






Bahasa
Halaman
Hukum


Author index to volume 28 (2002)
Abbas, H.M. and M.M. Bayoumi, Parallel codebook design for vector quantization on a
message passing MIMD architecture 1079
Agrawal, G., see Ferreira, R. 725
Ahmad, I., Y. He and M.L. Liou, Video compression with parallel processing 1039
Allcock, B., J. Bester, J. Bresnahan, A.L. Chervenak, I. Foster, C. Kesselman, S. Meder,
V. Nefedova, D. Quesnel and S. Tuecke, Data management and transfer in high-perfor-
mance computational grid environments 749
Aloisio, G., see Yang, Y. 773
Amiot, F., see Pissaloux, E. 1205
Andrade, H., see Beynon, M. 827
Anvik, J., see MacDonald, S. 1663
Arg€uuello, F., J. L�oopez, M.A. Trenas and E.L. Zapata, Architecture for wavelet packet trans-
form based on lifting steps 1023
Arnold, D., see Beck, M. 1773
Aumage, O., L. Boug�ee, J.-F. M�eehaut and R. Namyst, Madeleine II: a portable and efficient
communication library for high-performance cluster computing 607
Balay, S., see Norris, B. 1811
Bassi, A., see Beck, M. 1773
Bayoumi, M.M., see Abbas, H.M. 1079
Beaumont, O., A. Legrand, F. Rastello and Y. Robert, Dense linear algebra kernels on
heterogeneous platforms: Redistribution issues 155
Be�ccka, M., G. Ok�ssa and M. Vajter�ssic, Dynamic ordering for a parallel block-Jacobi SVD
algorithm 243
Beck, M., D. Arnold, A. Bassi, F. Berman, H. Casanova, J. Dongarra, T. Moore, G. Obertelli,
J. Plank, M. Swany, S. Vadhiyar and R. Wolski, Middleware for the use of storage in
communication 1773
Bekas, C. and E. Gallopoulos, Parallel computation of pseudospectra by fast descent 223
Ben-Asher, Y., The parallel client–server paradigm 503
Benkrid, A., see Benkrid, K. 1141
Benkrid, K., D. Crookes and A. Benkrid, Towards a general framework for FPGA based
image processing using hardware skeletons 1141
Benson, S., see Norris, B. 1811
Berman, F., see Beck, M. 1773
Bester, J., see Allcock, B. 749
Beynon, M., C. Chang, U. Catalyurek, T. Kurc, A. Sussman, H. Andrade, R. Ferreira and
J. Saltz, Processing large-scale multi-dimensional data in parallel and distributed envir-
onments 827
Biancardi, A. and A. M�eerigot, Extending the data parallel paradigm with data-dependent
operators 995
Boug�ee, L., see Aumage, O. 607
Bresnahan, J., see Allcock, B. 749
www.elsevier.com/locate/parco
Parallel Computing 28 (2002) 1833–1839
PII: S0167-8191 (02 )00209-0

Brill, S.H. and G.F. Pinder, Parallel implementation of the Bi-CGSTAB method with block
red–black Gauss–Seidel preconditioner applied to the Hermite collocation discretization
of partial differential equations 399
Bromling, S., see MacDonald, S. 1663
Cai, W., see Xue, J. 915
Cannataro, M., D. Talia and P.K. Srimani, Parallel data intensive computing in scientific and
commercial applications 673
Casanova, H., see Beck, M. 1773
Catalyurek, U., see Beynon, M. 827
Chang, C., see Beynon, M. 827
Chang, F.-J., see Chang, L.-C. 1611
Chang, H.-H. and G.-M. Chiu, An improved fault-tolerant routing algorithm in meshes with
convex faultss 133
Chang, L.-C. and F.-J. Chang, An efficient parallel algorithm for LISSOM neural network 1611
Charrier, P., see Nkonga, B. 369
Chen, K. and C.H. Lai, Parallel algorithms of the Purcell method for direct solution of linear
systems 1275
Chen, S.D., H. Shen and R. Topor, An efficient algorithm for constructing Hamiltonian
paths in meshes 1293
Chen, W.-Y., see Lee, P.-Z. 1329
Chervenak, A.L., see Allcock, B. 749
Chiu, G.-M., see Chang, H.-H. 133
Choi, H.-I., see Tarkov, M.S. 1239
Choi, J., see Tarkov, M.S. 1239
Christiaens, M., M. Ronsse and K. De Bosschere, Bounding the number of segment histories
during data race detection 1221
Ciciani, B., see Quaglia, F. 485
Colajanni, M., see Quaglia, F. 485
Coppola, M. and M. Vanneschi, High-performance data mining with skeleton-based struc-
tured parallel programming 793
Crookes, D., see Benkrid, K. 1141
Cwik, T., see Wang, P. 53
D’Ambra, P., M. Danelutto, D. di Serafino and M. Lapegna, Advanced environments for
parallel and distributed applications: a view of current status 1637
Danelutto, M., see D’Ambra, P. 1637
Darlington, J., see Furmento, N. 1753
Dasu, A. and S. Panchanathan, Reconfigurable media processing 1111
De Bosschere, K., see Christiaens, M. 1221
Deforges, O., see Fresse, V. 1179
Dillon, T., see Pissaloux, E. 1203
Di Santo, M., F. Frattolillo, W. Russo and E. Zimeo, A component-based approach to build
a portable and flexible middleware for metacomputing 1789
di Serafino, D., see D’Ambra, P. 1637
Dongarra, J., see Beck, M. 1773
Du, Q., see Ju, L. 1477
Dumas, J.-G. and J.-L. Roch, On parallel block algorithms for exact triangularizations 1531
Dunn, I.N. and G.G.L. Meyer, QR factorization for shared memory and message passing 1507
Ehold, H.J., W.N. Gansterer, D.F. Kvasnicka and C.W. Ueberhuber, Optimizing Local Per-
formance in HPF 415
Est�eevez, P.A., H. Paugam-Moisy, D. Puzenat and M. Ugarte, A scalable parallel algorithm
for training a hierarchical mixture of neural experts 861
1834 Author index / Parallel Computing 28 (2002) 1833–1839

Ferreira, R., see Beynon, M. 827
Ferreira, R., G. Agrawal and J. Saltz, Data parallel language and compiler support for data
intensive applications 725
Field, T., see Furmento, N. 1753
Foster, I., see Allcock, B. 749
Frattolillo, F., see Di Santo, M. 1789
Freitag, L., see Norris, B. 1811
Fresse, V. and O. Deforges, ARIAL: rapid prototyping for mixed and parallel platforms 1179
Furmento, N., A. Mayer, S. McGough, S. Newhouse, T. Field and J. Darlington, ICENI:
Optimisation of component applications within a Grid environment 1753
G€aartner, K., see Schenk, O. 187
Gallopoulos, E., see Bekas, C. 223
Gansterer, W.N., see Ehold, H.J. 415
Georgousopoulos, C., see Yang, Y. 773
Geusebroek, J.M., see Seinstra, F.J. 967
Ginhac, D., see S�eerot, J. 1685
Girault, A., Elimination of redundant messages with a two-pass static analysis algorithm 433
Goscinski, A., M. Hobbs and J. Silcock, GENESIS: an efficient, transparent and easy to use
cluster operating system 557
Green, R., see Wang, P. 53
Gropp, W., see Thakur, R. 83
Gunzburger, M., see Ju, L. 1477
Gutknecht, M.H. and S. R€oollin, The Chebyshev iteration revisited 263
Hameurlain, A. and F. Morvan, CPU and incremental memory allocation in dynamic paral-
lelization of SQL queries 525
Hanen, C. and A.M. Kordon, Minimizing the volume in scheduling an out-tree with
communication delays and duplication 1573
H�eenon, P., P. Ramet and J. Roman, PAASTITIX: a high-performance parallel direct solver for
sparse symmetric positive definite systems 301
He, F. and J. Wu, An efficient parallel implementation of the Everglades Landscape Fire
Model using checkpointing 65
He, Y., see Ahmad, I. 1039
Hill, J.M.D., see Jarvis, S.A. 1587
Hobbs, M., see Goscinski, A. 557
Hovland, P., see Norris, B. 1811
Hsiao, H.-C. and C.-T. King, Implementation and evaluation of directory hints in CC-
NUMA multiprocessors 107
Hsien, N.-C., see Lin, J.-C. 471
Hwang, Y.-S., Parallelizing graph construction operations in programs with cyclic graphs 1307
Ivey, P.A., see Zawada, A.C. 1155
Jarvis, S.A., J.M.D. Hill, C.J. Siniolakis and V.P. Vasilev, Portable and architecture inde-
pendent parallel performance tuning using BSP 1587
Jonker, P., see Nicolescu, C. 945
Ju, L., Q. Du and M. Gunzburger, Probabilistic methods for centroidal Voronoi tessellations
and their parallel implementations 1477
Kesselman, C., see Allcock, B. 749
King, C.-T., see Hsiao, H.-C. 107
Koelma, D., see Seinstra, F.J. 967
Author index / Parallel Computing 28 (2002) 1833–1839 1835

Kordon, A.M., see Hansen, C. 1573
Kontoghiorghes, E.J., Greedy Givens algorithms for computing the rank-k updating of the
QR decomposition 1257
Kurc, T., see Beynon, M. 827
Kutil, R., Approaches to zerotree image and video coding on MIMD architectures 1095
Kvasnicka, D.F., see Ehold, H.J. 415
Laforenza, D., Grid programming: some indications where we are headed 1733
Lai, C.H., see Chen, K. 1275
Lapegna, M., see D’Ambra, P. 1637
Lastovetsky, A., Adaptive parallel computing on heterogeneous networks with mpC 1369
Lee, I., see Park, T. 1549
Lee, P.-Z. and W.-Y. Chen, Generating communication sets of array assignment statements
for block-cyclic distribution on distributed memory parallel computers 1329
Legrand, A., see Beaumont, O. 155
Li, J.-Q., see Liang, T.-Y. 893
Liang, T.-Y., Ce-K. Shieh and J.-Q. Li, Selecting threads for workload migration in software
distributed shared memory systems 893
Liang, Y., J. Weston and M. Szularz, Generalized least-squares polynomial preconditioners
for symmetric indefinite linear equations 323
Lin, J.-C. and N.-C. Hsien, Reconfiguring binary tree structures in a faulty supercube with
unbounded expansion 471
Liou, M.L., see Ahmad, I. 1039
Liu, K.Y., see Wang, P. 53
L�oopez, J., see Arg€uuello, F. 1023
Lusk, E., see Thakur, R. 83
MacDonald, S., J. Anvik, S. Bromling, J. Schaeffer, D. Szafron and K. Tan, From patterns to
frameworks to parallel programs 1663
Malard, J.M., Parallel restricted maximum likelihood estimation for linear models with a
dense exogenous matrix 343
Mayer, A., see Furmento, N. 1753
McGough, S., see Furmento, N. 1753
McInnes, L., see Norris, B. 1811
M�eehaut, J.-F., see Aumage, O. 607
M�eerigot, A., see Biancardi, A. 995
Meder, S., see Allcock, B. 749
Meyer, G.G.L., see Dunn, I.N. 1507
Mezher, D. and B. Philippe, Parallel computation of pseudospectra of large sparse matrices 199
Moore, T., see Beck, M. 1773
Morvan, F., see Hameurlain, A. 525
Mun, Y., see Tarkov, M.S. 1239
Namyst, R., see Aumage, O. 607
Nefedova, V., see Allcock, B. 749
Nesheiwat, J. and Szymanski, B.K., Instrumentation database system for performance
analysis of parallel scientific applications 1409
Newhouse, S., see Furmento, N. 1753
Nicolescu, C. and P. Jonker, A data and task parallel image processing environment 945
Nkonga, B. and P. Charrier, Generalized parcel method for dispersed spray and message
passing strategy on unstructured meshes 369
Norris, B., S. Balay, S. Benson, L. Freitag, P. Hovland, L. McInnes and B. Smith, Parallel
components for PDEs and optimization: some issues and experiences 1811
1836 Author index / Parallel Computing 28 (2002) 1833–1839

Obertelli, G., see Beck, M. 1773
Ok�ssa, G., see Be�ccka, M. 243
Owczarz, W. and Z. Zlatev, Parallel matrix computations in air pollution modelling 355
Panchanathan, S., see Dasu, A. 1111
Park, T., I. Lee and H.Y. Yeom, An efficient causal logging scheme for recoverable distri-
buted shared memory systems 1549
Paugam-Moisy, H., see Est�eevez, P.A. 861
Philippe, B., see Mezher, D. 199
Pinder, G.F., see Brill, S.H. 399
Pissaloux, E., F. Amiot and T. Dillon, A vision-application adaptable computer concept and
its implementation in FreeTIV computer 1203
Plank, J., see Beck, M. 1773
Psarris, K., Program analysis techniques for transforming programs for parallel execution 455
Puzenat, D., see Est�eevez, P.A. 861
Quaglia, F., B. Ciciani and M. Colajanni, Performance analysis of adaptive wormhole rout-
ing in a two-dimensional torus 485
Quesnel, D., see Allcock, B. 749
Ramet, P., see H�eenon, P. 301
Rana, O.F., see Yang, Y. 773
Rastello, F., see Beaumont, O. 155
R€oollin, S., see Gutknecht, M.H. 263
Robert, Y., see Beaumont, O. 155
Roch, J.-L., see Dumas, J.-G. 1531
Roman, J., see H�eenon, P. 301
Ronsse, M., see Christiaens, M. 1221
Russo, W., see Di Santo, M. 1789
Salinger, P. and P. Tvrd�ıık, Optimal broadcasting and gossiping in one-port meshes of trees
with distance-insensitive routing 627
Saltz, J., see Beynon, M. 827
Saltz, J., see Ferreira, R. 725
Salvemini, A., see Serra, R. 667
Sameh, A.H. and V. Sarin, Parallel algorithms for indefinite linear systems 285
Sanches, C.A.A., N.Y. Soma and H.H. Yanasse, Comments on parallel algorithms for the
knapsack problem 1501
Sanders, P., Reconciling simplicity and realism in parallel disk models 705
Sarin, V., see Sameh, A.H. 285
Schaeffer, J., see MacDonald, S. 1663
Schenk, O. and K. G€aartner, Two-level dynamic scheduling in PARDISO: Improved scalabi-
lity on shared memory multiprocessing systems 187
S�eerot, J. and D. Ginhac, Skeletons for parallel image processing: an overview of the
SKIPPER project 1685
Seed, N.L., see Zawada, A.C. 1155
Seinstra, F.J., D. Koelma and J.M. Geusebroek, A software architecture for user transparent
parallel image processing 967
Serra, R., M. Villani and A. Salvemini, Erratum to ‘‘Continuous genetic networks’’ [Parallel
Comput. 27 (5) (2001) 663–683] 667
Shen, C. and J. Zhang, Parallel two level block ILU preconditioning techniques for solving
large sparse linear systems 1451
Shen, H., see Chen, S.D. 1293
Author index / Parallel Computing 28 (2002) 1833–1839 1837

Shieh, Ce-K., see Liang, T.-Y. 893
Silcock, J., see Goscinski, A. 557
Siniolakis, C.J., see Jarvis, S.A. 1587
Skillicorn, D.B., Parallel frequent set counting 815
Smith, B., see Norris, B. 1811
Sodan, A.C., Applications on a multithreaded architecture: A case study with EARTH–
MANNA 3
Soma, N.Y., see Sanches, C.A.A. 1501
Srimani, P.K., see Cannataro, M. 673
Srimani, P.K., see Talia, D. 669
Sussman, A., see Beynon, M. 827
Swany, M., see Beck, M. 1773
Szafron, D., see MacDonald, S. 1663
Szularz, M., see Liang, Y. 323
Szymanski, B.K., see Nesheiwat, J. 1409
Talia, D. and P.K. Srimani, Parallel data-intensive algorithms and applications 669
Talia, D., see Cannataro, M. 673
Tan, K., see MacDonald, S. 1663
Tarkov, M.S., Y. Mun, J. Choi and H.-I. Choi, Mapping adaptive fuzzy Kohonen clustering
network onto distributed image processing system 1239
Thakur, R., W. Gropp and E. Lusk, Optimizing noncontiguous accesses in MPI–IO 83
Tolman, H.L., Distributed-memory concepts in the wave model WAVEWATCH III 35
Topor, R., see Chen, S.D. 1293
Touzene, A., Edges-disjoint spanning trees on the binary wrapped butterfly network with ap-
plications to fault tolerance 649
Trenas, M.A., see Arg€uuello, F. 1023
Tuecke, S., see Allcock, B. 749
Tvrd�ıık, P., see Salinger, P. 627
Ueberhuber, C.W., see Ehold, H.J. 415
Ugarte, M., see Est�eevez, P.A. 861
Vadhiyar, S., see Beck, M. 1773
Vajter�ssic, M., see Be�ccka, M. 243
Vanneschi, M., The programming model of ASSIST, an environment for parallel and dis-
tributed portable applications 1709
Vanneschi, M., see Coppola, M. 793
Vasilev, V.P., see Jarvis, S.A. 1587
Villani, M., see Serra, R. 667
Walker, D.W., see Yang, Y. 773
Wang, P., K.Y. Liu, T. Cwik and R. Green, MODTRAN on supercomputers and parallel
computers 53
Weston, J., see Liang, Y. 323
Williams, R., see Yang, Y. 773
Wolski, R., see Beck, M. 1773
Wu, J., see He, F. 65
Xue, J. and W. Cai, Time-minimal tiling when rise is larger than zero 915
Yanasse, H.H., see Sanches, C.A.A. 1501
Yang, Y., O.F. Rana, D.W. Walker, C. Georgousopoulos, G. Aloisio and R. Williams, Agent
based data management in digital libraries 773
Yeom, H.Y., see Park, T. 1549
1838 Author index / Parallel Computing 28 (2002) 1833–1839

Zapata, E.L., see Arg€uuello, F. 1023
Zawada, A.C., N.L. Seed and P.A. Ivey, Continuous and high coverage self-testing of dyna-
mically re-configurable systems 1155
Zhang, J., see Shen, C. 1451
Zimeo, E., see Di Santo, M. 1789
Zlatev, Z., see Owczarz, W. 355
Author index / Parallel Computing 28 (2002) 1833–1839 1839

A component-based approach tobuild a portable and flexible
middleware for metacomputing q
M. Di Santo a, F. Frattolillo a, W. Russo b, E. Zimeo a,*
a Research Centre on Software Technology, Department of Engineering, University of Sannio,
Corso Garibaldi 107, Benevento, Italyb DEIS, University of Calabria, Arcavacata di Rende (CS), Italy
Received 18 February 2002; received in revised form 14 May 2002; accepted 17 June 2002
Abstract
The huge amount of computing resources in the Internet makes it possible to build meta-
computers for solving large-scale problems. Despite the great availability of software infra-
structures for managing such systems, metacomputer programming is often based on
models that do not appear to be suitable to run applications on wide-area, unreliable,
highly-variable networks of computers. In this paper, we present a customisable, Java-based
middleware which provides programmers with a portable and flexible framework to run appli-
cations over a hierarchical, virtual network architecture. The middleware is designed accord-
ing to a component-based approach that enables the execution behaviour of each computing
node to be customised in order to satisfy application needs. The paper shows some examples
of programming model customisation and demonstrates that flexibility can be achieved with-
out significantly compromising performance.
� 2002 Elsevier Science B.V. All rights reserved.
Keywords: Metacomputing; Middleware; Component framework; Grid computing
www.elsevier.com/locate/parco
Parallel Computing 28 (2002) 1789–1810
qResearch partially supported by the Regione Campania under grants ‘‘Law n.41/94’’, BURC N.3,
January 17, 2000.* Corresponding author.
E-mail address: [email protected] (E. Zimeo).
0167-8191/02/$ - see front matter � 2002 Elsevier Science B.V. All rights reserved.
PII: S0167-8191 (02 )00184-9

1. Introduction and motivations
The enormous amount of computing power available across the Internet makes
the idea of harnessing such power to solve large-scale problems more and more
attractive. Grabbing computing power to satisfy the calculation requirements ofnetworked users is typically accomplished by special software infrastructures, called
middlewares. Such infrastructures extend the concept, introduced by PVM [34], of a
‘‘parallel virtual machine’’ restricted and controlled by a single user, making it
possible to build computing systems, called metacomputers, based on network
contexts characterised by different administrative domains, physical networks and
communication protocols [1,2,7].
In such a scenario, managing a flat, wide-area, distributed architecture is a com-
plex task: many resources (especially clusters of workstations) are often not directlyaccessible via the Internet and use dedicated, high-performance networks whose pro-
tocols may not be IP compliant. Therefore, in order to separately control each ad-
ministrative domain, a more flexible organisation is required, in which resources
can be abstractly arranged according to a hierarchical topology atop the physical
metacomputing network.
Moreover, the traditional approach followed to develop middleware for small,
well-defined distributed systems is not suitable for metacomputing systems. The need
for adaptability requires that a middleware for metacomputing is built according to acomponent-based, reflective architecture [29] to facilitate dynamic changes in com-
ponent configurations.
An interesting and common approach to develop middleware for metacomputing
is based on the exploitation of Java, since the language and its underlying virtual
machine have been designed for programming in heterogeneous computing environ-
ments, provide a direct support to multithreading, code mobility, security, and facil-
itate the development of concurrent and distributed applications by using more
sophisticated design patterns [23].Although a lot of environments for wide-area, high-performance computing tend
to exploit the Java distributed object model implemented by the RMI package [33], it
is worth noting that this package does not adequately support the programming of
dynamic parallel applications, their efficient execution on wide-area networks, and
the management of complex network architectures. To overcome these drawbacks,
different solutions supporting parallel programming based on the message-passing
communication model have been proposed [6,12]. However, these solutions are
not easily usable in a wide-area environment, since the tightly coupled interactionparadigm supported by message-passing is not suitable to program dynamic compu-
tational architectures, and the lack of a coordination infrastructure prevents users
from suitably exploiting the available resources and from managing configuration
variability.
Nevertheless, the extreme flexibility provided by the Java Virtual Machine, and in
particular dynamic code loading, code verification and programmable security, are
valid reasons to use Java to develop flexible middlewares for open distributed sys-
tems, as demonstrated by the growing efforts made in the research area concerning
1790 M. Di Santo et al. / Parallel Computing 28 (2002) 1789–1810

the Java parallel and distributed programming [21]. Unfortunately, flexibility in Java
is achieved by means of an interpreter, which may reduce performance with respect
to native code execution. To this end, recent technologies, i.e. JIT and Hot Spot [32],
have drastically reduced the historical performance gap existing between Java and
traditional compiler-based languages, such as C. Moreover, by accepting some re-duction of middleware portability, specific components can be developed using the
Java Native Interface [17,24], which assures performances very close to the ones of-
fered by pure native code. In particular, the research developed in the context of par-
allel and distributed computing based on Java has demonstrated that the language
induces a limited overhead when it is used to program byte-oriented communication
libraries [27], no matter if they are based on TCP sockets or specific high-perfor-
mance communication protocols [30]. On the contrary, when Java is used to develop
object-oriented communication libraries, it induces a high overhead tied to objectscommunication, due to the dynamic serialisation. However, many researchers have
proposed optimisations (more or less portable) to the native Java serialisation pro-
tocol in order to increase the object communication throughput [18,26].
In this paper, we present and discuss a customisable middleware that can be used
as a flexible framework to run applications over the Internet. The proposed middle-
ware, defined as Hierarchical Metacomputer Middleware (HiMM), supports parallel
and distributed programming based on objects and runs applications in hetero-
geneous environments thanks to a minimal set of basic services implemented in Javain order to guarantee portability and flexibility. The middleware is designed accord-
ing to the Grid reference model introduced in [15] and is structured as a collection of
abstract components whose implementation can be dynamically installed to satisfy
application requirements.
The rest of the paper is organised as follows. Section 2 briefly reports a Grid ref-
erence model. Section 3 presents HiMM and describes the distributed virtual archi-
tecture of metacomputers built by using the middleware. In Section 4 the design
principles followed to build HiMM are discussed and then the customisable architec-ture of a metacomputer node as well as the interactions among the framework com-
ponents are described. Section 5 shows how the reflective behaviour of a node is used
to install different programming models in a metacomputer. In Section 6 some
performance figures are reported and discussed. Section 7 presents some projects re-
lated to our work. Finally, Section 8 concludes the work and proposes some future
enhancements.
2. A reference model for metacomputing
Metacomputing, Grid computing, Global computing are different terms used to de-
note a common approach to the use of wide-area, distributed resources in a coordi-
nated way to support: (1) high-throughput computing, (2) collaborative computing,
(3) on-demand computing.
In 90�s a great amount of research effort produced a lot of middleware infrastruc-tures [4,13,19,25,28] for programming and managing resources dislocated in different
M. Di Santo et al. / Parallel Computing 28 (2002) 1789–1810 1791

virtual organisations, but only in the last years a first attempt to systematically or-
ganise the different concepts underlying a Grid has been made. An interesting char-
acterisation of Grid systems based on a layer model (see Fig. 1) has been proposed in
[15]. In this model, the lowest layer, called fabric, defines the hardware (computa-
tional, storage and network) resources used for metacomputing. The connectivity
layer provides both communication facilities based on some transport protocol
and client authentication and authorisation. The connectivity layer is then used tobuild the information and management protocols provided by the resource layer
in order to allocate application processes and to monitor system status and resources
availability. The collective layer provides directory, scheduling and brokering ser-
vices, and enables familiar programming models to be used in a Grid environment.
Typically, the services exported by the layers, except the fabric one, are integrated
inside a middleware for metacomputing.
3. The proposed middleware
HiMM is a Java-based middleware for metacomputing designed according to
the architecture shown in Fig. 2 and by which users can: (1) build and dynamically
reconfigure a metacomputer; (2) program and run applications on it.
3.1. Services
HiMM offers services that help in coupling a user and remote resources through
either a Grid enabled application or a graphical tool (console). The core services are:
remote process creation and management, dynamic allocation of tasks, information
service, directory service, authentication of remote commands, performance moni-
toring, communication model programmability, transport protocol selection and
dynamic loading of components. All services are accessible by an application at
run-time, whereas only some of them are accessible also through the console.
The console provides the user with different views of a metacomputer: connectiv-ity, resource and collective.
Fig. 1. A Grid reference model.
1792 M. Di Santo et al. / Parallel Computing 28 (2002) 1789–1810

The connectivity view allows the user to discover the resources available on the
network and to get information about their computing power. By exploiting this in-
formation, the user can select a subset of the available resources and create a meta-
computer. This phase can be customised by the selection of: (1) the softwarecomponents to be installed on each node; (2) the transport protocol to be used for
the communication among nodes.
The resource view allows the user to issue a resource reservation query through an
XML file in order to: (1) automatically discover the required resources; (2) reserve
them for the incoming computation; (3) configure the transport protocols to be used.
The collective view (in an advanced development phase) allows the user to start an
application whose jobs are passed to a broker, which negotiates the application needs
with the available computing resources in order to allocate tasks on the right hosts.
3.2. Distributed virtual architecture
At the fabric layer, HiMM allows a user to exploit collections of computers
(hosts), which can be workstations or computing units of parallel systems, intercon-
nected by heterogeneous networks.
At the connectivity layer the metacomputer is composed of abstract nodes inter-
connected by a virtual network based on a multi-protocol transport layer able to ex-ploit the features of the underlying physical networks in a user transparent way. In
particular, in order to meet the constraints of the Internet organisation, to better ex-
ploit the performances of dedicated interconnects and to assure scalability, the net-
worked nodes can be arranged according to a hierarchical virtual topology which we
refer to as Hierarchical Metacomputer (HiM) (see Fig. 3).
In such an organisation, the nodes allocated onto hosts hidden from the Internet
or connected by dedicated, fast networks can be grouped in macro-nodes, which thus
abstractly appear as single, more powerful, virtual computing units. The internalnodes of a macro-node may be in turn macro-nodes and this induces a level-based
Fig. 2. The HiMM architectural components mapped on the Grid reference model.
M. Di Santo et al. / Parallel Computing 28 (2002) 1789–1810 1793

organisation in the metacomputer network, in which all the nodes grouped in a
macro-node belong to the same level and are fully interconnected. This means thata node belonging to a macro-node can directly communicate only with the nodes
belonging to its level.
Each node maintains status information about the dynamic architecture of the
HiM, such as information about the identity and liveness of the other nodes. In
particular, thanks to the hierarchical organisation, each node has to keep and update
only information about the configuration of the macro-node which it belongs to, so
promoting scalability, since the updating information has not to be exchanged
among all the nodes of a HiM.Each macro-node is controlled by a special node, the Coordinator (C), which:
• creates the macro-node by activating nodes onto available hosts (Fig. 4(a));
• takes charge of updating the status information of each node grouped by the
macro-node;
• monitors the liveness of nodes to dynamically change the configuration of the
macro-node (Fig. 4(b));
• causes, when it crashes, the automatic ‘‘garbage collection’’ of the nodes in themacro-node (Fig. 4(c));
• acts, from the application point of view, as a sort of gateway, in that it allows for
communication among nodes of two adjacent levels (Fig. 4(d)).
N et- IPN et- IP
R o o t
W SW S
M ac ro -n o d eM ac ro -n o d e
M ac ro -n o d e
C C
C
N et- IP
N et-F P
C lus te r
D o m a inX M L c f g f ile
C o nso le
C
D o m a inX M L c f g f ile
C lust e rX M L c f g f ile
U se rX M L c f g f ile
N o d e
H M H M
C reat e a node
N ode cre a tioncom m and
Fig. 3. The hierarchical organisation of a HiM at the connectivity layer.
1794 M. Di Santo et al. / Parallel Computing 28 (2002) 1789–1810

The coordinator of the highest hierarchical level is the root of a HiM. Differently
from the other coordinators, it sees only one level, since, at the upper level, it is inter-
faced directly with the user through the console, by which it is possible to dynamically
control the configuration of the HiM (see Fig. 3). To this end, each host wanting to do-nate its computingpower runs a special server, theHostManager (HM),which receives
creation commands by the console, authenticates them and, if the host on which the
console runs is authorised, creates the required nodes as processes running the JVMs.
It is worth noting that the console can create nodes only at the highest hierarchical level
of a HiM. However, if a creation command reaches a coordinator, this takes charge of
creating nodes inside themacro-node that it controls according to the configuration in-
formation stored in anXML [36] file provided by the domain administrator (seeFig. 3).
All the nodes of a HiM communicate by exchanging messages through an interfaceindependent of the transport protocol adopted and whose semantics is based on the
‘‘one-sided’’ model [11]. In particular, the communication interface is designed so that
each node can directly send objects. Objects can be either simplemessages or tasks, and
N et- IP
C
N ode
N et- IP
C
H M
H os t
H MH os t
create create
execexec
( a)
N et- IP
C
n1 n2 n3
auto-k ill
Iam Aliv e
auto-k ill auto-k ill
( c )
N et- IP
C
Iam Aliv eIam Aliv e ackack
n1n2n3
crashedaliv ealiv e
n1 n2 n3
(b )
N et- IP
C
n1 n2 n3
m 1
m 1
m 2
m 2
(d )
Fig. 4. The management of a macro-node.
M. Di Santo et al. / Parallel Computing 28 (2002) 1789–1810 1795

can be sent also to the nodes that do not store the object code. To this end, each node is
provided with a code loader able to retrieve the object code from a code repository al-
located on the network. In particular, to ensure scalability, HiMM implements a dis-
tributed code repository managed by the Distributed Class Storage System (see
Fig. 5). The architecture of this system reflects the HiM one: each macro-node is pro-vided with a dedicated code-base managed by the coordinator. When a coordinator
lacks the code required by a node, it asks the upper level coordinator for the code, so
inducing a recursive query that may reach the HiM root, which stores all the code of
the running application. Whenever a coordinator obtains the code from the upper
level, it stores the code in a local cache, in order to reduce the loading time of successive
code requests.
At the resource layer, HiMM provides a publish/subscribe information service
based on the interaction between two distributed components: the Resource Manager(RM) and theHM (see Fig. 6). In particular, eachmacro-node has anRMallocated on
one of the hosts taking part in the macro-node. A RM is periodically contacted by the
HMs of the hosts belonging to the macro-node and wanting to publish information
about: (1) the CPU power and its utilisation; (2) the available memory; (3) the com-
munication performance, if the host allocates the coordinator of a lower level
macro-node. Information is collected by the RM and made available to subscribers
(at each level, the coordinators belonging to different HiMs). Thus, the macro-node
coordinator can know the maximum computing/communication power made avail-able by its level and considered at the upper level as the power of the macro-node.
At the highest level, the user can know the globally available computing power and
N et- IPN et- IP
R o o t
W SW SC C
C
N et- IP
N et-F P
C lus te r
C o nso le
C
C lust e r c o de - c a c h e
D o m a in c o de - c a c h e
C o de ba seA ll t h e a p p lic a t io n c o de
A sk f o r t h e c o de
R e t r ie v e t h e c o de N o de c o de - c a c h e
Fig. 5. The Distributed Class Storage System.
1796 M. Di Santo et al. / Parallel Computing 28 (2002) 1789–1810

reserve a part of it by issuing a subscription request to the RM of the level through the
console.
Currently, the HiMM collective layer provides only the directory service. A user,
by interacting with the console, can ask the RM of the highest level of a HiM for
selecting and reserving only the computing resources required. The result of a query
is an XML file containing all the current system information to create a meta-
computer without having to consult anew the RM.
4. Implementation of HiMM
HiMM has been developed according to a component-based, reflective architec-
ture. Therefore, it can dynamically adapt to changes in the configuration of physical
components. This is a strategic feature in the context of metacomputing, in which the
necessity to follow the rapid progress of technology or to manage the heterogeneityof resources may require frequent changes in the middleware architecture.
4.1. Design principles
To support adaptability and to easily add extended services in the future, HiMM
implements its services in several software components whose interfaces are designed
according to a Component Framework approach [35].
Net- IPNet- IP
Root
WSWS
Macro-node Macro-node
Macro-node
C C
C
Net- IP
Net- FP
RM
RM RM
RM
Cluster
Console
subscribe
publish
p1.3.2.1 p1.3.2.3
p1.3.2.2
p1.3.2 = p1.3.2.1 +p1.3.2.2 +p1.3.2.3p1.3.1
p1.3 =p2.1 +p2.2p1.1p1.2
p1.4
p1.1 = p1.1.1 +p1.1.2 +p1.1.3p1.2p1.3 = p1.3.1 +( p1.3.2.1 +p1.3.2.2 +p1.3.2.3)p1.4
HM HMHMHM
HM HM HM
p : computing power of a hostor a macro-node
HM HM
C
p1.1.1 p1.1.2 p1.1.3
Fig. 6. The hierarchical organisation of a HiM at the resource layer.
M. Di Santo et al. / Parallel Computing 28 (2002) 1789–1810 1797

A component is an encapsulated software module defined by its public interfaces,
which follows a strict set of behaviour rules defined by the environment in which it
runs.
A component framework is a software environment able to simplify the develop-
ment of complex applications by defining a set of rules and contracts governing theinteraction of a targeted set of components in a constrained domain [22]. In parti-
cular, the proposed framework is a set of co-operating interfaces that define an ab-
stract design useful to provide solutions for metacomputing problems. The abstract
design is concretised by the definition of classes which implement the interfaces of
the abstract design and interact with the basic classes representing the skeleton of
the framework. Such an approach makes system management easier, thanks to the
possibility of modifying or substituting a component implementation without affect-
ing other parts of the middleware. In addition, it allows a component to have differ-ent implementations, each of which can be selected and dynamically loaded and
integrated in the system. Therefore, HiMM is designed as a collection of conceptual
loosely tied components, whose customisation allows programmers to extend the
basic services, as well as program and run specific applications. In particular, the
HiMM�s architecture provides a set of integrated and interacting components, someof which represent the skeleton of the framework, whereas the others can be custo-
mised by the user in order to adapt the system to the specific needs of an application.
To facilitate component integration, we have used two design patterns [16]: inver-sion of control and separation of concerns. The former suggests that the execution of
application components has to be controlled by the framework: everything a compo-
nent needs to carry out its tasks is provided by the hosting environment. So, the flow
of control is determined by the framework that coordinates and serialises all the
events produced by the running application. The latter allows a problem to be ana-
lysed from several points of view, each of which is addressed independently from the
others. Therefore an application can be implemented as a collection of well-defined,
reusable, easily understandable modules. The clear separation of interest areas, infact, reduces the coupling among modules, so helping their cohesion.
4.2. Implementation of nodes and coordinators
Both nodes and coordinators are implemented as processes in which a set of soft-
ware components are loaded either at start-up or at run-time. The main components
are (see Fig. 7):
(1) the Node Manager (NM), whose main task is to store system information and to
interact with the coordinator in order to guarantee macro-node consistency;
(2) the Node Engine (NE), which takes charge of receiving application messages
from the network and processing them.
The NM provides users with services to write distributed applications and takes
charge of some system tasks. In particular, it: (1) monitors the liveness of the
HiM, by periodically sending control messages to the macro-node coordinator; (2)
1798 M. Di Santo et al. / Parallel Computing 28 (2002) 1789–1810

kills the node when the macro-node coordinator is considered crashed; (3) creates the
NE by using the configuration information supplied by the coordinator of the level.
Moreover, if the node is a coordinator, the NM takes charge also of setting-up the
macro-node sub-network according to information retrieved either from the RM of
the level or from an XML file locally stored.The NE contains and integrates a collection of configurable components which
allow the node behaviour to be customised in order to provide applications with the
necessary programming or run-time support. The NE components can be installed in
the framework by a specific component of the NM that directly interfaces the node to
the network level: the Level Manager (LM). After having loaded and initialised the
components according to the ‘‘inversion of control’’ pattern, an LM invokes the
methods that characterise their life cycle in response to system generated events.
Application components do not directly access the NE, but they can use its fea-tures or change its behaviour through the NM. As a consequence, the NM also rep-
resents the interface between the application and the services provided by the
framework, such as machine reconfiguration and management.
The configurable components of the NE are: the Execution Environment (EE),
the Level Sender (LS) and the Message Consumer (MC) (see Fig. 7). They constitute
abstractions that capture the execution behaviour of a node: a message, extracted
from the network, is passed to the MC, which represents the interface between an
incoming communication channel and the EE. Then, the message is synchronouslyor asynchronously delivered to the EE, which processes it according to the policy
coded in the EE implementation. As a result of message processing, new messages
can be created and sent to other nodes by using the LS, which represents the
communication interface towards the nodes of a level. Differently from a simple
node, a coordinator has two LSs: each of them interfaces the coordinator to a differ-
ent network level (called up and down levels).
Node Engine Node Manager
ExecutionEnvironment
MessageConsumerLevel Sender
EPs
Loada component
Installa component
a Component
Fig. 7. Node components and their interactions.
M. Di Santo et al. / Parallel Computing 28 (2002) 1789–1810 1799

The EE defines the node behaviour. Each node can handle a different EE imple-
mentation. Thus, HiMM can run MIMD applications by distributing their compo-
nents wrapped in the implementations of the EE of each node. The EE of a node
may contain either application components or data structures necessary to run
parallel and distributed applications according to a specific programming model.Anyway, for the EE to control the virtual machine and to use services offered by
the other node components, it must have access to the NM. This way, the running
application can both evolve on the basis of configuration information related to a
level (such as the level size) and dynamically control the virtual machine (such as
adding a node if more computing power is necessary).
The LS exports services for routing the messages generated on a node towards the
other nodes reachable through the controlled level. If a user does not install any specific
LS, HiMM provides a default implementation, called Default Level Sender (DLS).The DLS implements basic communication mechanisms able to exploit the hier-
archical organisation of a HiM and to support the development of more sophisti-
cated communication primitives, such as the ones based on synchronous or
collective messaging (see Fig. 8). More precisely, the DLS allows an application to
asynchronously send a message to:
(1) a node at the same level of the sender (send);
(2) all the nodes at the same level of the sender (limited broadcast);(3) all the nodes at the same level of the sender and all the other nodes recursively
met in each macro-node belonging to the level of the sender (deep broadcast).
N et-IPN et-IP
Console
M ac ro-node M ac ro-node
M ac ro-node
C C
C
N et-IP
N et-F P
D e e p B ro a d c a s t
Send
L im i t e dB ro a d c a s t
Fig. 8. Communication mechanisms provided by the DLS.
1800 M. Di Santo et al. / Parallel Computing 28 (2002) 1789–1810

The DLS provides these services by using some NE components not accessible
to the user: the End Points (EPs). An EP is the local image of a remote node be-
longing to the same level. It stores some state information and a link to a trans-
port module selected during the configuration phase of the HiM in order to
enable communication, through a specific protocol, towards the node representedby the EP. The communication interface of the transport module is independent
of the underlying transport protocol used. This way, a new transport protocol
can be easily integrated in HiMM by only implementing a specific module, called
adapter, atop a native communication library. Every adapter has to take charge of
serialising the objects sent by the application according to the specific features of
the employed protocol in order to improve communication efficiency. Currently,
we have implemented three adapters. The first is based on TCP, the second ex-
tends UDP by adding reliability, and the third is based on Fast Messages forMyrinet.
A MC implements the actions which have to be performed by a node whenever a
message is received from the network. In particular, when the component is installed,
its reference is passed to all the transport modules currently installed on the node in
order to enable message consuming according to the policy specified by program-
mers.
5. Implementation of custom programming models on HIMM
Users can define specific programming models by implementing the NE compo-
nents. To this end, each component of the NE has to implement a method (init( ))that is automatically invoked by the system to pass the framework skeleton reference
to the newly installed component (inversion of control).
To illustrate how to define a new programming model, two examples are reported:
the implementations of the ‘‘Send/Receive’’ and the ‘‘Active Object’’ models. Theformer is the well-known message-passing model used to program parallel and dis-
tributed applications; the latter is the model proposed by the authors in [9,10] to
overcome some limitations of the message-passing and RPC models.
To implement the basic Send/Receive (S/R) model, the NE components have to
provide only two primitives, send( ) and receive( ). While send( ) is directly providedby the DLS component, receive( ) can be implemented by extending the MC inter-
face. The correct coupling between the new MC interface and the application com-
ponents is ensured by an ‘‘ad hoc’’ implementation of the EE interface, whichcontains the application code (see Fig. 9). The code can be written using either the
SPMD or MIMD model, thanks to the possibility of checking node type and of dis-
tributing a different EE implementation to each node. To this end, the EE is pro-
vided with the method start( ), which is invoked when the configuration phase iscompleted and the start event is propagated by the console to all the nodes of the
metacomputer (see Figs. 9 and 10).
Before illustrating how the Active Object model can be implemented, a brief de-
scription of its main features is reported. The model is a generalisation of the active
M. Di Santo et al. / Parallel Computing 28 (2002) 1789–1810 1801

message model [11] in the context of object-oriented programming. It is based on the
following three concepts: threads, which represent the active entities of a computa-
tion; global objects, which are common Java objects globally accessible through
the HiM by using a global name space; active objects (AOs), which are auto-execut-
able messages used by threads to modify global objects. Threads are not given anidentity; so they can interact only by accessing global objects through the asynchro-
nous sending of AOs to the nodes hosting the implementations of the global objects
themselves. At destination, an AO can access the local pool of global objects� imple-mentations and so select and modify them. In particular, the code tied to an AO is
executed by a thread: the only one activated by the system (‘‘single threaded up-call’’
model) or the one started when an AO is received (‘‘popup-threads’’ model). This
way, an AO can become, in turn, a thread.
AOs can be also exploited to perform deferred synchronous interactions withremote global objects. In this case, a place holder (promise) of the future result is
returned as soon as the remote invocation is performed (see Fig. 11 for details).
The caller is synchronised with the callee only when it attempts to use the result
of a remote method that has not been completed yet (wait by necessity [5]). Our im-
plementation of wait by necessity uses a special AO whose handler returns a result.
<<interface>>
Component
+ init(NodeMgr )+ start()+ stop()
<<interface>>
MessageConsumer
+ processM sg(Message)
<<interface>>
LevelSender
SRMC
+ init(NodeMgr)+ start()+ stop()+ processMsg (Message)+ receive(node: int, fromLevel :int)
DefaultLevelSender
+ init(NodeMgr)+ start()+ stop()+ send(Object, node: int)+ broadcast(Object)+ deepbroadcast (Object)
<<interface>>
ExecutionEnvironment
ApplEE
+ init(NodeMgr)+ start()+ stop()
NodeMgr
+ isCoordinator():boolean+ isRoot():boolean+ upLevelMgr ():LevelMgr+ downLevelMgr ():LevelMgr
1
1
LevelMgr
+ addNode(address): int+ setProtocol (node1:int, node2:int, p:Prot)+ setProtocol (node: int, p:Prot)+ setComponent (node: int, m:Component)+ size(): int+ thisNode(): int
1 1..2
Fig. 9. Class diagram of the NE components that support the S/R model.
1802 M. Di Santo et al. / Parallel Computing 28 (2002) 1789–1810

The handler result is encapsulated in an AO that is sent to the caller node. Upon its
reception, the AO initialises the promise value with the transported result (see Fig.
11). It is worth noting that the return value of a deferred synchronous invocation
can be the result of several remote method invocations, due to the support for code
mobility and AO migration.
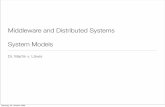
The implementation of the AO model requires a specific organisation of the NE
components (see Fig. 12). In fact, the model is message driven: a message is asyn-
chronously and immediately processed as soon as it arrives on a node. So, messageprocessing is carried out directly by the MC, while the EE is used to store the data
structures that guarantee coordination among the activities generated by message
processing. To this end, the EE of each node stores a local representation of a global
name space, whose reference is passed to each incoming message in order to allow it
to save a result in globally accessible objects. This way, the computation can evolve
asynchronously, while the coordination and synchronisation are guaranteed through
the shared global objects. Differently from the S/R model, the customisation of the
LS component has to be performed in the implementation of the AO model, both toenable the AOs sending and to support deferred synchronous communication prim-
itives based on future messaging.
ee1 :ApplEE
nm1 :NodeMgr
new
init(nm1)
start()start()
addNode(addr)
lm1:LevelMgrnew
nm2 :NodeMgrnew
ee2 :ApplEEnew
init(nm2)
mc1 :SRMC
receive(node2, UP)
obj
dls2 :DefaultLevelSendernew
init(nm2)
start()send(o,node1)
init(nm1)
new
a Console
newbuild HiM
exec [HiM created]
[permissions checked]
created
created
[permissions checked]
Fig. 10. Sequence diagram of node creation and send/receive interaction between two nodes.
M. Di Santo et al. / Parallel Computing 28 (2002) 1789–1810 1803
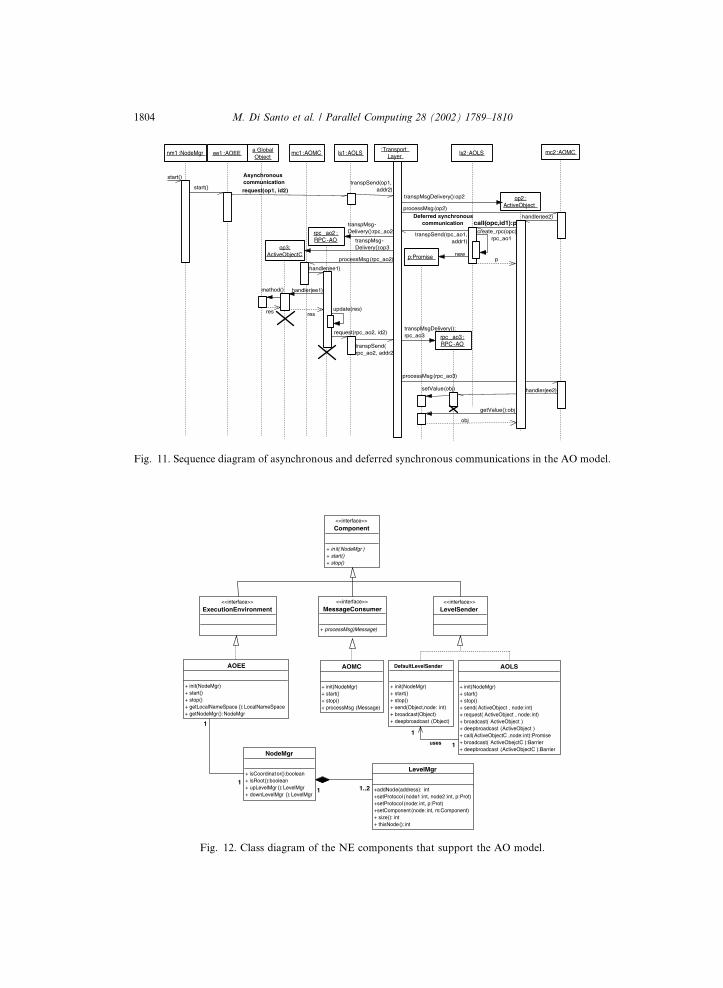
Fig. 12. Class diagram of the NE components that support the AO model.
nm1 :NodeMgr
start()
start()
mc1 :AOMC
request(op1, id2)
ls1 :AOLS :TransportLayer
processMsg(op2)
handler(ee2)
op2 :ActiveObject
transpMsgDelivery():rpc_ao3
transpSend(op1,addr2)
ls2 :AOLS
call(opc,id1):p
mc2 :AOMC
transpSend(rpc_ao1,addr1)
getValue():obj
transpMsgDelivery():op2
transpMsg-Delivery():rpc_ao2rpc _ao2 :
RPC -AO
processMsg(rpc_ao2)
handler(ee1)
request(rpc_ao2, id2)
transpSend(rpc_ao2, addr2)
rpc _ao3 :RPC -AO
obj
processMsg(rpc_ao3)
handler(ee2)
p:Promise
setValue(obj)
new
Asynchronouscommunication
Deferred synchronouscommunication
op3:ActiveObjectC
handler(ee1)
transpMsg-Delivery():op3
a GlobalObject
method()
res res
create_rpc(opc
p
):rpc_ao1
update(res)
ee1 :AOEE
Fig. 11. Sequence diagram of asynchronous and deferred synchronous communications in the AO model.
1804 M. Di Santo et al. / Parallel Computing 28 (2002) 1789–1810
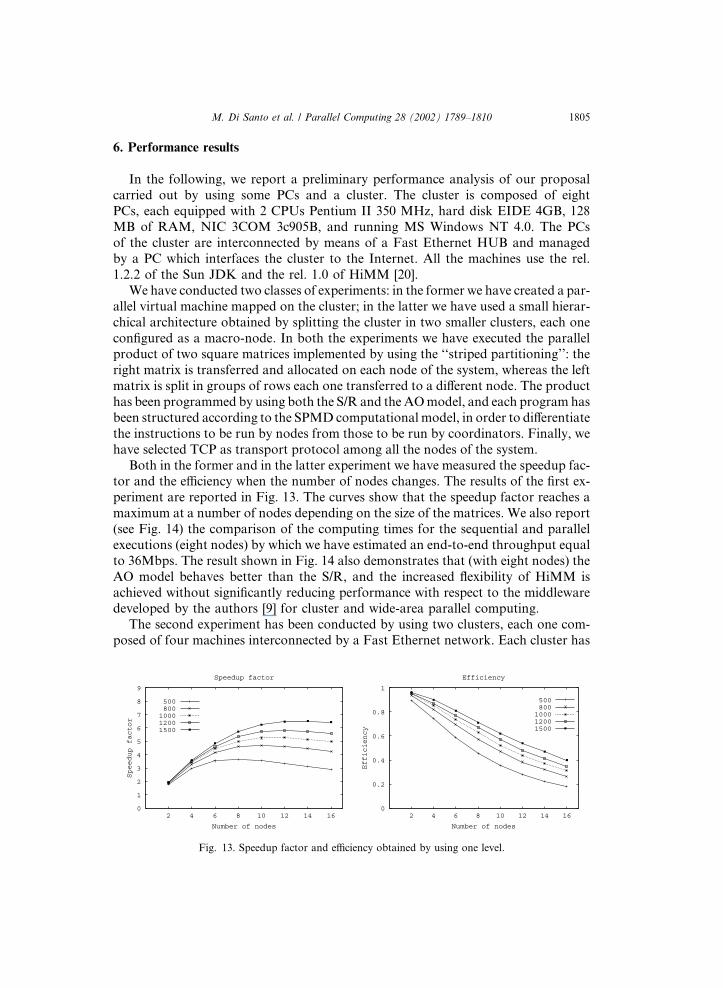
6. Performance results
In the following, we report a preliminary performance analysis of our proposal
carried out by using some PCs and a cluster. The cluster is composed of eight
PCs, each equipped with 2 CPUs Pentium II 350 MHz, hard disk EIDE 4GB, 128MB of RAM, NIC 3COM 3c905B, and running MS Windows NT 4.0. The PCs
of the cluster are interconnected by means of a Fast Ethernet HUB and managed
by a PC which interfaces the cluster to the Internet. All the machines use the rel.
1.2.2 of the Sun JDK and the rel. 1.0 of HiMM [20].
We have conducted two classes of experiments: in the former we have created a par-
allel virtual machine mapped on the cluster; in the latter we have used a small hierar-
chical architecture obtained by splitting the cluster in two smaller clusters, each one
configured as a macro-node. In both the experiments we have executed the parallelproduct of two square matrices implemented by using the ‘‘striped partitioning’’: the
right matrix is transferred and allocated on each node of the system, whereas the left
matrix is split in groups of rows each one transferred to a different node. The product
has been programmed by using both the S/R and the AOmodel, and each program has
been structured according to the SPMD computational model, in order to differentiate
the instructions to be run by nodes from those to be run by coordinators. Finally, we
have selected TCP as transport protocol among all the nodes of the system.
Both in the former and in the latter experiment we have measured the speedup fac-tor and the efficiency when the number of nodes changes. The results of the first ex-
periment are reported in Fig. 13. The curves show that the speedup factor reaches a
maximum at a number of nodes depending on the size of the matrices. We also report
(see Fig. 14) the comparison of the computing times for the sequential and parallel
executions (eight nodes) by which we have estimated an end-to-end throughput equal
to 36Mbps. The result shown in Fig. 14 also demonstrates that (with eight nodes) the
AO model behaves better than the S/R, and the increased flexibility of HiMM is
achieved without significantly reducing performance with respect to the middlewaredeveloped by the authors [9] for cluster and wide-area parallel computing.
The second experiment has been conducted by using two clusters, each one com-
posed of four machines interconnected by a Fast Ethernet network. Each cluster has
0
1
2
3
4
5
6
7
8
9
2 4 6 8 10 12 14 16
Speedup factor
Number of nodes
Speedup factor
500800100012001500
0
0.2
0.4
0.6
0.8
1
2 4 6 8 10 12 14 16
Efficiency
Number of nodes
Efficiency
500800100012001500
Fig. 13. Speedup factor and efficiency obtained by using one level.
M. Di Santo et al. / Parallel Computing 28 (2002) 1789–1810 1805
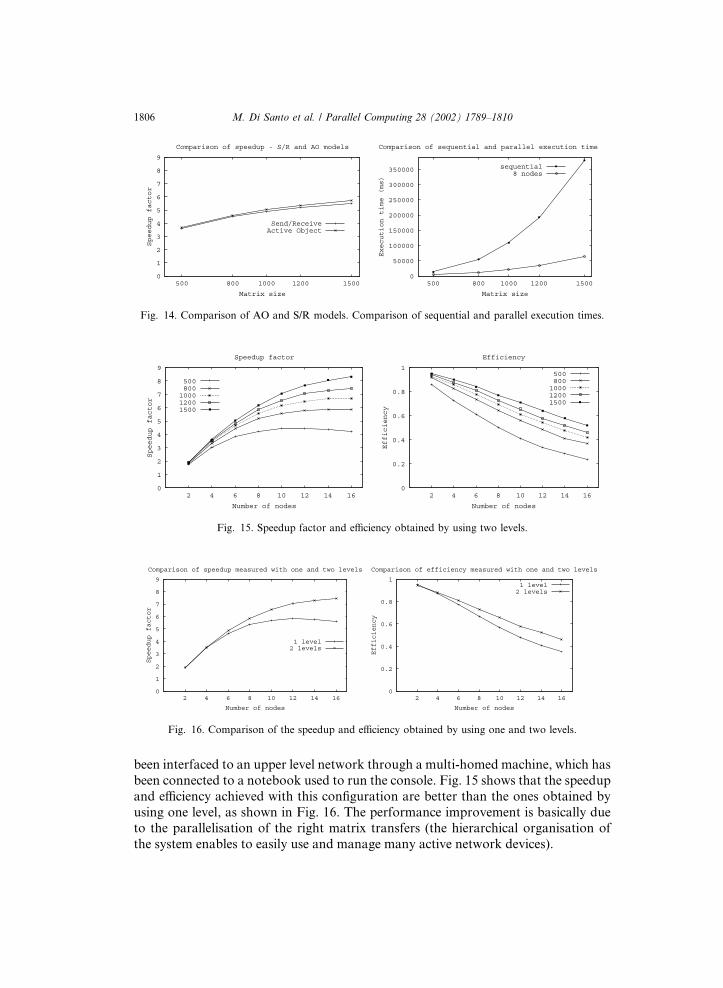
been interfaced to an upper level network through a multi-homed machine, which has
been connected to a notebook used to run the console. Fig. 15 shows that the speedup
and efficiency achieved with this configuration are better than the ones obtained by
using one level, as shown in Fig. 16. The performance improvement is basically dueto the parallelisation of the right matrix transfers (the hierarchical organisation of
the system enables to easily use and manage many active network devices).
0
1
2
3
4
5
6
7
8
9
2 4 6 8 10 12 14 16
Speedup factor
Number of nodes
Speedup factor
500800100012001500
0
0.2
0.4
0.6
0.8
1
2 4 6 8 10 12 14 16
Efficiency
Number of nodes
Efficiency
500800100012001500
Fig. 15. Speedup factor and efficiency obtained by using two levels.
0
1
2
3
4
5
6
7
8
9
500 800 1000 1200 1500
Speedup factor
Matrix size
Comparison of speedup - S/R and AO models
Send/ReceiveActive Object
0
50000
100000
150000
200000
250000
300000
350000
500 800 1000 1200 1500
Execution time (ms)
Matrix size
Comparison of sequential and parallel execution time
sequential8 nodes
Fig. 14. Comparison of AO and S/R models. Comparison of sequential and parallel execution times.
0
1
2
3
4
5
6
7
8
9
2 4 6 8 10 12 14 16
Speedup factor
Number of nodes
Comparison of speedup measured with one and two levels
1 level2 levels
0
0.2
0.4
0.6
0.8
1
2 4 6 8 10 12 14 16
Efficiency
Number of nodes
Comparison of efficiency measured with one and two levels
1 level2 levels
Fig. 16. Comparison of the speedup and efficiency obtained by using one and two levels.
1806 M. Di Santo et al. / Parallel Computing 28 (2002) 1789–1810

7. Related work
In the last decade the idea of grabbing and managing distributed, heterogeneous
resources has promoted the development of a lot of software infrastructures for meta-
computing. One of the most famous and widespread is Globus [13]. This infrastruc-ture is built upon the Nexus [14] communication framework and is based on a toolkit
(GMT––GlobusMetacomputing Toolkit) that consists of predefinedmodules dealing
with communication, resource allocation, information and brokering services. Differ-
ently from HiMM, Globus does not allow software modules to be loaded and inte-
grated at run-time in a coherent, dynamically extensible, software architecture.
Legion [19] is an object-oriented metacomputing system whose focus is in provid-
ing transparent access to an enterprise-wide distributed computing framework. It
provides every object with a globally unique identifier by which the object can bereferenced from anywhere. Legion supports the wide-area distributed execution of
two kinds of programs: programs linked with Legion libraries and independent pro-
grams. In particular, Legion can completely control the execution of the first kind of
programs but can not control the checkpointing and the job restart for the second
kind of programs. Legion does not aim at providing features to easily change the
middleware implementation and the programming models supported.
The Condor framework [25] has many low-level features similar to HiMM. It is
mainly designed to solve problems concerning resource gathering, task schedulingand allocation. To support transparent task scheduling, Condor requires that pro-
grams are linked to a specific library, which also enables dynamic checkpointing.
However, Condor does not adequately support heterogeneity, in that an application
can run on different platforms only if specific binaries are locally provided. More-
over, it does not envision dynamic reconfigurability of the services provided by
the computational resources and does not well support programming models that
are not based on the master-worker metaphor.
Harness [4] is based on the concept of a Distributed Virtual Machine (DVM) that,like a HiM, can be configured and customised by the user. A DVM is a set of kernels,
each mapped onto a host, managed by a Status Server. Several DVMs can be merged
to create a bigger, more powerful DVM. The execution environment is flexible and
customisable, in that it can dynamically install plug-ins. However, from the architec-
tural point of view, Harness manages a flat, distributed architecture that does not
assure a good scalability when the number of machines increases. Moreover, it sup-
ports only a simple information service based on a centralised Name Server.
Javelin [28] is a Grid computing software infrastructure that aims at using idle pro-cessors through a Web-based architecture. It is centred on three main components:
clients, brokers and hosts. Hosts wanting to donate computing cycles run an applet
in a Web browser, which then contacts a broker to ask for a job. A job is encapsu-
lated in a html page by a client and sent to the broker. As the authors state, Javelin is
a cost-effective, simple solution only for coarse-grained parallel computations.
Other existing Java-based, global computing software infrastructures exhibit
bottlenecks that currently prevent metacomputers from scaling to many nodes on
wide-area [3,31].
M. Di Santo et al. / Parallel Computing 28 (2002) 1789–1810 1807

8. Conclusions and future work
We have presented HiMM, a customisable, reflective middleware which provides
programmers with a flexible framework to run distributed applications based on ob-
jects in heterogeneous environments. The work is focused both on describing thehierarchical, virtual architecture managed by HiMM and on modelling each meta-
computer node by means of interacting components. Such components can be cus-
tomised in order to adapt the programming model of a metacomputer to the
application needs.
To validate our proposal, the paper shows some examples of node customisation
for supporting programming based on the message-passing and AO models. These
models have been used to program a benchmark application whose execution has
been performed on different networks of PCs. The results are interesting, suggest so-lutions for improving the middleware, and demonstrate that flexibility can be
achieved without reducing performance. Moreover, we think that our approach will
assure more interesting performance when a large-scale, distributed system is used.
In the future, we will focus on:
• the enhancement of the performance monitor already integrated in the middle-
ware, in order to aid running applications to take correct decisions about their
tasks and data placement on the network;• the implementation of the brokering service mapped on the hierarchical architec-
ture;
• the interoperability with other Grid enabled middleware platforms or toolkits,
such as Globus and Legion, by using Web Services [8];
• the performance analysis of HiMM on both high-speed networks and hetero-
geneous, large-scale ones.
Acknowledgements
We are grateful to Nadia Ranaldo and Maria Riccio for their contribution in the
implementation and testing phases of HiMM. Moreover we thank Giancarlo For-
tino for providing us with useful comments during the preparation of the paper.
References
[1] M.A. Baker, R. Buyya, D. Laforenza, The Grid: International efforts in global computing,
Proceedings of the International Conference on Advances in Infrastructure for Electronic Business,
Science, and Education on the Internet, SSGRR, L�Aquila, Italy, August 6, 2000.[2] M.A. Baker, G.C. Fox, Metacomputing: Harnessing informal supercomputers, in: R. Buyya (Ed.),
High Performance Cluster Computing: Architectures and Systems, vol. 1, Prentice Hall PTR, NJ,
USA, 1999, pp. 154–185.
[3] A. Baratloo, M. Karaoul, Z. Kedem, P. Wyckoff, Charlotte: Metacomputing on the web,
International Journal on Future Generation Computer Systems 15 (1999) 559–570.
1808 M. Di Santo et al. / Parallel Computing 28 (2002) 1789–1810

[4] M. Beck, J.J. Dongarra, G.E. Fagg, G. Al Geist, P. Gray, J. Kohl, M. Migliardi, K. Moore,
T. Moore, P. Papadopoulous, S.L. Scott, V. Sunderam, HARNESS: A next generation distrib-
uted virtual machine, International Journal on Future Generation Computer Systems 15 (5–6) (1999)
571–582.
[5] D. Caromel, Service, asynchrony, and wait-by-necessity, Journal of Object-Oriented Programming 2
(4) (1989) 12–18.
[6] B. Carpenter, V. Getov, G. Judd, A. Skjellum, G.C. Fox, MPJ: MPI-like message passing for Java,
Concurrency: Practice & Experience 12 (11) (2000) 1019–1038.
[7] C. Catlett, L. Smarr, Metacomputing, Communication of the ACM 35 (6) (1992) 44–52.
[8] F. Curbera, M. Duftler, R. Khalaf, W. Nagy, N. Mukhi, S. Weerawarana, Unraveling the web
services web: An introduction to SOAP, WSDL, and UDDI, IEEE Internet Computing 6 (2) (2002)
86–93.
[9] M. Di Santo, F. Frattolillo, W. Russo, E. Zimeo, An approach to asynchronous object-oriented
parallel and distributed computing on wide-area systems, in: J. Rolim et al. (Eds.), Proceedings of the
International Workshop on Java for Parallel and Distributed Computing, LNCS 1800, Springer,
Berlin, 2000, pp. 536–543.
[10] M. Di Santo, F. Frattolillo, W. Russo, E. Zimeo, A portable middleware for building high
performance metacomputers, in: Proceedings of the International Conference on PARCO�01, Naples,Italy, September 2001.
[11] T. von Eicken, D.E. Culler, S.C. Goldstein, K.E. Schauser, Active messages: A mechanism for
integrated communication and computation, in: D. Abramson, J. Gaudiot (Eds.), Proceedings 19th
ACM Annual International Symposium on Computer Architecture, May, ACM Press, Gold Coast,
Queensland, Australia, 1992, pp. 256–266.
[12] A. Ferrari, JPVM: Network parallel computing in Java, Concurrency: Practice & Experience 10 (11–
13) (1998) 985–992.
[13] I. Foster, C. Kesselman, Globus: A metacomputing infrastructure toolkit, International Journal of
Supercomputer Applications 11 (2) (1997) 115–128.
[14] I. Foster, C. Kesselman, S. Tuecke, The nexus approach to integrating multithreading and
communication, International Journal on Parallel and Distributed Computing 37 (1996) 70–82.
[15] I. Foster, C. Kesselman, S. Tuecke, The anatomy of the Grid: Enabling scalable virtual organizations,
International Journal of Supercomputer Applications 15 (3) (2001).
[16] E. Gamma, R. Helm, R. Johnson, J. Vlissides, Design Patterns, first ed., Addison Wesley, 1995.
[17] V. Getov, High-performance parallel programming in java: Exploiting native libraries, Concurrency:
Practice & Experience 10 (11–13) (1998) 863–872.
[18] V. Getov, G. von Laszewski, M. Philippsen, I. Foster, Multiparadigm communication in Java for
Grid computing, Communications of the ACM 44 (10) (2001) 118–125.
[19] A. Grimshaw, A. Ferrari, F. Knabe, M. Humphrey, Legion: An operating system for wide-area
computing, IEEE Computer 32 (5) (1999) 29–37.
[20] HiMM 1.0, 2002. Available from http://paradise.ing.unisannio.it.
[21] Java Grande Forum. http://www.javagrande.org.
[22] R. Johnson, B. Foote, Designing reusable classes, Journal of Object-Oriented Programming 1 (2)
(1988) 22–35.
[23] D. Lea, Concurrent Programming in Java: Design Principles and Patterns, second ed., Addison
Wesley, 2000.
[24] S. Liang, The Java Native Interface: Programming Guide and Reference, Addison Wesley, 1998.
[25] M.J. Litzkow, M. Livny, M.W. Mutka, Condor––a hunter of idle workstations, in: Proceedings 8th
International Conference of Distributed Computing Systems, San Jose, CA, June 1988.
[26] J. Maassen, R. van Nieuwpoort, R. Veldema, H. Bal, T. Kielmann, C. Jacobs, R. Hofman, Efficient
Java RMI for parallel programming, ACM Transactions on Programming Languages and Systems
(TOPLAS) 23 (6) (2001) 747–775.
[27] M. Migliardi, V. Sunderam, Networking performance for distributed objects in Java, in: Proceedings
of the International Conference on Parallel and Distributed Processing and Techinques and
Applications PDPTA�01, Las Vegas, June 2001.
M. Di Santo et al. / Parallel Computing 28 (2002) 1789–1810 1809

[28] M.O. Neary, B.O. Christiansen, P. Cappello, K.E. Schauser, Javelin: Parallel computing on the
internet, International Journal on Future Generation Computer Systems 15 (5–6) (1999) 659–674.
[29] N. Parlavantzas, G. Coulson, M. Clarke, G. Blair, Towards a reflective component based middleware
architecture, in: W. Cazzola, S. Chiba, T. Ledoux (Eds.), On-line Proceedings ECOOP 2000
Workshop on Reflection and Metalevel Architectures, Sophia Antipolis and Cannes, France, June
2000. Available from <http://www.disi.unige.it/RMA2000>.
[30] M. Philippsen, M. Zenger, JavaParty: Transparent remote objects in Java, Concurrency: Practice &
Experience 9 (11) (1997) 1225–1242.
[31] L.F.G. Sarmenta, S. Hirago, Bayanihan: Building and studying web-based volunteer computing
systems using Java, Future Generation Computing Systems 15 (5-6) (1999) 675–686.
[32] Sun Microsystem Inc., HotSpot, 2002. Available from http://java.sun.com/products/hotspot/white-
paper.html.
[33] Sun Microsystems Inc., Java Remote Method Invocation Specification, 2002. Available from http://
java.sun.com/products/jdk/rmi/index.html.
[34] V. Sunderam, J. Dongarra, A. Geist, R. Manchek, The PVM concurrent computing system:
Evolution experiences and trends, Parallel Computing 20 (4) (1994) 531–547.
[35] C. Szyperski, Component Software. Beyond Object-Oriented Programming, Addison Wesley, 1997.
[36] World Wide Web Consortium, XML 1.0 Recommendation, 2002. Available from http://www.w3.org/
XML.
1810 M. Di Santo et al. / Parallel Computing 28 (2002) 1789–1810
Top Related
Copyright © 2022 FDOKUMEN

