
The epidemic of innovation – playing around with an agent-based model
13
The Epidemic of Innovation – Playing Around with an Agent Based Model Pietro Terna Dipartimento di Scienze economiche e finanziarie, Università di Torino, Italia [email protected] Abstract. The artificial units of an agent based model can play around to diffuse innovation and new ideas, or act to conserve the status quo, escaping from advances in technology or organizational methods, or new ideas and proposals, exactly as the agents in an epidemic situation can act to diffuse or to avoid the contagion. The emerging structure is obviously a function of the density of the agents, but its behavior can vary in a dramatic way if a few agents are able to evolve some form of intelligent behavior. In our case intelligent behavior is developed allowing the agents to plan actions using artificial neural networks or, as an alternative, reinforcement learning techniques. The proposed structure of the neural networks is self developed via a trial and errors process: the cross target method develops the structure of the neural function correcting both the guesses about the actions to be done and those about the related consequences. The reinforcement learning model is built upon the Swarm Like Agent Protocol in Python (SLAPP) tool, a recent implementation of the standard Swarm function library for agent based simulation (www.swarm.org), wrote using Python (www.python.org), a powerful and simple language: the result is very useful also in a didactical perspective. CTs at present are running only in Swarm, but a SLAPP version is under development. A control implementation of the SLAPP code has been also introduced, using NetLogo (http://ccl.northwestern.edu/netlogo/). Keywords: Artificial Neural Networks, Reinforcement learning, Innovation, Agent Based Simulation, Swarm protocol. 1 Introduction to the ERA (Environment, Rules, Agents) and CTs (Cross Targets) schemes To evaluate the consequences of the different behavioral schemes adopted by agents from the point of view of the innovation and complexity framework, we propose here two original structures that are useful to build agent based simulation models in a standardized way, adding a third classical structure, that of the reinforcement leaning. The first one (ERA) is related to the structure of the models; the second one (CTs) to the possibility of using Artificial Neural Networks to regulate agent
Transcript of The epidemic of innovation – playing around with an agent-based model

The Epidemic of Innovation – Playing Around with an Agent
Based Model
Pietro Terna
Dipartimento di Scienze economiche e finanziarie, Università di Torino, Italia [email protected]
Abstract. The artificial units of an agent based model can play around to
diffuse innovation and new ideas, or act to conserve the status quo, escaping
from advances in technology or organizational methods, or new ideas and
proposals, exactly as the agents in an epidemic situation can act to diffuse or
to avoid the contagion. The emerging structure is obviously a function of the
density of the agents, but its behavior can vary in a dramatic way if a few
agents are able to evolve some form of intelligent behavior. In our case
intelligent behavior is developed allowing the agents to plan actions using
artificial neural networks or, as an alternative, reinforcement learning
techniques.
The proposed structure of the neural networks is self developed via a trial
and errors process: the cross target method develops the structure of the
neural function correcting both the guesses about the actions to be done and
those about the related consequences. The reinforcement learning model is
built upon the Swarm Like Agent Protocol in Python (SLAPP) tool, a recent
implementation of the standard Swarm function library for agent based
simulation (www.swarm.org), wrote using Python (www.python.org), a
powerful and simple language: the result is very useful also in a didactical
perspective. CTs at present are running only in Swarm, but a SLAPP version
is under development. A control implementation of the SLAPP code has
been also introduced, using NetLogo (http://ccl.northwestern.edu/netlogo/).
Keywords: Artificial Neural Networks, Reinforcement learning, Innovation,
Agent Based Simulation, Swarm protocol.
1 Introduction to the ERA (Environment, Rules, Agents)
and CTs (Cross Targets) schemes
To evaluate the consequences of the different behavioral schemes adopted by
agents from the point of view of the innovation and complexity framework, we
propose here two original structures that are useful to build agent based simulation
models in a standardized way, adding a third classical structure, that of the
reinforcement leaning.
The first one (ERA) is related to the structure of the models; the second one
(CTs) to the possibility of using Artificial Neural Networks to regulate agent

2
behavior in a plausible way. We introduce also a straightforward protocol, coming
from the Swarm heritage, to code this kind of models using Python, or using other
modern simple object oriented languages, such as Ruby.
The main goal is a didactic one: to expose undergraduate and graduate students
to the construction of agent based simulation models using a simple low level
language, in order to avoid any black box effect; but we have also a second goal,
that of promoting openness of this kind of models, to make replication simpler or
simplify direct use and re-use.
1.1 The ERA scheme
The building process of agent based simulation models needs some degree of
standardization, mainly when we go from simple models to complex results.
Fig. 1. The Environment, Agents and Rules (ERA) scheme.
The main value of the Environment-Rules-Agents (ERA) scheme, introduced in
Gilbert and Terna (2006) and shown in Fig. 1, is that it keeps both the
environment, which models the context by means of rules and general data, and
the agents, with their private data, at different conceptual levels. With the aim of
simplifying the code design, agent behavior is determined by external objects,

3
named Rule Masters, that can be interpreted as abstract representations of the
cognition of the agent or, practically, as its “brain”. Production systems, classifier
systems, neural networks and genetic algorithms are all candidates for the
implementation of Rule Masters. We also need to employ meta-rules, i.e., rules
used to modify rules (for example, the training side of a neural network). The
Rule Master objects are therefore linked to Rule Maker objects, whose role is to
modify the rules mastering agent behavior.
Agents may store their data in a specialized object, the DataWarehouse, and
may interact both with the environment and other agents via another specialized
object, the Interface (DataWarehouse and Interface are not represented in Fig. 1,
having a simple one to one link with their agent.
In the case of the reinforcement learning techniques, typically the creation of
the rules is made off line, by a sort of stand alone rule making step; then the
learned solution will be used to run the model, as an efficient Rule Master;
obviously intermediate solutions exist.
Although this code structure appears to be complex, there is a benefit when we
have to modify a simulation. The rigidity of the structure then becomes a source
of clarity.
1.2 The CTs scheme to use neural networks
To develop our agent based experiments, we introduce the following general
hypothesis (GH): an agent, acting in an economic environment, must develop and
adapt her capability of evaluating, in a coherent way, (1) what she has to do in
order to obtain a specific result and (2) how to foresee the consequences of her
actions. The same is true if the agent is interacting with other agents. Beyond this
kind of internal consistency (IC), agents can develop other characteristics, for
example the capability of adopting actions (following external proposals, EPs) or
evaluations of effects (following external objectives, EOs) suggested by the
environment (for example, following rules) or by other agents (for examples,
imitating them). Those additional characteristics are useful for a better tuning of
the agents in making experiments.
Economic behavior, simple or complex, can appear directly as a by-product of
IC, EPs and EOs. With our GH, and hereafter with the Cross Target (CT) method,
we work at the edge of Alife techniques to develop Artificial Worlds of simple
bounded rationality adaptive agents: complexity, optimizing behavior and
Olympic rationality can emerge from their interaction, but they do not belong
directly to the agents.
The name cross-targets (CTs) comes from the technique used to figure out the
targets necessary to train the Artificial Neural Networks (ANNs) representing the
adaptive agents that populate our experiments.

4
Both the targets necessary to train the network from the point of view of the
actions and those connected with the effects are built in a crossed way reported
here in Fig. 2 (indeed, “Cross Targets”). The former are built in a consistent way
with the outputs of the network concerning the guesses of the effects, in order to
develop the capability to decide actions close to the expected results. The latter,
similarly, are built in a consistent way with the outputs of the network concerning
the guesses of the actions, in order to improve the agent's capability of estimating
the effects emerging from the actions that the agent herself is deciding.
Fig. 2. The Cross Targets (CTs) scheme.
The method of CTs, introduced to develop economic subjects' autonomous
behavior, can also be interpreted as a general algorithm useful for building
behavioral models without using constrained or unconstrained optimization
techniques. The kernel of the method, conveniently based upon artificial neural
networks (but it could also be conceivable with the aid of other mathematical
tools), is learning by guessing and doing: the subject control capabilities can be
developed without defining either goals or maximizing objectives.
We choose the neural networks approach to develop CTs, mostly as a
consequence of the intrinsic adaptive capabilities of neural functions. Here we
will use feed forward multilayer networks.
Fig. 2 describes an artificial agent learning and behaving in a CT scheme. The
AAA has to produce guesses about its own actions and related effects, on the
basis of an information set (the input elements are I1,...,Ik). Remembering the
requirement of IC, targets in learning process are: (i) on one side, the actual
effects - measured through accounting rules - of the actions made by the simulated
subject; (ii) on the other side, the actions needed to match guessed effects. In the

5
last case we have to use inverse rules, even though some problems arise when the
inverse is indeterminate.
A first remark, about learning and CT: analyzing the changes of the weights
during the process we can show that the matrix of weights linking input elements
to hidden ones has little or no changes, while the matrix of weights from hidden to
output layer changes in a relevant way. Only hidden-output weight changes
determine the continuous adaptation of ANN responses to the environment
modifications, as the output values of hidden layer elements stay almost constant.
This situation is the consequence both of very small changes in targets (generated
by CT method) and of a reduced number of learning cycles.
The resulting network is certainly under trained: consequently, the simulated
economic agent develops a local ability to make decisions, but only by
adaptations of outputs to the last targets, regardless to input values. This is short
term learning as opposed to long term learning.
Some definitions: we have (i) short term learning, in the acting phase, when
agents continuously modify their weights (mainly from the hidden layer to the
output one), to adapt to the targets self-generated via CT; (ii) long term learning,
ex post, when we effectively map inputs to targets (the same generated in the
acting phase) with a large number of learning cycles, producing ANNs able to
definitively apply the rules implicitly developed in the acting and learning phase.
A second remark, about both external objectives (EOs) and external proposals
(EPs): if used, these values substitute the cross targets in the acting and adapting
phase and are consistently included in the data set for ex post learning. Despite the
target coming from actions, the guess of an effect can be trained to approximate a
value suggested by a simple rule, for example increasing wealth. This is an EO in
CT terminology. Its indirect effect, via CT, will modify actions, making them
more consistent with the (modified) guesses of effects. Vice versa, the guess about
an action to be accomplished can be modified via an EP, affecting indirectly also
the corresponding guesses of effects. If EO, EP and IC conflict in determining
behavior, complexity may emerge also within agents, but in a bounded rationality
perspective, always without the optimization and full rationality apparatus.
1.1 The reinforcement learning algorithm
CTs gave useful results in other domains, as in Terna (2002) and will be used here
to obtain further results.
To start the exploration of the field we need a more direct tool, like
reinforcement learning.
We can introduce it as follows, referring to Sutton and Barto (1998) for the
methodological basis.
We have
1. a set of states S, related to an environment;

6
2. a set of possible actions A;
3. a set of scalar rewards, in �.
At any time t we have an agent in a state st of S and we can chose the action a in
A(st). After the action the agent will be in st+1 with a reward rt+1. Rewards are
summed over time with a discount rate factor. Our agent develops the capability
of mapping all the possible actions A in a state S to all the related rewards.
In our case the map is based on a set of neural networks, in some way
simplifying the CTs perspective, but operating in the same direction.
2 Using our schemes in SLAPP
Our proposal is that of using SLAPP, that can be found at
http://eco83.econ.unito.it/terna/slapp, to develop this kind of models. The basic
code demonstrates that we can implement a rigorous protocol like that of Swarm
(http://www.swarm.org) with a simple coding system, consistently with the goals
exposed in the premise. At the same SLAPP web address the Chameleons
application may also be found, both in the SLAPP and in the NetLogo versions.
2.1 The Chameleon metaphor to play around with the epidemic of
innovation: the basic tool, implemented by reinforcement learning
The metaphorical model we use here is that of the changing color chameleons
and, more precisely, that of the Taormina’s Chameleons1.
In the starting phase we have chameleons of three colors: red, green and blue.
When two chameleons of different colors meet, they both change their color,
assuming the third one. If all chameleons get the same color, we have a steady
state situation. This case is possible, although rare.
The metaphor is interpreted in the following way: an agent diffusing innovation
(or political ideas) can change itself through the interaction with other agents: as
an example think about an academic scholar working in a completely isolated
context or, on the contrary, interacting with other scholars or with private
entrepreneurs to apply the results of her work. On the opposite side an agent
diffusing epidemics modifies the others without changing itself: we will introduce
also hyper-chameleons, able in doing that. The simple model moves agents and
changes their colors, when necessary. But what if the chameleons of a given color
want to preserve their identity?
1 I have to thank Riccardo Taormina, an undergraduate student of mine, for developing this kind of
application with great involvement and creativity. Many thanks also to Marco Lamieri, a former PhD
student of mine, for introducing the powerful chameleon idea.

7
Going back the reinforcement learning, the states of the world s here are
represented by the 5×5 matrixes related to the different spaces, like that of Fig. 3a,
defined in a bounded rationality perspective, being the agent unable to see a larger
portion of its world.
(a) (b)
Fig. 3. (a) The bounded rationality view of the agent2 and (b) its possible moves.
In Fig.3 (a), from the point of view of the central red chameleon, the “enemies”
are contained in the cells containing 1 in the numerical matrix; the possible moves
are in part (b) of Fig. 3.
The evaluation of the rewards is very simple: considering only a 3×3 space, as
in Fig.4, the red chameleons in the central position of the red square has three
enemies around it; moving to the north in the center of the green square, it would
have only two (visible) enemies, with a +1 reward; the reward can also be
negative.
Fig. 4. Two different situations: being in the center of the red or of the green square.
We are here always considering two steps jointly, summing up their rewards,
without the use of a discount rate. The double step analysis compensates the
highly bounded rationality applied both to the knowledge of the word (limited in
each step to a 5×5 space) and to the evaluation of the rewards, on a 3×3 area.
We have 9 neural networks, one for each of the possible moves in the 3×3
space, with 25 input elements (the 5×5 space), 10 hidden elements and a unique
2 We know that the small pictures do not represent chameleons, but geckos; we will correct the aesthetic side
of the model in the next future …
8
output, which is a guess of the reward that can be obtained choosing each one of
the 9 possible moves in presence of that specific situation of the 5×5 space. The
reward here is the moving sum of the rewards of two subsequent moves.
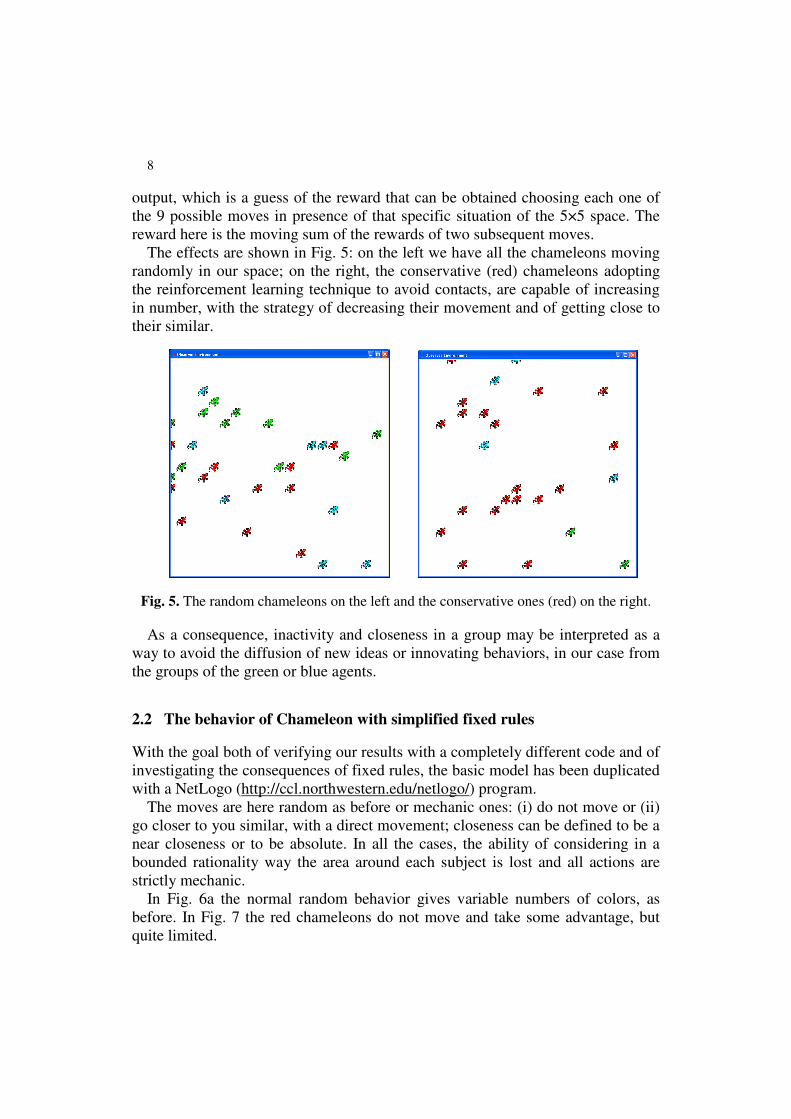
The effects are shown in Fig. 5: on the left we have all the chameleons moving
randomly in our space; on the right, the conservative (red) chameleons adopting
the reinforcement learning technique to avoid contacts, are capable of increasing
in number, with the strategy of decreasing their movement and of getting close to
their similar.
Fig. 5. The random chameleons on the left and the conservative ones (red) on the right.
As a consequence, inactivity and closeness in a group may be interpreted as a
way to avoid the diffusion of new ideas or innovating behaviors, in our case from
the groups of the green or blue agents.
2.2 The behavior of Chameleon with simplified fixed rules
With the goal both of verifying our results with a completely different code and of
investigating the consequences of fixed rules, the basic model has been duplicated
with a NetLogo (http://ccl.northwestern.edu/netlogo/) program.
The moves are here random as before or mechanic ones: (i) do not move or (ii)
go closer to you similar, with a direct movement; closeness can be defined to be a
near closeness or to be absolute. In all the cases, the ability of considering in a
bounded rationality way the area around each subject is lost and all actions are
strictly mechanic.
In Fig. 6a the normal random behavior gives variable numbers of colors, as
before. In Fig. 7 the red chameleons do not move and take some advantage, but
quite limited.

9
In Fig. 7a we see that staying close without intelligence does not give any
advantage to the conservative group, which is anyway moving around for the
internal interactions (some hope for innovation?); the advantage arises only from
absolute closeness, that gives also the by-product of immobility. (Is that the
strategy adopted by academia to avoid interaction with other cultures and the
related changes?)
(a) (b)
Fig. 6. (a) The random chameleons again; (b) the winning red chameleons do not move.
(a) (b)
Fig. 7. (a) The red chameleons looking for their similar, going near close; (b) the same
looking for absolute closeness (all the red agents are in the same place).
We can underline the difference between the more sophisticated reinforcement
learning behavioral rules (see above and below) and this fixed rules machineries
guiding our agents.
2.3 Introducing Hyper-Chameleons
We now consider the introduction of more sophisticated agents: the hyper-
chameleons, with (i) the possibility of using simultaneously more than three type
10
of agents with different colors, (ii) the presence of agents avoiding contacts (as
before, the conservative one) now named “runners” and (iii) that one of agents
looking for contacts, named “chasers”; the last ones are able to change their world
and can be considered to be the innovators.
All the combinations of colors are now possible: if A hits B the resulting color
can be C (or D or F … following probabilistic schemes), but also A can keep its
color, B can keep its color, both can adopt the A or the B color, with the
possibility of setting these conditions directly in the interface of the model. The
brains of the agents are developed as before, with two different types (chaser and
runner) and with the possibility of developing and adopting other brains, changing
the Rule Masters as introduced in Fig. 1.
We present below a few starting cases and introduce a dictionary: adaptation =
changing color; chaser = using intelligent rules of chasing, to diffuse innovation
or new ideas, with adaptation; runner = conservative agent using intelligent rules
to avoid innovation and new ideas, with adaptation; super-chaser = using
intelligent rules as before, but without adaptation; zero intelligence = acting
randomly, with or without adaptation. Remember that in our scheme an agent
diffusing innovation (or political ideas) can change itself via the interaction with
other agents; an agent diffusing epidemics does not change itself.
-10
0
10
20
30
40
50
60
70
0 50 100 150 200 250 300
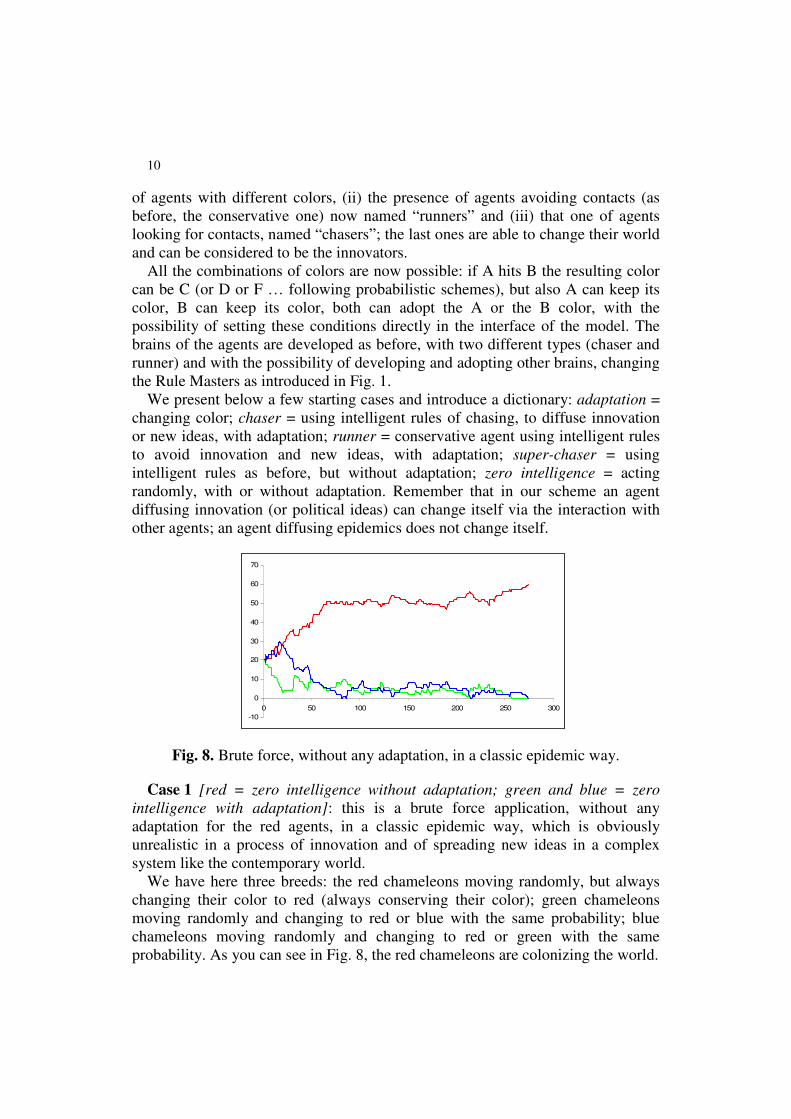
Fig. 8. Brute force, without any adaptation, in a classic epidemic way.
Case 1 [red = zero intelligence without adaptation; green and blue = zero
intelligence with adaptation]: this is a brute force application, without any
adaptation for the red agents, in a classic epidemic way, which is obviously
unrealistic in a process of innovation and of spreading new ideas in a complex
system like the contemporary world.
We have here three breeds: the red chameleons moving randomly, but always
changing their color to red (always conserving their color); green chameleons
moving randomly and changing to red or blue with the same probability; blue
chameleons moving randomly and changing to red or green with the same
probability. As you can see in Fig. 8, the red chameleons are colonizing the world.

11
Case 2 [red = super-chaser; green and blue = zero intelligence with
adaptation]: red chameleons are super-chaser, adopting intelligence (using a
“chaser brain”) to act in a classic epidemic way, without any adaptation; the
scheme is again unrealistic if adopted in a process of innovation or of spreading
off new ideas in a complex contemporary world.
-10
0
10
20
30
40
50
60
70
0 20 40 60 80 100 120 140
Fig. 9. A super-chaser, adopting intelligence (using a “chaser brain”) acting in a
classic epidemic way.
We have always three breeds: the red chameleons moving as chaser and always
changing their color to red (always conserving their color); green chameleons
moving randomly and changing color to red or blue with the same probability;
blue chameleons moving randomly and changing color to red or green with the
same probability. As you can see in Fig. 9, the red chameleons are again
colonizing the world.
Case 3 [red = chaser; green = runner; blue = zero intelligence with
adaptation]: chasers and runners both acting with intelligence and adaptation,
with the conservative behavior winning. The first ones are using a chaser brain,
but now changing their color; the second ones use a runner brain to avoid
innovation and ideas, changing their color.
Three breeds: the red chameleons moving as chaser and changing color to green
or blue with the same probability; the green chameleons moving as runner and
changing color to red or blue with the same probability; blue chameleons moving
randomly and changing to red or green with the same probability. As you can see
in Fig. 10, the conservative intelligent behavior of green chameleons wins.
Case 4 [red = super-chaser; green = runner; blue = zero intelligence with
adaptation]: super-chasers and a runners both acting with intelligence, but the
super-chasers without adaptation; is that a necessary condition, practically
impossible to adopt in a modern complex world, to diffuse innovation and new
ideas?

12
-10
0
10
20
30
40
50
60
70
0 200 400 600 800 1000 1200
Fig. 10. The conservative intelligent behavior of green chameleons wins.
-10
0
10
20
30
40
50
60
70
0 100 200 300 400 500 600 700 800
Fig. 11. The red super-chaser chameleons win against the conservative intelligent
behavior of green chameleons.
Three breeds: the red chameleons moving as chaser and always changing their
color to red (always conserving their color); the green chameleons moving as
runner and changing color to red or blue with the same probability; blue
chameleons moving randomly and changing to red or green with the same
probability. As you can see in Fig. 11, the red super-chaser chameleons win
against the conservative intelligent behavior of green chameleons.
2 Further steps and improvements
We have now to play around with our models, experimenting the consequences of
a lot of possible initial hypotheses, as in a artificial laboratory; we have also to
add a full CTs strategy, with learning neural networks building internally their
targets; we can verify the consequences of adopting a larger area of knowledge
and of movement, also relating these different dimensions to the presence or
absence of some form of cooperation and of social capital.

13
Finally, easier ways to show our results possibly can be found through the
adoption of the more recent tools, able to produce simulations with an appearance
close to that of a videogame.
Finally, to adopt more easy ways to show our results we have also to investigate
the possibility of rendering our simulation via the more recent tools able to
produce simulation with an appearance close to that of a videogame.
We are looking in particular to programs like (i) StarLogo TNG (TNG = the
next generation), at http://education.mit.edu/starlogo-tng/, coming from Logo and
StarLogo, or (ii), from the same institution and with similar characteristics, the
newborn Scratch, at http://weblogs.media.mit.edu/llk/scratch/.
References
Gilbert N. and Terna P. (2000), How to build and use agent-based models in
social science, in «Mind & Society», 1, 1, pp. 57-72.
Sutton R. S. and Barto A. G. (1998), Reinforcement Learning: An Introduction,
Cambridge MA, MIT Press.
Terna P. (2002), Cognitive Agents Behaving in a Simple Stock Market Structure,
in F. Luna and A. Perrone (eds.), Agent-Based Methods in Economics and
Finance: Simulations in Swarm. Dordrecht and London, Kluwer Academic,
pp.188-227.




















