
Smartphone-based Public Health Information Systems: Anonymity, Privacy and Intervention
13
Smartphone-Based Public Health Information Systems: Anonymity, Privacy and Intervention Andrew Clarke Discipline of Health Informatics, University of Sydney, Sydney, NSW 2006, Australia. E-mail: [email protected] Robert Steele Division of Health Informatics, Medical University of South Carolina, Charleston, SC, 29425, USA. E-mail: [email protected] The pervasive availability of smartphones and their con- nected external sensors or wearable devices can provide a new public health data collection capability. Current research and commercial efforts have concen- trated on sensor-based collection of health data for per- sonal fitness and healthcare feedback purposes. However, to date there has not been a detailed investi- gation of how such smartphones and sensors can be utilized for public health data collection purposes. Public health data have the characteristic of being cap- turable while still not infringing upon privacy, as the full detailed data of individuals are not needed but rather only anonymized, aggregate, de-identified, and non- unique data for an individual. For example, rather than details of physical activity including specific route, just total caloric burn over a week or month could be submitted, thereby strongly assisting non-re- identification. In this paper we introduce, prototype, and evaluate a new type of public health information system to provide aggregate population health data capture and public health intervention capabilities via utilizing smart- phone and sensor capabilities, while fully maintaining the anonymity and privacy of each individual. We con- sider in particular the key aspects of privacy, anonymity, and intervention capabilities of these emerging systems and provide a detailed evaluation of anonymity preser- vation characteristics. Introduction The rapid growth in both the capabilities and uptake of smartphones suitable to act as health sensor platforms has the potential to advance public health data collection and intervention in significant ways. Although, increasingly, research and development is concentrating on how mobile devices and sensors can be used as a tool for individual health data capture and feedback, this has not extended into inves- tigation of how these devices can be used for public health data capture. Interestingly, the case for public health usage does not require the same level of precise data that would often be required in participatory sensing (Burke et al., 2006) applications in other domains. For example, the exact loca- tion and time of a measured sensor value is less important than the aggregate value over a period of time or the trend or change for a community as a whole. This article is a significantly extended version of a pre- vious conference work (Clarke & Steele, 2014). In particular this article differs in that it analyzes these novel smartphone- based public health information systems as a generic new type of system, describes the results from building a signifi- cant prototype system and carries out a substantially more detailed privacy and anonymity analysis. We describe a class of smartphone-based information systems for anonymized public health data capture and intervention. Interventions (Klasnja & Pratt, 2012) in this work are in the form of informational messages sent to an individual’s smartphone, intended to create a health-related behavioral change, and are a key component of future Health Participatory Sensing Networks (HPSNs). In particular, as we later describe, a significant new capability enabled by these systems is that a targeted public health intervention can be distributed, per- formed, and evaluated without the need for the identifying details of an individual to ever leave their mobile device. The introduced system eschews the need for a fully trusted central server, which might prove impractical or itself a significant privacy risk on population-scale applications, instead adopting an architecture that has a central aggregation server in communication with the end-user mobile devices, only via an intervening anonymizing layer, and uses local processing on each mobile device to ensure nonre- identifiability of the user from their submitted sensor data. Received March 6, 2014; revised May 28, 2014; accepted May 29, 2014 V C 2015 ASIS&T Published online 2 April 2015 in Wiley Online Library (wileyonlinelibrary.com). DOI: 10.1002/asi.23356 JOURNAL OF THE ASSOCIATION FOR INFORMATION SCIENCE AND TECHNOLOGY, 66(12):2596–2608, 2015
Transcript of Smartphone-based Public Health Information Systems: Anonymity, Privacy and Intervention

Smartphone-Based Public Health Information Systems:Anonymity, Privacy and Intervention
Andrew ClarkeDiscipline of Health Informatics, University of Sydney, Sydney, NSW 2006, Australia. E-mail:
Robert SteeleDivision of Health Informatics, Medical University of South Carolina, Charleston, SC, 29425, USA. E-mail:
The pervasive availability of smartphones and their con-nected external sensors or wearable devices canprovide a new public health data collection capability.Current research and commercial efforts have concen-trated on sensor-based collection of health data for per-sonal fitness and healthcare feedback purposes.However, to date there has not been a detailed investi-gation of how such smartphones and sensors can beutilized for public health data collection purposes.Public health data have the characteristic of being cap-turable while still not infringing upon privacy, as the fulldetailed data of individuals are not needed but ratheronly anonymized, aggregate, de-identified, and non-unique data for an individual. For example, ratherthan details of physical activity including specificroute, just total caloric burn over a week or month couldbe submitted, thereby strongly assisting non-re-identification. In this paper we introduce, prototype, andevaluate a new type of public health information systemto provide aggregate population health data capture andpublic health intervention capabilities via utilizing smart-phone and sensor capabilities, while fully maintainingthe anonymity and privacy of each individual. We con-sider in particular the key aspects of privacy, anonymity,and intervention capabilities of these emerging systemsand provide a detailed evaluation of anonymity preser-vation characteristics.
Introduction
The rapid growth in both the capabilities and uptake of
smartphones suitable to act as health sensor platforms has
the potential to advance public health data collection and
intervention in significant ways. Although, increasingly,
research and development is concentrating on how mobile
devices and sensors can be used as a tool for individual health
data capture and feedback, this has not extended into inves-
tigation of how these devices can be used for public health
data capture. Interestingly, the case for public health usage
does not require the same level of precise data that would
often be required in participatory sensing (Burke et al., 2006)
applications in other domains. For example, the exact loca-
tion and time of a measured sensor value is less important
than the aggregate value over a period of time or the trend or
change for a community as a whole.
This article is a significantly extended version of a pre-
vious conference work (Clarke & Steele, 2014). In particular
this article differs in that it analyzes these novel smartphone-
based public health information systems as a generic new
type of system, describes the results from building a signifi-
cant prototype system and carries out a substantially more
detailed privacy and anonymity analysis. We describe a class
of smartphone-based information systems for anonymized
public health data capture and intervention. Interventions
(Klasnja & Pratt, 2012) in this work are in the form of
informational messages sent to an individual’s smartphone,
intended to create a health-related behavioral change, and
are a key component of future Health Participatory Sensing
Networks (HPSNs). In particular, as we later describe, a
significant new capability enabled by these systems is that a
targeted public health intervention can be distributed, per-
formed, and evaluated without the need for the identifying
details of an individual to ever leave their mobile device.
The introduced system eschews the need for a fully trusted
central server, which might prove impractical or itself a
significant privacy risk on population-scale applications,
instead adopting an architecture that has a central aggregation
server in communication with the end-user mobile devices,
only via an intervening anonymizing layer, and uses
local processing on each mobile device to ensure nonre-
identifiability of the user from their submitted sensor data.
Received March 6, 2014; revised May 28, 2014; accepted May 29, 2014
© 2015 ASIS&T • Published online in Wiley Online Library
(wileyonlinelibrary.com). DOI: 10.1002/asi.23356
JOURNAL OF THE ASSOCIATION FOR INFORMATION SCIENCE AND TECHNOLOGY, ••(••):••–••, 2015
VC 2015 ASIS&T � Published online 2 April 2015 in Wiley Online
Library (wileyonlinelibrary.com). DOI: 10.1002/asi.23356
JOURNAL OF THE ASSOCIATION FOR INFORMATION SCIENCE AND TECHNOLOGY, 66(12):2596–2608, 2015

The anonymous communications layer could utilize
onion routing (Mauw, Verschuren, & Vink, 2004) or mix
networks (Sampigethaya & Poovendran, 2006), which are
techniques for anonymous communication over a computer
network using multiple intermediate nodes and encryption
to protect privacy—these networks make it hard to trace the
source and destination of an end-to-end communication.
The system uses the anonymizing layer in combination with
de-identification of data submitted, meaning that the content
of the data submitted does not identify an individual, to
provide anonymous submission or interaction between the
participant and the HPSN. Beyond de-identification, the
approach also addresses the risk of re-identification based on
quasi-identifiers, such as information known about individu-
als outside the HPSN that could potentially be used to match
with and re-identify the submitting individual. The conven-
tional approach to address this type of risk is to use a trusted
server or aggregation point to combine and obfuscate or alter
data to the point where k-anonymity (Kalnis & Ghinita,
2009) is assured for a data set, such that any individual is
indiscernible from k other records based on quasi-identifiers.
However, the type of public health information system
introduced in this article instead performs de-identification
without a trusted aggregator or server, which significantly
reduces privacy risks as there is no central point where
sensitive information is stored that can itself pose a privacy
threat to participants, or become a site for security lapses or
target of malicious activity. Rather, anonymity and nonre-
identifiability can be provided by first locally processing
collected data on the user’s mobile device into an aggre-
gated, generalized form that can still meet the desired public
health data collection purposes. This is achieved in the
system by utilizing quasi-identifier scores (QISs) as a quan-
tified measurement of approximate risk of possible
re-identification and thereby enables a threshold approach to
privacy limits. The threshold approach allows for auto-
mated, on-device calculation of the quantified privacy and
re-identification risk of submitting various levels of detailed
health sensor information in terms of QISs.
Sensor Capabilities and Public Health Measures
In this section we describe how data relevant to many
public health measures can already be captured automati-
cally via current or commercially available sensor capabili-
ties. By measures we mean items that are indicators of
health or healthy lifestyle or disease risk or disease. That is,
the use of sensors for public health-relevant data is not a
speculative proposal; many current commercial sensors
already provide relevant functionalities.
Sensor Capabilities
The proliferation of commercial fitness and health
sensors provides new mechanisms for population health data
capture, even though these are currently targeted for use in
relation to an individual’s health and fitness. Commercially
available sensors are also already able to capture many
biomedical measures collected in public health data surveys.
Such sensors include wearable patches, stretchable
electronic tattoos, smartwatches, other wearables and
implantable sensors along with the more widely deployed
smartphones and connected sensors. In addition, such public
health data capture would have a number of characteristics
distinct from traditional survey-based public health data
capture approaches. These include:
• Being real-time or near real-time
• Larger participant numbers and proportion of population
• More detailed data
• Captured electronically
• Direct measurement, not human response
• Anonymized, as we discuss in this work
The area of personal health sensor and software develop-
ment and commercialization (Swan, 2012) is currently a
highly active area. This is possibly because of the relevance
of these individual sensors to both the rapidly developing
smartphone market and technologies, and the increasing
interest in leveraging smartphones for personal wellness,
fitness, and healthcare purposes (Steele, 2011; Steele, Lo,
Secombe, & Wong, 2009).
Fitness and physical activity sensors. Commercial imple-
mentations such as Nike Fuel and Jawbone Up demonstrate
the potential for and achievability of continuous physical
activity sensing. Jawbone Up extends beyond physical activ-
ity monitoring to include sleep patterns and sleep quality,
and a nutritional diary. Other well-known examples of such
wearable sensors include FitBit, RunKeeper, myFitnessPal,
Pebble Watch, the Basis Watch, and Google Glass. Such
fitness and health sensors are the most contemporarily avail-
able type of sensor that can be utilized for public health
purposes, because such sensors are already achieving wide-
spread interest and a level of mass adoption.
Also of significant relevance is Google Now’s Activity
Summary (MobiHealthNews, 2012), which automatically
provides a monthly estimate of how far an individual has
walked and cycled, and is part of Google’s Android mobile
operating system—hence is already extremely widely
deployed.
Vital signs sensors. Smartwatches such as the Mio Active
are able to capture heart rate, the Amiigo wristband captures
blood oxygen levels, Somaxis provides electrocardiogram
(ECG) and Electromyography (EMG) sensors and the mc10
stretchable electronic tattoo can transmit heart rate and brain
activity (Swan, 2012). The capturing of vital signs is often
more beneficial for individual health care, but it also adds
new capabilities for public health data systems. Another
example, the Sense A/S monitoring patch is able to measure
blood pressure (Swan, 2012).
Blood constituent sensors. Increasingly there are wireless-
enabled patch technologies emerging that may be able to
2 JOURNAL OF THE ASSOCIATION FOR INFORMATION SCIENCE AND TECHNOLOGY—•• 2015
DOI: 10.1002/asiJOURNAL OF THE ASSOCIATION FOR INFORMATION SCIENCE AND TECHNOLOGY—December 2015
DOI: 10.1002/asi
2597

capture the levels of some blood constituents. Examples
include the forthcoming Sano Intelligence (Sano
Intelligence, 2013) wearable patch, which is touted to allow
the capture of blood glucose and potassium levels, with
further blood constituent capture planned for the future.
Numerous continuous blood glucose monitoring systems are
also currently available, particularly of relevance to the man-
agement of diabetes.
Such sensor capabilities in a cheap and accurate form
have the potential to revolutionize individual health care,
early detection, and preventative health; and by extension
also public health. That is, because such capabilities may be
beneficial in terms of individual health monitoring, health
maintenance, and early detection they could achieve wide
adoption. If so, their possible role in public health data
capture can also be proportionately significant.
Ambient sensors. Other initiatives such as Riderlog
(Bicycle Network, 2011) and the Copenhagen Wheel
(Outram, Ratti, & Biderman, 2010) are moving towards
capturing physical activity levels and at the same time, addi-
tional contextual and environmental data. The Copenhagen
wheel goes beyond physical activity sensing, to urban envi-
ronment monitoring with air quality and noise sensors
included in the implementation to provide additional data
beyond just the activity of the individual.
Public Health Risk Factors
The various types of health data that can be collected via
the aforementioned sensors, already relate to a majority of
public health measures:
• Physical Activity Level—This is one of the most important
lifestyle factors for chronic health conditions, other health
risks and health in general (Warburton, Nicol, & Bredin,
2006). This can now be quite accurately captured with already
commercially available sensors and even via in-built smart-
phone capabilities alone (MobiHealthNews, 2012).
• Caloric Burn and Caloric Intake—Caloric burn information
can be captured by a range of activity sensors as described,
and caloric intake can also be increasingly automatically cap-
tured (Steele, 2014).
• Nutritional Data—As mentioned, wearable patches have the
ability to measure potassium levels, one of the markers of
nutrition status (AIHW, 2011).
• Blood Pressure—Blood pressure is a public health marker of
cardiovascular disease (AIHW, 2011), which is one of the
most significant morbidity and mortality risks. As described,
blood pressure can be captured via a wearable patch such as
the Sense A/S among others.
• Blood Glucose—a marker of diabetes (AIHW, 2011) can be
captured by wearable patches and other continuous glucose
monitoring (CGM) devices. The use of wirelessly connected
contact lenses for measuring blood glucose levels from the
surface of the eye has also been described (Gibbs, 2014).
• Body Mass Index (BMI)—Height is roughly invariant for
adults and Bluetooth-enabled scales are increasingly available
to capture weight.
• Body Fat Percentage and Lean Mass—Increasingly consumer
grade scales and other measurement devices include body fat
percentage and lean mass.
• Sleep Pattern and Regularity—Sleep patterns are both an indi-
cator of and a preventative/risk factor for a number of condi-
tions. Sleep quality can be captured by currently available
commercial wristbands and other sensors.
Related Work
The use of participatory sensing (Burke et al., 2006) is of
increasing interest in a number of application areas includ-
ing air quality and pollution sensing (Predic, Zhixian,
Eberle, Stojanovic, & Aberer, 2013) through the use of
external air quality sensors, urban area noise level data
(Wisniewski, Demartini, Malatras, & Cudré-Mauroux,
2013), urban traffic analysis through the use of vehicle-
mounted sensors (Ganti, Mohomed, Raghavendra, &
Ranganathan, 2012), and vehicle fuel efficiency (Ganti,
Pham, Ahmadi, Nangia, & Abdelzaher, 2010), among many
other applications.
The rich capabilities of participatory sensing have led to
usage in a range of applications, though prior to our work
(Clarke & Steele, 2014), the application to the area of public
health has not been elaborated in detail. The broader interest
in participatory sensing has in turn spurred a number of
different approaches to resolving or decreasing the implicit
security and privacy concerns when involving individuals in
sensing and data collection. The more conventional
approach uses a trusted server, then k-anonymity (Kalnis &
Ghinita, 2009) or a variant, to anonymize the data before it
is accessible for research or analysis. Of course this
approach suffers from the need for a fully trusted server as
well as issues of a single point of failure in terms of privacy
breaches. Alternatively, other approaches have improved on
this by removing some sensitive information before submis-
sion (removal of identifiers and communications anonymity)
with a central point of trust (Cornelius, Kapadia, Kotz,
Peebles, & Shin, 2008) to provide an anonymous approach.
Although this is quite effective when the participatory
sensing network is collecting data on something not specific
to the individual, this alone is not well suited to a model
where quasi-identifiers are a key submission component
(such as in the case of collection of public health data) as
de-identification protection is still implemented at a central
trusted point.
To resolve the issue of requiring a fully trusted server,
alternative approaches include decentralized participatory
sensing networks (Christin, 2010) using user interaction and
awareness as part of the approach or keeping the data
managed by the participant (Choi, Chakraborty, Charbiwala,
& Srivastava, 2011; Mun et al., 2010) and stringent user-
definable access control mechanisms to manage sharing.
Although these approaches may be extensible to some
aspects of HPSNs, they typically have not incorporated the
need and importance of health interventions in HPSNs, a
capability that does not have a direct parallel in most
JOURNAL OF THE ASSOCIATION FOR INFORMATION SCIENCE AND TECHNOLOGY—•• 2015 3
DOI: 10.1002/asi2598 JOURNAL OF THE ASSOCIATION FOR INFORMATION SCIENCE AND TECHNOLOGY—December 2015
DOI: 10.1002/asi

participatory sensing systems. Additionally, the capabilitiesthat are beneficial in other areas may make these approachesoverly complex for individuals, limiting their feasibility fora large scale implementation.
Public Health Information System Architecture
The overall public health information system architecture(Figure 1) involves one or many central Health Participatory
FIG. 1. Public health information system architecture. [Color figure can be viewed in the online issue, which is available at wileyonlinelibrary.com.]
4 JOURNAL OF THE ASSOCIATION FOR INFORMATION SCIENCE AND TECHNOLOGY—•• 2015DOI: 10.1002/asi
JOURNAL OF THE ASSOCIATION FOR INFORMATION SCIENCE AND TECHNOLOGY—December 2015
DOI: 10.1002/asi
2599

Sensing Servers (HPSSs) that communicate with mobile
devices through a mix network or onion routing network to
provide communications anonymity, and mobile devices
that incorporate local processing and privacy thresholds to
maintain data anonymity, privacy, and de-identification.
The same HPSN and HPSS could be utilized by multiple
health organizations (Public Health Groups) that is, organi-
zations involved in public health-related activities. The
HPSN interfaces with Public Health Groups, which could
include state or federal health departments, public health
research institutions, or other public health organizations.
There are two primary data transmissions from and to the
HPSS, respectively: (a) data requests and public health inter-
ventions are distributed from the HPSS; and (b) anonymized
data collection submissions are sent to the HPSS. The core
functionality components of the HPSS are (a) Data Aggre-
gation, (b) Analysis, (c) Intervention and Data Requests, and
(d) Administration.
The fundamental architecture can support different levels
of both data collection and optionally public health interven-
tion, depending largely on the capabilities of the end-user
mobile devices as well as the level of participation in the
public health data collection task of the individual users of
these devices. We introduce these configurations in the fol-
lowing subsections.
Smartphone with or without External Sensors
This is the base-case of a user utilizing a smartphone with
or without additional external sensors, where the user is not
required to take additional actions to participate in the public
health data capture. This configuration has the advantage
that it has the greatest level of existing hardware deployment
and ease of adoption—that is, smartphones without addi-
tional external sensors are currently the most prolific smart-
phone deployment case, whereas external sensors are
gaining in popularity. Various types of data can prove to be
important public health or epidemiological data sources. An
example would be physical activity tracking (Klasnja,
Consolvo, McDonald, Landay, & Pratt, 2009), which has
become increasing widespread in recent years, and for
which we have discussed its potential secondary usage for
smart cities in our previous work (Clarke & Steele, 2011).
Intervention Capabilities
This configuration additionally provides inputs to the
individual to alter the actions they would have taken whilst
participating in the HPSN, in addition to the sensing capa-
bilities arising from smartphones, with or without additional
external sensors. Such participatory sensing in the health
context has a somewhat different goal to that of “active”
participatory sensing in many other contexts. Although an
“active” participatory sensing model for a typical sensing
task might focus on achieving more complete data collection
in terms of spatial or temporal range, health and
epidemiological-related active sensing would be more con-
cerned with affecting a health-impacting behavior change.
As such, the instigation to carry out “active” sensing activi-
ties essentially constitutes a public health intervention input.
Additionally for public health purposes, this can allow for
immediate and continuous feedback of the effectiveness of
campaigns upon population groups and subgroups—a pow-
erful new capability. This can contribute to the further
understanding of the effect of informational inputs on such
health-related behavior change as exercise behavior change
(Hirvonen, Huotari, Niemelä, & Korpelainen, 2012) and
for many other public health-related behavioral change
campaigns.
Extension via Manual Input
This configuration combines the potential sensing capa-
bilities of smartphones and external sensors with additional
“human-sensing” capabilities, allowing for larger volumes
of sensor-based data to be complemented with subjective
human-generated data and feedback. Further, this configu-
ration can be implemented with or without intervention
capabilities. Even without the benefits of interventions the
motivation for contributing data could be self monitoring or
altruistic or citizen-scientist contribution, with the combina-
tion allowing the additional capability of providing human
feedback in regards to interventions.
This is implemented through the addition of context-
sensitive micro-surveys that are requested to be filled by
users and attached to relevant collected sensor data. This
allows for both data that are difficult to record through
sensors alone such as the context or purpose of physical
activity (work, transport, or recreation) and in some cases
data that may have been missed perhaps because of not
wearing the sensors or mobile device for a period of time, to
be added to the overall collection.
System and Prototype Components
The public health information system includes four major
components: the HPSS, network layer, anonymizing layer,
and user mobile device. These architectural components and
details of their prototype characteristics are described here.
Health Participatory Sensing Server
The HPSS provides the central component of the public
health sensing system. In this section we describe its key
modules, which are: (a) the data requests and interventions
module; (b) the data aggregation module; and (c) the analy-
sis module.
First, the data requests and interventions module on the
HPSN server addresses the sending of data requests or inter-
ventions to end-user mobile devices, but through the inter-
mediary of the anonymizing layer.
Second, the data aggregation module receives incoming
sensing data, but once again via the intermediary anonymiz-
ing layer.
JOURNAL OF THE ASSOCIATION FOR INFORMATION SCIENCE AND TECHNOLOGY—•• 2015 5
DOI: 10.1002/asi2600 JOURNAL OF THE ASSOCIATION FOR INFORMATION SCIENCE AND TECHNOLOGY—December 2015
DOI: 10.1002/asi

As the public health information system incorporates
submissions of variable resolution (that is, submissions for
the same public health data collection task can provide more
or less detail), the aggregation module primarily works to
integrate this data and provide any data cleansing as neces-
sary. Third, the analysis module calculates metrics of inter-
est for public health analysis by the Public Health Groups
from the received sensing data.
Network and Anonymizing Layers
The network layer supports communication between the
HPSS and the onion routing network (or mix network).
The anonymizing layer consists of a mix network
(Sampigethaya & Poovendran, 2006) or onion network
(Mauw et al., 2004), which provides for anonymity of
the submitter as well as secure communication. Such
approaches utilize a chain of proxy servers between the
participant and HPSS, which can provide anonymity for
both parties, though in this case it is only required for the
mobile device user. Though this creates additional imple-
mentation complexity the potential benefit to real privacy is
significant, with the only remaining significant privacy
threat being the content of the data submitted allowing iden-
tification or re-identification. In this system these proxy
servers are referred to as HPSN data nodes.
A limitation of anonymous submission is that it reduces
the practicality of detecting and removing invalid or pur-
posefully erroneous data as there is no history of submis-
sions attached to an individual participant.
User Mobile Device
Again the user’s mobile device can operate according to
the different levels of configuration and user choice identi-
fied in the Public Health Information System Architecture
section. This level of choice would be manifested at both the
application level—that is an overall opt-in or out of data
collection, health interventions, and micro-surveys, as well
as allowing controls over specific Public Health Group inter-
actions. This could allow the user to opt in for example to
health interventions from one health organization on a spe-
cific topic and opt-in to just data submission with a second
health organization.
Software incorporating the following modules is present
on the end user’s mobile device: (a) on-device communica-
tion module; (b) local processing module; and (c) sensor
interface module
First, the on-device communication module interfaces
with the onion routing network. However, to complement
the privacy approach the on-device communications module
operates entirely on a pull approach through the distributed
HPSN data nodes for requesting new data submission
polices and public health interventions. This is because a
push-based approach could be used to selectively distribute
narrow policies for short periods of time that could poten-
tially impact on re-identification privacy.
As such, distributed policies have associated distribution
timestamps (period after which the policy should no longer
be distributed) and expiry timestamps (period after which
the policy should no longer be used on the local device, and
needs to be replaced). The on-device communication
module checks the distribution timestamp on receipt of new
data submission policies and public health interventions and
if it has passed, these can be discarded. A similar approach is
taken with expiry timestamps, an expired policy and inter-
vention should be discarded and no longer used on the local
device and should be replaced.
The other capability of the on-device communications
module is the submission of aggregate de-identified anony-
mized data. The preparation of these data is handled by the
local processing module with the on-device communication
module packaging the data for submission through the onion
routing network.
Second, in relation to the local processing module, the
section, Privacy Threshold Approach to Public Health Data
Aggregation, describes the local processing provided by this
module.
Third, the sensor interface module incorporates all capa-
bilities required to support integration of on-device sensors,
external sensors and environmental sensors that may con-
tribute to data collection. This module can make use of
existing communications standards such as the ISO/IEEE
11073 Personal Health Data standard (Clarke et al., 2007) to
carry out standardized interfacing with external sensors
where such standards are adopted.
Privacy Threshold Approach to Public HealthData Aggregation
The public health information system, by applying
granular and modular restrictions upon data collection con-
trolled by the user, reduces real privacy risks though high
levels of user control of contribution and restrictions on data
potentially utilizable for re-identification. Additionally, the
use of a local processing approach (Clarke & Steele, 2012)
to data submission and health intervention policies allows
the on-device adaptation to achieve a data submission that
matches the data request as closely as possible without
breaching variable user defined privacy conditions. This
approach to privacy thresholds encourages the request of
summary, calculated, classified and grouped data rather than
individually specific raw data that would be likely to pose a
privacy risk through potentially allowing re-identification.
Data Submission Components
The core concept of local processing (on the user mobile
device) of health data for anonymized submission requires
that individual components of a data submission have an
associated quasi-identifier score (QIS). Additionally, as the
components are made more generalized such as, for
example, a submission including the city of submission
rather than a specific zip code or postcode, the QIS would be
6 JOURNAL OF THE ASSOCIATION FOR INFORMATION SCIENCE AND TECHNOLOGY—•• 2015
DOI: 10.1002/asiJOURNAL OF THE ASSOCIATION FOR INFORMATION SCIENCE AND TECHNOLOGY—December 2015
DOI: 10.1002/asi
2601

lower to reflect the increased generality. The approach alsotakes into account the case where multiple quasi-identifiersare submitted together as such a group of quasi-identifierswill have a combined QIS value that is assessed againstprivacy thresholds. The four core data components in deter-mining the combined QIS are: Measures, Location, Tempo-ral, and Demographic and will be described here.
Measures are aggregate or calculated values that refer toa specific health-related value to be collected. A data collec-tion can include multiple measures. Examples of possiblepopulation-wide anonymized health or wellness measuresare discussed in our previous work (Clarke & Steele, 2012)and include values such as physical activity patterns andintensity, caloric burn and caloric intake, nutritional data,BMI, and sleep regularity and patterns—however this is notan exhaustive list and rather just representative of contem-porary sensing capabilities. Emerging wearable patches thatmay be able to capture some blood constituent information(Schwartz, 2012), future lab-on-a-chip technologies, smart-watches, and wirelessly enabled “tattoos,” all seem likelyto significantly extend the capabilities of the proposedsmartphone-based population health data capture system.
Location is a pivotal component—the place a measureoccurred can be of material relevance to public health.Although fine-grained location information would not begenerally required for public health some examples includeplaces physical activity occurred as a location type (e.g.,work, home, gym, or parks), active transport data (wherephysical activity is combined with commuting and transpor-tation), etc. A fine location resolution would have a high QISscore, whereas a more general location would have a lowerQIS score.
The Temporal component indicates the period of time inwhich a measure occurred. Rather than submitting the spe-cific time of a measure the time period in which it occurredcan be submitted, lowering the potential risk ofre-identification. Additionally, to keep the QIS value low, thetemporal value of the returned result can be less precise.
The demographic component includes all the other dataabout the participant that may be additionally submitted fordata analysis for example gender, age, ethnicity, etc.
Data Submission Policies
Data submission policies will have:
1. Mandatory data requirements—typically a Measure valueand high priority demographic dimensions. If this is notsubmittable without breaching an individual’s privacythreshold the submission is not made for that individual.
2. Optional data requirements—additional data componentsthat can be submitted alongside the mandatory datarequirements. To allow for the calculation of the highestlevel of data that can be submitted without breaching thethreshold, the optional data components will be weightedby importance and whether a less specific data submis-sion is acceptable for a data component as a secondaryweighting.
An algorithm (see Algorithm For Data Collection PolicyProcessing subsection) will calculate the inclusion of datacomponents versus the resolution (the detail) of data tocreate the most suitable data submission (based on weight-ings) that can be achieved. This will allow beyond the inclu-sion decision, the level of detail that is submitted to also beadjusted.
Additionally, as shown in Figure 2 a tree-based approachto the privacy threshold structure is utilized, where all lowerlevel thresholds as well as the overall threshold cannot beexceeded by a data submission’s QIS. Apart from the thresh-old related to the data components we identified in the pre-vious subsection, there are the additional thresholds of“Historic” and “Custom User Defined.” Historic relates to alimitation as to how often and how many times a mobiledevice will submit similar data (typically based on the samemeasure for a specific temporal range) to a given datarequester or to all requesters generally. Finally, the user
FIG. 2. Privacy threshold structure. [Color figure can be viewed in the online issue, which is available at wileyonlinelibrary.com.]
JOURNAL OF THE ASSOCIATION FOR INFORMATION SCIENCE AND TECHNOLOGY—•• 2015 7DOI: 10.1002/asi
2602 JOURNAL OF THE ASSOCIATION FOR INFORMATION SCIENCE AND TECHNOLOGY—December 2015
DOI: 10.1002/asi

defined threshold allows for the limitation of certain con-texts, such as not reporting on measures in certain locationsor time periods or combinations of data components thatthey would like to restrict in addition to the standardthresholds.
Algorithm for Data Collection Policy Processing
The data request is processed by the local processingmodule by adapting the data submission request to theanonymous submission settings on the local device. First(Figure 3), it is confirmed that the required minimum datacan be submitted (data components with an inclusionweighting greater than the required inclusion threshold), atthe minimal level of precision, without exceeding anyprivacy constraints.
Second, the level of precision of the required minimumdata is increased based on the resolution rating up to thelevel that the maximum precision or privacy threshold ismet.
Third, if there is additional QIS margin to the threshold atthis point, optional data components are included. The inclu-sion of the optional components is calculated based on theinclusion weighting and precision weighting giving anoptimal inclusion structure. This approach is performed forall the lower level thresholds of the privacy threshold struc-ture individually then adjusted to meet and balance at theparent node threshold, then adjusted to meet the root thresh-old and re-balanced. This process is illustrated in Figure 3.
This provides for a personalized adjustment of the sub-mission requirement to meet the previously describedprivacy rules on specific data or overall data components.This facilitates an easy-to-manage system of user-levelprivacy control that does not remove the usefulness of thedata for public health data collection.
Privacy
We consider privacy in relation to each of the types ofdata component: Location, Temporal, Demographics, andMeasures.
Location
Although exact GPS location information is typicallyused as a component for on-device calculation of physicalactivity, largely this location information can be dispensedwith before submission to the public health data system. Forexample, although the on-device data could show that anindividual cycled 50 km along a particular route betweentown A and town B, the aggregate data to be submitted forthis event can be simply the physical activity level or caloricburn of cycling 50 km rather than the distance and locations(or alternatively the distance in combination with conditionsi.e., elevation, wind, pace intensity, etc. could be submitted).This is because it is overall physical activity levels or alter-nately sedentary behavior levels that are of interest in rela-tion to public health. By submitting only the caloric burnarising from 50 km of cycling, the re-identification level canbe shown to be close to zero. This is because the measure(caloric burn of 50 km cycling), location, and temporaldetails are unlikely to be statistically unique. For example inAustralia, which has a fairly low cycling participation ratecompared to the international community, in an averageweek 3.6 million Australians (18% of the population)(Austroads, 2011) use a bicycle for transport or recreation.Though this is more or less common based on particulardemographic groups, with that scale it is unlikely that anindividual contribution would be statistically unique. Addi-tionally, using the known demographic distributions fromprevious research the submission can be dynamicallyadapted to minimize the re-identification risk for, forexample, rarer demographics (see analysis in the Evaluationsection).
FIG. 3. Data collection rule processing algorithm. [Color figure can beviewed in the online issue, which is available at wileyonlinelibrary.com.]
8 JOURNAL OF THE ASSOCIATION FOR INFORMATION SCIENCE AND TECHNOLOGY—•• 2015DOI: 10.1002/asi
JOURNAL OF THE ASSOCIATION FOR INFORMATION SCIENCE AND TECHNOLOGY—December 2015
DOI: 10.1002/asi
2603

An additional way that location data could be used in
public health data collection is through location classifica-
tion. That is, rather than submitting the coarse or fine-
grained location data the type of location is instead
submitted. This could incorporate reporting that a measure is
linked to a work or home location (without revealing the
location of either), or, for example, for physical activity that
it is linked to a park, gym, trail and track, urban street, etc.
Similar classifications would be possible for many types of
measures collected for public health and the privacy advan-
tage of processing that classification locally rather than sub-
mitting sensitive data is significant. In the case of location
classification, individual classifications are unlikely to be
used to re-identify an individual. However, it would be rea-
sonable to apply a threshold on the number of locations
submitted to avoid potential exploitation. An example of
such exploitation might be where an individual could be
potentially re-identified because of having a unique set of
locations for a given demographic set that can be correlated
with known external data, perhaps from social media.
However, though not required for the core purpose of
public health data collection, there are niche analyses that
could benefit from more detailed location information which
would operate on a privacy threshold approach. A simple
calculation of Location QIS such as the one given here could
be used:
L *QIS = 1 d λ
In the this formula d is the population density of the area and
λ is the location resolution.
Temporal
Although a participatory network seeking to capture food
intake might in theory involve capturing this information per
meal and submitting this for the purposes of public health
data capture, such time-specific data are not required. For
example, simply submitting the aggregate nutritional intake
for a week may be more than sufficient for public health
measures.
Knowing more specific details of the time in which a
measure occurred can be considered to affect risks of
re-identification. As such, we identify the following charac-
teristics of a temporal period to be considered in terms of
calculating its QIS:
• Length (L)—the duration of the time period. Longer periods
will have a higher number of potential submissions and as
such are less likely to result in re-identification.
• Granule length (G)—where it is possible to break the total
period (and the associated measure) into subperiods or gran-
ules, G is the granule length.
• Start time (S)—whether the start time is standard or targeted
(standard would imply typical data submission breakdowns
such as start of day, start of week, morning, evening, night,
etc.) for example, 00:00am or 9:15am
• End time (E)—whether the end time is standard or targeted
for example, 23:59 pm or 9:33 am
As such we use the following formula to calculate the
Temporal QIS:
T T S E L GQIS calc= ( ) +,
In this formula Tcalc evaluates the start and end time of the
data submission request, where the start and end date are
related to common time periods for example, day, week,
month, quarter, etc. a set value is used relative to the broad
or narrow nature of the period. Where the start or end time is
more targeted an additional weighting is added to the most
closely matching set value for a common period.
Demographics
In public health data capture systems, the types of demo-
graphic data needed such as age or age range, gender, major
ethnicities, city, or zip and postcode are typically noniden-
tifying so long as they represent a large enough share of the
population. The population demographics of regions and
countries are already collected for public planning and
research because of collection of census data or similar
large-scale data collections giving us good baseline data for
demographic thresholds. Additionally, in some cases aver-
ages are known for specific activities that may be used in
measures, such as the cycling example discussed in relation
to the Location component (Austroads, 2011). As such,
based on this existing data the probability of a combination
of demographics can be calculated and compared against a
privacy threshold setting. Such as in the formula given here
where λ is the individual demographic details.
D PrQIS n= − ( )1 1 2 3λ λ λ λ, , , ,…
Measures
The identifiability arising from specific measures can be
decreased to near zero simply by decreasing the location and
temporal resolution as described earlier. Additionally, in
most public health data submissions that do not require
specific location or temporal details, the only potentially
privileged data that would be at risk is the measure value.
Therefore, if re-identification is achieved through external
knowledge of an individual’s measure value no actual leak
of information has occurred.
However, in cases of multiple measures in a single sub-
mission, though unlikely it would be possible that one
measure could provide re-identification and exposure of an
additional measure. As such, it is required to impose a
threshold on the measure component of the submission,
which can require obfuscation or exclusion of measures
from the submission.
M A B C DQIS A B C D n= + + + +λ λ λ λ1 2 3 …
In this formula A, B, C, and D are individual measures and
λX is the resolution for the measure. This reduces the
JOURNAL OF THE ASSOCIATION FOR INFORMATION SCIENCE AND TECHNOLOGY—•• 2015 9
DOI: 10.1002/asi2604 JOURNAL OF THE ASSOCIATION FOR INFORMATION SCIENCE AND TECHNOLOGY—December 2015
DOI: 10.1002/asi

identified risk by limiting the number and detail of addi-
tional measures on a submission.
Public Health Interventions and Feedback
Although other participatory sensing applications do not
have a public health intervention component, parallels can
be drawn between some interventions and participatory
sensing that involves tasking, that is assigning specific
sensing “tasks” to individuals. The use of targeted or per-
sonalized tasks and interventions would usually involve the
HPSS knowing enough detail about the individual to provide
this capability. However, to provide a higher level of privacy,
targeting and personalization can be performed on the local
device based on the much more specific detail available
there. Additionally, the use of an onion routing network
restricts the risk of the HPSS being aware of which indi-
vidual mobile devices have received particular interventions.
After interventions are performed on a mobile device,
feedback regarding the effectiveness and suitability of the
intervention would be required for public health program
refinement. For example, for a specific public health cam-
paign it may be necessary to know which interventions were
initiated and what effect they had on an individual over a 3
month period. As with other data submissions the type of
intervention and the metrics of success can be considered the
“measure” and the other details, the additional data compo-
nents. The same approach can be taken in regard to privacy
thresholds to ensure that, although a very specific interven-
tion can be issued, it is not reported as the specific interven-
tion type, if to do so would violate a privacy threshold.
Overall Threshold
The overall threshold is calculated by combining the LQIS,
TQIS, DQIS, and MQIS in two stages, where there is a first stage
threshold over LQIS and TQIS as there are close connections
between location and temporal privacy and a second stage
over all QIS values.
Stage 1:θ ω ωL T L QIS T QISL T> +
Stage 2:θ ω θ ω ωLTDM LT L T D QIS M QISD M> + +
In this formulae θx refers to the threshold for x and ωy refers
to the weighting on individual thresholds and QIS compo-
nents of a higher level threshold.
Evaluation
To demonstrate the operation of this approach we con-
structed a prototype system focusing on the local processing
submission components. To achieve this, the prototype
system generates a set of clients each with randomized
demographics, measures, location and time records, and in
the case of this evaluation 100,000 clients were generated.
These clients then process a set of data submission requests,
which are submitted to the prototype server and evaluated
for privacy considerations.
The prototype evaluation used population distributions
from the Greater Sydney Metropolitian area to generate the
individual client’s demographics including five demograph-
ics: age, gender, ethnicity, income, and education. The pro-
totype client and server are both developed in Java (1.6), the
client uses SQLITE for its data storage and the server uses
Microsoft SQL Server Enterprise Edition for its data
storage.
The evaluation measures the approach’s effectiveness at
specific privacy levels in the following areas:
• Reduction of potentially re-identifiable unique demographic
combinations.
• The proportion of submissions that met maximum submission
detail including all optional dimensions.
• The proportion of dimensions and measures not submitted or
submitted at a diminished precision.
The submission rule approach allows for a great deal of
specification in the types of flexibility the client has avail-
able to adjust the data before submission. To demonstrate
this our test submission includes all identified data compo-
nents, including five demographic dimensions, three
measure dimensions, temporal dimension, and a location
dimension using location type classification.
Thresholds are set for each of the data components then
executed on the local device based on the specific data set.
The dimensions are grouped into mandatory and optional
components of the submission. As such, two demographic,
one measure, temporal at lowest resolution and location
(min level of granularity) dimensions are set as mandatory.
A further three demographics, two measures, temporal at
highest resolution and location (max level of granularity)
dimensions are set as optional.
Results
Our approach to local processing for re-identification
protection is based on the premise of a trade-off between the
amount of individually specific data requested and the
amount of submission and privacy thresholds a system will
have. As such, a comparison against the more typical
approach is relevant. In a more typical case rather than
making the decision on the local device, the number of
demographics required would be adjusted at a system-wide
level. As such, the reduction of the number of demographics
reduces the overall unique combinations and hence the
chance of re-identification. The results of this type of
approach, for a sample of 100,000 submissions are dis-
played in Figure 4 where there is a clear benefit of decreas-
ing the number of demographics required for submission if
keeping a low k-anonymity value is a priority.
However, in a more adaptive approach such as using local
processing to make decisions based on greater knowledge of
10 JOURNAL OF THE ASSOCIATION FOR INFORMATION SCIENCE AND TECHNOLOGY—•• 2015
DOI: 10.1002/asiJOURNAL OF THE ASSOCIATION FOR INFORMATION SCIENCE AND TECHNOLOGY—December 2015
DOI: 10.1002/asi
2605
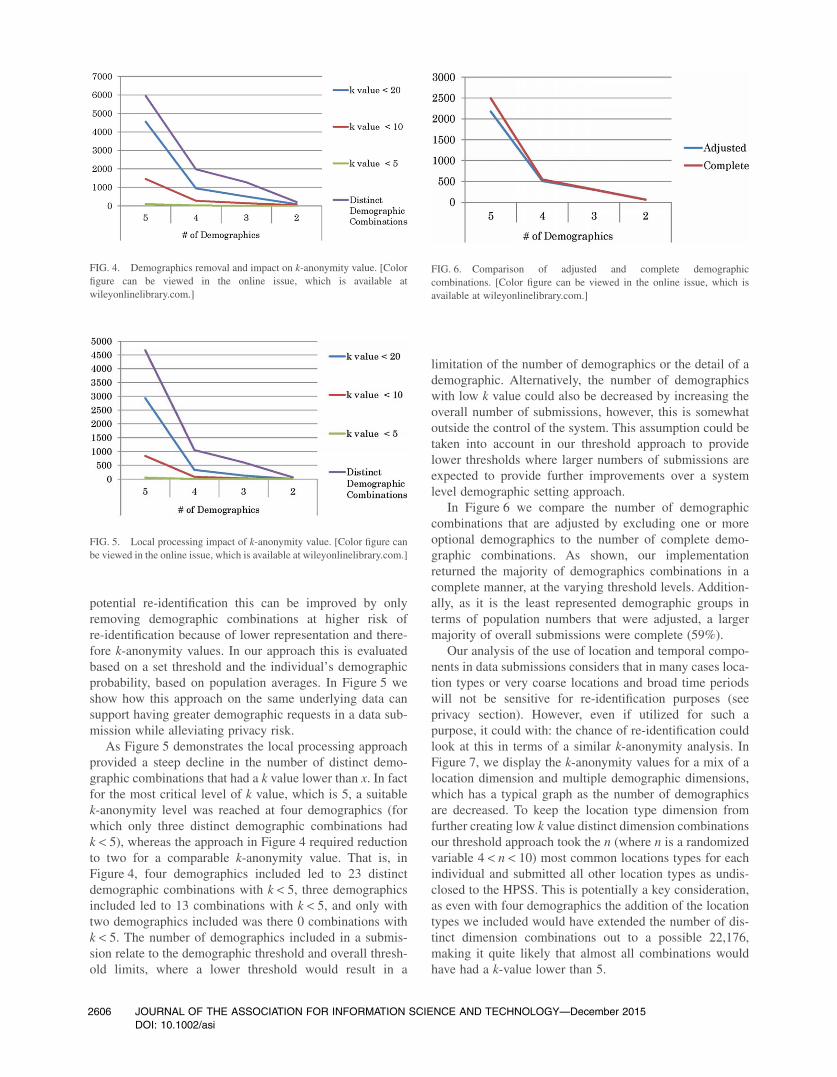
potential re-identification this can be improved by onlyremoving demographic combinations at higher risk ofre-identification because of lower representation and there-fore k-anonymity values. In our approach this is evaluatedbased on a set threshold and the individual’s demographicprobability, based on population averages. In Figure 5 weshow how this approach on the same underlying data cansupport having greater demographic requests in a data sub-mission while alleviating privacy risk.
As Figure 5 demonstrates the local processing approachprovided a steep decline in the number of distinct demo-graphic combinations that had a k value lower than x. In factfor the most critical level of k value, which is 5, a suitablek-anonymity level was reached at four demographics (forwhich only three distinct demographic combinations hadk < 5), whereas the approach in Figure 4 required reductionto two for a comparable k-anonymity value. That is, inFigure 4, four demographics included led to 23 distinctdemographic combinations with k < 5, three demographicsincluded led to 13 combinations with k < 5, and only withtwo demographics included was there 0 combinations withk < 5. The number of demographics included in a submis-sion relate to the demographic threshold and overall thresh-old limits, where a lower threshold would result in a
limitation of the number of demographics or the detail of ademographic. Alternatively, the number of demographicswith low k value could also be decreased by increasing theoverall number of submissions, however, this is somewhatoutside the control of the system. This assumption could betaken into account in our threshold approach to providelower thresholds where larger numbers of submissions areexpected to provide further improvements over a systemlevel demographic setting approach.
In Figure 6 we compare the number of demographiccombinations that are adjusted by excluding one or moreoptional demographics to the number of complete demo-graphic combinations. As shown, our implementationreturned the majority of demographics combinations in acomplete manner, at the varying threshold levels. Addition-ally, as it is the least represented demographic groups interms of population numbers that were adjusted, a largermajority of overall submissions were complete (59%).
Our analysis of the use of location and temporal compo-nents in data submissions considers that in many cases loca-tion types or very coarse locations and broad time periodswill not be sensitive for re-identification purposes (seeprivacy section). However, even if utilized for such apurpose, it could with: the chance of re-identification couldlook at this in terms of a similar k-anonymity analysis. InFigure 7, we display the k-anonymity values for a mix of alocation dimension and multiple demographic dimensions,which has a typical graph as the number of demographicsare decreased. To keep the location type dimension fromfurther creating low k value distinct dimension combinationsour threshold approach took the n (where n is a randomizedvariable 4 < n < 10) most common locations types for eachindividual and submitted all other location types as undis-closed to the HPSS. This is potentially a key consideration,as even with four demographics the addition of the locationtypes we included would have extended the number of dis-tinct dimension combinations out to a possible 22,176,making it quite likely that almost all combinations wouldhave had a k-value lower than 5.
FIG. 4. Demographics removal and impact on k-anonymity value. [Colorfigure can be viewed in the online issue, which is available atwileyonlinelibrary.com.]
FIG. 5. Local processing impact of k-anonymity value. [Color figure canbe viewed in the online issue, which is available at wileyonlinelibrary.com.]
FIG. 6. Comparison of adjusted and complete demographiccombinations. [Color figure can be viewed in the online issue, which isavailable at wileyonlinelibrary.com.]
JOURNAL OF THE ASSOCIATION FOR INFORMATION SCIENCE AND TECHNOLOGY—•• 2015 11DOI: 10.1002/asi
2606 JOURNAL OF THE ASSOCIATION FOR INFORMATION SCIENCE AND TECHNOLOGY—December 2015
DOI: 10.1002/asi

Overall, the threshold approaches and local processingmodification of public health relevant data collection asshown in these results can be effective in improving thek-anonymity value of demographic groups and hence areduction in potential re-identification and misuse of col-lected data. In terms of demographics the types of demo-graphics with less even distributions create moremodifications. The cost of this approach in terms ofdecreased information collection as compared to justexcluding entire dimensions is also an improvement, whichcould be further improved through calibration of the HPSNover time.
Discussion and Future Work
Systems that collect public health related data have sig-nificant implications in terms of privacy, anonymity, ethicalconsiderations, and technical challenges that need to be con-sidered in development of a public health informationsystems approach.
The ongoing development of participatory sensing tech-nologies and the greater understanding of participant valuesand requirements of systems gathered from early adopterswill continue to influence and extend the types of participa-tory sensing possible and its potential in the health context.Of significance to health participatory sensing is the devel-opment of new and advanced sensors that continue to extendthe range of what can be sensed and detected (Swan, 2012).Additionally, the growth in smart device ownership and per-sonal health tracking and quantification will continue todrive the potential of health participatory sensing.
The proposed smartphone-based public health informa-tion system focuses on alleviating privacy issues that wouldbe inherent in developing public health data collection capa-bilities from participatory sensing and personalized inter-vention platforms. As such, the system would be quiteresilient to extension via new sensors or sensor capabilitiesas they would present just an additional data measure, wherethe key privacy restrictions are demographic, temporal, andspatial-based. However, the extension of sensor capabilities
potentially may reach the point where sensor systems arediagnostic in nature which would result in the measure itselfbeing of a sensitive nature, in a similar manner to portions ofa private electronic health record (Steele, Min & Lo, 2012).These considerations could potentially also be resolvedwithin the bounds of the existing described approach.
However, privacy and public perceptions of such partici-patory sensing approaches need to be further researched. Assuch, future work could include studies of perceived privacyof participatory sensing applications specific to the healthdomain. A useful extension in this regard would be to alsoconsider incentivization, adoption, and health organizationacceptance of such approaches.
Conclusion
This article described smartphone-based public healthinformation systems for population-scale anonymouscapture of public health data and intervention. The type ofsystem described also has the new and powerful capabilitythat data requests and public health interventions can bedistributed, performed, and evaluated without the need foridentifying details of an individual participant to ever leavetheir mobile device. Additionally we have considered theprivacy, anonymity, and intervention properties and impli-cations of such systems.
The smartphone-based public health information systemsinclude an approach based on local processing to aggregatedata for public health use that utilizes privacy thresholds andan adaptable approach to data submission. To this end weincluded an approach to submission rules/health interven-tion rules that allows a compromise between individualprivacy and public health application requirements and analgorithmic approach to computing QIS to compare tothreshold privacy values. We provided a detailed evaluationof the privacy preserving characteristics of such systems atthe level of large user numbers.
References
AIHW. (2011). Biomedical Component of the Australian Health Survey:Public Health Objectives.
Austroads. (2011). Australian Cycling Participation: Reporting for theNational Cycling Strategy 2011–2016. Retrieved from http://www.bicyclecouncil.com.au/files/publication/NCP2011_National.pdf
Bicycle Network. (2011). Riderlog, Retrieved from https://www.bicyclenetwork.com.au/general/programs/1006/
Choi, H., Chakraborty, S., Charbiwala, Z.M., & Srivastava, M.B. (2011).Sensorsafe: a framework for privacy-preserving management of personalsensory information. In Secure Data Management (pp. 85–100). Heidel-berg: Springer-Verlag Berlin.
Christin, D. (2010). Impenetrable obscurity versus informed decisions:Privacy solutions for Participatory Sensing. In Proceedings of the 20108th IEEE International Conference on Pervasive Computing andCommunications Workshops (PERCOM Workshops) (pp. 847–848). Pis-cataway, NJ: IEEE.
Clarke, A., & Steele, R. (2011). How personal fitness data can be re-usedby smart cities. In Proceedings of the 2011 Seventh InternationalConference on Intelligent Sensors, Sensor Networks and InformationProcessing (ISSNIP) (pp. 395–400). Piscataway, NJ: IEEE.
FIG. 7. Local processing impact of k-anonymity value with locationtypes. [Color figure can be viewed in the online issue, which is available atwileyonlinelibrary.com.]
12 JOURNAL OF THE ASSOCIATION FOR INFORMATION SCIENCE AND TECHNOLOGY—•• 2015DOI: 10.1002/asi
JOURNAL OF THE ASSOCIATION FOR INFORMATION SCIENCE AND TECHNOLOGY—December 2015
DOI: 10.1002/asi
2607

Clarke, A., & Steele, R. (2012). Summarized data to achieve population-
wide anonymized wellness measures. In Proccedings of the 2012 Annual
International Conference of the IEEE Engineering in Medicine and
Biology Society (EMBC 2012) (pp. 2158–2161). Piscataway, NJ: IEEE.
Clarke, A., & Steele, R. (2014). A smartphone-based system for population-
scale anonymized public health data collection and intervention. In Pro-
ceedings of the 47th Hawaii International Conference on System
Sciences (HICSS-47) (pp. 2908–2917). Piscataway, NJ: IEEE.
Clarke, M., Bogia, D., Hassing, K., Steubesand, L., Chan, T., & Ayyagari,
D. (2007). Developing a standard for personal health devices based on
11073. In Proccedings of the 2007 Annual International Conference of
the IEEE Engineering in Medicine and Biology Society (EMBC 2007)
(pp. 6174–6176). Piscataway, NJ: IEEE.
Cornelius, C., Kapadia, A., Kotz, D., Peebles, D., Shin, M., &
Triandopoulos, N. (2008, June). Anonysense: privacy-aware people-
centric sensing. In Proceedings of the 6th International Conference on
Mobile Systems, Applications, and Services (pp. 211–224). New York:
ACM.
Ganti, R.K., Pham, N., Ahmadi, H., Nangia, S., & Abdelzaher, T.F. (2010,
June). GreenGPS: a participatory sensing fuel-efficient maps application.
In Proceedings of the 8th international conference on Mobile systems,
applications, and services (pp. 151–164). New York: ACM.
Ganti, R., Mohomed, I., Raghavendra, R., & Ranganathan, A. (2012).
Analysis of data from a taxi cab participatory sensor network. In A.
Puiatti & T. Gu (Eds.), Mobile and ubiquitous systems: Computing,
networking, and services (Vol. 104, pp. 197–208). Heidelberg: Springer
Berlin Heidelberg.
Gibbs, S. (2014). Sweet solution? Google tests smart contact lens for
diabetics, the guardian. Retrieved from http://www.theguardian.com/
technology/2014/jan/17/google-tests-smart-contact-lens-diabetics
Hirvonen, N., Huotari, M.L., Niemelä, R., & Korpelainen, R. (2012). Infor-
mation behavior in stages of exercise behavior change. Journal of the
American Society for Information Science and Technology, 63(9), 1804–
1819.
Kalnis, P., & Ghinita, G. (2009). Spatial k-anonymity. In L. Liu & M.T.
ÖZsu (Eds.), Encyclopedia of database systems (pp. 2714–2714). New
York: Springer US.
Klasnja, P., & Pratt, W. (2012). Methodological review: Healthcare in the
pocket: Mapping the space of mobile-phone health interventions. Journal
of Biomedical Informatics, 45(1), 184–198. doi: 10.1016/j.jbi.2011.08
.017
Klasnja, P., Consolvo, S., McDonald, D.W., Landay, J.A., & Pratt, W.
(2009). Using mobile & personal sensing technologies to support health
behavior change in everyday life: Lessons learned. AMIA Annual Sym-
posium Proceedings, 2009, 338–342.
Mauw, S., Verschuren, J.H.S., & Vink, E.P. (2004). A formalization of
anonymity and onion routing. In P. Samarati, P. Ryan, D. Gollmann, & R.
Molva (Eds.), Computer security—ESORICS 2004 (Vol. 3193, pp. 109–
124). Heidelberg: Springer Berlin Heidelberg.
MobiHealthNews. (2012). Google adds activity tracking to Android app.
Retrieved from http://mobihealthnews.com/19551/google-adds-activity-
tracking-to-android-app/
Mun, M., Hao, S., Mishra, N., Shilton, K., Burke, J., Estrin, D., &
Govindan, R. (2010). Personal data vaults: A locus of control for personal
data streams. In Proceedings of the 6th International Conference on
Emerging Networking EXperiments and Technologies (CoNEXT) (p.
17). Philadelphia, PA: ACM.
Outram, C., Ratti, C., & Biderman, A. (2010). The Copenhagen Wheel: An
innovative electric bicycle system that harnesses the power of real-time
information and crowd sourcing. Paper presented at the EVER Monaco
International Exhibition & Conference on Ecologic Vehicles & Renew-
able Energies.
Predic, B., Zhixian, Y., Eberle, J., Stojanovic, D., & Aberer, K. (2013).
ExposureSense: Integrating daily activities with air quality using mobile
participatory sensing. Paper presented at the Pervasive Computing and
Communications Workshops (PERCOM Workshops), 2013 IEEE Inter-
national Conference on.
Sampigethaya, K., & Poovendran, R. (2006). A survey on mix networks and
their secure applications. Proceedings of the IEEE, 94(12), 2142–2181.
doi: 10.1109/jproc.2006.889687
Sano Intelligence. (2013) Sano. Retrieved from http://sano.co/
Schwartz, A. (2012). No More Needles: A Crazy New Patch Will Con-
stantly Monitor Your Blood. Co.EXIST. Retrieved from http://
www.fastcoexist.com/1680025/no-more-needles-a-crazy-newpatch-will
-constantly-monitor-your-blood
Steele, R. (2011). Social media, mobile devices and sensors: Categorizing
new techniques for health communication. In Proceedings of the 5th
International Conference on Sensing Technology (ICST 2011) (pp. 187–
192). Piscataway, NJ: IEEE.
Steele, R. (2014). An overview of the state of the art of automated capture
of dietary intake information. Critical Reviews in Food Science and
Nutrition, doi: 10.1080/10408398.2013.765828. in press.
Steele, R., Lo, A., Secombe, C., & Wong, Y.K. (2009). Elderly persons’
perception and acceptance of using wireless sensor networks to assist
healthcare. International Journal of Medical Informatics, 78(12), 788–
801. doi: 10.1016/j.ijmedinf.2009.08.001
Steele, R., Min, K., & Lo, A. (2012). Personal health record architectures:
Technology infrastructure implications and dependencies. Journal of the
American Society for Information Science and Technology, 63(6), 1079–
1091.
Swan, M. (2012). Sensor mania! The Internet of things, wearable comput-
ing, objective metrics, and the quantified self 2.0. Journal of Sensor and
Actuator Networks, 1(3), 217–253.
Warburton, D.E.R., Nicol, C.W., & Bredin, S.S.D. (2006). Health benefits
of physical activity: The evidence. Canadian Medical Association
Journal, 174(6), 801–809. doi: 10.1503/cmaj.051351
Wisniewski, M., Demartini, G., Malatras, A., & Cudré-Mauroux, P. (2013).
NoizCrowd: A crowd-based data gathering and management system for
noise level data. In F. Daniel, G. Papadopoulos, & P. Thiran (Eds.),
Mobile web and information systems (Vol. 8093, pp. 172–186), Heidel-
berg: Springer Berlin Heidelberg.
JOURNAL OF THE ASSOCIATION FOR INFORMATION SCIENCE AND TECHNOLOGY—•• 2015 13
DOI: 10.1002/asi2608 JOURNAL OF THE ASSOCIATION FOR INFORMATION SCIENCE AND TECHNOLOGY—December 2015
DOI: 10.1002/asi




















