






Bahasa
Halaman
Hukum


1 23
Cluster ComputingThe Journal of Networks, Software Toolsand Applications ISSN 1386-7857Volume 18Number 2 Cluster Comput (2015) 18:829-844DOI 10.1007/s10586-014-0420-x
FUGE: A joint meta-heuristic approach tocloud job scheduling algorithm using fuzzytheory and a genetic method
Mohammad Shojafar, Saeed Javanmardi,Saeid Abolfazli & Nicola Cordeschi

1 23
Your article is protected by copyright and all
rights are held exclusively by Springer Science
+Business Media New York. This e-offprint is
for personal use only and shall not be self-
archived in electronic repositories. If you wish
to self-archive your article, please use the
accepted manuscript version for posting on
your own website. You may further deposit
the accepted manuscript version in any
repository, provided it is only made publicly
available 12 months after official publication
or later and provided acknowledgement is
given to the original source of publication
and a link is inserted to the published article
on Springer's website. The link must be
accompanied by the following text: "The final
publication is available at link.springer.com”.

Cluster Comput (2015) 18:829–844DOI 10.1007/s10586-014-0420-x
FUGE: A joint meta-heuristic approach to cloud job schedulingalgorithm using fuzzy theory and a genetic method
Mohammad Shojafar · Saeed Javanmardi ·Saeid Abolfazli · Nicola Cordeschi
Received: 11 July 2014 / Revised: 20 September 2014 / Accepted: 29 December 2014 / Published online: 15 January 2015© Springer Science+Business Media New York 2015
Abstract Job scheduling is one of the most importantresearch problems in distributed systems, particularly cloudenvironments/computing. The dynamic and heterogeneousnature of resources in such distributed systems makes opti-mum job scheduling a non-trivial task. Maximal resourceutilization in cloud computing demands/necessitates an algo-rithm that allocates resources to jobs with optimal execu-tion time and cost. The critical issue for job scheduling isassigning jobs to the most suitable resources, consideringuser preferences and requirements. In this paper, we presenta hybrid approach called FUGE that is based on fuzzy the-ory and a genetic algorithm (GA) that aims to perform opti-mal load balancing considering execution time and cost. Wemodify the standard genetic algorithm (SGA) and use fuzzytheory to devise a fuzzy-based steady-state GA in order toimprove SGA performance in term of makespan. In details,theFUGE algorithm assigns jobs to resources by consideringvirtual machine (VM) processing speed, VM memory, VMbandwidth, and the job lengths.Wemathematically prove our
M. Shojafar (B) · N. CordeschiDepartment of Information Engineering Electronicsand Telecommunications (DIET), University Sapienzaof Rome, via Eudossiana 18, 00184 Rome, Italye-mail: [email protected]; [email protected]: http://www.mshojafar.com
N. Cordeschie-mail: [email protected]
S. JavanmardiResearch and Education center,Nikan network Company, Shiraz, Fars, Irane-mail: [email protected]; [email protected]
S. AbolfazliCenter for Mobile Cloud Computing, University of Malaya,Kuala Lumpur, Malaysiae-mail: [email protected]
optimization problemwhich is convex with well-known ana-lytical conditions (specifically, Karush–Kuhn–Tucker con-ditions). We compare the performance of our approach toseveral other cloud scheduling models. The results of theexperiments show the efficiency of the FUGE approach interms of execution time, execution cost, and average degreeof imbalance.
Keywords Cloud computing ·Mathematical optimization ·Job scheduling · Genetic algorithm (GA) · Fuzzy theory ·Makespan
1 Introduction
Advances in web technologies have facilitated the migra-tion of traditional desktop applications to the cloud. In paral-lel, the proliferation of hand-held devices leads us to expectthat future end-users will, for the most part, use hand-held,mobile devices to access cloud-hosted applications [1]. Incloud computing, users do not know where the services arelocated in the infrastructure. The users only use the servicesthrough the cloud service deliverymodel and pay for the usedservices [2]. The cloud infrastructure provides on-demandaccess to shared pool of resources and services. These areprovided as a service over a network, and can be accessedthrough the Internet [3].
Cloud job scheduling is a NP-hard problem which con-sists of n jobs andm machines. Each job should be processedby each of the m machines in order to minimize makespan.Scheduling algorithms are used mainly to minimize execu-tion time and execution cost [4]. Schedulinghandles the prob-lem of which resources need to assign to the received job. Anefficient scheduling algorithm considers balancing the loadof the systemconsidering the total execution time of available
123
Author's personal copy

830 Cluster Comput (2015) 18:829–844
resources. It reduces the execution time leading to least theexecution cost. To achieve both of the goals, the underly-ing principal is not to waste high-capacity resources on low-length jobs. (Note that for the remainder of this paper, we usethe term low-length rather than short-length.) The schedulerassigns resources to the jobs according to the job lengths andavailable resources’ capacities [5].
Recently, much attention has been devoted to the useof mathematical and intelligent approaches in cloud jobscheduling and load balancing [6]. Genetic algorithms (GA)[7] and fuzzy theory [8] are two well-known artificial intel-ligence approaches that are used in this paper. There are twotypes of GAs: steady-state GA and generational GA. Thesteady-state GA is simpler than generational one in whichtwo parents are selected, crossed-over and inserted in thepopulation, but in the generational GA a large part of thepopulation is selected and crossed over and inserted into thepopulation. In principle, a GA begins with a set of chromo-somes called the population. A fitness function is used tocalculate the fitness values of the chromosomes, and the twobest chromosomes are selected and a crossover operation isperformed. Then, a SGA performs a mutation operation. Itmutates the new child at some positions. Finally, the algo-rithm adds the new chromosome to the population. This isrepeated until the termination condition is met. Fuzzy opti-mization is appropriate for environmentswere the parametersare not precisely defined or are not known in advance. Fuzzylogic has various unique characteristics that make it a partic-ular choice for varied types of control problems. Fuzzy logicmanages the examination of knowledge by utilizing fuzzysets, each of which can model a linguistic phrase, such asBad and Medium [9].
Our proposed approach, called FUGE, uses fuzzy the-ory to modify the GA; we use a fuzzy system for the fitnesscrossover steps and crossover steps. Thiswork is the extendedversion of our previous work [10]. This work complementsour previous work from several aspects of quality services,mathematical proofs, and general architecture. Themain goalof this paper is to alter standard GA in order to assign jobsto the most optimal resources. Specifically, the FUGE algo-rithmobtains the best chromosomes in the first generation. Toclarify the usage of the new scheduling algorithm, we presenta concrete example to exhibit how FUGE can be applied inreality. In cloud operating systems (OSs), users can consumeservices anywhere, anytime, from any device. Novel cloudOSs unify variety of distributed OSs’ features and the Inter-net to represent the OS accessible from any location. CloudOS is placed on the Internet which enables users to accessit from any location with a browser. This kind of OS makesan entry ready for a variety of web-based applications andenables the user to perform desired tasks from their browsers[11]. Educative engine (resourcemanager) is themain part ofCloud OS and Web OS in which an agent is responsible for
resource management and scheduler is the major part of theresource management part. Use of FUGE in cloud OSs canimprove the resource management through efficient resourcescheduling with the aid of an intelligent scheduler based ona fuzzified GA.
The rest of this paper is organized as follows. In the nextsection (Sect. 2), we review related works and take a brieflook at some works on cloud job scheduling. In Sect. 3, wepresent our proposed model and explain it in Sect. 4. In Sect.5, the performance evaluation and experimental results arepresented. Finally, in Sect. 6, we highlight our conclusionsand future directions.
2 Related work
In this section,webrieflypresent a reviewof themost relevantresearch efforts and highlight that how our work complimentthe current research and advance the state-of-the-art load bal-ancing and resource scheduling. Resource scheduling andload balancing are major techniques in large-scale distrib-uted computing models such as cloud computing which aimto guarantee that the most efficient resources are allocated tojobs in distributed computingmodel [12]. In the core of cloudcomputing, load balancer aims to assign jobs across numer-ous distributed resources. In recent years, researchers in loadbalancing domain have devoted much attention to artificialintelligence methods such as GAs and fuzzy theory becauseof the intelligence and parallelism [13]. GAs are appropriatefor solving the cloud resource-scheduling problem [14].
Hu et al. [15] proposed a cloud scheduling approachfor virtual machine (VM) load balancing using a GA. Sys-tem reliability and availability are features of cloud systemsthat should be considered, and the authors claim that theirapproach effectively improves overall system reliability andavailability. This approach obtains a proper load balancingand reduces dynamic migration by using a GA. It resolvesthe issue of load-imbalance thus obtaining better resourceutilization. Whilst the approach is promising, it is unableto reach local optimal solution. Instead, FUGE schedules theresources according to the complete view of the system state.
The authors in [16] described and compared several jobscheduling algorithms. Various scheduling algorithms havebeen presented for resource scheduling, but each one hasits own limitations. These algorithms represent optimal ornon-optimal solutions to the problem. At present, we requirean efficient algorithm for resource scheduling, and this is themajor research challenge. In ant colony optimization (ACO),when more resources are engaged, the algorithm producescolonies so that an ant follows a less likely pheromone trailfrom another colony. For particle swarm optimization (PSO),it is possible for the solution space or search space to bevery large. ACO suffers from some shortcoming such as the
123
Author's personal copy

Cluster Comput (2015) 18:829–844 831
table updating seems to be perfect but in case of asymmetricdistributed networks such as cloud environment, it cannotdeliver proper results due to the ACO table updating strate-gies. For brevity, when the number of VMs increased, theants may not follow a pheromone trail from another colonywhich is the main part for updating ACO table. Instead inFUGE, as the fuzzy inference engine is the pain part of thescheduler and it uses fuzzy Mamdani table [17] and it pre-serve the status of VMs and jobs dynamically in a parallelmanner, as a result, it is able to resolve this problem.
The authors in [18] proposed a job-oriented model forcloud resource scheduling. This model assigns jobs toresources according to the ranks of the jobs. This paper alsoanalyzes aspects of resource scheduling algorithms such asthe time parameters for round robin, preemptive priority, andshortest remaining time first. In this paper, the authors con-sider the problem of VM allocation in a distributed cloudnetwork. The main objective of this paper is to reduce thetotal cost of power consumption. This work improves thecloud job scheduling in terms of average waiting and turn-around time. This work does not consider jobs featuresand resources properties dynamically altogether; instead aswe use fuzzy Mamdani inference system [17], FUGE con-siders both jobs features and resources properties dynami-cally.
A different perspective is taken by the authors in [19],which proposed a model to handle the job scheduling prob-lem for a group of cloud user requests. Each data centerhas different services with various resources. This modelassumes that resource provisioning is an important issue forjob scheduling. The main goal of the model is to reducethe average delay and energy consumption in granting con-nection requests. This paper presents four merged schedul-ing algorithms that can be used to schedule a VM on thedata centers. Of the four methods, the method that mergesa resource-based distribution technique and a duration pri-ority technique showed the best performance in minimizingtardiness while satisfying problem constraints. This modelreduces the average delay in granting connection requestsand the percentage of connections that are blocked. Besides,their results of simulation-driven evaluation of heuristics fordynamic re-allocation of VMs using live-migration accord-ing to current requirements for CPU performance. Thiswork focused on energy-efficient hob scheduling approacheswhich can be applied to a VM by a cloud provider. Theapproach uses a live migration strategy to dynamically real-locate VMs in order to reduce energy consumption. Whilstthis approach takes into account the preserve to minimizedatacenter energy consumption by using proper virtualizedresource scheduling strategy, but, it does not consider jobsproperties such as job length, job’s execution time andjob’s execution cost as quality of services (QoSs) into thesystem.
Chen et al. [20] proposed a genetic job-scheduling algo-rithm in which the fitness function is divided into three sub-fitness functions and a linear combination of the sub-fitnessvalues is used to obtain the fitness value. This paper uses apre-migration strategy based on three load dimensions: CPUutilization, network throughput, and disk I/O rate. To achievea nearly optimum solution, this model applies a hybrid GAmerged with a knapsack problem with multiple fitness func-tions. The authors claim that the algorithm can achieve thegoal of increasing resource utilization and lowering energyconsumption.
Sawant [21] proposed a genetic-based approach to jobscheduling to balance the loads on the VMs in a large-scalecloud infrastructure. The author claims that his proposalsolves the problems of load imbalances and high migrationcosts. The approachmodifies the SGA to obtain these results.The algorithm has six steps, and the stopping condition forthe algorithm is when there exists a tree that meets the heatlimit requirement. The major goal of this work is by usingthe GA to find the best mapping solution. This paper increasethe performance of cloud job scheduling in terms of ‘variantload on physical servers’, ‘stable load on physical servers’and ‘number of VM migrations with stable system load’.For fitness function step, this work uses an innovative fitnessfunction in which load balancing is considered and currentjob features is neglected. FUGE considers both VMs andjobs features in fitness function step with the aid of fuzzyinference system.
The authors in [22] proposed a modified GA in which thefitness function is designed to support solutions thatminimizeexecution time, and they compared it with existing heuristicapproaches. The authors claim that under heavy-loads, theiralgorithm shows fine performance. This method has a limita-tion: it is a single-user method and therefore not suitable forgeneral cloud applications. However, it has a clearly desir-able feature: all the jobs can be carried out in a way thatoptimizes execution time and execution cost.
Kumar and Dinesh [23] introduced a cloud job schedulingmethod that uses fuzzy theory to obtain good performancein terms of execution time, memory utilization and band-width utilization. This approach classifies jobs according tobandwidth, memory, CPU utilization and size, then, the clas-sified jobs are then given to a fuzzifier. Training data in acentralized database are used as input for a neural networkthat determines suitable resources for user jobs. This paperuses CloudSim [24] for performance evaluation.
Abirami and Ramanathan [25] devised a novel schedul-ing algorithm named linear scheduling for jobs and resourcesin cloud environment. This approach principally focuses iseradicating the starvation and deadlock conditions. The vir-tualization technique along with the scheduling approach isyield better resource utilization, system throughput, thereforeimproving the performance of the cloud resources. This work
123
Author's personal copy

832 Cluster Comput (2015) 18:829–844
Fig. 1 FUGEified cloudarchitecture
considers the processing time, resource utilization, memoryusage and throughput in a linear scheduling strategy. Thiswork has an assumption in which the task requests must sat-isfy linear scheduling mode. This paper presents a flavor ofthe significant ongoing work, but, it did to use artificial tech-nology to decrease makespan and provide load balancingcompared to FUGE algorithm.
3 System model
In this section, we present our proposed model. Cloud com-puting consists of several technologies such as virtualization,utility computing, services computing, distributed comput-ing, and aims to present IT management as a service in thenetwork [26]. The core of cloud computing consists of hard-ware and software architectures that enable virtualization[27].
3.1 Architectural layers of proposed model
Cloud computing has three levels of service offerings:Software-as-a-Service (SaaS), which is in the applicationlayer, Platform-as-a-Service (PaaS), which is in the platformlayer, and Infrastructure-as-a-Service (IaaS), which is in theunified resource and fabric layer. Together these groups sup-port virtualization [28]. SaaS includes a complete applica-tion that presents a service on demand. For example, a sin-
gle instance of software executes on the cloud and presentsparticular services to the end user or enterprise customer.PaaS presents a layer of software as a service that is usedto build higher-level services. PaaS includes infrastructuresoftware, a database, middleware, access management, datamanagement and FUGE scheduler. Our scheduler is as a ser-vice which can be added into this layer on top of the unifiedresources to provide a development and/or deployment plat-form. For commercial examples of PaaS, we can point to theGoogle Apps. engine in which developers write in Python orJava.
IaaS presents basic storage as a standardized service overthe network. Servers, storage systems, switches, routers,operating systems virtualization technology, and file systemsare joined together as a service. Joyent [29] is an exemplaryIaaS in which a line of virtualized servers provide an on-demand infrastructure, Microsoft’sWindows Azure [30] andRackspace [31].
The architecture of our approach consists of four lay-ers: the fabric layer, unified resource layer, platform layer,and application layer. The fabric layer contains hardwareresources such as computing, storage, and network resources.The unified resource layer contains resources that are encap-sulated by virtualization. The platform layer places a col-lection of middleware and services on top of the unifiedresources to provide a development platform. Finally, theapplication layer contains the applications that run in theCloud. Figure 1 shows our model architectures.
123
Author's personal copy

Cluster Comput (2015) 18:829–844 833
3.2 The building blocks of the new model
The building blocks of the new model are based on hard-ware and software architectures that enable fuzzified genetic-based service scheduling and virtualization. The buildingblocks of the newmodel contains of enterprise management,VM manager and cloud resources. Enterprise managementprovides the management tools for configuration, data, ser-vices and application management. FUGE scheduler, virtu-alized infrastructure and virtualized application are placedin VM manager. VM manager takes into account the orga-nizing the jobs to the appropriate resources respecting to theQoS policy and availability of the resources. The virtual-ized infrastructure presents the abstraction to ensure that anapplication or service is not directly bound to the underlyinginfrastructure such as servers, storage, or networks. Virtual-ized applications separate the application from the underly-ing infrastructure to ensure more flexibility in deployment. Agenetics fuzzy based algorithm is placed in FUGE schedulerthat assigns jobs to the resources based on genetics and fuzzyrules. Cloud resources contain necessary physical resourcessuch as storage resources. Note that, we neglect the dura-tion takes to send jobs to the physical server in the proposedmodel. Figure 2 illustrates the building blocks of the newmodel.
4 The FUGE approach
We propose an approach in which jobs are represented asgenes; and computational resources assigned to these genes,and sets of genes create chromosomes. We create two typesof chromosomes based on different criteria. The first type isbased on the job length (i.e., the length is variations), theCPUspeed of the resources, and the RAM size of the resources.The second type is created based on the job length and thebandwidth of the resources. These criteria are the input para-meters for the fuzzy system. For each type of chromosome,some random populations of genes (jobs) are created andrepresented as chromosomes (i.e., we did not propose a lim-itation for the numbers of chromosomes for each group butthe number for both groups should be the same), then thecomputational resources are assigned to the gene randomly(standard random) and the algorithm calculates the fitnessvalue of every chromosome of each type. The fitness valueis calculated by a fuzzy function. The fitness function of thechromosome is achieved by the summation of fitness func-tion values calculated for each genes (jobs). The algorithmcontinues by selecting an individual chromosome from eachof the two types of chromosomes according to their fitnessvalue (i.e., the largest fitness values among the chromosomesin each type; the fitness function value of the chromosome iscalculated based on summation of fitness function values of
Fig. 2 FUGE: building blocks of proposed model
its gens). Consequently, the algorithmperforms the crossoveroperation on these two selected chromosomes (each one ineach type)with the aid of fuzzy theory and produce new chro-mosome based on two selected chromosomes. At the end ofthis step, a new chromosome that is the best chromosome(i.e., largest fitness value) of the first generation is created.This chromosome is added back into the first generation anda new population is generated. The recursive algorithm thatrepeats the entire process again on the new population. Thebreaking condition is the iteration number (let say 100) orboth selected chromosoemes are the same (i.e., same VMspositions and jobs). In practice, the result is available less thanten iterations. The details of our approach are described inthe next two subsections: in Sect. 4.1, we explain the geneticaspect of the approach, and continue in Sect. 4.2 to explainthe fuzzy rules of the approach.
4.1 Genetic approach
The main purpose of our algorithm is to assign the mostsuitable resources to jobs based on the bandwidth, compu-
123
Author's personal copy

834 Cluster Comput (2015) 18:829–844
tational capabilities of the resources and the jobs’ lengths.The algorithm tries to find a match between job length andbandwidth/resources.We use fuzzy theory in two steps of ouralgorithm. First, it is used to calculate the fitness value f (x)of every chromosome of the two previously described typesof chromosomes. Second, it is used in the crossover step ofour algorithm. We do not use the usual crossover approachessuch as single-point crossover or two-point crossover. Theirresults are stochastic, it means they maybe better or worsethan before. Instead,weuse a fuzzy based crossover approachwhich is oneof the novel aspects of this research.Thismethodhelps the GA to converge to the optimum (i.e., related to theobjective of the problem) value based of the fitness values ineach iterations. In this way, the crossover operation will bemore targeted.
The objective of using fuzzy theory in these two steps isassigning jobs to themost suitable resources based on the jobsand VMs states (i.e., it is specific for proposed approach).Fuzzy theory is used to target the selection of genes andassigning the resources to jobs. There are two common typesof fuzzy inference systems: Mamdani and Sugeno [32]. Weuse a Mamdani [17] inference system because of its simplic-ity (in terms of low cost or low overhead) and its definingrules that are based on the experiences of the previous stateof fuzzification. We use fuzzy rules to define the priority ofthe algorithm’s input parameters. As an example, considerthe following rule: If the job length is high, bandwidth is low,the amount of RAM is medium and the CPU speed is highthen the result is adequate. In this rule, we define the priorityof the input parameters: for a job with high length, the fuzzypriority of the CPU speed is high and the fuzzy priority ofthe RAM is medium and the fuzzy priority of the bandwidthis low.
In detail, the algorithm produces a random population oftwo types of chromosomes. The first type is created basedon the job length, the CPU speeds of the resources, andthe amount of RAM the resources have. The second typeis created based on the job length and the bandwidths ofthe resources. The algorithm then calculates the fitness valuef (x) for every chromosome x in the two populations. Thefitness value is calculated with the aid of fuzzy theory.
4.2 Fuzzy approach
The previously mentioned parameters are the inputs to thefuzzy inference system that performs the fuzzy reasoning.The output of the fuzzy inference system is a non-fuzzy num-ber that determines the fitness value for each chromosome.Figure 3 shows the structure of the fuzzy inference system.
To calculate the fitness value, the fuzzy inference systemuses membership functions to determine the degree to whichits input parameters belong to each of the relevant fuzzy sets.For this purpose, three overlapping fuzzy sets are created. For
Fig. 3 The structure of the fuzzy inference engine
example, for the bandwidth parameter, values between 500and 750 are in the low range, values between 530 and 970are in the medium range, and values between 750 and 1,000are in the high range. It is best to define the intervals in sucha way that the end-point of the first fuzzy set is the startingpoint of the third fuzzy set. In this way, the fuzzy features offuzzy sets will be increased and these fuzzy sets will havemore overlap with each-other. A membership function is aquadratic function that defines how each point in the inputspace is mapped to a membership degree between 0 and 1[33]. µA(x) shows the membership degree for membershipfunction A. Generally, we have the Eq. (1):
∀x ∈ X : µA(x) ∈ [0, 1], (1)
Figure 4a, b, c, and d, respectively, show the fuzzy sets forthe job length, VM frequency (CPU processing speed), VMmemory (RAM), andVMbandwidth parameters,whichwerecreated using the Matlab-based fuzzy logic toolbox [33].
Figure 4e shows the output fuzzy sets that represent a non-fuzzy value between 0 and 1. These fuzzy sets were used forthe first and second experiments in the performance evalua-tion. For the rest of the performance evaluation experiments,the fuzzy set values were different.
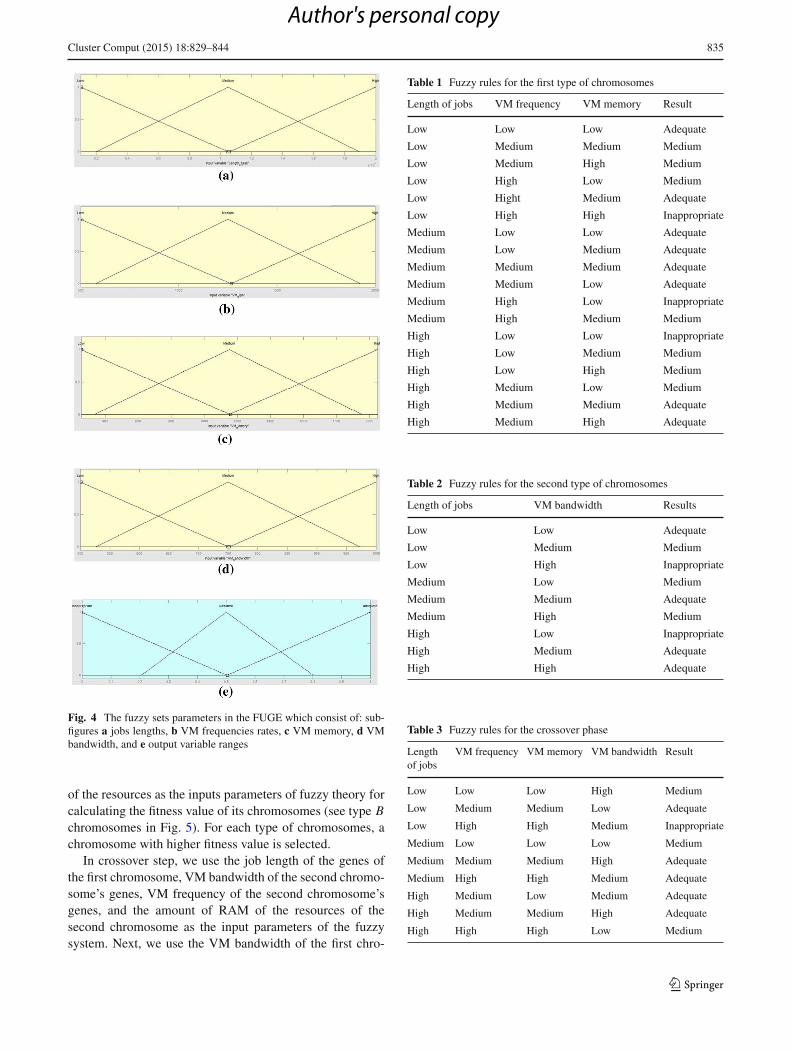
For example, in Fig. 4b, the bandwidth 700 has mem-bership degree 0.3 in the low interval, 0.7 in the mediuminterval, and 0 in the high interval. These values are used forthe fuzzy rules in the fuzzy reasoning step. The fuzzy rulesfor our Mamdani inference system [17] are defined based onthe cloud environment and its administrative policy. We havefuzzy rules for thefirst and second chromosomes that are usedin the fitness phase as well as fuzzy rules that are used in thecrossover phase. The fuzzy rules are shown in Tables 1, 2, 3.
Now, we present a simple example which can help to bet-ter understand the crossover method. As we mentioned ear-lier, a chromosome is created by a sequence of n gens. Thegenes manipulated by the GA contain pairs of (job runningtime, computing resource performance and memory) thathave been randomly assigned.We have two types of chromo-somes in which VMs are the mentioned chromosomes gens.In population step for each type of chromosomes, we createsome chromosomes and assign the VMs to the jobs. Geneis defined by a VM which assigns to a job. For the chro-mosomes type A, we use the job length, the CPU speed ofthe resources, and the RAM size of the resources as the inputparameters of fuzzy theory for calculating the fitness value ofits chromosomes (see type A chromosomes in Fig. 5). For thechromosomes type B, we use job length and the bandwidth
123
Author's personal copy
Cluster Comput (2015) 18:829–844 835
Fig. 4 The fuzzy sets parameters in the FUGE which consist of: sub-figures a jobs lengths, b VM frequencies rates, c VM memory, d VMbandwidth, and e output variable ranges
of the resources as the inputs parameters of fuzzy theory forcalculating the fitness value of its chromosomes (see type Bchromosomes in Fig. 5). For each type of chromosomes, achromosome with higher fitness value is selected.
In crossover step, we use the job length of the genes ofthe first chromosome, VM bandwidth of the second chromo-some’s genes, VM frequency of the second chromosome’sgenes, and the amount of RAM of the resources of thesecond chromosome as the input parameters of the fuzzysystem. Next, we use the VM bandwidth of the first chro-
Table 1 Fuzzy rules for the first type of chromosomes
Length of jobs VM frequency VM memory Result
Low Low Low Adequate
Low Medium Medium Medium
Low Medium High Medium
Low High Low Medium
Low Hight Medium Adequate
Low High High Inappropriate
Medium Low Low Adequate
Medium Low Medium Adequate
Medium Medium Medium Adequate
Medium Medium Low Adequate
Medium High Low Inappropriate
Medium High Medium Medium
High Low Low Inappropriate
High Low Medium Medium
High Low High Medium
High Medium Low Medium
High Medium Medium Adequate
High Medium High Adequate
Table 2 Fuzzy rules for the second type of chromosomes
Length of jobs VM bandwidth Results
Low Low Adequate
Low Medium Medium
Low High Inappropriate
Medium Low Medium
Medium Medium Adequate
Medium High Medium
High Low Inappropriate
High Medium Adequate
High High Adequate
Table 3 Fuzzy rules for the crossover phase
Lengthof jobs
VM frequency VM memory VM bandwidth Result
Low Low Low High Medium
Low Medium Medium Low Adequate
Low High High Medium Inappropriate
Medium Low Low Low Medium
Medium Medium Medium High Adequate
Medium High High Medium Adequate
High Medium Low Medium Adequate
High Medium Medium High Adequate
High High High Low Medium
123
Author's personal copy

836 Cluster Comput (2015) 18:829–844
Fig. 5 A simple example of the proposed crossover (i.e., n = 8; num-bers of genes or jobs and m = 8; number of machines or resource orVMs)
mosome’s genes, VM frequency of the first chromosome’sgenes, amount of RAMof the resources assigned to the genesof the first chromosome, and the job lengths of the genes ofthe second chromosome as the input parameters of the fuzzysystem. Next, we compare the two output values of fuzzysystem and according to these values we exchange the jobwhich assigns the VMs (genes).
In other words, in crossover step, the goal is to merge theselected two chromosomes and obtain a better chromosome.Suppose that chromosome A has eight genes (job number 1(T 1) till job number 8 (T 8)) in which each job is assigned toa separate VM. Chromosome B has eight genes (job number1 (T 1) till job number 8 (T 8)) in which each job is assignedto a separate VM too. The obtained output chromosome hassome genes in which the jobs are assigned the amore suitableVM. In another word, jobs may be re-assigned to the VMs.As an example, chromosome A and chromosome B in Fig.5 are separately composed of eight genes in which each jobis assigned to a separate VM. According to the output valueof fuzzy system in crossover step, some jobs are re-assignedto the different VMs. As it is illustrated in the figure, beforecrossover, T 1 from chromosome A was assigned to V M4and T 1 from chromosome B was assigned to V M2. Aftercrossover, the obtained output chromosome is assigned toV M2; the second gene of chromosome B is selected as thesecond gene of the obtained chromosome and etc. Crossoverselects the first gene of chromosome B as the obtained outputchromosome. As all jobs should be assigned to the VMs,the obtained chromosome’s genes have all jobs; but it caneliminate some VMs (see Fig. 5). After crossover operation,the obtained chromosome is added-back into the population;therefore, the population size remains constant.
Table 1 demonstrates fuzzy rules for the first type of chro-mosomes. The fuzzy rules of these chromosomes consist ofjob length, CPU speeds, and RAM resources for each VM.
Table 2 demonstrates fuzzy rules for the second type ofchromosomes. The fuzzy rules for these chromosomes con-sist of job length and bandwidth of resources.
Table 3 represents fuzzy rules for the hybrid chromo-some rules. The fuzzy rules for these chromosomes consist ofcrossover situations based on the genetic approach discussedin Sect. 4.1.
For selecting the best two chromosomes of each type weuse fuzzy approach as follow: Based on the input parameters,some fuzzy rules are fired. The fired fuzzy rules are integratedin such a way that decisions are made according to the aggre-gation of the fired fuzzy rules. In the step that aggregatesthe fired fuzzy rules, the fuzzy sets that show the outputs ofthe fired fuzzy rules are integrated into a single fuzzy set.This single fuzzy set is the input for the defuzzification step.The output of the defuzzification step is a non-fuzzy number.There are five common defuzzification methods: centroid,bisector,mean of maximum, smallest value of maximum, andlargest value of maximum [34].
The centroid method calculates the center of gravity forthe area under the curve. The bisector method uses a verticalline that divides the region into two sub-regions of equal area.It is sometimes, but not always, coincident with the centroidline. In the mean of maximum method, there is a plateau atthe maximum value of the final function that is assumed totake the mean of the values it spans. In the smallest value ofmaximum method, there is a plateau at the maximum valueof the final function that takes the smallest of the values itspans, and the final function takes the largest of the valuesit spans, called the largest value of maximum. The centroidmethod favors the rule with the output of greatest area, whilethe height method obviously favors the rule with the greatestoutput value. The centroidmethod [33] is themost commonlyusedmethod. Equation 2 presents the centroidmethod,whereµ shows the membership degree of the fired rules.
a =∫z µA(z)zdz∫z µA(z)dz
, (2)
Here a is the result that a rule of the proposed method hasa% risk associated with it, given the aforementioned defini-tion. This non-fuzzy number is used to calculate the fitnessvalue of the chromosomes. Based on the calculated fitnessvalues, the best two chromosomes (two parent individuals)of each type are selected, that is, the best chromosome of thefirst-type and the best chromosome of the second-type. Fig-ure 6 shows the aggregation operations of fired fuzzy rulesand the defuzzification step performed by the Matlab-basedfuzzy logic toolbox for the second type of chromosomes.Aggregation operations on fuzzy sets combine several fuzzysets in a proper way to produce a single fuzzy set. Basedon the input parameters, some rules are fired (blue sections);
123
Author's personal copy

Cluster Comput (2015) 18:829–844 837
Fig. 6 The aggregation of firedfuzzy rules
the aggregation of blue sections is the result of the fuzzyinference system.
After selecting the best two chromosomes of each type(the parents), the algorithm performs the crossover opera-tion. In this step, the job lengths of the genes of the firstchromosome are the first parameter of the fuzzy system. TheVM bandwidth, VM frequency, and the amount of RAM ofthe resources assigned to the genes of the second chromo-some are the second parameter of the fuzzy system. Next, thejob lengths of the genes of the second chromosome are thefirst parameter of the fuzzy system, and the bandwidth, VMfrequency, and amount of RAM of the resources assigned tothe genes of the first chromosome are the second parameterof the fuzzy system.
We formulate a linear programming model for the job-scheduling problem
minf j ,R j
n∑
i=1
m∑
j=1
di j =n∑
i=1
m∑
j=1
Ltot ( j)
Ai j f j+ Li
Bi j R j, (3.1)
subject to:
n∑
i=1
Ai j = 1, ∀ j = 1, 2, . . . ,m (3.2)
n∑
i=1
Bi j = 1, ∀ j = 1, 2, . . . ,m (3.3)
di j ≥ 0, ∀i = 1, 2, . . . , n, ∀ j = 1, 2, . . . ,m, (3.4)
R j ≥ 0, ∀ j = 1, 2, . . . ,m, (3.5)
0 ≤ f j ≤ fmax , ∀ j = 1, 2, . . . ,m, (3.6)
n,m ∈ Z+, Ltot ( j), j ∈ {1, . . . ,m}, (3.7)
where the goal is to minimize the total time needed to fin-ish all jobs which is subjected to eight brands of constraints,where n is the number of jobs and m is the number of (vir-tual) machines. The first term presents the execution durationtakes to compute on V M( j) with frequency f j , in details,Ltot ( j) denotes total job lengths in V M( j) (all executed jobsin machine j): the processor speed for V M( j) demonstratesas f j . Moreover, the second term expresses that the dura-tion takes to transfer the initial job to broker. Specifically,Li is the length of job i before execution over the chan-nel bandwidth for each VM for transferring the computedworkload (i.e., jobs) to broker. In next formulation (e.g., Eq.(3.2)), the uncertainty represents the imprecise processingtime or membership degree (i.e., see Eq. (1)), as fuzzy coef-ficients of the constraints, identified by the “tilde” on top ofthe f j which is calculated in Eq. (1) for each VM. Equation(3.3) presents fuzzy membership degree for the bandwidthrate for V M( j). Both aforementioned constrains are affineand convex in their ranges. Equation (3.4) ensures that forthe calculation, time consumption for each job i in V M( j)is greater than zero (i.e., each job should serve and eachresource should work, so no VM/ failure and no job elimina-tion are considered). Equation (3.5) ensures that each VM’sbandwidth should be greater than zero. Equation (3.6) provesthat the processing frequency for V M( j) which is called f jis equal or greater than zero and less than maximum capa-bilities frequency defied for each VM which is called fmax .Specially, each VM can be OFF/ON and response the work-load (jobs) which assigned to it. Finally, Eq. (3.7) indicatesthat {Ltot ( j) : j = 1 . . . ,m} is the fraction of incoming jobsfor each VM, n is the number of jobs, m is the number ofVMs, are integer values.
We show that objective function is concave for two controlvariables f j and R j . according to the following simplicityfunction which is elicit from the Eq. (3.1):
g(x, y) � minx,y
n∑
i=1
m∑
j=1
f (x, y)
123
Author's personal copy

838 Cluster Comput (2015) 18:829–844
where :x � f j ,
y � R j ,
C � Ltot ( j)
Ai j,
D � Li
Bi j,
→ f (x, y) � C
x+ D
y(4)
where function f (x, y) is independent from the outer-sumand can be modeled independently for each VM. Hence, weare able to consider f (x, y) without the summations, Notethat, the results will be the same for the summations whilsteach one is calculated interdependently.
According to the Eq. (4), f is order one (linear) for x andy, so we can easily calculate Hessian matrix for evaluatingconvexity. Therefore, we have in following:
f (x, y) = C
x+ D
y,
f ′x = −C/x2 ≤ 0, f ′
y = −D/y2 ≤ 0,
f′′xx = +2C/x3, f
′′yy = +2D/y3,
f′′xy = f
′′yx = 0,
Det.: = f′′xx f
′′yy − f
′′xy f
′′yx = 4CD
x3y3≥ 0 (5)
where Eq. (5) is the Hessian Determinant for the objectivefunction (4). Therefore, objective function is concave (i.e.,f ′x ≤ 0 and Det (Hessian) ≥ 0), so we can use maximize
instead of minimization and resolve it by Karush–Kuhn–Tucker (KKT) conditions and resolve the aforementionedobjective problems [6].
When the number of VMs connected to scheduling nodesis not very large, the solution for this linear program-ming could be obtained in a short period. We resolved thismakespan by the help of new hybrid meta-heuristic approachwith iterative method and update the chromosome of jobordering for each VM which are detailed.
For the output of the fuzzy system, the resources assignedto the genes (the first gene of the first chromosome withthe first gene of the second chromosome, the second geneof the first chromosome with the second gene of the secondchromosome) are exchanged. The output chromosome of thecrossover operation has the genes that assign the jobs to themost suitable resources. The genes of the output chromosomeassign the most suitable resources to the jobs in order toreduce makespan and cost. This output chromosome is thebest chromosome of the first generation; it is added back intothe first generation and a new population is generated. This
operation is done till the output chromosome of both type ofchromosomes are homolog. Homolog means that the inputchromosomes are completely same as each other. In detail,all genes and VMs for both of them are the same. Algorithm1 shows the steps of resource discovery.
Algorithm 1 FUGE Algorithm
1: Input:m∑
j=1Ltot ( j), n, m, , k
2: Output: g (x, y)3: int ch_t ype1 (k, n)4: int ch_t ype2 (k, n)5: lp ← 06: while (lp < 100) or (sel_t ype1 = sel_t ype2) do7: A(k, n) ← f (ch_t ype1 (k, n))8: B(k, n) ← f (ch_t ype2 (k, n))
9: f i t_sum1(k) ←n∑
i=1A(k, i) ∀k(in parallel)
10: f i t_sum2(k) ←n∑
i=1B(k, i) ∀k(in parallel)
11: sel_t ype1 ← max ( f i t_sum1(:)) ∀k12: sel_t ype2 ← max ( f i t_sum2(:)) ∀k13: ch_new ← crossover (sel_t ype1, sel_t ype2)14: add ch_new15: generate (ch_t ype1 (k, n))16: generate (ch_t ype2 (k, n))17: lp ← lp + 118: Endwhile19: g(x, y) ← makespan (sel_t ype1)
where the input of the Algorithm 1 in line 1 (#1) explainsthe jobs that have been received for scheduling for each VM,VMs and jobs number. The #2 is the output of the algo-rithm which includes the minimization of the makespan ofthe objective problem of Eq. (3.1) after selecting the finalchromosome (job transmitting duration is calculated accord-ing to place of eachVMand the channel bandwidthwhich aredifferent). The #3 and #4 create two types of aforementionedchromosomes according to these steps: (i) create some chro-mosomes in which gens are the received jobs, and (ii) in eachtypes of chromosomes the jobs are considered to be assignedto the VMs, put it simply, gene of each chromosome is con-sidered for a particular VM randomly. The while loop in theAlgorithm 1 is the main loop of the system that the stepsof FUGEified approach is described. The termination condi-tions in the while circle is the iteration number (i.e., here wehave assumed 100) or the homolog condition or similarity ofselected chromosomes of both considered types. The #7 and#8 are the results of first and second types of fuzzy functionover cells of each chromosome as two 2-dimensional matri-ces (i.e., k numbers of chromosomes for each type and eachchromosome considered a array with n elements) A and Bare for type 1 and type 2, simultaneously. The #9 and #10represent the summation of the fitness values for both typesof chromosomes in parallel and assigned in f i t_sum1 and
123
Author's personal copy

Cluster Comput (2015) 18:829–844 839
f i t_sum2 for type 1 and type 2, simultaneously. The #11and #12 select the two best (i.e., biggest) chromosomes forthe two types of chromosomes according to their fitness val-ues (i.e., from each type, one chromosome will be selected)and put in sel_t ype1 and sel_t ype2. The line 13 performscrossover operation between the selected chromosomes withthe aid of fuzzy theory (i.e., perform the fuzzy function foreach cell of the two selected chromosomes with job length,VM frequency, VM RAM and VM bandwidth to make anew value between 0 and 1) then compare the values of samejobs/genes of both chromosomes and select the higher valuefor each cell (and assign the cell to its corresponding VMnumber) and produce new chromosome denoted ch_new,then add back the obtained chromosome to the population ofboth types chromosomes (i.e., #14). The #15 and #16performthe new generation as the current generation. Finally, we usethe obtained chromosome for scheduling. It means, we cal-culate the makespan of the obtained chromosome, which is,contains the genes in which the jobs are assigned to the bestresources according to the resource capacities/locations.
5 Performance evaluation
In the following subsections,we discuss the experimental set-up and metrics, types, and results for our simulation study.
5.1 Experimental set-up and metrics
The performance evaluations for the FUGE approach andthe comparison with other algorithms were implemented onCloudSim [24]. CloudSim was developed to support mod-eling and simulation of large-scale cloud computing envi-ronments such as data centers on a single physical machine.CloudSim is used tomodel data centers, hosts, VMs, brokers,and scheduling on a large-scale cloud platform. We assumethat jobs are mutually independent, i.e., there is no prece-dence constraint between jobs, and jobs are not preemptiveand cannot be interrupted or moved to another processor dur-ing their execution. In detail, we set VMs and cloudlets para-meters according to the comparing approaches and choosea selected cloudlet for the VMs assignments. We dynami-cally input thematlab-based fuzzy results into the CloudSim.Then, we consider two chromosomes which are the resultsof crossover based on the fuzzy rules in the matlab as out-puts (i.e., we use VMs and cloudlet parameters as fuzzy inputand select the best VM for each gene of chromosome, notethat jobs for both genes are the same). Finally, in CloudSim,we assign selected cloudlet according to the final output ofthe algorithm (after iterations or finding the proper chromo-some) and calculate the makespan. As a result, the base fun-damental and the heart of the approach is based on fuzzyfunction. There are several existing scheduling optimiza-
tion techniques for clouds; these consider various parameterssuch as performance, resource utilization, matching prox-imity, total weighted completion time, weighted number oftardy jobs, weighted response time, makespan, cost, scala-bility, throughput, resource utilization, load balancing, faulttolerance, migration time, or associated overhead. The per-formance metrics are defined in the paper as follows:
(i) Degree of imbalance (DI): Degree of imbalance is thefactor that is related to load balancing. The DI is calcu-lated by Eq. (6):
DI = Tmax − Tmin
Tavg(6)
where Tmax , Tmin , and Tavg are the maximum, mini-mum, and average total execution times, respectively,among all VMs.
(ii) Makespan: One of the most popular optimization cri-teria is the minimization of the makespan. Makespanindicates the time when the last job finishes. Smallmakespan values mean that the scheduler is providinggood and efficient assignment of jobs to resources. Ingeneral, makespan is calculated by Eq. (7):
minS j∈Schedlist
{
maxj∈ joblist
Fin j
}
(7)
where Fin j denotes the time when job j finalizes, S j
is the current schedule list, Schedlist is the set of allpossible schedules, and joblist is the list of jobs thatare ready in each chromosome.
(iii) Execution time and cost: Execution time is the time thata program is working for each group of chromosomesand the program decides the proper scheduling for thecurrent jobs based on available VMs. Note that machineheterogeneity indicates the variance of the executiontimes of all machines for a given job. It is calculated byEq. (8):
di j = Ltot ( j)
Ai j f j+ Li
Bi j R j, (8)
where di j expresses the expected execution time andtransfer time of job i on V M( j), Ltot ( j) is the totallength of the jobs that has been submitted to V M( j),mis the number of V Mj processors, f j is the frequencyof the processor of V M( j), Ai j and Bi j are the fuzzymembership functions for f j and R j , which are delin-eated in (1), simultaneously. Li is the length of job ibefore execution, and R j is the communication band-width ability of V M( j).
123
Author's personal copy
840 Cluster Comput (2015) 18:829–844
5.2 Experimental types
We have tested our approach based on two separate settingparameters with three groups of similar approaches as fol-lowing:
(i) Type 1: (FUGE-vs.-ACO-vs.-MACO): For the first andsecond experiments, FUGE is compared with the ACOand Multiple ACO (MACO) algorithms [35] in termsof makespan and the degree of imbalance (DI);
(ii) Type 2: (FUGE-vs.-SGA-vs.-MGA): For the third andfourth experiments, FUGE is compared with a SGAand a Modified GA (MGA) [22] with respect to aver-age makespan and execution cost;
(iii) Type 3: (FUGE-vs.-fuzzy neural network): For the fifthexperiment, FUGE is comparedwith a fuzzy neural net-work [23] that implements a fuzzy-based cloud schedul-ing approach.
5.3 Experimental results
5.3.1 Type 1: (FUGE-vs.-ACO-vs.-MACO)
For the first and second experiments, we compared ourapproach with the ACO and multiple ACO (MACO) Algo-rithms [35] in terms of makespan and the DI. These twoexperiments were carried out with 10 data centers, 50 VMs,and 100 to 1,000 cloudlets (jobs) on the simulation platform.Note that, chromosome includes VMs, which are able to bebelong to various data centers. We did not consider channel(network) cost (neither energy nor time) for transferring jobsinto various hosts/data centers. The job lengths ranged from1,000 MI (Million Instructions) to 20,000 MI. The VM fre-quency is Mips (Megabyte per second), VM RAM is MegaByte, Bandwidth isMega Byte per second. Table 4 shows theparameter settings for the first and second experiments.
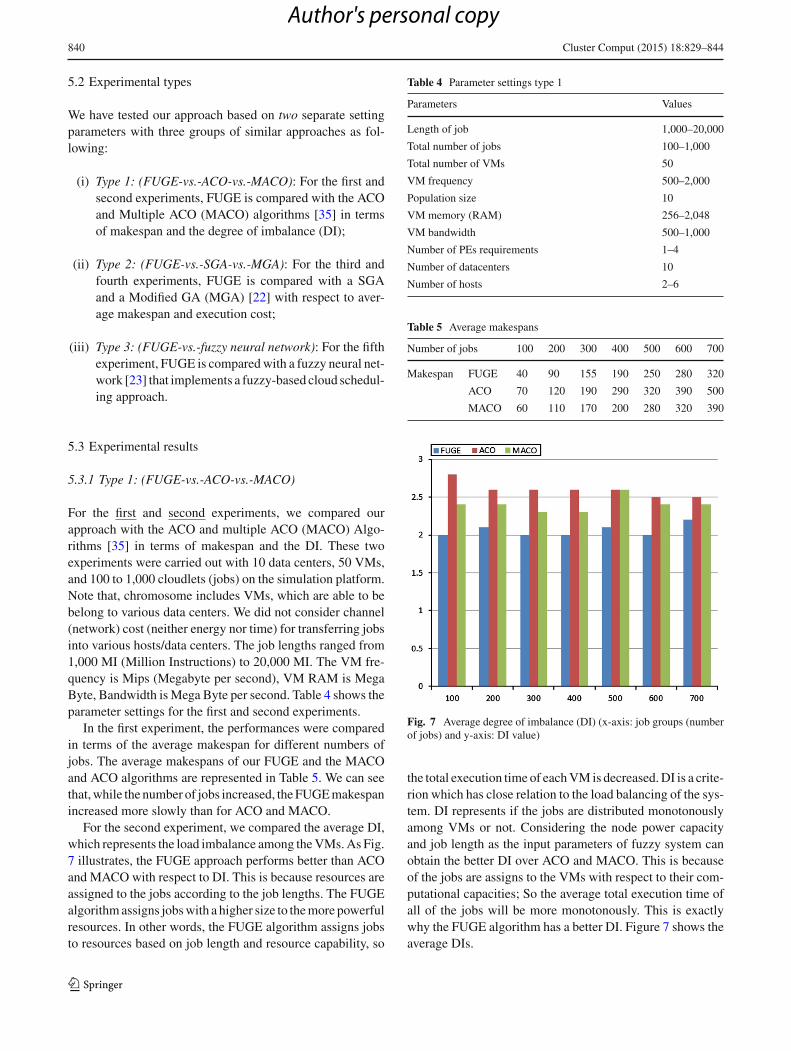
In the first experiment, the performances were comparedin terms of the average makespan for different numbers ofjobs. The average makespans of our FUGE and the MACOand ACO algorithms are represented in Table 5. We can seethat,while the number of jobs increased, theFUGEmakespanincreased more slowly than for ACO and MACO.
For the second experiment, we compared the average DI,which represents the load imbalance among theVMs.As Fig.7 illustrates, the FUGE approach performs better than ACOand MACO with respect to DI. This is because resources areassigned to the jobs according to the job lengths. The FUGEalgorithmassigns jobswith a higher size to themore powerfulresources. In other words, the FUGE algorithm assigns jobsto resources based on job length and resource capability, so
Table 4 Parameter settings type 1
Parameters Values
Length of job 1,000–20,000
Total number of jobs 100–1,000
Total number of VMs 50
VM frequency 500–2,000
Population size 10
VM memory (RAM) 256–2,048
VM bandwidth 500–1,000
Number of PEs requirements 1–4
Number of datacenters 10
Number of hosts 2–6
Table 5 Average makespans
Number of jobs 100 200 300 400 500 600 700
Makespan FUGE 40 90 155 190 250 280 320
ACO 70 120 190 290 320 390 500
MACO 60 110 170 200 280 320 390
Fig. 7 Average degree of imbalance (DI) (x-axis: job groups (numberof jobs) and y-axis: DI value)
the total execution time of eachVM is decreased.DI is a crite-rion which has close relation to the load balancing of the sys-tem. DI represents if the jobs are distributed monotonouslyamong VMs or not. Considering the node power capacityand job length as the input parameters of fuzzy system canobtain the better DI over ACO and MACO. This is becauseof the jobs are assigns to the VMs with respect to their com-putational capacities; So the average total execution time ofall of the jobs will be more monotonously. This is exactlywhy the FUGE algorithm has a better DI. Figure 7 shows theaverage DIs.
123
Author's personal copy
Cluster Comput (2015) 18:829–844 841
Table 6 Parameter settings type 2
Parameters Values
Length of job 10,000–00,000
Total number of jobs 10–30
Total number of VMs 10
VM frequency 100–500
Population size 10
VM memory (RAM) 512–2,048
VM bandwidth 500–1,000
Number of PEs requirements 1–2
Number of datacenters 2
Number of hosts 2
Fig. 8 Average makespan (x-axis: Job numbers and y-axis: makespanin seconds unit)
5.3.2 Type 2: (FUGE-vs.-SGA-vs.-MGA)
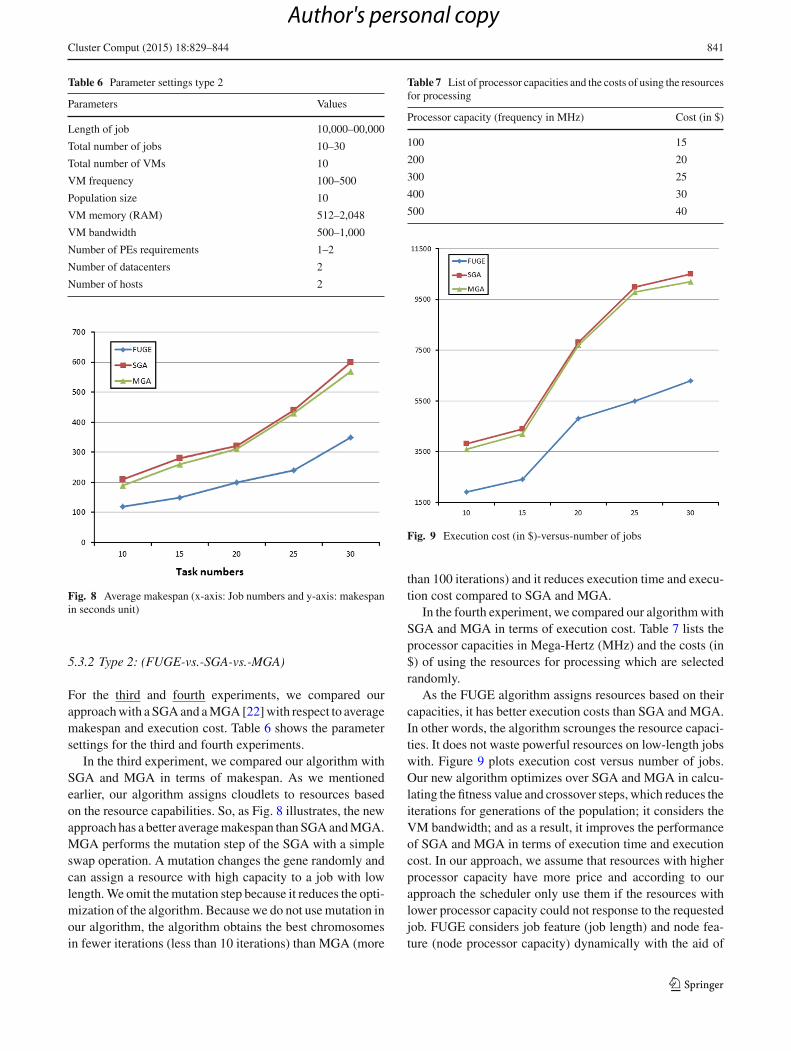
For the third and fourth experiments, we compared ourapproachwith a SGAand aMGA[22]with respect to averagemakespan and execution cost. Table 6 shows the parametersettings for the third and fourth experiments.
In the third experiment, we compared our algorithm withSGA and MGA in terms of makespan. As we mentionedearlier, our algorithm assigns cloudlets to resources basedon the resource capabilities. So, as Fig. 8 illustrates, the newapproach has a better averagemakespan thanSGAandMGA.MGA performs the mutation step of the SGA with a simpleswap operation. A mutation changes the gene randomly andcan assign a resource with high capacity to a job with lowlength.We omit themutation step because it reduces the opti-mization of the algorithm. Because we do not usemutation inour algorithm, the algorithm obtains the best chromosomesin fewer iterations (less than 10 iterations) than MGA (more
Table 7 List of processor capacities and the costs of using the resourcesfor processing
Processor capacity (frequency in MHz) Cost (in $)
100 15
200 20
300 25
400 30
500 40
Fig. 9 Execution cost (in $)-versus-number of jobs
than 100 iterations) and it reduces execution time and execu-tion cost compared to SGA and MGA.
In the fourth experiment, we compared our algorithmwithSGA and MGA in terms of execution cost. Table 7 lists theprocessor capacities in Mega-Hertz (MHz) and the costs (in$) of using the resources for processing which are selectedrandomly.
As the FUGE algorithm assigns resources based on theircapacities, it has better execution costs than SGA and MGA.In other words, the algorithm scrounges the resource capaci-ties. It does not waste powerful resources on low-length jobswith. Figure 9 plots execution cost versus number of jobs.Our new algorithm optimizes over SGA and MGA in calcu-lating the fitness value and crossover steps, which reduces theiterations for generations of the population; it considers theVM bandwidth; and as a result, it improves the performanceof SGA and MGA in terms of execution time and executioncost. In our approach, we assume that resources with higherprocessor capacity have more price and according to ourapproach the scheduler only use them if the resources withlower processor capacity could not response to the requestedjob. FUGE considers job feature (job length) and node fea-ture (node processor capacity) dynamically with the aid of
123
Author's personal copy
842 Cluster Comput (2015) 18:829–844
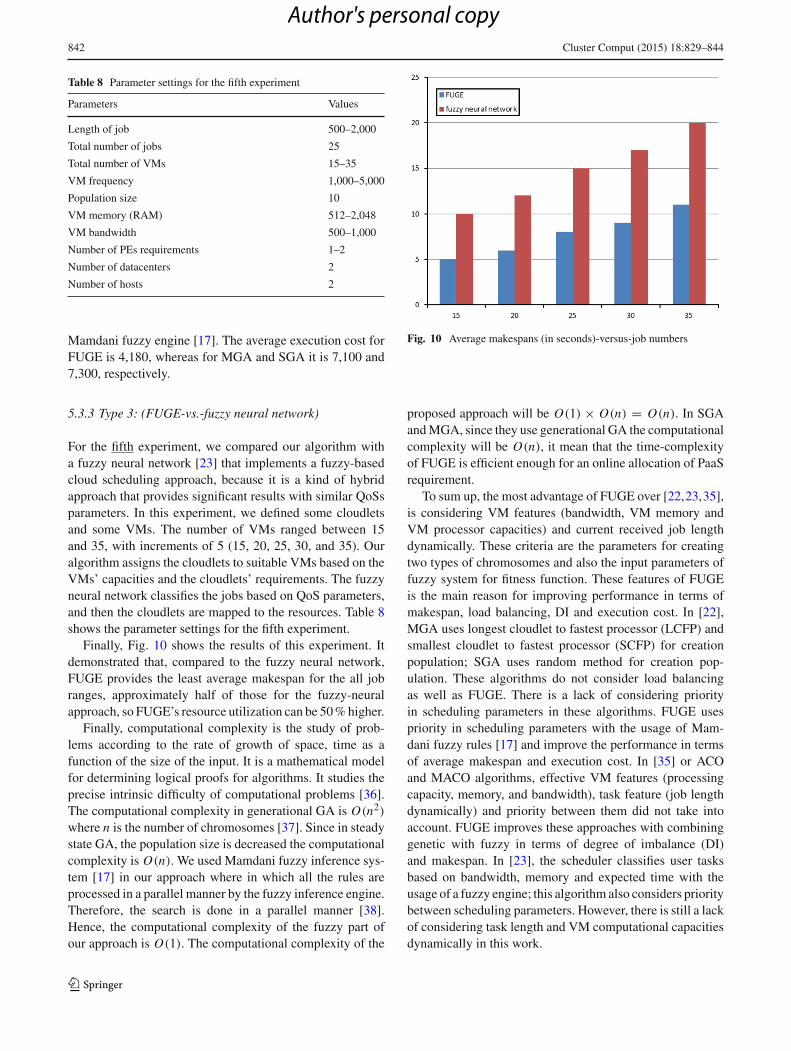
Table 8 Parameter settings for the fifth experiment
Parameters Values
Length of job 500–2,000
Total number of jobs 25
Total number of VMs 15–35
VM frequency 1,000–5,000
Population size 10
VM memory (RAM) 512–2,048
VM bandwidth 500–1,000
Number of PEs requirements 1–2
Number of datacenters 2
Number of hosts 2
Mamdani fuzzy engine [17]. The average execution cost forFUGE is 4,180, whereas for MGA and SGA it is 7,100 and7,300, respectively.
5.3.3 Type 3: (FUGE-vs.-fuzzy neural network)
For the fifth experiment, we compared our algorithm witha fuzzy neural network [23] that implements a fuzzy-basedcloud scheduling approach, because it is a kind of hybridapproach that provides significant results with similar QoSsparameters. In this experiment, we defined some cloudletsand some VMs. The number of VMs ranged between 15and 35, with increments of 5 (15, 20, 25, 30, and 35). Ouralgorithm assigns the cloudlets to suitable VMs based on theVMs’ capacities and the cloudlets’ requirements. The fuzzyneural network classifies the jobs based on QoS parameters,and then the cloudlets are mapped to the resources. Table 8shows the parameter settings for the fifth experiment.
Finally, Fig. 10 shows the results of this experiment. Itdemonstrated that, compared to the fuzzy neural network,FUGE provides the least average makespan for the all jobranges, approximately half of those for the fuzzy-neuralapproach, so FUGE’s resource utilization can be 50%higher.
Finally, computational complexity is the study of prob-lems according to the rate of growth of space, time as afunction of the size of the input. It is a mathematical modelfor determining logical proofs for algorithms. It studies theprecise intrinsic difficulty of computational problems [36].The computational complexity in generational GA is O(n2)where n is the number of chromosomes [37]. Since in steadystate GA, the population size is decreased the computationalcomplexity is O(n). We used Mamdani fuzzy inference sys-tem [17] in our approach where in which all the rules areprocessed in a parallel manner by the fuzzy inference engine.Therefore, the search is done in a parallel manner [38].Hence, the computational complexity of the fuzzy part ofour approach is O(1). The computational complexity of the
Fig. 10 Average makespans (in seconds)-versus-job numbers
proposed approach will be O(1) × O(n) = O(n). In SGAandMGA, since they use generational GA the computationalcomplexity will be O(n), it mean that the time-complexityof FUGE is efficient enough for an online allocation of PaaSrequirement.
To sum up, the most advantage of FUGE over [22,23,35],is considering VM features (bandwidth, VM memory andVM processor capacities) and current received job lengthdynamically. These criteria are the parameters for creatingtwo types of chromosomes and also the input parameters offuzzy system for fitness function. These features of FUGEis the main reason for improving performance in terms ofmakespan, load balancing, DI and execution cost. In [22],MGA uses longest cloudlet to fastest processor (LCFP) andsmallest cloudlet to fastest processor (SCFP) for creationpopulation; SGA uses random method for creation pop-ulation. These algorithms do not consider load balancingas well as FUGE. There is a lack of considering priorityin scheduling parameters in these algorithms. FUGE usespriority in scheduling parameters with the usage of Mam-dani fuzzy rules [17] and improve the performance in termsof average makespan and execution cost. In [35] or ACOand MACO algorithms, effective VM features (processingcapacity, memory, and bandwidth), task feature (job lengthdynamically) and priority between them did not take intoaccount. FUGE improves these approaches with combininggenetic with fuzzy in terms of degree of imbalance (DI)and makespan. In [23], the scheduler classifies user tasksbased on bandwidth, memory and expected time with theusage of a fuzzy engine; this algorithm also considers prioritybetween scheduling parameters. However, there is still a lackof considering task length and VM computational capacitiesdynamically in this work.
123
Author's personal copy

Cluster Comput (2015) 18:829–844 843
6 Conclusions and future directions
In recent years, much attention has been paid to the use ofartificial intelligence approaches such as GAs and fuzzy the-ory in cloud job scheduling. Cloud computing consists ofseveral large numbers of computers connected through a real-time communication network such as the Internet. A cloudprovides the ability to simultaneously run an application onmany connected computers. In this paper, we used a GAas the basis of our approach and modified it with the aid offuzzy theory to assign jobs to the most suitable resources; wecall our approach FUGE . In the FUGE approach, we definetwo types of chromosomes with different QoS parameters.Then, with the aid of fuzzy theory, we obtain the fitness val-ues for all chromosomes of the two types. After that, weperform a modified fuzzy-based crossover operation on thetwo best selected chromosomes. The resulting chromosomeis the output of the first generation; it will be added back intothe population and a new population is created. We assignjobs to resources by considering the job lengths and resourcecapacities. We compared the performance of our approach toseveral other cloud job scheduling models; the results of theexperiments proved the efficiency of our FUGE approach interms of execution time, execution cost, and average degreeof imbalance. The FUGE approach modifies the SGA withthe use of fuzzy theory and improves over the SGA perfor-mance in terms of execution cost by about 45% and in termsof total execution time by about 50%, which are the maingoals of this research.
Our next research plan is to consider energy consump-tion and VMmigration to make efficient, consistence power-saving model. This research will define the types of popu-lation by considering energy needs and execution time. Weplan to propose a new fuzzy-based hybrid GA that considersnot only makespan, but also energy consumption. We wantto further optimize the calculation of the fitness value andcrossover steps by considering the VM energy consumptionas input parameters of the fuzzy system. In this way the algo-rithm can assign resources for reducing the execution timeand VM energy consumption.
References
1. Mezmaz,M., et al.: A parallel bi-objective hybrid metaheuristic forenergy-aware scheduling for cloud computing systems. J. ParallelDistrib. Comput. 71(11), 1497–1508 (2011)
2. Armbrust, M., et al.: A view of cloud computing. Commun ACM53(4), 50–58 (2010)
3. Dikaiakos, M.D., Pallis, G., Katsaros, D., Mehra, P., Vakali, A.:Cloud computing: distributed Internet computing for IT and scien-tific research. IEEE Internet Comput. 13(5), 10–13 (2009)
4. Rimal, B. P., Eunmi, C., Lumb, I. A.: Taxonomy and Survey ofCloudComputingSystems. In: Fifth International JointConferenceon INC, IMS and IDC, Seoul, 2009, pp. 44–51.
5. Li, Q., Yike, G.: Optimization of resource scheduling in cloud com-puting. IEEE SYNASC, Timisoara (2010)
6. Cordeschi, N., Shojafar, M., Baccarelli, E.: Energy-saving self-configuring networked data centers. Computer Networks 57(17),3479–3491 (2013)
7. Goldberg, D.E., Holland, J.H.: Genetic algorithms and machinelearning. Mach. Learn. 3(2–3), 95–99 (1988)
8. Vas, P.: Artificial-intelligence-based electrical machines anddrives: application of fuzzy, neural, fuzzy-neural, and genetic-algorithm-based techniques. Oxford University Press, Oxford(1999)
9. T. Takagi,M. Sugeno, Fuzzy identification of systems and its appli-cations tomodeling and control. In: IEEETransactions on Systems,Man and Cybernetics, SMC- 15(1)1 116–132 (1985).
10. Javanmardi, S., Shojafar, M., Amendola, D., Cordeschi, N., Liu,H., Abraham, A.: Hybrid job scheduling algorithm for cloudcomputing environment. Adv. Intell. Syst. Comput. 303, 43–52(2014)
11. Javanmardi, S., Shojafar, M., Shariatmadari, Sh, Abawajy, J.H.,Singhal, M.: PGSW-OS: a novel approach for resource manage-ment in a semantic web operating system based on a P2P grid archi-tecture. The Journal of Supercomputing 69(2), 955–975 (2014)
12. Randles, M., Lamb, D., Taleb-Bendiab, A.: A comparative studyinto distributed load balancing algorithms for cloud computing. In:IEEE Advanced Information Networking and Applications Work-shops (WAINA), pp. 551–556. WA, Perth (2010)
13. X. Baowen, G. Yu, Ch. Zhenqiang, K. R. P. H. Leung, Parallelgenetic algorithms with schema migration. In: Computer Softwareand Applications Conference (COMPSAC), pp. 879–884 (2002).
14. Zhongni, Z., Wang, R., Hai, Z., Xuejie, Z.: An approach forcloud resource scheduling based on Parallel Genetic Algorithm.In: ICCRD IEEE Shanghai, China, 2, 444–447 (2011)
15. Hu, J., Jianhua, G., Guofei, S., Tianhai, Z.: A Scheduling Strategyon Load Balancing of Virtual Machine Resources in Cloud Com-puting Environment. In: IEEE PAAP. pp. 89–96. Dalian, China(2010)
16. Singh, R.M., Sendhil Kumar, K.S., Jaisankar, N.: Comparison ofprobabilistic optimization algorithms for resource scheduling incloud computing environment. Int. J. Eng. Technol. 5(2), 1419–1427 (2013)
17. Mamdani, E.H.: Application of fuzzy algorithms for control of sim-ple dynamic plant. In: Proceedings of the Institution of ElectricalEngineer, IET Digital Library 121(12), 1585–1588 (1974)
18. Vignesh, V., Sendhil, K.S., Jaisankar, N.: Resource Managementand Scheduling in Cloud Environment. Int. J. Sci. Res. Publ. 3(6),1–6 (2013)
19. Beloglazov, A., Buyya, R.: Energy Efficient Resource Manage-ment in Virtualized Cloud Data Centers. In: 10th IEEE/ACMInternational Conference on Cluster, Cloud and Grid Computing(CCGRID), Melbourne, Australia, pp. 826–831 (2010).
20. Chen, S., Wu, J., Lu, Z.: A Cloud Computing Resource Schedul-ing Policy Based on Genetic Algorithm with Multiple Fitness. In:IEEE 12th International Conference on Computer and InformationTechnology, Chengdu, pp. 177–184 (2012)
21. Sh. Sawant, A Genetic Algorithm Scheduling Approach for Vir-tual Machine Resources in a Cloud Computing Environment, MscThesis, (2011)
22. Kaur, S., Verma, A.: An efficient approach to genetic algorithmfor job scheduling in cloud computing environment. Int. J. Info.Technol. Comput. Sci. 4(10), 74–79 (2012)
23. Kumar, V.V., Dinesh, K.: Job scheduling using fuzzy neural net-work algorithm in cloud environment. Int. J. Man Mach. Interface2(1), 1–6 (2012)
24. Calheiros, R.N., Ranjan, R., Beloglazov, A., De Rose, C.A.F.,Buyya, R.: CloudSim: a toolkit for modeling and simulation ofcloud computing environments and evaluation of resource pro-
123
Author's personal copy

844 Cluster Comput (2015) 18:829–844
visioning algorithms. Software: Pract. Experience 41(1), 23–50(2011)
25. Abirami, S.P., Ramanathan, Sh: Linear scheduling strategy forresource allocation in cloud environment. International Journal onCloud Computing: Services and Architecture (IJCCSA) 2(1), 9–17(2012)
26. Foster, I., Zhao, Y., Raicu, I., Lu, S.: Cloud Computing and GridComputing 360-DegreeCompared,GridComputingEnvironmentsWorkshop (GCE ’08), pp. 1–10. Austin, TX, (2008)
27. Beloglazov, A., Buyya, R.: Managing Overloaded Hosts forDynamic Consolidation of VirtualMachines in CloudData Centersunder Quality of Service Constraints. IEEE Trans. Parallel Distrib.Syst. 24(7), 1366–1379 (2013)
28. Buyya, R., Broberg, J., Goscinski, A.M.: Cloud computing: prin-ciples and paradigms. John Wiley and Sons, New York (2011)
29. Joyent official Site. http://www.joyent.com/. Accessed 201430. Microsoft’s Windows Azure official Site. https://azure.microsoft.
com/. Accessed 201431. Rackspace official Site. www.rackspace.com/. Accessed 201432. Dadgar, M., Hosseini, M.V., Merati, A.A., Sarkheyli, A.: Compar-
ison of Mamdani and Sugeno fuzzy inference system in predictionof residual frieze effect of frieze carpet yarns. Tekstilna Industrija61(2), 16–25 (2013)
33. Javanmardi, S., Shariatmadari, Sh, Mosleh, M.: A novel decentral-ized fuzzy based approach for grid resource discovery. Int. J. Innov.Comput. 3(1), 23–32 (2013)
34. Javanmardi, S., Shojafar, M., Shariatmadari, Sh, Ahrabi, S.S.: FRTRUST: a fuzzy reputation based model for Trust management insemantic P2P grids. Int. J. Grid Utility Comput. 6(1), 57–66 (2015)
35. Medhat, A.T., Ashraf, E.S., Arabi, E.K., Fawzy, A.T.: Hybridjob scheduling algorithm for cloud computing environment. Adv.Intell. Syst. Comput. 303, 43-52 (2014), Atlantis Press, pp. 169–172 (2013)
36. Du, D.-Z., Ko, K.-I.: Theory of computational complexity. JohnWiley and Sons, New York (2011)
37. Ephzibah, E.P.: Time complexity analysis of genetic-fuzzy systemfor disease diagnosis, Advanced Computing, 2(4), 23–31 (2011)
38. Lotfi Zadeh, A.: A computational approach to fuzzy quantifiers innatural languages. Computers Math. Appl. 9(1), 149–184 (1983)
Mohammad Shojafar is cur-rently aPh.D. student in Informa-tion and Communication Engi-neering at DIET Dept. of the “LaSapienza” University of Rome.He Received hisMsc in SoftwareEngineering in Qazvin IslamicAzad University, Qazvin, Iranin 2010. Also, he Received hisBsc in Computer Engineering-Software major in Iran Univer-sity Science and Technology,Tehran, Iran in 2006. His cur-rent research focuses on wire-less communications, distributed
computing and mathematical and AI optimization. He is an author/co-author of 35+ peer-reviewed publications (h-index=7) in well-knownconferences (e.g., IEEE PIMRC, HIS, ISDA) and journals in IEEE,Elsevier, IOS press and Springer publishers. Since 2013, he is themembership of IEEE Systems Man and Cybernetics Society Techni-cal Committee on Soft Computing and a Distinguished Lecturer ofIEEE Computer Society representing Europe. In addition, Mohammadwas a Programmer and Analyzer in Exploration Directorate Section atN.I.O.C in Iran from 2012-2013.
Saeed Javanmardi is theresearcher and programmer inresearch and educational cen-ter in Nikan network com-pany in Fars, Iran since Janu-ary 2015. Saeed received theMscin computer engineering fromIslamic Azad University, Dez-foul Branch, Iran (2010-2013).His current research interestsare in Fuzzy theory, Seman-tic Web,Grid resource discoverybased on P2P and cloud comput-ing. He published several con-ference and journal papers in his
interests such IJGUS, International Journal of Innovative Computing,and Springer SUPE.
Saeid Abolfazli is currently aPh.D. candidate, research assis-tant in High Impact ResearchProject (Mobile Cloud Comput-ing: Device and Connectivity)fully funded by Malaysian Min-istry of Higher Education, andpart time lecturer in the Depart-ment of Computer Systems andTechnology at the University ofMalaya, Malaysia. He receivedhis M.Sc. in Information Sys-tems in 2008 from India and B.E.(Software Engineering) in 2001from Iran. He has been serving as
CEO of Espanta Information Complex during 1999–2006 in Iran. Healso was part time lecturer to the ministry of education and KhorasanTechnical and Vocational Organization between 2000 and 2006. He isa member of IEEE society and IEEE CS Cloud Computing STC. Hehas been serving as a reviewer for several international conference andISI journals of computer science. His main research interests includeMobile Cloud Computing, lightweight protocols, and service orientedcomputing (SOC).
Nicola Cordeschi received theLaurea degree (bachelor) inCommunication Engineeringfrom the University of Rome “LaSapienza” in 2004. He receivedthe Ph.D. degree in Informationand Communication Engineer-ing in 2008. His Ph.D. disser-tation was on the adaptive QoSTransport of Multimedia overWireless Connections via cross-layer approaches based on theCalculus of Variations. He is cur-rently a Contractor-Researcherwith the DIET Dept., University
of Rome “La Sapienza”. His research activity is focused on wirelesscommunications and deals with the design and optimization of high per-formance transmission systems for wireless multimedia applications.Nicola published more 70+ papers in several well-known IEEE Trans-action and Elsevier journals in his research.
123
Author's personal copy
Top Related

Copyright © 2022 FDOKUMEN

