







Bahasa
Halaman
Hukum


OntoExtractor:A Fuzzy-Based Approach to Content and
Structure-Based Metadata Extraction
Paolo Ceravolo, Ernesto Damiani, Marcello Leida, and Marco Viviani
Universita degli studi di Milano,Dipartimento di Tecnologie dell’Informazione, via Bramante, 65
26013 Crema (CR), Italy{ceravolo, damiani, leida, viviani}@dti.unimi.it
http://ra.crema.unimi.it/kiwi
Abstract. This paper describes OntoExtractor a tool for extract-ing metadata from heterogeneous sources of information, producing a“quick-and-dirty” hierarchy of knowledge. This tool is specifically tai-lored for a quick classification of semi-structured data. By this feature,OntoExtractor is convenient for dealing with a web-based data source.
1 Introduction
Typically, knowledge management techniques use metadata in order to specifycontent, quality, type, creation, and context of a data item. A number of spe-cialized formats for the creation of metadata exist. A typical example is theResource Description Framework (RDF). But metadata can be stored in anyformat such as free text, Extensible Markup Language (XML), or database en-tries. All of these formats must relay on a vocabulary that can have differentdegree of formality. If this vocabulary is compliant to a set of logical axioms itis called an ontology.
There are a number of well-known advantages in using information extractedfrom data instead of data themselves. On one hand, because of their small sizecompared to the data they describe, metadata are more easily shareable thandata. Thanks to metadata sharing, information about data becomes readily avail-able to anyone seeking it. Thus, metadata make data discovery easier and reducesdata duplication. But on the other hand some important drawbacks are restrain-ing the diffusion of metadata format. First of all, building a knowledge-base isan onerous process. The domain analysis involves different activities often dif-ficult to integrate, because they are usually performed by different professionalroles. In addition, the high cost of knowledge-base building is in contradiction toimportant characteristics of knowledge management principles. Any knowledgemanagement activity need to be configured for a given domain. But every domainevolves and the knowledge-bases related to it have to evolve as well. If the do-main is evolving rapidly, a dis-alignment may result between the actual domain’s
R. Meersman, Z. Tari, P. Herrero et al. (Eds.): OTM Workshops 2006, LNCS 4278, pp. 1825–1834, 2006.c© Springer-Verlag Berlin Heidelberg 2006

1826 P. Ceravolo et al.
state of affairs and the knowledge-base. In addition, classical knowledge extrac-tion technologies are not tailored for web-based data. These techniques werelargely experimented with successful results. Anyhow they present some limita-tions. First, they need a high number of documents (typically, many thousands)to work properly. Secondly, they hardly take into account document structureand are therefore unsuitable for semi-structured document formats used on theWeb.
In this paper we present OntoExtractor a tool supporting knowledge ex-traction activities in a web-based environment. OntoExtractor was designed tobe inserted in a more general system aimed at managing the whole OntologyLife Cycle [5]. The classification produced as output is transformed in a stan-dard metadata format and proposed to a community of used. Feedbacks from thecommunity are collected in order to refine the classification, discarding metadataexpressing not relevant classes or misclassified documents [4]. In order to supportcontinuos domain evolutions, OntoExtractor is designed for quickly producing apreliminary classification of a knowledge base. This tool supports heterogeneoussource of information, including semi-strucutred data. A fuzzy representationof document vectors allows to segment documents according to their structuraltopology, assigning different relevance values to each segment. Another impor-tant feature of OntoExtractor is to produce different classifications organizingthe classes of documents according to different degree of cohesion. This featureallows the user to quickly discard a classification not coherent to his vision ofthe domain.
The paper is organized as follows: Section 2, introduces the tool, Section 3describes the format adopted for document representation, Section 4 explains thetechniques used in the structural classification of documents, Section 5 explainsthe techniques used in the content classification, while Section 6 goes to theconclusions.
2 OntoExtractor
OntoExtractor is a tool, developed in the context of the KIWI project 1,which extracts metadata from heterogeneous sources of information, producinga “quick-and-dirty” hierarchy of knowledge. The construction of the hierarchyoccurs in a bottom-up fashion: starting from the heterogeneous document set aclustering process groups documents in meaningful clusters. These clusters iden-tify the backbone hierarchy of the ontology. Construction of the hierarchy is athree-step process, composed of the following phases:
1. Normalize the incoming documents into XML format [9].2. Clustering the documents according to their structure using a Fuzzy Bag
representation of the XML tree [3] [6].
1 This work was partly funded by the Italian Ministry of Research Fund for BasicResearch (FIRB) under projects RBAU01CLNB 001 “Knowledge Managementfor the Web Infrastructure” (KIWI).

OntoExtractor: A Fuzzy-Based Approach to Content 1827
Fig. 1. Overview of the OntoExtractor process
3. Refine the structural clustering analyzing the content of the document, pro-ducing a semantic clustering of the documents.
3 Normalize the Knowledge Base
This first step in our process is choosing a common representation format for theinformation to be managed. Data may come from different and heterogeneoussources: including unstructured, semi-structured or structured information, suchas textual documents, HTML files, XML files or records in a database. In or-der to conciliate these different data sources we developed a set of wrapperapplications transforming most used document formats in a XML target rep-resentation. The wrapping process is shown in Figure 2: for semi-structuredand structured sources the wrapper does not have much to do. All it has toperform is applying a mapping between the original data and elements in thetarget XML tree. Unstructured sources of information need additional process-ing aimed to extracting the hidden structure of the documents. This phase useswell-known text-segmentation techniques [9] in order to find relations amongparts of a text. This is an iterative process that takes as input a text blob(which is a continuous flow of characters, representing the whole content of adocument) and gives as output a set of text-segments identified by the textsegmentation process. The process stops when no text blob can be segmentedfurther. At this point, a post-processing phase analyzes the resulting tree struc-ture and generates the corresponding XML document. In the current version ofthe OntoExtractor software, a Regular Expressions matching approach is alsoavailable in order to discover regular patterns like titles of sections in the docu-ments, helping controlling the text segmentation process. This is a preliminaryapproach that compares each row of the document with the regular expres-sion (i.e. [0 − 9] + (([.]?)|([.]?[0 − 9]+)) ∗ (\s + \w+)+ we used this expression tomatch chapter, sections and paragraph headlines, which are usually proceededby numbers separated by a ”.”).
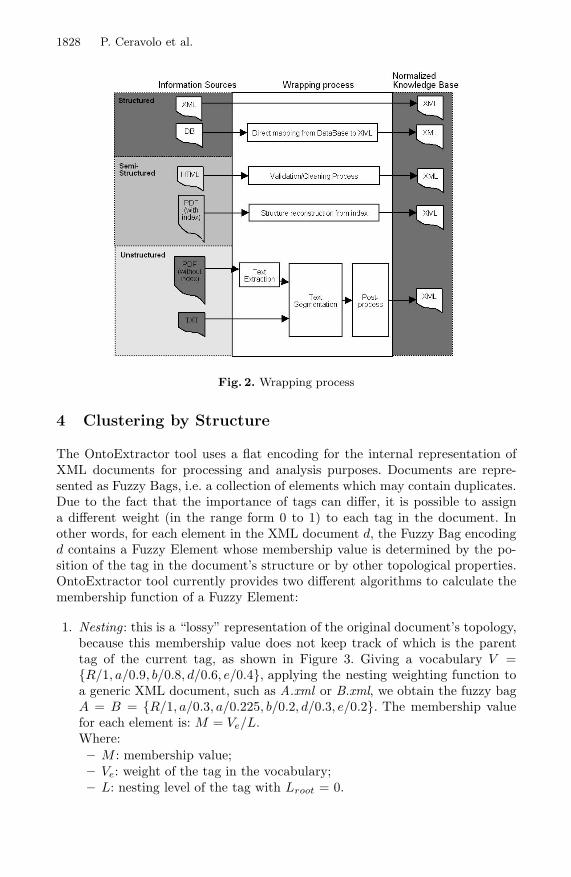
1828 P. Ceravolo et al.
Fig. 2. Wrapping process
4 Clustering by Structure
The OntoExtractor tool uses a flat encoding for the internal representation ofXML documents for processing and analysis purposes. Documents are repre-sented as Fuzzy Bags, i.e. a collection of elements which may contain duplicates.Due to the fact that the importance of tags can differ, it is possible to assigna different weight (in the range form 0 to 1) to each tag in the document. Inother words, for each element in the XML document d, the Fuzzy Bag encodingd contains a Fuzzy Element whose membership value is determined by the po-sition of the tag in the document’s structure or by other topological properties.OntoExtractor tool currently provides two different algorithms to calculate themembership function of a Fuzzy Element:
1. Nesting: this is a “lossy” representation of the original document’s topology,because this membership value does not keep track of which is the parenttag of the current tag, as shown in Figure 3. Giving a vocabulary V ={R/1, a/0.9, b/0.8, d/0.6, e/0.4}, applying the nesting weighting function toa generic XML document, such as A.xml or B.xml, we obtain the fuzzy bagA = B = {R/1, a/0.3, a/0.225, b/0.2, d/0.3, e/0.2}. The membership valuefor each element is: M = Ve/L.Where:– M : membership value;– Ve: weight of the tag in the vocabulary;– L: nesting level of the tag with Lroot = 0.

OntoExtractor: A Fuzzy-Based Approach to Content 1829
Fig. 3. Two generic XML documents A.XML and B.XML
2. MV : this is an experimental algorithm introduced by our group, which keepsmemory of the parent tag. The membership value for each element is: M =(Ve + Mp)/L.Where:– M : membership value;– Mp: membership value of the parent tag with Mroot = 0;– Ve: weight of the tag in the vocabulary;– L: nesting level of the tag with Lroot = 0.
The MV membership value helps, in certain cases, to keep mem-ory of the tree structure of the original document, referring to fig-ure 3: using the same vocabulary V, applying the MV weighting func-tion to the tree representation of the two XML documents A.xml andB.xml we obtain A = {R/1, a/0.53, a/0.36, b/0.33, d/0.8, e/0.7} and B ={R/1, a/0.56, a/0.37, b/0.34, d/0.8, e/0.7} which are different. Figure 4 showsthe differences in processing an XML document coming from Amazon, al-ternatively by Nesting and MV algorithms.
In order to compare the XML documents modeled as fuzzy bags well knownsimilarity measures studied in [1] [2]. We privileged measures giving higher simi-larity weight to the bags where elements (tags) belonging to the intersection areless nested. This is motivated by the fact that, if a tag is near to the root it seemsreasonable to assume that it has a higher semantic value. In OntoExtractor thecomparison between two Fuzzy Bags is computed using Jaccard norm:
S(B1, B2) = Approx
(|Bag1 ∩ Bag2||Bag1 ∪ Bag2|
)
Where:
– B1 and B2 are the input fuzzy bags;–
⋂is the intersection operator;
–⋃
is the union operator;– || is the cardinality operator;– Approx() is the approximation operator;– S is the similarity value between B1 and B2.

1830 P. Ceravolo et al.
Fig. 4. Fuzzy Bags generated by Nesting and MV algorithms. And the XML represen-tation of the document.
For more theoretical information about this norm and how the union, intersec-tion, approximation and cardinality operations are expressed, please refer to [3]and [6]. Using this norm the tool can perform a partitioned clustering techniquethat is an hybrid version between K-means and K-NN clustering algorithms.OntoExtractor uses an alpha-cut value as a threshold for the clustering process,in order to avoid to suggest the initial number of clusters (k) and skipping thisway some clustering problems related to the k-means algorithm. The clusteringalgorithm compares all the documents with the centroid of each cluster, consid-ering only the bigger resemblance value. If this value is bigger than the givenalpha the document is inserted in the cluster, otherwise a new empty cluster isgenerated and the document is inserted in it.
OntoExtractor tool offers two different ways to calculate the centroid of eachcluster: one method chooses the document that has the smaller representativeFuzzy Bag. In this method the centroid always corresponds to a real document.The other method generates a new Fuzzy Bag as the union of all the Fuzzy Bagsin the cluster. This way the generated Fuzzy Bag does not have a compulsorycorrespondence in a real document.
5 Clustering by Content
The second clustering process that we propose is based on the content connectedto leaf nodes. Content-based clustering is independent for each structural cluster
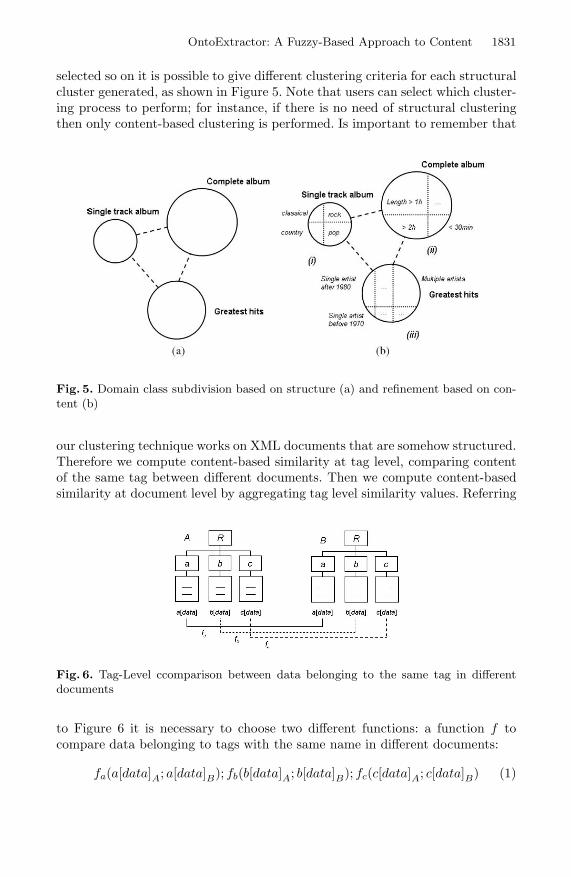
OntoExtractor: A Fuzzy-Based Approach to Content 1831
selected so on it is possible to give different clustering criteria for each structuralcluster generated, as shown in Figure 5. Note that users can select which cluster-ing process to perform; for instance, if there is no need of structural clusteringthen only content-based clustering is performed. Is important to remember that
Fig. 5. Domain class subdivision based on structure (a) and refinement based on con-tent (b)
our clustering technique works on XML documents that are somehow structured.Therefore we compute content-based similarity at tag level, comparing contentof the same tag between different documents. Then we compute content-basedsimilarity at document level by aggregating tag level similarity values. Referring
Fig. 6. Tag-Level ccomparison between data belonging to the same tag in differentdocuments
to Figure 6 it is necessary to choose two different functions: a function f tocompare data belonging to tags with the same name in different documents:
fa(a[data]A; a[data]B); fb(b[data]A; b[data]B); fc(c[data]A; c[data]B) (1)

1832 P. Ceravolo et al.
and a function F to aggregate the individual fs: F (fa, fb, fc). We have twopossibilities for choosing the F function:
– F is a t-norm: conjunction of the single values (fa ∧ fb ∧ fc);– F is a t-conorm: disjunction of the single values (fa ∨ fb ∨ fc).
Fig. 7. A: comparison in case of null values. B: comparison in case of nested values.
Referring to Figure 7 it is evident that we need to consider also cases wherethe tag is not present in the document and cases of documents having multipleinstances of the same tag at different nesting levels. So in the first case we have:
fb(null; b[data]B) = 0; (2)
and in the second case we evaluate the distance between the tags using theformula:
fx = maxp,k
11 + Δp,k
fxp,k(xp[data]A; xk[data]B); (3)
Δ = |μ(xp) − μ(xk)| . (4)
Occurrences of terms have distinct informative roles depending on the tags theybelong to. So, it is possible either to define a different function f for each groupof data of the same tag in different documents, or choosing a function consid-ering the membership value μ(xi) associated to the i-th tag. We represent thecontent of each tag (An[data], Bn[data, ]Cn[data], ... in (1)) with the well-knownVector Space Model, widely used in the modern information retrieval system. Thevector space model (VSM) is an algebraic model used for information filteringand information retrieval. It represents natural language documents in a formalmanner by the use of vectors in a multi-dimensional space. The vector spacemodel usually builds a documents-terms matrix and processes it to generate thedocument-terms vectors. Our approach is similar but we generate one matrixfor each tag in the document; correspondingly, we generate a tag-terms vector.There are several methods to generate the tag-terms vector, such as LSA (LatentSemantic Analysis [7]) or SVD (Singular Value Decomposition), a well-knownmethod of matrix reduction that adds latent semantic meaning to the vectors.In OntoExtractor, generating the tag-terms vectors is a three-step process:

OntoExtractor: A Fuzzy-Based Approach to Content 1833
– Generating the tags-terms matrix : for each tag in the document, adocuments-terms matrix is produced. It is important to remember thatwe do not consider the document as a unique text-blob, but we build thedocuments-terms matrix at the tag level. If a tag is not present in a docu-ment, a row of zeros is added to the matrix. Each entry in the matrix can becomputed in several ways as well, by choosing one of the weighting methodsimplemented in the tool. At now it is possible to choose among: tf − idf ,tf − df , tf and term occurrency.
– Transforming the matrix : once the matrix has been generated we processit by some matrix tranformations. We allow to choose between keeping theoriginal matrix or transform it LSA by SVD. This method relies on theassumption that any m ∗ n matrix A (with (m ≥ n)) can be written as theproduct of an m ∗ n column-orthogonal matrix U , an n ∗ n diagonal matrixwith positive or zero elements(Σ), and the transpose of an n ∗ n orthogonalmatrix V . Suppose M is an m ∗ n matrix whose entries come from the fieldK, which is either the field of real numbers or the field of complex numbers.Then there exists a factorization of the form: M = UΣV ∗; where U is anm∗m unitary matrix over K, the matrix S is m∗n with non-negative numberson the diagonal and zeros off the diagonal, and V ∗ denotes the conjugatetranspose of V , an n ∗ n unitary matrix over K. Such a factorization iscalled a singular-value decomposition of M . The matrix V thus contains aset of orthogonal “input” or “analysing” base-vector directions for M . Thematrix U contains a set of orthogonal “output” base-vector directions forM . The matrix S contains the singular values, which can be thought of asscalar “gain controls” by which each corresponding input is multiplied togive a corresponding output. After the matrix decomposition we generate anew n ∗ m matrix using an r-reduction of the original SVD decomposition:M = UrΣrV
∗r .
Only the r column vectors of U and r row vectors of V ∗ corresponding to thenon-zero singular values Sr are calculated. The resulting new matrix is nota sparse matrix anymore but it is densely populated by values, with hiddensemantic meaning.
– Storing the vectors : each row in the matrix is stored in the associated tagin the document model as a new Fuzzy Bag with the terms as the elementand the entry in the vector as membership value. Now tags’ contents arerepresented by Fuzzy Bags and we can compare them by mean of differentdistances measures: we can use traditional Euclidean distances such as theCosine distance.
6 Conclusions and Further Work
In order to avoid the siononimy and polisemy problem in the next versions ofOntoExtractor will be added new processors using external ontologies to iden-tify concept. Anyway this approach introduces other problems that have to beconsidered. One of this is the Word Sense Disambiguation (WSD). The validity

1834 P. Ceravolo et al.
of this tool must be evaluated in the complete system it inserted on. Furtherworks will provide a report on evaluations of the KIWI system.
References
1. B. Bouchon-Meunier, M. Rifqi, S. Bothorel: “Towards general measures of compar-ison of objects”. Fuzzy Sets and Systems, volume 84, pages 143-153, 1996.
2. P. Bosc, E. Damiani: “Fuzzy Service Selection in a Distributed Object-OrientedEnvironment”. IEEE Transactions on Fussy Systems, volume 9, no. 5, pages 682-698, 2001.
3. P. Ceravolo, M.C. Nocerino, M. Viviani: “Knowledge extraction from semi-structured data based on fuzzy techniques”. Knowledge-Based Intelligent Informa-tion and Engineering Systems, Proceedings of the 8th International Conference,KES 2004, Part III, pages 328-334, 2004.
4. P. Ceravolo, E. Damiani, M. Viviani: “Adding a Peer-to-Peer Trust Layer to Meta-data Generators”. Lecture Notes in Computer Science, Volume 3762, pages 809 -815, 2005.
5. P. Ceravolo, A. Corallo, E. Damiani, G. Elia, M. Viviani, and A. Zilli: “Bottom-up extraction and maintenance of ontology-based metadata”. Fuzzy Logic and theSemantic Web, Computer Intelligence, Elsevier, 2006.
6. E. Damiani, M.C. Nocerino, M. Viviani: “Knowledge extraction from an XML dataflow: building a taxonomy based on clustering technique”. Current Issues in Dataand Knowledge Engineering, Proceedings of EUROFUSE 2004: 8th Meeting of theEURO Working Group on Fuzzy Sets, pages 133-142, 2004.
7. T. K. Landauer, P. W. Foltz, & D. Laham: “Introduction to Latent Semantic Anal-ysis”. Discourse Processes, 25, pages 259-284, 1998.
8. G. Salton. and C. Buckley: “Term Weighting Approaches in Automatic Text Re-trieval”. Technical Report. UMI Order Number: TR87-881., Cornell University.1987,
9. G. Salton, A. Singhal, C. Buckley and M. Mitra: “Automatic Text DecompositionUsing Text Segments and Text Themes”. Conference on Hypertext, pages 53-65,1996.
Top Related
Copyright © 2022 FDOKUMEN

