







Bahasa
Halaman
Hukum


Prosody,
Gesture
and Paralinguistics
Ewa Jarmołowicz-Nowikow, Katarzyna Klessa
Maciej Karpiński
Institute of Linguistics AMU

➔ Articulation: complex movements, some of them produce sounds, some don't
➔ There is a strong interaction between prosody and gesture, both in utterance production and perception
➔ Both prosody and gesture can bear „linguistic” and „paralinguistic” meaning
➔ Linguistic (or „linguistics-inspired”) methodology can be successfully applied to gesture analysis

➔ There are many culture-specific as well as culture-independent phenomena that play crucial roles in language-based communication while being itself placed behind language boundaries.
➔ Anyway, the boundaries of language seem to be imprecisely defined, vague, hazy – maybe we look for them in wrong dimensions?
➔ It is rather risky to analyse discourse without taking its multimodality, dynamics and context into account – and these are often found in the „paralinguistic” domain

SPEECH PROSODY
Katarzyna Klessa & Maciej Karpiński

Speech and Speech Perception

➔ Articulation (Articulatory Phonetics)
➔ Signal (Acoustic Phonetics)
➔ Perception (Psycholinguistics)
➔ 'Linguistic meaning' (Phonology)
Speech signal (acoustic signal)
What we can hear ('acoustically')
What we can hear ('linguistically')
Due to top-down, Competence-based processes

● In the perception of CV syllables, the vocalic segment can be perceptually available before the consonantal one (Remington 1977)
● The perceived duration of a segment may depend on the duration of silence that follows it (Nooteboom & Doodeman 1979)
● Phoneme restoration (Warren & Sherman 1974) (Listen to it on YouTube, e.g. http://www.youtube.com/watch?v=ZyvyGMkzNQc)

● Bi-modality: ● McGurk & MacDonald (find it on YouTube)
visual /ga/ + auditory /ba/ = (perceived as) /da/
● …and other cross-modal phenomena (e.g., speech – gesture interface)
● Talker voice effect (Nygaard, Sommers &Pisoni 1994) – some voice characteristics are long-term stored
● Sinewave speech and other priming- or top-down processing based phenomena
● Sinewave: http://www.lifesci.sussex.ac.uk/home/Chris_Darwin/SWS/
● A step towards art:
● http://www.youtube.com/watch?v=vLlYExpYnSw

What is Prosody?

(Sometimes) defined as the suprasegmental component of speech, i.e., the phenomena that can be traced only when the scope is wider than a single phonetic segment (phone)
Components:
● pitch (fundamental frequency)
● loudness (acoustic intensity)
● rhythm (phoneme and syllable duration)
NB Acoustic parameters (e.g., the values of pitch) do not totaly determine the percept (e.g., perceived melody of an utterance).

Functions of prosody:
● supports segmentation into linguistic units
● helps making some parts of utterances prominent
● may modify the lexical meaning
● may modify sentential category
● may modify discourse function
● conveys emotions and attitudes

Gets more noticeable when it gets disturbed…
Go go Kochanski/Shin web page on prosody to listen „robot speech”): http://kochanski.org/gpk/prosodies/section1/index.html
How „meaningful” it can be… Examples: (1) Emotionality (go to Berlin Emotional Speech Database to listen to some examples: http://pascal.kgw.tu-berlin.de/emodb/index-1280.html (2) Various realisations of Polish „tak” and „nie”

● Acoustics – measurements of „objective” acoustic parameters
● Phonetics/perception
● Phonology – taking into account linguistic competence (but also perception mechanisms that are under its influence, too)
● (Hirst, Di Cristo, Espesser, R. 2000; Jassem, 2002)

Duration and Rhythm

● Segmental duration as a phonological feature in some languages;
● Duration of higher level units as dependent on segmentals and suprasegmentals (e.g. models of timing in speech technology assume a wide range of factors potentially modifying segmental duration);
● Duration of segments as dependant on the higher level units (e.g. syllable, cf. N. Campbell, 1992).

● Speech rhythm as related to speech production (air pulses, cf. Abercrombie, 1967)
● Perception of rhythm (promincences) – confirmed but not obvious, e.g. sometimes irregular sequences are perceptually assessed as regular (Benguerel & D‘Arcy, 1986)
An open question:
● Acoustic correlates of rhythm? Are they easy to measure?

● Isochrony – a tendency to adjust duration as dependent on rhythm foot as a unit (distance between two stressed vowels, Jassem et al.., 1984)
● Stress-timed vs. syllable-timed languages (Roach, 1982)
● PVI Pairwise variability Index - duration differences between neighbouring vocalic/consonant intervals (Grabe & Low, 2002)
● Coupled syllable and stress oscillators model (Barbosa: duration compensation within a vowel-to-vowel unit)

Gibbon, 2003, Gibbon et al., 2013:
● The base unit of a rhythm is pattern (syllable or foot)
● Sequences of units are characterised by: alternation (e.g. long-short)
● iteration (base pattern must repeat with at least two occurrences)
● isochrony (units must display a tendency towards being (un)equal in length

● Segmental and suprasegmental properties may vary depending on speech tempo
● Segments tend to shorten in fast rates but not in the proportion for various sounds

● Objective (articulated / measurable) vs. Subjective (intended / perceived) tempo
● Long-term (realted to longer utterance, or characterising a speaker) vs. Short term tempo (local variations of tempo)
● Gross (including pauses etc.) vs. Net (excluding pauses)
● The base unit? – sound, syllable, word, phrase? The choice depends on application

● Material: read speech - 14 recordings realized in varied articulation rates
● Listeners: a group of students of the same faculty
● Task: to subjectively judge the overall, global speaking rate of the speakers (Gibbon et al. 2013)
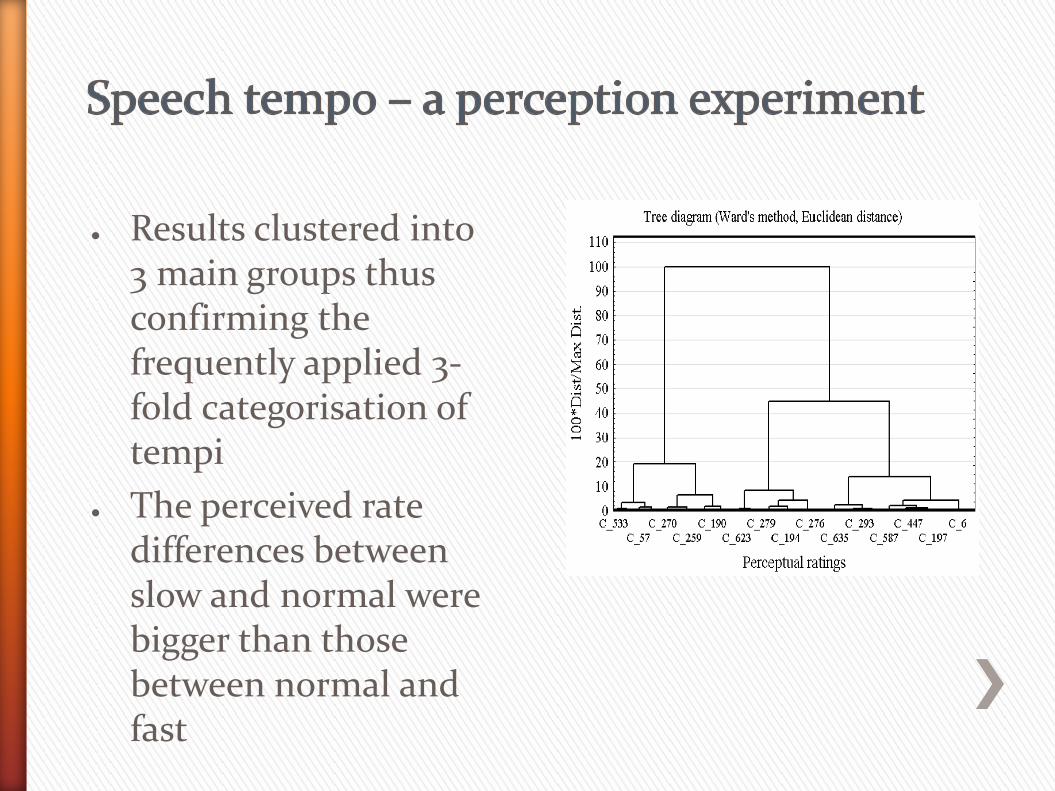
● Results clustered into 3 main groups thus confirming the frequently applied 3-fold categorisation of tempi
● The perceived rate differences between slow and normal were bigger than those between normal and fast

Pitch and Intonation

➔ fo frequency – the best correlate of pitch, but still far away from what we obtain as a percept
➔ perception of intonation – yes, but whose perception? Which top-down processes are involved and influence the final shape of the percept?
Praat

● Targets (e.g., maxima and minima)
● Directions (e.g., rise, fall)
● Shapes (e.g., steep rise and then slow rise)
● Boundaries/units (e.g., intonational phrases)
● Perception (native speakers? experts? naive labellers? What about listening conditions and signal presentation?)
● Visual inspection (based on intonograms etc.)
● (Semi-)Automatic analysis and labelling
● Combined methods (but what the results will tell us?)
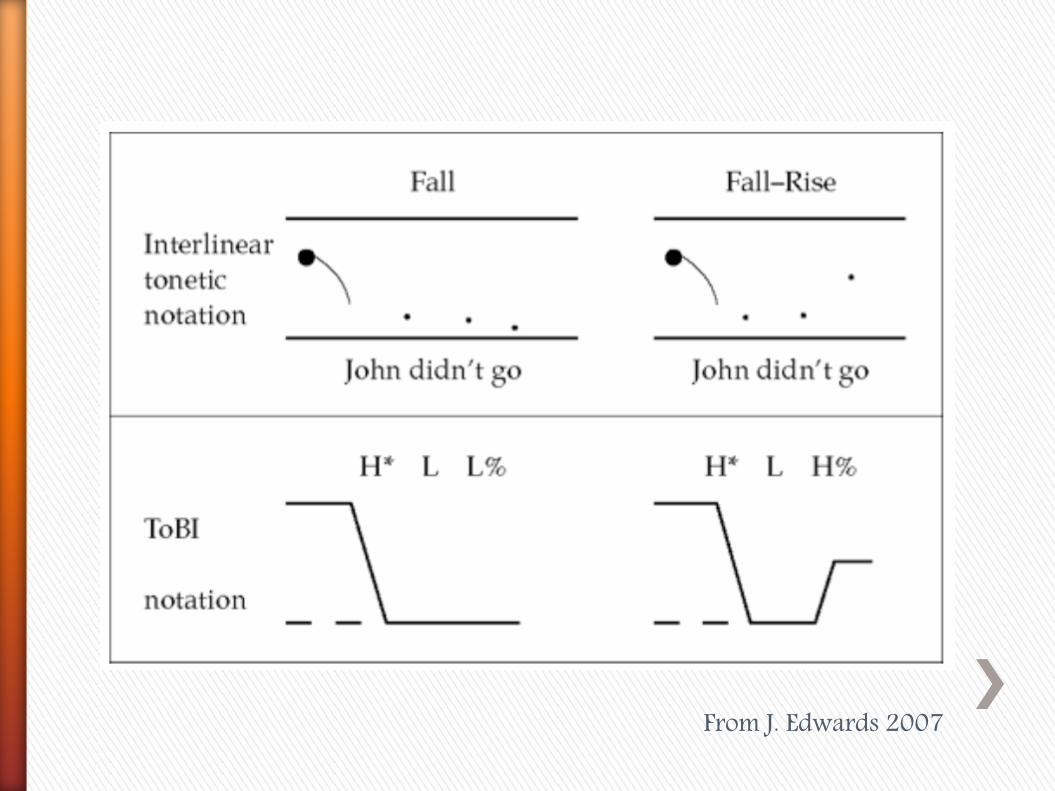
From J. Edwards 2007
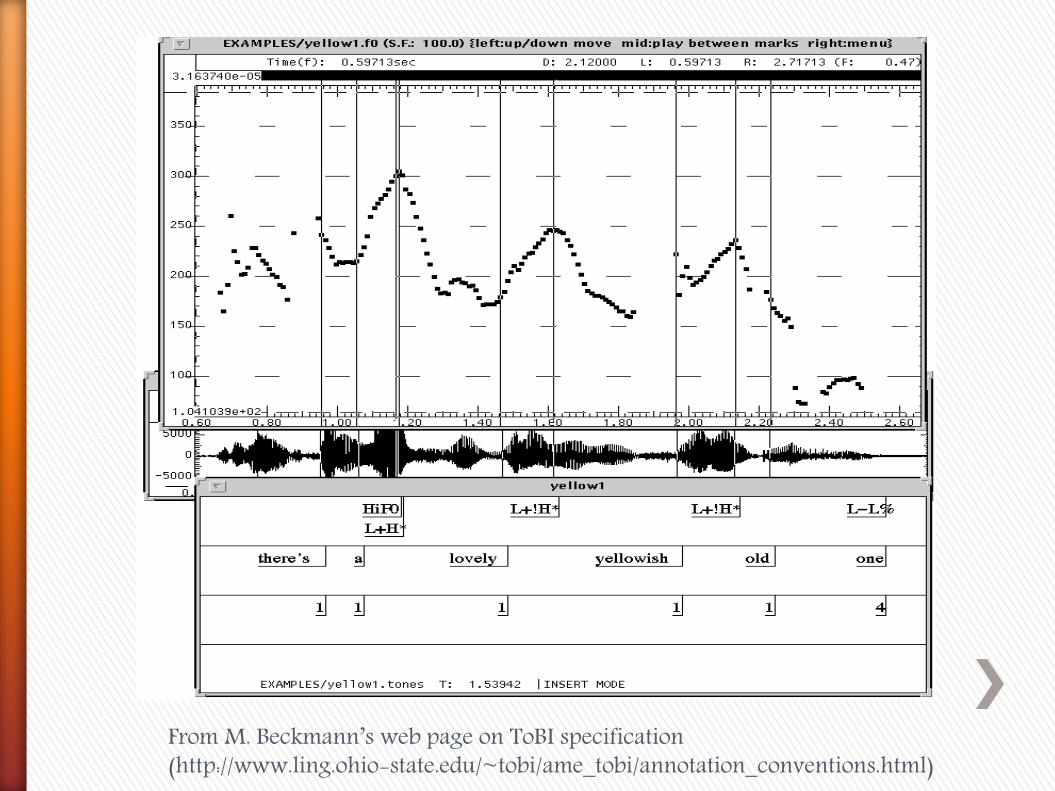
From M. Beckmann’s web page on ToBI specification (http://www.ling.ohio-state.edu/~tobi/ame_tobi/annotation_conventions.html)

From Baumann, Grice & Benzmueller’s specification of GToBI
GToBI Schematic Contour Context Example
Fall H*
L-%
Neutral statement Mein ZAHN tut WEH.1
My tooth hurts.
Neutral
W-question
Wo hast du den WAgen
gePARKT?1
Where did you park the car?
L+H*
L-%
Contrastive
assertion
Schon der VerSUCH ist
STRAFbar!2
Even to attempt is an offence!
Rise-Fall
(Late
Peak)
L*+H
L-%
Self-evident
assertion Das WEISS ich SCHON!
6
I already know that!
Emotionally
committed or
sarcastic assertion
Der Blick ist ja FAbelhaft!3
The view is fantastic!
Rise L*
H-^H%
Neutral yes/no-
question
Tauschen Sie auch
BRIEFMARken?1
Do you also exchange stamps?
Echo question Von wem ich das HAbe?2
From whom I have it?
L*
L-H%
Indignation
DOCH!
It is!
Answering phone BECkenBAUer?4
(L+)H*
H-^H%
Follow-up question
...oder ist Ihr BRUder HIER?5
...or is your brother in?
Level L+H*
H-(%)
Incompleteness ANdererSEITS...6
But then again...
Ritual expression Guten MORgen! 3
Good morning!
Fall-Rise H*
L-H%
Polite offer
Mögen Sie
ROGgenBRÖTchen?1
Would you like rye rolls?
Early
Peak
H+!H*
L-%
Established fact Hab’ ich mir schon geDACHT.7
That’s what I thought.
H+L*
L-%
Soothing / Polite
request Nun er ZÄHle doch MAL!
2
Just tell me about it!
Stylised
Step
Down
(L+)H*
!H-%
Calling contour
BECkenBAUer!

Automatic and Semi-automatic
Annotation of Prosody

Physical level – acoustic data, physiological measurement Phonetic level - at the phonetic level, the fundamental frequency curve is a sum of two components : ● a macroprosodic component - a smooth continuous curve
reflecting the intonation contour with which the utterance is spoken, can be modelled with a quadratic spline function)
● a microprosodic component consists of deviations from the smooth continuous macroprosodic curve reflecting the influence of the segmental content of the utterance.
Surface phonological level ● Phonology - phonetics boundary is the borderline between
continuously variable and discrete phenomena. ● surface phonological form - which is interfaced with phonetics Underlying phonological form ● the level which is interpreted as meaningful

At a surface phonological level can be represented as a sequence of tonal segments.
Tonal segments are of two types :
● interpreted GLOBALLY with reference to the speakers pitch-range:
● Top (T)
● Mid (M)
● Bottom (B)
● interpreted LOCALLY with reference to the preceding pitch-target.
● Higher (H) : a peak
● Lower (L): a trough
● Same (S): an F0 plateau
● Upstep (U): a raised plateau or a smaller peak than H
● Downstepped (D) : a lowered plateau or a smaller trough than L
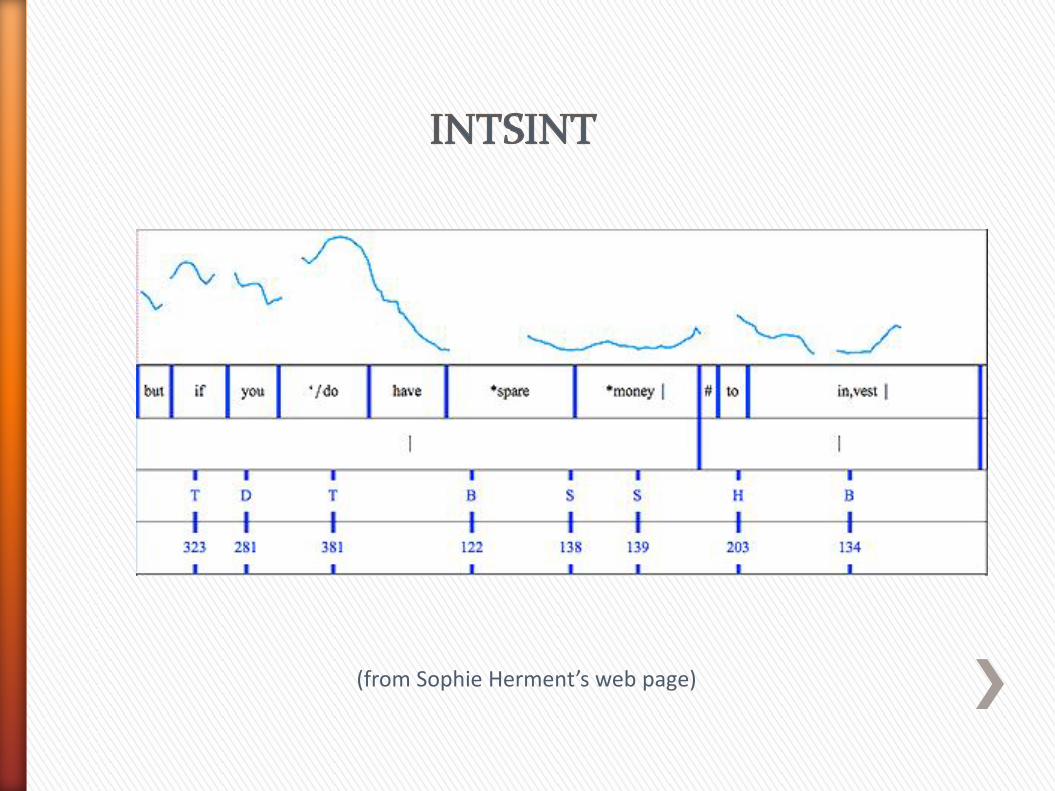
(from Sophie Herment’s web page)

The shape of the mental representation of intonation of a given stretch of speech depends on more factors than pitch frequency alone. Among them, there are the properties of human speech perception mechanisms.
Mertens proposes stylisation of pitch contours that takes into account some properties of pitch perception, especially reaction to:
- rapid and slow changes in pitch;
- changes in the way the pitch changes;
- energy f the speech signal.
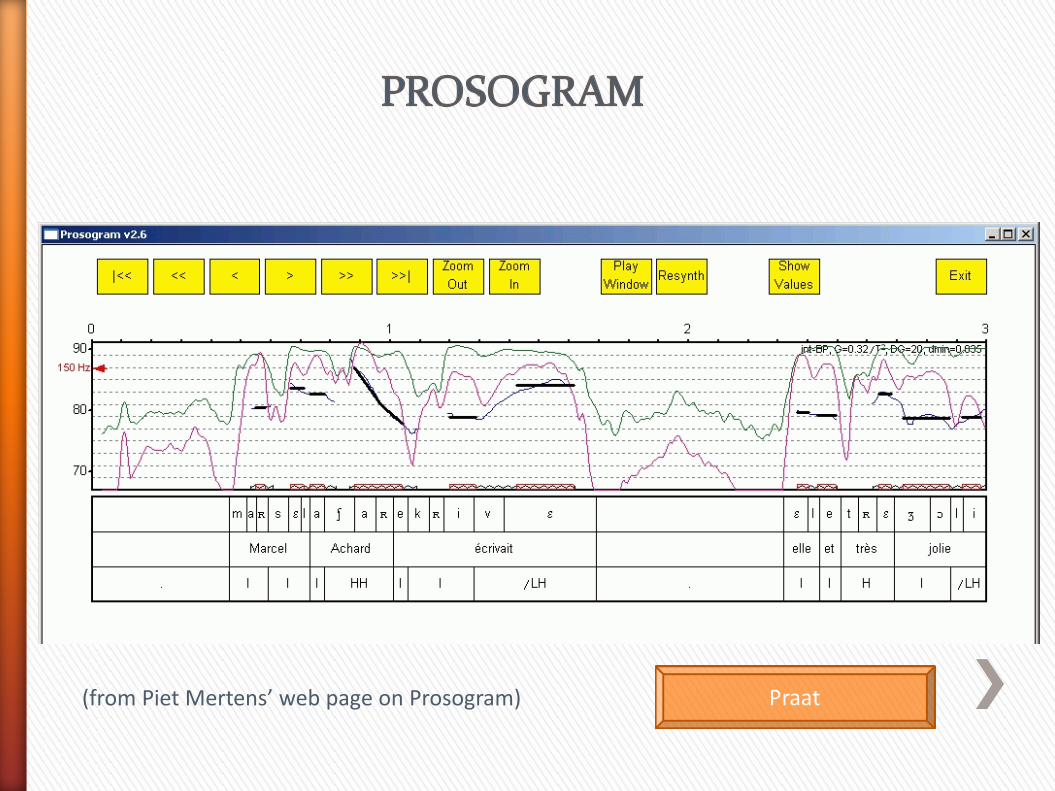
(from Piet Mertens’ web page on Prosogram)

Paralinguistic components of utterances

Gussenhoven (2002) says that “the linguistic component of intonation is characterised by arbitrariness, discreteness and duality”. Paralinguistic application of pitch is related to three „biological codes”.
It turns out that the boundaries between the linguistic and the non-linguistic remain hazily defined.

● We define paralinguistic features as all the components of utterances that are not included in the language system but somehow contribute to the meaning of these utterances, providing cues to its contextualised interpretation and by extending the characteristics of the speaker (Karpiński & Klessa)
Accordingly, we can list the following sets:
● features of “regular”, well-formed utterances (e.g., voice quality);
● Sequences of sounds not included in the „linguistic component” of well-formed utterances (e.g., filled pauses);
● Peculiar usage of linguistic units and structures that goes or doesn’t go behind the rules of a given natural language (e.g., multiple repetition);
● Behaviour of the speaker that accompanies the utterances somehow influences its interpretation (e.g., facial expression, body position, gesticulation).

DiaGest2 – a corpus of task-oriented dialogues is annotated also for the following units/phenomena:
● Filled pauses
● Quasi-lexical units (mhm, oh, ah, and others)
● Pronounciation problems
● Hands movement (gesticulation)
● Position of the body
● Head movements
● Gaze direction

Annotation specifications
● a range of specifications available for use or adaptation
● creating new specifications from scratch
● the choice of rating scales: categorial vs. continuous rating scales
The level of automatisation of annotation procedures:
● Strong need for automatisation esp. In technology (data sizes)
● only SOME can be currently automatised
● manual annotation as a prerequisite for further automatising: bottom-up approach, e.g. Annotation Pro’s continuous rating scales

Thank you
…and let's meet in the afternoon
to put our hands on it!
Top Related
Copyright © 2022 FDOKUMEN

