,Fadiga, L., Keysers, C., et al. (2001). I know whatyou are doing: A neurophysiological study. Neuron,31, 155�165.
Von Bonin, G., & Bailey, P. (1947). The neocortex ofMacaca mulatta. Urbana, IL: University of IllinoisPress.
Wilson, S. M., Saygin, A. P., Sereno, M. I., & Iacoboni,M. (2004). Listening to speech activates motor areasinvolved in speech production. Nature Neuroscience,7(7), 701�702.
LANGUAGE AREAS ACTIVATED BY HAND SHADOWS 13
C:/3B2WIN/temp files/PSNS197544_S100.3d[x] Tuesday, 5th September 2006 15:25:12

Infants predict other people’saction goalsTerje Falck-Ytter, Gustaf Gredeback & Claes von Hofsten
Do infants come to understand other people’s actions through
a mirror neuron system that maps an observed action onto
motor representations of that action? We demonstrate that
a specialized system for action perception guides proactive
goal-directed eye movements in 12-month-old but not in
6-month-old infants, providing direct support for this view.
The activation of this system requires observing an interaction
between the hand of the agent and an object.
Neurophysiological1,2 and brain-imaging3 studies indicate that a mir-ror neuron system (MNS) mediates action understanding in humanadults and monkeys. Mirror neurons were first discovered in thepremotor area (F5) of the macaque, and they respond both when theanimal performs a particular object-related action and when the animalobserves another individual perform a similar action. Thus, mirrorneurons mediate a direct matching process, in which observed actionsare mapped onto motor representations of that action4,5.
When performing visually guided actions, action plans encodeproactive goal-directed eye movements, which are crucial for planningand control6,7. Adults also perform such eye movements when theobserved actions are performed by others8, indicating that action plansguide the oculomotor system when people are observing others’ actionsas well. As the MNS mediates such matching processes1,3,4, there is adirect link between MNS activity and proactive goal-directed eyemovements during action observation8.
Recently, a strong claim has been presented about the role of theMNS in human ontogeny. According to the MNS hypothesis of socialcognition, the MNS constitutes a basis for important social compe-tences such as imitation, ‘theory of mind’ and communication bymeans of gesture and language4,9. If this hypothesis is correct, the MNSshould be functional simultaneous with or before the infant’s devel-opment of such competencies, which emerge around 8–12 months oflife10. Furthermore, according to the MNS theory, proactive goal-directed eye movements during the observation of actions reflect thefact that the observer maps the observed actions onto the motorrepresentations of those actions8. This implies that the developmentof such eye movements is dependent on action development. There-fore, infants are not expected to predict others’ action goals before theycan perform the actions themselves. Infants begin to master the actionshown in our study at around 7–9 months of life11. Thus, if the MNS isa basis of early social cognition, proactive goal-directed eye movementsshould be present at 12 but not at 6 months.
Although habituation studies indicate that young infants distinguishbetween means and ends when observing actions12,13, no one hastested the critical question of when infants come to predict the goals ofothers’ actions. Using a gaze-recording technique, we tested the MNShypothesis by comparing the eye movements of adults (n ¼ 11),12-month-old infants (n ¼ 11) and 6-month-old infants (n ¼ 11)during video presentations showing nine identical trials in which threetoys were moved by an actor’s hand into a bucket (Test 1). Wecompared gaze behavior, consisting of (i) timing (ms) of gaze arrivalat the goal (the bucket) relative to the arrival of the moving targetand (ii) ratio of looking time in the goal area to total looking timein combined goal and trajectory areas during object movement(see Supplementary Methods online and Fig. 1a).
In adults, the MNS is only activated when someone is seeing an agentperform actions, not when objects move alone8. However, according tothe teleological stance theory14, seeing a human agent is not necessaryfor infants to ascribe goal-directedness to observed events. This theorystates that objects that are clearly directed toward a goal and moverationally within the constraints of the situation are perceived as goal-directed by 12-month-old infants. This implies that seeing an interac-tion between the actor’s hand and the toys is not necessary for elicitingproactive, goal-directed eye movements. By comparing the gaze per-formance of adults (n ¼ 33) and 12-month-olds (n ¼ 33) in threeconditions, we evaluated this alternative hypothesis (Test 2). The firstcondition, ‘human agent’, was identical to the one in Test 1 (same dataused in both tests). In the ‘self-propelled’ condition (Fig. 1a), themotion was identical to that in the human agent condition except thatno hand moved the toys. We also included a ‘mechanical motion’
a
b
Figure 1 Sample pictures of stimulus videos. (a) Stimulus in the human
agent and self-propelled conditions with areas of interest (AOIs; black
rectangles) and trajectories for each object (colored lines) superimposed.
Left AOI was labeled ‘‘goal AOI,’’ right AOI was labeled ‘‘object AOI,’’ and
upper AOI was labeled ‘‘trajectory AOI.’’ (b) Stimulus in the mechanical
motion condition.
Received 22 February; accepted 26 May; published online 18 June 2006; doi:10.1038/nn1729
Department of Psychology, Uppsala University, Box 1225, 751 42 Uppsala, Sweden. Correspondence should be addressed to T.F.-Y. ([email protected]).
878 VOLUME 9 [ NUMBER 7 [ JULY 2006 NATURE NEUROSCIENCE
BR I E F COMMUNICAT IONS©
2006
Nat
ure
Pub
lishi
ng G
roup
ht
tp://
ww
w.n
atur
e.co
m/n
atur
eneu
rosc
ienc
e

condition (Fig. 1b). We assigned subjects randomly to the conditions,and sample sizes were equal.
Parents and adult subjects provided written consent according to theguidelines specified by the Ethical Committee at Uppsala University,and the study was conducted in accordance with the standards specifiedin the 1964 Declaration of Helsinki. Preliminary analyses of the datadistributions confirmed normality and homogeneity of variance. Weused statistical tests (one-way ANOVAs and single-sample t-tests) withtwo-tailed probabilities (a ¼ 0.05) unless otherwise stated.
In Test 1, we found that in the human agent condition, there was astrong effect of age on predictive eye movements to the action goal(F2,30 ¼ 19.845, P o 0.001; Fig. 2a and Supplementary Table 1online). Post hoc testing (Bonferroni) showed that there was nosignificant difference between the adults and the 12-month-olds,whereas the differences between both these groups and the 6-month-olds were significant (P o 0.001). Furthermore, both adults (t10 ¼5.498, Po 0.001) and 12-month-olds (t10 ¼ 2.425, P ¼ 0.036) shiftedtheir gaze to the goal of the action before the hand arrived, whereas6-month-olds shifted their gaze to the goal after the hand arrived(t10 ¼ 3.165, P ¼ 0.01). The two predictive groups were furtheranalyzed to check for learning effects using Bonferroni correctedpaired-samples t-tests. There was no effect of trial number (n ¼ 9)on timing. From the first to the second action of each trial, gaze leadtimes increased from 247 to 465 ms in adults (t10 ¼ 3.186, P ¼ 0.01)and from –18 to 334 ms in 12-month-olds (t10¼ 3.516, P ¼ 0.006; forfurther details see Supplementary Table 2 online).
In the human agent condition, the subjects in the different age groupsdistributed their fixations differently across the movement trajectory(F2,30¼ 12.015, Po 0.001; Fig. 2b and Supplementary Table 3 online).Post hoc testing (Bonferroni) showed that there was no significantdifference between the adults and the 12-month-olds, whereas boththese groups differed from the 6-month-olds (P o 0.001). Adults(t10 ¼ 8.073, P o 0.001) and 12-month-olds (t10 ¼ 8.625, P o 0.001)looked significantly longer at the goal area during target movement thanwould be expected if subjects tracked the target, whereas the 6-month-olds did not (see Supplementary Methods online).
In Test 2, we found that in adults and 12-month-olds, predictive eyemovements were only activated by a human hand moving the objects(F2,30 ¼ 7.637, P ¼ 0.002 and F2,30 ¼ 7.180, P ¼ 0.003, respectively;Fig. 2a). Post hoc testing (Bonferroni) showed that for adults, thehuman agent condition was significantly different from the self-
propelled (P¼ 0.004) and mechanical motion (P ¼ 0.009) conditions.12-month-olds showed the same pattern (P ¼ 0.019 and 0.004,respectively). Gaze did not arrive significantly ahead of the movingobject in the two control conditions for adults and in the self-propelledcondition for the 12-month-olds. The gaze of the 12-month-oldsarrived at the goal significantly after the object in the mechanicalmotion condition (t10 ¼ 4.253, P ¼ 0.002).
Spatial distribution of fixations was different between the conditions(Fig. 2b) in both adults (F2,30¼ 17.782, Po 0.001) and 12-month-olds(F2,30¼ 36.055, Po 0.001). Post hoc testing (Bonferroni) showed thatboth adults and 12-month-olds were more goal-directed in the humanagent condition than in the self-propelled and mechanical motionconditions (P o 0.001 in all cases). Furthermore, in the two controlconditions, the distributions of fixations for both adults and12-month-olds did not differ significantly from what would beexpected if subjects tracked the objects.
The present study supports the view that action understanding inadults results from a mirror neuron system that maps an observedaction onto motor representations of that action1,3,5,8. More impor-tantly, we have demonstrated that when observing actions, 12-month-old infants focus on goals in the same way as adults do, whereas6-month-olds do not (Test 1). The performance of the 6-month-oldscannot originate from a general inability to predict future events withtheir gaze, because 6-month-olds predict the reappearance of tempora-rily occluded objects15. Finally, in terms of proactive goal-directed eyemovements, we found no support for the teleological stance theoryclaiming that 12-month-old infants perceive self-propelled objects asgoal-directed (Test 2).
In conclusion, proactive goal-directed eye movements seem torequire observing an interaction between the hand of an agent andan object, supporting the mirror neuron account in general. Further-more, infants develop such gaze behavior during the very limited timeframe derived from the MNS hypothesis of social cognition. During thesecond half of their first year, infants come to predict others’ actions.The mirror neuron system is likely to mediate this process.
Note: Supplementary information is available on the Nature Neuroscience website.
ACKNOWLEDGMENTSThis research was supported by grants to C.v.H. from the Tercentennial Fund ofthe Bank of Sweden (J2004-0511), McDonnell Foundation (21002089), andEuropean Union (EU004370: robot-cub).
COMPETING INTERESTS STATEMENTThe authors declare that they have no competing financial interests.
Published online at http://www.nature.com/natureneuroscience
Reprints and permissions information is available online at http://npg.nature.com/
reprintsandpermissions/
1. Fadiga, L., Fogassi, L., Pavesi, G. & Rizzolatti, G. J. Neurophysiol. 73, 2608–2611(1995).
2. Kohler, E. et al. Science 297, 846–848 (2002).3. Buccino, G. et al. Eur. J. Neurosci. 13, 400–404 (2001).4. Rizzolatti, G. & Craighero, L. Annu. Rev. Neurosci. 27, 169–192 (2004).5. Keysers, C. & Perrett, D.I. Trends Cogn. Sci. 8, 501–507 (2004).6. Land, M.F. & Furneaux, S. Phil. Trans. R. Soc. Lond. B 352, 1231–1239 (1997).7. Johansson, R.S., Westling, G.R., Backstrom, A. & Flanagan, J.R. J. Neurosci. 21, 6917–
6932 (2001).8. Flanagan, J.R. & Johansson, R.S. Nature 424, 769–771 (2003).9. Gallese, V., Keysers, C. & Rizzolatti, G. Trends Cogn. Sci. 8, 396–403 (2004).10. Tomasello, M. The Cultural Origins of Human Cognition (Harvard Univ. Press, London,
1999).11. Bruner, J.S. in Mechanisms of Motor Skill Development (ed. Connolly, K.J.) 63–91
(Academic, London, 1970).12. Sommerville, J.A., Woodward, A.L. & Needham, A. Cognition 96, B1–B11 (2005).13. Luo, Y. & Baillargeon, R. Psychol. Sci. 16, 601–608 (2005).14. Gergely, G. & Csibra, G. Trends Cogn. Sci. 7, 287–292 (2003).15. Rosander, K. & vonHofsten, C. Cognition 91, 1–22 (2004).
HA SPM
M HA HASPM
M HA SPM
M HA HASPM
M–300
–200
–100
0
100
Gaz
e ar
rival
at g
oal r
elat
ive
toar
rival
of m
ovin
g ta
rget
(m
s)
Rat
io o
f loo
king
tim
e (g
oal)
tolo
okin
g tim
e (g
oal +
traj
ecto
ry)
200
300
400Adults 12-month-
olds6-month-
oldsAdults 12-month-
olds6-month-
olds
MM = mechanical motionSM = self-propelledHA = human agent
00.10.20.30.40.50.60.70.8
a b
Figure 2 Gaze performance during observation of actions and moving objects.
Statistics (means and s.e.m.) are based on all data points for adults (left),
12-month-old infants (middle) and 6-month-old infants (right), respectively.
(a) Timing (ms) of gaze arrival at the goal relative to the arrival of the moving
target. Target arrival is represented by the horizontal line at 0 ms. Positive
values correspond to early arrival of gaze at the goal area. (b) Ratios of
looking time at the goal area to total looking time in both goal and trajectory
areas during object movement. The horizontal line at 0.2 represents the ratioexpected if subjects tracked the moving target.
NATURE NEUROSCIENCE VOLUME 9 [ NUMBER 7 [ JULY 2006 879
BR I E F COMMUNICAT IONS©
2006
Nat
ure
Pub
lishi
ng G
roup
ht
tp://
ww
w.n
atur
e.co
m/n
atur
eneu
rosc
ienc
e

Shared Challenges in Object Perception
for Robots and Infants†
Paul Fitzpatrick∗ Amy Needham∗∗ Lorenzo Natale∗∗∗ Giorgio Metta∗
∗LIRA-Lab, DISTUniversity of GenovaViale F. Causa 13
16145 Genova, Italy
∗∗ Duke University9 Flowers Drive
Durham, NC 27798North Carolina, USA
∗∗∗ MIT CSAIL32 Vassar St
Cambridge, MA 02139Massachusetts, USA
Abstract
Robots and humans receive partial, fragmentary hints about the world’s state through their respective
sensors. In this paper, we focus on some fundamental problems in perception that have attracted the
attention of researchers in both robotics and infant development: object segregation, intermodal inte-
gration, and the role of embodiment. We concentrate on identifying points of contact between the two
fields, and also important questions identified in one field and not yet addressed in the other. For object
segregation, both fields have examined the idea of using “key events” where perception is in some way
simplified and the infant or robot acquires knowledge that can be exploited at other times. We examine
this parallel research in some detail. We propose that the identification of the key events themselves
constitutes a point of contact between the fields. And although the specific algorithms used in robots
are not easy to relate to infant development, the overall “algorithmic skeleton” formed by the set of
algorithms needed to identify and exploit key events may in fact form a basis for mutual dialogue.
Keywords: Infant development, robotics, object segregation, intermodal integration, embodiment.
Address correspondence to the first author, Paul Fitzpatrick, at:
email [email protected] +39-010-3532946fax +39-010-3532144address LIRA-Lab, DIST, University of Genova, Viale F. Causa 13, 16145 Genova, Italy
†Due to time constraints, the final draft of this paper was not seen by all authors at the time of submission. Since the size limit on thepaper required much review material to be discarded and arguments to be shortened, any factual errors or misrepresentations introducedare the responsibility the first author, and should not be attributed to any other author.

1. Introduction
Imagine if your body’s sensory experience were presented to you as column after column of numbers. One
number might represent the amount of light hitting a particular photoreceptor, another might be related to the
pressure on a tiny patch of skin. Imagine further if you could only control your body by putting numbers in a
spreadsheet, with different numbers controlling different muscles and organs in different ways.
This is how a robot experiences the world. It is also a (crude) model of how humans experience the world.
Of course, our sensing and actuation are not encoded as numbers in the same sense, but aspects of the world
and our bodies are transformed to and from internal signals that, in themselves, bear no trace of the signals’
origin. For example, a neuron firing selectively to a red stimulus is not itself necessarily red. The feasibility
of telepresence and virtual reality shows that this kind of model is not completely wrong-headed; if we place
digital transducers between a human and the world, they can still function well.
Understanding how to build robots requires understanding in a very concrete and detailed way how it is
possible to sense and respond to the world. Does this match the concerns of psychology? For work concerned
with modeling phenomena that exist at a high level of abstraction, or deeply rooted in culture, history, and
biology, the answer is perhaps “no”. But for immediate perception of the environment, the answer must be
at least partially “yes”, because the problems of perception are so great that intrinsic, physical, non-cultural,
non-biological, non-historical constraints must play a role. We expect that there will be commonality between
how infants and successful robots operate at the information-processing level, because natural environments
are of mixed, inconstant observability – there are properties of the environment that can be perceived easily
under some circumstances and with great difficulty (or not at all) under others. This network of opportunities
and frustrations should place limits on information processing that apply both to humans and robots with
human-like sensors.
In this paper, we focus on early perceptual development in infants. The perceptual judgements infants make
change over time, showing a changing sensitivity to various cues. This progression may be at least partially
due to knowledge gained from experience. We identify opportunities that can be exploited by both robots and
infants to perceive properties of their environment that cannot be directly perceived in other circumstances.
We review some of what is known of how robots and infants can exploit such opportunities to learn to make
reasonable inferences about object properties that are not directly given in the display through correlations
with observable properties, grounding those inferences in prior experience. The topics we focus on are object

segregation, intermodal integration, and embodiment.
2. Object segregation
[Figure 1 about here.]
The world around us has structure, and to an adult appears to be made up of more-or-less well-defined
objects. Perceiving the world this way sounds trivial, but from an engineering perspective, it is heart-breakingly
complex. As Spelke wrote in 1990:
... the ability to organize unexpected, cluttered, and changing arrays into objects is mysterious: so
mysterious that no existing mechanical vision system can accomplish this task in any general manner.
(Spelke, 1990)
This is still true today. This ability to assign boundaries to objects in visually presented scenes (called “object
segregation” in psychology or “object segmentation” in engineering) cannot yet be successfully automated for
arbitrary object sets in unconstrained environments (see Figure 1).
There has been algorithmic progress; for example, given local measures of similarity between each neighboring
element of a visual scene, a globally appropriate set of boundaries can be inferred in efficient and well-founded
ways (see for example Felzenszwalb and Huttenlocher (2004)). Just as importantly, there is also a growing
awareness of the importance of collecting and exploiting empirical knowledge about the statistical combinations
of materials, shapes, lighting, and viewpoints that actually occur in our world (see for example Martin et al.
(2004)). Of course, such knowledge can only be captured and used effectively because of algorithmic advances
in machine learning, but the knowledge itself is not specified by an algorithm.
Empirical, non-algorithmic knowledge of this kind now plays a key role in machine perception tasks of
all sorts. For example, face detection took a step forward with Viola and Jones (2004); the success of this
work was due both to algorithmic innovation and better exploitation of knowledge (features learned from 5000
hand-labelled face examples). The success of automatic speech recognition is successful largely because of the
collection and exploitation of extensive corpuses of clearly labelled phoneme or phoneme-pair examples that
cover well the domain of utterances to be recognized.
These two examples clarify ways “knowledge” can play a role in machine perception. The bulk of the
“knowledge” used in such systems takes the form of labelled examples – examples of input from the sensors (a
vector of numbers), and the corresponding desired output interpretation (another vector of numbers). More-

or-less general purpose machine learning algorithms can then approximate the mapping from sensor input to
desired output interpretation based on the examples (called the training set), and apply that approximation
to novel situations (called the test set). Generally, this approximation will be very poor unless we transform
the sensory input in a manner that highlights properties that the programmer believes may be relevant. This
transformation is called preprocessing and feature selection. There is a great deal of infrastructure wrapped
around the learning system to break the problem down into tractable parts and apply the results of learning
back to the original problem. For this paper, we will group all this infrastructure and call it the algorithmic
skeleton. This set of carefully interlocking algorithms is designed so that, when fed with appropriate training
data, it fleshes out into a functional system. Without the algorithmic skeleton, there would be no way to make
sense of the training data, and without the data, perception would be crude and uninformed.
What, then, is the right algorithmic skeleton for object segregation? What set of algorithms, coupled with
what kind of training data, would lead to best performance? We review suggestive work in infant development
research and robotics.
[Figure 2 about here.]
2.1 Segregation skills in infants
By 4 to 5 months of age, infants can parse simple displays like the one in Figure 2 into units, based on something
like a subset of static Gestalt principles – see for example Needham (1998, 2000). Initial studies indicated that
infants use a collection of features to parse the displays (Needham, 1998; Needham and Baillargeon, 1997, 1998);
subsequent studies suggested that object shape is the key feature that young infants use to identify boundaries
between adjacent objects (Needham, 1999). Compared to adult judgements, we would expect such strategies
to lead to many incorrect parsings, but they will also provide reasonable best guess interpretations of uniform
objects in complex displays.
Infants do not come prepared from birth to segregate objects into units that match adult judgement. It
appears that infants learn over time how object features can be used to predict object boundaries. More than
twenty years ago, Kellman and Spelke (1983) suggested that infants may be born with knowledge about solid,
three-dimensional objects and that this knowledge could help them interpret portions of a moving object as
connected to other portions that were moving in unison. This assertion was put to the test by Slater and his
colleagues (Slater et al., 1990), a test that resulted in a new conception of the neonate’s visual world. Rather
than interpreting common motion as a cue to object unity, neonates appeared to interpret the visible portions

of a partly occluded object as clearly separate from each other, even when undergoing common motion. This
finding was important because it revealed one way in which learning likely changes how infants interpret their
visual world.
Although segregating adjacent objects present a very similar kind of perceptual problem (“are these surfaces
connected or not”), the critical components of success might be quite different. Early work with adjacent objects
indicated that at 3 months of age, infants tend to group all touching surfaces into a single unit (Kestenbaum
et al., 1987). Subsequent experiments have revealed that soon after this point in development, infants begin to
analyze the perceptual differences between adjacent surfaces and segregate surfaces with different features (but
not those with similar features) into separate units (Needham 2000). 8.5 month old infants have been shown to
also use information about specific objects or classes of objects to guide their judgement (Needham, Cantlon,
& Ormsby, 2005).
It might be that extensive amounts of experience are required to ‘train up’ this system. However, it might
also be that infants learn on the basis of relatively few exposures to key events (Baillargeon, 1999). This
possibility was investigated within the context of object segregation by asking how infants’ parsing of a display
would be altered by a brief prior exposure to one of the objects in the test display.
In this paradigm, a test display was used that was ambiguous to 4.5-month-old infants who had no prior
experience with the display. Prior experience was then given that would help disambiguate the display for
infants. This experience consisted of a brief prior exposure (visual only) to a portion of the test display. If
infants used this prior experience to help them parse the test display, they should see the display as two separate
objects and look reliably longer when they moved as a whole than when they move separately. Alternately,
if the prior experience was ineffective in altering infants’ interpretation of the display, they should look about
equally at the display, just as the infants in the initial study with no particular prior experience did (Needham
and Baillargeon, 1998). Prior experiences with either portion of the test display were effective in facilitating
infants’ parsing of the test display.
2.2 Segregation skills in robots
This idea that exposure to key events could influence segregation is intuitive, and evidently operative in infants.
Yet it is not generally studied or used in mechanical systems for object segregation. In this section, we attempt
to reformulate robotics work by the authors in these terms.
For object segregation in robotics, we will interpret “key events” as moments in the robot’s experience where

the true boundary of an object can be reliably inferred. They offer an opportunity to determine correlates of
the boundary that can be detected outside of the limited context of the key events themselves. Thus, with an
appropriate algorithmic skeleton, information learned during key events can be applied more broadly.
Key events in infants include seeing an object in isolation or seeing objects in relative motion. In the authors’
work, algorithmic skeletons have been developed for exploiting constrained analogues of these situations.
In Natale et al. (2005b), a very simple key event is used to learn about objects – holding an object up to the
face. The robot can be handed an object or happen to grasp it, and will then hold it up close to its cameras. This
gives a good view of its surface features, allowing the robot to do some learning and later correctly segregate the
object out from the background visually even when out of its grasp (see Figure 3). This is similar an isolated
presentation of an object, as in Needham’s experiments. In real environments, true isolation is very unlikely,
and actively moving an object so that it dominates the scene can be beneficial.
In Fitzpatrick and Metta (2003), the “key event” used is hitting an object with the hand/arm. This is a
constrained form of relative object motion. In the real world, all sorts of strange motions happen which can
be hard to parse, so it is simpler at least to begin with to focus on situations the robot can initiate and at
least partially control. Motion caused by body impact has some technical advantages; the impactor (the arm)
is understood and can be tracked, and since the moment and place of impact can be detected quite precisely,
unrelated motion in the scene can be largely filtered out.
The algorithmic skeleton in (Fitzpatrick and Metta, 2003) processes views of the arm moving, detects
impacts, and outputs boundary estimates of whatever the arm collides with based on motion. These boundaries,
and what they contain, are used as training data for another algorithm, whose purpose is to estimate boundaries
from visual appearance when motion information is not available. See Fitzpatrick (2003) for technical details.
As a basic overview, the classes of algorithms involved are these:
1. Behavior system: an algorithm that drives the robot’s behavior, so that it is likely to hit things. This system
has a broader agenda than just this specific outcome; if
2. Key event detection: an algorithm that detects the key event of when the arm/hand hits an object.
3. Training data extraction: an algorithm that, within a key event, extracts boundary information from object
motion caused by hitting.
4. Machine learning: an algorithm that discovers features predictive of boundaries that can be extracted in
other situations without motion (in this case edge and color combinations).
5. Application of learning: an algorithm that actually uses those features to predict boundaries. This must

be integrated with the very first algorithm, to influence the robot’s behavior in useful ways. In terms of
observable behavior, the robot’s ability to attend and fixate specific objects increases, since they become
segregated from the background.
This skeleton gets fleshed out through learning, once the robot actually starts hitting objects and extracting
specific features predictive of the boundaries of specific objects. A set of different algorithms performing
analogous roles are used for the Natale et al. (2005b) example. At the algorithmic level, the technical concerns
in either case are hard to relate to infant development, although in some cases there are correspondences. But
at the skeletal level, the concerns are coming closer to those of infant development.
[Figure 3 about here.]
2.3 Specificity of knowledge gained from experience
In the robotic learning examples in the previous section (Fitzpatrick, 2003; Natale et al., 2005b), information
learned by the robot is intended to be specific to one particular object. The specificity could be varied algorith-
mically, by adding or removing parts of a feature’s “identity”. Too much specificity, and the feature will not be
recognized in another context. Too little, and it will be “hallucinated” everywhere.
We return to Needham’s experiments, which probed the question of generalization in the same experimental
scenario described in Section 2.1.
When changes were introduced between the object seen during familiarization and that seen as part of the
test display, an unexpected pattern emerged. Nearly any change in the object’s features introduced between
familiarization and test prevented infants from benefiting from this prior experience. So, even when infants saw
a blue box with yellow squares prior to testing, and the box used in testing had white squares but was otherwise
identical, they did not apply this prior experience to the parsing of the test display. However, infants did benefit
from the prior exposure when it was not in the features of the object but rather in its orientation (Needham,
2001). A change in the orientation of the box from horizontally to vertically oriented led to the facilitation in
parsing seen in some prior experiments. Thus, infants even as young as 4.5- to 5-months of age know that to
probe whether they have seen an object before, they must attend to the object’s features rather than its spatial
orientation (Needham, 2001).
These results also support two additional conclusions. First, infants’ object representations include detailed
information about the object’s features. Because infants’ application of their prior experience to the parsing of

the test display was so dependent on something close to an exact match between the features, one much conclude
that a highly detailed representation is formed on the initial exposure and maintained during the inter-trial-
interval. Because these features are remembered and used in the absence of the initial item and in the presence
of a different item, this is strong evidence for infants’ representational abilities. Secondly, 4.5-month-old infants
are conservative generalizers – they do not extend information from one object to another very readily. But
would they extend information from a group of objects to a new object that is a member of that group?
2.4 Generalization of of knowledge gained from experience
This question was investigated by Needham et al. (2005) in a study using the same test display and a similar
procedure as in Needham (2001). Infants were given prior experiences with collections of objects, no one of
which was an effective cue to the composition of the test display when seen prior to testing. A set of three similar
objects seen simultaneously prior to test did facilitate 4.5-month-old infants segregation of the test display. But
no subset of these three objects seen prior to testing facilitated infants’ segregation of the test display. Also,
not just any three objects functioned in this way – sets that had no variation within them or that were too
different from the relevant test item provided no facilitation. Thus, experience with multiple objects that are
varied but that are similar to the target item is important to infants’ transfer of their experience to the target
display.
This finding was brought into the “real” world by investigating infants’ parsing of a test display consisting
of a novel key ring (Needham et al., submitted). According to a strict application of organizational principles
using object features, the display should be seen as composed of (at least) two separate objects – the keys on
one side of the screen and the separate ring on the other side. However, to the extent that infants recognize the
display as a member of a familiar category – key rings – they should group the keys and ring into a single unit
that should move as a whole. The findings indicate that by 8.5 months of age, infants parse the display into a
single unit, expecting the keys and ring to move together. Younger infants do not see the display as a single unit,
and instead parse the keys and ring into separate units. Infants of both ages parsed an altered display, in which
the identifiable portions of the key ring were hidden by patterned covers, as composed of two separate units.
Together, these findings provide evidence that the studies of controlled prior exposure described in the previous
section are consistent with the process as it occurs under natural circumstances. Infants’ ordinary experiences
present them with multiple similar exemplars of key rings, and these exposures build a representation that can
then be applied to novel (and yet similar) instances of the key ring category, altering the interpretation that

would come from feature-based principles alone.
These results from infant development suggest a path for robotics to follow. There is currently no serious
robotics work to point to in this area, despite its importance. Robotics work in this area could potentially aid
infant psychologists since there is a strong theoretical framework in machine learning for issues of generalization.
3. Intermodal integration
We have talked about “key events” in which object boundaries are easier to perceive. In general, the ease with
which any particular object property can be estimated varies from situation to situation. Robots and infants
can exploit the easy times to learn statistical correlates that are available in less clear-cut situations. For
example, cross-modal signals are a particularly rich source of correlates, and have been investigated in robotics
and machine perception. Most events have components that are accessible through different senses: A bouncing
ball can be seen as well as heard; the position of the observer’s own hand can be seen and felt as it moves
through the visual field. Although these perceptual experiences are clearly separate from each other, composing
separate ‘channels’, we also recognize meaningful correspondences between the input from these channels. How
these channels are related in humans is not entirely clear. Different approaches to the development of intermodal
perception posit that infants’ sensory experiences are (a) unified at birth and must be differentiated from each
other over development, or (b) separated at birth and must be linked through repeated pairings. Although the
time frame over which either of these processes would occur has not been well defined, research findings do
suggest that intermodal correspondences are detected early in development.
On what basis do infants detect these correspondences? Some of the earliest work on this topic revealed
that even newborn infants look for the source of a sound (Butterworth and Castillo, 1976) and by 4 months
of age have specific expectations about what they should see when they find the source of the sound (Spelke,
1976). More recent investigations of infants’ auditory-visual correspondences have identified important roles for
synchrony and other amodal properties of objects – properties that can be detected across multiple perceptual
modalities. An impact (e.g., a ball bouncing) provides amodal information because the sound of the ball hitting
the surface is coincident with a sudden change in direction of the ball’s path of motion. Some researchers
have argued (Bahrick) that detection and use of amodal object properties serves to bootstrap the use of more
idiosyncratic properties (e.g., the kind of sound made by an object when it hits a surface). Bahrick & Lickliter
have shown that babies (and bobwhite quail) learn better and faster from multimodal stimulation (see their
Intermodal Redundancy Hypothesis (Bahrick and Lickliter, 2000)).

In robotics, amodal properties such as location have been used – for example, sound localization can aid
visual detection of a talking person. Timing has also been used. Prince and Hollich (2005) develop specific
models of audio-visual synchrony detection and evaluates compatibility with infant performance. Arsenio and
Fitzpatrick (2005) exploit the specific timing cue of regular repetition to form correspondences across sensor
modalities. From an engineering perspective, the redundant information supplied by repetition makes this form
of timing information easier to detect reliably than synchrony of a single event in the presence of background
activity. However, in the model of Lewkowicz (2000), the ordering during infant development is opposite. This
suggests the engineers just haven’t found a good enough algorithm, or regular repetition just doesn’t happen
enough to be important.
4. The role of embodiment
The study of perception in biological systems cannot neglect the role of the body in the generation of the sensory
information reaching the brain. The morphology of the body affects perception in numerous ways. In primates,
for example, the visual information that reaches the visual cortex has a non-uniform distribution, due to the
peculiar arrangement and size of the photoreceptors in the retina. In many species the outer ears and the head
filter the sound in a way that facilitate auditory localization. The intrinsic elasticity of the muscles acts as a
low pass filter during the interaction between the limbs and the environment.
Through the body the brain performs actions to explore the environment and collect information about
its properties and rules. In their experiments with human subjects Lederman and Klazky (Lederman and
Klatzky, 1987) have identified a set of stereotyped hand movements (exploratory procedures) that adults use when
haptically exploring objects to determine properties like weight, shape, texture and temperature. Lederman
and Klatzky show that to each property can be associated a preferential exploratory procedure which is, if not
required, at least optimal for its identification.
These observations support the theory that motor development and the body play an important role in
perceptual development in infancy (Bushnell and Boudreau, 1993). Proper control of at least the head, the arm
and the hand is required before infants can reliably and repetitively engage in interaction with objects. During
the first months of life the inability of infants to perform skillful movements with the hand would prevent them
from haptically exploring the environment and perceive properties of objects like weight, volume, hardness and
shape. But, even more surprisingly, motor development could affect the developmental course of object visual
perception (like three dimensional shape). Further support to this theory comes from the recent experiment by

Needham and colleagues (A. Needham and Peterman, 2002), where the ability of pre-reaching infants to grasp
objects was artificially anticipated by means of mittens with palms covered with velcro that stuck to some toys
prepared by the experimenters. The results showed that those infants whose grasping ability had been enhanced
by the glove, were more interested in objects than a reference group of the same age that developed ’normally’.
This suggests that, although artificial, the boost in motor development produced by the glove anticipated the
infants’ interest towards objects.
Exploiting actions for learning and perception requires the ability to match actions with the agents that
caused it. The sense of agency (Jeannerod, 2002) gives humans the sense of ownership of their actions and
implies the existence of an internal representation of the body. Although some sort of self-recognition is already
present at birth, at least in the form of a simple hand-eye coordination (van der Meer et al., 1995), it is during
the first months of development that infants learn to recognize their body as a separate entity acting in the
world (Rochat and Striano, 2000). It is believed that to develop this ability infants exploit correlations across
different sensorial channels (combined double touch/correlation between proprioception and vision).
In robotics we have the possibility to study the link between action and perception, and its implications
on the realization of artificial systems. Robots, like infants, can exploit the physical interaction with the
environment to enrich and control their sensorial experience. However these abilities do not come for free. Very
much like an infant, the robot must first learn to identify and control its body, so that the interaction with the
environment is meaningful and, at least to a certain extent, safe. Indeed, motor control is challenging especially
when it involves the physical interaction between the robot and the world.
Inspired by the developmental psychology literature, roboticists have begun to investigate the problem of self-
recognition in robotics (Gold and Scassellati, 2005; Metta and Fitzpatrick, 2003; Natale et al., 2005b; Yoshikawa
et al., 2003). Although different in several aspects, in all these work the robot looks for intermodal similarities
and invariances to identify its body from the rest of the world. In the work of Yoshikawa (Yoshikawa et al.,
2003) the rationale is that for any given posture the body of the robot is invariant with respect to the rest
of the world. The correlation between visual information and proprioceptive feedback is learned by a neural
network which is trained to predict the position of the arms in the visual field. Gold and Scassellati (Gold
and Scassellati, 2005) solve the self-recognition problem by exploiting knowledge of the time elapsing between
the actions of the robot and the associated sensorial feedback. In the work of Metta and Fitzpatrick (Metta
and Fitzpatrick, 2003) and Natale et al. (Natale et al., 2005b) actions are instead used to generate visual
motion with a known pattern. Similarities in the proprioceptive and visual flow are searched to visually identify

the hand of the robot. Periodicity in this case enhances and simplifies the identification. The robot learns a
multimodal representation of its hand that allows a robust identification in the visual field.
In our experience with robots we identified three scenarios in which the body proved to be useful in solving
perceptual tasks:
1. direct exploration: the body in this case is the interface to extract information about the objects. For
example in (Natale et al., 2004) haptic information was employed to distinguish object of different shape, a
task that would be much more difficult if performed visually. In (Torres-Jara et al., 2005) the robot learned
to recognize a few objects by using the sound they generate upon contact with the fingers.
2. controlled exploration: use the body to perform actions to simplify perception. The robot can deliberately
generate redundant information by performing periodic actions in the environment.
3. the body as a reference frame: during action the hand is the place where important events are most likely
to occur. The ability to direct the attention of the robot towards the hand is particularly helpful during
learning; in (Natale et al., 2005b) we show how this ability allows the robot to learn a visual model of the
objects it manages to grasp by simply inspecting the hand when touch is detected on the palm (see Figure 3).
In similar situations the same behavior could allow the robot to direct the gaze to the hand if something
unexpected touches it. Eye-hand coordination seems thus important to establish a link between different
sensory channels like touch and vision.
5. Conclusions
In the field of humanoid robotics, researchers have a special respect and admiration for the abilities of infants.
They watch their newborn children with particular interest, and their spouses have to constantly be alert for the
tell-tale signs of them running an ad-hoc experiment. It can be depressing to compare the outcome of a five-year,
multi-million-euro/dollar/yen project with what an infant can do after four months. Infants are so clearly doing
what we want to robots to do; is there any way to learn from research on infant development? Conversely, can
infant development research be illuminated by the struggles faced by robotics, perhaps pointing out fundamental
perceptual difficulties taken for granted? Is there a way to create a model of development which applies both
to infants and robots? It seems possible that similar sensorial constraints and opportunities will mold both
the unfolding of an infant’s sensitivities to different cues, and the organization of the set of algorithms used by
robots to achieve sophisticated perception. So, at least at the level of identifying “key events” and mutually

reinforcing cues, a shared model is possible. Of course, there is a lot that would not fit in the model, and this
is as it should be. It would be solely concerned with the class of functional, information-driven constraints. We
have not in this paper developed such a model; that would be premature. We have at identified some points
of connection that could grow into much more. We hope the paper will serve as one more link in the growing
contact between the fields.
References
A. Needham, T. B. and Peterman, K. (2002). A pick-me-up for infants’ exploratory skills: Early simulated
experiences reaching for objects using ’sticky mittens’ enhances young infants’ object exploration skills. Infant
Behavior and Development, 25:279–295.
Arsenio, A. M. and Fitzpatrick, P. M. (2005). Exploiting amodal cues for robot perception. International
Journal of Humanoid Robotics, 2(2):125–143.
Bahrick, L. E. and Lickliter, R. (2000). Intersensory redundancy guides attentional selectivity and perceptual
learning in infancy. Developmental Psychology, 36:190–201.
Bushnell, E. and Boudreau, J. (1993). Motor development and the mind: the potential role of motor abilities
as a determinant of aspects of perceptual development. Child Development, 64(4):1005–10021.
Butterworth, G. and Castillo, M. (1976). Coordination of auditory and visual space in newborn human infants.
Perception, 5(2):155–160.
Felzenszwalb, P. F. and Huttenlocher, D. P. (2004). Efficient graph-based image segmentation. International
Journal of Computer Vision, 59(2):167–181.
Fitzpatrick, P. (2003). Object Lesson: discovering and learning to recognize objects. In Proceedings of the 3rd
International IEEE/RAS Conference on Humanoid Robots, Karlsruhe, Germany.
Fitzpatrick, P. and Metta, G. (2003). Grounding vision through experimental manipulation. Philosophical
Transactions of the Royal Society: Mathematical, Physical, and Engineering Sciences, 361(1811):2165–2185.
Gold, K. and Scassellati, B. (2005). Learning about the self and others through contingency. In Developmental
Robotics AAAI Spring Symposium, Stanford, CA.
Jeannerod, M. (2002). The mechanism of self-recognition in humans. Behavioural Brain Research, 142:1–15.

Kellman, P. J. and Spelke, E. S. (1983). Perception of partly occluded objects in infancy. Cognitive Psychology,
15:483–524.
Kestenbaum, R., Termine, N., and Spelke, E. S. (1987). Perception of objects and object boundaries by three-
month-old infants. British Journal of Developmental Psychology, 5:367–383.
Lederman, S. J. and Klatzky, R. L. (1987). Hand movements: A window into haptic object recognition. Cognitive
Psychology, 19(3):342–368.
Lewkowicz, D. J. (2000). The development of intersensory temporal perception: an epigenetic sys-
tems/limitations view. Psych. Bull., 126:281–308.
Martin, D., Fowlkes, C., and Malik, J. (2004). Learning to detect natural image boundaries using local bright-
ness, color and texture cues. IEEE Transactions on Pattern Analysis and Machine Intelligence, 26(5):530–549.
Metta, G. and Fitzpatrick, P. (2003). Early integration of vision and manipulation. Adaptive Behavior,
11(2):109–128.
Natale, L., Metta, G., and Sandini, G. (2004). Learning haptic representation of objects. In International
Conference on Intelligent Manipulation and Grasping, Genoa, Italy.
Natale, L., Metta, G., and Sandini, G. (2005a). A developmental approach to grasping. In Developmental
Robotics AAAI Spring Symposium, Stanford, CA.
Natale, L., Orabona, F., Metta, G., and Sandini, G. (2005b). Exploring the world through grasping: a devel-
opmental approach. In Proceedings of the 6th CIRA Symposium, Espoo, Finland.
Needham, A. (1998). Infants’ use of featural information in the segregation of stationary objects. Infant Behavior
and Development, 21:47–76.
Needham, A. (1999). The role of shape in 4-month-old infants’ segregation of adjacent objects. Infant Behavior
and Development, 22:161–178.
Needham, A. (2000). Improvements in object exploration skills may facilitate the development of object segre-
gation in early infancy. Journal of Cognition and Development, 1:131–156.
Needham, A. (2001). Object recognition and object segregation in 4.5-month-old infants. Journal of Experi-
mental Child Psychology, 78(1):3–22.

Needham, A. and Baillargeon, R. (1997). Object segregation in 8-month-old infants. Cognition, 62:121–149.
Needham, A. and Baillargeon, R. (1998). Effects of prior experience in 4.5-month-old infants’ object segregation.
Infant Behavior and Development, 21:1–24.
Needham, A., Dueker, G., and Lockhead, G. (2005). Infants’ formation and use of categories to segregate
objects. Cognition, 94(3):215–240.
Prince, C. G. and Hollich, G. J. (2005). Synching models with infants: a perceptual-level model of infant
audio-visual synchrony detection. Journal of Cognitive Systems Research, 6:205–228.
Rochat, P. and Striano, T. (2000). Perceived self in infancy. Infant Behavior and Development, 23:513–530.
Slater, A., Morison, V., Somers, M., Mattock, A., Brown, E., and Taylor, D. (1990). Newborn and older infants’
perception of partly occluded objects. Infant Behavior and Development, 13(1):33–49.
Spelke, E. S. (1976). Infants’ intermodal perception of events. Cognitive Psychology, 8:553–560.
Spelke, E. S. (1990). Principles of object perception. Cognitive Science, 14:29–56.
Torres-Jara, E., Natale, L., and Fitzpatrick, P. (2005). Tapping into touch. In Fith International Workshop on
Epigenetic Robotics (forthcoming), Nara, Japan. Lund University Cognitive Studies.
van der Meer, A., van der Weel, F., and Weel, D. (1995). The functional significance of arm movements in
neonates. Science, 267:693–5.
Viola, P. and Jones, M. (2004). Robust real-time object detection. International Journal of Computer Vision,
57(2):137–154.
Yoshikawa, Y., Hosoda, K., and Asada, M. (2003). Does the invariance in multi-modalities represent the body
scheme ? - a case study with vision and proprioception -. In 2nd Intelligent Symposium on Adaptive Motion
of Animals and Machines, Kyoto, Japan.

List of Figures
1 Object segregation is difficult for machines . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 172 Object segregation is not always well-defined . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 183 Exploitation of key moments in robotics . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19

Figure 1: An example from Martin et al. (2004), to highlight the difficulties of bottom-up segmentation. For the
image shown on the left, humans see the definite boundaries shown in white in the middle image. The best machine
segmentation of a set of algorithms gives the result shown on this right – a mess. This seems a very difficult scene to
segment without having some training at least for the specific kinds of materials in the scene.

Figure 2: Object segregation is not necessarily well-defined. On the left, there is a simple scenario, taken from Needham
(2001), showing a rectangle attached to a yellow tube. Two plausible ways to segregate this scene are shown in the
middle, depending on whether the tube and rectangle make up a single object. For comparison, automatically acquired
boundaries are shown on the right, produced using the algorithm in Felzenszwalb and Huttenlocher (2004). This algorithm
does image segmentation, seeking to produce regions that correspond to whole objects (such as the yellow tube) or at
least to object parts (such all the blue rectangle and all the small white patches on its surface, and various parts of the
background). Ideally, regions that extend across object boundaries are avoided. Image segmentation is less ambitious
than object segregation, and allows context information to be factored in as a higher level process operating on a region
level rather than pixel level.

Figure 3: The upper row shows object segregation by the robot “Babybot” based on prior experience. The robot explores
the visual appearances of an object that it has grasped; the information collected in this way is used later on to segment
the object (Natale et al., 2005b). Left: the robot. Middle: the robot’s view when holding up an object. Right: later
segmentation of the object. The lower row shows the robot “Cog” detecting object boundaries experimentally by poking
(Fitzpatrick, 2003). During object motion, if finds features of the object that contrast with other objects, and that are
stable with respect to certain geometric transformations. These features are then used to jointly detect and segment
the object in future views. Left: the robot. Middle: segmentations of a poked object. Right: later segmentation of the
object on a similarly-colored table.

RESEARCH ARTICLE
Gustaf Gredeback Æ Helena Ornkloo
Claes von Hofsten
The development of reactive saccade latencies
Received: 17 October 2005 / Accepted: 19 January 2006 / Published online: 18 February 2006� Springer-Verlag 2006
Abstract Saccadic reaction time (SRT) of 4-, 6- and 8-month-old infants’ was measured during tracking ofabruptly changing trajectories, using a longitudinaldesign. SRTs decreased from 595 ms (SE=30) at4 months of age to 442 ms (SE=13) at 8 months ofage. In addition, SRTs were lower during high veloci-ties (comparing 4.5 and 9�/s) and vertical (compared tohorizontal) saccades.
Keywords Infant Æ Saccade Æ Reaction time Æ SRT ÆTracking Æ ASL
Introduction
A newborn child is unable to discriminate motiondirection (Atkinson 2000) and track objects with smoothpursuit. They can, however, perform saccadic eyemovements (Aslin 1986). This means that newborns canredirect gaze swiftly to new locations within the visualfield. As infants grow older they become more proficientin combining saccades, smooth pursuit, and headmovements to track moving targets (von Hofsten 2004).
Several studies have investigated the dynamics ofsaccade development, often during continuous trackingof sinusoidal trajectories (Gredeback et al. 2005; Rich-ards and Holley 1999; Phillips et al. 1997; Rosander andvon Hofsten 2002; von Hofsten and Rosander 1996,1997) In such tasks saccadic performance is most oftendescribed in terms of frequency and amplitude of sac-cades. Latencies of individual saccades cannot bereported since saccade initiation is not triggered by aspecific external event but occurs as a consequence ofinsufficient smooth pursuit or in anticipation of futureevents (Leigh and Zee 1999).
Within this paradigm numerous studies havereported that infants produce more saccades as taskdemands increase. von Hofsten and Rosander (1996)demonstrated that infants produced more saccades asthe frequency of the stimulus motion increased(�1 saccade/s at 0.1 Hz and �1.75 saccades/s at0.3 Hz). Similar effects of frequency, as well as ampli-tude and velocity, have been reported elsewhere (Gre-deback et al. 2005; Phillips et al. 1997; von Hofsten andRosander 1997). In a similar fashion, increasing thetarget frequency, amplitude, or velocity will enhance theamplitude (von Hofsten and Rosander 1997) andvelocity (Phillips et al. 1997) of initiated saccades.
In addition, reliance on saccadic tracking appears tochance with age and be different for horizontal andvertical trajectories. Comparative studies of children andadults saccadic performance indicate that adult levelsare not reached until children are between 10 and12 years old (Yang et al. 2002). In younger infants sac-cade frequency has been reported to drop from�1.75 saccades/s at 6.5 weeks to �0.75 saccades/s at12 weeks of age in response to small target whereaslarger targets resulted in fewer saccades/s (target sizeranged from 2.5 to 35�; Rosander and von Hofsten2002). von Hofsten and Rosander (1997) also reported adecrease in saccade amplitude between 2 and 3 monthsof age (average saccade amplitude=4.4� at 2 monthsand 3.4� at 3 months1) whereas Richards and Holley(1999) described an increase in saccadic amplitudebetween 2 and 6.5 months of age (from �8 to �16�) anda shift from smooth tracking to saccade reliance at highvelocities. The later study presented infants with a ver-tical bar (2� horizontal ·6� vertical extension) moving onboth horizontal and vertical trajectories.
Another study that investigated two-dimensionaltracking in older infants reported an increase in saccadefrequency between 6 months (from �0 saccades/s at0.1 Hz to �0.5 saccades/s at 0.4 Hz) and 12 monthsG. Gredeback (&) Æ H. Ornkloo Æ C. von Hofsten
Department of Psychology, Uppsala University, Box 1225,75142, Uppsala, SwedenE-mail: [email protected]: +46-18-4712123
1Reported means are calculated from the group means presented inTable 2 of von Hofsten and Rosander (1997).
Exp Brain Res (2006) 173: 159–164DOI 10.1007/s00221-006-0376-z

(�0.1 saccades/s at 0.1 Hz to �1.2 saccades/s at 0.4 Hz)of age (Gredeback et al. 2005). The same study alsoreported more vertical than horizontal saccades.
Some of the above mentioned effects converge; thosethat describe an increased reliance on saccades with in-creased task demands (defined by increased targetvelocity, amplitude, and frequency). Other results areless consistent, particularly effects of age and dimen-sionality (comparing horizontal and vertical tracking).Given the composite nature of the task (to use saccades,smooth pursuit, and head movements to keep gaze ontarget) it is difficult to evaluate whether these effects canbe attributed to properties of the saccade system or ifthey arise as compensatory actions governed by, forexample, changes in smooth pursuit proficiency.
Alternative approaches in which infants are presentedwith sequences of pictures that alternate between twolocations engage the saccadic system in a more directmanner and enable reports of individual saccade laten-cies. In a series of studies, Canfield et al. (1997) inves-tigated 2- to 12-month-old infants’ saccadic reactiontime (SRT) to static stimuli that alternated betweendifferent locations. In this study infants were presentedwith different sequences of left–right located pictures.These sequences ranged from highly predictable oneswere the pictures alternated between two positions (L–R), sequences that included repetitions (L–L–R), andirregular presentations without a set sequence. Theirconclusion was that infants average SRT decreased from440 ms at 2 months to 285 ms at 12 months of age (seealso, Rensink et al. 2000).
Substantially longer latencies for reactive saccadeshave been reported elsewhere (Aslin and Salapatek 1975;Bronson 1982). Bronson (1982) examined SRTs toperipheral targets and found that the SRTs equaled 1 sat 2 months of age and 0.5 s at 5 months of age. Aslinand Salapatek (1975) measured the latency and ampli-tude of 1- and 2-month-old infants’ reactive saccades.They found that the SRT in both age groups dependedon the size of the target offset. At 1 month of age, themedian SRT ranged from 800 ms (10� offset) to1,480 ms (30� offset). One month later a significant de-crease was observed with corresponding SRTs being 480and 1,280 ms. It thus appears that SRTs vary substan-tially over different tasks.
Measuring SRTs to repetitive stimuli, as describedabove, induce its own set of confounds. Richards (2000)demonstrated that priming effects emerge between 3 and6 months of age in response to repetitive presentationsof target locations. In addition, Wentworth and Haith(1992) reported that predictable cues were followed by ahigher degree of anticipation and speedier reactions. Assuch, there appear to be two slightly different effects thatboth affect SRTs in response to repetitive static stimuli,both priming effects and an increased tendency to pre-dict the next stimulus location. These effects might havelowered the average SRT in some studies.
The current study attempts to bridge the gapbetween these two paradigms by presenting 4-, 6-, and
8-month-old infants with targets that move on lineartrajectories that suddenly alter their direction ofmotion. This gives us the opportunity to observe hor-izontal and vertical saccades during ongoing tracking[in accordance with the paradigm used by Gredebacket al. (2005), von Hofsten and Rosander (1997) andRichards and Holley (1999)] and to measure SRTsof individual saccades [in accordance to the para-digm used by Canfield et al. (1997) and Bronson (-1982)]. Abruptly changing the trajectory makes itpossible to evaluate individual saccades fairly inde-pendent of smooth pursuit performance and since eachtrajectory is unique the risk of priming effects andpredictive saccades are brought to a minimum.
Similar tasks have been successfully carried out withadult participants. In an influential study by Engel et al.(1999), adult SRTs were measured during continuoustracking of linear trajectories that suddenly altered theirdirection of motion. The target moved with one of twovelocities (15 or 30�/s) and changed trajectory at a ran-dom position near the center of the screen to one of11 alternative trajectories. In their study adult SRTsaveraged 197 ms (SD=28 ms).
Method
Participants
Sixteen infants participated in this longitudinal study (10males and 6 females). They visited the lab at 4 months(126±4 days), 6 months (178±4 days), and 8 monthsof age (234±8 days). Participants were contacted bymail based on birth records; before sending out the let-ters these were also checked by the health authorities toensure that only families with healthy infants werecontacted. The study was approved by the ethics com-mittee at the Research Council in the Humanities andSocial Sciences and therefore in accordance with theethical standards specified in the 1964 Declaration ofHelsinki. Before each session participating families wereinformed about the purpose of the study and signed aconsent form. As compensation for their participationeach family received either two movie tickets or eightbus tickets with a total value of �20 €.
Apparatus
Infants gaze was measured with an infrared cornealreflection technique (ASL, Bedford, MA, USA) incombination with a magnetic head tracker (Flock ofBirds, Ascension, Burlington, VT, USA). The ASL 504calculates gaze from the reflection of near infrared lightin the pupil and on the cornea (sampling frequency60 Hz, precision 0.5�, accuracy <1�). Head position wascalculated from changes in an electromagnetic fieldgenerated by a magnet and detected by a small sensor
160

(miniBird, 18·8·8 mm) attached to the Flock of Birdscontrol unit with a cable. The ASL 504 camera movedwith two degrees of freedom (azimuth and elevation)and was accessible via remote control and keyboard.During slow translations of the head and torso an autocorrection function rotated the camera to the center ofthe eye. During fast translations and prolonged blinking,the ASL 504 utilized information from the Flock ofBirds to relocate the eye.
Infants were presented with a 3D ‘happy face’ thatmoved over a blue colored screen. Its motion was con-trolled by two servomotors (one for horizontal and onefor vertical motion). The motors controlled the targetusing two magnets, one attached to the engines on theback of the screen and the other to the target at the frontof the screen. Both magnets were covered in cloth toreduce friction and ensure a minimum of movementrelated noise. A similar device has previously been usedto produce moving objects on a screen (Hespos et al.2002; von Hofsten and Spelke 1985; von Hofsten.et al.1998). The steel sheath covered an area of 1 m2 and0.42 cm2 could be used to produce stimulus motions.This presentation device was located 128 cm in front ofthe experimental booth. The side panels between thescreen and the experimental booth was covered withthick black fabric to reduce external light sources.
Infants were seated inside a semi-enclosed experi-mental booth (106·122·204 cm). The stimulus wasvisible through an opening (30·30 cm) in one of theshort walls of this booth; its lower edge was 100 cmfrom the floor. A shelf below the opening (82 cm fromfloor) held the ASL 504 camera unit. Outside theexperimental booth a loudspeaker was located on eachside of the opening. On the backside of the booth aPlexiglas frame held the Flock of Birds magnet. TheminiBird sensor cable entered the booth through anopening in the same wall below the Flock of Birdsmagnet. Light-blocking curtains covered the entranceto the experimental booth to eliminate outside lightfrom entering the booth.
Visual stimuli
A combination of a bell, a bright colored face, and a redlight attached to a rod was used to attract the infants’attention during calibration. This stimulus was movedback and forth between the upper left and lower rightcorners of the screen during calibration. To test cali-bration quality this target moved around the screen,stopping at each of its four corners.
The experimental stimulus consisted of a head (yel-low), a nose (blue), a painted mouth (red), and twoglowing eyes (red LEDs) under black eye brows.Underneath the target and above the magnet was apaper circle (yellow and black) that effectively doubledthe size of the target (radius=1 visual degree). Thecurrent setup only used the lower half of the displayscreen (35·65 cm).
The target moved with one of two velocities (4.5 and9�/s) starting from the upper right or the lower leftcorner of the screen. The initial trajectory was alwaysdiagonal and directed towards the center of the stimuluspresentation area. From its starting position the targetmoved on the same diagonal trajectory for either 8.9 or12.4 visual degrees, thereafter the target turned to astraight vertical or horizontal trajectory. Trajectoriesstarting at the upper right corner of the screen shifted toeither a linear upward or rightward motion. Stimulistarting in the lower left corner turned to either a left-ward or downward motion. The distance between theturning point and the end location of the trajectory was4.6, 6.4, 7.6, or 10.6 visual degrees (see Fig. 1).
After each trial the target moved to the new startinglocation of the next presentation. The next trial did notstart until the infant attentively focused on the target.All in all, the target moved on 16 unique trajectories (2starting locations · 2 velocities · 2 turning loca-tions · 2 post-turning trajectories; horizontal and ver-tical) that were presented to each infant only once.
Procedure
Upon arrival at the lab parents were briefed about thepurpose of the study. They were provided with a basicdescription on how the eye and head trackers worked,after which a consent form was signed. One of the par-ents was seated inside the experimental booth, facing thestimuli presentation device. Infants were fastened in aninfant car safety-seat that was placed on the parent’s lapfacing the same direction. During the entire experimen-tal procedure parents were encouraged to talk and singto their infants. As a whole this procedure provided asafe and reassuring atmosphere for the infants with bothparental closeness and an unobstructed visual field.Once the infant and parent were comfortably seatedinfants were dressed in a baby cap that held the mini-Bird. This head tracker was placed above the infants’right eye.
After this initial procedure, a number of steps weretaken before the actual stimuli presentations could be-gin. The distance between the miniBird and the infant’seye as well as thresholds for cornea and pupil detectionhad to be set. This was followed by a two-point cali-bration procedure (upper left and lower right corner ofthe screen) and a four-point calibration test (each of thefour corners of the screen). If the eye tracker did notlocate the fixation inside the extended calibration stim-ulus at each of the four corners of the screen the entirecalibration procedure was redone.
This entire procedure rarely took more than a min-ute. With the exception of the calibration procedure allabove-mentioned preparations were accompanied by areal-life puppet show, intended to focus the infantsattention forward. For a more thorough description ofthe general methods used, see Gredeback and vonHofsten (2004).
161

During the stimuli presentations each of the 16 tra-jectories were presented to the infants in a randomizedorder. Lack of attention to any stimulus resulted in anadditional presentation of that stimulus after the entireseries. Each presentation lasted less than 5 s and allpresentations rarely took more than 10 min.
Data analysis
Saccades were identified as eye movements with veloci-ties of 30�/s or more. They were separately analyzed forvertical and horizontal dimensions. SRTs were based onthe onset of the first saccade in the direction of thetarget’s new trajectory following its directional shift (oneither vertical or horizontal direction) with amplitudeextending at least 1�.
The inclusion criteria limited the analyzed dataset tothose trials in which target related smooth pursuit bothpreceded and succeeded the saccade. By this criterion wereduced the number of non-target related saccades andreduced noise.
Only horizontal components were analyzed for hori-zontal stimuli and vertical components for verticalstimuli. A multiple regression analysis of SRTs wereperformed with age (4, 6, and 8 months of age), velocity(4.5 and 9�/s), and dimension (horizontal and verticalsaccades) as regressors. In the results, the mean SRT isreported, not the median. This is based on recommen-dations by Miller (1988) who argues against the medianas a central measurement for small positively skewedsamples, particularly if groups differ in size.
Results
One infant was excluded from the analysis due to lack ofattention at both 4 and 6 months of age. Among the
remaining 15 participants the independent variables(age, velocity, and dimension) were significantly associ-ated with SRT, radj
2 =0.21, F(4,142)=13.87, P<0.00001.All regressors made significant individual contributions;SRTs decreased from 595 ms at 4 months of age(SE=30; n=76) to 485 ms at 6 months of age (SE=23;n=105) and 442 ms at 8 months of age (SE=13;n=136), (=�0.27, t(142)=12.4, P<0.00001.
In addition, both higher target velocities, (=�0.31,t(142)=�4.3, P<0.00005, and vertical saccades,(=�0.22, t(142)=�3.0, P<0.005, are related to lowersaccadic latencies. These effects are visible in Fig. 2a, b.Figure 2c displays individual SRTs at each age. Thecorrelation between SRTs at 4 and 6 months equaled0.51, this correlation decreased to 0.22 when comparing4- and 8-month-old infants and to �0.15 when com-paring 6-and 8-month-old infants.
Discussion
When infants track a moving target that abruptlychanges its direction of motion they produce a correctivesaccade in order to fixate the target and continue smoothpursuit tracking. The current paper describes how theability to reorient gaze in this way develops between 4and 8 months of age, with a focus on saccadic latency.All in all, SRTs decreased as infants got older. Inaddition, both the velocity of the target and whetherinfants performed a horizontal or vertical saccadeinfluenced SRT. Each of these effects will be discussedseparately below, starting with age differences.
Age differences
Tracking studies have reported many changes in saccadeusage, as infants grow older. Some studies have reported
Fig. 1 Trajectories presented tothe infants; 1–8 endpoints of themotion and s the starting pointsof the motion
162

a decrease in frequency and amplitude of saccadesduring the first few months of life (von Hofsten andRosander 1997; Rosander and von Hofsten 2002).Others have reported the opposite results (Gredebacket al. 2005; Richards and Holley 1999). It is difficult torelate these diverse findings to the current study. It isperhaps more fruitful to relate the current age effectsto those found by Canfield et al. (1997). In their studySRTs decreased from 400 ms at 2 months to 285 ms at12 months. Both of these values are lower than theaverage performance reported above (595 ms at4 months and 442 ms at 8 months).
It is possible that the reported differences can beattributed to differences in the predictability of the tar-gets. The current study presented infants with 16 noveltrajectories without repetition whereas Canfield et al.presented pictures that alternated between two locations(L–R). During highly predictable presentations thelocation of the next picture could be determined from theprevious locations (L–R). Even during irregular se-quences any random saccade would have had a 0.5 suc-cess rate, because there were only two stimulus locations.
In fact, a number of studies have reported that rep-etitions decrease SRT. Richards (2000) demonstratedthat attention to locations other than those fixated (asmeasured by saccade response facilitation) emerges be-tween 3 and 6 months of age. In a study by Johnsonet al. (1994) SRTs decreased with experience in 4-month-old infants. Their interpretation was based on a facili-tation of covertly attended locations, places that heldcues for future target appearances. Wentworth andHaith (1992) demonstrated that a picture, whichstrongly predicted the location of the next picture, wasfollowed by a higher rate of anticipation and speedierreactions than demonstrated at baseline in 2- and 3-month-old infants. Likewise, Canfield and Haith (1991)found similar effects; they reported that infants at3 months of age decrease their SRT over presentations.
This difference between repetitive and non-repetitivestimuli provides a good illustration of infants’ predic-tive abilities and how important it is for researchers torelate their findings to infants’ expectations and thedevelopment of predictive mechanisms.
Horizontal and vertical saccade latencies
The current study reports that infants’ SRTs are lowerfor vertical than horizontal saccades. Richards andHolley (1999) reported more horizontal than verticalsaccades but used a non-uniform stimulus that couldaccount for differences between vertical and horizontaldimensions. Few other studies have reported on verticaland horizontal tracking in infancy. Gredeback et al.(2003) measured gaze in response to circular trajectories.Nine-month-old infants displayed a higher gain (withhigher variance) and larger lags with vertical gaze.Gredeback et al. (2005) reported similar effects. In thisstudy, infants also produced more vertical that hori-zontal saccades. These saccades were responsible for41% of gain in vertical components of a circular tra-jectory, compared to 21% for horizontal components;see Collewijn and Tamminga (1984) for similar effects inadults.
The argument has been brought forward that dif-ferences in timing of both gaze and smooth pursuittracking is due to differences in experience. Accordingto this argument, (1) horizontal motion is more com-mon than vertical, (2) infants produce more smoothhorizontal tracking as a consequence thereof, and (3)this increased experience give rise to enhanced perfor-mance (Gredeback et al. 2003; Gredeback and vonHofsten 2004).
The same argument could possibly be applied to ahigher reliance on saccades during vertical tracking. (1)We know that an infants’ smooth vertical tracking is
Fig. 2 Saccadic latency at eachage (4, 6, and 8 months) dividedinto a horizontal (closed circles)and vertical (open squares)corrective saccades, b targetvelocity (4.5�/s=closed circlesand 9�/s=open squares), and cindividual data (averagesaccadic latency at each age)
163

inferior to smooth horizontal tracking, (2) this results ina high dependency on vertical saccades (Gredeback et al.2005). (3) This increased experience might give rise toenhanced performance, as defined by facilitated SRTs.
If this (admittedly speculative) argument is valid thenthe current results provide a nice illustration of theimportance of experience to ocular performance. It alsohighlights the strong functional dependency that eachcomponent of gaze tracking (in this case smooth pursuitand saccades) has on the development and execution ofother components.
Velocity
It is difficult to discuss velocity related effects sincenumerous variables by definition co-vary with differentvelocities. It is highly likely that there exists an optimaltracking velocity and that performance decreases onboth sides of this point (curvilinear effect). Findingshorter latencies at 9�/s (compared to 4.5�/s) couldindicate that the higher velocity is closer to this optimalvelocity.
On the other hand, it is equally likely that this dif-ference is due to changes in the attractiveness or salienceof the stimuli. In fact, Hainline et al. (1984) demon-strated that the attentional value of presented stimulihas a clear effect on saccade dynamics. Regardless ofwhich of these accounts produced the high velocityproficiency found in the current paper we can concludethat it is essential to include multiple velocities in studiesof infants’ saccadic latencies.
References
Atkinson J (2000) The developing visual brain. Oxford MedicalPublication, Oxford
Aslin R (1986) Anatomical constraints on oculomotor develop-ment: implications for infant perception. In: Yonas A (ed) TheMinnesota symposium on child psychology, Hillsdale NJ
Aslin RN, Salapatek P (1975) Saccadic localization of visual targetsby the very young human infant. Percept Psychophys 17(3):293–302
Bronson GW (1982) The scanning patterns of human infants:implication for visual learning. Ablex Publishing, Norwood NJ
Canfield RL, Haith MM (1991) Young infants’ visual expectationsfor symmetric and asymmetric stimulus sequences. Dev Psychol27(2):198–208
Canfield RL, Smith EG, Brezsnyak MP, Snow KL (1997) Infor-mation processing through the first year of life: a longitudinal
study using the visual expectation paradigm. Monogr Soc ResChild Dev 62(2):1–145
Collewijn H, Tamminga EP (1984) Human smooth and saccadiceye movements during voluntary pursuit of different targetmotions on different backgrounds. J Physiol 351:217–250
Engel KC, Anderson JH, Soechting JF (1999) Oculomotor trackingin two dimensions. J Neurophysiol 81(4):1597–1602
Gredeback G, von Hofsten C (2004) Infants’ evolving representa-tion of moving objects between 6 and 12 months of age. Infancy6(2):165–184
Gredeback G, von Hofsten C, Boudreau JP (2003) Infants’ visualtracking of continuous circular motion under conditions ofocclusion and non-occlusion. Infant Behav Dev 25:161–182
Gredeback G, von Hofsten C, Karlsson J, Aus K (2005) Thedevelopment of two-dimensional tracking: a longitudinal studyof circular pursuit. Exp Brain Res 163(2):204–213
Hainline L, Turkel J, Abramov I, Lemerise E, Harris CM (1984)Characteristics of saccades in human infants. Vis Res24(12):1771–1780
Hespos SJ, von Hofsten C, Spelke ES, Gredeback G (2002) Objectrepresentation and predictive reaching: evidence for continuityfrom infants and adults. Poster presented at ICIS, Toronto
von Hofsten C (2004) An action perspective on motor develop-ment. Trends Cogn Sci 8:266–272
von Hofsten C, Rosander K (1996) The development of gazecontrol and predictive tracking in young infants. Vis Res 36:81–96
von Hofsten C, Rosander K (1997) Development of smooth pursuittracking in young infants. Vis Res 37:1799–1810
von Hofsten C, Spelke ES (1985) Object perception and object-directed reaching in infancy. J Exp Psychology: General114:198–212
von Hofsten C, Vishton P, Spelke ES, Feng Q, Rosander R (1998)Predictive action in infancy: tracking and reaching for movingobjects. Cognition 67:255–285
Johnson MH, Posner MI, Rothbart MK (1994) Facilitation ofsaccades towards a covertly attended location in early infancy.Psychol Sci 5(2):90–93
Leigh RJ, Zee DS (1999) The neurology of eye movements, 3rdedn. Oxford University Press, New York
Miller J (1988) A warning about median reaction time. J ExpPsychol Human Percept Perform 14(3):539–543
Phillips JO, Finoccio DV, Ong L, Fuchs AF (1997) Smooth pursuitin 1–4-month-old human infants. Vis Res 37:3009–3020
Rensink RA, Chawarska K, Betts S (2000) The development ofvisual expectations in the first year. Child Dev 71(5):1191–1204
Richards JE (2000) Localizing the development of covert attentionin infants with scalp event-related potentials. Dev Psychol36(1):91–108
Rosander K, von Hofsten C (2002) Development of gaze trackingof small and large objects. Exp Brain Res 146:257–264
Richards JE, Holley FB (1999) Infants’ attention and the devel-opment of smooth pursuit tracking. Dev Psychol 35:856–867
Wentworth N, Haith MM (1992) Event-specific expectations of 2-and 3-month old infants. Dev Psychol 28(5):842–850
Yang Q, Bucci M P, Kapoula Z (2002) The latency of saccades,vergence, and combined eye movements in children and adults.Invest Ophthalmol Vis Sci 43: 2939–2939
164

Directional Hearing in a Humanoid Robot Evaluation of Microphones Regarding HRTF and Azimuthal Dependence Lisa Gustavsson, Ellen Marklund, Eeva Klintfors and Francisco Lacerda Department of Linguistics/Phonetics, Stockholm University {lisag|ellen|eevak|frasse}@ling.su.se
Abstract As a first step of implementing directional hearing in a humanoid robot two types of microphones were evaluated regarding HRTF (head related transfer function) and azimuthal dependence. The sound level difference between a signal from the right ear and the left ear is one of the cues humans use to localize a sound source. In the same way this process could be applied in robotics where the sound level difference between a signal from the right microphone and the left microphone is calculated for orienting towards a sound source. The microphones were attached as ears on the robot-head and tested regarding frequency response with logarithmic sweep-tones at azimuth angles in 45º increments around the head. The directional type of microphone was more sensitive to azimuth and head shadow and probably more suitable for directional hearing in the robot.
1 Introduction As part of the CONTACT project1 a microphone evaluation regarding head related transfer function (HRTF), and azimuthal2 dependence was carried out as a first step in implementing directional hearing in a humanoid robot (see Figure 1). Sound pressure level by the robot ears (microphones) as a function of frequency and azimuth in the horizontal plane was studied.
The hearing system in humans has many features that together enable fairly good spatial perception of sound, such as timing differences between left and right ear in the arrival of a signal (interaural time difference), the cavities of the pinnae that enhance certain frequencies depending on direction and the neural processing of these two perceived signals (Pickles, 1988). The shape of the outer ears is indeed of great importance in localization of a sound source, but as a first step of implementing directional hearing in a robot, we want to start up by investigating the effect of a spherical head shape between the two microphones and the angle in relation to the sound source. So this study was done with reference to the interaural level difference (ILD)3 between two ears (microphones, no outer ears) in the sound signal that is caused by the distance between the ears and HRTF or head shadowing effects (Gelfand, 1998). This means that the ear furthest away from the sound source will to some extent be blocked by the head in such a way that the shorter wavelengths (higher frequencies) are reflected by the head (Feddersen et al., 1957). Such frequency-dependent differences in intensity associated with different sound source locations will be used as an indication to the robot to turn his head in the horizontal plane. The principle here is to make the robot look in the direction that minimizes the ILD4. Two types of microphones, mounted on the robot head, 1 "Learning and development of Contextual Action" European Union NEST project 5010 2 Azimuth = angles around the head 3 The abbreviation IID can also be found in the literature and stands for Interaural Intensity Difference. 4 This is done using a perturbation technique. The robot’s head orientation is incrementally changed in order to detect the direction associated with a minimum of ILD.

were tested regarding frequency response at azimuth angles in 45º increments from the sound source (Shaw & Vaillancourt, 1985; Shaw, 1974).
The study reported in this paper was carried out by the CONTACT vision group (Computer Vision and Robotics Lab, IST Lisbon) and the CONTACT speech group (Phonetics Lab, Stockholm University) assisted by Hassan Djamshidpey and Peter Branderud. The tests were performed in the anechoic chamber at Stockholm University in December 2005.
2 Method The microphones evaluated in this study were wired Lavalier microphones of the Microflex MX100 model by Shure. These microphones were chosen because they are small electret condenser microphones designed for speech and vocal pickup. The two types tested were omni-directional (360º) and directional (cardoid 130º). The frequency response is 50 to 17000 Hz and its max SPL is 116 dB (omni-directional), 124 dB (directional) with a s/n ratio of 73 dB (omni-directional), 66 dB (directional). The robotic head was developed at Computer Vision and Robotics Lab, IST Lisbon (Beira et al., 2006).
Figure 1. Robot head. 2.1 Setup The experimental setup is illustrated in Figure 2a. The robot-head is attached to a couple of ball bearing arms (imagined to correspond to a neck) on a box (containing the motor for driving head and neck movements). The microphones were attached and tilted by about 30 degrees towards the front, with play-dough in the holes made in the skull for the future ears of the robot. The wires run through the head and out to the external amplifier. The sound source was a Brüel&Kjær 4215, Artificial Voice Loud Speaker, located 90 cm away from the head in the horizontal plane (Figures 2a and 2b). A reference microphone was connected to the loudspeaker for audio level compression (300 dB/sec).
Figure 2a and 2b. a) Wiring diagram of experimental setup (left). b) Azimuth angles in relation to robot head and loudspeaker (right). 2.2 Test Sweep-tones were presented through the loud-speaker at azimuth angles in 45º increments obtained by turning the robot-head (Figure 2b). The frequency range of the tone was between 20 Hz5 and 20 kHz with a logarithmic sweep control and writing speed of 160mm/sec (approximate averaging time 0.03 sec). The signal response of the microphones was registered and printed in dB/Hz diagrams (using Brüel&Kjær 2307, Printer/Level Recorder) and a back-up recording was made on a hard-drive. The dB values as a function of frequency were also plotted in Excel diagrams for a better overview of superimposed curves of different azimuths (and for presentation in this paper). 5 Because the compression was unstable up until about 200 Hz, the data below 200 Hz will not be reported here. Furthermore, the lower frequencies are not affected that much in terms of ILD.
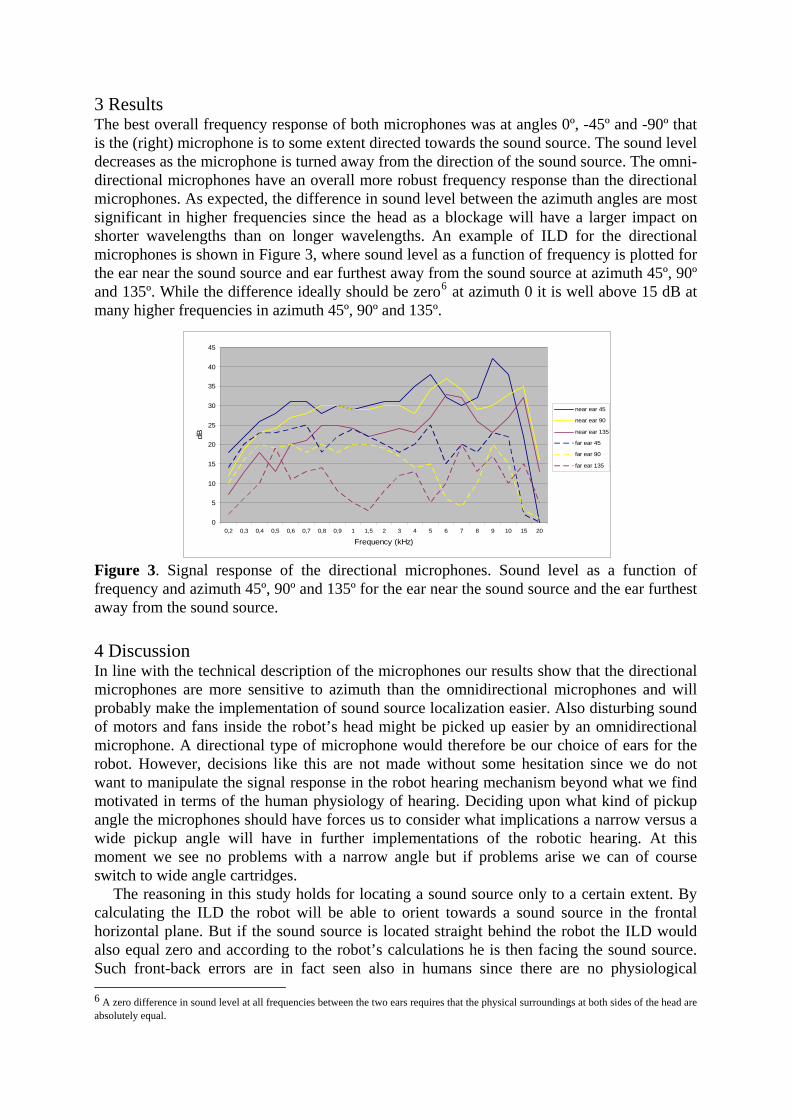
3 Results The best overall frequency response of both microphones was at angles 0º, -45º and -90º that is the (right) microphone is to some extent directed towards the sound source. The sound level decreases as the microphone is turned away from the direction of the sound source. The omni-directional microphones have an overall more robust frequency response than the directional microphones. As expected, the difference in sound level between the azimuth angles are most significant in higher frequencies since the head as a blockage will have a larger impact on shorter wavelengths than on longer wavelengths. An example of ILD for the directional microphones is shown in Figure 3, where sound level as a function of frequency is plotted for the ear near the sound source and ear furthest away from the sound source at azimuth 45º, 90º and 135º. While the difference ideally should be zero6 at azimuth 0 it is well above 15 dB at many higher frequencies in azimuth 45º, 90º and 135º.
0
5
10
15
20
25
30
35
40
45
0,2 0,3 0,4 0,5 0,6 0,7 0,8 0,9 1 1,5 2 3 4 5 6 7 8 9 10 15 20
Frequency (kHz)
dB
near ear 45
near ear 90
near ear 135
far ear 45
far ear 90
far ear 135
Figure 3. Signal response of the directional microphones. Sound level as a function of frequency and azimuth 45º, 90º and 135º for the ear near the sound source and the ear furthest away from the sound source.
4 Discussion In line with the technical description of the microphones our results show that the directional microphones are more sensitive to azimuth than the omnidirectional microphones and will probably make the implementation of sound source localization easier. Also disturbing sound of motors and fans inside the robot’s head might be picked up easier by an omnidirectional microphone. A directional type of microphone would therefore be our choice of ears for the robot. However, decisions like this are not made without some hesitation since we do not want to manipulate the signal response in the robot hearing mechanism beyond what we find motivated in terms of the human physiology of hearing. Deciding upon what kind of pickup angle the microphones should have forces us to consider what implications a narrow versus a wide pickup angle will have in further implementations of the robotic hearing. At this moment we see no problems with a narrow angle but if problems arise we can of course switch to wide angle cartridges.
The reasoning in this study holds for locating a sound source only to a certain extent. By calculating the ILD the robot will be able to orient towards a sound source in the frontal horizontal plane. But if the sound source is located straight behind the robot the ILD would also equal zero and according to the robot’s calculations he is then facing the sound source. Such front-back errors are in fact seen also in humans since there are no physiological 6 A zero difference in sound level at all frequencies between the two ears requires that the physical surroundings at both sides of the head are absolutely equal.

attributes of the ear that in a straightforward manner differentiate signals from the front and rear. Many animals have the ability to localize a sound source by wiggling their ears, humans can instead move themselves or the head to explore the sound source direction (Wightman & Kistler, 1999). As mentioned earlier the outer ear is however of great importance for locating a sound source, the shape of the pinnae does enhance sound from the front in certain ways but it takes practice to make use of such cues. In the same way the shape of the pinnae can be of importance for locating sound sources in the medial plane (Gardner & Gardner, 1973; Musicant & Butler, 1984). Subtle movements of the head, experience of sound reflections in different acoustic settings and learning how to use pinnae related cues are some solutions to the front-back-up-down ambiguity that could be adopted also by the robot. We should not forget though, that humans always use multiple sources of information for on-line problem solving and this is most probably the case also when locating sound sources. When we hear a sound there is usually an event or an object that caused that sound, a sound source that we easily could spot with our eyes. So the next question we need to ask is how important vision is in localizing sound sources or in the process of learning how to trace sound sources with our ears and how vision can be used in the implementation of directional hearing of the robot.
5 Concluding remarks Directional hearing is only one of the many aspects of human information processing that we have to consider when mimicking human behaviour in an embodied robot system. In this paper we have discussed how the head has an impact on the intensity of signals at different frequencies and how this principle can be used also for sound source localization in robotics. The signal responses of two types of microphones were tested regarding HRTF at different azimuths as a first step of implementing directional hearing in a humanoid robot. The next steps are designing outer ears and formalizing the processes of directional hearing for implementation and on-line evaluations (Hörnstein et al., 2006).
References Beira, R., Lopes, M., Miguel, C., Santos-Victor, J., Bernardino, A., Metta, G. et al. Design of
the robot-cub (icub) head. IEEE ICRA, (in press). Feddersen, W. E., Sandel, T. T., Teas, D. C., & Jeffress, L. A. (1957). Localization of High-
Frequency Tones. The Journal of the Acoustical Society of America, 29, 988-991. Gardner, M. B. & Gardner, R. S. (1973). Problem of localization in the median plane: effect
of pinnae cavity occlusion. The Journal of the Acoustical Society of America, 53, 400-408. Gelfand, S. (1998). An introduction to psychological and physiological acoustics. In ( New
York: Marcel Dekker, Inc. Hörnstein, J., Lopes, M., & Santos-Victor, J. (2006). Sound localization for humanoid robots
- building audio-motor maps based on the HRTF. CONTACT project report . Musicant, A. D. & Butler, R. A. (1984). The influence of pinnae-based spectral cues on sound
localization. The Journal of the Acoustical Society of America, 75, 1195-1200. Pickles, J. O. (1988). An Introduction to the Physiology of Hearing. (Second ed.) London:
Academic Press. Shaw, E. A. G. (1974). Transformation of sound pressure level from the free field to the
eardrum in the horizontal plane. The Journal of the Acoustical Society of America, 56. Shaw, E. A. G. & Vaillancourt, M. M. (1985). Transformation of sound-pressure level from
the free field to the eardrum presented in numerical form. The Journal of the Acoustical Society of America, 78, 1120-1123.
Wightman, F. L. & Kistler, D. J. (1999). Resolution of front--back ambiguity in spatial hearing by listener and source movement. The Journal of the Acoustical Society of America, 105, 2841-2853.

Sound localization for humanoid robots - buildingaudio-motor maps based on the HRTF
Jonas Hörnstein, Manuel Lopes, José Santos-VictorInstituto de Sistemas e Robótica
Instituto Superior TécnicoLisboa, Portugal
Email: {jhornstein,macl,jasv}@isr.ist.utl.pt
Francisco LacerdaDepartment of Linguistics
Stockholm UniversityStockholm, Sweden
Email: [email protected]
Abstract— Being able to localize the origin of a sound isimportant for our capability to interact with the environme nt.Humans can localize a sound source in both the horizontal andvertical plane with only two ears, using the head related transferfunction HRTF, or more specifically features like interaural timedifference ITD, interaural level difference ILD, and notches inthe frequency spectra. In robotics notches have been left outsince they are considered complex and difficult to use. As theyare the main cue for humans’ ability to estimate the elevationof the sound source this have to be compensated by addingmore microphones or very large and asymmetric ears. In thispaper, we present a novel method to extract the notches thatmakes it possible to accurately estimate the location of a soundsource in both the horizontal and vertical plane using only twomicrophones and human-like ears. We suggest the use of simplespiral-shaped ears that has similar properties to the humanearsand make it easy to calculate the position of the notches. Finallywe show how the robot can learn its HRTF and build audio-motor maps using supervised learning and how it automaticallycan update its map using vision and compensate for changes inthe HRTF due to changes to the ears or the environment.
I. I NTRODUCTION
Sound plays an important role in directing humans’ attentionto events in their ecological setting. The human ability to lo-cate sound sources in potentially dangerous situations, like anapproaching car, or locating and paying attention to a speakerin social interaction settings, is a very important componentof human behaviour. In designing a humanoid robot that isexpected to mimic human behaviour, the implementation of ahuman-like sound location capability as a source of integratedinformation is therefore an important goal.
Humans are able of locating the sound sources in boththe horizontal and vertical plane from exploring acousticinformation conveyed by the auditory system, but in a robotthat uses two simple microphones as ears there is not enoughinformation to do the same. Typically the robot would beable to calculate or learn the positions of the sound source inthe plane of the microphones, i.e. the azimuth which usuallycorresponds to the horizontal plane. This can be done bycalculating the difference in time between the signal reachingthe left and the right microphone respectively. This is calledthe interaural time difference (ITD) or the interaural phasedifference (IPD) if we have a continuous sound signal andcalculate the phase difference of the signal from the two
microphones by cross-correlation. However, the ITD/IPD doesnot give any information about the elevation of the soundsource. Furthermore it cannot tell whether a sound comes fromthe front or the back of the head. In robotics this is usuallysolved by adding more microphones. The SIG robot [1] [2] hasfour microphones even though two are mainly used to filter thesound caused by the motors and the tracking is mainly donein the horizontal plane. In [3] eight microphones are used, andin [4][5] a whole array of microphones is used to estimate thelocation of the sound.
While adding more microphones simplifies the task of soundlocalization, humans and other animals manage to localize thesound with only two ears. This comes from the fact that theform of our head and ears change the sound as a function ofthe location of the sound source, a phenomenon known as thehead related transfer function (HRTF). The HRTF describeshow the free field sound is changed before it hits the eardrum,and is a functionH(f, θ, φ) of the frequency, f, the horizontalangle,θ, and the vertical angle,φ, between the ears and soundsource. The IPD is one important part of the HRTF. Anotherimportant part is that the level of the sound is higher whenthe sound is directed straight into the ear compared to soundcoming from the sides or behind. Many animals, like cats,have the possibility to turn their ears around in order to getabetter estimate of the localization of the sound source. Evenwithout turning the ears, it is possible to estimate the locationof the sound by calculating the difference in level intensitybetween the two ears. This is referred to as the interaurallevel difference (ILD). However, if the ears are positionedon each side of the head as for humans, ILD will mainlygive us information about on which side of the head that thesound source is located, i.e. information about the azimuthwhich we already have from the ITD/IPD. In order to get newinformation from the ILD we have to create an asymmetryin the vertical plane rather than in the horizontal. This canbedone by putting the ears on top of the head and letting one earbe pointing up while the other is pointing forwards as done in[6]. The problem with this approach is that a big asymmetry isneeded to get an acceptable precision and ILD of human-likeears does not give sufficient information about the elevationof the sound source.
For humans it has been found that the main cue for

estimating the elevation of the sound source comes fromresonances and cancellation (notches) of certain frequenciesdue to the pinna and concha of the ear. This phenomenonhas been quite well studied in humans both in neuroscienceand in the field of audio reproduction for creating 3D-stereosound [7][8][9][10][11][12][13], but has often been left out inrobotics due to the complex nature of the frequency responseand the difficulty to extract the notches. In this paper wesuggest a simple and effective way of extracting the notchesfrom the frequency response and we show how a robot canuse information about ITD/IPD, ILD, and notches in order toaccurately estimate the location of the sound source in bothvertical and horizontal space.
Knowing the form of the head and ears it is possible tocalculate the relationship between the features (ITD, ILD,andthe frequencies for the notches) and the position the soundsource, or even estimate the complete HRTF. However, herewe are only interested in the relationship between the featuresand the position. Alternatively we can get the relationshipbymeasuring the value of the features for some known positionsof the sound source and let the robot learn the maps. Sincethe HRTF changes if there is some changes to the ears ormicrophones or if some object like for example a hat isput close to the ears, it is important to be able to updatethe maps. Indeed, although human ears undergo big changesfrom birth to adulthood, humans are capable of adapting theirauditory maps to compensate for acoustic consequences ofthe anatomical changes. It has been shown that vision is animportant cue for updating the maps [14], and it can also beused as a mean for the robot to update its maps [6].
In the rest of this paper, Section 2 will show how we candesign a simple head and ears that give a HRTF similiar tothe human head and ears’ HRTF. In Section 3 we discuss howto extract features such as ITD/IPD, ILD, and notches fromthe signals provided from the ears. In Section 4 we show howthe robot can use the features to learn its audio-motor-map.In Section 5 we show some experimental results. Conclusionsand directions for future work are given in Section 6.
II. D ESIGN OFHEAD AND EARS
In this section we want to describe the design of a robot’shead and ears with a human-like HRTF, and hence withacoustic properties for the ITD, ILD, and frequency notchessimilar to those observed in humans. The HRTF dependson the form of both the head and the ears. The ITD/IPDdepends on distance between the ears and the ILD is primarilydependent on the form of the head and to less extent also theform of the ears, while the peaks and notches in the frequencyresponse mainly are related to the form of the ears.
For the sake of calculating the HRTF, a human head can bemodeled by a spheroid [15] [16]. The head used in this workis the iCUB head which is close enough to a human head toexpect the same acoustic properties. The detailed design ofthehead is described in [17] but here we can simply consider ita sphere with a diameter of 14 cm.
The ears are more complex. Each of the robot’s ears wasbuilt by a microphone placed on the surface of the head anda reflector simulating the pinna/concha, as will be describedin detail below. The shape of human ears differs substantiallybetween individuals, but a database with HRTF for differentindividuals [18] provides some general information on thefrequency spectra created for various positions of the soundsource by human ears. Obviously one way to create ears fora humanoid robot would be simply to copy the shape of apair of human ears. That way we can assure that they willhave similar properties. However we want to find a shapethat is easier to model and produce while preserving the mainacoustic characteristics of the human ear. The most importantproperty of the pinna/concha, for the purpose of locating thesound source, is to give different frequency responses fordifferent elevation angels. We will be looking for notches inthe frequency spectra, created by interferences between theincident waves, reaching directly the microphone, and theirreflections by the artificial concha, and want the notches tobe produced at different frequencies for different elevations.A notch is created when a quarter of the wavelength of thesound,λ, (plus any multiple ofλ/2) is equal to the distance,d, between the concha and the microphone:
n ∗λ
2+
λ
4= d (n = 0, 1, 2, ...)
For these wavelengths, the sound wave that reaches themicrphone directly are cancelled by the wave reflected by theconcha. Hence the frequency spectra will have notches for thecorresponding frequencies:
f =c
λ=
(2 ∗ n + 1) ∗ v
4 ∗ d(1)
c = {speed of sound} ≈ 340 m/s (2)
To get the notches at different frequencies for all elevationswe want an ear-shape that has different distance between themicrophone and the ear for all elevations. Lopez-Poveda andMeddis suggest the use of a spiral shape to model human earsand simulate the HRTF [19]. In a spiral the distance betweenthe microphone, placed in the center of the spiral, and theear increases linearly with the angle. We can therefore expectthe position of the notches in the frequency response to alsochange linearly with the elevation of the sound source.
We used a spiral with the distance to the center varying from2 cm below to 4 cm in the top, Figure 1. That should give usthe first notch at around 2800 Hz for sound coming straightfrom the front and with the frequency increasing linearly astheelevation angle increases, Figure 2. When the free field soundis white noise as in the figure it is easy to find the notchesdirectly in the frequency spectra of either ear. However, soundlike spoken language will have its own maxima and minimain the frequency spectra depending on what is said. It is notclear how humans separate what is said from where it is said[20]. One hypothesis is that we perform a binaural comparisonof the spectral patterns, as have also been suggested for owls[21]. Both humans and owls have small asymmetries between

Fig. 1. Pinna and concha of a human ear (right), and the artificialpinna/concha (left)
Fig. 2. Example of the HRTF for a sound source at a) 50 degrees above, b)front, and c) 50 degrees below
the left and right ear that can give excellent cues to verticallocalization in the higher frequencies. These relatively smallasymmetries that provide different spectral behaviour betweenthe ears should not be confused with the large asymmetriesneeded to give any substantial difference for the ILD. Here weonly need the difference in distance between the microphoneand the ear for the right and left ear to be enought to separatethe spectral notches. In the optimal case we would like theright ear to give a maximum for the same frequency that theleft ear has a notch and hence amplify that notch. This can bedone by choosing the distance for the right ear,dr, as:
dr(φ) = 2mr + 1
2 ∗ nl + 1∗ dl(φ)
wheremr=maxima number for right ear,nl=notch number forleft ear, anddl=distance between the microphone and ear forleft ear.
If we for example want to detect the third notch of the leftear, and want the right ear to have its second maxima for thesame frequency, we should chose the distance between themicrophone and ear for the right ear as:
dr(φ) = 22 + 1
2 ∗ 3 + 1∗ dl(φ) = 6/7 ∗ dl(φ)
In the case of two identical ears we can not have a maximaof the right ear at the same place as the left ear has a notchfor all elevations. The best we can do is to choose the anglebetween the ear so that the right ear has a maxima for thewanted notch when the sound comes from the front. In thespecific case of the ears in Figure 1 the optimal angle becomes18 degrees.
The ears were constructed from a thin metal band whichwas easy to bend into a spiral shape. Metal also has theproperty that it almost completely reflects the sound whichmakes it a good material for making ears. The metal bandwas then fixed onto a of thick paper with holes in the centerfor the microphone. For the first experiments presented in thispaper we used professional omnidirectional condenser micro-phones fixed directly to the head pointing sideways/forwardat an angle of 45 degrees with the tip of the microphoneapproximately 7 mm outside the head. We then changed tocheap web-microphones pointing straight to the side withoutany notable effect on the results. The final setup is shown inFigure 3.
Fig. 3. icub with ears
III. F EATURES
As discussed in the introduction, humans mainly depend onthree different features for localizing the sound source: theinteraural time difference ITD, the interaural level differenceILD, and the notches in the frequency response of each ear.In this section we show how to extract the features given thesignalssl(t) andsr(t) from the left and right ear respectively.

The first step is to sample the sound. We sample the soundfor 1/10 s using the sample frequencyFs=44100 Hz. Thisgives usk=4410 samples. We then calculate the mean energyas a sum of square of the given samples divided by the numberof samples:
∑
k
(
s2l (k) + s2
r(k))
/k. A simple threshold valueis used to decide if the sound has enough energy to make itmeaningful to try to extract the features and try to localizethe sound source. The calculation of the individual features isexplained below.
A. Interaural time difference, ITD
The interaural phase difference is calculated by doing across-correlation between the signals arriving to the leftandright ear/microphone. If the signals have the same shape wecan expect to find a peak in the cross-correlation for thenumber of samples that corresponds to the interaural timedifference, i.e. the difference in time at which the signal arrivesat the microphones. We can easily find this by searching forthe maximum in the cross correlation function. Knowing thesampling frequencyFs and the number of samplesn thatcorresponds to the maximum in the cross-correlation functionwe can calculate the interaural time difference as:
ITD =n
Fs
If the distance to the sound source is big enough in compar-ison to the distance between the ears,l, we can approximatethe incoming wave front with a straight line and the differencein distance∆l traveled by the wave for the left and right earcan easily be calculated as:
∆l = l sin(θ)
Fig. 4. Interaural time difference
where θ is the horizontal angle between the head’s midsagittal plane and the sound source, Figure 4. Knowing thatthe distance traveled is equal to the time multiplied with thevelocity of the sound we can now express the angle directlyas a function of the ITD:
θ = arcsin(
ITD ∗c
l
)
However for the sake of controlling the robot we are notinterested in the exact formula since we want the robot tobe able to learn the relationship between the ITD and theangle rather than hard coding this into the robot. The importantthing is that there exists a relationship that we will be abletolearn. We therefore measured the ITD for a number of differentangles in an anechoic room, figure 5.
−0.5−0.4
−0.3−0.2
−0.10
0.10.2
0.30.4
0.5
−0.8
−0.6
−0.4
−0.2
0
0.2
0.4
0.6−0.3
−0.25
−0.2
−0.15
−0.1
−0.05
0
0.05
0.1
0.15
0.2
azimuth (rad)
ITD
elevation (rad)
time
(ms)
Fig. 5. ITD for different positions of the sound source
B. Interaural level difference, ILD
The interaural level difference ILD, is calculated as afunction of the avarage power of the sound signals reachingthe left and right ear.
ILD = 10 ∗ log10
(∑
k s2l (k)
∑
k s2r(k)
)
Sometimes the ILD is calculated from the frequency re-sponse rather than directly from the temporal signal. It iseasy to go from the temporal signal to the frequency responseby applying a fast Fourier transform FFT. The reason forworking with the frequency response instead of the temporalsignal is that it makes it easy to apply a high-pass, low-pass, or band-filter on the signal before calculating its averagepower. Different frequencies have different properties. Lowfrequencies typically pass more easily through the head andears while higher frequencies tend to be reflected and theirintensity more reduced. One type of filtering that is oftenused is dBA which corresponds to the type of filtering thatgoes on in human ears and which mainly takes into accountthe frequencies between 1000 Hz and 5000 Hz. In [6] a band-pass filter between 3-10 kHz have been used which gives thema better calculation of ILD. Different types of head and earsmay benefit from enhancing different frequencies. Here wecalculate the ILD directly from the temporal signal which is

equivalent to considering all frequencies. The response for asound source placed at different angles from the head is shownin figure 6.
−0.5
0
0.5
−0.8
−0.6
−0.4
−0.2
0
0.2
0.4
0.6−600
−400
−200
0
200
400
600
800
azimuth (rad)
ILD
elevation (rad)
leve
l diff
eren
ce (
dB 2 )
Fig. 6. ILD for different positions of the sound source
C. Spectral notches
Existing methods for extracting spectral notches such as[22][23][24] focus on finding the notches in spectral diagramsobtained in anechoic chambers using white noise, such as thediagrams presented in Figure 2. For a humanoid robot that hasto be able to turn towards any type of sound these methodsare not suitable. In this section we suggest a novel method toextract the frequency notches that is reasonable fast and simpleto implement while giving better accuracy for calculating theelevation of the sound source than methods based on ILD. Themethod makes use of the fact that we have a slight asymmetrybetween the ears and has the following steps:
1) Calculate the power spectra density for each ear2) Calculate the interaural spectral differences3) Fit a curve to the resulting differences4) Find minima for the fitted curve
To calculate the power spectra we use the Welch spectra[25]. Typical results for the power spectra density,Hl(f) andHr(f), for the left and right ear respectively are shown infigure 7. As seen the notches disappears in the complex spectraof the sound, which makes it very hard to extract them directlyfrom the power spectra. To get rid of the maxima and minimacaused by the form of the free field sound, i.e. what is said,we calculate the interaural spectral difference as:
∆H(f) = 10 ∗ log10 Hl(f) − 10 ∗ log10 Hr(f) =
= 10 ∗ log10
(
Hl(f)
Hr(f)
)
Finally we fit a 12 degree polynomial to the interauralspectral difference. The interaural spectral difference and the
fitted polynomial are shown in Figure 7. From the fittedfunction it is easy to extract the minima. In this work we havechosen to use the first minima over 5000 Hz as a feature.In this specific setup that corresponds to the second notch.However the position of the notches depends on the designof the ears and for other types of ears other frequencies willhave to be used.
0 2.800 8.500 14.100 19.800−190
−180
−170
−160
−150
−140
−130
−120
−110
−100
−90
Hz
dB
0 2.800 8.500 14.100 19.800−10
−5
0
5
10
15
20
25
Hz
dB
Fig. 7. Above: The power spectra for left ear (solid line) andright ear(dotted line). Note that the spectras are shown in dB, i.e.10 ∗ log(Hx(f)).The vertical lines represent the expected frequencies for the notches. Below:The interaural spectral difference (dotted line) and the fitted curve (solid line)
As seen in Figure 7 the minima more or less corresponds tothe expected frequencies of the notches for the left ear. Thisis because we carefully designed the ears so that the notchesfrom the two ears would not interfere with each other. In thiscase we could actually calculate the relationship between thefrequency of the notch and the position of the sound source.However, in the general case it is better to let the robot learn

the HRTF than to actually calculate it since the position of thenotches is critically affected by small changes in the shapeofthe conchas or the acoustic environment. Also, if we learnthe relationship rather than calculating it we do not have toworry about the fact that the minimas that we find do notdirectly correspond to the notches as long as they change withthe elevation of the sound source. In figure 8 we show theextracted feature with the sound source placed at a number ofdifferent positions in relation to the head.
−0.5−0.4
−0.3−0.2
−0.10
0.10.2
0.30.4
0.5
−0.8
−0.6
−0.4
−0.2
0
0.2
0.4
0.6
5500
6000
6500
7000
7500
8000
8500
9000
9500
azimuth (rad)
notch
elevation (rad)
notc
h fr
eque
ncy
(Hz)
Fig. 8. Notch frequencies for different position of the sound source
IV. A UDIO-MOTOR MAPS
In this section we are going to map sound features to thecorresponding3D localization of sound sources. We presentsolutions to: i) learn this map, ii) use it to control a robottoward a target and iii) to improve its quality online.
As seen before, differences in the head size, ear shapes oreven a hat in the robot can dramatically change the frequencyresponse of the microphones. The coordinate transformationfrom the ears to the vision and the control motors is difficultto calibrate. Because of this, the system should be able toadapt to these variations. The exact solution we have for thepan localization is only valid when the sound source is in thesame plane as the receptors, by having a learning mechanismwe can combine the vertical and horizontal information to havea better localization.
A map m from the sound featuresC to its localizationwritten in head spherical coordinatesSH can be used to directthe head toward a sound source. This map can be representedby SH = m(C). A simple way to move the head toward thetarget is to move the head pan and tilt by an increment∆θequal to the position of the sound source, i.e.∆θ = SH .
Although the function is not linear, if we restrict to the spaceof motion of the head in can be considered as such, we canobserve this by noting that the features in Figures 5 and 8 arealmost planar. Because of this, the nonlinear function can beapproximated by a linear function:
SH = MC
This simpler model allows a faster and more robust learning.To estimate the value ofM a linear regression with thestandard error criteria was selected:
M = arg minM
∑
i=1
‖∆θ − MCi‖2 (3)
This solution gives an offline batch estimate, for onlineestimation a Broyden update rule [26] was used. This ruleis very robust, fast, has just one parameter and only keeps inmemory the actual estimative ofM . Its structure is as follows:
M(t + 1) = M(t) + α
(
∆θ − M(t)C)
C>
CTC(4)
whereα is the learning rate. This method is useful to be usedin a supervised learning method, where the positions corre-sponding to a certain sound are given. This is not the case foran autonomous system. A robot needs an automatic feedbackmechanism to learn the audio-motor relation autonomously.Vision can provide information in a robust and non-intrusiveway. As the goal of this robot is to interact with humans thetest sound will be produced by humans and so the robot knowsthe visual appearance of the sound source. A face detectionalgorithm based on [27] and [28] was used and Figure 9presents the result of the algorithm. After hearing a soundthe robot moves to the position given by the map. If thehuman head is not centered in the image then a visual servoingbehavior is activated in order to bring the observed face to theimage center, for this the robot is controlled with the followingrule:
θ = J+
H Fp
whereθ is the velocity for the head motors,J+
H is the pseudo-inverse of the head jacobian andFp is the desired motion ofthe face in the image. When the face is in the center of theimage the audio-motor map can be updated using the learningrule of Eq. 4. Table I presents the final algorithm.
TABLE I
ALGORITHM FOR AUTONOMOUSLY LEARNING A AUDIO-MOTOR MAP BY
INTERACTING WITH A HUMAN
1) listen to sound2) move head toward the sound using the map3) locate human face in the image4) if face not close enough to the center
a) do a visual servoing loop to center the faceb) update the map

Fig. 9. Result of the face detection algorithm used as a feedback signal forthe sound localization algorithm.
V. EXPERIMENTAL RESULTS
We acquired a dataset in a silent room with a white-noise sound-source located1.5m from the robot. We recorded1 second of sound in132 different head positionsθ by movingthe head with its own motors. A set of features was evaluatedfrom this data consisting ofITD and the notch frequencyevaluate on0.1 second. Figure 8 shows the resulting featuresurfaces after averaging them on11 samples. This is used asthe training dataset.
A second dataset was created to test the learning method.The procedure was similar to the previous one but the sound-source was replaced by a human voice sound. This wasdone because the system should operate in an human-robotinteraction and also to evaluate the generalization propertiesof the method.
The map was then estimated with the optimization problemin Eq. 3, Figure 10 presents the reconstruction error byshowing for each head position the corresponding error inreconstruction. We can see that the worst case corresponds tothe joint limits of the head but it is always less than0.1 rad,which is very small. As a comparison we can note that0.1 radis the size of a adult human face when seen from1.5 m ofdistance. The error increase near the limits is due to the non-linearity of the features being approximated by a linear model,however with this small error the computational efficiency androbustness makes us choose this model.
Finally we have done a test in a real world environmentand interaction. The test was done in our offices and afterhearing a sound the head moves to the corresponding position.The previously learned function was used as a bootstrap. Themap quality would always guaranty that the sound source waslocated in the camera images, even though it was not learnedneither in the same environment nor considering the eye-neckcoordinate transformation. In order to improve even furtherthe results we followed the steps of the algorithm presentedin Table I. Figure 11 presents the evolution of the errorduring the experiment. The error represents the difference, inradians, from the position mapped by the model and the reallocalization of the person. We can see that this error decreased
−0.5−0.4
−0.3−0.2
−0.10
0.10.2
0.30.4
0.5
−0.8
−0.6
−0.4
−0.2
0
0.2
0.4
0.60
0.01
0.02
0.03
0.04
0.05
0.06
0.07
pan
pan error
tilt
−0.5−0.4
−0.3−0.2
−0.10
0.10.2
0.30.4
0.5
−0.8
−0.6
−0.4
−0.2
0
0.2
0.4
0.60
0.02
0.04
0.06
0.08
0.1
0.12
pan
tilt error
tilt
−0.5−0.4
−0.3−0.2
−0.10
0.10.2
0.30.4
0.5
−0.8
−0.6
−0.4
−0.2
0
0.2
0.4
0.60
0.02
0.04
0.06
0.08
0.1
0.12
pan
error
tilt
Fig. 10. Audio-motor map reconstruction error for each headposition (Top:error in pan, Middle: error in tilt, Bottom: total error)
towards less than one degree.
VI. CONCLUSION
In this paper we have presented a novel method for estimat-ing the location of a sound source using only two ears. Themethod is inspired by the way humans estimate the locationfrom features such as interaural time difference ITD, interaurallevel difference ILD, and spectral notches. We suggest the useof spiral formed ears of slightly different size or with differentinclination to make it easy to extract the notches. The spiral

0 5 10 15 20 25 30−0.2
−0.1
0
0.1
0.05
−0.05
−0.15
trial
erro
r (r
ad)
pan
tilt
Fig. 11. Convergence rate of the audio-motor map learning algorithm whenrunning online with feedback given by a face detector.
form also makes it easy to mathematically derive the HRTFfor the robot, thus making it possible to simulate the featuresand/or building controllers based on the HRTF.
We have also shown that the robot can learn the HRTFeither by supervised learning or by using vision. Initial audio-motor maps either calculated or learnt combined with an onlinevision-based update of the maps are suggested for the controlof the robot. This makes it possible for the robot to compensatefor small changes in the HRTF caused by dislocations of theears, exchange of microphones, or placement of objects likeahat close to the ear.
The suggested method has good accuracy within the pos-sible movements of the head used in the experiments. Theerror in the estimated azimuth and elevation is less than 0.1radians for all angles, and less than 0.02 radians for the centerposition.
The method is especially suitable for humanoid robotswhere we want ears that both look like human ears andperform like them. The precision in the estimate of the positionis more than enough for typical applications for a humanoidlike turning towards the sound.
Future work includes resolving front-back ambiguities andlearning the HRTF for wider angles than the movements of thehead which demands other approximations of the audio-motormap than linear.
ACKNOWLEDGMENT
EU - Contact, FCT, Lisa Gustavsson, Eeva Klintfors, EllenMarklund, Peter Branderud, Hassan Djamshidpey
REFERENCES
[1] H. Okuno, K. Nakadai, and H. Kitano, “Social interactionof humanoidrobot based on audio-visual tracking,” inProc. of 18th Intern. Conf. onIndustrial and Engineering Applications of Artificial Intelligence andExpert Systems (IEA/AIE-2002), June 2002.
[2] H. Okuno, “Human-robot interaction through real-time auditory andvisual multipletalker tracking,” inIROS, 2001.
[3] J. Valin, F. Michaud, J. Rouat, and D. Létourneau, “Robust sound sourcelocalization using a microphone array on a mobile robot,” inProceedingsInternational Conference on Intelligent Robots and Systems, 2003.
[4] D. Sturim and H. Silverman, “Tracking multiple talkers usingmicrophone-array measurements,”Journal of the Acoustical Societyof America, (In preparation), –:–, – 1996. [Online]. Available:citeseer.csail.mit.edu/sturim96tracking.html
[5] K. Guentchev and J. Weng, “Learning based three dimensional soundlocalization using a compact non-coplanar array of microphones,” inAAAI Spring Symp. on Int. Env., Stanford CA, March 1998.
[6] S. G. Natale L., Metta G., “Development of auditory-evoked reflexes:Visuo-acoustic cues integration in a binocular head,”Robotica andAutonomous Systems, vol. 39, pp. 87–106, 2002.
[7] V. Algazi, R. Duda, R. Morrison, and D. Thompson, “Structural com-position and decomposition of hrtfs,” inProc. IEEE WASPAA01, NewPaltz, NY, 2001, pp. 103–106.
[8] B. Gardner and K. Martin, “Hrtf measurements of a kemar dummy-headmicrophone,” MIT Media Lab Perceptual Computing, Tech. Rep. 280,May 1994.
[9] S. Hwang, Y. Park, and Y. Park, “Sound source localization using hrtfdatabase,” inICCAS2005, Gyenggi-Do, Korea, June 2005.
[10] L. Savioja, J. Houpaniemi, T. Huotilainen, and T. Takala, “Real-timevirtual audio reality,” inProceedings of ICMC, 1986, pp. 107–110.
[11] J. Huopaniemi, L. Savioja, and T. Takala, “Diva virtualaudio realitysystem,” in Proc. Int. Conf. Auditory Display (ICAD’96), Palo Alto,California, Nov 1996, pp. 111–116.
[12] C. Avendano, R. Duda, and V. Algazi, “Modeling the contralateralhrtf,” in Proc. AES 16th International Conference on Spatial SoundReproduction, Rovaniemi, Finland, 1999, pp. 313–318.
[13] B. C. J. Moore, “Interference effects and phase sensitivity in hearing,”Philosophical Transactions: Mathematical, Physical and EngineeringSciences, vol. 360, no. 1794, pp. 833 – 858, May 2002.
[14] M. Zwiers, A. V. Opstal, and J. Cruysberg, “A spatial hearing deficit inearly-blind humans,”JNeurosci, vol. 21, 2001.
[15] V. Algazi, C. Avendano, and R. Duda, “Estimation of a spherical-headmodel from anthropometry,”J. Aud. Eng. Soc., 2001.
[16] R. Duda, C. Avendano, and V. Algazi, “An adaptable ellipsoidal headmodel for the interaural time difference,” inProc. ICASSP, 1999.[Online]. Available: citeseer.csail.mit.edu/duda99adaptable.html
[17] R. Beira, M. Lopes, c. Miguel Pra J. Santos-Victor, A. Bernardino,G. Metta, F. Becchi, and R. Saltaren, “Design of the robot-cub (icub)head,” in IEEE ICRA, 2006, p. to appear.
[18] V. Algazi, R. Duda, and D. Thompson, “The cipic hrtf database,” inIEEE ASSP Workshop on Applications of Signal Processing to Audioand Acoustics, NY, USA, 2001.
[19] E. A. Lopez-Poveda and R. Meddis, “Sound diffraction and reflectionsin the human concha,”J. Acoust. Soc. Amer., vol. 100, pp. 3248–3259,1996.
[20] C. Jin, A. Corderoy, S. Carlile, and A. van Schaik, “Contrastingmonaural and inteaural spectral cues for human sound localization,” J.Acoust. Soc. Am., vol. 6, no. 115, pp. 3124–3141, June 2004.
[21] R. A. Norberg, “Skull asymmetry, ear structure and function, andauditory localization in tengmalm’s owl, aegolius funereus (linne),”Philosophical Transactions of the Royal Society of London.Series B,Biological Sciences, vol. 282, no. 991, pp. 325–410, Mar 1978.
[22] S. G. R. M. A.Ramírez, “Extracting and modeling approximated pinna-related transfer functions from hrtf data,” inProceedings of ICAD 05-Eleventh Meeting of the International Conference on Auditory Display,Limerick, Ireland, July 2005.
[23] V. C. Raykar, R. Duraiswami, L. Davis, and B. Yegnanarayana, “Ex-tracting significant features from the hrtf,” inProceedings of the 2003International Conference on Auditory Display, Boston, MA, USA, July2003.
[24] V. C. Raykar and R. Duraiswami, “Extracting the frequencies of thepinna spectral notches in measured head related impulse responses,”J.Acoust. Soc. Am., vol. 118, no. 1, pp. 364–374, July 2005.
[25] P. Welch, “The use of fast fourier transform for the estimation ofpower spectra: A method based on time averaging over short, modifiedperiodograms,”IEEE Trans. Audio Electroacoust., vol. AU-15, pp. 70–73, June 1967.
[26] R. Fletcher,Practical Methods of Optimization, 2nd ed. Chichester,1987.
[27] P. Viola and M. J. Jones, “Rapid object detection using aboosted cascadeof simple features,”IEEE CVPR, 2001.
[28] R. Lienhart and J. Maydt, “An extended set of haar-like features forrapid object detection,” inIEEE ICIP, Sep 2002, pp. 900–903.

James: A Humanoid Robot Actingover an Unstructured World
Lorenzo Jamone, Giorgio Metta, Francesco Nori and Giulio SandiniLira-Lab, DIST
University of Genoa, Italy{lorejam,pasa,iron,giulio}@liralab.it
Abstract— The recent trend of humanoid robotics researchhas been deeply influenced by concepts such as embodiment,embodied interaction and emergence. In our view, these concepts,beside shaping the controller, should guide the very designprocess of the modern humanoid robotic platforms. In this paper,we discuss how these principles have been applied to the designof a humanoid robot called James. James has been designedby considering an object manipulation scenario and by explicitlytaking into account embodiment, interaction and the exploitationof smart design solutions. The robot is equipped with movingeyes, neck, arm and hand, and a rich set of sensors, enablingproprioceptive, kinesthetic, tactile and visual sensing. A greatdeal of effort has been devoted to the design of the hand andtouch sensors. Experiments, e.g. tactile object classification, havebeen performed, to validate the quality of the robot perceptualcapabilities.
I. INTRODUCTION
Flexible and adaptive behavior is not only the result of asmart controller but also of the careful design of the body, thesensors, and of the actuators. This has been shown to be trueboth in artificial and biological systems [1], [2], [3]. Specifi-cally, this consideration has underlined the necessity of provid-ing robots with a physical structure suited for interacting withan unknown external world. Within this framework, learningis the result of the continuous interaction with the environmentand not the outcome of abstract reasoning. Knowledge aboutthe external unstructured world is incrementally developed andbecomes detailed only after extensive exploration. Followingthese new ideas, we are doomed to consider actions as themain tool for cognitive development, see for example [3].When implementing such a general principle, two issuesbecome apparent. On one hand, actions require the existenceof a physical body (embodiment, [2]), which ‘safely’ interactswith a continuously changing, dynamic, unstructured and, inone word, “real” environment. On the other hand, the necessityof understanding the consequences of actions requires fineperceptual capabilities, i.e. the ability of retrieving infor-mation about the world (exteroception) and about the body(proprioception). Therefore, action and perception need tobe considered as a unique tool for the development of thebehavior of the robot, mutually affecting each other in a self-maintaining process of co-development [1]. Clearly, there is adirect relationship between the complexity of the action systemand the quality of the data that the robot can have access to bymeans of action [3]. At the same time, actions can be improved
because of the improvement of the perceptual system throughlearning and adaptation.
II. OVERVIEW OF THE PAPER
In the previous section we have discussed the importanceof three fundamental concepts in humanoid robotics: embod-iment, action, and perception. In the light of these ideas, thedesign and realization of a robot has become a research topicin itself. This paper focuses on the design of the humanoidrobot called James (see Figure 1), primarily reporting the de-sign choices which have been suggested/required by seriouslyconsidering embodiment, action, and perception. Some of thedesign aspects are related to the fact that the robot is intendedto operate in the context of object manipulation, which will bethe test-bed on which these new principles will be validated.James is a 22-DOF torso with moving eyes and neck, anarm and a highly anthropomorphic hand. In the next sectionswe cover the robot design, its actuation, and sensorization.Experiments are reported.
Fig. 1. The humanoid robot James.
The structure of the following sections has to be understoodin terms of the three principles mentioned above: embodiment,action, and perception.
- Section III deals with the body, i.e. the physical structureof the robot. The robot structure is similar to that ofhumans, both in size, number of DOFs and range ofmovements. Such a complex structure is, in our view,

mandatory when studying complex tasks like manipula-tion. Specific attention has been devoted to the structureof the hand, which, through a necessary simplification re-tains most of the joints of a human hand. The complexityof the structure makes modeling a challenging problem.Therefore, the platform seems to be ideal for exploringthe expressive potentialities of the principles describedabove.
- Section IV deals with the actuation system. As alreadypointed out, ‘safe’ interaction with the external world isa fundamental process. Therefore, when designing therobot, we decided to make it intrinsically compliant to actsafely over an unknown and unstructured world, withoutdamaging itself and the objects around it. This has beenachieved by an accurate choice of the the actuationsystem. Specifically, movements are made intrinsicallycompliant by using plastic belts, stainless-steel tendonswhich transmit torques from motors to joints, and springsat critical locations along the tendons. A great deal ofattention has been focused on the actuation of the hand.Being impossible to actuate all the 17 joints1, an under-actuated mechanism was designed. Roughly speaking,some of the joints are weakly coupled in such a way thatblocking one of them does not prevent the movement ofthe remaining joints.
- Section V deals with sensors. Once again, we shouldstress the fact that sensors are fundamental to retrieveinformation about the external world and about the bodyof the robot. Perception is provided by visual, kinesthetic,proprioceptive and tactile sensors, some of which havebeen created specifically for James. We will describe thedesign and realization of a novel silicone-made tactilesensor. Touch is indeed critical in manipulation tasks.
Furthermore, to prove the crucial role of tactile sensing andproprioception in getting information about grasped objects,we describe a set of classification experiments on objects withdifferent shape and/or softness.
III. PHYSICAL STRUCTURE
James consists of 22 DOFs, actuated by a total of 23 motors,whose torque is transmitted to the joints by belts and stainless-steel tendons. The head is equipped with two eyes, whichcan pan and tilt independently (4 DOFs), and is mounted ona 3-DOF neck, which allows the movement of the head asneeded in the 3D rotational space. The arm has 7 DOFs: threeof them are located in the shoulder, one in the elbow andthree in the wrist. The hand has five fingers. Each of themhas three joints (flexion/extension of the distal, middle andproximal phalanxes). Two additional degrees of freedom arerepresented by the thumb opposition and by the coordinatedabduction/adduction of four fingers (index, middle, ring, andlittle finger). Therefore, the hand has a total of 17 joints. Theiractuation will be described later in Section IV. The overall size
1All the motors for actuating the hand are located in the arm and forearm.Therefore, it was impossible to have one motor for each degree of freedomof the hand.
Fig. 2. On the left, a picture of the tendon actuation; wires slide insideflexible tubes. On the right, a picture of the tendon-spring actuation.
of James is that of a ten-year-old boy, with the appropriateproportions for a total weight of about 8 kg: 2 kg the head, 4kg the torso and 2 kg arm and hand together (the robot partsare made of aluminum and Ergal).
IV. ACTUATION SYSTEM
This section describes how compliance has guided thedesign of the actuation system. Special attention has beendevoted to the hand actuation, which is crucial in manipulationtasks.
A. Overall actuation structure
The robot is equipped with 23 rotary motors (Faulhaber),most of which directly drive a single DOF. Exceptions are inthe neck, where three motors are employed to roll and tilt thehead, and in the shoulder, where three motors are coupledto actuate three consecutive rotations. Transmission of thetorques generated by the motors is obtained through plastictoothed belts and stainless-steel made tendons; this solutionis particularly useful in designing the hand since it allowslocating most of the hand actuators in the wrist and forearmrather than in the hand itself, where strict size and weightconstraints are present. Furthermore, tendon actuation gives anoteworthy compliance to the system2, easing the interactionover an unknown and unstructured world. Indeed, the elasticityof the transmission prevents damages to the external worldand the robot itself, especially in presence of undesired andunexpected conditions, which are usual in the “real” world:small positional errors when the hand is very close to thetarget, obstacles in the path of the desired movements, strokesinflicted by external agents. Extra intrinsic compliance hasbeen added by means of springs in series with the tendons tofurther help the coupling/decoupling of the fingers (see Figure2).
B. Shoulder actuation structure
The design of the tendon driven shoulder was developedwith the main intent of allowing a wide range of movements.The current design, consists of three successive rotationscorresponding to pitch, yaw and roll respectively (see Figure3 for details). The three motors that actuate these rotations are
2Stainless-steel tendons are extremely elastic especially when the appliedtension exceeds a certain threshold.

Fig. 3. The picture shows the three degrees of freedom of the shoulder.Notice in particular how the yaw rotation is obtained by a double rotationaround two parallel axes.
Fig. 4. Picture of the shoulder. Notice the two mechanically coupled yawjoints. This specific design allows a good range of yaw rotation (more than180 degrees).
located in the torso3. Actuation is achieved by exploiting thedesign of tendons and pulleys. Special care has been takenin designing the abduction (yaw) movement. The abductionrotation is divided along two mechanically coupled joints(see Figure 4). The two joints correspond to a sequence oftwo rotations around two parallel axes. A mechanical tightcoupling forces the two angles of rotation to be equal. This‘ad hoc’ solution allows the arm to gain an impressive rangeof movement (pitch' 360o, yaw≥ 180o, roll' 180o) and toperform special tasks (e.g. position the hand behind the head)at the expense of a multiplication of the required torque by asimilar amount.
C. Head actuation structure
The head structure has a total of 7 degrees of freedom,actuated by 8 motors. Four of these motors are used to actuatethe pan and tilt movements of the two independent eyes (seeFigure 5 for a scheme of the tendon actuation). One motor
3This design is evidently non-standard. Standard manipulators (e.g. theUnimate Puma) have the shoulder motors in a serial configuration, with asingle motor directly actuating a single degree of freedom. In the Pumaexample, a pure pitch/yaw/roll rotation can be obtained by simply movingone motor and keeping the others fixed. On James instead, shoulder rotationsare the result of the coordinated movement of the three motors. The motorpositions (θ1, θ2, θ3) are related to the pitch, yaw and roll rotations (θp, θy ,θr) by a lower triangular matrix:
24
θp
θy
θr
35 =
24
1 0 0−1 1 01 2 1
3524
θ1
θ2
θ3
35 .
Fig. 5. The left picture shows the tendon driven eye. The two tendonsare actuated by two motors. The first motor moves the vertical tendon (tiltmotion). The second motor moves the horizontal tendon (pan motion). Theright figure sketches the actuation scheme.
Fig. 6. The two mechanically coupled joints of the shoulder allow the armto have the maximum range of the abduction (yaw) movement.
directly actuates the head pan. The remaining three motorsactuate the head’s two additional rotations: tilt and roll. Thesetwo rotations are achieved with an unconventional actuationsystem (see Figure 6). Each motor pulls a tendon; the tensionof the three tendons determines the equilibrium configurationof the spring on which the head is mounted. The structurehas an implicit compliance but it can become fairly stiff whenneeded by pulling the three tendons simultaneously.
D. Hand actuation structure
The main constraint in designing the hand is representedby the number of motors which can be embedded in thearm, assuming there is very little space in the hand itself.The current solution uses 8 motors to actuate the hand. Notethat the motors are insufficient to independently drive everyjoint singularly. After extensive studies, we ended up with asolution based on coupling some of the joints with springs.This solution does not prevent movement of the coupled jointswhen one of them is blocked (because of an obstacle) andtherefore results in an intrinsic compliance. Details of theactuation for each finger are given in the following.
- Thumb. The flexion/extension of the proximal and middlephalanxes is actuated by a single motor. However, themovement is not tightly coupled. The actuation systemallows movement of one phalanx if the other is blocked.

Two more motors are used to directly actuate the distalphalanx and the opposition movement.
- Index finger. The flexion/extension of the proximal pha-lanx is actuated by a single motor. One more motor isused to move the two more distal phalanxes.
- Middle, ring and little fingers. A unique motor is usedto move the distal phalanxes of the three fingers (flex-ion/extension). Once again, blocking one of the fingersdoes not prevent the others from moving. One additionalmotor actuates the proximal phalanxes and, similarly, themovement transfer to the others when one of the fingersis blocked.
Finally, an additional motor (for a total of 8 motors) isused to actuate the abduction/adduction of four fingers (index,middle, ring and little fingers). In this case, fingers are tightlycoupled and blocking one of the fingers blocks the others.
E. Motor control strategy
Low-level motor control is distributed on 12 C-programmable DSP-cards, some of which are embedded inthe robot’s arm and head. Communication between cards andan external cluster of PCs is achieved by the use of a CAN-BUS connection. Robot movement is controlled by the userwith positional/velocity commands which are processed by theDSPs which generate trajectories appropriately. Most of themotors are controlled with a standard PID control except forthe shoulder, the neck and the eyes motors where mechanicalconstraints require the use of more sophisticated and coordi-nated control strategies. These specific control strategies falloutside the scope and size of this paper.
V. SENSORS
The sensory system allows James to gather informationabout its own body and about the external world. The robotis equipped with vision, proprioception, kinesthetic and tactileinputs. As previously mentioned, the robot perceptual capabil-ities have been designed in line with the necessity of using itfor manipulation.
Vision is provided by two digital CCD cameras (PointGreyDragonfly remote head), located in the eyeballs, with thecontrolling electronics mounted inside the head and connectedvia FireWire to the external PCs.
The proprioceptive and kinesthetic senses are achievedthrough position sensors. Besides the magnetic incrementalencoders connected to all motors, absolute-position sensorshave been mounted on the shoulder to ease calibration, in thefingers (in every phalanx, for a total of 15) and in the twomotors that drive the abduction of fingers and of the thumb.In particular, the hand position sensors have been designedand built expressly for this robot, combining magnets and Halleffect sensors. In order to understand the sensor’s structure andfunctioning, consider one of the flexion joints of the fingers,between a pair of links (phalanxes). One metal ring holds a setof magnets and moves with the more distal link (of the two weconsider here). The Hall-effect sensor is mounted on the firstlink. Magnets are laid as to generate a specific magnetic field
sensed by the Hall-effect sensor, monotonically increasingwhen the finger moves from a fully-bended position to a fully-extended one: from the sensor output, the information aboutflexion angle is derived. Furthermore, a 3-axis inertial sensor(Intersense iCube2) has been mounted on top of the head, toemulate the vestibular system.
Tactile information is extracted from sensors which havebeen specifically designed and developed for James, and havebeen realized using a two-part silicone elastomer (Sylgard186), a Miniature Ratiometric Linear Hall Effect Sensor (Hon-eywell, mod. SS495A) and a little cylindrical magnet (gradeN35; dim. 2x1.5 mm).
Fig. 7. Description of the sensing method.
The sensor structure is shown in Figure 7: any externalpressure on the silicone surface causes a movement of themagnet and therefore a change in the magnetic field sensed bythe Hall-effect sensor, which measures indirectly the normalcomponent of the force which has generated the pressure.An air gap between the magnet and the Hall-effect sensorincreases the sensor sensitivity while keeping the structurerobust enough. Two kinds of sensors have been realized, witha different geometric structure depending on the mountinglocation: phalangeal-sensors for some of the phalanxes andfingertip-sensors for the distal ends of each finger (Figure 8).The former present one sensing element, which can measureonly a limited range of forces, even if with a high sensitivity.In practice, the response of the phalangeal sensors can beregarded as an on/off response. The fingertip-sensors, instead,have two sensing elements capable of sensing a larger rangeof stimuli.
In order to realize the silicone parts two different moldshave been used (Figure 9 and Figure 10), employing the samebuilding procedure. Two different covers for each mold canbe seen in the figures: cover A, with little cylindrical bulgesto produce suitable holes for the magnets, and cover B, withrabbets on some edges to create the already mentioned airgaps. Molds are first filled with some viscous silicone (mixtureof the two parts, base and curing agent), covered with cover Aand left drying under progressive heating: this latter processlasts 24 hours at room temperature and then, in the oven, 4

Fig. 8. On the left, the fingertip-sensor, with its two sensing elements. Onthe right, the phalangeal-sensor, with a unique sensing element.
hours at 65◦C, 1 hour at 100◦C and 20 minutes at 150◦C.Afterward, magnets are inserted, some more silicone is poured,and molds are covered with cover B and left drying again.When ready, silicone parts are fixed on the fingers with asealing silicone, next to the Hall effect sensors previouslyglued in the desired positions.
Fig. 9. Mold and covers for the fingertip-sensor.
Fig. 10. Mold and covers for the phalangeal-sensor.
The fingertip-sensor characteristic curve is reported in Fig-ure 11, where the thicker line is the mean value over seriesof several measurements and the vertical bars are the standarddeviation. The fact that the standard deviation is reasonablylow is due to the robustness of the mechanical structure,which is robust to pressure applied at different positions andfrom different directions, even if with substantially differentintensities.
The non-linear response of the sensor is a feature because ofits similarity with the log-shaped response curve observed inhumans, whose sensitivity decreases with the stimulus inten-sity [4]. Furthermore, the minimum force intensity detected bythe sensor (less than 10 grams for fingertip-sensors and about1-2 grams for phalangeal-sensors) is very low, an aspect which
Fig. 11. Fingertip-sensor’s characteristic curve.
has been pursued as the main feature of the device during thedesign and development of its mechanical structure. Finally,the use of the soft silicone shows an intrinsic compliance andincreases the friction cone of the grasping forces. Siliconeadapts its shape to that of touched object without being subjectto plastic deformations, easing the interaction with unknownenvironments.12 tactile sensors have been mounted on the James’s hand:5 fingertip-sensors, one for each finger, and 7 phalangeal-sensors, two on the thumb, ring finger and middle finger, andone on the index finger, as shown in Figure 12.
Fig. 12. James’s antropomorphic hand equipped with the 12 tactile sensors.
All the 32 Hall-effect sensors of the hand (employed intactile and proprioceptive sensing) are connected to an ac-quisition board, mounted on the hand back and interfacedto the CAN-BUS as for the DSP-based control boards. Theacquisition card is based on a PIC18F448 microcontroller, anADC and multiplexer, and a 40-cable connector, which holdsthe 32 signals and provides the 5 Volt DC power supply tothe sensors. To wire such a considerable number of devices

in such a little space, with a reasonable resiliency (requiredbecause of the constant interaction of the hand with theexternal environment), we have chosen a very thin stainless-steel cable, coated in Teflon, with a 0.23 mm external diameter.Moreover, in order to further increase system robustness,cables are grouped into silicone catheters along their routebetween different sensors and toward the acquisition card.
VI. EXPERIMENTS
Experiments have been carried out to validate the design andquality of proprioceptive signals to gather useful informationabout grasped objects. Proprioception can be further combinedwith touch in object clustering and recognition showing anotable improvement. The importance of proprioception inobject clustering and recognition has been proved both inhuman subjects [5] and in artificial systems [6]; our aimhere is to show how tactile information improves the systemperformance, providing a richer haptic perception of graspedobjects. A Self Organizing Map (SOM) has been employed tocluster and display data. The object representation is simplygiven by the data acquired by the proprioceptive and tactilesensors of the hand, which provides information about objectshape and softness.
The experiment is divided into three stages: data gather-ing, SOM training and SOM testing. During the first stage,six different objects (bottle, ball, mobile phone, scarf, foamblob and furry toy) have been brought metaphorically to therobot’s attention. James performed several times the samepre-programmed action of grasping and releasing the objects.A simple motor grasping strategy turned out to be effectivebecause of the overall design of the hand. Data provided byproprioceptive and tactile sensors have been acquired every50 ms, recorded, and organized in 25,000 32-sized vectors,each representing the haptic configuration of the hand in aspecific time instant. Afterward, data have been fed for 50epochs to the SOM, which is formed, in our case, by a mainlayer (Kohonen layer) of 225 neurons, organized in a 15x15bi-dimensional grid, with hexagonal topology, and an inputlayer of 32 neurons, that receive the recorded vectors of handconfigurations. During this training stage, main layer neuronsself-organize their position according to the distribution of theinput vectors, creating separate areas of neurons respondingto similar stimuli.
Finally, the neural network has been tested with bothdynamic and static inputs, to see how the grasping actionis represented and to check the classification and recognitioncapabilities of the trained system. Results are shown in Figure13 and Figure 14.
Figure 13 shows the state of the SOM main layer aftertraining. Each small diagram accounts for the values of thecorresponding weights of the neuron in that particular position.It is worth noting that nearby neurons show similar curves,which gradually change moving across the network. The pathindicated by the black arrows represents the temporal sequenceof the neurons activated during a ball grasping. Neurons layon a continuous path, because of the gradual changes in sensor
Fig. 13. Path of neural activations on the main layer’s bi-dimensional grid,due to the grasping of a ball.
Fig. 14. Results of object classification. The left picture shows the SOMresponse to an empty, open hand. The picture on the right shows the SOMresponse to six different objects.
outputs during a continuous movement. Figure 14 shows theresponse to static inputs: the spikes on both graphs indicatethe number of activations of the neuron in that position afterthe presentation of inputs describing hand haptic configurationwhen grasping a particular object or when free and open. Itis worth noting that different objects are well classified andsimilar objects lay in adjacent regions.
Another experiment has been carried out to prove thespecial importance of tactile stimuli, focusing on situationswhere the use of proprioception alone may lead to ambiguousresults. A first SOM has been trained only with proprioceptiveinformation. A second SOM was instead trained with bothtactile and proprioceptive inputs. Figure 15 demonstrates thattactile sensing improves the system performance: indeed, thegrasp of a scarf and a bottle is only distinguished by the secondneural network. In fact, with these two objects the final handposture is very similar, as a consequence of the fact that thetwo objects have approximatively the same shape. Therefore,the only way to distinguish the two objects is by the use

Fig. 15. Comparison between the use of proprioception alone, on the left,and the combined use of proprioceptive and tactile informations, on the right.
of tactile information. The two objects have indeed differentmaterial characteristics (softness) and therefore only the useof touch can sense their difference.
VII. FUTURE WORK
Future work is already planned, concerning both the armand the hand control. In particular, adaptive modular controland the exploration of grasping strategies will be investigated.
Remarkably, Bizzi and Mussa-Ivaldi [7] have proposed aninteresting experimental evidence supporting the idea thatbiological sensorimotor control is partitioned and organized ina set of modular structures. At the same time, Shadmehr [8]and Brashers-Krug [9] have shown the extreme adaptabilityof the human motor control system. So far, adaptation hasbeen proved to depend on performance errors (see [8]) andcontext related sensory information (see [10]). Following theseresults, a dynamic control law which consists of the linearcombination of a minimum set of motion primitives have beenexamined. Interestingly, the way of combining these primitivescan be parametrized on the actual context of movement [11].Even more remarkably, primitives can be combined in approx-imately the same way forces combine in nature. Adaptation(i.e. by means of combining primitives with different mixingcoefficients) can arise both from error-based updating ofparameters (where the error represent the difference betweenthe desired and measured position and velocity of the joints)and from previously learned context/parameters associations(even combining some of them in a new and unexperiencedcontext can be seen as the combination of some experiencedcontexts).
As far as the hand movement is concerned, in the experi-ment described in this paper, the grasping action used, even ifeffective, is still very simple: fingers are just driven to a genericclosed posture, wrapping the object by means of the elasticactuation system. Following cues from existing examples [12],future development include the implementation of a system for
choosing the best grasping action among a series of basic mo-tor synergies, combining some of them, in trying to maximizethe number of stimulated tactile sensors and hence obtaininga more comprehensive and effective object perception. Ofcourse, in order to show this ability of evaluation and improve-ment of performances (i.e. move the grasped object toward theunstimulated sensors) a topological map of the sensors withinthe hand is needed. Following the developmental approach,we want this map to be autonomously learned by the robotby random interactions with the environment. It is reasonableto assume [13] that this could be possible by analyzingthe correlation between channels from the recorded data asprovided by touch and proprioception, exploiting multisensoryintegration as suggested by generic neural science results[14].
VIII. CONCLUSIONS
We have described James, a 22-DOF humanoid robotequipped with moving eyes and neck, a 7 DOF arm and ahighly anthropomorphic hand. The design of James has beenguided by the concept of embodiment, material complianceand embodied interaction. Since James is intended to operatein a manipulation scenario, special care has been taken on thedesign of novel silicone-made tactile sensors. These sensorshave been designed, realized, tested and integrated within theJames’s anthropomorphic hand. Hence, to prove the impor-tance of proprioceptive and tactile information, experimentsof classification and recognition of grasped objects have beencarried out using a Self Organizing Map to cluster and visu-alize data. As expected, results have shown the improvementsoffered by tactile sensing in building object representations,enabling the system to classify and recognize objects accord-ing to their softness and elasticity. Shape information providedby the measured posture of the grasping hand are indeed notsufficient to discriminate two objects with similar size butdifferent softness. Finally, the future development of efficientand flexible grasping strategies has been outlined.
ACKNOWLEDGMENT
The work presented in this paper has been supported bythe ROBOTCUB project, funded by the European Commissionthrough Unit E5 “Cognition”. Moreover, it has been partiallysupported by NEUROBOTICS, a European FP6 project (IST-2003-511492).
REFERENCES
[1] G. Sandini, G. Metta, and D. Vernon, “Robotcub: An open frameworkfor research in embodied cognition,” in In IEEE-RAS/RSJ InternationalConference on Humanoid Robots (Humanoids 2004), 2004.
[2] R. Pfeifer and C. Scheier, “Representation in natural and artificial agents:a perspective from embodied cognitive science perspective,” NaturalOrganisms, Artificial Organisms and Their Brain, pp. 480–503, 1998.
[3] P. Fitzpatrick, G. Metta, L. Natale, S. Rao, and G. Sandini, “Learningabout objects through action: Initial steps towards artificial cognition,”in IEEE International Conference on Robotics and Automation (ICRA),Taipei, Taiwan, 2003.
[4] J. Wolfe, K. Kluender, and D. Levi, Sensation and Perception. SinauerAssociates Incorporated, 2005.
[5] M. Jeannerod, The Cognitive Neuroscience of Action. BlackwellScience, 1997.

[6] L. Natale, G. Metta, and G. Sandini, “Learning haptic representation ofobjects,” in International Conference on Intelligent Manipulation andGrasping. Genoa, Italy, 2004.
[7] F. A. Mussa-Ivaldi and E. Bizzi, “Motor learning through the combi-nation of primitives,” Philosophical Transactions of the Royal Society:Biological Sciences, vol. 355, pp. 1755–1769, 2000.
[8] R. Shadmehr and F. A. Mussa-Ivaldi, “Adaptive representation ofdynamics during learning of a motor task,” Journal of Neuroscience,vol. 74, no. 5, pp. 3208–3224, 1994.
[9] T. Brashers-Krug, R. Shadmehr, and E. Bizzi, “Consolidation in humanmotor memory,” Nature, vol. 382, pp. 252–255, 1996.
[10] M. Shelhamer, D. Robinson, and H. Tan, “Context-specific gain switch-ing in the human vestibuloocular reflex,” Annals of the New YorkAcademy of Sciences, vol. 656, no. 5, pp. 889–891, 1991.
[11] F. Nori, G.Metta, L.Jamone, and G.Sandini, “Adaptive combinationof motor primitives,” in In Workshop on Motor Development part ofAISB’06: Adaptation in Artificial and Biological Systems. University ofBristol, Bristol, England, 2006.
[12] J. Fernandez and I. Walker, “Biologically inspired robot grasping usinggenetic programming,” in IEEE International Conference on Robotics& Automation, 1998.
[13] L. Olsson, C. Nehaniv, and D. Polani, “Discovering motion flow bytemporal-informational correlations in sensors,” in Epigenetic Robotics2005, 2005.
[14] E. Kandel, J. Schwartz, and T. Jessell, Principles of Neural Science,4th ed. McGraw-Hill, 2000.

Potential relevance of audio-visuacomputational
Eeva Klintfors and Fran
Department of LinStockholm University, Sto
ABSTRACT The purpose of this study was to examine typically developing infants’ integration of audio-visual sensory information as a fundamental process involved in early word learning. One hundred sixty pre-linguistic children were randomly assigned to watch one of four counterbalanced versions of audio-visual video sequences. The infants’ eye-movements were recorded and their looking behavior was analyzed throughout three repetitions of exposure-test-phases. The results indicate that the infants were able to learn covariance between shapes and colors of arbitrary geometrical objects and to them corresponding nonsense words. Implications of audio-visual integration in infants and in non-human animals for modeling within speech recognition systems, neural networks and robotics are discussed. Index Terms: language acquisition, audio-visual, modeling
1. INTRODUCTION This study is part of the “MILLE” project (Modeling Interactive Language Learning, supported by the Bank of Sweden Tercentenary Foundation), interdisciplinary research collaboration between three research groups – Department of Linguistics, Stockholm University (SU, Sweden), Department of Psychology, Carnegie Mellon University (CMU, USA) and Department of Speech, Music and Hearing, Royal Institute of Technology (KTH, Sweden). The general goals of the co-work are to investigate fundamental processes involved in language acquisition and to develop computational models to simulate these processes.
As a first step towards these goals, perceptual experiments with human infants were performed at the SU. These experiments were designed to investigate infants’ early word acquisition as an implicit learning process based on integration of multi-sensory (audio-visual) information. The current study specifically provides data on integration of arbitrary visual geometrical objects and “nonsense” words corresponding to attributes of these objects.
2. BACKGROUND
2.1 Research in mammals As a theoretical starting point for the current study it is assumed that infants do not have a priori specified linguistic
kggstthinacLocoliimanank
inablemcoin[5mv(“mppcoBanmstexdpinsuro
2nAchen
INTERSPEECH 2006
1
l integration in mammals for modeling
cisco Lacerda
guistics ckholm, Sweden se
nowledge and that the acquisition of the ambient language is uided by general perception and memory processes. These eneral purpose mechanisms are assumed to lead to linguistic ructure through learning of implicit regularities available in e ambient language. Thus, as opposed to the belief that itial innate guidance is a prerequisite for language quisition [1], [2], the proposed Ecological Theory of
anguage Acquisition (ETLA) suggests that the early phases f the language acquisition processes are an emergent nsequence of the interplay between the infant and its
nguistic environment [3]. To be sure, observations based on plicit regularities may indeed lead to wrong assumptions d, just like other experience-based-learning, this type of trial d error use of words tends initially to create situated
nowledge [4]. To be able to extract and organize implicit sensory
formation available from several modalities is an important ility for an organism’s success in its environment. Implicit arning processes are presumed to occur also in non-human ammals – a hypothesis being currently investigated by our llaborators at CMU. Explicitly concerning audio-visual tegration in non-human animals – Ghazanfar & Logothetis ] showed using preferential-looking technique that rhesus onkeys (Macaca mulatta) were able to recognize auditory-
isual correspondence between their conspecific vocalizations coo” or “threat” calls) and appropriate facial gestures (small outh opening/protruding lips or big mouth opening/no lip
rotrusion). Just like the perception of human speech, the erception of monkey calls may thereby be enhanced by a mbination of auditory signals and visual facial expressions.
imodal perception in animals was viewed by the authors as evolutionary precursor of human’s ability to make ultimodal associations necessary for speech perception. Such udies on non-human mammals are obviously important to amine questions that are impossible, unethical, or extremely
ifficult to answer with human listeners [6], like the pre and ost operative comparisons of rhesus monkeys’ performance auditory-visual (e.g. noise-shape pairs) association tasks pporting the notion that left prefrontal cortex plays a central le in integration of auditory and visual information [7].
.2 Modeling within speech recognition systems, eural networks and robotics fter about one year’s exposure to their ambient language, ildren typically start to speak to interact with their vironment. Despite of its complexity, children soon learn
September 17-21, Pittsburgh, Pennsylvania

the linguistic principles of their ambient language. However, this seemingly simple task is not easily transferred to formalized knowledge about language acquisition, nor is it easily integrated within speech recognition or operational models. Part of the problem that speech recognition systems battle with is presumably caused by the focus on the speech signal as the primary component of the speech communication process. Within natural speech communication speech is only one, albeit crucial, part of the process and the latest systems have started to make use of multimodal information to improve the systems’ communication efficiency. As an example, Salvi [8] analyzed the behavior of Incremental Model-Based Clustering on infant directed speech data in order to describe acquisition of phonetic classes by an infant. Salvi analyzed the effects of two factors within the model, namely the number of coefficients describing the signal and the frame length of the incremental clustering. His results showed that despite varying amount of clusters, the classifications obtained were essentially consistent. In addition to the model by Salvi the current co-work with the KTH further aims to develop a computational model able to handle information received from at least two different sensory dimensions.
We have recently reported [9] that two neural network models submitted to process encoded video materials that were earlier tested on a group of adult subjects in a simple inference task (similar to the task in the current study), performed well on both classification and generalization tasks. The task of the first type of architecture was simply to associate colors and shapes of the visual objects to the words corresponding to these two attributes, i.e. the model merely reproduced its input at the output level. The second architecture of the model attempted to simulate the adult subjects’ ability to apply their just learned concepts to new contexts. The performance of the model was tested with novel data not previously seen by the network (either new colors or new shapes). The performance of both network models was robust and mimicked the adults’ results well. Since the outcome of a neural network is dependent on the peculiarities of the input coding, its architecture and specific training constraints, the type of neural network models described here would presumably not mimic well enough the behavior of the infants in the current study. One reason for a vague match of behavior would probably be caused by the unlimited memory of the network which enables it to process data unrestricted as compared with infants’ restricted memory capacities. Also neural networks, often using sigmoid activation function for nodes, are non-linear regression models in which small differences in input value may cause large differences in neural computation behavior. Hence, a better way of modeling infant behavior would be to calculate effects of memory constraints when predicting audio-visual integration.
In addition to development of communicative ability leading to more sophisticated use of language, children quickly learn to interact with their environment through observation and imitation of manipulative gestures. To explore whether these motor abilities are developing independently, or if there are fundamentally similar mechanisms involved in development of perception and production of speech and manipulation of gestures, results from the current study and similar other experimental studies are tested within an embodied humanoid robot system. The hypothesis deals with a recent scientific finding pointing at the fact that action representations can be addressed not only during execution but
alwcospmm[1thanBlaFinoresy
mpohC
3Tfrbexcrd(a3dfopwapmwwin5stM
3T(2EmFca
insewsudre
INTERSPEECH 2006
2
so by the perception of action-related stimuli. Experiments ith monkeys have shown that mirror neurons in premotor rtex (area F5) discharge both when a monkey makes a ecific action and when it observes another individual who is aking a similar action [10], [11] that is meaningful for the onkey. A mirror system is proposed also to exist in humans 2] and F5, the area for hand movements, is suggested to be e monkey homolog of Broca’s area, commonly thought of as area for speech, in the human brain [13]. Both F5 and
roca’s area have the neural structures for controlling oro-ryngeal, oro-facial, and brachio-manual movements [14]. urther studies in neuroscience suggest that there are parallels mechanisms underlying actions such as to manipulate, tear,
r put an object on a plate and mechanisms underlying actions cognized by their sound or mechanisms underlying speech stems [15].
For our research group at the SU the importance of odeling language acquisition lies unquestionably within the
ossibility of experimentally manipulating learning processes n the basis of experimental achievements and theoretical ypothesis formulated by us and other Neuroscience and hild-development partners.
3. METHOD
.1 Subjects and procedure he subjects were 160 Swedish infants randomly selected om the National Swedish address register (SPAR) on the asis of age and geographical criteria. Thirty-one infants were cluded from the study due to interrupted recordings (infant ying or technical problems). The remaining 129 infants were
ivided in two age groups: 26 boys and 27 girls in age-group I ge range 90-135days, mean age 120 days) and 42 boys and
4 girls in age-group II (age range 136-180days, mean age 156 ays). The subjects were randomly assigned to watch one of ur counterbalanced film sequences. The subjects and their
arents were not paid to participate in the study. The infant as seated in a safe baby-chair or on the parent’s lap at proximately 60 cm from the screen. The parent listened to asking music through soundproof headphones during the hole session. The infants’ eye-movements were recorded ith Tobii (1750, 17” TFT) Eye-tracking system using low-tensity infra-red light. The gaze estimation frequency was
0Hz, and accuracy 0.5 degrees. Software used for data orage was ClearView 2.2.0. The data was analyzed in athematica 5.0 and SPSS 14.0.
.2 Materials he films’ structure was: BASELINE (20 s), EXPOSURE1 5 s), TEST1 (20 s), EXPOSURE2 (25 s), TEST2 (20 s), XPOSURE3 (25 s), and TEST3 (20 s). The image used to easure infants’ pre-exposure bias in BASELINE is shown in igure 1. During BASELINE the audio played a lullaby to tch the infant’s attention towards the screen.
The elements used in the EXPOSURE phases are shown Figure 2. Each of the elements was shown in 6 s long film quences. Each object moved smoothly across the screen hile the audio played 2 × repetitions of two-word phrases, ch as nela dulle (red cube), nela bimma (red ball), lame
ulle (yellow cube), lame bimma (yellow ball), implicitly ferring to the color and shape of the object. The two-word

phrases were read aloud by a female speaker of an artificial language in infant-directed speech style. The “nonsense” words were constructed according to the phonotactic and morphotactic rules of Swedish. However, the prosody of the phrases did not mimic Swedish prosody of two-word phrases – the words were instead pronounced as if they occurred in isolation, without sentence accent on either one of the words.
During TEST1, TEST2 and TEST3 the image shown in Figure 1 appeared again while questions such as Vur bu skrett dulle? (Have you seen the cube?) or Vur bu skrett nela? (Have you seen the red one?) were asked. The questions were naturally produced using question intonation.
In each one of the four counterbalanced versions of the film there was one question on shape of an object and another on color of an object. In the test phases the target shapes appeared in new colors and the target colors appeared in new shapes – as compared with the shape-color combinations during exposure phases – in order to address generalization of learned associations into new contexts.
4. RESULTS We predicted that if infants are capable of extracting the objects’ underlying properties, their looking times towards the relevant target color (Red or Yellow) and target shape (Cubeor Ball) of an object will increase from BASELINE (Pre-exposure bias) to TEST1-3 (Post-exposure).
TtoloBwcopmre
Figure 1: Split-screen displaying four objects shown during the BASELINE along with a lullaby to measure infants’ spontaneous looking bias before the three repetitions of exposure and subsequent test phases.
After presentation (EXPOSURE1-3) of the objects (Figure 2) the split-screen was displayed again during TEST1-3 along with questions such as Vur bu skrett dulle?(Have you seen the cube?) and Vur bu skrett nela? (Have you seen the red one?). The films were counterbalanced regarding choice of words corresponding to colors/shapes of the objects.
ergwfoin
spto(llod<
(Ufr(nanat
Figure 2: An illustration of the elements shown during EXPOSURE1-3. Each object moved smoothly across the screen (in 6 s long film sequences) while the audio played 2 × repetitions of two-word phrases, such as nela dulle (red cube), nela bimma (red ball) lame dulle (yellow cube), lame bimma (yellow ball), implicitly referring to the color and shape of the object. The films were counterbalanced regarding the presentation order of the objects during exposure.
Wfosostfrstad
INTERSPEECH 2006
3
he results (Figure 3) showed increased looking times wards Red upper-left (UL), Cube upper-right (UR), Ballwer-left (LL) and Yellow lower-right (LR) from ASELINE to TEST1-3. The increments in looking time ere larger in response to target shapes (Cube and Ball) as mpared with target colors (Red and Yellow). This was in
articular true for age-group II. Furthermore, repeated easures ANOVA on BASELINE to TEST1-3 contrasts vealed significant differences for Red, Cube and Ball.
The looking behavior of age-group II – as indicated by the ror bars – was more stable than the looking behavior of age-
roup I. An analysis on BASELINE to TEST1-3 contrasts ith age as a factor, revealed an overall age-group tendency r Red (F = 4.106, d.f. = 18, P < 0.058) indicating disparity the looking behavior of infants in age-group I and II.
There were no significant interactions between the times ent looking at target and the choice of words corresponding the colors and shapes of the objects or the object-position eft or right) on the split-screen. Infants did, however, look nger towards the upper quadrants (target Red F = 37.564,
.f. = 54, P < 0.0005 and target Cube F =26.758, d.f. = 63, P 0.0005) than towards the lower quadrants.
Figure 3: The attribute targets were Red (UL), CubeR), Ball (LL) and Yellow (LR). The bars in each quadrant
om left to right respectively indicate: Pre-exposure bias ormalized looking time at future target during BASELINE), d Post-exposure target dominance (normalized looking time target during TEST1-3) for age-group I and II respectively.
5. DISCUSSION hereas early studies on language acquisition in infants were cused on production and perception of isolated speech unds [16], recent experimental studies have addressed the ructure of perceptual categories [17], and word extraction om connected speech [18], [19], [20], [21]. The current udy further expands the scope of these investigations by dressing the emergence of referential function, integrating

recognition of patterns in auditory with the recognition of patterns in the visual input. In addition, our theoretical outline views early language acquisition as a consequence of general sensory and memory processes. Through these processes auditory representations of sound sequences are linked to co-occurring sensory stimuli and since spoken language is used to refer to objects and actions in the world, the implicit correlation between hearing words relating to objects and seeing (or feeling, smelling or otherwise perceiving) the referents can be expected to underline the acquisition of spoken language.
The materials in the current study were, as opposed to synthetic stimuli, naturally produced two-word phrases, whose linguistic meaning emerges from their situated implicit reference to the shapes and colors of the visual geometrical objects. The adjective-noun pattern in the two-word phrases followed the Swedish syntactical pattern. This situation, in which four new words were mapped onto a known grammatical structure, is of course different from the challenge faced by a pre-linguistic child, but simplifying the experimental materials (to only two shapes and two colors) was necessary for revealing the essential process of audio-visual integration during short exposure (about 1 minute) in young infants (< 6mos). Also, because success in the test phases required generalization of learned associations into new visual contexts, finding the correct visual target cannot be seen as simple “translation process”.
The age range of the subjects was 90-135 days (age-group I) and 136-180 days (age-group II). These age-groups were selected to investigate the extent of the age-related differences in the infants’ capacity to learn covariance between the two different types of attribute targets (shapes and colors) and to them corresponding words. Indeed, despite of the fact that color words typically appear first after about ten months, these young infants showed some evidence of being able to pick up the color references implicit in the current experiment. Thus, although infants in this age range may not have the capacity to handle the concept of color as such, they at least demonstrate, as observed in other mammals, an underlying capacity to associate recurrent visual dimensions with their implicit acoustic labels.
6. ACKNOWLEDGEMENTS Research supported by the Swedish Research Council (421-2001-4876), the Bank of Sweden Tercentenary Foundation (K2003-0867) and Birgit & Gad Rausing’s Foundation.
7. REFERENCES [1] N. Chomsky, Language and mind. New York: Harcourt
Brace Jovanovich, 1968. [2] S. Pinker, The Language Instinct: How the Mind Creates
Language, 1 ed. New York: William Morrow and Company, Inc., 1994, pp. 15-472.
[3] F. Lacerda, E. Klintfors, L. Gustavsson, L. Lagerkvist, E. Marklund, and U. Sundberg, "Ecological Theory of Language Acquisition,", Epigenetics and Robotics 2004 ed Genova: Epirob 2004, 2004.
[4] E. J. Gibson and A. D. Pick, An Ecological Approach to Perceptual Learning and Development Oxford University Press US, 2006.
[5
[6
[7
[8
[9
[1
[1
[1
[1
[1
[1
[1
[1
[1
[1
[2
[2
INTERSPEECH 2006
4
] A. A. Ghazanfar and N. K. Logothetis, "Neuroperception: Facial expressions linked to monkey calls," Nature, vol. 423, pp. 937-938, 2003.
] K. R. Kluender, A. J. Lotto, and L. L. Holt, "Contributions of nonhuman animal models to understanding human speech perception," in Listening to Speech: An Auditory Perspective. S. Greenberg and W. Ainsworth, Eds. New York, NY: Oxford University Press, 2005.
] D. Gaffan and S. Harrison, "Auditory-visual associations, hemispheric specialization and temporal-frontal interaction in the rhesus monkey," Brain, vol. Oct; 114, no. Pt 5, pp. 2133-2144, 1991.
] G. Salvi, "Ecological Language Acquisition via Incremental Model-Based Clustering,", InterSpeech'2005 - Eurospeech, 9th European Conference on Speech Communication and Technology ed Lissabon: InterSpeech'2005, 2005.
] F. Lacerda, E. Klintfors, and L. Gustavsson, "Multi-sensory information as an improvement for communication systems efficiency,", Fonetik 2005 ed Gothenburg: Fonetik 2005, 2005, pp. 83-86.
0] G. Rizzolatti and M. A. Arbib, "Language within our grasp," Trends in Neurosciences, vol. 21, no. 5, pp. 188-194, May1998.
1] C. Keysers, E. Kohler, M. A. Umilta, L. Nanetti, L. Fogassi, and V. Gallese, "Audiovisual mirror neurons and action recognition," Experimental Brain Research, vol. 4, pp. 628-636, 2003.
2] L. Fadiga, L. Fogassi, G. Pavesi, and G. Rizzolatti, "Motor Facilitation During Action Observation - A Magnetic Stimulation Study," Journal of Neurophysiology, vol. 73, no. 6, pp. 2608-2611, June1995.
3] G. Rizzolatti and M. A. Arbib, "Language within our grasp," Trends in Neurosciences, vol. 21, no. 5, pp. 188-194, May1998.
4] G. Rizzolatti and M. A. Arbib, "Language within our grasp," Trends in Neurosciences, vol. 21, no. 5, pp. 188-194, May1998.
5] E. Kohler, C. Keysers, M. A. Umilta, L. Fogassi, V. Gallese, and G. Rizzolatti, "Hearing sounds, understanding actions: action representation in mirror neurons," Science, vol. 297, no. 5582, pp. 846-848, Aug.2002.
6] P. D. Eimas, E. R. Siqueland, P. Jusczyk, and J. Vigorito, "Speech perception in infants," Science, vol. 171, pp. 303-306, 1971.
7] P. Kuhl, K. Williams, F. Lacerda, K. N. Stevens, and B. Lindblom, "Linguistic experience alters phonetic perception in infants by 6 months of age," Science, vol. 255, no. 5044, pp. 606-608, Jan.1992.
8] P. Jusczyk, "How infants begin to extract words from speech," Trends Cogn Sci., vol. 3, no. 9, pp. 323-328, Sept.1999.
9] P. Jusczyk and R. N. Aslin, "Infants' Detection of the Sound Patterns of Words in Fluent Speech," Cognitive Psychology, vol. 29, no. 1, pp. 1-23, Aug.1995.
0] P. Jusczyk and E. Hohne, "Infants' Memory for Spoken Words," Science, vol. 277, no. 5334, pp. 1984-1986, Sept.1997.
1] J. R. Saffran, R. N. Aslin, and E. Newport, "Statistical learning by 8-month old infants," Science, vol. 274, pp. 1926-1928, 1996.

Ett ekologiskt perspektiv på tidig talspråksutveckling Francisco Lacerda
Institutionen för Lingvistik
Stokcholms universitet
Språkets begynnelse… Föreställ dig att du är en nykomling till en jordliknande planet vars invånare också
använder sig av språk för att kommunicera med varandra. Föreställ dig också att du till
råga på allt glömt allt du viste, inklusive ditt eget språk, under din långa resa. I praktiken
är du som ett spädbarn som anlände i ett rymdskepp som snart upptäckts av planeternas
invånare. Du blir omhändertagen och till en början kan använda dina sinnesorgan för att
känna av ljud, ljus, tyngd, skrovlighet, o.s.v. Du är allmän nyfiken på det som sker
omkring dig men har samtidigt inte några förväntningar på eller kunskap om din omvärld.
Vilka förutsättningar behövs för att du skall kunna lära dig detta nya språk?
Om du bara har tillgång till ljudet som invånarna använder när de kommunicerar med
varandra (du kan varken se eller interagera med invånarna) kommer det sannolikt att vara
omöjligt för dig att lista ut vad dessa ljud står för. Eftersom du inte ens vet att ljuden kan
användas i kommunikativt syfte och än mindre att de ljudsekvenserna som du hör kan
betraktas som strängar av ordliknande element, kommer du i första hand att uppfatta
dessa ljudsekvenser som ostrukturerade och isolerade akustiska händelser. Till en början
kommer du till och med att blanda ihop dessa kommunikativa akustiska händelser med
andra akustiska händelser som inte har kommunikations innebörd. I din naiva betraktelse
av omvärldens akustiska egenskaper är deras mest framträdande egenskap själva
kontrasten med tystnaden som du upplever när det inte finns tillräckligt med akustisk
energi för att stimulera ditt hörselsystem. Men risken är att du till en början blandar ihop
alla slags ljud, kommunikativa och icke-kommunikativa, för att det du märker först bara
är att det finns ljud som på något sätt avviker från bakgrunden. På så sätt, och utan att
vara medveten om det, åstadkommer du en grundläggande binär kategorisering som
utnyttjar ljudintensiteten. I nästa steg börjar du att lägga märke till skillnader som också
finns bland ljuden som ingår i kategorin ”ljud” och än en gång sorterar du dessa i två

olika kategorier enligt andra akustiska dimensioner. Notera att kategorisering, i sig, är
varken rätt eller fel. Den är inte anpassad till vad ljuden skulle kunna betyda utan
avspeglar bara ett sätt att organisera akustiska förnimmelser beroende på uppmärksamhet,
som i sin tur påverkas av själva iakttagelserna. Parallellt med ökningen av
ljudkategorierna kan även upptäckten av sekventiella relationer mellan kategorierna
iakttas, som t.ex. att en viss ljudkategori ofta följs av en annan. På det hela taget kan man
säga att din exponering till ljuden på denna främmande planet leder till att du kan lära dig
att kategorisera dessa ljud enligt olika akustiska kriterier och att du även kan lära dig att
förvänta att vissa ljudkategorier kommer efter vissa andra. Trots detta kan du ändå
knappast förstå hur dessa ljud används i kommunikativt syfte. I själva verket är
”kommunikativt syfte” inte ens ett problem för dig eftersom du i detta scenario hör bara
ljud som ur ditt perspektiv inte sätts i relation med någonting annat.
Situationen ändras dock radikalt om du, till skillnad från situationen ovan, också har
tillgång till minst ett annat sinnesintryck samtidigt som du hör ljuden omkring dig. Anta,
för enkelhetsskull, att samma typ av kategoriseringsprocess tillämpas på stimuli
representerade av de nya sensoriska dimensionerna. Den avgörande skillnaden är att
händelserna i din omvärld inte längre är endimensionella (representerade endast av dess
akustiska dimension). Varje händelse representeras nu av en punkt i en flerdimensionell
rymd där punktens placering vid varje ögonblick direkt motsvarar den löpande statusen
på dina samlade sinnesintryck. Notera dock att medan övergången från en sensorisk
dimension till flera sensoriska dimensioner är av avgörande betydelse för vårt
resonemang, antal dimensionerna hos den multisensoriska representationsrymd är inte.
Det principiella resonemanget som förs på två-dimensioner kan direkt generaliseras till
flerdimensionella representationsrymder. Detta beror på att språk bygger, per definition,
på användningen av något slags symboler som refererar till något annat än själva
symbolen, vilket innebär att det måste finnas minst två element som relateras till
varandra. Dessa element tillhör vanligtvis olika sensoriska dimensioner, så som den
auditiva och den visuella, men kan i princip bestå av mycket generella relationer mellan
olika dimensioner förutsatt att relationerna är kända bland individerna som använder
detta språk för att kommunicerar med varandra. I vårt nya scenario kan vi då föreställa
oss om att du naivt betraktar både auditiva och visuella sinnesintryck runtomkring dig i

denna främmande planet. Frågan är om du nu har bättre förutsättningar än tidigare för att
lära dig invånarnas språk.
I den nya situationen kan du både höra vad invånarna säger och samtidigt se vad de gör.
Eftersom vi antar att invånarna har ett språk baserat på ljudsymboler kan vi utgå ifrån att
dessa symboler kommer att ha bestämda (men för dig okända) relationer till visuella
objekten i denna ”tvåsensoriska” värld. Du vet dock inte om hur dessa audiovisuella
relationer ser ut och inte heller om att sådana relationer överhuvudtaget finns. Vad krävs
för att du, trots detta, ändå skall komma fram till hur invånarna använder sig av sitt
språk?
Om vi utgår från att du också tillämpar till den visuella dimensionen samma
kategoriseringsprincip som inom den auditiva domänen, kommer du till en början att ha
bara ett fåtal kategorier att hålla reda på. Ljud kontra icke-ljud kombinerat med ”synliga”
kontra icke-synliga objekt skapar fyra möjliga klasser i denna tvådimensionella rymd.
Med två tillgängliga dimensioner kommer dock antalet audiovisuella kategorier snabbt att
växa eftersom den totala mängd möjliga kategorier ges alltid av produkten av antal olika
kategorier längst varje dimension, i.e. , där kat∏=N
iikatkatTot _ i står för antalet kategorier
längst dimensionen i och Tot_kat representerar antalet möjliga kategorier när alla N
dimensioner utnyttjas (i detta exempel är N=2). Eftersom invånarna använder sig av ljud
för att referera till visuella objekt, kommer din ursprungligen binära kategorisering längst
dessa två dimensioner att leda dig till att upptäcka att just ljud förekommer ofta i
samband med synliga objekt medan icke-ljud hänger ihop med icke-synliga objekt. Dessa
samband är naturligtvis inte deterministiska men avspeglar en generell relation mellan
invånarnas ljudsymboler och de visuella objekten som symbolerna refererar till. Det
väsentliga här är att genom observationen av de konkreta fallen där den manifesterar sig
kommer du att koppla kategorin ”ljud” med kategorin ”synligt objekt” utan att ens veta
vilka lingvistiska principer använder. Att dessa två kategorier dyker ofta upp tillsammans
avspeglar, i sig, invånarnas lingvistiska principer. Som i det endimensionella fallet
kommer även här dina kategoriseringar att visa sig uppdelbara i ytterligare kategorier. Att
du inser att det går att göra finare uppdelningar längst dessa dimensioner innebär på
samma gång att du faktiskt kan upptäcka snävare audiovisuella samband. Utan att

nödvändigtvis få insikt om själva lingvistiska relationen mellan ljudsymbolerna och dess
referenter, innebär din betraktelse dessa ihopkopplade företeelser att du i praktiken agerar
som om du behärskade den lingvistiska processen. Men när du väl har upptäckt att det
finns systematiska samband mellan ljud och visuella föremål i vissa fall ligger det nära
till hands att generalisera iakttagelsen och inleda en hypotesdriven sökning efter
ytterliggare auditiva-visuella samband. Så som processen beskrivs här kommer du att gå
från en exemplar-baserad representation av observerade audiovisuella samband till en
aktiv och principiell insikt om att denna typ av relationer förekommer. Du har, med andra
ord, fått insikt om hur invånarna använder sig av ljud för att refererar till visuella objekt
och det var nu möjligt att komma till denna insikt just för att du fick tillgång till en
tvådimensionell representation av din omvärld.
En viktig slutsats av denna galaktiska övning är att multisensorisk betraktelse av
lingvistiska scenarion kan anses innehålla tillräckligt med information för att spontant
härleda upptäckten av lingvistiska symboliska referenser eftersom aktörer som använder
sig av ett språk för att kommunicera med varandra utnyttjar (relativt) stabila symboliska
relationer mellan olika sensoriska dimensioner (Minsky, 1985).
En ekologisk teori av tidig talspråksinlärning Mot bakgrund av tankexercisen här ovan, låt oss nu försöka formulera det som vi
kommer att kalla för en ekologisk teori av tidig språkinlärning (ETLA, Ecological Theory
of Language Acquisition). Vår ambition är att kunna förklara hur spädbarnets tidiga
talspråksinlärning kan vara en oavsiktlig emergent konsekvens av samspelet mellan
spädbarnets allmänna biologiska förutsättningar och dess typiska ekologiska kontext,
samt skapa en testbar ETLA modell som formaliserar våra teoretiska antaganden
(Lacerda et al., 2004).
ETLA:s utgångspunkt är att den tidiga talspråksinlärningen skapas genom samspelet
mellan spädbarnets icke-språkspecifika biologiska förutsättningar och barnets språkliga
miljö. Spädbarnets biologiska förutsättningar omfattar egentligen alla anatomiska och
fysiologiska aspekter samt alla sensoriska dimensioner men teorins grunddrag kan med
fördel illustreras utifrån ett mera begränsat och hanterbart perspektiv. Vi kommer därför
att inskränka oss till att huvudsakligen betrakta spädbarnets ansatsrörs anatomiska

konfiguration och dess rörelsemöjligheter samt barnets auditiva och visuella
representationsförmåga. Vi antar att barnet har en allmän minnesförmåga som möjliggör
igenkänningen av stimuli som det har exponerats för tidigare. För tillfället ignorerar vi
dock barnets handlingsförmåga, som i praktiken leder till att barnet avslöjar sina
tolkningar av omvärlden genom att barnet agerar utifrån sina förväntningar och intressen.
Dessa aktiva handlingar kommer att visa sig kunna spela en viktig roll för
talspråksutvecklingen och vi skall därför återkomma till denna aspekt. Beträffande
barnets språkliga miljö måste vi betrakta s.k. ”barnriktat tal”, som i vårt sammanhang
kommer att visa sig vara en väsentlig komponent av barnets tidiga talspråksutveckling.
Visserligen är barnriktat tal endast en liten del av all tal som ett spädbarn får höra (van
der Weijer, 1999) men det är kvalitativt så annorlunda de övriga talsignalerna att det är
rimligt att tillskriva barnriktat tal ett särskilt status vid tidig talspråksutveckling. Vi börjar
med att utgå från barnriktat tal och återkommer sedan till resonemanget kring hur
representativt denna talstil är i förhållande till övriga talstilar som barnet också får höra.
Våra explicita initiala antaganden är följande:
• Spädbarnet
o Har allmän multisensorisk minneskapacitet (känner igen återkommande
stimuli och har proprioceptivt minne)
o Har allmän förmåga till att diskriminera och representera ljud
o Har allmän förmåga till att diskriminera och representera visuella stimuli
o Ansatsrörets anatomi skiljer sig (i proportionerna) från den vuxnes
o Producerar gärna ljud med talapparaten
• Barnets språkliga miljö
o Vuxna använder barnriktat tal när de pratar med spädbarnet
Antaganden
Allmän minneskapacitet På det perceptuella planet vet vi att spädbarn visar förmågan att känna igen föremål och
ljud de sett förut. Eftersom denna igenkänningsförmåga utnyttjas i

habituering/dishabituerings tekniker som fungerar även med nyfödda barn kan man utgå
ifrån att det sannolikt rör sig om mycket basala och generella igenkänningsprocesser.
Denna sorts allmänna igenkänningsförmåga spelar dessutom en viktig roll för
organismens överlevnad i sin ekologiska nisch eftersom den möjliggör för organismen
att, bl.a., åter söka sig till tidigare gynnsamma miljöer eller att undvika de som skapade
obehagliga minnen.
Diskrimination och representation av ljud Denna förmåga är väl dokumenterad och olika experiment med nyfödda barn
demonstrerar att förmågan finns redan från födelsen. Nyfödda spädbarn har visat sig
kunna diskriminera i stort sätt alla språkligt relevanta ljudkontraster som de har testats
med. Mera generellt har frekvensdiskrimination och hörseltröskeln visat sig följa ungefär
den vuxna kapaciteten Den absoluta hörseltröskeln är dock något förhöjd i förhållande till
vuxnas när den mäts med beteendemetoder, vilket kan avspegla spädbarnets oförmåga att
koncentrera sig på en upptäcka en ton vars intensitet under visa tidsintervaller kan ligga
under hörseltröskeln. Till skillnad från en kognitivt mognare försöksperson, kan
spädbarnet inte följa instruktioner om att uppmärksamma det svagaste ljudet som går att
upptäcka och signalera detta genom att trycka på en knapp.
Diskrimination och representation av visuella stimuli Även här visar det sig att spädbarn har tillräcklig god visuell diskriminations- och
representationsförmåga från åtminstone c:a 2 månaders ålder. Vi kan därför anta att
spädbarn i den åldern iakttar visuella scener ungefär på samma sätt som vuxna gör.
Ansatsrörets anatomiska skillnader i förhållande till vuxna Spädbarnets ansatsrör är inte en skalenlig version av den vuxnes. Spädbarnets farynx är
förhållandevis mycket kortare är vuxnas och proportionerna mellan farynx längd och den
orala kavitetens längd förändrar sig dramatiskt under spädbarnets första levnadsår.
Farynx fortsätter visserligen att växa även efter spädbarnsåldern men i betydligt
långsammare takt än under spädbarnets första år i livet.
Spädbarns joller under det första levnadsåret Spädbarn låter och tycks njuta av att undersöka gränserna för sina vokaliseringar. Trots
starka individuella preferenser, visar sig spädbarns jollerutveckling generellt börja med

bakre vokaliseringar som så småningom ”flyttas fram” i munnen. Denna utvecklingstrend
kan anses skapa en viss struktur i barnets väg mot det omgivande språket.
Barnriktat tal Denna talstil karaktäriseras av stora modulationer av gruntonsfrekvensen, relativt
förenklade yttrandestrukturer, korta yttranden och ofta upprepningar.
Kontextberoende inlärning
Barnriktat tal Under typiska förhållanden utsätts spädbarn för det talade språket direkt efter födelsen
och det nyfödda barnet brukar visar påtagligt intresse för det omgivande talade språket,
särskilt moderns tal (Spence & de Casper, 1987; de Casper & Spence, 1986; de Casper &
Fifer, 1980). Detta spontana intresse för det omgivande språket har ofta tolkats som
tecken på medfödd och genetiskt betingad benägenhet att lära sig det omgivande språket
men vi föreslår att även detta intresse kan en rimlig ekologisk förklaring. Eftersom
fostrets hörselsystem mognar vid ungefär den femte graviditetsmånaden, kan fostret höra
externa ljud som överförs genom den havande kvinnans vävnader samt höra mammans
talljud som överförs direkt, via kvinnans anatomiska strukturer, från stämbandens
vibration och resonanskaviteter associerade till själva talproduktionen till den amniotiska
vätskan i vilken fostret utvecklas. Det faktum att fostret exponeras för ljud redan före
födelsen innebär ett slags bekantskap med, framförallt, de prosodiska aspekterna av
mammas tal, vilket förklarar det nyfödda barnets preferens för omgivningens talspråk
som en konsekvens av allmängiltiga minnesprocesser, utan behovet att åberopa
språkspecifika medfödda benägenheter.
Även de typiska aspekterna av det så kallade barnriktade talet kan betraktas som en
konsekvens av fostrets prenatala exponering till mammans tal. Den strikt fonetiska
utgångspunkten är att det nyfödda spädbarnet visar tecken på att känna igen de
prosodiska mönster som används av mamman och, i stor utsträckning, andra talare av
modersmålet. Barnets igenkänning uttrycker sig i orientering mot talaren som använder
de bekanta prosodiska mönstren samtidigt som barnets intresse för talet också upptäcks
av talaren. Eftersom i detta scenario är det i första hand själva prosodin som det nyfödda

barnet intresserar sig för, reagerar talaren med att förtydliga just dessa fonetiska drag som
det nyfödda barnet verkar reagerar på. Barnets intresse för talet upprätthålls och talaren
leds intuitivt till att framhäva de fonetiska dragen som hade lett till att upprätthålla
kontakten med det nyfödda barnet. Interaktionen mellan det nyfödda barnet och en
(vuxen) talare omfattar naturligtvis viktiga emotionella aspekter som inte betraktas här
men den emotionella laddningen som omger denna typ av interaktion spelar sannolikt en
viktig roll för att bekräfta och stabilisera barnets intresse för detta barnriktade tal. Det
sammanlagda resultatet av spädbarnets samspel med talaren i denna ekologiska kontext
är då en framhävning av de fonetiska dragen som tenderar att upprätthålla samspelet, dvs.
främst de prosodiska drag som känns igen av barnet och bidrar till att upprätthålla
kommunikationsutbytet. Figuren 1 visar F0 konturerna som skapades av en mamma när
hon pratade med sitt 3 månaders gammalt spädbarn (vänster) och när hon pratade med en
vuxen, under samma inspelningstillfälle.
Figur 1. Vågformer och F0 konturer från samma talare som producerar barnriktat tal
(vänster, 3 månaders gammalt barn) och vuxenriktat tal (höger). Y-axelns övre del visar
signalens amplitud, Y-axelns nedre del visar F0 frekvens i cents (1 oktav = 1200 cents)
och tiden visas i sekund (olika tidsskalor).
Ytterligare en fonetisk konsekvens av talarens framhävning av prosodiska drag är att
sonoranta ljud kommer att ha huvudrollen i sammanhanget eftersom det är denna typ av
ljud som lättaste kan bära de F0 modulationerna som fångar barnets intresse. Om vi
dessutom utgår från att det unga spädbarnet inte har lingvistiska grunder för att intressera
sig för att fokusera på en eller en annan kategori av talljud, förefaller det rimligt att
förvänta sig att spädbarnets uppmärksamhet för olika typer av talljud styrs i första hand
av relativt grova akustiska kriterier, så som ljudstyrkan. Enligt denna hypotes är då ljud
vars intensitet ligger över den övriga akustiska miljön som spädbarnet uppmärksammar
0 2 4 6 8 10 12 14 16
Input signal
-1
-0.5
0
0.5
[cent] F0 trend
-1500-1000 -500 0
500 1000 1500 2000
En oktav
0 2 4 6 8
Input signal
-1
-0.5
0
0.5
[cent] F0 trend
-2000-1500-1000 -500 0
500 10001500

men hur kan barnet skilja relevanta talljud från andra, ungefär lika starka, akustiska
företeelser i omgivningen?
Det principiella svaret på denna fråga är att det kan spädbarnet inte göra. Det finns alltså
risk för att framträdande ljud som fångar barnets uppmärksamhet inte har någon som
helst lingvistisk betydelse. Barnet uppmärksammar säkert något instrument som spelas
eller ljud från något slags utrustning och skulle, i princip, bli vilseledd av dessa
”meningslösa” men tillräckligt starka ljud från omgivningen. Men om det lilla barnets
ekologiska miljö tas i beräkningen förefaller denna risk som avsevärt mindre än det som i
första hand kan befaras. Dels skapar fostrets prenatala auditiva erfarenhet benägenhet att
fokusera just på akustiska signaler vars prosodiska egenskaper liknar mammans tal. Detta
i sig innebär att talliknande signaler kommer generellt att betraktas som mera bekanta än
andra akustiska signaler som saknar talets prosodiska drag. Dessutom sker den typiska
vuxen-barn kommunikationen där talsignalen är inblandad i en ekologisk kontext som
karaktäriseras av närhet mellan talaren och barnet och relativt lugnt akustiskt bakgrund.
När dessa två aspekter tas i beräkningen blir talsignalens fysikaliska intensitet plötsligt en
viktig variabel, som trots sin generiska och annars inte särskild relevanta lingvistiska
betydelse, kan lägga grund till barnets första steg mot det omgivande språk. Enligt denna
hypotes bör sonoranter vara talljuden som lättaste fångar barnets uppmärksamhet,
eftersom dessa ljud typiskt har relativt hög akustisk energi. Även det lilla barnets tidiga
intresse för modulationer av talsignalens grundtonsfrekvens leder till att sonoranter
implicit hamnar i barnets spontana auditiva fokus eftersom de tydligt förmedlar just de
F0-variationerna som barnet intresserar sig för. Tar man hänsyn till spektrala aspekter kan
bilden av de ”mest auditivt framträdande” talljuden förändras något, eftersom frikativor
kan kontrastera med den akustiska omgivningens spektrala drag. Frikativor är inte särskilt
energirika talljud i förhållande till sonoranter men innehåller ofta högfrekvent akustisk
energi vilket innebär att deras spektra generellt avviker från sonoranternas karaktäristiska
medel- och lågfrekventa spektralenergi. På grund av att frikativor levererar akustisk
energi vid frekvensband som de mer lågfrekventa sonoranter lämnar relativt fria, kan
frikativor ändå skapa tillräckligt auditivt i förhållande till sonoranter och därför träda
fram trots sin totalt lägre akustiska energi.

Spädbarnets perception av talljud Resonemanget här ovan kan ses som något onödigt mot bakgrunden av studier, under
1970-1980, av spädbarns förmåga till att diskriminera mellan olika talljud. Resultaten
från dessa studier pekar på spädbarnets förmåga att hålla isär de flesta talljudkontraster
som de har testats med (Jusczyk et al., 1993; Bertoncini et al., 1988; Mehler et al., 1988;
Jusczyk & Derrah, 1987) och då ligger det nära till hands att anse att spädbarnet inte
skulle ha några problem med att iaktta samma ljudkontraster när dessa förekommer i
löpande tal, i spädbarnets omgivning. I själva verket är dock risken stor för att
diskriminationsresultaten från perceptionsexperiment med enstaka ljudkontraster inte kan
överföras till löpande tal. I ett perceptionsexperiment presenteras talljuden ofta isolerade
och under optimala akustiska förhållanden, medan i ekologiskt relevant löpande tal
påverkas samma talljud av fonetiska kontexten samtidigt som barnets fokusering på just
dessa kontraster störs av andra konkurrerande talljud. Med andra ord, förmedlar
resultaten från dessa tidiga talperceptionsstudier med spädbarn ett slags principiell
förmåga att diskriminera lingvistiskt relevanta segmentella kontraster men det är inte
givet att spädbarnet kommer att lyckas utnyttja denna principiella förmåga för att härleda
dessa kontrasters lingvistiska funktion. Studier av hur spädbarnets förmåga att
diskriminera olika vokal- och konsonantkontraster tyder faktiskt på att dessa kontraster
behandlas på ett sätt som förändras med barnets mognad. Det sammanlagda budskapet
från dessa studier är att spädbarnets diskrimination av isolerade talljud utgår från
övervägande akustisk-betingad diskrimination till en mera lingvistisk baserad
diskrimination, i takt med att barnet mognar. Kontraster som initialt diskriminerades
förmodligen för att ljuden i sig lätt akustiskt olika, börjar så småningom ignoreras för att
de faktiskt är ”lingvistisk irrelevanta” allofoniska variationer i barnets omgivande språk.
Alltså, den ”förlorade” diskriminationsförmågan avslöjar en lingvistisk mognadsprocess
som kan innebära att barnet börjar förstå vilka de lingvistiskt relevanta akustiska dragen
är.
I stora drag, tyder scenariot som har skissats ovan på att allmänna auditiva- och
minnesprocesser kan leda det unga spädbarnet att fokusera på vissa kategorier av
språkljud. Utgångspunkten för denna ekologiska teori av tidig talspråksinlärning är just
att spädbarnets intresse för talet och förmodligen för vissa kategorier av talljud uppstår

som konsekvens av den ekologiska kontexten i vilken vuxen-barn interaktion sker,
snarare än på grund av specialiserade språkinriktade färdigheter som det nyfödda barnet
kommer utrustat med. Nästa fråga är hur lingvistiska funktioner skall kunna härledas
utifrån detta nyfödda barns allmänna intresse för det omgivande talet, särskilt mammas
tal. Med andra ord, finns det tillräckligt lingvistisk information i talsignalen som typiskt
riktas mot unga spädbarn för att överhuvudtaget kunna härleda grundläggande
lingvistiska funktioner?
Att härleda lingvistisk struktur ur barnriktat tal Vid institutionen för lingvistik, Stockholms universitet undersöker vår grupp för studier
av tidig talspråksutveckling hur talet som vuxna riktar till sina spädbarn eventuellt
anpassas till barnets ålder, eller det som vuxna uppfattar som barnets mognadsnivå. Våra
preliminära resultat pekar tydligt på att mammans talstil förändras beroende på barnets
ålder. Som förväntat utnyttjar mammorna variationer i F0 för att fånga det unga
spädbarnets uppmärksamhet men utöver det tenderar mammorna att också använda en
mycket repetitiv talstil när de adresserar sina c:a 3 månaders gamla spädbarn. Dessa
upprepningar verkar dock minskar kraftigt i takt med att barnet närmar sig 12 månaders
ålder.
Figuren 2a illustrerar hur förra figurens barnriktat talet kan uppfattas utifrån spädbarnets
naiva perspektiv. Eftersom man utgår från att spädbarnet ännu inte har lärt sig vad språk
är för någonting, representerar transkriptionen de ljudsjok som hörs av barnet. I denna
representation finns därför inga mellanslag mellan orden, eftersom enligt hypotesen ord
ännu inte finns i barnets språkvärld. Enligt principen som skissades ovan, det som finns
ur spädbarnets perspektiv är ljudsekvenser med tillräckligt hög intensitet för att bli
uppmärksammade och som kontrasterar med den övriga akustiska bakgrunden. I denna
illustration representerar mellanslagen endast pauser som avgränsar de holistiska
ljudsekvenserna.

Enligt ETLA kan lingvistisk struktur härledas utifrån dessa holistiska, icke analyserade,
ljudsekvenser, för att den vuxne upprepar ljudsjok och att dessa sjok ofta integreras i
längre ljudsekvenser. ETLA:s modell tillämpad till detta material visar just att relativt
enkla igenkänningsprocesser leder till upptäckten av ljudsträngar som återanvänds och
kombineras i olika sekvenser. Med andra ord, de holistiska ljudsekvenserna som
spädbarnet exponeras för kan organiseras i termer av rekursiv kombinatorisk användning
av delar av de ursprungliga ljudsträngarna. Figurerna 2b och 2c visar ett antal möjliga
”lexikala kandidater” som är möjliga att härleda ur detta material, under förutsättning att
spädbarnet skulle lagra samtliga ljudsekvenser i minnet och upptäcka alla upprepningar
och återanvändningar av dessa. Antagandet är, i sig, orealistiskt eftersom spädbarnets
uppmärksamhet sannolikt fluktuerar under tiden det exponeras för talmaterialet som
användes i illustrationen, men visar ändå potentialen av ETLA:s princip. Ett annat
8hej, skavilekamedleksakidag, skavigöradet,ha, skavileka, tittahär, kommerduihågdenhärmyran,hardusett, titta, nukommermyran, dumpadumpadump,hej, hejsamyran, kommerduihågdenhärmyranmaria,ådenhärmyransomdublevalldelesräddförförragången, ja,mariablevalldelesräddfördenhärmyran, ädemyranoskar,myranoskaräde, tittavafinmyranä, åvamångaarmarhanhar,hardusettvamångaarmarmaria, hejhejmaria, hallå,hallå, hallåhallå, hejhej, ojojsågladsäjerOskar,ämariagladidag, ämariagladidag, ha, hejmariasäjermyran<
ämariagladidag, ha, hallå, hardusett, hej, hejhej, kommerduihågdenhärmyran, skavileka, titta
medleksakidag, här, samyran, maria, vafinmyranä, åvamångaarmarnr, vamångaarmarmaria, maria, mariasäjermyran
Figur 2. (a) Transkription av ett stycke tal riktat mot ett 3 månaders gammalt spädbarn. Orden som uttalas i följd representeras här utan mellanslag. Kommateringen representerar pauser i mammans tal. (b) Lexikala kandidater efter första matchning av upprepade sjok. (c) Ytterligare lexikala kandidater som finns kvar i sjoken efter subtraktion av lexikala kandidaterna som erhölls i (b).
(2a)
(2b)
(2c)

orealistiskt antagande i exemplet ovan är dessutom att spädbarnet bara skulle ha tillgång
till den akustiska signalen.
När även den visuella informationen tas i beräkningen, i kombination med mera
begränsad minneskapacitet, blir resultaten genast mera realistiska. En modell som
kombinerar spädbarnets visuella fokus och också inkluderar en begränsning i
minneskapacitet för att simulera att spädbarnet bara kan hålla de sista fem yttranden som
uttalades vid varje tidpunkt i närminnet ger mera realistiska resultat. Resultaten pekar nu
på ett fåtal lexikala kandidater, men som i gengäld effektivt binder föremålets visuella
representation med yttranden som innehåller föremålets namn. Denna sorts audiovisuella
upprepningar anses, enligt ETLA, ligga till grund för vidare upptäckt av lingvistiska
funktioner, i synnerhet associationen mellan ett föremåls visuella representation och dess
namn, representerat av en ljudsekvens. Antalet lexikala kandidater som kan härledas ur
talet riktat mot äldre barn minskar dramatiskt i takt med att barnet börjar visa tecken på
att kunna namn på vissa objekt eller händelser. Den vuxna verkar ersätta sin repetitiva
talstil med mer innehållsinriktat tal som använder barnets begynnande lingvistiska
begrepp som utgångspunkt. I vuxenriktat tal verkar upprepningarna som förekommer i
barnriktat tal (2-3 mån) överhuvudtaget inte finnas.
Spädbarnets egna handlingar och dess tolkning Trots att det lilla spädbarnet är helt beroende av sin omgivning för överlevnaden är det
långt ifrån passivt. Spädbarnet kan påkalla den vuxnas uppmärksamhet genom att självt
skapa handlingar som t.ex. att skrika, gråta, vokalisera, gestikulera eller le, beroende på
spädbarnets utvecklingsnivå. Genom denna sorts handlingar kan spädbarnet initiera
interaktion med eller svara på omgivningen. Spädbarnets förmåga att generera och
kontrollera handlingar, om än i begränsad utsträckning, är i sig en viktig komponent av
den tidiga talspråksutvecklingen så som den betraktas av ETLA. Det innebär att
spädbarnet i princip kan ha informationsutbyte med omgivningen, vilket i sig är grunden
till den tidiga talspråksutvecklingen som ETLA avser förklara.
Spädbarnets möjligheter till differentierade och välkontrollerade vokaliseringar och
motoriska handlingar är dock begränsade, vilket ofta ses som ett hinder för det lilla
barnets tidiga talspråksutveckling. Utifrån ETLA:s perspektiv anses dock dessa initiala

begränsningar i spädbarnets vokaliska och motoriska sökrum vara till fördel för barnet
eftersom detta initialt begränsat urval av artikulatoriska möjligheter faktiskt innebär att
spädbarnets sökrum implicit struktureras och förenklas något. De anatomiska
skillnaderna mellan det nyfödda spädbarnets ansatsrör och den vuxnas ansatsrör erbjuder
ett bra exempel på hur det akustisko-artikulatoriska sökrummet kan de facto struktureras
på grund av initiala ”begränsningar”.
Hos nyfödda spädbarn ligger glottis mycket högt upp och epiglottis kan ofta ses göra
kontakt med uvula när det lilla barnet gapar. Med andra ord, det faryngeala området hos
ett nyfött spädbarn är så pass kort att spädbarnets ansatsrör kan anses bestå av nästan bara
den orala kaviteten, vid jämförelse med det vuxnes. En direkt akustisk konsekvens av
detta är att när spädbarnet öppnar och stänger underkäken samtidigt som det vokaliserar
blir det i stort sätt nästan bara F1 som påverkas, medan alla de högre formanterna tenderar
att vara relativt opåverkade av denna artikulatoriska rörelse (Lacerda, 2003). I praktiken
innebär detta att det unga spädbarnets vokalproduktion blir effektivt begränsat till
kontraster längst öppen-sluten dimensionen. Under spädbarnets första levnadsår sker
dock en dramatisk förlängning av barnets farynx i och med att glottis position relativt
halskotorna sjunker kraftigt fram till slutet av det första levnadsåret. Generellt innebär
den oproportionella placeringen av olika artikulatoriska strukturer i spädbarnets
respektive vuxnas ansatsrör att spädbarnet och vuxna i princip måste använda olika
artikulatoriska lösningar för att åstadkomma fonetiskt likvärdiga talljud. Samma
resonemang kan användas för att förklara dominansen av faryngeala ljud vid tidig
jollerproduktion. Anledningen till att unga spädbarn uppfattas producera dessa faryngeala
ljud (Roug et al., 1989), figur 3) kan helt enkelt bero på att spädbarnet artikulerar
”vanligare” velara eller palatala ljud som dock uppfattas som faryngeala eftersom
artikulationsstället, på grund av den korta farynx, ligger relativt mycket längre bak hos
spädbarnet än hos den vuxne.

När spädbarnets ”begränsningar” av akustisko-artikulatoriska möjligheter läggs ihop med
vuxnas spontana uppfattningar av joller (Lacerda & Ichijima, 1995) och spädbarnets
benägenhet till lättare uppfattning av ljudkontraster förmedlade av F1 än av F2 (Lacerda,
1992b; Lacerda, 1992a), konvergerar alla dessa komponenter mot en bild av tidig
talperceptionsutveckling där initiala ojämnheter kan anses hjälpa spädbarnet att i första
hand fokusera på ett urval av tillängliga dimensioner i detta enorma sökrum. Den positiva
betydelsen av initiala begränsningar av sökmöjligheter har tidigare demonstrerats i arbete
med neurala nätverk och det finns all anledning till att ta detta budskap på allvar i
ekologiskt förankrade teorier om talspråksutveckling.
Age in months
20181614121086420
% o
ccur
renc
e
100
90
80
70
60
50
40
30
20
10
0
Place
glottal
velar/uvular
dental/alveolar
bilabial
Figur 3. Typisk jollerutveckling för ett svenskt barn. Notera den initiala dominansen av glottala artikulationer, som kan anses bero på spädbarnets anatomiska förutsättningar. Data från (Roug et al., 1989).
Testning av inlärningsmodellen med hjälp av en humanoid robot
Att skapa realistiska modeller av tidig talspråksutveckling kräver omfattande integrering
av en rad olika processer som pågår parallellt och interagerar med varandra. Det gäller till
exempel att modellera hur allmängiltiga produktions- och perceptionsmekanismer skall
kunna samspela med varandra för att härleda lingvistisk information ur interaktionen med
omgivningen. Det gäller också att kunna integrera dessa mekanismer i en modell som kan
generera handlingar utifrån ett slags allmän bakgrundsaktivitet som driver systemet mot
nya situationer, som i sin tur kan innebära nya inlärningsmöjligheter för detta system.
I syfte att kunna studera olika allmänna inlärningsprinciper och hur de interagerar med
varandra, testas för närvarande den ekologiska modellen av tidig talspråksinlärning med

hjälp av en humanoid robot, BabyBot, som skall kunna visa på paralleller mellan den
tidiga språk- och motoriska utvecklingen.
Vi ser med spänning fram till hur BabyBot, vår ställföreträdande galaktisk resenär,
kommer att klara sin talspråkutveckling under olika experimentella betingelser!
_________________
Denna översiktsartikel har producerats inom ramen för projekten ”Språkets begynnelse”
(Vetenskapsrådet), ”MILLE: Modelling Interactive Language Learning” (Riksbankens
Jubileumsfond) och ”CONTACT: Learning and Development of Contextual Action”
(NEST, EU).
Referenser
Bertoncini, J., Bijeljac-Babic, R., Kennedy, L., Jusczyk, P., & Mehler, J. (1988). An investigation of young infants' perceptual representation of speech sounds. Journal of Experimental Psychology: General, 117, 21-33.
de Casper, A. & Fifer, W. P. (1980). On human bonding: Newborns prefer their mothers' voices. Science, 208, 1174-1176.
de Casper, A. & Spence, M. (1986). Prenatal maternal speech influences newborns' perception of speech sounds. Infant Behavior and Development, 9, 133-150.
Jusczyk, P. & Derrah, C. (1987). Representation of speech sounds by young infants. Developmental Psychology, 23, 648-654.
Jusczyk, P., Friederici, A. D., Wessels, J. M., I, Svenkerud, V. Y., & Jusczyk, A. M. (1993). Infants' Sensitivity to the Sound Patterns of Native Language Words. Journal of Memory and Language, 32, 402-420.
Lacerda, F. (1992a). Does Young Infants Vowel Perception Favor High-Low Contrasts. International Journal of Psychology, 27, 58-59.
Lacerda, F. (1992b). Young Infants' Discrimination of Confusable Speech Signals. In M.E.H.Schouten (Ed.), THE AUDITORY PROCESSING OF SPEECH: FROM SOUNDS TO WORDS (pp. 229-238). Berlin, Federal Republic of Germany: Mouton de Gruyter.
Lacerda, F. (2003). Phonolgoy: An emergent consequence of memory constraints and sensory input. Reading and Writing: An Interdisciplinary Journal, 16, 41-59.
Lacerda, F. & Ichijima, T. (1995). Adult judgements of infant vocalizations. In K. Ellenius & P. Branderud (Eds.), (pp. 142-145). Stockholm: KTH and Stockholm University.

Lacerda, F., Klintfors, E., Gustavsson, L., Lagerkvist, L., Marklund, E., & Sundberg, U. (2004). Ecological Theory of Language Acquisition. In Genova: Epirob 2004.
Mehler, J., Jusczyk, P., Lambertz, G., Halsted, N., Bertoncini, J., & Amiel-Tison, C. (1988). A precursor of language acquisition in young infants. Cognition, 29, 143-178.
Minsky, M. (1985). Why intelligent aliens will be intelligible. In E.Regis (Ed.), Extraterrestrials (pp. 117-128). Cambridge: Cambridge Univ. Press.
Roug, L., Landberg, I., & Lundberg, L. J. (1989). Phonetic development in early infancy: a study of four Swedish children during the first eighteen months of life. J.Child Lang, 16, 19-40.
Spence, M. J. & de Casper, A. (1987). Prenatal experience with low-frequency maternal-voice sounds influence neonatal perception of maternal voice samples. Infant Behavior and Development, 10, 133-142.
van der Weijer, J. (1999). Language Input for Word Discovery. MPI Series in Psycholinguistics.

E:\My Documents\Fra\JOLLER\Univ_Porto_RevistaDeLinguistica_060228.doc 2006-09-13, 14:57
Proposing ETLA An Ecological Theory of Language Acquisition
Revista de Estudos Linguísticos da Universidade do Porto
Francisco Lacerda and Ulla Sundberg Department of Linguistics
Stockholm University SE-106 91 Stockholm
Sweden [email protected]
1

E:\My Documents\Fra\JOLLER\Univ_Porto_RevistaDeLinguistica_060228.doc 2006-09-13, 14:57
ABSTRACT An ecological approach to early language acquisition is presented in this article. The general view is that the ability of language communication must have arisen as an evolutionary adaptation to the representational needs of Homo sapiens and that about the same process is observed in language acquisition, although under different ecological settings. It is argued that the basic principles of human language communication are observed even in non-human species and that it is possible to account for the emergence of an initial linguistic referential function on the basis of general-purpose perceptual, production and memory mechanisms, if there language learner interacts with the ecological environment. A simple computational model of how early language learning may be initiated in today’s human infants is proposed.
INTRODUCTION The ability for language communication is a unique human trait differentiating us from all other species, including those most closely related in genetic terms. In spite of the morphological and molecular proximity to closely related species in the family Hominidae, like Pongo (orangutan), Gorilla (gorilla) and Pan (chimpanzees) (Futuyama, 1998: p730), it is obvious that only Homo (human), and most likely only Homo sapiens, has evolved the faculty of language. In evolutionary terms, the capacity for language communication appears to be a relatively recent invention that nowadays is “rediscovered” by typical human infants. From this broad perspective it may be valuable to investigate parallels between the phylogenetic and ontogenetic components of the process of language communication, while keeping in mind that Ernst Haeckel’s (1834-1919) biogenetic law, “ontogeny recapitulates phylogeny” (1866), is indeed far too simplistic to be taken in strict sense (Gould, 1977). This article opens with a broad look at the evolutionary aspects presumably associated with the discovery of language as a communication system. This evolutionary perspective will focus on general notions regarding the emergence of the language communication ability in the Homo’s ecological system. In the reminder of the article, an ecologically inspired developmental perspective on early language acquisition in human infants will be presented, enhancing potential similarities and differences between the developmental and evolutionary accounts.
From the phylogenetic perspective, language communication, in the sense that it has today, may have emerged about 200 to 300 thousand years ago (Gärdenfors, 2000) with the advent of Homo sapiens1. Until then it is assumed that hominids might have communicated mainly by calls and gestures. Derek Bickerton (Bickerton, 1990), for instance, speculates that a protolanguage, assigning referential meaning to arbitrary vocalizations, may have been used already by Homo erectus, about 1.5 Mya to 0.5 Mya (Futuyama, 1998: p731). Such a protolanguage must have been essentially a “referential lexicon” and somewhat of a “phylogenetic precursor of true language that is recapitulated in the child (…), and can be elicited by training from the chimpanzee” (Knight et al., 2000: p4). While this protolanguage may have consisted of both vocalizations and gestures used referentially, the anatomy of the jaw and skull in earlier hominids must necessarily have constrained the range of differentiated vocalizations that might have been used referentially. Considerations on the relative positions of the skull, jaw and vertebral column in early hominids clearly indicate significant changes in the mobility of those structures, from the Australopithecus afarensis (4.0-2.5 Mya) to Homo sapiens (0.3 Mya), changes that must have had important consequences for the capacity to produce differentiated vocalizations. An important aspect of these changes is the lowering of 1 “Most hominid fossils from about 0.3 Mya onward, as well as some African fossils about 0.4 My old, are referred to as Homo sapiens.”, (Futuyama, 1998)
2

E:\My Documents\Fra\JOLLER\Univ_Porto_RevistaDeLinguistica_060228.doc 2006-09-13, 14:57
the pharynx throughout the evolutionary process. This lowering of the pharynx is also observed on the ontogenetic time scale. Newborn human infants have at birth a very short pharynx, with high placement of their vocal folds, but they undergo a rather dramatic lengthening of the pharynx within the first years of life, in particular within about the first 6 months of life. As will be discussed later in this article, this short pharynx in relation to the oral cavity has some important phonetic consequences that can be summarized as a reduction in the control that the infant may have over the acoustic properties of its vocalizations. And from the acoustic-articulatory point of view, there are essentially no differences between the expected acoustic-articulatory relationships in the infant or in the adult since it seems that the infant’s vocal tract in this case can be considered as a downscaled version of an Australopithecus afarensis adult. A more difficult question is to determine at which point of the evolutionary process did the laryngeal position reach the placement it has nowadays but the general consensus is that Homo erectus probably marks the transition from high to low laryngeal positions (Deacon, 1997: p56). However, in evolutionary terms the emergence of a new anatomical trait does not directly lead to the long-term consequences that are found retrospectively. Changes are typically much more local, opportunistic and less dramatic than what they appear to be on the back-mirror perspective, reflecting Nature’s tinkering rather than design or goal-oriented strategies (Jacob, 1982) and Homo erectus probably did not engage in speech-like communication just to explore the new emerging anatomical possibility. A more plausible view is then that Homo erectus might have expanded the number of vocalizations used to signal objects and events available in the ecological environment, nevertheless without exploring the potential combinatorial and recursive power of the vocalizations’ and gestures’ inventories. Indeed, as recently pointed out by Nishimura and colleagues (Nishimura et al., ), the descent of the larynx is observed also in chimpanzees, leading to changes in the proportions of the vocal tract during infancy, just like in humans, and the authors argue that descent of the larynx may have evolved in common ancestor and for reasons that did not have to do with the ability to produce differentiated vocalizations that might be advantageously used in speech-like communication. In particular with regard to gestures, it is also plausible that Homo erectus might not have used gestures in the typically integrated and recursive way in which they spontaneous develop in nowadays Homo sapiens’ sign language (Schick et al., 2006), although their gestural anatomic and physiologic capacity for sign language must have been about the same. Thus, in this line of reasoning the question of how nowadays language communication ability did arise is not settled by the lowering of the larynx, per se, and the added differential acoustic capacity that it confers to vocalizations.
Since communication using sounds or gestures does not leave material fossil evidence it is necessary to speculate how vocalizations might have evolved into today’s spoken language and draw on useful parallels based on the general communicative behaviour among related hominid species. Situation-specific calls used by primates, such as the differentiated alarm calls observed in Old World monkeys like the vervet monkeys (Cercopithecus aethiops) (Cheney & Seyfarth, 1990), may in fact be seen as an early precursor of humanoid communication. To be sure, the calls used by the vervet monkeys to signal different kinds of predators and prompt the group to take appropriate action are rather primitive as compared to the symbolic functions of modern human language communication but they surely demonstrate a multi-sensory associative process from which further linguistic referential function may emerge. The ability to learn sound-meaning relationships is present in primates at a variety of levels and animals tend to learn the meaning of different alarm calls, even those used by other species, if those calls provide them with meaningful information and they can even modify their vocalizations to introduce novel components in the established sound-meaning coding system (Gil-da-Costa et al., 2003; Hauser, 1992; Hauser, 1989; Hauser & Wrangham, 1987). But using multi-sensory associations does not pay-off in the long run
3

E:\My Documents\Fra\JOLLER\Univ_Porto_RevistaDeLinguistica_060228.doc 2006-09-13, 14:57
under the pressure of increasingly large representational demands and once the need for representation of objects or events in the ecological setting reach a critical mass of about 50 items, sorting out those items in terms of rules becomes a much more efficient strategy (Nowak et al., 2000; Nowak et al., 2001). In line with this, the driving force towards linguistic representation and the emergence of syntactic structure appears to come from increased complexity in the representation of events in the species ecological environment and again there are plausible evolutionary accounts for such an increase in representational complexity with the advent of Homo erectus. One line of speculation is linked to bipedalism. Bipedal locomotion is definitely not exclusive of humans (avian species have also discovered it and use it efficiently, like in the case of the ostrich) but provided humanoids with the rather unique capacity of using the arms for foraging and effectively carrying food over larger distances. Again, mobility, per se, does not account for the need to increase representational power (migration birds travel over large distances and must solve navigation problems and yet have not developed the faculty of language because of that) but it adds to the complexity of the species ecological setting, posing increasing demands on representational capacity. Another type of navigational needs that has been suggested as potentially demanding more sophisticated representation and communication abilities is the more abstract navigation in social groups (Tomasello & Carpenter, 2005) and the abstract demands raised by the establishment of “social contracts”, as Terrence Deacon had pointed out in his 1997 book (Deacon, 1997). To be sure, abstract representation capacity can even be observed, at least to a certain extent, in non-human primates (Savage-Rumbaugh et al., 1993; Tomasello et al., 1993) but nevertheless they fall short of human language as far as syntax and combinatorial ability is concerned.
The general notion conveyed by this overview of the possible evolution of language communication is that the capacity for language communication must have emerged as a gradual adaptation, building on available anatomic and physiologic structures whose functionality enables small representational advantages in the humanoids’ increasingly complex ecological contexts. Of course, because evolution is not goal-oriented, the successive adaptations must be seen more as accidental and local consequences of a general “arms-race” process that although not aimed at language communication still got there, as it can be observed in retrospective. Evolutionary processes are typically like this, lacking purpose or road-map but conveying a strong feeling of purposeful design when looked upon in the back-mirror. William Paley’s proposal of the “watchmaker argument” is an example of how deep rooted the notion of intelligent design can be when viewing evolutionary history in retrospective (and knowing its endpoint from the very beginning of the reasoning). Yet it is well known that complex or effective results do not have to be necessarily achieved by dramatic or complex design, but that they are rather often the consequence of deceivingly simple interactions that eventually produce relatively stable long-term consequences (Enquist & Ghirlanda, 2005; Dawkins, 1998; Dawkins, 1987). The problem is accepting non-teleological explanations when the final results appear to be so overwhelmingly clear in their message of an underlying essential order. But how could that be otherwise? How could the current state of the evolutionary process not look like a perfectly designed adaptation to the present ecological settings if non-adapted behaviour or structures confer disadvantages that undermine the species’ survival? Obviously the potential advantages that small and purposeless anatomic and physiological changes might confer are strictly linked to the ecological context in which they occur. Suppose, for instance that or recently discovered ancestor, Tiktaalik (Daeschler et al., 2006), the missing link between fish and tetrapods, had appeared now rather than under the Devonian-Carboniferous Period, between 409 Mya and 354 Mya (Futuyama, 1998): How long would Tiktaalik have survived in today’s ecological settings? Probably not very long. The bony fins that the animal successfully used as
4

E:\My Documents\Fra\JOLLER\Univ_Porto_RevistaDeLinguistica_060228.doc 2006-09-13, 14:57
rudimentary legs conveyed significant advantage in an ecological context where land life was limited to the immediate proximity of water and therefore there were no land competitors. Under these circumstances, the ability to move on the water bank just long enough to search for fish that might have been trapped in shallow waters was obviously a big advantage but would have made the animal an easy prey nowadays, unless it had evolved shielding, poisoning or stealth strategies to compensate for its low mobility. In other words, the potential success of traits emerging at some point in the evolutionary process is intimately dependent on the ecological context in which they appear, suggesting that even a rudimentary ability to convey information via vocalizations may have offered small but systematic and significant advantages to certain groups of hominids. Indeed, an important aspect of this ecological context is that the innovation presented by even a rudimentary discovery of representational principles is likely to spread through cultural evolution processes (Enquist et al., 2002; Kamo et al., 2002; Enquist & Ghirlanda, 1998), propagating the innovation to individuals that may be both upstream, downstream or peers in the specie’s genetic lineage. From this perspective language evolution must be seen as the combined result of both cultural and genetic evolutionary processes.
The ability to use vocal or sign symbols to represent events or objects in the ecological context was probably common at least within several hominid species (Johansson, 2005) but its recursive use must have been discovered by Homo sapiens whose brain capacity developed (Jones et al., 1992) in an “arms-race” with the increasingly complex symbolic representational demands. From this evolutionary perspective, the language acquisition process observed in nowadays infants can be seen as a process that in a sense repeats the species’ evolutionary story, keeping in mind that it starts off from an ecological context where language communication per se does not have to be re-discovered and is profusely used by humans in the infant’s immediate environment. Of course, since both the early Homo sapiens and today’s infants adjusted and adjust to the existing ecological context, the dramatic contrast of the communicative settings of their respective ecological scenarios must account for much of the observed differences in outcome. The challenge here is to account for how this language acquisition process may unfold as a consequence of the general interaction between the infant and it’s ambient.
THE INFANT’S PRE-CONDITIONS FOR SPEECH COMMUNICATION To appreciate the biological setting for language acquisition it is appropriate to take a closer look at some of the infant’s capabilities at the onset of life.
Among the range of abilities displayed by the young infant, perceiving and producing sounds are traditionally considered to be the most relevant to the language acquisition process. These capabilities are not the only determinants of the language acquisition process (language acquisition demands multi-sensory context information, as it will be argued below) but they certainly play an important role in the shaping of the individual developmental path. If there are biologically determined general propensities to perceive or generate sounds in particular ways, these propensities are likely to contribute with significant developmental biases that ought to become apparent components of language acquisition, although such biological biases are dynamic plastic components of the language acquisition process that will necessarily influence and be influenced by the process itself (Sundberg, 1998) but here the focus will be on just some production and perception biases.
Production constraints To estimate the infant’s production strategies, one may use the evidence provided by infant vocalizations in order to derive underlying articulatory gestures. However the acoustic analysis of high pitch vocalizations is not a trivial task, since high fundamental frequencies
5

E:\My Documents\Fra\JOLLER\Univ_Porto_RevistaDeLinguistica_060228.doc 2006-09-13, 14:57
effectively reduce the resolution of the available spectral representations. An additional difficulty is caused by the anatomic differences between the infant’s and the adult’s vocal tracts. The vocal tract of the newborn infant is not a downscaled version of the adult vocal tract. One of the most conspicuous departures from proportionality with the adult vocal tract is the exceedingly short pharyngeal tract in relation to the oral cavity observed in the newborn infant (Fort & Manfredi, 1998). If the infant’s vocal tract anatomy was proportionally the same as the adult, the expected spectral characteristics of the infant’s utterances would be essentially the same as the adult’s although proportionally shifted to higher frequencies. However this is not the case, in particular during early infancy, and therefore articulatory gestures involving analogous anatomic and physiologic structures in the adult and the young infant will tend to result in acoustic outputs that are not linearly related to each other. To be sure, if the adult vocal tract were proportionally larger than the infant’s, equivalent articulatory gestures would generally tend to result in proportional acoustic results.2 Conversely, due to the lack of articulatory proportionality, when anatomic and physiologic equivalent actions are applied to each of the vocal tracts the adult’s and the infant’s vocal tracts will simply acquire different articulatory configurations. The fact that analogous articulatory gestures in young infants and adults lead to different acoustic consequences raises the question of the alleged phonetic equivalence between the infant’s and adult’s speech sound production. In fact it is not trivial to equate production data from infants with their supposed adult counterparts since phonetic equivalence will lead to different answers if addressed in articulatory, acoustic or auditory terms.
To gain some insight on this issue a crude articulatory model of the infant’s vocal tract was used to calculate the resonance frequencies associated with different articulatory configurations. The model allows a virtual up-scaling of the infant’s vocal tract model, to “match” a typical adult length, enabling the “infant’s formant data” to be plotted directly on the adult formant domain. With this model the acoustic consequences of vocalizations while swinging the jaw to create a stereotypical opening and closure gesture could be estimated for between larynx and vocal tract length corresponding to an infant, a child and an adult speaker (Lacerda, 2003). An important outcome of this model is that the vowel sounds produced by the “young infant” vocalizing while opening and closing the jaw are differentiated almost exclusively in terms of their F1 values. Variation in F2 appears only once the larynx length increases towards adult proportions (Robb & Cacace, 1995). Equivalent opening and closing gestures in the adult introduce some variation in F2, in particular when the jaw is wide open because the ramus tends to push back and squeeze the pharynx. Since the infant’s pharynx is much shorter, an infant producing the same swinging gesture will not generate appreciable variation in F2. To be able to modulate F2 in a similar way, the infant would have to pull the tongue body upwards toward the velum, probably by contracting the palatoglossus and the styloglossus muscles. For this configuration the infant’s vocalization would have approximately the same formant structure as an adult [ɑ] vowel. To produce more front vowels, the infant would have to create a constriction in a vocal tract region at a distance about 70% full vocal tract length from the glottis, as predicted by the Acoustical Theory of Speech Production (Fant, 1960; Stevens, 1998).
A clear implication of the anatomical disproportion between infants and adults is that the early infant babbling sounds in general cannot be directly interpreted in adult articulatory phonetic terms. Of course acoustic-articulatory relations are even problematic in the adult case because the acoustic-articulatory mapping is not biunivocal, as demonstrated by the 2 Departures from this acoustic proportionality would however be observed for situations where the cross sectional area of the infant’s proportional vocal tract would turn out to be under absolute critical values associated with turbulent or laminar flow through constrictions.
6

E:\My Documents\Fra\JOLLER\Univ_Porto_RevistaDeLinguistica_060228.doc 2006-09-13, 14:57
everyday examples of individual compensatory strategies and byte-block experiments (Gay et al., 1981; Gay et al., 1980; Lindblom et al., 1977; Lane et al., 2005), but the problem is even more pertinent in the case of the infant’s production of speech sounds (Menard et al., 2004). Indeed, in addition to the non-proportional anatomic transformation, the infant, in contrast with the adult speaker, does not necessarily have underlying phonological targets, implying that infant vocalizations in general ought to be taken at the face-values of the acoustic output rather than interpreted in terms of phonetically motivated articulatory gestures. Disregarding for a moment experimental results suggesting that the young infant has the ability to imitate certain gestures (Meltzoff & Moore, 1983; Meltzoff & Moore, 1977) and even appears to be able to relate articulatory gestures with their acoustic outputs (Kuhl & Meltzoff, 1996; Kuhl & Meltzoff, 1988; Kuhl & Meltzoff, 1984; Kuhl & Meltzoff, 1982; Meltzoff & Borton, 1979), the assumption here is that the infant is initially not even attempting to aim at an adult target sound. Thus in a situation of spontaneous babbling, where the infant is not presented with a “target” sound produced by a model, the phonetic content of the infant’s productions must be strongly determined by the infant’s articulatory biases and preferences while the infant’s productions (which often are rather diffuse in phonetic terms) will be perceived according to the expectations of the adult listener. As a consequence, the infant’s vocalizations in a normal communicative setting are prone to be influenced from the very beginning by the adult’s knowledge and expectation on the language. This type of interpretative circularity is indeed an integrate component of the very speech communication process and must be taken into account in studies of language development as well as in linguistic analyses.
Consider, for instance, the Swedish infants’ preferences for different articulatory positions illustrated in figure 1, redrawn here after data from Roug, Landberg and Lundberg (Roug et al., 1989).
7

E:\My Documents\Fra\JOLLER\Univ_Porto_RevistaDeLinguistica_060228.doc 2006-09-13, 14:57
Age in months
20181614121086420
% o
ccur
renc
e
100
90
80
70
60
50
40
30
20
10
0
Place
glottal
velar/uvular
dental/alveolar
bilabial
Age in months
20181614121086420
% o
ccur
renc
e
100
90
80
70
60
50
40
30
20
10
0
Place
glottal
velar/uvular
dental/alveolar
bilabial
Age in months
20181614121086420
% o
ccur
renc
e
100
90
80
70
60
50
40
30
20
10
0
Place
glottal
velar/uvular
dental/alveolar
bilabial
Age in months
20181614121086420
% o
ccur
renc
es
100
90
80
70
60
50
40
30
20
10
0
Place
glottal
velar/uvular
dental/alveolar
bilabial
Figure 1. Occurrence of place of different places of articulation in babbling produced by four Swedish infants. Original data from Roug et al. (1989).
In spite of the individual preferences, the overall trend of these data indicates a preference for velar and pharyngeal places of articulation during the first months of life. Pharyngeal places of articulation are typologically less frequent than places of articulation involving contact somewhere between the lips and the velum but they were nevertheless dominating in these infants’ early babbling. But although the bias towards the pharyngeal places of articulation is likely to be a consequence of the vocal tract anatomy, where the young infant’s extremely short pharynx leads to pharyngeal-like formant patterns when the infant’s tongue actually makes contact with the velum or palate, the infant’s productions are actually perceived by the adult as being produced far back in the vocal tract, which translated in adult proportions means pharyngeal articulations. In a sense there is nothing wrong with this adult interpretation. It is correct from the acoustic perspective; the problem is that it is mapped into an adult vocal-tract that is not an up-scaled version of the infant’s. Thus, because of this non-proportional mapping, acoustic or articulatory equivalence between sounds produced by the infant or the adult lead necessarily to different results and may lead to in overestimation of the backness of the consonantal sounds produced by the infant early in life (Menard et al., 2004).
Interactive constraints All living systems interact one way or the other with their environment. At any given time the state of a living system is therefore the result of the system’s history of interaction with its ecological context. Humans are no exception. They are simultaneously “victims” and actors in their ecologic setting. They are the living result of long-term cross-interactions between internal genetic factors, the organism’s life history and external ambient factors. Among the multivariable interactions observed in natural systems, language development is certainly an
8

E:\My Documents\Fra\JOLLER\Univ_Porto_RevistaDeLinguistica_060228.doc 2006-09-13, 14:57
outstanding example of endogenous plasticity and context interactivity. As pointed out above, the infant’s language acquisition process must be seen as an interactive process between the infant and its environment. In principle, in this mutual interaction perspective, both the infant and its environment are likely to be affected by the interaction. However, because the infant is born in a linguistic community that has already developed crystallized conventions for the use of sound symbols in communication, the newcomer has in fact little power against the community’s organized structure. Obviously, the conventions used by the community are not themselves static but this aspect has very limited bearing on the general view of language acquisition. Not only do the users of the established language outnumber the infant but also the community language represents a coherent and ecologically integrated communication system, whose organization the individual newcomer can hardly threaten. In line with this, a crucial determinant of the infant’s initial language development must be given by the feedback that the community in general and the immediate caregivers, in particular, provide. Thus, if ambient speakers implicitly (and rightly) assume that the infant will eventually learn to master the community’s language, they are likely to interpret the infant’s utterances within the framework of their own language. In other words, adult speakers will tend to assign phonetic value to the infant’s vocalizations, relating them to the pool of speech sounds used in the established ambient language and the adult will tend to reward and encourage the infant if some sort of match between the infant’s productions and the adult expectations is detected.
To address this question (Lacerda & Ichijima, 1995) investigated adult spontaneous interpretations of infant vocalizations. The infant vocalizations were a random selection of 96 babbled vowel-like utterances obtained from a longitudinal recording of two Japanese infants at 17, 34 and 78 weeks of age. The subjects were 12 Swedish students attending the second term of Phonetics3 who were requested to estimate the tongue positions that the infant might have used to produce the utterances. The subjects indicated their estimates in a crude 5×5 matrix representing the tongue body’s frontness and height parameters. In an attempt to simulate spontaneous adult responses in a natural adult-infant interaction situation, the students’ judgements had to be given within a short time window to encourage responses on the basis of their first impressions. The answer forms consisted of a series of response matrices, one for each stimulus. The subjects’ task was to mark in the matrices the cell that best represented tongue height and frontness for each presented utterance. If all the subjects would agree on a specific height and frontness level for a given stimulus, the overall matrix for that stimulus would contain 12 response units on the cell representing those coordinates and zero for all the other cells.
3 Although students at this level are not strictly speaking naïve listeners, they represented a good enough balance between non-trained adults and the ability to express crude phonetic dimensions.
9
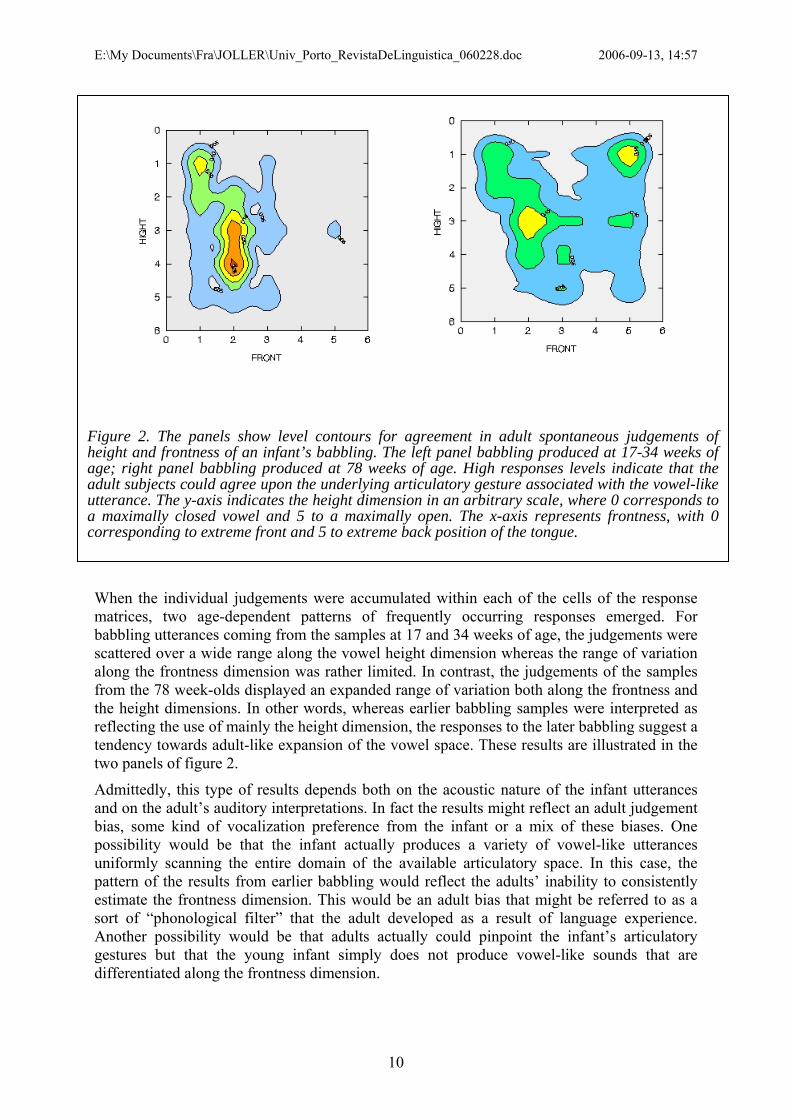
E:\My Documents\Fra\JOLLER\Univ_Porto_RevistaDeLinguistica_060228.doc 2006-09-13, 14:57
Figure 2. The panels show level contours for agreement in adult spontaneous judgements of height and frontness of an infant’s babbling. The left panel babbling produced at 17-34 weeks of age; right panel babbling produced at 78 weeks of age. High responses levels indicate that the adult subjects could agree upon the underlying articulatory gesture associated with the vowel-like utterance. The y-axis indicates the height dimension in an arbitrary scale, where 0 corresponds to a maximally closed vowel and 5 to a maximally open. The x-axis represents frontness, with 0 corresponding to extreme front and 5 to extreme back position of the tongue.
When the individual judgements were accumulated within each of the cells of the response matrices, two age-dependent patterns of frequently occurring responses emerged. For babbling utterances coming from the samples at 17 and 34 weeks of age, the judgements were scattered over a wide range along the vowel height dimension whereas the range of variation along the frontness dimension was rather limited. In contrast, the judgements of the samples from the 78 week-olds displayed an expanded range of variation both along the frontness and the height dimensions. In other words, whereas earlier babbling samples were interpreted as reflecting the use of mainly the height dimension, the responses to the later babbling suggest a tendency towards adult-like expansion of the vowel space. These results are illustrated in the two panels of figure 2.
Admittedly, this type of results depends both on the acoustic nature of the infant utterances and on the adult’s auditory interpretations. In fact the results might reflect an adult judgement bias, some kind of vocalization preference from the infant or a mix of these biases. One possibility would be that the infant actually produces a variety of vowel-like utterances uniformly scanning the entire domain of the available articulatory space. In this case, the pattern of the results from earlier babbling would reflect the adults’ inability to consistently estimate the frontness dimension. This would be an adult bias that might be referred to as a sort of “phonological filter” that the adult developed as a result of language experience. Another possibility would be that adults actually could pinpoint the infant’s articulatory gestures but that the young infant simply does not produce vowel-like sounds that are differentiated along the frontness dimension.
10

E:\My Documents\Fra\JOLLER\Univ_Porto_RevistaDeLinguistica_060228.doc 2006-09-13, 14:57
Whatever the underlying reason for the observed response patterns, they reflect an actual interactive situation where adults and infants meet each other, linked by phonetics. Indeed, the adult and the infant are intimately connected with each other in the language communication process and the actual causes of the observed response patterns cannot be disentangled without the independent information provided by general theoretical models. At this point an acoustic-articulatory model of the infant vocal tract is a useful research tool because it provides some insight on the potential acoustic domain of the infant’s articulatory gestures. Interestingly, as implied by the acoustic-articulatory considerations addressed in the former section, the infant’s short pharyngeal length clearly curtails acoustic variance in F2, which is the acoustic correlate of the frontness dimension. Indeed, the notion that young infants might be mainly exploring the height dimension of the vowel space was corroborated in a follow-up listening test where a group of four trained phoneticians was asked to make narrow phonetic transcriptions of the babbling materials that had been evaluated by the students. The phoneticians carried out their task in an individual self-paced fashion. They were allowed to listen repeatedly to the stimuli, without response-time constraints, and requested to rely on the IPA symbols, with any necessary diacritics, to characterize the vowel-like utterances as well as possible. However, contrary to the typical procedures used in phonetic transcriptions of babbling, these phoneticians were not allowed to reach consensus decisions nor were they aware that their colleagues had been assigned the same task. The phoneticians’ data were subsequently mapped onto the 5×5 matrices that had been used by the students by imposing the 5×5 matrix on the IPA vowel chart, assuming that the “corners” of the vowel quadrilateral would fit on the corners of the domain defined by the matrix. The results of the phoneticians’ IPA transcriptions and the subsequent mapping procedure essentially corroborated the overall pattern of the students. The consistency between the judgements by the students and by the trained phoneticians discloses a provocative agreement between the two groups’ spontaneous interpretations of infant babbling. Once again, it is not possible to resolve the issue of whether this agreement is a consequence of a strong phonological filter or of acoustic-articulatory constraints in the infant’s sound production. The data can also be interpreted as suggesting that the infant’s utterances are articulatorily so undifferentiated that only main aspects of their production can consistently be agreed upon by a panel of listeners. Apparently, it is only the height dimension that is differentiated enough to generate consistent variance in the adult estimates. To be sure, it cannot be excluded that all that the young infant is doing during these vocalizations is to open and close the mouth keeping the tongue essentially locked to the lower jaw (Davis & Lindblom, 2001; MacNeilage & Davis, 2000a; MacNeilage & Davis, 2000b; Davis & MacNeilage, 1995). This account is supported by the theoretical evidence from the previous acoustic-articulatory model using short pharyngeal length (Lacerda, 2003) and suggests that the spontaneous adult judgements of the infant’s babbling reflect rather accurately the major features of the infant’s actual phonetic output.
In summary, the acoustic-articulatory data, the adult perception data and the acoustic-articulatory model, all provide consistent support to the notion that the infant initially uses mainly the high-low dimension of the vowel space. The full exploration of the vowel space, including the use of the front-back dimension, comes at a later age.
Clearly, the interactive constraints affect much more than just vowel perception. As stated above, the infant and the adult interacting with each other create a particular setting of mutual adjustments to reach the overall common goal of maintaining speech communication (cf. Jakobson’s (1968) phatic function of speech communication), where adults modify their speaking styles in response to their own assumptions on the infant’s communication needs and intentions. These speech and language adjustments involve modifications at all linguistic levels, like frequent prosodic and lexical repetitions, expanded intonation contours and longer
11

E:\My Documents\Fra\JOLLER\Univ_Porto_RevistaDeLinguistica_060228.doc 2006-09-13, 14:57
pauses between utterances. In addition to these supra-segmental modifications, there is evidence of more detailed modifications observed at the segmental level. For instance, when addressing 3-month-olds adults seem to expand their vowel space in semantic morphemes (van der Weijer, 1999), as demonstrated by cross-linguistic data from mothers speaking American English, Russian and Swedish (Kuhl et al., 1997). The adult production of consonants is also affected in the adult-infant communication. The voice/voiceless distinction expressed by VOT (Voice Onset Time) seems to be systematically changed as a function of the infant’s age while preserving the main pattern of durational relations that occur in the adult language4. In infant-directed speech (IDS) to 3-month-olds, the VOT is significantly shorter than in corresponding utterances in adult-directed speech (ADS), leading to an increased overlap of the voiced and voiceless stops (Sundberg & Lacerda, 1999). In contrast, as suggested by preliminary results (Sundberg & Lacerda, under review), VOT in IDS to 12-month-olds seems to provide a higher differentiation between voiced and voiceless stops than is typically observed in ADS. Within the framework of the communication setting, such adult phonetic and linguistic modifications can be interpreted as an indication that the adult adjusts to the communicative demands created by the situation. Putting together the suprasegmental, the VOT and the vowel formant data a picture of adjustments to the infant needs emerges. Exploring the significance of variations in F0, the adult may modulate the infant’s attention during the adult-infant interaction in order to keep the infant at an adequate state of alertness. When the adult-infant communication link is established, the adult seems to intuitively offer speech containing clear examples of language-specific vowel qualities embedded in a rich emotional content. Because F0 modulation is essentially conveyed by the vowels, their phonetic enhancement is quite natural, while VOT distinctions may be less phonetic specification at this stage. Although the perceptual relevance vowel enhancement and VOT reduction have not been experimentally assessed from the infant’s perspective, a plausible interpretation is that the adult intuitively guides the infant towards language.
One possibility is that the adult opportunistically explores the infant’s general auditory preference for F0 modulations. The adult adds some excitement to the infant perception by spicing the F0 contours with “crispy” consonants that by contrast enhance the vowel segments (Stern et al., 1983). This patterning of the speech signal is likely to draw the infant’s attention to the vocalic segments. A further indication of the adult’s adaptation to the perceived demands of the infant is provided by the change in phonetic strategy that is observed when adults address infants at about 12 months of age. Triggered by the clear signs of language development provided by the first word productions and proto-conversations, the adult introduces phonetic explicitness also to the stop-consonants, as suggested by data being processed at Stockholm University’s Phonetics laboratory. Obviously, in this scenario, the communication process between the adult and the infant cannot be equated to an adult-to-adult conversation. Rather, the adult appears to use language as an efficient and interactive playing tool, where speech sounds are the toys themselves. Through this adaptive use of the language, the adult explicitly provides the infant with proper linguistic information wrapped in the playful and efficient setting of the adult-infant interaction. The infant is spontaneously guided by the adult’s clear cues towards the general conventions of the speech communication act, like phonetic markers of turn-taking such as F0 declination, final lengthening and pause duration (Bruce, 1982).
Yet another conspicuous aspect of interaction constraints is the frequent use of repetitive patterns in infant-directed speech. As evidenced by a number of cross-language studies, adults interacting with infants tend to repeat target words and phrases as well as intonation patterns 4 This is true at least for Swedish, where it has been observed that the complementary quantity distinctions were preserved in IDS to 3-month-olds.
12

E:\My Documents\Fra\JOLLER\Univ_Porto_RevistaDeLinguistica_060228.doc 2006-09-13, 14:57
(Papousek & Hwang, 1991; Papousek & Papousek, 1989; Fernald et al., 1989). Stockholm University’s experimental data on mother-infant interactions clearly indicates that adults are extremely persistent in using, for example, words and phrases in a highly repetitive manner when addressing young infants. In the context of memory processes and brain plasticity this is likely to be a powerful strategy, as predicted by the language acquisition model that generates emergent patterns as a direct consequence of the interaction between memory decay and exposure frequency (Lacerda et al., 2004a).
To take the infant’s perspective, it is mandatory to discuss the impact that the adult’s phonetic modifications and repetition patterns may have for the infant.
Perceptual constraints The newborn infant is exposed to a wide variety of information from the onset of its post-natal life. The infant’s contact with its external environment is mediated by the information from all the sensory input channels, in continuous interaction with the infant’s endogenous system. Clearly, the infant’s initial perception of the world has to rely on the range of the physical dimensions in the environment that the infant’s sensory system can represent.5 From the current point of view, because the infant is not assumed to be endowed with specific language-learning capabilities, the infant’s perceptual capabilities at birth can be expected to be important determinants of the infant’s development. The infant’s auditory capability, in particular, is likely to be an important, though not sufficient, pre-requisite for the development of the speech communication ability, so let us try to get a picture of the infant’s initial auditory capacity by relating it to the adult’s.
From the onset of its post-natal life, the infant seems to have an overall frequency response curve that is essentially similar to the adult’s, though shifted upwards by about 10 dB (Werner, 1992). Also the quality factors of the infant’s tuning curves are comparable to the adult’s, at least in the low frequency region up to about 1 kHz. Given this resemblance, the infant’s and the adult’s auditory systems may be expected to mediate similar sensory representations of the speech signals, implying that differences in behavioural response patterns to speech stimuli may be attributed to higher-level integrative factors rather than peripheral psychoacoustic constraints.
Infant speech discrimination studies involving isolated speech sounds, typically demonstrate that young infants are able to discriminate a wide variety of contrasts, virtually all the speech sound contrasts that they have been tested with. In fact, even 4-days old infants have been shown to discriminate between CV bursts as short as 20 ms (Bertoncini et al., 1987), suggesting that the newborn infant is equipped with the necessary processing mechanisms to differentiate between bilabial, dentoalveolar and velar stop consonants. These and similar results from speech discrimination experiments (Eimas, 1974) with young infants demonstrate that there is enough acoustic information to discriminate the stimuli. This is likely to be a pre-requisite for linguistic development but discrimination ability, by itself, is clearly not enough. In fact, discrimination alone is likely to generate a non-functional overcapacity of separating sounds on the basis of their acoustic details alone. Linguistically relevant categories explore similarities among speech sounds that go beyond the immediate acoustic characteristics, as it is the case of allophonic variation or the same vowel uttered by female or male speakers. Such
5 An organism’s sensory system can be seen as a filter attending to a limited range within each of the environment’s physical dimensions. The human visual system, for instance, is adapted to represent the range of electromagnetic radiation with frequencies between the infrared and ultra-violet and the auditory system reacts to changes in the atmospheric pressure falling within a limited range of amplitude and frequency whereas other species pick up other ranges of these physical dimensions. Given the differences in the representation ranges, the “reality” available to the different species is likely to be different too.
13

E:\My Documents\Fra\JOLLER\Univ_Porto_RevistaDeLinguistica_060228.doc 2006-09-13, 14:57
sounds are easily discriminable on pure acoustic basis but are obviously linguistically equated by competent speakers. Thus, a relevant question that has to be addressed by the model concerns the processes of early handling of phonetic variance underlying the formation of linguistically equivalent classes and the question of how the infant’s initial discrimination ability relates to potential initial structure in the infant’s perceptual organisation must be addressed. Parallel to the main trend of the experimental results pointing to a general ability to discriminate among speech sound contrasts, a remarkable asymmetry in the discrimination of vowel contrasts was observed in Stockholm University’s Phonetics laboratory. Experiments addressing the young infants’ ability to discriminate [ɑ] vs. [a] and [ɑ] vs. [^], indicated that the latter contrast was more consistently discriminated than the former (Lacerda, 1992b; Lacerda, 1992a; Lacerda & Sundberg, 1996). The stimuli were synthetic vowels that differed only in their F1 or F2 values6, reflecting a contrast in sonority (i.e. vowel height dimension, F1) or in chromaticity (i.e. vowel frontness dimension, F2). The contrasts were conveyed by equal shifts in F1 or F2, expressed in Bark. The results were obtained from two different age ranges and subject groups, using age-adequate techniques. The younger infants, around 3 months of age, were tested using the High Amplitude Sucking technique (Eimas et al., 1971) and the older subjects, 6 to 7 month old, were tested with the Head-Turn technique (Kuhl, 1985). In both cases the outcome was that discrimination of the contrasts involving differences in F1 dimension was more successful than for the corresponding contrasts conveyed by F2 differences, in spite of the fact that equal steps in Bark actually mean larger differences in F2 than in F1 if expressed in Hz. In principle this discrimination advantage for the F1 contrasts might be attributed to the concomitant intensity differences that are associated with changes in F1 frequency but intensity was also strictly controlled in follow-up experiments using a parallel synthesis technique (where overall intensity is not dependent on formant frequency) and yet the F1 advantage in discrimination performance persisted. Thus, these experiments suggest that the infant’s perceptual space for vowels is asymmetric in terms of height and frontness contrasts, with a positive discrimination bias towards height.
Putting the infant in its global context of production, perception and interaction, there seems to be an inescapable pattern of asymmetry that tends to enhance vowel contrasts along the height dimension. As stated above, data from infant vowel production, adult-infant interaction and infant vowel perception, all converge towards a pattern of dominance of the height dimension in early language acquisition. These results are also consistent with typological data from natural vowel systems (Maddieson & Emmorey, 1985; Maddieson, 1980; Liljencrants & Lindblom, 1972). To the extent that infant speech perception and the adult’s interpretation of babbling provide an indication of the biases underlying language development in general, vowel height may be expected to play a dominant role in the organization of vowel systems. In fact, this is in good agreement with the typological data showing that vowel height seems to be the first single explored dimension in vowel systems of increasing complexity whereas frontness contrasts usually are accompanied by rounding gestures, as if to underline the frontness distinction (Liljencrants & Lindblom, 1972).
In summary, the overall message provided by the speech perception experiments with infants is indeed compatible with the notion that the infant starts off with a general auditory process that gains linguistic content in the course of the language acquisition process. Young infants are reportedly good at discriminating speech sound contrasts but their discrimination can largely be accounted for by sensitivity to acoustic differences per se, not necessarily liked to underlying linguistic strategies. A large body of speech perception studies in which infants
6 F1 and F2 refer to the first and second resonance frequencies of the vocal tract, i.e. formants. The first two formants are usually enough to specify the main characteristics of a vowel’s phonetic quality.
14

E:\My Documents\Fra\JOLLER\Univ_Porto_RevistaDeLinguistica_060228.doc 2006-09-13, 14:57
were tested on discrimination of both native and non-native speech sound contrasts indicates a progressive attention focus towards sound contrasts that are relevant in the ambient language. With respect to vowel perception, for instance, it was observed that 6-month-old infants tend to display a vowel discrimination behaviour that seems to have been influenced by their exposure to the ambient language (Kuhl et al., 1992). Infants at this age show a higher tolerance to allophonic variation for the vowels occurring in their native language than for non-native vowels, a phenomenon often referred to as the “perceptual magnet effect” (Iverson & Kuhl, 2000; Iverson & Kuhl, 1995; Kuhl, 1991; Lotto et al., 1998). This process seems to be accompanied by increasing attention focus on the ambient language and, by about 10 months of age, infants may no longer be able to discriminate foreign vowel contrasts (Polka & Werker, 1994). Also the perception of consonantal contrasts appears to follow a similar developmental path, although the development is shifted upwards in age. Whereas by about 6 to 7 months of age no particular differences in the discrimination ability for native and non-native consonantal contrasts have been observed, at 12 months of age infants seem to be more focused on the native than on the non-native consonant contrasts (Werker & Tees, 1992) (Best et al., 2001; Werker & Logan, 1985; Tees & Werker, 1984; Werker & Tees, 1983; Werker et al., 1981). Taken together, these experimental results seem to be that exposure to the ambient language shifts the infant’s focus from a general to more a differentiated and language-bound discrimination ability (Polka & Werker, 1994; Polka & Bohn, 2003).
Much of the speech discrimination studies assessing the infant’s early capabilities have been carried out using isolated speech sounds. Isolated speech sounds and their underlying phonemic representations, as portrayed in linguistic theories, are useful for logical and formal descriptions of language. Nevertheless the phonemic concept is not obviously connected to the speech sounds that supposedly materialize it. Phonemes are idealizations that capture the essential contrastive function in language and are therefore not immediately available to the young language learner. What the infant is exposed to are strings of interwoven speech sounds, with all the concomitant co-articulation effects and non-canonical aspects affecting all levels of connected natural speech. Isolated speech sounds are rare in natural interaction, raising problems to the linguistic interpretation of many infant speech discrimination experiments, in particular when single speech sound tokens are taken to represent a phonemic category. In particular, the lack of variance in the stimuli presented to the infant is likely to severely limit the ecological validity of the results but the linguistically relevant issue is to try to find out how the infant, handling natural variance, nevertheless homes in an adult-compatible linguistic representation. The challenge is to account for language acquisition building on the fuzziness and variability that are characteristic of the infant’s natural environment.
About a decade ago, infant speech perception studies started to address this issue using a variety of experimental approaches. For example, in an attempt to assess the significance of repetitive structures embedded in a continuous speech signal, Saffran and colleagues (Saffran et al., 1996) presented 8-month old infants with sequences of concatenated CV-sequences drawn from a set of four basic CV-sequences. The Bayesian conditional probability of the concatenated CV-sequences was manipulated to ensure that certain CV pairs would occur with higher probability than others. This was done to reflect natural language structure, in which syllable sequences within words tend to have higher transitional probabilities than syllable sequences across words. After a 2 minutes exposure to this type of material, the infants showed a significant preference for the pseudo-words formed by syllables of high transitional probability, suggesting that they had been able to pick up implicit statistical properties of the speech material (Saffran & Thiessen, 2003; Saffran, 2003; Saffran, 2002; Seidenberg et al., 2002). Also a number of studies carried out by the late Peter Jusczyk and
15

E:\My Documents\Fra\JOLLER\Univ_Porto_RevistaDeLinguistica_060228.doc 2006-09-13, 14:57
colleagues suggest that infants are sensitive to high frequency words in their ambient language. The group reported, for instance, that four-month-old infants were sensitive to the high frequency exposure to their own names (Mandel & Jusczyk, 1996; Mandel et al., 1996) and also that nine-month-olds, in contrast with 7½-month-olds, were able to pick up high frequency words from the speech stream of a story telling (Johnson & Jusczyk, 2001; Mattys & Jusczyk, 2001; Houston et al., 2000; Nazzi et al., 2000; Jusczyk, 1999).
These experiments represent different scenarios of language exposure. In the experimental set up Saffran et al. only the acoustic information provided by synthetic utterances was available to the infants, who nevertheless could use the statistical regularities to structure the continuous sound streams in spite of the limited exposure and sparse information load of the signal. Jusczyk’s work provides a closer match to a natural language acquisition setting since, in addition to the audio signal, the infants also had access to picture books providing visual support to the story they were exposed to. In comparison with Saffran and colleagues’s set up, Mandel and Jusczyk’s experiment clearly offered a much richer linguistic environment due to the variance in the speech material that the infants were exposed to (Mandel & Jusczyk, 1996). By itself, the audio signal available to Mandel and Jusczyk’s subjects during the training sessions is not nearly as explicit as in Saffran’s set up. However, the total amount of exposure (with daily exposure sessions carried out for about two weeks) was far more extensive in Jusczyk’s experiment. In addition to this longer exposure, the infants were also encouraged to look at a picture book, which may have been a critical component for the positive outcome of the experiment. Indeed, in line with the ideas expressed in this article, linguistic meaning emerges from the co-varying multi-sensory information available during exposure – in Mandel and Jusczyk’s case, the naturalistic speech co-varying with the visual information.
To study the significance of co-varying multi-sensory information a series of experiments designed to create learning situations from controlled multi-sensorial information was recently started. To assess the infant’s ability to link acoustic and visual information in a linguistically relevant way a variant of the visual preference technique has been used. The preliminary results suggest that 8-month-old infants are able to establish linguistic categories, such as nouns, from exposure to variable but consistent audio-visual information (Lacerda et al.).
MODELLING THE INFANT IN AN ECOLOGICAL SETTING
Background and overview of an Ecological Theory of Language Acquisition This section presents a general model of a system capable of learning linguistic referential functions from its exposure to multi-sensory information (Lacerda et al., 2004a). By itself, the model has a wider and more abstract scope than what has traditionally been considered as language learning. Rather than focusing on the acoustic signal per se, as the main determinant of the acquisition of spoken language, it is here suggested that the language acquisition should be addressed as a particular case of a general process capturing relations between different sensory dimensions. In this view linguistic information is implicitly available in the infant’s multi-sensory ecological context, and is derivable from the implicit relationships between auditory sensory information and other sensory information reaching the infant. Early language acquisition becomes therefore a particular case of a more general process of detection of contingencies available in the sensory representation space.
Two initial assumptions are made in this model: one is that there is multi-sensory information available to the system and the other is that the system has a general capacity of storing the incoming sensory information but this latter assumption does not mean that the system will permanently store information or even all the incoming information.
16

E:\My Documents\Fra\JOLLER\Univ_Porto_RevistaDeLinguistica_060228.doc 2006-09-13, 14:57
In the case of the infant, this input is thought to consist of all the visual, auditory, olfactory, gustatory, tactile as well as kinaesthetic information. Maintaining life requires continuous interaction between the living system and its environment, e.g. the complex organisms’ basic life-supporting functions like breathing and eating. To succeed, the biological system must be able to handle information available in its environment and use it to acquire the necessary life-supporting resources. In this sense, information obviously refers to a vast range of physical and chemical properties of the organism’s immediate environment (like harshness and structure of surfaces with which the organism makes contact, chemical properties of the environment, pressure gradients, electromagnetic radiation, etc.) as well as information conveyed by potential relationships between these elements, like the underlying relation between sounds of speech and the visual properties of the objects that the speech signal might refer to. To be sure, living organisms tend to specialize on processing quite a limited range of the potentially available physical and biochemical diversity available in their environments, i.e. different systems specialize in more or less different segments of the available environment, exploring the potential advantages of focusing on specific ecological niches. Numerous examples, like bats exploring echolocation to survive in the ecological niche left open by their daylight competitors, or the specialized bugs, like the Agonum quadripunctatum or the Denticollis borealis (Nylin, 2006), that only emerge in the special environment created by the aftermath of forest fires. In these very general terms, the external environment is represented by changes in the system itself, changes that may in turn be responses and generate further interaction with the environment, and that a species evolutionary history has prompted the organism to select a segment of.
Also the infant must be regarded as biological system integrated and interacting with its environment. The infant’s environment is represented by sensory information conveyed by the sensory transducers interfacing with the environment, i.e. the changes that the environment variables induce in the specialized sensory transducers. To be sure, the infant’s sensory system’s response to the environment variables is not time-independent. Typically, as the infant learns and develops, its responses will change not only of the exposure to external stimuli but also as a consequence of the very changes in internal, global variables that are induced by that exposure. Given that the infant is continuously exposed to parallel sensory input simultaneously available from different sensory modalities, there the potential for combining this multimodal information into different layers of interaction. The hippocampus, for instance, is thought to be a structure capable of integrating different sources of sensory information in implicit memory representations (Degonda et al., 2005). However the perspective in this article is more functional and somewhat abstract. Sensory inputs are seen as n-dimensional representations of the external variables, and that such representations may be continuously passed to a general-purpose memory that will retain at least part of that information. Also the concept of memory is very general. It is a general-purpose memory space on which continuous sensory input is represented by changes in the detail-state of the organism that can be modelled as Hebbian learning (Munakata & Pfaffly, 2004). The sensory input is continuously mapped in this memory space, in a purposeless and automatic way but representations that are not maintained tend to fade out with time.
The infant’s ecologic settings In its ecologic setting, the infant is inevitably exposed to huge amounts of sensory input that at first sight may appear to be unstructured. At a closer look, however, the infant’s immediate world is indeed highly structured in the sense that the status of the parallel sensory inputs implicitly reflects the aspects of the structure of objects and events that are being perceived (Gibson & Pick, 2000). Language is part of this and the infant’s early exposure to it is indeed also highly context-bound and structured. In typical infant-adult interactions, the speech used
17

E:\My Documents\Fra\JOLLER\Univ_Porto_RevistaDeLinguistica_060228.doc 2006-09-13, 14:57
by the adult is attention catching, circumstantial and repetitive, making this sort of speech attractive for the infant, context bound and easily related to external objects and actors. Under these circumstances, constantly storing general sensory input under the exposure to the statistic regularities embedded in the external world must lead to the emergence of the underlying structure because memory decay effectively filters out infrequent exposures. So far, this formulation may seem rather close to classic Skinnerian reasoning and exposed to the classical criticism calling on the “poverty of the stimulus” argument. However, taking into account the very variance of the input, it is possible to tip the argument over its head and instead used as a resource for language learning.
From a global and long-term perspective language obviously builds on regularities at many levels, reflecting the conventionalized communication system with which individuals can share references to objects and actions in their common external, as well as internal and imaginary, worlds. On a short-term basis, the statistical stability of those regularities may not always be apparent, especially for the newborn. However, lacking long-term experience with language and knowledge of the world, the newborn is happily unaware of the potential problems that linguists assume infants to have. In other words, early language acquisition is not seen as a problem since the infant presumably does not have a teleological perspective. The infant may very well converge to adult language as a result of a parsimonious and “low-key tinkering process” that, under the pressure of local contingencies, leads to disclosure of the implicit structure of language. In fact, just because language is always used in a context – particularly at the early stages of infant-adult interactions, where language tends the focus on the proximate context – there are plenty of systematic relations between the acoustic manifestations of language and their referents.
Sketching an ecological setting of early language acquisition General background The present sketch of the language acquisition model assumes that sensory input is represented by values in an n-dimensional space, where each dimension arbitrarily corresponds to a single sensory dimension. Obviously, in this generic model, sensory dimensions like auditory input may themselves be further represented by m-dimensional spaces to accommodate different relevant auditory dimensions, but for this sketch a general and principled description will be sufficient. These external stimuli are mapped by the sensory system into the internal representation space. The mapping process does not involve any explicit interpretation of the input stimulus. It is viewed essentially as a sensory map affected by sensory limitations and the stochastic representation noise inherent to the system. This means that rather than directly converting the input into coordinates on the representation space, the sensory system adds a certain amount of noise to the input, reflecting the stochastic nature of neuronal activity. As a consequence of the added noise physically identical external stimuli will tend to be mapped onto overlapping activity distributions centred at neighbouring rather than identical coordinates on the representation space. At this stage it is assumed that the neuronal noise is uncorrelated with the input and that it has zero mean value, an assumption that essentially means that the noise’s long-term effect can be disregarded.
To calibrate the proposed model, taking into consideration its ecological context it is convenient to start out with an estimate of the magnitude and range of variation available in the model’s n-dimensional sensory space. To create a manageable model, a 2-dimensional space, supposedly representing the auditory and visual (A-V) sensory inputs7, was chosen
7 This implies a linearization of the auditory and visual components, meaning that each possible auditory spectrum is assigned a unique point along the “auditory axis” and a similar representation for the visual stimuli, a transformation that indeed does not really capture the natural dimensionality of the auditory and visual spaces.
18

E:\My Documents\Fra\JOLLER\Univ_Porto_RevistaDeLinguistica_060228.doc 2006-09-13, 14:57
here. Activity on a location of the representational space corresponding to these two dimensions is a manifestation of co-occurrences of rather specific auditory and visual stimulations that are stochastically associated with the location’s coordinates. Uncorrelated occurrences of auditory and visual sensory inputs will tend to scatter the corresponding representation activities. As a consequence, uncorrelated or random A-V activity tends not to build up at specific locations and does not contribute to structuring the representation space because activity will be smeared over a wide region. Looking at the sensory input from the perspective of the representational space, this lack of heightened localized activity means that there is no systematic relation between the input stimuli. But in the context of early language acquisition, uncorrelated A-V representations are not much more than a simple academic abstraction. Because language is used in a coherent way with its referents, ecologically relevant language acquisition settings are much more likely to provide correlated audio-visual information than not. In terms of the model, this will tend to raise the activity level in specific locations in the representation space. Put in these terms, a crucial question concerns the probability of hitting approximately the same location in the representation space, when the sensory input is mediating random, uncorrelated events.
However the notion of underlying sensory contingencies is not new. Behaviourists have attempted to account for learning in terms of reinforced stimulus-response correlations and been confronted with the “poverty of stimulus” argument. Therefore it is convenient to take a look at the dimensionality of this A-V search space in order to estimate of the number of possible discriminable events in the auditory space that may be created by all possible combinations of discriminable intensity levels and frequency bands. To simplify the calculations aspects like lateral suppression and masking effects that might affect the ability to discriminate between some of the theoretical sounds in this set are not taken into account. In reality, those effects would slightly reduce the number of distinct sounds but that is largely compensated by the rather the rather conservative assumptions on frequency and intensity discriminable steps. On the intensity dimension, it is assumed that level differences of at least 5 dB can be discriminated which yields approximately 17 intensity steps along the intensity dimension throughout the audible spectrum, taking into account the frequency dependency of the hearing threshold. The frequency range between 100 Hz and 4000 Hz is assumed to be discriminable also in 17 steps, corresponding approximately to 17 Bark scale intervals. It is assumed that the linguistically relevant sounds can be represented by their crude energy distribution along these 17 Bark bands, a rather conservative frequency range from which speech sounds like many fricatives tend to be excluded.
Viewing the auditory stimuli as instances of 17-band spectra with 17 possible intensity steps per band leads to an estimate of 1717 (≈ 1020) potentially discriminable spectral contours. This is, of course, a crude estimate whose main goal is to map possible acoustic stimuli onto a one-dimensional linear representation but it gives nevertheless a feeling for the range of possible spectral variation of relevant acoustic stimuli. An important consequence of estimating the domain of acoustic variation is that it gives an indication of the likelihood of hitting a given point in this space under a plausible time-window. 1020 is an amazingly large number. To get a feeling for its magnitude it may be imagined that each of those possible 1020 spectra is represented by a cell in a human body. With this analogy, it would be necessary to have about 10 million individuals, weighting 100 kg each, in order to obtain the 1020 cells corresponding to this crude estimate of the acoustic search space8. In such a space, hitting twice a given neighbourhood is an extremely significant even. Indeed, exploring the cell analogy, if one assumes that all those 10 million people pick up at random their travel destinations on the 8 The calculation is based on the assumption that there are approximately 100 million cells per gram of biological tissue, relatively independent of the tissue (Werner, 2006).
19

E:\My Documents\Fra\JOLLER\Univ_Porto_RevistaDeLinguistica_060228.doc 2006-09-13, 14:57
earth, chances are vanishing small that the same two people will happen to meet twice on those trips. Therefore, if one happens to meet the same neighbour of two trips, it is reasonable to view that second meeting as a very significant event, potentially suggesting that one is being followed by that neighbour. But even if it is not exactly the same neighbour that is met twice but just one of the nearest neighbours, the assumption of random trips suggests that even this is highly significant given the vanishingly small probability of that recurring random event. In other words, because of the extremely vast acoustic search space, recurrent events are extremely unlikely at random and therefore highly significant if they occur. Adding to the auditory space another sensory dimension, like the visual dimension, enhances even more the significance of recurrent correlated audio-visual events. Given the extremely low probabilities of repeated audio-visual events generated by random associations such repeated instances of correlated audio-visual events are even more unlikely than when the auditory dimension was considered alone. Thus, under ecologically relevant conditions an organism can “take for granted” these highly significant events and interpret them as systematic associations. In other words, events recurring a couple of times in this audio-visual space are so unlikely to happen at random that the organism can take them for granted. Of course such a generalization is not “safe” in absolute terms since the organism “jumps into conclusions” that are not clearly supported by the available data. However, the generalization risks involved in such “hasty” conclusions provide the organism with useful power in structuring its immediate environment and humans seem to be prone to jump into conclusions regarding potential relationships between different observed phenomena (Dawkins, 1998). Such a generalization power has to be captured by the language acquisition model because it introduces a very important qualitative discontinuity in the interactive process between the organism and its environment. The over-generalization provides the organism with a hypothesis about the structure of the environment, a hypothesis that is taken for granted and used as an axiomatic building block in the on-going interaction with the organism’s context. In other words, the organism generates a hypothesis about its relation with the environment and uses it as a framework to structure future interactions although it does not necessarily have full information about the potential correctness of that decision (Bechara et al., 1997).9 George Kelly’s Theory of Personality and his psychology of personal “constructs” (Kelly, 1963) also provides an interesting insight on the potential early mechanisms learning because it can be used to draw parallels between associations that individuals learn to view as unquestionable truths playing a fundamental role on their personality traits and the type of fundamental and unquestioned links that individuals learn to establish between the sounds of words and the objects (or actions) they refer to. Indeed, just like in the establishment of constructs that are accepted as self evident truths, although they may be based on a few observations and sometimes wrong generalizations that become integrated in the individual’s personality traits, early language acquisition is likely to be full of similarly obvious “constructs” between sound sequences and events that they are likely to refer to. Such “constructs” in the domain of language acquisition are also obvious and unquestioned sound-meaning relations that are simply assumed to be unquestionable truths and just because of that are useful as obvious building blocks in that emerging speech communication process.
The significance of co-occurrences The domain of possible audio-visual variance is, as mentioned above, enormous and is therefore not practical to deal with directly. To simulate a realistic learning situation the 9 According to these authors frontal lobe injured patients lacked the ability to “jump into conclusions” until enough data were gathered to support a less risky conclusion. Although the particular mechanism of non-conscious somatic markers proposed by the authors have subsequently been questioned (Maia & McClelland, 2004) is the object of further discussion (Bechara et al., 2005), their study still illustrates the healthy subjects’ propensity to integrate whatever information they have available in order to reach a quick and correct decision.
20

E:\My Documents\Fra\JOLLER\Univ_Porto_RevistaDeLinguistica_060228.doc 2006-09-13, 14:57
model was scaled down for computational purposes, although reducing the domain of the audio-visual space impacts on the l cific coordinates in that domain. Thus, to maintain realistic proportions between the domain and the likelihood of random hits, it is necessary to downscale the time-dimension as well. This means that reducing the number of cells in the audio-visual space must lead to a proportional reduction in the number of events processed by the model.
ikelihood of hitting spe
These data come from a 12 minutes’ mother-infant session to calibrate the model. The session was transcribed and the absolute and relative frequencies of word types and tokens calculated. The total number of word types throughout the session was 172, including play and hesitation utterances. The relative and absolute numbers of the top 80% word occurrences is shown in figure 3.
21
A typical aspect of this kind of token distributions is the high frequency use of a very limited number of these tokens. Of the 960 words used during the session, no more than 17 words (about 1.7%) account for 475 uses (i.e. nearly 50%), as listed in the table below. This distribution is somewhat similar to the observations of word use in adult speech communication but the proportions of item re-use are rather different. In a typical 3 minutes sample of adult-directed speech recorded from a radio interview with a Swedish politician, about 10% of the items accounted for the same 50% of word use, indicating therefore a much wider variation in the lexical items than in the case of infant-directed speech. Thus, the high repetition rate of a limited number of words embedded in slightly different linguistic and prosodic frames is likely to provide the infant with a highly efficient exposure to linguistic material from which the phonetic core of the tokens emerges.
To(to
5.0
6.0
50
60
ken frequency and percentages in IDS word usep 80% from a 12 min session)
0.0
1.0
2.0
du va harpu
ss ri a settbru
m jtitt
ade ja d då
godd
a härsä
jertittut å fin
nalle
björne så sk oj på nu
båpa en tutso
marm
rfin
a g hurka
nmoro
t
morotenvilk
enbil
en biphe
t rOsk
ar l rom
i för gårgö
raha
llåha erlek ter me
mångamår
spad
e
Word tokens
0
10
20
PercentFrequency
3.0
4.0
Perc
enta
ges
30
40
Mamyra n ä he n e n a ar ila å
be o uk
tpä
r d dn a
komm lå
Figure 3. Relative frequency and percentages of the top80% forms used in a 12 minutes Infant-Directed Speeech session.
säjer says 16 491 1.7% 51.1%
here 16 475 1.7% 49.5%
Word Word translation Frequency
Cumulative frequency Percent
Cumulative percent
du you 53 53 5.5% 5.5%
va was, how 43 96 4.5% 10.0%
har has 40 136 4.2% 14.2%
puss kiss 36 172 3.8% 17.9%
Maria Maria 30 202 3.1% 21.0%
myran ant 30 232 3.1% 24.2%
är is 29 261 3.0% 27.2%
sett seen 28 289 2.9% 30.1%
brum (play sound) 27 316 2.8% 32.9%
hej hi 25 341 2.6% 35.5%
titta look 23 364 2.4% 37.9%
den the 20 384 2.1% 40.0%
ja yes 20 404 2.1% 42.1%
de they, them 19 423 2.0% 44.1%
då then 19 442 2.0% 46.0%
goddag hello 17 459 1.8% 47.8%
här
Table 1. Tokens accounting for 50% of the occurrences in a 12 minute’s Infant-Directed Speech session.

E:\My Documents\Fra\JOLLER\Univ_Porto_RevistaDeLinguistica_060228.doc 2006-09-13, 14:57
A more detailed analysis of the material from the infant-directed speech, segmented in 60 s chunks, discloses an even more focused structure in the linguistic content of the infant directed speech. Indeed, during the first and the second minutes of the session the mother introduces a toy that she refers to as “myra” (eng ant) and the target word “myra” is repeated over and over again, as long as the infant’s visual focus of attention is directed towards the toy. During the first minute the mother produces 122 word tokens, within which there are 10 occurrences of the target word, 8 occurrences of the attention modulating interjection “hej” (hi), 7 occurrences of the infant’s name “Maria” and 5 occurrences of the words “du”, “här” and “är” (you, here and is/are). In other words, only six word types account for about 1/3 of the total number of words during the first minute. Using the binomial distribution to estimate the probability of 10 occurrences of the same word type to be produced within this 60 s time window, under the assumption that all types would have equal probabilities of being produced, yields a probability of p<0.000235. Obviously, the probability of having one of the 47 types being repeated by chance 10 times among the 122 produced tokens is extremely low. Therefore the fact that such repetitions actually occur in infant-directed speech is an extremely significant event, whose importance can be taken for granted. Figure 4 displays the probabilities of different number of random occurrence of a given type for this first minute of the session. This pattern of significant repetitions is maintained throughout the session. For the second minute, for instance, the probability of random token repetitions associated with the target word is still as low as p<0.000984, for 28 types, 105 tokens and 11 repetitions of the most frequent word.
One might object that to this kind of technical analysis as being a too simplistic exercise to account for a situation that is complex, very natural and familiar to many people. However, the value of the current approach is just that such rudimentary assumptions do expose essential aspects of the linguistic structure involved in the early language acquisition process. From a naturalistic point of view, repetitions occur as a consequence of the introduction of a new object that the mother intends to present to the infant. But from a human communication point of view referring to objects in the shared external world is exactly one of the essential functions of language, particularly at its early stages of development.10 This is also the message from the probability estimates. If words were used at random it would be unlikely to observe the number of token repetitions that the infant is faced with in natural situations. Thus, it is the very obvious fact that language is not based on random use that underlines the significance of token repetitions. This is, of course, true both for adult-directed and for infant-speech but the number of repetitions occurring in infant-directed speech is more unlikely than that observed in adult-directed speech and this may very well trigger the infant’s initial focus on the audio-visual contingencies that are thought to underlie the early language acquisition process. Indeed, these repetitions are not solely an auditory phenomenon and because they tend to be highly correlated with other sensory inputs, such as the visual and often tactile input, they build up salient multi-sensorial representations in the environment shared to the mother-infant dyad. In other words, recurrent audio-visual contingencies against the background of overall possible sensory variation are so unlikely to occur at random that a few repeated co-occurrences in this multi-sensory information domain can be treated as “sure indications” of the outside world’s structure. However the current theoretical model does not propose that the infant will actually be seeking this type of correlations in order to learn its ambient language. In fact, it is assumed that detection of those important contingencies may initially be underlined by general purpose memory processes, provided the processes’ time-windows are long enough to store some of these repeated events. Given the probability of
10 It goes without saying that function of spoken language also includes other complex aspects such as behaviour regulation and information exchange.
22

E:\My Documents\Fra\JOLLER\Univ_Porto_RevistaDeLinguistica_060228.doc 2006-09-13, 14:57
repetitions in the early infant-directed speech, time windows of a few seconds will initially be enough to detect some of the recurrent audio-visual patterns in infant-directed speech.
Probability of random token repetitionsfrom a pool of 47 types and 122 trials
0.0000
0.0500
0.1000
0.1500
0.2000
0.2500
0.3000
0 2 4 6 8 10 12 14 16 18 20
Number of repetitions
Pro
babi
lity
significance
Figure 4. Probability of random token repetitions considering a pool of 147 types and 122 trials.
While the audio-visual contingencies described above may trigger the early language acquisition process in infants, it is obvious that adults’ speech does not consist of series of isolated words like the ones depicted above, but rather of chains of coarticulated speech sounds that the young language learner has to deal with in order to learn its ambient language. Dealing with chunks of speech sounds that are not “properly” that are essentially continuous and not properly separated n word-like sequences raises a new challenge to the language acquisition process: How can words emerge from a continuous speech signal at the same time that the young language learner is assumed to lack linguistic insights?
An ecological theory of early language acquisition What is the potential significance of repetitions in the speech material that the infant is exposed to? In order to have an ecologically relevant processing time frame, it is assumed that the young infant has a holistic auditory assessment of the speech signal. This means that in the absence of linguistic knowledge the infant will partition the incoming speech signal mainly on the basis of its acoustic level contour. In other words, the infant is assumed to perceive the signal as a non-segmented train of on and off sequences of sounds where silences in between utterances are the only delimiters. To mimic this situation the utterances produced by one mother were represented as a series of character strings corresponding to the utterances’ orthographic transcriptions but without considering any between-word boundaries that were not associated with an actual pause in the speech material (Lacerda et al., 2004a; Lacerda et al., 2004b). The actual model input, corresponding to the first 60 s of mother-infant interaction was represented as shown below, where the commas simply represent pauses
23

E:\My Documents\Fra\JOLLER\Univ_Porto_RevistaDeLinguistica_060228.doc 2006-09-13, 14:57
between successive utterances. The timeline of the original recording is kept in this sequence (figure 5).
hej, skavilekamedleksakidag, skavigöradet, ha, skavileka, tittahär, kommerduihågdenhärmyran, hardusett, titta, nukommermyran, dumpadumpadump, hej, hejsamyran, kommerduihågdenhärmyranmaria, ådenhärmyransomdublevalldelesräddförförragången, ja, mariablevalldelesräddfördenhärmyran, ädemyranoskar, myranoskaräde, tittavafinmyranä, åvamångaarmarhanhar, hardusettvamångaarmarmaria, hejhejmaria, hallå, hallå, hallåhallå, hejhej, ojojsågladsäjerOskar, ämariagladidag, ämariagladidag, ha, hejmariasäjermyran
Figure 5. Transcript of the input sumtted to the model. The strings represent utterances separated by pauses. Words are concatenated if produced without pause in between.
Once a pause is detected, the on-going recording of the utterance is stopped and the utterance is stored unanalyzed in memory. The new utterance is then compared with previously stored utterances on a purely holistic basis, in order to find a possible match between the new
utterance and those already stored. The search for a possible match is performed by considering two utterances at a time, one the newly stored utterance and the other an utterance drawn from the set already stored in memory. The shortest utterance in the pair is taken as a pattern reference and the other sequence is searched for a partial match with the pattern defined by the reference. If a match is found (figure 6) the common portion is assumed to be significant, in accordance with the principles presented in the previous section, and gets its level of memory activity increased. The rationale here is that in the huge audio-visual space the likelihood of randomly finding two similar strings is vanishingly small, as discussed above, which means that repeated items can immediately be taken as good lexical candidates. The first loop of matches is displayed in the table below, where n1 and n2 refer to the items being compared and the pairs in curly brackets indicate the position of the matched elements on n2. The result of this process yields the activated items that are displayed in figure 7. These items become now part of the model’s “lexical inventory”.
n1=5 n2=2−>88 <<1, 9 n1=8 n2=4−>88 <<1, 2
Items in this lexical inventory are now matched against both new and old (unanalyzed but stored in memory) input utterances. The effect of this procedure is that the items in the lexical inventory can now be treated as (temporarily) acquired and therefore removed from the input utterances, thereby exposing the non-analyzed portions of the utterances. Applying this procedure to the original material leads to the non-analyzed chunks listed below. The procedure can be applied recursively to the list of non-analyzed chunks and in this case a new lexical item (“maria”) can be derived.
n1=9 n2=6−> 1, 588 << n1=12 n2=1−> 1, 388 << n1=13 n2=12−> 1, 388 << n1=13 n2=1−> 1, 388 << n1=14 n2=7−> 1, 2388 << n1=20 n2=9−> 1, 588 << n1=21 n2=4−> 14, 15 , 817, 18<<88 < n1=22 n2=8−> 1, 988 << n1=22 n2=4−>881, 2<< n1=23 n2=12−>881, 3<, 84, 6<<
Figure 6. Example of identification of recurrent patterns: n1 and n2 indicate the positions in the transcript displayed in figure 5 of the utterances being compared. The numbers within curly brackets specify the substrings of n2 that match the content of n1.
24

E:\My Documents\Fra\JOLLER\Univ_Porto_RevistaDeLinguistica_060228.doc 2006-09-13, 14:57
Raw matches across utterances skavileka, ha, titta, hej, hej, hej, kommerduihågdenhärmyran, titta, ha, hardusett, ha, hej, hej, ha, hallå, ha, hallå, hallå, ha, hejhej, hej, hej, ämariagladidag, ha, ha, ha, ha, ha, ha, ha, hej, hej
Independent lexical items: ämariagladidag, ha, hallå, hardusett, hej, hejhej, kommerduihågdenhärmyran, skavileka, titta
Figure 7. Raw matches and unique lexical items detected in the utterances of figure 5.
Further runs of the procedure on this limited material do not add to the number of stored lexical candidates. In a more realistic version of the model, the representations of both the audio input and of the lexical candidates have to be affected by memory decay but that is disregarded in the present example, as if the memory span would be long enough to represent the 60 s of input without appreciable degradation.
The procedure used for the simulated audio input can also be applied to the visual input. The visual component can be thought of as a series of images entering a short-term visual memory. This series of images is associated with a series of visual representations that will
tend to overlap to the extent that there are common elements throughout the series.11 Thus, the overlapping regions of the visual representations will implicitly yield information on recognizable visual patterns. And, just as in the case of the audio input, recurring visual patterns can be treated as significant elements, given the low likelihood of observing the same visual input would be repeated at random. This is illustrated in the following example.
medleksakidag, här, samyran, maria, vafinmyranä, åvamångaarmarnr, vamångaarmarmaria, maria, mariasäjermyran
Figure 8. Additional lexical candidates identified in a second iteration, using the lexical items identified on the first interaction.
Working on the audio-visual space In this example it is assumed that the auditory and the visual dimensions can be linearized and arbitrarily represented by 100 steps along each of the dimensions.12 A series of 5000 audio-visual possible events was created by combining uniform random distributions for both the audio and the visual dimensions. To mimic real-life audio-visual presentations of objects, the probability of three arbitrary but correlated audio-visual events was increased. Figure 9 illustrates this generated audio-visual space, where the three areas with heightened dot density reflect the referential use of the auditory information.
11 This is obviously only a principle description of how visual similarity may be detected. The computational processing required to establish matches between similar images has ultimately to be expressed in terms of convolutions, rotations, translations and scaling transformations, but at this point the focus is on the very general principles of visual processing, not with their explicit mathematical implementation. 12 This is, of course, a microscopic domain in comparison with the actual physical world but it has the advantage of allowing the computations to be completed before retirement.
25

E:\My Documents\Fra\JOLLER\Univ_Porto_RevistaDeLinguistica_060228.doc 2006-09-13, 14:57
20 40 60 80 100
20
40
60
80
100
Figure 9. Illustration of random A-V occurrences containing three recurrent A-V associations. One of the axis represents the visual dimension and the other represents the auditory dimension.
As the sensory input is mapped onto the representation space, it is affected by both sensory smearing and memory decay. Memory decay reflects a decreasing activity in the representation space, as a function of time. In this model memory is simply a volatile storage of mapped exemplars associated with the multi-sensory synchronic inputs.13 New representations in this space add activity to the previously existing activity profile. In this representation space, overlapping neighbouring distributions convey an implicit similarity measure which makes sensory smearing crucial for the establishment of similarity patterns. The smearing value is thus critical for the model output. A too narrow smearing value leads to an overestimation of the number of categories in the representation space, whereas a too broad smearing spreads information in a meaningless way all over the representation space.14 In this model smearing is viewed as two-dimensional Gaussian distributions centred on the incoming auditory-visual stimuli values. In the present example, based on 5000 simulated events, the memory decay was set so that a level of 30% of the initial activity would be reached after about 2000 time units (events). The sensory smearing was set to 30 sensory units in each of the two dimensions. Figure 10 displays the activity landscape after exposure to the 5000 stimuli shown above. The height of the hills in this landscape reflects both the cumulative effect of similar sensory inputs and proximity in time (memory decay implies that older representations tend to vanish).
13 Synchrony does not introduce a lack of generality since asynchronic but systematically related events can be mapped onto synchronic representations simply by introducing adequate time delays. 14 The ability to organize information into equivalence classes is undoubtedly a central aspect of the organism’s information handling capacities. Narrow discrimination ability may, by itself, become an obstacle to the information structuring process. Some of the language and learning disabilities observed in children may in fact be attributed to inability to disregard details in the incoming sensory information.
26

E:\My Documents\Fra\JOLLER\Univ_Porto_RevistaDeLinguistica_060228.doc 2006-09-13, 14:57
0
25
50
75
100
0
25
50
75
100
0
0.000025
0.00005
0.000075
0.0001
0
25
50
75
100
Figure 10. Illustration of the memory activity created by the A-V stimuli simulated in figure 9, taking into account memory decay.
The model generates a representational space in which correlated external information tends to cluster into denser clouds, as a result of memory decay interacting with frequency of co-occurrence of the different sensory inputs. In the context of language acquisition, it may be expected that the initial regularities conveyed by the use of frequent expressions to refer to objects or actors in the infant’s immediate neighbourhood will suffice to generate stable enough correlations between the recurrent sounds of the expressions and the referents they are associated to. Such stable representations form specific lexical candidates, both words and lexical phrases, that somehow correspond to events or objects in the linguistic scene. Obviously “words” do not necessarily correspond to established adult forms. They simply are relatively stable and non-analyzed sound sequences, like the ones picked up by the first model above, that can be associated with other sensory inputs. Once this holistic correspondence between sound sequences and their referents is discovered, it is possible for the infant to focus and explore similar regularities, thereby bringing potential structure to the speech signal that the infant is exposed to. In summary, the current model starts off with a crude associative process but it can rapidly evolve towards an active exploration and crystallization of linguistic regularities. Applied to actual language acquisition settings, the model suggests that the infant quickly becomes an active component of the language discovery process. Language acquisition starts by capitalizing on general sensory processing and memory mechanisms which tend to capture sensory regularities in the typical use of language. Recurrent consistency in the structure of the input stimuli leads to clustering in the representation space. The sensory relationships implicit in these clusters can subsequently be used in cognitive and explorative processes, that although not designed to aim at language, converge to it as a result of playful and internally rewarding actions (Locke, 1996).
CONCLUSION The question of how language communication in general and language development in particular have to rely on specialized language-learning mechanisms opened this article and it was argued that both may perhaps be seen as unfolding from general biological and ecological principles. Resolving the issue of specialized versus general mechanism is virtually impossible, if based on empirical data alone. All living organisms are the result of their own cumulative ontogenetic history, reflecting the combined influences of biological, ecological and interactive components.
27

E:\My Documents\Fra\JOLLER\Univ_Porto_RevistaDeLinguistica_060228.doc 2006-09-13, 14:57
To pave the way for the view that language acquisition may largely be accounted for by general principles this article started with a short overview and discussion of possible evolutionary scenarios leading to the emergence of language communication. From the evolutionary perspective the ability to communicate using symbols does not seem to be exclusive for Homo sapiens. A number of other species do also represent relevant events of their ecological environment by using codes like sound, mimic or gestures but yet they fall short of human language because they seem to lack the capacity to use those symbols recursively (Hauser et al., 2002). In some sense, the process of early language acquisition can be seen as a modern revival of the evolutionary origins of language communication and from this perspective the study of early language acquisition may provide unique insights on how intelligent beings learn to pick up the regularities of symbolic representation available in their immediate ecological environment. There are, of course, very important differences between the modern situation of language acquisition and the evolution of language communication itself. One of those differences is the fact that infants now are born in an ecological context where language is already established and coherently and profusely used in their natural ambient. Another difference may be that Homo sapiens have evolved a propensity to attend spontaneously to relations between events and their sensory representations, a propensity that leads them to attend to rules linking events. Recent discoveries on mirror neurons (Rizzolatti, 2005; Iacoboni et al., 2005; Rizzolatti & Craighero, 2004; Rizzolatti et al., 2000), for instance, indicate that primates do perceive meaningful actions performed by others by referring to the motor activation that would be generated if they were to perform the same action that they are perceiving and understanding. Activation of mirror neurons seems to be a requirement for understanding action (Falck-Ytter et al., 2006) and may also be relevant for the perception of speech (Liberman & Mattingly, 1985; Liberman et al., 1967).
The general importance of implicit information and our ability to extract embedded rules from experience with recurrent patterns has been recently demonstrated in experiments exploring more or less complex computer games with hidden principles (Holt & Wade, 2005). The situation created by these games is structurally similar to the typical adult-infant interaction situations described above, with the addition that in the actual adult-infant interaction, the adult tends to help the infant by responding on-line to the infant’s focus of attention and making the “hidden” rules much more explicit than in a game-like situation. At the same time, the complexity of the ecological scenario of adult-infant interaction is potentially much larger than what often is achieved in a computer game situation. But in this respect the infant’s own perceptual and production limitations will actually help constraining the vast search space that it has to deal with. This is why some of the experimental evidence on infant speech perception, speech production and on the interaction between adults and infants was reviewed here. The combined message from these three areas of research all converge towards an image of the infant as being exposed to and processing its ambient language in a differentiated fashion. The recurrent asymmetry favouring high-low distinctions in infant perception and production, along with the adult’s interpretation and reinforcement of that asymmetry, provides a relevant bias for the infant’s future language development as the acoustic signal may effectively be structured along this dominant dimension already in the early stages of the language acquisition process. However, going from exposure to speech signals to the acquisition of linguistic structure is not possible using acoustic information alone. An emerging linguistic structure must necessarily rely on the very essence of the speech communication process, i.e. the link between the acoustic nature of speech and other sensory dimensions. Since these aspects are necessarily interwoven in real-life data, a simplified model of the early stages of the language acquisition process was created to study the impact of simple assumptions. An important venue of further model work is to investigate the basic constraints enabling the emergence of grammatical structure. By systematic control of the
28

E:\My Documents\Fra\JOLLER\Univ_Porto_RevistaDeLinguistica_060228.doc 2006-09-13, 14:57
model constraints and its linguistic input, it may be possible to get some insight on the necessary and sufficient conditions for higher levels of linguistic development. At any rate, future mismatches between the model predictions and empirical data will hopefully lead to a better understanding of the real language acquisition process.
AKNOWLEDGEMENTS This work was supported by project grants from The Swedish Research Council, The Bank of Sweden Tercentenary Foundation (MILLE, K2003-0867) and EU NEST program (CONTACT, 5010). The first author was also supported by a grant from the Faculty of Humanities, Stockholm University and the second author received additional support from The Anna Ahlström and Ellen Terserus Foundation. The authors are also indebted to the senior members of the staff at the Dept of Linguistics, for their critical and helpful comments on earlier versions of this manuscript.
REFERENCES Bechara, A., Damasio, H., Tranel, D., & Damasio, A. R. (2005). The Iowa Gambling Task and the somatic
marker hypothesis: some questions and answers. Trends Cogn Sci., 9, 159-162. Bechara, A., Damasio, H., Tranel, D., & Damasio, A. R. (1997). Deciding Advantageously Before Knowing the
Advantageous Strategy. Science, 275, 1293-1295. Bertoncini, J., Bijeljac-Babic, R., Blumstein, S. E., & Mehler, J. (1987). Discrimination in neonates of very short
CVs. J.Acoust.Soc.Am., 82, 31-37. Best, C. T., McRoberts, G. W., & Goodell, E. (2001). Discrimination of non-native consonant contrasts varying
in perceptual assimilation to the listener's native phonological system. J.Acoust.Soc.Am., 109, 775-794. Bickerton, D. (1990). Language & species. Chicago: University of Chicago Press. Bruce, G. (1982). Textual aspects of prosody in Swedish. Phonetica, 39, 274-287. Cheney, D. L. & Seyfarth, R. M. (1990). How monkeys see the world
inside the mind of another species. Chicago: University of Chicago Press. Daeschler, E. B., Shubin, N. H., & Jenkins, F. A. (2006). A Devonian tetrapod-like fish and the evolution of the
tetrapod body plan. Nature, 440, 757-763. Davis, B. L. & Lindblom, B. (2001). Phonetic Variability in Baby Talk and Development of Vowel Categories.
In F.Lacerda, C. von Hofsten, & M. Heimann (Eds.), Emerging Cognitive Abilities in Early Infancy (pp. 135-171). Mahwah, New Jersey: Lawrence Erlbaum Associates.
Davis, B. L. & MacNeilage, P. (1995). The articulatory basis of babbling. Journal of Speech and Hearing Research, 0000, 0000.
Dawkins, R. (1987). The Blind Watchmaker. New York: W.W.Norton & Company. Dawkins, R. (1998). Unweaving the Rainbow. London: The Penguin Group. Deacon, T. W. (1997). The symbolic species
the co-evolution of language and the brain. (1st ed ed.) New York: W.W. Norton. Degonda, N., Mondadori, C. R., Bosshardt, S., Schmidt, C. F., Boesiger, P., Nitsch, R. M. et al. (2005). Implicit
associative learning engages the hippocampus and interacts with explicit associative learning. Neuron, 46, 505-520.
Eimas, P. D. (1974). Auditory and linguistic processing of cues for place of articulation by infants. Perception and Psychophysics, 16, 513-521.
Eimas, P. D., Siqueland, E. R., Jusczyk, P., & Vigorito, J. (1971). Speech perception in infants. Science, 171, 303-306.
Enquist, M., Arak, A., Ghirlanda, S., & Wachtmeister, C. A. (2002). Spectacular phenomena and limits to rationality in genetic and cultural evolution. Philos.Trans.R.Soc.Lond B Biol.Sci., 357, 1585-1594.
Enquist, M. & Ghirlanda, S. (1998). Evolutionary biology. The secrets of faces. Nature, 394, 826-827. Enquist, M. & Ghirlanda, S. (2005). Neural Networks and Animal Behavior. Princeton and Oxford: Princeton
University Press. Falck-Ytter, T., Gredeback, G., & von, H. C. (2006). Infants predict other people's action goals. Nat.Neurosci., 9,
878-879. Fant, G. (1960). Acoustic theory of speech production. The Hague, Netherlands: Mouton. Fernald, A., Taeschner, T., Dunn, J., Papousek, M., de Boysson-Bardies, B., & Fukui, I. (1989). A cross-
language study of prosodic modifications in mothers' and fathers' speech to preverbal infants. J.Child Lang, 16, 477-501.
Fort, A. & Manfredi, C. (1998). Acoustic analysis of newborn infant cry signals. Med.Eng Phys., 20, 432-442. Futuyama, D. J. (1998). Evolutionary Biology. Sunderland, Massachusetts: Sinauer Associates, Inc.
29

E:\My Documents\Fra\JOLLER\Univ_Porto_RevistaDeLinguistica_060228.doc 2006-09-13, 14:57
Gärdenfors, P. (2000). Hur Homo blev sapiens: om tänkandets evolution. Nora: Bokförlaget Nya Doxa. Gay, T., Lindblom, B., & Lubker, J. (1980). The production of bite block vowels: Acoustic equivalence by
selective compensation. The Journal of the Acoustical Society of America, 68, S31. Gay, T., Lindblom, B., & Lubker, J. (1981). Production of bite-block vowels: Acoustic equivalence by selective
compensation. The Journal of the Acoustical Society of America, 69, 802-810. Gibson, E. J. & Pick, A. D. (2000). An Ecological Approach to Perceptual Learning and Development. Oxford:
Oxford University Press. Gil-da-Costa, R., Palleroni, A., Hauser, M. D., Touchton, J., & Kelley, J. P. (2003). Rapid acquisition of an
alarm response by a neotropical primate to a newly introduced avian predator. Proc.Biol.Sci., 270, 605-610.
Gould, S. J. (1977). Ontogeny and phylogeny. Cambridge, Mass: Belknap Press of Harvard University Press. Hauser, M. D. (1989). Ontogenetic changes in the comprehension and production of Vervet monkey
(Cercopithecus aethiops) vocalizations. Journal of Comparative Psychology, 103, 149-158. Hauser, M. D. (1992). Articulatory and social factors influence the acoustic structure of rhesus monkey
vocalizations: a learned mode of production? J.Acoust.Soc.Am., 91, 2175-2179. Hauser, M. D., Chomsky, N., & Fitch, W. T. (2002). The Faculty of Language: What Is It, Who Has It, and How
Did It Evolve? Science, 298, 1569-1579. Hauser, M. D. & Wrangham, R. W. (1987). Manipulation of food calls in captive chimpanzees. A preliminary
report. Folia Primatol.(Basel), 48, 207-210. Holt, L. L. & Wade, T. (2005). Categorization of spectrally complex non-invariant auditory stimuli in a
computer game task. In (pp. 1038). JASA. Houston, D., Jusczyk, P., Kuijpers, C., Coolen, R., & Cutler, A. (2000). Cross-language word segmentation by
9-month-olds. Psychon.Bull.Rev., 7, 504-509. Iacoboni, M., Molnar-Szakacs, I., Gallese, V., Buccino, G., Mazziotta, J. C., & Rizzolatti, G. (2005). Grasping
the intentions of others with one's own mirror neuron system. PLoS.Biol., 3, e79. Iverson, P. & Kuhl, P. (1995). Mapping the perceptual magnet effect for speech using signal detection theory
and multidimensional scaling. J.Acoust.Soc.Am., 97, 553-562. Iverson, P. & Kuhl, P. (2000). Perceptual magnet and phoneme boundary effects in speech perception: do they
arise from a common mechanism? Percept.Psychophys., 62, 874-886. Jacob, F. (1982). The possible and the actual. New York: Pantheon. Jakobson, R. (1968). Child language. Aphasia and phonological universals. --. (72 ed.) The Hague: Mouton. Johansson, S. (2005). Origins of language : constraints on hypotheses. Amsterdam; Philadelphia, PA: John
Benjamins Publishing Company. Johnson, E. K. & Jusczyk, P. (2001). Word segmentation by 8-month-olds: when speech cues count more than
statistics. J.Mem.Lang., 44, 548-567. Jones, S., Martin, R., & Pilbeam, D. (1992). The Cambridge Encyclopedia of Human Evolution. Cambridge:
Cambridge University Press. Jusczyk, P. (1999). How infants begin to extract words from speech. Trends Cogn Sci., 3, 323-328. Kamo, M., Ghirlanda, S., & Enquist, M. (2002). The evolution of signal form: effects of learned versus inherited
recognition. Proc.Biol.Sci., 269, 1765-1771. Kelly, G. A. (1963). A theroy of personality: The psychology of personal constructs. New York: W. W. Norton. Knight, C., Studdert-Kennedy, M., & Hurford, J. R. (2000). Language: A Darwinian adaptation? In C.Knight
(Ed.), Evolutionary Emergence of Language: Social Function and the Origins of Linguistic Form (pp. 1-15). New York: Cambridge University Press.
Kuhl, P. (1991). Human adults and human infants show a perceptual magnet effect for the prototypes of speech categories, monkeys do not. Perception and Psychophysics, 50, 93-107.
Kuhl, P., Andruski, J. E., Chistovich, I. A., Chistovich, L. A., Kozhevnikova, E. V., Ryskina, V. L. et al. (1997). Cross-language analysis of phonetic units in language addressed to infants. Science, 277, 684-686.
Kuhl, P. & Meltzoff, A. N. (1982). The bimodal perception of speech in infancy. Science, 218, 1138-1141. Kuhl, P. & Meltzoff, A. N. (1984). The intermodal representation of speech in infants. Infant Behavior and
Development, 7, 361-381. Kuhl, P. & Meltzoff, A. N. (1988). The bimodal perception of speech in infancy. Science, 218, 1138-1141. Kuhl, P. & Meltzoff, A. N. (1996). Infant vocalizations in response to speech: vocal imitation and developmental
change. J.Acoust.Soc.Am., 100, 2425-2438. Kuhl, P., Williams, K., Lacerda, F., Stevens, K. N., & Lindblom, B. (1992). Linguistic experience alters phonetic
perception in infants by 6 months of age. Science, 255, 606-608. Kuhl, P. K. (1985). Categorization of speech by infants. In J.Mehler & R. Fox (Eds.), Neonate Cognition:
Beyond the Bloming Buzzing Confusion (pp. 231-262). Hillsdale, New Jersey: Laurence Earlbaum Associates.
30

E:\My Documents\Fra\JOLLER\Univ_Porto_RevistaDeLinguistica_060228.doc 2006-09-13, 14:57
Lacerda, F. (1992a). Does Young Infants Vowel Perception Favor High-Low Contrasts? International Journal of Psychology, 27, 58-59.
Lacerda, F. (1992b). Young Infants' Discrimination of Confusable Speech Signals. In M.E.H.Schouten (Ed.), THE AUDITORY PROCESSING OF SPEECH: FROM SOUNDS TO WORDS (pp. 229-238). Berlin, Federal Republic of Germany: Mouton de Gruyter.
Lacerda, F. (2003). Phonolgoy: An emergent consequence of memory constraints and sensory input. Reading and Writing: An Interdisciplinary Journal, 16, 41-59.
Lacerda, F. & Ichijima, T. (1995). Adult judgements of infant vocalizations. In K. Ellenius & P. Branderud (Eds.), (pp. 142-145). Stockholm: KTH and Stockholm University.
Lacerda, F., Klintfors, E., Gustavsson, L., Lagerkvist, L., Marklund, E., & Sundberg, U. (2004a). Ecological Theory of Language Acquisition. In Genova: Epirob 2004.
Lacerda, F., Marklund, E., Lagerkvist, L., Gustavsson, L., Klintfors, E., & Sundberg, U. (2004b). On the linguistic implications of context-bound adult-infant interactions. In Genova: Epirob 204.
Lacerda, F. & Sundberg, U. (1996). Linguistic strategies in the first 6-months of life. In (pp. 2574). JASA. Lacerda, F., Sundberg, U., Klintfors, E., & Gustavsson, L. (forthc.). Infants learn nouns from audio-visual
contingencies. Ref Type: Unpublished Work Lane, H., Denny, M., Guenther, F. H., Matthies, M. L., Menard, L., Perkell, J. S. et al. (2005). Effects of bite
blocks and hearing status on vowel production. J.Acoust.Soc.Am., 118, 1636-1646. Liberman, A., Cooper, F. S., Shankweiler, D. P., & Studdert-Kennedy, M. (1967). Perception of the speech code.
Psychological Review, 74, 431-461. Liberman, A. & Mattingly, I. (1985). The motor theory of speech perception revised. Cognition, 21, 1-36. Liljencrants, J. & Lindblom, B. (1972). Numerical simulation of vowel quality systems: The role of perceptual
contrast. Language, 48, 839-862. Lindblom, B., Lubker, J., & Gay, T. (1977). Formant frequencies of some fixed-mandible vowels and a model of
speech motor programming by predictive simulation. The Journal of the Acoustical Society of America, 62, S15.
Locke, J. L. (1996). Why do infants begin to talk? Language as an unintended consequence. J.Child Lang, 23, 251-268.
Lotto, A. J., Kluender, K. R., & Holt, L. L. (1998). Depolarizing the perceptual magnet effect. J.Acoust.Soc.Am., 103, 3648-3655.
MacNeilage, P. & Davis, B. L. (2000a). Deriving speech from nonspeech: a view from ontogeny. Phonetica, 57(2-4), 284-296.
MacNeilage, P. & Davis, B. L. (2000b). On the Origin of Internal Structure of Word Forms. Science, 288, 527-531.
Maddieson, I. (1980). Phonological generalizations from the UCLA Phonological Segment Inventory Database. UCLA Working Papers in Phonetics, 50, 57-68.
Maddieson, I. & Emmorey, K. (1985). Relationship between semivowels and vowels: cross-linguistic investigations of acoustic difference and coarticulation. Phonetica, 42, 163-174.
Maia, T. V. & McClelland, J. L. (2004). A reexamination of the evidence for the somatic marker hypothesis: what participants really know in the Iowa gambling task. Proc.Natl Acad.Sci.U.S.A, 101, 16075-16080.
Mandel, D. & Jusczyk, P. (1996). When do infants respond to their names in sentences? Infant Behavior and Development, 19, 598.
Mandel, D., Kemler Nelson, D. G., & Jusczyk, P. (1996). Infants remember the order of words in a spoken sentence. Cognitive Development, 11, 181-196.
Mattys, S. L. & Jusczyk, P. (2001). Do infants segment words or recurring contiguous patterns? J.Exp.Psychol.Hum.Percept.Perform., 27, 644-655.
Meltzoff, A. N. & Borton, R. W. (1979). Intermodal matching by human neo-nates. Nature, 282, 403-404. Meltzoff, A. N. & Moore, M. K. (1977). Imitation of facial and manual gestures by human neonates. Science,
198, 75-78. Meltzoff, A. N. & Moore, M. K. (1983). Newborn infants imitate adult facial gestures. Child Development, 54,
702-709. Menard, L., Schwartz, J. L., & Boe, L. J. (2004). Role of vocal tract morphology in speech development:
perceptual targets and sensorimotor maps for synthesized French vowels from birth to adulthood. J.Speech Lang Hear.Res., 47, 1059-1080.
Munakata, Y. & Pfaffly, J. (2004). Hebbian learning and development. Dev.Sci., 7, 141-148. Nazzi, T., Jusczyk, P., & Johnson, E. K. (2000). Language Discrimination by English-Learning 5-Month-Olds:
Effects of Rhythm and Familiarity. Journal of Memory and Language, 43, 1-19. Nishimura, T., Mikami, A., Suzuki, J., & Matsuzawa, T. Descent of the hyoid in chimpanzees: evolution of face
flattening and speech. Journal of Human Evolution, In Press, Corrected Proof. Nowak, M. A., Komarova, N., & Niyogi, P. (2001). Evolution of Universal Grammar. Science, 291, 114-118.
31

E:\My Documents\Fra\JOLLER\Univ_Porto_RevistaDeLinguistica_060228.doc 2006-09-13, 14:57
Nowak, M. A., Plotkin, J. B., & Jansen, V. A. A. (2000). The evolution of syntactic communication. Nature, 404, 495-498.
Nylin, S. (6-7-2006). Ref Type: Personal Communication
Papousek, M. & Hwang, S. F. C. (1991). Tone and intonation in Mandarin babytalk topresyllabic infants: Comparison with registers of adult conversation and foreign languageinstruction. Applied Psycholinguistics, 12, 481-504.
Papousek, M. & Papousek, H. (1989). Forms and functions of vocal matching in interactions between mothers and their precanonical infants. First Language, 9, 137-158.
Polka, L. & Werker, J. F. (1994). Developmental changes in perception of nonnative vowel contrasts. J.Exp.Psychol.Hum.Percept.Perform., 20, 421-435.
Polka, L. & Bohn, O. S. (2003). Asymmetries in vowel perception. Speech Communication, 41, 221-231. Rizzolatti, G. (2005). The mirror neuron system and its function in humans. Anat.Embryol.(Berl), 210, 419-421. Rizzolatti, G. & Craighero, L. (2004). The mirror-neuron system. Annu.Rev.Neurosci., 27, 169-192. Rizzolatti, G., Fogassi, L., & Gallese, V. (2000). Mirror neurons: Intentionality detectors? International Journal
of Psychology, 35, 205. Robb, M. P. & Cacace, A. T. (1995). Estimation of formant frequencies in infant cry.
Int.J.Pediatr.Otorhinolaryngol., 32, 57-67. Roug, L., Landberg, I., & Lundberg, L. J. (1989). Phonetic development in early infancy: a study of four
Swedish children during the first eighteen months of life. J.Child Lang, 16, 19-40. Saffran, J. R. (2002). Constraints on statistical language learning. J.Mem.Lang., 47, 172-196. Saffran, J. R., Aslin, R. N., & Newport, E. (1996). Statistical learning by 8-month old infants. Science, 274,
1926-1928. Saffran, J. R. & Thiessen, E. D. (2003). Pattern induction by infant language learners. Dev.Psychol., 39, 484-
494. Saffran, J. R. (2003). Statistical language learning: mechanisms and constraints. Current Directions in
Psychological Science, 12, 110-114. Savage-Rumbaugh, E. S., Murphy, J., Sevcik, R. A., Brakke, K. E., Williams, S. L., & Rumbaugh, D. M. (1993).
Language comprehension in ape and child. Monogr Soc.Res.Child Dev., 58, 1-222. Schick, B. S., Marschark, M., Spencer, P. E., & ebrary, I. (2006). Advances in the sign language development of
deaf children. Oxford: Oxford University Press. Seidenberg, M. S., MacDonald, M. C., & Saffran, J. R. (2002). Does grammar start where statistics stop?
Science, 298, 553-554. Stern, D. N., Spieker, S., Barnett, R. K., & MacKain, K. (1983). The prosody of maternal speech: Infant age and
context related changes. Journal of Child Language, 10, 1-15. Stevens, K. N. (1998). Acoustic Phonetics. Cambridge, Mass.: MIT Press. Sundberg, U. (1998). Mother tongue - Phonetic Aspects of Infant-Directed Speech. Stockholm University. Sundberg, U. & Lacerda, F. (1999). Voice onset time in speech to infants and adults. Phonetica, 56, 186-199. Tees, R. C. & Werker, J. F. (1984). Perceptual flexibility: maintenance or recovery of the ability to discriminate
non-native speech sounds. Can.J.Psychol., 38, 579-590. Tomasello, M. & Carpenter, M. (2005). The emergence of social cognition in three young chimpanzees. Monogr
Soc.Res.Child Dev., 70, vii-132. Tomasello, M., Savage-Rumbaugh, S., & Kruger, A. C. (1993). Imitative learning of actions on objects by
children, chimpanzees, and enculturated chimpanzees. Child Dev., 64, 1688-1705. van der Weijer, J. (1999). Language Input for Word Discovery. MPI Series in Psycholinguistics. Werker, J. F., Gilbert, J. H. V., Humphrey, K., & Tees, R. C. (1981). Developmental aspects of cross-language
speech perception. Child Development, 52, 349-355. Werker, J. F. & Logan, J. S. (1985). Cross-language evidence for three factors in speech perception. Perception
and Psychophysics, 37, 35-44. Werker, J. F. & Tees, R. C. (1983). Developmental changes across childhood in the perception of non-native
speech sounds. Canadian Journal of Psychology, 37, 278-296. Werker, J. F. & Tees, R. C. (1992). The organization and reorganization of human speech perception.
Annu.Rev.Neurosci., 15, 377-402. Werner, L. (1992). Interpreting Developmental Psychoacoustics. In L.Werner & E. Rubel (Eds.), Develpmental
Psycholinguistics (1 ed., pp. 47-88). Washington: American Psychological Association. Werner, S. (3-15-2006). Cellular density in human tissues.
Ref Type: Personal Communication
32

Infants’ ability to extract verbs from continuous speech
Ellen Marklund and Francisco Lacerda
Department of Linguistics Stockholm University, Stockholm, Sweden
ABSTRACT Early language acquisition is a result of the infant’s general associative and memory processes in combination with its’ ecological surroundings. Extracting a part of a continuous speech signal and associate it to for instance an object, is made possible by the structure provided by characteristically repetitive Infant Directed Speech. The parents adjust the way they speak to their infant based on the response they are given, which in turn is dependent on the infant’s age and cognitive development.
It seems probable that the ability to extract lexical candidates referring to visually presented actions is developed at a later stage than the ability to extract lexical candidates referring to visually presented objects – actions are more abstract and there is a time aspect involved.
Using the Visual Preference Paradigm, the ability to extract lexical candidates referring to actions was studied in infants at the age of 4 to 8 months. The results suggest that while the ability at this age is not greatly apparent, it seems to increase slightly with age.
1. INTRODUCTION This study is a part of the MILLE-project (Modeling Interactive Language Learning), which is a collaboration between the Department of Linguistics at Stockholm University (Sweden), the Department of Speech Music and Hearing at the Royal Institute of Technology (Sweden) and the Department of Psychology at Carnegie Mellon University (PA, USA). The project’s aim is to investigate the processes behind early language acquisition and to implement them in computational models.
1.1 Infant directed speech According to the Ecological Theory of Language Acquisition (ETLA) early language acquisition can be seen as an emergent consequence of the multi-modal interaction between the infant and its surroundings. Parents verbally interpret the world to their infant, and by doing so they provide the structure necessary for linguistic references and systems to emerge [1].
Infant Directed Speech (IDS) differs from Adult Directed Speech (ADS) mainly in that it is more repetitive, and has greater pitch variations. IDS varies with the age of the infant, as the parent adjusts to the cognitive and
communicative development of the infant and adapts the language accordingly [2].
At a very early age the main goal of speaking is general social interaction – to maintain the communications link with the infant, as opposed to ADS and later IDS, where the goal mainly is to convey information of some sort [3]. Recent studies at our lab shows that early IDS is also highly focused on what’s in the field-of-view of the infant; if the infant’s attention shifts, the parent tend to follow the infant’s lead and focus on the new center of attention (report in preparation). 1.2 Modeling early language acquisition The principles of ETLA will be implemented in a humanoid robot, in an effort to develop a system that acquires language in a manner comparable to human language acquisition.
The system’s learning will at some stage be dependent on IDS input, and thus some of the questions that need to be answered in order to accomplish this are in which way the parent adjusts the IDS with the infant’s age, and on what cues those adjustments are based? To answer those questions, the infant’s word-learning behavior needs to be understood.
1.3 Learning lexical labels To a naive listener – for example an infant – speech is not perceived as a combination of words building up sentences, but rather as a continuous stream of sounds with no apparent boundaries. According to ETLA early word learning is based on general multi-sensory association and memory processes, which in combination with the structured characteristics of IDS provides opportunities for lexical candidates – smaller chunks of speech, referring to for example an object – to emerge and be extracted from a continuous speech signal.
Studies have shown that infants at an early age are able to integrate multi-modal information and extract lexical candidates from a flow of continuous speech, and learn to associate those with objects [4], and other studies show that they are capable of extracting and associating lexical candidates with attributes, such as colors and shapes [5].
Regarding lexical candidates referring to actions or events – verb-like lexical candidates, Echols has, by directing infants’ attention with labeled objects or events, shown that while infants of 9 months generally focus more

on objects when an event is labeled, while older infants to a greater extent focused on events or actions [6].
The goal of this experiment is to study how infants’ ability to associate visually perceived actions with linguistic references differs with age, in order to gain further understanding of the development of general cognitive processes and abilities essential for language acquisition.
2. METHOD The method used (Visual Preference Procedure) is a variation of the Intermodal Preferential Looking Paradigm; a method originally developed by Spelke [7]. The subjects were shown a film with corresponding visual and auditory stimuli while their eye-movements were recorded. The looking time for each sequence of the film and for each quadrant of the screen was calculated and analysed using Mathematica 5.0 and SPSS 14.0.
2.1 Subjects The subjects were 55 Swedish infants between 4 and 8 months old, randomly selected from the National Swedish address register (SPAR) on the basis of age and geographical criteria.
During the recording of the eye-movements, the infant was seated in the parent’s lap or in an infant chair close to the parent. The parent wore Active Noise Reduction headphones, listening to music.
The 23 infants whose total looking time did not exceed 30% of the duration of the film were not considered sufficiently exposed to the stimuli; hence those recordings were excluded leaving a total of 32 recording sessions.
2.2 Stimuli The auditory stimuli of the films were non-sense words read by a Swedish female and concatenated to three-word phrases. The films had three sequences each; a baseline, an exposure and a test. The baseline showed a split-screen with four different scenes in which cartoon figures were moving towards or away from each other in silence (Figure 1).
Figure 1: In each scene of the baseline one cartoon figure was moving towards or away from an other, stationary figure.
The exposure phase showed eight subsequent scenes similar to those in the baseline, where the direction of the target movements was balanced regarding actor and direction on the screen (Figure 2). In each of the scenes only two cartoon figures were involved – a kangaroo (K) and an elephant (E).
Figure 2: In the eight subsequent scenes of the exposure, only two cartoon figures were involved – a kangaroo and an elephant.
During the exposure, three-word non-sense phrases were played referring to the objects and actions involved. The target word, the one referring to the action, always held the medial position (Table 1). The phrases were repeated three times during each scene.
Scene Audio film 1 Audio film 2 Video Movement1 nima bysa pobi fugga pobi bysa E K Away 2 pobi fugga nima bysa nima fugga K E towards 3 nima bysa pobi fugga pobi bysa K E away 4 nima fugga pobi fugga nima bysa K E towards 5 nima fugga pobi fugga nima bysa E K towards 6 pobi bysa nima bysa pobi fugga K E away 7 pobi fugga nima bysa nima fugga E K towards 8 pobi bysa nima bysa pobi fugga K E away
Table 1: The auditory stimuli and the visual balancing of the eight scenes in the exposure phase.
The test was visually identical to the baseline, while the non-sense word referring to the action was repeated twice (Table 2).
Film Audio Target 1 bysa away 2 nima towards
Table 2: Auditory stimuli of the test phase; the word referring to the target movement was repeated twice.
2.3 Eye-tracking A Tobii Eye-Tracker integrated with a 17” TFT monitor was used to record the eye-movements of the infants. Near infra-red light-emitting diods (NIR-LEDs) and a high-resolution camera with a large field-of-view are mounted on the screen. The light from the NIR-LEDs is reflected on the surface of the subject’s eye, which is captured by the camera, as is the position of the pupil. During a calibration the subject is encouraged to look at pre-specified points at the screen while the system measures the pupils position in relation to the reflections, providing data for the system to use in order to calculate the gaze point on the screen during the recording. Software used for data storage was ClearView 2.5.1.

3. RESULTS AND DISCUSSION The results showed a slight increase with age in looking time at the target compared to the non-target (Figure 3). Regression coefficient is R=0,261, p<0,148.
Figure 3: The y-axis shows the normalized difference in gain in percentage of looking time towards the target with non-target as baseline. The x-axis is age in days.
The results suggest that the infants’ ability to extract a part of a continuous stream of speech and associate it with an action increases over age.
To expand this study to encompass older infants would be of interest in order to determine if there is a period where the ability increases drastically; hypothetically between 9 and 13 months of age, which would be in accordance with Echols’ results [6] and might indicate a leap in cognitive development.
One could also consider a replicating this study but using less complex actions as target, so the infant doesn’t have to grasp the concept of changes in spatial relationship between different agents in order to understand the event.
4. ACKNOWLEDGEMENTS The research was financed by grants from The Bank of Sweden Tercentenary Foundation and the European Commission.
5. REFERENCES
[1] F. Lacerda, E. Klintfors, L. Gustavsson, L. Lagerkvist, E. Marklund, and U. Sundberg, "Ecological Theory of Language Acquisition" Proceedings of the 4th International Workshop on Eigenetic Robotics, pp. 147-148. Genoa, 2004.
[2] U. Sundberg, "Mother Tongue: Phonetic aspects of infant-directed speech" PERILUS XXI, Institutionen för lingvistik, Stockholms Universitet, 1998.
[3] F. Lacerda, E. Marklund, L. Lagerkvist, L. Gustavsson, E. Klintfors, and U. Sundberg, "On the linguistic implications of context-bound adult-infant interactions" Proceedings of the 4th International
Workshop on Eigenetic Robotics, pp. 147-148. Genoa, 2004.
[4] L. Gustavsson, U. Sundberg, E. Klintfors, E. Marklund, L. Lagerkvist, and F. Lacerda, "Integration of audio-visual information in 8-month-old infants" Proceedings of the 4th International Workshop on Eigenetic Robotics, pp. 149-150. Genoa, 2004.
[5] E. Klintfors and F. Lacerda, "Potential relevance of audio-visual integration in mammals for computational modeling" This conference, 2006.
[6] C. H. Echols, "Attentional predispositions and linguistic sensitivity in the acquisition of object words.," Paper presented at the Biennial Meeting of the Society for Research in Child Development. New Orleans, LA, 1993.
[7] E. S. Spelke and C. J. Owsley, "Intermodal exploration and knowledge in infancy," Infant Behavior and Development, vol. 2, pp. 13-24, 1979.

Interaction Studies 7:2 (2006), 97–23.issn 1572–0373 / e-issn 1572–0381 © John Benjamins Publishing Company
Understanding mirror neuronsA bio-robotic approach
1Giorgio Metta, 1Giulio Sandini, 1Lorenzo Natale, 2Laila Craighero and 2Luciano Fadiga1LIRA-Lab, DIST, University of Genoa / 2Neurolab, Section of Human Physiology, University of Ferrara
This paper reports about our investigation on action understanding in the brain. We review recent results of the neurophysiology of the mirror system in the monkey. Based on these observations we propose a model of this brain system which is responsible for action recognition. The link between object affordances and action understanding is considered. To support our hypothesis we describe two experiments where some aspects of the model have been implemented. In the first experiment an action recognition system is trained by using data recorded from human movements. In the second experiment, the model is partially implemented on a humanoid robot which learns to mimic simple actions performed by a human subject on different objects. These experiments show that motor information can have a signifi-cant role in action interpretation and that a mirror-like representation can be developed autonomously as a result of the interaction between an individual and the environment.
Keywords: mirror neurons, neurophysiology, robotics, action recognition
. Introduction
Animals continuously act on objects, interact with other individuals, clean their fur or scratch their skin and, in fact, actions represent the only way they have to manifest their desires and goals. However, actions do not constitute a semantic category such as trees, objects, people or buildings: the best way to describe a complex act to someone else is to demonstrate it directly (Jeannerod, 1988). This is not true for objects such as trees or buildings that we describe by using size, weight, color, texture, etc. In other words we describe ‘things’ by using

98 Giorgio Metta et al.
visual categories and ‘actions’ by using motor categories. Actions are defined as ‘actions’ because they are external, physical expressions of our intentions. It is true that often actions are the response to external contingencies and/or stimuli but it is also certainly true that — at least in the case of human beings — actions can be generated on the basis of internal aims and goals; they are possibly symbolic and not related to immediate needs. Typical examples of this last category include most communicative actions.
Perhaps one of the first attempts of modeling perception and action as a whole was started decades ago by Alvin Liberman who initiated the construc-tion of a ‘speech understanding’ machine (Liberman, Cooper, Shankweiler, & Studdert-Kennedy, 1967; Liberman & Mattingly, 1985; Liberman & Wahlen, 2000). As one can easily imagine, the first effort of Liberman’s team was di-rected at analyzing the acoustic characteristics of spoken words, to investigate whether the same speech event, as uttered by different subjects in different contexts, possessed any common invariant phonetic percept.1 Soon Liberman and his colleagues realized that speech recognition on the basis of acoustic cues alone was beyond reach with the limited computational power available at that time. Somewhat stimulated by the negative result, they put forward the hypothesis that the ultimate constituents of speech (the events of speech) are not sounds but rather articulatory gestures that have evolved exclusively at the service of language. As Liberman states:
“A result in all cases is that there is not, first, a cognitive representation of the proximal pattern that is modality-general, followed by a translation to a par-ticular distal property; rather, perception of the distal property is immediate, which is to say that the module2 has done all the hard work (Liberman & Mat-tingly, 1985, page 7)”.
This elegant idea was however strongly debated at the time mostly because it was difficult to test, validation through the implementation on a computer system was impossible, and in fact only recently has the theory gained support from experimental evidence (Fadiga, Craighero, Buccino, & Rizzolatti, 2002; Kerzel & Bekkering, 2000).
Why is it that, normally, humans can visually recognize actions (or, acous-tically, speech) with a recognition rate of about 99–100%? Why doesn’t the inter-subject variability typical of motor behavior pose a problem for the brain while it is troublesome for machines? Sadly, if we had to rank speech recogni-tion software by human standards, even our best computers would be regarded at the level of an aphasic patient. One possible alternative is for Liberman to be right and that speech perception and speech production use a common reper-

Understanding mirror neurons 99
toire of motor primitives that during production are at the basis of the genera-tion of articulatory gestures, and during perception are activated in the listener as the result of an acoustically-evoked motor “resonance” (Fadiga, Craighero, Buccino, & Rizzolatti, 2002; Wilson, Saygin, Sereno, & Iacoboni, 2004).
Perhaps it is the case that if the acoustic modality were replaced, for ex-ample, by vision then this principle would still hold. In both cases, the brain requires a “resonant” system that matches the observed/heard actions to the observer/listener motor repertoire. It is interesting also to note that an animal equipped with an empathic system of this sort would be able to automatically “predict”, to some extent, the future development of somebody else’s action on the basis of the onset of the action and the implicit knowledge of its dynam-ics. Recent neurophysiological experiments show that such a motor resonant system indeed exists in the monkey’s brain (Gallese, Fadiga, Fogassi, & Riz-zolatti, 1996). Most interesting, this system is located in a premotor area where neurons not only discharge during action execution but to specific visual cues as well.
The remainder of the paper is organized to lead the reader from the ba-sic understanding of the physiology of the mirror system, to a formulation of a model whose components are in agreement with what we know about the neural response of the rostroventral premotor area (area F5), and finally to the presentation of a set of two robotic experiments which elucidate several aspects of the model. The model presented in this paper is used to lay down knowledge about the mirror system rather than being the subject of direct neural network modelling. The two experiments cover different parts of the model but there is not a full implementation as such yet. The goal of this paper is that of present-ing these results, mainly robotics, into a common context.
2. Physiological properties of monkey rostroventral premotor area (F5)
Area F5 forms the rostral part of inferior premotor area 6 (Figure 1). Elec-trical microstimulation and single neuron recordings show that F5 neurons discharge during planning/execution of hand and mouth movements. The two representations tend to be spatially segregated with hand movements mostly represented in the dorsal part of F5, whereas mouth movements are mostly located in its ventral part. Although not much is known about the functional properties of “mouth” neurons, the properties of “hand” neurons have been extensively investigated.
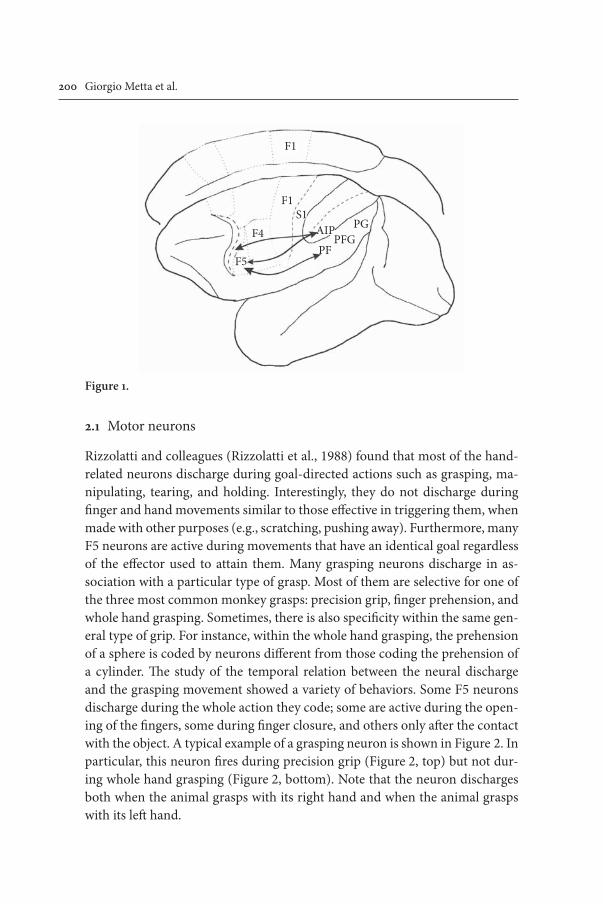
200 Giorgio Metta et al.
2. Motor neurons
Rizzolatti and colleagues (Rizzolatti et al., 1988) found that most of the hand-related neurons discharge during goal-directed actions such as grasping, ma-nipulating, tearing, and holding. Interestingly, they do not discharge during finger and hand movements similar to those effective in triggering them, when made with other purposes (e.g., scratching, pushing away). Furthermore, many F5 neurons are active during movements that have an identical goal regardless of the effector used to attain them. Many grasping neurons discharge in as-sociation with a particular type of grasp. Most of them are selective for one of the three most common monkey grasps: precision grip, finger prehension, and whole hand grasping. Sometimes, there is also specificity within the same gen-eral type of grip. For instance, within the whole hand grasping, the prehension of a sphere is coded by neurons different from those coding the prehension of a cylinder. The study of the temporal relation between the neural discharge and the grasping movement showed a variety of behaviors. Some F5 neurons discharge during the whole action they code; some are active during the open-ing of the fingers, some during finger closure, and others only after the contact with the object. A typical example of a grasping neuron is shown in Figure 2. In particular, this neuron fires during precision grip (Figure 2, top) but not dur-ing whole hand grasping (Figure 2, bottom). Note that the neuron discharges both when the animal grasps with its right hand and when the animal grasps with its left hand.
F1
F1S1
PFPFG
PGAIPF4
F5
Figure .

Understanding mirror neurons 20
Taken together, these data suggest that area F5 forms a repository (a “vo-cabulary”) of motor actions. The “words” of the vocabulary are represented by populations of neurons. Each indicates a particular motor action or an aspect of it. Some indicate a complete action in general terms (e.g., take, hold, and tear). Others specify how objects must be grasped, held, or torn (e.g., precision grip, finger prehension, and whole hand prehension). Finally, some of them subdivide the action in smaller segments (e.g., fingers flexion or extension).
2.2 Visuomotor neurons
Some F5 neurons in addition to their motor discharge, respond also to the presentation of visual stimuli. F5 visuomotor neurons pertain to two com-pletely different categories. Neurons of the first category discharge when the monkey observes graspable objects (“canonical” F5 neurons, (Murata et al.,
Figure 2.

202 Giorgio Metta et al.
1997; Rizzolatti et al., 1988; Rizzolatti & Fadiga, 1998)). Neurons of the second category discharge when the monkey observes another individual making an action in front of it (Di Pellegrino, Fadiga, Fogassi, Gallese, & Rizzolatti, 1992; Gallese, Fadiga, Fogassi, & Rizzolatti, 1996; Rizzolatti, Fadiga, Gallese, & Fo-gassi, 1996). For these peculiar “resonant” properties, neurons belonging to the second category have been named “mirror” neurons (Gallese, Fadiga, Fogassi, & Rizzolatti, 1996).
The two categories of F5 neurons are located in two different sub-regions of area F5: “canonical” neurons are mainly found in that sector of area F5 bur-ied inside the arcuate sulcus, whereas “mirror” neurons are almost exclusively located in the cortical convexity of F5 (see Figure 1).
2.2. Canonical neuronsRecently, the visual responses of F5 “canonical” neurons have been re-exam-ined using a formal behavioral paradigm, which allowed testing the response related to object observation both during the waiting phase between object presentation and movement onset and during movement execution (Murata et al., 1997). The results showed that a high percentage of the tested neurons, in addition to the “traditional” motor response, responded also to the visual presentation of 3D graspable object. Among these visuomotor neurons, two thirds were selective to one or few specific objects.
Figure 3A shows the responses of an F5 visually selective neuron. While observation and grasping of a ring produced strong responses, responses to the other objects were modest (sphere) or virtually absent (cylinder). Figure 3B (object fixation) shows the behavior of the same neuron of Figure 3A during the fixation of the same objects. In this condition the objects were presented as during the task in Figure 2A, but grasping was not allowed and, at the go-signal, the monkey had simply to release a key. Note that, in this condition, the object is totally irrelevant for task execution, which only requires the de-tection of the go-signal. Nevertheless, the neuron strongly discharged at the presentation of the preferred object. To recapitulate, when visual and motor properties of F5 neurons are compared, it becomes clear that there is a strict congruence between the two types of responses. Neurons that are activated when the monkey observes small sized objects discharge also during precision grip. In contrast, neurons selectively active when the monkey looks at large objects discharge also during actions directed towards large objects (e.g. whole hand prehension).

Understanding mirror neurons 203
2.2.2 Mirror neuronsMirror neurons are F5 visuomotor neurons that activate when the monkey both acts on an object and when it observes another monkey or the experi-menter making a similar goal-directed action (Di Pellegrino, Fadiga, Fogassi, Gallese, & Rizzolatti, 1992; Gallese, Fadiga, Fogassi, & Rizzolatti, 1996). Re-cently, mirror neurons have been found also in area PF of the inferior pari-etal lobule, which is bidirectionally connected with area F5 (Fogassi, Gallese, Fadiga, & Rizzolatti, 1998). Therefore, mirror neurons seem to be identical to canonical neurons in terms of motor properties, but they radically differ from the canonical neurons as far as visual properties are concerned (Rizzolatti & Fadiga, 1998). The visual stimuli most effective in evoking mirror neurons dis-charge are actions in which the experimenter’s hand or mouth interacts with objects. The mere presentation of objects or food is ineffective in evoking mir-ror neurons discharge. Similarly, actions made by tools, even when conceptu-ally identical to those made by hands (e.g. grasping with pliers), do not activate the neurons or activate them very weakly. The observed actions which most often activate mirror neurons are grasping, placing, manipulating, and hold-ing. Most mirror neurons respond selectively to only one type of action (e.g. grasping). Some are highly specific, coding not only the type of action, but
Figure 3.

204 Giorgio Metta et al.
also how that action is executed. They fire, for example, during observation of grasping movements, but only when the object is grasped with the index finger and the thumb.
Typically, mirror neurons show congruence between the observed and ex-ecuted action. This congruence can be extremely precise: that is, the effective motor action (e.g. precision grip) coincides with the action that, when seen, triggers the neurons (e.g. precision grip). For other neurons the congruence is somehow weaker: the motor requirements (e.g. precision grip) are usually stricter than the visual ones (any type of hand grasping). One representative of the highly congruent mirror neurons is shown in Figure 4.
3. A model of area F5 and the mirror system
The results summarized in the previous sections tell us of the central role of F5 in the control and recognition of manipulative actions: the common interpre-tation proposed by (Luppino & Rizzolatti, 2000) and (Fagg & Arbib, 1998) con-siders F5 a part of a larger circuit comprising various areas in the parietal lobe (a large reciprocal connection with AIP), indirectly from STs (Perrett, Mistlin, Harries, & Chitty, 1990) and other premotor and frontal areas (Luppino & Riz-zolatti, 2000). Certainly F5 is strongly involved in the generation and control of action indirectly through F1, and directly by projecting to motor and medullar interneurons in the spinal cord (an in-depth study is described in (Shimazu, Maier, Cerri, Kirkwood, & Lemon, 2004)). A good survey of the physiology of the frontal motor cortex is given in (Rizzolatti & Luppino, 2001).
A graphical representation of the F5 circuitry is shown in Figure 5. In par-ticular, we can note how the response of F5 is constructed of various elements these being the elaboration of object affordances (canonical F5 neurons and AIP), of the visual appearance of the hand occurring in the Superior Temporal sulcus region (STs), and of the timing, synchronization of the action (Luppino & Rizzolatti, 2000). Parallel to F5-AIP, we find the circuit formed by F4-VIP that has been shown to correlate to the control of reaching. Further, a degree of coordination between these circuits is needed since manipulation requires both a transport and a grasping ability (Jeannerod, Arbib, Rizzolatti, & Sakata, 1995).
In practice, the parieto-frontal circuit can be seen as the transformation of the visual information about objects into its motor counterpart, and with the addition of the Inferior Temporal (IT) and Superior Temporal Sulcus (STs) areas, this description is completed with the semantic/identity of objects and

Understanding mirror neurons 205
Figure 4.

206 Giorgio Metta et al.
the state of the hand. This description is also in good agreement with previous models such as the FARS (Fagg, Arbib, Rizzolatti, and Sakata model) and MN1 (Mirror Neuron model 1) (Fagg & Arbib, 1998). Our model is different in try-ing to explicitly identify a developmental route to mirror neurons by looking at how these different transformations could be learned without posing implau-sible constraints.
The model of area F5 we propose here revolves around two concepts that are likely related to the development of this unique area of the brain. The mir-ror system has a double role being both a controller (70% of the neurons of F5 are pure motor neurons) and a “classifier” system (being activated by the sight of specific grasping actions). If we then pose the problem in terms of un-derstanding how such a neural system might actually autonomously develop (be shaped and learned by/through experience during ontogenesis), the role of canonical neurons — and in general that of contextual information specifying the goal of the action — has to be reconsidered. Since purely motor, canonical, and mirror neurons are found together in F5, it is very plausible that local con-nections determine part of the activation of F5.
3. Controller–predictor formulation
For explanatory purpose, the description of our model of the mirror system can be divided in two parts. The first part describes what happens in the actor’s brain, the second what happens in the observer’s brain when watching the ac-tor (or another individual). As we will see the same structures are used both when acting and when observing an action.
Figure 5.

Understanding mirror neurons 207
We consider first what happens from the actor’s point of view (see Figure 6): in her/his perspective, the decision to undertake a particular grasping action is attained by the convergence in area F5 of many factors including context and object related information. The presence of the object and of contextual infor-mation bias the activation of a specific motor plan among many potentially relevant plans stored in F5. The one which is most fit to the context is then enacted through the activation of a population of motor neurons. The motor plan specifies the goal of the motor system in motoric terms and, although not detailed here, we can imagine that it also includes temporal information. Con-textual information is represented by the activation of F5’s canonical neurons and by additional signals from parietal (AIP for instance) and other frontal areas (mesial or dorsal area 6) as in other models of motor control systems (Fagg & Arbib, 1998; Haruno, Wolpert, & Kawato, 2001; Oztop & Arbib, 2002). For example, the contextual information required to switch from one model to another (determining eventually the grasp type) is represented exactly by the detection of affordances performed by AIP-F5.
With reference to Figure 6, our model hypothesizes that the intention to grasp is initially “described” in the frontal areas of the brain in some internal reference frame and then transformed into the motor plan by an appropriate controller in premotor cortex (F5). The action plan unfolds mostly open loop (i.e. without employing feedback). A form of feedback (closed loop) is required though to counteract disturbances and to learn from mistakes. This is obtained by relying on a forward or direct model that predicts the outcome of the action as it unfolds in real-time. The output of the forward model can be compared with the signals derived from sensory feedback, and differences accounted for (the cerebellum is believed to have a role in this (Miall, Weir, Wolpert, & Stein, 1993; Wolpert & Miall, 1996)). A delay module is included in the model to take into account the different propagation times of the neural pathways carrying the predicted and actual outcome of the action. Note that the forward model is relatively simple, predicting only the motor output in advance: since motor commands are generated internally it is easy to imagine a predictor for these signals. The inverse model (indicated with VMM for Visuo-Motor Map), on the other hand, is much more complicated since it maps sensory feedback (vi-sion mainly) back into motor terms. Visual feedback clearly includes both the hand-related information (STs response) and the object information (AIP, IT, F5 canonical). Finally the predicted and the sensed signals arising from the motor act are compared and their difference (feedback error) sent back to the controller.

208 Giorgio Metta et al.
There are two ways of using the mismatch between the planned and ac-tual action: (i) compensate on the fly by means of a feedback controller, and (ii) adjust over longer periods of time through learning (Kawato, Furukawa, & Suzuki, 1987).
The output of area F5, finally activates the motor neurons in the spinal cord (directly or indirectly through medullar circuits) to produce the desired action. This is indicated in the schematics by a connection to appropriate muscular synergies representing the spinal cord circuits.
Learning of the direct and inverse models can be carried out during onto-genesis by a procedure of self-observation and exploration of the state space of the system: grossly speaking, simply by “detecting” the sensorial consequences of motor commands — examples of similar procedures are well known in the literature of computational motor control (Jordan & Rumelhart, 1992; Kawato, Furukawa, & Suzuki, 1987; Wolpert, 1997). Learning of the affordances of ob-jects with respect to grasping can also be achieved autonomously by a trial and error procedure, which explores the consequences of many different actions of the agent’s motor repertoire (different grasp types) to different objects. This includes things such as discovering that small objects are optimally grasped by a pinch or precision grip, while big and heavy objects require a power grasp.
In the observer situation (see Figure 7) motor and proprioceptive informa-tion is not directly available. The only readily available information is vision or sound. The central assumption of our model is that the structure of F5 could be co-opted in recognizing the observed actions by transforming visual cues into motor information as before. In practice, the inverse model is accessed by visu-al information and since the observer is not acting herself, visual information
Figure 6.

Understanding mirror neurons 209
is directly reaching in parallel the sensorimotor primitives in F5. Only some of them are actually activated because of the “filtering” effect of the canonical neurons and other contextual information (possibly at a higher level, knowl-edge of the actor, etc.). A successive filtering is carried out by considering the actual visual evidence of the action being watched (implausible hand postures should be weighed less than plausible ones). This procedure could be used then to recognize the action by measuring the most active motor primitive. It is im-portant to note that canonical neurons are known to fire when the monkey is fixating an object irrespective of the actual context (tests were performed with the object behind a transparent screen or the monkey restrained to the chair).
Comparison is theoretically done, in parallel, across all the active motor primitives (actions); the actual brain circuitry is likely to be different with visual information setting the various F5 populations to certain equilibrium states. The net effect can be imagined as that of many comparisons being per-formed in parallel and one motor primitive resulting predominantly activated (plausible implementations of this mechanism by means of a gating network is described in (Y. Demiris & Johnson, 2003; Haruno, Wolpert, & Kawato, 2001). While the predictor–controller formulation is somewhat well-established and several variants have been described in the literature (Wolpert, Ghahramani, & Flanagan, 2001), the evidence on the mirror system we reviewed earlier seems to support the idea that many factors, including the affordances of the target object, determine the recognition and interpretation of the observed action.
The action recognition system we have just outlined can be interpreted by following a Bayesian approach (Lopes & Santos-Victor, 2005). The details of the formulation are reported in the Appendix I.
3.2 Ontogenesis of mirror neurons
The presence of a goal is fundamental to elicit mirror neuron responses (Gal-lese, Fadiga, Fogassi, & Rizzolatti, 1996) and we believe it is also particularly
Figure 7.

20 Giorgio Metta et al.
important during the ontogenesis of the mirror system. Supporting evidence is described in the work of Woodward and colleagues (Woodward, 1998) who have shown that the identity of the target is specifically encoded during reach-ing and grasping movements: in particular, already at nine months of age, in-fants recognized as novel an action directed toward a novel object rather than an action with a different kinematics, thus showing that the goal is more fun-damental than the enacted trajectory.
The Bayesian interpretation we detail in Appendix I is substantially a su-pervised learning model. To relax the hypothesis of having to “supervise” the machine during training by indicating which action is which, we need to re-mind ourselves of the significance of the evidence on mirror neurons. First of all, it is plausible that the ‘canonical’ representation is acquired by self explora-tion and manipulation of a large set of different objects. F5 canonical neurons represent an association between objects’ physical properties and the actions they afford: e.g. a small object affords a precision grip, or a coffee mug affords being grasped by the handle. This understanding of object properties and the goal of actions is what can be subsequently factored in while disambiguating visual information. There are at least two levels of reasoning: i) certain actions are more likely to be applied to a particular object — that is, probabilities can be estimated linking each action to every object, and ii) objects are used to perform actions — e.g. the coffee mug is used to drink coffee. Clearly, we tend to use actions that proved to lead to certain results or, in other words, we trace backward the link between action and effects: to obtain the effects apply the same action that earlier led to those effects.
Bearing this is mind, when observing some other individual’s actions; our understanding can be framed in terms of what we already know about actions. In short, if I see someone drinking from a coffee mug then I can hypothesize that a particular action (that I know already in motor terms) is used to obtain that particular effect (of drinking). This link between mirror neurons and the goal of the motor act is clearly present in the neural responses observed in the monkey. It is a plausible way of autonomously learning a mirror representation. The learning problem is still a supervised3 one but the information can now be collected autonomously through a procedure of exploration of the environ-ment. The association between the canonical response (object-action) and the mirror one (including vision) is made when the observed consequences (or goal) are recognized as similar in the two cases — self or the other individual acting. Similarity can be evaluated following different criteria ranging from kinematic (e.g. the object moving along a certain trajectory) to very abstract (e.g. social consequences such as in speech).

Understanding mirror neurons 2
Finally, also the Visuo-Motor Map (VMM) as already mentioned can be learned through a procedure of self exploration. Motor commands and corre-lated visual information are two quantities that are readily available to the de-veloping infant. It is easy to imagine a procedure that learns the inverse model on the basis of this information.
4. A machine with hands
The simplest way of confirming the hypothesis that motor gestures are the basis of action recognition, as amply discussed in the previous sections, is to equip a computer with means of “acting” on objects, collect visual and motor data and build a recognition system that embeds some of the principles of operation that we identified in our model (see Figure 8). In particular, the hypothesis we would like to test is whether the extra information available during learning (e.g. kinesthetic and tactile) can improve and simplify the recognition of the same actions when they are just observed: i.e. when only visual information is available. Given the current limitations of robotic systems the simplest way to provide “motor awareness” to a machine is by recording grasping actions of human subjects from multiple sources of information including joint angles, spatial position of the hand/fingers, vision, and touch. In this sense we speak of a machine (the recognition system) with hands.
For this purpose we assembled a computerized system composed of a cy-ber glove (CyberGlove by Immersion), a pair of CCD cameras (Watek 202D), a magnetic tracker (Flock of birds, Ascension), and two touch sensors (FSR). Data was sampled at frame rate, synchronized, and stored to disk by a Pentium class PC. The cyber glove has 22 sensors and allows recording the kinematics of the hand at up to 112Hz. The tracker was mounted on the wrist and provides the position and the orientation of the hand in space with respect to a base frame. The two touch sensors were mounted on the thumb and index finger to detect the moment of contact with the object. Cameras were mounted at ap-propriate distance with respect to their focal length to acquire the execution of the whole grasping action with maximum possible resolution.
The glove is lightweight and does not limit in any way the movement of the arm and hand as long as the subject is sitting not too far from the glove interface. Data recording was carried out with the subject sitting comfortably in front of a table and performing grasping actions naturally toward objects approximately at the center of the table. Data recording and storage were carried out through a custom-designed application; Matlab was employed for post-processing.

22 Giorgio Metta et al.
We collected a large data set and processing was then performed off-line. The selected grasping types approximately followed Napier’s taxonomy (Na-pier, 1956) and for our purpose they were limited to only three types: power grasp (cylindrical), power grasp (spherical), and precision grip. Since the goal was to investigate to what extent the system could learn invariances across dif-ferent grasping types by relying on motor information for classification, the experiment included gathering data from a multiplicity of viewpoints. The da-tabase contains objects which afford several grasp types to assure that recogni-tion cannot simply rely on exclusively extracting object features. Rather, ac-cording to our model, this is supposed to be a confluence of object recognition with hand visual analysis. Two exemplar grasp types are shown in Figure 9: on the left panel a precision grip using all fingers; on the right one a two-finger precision grip.
A set of three objects was employed in all our experiments: a small glass ball, a rectangular solid which affords multiple grasps, and a large sphere re-quiring power grasp. Each grasping action was recorded from six different sub-jects (right handed, age 23–29, male/female equally distributed), and moving
Figure 8.
Understanding mirror neurons 23
the cameras to 12 different locations around the subject including two different elevations with respect to the table top which amounts to 168 sequences per subject. Each sequence contains images of the scene from the two cameras syn-chronized with the cyber glove and the magnetic tracker data. This is the data set that is used for building the Bayesian classifier outlined in the Appendix I (Lopes & Santos-Victor, 2005).
The visual features were extracted from pre-processed image data. The hand was segmented from the images through a simple color segmentation algorithm. The bounding box of the segmented region was then used as a refer-ence to map the view of the hand to a standard reference size. The orientation of the color blob in the image was also used to rotate the hand to a standard ori-entation. This data set was then filtered through Principal Component Analy-sis (PCA) by maintaining only a limited set of eigenvectors corresponding to the first 2 to 15 largest eigenvalues.
One possibility to test the influence of motor information in learning ac-tion recognition is to contrast the situation where motor-kinesthetic informa-tion is available in addition to visual information with the control situation where only visual information is available.
The first experiment uses the output of the VMM as shown in Section 3.1 and thus employed motor features for classification. The VMM was approxi-mated from data by using a simple backpropagation neural network with
Figure 9.

24 Giorgio Metta et al.
sigmoidal units. The input of the VMM was the vector of the mapping of the images onto the space spanned by the first N PCA vectors; the output was the vector of joint angles acquired from the data glove.
As a control, a second experiment employed the same procedure but the VMM, and thus the classification was performed in visual space. The result of the two experiments is reported in the following Table 2.
The experiments were set up by dividing the database in two parts and train-ing the classifier on one half and testing on the other. The number of training sequences is different since we chose to train the classifier with the maximum available data but from all points of view only in the control experiment. The clearest result of this experiment is that the classification in motor space is easier and thus the classifier performs better on the test set. Also, the number of Gauss-ians required by the EM algorithm to approximate the likelihood as per equation (1) within a given precision is smaller for the experiment than the control (1–2 vs. 5–7): that is, the distribution of data is more “regular” in motor space than in visual space. This is to be expected since the variation of the visual appearance of the hand is larger and depends strongly on the point of view, while the sequence of joint angles tends to be the same across repetitions of the same action. It is also clear that in the experiment the classifier is much less concerned with the variation of the data since this variation has been taken out by the VMM.
Overall, our interpretation of these results is that by mapping in motor space we are allowing the classifier to choose features that are much better suited for performing optimally, which in turn facilitates generalization. The same is not true in visual space.
Table . Summary of the results of the experiments. Left: motor information is avail-able to the classifier. Right: only visual information is used by the classifier. Training was always performed with all available sequences after partitioning the data into equally-sized training and test set.
Experiment (motor space) Control (visual space)Training
# of sequences 24 (+ VMM) 64# of points of view 1 4Classification rate (on the training set)
98% 97%
Test# of sequences 96 32# of points of view 4 4Classification rate 97% 80%

Understanding mirror neurons 25
5. Robotic experiment
Following the insight that it might be important to uncover the sequence of de-velopmental events that moves either the machine or humans to a motoric rep-resentation of observed actions, we set forth to the implementation of a complete experiment on a humanoid robot called Cog (Brooks, Breazeal, Marjanović, & Scassellati, 1999). This is an upper-torso human shaped robot with 22 degrees of freedom distributed along the head, arms and torso (Figure 10). It lacks hands, it has instead simple flippers that could use to push and prod objects. It cannot move from its stand so that the objects it interacted with had to be presented to the robot by a human experimenter. The robot is controlled by a distributed parallel control system based on a real-time operating system and running on a set of Pentium based computers. The robot is equipped with cameras (for vision), gyroscopes simulating the human vestibular system, and joint sensors providing information about the position and torque exerted at each joint.
The aim of experimenting on the humanoid robot was that of showing that a mirror neuron-like representation could be acquired by simply relying on the information exchanged during the robot-environment interaction. This proof of concept can be used to analyze the gross features of our model or evidence
Figure 0.

26 Giorgio Metta et al.
any lacuna in it. We were especially interested in determining a plausible se-quence that starting from minimal initial hypotheses steers the system toward the construction of units with responses similar to mirror neurons. The re-sulting developmental pathway should gently move the robot through probing different levels of the causal structure of the environment. Table 2 shows four levels of this causal structure and some intuition about the areas of the brain related to these functions. It is important to note as the complexity of causation evolves from strict synchrony to more delayed effects and thus it becomes more difficult to identify and learn anything from. Naturally, this is not to say that the brain develops following this step-like progression. Rather, brain develop-ment is thought to be fluidic, messy, and above all dynamic (Thelen & Smith, 1998); the identification of “developmental levels” here simplifies though our comprehension of the mechanisms of learning and development.
The first level in Table 2 suggests that learning to reach for externally iden-tified objects requires the identification of a direct causal chain linking the gen-eration of action to its immediate and direct visual consequences. Clearly, in humans the development of full-blown reaching requires also the simultaneous development of visual acuity, binocular vision and, as suggested by Bertenthal and von Hofsten (Bertenthal & von Hofsten, 1998), the proper support of the body freeing the hand and arm from its supporting role.
Only when reaching has developed then the interaction between the hand and the external world might start generating useful and reliable responses from touch and grasp. This new source of information requires simultaneously
Table 2. degrees of causal indirection, brain areas and function in the brain (this table has been compiled from the data in (Rizzolatti & Luppino, 2001).
Level Nature of causation
Brain areas Function and behavior
Time profile
1 Direct causal chain VC-(VIP/7b)-F4-F1 Reaching Strict synchrony2 On level of
indirectionVC-AIP-F5-F1 Object affor-
dances, grasping (rolling in this experiment)
Fast onset upon contact, potential for delayed effects
3 Complex causation involving multiple causal chains
VC-AIP-F5-F1-STs-IT Mirror neurons, mimicry
Arbitrarily delayed onset and effects
4 Complex causation involving multiple instances of ma-nipulative acts
STs-TE-TEO-F5-AIP Object recogni-tion
Arbitrarily delayed onset and effects

Understanding mirror neurons 27
new means of detecting causally connected events since the initiation of an action causes certain delayed effects. The payoff is particularly rich, since in-teraction with objects leads to the formation of a “well defined” concept of objecthood — this, in robotics, is a tricky concept as it has been discussed for example in (Metta & Fitzpatrick, 2003).
It is interesting to study subsequently whether this same knowledge about objects and the interaction between the hand and objects could be exploited in interpreting actions performed by others. It leads us to the next level of causal understanding where the delay between the acquisition of object knowledge and the exploitation of this knowledge when observing someone else might be very large. If any neural unit is active in these two situations (both when acting and observing) then it can be regarded in all respects as a “mirror” unit.
Finally we mention object recognition as belonging to an even higher level of causal understanding where object identity is constructed by repetitive ex-posure and manipulation of the same object. In the following experiments we concentrate on step 2 and 3 assuming step 1 is already functional. We shall not discuss about step 4 any longer since it is relatively more advanced with respect to the scope of this paper. The robot also possesses, and we are not going to enter much into the details here, some basic attention capabilities that allows selecting relevant objects in the environment and tracking them if they move, binocular disparity which is used to control vergence and estimate distances, and enough motor control abilities to reach for an object. In a typical experi-ment, the human operator waves an object in front of the robot which reacts by looking at it; if the object is dropped on the table, a reaching action is initiated, and the robot possibly makes a contact with the object. Vision is used during the reaching and touching movement for guiding the robot’s flipper toward the object, to segment the hand from the object upon contact, and to collect information about the behavior of the object caused by the application of a certain action.
6. Learning object affordances
Since the robot does not have hands, it cannot really grasp objects from the ta-ble. Nonetheless there are other actions that can be employed in exploring the physical properties of objects. Touching, poking, prodding, and sweeping form a nice class of actions that can be used for this purpose. The sequence of images acquired during reaching for the object, the moment of impact, and the effects of the action are measured following the approach of Fitzpatrick (Fitzpatrick,

28 Giorgio Metta et al.
2003a). An example of the quality of segmentation obtained is shown in Fig-ure 11. Clearly, having identified the object boundaries allows measuring any visual feature about the object, such as color, shape, texture, etc.
Unfortunately, the interaction of the robot’s flipper (the manipulator end-point) with objects does not result in a wide class of different affordances. In practice the only possibility was to employ objects that show a characteristic behavior depending on how they are approached. This possibility is offered by rolling affordances: in our experiments we used a toy car, an orange juice bottle, a ball, and a colored toy cube.
The robot’s motor repertoire besides reaching consists of four different stereotyped approach movements covering a range of directions of about 180 degrees around the object.
The experiment consisted in presenting repetitively each of the four objects to the robot. During this stage also other objects were presented at random; the experiment ran for several days and sometimes people walked by the robot and managed to make it poke (and segment) the most disparate objects. The robot “stored” for each successful trial the result of the segmentation, the object’s principal axis which was selected as representative shape parameter, the action — initially selected randomly from the set of four approach directions —, and the movement of the center of mass of the object for some hundreds millisec-onds after the impact was detected. We grouped (clustered) data belonging to the same object by employing a color based clustering technique similar to Crowley et al. (Schiele & Crowley, 2000). In fact in our experiments the toy car was mostly yellow in color, the ball violet, the bottle orange, etc. In different situations the requirements for the visual clustering might change and more sophisticated algorithms could be used (Fitzpatrick, 2003b).
Figure 12 shows the results of the clustering, segmentation, and examina-tion of the object behavior procedure. We plotted here an estimation of the probability of observing object motion relative to the object’s own principal axis. Intuitively, this gives information about the rolling properties of the dif-ferent objects: e.g. the car tends to roll along its principal axis, the bottle at
Figure .
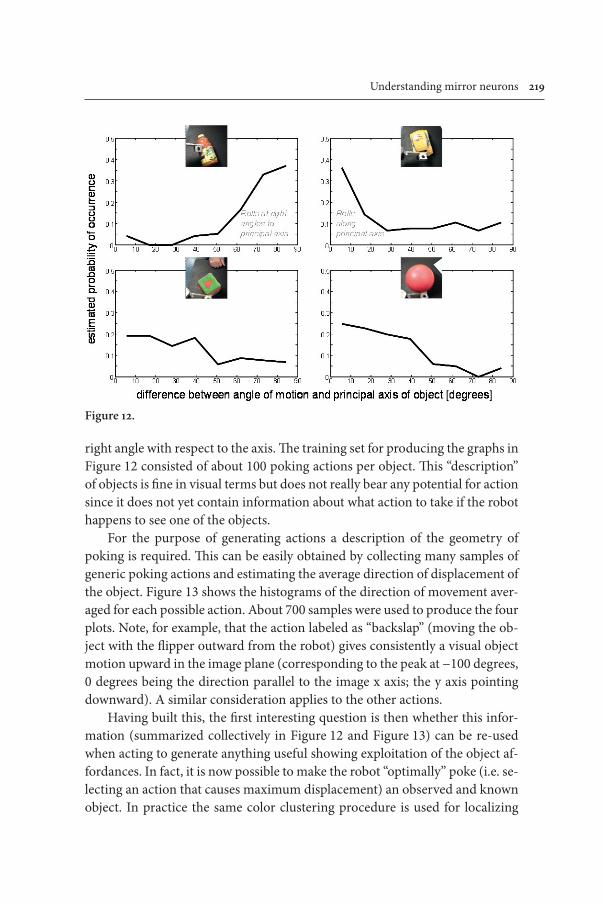
Understanding mirror neurons 29
right angle with respect to the axis. The training set for producing the graphs in Figure 12 consisted of about 100 poking actions per object. This “description” of objects is fine in visual terms but does not really bear any potential for action since it does not yet contain information about what action to take if the robot happens to see one of the objects.
For the purpose of generating actions a description of the geometry of poking is required. This can be easily obtained by collecting many samples of generic poking actions and estimating the average direction of displacement of the object. Figure 13 shows the histograms of the direction of movement aver-aged for each possible action. About 700 samples were used to produce the four plots. Note, for example, that the action labeled as “backslap” (moving the ob-ject with the flipper outward from the robot) gives consistently a visual object motion upward in the image plane (corresponding to the peak at −100 degrees, 0 degrees being the direction parallel to the image x axis; the y axis pointing downward). A similar consideration applies to the other actions.
Having built this, the first interesting question is then whether this infor-mation (summarized collectively in Figure 12 and Figure 13) can be re-used when acting to generate anything useful showing exploitation of the object af-fordances. In fact, it is now possible to make the robot “optimally” poke (i.e. se-lecting an action that causes maximum displacement) an observed and known object. In practice the same color clustering procedure is used for localizing
Figure 2.

220 Giorgio Metta et al.
and recognizing the object, to determine its orientation on the table, its affor-dance, and finally to select the action that it is most likely to elicit the principal affordance (roll).
A simple qualitative test of the performance determined that out of 100 trials the robot made 15 mistakes. Further analysis showed that 12 of the 15 mistakes were due to poor control of reaching (e.g. the flipper touched the object too early bringing it outside the field of view), and only three to a wrong estimate of the orientation.
Although crude, this implementation shows that with little pre-existing structure the robot could acquire the crucial elements for building knowledge of objects in terms of their affordances. Given a sufficient level of abstraction, our implementation is close to the response of canonical neurons in F5 and their interaction with neurons observed in AIP that respond to object orienta-tion (Sakata, Taira, Kusunoki, Murata, & Tanaka, 1997). Another interesting question is whether knowledge about object directed actions can be reused in interpreting observed actions performed perhaps by a human experimenter. It leads directly to the question of how mirror neurons can be developed from the interaction of canonical neurons and some additional processing.
Figure 3.

Understanding mirror neurons 22
To link with the concept of feedback from the action system, here, after the actual action has unfolded, the robot applied exactly the same procedure employed to learn the object affordances to measure the error between the planned and executed action. This feedback signal could then be exploited to incrementally update the internal model of the affordances. This feedback sig-nal is fairly similar to the feedback signal identified in our conceptual model in Section 3 (Figure 6).
7. Developing mirror neurons
In answering the question of what is further required for interpreting observed actions, we could reason backward through the chain of causality employed in the previous section. Whereas the robot identified the motion of the object because of a certain action applied to it, here it could backtrack and derive the type of action from the observed motion of the object. It can further explore what is causing motion and learn about the concept of manipulator in a more general setting (Fitzpatrick & Metta, 2003).
In fact, the same segmentation procedure cited in Section 6 could visually interpret poking actions generated by a human as well as those generated by the robot. One might argue that observation could be exploited for learning about object affordances. This is possibly true to the extent passive vision is reliable and action is not required. In the architecture proposed by Demiris and Hayes (J. Demiris & Hayes, 2002), the authors make a distinction between active and passive imitation. In the former case the agent is already capable of imitating the observed action and recognizes it by simulating it (a set of inverse and forward models are simultaneously activated). In the latter case the agent passively observes the action and memorizes the set of postures that character-izes it. This view is not in contrast with our approach. In Demiris and Hayes, in fact, the system converts the available visual information and estimates the posture of the demonstrator (joint angles). Learning this transformation dur-ing ontogenesis is indeed an active process which requires access to both visual and proprioceptive information. The advantage of the active approach, at least for the robot, is that it allows controlling the amount of information impinging on the visual sensors by, for instance, controlling the speed and type of action. This strategy might be especially useful given the limitations of artificial per-ceptual systems.
Thus, observations can be converted into interpreted actions. The action whose effects are closest to the observed consequences on the object (which

222 Giorgio Metta et al.
we might translate into the goal of the action) is selected as the most plausible interpretation given the observation. Most importantly, the interpretation re-duces to the interpretation of the “simple” kinematics of the goal and conse-quences of the action rather than to understanding the “complex” kinematics of the human manipulator. The robot understands only to the extent it has learned to act.
One might note that a refined model should probably include visual cues from the appearance of the manipulator into the interpretation process. This is possibly true for the case of manipulation with real hands where the configu-ration of fingers might be important. Given our experimental setup the sole causal relationship was instantiated between the approach/poking direction and the object behavior; consequently there was not any apparent benefit in including additional visual cues.
The last question we propound to address is whether the robot can imitate the “goal” of a poking action. The step is indeed small since most of the work is actually in interpreting observations. Imitation was generated in the following by replicating the latest observed human movement with respect to the object and irrespective of its orientation. For example, in case the experimenter poked the toy car sideways, the robot imitated him/her by pushing the car sideways. Figure 14 shows an extended mimicry experiment with different situations originated by playing with a single object.
In humans there is now considerable evidence that a similar strict interac-tion of visual and motor information is at the basis of action understanding at many levels, and if exchanging vision for audition, it applies unchanged to speech (Fadiga, Craighero, Buccino, & Rizzolatti, 2002). This implementation, besides serving as a sanity check to our current understanding of the mirror system, provides hints that learning of mirror neurons can be carried out by a process of autonomous development.
However, these results have to be considered at the appropriate level of abstraction and comparing too closely to neural structure might even be mis-leading: simply this implementation was not meant to reproduce closely the neural substrate (the neural implementation) of imitation. Robotics, we be-lieve, might serve as a reference point from which to investigate the biological solution to the same problem — and although it cannot provide the answers, it can at least suggest useful questions.

Understanding mirror neurons 223
8. Conclusions
This paper put forward a model of the functioning of the mirror system which considers at each stage plausible unsupervised learning mechanisms. In addi-tion, the results from our experiments seem to confirm two facts of the pro-posed model: first, that motor information plays a role in the recognition pro-cess — as would be following the hypothesis of the implication of feedback signals into recognition — and, second, that a mirror-like representation can be developed autonomously on the basis of the interaction between an indi-vidual and the environment.
Other authors have proposed biologically inspired architectures for im-itation and learning in robotics (Y. Demiris & Johnson, 2003; Y. Demiris & Khadhouri, 2005; Haruno, Wolpert, & Kawato, 2001). In (J. Demiris & Hayes, 2002) a set of forward-inverse models coupled with a selection mechanism is employed to control a dynamical simulation of a humanoid robot which learns to perform and imitate gestures. A similar architecture is employed on a planar robot manipulator (Simmons & Demiris, 2004) and on a mobile robot with a gripper (Johnson & Demiris, 2005).
Although with some differences, in all these examples the forward-inverse model pairs are activated both when the robot is performing a motor task and when the robot is attending the demonstrator. During the demonstration of an action, the perceptual input from the scene is fed in parallel to all the inverse models. In turn, the output of the inverse models is sent to the forward models which act as simulators (at the same time the output of the inverse models is inhibited, so no action is actually executed by the robot). The idea is that the predictions of all the forward models are compared to the next state of the demonstrator and the resulting error taken as a confidence measure to select the appropriate action for imitation. In these respects, these various imple-mentations are very similar to the one presented in this paper. Each inverse-forward model pair gives a hypothesis to recognize the observed action. The confidence measure that is accumulated during action observation can be in-terpreted as an estimation of the probability that that hypothesis is true, given the perceptual input. More recently the same architecture has been extended to cope with the obvious differences in human versus robot morphology, and applied to an object manipulation task (Johnson & Demiris, 2005). In the ar-chitecture, in this case, the set of coupled internal inverse and forward models are organized hierarchically, from the higher level, concerned with actions and goals in abstract terms, to the lower level, concerned with the motoric conse-quences of each action.

224 Giorgio Metta et al.
The MOSAIC model by Haruno, Wolpert and Kawato (Haruno, Wolpert, & Kawato, 2001) is also close to our model in the sense of explicitly considering the likelihood and priors in deciding which of the many forward-inverse pairs to activate for controlling the robot. In this case no explicit imitation schema is considered, but the context is properly accounted for by the selection mecha-nism (a Hidden Markov Model).
Our proposal of the functioning of the mirror system includes aspects of both solutions by considering the forward-inverse mapping and the contribu-tion of the contextual information. In our model, and in contrast with Demiris’ architecture, the goal of the action is explicitly taken into account. As we dis-cussed in Section 2 the mirror system is activated only when a goal-directed action is generated or observed. Recognizing the goal is also the key aspect of the learning process and subsequently it works as a prior to bias recognition by filtering out actions that are not applicable or simply less likely to be executed, given the current context. This is related to what happens in the (Johnson & Demiris, 2005) paper where the architecture filters out the actions that can-not be executed. In our model, however, the affordances of a given object are specified in terms of the probabilities of all actions that can be performed on the object (estimated from experience). These probabilities do not only filter out impossible actions, but bias the recognition toward the action that is more plausible given the particular object. The actions considered in this paper are all transitive (i.e. directed towards objects), coherently with the neurophysi-ological view on the mirror system. In the same paper (Johnson & Demiris, 2005), moreover, the recognition of the action is performed by comparing the output of the forward models to the state of the demonstrator. In our model this is always performed in the motor space. In the experiments reported in this paper we show that this simplifies the classification problem and leads to better generalization.
The outcome from a first set of experiments using the data set collected with the cyber glove setup has shown that there are at least two advantages whether the action classification is performed in visual rather than motor space: i) simpler classifier, since the classification or clustering is much simpler in motor space, and ii) better generalization, since motor information is invari-ant to changes of the point of view. Some of these aspects are further discussed in (Lopes & Santos-Victor, 2005).

Understanding mirror neurons 225
[Figure 14 about here]
The robotic experiment shows, on the other hand, that indeed only minimal initial skills are required in learning a mirror neuron representation. In prac-tice, we only had to assume reaching to guarantee interaction with objects and a method to visually measure the results of this interaction. Surely, this is a gross simplification in many respects since, for example, aspects of the development of grasping per se were not considered at this stage and aspects of agency were neglected (the robot was not measuring the posture and behavior of the hu-man manipulator). Though, this shows that, in principle, the acquisition of the mirror neuron structure is the almost natural outcome of the development of a control system for grasping. Also, we have put forward a plausible sequence of learning phases involving the interaction between canonical and mirror neurons. This, we believe, is well in accordance with the evidence gathered by neurophysiology. In conclusion, we have embarked in an investigation that is somewhat similar to the already cited Liberman’s speech recognition attempts. Perhaps, also this time, the mutual rapprochement of neural and engineering sciences might lead to a better understanding of brain functions.
Acknowledgments
The research described in this paper is supported by the EU project MIRROR (IST-2000-28159) and ROBOTCUB (IST-2004-004370). The authors wish to thank Claes von Hofsten, Kerstin Rosander, José Santos-Victor, Manuel Cabido-Lopes, Alexandre Bernardino, Mat-teo Schenatti, and Paul Fitzpatrick for the stimulating discussion on the topic of this paper. The authors wish also to thank the anonymous reviewers for the comments on the early version of this manuscript.
Notes
. (Liberman & Mattingly, 1985)
2. The module of language perception.
3. In supervised learning, training information is previously labeled by an external teacher or a set of correct examples are available.

226 Giorgio Metta et al.
References
Bertenthal, B., & von Hofsten, C. (1998). Eye, Head and Trunk Control: the Foundation for Manual Development. Neuroscience and Behavioral Reviews, 22(4), 515–520.
Brooks, R. A., Breazeal, C. L., Marjanović, M., & Scassellati, B. (1999). The COG project: Building a Humanoid Robot. In C. L. Nehaniv (Ed.), Computation for Metaphor, Anal-ogy and Agents (Lecture Notes in Artificial Intelligence, Vol. 1562, pp. 52–87): Springer-Verlag.
Demiris, J., & Hayes, G. (2002). Imitation as a Dual-Route Process Featuring Predictive and Learning Components: A Biologically-Plausible Computational Model. In K. Dauten-hahn & C. L. Nehaniv (Eds.), Imitation in Animals and Artifacts (pp. 327–361). Cam-bridge, MA, USA: MIT Press.
Demiris, Y., & Johnson, M. H. (2003). Distributed, predictive perception of actions: a bio-logically inspired robotics architecture for imitation and learning. Connection Science, 15(4), 231–243.
Demiris, Y., & Khadhouri, B. (2005). Hierarchical Attentive Multiple Models for Execution and Recognition (HAMMER). Robotics and Autonomous Systems Journal(In press).
Di Pellegrino, G., Fadiga, L., Fogassi, L., Gallese, V., & Rizzolatti, G. (1992). Understand-ing motor events: a neurophysiological study. Experimental Brain Research, 91(1), 176–180.
Fadiga, L., Craighero, L., Buccino, G., & Rizzolatti, G. (2002). Speech listening specifically modulates the excitability of tongue muscles: a TMS study. European Journal of Neuro-science, 15(2), 399–402.
Fagg, A. H., & Arbib, M. A. (1998). Modeling parietal-premotor interaction in primate con-trol of grasping. Neural Networks, 11(7–8), 1277–1303.
Fitzpatrick, P. (2003a, October 27–31). First Contact: an active vision approach to segmen-tation. In proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2161–2166 Vol. 3, Las Vagas, Nevada, USA.
Fitzpatrick, P. (2003b). From First Contact to Close Encounters: A developmentally deep per-ceptual system for a humanoid robot. Unpublished PhD thesis, MIT, Cambridge, MA.
Fitzpatrick, P., & Metta, G. (2003). Grounding vision through experimental manipulation. Philosophical Transactions of the Royal Society: Mathematical, Physical, and Engineering Sciences, 361(1811), 2165–2185.
Fogassi, L., Gallese, V., Fadiga, L., & Rizzolatti, G. (1998). Neurons responding to the sight of goal directed hand/arm actions in the parietal area PF (7b) of the macaque monkey. Society of Neuroscience Abstracts, 24, 257.255.
Gallese, V., Fadiga, L., Fogassi, L., & Rizzolatti, G. (1996). Action recognition in the premo-tor cortex. Brain, 119, 593–609.
Haruno, M., Wolpert, D. M., & Kawato, M. (2001). MOSAIC Model for sensorimotor learn-ing and control. Neural Computation, 13, 2201–2220.
Jeannerod, M. (1988). The Neural and Behavioural Organization of Goal-Directed Move-ments (Vol. 15). Oxford: Clarendon Press.
Jeannerod, M., Arbib, M. A., Rizzolatti, G., & Sakata, H. (1995). Grasping objects: the cortical mechanisms of visuomotor transformation. Trends in Neurosciences, 18(7), 314–320.

Understanding mirror neurons 227
Johnson, M., & Demiris, Y. (2005). Hierarchies of Coupled Inverse and Forward Models for Abstraction in Robot Action Planning, Recognition and Imitation. In proceedings of the AISB 2005 Symposium on Imitation in Animals and Artifacts, 69–76, Hertfordshire, UK.
Jordan, M. I., & Rumelhart, D. E. (1992). Forward models: Supervised learning with a distal teacher. Cognitive Science, 16(3), 307–354.
Kawato, M., Furukawa, K., & Suzuki, R. (1987). A hierarchical neural network model for control and learning of voluntary movement. Biological Cybernetics, 57, 169–185.
Kerzel, D., & Bekkering, H. (2000). Motor activation from visible speech: Evidence from stimulus response compatibility. Journal of Experimental Psychology: Human Perception and Performance, 26(2), 634–647.
Liberman, A. M., Cooper, F. S., Shankweiler, D. P., & Studdert-Kennedy, M. (1967). Percep-tion of the speech code. Psychological Review, 74, 431–461.
Liberman, A. M., & Mattingly, I. G. (1985). The motor theory of speech perception revised. Cognition, 21(1), 1–36.
Liberman, A. M., & Mattingly, I. G. (1985, page 7). The motor theory of speech perception revised. Cognition, 21(1), 1–36.
Liberman, A. M., & Wahlen, D. H. (2000). On the relation of speech to language. Trends in Cognitive Neuroscience, 4(5), 187–196.
Lopes, M., & Santos-Victor, J. (2005). Visual learning by imitation with motor representa-tions. IEEE Transactions on Systems, Man, and Cybernetics, Part B Cybernetics, 35(3), 438–449.
Luppino, G., & Rizzolatti, G. (2000). The organization of the frontal motor cortex. News in Physiological Sciences, 15, 219–224.
Metta, G., & Fitzpatrick, P. (2003). Early Integration of Vision and Manipulation. Adaptive Behavior, 11(2), 109–128.
Miall, R. C., Weir, D. J., Wolpert, D. M., & Stein, J. F. (1993). Is the cerebellum a Smith pre-dictor? Journal of Motor Behavior, 25(3), 203–216.
Murata, A., Fadiga, L., Fogassi, L., Gallese, V., Raos, V., & Rizzolatti, G. (1997). Object rep-resentation in the ventral premotor cortex (area F5) of the monkey. Journal of Neuro-physiology, (78), 2226–2230.
Napier, J. (1956). The prehensile movement of the human hand. Journal of Bone and Joint Surgery, 38B(4), 902–913.
Oztop, E., & Arbib, M. A. (2002). Schema design and implementation of the grasp-related mirror neuron system. Biological Cybernetics, 87, 116–140.
Perrett, D. I., Mistlin, A. J., Harries, M. H., & Chitty, A. J. (1990). Understanding the visual appearance and consequence of hand action. In M. A. Goodale (Ed.), Vision and action: the control of grasping (pp. 163–180). Norwood (NJ): Ablex.
Rizzolatti, G., Camarda, R., Fogassi, L., Gentilucci, M., Luppino, G., & Matelli, M. (1988). Functional organization of inferior area 6 in the macaque monkey: II. Area F5 and the control of distal movements. Experimental Brain Research, 71(3), 491–507.
Rizzolatti, G., & Fadiga, L. (1998). Grasping objects and grasping action meanings: the dual role of monkey rostroventral premotor cortex (area F5). In G. R. Bock & J. A. Goode (Eds.), Sensory Guidance of Movement, Novartis Foundation Symposium (pp. 81–103). Chichester: John Wiley and Sons.

228 Giorgio Metta et al.
Rizzolatti, G., Fadiga, L., Gallese, V., & Fogassi, L. (1996). Premotor cortex and the recogni-tion of motor actions. Cognitive Brain Research, 3(2), 131–141.
Rizzolatti, G., & Luppino, G. (2001). The cortical motor system. Neuron, 31, 889–901.Sakata, H., Taira, M., Kusunoki, M., Murata, A., & Tanaka, Y. (1997). The TINS lecture
— The parietal association cortex in depth perception and visual control of action. Trends in Neurosciences, 20(8), 350–358.
Schiele, B., & Crowley, J. L. (2000). Recognition without correspondence using multidi-mensional receptive field histograms. International Journal of Computer Vision, 36(1), 31–50.
Shimazu, H., Maier, M. A., Cerri, G., Kirkwood, P. A., & Lemon, R. N. (2004). Macaque ventral premotor cortex exerts powerful facilitation of motor cortex outputs to limb motoneurons. The Journal of Neuroscience, 24(5), 1200–1211.
Simmons, G., & Demiris, Y. (2004). Imitation of Human Demonstration Using A Biologi-cally Inspired Modular Optimal Control Scheme. In proceedings of the IEEE-RAS/RSJ International Conference on Humanoid Robots, 215–234, Los Angeles, USA.
Thelen, E., & Smith, L. B. (1998). A Dynamic System Approach to the Development of Cogni-tion and Action (3rd ed.). Cambridge, MA: MIT Press.
Wilson, S. M., Saygin, A. P., Sereno, M. I., & Iacoboni, M. (2004). Listening to speech acti-vates motor areas involved in speech production. Nature Neuroscience, 7, 701–702.
Wolpert, D. M. (1997). Computational approaches to motor control. Trends in Cognitive Sciences, 1(6), 209–216.
Wolpert, D. M., Ghahramani, Z., & Flanagan, R. J. (2001). Perspectives and problems in mo-tor learning. Trends in Cognitive Sciences, 5(11), 487–494.
Wolpert, D. M., & Miall, R. C. (1996). Forward models for physiological motor control. Neural Networks, 9(8), 1265–1279.
Woodward, A. L. (1998). Infant selectively encode the goal object of an actor’s reach. Cogni-tion, 69, 1–34.
Authors’ addresses
Giorgio MettaLIRA-Lab, University of GenoaViale Causa, 13 — 16145 — ItalyEmail: [email protected]
Giulio SandiniLIRA-Lab, University of GenoaViale Causa, 13 — 16145 — ItalyEmail: [email protected] NataleLIRA-Lab, University of GenoaViale Causa, 13 — 16145 — ItalyEmail: [email protected]
Laila CraigheroFaculty of Medicine — D.S.B.T.A. Section of Human PhysiologyVia Fossato di Mortara 17/19 — 44100 Ferrara — ItalyEmail: [email protected]
Luciano FadigaFaculty of Medicine — D.S.B.T.A. Section of Human PhysiologyVia Fossato di Mortara 17/19 — 44100 Ferrara — ItalyEmail: [email protected]

Understanding mirror neurons 229
About the authors
Giorgio Metta: Assistant Professor at the University of Genoa where he teaches the courses of “Anthropomorphic Robotics and Operating Systems”. Ph.D. in Electronic Engineering in 2000. Postdoctoral associate at MIT, AI-Lab from 2001 to 2002. Since 1993 at LIRA-Lab where he developed various robotic platforms with the aim of implementing bioinspired models of sensorimotor control. For more information: http://pasa.liralab.it and http://www.robotcub.org.
Giulio Sandini: Full Professor of bioengineering at the University of Genova where he teaches the course of “Natural and Artificial Intelligent Systems”. Degree in Bioengineering at the University of Genova; Assistant Professor at the Scuola Normale Superiore in Pisa studying aspects of visual processing in cortical neurons and visual perception in human adults and children. Visiting Research Associate at Harvard Medical School in Boston work-ing on electrical brain activity mapping. In 1990 he founded the LIRA-Lab (www.liralab.it) investigating the field of Computational and Cognitive Neuroscience and Robotics with the objective of understanding the neural mechanisms of human sensorimotor coordination and cognitive development by realizing anthropomorphic artificial systems such as human-oids.
Lorenzo Natale was born in Genoa, Italy, in 1975. He received the M.S. degree in Electronic Engineering in 2000 and Ph.D. in Robotics from the University of Genoa, Italy, in 2004. He is currently Postdoctoral Associate at MIT, Computer Science and Artificial Intelligence Laboratory. His research involves the study of sensorimotor development and motor control in artificial and natural systems.
Laila Craighero: Born in 1968, degree in Psychology, Ph.D. in Neuroscience. Assistant Pro-fessor of Human Physiology at the University of Ferrara. Scientific interests: neural mecha-nisms underlying orienting of visuospatial attention. Experience in transcranial magnetic stimulation and electrophysiological investigation in monkeys (single neurons recordings). Among her contributions, in the frame of premotor theory of attention, it is the investigation of the role played by the motor preparation on attentional orienting. More recently, she collaborated to the study of motor cortex and spi-nal cord excitability during observation of actions made by other individuals (‘mirror’ and ‘canonical’ neurons). Laila Craighero is co-investigator in E.C. funded projects on action understanding and sensorimotor coordination.
Luciano Fadiga: Born in 1961. M.D., Ph.D. in Neuroscience, Full Professor of Human Phys-iology at the University of Ferrara. He has a consolidated experience in electrophysiological investigation in monkeys (single neurons recordings) and humans (transcranial magnetic stimulation, study of spinal excitability and brain imaging). Among his contributions is the discovery of monkey mirror neurons in collaboration with the team leaded by G. Rizzolatti at the University of Parma and the first demonstration by TMS that a mirror system exists also in humans. Other fields of his research concern visual attention and speech processing. He is responsible for a research unit funded by the European Commission for the study of the brain mechanisms at the basis of action understanding.

230 Giorgio Metta et al.
Appendix I
The role of the mirror system during action recognition can be framed in a Bayesian context (Lopes & Santos-Victor, 2005). In the Bayesian formulation the posterior probabilities can be written as:
Posterior =Likelihood × Prior
(1)Normalization
and the classification is performed by looking at the maximum of the posterior probabilities with respect to the set of available actions. The normalization factor can be neglected since it does not influence the determination of the maximum. We equated the prior probabilities with the object affordances and estimated them by counting the occurrences of the grasp types vs. the object type. In this interpretation, in fact, the affordances of an object identify the set of actions that are most likely to be executed. The likelihood was approximated by a mixture of Gaussians whose number and parameters were estimated with the Expectation Maximization (EM) algorithm.More specifically the mirror activation of F5 can be thought as:
p(Ai | F, Ok) (2)
where Ai is the ith action from a motor repertoire of I actions, F are the features determining the activation of this particular action and Ok is the target object of the grasping action out of a set of K possible objects. This probability can be computed from Bayes rule as:
p(Ai | F, Ok) = p(F | Ai, Ok) p(Ai | Ok) / p(F | Ok) (3)
and a classifier can be constructed by taking the maximum over the possible actions as fol-lows:
 = maix p(Ai | F, Ok) (4)
The term p(F | Ok) can be discarded since it does not influence the maximization. For the other terms we can give the following interpretation:
p(Ai | F, Ok) Mirror neurons responses, obtained by a combination of the informa-tion as in equation 1.
p(F | Ai, Ok) The activity of the F5 motor neurons generating certain motor patterns given the selected action and the target object
p(Ai | Ok) Canonical neurons responses, that is the probability of invoking a cer-tain action given an object
The feature vector F can also be considered over a certain time period and thus we should apply the following substitution to equations 1 to 3:
F = Ft, …, Ft−N (5)
which takes into account the temporal evolution of the action.
The posterior probability distribution can be estimated using a naive approach, assuming independence between the observations at different time instants. The justification for this

Understanding mirror neurons 23
assumption is that recognition does not necessarily require the accurate modelling of the probability density functions. We have:
p(Ai | Fi, … Ft−N, Ok) =N
∏j=0
p(Ft−j | Ai, Ok) p(Ai | Ok)(6)
p(Ft−j | Ok)
This clearly does not have to be close to the actual brain responses but it was considered since it simplifies computation if compared to the full joint probabilities.

95sistemi intelligenti / a. XViii, n. 1, aprile 2006
lorenzo natale giorgio metta giulio sandini
SVILUPPO SENSOMOTORIO IN UN ROBOT UMANOIDE
1. introduzione
Spesso nei sistemi intelligenti artificiali la rappresentazione del mondo è determinata a priori durante la fase di progettazione. Questo tipo di approccio ha portato alla realizzazione di sistemi in grado di risolvere efficientemente i problemi per i quali sono stati progettati, ma che falliscono in contesti più generali. Nonostante i recenti progressi tecnologici, non si è ancora riusciti a realizzare sistemi intelligenti in grado di affrontare la complessità e l’estrema variabilità del mondo reale. Caratteristica comune a tutti i sistemi biologici, al contrario, è la capacità di adattarsi a situazioni e ad ambienti diversi. Soprattutto nel-l’uomo, la rappresentazione del mondo non è definita a priori ma viene costruita dall’individuo in maniera autonoma attraverso l’interazione fisica tra corpo e ambiente. Questa rappresentazione è estremamente ricca e include informazioni provenienti dagli organi sensoriali esterocettivi (quali visione, olfatto e udito), e propriocettivi (fusi muscolari, sistema vestibolare). I primi anni di vita rappresentano il momento di maggiore cambia-mento delle capacità cognitive e sensomotorie di un individuo. In questo periodo le abilità motorie, percettive e cognitive maturano, mentre, da un punto di vista fisico, il corpo cambia in maniera drammatica. Nonostante questi aspetti siano ancora in fase di studio, è possibile identificare un insieme di principi e regole che governano il corretto sviluppo e l’appren-dimento nei bambini. Nell’ambito della nostra ricerca abbiamo cercato di replicare alcuni di questi principi in un sistema robotico antropomorfo. In questo articolo presentiamo una panoramica dei risultati ottenuti e discutiamo le possibili implicazioni di questa ricerca per lo studio dei sistemi intelligenti.

96
2. sviluppo nei sistemi biologici
Neuroscienze e scienze cognitive sembrano concordare sull’impor-tanza dell’attività motoria e sul suo ruolo nella percezione (Arbib et al. 2000; Jeannerod 1997; Milner e Goodale 1995; Rizzolatti e Gentilucci 1988). In parte questo è dovuto alla recente scoperta nelle aree della corteccia premotoria di neuroni la cui attività è modulata dall’infor-mazione visiva (Fogassi et al. 1996; Graziano et al. 1997). La stessa conclusione è supportata da vari studi nel campo della psicologia dello sviluppo (Konczak e Dichgans 1997; Streri 1993; von Hofsten et al. 1998). Questo aspetto non è sorprendente se si pensa che alcune pro-prietà dell’ambiente possono essere percepite in maniera diretta solo attraverso l’interazione fisica con l’ambiente stesso. Ad esempio, la forma di un oggetto, la sua consistenza o la natura della sua superficie sono qualità che sono meglio percepite attraverso il tatto. L’acquisizione dell’informazione sensoriale pertanto è quasi sempre un processo attivo. Nell’uomo – e in tutti gli animali dotati di fovea – gli occhi sono in continuo movimento ed esplorano l’ambiente per acquisire l’informa-zione visiva in maniera efficiente. Altre modalità sensoriali, quali ad esempio il tatto, richiedono vere e proprie strategie di esplorazione che coinvolgono l’interazione tra corpo e ambiente. L’attività motoria ha pertanto un ruolo fondamentale per il corretto sviluppo percettivo dell’uomo (Bushnell e Boudreau 1993). Una possibile ipotesi è che sviluppo percettivo e motorio progrediscano di pari passo. Per esempio, sembra che l’abilità di percepire visivamente le caratteristiche degli oggetti quali ad esempio volume, durezza e tessitura, non emerga prima dei 6-9 mesi, mentre la capacità di discriminare forme tridimensionali si sviluppi solamente verso i 12-15 mesi di vita. Non è sorprendente che questa tempistica corrisponda con quella dello sviluppo motorio se si pensa che l’esplorazione degli oggetti e la conseguente abilità di percepirne determinate proprietà richiede un elevato grado di controllo del movimento. Gli esperimenti di Lederman e Klatzky (1987) dimostra-rono come negli adulti la determinazione di certe proprietà degli oggetti si accompagni a specifiche azioni esplorative. Nei bambini, durante lo sviluppo, l’impossibilità di eseguire una certa azione potrebbe quindi impedire la percezione della corrispondente proprietà. Nei primi mesi di vita le capacità motorie dei neonati sono limitate. La coordinazione e il controllo dei movimenti delle braccia risultano poco accurati; solo in rari casi e in maniera quasi casuale il bambino riesce a guadagnare il contatto con gli oggetti e afferrarli (von Hofsten 1982). Intorno ai 3 mesi queste abilità migliorano e i movimenti di prensione diventano più affidabili. In questo periodo tuttavia gli oggetti sono quasi sempre afferrati con la mano aperta sfruttando l’opposizione tra le dita e il palmo (power grasp). Questa semplice interazione con gli oggetti è comunque sufficiente a rendere accessibili proprietà quali

97
temperatura, dimensione/volume, e durezza. Infine, verso i 6-9 mesi, i bambini iniziano a manipolare gli oggetti con una certa abilità e con differenti strategie che includono l’uso delle dita in differenti configura-zioni (von Hofsten e Ronnqvist 1993). A questo punto dello sviluppo il maggior controllo sull’esplorazione degli oggetti permette ai bambini di iniziare a percepire proprietà più complesse quali la forma e la rugosità degli oggetti. Ulteriore evidenza a supporto di questa teoria si trova nel lavoro di Needham et al. (2002), dove l’abilità di alcuni bambini di 3 mesi nell’afferrare oggetti è artificialmente aumentata per mezzo di un apposito guanto ricoperto di velcro. Il guanto incrementa in modo rilevante la possibilità di afferrare ed esplorare alcuni oggetti preventivamente preparati dai ricercatori (questi oggetti erano ricoperti ai bordi con lo stesso tipo di velcro). I risultati dimostrano che i bambini sottoposti al test mostrano un maggior interesse nei confronti degli oggetti rispetto a un gruppo di riferimento. Questo interesse si manifesta, tra le altre cose, in una prolungata esplorazione visiva e permane anche in assenza del guanto. È come se l’anticipato sviluppo dell’abilità motoria, provocato artificialmente dal guanto, induca un maggior interesse verso l’esplora-zione visiva degli oggetti. L’identificazione delle regolarità nel flusso sensoriale, e quindi di certe proprietà costanti dell’ambiente, è un processo che caratterizza lo sviluppo sensomotorio che è particolarmente interessante perché ci permette di predire gli eventi che osserviamo (Rosander e von Hofsten 2004; von Hofsten et al. 1998). Le capacità predittive portano a un ulteriore incremento dell’abilità di interagire con l’ambiente, ma cosa forse più importante, forniscono una chiave per interpretare gli eventi intorno a noi. Intorno ai 9 mesi d’età, la capacità di interagire con gli oggetti in maniera ripetitiva e accurata consente di estendere ulteriormente le capacità cognitive. Le azioni di prensione sugli oggetti permettono di costruire una rappresentazione multisensoriale che combina opportuna-mente esperienza visiva, tattile e chinestetica.
3. babybot, un robot che cresce
Motivati da queste osservazioni abbiamo realizzato un robot antro-pomorfo con alcune delle caratteristiche richieste per studiare lo svi-luppo sensomotorio. Il robot, chiamato Babybot, consiste in una testa, un braccio e una mano antropomorfa. Da un punto di vista sensoriale il robot è equipaggiato con visione stereoscopica, un sistema acustico, un sistema vestibolare e sensori tattili (maggiori dettagli sono riportati in fig. 1). Lo sviluppo del robot segue un percorso che per semplicità può es-sere diviso in tre fasi: apprendimento della rappresentazione del proprio

98
corpo, apprendimento dell’interazione con gli oggetti e apprendimento dell’interpretazione degli eventi. Durante la prima fase il robot esplora le capacità sensoriali e motorie del proprio corpo e ne costruisce un’op-portuna rappresentazione interna. Nella seconda fase l’esplorazione si sposta verso il mondo esterno: il robot impara a controllare il corpo in modo da eseguire azioni per interagire con gli oggetti che lo circondano. Un esempio in questo senso consiste nell’abilità di muovere il braccio in modo da toccare o afferrare un oggetto con la mano. Nella terza fase il robot usa la sua conoscenza delle regolarità del mondo esterno per imparare a predire le conseguenze delle proprie azioni sull’ambiente. L’esperienza accumulata dal robot può essere usata in questa fase per interpretare gli eventi osservati sulla base di quelli generati dal robot stesso (Fitzpatrick et al. 2003). Nel seguito riportiamo alcuni esperimenti relativi alle prime due fasi.
Fig. 1. Il Babybot. Il setup utilizzato consiste in un robot antropomorfo chiamato Baby-bot (Metta 2000; Natale 2004) avente un totale di 18 gradi di libertà. Dal punto di vista sensoriale il robot è equipaggiato con una coppia di telecamere CCD, due microfoni, un sensore inerziale, sensori tattili e propriocettivi (quest’ultimi costituiti da encoder che forniscono informazioni sulla posizione dei giunti).

99
4. il corpo
L’esecuzione di un movimento richiede la trasformazione dell’in-formazione sensoriale corrispondente allo stato1 desiderato del sistema nella sequenza di comandi necessaria a eseguire il movimento stesso. In alcuni casi questa trasformazione è piuttosto semplice. Si consideri per esempio il sistema oculomotorio nell’uomo e il problema di controllare i muscoli degli occhi per dirigere lo sguardo verso un oggetto identificato visivamente. L’informazione visiva in questo caso è già espressa in un sistema di riferimento in qualche modo «compatibile» con il sistema motorio. Il sistema di controllo degli occhi deve portare l’oggetto al centro della retina o, in altre parole, azzerare l’errore retinico corri-spondente. Il problema può essere risolto con un controllore in anello chiuso, e l’apprendimento in questo caso si riduce ad una semplice stima dei guadagni del controllore. La situazione si complica, però, se l’oggetto non è visibile e la sua posizione è identificata grazie al suono che produce (ad es. un oggetto che cade al di fuori del campo visivo o in assenza di luce). In questo caso la conversione di coordinate avviene a partire dallo spazio nel quale è rappresentata la posizione dell’evento sonoro (ad es. la differenza di fase tra il suono percepito dall’orecchio destro e quello sinistro) e non è possibile impiegare un controllore in anello chiuso poiché la posizione degli occhi non influenza la percezione sonora. È quindi necessaria una trasformazione più complessa. In alcuni casi le conversioni tra i sistemi di riferimento possono essere rappresentate come una generica trasformazione Dq = f(s) dove s è il segnale sensoriale e Dq il comando motorio necessario per l’esecu-zione del compito considerato. La funzione f(·) racchiude la conoscenza sia dei parametri interni del robot che dell’ambiente esterno e viene detta trasformazione inversa (o modello inverso) poiché converte una sensazione sensoriale nel comando motorio necessario per ottenerla. In alcuni casi la funzione inversa non è definita; ad esempio nel caso di un braccio ridondante2 non esiste una funzione che, data la posizione del punto finale del braccio (mano), fornisce un unico valore dei giunti per realizzarla (in questi casi i meccanismi utilizzati dal cervello per risol-vere il problema non sono del tutto noti; un’ipotesi può essere trovata in Jordan e Rumelhart 1992). Il problema opposto riguarda invece la predizione delle conseguenze sensoriali di una data azione motoria. In questo caso la trasformazione è detta diretta e può essere scritta come una funzione s = f (Dq) che converte un comando motorio Dq nel conseguente effetto sensoriale
1 Per stato in questo caso si intende sia il corpo che l’ambiente esterno. 2 Un sistema meccanico è detto ridondante quando ha un numero di gradi di libertà superiore a quello minimo per eseguire un determinato movimento.

100
s. In altre parole, questo modello diretto fornisce una predizione sullo stato del sistema a seguito di un comando motorio. L’aspetto interessante dei modelli diretti è che sono sempre definiti, dato che ad ogni azione corrisponde una conseguenza unica. In questi casi lo scopo finale dell’apprendimento si riduce ad un generico problema di approssimazione funzionale che può essere risolto tramite reti neurali, metodi di ottimizzazione o, talvolta, utilizzando una semplice tabella di look-up. Purtroppo non è sempre immediato realiz-zare una procedura che permetta al sistema di raccogliere in maniera autonoma gli esempi utilizzati per l’apprendimento delle trasformazioni dirette e inverse. Una possibile soluzione consiste nel generare movimenti casuali e di misurarne gli effetti sul sistema sensoriale (nel robot una procedura simile è utilizzata da Metta (2000) per i movimenti oculari e da Natale (2004) per la compensazione degli effetti della forza peso sul braccio del robot). Un’altra soluzione sostituisce i movimenti casuali con comandi generati da un semplice controllore proporzionale in anello chiuso (Gomi e Kawato 1993). In entrambi i casi il sistema utilizza una procedura di inizializzazione (movimenti casuali o controllore in anello chiuso) che permette al robot di muoversi e contemporaneamente di avviare l’apprendimento. Nel Babybot abbiamo affrontato il problema dell’acquisizione di modelli inversi per il controllo dei movimenti oculari a partire da informazione visiva, inerziale e uditiva (Metta 2000; Natale et al. 2002; Panerai et al. 2002). Un’altra possibile procedura di apprendimento, ricerca le similarità tra modalità sensoriali diverse. Questo meccanismo è stato per esempio utilizzato nell’acquisizione di un modello del corpo del robot. Il problema, in pratica, consiste nell’identificazione visiva della mano del robot e la distinzione di quest’ultima rispetto al resto dell’ambiente. Nella soluzione adottata il robot è stato programmato per eseguire, se necessario, delle azioni con la mano che permettono di semplificare l’elaborazione dei dati visivi. In questo caso l’apprendimento avviene durante una fase di esplorazione nella quale il robot esegue dei movimenti periodici con la mano, mentre un modulo dedicato si occupa di identificare movimenti periodici all’interno dei segnali propriocettivi e visivi. Se sono identi-ficati dei movimenti periodici in entrambi i canali sensoriali, il periodo di oscillazione viene estratto e confrontato. Qualora tale confronto sia positivo, i punti dell’immagine che hanno superato il test sono sele-zionati come parte della mano. La procedura permette di collezionare esempi per risolvere un problema di apprendimento supervisionato e addestrare un modello diretto che predice la posizione della mano nel campo visivo a partire dalla sola informazione propriocettiva (segnale in retroazione degli encoder dei motori). In figura 2 viene mostrato il risultato dell’apprendimento della trasformazione sensomotoria che consente la localizzazione della mano.

101
5. controllo del movimento
Nel paragrafo precedente abbiamo descritto diversi meccanismi di apprendimento che consentono al robot di imparare alcuni modelli di-retti e inversi del proprio corpo e dell’ambiente. In generale un modello inverso permette di risolvere un problema di pianificazione o controllo, mentre un modello diretto permette di anticipare la conseguenza di una determinata azione. La distinzione tuttavia non è così netta: un modello diretto può essere impiegato per risolvere un problema inverso (Jordan e Rumelhart 1992). Si consideri ad esempio il problema di controllare la mano per raggiungere un oggetto. Il problema può essere formulato in termini di una funzione inversa che lega la posizione dell’oggetto nel-l’immagine con il corrispondente comando motorio necessario a spostare il braccio. Nello spazio dei giunti il comando motorio corrisponde alla posizione del braccio che minimizza la distanza tra la mano e il bersaglio e può essere trovato, in alternativa, utilizzando una procedura iterativa che impiega la funzione diretta descritta nel paragrafo precedente (per i dettagli si veda l’Appendice). Un esempio dell’uso di questa tecnica per raggiungere un oggetto è mostrato in figura 2.
6. conclusioni
In questo articolo abbiamo presentato un approccio per la realizzazione di un robot umanoide ispirato alle prime fasi dello sviluppo sensomotorio
Fig. 2. A sinistra: apprendimento della localizzazione della mano. La croce scura rappre-senta la posizione della mano mentre l’ellisse ne approssima forma e orientamento. A destra: raggiungimento di un ipotetico bersaglio al centro dell’immagine. T0 e T1 segnano rispettivamente l’inizio e la fine della traiettoria.

102
dell’uomo. La possibilità di manipolare l’ambiente circostante si ritiene essere uno degli aspetti cruciali dello sviluppo dell’intelligenza negli esseri umani. Lo studio della manipolazione in robotica è stato tradizio-nalmente finalizzato alla semplice esecuzione di compiti di assemblaggio o assistenza. Il controllo dell’interazione tra robot e ambiente è uno degli aspetti più difficili della robotica, ma allo stesso tempo il suo punto di forza poiché permette al sistema l’esplorazione autonoma dell’ambiente e del legame tra attività motoria e percezione. Abbiamo visto come questi aspetti si trovino alla base dei meccanismi che consentono all’uomo di adattarsi all’ambiente e di comprenderne struttura e regole. Per questi motivi riteniamo che l’approccio presentato offra non solo l’opportunità di realizzare robot più adattabili, ma anche un nuovo modo di affrontare lo studio dell’intelligenza nei sistemi artificiali.
appendice
Matematicamente il problema del controllo del braccio per raggiungere un oggetto può essere formulato come la minimizzazione del seguente costo:
min (f(q) – x)2
q
dove x è la posizione del bersaglio, e f(q) la posizione del braccio, calcolata utilizzando il suo modello diretto. Il valore di q che risolve l’equazione precedente corrisponde alla soluzione cercata e può essere determinato in maniera iterativa ad esempio utilizzando il metodo della discesa del gradiente:
qt+1 = qt + k · (f(q) – x) ∇f (q)
dove k è una costante positiva che regola la velocità di discesa e ∇f(q) è il gradiente del modello diretto:
∇f(q) =
Quest’ultimo può essere calcolato in maniera analitica oppure sosti-tuito con una sua stima locale. Questa tecnica non richiede un’inversione esplicita, e come tale, può essere applicata anche quando il braccio è ridondante o in presenza di singolarità.
∂f(q)
∂q

103
riFerimenti bibliograFici
arbib M.A., billard A., iacoboni M. e oztop E. (2000), Synthetic brain ima-ging: grasping, mirror neurons and imitation, in «Neural Networks», 13, pp. 975-997.
bushnell E. e boudreau J. (1993), Motor development and the mind: the potential role of motor abilities as a determinant of aspects of perceptual development, in «Child Development», 64, pp. 1005-1021.
Fitzpatrick P., metta G., natale L., rao S. e sandini G. (2003), Learning about objects through action: Initial steps towards artificial cognition, in ieee International Conference on Robotics and Automation (icra 2003, Taipei, Taiwan.
Fogassi L., gallese V., Fadiga L., luppino G., matelli M. e rizzolatti G. (1996), Coding of peripersonal space in inferior premotor cortex (area F4), in «Journal of Neurophysiology», 76, pp. 141-157.
gomi H. e kawato M. (1993), Neural network control for a closed-loop system using feedback-error-learning, in «Neural Networks», 6, pp. 933-946.
graziano M.S.A., hu X. e gross C.G. (1997), Visuo-spatial properties of ventral premotor cortex, in «Journal of Neurophysiology», 77, pp. 2268-2292.
Jeannerod M. (1997), The cognitive neuroscience of action, Cambrige, Mass. - Oxford, Blackwell Publishers.
Jordan M.I. e rumelhart D.E. (1992), Forward models: Supervised learning with a distal teacher, in «Cognitive Science», 16, pp. 307-354.
konczak J. e dichgans J. (1997), Goal-directed reaching: development toward stereotypic arm kinematics in the first three years of life, in «Experimental Brain Research», 117, pp. 346-354.
lederman S.J. e klatzky R.L. (1987), Hand movements: A window into haptic object recognition, in «Cognitive Psychology», 19, pp. 342-368.
metta G. (2000), Babyrobot: A study into sensori-motor development, PhD Thesislira-Lab, dist, University of Genoa.
milner D.A. e goodale M.A. (1995), The visual brain in action, Oxford, Oxford University Press.
natale L. (2004), Linking action to perception in a humanoid robot: A deve-lopmental approach to grasping, PhD Thesis, dist, University of Genoa.
natale L., metta G. e sandini G. (2002), Development of auditory-evoked reflexes: Visuo-acoustic cues integration in a binocular head, in «Robotics and Autonomous Systems», 39, pp. 87-106.
needham A., barret T. e peterman K. (2002), A pick-me-up for infants’ exploratory skills: Early simulated experiences reaching for objects using «sticky mittens» enhances young infants’ object exploration skills, in «Infant Behavior & Development», 25, pp. 279-295.
panerai F., metta G. e sandini G. (2002), Learning stabilization reflexes in robots with moving eyes, in «Neurocomputing», 48, pp. 323-337.
rizzolatti G. e gentilucci M. (1988), Motor and visual-motor functions of the premotor cortex, in Neurobiology of neocortex, Chichester, Wiley, pp. 269-284.
rosander K. e von hoFsten C. (2004), Infants’ emerging ability to represent object motion, in «Cognition», 91, pp. 1-22.

104
streri A. (1993), Seeing, reaching, touching: The relations between vision and touch in infancy, Cambridge, Mass., mit Press.
von hoFsten C. (1982), Eye-hand coordination in newborns, in «Developmental Psychology», 18, pp. 450-461.
von hoFsten C. e ronnqvist L. (1993), The structuring of neonatal arm mo-vements, in «Child Development», 64, pp. 1046-1057.
von hoFsten C., vishton P., spelke E.S., Feng Q. e rosander K. (1998), Predictive action in infancy: Tracking and reaching for moving objects, in «Cognition», 67, pp. 255-285.
Lorenzo Natale, Mit Csail, 32 Vassar Street, Cambridge, Mass., 02139, Usa e lira-Lab, Dist, Università di Genova, Viale Causa 13, 16145 Genova. E-mail: [email protected] Giorgio Metta e Giulio Sandini, lira-Lab, Dist, Università di Genova, Viale Causa 13, 16145 Genova. E-mail: [email protected] / [email protected]
La ricerca descritta in queso articolo è finanziata in parte dalla Commissione Europea con i progetti RobotCub FP6-IST-004370 e Contact NEST-5010.

Learning Association Fields from Natural Images
Francesco Orabona, Giorgio Metta and Giulio SandiniLIRA-Lab, DIST
University of Genoa, Genoa, ITALY 16145{bremen,pasa,giulio}@liralab.it
Abstract
Previous studies have shown that it is possible to learncertain properties of the responses of the neurons of the vi-sual cortex, as for example the receptive fields of complexand simple cells, through the analysis of the statistics of nat-ural images and by employing principles of efficient signalencoding from information theory. Here we want to go fur-ther and consider how the output signals of ‘complex cells’are correlated and which information is likely to be groupedtogether. We want to learn ‘association fields’, which are amechanism to integrate the output of filters with differentpreferred orientation, in particular to link together and en-hance contours. We used static natural images as trainingset and the tensor notation to express the learned fields. Fi-nally we tested these association fields in a computer modelto measure their performance.
1. Introduction
The goal of perceptual grouping in computer vision is toorganize visual primitives into higher-level primitives thusexplicitly representing the structure contained in the data.The idea of perceptual grouping for computer vision has itsroots in the well-known work of the Gestalt psychologistsback at the beginning of the last century who described,among other things, the ability of the human visual systemto organize parts of the retinal stimulus into ”Gestalten”,that is, into organized structures. They formulated a num-ber of so-called Gestalt laws (proximity, common fate, goodcontinuation, closure, etc.) that are believed to govern ourperception. It is logical to ask if these laws are present inthe statistics of the world.
On the other hand it has been long hypothesized that theearly visual system is adapted to the input statistics [1].Such an adaptation is thought to be the result of the jointwork of evolution and learning during development. Neu-rons, acting as coincidence detectors, can discover and useregularities in the incoming flow of sensory information,which eventually represent the Gestalt laws. It has been pro-
posed that, for example, the mechanism that link togetherthe elements of a contour is rooted in our biology, with neu-rons with lateral and feedback connections implementingthese laws.
There is a large body of literature about computationalmodeling of various parts of the visual cortex, starting fromthe assumption that certain principles guide the neural code([21] for a review). In this view it is important to understandwhy the neural code is as it is. Bell and Sejnowski [2], forexample, demonstrated that it is possible to learn receptivefields similar to those of simple cells starting from naturalimages. In particular they demonstrated that it is possibleto reproduce these receptive fields hypothesizing the spar-sity and independence of the neural code. In spite of this,there is very little literature on learning an entire hierarchyof features, that is not only the first layer, and possibly start-ing from these initial receptive fields.
A step in the construction of this hierarchy is the useof ‘association fields’ [5]. In the literature, these fields areoften hand-coded and employed in many different modelswith the aim to reproduce the human performance in con-tour integration. These fields are supposed to resemble thepattern of excitatory and inhibitory lateral connection be-tween different orientation detector neurons as found, forinstance, by Schmidt et al. [19]. In fact, Schmidt has shownthat cells with an orientation preference in area 17 of thecat are preferentially linked to iso-oriented cells. Further-more, the coupling strength decrease with the differencein the preferred orientation of pre- and post-synaptic cell.Models typically consider variations of the co-circular ap-proach [8, 9, 13], that is two oriented elements are part ofthe same curve if they are tangent to the same circle. Others[22] have considered exponential curves instead of circlesobtaining similar results.
Our question is whether it is possible to learn these asso-ciation fields from the statistics of natural images. Differentauthors have used different approaches: using a databaseof tagged images [4, 6], using motion as an implicit tagger[18] or hypothesizing certain coding properties of the corti-cal layer [10].

Figure 1. Example image of the dataset.
Our approach is similar to to one of Sigman et al. [20],which uses images as the sole input. Further, we aim toobtain precise association fields, useful to link contours in acomputer model.
The rest of the paper is organized as follows: section 2contains a description of the method. Section 3 describes afirst set of experimental results and a method to overcomeproblems due to the non-uniform distribution of the imagestatistics. In section 4 we show the fields computed withthis last modification and finally in section 5 and 6 we showthe performance of the fields in edge detection on a databaseof natural images and we draw some conclusions.
2. Learning from images
We assume the existence of a first layer that simulatesthe behavior of the complex cells; in this paper we do notaddress the issue on how to learn them since we are inter-ested in the next level of the hierarchy. Using the outputof this layer we want to estimate the mean activity aroundpoints with a given orientation. For example it is likely thatif a certain image position contains a horizontal orientation,then the adjacent pixels on the same line would be pointswith an orientation almost horizontal.
To have a precise representation of the orientations andat the same time something mathematically convenient wehave chosen to use the tensor notation. Second order sym-metric tensors can capture the information about the firstorder differential geometry of an image. Each tensor de-scribes both the orientation of an edge and its confidencefor each point. The tensor can be visualized as an ellipse,whose major axis represents the estimated tangential direc-tion and the difference between the major and minor axisthe confidence of this estimate. Hence a point on a line willbe associated with a thin ellipse while a corner with a circle.Consequently given the orientation of a reference pixel, weestimate the mean tensor associated with the surroundingpixels. The use of the tensor notation give us the possibilityto exactly estimate the preferred orientation in each point of
the field and also to quantify its strength and confidence.
We have chosen to learn a separate association field foreach possible orientation. This is done for two main rea-sons:
• It is possible to find differences between the associa-tion fields. For example, it is possible to verify thatthe association field for the orientation of 0 degrees isstronger than that of 45 degrees.
• For applications of computer vision, considering thediscrete nature of digital images, it is better to separatethe masks for each orientation, instead of combiningthe data in a single mask that has to be rotated leadingto sampling problems. The rotation can be done safelyonly if there is a mathematical formula that representsthe field, while on the other hand we are inferring thefield numerically.
We have chosen to learn 8 association fields, one for eachdiscretized orientation. The extension of the fields is cho-sen of 41x41 pixels taken around each point. It should benoted that even if we quantized the orientation of the (cen-tral) reference pixel to classify the fields, the informationabout the remaining pixels in the neighbor were not quan-tized, differently to [6, 20]. There is neither a threshold nora pre-specified number of bins for discretization and thuswe obtain a precise representation of the association field.
Images used for the experiments were taken fromthe publicly available database (Berkeley SegmentationDatabase [15]) which consists of 300 color images of321x481 and 481x321 pixels; 200 of them were convertedto black and white and used to learn the fields, collecting41x41 patches; an example image from the dataset is shownin figure 1.
Figure 2. Complex cells output to the image in figure 1 for 0 de-grees filter of formula (1).

2.1. Feature extraction stage
There are several models of the complex cells of V1, butwe have chosen to use the classic energy model [16] on theintensity channel. The response is calculated as:
Eθ =√
(I ∗ feθ )2 + (I ∗ fo
θ )2 (1)
where feθ and fo
θ are a quadrature pair of even and odd-symmetric filters at orientation θ. Our even-symmetric filteris a Gaussian second-derivative, and the corresponding odd-symmetric is its Hilbert transform. In figure 2 there is anexample of the output of the complex cells model for the 0degrees orientation.
Then the edges are thinned using a standard non-maximum suppression algorithm. This is equivalent to find-ing edges with a Laplacian of Gaussian and zero crossing.The outputs of these filters are used to construct our localtensor representation.
2.2. Tensors
In practice a second order tensor is denoted by a 2x2matrix of values:
T =[
a11 a12
a21 a22
](2)
It is constructed by direct summation of three quadraturefilter pair output magnitudes as in[11]:
T =3∑
k=1
Eθk
(43nT
k nk − 13I
)(3)
where Eθkis the filter output as calculated in (1), I is the
2x2 identity matrix and the filter directions nk are:
n1 = (1, 0)n2 =
(12 ,
√3
2
)n3 =
(− 1
2 ,√
32
) (4)
The greatest eigenvalue λ1 and its corresponding eigen-vector e1 of a tensor associated to a pixel represent respec-tively the strength and the direction of the main orientation.The second eigenvalue λ1 and its eigenvector e1 have thesame meaning for the orthogonal orientation. The differ-ence λ1 − λ2 is proportional to the likelihood that a pixelcontains a distinct orientation.
3. Preliminary results
We have run our test only for a single scale, choosingthe σ of the Gaussian filters equal to 2, since preliminarytests have shown that a similar version of the fields is ob-tained with other scales as well. Two of the obtained fields
Figure 3. Main directions for the association field for the orienta-tion of 0 degrees in the central pixel.
Figure 4. Main directions for the association field for the orienta-tion of 67.5 degrees in the central pixel.
are in figures 3 and 4. It is clear that they are somewhatcorrupted by the presence of horizontal and vertical orien-tations in any of the considered neighbors and by the factthat in each image patch there are edges that are not passingacross the central pixel. On the other hand we want to learnassociation field for curves that do pass through the centralpixel. Geisler et al. [6] used a human labeled database ofimages to infer the likelihood of finding edges with a cer-tain orientation relative to the reference point. On the otherhand, Sigman et al. [20] using only relative orientation andnot absolute ones, could not have seen this problem. In ourcase we want to use unlabeled data to demonstrate that it ispossible to learn from raw images and, as mentioned earlier,we do not want to consider only the relative orientations, butrather a different field for each orientation. We believe thatthis is the same problem that Prodohl et al. [18] experiencedusing static images: the learned fields supported collinear-ity in the horizontal and vertical orientations but hardly inthe oblique ones. They solved this problem using motion toimplicitly tag only the important edges inside each patch.
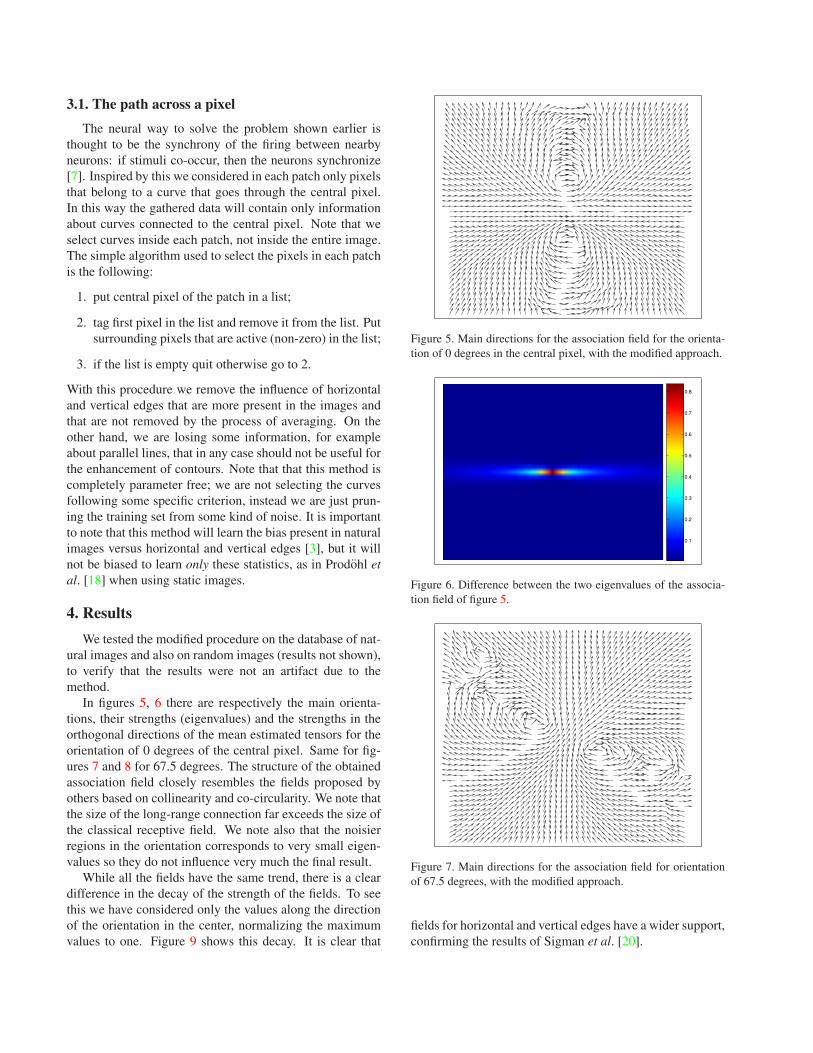
3.1. The path across a pixel
The neural way to solve the problem shown earlier isthought to be the synchrony of the firing between nearbyneurons: if stimuli co-occur, then the neurons synchronize[7]. Inspired by this we considered in each patch only pixelsthat belong to a curve that goes through the central pixel.In this way the gathered data will contain only informationabout curves connected to the central pixel. Note that weselect curves inside each patch, not inside the entire image.The simple algorithm used to select the pixels in each patchis the following:
1. put central pixel of the patch in a list;
2. tag first pixel in the list and remove it from the list. Putsurrounding pixels that are active (non-zero) in the list;
3. if the list is empty quit otherwise go to 2.
With this procedure we remove the influence of horizontaland vertical edges that are more present in the images andthat are not removed by the process of averaging. On theother hand, we are losing some information, for exampleabout parallel lines, that in any case should not be useful forthe enhancement of contours. Note that that this method iscompletely parameter free; we are not selecting the curvesfollowing some specific criterion, instead we are just prun-ing the training set from some kind of noise. It is importantto note that this method will learn the bias present in naturalimages versus horizontal and vertical edges [3], but it willnot be biased to learn only these statistics, as in Prodohl etal. [18] when using static images.
4. Results
We tested the modified procedure on the database of nat-ural images and also on random images (results not shown),to verify that the results were not an artifact due to themethod.
In figures 5, 6 there are respectively the main orienta-tions, their strengths (eigenvalues) and the strengths in theorthogonal directions of the mean estimated tensors for theorientation of 0 degrees of the central pixel. Same for fig-ures 7 and 8 for 67.5 degrees. The structure of the obtainedassociation field closely resembles the fields proposed byothers based on collinearity and co-circularity. We note thatthe size of the long-range connection far exceeds the size ofthe classical receptive field. We note also that the noisierregions in the orientation corresponds to very small eigen-values so they do not influence very much the final result.
While all the fields have the same trend, there is a cleardifference in the decay of the strength of the fields. To seethis we have considered only the values along the directionof the orientation in the center, normalizing the maximumvalues to one. Figure 9 shows this decay. It is clear that
Figure 5. Main directions for the association field for the orienta-tion of 0 degrees in the central pixel, with the modified approach.
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
Figure 6. Difference between the two eigenvalues of the associa-tion field of figure 5.
Figure 7. Main directions for the association field for orientationof 67.5 degrees, with the modified approach.
fields for horizontal and vertical edges have a wider support,confirming the results of Sigman et al. [20].

0.1
0.2
0.3
0.4
0.5
0.6
0.7
Figure 8. Difference between the two eigenvalues of the associa-tion field of figure 7.
−20 −15 −10 −5 0 5 10 15 200
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
0 degrees22.5 degrees45 degrees67.5 degrees90 degrees
Figure 9. Comparison of the decay for the various orientations. Onthe y axis there are the first eigenvalues normalized to a maximumof 1, on the x axis is the distance from the reference point alongthe main field direction.
5. Using the fields
The obtained fields can be used with any existing modelof contour enhancement, but to test them we have used thetensor voting scheme proposed by Guy and Medioni et al.[9]. The choice is somewhat logical considering to the factthat the obtained fields are already tensors. In the tensor vot-ing framework points communicate with each other in orderto refine and derive the most preferred orientation informa-tion. Differently to the original tensor voting algorithm wedon’t have to choose the right scale of the fields [12] sinceit is implicitly in the learnt fields. We compared the per-formances of the tensor voting algorithm using the learnedfields versus the simple output of the complex cell layer,using the Berkeley Segmentation Database and the method-ology proposed by Martin et al. [14, 15]. We can see theresults in figure 10: there is a clear improvement using thetensor voting and the learned association fields instead ofjust using the simulated outputs of the complex cells alone.
0 0.25 0.5 0.75 10
0.25
0.5
0.75
1
Recall
Pre
cisi
on
PG
OE
Figure 10. Comparison between tensor voting with learned fields(PG label) and the complex cell layer alone (OE label).
Figure 11. Test image contours using the complex cell layer alone.
Figure 12. Test image contours using tensor voting with thelearned fields.
An example of the results on the test image in 1, after thenon-maximum suppression procedure, are shown in figures11 and 12.

6. Conclusion
Several authors have studied the mutual dependencies ofsimulated complex cells responses to natural images. Themain result from these studies is that these responses are notindependent and they are highly correlated when they are ar-ranged collinearly or on a common circle. In the present pa-per we have presented a method to learn precise associationfield from natural images. A bio-inspired procedure to getrid of the non-uniform distribution of orientations is used,without the need of a tagged database of images [4, 6], theuse of motion [18] or supposing the cortical signals sparseand independent [10]. The learned fields were used in acomputer model, using the tensor voting method, and theresults were compared using a database of human taggedimages which helps in providing clear numerical results.
However the problem of learning useful complex fea-tures from natural images could in any case find a limitbeyond these contour enhancement networks. In fact theusefulness of a feature is not directly related to image statis-tics but supposes the existence of an embodied agent actingin the natural environment, not just perceiving it. In thissense in the future we would like to link strategies like theone used by Natale et al. [17] and the approach in the cur-rent paper, to link the first stages of unsupervised learning,to reduce the dimensionality of the inputs, to other stagesof supervised learning for the definition of the extraction ofuseful features for a given task.
Acknowledgment
This work was supported by EU project RobotCub (IST-2004-004370) and CONTACT (NEST-5010). The authorswould like to thank Harm Aarts for the discussion on theearlier version of the manuscript.
References
[1] H. B. Barlow. Possible principles underlying the trasforma-tions of sensory messages. In W. A. Rosenblith, editor, Sen-sory Communication, pages 217–234. MIT Press, 1961. 1
[2] A. J. Bell and T. J. Seinowski. The ’indipendent components’of natural scenes are edge filters. Vision Research, 37:3327–3338, 1997. 1
[3] D. M. Coppola, H. R. Purves, A. N. McCoy, and D. Purves.The distribution of oriented contours in the real world.PNAS, 95:4002–4006, 1998. 4
[4] J. H. Elder and R. M. Goldberg. Ecological statistics ofgestalt laws for the perceptual organization of contours.Journal of Vision, 2:324–353, 2002. 1, 6
[5] D. J. Field, A. Hayes, and R. F. Hess. Contour integrationby the human visual system: evidence for local ”associationfield”. Vision Research, 33(2):173–193, 1993. 1
[6] W. S. Geisler, J. S. Perry, B. J. Super, and D. P. Gallo-gly. Edge co-occurrence in natural images predicts contour
grouping performance. Vision Research, 41:711–724, 2001.1, 2, 3, 6
[7] C. M. Gray, P. Konig, A. K. Engel, and W. Singer. Oscil-latory responses in cat visual cortex exhibit inter-columnarsynchronization which reflects global stimulus properties.Nature, 338:334–336, 1989. 4
[8] S. Grossberg and E. Mingolla. Neural dynamics of percep-tual grouping: textures, boundaries, and emergent segmenta-tions. Perceptual Psychophysics, 38:141–171, 1985. 1
[9] G. Guy and G. Medioni. Inferring global perceptual contoursfrom local features. Int. J. of Computer Vision, 20:113–133,1996. 1, 5
[10] P. O. Hoyer and A. Hyvarinen. A multilayer sparse codingnetwork learns contour coding from natural images. VisionResearch, 42(12):1593–1605, 2002. 1, 6
[11] H. Knutsson. Representing local structure using tensors.In Proc. 6th Scandinavian Conference on Image Analysis,pages 244–251, Oulu, Finland, 1989. 3
[12] M.-S. Lee and G. Medioni. Grouping ., -, →, θ, into regions,curves and junctions. Journal of Computer Vision and ImageUnderstanding, 76(1):54–69, 1999. 5
[13] Z. Li. A neural model of contour integration in the primaryvisual cortex. Neural Computation, 10:903–940, 1998. 1
[14] D. Martin, C. Fowlkes, and J. Malik. Learning to detect nat-ural image boundaries using local brightness, color and tex-ture cues. IEEE Transactions on Pattern Analysis and Ma-chine intelligence, 26(5):530–549, 2004. 5
[15] D. Martin, C. Fowlkes, D. Tal, and J. Malik. A databaseof human segmented natural images and its application toevaluating segmentation algorithms and measuring ecologi-cal statistics. In Proc. 8th Int’l Conf. Computer Vision, vol-ume 2, pages 416–423, July 2001. 2, 5
[16] M. Morrone and D. Burr. Feature detection in human vi-sion: A phase dependent energy model. Proc. Royal Soc. ofLondon B, 235:221–245, 1988. 3
[17] L. Natale, F. Orabona, G. Metta, and G. Sandini. Exploringthe world through grasping: a developmental approach. InProc. 6th CIRA Symposium, pages 27–30, June 2005. 6
[18] C. Prodohl, R. P. Wurtz, and C. von der Malsburg. Learningthe gestalt rule of collinearity from object motion. NeuralComputation, 15:1865–1896, 2003. 1, 3, 4, 6
[19] K. Schmidt, R. Goebel, S. Lowel, and W. Singer. Theperceptual grouping criterion of collinearity is reflected byanisotropies of connections in the primary visual cortex. Eu-ropean Journal of Neuroscience, 5(9):1083–1084, 1997. 1
[20] M. Sigman, G. A. Cecchi, C. D. Gilbert, and M. O. Mag-nasco. On a common circle: Natural scenes and gestalt rules.PNAS, 98(4):1935–1940, 2001. 2, 3, 4
[21] E. Simoncelli and B. Olshausen. Natural images statisticsand neural representation. Annual Review of Neuroscience,24:1193–1216, 2001. 1
[22] V. Vonikakis, A. Gasteratos, and I. Andreandis. Enhance-ment of perceptually salient contours using a parallel artifi-cial cortical network. Biological Cybernetics, 94:194–214,2006. 1

Mirror neuron: a neurological approach to empathy Giacomo Rizzolatti1,3 and Laila Craighero2
1 Dipartimento di Neuroscienze, Sezione di Fisiologia, via Volturno, 3, Università di Parma, 43100, Parma, Italy;
2 Dip. SBTA, Sezione di Fisiologia Umana, via Fossato di Mortara, 17/19, Università di Ferrara, 44100 Ferrara, Italy;
3 Corresponding author: Giacomo Rizzolatti, e-mail: [email protected]
Changeux et al. Neurobiology of Human Values © Springer-Verlag Berlin Heidelberg 2005
Summary
Humans are an exquisitely social species. Our survival and success depend criti-cally on our ability to thrive in complex social situations. But how do we under-stand others? Which are the mechanisms underlying this capacity?
In the present essay we discuss a general neural mechanism (“mirror mecha-nism”) that enables individuals to understand the meaning of actions done by others, their intentions, and their emotions, through activation of internal repre-sentations coding motorically the observed actions and emotions.
In the first part of the essay we will show that the mirror mechanism for “cold” actions, those devoid of emotional content, is localized in parieto-frontal cortical circuits. These circuits become active both when we do an action and when we ob-serve another individual doing the same action. Their activity allows the observer to understand the “what” of an action.
We will show, then, that a “chained” organization of motor acts plus the mir-ror mechanism enable the observer to understand the intention behind an action (the “why” of an action) by observing the first motor act of an action.
Finally, we will discuss some recent data showing that the mirror mechanism localized in other centers, like the insula, enables the observer to understand the emotions of others. We will conclude briefly discussing whether these biological data allow inferences about moral behavior.
Introduction
“How selfish soever man may be supposed, there are evidently some principles in his nature, which interest him in the fortune of others, and render their happiness necessary to him, though he derives nothing from it except the pleasure of seeing it.” This famous sentence by Adam Smith (1759), which so nicely describes our empathic relation with others, contains two distinct concepts.

108 Giacomo Rizzolatti and Laila Craighero
The first is that individuals are endowed with a mechanism that makes them share the “fortunes” of others. By observing others, we enter in an “empathic” re-lation with them. This empathic relation concerns not only the emotions that oth-ers feel but also their actions. “The mob, when they are gazing at a dancer on the slack rope, naturally writhe and twist and balance their own bodies, as they see him do, and as they feel that they themselves must do if in his situation.”(Smith 1759).
The second idea is that, because of our empathy with others, we are compelled to desire their happiness. If others are unhappy, we are also unhappy, because the other’s unhappiness somehow intrudes into us.
According to Smith, the way in which we enter into empathic relation may be voluntary (“As we have no immediate experience of what other men feel, we can form no idea of the manner in which they are affected, but by conceiving what we ourselves should feel in the like situation”), but also, as shown in the above-cited example of the “dancer,” may be automatically triggered by the observation of the behavior of others.
The aim of this essay is to discuss the existence of a neural mechanism, resem-bling that described by Adam Smith, that puts the individual in empathic contact with others. This mechanism – the mirror mechanism – enables the observer to understand the actions of others, the intention behind their actions, and their feelings. In a short “coda,” we will discuss the validity of the second idea of Adam Smith, the obligatory link between our happiness and that of others.
Action understanding
Humans are social beings. They spend a large part of their time observing others and trying to understand what they are doing and why. Not only humans but also apes and monkeys have a strongly developed interest in others.
How are actions recognized? The traditional view is that action recognition is based exclusively on the visual system. The understanding of an action done by another individual depends on the activity of the higher order visual areas and, in particular, of those of the superior temporal sulcus, where there are neurons selectively activated by biological motions (Perrett et al. 1989; Carey et al. 1997; Allison et al. 2000; Puce and Perrett 2003).
Another hypothesis is that an action is recognized when the observed action activates, in the observer’s brain, an analogous motor representation. The ob-server does not execute that action, because control mechanisms prevent its overt occurrence, but the evoked motor representation (“motor knowledge”) allows him to understand the meaning of what he saw (Rizzolatti et al. 2001).
It is important to note that the two hypotheses are not in contraposition. Rath-er, they describe two different ways in which an action may be understood. The “visual” hypothesis describes a “third person” relation between the observer and the observed action. The action, albeit recognized in its general meaning, is not understood in all its implications, because it does not enter into the semantic mo-tor network of the observing individual as well as in his/her private knowledge of what doing that action means. “Visual” understanding is similar to that a robot,

Mirror neuron: a neurological approach to empathy 109
able to differentiate an action from another, may have, or humans have when they see a bird flying or a dog barking (see below). In contrast, the “motor” hypothesis describes the “first person” understanding of what the individual is seeing. The observed action enters into the observer’s motor representation and recalls his/her similar experiences when doing that action. It is an empathic recognition that makes the observer share the experience of the action agent.
Mirror Neuron System and Action Understanding
The strongest evidence in favor of the “motor hypothesis” is represented by mir-ror neurons. These neurons, originally found in the monkey ventral premotor cortex (area F5), are active both when the monkey does a particular action and when it observes another individual doing a similar action. The mirror neurons do not respond to object presentation. Similarly, they do not respond to the sight of an agent mimicking actions or performing non-object-directed gestures. Mirror neurons have also been described in the monkey parietal lobe (Fogassi et al. 1998: Gallese et al. 2002).
The mirror mechanism appears to be a mechanism particularly well suited for imitation. Imitation, however, appeared only late in evolution. Monkeys, which have a well-developed mirror system, lack this capacity and even apes have it only in a rather rudimentary form (see Tomasello and Call 1997; Visalberghi and Fragaszy 2002).
The properties of monkey mirror neurons also indicate that this system ini-tially evolved not for imitation. Mirror neurons typically show a good congruence between the visual actions they respond to and the motor responses they code, yet only in a minority of them do the effective observed and effective executed actions correspond in terms of both goal and means for reaching the goal. Most of them code the goal of the action (e.g., grasping) but not the way in which the observed action is done. These neurons are, therefore, of little use for imitation in the proper sense, that is the capacity to imitate an action as it has been performed (Rizzolatti and Craighero 2004).
Summing up, it is very likely that the faculty for imitation developed on the top of the mirror system. However, its initial basic function was not imitation but enabling an individual to understand actions done by others (see Rizzolatti et al. 2001).
Evidence in favor of the notion that mirror neurons are involved in action understanding comes from a recent series of studies in which mirror neurons were tested in experimental conditions in which the monkey could understand the meaning of an occurring action but had no visual information about it. The rationale of these studies was the following: if mirror neurons mediate action un-derstanding, they should become active when the meaning of the observed action is understood, even in the absence of visual information.
The results showed that this is the case. In one study, F5 mirror neurons were recorded while the monkey was observing a “noisy” action (e.g., ripping a piece of paper) and then was presented with the same noise without seeing the action . The results showed that a large number of mirror neurons, responsive to the ob-

110 Giacomo Rizzolatti and Laila Craighero
servation of noisy actions, also responded to the presentation of the sound proper of that action, alone. Responses to white noise or to the sound of other actions were absent or much weaker than responses to the preferred action. Neurons re-sponding selectively to specific action sounds were named “audio-visual” mirror neurons (Kohler et al. 2002).
In another study, mirror neurons were tested by introducing a screen between the monkey and the location of an object (Umiltà et al. 2001). The idea underlying the experiment was that, if mirror neurons are involved in action understanding, they should also discharge in conditions in which the monkey does not see the occurring action but has sufficient clues to create a mental representation of what the experimenter does. The monkeys were tested in four conditions: 1) the experi-menter is grasping an object; 2) the experimenter is miming grasping, and 3) and 4), the monkey observes the actions of 1) and 2) but the final critical part of them (hand-object interaction) is hidden by a screen. It is known that mirror neurons typically do not fire during the observation of mimed actions. At the beginning of each “hidden “ trial, the monkey was shown whether there was or was not an ob-ject behind the screen. Thus, in the hidden condition, the monkey “knew” that the object was present behind the screen and could mentally represent the action.
The results showed that more than half of the tested neurons discharged in the hidden condition, thus indicating that the monkey was able to understand the goal of the action even in the absence of the visual aspect describing the action.
In conclusion, both the experiments show that the activity of mirror neurons correlates with action understanding. The visual features of the observed actions are necessary to trigger mirror neurons only insomuch as they allow the under-standing of the observed actions. If action comprehension is possible on other bases, mirror neurons signal the action even in the absence of visual stimuli.
The Mirror Neuron System in Humans
Evidence, based on single neuron recordings, of the existence of mirror neurons in humans is lacking. Their existence is, however, indicated by EEG and MEG studies, TMS experiments, and brain imaging studies (see Rizzolatti and Craigh-ero 2004). For the sake of space, we will review here only a tiny fraction of these studies.
MEG and EEG studies showed that the desynchronization of the motor cortex observed during active movements was also present during the observation of action done by others (Hari et al. 1998: Cochin et al. 1999). Recently, desynchro-nization of cortical rhythms was found in functionally delimited language and hand motor areas in a patient with implanted subdural electrodes, both during observation and execution of finger movements (Tremblay et al. 2004).
TMS studies showed that the observation of actions done by others determines an increase of corticospinal excitability with respect to the control conditions. This increase concerned specifically those muscles that the individuals use for producing the observed movements (e.g., Fadiga et al. 1995; Strafella and Paus 2000; Gangitano et al. 2001, 2004).

Mirror neuron: a neurological approach to empathy 111
Brain imaging studies allowed the localization of the cortical areas forming the human mirror neuron system. They showed that the observation of actions done by others activates, besides visual areas, two cortical regions whose function is classically considered to be fundamentally or predominantly a motor one: the inferior parietal lobule (area PF/PFG), and the lower part of the precentral gy-rus (ventral premotor cortex) plus the posterior part of the inferior frontal gyrus (IFG). (Rizzolatti et al. 1996; Grafton et al. 1996; Grèzes et al. 1998, 2003; Iacoboni et al. 1999, 2001; Nishitani and Hari 2000, 2002; Buccino et al. 2001; Koski et al. 2002, 2003; Manthey et al. 2003, Johnson-Frey et al. 2003). These two regions form the core of the mirror neuron system in humans.
Recently, an fMRI experiment was carried out to see which type of observed actions is recognized using the mirror neuron system (Buccino et al. 2004). Vid-eo-clips showing silent mouth actions done by humans, monkeys and dogs were presented to normal volunteers. Two types of actions were shown: biting and oral communicative actions (speech reading, lip-smacking, barking). Static images of the same actions were presented as a control.
The results showed that the observation of biting, regardless of whether done by a man, a monkey or a dog, determined the same two activation foci in the inferior parietal lobule, and in the pars opercularis of IFG and the adjacent pre-central gyrus. Speech reading activated the left pars opercularis of IFG, whereas the observation of lip smacking activated a small focus in the right and left pars opercularis of IFG. Most interestingly, the observation of barking did not produce any mirror neuron system activation.
These results strongly support the notion mentioned above that actions done by other individuals can be recognized through different mechanisms. Actions belonging to the motor repertoire of the observer are mapped on his/her mo-tor system. Actions that do not belong to this repertoire do not excite the motor system of the observer and appear to be recognized essentially on a visual basis. Thus, in the first case, the motor activation translates the visual experience into an empathic, first person knowledge, whereas this knowledge is lacking in the second case.
Intention understanding
The data discussed above indicate that the premotor and parietal cortices of pri-mates contain a mechanism that allows individuals to understand the actions of others. Typically, an individual observing an action done by another person not only understands what that person is doing, but also why he/she is doing it. Let us imagine a boy grasping a mug. There are many reasons why the boy could grasp it, but the observer usually is able to infer why he did it. For example, if the boy grasped the cup by the handle, it is likely that he wants to drink the coffee, while if he grasped it by the top it is more likely that he wants to place it in a new loca-tion.
The issue of whether the intention comprehension (the “why” of an observed action) could be mediated by the mirror neurons has been recently addressed in a study in which the motor and visual properties of mirror neurons of the infe-

112 Giacomo Rizzolatti and Laila Craighero
rior parietal lobule (IPL) were investigated (Fogassi et al., manuscript in prepara-tion).
IPL neurons that discharge during active grasping were selected. Subsequently, their motor activity was studied in two main conditions. In the first, the monkey grasped a piece of food located in front of it and brought it to its mouth (eating condition). In the second, the monkey grasped an object and placed it into a con-tainer (placing condition).
The results showed that the large majority of IPL grasping neurons (about 65% of them) were significantly influenced by the action in which the grasping was embedded. Examples are shown in Figure 1. Neurons coding grasping for eating were much more common than neurons coding grasping for placing, with a ratio of two to one.
Studies in humans showed that the kinematics of the first motor act of an action is influenced by the subsequent motor acts of that action (see Jeannerod 1988). The recordings of reaching-to-grasp kinematics of the monkeys in the two experi-mental conditions described above confirmed these findings. Reaching-to-grasp movement followed by arm flexion (bringing the food to the mouth) was faster than the same movement followed by arm abduction (placing the food into the container). To control for whether the differential discharge of grasping neurons in eating and placing conditions were due to this difference in kinematics rather than to the action goal, a new placing condition was introduced (see Fig. 1). In this condition the monkey had to grasp a piece of food and place it into a container located near its mouth. Thus, the new place condition was identical in terms of goal to the original one but required, after grasping, arm flexion rather than arm abduction. The kinematics analysis of the reaching-to-grasp movement showed that the wrist peak velocity was fastest in the new placing condition, intermediate in the eating condition, and slowest in the original placing condition.
Neuron activity showed that, regardless of arm kinematics, the neuron se-lectivity remained unmodified. Neurons selective for placing in the far contain-er showed the same selectivity for placing in the container near the monkey’s mouth. Thus, it is the goal of the action that determines the motor selectivity of IPL neurons in coding a given motor act, rather than factors related to movement kinematics.
As in the premotor cortex, there are neurons in IPL that are endowed with mirror properties, discharging both during the observation and execution of the
Fig. 1. A. Lateral view of the monkey brain showing the sector of IPL (gray shading) from which the neurons were recorded; cs, central sulcus; ips, inferior parietal sulcus. B Schematic drawing illustrating the apparatus and the paradigm used for the motor task. Left: starting position of the task. A screen prevents the monkey from seeing the target. Right: after the screen is removed, the monkey could release the hand from the starting position, reach and grasp the object to bring it to its mouth (Condition I) or to place it into a container located near the target (II) or near its mouth (III). C Activity of three IPL neurons during grasping in Conditions I and II. Rasters and the histograms are synchronized with the moment when the monkey touched the object to be grasped. Red bars indicate the moment when the monkey released its hand from the starting position. Green bars indicate the moment when the monkey touched the container. Abscissa: time, bin = 20 ms; ordinate: discharge frequency. (From Fogassi et al., in preparation)

Mirror neuron: a neurological approach to empathy 113

114 Giacomo Rizzolatti and Laila Craighero
same motor act (Fogassi et al. 1998, Gallese et al. 2002). To see whether these neu-rons also discharge differentially during the observation of the same motor act but embedded in different actions, their visual properties were tested in the same two conditions as those used for studying their motor properties. The actions were performed by an experimenter in front of the monkey. In one condition, the monkey observed the experimenter grasping a piece of food and bringing it to his mouth; in the other, the monkey observed the experimenter placing an object into the container.
The results showed that more than two-thirds of IPL neurons were differen-tially activated during the observation of grasping in placing and eating condi-tions. Examples are shown in Figure 2. Neurons responding to the observation of grasping for eating were more represented than neurons responding to the observation of grasping for placing, again with a two to one ratio.
A comparison between neuron selectivity during the execution of a motor act and motor act observation showed that the great majority of neurons (84%) have the same specificity during grasping execution and grasping observation. Thus, a mirror neuron whose discharge was higher during the observation of grasping for eating than during the observation of grasping for placing also had a higher discharge when the monkey grasped for eating than when it grasped for placing. The same was true for neurons selective for grasping for placing.
The motor and visual organization of IPL, just described, is of great interest for two reasons. First, it indicates that motor actions are organized in the pari-etal cortex in specific chains of motor acts; second, it strongly suggests that this chained organization might constitute the neural basis for understanding the in-tentions of others.
In favor of the existence of action chains in IPL, it is not only the activation of neurons coding the same motor act in one condition and not in another, but also the organization of IPL neuron-receptive fields. This organization shows that there is a predictive facilitatory link between subsequent motor acts. To give an example, there are IPL neurons that respond to the passive flexion of the forearm, have tactile receptive fields on the mouth, and in addition discharge during mouth grasping (Ferrari et al., manuscript in preparation). These neurons facilitated the mouth opening when an object touched the mouth, but also when the monkey grasped it, producing a contact between the object and the hand tactile-receptive field. Recently, several examples of predictive chained organization in IPL have been described by Yokochi et al. (2003). If one considers that a fundamental as-pect of action execution is its fluidity, the link between the subsequent motor acts forming an action and the specificity of neurons coding them appears to be an optimal solution for executing an action without intervening pauses between the individual motor acts forming it.
The presence of chained motor organization of IPL neurons has deep impli-cations for intention understanding. The interpretation of the functional role of mirror neurons, as described above, was that of action understanding. A motor act done by another individual is recognized when this act triggers the same set of neurons that are active during that act execution. The action-related IPL mirror neurons allow one to extend this concept. These neurons discriminate one motor act from another, thus activating a motor act chain that codes the final goal of the

Mirror neuron: a neurological approach to empathy 115
action. In this way the observing individual may re-enact internally the observed action and thus predict the goal of the observed action. In this way, the observer can “read” the intention of the acting individual.
This intention-reading interpretation predicts that, in addition to mirror neu-rons that fire during the execution and observation of the same motor act (“clas-sical mirror neurons”), there should be neurons that are visually triggered by a given motor act but discharge during the execution not of the same motor act, but of another one that is functionally related to the former and part of the same action chain. Neurons of this type have been previously described both in F5 (Di Pellegrino et al. 1992) and in IPL (Gallese et al. 2002) and referred to as “logically related” mirror neurons. These “logic” mirror neurons were never theoretically discussed because their functional role was not clear. The findings just discussed allow us to not only account for their occurrence but also to indicate their neces-sity, if the chain organization is at the basis of intention understanding.
While the mechanism of intention understanding just described appears to be rather simple, it would be more complex to specify how the selection of a particu-lar chain occurs. After all, what the observer sees is just a hand grasping a piece of food or an object.
There are various factors that may determine this selection. The first is the context in which the action is executed. In the study described above, the clue for possible understanding of the intention of the acting experimenter was either the presence of the container (placing condition) or its absence (eating condition). The second factor that may intervene in chain selection is the type of object that the experimenter grasped. Typically, food is grasped in order to be eaten. Thus, the observation of a motor act directed towards food is more likely to trigger grasping-for-eating neurons than neurons that code grasping for other purposes. This food-eating association is, of course, not mandatory but could be modified by other factors.
One of these factors is the standard repetition of an action. Another is, as men-tioned before, the context in which the action is performed. Context and object type were found to interact in some neurons. For example, some neurons that se-lectively discharged during the observation of grasping for eating also discharged, although weakly, during the observation of grasping for placing when the object to be placed was food, but not when it was a solid. It was as if the eating chain was activated, although slightly, by food in spite of the presence of a contextual clue indicating that placing was the most likely action. A few neurons, instead of showing an intermediate discharge when the nature of the stimulus (food) and context conflicted, decreased their discharge with time when the same action was repeated. It was as if the activity of the placing chain progressively inhibited the activity of neurons of the eating chain.
Understanding “other minds” constitutes a special domain of cognition Devel-opmental studies clearly show that this cognitive faculty has various components and that there are various steps through which infants acquire it (see Saxe et al. 2004). Brain imaging studies also tend to indicate the possibility of an involve-ment of many areas in this function (Blakemore and Decety 2001; Frith and Frith 2003; Gallagher and Frith 2003).

116 Giacomo Rizzolatti and Laila Craighero
Given the complexity of the problem, it would be naive to claim that the mech-anism described in the present study is the mechanism at the basis of mind read-ing. Yet, the present data show for the first time a neural mechanism through which an important aspect of mind reading, understanding the intention of oth-ers, may be solved.
Emotion understanding
Up to now we have dealt with the neural mechanisms that enable individuals to understand “cold actions,” that is, actions without any obvious emotional con-tent. In social life, however, equally important, and maybe even more so, is the capacity to decipher emotions. Which mechanisms enable us to understand what others feel? Is there a mirror mechanism for emotions similar to that for cold ac-tion understanding?
It is reasonable to postulate that, as for action understanding, there are two basic mechanisms for emotion understanding that are conceptually different one from another. The first consists in cognitive elaboration of sensory aspects of oth-ers’ emotional behaviors. The other consists in a direct mapping of sensory as-pects of the observed emotional behavior on the motor structures that determine, in the observer, the experience of the observed emotion.
These two ways of recognizing emotions are experientially radically differ-ent. With the first, the observer understands the emotions expressed by others but does not feel them. He deduces them. A certain facial or body pattern means
Fig. 2. Visual responses of IPL mirror neurons during the observation of grasping-to-eat and grasping-to-place done by an experimenter. Condtions as in Figure 1. (From Fogasso et al., in preparation)

Mirror neuron: a neurological approach to empathy 117
fear,another happiness, and that is it. No emotional involvement. Different is the case for sensory-motor mapping mechanism. In this case, the recognition occurs because the observed emotion triggers the feeling of the same emotion in the ob-serving person. It is a first-person recognition. The emotion of the other pene-trates the emotional life of the observer, evoking in him/her not only the observed emotion but also related emotional states and nuances of similar experiences.
As for cold action, our interest in this essay is the mechanisms underlying the direct sensory-motor mapping. For the sake of space, we will review data on one emotion only – disgust – for which rich empirical evidence has been recently ac-quired.
Disgust is a very basic emotion whose expression has an important survival values for the conspecifics. In its most basic, primitive form (“core disgust;” Rozin et al. 2000) disgust indicates that something (e.g., food) that the individual tastes or smells is bad and, most likely, dangerous. Because of its strong communicative value, disgust is an ideal emotion for testing the direct mapping hypothesis.
Brain imaging studies showed that when an individual is exposed to disgust-ing odors or tastes, there is an intense activation of two structures: the amygdala and the insula (Augustine 1996; Royet et al. 2003; Small et al. 2003; Zald et al. 1998; Zald and Pardo 2000). The amygdala is a heterogeneous structure formed by several subnuclei. Functionally, these subnuclei form two major groups: the cor-ticomedial group and the basolateral group. The former, phylogenetically more ancient, is related to the olfactory modality. It is likely that it is the signal increase in the corticomedial group that is responsible for the amygdala activation in re-sponse to disgusting stimuli.
Similarly to the amygdala, the insula is a heterogeneous structure. Anatomical connections revealed two main functional subdivisions: an anterior “visceral” sec-tor and a multimodal posterior sector (Mesulam and Mufson 1982). The anterior sector receives a rich input from olfactory and gustatory centers. In addition, the anterior insula receives an important input from the inferotemporal lobe, where, in the monkey, neurons have been found to respond to the sight of faces (Gross et al. 1972; Tanaka 1996). Recent data demonstrated that the insula is the main cortical target of interoceptive afferents (Craig 2002). Thus, the insula is not only the primary cortical area for chemical exteroception (e.g., taste and olfaction) but also for the interoceptive state of the body (“body state representation”).
The insula is not an exclusively sensory area. In both monkeys and humans, electrical stimulation of insula produces body movements (Kaada et al. 1949; Pen-field and Faulk 1955; Frontera 1956; Showers and Lauer 1961; Krolak-Salmon et al. 2003). These movements, unlike those evoked by stimulation of classical mo-tor areas, are typically accompanied by autonomic and viscero-motor responses.
Functional imaging studies in humans showed that, as in the monkey, the an-terior insula receives, in addition to olfactory and gustatory stimuli, higher order visual information. Observation of disgusted facial expressions produces signal increase in the anterior insula. (Phillips et al. 1997, 1998; Sprengelmeyer et al. 1998; Schienle et al, 2002).
Recently, Wicker et al. (2003) carried out an fMRI study in which they tested whether the same insula sites that show signal increase during the experience of

118 Giacomo Rizzolatti and Laila Craighero
disgust also show signal increase during the observation of facial expressions of disgust.
The study consisted of olfactory and visual runs. In the olfactory runs, indi-viduals inhaled disgusting and pleasant odorants. In the visual runs, the same participants viewed video-clips of individuals smelling a glass containing disgust-ing, pleasant and neutral odorants and expressing their emotions.
Disgusting odorants produced, as expected, a very strong signal increase in the amygdala and in the insula, with a right prevalence. In the amygdala, activa-tion was also observed with pleasant odorants, with a clear overlap between the activations obtained with disgusting and pleasant odorants. In the insula, pleas-ant odorants produced a relatively weak activation located in a posterior part of the right insula; disgusting odorants activated the anterior sector bilaterally. The results of visual runs showed signal increases in various cortical and subcortical centers but not in the amygdala. The insula (anterior part, left side) was activated only during the observation of disgust.
The most important result of the study was the demonstration that precisely the same sector within the anterior insula that was activated by the exposure to disgusting odorants was also activated by the observation of disgust in others (Fig. 3). These data strongly suggest that the insula contains neural populations that become active both when the participants experience disgust and when they see it in others.
The notion that the insula mediates both recognition and experience of disgust is supported by clinical studies showing that, following lesions of the insula, pa-tients have a severe deficit in understanding disgust expressed by others (Calder
Fig. 3. Illustration of the overlap (white) between the brain activation during the observation (blue) and the feeling (red) of disgust. The olfactory and visual analyses were performed sepa-rately as random-effect analyses. The results are superimposed on parasagittal slices of a stan-dard MNI brain.

Mirror neuron: a neurological approach to empathy 119
et al. 2000; Adolphs et al. 2003). This deficit is accompanied by blunted and re-duced sensation of disgust. In addition, electrophysiological studies showed that sites in the anterior insula, whose electrical stimulation produced unpleasant sen-sations in the patient’s mouth and throat, are activated by the observation of a face expressing disgust.
Taken together, these data strongly suggest that humans understand disgust, and most likely other emotions (see Carr et al. 2003, Singer et al., 2004), through a direct mapping mechanism. The observation of emotionally laden actions acti-vates those structures that give a first-person experience of the same actions. By means of this activation, a bridge is created between others and us.
The hypothesis that we perceive emotion in others by activating the same emo-tion in ourselves has been advanced by various authors (e.g., Phillips et al. 1997; Adolphs 2003: Damasio 2003a; Calder et al, 2000; Carr et al. 2003; Goldman and Sripada 2003; Gallese et al. 2004). Particulary influential in this respect has been the work by Damasio and his coworkers (Adolphs et al. 2000; Damasio 2003a, b) According to these authors, the neural basis of empathy is the activation of an “as-if-loop,” the core structure of which is the insula (Damasio 2003). These authors attributed a role in the “as-if-loop” also to somatosensory areas like SI and SII, conceiving the basis of empathy to be in the activation in the observer of those cortical areas where the body is represented.
Although this hypothesis is certainly possible, the crucial role of the insula, rather than of the primary somatosensory cortices, in emotion feeling strongly suggests that the neural substrate for emotions is not merely sensorial. It is more likely that the activation of the insula representation of the viscero-motor activity is responsible for the first-person feeling of disgust. As for the premotor cortex, it is plausible that in the insula there is a specific type of mirror neurons that match the visual aspect of disgust with its viscero-motor aspects. The activation of these (hypothetical) viscero-motor mirror neurons should underlie the first-per-son knowledge of what it means to be disgusted. The activation of these insular neurons should not necessarily produce the overt viscero-motor response. The overt response should depend on the strength of the stimuli and other factors. A neurophysiological study of insula neuron properties could be the direct test of this hypothesis.
Coda
The data reviewed in this essay show that the intuition of Adam Smith – that in-dividuals are endowed with an altruistic mechanism that makes them share the “fortunes” of others – is strongly supported by neurophysiological data. When we observe others, we enact their actions inside ourselves and we share their emo-tions.
Can we deduce from this that the mirror mechanism is the mechanism from which altruistic behavior evolved? This is obviously a very hard question to an-swer. Yet, it is very plausible that the mirror mechanism played a fundamental role in the evolution of altruism. The mirror mechanism transforms what oth-ers do and feel in the observer’s own experience. The disappearance of unhappi-

120 Giacomo Rizzolatti and Laila Craighero
ness in others means the disappearance of unhappiness in us and, conversely, the observation of happiness in others provides a similar feeling in ourselves. Thus, acting to render others happy – an altruistic behavior – is transformed into an egoistic behavior – we are happy.
Adam Smith postulated that the presence of this sharing mechanism renders the happiness of others “necessary” for human beings, “though he derives noth-ing from it except the pleasure of seeing it.” This, however, appears to be a very optimist view. In fact, an empathic relationship between others and ourselves does not necessarily bring positive consequences to the others. The presence of an unhappy person may compel another individual to eliminate the unpleasant feeling determined by that presence, acting in a way that is not necessary the most pleasant for the unhappy person.
To use the mirror mechanism – a biological mechanism – strictly in a positive way, a further – cultural – addition is necessary. It can be summarized in the pre-scription: “Therefore all things whatsoever ye would that men should do to you, do ye even so to them: for this is the law and the prophets” (Matthew 7, 12) . This “golden rule,” which is present in many cultures besides ours (see Changeux and Ricoeur 1998), uses the positive aspects of a basic biological mechanism inherent in all individuals to give ethical norms that eliminate the negative aspects that are also present in the same biological mechanism.
Acknowledgment
The study was supported by EU Contract QLG3-CT-2002–00746, Mirror, EU Con-tract IST-2000–29689, Artesimit, by Cofin 2004, and FIRB n. RBNE01SZB4.
References
Adolphs R (2003) Cognitive neuroscience of human social behaviour. Nature Rev Neurosci 4: 165–178.
Adolphs R, Damasio H, Tranel D, Cooper G, Damasio AR (2000) A role for somatosensory cor-tices in the visual recognition of emotion as revealed by three-dimensional lesion mapping. J Neurosci 20: 2683–2690.
Adolphs R, Tranel D, Damasio AR (2003) Dissociable neural systems for recognizing emotions. Brain Cogn 52: 61–69.
Allison T, Puce A, McCarthy G. (2000) Social perception from visual cues: role of the STS region. Trends Cogn Sci 4: 267–278.
Augustine JR (1996) Circuitry and functional aspects of the insular lobe in primates including humans. Brain Res Rev 22: 229–244.
Blakemore SJ, Decety J (2001) From the perception of action to the understanding of intention. Nature Rev Neurosci 2: 561.
Bruce C, Desimone R, Gross CG (1981) Visual properties of neurons in a polysensory area in superior temporal sulcus of the macaque. J Neurophysiol 46: 369–384.

Mirror neuron: a neurological approach to empathy 121
Buccino G, Binkofski F, Fink GR, Fadiga L, Fogassi L, Gallese V, Seitz RJ, Zilles K, Rizzolatti G, Freund HJ (2001) Action observation activates premotor and parietal areas in a somatotopic manner: an fMRI study. Eur J Neurosci 13: 400–404.
Buccino G, Vogt S, Ritzl A, Fink GR, Zilles K, Freund HJ, Rizzolatti G (2004) Neural circuits un-derlying imitation of hand actions: an event related fMRI study. Neuron 42: 323–34.
Calder AJ, Keane J, Manes F, Antoun N, Young AW (2000) Impaired recognition and experience of disgust following brain injury. Nature Neurosci 3: 1077–1078.
Carey DP, Perrett DI, Oram MW (1997) Recognizing, understanding and reproducing actions. In: Jeannerod M, Grafman J (eds) Handbook of neuropsychology. Vol. 11: Action and cogni-tion. Elsevier, Amsterdam.
Carr L, Iacoboni M, Dubeau MC, Mazziotta JC, Lenzi GL (2003) Neural mechanisms of empathy in humans: a relay from neural systems for imitation to limbic areas. Proc Natl Acad Sci USA 100: 5497–5502.
Changeux JP, Ricoeur P (1998) La nature et la règle. Odile Jacob, Paris.Cochin S, Barthelemy C, Roux S, Martineau J (1999) Observation and execution of movement:
similarities demonstrated by quantified electroencephalograpy. Eur J Neurosci 11: 1839–1842.
Craig AD (2002) How do you feel? Interoception: the sense of the physiological condition of the body. Nature Rev Neurosci 3: 655–666.
Damasio, A (2003a) Looking for Spinoza. Harcourt Inc.Damasio A (2003b) Feeling of emotion and the self. Ann NY Acad Sci 1001: 253–261.Di Pellegrino G, Fadiga L, Fogassi L, Gallese V, Rizzolatti G (1992) Understanding motor events:
A neurophysiological study. Exp Brain Res 91: 176–80.Fadiga L, Fogassi L, Pavesi G, Rizzolatti G (1995) Motor facilitation during action observation: a
magnetic stimulation study. J Neurophysiol 73: 2608–2611.Fogassi L, Gallese V, Fadiga L, Rizzolatti G (1998) Neurons responding to the sight of goal di-
rected hand/arm actions in the parietal area PF (7b) of the macaque monkey. Soc Neurosci Abs 24:257.5.
Frith U, Frith CD (2003) Development and neurophysiology of mentalizing. Philos Trans R Soc Lond B Biol Sci 358: 459.
Frontera JG (1956) Some results obtained by electrical stimulation of the cortex of the island of Reil in the brain of the monkey (Macaca mulatta). J Comp Neurol 105: 365–394.
Gallagher HL, Frith CD (2003) Functional imaging of ‘theory of mind’. Trends Cogn Sci 7: 77.Gallese V, Fogassi L, Fadiga L, Rizzolatti G (2002) Action representation and the inferior parietal
lobule. In: Prinz W, Hommel B (eds) Attention & Performance XIX. Common mechanisms in perception and action. Oxford University Press, Oxford.
Gallese V, Keysers C, Rizzolatti G (2004) A unifying view of the basis of social cognition. Trends Cogn Sci 8: 396–403.
Gangitano M, Mottaghy FM, Pascual-Leone A (2001) Phase specific modulation of cortical mo-tor output during movement observation. NeuroReport 12: 1489–1492.
Gangitano M, Mottaghy FM, Pascual-Leone A (2004) Modulation of premotor mirror neuron activity during observation of unpredictable grasping movements. Eur J Neurosci 20: 2193–2202.
Goldman AI, Sripada CS (2004) Simulationist models of face-based emotion recognition. Cogni-tion 94: 193–213.
Grafton ST, Arbib MA, Fadiga L, Rizzolatti G (1996) Localization of grasp representations in humans by PET: 2. Observation compared with imagination. Exp Brain Res 112: 103–111.
Grèzes J, Costes N, Decety J (1998) Top-down effect of strategy on the perception of human biological motion: a PET investigation. Cogn Neuropsychol 15: 553–582.
Grèzes J, Armony JL, Rowe J, Passingham RE (2003) Activations related to “mirror” and “ca-nonical” neurones in the human brain: an fMRI study. Neuroimage 18: 928–937.
Gross CG, Rocha-Miranda CE, Bender DB (1972) Visual properties of neurons in the inferotem-poral cortex of the macaque. J Neurophysiol 35: 96–111.

122 Giacomo Rizzolatti and Laila Craighero
Hari R, Forss N, Avikainen S, Kirveskari S, Salenius S, Rizzolatti G (1998) Activation of human primary motor cortex during action observation: a neuromagnetic study. Proc. Natl Acad Sci USA 95: 15061–15065.
Iacoboni M, Woods RP, Brass M, Bekkering H, Mazziotta JC, Rizzolatti G (1999) Cortical mecha-nisms of human imitation. Science 286: 2526–2528.
Iacoboni M, Koski LM, Brass M, Bekkering H, Woods RP, Dubeau MC, Mazziotta JC, Rizzolatti G (2001) Reafferent copies of imitated actions in the right superior temporal cortex. Proc Natl Acad Sci USA 98: 13995–13999.
Jeannerod M (1988) The neural and behavioural organization of goal-directed movements. Clarendon Press, Oxford.
Johnson-Frey SH, Maloof FR, Newman-Norlund R, Farrer C, Inati S, Grafton ST (2003) Actions or hand-objects interactions? Human inferior frontal cortex and action observation. Neuron 39: 1053–1058.
Kaada BR, Pribram KH, Epstein JA (1949) Respiratory and vascular responses in monkeys from temporal pole, insula, orbital surface and cingulate gyrus: a preliminary report. J Neurophy-siol 12: 347–356.
Kohler E, Keysers C, Umiltà MA, Fogassi L, Gallese V, Rizzolatti G (2002). Hearing sounds, un-derstanding actions: action Rrepresentation in mirror neurons. Science 297: 846–848.
Koski L, Wohlschlager A, Bekkering H, Woods RP, Dubeau MC (2002) Modulation of motor and premotor activity during imitation of target-directed actions. Cereb Cortex 12: 847–855.
Koski L, Iacoboni M, Dubeau MC, Woods RP, Mazziotta JC (2003) Modulation of cortical activ-ity during different imitative behaviors. J Neurophysiol 89: 460–471.
Krolak-Salmon P, Henaff MA, Isnard J, Tallon-Baudry C, Guenot M, Vighetto A, Bertrand O, Mauguiere F (2003) An attention modulated response to disgust in human ventral anterior insula. Ann Neurol 53: 446–453.
Manthey S, Schubotz RI, von Cramon DY (2003). Premotor cortex in observing erroneous ac-tion: an fMRI study. Brain Res Cogn Brain Res 15: 296–307.
Mesulam MM, Mufson EJ (1982) Insula of the old world monkey. III: Efferent cortical output and comments on function. J Comp Neurol 212: 38–52.
Nishitani N, Hari R (2000) Temporal dynamics of cortical representation for action. Proc Natl Acad Sci USA 97: 913–918.
Nishitani N, Hari R (2002) Viewing lip forms: cortical dynamics. Neuron 36: 1211–1220.Penfield W, Faulk ME (1955) The insula: further observations on its function. Brain 78: 445–
470.Perrett DI, Harries MH, Bevan R, Thomas S, Benson PJ, Mistlin AJ, Chitty AJ, Hietanen JK,
Ortega JE (1989) Frameworks of analysis for the neural representation of animate objects and actions. J Exp Bio 146: 87–113.
Phillips ML, Young AW, Senior C, Brammer M, Andrew C, Calder AJ, Bullmore ET, Perrett DI, Rowland D, Williams SC, Gray JA, David AS (1997) A specific neural substrate for perceiving facial expressions of disgust. Nature 389: 495–498.
Phillips ML, Young AW, Scott SK, Calder AJ, Andrew C, Giampietro V, Williams SC, Bullmore ET, Brammer M, Gray JA (1998) Neural responses to facial and vocal expressions of fear and disgust. Proc R Soc Lond B Biol Sci 265: 1809–1817.
Puce A, Perrett D (2003) Electrophysiological and brain imaging of biological motion. Philosoph Trans Royal Soc Lond, Series B, 358: 435–445.
Rizzolatti G, Craighero L (2004) The mirror-neuron system. Annu Rev Neurosci 27: 169–192.Rizzolatti G, Scandolara C, Matelli M, Gentilucci M (1981) Afferent properties of periarcuate
neurons in macaque monkeys. I. Somatosensory responses. Behav Brain Res 2: 125–146.Rizzolatti G, Fadiga L, Matelli M, Bettinardi V, Paulesu E, Perani D, Fazio F (1996) Localization
of grasp representation in humans by PET: 1. Observation versus execution. Exp Brain Res 111: 246–252.
Rizzolatti G, Fogassi L, Gallese V (2001) Neurophysiological mechanisms underlying the under-standing and imitation of action. Nature Rev Neurosci 2:661–670.

Mirror neuron: a neurological approach to empathy 123
Royet JP, Plailly J, Delon-Martin C, Kareken DA, Segebarth C (2003) fMRI of emotional respons-es to odors: influence of hedonic valence and judgment, handedness, and gender. Neuroim-age 20: 713–728.
Rozin R Haidt J and McCauley CR (2000) Disgust. In: Lewis M, Haviland-Jones JM (eds) Hand-book of Emotion. 2nd Edition. Guilford Press, New York, pp 637–653.
Saxe R, Carey S, Kanwisher N (2004) Understanding other minds: linking developmental psy-chology and functional neuroimaging. Annu Rev Psychol 55: 87–124.
Schienle A, Stark R, Walter B, Blecker C, Ott U, Kirsch P, Sammer G, Vaitl D (2002) The insula is not specifically involved in disgust processing: an fMRI study. Neuroreport 13: 2023–2026.
Showers MJC, Lauer EW (1961) Somatovisceral motor patterns in the insula. J Comp Neurol 117: 107–115.
Singer T, Seymour B, O’Doherty J, Kaube H, Dolan RJ, Frith CD (2004) Empathy for pain in-volves the affective but not the sensory components of pain. Science 303: 1157–1162.
Small DM, Gregory MD, Mak YE, Gitelman D, Mesulam MM, Parrish T (2003) Dissociation of neural representation of intensity and affective valuation in human gustation Neuron 39: 701–711.
Smith A (1759) The theory of moral sentiments (ed. 1976). Clarendon Press, Oxford.Sprengelmeyer R, Rausch M, Eysel UT, Przuntek H (1998) Neural structures associated with rec-
ognition of facial expressions of basic emotions Proc R Soc Lond B Biol Sci 265: 1927–1931.Strafella AP, Paus T (2000) Modulation of cortical excitability during action observation: a tran-
scranial magnetic stimulation study. NeuroReport 11: 2289–2292.Tanaka K (1996) Inferotemporal cortex and object vision. Ann Rev Neurosci. 19: 109–140.Tomasello M, Call J (1997) Primate cognition. Oxford University Press, Oxford.Tremblay C, Robert M, Pascual-Leone A, Lepore F, Nguyen DK, Carmant L, Bouthillier A, Theo-
ret H (2004) Action observation and execution: intracranial recordings in a human subject. Neurology. 63: 937–938.
Umilta MA, Kohler E, Gallese V, Fogassi L, Fadiga L, Keysers C, Rizzolatti G (2001) “I know what you are doing”: a neurophysiological study. Neuron 32: 91–101.
Visalberghi E, Fragaszy D. (2002). Do monkeys ape? Ten years after. In: Dautenhahn K, Nehaniv C (eds) Imitation in animals and artifacts. MIT Press, Boston. Pp. 471–500
Wicker B, Keysers C, Plailly J, Royet JP, Gallese V, Rizzolatti G (2003) Both of us disgusted in my insula: the common neural basis of seeing and feeling disgust. Neuron 40: 655–664.
Yokochi H, Tanaka M, Kumashiro M, Iriki A (2003) Inferior parietal somatosensory neurons coding face-hand coordination in Japanese macaques. Somatosens Mot Res 20 : 115–125.
Zald DH, Pardo JV (2000) Functional neuroimaging of the olfactory system in humans. Int J Psychophysiol 36: 165–181.
Zald DH, Donndelinger MJ, Pardo JV (1998) Elucidating dynamic brain interactions with across-subjects correlational analyses of positron emission tomographic data: the functional connectivity of the amygdala and orbitofrontal cortex during olfactory tasks. J Cereb Blood Flow Metab 18: 896–905.

Object Processing 1
Running head: Object Processing
Object Processing during a Joint Gaze Following Task
Carolin Theuring1, Gustaf Gredebäck2, & Petra Hauf1,3
1Max-Planck Institute for Human Cognitive and Brain Sciences, Munich, Germany
2Department of Psychology, Uppsala University, Uppsala, Sweden
3Institute of Psychology, J. W. Goethe University, Frankfurt, Germany
Key words: gaze following, object processing, eye tracking, infants, social cognition
Carolin Theuring Max Planck Institute for Human Cognitive and Brain Sciences Department of Psychology/Babylab Amalienstr. 33 D-80799 München Germany [email protected]

Object Processing 2
Abstract
To investigate object processing in a gaze following task, 12-months-old infants were
presented with 4 movies in which a female model turned and looked at one of two objects.
This was followed by 2 test trials showing the two objects alone without the model. Eye
movements were recorded with a Tobii-1750 eye tracker. Infants reliably followed gaze and
displayed longer looking times towards the attended object when the model was present.
During the first test trial infants displayed a brief novelty preference for the unattended object.
These findings suggest that enhanced object processing is a temporarily restricted
phenomenon that has little effect on 12 month old infant’s long term interaction with the
environment.

Object Processing 3
Object processing during a Joint Gaze Following Task
Gaze following is an essential element of joint visual attention and an important
ingredient of the development of early social cognition (Tomasello, 1999; Moore & Corkum,
1994). It enables an individual to obtain useful information about his/her surrounding by
observing others behavior. This ability is not restricted to humans but occurs in numerous
other species, e.g. great apes, or domestic dogs (e.g. Bräuer, Call, & Tomasello, 2005; Hare,
Call, & Tomasello, 1999). Typically, gaze following has been studied in “live” social
situations, where an adult initially establishes eye contact with the infant and thereafter turns
to and fixates one of several objects. Infants’ tendency to follow others gaze is typically
measured by relating the infants first eye turn to the direction of the adults attention
(D’Entremont, Hains, & Muir, 1997; Hood, Willen, & Driver, 1998; Johnson, Slaughter, &
Carey, 1998; Moore & Corkum, 1998; Scaife & Bruner, 1975) or by comparing looking
durations towards attended and unattended locations (Reid & Striano, 2005; von Hofsten,
Dahlström, & Fredriksson, 2005).
Some authors argue that infants can follow others gaze direction from 6 months of age
(e.g. Butterworth, & Cochran, 1980; D'Entremont, Hains, & Muir, 1997; Morales, Mundy, &
Rojas, 1998). Others have not found evidence of gaze following until infants are between 9
and 12 months of age (Corkum & Moore, 1998; Flom, Deák, Phill, & Pick, 2000; Moore &
Corkum, 1998; Morissette, Ricard, and D'ecarie, 1995). The exact onset of this ability might
still be debated. However, it appears safe to say that infants at 12 months of age follow others
gaze; responding to the behavioral manifestations of others’ psychological orientations
(Moore and Corkum, 1994; see also Johnson et al., 1998; Woodward, 2003).
Despite this, little is known about how infants at this age process the object of others
attention. It is tempting to assume that an infant by following the gaze of another person to an
object naturally also understands the psychological relationship between the person and the

Object Processing 4
attended object, as if saying: “this specific thing was interesting for this person”, but de facto
little is known about the development of the actual function of gaze following beyond target
localization. This study aims at increasing our understanding of how infants object processing
is influenced by the direction of others gaze.
In a study by Reid, Striano, Kaufman, and Johnson (2004), four-month old infants
were presented with a frontal face and one object either to the left or to the right side; these
events were presented on a video screen. After one second the eyes rotated either towards
(cued) or away (non-cued) from the object and fixated that location for one additional second.
Following this period the face disappeared and the previously presented object appeared in its
place. Throughout the experiment EEG was recorded. The results demonstrate lower peak
amplitudes for slow wave ERP’s in response to previously cued as opposed to non-cued
objects. This effect was interpreted as a novelty preference to non-cued objects, resulting from
enhanced object processing to the attended (cued) compared to the unattended (non-cued)
object.
In a different experiment by Reid and Striano (2005) four-month-olds were similarly
presented with an adult face, but this time with two objects present, one to either side of the
face. The adult’s eyes were initially directed forward, shifting to one side and fixating one of
the objects after one second. After a brief intermission the two objects were presented without
the face. During this later phase infants looking durations to each of the two objects were
recorded. Infants looked reliably longer at the non-cued compared to the cued object; this
novelty preference indicates that infants were influenced by the model’s gaze shift and that
the non-cued object was more interesting than the object previously attended by the adult
face. This result again demonstrates an enhanced object processing as a function of others
gaze direction.
These studies clearly demonstrate that infants at 4 months of age are sensitive to
others gaze direction. They are however unable to inform us about what impact this enhanced

Object Processing 5
object processing has on infant’s future interaction with the attended object for two reasons.
First of all, both studies were performed on an age group that is not frequently reported to
follow others gaze direction. Reid, Striano, Kaufman, and Johnson (2004) clearly state that
“no infants overtly followed the gaze to the object location“, suggesting that the reported
effects are not the result of shifts in overt attention but rather result from subtle shifts in covert
attention without behavioral correlates. A lack of eye movements is obviously a prerequisite
of high quality ERP data (reducing the noise level by minimizing eye movements); however,
this gives us no indication that the studied infants could follow gaze direction. In the other
study Reid and Striano (2005) did not report whether infants follow the models gaze direction
or not.
In addition, it is still unclear what is meant by “enhanced object processing”. One
interpretation is that infants’ simply follow the models gaze direction without attributing any
meaning to the models behavior. In this case infants’ preference for non-attended objects
should appear as a temporarily restricted novelty preference with little bearing on infants’
long term interaction with the attended object. Another interpretation is that infants’ attribute
some kind of meaning to the attended object, perhaps infants understand the relationship
between the model’s attention and the object, and as a consequence thereof differentiate this
object from the other object over time.
If one wishes to gain a better understanding of how others gaze direction influences
infants’ object processing it is important to focus on an age group that has a well documented
ability to follow others gaze direction and to use a paradigm with a high spatial-temporal
resolution that allows us to evaluate whether infants follow the models gaze and to evaluate
the temporal restraints of infants’ object processing. The current study attempts to answer
these questions by measuring gaze following and object processing in 12-month-old infants
using high resolution eye tracking technology.

Object Processing 6
Method
Participants.
Sixteen 12 month old healthy term infants (mean age 11 months and 28 days, SD
= 2 days) participated in this study. Four infants were eliminated because of refusal to remain
seated or because of technical problems. Participants were contacted by mail based on birth
records. As compensation for their participation each family received either two movie tickets
or a CD voucher with a total value of 15 €.
Stimuli and apparatus.
Gaze was measured using a Tobii 1750 near infrared eye tracker with an infant
add-on (Tobii Technology; www.Tobii.se). The system records the reflection of near infrared
light in the pupil and cornea of both eyes at 50 Hz (Accuracy = 0.5°, Spatial resolution =
0.25°) as participants watch an integrated 17 inch monitor. During calibration infants were
presented with a looming and sounding blue and white sphere (extended diameter = 3.3°;
Gredebäck & von Hofsten, 2004). The calibration stimulus could be briefly exchanged for an
attention grabbing movie (horizontal and vertical extension = 5.7°) if infants temporarily
looked away from the calibration stimulus.
The stimuli set consisted of 30 movies. Twenty included a female model that
shifted her gaze (head and eyes) to one of two toys placed on either side of the model (Figure
1A). Each movie included two toys randomly selected from a set of 5 unique toy pairs. The
toy pairs were counterbalanced with regards to which toy the model attended and their
respective locations, which equal 5 x 2 x 2 variations. Ten additional movies without the
model were also included (Figure 1B). Again the five toy pairs were counterbalanced for
location, which equal 5 x 2 variations.

Object Processing 7
Movies that included the model lasted on average for 13 seconds. Each movie
started with a 5 second period in which the model looked down at a table in front of her with
the two toys visible on either side (see Figure 1-A1). After 5 seconds the model moved her
face upwards and fixated straight ahead (see Figure 1-A2 for endpoint of upwards motion),
this movement lasted 1.5 seconds. During these 6.5 seconds the model had not yet attended to
either toy. This part is referred to as the Baseline block. The following 1.5 seconds involved a
sideways downwards movement of the model’s head and eyes towards one of the toys,
accompanied by a smile. The movie ended with a 5 second interval in which the model kept
fixating the toy. These last 6.5 seconds of the sequence is referred to as the Gaze Direction
block (see Figure 1-A3). The purpose of the current study is to investigate the depth of
infants’ object processing during a joint gaze following task. The stimulus material was
therefore designed to simulate the natural interaction between an infant and an adult. As such,
the model shifted her gaze and directed positive regard to a near object. For the same purpose
the action was presented over the extended period of 13 seconds altogether. The infants
should been given time to encode and react to the full situation, as if in any playful situation
with an adult. Movies that did not include a model lasted for 10 seconds. In these movies the
two objects are displayed on their own (Figure 1B).
--- insert Figure 1 about here ---
Procedure.
Infants were seated in a safety car seat and placed on the parents’ lap with their
eyes about 60 cm from the eye tracker. During calibration the looming stimulus described
above was presented at nine different locations in a random order. If infants’ attention was
drawn to other parts of the visual field during this procedure the experimenter exchanged the

Object Processing 8
calibration stimulus for an alternative attention grabbing movie at the current location. If any
points were unsuccessfully calibrated these points were recalibrated.
Infants were always presented with four trials that included the model. During
these presentations the model always attended to the same toy but its location changed
between presentations according to an ABBA design. For example, the attended toy might
first appear to the left followed by two movies in which the toy appeared to the right, and a
final movie in which the attended toy appeared to the left. These presentations were followed
by two test trials in which the toys appeared on their own, again at switched locations. Each
infant was presented with one of two presentation orders ABBA-BA or BAAB-AB.
This presentation order was necessary to ensure the infants would interpret the models
behavior as object directed and not as directed to a particular side of their visual field. In
addition, reversing the location of the objects between the last trial with the model and the
first test trials (and between the first and second test trial) ensure that infants pay attention to
the objects and not just the disappearance of the model.
After the experiment parents were given the opportunity to look at a replay of the stimuli that
included the infants gaze. In general each family spent 15 to 20 minutes in the lab.
Data reduction.
Infants had to fixate the models face and then shifted their gaze to one of the toys
after the model started moving her head on at least three trials to be included in the analysis.
These infants further fixated each object location at least once during the Gaze Direction
block. Gaze data were transformed to fixation data with a spatial-temporal filter covering 200
ms and 50 pixels (approximately 1 visual degree) in ClearView (Tobii). All analyses were
performed using a custom made analysis program in Matlab (Mathworks).
Data from each trial that included the model were separated into a Baseline
block, including the beginning of each trial until the model had raised her head, and a Gaze

Object Processing 9
Direction block, including the entire head movement and the models subsequent fixation on
an object. Data from the Test block were analyzed as a whole. Each trial of these blocks was
analyzed separately. The blocks were used in an area-of-interest (AOI) analysis including
only fixations within any one of three equally sized areas, covering face, left toy and right toy.
These analyses calculated effects in two ways, according to the location of each fixation and
with respect to the AOIs covering the attended or unattended toy (see Figure 2 for
approximate size and location of AOIs). Note that the AOI analysis includes more detailed
information by separating the face from the toys and excluding fixations at other parts of the
screen than typically used preferential looking paradigms for which the screen would have
been divided in a left and a right section only. Observe that during test trials AOI analysis was
based on the AOIs covering the attended or unattended toy (see Figure 2B).
As infants differ in overall fixation duration, proportional fixation duration was
calculated (attended = fixation duration attended / fixation duration attended + fixation
duration unattended; unattended = fixation duration unattended / fixation duration attended +
fixation duration unattended). Only this proportional fixation duration is reported in the result
section below.
--- insert Figure 2 about here ---
Focus was also directed at the first fixations and individual gaze shifts. Infants’
first fixation of the models face and the two toys during the Baseline block and the Gaze
Direction block was registered (after infants had fixated the models face for at least 200 ms
during this block) together with the duration of this fixation. During Baseline and Gaze
Direction blocks the fixated target was registered and whether the attended target was the one
being fixated or not. Additionally, infants’ first gaze shift from the model’s face to a toy (as

Object Processing 10
defined by the AOIs) during the Gaze Direction Block was registered. During the Test block
infants’ proportional fixation duration was analyzed in respect to the AOIs covering the two
toys (see Figure 2B) as well as the first fixation of a toy. Also the first fixated toy was
included.
In addition a difference score (DS; cf. Corkum & Moore, 1998; Moore &
Corkum, 1998) was calculated for each infant in order to investigate reliably gaze following
during the Gaze Direction block. This DS is determined by the number of trials where the
infant’s first gaze shifted from the face to the attended toy, minus the number of trials where
infants went to the unattended toy first and thus could vary from +4 (shifting in all trials to the
attended toy) to –4 (shifting in all trials to the unattended toy).
Results
Baseline block.
The mean fixation duration during the four baseline trials within all three AOIs
equalled 4405 ms (SE = 202ms). More time was spent looking at the face (M = 49.48%, SE =
2.64%) than at either toy (Mleft = 20.52%, SE = 2.17% and Mright = 30.00%, SE = 2.92%), F(2,
45) = 27.613, p = .000, η2 = 0.551. Separated t-tests differentiated the face from both the left
toy, t(46) = 7.505, p = .0000 as well as from the right toy, t(46) = 3.794, p = .0004, which
additionally differed from each other, t(46) = 2.146, p = .037. Note that even though infants
spent more time looking at the right AOI than at the left AOI there were no significant
differences between the AOI that later would be the attended (45.8%, SE = 4.7%) and the
unattended AOI (54.2%, SE = 4.7%), t(47) = 0.887, p = .380 (see Figure 3).
--- insert Figure 3 about here ---

Object Processing 11
Gaze Direction block.
During the Gaze Direction block 4625 ms (SE = 259ms) was spent fixating the
three AOIs on average. More time was spent fixating the face (M = 59.11%, SE = 3.04%) than
either the left (M = 19.7%, SE = 2.8%) or the right (M = 21.2%, SE = 2.5%) toy, F(2, 45) =
34.806, p = .000, η2 = 0.607. Post-hoc tests differentiated the face from both the left, t(46) =
7.609, p = .000 as well as from the right toy, t(46) = 7.628, p = .000, which did not differ (p =
.570; see Figure 3). In contrast to the Baseline block now the attended toy was fixated to a
higher degree (M = 67.5%, SE = 4.5%) than the unattended toy (M = 32.5%, SE = 4.5%; t(43)
= 3.797, p = .0005).
Test block.
In total infants spent 6588 ms (SE = 487ms) fixating the two AOIs during the
Test block. Thereby infants looked equally long at the right (M = 50.88%, SE = 5.47%) and
the left (M = 49.12%, SE = 5.47%) toy, t(23) = 0.164, p = .871. The proportional fixation of
the toys during the Test block was analyzed by a 2 x 2 analysis of variance (ANOVA) with
the within-subject factors test (trial 1 and trial 2) and toy (attended or unattended). The
analysis yielded a marginally significant test trial x toy interaction, F(1, 11) = 3.981, p = .071,
η2 = 0.266, but no significant main effects (ps > .189). Even though infants’ overall fixation
times did not differ between the attended toy (M = 45.8%, SE = 5.4) and the unattended (M =
54.2%, SE = 5.4) toy during the entire Test block, t(23) = 0.795, p = .435, post-hoc tests
differentiated the fixation duration of the first test trial from the fixation duration of the
second test trial (see Figure 3). The previously unattended toy was fixated to a higher degree
(M = 66.2%, SE = 5.4%) than the previously attended toy (M = 33.8%, SE = 5.4%) during the
first of two test trials, t(11) = 3.166, p = .009. However during the second test trial infants
fixated both toys equally long (previously unattended toy: M = 42.2%, SE = 8.4%; previously
attended toy: M = 57.8%, SE = 8.4%; t(11) = 0.971, p = .352). In addition, the fixation

Object Processing 12
duration during the first test trial did not correlate with the fixation duration during the Gaze
Direction block, rxy = 0.103, p = .750.
The analysis of the fixation duration demonstrated that infants spent a different
amount of time looking at the two toys during both the Gaze Direction block and the Test
block. Interestingly, infants showed no preference at all during the Baseline block. An
especially detailed analysis was conducted covering the first fixation and the order of
presentation.
Analysis of first gaze shift and first fixation.
The first gaze shift from the model’s face to a toy during the Gaze Direction
block was analyzed separately. Infants’ first gaze shifts were directed to the attended toy in 38
of 46 trials, χ²(1) = 19.565, p = .000, with an averaged DS of 2.17 (SE = 0.48), indicating that
infants were reliably following the model’s gaze. This first gaze shift did not correlate with
the fixation duration during the first test trial, r = 0.089, p = .783. The first fixation of a toy
was analyzed by a 3 x 2 ANOVA with the within-subject factors block (baseline, gaze
direction, and test) and toy (attended or unattended). The analysis yielded a significant block
x toy interaction, F(2, 10) = 6.297, p = .017, η2 = 0.557, but no significant main effects (ps >
.312) indicating that the infants’ first fixations to the attended toy differed among the blocks;
see Figure 4 for the percentage of first fixation at the toys. Accordingly, separated t-tests
revealed that the first fixation was significantly directed to the attended toy during the Gaze
Direction block (M = 82.7%, SE = 6.8%), t(11) = 5.011, p = .0004, whereas no differences
occurred in the first fixation between the attended toy (M = 44.4%, SE = 8.5%) and the
unattended toy (M = 55.6%, SE = 8.5%) during the Baseline block [t(11) = 0.689, p = .505]
and the Test block [attended toy: M = 45.8%, SE = 10.1%; unattended toy: M = 54.2%, SE =
10.1%, t(11) = 0.432, p = .674. In addition the percentage of first fixation directed to the left

Object Processing 13
toy was not significantly different from the percentage of first fixation directed to the right toy
during all blocks (all ps > .522).
--- insert Figure 4 about here ---
Analysis of the presentation order.
Each infant was presented with four trials where the model always attended to the same
toy but its location was changed between trials according to an ABBA design (cf. procedure).
The subsequent test trial without the model presented the toys again in changed location (B).
In order to investigate the responsibility of the presentation order for the fixation times of both
Baseline trials and Gaze Direction trials, differences scores were calculated for the fixation
duration in each trial separately. Positive scores indicate longer fixations of the attended toy
whereas negative scores demonstrate longer fixations of the unattended toy (see Figure 5).
The differences of these scores were analyzed by an one-way Anova of the changed locations
(GD1 to B2, GD2 to B3, GD3 to B4). This analysis revealed no significant main effect, F(2,
10) = 1.907, p = .199 ruling out an overall influence of the presentation order. Of special
interest was the alteration between GD1 and B2 (A followed by B) as well as between GD3
and B4 (B followed by A). Planned contrasts yielded a significant difference of the scores
between GD1 (M = 0.49, SE = 0.17) and B2 (M = -0.20, SE = 0.18, t(11) = 3.728, p = .003)
indicating a location cueing at the beginning (see Figure 5). Nevertheless, this difference
disappeared over trials. Accordingly, the difference scores did not vary anymore during the
last changed location between GD3 (M = 0.23, SE = 0.16) and B4 (M = 0.08, SE = 0.21, t(11)
= 0.678, p = .512).
--- insert Figure 5 about here ---

Object Processing 14
Discussion
In order to investigate object processing in a gaze following task, we presented 12-
month-old infants with different movies on an eye tracker. The first four movies showed a
female model turning and looking to one of two objects, this was followed by two test trials
showing only the two objects without the model. Infants did not differentiate between the two
objects during the Baseline block. In the Gaze Direction block infants consistently followed
the models gaze to the attended object and fixated the attended longer than the unattended
object. No overall difference was found during the Test block; there was however a
significant difference in the first test trial, here infants fixated the unattended object for a
longer duration than the attended object.
First of all, it is important to emphasize that these results complement previous
findings that infants by the end of the first year of life follow gaze (Carpenter et al., 1998;
Corkum & Moore, 1995; Johnson et al., 1998; Scaife et al., 1975; von Hofsten et al., 2005),
which is an important precondition for our question at hand. In fact, even though the model
was presented on a monitor (as opposed to “live”), infants reliably followed the models gaze
to the attended object. This suggests that movies can substitute “live” interactions in order to
take advantage of the high resolution provided by current eye tracking technology.
In addition to demonstrating the basic finding of gaze following, the high spatial-
temporal resolution of the eye tracking system allowed us to obtain additional details about
the infants’ gaze following behaviour. We were able to differentiate the trials temporally into
Baseline, Gaze Direction, and Test blocks, as well as spatially into the three specific areas of
interest: face, attended and unattended objects. This made it possible to show that infants’ first
fixation of the attended toy differed among the blocks; it was only during the Gaze Direction
block significantly directed towards the attended toy. The analysis of the AOIs revealed that
the main location of attention was the model’s face where infants spent altogether up to 60%

Object Processing 15
of their looking duration. The first gaze shift from the model’s face to a toy during the Gaze
Direction block was in 83% of the trials directed towards the attended toy.
Despite the fact that infants readily followed the model’s gaze to an object, we cannot
find evidence that following another person’s gaze direction had a long term effect on infants’
object processing at 12 months of age. The only detectable difference in behaviour towards
the attended and the unattended object in the Test block was a brief novelty preference for the
previously unattended object. This effect was only evident in the first test trial. We suggest
that this result represents a temporarily restricted novelty effect caused by prolonged looking
durations to the attended object during the Gaze Direction block.
These results harmonize well with the enhanced object processing documented by
Reid and collegues (2004; 2005). Both studies demonstrate a novelty preference for the
previously unattended object. These similarities exist despite differences in the design. In the
current study infants are being presented with far more ecologically relevant stimuli that
simulate the natural interaction between an infant and an adult.
At the same time the current design allows us to look at the depth of this enhanced
object processing by presenting infants with multiple test trials. We demonstrate that this
novelty effect is brief and only influences infants’ behaviour for a single test trial. The current
finding suggests that infants do not attribute any strong meaning to the relationship between
the model’s gaze and the attended object. At least not to such a degree that it has a profound
impact on infant’s long term interaction with the attended object. This suggests that a careful
interpretation of the phrase “enhanced object processing” should be applied to future studies
of perception of gaze direction. According to our findings 12 month-old infants follow others
gaze but are unable to represent the relationship between the model’s gaze and the attended
object, or alternatively are unable to attribute any specificity to the regarded object.
The notion that infants are unable to transfer the perceived relationship between the
model and the object across trials receives further support from infants’ performance during

Object Processing 16
the Baseline block. With the exception of the first baseline infants have previous experience
with the model and have perceived her attend to one of the two objects. As such, later parts of
the Baseline block could be considered an additional test of infants’ object processing.
However, as mentioned, no difference in fixation duration was found in this part of each trial.
In addition there was no significant correlation between fixation durations in Gaze Direction
and Baseline blocks or between the first gaze shift in the Gaze Direction block and fixation
durations during the first test trial. The missing correlation between the looking behaviour
during the Gaze direction block and the looking behaviour during the Test block further
supports the argument that gaze following does not automatically goes hand in hand with
object processing.
It is of course possible that infants by the end of the first test trial have fixated the
previously unattended object enough to cancel out the novelty effect from the first test trial.
Such an alternative interpretation of the current results would produce a similar null-effect in
the second test trial. The current design is however unable to differentiate the two.
Interestingly a study of Itakura (2001) showed that 12-month-old infants looked
significantly longer to one of two objects on a screen, if their mother previously has been
drawing their attention to it through pointing and vocalizing. In this experiment the infants
were sitting on the mothers lap and followed her pointing gesture, not her gaze. The mother’s
pointing here had a clear impact on the interest of the infant towards the attended object.
Consequently, future studies should aim at describing how infants come to attribute a
more profound meaning to objects that have been attended by others and to investigate at
what age infants attribute sufficient meaning to others gaze direction to display a stable
behavioural change that enhance the acquisition of knowledge about the environment. Related
studies (e.g. Itakura, 2001) suggest that additional gestures as pointing might enhance the
processing of the object of interest.
Conclusion

Object Processing 17
The results indicate that infants at the age of 12 months reliably follow others gaze
direction. Nevertheless there is no implication that retrieving specific information about the
objects during a gaze following task is a fundamental property of gaze following at this age.
Following a models gaze does not influence infants’ looking behaviour beyond a temporarily
restricted response. The study further demonstrates that eye tracking technology represents a
promising paradigm for obtaining detailed information of infant gaze following. Further
investigations are required to observe at what age gaze following results in object processing,
which is stable enough to guide long term interactions with attended objects.
References
Bräuer, J., Call, J., & Tomasello, M. (2005). All great apes species follow gaze to distant
locations and around barriers. Journal of Comparative Psychology, 119(2), 145-154.
Butterworth, G., & Cochran, E. (1980). Towards a mechanism of joint visual attention in
human infancy. International Journal of Behavioral Development, 3, 253-272.
Carpenter, M., Nagell, K., & Tomasello, M. (1998). Social cognition, joint attention, and
communicative competence from 9 to 15 months of age. Monographs of the Society
for Research in Child Development, 63 (4, No. 255), pp. 1-143.
Corkum, V., & Moore, C. (1995). Development of joint visual attention in infants. In: C.
Moore, & P. Dunham (Eds.), Joint attention. Its origins and role in development. (pp.
61-83). Hillsdale, NJ: Lawrence Erlbaum Associates.
Corkum, V., & Moore, C. (1998). The origins of joint visual attention in infants.
Developmental Psychology, 34(1), 28-38.

Object Processing 18
D’Entremont, B., Hains, S.M.J., & Muir, D.W. (1997). A demonstration of gaze following in
3- to 6-month-olds. Infant Behavior and Development, 20(4), 569-572.
Flom, R., Deák, G.O., Phill,C.G., & Pick, A.D. (2004). Nine-month-olds’ shared visual
attention as a function of gesture and object location. Infant Behavior and
Development, 27, 181-194.
Gredebäck, G., & von Hofsten, C. (2004). Infants’ evolving representations of object motion
during occlusion: A longitudinal study of 6- to 12-month-old infants. Infancy, 6(2),
165-184.
Hare, B., Call, J., & Tomasello, M.(1999). Domestic dogs (Canis familiaris) use human and
conspecific social cues to locate hidden food. Journal of Comparative Psycholgy, 113,
1-5.
Hood, B.M., Willen, J.D., & Driver, J. (1998). Adult’s eyes trigger shifts of visual attention in
human infants. Psychological Science, 9(2), 131-134.
Itakura, S. (2001). Attention to repeated events in human infants (Homo sapiens): effects of
joint visual attention versus stimulus change. Animal Cognition, 4, 281-284.
Johnson, S., Slaughter, V., & Carey, S. (1998). Whose gaze will infants follow? The
elicitation of gaze following in 12-months-olds. Developmental Science, 1(2), 233-
238.
Moore, C., & Corkum, V. (1994). Social understanding at the end of the first year of life.
Developmental Review,14, 349-372.
Moore, C., & Corkum, V. (1998). Infants gaze following based on eye direction. British
Journal of Developmental Psychology, 16, 495-503.
Morales, M., Mundy, P., & Rojas, J. (1998). Following the direction of gaze and language
development in 6-month-olds. Infant Behavior and Development, 21(2), 373-377.

Object Processing 19
Morissette, P., Ricard, M., & Gouin Décarie, T. (1995). Joint visual attention and pointing in
infancy: A longitudinal study of comprehension. British Journal of Developmental
Psychology, 13, 163-175.
Reid, V. M., & Striano, T.(2005). Adult gaze influences infant attention and object
processing: Implications for cognitive neuroscience. European Journal of
Neuroscience, 21, 1763-1766.
Reid, V.M., Striano, T., Kaufman, J., & Johnson, M.H. (2004). Eye gaze cueing facilitates
neural processing of objects in 4-month-old infants. Neuroreport, 15(16), 2553-2555.
Scaife, M., & Bruner, J.S. (1975). The capacity for joint visual attention in the infant. Nature,
253(24), 265-266.
Tomasello, M. (1999). Joint attention and cultural learning. In: M. Tomasello (Ed.), The
cultural origins of human cognition (pp. 56-93). Cambridge, MA: Harvard University
Press.
von Hofsten, C., Dahlström, E., & Fredriksson, Y. (2005). 12-months-old infants’ perception
of attention direction in static video images. Infancy, 8(3), 217-231.
Woodward, A. (2003). Infants’ developing understanding of the link between looker and
object. Developmental Science, 6(3), 297-311.

Object Processing 20
Figure captions
Figure 1. Timeline and sample stimuli with the model present (A) and during the Test block
(B). The Baseline includes the first 5 seconds (A1) and the duration when the model looks up
(up to the frame depicted in A2). The Gaze Direction block starts when the model indicates
the direction of gaze (following the frame depicted in A2) and ends with the termination of
the movie (A3).
Figure 2. White squares represent AOIs covering the face and any of the two toys during
trials with the model present (A) and during test trials (B). AOI squares do not represent the
exact size used for analysis.
Figure 3. Average proportional fixation durations to the attended (A+) and unattended (A-)
toy, based on AOI, in Baseline (B) and Gaze Direction (GD) blocks and the two test trials.
Error bars indicate standard error and (**) depict significant differences.
Figure 4. Average percentage scores of the first saccade directed to the attended (A+) and
unattended (A-) target based on AOI, in Baseline (B), Gaze Direction (GD) and Test blocks.
Error bars indicate standard error and (**) depict significant differences.
Figure 5. Average difference scores of the fixation duration to the attended and unattended
toy, based on AOI, in Baseline trials and Gaze Direction trials in reference to the presentation
order. Positive scores indicate longer fixation to the attended toy, negative scores to the
unattended toy, respectively. Error bars indicate standard error and (**) depict significant
differences.

Object Processing 21
Fig 1.
A1 A2
A3
5 seconds ~3 seconds 5 seconds
B
10 seconds

Object Processing 22
Fig 2.
BA

Object Processing 23
Fig 3.

Object Processing 24
Fig 4.

Object Processing 25
Fig. 5
-0,75
-0,25
0,25
0,75
unat
tend
ed to
y
a
ttend
ed to
y
**
Presentation order
A followed by B B followed by A
GD1 B2 GD3 B4

Developmental Science, in press
Action in development Claes von Hofsten1
Uppsala University
1 Department of Psychology Uppsala University Box 1225, S-75142 Uppsala, Sweden tel. (46)184712133 email: [email protected] www.babylab.se

Abstract
It is argued that cognitive development has to be understood in the functional
perspective provided by actions. Actions reflect all aspects of cognitive development
including the motives of the child, the problems to be solved, and the constraints and
possibilities of the child’s body and sensori-motor system. Actions are directed into the future
and their control is based on knowledge of what is going to happen next. Such knowledge is
available because events are governed by rules and regularities. The planning of actions also
requires knowledge of the affordances of objects and events. An important aspect of cognitive
development is about how the child acquires such knowledge.

Cognition and action are mutually dependent. Together they form functional systems,
driven by motives, around which adaptive behaviour develops (von Hofsten, 1994, 2003,
2004). From this perspective, the starting point of development is not a set of reflexes
triggered by external stimuli, but a set of action systems activated by the infant. Thus,
dynamic systems are formed in which the development of the nervous system and the
development of action mutually influence each other through activity and experience. With
development, the different action systems become increasingly future oriented and integrated
with each other and ultimately each action will engage multiple coordinated action systems.
Adaptive behaviour has to deal with the fact that events precede the feedback signals
about them. Relying on feedback is therefore non-adaptive. The only way to overcome this
problem is to anticipate what is going to happen next and use that information to control ones
behaviour. Furthermore, most events in the outside world do not wait for us to act. Interacting
with them require us to move to specific places at specific times while being prepared to do
specific things. This entails foreseeing the ongoing stream of events in the surrounding world
as well as the unfolding of our own actions. Such prospective control is possible because
events are governed by rules and regularities. The most general ones are the laws of nature.
Inertia and gravity for instance apply to all mechanical motions and determine how they
evolve. Other rules are more task specific, like those that enable a child to grasp an object or
use a spoon. Finally, there are socially determined rules that we have agreed upon to facilitate
social behaviour and to enable us to communicate and exchange information with each other.
Knowledge of rules makes smooth and skilful actions possible. It is accessible to us through
our sensory and cognitive systems.
The kind of knowledge needed to control actions depend on the problems to be solved
and the goals to be attained. Therefore, motives are at the core of cognitive processes and

actions are organized by goals and not by the trajectories they form. A reach, for instance, can
be executed in an infinite number of ways. We still define it as the same action, however, if
the goal remains the same. Not only do we categorize movements in terms of goals, but the
same organizing principle is also valid for the way the nervous system represents movements
(Bizzi & Mussa-Ivaldi, 1998; Poggio & Bizzi, 2004). When performing actions, subjects
fixate goals and sub-goals of the movements before they are implemented demonstrating that
the goal state is already represented when actions are planned. (Johansson, Westling,
Bäckström & Flanagan, 2001).
The developmental primitives
An organism cannot develop without some built-in abilities. If all the abilities needed
during the lifetime are built in, however, then it does not develop either. There is an optimal
level for how much phylogeny should provide and how much should be acquired during the
life time. Most of our early abilities have some kind of built-in base. It shows up in the
morphology of the body, the design of the sensory-motor system, and in the basic abilities to
perceive and conceive of the world. One of the greatest challenges of development is to find
out what those core abilities are, what kind of knowledge about the self and the outside world
they rely on, and how they interact with experience in developing action and cognition.
Some of the core abilities are present at birth. Although newborn infants have a rather
restricted behavioural repertoire, converging evidence shows that behaviours performed by
neonates are prospective and flexible goal-directed actions rather than primitive reflexes. For
instance, the rooting response is not elicited if the infant touches him or herself on the cheek
or if they are not hungry (Rochat & Hespos, 1997). When sucking, neonates monitor the flow
of milk prospectively (Craig & Lee, 1999). They can visually control their arm movements in
space and aim them towards objects when fixating them (von Hofsten, 1982; van der Meer,

1997). Van der Meer (op.cit.) showed that when a beam of light was positioned so that the
light passed in front of the neonates without reflecting on their body, they controlled the
position, velocity and deceleration of their arms so as to keep them visible in the light beam.
The function of all these built in skills, in addition to enabling the newborn child to act, I
suggest, is to provide activity-dependent input to the sensorimotor and cognitive systems. By
closing the perception-action loop the infant can begin to explore the relationship between
commands and movements, between vision and proprioception, and discover the possibilities
and constraints of their actions. It is important to note that the core abilities rarely appear as
ready made skills but rather as something that facilitates the development of skills.
Actions directed at the outside world require knowledge about space, objects, and
people. For instance, we need some kind of mental map of the environment around us so that
enables us to move about and know where we are. We need to be able to parse the visual
array into relatively independent units with inner unity and outer boundaries that can be
handled and interacted with, i.e. objects, and we need to be able to distinguish the critical
features of other people that makes it possible to recognize them and their expressions,
communicate with them, and perceive the goal-directedness of their actions. Infants are
endowed with such knowledge providing a foundation for cognitive development.
Nevertheless, Spelke (2000) suggests that core knowledge systems are limited in a number of
ways: They are domain specific (each system represents only a small subset of the things and
events that infants perceive), task specific (each system functions to solve a limited set
problems), and encapsulated (each system operates with a fair degree of independence from
other cognitive systems).
Motives

The development of an autonomic organism is crucially dependent on motives. They define
the goals of actions and provide the energy for getting there. The two most important motives
that drive actions and thus development are social and explorative. They both function from
birth and provide the driving force for action throughout life. The social motive puts the
subject in a broader context of other humans that provide comfort, security, and satisfaction.
From these others, the subject can learn new skills, find out new things about the world, and
exchange information through communication. The social motive is so important that it has
even been suggested that without it a person will stop developing altogether. The social
motive is expressed from birth in the tendency to fixate social stimuli, imitate basic gestures,
and engage in social interaction.
There are at least 2 exploratory motives. The first one has to do with finding out about
the surrounding world. New and interesting objects (regularities) and events attract infants’
visual attention, but after a few exposures they are not attracted any more. This fact has given
rise to a much used paradigm for the investigation of infant perception, the habituation
method. The second exploratory motive has to do with finding out about ones own action
capabilities. For example, before infants master reaching, they spend hours and hours trying
to get the hand to an object in spite of the fact that they will fail, at least to begin with. For the
same reason, children abandon established patterns of behaviour in favour of new ones. For
instance, infants stubbornly try to walk at an age when they can locomote much more
efficiently by crawling. In these examples there is no external reward. It is as if the infants
knew that sometime in the future they would be much better off if they could master the new
activities. The direct motives are, of course, different. It seems that expanding ones action
capabilities is extremely rewarding in itself. When new possibilities open up as a result of, for
example, the establishment of new neuronal pathways, improved perception, or
biomechanical changes, children are eager to explore them. At the same time, they are eager

to explore what the objects and events in their surrounding afford in terms of their new modes
of action (Gibson & Pick, 2000). The pleasure of moving makes the child less focused on
what is to be achieved and more on its movement possibilities. It makes the child try many
different procedures and introduces necessary variability into the learning process.
Development of prospective control of action
Actions are organized around goals, directed into the future and rely on information
about what is going to happen next. Such prospective control develops simultaneously with
the emergence of all new forms of behaviour. Here I will discuss posture and locomotion,
looking, manual actions, and social behaviour.
Posture and locomotion.
Basic orientation is a prerequisite for any other functional activity (Gibson, 1966; Reed,
1996) and purposeful movements are not possible without it. This includes balancing the body
relative to gravity and maintaining a stable orientation relative to the environment. Gravity is
a potent force and when body equilibrium is disturbed, posture becomes quickly
uncontrollable. Therefore, any reaction to a balance threat has to be very fast and automatic.
Several reflexes have been identified that serve that purpose. Postural reflexes, however, are
insufficient to maintain continuous control of balance during action. They typically interrupt
action. Disturbance to balance are better handled in a prospective way, because if the
disturbance can be foreseen there is no need for an emergency reaction and ongoing actions
can continue. Infants develop such anticipations in parallel with their mastery of the different
modes of postural control (Barela, Jeka, and Clark, 1999; Whitherington et al., 2001).
Looking:
Although each perceptual system has its own privileged procedures for exploration, the
visual system has the most specialized one. The whole purpose of movable eyes is to enable

the visual system to explore the world more efficiently and to stabilize gaze on objects of
interest. The development of oculomotor control is one the earliest appearing skills and marks
a profound improvement in the competence of the young infant. It is of crucial importance for
the extraction of visual information about the world, for directing attention, and for the
establishment of social communication. Gaze control involves both head and eye movements
and is guided by at least three types of information: visual, vestibular, and proprioceptive.
Two kinds of task need to be mastered, moving the eyes to significant visual targets and
stabilizing gaze on these targets. Shifting gaze is done with high speed saccadic eye
movements and stabilizing them on points of interests is done with smooth pursuit eye
adjustments. The latter task is, in fact, the more complicated one. To avoid slipping away
from the target, the system is required to anticipate forthcoming events. When the subject is
moving relative to the target, which is almost always the case, the smooth eye movements
need to anticipate the upcoming movement n order to compensate for it correctly. When the
fixated object moves, the eyes must anticipate its forthcoming motion.
Maintaining a stable gaze while moving is primarily controlled by the vestibular system.
It functions at an adult level already a few weeks after birth. From at least 4 weeks of age the
compensatory eye movements anticipate the upcoming body movements (Rosander & von
Hofsten, 2000, von Hofsten & Rosander, 1996). From about 6 weeks of age, the smooth part
of the tracking improves rapidly. Von Hofsten and Rosander (1997) recorded eye and head
movements in unrestrained 1- to 5-month-old infants as they tracked a happy face moving
sinusoidally back and forth in front of them. They found that the improvement in smooth
pursuit tracking was very rapid and consistent between individual subjects. Smooth pursuit
starts to develop at around 6 weeks of age and reaches adult performance at around 14 weeks.
When attending to a moving object in the surroundings, the view of it gets frequently
interrupted by other objects in the visual field. In order to maintain attention across such

occlusions and continue to track the object when it reappears, the spatio-temporal continuity
of the observed motion must somehow be represented over the occlusion interval. From about
4 months of age, infants show such ability (Rosander & von Hofsten, 2004; von Hofsten,
Kochukhova, & Rosander, 2006). The tracking is typically interrupted by the disappearance
of the object and just before the object reappears, gaze moved to the reappearance position.
This behaviour is demonstrated over a large range of occlusion intervals suggesting that the
infants track the object behind the occluder in their “minds eye”. This representation might
not, however, have anything to do with the notion of a permanent object that exists over time
or with infants’ conscious experience of where the occluded object is at a specific time behind
the occluder. It could rather be expressed as a preparedness of when and where the object
will reappear. In support of the hypothesis that infants’ represent the velocity of the occluded
object are the findings that object velocity is represented in the frontal eye field (FEF) of
rhesus monkeys during the occlusion of a moving object (Barborica & Ferrera, 2003).
Reaching and manipulation.
In the act of reaching for an object there are several problems that need to be dealt with
in advance, if the encounter with the object is going to be smooth and efficient. The reaching
hand needs to adjust to the orientation, form, and size of the object. The securing of the target
must be timed in such a way that the hand starts to close around the object in anticipation of
and not as a reaction to the encounter. Such timing has to be planned and can only occur
under visual control. Infants do this from the age they begin to successfully reach for objects
around 4-5 months of age (von Hofsten and Rönnqvist, 1988).
From the age when infants start to reach for objects they have been found to adjust the
orientation of the hand to the orientation of an elongated object reached for (Lockman,
Ashmead, & Bushnell, 1984; von Hofsten, & Fazel-Zandy, 1984). When reaching for a
rotating rod, infants prepare the grasping of it by aligning the orientation of the hand to a

future orientation of the rod (von Hofsten and Johansson, 2006). Von Hofsten and Rönnqvist
(1988) found that 9 and 13 month-old infants, but not 5-month-olds, adjusted the opening of
the hand to the size of the object reached for. They also monitored the timing of the grasps.
For each reach it was determined when the distance between thumb and index finger started to
diminish and when the object was encountered. It was found that all the infants studied began
to close the hand around the object before it was encountered. For the 5- and 9-month-old
infants the hand first moved to the vicinity of the target and then started to close around it. For
the 13 month-olds, however, the grasping action typically started during the approach, well
before touch. In other words, at this age grasping started to become integrated with the reach
to become one continuous reach-and-grasp act.
A remarkable ability of infants to time their manual actions relative to an external
event is demonstrated in early catching behavior (von Hofsten, 1980, 1983; von Hofsten,
Vishton, Spelke, Feng & Rosander al., 1998). Von Hofsten (1980) found that infants
reached successfully for moving objects at the very age they began mastering reaching for
stationary ones. Eighteen-week-old infants were found to catch an object that moved at 30
cm/sec. The reaches were aimed towards the meeting point with the object and not towards
the position were the object was seen at the beginning of the reach. In experiments by von
Hofsten et al. (1998) 6-month-old infants were presented with an object that approached
them on one of four trajectories. On 2 of them the trajectories were linear: The object
began from a position above and to the left or right of the infant, it moved downward on a
diagonal path through the center of the display, and it entered the infant’s reaching space on
the side opposite to its starting point. The other two trajectories were nonlinear: The object
moved to the center as on the linear trials and then turned abruptly and moved into the
infant’s reaching space on the same side as its starting point. Because the object was out of
reach until after it had crossed the central point where the paths intersected, infants could

only reach for the object by aiming appropriately to the left or right side of their reaching
space. Because the object moved rapidly, however, infants could only hope to attain it if
they began their reach before the object arrived at the central intersection point. In this
situation, 6-month-old infants reached predictively by extrapolating a linear path of object
motion. On linear trials that began on the left, for example, infants began to reach for the
object when it was still on the left side of the display, aiming their reach to a position on the
right side of reaching space and timing the reach so that their hand intersected the object as
it arrived on that side of reaching space. On nonlinear trials that began on the left, infants
showed the same pattern of rightward reaching and aiming until about 200 ms after the
object had turned leftward, and therefore they typically missed the object: a pattern that
provides further evidence that the infants assumed that the object would continue to move
on a linear path.
Manipulation
When manipulating objects, the subject needs to imagine the goal state of the manipulation
and the procedures of how to get there. Von Hofsten & Örnkloo (2006) studied how infants
develop their ability to insert blocks into apertures. The task was to insert elongated objects
with various cross-sections (circular, square, rectangular, elliptic, and triangular) into
apertures in which they fitted snugly. All objects had the same length and the difficulty was
manipulated by using different cross sections. The objects were both presented standing up
and lying down. It was found that although infants 18 months and younger understood the
task of inserting the blocks into the apertures and tried very hard, they had no idea how to do
it. They did not even raise up elongated blocks, but just put them on the aperture and tried to
press them in. The 22-month-old children, however, systematically rose up the horizontally
placed objects when transporting them to the aperture and the 26-month-olds turned the
objects before arriving at the aperture, in such a way that they approximately fit the aperture.

This achievement is the end point of several important developments that includes motor
competence, perception of the spatial relationship between the object and the aperture, mental
rotation, anticipation of goal states, and an understanding of means-end relationships. The
results indicate that a pure feedback strategy does not work for this task. The infants need to
have an idea of how to reorient the objects to make them fit. Such an idea can only arise if the
infants can mentally rotate the manipulated object into the fitting position. The ability to
imagine objects at different positions and in different orientations greatly improves the child’s
action capabilities. It enables them to plan actions on objects more efficiently, to relate objects
to each other, and plan actions involving more than one object.
Development of social abilities
There is an important difference between social actions and those used for negotiating
the physical world. The fact that one’s own actions affect the behaviour of the person towards
whom they are directed creates a much more dynamic situation than when actions are directed
towards objects. Intentions and emotions are readily displayed by elaborate and specific
movements, gestures, and sounds which become important to perceive and control. Some of
these abilities are already present in newborn infants and reflect their preparedness for social
interaction. Neonates are very attracted by people, especially to the sounds, movements, and
features of the human face (Johnson & Morton, 1991; Maurer, 1985). They also engage in
social interaction and turn-taking that, among other things, is expressed in their imitation of
facial gestures. Finally, they perceive and communicate emotions such as pain, hunger and
disgust through their innate display systems (Wolff, 1987). These innate dispositions give
social interaction a flying start and open up a window for the learning of the more intricate
regularities of human social behaviour.
Important social information is provided by vision. Primarily, it has to do with
perceiving the facial gestures of other people. Such gestures convey information about

emotions, intentions, and direction of attention. Perceiving what another person is looking at
is an important social skill. It facilitates referential communication. One can comment on
objects and immediately be understood by other people, convey information about them, and
communicate emotional attitudes towards them (see e.g. Corkum & Moore, 1998;
D´Entremont, Hains, & Muir, 1997; Striano & Tomasello, 2001). Most researchers agree that
infants reliably follow gaze from 10-12 months of age (see e.g. Corkum and Moore, 1998;
Deák, Flom, & Pick, 2000; von Hofsten, Dahlström, & Fredriksson, 2005). Gaze following,
however, seems to be present much earlier. Farroni, Mansfield, Lai & Johnson (2003)
showed that 4-month-olds moved gaze in the same direction as a model face shown in front of
them.
The understanding of other people’s actions seems to be accomplished by the
same neural system by which we understand our own actions. A specific set of neurons,
‘mirror neurons’, are activated when perceiving as well as when performing an action
(Craighero & Rizzolatti, 2004). They were first demonstrated in rhesus monkeys. These
neurons are specific to the goals of actions. They fire equally when a monkey observes a hand
reaching for a visible object or for an object hidden behind an occluder (Umilta et al, 2001).
However, the same neurons did not fire when the hand mimed the reaching action, that is, the
movement was the same but there was no object to be reached for. When humans perform an
action, like moving an object from one position to another, they consistently shift gaze to the
goals of these actions before the hand arrives there with the object (Johansson et al., 2001,
Land,Mennie & Rusted, 1999). When observing someone else perform the actions, adults
(Flanagan & Johansson, 2003) move gaze predictively to the goal in the same manner as
when they perform the actions themselves. Such predictive gaze behaviour is not present
when moving objects are observed outside the context of an agent (Flanagan & Johansson,
2003).

The ability to predict other people’s action goals by looking there ahead of time seems
to develop during the first year of life. Falck-Ytter, Gredebäck & von Hofsten, (2006) found
that 12-month-old but not 6-month-old infants predict other people’s manual actions in this
way. Thus, infants, like adults, seems to understand others actions by mapping them onto their
motor representations of the same actions. The suggestion that cognition is anchored in action
at an inter-individual level early in life has important implications for the development of
such complex and diverse social competences as imitation, language and empathy.
Conclusions
Cognitive development cannot be understood in isolation. It has to be related to the
motives of the child, the action problems to be solved, and the constraints and possibilities of
the child’s body and sensori-motor system. Actions cannot be constructed ad-hoc. They must
be planned. From a functional perspective, cognitive development has to do with expanding
the prospective control of actions. This is done by extracting more appropriate information
about what is going to happen next, by getting to understand the rules that govern events, and
by becoming able to represent events that are not directly available to our senses. Cognitive
development, however, has to be understood in a still wider context. We need to relate our
own actions to the actions of other people. Recent research shows that we spontaneously
perceive the movements of other people as actions, that specific areas in the brain encode our
own and other people’s actions alike, and that this forms a basis for understanding how the
actions of others are carried out as well as the goals and motives that drive them.

References
Barela, J.A., Jeka, J.J. and Clark, J.E. (1999). The use of somatosensory information during
the aquisition of independent upright stance. Infant Behavior and Development, 22, 87-
102.
Barborica, A. and Ferrera, V.P. (2003) Estimating invisible target speed from neuronal
activity in monkey frontal eye field. Nature Neuroscience, 6, 66–74.
Bizzi, E. and Mussa-Ivaldi, F.A. (1998) Neural basis of motor control and its cognitive
implications. Trends in Cognitive Science, 2, 97-102.
Corkum, V., & Moore, C. (1998). The origins of joint visual attention in infants.
Developmental Psychology, 34, 28–38.
Craig, C.M. and Lee, D.N. (1999) Neonatal control of sucking pressure: evidence for an
intrinsic tau-guide. Experimental Brain Research, 124, 371–382.
Deák, G. O., Flom, R. A.,&Pick, A. D. (2000). Effects of gesture and target on 12- and 18-
month-olds’ joint visual attention to objects in front of or behind them. Developmental
Psychology, 36, 511–523.
D’Entremont, B., Hains, S. M. J., & Muir, D. W. (1997). A demonstration of gaze following
in 3- to 6-month-olds. Infant Behavior and Development, 20, 569–572.
Falck-Ytter T., Gredebäck G. & von Hofsten C.(2006) Infants predict other people’s action
goals. Nature Neuroscience, 9, 878 – 879.

Farroni, T., Mansfield, E.M.,Lai, C. and. Johnson M.H. Infants perceiving and acting on the
eyes: Tests of an evolutionary hypothesis. Journal of Experimental Child Psychology, 85,
199-212.
Flanagan J-R; Johansson R-S. (2003)Action plans used in action observation. Nature, 424,
769-71.
Gibson, J.J. (1966) The senses considered as perceptual systems. New York: Houghton
Mifflin.
Gibson, E.J. and Pick, A. (2000) An Ecological Approach to Perceptual Learning and
Development, Oxford University Press
Jacobsen, K., Magnussen, S. And Smith, L. (1997). Hidden visual capabilities in mentally
retarded subjects diagnosed as deaf-blind. Vision Research, 37, 2931-2935.
Johansson, RS, Westling G, Bäckström A, Flanagan J R. (2001) Eye-hand coordination in
object manipulation. Journal of Neuroscience, 21, 6917-6932.
Johnson, M.H. and Morton, J. (1991). Biology and Cognitive Development: The case of face
recognition. Oxford: Blackwell.
Land M.F., Mennie N., Rusted J. (1999). The roles of vision and eye movements in the
control of activities of daily living. Perception 28, 1311 - 1328.
Lockman, J.J., Ashmead, D.H. & Bushnell, E.W. (1984) The development of anticipatory
hand orientation during infancy. Journal of Experimental Child Psychology, 37, 176 –
186.
Maurer, D. (1985). Infants’ perception of faceness. In T.N. Field and N. Fox (Eds.) Social
Perception in Infants. (pp. 37-66). Hillsdale, N.J.: Lawrence Erlbaum Associates.
Örnkloo, H. & von Hofsten, C. (2006) Fitting objects into holes: on the development of
spatial cognition skills. Developmental Psychology, in press.
Poggio, T. Bizzi, E. (2004) Generalization in vision and motor control. Nature, 431, 768-774.

Reed, E. S. (1996) Encountering the world: Towards an Ecological Psychology. New York:
Oxford University Press.
Rizzolatti, G. and Craighero, L. (2004) The mirror-neuron system. Annual Review of
Neuroscience, 27, 169–92
Rochat, P. and Hespos, S.J. (1997) Differential rooting reponses by neonates: evidence for an
early sense of self. Early Development and Parenting 6, 105–112.
Rosander, K. and von Hofsten, C. (2002) Development of gaze tracking of small and large
objects. Experimental Brain Research, 146, 257-264.
Rosander, R. and von Hofsten, C. (2004) Infants' emerging ability to represent object motion.
Cognition, 91, 1-22.
Spelke, E.S. (2000) Core knowledge. American Psychologist, 55, 1233-1243.
Striano, T., & Tomasello, M. (2001). Infant development: Physical and social cognition. In
International encyclopedia of the social and behavioral sciences (pp. 7410–7414).
Umilt`a MA, Kohler E, Gallese V, Fogassi L, Fadiga L, et al. 2001. “I know what you are
doing”: a neurophysiological study. Neuron 32, 91–101
van der Meer, A.L.H. (1997) Keeping the arm in the limelight: advanced visual control of arm
movements in neonates. Eur. J. Paediatr. Neurol. 4, 103–108
von Hofsten, C. (1980) Predictive reaching for moving objects by human infants. Journal of
Experimental Child Psychology, 30, 369-382.
von Hofsten, C. (1982). Eye-hand coordination in newborns. Developmental Psychology , 18,
450-461.
von Hofsten, C.. (1983). Catching skills in infancy. Journal of Experimental Psychology:
Human Perception and Performance, 9, 75-85.
von Hofsten, C. (1993) Prospective control: A basic aspect of action development. Human
Development, 36, 253-270.

von Hofsten, C., Dahlström, E., & Fredriksson, Y. (2005) 12-month–old infants’ perception
of attention direction in static video images. Infancy, 8, 217-231.
von Hofsten, C. and Fazel-Zandy, S.(1984). Development of visually guided hand orientation
in reaching. Journal of Experimental Child Psychology, 38, 208-219.
von Hofsten, C. & Johansson, K. (2006) Infants’ emerging ability to capture a rotating rod.
Unpublished manuscript.
von Hofsten, C., Kochukhova, O., & Rosander, K. (2006) Predictive occluder tracking in 4-
month-old infants. Submitted manuscript.
von Hofsten, C. and Rosander, K. (1996) The development of gaze control and predictive
tracking in young infants. Vision Research, 36, 81-96.
von Hofsten, C and Rosander, K. (1997) Development of smooth pursuit tracking in young
infants. Vision Research, 37, 1799-1810.
von Hofsten, C. and Rönnqvist, L. (1988) Preparation for grasping an object: A
developmental study. Journal of Experimental Psychology: Human Perception and
Performance, 14, 610-621.
von Hofsten, C., Vishton, P., Spelke, E.S., Feng, Q., and Rosander, K. (1998) Predictive
action in infancy: Tracking and reaching for moving objects. Cognition, 67, 255-285.
von Hofsten, C. (2003) On the development of perception and action. In J. Valsiner and K. J.
Connolly (Eds.) Handbook of Developmental Psychology. London: Sage. pp: 114-140.
von Hofsten, C. (2004) An action perspective on motor development. Trends in Cognitive
Science, 8, 266-272.
Witherington, D. C., von Hofsten, C., Rosander K., Robinette, A.Woollacott, M. H., and
Bertenthal, B. I. (2002) The Development of Anticipatory Postural Adjustments in
Infancy. Infancy, 3, 495-517.

Wolff, P.H. (1987). The development of behavioral states and the expression of emotions in
early infancy. Chicago: Chicago University Press.

1
Developmental Science, in press
Predictive tracking over occlusions by 4-month-old infants
Claes von Hofsten, Olga Kochukhova, and Kerstin Rosander* Department of Psychology, Uppsala University
* Address for correspondence: Department of Psychology, Uppsala University, Box1225, S-75142 Uppsala, Sweden. Email: [email protected], [email protected], [email protected]

2
Abstract Two experiments investigated how 16-20-week-old infants visually track an object that
oscillated on a horizontal trajectory with a centrally placed occluder. To determine the
principles underlying infants’ tendency to shift gaze to the exiting side before the object
arrives, occluder width, oscillation frequency, and motion amplitude were manipulated
resulting in occlusion durations between 0.20 and 1.66 s. Through these manipulations, we
were able to distinguish between several possible modes of behavior underlying ‘predictive’
actions at occluders. Four such modes were tested. First, if passage-of-time determines when
saccades are made, the tendency to shift gaze over the occluder is expected to be a function of
time since disappearance. Secondly, if visual salience of the exiting occluder edge determines
when saccades are made, occluder width would determine the pre-reappearance gaze shifts
but not oscillation frequency, amplitude, or velocity. Thirdly, if memory of the duration of the
previous occlusion determines when the subjects shift gaze over the occluder, it is expected
that the gaze will shift after the same latency at the next occlusion irrespective of whether
occlusion duration is changed or not. Finally, if infants base their pre-reapperance gaze shifts
on their ability to represent object motion (cognitive mode), it is expected that the latency of
the gaze shifts over the occluder are scaled to occlusion duration. Eye and head movements
as well as object motion were measured at 240 Hz. In 49% of the passages, the infants shifted
gaze to the opposite side of the occluder before the object arrived there. The tendency to make
such gaze shifts could not be explained by the passage of time since disappearance. Neither
could it be fully explained in terms of visual information present during occlusion, i.e.
occluder width. On the contrary, it was found that the latency of the pre-reappearance gaze
shifts was determined by the time of object reappearance and that it was a function of all the 3
factors manipulated. The results suggest that object velocity is represented during occlusion
and that infants track the object behind the occluder in their “minds eye”.

3
Introduction
The observation of objects that move in a cluttered environment is frequently
interrupted as they pass behind other objects. To keep track of them requires that their motion
is somehow represented over such periods of non-visibility. The present article asks whether
4-month-old infants have this ability, and if so, how it is accomplished.
Piaget (1954) was one of the first to reflect on the problem of early object representation
and he hypothesized that it would start to evolve from about 4 months of age. Later research
supports and expands Piaget’s assumptions. One frequently used paradigm has studied
looking at displays where the spatio-temporal continuity has been violated with the
assumption that infants will look longer at such displays. These experiments strongly suggest
that 4-month-olds and maybe even younger infants maintain some kind of representation of
the motion of an occluded object. For instance, Baillargeon and associates (Baillargeon &
Graber, 1987; Baillargeon & deVos, 1991, Aguiar & Baillargeon, 1999) habituated infants to
a tall and a short rabbit moving behind a solid screen. This screen was then replaced by one
with a gap in the top. The tall rabbit should have appeared in the gap but did not. Infants from
2.5 month of age looked longer at the tall rabbit event suggesting that they had detected a
discrepancy between the expected and the actual event in that display. These studies indicate
that infants are somehow aware of the motion of a temporary occluded moving object but not
how.
Visual tracking studies are also informative about infants’ developing ability to
represent object motion. The eyes are not subject to drift under normal circumstance, not even
in young infants, and smooth gradual eye movements only appear when a moving object is
pursued (von Hofsten & Rosander, 1997; Rosander & von Hofsten, 2002). Tracking is
interrupted when the motion is stopped. Muller & Aslin (1978) found that 2-, 4-, and 6-
month-old infants stopped tracking when an object that moved on a horizontal path stopped

4
just in front of an occluder. When the pursued object is occluded, the smooth eye movements
get effectively interrupted (Rosander& von Hofsten, 2004). This is also valid for visual
tracking in adults (Lisberger, Morris, & Tyschen, 1987; Kowler, 1990). To continue tracking
when the object reappears, subjects shift gaze saccadicly across the occluder. As smooth
pursuit and saccades are radically different kinds of eye movements requiring different motor
programs, the saccades cannot be accounted for by a continuation of the smooth pursuit (see
e.g. Leigh, R. J., & Zee, D.S., 1999). If they are elicited before the object reappears they have
to be guided by some kind of anticipation of the object’s continuing motion. In the past, only
a few studies have measured infants’ eye movements to determine at what age such
anticipations appear. Van der Meer, van der Weel and Lee (1994) found that 5-month-old
infants observing a temporarily occluded, linearly moving object looked towards the
reappearance side in an anticipatory way. In their study the object was occluded during 0.3 -
0.6 s.
Two recent studies have addressed the question of when such ability appears and
the role of learning in its establishment (Johnson, Amso & Slemmer, 2003, Rosander &
von Hofsten, 2004). Rosander & von Hofsten (2004) examined the tracking over occlusion
in 7-, 9-, 12-, 17- and 21-week-old infants. The infants viewed an object oscillating on a
horizontal track that either had an occluder placed at its center where the object
disappeared for 0.3 s, or one at one of the trajectory end points where it became occluded
for 0.6 s. In the former case, the object reappeared on the opposite side of the occluder and
in the latter case on the same side. The level of performance in the central occluder
condition improved rapidly between the ages studied and several of the 17-week-old
infants moved gaze to the reappearing side of the occluder from the first passage in a trial.
When the object was occluded at the endpoint of the trajectory, there was an increasing
tendency with age to shift gaze over the occluder. These results indicate that 4-5-month-old

5
infants have anticipations of where and when an occluded moving object will reappear
when moving on a linear trajectory. All the infants in Rosander & von Hofsten (2004)
experienced two trials with un-occluded motion before the occlusion trials began.
Johnson, Amso & Slemmer (2003) examined the eye tracking of 4- and 6-month-old
infants who viewed an object that oscillated back and forth behind an occluder. Some of the
infants experienced an initial period of un-occluded motion and others received no experience
of such a stimulus. Johnson et al. (2003) reported that 4-month-old infants, who saw the un-
occluded motion, showed anticipatory eye movements over the occluder, but not the infants
who did not see the un-occluded motion.
One problem with studies of anticipatory gaze shifts at temporary occlusions is that
anticipations do not occur on every trial. In Rosander & von Hofsten (2004) the 4-month-old
infants moved gaze over the occluder ahead of time in 47% of the trials and in Johnson et al.
(2003) it happened in 29-46% depending on condition and age. Is it possible that infants stop
tracking at the occluder edge when the object disappears, wait there for a while and then shift
gaze anyway. Some of those spontaneous gaze shifts might arrive to the other side of the
occluder before the object reappears there. Thus, they appear to be predictive although they
are not.
In experiments with only one occlusion duration, it is not possible to determine whether
the saccades arriving at the reappearance edge before the object are truly predictive or just
appear to be so. In order to determine the principles underlying infants’ tendency to shift gaze
to the reappearing side of an occluder before the object arrives there, a different set of studies
is required where occlusion duration is systematically varied. Such manipulations are able to
distinguish between several modes of behavior underlying ‘predictive’ actions at occluders. It
is the gaze shifts that arrive before the reappearing object that are informative in this respect.
They are here called pre-reappearance gaze shifts (PRGS). Those that arrives later need to be

6
excluded from this analysis because they may have been elicited by the sight of the
reappearing object.
First, let’s entertain the possibility that infants stop their gaze at the occluder edge
when the object disappears, linger a little there and then shift attention to the other occluder
edge. If passage-of-time determines when saccades are made, the tendency to shift gaze over
the occluder is expected to be a function of time since disappearance. An implication of this
mode is that the longer the occlusion duration, the higher the number of these saccades will be
counted as predictive purely because the average mean is based on a larger range of values.
Secondly, it is possible that subjects move gaze over the occluder before the object
reappears because of the visual salience of the exiting occluder edge. The greater the visual
salience of a stimulus, the earlier will gaze be shifted to this stimulus. It is expected that
visual salience is greater for high contrast than for low contrast stimuli. As contrast sensitivity
decreases with increasing eccentricity in the visual field, it is possible that PRGS in the
presence of a wide occluder will have a longer latency, not because the subject expects the
object to reappear later, but because the visual salience of the exiting occluder edge is then
lower. Thus, varying just the width of the occluder will not distinguish the visual salience
hypothesis from a more cognitive one. Another problem with a salient occluder is that it may
attract attention to such a degree that tracking is interrupted altogether and instead fixate the
salient occluder (Muller & Aslin, 1978). To avoid effects of visual salience of the occluder it
is therefore of utmost importance to use occluders that deviate from the background as little
as possible. In the present experiments both the occluder and the background had the same
white colour.
If the salience of the exiting occluder edge varies depending on how far into the
peripheral visual field it is presented, it is expected that this would also be valid for any
salient visual stimulus. The colour and luminance of the reappearing object deviated quite

7
distinctly from the background and saccadic latency to it should therefore be related to its
eccentricity in the visual field. If it is, the visual salience hypothesis would be strengthened.
If, on the other hand, non-visual factors such as oscillation frequency and object velocity
affect the latency of the PRGS, it means that the attractiveness of the exiting occluder edge is,
at least, moderated by these other variables. Thus the visual salience hypothesis cannot be
properly tested unless both occluder width and object velocity are manipulated. This was done
in the present study by varying oscillation frequency and motion amplitude.
Another possible explanation of why PRGS are performed is that it may just be a
contingency effect without any anchoring in continuous physical events. The subjects could
just remember the duration of the previous occlusion and expect the object to be absent for the
same period at the next occlusion (the memory hypothesis). Haith and associates (Canfield &
Haith, 1991; Haith, 1994; Haith, Hazan, & Goodman, 1988) investigated infants’ anticipatory
saccades to when and where the next picture in a predictable left–right sequence was going to
be shown. Saccades arriving at the position of the next picture within 200 ms of its
presentation were considered anticipatory. From about 3 months of age, such anticipations
were found to be significantly more frequent for a predictable than for an unpredictable
sequence (Canfield & Haith, 1991). As the pictures were distinctly different, it is doubtful
whether they were perceived as one continuous event. In addition, the left–right sequence of
pictures followed an arbitrary rule rather than a physical principle. In spite of this, temporal
regularities were rapidly learnt suggesting that infants are sensitive to spatio-temporal
contingencies and use them to predict what is going to happen next. Whether infants’ gaze
shifts over the occluder are determined in this way cannot be tested with a single duration of
occlusion. If several durations are included in the experiment, however, it is expected that the
subjects will systematically misjudge the duration every time it is changed. When duration is
made shorter, the subjects will overestimate it and consequently shift gaze too late. If the

8
duration is made longer, they will underestimate duration and shift gaze over the occluder too
early.
Finally, the PRGS might be based on information about occlusion duration derived
from oscillation frequency and amplitude, object velocity, and occluder width. This will be
called the cognitive hypothesis. Object velocity is linearly related to oscillation frequency
and motion amplitude. If frequency or amplitude is doubled, so is velocity. Occlusion
duration is obtained by dividing occluder width with object velocity. Instead of having
explicit knowledge of this relationship, infants could simply maintain a representation of the
object motion while the object is occluded and shift gaze to the other side of the occluder
when the conceived object is about to arrive there. In support of this alternative are the
findings that object velocity is represented in the frontal eye field (FEF) of rhesus monkeys
during the occlusion of a moving object (Barborica & Ferrera, 2003). It is only by
simultaneously varying object velocity and occluder width that such a strategy can be
revealed.
In the past, there are very few developmental studies that varied both object velocity
and occluder width. Muller & Aslin (1978) showed 6-month-old infants a sphere (8
cm/diameter) that moved with either10 or 20 cm/s on a horizontal trajectory and disappeared
temporarily behind a 20 or 40 cm wide occluder. They had no possibility to measure exact
timing of the gaze shifts over the occluder but found that the instances of tracking
interruptions larger than 1 s increased dramatically when the complete occlusion duration
increased from 0.6 to 1.2 s ( i.e. partial occlusion increased from 1 to 2 s). This indicates that
the length of the tracking interruptions was related to occlusion duration. Gredebäck, von
Hofsten & Boudreau, (2002) studied 9-month-old infants who tracked an object moving on a
circular trajectory. The results showed that the infants’ performance was determined by
occlusion duration, that is, by the joint relationship between object velocity and occluder

9
width. For a range of occlusion durations from 0.25 to 5 s, gaze was shifted over the occluder
at around 2/3 of the occlusion time. Similar results were obtained by Gredebäck & von
Hofsten (2004) with 6-month-old infants and older. In that study, however, occluder width
was not varied and the joint effect of these two variables could therefore not be evaluated. The
purpose of the present study was to determine how 4-month-old infants behave in a situation
with temporarily occluded objects when occluder width and object velocity are
simultaneously manipulated.
Two experiments were performed in which infants were presented with objects
oscillating on a horizontal trajectory. We created a set of occlusion durations by systematic
manipulation of oscillation frequency, occluder width (Experiment 1 and 2), and motion
amplitude (Experiment 2). In order to minimize the effect of visual salience of the exiting
occluder edge, the occluder had the same white colour as the background (the inside of the
cylinder). Three oscillation frequencies and 3 occluders were used in Experiment 1 creating 7
different occlusion durations between 0.22 and 0.61 s. In Experiment 2, oscillation amplitude
in addition to oscillation frequency and occluder width was varied creating 8 different
occlusion durations between 0.2 and 1.66 s. The object velocities used ranged from 15 to
30°/s in Experiment 1 and from 8 to 30°/s in Experiment 2. Earlier research has shown that
infants track objects optimally within this interval (von Hofsten & Rosander, 1996,
Mareschal, Harris & Plunkett, 1997). The infants were between 16 and 20 weeks of age. Our
earlier studies indicate that PRGS emerge during this age period (Rosander & von Hofsten,
2004)
General method
Subjects.

10
Twenty-three 16-20-week-old infants participated in the study. They were all healthy and
born within 2 weeks of the expected date. The study was in accordance with the ethical
standards specified in the 1964 Declaration of Helsinki.
Apparatus.
The experiments were performed with the same apparatus as earlier described in detail (von
Hofsten & Rosander, 1996, 1997; Rosander & von Hofsten, 2002, 2004). The infants were
placed in a specially designed infant chair positioned at the center of a cylinder, 1 m in
diameter and 1 m high. This cylinder shielded off essentially all potentially distracting stimuli
around the infant. The chair was positioned in the cylinder in such a way that its axis
corresponded approximately to the body axis of the infant. His or her head was lightly
supported with pads. In the experiments the setup was comfortably inclined at an angle of 40
deg. Figure 1 shows a subject in the cylinder.
------------------------Insert Figure 1 about here----------------------- Stimuli.
In front of the infant the cylinder had a narrow horizontal slit where the movable object was
placed. A circular orange colored "happy" face was used as the stimulus to be tracked. It was
5 cm in diameter corresponding to a visual angle of approximately 7°, with black eyes, a
black smiling mouth, and a black wide contour around it. In the middle of the schematic face,
at the position of the nose, a mini video camera (Panasonic WV-KS152) was placed. Its black
front had a diameter of 15 mm or 2.2° of visual angle. Below the face, a red LED was placed.
It could be blinked to attract the infant’s gaze. The motion of the object was controlled by a
function generator (Hung Chang, model 8205A). In the experimental trials, the "happy face"
object oscillated in front of the infant according to a triangular function (i.e. constant velocity
that abruptly reversed direction at the endpoints of the trajectory). To minimize visual
salience of the non-moving parts of the setup, the moving object was occluded by a
rectangular piece of cardboard at the center of its trajectory with the same white color as the

11
inner side of the cylinder (see Figure 1). The edges of the slit in which the object moved were
also white. Finally, from the infant’s point of view, the background behind the slit was the
white ceiling of the experimental room. Different sized occluders were used in the different
conditions. They were placed over the motion-trajectory at a distance of 2 cm from the
cylinder wall to which it was attached to by means of Velcro.
Measurements
Eye movements: Electrooculogram (EOG) was used to measure eye movements. The
electrodes were of miniature type (Beckman) and had been soaked in physiological saline for
at least 30 minutes before use. They were then filled with conductive electrode cream
(Synapse, Med-Tek Corp.) and attached to the outer canthi of each eye. The ground electrode,
a standard EEG child electrode, was attached to the ear lobe. The signals from the two
electrodes were fed via 10 cm long cables into a preamplifier attached to the head of the infant
(see Figure 1). The preamplifier was introduced to eliminate the impedance problems of
traditional EOG measurements associated with long wires (Westling, 1992). The amplifier
was powered by a battery and completely isolated from the rest of the equipment for safety
reasons. The signal was relayed to the outer system by means of optical switches. The EOG
signal was low-pass filtered at 20 Hz by means of a third-order Butterworth filter. The
position accuracy of the filtered EOG data was +0.4° visual angle or better. This introduced a
constant time delay of 0.015 s that was compensated for in the data analysis. As EOG
measurements are based on the difference in potential level between the electrodes, it is
subject to a slow drift over time. This drift was eliminated before analysis. The drift, however,
could cause the amplified potential to reach saturation values in the recording window.
Therefore, the base level of EOG was reset between trials. This does not affect the calibration
of the EOG or distort the data in any other way (cf Juhola 1987). For more detailed

12
information about the EOG setup, see Rosander & von Hofsten (2000, 2002, 2004) and von
Hofsten & Rosander (1996, 1997).
Head and object motions: A motion analyzing system, “Proreflex (Qualisys)”, was used to
measure the movements in 3-D space. This system uses high-speed cameras that register the
position of passive reflective markers illuminated by infrared light positioned around the lens
of each camera. In the present setup, 3 cameras were used, each of which had an infrared light
source. Three markers were placed on the head to make it possible to record its translational
as well as rotational movements and one marker was placed at the center of the moving
object. The position accuracy of each measured marker was 0.5 mm. The markers had a
diameter of 4 mm and can be seen in Figure 1. The EOG and the head movement data were
recorded in synchrony at 240 Hz.
Procedure
Two experiments with identical procedures were carried out. First, the accompanying parent
was informed about the experiment and signed the consensus form. Then it was assured that
the infant had been recently fed and was in an alert state. The video camera at the center of
the stimulus monitored the face of the infant so that the parent and the experimenter could
observe the infant during the experiment. As the camera was always directed towards the face
of the infant, it gave excellent records of whether the infant attended to the object or not in
between occlusions. Each experimental session was video-recorded with this device. If the
infant fussed or fell asleep during a trial, the experiment was interrupted temporarily, after
which the last trial was repeated and the experiment continued. Such interruptions were
uncommon. Before each trial the stimulus parameters were set to the appropriate values. This
included changing the occluder and setting the amplitude and frequency of the oscillations to
be used on the function generator. The duration of each trial was 25 s and the whole
experimental session had duration of around 7 minutes.

13
Calibration of EOG: This procedure has been described earlier (Rosander & von Hofsten,
2002, 2004; von Hofsten & Rosander, 1996). The experimenter moved the object swiftly from
one extreme position to the middle of the path, and then to the extreme distance on the other
side (Finocchio, Preston, &Fuchs, 1990). Each position was defined and measured by the
motion analyzing system (Qualisys). Each stop lasted 1-2 s and during that time the
experimenter flashed the red LED placed below the face. This attracted the infant’s gaze. The
flashing of the LED also made it possible to determine if the infant fixated the object
(Rosander & von Hofsten, 2002). During the 25 s period of calibration, the experimenter
covered about 4 cycles of motion corresponding to 16 fixation stops.
Data analysis
The video records were inspected to determine whether the subjects attended to the
object both before and after the occlusion of the object at each passage. Gaze shifts over the
occluder launched earlier than 0.3 s before total occlusion or later than 1 s after the object had
reappeared were regarded as unrelated to the occlusion event and were therefore not included
in the analysis. They constituted merely 2.5% of the total number of gaze shifts. Data were
analyzed with programs written in the MATLAB environment. The statistical analysis was
performed in SPSS. A specific trial was considered to have started when the infant first
directed its gaze toward the object. Thus, if the infant looked somewhere else after the object
had started to move and therefore missed one occluder passage, this passage was not included
in the analysis of the trial. Instead the 2nd passage was considered as the first. The gaze
direction was calculated as a sum of head and eye direction, where the head direction was
calculated from the relative positions of the three markers on the infant's head.
Calculation of gaze direction: All calculations were performed in the plane of rotation (xz-
plane) of the cylinder which had its origin at the axis of rotation (the y-axis), see Figure 2.

14
The position of the object on the cylinder was transferred to angular coordinates. We can find
the time dependent angles of the head (αhead) and the object (βobject) using Equation 1 and 2:
( ) ( ) [ ] [ ]{ } )1....(arctan21
21
21arctan
21
BCCBBCABCAhead XXZZZZZXXX −−+⎭⎬⎫
⎩⎨⎧
⎥⎦⎤
⎢⎣⎡ +−⎥⎦
⎤⎢⎣⎡ +−=α
and
βobject = ( ) ( )⎭⎬⎫
⎩⎨⎧
⎥⎦⎤
⎢⎣⎡ +−⎥⎦
⎤⎢⎣⎡ +− BCDBCD ZZZXXX
21
21arctan ……..………………(2)
where X and Z are time dependent coordinates of the markers A, B, C and D (see Figure 2);
--------------------Figure 2 about here--------------------------------------
The calibration factor of the EOG in mV/deg was obtained by dividing the
difference between the values of the EOG signal at different calibration positions with the
difference in degrees between head and object at those positions. A linear relation was then
assumed between the EOG signal and the radial displacement according to Davis & Shackel
(1960), Finocchio, et al. (1990), and von Hofsten & Rosander (1996). Eye movements were
calibrated in the same angular reference system as the head, i.e. in terms of how much head
movement would be required to shift gaze an equal amount. Amplitudes of eye movements
were regarded as proportional to the corresponding head movements. If the eyes are displaced
6 cm relative to the rotation axis of the head (this value was estimated from measurements on
a few of the participating infants) and the object is positioned 44-46 cm from head axis as was
the case in the present experiment, the exact relationship between head and eye angles
deviates from proportionality with less than 0.5% within the interval used (+24°). The gaze

15
was estimated as the sum of eye and head positions. Angular velocities were estimated as the
difference between consecutive co-ordinates. The velocities of the eyes, head, and gaze were
routinely calculated in this way.
Analysis of visual tracking over the occluder: First, the occluder boundaries were identified
from the object motion record. This happened when the reflective marker on the object
became occluded and dis-occluded. Then the interval where the object was completely
occluded was identified. As the marker on the object was placed at its center, the position in
space-time of the full occlusions corresponded to a marker position half an object width inside
the occluder (see Figure 3). Gaze was considered to have arrived to the other side of the
occluder when it was within 2° of its opposite boundary. The boundary will then be within the
foveal region of the infants’ visual field (Yudelis &Hendrickson, 1986). The time when gaze
arrived at the exiting occluder edge relative to the time when the object started to reappear
was defined as the lag or lead of the gaze shift. The time from the total disappearance of the
object to the time when gaze arrived to the opposite boundary was defined as the gaze shift
latency. When the lag was less than 0.2 s the gaze shift was defined as a pre-reappearance
gaze shift (PRGS), as this is the minimum time required to program a saccade to an
unexpected event in adults (Engel, Anderson, & Soechting, 1999). As PRGS is a different
mode of responding than reacting to the seen object after it has reappeared, separate analyses
were conducted on each of these two subsets of data.
----------------Figure 3 about here -----------------
Data was evaluated with correlation analysis and General linear model repeated
measurement ANOVAS. To control for sphericity the Geisser-Greenhouse correction was
used when needed. Individual trial subject means were then used as input.

16
Experiment 1
The purpose of Experiment 1 was to investigate how 3.5 to 4.5-month-old infants are
able to take occlusion duration into account when making pre-reappearance gaze shifts
(PRGS). Duration was varied by orthogonal manipulation of Oscillation Frequency and
Occluder Width. This made it also possible to evaluate each of the 4 possible strategies
outlined in the introduction, the passage-of-time, visual salience, memory mode, and the
cognitive mode. Apart from being a determining factor of occlusion duration, object velocity
might be of importance for another reason. A higher velocity gives rise to more rapid
accretion and deletion of the visible object at the occluder edges. Gradual accretion and
deletion has been shown to be of importance for being able to perceive continued motion
behind an occluder (Scholl & Pylyshyn, 1999, Kaufman, Csibra & Johnson, 2005). It is
therefore possible that the strength and clarity of the represented motion improves when the
deletion is made more gradual.
Although earlier research (Johnson et al., 2003; Rosander & von Hofsten, 2004)
showed un-occluded motion at the beginning of the experiment, this was not done in the
present experiment. Piloting indicated that presenting a trial with un-occluded motion at the
beginning of the experiment was not necessary for attaining predictive tracking over
occlusion in 4-month-old infants. In experimental situations, young infants tend to get rapidly
bored and therefore we wanted to keep the experiment as short as possible. It is important to
point out that the calibration procedure does not correspond to a learning trial with un-
occluded motion. Instead of being moved with constant velocity as in the experimental trials,
the object was moved rapidly between positions where it stopped for 1-2 s. For instance, it
stopped at the center of the trajectory. If the infants learned the temporal pattern of this
procedure, they would expect the object to stop behind the occluder. However, although the
calibration procedure did not provide a learning opportunity for the temporal properties of the
oscillatory motion, it made the infants familiar with the horizontal trajectory used.

17
Method
Experiment 1 included 5 girls and 6 boys. Their age varied from 15:6 to 19:5 weeks
with a mean age of 18 weeks. The amplitude of the oscillating motion was always the same
(24° visual angle). Occluder Width was 8.2, 11, or 14 cm corresponding to 11.6°, 15.5° and
20° of visual angle at a distance of 45 cm from the eyes. Oscillation Frequency was 0.15, 0.21
or 0.30 Hz. Before each trial these values were adjusted by hand on the function generator and
occlusion durations could therefore deviate somewhat at a given condition for the different
subjects (+8%). The resulting angular velocities of the object were 15°/s, 21.4°/s and 30°/s at
45 cm viewing distance.
Seven combinations of Oscillation Frequency and Occluder Width were included in
the experiment instead of the possible 9. The largest occluder was not combined with the
slowest velocity and the smallest occluder was not combined with the fastest velocity. The
decision to exclude those two conditions was made in order to reduce the number of
conditions. It was judged that 9 conditions were going to make the infants too tired and
deteriorate their performance. The measured duration of total occlusion was, on the average
0.22, 0.28, 0.31, 0.39, 0.43, 0.56, and 0.61 s. These figures are given in Table 1. The
conditions were presented in randomized order. The slowest Oscillation Frequency (0.15 Hz)
included 7-8 occluder events per trial, the middle Oscillation Frequency (0.22 Hz) 11-12
occluder events, and the fastest Oscillation Frequency y (0.30 Hz) 14-15 occluder events.
Results
One boy did not complete the experiment because of inattention leaving 10 subjects to
be analyzed (5 girls and 5 boys). Seven of the 70 individual trials from these subjects were
also excluded for the same reason (4 subjects missed one trial and one missed 3 trials). In the
remaining trials, the infants attended to the object both before and after the occlusion in 559
passages (83%), while at 113 passages they were distracted and looked away. In 294 cases,

18
gaze arrive at the reappearance side of the occluder more than 0.2 s after the object had started
to reappear and those were considered reactive saccades. The reactive saccades arrived at the
reappearance side on the average 0.45 s (sd = 0.16) after the object started to appear.
In 265 cases (47.4 %) the gaze shifts over the occluder arrived at the opposite side less
than 0.2 s after the object arrived there (PRGS). In 234 of these passages (88%) the gaze
stopped at the occluder edge until making saccadic shift(s) over to the other side. In the 31
remaining cases (12%) the subject made a gaze shift over to the other side of the occluder and
then returned to the original edge where gaze stayed until making a final shift over the
occluder. In those cases, it was the second gaze shift that was analyzed. Table 1 shows the
average duration of occlusion, number of presented occluder passages, number of passages
analyzed, number and percentage of PRGS, and mean latency of these gaze shifts in
Experiment 1.
-------------------Insert Table 1 about here-----------------
Determinants of gaze shifts over the occluder
The passage-of-time hypothesis: Infants did not show an overall greater tendency to shift gaze
over the occluder during occlusion with the passage of time. There was no correlation
between occlusion duration and proportion of PRGS for individual subjects (r = -0.02, n=63).
Neither were there significant correlations between proportion of PRGS and Occluder Width
(r= -0.192, n=27) for the middle frequency or between proportion of PRGS and Oscillation
Frequency for the middle Occluder Width (r= 0.156, n=27).
------------------Figure 4 about here--------------------
The memory hypothesis: To test whether the saccade latencies were based on the remembered
duration of the previous occlusion, we compared the performance on the last occlusion in one
condition with the first occlusion in the next condition. If infants follow this rule, they should
overestimate the occlusion duration and arrive too late every time the duration is made

19
shorter, and underestimate the duration and arrive too early every time the duration is made
longer. When the duration of occlusion increased between conditions there were 12 cases of
PRGS on the first passage and 14 cases of post-reappearance gaze shifts. When the duration
of occlusion decreased between the conditions there were 13 cases of PRGS and 15 cases of
post-reappearance ones on the first passage. Thus, altogether there were 27 cases in
accordance with the carry-over hypothesis and 27 against that hypothesis. On the average,
gaze arrive 0.22 s after object reappearance at the first passage after occlusion was made
longer and 0.21 s after object reappearance on the first passage after occlusion was made
shorter.
The visual salience and the cognitive hypotheses: The effects of occluder width and
oscillation frequency on PRGS are related to both of these hypotheses. The PRGS were not
determined by the time of disappearance but rather on the time of reappearance of the
occluded object. This can be seen in Figure 4. The correlation between individual mean
latencies for the different conditions and occlusion duration was 0.658 (p<0.001, n=62). The
effects of Occluder Width and Oscillation Frequency were tested in two separate general
linear model repeated measurements ANOVAs. Due to the design of the experiment, each
variable was tested for the middle condition of the other variable. We tested the effect of
Occluder Width on the timing of PRGS for the middle Oscillation Frequency (21°/s). It was
found that the effect of Occluder Width was statistically significant (F(2,18) = 13.68, p<0.01,
η2 = 0.60). The effect of Oscillation Frequency was tested for the middle Occluder Width
(16°). It was found that the effect of Oscillation Frequency was statistically significant
(F(2,18) = 5.539, p<0.02, η2 = 0.38).
The reactive saccades: To decide whether visual salience of a stimulus presented at the exiting
occluder edge affected the saccade latency to it, a general linear model repeated
measurements ANOVA based on the mean individual latencies of post reappearance saccades

20
for the different Occluder Widths was performed. Only the middle velocity (21°/s) was
included in this analysis. It indicated that the eccentricity in the visual field of the exiting
occluder edge had no systematic effect on the latency of these saccades (F(1,9) <1.0). A
similar analysis of the effect of velocity for the middle Occluder Width (16°) gave similar
non-significant results (F(1,9)<1.0).
Discussion
The results of Experiment 1 suggested that neither passage-of-time, nor visual salience
of the opposite occluder edge, or memory of the previous occlusion duration determine
PRGS. The infants did not show a greater tendency to shift gaze over the occluder before the
object reappeared when the occlusion duration was longer. Two kinds of evidence weakened
the hypothesis that visual salience of the exiting occluder edge determines the timing of the
PRGS. First, it was found that Oscillation Frequency (i.e. Object Velocity) had a significant
effect on the timing of PRGS and this effect cannot be derived from visual salience. In
addition, the reappearance position in the peripheral visual field of the salient moving object
did not have a significant effect on the timing of the post reappearance saccades. Memory of
the previous occlusion neither affected the number of PRGS on the first occlusion in the next
trial nor the latency of the saccades to the exiting side of the occluder. In summary, the results
of Experiment 1 suggest that the PRGS were determined by the combination of Occluder
Width and Object Velocity, i.e. by the Occlusion Duration.
The factorial design of Experiment 1 was incomplete. It was judged that the young
infants would not be able to keep optimal attention for more than 7 trials. The results,
however, proved that failing attention was not a problem with the present experimental setting
and design. Therefore a complete factorial design was used in Experiment 2.
Experiment 2

21
The purpose of Experiment 2 was to expand the range of occlusion durations to confirm
the relationships found in Experiment 1 (see Figure 4) and expand them to include faster and
slower motions and thus shorter and longer durations. This was made possible by
manipulating motion amplitude in addition to oscillation frequency and occluder width. By
varying amplitude, object velocity and oscillation frequency could also be disentangled.
Furthermore, it is possible that subjects need to view a moving object for a certain distance
and/or time in order to form stable representations that would last over the temporary
occlusion. Sekuler, Sekuler, & Sekuler (1990) measured response times (RTs) to changes in
target motion direction following initial trajectories of varying time and distance. When the
initial trajectories were at least 500 ms, the directional uncertainty ceased to affect RTs.
Infants may require more time. Two amplitudes were used in Experiment 2. The larger was
the same as in Experiment 1 and the smaller was 50% of it. It should be added that the object
was never fully visible when the smaller amplitude was used in combination with the larger
occluder.
Method
Experiment 2 included 6 girls and 7 boys ranging in age from 17:1 to 20:3 weeks, with a
mean age of 18:6 weeks. Altogether 8 stimuli were shown to each subject in a factorial design
with Occluder Width, Oscillation Frequency, and Motion Amplitude as factors. Occluder Width
was either 8.2 or 14 cm, corresponding to 11.6° and 20° of visual angle at 45 cm viewing
distance. Oscillation Frequency was 0.15 or 0.30 Hz. Motion Amplitude was 24° or 12.8° at
45 cm viewing distance. Both the oscillation frequency and the motion amplitude were
adjusted manually on a function generator before each trial and occlusion durations could
therefore deviate somewhat at a given condition for the different subjects (+12%). At the
higher amplitude, the velocities were 15 and 30°/s and at the lower amplitude they were 8 and
16°/s on the average.

22
Results
Three boys and one girl provided data in less than 6 of the 8 conditions and were
therefore excluded from the data analysis. The data from the remaining 9 subjects (5 girls and
4 boys) were analyzed. Three of the 72 individual trials of these subjects were excluded
because of fussing or inattention. On the remaining occluder passages, infants attended to the
object both before and after the occlusion in 559 cases (77%), while in 167 cases they were
distracted and looked away. There were 287 gaze shifts over the occluder that arrived more
than 0.2 s after the object had started to reappear.
There were 280 cases of PRGS (50%). In 249 of these passages (89%) the gaze stopped
at the occluder until a saccadic shift was made over to the other side. In the 31 remaining
cases (11%) the subject made a gaze shift over to the other side of the occluder just after the
object disappeared and then returned to the original edge where gaze stayed until making a
final shift over the occluder. In these cases, the second shift was analyzed. Table 2 shows the
average occlusion duration, number of presented occluder passages, number of passages
analyzed, number and percentage of PRGS and mean latency of these gaze shifts for the
different conditions in Experiment 2.
------------------------ Insert Table 2 about here ----------------------
Determinants of gaze shifts over the occluder.
The passage-of time hypothesis was not supported by Experiment 2 (see Table 2). There
was no significant correlation between occlusion duration and proportion of PRGS (r = 0.116,
n = 69, p=0.34). The proportion of PRGS was not greater for the shorter occlusions than for
the longer ones. The visual salience hypothesis stating that the timing of PRGS is determined
by Occluder Width was further weakened. Strong effects of Oscillation Frequency and
Motion Amplitude on the timing of PRGS were obtained. Furthermore, it was shown that
there was an effect of visual salience of the reappearing moving object on the saccadic

23
reaction time to it, but that this effect was small compared to the effect of occluder width on
PRGS. The memory hypothesis stating that PRGS is determined by the memory of the
previous occlusion duration did not receive any support by the results of Experiment 2. The
proportion of PRGS at the first occlusion when its duration was increased was not greater
than when it was decreased and the timing relative to object reappearance was unaffected.
Finally, the cognitive hypothesis was strengthened. It was found that the timing of the PRGS
was strongly determined by the time of reappearance of the object. Figure 5 shows the
relationship between PRGS and occlusion duration for individual subjects. The correlation
between individual mean latencies for the different conditions and occlusion duration was
very high (r = 0.902 p<0.0001, n = 66). The analysis of the relative timing of PRGS
(independent of occlusion duration) showed that subjects shifted gaze to the exiting side after,
on the average, after 89% of the occlusion interval. The analysis of the relative timing also
showed that PRGS were elicited relatively earlier for the longer than for the shorter
occlusions (r = -0.35, p<0.01, n = 66). The statistical analyses of these effects are further
elaborated below.
The passage-of-time hypothesis: A general linear model repeated measurements ANOVA
showed that there were no main effects of either Occluder Width, Oscillation Frequency, or
Motion Amplitude (all F:s<1.0). At the high and low frequency, the proportion PRGS was
0.48 and 0.53, respectively. At the high and low amplitude the proportion PRGS was 0.50 and
0.51, respectively. Finally, for the narrow and wide occluder the proportion PRGS was 0.49
and 0.53, respectively. The same analysis showed that there were no interactions except for
the one between Oscillation Frequency and Motion Amplitude (F(1,8)=8.01, p<0.05, η2 =
0.50). At the lower frequency, there was a greater average proportion of PRGS for the higher
(0.55) than for the lower amplitude (0.51). At the higher frequency, there was a greater
proportion of PRGS for the lower (0.54) than for the higher amplitude (0.42).

24
-----------------Insert Figure 5 about here------------------
The memory hypothesis: The results of Experiment 2 did not support the memory hypothesis.
Gaze did not arrive at the exiting side of the occluder systematically later when the duration
was made shorter and systematically earlier when it was made longer. When the duration of
occlusion increased between conditions there were 18 PRGS on the first passage and 16 post-
reappearance gaze shifts. When the duration of occlusion decreased between the conditions
there were 13 PRGS and 14 cases of post-reappearance ones on the first passage. Thus,
altogether there were 32 cases in accordance with the carry-over hypothesis and 29 against it.
On the average, gaze arrive 0.21 s after object reappearance when occlusion was made longer
and 0.20 s after object reappearance when occlusion was made shorter. This difference was
not statistically significant (p=0.9).
The visual salience and the cognitive hypotheses are both addressed by the analyses of
absolute and relative latency of the PGRS. Because the proportions of PRGS for the different
conditions were not significantly different, it was possible to compare their timing (with the
exception for the interaction between Oscillation Frequency and Motion Amplitude). A
general linear model repeated measurements ANOVA was performed on the PRGS latencies.
Significant effects were obtained of Occluder Width (F(1,8) = 120.2, p < 0.0001, η2 = 0.94),
Motion Amplitude (F(1,8)=87.35, p<0.0001, η2 = 0.92), and Oscillation Frequency (F(1,8) =
15.20, p<0.005, η2 = 0.66). The average latency of PRGS for the narrow and wide occluder
was 0.33 s and 0.79 respectively. Corresponding figures for the high and low frequency was
0.46 and 0.66, and for the high and low amplitude 0.39 and 0.73. There was a significant
interaction between Occluder Width and Oscillation Frequency (F(1,8) = 16.35, p < 0.005, η2
= 0.67). While the latency of the PRGS for the wider occluder decreased with oscillation
frequency, this was not the case for the narrow occluder. There also an interaction between

25
Motion Amplitude and Occluder Width (F(1,6) = 28.28, p <0.001, η2 = 0.78). The effect of
amplitude was greater for the wide than for the narrow occluder. Finally, there was an
interaction between Oscillation Frequency and Motion Amplitude (F(1,6) = 9.483, p <0.02, η2
= 0.54). The effect of Oscillation Frequency was smaller for the large amplitude than for the
small one.
To determine how the PRGS were distributed within the occlusion interval, their relative
timing was analyzed by dividing PRGS with occlusion duration. This set of analyses show the
relative distribution of PRGS independent of occlusion duration. If the PRGS were
completely determined by the reappearance time of the object, the relative latencies would be
the same independently of the condition. This was not the case. A general linear model
repeated measurements ANOVA tested these relative latencies. Significant effects were
obtained of Occluder Width (F(1,8) = 9.296, p < 0.02, η2 = 0.54) and Oscillation Frequency
(F(1,8) = 29.07, p<0.001, η2 = 0.78), but not for motion amplitude. On the average, gaze
arrived at the reappearance side of the occluder after 0.96 of the occlusion duration for the
narrow and at 0.83 for the wider occluder. Corresponding figures were 0.72 for the lower
frequency and 1.06 for the higher one. An interaction was obtained between Occluder Width
and Oscillation Frequency (F(1,8) = 9.779, p < 0.02, η2 = 0.55). For the low frequency, the
relative latency of PRGS was the similar for the wide and the narrow occluder, but for the
high frequency, the relative latency was larger for the narrow occluder than for the wide one.
This is depicted in Figure 6. There was also an interaction between Occluder Width and
Motion Amplitude (F(1,8) = 5.791, p <0.05, η2 = 0.42). For the small amplitude, the relative
latency of PRGS was the same for both the wide and the narrow occluder 0.85, but for the
large amplitude the relative latency was larger for the narrow (1.06) than for the wide
occluder (0.80. Another way to describe these interactions is to say that the shortest occlusion
durations produced relatively longer relative latencies.

26
--------------------- Insert Figure 6 about here ------------------------
The reactive saccades: A general linear model repeated measurements ANOVA was
performed on the reactive saccades (latencies 0.2 s longer than the occlusion duration).
Significant effects were only obtained of Occluder Width (F(1,8) = 11.46, p<0.01, η2 = 0.56).
The average reaction time for the narrow occluder was 0.45 s and for the wider one 0.54 s.
The difference in reaction time for the narrow and wide occluder was much smaller than the
difference in PRGS for the same occluders (F(1,8)=71.72, p<0.0001, η2 = 0.90).
General Discussion
When 4-month-old infants visually track an object that moves behind an occluder, they
tend to shift gaze to the reappearing side ahead of the object. The present experiments asked
whether the PRGS reflect an ability to preserve information about the moving object while it
is hidden or if they are just an expression of low-level visual processing or a randomly
determined process. The PRGS cannot just be a continuation of the pre-occlusion visual
tracking, because the smooth pursuit used to track a visible object and the saccades used to
reconnect to the object on the other side of the occluder are radically different modes of eye
movements (see e.g. Lisberger, Morris, & Tyschen, 1987; Leigh, R. J., & Zee, D.S., 1999).
None of the infants pursued the object smoothly over the occluder. They all used saccades to
shift gaze to the other side.
The determinants of PRGS
The passage-of-time hypothesis: The PRGS could not be explained in terms of passage-of
time. The subjects’ gaze did not just linger at the disappearing edge after the object
disappeared and then, after a random time interval, turn to the next thing along the path – the
reappearing edge. If this had been the case, proportionally more saccades would end up on the
other side of the occluder within the occlusion interval for the longer occlusions. On the
contrary, the proportion of PRGS showed no such relationship with occlusion duration in

27
either Experiment 1 or 2. Furthermore, there was no indication in that either Occluder Width
and Oscillation Frequency or Occluder Width and Motion Amplitude had opposite effects that
counteracted each other.
Visual salience hypothesis: What is the likelihood that Occluder Width has an effect on
“predictive saccades” purely because of the visual salience of the exiting occluder edge and
not because a wider occluder implies a longer occlusion? This is not easily tested because
both hypotheses have the same implications on the latency of saccades over the occluder but
for different reasons. The most important precaution to ensure that salience does not
determine saccade latency is to make the occluder as non-salient as possible. In the reported
experiments this was done by matching the white color of the occluder to the white
background (the inside of the cylinder). Thus, although it can be argued that the exiting
occluder edge is visible, it was not salient.
One argument against the visual salience hypothesis comes from the reactive saccades.
They are by definition elicited by the detection of the reappearing object in the periphery of
the visual field. The results indicate that the latency of those saccades is influenced by the
eccentricity in the visual field of the reappearing stimulus. It can thus be argued that although
efforts were made to make the occluder edges as non-salient as possible, the visibility of the
exiting occluder edge could have influenced the effects of Occluder Width on PRGS.
However, the difference in reactive saccade latency for the two occluders in Experiment 2
was small (0.45 s for the narrow and 0.54 for the wide) in comparison to the difference in the
latency of the PRGS (0.33 s for the narrow and 0.79 for the wide occluder). It is therefore
unlikely that visual salience of the exiting occluder edge is the only determinant of the
difference in saccade latency for the different occluder widths. One can, of course, argue that
a non-salient stimulus in the periphery of the visual field like the occluder edge will take
longer to detect than a salient one like the reappearing object. However, the results show that

28
the latency of PRGS for the narrow occluder is shorter than the reaction time to the salient
reappearing object in the same condition.
A second argument against the visual salience hypothesis comes from the relative
latencies of PRGS. They showed that gaze arrived proportionally later in the occlusion
interval for the narrow occluder than for the wide occluder. This is contrary to what would be
expected from the visual salience hypothesis. Visual salience of the occluder may also have a
different effect on tracking over occlusion. Muller and Aslin (1978) found that a salient
occluder made infants interrupt tracking and look at the occluder instead.
Finally and most importantly, visual salience could not be the only determinant of
PRGS. The effects of oscillation frequency and motion amplitude were found to be just as
important. Motion amplitude and oscillation frequency refer to variables that are not visually
present during occlusion and therefore it is inevitable that some information from the seen
pre-occlusion motion is preserved during occlusion.
The memory hypothesis: Neither of the two experiments supported the hypothesis that infants
remembered the duration of the previous occlusion and expected the object to be absent for
the same period at the next occlusion. The saccade latency at the first passages of a new
condition was not influenced in a systematic way by the last occlusion of the previous
condition with a different duration.
The cognitive hypothesis: This hypothesis states that the subjects moderate their PRGS from
information that is not visually present during the occlusion. The cognitive hypothesis was
strongly supported by the results. There was not a single stimulus variable like Occluder
Width, Oscillation Frequency, or Motion Amplitude that determined the latency of the PRGS.
On the contrary, the timing of the PRGS was determined by a combination of these variables
that resulted in a rather close fit between the latency of PRGS and occlusion duration.
Occlusion duration could be obtained by dividing occluder width with object velocity but it

29
seems more parsimonious to assume that the infants maintained a representation of the object
motion while the object was occluded and shifted gaze to the other side of the occluder when
the conceived object was about to arrive there. Thus, instead of tracking the moving object
visually, the infants could track it in their “minds eye”. If object velocity is represented in this
way while the object is occluded, the effects of Occluder Width, Oscillation Frequency, as
well as Motion Amplitude could all be explained. However, this representation might not
have anything to do with the notion of a permanent object that exists over time or with
infants’ conscious experience of where the occluded object is at a specific time behind the
occluder. Object velocity may rather be represented by some kind of buffer during visible as
well as non-visible parts of the motion. This would also explain why the timing of PRGS
could be so good, irrespective of whether the occlusion duration was 0.2 or 1.6 s. In support
of this hypothesis are the findings that object velocity is represented in the frontal eye field
(FEF) of rhesus monkeys during the occlusion of a moving object (Barborica & Ferrera,
2003). 4-month-old infants might represent object motion during occlusion in a similar way.
The critical stimulus variable for preserving a representation of object motion over occlusion
could be accretion-deletion of the seen object at the occluder edges as suggested by Kaufman,
Csibra & Johnson, (2005). If this is the case, the accretion and deletion used in the present
experiments was never too rapid or too slow to be perceived by the infants. The most rapid
accretion-deletion had duration of 0.23 s and the slowest one a duration of 0.87 s in the
present experiments. The results also suggest that such a representation is by no means
perfect. There was a clear tendency to overestimate the duration of short occlusions and
underestimate the duration of long ones.
Other issues
The reactive gaze shifts : The subjects failed to predict the reappearance of the object on
about half the occlusions. On some of those passages the subjects might have expected the

30
object to reappear at a later time. However, the fact that the proportions of reactive gaze shifts
were not systematically greater for the short occlusions than for the long ones argues against
this suggestion. On the average, the reactive gaze shifts arrived almost half a second after
reappearance of the object. This is in accordance with other reaction time studies on infants
(Aslin & Salapatek, 1975; Canfield, Smith, Brezsnyak, and Snow, 1997; Gredebäck, Örnkloo
& von Hofsten, 2006).
Motion amplitude: The low motion amplitude in Experiment 2 did not result in impaired
timing of the PRGS. It should be noted that in the conditions with low amplitude, the object
was only visible for 50% of the total viewing time, corresponding to about 0.8 and 1.6 s
exposure on each side of the occluder. In the small amplitude and large occluder condition the
object was never fully visible. The results suggest that infants do not require much more
prolonged exposure of the moving object to anticipate its reappearance than adults do
(compare Sekuler et al., 1990).
Effects of earlier exposure to visual motion: Johnson et al. (2003) reported that such
experience was of critical importance for 4-month-old infants’ ability to predict the
reappearance of an occluded object. In the present study, the subjects had only initial
experience with the stimulus at the calibration procedure. Then the object was rapidly
transferred between the extreme positions of the trajectory and the center of it. If this in any
way primed the infants, it would be to expect the object to stop at the middle of the trajectory,
i.e. behind the occluder like it did at the calibration. Thus, it is unlikely that presentation of
un-occluded motion before a set of occlusion trials is necessary for eliciting PRGS in 4-
month-old infants.
Attention effects: Comparing the present results with that of Johnson et al. (2003) strongly
suggests that their experimental situation was more distracting than the present one. First, the
proportion of passages included and the proportion predictive gaze shifts over the occluder

31
were much lower in their study. The proportion of ‘predictive’ gaze shifts in their baseline
condition was 29% compared to 47% in Experiment 1 and 50% in Experiment 2 of the
present study. The obtained proportions are comparable to that found for older infants.
Gredebäck, von Hofsten & Boudreau (2002) found that 9-month-olds tracked predictively
over occlusion in 52% of the trials. Secondly, the number of predictive gaze shifts over the
occluder decreased substantially over the experiment in Johnson et al. (2003). Such a
deterioration of performance is a clear sign of distraction and it was not observed in the
present study. At the transition age to predictive tracking over occlusion, it is expected that
the expression of the ability is crucially dependent on the experimental setting. The present
procedure of placing the infant in a sheltered environment apparently provided more optimal
conditions for attentive tracking than in Johnson et al. (2003). Another difference that might
have an effect on attention is the fact the Johnson et al. (2003) used 2D images while the
present study used real objects.
Future research: The next sets of questions that need to be answered concern the role of
learning and neural maturation in the development of these abilities. While experience, no
doubt, plays an important role in the development of predictive tracking over occlusion, it is
also important to investigate the importance of the maturation of specific neural structures
associated with this ability. In adults, the representation of occluded objects involves several
specific parts of the cerebral cortex. These areas include the frontal eye field (Barborica &
Ferrera, 2003) the temporal area (Baker, Keyser, Jellema, Wicker & Perrett, 2001, ) and
especially the middle temporal region (MT/MST) (Olson, Gatenby, Leung, Skudlarski, &
Gore, 2004), the intraparietal sulcus (IPS) (Assad & Maunsell, 1995) and the lateral
intraparietal area (LIP) (Tian & Lynch, 1996). When and how do the different parts of this
network become engaged in the neural processing of occlusion? Kaufman et al. (2003, 2005)

32
have led the way by showing that the temporal areas of 6-month-old infants are activated
when they view object occlusion.
Conclusions
When 4-month-old infants track an object over occlusion and shift gaze to the exiting
side of the occluder ahead of time, the latency of these gaze shifts is primarily determined by
the duration of occlusion. It may be argued that because PRGS is never longer than the
occlusion interval ( plus 0.2 s), they are inevitably related to it. There are several arguments
against such a conclusion. The first has to do with the proportions of PRGS in the different
conditions. If the tendency to shift gaze ahead of time to the exiting side of the occluder was
independent of occlusion duration, there would have been much more PRGS for the long
occlusions than for the short ones. The results show that the proportions of PRGS were
similar over a range of occlusion duration from 0.2 to 1.6 s. It is, of course, possible that all
PRGS have shorter latencies than the shortest occlusion interval. Then the proportions would
be independent of occlusion duration. The results show that this was not the case. On the
contrary, the PRGS arrived close to the reappearance time independently of occlusion
duration (r = 0.902). This tendency could not be explained by the visual salience of the exiting
occluder edge. In addition, Oscillation Frequency and Motion Amplitude were equally
important determinants of PRGS latency. Neither could it be explained in terms of a memory
for the previous occluder duration. This suggests that object velocity is represented during
occlusion and that the infants track the object behind the occluder in their “minds eye”. This
brings continuity to events in a world where vision of moving objects is frequently obstructed
by other objects. Seeing the object for an extended distance before each occlusion did not
make these gaze shifts more precisely timed.
When does such intelligent behaviour appear in development? Rosander & von Hofsten
(2004) found that smooth pursuit gain and the timing of saccades when tracking a temporary

33
occluded object were highly correlated (r = 0.85). Thus the developmental onset of predictive
smooth pursuit and predictive saccadic tracking might both be related to the onset of ability to
represent occluded motion. Rosander & von Hofsten (2002) found that by 12 weeks of age
both modes of tracking are predictive. The present results show that it takes at least another
month before these predictive abilities manifest themselves in the launching of predictive
saccades over occlusion.
Finally, the present results demonstrate the advantages of using parametric studies in
infant research. A design with only one occlusion condition could not have determined
whether the pre-reappearance saccades over the occluder were predictive or not. Neither could
a design where only occluder width is manipulated. To answer the questions posed, both
occluder width and object velocity had to be manipulated.

34
Acknowledgement: We like to thank the enthusiastic parents and infants who made this
research possible. The research was supported by grants to CvH from from The Swedish
Research Council, the Tercentennial Fund of the Bank of Sweden, and EU integrated project
FP6-004370 (Robotcub).

35
References
Aguiar, A. & Baillargeon, R. (2002) Developments in young infants’ reasoning about
occluded objects. Cognitive Psychology, 45, 267-336.
Aslin, R. N. & Salapatek, P. (1975). Saccadic localization of visual targets by the very young
human infant. Perception and Pshychophysics, 17(3), 293-302.
Assad, J.A. & Maunsell, J.H.R. (1995) Neural correlates of inferred motion in primate
posterior parietal cortex. Nature, 373, 167-170.
Baillargeon, R. & Graber, M. (1987) Where’s the rabbit? 5.5-month-old infants’
representation of the height of a hidden object. Cognitive Development, 2, 375-392.
Baillargeon, R. & deVos, J. (1991) Object permanence in young infants: Further evidence.
Child Development, 62, 1227-1246.
Baker C.I., Keysers C., Jellema T., Wicker B., Perrett D.I. (2001) Neuronal representation of
disappearing and hidden objects in temporal cortex of the macaque. Experimental Brain
Research, 140, 375-81.
Barborica, A. & Ferrera, V.P. (2003) Estimating invisible target speed from neuronal activity
in monkey frontal eye field. Nature Neuroscience, 6, 66-74.
Canfield, R. L., & Haith, M. M. (1991). Young infants’ visual expectations for symmetric and
asymmetric stimulus sequences. Developmental Psychology, 27, 198–208.
Canfield, R. L., Smith, E. G., Brezsnyak, M. P., & Snow K. L. (1997) Information processing
through the first year of life: A longitudinal study using the visual expectation paradigm.
Monographs of the Society for Research in Child Development, No. 250, Vol. 62.
Davis, J.R., & Shackel, B. (1960) Changes in the electro-oculogram potential level. Brit. J.
Ophtalmology, 44, 606-614.
Engel, K. C., Anderson, J. H., & Soechting, J. F. (1999) Oculomotor tracking in two
dimensions. Journal of Neurophysiology, 81, 1597-1602.

36
Finocchio, D., Preston,K.L., & Fuchs,A.F. (1990) Obtaining a quantitative measure of eye
movements in human infants: A method of calibrating the electro-oculogram. Vision
Research, 30, 1119-1128.
Gredebäck, G., von Hofsten, C., & Boudreau, J. P. (2002) Infants' visual tracking of
continuous circular motion under conditions of occlusion and non-occlusion. Infant
Behavior and Development, 25, 161 - 182.
Gredebäck, G., Ornkloo,H., & von Hofsten, C. (in press) The development of reactive
saccade latencies. Experimental Brain Research.
Gredebäck, G., & von Hofsten, C. (2004) Infants' evolving representation of moving objects
between 6 and 12 months of age. Infancy, 6,165-184.
Haith, M. M. (1994). Visual expectation as the first step toward the development of future-
oriented processes. In M. M. Haith, J. B. Benson, R. J. Roberts, Jr., & B. Pennington
(Eds.), The development of future oriented processes. Chicago, IL: University of Chicago
Press.
Haith, M. M., Hazan, C., & Goodman, G. S. (1988). Expectation and anticipation of dynamic
visual events by 3.5-month-old babies. Child Development, 59, 467–479.
Johnson, S. P., Amos, D., & Slemmer, J. A. (2003) Development of object concepts in
infancy. Evidence for early learning in an eye tracking paradigm. Proceedings of the
National Academy of Sciences, 100, 10568-10573.
Juhola, M. (1987) On computer analysis of digital signals applied to eye movements. Report
A 48, University of Turku, Dep of Mathematical sciences, Computer Science, SF-20500
Turku, Finland
Kaufman, J., Csibra, G., & Johnson, M.H. (2003) Representing occluded objects in the human
infant brain. Proc. R. Soc. Lond. B (Suppl.), 270, 140-143.

37
Kaufman, J., Csibra, G., & Johnson, M.H. (2005) Oscillatory activity in the infant brain
reflects object maintenance. Proceedings of the National Academy of Sciences, 102,
15271-15274.
Kowler, E. (1990) The role of visual and cognitive processes in the control of eye movement.
In E. Kowler (Ed.) Eye movements and their role in visual and cognitive processes.
Reviews of Oculomotor Research, vol. 4. New york: Elsevier. Pp.1-63.
Leigh, R. J., & Zee, D.S. (1999). The neurology of eye movements (3rd ed). New York, NY:
Oxford University Press.
Lisberger, S.G., Morris, E.J., & Tyschen, L. (1987). Visual motion processing and sensory-
motor integration for smooth pursuit eye movements. Annual Review of Neuroscience,
10, 97-129.
Mareschal, D., Harris, P., & Plunkett, K. (1997) Effects of linear and angular velocity on 2-,
4-, and 6-month-olds' visual pursuit behaviours. Infant Behavior and Development, 20,
435-448.
Muller, A.A. and Aslin, R.N. (1978) Visual tracking as an index of the object concept. Infant
Behavior and Development, 1, 309 – 319.
Olson, I.R., Gatenby, J.C., Leung, H-C, Skudlarski, P., & Gore, J.C. (2004) Neuronal
representation of occluded objects in the human brain. Neuropsychologia, 42, 95-104.
Piaget, J. (1954). The construction of reality in the child. New York: Basic Books.
Rosander, K. and von Hofsten, C. (2000) Visual-vestibular interaction in early infancy.
Experimental Brain Research, 133, 321-333. .
Rosander, K. and von Hofsten, C. (2002) Development of gaze tracking of small and large
objects. Experimental Brain Research, 146, 257-264.
Rosander, R. and von Hofsten, C. (2004) Infants' emerging ability to represent object motion.
Cognition, 91, 1-22.

38
Scholl, B.J & Pylyshyn, Z.W. (1999) Tracking multiple items through occlusion: Clues to
visual objecthood. Cognitive Psychology, 38, 259-290.
Sekuler, A. B., Sekuler, R. & Sekuler, E.B. (1990) How the visual system detects change in
the direction of moving targets. Perception, 19, 181-195.
Tian, J.R. & Lynch, J.C. (1996) Corticocortical input to the smooth and saccadic eye
movement subregions of the frontal eye field in Cebus monkeys. Journal of
Neurophysiology, 76, 2754-2771.
van der Meer, A. L. H., van der Weel, F. & Lee, D.N. (1994) Prospective control in catching
by infants. Perception. 23, 287-302.
von Hofsten, C. and Rosander, K. (1996) The development of gaze control and predictive
tracking in young infants. Vision Research, 36, 81-96.
Von Hofsten, C. and Rosander, K. (1997) Development of smooth pursuit tracking in young
infants. Vision Research, 37, 1799-1810.
Westling, G. Wiring diagram of EOG amplifiers. Dep of Physiology, Umeå University,1992
Yudelis,C., & Hendrickson, A. (1986) A qualitative and quantitative analysis of the human
fovea during development. Vision Research 26 (6), 847-855.

39
Table 1. Average occlusion duration, number of presented occluder passages, number of passages analyzed, number of and percentage of pre-reappearance gaze shifts over the occluder, and mean latency of these gaze shifts for the different conditions in Experiment 1. Velocity Occluder width
15°/s
0.15Hz
21.4°/s
0.21Hz
30°/s
0.30Hz
11.6°
Occlusion duration (s) Passages Passages analyzed Pre-reappearance gaze shifts Proportion (%) Mean latency (s)
0.31 64 54 27 50
0.26
0.22 110 89 45
50.6 0.19
⎯
15.5°
Occlusion duration (s) Passages Passages analyzed Pre-reappearance gaze shifts Proportion (%) Mean latency (s)
0.57 72 55 30
54.6 0.41
0.39 85 67 42
62.7 0.29
0.28 128 115 50 43.5 0.26
20°
Occlusion duration (s) Passages Passages analyzed Pre-reappearance gaze shifts Proportion (%) Mean latency (s)
⎯
0.61 100 83 31
37.3 0.49
0.43 113 96 40
41.7 0.35

40
Table 2. Average duration of occlusion, number of presented occluder passages, number of passages analyzed, number and percentage of pre-reappearance gaze shifts over the occluder and mean latency of those gaze shifts for the different conditions in Experiment 2. 0.15 Hz 0.30 Hz
Occluder width
8°/s
small amp
15°/s
large amp
16°/s
small amp
30°/s
large amp
11.6°
Occlusion duration (s) Passages Passages analyzed Pre-reappearance gaze shifts Proportion (%) Mean latency (s)
0.64 64 49 24 49
0.35
0.35 65 60 35 58
0.25
0.34 112 88 55 63
0.36
0.20 126 117 50 43
0.27
20°
Occlusion duration (s) Passages Passages analyzed Pre-reappearance gaze shifts Proportion (%) Mean latency (s)
1.66 63 38 22 58
1.37
0.88 58 49 33 67
0.59
0.86 126 74 31 42
0.77
0.48 112 84 30 36
0.43

41
Figure captions Figure 1. The experimental situation. The inside of the cylinder and the occluders had
matched white colors. The borders of the slit in which the object moved were also white. The
slit was 60 cm long and had a movable object placed in it. Note the EOG preamplifier and the
reflective markers on the infant’s head and the reflective marker on the “happy-face “object.
The object holder visible through the slit in the picture was not visible from the infant’s point
of view.
Figure 2. Illustration of how the positions of the head (markers A,B,C) and object (marker D)
were calculated, referring to Figure 1 and equations 1 and 2.
Figure 3. An example of a trial from Experiment 1 showing gaze tracking plotted together
with the object motion. The outer horizontal lines in the figure signify the occluder
boundaries. As a centrally placed marker measured the position of the object, only half the
object was occluded when the marker passed the occluder boundaries. Therefore the inner
horizontal lines are needed to signify the position of the object marker when the object was
totally occluded. These are thus positioned half the object width inside the occluder. The
horizontal lines in between the inner and outer ones signify the 2° tolerance outside which
gaze was considered to have arrived to the other side of the occluder.
Figure 4. The relationship between occlusion duration and PRGS for individual subjects in
Experiment 1. In the figure the latencies for following adjacent occlusion durations are
averaged (0.28 and 0.31 s, 0.39 and 0.43 s, and 0.57 and 0.61 s) to make the individual curves
easier to distinguish. The dashed line shows the hypothetical relationship with saccade latency
equal to occlusion duration.
Figure 5. The relationship between occlusion duration and PRGS for individual subjects in
Experiment 2. In the figure the latencies for the following adjacent occlusion durations are
averaged (0.34 and 0.35 s, 0.48 and 0.64 s, and 0.86 and 0.88 s) to make the individual curves

42
easier to distinguish. The dashed line shows the hypothetical relationship with saccade latency
equal to occlusion duration.
Figure 6. The relative latency of PRGS for the combinations of occluder width and
oscillation frequency.

43
Figure 1.

44
Figure 2.

45
Figure 3.

46
Figure 4.
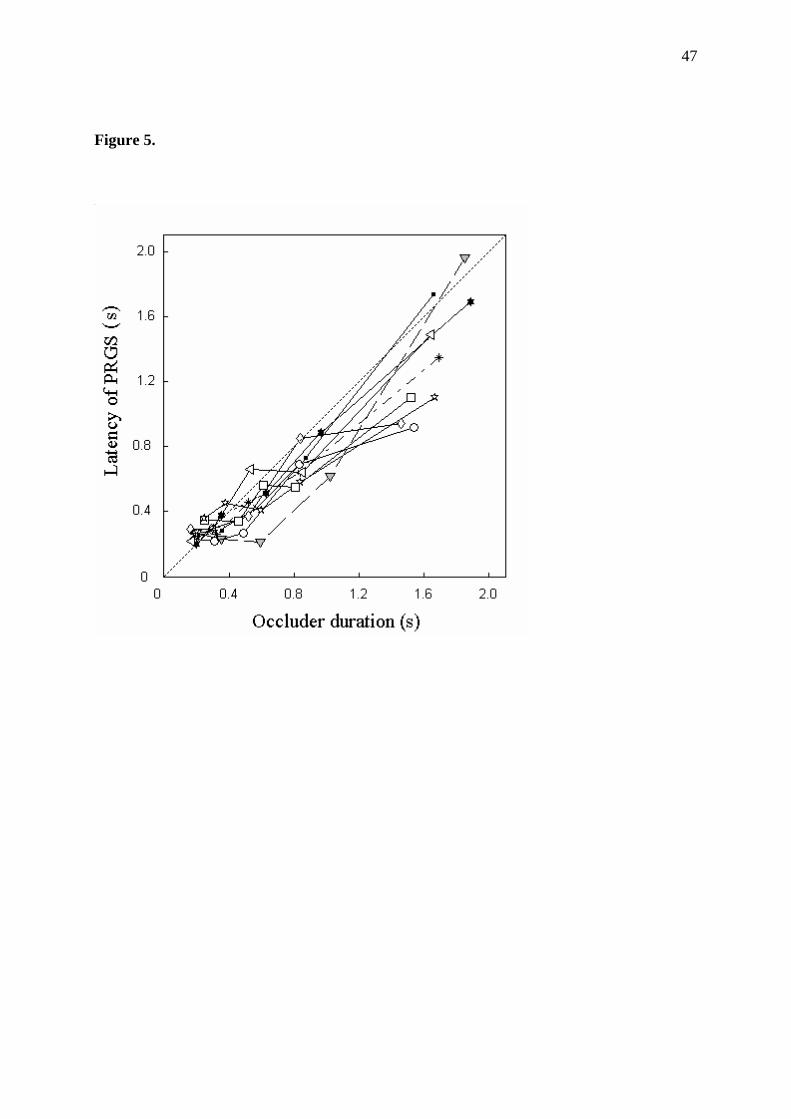
47
Figure 5.
48
Figure 6
Copyright © 2022 FDOKUMEN

