







Bahasa
Halaman
Hukum


Enabling Task-level Scheduling on HeterogeneousPlatforms ∗
Enqiang Sun1, Dana Schaa1, Richard Bagley2, Norman Rubin2, and David Kaeli1
1Department of Electrical and Computer Engineering, Northeastern University, Boston MA, USA
{esun, dschaa, kaeli}@ece.neu.edu
2Graphics Product Group, Advanced Micro Devices, Boxborough MA, USA
{Richard.Bagley, Norman.Rubin}@amd.com
ABSTRACTOpenCL is an industry standard for parallel programmingon heterogeneous devices. With OpenCL, compute-intensiveportions of an application can be offloaded to a variety ofprocessing units within a system. OpenCL is the first s-tandard that focuses on portability, allowing programs tobe written once and run seamlessly on multiple, heteroge-neous devices, regardless of vendor. While OpenCL has beenwidely adopted, there still remains a lack of support for au-tomatic task scheduling and data consistency when multipledevices appear in the system. To address this need, we havedesigned a task queueing extension for OpenCL that pro-vides a high-level, unified execution model tightly coupledwith a resource management facility. The main motivationfor developing this extension is to provide OpenCL program-mers with a convenient programming paradigm to fully uti-lize all possible devices in a system and incorporate flexiblescheduling schemes. To demonstrate the value and utility ofthis extension, we have utilized an advanced OpenCL-basedimaging toolkit called clSURF. Using our task queueing ex-tension, we demonstrate the potential performance opportu-nities and limitations given current vendor implementationsof OpenCL. Using a state-of-art implementation on a sin-gle GPU device as the baseline, our task queueing extensionachieves a speedup up to 72.4%. Our extension also achievesscalable performance gains on multiple heterogeneous GPUdevices. The performance trade-offs of using the host CPUas an accelerator are also evaluated.
Categories and Subject DescriptorsC.1.3 [Processor Architectures]: Other Architecture Styles– Heterogeneous (hybrid) systems
∗The work in this paper began while Enqiang Sun and DanaSchaa were interns at Advanced Micro Devices.
Permission to make digital or hard copies of part or all of this work forpersonal or classroom use is granted without fee provided that copies are notmade or distributed for profit or commercial advantage and that copies bearthis notice and the full citation on the first page. Copyrights for componentsof this work owned by others than ACM must be honored. Abstracting withcredit is permitted. To copy otherwise, to republish, to post on servers or toredistribute to lists, requires prior specific permission and/or a fee.GPGPU-5, March 03 2012, London, United KingdomCopyright 2012 ACM 978-1-4503-1233-2/12/03...$10.00.
KeywordsHeterogeneous computing, Task scheduling, OpenCL, Par-allel programming
1. INTRODUCTIONHeterogeneous platforms such as AMD’s Fusion [10] andIntel’s Sandybridge [5] augment the superscalar power ofmainstream CPUs with on-chip, high-throughput, GPUs.Although GPUs were historically used almost exclusivelyfor graphics, they have now also emerged as the platformof choice for accelerating data parallel applications. Unlikethe ubiquity of the x86 architecture and the long lifecycle ofCPU designs, GPUs often have much shorter release cyclesand ever-changing ISAs and hardware features. As such,the need has arisen for a programming interface that allowsa single, general-purpose (i.e., non-graphics) program to beportable to a wide range of accelerator hardware.
1.1 Heterogeneous Computing with OpenCLThe emerging software framework for programming for het-erogeneous devices is the Open Computing Language (Open-CL) [8]. OpenCL is an open industry standard managed bythe non-profit technology consortium Khronos Group, andsupport for OpenCL has been increasing from major compa-nies such as Apple, AMD, NVIDIA, Intel, Imagination andS3.
The aim of OpenCL is to become a universal language forprogramming heterogeneous platforms such as GPUs, C-PUs, DSPs, and FPGAs. In order to support such a widevariety of heterogeneous devices, some elements of the Open-CL API are necessarily low-level. As with the CUDA/C lan-guage [7], OpenCL does not provide support for automat-ic task scheduling nor guarantee global data consistency–itis up to the programmer to explicitly define tasks and en-queue them on devices, and to move data between deviceswhen necessary. Furthermore, when OpenCL implementa-tions from different vendors are used, OpenCL objects in thecontext of one vendor’s implementation are not valid in an-other’s. Given these limitations, there is still remain barriersto achieving straightforward heterogeneous computing.
1.2 An Improved Task Queueing APIIn this work we propose a task-queueing API extension forOpenCL that helps ameliorate many of the burdens faced
84

when performing heterogeneous programming. Our task-queueing interface is based on the concepts of work pools andwork units, and provides a convenient mechanism to executeapplications on heterogeneous hardware platforms. Usingthe API, programmers can easily develop and tune flexiblescheduling schemes according to the hardware configuration.
In the task-queueing API, OpenCL kernels within an appli-cation are wrapped with metadata into work units. Thesework units are then enqueued into a work pool and assignedto computing devices by a scheduler. A resource manage-ment system is seamlessly integrated in this API to pro-vide for migration of kernels between devices and platforms.We demonstrate the utility of this class of task queueingextension by implementing a large, non-trivial application,clSURF, which is an OpenCL open-source implementation ofOpenSURF (Open source Speeded Up Robust Feature) [17].
Our work pool-based, task-queueing API provides the fol-lowing benefits for OpenCL programmers:
• simple extensions to OpenCL built on top of the cur-rent API,
• automated utilization of all devices present in a sys-tem,
• a mechanism for easily applying different schedulingschemes to investigate execution on cooperating de-vices, and
• a means to evaluate the potential benefits of heteroge-neous versus discrete architectures by profiling multi-device performance.
The rest of the paper is organized as follows. In Section 2we provide a review of heterogeneous computing interfaces,and the SURF algorithm with existing implementations. InSection 3, we describe our OpenCL task-queueing extensionand how it facilitates the effective use of heterogeneous plat-forms. In Section 4, we demonstrate the capabilities of ourAPI by evaluating the performance of the SURF algorithmon heterogeneous platforms. Finally, in Section 5, we con-clude and discuss directions for future work.
2. BACKGROUND AND RELATED WORK2.1 Heterogeneous ComputingSeveral projects have investigated how to alleviate the pro-grammer from the burden of managing hybrid or heteroge-neous platforms.
Qilin [24] uses offline profiling to obtain information abouteach task on each computing device. This information isthen used to partition tasks and create an appropriate per-formance model for the targeted heterogeneous platforms.However, the overhead to carry out the initial profiling phasecan be prohibitive and may be inaccurate if computation be-havior is heavily input dependent.
IBM’s OpenCL Common Runtime [4] is an OpenCL abstrac-tion layer designed for improving the OpenCL programmingexperience by managing multiple OpenCL platforms and du-plicated resources. It minimizes application complexity by
presenting the programming environment as a single Open-CL platform. Shared OpenCL resources, such as data buffer-s, events, and kernel programs are transparently managedacross the installed vendor implementations. The result issimpler programming in heterogeneous environments. How-ever, even equipped with this commercially-developed Com-mon Runtime, scheduling decisions, data synchronization,and other multi-device functionality must still be manuallyperformed by the programmer.
StarPU [14] is a simple tasking API that provides numericalkernel designers with a convenient way to execute paralleltasks on heterogeneous platforms, and incorporates a num-ber of different scheduling policies. StarPU is based on theintegration of a resource management facility with a taskexecution engine. Several scientific kernels [22][13] [12][11]have been deployed on StarPU to utilize the computing pow-er of heterogeneous platforms. However, StarPU is imple-mented in C and the basic schedulable units (codelets) haveto be implemented multiple times if they are targeting mul-tiple devices. This limits the migration of the codelets acrossplatforms, and increases the programmer’s burden. To over-come this limitation, StarPU has initiated a recent effort toincorporate OpenCL [21] as the frontend.
Build Integral Image
Calculate Hessian Determinant
Non-max Suppression
Calculate Orientation
Calculate and Normalize Descriptors
I
II
Figure 1: The Program Flow of clSURF
Maestro [27] is an open source library for data orchestra-tion on OpenCL devices. It provides automatic data trans-fer, task decomposition across multiple devices, and auto-tuning of dynamic execution parameters for selected prob-lems. However, Maestro focuses mainly on data manage-ment, and lacks the ability to run on applications with com-plex program flow and/or data dependencies.
Grewe et al. [20] propose a static partitioning model forOpenCL programs on heterogeneous CPU-GPU systems.The model focuses on how to predict and partition the dif-ferent tasks according to their computational characteristics,and does not abstract to any common programming inter-
85

face that would enable more rapid adoption.
Apart from StarPU [14], none of the above approaches fo-cus on task partitioning and do not discuss how to exploittask-level parallelism that is commonly present in large anddiverse applications. We address this issue by enhancingOpenCL programming with a resource management facility.
2.2 SURF in OpenCLThe SURF application was first presented by Bay et al. [15].The basic idea of SURF is to summarize images by using on-ly a relatively small number of interesting points. The algo-rithm analyzes an image and produces feature vectors for ev-ery interesting point. SURF features have been widely usedin the real life applications such as object recognition [25],feature comparison and face recognition [23]. Numerousprojects have implemented elements of SURF in parallel us-ing OpenMP [28], CUDA [29, 19] and OpenCL [26]. Wereference the state-of-art OpenCL implementation, clSUR-F, and use it as the baseline for performance comparison inthis paper.
Figure 1 shows the program flow of clSURF for processing animage or one frame of a video stream. The whole programflow of clSURF is implemented as several stages, and thesestages can be further separated into two phases. In the firstphase, the amount of computation is mainly influenced bythe size of the image. In the second phase, the amount of thecomputation depends more on the number of the interestingpoints, which is a reflection of the complexity of the image.
Previous work has also evaluated SURF on hybrid or hetero-geneous platforms[18]. However, they concentrate on speed-ing up the algorithm and do not explore scheduling on mul-tiple devices of a platform.
3. A TASK QUEUEING EXTENSION FOROPENCL
Next, we describe our OpenCL extension in detail, and con-sider some of the design decisions made before arriving atour task queueing extension.
3.1 Limitations of the OpenCL Command–Queue Approach
In OpenCL, command queues are the mechanisms for thehost to interact with devices. Via a command queue, thehost submits commands to be executed by a device. Thesecommands include the execution of programs (called kernel-s), as well as data transfers. The OpenCL standard specifiesthat each command queue is only associated with a singledevice; therefore if N devices are used, then N commandqueues are required. There are a number of factors that canlimit performance when kernel execution runs across multi-ple devices.
3.1.1 Working with Multiple DevicesWhen a CPU and GPU are present in a system, the CPUcan potentially help with the processing of some workloadsthat would normally be offloaded entirely to the GPU. Usingthe CPU as a compute device requires creating a separatecommand queue, and specifying which commands should be
sent to that queue. To allow for this, we need to decidewhich workloads will target the CPU at compile time. Atruntime, once a kernel is enqueued on a command queue,there is no mechanism for a command to be removed froma queue or assigned to another queue. Effective schedulingthus requires that we profile the kernel on both platforms,compute the relative performance, and divide the work ac-cordingly. The disadvantages of this approach are: 1) theCPU may have some unknown amount of work to do be-tween calls, 2) the performance of one or both devices mayvary based on the exact input data used, 3) the host CPUmay be executing unrelated tasks which may be difficult toidentify and throw noise into the profile.
Working with multiple GPU devices presents a similar prob-lem. If multiple devices are used to accelerate the execu-tion of a single kernel, we would still need to statically pre-partition the data. This is especially tricky with heteroge-neous GPUs, as it does not allow for the consideration ofruntime factors such as delays from bus contention, compu-tation time changes based on input data sets used, relativecomputational power, etc..
If multiple devices are used for separate kernels, we wouldhave to add code to either split the kernels between devices,or change the targeted command queue based on some otherfactors (e.g., number of loop iterations). Creating an algo-rithm that divides multiple tasks between a variable numberof devices is not a trivial undertaking.
Perhaps the most persuasive argument for changing the cur-rent queueing model is the fact that it limits effective useof Fusion-like devices. If multiple tasks are competing torun concurrently a Fusion processor, one of the tasks mayelect to run on the GPU, but if the device is already busy,it may be acceptable to run the specific tasks or kernel onthe CPU. Unless we introduce new functionality that al-lows swapping contexts on the GPU, we are limited to usingthe current model which restricts programs that target theGPU to wait until all previous kernels have completed exe-cution. Even if swapping is implemented, there may be justtoo many tasks attempting to share the GPU, and executionmay be preferable to waiting a long time.
3.2 The Task Queueing APIInstead of using command queues to communicate with de-vices (one command queue per device), we introduce workpools as an improved task queueing extension to OpenCL.Work pools function similarly to command queues, exceptthat a work pool can automatically target any device in thesystem. In order to manage execution between multiple de-vices, OpenCL kernels need to be combined with additionalinformation and wrapped into structures called work units.
Figure 2 shows the components in the work pool-based taskqueueing extension layer that runs on top of OpenCL. Oncekernels are wrapped into work units, they can be enqueuedinto a work pool by the enqueue engine. On the back end,the scheduler can dequeue work units which are ready toexecute (i.e., have all dependencies resolved) on one of thedevices in the system. Each work pool has access to all ofthe devices on the platform. It is possible to define multiplework pools and enqueue/dequeue engines.
86

Dequeue
Engine
Enqueue
Engine
OpenCL Interface and Device Driver
Task-Queueing Extension Application Program Interface
Enqueue
Engine
Dequeue
Engine
Work Unit Queue
Resource Management Unit
Figure 2: Scheduling work units from work pools to multiple devices.
If there is task-level parallelism in the host code, it maymake sense to create multiple work pools that correspondto different scheduling algorithms. From a practical stand-point, creating multiple work pools to assign kernels to thesame device may increase device utilization.
The following subsections more clearly define the concept-s used in our task queueing API. The API functions thatimplement these concepts are described in detail in Sec-tion 3.2.7.
3.2.1 Work UnitsIn the task-queueing API, work units are the basic schedula-ble units of execution. A work unit consists of dependenciesthat need to be resolved prior to execution of the OpenCLkernel (cl_kernel).
When a work unit is created, the programmer optionallysupplies a list of work units that must complete execution be-fore the current work unit can be scheduled. This function-ality is similar to the current OpenCL standard, where eachclEnqueue function takes as an argument a list of cl_eventsthat must be complete before the command is executed.
To enable a work unit to execute on any device, the OpenCLkernel is pre-compiled for all devices in the system. Whenthe work unit is scheduled for execution, the kernel corre-sponding to the chosen device is selected.
3.2.2 Work PoolsA work pool is a structure that contains a collection ofwork units to be executed, and details related to resourcemanagement functionality (Section 3.2.5). A scheduler (Sec-tion 3.2.6) interacts with each work pool, dequeueing and ex-ecuting work units according to their accompanying depen-dency information. Equipped with dependency informationfor each work unit, the work pool has available system-wideinformation so it can make informed scheduling decisions.
The work pool also has detailed knowledge of the system(such as the number and types of devices), and has the a-bility to work with multiple devices from different vendors(Section 3.2.4). The resource management unit tracks the
status of all the resources, including memory objects andevents, and does so on a device-by-device basis.
3.2.3 Enqueue and Dequeue Engine
CPU Execution
CPU Idle
GPU Execution
GPU Idle
(a)Baseline Implementation (b)Work Pool Implementation
CPU Enqueue
CPU Dequeue
Figure 3: CPU and GPU execution
The enqueue and dequeue operations on the work pool are t-wo independent CPU threads, and a mutex is used to protectthe queue of the work units. During the enqueue operation,if the kernel arguments and work-item configuration infor-mation (i.e., the NDRange and work group dimensions) arealready available, they will be packaged together with thework units; if the information is dynamically generated bya dependent work unit, we rely on a callback mechanismthat allows the user to inject initialization and finalization
87

functions which are executed before and after the executionof the work unit, respectively.
In the baseline implementation of clSURF application, thekernel execution on the GPU and the host program execu-tion on the CPU (e.g. program flow control, data structureinitialization and image display, etc), are synchronized witheach other, as illustrated in Figure 3(a). By using separateenqueue and dequeue threads and the callback mechanis-m, we can execute some of the CPU host programs asyn-chronously with the GPU kernel execution. This usually re-sults in achieving higher utilization for the GPU commandqueue and an overall performance gain for the application(Section 4.2).
3.2.4 Common Runtime LayerIn OpenCL, the scope of objects (such as kernels, buffers,events, etc) are limited to a context. When an object is cre-ated, a context must always be specified, and objects thatare created in one context are not visible by another context.This becomes a problem when devices from different vendorsare used. If a programmer wanted to use an AMD GPU andan NVIDIA GPU simultaneously, they would need to installboth vendors’ OpenCL implementations–AMD’s implemen-tation can interact with AMD GPUs and any x86 CPU;NVIDIA’s implementation can only interact with NVIDI-A GPUs. With the current OpenCL specification, contextscannot span different vendor implementations. This mean-s that the programmer would have to create two contexts(one per implementation), and initialize both of them. Theprogrammer would also have to explicitly manage synchro-nization between contexts, including transferring data andensuring dependencies are satisfied.
Using our work pool-based approach, we remove the handi-cap of restricting object scope by device type and implementa common runtime layer in the work pool back-end. Eachindividual work pool directly manages the task of objec-t consistency and synchronization across multiple contexts.Providing this new level of flexibility can avoid some of theoverhead associated with dependence on a full-blown com-mon runtime layer.
3.2.5 Resource ManagerIn the current OpenCL environment, when many devicesare used with OpenCL, memory objects must be managedexplicitly by the programmer. If kernels that use the samedata run on different devices, the programmer must alwaysbe aware of which device updated the buffer last, and trans-fer data accordingly. Using our task queueing API, the pro-grammer cannot predict apriori which device each kernel willexecute on, so we have designed it to act as an automatedresource manager that manages memory object consistencybetween devices.
When using our new OpenCL task queuing API, prior toexecution, the programmer must explicitly inform the APIthat it wishes to use a block of memory as the input to akernel by passing the associated data pointer. The resourcemanager then determines whether the data buffer is alreadypresent on that device. If this is the first time the data isused or if the valid version of the data is on another device, adata transfer will be initiated, and the new valid data buffer
will be moved to the target device. If the data is alreadypresent on the correct device, no action is required. Sincethe data transfer time overhead is not negligible, memory co-herency between data buffers could be an issue. Instead, da-ta is transferred as necessary prior to kernel dispatch. Thisdata management scheme can be easily extended to avoiddata transfers altogether if all devices use a unified memory(such as the AMD Fusion). In the current implementation,the resource manager assumes that data sizes are smallerthan the capacity of any one single device.
Table 1: The Extension API Classes and Methodsclass work pool Descriptioninit Initialize a work pool, define the
capacity and initialize a buffer tableget context Get information of all possible OpenCL
devices in the systemenqueue Enqueue a new work unit into the work
pooldequeue Extract a ready work unit and
distribute to devicerequest buffer Request a new or existing buffer for the
data represented in pointersquery Query the information about next work
unitclass work unit Descriptioninit Initialize a work unit
compile program Compile the OpenCL kernel file for allpossible devices
create kernel Create the OpenCL kernel for allpossible devices
set argument Register the arguments to themetadata of the work unit
set worksize Register the work item configurationinformation to the metadata
describe dep Incorporate dependency informationtogether with the work unit
3.2.6 SchedulerThe scheduler continuously dequeues ready work units outof work pool according to the defined scheduling policy. Itevaluates the dependency information associated with thework units enqueued in the work pool and uses the specifiedpolicy to determine which work unit to execute next and onwhich device.
When work units are created, the values of the kernel argu-ments and work-item configuration information may or maynot be available. If the information is not available, workunits can still be enqueued into the work pool, but cannotbe executed until the information is provided. To updatea work unit with this information, a callback mechanism isprovided for the programmer.
For example, in the clSURF application, the work-item con-figuration information for the work units in the second phaseis determined by the number of interest points, which is theoutput data that was computed during the first phase of theapplication. We program the initialization and finalizationin the callback functions of related work units so that thenumber of interesting points is updated after the work units
88

are already enqueued.
The scheduler currently employs a static scheduling policy,where the programmer decides which device a kernel will beexecuted on. In future work we will improve the schedulerto make this mapping at runtime, allowing for decisions tobe made more dynamically.
3.2.7 Task-Queueing APIThe task-queueing API extension is designed to facilitate theexecution of OpenCL applications on multiple devices in aneasy and efficient way. On top of OpenCL programmingAPI, the extension API includes two basic classes: workpool and work unit. Table 1 shows a brief description ofthese two classes and their methods.
The work pool class initializes the whole task queue system,and has the knowledge of all OpenCL devices present in thesystem. It also allocates and coordinates resources acrossdevices.
The work unit class concentrates more on the kernel itself.Besides packaging the compiled kernels for all possible de-vices, it also incorporates any dependency information.
Code listing 1 shows an example of how to declare a workunit and provides commands to enqueue/dequeue this workunit to the work pool.
work unit i n t e g r a l s c a n ( work pool in ,NULL,‘ ‘ scan . c l ’ ’ ,‘ ‘ scan ’ ’ ,dep frame [SCAN] ,k e r n e l l i s t ,SCAN,&s t a t u s ) ;
i n t e g r a l s c a n . set argument ( index ,da ta s i z e ,ARG TYPE CL MEM,( void ∗)&data ,CL TRUE) ;
i n t e g r a l s c a n . s e t w o r k s i z e ( globalWorkSize ,localWorkSize ,dim ) ;
work pool−>enqueue(& i n t e g r a l s c a n , &s t a t u s ) ;
work pool−>dequeue ( poo l contex t [ d e v i c e i d x ] ,initFun ,&args ,f i na l i z eFun ,&args ,&s t a t u s ) ;
Listing 1: Example code of enqueueing or dequeue-ing work unit
4. EXPERIMENTS AND RESULTS4.1 Experimental EnvironmentTo evaluate our new work pool-based implementation of theclSURF algorithm, the application is benchmarked on three
different heterogeneous platforms: two platforms containingmultiple GPUs of different type, and one AMD Fusion A-PU (CPU and GPU on the same chip). Section 4.2 andSection 4.3 evaluates our task-queueing extension and theperformance on single and multiple discrete GPUs, whileSection 4.4 evaluates the usefulness of using the host CPUas a compute device.
The first platform has installed one AMD FirePro V9800PGPU [2] and one AMD Radeon HD6970 GPU [3]. The AMDFirePro V9800P GPU has 20 SIMD engines (16-wide) whereeach core is a 5-way VLIW, for a total of 1600 streamingprocessors running at 850MHz. The AMD Radeon HD6970GPU has 24 SIMD engines (16-wide) but is a 4-way VLIWfor a total of 1536 streaming processors running at 880MHz.
The second platform has one AMD FirePro V9800P GPUand one NVIDIA GTX 285 GPU [6]. The NVIDIA GTX285 GPU has 15 SIMD engines (16-wide) with scalar coresfor a total of 240 streaming cores running at 1401MHz.
An AMD A8-3850 Fusion APU [1] is used as the host deviceon the above two platforms. We also evaluate this APU asthe third platform. On the single chip of the A8-3850 wehave four x86-64 CPU cores running at 2.9GHz integratedtogether with a Radeon HD6550D Radeon GPU, which has5 SIMD engines (16-wide) with 5-way VLIW cores, for atotal of 400 streaming processors.
All experiments were performed using the AMD Acceler-ated Parallel Processing (APP) SDK 2.5 on top of vendorspecific drivers (Catalyst 11.12 for AMD’s GPU and CUD-A 4.0.1 for NVIDIA’s GPU). The Open Source ComputerVision (OpenCV) library v2.2[16] is used by clSURF to han-dle extracting of frames from video files and displaying theprocessed video frames.
Table 2: Input sets emphasizing different phases ofthe SURF algorithm.
Input Size Number of DescriptionInteresting
PointsSmall video size
Video1 240 x 320 312 & small number ofinteresting pointsSmall video size
Video2 704 x 790 3178 & large number ofinteresting pointsLarge video size
Video3 720 x 1280 569 & small number ofinteresting pointsLarge video size
Video4 720 x 1280 4123 & large number ofinteresting points
When processing a video in clSURF, the characteristics ofthe video frames can dramatically impact the execution onspecific kernels in the application. For each frame, the per-formance of the kernels in the first stage is a function of thesize of the image, and the performance of the kernels in thesecond stage is dependent on the number of interest pointsfound in the image. To provide coverage of the entire perfor-
89
0
0.2
0.4
0.6
0.8
1
1.2
1.4
1.6
1.8
Video1 Video2 Video3 Video4
GTX 285 V9800P HD 6970 HD 6550D
(a) With Display
0
0.2
0.4
0.6
0.8
1
1.2
1.4
1.6
1.8
Video1 Video2 Video3 Video4
GTX 285 V9800P HD 6970 HD 6550D
(b) Without Display
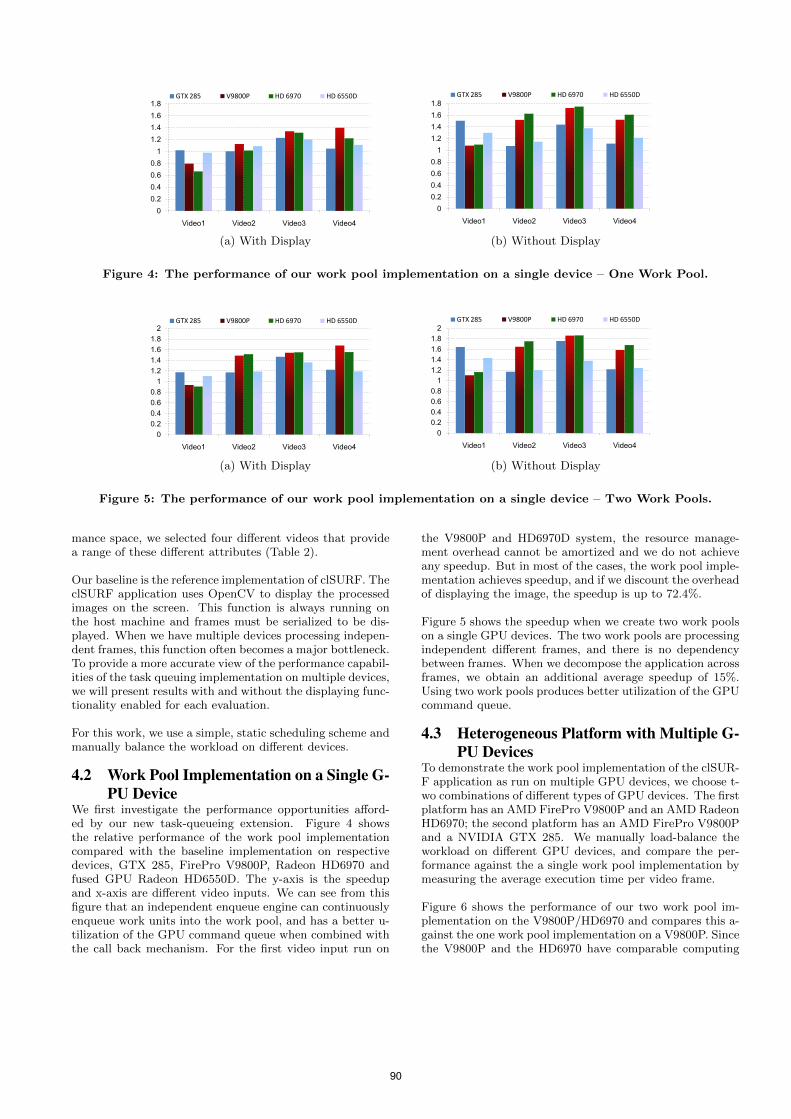
Figure 4: The performance of our work pool implementation on a single device – One Work Pool.
0
0.2
0.4
0.6
0.8
1
1.2
1.4
1.6
1.8
2
Video1 Video2 Video3 Video4
GTX 285 V9800P HD 6970 HD 6550D
(a) With Display
0
0.2
0.4
0.6
0.8
1
1.2
1.4
1.6
1.8
2
Video1 Video2 Video3 Video4
GTX 285 V9800P HD 6970 HD 6550D
(b) Without Display
Figure 5: The performance of our work pool implementation on a single device – Two Work Pools.
mance space, we selected four different videos that providea range of these different attributes (Table 2).
Our baseline is the reference implementation of clSURF. TheclSURF application uses OpenCV to display the processedimages on the screen. This function is always running onthe host machine and frames must be serialized to be dis-played. When we have multiple devices processing indepen-dent frames, this function often becomes a major bottleneck.To provide a more accurate view of the performance capabil-ities of the task queuing implementation on multiple devices,we will present results with and without the displaying func-tionality enabled for each evaluation.
For this work, we use a simple, static scheduling scheme andmanually balance the workload on different devices.
4.2 Work Pool Implementation on a Single G-PU Device
We first investigate the performance opportunities afford-ed by our new task-queueing extension. Figure 4 showsthe relative performance of the work pool implementationcompared with the baseline implementation on respectivedevices, GTX 285, FirePro V9800P, Radeon HD6970 andfused GPU Radeon HD6550D. The y-axis is the speedupand x-axis are different video inputs. We can see from thisfigure that an independent enqueue engine can continuouslyenqueue work units into the work pool, and has a better u-tilization of the GPU command queue when combined withthe call back mechanism. For the first video input run on
the V9800P and HD6970D system, the resource manage-ment overhead cannot be amortized and we do not achieveany speedup. But in most of the cases, the work pool imple-mentation achieves speedup, and if we discount the overheadof displaying the image, the speedup is up to 72.4%.
Figure 5 shows the speedup when we create two work poolson a single GPU devices. The two work pools are processingindependent different frames, and there is no dependencybetween frames. When we decompose the application acrossframes, we obtain an additional average speedup of 15%.Using two work pools produces better utilization of the GPUcommand queue.
4.3 Heterogeneous Platform with Multiple G-PU Devices
To demonstrate the work pool implementation of the clSUR-F application as run on multiple GPU devices, we choose t-wo combinations of different types of GPU devices. The firstplatform has an AMD FirePro V9800P and an AMD RadeonHD6970; the second platform has an AMD FirePro V9800Pand a NVIDIA GTX 285. We manually load-balance theworkload on different GPU devices, and compare the per-formance against the a single work pool implementation bymeasuring the average execution time per video frame.
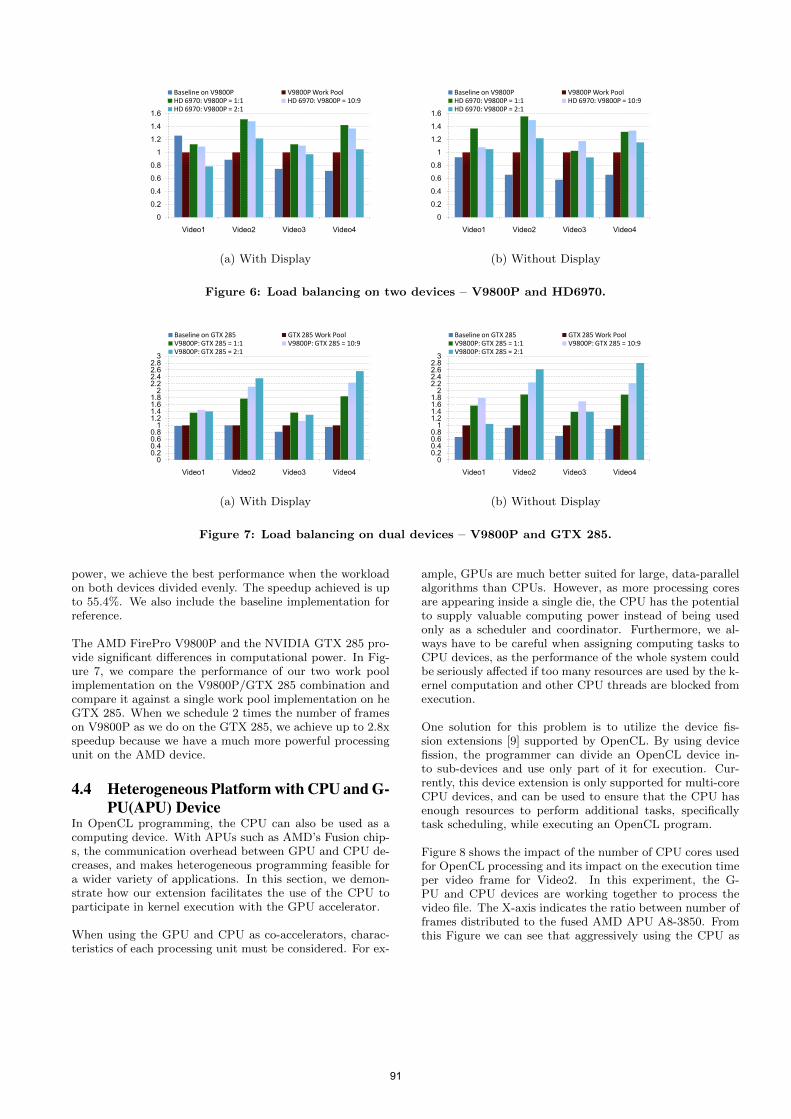
Figure 6 shows the performance of our two work pool im-plementation on the V9800P/HD6970 and compares this a-gainst the one work pool implementation on a V9800P. Sincethe V9800P and the HD6970 have comparable computing
90
0
0.2
0.4
0.6
0.8
1
1.2
1.4
1.6
Video1 Video2 Video3 Video4
Baseline on V9800P V9800P Work Pool HD 6970: V9800P = 1:1 HD 6970: V9800P = 10:9 HD 6970: V9800P = 2:1
(a) With Display
0
0.2
0.4
0.6
0.8
1
1.2
1.4
1.6
Video1 Video2 Video3 Video4
Baseline on V9800P V9800P Work Pool HD 6970: V9800P = 1:1 HD 6970: V9800P = 10:9 HD 6970: V9800P = 2:1
(b) Without Display
Figure 6: Load balancing on two devices – V9800P and HD6970.
0 0.2 0.4 0.6 0.8
1 1.2 1.4 1.6 1.8
2 2.2 2.4 2.6 2.8
3
Video1 Video2 Video3 Video4
Baseline on GTX 285 GTX 285 Work Pool V9800P: GTX 285 = 1:1 V9800P: GTX 285 = 10:9 V9800P: GTX 285 = 2:1
(a) With Display
0 0.2 0.4 0.6 0.8
1 1.2 1.4 1.6 1.8
2 2.2 2.4 2.6 2.8
3
Video1 Video2 Video3 Video4
Baseline on GTX 285 GTX 285 Work Pool V9800P: GTX 285 = 1:1 V9800P: GTX 285 = 10:9 V9800P: GTX 285 = 2:1
(b) Without Display
Figure 7: Load balancing on dual devices – V9800P and GTX 285.
power, we achieve the best performance when the workloadon both devices divided evenly. The speedup achieved is upto 55.4%. We also include the baseline implementation forreference.
The AMD FirePro V9800P and the NVIDIA GTX 285 pro-vide significant differences in computational power. In Fig-ure 7, we compare the performance of our two work poolimplementation on the V9800P/GTX 285 combination andcompare it against a single work pool implementation on heGTX 285. When we schedule 2 times the number of frameson V9800P as we do on the GTX 285, we achieve up to 2.8xspeedup because we have a much more powerful processingunit on the AMD device.
4.4 Heterogeneous Platform with CPU and G-PU(APU) Device
In OpenCL programming, the CPU can also be used as acomputing device. With APUs such as AMD’s Fusion chip-s, the communication overhead between GPU and CPU de-creases, and makes heterogeneous programming feasible fora wider variety of applications. In this section, we demon-strate how our extension facilitates the use of the CPU toparticipate in kernel execution with the GPU accelerator.
When using the GPU and CPU as co-accelerators, charac-teristics of each processing unit must be considered. For ex-
ample, GPUs are much better suited for large, data-parallelalgorithms than CPUs. However, as more processing coresare appearing inside a single die, the CPU has the potentialto supply valuable computing power instead of being usedonly as a scheduler and coordinator. Furthermore, we al-ways have to be careful when assigning computing tasks toCPU devices, as the performance of the whole system couldbe seriously affected if too many resources are used by the k-ernel computation and other CPU threads are blocked fromexecution.
One solution for this problem is to utilize the device fis-sion extensions [9] supported by OpenCL. By using devicefission, the programmer can divide an OpenCL device in-to sub-devices and use only part of it for execution. Cur-rently, this device extension is only supported for multi-coreCPU devices, and can be used to ensure that the CPU hasenough resources to perform additional tasks, specificallytask scheduling, while executing an OpenCL program.
Figure 8 shows the impact of the number of CPU cores usedfor OpenCL processing and its impact on the execution timeper video frame for Video2. In this experiment, the G-PU and CPU devices are working together to process thevideo file. The X-axis indicates the ratio between number offrames distributed to the fused AMD APU A8-3850. Fromthis Figure we can see that aggressively using the CPU as
91

20
22
24
26
28
30
32
34
36
38
40
42
44
46
0.04 0.03 0.02 0.01
4
3
2
1
Exe
cu
tio
n T
ime p
er
Fra
me
(m
s)
Processed Frame Ratio between CPU and Fused GPU
Nu
mb
er
of
Co
res u
se
d f
or
Co
mp
utin
g
Figure 8: Performance with different device fissionconfigurations and load balancing schemes betweenCPU and Fused HD6550D GPU.
the computing device is detrimental to performance, as k-ernel execution impacts the CPU’s ability to function as anefficient host device.
Figure 9 shows the performance of the work pool imple-mentation while using both a CPU and a GPU as com-pute devices, compared with the baseline execution on afused HD6550D GPU. We configure the CPU using the de-vice fission extension and only use part of the CPU as thecomputing device. From this Figure we can see that ourextension enables programmers to utilize all possible com-puting resources on the GPU and the CPU. However, weonly achieve speedup in one scenario, and in most of thecases, kernel execution on the CPU slows down the wholeapplication. Since the CPU in the AMD APU A8-3850 is aquad-core CPU, using it as a computing device severely im-pacts its ability as a scheduling unit, although we’ve alreadyonly use some of the cores by configuring it using the fissionextension. The enqueue operation on the GPU work pool isfrequently blocked when part of the CPU is reserved for thecomputing task. This results in a slow down of the overallexecution.
5. CONCLUSIONThis paper presents a work pool-based task queueing exten-sion for OpenCL that allows programmers to easily harnessthe power of heterogeneous computing environments. Us-ing the task queueing API, and a large, diverse application,clSURF, we show that work pools can provide substantialbenefit to OpenCL programmers. In multi-GPU environ-ments, work pools allow the programmer to easily adapt thescheduling policy of OpenCL kernels to fit the environment.Even with a single GPU, work pools allow for higher utiliza-tion of the device, resulting in speedups.
In this work, we also evaluated the potential for the CPUto be used a compute device. Our results show that onlywhen enough CPU resources are reserved for the system toperform required operations (including running the OpenCLhost code), the CPU can be an effective co-accelerator.
The natural extension of this paper is to implement dynamic
0
0.2
0.4
0.6
0.8
1
1.2
Video1 Video2 Video3 Video4
Baseline on HD6550D
HD6550D with the work pool and last work unit on CPU
HD6550D: CPU = 100:2
HD6550D:CPU = 100:4
Figure 9: The Load Balancing on Dual Devices –HD6550D and CPU
scheduling of tasks among different computing devices us-ing the task queueing scheduler. With a proper runtimeprofiling framework, the scheduler should be able to makescheduling decisions dynamically and distribute work unitsto devices based on data location, computing power, load,etc.
The current implementation of the task queueing API isbuilt entirely on existing OpenCL structures, making a cleaninterface difficult. Future work will attempt to design a moreintuitive API for creating and enqueueing work units, withless effort for the programmer, so that our work pool conceptcan be easily adapted into the design of future applications.
6. ACKNOWLEDGEMENTSThe authors would like to thank Perhaad Mistry and ChrisGregg for the source code of their OpenCL implementationof SURF algorithm.
7. REFERENCES[1] AMD Accelerated Processors for Desktop PCs.
http://www.amd.com/us/products/desktop/apu/mai-nstream/pages/mainstream.aspx.
[2] AMD FirePro V9800P Professional Graphics.http://www.amd.com/us/products/workstation/grap-hics/ati-firepro-3d/v9800p/Pages/v9800p.aspx.
[3] AMD Radeon HD 6970 Graphics.http://www.amd.com/us/products/desktop/graphics-/amd-radeon-hd-6000/hd-6970-/Pages/amd-radeon-hd-6970-overview.aspx.
[4] IBM OpenCL Common Runtime for Linux on x86Architecture.http://www.alphaworks.ibm.com/tech/ocr.
[5] Intel CORE Processors.
92

http://www.intel.com/SandyBridge.
[6] NVIDIA GeForce GTX 285 Graphics.http://www.nvidia.com/object/product geforce gtx285 us.html.
[7] NVIDIA’s parallel computing architecture.http://www.nvidia.com/object/cuda home new.html.
[8] OpenCL - The open standard for parallelprogramming of heterogeneous systems.http://www.khronos.org/opencl/.
[9] OpenCL device extension: Device fission.http://www.khronos.org/registry/cl/extensions/ext/cl ext device fission.txt.
[10] The AMD Fusion Family of APUs.http://sites.amd.com/us/fusion/apu/Pages/fusion.aspx.
[11] E. Agullo, C. Augonnet, J. Dongarra, M. Faverge,J. Langou, H. Ltaief, and S. Tomov. LU factorizationfor accelerator-based systems. In 9th ACS/IEEEInternational Conference on Computer Systems andApplications (AICCSA 11), Sharm El-Sheikh, Egypt,2011.
[12] E. Agullo, C. Augonnet, J. Dongarra, M. Faverge,H. Ltaief, S. Thibault, and S. Tomov. QRFactorization on a Multicore Node Enhanced withMultiple GPU Accelerators. In 25th IEEEInternational Parallel & Distributed ProcessingSymposium, Anchorage, Etats-Unis, May 2011.
[13] E. Agullo, C. Augonnet, J. Dongarra, H. Ltaief,R. Namyst, S. Thibault, and S. Tomov. Faster,Cheaper, Better – a Hybridization Methodology toDevelop Linear Algebra Software for GPUs. In GPUComputing Gems, volume 2. Morgan Kaufmann, Sept.2010.
[14] C. Augonnet, S. Thibault, R. Namyst, and P.-A.Wacrenier. Starpu: A unified platform for taskscheduling on heterogeneous multicore architectures.In Proceedings of the 15th International Euro-ParConference on Parallel Processing, Euro-Par ’09, pages863–874, Berlin, Heidelberg, 2009. Springer-Verlag.
[15] H. Bay, A. Ess, T. Tuytelaars, and L. Van Gool.Speeded-up robust features (surf). Comput. Vis.Image Underst., 110:346–359, June 2008.
[16] G. Bradski. The OpenCV Library. Dr. Dobb’s Journalof Software Tools, 2000.
[17] C. Evans. Notes on the opensurf library. TechnicalReport CSTR-09-001, University of Bristol, January2009.
[18] Z. Fang, D. Yang, WeihuaZhang, H. Chen, andB. Zang. A comprehensive analysis and parallelizationof an image retrieval algorithm. In PerformanceAnalysis of Systems and Software (ISPASS), 2011IEEE International Symposium on, pages 154 –164,april 2011.
[19] P. Furgale, C. H. Tong, and G. Kenway. Ece 1724project report: Speed-up speed-up robust features.2009.
[20] D. Grewe and M. F. P. O’Boyle. A static taskpartitioning approach for heterogeneous systems usingopencl. In Proceedings of the 20th internationalconference on Compiler construction: part of the jointEuropean conferences on theory and practice ofsoftware, CC’11/ETAPS’11, pages 286–305, Berlin,Heidelberg, 2011. Springer-Verlag.
[21] S. Henry. Opencl as Starpu frontend. Technical report,National Institute for Research in Computer Scienceand Control, INRIA, March 2010.
[22] E. Hermann, B. Raffin, F. Faure, T. Gautier, andJ. Allard. Multi-gpu and multi-cpu parallelization forinteractive physics simulations. In Proceedings of the16th international Euro-Par conference on Parallelprocessing: Part II, Euro-Par’10, pages 235–246,Berlin, Heidelberg, 2010. Springer-Verlag.
[23] D. Kim and R. Dahyot. Face components detectionusing surf descriptors and svms. In Machine Visionand Image Processing Conference, 2008. IMVIP ’08.International, pages 51 –56, sept. 2008.
[24] C.-K. Luk, S. Hong, and H. Kim. Qilin: Exploitingparallelism on heterogeneous multiprocessors withadaptive mapping. In Microarchitecture, 2009.MICRO-42. 42nd Annual IEEE/ACM InternationalSymposium on, pages 45 –55, dec. 2009.
[25] J. Luo, Y. Ma, E. Takikawa, S. Lao, M. Kawade, andB.-L. Lu. Person-specific sift features for facerecognition. In Acoustics, Speech and SignalProcessing, 2007. ICASSP 2007. IEEE InternationalConference on, volume 2, pages II–593 –II–596, april2007.
[26] P. Mistry, C. Gregg, N. Rubin, D. Kaeli, andK. Hazelwood. Analyzing program flow within amany-kernel opencl application. In Proceedings of theFourth Workshop on General Purpose Processing onGraphics Processing Units, GPGPU-4, pages10:1–10:8, New York, NY, USA, 2011. ACM.
[27] K. Spafford, J. Meredith, and J. Vetter. Maestro: dataorchestration and tuning for opencl devices. InProceedings of the 16th international Euro-Parconference on Parallel processing: Part II,Euro-Par’10, pages 275–286, Berlin, Heidelberg, 2010.Springer-Verlag.
[28] S. Srinivasan, Z. Fang, R. Iyer, S. Zhang, M. Espig,D. Newell, D. Cermak, Y. Wu, I. Kozintsev, andH. Haussecker. Performance characterization andoptimization of mobile augmented reality on handheldplatforms. IEEE Workload CharacterizationSymposium, 0:128–137, 2009.
[29] N. Zhang. Computing parallel speeded-up robustfeatures (p-surf) via posix threads. In Proceedings ofthe 5th international conference on Emergingintelligent computing technology and applications,ICIC’09, pages 287–296, Berlin, Heidelberg, 2009.Springer-Verlag.
93
Top Related
Copyright © 2022 FDOKUMEN

